Windows Azure and Cloud Computing Posts for 9/8/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Tip: If you encounter articles from MSDN or TechNet blogs that are missing screen shots or other images, click the empty frame to generate an HTTP 404 (Not Found) error, and then click the back button to load the image.
Azure Blob, Drive, Table and Queue Services
Ayende Rahien (@ayende) showed how important minimizing write operations are in entity-attribute-value (EAV) tables in his RavenDB performance optimizations post of 9/8/2010:
Just to note, you’ll probably read this post about a month after the change was actually committed.
I spent the day working on a very simple task, reducing the number of writes that RavenDB makes when we perform a PUT operation. I managed to reduce one write operation from the process, but it took a lot of work.
I thought that I might show you what removing a single write operation means, so I built a simple test harness to give me consistent numbers (in the source, look for Raven.Performance).
Please note that the perf numbers are for vanilla RavenDB, with the default configuration, running in debug mode. We can do better than that, but what I am interested in is not absolute numbers, but the change in those numbers.
Here are the results for build 124, before the change:
Wrote 5,163 documents in 5,134ms: 1.01: docs/ms
Finished indexing in 8,032ms after last document writeAnd here are the numbers for build 126, after the change:
Wrote 5,163 documents in 2,559ms: 2.02: docs/ms
Finished indexing in 2,697ms after last document writeSo we get double the speed at write time, but we also get much better indexing speed, this is sort of an accidental by product, because now we index documents based on range, rather than on specific key. But it is a very pleasant accident.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Wayne Walter Berry (@WayneBerry) continued his SQL Azure blog series with Securing Your Connection String in Windows Azure: Part 2 on 9/8/2010:
This is the second part in a multi-part blog series about securing your connection string in Windows Azure. In the first blog post (found here) a technique was discussed for creating a public/private key pair, using the Windows Azure Certificate Store to store and decrypt the secure connection string. In this blog posts we are going to cover how to import the private key to Windows Azure.
In this technique, there is a role of the Windows Azure administrator who is the private key holder. His job is to:
- Create the private/public key pair and choose the password to secure the private key. Find out how to create the key in the previous blog post.
- Backup the private key and password.
- Deploy the private key to the Windows Azure Certificate Store.
Because the Windows Azure administrator has access to the private key, he can decode the connection string and figure out the password to the production database. He has the same access as the code running on Windows Azure.
Importing the Private Key to Windows Azure
As the Windows Azure administrator you need to upload the private key to Windows Azure, here are the steps to do that:
- Using your browser navigate to the Windows Azure Developer Portal.
- Select the Hosted Service component to deploy to. Under the Certificates heading, select Manage.
- Upload the private certificate that we created in part 1 and use the password used when creating the private certificate.
- Copy the thumbprint given by Windows Azure to your clipboard; you will need this for the web.config file.
The thumbprint is hexadecimal string that contains the SHA-1 hash of the certificate. It can be used by the code running on Windows Azure to gain access to the private keys installed on Windows Azure. We will use this in our web.config to tell the custom encryption provider the certificate that we just uploaded. There is nothing secure about the Thumbprint, it can be seen by everyone but only code with access to the private key can decrypt the connection string.
Summary
In part three of the blog series I will show how the SQL Server Administrator uses the public key to encrypt the connection string.



Glenn Gailey posted Data Services Streaming Provider Series-Part 2: Accessing a Media Resource Stream from the Client to the WCF Data Services (formerly Astoria) blog on 9/8/2010:
In this second post in the series on implementing a streaming data provider, we show how to use the WCF Data Services client library to access binary data exposed by an Open Data Protocol (OData) feed, as well as has how to upload binary data to the data service. For more information on the streaming provider, see the first blog post in this series: Implementing a Streaming Provider.
PhotoData Sample Client Application
In the previous post, we showed how to implement IDataServiceStreamProvider to create a data service that uses OData to store and retrieve binary image files, the media resource (MR) in OData terms, along with metadata about the photos, the media link entry (MLE) in OData terms. The Visual Studio solution for this sample data service, which is published to this MSDN Code Gallery page, also contains a client application project. This client, which consumes feeds from the PhotoData service, accesses and displays image files stored by the data service. Creating a client application that can display photos from and send photos to our PhotoData sample data service requires the following basic steps:
Create the client project and add a reference to the data service.
Create the UI elements to display the MLE and MR data for the photo.
Request a data feed from the service, get the URI of the MR for a specific MLE, and then use this URI to create an image based on the MR.
When we are adding a new photo, create a new MLE object on the client, set any properties, and add the object to the DataServiceContext.
Read an image from the local computer into a stream, pass the stream and the object to the SetSaveStream method, and then call SaveChanges.
As you may recall, the PhotoData sample data service exposes a single PhotoInfo entity (an MLE) which has a related image file (the MR). The HasStream attribute applied to the PhotoInfo entity tells the client that it is an MLE, as you can see in the PhotoInfo entity metadata returned by the data service:
Now, let’s get started on creating the client application.
Creating the WPF Client Application
Our client application is a Windows Presentation Foundation (WPF) application. This enables us to use data binding of PhotoInfo objects to UI elements.
First let’s create the WPF client application (I won’t go into too much detail here…you can review the XAML that defines these windows in the client project included with the sample PhotoData streaming data service):
Create the WPF project.
Use the Add Service Reference dialog in Visual Studio to add a reference to the PhotoData service that we implemented in the previous post.
The PhotoWindow displays the FileName property of the PhotoInfo objects materialized from the data feed in the photoComboBox:
When one of the PhotoInfo objects is selected, by file name, from the photoComboBox, the related image MR is requested from the data service and displayed as an image in the page.
The PhotoDetailsWindow displays the properties of the selected PhotoInfo object:
This window is displayed when you click Add Photo or Photo Details in the PhotoWindow.
Now let’s see how the MLE and MR data from the data service is propagated into these UI elements.
Querying the Data Service and Displaying the Streamed Data
The following steps are required to query the PhotoData service for the data feed and get images for a specific PhotoInfo object.
Declare the DataServiceContext used to access the data service and the DataServiceCollection used for data binding:
private PhotoDataContainer context;
private DataServiceCollection<PhotoInfo> trackedPhotos;
private PhotoInfo currentPhoto;// Get the service URI from the settings file.
private Uri svcUri =
new Uri(Properties.Settings.Default.svcUri);Note that the data service URI is stored in the app.config file.
When the PhotoWindow is loaded, execute the query that loads the binding collection with objects from the PhotoInfo feed returned by the data service:
// Define a query that returns a feed with all PhotoInfo objects.
var query = context.PhotoInfo;// Create a new collection for binding based on the executed query.
trackedPhotos = new DataServiceCollection<PhotoInfo>(query);// Load all pages of the response into the binding collection.
while (trackedPhotos.Continuation != null)
{
trackedPhotos.Load(
context.Execute<PhotoInfo>(trackedPhotos.Continuation.NextLinkUri));
}When the user selects a file name from the photoComboBox, call the GetReadStreamUri method to request the MR from the data service, as follows:
// Use the ReadStreamUri of the Media Resource for selected PhotoInfo object
// as the URI source of a new bitmap image.
photoImage.Source = new BitmapImage(context.GetReadStreamUri(currentPhoto));The returned URI is used to create the image on the client that is displayed in the UI.
Note: The URI of the MR works very well for creating an image on the client. However, when you need the MR returned as a binary stream instead of just the URI, you must instead use the GetReadStream method. This method returns a DataServiceStreamResponse object that contains the binary stream of MR data, accessible from the Stream property.
Uploading a New Image to the Data Service
The following steps are required to create a new PhotoInfo entity and binary image file in the data service.
When adding a new photo, we must create a new MLE object on the client. We do this by calling DataServiceCollection.Add in the PhotoWindow code-behind page:
// Create a new PhotoInfo object.
PhotoInfo newPhotoEntity = new PhotoInfo();// Ceate an new PhotoDetailsWindow instance with the current
// context and the new photo entity.
PhotoDetailsWindow addPhotoWindow =
new PhotoDetailsWindow(newPhotoEntity, context);addPhotoWindow.Title = "Select a new photo to upload...";
// We need to have the new entity tracked to be able to
// call DataServiceContext.SetSaveStream.
trackedPhotos.Add(newPhotoEntity);// If we successfully created the new image, then display it.
if (addPhotoWindow.ShowDialog() == true)
{
// Set the index to the new photo.
photoComboBox.SelectedItem = newPhotoEntity;
}
else
{
// Remove the new entity since the add operation failed.
trackedPhotos.Remove(newPhotoEntity);
}This code instantiates and displays the PhotoDetailsWindow to sets properties of the new PhotoInfo object and the binary stream. When we are updating an existing PhotoInfo object, we just pass the existing PhotoInfo object. In this case, we pass a new PhotoInfo object, but we don’t need to call AddObject on the context because we are using a DataServiceCollection for data binding.
In the code-behind for the PhotoDetailsWindow, we use a FileStream to read an image from the local computer and pass this stream and the PhotoInfo object to the SetSaveStream method:
// Create a dialog to select the image file to stream to the data service.
