Windows Azure and Cloud Computing Posts for 1/19/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
My (@rogerjenn) updated Resource Links for SQL Azure Federations and Sharding Topics post of 1/19/2010 has taken over from an earlier article:
This post originated in the “SQL Azure Database and Reporting” section of my Windows Azure and Cloud Computing Posts for 1/15/2011+ post. I’ve been adding to the links on an almost daily basis, so I decided to create a free-standing article that I’ll update independently.
The earlier article no longer will be updated.
The Programming4Us blog presented OData with SQL Azure - OData Overview on 1/19/2010:
OData stands for Open Data protocol. It's a REST-based web protocol for querying and updating data completely independent of the platform or source. OData accomplishes this by utilizing and enhancing existing web technologies such as HTTP, JavaScript Object Notation (JSON), and the Atom Publishing Protocol (AtomPub). Through OData, you can gain access to a multitude of different applications and services from a variety of sources including relational databases, file systems, and even content-management systems.
The OData protocol came about from experiences implementing AtomPub clients and servers in an assortment of products over the past few years. OData relies on URIs for resource identification, which provides consistent interoperation with the Web, committing to an HTTP-based and uniform interface for interacting with the different sources. OData is committed to the fundamental web principles; this gives OData its great ability to integrate and interoperate with a plethora of services, clients, tools, and servers.
It doesn't matter if you have a basic set of reference data or are architecting an enterprise-size web application: OData facilitates the exposure of your data and associated logic as OData feeds, thus making the data available to be consumed by any OData-aware consumers such as business intelligence tools and products as well as developer tools and libraries.
1. OData Producers
An OData producer is a service or application that exposes its data using the OData protocol. This article —pertains to SQL Azure and OData, SQL Azure can expose data as OData. But so can SQL Server Reporting Services and SharePoint 2010, among other applications.
Many public (or live) OData services have been made available, which anyone can consume in an application. For example, Stack Overflow, NerdDinner, and even Netflix have partnered with Microsoft to create an OData API. You can view a complete list of such OData producers, or services, at www.odata.org/producers.
In the browser, you see a list of the categories by which you can browse or search for a movie offered by Netflix, as shown in Figure 1. You probably look at Figure 1 and think, "This looks a lot like WCF Data Services." That is correct, because, as stated earlier, OData facilitates the exposure of your data and associated logic as OData feeds, making it much easier via a standardized method to consume data regardless of the source or consuming application.
Thus, in Figure 1 you can see the categories via which you can search Netflix movie catalog. For example, you can see the different endpoints of the API through which to find a movie, such as Titles, People, Languages, and Genres.
You can begin navigating through the vast Netflix catalog by entering your query as a URI. For example, let's look at all the different genres offered by Netflix. The URI is http://OData.netflix.com/Catalog/Genres
You're given a list of genres, each of which is in an <entry> element with the name of the genre in the <Name> element in the feed, shown in Figure 2.
Figure 1. Netflix catalog
Figure 2. Netflix genres
Figure 2 shows the Comedy genre. Additional information lets you know what you need to add to the URI to drill down into more detail. For example, look at the <id> element. If you copy the value of that element into your browser, you see the detailed information for that genre.
Continuing the Comedy example, let's return all the titles in the Comedy genre. To do that, you need to append the /Titles filter to the end of the URI:
http://OData.netflix.com/Catalog/Genres('Comedy')/Titles
The Netflix OData service returns all the information for the movies in the Comedy genre. Figure 3 shows one of the movies returned from the service, displayed in the browser.
Figure 3. Viewing Netflix titles
At this point you're just scratching the surface—you can go much further. Although this article isn't intended to be a complete OData tutorial, here are some basic examples of queries you can execute:
To count how many movies Netflix has in its Comedy genre, the URI is http://netflix.cloudapp.net/Catalog/Genres('Comedy')/Titles/$count?$filter=Type%20eq%20'Movie'.
Your browser displays a number, and as of this writing, it's 4642.
To list all the comedies made in the 1980s, the URI is http://OData.netflix.com/Catalog/Genres('Comedy')/Titles?$filter=ReleaseYear%20le%201989%20and%20ReleaseYear%20ge%201980.
To see all the movies Brad Pitt has acted in, the URI is http://OData.netflix.com/Catalog/People?$filter=Name%20eq%20'Brad%20Pitt'&$expand=TitlesActedIn.
The key to knowing what to add to the URL to apply additional filters is in the information returned by the service. For example, let's modify the previous example as follows:
http://OData.netflix.com/Catalog/People?$filter=Name%20eq%20'Brad%20Pitt'
On the resulting page, several <link> elements tell you what additional filters you can apply to your URI:
<link rel="http://schemas.microsoft.com/ado/2007/08/dataservices/related/Awards"...
<link rel="http://schemas.microsoft.com/ado/2007/08/dataservices/related/TitlesActedIn"...
<link rel="http://schemas.microsoft.com/ado/2007/08/dataservices/related/TitlesDirected"...
These links let you know the information by which you can filter the data.
2. OData Consumers
An OData consumer is an application that consumes data exposed via the OData protocol. An application that consumes OData can range from a simple web browser (as you've just seen) to an enterprise custom application. The follow is a list of the consumers that support the OData protocol:
Browsers. Most modern browsers allow you to browse OData services and Atom-based feeds.
OData Explorer. A Silverlight application that allows you to browse OData services.
Excel 2010. Via PowerPivot for Excel 2010. This is a plug-in to Excel that has OData support.
Client libraries. Programming libraries such as .NET, PHP, Java, and Windows Phone 7 that make it easy to consume OData services.
Sesame (an OData browser). A browser built by Fabrice Marguerie specifically for browsing OData.
OData Helper for webMatrix. Along with ASP.NET, let's you retrieve and update data from any service that exposes its data via the OData protocol.
There are several more supported client libraries. You can find a complete list of consumers at www.odata.org/consumers.
OK, enough about OData. If you want to learn more, the OData home page is www.OData.org/home.
You should spend some time reading up on OData and start playing with some of the services provided by the listed producers. When people began getting into web services and WCF services, there was an obvious learning curve involved in understanding and implementing these technologies. Not so much with OData—it has the great benefit of using existing technologies to build on, so understanding and implementing OData is much faster and simpler.



Cihan Biyikoglu explained SQL Azure Federations: Robust Connectivity Model for Federated Data in a 1/18/2010 post:
In this post I wanted to focus on connectivity enhancements that come with SQL Azure Federations. SQL Azure Federation comes with a special FILTERING connection option that makes is safe to work with federated data and is critical for the fully-available-repartitioning component of federations. We’ll take an in depth look at this and build towards a great side effect of FILTERING connections; safe model for programming federated data and a great migration utility for multi-tenant applications. Let’s rewind back to the top. First; what sharded applications typically have to do for connectivity today, then look at how federation improve that…
Connecting to Sharded Databases [Today]
1: SqlConnection cn = new SqlConnection(“Server=tcp:servername.db.windows.net;"+2: "Db=salesdb_”+dbname_postfix+”;User ID=username;Password=password;"+3: "Trusted_Connection=False;Encrypt=True”);4: cn.Open();5: …6: SqlCommand cm = new SqlCommand(“SELECT … FROM dbo.customers "+7: WHERE customer_id=55 and …”);8: cm.ExecuteQuery();9: …Connection Pool Management: One issue that is obvious here is that once you reach to large number of databases, your connection pool will start fragmenting. Connection pooling today creates a connection pool per hash of a connection string. Imagine this, 200 databases in your sharded app… You will end up with 200 connection pools per application instance with mostly each connection pool containing a few connection to the database. This setup typically means that you don’t get much connection reuse. Idle connections after a while will get disconnected you will have to reestablish connections from scratch.
Cache Coherency: Caching the shard map also comes with another problem; cache coherency. As you repartition data, you need to build logic to invalidate the shard directory that is cached and ensure that during repartitioning operation, you are either offline or have the code to handle race conditions around invalidation of the cache and moment of physical movement of data to ensure connection always get routed to the correct database. Imagine a case where you are moving customer 55 to a new database. During the data movement you need to be able to capture all changes to customer 55 and at the moment of the switchover you need to make sure connection routed to the old database needs to be routed to the new database or could suffer from invalid results to queries such as the one above.
Connecting to Federations
Connection String: With SQL Azure Federations, connection string for the application always point to the root database name. Here is what the code would look like to the example above. Imagine in this case that you have a root database called salesdb. Realize there is no dbname_postfix anymore. Instead USE FEDERATION statement does the routing right after connection is opened.
1: SqlConnection cn = new SqlConnection(“Server=tcp:servername.db.windows.net;"+2: "Db=salesdb;User ID=username;Password=password;"+3: "Trusted_Connection=False;Encrypt=True”);4: cn.Open();5: …Safety in Atomic Units: Atomic units refer to instances of federation key, such as all rows in all federated tables of a federation that contain customer_id=55. In federations, atomic units provide the one important guarantee about physical placement of partitioned data. All federation operations guarantee that rows that belong to the same atomic unit are always physically in the same federation member. That is, we never split the atomic unit to multiple federation members. (you can find a good review of the federation concepts such as atomic units and federated tables here).
Large part of federated application workloads target a single atomic unit at a time and depend on this guarantee. In fact the default connection type to federation members scope connections to atomic units through the USE FEDERATION statement such as the one below.
1: USE FEDERATION orders_federation(customer_id=55) WITH RESET, FILTERING=ONWhat does USE FEDERATION give you? #1 you are guaranteed to land in the correct federation member even if data is being repartitioned. #2 with the FILTERING option set, your connection is scoped to data that is part of customer_id=55 and you no longer have to remember to include the filter in your WHERE clause. Here is the refactored version of the above sample with USE FEDERATION. Realize that, with the FITLERING connection option set below, the query no longer needs to include the customer_id=55 predicate in the where clause. However if the application did include customer_id=55 in the WHERE clause, things would still work as expected.
1: SqlCommand cm = new SqlCommand(“USE FEDERATION orders_federation(customer_id=55) ”+
2: cm.ExecuteNoneQuery();3: SqlCommand cm = new SqlCommand(“SELECT … FROM dbo.customers WHERE …”)4: cm.ExecuteQuery();5: …With the FILTERING connection option set, the query on customers table “SELECT … FROM dbo.customers” will return only rows that have customer_id=55. That is the query execution engine will insert the predicate, customer_id=55” automagically for you when the target of your query is a federated table. This is true for all types of statements including INSERT, DELETE and UPDATE statements. The connection works just like a constraint. If you try to INSERT or UPDATE a row to a different customer_id instance, you get an error. However DELETE and SELECT statements simply effect no rows if you try to reach outside of the scope of customer_id=55.
Federations also support turning FILTERING off. This is useful when doing global changes to the federation member such as schema changes, modifications to reference tables such as updating data in your zipcode lookup table in a federation member, in cases where you want to do bulk operations or querying over many atomic units at the same time for efficiency.
Migrating to Multi-Tenant Model with Federations: Multi-tenancy is a great way to improve economics of your app by improving density of your tenants. In most classic apps, typically the tenants get a first class database. However with large number of tenants, it is easy to see that database management overhead gets out of control fast. If you can pack more tenants to each database by allowing multiple tenants in a single database, you can reduce the number of databases you need to manage.
Not so obvious at first, but a great side effect of FILTERING connection is, they make migration of business logic to a multi-tenant model much easier… Most classic apps today are built with database-per-tenant model. With single-database-per-tenant approach, your business logic and queries won’t have the tenant filtering in place. That is, you won’t have the customer_id filtering in your database traffic. If you have a large number of queries and stored procedures, it could be a pain to port to a multi-tenant solution and validate your solution. With FILTERING connection option set, it could be much easier to migrate over to a multi-tenant model with SQL Azure Federations. Your application would still have to migrate to use SQL Azure federations, however cost savings would be greatly amplified for some apps.
<Return to section navigation list>
MarketPlace DataMarket and OData
Anton Paramosh described Dynamics CRM 2011 support for Silverlight Web Resources in an 11/19/2010 post:
Dynamics CRM 2011 supports Silverlight application as Web Resource. I have created with testing purpose my first Silverlight Web Resource.
How to do that you can find out in file crmsdk2011.chm in SDK folder. I can't give you direct web link for now because Microsoft still not published this in MSDN. But you can download SDK here.
When you are developing Silverlight Web Resource you need to know does your Web Resource need some contextual information or not. If not you are able to place your web resource either on some entity edit form or in another HTML Web Resource. In case if Silverlight Web Resource need context information but it's placed not on entity form, you have to add reference to ClientGlobalContext.js.aspx.
In SDK is available sample of Silverlight Web Resource sdk\samplecode\cs\generalprogramming\dataservices\crmodatasilverlight. Look at crmodatasilverlight\utilities\serverutility.cs file. It's designed to retrieve server url from context. But there available another properties. I've extended these class in order to able you retrieve them all.
public static class ServerUtility
{
private static ScriptObject PageContext
{
get
{
var xrm = (ScriptObject)HtmlPage.Window.GetProperty("Xrm");
var page = (ScriptObject)xrm.GetProperty("Page");
return (ScriptObject)page.GetProperty("context");
}
}
public static string GetAuthenticationHeader()
{
return (string)PageContext.Invoke("getAuthenticationHeader");
}
public static double GetOrgLcid()
{
return (double)PageContext.Invoke("getOrgLcid");
}
public static string GetOrgUniqueName()
{
return (string)PageContext.Invoke("getOrgUniqueName");
}
public static JsonValue GetQueryStringParameters()
{
ScriptObject a = (ScriptObject)PageContext.Invoke("getQueryStringParameters");
DataContractJsonSerializer sr = new DataContractJsonSerializer(a.GetType());
MemoryStream ms = new MemoryStream();
sr.WriteObject(ms, a);
JsonValue o = JsonObject.Load(ms);
ms.Close();
return o;
}
public static string GetServerUrl()
{
return (string)PageContext.Invoke("getServerUrl");
}
public static Guid GetUserId()
{
return new Guid ((string)PageContext.Invoke("getUserId"));
}
public static double GetUserLcid()
{
return (double)PageContext.Invoke("getUserLcid");
}
public static Guid[] GetUserRoles()
{
IList<Object> nonCastedRoles = ((ScriptObject)PageContext.Invoke("getUserRoles")).ConvertTo<List<Object>>();
List<Guid> castedRoles = new List<Guid>(nonCastedRoles.Count);
foreach (var currentNonCastedRole in nonCastedRoles)
{
castedRoles.Add(new Guid((string)currentNonCastedRole));
}
return castedRoles.ToArray();
}
}Context is ScriptObject class object. And you can access its properties using Invoke method like PageContext.Invoke("getAuthenticationHeader"). GetUserRoles and GetQueryStringParameters methods are more complicated than other. They returns not single value but JsonValue and array of Guid. In case GetUserRoles of we used ConvertTo to convert value to List<Object>
IList<Object> nonCastedRoles = ((ScriptObject)PageContext.Invoke("getUserRoles")).ConvertTo<List<Object>>();
But in case of GetQueryStringParameters we have Json object as ScriptObject. We do ScriptObject serialization and next deserialize them into JsonValue.ScriptObject a = (ScriptObject)PageContext.Invoke("getQueryStringParameters");
DataContractJsonSerializer sr = new DataContractJsonSerializer(a.GetType());
MemoryStream ms = new MemoryStream();
sr.WriteObject(ms, a);
JsonValue o = JsonObject.Load(ms);
Also you can use Json.Net to convert Json object directly into Dictionary<string, string>:
public static IDictionary<String, String> GetQueryStringParameters2()
{
ScriptObject json = (ScriptObject)PageContext.Invoke("getQueryStringParameters");
DataContractJsonSerializer sr = new DataContractJsonSerializer(json.GetType());
MemoryStream ms = new MemoryStream();
sr.WriteObject(ms, json);
ms.Position = 0;
var srd = new StreamReader(ms);
var jsonstring = srd.ReadToEnd();
IDictionary<String, String> dic = JsonConvert.DeserializeObject<Dictionary<string, string>>(jsonstring);
ms.Close();
return dic;
}
Anton is a Dynamics CRM and .NET Developer in Lviv, Ukraine.
The Microsoft Public Sector Developer Evangelism team at http://dev.govdata.eu recently published several sample data sets from the Netherlands as an element of the Open Government Data Initiative:
Welcome to Open Government Data Initiative (OGDI)
Whether you are a business wishing to use government data, a government developer, or a 'citizen developer', these open API's will enable you to build innovative applications, visualizations and mash-ups that empower people through access to government information. This site is built using the OGDI starter kit software assets and provides interactive access to some publicly-available data sets along with sample code and resources for writing applications using the OGDI API's.
Email us at askogdi@microsoft.com if you have government data sets that you would like us to publish or if you have other questions.
Here’s part of the first page of a geocoded list of 1,000 Dutch primary schools:

