Windows Azure and Cloud Computing Posts for 9/20/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
The Cloud Computing Architect regurgitated a Nasuni Filer 2.0 unveiled: Hyper-V, Azure, and private cloud options press release on 9/21/2010:
Nasuni, creator of the storage industry’s leading cloud gateway, today announced its new Nasuni Filer 2.0, with enhanced performance in Microsoft Windows environments, including full support for Hyper-V server virtualization, Windows Azure, Distributed File System (DFS) namespaces, and Windows Previous Versions. The Nasuni Filer also now supports private clouds and allows customers to provide their own cloud credentials, increasing the flexibility of the product. The most significant update to the Nasuni Filer since its launch, the new release improves the user experience, opens up the cloud to a broader spectrum of Microsoft customers, and creates new opportunities for partners.
“With every new release, we have a two-fold mission: introducing more customers to the cloud and expanding what a file server can do. Our 1.0, a NAS with unlimited primary storage and integrated backup, was already a strong, innovative foundation, and we’re building from there, pushing the file server to ease even more IT pain,” said Andres Rodriguez, CEO of Nasuni. “Our goal is to make the Nasuni Filer the storage device of choice for coping with data sprawl and the daily demands of the IT workplace. The 2.0 release offers primary storage to the cloud to more users and has exciting new pain-killing features, such as one allowing end users to restore their own files so IT does not have to be dragged into every file restore. We are staying ahead of this market and are excited about fund raising in the fall.”
The Nasuni Filer, a virtual appliance, now works seamlessly with Hyper-V – which comes included with Windows Server 2008 – as well as VMware, to deliver primary storage from the cloud that is indistinguishable from local storage. In addition to the previous menu of leading cloud storage providers, Nasuni users can now create volumes on Windows Azure, Microsoft’s cloud services platform. No additional plug-ins or software is required for leveraging the Nasuni Filer 2.0 on Hyper-V or Azure. [Emphasis added.]
“Windows Azure storage services allow customers to scale to store large amounts of data, in any format, for any length of time, only paying for what they use or store," said Jason De Lorme, ISV Architect Evangelist at Microsoft. "Windows Azure Platform customers can easily integrate with partners such as Nasuni to simplify file access capabilities in a cloud environment." [Emphasis added.]
Nasuni has also simplified file access with Microsoft DFS, enabling customers to set up a DFS namespace and add the desired share from the Filer as a folder target. The new support for Windows Previous Versions, in conjunction with the Filer’s snapshot feature, enables end users to restore previous versions of their own files without the assistance of an administrator. Customers can now use their own cloud credentials with the Nasuni Filer, a convenience for those who have a preexisting account with a cloud provider. …
Rob Gillen continued his study of Maximizing Throughput in Windows Azure – Part 2 in this 9/20/2010 post:
This is the second in a series of posts I’m writing while working on a writing a paper dealing with the issue of maximizing data throughput when interacting with the Windows Azure compute cloud. You can read the first part here. I’m still running some different test scenarios so I expect there to be another post or two in the series.
Detail: During the testing described in Part 1, we saw that the attempts to parallelize at the sub-file level for downloads within the Azure datacenter was significantly more expensive (on average 76.8% lower throughput) as compared to direct transfers. As such sub-file parallelization is not recommended for downloads within the Azure datacenter.
As I considered these results and thought through where the bottleneck might be, I went back through and re-instrumented the test so I could get a time snap in midst of the parallel download routine at the spot after the file blocks have been downloaded and prior to reassembling the file. What I found was that roughly 50% of the time of an individual operation was consumed in network transfer while the other half was spent assembling the individual blocks into a single file. While this gave me some ideas for further optimization, the 50% time for transfer was still significantly longer than the entire non-blocked operation (by almost 50%). As such, it seemed beneficial to take a completely different approach to improving the transfer speed.
What we came up with was to parallelize at the whole file level rather than at the sub-file level. This effectively eliminated half of the prior parallelization effort cost (no reassembly) and wouldn’t involve the overhead of querying the storage platform for the size, and then issuing a collection of range-gets.
As you can see from the chart above, even in the worse case, there is a significant improvement in the overall throughput when files are transferred simultaneously rather than sequentially. While the individual-file transfer rate dropped (average 40.1% worse), the overall transfer rate averaged 86.21% better.
Consistent with our prior results, instance size plays a role in the bandwidth. Our tests showed an average improvement in realized throughput per step increase in instance size of 14.46% (please see following note)
Note: A review of the chart hints that the small instance size takes a significant hit in the area of total network throughput and, while this accurately reflects the data collected, the third run took abnormally longer than the first two and pulled down the total results. This can be explained by a number of different factors (e.g. heavy contention on the host for network resources). I ran the test for that scenario a 4th time to satisfy my curiosity as to whether or not the third run was reflective of a larger trend and the results of the fourth run were much closer to that of the first two. So much so that if I were to substitute the fourth run results for the third run results, the overall improvement due to parallelism raises to 89.46% and the average improvement in throughput by step increase in node size goes to 10.75%. It is my belief that if I were to have run these tests/scenarios more, the outliers would have reduced and the results would be closer to those ignoring the 3rd run rather than including it.
Approach: Rather than doing a parameter sweep on a number of file sizes, I selected a specific file size (500 MB) of randomly generated data and executed my tests with that. For each parameter set, I ran executed 3 runs of 50 transfers each (150 total per parameter set). While the transfer time of each file was tracked, the total time transfer time (for all 50 files in the run) was the primary value being collected and represented in the charts above. It should be noted that this total time includes a little bit of time per file for tracing data so, in a scenario wherein that tracing activity was not present, the numbers above might be slightly better. I also tore down and re-published my platform between each run to increase my chances of being provisioned to different hardware nodes within the Azure datacenter and – theoretically, a different contention ratio with other instances on the same physical host. Also, I performed a run for all parameter sets before starting subsequent runs to decrease the likelihood that one parameter set would be inappropriately benefited (or harmed) by the time of day in which it was executed. In each test, a single worker role instance was run targeting a single storage account. There were no other applications or activities targeting that storage account during the tests runs. All of these tests were performed in the Windows Azure US North Central region between the dates of August 27, 2010 and September 2, 2010
Research sponsored by the Laboratory Directed Research and Development Program of Oak Ridge National Laboratory, managed by UT-Battelle, LLC, for the U. S. Department of Energy.

Rob is a a developer working for Planet Technologies and on site at Oak Ridge National Laboratory. I'm currently a member of the computer science research group and am studying the applicability of cloud computing to ORNL's mid-range computing portfolio. [more...].
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
My (@rogerjenn) Exploring OData Feeds from Microsoft Dynamics CRM 2011 Beta Online’s xRM Services post of 9/20/2010 (updated 9/21/2010) explained:
Microsoft Dynamics CRM 2011 is the first version to include a full-scale OData provider.
Updated 9/21/2010 with Dynamics CRM 2011 WCF Web Services and Capturing OData Documents with Fiddler 2 sections.
I’ve been testing the Dynamics CRM 2011 Beta Online version’s capability to import Account and Contact data from various file formats to the OakLeaf Systems organization account.
After importing 91 Account and 91 Contact items imported from a comma-separated-values (CSV) file created by Access 2010 from the Northwind Customers table, I had enough content to begin examining the OData feeds with IE 8 and Fiddler 2:
Note: Primary Contact data is missing despite having been specified during data mapping.
Note: Parent Customer and Business Phone data is missing despite having been specified during data mapping.
The URLs in this post are examples only. Authentication is required to access Dynamics xRM content; you must be logged into your Dynamics CRM Online account to download OData content with a browser.
Default Collection List
https://oakleafsystems.crm.dynamics.com/xrmservices/2011/organizationdata.svc/ is the entry point to the OakLeaf Systems instance, which identifies 237 collections, of which the first 10 are shown here:
Fiddler 2 reports the response’s body size as ~27 kB. The DynamicsCrmOnlineXrmMetadata.txt contains the data.
Note: The DynamicsCrmOnlineOData.zip file on Windows Live SkyDrive contains all this post’s sample text files. …



The post continues with examples of OData metadata, Account and Contact documents.
If you’re into Dynamics CRM, you might be interested in my Solve Problems Synchronizing the 64-bit Outlook Client for Dynamics CRM 2010 Beta with the Online Server post of 9/19/2010 also.
