Windows Azure and Cloud Computing Posts for 1/7/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, VM Roles, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
My Testing IndexedDB with the Trial Tool Web App and Microsoft Internet Explorer 8 or 9 Beta tutorial of 1/7/2011 described Narasimhan Parashuram’s new IndexedDB API for IE:

The similarity of Microsoft’s IndexedDB implementation with SQL Compact to the Windows Azure Platform’s early SQL Server Data Services (SSDS) and later SQL Data Services (SDS) running on SQL Server in the cloud is interesting.
IndexedDB also shares some characteristics of Windows Azure blobs.
<Return to section navigation list>
SQL Azure Database and Reporting
Vincent-Philippe Lauzon described 7 Things You Need To Know about SQL Azure Reporting on 1/7/2011:
The SQL Azure Team had a quite interesting blog back in mid-November around the newly released SQL Azure Reporting. Here’s a summary of their nuggets about the new technology.
- It’s Based on SQL Server Reporting Services (SSRS)
SQL Azure Reporting provides a subset of the features of SSRS, therefore, the same tooling & artefacts apply: Business Intelligence Studio, tables, widgets (e.g. gauge, charts, maps) and the result is an RDL file.- Report Execution Happens in the Cloud
The cloud is going to absorb the execution of report.- SQL Azure Reporting is Part of the Windows Azure Platform
Which means the same advantages as the rest of the platform: scalability, quick provisioning & integration with the Azure Portal.- The Data Source is SQL Azure
This is more of a limitation than anything at the moment. Basically the paradigm is that you run reports in the cloud against a DB in the cloud.- Reports Are Exactly the Same Format
Nothing special needs to be put in the .rdl. It is an output of Business Intelligence Studio like any other report.- There is Nothing New to Download and Install
Again, the same toolset- You Can Access SQL Azure Reporting With a Browser
You do not need to deploy a web site and embed your reports into it (although you can): you can view the reports directly from SQL Azure Reporting. The reports are secured with Live ID by default.
A nice introduction to Azure SQL Reporting is the PDC 2010 Video by Nino Bice.
Pakt Publishing posted on 1/7/2011 a special offer on a print/ebook bundle of Jayaram Krishnaswamy’s Microsoft SQL Azure Enterprise Application Development title:
Overview of Microsoft SQL Azure Enterprise Application Development
- Understand how to use the various third party programs such as DB Artisan, RedGate, ToadSoft etc developed for SQL Azure
- Master the exhaustive Data migration and Data Synchronization aspects of SQL Azure.
- Includes SQL Azure projects in incubation and more recent developments including all 2010 updates
- eBook available as PDF and ePub downloads and also on PacktLib

<Return to section navigation list>
MarketPlace DataMarket and OData
The Windows Azure Team encourages developers to Enter the Windows Azure Marketplace DataMarket Contest on Code Project For A Chance to Win an Xbox 360 with Kinect! in a 1/7/2011 post:
Would you like a chance to win an Xbox 360 with Kinect or an Intel i7 laptop? If so, build an innovative cloud application on the Windows Azure Platform using datasets from the Windows Azure Marketplace DataMarket and submit the URL to contest@codeproject.com no later than March 31, 2011*. At the end of the contest, the best eight** apps will be selected and the winners will each receive an Intel i7 laptop. One of these eight winners could also win the grand prize, an Xbox 360 with Kinect. Learn more about the contest here.
The Windows Azure Marketplace allows you to share, buy and sell building block components, training, premium data sets plus finished services and applications. The DataMarket section of the Windows Azure Marketplace provides trusted public domain and premium datasets from leading data providers in the industry such as United Nations, Data.gov, World Bank, Weather Bug, Weather Central, Alteryx, STATS, and Wolfram Alpha.
To make it easier to get started, all USA Code Project members also get a FREE Windows Azure platform 30-day pass, so you can put Windows Azure and SQL Azure through their paces. No credit card required: enter promo code: CP001.
* This competition is open to software development professionals & enthusiasts who are of the age of majority in their jurisdiction of residence; however, residents of Quebec and of the following countries are ineligible to participate due to legal constraints: Cuba, Iran, Iraq, Libya, North Korea, Sudan, and Syria.
** Prizes are awarded based on how tightly an entry adhered to the conditions of entry, such as: focus and scope, overall quality, coherence, and structure.
I’m surprise to see Quebec associated with embargoed dealings with Cuba, Iran, Iraq, Libya, North Korea, Sudan, and Syria.
Jon Galloway posted Entity Framework Code-First, OData & Windows Phone Client on 1/6/2011:
Entity Framework Code-First is the coolest thing since sliced bread, Windows Phone is the hottest thing since Tickle-Me-Elmo and OData is just too great to ignore.
As part of the Full Stack project, we wanted to put them together, which turns out to be pretty easy… once you know how.
EF Code-First CTP5 is available now and there should be very few breaking changes in the release edition, which is due early in 2011.
Note: EF Code-First evolved rapidly and many of the existing documents and blog posts which were written with earlier versions, may now be obsolete or at least misleading.
Code-First?
With traditional Entity Framework you start with a database and from that you generate “entities” – classes that bridge between the relational database and your object oriented program.
With Code-First (Magic-Unicorn) (see Hanselman’s write up and this later write up by Scott Guthrie) the Entity Framework looks at classes you created and says “if I had created these classes, the database would have to have looked like this…” and creates the database for you! By deriving your entity collections from DbSet and exposing them via a class that derives from DbContext, you "turn on" database backing for your POCO with a minimum of code and no hidden designer or configuration files.
POCO == Plain Old CLR Objects
Your entity objects can be used throughout your applications - in web applications, console applications, Silverlight and Windows Phone applications, etc. In our case, we'll want to read and update data from a Windows Phone client application, so we'll expose the entities through a DataService and hook the Windows Phone client application to that data via proxies. Piece of Pie. Easy as cake.
The Demo Architecture
To see this at work, we’ll create an ASP.NET/MVC application which will act as the host for our Data Service. We’ll create an incredibly simple data layer using EF Code-First on top of SQLCE4 and we’ll expose the data in a WCF Data Service using the oData protocol. Our Windows Phone 7 client will instantiate the data context via a URI and load the data asynchronously.
Setting up the Server project with MVC 3, EF Code First, and SQL CE 4
Create a new application of type ASP.NET MVC 3 and name it DeadSimpleServer.
We need to add the latest SQLCE4 and Entity Framework Code First CTP's to our project. Fortunately, NuGet makes that really easy. Open the Package Manager Console (View / Other Windows / Package Manager Console) and type in "Install-Package EFCodeFirst.SqlServerCompact" at the PM> command prompt. Since NuGet handles dependencies for you, you'll see that it installs everything you need to use Entity Framework Code First in your project.


Note: We're using SQLCE 4 with Entity Framework here because they work really well together from a development scenario, but you can of course use Entity Framework Code First with other databases supported by Entity framework.
Creating The Model using EF Code First
Now we can create our model class. Right-click the Models folder and select Add/Class. Name the Class Person.cs and add the following code:
using System.Data.Entity; namespace DeadSimpleServer.Models { public class Person { public int ID { get; set; } public string Name { get; set; } } public class PersonContext : DbContext { public DbSet<Person> People { get; set; } } }
Notice that the entity class Person has no special interfaces or base class. There's nothing special needed to make it work - it's just a POCO. The context we'll use to access the entities in the application is called PersonContext, but you could name it anything you wanted. The important thing is that it inherits DbContext and contains one or more DbSet which holds our entity collections.
Adding Seed Data
We need some testing data to expose from our service. The simplest way to get that into our database is to modify the CreateCeDatabaseIfNotExists class in AppStart_SQLCEEntityFramework.cs by adding some seed data to the Seed method:
protected virtual void Seed( TContext context ) { var personContext = context as PersonContext; personContext.People.Add( new Person { ID = 1, Name = "George Washington" } ); personContext.People.Add( new Person { ID = 2, Name = "John Adams" } ); personContext.People.Add( new Person { ID = 3, Name = "Thomas Jefferson" } ); personContext.SaveChanges(); }The CreateCeDatabaseIfNotExists class name is pretty self-explanatory - when our DbContext is accessed and the database isn't found, a new one will be created and populated with the data in the Seed method. There's one more step to make that work - we need to uncomment a line in the Start method at the top of of the AppStart_SQLCEEntityFramework class and set the context name, as shown here:
public static class AppStart_SQLCEEntityFramework { public static void Start() { DbDatabase.DefaultConnectionFactory = new SqlCeConnectionFactory("System.Data.SqlServerCe.4.0"); // Sets the default database initialization code for working with Sql Server Compact databases // Uncomment this line and replace CONTEXT_NAME with the name of your DbContext if you are // using your DbContext to create and manage your database DbDatabase.SetInitializer(new CreateCeDatabaseIfNotExists<PersonContext>()); } }
Now our database and entity framework are set up, so we can expose data via WCF Data Services.
Note: This is a bare-bones implementation with no administration screens. If you'd like to see how those are added, check out The Full Stack screencast series.
Creating the oData Service using WCF Data Services
Add a new WCF Data Service to the project (right-click the project / Add New Item / Web / WCF Data Service).