And the map view of part of the Netherlands with a maximum of 50 placemarks:

Here’s the entry for openbare basisschool vinckhuysen (Public School Vinckhuysen) selected in the preceding capture with PartitionKey and RowKey values for its Windows Azure Table entity:

<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
The Windows Azure AppFabric CTP Team started a new Windows Azure AppFabric CTP MSDN forum on 1/19/2011.
This Windows Azure AppFabric CTP forum includes discussions on ideas, questions or defects from the Windows Azure AppFabric CTP versions available in the AppFabric Labs environment (Service Bus CTP & Caching CTP).
You’ll see six initial posts, ranging in date from 11/1/2010 to 1/10/2011. These have been moved from other fora by Microsoft’s Brian Aurich.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, RDP and CDN
Alan Naim asked and answered Windows Azure Connect - What is it? in a 1/13/2011 post (missed when published):
Some application scenarios for Windows Azure Connect include:
- Enable enterprise apps, which have migrated to Windows Azure, to connect on-premises servers (e.g. SQL Server ).
- Help applications running on Windows Azure to domain join on-premises Active Directory. Control access to Windows Azure roles based on existing AD accounts and groups.
- Remote administration and trouble-shooting of Windows Azure roles. E.g. Remote PowerShell to access info from Windows Azure instances.
You might also be asking – “How is Windows Azure Connect different from the Windows Azure AppFabric Service Bus?”
Windows Azure Connect and Windows Azure AppFabric Service Bus are complementary technologies. Windows Azure Connect provides IP-based network connectivity between on-premises and Windows Azure resources. Windows Azure Connect enables cloud-hosted virtual machines and on-premises resources to communicate as if they were on the same network. The Windows Azure AppFabric Service Bus provides application-level federation and connectivity for HTTP-based services using claims-based access control. Based upon their requirements, customers can choose the technology that is most appropriate for their needs. Service Bus offers “cloud presence” for enterprise services, both for internal use as well as partner use outside of the corporate network. It does this via a relay infrastructure that does not require opening up inbound ports allowing for secure and seamless NAT and firewall traversal. Service Bus is an application level connectivity service, and is particularly well-suited for situations where some of the end points being connected are not under the control of a single enterprise, or where application-level access control is desired. In combination with Access Control Service (ACS), Service Bus also simplifies federated security scenarios.
There are a couple of PDC talks on Azure Connect (http://bit.ly/cSXOaC) and “Connecting Cloud & On-Premise Apps” (http://bit.ly/bhoUkt) which goes through some of the considerations / trade-offs in moving to a hybrid distributed architecture & also various technologies that can be used for this.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
David Hardin explained how to use Azure IntelliTrace in a 1/19/2011 post:
Here is some great information on using IntelliTrace with Azure:
- IntelliTrace is specifically licensed in Visual Studio 2010 Ultimate (VS) as a Dev and Test tool for non-production environments.
- When IntelliTrace is enabled, the Azure role instances do not automatically restart after a failure. This allows Windows Azure to persist the IntelliTrace data after the failure; Azure waits for a developer to download the data and manually restart the role instance.
- IntelliTrace is implemented via IL rewriting, similar to a profiler.
- Specific events are configured in the CollectionPlan.xml file located in C:\Program Files (x86)\Microsoft Visual Studio 10.0\Team Tools\TraceDebugger Tools\en. The file’s content controls which methods are rewritten along with how trace data is later displayed in the VS debugger. There isn't a supported way to add custom events.
- Including the "call information" option basically rewrites all methods; there is a one-size-fits-all way to display the methods not present in the CollectionPlan.xml file.
- Visual Studio rewrites the IL before deployment.
- The "Enable IntelliTrace" check box is only enabled when deploying from VS. IntelliTrace is not supported when only creating a service package which Op's will later upload to Azure, notice check box is disabled:
- IL rewriting adds calls to an API which logs the data through named pipes. Another process receives the data from the named pipe and writes it to local disk.
- When a developer right clicks an instance in VS Server Explorer and selects “View IntelliTrace logs”, VS copies the trace data from the instance's local disk to an Azure Storage blob named “intelitrace” and then to the developer’s local disk. After the logs are on the developer's disk the copy in Azure Storage is automatically deleted.
- In addition to viewing the data in VS there is an API for reading the data for custom tooling.

Adron Hall (@adronbh) announced his desire for better support for Test-Driven Design (TDD) in his Windows Azure SDK Unit Testing Dilemma — F5DD Plz K Thx Bye post of 1/19/2011:
I’m a huge advocate for high quality code. I will admit I don’t always get to write, or am always able to write high quality code. But day in and out I make my best effort at figuring out the best way to write solid, high quality, easy to maintain, easy to read code.
I’ll be the first to stand up and point out why F5 Driven Development (for more on this, check out Jeff Schumacher‘s Blog Entry) is the slowest & distracting ways to build high quality code. I’d also be one to admit that F5 Development encourages poor design and development. A developer has to juggle far too many things to waste time hitting F5 every few seconds to assure that the build is running and code changes, additions, or deletions have been made correctly. If a developer disregards running the application when forced to do F5 Development the tendancy is to produce a lot of code, most likely not refactored or tested, during each run of the application. The list of reasons to not develop this way can get long pretty quick. A developer needs to be able to write a test, implement the code, and run the test without a framework launching the development fabric, or worse being forced to not write a test and running code that launches a whole development fabric framework.
Now don’t get me wrong, the development fabric is freaking AWESOME!! It is one of the things that really sets Windows Azure apart from other platforms and infrastructure models that one can develop to. But the level of work and effort makes effectively, cleanly, and intelligently unit testing code against Windows Azure with the development fabric almost impossible.
But with that context, I’m on a search to find some effective ways, with the current SDK limitations and frustrations, to write unit tests and encourage test driven design (TDD) or behaviour driven design (BDD) against Windows Azure, preferably using the SDK.
So far I’ve found the following methods of doing TDD against Windows Azure.
- Don’t use the SDK. The easiest way to go TDD or BDD against Windows Azure and not being tightly bound to the SDK & Development Fabric is to ignore the SDK altogether and use regular service calls against the Windows Azure service end points. The problem with this however, is that it basically requires one rewrite all the things that the SDK wraps (albeit with better design principles). This is very time consuming but truly gives one absolute control over what they’re writing and also releases one from the issues/nuances that the Windows Azure SDK (1.3 comes to mind) has had.
- Abstract, abstract, and abstract with a lock of stubbing, mocking, more stubbing, and some more abstractions underneath all of that to make sure the development fabric doesn’t kick off every time the tests are run. I don’t want to abstract something just to fake, stub, or mock it. The level of indirection needed gets a bit absurd because of the design issues with the SDK. The big problem with this design process to move forward with TDD and BDD is that it requires the SDK to basically be rewritten as a whole virtual stubbed, faked, and mocked layer. Reminds me of many of the reasons the Entity Framework is so difficult to work with for testing (has the EF been cleaned up, opened up, and those nasty sealed classes removed yet??)
Now I’ll admit, sometimes I miss the obvious things and maybe there is a magic “build tests real easy right here” button for Windows Azure, but I haven’t found it. I’d love to hear what else people are doing to enable good design principles around Windows Azure’s SDK. Any thoughts, ideas, or things I ought to try would be absolutely great – I’d love to read them. Please do comment!
Benko offered a Benko-Quick-Tip: How to setup Windows Azure for Web Publish on 1/19/2011:
Benko includes an embedded video segment here.
The basic process that happens is that thru the magic of Startup tasks you can run the Web Platform Installer to do the work of adding the WebDAV publishing for you. Ryan bundled up the loose files into a plug-in zip file that you can add to your SDK’s plug in folder, to be able to complete the task quick and easily. You can download the plug-in from his site, simply download the file from the link and extract the contents to your "%programfiles%\Windows Azure SDK\v1.3\bin\plugins\WebDeploy" folder, and then adding the imports code to your Service Definition file:
Caution: This work around is meant only for a development purposes in which you have a single instance you’re deploying to. Because we make changes to the instance after deploy, if you re-publish the package whatever changes you’ve made and pushed to Windows Azure thru this method will be overwritten with whatever the last uploaded package contained. For that reason when you’re done working thru your changes you should go thru a re-deploy of your cloud package. I’ve created a new “Benko-Quick-Tip” video that shows how to do this at http://bit.ly/bqtAzWebDeploy.
By the way – if you’ve got an MSDN Subscription and want to see how to activate your benefits I’ve created a quick-tip video for that too – http://bit.ly/bqtAzAct1.

iq | cloud consulting reported on 1/19/2010 that it’s Ready to flaunt in record time with Windows Azure Solution:
flaunt-it.biz is a leading Social Commerce service. flaunt-it work with leading luxury and premium brands to help them engage with customers through Social Media to enhance brand awareness and drive sales. flaunt-it help their customers achieve competitive advantage through superior customer interaction and a flexible, insightful service.
As a start-up with big ambitions and a limited budget, flaunt-it wanted the maximum bang for their buck, but without compromising on their ability to scale quickly as their business takes off.
flaunt-it asked IQ to help them quickly and cost-effectively design, pilot and develop a facebook-integrated application that can easily scale up without investing £££'s in hardware and long-term hosting contracts. We designed a pilot for flaunt-it's launch customer and using our Agile Software Development methodology had the service ready for launch in only six elapsed weeks!
- Windows Azure Cloud Application Hosting with Web Roles and Worker Roles
- Windows Azure Storage Queues to enable scalable, manageable growth without affecting end-user experience or application performance
- Microsoft Tag extending Social Media Integration into the 'real world'

Srinivasan Sundara Rajan prefaced his Cloud Computing: Dynamic Scaling in Windows Azure Revisited post of 1/19/2011 with “Third-party tool support for dynamic scaling in Windows Azure”:
One such third-party auto scaling product company, Paraleap Technologies, has recently released a product called AzureWatch that provides a SaaS-based approach to scale the Windows Azure compute roles. Some of the observations about the product are mentioned below. The company also provides a free 14-day trial of the product whereby some of the facts can be ascertained in a live situation.
The following aspects of the product were observed, based on the technical documentation available with the product vendor.
SaaS-Based Solution
The core of the Azurewatch data collection and aggregation and decision-making process is available as a SaaS-based solution in the form of Azure Watch Service. The AzureWatch Service aggregates and analyzes performance metrics and matches these metrics against user-defined rules on a regular and configurable basis. When a rule produces a "hit," a scaling action occurs.However, there are some glue or controlling components installed on the ‘On Premise' systems in the form of the AzureWatch Monitor and Control Panel. The Monitor is responsible for sending raw metrics to SaaS-based systems and executing scaling actions. The Control Panel is a simple but powerful configuration and monitoring utility that allows you to configure custom rules and to monitor your instances.
This approach is useful, because much of the overhead of the Data Storage and maintenance of the metrics data is kept away from the enterprises and only a lightweight component in the form of the AzureWatch Monitor and Control Panel needs to be installed ‘On Premise.'
The following diagram, courtesy of vendor, explains the solution.
Rules Engine-Based Interface
As we have seen, Auto Scaling is typically handled by the Pro Active Monitoring, which is done by the AzureWatch Monitor coupled with the analysis and the metrics gathered by the AzureWatch Service. Finally the scaling action is taken based on the rules configured using an easy-to-use GUI tool.For each of the roles as part of your Azure subscription, Azurewatch provides simple predefined rules that can be tailored further. The two sample rules offered are simple rules that rely upon calculating a 60-minute average CPU usage across all instances within a Role. The Rule Edit screen is simple yet powerful. You can specify what formula needs to be evaluated, what happens when the evaluation returns TRUE, and what time of day should evaluation be restricted to.
Dashboards & Reports
The success of the monitoring tools are measured by the nature of the dashboards and reports, as the metrics data in the raw form is very difficult to understand. Dashboards in AzureWatch provide the following information.
- Instance Count
- Instance History
- Metrics Display based on Windows Counters
Proactive Monitoring
Like traditional data center-based monitoring tools, AzureWatch has built in notification capabilities so that emails are sent based on scaling conditions that happen. AzureWatch can track active/unresponsive/other instance counts for you. You can create rules that either trigger scaling actions or notification emails based upon conditions that rely on instance counts.Nice to Have
Currently the metrics watch service needs to be carefully watched, and metrics can get stale if the service stopped for some reason. It would be nice to have more ways to avoid the metrics getting stale.If new packages are installed, they may get missed from monitoring if the instructions are not followed.
If there are options to manually set the Metrics for some special reasons that may provide more control. It's similar to the way in which Oracle and other databases handle Stale statistics.
Summary
Over all AzureWatch and similar third-party tools will make the Cloud Deployments really fruitful because they're meant to improve the core tenant of the Cloud-based deployment, namely the elasticity and dynamic scaling.