SQL Bits (UK) announced SQL Bits 7 – The Seven Wonders of SQL will take place 9/20 through 10/2/2010 at the University of York, Heslington Campus, York, UK and will include the following session:
Extreme scaling with SQL Azure
SQL Azure is Microsoft’s new strategy for storing your data in the cloud, but what to do when you exceed the 10/50GB limit. This is where sharding or partitioning comes into play – this session shows you how it can be done in an OLTP system and show you some of the common pitfalls of SQL azure as we have discoverd in analyzing SQL Azure as an alternative to onsite SQL Server instances at different clients.
Presented by Martin Schmidt:
Martin has a dream, that one day he will wake up and the whole world will speakin the same language. That language is T-SQL. Martin has extensive experience in regular DBA tasks but making systems run and doing day to day maintanance is just to trivial for a SQL Server rockstar like Martin, thats why he enjoys making things go fast, Martin's specialities includes working with optimizing ETL flows, increasing backup speed and of course statement tuning!
Martin works with a wide range of some of the largest coorperations in Denmark with various SQL tasks mostly focused around performance and high availability.
Register here.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Mary Jo Foley (@maryjofoley) reported on 9/21/2010 Microsoft seeks to unify its coming Microsoft 'Union' Services, ERP and CRM wares, some of which will use Windows Azure and the Windows Azure AppFabric for payment and commerce components:
Earlier this summer, Microsoft officials shared roadmaps for what’s coming next with the company’s bundle of enterprise online services, currently known as Business Productivity Online Suite (BPOS). But there was little, if any, mention of what the company is doing to bring its CRM and ERP products in line with its Microsoft-hosted service offerings.
First, it seems there’s a new brand-name coming. According to Directions on Microsoft researcher Paul DeGroot, Microsoft told partners last week that BPOS (which, more than a few Microsoft critics have referred to as “Big Piece of S*it”) is about to be renamed “Union.”
I asked Microsoft officials to confirm this and they wouldn’t, claiming it was in the “rumors and speculation” category. I won’t be surprised to see the Union name unveiled soon — maybe as soon as the next month or two, when Microsoft fields its promised test version of BPOS v.Next.
Secondly, in order to get its reseller partners to step up their push to sell BPOS/Union, Microsoft is sweetening the deal, doubling the margins for those who sell the hosted bundle.
Now on to the bigger picture. We know that Microsoft is working on refreshing the entire BPOS/Union bundle with the many of the latest features it introduced in the on-premises versions of these products (Exchange Server 2010, SharePoint 2010, and, before the end of this year, Lync Server 2010). We also know that’s when Microsoft is going to add some management and other refinements, including two-phase authentication support for the suite. (Two-phase authentication was announced with much fanfare by Google for its Google Apps suite on September 20.)
But there are other things happening under the BPOS/Union covers, too, Microsoft’s Park told me, that should give Microsoft more of a unified story across its enterprise apps and services.
Microsoft’s plan is to follow BPOS’s lead with its ERP and CRM products, Park said.
That means the Dynamics products and the BPOS services with use the same payments and commerce infrastructure. These payment and commerce components will be built on top of Windows Azure and Azure’s service bus (the AppFabric), Park said. Microsoft plans to introduce support for this unified payments and commerce infrastructure to the next releases of its GP, NAV and AX ERP wares, he said.
Microsoft also is planning to unify the underlying infrastructure supporting BPOS and CRM, Park said. In the longer term, Microsoft is likely to add CRM to its BPOS bundle, though it’s not clear whether the company will do so by making it an optional add-on or in some other way, he said. Though Park didn’t provide a clear-cut timetable for this, it sounded like the goal is to have this happen in the next one to two years.
In the even longer term, Microsoft is working to add hosted ERP workloads to its mix of supported Online Services, Park said. That would entail somehow wrapping ERP elements as services and provisioning these instances using Windows Azure, he said.
Microsoft is taking increasing steps to bring the same kind of unity to its ERP suite that Oracle is touting this week at its Open World conference with Fusion. Although the Softies are attempting to cast doubt on how open Fusion will be and how it will protect customer investments, Microsoft is probably going to face those same kinds of questions as it rolls out its broader unification plan.
I’m curious what else current and potential Microsoft enterprise customers want to know about Microsoft’s future plans for BPOS and Dynamics. Got anything you’re wondering/worrying about (beyond online service uptimes, that is)?

See Alex Williams reported Google Apps Adopts 2-Factor Authentication in a 9/20/2010 post to the ReadWriteCloud blog in the Other Cloud Computing Platforms and Services section below.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The HPC in the Cloud blog reported Cloud Middleware Company Apprenda Selected by Microsoft for Two Elite Programs on 9/21/2010:
The Windows Azure TAP is designed to improve and drive adoption of the Windows Azure Platform by making select, highly strategic technology partner solutions available on the platform. Apprenda’s SaaSGrid middleware for SaaS enabling software companies was selected from over 300 partner candidates due to its unique capabilities and market changing potential. Working together with Microsoft, Apprenda is integrating the SaaSGrid application server with the Windows Azure platform capabilities to create a highly advanced foundation for the optimized delivery of software in the cloud. “As software vendors begin to consider and migrate from on-premises solutions to the cloud, Apprenda’s SaaSGrid middleware solution will help provide these ISVs with the core functionality they need in order to embrace the SaaS model and utilize the full power of the Windows Azure platform. Apprenda is a welcome addition to the Azure TAP,” said Prashant Ketkar, senior director, Marketing, Windows Azure at Microsoft Corporation.
Apprenda was also selected for BizSpark One, an invitation only program, designed to help accelerate the growth of high potential startups that take advantage of the capabilities and value of Microsoft products and services. A small number of participants are selected from a global pool of tens of thousands of companies for their unique technology attributes, ability to succeed in market and potential to impact their target industry. Participants benefit from a one on one relationship with Microsoft to mutually aid product development, tap marketing initiatives and participate in the BizSpark One community of investors, entrepreneurs, partners and potential customers.
Apprenda’s CEO, Sinclair Schuller, commented, “Everyone at Apprenda is flattered and energized to be recognized in such a big way by Microsoft. We see ourselves solving some very important challenges for software companies who build their applications on the Microsoft stack and it’s nice to be recognized for our technology and potential. We’re looking forward to a long and fruitful relationship as we help Microsoft’s software partners move their businesses to a SaaS model in the cloud and start to leverage the power of Microsoft’s Windows Azure platform.”


Nitinsha announced a new patterns & practices guide, Developing Applications for the Cloud, on 9/21/2010:

How can a company create an application that has truly global reach and that can scale rapidly to meet sudden, massive spikes in demand? Historically, companies had to invest in building an infrastructure capable of supporting such an application themselves and, typically, only large companies would have the available resources to risk such an enterprise. Building and managing this kind of infrastructure is not cheap, especially because you have to plan for peak demand, which often means that much of the capacity sits idle for much of the time. The cloud has changed the rules of the game: by making the infrastructure available on a "pay as you go" basis, creating a massively scalable, global application is within the reach of both large and small companies.
The cloud platform provides you with access to capacity on demand, fault tolerance, distributed computing, data centers located around the globe, and the capability to integrate with other platforms. Someone else is responsible for managing and maintaining the entire infrastructure, and you only pay for the resources that you use in each billing period. You can focus on using your core domain expertise to build and then deploy your application to the data center or data centers closest to the people who use it. You can then monitor your applications, and scale up or scale back as and when the capacity is required.
This book is the second volume in a planned series about Windows Azure™ technology platform. Volume 1, Moving Applications to the Cloud on the Windows Azure Platform, provides an introduction to Windows Azure, discusses the cost model and application life cycle management for cloud-based applications, and describes how to migrate an existing ASP.NET application to the cloud. This book demonstrates how you can create from scratch a multi-tenant, Software as a Service (SaaS) application to run in the cloud by using the latest versions of the Windows Azure tools and the latest features of the Windows Azure platform.
What’s in the “Developing Applications for the Cloud”

The Windows Azure Team posted Announcing Compute Hours Notifications for Windows Azure Customers on 9/21/2010:
Jim O’Neill showed how to use Windows Azure Companion: PHP and WordPress in Azure on 9/19/2010:
I love the name of this newly announced tool, currently available as a Customer Technology Preview… but I just can’t get Garrison Keillor out of my mind!