We’ll be exposing all the data as read/write. Remember to reconfigure to control and minimize access as appropriate for your own application.
Open the code behind for your service. In our case, the service was called PersonTestDataService.svc so the code behind class file is PersonTestDataService.svc.cs.
using System.Data.Services; using System.Data.Services.Common; using System.ServiceModel; using DeadSimpleServer.Models; namespace DeadSimpleServer { [ServiceBehavior( IncludeExceptionDetailInFaults = true )] public class PersonTestDataService : DataService<PersonContext> { // This method is called only once to initialize service-wide policies. public static void InitializeService( DataServiceConfiguration config ) { config.SetEntitySetAccessRule( "*", EntitySetRights.All ); config.DataServiceBehavior.MaxProtocolVersion = DataServiceProtocolVersion.V2; config.UseVerboseErrors = true; } } }We're enabling a few additional settings to make it easier to debug if you run into trouble. The ServiceBehavior attribute is set to include exception details in faults, and we're using verbose errors. You can remove both of these when your service is working, as your public production service shouldn't be revealing exception information.
You can view the output of the service by running the application and browsing to http://localhost:[portnumber]/PersonTestDataService.svc/:
<?xml version="1.0" encoding="iso-8859-1" standalone="yes"?> <feed xml:base=http://localhost:49786/PersonTestDataService.svc/ xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom"> <title type="text">People</title> <id>http://localhost:49786/PersonTestDataService.svc/People</id> <updated>2010-12-29T01:01:50Z</updated> <link rel="self" title="People" href="People" /> <entry> <id>http://localhost:49786/PersonTestDataService.svc/People(1)</id> <title type="text"></title> <updated>2010-12-29T01:01:50Z</updated> <author> <name /> </author> <link rel="edit" title="Person" href="People(1)" /> <category term="DeadSimpleServer.Models.Person" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" /> <content type="application/xml"> <m:properties> <d:ID m:type="Edm.Int32">1</d:ID> <d:Name>George Washington</d:Name> </m:properties> </content> </entry> <entry> ... </entry> </feed>Let's recap what we've done so far.

But enough with services and XML - let's get this into our Windows Phone client application.
Creating the DataServiceContext for the Client
Use the latest DataSvcUtil.exe from http://odata.codeplex.com. As of today, that's in this download: http://odata.codeplex.com/releases/view/54698
You need to run it with a few options:
/uri - This will point to the service URI. In this case, it's http://localhost:59342/PersonTestDataService.svc Pick up the port number from your running server (e.g., the server formerly known as Cassini).
/out - This is the DataServiceContext class that will be generated. You can name it whatever you'd like.
/Version - should be set to 2.0
/DataServiceCollection - Include this flag to generate collections derived from the DataServiceCollection base, which brings in all the ObservableCollection goodness that handles your INotifyPropertyChanged events for you.
Here's the console session from when we ran it:
E:\WhoIsThatPhone\WhoIsThatPhone>D:\oData\DataSvcUtil.exe /out:ContactService.cs /Version:2.0 /DataServiceCollection /uri:http://localhost:59342/PersonTestDataService.svc Microsoft
<ListBox x:Name="MainListBox" Margin="0,0,-12,0" ItemsSource="{Binding}" SelectionChanged="MainListBox_SelectionChanged"> <ListBox.ItemTemplate> <DataTemplate> <StackPanel Margin="0,0,0,17" Width="432"> <TextBlock Text="{Binding Name}" TextWrapping="Wrap" Style="{StaticResource PhoneTextExtraLargeStyle}" /> <TextBlock Text="{Binding ID}" TextWrapping="Wrap" Margin="12,-6,12,0" Style="{StaticResource PhoneTextSubtleStyle}" /> </StackPanel> </DataTemplate> </ListBox.ItemTemplate> </ListBox>In the code-behind you’ll first declare a member variable to hold the context from the Entity Framework. This is named using convention over configuration.
The db type is Person and the context is of type PersonContext, You initialize it by providing the URI, in this case using the URL obtained from the Cassini web server,
PersonContext context = new PersonContext( new Uri( "http://localhost:49786/PersonTestDataService.svc/" ) );Create a second member variable of type DataServiceCollection<Person> but do not initialize it,
DataServiceCollection<Person> people;In the constructor you’ll initialize the DataServiceCollection using the PersonContext,
public MainPage() { InitializeComponent(); people = new DataServiceCollection<Person>( context );Finally, you’ll load the people collection using the LoadAsync method, passing in the fully specified URI for the People collection in the web service,
people.LoadAsync( new Uri( "http://localhost:49786/PersonTestDataService.svc/People" ) );Note that this method runs asynchronously and when it is finished the people collection is already populated. Thus, since we didn’t need or want to override any of the behavior we don’t implement the LoadCompleted.
You can use the LoadCompleted event if you need to do any other UI updates, but you don't need to. The final code is as shown below:
using System; using System.Data.Services.Client; using System.Windows; using System.Windows.Controls; using DeadSimpleServer.Models; using Microsoft.Phone.Controls; namespace WindowsPhoneODataTest { public partial class MainPage : PhoneApplicationPage { PersonContext context = new PersonContext( new Uri( "http://localhost:49786/PersonTestDataService.svc/" ) ); DataServiceCollection<Person> people; // Constructor public MainPage() { InitializeComponent(); // Set the data context of the listbox control to the sample data // DataContext = App.ViewModel; people = new DataServiceCollection<Person>( context ); people.LoadAsync( new Uri( "http://localhost:49786/PersonTestDataService.svc/People" ) ); DataContext = people; this.Loaded += new RoutedEventHandler( MainPage_Loaded ); } // Handle selection changed on ListBox private void MainListBox_SelectionChanged( object sender, SelectionChangedEventArgs e ) { // If selected index is -1 (no selection) do nothing if ( MainListBox.SelectedIndex == -1 ) return; // Navigate to the new page NavigationService.Navigate( new Uri( "/DetailsPage.xaml?selectedItem=" + MainListBox.SelectedIndex, UriKind.Relative ) ); // Reset selected index to -1 (no selection) MainListBox.SelectedIndex = -1; } // Load data for the ViewModel Items private void MainPage_Loaded( object sender, RoutedEventArgs e ) { if ( !App.ViewModel.IsDataLoaded ) { App.ViewModel.LoadData(); } } } }With people populated we can set it as the DataContext and run the application; you’ll find that the Name and ID are displayed in the list on the Mainpage. Here's how the pieces in the client fit together:
Complete source code available here
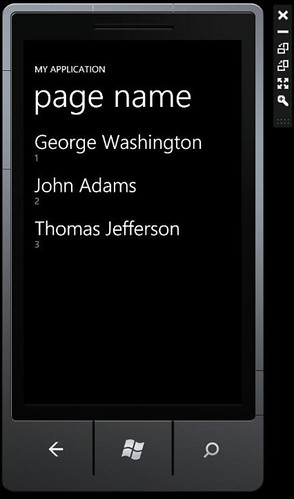

Sebastien Aube reported the availability of Samples from last month’s OData Presentation at Fredericton on 1/4/2011:
OData samples from last month’s meeting can be found on the Fredericton UG Codeplex site at http://fnug.codeplex.com
Once again a big thanks to @adtrevors for presenting.
Sebastien
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, VM Roles, RDP and CDN
Jim O’Neil continued his series with Azure@home Part 14: Inside the VMs on 1/3/2011:
This post is part of a series diving into the implementation of the @home With Windows Azure project, which formed the basis of a webcast series by Developer Evangelists Brian Hitney and Jim O’Neil. Be sure to read the introductory post for the context of this and subsequent articles in the series.
In the previous post, I covered how to configure the deployment of Azure@home to allow Remote Desktop access, a feature introduced with the recent release of the Azure 1.3 SDK. Now that we know how to get into the VMs, I want to take you on a tour of what’s actually running the code in the cloud. As you might know, the web role and worker role functionality in Azure have converged over time, with the only notable difference being the existence of IIS in a web role (and with 1.3, that’s now full IIS not the Hosted Web Core as was the case previously). So, let’s start by looking at the common aspects of the VMs running Azure@home, and then we’ll dig individually into what’s running (and where) for both the WebRole and WorkerRole implementations.
Repeat after me: Windows Azure is a Platform-as-a-Service (PaaS) Offering! Why is that significant? Well, as much as we (ok, I) love to geek out wondering how everything works under the covers, the beauty of Windows Azure is you can be oblivious to most of the details in this post and still build solid, scalable cloud applications – just as you can be an expert driver without knowing the details of how an internal combustion engine works. So do read on to get an appreciation of all that Windows Azure is doing for you as a developer, but don’t lose sight of Azure’s raison d'être to be the most flexible, productive, and open PaaS offering in the cloud computing landscape.
Azure@home VMs
One of the first things I did when getting into my role VMs via Remote Desktop was to take a peek at the hardware specs - via Computer properties from the Start menu. Both the WebRole and WorkerRole instances in my deployment were hosted on VMs exhibiting the specifications you see to the right, namely:
- Windows Server 2008 Service Pack 2 (64-bit OS)
- 2.10 GHz Quad-core processor
- 1.75 GB of RAM
Ultimately, it’s the Windows Azure Fabric Controller running in the data center that has decided upon that specific machine, but it’s the service configuration deployed from the Visual Studio cloud project that tells the Fabric Controller the characteristics of the VM you’re requesting.