Microsoft.Win32.OpenFileDialog openImage = new Microsoft.Win32.OpenFileDialog();
openImage.FileName = "image";
openImage.DefaultExt = ".*";
openImage.Filter = "Images File|*.jpg;*.png;*.gif;*.bmp";
openImage.Title = "Select the image file to upload...";
openImage.Multiselect = false;
openImage.CheckFileExists = true;// Reset the image stream.
imageStream = null;try
{
if (openImage.ShowDialog(this) == true)
{
if (photoEntity.PhotoId == 0)
{
// Set the image name from the selected file.
photoEntity.FileName = openImage.SafeFileName;photoEntity.DateAdded = DateTime.Today;
// Set the content type and the file name for the slug header.
photoEntity.ContentType =
GetContentTypeFromFileName(photoEntity.FileName);
}photoEntity.DateModified = DateTime.Today;
// Use a FileStream to open the existing image file.
imageStream = new FileStream(openImage.FileName, FileMode.Open);photoEntity.FileSize = (int)imageStream.Length;
// Create a new image using the memory stream.
BitmapImage imageFromStream = new BitmapImage();
imageFromStream.BeginInit();
imageFromStream.StreamSource = imageStream;
imageFromStream.CacheOption = BitmapCacheOption.OnLoad;
imageFromStream.EndInit();// Set the height and width of the image.
photoEntity.Dimensions.Height = (short?)imageFromStream.PixelHeight;
photoEntity.Dimensions.Width = (short?)imageFromStream.PixelWidth;// Reset to the beginning of the stream before we pass it to the service.
imageStream.Position = 0;// Set the file stream as the source of binary stream
// to send to the data service. The Slug header is the file name and
// the content type is determined from the file extension.
// A value of 'true' means that the stream is closed by the client when
// the upload is complete.
context.SetSaveStream(photoEntity, imageStream, true,
photoEntity.ContentType, photoEntity.FileName);return true;
}
else
{
MessageBox.Show("The selected file could not be opened.");
return false;
}
}
catch (IOException ex)
{
MessageBox.Show(
string.Format("The selected image file could not be opened. {0}",
ex.Message), "Operation Failed");
return false;
}Note that we use the image stream to create a new BitmapImage, which is only used to automatically set the height and width properties of the image.
When the savePhotoDetails button in the PhotoDetailsWindow is clicked, we call SaveChanges to send the MR as a binary stream (and any PhotoInfo object updates) to the data service:
// Send the update (POST or MERGE) request to the data service and
// capture the added or updated entity in the response.
ChangeOperationResponse response =
context.SaveChanges().FirstOrDefault() as ChangeOperationResponse;When SaveChanges is called to create a new photo, the client sends a POST request to create the MR in the data service using the supplied stream. After it processes the stream, the data service creates an empty MLE. The client then sends a subsequent MERGE request to update this new PhotoInfo entity with data from the client.
When uploading a new photo (POST), we also need need to execute a query to get the new media link entry by using a MergeOption.OverwriteChanges to update the client object instance to to get all of the data from the newly created MLE from the data service, as follows.
// When we issue a POST request, the photo ID and edit-media link are not updated
// on the client (a bug), so we need to get the server values.
if (photoEntity.PhotoId == 0)
{
if (response != null)
{
entity = response.Descriptor as EntityDescriptor;
}// Verify that the entity was created correctly.
if (entity != null && entity.EditLink != null)
{
// Cache the current merge option (we reset to the cached
// value in the finally block).
cachedMergeOption = context.MergeOption;// Set the merge option so that server changes win.
context.MergeOption = MergeOption.OverwriteChanges;// Get the updated entity from the service.
// Note: we need Count() just to execute the query.
context.Execute<PhotoInfo>(entity.EditLink).Count();
}
}We have to do this because of a limitation in the WCF Data Services client POST behavior where it does not update the object on the client with the server-generated values or the edit-media link URI.



Glenn is a Senior Programming Writer for WCF Data Services.
The first part of the series is Data Services Streaming Provider Series: Implementing a Streaming Provider (Part 1) of 8/5/2010.
Thomas Conté explained WCF Data Services: customizing your OData feeds and making them GeoRSS compliant in this 9/7/2010 post:
Version 4.0 of the .NET Framework brings a good deal of new features to the WCF Data Services module (ex-Astoria, ex-ADO.NET Data Services), including OData protocol version 2 support; you will find on MSDN a summary page of these new features.
The main idea with this feature is to allow you to personalize the Atom/AtomPub feed that is otherwise automatically generated, so that you can specify for instance how the standard Atom elements should be filled, and even add completely custom elements to the feed.
I see two main usages for this feature:
- Make the default standard Atom feed more relevant by specifying values for the default fields that are not filled by default; for example, elements like Title or Summary are empty by default, like AuthorName or AuthorEmail, etc. Giving values to these fields will make the feed much easier to consume for application that only understand vanilla Atom feeds and/or ignore the OData extensions, where one can find all the exposed properties.
- Enrich the Atom feed by following well-known extensions, like for example the GeoRSS standard that allows you to add geolocation information to an Atom or RSS feed.
To illustrate the first point, let’s consider a vanilla OData feed that represents, in my example, Vélib’ rental stations in Paris (Vélib’ is a public bicycle rental program in Paris). Entries in this feed show the station’s name and address, as well as its location by way of longitude / latitude properties. Here is one such entry:
<entry>
<id>http://localhost:10420/Stations.svc/StationsVelib(16122)</id>
<title type="text"></title>
<updated>2010-08-12T15:18:43Z</updated>
<author>
<name />
</author>
<link rel="edit" title="StationsVelib" href="StationsVelib(16122)" />
<category term="ODataModel.StationsVelib" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<content type="application/xml">
<m:properties>
<d:id m:type="Edm.Int32">16122</d:id>
<d:arrd>16</d:arrd>
<d:nom_arrd>16ème arrondissement</d:nom_arrd>
<d:nom>station_16122</d:nom>
<d:description xml:space="preserve">...</d:description>
<d:adresse>Route de la muette a neuilly - 75016 paris</d:adresse>
<d:lat m:type="Edm.Double">2.2585</d:lat>
<d:long m:type="Edm.Double">48.8798</d:long>
</m:properties>
</content>
</entry>This XML snippet is perfectly usable as is, but what happens if we try to use it in an application that only understands the standard Atom format? Let’s try for example with Internet Explorer 8; when browsing the full feed, we will see something like this:
Not really useful! We have tons of information in the OData feed that we could display at this stage, like the name of the rental station or its description. This data is of course present in the OData properties, but IE8 doesn’t know about that. Once we have personalized our feed, we will see something like this:
Better, don’t you think? Furthermore, if we look at the generated XML feed, we can see another change:
<entry></HTML
<id>http://localhost:10420/Stations.svc/StationsVelib(16122)</id>
<title type="text">station_16122</title>
<summary type="html">Route de la muette a neuilly - 75016 paris</summary>
<updated>2010-08-12T15:22:39Z</updated>
<author>
<name />
</author>
<link rel="edit" title="StationsVelib" href="StationsVelib(16122)" />
<category term="ODataModel.StationsVelib" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<content type="application/xml">
<m:properties>
<d:id m:type="Edm.Int32">16122</d:id>
<d:arrd>16</d:arrd>
<d:nom_arrd>16ème arrondissement</d:nom_arrd>
<d:nom>station_16122</d:nom>
<d:description xml:space="preserve">...</d:description>
<d:adresse>Route de la muette a neuilly - 75016 paris</d:adresse>
<d:lat m:type="Edm.Double">2.2585</d:lat>
<d:long m:type="Edm.Double">48.8798</d:long>
</m:properties>
</content>
<geo:lat xmlns:geo="http://www.georss.org/georss">2.2585</geo:lat>
<geo:long xmlns:geo="http://www.georss.org/georss">48.8798</geo:long>
</entry>In addition to the fact that th standard Atom elements are now correctly filled in, we can see that the geographic location of the rental station is now exposed in the form of geo:lat and geo:long elements, with the entry element itself, which makes our feed compliant with GeoRSS. We can now directly consume this feed in mapping applications that understand GeoRSS, like, for example, Bing Maps:
So… How did we DO this?
In summary, the idea is to modify the EDMX (Entity Data Model) file, that is generated by Visual Studio when you add an ADO.NET Entity Data Model to your project, in order to add in the CSDL part (Conceptual Schema Definition) some additional attributes that will allow us to tell WCF Data Services what it should do. These additional attributes are not part of the standard CSDL format and are thus not directly supported by Visual Studio’s tooling; we must hence edit the EDMX file by hand.
In order to do this, you will open your EDMX file with the XML editor (by right-clicking on the file). You can collapse the edmx:StorageModels section, and we will focus on our EntityType element, when the modifications are to be made.
Here is my original EntityType:
<EntityType Name="StationsVelib">
<Key>
<PropertyRef Name="id" />
</Key>
<Property Name="id" Type="Int32" Nullable="false" />
<Property Name="arrd" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="nom_arrd" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="nom" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="description" Type="String" MaxLength="Max" Unicode="true" FixedLength="false" />
<Property Name="adresse" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="lat" Type="Double" />
<Property Name="long" Type="Double" />
</EntityType>The extensions offered by WCF Data Services will materialize as additional attributes that we will add to the Property elements that we want to change. Here are the attributes I am going to use in this example:
FC_TargetPath
The element where we want the property to appear in the generated feed. We can specify the path of any element, or we can use predefined identifiers for standard Atom fields like SyndicationTitle, SyndicationSummary, etc.FC_ContentKind
The content type, i.e. plain text or HTMLFC_NsPrefix
For a non-Atom element, the prefix to useFC_NsUri
Again for a non-Atom element, the URI of the namespacesFC_KeepInContent
Should the original property be kept in the feed?Again, these attributes are extensively documented in MSDN.
