Windows Azure and Cloud Computing Posts for 1/13/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Panagiotis Kefalidis described Patterns: Windows Azure – Upgrading your table storage schema without disrupting your service in an 8/19/2010 post (missed when published):
In general, there are two kind of updates you’ll mainly perform on Windows Azure. One of them is changing your application’s logic (or so called business logic) e.g. the way you handle/read queues, or how you process data or even protocol updates etc and the other is schema updates/changes. I’m not referring to SQL Azure schema changes, which is a different scenario and approach but in Table storage schema changes and to be more precise only on specific entity types because, as you already now, Table storage is schema-less. As in In-Place upgrades, the same logic applies here too. Introduce a hybrid version, which handles both the new and the old version of your entity (newly introduced properties) and then proceed to your “final” version which handles the new version of your entities (and properties) only. It’s a very easy technique and I’m explaining how to add new properties and of course remove although it’s a less likely scenario.
During my presentation at Microsoft DevDays “Make Web not War”, I’ve created an example using a Weather service and an entity called WeatherEntry, so let’s use it. My class looks like this:
[DataServiceKey("PartitionKey","RowKey")] public class WeatherEntry : TableServiceEntity { public WeatherEntry() { PartitionKey = "athgr"; RowKey = string.Format("{0:10}_{1}", DateTime.MaxValue.Ticks - DateTime.Now.Ticks, Guid.NewGuid()); } public DateTime TimeOfCapture{ get; set; } public string Temperature{ get; set; } }There is nothing special at this class. I use two custom properties, TimeOfCapture and Temperature and I’m going to make small change and I’ll add “SchemaVersion” which is needed to achieve the functionality I want. When I want to create a new entry, all I do now is instantiate a WeatherEntry, set the values and use a helper method called AddEntry to persist my changes.
public void AddEntry(string temperature, DateTime timeofc) { this.AddObject("WeatherData", new WeatherEntry { TimeOfCapture = timeofc, Temperature = temperature, SchemaVersion = "1.0" }); this.SaveChanges(); }I’m using TableServiceContext from the newly released StorageClient and methods like UpdateObject, DeleteObject, AddObject etc, exist in my data service context where AddEntry helper method relies. At the moment my Table schema looks like this:

It’s pretty obvious there is no special handling during saving of my entities but this is about to change in my hybrid version.The hybrid
I did some changes at my base class and I’ve added a new property. It’s holding the temperature sample area, in my case Spata where Athens International Airport is.
My class looks like this now:
[DataServiceKey("PartitionKey","RowKey")] public class WeatherEntry : TableServiceEntity { public WeatherEntry() { PartitionKey = "athgr"; RowKey = string.Format("{0:10}_{1}", DateTime.MaxValue.Ticks - DateTime.Now.Ticks, Guid.NewGuid()); } public DateTime TimeOfCapture{ get; set; } public string Temperature{ get; set; } public string SampleArea{ get; set; } public string SchemaVersion{ get; set;} }So, this hybrid client has somehow to handle entities from version 1 and entities from version 2 because my schema is already on version 2. How do you do that? The main idea is that you retrieve an entity from table storage and you check if SampleArea and SchemaVersion have a value. If they don’t, put a default value and save them. In my case my schema version number has to be 1.5 as this is the default schema number for this hybrid solution. One key point to this procedure is before you upgrade your client to this hybrid, you roll-out an update enabling “IgnoreMissingProperties” flag on your TableServiceContext. If IgnoreMissingProperties is true, when a version 1 client is trying to access your entities which are on version 2 and have those new properties, it WON’T raise an exception and it will just ignore them.
var account = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); var context = new WeatherServiceContext(account.TableEndpoint.ToString(), account.Credentials); /* Ignore missing properties on my entities */ context.IgnoreMissingProperties = true;Remember, you have to roll-out an update BEFORE you upgrade to this hybrid.
Whenever I’m updating an entity to Table Storage, I’m checking its version Schema and if it’s not “1.5” I update it and put a default value on SampleArea:
public void UpdateEntry(WeatherEntry wEntry) { if (wEntry.SchemaVersion.Equals("1.0")) { /* If schema version is 1.0, update it to 1.5 * and set a default value on SampleArea */ wEntry.SchemaVersion = "1.5"; wEntry.SampleArea = "Spata"; } /* Put some try catch here to * catch concurrency exceptions */ this.UpdateObject(wEntry); this.SaveChanges(); }My schema now looks like this. Notice that both versions of my entities co-exist and are handled just fine by my application.
Upgrading to version 2.0
Upgrading to version 2.0 is now easy. All you have to do is change the default schema number when you create a new entity to version 2.0 and of course update your “UpdateEntry” helper method to check if version is 1.5 and update the value to 2.0.
this.AddObject("WeatherData", new WeatherEntry { TimeOfCapture = timeofc, Temperature = temperature, SchemaVersion = "2.0" });and
public void UpdateEntry(WeatherEntry wEntry) { if (wEntry.SchemaVersion.Equals("1.5")) { /* If schema is version 1.5 it already has a default value, all we have to do is update schema version so our system won't ignore the default value */ wEntry.SchemaVersion = "2.0"; } /* Put some try catch here to * catch concurrency exceptions */ this.UpdateObject(wEntry); this.SaveChanges(); }Whenever you retrieve a value from Table Storage, you have to check if it’s on version 2.0. If it is, you can safely use its SampleArea value which is not the default any more. That’s because schema version is changed when you actually call “UpdateEntry” which means you had the chance to change SampleArea to a non-default value. But if it’s on version 1.5 you have to ignore it or update it to a new, correct value.
If you do want to use the default value anyway, you can create a temporary worker role which will scan the whole table and update all of your schema version numbers to 2.0.
How about when you remove properties
That’s a really easy modification. If you remove a property, you can use a SaveChangesOption called ReplaceOnUpdate during SaveChanges() which will override your entity with the new schema. Don’t forget to update your schema version number to something unique and put some checks into your application to avoid failures when trying to read non-existent properties due to newer schema version.
this.SaveChanges(SaveChangesOptions.ReplaceOnUpdate);

The Windows Management and Scripting Blog published Introduction to Table Storage in Windows and SQL Azure in January 2011:
In addition to SQL Azure, Windows Azure features four persistent storage forms Tables, Queues , Blobs and Drives. In this article we will focus on Tables.
Table Storage
Tables are a very fascinating new storage method offered in Windows Azure and are Microsoft’s Azure answer to Amazon SimpleDB. The SQL Azure database offers a wealth of features a modern database might be expected to provide. But for many purposes it is overkill. In the past nearly any structured data had to go into the database and incur the performance penalty that entailed. With Azure Tables data which has a relatively simple structure (below we use the example of a Movies data, which is a listing of Movies with different attributes such as title, category, date etc but is not a very complex dataset).
Tables offer structured data storage for data that has relatively simple relationships. Data is stored in rows and as tables are less structured and don’t have the overhead of a full database it is massively scalable and offers very high performance. The interface to Azure Tables is the familiar .NET suite of classes, LINQ, and REST.
To make an Azure Table first make a storage service in the Windows Azure Developer Portal, then make a storage account and from make tables. Each table is scoped to its storage account so different tables with the same name can be used but scoped to different storage accounts.
Table Data Model
Tables are composed of rows and columns. For the purposes of the Azure Table Data Model, rows are entities and columns are properties. For an Entity a set of Properties can be defined but several properties are mandatory – PartitionKey, RowKey and TimeStamp. PartitionKey and RowKey can be thought of as a clustered index which uniquely identifies an entity and defines the sort order. TimeStamp is a read-only property.
Partitions
Table partitions can be thought of as units of scale within Windows Azure which are used for load balancing. Tables are partitioned based on the PartitionKey, all entities on the same PartitionKey will be served by a single server. Therefore selection of an appropriate PartitionKey is central to achieving scalability and higher throughput on Windows Azure. It is vital to note that Azure implements throttling of an account when the resource utilization is very high, appropriate partitioning greatly reduces the potential for this happening by allowing the load to be distributed over different servers. The RowKey provides uniqueness within a single partition.
Partitions can be thought of as a higher level categories for the data with RowKeys are lower level data details. For example, for a ‘Movies’ table the PartitionKey could be the category of the movie such as comedy or sci-fi, RowKey could be the movie title (hopefully the combination of category and title would ensure uniqueness). Under load the table cold be split onto different servers based on the category.
For a write intensive scenario such as logging the PartitionKey would normally be a timestamp. In this instance there is a problem in partitioning as the write will also append to the bottom of the Table and partitioning based on a range will not be efficient as the final partition will always be the only active partition. The recommended solution to this is to add a prefix to the timestamp to ensure that the latest write operations are sent to different partitions.
In database design, tables should be split based on the data type. For example in an retailer’ s database, data of the type ‘customer’ with fields such as ‘name’, ‘address’ etc should be in a separate table to the ‘orders’ which only contains data on orders such as ‘product’, ‘order_date’ etc. But in Azure Tables these could both be efficiently stored in the same table as no space would be taken up by the empty fields (such as ‘order_date’ for a ‘customer’). To differentiate between the two types of data a ‘Kind’ property (column) can be added to each entity (row) which is in effect the table name if they were separated into two tables.
Table Operations
The operations are relatively similar to those of a conventional database – tables (which are analogous to the database) can be made, queried and deleted. Entities (rows) can have insert operations performed, delete operations, queries, and updated. There are two methods of update – Merge and Replace. Merge allows a partial update of the entity, thus if some of the properties of the entity are not given with the update they would not be updated (only the properties provided in the update are updated). Replace updates all the properties of an entity, if a property is not provided in the update it is removed from the entity. A newly introduced feature is Entity Group Transaction which is a transaction over a single partition.
Continuation Tokens
When a single entity(row is queried) the result is returned as with a database query. But when a range is requested Azure Tables can only return 1000 rows in a result set. If the result set is less than 1000 rows that result set is returned, if the result set is larger than 999 , the first 1000 rows of the result set are return together with a Continuation Token. The Table is then re-queried with the Continuation Token passed back to the Table until the query completes.
Continuation Tokens are returned for all results where the results is greater than one. They will also be returned if a query takes longer than 5 seconds (this is the maximum allowed by Azure after which the results are returned with a continuation token and the query must be rerun). Furthermore, continuation tokens are returned when the end of a partition range boundary is hit.Optimizing Queries
Querying a table with a range is a very serial process, with result sets being sent to the client and continuation tokens being sent back for processing until the query completes. This structure doe not allow for any parallel processing. To take advantage of parallel processing the query should be split into ranges based on the PartitionKey, for example instead of
[cc lang='sql' ]Select * from Movies where Rating > 4[/cc]
Use
[cc lang='sql' ]
Select * from Movies where PartitionKey >= ‘A’ and PartitionKey < ‘D’ and Rating > 4
Select * from Movies where PartitionKey >= ‘D’ and PartitionKey < ‘G’ and Rating > 4[/cc]
This enables the query to run in a parallel manner.
Similar to SQL Server, views can also be made to handle well loved queries.
Be careful using ‘OR’ in queries. SQL Azure Tables do not do any optimization on these queries. It is optimal to split the query into several separate queries.
Entity Group Transactions
EGT’s offer transaction-like operations on an Azure table. Up to 100 insert/update/delete commands can be performed in a single transaction provided the payload is under 4MB.
Related posts
<Return to section navigation list>
SQL Azure Database and Reporting
Intertech reported on 1/13/2011 the availability of an Intro to Azure Data Synch Recording video segment:
A big thanks to Liam Cavanagh from the SQL Azure team for presenting to our user group yesterday. To view the recording click here. To find out more about the Windows Azure User Group, click here. We encourage you to register for the group (free) and you will be notified of upcoming events. We also raffle off $1,000's of products from our sponsors. Hope to see you at an upcoming meeting.
Steve Yi [pictured below] posted Real-World SQL Azure: Interview with James Chen, Chief Technology Officer at LinkShare Labs on 1/12/2011:
As part of the Real-World SQL Azure series, we talked to James Chen, the Chief Technology Officer at LinkShare Labs, a division of Rakuten, about how his company is taking advantage of the Windows Azure platform, and particularly Microsoft SQL Azure, to power its new LinkShare Lightning application.
MSDN: Tell us about LinkShare. What services do you offer and what is your corporate vision?
Chen: LinkShare offers online marketing services, such as search engine marketing, lead generation, and affiliate marketing to connect advertisers with publishers, to help them both profitably grow their revenue. Going forward, our vision is to provide a single, flexible performance-marketing platform for the world. It will be the bridge from any publisher to any advertiser in any country. That means, for example, that a publisher in the U.S. could get compensated for lead generation in Japan.