Operating System
The operating system type and version are parameters taken directly from the ServiceConfiguration.cscfg file via the osFamily and osVersion attributes of the ServiceConfiguration element. In Azure@home, these values aren’t explicit and so default to ‘1’ and ‘*’, respectively, denoting an OS version roughly equivalent to Windows Server 2008 SP2 (versus Windows Server 2008 R2) and indicating that the latest OS patches should be applied automatically when available, which is roughly on a monthly cadence. If you’d like to lock your deployment on a specific OS release (and assume responsibility for manually upgrading to subsequent OS patches), consult the Windows Azure Guest OS Releases and SDK Compatibility Matrix for the appropriate configuration value setting. Within the Windows Azure Management Portal you can also view and update the Operating System settings as shown below.
Processor
The processor specs (and RAM and local storage, for that matter) are based on another configuration parameter, the vmSize attribute for each of the role elements in the ServiceDefinition.csdef file; the default value is “Small.” That attribute is also exposed via the Properties dialog for each role project within Visual Studio (as shown below). From this configuration, it follows that all instances of a given role type will use the same vmSize, but you can have combinations of worker roles and web roles in your cloud service project that run on different VM sizes.
As noted in the MSDN article, selection of vmSize determines the processor characteristics as shown in the chart below (augmented to include clock speeds published on the Windows Azure site.)

Given this chart, each of the Azure@home VM instances should be running a single CPU with a clock speed of 1.6 GHz. From the Computer properties dialog (above), you can see that the machine hosting the VM has a Quad-Core AMD Opteron 2.10 GHz processor, but that’s the physical box, and a little PowerShell magic on the VM itself shows that the instance is assigned a single core with the 2.1 GHz (2100 MHz) clock speed:
A 2.1 GHz processor is a bit of an upgrade from the 1.6 GHz that’s advertised, but note that there is some overhead here. Code you’ve deployed is sharing that CPU with some of the infrastructure that is Windows Azure. Virtualization is part of it, but there are also agent processes running in each VM (and reporting to the Fabric Controller) to monitor the health of the instances, restart non-responsive roles, handle updates, etc. That functionality also requires processing power, so look at the 1.6 GHz value as a net CPU speed that you can assume will be available to run your code.
RAM
RAM allocation is straightforward given the correlation with vmSize. Azure@home employs small VMs; each small VM comes with 1.75 GB of RAM, and the Computer properties definitely reflect that. From PowerShell, you’ll note the exact amount is just tad less than 1.75 GB (1252 KB short to be exact). Azure nostalgia buffs might notice the PrimaryOwnerName of RedDog Lab – RedDog was the code name for Windows Azure prior to its announcement at PDC 2008!
Disk Space
Local disk space allotments for the VM are also determined by the vmSize selected for the deployed role, and for a small VM, you get 225 GB of memory, which includes space to house diagnostic files and other transient application-specific data. Local disk space is just that, local to the VM, so it is neither persistent nor covered by any service-level agreement (SLA), as both Windows Azure storage and SQL Azure are; therefore, local storage is really only useful for non-critical functions, like caching, or if storage is designed to be reinitialized every time the role restarts. The latter is the case with Azure@home, and you can review part 9 of this series to see how local storage is leveraged in the WorkerRole.
Using the Disk Management utility (diskmgmt.msc) on either VM, you’ll note three partitions (each is a VHD attached by an agent running on the host OS managing your VMs). Role code binaries will typically be found on the E: drive, which is programmatically accessible via the
ROLEROOTenvironment variable; D: contains the guest OS release (determined by the choice of osVersion and osFamily discussed earlier). The local disk allotment (225 GB for a small instance) is provided via the C: drive. Here are stored some of the diagnostic files like crash dumps and failed requests prior to being transferred to blob or table storage. As noted earlier, application code in web and worker roles can also access this drive - via named ‘partitions’ specified in the role configuration file (as defined by LocalStorage elements in ServiceDefinition.csdef).

Note: values in parentheses refer to number of instances of that process running when tasks were sampled
Boiling this chart down, for both web and worker roles:
- clouddrivesvc - is the CloudDrive Service supporting access to Windows Azure Drives. Azure@home doesn’t use that feature, but there seems no way to signal the service configuration that Windows Azure Drives aren’t part of the role implementation.
- MonAgentHost – manages Windows Azure diagnostics.
RemoteAccessAgent – supports access via Remote Desktop (and so is optional, but rather necessary for this post!) .
- RemoteForwarderAgent – manages forwarding Remote Desktop traffic to the correct role instance; it’s only required on one of the roles in the application, and for this deployment it happens to be part of the WorkerRole.
- WaAppAgent – is the Windows Azure guest agent which the Fabric Controller injects into the role deployment to start up your role implementation. This process is actually a parent process of most of the other Azure-related processes (see right).
- WaHostBoostrapper – is a bootstrapper process spawned by WaAppAgent which then spawns either WaIISHost for a web role or WaWorkerHost for a worker role.
The WebRole VM
A web role really consists of two parts, the actual web application (typically ASP.NET) and the role startup code that implements RoleEntryPoint (by default, it’s in WebRole.cs created for you by Visual Studio). Prior to the 1.3 release, both the entry point code and the actual web site were executed within a Hosted Web Core process (WaWebHost.exe). In 1.3, which I’m using here, the entry point code is executed by the WaIISHost.exe process, and the site itself is managed by a w3wp.exe process in IIS.
Since it’s just IIS, you can use IIS Manager to poke around on the VM just as you might use it to manage a site that you’re hosting on premises. Below, for instance, is IIS Manager within one of the two live Azure@home WebRole instances. Via the Basic Settings… option, it’s easy to find just where the site files are located:
E:\approot\_WASR_\0.
Navigate to that location in the VM, and you can make changes (or cause all kinds of damage!) to the running application. For instance, if I simply edit the markup in status.aspx to have a red background and then navigate to the site from my local machine, the resulting page takes on the rather jarring new color. Now, if I refresh that page, or got to a second browser and view it, I see the original baby blue background! Why is that? There are two web role instances running in Azure for Azure@home, and the Windows Azure load balancer uses a round-robin approach, so every other request to status.aspx will hit the updated, red-background site.
Beware of drift! The scenario with the alternating background colors may be a bit contrived, but it very clearly shows that you need to proceed cautiously when making any modifications to a deployed application in a role instance. The changes you are making are out of band, and will not be saved should that role instance be recycled. Additionally, if you have multiple instances of a role in your applications, applying a change to one of those instances and not another can bring your app crashing down at best or make for some very difficult-to-diagnose runtime issues at worst.
If you poke around a bit more on that E: drive, you’ll also find a number of modules supporting diagnostics, various plug-ins (RemoteAccess and RemoteForwarder, for example), and binaries for Windows Azure Drive storage. And if you poke around even more, you might notice that the Azure@home web site (ASPX pages, bin directory, images, the whole nine yards) appears to be deployed twice – once to
E:\approotand then again toE:\approot\_WASR_\0! The redundancy brings us back to the observation made at the beginning of this section: a web role has two parts, namely, the startup code and the actual web site run in IIS. We know that IIS sees the site atE:\approot\_WASR_\0, and as you can verify via Process Explorer, it’s the binary atE:\approot\binthat the WaIISHost process accesses to invoke the methods of the RoleEntryPoint interface (OnStart, OnStop, and Run).The WorkerRole VM
Worker roles don’t have IIS running, so the runtime infrastructure in the VM hosting the role is a bit less complex (at least for Azure@home). With Process Explorer it’s pretty easy to see how the code is handled at runtime.
Similar to a web role, WaAppAgent gets the role started via the WaHostBoostrapper. Since this is a worker role, WaWorkerHost (instead of WaIISHost) loads the role implementation you provided – the code that implements the RoleEntryPoint interface. That code was compiled and deployed from Visual Studio as the WorkerRole.dll assembly, which you can see has been loaded (twice – for some reason) by the worker host process. As you can see from the Explorer screen shot, WorkerRole.dll is loaded from essentially the same location as its analog in the WebRole –
E:\approot. Remember, that theROLEROOTenvironment variable is the way to programmatically determine the location where the code resides; it may not always be the E: drive.Additionally, Process Explorer shows that WaWorkerHost has spawned the Folding@home-Win32-x86.exe process. That’s occurring because the WorkerRole code we wrote (in part 10 of this series) invokes Process.Start on that executable image. The image itself is the one downloaded from Stanford’s Folding@home site. The FahCore_b4.exe process is something that is launched by Stanford’s console client, which from the perspective of Azure@home is a black box.
Take a look at the CPU utilization, by the way. This worker role (or more exactly, FahCore_b4.exe) is pegging the CPU – as we’d expect given that it’s performing some type of computationally intensive simulation under the covers. This is great too from the perspective of our pocketbook: we’re paying 12 cents an hour for this VM whether or not it’s doing anything, so it’s nice to know it’s as busy as possible!
