Windows Azure and Cloud Computing Posts for 5/27/2013+
•• Top technical paper: Hanu Kommalapati's (@hanuk) two part Introducing Windows 8 for Android Developers, which could be equally well-titled Android for Windows and .NET Developers, in the Windows Azure SQL Database, Federations and Reporting, Mobile Services section.
• Top tutorial this and last week: Michael Washam (@MWashamMS) described Automating SharePoint Deployments in Windows Azure using PowerShell on 5/24/2013 also in the Windows Azure Infrastructure and DevOps section.
Top news this and last week: Satya Nadella reported Microsoft announces major expansion of Windows Azure services in Asia on 5/22/2013 in the Windows Azure Infrastructure and DevOps section.
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
‡ Updated 6/01/2013 with new articles marked ‡.
•• Updated 5/31/2013 with new articles marked ••.
• Updated 5/30/2013 with new articles marked •.
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
Ayad Shammout (@aashammout) described how to Import Hadoop Data into SQL BI Semantic Model Tabular in a 5/27/2013 post:
Hadoop brings scale and flexibility that don’t exist in the traditional data warehouse. Using Hive as a data warehouse for Hadoop to facilitate easy data summarization, ad-hoc queries, and the analysis of large datasets. Although Hive supports ad-hoc queries for Hadoop through HiveQL, query performance is often prohibitive for even the most common BI scenarios.
A better solution is to bring relevant Hadoop data into SQL Server Analysis Services Tabular model by using HiveQL. Analysis Services can then serve up the data for ad-hoc analysis and reporting. But, there is no direct way to connect an Analysis Services Tabular database to Hadoop. A common workaround is to create a Linked Server in a SQL Server instance using HiveODBC which uses it through OLE DB for ODBC. The HiveODBC driver can be downloaded from here.
Create a Hive ODBC Data Source
The following steps show you how to create a Hive ODBC Data Source.
- Click Start -> Control Panel to launch the Control Panel for Microsoft Windows.
- In the Control Panel, click System and Security->Administrative Tools. Then click Data Sources. This will launch the ODBC Data Source Administrator dialog.
- In the ODBC Data Source Administrator dialog, click the System DSN tab.
- Click Add to add a new data source.
- Click the HIVE driver in the ODBC driver list.
- Click the Finish button. This will launch the Hive Data Source Configuration dialog.
- Enter a data source a name in the Data Source Name box. In this example, SQLHive.
- In this example, we are connecting to HDInsight (Hadoop on Windows Azure). In the Host box, replace the clustername placeholder variable with the actual name of the cluster that you created. For example, if your cluster name is “HDCluster1″ then the final value for host should be “HDCluster1.azurehdinsight.net”. Do not change the default port number of 563 or the default value of the Hive Server HTTP Path, /servlets/thrifths2. If you are connecting to Hadoop cluster, the port number would be 10000.
- Click OK to close the ODBC Hive Setup dialog.
Once the HiveODBC driver is installed and created, next you will create a SQL Server Linked Server connection for HiveODBC.
SQL Server can serve as an intermediary and Analysis Server can connect to Hadoop via Hive Linked Server connection in SQL Server, so Hive appears as an OLE DB-based data source to Analysis Services.
The following components need to be configured to establish connectivity between a relational SQL Server instance and the Hadoop/Hive table:
- A system data source name (DSN) “SQLHive” for the Hive ODBC connection that we created in the steps above.
- A linked server object. The Transact-SQL script illustrates how to create a linked server that points to a Hive data source via MSDASQL. The system DSN in this example is called “SQLHive”.
EXEC master.dbo.sp_addlinkedserver
@server = N’SQLHive’, @srvproduct=N’HIVE’,
@provider=N’MSDASQL’, @datasrc=N’SQLHive’,
@provstr=N’Provider=MSDASQL.1;Persist Security Info=True;
User ID=UserName; Password=pa$$word;Note: Replace the User ID “UserName” and password “pa$$word” with a valid username and password to connect to Hadoop.
- SQL statement that is based on an OpenQuery Transact-SQL command. The OpenQuery command connects to the data source, runs the query on the target system, and returns the ResultSet to SQL Server. The following Transact-SQL script illustrates how to query a Hive table from SQL Server:
SELECT * FROM OpenQuery(SQLHive, ‘SELECT * FROM HiveTable;’)
Where “HiveTable” is the name of Hadoop Hive table, you can replace the name with the actual Hive table name.
Once the Linked Server is created on the computer running SQL Server, it is straightforward to connect Analysis Services to Hive in SQL Server Data Tools. …






Ayad continues by describing how to Create a BI Semantic Model Tabular project and connect to a Hadoop Hive table. Read his entire post here.
• Joe Giardino, Serdar Ozler, and Jean Ghanem described .NET Clients encountering Port Exhaustion after installing KB2750149 in a 5/25/2013 post to the Windows Azure Storage blog:
A recent update for .Net 4.5 introduced a regression to HttpWebRequest that may affect high scale applications. This blog post will cover the details of this change, how it impacts clients, and mitigations clients may take to avoid this issue altogether.
What is the affect?
Client would observe long latencies for their storage requests and may find either that that their requests to storage are dispatched after a delay or it is not dispatching requests to storage and instead see System.Net.WebException being thrown from their application when trying to access storage. The details about the exception is explained below. Running a netstat as described in the next section would show that the process has consumed many ports causing port exhaustion.
Who is affected?
Any client that is accessing Windows Azure Storage from a .NET platform with KB2750149 installed that does not consume the entire response stream will be affected. This includes clients that are accessing the REST API directly via HttpWebRequest and HttpClient, the Storage Client for Windows RT, as well as the .NET Storage Client Library (2.0.5.0 and below provided via nuget, github, and the sdk). You can read more about the specifics of this update here.
In many cases the Storage Client Libraries do not expect a body to be returned from the server based on the REST API and subsequently do not attempt to read the response stream. Under previous behavior this “empty” response consisting of a single 0 length chunk would have been automatically consumed by the .NET networking layer allowing the socket to be reused. To address this change proactively we have added a fix to the .Net Client library in version 2.0.5.1 to explicitly drain the response stream.
A client can use the netstat utility to check for processes that are holding many ports open in the TIME_WAIT or ESTABLISHED states by issuing a nestat –a –o ( The –a will show all connections, and the -o option will display the owner process ID).
Running this command on an affected machine shows the following:
You can see above that a single process with ID 3024 is holding numerous connections open to the server.
Description
Users installing the recent update (KB2750149) will observe slightly different behavior when leveraging the HttpWebRequest to communicate with a server that returns a chunked encoded response. (For more on Chunked encoded data see here).
When a server responds to an HTTP request with a chunked encoded response the client may be unaware of the entire length of the body, and therefore will read the body in a series of chunks from the response stream. The response stream is terminated when the server sends a zero length “chunk” followed by a CRLF sequence (see the article above for more details). When the server responds with an empty body this entire payload will consists of a single zero-length chunk to terminate the stream.
Prior to this update the default behavior of the HttpWebRequest was to attempt to “drain” the response stream whenever the users closes the HttpWebResponse. If the request can successfully read the rest of the response then the socket may be reused by another request in the application and is subsequently returned back to the shared pool. However, if a request still contains unread data then the underlying socket will remain open for some period of time before being explicitly disposed. This behavior will not allow the socket to be reused by the shared pool causing additional performance degradation as each request will be required to establish a new socket connection with the service.
Client Observed Behavior
In some cases the Storage Client libraries provided will not retrieve the response stream from the HttpWebRequest (i.e. PUT operations), and therefore will not drain it, even though data is not sent by the server. Clients with KB2750149 installed that leverage these libraries may begin to encounter TCP/IP port exhaustion. When TCP/IP port exhaustion does occur a client will encounter the following Web and Socket Exceptions:
System.Net.WebException: The underlying connection was closed: An unexpected error occurred on a send.- or -
System.Net.WebException: Unable to connect to the remote server
System.Net.Sockets.SocketException: Only one usage of each socket address (protocol/network address/port) is normally permitted.Note, if you are accessing storage via the Storage Client library these exceptions will be wrapped in a StorageException:
Microsoft.WindowsAzure.Storage.StorageException: Unable to connect to the remote server
System.Net.WebException: Unable to connect to the remote server
System.Net.Sockets.SocketException: Only one usage of each socket address (protocol/network address/port) is normally permittedMitigations
We have been working with the .NET team to address this issue. A permanent fix will be made available in the coming months which will reinstate this read ahead semantic in a time bounded manner. Until then clients can take the following actions to mitigate this issue in their applications:
Upgrade to latest version of the Storage Client (2.0.5.1)
An update was made for the 2.0.5.1 (nuget, github) version of the Storage Client library to address this issue, if possible please upgrade your application to use the latest assembly.
Uninstall KB2750149
We also recognize that some clients may be running applications that still utilize the 1.7 version of the storage client and may not be able to easily upgrade to the latest version without additional effort. For such users, consider uninstalling the update until the .NET team releases a permanent fix for this issue. We will update this blog, once such fix is available.
Update applications that leverage the REST API directly to explicitly drain the response stream
Any client application that directly references the Windows Azure REST API can be updated to explicitly retrieve the response stream from the HttpWebRequest via [Begin/End]GetResponseStream() and drain it manually i.e. by calling the Read or BeginRead methods until end of stream
Summary
We apologize for any inconvenience this may have caused. We are actively working with the .NET team to provide a permanent resolution to this issue that will not require any modification of client source code.
Resources
- Windows Azure Storage Client library 2.0.5.1 (nuget, github)
- Original KB article: http://support.microsoft.com/kb/2750149




<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
‡ Sanjay Mishra posted a Performance Guidance for SQL Server in Windows Azure Virtual Machines white paper to the sqlCAT blog on 5/31/2013:
Summary: Developers and IT professionals should be fully knowledgeable about how to optimize the performance of SQL Server workloads running in Windows Azure Infrastructure Services and in more traditional on-premises environments. This technical article discusses the key factors to consider when evaluating performance and planning a migration to SQL Server in Windows Azure Virtual Machines. It also provides certain best practices and techniques for performance tuning and troubleshooting when using SQL Server in Windows Azure Infrastructure Services.
Read on: Performance Guidance for SQL Server in Windows Azure Virtual Machines.