MSDN: What differentiates LinkShare in the online advertising marketplace?
Chen: Unlike a generic ad network, LinkShare gets paid based on conversions—actual completed sales—not just the number of ad impressions or users’ clicks. But more than that, what differentiates us from competitors is that we focus on big, name-brand advertisers, and we offer expert consultative services along with our advanced patented technologies.
MSDN: What prompted LinkShare to start looking at cloud-based solutions?
Chen: It comes back to our vision. We wanted to provide a truly global system so that we could develop advertising applications that can be used anywhere. Behind this goal were two drivers: performance and cost. We needed a technology platform to build and run our applications on that could scale cost-effectively and that would require minimal development effort and support global deployment. Only a cloud platform—and cloud-based databases in particular—could meet those criteria. As a first step, we wanted to build and deploy our LinkShare Lightning cost-per-action marketing solution as a cloud-based application.
MSDN: Did you consider any cloud platforms besides the Windows Azure platform?
Chen: We looked at the other two leading providers. The first one would have required too much investment to make it productive for our developers. What made Windows Azure platform the clear winner over the second one is that Microsoft is a world-class provider of ‘platform as a service.’ Additionally, the commitment of Microsoft to cloud innovation and feature development is very important to us. Every quarter, new Windows Azure platform tools come out to support easy development, whereas with some competitors’ platforms, you have to do a lot of the work yourself by piecing together open source solutions to complete your development stack.
MSDN: LinkShare Lightning is highly data intensive. How does SQL Azure meet your database needs?
Chen: SQL Azure offers cost-effective, on-demand scalability. We have peak demand during the holiday shopping season that’s 10 times higher the rest of the year. We don’t want to add hardware for extra seasonal capacity, or change our software to handle the load for a short period of time; and with SQL Azure, we don’t have to. The best part of using SQL Azure is that we know our application is going to work no matter how big we scale it out.
MSDN: What are your plans for the platform going forward, and what benefits do you expect?
Chen: In order for us to scale our business globally and also profitably, we need a solution like the Windows Azure platform. Over time, this will save tens of millions of dollars a year and enable us to expand rapidly.
This main benefit of the platform is that we really don’t have to manage Windows Azure or SQL Azure in the traditional way that on-premises software and data centers require. I think almost all of the software development shops in the world will move in the direction we’re going—we'll handle development full time, and everything else will be taken care of for us in the cloud. When it comes to providing the best ‘platform as a service’ to developers, I think Microsoft is the visionary leader by far.
Read the full story at: http://www.microsoft.com/casestudies/casestudy.aspx?casestudyid=4000008989
To learn more, visit: www.sqlazure.com
The Windows Management and Scripting blog published SQL Azure migration to the cloud and back in January 2011:

In this article, the first in a two-part series on SQL Azure migration and synchronization, I will examine several options for moving data. The second will focus on more complex scenarios in which ongoing data synchronization is needed.
For one-directional data movement, use one of the following technologies – SQL Server Import and Export Wizard, the bcp utility, SQL Server Integration Services (SSIS), or a community software called SQL Azure Migration Wizard. Let’s discuss these in detail.
SQL Server Import and Export Wizard.
This utility in general works fantastic for a one-time data migration, or for an occasional data refresh if you don’t mind doing it manually. The interface is simple — you run the wizard, select the tables you want to migrate, determine their destinations and perhaps tweak column mapping. You can run it from SQL Server Management Studio and connect to SQL Azure as long as you are using the SQL Server 2008 R2 client tools. Running it is a small tough because you will not see SQL Azure as an option for data source or destination. Instead, select the “.NET Framework Data Provider for SQL Server” option and then configure the properties dialog by supplying SQL Azure Server, username and password as shown in the dialog box in Figure 1.
Figure 1
If your data is sensitive, make sure to set the Encrypt option to “Right” so that your data goes over the Internet encrypted. You may find that your wizard might fail because it scripts tables without indexes by default. In SQL Azure it is required for a table to have a clustered index. If you are making a new table, the wizard doesn’t make any indexes, and data inserts fail. Therefore, you have to either make tables with a clustered index on the destination first, or in the wizard click on “Edit Mappings” for each table and manually modify the “MAKE TABLE” script to make a primary key as well.
Aside from this, my experiences with the wizard and SQL Azure haven’t been very excellent. Small tables migrated OK, but I was getting timeouts on larger tables. You get very small control over the handling of failures and you cannot set the batch size. For that reason, I recommend using SSIS over the wizard, especially if you have large tables and need more control over the migration process.
SQL Server Integration Services. Using SSIS with Azure is pretty straightforward, as long as you configure your connection in the way I described above. Also, you need to have the R2 version of SSIS to connect to SQL Azure. There are several differences from working with the SQL Server back end. Data transfers are much slower because you are sending data over the Internet, and also because the disk I/O in Azure in many cases doesn’t measure up to high-end database servers. You should encrypt the data, but that slows down data transfers as well.
Like with the wizard, I experienced frequent timeouts with data uploads. Keep in mind that your package might fail if there is a connectivity blip. Therefore, it might make sense to design the packages in a way so that when you restart them, they resume the work at the point of failure, as opposed to restarting all table migrations.
One way of doing that is to implement a logging table that keeps track of what tables have been uploaded. SSIS is the best tool for the job if you need to implement workflow logic, use transformations or send over data from flat files. If you use SSIS, make sure that in the Data Flow task you configure the ADO.NET destination to use the “Use Bulk Insert when possible” option. That allows you to use bulk load capabilities, and in my experience, using that option made data transfers run about four times quicker. Also, you may consider changing the default Batch Size to 1,000 or so.
If you lose the connection during data upload, you will not have to start over as you would with a batch size of 0. The data would be committed to the server in batches of 1,000, and you might be able to resume transfer without starting over, as long as you can start sending data from the point where the package failed.
The bcp utility. Another option for uploading or downloading data is using the bcp utility. There is a learning curve associated with using this command-line utility. But if you are comfortable with it, there is a compelling reason for using it — in general, bcp is the fastest way to load data. In most cases, it outperforms Data Transformation Services or SSIS. Other than that, using bcp with Azure works the same as it does when used against local servers.
SQL Azure Migration Wizard.
This tool (SQLAzureMW for small) is an open source utility that can help with your SQL Azure migration. It works really well, and I found it to be much more reliable and flexible than the wizard built into SQL Server Management Studio. You can get it from the CodePlex website, including the source code. The wizard supports the migration of many types of database objects, as you can see in Figure 2.
Figure 2
Once you select the objects you want to migrate, SQLAzureMW scripts out the objects and modifies them behind the scenes to make the syntax compatible with SQL Azure syntax. Then it uses the bcp utility and generates a DAT file for each table, and that contains the data in binary format, as in Figure 3.
Figure 3
Once SQLAzureMW connects to the SQL Azure server, it recreates the objects from generated scripts. Finally, it runs the bcp utility to upload data to the cloud, as seen in Figure 4.
Figure 4
SQLAzureMW provides a user-friendly interface and a lot of options for migrating your data and other objects. Keep in mind though that since it generates a data file for each table, you need to make sure you have sufficient space on the disk. You might still be better off using SSIS for very large tables or for using its workflow capabilities.




Here the related SQL Azure data synchronization post:

Implementing data synchronization typically requires some up-front analysis to determine the best process and most suitable tools and technologies for the job. Among other things, you need to consider the number of tables to synchronize, required refresh frequency (this could differ greatly among tables in the same database), application uptime requirements and size of the tables. In general, the larger the tables are and the higher the required uptime, the more work is required on your part to implement data synchronization so that it doesn’t interfere with the applications using the database.
One of the simplest approaches to data synchronization is to make staging tables in the destination database and load them with data from the source database. In SQL Azure, do this using SQL Server Integration Services or the bcp utility, as discussed in the previous article. Once the data is in staging tables, run a series of T-SQL statements to compare the data between staging and “master” tables and get them in sync. Here is a simple sequence I’ve been using successfully on many projects:
- Use DELETE FROM command to join the staging and the master table and delete all rows from the master table that have no match in the staging table.
- Use UPDATE FROM command to join the staging table and the master table and update the records in the master table.
- Use INSERT command and insert into the master tables the rows that exist only in the staging table.
If you are using SQL Server 2008 or newer, utilize the MERGE statement to combine the second and third part into a single command. The MERGE statement is nicknamed UPSERTbecause it combines the ability to insert new rows and update existing rows in a single statement. So, it lends itself nicely for data synchronization.
Using the technique I described works well mainly for small to medium-sized tables because the table will be temporarily locked and therefore unavailable while these updates are taking place. But in my experience, it is a minor disruption that can be mitigated by synchronizing during low database usage times or by breaking up the updates into batches. The disadvantage here is that you have to implement custom code for each table.
I’ve also had success with a slightly modified approach, which takes away the need to implement a set of scripts for each table. After you load the staging tables, do the sp_rename stored procedure and swap the names of the master and the staging table. This can be done very quickly, even on many tables. Run each table swap inside of a TRY/CATCH block and roll back the transaction if the swap does not succeed.
Another technique many companies use to refresh data and at the same time keep it available is to simply maintain two copies of the database. One database is used by applications and the other one is used by the load process to truncate and reload tables. Once the load is done, you can rename both databases and swap them so that the one with the fresh data becomes the current database. SQL Azure initially didn’t support renaming of databases, but that feature works now. As an alternative to renaming, store a connection string pointing to a SQL Azure database in a local database and have your data load process modify the connection string and point to the refreshed database, that is, if the data load completed successfully.
Another option is to use the Microsoft Sync Framework, a platform for synchronizing databases, files, folders and other items. It allows you to programmatically synchronize database via ADO.NET providers and as of the 2.1 version, you can use the framework to synchronize between SQL Server and SQL Azure. Describing all the features and capabilities of the Sync Framework is beyond the scope of this article. For more information visit the Microsoft Sync Framework Developer Center. One of the advantages of the framework is that once you get up to speed with the basics, you can write applications that give you full control over SQL Azure data synchronization. Among other things, you will be able to utilize its features, such as custom conflict detection and resolution, and change tracking. Both of those features come in handy if you need to implement bidirectional data synchronization.
Microsoft developers used the Sync Framework to develop and release an application called Sync Framework Power Pack for SQL Azure. You can download and install this application, but first install the Microsoft Sync Framework SDK. The application runs as a wizard. After you specify the local and the SQL Azure database, select the tables you want to synchronize. You can also specify how you want to handle the situation in which the same row is updated in both databases. Figure 1 illustrates how you can choose whether the local database or SQL Azure database wins the resolution.
Figure 1
In the last step of the wizard, specify whether it should make a 1 GB or a 10 GB database in SQL Azure. The tool makes the specified database in SQL Azure and sets up both databases with objects needed for synchronization. It will make INSERT/UPDATE/DELETE triggers on each synchronized table. Also, for each table it will make another table with the “_tracking” suffix. It also makes a couple of database configuration tables called scope_config and scope_info. As data gets modified in either database, the triggers update the tracking tables with the details that will be used by the Sync Framework when it’s time to synchronize.
The wizard also makes a SQL Agent job that kicks off the sync executable passing the appropriate parameters. All you need to do is schedule the job to synchronize as often as needed. The tool is not super quick, but it works honestly well and, in many cases, it can handle your synchronization requirements. The largest drawback is that when you run the wizard, it insists on making a new SQL Azure database, and it fails if you specify an existing database. So, if you ever want to modify what tables should be synchronized, drop the Azure database and start over.
Related posts

<Return to section navigation list>
MarketPlace DataMarket and OData
Health 2.0 LLC offered a $5,000 prize, a ticket to the Health 2.0 2.0 San Diego conference, and a live on-stage demo in an Analyze This post of January 2011:
Analyze the free medical record dataset from Microsoft Azure DataMarket and Practice Fusion to answer the biggest healthcare questions in the US today. Use the de-identified data however you’d like: visualize healthcare trends, find adverse drug reactions, chart chronic disease, mashup the results with other Azure data or build an app. Basically, pick a pressing healthcare question and answer it using the tools provided by Microsoft and Practice Fusion.
We’re looking for the wow factor. Focus on data visualization to create healthcare studies and powerful apps built around the free dataset.
Bonus points for:
- Solutions that can be used to deliver better care, improve public health
- Ideas that can be directly applied by patients or doctors
- Entries related to chronic disease
- Applications that are accessible from anywhere by anyone (i.e. non-platform-specific applications that would work on any mobile device, generic HTML, etc.)