In order to use these extensions, we must first reference the new schema in our EDMX file:
<edmx:Edmx Version="2.0" xmlns:edmx="http://schemas.microsoft.com/ado/2008/10/edmx" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata">Then we can make our changes. Here is my modified EntityType:
<EntityType Name="StationsVelib">
<Key>
<PropertyRef Name="id" />
</Key>
<Property Name="id" Type="Int32" Nullable="false" />
<Property Name="arrd" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="nom_arrd" Type="String" MaxLength="255" Unicode="true" FixedLength="false" />
<Property Name="nom" Type="String" MaxLength="255" Unicode="true" FixedLength="false"
m:FC_TargetPath="SyndicationTitle"
m:FC_ContentKind="text"
m:FC_EpmKeepInContent="true" />
<Property Name="description" Type="String" MaxLength="Max" Unicode="true" FixedLength="false" />
<Property Name="adresse" Type="String" MaxLength="255" Unicode="true" FixedLength="false"
m:FC_TargetPath="SyndicationSummary"
m:FC_ContentKind="html"
m:FC_EpmKeepInContent="true" />
<Property Name="lat" Type="Double"
m:FC_TargetPath="lat"
m:FC_NsUri="http://www.georss.org/georss"
m:FC_NsPrefix="geo" m:FC_KeepContent="true" />
<Property Name="long" Type="Double"
m:FC_TargetPath="long"
m:FC_NsUri="http://www.georss.org/georss"
m:FC_NsPrefix="geo" m:FC_KeepContent="true" />
</EntityType>You can see I have added attributes to the properties I wanted to exposed in a different way. In my case, I have mapped the station name to the Atom SyndicationTitle, the address to the Atom SyndicationSummary, and I have mapped the lat and long fields to brand new elements following the GeoRSS specification.
I hope this example was useful to show you how you can easily customize your WCF Data Services OData feeds in order to make them easier to read and consume, and to expose your geolocation data as standard GeoRSS feeds.



<Return to section navigation list>
AppFabric: Access Control and Service Bus
Vittorio Bertocci (@vibronet) continues pimping his new Programming Windows Identity Foundation book in an In Stock! Also, First Review post of 9/7/2010:
Inching closer & closer… Amazon and OReilly now have Programming WIF in stock, although Amazon didn’t ship the copy I pre-ordered yet.
Also, first review! Thank you Israel for your kind words :-)


I ordered my copy from Amazon on 8/31/2010. Hasn’t arrived yet.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Eric Nelson reminds Azure developers about this Handy tool which checks if you have left Windows Azure applications running and simplifies “killing” them in a 9/8/2010 post:
This is a great tool for anyone playing with Windows Azure who would like to avoid surprises on their credit card :-) It has only had 85 downloads – I suspect we see that many folks caught out by a demo/poc being “left on” per week :)
Check it out at http://greybox.codeplex.com/
Project Description
The GreyBox application is designed to alert a user if their Windows Azure compute services are currently running, or are even simply deployed. Great for Azure speakers and POCs you don't want left running.
With the popularity of Windows Azure growing more Microsoft and third party speakers are talking about Azure to your communities, classes and clients. These speakers are often utilizing their own MSDN or partner benefits for Microsoft Azure services. Unexpected costs can arise if Azure compute services are accidentally left running in the cloud after a presentation or class.
The GreyBox application is designed to alert a user if their Windows Azure compute services are currently running, or are even simply deployed. The names GreyBox comes from the concept of wanting to have the compute service slots empty, which the Azure Portal represents as a graphical grey box.
Thomas Erl continues his series with “Hello World in Windows Azure” in Cloud Computing, SOA and Windows Azure - Part 4 of 9/8/2010:
The following section demonstrates the creation of a simple "Hello World" service in a Windows Azure hosted application.
Note: If you are carrying out the upcoming steps with Visual Studio 2008, you will need to be in an elevated mode (such as Administrator). A convenient way of determining whether the mode setting is correct is to press the F5 key in order to enter debug mode. If you receive an error stating "the development fabric must be run elevated," then you will need to restart Visual Studio as an administrator.
Also, ensure the following on your SQL Express setup:
- SQL Server Express Edition 2008 must be running under the ‘.\SQLEXPRESS' instance
- Your Windows account must have a login in .\SQLEXPRESS
- Your login account is a member of the sysadmin role
If SQL Express isn't configured properly, you will get a permissions error.
1. Create a Cloud Service Project
Figure 5: The New Project window
2. Choose an ASP.NET Web Role
After you click OK on the New Project window, the New Cloud Service Project wizard will start. You will then see a window (see Figure 6) that will allow you to choose the type of role that you would like as part of your service deployment.
Figure 6: The New Cloud Service Project Window
Mainstream SOA design patterns and service-orientation principles can be applied to Windows Azure-hosted services very similarly to how they are applied to internal enterprise-hosted services. Furthermore, Windows Azure-hosted services support different service implementation mediums (such as Web services and REST services) and allow for the same service to be accessed via multiple protocols. This supports the creative application of specialized patterns, such as Concurrent Contracts [726] and Dual Protocols [739].
For the Hello World project, you will only need the ASP.NET Web Role type. Once you select this role, you can choose the role name.
3. Create the Solution
After clicking OK, the wizard will generate the solution, which you can then view using the Solution Explorer window (see Figure 7).
Figure 7: The HelloWorld solution structure displayed in the Solution Explorer window
4. Instantiate the Service
Now you can open the Default.aspx file using the Solution Explorer window, put "Hello, Cloud!" in the Body element and press F5 to run. You should see something like what is shown in Figure 8.
Figure 8: The HelloWorld service in action
This example was executed locally on IIS. If we were to deploy this service into the Windows Azure cloud, it would still be running in IIS because it is hosted in a Web role.
Summary of Key Points
- The development environment for Windows Azure is fully integrated into Visual Studio, which provides a simulated runtime for Windows Azure for local desktop-based development and unit testing.
- Creating and deploying cloud-based services with Windows Azure is simplified using available wizards and development UIs.




First time I’ve seen monochrome screen captures in ages!
Return to section navigation list>
VisualStudio LightSwitch
Garth F. Henderson started a new Silverlight and LightSwitch – Considerations for Beta 2 thread on 9/8/2010 in the Visual Studio LightSwitch - General (Beta1) forum:
A few months ago we witnessed historical phenomenon as Silverlight, RIA, T4, MEF, dynamic languages, WF4, and a general evolution the .NET stack for 2010 all fell into place as a result of massive collaboration. LightSwitch continues to carry the torch forward.
Jay Schemeizer (MS Group Program Manager responsible for LightSwitch) let us know that LightSwitch was a secret project that has been in the making for a couple of years now. LightSwitch started as a WPF product and switched to Silverlight due to the strengths of SL4 and the supporting 2010 stack. Reference Link: http://channel9.msdn.com/posts/egibson/MSDN-Radio-Visual-Studio-LightSwitch-with-John-Stallo-and-Jay-Schmelzer/
The amazing architecture of LightSwitch has been succinctly explained by John Rivard and Steve Anonsen: http://channel9.msdn.com/posts/egibson/MSDN-Radio-Visual-Studio-LightSwitch-with-John-Stallo-and-Jay-Schmelzer/
The architecture overview includes requirements and goals that have the broadest reach for both LOB and its big brother, ERP. As conveyed by the architects, LightSwitch has tackled some of the most difficult requirements of web based ERP.
Even in its infancy, LightSwitch is a leading Silverlight application as well as tribute to the extensibility of the new Visual Studio 2010 written in WPF. The runtime screen designer begins to show the true power of SL.
It seems appropriate to write up and continue to build the LightSwitch architecture so that it is a supporting toolkit for RAD Silverlight ERP development.
Logically, LightSwitch should be to ERP what Blend is to XAML. Non-programmers and programmers can both use Blend together. LightSwitch should be considered in the same light. LightSwitch should be able to generate XAML which can be used in Blend for UserControls within screens. Karl Shifflett’s PowerToys was an early innovation toward this goal.
Let’s take a deep look into using the architecture of LightSwitch classes directly with SilverLight. LightSwitch is one of the strongest implementations of MEF today. Let’s work together with the SilverLight developer community to rapidly accelerate the completion of BOTH LightSwitch and required Silverlight RAD tools for ERP.
SilverLight ERP developers require preset screen layouts with flexible themes. We need a series of base ModelView classes that wire together CRUD transactions with built in Lazy object management. LightSwitch has already accomplished these goals.
Business application developers finally have a true OO web based platform with SL4 and the 2010 stack. We need a standard plug-and-play modular environment for application packages so that separate companies may develop General Ledger, Inventory, Accounts Payable, Sales Order, Human Resource, etc. modules that them seamlessly integrate together within commercially hosted sites. Like all ERP solutions, it is a requirement to have a databased menu security system that is managed by users in an administrative group.