Local Storage in the WorkerRole VM
If you’ve followed the implementation of the WorkerRole, you know that it makes use of local storage on the VM. As part of the Visual Studio project, a resource called FoldingClientStorage was defined of size 1024 MB. From the discussion at the beginning of this post, recall that the 225 GB local storage allotment for the small VM size used for this deployment is reserved for us as the C: drive.
The precise physical location of the 1GB reserved for FoldingClientStorage on the drive can be determined programmatically by code such as this:
String storageRoot = RoleEnvironment.GetLocalResource("FoldingClientStorage").RootPath;In the role instance I peered into, storageRoot resolves to the physical directory
C:\Resources\Directory\hexstring.WorkerRole.FoldingClientStorage.It’s in a subdirectory thereof (client) that the Azure@home SetupStorage method of the WorkerRole (code we wrote back in Part 9) copied the Folding@home-Win32-x86 executable that, in turn, was originally included as content in the Visual Studio project. The other files you see in the Explorer screen shot below are by-products of the Folding@home-Win32-x86 application churning away. The unitinfo.txt file is the most interesting of the files, because that’s what the Azure@home WorkerRole’s ReadStatusFile accesses periodically to parse out the Folding@home work unit progress and write it to the Azure Storage table called workunit, where it’s then read by the status.aspx page of the WebRole.
To wrap this post up, I’ll leave you with a couple of references to sessions at PDC 2010 that were a great help to me and are likewise available to you to learn more about what’s going on under the hood in Windows Azure.
- Inside Windows Azure, with Mark Russinovich
- Inside Windows Azure Virtual Machines, with Hoi Vo
- Migrating and Building Apps for Windows Azure with VM Role and Admin Mode, with Mohit Srivastava
I still have a few blog posts in mind to explore some of the new and enhanced features as they might apply to Azure@home – including changes to Azure diagnostics in SDK 1.3, utilizing startup tasks and the VM Role, and even playing with the Access Control Service, so stay tuned!











Jim is a Developer Evangelist for Microsoft covering the Northeast District
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Cory Fowler (@SyntaxC4) explained Changing the Windows Azure Compute Emulator IP Address in a 1/7/2011 post:
While monitoring twitter tonight I noticed a tweet from Ryan Graham looking for a solution to change the Host Headers for the Windows Azure Compute Emulator (formerly known as DevFabric). With a little bit of investigation I figured out a solution to change the default IP Address that the Compute Emulator is bound to.
Navigate to %ProgramFiles%\Windows Azure SDK\v1.3\
This is the home of the Windows Azure SDK Version 1.3 [Unfortunately, SDK Versions cannot be installed side-by-side].
Navigate to the bin folder. The bin folder contains all of the Command-Line Tools for the Windows Azure SDK which includes:
- CSPack – For Packaging Deployments into CSPKG Files.
- CSRun – For Deploying your application to Windows Azure Compute Emulator.
- CSUpload – For Uploading VHDs to a VM Role.
Navigate to the DevFabric Folder, this is the home of the newly named Compute Emulator.
You’ll notice IISConfigurator.exe which bootstraps the Role into IIS. You’ll also notice that there is a IISConfigurator.exe.config which contains the configuration for the Executable.
Changing the Value for the FixedSiteBindingIpAddress will change the IP Address that the instance is bound to within IIS.
Once you have changed the IP Address to something more appropriate or unused by other websites on your local machine you can then change the Windows Hosts file to assign a URL to the IP Address that was just assigned to your new compute instance.
The Windows Hosts file is located in %windir%\System32\drivers\etc
By following the instructions in the hosts file to associate a URL to the IP Address that you set in the IISConfigurator.exe.config file.




Bill Zack announced the availability of a Moving an Application to Windows Azure - Brian Hitney Talks About Migrating World Maps To Windows Azure podcast in a 1/7/2011 post to the Ignition Showcase blog:
If you are an ISV contemplating moving an existing web based application to the cloud you may be interested in this podcast.
Peter Laudati & Dmitry Lyalin host the edu-taining Connected Show developer podcast on cloud computing and interoperability. A new year, a new episode! Check out episode #40, “Migrating World Maps to Azure”.
A new year, a new episode. This time, the Connected Show hits 40! In this episode, guest Brian Hitney from Microsoft joins Peter to discuss how he migrated his My World Maps application to Windows Azure. Fresh off his Azure Firestarter tour through the eastern US, Brian talks about migration issues, scalability challenges, and blowing up shared hosting.
If you like what you hear, check out previous episodes of the Connected Show at www.connectedshow.com. You can subscribe on iTunes or Zune. New episodes approximately every two or three weeks!


Craig Kitterman (@craigkitterman) posted Offloading work to PHP Worker Roles on Windows Azure to the Iteroperability @ Microsoft blog on 1/7/2011:
There are many common scenarios in web development that require processing of information, gathering data, or handling message traffic that can be accomplished asynchronously – meaning in the background while the user is doing other things with the application. A common example of this is sending email or when thousands of users are posting comments on your blog. When you open an account or change your password, often web applications will send you some kind of confirmation email as part of the workflow. This is typically done from the server using SMTP relay. Anytime an application is connecting to an internal service there are times when network issues can cause problems. These problems range from slow bandwidth to high latency to server outages – each having the possibility to cause a connection timeout or just simply take a long, long time.
When doing this type of processing, you have two options: to “block” and process the message while the user waits on a response from the server, or to allow the user to simply carry on and queue the work for background processing. Windows Azure provides simple tools to make this type of background processing a snap.
That's one more update for this week on the http://azurephp.interoperabilitybridges.com site (see others here).
I hope this is useful and I look forward to sharing many more tutorials and demos on simple ways to achieve powerful things with PHP and Windows Azure in the coming weeks.
Craig is a Sr. Interop Evangelist for Microsoft.
Jean-Christophe Cimetiere reported Windows Azure tools for PHP get an update and refreshed content on 1/6/2011:
The Windows Azure tools for PHP (see the list below) got an update for Christmas (well a little bit before, to be honest ;-), following up with the new version of the Windows Azure SDK 1.3 that was updated in November. As a reminder, here is what these three are doing:
- Windows Azure Command-line Tools for PHP: Enables PHP developers to easily package and deploy applications to Windows Azure, using a simple command-line tool
- Windows Azure Tools for Eclipse/PHP : Provides PHP developers using Eclipse with tools to create and deploy web applications targeting Windows Azure.
- Windows Azure Companion : Provides a seamless experience when installing and configuring PHP platform-elements (PHP runtime, extensions) and web applications running on Windows Azure
No big changes or real new features for now, but we wanted to mention as well the new and updated technical content that we are steadily publishing on the http://azurephp.interoperabilitybridges.com/ site. Brian Swan has updated his tutorial, Using the Windows Azure Tools for Eclipse with PHP. And don’t forget, Jas Sandhu’s Quicksteps to get started with PHP on Windows Azure published last week, which will help you quickly set up your machine in a "few clicks" with all the necessary tools and settings you will need.
Jean-Christophe is Senior Technical Evangelist in the Interoperability Technical Strategy team lead by Jean Paoli.
<Return to section navigation list>
Visual Studio LightSwitch

Return to section navigation list>
Windows Azure Infrastructure
Joe Weinman (@joeweinman) published the 30-page PDF working version of his Time is Money: The Value of “On-Demand” white paper on 1/7/2010. From the Abstract:
Cloud computing and related services offer resources and services ―on demand.‖ Examples include access to ―video on demand via IPTV or over-the-top streaming; servers and storage allocated on demand in ―infrastructure as a service; or ―software as a service‖ such as customer relationship management or sales force automation. Services delivered ―on demand‖ certainly sound better than ones provided ―after an interminable wait, but how can we quantify the value of on-demand, and the scenarios in which it creates compelling value?
We show that the benefits of on-demand provisioning depend on the interplay of demand with forecasting, monitoring, and resource provisioning and de-provisioning processes and intervals, as well as likely asymmetries between excess capacity and unserved demand.
In any environment with constant demand or demand which may be accurately forecasted to an interval greater than the provisioning interval, on-demand provisioning has no value.
However, in most cases, time is money. For linear demand, loss is proportional to demand monitoring and resource provisioning intervals. However, linear demand functions are easy to forecast, so this benefit may not arise empirically.
For exponential growth, such as found in social networks and games, any non-zero provisioning interval leads to an exponentially growing loss, underscoring the critical importance of on-demand in such environments.
For environments with randomly varying demand where the value at a given time is independent of the prior interval—similar to repeated rolls of a die—on-demand is essential, and generates clear value relative to a strategy of fixed resources, which in turn are best overprovisioned.
For demand where the value is a random delta from the prior interval—similar to a Random Walk—there is a moderate benefit from time compression. Specifically, reducing process intervals by a factor of results in loss being reduced to a level of of its prior value. Thus, a two-fold reduction in cost requires a four-fold reduction in time.
Finally, behavioral economic factors and cognitive biases such as hyperbolic discounting, perception of wait times, neglect of probability, and normalcy and other biases modulate the hard dollar costs addressed here.
