Windows Azure and Cloud Computing Posts for 9/22/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Update 9/23/2010: Chris “Woody” Woodruff added a clientaccesspolicy.xml file on the server to enable opening the baseballstats.svc file in the Sesame Data Browser running in your Web browser, rather than on the desktop. See the end of the Chris “Woody” Woodruff (@cwoodruff) ran into a known bug when applying OData’s $expand operator as chronicled in his Bug Found? -- $expand and Composite Keys thread of 9/21/2010 in the OData Mailing List item in the SQL Azure Database, Codename “Dallas” and OData
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
 Azure Blob, Drive, Table and Queue Services
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
My (@rogerjenn) Windows Azure, SQL Azure, BPOS and OData Sessions at Tech*Ed Europe 2010 post is a list of Tech•Ed Europe 2010 sessions within the Cloud Computing and Online Services and Architecture tracks, as well as hits with OData as a search keyword, categorized as Breakout and Interactive sessions. Data is current as of 9/22/2010.
Tech•Ed Europe will be held 11/8 through 11/12/2010 at Messe Berlin, Berlin, Germany.
This article will be updated, like others before it, as more information becomes available about the sessions, an OData-formatted session list goes on line, and videos of sessions are posted.
Mary Jo Foley (@maryjofoley) reported Microsoft Oslo modeling platform unravels further; M's future remains vague in a 9/22/2010 post to her All About Microsoft ZDNet blog:
Microsoft officials confirmed today what I reported last month: Its Oslo data-modeling platform has been almost completely obliterated.
In August, I noted that Microsoft had discontinued Quadrant,one of its Oslo data-modeling tools. In a blog post on September 22, Microsoft officials confirmed Quadrant and the related Oslo Repository components have both been eliminated.
Oslo is a true shadow of its former self. Microsoft first discussed publicly its plans for “Oslo” — an amorphous multi-product effort that encompased future releases of .Net, Visual Studio, BizTalk and SQL Server. By the fall of 2008, Microsoft had decoupled .Net, Visual Studio, BizTalk and SQL Server from Oslo. When officials said Oslo, they meant Microsoft’s evolving modeling strategy and technologies, specifically the M language, the Quadrant tool and the associated metadata repository.
In the summer of 2009, as part of one of Microsoft’s countless reorgs, the Oslo team was combined with Microsoft’s Data Programability team (which manages Astoria, Entity Data Model (EDM), Entity Framework (EF), XML, ADO.Net and tools/designers). Microsoft officials said the new Oslo plan was to combine the remaining elements with some future version of SQL Server.
On September 22, Microsoft officials reiterated last year’s message that partners and customers “prefer a more loosely-coupled approach for model-driven application development based on a common protocol and data model, rather than a single repository.” The Open Data Protocol (OData) and the underlying EDM are the data-modeling horses on which the Redmondians are now betting. “We’ve also heard partners and customers want to use their existing tools, specifically Visual Studio and Office, to access application information,” officials said today. [Emphasis added.]
One of the champions of Oslo, Doug Purdy, resigned from Microsoft in September, announcing he had taken a job at Facebook.
The one element of Oslo that remains in question is the M data-modeling language. I reported in August that Microsoft was “refocusing” M, but couldn’t get company officials to comment.
Today, Microsoft Distinguished Engineer Don Box offered the first comment on M in ages, via a blog post on the Microsoft site. Box blogged:
“While we used ‘M’ to build the ‘Oslo’ repository and ‘Quadrant,’ there has been significant interest both inside and outside of Microsoft in using “M” for other applications. We are continuing our investment in this technology and will share our plans for productization once they are concrete.”
I did notice a new reference to “M” in a Microsoft Research Download I saw yesterday. The “DMinor” modeling language is based on the M language, according to the research site.
I asked the spokesperson whether DMinor was all that was left of M — the data-modeling language on which the Softies have been working for at least two years (when it was known as “D”). The spokesperson denied that was the case.
“We are continuing to invest in the core technology but, like many things, interesting innovation spins off other areas to pursue. Just look at how C-Omega, begat LINQ, which begat Reactive Framework. Many times these things start in either research or product development and jump back and forth,” he said.
When I learned that Doug Purdy had left Microsoft, I knew it was “mene mene tekel upharsin” for Oslo and Quadrant. I’m not sanguine about the prospects for M, either.
Marcelo Lopez Ruiz provided a Bookmarklet to find OData service for SharePoint site in this 9/22/2010 post:
As you probably already know, SharePoint has great support for OData, providing access to lists, documents and all sorts of goodies.
I always seem to forget how the link to the OData endpoint is constructed, though. So I created this short bookmarklet that does the trick. Just navigate to a SharePoint site and click on it, and you'll navigate to the OData endpoint for it.
javascript:(function(){var url=_spPageContextInfo.webServerRelativeUrl+'/_vti_bin/listdata.svc/';window.navigate(url);})()
If you want to right-click to add to favorites, here is the link form.
You can then query directly from the browser or add a service reference in Visual Studio and write a full SharePoint-enabled application - at this point the sky's the limit.
David Lemphers asserted Data as a Service! DaaS Hot! in a 9/22/2010 post that covers Dun & Bradstreet, Amazon’s Public Data Sets, Microsoft’s Codename “Dallas” and Google’s Data Explorer:
Great thing about the Cloud is you can take any traditional asset, and turn it into a service. Service’afying stuff has become quite the little business enterprise, and one of the most interesting is data.
Take this weeks announcement by Dun & Bradstreet that they’ll be offering their vast database of commercial information via the Cloud. D&B360, their DaaS service, will not only serve up their highly valuable business insight, it will also provide a platform for consumers to integrate said data into their own systems.
This is a crucial distinction between merely storing data in the cloud, and Data as a Service. Without the interface or integration layer, merely providing your data online is not as useful. What excites me about D&B’s offering (not that it takes much to excite me) is that they’ve taken a very lucrative and valuable business asset, transformed it into a Cloud service, and will now be able to reach more users in more locations, in a completely integrated way.
DaaS as an area of Cloud has been fairly active for the past two years though, with services operating at multiple levels, both at the pure data provision level, and the higher business vertical level. Amazon’s Public Data Sets (information such as US Census Databases, etc), Microsoft’s “Dallas” project (Mars Rover images!), and Google’s Public Data Explorer (Australian Population Estimates) are all great examples of diverse DaaS offerings.
And the scenarios are pretty powerful as well. When you think about providing real-time decision making capability to a range of clients, whether they be Intranet applications, mobile solutions or pure web, being able to integrate rich (and sometimes very large) datasets in a shaped way over the Internet is critical to success. What’s more, paying for only the data nuggets you use makes consuming these data sets very easy and affordable. And finally, being able to rely on the accuracy and freshness of the data is also a huge value-add, having the data centrally managed and updated takes the load off the user.
So have a quick look at your organizations data, maybe you have a great DaaS offering just lying around.
David was a major player in developing the Window Azure infrastructure before moving recently to PriceWaterhouseCoopers.
See Beth Massi reported Silicon Valley Code Camp Session Schedules are up! in a 9/22/2010 post in the Cloud Computing Events section below.
Mihail Mateev explained Migrating Spatial Data from SQL Server 2008 to SQL Azure with the SQL Azure Migration Wizard in a very detailed, fully illustrated tutorial of 9/21/2010 on the Infragistics Community blog:
Introduction
SQL Azure now supports Spatial Data. Unfortunately not all tools offer migration of spatial data..
Microsoft SQL Management Studio for SQL Server 2008 R2 [was] released when SQL Azure didn’t support spatial data and now [it is not] updated to
support this feature.One possibility is to use SQL Azure Migration Wizard: http://sqlazuremw.codeplex.com/. The actual version [used] is SQL Azure Migration Wizard v3.3.7.
SQL Azure Migration Wizard offers a simple way to import Sql Server data, including a spatial data (from the geometry or geography type).
More detailed information how to publish a Windows Azure you could find in the article:
“How to publish your Windows Azure application right from Visual Studio 2010”This post explains mainly how to migrate spatial data and change configuration changes to be possible to use a spatial data in SQL Azure from Windows Azure Application
Sample Application
Demo application is a Silverlight application with Infragistics XamMap control, that uses spatial data from SQL Azure.
The sample application is based on application from article “Using Infragistics XamMap Silverlight/WPF control with SQL Server Spatial”
Requirements to build a sample application:
- Visual Studio 2010
- SQL Server 2008 R2 Express or higher license.
- NetAdvantage for Silverlight Data Visualization 2010 vol.2
- http://www.infragistics.com/dotnet/netadvantage/silverlight/data-visualization.aspx#Downloads
- SQL Azure Migration Wizard v3.3.7.
- The most recent version of Windows Azure Tools for Visual Studio
- Windows Azure account
Steps to create the sample application
- Create a new SQL Azure database
- Migrate a sample database – SqlSpatialDemo from Local SQL Server to SQL Azure
- Create a new Windows Azure Storage Account and a Hosted Service
- Add a Web Role project in Solution
- Edit settings in Web.config and ServiceReferences.ClientConfig
- Publish the Windows Azure Cloud Service:
- Run the demo application …

Mihail continues with many feet of detail for the above steps.
Source code of the demo application you could find here: SQLAzureMigration.zip
Thanks to @korymcc for the heads-up.