The menu security would tie into a billing system that would process micro charges back to each of the modular vendors based on monthly user usage. Silverlight ERP software usage is similar to cell phone usage and the same business model is applicable.
It is logical to incorporate DataTemplate and ItemsControl.ItemTemplate with XAML technology that is driven by data values and workflow values. DataTemplate variations of screen sections would all share the same ModelView code. Access to the multiple DataTemplate layouts would be determined by the menu security system and Workflow 4 rules.
Everyone realizes that Silverlight business apps must have the ability to support the Workflow Designer and runtime WF process diagrams so that users can interactively drill through their work queue management. Workflow should be incorporated into LightSwitch, as well as, all Silverlight business applications. Of course, document management (SharePoint) goes hand-in-hand with workflow. LightSwitch has already established a strong integration with SharePoint. It seems reasonable to build a LightSwitch/Silverlight namespace that supports the SharePoint Client Object within screens.
From a developers’ perspective, we should consider LightSwitch as an ERP Toolkit that has no limitations. From a non-programmer perspective, we should offer a simple friendly pared down VS experience that allows them to do as much as they can for themselves prior to requiring a programmer’s skill set.
M-V-MV technology with Silverlight provides development companies and investors stability and longevity for their software product assets. The advanced LightSwitch architecture that currently manages ModelView business logic should be developed as namespaces that are assessable to all Silverlight development.
Business application developers need to have a commercially supported open ERP technology that is both affordable and scalable for our clients. Our work efforts should be to engineer long term profitability with a continuous improvement program for our clients that brings together workflow, technology, and accounting. We have all the tools with need with Silverlight, .NET, SharePoint, and WP7 to build profitable development businesses through “eyes open” collaborative business models.
Thoughts?
Garth works at Vanguard Business Technology in the real estate industry.
Making LightSwitch into an ERP toolkit seems a bit of a stretch to me.
Mihail Mateev described Creating a Visual Studio LightSwitch Custom Silverlight Control (Using Infragistics Components) on 9/4/2010 (missed when posted):
Using Visual Studio LightSwitch, you have a possibility in the use of Custom Silverlight Controls. With a Custom Silverlight Control, you can implement functionality that is outside the normal abilities of LightSwitch.
The first question if some company has an interest in Visual Studio LightSwitch applications is how to now be re-written as a regular Silverlight application because it “can’t perform the new requirements”.
To extent a Visual Studio LightSwitch application you may find that in most cases, you just need to create Silverlight Custom Controls, and plug them into LightSwitch.
Note: You need Visual Studio Professional (or higher) to create Custom Silverlight Controls.
This article demonstrates how to use a ready to use Silverlight Custom Control in Visual Studio LightSwitch.
The LightSwitch Sample Project
Requirements:
Software:
• Visual Studio 2010
• Visual Studio LightSwitch Beta 1: details.aspx-FamilyID=37551a54-bfd3-4af6-a513-676bbb2dfb69&displaylang=en
• Infragistics XamMap component: NetAdvantage for Silverlight Data Visualization 2010 vol.2
http://www.infragistics.com/dotnet/netadvantage/silverlight/data-visualization.aspx#DownloadsSample data:
- Free shapefiles for this demo could be downloaded from http://www.cdc.gov/epiinfo/shape.htm
Demo application is based on an application, used for the article:"Introduction to Visual Studio LightSwitch”
Steps to cerate a sample application:
- Get a sample from article: "Introduction to Visual Studio LightSwitch”
- In the LightSwitch application add in IGCustomers table a field, named Country.
- Add a new project from type Silverlight Class Library named XamMapLibrary
- Add a new item (Silverlight User Control) to the project, named XamMapControl
- Implement additional logic in the XamMapControl to highlight a country by name.
- Add a new Silverlight User Control to the project, named LightSwitchMap. This control will contain
code for binding to specific properties from the screen DataContext.- Run the application
Get a sample from article: "Introduction to Visual Studio LightSwitch”
In the LightSwitch application add in IGCustomers table a field, named Country.
Add a new project from type Silverlight Class Library named XamMapLibrary
Add references, required for Infragistics XamMap (if XamMap component is added from code (C# or XAML),
otherwise references will be added automatically if drag a XamMap control in a layout from toolbox.
Add a new item (Silverlight User Control) to the project, named XamMapControl
Copy a code from a sample application for the article "Customizing the XamMap MapNavigationPane Control Template"




Several hundred lines of source code excised for brevity. A link to download the sample code is at the end of this post.
Add a new Silverlight User Control to the project, named LightSwitchMap.
This control will contain code for binding to specific properties from the screen DataContext.

Edit a LightSwitchMap.xaml file:
A few lines of XAML removed for brevity.
Edit the screen IGCustomersListDetail.
From menu select: Add Layout Item –> Custom Control.
Add a reference to XamMapLibrary. From XamMapLibrary
select LightSwitchMap control.Custom control with a name ScreenContent is added in the IGCustomersListDetail screen.
Leave all properties with a default values.Open the default startup folder %Projects Folder%\InfraOrdersCustom\InfraOrders\Bin\Debug\Web
and add there a folder ShapeFiles with files, used as a data source
from XamMap controlRun the application
Select from the navigation pane: Customers Detail List
Detail list for the customers contains a map with a country of the customer in the detail part of the screen.
Select a different customer.
In the detail part is displayed the country of the selected customer.
Conclusion:
Visual Studio LightSwitch custom Silverlight controls proposes a quick way to
extend LightSwitch application. It is very easy to use existing Silverlight controls in the LightSwitch custom controls.Source code of the demo application you could download here: InfraOrdersCustom.zip







<Return to section navigation list>
Windows Azure Infrastructure
Nicole Hemsoth explained Why Mission Critical Applications Are Staying Put in this 9/8/2010 post to the HPC in the Cloud blog:
Perhaps a better title would be, “yet another reason why mission critical applications are staying put” since this is so frequently a topic of discussion. However, to break from the string of latency, performance and development challenges for a moment, we are left with the more nebulous issue of IT culture; namely, the clearly defined tensions between virtualization advocates and the stalwart owners of core, revenue-critical applications.
Application performance management firm AppDynamics released a survey that revealed “a significant divide in the pace of adoption of virtualization for non-critical systems versus mission-critical systems.” More specifically, the survey results suggest that only 14% of the approximately 3500 large-scale enterprise leaders surveyed virtualized any of their essential operations, in part due to worries about application performance degradation but also in part due to some larger cultural issues that are the core of such decisions—a point that we’ll explore in greater depth momentarily.
The survey asked another layer of questions to that slim 14% of enterprise IT leaders who stated they had already virtualized mission critical applications by inquiring about the nature of those applications. For nearly all of the respondents in this small minority, the mission-critical applications that were actually virtualized were overwhelmingly employee-facing versus customer-facing, which still indicates at least some degree of trepidation about the reliability of virtualizing anything that led to profitability. As Roop stated, “if there is a performance degradation that comes with employee-facing applications, the company is willing to bear it and figure the employees can do so the same, especially if there are clear cost savings associated with virtualization.”
Without a doubt, virtualization, while heralded as the best technological development for cost savings since barcodes on coupons, does strike fear into the hearts of many IT stakeholders. The virtualization administrators need to deliver on these cost promises, the application owners need to be able to feel that they will be able to deliver the same level of performance and uptime as usual—if not better, and the rest of the organization needs to be able to keep pace with the change. However, this change is clearly very slow in coming—but is it all based on security, multitenancy, and the host of other dirty words in the cloud ecosystem or is it really just about culture and a lack of communication?
The Cultural Factor in Virtualizing the Mission Critical
It is difficult to find extensive case studies of large-scale enterprises that have virtualized any significant part of their mission-critical operations, in part simply because if they have they might not be particularly excited to share these details with their competitors, but in larger part, because there are several barriers preventing any wholesale move to a virtualized infrastructure, not the least of which is general IT culture itself and the performance standards it sets within its firmly entrenched camps.
For every virtualization administrator there’s an application owner that must be convinced that his or her application would thrive (or even function) off the physical hardware. And since the two parties have little in common outside of the fact that they might be working for the same CEO, there’s naturally a bit of tension present, due in part to a lack of communication about what is at stake for both parties and how they might share tools and measurement standards to thoroughly evaluate the possibility of application virtualization.
According to Steve Roop of AppDynamics who spoke with us following the release of the survey, this struggle in IT departments is based far more on tools, measurements and accountability rather than a fundamental divide. Since a virtualization admin’s superiors rate their underlings on the level of virtualization achieved and an application owner’s superiors look for constant uptime and SLA adherence to high performing core applications, it’s no wonder why these two camps have become impenetrable silos—both retain (and perhaps guard) their specialized knowledge and have no understanding of the measurements and standards by which the other functions.
On the surface, all that might be at issue here is a simple lack of communication on both sides, but if that issue has already been recognized and there’s still no progress, Roop suggest that perhaps a more fine-tuned approach is necessary to help the virtualization advocates convince the application owners that they are onto something useful (and even beneficial) that fits with their requirements while conversely, the application owners open their silos to help virtualization administrators understand what their unique concerns are.