Joe leads Communications, Media and Entertainment Industry Solutions for Hewlett-Packard. The views expressed herein are his own. Contact information is at http://www.joeweinman.com/contact.htm.
You might find Joe’s "The Market for 'Melons': Quantity Uncertainty and the Market Mechanism" (PDF) white paper of interest also.
Bill Zack posted links to the first three parts of Windows Azure for IT Pros on 1/7/2011 to the Ignition Showcase blog:
There is a lot of developer-focused information on the web about the Windows Azure Platform. This blog post series is one designed for the non-developer IT professional. I was planning to wait until the series was finished before telling you about it, but it is too good not to share. Currently it is only up to Part 4 but it should prove interesting to you.
The Cloud Computing for IT Pros series focuses on the Windows Azure Platform and includes:
- Part 1: What Is Service
- Part 2: What Is Cloud
- Part 3: Windows Azure Computing Model
- Part 4: Fabric Controller and AppFabric
- Part 5: Publishing Windows Azure Application to Public Cloud
- Part 6: Building Private Cloud
Note that the last session will not be about Windows Azure. It is about Private Clouds. I assume that it will be about Hyper-V Cloud, a subject that I have also been covering in this blog.
See: New EMC information infrastructure solutions for Microsoft Hyper-V help customers accelerate journey to private cloud and Hyper-V Survival Guide
K. Scott Morrison posted Dilbert on Cloud Computing on 1/7/2011:
Scott Adams nails it once again:

Perfect!
Alex Williams asked on the same date What Really Matters: Will Dilbert Do More Cartoons About the Cloud?
Stephen O’Grady (@sogrady) posted What’s in Store for 2011: A Few Predictions to the Redmonk blog on 1/7/2011. Here’s the introduction and a few examples:
It is true that predictions for the new year are best made before it begins. And predictions regarding consumer technology trends specifically should certainly be made prior to CES. All fair complaints.
Which I will now ignore.
The following are my predictions for the upcoming calendar year. They are informed by historical context and built off my research, quantitative data that’s available to me externally or via RedMonk Analytics, and the conversations I’ve had over the past twelve months, both digital and otherwise. They cover a wide range of subjects because we at RedMonk do.
With respect to their accuracy, as with all predictions these are best considered for what they are: educated guesses. For context, last year’s predictions graded out as approximately 66% correct.
On to the predictions.
Browsers
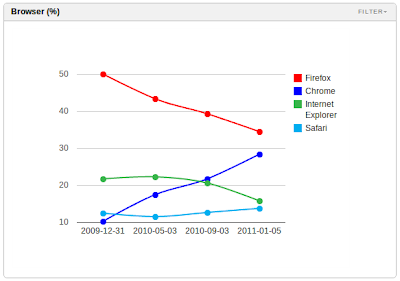
Firefox Will Cede First Place to Chrome, But Not Without a Fight
From Screenshots
We built RedMonk Analytics to track developer behaviors, and what it is telling us at present is that Firefox and IE both are losing share amongst developer populations to Chrome. Chrome is highly performant, but also benefiting from significant marketing investment (e.g. billboards, site sponsorships) and related product development (e.g. Chrome Web Store). The conclusion from this data is that Chrome will eclipse Firefox from a marketshare standpoint (speaking specifically of developers, not the wider market where Firefox is sustainably ahead), likely within a quarter.
But having tested the 4.0 version of Firefox for several weeks, it’s clear that Mozilla’s browser is responding to the evolutionary threat. Firefox 4.0 is faster and less stale from a user interface perspective, but more importantly differentiated via features like Panorama.
The 4.0 release is unlikely to be sufficient in preventing Chrome from assuming the top spot among developer browser usage, but it is likely to arrest the free fall. Expect Chrome and Firefox to be heavily competitive in 2011.
Cloud
PaaS Adoption Will Begin to Show Traction, With Little Impact on IaaS Traction
The conventional wisdom asserts that, at present, the majority of cloud revenue derives from IaaS offerings over PaaS alternatives. The conventional wisdom is correct. Infrastructure-as-a-Service has benefited from its relative simplicity and by virtue of its familiarity: IaaS offerings more closely resemble traditional infrastructure than PaaS. Platform-as-a-Service adoption, for its part, has been slowed by a variety of factors from legitimate concerns regarding platform lock-in to vendor design decisions. The result has been a marketplace that heavily advantages IaaS.
This will not invert in 2011, but the wide disparity in relative adoption will narrow as PaaS adoption climbs. With a multiple year track record of of anemic adoption, PaaS vendors will adapt to customer demand or they will lose ground. Specifically, expect PaaS vendors to borrow from Heroku’s model [coverage], offering platforms assembled from standard or near standard componentry.
Assuming that PaaS will never be successful because it has yet to be successful is illogical. Historical precedent demonstrates adequately that some markets take longer to establish than others (e.g. SaaS). Watch PaaS in 2011.
Interestingly, the rise in PaaS adoption will have little impact on Amazon. Most obviously because its traction has become, to some extent, self-fulfilling, but also because the vendor has anticipated demand and added platform-like features to its infrastructure offerings. With cloud being far from a zero sum market, it’s reasonable to expect Amazon and select PaaS vendors to both be successful.
Developers
Talent Shortages Will Continue
It is counterintuitive to speak of talent shortages when the overall labor market hovers near 10% unemployment, but the data supports no other conclusion. Employers that we speak with, large and small, are desperate for people. RedMonk Analytics query histories regularly feature searches on named individuals, a frequent precursor to recruiting efforts. Our @monkjobs account, for its part, has more positions that we can reasonably post.
It is unclear where this demand will lead. Fred Wilson is correct when he argues that the fundamentals of this hiring war are unsustainable in the longer term. But even should the hypercompetitive Silicon Valley market experience a major correction, it is probable that wider industry trends will remain biased towards talent, assuming the economy does not substantially recede in the next twelve months.
What this means, then, is that employers will be forced to be creative about talent acquisition. Besides traditional benefits such as high end workstations and stock options, employers may be forced to consider allowing employees to release their work as open source, granting them access to data not available elsewhere or giving them the right to work relatively autonomously within the larger organization. In many cases, it may involve leaving positions unfilled in favor of consumption of externally produced software. Other counterintuitive approaches to easing hiring pains include publishing guidelines on your proprietary engineering approaches (e.g. Hadoop), which affords some of the benefits of open source software – namely academic familiarity – without the attendant risks to competitive advantage.
Expect hiring to be a challenge in 2011. If identifying and employing qualified resources proved challenging during the worst recession since 1930, it is unlikely to become less so as global economies gradually recover. …
Stephen continues with “Frameworks”, “Data”, “Hardware”, “Mobile”, “NoSQL”, “Open Source” and “Programming Languages” topics.
James Governor asked and answered 2010 Predictions: How’d I Do? in a 1/7/2011 post to another Redmonk blog. Here’s his report for cloud-oriented prognostication:
Hybrid Cloud and On Premise models for the enterprise. Hybrid is now just the reality of how we get things done. Just as open source began as a fringe activity, but captured the mainstream, so SaaS and Cloud are increasingly just an economic and technical reality. Cloud doesn’t replace on premise, it augments it.
I called this perfectly.
That said, the Big Cloud Backlash will be in full effect in 2010, after all the hype in 2009.
Nope – 2010 was yet more hype. Backlash for this year?
SOA without the SOA. The hard work done by Oracle, SAP and others will begin to bear fruit. Not in terms of the acronyms loved by Architecture Astronauts such as XML Web Services, WSDL, UDDI and other acronyms – but the componentisation of application suites into more modular services makes them far more amenable to web-based integration.
This happened, if quietly. Check out how AMEE integrates with SAP using Mulesource.
Mark Michaelis wrote .NET Survival Guide: Cloud and Software as a Service for Visual Studio Magazine’s 1/2011 issue on 1/2/2011:
Cloud and Software as a Service
Cloud computing solutions vary considerably, yet claim superior privacy, security and scalability over on-premises deployments that also require the expense of an IT department to manage them. Different cloud approaches differ in implementation, however, with various models allowing for the renting of rack space, dedicated servers, virtual machine (VM) time and even application CPU time.
Tool Box
- ASP.NET Hosting
- Microsoft Azure AppFabric
- SQL Azure (with OData support)
- Azure Service Bus
- Software as a Service
- Windows Communication Foundation
This diversity of cloud computing solutions can be broken down into three primary categories, each building on top of the other:
- Infrastructure as a Service (IaaS): IaaS provides the hardware (rack space, servers, network connectivity, electrical power and so on) along with the base OS installation and (optionally) database platforms. Customers with this level of service generally have remote access to the environment, along with the responsibility for all software-related installation, updates and configuration. Support for scalability is through the explicit requisitioning of additional hardware and then configuration to manage and enable the scalability.
Examples: Amazon Web Services and Windows Azure Virtual Machine Role- Platform as a Service (PaaS): PaaS enables the deployment of applications into a hosting environment on which the applications run. It includes automated service management with application-lifetime management, load balancing, platform patches and more, leaving only configuration of the app to the customer. PaaS allows the application to automatically scale to demand, so that even the concept of how many servers are executing the application is abstracted away.