Jon Udel explained how How to visualize an Azure table in Excel, using OData in this 9/21/2010 post to the O’Reilly Answers blog:
Introduction
The elmcity service makes extensive use of the Azure table service. Why use this cloud-based key/value store instead of the corresponding SQL-based offering, SQL Azure? The standard answer is that NoSQL scales, and that's true, but it's not the only answer. Sometimes NoSQL is just an easy way to park a hashtable in the cloud. The venerable hashtable, aka dictionary, has long been my favorite all-purpose data structure. Even in C#, where fully-defined types are the norm, and where powerful ORMs (object-relational mappers) connect the language to SQL stores, it's still easier to dump things into a dictionary.
One way to park that dictionary in the cloud is to pickle (serialize) it as a binary object and post it as a blob. The elmcity service does that regularly, using the Azure blob service. Another way leverages the natural correspondence between a dictionary, which is a bag of named properties, and an entity stored in the Azure table service, which is also a bag of named properties. The elmcity service uses that strategy a lot too.
One reason to use the table service, versus the blog service, is that the table service enables you to query for sets of entities. Another reason is that the results of those queries are OData feeds that you can work with directly using generic tools. One such tool is Excel which, when coupled with PowerPivot (a free add-in for Excel 2010) can help you visualize query results. In this week's companion article on the Radar blog, I chart the numbers of events flowing into the elmcity hubs from five kinds of sources. Here I'll show how the data behind that chart flows from C# to the Azure table service to Excel.
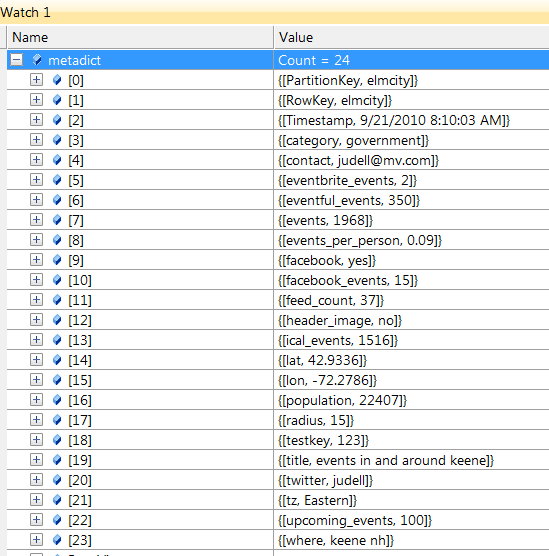
The metadata property bag as a C# dictionary and an Azure entity
For each elmcity hub, there's a set of entities stored in an Azure table named metadata. All but one of them represent the iCalendar feeds associated with the hub. But one is special: It's a property bag that's been expanding as I discover new things I want to keep track of for each hub. Here's what it looks like when represented in C# and displayed in the Visual Studio debugger:
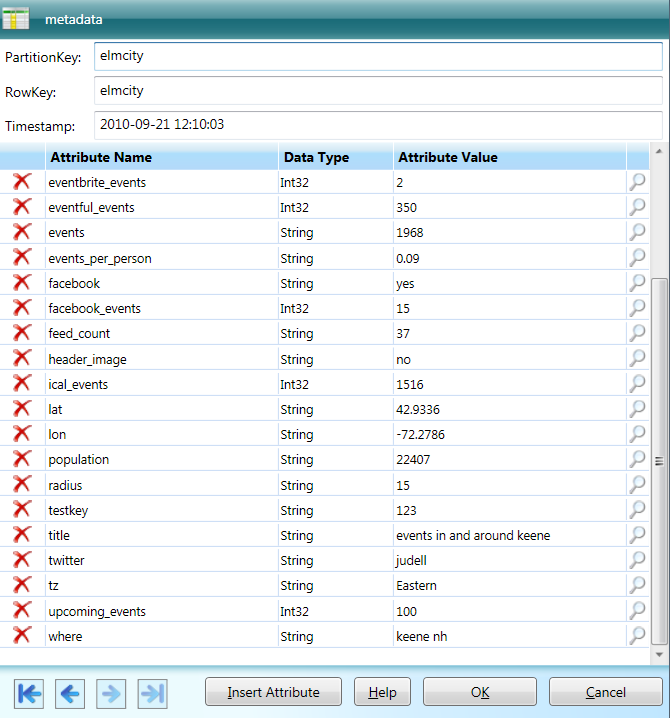
And here's what it looks like when stored in an Azure table and displayed using Cerebrata's Cloud Storage Studio:
Until last week I was only tracking the total number of events flowing into each hub. When I decided to look in more detail at the five tributaries, I added these attributes to each hub's Azure entity:
facebook_events
eventbrite_events
upcoming_events
eventful_events
ical_events
This required no database administration. I just modified the aggregator to inject these new properties into the C# dictionary representing each hub, and then merge the dictionaries into their corresponding Azure entities.
Querying for hub metadata
Although the Azure SDK exposes the table store using the conventions of ADO.NET Data Services and LINQ, the underlying machinery is RESTful. For the elmcity project I made an alternate interface that talks directly to the RESTful core.
Either way, retrieving a hub's metadata entity boils down to this HTTP request, when the hub's ID is elmcity (i.e., Keene):
This works because my convention is to use the ID as the value for both halves of the dual key that indexes entities in an Azure table. Similarly, here's the query to fetch the rest of hub's entities that represent iCalendar feeds:
(Note that although these are the actual URLs, they're protected so you can't click through from here to the data.)
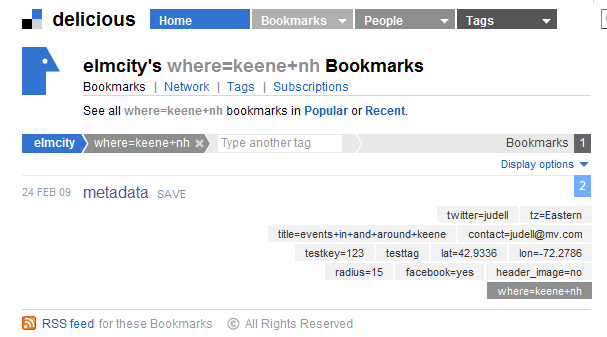
For this example, we want to fetch the metadata entities for each hub. Or rather, since there are two classes of hub -- one for places, one for topics -- we want to fetch metadata entities for each place hub. Curators define the characteristics of their hubs using yet another representation of this same property bag, based on a convention for using the delicious bookmarking service. Here's what the property bag looks like in delicious:
Place hubs are defined by having a property called where. Topic hubs are defined by having a property called what. So to find just the place hubs, the query is:
GET https://elmcity.table.core.windows.net/metadata?filter=where+ne+''
Note that this query includes neither the PartitionKey or the RowKey. Since the Azure table service doesn't index other attributes, this query will require a table scan. How can that possibly be efficient? Well, it isn't. If there were huge numbers of entities in the table, it would take a long time. But for tens, hundreds, or even low thousands of entities, and when as in this case there's no need for subsecond response, it's no problem. If I end up with more than a few thousand hubs, that will be a good problem to have, and I'll happily migrate this table into SQL Azure. Meanwhile, simpler is better.
Viewing the OData feed
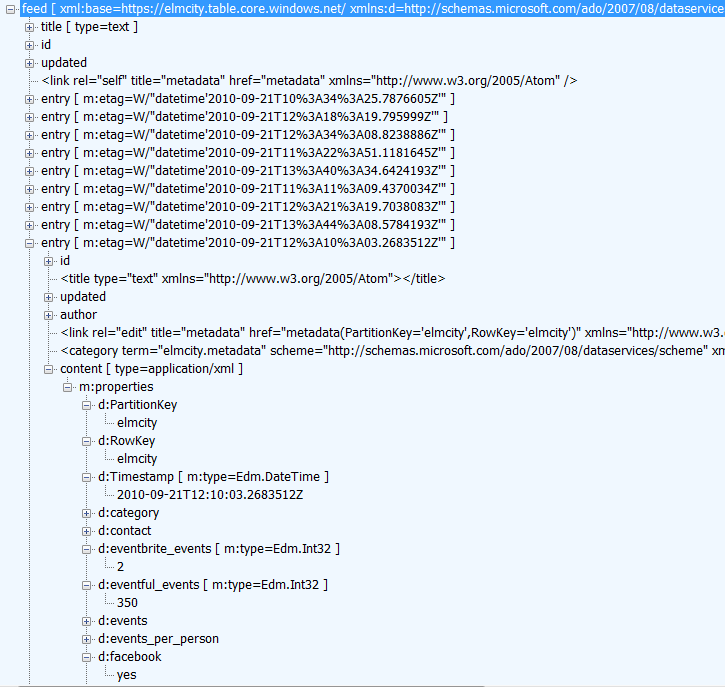
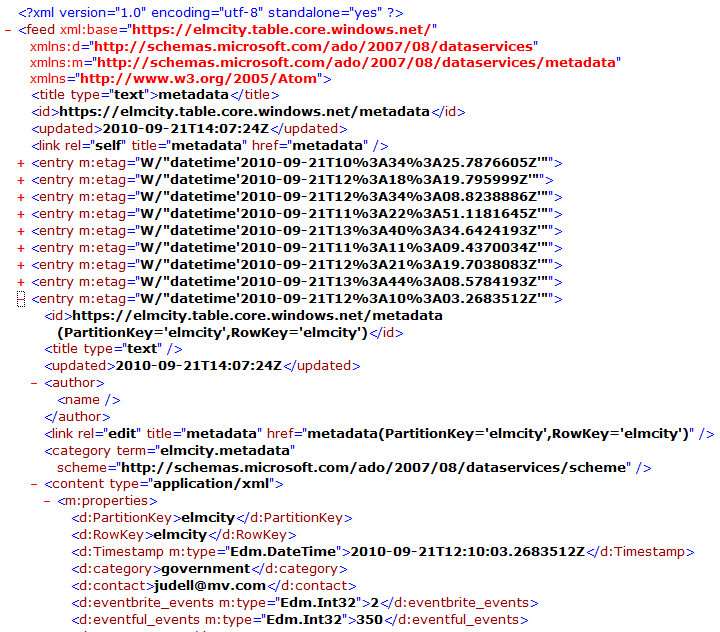
The output of the HTTP request that queries for topic hubs is an OData feed, shown here in Fiddler's XML view:
This is an Atom feed extended with a type system used here to annotate the TimeStamp property as an Edm.DateTime and the eventful_events and eventbrite_properties as Edm.Int32. If you open this feed in a browser that presents a friendly view of feeds, you'll see a list of (not very interesting) items as shown here in Firefox:
If you disable the browser's friendly view of feeds, you'll see the raw XML as shown here in IE:
Jon continues with a very detailed and well illustrated “Using the OData feed” topic.