Andy Cross (@andybareweb) described Implementing Windows Azure Custom Domain Names in a 1/18/2011 post:
Windows Azure provides a number of ways to customise the endpoints of your applications by using Custom Domain names.
- Custom Blob Domain Names
- Custom CDN Domain Names
- Custom Compute Domain Names
- Composite Custom Domain Names
Storage Custom Domains
Blob Storage is a great way to store files in the Cloud without having to worry about the load it may put on your servers. Blob Storage is hosted centrally by Microsoft, and so they will worry about load on the service for you. The downside to this is that you have to address the files in this system centrally too. To access my public file Azure.png, you construct a url with your account name, the service identifier (of blob), the windows.net domain name, the container and then the filename:
http://azurefiddlerstore.blob.core.windows.net/public/Azure.pngThis will initialize a download of the blob, since it is inside a public container. However, you may be unhappy with the domain name of “windows.net”. It is possible to apply a custom domain name over this, to prettify these urls. The next steps will show these steps in order to make the url:
http://azurefiddlerstore.bareweb.eu/public/Azure.pngNote that this is an arbitrary choice of subdomain, it could just as easily be the reverse:
http://erotsrelddiferuza.bareweb.eu/public/Azure.pngOr it could be any other arbitrary string
http://afs.bareweb.eu/public/Azure.pngConfiguring Storage Custom Domain Names
For configuring custom domain names, we do much of our work in two different control panels. Firstly the Windows Azure Management Portal (http://windows.azure.com) and secondly whatever DNS Management Portal your provider supplies. I work with GoDaddy, and so that’s the portal I will be using. I will try to make the DNS part as generic as possible, since yours may well differ.
To start with, log into the Windows Azure Management Portal, navigate to your Storage Accounts, click on the particular storage account you wish to add a domain for, and click the AddDomain button.
Click the Add Domain button in Management Portal
Once you have clicked this button, you are given a screen telling you what steps to take with your DNS provider.
Custom Domain Verification Details
Now it’s time to swap over to your DNS provider portal, and enter these details. You can’t copy and paste the above GUID based CNAME details, so you have to type it in manually. CAREFULLY!
Entering the CNAME
83d05958-fedc-437f-8db4-9dbc2fec7ae6.azurefiddlerstore 3600 IN CNAME verify.azure.com
Once you have done this, you can go back to the Windows Azure Management Portal and close the popup window that sits there. Doing this update the screen, and gives you a new row in the view with the type “Storage Custom Domain” and the status of “Pending”. Click the Validate Domain once you are happy with everything at the DNS side. It may be worth checking the dns entry resolves by using nslookup – to make sure your DNS provider has made the change.
Pending Validation
When you click on the Validate Domain button you are given a brief popup progress bar saying “Verifying”, and any errors are shown there. It could be that you need to wait to ensure your DNS settings are correctly propagated by your provider, or you may need to recheck your settings. Once this is successful, your screen will look like the below:
Successful added domain
On the write side of the screen, you are given some further information about the status of your domain:
Domain Status
There is one final step you need to take. If you try to access your asset by its new prettified name, you will get a dns error.
http://azurefiddlerstore.bareweb.eu/public/Azure.png
This is because the dns is not ready yet!
If we take a step back, it’s clear to see why this is. We have created a CNAME on our DNS record for verification: 83d05958-fedc-437f-8db4-9dbc2fec7ae6.azurefiddlerstore, but we haven’t actually created the real CNAME yet! So go back to your DNS Provider and enter the real CNAME, with it pointing to the central domain name:
Entering the cname
azurefiddlerstore 3600 IN CNAME azurefiddlerstore.blob.core.windows.netOnce you have done this, you can check the DNS propogate by firing up a command window and checking it resolves correctly to a Microsoft domain:
NSLOOKUP
Once you are happy that this is working, you can access the new CNAME in a web browser to see that it connects to Azure:
Message from Azure when no blob uri is specified
Accessing the file now over the full url (note that it is case-sensitive) of
http://azurefiddlerstore.bareweb.eu/public/Azure.pnggives a correct download:
Successful download
Enabling CDN with a Custom Domain Name
Enabling a Custom Domain Name for the CDN is very similar to the above process. There is an additional 60 minute wait in this process while the CDN propagates the files in your blob storage.
Start of by navigating back to the Windows Azure Management Portal and the Storage Accounts page in particular. Click the account name you wish to enable the CDN for, and the “Enable CDN” button will become enabled. Click this to continue:
Click Enable CDN
This will give you a slash screen with the warning I mentioned earlier, that there is a 60 minute background task that will happen before your CDN will be usable. It is worth checking out the link provided in the popup for pricing.
60 Minute warning
Once you click “Enable”, this propagation will begin. There will be a brief pause first, with the status of the CDN being “Creating” and then “CDN Enabled”:
CDN Enabling
CDN Enabled
Now what we have is a CDN account, but it has the rather ugly domain name:
az20608.vo.msecnd.netAs soon as the CDN has propagated you will be able to access the url:
http://az20608.vo.msecnd.net/public/Azure.pngClick on the CDN entry, and at the top of the screen the “Add Domain” button will become visible again. This process is very similar to the earlier process of adding a domain to blobstorage account. You need to get your DNS portal open again!
Add a domain to a CDN
This will ask you for a custom domain for your CDN. Enter the url you want. I went for afscdn.bareweb.eu, but just to prove how it’s not a pattern you have to follow, I misspelt it and it all worked
Enter CDN custom domain name
Once you have entered this, you get a prompt similar to the earlier, asking to enter the verification domain CNAME records:
CDN Domain verification prompt
Skipping ahead as this is the same process as earlier:
Enter the verification CDN CNAME
After adding the CNAME, click Validate
Successful CDN CNAME verification
Remember to add the real CNAME as well!
Add the CNAME for the CDN
Now you have successfully set up the CDN with a custom domain name. Depending on how quickly you were able to follow the steps, the 60 minutes may well not be anywhere near up yet. Indeed, the 60 minutes is a guideline, and in my experience it may be more than 60 minutes, up to 180 minutes. If you get any DNS failures, it’s worth waiting another 60 minutes before calling on MS Support.
Eventually you will be able to resolve:
http://afscnd.bareweb.eu/public/Azure.pngCustom Compute Domain Names
Running an application in Windows Azure will give you a DNS name such as [mycloudaccount].cloudapp.net. This obviously isn’t ideal for production, where a domain name goes a long way to differentiating a brand and as any SEO expert will say will affect your rankings in major search engines. I will give two examples of how to achieve this, from a simple WebRole to the complex one defined in my blog post Azure: Running Multiple Web Sites in a Single WebRole.
Adding a Custom Compute domain name is actually much simpler than the above examples. This is because when you are configuring BlobStorage or CDNs, the remote services have to be configured to accept the incoming url and differentiate your request from others coming in with a custom URL, mapping back to your blobstorage account. Since your application doesn’t have that overhead, you can achieve it much fewer steps. I am using Staging environments in this example, but the process is if anything easier with production accounts.
I want to make sure that my application is available at:
http://azure.bareweb.euSimple Web Role
Whilst I call this a simple web role, it does include multiple Sites inside the single Role. The reason I refer to it as simple is that it runs its Sites on different Ports within that Role, so one domain name will apply across both entries. This is the ServiceDefinition.csdef
<?xml version="1.0" encoding="utf-8"?>
<ServiceDefinition name="MultipleWebSites" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WebRole name="MasterWebRole">
<Sites>
<Site name="Web" physicalDirectory="../MasterWebRole">
<VirtualApplication name="child" physicalDirectory="../ChildVirtualApplication" />
<VirtualDirectory name="assets" physicalDirectory="../AssetsVirtualDirectory" />
<Bindings>
<Binding name="Endpoint1" endpointName="Endpoint1" />
</Bindings>
</Site>
<Site name="Second" physicalDirectory="../SecondMasterSite">
<VirtualApplication name="child" physicalDirectory="../ChildVirtualApplication" />
<VirtualDirectory name="assets" physicalDirectory="../AssetsVirtualDirectory" />
<Bindings>
<Binding name="Endpoint2" endpointName="Endpoint2" />
</Bindings>
</Site>
</Sites>
<Endpoints>
<InputEndpoint name="Endpoint1" protocol="http" port="80" />
<InputEndpoint name="Endpoint2" protocol="http" port="81" />
</Endpoints>
<Imports>
<Import moduleName="Diagnostics" />
</Imports>
</WebRole>
</ServiceDefinition>Firstly, deploy your service to Windows Azure as per the normal process. This will give you a DNS endpoint.
A started WebRole with DNS Name
In my case this was:
http://259c6a7dae974ba5bf80acd0e9aa81a1.cloudapp.netGoing to this in a browser with the original configuration (of two web sites in one web role on port :80 and :81) gave the following:
Built in DNS name on port 80
Built in DNS name on port 81
Now to make this work with a our domain (azure.bareweb.eu), we simply go to our DNS portal and add a CNAME of azure.bareweb.eu pointing to
259c6a7dae974ba5bf80acd0e9aa81a1.cloudapp.net
Define CNAME for Azure Compute
Now, once we have saved this and our DNS provider has propagated the change, we can go to
http://azure.bareweb.eu/and
http://azure.bareweb.eu:81/
Custom Domain Name azure.bareweb.eu port 80
Custom Domain Name azure.bareweb.eu port 81
Composite WebRole
The composite WebRole takes the above a step further, and uses the Host Header method of differentiating the Websites within a single Web Role. This means that each Site will run on a separate domain name.
Deploy the site as you have done before, but with the ServiceDefinition.csdef as below:
<?xml version="1.0" encoding="utf-8"?>
<ServiceDefinition name="MultipleWebSites" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WebRole name="MasterWebRole">
<Sites>
<Site name="Web" physicalDirectory="../MasterWebRole">
<VirtualApplication name="child" physicalDirectory="../ChildVirtualApplication" />
<VirtualDirectory name="assets" physicalDirectory="../AssetsVirtualDirectory" />
<Bindings>
<Binding name="Endpoint1" endpointName="Endpoint1" hostHeader="azure.bareweb.eu" />
</Bindings>
</Site>
<Site name="Second" physicalDirectory="../SecondMasterSite">
<VirtualApplication name="child" physicalDirectory="../ChildVirtualApplication" />
<VirtualDirectory name="assets" physicalDirectory="../AssetsVirtualDirectory" />
<Bindings>
<Binding name="Endpoint2" endpointName="Endpoint1" hostHeader="azuresecond.bareweb.eu" />
</Bindings>
</Site>
</Sites>
<Endpoints>
<InputEndpoint name="Endpoint1" protocol="http" port="80" />
</Endpoints>
<Imports>
</Imports>
</WebRole>
</ServiceDefinition>You will note that there is only a single InputEndpoint, and that where it is referenced, it uses the hostHeader attributes of
azure.bareweb.euand
azuresecond.bareweb.euOnce we have deployed this to Windows Azure, it will gives us a DNS name. In my case, this was:
a8b07a597f614059a227d946e25bcae4.cloudapp.netNote that we can’t access this URL directly anymore. Doing so will cause an error “Service Unavailable” since there is nothing set to run without a specific host header.
We can use this as the points to attribute of two new CNAME records:
Setting up CNAMES for composite web role
Now we can navigate to our web sites with these DNS CNAMES:
Accessing Azure.BareWeb.eu
Accessing azuresecond.bareweb.eu
Conclusion
Windows Azure has a number of ways of modifying the domain name endpoints of your application. With little effort you can completely brand the application to your own business name, removing any mention of core.windows.net or cloudapp.net from your end user experience.
I hope you have found this useful,
























Wes Yanaga announced New Windows Azure and PHP Tutorials in a 1/18/2011 post to the US ISV Evangelism blog:
If you’re a PHP developer and new to Windows Azure, here are some updated tutorials and links to several tools.
- New Tutorials posted on http://azurephp.interoperabilitybridges.com/,
- Windows Azure tools for PHP updated to align with Windows Azure SDK1.3
- Windows Azure tools for PHP get an update and refreshed content by jccim
- The 3 following tools have been updated
- These updates are Windows Azure 1.3 SDK compatibility updates.
Important to know: Only the Windows Azure Companion leverages the “Full IIS” mode for now. The Cmd Line and Eclipse plug-in still deploy using the Hosted Web Core. It will come with next update – date still TBD.- If you haven’t had a chance to try the Windows Azure platform – click this link for a 30 day free trial and Use Promo Code: DPWE01
- Sign up for Microsoft Platform Ready to get access to technical, application certification testing and marketing support.