•• Hanu Kommalapati (@hanuk) published a two part Introducing Windows 8 for Android Developers series on 4/18/2013 (missed when posted), which is very useful for Windows Azure developers creating Mobile Services for Android:
This two-part series (Part 1 & Part 2) is aimed at the Android developers who are looking for opportunities to build Windows Store applications. In order for the easy onboarding of an Android developer to the Windows 8 platform, we will take a fundamental approach towards outlining the mobile development tasks and show how to accomplish them on Windows 8. The tasks include the setting up of the development environment, UI design, handling widget events, local storage, integration with external systems and device notifications. Given the similarities between the two platforms in the mobile space, Android developers will feel right at home with application development for Windows Store.
Please note that the intention of this article is not to show that one is superior to the other but to simply outline how a developer can mentally map the development tasks from one platform to the other. You may see Windows 8 being treated at a more detail level as I know Windows 8 a little better than Android and any bias you may see is unintentional.
Most of the Windows 8 discussion in this series focuses on XAML and C# programming model. However, this is one of the many programming models supported in Windows 8; others include HTML5/Javascript, VB.NET, C++ and DirectX.
The Platform
Windows 8 is available on various device types including desktops, tablets, and yet to be built devices of various form factors; however, our focus for this article is Windows 8 in the context of tablets. With very little effort Android developers can be at home with Windows 8 as it has a lot of similarities with Android from the OS architecture, mobile development concepts, developer tools and SDKs perspective. Figure 1 shows both platforms side-by-side illustrating components that are important to developers.
Android: Kernel
Android is built on top of the Linux kernel that is adapted for mobile devices; the changes to the kernel include efficient power management, increase in security, support new hardware, improve performance of the flash file system, and improved error reporting. User programs on Android are hosted inside Java virtual machine at run time and consequently the developers can take advantage of the subset of Java APIs fundamental to JDK. Android also provides Java binding under android namespace for platform specific programming like power management, user interface, location based programming, local storage and cloud integration.
Windows 8: Kernel
Enhancements to the Windows 8 kernel are too numerous to mention however, here are a few: enhance boot performance, enable System-on-Chip features, improve run-time power management of the devices, performance enhancements to user mode driver framework, and security enhancements to user mode driver framework.
Most developers probably don’t care about the finer details of the driver architecture however, it is worth to note that, Windows 8 supports a driver architecture that allows user mode as well as kernel mode drivers. User mode drivers (e.g. camera, printer) run in a low privileged environment (in user mode) which prevents system crashes resulting from driver quality issues. Note that the diagram shows all the Windows 8 drivers running in kernel-mode just for the sake of showing the symmetry between Android and Windows 8.
Figure 1: Architecture Side-by-side
Android: Runtime
Typical applications created by developers for Android run inside a Dalvik VM instance which is a register based Java Virtual Machine that is optimized for low memory and devices with mobile friendly processors. Java class files gets converted into Dalvik Executable files which are known as DEX files. These DEX files are interpreted excepting cases where the runtime can JIT compile a hot trace. A subset of the Java libraries are distributed as a part of the Android SDK. Natively coded Android libraries are available to the Java programming environment as language specific bindings. These Android API calls from Java will be dispatched to native code through JNI which is totally opaque to the developers.
Windows 8: Runtime
Android Runtime equivalent in Windows 8 is WinRT which is a sand box for running Windows Store applications. Windows 8 supports two types of applications – desktop applications and Windows Store applications. Windows Store applications run inside a security sand box which tightly controls access to system resources while the traditional desktop applications run with privileges implicitly inherited from the user principal that started the application. In case of desktop applications, the code is completely trusted and hence no discretionary permission grants required by the end user unless the code originated from a mobile location like an external share or internet.
WinRT makes no such assumptions about Windows Store applications; permissions for accessing system resources (e.g. network, file system, location) will have to be explicitly requested by the application at development time. At run time when the protected resource is accessed end user grants permission through consent dialogs. Another difference is that desktop applications can be installed from any source while Windows Store applications targeting WinRT can only be installed from trusted sources like Windows Store or an on premise repository in a controlled setting.
For this discussion we will only be focusing on Windows Store applications (aka Windows Store apps) as these are the equivalent of Android applications. Windows Store applications are published into Windows Store which is analogous to Google Play and other Android stores into which developers must submit their applications for the certification and subsequent publication.
Windows 8’s equivalent of Android’s Dalivik VM is .NET CLR; each process in Windows Store application creates an instance of .NET CLR (Common Language Runtime) for running application code written in .NET languages like C# and VB.net. .NET code gets deployed as MSIL (Microsoft Intermediate Language) byte code that gets JIT compiled into X86 or ARM instruction set at run time. This is similar to compiling Java source code to DEX files and the interpretation of DEX files at run time in Android.
WinRT allows only a subset of .NET to be used inside Windows Store applications written with .NET languages. This includes IO, LINQ collections, networking, http, object serialization, threading, WCF (Windows Communications Foundation) and XML. Complete list of .NET APIs for Windows Store applications can be found at: .NET for Windows Store apps - supported APIs.
Windows Store applications written using HTML/Javascript and C++ will directly call into WinRT API for implementing application functionality. WinRT API is a collection of COM components that sit on top of Windows Core; these components are made available to various languages including C#, VB.NET, C++ and Javascript through language specific projections. The projections are metadata files which will be used by Visual Studio IDE and the language compiler to replace language specific API calls with native WinRT API calls.
Libraries
WinRT API is a collection of native components implemented in COM (Component Object Model) that is familiar to most of the Windows programmers. For Android developers who are new to Windows platform, COM is an RPC based technology that creates and manages object life cycle through class factories and reference counting. The developers are shielded from the complexity of the COM part of the WinRT APIs through language projections.
Similar to Android, WinRT has libraries for media playback, networking, storage, geo location and other important components for developing mobile applications. Some of the libraries shown for Android like SGL, libc and SSL have their counterparts in Windows 8 through XAML rendering engine, C runtime and SSL implementation. Even though SQLite is not distributed as part of the WinRT, there are WinRT compatible open source libraries that allows developers to embed server-less relational database functionality inside Windows 8 Windows Store applications.
Equivalent to WebKit on Android, HTML rendering is done through IE10’s Trident which helps HTML rendering on Windows 8. Both the platforms have similarly named class– WebView for embedding web sites within applications. …




Hanuk continues with Development Environment:

User Interface Concepts:

UI Navigation:

Widget/Control Map:

Event Handling, Screen Layout, and Storage comparisons.
Here’s the link to Introducing Windows 8 for Android Developers - Part 2:
Part 1 covered a few fundamental aspects of Android and Windows 8 development from the perspective of applications that are self-contained. In part 2 we will focus on the application integration with external services through the platform’s built-in networking capabilities.
Android-oriented developers also might be interested in Hanuk’s Data Binding in Windows 8 compared to Android post of 5/29/2013 and Enabling USB Debugging for Nexus 7 on Windows 8 of 5/24/2013. I was particularly interested in the latter, because I use a Nexus 7 tablet, in addition to a Surface Pro and my wife’s Surface RT. Check my Android MiniPCs and TVBoxes blog for Technical Details of Low-Cost MiniPCs with HDMI Outputs Running Android JellyBean 4.1+ and Emphasis on High-Definition 1080p Video Rendition.
‡ Mr. Worldwide posted How to use ADB, DDMS and take a LOGCAT, a pictorial explanation, on the XDA Developers website on 5/31/2013. The article explains the following:
What is ADB?
- Setting up ADB
- Enabling USB Debugging
- Installing ADB Device Drivers
- What is a LOGCAT?
- Taking a LOGCAT

• Haishi Bai (@HaishiBai2010) continued his series for the gadget-inclined with a Cloud + Devices Scenarios (2): Intruder Detection System post on 5/27/2013:
Intruder Detection System is a sample solution that combines embedded system with Windows Azure Mobile Services to construct a simple intruder detection system. In this system, I’ll use GHI Electronics’ Fez Spider Starter Kit to build a simple motion detection system using its camera.
The motion detection algorithm will send detected motions to Mobile Service by inserting a record to Mobile Service’s backend table, and Mobile Service will push the alerts to end users via Push Notifications.
Prerequisite
Visual Studio 2012
- .Net Micro Framework SDK 4.3
- GHI Electronics Fez Spider Starter Kit
- GHI Software Package 4.2 (You need to register and download from GHI Electronics' support site)
- You should also download FEZ Config (beta) and use it to update the firmware. To update firmware, connect USB/power module to slot 1 on the motherboard, and then connect the USB module to CP via a USB cable. FEZ Config should be able to detect the circuit and you can use it to update the firmware.
Warm-up project
Before we take on the real project, let’s first build a warm-up project to learn the basics of .Micro Framework development. In this warm-up project we’ll use the Fez Spider Starter Kit to build a simple video camera: we use the camera to take in images and display live images on the LCD monitor.
- In Visual Studio 2012, create a new Gadgeteer -> .Net Gadgeteer Application project.
- In .NET Gadget Application Wizard, select FEZSpider and click on Create button.
- In .NET Gadgeter Application Wizard, select FEZ Spider, and then click Create button.