Consider the following statement from the survey: “52 percent of companies noted that application owners have blocked the project to virtualize a Tier 1 application. At the same time, 49 percent worry that the applications aren’t designed to support virtualization and 45 percent cited concerns about performance degradation once virtualized. “ While these sound like respectable technical reasons for concern on the part of the application owners who have very stringent demands for performance and uptime (among a host of other deliverables to constantly contend with) Steve Roop suggests that this is all still rooted in culture—in an unwillingness to open the silos and explore new ideas.
Read more: Page 1 of 2, 1 | 2, All »
Windows Azure Compute, North Central US reported a Yellow RSS 2.0 provisioning alert in Windows Azure networking issue in North Central US of 9/8/2010:
- Sep 7 2010 10:57PM The team is still actively working on repairing the networking issue.
- Sep 8 2010 2:20AM The team is still actively working on repairing the networking issue and the necessary steps have been taken to prevent it from happening to any new deployments in this region.
This is the type of report I suggested the SQL Azure team institute for SQL Azure provisioning problems in my SQL Azure Portal Database Provisioning Outage on 9/7/2010 post updated 9/8/2010.
Joe Panettieri asked Can Microsoft Properly Host Its Own Cloud Applications? in a 9/7/2010 post to the MSPMentors blog:
Consider the following scenario: You’re a managed services provider. Instead of investing big bucks to build your own hosted applications, you entrust your end-customers to Microsoft’s cloud — including Exchange Online and SharePoint Online. But in the past few weeks, that Microsoft cloud — called BPOS (Business Productivity Online Suite) — has gone dark at least three times. The big question: Will end-customers remain patient amid Microsoft’s SaaS growing pains? Or is there something fundamentally wrong with Microsoft’s hosting strategy?
Please note: Generally speaking I’m optimistic about Microsoft’s cloud strategy. I think Windows Azure holds a lot of promise. And despite potentially thin margins for partners, I see why end-customers potentially value hosted versions of Exchange and SharePoint.
Software Development vs. Application Hosting
But here’s the challenge: Some skeptics say Microsoft is a software development company rather than a hosting company. And yes: There’s a big difference between…
- (A) writing code for a living; and
- (B) building massive, mission-critical data centers that host applications for customers.
Given Microsoft’s most recent BPOS bumps, I’m starting to wonder: Should Microsoft pull the plug on BPOS, leaving the hosted Exchange market to big service providers and hosting provider specialists? Such a move would mitigate some of the cloud channel conflict that Microsoft currently faces with partners.
Microsoft could, after all, emulate Oracle’s cloud strategy. Oracle CEO Larry Ellison has avoided the temptation to build an Oracle cloud. Instead, Oracle has introduced service provider pricing to hosting partners, under the direction of Kevin O’Brien, senior director of ISV and SaaS strategy for Oracle. Take a close look at the top 20 or so cloud software companies, and the vast majority (if not all of them) run Oracle software behind the curtains.
Can’t Quit Yet
Ultimately, I think Microsoft will get BPOS right. And I think Windows Azure will provide even better opportunities for partners and ISVs. But I wonder: How many SaaS and cloud outages can Microsoft experience before a few customers and partners start heading for the exits?
Mitch Denny posted Windows Azure & BPOS: New challenges, and opportunities for systems integrators to his NotGartner blog on 9/7/2010:
Last week I attended some of the Australian Partner Conference where we were lucky enough to win the Microsoft Partner Network MAPA award for Software Application Partner of the Year for the work that we did on the Grays Online web-site. There was quite a bit of buzz on Twitter about it.
Readify as usual tends to get involved pretty early with these technologies and we’ve worked behind the scenes on what is probably the largest single SQL Azure deal in the world and we are starting to approach customers about building Windows Phone 7 applications, particularly in the financial services market.
We’ve also got our first internal line of business application running on Windows Azure (Compute & Storage Services) which authenticates via WIF/ADFS to an Active Directory instance that we have running in a Texas data centre, pulling data from our CRM instance in another data centre in Melbourne, and the application itself is hosted in the Singapore availability region for Windows Azure. We’ve also moved our e-mail hosting to Microsoft Online (BPOS) so I think it is safe to say we’ve embraced the cloud.
But it was at the APC that I made an interesting observation that systems integrators are going to have to start talking to software solution development organisations like Readify to strike up partnering arrangements. The traditional profit domain of the systems integrator (hardware, licensing and associated services) are not going away, but it will be getting squeezed and they are going to need partners to provide value add services.
By the same token software solution partners are going to be enabled to provide more complete solutions because they can purchase off the shelf hosting services such as BPOS & Windows Azure to get the job done without the need for a major IT staff, or even needing to consider things such as storage and compute redundancy.
Its a brave new world that we are entering and I’m excited about the possibilities.
Mitch is Chief Technology Officer at Readify.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA)
David Linthicum claimed “The real reason HP and IBM are pushing for private cloud computing: To protect their market share” as a deck for his The selfish agendas behind private clouds in this 9/8/2010 post to InfoWorld’s Cloud Computing blog:
The VMworld hangover has hit, and I found InfoWorld's own Matt Prigge offered the best coverage of VMworld when he pointed out that the theme this year: Run -- don't walk -- to the private cloud. Even InfoWorld editor in chief Eric Knorr, who's been critical of the concept in the past, has a new respect for private clouds, as he states in his blog: "Without question, the private cloud comes with a large dose of hogwash. Nonetheless, the model of providing commodity services on top of pooled, well-managed virtual resources has legs, because it has the potential to take a big chunk of cost and menial labor out of the IT equation."
If you've been following this blog, you know I'm an avid proponent of private clouds in a company's architecture. Private clouds should always be considered if the goal is to reinvent existing IT infrastructure for better efficiency and security. That said, we need to stay grounded regarding the true value of private cloud computing, especially in light of emerging cloud enabling technology, some of which is real, some of which is just cloud washing.
Thus, you need to understand why the larger hardware and software names, including HP and IBM, are encouraging the move to private cloud computing. They sense a sea change coming in which public cloud computing providers are becoming realistic alternatives to internal IT. As a result, their goals is to cement their hold on data centers for as long as possible.
Take, for instance, HP CloudStart, a "private cloud in a box," as HP calls it. While indeed providing a quick and private alternative to the public cloud, HP CloudStart also allows HP to sell yet another bundle of hardware and software to enterprises considering a move to the cloud. In the process, HP protects its market share.
Microsoft’s WAPA is conspicuous by its absence in David’s analysis.
Lori MacVittie (@lmacvittie) asserted The underlying premise of delivering information technology “as a service” is that the services exist to be delivered in the first place as a preface to her You Can’t Have IT as a Service Until IT Has Infrastructure as a Service post of 9/7/2010 to F5’s DevCentral blog:
Oh, it’s on now. IT has been served with a declaration of intent and that is to eliminate IT and its associated bottlenecks that are apparently at the heart of a long application deployment lifecycle. Ignoring reality, the concept of IT as a Service in many ways is well-suited to solving both issues (real and perceived) on the business and the IT sides of the house. By making the acquisition and deployment of server infrastructure a self-service process, IT abrogates responsibility for deploying applications. It means if a project is late, business stakeholders can no longer point to the easy scapegoat of IT and must accept accountability.
Or does it?
WHAT does “IT as a SERVICE” MEAN ANYWAY?
We can’t really answer that question until we understand what all this “IT as a Service” hype is about, can we?
The way tech journalists report on “IT as a Service” and its underlying business drivers you’d think the concept is essentially centered on the elimination of IT in general. That’s not the case, not really. On the surface it appears to be, but appearances are only skin deep. What businesses want is a faster provisioning cycle across IT: access, server infrastructure, applications, data. They want “push-button IT”, they want IT as a vending machine with a cornucopia of services available for their use with as little human interaction as possible.
What that all boils down is this: the business stakeholders want efficiency of process.
Eric Knorr of InfoWorld summed it well when he recently wrote in “What the ‘private cloud’ really means”:
Nonetheless, the model of providing commodity services on top of pooled, well-managed virtual resources has legs, because it has the potential to take a big chunk of cost and menial labor out of the IT equation. The lights in the data center will never go out. The drive for greater efficiency, though, has had a dozen names in the history of IT, and the private cloud just happens to be the latest one.
In reality all we’re talking about with “IT as a Service” really is private cloud, but it appears that “IT as a Service” has a strong(er) set of legs upon which to stand primarily because purists and pundits prefer to distinguish between the two. So be it, what you call it is not nearly as important as what it does – or is intended to do.
Interestingly enough, VMware made a huge push for “IT as a Service” at VMworld last month and, in conjunction with that, released a number of product offerings to support the vision of “IT as a Service.” But while there was much brouhaha regarding the flexibility of a virtualized infrastructure there was very little to support the longer vision of “IT as a Service.” It was more “IT as a Bunch of Virtual Machines and Provisioning Services” than anything else. Now, that’s not to say that virtualization of infrastructure doesn’t enable “IT as a Service”; it does in the sense that it makes one piece of the overall concept possible: self-service provisioning. But it does not in any way, shape or form assist in the much larger and complex task of actually enabling the services that need to be provisioned. Even the integration across the application delivery network with the core server infrastructure provisioning services – so necessary to accomplish something like live cloudbursting on-demand – relies upon virtualization only for the server/application resources. The integration to instruct and integrate the application delivery network is accomplished via services, via an API, and whether the underlying form-factor is virtual or iron is completely irrelevant.