Samara Lynn reported Microsoft Dynamics CRM Poised for Cloud Battle in a 1/18/2010 article for PC Magazine:
On Monday, Microsoft chief executive Steve Ballmer and Kirill Tatarinov, corporate vice president of Microsoft Business Solutions, officially unveiled the new Microsoft Dynamics CRM online service at a launch event in Redmond. Microsoft Dynamics CRM Online is now available to businesses worldwide at a promotional price of $34 dollars per user, per month. The online CRM offering is based on Microsoft's on-premise CRM solution, Microsoft Dynamics CRM 2011.
- The delivery of a familiar experience to sales, service, and marketing user via a next-generation native Microsoft Outlook client, browser, and mobile devices.
- An intelligent experience through real-time dashboards, inline business intelligence, and guided process dialogs.
Microsoft is not being subtle in its attempts to snatch market share away from Salesforce.com and Oracle. Customers of either those services that switch to Microsoft Dynamics CRM between now and June 30, 2011 qualify for the Cloud CRM for Less offer. Customers will receive up to $200 per user, applicable to services much as migrating data or customizing the solution.
<Return to section navigation list>
Visual Studio LightSwitch

Return to section navigation list>
Windows Azure Infrastructure
Bill Zack reported Microsoft Survey on Cloud Computing Released in a 1/19/2011 post to his Ignition Showcase blog:
Microsoft has just released a study of how 2,000 IT Decision makers are adopting and using Cloud Computing. If you are a software company that is interested in the market for your products and services and the impact of the cloud you need to read this study.
The study identifies the top cities across 10 markets including: New York, Philadelphia, Boston, Atlanta, Washington DC, Los Angeles, Chicago Dallas, San Francisco, and Detroit. It ranks them in terms of cloud-friendliness of enterprises and small businesses in those markets.
Some highlights from the study:
- Businesses of any size are highly reliant on partners to bring cloud into their organizations.
- Among enterprise-sized companies Boston ranks at the top cloud-friendly city while Washington DC ranks first among small-to-midsize companies.
- 54% of the national respondents say that they are hiring as a result of cloud services.
- Small-to-medium businesses have not fully embraced the cloud – yet.
See here for more details and how to get the study.

Derrick Harris reported Big Data, ARM and Legal Concerns on the Rise in Q4 in a 1/19/2011 post to GigaOm’s Structure blog:
Some might call the fourth quarter in the infrastructure space transformative. The rise of ARM-based processing suggests the days of x86 dominance might be coming to an end, while the Amazon Web Services-WikiLeaks controversy cast new light on the legal aspects of cloud computing.
Big data got bigger, meanwhile, as the Hadoop ecosystem expanded, and amid all these cutting-edge technologies, two archaic topics — Novell and Java — proved they aren’t going anywhere soon. From giants like VMware and IBM to smaller startups like Nimbula and Abiquo, news came from all corners of the Infrastructure market during the fourth quarter. Let’s take a look at some of the most noteworthy trends:
- The Amazon-WikiLeaks controversy shed light on the fact that many pundits appear oblivious to the legal aspects of cloud computing, which leads to overreaction when it appears that cloud providers are acting questionably. The reality is that providers are almost certainly acting within the rights granted to them by their terms of services, as well as by the Constitution. If it comes down to a decision between potentially facing legal action or removing questionably legal (or moral) content, it’s kind of crazy to expect cloud providers — especially publicly traded ones such as Amazon — to do anything other than what’s prudent.
- The x86 processor architecture appears down, but certainly not out. Alternative CPU architectures (particularly ARM) and GPUs are squeezing x86 from all directions, and are beginning to steal workloads in traditionally x86-dominant fields, such as HPC. However, it will take years before ARM processors or GPUs can ever really make a dent in x86 market share (or, in some cases, will even be on the market). So chipmakers such as Intel and AMD have some time to get creative if they’re determined to hitch their wagons to x86 for the foreseeable future.
- Platform as a service (PaaS) is no longer just infrastructure as a service’s (IaaS) younger, cooler brother. The acquisitions of Makara and Heroku by Red Hat and Salesforce.com, respectively, as well as VMware’s hosted PaaS project, illustrate that PaaS is a legitimate IT delivery model, even if mainstream adoption is still a few years away. Of course, anyone following the evolution of VMware’s vFabric or Microsoft Windows Azure might have realized this a while ago.
- Analysts and investors don’t really understand cloud computing, web infrastructure or the related data-center operation market. From complaints about web companies such as Google spending hundreds of millions on CAPEX to investors bailing because Equinix had a lackluster quarter, the fourth quarter illustrated reactionary thinking that’s contrary to the facts. Internet traffic and demand for data center space both keep growing, and will continue to do so as cloud computing actually starts catching on among mainstream businesses. All that space will make money at some point.
- Oracle really doesn’t care about open source. Its actions within the various Java governance bodies have done nothing but produce hurt feelings and flat-out animosity, which are only compounded by its ongoing lawsuit against Google. Whether Oracle is technically correct in either matter isn’t really the issue as far as open source advocates are concerned; they’re more concerned with things like openness and cooperation. Oracle, on the other hand, cares about making money. The question is whether it can do so without broad Java community support.
- The Hadoop ecosystem shows no signs of slowing its growth, but it’s unclear what will come of the web of partnerships and integrations. There are a few competing approaches to selling Hadoop shaping up, and there’s no guarantee that Cloudera’s partner-centric strategy, for example, will prevail against IBM’s Hadoop-as-application strategy. What’s certain, however, is that even companies nowhere near the cutting edge will utilize Hadoop at some point, because it’s becoming too ubiquitous to avoid forever.
- We’re a long way off from where we need to be on Green IT. Many energy-efficiency players still focus on saving money rather than actually reducing energy use, and even generally accepted notions (i.e., cloud computing is a net positive in terms of energy use) are coming under increased scrutiny. Startups selling software for monitoring energy use are raising money but are not necessarily attracting customers. Might it take a string of brownouts or governmental action to spur action toward truly green IT?
For more analysis of these events and a look forward into the next 18 to 24 months, read my latest report at GigaOM Pro.
Related Content From GigaOM Pro (subscription required)

Tim Huckaby (left) interviewed Wally McClure (right) on 1/11/2011 in a 00:04:21 Wally McClure and Tim Huckaby Bytes by MSDN video segment:

Do you believe in the Cloud? Wallace McClure, Founder and Architect of Scalable Development, Inc., does. His customers are extremely interested in the value and economies of scale that Cloud Computing, and more specifically, Windows Azure can bring. Building out an infrastructure that supports your web service or application can be expensive, complicated and time consuming. Or you could look to the Microsoft cloud. The Windows Azure platform is a flexible cloud–computing platform that lets you focus on solving business problems and addressing customer needs. Wally talks about all this, and more, in this interview with Tim Huckaby, and in his Windows Azure podcasts.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
John Brodkin (@jbrodkin) reported Microsoft, HP selling $2M data warehouse appliance on 1/19/2011 in a NetworkWorld article via ComputerWorld:
Microsoft and Hewlett-Packard are teaming up to deliver a $2 million data warehouse appliance and four other hardware/software products in a bid to outshine recent moves by Oracle and IBM.
The HP Enterprise Data Warehouse Appliance is available this week starting at nearly $2 million, which does not include the price of Microsoft software, HP and Microsoft said. The big appliance, advertised as 200 times faster and 10 times more scalable than traditional SQL Server deployments, will include at least two racks of servers and storage, built around the HP ProLiant DL980 systems. Microsoft's SQL Server 2008 R2 Parallel Data Warehouse will be licensed separately.
A joint announcement by HP and Microsoft on Wednesday continues a $250 million partnership unveiled a year ago, and potentially gives the vendors a bigger stake in the market for integrated hardware-and-software appliances designed to run business applications. The moves could be seen as countering Oracle's Exadata database machine, a result of the Sun acquisition; and IBM's acquisition of Netezza, a maker of data warehouse appliances.
But Microsoft SQL Server general manager Doug Leland says the Microsoft/HP partnership is unique because it combines "the best software company on the planet with the best hardware company." Microsoft does not have any other partnerships "on a similar scale, in this particular arena," he says.
The appliances delivered by HP and Microsoft target a wide range of "application services such as business intelligence, data warehousing, online transaction processing and messaging," the vendors say in a press release. "The jointly engineered appliances, and related consulting and support services, enable IT to deliver critical business applications in as little as one hour, compared with potentially months needed for traditional systems."
The other systems won't be nearly as pricey as the HP Enterprise Data Warehouse Appliance.
The HP Business Decision Appliance, a business intelligence system built on top of an HP ProLiant DL380 server with eight cores, will start at nearly $28,000, not including the cost of SQL Server 2008 R2 and SharePoint 2010. The appliance, available today from HP and so-called HP/Microsoft Frontline channel partners, comes with three years of hardware and software support services. The three years of services will also be applied to the Enterprise Data Warehouse Appliance and a third product called the HP E5000 Messaging System.
The messaging system will be available in March and start at $36,000, not including the price of Microsoft Exchange Server 2010.
The new systems are rounded out with the HP Business Data Warehouse Appliance, designed for small and midsized businesses; and the HP Database Consolidation Appliance, which uses Hyper-V and SQL Server 2008 R2 to consolidate hundreds of databases into a smaller virtual environment. The Business Data Warehouse Appliance will be available in June and the Database Consolidation Appliance will be available in the second half of 2011.
Dana Kaufman of the SQL Server Team posted HP Business Decision Appliance – A Closer Look at Backup and Availability Features on 1/19/2011:
Today we announced the availability of the HP Business Decision Appliance. This is the culmination of many months of engineering work between HP and Microsoft to develop a software/hardware solution to enable easy access to self-service business intelligence technology. The solution is designed for medium size businesses and departmental enterprise deployments.
The appliance is optimized for Windows Server 2008 R2, SQL Server 2008 R2, SharePoint 2010 and PowerPivot for SharePoint. One of our goals was for a simplified installation and configuration. Talking with customers, we found that for some businesses, deploying the above software stack took many months and required outside experts. We created a single installation program that prompts the users for a small set of questions and then installs and configures SharePoint, SQL Server and PowerPivot. From power up to a running SharePoint server takes about an hour in most cases.
I wanted to share with you a few items you might not have picked up from the announcements. The appliance installs SharePoint 2010 and PowerPivot for SharePoint as a Single Server Farm Installation. That means that the appliance is completely self-contained. SQL Server and all the SharePoint services are installed on this single appliance. The only external software requirement is that the customer has an Active Directory domain available. The appliance is joined to the domain as part of the appliance installation.
Because the solution is self-contained, we designed a good deal of redundancy into the appliance. The hardware has dual-power supplies, dual fans and multiple gigabit network cards. There are 8 SAS 300GB hard disks. Two of them are used for a mirrored system disk that contains the operating system and the recovery partition. The other 6 hard disks are configured in a RAID 5 array where the data and backup partitions are located. This disk configuration allows the appliance to survive a physical disk failure.
The appliance also has built-in backup and recovery capabilities. An Appliance Management Console is added to the SharePoint Central Administration during installation. In the Appliance Management Console, you will find options to backup the appliance and perform a factory reset. The appliance backup image uses Windows Server Backup to capture a complete image of the running server. Backups are stored in the Backup partition. Windows Backup can store multiple backups on the partition and will overwrite the older backup images when space is needed for the current backup. The Appliance Management Console also has a screen that allows you to view the appliance backup history.
NOTE: The onboard backup is meant as an interim backup solution. As your needs grow, you should consider moving to network backup storage or using a product like System Center Data Protection Manager, which has features to backup Windows Server 2008, SharePoint 2010, and SQL Server 2008 R2.
Factory reset lets you re-image the appliance back to the factory state. The appliance is returned to the state it was in when leaving the manufacturer. This re-initializes all of the hard drives and extracts and configures the boot image onto the disks. This allows you to re-image the box if you make a mistake or want to restart the configuration from the original state.
NOTE: Yes, it’s cool, but be careful with Factory Reset if you have used the onboard backup capabilities! Factory Reset re-initializes all drives, which means it will erase any backups that you have done previously to the backup partition.
A screenshot of the Appliance Management Console is shown below:
As you can see, the appliance has a good deal of availably features right out of the box. In future posts I will cover additional features we added to the appliance and provide insight into some of the configuration changes we make to optimize the software running on the appliance.
Learn more about the HP Business Decision Appliance here and buy the appliance from HP here.
Dana Kaufman, Principle Program Manager, SQL Server Appliance Engineering Team
Twitter: www.twitter.com/dskaufman1
![clip_image002[10]](http://blogs.technet.com/cfs-file.ashx/__key/CommunityServer-Blogs-Components-WeblogFiles/00-00-00-60-54-metablogapi/4571.clip_5F00_image002_5B00_10_5D00_.jpg "clip_image002[10]")