Chris “Woody” Woodruff (@cwoodruff) ran into a known bug when applying OData’s $expand operator as chronicled in his Bug Found? -- $expand and Composite Keys thread of 9/21/2010 in the OData Mailing List:
I may have found a bug in WCF Data Services with the $expand command when targeting an entity collection with composite keys in the EDM. Attached is the database diagram image for 2 tables (ODataExampleBaseballStats1.png) in the baseball stats OData project I have been working on.
http://baseball-stats.info/OData/baseballstats.svc
You will see in ODataExampleBaseballStats1.png that the Batting table has 5 fields that comprise the PK of the table. I don't want to debate about using composite keys since I did not create this data model :-)
After creating the EDM and the WCF Data Service, I am finding that when I use the $expand command I only get 1 Batting entity record returning for a Player entity.
An example is this URI that is supposed to return the Batting data for Hank Aaron with his Player data.
http://www.baseball-stats.info/OData/baseballstats.svc/Player('aaronha01')?$expand=Batting
It does work for this expand. I have attached the second image (ODataExampleBaseballStats2.png) showing this association in the database. This is another composite key join (3 fields in underlying table). I am looking into why this works and the first does not.
http://www.baseball-stats.info/OData/baseballstats.svc/TeamFranchise('ARI')?$expand=Team
Has anyone seen this and have a workaround? Thanks
Chris Woodruff aka “Woody”
The OData Mailing List is for anyone interested in OData to ask questions about the protocol and to discuss how it should evolve over time. If you want to contribute, sign up here.
Here’s a screen capture of Fabrice Marguerie’s Silverlight-based Sesame Data Browser on my desktop displaying the first 17 AllstarFull entries (Hank Aaron):

Update 9/23/2010: Woody added a clientaccesspolicy.xml (CAP) file on the server to enable opening the baseballstats.svc file in the Sesame [O]Data Browser running in your Web browser by clicking here. Without the CAP file, you must save and run Sesame locally.
Phani Raj of the Astoria (OData) team replied to Chris in Re: Bug Found? -- $expand and Composite Keys of 9/21/2010:
This bug only affects expansions, navigations work fine : http://www.baseball-stats.info/OData/baseballstats.svc/Player('aaronha01')/Batting should return the complete set of results.
Phani
Steve Yi will share some of the SQL Azure Team blog’s posting load with Wayne Berry, according to Steve’s Hi, I’m Steve post of 9/21/2001:
Hi everyone. I’m Steve Yi, technical product manager for SQL Azure. You’ll start seeing posts from me on the SQL Azure blog so I wanted to start off by saying hi and introducing myself. I work closely with the engineering teams on listening to customer feedback and providing developers the info they need to successfully utilize our cloud database service. With PDC less than six weeks away (Oct 28-29) and SQL PASS in early November, we are working on the latest evolution for the SQL Azure line of services and I’m excited about the opportunity to share them with you right here – so stay tuned by signing up to the RSS feed.
Outside of work I’m an avid rock climber, mountaineer, and amateur photographer. Photos and tales of my outdoor adventures can be founds here and on my personal blog. My wife and I are staunch believers in philanthropy and giving and are strong and consistent supporters of World Vision and Northwest Harvest. More details about my experience and technical background can be found here.
Thanks for your interest in SQL Azure. Keep coming back. I look forward to the journey with you!
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Santosh Benjamin announced on 9/22/2010 that he will be Presenting Azure AppFabric @ TechDays 2010 Online on 10/8/2010:
In case you weren’t aware, we are organizing the TechDays Online Conference on Oct8th. Check out the agenda. You’ll find some well known names and an unknown one in the middle
Yep, lil ol’ me speaking on a “Lap Around Azure AppFabric” at 1pm in Track-1.
In general the track is supposed to be a high level one but i will be talking about getting to grips with the AppFabric vision, components that are on-premises, in the cloud and the general plan for convergence. We’ll also talk about how good ol BizTalk Server fits into this vision. We’ll discuss common patterns of usage in the Service Bus and ACS.
If you can make it, do register for the conference and it would be cool to have you attend my talk !!
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Aashish Dhamdhere (@dhamdhere) posted Announcing the 'Powered by Windows Azure' logo program to the Windows Azure Team blog on 9/22/2010:
An important part of my charter on the Windows Azure marketing team is to help customers, partners and developers be successful on the platform. Over the last few months, I've heard from many partners and customers that they would like to identify and showcase the fact that an application is running on Windows Azure. To help meet this need, I'm excited to announce a new 'Powered by Windows Azure' logo program that developers can use to promote their Windows Azure applications.
Aashish Dhamdhere, Senior Product Manager, Windows Azure
Jim Galasyn announced Patterns and Practices guide: Developing Applications for the Cloud in this 9/21/2010 post:
The MSFT P&P folks have come up with some great stuff over the years – I have a particular fondness for the original .NET Framework Application Blocks, which made life so much easier, what with the database access and the event logging. So nice.
Now they’ve published a new tome, Developing Applications for the Cloud on the Microsoft Windows Azure™ Platform, comprising full example applications and sample code.
It’s the followup volume to Moving Applications to the Cloud on the Windows Azure Platform, and provides best-practices guidance for building cloud apps on Azure.
(If you’re interested in cloud development for Windows Phone, check out Cloud Services and Windows Phone and the Cloud--an Introduction.)
Here’s what you’ll get:
"The Tailspin Scenario" introduces you to the Tailspin company and the Surveys application. It provides an architectural overview of the Surveys application; the following chapters provide more information about how Tailspin designed and implemented the Surveys application for the cloud. Reading this chapter will help you understand Tailspin's business model, its strategy for adopting the cloud platform, and some of its concerns.
"Hosting a Multi-Tenant Application on Windows Azure" discusses some of the issues that surround architecting and building multi-tenant applications to run on Windows Azure. It describes the benefits of a multi-tenant architecture and the trade-offs that you must consider. This chapter provides a conceptual framework that helps the reader understand some of the topics discussed in more detail in the subsequent chapters.
"Accessing the Surveys Application" describes some of the challenges that the developers at Tailspin faced when they designed and implemented some of the customer-facing components of the application. Topics include the choice of URLs for accessing the surveys application, security, hosting the application in multiple geographic locations, and using the Content Delivery Network to cache content.
"Building a Scalable, Multi-Tenant Application for Windows Azure" examines how Tailspin ensured the scalability of the multi-tenant Surveys application. It describes how the application is partitioned, how the application uses worker roles, and how the application supports on-boarding, customization, and billing for customers.
"Working with Data in the Surveys Application" describes how the application uses data. It begins by describing how the Surveys application stores data in both Windows Azure tables and blobs, and how the developers at Tailspin designed their storage classes to be testable. The chapter also describes how Tailspin solved some specific problems related to data, including paging through data, and implementing session state. Finally, this chapter describes the role that SQL Azure™ technology platform plays in the Surveys application.
"Updating a Windows Azure Service" describes the options for updating a Windows Azure application and how you can update an application with no interruption in service.
"Debugging and Troubleshooting Windows Azure Applications" describes some of the techniques specific to Windows Azure applications that will help you to detect and resolve issues when building, deploying, and running Windows Azure applications. It includes descriptions of how to use Windows Azure Diagnostics and how to use Microsoft IntelliTrace™ with applications deployed to Windows Azure.
Visit MSDN to read Developing Applications for the Cloud on the Microsoft Windows Azure™ Platform. Download the code samples from here. And drop in to visit the P&P folks on Codeplex.

Return to section navigation list>
VisualStudio LightSwitch

<Return to section navigation list>
Windows Azure Infrastructure
Geva Perry asked Have Google App Engine and Microsoft Azure Surpassed Rackspace? in a 9/22/2010 post to his Thinking Out Cloud blog:
Today Zenoss released a survey it conducted about cloud computing and virtualization. It has some interesting data and they created a very nice looking Infographic with the key findings.
Here's the data point I found most interesting:
Also, GoGrid's penetration, as well as RightScale's (which is a very different animal than the other players on the list) is very impressive.
