Windows Azure and Cloud Computing Posts for 1/27/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 1/29/2012 with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
• Avkash Chauhan (@avkashchauhan) described Creating your own Hadoop cluster on Windows Azure by using your own Windows Azure Subscription account in a 1/28/2012 post:
[The] Apache Hadoop distribution (currently in CTP) allows you to setup your own Hadoop cluster in Windows Azure cloud. This is article is written keeping those users in mind, who are very new to “Windows Azure” and “Hadoop on Windows Azure”. To have it running you would need the following:
Active Windows Azure Subscription
- Preconfigured Windows Azure Storage service
- About 16 available cores
- You would need Extra Large instance – 8 Core for the head node
- The default installer creates 4 worker node each with medium instance – 2 core[s for] each medium instance
- So, to start the default creation, you would need 8 + 8 = 16 empty cores
- You
surecan change the number of worker node later to a desired number- The machine you will use to deploy IsotopeEMR must
chhave direct connectivity to Azure Management Portal
- You would need the management certificate thumbprint
Get IsotopeEMR package and unzip it on your development machine which has connectivity to Azure Portal. After that edit IsotopEMR.exe.config as below:
<appSettings> <add key="SubscriptionId" value="Your_Azure_Subscription_ID"/> <add key="StorageAccount" value=" Your_Azure_Storage_Key"/> <add key="CertificateThumbprint" value=" Your_Azure_Management_Certificate_Thumbprint"/> <add key="ServiceVersion" value="CTP"/> <add key="ServiceAccount" value="UserName_To_Login_Cluster"/> <add key="ServicePassword" value=" Password_To_Login_Cluster "/> <add key=”DeploymentLocation” value=”Chooce_Any_Datacenter_location(Do_Not_Use_Any*)”/> </appSettings>After that launch the following command:
>isotopeEMR prep
This command [will] access you[r] Windows Azure storage and drop the package which will be used to build you[r] head node and worker node machine within [the] Hadoop Cluster.
C:\Azure\isotopeNew\isotopeEMR>isotopeemr prep
PrepStorageService
DoneOnce prep command is completed successfully now you can start the cluster creation. Try to consider a unique name for your cluster because this name will be used as <your_hadoop_cluster_name>.cloudapp.net. Now launch the following command to start the cluster creation:
>> isotopeEMR create hadoopultra
Within a few seconds you will see a new service crated at your Windows Azure management portal as below:
After a little while, you will see one full IIS Web Role as Headnode and 4 worker nodes are being created as below:
Then you will see some progress on your command windows as below explaining Bootstrapping is completed:
Now you will see “Creating VM” message on command prompt:
.. which shows that your roles are initializing and all the nodes are starting…
Finally you will see “Starting VM” message ….
And then you might find status showing “RoleStateUnknown” which is possible while your instance is getting ready:
While looking at your Windows Azure Management portal you will see roles are in transitioning state:
For those who are very well known to Windows Azure role status they may see the familiar ‘Busy” status..
Portal will back the command windows status as well:
Finally the command windows will show the Hadoop cluster creation is completed:
And you will see all of you[r] roles are running fine in “Ready” state:
Now you can take a look [at your] Azure service details and you will find all the endpoint[s] in your service as well as how you
useaccess most of cluster functionalities which are available in any Hadoop cluster:
Now you can open your browser and open your service at https://<yourservicename>.cloudapp.net. Opening the page will ask you to enter credentials which you have used in IsotopeEMR.exe.config:
And finally the web page will be open where you could explore all the Hadoop cluster management functions:
In my next blog entry I will dig further and provide more info on how to use your cluster and run map/reduce jobs.

















Don’t forget that 16 cores will cost you US$0.12 per hour each = US$1.92/hour = US$46.08/day. I ran up a US$75.00 bill trying to get Microsoft Codename “Cloud Numerics” to run a job on 18 cores. (See the Live Windows Azure Apps, APIs, Tools and Test Harnesses section below for more details.)
• Denny Lee (@dennylee) described Connecting PowerPivot to Hadoop on Azure – Self Service BI to Big Data in the Cloud in a 1/21/2012 post (missed when published):
During the PASS 2011 Keynote (back in October 2011), I had the honor to demo Hadoop on Windows / Azure. One of the key showcases during that presentation was to show how to connect PowerPivot to Hadoop on Windows. In this post, I show the steps on how to connect PowerPivot to Hadoop on Azure.
Pre-requisites
PowerPivot for Excel (as of this post, using SQL Server 2012 RC1 version)
- Access to Hadoop on Azure CTP
Configuration Steps
1) Reference the following steps from How To Connect Excel to Hadoop on Azure via HiveODBC
The steps to follow are the:
- Install the HiveODBC Driver (we will configure the DSN later)
- Steps 1 – 3 from Using the Excel Hive Add-In to open the ports in Hadoop on Azure

.
.
2) Create a Hive ODBC Data Source > File DSNHere, we will go about creating a File DSN Hive ODBC Data Source.
Thanks to Andrew Brust (@andrewbrust), the better way to make a connection from PowerPivot to Hadoop on Azure is to create a File DSN. This allows the full connection string to be stored directly within the PowerPivot workbook instead of relying on an existing DSN.
To do this:
- Go to the ODBC Data Sources Administrator and click on the File DSN tab.
- Click on Add, Choose HIVE, Click Next, Click Browse to choose a location of the file; click Finish.
- Open the File DSN you just created and click Configure. The ODBC Hive Setup and configure the host (e.g. [clustername].cloudapp.net) and authentication information (the username is what you had specified when you had created the cluster)

.
.
3) Connect PowerPivot to Hadoop on Azure via the HiveODBC File DSN
- Open up the PowerPivot ribbon and click on the Get External Data from Other Sources.
- From the Table Import Wizard, click on the Others (OLEDB/ODBC) and click Next.
- From here, click Build and the Data Link Properties, click on Provider, and ensure the Microsoft OLEDB Provider for ODBC Drivers is selected. Click Next.
- In the Data Link Properties dialog, choose “Use connection string”, and click Build and choose the File DSN you had created from Step #2. Enter in the password to your Hadoop on Azure cluster. Click OK.
- The Data Link Properties now contains a connection string do the Hadoop on Azure cluster.
Note, after this dialog, verify that the password has been entered into the connection string that that has been built into the Table Import Wizard. Note, the blue arrow points to a lack of a PWD=<password> clause. If the password isn’t specified, make sure to add it back in.
- Click OK, click Next. From here you will get the Table Import Wizard and we are back to the usual PowerPivot steps.
- Click on “Select from a list of tables and views to choose the data to import”
- Choose your table (e.g. hivesampletable) and import the data in.
It looks like a lot of steps but once you get into the flow of things, it’s actually a relatively easy flow.












Bruce Kyle explained How to Choose Between Windows Azure Queues, Windows Azure Service Bus Queues in a 1/27/2012 post:
One of the key patterns in building scalable applications is queues. Let’s say you have a Website or Web Service (in your Web Role) that responds quickly to a user request, but there’s another process that takes longer. It might be a long data base inquiry or video encoding or extensive calculation would be in a Worker Role. You may want to spin up more processors to work on those long term items too. The way the Web Role talks to your Worker Role is through queues.
You could choose Windows Azure Queues as a dedicated queue storage mechanism built on top of the Windows Azure storage services. You add an item on the queue, and the Worker Role checks the queue and performs the work.
Of you might choose to use a Service Bus Queue when you want to run process messages in a particular order (guaranteed first-in-first-out. Or maybe you need to hold the item in a queue and store it for a while. Or maybe you need automatic duplicate detection.
A new article on MSDN analyzes the differences and similarities between the two types of queues offered by Windows Azure today.
- Windows Azure Queues.
- Windows Azure Service Bus Queues.