- Utilizing bleeding/cutting-edge technology (i.e. HTML5, GPS-based/location-aware tagging, social media, etc.)
- Plain English – translation of complex medical findings or technology into something easily understood
Terms and Conditions
Please submit your final challenge entry with three elements:
- One page write-up about the health question you asked and the solution you created
- Instructions for how we can demo the app, visualization or other tool you created
- A short DIY video showcasing your entry
Deadline for Submissions: February 28, 2011
-
Prize
$5,000 + ticket to Health 2.0 San Diego + live demo on stage -
Challenger
Microsoft Azure DataMarket & Practice Fusion -
Additional Resources
Visit the Microsoft Azure DataMarket to download the free Practice Fusion medical research dataset online. This HIPAA-compliant, clinical data contains 5,000 records including patient vitals, diagnoses, medications, prescriptions, immunizations and allergies.
While in the DataMarket, you can browse over 70 other trusted commercial and premium public domain data to potentially including in your entry. You can also visit www.practicefusion.com/research to learn more about the power of clinical data.
-
Judges
- Sudhir Hasbe, Sr. Product Manager, Microsoft
- Ryan Howard, CEO, Practice Fusion
- Matthew Douglass, VP of Product Development, Practice Fusion
-
Contact Information
healthchallenge@practicefusion.com
You can preview a simple analytic demo at Practice Solutions’ Prescription Index: Top 20 Prescriptions by Specialty page.
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
Vittorio Bertocci (@vibronet) reported New WIF Runtime EULA Allows for Redistribution! And Since I’m at it, Let’s Talk Windows Azure Startup Tasks in a 1/13/2011 post (images are missing due to MSDN blogs being down for maintenance):
Back in December one pretty important piece of news didn’t get as much air time as it would have deserved: we recently changed the WIF SDK EULA so that you can now freely (and happily) include & redistribute the WIF runtime (& samples) with your applications. Isn’t that awesome?
This came back to mind as I was presenting FabrikamShipping SaaS to some internal folks yesterday. As you recall, Monday we released the Windows Azure SDK 1.3-compliant version of the source code, where we take advantage of some of the cool new features of the platform.
One such new feature is the chance of telling Windows Azure to run some startup tasks as it brings instances to life, typically for preparing the execution environment, installing software your application needs, and so on. Can you already see where I am going with this?
From the very first version of the WIF on Windows Azure guide, one of the first problems we had to solve was to make the WIF runtime available to applications running in a Windows Azure role. The solution so far has been to set the copy local property of the WIF assembly reference to true, so that it would end up in the application package: but now that you have Startup Tasks in Windows Azure, you also have the option of installing the WIF runtime! That’s pretty neat, uh?
<Return to section navigation list>
Windows Azure Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Scott Densmore announced Windows Azure & Windows Phone 7 Hands On Labs Available on 1/13/2011:
Moving Applications to the Cloud
- Developing Applications for the Cloud
- Windows Phone 7 Developer Guide
Feed back always welcome.
Note:
These HOLs are using the Windows Azure 1.2 SDK. We are working on updating the content and HOLs to the Windows Azure 1.3 SDK. These will be available on CodePlex as soon as we get them done. [Emphasis added.]
Manu Cohen-Yashur and David S. Platt started a Channel9 Windows Azure Jump Start (#) series with Windows Azure Jump Start (01): Windows Azure Overview on 1/12/2011:
Building Cloud Applications with the Windows Azure Platform
This session provides an engaging overview of why the Cloud is such a popular choice for applications, and how the Windows Azure Platform is the best alternative for you and your team.The Windows Azure Jump Start video series is for all architects and developers interested in designing, developing and delivering cloud-based applications leveraging the Windows Azure Platform. The overall target of this course is to help development teams make the right decisions with regard to cloud technology, the Azure environment and application lifecycle, Storage options, Diagnostics, Security and Scalability. The course is based on the Windows Azure Platform Training Course and taught by Microsoft Press authors, Manu Cohen-Yashur and David S. Platt.
As you’re enjoying the videos, you can access the content for this class, student files and links to demo code at the Windows Azure Born To Learn Forum.
Access to Windows Azure for the labs:
● Free Windows Azure Platform 30-day pass for US-based students (use promo code: MSL001)
● MSDN Subscribers: http://msdn.microsoft.com/subscriptions/ee461076.aspx
● Free access for CPLS, Partners: https://partner.microsoft.com/40118760
● Options for all others: http://www.microsoft.com/windowsazure/offersLearn more about the Windows Azure Platform through training and certification options from Microsoft Learning.

Following are links to all 12 current members of the series:
Session 01: Windows Azure Overview
Session 02: Introduction to Compute
Session 03: Windows Azure Lifecycle, Part 1
Session 04: Windows Azure Lifecycle, Part 2
Session 05: Windows Azure Storage, Part 1
Session 06: Windows Azure Storage, Part 2
Session 07: Introduction to SQL Azure
Session 08: Windows Azure Diagnostics
Session 09: Windows Azure Security, Part 1
Session 10: Windows Azure Security, Part 2
Session 11: Scalability, Caching & Elasticity, Part 1
Session 12: Scalability, Caching & Elasticity, Part 2, and Q&A
David Aiken (@TheDavidAiken) described how to Enable PowerShell Remoting on Windows Azure in a 10/12/2011 post:
If it takes you more than 1 line of code, you aren’t doing it right!
I started writing this post a week ago in response to a customer request, so excited I was I even tweeted about writing a post on PowerShell. My Bad – because right after I tweeted I hit a snag – which is worthy of a whole post on its own. Ignoring the snag right now – let me tell you how to do the above.
First – a BIG shout out to the PowerShell team at Microsoft who answered my endless questions. Also a big shout out to Lee Holmes – who once again saved my bacon.
Anyway…
At long last I’ve had a chance to “play” around with the new Windows Azure features we announced at PDC 2010. I thought it would be fun to enable PowerShell Remoting in Windows Azure Roles. (Note I’m talking about Web and Worker roles here – not VM Role).
With new features such as remote desktop, startup tasks and Azure Connect – setting up PowerShell should be easy.
First, I’m going to assume you have worked through the notes/tutorials/stuff to enable Azure Connect & Remote Desktop – that way this post stays within the realms of being relatively small.
Here is our checklist:
- Make sure the OS Family in the ServiceConfiguration.cscfg is set to “2” to enable R2.
- Create a user account so you can connect to the server.
- Add a startup task to open the firewall port.
- Add the Role to Azure Connect.
- Execute Lee’s magic script to enable PowerShell Remoting
PowerShell v2 is the version you need to do remoting. Server 2008 R2 contains PowerShell v2 in the box. We can tell Windows Azure to use an R2 server by changing the OSFamily in the ServiceCOnfiguration.cscfg to 2 as shown below:
<ServiceConfiguration serviceName="AzureMemcachedTest" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration" osFamily="2" osVersion="*">Next step is to create a user account so that you can actually connect to the server. The easiest way to do this is to enable remote desktop, which creates a user on the host.
Now to make sure the firewall port is open we will need. I created a .cmd file containing the following 2 commands. The first opens the firewall for WINRM, the second for ping. This was added in the root folder of my role project.
netsh advfirewall firewall add rule name="Windows Remote Management (HTTP-In)" dir=in action=allow service=any enable=yes profile=any localport=5985 protocol=tcpnetsh advfirewall firewall add rule name="ICMPv6 echo" dir=in action=allow enable=yes protocol=icmpv6:128,anyThen I added a startup task to ServiceDefinition.csdef:
<Startup><Task commandLine="EnablePowershellRemoting.cmd" executionContext="elevated" taskType="foreground"/></Startup>Next add the Role to Azure Connect. I’ll assume you know how to do this.
Now deploy your service. Once deployed, do the final step to connect the Azure connect network, and make sure the agent is installed on your computer.
The final step is to “turn on” PowerShell Remoting. For numerous reasons, you cannot just run a startup task with “Enable-PSRemoting” as the command. The biggest reason is that startup tasks run as local system and thus cannot actually complete the Enable-PSRemoting command.
This is where I got stuck for 3 days until Lee shared his script. The script is below and is fairly easy to follow. Basically it will connect to the VM and create a scheduled task to enable-psremoting.
##############################################################################
## Enable-RemotePsRemoting
##
## From Windows PowerShell Cookbook (O'Reilly)
## by Lee Holmes (http://www.leeholmes.com/guide)
##############################################################################
<#
.SYNOPSIS
Enables PowerShell Remoting on a remote computer. Requires that the machine
responds to WMI requests, and that its operating system is Windows Vista or
later.
.EXAMPLE
Enable-RemotePsRemoting <Computer>
#>
param(
## The computer on which to enable remoting
$Computername,
## The credential to use when connecting
$Credential = (Get-Credential)
)
Set-StrictMode -Version Latest
$VerbosePreference = "Continue"
$credential = Get-Credential $credential
$username = $credential.Username
$password = $credential.GetNetworkCredential().Password
$script = @"
`$log = Join-Path `$env:TEMP Enable-RemotePsRemoting.output.txt
Remove-Item -Force `$log -ErrorAction SilentlyContinue
Start-Transcript -Path `$log
## Create a task that will run with full network privileges.
## In this task, we call Enable-PsRemoting
schtasks /CREATE /TN 'Enable Remoting' /SC WEEKLY /RL HIGHEST ``
/RU $username /RP $password ``
/TR "powershell -noprofile -command Enable-PsRemoting -Force" /F |
Out-String
schtasks /RUN /TN 'Enable Remoting' | Out-String
`$securePass = ConvertTo-SecureString $password -AsPlainText -Force
`$credential =
New-Object Management.Automation.PsCredential $username,`$securepass
## Wait for the remoting changes to come into effect
for(`$count = 1; `$count -le 10; `$count++)
{
`$output = Invoke-Command localhost { 1 } -Cred `$credential ``
-ErrorAction SilentlyContinue
if(`$output -eq 1) { break; }
"Attempt `$count : Not ready yet."
Sleep 5
}
## Delete the temporary task
schtasks /DELETE /TN 'Enable Remoting' /F | Out-String
Stop-Transcript
"@
$commandBytes = [System.Text.Encoding]::Unicode.GetBytes($script)
$encoded = [Convert]::ToBase64String($commandBytes)
Write-Verbose "Configuring $computername"
$command = "powershell -NoProfile -EncodedCommand $encoded"
$null = Invoke-WmiMethod -Computer $computername -Credential $credential `
Win32_Process Create -Args $command
Write-Verbose "Testing connection"
Invoke-Command $computername {
Get-WmiObject Win32_ComputerSystem } -Credential $credentialOnce it finishes executing, you should be able to connect using:
PS> Enter-PSSession –ComputerName $computername –Credential RemoteDesktopUsername
Then you can work interactively – try get-process as an example.
Pretty neat, and great for debugging!
THIS POSTING IS PROVIDED “AS IS” WITH NO WARRANTIES, AND CONFERS NO RIGHTS
The MSDN Library updated its Managing Management Certificates for the Windows Azure Platform topic on 1/10/2011:
Management certificates permit client access to resources in your Windows Azure subscription. Management certificates are x.509 certificates that are saved as a .cer file and uploaded to Windows Azure. They are stored at the subscription level as opposed to service certificates that are stored with a specific hosted service.
- The CSUpload Command-Line Tool uses management certificates for authentication when deploying VM role images. For more information one using CSUpload to deploy VM role images, see How to Deploy an Image to Windows Azure.
- Requests made using the Windows Azure Service Management REST API require authentication against a certificate that you provide to Windows Azure; see Authenticating Service Management Requests for details. Using the Windows Azure Tools for Microsoft Visual Studio to deploy a service or view storage account data similarly requires authentication against a management certificate. You must upload a management certificate to Windows Azure using the Windows Azure Platform Management Portal .
- Windows Azure Tools for Microsoft Visual Studio use management certificates to authenticate a user to create and manage your deployments. For more information on using the Visual Studio tools to deploy applications, see Deploying the Windows Azure Application from Visual Studio.
See Also: Concepts
Managing Service Certificates
<Return to section navigation list>
Visual Studio LightSwitch
Karol Zadora-Przylecki posted Using Custom Controls to Enhance Your LightSwitch Application UI - Part 1 on 1/13/2011 (screen shots are missing because the MSDN blogs were down for maintenance when this item was being written:
Visual Studio LightSwitch provides a set of standard UI controls for displaying application data. These controls include common Windows UI elements like text boxes, as well as controls tailored for the data entry and editing tasks (like address viewer or data grid). Many applications can be built with only standard LightSwitch controls, but there are applications that require more advanced visualizations (e.g. charts or maps), or just have specific requirements that are not covered by standard control set. One possibility to address these requirements is to use a non-standard LightSwitch control. LightSwitch provides extensibility points for the 3rd party control vendors to extend the set of control available inside the IDE. From application development perspective they behave just like built-in controls—they show up in the same places in the IDE and their general working is no different from standard controls, so using them is very easy. The downside is that if a 3rd party control that satisfies the given scenario is not available, implementing one might be a task too difficult or labor-intensive for typical LightSwitch user. Fortunately there is an easier way: LightSwitch applications can use Silverlight “custom” controls directly, and re-using or authoring custom controls is much easier.