The Windows Azure Companion is one of several tools and updates (announced at OSI Days 2010) that are focused on PHP developers looking to leverage the Windows Azure cloud computing platform. In addition to the “Companion”, which is the main topic of this post, there are updates for three other offerings of interest to the PHP audience:
Windows Azure Tools for Eclipse has been updated, and you can now deploy an application directly to Azure without leaving Eclipse, just like you’ve seen in all those Visual Studio demos! Support for Windows Azure Diagnostics and Windows Azure Drives has been added as well.
The update for Windows Azure Command-line Tools for PHP includes support for running the Hosted Web Core on a Worker Role. That may seem a tad redundant given that a Web Role already contains a hosted web core and supports PHP via FastCGI, but what this now allows you to do is share cycles of a potentially underutilized worker role between serving up the PHP site and performing background processing (read: save you money on compute costs in Azure!)
Lastly, there’s an update for the Windows Azure SDK for PHP, now at Version 2.0. The SDK enables PHP developers to leverage Azure storage services (blobs, tables and queues) and the content delivery network (CDN), regardless of where they are hosting the PHP application.
What is the Windows Azure Companion?
The Windows Azure Companion is a ready-made administrative web site that you run on your account in Azure. The site allows you to install frameworks, like PHP, and other 3rd party applications, like WordPress, Drupal and Joomla!, directly into the same Azure service instance hosting the Companion (a worker role, by the way) If this kind of thing sounds familiar, well it is; think of the Windows Azure Companion as the cloud analogy of the Web Platform Installer.
You may be aware that you can already host PHP, MySQL, Java, and a host of other non-Microsoft frameworks and applications on Windows Azure, and there are a number of solution accelerators (PHP/MySQL, Tomcat, memcached, etc.) available to help you out. The Windows Azure Companion takes things to the next level, providing a single point of administration for hosting and managing frameworks and applications in Azure. Right now it’s focused on PHP-based applications, given the popularity of CMSes like WordPress and Drupal, but it certainly seems like a platform that could be easily extended in the future.
Getting Started with the Windows Azure Companion
To put this new tool through its paces, I thought I’d try installing WordPress on Azure, so the rest of this post will walk through doing just that, and in doing so we should touch upon most of the features.
Window Azure Companion is hosted on the MSDN Code Gallery, and when you visit the project site, you’ll see the five download options shown below. The first four are variants of an Azure cloud service which you can quickly upload within a provisioned Azure account (don’t have an Azure account? check out AzurePassUSA!). Those options differ only by the VM size of the worker role to which you’re deploying – the same worker role that will host whatever applications you install via the Windows Azure Companion. The code is available, so the last option can be used to tailor the utility to your own needs or just to satisfy your own curiosity as to how it all works under the covers.
We’ll start simple, with the small VM prepackaged option (WindowsAzureCompanion-SmallVM-Sep2010CTP.zip). When you download that ZIP file, you’ll get two files in the archive (ok, there’s three, but does anyone actually read the license.txt?). If you’ve done deployments on Windows Azure before, you’ll recognize the files as a .cspkg, which contains your compiled application code, and a .cscfg file, which contains the service configuration XML document (kind of like a web.config for you ASP.NET developers, but applying to the entire cloud service).
If you don’t have a storage account configured on Windows Azure, you’ll need to do so now (check out “Provisioning an Azure Storage Account” in my blog post if you need help here).
Before you deploy the service to Windows Azure, a few modifications to the service configuration file are required:
- Specify your Azure storage account (Lines 2 and 3, below),
- Set up an admin account for accessing the Windows Azure Companion once it’s running (Lines 6 through 8), and
- Specify a feed (Line 11) that indicates what applications are available to be installed. For this example, I’ve piggybacked off of a feed that Maarten Balliauw has made available, but you can generate your own following the Windows Azure Companion Feed Schema.
1: <!-- Windows Azure Storage Account Details. -->2: <Setting name="WindowsAzureStorageAccountName" value="wacstorage" />3: <Setting name="WindowsAzureStorageAccountKey" value="redacted" />4:5: <!-- Admin user name, password and e-mail. Please user strong username and password -->6: <Setting name="AdminUserName" value="admin" />7: <Setting name="AdminPassword" value="redacted" />8: <Setting name="AdminEmail" value="jim.oneil@live.com" />9:10: <!-- Atom Feed for Product items to be installed. This URL should be internet addressable -->11: <Setting name="ProductListXmlFeed" value="http://wazstorage.blob.core.windows.net/azurecompanion/default/WindowsAzureCompanionFeed.xml" />Next, deploy your application to a new hosted service on your Azure account. If you need a refresher for this part, refer to the “To select a project and create a compute service” section of this walkthrough on MSDN, using the .cspkg and (just updated) .cscfg files comprising the Windows Azure Companion application. Once it’s deployed you can browse to it at port 8080 (don’t forget that part!) of whatever URL you specified when you set up the Azure hosted service (compute) instance. …

Jim continues with his detailed, illustrated tutorial.
Return to section navigation list>
VisualStudio LightSwitch
Matt Thalman explaind How to reference security entities in LightSwitch in this 9/19/2010 post:
In Beta 1 of Visual Studio LightSwitch, there are a set of security entities defined by the runtime such as UserRegistration, Role, and Permission. Numerous people have asked how they can create relationships to these entities. In Beta 1, these entities can’t be referenced within a developer’s application model. They are only available programmatically. There are potentially multiple solutions for working around this limitation. The following is a solution that makes use of LightSwitch’s support for custom WCF RIA Services.
This solution involves defining a custom WCF RIA Service that exposes proxy entities that delegate to the underlying LightSwitch SecurityDataService (the data service that provides programmatic access to the security data). For purposes of brevity, this solution will only expose read access to the Role data.
The first task is to create an assembly that will host the WCF RIA Service. To do this, create a new project using the “Windows\Class Library” template.
The project needs to have access to the SecurityDataService API so a reference to the Microsoft.LightSwitch.dll assembly will need to be added. This assembly can be located at “%ProgramFiles%\Microsoft Visual Studio 10.0\Common7\IDE\LightSwitch\1.0\Client\Microsoft.LightSwitch.dll”. Part of this implementation will need to work with transactions, so an assembly reference to System.Transactions.dll needs to be added to this project as well.
Next, the proxy entity for Role needs to be defined. This entity should contain properties to expose whatever data you’d like from the underlying system security entities. In this case, the Role entity just has a Name property. Define a new class with the following code:
public class Role { [Key] [ReadOnly(true)] public string Name { get; set; } }WCF RIA Services exposes data through a DomainService class. To create this class, open the Add New Item dialog for the project and select the “Web\Domain Service Class” template.
In the dialog that opens, choose a name for the service (e.g. ProxySecurityDataService) and uncheck the “Enable client access” checkbox. This ensures that the service won’t be exposed as general-purpose web service so only your LightSwitch app will have access to it.
To expose the role data, a GetRoles query method is defined on the domain service as shown below:
using System.Collections.Generic; using System.Linq; using System.ServiceModel.DomainServices.Server; using System.Transactions; using Microsoft.LightSwitch; using Microsoft.LightSwitch.Framework.Base; public class ProxySecurityDataService : DomainService { [Query(IsDefault = true)] public IEnumerable<Role> GetRoles() { Transaction currentTrx = Transaction.Current; Transaction.Current = null; try { IDataWorkspace workspace = ApplicationProvider.Current.CreateDataWorkspace(); IEnumerable<Microsoft.LightSwitch.Security.Role> roles = workspace.SecurityDataService.RoleSet.GetQuery().Execute(); return roles.Select(r => new Role { Name = r.Name }); } finally { Transaction.Current = currentTrx; } } }One note about this implementation:
The current transaction is set to null during the execution of the query for roles. This is necessary to avoid the need for a distributed transaction. By default, the LightSwitch runtime creates a transaction before invoking this custom domain service to ensure that data is accessed with a ReadCommitted isolation level. If we left that transaction set as the current transaction then the query for roles would result in an exception if the MSDTC service was not running because it would detect an attempt for a distributed transaction. However, since the implementation of this domain service is simply acting as a proxy and not doing any data access of its own, it’s safe to set that transaction to null. This ensures that when the role query on SecurityDataService executes, there is not an existing transaction so there is no issue of a distributed transaction attempt.
This is all that needs to be done for the implementation of the WCF RIA Service. Now just compile this project and let’s move on.
At this point, we’re ready to move to the LightSwitch application itself. From the LightSwitch app, a reference to the WCF RIA Service is made by right-clicking the Data Sources node in the Solution Explorer and selecting “Add Data Source”. In this wizard, choose WCF RIA Service and click Next to continue.