The article helps you compare and contrast the respective technologies and be able to make a more informed decision about which solution best meets your needs.
While both queuing technologies exist concurrently, Windows Azure Queues were introduced first, as a dedicated queue storage mechanism built on top of the Windows Azure storage services. Service Bus Queues, introduced with the latest release of the Service Bus, are built on top of the broader “brokered messaging” infrastructure designed to integrate applications or application components that may span multiple communication protocols, data contracts, trust domains, and/or network environments.
See Windows Azure Queues and Windows Azure Service Bus Queues - Compared and Contrasted.
The article describes scenarios and does a feature by feature comparison.
About Queuing in Windows Azure
Both Windows Azure Queues and Service Bus Queues are implementations of the message queuing service currently offered on Windows Azure. Each has a slightly different feature set, which means you can choose one or the other, or use both, depending on the needs of your particular solution or business/technical problem you are solving.
Windows Azure Queues, which are part of the Windows Azure storage infrastructure, feature a simple REST-based Get/Put/Peek interface, providing reliable, persistent messaging within and between services.
Service Bus Queues are part of a broader Windows Azure messaging infrastructure that supports queuing as well as publish/subscribe, Web service remoting, and integration patterns.
In the Article
Compares Windows Azure Queues and Service Bus Queues:
- Ordering guarantee
- Delivery guarantee
- Transaction support
- Receive behavior
- Receive mode
- Exclusive access mode
- Lease/Lock duration and granularity
- Batched send and receive
Overviews
Service Bus Queues
- Building loosely-coupled apps with Windows Azure Service Bus Topics and Queues (video)
- An Introduction to Service Bus Queues
- Creating Applications that Use Service Bus Queues in Windows Azure Developer Guidance
- Creating Applications that Use Service Bus Topics and Subscriptions in Windows Azure Developer Guidance
Windows Azure Queues
Getting Started with Code

Nuno Godinho (@NunoGodinho) described 8 Essential Best Practices in Windows Azure Blob Storage in a 1/27/20 post to Red Gate Software’s ACloudyPlace blog:
The Windows Azure platform has been growing rapidly, both in terms of functionality and number of active users. Key to this growth is Windows Azure Storage, which allows users to store several different types of data for a very low cost. However, this is not the only benefit as it also provides a means to auto scale data to deliver seamless availability with minimal effort.
- Files, inside Blob Storage ( as either Block or Page Blobs)
- Data, inside Table Storage
- Messages, inside Queue Storage
Additionally, the Cloud Drive (a special form of ‘Blob’) provides a means to store NTFS VHDs inside Blob Storage; however, this won’t be covered in this article.
When using Windows Azure Storage, users are billed for 3 components: traffic (outbound), storage space and transactions (operations performed on storage contents). All of these influence the costs and the availability of the contents. Throughout this article I’ll discuss 8 essential best practices to support you in maintaining and controlling both cost and availability. In this article I’ll look only at the best practices for the Public Containers inside Blob Storage and in future articles we’ll talk about the other types of storage.
Best Practices for Blob Storage
1. Always define content-type of each element
It’s crucial to correctly define the content type of each Storage Blob in order for the client to correctly handle the contents being sent.2. Always define the Cache-Control header for each element
The Cache-Control header is very important as it allows you to improve the availability of a Blob and at the same time decrease significantly the number of transactions that are made in each storage control. For example, imagine you have a static website placed inside the Blob Storage, if the Cache-Control header is configured correctly; the cache can be placed on the client-side in order to decrease the traffic being served as the Blob already exists on the client side.3. Always upload contents to Blob Storage in parallel
Uploading contents data to Blob Storage can be time consuming. Obviously, performance depends on the volume of data being sent, however it is possible to perform this operation faster by uploading data in parallel, which is supported by both Page and Block Blobs (I’ll discuss these below). This way you can reduce the amount of time needed to upload Blob contents. For example, I uploaded 70GB of data to Windows Azure Storage the other day using a third-party tool, and suddenly it was telling me that it would take over 1700 hours to complete! However, when I performed a parallel upload, I was able to upload everything in just approximately 8 hours.4. Choose the right type of Blob
Windows Azure Blob Storage comes in two varieties: Block and Page Blobs, both with differing characteristics. It is crucial to select the correct type of Blob in order to get the best results. Choose Block Blob if you want to stream your contents, as it can be consumed in blocks, rendering it easier and simpler for streaming solutions; it’s also crucial to parallel the upload and downloads of those blobs. Choose Page Blob if you need to write intensively to the Blob; for example a VHD (Cloud Drive is a Page Blob), as Page Blobs allow you to write to a particular part, or ‘page’ of the Blob. As a result this leaves all other contents unaffected if they are being accessed.5. Use ‘Get Blob Properties’ or ‘Get Blob Metadata’ whenever you only need that specific information
Blobs have distinct information in properties and metadata. Properties are defined by default by Windows Azure, and Metadata are additional properties you can add to the Blob. In order to avoid unnecessary usage of the Blob, use the correct GET method, as well as not getting the entire Blob if we only require its metadata or property information.6. Take snapshots to improve availability and caching
To increase the availability of Storage Blobs, it’s possible to create a snapshot of the Blob. This will allow you to have a kind of ‘copy’ of the Blob without needing to pay extra for it, as long as the snapshot does not differ from the original. Consequently snapshots may be used to increase the availability of the system since we can have several ‘copies’ of the same Blob and serve them to the customer. Furthermore, and more importantly snapshots may be used as a way to improve availability by assigning them as the default Storage Blob to be accessed by all clients performing read operations, leaving the original Blob only for writes. Overall snapshots allow the user to perform caching of data at the Blob level, thus increasing the availability of the Blob.7. Enable the ‘Content Delivery Network’ for better availability
Another very important part of improving availability and reducing latency is the usage of the Content Delivery Network (CDN). The CDN reduces latency and increases availability by placing a duplicate of your Blob closer to the client. Accordingly each client is redirected to the closest CDN node, of the Blobs. It is important to note that since a copy of the Blob will be placed on a CDN Node closest to the client, the costs will increase, however you will not be charged for Storage transaction costs for each client access to the Blob since the client is hitting the CDN node and not the Storage. This happens because the “copy” already exists in the CDN. But let’s explain this more in terms of cost when using CDN. Once you enable CDN your blob will be automatically replicated to all CDN nodes, so there will be costs in terms of Storage Transactions and Transfer (From Storage to each CDN node) since the blob is being downloaded, but after that every client that accesses it will be served with the “copy” that exists in the CDN node closest to him. Only Traffic costs will be charged due to the download. The process will restart once the “copy” that exists in the CDN node expires due to the TTL.Quick Note: CDN is in Windows Azure Storage and is only available for public containers, so the process will be different for private containers.
8. Serve static contents directly from Blob Storage
Windows Azure Blob Storage is ideal for hosting static websites, since it doesn’t require any scaling work in order to improve availability, because this will be done automatically by the platform. It’s also possible to reduce your costs if the best practices presented previously are followed. Consequently this is an effective and economical way to host a static website.Summary
In summary, how Blob Storage is managed is a very important consideration while using Windows Azure as it not only provides storage, but also delivers better availability through an auto scaling environment. Blob Storage also allows you to focus on your applications and data as opposed to infrastructure, and even provides a way to host simple or, static websites in a very cost effective manner.