- After the project has been created, you can start to design your circuit on Program.gadgeteer design surface. The UI is really intuitive – simply drag the components on to the service and link them together by dragging wires between slots. The designer is smart enough to give you hints of where your wires can go. You can also use “Connect all modules” shortcut menu to automatically link the modules. Drag these modules onto the surface:
* Camera (Premium)
* Button
* Display_T35
* UsbClientDP
Then, right-click on the design surface and select “Connect all modules” to connect all modules. The result diagram looks like this:
- Now we are ready to edit Program.cs to put in our camera control code. The code is very straightforward – we use a button to turn on/off image streaming from the camera, and when an image is captured, we send the picture directly to the display. In order to get a reasonable frame rate, I’m using a Bitmap variable as a shared buffer between the camera and the display. It works great when camera is stationary and it gives me a few frames per second. However when camera is in motion the image is distorted. I’ll leave it to interested readers to implement some sort of double-buffering, but probably the performance will suffer. Because in my scenario the camera will be stationary (hidden in some secret place), I choose to ignore this issue.
public partial class Program { Bitmap mBitmap; //shared image buffer between camera and display void ProgramStarted() { mBitmap = new Bitmap(camera.CurrentPictureResolution.Width, camera.CurrentPictureResolution.Height); //initialize buffer to camera view size camera.BitmapStreamed += camera_BitmapStreamed; button.ButtonPressed += button_ButtonPressed; button.TurnLEDOff(); //mark button as "off" } void button_ButtonPressed(GTM.GHIElectronics.Button sender, GTM.GHIElectronics.Button.ButtonState state) { if (button.IsLedOn) //check if button is “on" { camera.StopStreamingBitmaps(); //stop streaming button.TurnLEDOff(); //mark button as "off" } else { if (camera.CameraReady) { camera.StartStreamingBitmaps(mBitmap); //start streaming button.TurnLEDOn(); //mark button as "on" } } } void camera_BitmapStreamed(GTM.GHIElectronics.Camera sender, Bitmap bitmap) { display_T35.SimpleGraphics.DisplayImage(mBitmap, 0, 0); //display captured image } }- Connect all the wires according to step 4, and then connect the whole circuit to your PC using an USB cable.
- Now is the magic part! In Visual Studio, press F5. The code will be compiled and deployed to your device. Wait for the LED light on the button to turn off. Press the button, observe the LED light is turned on and image stream from the camera is displayed on the LCD screen. Press the button again to take a snapshot, and press again to resume streaming.
- [Optionally] Try to set up a breakpoint somewhere and experience the debugging experience as well!
- The following picture shows such a system capturing video from my work desk.
The real project
Now we are ready to take on the actual project. Just to make sure the design is clear to you, the following is a diagram showing how the system works: The camera captures images; the images are fed to motion detection algorithm; the algorithm generates alerts and insert them into a Mobile Service table; Insert trigger on the Mobile Service table will send push notifications to Windows Tablets/phones via WNS.
- First, let’s extend above circuit by adding a network card. Drop an ethernet_J11D component to design surface and wire it up:

- Then, let’s modify camera_BitmapStreamed() method to add in simple motion detection. This over-simplified algorithm observes only the center pixel and triggers an alert if the pixel value makes a sudden change. The algorithm throttles number of alerts so that it doesn’t trigger alerts more than once within 5 seconds. It also keep updating last observed pixel so that accumulated small changes don’t trigger a false alarm.
bool mFirst = true; byte mLastR = 0; byte mLastG = 0; byte mLastB = 0; DateTime mLastWarn = DateTime.MinValue; ... void camera_BitmapStreamed(GTM.GHIElectronics.Camera sender, Bitmap bitmap) { var newColor = bitmap.GetPixel(bitmap.Width / 2, bitmap.Height / 2); var r = ColorUtility.GetRValue(newColor); var g = ColorUtility.GetGValue(newColor); var b = ColorUtility.GetBValue(newColor); if (mFirst) mFirst = false; else { if (System.Math.Abs(r - mLastR) + System.Math.Abs(g - mLastG) + System.Math.Abs(b - mLastB) >= 100) { try { if ((DateTime.Now - mLastWarn).Seconds > 5) //throttling to avoid too many alerts { mLastWarn = DateTime.Now; //last alert time //Send alert } } catch { //TODO: handle exception } } } mLastR = r; mLastB = b; mLastG = g; //This part is optional display_T35.SimpleGraphics.DisplayImage(mBitmap, 0, 0); if ((DateTime.Now - mLastWarn).Seconds <= 5) //display alert for 5 seconds display_T35.SimpleGraphics.DisplayText("ALERT!", Resources.GetFont(Resources.FontResources.NinaB), Color.White, (uint)bitmap.Width / 2, (uint)bitmap.Height / 2); }- Now we need to send the alerts to Mobile Services. We’ll do this by inserting a new record to a Mobile Service table. Here I assume you’ve created a standard “ToDo” Mobile Service. We’ll insert alerts into its ToDoItem table. In order to do this we need to solve three problems: 1) Use SSL from embedded system – Mobile Service REST API requires HTTTPS; 2) Sync system time on embedded system – Mobile Service REST API requires the clock of calling client to be within clock skew; 3) Authenticate with Mobile Service REST API.
- First let’s enable SSL. Run MFDeploy.exe under c:\Program Files (x86)\Microsoft .NET Micro Framework\v4.2\Tools。Then, select Target –> Manage Device Keys –> Update SSL Seed:

- Update only takes a few seconds:

- Next we need to sync up embedded system clock. Here I’m using code from this blog:
void ProgramStarted() { ... Utility.SetLocalTime(GetNetworkTime()); } private DateTime GetNetworkTime() { IPEndPoint ep = new IPEndPoint(Dns.GetHostEntry("time-a.nist.gov").AddressList[0], 123); ... }- And finally we can send the alerts to Mobile Service. Note you’ll need to set X-ZUMO-APPLICATION header to your Mobile Service application key (assuming your table assess permission is set to Anybody with the Application Key):
var timestamp = DateTime.Now; string data = "{\"text\":\"Intruder at " + timestamp.Hour + ":" + timestamp.Minute + ":" + timestamp.Second + "\", \"complete\":false}"; byte[] bytes = System.Text.Encoding.UTF8.GetBytes(data); HttpWebRequest request = (HttpWebRequest)HttpWebRequest.Create("https://intruder.azure-mobile.net/tables/TodoItem"); request.Method = "POST"; request.Accept = "applicaiton/json"; request.ContentType = "application/json"; request.ContentLength = bytes.Length; request.Headers.Add("X-ZUMO-APPLICATION", "[Your Mobile Service application key]"); using (var stream = request.GetRequestStream()) { stream.Write(bytes, 0, bytes.Length); } var response = request.GetResponse(); response.Close();- Launch your Windows store app, wave your hand in front of the camera, and observe push notifications!











<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
• Mark Gayler (@MarkGayler) reported Momentum Grows as OData v4 Achieves Standards Milestone in a 5/30/2013 post to the Interoperability @ Microsoft blog:
Based on the industry collaboration between Citrix, IBM, Microsoft, Progress Software, SAP AG, WSO2, and others, we are pleased to report that the OASIS OData Technical Committee recently approved Committee Specification Draft 01 (CSD01) of OData version 4.0 and has initiated a public review of OData v4.0 during May 3, 2013 through June 2, 2013. OData v4.0 is expected to become an OASIS Standard in 2013.
Much of the data on the Web today lives in silos, needing different protocols, APIs, and formats to query and update the data. With the rapid growth of online information and big data sources, open data protocols and services are in demand more than ever before.
OData is a Web protocol for querying and updating data. OData is built on a set of RESTful conventions that provide interoperability for services that expose data. It builds on standardized web technologies such as HTTP, REST, Atom/XML, and JSON. It provides an entity data model and has support for vocabularies for common ontologies such as Sales (with Customers, SalesOrder, Product, ...), Movies (with Title, Actor, Director, …), or Calendars (with Event, Venue, …), etc. OData enables the creation of REST-based data services which means that resources identified using Uniform Resource Identifiers (URIs) and defined in an Entity Data Model (EDM), can be published and edited by Web clients using simple HTTP messages.
The OASIS OData version 4.0 specification is based on the popular OData version 3.0. OData version 4.0 defines data model changes to significantly simplify and expand how relationships are expressed and used as well as how metadata is described and partitioned, expanded query capabilities for inline collections and fulltext search, and extended functionality for change tracking and asynchronous processing.
The OASIS Technical Committee has produced three work products; OData version 4.0 defines the core semantics and facilities of the protocol, including a set of conventions for addressing resources, query string operators for querying a service, and an XML representation of the Entity Data Model exposed by an OData service. OData JSON Format version 4.0 defines representations for OData request and response bodies using a JSON format. OData Atom Format version 4.0 defines an equivalent representation for OData request and response bodies using an Atom/XML format.
Many organizations are already working with OData, and it has proven to be a useful and flexible technology for enabling interoperability between disparate data sources, applications, services, and clients. Here are some recent examples:
- SAP have published the initial contribution of their OData Java library to GitHub - https://github.com/SAP/cloud-odata-java. SAP has a strong interest in OData and you will find it utilized across many of their platforms and services.
- Earlier this year, SAP gave a presentation on their open source OData Eclipse Plugin at EclipseCon. The presentation describes the OData service creation, and discusses how the service can be consumed from a lightweight Java-based (Android) application - OData Unleashed! Let’s Learn How to Exploit It (Presented by SAP)
- Flatmerge recently added OData output to their current output formats of plain XML and JSON - Get OData Output from Flatmerge
- JayData is a unified data access library for JavaScript to work with data APIs including OData. They recently published a Blog Calling OData actions and service operations with JayData.
- Earlier this month, the White House released an executive order on open data Making Open & Machine Readable the New Default for Government Information. The folks at Layer 7 published a Blog discussing how to open up government data with OData Making Government Data “Easy to Find, Accessible & Usable”.
Microsoft Research Explores OData and the Semantic Web
Microsoft Research (MSR), in collaboration with The British Library and the Digital Enterprise Research Institute (DERI), has just published a whitepaper Linking Structured Data that explores how OData can be used to expose data within an RDF triple store through an end-user oriented model, and consumed by a broad range of consumer-oriented tools and applications. To better understand how RDF data could be exposed and consumed by OData clients in a real world example, MSR went from theory to practice by focusing on some scenarios from The British Library which publishes its metadata on the Web according to Linked Data principles.
Join the OData Community
If you’re interested in using or implementing the OData protocol or contributing to the OData standard, now’s the time to get involved.
- Learn more about OData and the ecosystem of open data producer and consumer services by visiting the recently revamped OData.org web site for information, content, videos, and documentation.
- Get the latest information for what's going on in OData by join the OData.org mailing list.
- Get involved in the #OData discussion and contribute to the OData community.
- Join the OASIS OData technical committee (OData TC) to contribute to the standard.
- Send comments on OData version 4.0 to the OASIS OData Technical Committee
We’re looking forward to continued collaboration with the community to develop OData into a formal standard through OASIS.