Note that the wording of the question in the survey was a bit ambiguous: "What are your cloud computing plans for 2010?". I say ambiguous because the survey was conducted Q2 2010, so probably close to the middle of the year. But in any case, it has a forward looking element to it, which gives a little indication of the trends as they are happening.
Anyway, lots of interesting info on both cloud and virtualization. Check out the full survey results (requires registration).
Jeffrey M. Kaplan attempts to answer How Do You Measure the Economic Value of the Cloud? in this 9/22/2010 post to SandHill.com’s Opinion blog:
Everyone agrees that the key driver of cloud computing's rapid growth is economics. Yet, like the debate about the definition of the term itself, accurately calculating the economic benefit of cloud computing is also debatable.
Part of the problem is that the market is still embryonic and capturing a full picture of the financial impact of initial cloud computing deployments among the industry's early adopters is not easy.
Sure, there are a growing number of customer success stories from a widening array of "lighthouse" accounts that clearly illustrate the raw cost-savings generated by the leading public cloud computing services.
Thankfully, these savings have been clear and compelling. And, in today's uncertain economic environment, simply producing substantial cost-savings is enough to generate plenty of demand for a growing assortment of cloud computing services.
Yet, every major market research firm and many trade publications are also publishing survey reports that show that most enterprise decision-makers are not being persuaded to move to the cloud by these upfront cost-savings because they are still apprehensive about the risks associated with public cloud services.
Instead, their concerns about security, reliability, compliance, and other issues are driving them to pursue private cloud alternatives, rather than entrusting their core operations to shared cloud services.
Ironically, while the cost-savings of public cloud services are clear, the same can't be said of the private cloud alternatives. In fact, in most cases the organizations pursing this approach aren't swapping their old, inefficient, legacy software and systems for new private clouds. They are augmenting their existing systems and software with additional private cloud resources and incurring added costs to achieve specific business objectives.
So, what is the economic driver in these cases? It isn't cost-savings.
Management consulting firms and major vendors hawking their "thought-leadership" would suggest that the economic driver is innovation and/or agility. Sounds good in theory, but when was the last time they could produce a customer success story that quantifies or puts a dollar value on these benefits?
Maybe the economic incentive is really mitigating risks or preserving a company's brand-equity. For instance, despite lingering questions about the reliability, security, and performance of cloud computing, companies can employ today's cloud computing services and resources in an incremental fashion to avoid making a "big bet" on a new corporate initiative. Or, they can say they're "moving to the cloud" in the same way they are "going green". It makes for good PR.
None of this is to poke holes into the value of cloud computing. Anyone who knows me knows that I look at the world through cloud-colored glasses. However, I think we have a long way to go in fully understanding and appealing to the motivations of corporate decision-makers.
The sooner we understand these motivations, the faster the cloud computing movement will truly become a mainstream phenomenon.
However, it is also important to recognize that successfully tapping into these motivations means keeping pace with their changing dynamics. For instance, many early adopters of cloud services may have been prompted by the upfront cost-savings, but are now more focused on the added functional benefits that cloud computing brings.
An analogy is how my youngest son's attitudes toward his Pokemon cards have evolved overtime. He bought his first deck of cards to keep up with his peers, because it was the popular thing to do. He continued to buy deck after deck because having more meant being at a competitive advantage, especially if you had cards with superior powers. Now that he is outgrowing the game, he views the cards in a different light: their supposed resale value according to various websites. At each stage, the perceived value of the Pokemon cards has changed.
By the same token, my view of the cards has also changed. When I first watched him acquire the cards, I thought they were a tremendous waste of money and time, despite the social value. As I watched my son learn how to strategize and quickly calculate scores playing the game, my view of the value of the cards changed. And, now as I watch him search for an economic return from the cards, I see them having a new value.
Weighing the economic value of the various variables in the cloud computing equation is an equally complex and evolving challenge. As a growing number corporate decision-makers are recognizing, the value of cloud computing is more than just calculating its simple cost-savings.
Lori MacVittie (@lmacvittie) claimed “If you’re replicating session state across application servers you probably need to rethink your strategy. There’s other options – more efficient options – than wasting RAM and, ultimately, money” in a preface to her Sessions, Sessions Everywhere post of 9/22/2010 to F5’s Dev Central blog:
Although the discussion of Oracle’s “cloud in a box” announcement at OpenWorld dominated much of the tweet-stream this week there were other discussions going on that proved to not only interesting but a good reminder of how cloud computing has brought to the fore the importance of architecture.
Foremost in my mind was what started as a lamentation on the fact that Amazon EC2 does not support multicasting that evolved into a discussion on why that would cause grief for those deploying applications in the environment.
Remember that multicast is essentially spraying the same data to a group of endpoints and is usually leveraged for streaming media topologies:
In computer networking, multicast is the delivery of a message or information to a group of destination computers simultaneously in a single transmission from the source creating copies automatically in other network elements, such as routers, only when the topology of the network requires it. -- Wikipedia, multicast
As it turns out, a primary reason behind the need for multicasting in the application architecture revolves around the mirroring of session state across a pool of application servers. Yeah, you heard that right – mirroring session state across a pool of application servers.
The first question has to be: why? What is it about an application that requires this level of duplication?
MULTICASTING for SESSIONS
There are three reasons why someone would want to use multicasting to mirror session state across a pool of application servers. There may be additional reasons that aren’t as common and if so, feel free to share.
The application relies on session state and, when deployed in a load balanced environment, broke because the tight-coupling between user and session state was not respected by the Load balancer. This is a common problem when moving from dev/qa to production and is generally caused by using a load balancing algorithm without enabling persistence, a.k.a. sticky sessions.
The application requires high-availability that necessitates architecting a stateful-failover architecture. By mirroring sessions to all application servers if one fails (or is decommissioned in an elastic environment) another can easily re-establish the coupling between the user and their session. This is not peculiar to application architecture – load balancers and application delivery controllers mirror their own “session” state across redundant pairs to achieve a stateful failover architecture as well.
Some applications, particularly those that are collaborative in nature (think white-boarding and online conferences) “spray” data across a number of sessions in order to enable the sharing in real time aspect of the application. There are other architectural choices that can achieve this functionality, but there are tradeoffs to all of them and in this case it is simply one of several options.
THE COST of REPLICATING SESSIONS
With the exception of addressing the needs of collaborative applications (and even then there are better options from an architectural point of view) there are much more efficient ways to handle the tight-coupling of user and session state in an elastic or scaled-out environment. The arguments
against multicasting session state are primarily around resource consumption, which is particularly important in a cloud computing environment. Consider that the typical session state is 3-200 KB in size (Session State: Beyond Soft State
). Remember that if you’re mirroring every session across an entire cluster (pool) of application servers, that each server must use memory to store that session.
Each mirrored session, then, is going to consume resources on every application server. Every application server has, of course, a limited amount of memory it can utilize. It needs that memory for more than just storing session state – it must also store connection tables, its own configuration data, and of course it needs memory in which to execute application logic.
If you consume a lot of the available memory storing the session state from every other application server, you are necessarily reducing the amount of memory available to perform other important tasks. This reduces the capacity of the server in terms of users and connections, it reduces the speed with which it can execute application logic (which translates into reduced response times for users), and it operates on a diminishing returns principle. The more application servers you need to scale – and you’ll need more, more frequently, using this technique – the less efficient each added application server becomes because a good portion of its memory is required simply to maintain session state of all the other servers in the pool.
It is exceedingly inefficient and, when leveraging a public cloud computing environment, more expensive. It’s a very good example of the diseconomy of scale associated with traditional architectures – it results in a “throw more ‘hardware’ at the problem, faster” approach to scalability.
BETTER ARCHITECTURAL SOLUTIONS
There are better architectural solutions to maintaining session state for every user.
SHARED DATABASE
Storing session state in a shared database is a much more efficient means of mirroring session state and allows for the same guarantees of consistency when experiencing a failure. If session state is stored in a database then regardless of which application server instance a user is directed to that application server has access to its session state.
The interaction between the user and application becomes:
- User sends request
- Clustering/load balancing solution routes to application server
- Application server receives request, looks up session in database
- Application server processes request, creates response
- Application server stores updated session in database
- Application server returns response
If a single database is problematic (because it is a single point of failure) then multicasting or other replication techniques can be used to implement a dual-database architecture. This is somewhat inefficient, but far less so than doing the same at the application server layer.
PERSISTENCE-BASED LOAD BALANCING
It is often the case that the replication of session state is implemented in response to wonky application behavior occurring only when the application is deployed in a scalable environment, a.k.a a load balancing solution is introduced into the architecture. This is almost always because
the application requires tight-coupling between user and session and the load balancing is incorrectly configured to support this requirement. Almost every load balancing solution – hardware, software, virtual network appliance, infrastructure service – is capable of supporting persistence, a.k.a. sticky sessions.
This solution requires, however, that the load balancing solution of choice be configured to support the persistence. Persistence (also sometimes referred to as “server affinity” when implemented by a clustering solution) can be configured in a number of ways. The most common configuration is to leverage the automated session IDs generated by application servers, e.g. PHPSESSIONID, ASPSESSIONID. These ids are contained in the HTTP headers and are, as a matter of fact, how the application server “finds” the appropriate session for any given user’s request. The load balancer intercepts every request (it does anyway) and performs the same type of lookup on its own session table (which is much, much higher capacity than an application server and leverages the same high-performance lookups used to store connection and network session tables) and routes the user to the appropriate application server based on the session ID.