Full disclosure: I’m a paid contributor to ACloudyPlace.com
Avkash Chauhan (@avkashchauhan) described Setting Windows Amazon S3 (s3n://) as data source directly at Hadoop on Azure (hadooponazure.com) portal in a 1/27/2012 post:
To get your Amazon S3 account setup with Apache Hadoop cluster on Windows Azure you just need your AWS security credentials, which pretty much look like as below:
After you completed creating Hadoop cluster in Windows Azure, you can log into your Hadoop Portal. In the portal, you can select “Manage Data” tile as below:
On the next screen you can select:
- “Set up ASV” to set your Windows Azure Blob Storage as data source
- “Set up S3” to set your Amazon S3 Storage as data source
When you select “Set up S3”, in the next screen you would need to enter your Amazon S3 credentials as below:
After you select “Save Settings”, if you Amazon S3 Storage credentials are correct you will get the following message:
Now your Amazon S3 Storage is set up to use with Interactive JavaScript shell or you can remote into your cluster to access from there as well. You can test it directly at from Hadoop Command shell in your cluster as below:
Just to verify you can look your Amazon S3 storage in any S3 explorer tool as below:
Note: If you really want to know how Amazon S3 Storage was configured with Hadoop cluster, it was done by adding proper Amazon S3 Storage credentials into core-site.xml as below (Open C:\Apps\Dist\conf\core-site.xml you will see the following parameters related with Amazon S3 Storage access from Hadoop Cluster):
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>hadoop.tmp.dir</name> <value>/hdfs/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://10.26.104.57:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>fs.s3n.awsAccessKeyId</name> <value>YOUR_S3_ACCESS_KEY</value> </property> <property> <name>fs.s3n.awsSecretAccessKey</name> <value> YOUR_S3_SECRET_KEY </value> </property> </configuration>Resources:









The Datanami Team (@datanami) reported Hadoop Events Crowd 2012 Calendar on 1/27/2012:
If this is indeed the “year of Hadoop” then it’s only fitting that the technology events lineup for the year is going to focus on the big data platform. While few events can match the size and scope of Hadoop World, a number of events are cropping up to offer training, user experiences and of course, plenty of excited vendor chatter.
And speaking of Hadoop World, this week quite a bit of buzz was generated when Cloudera announced that it would be partnering with O’Reilly media to take over the Hadoop World franchise. The popular event, which sold out completely in 2011, will now be a featured part of the overall program at the 2012 Strata Conference, set to take place in October in New York.
For those who fail in scrambling for early tickets to the Hadoop World event, never fear—a host of other events promise some fulfilling sessions on all aspects of Hadoop.
For instance, in the near term, those in the Denver area will be pleased to hear about a free seminar on February 2, sponsored by Dell and Cloudera that covers Hadoop and big data. The day-long event features an introduction to Hadoop tutorial for the morning, followed by sessions from Doug Cutting, Apache Chairman and co-founder of Hadoop, Cloudera’s CEO and co-founder, Mike Olson, Matt Newom from Dell and speakers from Comcast to offer a user view of how Hadoop is being used to manage next-generation video capabilities.
Also around the corner is the O’Reilly Strata Conference from February 28-March 1 in Santa Clara, CA. While this is not the Hadoop World event by any means, the lineup for this event puts great emphasis on big data and its enabling technologies, both on the user group and session side. Those present will hear from vendors, including HPCC Systems, Cloudera, MarkLogic, Microsoft and others and can find deep-dive sessions on Hadoop and all of its many moving parts (Pig, HBase, HDFS and so on).
March is a big month for Hadoop conference, with the Structure event from GigaOm taking over New York for two days. While the emphasis here is on big data generally, the role of the Hadoop ecosystem is expected to be of great importance.
Additionally, Hadoop Summit 2012, which is sponsored by Hortonworks and Yahoo, will be coming to Silicon Valley for two days in mid-June. According to organizers, the event will outline the evolution of Hadoop into a next-generation data platform by featuring presentations from the developer, administrator and user ends of the Hadoop spectrum.
The program currently is set to contain over 60 sessions with six separate tracks backed by case studies, user experiences, and technology insights from developers and administrators. The organizers say the tracks will cover the future of Hadoop; deployment and operations; enterprise data architecture; applications and data science; and a track dedicated to “Hadoop in Action” featuring examples of how the platform is being leveraged in a number of settings.
Hadoop Summit 2012 will also feature a Hadoop training and certification program offered by Hortononworks, which will take place during the same week as the summit.
Also during the same week, Cloudera will be taking advantage of the interested crowd in town for the conference with its own week full of training sessions, including a developer “bootcamp” and Hadoop training programs for managers and administrators. The Cloudera training week also will include Cloudera training for Hive, Pig and HBase as well as exam possibilities for those seeking to become Cloudera Certified Developers and Cloudera Certified Administrators.
More events will emerge as the year goes on and of course, this is a small sampling of what’s available. We’ll do our best to keep you up to date via our events listings.
Edd Dumbill (@edd) asserted “Hadoop is a central part of Microsoft's data strategy” in an introduction to his Microsoft's plan for Hadoop and big data post of 1/25/2012 to the O’Reilly Radar blog:
Microsoft has placed Apache Hadoop at the core of its big data strategy. It's a move that might seem surprising to the casual observer, being a somewhat enthusiastic adoption of a significant open source product.
The reason for this move is that Hadoop, by its sheer popularity, has become the de facto standard for distributed data crunching. By embracing Hadoop, Microsoft allows its customers to access the rapidly-growing Hadoop ecosystem and take advantage of a growing talent pool of Hadoop-savvy developers.
Microsoft's goals go beyond integrating Hadoop into Windows. It intends to contribute the adaptions it makes back to the Apache Hadoop project, so that anybody can run a purely open source Hadoop on Windows.
Microsoft's Hadoop distribution
The Microsoft distribution of Hadoop is currently in "Customer Technology Preview" phase. This means it is undergoing evaluation in the field by groups of customers. The expected release time is toward the middle of 2012, but will be influenced by the results of the technology preview program.
Microsoft's Hadoop distribution is usable either on-premise with Windows Server, or in Microsoft's cloud platform, Windows Azure. The core of the product is in the MapReduce, HDFS, Pig and Hive components of Hadoop. These are certain to ship in the 1.0 release.
As Microsoft's aim is for 100% Hadoop compatibility, it is likely that additional components of the Hadoop ecosystem such as Zookeeper, HBase, HCatalog and Mahout will also be shipped.
Additional components integrate Hadoop with Microsoft's ecosystem of business intelligence and analytical products:
- Connectors for Hadoop, integrating it with SQL Server and SQL Sever Parallel Data Warehouse.
- An ODBC driver for Hive, permitting any Windows application to access and run queries against the Hive data warehouse.
- An Excel Hive Add-in, which enables the movement of data directly from Hive into Excel or PowerPivot.
On the back end, Microsoft offers Hadoop performance improvements, integration with Active Directory to facilitate access control, and with System Center for administration and management.
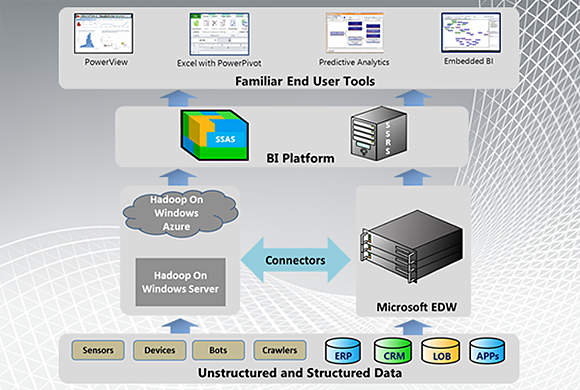
How Hadoop integrates with the Microsoft ecosystem. (Source: microsoft.com.)Developers, developers, developers
One of the most interesting features of Microsoft's work with Hadoop is the addition of a JavaScript API. Working with Hadoop at a programmatic level can be tedious: this is why higher-level languages such as Pig emerged.
Driven by its focus on the software developer as an important customer, Microsoft chose to add a JavaScript layer to the Hadoop ecosystem. Developers can use it to create MapReduce jobs, and even interact with Pig and Hive from a browser environment.