• See Matt Sampson (@TrampSansTom) explained OData Apps in Update 2 - Querying Data from Stack Overflow in the Visual Studio LightSwitch and Entity Framework v4+ section below.
The WCF Data Services Team announced WCF Data Services 5.5.0 Prerelease on 5/15/2013:
It’s that time again: yesterday we uploaded an RC for the upcoming 5.5.0 release. The 5.5.0 release will be another NuGet-only release.
What is in the release:
This release has two primary features: 1) significant enhancements to the URI parser and 2) public data source providers.
URI Parser
In the 5.2.0 release ODataLib provided a way to parse $filter and $orderby expressions into a metadata-bound abstract syntax tree (AST). In the 5.5.0 release we have updated the URI parser with support for most OData URIs. The newly introduced support for parsing $select and $expand is particularly notable. With the 5.5.0 release the URI Parser is mostly done. Future releases will focus on higher-order functions to further improve the developer experience.
Note: We are still trying to determine what the right API is for $select and $expand. While the API may change before RTM, the feature is functionally complete.
Public Data Source Providers
In this release we have made the Entity Framework and Reflection data source providers public. This gives more control to service writers. There is more work planned in the future but the work we’ve completed allows some advanced scenarios which were not possible earlier. For example, a service writer can now make use of the Entity Framework query-caching feature by intercepting the request and parameterizing the LINQ query before handing it off to Entity Framework. (Note that parameterizing a LINQ query is not the same as parameterizing a SQL query; EF always does the latter and therefore there is no security implications to failing to parameterize a LINQ to Entities query, the only impact is performance related.)
While the potential unlocked with this release is limited, this is the first move in a direction which will unlock many previously unachievable scenarios with the built in providers.
<Return to section navigation list>
Windows Azure Service Bus, Caching Access Control, Active Directory, Identity and Workflow
‡ Vittorio Bertocci (@vibronet), Nathan Totten (@ntotten) and Nick Harris (@CloudNick) producted Cloud Cover Episode 109 - Using Windows Azure Active Directory from Windows Store apps on 5/31/2013:
In this episode Nick Harris and Nathan Totten are joined by Vittorio Bertocci, Principle Program Manager on Windows Azure Active Directory. … Vittorio demonstrates how you can easily use Windows Azure Active Directory to authenticate users of your Windows Store apps hence allowing users of your Windows Store apps to make authorized call a Web API. In addition he demonstrates how to add Multi-factor authentication allowing you approve sign in to your Windows Store application by [a] text message on your phone.
Links to content demonstrated and discussed by Vittorio:
- Walkthroughs for GA and preview
- Graph explorer
- AAL for Windows Store
- Using the OAuth endpoints directly form a Windows Phone 8 app
- NodeJS announcement
- My new blog - http://www.cloudidentity.com
- Twitter: @vibronet
Attending TechEd or watching online?:
- Vittorio provides a deeper dive on Windows Azure Active Directory in his session: Securing Cloud Line-of-Business and SaaS Web Applications Using Windows Azure Active Directory
In the News:



<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
‡ 
Microsoft server products, like SharePoint Server, only run on Windows Server and will not run on Linux. As a result, Microsoft does not have a virtual server offering. Windows Azure fits the bill with of [sic] a virtual server with the operating system product. The difference between a virtual server offering like Amazon and the Azure offering is that with Azure you must use Windows. If you are choosing a Microsoft software product then it makes sense to use Azure. If you want to run software products made for Linux then Azure will not work for you. [Emphasis added.]
The white paper’s author apparently didn’t get the memo about Windows Azure Infrastructure as a Service (IaaS), which became generally available (GA) on April 16, 2013 after a lengthy preview period, and ceded the Linux IaaS market to Amazon Web Services.

Update 5/31/2013: Timeouts began reoccurring on 5/18/2013 for unknown reasons and uptime just squeaked by the expected 99.5% SLA when WAWS reaches the General Availability stage:
Here’s the first full month of response time values:
Response time has definitely leveled off at about half the original values before enabling WordPress Super Cache, so I replaced “Temporarily” with “Substantially” in the post’s title.


My (@rogerjenn) WordPress Super Cache Improves Site Response Time Temporarily post updated 5/20/2013 deals with response time issues with Windows Azure Web sites:
Update 5/20/2013: Changed post title from “WordPress Super Cache Improves Site Response Time Dramatically” to “WordPress Super Cache Improves Site Response Time Temporarily” due to recent increase of cached-page response time and timeouts (see updated screen captures below).
My new Android MiniPCs and TVBoxes Windows Azure Web Site has exhibited slow page response times and intermittent timeouts since its inception in late April. The Windows Azure
team’s Mark Brown (@markjbrown) recommended that I install the WordPress Super Cache plug-in to improve performance.
The WordPress Plugin Directory describes WP Super Cache as:
A very fast caching engine for WordPress that produces static html files.
This plugin generates static html files from your dynamic WordPress blog. After a html file is generated your webserver will serve that file instead of processing the comparatively heavier and more expensive WordPress PHP scripts.
The static html files will be served to the vast majority of your users, but because a user’s details are displayed in the comment form after they leave a comment those requests are handled by the legacy caching engine. Static files are served to:
- Users who are not logged in.
- Users who have not left a comment on your blog.
- Or users who have not viewed a password protected post.
99% of your visitors will be served static html files. Those users who don’t see the static files will still benefit because they will see different cached files that aren’t quite as efficient but still better than uncached. This plugin will help your server cope with a front page appearance on digg.com or other social networking site. …
I chose the PHP Caching option because I’m new to WordPress and it’s simpler to install than Apache mod_rewrite or Legacy Caching.
Here’s Pingdom’s Response Time report as of 3/16/2013 8:00 AM PDT, which shows a dramatic decrease in average hourly response time as of 5/15/2013, the date on which I installed the SuperCache plug-in:
Update 5/20/2013: Here’s the latest Pingdom report showing a return to almost pre-cached response times:
Pingdom has reported no downtime
sinceduring the two days after I installed SuperCache, as shown here:
Update: Timeouts began reoccurring on 5/18/2013 for unknown reasons:
I’ll update this report again on 5/31/2013 with an entire month’s data.







Nuno Godinho (@NunoGodinho) posted Lessons Learned: Taking the best out of Windows Azure Virtual Machines to the Aditi Technologies blog on 5/13/2013 (missed when published):
Windows Azure Virtual Machines are a great addition to Windows Azure but there are a lot of tricks in order to make it better. Now that Windows Azure IaaS offerings are out and made GA a lot of new workloads can be enabled with Windows Azure.
Workloads like, SQL Server, SharePoint, System Center 2012, Server Roles like AD, ADFS DNS and so on, and even Team Foundation Server. More of the supported list of server software that is currently supported in Windows Azure Virtual Machines can be found here.
But knowing what we can leverage in the Cloud isn’t enough, every features has its tricks in order to take the best out of it. In this case in order to take the best performance out of the Windows Azure Virtual Machines, I’ll provide you with a list of things you should always do, and so making your life easier and the performance a lot better.
Additionally, you can check Aditi’s offerings around Windows Azure Infrastructure Services (WAIS) here.
1. Place each data disk in a single storage account to improve IOPS
Last November 2012 Windows Azure Storage had an update which was called “Windows Azure’s Flat Network Storage” which provided some new scalability targets to the blob storage accounts. In this case it went from 5,000 to 20,000, which means that we can actually have something like 20,000 IOPS now.
Having 20,000 IOPS is good but if we have several disks for the same Virtual Machine this means that we’ll need to share those IOPS with all those disks, so if we have 2 disks in the same storage account we’ll have 10,000 IOPS for each one (roughly). This isn’t optimal.
So, in order to achieve optimal we should create each disk in a separate storage account, because that will mean that each disk has its 20,000 IOPS just for itself and not sharing with any other disk.
2. Always use Data Disks for Read/Write intensive operations, never the OS Disk
Windows Azure Virtual Machines have two types of disks, which are OS and Data Disks. The OS Disk goal is to have everything that has to do with OS installation or any other product installation information, but isn’t actually a good place to install your highly intensive read/write software. In order to do that, you should actually leverage Data Disks, because their goal is to provide a faster and read/write capability and also separate this from the OS Disk.
So since data disks are better than OS Disks it’s easy to understand why we should always place read/write intensive operations on data disks. Just be careful on the maximum number of data disks you can associate to your virtual machine, since it will differ. 16 Data Disks is the maximum you are allowed but for that you need to have an extra-large virtual machine.
3. Use striped disks to achieve better performance
So we told that you should always place your read/write intensive operations software on data disks and in different storage accounts because of the IOPS you can get, and we told it was 20k IOPS, but is that enough? Can we live with only 20k IOPS in a disk?
Sometimes the answer might be yes, but in some cases it won’t because we need more. For example if we think about SQL Server or SharePoint they will require a lot more, and so how can we get more IOPS?
The answer is data disks striped together. What this means is that you’ll need to understand your requirements and know what’s the IOPS you’re going to need and based on that you’ll create several data disks and attach them to the virtual machine and finally stripe them together like they were a single disk. For the user of the virtual machine it will look like a single disk but it’s actually several ones striped together, which means each of the parts of that “large disk presented to the user” has 20k IOPS capability.
For example, imagine we’re building a virtual machine for SQL Server and that the size of the database is 1TB but requires at least 60k IOPS. What can we do?
Option 1, we could create a 1TB Data Disk and place the database files in there but that would max out to 20k IOPS only and not the 60k we need.
Option 2, we will create 4 data disks of 250GB each and place each of them in a single storage account. Then we’ll attach it to the virtual machine and in the Disk Management we’ll choose to stripe them together. Now this means that we have a 1TB disk in the virtual machine that is actually composed by 4 data disks. So this means that we can actually get something like a max of 80k IOPS for this. So a lot better than before.
4. Configure Data Disks HostCache for ReadWrite
By now you already understood that data disks are your friends, and so one of the ways to achieve better performance with them is leveraging the HostCache. Windows Azure provides three options for data disk HostCache, which are None, ReadOnly and ReadWrite. Of course most of the times you would choose the ReadWrite because it will provide you a lot better performance, since now instead of going directly to the data disk in the storage account it will have some cached content making IOPS even better, but that doesn’t work in all cases. For example in SQL Server you should never use it since they don’t play well together, in that case you should use None instead.
5. Always create VMs inside a Affinity Group or VNET to decrease latency
Also another big improvement you can do is to place always de VM inside an affinity group or a VNET, which in turn will live inside the affinity group. This is important because when you’re creating the several different storage accounts that will have data disks, OS disks and so on, you’ want to make sure the latency is decreased to the max and so affinity groups will provide you with that.
6. Always leverage Availability Sets to get SLA
Windows Azure Virtual Machines provide a 99,95% SLA but only if you have 2 or more virtual machines running inside an availability set, so leverage it, always create your virtual machines inside an availability set.
7. Always sysprep your machines
One of the important parts of the work when we take on Windows Azure Virtual Machines is to create a generalized machine that we can use later as a base image. Some people ask me, why is this important? Why should I care?
The answer is simple, because we need to be able to quickly provision a new machine if it’s required and if we have it syspreped we’ll be able to use it as a base and then reducing the time of installation and provisioning.
Examples of where we would need this would be for Disaster Recovery and Scaling.
8. Never place intensive read/write information on the Windows System Drive for improved performance
As stated before, OS Disks aren’t good for intensive IOPS so avoid leveraging them for read/write intensive work, leverage data disks instead.
9. Never place persistent information on the Temporary Drive (D:)
Careful what you place inside the Temporary Drive (D: ) since that’s temporary and so if the machine recycles it will go away, so only place there something that can be deleted without issues. Things like the IIS Temporary files, ASP.NET Temp files, SQL Server TempDB (this has some challenges but can be achieved like it’s shown here, and it’s actually a best practice).
Summary:
With general availability of Windows Azure Infrastructure Services (WAIS) recently, workloads like SQL Server, SharePoint, System Center 2012, and Server Roles like AD, ADFS DNS and so on, and even Team Foundation Server are supported. Optimizing Windows Azure Virtual Machine performance requires a few tweaks making your life easier and the performance a lot better.
Additionally, you can download Azure IaaS Data Sheets in the following links – Azure IaaS Core Infrastructure, Azure IaaS Hybrid Cloud, SQL on Azure IaaS, SharePoint on Azure IaaS and Dev/Test workload environments on Azure IaaS.