In the next wizard step, add a reference to the assembly you created previously that hosts the WCF RIA Service.
In the last wizard step, check the Entities box to indicate that all the entities defined in the WCF RIA Service should be imported.
Now the Role proxy entity is exposed in the application model and can be referenced just like any other entity. For example, you could create a screen that exposes the list of roles that are defined.
For more information on how to implement custom WCF RIA Services consumable by LightSwitch, check out the Visual Studio LightSwitch Beta 1 Training Kit. It includes a section on LightSwitch Data Source Extensions.





<Return to section navigation list>
Windows Azure Infrastructure
Lori MacVittie (@lmacvittie) asserted “Managing datacenters is often like managing a multi-generational family – you’ve got applications across a variety of life stages that need to be managed individually, and keeping costs down while doing so is a concern” in a preface to her 9/21/2010 The Multi-Generational Datacenter: From Toddlers to Teenagers post to F5’s DevCentral blog:
Those who know Don and I know we have a multi-generational family. Our oldest son is twenty-three and “The Toddler” is, well, almost three. There’s still “The Teenager” at home, and there’s also a granddaughter in there who is, well, almost three, so we’ve got a wide variety of children across which we have to share our limited resources.
Each one, of course, ends up consuming resources in a very different pattern. The Toddler grazes. All day and sometimes into the night. The Teenager eats very sporadically and seems to enjoy consuming my resources, perhaps because they’re often frozen, sweet, and smothered in chocolate. Our oldest son will consume resources voraciously when he is at home, a fairly regular event that generally follows a set pattern. The oldest daughter and The Granddaughter are generally speaking fairly minimal consumers of whatever might be in the refrigerator when they visit and their pattern of visiting is more sporadic than that of the oldest son.
Now I’m a mom so I try to make certain that each one of these very different children is able to consume the resources they enjoy/need when they need it. On-demand. And it’s not just resource consumption in terms of tasty treats that varies over time and across children, it’s also our time and, of course, money. If there’s one thing managing a data center and a family share, it’s the financial considerations of spreading a limited budget across multiple children (applications).
If you extrapolate the difficulties (and there are difficulties, I assure you) in trying to manage the needs of four children who span two different generations you can also see then why it’s so difficult to manage the needs of a multi-generational datacenter. Just replace “children” with “applications” and you’ll start to see what I mean.
MULTI-GENERATIONAL DATACENTERS
Most enterprise folks understand the lifecycle of an application and that its lifecycle spans years (and sometimes decades). They also understand that as applications move through their lifecycle from Toddler to Teenager to Adult that they have different resource consumption patterns. And not just compute resource, but storage, network, application delivery network, financial and people resources. Not only does the rate of resource consumption change over time but the patterns also change over time.
That means, necessarily, that the policies and processes in place to manage the resource consumption of those applications must also change over time based on the stage of “life” the application is in. That’s in addition to the differences in policies and processes between applications at any given point in time. After all, while I might respond favorably and without question to a request from The Granddaughter for a cookie, the same isn’t always true for The Toddler even though they’re both a the same stage of life.
What you need is to be able to ensure that application which only occasionally consumes vast amounts of resources can do so but that the resources aren’t just sitting idle when they aren’t needed. Unlike foodstuffs, the resources won’t spoil and go to waste, but they will “go to waste” in that you’re paying for them to sit around doing nothing. Now certainly virtualization is a solution to ensuring that the application has what it needs, when it needs it, without wasting resources. The challenges really aren’t necessarily about leveraging virtualization to solve that problem, they’re more around balancing and prioritizing – you know, managing – the resources than anything else.
MANAGING MULTI-GENERATIONAL DATACENTERS
The problem is, of course, that some of these applications were developed or acquired “way back when” and thus the task of updating/upgrading them to meet current data center delivery policies – especially security –may be troublesome to say the least. Everyone in IT has a story about “that” application; the one that is kept humming along by one guy sitting in the basement and God forbid something happen to him. Applications simply can’t be “turned off” because there’s a new data center model being promoted. That’s the fallacy of the “data center.next” marketing hype: that datacenters will magically transform into this new, pristine image of the latest, greatest model.
Doesn’t happen that way. Most enterprise data centers are not green fields and they don’t transform entirely because they are multi-generational. They have aging applications that are still in use because they’re necessary to some piece of the business. The problem is that modifying them may be nigh-unto-impossible because of a variety of reasons including (1) the vendor no longer updates the application (or exists), (2) no one understands it, (3) the reward (ROI) is not worth the effort.
And yet the business will invariably demand that these applications be included; that they be accessible via the web or be incorporated into a single-sign on initiative or secured against some attack. The answer becomes a solution external to the application. But the cost of acquiring those solutions to achieve such goals is oft times far greater than the reward.
STRATEGIC POINTS of CONTROL
This is where it becomes necessary to apply some architectural flexibility. There already exist strategic points of control within the data center that can be more effectively leveraged to enable the application and enforcement of data center policies across all applications – from Toddler to Teenager. The application delivery network provides a strategic point at which security, availability, and access control can be applied without modifying applications. This is particularly beneficial in situations in which there exist applications which cannot be modified, such as third-party sourced applications or those for which it is no longer financially feasible to update.
Remember that an application delivery controller is, in its simplest form, a proxy. That means it can provide a broad set of functions for applications it manages. Early web-based applications, for example, leveraged their own proprietary methods of identity management. They stored simple username-password combinations in a simple database, or leveraged something like Apache’s HTTP basic authentication. In today’s highly complex and rapidly changing environments, managing such a store is not only tedious, but it offers very little return on investment. The optimal solution is to leverage a central, authoritative source of credentials such as a directory (AD, LDAP, etc…) such that changes to the single-identity will automatically propagate across all applications. Enabling an elderly application that is managed by a full-proxy such as application delivery controller – provided the application delivery platform is enabled with the ability to provide application access control – with such an integration is not only possible but feasible and reduces the OPEX associated with later-life application maintenance.
And make no mistake, it is the maintenance and support and people costs associated with applications over their lengthy lives that add up. Reducing those investments can reap a much greater reward than the actual cost of acquisition.
THINK OUTSIDE the BOX
One of the exciting, hopefully, side-effects of the emerging devops role is the potential impact on overall architecture. Developers tend to think only of code as a solution while router jockeys tend to think only in terms of networking components. Devops bridges the seemingly bottomless chasm between them and brings to the table not only a new set of skills but a different perspective on the datacenter.
This is true not only for applications - leveraging the network to enable more modern capabilities - but for the network, too by leveraging development to automate operational processes and enable greater collaboration across the network infrastructure. Architectural solutions can be as effective and in many cases more efficient – operationally and financially – than traditional answers, but in order to architect such solutions one must first be aware that such possibilities exist.

David Lemphers posted Build Your Own Cloud? What You’ll Need! on 9/20/2010:
One question I hear a lot is “Do I have to use Google, Amazon or Microsoft if I want to leverage the cloud?”
The short answer is no. There are fundamentally two types of cloud models, private and public.
Public is pretty straight forward; a vendor will stand-up a collection of resources that are made available to customers in a multi-tenant way, with certain safeguards in place to provide containment and security, with shared infrastructure (network, etc) for all users managed to ensure no one user can affect anyone else.
Private is a lot more fun, and a lot more dynamic. Private is the concept that you have access to cloud resources which are dedicated for your use. So an interchangeable term you might hear is “dedicated” cloud.
Private clouds can be managed by a provider, so there might be a set of resources in a vendor datacenter which is carved off for your use. It’s very similar to dedicated hosting, except you generally have more control over how you manage and allocate the resources, but for all intents and purposes, they seem identical.
Private clouds become very interesting and potentially valuable when you consider creating them yourself. “Why?” you ask? If we agree that a cloud is more than just some servers and network gear exposed to the Internet, and that it’s more about the ability to dynamically allocate resources to workloads as demand requires, and that the system as a whole is capable of managing failure and operations, then there are a number of scenarios where building your own cloud inspired infrastructure is a good thing.
Let’s take a simple example. Let’s say you have a team that does project work, for example, financial modeling. This team has the following characteristics:
- They are extremely mobile. They move from location to location, frequently.
- They deal with extremely sensitive data. Data that cannot reside in any public or shared facility.
- There workloads are mission critical, therefore, the platform they run on must be capable of dealing with failures in a robust way.
- Their workloads change dramatically based on the project. On one project, they may be using a heavy financial analysis tool, on another, a sophisticated modeling product.