The real advantage of the JavaScript layer should show itself in integrating Hadoop into a business environment, making it easy for developers to create intranet analytical environments accessible by business users. Combined with Microsoft's focus on bringing server-side JavaScript to Windows and Azure through Node.js, this gives an interesting glimpse into Microsoft's view of where developer enthusiasm and talent will lie.
It's also good news for the broader Hadoop community, as Microsoft intends to contribute its JavaScript API to the Apache Hadoop open source project itself.
The other half of Microsoft's software development environment is of course the .NET platform. With Microsoft's Hadoop distribution, it will be possible to create MapReduce jobs from .NET, though using the Hadoop APIs directly. It is likely that higher-level interfaces will emerge in future releases. The same applies to Visual Studio, which over time will get increasing levels of Hadoop project support.
Streaming data and NoSQL
Hadoop covers part of the big data problem, but what about streaming data processing or NoSQL databases? The answer comes in two parts, covering existing Microsoft products and future Hadoop-compatible solutions.
Microsoft has some established products: Its streaming data solution called StreamInsight, and for NoSQL, Windows Azure has a product called Azure Tables.
Looking to the future, the commitment of Hadoop compatibility means that streaming data solutions and NoSQL databases designed to be part of the Hadoop ecosystem should work with the Microsoft distribution — HBase itself will ship as a core offering. It seems likely that solutions such as S4 will prove compatible.
Toward an integrated environment
Now that Microsoft is on the way to integrating the major components of big data tooling, does it intend to join it all together to provide an integrated data science platform for businesses?
That's certainly the vision, according to Madhu Reddy, senior product planner for Microsoft Big Data: "Hadoop is primarily for developers. We want to enable people to use the tools they like."
The strategy to achieve this involves entry points at multiple levels: for developers, analysts and business users. Instead of choosing one particular analytical platform of choice, Microsoft will focus on interoperability with existing tools. Excel is an obvious priority, but other tools are also important to the company.
According to Reddy, data scientists represent a spectrum of preferences. While Excel is a ubiquitous and popular choice, other customers use Matlab, SAS, or R, for example.
The data marketplace
One thing unique to Microsoft as a big data and cloud platform is its data market, Windows Azure Marketplace. Mixing external data, such as geographical or social, with your own, can generate revealing insights. But it's hard to find data, be confident of its quality, and purchase it conveniently. That's where data marketplaces meet a need.
The availability of the Azure marketplace integrated with Microsoft's tools gives analysts a ready source of external data with some guarantees of quality. Marketplaces are in their infancy now, but will play a growing role in the future of data-driven business.
Summary
The Microsoft approach to big data has ensured the continuing relevance of its Windows platform for web-era organizations, and makes its cloud services a competitive choice for data-centered businesses.
Appropriately enough for a company with a large and diverse software ecosystem of its own, the Microsoft approach is one of interoperability. Rather than laying out a golden path for big data, as suggested by the appliance-oriented approach of others, Microsoft is focusing heavily on integration.
The guarantee of this approach lies in Microsoft's choice to embrace and work with the Apache Hadoop community, enabling the migration of new tools and talented developers to its platform.
Michael Kopp posted About the Performance of Map Reduce Jobs to the DynaTrace blog on 1/25/2012:
One of the big topics in the BigData community is Map/Reduce. There are a lot of good blogs that explain what Map/Reduce does and how it works logically, so I won’t repeat it (look here, here and here for a few). Very few of them however explain the technical flow of things, which I at least need, to understand the performance implications. You can always throw more hardware at a map reduce job to improve the overall time. I don’t like that as a general solution and many Map/Reduce programs can be optimized quite easily, if you know what too look for. And optimizing a large map/reduce jobs can be instantly translated into ROI!
The Word Count Example
I went over some blogs and tutorials about performance of Map/Reduce. Here is one that I liked. While there are a lot of good tips out there, none, except the one mentioned, talk about the Map/Reduce program itself. Most dive right into the various hadoop options to improve distribution and utilization. While this is important, I think we should start the actual problem we try to solve, that means the Map/Reduce Job.
To make things simple I am using Amazons Elastic Map Reduce. In my setup I started a new Job Flow with multiple steps for every execution. The Job Flow consisted of one master node and two task nodes. All of them were using the Small Standard instance.
While AWS Elastic Map/Reduce has its drawbacks in terms of startup and file latency (Amazon S3 has a high volatility), it is a very easy and consistent way to execute Map/Reduce jobs without needing to setup your own hadoop cluster. And you only pay for what you need! I started out with the word count example that you see in every map reduce documentation, tutorial or Blog. The result of the job always produces files that look something like this:
the: 5967
all: 611
a: 21586That idea is to count the occurrence of every word in a large number of text files. I processed around 30 files totaling somewhere around 200MB in size. I ran the original python version and then made a very small change to it. Without touching the configuration of hadoop I cut the execution time in half:
The Original Code:
#!/usr/bin/python import sys import re def main(argv): line = sys.stdin.readline() pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*") try: while line: for word in pattern.findall(line): print "LongValueSum:" + word.lower() + "\t" + "1" line = sys.stdin.readline() except "end of file": return None if __name__ == "__main__": main(sys.argv)The Optimized Code:
#!/usr/bin/python import sys import re def main(argv): line = sys.stdin.readline() pattern = re.compile("[a-zA-Z][a-zA-Z0-9]*") map = dict() try: while line: for word in pattern.findall(line): map[word.lower()] = map.get(word.lower(), 0) + 1 if ( len(map) > 10000 ): for item in map.iteritems(): print "LongValueSum:" + item[0] + "\t" + str(item[1]) map.clear() line = sys.stdin.readline() for item in map.iteritems(): print "LongValueSum:" + item[0] + "\t" + str(item[1]) except "end of file": return None if __name__ == "__main__": main(sys.argv)Instead of “emitting” every word with value 1 to the OutputCollector, I did an internal reduce before emitting it. The result is that instead of emitted the word ‘a’ 1000 times with value 1, I emitted it 1 time with value 1000. The end result of the job is the same, but in half the time. To understand this we need to look at the execution flow of map reduce.
Execution Path and Distribution
Look at the following Flow Diagram taken from the “Hadoop Tutorial from Yahoo!” (Yahoo! Inc.) / CC BY 3.0
Map Reduce Flow
Elastic Map Reduce first schedules a Map Task task per file (or parts of the file). It then feeds each line of the file into the map function. The map function will emit each key/value, in this case each word of the line, to the OutputCollector. Each emitted key/value will be written to an intermediate file for later reduce. The Shuffle Process will make sure that each key, in this case each word, will be sent to the same reduce task (meaning hadoop node) for aggregation. If we emit the same word multiple times it also needs to be written and sent multiple times, which results in more I/O (disk and network). The logical conclusion is that we should „pre-reduce“ this on a per task node basis and send the minimal amount of data. This is what the Combiner is for, which is really a Reducer that is run locally on the same node after the Mapping. So we should be fine, right? Not really.
Inside of Amazons Elastic Map Reduce
To get a better idea of where I spent the time, I deployed dynaTrace into Amazons Map Reduce environment. This can be done fully automated with a simple bootstrap action (I will publish the result as a Fastpack on our community at a later time).
The original python run lasted roughly 5 minutes each run (between 290 and 320 seconds), while the optimized ran around 3 minutes (160-170 seconds). I used dynaTrace to split those run times into their different components to get a feel for where we spend time. Some numbers have a rather high volatility which, as I found out, is due to Amazon S3 and to a smaller degree garbage collection. I executed it several times and the volatility did not have a big impact on the overall job execution time.
Map Reduce Job Business Transaction that details where we spend our time
Click on the picture to analyze the details and you will see dramatic improvements on the mapping, combine and sort times. The Total Mapping time in this example is the overall execution time of all scheduled map tasks. The optimized code executed in less than 60% of the time. To a large degree this is due the map function itself (Map Only Time), which is actually quite surprising, after all we were not doing anything less really?