<Return to section navigation list>
Windows Azure Cloud Services, APIs, Tools and Test Harnesses
• Cory Fowler (@SyntaxC4) described a New Windows Azure SDK for PHP Feature: RunPHP (on Windows) in a 5/25/2013 post:
If you are developing PHP on Windows for use on Windows Azure, there is a fancy new feature which may catch your attention. First things first, let’s run through the basics of installing the Windows Azure SDK for PHP in order to set up your environment to get ready for PHP development for Windows Azure.
This new feature is part of the Windows Azure PowerShell and Windows Azure Emulators components which is downloadable through the Web Platform Installer.
Install Windows Azure PowerShell and Windows Azure Emulators for PHP
- Open Web Platform Installer via the Windows Azure PowerShell and Windows Azure Emulators deep link.
- Click Run.
- Accept UAC prompt.
- Click Install.
- Click I Accept.
- Go to the kitchen and grab a cup of coffee.
- Click Finish.
How To: Use RunPHP to test a PHP Application on Windows
In order to understand how to use
runphp, let’s quickly build a sample PHP application to show off the functionality ofrunphp.12345
<?php
echo phpinfo();
?>
view raw info.php This Gist brought to you by GitHub.
Now that we have a simple application set up, let’s open a command prompt to use
runphp. I will use Windows PowerShell to execute commands, in order to use runphp, PowerShell will need to be run as Administrator.To run PowerShell as Administrator, right click on the PowerShell icon and select Run as Administrator.
Navigate to the path which contains your application, then execute the command
runphp.
There are a number of things going on when executing RunPHP, let’s enumerate the high level steps:
- Copies an
apphost.configfile to the current directory- Runs
appcmd.exefrom IIS Express
- Creates a new Website based on the current directory
- Configures a HTTP Handler to map *.php files to
php-cgi.exeinterpreter- Starts IIS Express and binds the website to an open port.
To view and test your website, open a browser visit the
localhostaddress with the appropriate port which the website was bound to during therunphpprocess.
Once you finish testing, you can shut down IIS Express by opening the PowerShell window and pressing the ‘Q’ key.
Now that you’ve finishing testing your application on your local machine, you can deploy to Windows Azure Web Sites.




![clip_image001[6]](http://blog.syntaxc4.net/wp-content/uploads/2013/05/clip_image0016.jpg "clip_image001[6]")
![clip_image001[9]](http://blog.syntaxc4.net/wp-content/uploads/2013/05/clip_image0019.jpg "clip_image001[9]")





<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Matt Sampson (@TrampSansTom) explained OData Apps in Update 2 - Querying Data from Stack Overflow and linked to a live Windows Azure example in a 5/23/2013 post to the Visual Studio LightSwitch blog:
Matt Sampson's got a blog about making a LightSwitch HTML App that queries data from the one and only Stack Overflow by attaching to their very cool public OData Service.
(Now you can use a LightSwitch app to keep track of all the LightSwitch related posts on Stack Overflow!)
You can check out the blog post here - OData Apps in Update 2–Querying data from Stack Overflow
I published the HTML App up into azure if you'd like a preview of it - StackOverflow App.



Beth Massi (@BethMassi) described Saving Data Across One-to-One Relationships in a 5/09/2013 post:
I’ve had a couple questions recently on how you could add data to tables that have a one-to-zero-or-one relationship in Visual Studio LightSwitch. Depending on whether the related record is mandatory (required) or not you have a couple different options when inserting data. So in this post I’ll show you a couple different options for doing that in both the desktop and mobile clients.
Our Data Model
Let’s take a simple data model of Customer and a related table CustomerNote. A customer can have zero or one note as defined by the relationship.
When we create our Customer screens, LightSwitch will automatically bring the CustomerNote fields in as well. For edit screens this is exactly what we want because this allows the user to edit fields across both tables on one screen. However, on AddNew screens, LightSwitch will not automatically add a new record to the CustomerNote table – we need to write code for that depending on if the note is mandatory or not.
Adding Code to the Silverlight Client
In order to support this in the Silverlight desktop client we need to write some VB (or C#) code.
Mandatory: Always add a related record
If you want to always add a related record, use the _Created event. Open the data designer to the parent record (in my case Customer), select the DesktopClient perspective and then write code in the _Created event to add the related record every time the parent is inserted.
Write the code in bold.
VB:
Public Class Customer Private Sub Customer_Created() Me.CustomerNote = New CustomerNote() End Sub End ClassC#:
public partial class Customer { partial void Customer_Created() { this.CustomerNote = new CustomerNote(); } }Now when we run the desktop client and add a new customer, the note fields are enabled.
Optional: Allow the user to decide
If the related record is optional and you want to have the user decide, add a gesture (like a button) to your screen. Open the screen designer and add a button, select “Write my own method” and call it AddNote, then edit the CanExecute and Execute methods.
VB:
Private Sub AddNote_CanExecute(ByRef result As Boolean) 'Only enable the button if there is no note result = (Me.CustomerProperty.CustomerNote Is Nothing) End Sub Private Sub AddNote_Execute() ' Add the note Me.CustomerProperty.CustomerNote = New CustomerNote() End SubC#:
partial void AddNote_CanExecute(ref bool result) { // Only enable the button if there is no note result = (this.CustomerProperty.CustomerNote == null); } partial void AddNote_Execute() { // Add the note this.CustomerProperty.CustomerNote = new CustomerNote(); }Adding Code to the HTML Client
In order to support this in the html client we need to write some JavaScript code.
Mandatory: Always add a related record
Open the data designer to the parent record, but this time select the HTMLClient perspective. Then write JavaScript code in the _Created event to add the related record every time the parent is inserted.
myapp.Customer.created = function (entity) { entity.CustomerNote = new myapp.CustomerNote(); };Notice the use of the myapp object here. You can use the myapp object in a variety of ways in order to access data and screens in the HTML client. Check out some other uses here- How to: Modify an HTML Screen by Using Code
Now when we run the HTML client and add a new customer, the note fields are enabled.
Optional: Allow the user to decide
Open the screen designer and add a button, select “Write my own method” and call it AddNote, then edit the CanExecute and Execute methods. Then write this code:
myapp.AddEditCustomer.AddNote_canExecute = function (screen) { // enables the button (returns true) if the note doesn't exist return (screen.Customer.CustomerNote == null); }; myapp.AddEditCustomer.AddNote_execute = function (screen) { //Add a new note screen.Customer.CustomerNote = new myapp.CustomerNote(); };Wrap Up
So those are a couple different ways you can manage data participating in one-to-zero-or-one relationships. Keep in mind that these tables are in the same data source, but they don’t have to be, you can set up virtual relationships this way as well. If you do have separate data sources, however, you’ll also need to tell LightSwitch the order in which you want to update them. For more information on that see: Customize the Save command to save to multiple data sources