- They need high levels of data storage and redundancy.
What is great about cloud thinking, or should I say, the key to cloud thinking, is to embrace the wonderful aspects of traditional enterprise computing, and the emerging mobile and compact computing standards, with modular construction developments, and really purpose build something to your needs. This was not possible 5 or even 2 years ago, as the commodity hardware markets had not invested heavily in the mobile datacenter space. And mobile/modular construction techniques had to evolved either, however thanks to advanced medical environment research and development, modular and containerized construction techniques have become highly integrated and low-cost.
So where would be start? Let’s start down the list.
- Mobility – Let’s take ROCKLABS, they engineer fully mobile container labs. Capable of running full power, completely self contained, and certified for International shipping. It doesn’t get more portable/mobile than that. With a mobile environment built into a container, you can not only transport the thing via any container approved method (sea, land), you can install it anywhere you can establish a level surface!
- Security – We have a couple of areas of security we need to consider. Physical security, as in, access to the environment by bipods. Network security, so that we can ensure our network assets are secure. And software of course. Let’s tackle them in reverse order.
- Software security is as it is today for most datacenter environments, nothing cloud specific here.
- Network is a little different. We’re working in a highly constrained environment, where thermals are higher, space is lower, and needs are far more specific. Putting in a ton of network gear as you would in a datacenter is not only overkill, it’s a potential operations and repair nightmare. Going composite is the way to go. Something like a Cisco Nexus device meets multiple needs, is small in form factor (considering), and optimized for non-standard datacenter deployments.
- And finally, physical access. The great thing about a container is you can do anything you want to it. Installing the latest in container security and tamper-proof solutions is a breeze. As is installing interior and exterior CCTV devices. All of this can be routed through your containers network equipment for monitoring by remote teams. There are also destructive measures you can take. For example, Toshiba recently announced their new Wipe Technology. Someone pulls out the blade or drive, and the Wipe technology renders the physical device useless. Almost as good as a self-destruct mechanism, although, not as much fun.
- Failure Management – Planning for failure is smart. Always say to yourself, “When this fails”, as opposed to, “If this fails”. Things always fail, and most times, catastrophically, so designing your system to handle this is smart. The key thing here is to ask yourself, what level of failover/redundancy do I need. Don’t over invest, but also, don’t be cheap. Find the balance. With the computing workloads, this will come down to monitoring and excess capacity to handle taking virtual machines/servers out of the pool for repair and still being able to maintain your required service level. For data, it’s about balancing the amount of storage hardware you’re going to keep to meet your storage needs, with adequate data redundancy/integrity. This also includes off-site replication, in case the container burns to the ground or runs off the road. You also need to make a judgment about non-critical hardware, for example, what’s your plan for a router going down? Does it matter that it might take 48 hours to rip and replace? If so, keep a hot spare, if not, design your system to work around the issue.
- Image Repository – Part of the allure of a cloud is that it’s dynamic, not only from a scaling point of view, but also from a workload point of view. Having a repository of images ready for deployment to your computing virtual machines/servers is the best strategy. Not only can you repurpose the whole environment very quickly, you can add extra capacity when needed without having to keep those machines spinning. It saves power/$$$ too.
- Storage – We covered this in the Failure Management section above, but the key thing here is to make some decisions. For example, do you run commodity servers and run a software based storage platform that is capable of dealing with the redundancy/scale issues? Do you use a purpose built appliance, like an EMC Celerra? Each has their pros/cons, it’s about mapping these capabilities to your needs, and finding the one with the best fit, least gaps, and least “non-exploited functions”.
OK, now we’ve taken care of their “needs”, we also need to think about some basics that the overall solution will need.
- Power – You’re going to need two power solutions, the mains power distribution and stepping, so the big dirty public utility power can become nice, clean, smooth power for your gizmos. And some rack level solution, so you can remotely monitor each servers power use, as well as be able to control the power outlet through software, to turn it off/on, etc.
- UPS – Backup power is also critical, and depending on your needs, you’re going to need to balance size with time. There are traditional battery based solutions which will work, and more advanced solutions, like a FES style system available from folks like Pentadyne or ActivePower
- Cooling – Also known as HVAC, is absolutely critical. All your shiny bits of silicon will turn themselves into a hot mess unless you keep the temperature absolutely perfect. This is equally hard, when the whole idea of a container is that it can just be deployed anywhere, so anything that requires Perrier grade water is going to be problematic. There are also many options, traditional refrigerated cooling is common, but more advanced approaches, such as ventilated cooling and dry processes like adiabatic cooling.
- VESDA – Think glorified smoke detector, VESDA, or Very Early Smoke Detection Apparatus, now represents the complete fire management system. These now include monitoring, detection, and suppression.
- Seismic dampening – When you start moving your stuff around, if you haven’t taken into account movement being transferred from the exterior of the container to everything inside, you’re going to be hearing lots of rattling coming from inside your expensive box. Bracing the physical structure, investing in dampening technology, like APC’s NetShelter rack for the servers, and vibration dampening for the moving parts like hard-drives will save you much time, money and pain.
The above is just a starting place when thinking about building your own cloud, that is modular, self-contained, and portable. As you can see, it’s a big undertaking, but at the same time, presents huge opportunities for certain applications.
David was a major player in developing the Window Azure infrastructure before moving recently to PriceWaterhouseCoopers.
The Windows Azure Team posted Showcasing High-Performance Computing on Windows Azure on 9/20/2010:
To watch a step-by-step demo of an HPC server cluster using Windows Azure nodes, including policies, scheduling, node sizing and provisioning, please advance to 50:24 of today's keynote here.
You can also read more about the Windows HPC Server R2 announcement in a blog post from the Windows Server team here or read Bill's blog post about the potential of HPC in the cloud here.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
See The OnCloudComputing blog announced on 9/20/2010 Best practices for public, private and hybrid cloud solutions - An executive roundtable discussion will occur on 10/29/2010 at the Microsoft Technology Center in Alpharetta, Georgia from 3:00 to 5:00 PM EDT in the Cloud Computing Events section below.
<Return to section navigation list>
Cloud Security and Governance
Wade Baker reported Arriving soon: New study on PCI DSS on 9/21/2010 to the Verizon Business Security blog:
The PCI Council’s 2010 Community Meeting is going on this week, which reminds us – we’ve got a new study on the PCI DSS due out on October 4. The basic research model is the same as the DBIR and ICSA Labs Report (collect data from an internal service, see what we can learn, and publish findings), but this time, we’re teaming up with Verizon’s PCI services group.
The report analyzes findings from actual PCI DSS assessments conducted by Verizon’s team of QSAs. It examines the progress of organizations toward the goal of compliance and includes topics such as how and why some seem to struggle more than others. Also presented are statistics around which DSS requirements and sub-requirements are most and least often in place (or compensated for) during the assessment process. Finally, the report overlays PCI assessment data with findings from Verizon’s Investigative Response services to provide a unique risk-centric slant on the compliance process. We compare the compliance status of organizations assessed by our QSAs to those investigated by our IR team and discuss the top 10 threats to cardholder data in light of the DSS requirements.
Hope you’ll check it out and that you’ll find it worth your time.
Chris Hoff (@Beaker) insisted Don’t Hassle the Hoff: Recent & Upcoming Speaking Engagements on 9/202010":
Recent Speaking Engagements/Confirmed to speak at the following upcoming events:
FIRST, Miami, FL, keynote - June 13-18
- SANS What Works In Virtualization and Cloud, Washington, D.C., keynote – August 19th-20th
- Ping Identity Summit, Keystone, CO, Cloud session with Gunnar Peterson – July 20-23
- Black Hat 2010, Las Vegas, NV, July 26-29
- Defcon 18, Las Vegas, NV – July 30-August 1
- VMworld, San Francisco, CA – August 30-September 3
- RSA Japan, Tokyo, Japan – September 6-12
- Telfonica Cloud Security Event, Madrid, Spain – September 13-16
- NIST 2010 SCAP conference, Baltimore, Maryland – September 28
- IANS New England Information Security Forum, Boston, MA, keynote – September 29
- MassTLC Security Summit, Burlington, MA – October 1
- HacKid, Cambridge, MA – October 9-10
- RSA Europe, London, UK – October 11-15
- Security at University of Michigan Summit (SUMIT_10), Ann Arbor, MI – October 18-19
- Sector, Toronto, Canada – October 25-28
- Black Hat Abu Dhabi, UAE – November 10-11
- Cloud Security Alliance Congress, Orlando, FL – November 16-17
There are a ton of venues I haven’t added here because they are directly related to customer visits that may not wish to be disclosed. You can see the prior list of speaking engagements listed here.