Britt Johnson of the SQL Server Appliance Team posted SQL Server Appliances – A Workload-based Appliance Design Philosophy on 1/18/2011:
I run the Appliance Engineering team for SQL Server. One of the questions I get asked most often about building appliances, is how do we go about designing a new appliance. We don’t start with a cool piece of hardware and figure out what we might be able to build out of it, rather we start by understanding what an appliance needs to do and work our way to choosing the right hardware.
Our general approach is what I like to call “workload-based appliance design” and I thought I would share some of the thinking we have developed as part of engineering some of the new SQL Server appliances you may have heard about already such as the HP Enterprise Data Warehouse (HPEDW), the HP Business Decision Appliance (HPBDA) and others you may not know about that we are just starting to talk about. This is not rocket science, but it is good engineering and allows us to work with our key hardware partners to build general purpose appliances at a lower total cost that you might expect given their capabilities.
W is for Workload: Let’s assume that we know we want to build an appliance for a specific workload and identified that workload. For this discussion let’s choose the “Self-service BI” or SSBI workload targeting a small to medium business or enterprise departments that want to use PowerPivot. From this starting point our engineering effort kicks off by gaining a deep understanding of the workload specifics. We run the workload as we understand it on real hardware – we call a design proxy - varying many parameters to understand workload variability. We talk with customers, consultants, MVPs, our own SQL CAT experts and the developers of the products are thinking about using. From that collected expert knowledge we build a specific model for the workload – and in the case of SSBI that evolved into an automated workload we could run and measure. It can be tough to agree on general workload characteristics, but it is critical to gain that level of understanding so specific tools can be built for performance and testing work needed later.
A is for Architecture: After a workload is understood, a survey is done to understand for the target workload what approaches or system architectures are appropriate. You can imagine for SSBI we looked at best practices related to PowerPivot, SharePoint, and SQL Server. We explored running the workload on the metal in different mixes of physical servers and in VMs - splitting up into multiple virtual servers. We also talked with customers about what capabilities they expected to find in a complete solution and that led us to take an “ecosystem” approach, bringing all the components together into a single server. We ran an extensive battery of tests to see if we could really get the architecture to work well to narrow our approach.
S is for Software: Once we have an approach we believe is sound we start looking at how to build the solution, the required software components. There are many software components required for a SSBI workload as we have defined beyond the basic products, determining exactly how to combine those together takes some effort. Making decisions on what to enable by default, how to configure all the components so they work well together takes a great deal of iteration. I like to think of this process as learning how to set the 10,000 knobs that exist in the software – at least establishing an initial setting. Reviewing those decisions with workload experts is a key activity at this stage of the process and often we find that the “best solution” is not necessarily consistent with common “best practice”. At this point we are starting to add considerable value to the solution – value that is difficult for any single IT organization to create since we are working directly with the world’s leading experts on all the components being utilized,.
H is for Hardware: The final step, selecting specific hardware, is an iterative process. For example the SSBI workload is especially memory intensive, so selecting the proper amount of RAM for the system was an important decision. We bought our engineering prototype hardware with the max amount of available RAM, but through performance tuning and optimization we were able to reduce the total memory to 96GB without impacting overall performance of our workload. Again the resulting appliance hardware contains the knowledge of many experts - for example we review the configuration of our DIMMs with the engineers who designed the mainboard we are using, we reviewed the RAID configuration with the team that built the RAID controller. This final stage is marked by rapid iteration of both hardware and software configuration, extensive performance and reliability testing to reach a final configuration – that configuration we capture and deliver with our hardware partners as an appliance.
When you think about the SQL Server appliance products, hopefully this will provide some context for how we create those products – our workload-centric engineering approach is important in making sure we can deliver a compelling product at a low total cost. And when you need to explain why you think a specific SQL Server appliance might be a good solution for your organization’s workload needs, remember: SQL Server Appliances have nothing to do with laundry, but we do use Workload, Architecture, Software, Hardware (WASH) as the basis for our engineering design process.
Britt Johnston, Principal Group Manager, SQL Server Appliance Engineering Team
Twitter: www.twitter.com/brittjohnston