The next thing we see is that the combine time has dropped dramatically, we could say it nearly vanished! That makes sense after all we were making sure that we emitted less duplicates, thus less to combine. In fact it might make sense to stop combining at all as we will see later on. Another item that has dramatically improved is the sort. Again that makes a lot of sense, less data to sort. While the majority of the combine and sort happens in a separate thread, it still saves a lot of CPU and I/O time!
On the other hand neither shuffle nor reduce time itself have changed really. I identified the fluctuations the table does show, as being AWS S3 volatility issues via a hotspot analysis, so I ignored them. The fact that we see no significant improvements here makes sense. The resulting intermediate files of each map task do not look much different, whether we combine or use the optimized code.
So it really was the optimization of the map operation itself, that lead to overall improvement in job run time. While I might have achieved the same goal by doubling the number of map nodes, it would cost me more to do so.
What happens during mapping
To understand why that simple change has such a large impact we need to look at what happens to emitted keys in a Map Job.
flow of the data from the mapper to memory buffer, sort&combine and finally the merge
What most Map/Reduce tutorials forget to mention is that the collect method called by the Mapper serializes the key/value directly to an in-memory buffer, as can be seen in the diagram above and the hotspot below.
When the Mapper emits a key via collect, it gets written to an in memory buffer
Once that buffer has reached a certain saturation, the Spill Thread kicks in and writes the data to an intermediate file (this is controlled by several io.sort.spill. options). Map/Reduce normally deals with a large amount of potentially never repeating data, so it has to spill to file eventually.
The Spill Thread sorts, combines and writes the data to file in parallel to the mapping
It is not enough to simple dump the data to file, the content has to be sorted and combined first. The sort is a preparation for the shuffle process and relative efficient (it sorts based on binary bytes, because the actual order is not important). The combine however needs to de-serialize the key and values again prior to writing.
The combine in the spill thread needs to deserialize the data again
So emitting a key multiple times has
- a direct negative impact on the map time and CPU usage, due to more serialization
- an indirect negative impact on CPU due to more spilling and additional deserialization in the combine step
- a direct impact on the map task, due to more intermediate files, which makes the final merge more expensive
Slower mapping obviously impacts the overall Job time directly. The more data we emit, the more CPU and I/O is consumed by the Spill Thread. If the SpillThread is too slow (e.g. expensive combine, slow disk), the in memory buffer might get fully saturated, in which case the map task has to wait (this can be improved by adjusting the io.sort.spill.percent hadoop option).
The Mapper was paused by the Spill Thread, because there was too much data to sort and combine
Finally after the Map Task finishes the actual mapping, it writes, sorts and combines the remaining data to file. Finally it merges all intermediate files into a single output file (which it might combine again). More emitted key’s thus mean more intermediate files to merge as well.
The complete Map Task shows the mapping itself and the flush at the end, which sorts, combines, merges and combines again
While the final flush only “slows” us down for 1.5 seconds, this still amounts to roughly 8 percent of the Mapper task. So we see it really does make a lot of sense to optimize the output of the map operation, prior to the combine or reduce step. It will save CPU, Disk and Network I/O and this of course means less Nodes are needed for the same work!
The one million X factor
Until now I have tried to explain the I/O and CPU implications of emitting many keys, but there is also another factor that should be considered when writing Map/Reduce jobs. The map function is executed potentially millions of times. Every ms consumed here can potentially lead to minutes in job time. Indeed most of the gain of my “optimization” came from speeding up the mapping itself and not from more effective combine and disk writes. On average each map method call had a little less to do and that paid off.
What that struck me when looking at Map/Reduce first, was that most samples and tutorials use scripting languages like python, perl or something else. This is realized via the Hadoop Streaming framework. While I understand that this lowers the barrier to write Map/Reduce jobs, it should not be used for serious tasks! To illustrate this I ran a randomly selected java version of the Word Count sample. The result is another 50-60% improvement on top of the optimized python (it might be even better, in a larger task).
Several Java and Python Word Count Map Reduce Jobs, that show the vast differences in execution times
The table shows the various execution times for:
- Optimized Java: ~1.5 minutes job execution time
The same trick as in python, if anybody really wants to have the code, it let me know.- Optimized Java with no Combiner: roughly 10 seconds faster than the optimized one
As pointed out the pre-reduce in the map method makes the combine nearly redundant. The improvement in overall job time is minimal however due to the smallness of the job.- Original Java: ~2.5 minutes
We see that all the times (mapping, combining, sorting, spilling) are a lot higher, as we came to expect- Optimized Python: ~3 minutes
- Non-optimized python: ~5 minutes
Java is faster than Python every time and the optimized version of Java is twice as fast as the optimized python version. Remember that this is a small example and that the Hadoop parameters are the same for all runs . In addition CPU was never a limiting factor. If you execute the same small code millions of times, even small differences matter. The difference between a single line mapped in java and python is maybe not even measurable. With 200 MB of text it adds up to more than a minute! The same would be true for small changes in any Java Map/Reduce job. The difference between the original and the optimized java version is still more than 60% improvement!
Word Count is very simple compared to some of the map/reduce jobs are out there, but it illustrates quite nicely that performance of our own code still matters. The key take away is that we still need to analyze and optimize the map task and our own code. Only after that is satisfactory, do we need to play around with the various Hadoop options to improve distribution and utilization.
Conclusion
Map Reduce is a very powerful and elegant way to distribute processing of large amounts of data across many hosts. It is also a bit of a brute and it pays of to analyze and optimize the performance of the map and reduce tasks before we start playing with Hadoop options. While Map/Reduce can reduce the job time by throwing more hardware the problem, easy optimizations often reach a similar effect. In the cloud and AWS Elastic Map Reduce that means less cost!










<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Wade Wegner (@WadeWegner) and Steve Marx (@smarkx) posted CloudCover Episode 68 - Throttling in SQL Azure with Scott Klein on 1/27/2012:
Join Wade and Steve each week as they cover the Windows Azure platform. You can follow and interact with the show at @CloudCoverShow.
In this episode, Wade and Steve are joined by Scott Klein, Technical Evangelist for SQL Azure, who explains how to understand, diagnose, and handle throttling in SQL Azure. He also demonstrates how to use the Transient Fault Handling Application Block.