IT as a SERVICE REALLY MEANS a SERVICE-ORIENTED OPERATIONAL INFRASTRUCTURE
I’m going to go out on a limb and say that what we’re really doing here is applying the principles of SOA to IT and departmental function. Yeah, I said that. Again.
Take a close look at this diagram and tell me what you see. No, never mind, I’ll tell you what I see: a set of service across the entire IT infrastructure landscape that, when integrated together, form a holistic application deployment and delivery architecture. A service-oriented architecture. And what this whole “IT as a Service” thing is about is really offering up operational processes as a service to business folks. Just as SOA was meant to encapsulate business functions as services when it’s IT being pushed into the service-oriented mold you get operational functions as services: provisioning, metering, migration, scalability.
It’s Infrastructure as a Service, when you get down to it.
In order for IT to be a push-button, self-service, never-talk-to-the-geeks-in-the-basement again organization (which admittedly looks just as good from the other side as a never-talk-to-the-overly-demanding-business-folks again organization) IT not only has to enable provisioning of compute resources suitable for automated billing and management, but it also has to make available the rest of the infrastructure as services that can be (1) provisioned just as easily, (2) managed uniformly, and (3) integrated with some sort of human-readable/configurable policy creation tool that can translate business language, a la “make it faster”, into something that can actually be implemented in the infrastructure, a la “apply an application acceleration policy”. I’m simplifying, of course, but ultimately we really do want it that simply, don’t we? We’ll never get there if we don’t have the services available in the first place.
Sound familiar, SOA architects? Business analysts? It should. A complete application deployment consists of a set of dynamic services that can be provisioned in conjunction with application resources that provide for a unified “application” that is fast, reliable, and secure. A composite “application” that is essentially a mash-up comprised of infrastructure services that enforce application specific policies to meet the requirements of the business stakeholder.
It’s SOA. Pure and simple. And while rapid provisioning is made easier by virtualization of those components, it’s not a necessity. What’s necessary is that the components provide for and are managed through services. Remember, there’s no magical fairy dust that goes along with the hardware/software –> virtual network appliance transformation that suddenly springs forth a set of services like a freaking giant beanstalk out of a magic bean. The components must be enabled to both be and provide services and from those the components can be deployed, configured, integrated, and managed as a service.
WITHOUT the SERVICES IT IS IT as USUAL
If the only services available in this new “IT as a Service” paradigm are provisioning and metering and possibly migration, then IT as a Service does not actually exist. What happens then is the angst of the business regarding the lengthy acquisition cycles for compute resources simply becomes focused on the next phase of the deployment – the network, or the security, or the application delivery components. And as each set of components is servified and made available in the Burger King IT Infrastructure menu, the business will turn its baleful eye on the next set of components..and the next…and the next.
Until there exists an end-to-end set of services for deploying, managing, and migrating applications, “IT as a Service” will not truly exist and the role of IT will remain largely the same – manual configuration, integration, and management of a large and varied set of infrastructure components.


Guy Harrison posted Movements in the Private Cloud to Database Trends and Applications magazine on 9/7/2010:
The promises of public cloud computing - pay as you go, infinite scale and outsourced administration - are compelling. However, for most enterprises, security, geography and risk mitigation concerns make private cloud platforms more desirable. Enterprise customers like the idea of on-demand provisioning, but are often unwilling to take the performance, security and risk drawbacks of moving applications to remote hardware that is not under their direct control.
A private cloud goes beyond simply offering virtualized servers using VMware or another virtualization platform. It typically requires a framework that manages resource allocation, storage, security, multi-tenancy, chargeback, and other characteristics of the public cloud.
A number of vendors have created viable private cloud platforms. The platform offered by 3Tera - acquired by CA earlier this year - allows enterprises to create a grid environment in which complete application stacks can be rapidly configured and provisioned. The open source Eucalyptus platform provides a software stack that allows the user to create an Amazon-compatible cloud computing environment on local hardware.
The Azure appliance will be implemented by third-party hardware partners that currently include Dell, Fujitsu and HP, and eBay has announced it will at least trial the appliance.
The appeal of an Azure appliance for rapidly establishing a private Microsoft-centric cloud is clear. The built-in fabric management of Microsoft Azure should allow rapid provisioning and scaling of applications, as well as the possibility of migrating the applications to the public Azure cloud, or "cloud bursting," which adds resources from the public cloud during peak load periods.
While Azure offers some support for non-Microsoft technologies such as PHP and MySQL, applications that depend on these technologies are unlikely to be completely comfortable in the Azure appliance. These applications would prefer a non-Azure cloud appliance or private cloud platform. Such a platform would ideally be based on an open standard, so that applications written for the private cloud could run in a public equivalent or be portable across implementations.
Eucalyptus and similar frameworks have been proposed as the foundation for this open cloud platform, but the recently announced OpenStack alliance appears to offer the most immediately promising solution.
OpenStack is primarily produced by Rackspace, in collaboration with NASA, and combines elements of their internal infrastructure in a form that would allow sophisticated users to create their own private clouds. It also could be used by hardware vendors to create a private cloud appliance with capabilities similar to the Azure appliance. A variety of software and hardware vendors including Intel, Dell, Rightscale and Riptano have announced support for OpenStack, though, in many cases, the exact nature of their participation remains unclear.
Like Amazon AWS and other cloud platforms, OpenStack allows for elastic CPU and storage services, which can be combined to support a wide variety of application software stacks. However, unlike Azure, it does not require or encourage that applications be written in a specific language or framework, and OpenStack is clearly going to be very friendly to open source technologies. Rackspace contributes heavily to the Drizzle fork of MySQL, as well as the Cassandra NoSQL database. These and other related technologies probably will feel very much at home in the OpenStack framework.
Guy is a director of research and development at Quest Software.
<Return to section navigation list>
Cloud Security and Governance
Eric Chabow interviewed Michigan CIO Theis on the State's Cloud Computing Initiative in a 5 Critical Elements of a Cloud Framework podcast of 9/9/2010. From the transcript:
Michigan is in its eighth year of smaller budgets. As the state's chief information officer and director of the Department of Technology, Management and Budget, Kenneth Theis [pictured] is looking at ways to drive efficiencies through IT, and one of his initiatives is cloud computing.
"Cloud computing is a great alternative to lower costs and to be more agile in meeting the customers' needs," Theis says in an interview with GovInfoSecurity.com (transcript below). "But, going to the cloud has to be done right."
To get it right, Theis has identified five critical areas that the state's cloud initiative must encompass to assure its success. They are:
- Ownership of data;
- Security compliance;
- Compliance with federal and state legal requirements;
- Location of data; and
- Service-level agreements.
Most cloud computing providers offer different approaches to these five areas, a situation Theis says is untenable. "What we are trying to do in Michigan is to set the framework, which means that these cloud solution providers meet our requirements, not the other way around," he says.
In the interview, the first of two parts, Theis also discusses how the state will address cloud-computing security concerns at the Great Lakes Information Technology Center, a planned data processing center that should be operational by 2014. The center, to be owned and operated by Michigan, will host cloud computing applications for local governments and state agencies as well as some businesses.
In part two of the interview, Theis addresses how Michigan beenfits from being the first state to implement the federal Department of Homeland Security's Einstein intrusion detection system.
ERIC CHABROW: We now know there is a lot going on with the cloud in Michigan. First, tell us about the Michigan cloud computing framework.
KEN THEIS: Cloud computing is a great alternative, to lower costs and to be more agile in meeting the customers' needs. But, going to the cloud has to be done right. We have identified what we call our five key critical areas of things that really need to be encompassed, because a lot of cloud computing strategies offer their own different types of solutions for each one of these areas. It's important for every entity to create this framework. The cloud computing solutions are meeting the state's needs, not the state trying to meet their needs.
The first one is about ownership and ownership around the data, and who owns that data at the end of the day. What happens if that supplier or that solution provider goes bankrupt? The second one is obviously around security, compliance, identity and access management. Are there auditable records that are acceptable, and is it certified by a third-party auditor, that the security controls are appropriate for the type of business and the type of data that they are doing? The other issue is around legal issues. Is there a guarantee that the provider complies to all federal and state legal requirements? Is there a stipulation for the provider to make sure there is breach notification. Another area that we look at is location of the data. Where is the data located and can it be accessible, and whether it is within the state of Michigan, or not only the primary data but in a disaster recovery opportunity? The last area would be service-evel agreements. When you take a look at service-level agreements, are they in place? Are those performance methods in place, and are there associated penalties in place, to make sure that those things are required?
When you take a look at all those different cloud computer providers that are out there, for each of these five areas they are offering, each solution provider is offering different components and different elements for each of these five areas. What we are trying to do in Michigan is to set the framework, which means that these solution providers, these cloud solution providers meet our requirements, not the other way around.
CHABROW: What kind of reception have you gotten to that?
Read more: 1 | 2 | 3, Next Page », View On 1 Page
<Return to section navigation list>
Cloud Computing Events
Rachel F Collier (Rachfcollier) recommended on 9/8/2010 that you Get ahead with Windows Azure by attending some new Windows Azure workshops in the UK:
We’re in the midst of launching some new Windows Azure workshops, and here are the first two events, hot off the press, so to speak. We’ve also got a great new online conference coming up – details to follow very soon.
Online Windows Azure Platform – Accelerated Training Workshop
This course is aimed at software developers with at least 6 months practical experience using Visual Studio 2008 or Visual Studio 2010.