Cade Metz added “Round-Rock-as-a-Service” as a suffix to his Dell morphs into Amazonian 'public cloud' biz? title for an article of 1/18/2011 in The Register:
Dell will offer a public "infrastructure cloud" along the lines of Amazon's EC2 as well as a public "platform cloud" à la Microsoft Windows Azure, according to a tweet from inside Michael Dell's IT empire.
It would seem that the venerable PC and server outfit is morphing into an internet service provider.
In July, Dell told the world it had teamed with Microsoft to fashion server appliances that would let businesses build their own Azure-compatible clouds, and it said these Azure appliances would initially show up in Dell data centers. But with a post to Twitter last week, Logan McLeod – a "cloud technology strategist" with Dell's Services division – appeared to take the company's cloud plans several steps further.
Yes, Logan McLeod is a real person. And, yes, that's his real name. "Dell as a public cloud end-to-end service provider?" he tweeted. "Yes. IaaS & PaaS. Coming soon. Dell DC near you."
IaaS would be "infrastructure-as-a-service", a reference to something like Amazon's EC2, which gives you online access to raw processing power. PaaS is "platform-as-a-service", such as Azure, which serves up development tools and other services that let you build and host applications online without juggling virtual machine instances and other raw infrastructure resources.
"Dell DC" is, yes, a Dell data center. Following the acquisition of Perot Systems, Dell Services operates 36 data centers around the world. Today, these serve up old-school software-as-a-service (SaaS) applications for more than 10,000 customers. SaaS is not be confused with IaaS or PaaS or any other aaS. At the moment, Dell is merely hosting applications in these data centers. It's not serving up on-demand access to readily scalable computing resources.
With its announcement last July, Dell left no doubt that it would one day run Azure appliances in these data centers, operating private Azure-compatible clouds that are only available to a particular customer. But it's unclear whether the company also planned to offer its own public Azure service – i.e. a service that anyone can access over the web whenever they like.
"The Windows Azure platform appliance will allow Dell to deliver private and public cloud services for Dell and its enterprise, public, small, and medium-sized business customers," the company's press release [of 7/12/2010] read. As worded, does this mean Dell will deliver its own public cloud services? Or merely deliver public cloud services on behalf of its customers?
It's a subtle distinction. But it's the difference between a services company and an internet service provider.
What's more, McLeod's tweet indicates that Dell will offer a public infrastructure cloud, and Azure appliances don't drive infrastructure clouds. Presumably, the company will offer a service based on OpenStack, the build-your-own-infrastructure-cloud platform open sourced by Rackspace and NASA. Dell has been an OpenStack partner since the project debuted last summer. Last week, the Texas company joined Rackspace and other OpenStack partners in Washington, DC to discuss the open source project with White House chief technology officer Aneesh Chopra, according to tweets from Dell, Rackspace, and others. Rackspace confirmed the meeting with The Reg, but did not confirm Dell's involvement.
Neither McLeod nor Dell PR responded to requests to discuss McLeod's cloud tweet. And Barton George, another Dell "cloud evangelist" and friend of The Reg, responded with a "no comment." But the tweet seems clear. The move into public clouds is reminiscent of Sun's Grid project, which was intended as a public cloud until Oracle acquired the server and software maker. Dell has expanded from a server maker to a services company, and now, it's making the leap from services company to service provider.
In recent months, Dell's Services unit has heavily touted its ability to build clouds on behalf of its customers. In late November, the company announced the general availability of what it calls Dell Cloud Solutions, prepackaged and pre-tested hardware and software bundles that help businesses "build efficient and affordable IT infrastructures that are easy to deploy, manage, and run." Some of these bundles are meant to drive Amazon EC2-like public clouds, and others are designed for private clouds.
As more and more businesses look to services like Amazon and Azure, Dell is looking to maintain its role in the data center.
At a press event dedicated to these cloud bundles, we asked Dell if the rise of services like Amazon EC2 would ultimately hurt the company's bottom line. The short answer was "no," and company man Andy Rhodes told us that he didn't believe in "The Big Switch", the notion that all workload will eventually move to public cloud services. But apparently, Dell believes enough to offer its own public clouds
<Return to section navigation list>
Cloud Security and Governance
Dana Gardner (pictured below) described Bitzer Mobile’s Enterprise Virtualized Mobility solution (EVM) as a A Cloud Catalyst for Enterprises in a 1/19/2011 post to his Briefings Direct blog:
Back in the mid-1990s, then Microsoft CEO Bill Gates offered a prophetic observation. The impact of the web, he wrote, would be greater than most people thought, but would take longer to happen than was commonly supposed.
Turns out, happily for Microsoft, that he was right.Yet now, perhaps not so pleasantly for Redmond, the confluence of mobile computing, social online interactions and cloud computing are together supporting a wave of change that will both be more impactful than many think -- and also happen a lot quicker than is expected.
More evidence of this appeared this week, building on momentum that capped a very dynamic 2010. Start-up Bitzer Mobile Inc. this week announced its Enterprise Virtualized Mobility solution (EVM), which makes a strong case for an ecumenical yet native apps approach to mobile computing for enterprises.
Bitzer Mobile is banking on the urgency that enterprise IT departments are feeling to deliver apps and data to mobile devices -- from Blackberries to iOS, Android, and WebOS. But knowing the enterprise, they also know that adoption of such sweeping change needs to be future-proofed and architected for enterprise requirements. More on EVM later.
Another hastening development in the market is Salesforce.com's pending release the first week of February of the Spring '11 release of its flagship CRM SaaS applications. The upgrade includes deeper integrations with Chatter collaboration and analytics services, so that sales, marketing and service employees can be far more powerful and productive in how they innovate, learn and teach in their roles. The trend toward collaborative business process that mobile-delivered mobile web apps like Salesforce.com's CRM suite now offer are literally changing the culture of workers overnight.
Advancing cloud services
Last month, at its Dreamforce conference, Salesforce also debuted a database in the cloud service, Database.com, that combines attractive heterogeneous features for a virtual data tier for developers of all commercial, technical and open source persuasions. Salesforce also bought Heroku and teamed with BMC Software on its RemedyForce cloud configuration management offering.
Salesforce's developments and offerings provide a prime example of how social collaboration, mobile and cloud reinforce each other, spurring on adoption that fosters serious productivity improvements that then invite yet more use and an accelerating overall adoption effect. This is happening not at what we quaintly referred to as Internet Time, but at far more swiftly viral explosion time.
As I traveled at the end of 2010 , to both Europe and the U.S. coasts, I was struck by the pervasive use of Apple iPads by the very people who know a productivity boon when they see it and will do whatever they can to adopt it. Turns out they didn't have to do too much nor spend too much. Bam.
I also recently fielded calls from nearly frantic IT architects asking how they can hope to satisfy the demand to quickly move key apps and data to iPads and the most popular smartphones for their employees. My advice was an is: the mobile web. It's not a seamless segue, but it allows the most mobile extension benefits the soonest, does not burn any deployment bridges, and allows a sane and thoughtful approach to adopting native apps if and when that becomes desired.
Clearly, the decision now for apps providers is no longer Mac or PC, Java or .NET -- but rather native or web for mobile? The architecture discussion for supporting cloud is also shifting toward lightweight middleware.I still think that the leveraging of HTML5 and extending current web, portal, and RIA apps sets to the mobile tier (any of the major devices types) is the near-term best enterprise strategy, but Bitzer Mobile and its EVM has gotten me thinking. Their approach is architected to support the major mobile native apps AND the web complements.
IT wants to leverage and exploit all the remote access investments they've made. They want to extend the interception of business processes to anyone anywhere with control and authenticity. And they do not necessarily want to buy, support and maintain an arsenal of new mobile devices -- not when their power users already possess a PC equivalent in their shirt pockets. Not when their CFOs won't support the support costs.
A piece of mobile real estate
So Bitzer Mobile places a container on the user's personal mobile device and allows the IT department to control it. Its a virtual walled garden on the tablet or smartphone that, I'm told, does not degrade performance. The device does need a fair amount of memory, and RIM devices will need a SD card flash supplement (for now).
The Bitzer Mobile model also places a virtualization layer for presentation layer delivery at the app server tier for the apps and data to be delivered to the mobile containers. And there's a control panel (either SaaS or on-premises) that manages the deployments, access and operations of the mobile tier enablement arrangement. Native apps APIs and SKDs can be exploited, ISV apps can be made secure and tightly provisioned, and data can be delivered across the mobile networks and to the containers safely, Bitzer Mobile says.
That was fast. It's this kind of architected solution, I believe, that will ultimately appeal most to IT and service providers ... the best of the thin client, virtualized client, owner-managed client and centrally controlled presentation layer of existing apps and data model. It lets enterprise IT drive, but users get somewhere new fast.
Architecture is destiny in IT, but we're now seeing the shift to IT architecture as opposed to only enterprise architecture. Your going to need both. That's what happens when SaaS providers fulfill their potential, when data and analytics can come from many places, when an individual's iPhone is a safe enterprise end-point.
And so as cloud providers like Salesforce.com provide the new models, and the likes of Bitzer Mobile extend the older models, we will see the benefits of cloud, mobile and social happen bigger and faster than any of us would have guessed.
Bruce Kyle reported MSDEV Presents Video Series on Windows Azure Security in a 1/18/2011 to the ISV Developer Community blog:
MSDEV presents a series of videos on security of your application on Windows Azure. Graham Calladine, Security Architect with Microsoft Services, describes the issues, the shared responsibility, and what you need to do to secure your application.
Each video is between 15 and 45 minutes.
The Windows Azure Platform Security Essentials Series includes six free on-demand videos:
Windows Azure Platform Security Essentials: For Business Decision Makers
In this video, Graham answers the most common security concerns CxOs and other business decision-makers have regarding the security of their data in Windows Azure cloud platform.
You’ll learn about:
- The security controls that Azure has in place to help protect the customer applications and data
- A brief description of physical data storage and replication capabilities associated with Windows Azure Storage
- Security aspects of design of Azure infrastructure and how Microsoft secures its datacenters.
Windows Azure Platform Security Essentials: For Technical Decision Makers
In this video, Graham answers the most common security concerns CxOs and other technical decision-makers have regarding the security of their data in Windows Azure cloud platform.
The talk covers:
- The security controls that Azure has in place to help protect the customer applications and data
- An architecture overview of each of the Windows Azure Storage components (blobs, tables, queues and drives)
- SQL Azure and SQL Azure security (including similarities and differences to the on-premises installation of SQL Server)
- How Microsoft secures its datacenters.
Windows Azure Platform Security Essentials: Security Architecture
In this video module, Graham describes the security features of the Windows Azure platform, resources available to protect applications and data running on the Microsoft cloud and SQL Azure security and authentication options.
Windows Azure Platform Security Essentials: Identity Access Management
In this video module, Graham to describes the use of claims-based authentication to allow Active Directory and other on-premises identity providers to be used by Azure applications.
Windows Azure Platform Security Essentials: Storage Access
In this video module, Graham describes the options for controlling access to information stored in Windows Azure Storage or in SQL Azure.
Windows Azure Platform Security Essentials: Secure Development
In this video, Graham describes the best practices for designing and deployment secure applications in the Azure platform.
Other Security Resources
- Whitepaper: Security Best Practices for Developing Windows Azure Applications
- Microsoft Security Development Lifecycle
- Security Talk Series webcasts
Getting Started with Windows Azure
To get started working with Windows Azure:
- Get the free Windows Azure developer tools.
- See the online Windows Azure developer training course on MSDN.
- Get the free trial subscription of Windows Azure that does not require your credit. Use Promo Code: DPWE01.
- Free Support for your Windows Azure Project. Sign up today for free technical and marketing support for your Windows Azure project at Microsoft Platform Ready.
<Return to section navigation list>
Cloud Computing Events
The NRE Alliance announced an Enterprise Cloud Computing Seminar – Featuring Forrester Analyst James Saten (@staten7) on 1/27/2011 from 8:00 to 11:30 AM at the Westin Buckhead Hotel, Atlanta, GA:
The NRE Alliance, a coalition of newScale, rPath, and Eucalyptus Systems focused on bringing self-service private and hybrid clouds to the enterprise, today announced it will be presenting a best practices seminar, “Entry Points and Guideposts: Journey to the Enterprise Cloud.” The free seminar will be held in Atlanta on Thursday, January 27, 2011.
Keynote speaker James Staten [pictured at right], vice president and principal analyst from Forrester Research, will present the latest in enterprise cloud computing strategy.
You'll also hear from Jeff Schneider, CEO of MomentumSI, who will draw on large-scale cloud and application architecture projects to help you assess your readiness, and to leverage emerging practices and patterns to initiate and scale an enterprise cloud project.
- What: “Entry Points and Guideposts: Journey to the Enterprise Cloud” seminar
- When: Thursday, January 27, 2011, 8:00-11:30 a.m.
- Where: Westin Buckhead – Atlanta, 3391 Peachtree Road NE, Atlanta, GA 30326
- How: Register for this free event at http://www.nrecloud.com/roadshow.html.
- Attendees will learn: What is required to deliver IT services on demand How to automate for speed, scale and self-service provisioning Public, private and hybrid clouds—making sense of the options Organizational and culture issues and building the business case Entry points for getting started and guideposts for staying on track
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Werner Vogels (@werner) posted AWS Elastic Beanstalk: A Quick and Simple Way into the Cloud on 1/19/2011:
Flexibility is one of the key principles of Amazon Web Services - developers can select any programming language and software package, any operating system, any middleware and any database to build systems and applications that meet their requirements. Additionally customers are not restricted to AWS services; they can mix-and-match services from other providers to best meet their needs.
A whole range of innovative new services, ranging from media conversion to geo-location-context services have been developed by our customers using this flexibility and are available in the AWS ecosystem. To enable this broad choice, the core of AWS is composed of building blocks which customers and partners can use to build any system or application in the way they see fit. The upside of the primitive building block approach is ultimate flexibility but the flipside is that developers always have to put these blocks together and manage them before they can get started, even if they just quickly want to deploy a simple application.
To battle this complexity, developers who do not need control over the whole software stack often use development platforms that help them manage their application development, deployment and monitoring. There are some excellent platforms running on AWS that do precisely this; Ruby on Rails developers have Heroku and Engine Yard, Springsource users have CloudFoundry Drupal developers can use Acquia, and PHP aficionados can sign up for phpfog, just to name a few. These platforms take away much of the "muck" of software development to the extent that most RoR developers these days will choose to run on a platform instead of managing the whole stack themselves.
Developers have continuously asked us to create similar platforms to simplify development on AWS. However, given that there are probably as many different approaches to development as there are developers, instead of creating a particular platform, we are launching AWS Elastic Beanstalk, [see below] an application development container that can be the basis for the development of many different development platforms. It targets both the application developer by providing a set of simple tools to get started quickly and the platform developer by giving control over the underlying technology stack.
Elastic Beanstalk makes it easy for developers to deploy and manage scalable and fault-tolerant applications on the AWS cloud. It takes just minutes to get started and deploy your first application. AWS Elastic Beanstalk automatically creates the AWS resources and application stack needed to run the application, freeing developers from worrying about server capacity, load balancing, scaling their application, and version control. There is no charge to use Elastic Beanstalk and developers only pay for the AWS resources used to run their applications. Elastic Beanstalk stays true to the AWS principles by not locking customers into a black box; Elastic Beanstalk creates resources on behalf of the developer providing transparency and control over application operations as well making it easy to move applications out of the container at any time. An Elastic Beanstalk container comprises an application software stack running on Amazon EC2 compute resources with an Elastic Load Balancer, pre-configured EC2 Auto-Scaling, monitoring with Amazon CloudWatch, the ability to store data in Amazon S3, and multiple database options.
Developers who want even more control have access to the AWS resources supporting their application and can easily select more advanced deployment options such as using multiple Availability Zones for higher availability, logging into their Amazon EC2 servers, opening specific network ports for use, or taking control of Elastic Load Balancer or Auto-Scaling settings. The public beta release of AWS Elastic Beanstalk supports a container for Java developers using the familiar Linux / Apache Tomcat application stack. We plan to make additional containers available over time including support for customers and solution providers to develop and share their own containers.
AWS Elastic Beanstalk has been developed in such a way that other programming platforms can be created relatively easily. This is extremely important as the AWS developer ecosystem has always been very rich and we want to keep it that way. Our goal is to ensure every developer's favorite platform is always available on AWS so they can stop worrying about deploying and operating scalable and fault-tolerant application and focus on application development. In a nutshell, we want to let a thousand platforms bloom on AWS.
Last week I ran into an AWS customer at CES who was enthusiastic about how his digital production workflow and video encoding is now running reliably in the cloud. When discussing how AWS could improve to serve him even better he finished with "I have a bunch of smaller java apps that I really want to run in AWS but I just can't be bothered with picking the right instance size and setting up the load-balancing, etc." This is exactly where Elastic Beanstalk will help: to make it even simpler to get started and to run applications in the AWS cloud. "Easy to begin and impossible to outgrow" is an excellent characterization of Elastic Beanstalk which handles deployment, scaling and reliability such that its customers don't have to.
To get started using AWS Elastic Beanstalk, visit http://aws.amazon.com/elasticbeanstalk. More information on the launch can be found on the AWS developer blog.
Jeff Barr (@jeffbarr) posted Introducing AWS Elastic Beanstalk on 1/19/2010 to the Amazon Web Services blog:
I've been looking forward to being able to tell you about this new part of AWS for quite a while. Perhaps I'm biased, but I do think that this is a pretty big deal! I think we've managed to balance power and ease of use in a nice tidy package that will make AWS even more approachable for developers wishing to build powerful and highly scalable web applications.
AWS Elastic Beanstalk will make it even easier for you to create, deploy, and operate web applications at any scale. You simply upload your code and we'll take care of the rest. We'll create and configure all of the AWS resources (Amazon EC2 instances, an Elastic Load Balancer, and an Auto Scaling Group) needed to run your application. Your application will be up and running on AWS within minutes.
Much like the beanstalk in the popular fairy tale, Elastic Beanstalk allows you to start at ground level and climb toward the sky. However, as you will soon see, the beanstalk is built using a number of existing AWS services, not from magic beans.
When you use Elastic Beanstalk, you get to focus on the more creative and enjoyable aspects of application design and development while we take care of your software stack and your infrastructure. We do this in a very flexible way so that you still have complete control of what goes on. You can still access the underlying AWS resources if you'd like.
It has been years (1.5 decades to tell the truth) since I have done any serious Java development (Java Beans and the Java Native Interface, anyone?). Despite this, I was able to get the Elastic Beanstalk sample application up and running in less than five minutes. The application was effectively in production and ready to scale to meet the challenges of a world-wide load. Not too much later I was able to successfully compile and deploy some code of my very own.
If you are familiar with the market segment that is often called PaaS (short for Platform as a Service) you might be thinking "Ok, so what? Other environments have been able to do this for some time now. What's so special about this?" Well, lots of things. Here's a quick summary:
- Elastic Beanstalk is built on top of the proven AWS infrastructure. It takes full advantage of Amazon EC2, Elastic Load Balancing, Amazon CloudWatch, Auto Scaling, and other AWS services. You get all of the economy and scalability of AWS in a form that's easier and quicker to deploy than ever before.
- With Elastic Beanstalk you can choose to gradually assert control over a number of aspects of your application. You can start by tuning a number of parameters (see my post on the Elastic Beanstalk Console for more information about this). You can choose the EC2 instance type that provides the optimal amount of RAM and CPU power for your application. You can log in to the EC2 instances to troubleshoot application issues, and you can even take the default Elastic Beanstalk AMI (Amazon Machine Image), customize it, and then configure Amazon Beanstalk to use it for your application. This gradual assertion of control extends all the way to "eleven" -- you can choose to move your application off of Elastic Beanstalk and manage the raw components yourself if you so choose.
- Elastic Beanstalk was designed to support multiple languages and application environments. We are already working with solution providers to make this happen.
- Each of your Elastic Beanstalk applications will be run on one or more EC2 instances that are provisioned just for your application. Applications running on Elastic Beanstalk have the same degree of security as those running on an EC2 instance that you launch yourself.
- You can build an application that makes use of Elastic Beanstalk along with other services that you deploy on EC2 without having to worry about network latency across a wide-area network. You can launch the services in the same Region as your Elastic Beanstalk application. The ability to efficiently access existing services running on EC2 instances gives you additional flexibility and even more architectural and implementation options.
You can choose to remain blissfully unaware of the infrastructure that hosts your application and I fully expect that many of our customers will choose to do so. I also expect some of our customers to delve beneath the surface. Some will dip their toes in, others will take a deep dive. Either one is fine, and both are fully supported. When and if you choose to do this, you won't be entering some mysterious zone stuffed with undocumented code. Instead, you'll find that the Elastic Beanstalk AMI is based on the Amazon Linux AMI running the Apache Web Server, Tomcat, and the Enterprise Edition of the Java platform, all running on top of publicly documented AWS services.
The public beta release of AWS Elastic Beanstalk allows you to write Java code, compile it, package it up into a WAR (web archive) file, and upload it to a Tomcat environment. You can do the upload using a new tab on the AWS Management Console; read my AWS Elastic Beanstalk From The AWS Management Console post to learn more.
You can use the Elastic Beanstalk APIs and the Elastic Beanstalk command-line tools to connect your existing development tools and processes to Elastic Beanstalk. We've already used these APIs to extend the AWS Toolkit for Eclipse to allow developers to work with Elastic Beanstalk without needing to leave their IDE. See my post on AWS Elastic Beanstalk Eclipse Integration for additional information.
I hope that this post has given you enough information to give you an appreciation for AWS Elastic Beanstalk. If you are hungry for more, I've prepared a set of detailed posts with even more information for you. Each post is linked to the next one, so start with the Elastic Beanstalk Concepts and click your way through.
- Elastic Beanstalk Concepts.
- Elastic Beanstalk Under the Hood.
- Elastic Beanstalk Programming Model.
- Elastic Beanstalk from the AWS Management Console.
- Elastic Beanstalk and Eclipse.
- Elastic Beanstalk APIs and Command Line Tools.
This is an exciting step forward and we have a lot more in the works. Keep reading this blog and you'll be the first to know about each new development.
You may also want to attend the Introduction to AWS Elastic Beanstalk webinar at 11:00 AM (PST) on January 24th.
Keep Reading: Elastic Beanstalk Concepts or Werner Vogels' post: AWS Elastic Beanstalk: A Quick and Simple Way into the Cloud.
-- Jeff;
PS - I almost forgot! You can build and run Elastic Beanstalk applications at no charge beyond those for the AWS resources that you consume. If you are eligible for the AWS Free Usage Tier, you can run a small web application 24x7 without incurring any AWS usage fees. See the full details of this offer here.
Jeff continued with AWS Elastic Beanstalk Under the Hood on the same date:
The default configuration settings for your AWS Elastic Beanstalk application were chosen to work well under a wide variety of conditions. However, rest assured that you have the ability to view and to edit the settings as you'd like if and when you decide to "open the hood" (so to speak). You can do all of this from within the Elastic Beanstalk tab on the AWS Management Console.
Here's an outline of the settings available for each Elastic Beanstalk application. There is a tab in the console's Configuration Editor for each category:
- Server - EC2 instance type, security groups, key pair (for SSH login), CloudWatch monitoring interval, and AMI ID (for customization).
- Load Balancer - HTTP and HTTPS ports (each optional), the ID of a previously uploaded SSL Certificate, health check intervals, timeouts, and URL, and optional session stickiness with control over the cookie lifetime.
- Auto Scaling - Minimum and maximum instance count, and nine settings for the trigger that is used to drive scaling decisions.
- Notifications - An email address that can receive notification of important application events such as scale-up and scale-down actions initiated by Auto Scaling.
- Container - The settings in this tab are peculiar to each container type. With the default (Java / Tomcat 6) container, this tab lets you control the size of the Java Virtual Machine's heap and garbage collection parameters. You can also pass any desired arguments directly to the JVM. You can also choose to make your AWS credentials and a JDBC connection string available within each running EC2 instance.
You have the ability to fine tune your application's resource utilization, performance, and behavior, should you have the need to do so.
Keep Reading: AWS Elastic Beanstalk Programming Model.
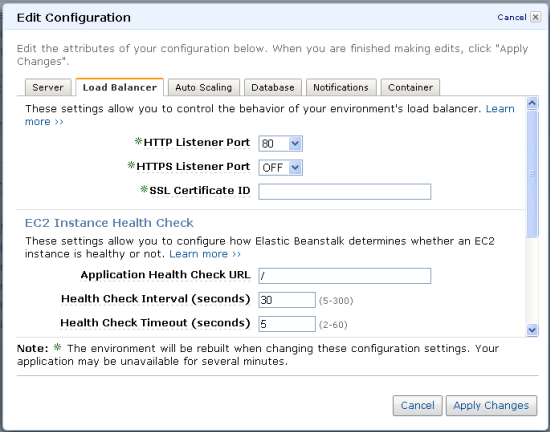
Jeff added AWS Elastic Beanstalk From The AWS Management Console
The AWS Management Console includes support for AWS Elastic Beanstalk. If you already have a Java WAR file that you want to use to try out Elastic Beanstalk, you can do so through its browser-based interface. If you don't happen to have an application of your own handy, you can use the sample application provided with Elastic Beanstalk to start learning more without writing any code.
Let's take a tour!
Here is the new Elastic Beanstalk tab on the Console. You can launch a sample application and use it to learn more about Elastic Beanstalk or you can upload your own application's WAR file.
If you choose to launch the sample application, it will be launched with a default environment. This should take a few minutes at most. Here's what the console looks like during the launch process:
You can check the event list at any time to see how things are progressing:
The environment's status will change to Ready as soon as the Elastic Load Balancer and Auto Scaling are set up, the EC2 instance(s) are launched, and Apache and Tomcat are up and running:
The console displays the URL of the application so you can access it with just a click (you can also click on the View Running Version Button):

orThe sample application provides you with links to additional Elastic Beanstalk resources:
In case you want to diagnose any issues, you can ask for a snapshot of the server's log files at any time.