Custom controls defined
LightSwitch client application uses Silverlight framework as the foundation to build upon. LightSwitch controls are at the core just Silverlight controls, but they are enhanced with information and functionality that makes it possible for LightSwitch runtime to relieve the developer from many routine tasks associated with UI data binding, UI layout and command enablement. A custom control is a regular Silverlight control that is part of LightSwitch application UI (a screen). The main difference between LightSwitch controls and custom controls is that a custom control does not have LightSwitch-specific information associated with it. Therefore LightSwitch treats it as a “black box” and it is up to the developer to specify what data the control should display (data-bind the control to the screen) and to handle any events the control might raise. There are two possibilities here:
- The control might be built for a particular screen or entity (with intimate knowledge of the members of some screen or entity). For example, if we are building a custom control to display Customer data in a visually-rich way, we might explicitly bind parts of the control to Customer properties such as Name and Address. The advantage of this approach is that using this control will require little or no code, but obviously it cannot be used to display any other piece of data other than a Customer, so we lose some flexibility and reuse opportunities.
- The control might have no knowledge of the data it will display or the screen it will use—all data binding and interaction with the control can be specified in screen code. With this approach the control can be reused across different screens and applications. The drawbacks include the fact that there is more code to write and furthermore, the screen code targets a specific control which makes the screen harder to modify down the road. This goes against the notion of screen code being pure business logic.
In practice both of these two approaches can be used, even for a single control, and it is up to the developer to decide which one is more advantageous, given unique application requirements. An example will make things clearer, but before we jump into it, we need to learn how exactly custom controls show up on a screen.
Screen content tree and (custom) controls
A screen in a LightSwitch application is built of three elements:
- Screen members are what you see on the left in the screen designer inside LightSwitch IDE. They are the data the screen is operating on. Screen members can include collections of entities, single entities and scalar values. They can also include commands (both built-in and user-defined)
- Screen content tree defines the visual layout of the screen. It determines what is shown on the screen and how the information is visually arranged. Content tree consists of content items and it is shown on the right side of the screen designer. Some content items are used just for layout, but most are there to show a specific piece of screen data. In other words they are bound to a piece of data, or have a data binding. Content items can also have an associated control (visual) that will be used to visualize the item when the application is running.
- Screens can also have user code, which can be used to customize screen behavior programmatically and implement business logic. Screen code can be shown by clicking “Write Code” button in screen designer toolbar.
The screenshot below shows design view of a screen called ShipperListDetail.
[Missing]
Note how screen designer shows the associated control and the data binding for content items that have them. If you want to know more how content tree, controls and screen members work together please see The Anatomy of a LightSwitch Application Series Part 2 – The Presentation Tier.
So what does all this have to do with custom controls? Well, the way you add a custom control to a screen is by replacing the standard (default) control that LightSwitch assigns to a content item with a custom control. In the example above we have done it for the last control in the content tree and we will now show you how
Example: using Rating control for showing shipper rating
Let’s say we have a database of shippers that are available to ship goods from our manufacturing facility to various parts of the country. For now we will focus only on three pieces of information: shipper’s name, phone number and rating. Open Visual Studio, create a new LightSwitch project (you can call it “CustomControls”) and add a Shippers entity:
[Missing]
Also, our business rules state that shipper rating, if known, must be a number between 1 and 5, so click the Rating column in table designer, go to Properties window, find the “Custom Validation” link at the bottom of the property sheet for the Rating column and add the following code (only the body of the Rating_Validate method needs to be modified)
C#
public partial class Shipper
{
partial void Rating_Validate(EntityValidationResultsBuilder results)
{
if (this.Rating.HasValue)
{
if (this.Rating < 1 || this.Rating > 5)
{
results.AddPropertyError("Shipper rating (if known) must be between 1 and 5");
}
}
}
}VB
Public Class Shipper
Private Sub Rating_Validate(ByVal results As EntityValidationResultsBuilder)
If Me.Rating.HasValue Then
If Me.Rating < 1 Or Me.Rating > 5 Then
results.AddPropertyError("Shipper rating (if known) must be between 1 and 5")
End If
End If
End Sub
End ClassNext create a List and Details screen for Shippers entity, including details for the entity on the screen. Your screen should look like this in the designer:
[Missing]
Now we are ready to create the custom control to display the rating. We will use the Rating control from Silverlight toolkit, so if you do not have the toolkit installed yet, you can get it from http://silverlight.codeplex.com/. After you have the toolkit installed, right-click the solution node in Solution Explorer and choose Add | New Project. Choose Silverlight Class Library project and name it RatingControlWrapper. Choose Silverlight 4 as the target Silverlight version and delete the Class1 class automatically created as part of the project.
Note: this you won’t be able to complete this portion of the example (creating custom control wrapper) if you have only Visual Studio LightSwitch Beta 1 installed on your machine. You need both Visual Studio Professional (or higher SKU) and Visual Studio LightSwitch. This is because Silverlight class library projects are not supported by Visual Studio LightSwitch alone. Later on I will show you how to use Rating control directly and set up control binding from LightSwitch code; that does not require anything other than Visual Studio LightSwitch. Also, this portion of the example assumes familiarity with Silverlight user controls and XAML; for more information about these topics see Getting Started with Controls in Silverlight documentation.
After the project is created, right-click the project node and choose Add | New Item. Choose a Silverlight User Control item type and name the new control RatingControlWrapper. After the project is created, add a reference to System.Windows.Controls.Input.Toolkit assembly. You will find it under the directory where Silverlight toolkit is installed; on my machine it was “C:\Program Files (x86)\Microsoft SDKs\Silverlight\v4.0\Toolkit\Apr10\Bin”. Next open the RatingControlWrapper.xaml file in XAML view, add a namespace declaration for the local and toolkit namespaces and finally add the Rating control itself to the content of our wrapper control. You should end up with XAML file that has the content shown below; we have highlighted the portions of the control XAML that we have changed. Note that we have replaced the default Grid layout for the content with a simpler StackPanel; this will come in handy later.
RatingControlWrapper.xaml
<UserControl x:Class="RatingControlWrapper.RatingControlWrapper"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:inputToolkit="clr-namespace:System.Windows.Controls;assembly=System.Windows.Controls.Input.Toolkit"
xmlns:local="clr-namespace:RatingControlWrapper"
mc:Ignorable="d"
d:DesignHeight="25" d:DesignWidth="300">
<StackPanel Orientation="Horizontal">
<inputToolkit:Rating ItemCount="5" HorizontalAlignment="Left" SelectionMode="Continuous" x:Name="RatingControl"
Value="{Binding Path=Screen.ShipperCollection.SelectedItem.Rating, Mode=TwoWay}">
</inputToolkit:Rating>
</StackPanel>
</UserControl>The most interesting portion of this code is the data binding specification: it binds the Rating control’s Value property (which controls how many rating “stars” the user sees, i.e. depicts the rating) to Screen.ShipperCollection.SelectedItem.Rating property. The TwoWay mode means that whenever one side of the binding changes, the other side will be updated. The default binding mode in Silverlight is OneWay, which means that UI reflects (screen) data; but changes in the UI do not affect the underlying data. We want the user to be able not only see the rating, but also to change the rating by clicking the control, giving a shipper desired number of “stars”, so we use TwoWay.
Now we can switch to our main project and replace the textbox that is used for the Shipper.Rating property with our custom control. Right-click the RatingControlWrapper project in the Solution Explorer and choose “Build”—it should build without errors. Open ShipperListDetail screen from our main application in the designer, select the Rating content item and open the control selection dropdown:
[Missing]
Choose “Custom Control” here. Switch to Properties window, scroll to Custom Control property and hit Change link—Add Custom Control window appears
[Missing]
Click “Add Reference” button, switch to Project tab and select RatingControlWrapper project. Hit OK to add project reference—you should now see the RatingControlWrapper assembly in the Add Custom Control dialog (see screenshot above). Expand the RatingControlWrapper namespace, select the RatingControlWrapper control and hit OK.
Handling data conversions and null values
At this point you could try to run the application and start adding some shippers. Our rating UI shows up, but does not quite work as expected—it seems like the only rating that sticks is five stars. Also there is no obvious way to clear the rating either. How can we fix this?
The first problem stems from the fact that the Value property of the Rating control is a floating-point number and Shippers.Rating column is an integer. We could store floating point numbers instead of integers for our rating otherwise we need to convert the Shipper’s rating of 1, 2, 3, 4 or 5 into 0.0 to 1.0 range that the Rating control can work with. Fortunately Silverlight has a concept of a value converter that is designed for just that. So let’s create a value converter for our control wrapper. Add a new class to the RatingControlWrapper project and name it Int2DoubleConverter. Then change the class code to this:
C#
using System;
using System.Diagnostics;
using System.Windows.Data;
namespace RatingControlWrapper
{
public class Int2DoubleConverter: IValueConverter
{
public object Convert(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture)
{
if (value == null) return null;
double retval = System.Convert.ToDouble(value);
double scalingFactor;
if (double.TryParse(parameter as string, out scalingFactor))
retval /= scalingFactor;
return retval;
}
public object ConvertBack(object value, Type targetType, object parameter, System.Globalization.CultureInfo culture)
{
if (value == null) return null;
double retval = (double) value;
double scalingFactor;
if (double.TryParse(parameter as string, out scalingFactor))
retval *= scalingFactor;
return System.Convert.ToInt32(retval);
}
}
}VB
Imports System.Diagnostics
Imports System.Windows.Data
Public Class Int2DoubleConverter
Implements IValueConverter
Public Function Convert(ByVal value As Object, ByVal targetType As Type, ByVal parameter As Object, ByVal culture As System.Globalization.CultureInfo) As Object _
Implements IValueConverter.Convert
If value Is Nothing Then
Return Nothing
End If
Dim retval As Double = System.Convert.ToDouble(value)
Dim scalingFactor As Double
If Double.TryParse(CStr(parameter), scalingFactor) Then
retval /= scalingFactor
End If
Return retval
End Function
Public Function ConvertBack(ByVal value As Object, ByVal targetType As Type, ByVal parameter As Object, ByVal culture As System.Globalization.CultureInfo) As Object _
Implements IValueConverter.ConvertBack
If value Is Nothing Then
Return Nothing
End If
Dim retval As Double = CDbl(value)
Dim scalingFactor As Double
If Double.TryParse(CStr(parameter), scalingFactor) Then
retval *= scalingFactor
End If
Return System.Convert.ToInt32(retval)
End Function
End ClassTo make the converter work for various number ranges we are going to use a parameter (scaling factor). In our case the maximum rating is 5 and we will use this value as the scaling factor. Now open the RatingWrapperControl in the designer and add the converter infromation to the binding:
RatingControlWrapper.xaml
<UserControl x:Class="RatingControlWrapper.RatingControlWrapper"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:inputToolkit="clr-namespace:System.Windows.Controls;assembly=System.Windows.Controls.Input.Toolkit"
xmlns:local="clr-namespace:RatingControlWrapper"
mc:Ignorable="d"
d:DesignHeight="25" d:DesignWidth="300">
<UserControl.Resources>
<local:Int2DoubleConverter x:Key="I2DConverter" />
</UserControl.Resources>
<StackPanel Orientation="Horizontal">
<inputToolkit:Rating x:Name="RatingControl" ItemCount="5" HorizontalAlignment="Left" SelectionMode="Continuous"
Value="{Binding Path=Screen.ShipperCollection.SelectedItem.Rating, Mode=TwoWay,
Converter={StaticResource I2DConverter}, ConverterParameter=5 }">
</inputToolkit:Rating>
</StackPanel>
</UserControl>Changing a shipper’s rating to unknown requires setting the underlying property to null, but the Rating control does not have this capability built-in. We can add it by using a link label and a bit of code. Add the following line to RatingControlWrapper.xaml:
RatingControlWrapper.xaml
<UserControl x:Class="RatingControlWrapper.RatingControlWrapper"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:inputToolkit="clr-namespace:System.Windows.Controls;assembly=System.Windows.Controls.Input.Toolkit"
xmlns:local="clr-namespace:RatingControlWrapper"
mc:Ignorable="d"
d:DesignHeight="25" d:DesignWidth="300">
<UserControl.Resources>
<local:Int2DoubleConverter x:Key="I2DConverter" />
</UserControl.Resources>
<StackPanel Orientation="Horizontal">
<inputToolkit:Rating x:Name="RatingControl" ItemCount="5" HorizontalAlignment="Left" SelectionMode="Continuous"
Value="{Binding Path=Screen.ShipperCollection.SelectedItem.Rating, Mode=TwoWay,
Converter={StaticResource I2DConverter}, ConverterParameter=5 }">
</inputToolkit:Rating>
<HyperlinkButton Content="Clear" x:Name="hyperlinkButton1" Padding="4,0,0,0"
VerticalContentAlignment="Center" Width="50" Click="OnClearAction" />
</StackPanel>
</UserControl>Double-click the OnClearAction in XAML editor—this should result in opening the code-behind file for the control (RapidControlWrapper.xaml.cs or RapidControlWrapper.xaml.vb, depending on the language you use). Change OnClearAction method body to
C#
private void OnClearAction(object sender, RoutedEventArgs e)
{
this.RatingControl.Value = null;
}VB
Private Sub OnClearAction(ByVal sender As System.Object, ByVal e As System.Windows.RoutedEventArgs)
Me.RatingControl.Value = Nothing
End SubThat is it. Now you can launch the application and it works as expected
[Missing]
Setting up data binding via code
Our application works, but the data binding for our control is hard-coded into control definition. If the screen members change and the data binding path becomes invalid, the application will no longer work. I will now show you how to specify data binding for custom controls in screen code. In this way each screen can data-bind to the control in its unique way, so you can reuse the control with multiple screens.