In the news:
- New Service Bus demo
- SendGrid and Windows Azure
- Windows Azure and Cloud9 IDE at Node Summit
- Import/export service for SQL Azure generally available
Tip of the week: Dealing with "cannot create database" in the Windows Azure storage emulator.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
• Rajeev Pentyala described how to Create [a] Record using OData and JQuery in CRM 2011 in a 1/29/2011 post:
Below is the code snippet to create a record (i.e., Account) using OData & JQuery:
//Prepare ‘Account’ object and call create function function createAccount() { //Create an object to represent an Account record and set properties var account = new Object(); // Set text field account.Name = “Rajeev Pentyala”; // Set Lookup field (Contact should exists in the system) var primaryContact = new Object(); primaryContact.ContactId = “”; primaryContact.FullName = “”; // if (primaryContact != null) { // account.PrimaryContactId = { Id: primaryContact.ContactId, LogicalName: “contact”, Name: primaryContact.FullName }; // } //Set a picklist value account.PreferredContactMethodCode = { Value: 2 }; //Set a money value (i.e., Annual Revenue) account.Revenue = { Value: “2000000.00″ }; //Set a Boolean value account.DoNotPhone = true; // Call create method by passing // (i) Entity Object (i.e.,account in this case) //(ii) Entity Set //(iii)SuccessCallback function // (iv) Error callback function createRecord(account, “AccountSet”, createAccountCompleted, null); } // This callback method executes on succesful account creation function createAccountCompleted(data, textStatus, XmlHttpRequest) { var account = data; alert(“Account created; Id: ” + account.AccountId.toString()); }// This function creates record by making OData call function createRecord(entityObject, odataSetName, successCallback, errorCallback) { //Parse the entity object into JSON var jsonEntity = window.JSON.stringify(entityObject); // Get Server URL var serverUrl = Xrm.Page.context.getServerUrl(); //The OData end-point var ODATA_ENDPOINT = “/XRMServices/2011/OrganizationData.svc”; //Asynchronous AJAX function to Create a CRM record using OData $.ajax({ type: “POST”, contentType: “application/json; charset=utf-8″, datatype: “json”, url: serverUrl + ODATA_ENDPOINT + “/” + odataSetName, data: jsonEntity, beforeSend: function (XMLHttpRequest) { //Specifying this header ensures that the results will be returned as JSON. XMLHttpRequest.setRequestHeader(“Accept”, “application/json”); }, success: function (data, textStatus, XmlHttpRequest) { if (successCallback) { successCallback(data.d, textStatus, XmlHttpRequest); } }, error: function (XmlHttpRequest, textStatus, errorThrown) { if (errorCallback) errorCallback(XmlHttpRequest, textStatus, errorThrown); else errorHandler(XmlHttpRequest, textStatus, errorThrown); } }); }How do I call this method :-
- Create a new .jscript file (i.e., ”account.js”)
- Copy & Paste above code
- Add “account.js” as a webresource in CRM
- Add “Json2.js” & “jquery1.4.1.min.js” helper script files as webresources
- Add “createAccount” function to form load method (Refer below)
Adding webresources to account form
- Save & Publish
- Open any account record and on loading of record our script fires and it creates new account name “Rajeev Pentyala”

<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Mick Badran (@mickba) reported Microsoft AppFabric 1.1 for Windows Server–released! in a 1/25/2012 post:
Recently there’s been an update to the ‘on-premise’ AppFabric for Windows Server. Grab the update here - http://www.microsoft.com/download/en/details.aspx?id=27115 (runs on win7, 2008, 2008R2)
What’s new
I’m in the process of updating my components, but the majority of updates seems to be around caching and performance.
http://msdn.microsoft.com/en-us/library/hh351389.aspx
Read-Through/Write-Behind
This allows a backend provider to be used on the cache servers to assist with retrieving and storing data to a backend, such as a database. Read-through enables the cache to "read-through" to a backend in the context of a Get request. Write-behind enables updates to cached data to be saved asynchronously to the backend. For more information, see Creating a Read-Through / Write-Behind Provider (AppFabric 1.1 Caching).
Graceful Shutdown
This is useful for moving data from a single cache hosts to rest of the servers in the cache cluster before shutting down the cache host for maintenance. This helps to prevent unexpected loss of cached data in a running cache cluster. This can be accomplished with the Graceful parameter of the Stop-CacheHost Windows PowerShell command.
Domain Accounts
In addition to running the AppFabric Caching Service with the NETWORK SERVICE account, you can now run the service as a domain account. For more information, see Change the Caching Service Account (AppFabric 1.1 Caching).
New ASP.NET Session State and Output Caching Provider
New ASP.NET session state and output caching providers are available. The new session state provider has support for the lazy-loading of individual session state items using AppFabric Caching as a backing store. This makes sites that have a mix of small and large session state data more efficient, because pages that don't need large session state items won't incur the cost of sending this data over the network. For more information, see Using the ASP.NET 4 Caching Providers for AppFabric 1.1.
Compression
You can now enable compression for cache clients. For more information, see Application Configuration Settings (AppFabric 1.1 Caching).
Multiple Cache Client Application Configuration Sections
A new
dataCacheClientssection is available that allows you to specify multiple nameddataCacheClientsections in an application configuration file. You can then programmatically specify which group of cache client settings to use at runtime. For more information, see Application Configuration Settings (AppFabric 1.1 Caching).
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
My (@rogerjenn) updated Introducing Microsoft Codename “Cloud Numerics” from SQL Azure Labs post of 1/28/2012 adds the following undocumented pre-requisite if you didn’t include Visual C++ in the programming languages for your Visual Studio 2010 installation:
*Update 1/28/2011: The build script expects to find msvcp100.dll and msvcr100.dll files installed by VS2010 in the C:\Program Files(x86)\Microsoft Visual Studio 10.0\VC\redist\x64\Microsoft.VC100.CRT folder and the msvcp100d.dll and msvcr100d.dll debug versions in the C:\Program Files(x86)\Microsoft Visual Studio 10.0\VC\redist\Debug_NonRedist\x64\Microsoft.VC100.DebugCRT folder. If these files aren’t present in the specified locations, the Windows Azure HPC Scheduler will fail when attempting to run MSCloudNumericsApp.exe as Job 1.
Note: You only need to take the following steps if you intend to submit the application to the Windows Azure and you don’t have the Visual C++ compilers installed:
- Download the Microsoft Visual C++ 2010 SP1 Redistributable Package (x64) (vcredist_x64.exe) to a well-known location
- Run vcredist_x64.exe to add the msvcp100.dll, msvcp100d.dll, msvcr100.dll and msvcr100d.dll files to the C:\Windows\System32 folder.
- Create a C:\Program Files(x86)\Microsoft Visual Studio 10.0\VC\redist\x64\Microsoft.VC100.CRT folder and copy the msvcp100.dll and msvcr100.dll files to it.
- C:\Program Files(x86)\Microsoft Visual Studio 10.0\VC\redist\Debug_NonRedist\x64\Microsoft.VC100.DebugCRT folder and add the msvcp100d.dll and msvcr100d.dll files to it.
Stay tuned for more details about this issue.

As noted in my Deploying “Cloud Numerics” Sample Applications to Windows Azure HPC Clusters post, also updated 1/28/2012, you must:
Choose Build, Configuration Manager to open the Configuration Manager dialog, select Release in the Active Solution Configurations list, and click OK to change the build configuration from Debug to Release:
Note: For currently unknown reasons, submitting a job built in the Debug configuration fails. This problem is under investigation. This step was added on 1/28/2012.

• The Windows Azure Team added a new Automating Builds for Windows Azure Packages page to the Windows Azure site’s “Develop” section in late January:
You can also run MSBuild at a command prompt. By setting properties at a command prompt, you can build specific configurations of a project. Similarly, you can also define the targets that the MSBuild command will build. For more information about command-line parameters and MSBuild, see MSBuild Command Line Reference.
The process described in this article is equivalent to the Package command in Visual Studio. By applying the methods described in this article, you can configure and define builds, in addition to automating the build and packaging process.
This task includes the following steps:
The page continues with detailed tutorials for each step. I’m surprised the team didn’t include specific details for using the new Windows Azure Team Foundation Services announced at the //BUILD/ conference in September 2011.
• Rick Garibay (@rickggaribay) explained why Node is Not Single Threaded is important in a 1/28/2012 post:
I recently got bitten by the Node.js bug. Hard.
If you are even remotely technically inclined, it is virtually impossible to not be seduced by the elegance, speed and low barrier to entry of getting started with Node.js. After all, its just another JavaScript API, only this time designed for running programs on the server. This in and of itself, is intriguing, but there has to be more, much more, to compel legions of open source developers to write entire libraries for Node almost over night, not to mention industry giants like Wal-Mart and Microsoft embracing this very new, fledgling technology that has yet to be proven over any significant period of time.
As such, this post is an attempt to collect my findings on how Node, and it’s alleged single-threaded approach to event-driven programming is different from what I know today. This is not a dissertation on event vs. thread-based concurrency or a detailed comparison of managed frameworks and Node.js. Instead, this is a naive attempt to capture my piecemeal understanding of how Node is different into a single post in hopes that comments and feedback will increase its accuracy in serving as a reference that helps to put in perspective for .NET developers how Node is different and what the hubbub is really all about.