You can also arrange for the application server logs to be sent to Amazon S3 every hour (these will be Tomcat logs if you are using the default container type):
Amazon CloudWatch monitoring is automatically enabled for the application and is visible in the Console:
You can also view and edit all of the configuration settings for each of your environments. The default settings will work well under a wide variety of conditions and are a good place to start if you are not very familiar with AWS. Let's take a look at each of tabs.
The Server tab lets you control the type of EC2 instance used to run your Elastic Beanstalk application. You can also associate one or more Security Groups to the instance and you can enable administrative shell access to the EC2 instances by designating a Key Pair.
The Load Balancer tab gives you control of ports, health checks, and session cookies.
The Auto Scaling tab lets you control scaling behavior. You can control the minimum and maximum number of EC2 instances and you can set up the Scaling Trigger as desired.
The Database tab provides information about the database options available to your Elastic Beanstalk application.
The Notifications tab lets you sign up to be notified when significant application events take place. The Amazon Simple Notification Service is used to deliver the notifications.
The Container tab lets you control very detailed aspects of the Tomcat configuration including memory allocation and log file rotation. You can also opt to pass your AWS credentials and a JDBC connection string to each instance.
When you do need to make changes to your configuration settings, the console gives you complete control. For example, here are the configurable parameters for the scaling triggers that drive the scale-up and scale-down activities:
As noted previously, you can create a new application by uploading a WAR file like this:
You can also upload a new version of an existing application:
As you can see from the screen shots above, the Elastic Beanstalk tab of the AWS Management Console gives you a lot of information, control, and power. For more information, please see the Elastic Beanstalk User Guide.
Keep Reading: AWS Elastic Beanstalk and Eclipse.