[I often get a bunch of guff as to why I make these lists: ego, horn-tooting, self-aggrandizement. I wish I thought I were that important.
The real reason is that it helps me keep track of useful stuff focused not only on my participation, but that of the rest of the blogosphere. It also allows folks to plan meet-ups]
<Return to section navigation list>
Cloud Computing Events
R “Ray” Wang delivered an Event Report: Oracle Open World 2010 – Beyond The Day 1 Hype on 9/21/2010:
Oracle Day 1 Focused On Showcasing Both Software And Hardware Prowess
The Day 1 keynote kick-off from Oracle’s CEO, Larry Ellison, touched on the wide spectrum of Oracle’s broad software and hardware portfolio. Despite an over-emphasis on hardware and appliances, Oracle also pre-announced the launch of Fusion Applications. A closer analysis of the announcements show:
Fusion Apps unveiled and announced for GA in Q1 2011. Joking about the length of time its taken since the halfway to fusion event on January 19, 2006, Larry Ellison finally announced the availability of Fusion Apps. The seven products include Financial Management, Procurement and Sourcing, Human Capital Management (HCM), Customer Relationship Management (CRM), Supply Chain Management (SCM), Governance Risk and Compliance (GRC), and Project and Portfolio Management (PPM). Oracle’s engineering team built 20,000 objects, 10,000 business processes, and 100 modules from scratch (see Figure 1). Fusion Applications meet 8 of the 10 criteria for next generation social enterprise applications. Oracle intends to target the best of breed SaaS products such as Concur, Salesforce.com, Success Factors, Taleo, and Workday. At this point, no pricing information has been provided but Oracle has promised like to like upgrade parity for existing customers.
Point of View (POV): Fusion Apps highlight a new level of design. The apps infuse Web 2.0 paradigms with enterprise class sensibilities. Role based screens present relevant task, alert, and analytics. Adoption will depend on the customer’s existing landscape. Oracle customers generally fall into 3 categories: Die Hard Red Stack Believers, Best of Breed Customers By Accident, and Net New Greenfield. Expect Net New Greenfields to consider the full Fusion App suites as they compare existing Apps Unlimited products and SAP. Best of Breed Customers By Accident will most likely be drawn to the 100 modules to be delivered on demand and on premises. Die Hard Red Stackers most likely have upgraded to the latest Fusion Middleware and will consider product replacements and module adoption. Fusion Apps remains fairly horizontal and those customers with rich and stable vertical capabilities will most likely hold off for future releases. Customers should keep an eye on the middleware pricing associated with Fusion Apps.
- Oracle Exalogic Elastic Cloud demonstrates one part of Oracle’s Cloud appliance strategy. The new Oracle Exalogic Elastic Cloud offering brings hardware and software together to run both Java and non-Java apps. The system sports 64-bit x86 processors, open standards high speed InfiniBand-based communications links, solid-state storage, and Oracle WebLogic middleware. The intent – provide a cloud in a box for customers seeking turnkey deployments.
POV: After hammering fellow competitor and friend Marc Benioff for not having a real cloud like Amazon, Larry Ellison likened Oracle’s Exalogic Elastic Cloud (E2C) to Amazon’s Elastic Compute Cloud (EC2). With many flavors of cloud computing, users and buyers should understand the various flavors of cloud computing before making their own comparisons. The main point – Oracle’s E2C is a cloud in a box that can run other applications including Fusion Applications. Attendees can expect part 2 of the Cloud strategy to take the On Demand route with applications delivery. The result – a range of deployment options from on-premises, appliance, and on-demand.- Fork in Linux explicitly reflects Oracle’s impatience with Red Hat. Oracle’s Unbreakable Enterprise Kernel is part of the new Oracle Linux. Oracle Linux builds off of the 2.6.32 mainline Linux kernel. Internal tests show up to a 75 percent performance improvement in OLTP tests over Red Hat compatible Linux. Existing customers have migration paths from Red Hat Linux to Oracle Linux.
Point of View (POV): Oracle takes Linux back into its own hands. By supporting existing Red Hat code lines of Linux, Oracle preserves stability for current customers. However, the go forward strategy will require all new Oracle apps to run exclusively on Oracle Linux. These actions highlight how Oracle will not let others hold the vendor or its customers back from the pace of innovation. However, vendors in Oracle’s path should take note at how Oracle responds to those who stand in its path to progress. Red Hat shareholders should remain nervous.- Oracle partner network (OPN) continues industry verticalization push. OPN Specialized, launched last year, now features 200 partners, 25,000 certified specialists, and 5000 implementation specialists. These partners have added over 50 specialization options.
(Read the full article @ A Software Insider's Point of View)
William Vambenepe (@vambenepe) blogged Exalogic, EC2-on-OVM, Oracle Linux: The Oracle Open World early recap on 9/21/2010:
Among all the announcements at Oracle Open World so far, here is a summary of those I was the most impatient to blog about.
Oracle Exalogic Elastic Cloud
If “Exalogic Elastic Cloud” is too taxing to say, you can shorten it to “Exalogic” or even just “EL”. Please, just don’t call it “E2C”. We don’t want to get into a trademark fight with our good friends at Amazon, especially since the next important announcement is…
Run certified Oracle software on OVM at Amazon
Oracle and Amazon have announced that AWS will offer virtual machines that run on top of OVM (Oracle’s hypervisor). Many Oracle products have been certified in this configuration; AMIs will soon be available. There is a joint support process in place between Amazon and Oracle. The virtual machines use hard partitioning and the licensing rules are the same as those that apply if you use OVM and hard partitioning in your own datacenter. You can transfer licenses between AWS and your data center.
One interesting aspect is that there is no extra fee on Amazon’s part for this. Which means that you can run an EC2 VM with Oracle Linux on OVM (an Oracle-tested combination) for the same price (without Oracle Linux support) as some other Linux distribution (also without support) on Amazon’s flavor of Xen. And install any software, including non-Oracle, on this VM. This is not the primary intent of this partnership, but I am curious to see if some people will take advantage of it.
Speaking of Oracle Linux, the next announcement is…
The Unbreakable Enterprise Kernel for Oracle Linux
In addition to the RedHat-compatible kernel that Oracle has been providing for a while (and will keep supporting), Oracle will also offer its own Linux kernel. I am not enough of a Linux geek to get teary-eyed about the birth announcement of a new kernel, but here is why I think this is an important milestone. The stratification of the application runtime stack is largely a relic of the past, when each layer had enough innovation to justify combining them as you see fit. Nowadays, the innovation is not in the hypervisor, in the OS or in the JVM as much as it is in how effectively they all combine. JRockit Virtual Edition is a clear indicator of things to come. Application runtimes will eventually be highly integrated and optimized. No more scheduler on top of a scheduler on top of a scheduler. If you squint, you’ll be able to recognize aspects of a hypervisor here, aspects of an OS there and aspects of a JVM somewhere else. But it will be mostly of interest to historians.
Oracle has by far the most expertise in JVMs and over the years has built a considerable amount of expertise in hypervisors. With the addition of Solaris and this new milestone in Linux access and expertise, what we are seeing is the emergence of a company for which there will be no technical barrier to innovation on making all these pieces work efficiently together. And, unlike many competitors who derive most of their revenues from parts of this infrastructure, no revenue-protection handcuffs hampering innovation either.
Fusion Apps
Larry also talked about Fusion Apps, but I believe he plans to spend more time on this during his Wednesday keynote, so I’ll leave this topic aside for now. Just remember that Enterprise Manager loves Fusion Apps.
And what about Enterprise Manager?
We don’t have many attention-grabbing Enterprise Manager product announcements at Oracle Open World 2010, because we had a big launch of Enterprise Manager 11g earlier this year, in which a lot of new features were released. Technically these are not Oracle Open World news anymore, but many attendees have not seen them yet so we are busy giving demos, hands-on labs and presentations. From an application and middleware perspective, we focus on end-to-end management (e.g. from user experience to BTM to SOA management to Java diagnostic to SQL) for faster resolution, application lifecycle integration (provisioning, configuration management, testing) for lower TCO and unified coverage of all the key parts of the Oracle portfolio for productivity and reliability. We are also sharing some plans and our vision on topics such as application management, Cloud, support integration etc. But in this post, I have chosen to only focus on new product announcements. Things that were not publicly known 48 hours ago. I am also not covering JavaOne (see Alexis). There is just too much going on this week…
Just kidding, we like it this way. And so do the customers I’ve been talking to.