The interaction between the user and application becomes:
- User sends request
- Clustering/load balancing solution finds, if existing, the session-app server mapping. If it does not, it chooses the application server based on the load balancing algorithm and configured parameters
- Application server receives request,
- Application server processes request, creates response
- Application server returns response
- Clustering/load balancing solution creates the session-app server mapping if it did not already exist
Persistence can generally be based on any data in the HTTP header or payload, but using the automatically generated session ids tends to be the most common implementation.
YOUR INFRASTRUCTURE, GIVE IT TO ME
Now, it may be the case when the multicasting architecture is the right one. It is impossible to say it’s never the right solution because there are always applications and specific scenarios in which an architecture that may not be a good idea in general is, in fact, the right solution.
It is likely the case, however, in most situations that it is not the right solution and has more than likely been implemented as a workaround in response to problems with application behavior when moving through a staged development environment. This is one of the best reasons why the use of a virtual edition of your production load balancing solution should be encouraged in development environments. The earlier a holistic strategy to application design and architecture can be employed the fewer complications will be experienced when the application moves into the production environment. Leveraging a virtual version of your load balancing solution during the early stages of the development lifecycle can also enable developers to become familiar with production-level infrastructure services such that they can employ a holistic, architectural approach to solving application issues.
See, it’s not always because developers don’t have the know how, it’s because they don’t have access to the tools during development and therefore can’t architect a complete solution. I recall a developer’s plaintive query after a keynote at [the now defunct] SD West conference a few years ago that clearly indicated a reluctance to even ask the network team for access to their load balancing solution to learn how to leverage its services in application development because he knew he would likely be denied. Network and application delivery network pros should encourage the use of and tinkering with virtual versions of application delivery controllers/load balancers in the application development environment as much as possible if they want to reduce infrastructure and application architectural-related issues from cropping up during production deployment.
A greater understanding of application-infrastructure interaction will enable more efficient, higher performing applications in general and reduce the operational expenses associated with deploying applications that use inefficient methods such as replication of session state to address application architectural constraints.






Douglas C. Schmidt and Ron Guida analyze Elastic Application Platforms for Cloud Computing in a 9/21/2010 post to the HPC in the Cloud blog:
Statisticians, engineers, scientists, and analysts in performance-intensive domains, such as financial services, multimedia systems, and bioinformatics, are trying to harness the processing power available in cloud computing environments to analyze financial trends, create test simulations, model climate, compile code, render video, decode genomes and other complex processing tasks.
The proliferation of cloud environments during the past several years has contributed to explosive growth in management and provisioning tools that enable unobtrusive access to—and control over—elastic hardware and the migration of software applications onto this hardware. Elastic hardware can substantially accelerate the performance of applications that can distribute and/or parallelize their internal workloads on co-located or distributed cores. Elastic software can accelerate and scale up data processing automatically by utilizing more hardware without changing application business logic or configurations.
Achievements in the area of automatic provisioning of hardware and software were sufficient for the first wave of “best-effort” application deployments in cloud environments. The potential for making mission-critical applications elastic remains largely untapped, however, due to the lack of software infrastructure and tool support that can simplify and automate the following three characteristics of elastic software applications:
• They are parallelized, i.e., their computations can run concurrently on multiple processors and/or cores.
• They are scaled dynamically, i.e., the number of processors and/or cores used by an application can expand or contract during runtime.
• They are deployment agnostic, i.e., they can seamlessly deploy on a single co-located multicore processor or distributed multicore processors.
Despite the price/performance advantages of clouds, it remains hard to accelerate and scale the performance of applications, which are often written for a single computer and thus cannot leverage the parallelism inherent in cloud environments without extensive refactoring and reprogramming. What is needed, therefore, are elastic application platforms that simplify the development and deployment of ultra-high-performance elastic applications.
Elastic application platforms provide tools to help developers rapidly transform sequential applications into powerful elastic applications that can be distributed and/or parallelized on a wide range of hardware, from multicore processors to clusters to private or public clouds. These tools help eliminate tradeoffs between co-located vs. distributed parallelism patterns via common “program once, run anywhere” APIs that enable software to run in deployments where the choice of co-location vs. distribution is hidden from application software on both clients and servers. These platforms also solve distribution challenges by transparently deploying applications on co-located and/or distributed processing cores via straightforward changes to declarative configuration parameters, rather than requiring tedious and error-prone imperative programming.
The Elastic Application Software Development Process
The process of developing elastic applications—or retrofitting legacy applications to scale elastically—involves mapping application elasticity technology onto the challenges of particular business logic. This process pinpoints potential parallelism in software and identifies the best approach to exploit it on available hardware, ranging from co-located cores to interconnected clouds. This effort can be as easy as flattening existing loops or as complex as refactoring software architectures to add new abstractions that parallelize critical program logic.Enabling such adjustments requires elastic application platforms to seamlessly integrate powerful programming patterns (such as task and data parallelism) with reusable services (such as intelligent load equalizers that identify routing destination dynamically based on real-time feedback from distributed services) to shield application developers from complex concurrency and networking mechanisms, while ensuring substantially higher performance on commodity cloud environments.
Page: 1 of 4; read more: 2 | 3 | 4 All »
Alan Le Marquand wants to Put the Cloud to Work For Your Organization, according to this 9/19/2010 post:
There are currently many misconceptions surrounding the Cloud and what it has to offer. The team I work on set out to help you becoming more knowledgeable. We think that once you get straight answers to questions about the Cloud you can also help guide others to a better understanding, thus take informed next steps to enable your organization to reap its benefits.
To start we’ve just created a new page to provide plain answers to some of the questions about the Cloud along with the resources to go into more depth.
Alan is a member of TechNet’s Technical Audience Team in the UK, where he intends “to spend more time in a field office and work closer with customers and the community in content development.”
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
Alan Le Marquand explained Creating a Private Cloud – Part 1: Setup with Windows Server and System Center in this 9/22/2010 post:
Can I offer IT as a Service?
Virtualization offers many benefits; it’s the technological change in our industry that underpins the Cloud Computing wave. With Virtualization, you can reduce the number of physical servers you own and maintain, reduce energy costs, even implement high availability solutions you thought beyond your budgets. Then you look at Windows Azure, and you see the ability to provision application instances from a web portal. Scale up and down as demand requires and only pay for what you consume. The thought then maybe crosses your mind that the Windows Azure model would be great to offer inside your organization on your own infrastructure. Do you have to choose one or the other or can you provide IT as a Service internally like Windows Azure?
What do I need?
For a Private Cloud or Customer Cloud, whichever name you prefer, to have an effective IT as a Service offering requires some key elements to be in-place.
- First you need a management tool that allows you to monitor the servers providing the virtualization services. The tool should also allow you to easily move services around the machines, and ideally provide you with guidance on what actions to take should resource become over utilised.
- Secondly, you need a tool that allows for the Business units in your organization to be self-sufficient in requesting and managing their services, while at the same time provide you with a method to calculate charge-back costs.
Windows Server 2008 R2 out-of-the-box does not provide all of these. It does have a number of management features you will need, but for the complete solution you need to add:-
- System Center Virtual Machine Manager 2008 R2 (SCVMM)
- System Center Virtual Machine Manager Self Service Portal 2.0 (SSP)
These two System Center products provide the management, monitoring and self-service capabilities needed to run an IT as a Service operation.
What do they do?
SCVMM provides the core management functionality. Allowing you to go beyond the Hyper-V management console in R2, you can group your servers into host groups and monitor more than one host at a time. Intelligent placement built into SCVMM helps you make the best decisions about where virtual machines (VMs) should go. SCVMM also provides a library service where you hold template images, ISO images and scripts that can be easily deployed to meet different requirements. Finally Performance Resource Optimization (PRO) provides you with the ability to monitor and correct problems for VMs. PRO allows the administrator to set up information that can be displayed when certain thresholds are reached. These “Tips”, can, for example, have a messaging saying “Add another Web Server to Order Tracking Web Farm”.
SSP provides the self-service functionality. At a high level, once enabled and configured by the IT Administrator, SSP allows registered Business Units to manage their own administrative team to request resources, start or stop VMs and be entirely self-sufficient in managing their resources. At the back end, the IT Administrator can set charge back costs for both reserved resources and allocated resources.
Armed with these products we can build our Private Cloud. To test this out, all three products can be downloaded from microsoft.com under the evaluation program. I used my TechNet subscription to access the full-version software and based these posts on my testing. The software required to build this test is available in all the subscriptions models.
Where to Start?
There are requirements for the installation to work. First, there are additional roles and features that need to be installed on Windows Server 2008 R2. These are primarily driven by SCVMM. So to install SCVMM, Windows Server must have:
- Hyper-V. The SCVMM Setup Wizard automatically adds this role, which will work as long as the machine being used supports virtualization.
- Windows Remote Management (WinRM). For SCVMM setup to work, the service must be installed and in a state other than disabled and stopped.
- Internet Information Services (IIS) 7.0. You must add the Web Server (IIS) role and then install the following server role services:
- IIS 6 Metabase Compatibility
- IIS 6 WMI Compatibility
- Static Content
- Default Document
- Directory Browsing
- HTTP Errors
- ASP.NET
- .NET Extensibility
- ISAPI Extensions
- ISAPI Filters
- Request Filtering
In addition to these, the SSP also requires some additional features be installed:
- Microsoft Message Queuing (MSMQ).
- Windows PowerShell 2.0. This requirement supersedes version 1.0 that SCVMM requires.