First, open control definition again and remove the whole Value property binding. You can also delete the Int2DoubleConverter declaration from control resources. On the other hand, we want to expose the inner Rating control from our wrapper so that we can set a binding on it, so we’ll add the FieldModifier attribute to the control declaration. The XAML should now look like this
RatingControlWrapper.xaml
<UserControl x:Class="RatingControlWrapper.RatingControlWrapper"
xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
xmlns:d="http://schemas.microsoft.com/expression/blend/2008"
xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006"
xmlns:inputToolkit="clr-namespace:System.Windows.Controls;assembly=System.Windows.Controls.Input.Toolkit"
xmlns:local="clr-namespace:RatingControlWrapper"
mc:Ignorable="d"
d:DesignHeight="25" d:DesignWidth="300">
<StackPanel Orientation="Horizontal">
<inputToolkit:Rating x:Name="RatingControl" x:FieldModifier="public" ItemCount="5" HorizontalAlignment="Left" SelectionMode="Continuous" />
<HyperlinkButton Content="Clear" x:Name="hyperlinkButton1" Padding="4,0,0,0" VerticalContentAlignment="Center" Width="50" Click="OnClearAction" />
</StackPanel>
</UserControl>Next open ShipperListDetails screen and override (screen)_Loaded method (in VB you will also have to add a reference to System.Windows.Controls.Input.Toolkit assembly to the client project). The Loaded method should look like this (including necessary namespace imports which you should put at the top of the file)
C#
using Microsoft.LightSwitch;
using System.Windows.Controls;
using System.Windows.Data;
using System.Diagnostics;
using RatingControlWrapper;
partial void ShipperListDetail_Loaded()
{
IContentItemProxy proxy = this.FindControl("RatingControl");
Debug.Assert(proxy != null);
if (proxy == null) return;
proxy.Invoke(() =>
{
var rw = proxy.Control as RatingControlWrapper.RatingControlWrapper;
Debug.Assert(rw != null);
if (rw == null) return;
var rc = rw.RatingControl;
var b = new Binding("Value");
b.Mode = BindingMode.TwoWay;
b.Converter = new Int2DoubleConverter();
b.ConverterParameter = "5";
rc.SetBinding(Rating.ValueProperty, b);
});
}VB
Imports System.Diagnostics
Imports System.Windows.Data
Imports System.Windows.Controls
Imports Microsoft.LightSwitch
Imports RatingControlWrapper
Private Sub ShipperListDetail_Loaded()
Dim proxy As IContentItemProxy = Me.FindControl("RatingControl")
Debug.Assert(proxy IsNot Nothing)
If proxy Is Nothing Then
Return
End If
proxy.Invoke(Sub()
Dim rw = TryCast(proxy.Control, RatingControlWrapper.RatingControlWrapper)
Debug.Assert(rw IsNot Nothing)
If rw Is Nothing Then
Return
End If
Dim rc = rw.RatingControl
Dim b = New Binding("Value")
b.Mode = BindingMode.TwoWay
b.Converter = New Int2DoubleConverter()
b.ConverterParameter = "5"
rc.SetBinding(Rating.ValueProperty, b)
End Sub)
End SubFor now let’s ignore the portion of the code that deals with finding controls and control proxies and focus on the last 5 lines where the data binding is set up. The binding mode and value converter setting look very similar to the previous example but where is the binding path?
Well, this is a different way to accomplish the same goal. Remember that the data context for a control is its content item. The binding specification here binds the Rating control’s Value property to the content item’s Value property. The content item does not just expose screen data; it has several properties that aid the UI layer (controls) in providing the best possible data editing experience. For example
- DisplayName property is used for showing a caption
- Description property can be used for a helpful tooltip
- IsProcessing property indicates whether underlying data is available or still being loaded from the database
- DataError property that contains error information if the data load fails
- (there is more)
The full list of properties exposed by content items is beyond the scope of this post; but for our purposes Value property is the most important and sufficient: this is the property that returns the underlying piece of screen data that the content item represents. In our case the content item represents Shipper.Rating property, so the Rating.Value will be bound to Shipper.Rating, which is exactly what we want. The only thing remaining is to make sure that the control has the Name property set to “RatingControl” in LightSwitch screen designer, otherwise our code won’t work.
[Missing]
Run the application and verify that it still behaves properly.
Summary
In this post we have seen how you can use custom Silverlight controls to enhance UI of LightSwitch applications. We have learned how custom controls plug into screen content tree and how to bind them to screen data, both from XAML as well as from code. We also used a value converter to overcome the problem of type mismatch between control property types and entity member types and added a control gesture to set the underlying data to null. In the second part of this post we will talk about how LightSwitch run time uses threads and what implications this has on controls and screen code. We will also cover some ways of making the screen and the control work together (interact) and we will show you how to make custom controls work with hierarchical data.
The SQL Server Team reported Microsoft SQL Server Compact 4.0 is available for download and use with WebMatrix on 1/13/2011. It sounds to me like a good candidate for a LightSwitch back end option in Beta 2:
The SQL Server Compact team is happy to announce that the next version of Microsoft SQL Server Compact 4.0 has been released, and is available for download and for use in the production systems at the location below:
http://www.microsoft.com/sql/compact
SQL Server Compact 4.0 has been designed, developed, tested and tuned over the course of last year and the release has been also vigorously verified by the vibrant MVP and developer community. The feedback from the developer community has helped to improve the quality of the SQL Server Compact 4.0 release and the Compact team would like to thank all the members of the community who participated in the release.
SQL Server Compact 4.0 and WebMatrix
- Default database for Microsoft WebMatrix: Compact 4.0 is the default database for Microsoft WebMatrix, which is the web stack that encapsulates all the technologies like ASP.NET, IIS Express, Editor and SQL Server Compact that are needed to develop, test and deploy ASP.NET websites to third party website hosting providers.
- Rapid website development with free, open source web applications: Popular open source web applications like mojoPortal, Orchard, Umbraco etc. support Compact 4.0 and can be used to rapidly develop, test and deploy websites.
- One click migration to SQL Server: As the requirements grow to the level of enterprise databases, the schema and data can be migrated from Compact to SQL Server using the migrate option in the WebMatrix IDE. This also adds a web.config xml file to the project that contains the connection string for the SQL Server. Once the migration completes, the website project seamlessly switches from using Compact to SQL Server.
- ADO.NET Entity Framework 4 (.NET FX 4) code-first and server generated keys: Compact 4.0 works with the code-first programming model of the ADO.NET Entity Framework. The columns that have server generated keys, like identity and rowguid for example, are also supported in Compact 4.0 when used with ADO.NET Entity Framework 4.0. Support for the code-first and for the server-generated keys rounds out the Compact support for ADO.NET Entity Framework.
- Improvements for setup, deployment, reliability, and encryption algorithms: The bases of Compact 4.0 have been strengthened to ensure that it can be installed without any problems, and can be deployed easily, and works reliably while providing the highest level of security for data.
WebMatrix Launch
WebMatrix v1 is ready to go, and starting Thursday, January 13, you'll be able to download it from http://www.microsoft.com/webmatrix
WebMatrix makes it easy for anyone to create a new web site using a template or an existing free open source application, customize it, and then publish it on the internet via a wide choice of hosting service providers. And yes, it's free.
WebMatrix lets you create web sites the way that you want to. We've spoken with countless web developers, and have learned what they want to create the next generation of web sites.
The main launch event for WebMatrix is CodeMash on January 13th. Microsoft will be simultaneously holding a live steaming event called Enter the WebMatrix, from http://microsoft.com/web/enter. This live event will be streamed as both an HD Smooth Stream as well as WMV for non-Silverlight users. The event starts with a one hour keynote where WebMatrix is introduced and demo’ed. Features will be highlighted as will special partners that have built special Helpers or Web Applications available within WebMatrix.
Return to section navigation list>
Windows Azure Infrastructure
TechNet’s Cloud Scenario Hub published Getting Business Done with the Cloud as its Home page in January 2011:
Microsoft’s cloud offerings build on familiar proven Windows technology and can be deployed both on-premise (“private cloud") or hosted services (“public cloud”). Public cloud solutions allow organizations to reduce capital costs and free up IT staff to concentrate on delivering greater business value. Private cloud solutions enable organizations to drive more efficiency and flexibility out of their existing IT investment. With the cloud, IT becomes the enabler to new business solutions and not the barrier.
Deciding if you can take advantage of cloud solutions requires answers to some basic questions. Finding those answers is not often straightforward, not to mention that no two business situations are exactly the same. The best way to make an informed decision is to compare common cloud implementation scenarios with your requirements.
This center provides resources and details on these common scenarios.
- Implementing Windows-based Applications for Burst Demand with Windows Azure
How to Manage Server Costs with Windows Azure
How to Grow Your Business in a New Region with SharePoint Online
How to Build and Manage a Business Database Application on SQL Azure
How to Grow Your Business in a New Region with Exchange Online
How You Can Avoid Outgrowing Your Email Infrastructure and IT Budget
How to Collaborate Securely with Business Partners through SharePoint Online
To learn more how IT Pros get IT done with the cloud services, check back monthly
The Downloads page offers the following links:
Additional Downloads
Explore
Plan & Deploy
- Microsoft SharePoint Online Dedicated Custom Solution Policies and Process (Word doc)
- Developing and Deploying with SQL Azure (Word doc)
- Microsoft SharePoint Online Dedicated Custom Solution Policies and Process (Word doc)
- Business Productivity Online Standard Suite Deployment Guide (PDF)
- Business Productivity Online Standard Suite Deployment Guide (PDF)
- Microsoft Online Migration Toolkit (Zip file)
- Business Productivity Online Standard Suite Deployment Guide (PDF)
- Microsoft SharePoint Online Dedicated Custom Solution Policies and Process (Word doc)
Manage
Maintain
The Windows Azure Platform Team appears to be trying to bury us with documentation.
Patrick Butler Monterde published Windows azure billing overview on 2/10/2010 but it bears repeating because of new Azure developers misunderstandings:
There have been a lot of questions regarding Windows Azure Platform billing and how it works. This diagram shows the relationship between components. The current diagram shows the current configuration. This configuration may change in the future:
Notes:
- The green components are the ones that you can upgrade.
- The 20 small computes instances could be any combination of VM sizes so long as the total number of cores across all slots and services within the project does not exceed 20.
Billing and Subscriptions
Account Administrator (Account Owner WLID). The Account Owner can create and manage subscription, view billing and usage data and specify the Service Administrator for each subscription. Large companies may need to create multiple accounts in order to design an effective account structure that supports/reflects their go-to-market strategy. The account Administrator cannot create services.
Service Administrator (Service Admin. WLID): Manages Services and deployments.
Note: The WLID for the Account owner and Service Administrator are not necessarily the same WLID. Refer to the Subscriptions explanation below.