William is a cloud application architect for Oracle Corp.
See SQL Bits (UK) announced SQL Bits 7 – The Seven Wonders of SQL will take place 9/20 through 10/2/2010 at the University of York, Heslington Campus, York, UK in the SQL Azure Database, Codename “Dallas” and OData section above.
The OnCloudComputing blog announced on 9/20/2010 Best practices for public, private and hybrid cloud solutions - An executive roundtable discussion will occur on 10/29/2010 at the Microsoft Technology Center in Alpharetta, Georgia from 3:00 to 5:00 PM EDT:
A team of industry leaders in cloud computing are hosting an executive roundtable discussion and reception on September 29 in Atlanta, GA to present insights and best practices for public, private and hybrid cloud solutions.
Experts from Intel Corporation, Univa UD, and Deopli Corporation will lead the free session which is designed to provide attendees with a real-world look at using cloud, with an opportunity to get their questions answered about how to evaluate, plan and implement a private or public cloud solution in their own organization.
The fourth in a series of similar events hosted by Univa and Intel, this roundtable is the first of its kind in the southeast. Titled “Cloud Computing: Realities and Recommendations,” the event takes place at the Microsoft Technology Center in Alpharetta, Georgia on Wednesday, September 29, 2010 from 3:00pm — 5:00pm ET, with a cocktail reception to follow.
Roundtable leaders:
- Gary Tyreman, CEO, Univa
- Billy Cox, director of Cloud Strategy & Planning, Software Solutions Group, Intel
- Scott Clark, CEO, Deopli Corporation
“These events have been popular because we’re giving the audience a view of cloud computing from the real world,” said Univa’s Gary Tyreman. “At the moment there are plenty of venues where general cloud information is being presented, but precious few where actual implementation details are shared. By discussing lessons learned based on actual customer projects, we’re giving our attendees the information they need to begin building a cloud computing strategy based on their specific needs and requirements.”
“Taking the concept of cloud and applying it to technology is best done by leveraging experience from teams working with IT providers and end users in the field,” said Intel’s Billy Cox. “These sessions apply that experience and provide a recipe for success.”
“We have spent the last 20 years building private clouds for use by individual companies,” said Clark of Deopli Corporation. “As natural evolution takes us into multi-tenant clouds, we need to make sure we carry forward all the lessons from our past that apply, while recognizing that this is a different beast and will have requirements we have not faced before. These roundtables give us an opportunity to share our experiences and hear new requirements, and then take the best of both to build a more appropriate solution for all to use.”
The event is limited to 25 seats. To reserve a seat or learn more, visit http://univaud.com/about/news/cloud-roundtable-4.php.
Brian Loesgen reported San Diego .NET User Group merges two Special Interest Groups on 9/19/2010:
I will co-lead the SIG along with Zoiner Tejada. The user group Website (and calendar) is http://SanDiegoDotNet.com.
The new Architecture SIG will meet on the 2nd Tuesday of the month at the Microsoft Office in La Jolla.
Ironically, earlier today I Tweeted this: Some great quotes/thoughts/truths here ('Traditional enterprise architecture is dead; long live SOA-inspired EA' ): http://bit.ly/b0PtYm.
The re-alignment of the SIGs is a good reflection of that!
<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum asserted “Yahoo researchers create the longest pi yet -- and hint at the cloud's potential for highly intense and complex computation” as a deck for hi sHadoop and MapReduce: Breaking records in the cloud post of 9/21/2010 to InfoWorld’s Cloud Computing blog:
Last week, a team of Yahoo researchers creating a long version of pi set a new record in the field of mathematics using the Yahoo cloud. According to Engadget's report, "The team, led by Nicholas Sze of Yahoo!, used the company's Hadoop cloud computing tech to break the previous record by more than double, creating the longest Pi yet."
The researchers leveraged Hadoop for this project. The widely distributed nature of Hadoop brought clear advantages by taking a divide-and-conquer approach. It cut up the problem into smaller pieces, then set different parts of the computer to work on different sections of the project.
As time passes, we'll see more of the massive amounts of resources now available in the cloud as-a-service being used to solve computationally intense and complex problems. Consider the options: You can purchase data centers full of servers, all working away on your problem for a very unreasonable price, or you can leverage the cloud to rent only the resources you need, just when you need them.
I've been pushing Hadoop as a killer system for the cloud, and this is just another instance of that value. While other databases are looking to scale through mechanisms such as hardware and software caching -- some with a million-dollar price tag -- Hadoop takes a more reasonable path. Hadoop uses MapReduce to spread out the data processing over a massive numbers of servers, then combines the results. It's an old approach in new open source wrapping, making use of the scalability and value of cloud computing.
This is just one example of new uses for the cloud over the next few years. As the growth of the cloud pushes down the cost of massive computing systems, both researchers and enterprises will find old problems with new solutions using cloud computing.
The Amazon Web Services team posted Amazon EC2 Introduces Tagging, Filtering, Import Key Pair, and Idempotency on 9/20/2010:
We are excited to let you know about four separate features that will make EC2 easier to use for customers with large deployments. First, we’ve added the ability to tag EC2 resources to simplify the administration of your cloud infrastructure. A form of metadata, tags can be used to create user-friendly names, enhance searchability, and improve coordination between multiple users. The AWS Management Console has also been updated to support tagging.
We’re also announcing the ability to filter among your EC2 resources to find ones that match specified criteria. For example, you can use filtering to quickly determine which instances are running in a particular Availability Zone or which snapshots are associated with a particular EBS volume. Filtering will make it easier to manage resources within your deployment.
Starting today, you can also use your own RSA keys to access your EC2 instances instead of relying on AWS generated keys. This feature gives you complete control over your private keys and will also allow you to use the same RSA key across different regions, simplifying resource management.
Last but not the least, you will also be able to idempotently launch instances so that timeouts or connection errors do not result in the launch of more instances than you originally intended, saving you time and money.
Jeff Barr provides additional details about these new features in the following blogs of 9/19/2010:
- New Amazon EC2 Feature: Idempotent Instance Creation
- New Amazon EC2 Feature: Resource Tagging
- New Amazon EC2 Feature: Filtering
- New Amazon EC2 Feature: Bring Your Own Keypair
Jeff Barr’s Now Available: Host Your Web Site in the Cloud post of 9/16/2010 describes his new book:
I am very happy to announce that my first book, Host Your Web Site in the Cloud is now available! Weighing in at over 355 pages, this book is designed to show developers how to build sophisticated AWS applications using PHP and the CloudFusion toolkit.

Here is the table of contents:
- Welcome to Cloud Computing.
- Amazon Web Services Overview.
- Tooling Up.
- Storing Data with Amazon S3.
- Web Hosting with Amazon EC2.
- Building a Scalable Architecture with Amazon SQS.
- EC2 Monitoring, Auto Scaling, and Elastic Load Balancing.
- Amazon SimpleDB: A Cloud Database.
- Amazon Relational Database Service.
- Advanced AWS.
- Putting It All Together: CloudList.
After an introduction to the concept of cloud computing and a review of each of the Amazon Web Services in the first two chapters, you will set up your development environment in chapter three. Each of the next six chapters focuses on a single service. In addition to a more detailed look at each service, each of these chapters include lots of full-functional code. The final chapter shows you how to use AWS to implement a simple classified advertising system.
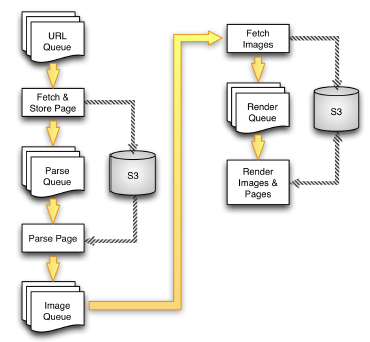
Although I am really happy with all of the chapters, I have to say that Chapter 6 is my favorite. In that chapter I show you how to use the Amazon Simple Queue Service to build a scalable multistage image crawling, processing, and rendering pipeline. I build the code step by step, creating a queue, writing the code for a single step, running it, and then turning my attention to the next step. Once I had it all up and running, I opened up five PuTTY windows, ran a stage in each, and watched the work flow through the pipeline with great rapidity. Here's what the finished pipeline looks like:
I had a really good time writing this book and I hope that you will have an equally good time as you read it and put what you learn to good use in your own AWS applications.