- Microsoft .NET Framework 3.5 SP1. R2 contains 3.5.1, so if this is installed then you have met this requirement.
The final requirement for both SCVMM and SSP is a database. When installed alone, SCVMM can use the SQL Express edition, which it will install automatically if you do not provide it with an alternative. However, SSP requires either Standard or Enterprise editions of SQL Server 2008 or higher.
The other requirement for the solutions is Active Directory. Both SCVMM and SSP work best in a domain environment. As we go through SSP, it will become clear why this is so.
In my test environment I’ve mixed and matched. The base OS is R2 Enterprise edition, the database server is SQL Server 2008 R2 Standard edition. At this point that you may consider installing the beta of Service Pack 1 for Windows Server 2008 R2 to take advantage of the Dynamic Memory feature. This is an extremely useful feature for maximizing the memory usage on Hyper-V hosts; the caveat here is that the SSP documentation doesn’t yet have any recommendation on how this feature interacts with the Charge-back process. I didn’t install SP1 beta for that very reason, but I do encourage you to evaluate it for potential use on production Hyper-V hosts.
Installing stuff!
We now have our shopping list of items to setup our test Private Cloud and the installation order is:
- Install Windows Server 2008 R2,
- Add the Hyper-V and IIS 7.0 roles with the IIS requirements.
- Add the additional features, MSMQ.
- Install Active Directory Domain Services (AD DS).
- Install SQL Server. Your choice of 2008 or 2008 R2, standard or enterprise editions.
- Check for updates.
- Install SCVMM Server
- Install SCVMM Administrator Console.
- Check for Updates
- VMMSSP server component
- VMMSSP website component
I used the default settings when installing the base products and only varied off the defaults where there were specific requirements, like with IIS 7.0. I had to run the SCVMM install twice in my environment. This is because the recommended configuration for SCVMM/SSP is at least a three server configuration with a minimum of the VMM Server, Admin Console and SQL Database on different machines. In my test environment I’ve used just one machine initially.
Generally one VMM server is all you need, it’s the hub of the system and is generally left alone. If you scale out the environment, you will need to install another VMM server, but we talking about where you have more than 400 hosts. The Admin console is like most admin consoles for server products, you install it on the machine used most to administer your environment, so it’s likely you won’t be doing that from the VMM Server.
The Interesting bit!
The interesting component of all these is SSP. It’s the interesting bit because it’s a combination of software and process. You are installing a web portal for others to use, so as
part of that you have to decide how to divide up your business units. Who the admins are for those units and then decide on the charge model you wish to follow. I’m using the diagrams from the “Getting Started” guide to illustrate the basics; the documentation that comes with SSP is very detailed.
The SSP interaction is a workflow, there are user roles pre-defined in the SSP to help manage the process. There are three; these are DataCenter IT Admin (DCIT Admin), Business Unit IT Admin (BUIT Admin), Advanced Operator, and Business Unit User. Throughout the process the DCIT Admin is the approver of all requests. The BUIT Admin only controls who from their unit can have access and what access. The DCIT Admin first defines a BUIT Admin. Once defined, that admin then registers their BU for the portal access. The DCIT Admin approves the request thus allowing the BUIT Admin to make infrastructure requests. Again the DCIT Admin provisions the request. This now allows the Business Unit Users to create virtual machines, again using the portal and forms and manage their machines.
As described previously, business units can use the self-service portal to manage their own infrastructures while using the physical resources of a central datacenter.
In the context of the self-service portal, an infrastructure is a collection of services that a business unit needs for a specific purpose. For example, a human resources business unit may create an infrastructure called “Payroll” that contains the services needed to run the payroll system. A single business unit can manage multiple infrastructures.
An infrastructure must contain at least one service. The service coordinates the resources needed for a specific function or set of related functions. These resources include networks, Active Directory domains and organizational units, users that have access to the service, memory and storage capacity available to the virtual machines, and locations of virtual machine templates to use in creating virtual machines. The diagram here shows the details of two infrastructures that a business unit creates. One with one service and service role, the other two services each with two service roles.
A service must contain at least one service role. A service role is a group of virtual machines that perform a single function and share some configuration settings. In our example, a Web application, a BUIT administrator can request a service role of load-balanced virtual Web servers. The load balancing configuration of the service role applies to each member virtual machine. The BUIT administrator can request new virtual machines for the service role as appropriate.
Next Steps
This post spent a lot of time on basics of SSP, which is key component for enabling users outside the IT Department to become self-sufficient. In the next post I’ll cover the actual configuration of the components.




See Alex Williams claimed Oracle Adopts the Worst Term for Cloud Computing to Describe an Impressive Machine in this 9/22/2010 post to the ReadWriteCloud in the Other Cloud Computing Platforms and Services section below.
Jeffrey Schwartz interviewed Microsoft’s Bill Hilf in a Q&A: Microsoft's Hilf sees HPC as the killer Azure app post to the Government Computer News blog of 9/21/2010:
Bill Hilf, general manager for technical computing at Microsoft [pictured right], launched Windows HPC Server 2008 R2 in a keynote address at the High Performance Computing Financial Markets conference in New York. In an interview following his presentation, Hilf explained why he believes this release will help bring HPC to a broader audience.
What you are seeing is native Azure with an HPC service on it so we're able to deploy from the scheduler on premise to Azure. We have the ability on the Azure side to say, 'Ah you're trying to send me an HPC job, and I need to go do something.' Technically, you can have only one head-node (the scheduler) on premise and have all your stuff up on Azure if you want to. But for a lot of these financial services customers they already have thousands of servers. They may want to add a couple of more, situationally.So you're not talking about a new Azure service?
Correct. We don't have a separate cluster on Azure.Are you seeing customers doing this yet?
This is part of our shipping product right now, so we're just bringing this to life. We have a lot of customers very interested in it. A lot of large customers have been asking us, that's what drove us to do this. I believe the technical computing workload will be the killer Azure app because the nature of these workloads consume a ton of computers. We believe having an infrastructure with hundreds of thousands of servers is going to be very compelling.Won't issues with compliance and security be show stoppers for Wall Street clients?
There's literally a list of issues related to data and security and all of this and we are approaching them, the whole situation, looking at what makes more sense. There are some cases where, for regulatory and security, maybe national defense reasons, people will never use the public cloud. That's why we announced the Azure appliance. Most of those customers of Azure appliances will be HPC customers because you're buying 1,000 servers at a time.
What's the pricing of the new HPC Server with Azure?
The way it works is you buy HPC Server and it has the technology inside to do this, and then you go and get your Azure subscriptions which is just normal Azure pricing.
Jeffrey Schwartz reported that the “New release of HPC Service includes enhanced cloud capabilities” as a deck for his Microsoft expands cloud effort post of 9/21/2010 to the Government Computer News blog:
Microsoft launched Windows HPC Server 2008 R2, with grealt expanded cloud-computing capabilties, at the High Performance Computing Financial Markets conference in New York.
The new release, announced Sept. 20, is Microsoft's third version of its HPC offering, featuring improved capabilities to run in large clusters both locally and in the cloud. The server is optimized for 1,000 nodes, although it can scale higher than that, especially when cores and sockets are taken into account, Microsoft said. The previous version was limited to 256 nodes.
Windows HPC Server 2008 R2 adds support for Excel, allowing power users to perform workbook computations much faster. An Excel user can run a computation that typically takes two hours in just two minutes, Microsoft said. For those looking for capacity in bursts, Windows HPC Server 2008 R2 can tap idle Windows 7 desktops to extend the capacity of a cluster and can access nodes via Windows Azure subscriptions.
"Think of this as one of the key shifts in our fleet for what we look at as this future of technical computing," said Bill Hilf, Microsoft's general manager for technical computing, speaking in the keynote address at the HPC conference.
(Read a full Q&A with Hilf about the new server and Microsoft's HPC vision here.)
Hilf said integration within existing enterprises is a key feature of the server. Windows HPC Server can run jobs with a user's Active Directory credentials, letting IT tie it together with their security management policies, he said. With this release, HPC is poised for more mainstream computing tasks, Hilf added.
"That's our fundamental strategy," Hilf said, in the Q&A interview, following his keynote. "That's fundamentally why we exist, so the way to make it mainstream is you have to make the apps very simple, so it's almost like a Visual Basic or PHP application that will take advantage of it and make it so the IT stuff in the back is almost invisible."
<Return to section navigation list>
Cloud Security and Governance
Simon Wardley (@swardley) asked about A run on your cloud? in this 9/22/2010 post:
When I use a bank, I'm fully aware that the statement I receive is just a set of digits outlining an agreement of how much money I have or owe. In the case of savings, this doesn't mean the bank has my money in a vault somewhere as in all likelihood it's been lent out or used elsewhere. The system works because a certain amount of reserve is kept in order to cover financial transactions and an assumption is made that most of my money will stay put.
Of course, as soon as large numbers of people try to get their money out, it causes a run on the bank and we discover just how little the reserves are. Fortunately, in the UK we have an FSA scheme to guarantee a minimum amount that will be returned.
So, what's this got to do with cloud? Well, cloud (as with banking) works on a utility model, though in the case of banking we get paid on both the amount we consume and provide (i.e interest) and in the cloud world we normally only have the option to consume.