Subscriptions (MOCP)
For each MOCP account, the Account Owner can create one or more subscriptions. For each subscription, the Account Owner can specify a different WLID as the Service Administrator. This WLID can be the same or different as the Account Owner. The Service Administrator is the user that actually uses the Windows Azure platform. Only the Account Owner can reassign a subscription’s Service Administrator.
These are the commercial subscriptions currently available through MOCP:
- Azure offers Link: http://www.microsoft.com/windowsazure/offers/
- Compare Azure Subscriptions link: http://www.microsoft.com/windowsazure/offers/popup.aspx?lang=en&locale=en-US&offer=COMPARE_PUBLIC
The creation of a subscription in the Microsoft Online Customer Service Portal (MOCP) portal results in a Project in the Windows Azure portal.
Project (on the Azure Portal)
A project can allocate up to twenty services. Resources in the Project are shared between all the services created. The resources are divided into compute instances/cores and Storage accounts:
- By default the account will have 20 Small Compute Instances that you can utilize. If you need to increase the number, just have to contact Microsoft Online Services customer support. There they will verify the billing account and provide the requested Small Compute Instances / cores, subject to a possible credit check. In addition, you can design how you want to have the cores allocated. By default, the available resources are counted as number of Small compute instances. This is the conversion on compute instances:
Compute Instance Size
CPU
Memory
Instance Storage
[Extra Small] 3.0 GHz 768 MB 20 GB Small
3.6 GHz
1.75 GB
225 GB
Medium
2 x 1.6 GHz
3.5 GB
490 GB
Large
4 x 1.6 GHz
7 GB
1,000 GB
Extra large
8 x 1.6 GHz
14 GB
2,040 GB
Table 1 Compute Instances comparison [Extra-Small instance added 1/13/2011]
- The compute instances are shared between all the running services in the project (including Production and Staging environments), so you can have multiple services with different number of compute instances, up to the number of maximum available for that project.
- 5 Storage accounts per Project. You can request to increase this up to 20 storage accounts per project by contacting Microsoft Online Services customer support. If you need more storage accounts than 20, you will need to order another subscription.
Services
You can have a total of 20 Services per project. The services are space where applications are deployed. Each service provides two environments: Production and Staging. This is visible when you create a service in the Windows Azure portal.
A service can have a maximum of five roles per application. This is any combinations of different web and worker roles on the same configuration file up to a maximum of 5. Each role can have any number of VMs. For Example:
Standard 3 tier application: Web-Business-Data Tiers to Windows Azure Roles
On this example the service has 2 roles, each role with a specific workers role. Web Role worker, web tier, takes care of the Web interface. The Worker Role, business tier, is responsible for the business logic. Each role can have any number of VMs/Cores, to the maximum available on the Project.
From the Azure resources perspective, if we deploy this service we will be using the following resources:
1 x Service
- Web Role = 3 Small Compute Nodes (3 x Small VMs)
- Worker Role = 4 Small Compute Nodes (2 x Medium VMs)
- 2 Roles used
Total resources left on the Project:
- Services (20 -1) = 19
- Small Compute Nodes (20 – 7)= 13 small compute Instances
- Storage accounts = 5
Notes about Services: You will get billed for role resources utilized on a deployed service, even if the roles on those services are not running (i.e., “suspended”). If you don’t want to get charged for a service, you need to delete the deployments associated with the service.


The primary reason for repeating this post is that I still see frequent complaints from neophyte Azure developers about charges for suspended or staged instances.
Emmanuel Huna referenced Patrick’s post in his Moving a subscription from one MOCP account to another? thread in the Microsoft Online Services Customer Portal forum. According to MSFT moderator Destinie B:
Please be advised that you can move all your subscriptions under one Windows Live ID. To complete this process please contact the Online Services Support Team at 866-676-6546 and request a Windows Live ID transfer for all your subscriptions to be under one email address.
As Emmanuel says: “It's too bad this can't be done online.”
For more information about Extra-Small Compute Instances, see my Windows Azure Compute Extra-Small VM Beta Now Available in the Cloud Essentials Pack and for General Use post of 1/9/2011.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
David Strom published Connecting to virtual servers in the cloud to SearchCloudComputing.com on 1/12/2010:
Setting up cloud-based servers with data and applications usually involves making remote connections to move content from your enterprise network or desktop to the virtual instance of your server.
There are at least three different ways to connect to virtual servers in the cloud. As examples, we'll use Amazon Web Services, hosted VMware provider Terremark and a free provider called Cloudshare.com, where IT shops can host up to three virtual servers for free.
If you're deeply involved in cloud computing, it's likely that you're using all three of these methods to connect to your servers. And if you are used to remotely administrating your physical servers using Windows Remote Desktop or Secure Shell (SSH), you probably will feel right at home. If you haven't yet used any of these tools, however, you'll need to understand which part of your virtual machine's resources can be accessed by each method.
Connecting through a VPN
The first, and most direct, way is to use a built-in virtual private network (VPN). Many cloud providers use something like Cisco's AnyConnect VPN client, which can be started through an Active-X or Java plug-in from inside your browser. This establishes a VPN between your desktop PC and the cloud network. Some of these VPN clients are fussy about which browser version you use; I would recommend starting with Internet Explorer 7 or Firefox 3 on Windows. Newer or older versions running on non-Windows clients may not work properly with AnyConnect or your particular provider.
Figure 1: Cisco's VPN client (Click to enlarge image)Amazon Web Services (AWS) has its own Virtual Private Cloud (VPC) that will set up a VPN connection between your entire enterprise network and its cloud. This can be useful, especially for hybrid cloud apps that reside partly on premise and partly in Amazon's cloud.
To set up, connect through the AWS Web management console for the VPC service. It will walk you through a series of steps to create your connection and then ask you to download a configuration file based on your VPN gateway. Amazon VPC supports a limited number of Cisco and Juniper VPN gateways, including the J-series, SSG, ISG and ISR series.
Figure 2: Amazon's VPC console (Click to enlarge image)After you have established a VPN connection and set up file sharing on a cloud-based server, you can map a network drive using your server's IP address. This method is useful for quick file transfers and to make small routine adjustments in your server's file system.
Connecting through a remote desktop client
If you want to manage the server directly, however, you'll have to use a second method. If you're running a Windows virtual server, this will be to run a remote desktop connection client. If you're using a Linux virtual server, you'll run an SSH client. Either way, set up the service on your virtual server to receive these connections, and make sure that the port (3389 for RDC) is open to the outside world.Once this is all set, bring up the server's desktop inside a window and run whatever commands you need to manage the server remotely. This method is good for the Windows Server management commands or Linux command lines that you need to run from the console, such as starting your Web and database server or setting up new file shares.
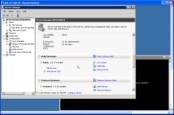
Figure 3: The Remote Desktop console (Click to enlarge image)Most cloud providers have ways to either initiate remote control sessions from within browser windows or use these remote desktop connections. Cloudshare.com doesn't offer any VPN connection for its free accounts, but it does puts all the connection information, including sign-on details, right where you need them: above the browser window.

Figure 4: Cloudshare.com's browser window (Click to enlarge image)Connecting through FTP
The third method is to use the file transfer protocol (FTP). Again, you have to set up the service on your virtual server and make sure that both ports 20 and 21 are seen by its outside IP address. Afterwards, you can either load up your FTP client on your local desktop or run the FTP command from the server directly and connect to an Internet resource in order to copy files. This is the best method for bulk transfer of files, such as setting up a new website or loading up a database.
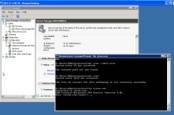
Figure 5: FTP transfers (Click to enlarge image)In comparison, Cloudshare.com offers a drag-and-drop file transfer between your desktop and the virtual server; this simplifies file transfer somewhat but is not as secure.
The hosted VMware services from Terremark offer another way to move information to the cloud. Once you connect via the VPN, you can bring up the remote VMware console to mount a local DVD drive on your desktop on the cloud server. This is handy for uploading ISO or installation disks to the cloud server, although its speed depends on your Internet connection.
Figure 6: Mounting a DVD drive through VMware's console (Click to enlarge image)Although the method depends on your cloud provider and the amount of data, there are numerous options when it comes to moving data to your server. For a summary, take a look at the chart below:
VPN Remote Desktop/SSH FTP VMware Remote Console Quick file transfer Best for management and console-oriented tasks Best for bulk transfer of files Mount local DVD across the Internet or install an ISO image Requires recent browser and Cisco AnyConnect VPN client or equivalent Requires Remote Desktop or SSH client FTP client Terremark and other hosted VMware providers
Full disclosure: I’m a contributor to SearchCloudComputing.com’s blog.
<Return to section navigation list>
Cloud Security and Governance
David Linthicum posted SOA Governance Starts with People and Processes, and Not Technology to ebizQ’s Where SOA Meets Cloud blog:
In the world of SOA, the concept of SOA governance is getting a lot of attention. However, how SOA governance is defined and implemented really depends on the SOA governance vendor who just left the building within most enterprises. Indeed, confusion is a huge issue when considering SOA governance, and the core issues are more about the fundamentals of people and processes, and not about the technology.
SOA governance is a concept used for activities related to exercising control over services in an SOA, including tracking the services, monitoring the service, and controlling changes made to the services, simple put. The trouble comes in when SOA governance vendors attempt to define SOA governance around their technology, all with different approaches to SOA governance. Thus, it's important that those building SOAs within the enterprise take a step back and understand what really need to support the concept of SOA governance.
The value of SOA governance is pretty simple. Since services make up the foundation of an SOA, and are at their essence the behavior and information from existing systems externalized, it's critical to make sure that those accessing, creating, and changing services do so using a well controlled and orderly mechanism. Those of you, who already have governance in place, typically around enterprise architecture efforts, will be happy to know that SOA governance does not replace those processes, but becomes a mechanism within the larger enterprise governance concept.
People and processes are first thing on the list to get under control before you begin to toss technology at this problem. This means establishing an understanding of SOA governance within the team members, including why it's important, who's involved, and the core processes that are to be follow to make SOA governance work. Indeed, when creating the core SOA governance strategy should really be independent of the technology. The technology will change over the years, but the core processes and discipline should be relatively durable over time.
David Linthicum claimed “Hackers are getting better at using the scalability of cloud computing to crack into the previously uncrackable” in a deck for his Turning white clouds into black clouds: Cloud-driven hacking is now real post of 1/13/2011 for InfoWorld’s Cloud Computing blog:
In November, I predicted the following: "With the rise of high-end, on-demand supercomputing, those who need CPU power to break encryptions and hack into major players will learn to use clouds to attack other clouds." Only a few days into 2011, we are seeing this come true. German security researcher Thomas Roth is using cloud computing to crack wireless networks that rely on preshared key passphrases, such as those found in homes and smaller businesses.
The trick to cracking codes such as this is high-end computing power, once out of reach for most. These days, you can rent the cycles you need for mere dollars a day. Roth has created a program that operates on Amazon.com's Elastic Cloud Computing (EC2) system, running through 400,000 possible passwords per second -- a feat not economically possible without cloud computing.
Roth is proving the potential for cloud computing to support bad actors, as well as legitimate businesses. In essence, he's turning the power of cloud computing on others -- perhaps including other clouds. I suspect more of this is going on than we know, and Roth is to be commended for revealing the danger here.
Sadly, there is little we can do about this problem, other than hold cloud computing providers somewhat responsible for the actions of their customers, as well as check and double-check our own security. Much of these kinds of shenanigans can be caught with simple monitoring, but we can't expect them to catch all of it.
We can expect to see a few more well-publicized cracks using the power of cloud computing. Some we'll read about; most will be handled quietly.
<Return to section navigation list>
Cloud Computing Events
Bruno Terkaly and the Azure Cloud Computing Developers Group announced a The Windows Azure AppFabric - Possibly the most compelling part of Azure session to be held on 1/27/2011 6:30 PM at Microsoft’s San Francisco office:
There is no question that there is a growing demand for high-performing, connected systems and applications. Windows Azure AppFabric has an interesting array of features today that can be used by ISVs and other developers to architect hybrid on-premise/in-cloud applications. Components like Service Bus, Access Control Service and the Caching Service. are very useful in their own right when used to build hybrid applications.
So why do you think we need the App Fabric?
(1) Operating systems are still located—trapped is often a better word—on a local computer, typically behind a firewall and perhaps network address translation (NAT) of some sort. This problem is true of smart devices and phones, too.
(2) As ubiquitous as Web browsers are, their reach into data is limited to an interactive exchange in a format they understand.