To that end, I sincerely would appreciate your comments and feedback to enrich the quality of this post as I found resources on the web that tackle this specific topic severely lacking (or I am just too dense to figure it all out).
I’m going to skip the hello world code samples, or showing you how easy it is to spin up an HTTP or TCP server capable of handling a ridiculous amount of concurrent requests on a laptop because this is all well documented elsewhere. If you haven’t ever looked at Node before, check out the following resources which will help to kick-start your node.js addiction (the first hit is free):
- SF PHP User’s Group talk by Ryan Dahl
- Node Beginner Book by Manuel Kiessling
- Cinco de Node talk by Ryan Dahl
Aside from the syntactic sugar that is immediately familiar to legions of web developers regardless of platform or language religion, you can’t come across any literature or talk on Node.js without a mention of the fact that what makes it all so wonderful is the fact that it is event-driven and single-threaded.
It is evident to me that there are either a lot of people that are much smarter than me and just instantly get that statement, as well as people that blindly accept it. Then there are those who haven’t slept well for the last week trying to figure out what the hell that means and how it’s different.
Event-driven. So what?
I’ve written lots of asynchronous code and designed many messaging solutions on event-driven architectures. As a Microsoft guy, I’m pretty familiar with writing imperative code using Begin/End, AsyncCallbacks, WaitHandles, IHttpAyncHandlers, etc. I’ve opted for ever permutation of WCF instancing and concurrency depending on the scenario at hand, and written some pretty slick WF 4 workflows that parallelize activities (yes, I know, its not really truly parallel, but in most cases, close enough). My point is, I get async and eventing, so what’s the big deal and how is Node any different than this, or the nice new async language features coming in C# 5?
IIS and .NET as a Learning Model
When learning something new, it is a tremendous advantage to know nothing about the topic and start fresh. Absent of that, it is usually helpful to have a familiar model that you can reference that helps you to compare and contrast a new concept, progressively iterating to understand the similarities and differences. As a career-long enterprise guy, working almost exclusively on the Microsoft platform, my model is IIS/WAS and .NET., so let’s summarize how a modern web server like IIS 7+ works which will provide the necessary infrastructure to help frame how .NET’s (or Java) execution model works.
As described on Learn.IIS.net, the following list describes the request-processing flow that is shown to your right:
- When a client browser initiates an HTTP request for a resource on the Web server, HTTP.sys intercepts the request.
- HTTP.sys contacts WAS to obtain information from the configuration store.
- WAS requests configuration information from the configuration store, applicationHost.config.
- The WWW Service receives configuration information, such as application pool and site configuration.
- The WWW Service uses the configuration information to configure HTTP.sys.
- WAS starts a worker process for the application pool to which the request was made.
- The worker process processes the request and returns a response to HTTP.sys.
- The client receives a response.
Step 7 is where your application (which might be an ASP.NET MVC app, a WCF or WF service) comes in. When WAS starts a worker process (w3wp.exe) the worker process allocates a thread for loading and executing your application. This is analogous to starting a program and inspecting the process in Windows Task Manager. If you open 3 instances of the program, you will see 3 processes in task manager and each process will have a minimum of one thread. If an unhandled exception occurs in the program, the entire process is torn down, but it doesn’t affect other processes because they are isolated for each other.
Processes, however, are not free. Starting and maintaining a process requires CPU time and memory, both of which are finite, and more processes and threads require more resources.
.NET improves resource consumption and adds an additional degree of isolation through Application Domains or AppDomains. AppDomains live within a process and your application runs inside an AppDomain.
K. Scott Allen summarizes the relationship between the worker process and AppDomains quite nicely:
You’ve created two ASP.NET applications on the same server, and have not done any special configuration. What is happening?
A single ASP.NET worker process will host both of the ASP.NET applications. On Windows XP and Windows 2000 this process is named aspnet_wp.exe, and the process runs under the security context of the local ASPNET account. On Windows 2003 the worker process has the name w3wp.exe and runs under the NETWORK SERVICE account by default.
An object lives in one AppDomain. Each ASP.NET application will have it’s own set of global variables: Cache, Application, and Session objects are not shared. Even though the code for both of the applications resides inside the same process, the unit of isolation is the .NET AppDomain. If there are classes with shared or static members, and those classes exist in both applications, each AppDomain will have it’s own copy of the static fields – the data is not shared. The code and data for each application is safely isolated and inside of a boundary provided by the AppDomain
In order to communicate or pass objects between AppDomains, you’ll need to look at techniques in .NET for communication across boundaries, such as .NET remoting or web services.
Here is a logical view borrowed from a post by Shiv Kumar that helps to show this relationship visually:
As outlined in steps 1 – 7 above, when a request comes in, IIS uses an I/O thread to dispatch the request off to ASP.NET. ASP.NET immediately sends the request to the CLR thread pool which returns immediately with a pending status. This frees the IIS I/O thread to handle the next request and so on. Now, if there is a thread available in the thread pool, life is good, and the work item is executed, returning back to the I/O thread in step 7. However, if all of the threads in the thread pool are busy, the request will queue until a CLR thread pool thread is available to process the work item, and if the queue length is too high, users will receive a somewhat terse request to go away and come back later.
This is a bit of an extreme trivialization of what happens. There are a number of knobs that can be set in IIS and ASP.NET that allow you to tune the number of concurrent requests, threads and connections that affect both IIS and the CLR thread pool. For example, the IIS thread pool has a maximum thread count of 256. ASP.NET initializes its thread pool to 100 threads per processor/core. You can adjust things like the maximum number of concurrent requests per CPU (which defaults to 5000) and maximum number of connections of 12 per CPU but this can be increased. This stuff is not easy to grasp, and system administrators dedicate entire careers to getting this right. In fact, it is so hard, that we are slowly moving away from having to manage this ourselves and just paying some really smart engineers to do it for us, at massive scale.
That said, if you are curious or want to read more, Thomas Marquardt and Fritz Onion cover IIS and CLR threading superbly in their respective posts.
Back to the example. If all of your code in step 7 (your app) is synchronous, then the number of concurrently executing requests is equal to the number of threads available to concurrently execute your requests and if you exceed this, your application/service will simply grind to a halt.
This is why asynchronous programming is so important. If your application/service (that runs in step 7) is well designed, and makes efficient use of IO by leveraging async so that work is distributed across multiple threads, then there are naturally more threads always ready to do work because the the total processing time of a request becomes that of the longest running operation instead of the sum of all operations. Do this right, and your app can scale pretty darn well as long as there are threads available to do the work.
However, as I mentioned, these threads are not free and in addition, there is a cost in switching from the kernel thread to the IIS thread and the CLR thread which results in additional CPU cycles, memory and, latency.
It is evident that to minimize latency, you apps must perform the work they need to as quickly as possible to keep threads free and ready to do more work. Leveraging asynchrony is key.
Even in era where scaling horizontally is simply a matter of pushing a button and swiping a credit card, an app that scales poorly on premise will scale poorly in the cloud, and both are expensive. Moreover, having written a lot of code, and worked with and mentored many teams in my career, I’ll admit that writing asynchronous code is just plain hard. I’ll even risk my nerd points in admitting that given the choice, I’ll write synchronous code all day long if I can get away with it.
So, what’s so different about Node?
My biggest source of confusion in digging into Node is the assertion that it is event-based and single threaded.
As we’ve just covered in our learning model, IIS and .NET are quite capable of async, but it certainly can’t do that on a single thread.
Well, guess what? Neither can Node. Wait, there’s more.
If you think about it for just a few seconds, highly concurrent, event-driven and single threaded do not mix. Intentional or otherwise, “single threaded” is a red herring and something that has simply been propagated over and over. Like a game of telephone, it’s meaning has been distorted and this is the main thing that was driving me NUTS.