In the case of infrastructure service providers, there are no standard units (i.e. there is no common cloud currency) but instead each provider offers it own range of units. Hence if I rent a thousand computer resource units, those units are defined by that provider as offering a certain amount of storage and CPU for a given level of quality at specified rate (often an hourly fee).
As with any utility there is no guarantee that when I want more, the provider is willing to offer this or has the capacity to do so. This is why the claims of infinite availability are no more than an illusion.
However, hidden in the depths of this is a problem with transparency which could cause a run on your cloud in much the same way that Credit Default Swaps hit many financial institutions as debt exceeded our capacity to service it.
When I rent a compute resource unit from a provider, I'm working on the assumption that what I'm getting is that compute resource unit and not some part of it. For example, if I'm renting on an hourly basis a 1Ghz core with 100Gb storage and 2Gb memory - I'm expecting exactly that.
However, I might not use the whole of this compute resource. This offers the service provider, if they were inclined, an opportunity to sell the excess to another user. In this way, a service provider running on a utility basis could be actively selling 200 of their self defined compute units to customers whilst it only has the capacity to provide for 100 of those units when fully used. This is quaintly given terms like improving utilisation or overbooking or oversubscription but fundamentally it's all about maximising service provider margin.
The problem occurs when everyone tries to use their compute resources fully with an overbooked provider, just like everyone trying to get their money out of a bank. The provider is unable to meet its obligations and partially collapses. The likely effect will be compute units being vastly below their specification or some units which have been sold are thrown off the service to make up for the shortfall (i.e. customers are bumped).
It's worth remembering that a key part of cloud computing is a componentisation effect which is likely to lead to massively increased usage of computer infrastructure in ever more ephemeral infrastructures and as a result our dependency on this commodity provision will increase. It's all worth remembering that black swan events, like bank runs do occur.
If one overbooked provider collapses, then this is likely to create increased strain on other providers as users seek alternative sources of computer resource. Due to such an event and unexpected demand, this might lead to a temporary condition where some providers are not able to hand out additional capacity (i.e. new compute units) - the banking equivalent of closing the doors or localised brown-outs in the electricity industry.
However, people being people will tend to maximise the use of what they already have. Hence, if I'm renting 100 units with one provider who is collapsing, 100 units with another who isn't and a situation where many providers are closing their doors temporarily, then I'll tend to double up the workload where possible on my fully working 100 units (i.e where I believe I have spare capacity).
Unfortunately, I won't be the only one doing this and if that provider has overbooked then it'll collapse to some degree. The net effect is a potential cascade failure.
Now, this failure would not be the result of poor utility planning but instead the overbooking and hence overselling of capacity which does not exist, in much the same way that debt was sold beyond our capacity to service it. The providers have no way of predicting black swan events, nor can they estimate the uncertainty with user consumption (users, however, are more capable of predicting there own likely demands).
There are several solutions to this, however all require clear transparency on the level of overbooking. In the case of Amazon, Werner has made a clear statement that they don't overbook and sell your unused capacity i.e. you get exactly what you paid for.
Rackspace also states that they offer guaranteed and reserved levels of CPU, RAM and Storage with no over subscription (i.e. overbooking).
In this case of VMWare's vCloud Director, then according to James Watters they provide a mechanism for buying a hard reservation from a provider (i.e. a defined unit), with any over commitment being done by the user and under their control.
When it comes to choosing an infrastructure cloud provider, I can only recommend that you first start by asking them what units of compute resource they sell? Then afterwords, ask them whether you actually get that unit or merely a capacity for such depending upon what others are doing? In short, does a compute unit of 1Ghz core with 100Gb storage and 2Gb memory actually mean that or could it mean a lot less?
It's worth knowing exactly what you're getting for your buck.
Tim Anderson (@timanderson) asked Crisis for ASP.Net – how serious is the Padding Oracle attack? on 9/21/2010:
Security vulnerabilities are reported constantly, but some have more impact than others. The one that came into prominence last weekend (though it had actually been revealed several months ago) strikes me as potentially high impact. Colourfully named the Padding Oracle attack, it was explained and demonstrated at the ekoparty security conference. In particular, the researchers showed how it can be used to compromise ASP.NET applications:
The most significant new discovery is an universal Padding Oracle affecting every ASP.NET web application. In short, you can decrypt cookies, view states, form authentication tickets, membership password, user data, and anything else encrypted using the framework’s API! … The impact of the attack depends on the applications installed on the server, from information disclosure to total system compromise.
This is alarming simply because of the huge number of ASP.NET applications out there. It is not only a popular framework for custom applications, but is also used by Microsoft for its own applications. If you have a SharePoint site, for example, or use Outlook Web Access, then you are running an ASP.NET application.
The report was taken seriously by Microsoft, keeping VP Scott Guthrie and his team up all night, eventually coming up with a security advisory and a workaround posted to his blog. It does not make comfortable reading, confirming that pretty much every ASP.NET installation is vulnerable. A further post confirms that SharePoint sites are affected.
It does not help that the precise way the attack works is hard to understand. It is a cryptographic attack that lets the attacker decrypt data encrypted by the server. One of the consequences, thanks to what looks like another weakness in ASP.NET, is that the attacker can then download any file on the web server, including web.config, a file which may contain security-critical data such as database connection strings with passwords, or even the credentials of a user in Active Directory. The researchers demonstrate in a YouTube video how to crack a site running the DotNetNuke content management application, gaining full administrative rights to the application and eventually a login to the server itself.
Guthrie acknowledges that the problem can only be fixed by patching ASP.NET itself. Microsoft is working on this; in the meantime his suggested workaround is to configure ASP.NET to return the same error page regardless of what the underlying error really is. The reason for this is that the vulnerability involves inspecting the error returned by ASP.NET when you submit a corrupt cookie or viewstate data.
The most conscientious ASP.NET administrators will have followed Guthrie’s recommendations, and will be hoping that they are sufficient; it is not completely clear to me whether it is. One of the things that makes me think “hmmm” is that a more sophisticated workaround, involving random time delays before an error is returned, is proposed for later versions of ASP.NET that support it. What does that suggest about the efficacy of the simpler workaround, which is a static error page?
The speed with which the ASP.NET team came up with the workaround is impressive; but it is a workaround and not a fix. It leaves me wondering what proportion of ASP.NET sites exposed to the public internet will have implemented the workaround or do so before attacks are widespread?
A characteristic of the attack is that the web server receives thousands of requests which trigger cryptographic errors. Rather than attempting to fix up ASP.NET and every instance of web.config on a server, a more robust approach might be to monitor the requests and block IP numbers that are triggering repeated errors of this kind.
More generally, what should you do if you run a security-critical web application and a flaw of this magnitude is reported? Applying recommended workarounds is one possibility, but frankly I wonder if they should simply be taken offline until more is known about how to protect against it.
One thing about which I have no idea is the extent to which hackers are already trying this attack against likely targets such as ecommerce and banking sites. Of course in principle virtually any site is an attractive target, because of the value of compromised web servers for serving spam and malware.
If you run Windows servers and have not yet investigated, I recommend that you follow the links, read the discussions on Scott Guthrie’s blog, and at least implement the suggested actions.
I’m surprised that the Windows Azure Team hasn’t rung in with their analysis of the [im]perviousness of Windows Azure instances to Padding Oracle attacks.
<Return to section navigation list>
Cloud Computing Events
My (@rogerjenn) Windows Azure, SQL Azure, BPOS and OData Sessions at Tech*Ed Europe 2010 post is a list of Tech•Ed Europe 2010 sessions within the Cloud Computing and Online Services and Architecture tracks, as well as hits with OData as a search keyword, categorized as Breakout and Interactive sessions. Data is current as of 9/22/2010.
John Bristowe announced Windows Azure Boot Camp in Calgary on October 2nd! in a 9/22/2010 post to the Canadian Developer Connection blog:
 Creative Commons photo by Oli-Oviyan. Click the photo to see the original.
Creative Commons photo by Oli-Oviyan. Click the photo to see the original.
Inspired by the supremely-talented R. Lee Ermey:
Listen up Cloud Cadets! On Saturday, October 2nd, Noel Tan from the Calgary PASS Chapter will host a Windows Azure Boot Camp! The purpose of this FREE boot camp is simple: To bring you up-to-speed on developing for Windows Azure, Microsoft’s flexible cloud–computing platform that lets you focus on solving business problems and addressing customer needs. …
You will join your fellow Cloud Cadets at the Annex Theatre at Nexen (801 - 7the Avenue SW) promptly at zero-nine-hundred on October 2nd! That’s 9:00 AM for those of you just joining us. You will show up on-time and ready to learn! Joining Noel for this great boot camp will be the one-and-only Scott Klein, a SQL Server MVP and managing partner of Blue Syntax. Scott will teach you how to develop for Windows Azure through hands-on learning with tools like Visual Studio 2010. He will show you what’s possible with Windows Azure, empowering you to apply what you’ll learn immediately! Here is the agenda for this event:
- 9:00 AM - Sponsor Presentation
- 9:10 AM - Feature Presentation: Windows Azure Boot Camp
- 12:00 PM - FREE Lunch by Ideaca
- 1:00 PM - Feature Presentation: Windows Azure Boot Camp
- 4:30 PM - Q&A
- 4:45 PM - Prizes/Giveaways
- 4:55 PM - Wrap up
Very important: Make sure to bring your laptop with the necessary tools installed so you can follow along. For more detailed information on this event, make sure to check out the Calgary PASS Chapter site.