Today (September 21) at 4 PM PT I will be participating in a webinar with the good folks from SitePoint. Sign up now if you would like to attend.
-- Jeff;
PS - If you are interested in the writing process and how I stayed focused, disciplined, and organized while I wrote the book, check out this post on my personal blog.
Chris Czarnecki asked Why Are Amazon EC2 Cloud Computing Costs Falling? in a 9/20/2010 post to the Learning Tree blog:
The release of the Amazon Linux and Windows Micro Instances recently is an example of their expanding range of available services. The release of these EC2 Micro instances received much attention and rightly so, but at the same time, at the other end of the scale, and with almost no publicity, Amazon lowered the price of its EC2 high memory double and XL instances. Such moves are welcome by all current users and also make it more attractive for new users considering entering the cloud.
Following the cost and adoption of the cloud is interesting. A major benefit of using the cloud is a reduced cost in IT expenditure. One of the questions I am often asked when consulting or teaching Cloud Computing is “Will the performance of the cloud suffer as more people adopt Cloud Computing?”. Such a question is a valid concern and there will be examples of a cloud provider failing to scale as required. This type of interruption can be expected as new technology evolves but is and will be rapidly resolved.
In the case of Amazon, they have a mature (4 years) infrastructure and proven scalability model and are now in a position that as they continue to grow at a rapid pace can expand their infrastructure accordingly with minimal glitches. The savings they are able to make in economies of scale are being passed onto customers also. The result of this is a more attractive proposition for all concerned. As other organisations develop their services the competition will help keep the prices low and the functionality and service levels high.
Stephen O’Grady (@sogrady) analyzed AWS in his Hiding in Plain Sight: The Rise of Amazon Web Services post of 9/20/2010:
Maybe it’s the lingering perception that they’re just a retailer, but the lack of a healthy fear of Amazon is still curious. Even as players large and small acknowledge the dominance of AWS within the public cloud computing market, the lack of an immune response to its continued expansion defies simple explanation.
If Amazon restricted itself to basic public cloud computing services, that would be one thing. Most of the large systems players have turned their attention to the burgeoning market for quote unquote private cloud services. Whether these same cloud players appreciate the fact that a large portion of their interest in the private cloud is a function of the public cloud economic realities established by Amazon is unclear, but unimportant. Amazon is singularly responsible for the framing that is the public cloud today, a framing which generally relegates those with traditional enterprise margins in mind to private cloud settings.
But Amazon has not, of course, restricted itself to basic public cloud computing services. Amazon’s steady but underacknowledged expansion into adjacent markets is no secret. Since those early days when it took a Master’s degree to apply DNS to a running EC2 instance, Amazon has steadily grown its footprint beyond basic compute and storage functions into core enterprise software markets like messaging (SQS, SNS), analytics (Elastic MapReduce), monitoring (CloudWatch), and databases (SimpleDB, RDS [coverage]). And, as of last Tuesday, enterprise Linux.
Initially believed to be an Ubuntu derivative, which would have been an even more interesting choice, Amazon’s new custom Linux distribution is actually binary compatible with CentOS, which is itself a clone of Red Hat Enterprise Linux. All of which means, effectively, that Amazon is following in the footsteps of Oracle [coverage] and getting into the Linux distribution game via Red Hat. By leveraging the availability of open source assets, they are systematically bootstrapping themselves into markets that have, historically, been vigorously defended by their respective dominant players.
The reaction from the marketplace? Understated, to say the least. Even the Hacker News thread garnered a mere 19 comments, over a third of which discuss nothing more than the availability of the source code.
While this apathy with respect to AWS announcements is typical, however, it seems increasingly inappropriate. Besides being to the public cloud market what Microsoft is to operating systems or VMware to virtualization, Amazon now maintains, supports and sells its own distributions of both Linux and MySQL. If this was HP or IBM, for example, it would be news. But when Amazon does, it barely registers on the public consciousness.
Whether that’s because of the aforementioned legacy impression of Amazon as a mere retailer, or because Amazon’s software assets are not distributed beyond the boundaries of their own public cloud (for now) is academic. The fact is that Amazon, by hiding in plain sight, is building an impressive array of weapons with which they can attack a variety of customer and market types. In spite of this, they have attracted minimal attention. How long that continues will be interesting to see, because while Savio’s right that Red Hat should be concerned about Amazon, so should everyone else.
Disclosure: IBM, Microsoft, and Red Hat, are RedMonk customers, while Amazon and VMware are not.
Stephen is Principal Analyst for RedMonk.
Alex Williams reported Google Apps Adopts 2-Factor Authentication in a 9/20/2010 post to the ReadWriteCloud blog:
Google Apps is launching two-factor authentication, allowing the capability to verify a person's identity with a code sent to the user's mobile device.
Most Web-based services still use systems that require people to sign in to their accounts with a user name and a password.
It's pretty insecure. People lose their passwords to phishing scams all the time. And traditional two-factor security systems require separate devices such as certificates, smart cards and tokens.
Integrating secure socket layer (SSL) and security assertion markup language (SAML) to use these devices can be complex, to say the least.
Google's move shows how security verification is moving to the cloud. The value of these cloud-based services came true with VMware's acquisition of TriCipher, a security and authentication provider. VMware will use TriCipher to connect infrastructures. It provides the capability for single sign-on across different systems.
Here's how the two-factor verification works with Google. The new system is now available for Google Apps users.
The customer provides their user name and password.
A code is then sent to the person's mobile device. The code is sent via SMS or a voice call.
The user then types in the number through Google Apps:
That's a more modern method for using a SaaS service.
But it's just a start. The need will intensify as more services ditch user name and password systems. The demand is giving rise to companies like Yubico. The company's Yubikey product is a USB-key for instant and strong authentication to networks and services. It sends the user's identity and a secure one time pass code. It works from any computer for any number of applications with no client software needed. Cloudkick is a cloud services provider that uses Yubico.
These forms of two-factor authentication are still pretty rare to see out in the wild. But expect these modern verification systems to be more commonly used as user name and password systems go more out of vogue.


Tim Anderson (@timanderson) asked is Oracle: a good home for MySQL? on 8/19/2010:
I’m not able to attend the whole of Oracle OpenWorld / JavaOne, but I have sneaked in to MySQL Sunday, which is a half-day pre-conference event. One of the questions that interests me: is MySQL in safe hands at Oracle, or will it be allowed to wither in order to safeguard Oracle’s closed-source database business?
Context: InnoDB is the grown-up database engine for MySQL, with support for transactions, and already belonged to Oracle from an earlier acquisition.
It is important to look at the actions as well as the words. Today Oracle announced the release candidate of MySQL 5.5, which uses InnoDB by default, and has performance and scalability improvements that are dramatic in certain scenarios, as well as new and improved tools. InnoDB is forging ahead, with the team working especially on taking better advantage of multi-core systems; we also heard about full text search coming to the engine.
The scalability of MySQL is demonstrated by some of its best-known deployments, including Facebook and Wikipedia. Facebook’s Mark Callaghan spoke today about making MySQL work well, and gave some statistics concerning peak usage: 450 million rows read per second, 3.5 million rows changed per second, query response time 4ms.
If pressed, Screven talks about complexity and reliability with critical data as factors that point to an Oracle rather than a MySQL solution, rather than lack of scalability.
In practice it matters little. No enterprise currently using an Oracle database is going to move to MySQL; aside from doubts over its capability, it is far too difficult and risky to switch your database manager to an alternative, since each one has its own language and its own optimisations. Further, Oracle’s application platform is built on its own database and that will not change. Customers are thoroughly locked in.
What this means is that Oracle can afford to support MySQL’s continuing development without risk of cannibalising its own business. In fact, MySQL presents an opportunity to get into new markets. Oracle is not the ideal steward for this important open source project, but it is working out OK so far.
Related posts:
<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, SQL Azure Database, SADB, Open Data Protocol, OData, Windows Azure AppFabric, Azure AppFabric, Windows Server AppFabric, Server AppFabric, Cloud Computing, Visual Studio LightSwitch, LightSwitch, Oracle, Exalogic, MySQL, Amazon Web Services, AWS, Amazon EC2, Hadoop, MapReduce, PHP, Windows Azure Companion

















0 comments:
Post a Comment