Brian Moore described Publishing LightSwitch apps for SharePoint to the Catalog in a 4/29/2013 post to the Visual Studio LightSwitch Team blog:
Ok, your app is done, you’ve learned how to authenticate it and publish it like I demonstrated in my previous post. When you’re done with the publish wizard on a SharePoint app, you’ll see an explorer window open with folders for each version of your app. Probably just 1.0.0.0 so far - in the folder is a .app package. This .app package will always contain the information SharePoint needs to install and run your app. Things like permissions, end points, project artifacts (like lists), etc. This .app package is what you give to SharePoint to make your app available to users.
If you published an autohosted app, then the package also contains the LightSwitch application itself. All the files that make up your web site. If you published a provider-hosted app, then all of those files that make up your web site are already on a live server somewhere (if you did a remote publish) or in a WebDeploy package waiting for you to deploy the package. In the provider-hosted case, you do want to make sure that your LightSwitch app is running before any users install the app package into SharePoint otherwise they’ll just see a 404 of some sort.
So now what do you do with this .app package?
Apps for SharePoint
First, a little background on the app model for SharePoint. Everything on SharePoint 2013 is an app. All the things you might be familiar with (list, libraries, code) are packaged into an app for SharePoint. This way, whenever the user wants something for the site, there’s an app for that. Where do you get apps? From the store. For Office365 there is a public store that contains public apps. Some are free, some have other licensing models. You can also get apps from a private app catalog for your SharePoint site. So basically you have access to public apps and private apps. LightSwitch can build apps for either scenario, though there are some things to be aware of which I’ll cover later.
So when you publish a LightSwitch app for SharePoint, you will publish not only your web application but also the app package that will be uploaded to the App Catalog or SharePoint store. So let’s take a look at this from end to beginning.
The App Catalog
Even though you can put your LightSwitch app in both the app catalog or the SharePoint Store, I’m going to walk through the App Catalog scenario. Your LOB apps written in LightSwitch (especially your first one) are likely to be “private” apps so first things first. When you want to add an app to your site, you can go to the site contents and, well, add an app.
When you click add, you’ll see all the apps that come with SharePoint, all the lists and libraries you might be familiar with. When you put your LightSwitch app in the app catalog, it will show up here as well. Since there are a lot of apps already for your site, you can look for apps just from your catalog by clicking the “From Your Organization” link.
Yours will probably look like this (empty). Also notice the link to the “public” store.
So we need to get our app into our catalog – and if this is the first time you’re working with the catalog, you might not even have a catalog yet. A private app catalog for apps “From Your Organization” is another SharePoint site collection in your tenant. It’s a special site template that any site in your tenant can attach to, to install apps. So to create one we need to go to Site Admin to create an app catalog. First step is to go to SharePoint central admin.
Then go to “apps” and select “App Catalog”
You’ll see an option to create a new catalog or use an existing one, if you don’t have one, just create a new one – you can change anything you need to later. It will take SharePoint a few minutes to provision the new site and the page won’t necessarily refresh on it’s own (in case you’re waiting for that spinning circle to go away to know when it’s done).
Now that you have the catalog you need to get the app in the catalog. Remember this catalog is just another site for SharePoint so you can navigate to it and that’s how you’ll add apps. You can see your app catalog listed in your site collections in the admin center.
Navigate to that URL and you are at your app catalog. Remember that URL because there isn’t really any other way to get to it other than what I just showed you (at least not that *I* know of). Drill down to the “Apps for SharePoint” section and you’ll see any apps you have that can be installed onto a SharePoint site. Since I just created this catalog I don’t have any apps.
Putting Your App in the Catalog
We’re almost there… now we just need to take the .app package we built and put it into the catalog. Just click the “new app” link and you’ll be prompted for the package. When the app is uploaded you will be prompted to fill in the metadata for the app catalog. There is a lot there, but it’s all optional except the name. You can provide a description, change the icon, add images to show case the app. You can even make it a “noteworthy” app that will pop it to the top of the list when users browse the catalog.
Once you’ve saved the app, you’ll see it in the list. Remember that this is our “private” catalog that contains apps just “From Your Organization” but your users will need permission to the app catalog site to see it. First, here’s what you should see in the catalog. Over time you’ll see more apps here and also versions of each app that you can manage throughout your organization.
To grant permission to the catalog you assign permissions to the catalog site just like you do any other SharePoint site collection – through the Site Settings for that site. This will let you determine which users on your site can *see* apps from this catalog. To install apps on a particular site, the user must have permission to install apps on that particular site. So seeing something in the catalog is necessary but not sufficient for installing it. And as you might guess, you may not want all users to install apps and by default they won’t be able to until you grant them permission. So, first they need permission to the catalog site to even see the apps. Then they need permissions on an individual site, to be able to install the app.
And finally, just to add another layer on here – just because an app is installed on a site, doesn’t mean all users can run the app. You may not want everyone to access an app that’s installed and you can again, control that by setting the appropriate permissions in SharePoint. That’s enough about permissions for now – suffice it to say, that just like any other LOB LightSwitch app, you can still control who accesses your application when it’s running on SharePoint, using what will become (if it’s not already) the familiar SharePoint permission model.
After all that, in this example we’re just going to keep using our own user account which owns the site collection for the app catalog and the dev site, but you can drill in here whenever you’re ready ;)
Installing Your App from the Catalog
Once you have the app in the catalog, there is one path your users will go through to install the app, or any app for that matter. Again, the user must have permission to install apps onto the site. Note, that when using a dev site, there are a few ways to install apps onto the site, but for now, let’s walk through what end users will see on non-developer sites. I used a project site template for this example, but it will look similar to most templates when it comes to installing apps. First, go to the site contents:
From there you will have the option to “add an app”. Once you click to add the app you’ll see a list of the apps available to the site. Here you can find your app in the list of all the apps - you see our CustEdit app below.
You can also filter the list to show only the apps in your catalog by choosing “From Your Organization” as we did at the beginning of the blog. Note, that this is the same catalog I was using above, this catalog is shared among all the sites in my tenant – it is “for my organization”. So everyone in my company or tenant can see this app if I give them permission. So you can configure permissions for installing or browsing apps in just about any configuration you can imagine. For example, even though your organization can share a single catalog, you can still restrict who can see particular apps in that catalog. And also restrict who can install apps on a given site. The flexibility that is there though is a bit beyond the scope of what I want to cover here (though it feels like I just covered it so I might as well summarize).
- Users need to be granted permission to the app catalog site to be able to see apps “From your Organizaition.” You just navigate to the catalog site, then the site settings and set perms like you do for any other SharePoint site
- Users need permission to install apps on a particular SharePoint site (for example Site Owners can install apps, Site Members cannot)
- You can restrict who can see an app in the catalog by setting permissions for a particular app. By default anyone who you gave access to in the first bullet above will be able to see the app (perms are inherited) but you can change that
- Once an app is installed on a site, you can further restrict who can run that app via permissions on the installed app
But for now, since you likely own everything you’re working with, you really don’t need to set any perms yet.
So that’s the app store experience. Once you install an app from the catalog it will show up under your Site Contents just like every other app installed on that site.
Installing Apps on a Dev Site
You might be wondering by now why you never had to do any of this while you were developing your app. Developer sites in SharePoint give you some extra functionality to make life as a SharePoint developer easier :) and that’s why. But that only works on dev sites, to get apps onto non-dev sites, you need to go through the catalog.
There is, as you might have guessed another way to install an app onto a dev site without going through the catalog. When you F5 your app from VS, the app package is technically installed on the SharePoint dev site and pointing to your application on localhost. VS does all of that for you. If you want to actually run your app from the cloud (in this case) instead of localhost, you can do that on a dev site without putting it into the catalog. You do that by going to the dev site’s “apps in testing” section and selecting “new app to deploy”.
There’s one thing to be aware of going down this path particularly if you’ve been developing your app against this same site. Remember that I said VS installs the app for you while you’re debugging? That means your app is probably still installed on this site and if you try to install it again, SharePoint will tell you it’s already installed. VS doesn’t uninstall it every time you stop debugging because, well, it would take longer to install it again the next time you started debugging, we might as well leave it there -- you probably debug much more often than you do this catalog stuff. Anyway, if you do get that error, just click in the ellipses by your app and remove it, then try the deploy again.
Finally, another option you have (and you may very well want test this out some day) is upgrading an app that’s already installed. This is what would happen if you release a new version into the app catalog and users had installed your app. They would get notification that a new version is available and SharePoint would upgrade your app. This would include upgrading your autohosted database if you had one. To try that out, go up to the ribbon and select “Upgrade an app”.
The SharePoint Store
You probably want me to wrap this up by now, but I do want to make a quick mention of the SharePoint Store or the public catalog. The process for getting your apps into the Office 365 SharePoint Store is, as you might well imagine, very different. I’m not going to cover that yet. A few notable things if you want to try this yourself before I get to it. You will need to make some changes to the manifest to get the store to “accept” your app. The error will be descriptive but if you need help leave a comment or post in the forum and we can try to cover it briefly. Also, the SharePoint Store does not *yet* accept autohosted SharePoint apps. That means you’d have to host the LightSwitch application yourself and deal with multi-tenancy in your LightSwitch app, not to mention pay for hosting it. So we have a few things we need to make much easier before I cover that in a post.
Finally…
That’s all for now, but before I go I want to mention one last thing – partially because I seem to get more comments on a blog when I mention Ms. Massi somehow. Beth got engaged a few weeks back and for someone who has done as much for our community as she has, we all certainly wish her the best. Congrats!
















Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Michael Washam (@MWashamMS) described Automating SharePoint Deployments in Windows Azure using PowerShell in a 5/24/2013 post to the Windows Azure blog:
SharePoint has proven to be one of the most popular Microsoft workloads running on Windows Azure Virtual Machines. Hosting highly customized SharePoint farms and building Internet facing websites that scale in-real time are some of the key scenarios where many customers and partners take advantage of cloud economics and scale with Windows Azure.
Now, it is even easier to provision SharePoint farms in Windows Azure. Using the new Remote PowerShell functionality and the Windows Azure PowerShell Cmdlets, we have put together new sample PowerShell scripts. You can use these new scripts to automate all the required steps when rolling out a SharePoint server farm, saving time and effort.
The sample scripts are available in the Windows Azure PowerShell Samples GitHub repository for download and use. These scripts serve as a starting point for spinning up SharePoint farms and you can customize them for your own use case.
Let’s take a closer look at what you can accomplish with these scripts…
Rolling Automated Deployments of SharePoint, SQL Server and Active Directory
The sample scripts allow automated provisioning of the following workloads as individual tiers or as a one complete deployment.
- Active Directory
- SQL Server 2012
- SharePoint 2013
Each tier can be deployed in a single virtual machine configuration or with multiple virtual machines for a highly available solution.
Example Deployment Topologies Available with the New Scripts and Templates
Single VM Template
This template is designed to produce a SharePoint farm for evaluation, development or testing.
- 1 Windows Virtual Machine for Active Directory - Small Instance Size (1 core and 1.75 GB memory)
- 1 SQL Server Virtual Machine - A6 Instance Size (4 cores and 28 GB memory)
- 1 SharePoint Server 2013 Virtual Machine with all Services - Large Instance Size (4 cores and 7 GB memory)
Highly Available Template
This template is designed to produce a highly available farm architecture. You can adjust and change the default instance sizes.
- 2 Windows Virtual Machines for Active Directory - Instance Size Small (1 core and 1.75 GB memory)
- 2 SQL Server VMs - Instance Size A6 (4 cores and 28 GB memory)
- 1 Windows VM for Quorum - - Small Instance Size (1 core and 1.75 GB memory)
- 2 SharePoint Application Servers - Instance Size Large (4 cores and 7 GB memory)
- 2 SharePoint Web Servers - Instance Size Large (4 cores and 7 GB memory)
You can expect us to provide similar scripts for additional scenarios in the near future. Documentation on how to configure and deploy the scripts can be found in the Windows Azure PowerShell samples GitHub Wiki. Please give them a spin and let us know what you think…We are looking for your feedback.
P.S. We have introduced a detailed technical white paper on deploying SharePoint that you should review along with the deployment wiki. For a refresher on Remote PowerShell and the Windows Azure PowerShell Cmdlets see my earlier post.