Lastly, yet most importantly, you and your fellow Cloud Cadets will register by visiting the following link: http://www.clicktoattend.com/?id=150724. Remember: Registration is essential so take five minutes and sign up NOW. Tell your friends and your co-workers. Better yet, bring them out!
Now, drop and give me 20 instances!
Beth Massi reported Silicon Valley Code Camp Session Schedules are up! in a 9/22/2010 post:
All the session schedules are now posted on the Silicon Valley Code Camp web site. SVCC is one of the biggest there is spanning many different technologies – you don’t want to miss this FREE event on October 9th – 10th at Foothill College in Los Altos. We’ve got over 1400 people registered so far with 193 sessions – what are you waiting for!?
This year I’ll be speaking on OData with Office & of course, some sessions on LightSwitch. Do me a favor and let me know if you’re coming by logging into the SVCC web site and then visiting my sessions page and selecting the “Will Attend” radio button under the session description.
This beginner-level session will be fun. We’ll build a 3-tier Silverlight business application using LightSwitch from scratch and deploy it. I’m not sure what I’ll do with the hour I’ll have left :-)Visual Studio LightSwitch – Beyond the Basics : 1:45 PM Saturday
This pro-developer session will focus on some more advanced features like how to create your own custom controls and data sources that can be used with LightSwitch.
One of my favorite talks, I’ll introduce you to OData and how to create and consume WCF Data Services in Visual Studio. I’ll also show how Office & SharePoint play in the OData space, making it easy to create powerful BI solutions.See you there!
Allessandro Teglia announced Microsoft Vizija 2010! in a 9/22/2010 post to TechNet’s Be_Lead blog:
I’m pleased to announce the Microsoft Vizija Conference (8th edition) which will include traditional IT Professionals, Developers and Managers everybody in one place on 13 – 14th of October 2010, in Skopje[, Republic of Macedonia] (Former Yugoslavian Republic Of Macedonia).
“With the large number of lectures and the presence of eminent National and International people, the conference will give the opportunity to attendees to learn about new products and long term strategies of Microsoft, and to exchange views and knowledge about the latest technologies.”
From the list of the speakers, I can recognize a lot of Microsoft MVPs coming from the whole EMEA Region: Paula Januszkiewicz (Enterprise Security, from Poland), Dejan Foro (Exchange Server from Switzerland), Tomislav Bronzin – (SQL Server from Croatia), Damir Dizdarevic (Management Infrastructure from Bosnia-Herzegovina), Serge Luca (SharePoint Services from Belgium), Aleksandar Talev (SQL Server from F.Y.R.O.M.), Boban Stojanovski (Visual C# from F.Y.R.O.M.), Vladimir Meloski (Exchange Server from F.Y.R.O.M.) and Daniel Joskovski (SQL Server from F.Y.R.O.M.).
Microsoft Vizija continues to be the most important IT Event in the Country for those who wants to know more about Microsoft Products & Technologies and mostly to get involved in technical discussions with some of the key players in the field !

Mithun Dhar announced he will be the keynote speaker for the Future Idaho Tech 2010–Keynote presentation on Cloud & Collaboration Computing! will occur on 10/19 and 10/20/2010 at Boise State University, Boise, ID:
If you are in and around Boise, ID I strongly recommend you to register for the Future Idaho Tech 2010 Conference. I am the keynote speaker for this event. I’ll be speaking about the new paradigm in the computing world, covering information about Cloud Computing. I’ll also touch base on Collaboration and how the software industry is going through a huge change in the way we perceive and use Services.
You can read more about the event here: Future Idaho Tech 2010
More information about the event:
Location: Boise State University, Student Union Building – Jordan Hall, 1910 University Dr, Boise, Idaho 83725 (208-426-4636)
Date and time: Oct 19th & 20th 2010, 8:00am to 5:00pm
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Brian Sommer had Lots of Questions at Oracle Open World, according to his 9/22/2010 post to the Enterprise Irregulars blog:
Questions from Oracle Open World (OOW) – I like a challenge and today’s OOW event made me do a lot of thinking. Here are some of the big ideas and announcements Oracle’s discussed. I post this as you might find my questions interesting.
I caught Thomas Kurian’s keynote this morning at Oracle Open World. Thomas outlined a number of advancements in Oracle product development to several thousand attendees.
Thomas showed how Oracle would support ‘cloud’ computing via the use of efficient and powerful servers, pre-configured with Oracle tools. This machine, Exalogic Elastic Cloud, is in Oracle’s terms, an integrated middleware machine. Oracle executives indicated that a large website, like Facebook, could operate on just two of these machines networked together (up to 8 can be networked currently), with each machine possessing the power of around 100 traditional servers.
That announcement, the presence of these machines at the show and more are convincing proof points that Oracle intends to be a full technology stack player â from computers to applications.
That strategy is totally appropriate for Oracle customers that will continue to have their own data centers, operate their own private clouds and want to find more efficient hardware and systems software to use. Some portion of the IT market will want this capability as not all firms are ready to move major applications to public clouds or entrust key applications to third parties (e.g., Salesforce).
Here though are some questions I had after this talk. If I had these questions, I would guess some of you might too. They are:
- Private clouds may be cheaper, greener and more efficient than the conventional data centers companies operate today. But, are the large scale operations from cloud providers like Google and Amazon even more efficient, more effective and greener still? Doesn’t Google also use Oracle’s database? Oracle’s on the right side of these issues but I’d like more proof points to find how just how much better Oracle or other providers solutions are.
- Private clouds are not always the same as those offered by third parties, especially third parties selling applications with their cloud capabilities. Usually a private cloud transfers some or all of a company’s data center capabilities to a provider or moves many data centers into a single cloud provisioned environment. These private clouds can take advantage of scale, virtualization and more to create more efficient processing environments. That consolidation can usually be accomplished without moving to a new platform if certain conditions exist (e.g., the application software licenses permit usage on a virtual environment). When these moves can be timed with a move to a more efficient, less power hungry and more powerful server, then additional economies are possible. That’s all goodness. But, this gets academic when a software user decides to utilize application software running on someone else’s cloud (not theirs) and not caring one bit about the usual data center concerns (e.g., backup, recovery, security). These customers value not only lower cost but also the ability to move IT people out of systems administration activities and into more strategic applications development roles. Itâs this part of the Oracle story I didn’t hear today and I’d like to get more on it.
- I can also see Oracle’s tools and Exalogic technology becoming a hit with BPO (business process outsourcing) providers as it lets them dynamically manage multiple applications for multiple clients on one powerful machine. But, how big is this market anyway?
- The Exalogic machines are big. There were several on display in front of the keynote auditorium area. It’s impressive that two of these can handle something like Facebook but I wondered whether the typical JD Edwards customer would find this machine overkill? Exalogic positions Oracle well against firms like IBM on the high end of the market but I’d like to learn how it plays with other Oracle users.
- Thomas stated that Oracle is building “elastic and scalable capabilities” with its cloud offerings. I would like to know if that applies to their software licenses as many software licenses I see have a cost structure that is elastic and scalable as long as costs continue to go up…


Alex Williams claimed Oracle Adopts the Worst Term for Cloud Computing to Describe an Impressive Machine in this 9/22/2010 post to the ReadWriteCloud:
A few weeks ago, we posed this question for our weekly poll: What are the top five worst terms for cloud computing?
"Cloud in a box," came in first out of the approximate 1,100 votes submitted.

Oracle will have you believe that its box is the cloud. That it's so powerful that two of its servers could handle all the traffic of Facebook's 500 million users. That it's the equivalent of hundreds if not thousands of virtual machines. That this one machine is the cloud.
We're not here to tell you what to believe. We think this is more an issue of the entire market, not just Oracle.
One analyst said to me that the industry is killing the potential of cloud computing. Fear, uncertainty and doubt are standard practices. Oracle used one keynote today to show a video of an imaginary retail company that has screwed its company beyond belief by adopting cloud computing. Data had been stolen. The e-commerce system had gone down. The IT manager was exasperated. The curious reporter kept asking questions. The sales person was raising hell. The developer was cynical. In the end, they looked at the reporter's notebook. What did it say? The company needed Oracle. Of course!
Oracle can not be blamed. The rest of the industry is heavily promoting the concept of the private cloud, too. Oracle just took it to a new level by shaping the language in the form of a box. One box. One private box.
It's no surprise that Oracle talks about a software suite fitting into a nice big stack. Not once did we hear any mention of Web Oriented Architecture or REST. We barely heard a word about SaaS except when he questioned Success Factors and Salesforce.com. In his Sunday keynote, Ellison said Salesforce.com has poor security because the data is all mixed up together. We're still tying to make sense of that one.
Out of all this, we can tell you that Exalogic Elastic Cloud is an impressive machine. It's the stack that Sun built. It has tremendous capabilities for heavy, intense data management.
It may eve represent the future of the data center as GigaOm points out. It can scale to eight racks. You can buy it in different configurations, It's OS combines Solaris and Linux. It's standardized on Java. Apps can be ported to Amazon EC2. And in some ways it simplifies things for companies. Manage 20,000 servers or invest in a few Exalogic machines.
But cloud in a box? We think the industry can do better than that. What do you think?
Disclaimer: Hewlett-Packard is a sponsor of ReadWriteWeb and paid for Alex Williams' airfare and hotel at Oracle Open World.

I believe Alex meant Disclosure rather than Disclaimer.
<Return to section navigation list>

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 comments:
Post a Comment