Examples: Microsoft Azure AppFabric and ASP.NET Hosting- Software as a Service (SaaS): This is where an application itself is hosted and customers subscribe to the functionality of the application. Although the application may be deployed across a myriad of devices and locations, the customer just sees it as a software application that's available when needed.
Examples: Gmail, bing.com and Microsoft Office 365PaaS provides the ideal solution for developers working to enable SaaS deployments for their organizations. PaaS enables focus on an app's business value, rather than the necessary but auxiliary infrastructure that hosts the app. PaaS also provides companies with the lowest level of commitment needed to provide SaaS to their customers.
There are some drawbacks to consider with PaaS, though these are growing less severe over time. First, there remains a significant level of complexity when it comes to managing connections to other applications that are still running on-premises. Providing secure access to intranet-based LOB systems is still non-trivial. Similarly, if data storage sizes are large, the costs of storage in the cloud can appear expensive.
PaaS platforms such as ASP.NET Hosting generally provide smooth migration of identical code from your own premises into the cloud. Windows Azure AppFabric[*] does require some application tweaks to make the jump, but as the technology improves, this pain point will almost certainly diminish. In both cases, there's an on-premises means for development testing prior to deployment, which is important because deploying to solutions such as Windows Azure is generally an order of magnitude slower than deploying to an on-premises server. This factor, coupled with the possibility that running in the cloud could expose discrepancies with the on-premises behavior, makes automated deployment (using Windows Azure SDK-provided Windows PowerShell cmdlets) an important time-saver in the ALM process.
There's little doubt that for startup organizations, the cloud is an intriguing target for application development. However, cloud computing may not make sense for organizations that have considerable investment in their own datacenters. In either case, managers must factor in the on-premises costs of disaster recovery, IT support staff, security, scalability and highly available connectivity when making a decision.
In Summary Microsoft AppFabric[*] and ASP.NET Hosting promise a seamless path for ASP.NET applications to reside both on-premises and in the cloud.
JUMP TO [OTHER] SECTIONS
Web and RIA Development
Line-of-Business Development
Multi-Core and Parallel Development
Mobile and Windows Phone 7
Data Access Technologies
Application Lifecycle Development
Back to Introduction
* I believe Mark meant the Windows Azure Platform when he referred to Microsoft/Windows Azure AppFabric.
Full disclosure: I’m a contributing editor for Visual Studio Magazine.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
See Lydia Leong (@cloudpundit) explained Why cloud IaaS customers care about a colo option in a 1/7/2011 post to her CloudPundit blog in the Other Cloud Computing Platforms and Services section below for her take on hybrid clouds.
Kevin Fogarty wrote 5 Most Surprising Things about the Cloud in 2010 for CIO.com, which NetworkWorld republished on 1/3/2011:
2010 was the year "cloud computing" became colloquialized to just "cloud," and everyone realized "cloud," "SAAS" and all the other xAAS's (PAAS, IAAS, DAAS) were all different implementations of the same idea -- a set of computing services available online that can expand or contract according to need.
Not all the confusion has been cleared up, of course. But seeing specific services offered by Amazon, Microsoft, Oracle, Citrix, VMware and a host of other companies gave many people in IT a more concrete idea of what "the cloud" actually is.
What were the five things even experienced IT managers learned about cloud computing during 2010 that weren't completely clear before? Here's my list.
1. "External" and "Internal" Clouds Aren't All That Different
At the beginning of 2010 the most common cloud question was whether clouds should be built inside the firewall or hired from outside.
Since the same corporate data and applications are involved -- whether they live on servers inside the firewall, live in the cloud or burst out of the firewall into the cloud during periods of peak demand -- the company owning the data faces the same risk.
So many more companies are building "hybrid" clouds than solely internal or external, according to Gartner virtualization guru Chris Wolf, that "hybrid" is becoming more the norm than either of the other two.
"With internal clouds you get a certain amount of benefit from resource sharing and efficiency, but you don't get the elasticity that's the real selling point for cloud," Wolf told CIO.com earlier this year.
2. What Are Clouds Made of? Other Clouds.
During 2010, many cloud computing companies downplayed the role of virtualization in cloud computing as a way of minimizing the impact of VMware's pitch for end-to-end cloud-computing vision -- in which enterprises build virtual-server infrastructures to support cloud-based resource-sharing and management inside the firewall, then expand outside.
Pure-play cloud providers, by contrast, offer applications, storage, compute power or other at-will increases in capacity through an Internet connection without requiring a virtual-server infrastructure inside the enterprise.
Both, by definition, are virtualized, analysts agree, not only because they satisfy a computer-scientific definition, but because they are almost always built on data-centers, hosted infrastructures, virtual-server-farms or even complete cloud services provided by other companies.
3. "Clouds" Don't Free IT from Nuts and Bolts
Cloud computing is supposed to abstract sophisticated IT services so far from the hardware and software running them that end users may not know who owns or maintains the servers on which their applications run.
That doesn't mean the people running the servers don't have to know their business, according to Bob Laliberte, analyst at the Enterprise Strategy Group. If anything, supporting clouds means making the servers, storage, networks and applications faster and more stable, with less jitter and lag than ever before, according to Vince DiMemmo, general manager of cloud and IT services at infrastructure and data-center services provider Equinix.
Joe Panettieri posted Microsoft Prepares Windows Azure Cloud Appliances for MSPs to the MSPMentors blog on 1/6/2011:
When Microsoft Channel Chief Jon Roskill (pictured) first spoke about Windows Azure appliances for private clouds in mid-2010, the software giant planned to target really big hardware deployments and large enterprises. But during a phone conversation today, Roskill said Microsoft plans to ensure Windows Azure appliances also appeal to smaller managed services providers (MSPs). Here’s how.
Our conversation covered a range of topics, including Microsoft’s cloud billing model for channel partners; virtualization trends in the channel; Microsoft’s channel momentum with CRM; and overall milestones since Roskill was named channel chief in mid-2010.
But for this blog entry, let’s focus on the Windows Azure Platform Appliance, which Microsoft first discussed during the Worldwide Partner Conference (WPC) in July 2010.
“I think you’ll see everything from big containers to a small footprint on the Windows Azure Appliances,” said Roskill. In some cases, the footprint could be as small as four servers, he added. The Azure Appliances use the same software design as Microsoft’s Windows Azure public cloud. However, the Azure Appliances are similar to cable boxes in terms of concept: VARs and MSPs can deploy them as private cloud solutions. Then Microsoft can remotely auto-update the appliances. “I do think what we’ll see in the Azure Appliance will be a great way for MSPs to play in [the private cloud] space,” Roskill said.
Still, the Azure Appliance effort will take some time to roll out. Roskill estimates that the first Azure Appliances from hardware vendors should debut around nine months from now.
Meanwhile, Roskill sees opportunities for MSPs to connect the dots between on-premise systems and cloud solutions. He noted that the Windows Azure Connect allows partners and customers to link an on-premise applications to a Web service up in the Azure cloud.
It’s clear that Roskill has been spending more time with MSPs since being named channel chief in mid-2010. During our discussion, Roskill pointed to multiple MSP-centric meetings he has hosted across the U.S. That’s encouraging. Rewind to the Microsoft Worldwide Partner Conference in July 2010, and Roskill had conceded he needed to study MSP trends more closely. …
Read More About This Topic
Sheng Liang and Peder Ulander described 7 Requirements for Building Your Cloud Infrastructure in a 12/21/2010 post to ComputerWorld (reprinted from CIO.com; missed when posted):
Today, service providers and enterprises interested in implementing clouds face the challenge of integrating complex software and hardware components from multiple vendors. The resulting system can end up being expensive to build and hard to operate, minimizing the original motives and benefits of moving to cloud computing. Cloud computing platforms are attractive because they let businesses quickly access hosted private and public resources on-demand without the complexities and time associated with the purchase, installation, configuration and deployment of traditional physical infrastructure.
While 2010 was the year for talking about the cloud, 2011 will be the year for implementation. It is for this reason that it is important for service providers and enterprises to gain a better understanding of exactly what they need to build their cloud infrastructure. For both enterprises and service providers, the successful creation and deployment of cloud services will become the foundation for their IT operations for years to come making it essential to get it right from the start.
For the architect employed with building out a cloud infrastructure, there are seven key requirements that need to be addressed when building their cloud strategy. These requirements include:
1. Heterogeneous Systems Support
Not only should cloud management solutions leverage the latest hardware, virtualization and software solutions, but they should also support a data center's existing infrastructure. While many of the early movers based their solutions on commodity and open source solutions like general x86 systems running open source Xen and distributions like CentOS, larger service providers and enterprises have requirements around both commodity and proprietary systems when building out their clouds. Additionally, cloud management providers must integrate with traditional IT systems in order to truly meet the requirements of the data center. Companies that don't support technologies from the likes of Cisco, Red Hat, NetApp, EMC, VMware and Microsoft will fall short in delivering a true cloud product that fits the needs of the data center.