Satya Nadella reported Microsoft announces major expansion of Windows Azure services in Asia in a 5/22/2013 post to The Official Microsoft Blog:
As the worldwide demand for cloud computing continues to grow, so does Windows Azure. Microsoft is the only at-scale global public cloud provider to deliver a hybrid cloud advantage and we’re excited to announce plans to invest hundreds of millions of dollars to expand the Windows Azure footprint in Asia – specifically in China, Japan and Australia.
On Wednesday in Shanghai, Microsoft CEO Steve Ballmer announced that a Public Preview for the Windows Azure service, operated by 21Vianet in China, will be available for sign-up starting June 6. The announcement in China builds on the agreements we signed November 1, 2012, with the Shanghai municipal government and 21Vianet. We are excited to be the first multinational organization to make public cloud services available in China, and encourage customers to sign up for the free trial at http://www.windowsazure.cn starting June 6.
Today, Steve also announced our intent to open a new major region in Japan, with two local sub-regions— Japan East in the Tokyo area and Japan West in the Kansai area. And earlier this week, we announced our intent to open a new major region in Australia, with two sub regions in New South Wales and Victoria. These new regions will offer Japanese and Australian customers all the benefits of Windows Azure plus the disaster recovery, data sovereignty and improved performance benefits of local deployments. Customers in Australia and Japan can get started using Window Azure today knowing that they will have the ability to use the same resources locally when the new regions come online.
With IDC forecasting that Asia's cloud computing market will reach US$16.3 billion by 2016 (excluding Japan), we’re working hard to bring these new Windows Azure regions and Windows Azure in China, operated by 21Vianet, online and we’ll have more to share closer to launch. Together with our global network and existing locations in Singapore and Hong Kong these new locations will help us satisfy the enormous cloud computing needs of the Asia region and the world. It’s been an exciting week, and I encourage you to learn more about each announcement at the links below:
• Public Preview of Windows Azure, operated by 21Vianet, in China
• Windows Azure Australia Expansion
• Windows Azure Japan Expansion

Timothy Prickett Morgan quoted “Cloudy beancounter Newvem: 'We're not trying to do 50 clouds ... half-way'” as a preface to his Amazon cloud-watcher shows some love for Microsoft's Azure article of 5/20/2013 for The Register:
Newvem has been peddling its Cloud Care monitoring and costing tools for virty public infrastructure since it uncloaked last November for Amazon Web Services.
Now the company is expanding Cloud Care so it can control-freak Microsoft's Windows Azure heavenly server and storage slices.
Support for Cloud Care plugging into Windows Azure is free at the moment, Cameron Peron, vice president of marketing, tells El Reg, but eventually there will be a for-fee version with premium features. (And for some reason the Cloud Care for Azure is being called Newvem Analytics for Azure instead of Cloud Care for Azure. Go figure.)
The company is not committing to a timetable to sling production-grade hooks into Azure until Newvem gets some experience with Azure users under its belt. Newvem is similarly not making any commitments about snapping Cloud Care into private clouds built on Windows Server 2012 and its System Center virtualization and orchestration tools, but clearly down the road this would be a particularly useful extension of Cloud Care if it can be done.
What Peron will confirm is that for now, having Cloud Care count beans for AWS and Azure is sufficient. After all, AWS utterly dominates the public cloud, and Newvem reckons Azure has around a 20 per cent share of cloud market - which it expects to account for around 35 per cent by the end of 2013.
"For now, we are focused on Amazon and Azure," says Peron. "Many companies are out there trying to cover as many clouds as possible, and many people think it is all about cost but it is about cost and usage. We do one cloud and we do it right, and then move to the next. We are not trying to do 50 clouds and do it half-way."
Newvem can play mother in law for Azure, telling you what you are doing wrong and where you are spending too much money
The Cloud Care service comes in two flavors. The Free Edition is a high-level tool that does regular checkups on EC2 compute slices on AWS and now on Azure Virtual Machines running either Windows or Linux. Cloud Care analyzes the configurations of the virtual machines on the public cloud and alerts admins to incorrect settings. It also analyzes workloads, suggesting how to right-size virtual machine instances, and provides a heat map of running workloads so you can visualize what is going on inside your public cloud capacity.
If you really want to manage your AWS and Azure capacity better, and be able to drill down into the heat map for lots more stats about what is going on inside that infrastructure, you have to pony up some cash for the Premium Edition of Cloud Care.
This edition will tell you what reserved instances of AWS EC2 compute slices should be converted to on-demand instances. At some future date, it will be able to give advice on spot pricing as well to help companies shave their AWS bills. Similarly, Cloud Care will have to be able to do the math on whether you should use pay-as-you-go slices on Azure or go with the six- or 12-month reserved options that Microsoft offers.
The Premium Edition also monitors S3 storage on AWS and Azure Storage services on Microsoft's cloud; it will presumably be able to do SQL Server and BizTalk Server instances on Azure at some point as well as. Basically, Cloud Care should be able to monitor any service that is on AWS or Azure if it is to be truly useful.
And, if El Reg can be so bold as to make a suggestion, Cloud Care should be able to recommend if a workload should be moved from AWS to Azure or vice versa.
In either case, AWS or Azure, you give Cloud Care read-only access to the management APIs on either AWS or Azure and all of the performance data is sucked out of your cloud and into Newvem's SaaS-style tool, which runs on AWS itself and is back-ended by a NoSQL database that stores copies of your operational data sucked out of the public clouds and compares how you are configured with best practices for similar workloads.
You can sign up for the open beta for Azure analytics here.
El Reg wonders how long it will take Microsoft to gin up a competing product, as Amazon Web Services has (sort of) done with its OpsWorks and Trusted Advisor tools for its cloud. It seems more likely that if Cloud Care is a good tool, Microsoft would just recommend customers use it... and if CEO Steve Ballmer is in the mood, maybe Redmond might even snap up Newvem all for itself.


No significant articles today
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Anders Ravnholt (@AndersRavnholt) asked and answered I have a Surface RT and going away for a few days, now what??? I have a MSDN subscription :-) (Part 1) on 5/16/2013:
I know many of you have seen the super cool blog post where my fellow team members build a private cloud out of their new Surface Pros. It was a cool idea and people really loved the video.
The cool thing about the Surface Pro is that it’s a normal PC and you can run any regular PC program (Silverlight, Java, Live Writer), as well as many other programs.
The problem:
I have not bought a Surface Pro yet (my mistake), but I do have a surface RT. I’m really happy with my Surface RT, but it has some limitations that prevent me from doing certain things on it. I recognized this the other day when I was planning on working while away on a trip – but I didn’t want to bring my PC.
Here is what I could not do from my Surface RT:
- Use live writer (the program I’m using to publish this post)
- Use Java (this is necessary for several websites I use on a regular basis)
- Use Silverlight
The Solution:
I started thinking about how I could solve this problem – and then I remembered that I have a MSDN subscription.
With MSDN you get the following every month in Windows Azure:
The Scenario:
I want to build a Windows machine running in Windows Azure, which I can connect to from my Surface RT.
In this first blog post, I will do the setup and configuration (This blog post)
In the second blog post, I will walk you through how the “gold image” can be uploaded to Azure (Can be found Here)
I want to run the following programs in my gold image
- Java
- Silverlight
- Windows Livewriter
Just for the fun of this blog post, all of it is written on the Windows machine already running in Azure from my Surface RT (except a few steps), and wanted to capture my learning's in this blog post.
The challenge
I have been using Windows Azure for a while and started to use a windows 2012 server to connect to form my Surface. One thing that started to irritate me was the entire configuration I needed to do every time. I just wanted to create a gold image that I could use every time I provision a Windows machine.
So in order to get my own image, I need to do the following:
- I need to sign up for Windows Azure (covered in this post)
- I need to install App. controller and configure Azure (covered in this post)
- I need to build my own image (covered in this post)
- I need to move my image to windows Azure from my PC (covered in the next post)
- I need to provision the VM based on my image in Azure (covered in the next post)
- I need to connect to the Windows machine using my Surface RT and start writing a blog post (covered in the next post)
Pre-requisites:
- MSDN subscription with access to Azure
- AD Domain for App controller
- Computer running Windows 8 / 2012 with Hyper-V enabled.
Sounds fun, right? Let’s get started. …

Anders continues part 1 with step-by-step directions for setting up his “Windows machine” on Windows Azure. Read his full post here.
<Return to section navigation list>
Cloud Security, Compliance and Governance