Find out more information and register
In Person Windows Azure Platform – Accelerated Training Workshop
If face to face learning is more your thing, this two-day intensive instructor-led workshop (£100) will provide you with an early opportunity to gain insight into the nature and benefits of the Windows Azure Platform. Delivered through workshop style presentations and hands-on lab exercises, the workshop will focus on three key services – Windows Azure, SQL Azure and AppFabric.
Agenda
- Module 1: Windows Azure Platform overview
- Module 2: Introduction to Windows Azure
- Module 3: Introduction to SQL Azure
- Module 4: Introduction to AppFabric
Objectives
At the end of the workshop delegates will:
- Gain an understanding of the nature and purpose of the Windows Azure Platform
- Understand the role played by the following components: Windows Azure; SQL Azure; AppFabric
Here are the locations and dates:
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Mary Jo Foley (@maryjofoley) reported Rackspace fills out its Windows cloud story in a 9/8/2010 post to her All About Microsoft ZDNet blog:
Cloud hosting provider Rackspace rolled out on September 8 a new toolkit for customers who want to develop and deploy to its Cloud Servers for Windows service.
The new tookit, known as the Rackspace Cloud Plug-In for Visual Studio 2010, was developed by Microsoft Gold partner Neudesic. Rackspace is touting the toolkit as reducing deployment and provisioning time for its hosted Windows servers, as well as providing users of those Windows servers with a single cloud-management portal.
Rackspace unveiled the beta of its Windows cloud offering (supporting Windows Server 2003 R2 and Windows Server 2008 R2) in November 2009. It rolled out the final version of its Windows cloud offering in August. Pricing for the Cloud Servers for Windows hosting service begins at $0.08 an hour for 1GB RAM and 40GB disk.
Like Amazon with its Windows instances on EC2, Rackspace is targeting customers who want to run Windows in the cloud but who don’t want or need Windows Azure, Microsoft’s cloud operating environment.
The HPC in the Cloud blog reported Rackspace Hosting Embraces Cloud Developers with Rackspace Cloud Plug-In for Microsoft Visual Studio 2010
- Launch, reboot and fully control all servers
- Rebuild servers from images and create custom images
- Schedule application backups
- Upsize and scale server configurations as needed
- Manage and share IP addresses
“Rackspace has again demonstrated it is a key player in the cloud by providing the entire MSDN community and all .NET developers a way to quickly develop, deploy and manage cloud applications written in a development environment familiar to them,” said Scott Guthrie, corporate vice president of the Developer Division at Microsoft Corp. “This effort highlights the openness of Visual Studio and Microsoft’s unique position within the cloud computing ecosystem, as both a partner to other cloud providers and a cloud provider itself. The Rackspace Plug-In for Visual Studio 2010 toolkit is intended to help with developers looking for an easier way to deploy their applications, websites and blogs to the cloud.”
Available through a single-download to Rackspace Cloud Servers for Windows users, the Rackspace Cloud Plug-In for Visual Studio 2010 provides .NET developers with a variety of templates and plug-ins that effectively make the developer platform a one-stop-shop for total cloud deployment and management. Built by Neudesic, a Microsoft Gold Certified Partner, the toolkit for Visual Studio 2010 is designed to eliminate the need for managing separate cloud and application environments by providing developers a full view of their environment.
“We’re committed to making development for the Rackspace Cloud as easy and intuitive as possible, and nothing makes more sense than giving developers the ability to manage their cloud from within the Visual Studio platform they’re already so accustomed to,” said Pat Matthews, VP and GM of Cloud, Rackspace. “By partnering with Neudesic and Microsoft, we hope to help the vast MSDN community streamline and simplify its deployment and management of applications on the cloud. This new toolkit will eliminate the need to toggle back and forth between the development platform and a separate cloud management panel, and save developers precious time.”
Read more: Page: 1 of 2, 1 | 2 All »
Alex Popescu posted CouchDB: A Gentle Introduction for Relational Practitioners to his myNoSQL blog on 9/8/2010:
Reads like a story:
CouchDB lets you store related data together even if it isn’t all the same type of data; you can store documents representing blog posts, users, and comments — all in the same database. This is not as chaotic as it sounds.
To get your data back out of CouchDB in sensible ways, you define views over the database. A view stores a subset of the database’s documents. You can think of them as materialized partial indexes. You can create a view of blog posts, and a view of comments, and so on. Each view is another B+Tree. It stays up-to-date with the changes you make to the database.
From the series Teach your boss CouchDB with small doses.
Alex Popescu asked Couchio or CouchOne? in a 9/8/2010 post to his myNoSQL blog:
So, CouchDB, CouchApp, and CouchOne.

Alex Popescu posted BigCouch: Java Map-Reduce with CouchDB on 9/8/2010:
Feels like a conspiracy to have the 3rd Java related post today, but the one from Cloudant is quite big:
Bringing the most popular VM and all the languages supported on it to CouchDB is definitely a very smart move.
Malick posted Cloud Computing Comparisons Between AWS, RackSpace and GoGrid Part 2 to the CloudTweaks blog on 9/8/2010:
As we saw in Part 1, Amazon Web Services being the pioneer in Cloud Services (Please see our earlier post about this topic: Link1, Link2, Link3), it has become common practice to compare other services with AWS. Amazon started offering its windows service back in early 2009.
As the cloud computing services are getting popular day by day, more companies have started evaluating the different offerings vis-à-vis their requirement. As we saw, it is not only the pricing models, but also service models and support plans differ. All these make it challenging for the companies to choose a cloud vendor suitable to the needs. The value of cloud services consists of its performance and cost.
One of the key values is the ‘Pay As You Go’ metered service. The other two are packages available and support.
Service Models:
For the same windows server operating system (Windows Server 2008, 32 bit / 64 bit), for the same virtualization type used (Xen based VM), the service delivery models of Gogrid, AWS and Rackspace are presented in their own way.
Gogrid:
(Gogrid is an offshoot of Servepath)
Gogrid can be termed as an Infrastructure as a Service (IaaS) provider. Gogrid’s bonding with Microsoft is thicker. Both Microsoft’s BizSpark program and WebsiteSpark program can get along with Gogrid service seamlessly. As we know now Microsoft is not allowing the same programs as with AWS. Microsoft WebMatrix is also available with Gogrid with a free $ 150 service credit.
Gogrid’s prime data center is available at San Francisco. The second data center has been started in Ashburn, VA. Gogrid’s SLA Service Level Agreement is clear with 100% uptime Guarantee against 99.95% of AWS. Gogrid’s availability status with Cloudharmony reports 99.999% both for US East and West.
AWS:
Amazon Web Services can be termed as an IaaS and Platform as a Service (PaaS) provider. The global coverage of AWS with 4 regions (US East- Virginia, US West N. California, Europe West Ireland, and Asia Pacific Singapore) speaks well for AWS. The practical difficulty is that Windows components should be added by the user. Amazon allows existing Windows Server licenses usage but subject to strict eligibility criteria. Amazon EC2 running with Windows Server and SQL Server is a popular use case.
Initially the users found the Gogrid’s user interface very easy to handle. Now AWS Management Console has improved a lot that it has become easy to handle. Automatic configuration of Windows Instances, particularly with .Net applications needs a lot of fiddling by developers.
Read More >
Jeff Barr reported AWS Management Console Support for the Amazon Virtual Private Cloud on 9/7/2010:
The AWS Management Console now supports the Amazon Virtual Private Cloud (VPC). You can now create and manage a VPC and all of the associated resources including subnets, DHCP Options Sets, Customer Gateways, VPN Gateways and the all-important VPN Connection from the comfort of your browser.
Put it all together and you can create a secure, seamless bridge between your existing IT infrastructure and the AWS cloud in a matter of minutes. You'll need to get some important network addressing information from your network administrator beforehand, and you'll will need their help to install a configuration file for your customer gateway.
Here are some key VPC terms that you should know before you should read the rest of this post (these were lifted from the Amazon VPC Getting Started Guide):
- VPC - An Amazon VPC is an isolated portion of the AWS cloud populated by infrastructure, platform, and application services that share common security and interconnection. You define a VPC's address space, security policies, and network connectivity.
- Subnet - A segment of a VPC's IP address range that Amazon EC2 instances can be attached to.
- VPN Connection - A connection between your VPC and data center, home network, or co-location facility. A VPN connection has two endpoints: a Customer Gateway and a VPN Gateway.
- Customer Gateway - Your side of a VPN connection that maintains connectivity.
- VPN Gateway - The Amazon side of a VPN connection that maintains connectivity.
Let's take a tour through the new VPC support in the console. As usual, it starts out with a new tab in the console's menu bar:
The first step is to create a VPC by specifying its IP address range using CIDR notation. I'll create a "/16" to allow up to 65536 instances (the actual number will be slightly less because VPC reserves a few IP addresses in each subnet) in my VPC:
The next step is to create one or more subnets within the IP address range of the VPC. I'll create a pair, each one covering half of the overall IP address range of my VPC:
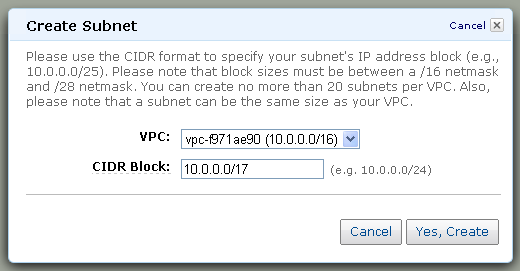
The console shows all of the subnets and the number of available IP addresses in each one:
You can choose to create a DHCP Option Set for additional control of domain names, IP addresses, NTP servers, and NetBIOS options. In many cases the default option set will suffice.