2. Service Management
To productize the functionality of cloud computing, it is important that administrators have a simple tool for defining and metering service offerings. A service offering is a quantified set of services and applications that end users can consume through the provider — whether the cloud is private or public. Service offerings should include resource guarantees, metering rules, resource management and billing cycles. The service management functionality should tie into the broader offering repository such that defined services can be quickly and easily deployed and managed by the end user.
3. Dynamic Workload and Resource Management
In order for a cloud to be truly on-demand and elastic while consistently able to meet consumer service level agreements (SLAs), the cloud must be workload- and resource- aware. Cloud computing raises the level of abstraction to make all components of the data center virtualized, not just compute and memory. Once abstracted and deployed, it is critical that management solutions have the ability to create policies around workload and data management to ensure that maximum efficiency and performance is delivered to the system running in the cloud. This becomes even more critical as systems hit peak demand. The system must be able to dynamically prioritize systems and resources on-the-fly based on business priorities of the various workloads to ensure that SLAs are met.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Brian Loesgen reported LA CloudCamp next week is sold out, San Diego CloudCamp registration open on 1/6/2011:
If you have not yet registered for CloudCamp LA next week, sorry, but it’s sold out.
I’ll be there doing a lightning talk. I’m trying something new, File|New|PowerPoint, and pretty radical and hip given it is, after all, Los Angeles. I’m pushing my creative limits to come up with a compelling yet non-commercial rapid-fire presentation. This could go either way, but I’m pretty sure you’ll be entertained!
Registration for the San Diego CloudCamp is open, at http://cloudcamp.org/sandiego/2011-02-09. It will be Feb 9, and I’ll be posting more details as the time gets closer. I’ll be doing a lightening talk there as well.
San Diego will also likely sell out, so… don’t procrastinate, sign up NOW to ensure your spot.
Mithun Dhar (@mithund) posted on 1/6/2011 SharePoint 2010 FireStarter Event | Jan 27th 2010 | Redmond, WA & Streamed live Online…, which includes an Integrating SharePoint with Azure session:
Happy New Year folks!
This new year marks another fresh FireStarter series. On January 27th, Microsoft is hosting the SharePoint 2010 FireStarter event in Redmond, WA. The entire event will be Streamed Live online. Be sure to Register to attend in-person or watch the action unfold Live online!
We have a fantastic Line up of speakers, including all the SharePoint Rockstars like Paul Stubbs, Steve Fox, etc. This event is day long with lunch and a few other breaks sponsored by Microsoft. The entire event is FREE! All the sessions will be recorded and made available to you online after the event. Take a peek at the agenda…
Agenda:
Time (PST)
Session
Speaker
8:00 am - 8:30 am
Breakfast
8:30 am - 9:00 am
Introduction to the day
9:00 am - 10:00 am
Keynote
10:00 am - 10:15 am
Break
10:15 am - 11:15 am
SharePoint 2010 Developer Overview
11:15 am - 12:15 pm
SharePoint 2010 Developer Tools
12:15 pm - 1:00 pm
Lunch
1:00 pm - 2:00 pm
SharePoint Development in the Cloud with SharePoint Online
2:00 pm - 3:00 pm
Integrating SharePoint with Office
3:00 pm - 3:15 pm
Break
3:15 pm - 4:15 pm
Integrating SharePoint with Azure
4:15 pm - 5:00 pm
Integrating SharePoint with Silverlight
Registration (Click below):
Time:
Thursday, January 27th 2011
8:30 AM – 5:00 PM PSTVenue:
Microsoft Conference Center
16070 NE 36th Way
Building 33
Redmond, WA 98052Contact:
Mithun Dhar – Leave a comment on my blog or tweet me at @mithund
We look forward to seeing you at the event! Let me know if you have any questions…
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr described Elastic MapReduce Updates - Hive, Multipart Upload, JDBC, Squirrel SQL on 1/7/2011:
I have a number of Elastic MapReduce updates for you:
- Support for S3's Large Objects and Multipart Upload
- Upgraded Hive Support
- JDBC Drivers for Hive
- A tutorial on the use of Squirrel SQL with Elastic MapReduce
Support for S3's Large Objects and Multipart Upload
We recently introduced an important new feature for Amazon S3 — the ability to break a single object into chunks and to upload two or more of the chunks to S3 concurrently. Applications that make use of this feature enjoy quicker uploads with better error recovery and can upload objects up to 5 TB in size.
Amazon Elastic MapReduce now supports this feature, but it is not enabled by default. Once it has been enabled, Elastic MapReduce can actually begin the upload process before the Hadoop task has finished. The combination of parallel uploads and an earlier start means that data-intensive applications will often finish more quickly.
In order to enable Multipart Upload to Amazon S3, you must add a new entry to your Hadoop configuration file. You can find complete information in the newest version of the Elastic MapReduce documentation. This feature is not enabled by default because your application becomes responsible for cleaning up after a failed upload. The AWS SDK for Java contains a helper method (AbortMultipartUploads) to simplify the cleanup process.
Upgraded Hive Support
You can now use Hive 0.7 with Elastic MapReduce. This version of Hive provides a number of new features including support for the HAVING clause, IN clause, and performance enhancements from local mode queries, improved column compression, and dynamic partitioning.You can also run versions 0.5 and 0.7 concurrently on the same cluster. You will need to use the Elastic MapReduce command-line tools to modify the default version of Hive for a particular job step.
JDBC Drivers for Hive
We have released a set of JDBC drivers for Apache Hive that have been optimized for use with Elastic MapReduce. Separate builds of the drivers are available for versions 0.5 and 0.7 of Hive:Squirrel SQL Tutorial
We have written a tutorial to show you how to use the open source Squirrel SQL client to connect to Elastic MapReduce using the new JDBC drivers. You will be able to query your data using a graphical query tool.
Lydia Leong (@cloudpundit) explained Why cloud IaaS customers care about a colo option in a 1/7/2011 post to her CloudPundit blog:
Ben Kepes has raised some perceived issues on the recent Cloud IaaS and Web Hosting Magic Quadrant, on his blog and on Quora. It seems to reflect some confusion that I want to address in public.
Ben seems to think that the Magic Quadrant mixes colocation and cloud IaaS. It doesn’t, not in the least, which is why it doesn’t include plain ol’ colo vendors. However, we always note if a cloud IaaS vendor does not have colocation available, or if they have colo but don’t have a way to cross-connect between equipment in the colo and their cloud.
The reason for this is that a substantial number of our clients need hybrid solutions. They’ve got a server or piece of equipment that can’t be put in the cloud. The most common scenario for this is that many people have big Oracle databases that need big-iron dedicated servers, which they stick in colo (or in managed hosting), and then cross-connect to the Web front-ends and app servers that sit in the cloud. However, there are other examples; for instance, our e-commerce clients sometimes have encryption “black boxes” that only come as hardware, so sit in colo while everything else is in the cloud. Also, we have a ton of clients who will put the bulk of their stuff into the colo — and then augment it with cloud capacity, either as burst capacity for their apps in colo, or for lighter-weight apps that they’re moving into the cloud but which still need fast, direct, secure communication with interrelated back-end systems.
We don’t care in the slightest whether a cloud provider actually owns their own data center, directly provides colocation, has any strategic interest in colocation, or even offers colocation as a formal product. We don’t even care about the quality of the colocation. What we care about is that they have a solution for customers with those hybrid needs. For instance, if Amazon were to go out and partner with Equinix, say, and customers could go colo in the same Equinix data center as Amazon and cross-connect directly into Amazon? Score. Or, for instance, Joyent doesn’t formally offer colocation — but if you need to colocate a piece of gear to complement your cloud solution, they’ll do it. This is purely a question of functionality.
Now, you can argue that plenty of people manage to use pure-play cloud without having anything that they can’t put in the cloud, and that’s true. But it becomes much less of a typical scenario the more you move away from forward-thinking Web-native companies, and towards the mixed application portfolios of mainstream business. It’s especially true among our mid-market clients, who are keenly interested in gradually migrating to cloud as their primary approach to infrastructure, hybrid models are critical to the migration path.
Lydia also wrote The impurity of cloud on the same date:
I’ve already agreed that people would find it useful to see a Magic Quadrant that is focused solely on a particular segment of the market — “pure” cloud IaaS. That’s why we’re going to be doing one in the middle of this year, as I noted previously. It’s also why our upcoming Critical Capabilities note, which focuses solely on product features, is cloud-only. (A Magic Quadrant, on the other hand, is about overall markets, which means we factor in sales, marketing, etc. — it’s not about fitness for use, whereas the Critical Capabilities are.)
However, I still think it’s important to understand the inherent messiness of this market, which is why we currently have an MQ that covers not just cloud IaaS, but also the hosting market.
I’ve previously talked about how customers have different levels of desire for managed services with the cloud. In that blog post, I also touched on the difference between trying to source cloud for a single important application (or a tightly-related group of apps), and sourcing cloud for a bunch of multiple less-critical applications.
Customers who are trying to source cloud for a single important application are essentially looking at hosting; the cloud is offering them on-demand, elastic resources. That’s why cloud has impacted the hosting industry so strongly — people want the flexibility and agility, but it doesn’t change the fact that they have traditional hosting requirements. As always with hosting, customers run the gamut from those who just want infrastructure, to those who want it fully managed. Customers often don’t know what they want, either, as I described in a blog post a while back, called, “I’m thinking about using Amazon, IBM, or Rackspace…” — which is how you get a weird mix of vendors in an RFP, as a customer tries to explore the possibilities available to them.