(3) Code re-use is low for many aspects of software. Think about server applications, desktop or portable computers, smart devices, and advanced cell phones. Microsoft leads the way in one developer experience across multiple paradigms.
(4) Legacy apps are hard to re-write, due to security concerns or privacy restrictions. Often times the codebase lacks the support of the original developers.
(5) The Internet is not always the network being used. Private networks are an important part of the application environment, and their insulation from the Internet is a simple fact of information technology (IT) life.
Come join me for some non-stop hands-on coding on January 27th. I've created a series of hands-on labs that will help you get started with the Windows Azure Platform, with an emphasis on the AppFabric.

1105 Media posted the Cloud Computing Track sessions for Visual Studio Live! Las Vegas 2011, to be held 4/18 through 4/22/2011 at the Rio All-Suite Hotel & Casino:
Many people believe the future of application development is in the cloud. Cloud computing offers flexible scalability and may provide a less expensive way to host many applications. Microsoft has introduced Azure as its platform for cloud computing, and has many other technologies that also work well in a cloud computing environment. Even if you aren’t ready for Azure today, you owe it to yourself to become familiar with cloud computing! This track includes coverage of the following:
- Windows Azure
- SQL Azure
- Azure DataMarket
T3 Azure Platform Overview Tuesday April 19 9:15 AM - 10:30 AM; Vishwas Lele, Architect, AIS; more T7 Building Azure Applications Tuesday April 19 10:45 AM - 12:00 PM; Vishwas Lele, Architect, AIS; more T11 Building Compute-Intensive Apps in Azure Tuesday April 19 2:30 PM - 3:45 PM; Vishwas Lele, Architect, AIS; more T15 Using C# and Visual Basic to Build a Cloud Application for Windows Phone 7 Tuesday April 19 4:00 PM - 5:15 PM; Srivatsan Narayanan, Microsoft Corporation, and Lucian Wischik, Specification Lead for Visual Basic, Microsoft Corporation; more TH20 Windows Azure and PHP Thursday April 21 3:00 PM - 4:15 PM; Jeffrey McManus, CEO, Platform Associates; more
Full disclosure: I’m a contributing editor for 1105 Media’s Visual Studio Magazine.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Lydian Leong answered Bob Warfield’s post (see below) with The cloud and customized contracts, posted to her Cloud Pundit blog on 1/12/2011:
Continuing the ongoing debate about the Cloud IaaS and Web Hosting Magic Quadrant, Bob Warfield has made a blog post called “Gartner: The Cloud is Not a Contract“. I want to address a number of points he made in his post. I’m going to address them out of order, starting with the points that I think are of more general interest, and then going into some of the MQ-quibble-specific stuff.
Bob goes into detail about why customized contracts can destroy what a customer was hoping to get out of the cloud in the first place. Bob writes something that I agree with but want to nuance in a number of ways. He says: How do we avoid having a contract destroy Cloudness? This is simple: Never sign a contract with your Cloud provider that interferes with their ability to commoditize through scale, sharing, and automation of operations.
I think that a cloud provider has to make decisions about how much they’re willing to compromise the purity of their model — what that costs them versus what that gains them. This is a business decision; a provider is not wrong for compromising purity, any more than a provider is right for being totally pure. It’s a question of what you want your business to be, and you can obtain success along the full spectrum. A provider has to ensure that their stance on customization is consistent with who and what they are, and they may also have to consider the trade off between short-term sales and long-term success.
Customers have to be educated that customization costs them more and may actually lower their quality of the service they receive, because part of the way that cloud providers drive availability is by driving repeatability. Similarly, the less you share, the more you pay. (These points are usually called out in gigantic bold caps in my conference presentations.) The cloud creates some harder choices for customers, because the cloud forces IT buyers to confront what “having it your way” is costing them, and will cost them in the future. The cloud is not, as it were, Burger King. The ability to take advantage of commodity cloud services will be a key factor in IT efficiency going forward.
But I believe that customers will continue to make choices along that spectrum. Most of them will walk into decisions with open eyes, and some will decide to sacrifice cost for customization. They are doing this today, and they will continue to do it. Importantly, they are segmenting their IT portfolios and consciously deciding what they can commoditize and what they can’t. Some will be better at embracing Smart Control than others, but ultimately, the most successful IT managers will be the ones who be the ones that manage IT to business goals. They are looking for cloud solutions that fit those goals, and many of those solutions are impure.
A significant percentage of my job is helping an IT buyer client talk through his requirements, challenging the reasoning for those requirements, explaining to him what his options are, and what vendors are likely to be good shortlist candidates — but also noting explicitly where his choices are preventing him from deriving greater value. I want him to consciously understand the trade-offs that he’s making, both short-term and long-term. And it’s also critical to understand their expectations of the future, so they can be advised on how to get there from here. Most organizations will transform gradually, not immediately or radically.
Bob wrote: The easy thing is to cave to your clients since they’re paying the bills and concoct a scenario where the clients get what they think they want. The hard thing is to show some leadership, earn your fees, and explain to the client, or at least to the vendors slighted, why your recommendation is right.
It is critical to understand that the MQ shows how vendors map in an overall market, which, as this MQ is titled, is, “Cloud IaaS and Web Hosting”, an impure market. As we repeatedly tell people, you should choose a solution that fits your use case — your technical and business needs. You should not read the MQ as saying that we don’t recommend Amazon (or other pure-plays) to clients. We recommend them plenty. And in fact, the MQ strengths text for Amazon is highly complimentary. (It starts with “Amazon is a thought leader; it is extraordinarily innovative, exceptionally agile and very responsive to the market. It has the richest cloud IaaS product portfolio, and is constantly expanding its service offerings and reducing its prices.” When I presented that bit of writing to my peers, some people thought it sounded too effusive for the usual Gartner tone of neutral objectivity!)
Any Gartner client trying to make a decision about the cloud is entitled to make an inquiry, and we’re happy to dive into the details of what they’re looking for, tease out what they need, and help them choose something that will be right for them. I did more than a thousand client phone inquiries during 2010. That’s a lot of people; each one represents a sourcing decision, and that number doesn’t include my conference one-on-ones, roundtables, sales visits, email exchanges, and so forth. I’m pretty confident about what our clients want to buy because I’ve talked to an awful lot of them. Most of those conversations are conducted without reference to the MQ, although many clients do look at the MQ first, and come prepared with questions about specific vendors.
But my job isn’t to tell clients the benefits of an “objectively right” decision. I’m not in the business of telling him what he should want, although I can tell him what other companies do as a best practice. And frankly, clients don’t need me to tell them to go be more innovative. In most cases, they want to be able to venture boldly into the benefits of cloud computing, but there are many business and technical circumstances that they need to factor into their decision-making, and most have serious needs for risk mitigation. Ihave to help a client come to a decision that will work for him. He’s going to pay for it, he’s going to be the one defending it to his management, and he’s going to be the one who pays the price if it goes all pear-shaped. I wrote previously about our IT buyer audience, and my belief that my formal research writing should highly pragmatic for their needs, not a reflection of what I think the market should want, so I won’t go into that again here — see that post instead.
By the way, on Bob’s “you ought to explain to the vendors slighted” gripe: Every single vendor on the MQ was entitled to a phone call with me — it’s a mandatory Gartner courtesy extended to all participants, regardless of client status, when they receive a draft for their review. I had long conversations on the phone, as well as in email, with many vendors (regardless of placement), about the MQ, their own placements, and the placements of other vendors. I assure you that they understand why things are the way they are (even if they don’t necessarily agree).
Bob wrote: It is obvious and absurd not to rank Amazon Web Services at least among the leaders. If youre going to take that step, it’s a bold one, and needs to be expressed up front with no ambiguity and leading with a willingness to have a big discussion about it. Gartner didn’t do that either. They just presented their typical blah, blah, blah report.
As I explained in my earlier post about the MQ process, we don’t position vendors arbitrarily. We decide scoring criteria, and we score vendors on those criteria, and they come out where they come out. In this case, we looked at the resulting MQ and the placement of the pure-plays and decided we should do a mid-year update that focused on purely self-managed cloud IaaS, in addition to the Critical Capabilities note due to be published soon, which is also pure-play focused. (I think much will become clearer once the Critical Capabilities is out, and I wish we’d been able to publish them near-simultaneously.)
We do not call out commentary about specific vendors in a Magic Quadrant, as a matter of policy; the document follows a very strict format. However, we’re always happy to discuss anything we write with our clients. Moreover, even though Gartner considers social media engagement (whether blogging or otherwise) for analysts to be personal time and not actual work, I think I’ve been pretty thoroughly engaged with people in discussing the MQ both in the blogosphere and on Twitter (@cloudpundit). I’m not sure how Bob is concluding that there’s not a willingness to have a big discussion about it (although I am specifically refraining from going into detail on Amazon’s rating on my blog, since it is against Gartner policy to do so).
Bob Warfield continued the Gartner Magic Quadrant (MQ) conflict with a Gartner: The Cloud is Not a Contract post to his Enterprise Irregulars blog on 1/12/2010:
There is a bit of a joust on between Gartner, GigaOm, and likely others over the recent Gartner Magic Quadrant for Cloud Infrastructure. The Internet loves a good fight!
Gartner launched their magic quadrant with some fanfare on December 22. Immediately after the holidays, on January 4, GigaOm’s Derrick Harris threw down the gauntlet by bluntly saying, “Gartner just flat got it wrong.” Can’t get much more black and white than that. His reasoning is as follows:
Initially, it seems inconceivable that anybody could rank IaaS providers and not list Amazon Web Services among the leaders. Until, that is, one looks at Gartner’s ranking criteria, which is skewed against ever placing a pure cloud provider in that quadrant. Large web hosts and telcos certainly have a wider range of offerings and more enterprise-friendly service levels, but those aren’t necessarily what cloud computing is all about. Cloud IaaS is about letting users get what they need, when they need it — ideally, with a credit card. It doesn’t require requisitioning servers from the IT department, signing a contract for any predefined time period or paying for services beyond the computing resources.
I have to say, he is right. It is obvious and absurd not to rank Amazon Web Services at least among the leaders. If you’re going to take that step, it’s a bold one, and needs to be expressed up front with no ambiguity and leading with a willingness to have a big discussion about it. Gartner didn’t do that either. They just presented their typical blah, blah, blah report. For weaknesses, which presumably got Amazon moved out of the ranks of leaders, they offer the following:
- No managed services.
- No collocation, dedicated nonvirtualized servers (often used for databases), or private non-Internet connectivity.
- The weakest cloud compute SLA of any of the evaluated competing public cloud compute services. They offer 99.95% uptimes instead of the 99.99% of many others and the penalties are capped.
- Support and other items are unbundled.
- Amazon’s offering is developer-centric, rather than enterprise-oriented, although it has significant traction in large enterprises. Its services are normally purchased online with a credit card; traditional corporate invoicing must be negotiated as a special request. Prospective customers who want to speak with a sales representative can fill out an online form to request contact; Amazon does have field sales and solutions engineering. Amazon will negotiate and sign contracts known as Enterprise Agreements, but customers often report that the negotiation process is frustrating.
My first reaction to reading those negatives is they make a pretty good list of criteria for differentiating an old-fashioned managed hosting data center from a real Cloud service. Does Gartner understand what the Cloud really is, what it is about, and how to engage with it successfully?
For her part, the lead analyst, Lydia Leong, responded the day after the GigaOm post. Here response, predictably, is to disagree with Derrick’s quoted paragraph above, saying:
I dispute Derrick’s assertion of what cloud IaaS is about. I think the things he cites above are cool, and represent a critical shake-up in thinking about IT access, but it’s not ultimately what the whole cloud IaaS market is about.
Lemme get this straight, the Cloud IaaS market is about (since I will negate Derrick’s remarks that Lydia disagrees with):
- Eliminating Pure Cloud vendors from serious consideration. You must have non-Cloud offerings to play.
- Eliminating the self-service aspect of letting users get what they need, when they need it–ideally, with a credit card.
- Eliminating the possibility for self-service without a contract negotiation.
Newsflash for you folks at Gartner: the Cloud is Not a Contract. It is a Service, but it is a not a legion of Warm Bodies. It’s not about sucking up with field sales and solutions engineering (“You’re a handsom and powerful man!”).
I can understand that Lydia’s clients mention the need for elaborate contracts with detailed provisions unique to their circumstances. When that happens, and when it is so at odds with the landscape of a fundamentally new development that respecting it will prevent you from naming legitimate leaders like Amazon as leaders, there are two ways you can proceed. The easy thing is to cave to your clients since they’re paying the bills and concoct a scenario where the clients get what they think they want. The hard thing is to show some leadership, earn your fees, and explain to the client, or at least to the vendors slighted, why your recommendation is right.