And the next step is to create a Customer Gateway to represent the VPN device on the existing network (be sure to use the BGP ASN and IP Address of your own network):
We're almost there! The next step is to create a VPN Gateway (to represent the VPN device on the AWS cloud) and to attach it to the VPC:
The VPC Console Dashboard displays the status of the key elements of the VPC:
With both ends of the connection ready, the next step is to make the connection between your existing network and the AWS cloud:
This step (as well as some of the others) can take a minute or two to complete.
Now it is time to download the configuration information for the customer gateway.

The configuration information is provided as a text file suitable for use with the specified type of customer gateway:
Once the configuration information has been loaded into the customer gateway, the VPN tunnel can be established and it will be possible to make connections from within the existing network to the newly launched EC2 instances.
I think that you'll agree that this new feature really simplifies the process of setting up a VPC, making it accessible to just about any AWS user. What do you think?

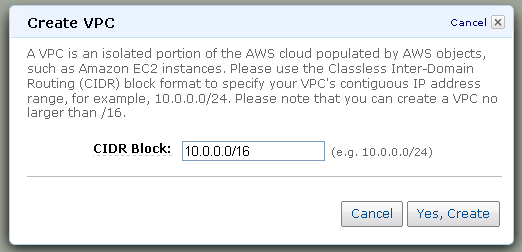
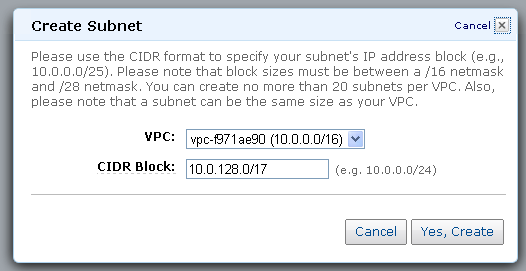
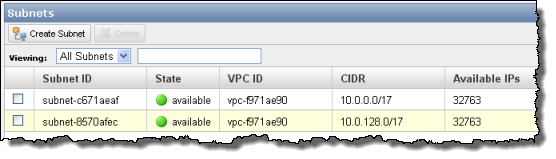
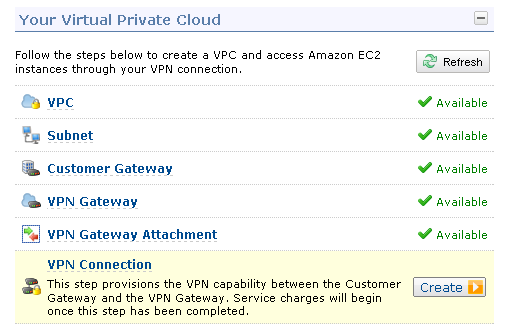
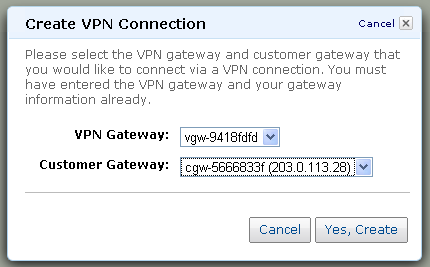
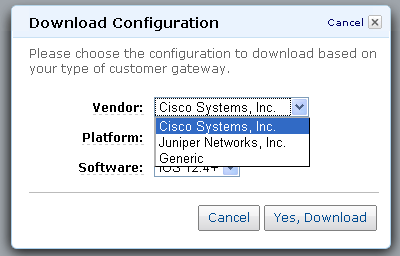
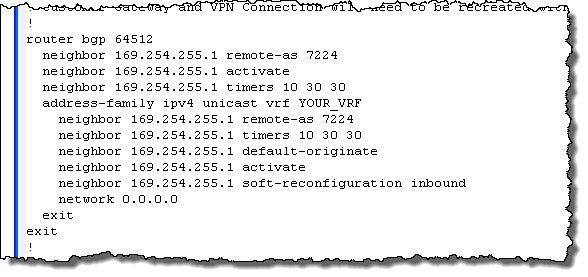
It doesn’t look very simple to me.
Doug Henschen reported “Popular management suite integrated with budding alternative for big-data transaction processing” in a deck for his Quest Software Supports Cassandra NoSQL Database post of 9/7/2010 to Information Week’s Software blog:
In ancient Greek mythology, Cassandra can see into the future, but Apollo places a curse on her so that nobody believes her prophesies.
In the context of today's NoSQL computing movement, Apache Cassandra is seen by some as the future of big data transaction processing. Quest Software on Tuesday confirmed that it's among the believers by announcing support for Cassandra through its Toad for Cloud Databases software.
Service-now.com's IT service management platform runs in the cloud, offering an array of IT services. It includes configuration management, a catalog for product and service ordering, a workflow engine, reporting and more.
"There are a lot of new data stores arising, but we think Cassandra is really here to stay," said Christian Hasker, director of product management for database management at Quest, in an interview with InformationWeek.
"We attended the Cassandra Summit in San Francisco last month and it was not only oversubscribed, there was a tremendous buzz about the platform," he said.
Created by FaceBook to support real-time searching across its vast social network, Cassandra is gaining recognition as an extremely scalable option for high-performance transaction processing. The database supports clustered deployments across low-cost commodity hardware, and it's a step up for MySQL users who want to avoid labor-intensive sharding and partitioning -- techniques required to make conventional relational database scale up.
Cassandra also has strong support for multi-data-center deployments, functionality that serves it well in cloud deployments.
Quest's Toad software has been popular database development, administration and data integration tool for more than a decade. The new Cloud version, first announced in June, gives users a way to manage non-relational databases such as Cassandra in the same environment they use to handle conventional relational databases such as Oracle, DB2, and Microsoft SQL Server.
The first beta release of Toad for Cloud Databases included support for Amazon Simple DB, HBase, Microsoft Azure Table Services and SQL Azure. With the 1.1 beta release announced Tuesday, Quest added support for Cassandra and it also announced plans to support Hive (a component of Hadoop) by year end.
Quest also announced that it has entered into an alliance with Riptano, a company that provides software, support, and services for Cassandra. The two companies said they will investigate the need for monitoring, diagnostic and data-movement tools for Cassandra for enterprise deployments. That could lead to development of related software in 2011, Quest said.
Cassandra is used by a prominent Internet companies including Facebook, Digg and Reddit, but Riptano said there are huge growth prospects among conventional enterprises with large-scale transactional environments that scaling into the tens of terabytes and beyond.
"We've been surprised to discover much higher use of Cassandra within traditional enterprises than we anticipated," said Matt Pfeil, CEO of Riptano.
More than 50 of the firms represented at the recent Cassandra Summit already have the database in production, according to Pfeil, and several of those are Fortune 100 companies, he said.
To foster the use of Cassandra, Quest also announced on Tuesday that Riptano will contribute content to CloudDBPedia. The Quest-hosted online knowledgebase is said to be product neutral, offering videos, podcasts, blogs and a community-run wiki focused on NoSQL technologies.
Alex Williams reported What the VMworld Labs Demonstrated About the Cloud on 9/7/2010 in a post to the ReadWriteCloud:
VMworld set up a lab this year that ran a hybrid cloud.
The VMware team set up a data center at the Moscone Convention Center in San Francisco that connected to public clouds provided by Terremark in Miami and Verizon in Ashburn, Va.
The hybrid cloud was redundant so if it went down, the load could be picked up elsewhere.
This was the first year that VMworld used a hybrid cloud environment. They called it Lab Cloud. The numbers demonstrate the difference in what can be accomplished in a multi-tenant environment.
Last year, there were 4,500 labs completed at VMword. This year there were more than 15,000 labs done.
Lab Cloud deployed and destroyed about 4000 Virtual Machines on a per hour basis. In total, Lab Cloud deployed a total of 145,097 virtual machines. Private cloud environments can not usually handle this kind of load, showing again the capabilities of what can be done when data centers and public cloud environments are connected.
To be fair, it is important to remember that this is a lab environment. The Lab Cloud was built from scratch. Any enterprise environment will face any number of obstacles in setting up a hybrid environment.
One thing it does show is the volume of virtual machines that are being spun into the cloud. The Lab Cloud demonstrated how much more extended a cloud environment can be compared to a traditional data center operation or a private cloud.
It also shows how VMware plans to do training at future VMworld events. VMware set up 480 seats for doing labs. Each lab took about an hour to do. A few people complete all of the labs. But more so, it helped give attendees hands-on experience in how to manage thousands of virtual machines that are being deployed and destroyed throughout a work day.
Source: Yellow Bricks
The enterprise needs this kind of training for a few reasons. Hybrid cloud computing is still very new to most people. The labs give people a chance to learn new skills that will be needed as enterprise operations evolve toward a hybrid cloud computing environment.
And perhaps just as much, it shows the IT knowledge worker the possibilities that the cloud brings to their work.

<Return to section navigation list>

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
0 comments:
Post a Comment