No significant articles today
<Return to section navigation list>
Cloud Computing Events
No significant articles today
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Brandon Butler (@BButlerNWW) asserted “Rumors of a shakeup at Dell from last week have been confirmed” in a deck for his Dell dumps OpenStack and VMware for public cloud, focuses on private clouds article of 5/20/2013 for Network World’s Insider blog:
Dell has dramatically shifted its cloud computing strategy, canceling plans it once had to launch a public cloud service based on the OpenStack open source platform, and discontinuing a VMware-based public cloud it already has on the market.
Instead, the company will focus on selling OpenStack-powered private clouds that run on Dell hardware and software. Using technology it acquired from cloud-management company Enstratius, Dell says its customers will be able to deploy resources to more than 20 public cloud providers. In announcing this change in strategy, Dell also said it has a new "partner ecosystem," consisting of just three providers now, but with plans to increase that number, which will provide integrations between those partner public cloud services and Dell customers' private clouds.
Launching an OpenStack-powered public cloud would have been an expensive investment for the company, which is mulling opportunities to go private, but Nnamdi Orakwue, vice president of Dell Cloud, said this shift is not related to the company's broader financial position as it deals with slumping revenues in some of its legacy business units.
Dell has been a cheerleader for OpenStack, and for more than a year has said it planned to launch an OpenStack-powered public cloud. At the very end of last year the company said those plans had been somewhat delayed and the cloud would not be ready until at least the end of 2013. Rumors began swirling last week when Network World reported that Dell is "refining" its cloud strategy and multiple members of the team working on Dell's public cloud have left the company. Today, Dell released details of its new strategy.
Orakwue says the focus now will be on private cloud deployments for customers, and then secondarily consulting with customers to help them determine what the best fit for a public cloud is. Dell will work with customers who are already using the company's VMware public cloud -- which will be discontinued -- to migrate to another platform. Orakwue would not say how many customers are in that situation, but the news comes on the eve of VMware announcing details of its plans to launch a public cloud. He added that the new strategy is in no way a commentary on OpenStack as a platform for building clouds and reiterated the company's commitment to using the open source platform for building private clouds for customers and partners.
Dell is working with three providers who are part of its partner ecosystem, whose services will be optimized to integrate with its private cloud deployments, including Joyent -- a company known for its ability to offer high-performance cloud computing -- along with ZeroLag and ScaleMatrix, two other small infrastructure as a service (IaaS) providers. Orakwue says Dell hopes to expand its partner program to include more providers.
Forrester cloud watcher James Staten says it's good that Dell is integrating technology it acquired less than a month ago from Enstratius, a powerful management platform that allows customers to deploy resources to a more than 20 public cloud providers, including all the major leading cloud companies like Amazon Web Services, Rackspace, Microsoft Azure and Google, among others.



Jeff Barr (@jeffbarr) described New Features for the Amazon Elastic Transcoder in a 5/17/2013 post:
We released the Amazon Elastic Transcoder with an initial set of features and a promise to iterate quickly based on customer feedback. You've supplied us with plenty of feedback (primarily via the Elastic Transcoder Forum) and have a set of powerful enhancements ready as a result.
Here's what's new:
- Apple HTTP Live Streaming (HLS) Support. Amazon Elastic Transcoder can create HLS-compliant pre-segmented files and playlists for delivery to compatible players on iOS and Android devices, set-top boxes and web browsers. You can use our new system-defined HLS presets to transcode an input file into adaptive-bitrate filesets for targeting multiple devices, resolutions and bitrates. You can also create your own presets.
- WebM Output Support. Amazon Elastic Transcoder can now transcode content into VP8 video and Vorbis audio, for playback in browsers, like Firefox, that do not natively support H.264 and AAC.
- MPEG2-TS Output Container Support. Amazon Elastic Transcoder can now transcode content into transport stream containing H.264 video and AAC audio, which are commonly used in broadcast systems.
- Multiple Outputs Per Job. Amazon Elastic Transcoder can now produce multiple renditions of the same input from a single transcoding job. For example, with a single job you can create H.264, HLS and WebM versions of the same video for delivery to multiple platforms, which is easier than creating multiple jobs and saves you time.
- Automatic Video Bit rate Optimization. With this feature, Amazon Elastic Transcoder will automatically adjust the bit rate in order to optimize the visual quality of your transcoded output. This takes the guesswork out of choosing the right bit rate for your video content.
- Enhanced Aspect Ratio and Sizing Policies. You can use these new settings in transcoding presets to precisely control scaling, cropping, matting and stretching options to get the output that you expect regardless of how the input is formatted.
- Enhanced S3 Options for Output Videos. Amazon Elastic Transcoder now enables you to set S3 Access Control Lists (ACLs) and storage type options without needing to use the Amazon S3 API or console. By using this feature, your files are then created with the right permissions in-place, ready for delivery to end-users.
To learn more about these features, visit the Elastic Transcoder Documentation and sign up for our free What's New with Amazon Elastic Transcoder webinar. The webinar will be held on May 29th at 10 AM PT.
As usual, these features are available now and you can start using them today.

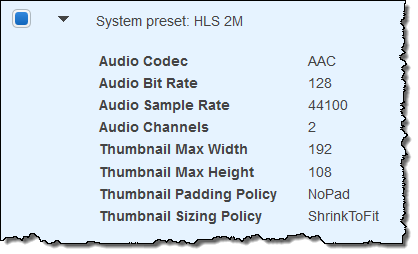
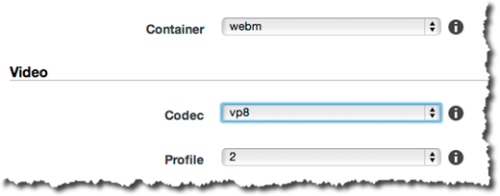
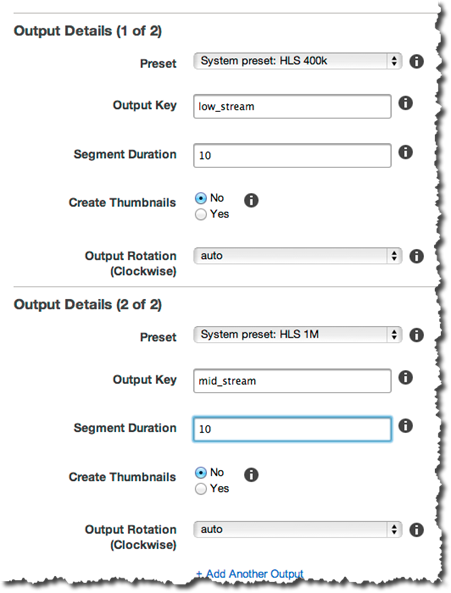

Werner Vogels (@werner) posted DynamoDB Keeps Getting Better (and cheaper!) on 5/15/2013:
We love getting feedback so we can deliver the improvements and new features that really matter to our customers. You can see from the pace at which we roll out new functionality that teams across AWS take this very seriously. One of the teams that’s iterating quickly is DynamoDB. They recently launched Local Secondary Indexes and today they are releasing several new features that will help customers build faster, cheaper, and more flexible applications:
Parallel Scans – To be able to increase the throughput of table scans, the team has introduce new functionality that allows you to scan through the table with multiple threads concurrently. Until now scans could only be performed sequentially, but with this new feature the scan can be split into multiple segments, each retrieved on their own thread.
Provisioned Throughput – To allow customer to respond to changes in load more rapidly, DynamoDB will allow the provisioned throughput to be decreased 4 times per day (was twice per day).
Read Capacity Metering – The read capacity unit will be increased from 1KB to 4KB. As a result many read scenarios will have their cost reduced to ¼ of the original cost. This also makes the DynamoDB/Redshift integration even more cost-effective, as exporting data from DynamoDB into Redshift could be up to four times cheaper.
We’re excited to give DynamoDB customers better read performance, lower costs, and more provisioning flexibility. Please keep the feedback coming – we’re listening.
For more details see the DynamoDB Developer Guide and for an overview visit the AWS developer blog.


Jeff Barr (@jeffbarr) reported Amazon DynamoDB - Parallel Scans, 4x Cheaper Reads, Other Good News on 5/15/2013:
We continue to make improvements, large and small, to Amazon DynamoDB. In addition to a new parallel scan feature, you can now change your provisioned throughput more quickly. We are also changing the way that we measure read capacity in a way that will reduce your costs by up to 4x for certain types of queries and scans.
Parallel Scans
As you may know, DynamoDB stores your data across multiple physical storage partitions for rapid access. the throughput of a DynamoDB Scan operation is constrained by the maximum throughput of a single partition. In some cases, this means that a Scan cannot take advantage of the table's full provisioned read capacity.
In order to give you the ability to retrieve data from your DynamoDB tables more rapidly, we are introducing a new parallel scan model today. To make use of this feature, you will need to run multiple worker threads or processes in parallel. Each worker will be able to scan a separate segment of a table concurently with the other workers. DynamoDB's Scan function now accepts two additional parameters:
- TotalSegments denotes the number of workers that will access the table concurrently.
- Segment denotes the segment of table to be accessed by the calling worker.
Let's say you have 4 workers. You would issue the following calls simultaneously to initiate a parallel scan:
- Scan(TotalSegments=4, Segment=0, ...)
- Scan(TotalSegments=4, Segment=1, ...)
- Scan(TotalSegments=4, Segment=2, ...)
- Scan(TotalSegments=4, Segment=3, ...)
The two parameters, when used together, limit the scan to a particular block of items in the table. You can also use the existing Limit parameter to control how much data is returned by an individual Scan request.
The AWS SDK for Java comes with high-level support for parallel scan. DynamoDBMapper implements a new method parallelScan, which handles threading and pagination of individual segments, which makes it even easier to try out this new feature.
To learn more about the parallel scan model, read the conceptual introduction and the best practices guide.
Provisioned Throughput Changes
You can now change the provisioned throughput of a particular DynamoDB table up to four times per day (the previous limit was twice per day). This will allow you to react more quickly to changes in load.Read Capacity Metering
We are changing the way that we measure read capacity. With this change, a single read capacity unit will allow you to do 1 read per second for an item up to 4 KB (formerly 1 KB). In other words, larger reads cost one-fourth as much as they did before.This change is being rolled out across all AWS Regions over the next week. Don't be alarmed if you see that your consumed capacity graph shows a lot less capacity than before.
With this change, scanning your DynamoDB table, running queries against the tables, copying data to Redshift using the DynamoDB/Redshift integration, or using Elastic MapReduce to query or export your tables, are all more cost-effective than ever before.
I hope that you can make good use of the new parallel scan model, and that the other two changes are of value to you as well.


<Return to section navigation list>

















0 comments:
Post a Comment