Let’s put on our analyst hats, leave Gartner’s misguided analysis, and look at the issue squarely of, “How should we be looking at the issue of Contracts and the Cloud?”
As I have already said, “The Cloud is not about contacts.” What it is about is commoditization through scale and through sharing of resources which leads to what we call elasticity. That’s the first tier. The second tier is that it is about the automation of operations through API’s, not feet in the datacenter cages. All the rest is hype. It is this unique combination of: scale, sharing of resources, elasticity, and the automation of ops through API’s that makes the Cloud a new paradigm. That’s how the Cloud delivers savings. It’s not that hard to understand once you look at it in those terms.
Now what is the impact of contracts on all that? First, a contract cannot make an ordinary datacenter into a Cloud no matter who owns it unless it addresses those issues. Clouds are Clouds because they have those qualities and not because some contract or marketer has labeled them as such. Second, arbitrary contracts have the power to turn Clouds into ordinary hosted data centers:
A contract can destroy a Cloud’s essential “Cloudness”!
I wanted to put that in bold and set apart because it is important. When you, Mr handsom and powerful IT leader, are negotiating hard with your Cloud vendor, you have the power to destroy what it was you thought you were buying. Your biggest risk is not that they will say, “No”, it is that they might say, “Yes” if you wave a big enough check. Those who have made the mistake of getting exactly what they want on a big Enterprise Software implementation that wound up going very far wrong because what you wanted was not what the software really did will know what I am talking about.
How do we avoid having a contract destroy “Cloudness?” This is simple:
Never sign a contract with your Cloud provider that interferes with their ability to commoditize through scale, sharing, and automation of operations.
If they are smart, the Cloud provider will never let it get to that stage. This is one reason Amazon won’t negotiate much in a contract. Negotiating fees for services offered is fine. That does not interfere with the critical “Cloudness” qualities (I am steadfastly refusing the term Cloudiness so as not to deprecate my central thesis!). BTW, there are very close corollaries for SaaS, which is why they are also much more limited relative to On-prem vendors in what they can negotiate and why they try to hew to the side that Amazon has. This stuff didn’t get invented for Cloud or out of disdain for customers, there are real economic impacts.
Let’s try a simple example. Your firm wants to secure Cloud resources from a provider who has some sort of maintenance outage provision for the infrastructure. It’s a made up example for Cloud (mostly), but is on point for SaaS and easy to understand, so let me continue. Your firm finds that maintenance window to be unacceptable because you have aligned your own maintenance windows with those of another vendor. If you accept the Cloud vendor’s window, you will now have two windows to present your constituents and that is unacceptable. So you want to negotiate a change in the contracts. Sounds very innocent, doesn’t it? I’ve been through this exact scenario at SaaS companies where customers wanted this to be done for the same legitimate and logical reasons.
But consider it from the Cloud provider’s point of view. If they have a special maintenance window for you, they have to take a portion of their infrastructure and change how it works. Unless they have other customers that want exactly the same terms, they will have to dedicate that infrastructure to your use. Can you see the problem? We have now eliminated the ability to scale that infrastructure through sharing and scale. In addition, depending on how their automated operations function, it may or may not be applicable to your specialized resources. It isn’t just a matter of changing a schedule for some ops people–the automated ops is either set up to deal with this kind of flexibility or it isn’t.
That was an example for a maintenance window, but any deviation you negotiate in a contract that impacts scale, sharing, or automated ops can have the same impact. Here are more examples:
- You want to change the disk quotas or cpus on your instances.
- Your SLA requirements damage some baked-in aspect of the providers automated ops infrastructure. This is easy to have happen. You insist on network bandwidth that requires a different switching fabric or whatever.
- You want to limit how and when machines can be patched by the provider.
- You want to put your machines on private subnets as Gartner suggests should be possible and has many who think the idea of a Private Cloud is Marketing BS decry.
That list can be a mile long. When you get done ruling out all the things you really can’t negotiate without un-Clouding your Cloud, you’re going to see that relatively simple contracts such as you can already negotiate with Amazon are all that’s left. Congratulations! Unlike Gartner, you now understand what a Cloud is and how to take advantage of it.
And remember, the next time you’re negotiating a Cloud contract, be careful what you wish for–you just might get it.

Jeffrey Breen described Abusing Amazon's Elastic MapReduce Hadoop service... easily, from R in a 1/10/2010 post:
I built my first Hadoop cluster this week and ran my first two test MapReduce jobs. It took about 15 minutes, 2 lines of R, and cost 55 cents. And you can too with JD Long’s (very, very experimental) ‘segue’ package.
But first, you may be wondering why I use the word “abusing” in this post’s title. Well, the Apache Hadoop project, and Google’s MapReduce processing system which inspired it, is all about Big Data. Its raison d’être is the distributed processing of large data sets. Huge data sets, actually. Huge like all the web logs from Yahoo! and Facebook huge. Its HDFS file system is designed for streaming reads of large, unchanging data files; its default block size is 64MB, in case that resonates with your inner geek. HDFS expects its files to be so big that it even makes replication decisions based on its knowledge of your network topology.
I use the term “abuse” because, well, we’re just not going to use any of that Big Data stuff. Instead, we’re going to take advantage of Hadoop’s core machinery to parcel out some embarrassingly parallel, computationally-intensive work, collect the results, and send them back to us. And to keep everything in the cloud and capex-free, we’ll do it all on a cluster of Amazon EC2 instances marshalled and managed by Amazon’s Elastic MapReduce service.
Could the same thing be done with MPI, PVM, SNOW, or any number of other parallel processing frameworks? Certainly. But with only a couple of lines of R? Probably not.
Start the cluster
> library(segue) Loading required package: rJava Loading required package: caTools Loading required package: bitops Segue did not find your AWS credentials. Please run the setCredentials() function. > setCredentials('YOUR_ACCESS_KEY_ID', 'YOUR_SECRET_ACCESS_KEY') > myCluster <- createCluster(numInstances=5) STARTING - 2011-01-04 15:07:53 STARTING - 2011-01-04 15:08:24 STARTING - 2011-01-04 15:08:54 STARTING - 2011-01-04 15:09:25 STARTING - 2011-01-04 15:09:56 STARTING - 2011-01-04 15:10:27 STARTING - 2011-01-04 15:10:58 BOOTSTRAPPING - 2011-01-04 15:11:28 BOOTSTRAPPING - 2011-01-04 15:11:59 BOOTSTRAPPING - 2011-01-04 15:12:30 BOOTSTRAPPING - 2011-01-04 15:13:01 BOOTSTRAPPING - 2011-01-04 15:13:32 BOOTSTRAPPING - 2011-01-04 15:14:03 BOOTSTRAPPING - 2011-01-04 15:14:34 BOOTSTRAPPING - 2011-01-04 15:15:04 WAITING - 2011-01-04 15:15:35 Your Amazon EMR Hadoop Cluster is ready for action. Remember to terminate your cluster with stopCluster(). Amazon is billing you!The
createCluster()function provisions the specified number of nodes from EC2, establishes a security zone so they can communicate, boots them, and, in its bootstrap phase, upgrades the version of R on each node and loads some helper functions. You can also distribute your own code and (small) data files to each node during the bootstrap phase. In any case, after a few minutes, the cluster is WAITING and the taxi meter is running… so now what?Try it out
Let’s make sure everything is working as expected by running the example from JD’s December announcement of his project on the R-sig-hpc mailing list:
> # first, let's generate a 10-element list of 999 random numbers + 1 NA: myList <- NULL set.seed(1) for (i in 1:10){ a <- c(rnorm(999), NA) myList[[i]] <- a } > # since this is a toy test case, we can run it locally to compare: > outputLocal <- lapply(myList, mean, na.rm=T) > # now run it on the cluster > outputEmr <- emrlapply(myCluster, myList, mean, na.rm=T) RUNNING - 2011-01-04 15:16:57 RUNNING - 2011-01-04 15:17:27 RUNNING - 2011-01-04 15:17:58 WAITING - 2011-01-04 15:18:29 > all.equal(outputEmr, outputLocal) [1] TRUEThe key is the
emrlapply()function. It works just likelapply(), but automagically spreads its work across the specified cluster. It just doesn’t get any cooler—or simpler—than that.Estimate pi stochastically
I first stumbled across JD’s R+MapReduce work in this video of his presentation to the Chicago area Hadoop User Group. As a demonstration, he estimates the value of pi stochastically, by throwing dots at random at a unit circle inscribed within a unit square. On average, the proportion of dots falling inside the circle should be related to its area compared to that of the square. And if you remember anything from what passed as math education in your younger years, you may recall that pi is somehow involved. Fortunately for us, JD has posted his code on github so we can put down our #2 pencils and cut-and-paste instead:
> estimatePi <- function(seed){ set.seed(seed) numDraws <- 1e6 r <- .5 #radius... in case the unit circle is too boring x <- runif(numDraws, min=-r, max=r) y <- runif(numDraws, min=-r, max=r) inCircle <- ifelse( (x^2 + y^2)^.5 < r , 1, 0) return(sum(inCircle) / length(inCircle) * 4) } > seedList <- as.list(1:1e3) > myEstimates <- emrlapply( myCluster, seedList, estimatePi ) RUNNING - 2011-01-04 15:22:28 RUNNING - 2011-01-04 15:22:59 RUNNING - 2011-01-04 15:23:30 RUNNING - 2011-01-04 15:24:01 RUNNING - 2011-01-04 15:24:32 RUNNING - 2011-01-04 15:25:02 RUNNING - 2011-01-04 15:25:34 RUNNING - 2011-01-04 15:26:04 RUNNING - 2011-01-04 15:26:39 RUNNING - 2011-01-04 15:27:10 RUNNING - 2011-01-04 15:27:41 RUNNING - 2011-01-04 15:28:11 RUNNING - 2011-01-04 15:28:42 RUNNING - 2011-01-04 15:29:13 RUNNING - 2011-01-04 15:29:44 RUNNING - 2011-01-04 15:30:14 RUNNING - 2011-01-04 15:30:45 RUNNING - 2011-01-04 15:31:16 RUNNING - 2011-01-04 15:31:47 WAITING - 2011-01-04 15:32:18 > stopCluster(myCluster) > head(myEstimates) [[1]] [1] 3.142512 [[2]] [1] 3.140052 [[3]] [1] 3.138796 [[4]] [1] 3.145028 [[5]] [1] 3.14204 [[6]] [1] 3.142136 > # Reduce() is R's Reduce() -- look it up! -- and not related to the cluster: > myPi <- Reduce(sum, myEstimates) / length(myEstimates) > format(myPi, digits=10) [1] "3.141586544" > format(pi, digits=10) [1] "3.141592654"So, a thousand simulations of a million throws each takes about 10 minutes on a 5-node cluster and gets us five decimal places. Not bad.
How does this example relate to MapReduce?
First of all, I am not MapReduce expert, but here’s what I understand based on JD’s talk and my skimming of Hadoop: The Definitive Guide (highly recommended and each purchase goes towards my beer
^H^H^H^Helastic computing budget):
- Instead of a terabyte or so of log files, we feed Hadoop a list of the numbers 1-1000. It dutifully doles each one to a “mapper” process running our
estimatePi()function.- Each invocation of our function uses this input as the seed for its random number generator. (It sure would be embarrassing to have all 1,000 simulations generate exactly the same results!)
- The output of the mappers is collected by Hadoop and normally sent on for reducing, but segue’s reduce step just concatenates all of the results so they can be sent back to our local instance as an R list.
All communication between Hadoop and the R code on the cluster is performed using Hadoop Streaming which allows map and reduce functions to be written in nearly any language [that] knows the difference between stdin and stdout.
Conclusion and alternatives
If you do your modeling in R and are looking for an easy way to spread around some CPU-intensive work, segue may be right up your alley. But if you’re looking to use Hadoop the right way—The Big Data Way—segue’s not for you. Instead, check out Saptarshi Guha’s RHIPE, the R and Hadoop Integrated Processing Environment.
If you’re just looking to run R on an EC2 node, you can start with this old post by Robert Grossman.
If you’re in Facebook’s data infrastructure engineering team, or are otherwise hooked on Hive, I bet you could use the RJDBC package and the HiveDriver JDBC driver, but I understand that most people just pass CSV files back and forth. The more things change….
But if you think all of this is unnatural and makes you want to take a shower, perhaps I can direct you to CRAN’s High-Performance and Parallel Computing with R task view for more traditional parallel processing options.
<Return to section navigation list>

















0 comments:
Post a Comment