Customers who are trying to source cloud for multiple, less-important applications — essentially, the first steps towards replacing a traditional data center with a cloud IaaS solution — have different needs. Their requirements are distinct, but many of the provider capabilities that are useful for hosting are also useful for delivering these solutions, which is why so many Web hosters have expanded into this market.
You can cross “single app or multiple app?” with “what level of managed services?” to derive a set of distinct market segments — in fact, I’m in the midst of writing a research note on market segmentation that does exactly that. I believe it’s still all one market, and that most providers will end up serving multiple segments of that market. I believe that all of those segments are important, not just the ones closest to the cloud pure-play model.
I think, as an analyst, that it can be tempting to follow only the most compelling, fast-growing, quickest-evolving pieces of a market — to get caught up in the excitement, so to speak. My IT buyer clients force me to be balanced, though, because they care about a lot more than just what’s hot. Clearly, right now, they need more help sourcing in specific segments, which is why we’re doing some narrower vendor ratings focused on a more “pure cloud” tilt — but that shouldn’t be taken as an indication that the other segments aren’t important.
Let me start by saying that I have drunk the cloud Kool-Aid. I am a believer in its transformative power, and in the business models that it is enabling. I believe that the IT world will look very different in 10 years, and the 5-year differences will be noticeable. I believe in the success stories of the fresh young cloud-native companies.
But I also believe that you’ve got to get there from here. While I have the privilege of working with many smaller technology companies, including cloud-based start-ups, the vast majority of Gartner’s clients are mid-sized businesses and enterprises. Those clients have a vast array of existing IT investments, in both infrastructure and applications, as well as people, process, policies, and the like. Most of our clients are excited by the possibilities that the cloud is offering, and they’re interested in adopting all of it — SaaS, PaaS, IaaS. But they’ve got to figure out how to do it, how to make a sensible, risk-controlled move from what they’ve got today, including, importantly, the mindset and culture of what they have today, to the cloud future.
Our clients are looking for solutions to business needs. Many of them are also explicitly looking for an opportunity to use cloud for the sake of using cloud — to get their feet wet, to learn things, to satisfy the demands of a CEO or CFO, and so forth. As an analyst, my goal is to help my clients find solutions that they’ll be successful with. That’s not just purely about technology; I need to help clients find solutions that also work for their culture, their appetite for risk, their ability to manage change, the way they budget, the way they approach operations and applications and governance, the way they source solutions and manage vendors, their available personnel and their ability to learn new things, their timeframes and business needs, and so forth.
IT buyers are slowly transforming the way they think about cloud, as hype begins to give way to reality. We see people doing very sensible, pragmatic things with cloud IaaS, these days. For most organizations, it will be a five to ten year gradual transformation. The successful blending of old and new models, and the transitional models, are both critical parts to that transformation.
I think my feeling on these things is: Get excited, but don’t get excitable. Most of my research is pitched to people making decisions right now, which is typically about IT buyer immediate needs, and vendor one-year and two-year plans. With cloud, I often look at three-year and five-year scenarios, and we’re doing some ten-year scenarios as well, but that also involves having to think about the sequence and timeline for how things occur in the market.
Fast-evolving markets create and destroy new approaches, and there will always be transitional approaches, artifacts of “what tech is available at this stage” and “what customer mindset exists at this point”. The desires of customers at any given point should not necessarily be taken as the future direction of the market and what will lead to vendor success (or even customer success, ironically). Frankly, some of the things customers will ask for during the transition will be flat-out wacky and wrong. But it won’t change the fact that they want them.
Alex Williams warned about Dimdim: The Risk of Using A Free Service in a 1/7/2011 post to the ReadWriteCloud blog:
There appears to be a bit of customer discontent about the news that Dimdim's free service will be discontinued after the closing of the sale to Salesforce.com.
The closing is without question. The Dimdim FAQ has 11 questions and answers to inform customers about the service's discontinuation.
Dimdim's closing is a study in the risks of using free services. What will happen now to Dimdim customers is all outlined in the FAQ. The first question states the timeline for closure:
How long will my service be available? Monthly accounts will be available until March 15. Annual accounts are available until their current subscription ends. You can determine the expiration date of your subscription by logging into your account at my.dimdim.com.Will I be able to access my recordings after my account is no longer available? How can I keep them??
Your recordings will no longer be available after your account expires. You can download your recording files and chat transcripts before then. See the Knowledge Base for instructions on downloading recordings and transcripts.Open-source code contributions will stop:
What will happen to the Open Source version of Dimdim? The open source code made available by Dimdim remains available on SourceForge.net. Dimdim will no longer be contributing to this project.The API will be maintained as long as the service is functioning:
We have integrated with the Dimdim API. Will you be preserving that functionality? Current API functionality will be maintained for all active subscriptions.Sameer Patel says the Dimdim acquisition is a wake up call about using free tools for business use. They do go away. There are few if any guarantees about your data. But people will get over it. They will move on.
"Loyalty to a free product is somewhat artificial," Patel said.
The services available to Dimdim customers are plenty. Dimdim will be forgotten by customers. But we'll see if the market makes note of what happens when a free service gets acquired.
Most freemium services that I’ve used have retained their free service quotas after being acquired, at least until now.
Chris Czarnecki claimed Philips Brings Cloud Computing to Consumer Electronics with CloudTV in a 1/7/2011 post to the Learning Tree blog:
This week the Consumer Electronics Show 2011 is running in Las Vegas and it is interesting to see that Philips has announced that is has brought Cloud Computing to home entertainment. The claim is that they will be the first brand to incorporate Cloud Computing into their lineup of televisions. The new CloudTV platform provides access to a number of Web applications such as social networking, user generated video games etc all accessed and navigated with standard remote controls.
This announcement by Philips is an example of Cloud Computing become part of everyday life for may people, in a way that is mainly transparent to them. However, is this really Cloud Computing or is it Philips making the most of the excitement around Cloud Computing to promote their products. I think the answer can be gleaned by going back three months and seeing Philips were prompting what they referred to as NetTV. The details sounded very much (exactly) the same as CloudTV !
I highlight this because it raises the question of what exactly is Cloud Computing? This is something that business and early adopters have been trying to work out for a while now as computing providers brand many products as Cloud Computing trying to increase sales, even when the products are not really Cloud Computing products. It appears now that the consumer market is following a similar trend with the same confusion for their customers.
The reality is that Philips CloudTV is not itself Cloud Computing, in the same way a home PC is not on its own Cloud Computing. What they both do provide is Access to Cloud Computing – they are a client to Cloud Computing, enabling users to access Cloud Computing applications and facilities. Vendors are not making it easy for people to determine exactly what Cloud Computing is and what the benefits are. That is why Learning Tree has developed the Cloud Computing Course, not only to define exactly what Cloud Computing is, but also to present its advantages and disadvantages. For those who want to know more but are time constrained, there is also the half day overview that can be attended remotely from your office or maybe from your home, using your TV if you have CloudTV !
In my opinion, CloudTV is a egregious case of cloudwashing.
Kevin Fogarty wrote Microsoft vs. Amazon Clouds: 5 Key Differences, for CIO.com and IT World republished it on 1/4/2011:
Spending on public cloud services is growing quickly--from 4% of overall IT spending in 2009 to 12% during 2014, a rate six times that of traditional systems, according to IDC. Gartner estimates cloud spending already accounts for 10% of IT spending.
Still, growth has never quite matched vendor and analyst projections, according to IDC analyst Frank Gens, whose blog posts summarizing annual surveys trace IDC's changing expectations.
Part of the reason is that cloud is designed to be a major and core part of an IT infrastructure--a role that no technology is allowed to fill without demonstrating its maturity, reliability and security, usually for several years, according to Bernard Golden, CEO of consultancy HyperStratus and a CIO.com blogger.
Cloud-computing technology is still relatively immature, though developing quickly, and has not been around in a stable form long enough for most CIOs to be able to be comfortable saying cloud as a category or a particular provider's service makes sense for his or her company, according to Sean Hackett, a research director at The 451 Group.
At the individual IT project level, however, many developers are doing projects using public cloud technology like Amazon's, in some cases without the CIO ever knowing--until the cost shows up on an expense report, Golden points out. (See Golden's recent blog, The Truth About What Runs on Amazon.)
The difference between even the best-known services--Microsoft's Azure and Amazon's EC2--aren't well understood by most potential customers, Hackett says.
1. Focus on PaaS vs. IaaS
While analysts and vendors acknowledge the endless discussion of what constitutes "cloud" computing and its various flavors can get tiring, the differences between Azure and EC2 are important, Golden says.
Azure can be classified as Platform as a Service (PaaS): a cloud model that offers hardware, operating systems and application-support, effectively offering a virtual server on which to load software, which can be accessed and managed through a Web browser.
<Return to section navigation list>

















0 comments:
Post a Comment