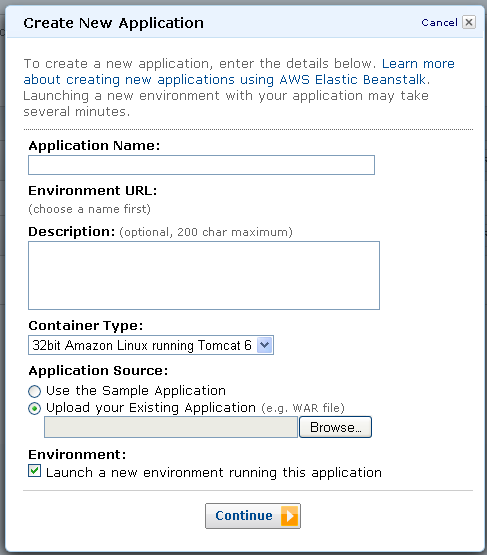
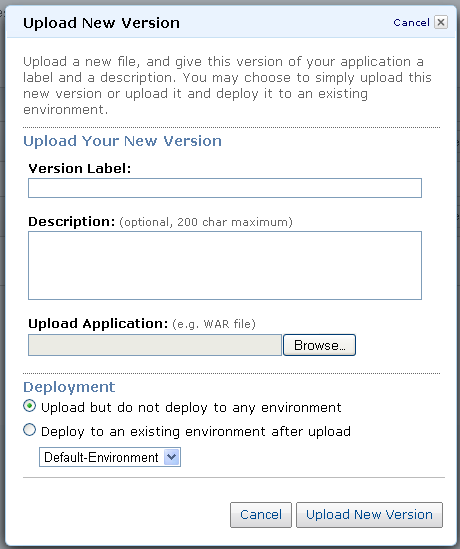
Jeff gives details about the AWS Elastic Beanstalk Programming Model in this 1/19/2011 post and continues with a couple of additional posts about AWS Elastic Beanstock APIs and Command-Line Tools, as well as Concepts.
Ellen Rubin posted Envisioning a World without Enterprise Data Centers to the CloudSwitch blog on 1/19/2011:
In discussions with our customers, we’ve seen an interesting trend emerge in recent months. A surprising number of customers are telling us that their goal is to never build another data center again, or even to do away with their data centers completely. They see the cloud as central to this goal. We’re seeing this trend from customers of many different sizes, from mid-size to large and very large companies. This new mindset seems to reflect a major shift in direction as enterprises rethink their IT strategies.
One interesting aspect of this trend is that customers are taking the lead in recognizing the possibilities of the cloud. As their confidence grows, they’re taking another look at their current infrastructure and adopting a new mindset around what enterprise computing should look like. While the traditional brick and mortar data center has been a staple of enterprise IT for decades, nobody really wants to have an expensive data center, and enterprises realize that now they’re in a position to do something about it. They want to get off the “data center treadmill” because they know where it leads: to ever-increasing operating costs, ever-larger capital investments, more and more manpower, and a huge distraction from their main mission. With the emergence of the cloud as a viable alternative, enterprises are taking a close look at the way they’ve been doing things and incorporating cloud into their overall infrastructure plans.
We’re actually seeing two flavors of this trend. Some companies in the mid-tier space are now trying to determine if they can get down to a very small data center footprint or none at all. They’ve already consolidated as much as they can, perhaps from several data centers down to one. They’ve virtualized much of their environment and squeezed as much efficiency as possible out of it, and now they’ve turned to the cloud to offload the next level of application infrastructure. As they shift operations to the cloud, they’ve decided to stop building out their data centers or taking more space at their colos. The argument (at least in the mid-tier space) is: “Data center management is not our core business, so why are we investing so much time, effort, and expense in it, instead of leveraging resources that are managed by the experts?”
We’re also engaged with much larger F1000 companies with more extensive operations. They may have had dozens of data centers at one point, and have been trying to scale down to less than ten. They’ve aggressively consolidated and virtualized, but know they’re not likely to be able to live without a data center in the foreseeable future since their operations are just too vast and fast-growing (especially when they engage in M&A activity). These companies also have “big iron” in their data centers (like mainframes, dedicated cluster hardware, and high performance SANs) that can’t be directly moved or hosted in the clouds. In addition, some critical data and computing will have to remain under tight control for compliance and business reasons. Thus there are factors at play that will slow down their ability to close their data centers — but they aspire to, and this long-term vision is starting to inform their strategic planning. The way they think about where to run their applications is changing, and they’re just as eager as mid-sized companies to get off the capital expenditure treadmill.
What will this new world look like? Enterprise computing is already in the midst of dramatic change, where the old brick and mortar data center is being replaced by pools of virtual resources that can be located anywhere as long as they perform and behave in the way that meets business requirements. Physical control of resources is being replaced by virtual control, by an administrator managing the virtual data centers across multiple clouds from their desktop or laptop.
How will it come about? Much of the cloud discussion over the past year has been dominated by hybrid clouds, where workloads can be allocated across internal and external resources. Using this approach, enterprises can take advantage of resources on demand for scaling and peak workloads rather than over-provisioning the internal environment. They can also use clouds in multiple regions so that processing and data can be placed near consumers, eliminating the latency of a distant internal server. And they can offload back-office, non-mission-critical apps from their internal environments given that many of these could really be run anywhere. Enterprises will use this hybrid model to make the transition to the virtual data center, choosing which workloads have to run on their internal infrastructure and which can run externally. Over time, the internal environment will shrink as companies run more and more workloads in the cloud.
The possibilities start to get very interesting. Rather than the current approach to cloud computing, where enterprises try to graft cloud capabilities on top of a legacy infrastructure, the cloud becomes a virtual private data center. A control point is still needed to manage those pools of resources across the different cloud environments, but this could be something extremely lightweight and portable such as an administrator’s laptop.
This is the next, upcoming chapter in the hybrid story — and once again, CloudSwitch is playing a leading role. As innovators in the hybrid space, we make it easy to provision, migrate, scale, and manage workloads in public clouds, while providing the security, control, and adherence to standards that an enterprise depends on. Using our technology, enterprises can orchestrate workloads across the cloud landscape (internal and external), as they start to phase out their current environments and get off the “data center treadmill.”
Cade Metz asserted “Microsoft doesn't want it. But everyone else does” as a deck for his HBase: Shops swap MySQL for open source Google mimic article of 1/19/2010 for The Register:
HBase is part of the Apache Hadoop project, a sweeping effort to mimic Google's proprietary infrastructure with open source code. It dovetails with HDFS, the Hadoop distributed file system, and Hadoop MapReduce, the distributed number-crunching platform. HBase is essentially a low-latency layer that sits atop HDFS, letting you rapidly store and retrieve data. It's fashioned after Google's BigTable platform, which Mountain View publicly described in a 2006 research paper. [Link added.]
HBase project chair Michael Stack is on staff at StumbleUpon, which has long used HBase for the real-time public counters that track users and pageviews across its service. StumbleUpon still employs MySQL in many areas and will continue to do so. But the idea is to swap in HBase wherever scale is an issue.
"I don't foresee StumbleUpon ever giving up on all of its MySQL instances. RDBMSs are just too useful," Stack tells The Reg. "The plan, though, is to shrink what MySQL does over time, let MySQL do what its good at and have HBase take over where MySQL is running up against limits handling ever-growing write rates, table sizes, etc."
In similar fashion, Canadian startup Tynt is moving from MySQL to HBase and Hadoop so it can readily scale its service, which lets websites distribute URLs whenever netizens cut-and-paste content. The service is meant to generate extra traffic for sites, but it also provides sites with data describing all the traffic – and cutting-and-pasting – it sees. Tynt is now used by over 600,000 online publishers, with the company logging over 20,000 events per second, and according to company CTO Cameron Befus, Tynt's MySQL infrastructure couldn't keep up with the service's growth.
The company is now using HDFS and MapReduce to store and analyze all that data, and this month it will begin to use HBase to serve up the data in real time. "We were growing at an exponential rate. The volume of data we were called on to produce was more than doubling every month," Befus says. "We knew that MySQL couldn't really handle effectively what we had, let alone what we expected. ... We're exceeding 20,000 events per second, and you've got to spread that across a large number of MySQL servers, and as you do that, it becomes very inefficient."
What's more, says Amr Awadallah, vice president of engineering and CTO at Cloudera, the commercial Hadoop outfit that helped erect the company's Hadoop platform, simply adding MySQL servers is more difficult. "The headache is that every time you want to add a new MySQL server, it doesn't just assimilate into the collective easily," Awadallah explains.
"You have to repartition your data and rebalance your hashing technique across the new server and [specify] which range of keys now fall on that server and so on. With HBase, this happens transparently. You add nodes and you tell HBase you've added nodes and you join the collective."
Cloudera is what you might call a Red Hat for Hadoop. It offers its support and services for its own Hadoop distros. Tynt received consulting help from Cloudera when setting up a back-end platform based on the completely open source Cloudera Distribution of Hadoop, and it now pays Cloudera for support and updates.
At Tynt, HBase will initially be used to provide realtime API access to the service's analytics data, and it will eventually be used for other real-time tools as well. "HBase will also provide analytics, but much faster [than just MapReduce]." Befus says. MapReduce does batch processing; it doesn't provide real-time access to data.
Meanwhile, Yahoo! – which bootstrapped the Hadoop's core HDFS and MapReduce projects – is using HBase as part of its COKE system (Content Optimization Knowledge Engine), a means of automatically selecting news stories for its front page. Mozilla has moved its Socorro crash-reporting system HBase. And Adobe is using the platform to drive services across the company.
Like these outfits, Facebook is a longtime MySQL house. But its new messaging system – unveiled this past fall – uses HBase to juggle email, chat, and SMS as well as traditional on-site Facebook messages. HBase stores the text and metadata for messages as well as the indices needed to search them. The previous system needed about 75TB to store a month's worth of messages, and that figure will only grow with the new setup.
"The email workload is a write-dominated workload. We need to make a lot of writes very quickly," Facebook infrastructure guru Karthik Ranganathan said in a recent Facebook webcast. "We used HBase for the data that grows very fast, which is essentially the metadata."
But for all its success, HBase has lost one big-name user.
HBase was founded by Powerset, a San Francisco-based semantic search startup. Michael Stack was among the Powerset developers who helped get the project off the ground. In the summer of 2008, Microsoft acquired Powerset, and it eventually gave Stack and fellow committer Jim Kellerman the go-ahead to continue their contributions to the project.
"This is the first time we have acquired a company with committers to a key open source project who have been able to continue to commit to that project in their old capacity as part of their new role," Sam Ramji, Microsoft's then senior director of platform strategy told us at the time.
The HBase-based Powerset was folded into Bing, making the search engine one of the first "shipping" Microsoft product to actually include open source code. But a year an a half on, Powerset is no longer running on Hadoop. "As far as I know, there is no Hadoop or HBase in operation at Powerset these days," Stack says. And Microsoft has confirmed this with The Reg.
Hadoop, you see, doesn't really run on Windows. As much as things change at Microsoft, they stay the same. It was 13 years ago that Redmond purchased Hotmail, ripped out its FreeBSD servers, and replaced them with Windows 2000.
Alex Popescu announced HBase 0.90.0 Released: Over 1000 Fixes and Improvements in a 1/19/2011 post to his myNoSQL Blog:
As far as I know this is the first major HBase release since becoming a top level Apache project (this using a new versioning too). Until now I thought that Hadoop 0.21.0 had the longest list of fixes, improvements, and new features, but I guess HBase 0.90.0 tops that with over 1000 tracked tickets.
From a slides, a quick what’s new in HBase 0.90.0:
- durability and stability
- HDFS appends + WAL improvements
- master rewrite
- cleanup of master, move region transitions to ZK
- inter-cluster/inter-DB replication
- Bloom filters
- bul loading improvements
- performance improvements
- peripheral improvements: REST/Stargate, Shell, Avro,
- HBaseFSCK
On a negative side, HBase 0.90.0 doesn’t run with Hadoop 0.21.0 nor with Hadoop TRUNK, the only compatible Hadoop version being 0.20.x. The release notes for HBase 0.90 release candidates are mentioning that HBase will lose data unless running on an Hadoop HDFS 0.20.x that has a durable sync. Though there is a Hadoop branch containing the necessary changes, but you’ll have to build that yourself.
Congrats to the HBase team for their first release as top Apache project!
I didn’t know about the The Apache HBase Book. But I’m eagerly awaiting my copy of Lars George’s HBase: The definitive guide.
I plan to read The Apache HBase Book, the official book of Apache HBase, a distributed, versioned, column-oriented database built on top of Apache Hadoop and Apache ZooKeeper, from the Apache Hadoop site.
Robert Duffner posted Thought Leaders in the Cloud: Talking with Aron Pilhofer, Editor of Interactive News Technologies at The New York Times [pictured below] in a 1/19/2011 post to the Windows Azure Team blog:
Aron Pilhofer acts as editor of interactive news technologies at The New York Times, overseeing a news-focused team of journalist/developers who build dynamic, data-driven applications to enhance the Times' reporting online. He joined The Times in 2005. Previously, he was at the Center for Public Integrity in Washington, and before that at Investigative Reporters and Editors (IRE.org).
In this interview, we discuss:
- The purpose served by DocumentCloud
- Lack of technology in newsrooms, and how the cloud is making information more attainable and process-able by journalists
- How the elastic capabilities of cloud computing match with the event-based spikes in demand around news
- How a "document dump" may cause thousands of documents to appear at one time, and are better processed by the elasticity of the cloud
- Use of "CloudCrowd", a Ruby based MapReduce library
Robert Duffner: Could you take a moment to introduce yourself and to give us some background on DocumentCloud?
Aron Pilhofer: Sure. I wear a couple of different hats. At The New York Times, I'm editor of interactive news, which is a team of developers in the newsroom who are journalists. What we do is both editorially and data-driven. We operate like a news desk, but we also were a technology team.
My other day job is on DocumentCloud, which is a nonprofit funded by the Knight Foundation. I proposed a grant to fund it with Eric Umansky and Scott Cline. We were awarded the grant, and we're entering our second year right now.
The goal of the project is to improve journalism by creating a site that allows journalists to analyze, upload, share, and search public source documents that would be otherwise extremely difficult to find or analyze.
Robert: There's an old issue in journalism that journalists often cite documents that aren't available to the reader. DocumentCloud lets the journalist post those source document in a public place, so the reader can go back to the source, just as a journalist could.
As far back as the '20s, though, guys like Walter Lippmann argued that the public just isn't that interested in the details. Do you find that people aside from journalists are benefiting from DocumentCloud?
Aron: Actually, no. Let me just explain a little bit what DocumentCloud is, how it started, and why the answer is no. There's DocumentCloud the software, which is one part of what we're building. It sort of sits on top of OpenCalais, which is an open API that does entity extraction and semantic markup.
Think of it as a set of tools we're providing to journalists to give them the ability to treat unstructured text more like structured data, so they can find links between documents that they could not have found through traditional means.
As an example, think of a case where you send through a document that includes a reference to the CIA. CIA is meaningful to a human being. You and I can look at that and go "Oh, that probably means the Central Intelligence Agency." Or, in other context, it might be the Culinary Institute of America. It's less clear to a traditional text search.
The Calais engine allows us, in an automated way, to go through and say "OK, that's the Central Intelligence Agency. And by the way, here's this other document also about the Central Intelligence Agency, and both of them reference the same individual that you are curious about." So, that's an example of some of the tools we're building with journalism in mind. That's DocumentCloud the software.
Then there's DocumentCloud the community, which is the other piece of what we're trying to put together. Right now, it includes about 150 journalists and journalism organizations, with that number growing by leaps and bounds. They're joining the community to use this tool to improve their reporting.
In order to join that community, you pretty much need to be a journalist, by our definition. That is, you must be someone whose job, either paid or unpaid, involves the acquisition, analysis, and ultimately publishing of public source documents to benefit the public. Normally that means government documents, and a lot of those documents are acquired through FOIA, or they might exist on some other site.
Having said all that, we have been approached by any number of non-journalism organizations, such as law firms. We've gotten the sense that there is a need out there for sort of a lightweight document management tool, and we may explore that as a potential revenue generator, but that isn't really our main focus.
Robert: You talked about this idea of document management. One of the reasons that self publishing has been so popular has been the ease by which you can actually publish to a platform. Can you talk a little bit about how DocumentCloud removes some of the impediments traditionally associated with IT departments?
Aron: The genesis of DocumentCloud was from a piece of software we developed at the Times called DocumentViewer, which is a really straightforward piece of software. It will take a PDF or a Word document, pretty much anything OpenOffice can open or a PDF, break it up, extract the text, make it searchable, and then publish it to the web in an attractive way.
Our thinking going in was that most news organizations, even the smallish ones, would want something similar. So our original conception was that DocumentCloud would be sort of the hub. We would want your metadata, but generally speaking, we thought that all the member organizations would want this sort of viewer to be on their hardware, behind their firewalls.
We could not have been more wrong about that, for both good reasons and unfortunate ones. My perception is that newsrooms lack fundamental technology to deal with documents, and that is sort of scary. The traditional way that newsrooms deal with big document dumps is to split them up and have people sit down with yellow legal pads and pens and highlighters.
That is the highest technology, really, that most newsrooms currently employ. A lot of newsrooms don't have access to the simplest things, like OCR. That's surprising to a lot of people, but it's true, and in this little area of public source documents, we think we can help.
That's why we pivoted early on away from thinking about DocumentCloud as a federated thing running on hundreds of websites, to a vision where fundamentally it all goes through us. For the most part, we actually host the documents on behalf of news organizations.
The way we made that simple and scalable was to make the entire DocumentViewer portion static. What you see on the website is just HTML, JavaScript, CSS, and JSON. The only live portion is search, which is provided dynamically as a service.
All a news organization has to do is get a little embed code from us, which they can embed anywhere they want in their CMS. They can put it within a blank page on their own site, in a blog post, or whatever. It's really simple and really straightforward.
Robert: Some of these technologies like DocumentCloud coming out are pretty exciting. Can you talk a little bit about some other ways that the cloud might be fundamentally shaping journalism practices?
Aron: My team here at the Times couldn't do what we do without the cloud. We run everything off of Amazon. On an election night, we can suddenly go from four or five servers to 22 servers to handle all that traffic. A day later, we can just spin back down to five servers. There's no way you could do that in a traditional IT environment.
Robert: One concern that governments and corporations have about the cloud is where data is stored. Typically they want or need the data to be stored within their country's borders. But what's a drawback for some companies in this scenario actually looks like an advantage for journalism. Is one benefit of the cloud that it's possible to store any potentially embarrassing government documents out of the reach of that government?
[laughter]
Aron: That thought certainly has occurred to me, and I don't know that it's been adjudicated anywhere, really. To flip that idea on its head, consider that in the UK, there's this notion of Crown copyright, where the public doesn't really own public documents and data.
It's sort of bizarre. For example, postal codes are copyrighted under Crown copyright, and you have to pay a huge amount of money to get boundaries of postal codes in the UK. I don't know what would happen if somebody were to make that data publically available on a server in the US. If there were some assertion of Crown copyright, would that even apply jurisdictionally to where that data is hosted?
It's a really good question, and I'm not sure I want to find out, because this is sort of new territory for everybody. We're pretty cautious about what we put up on the cloud and what we don't.
Robert: Looking at DocumentCloud, what was it that required something new to be built? I mean Microsoft has Office 365 with SkyDrive. Google obviously offers Google Docs. There's also Scribd. What did you need that you didn't find in these existing resources?
Aron: We looked at all those options early on, and while in 2007, this field obviously wasn't quite as crowded as it is now, none of them did what we wanted DocumentViewer to do. DocumentViewer is more than just a way of putting a document online.
For example, it also allows you to do annotations, which is kind of key from a journalistic standpoint. There's what we have come to refer to as kind of a journalistic layer on top of a document.
A reporter can go into DocumentViewer, highlight a key paragraph, click "Drag," and create an annotation. He or she can actually write a couple of paragraphs to identify the significance of a particular sentence, phrase, or paragraph and deep link into it.
That allows you to add a narrative to what is effectively a piece of raw data, and say to the reader, "OK, here's the document that we're basing our reporting on. But more that, here are the key paragraphs, and here's why they're key. Here's really what this means."
Scribd didn't do that. Docstoc didn't do that. There was really no technology we could find that did it in a way that we thought accomplished our goals. We also wanted something that wasn't Flash-based, which Scribd at that time was.
Robert: That makes a lot of sense, particularly to support standards, when you consider all of the form factors that you can use to access the Web. I imagine various reporters want to use something like an iPad, a mobile phone, you name it.
Aron: Right. It's not the world's greatest experience, but you can actually use DocumentViewer on an iPhone. This is not an anti-Flash rant, or anything like that. It's just we felt that the right technology for this was to stick to web standards, and what we've come to refer to as HTML5.
Robert: On your blog, you've talked about how to use Amazon EC2 behind the scenes. Can you explain how the elasticity of the cloud, scaling up and down on demand, gets put to use by DocumentCloud?
Aron: Sure. It's a big challenge. Document processing is a very CPU-intensive process, and so we needed to be able to scale up rapidly when there's a big uploaded document, so we did two things. One is that we have built and released a fairly lightweight parallel processing library we call CloudCrowd. DocumentCloud has actually released a number of open source libraries. We haven't released the entire project, but that will come soon.
But the first piece was CloudCrowd, and that was sort of a lightweight, Ruby-based parallel processing library, which allows us to quickly add additional processing nodes if we get a 3,000 document dump from AP, which actually happened last week.
Relatively easily, we can add two, three, four, or 100 servers to the processing pool and split that job up. It's basically a MapReduce project at that point. So that's how the elasticity helps us on DocumentCloud. The front end isn't as much of an issue, because once the documents are actually rendered, it's 100% static content. We just serve those off of S3.
Robert: Can you talk about how much you're processing and what you expect that to grow to?
Aron: It fluctuates, obviously, and it's pretty spiky, which is why we couldn't really do this in a traditional environment. If you're building a data center, you have to size it to the biggest spike you expect to have, which means you've got a lot of time where you're sitting and idling with unused resources. Because we don't need to worry about that, we can spin up 10, 20, or whatever at a time.
I think the most we've every processed in a day is a few thousand documents. And then there are certain days where it's just a few dozen. We opened our beta this summer, and I think we're over 400,000 pages now, closing in on 500,000.
Robert: You mentioned already that DocumentCloud uses open source, and is itself open source.
Aron: Actually, it's MapReduce, but we don't use Hadoop. Our version of Hadoop is CloudCrowd. Think of in the old Apple ad, CloudCrowd is Hadoop for the rest of us. It's a much simpler Ruby-based MapReduce library for doing parallel processing.
Robert: We definitely sense that investigative journalism is being cut from a lot of news organizations, because it's expensive and time-consuming. At the same time, computer assisted reporting, which includes things like web scraping and data mining, is on the rise and has actually led to Pulitzer Prize winning stories. Do you think that technology offers new hope to investigative journalism?
Aron: Certainly, and DocumentCloud, I think, is an example of how technology can be brought to bear on that. As I said before, most journalists do serious document reporting and analysis as a very analog process, and I think that the document piece is just one tiny fragment.
Part of what a lot of computer assisted reporting folks are doing these days in newsrooms is acquiring the data and making it searchable, so it's easier for non-technical journalists to work with. I think the smart application of technology in newsrooms can be a force multiplier for shrinking staff.
The Times obviously has made a significant commitment to investigative reporting, which not every news organization has. Anyone who reads a newspaper knows the industry is struggling, which is a very good reason why newspaper staffs are shrinking. The way I see it is that technology can help overcome some inefficiencies, which can help preserve journalistic quality.
Robert: Hey, thanks so much for your time. I greatly appreciate it.
Aron: You bet.
This interview is in the Other Cloud Computing Platforms and Services because the subject application, DocumentCloud, runs on Amazon EC2.
See Cade Metz added “Round-Rock-as-a-Service” as a suffix to his Dell morphs into Amazonian 'public cloud' biz? title for an article of 1/18/2011 in The Register in the Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds section above.
<Return to section navigation list>

















0 comments:
Post a Comment