Let’s take a closer look.
In Node, an program/application is created in a process, just like in the .NET world. If you run Node on Windows, you can see an instance of the process for each .js program you have running in Task Manager.
What makes Node unique is *not* that it is single-threaded, it’s the way in which it manages event-driven/async for you and this where the concept of an Event Loop comes in.
To provide an example, to open a WebSocket server that is compliant with the latest IETF and W3C standards, you write code like this written by my friend Adam Mokan:
1: var ws = require('websocket.io')2: , server = ws.listen(3000)3:4: server.on('connection', function (socket) {5:6: console.log('connected to client');7: socket.send('You connected to a web socket!');8:9: socket.on('message', function (data) {10: console.log('nessage received:', data);11: });12:13: socket.on('close', function () {14: console.log('socket closed!');15: });16: });As soon as ws.listen(3000) executes, a WebSocket server is created on a single thread which listens continuously on port 3000. When an HTML5 WebSocket compliant client connects to it, it fires the ‘connection’ event which the loop picks up and immediately publishes to the thread pool (see, I told you it was only half the story), and is ready to receive the next request. Thanks to the V8 Engine, this happens really, really fast.
What’s cool is that the program *is* the server. It doesn’t require a server like IIS or Apache to delegate requests to it. Node is fully capable of hosting an HTTP or TCP socket, and it does do this on a single thread. On the surface, this is actually quite similar to WCF which can be hosted in any CLR process or IIS, and to take this analogy one step further, you could configure a self-hosted WCF service as a singleton with multiple concurrency for a similar effect. But, as you well know, there is a ton of work that now needs to be done from a synchronization perspective and if you don’t use async to carry out the work, your performance will pretty much suck.
Wait! You say. Other than an (arguably) easier async programming model, how is this different than IIS/WAS and ASP.NET or WCF? Take a look at this drawing from from a great post by Aarron Stannard who just happens to be a Developer Evangelist at Microsoft:
As you can see, there is more than one thread involved. I don’t mean this to sound like a revelation, but it is a necessary refinement to explain how the concurrency is accomplished. But, and it’s a BIG but, unlike .NET, you don’t have a choice but to write your code asynchronously. As you can see in the code sample above, you simply can’t write synchronous code in Node. The work for each event is delegated work to an event handler by the loop immediately after the event fires . The work is picked up by a worker thread in the thread pool and then calls back to the event loop which send the request on its way. It is kind of subtle, but the single thread is *almost* never busy and when it is, it is only busy for a very short period of time.
This is different from our model in at least 3 ways I can think of:
- Your code is aysnc by default, period.
- There is no context switching as the Event Loop simply publishes and subscribes to the thread pool.
- The Event Loop never blocks.
Your code is aysnc by default, period.
This can’t be understated. Writing asynchronous code is hard, and given the option, most of us won’t. In a thread-based approach, particularly where all work isn’t guaranteed to be asynchronous, latency can become a problem. This isn’t optional in Node, so you either learn async or go away. Since it’s JavaScript, the language is pretty familiar to a very, very wide range of developers.
Node is very low level, but modules and frameworks like Express add sugar on top of it that help take some of the sting out of it and modules like Socket.IO and WebSocket.IO are pure awesome sauce.
There is no context switching as the Event Loop simply publishes and subscribes to the thread pool
I am not a threading expert, but simple physics tells me that that 0 thread hops is better than a minimum of 3.
I guess this might be analogous to a hypothetical example where HTTP.sys is the only gate, and WWW Publishing Service, WAS, ASP.NET are no longer in play, but unless HTTP.sys was changed from a threaded approach for concurrency to an Event Loop, I’m guessing it wouldn’t necessarily be apples to apples.
With Node, while there are worker threads involved, since they are each carrying out one and only one task at a time asynchronously, the CPU and memory footprint should be lower than a multi-treaded scenario, since less threads are required. This tends to be better for scalability in a highly concurrent environment, even on commodity hardware.
The Event Loop never blocks.
This is still something I’m trying to get my head around, but conceptually, what appears to be fundamentally different is that the Event Loop always runs on the same, single I/O thread. It is never blocking, but instead waits for something to happen (a connection, request, message, etc.) before doing anything, and then, like a good manager, simply delegates the work to an army of workers who report back when the work is done. In other words, the worker threads do all the work, while the Event Loop just kind of chills waiting for the next request and while it is waiting, it consumes 0 resources.
One of the things that I am not clear on is that when the callbacks are serialized back to the loop, only one callback can be handled at one time, so, if a request comes in at the exact same time that the loop is temporarily busy with the callback, will that request block, even if just for the slightest instant?
So?
Obviously, still being very new to Node, I have a ton to learn, but it is clear that for highly concurrent, real-time scenarios, Node has a lot of promise.
Does this mean that I’m abandoning .NET for Node? Of course not. For one, it will take a few years to see how things pan out in the wild, but the traction that Node is getting can’t be ignored, and it could very well signal the shift to event-based server programming and EDA in the large.
I’d love to know what you think, and as I mentioned in the introduction, welcome your comments and feedback.
Resources:
- http://www.matlus.com/instantiating-business-layers-asp-net-performance/
- http://odetocode.com/Articles/305.aspx
- http://learn.iis.net/page.aspx/101/introduction-to-iis-architecture/
- http://msdn.microsoft.com/en-us/magazine/cc164128.aspx
- http://blogs.msdn.com/b/tmarq/archive/2007/07/21/asp-net-thread-usage-on-iis-7-0-and-6-0.aspx
- http://blogs.msdn.com/b/tmarq/archive/2010/04/14/performing-asynchronous-work-or-tasks-in-asp-net-applications.aspx
- http://nodebeginner.org/
- http://www.beakkon.com/geek/node.js/why-node.js-single-thread-event-loop-javascript
- http://www.aaronstannard.com/post/2011/12/14/Intro-to-NodeJS-for-NET-Developers.aspx
- http://www.quora.com/How-does-an-event-loop-work
- http://debuggable.com/posts/understanding-node-js:4bd98440-45e4-4a9a-8ef7-0f7ecbdd56cb



• Hanu Kommalapati (@hanuk) listed five ECM / CMS Systems on Windows Azure in a 1/28/2012 post:
Here is a list of CMS systems that are available on Windows Azure from various ISVs:
- Ektron CMS for .NET on Windows Azure: http://www.ektron.com/Solutions/Technology-and-features/Features-and-Tools/Ektron-Azure-Edition/
- Telerik Sitefinity: http://www.sitefinity.com/asp-net-cms-features-for-it-managers/windows-azure.aspx
- Kentico CMS on Azure: http://www.kentico.com/Product/All-Features/Website/Windows-Azure
- Drupal on Azure: http://azurephp.interoperabilitybridges.com/articles/how-to-deploy-drupal-to-windows-azure-using-the-drupal-scaffold

Steve Marx (@smarx) announced his departure from Microsoft for life as an entrepreneur in 1/27/2012 post:
I joined Microsoft in 2002, right out of college. Since then, every few years, I've looked for a new challenge, whether that's a new role (tester, developer, evangelist, program manager, two kinds of "strategist," technical product manager) or a new technology (Windows, static code analysis, ASP.NET AJAX, Windows Azure). For the past almost-decade, I've found all those new challenges within Microsoft. In my opinion, one of the biggest advantages of working at Microsoft is that it's easy to move around the company and find the right role. There's no shortage of interesting work to do and great people to work with.
After more than four years working on Windows Azure, I'm ready to find a new challenge again. This time, however, I'd like to create something all of my own. To that end, I'm cofounding a company with a friend (and former coworker). I won't say what we're going to be working on because we honestly don't know yet!
I'm sad to leave Microsoft and Windows Azure. I think this is going to be an amazing year for Windows Azure, and it's going to be strange for me to watch it from the outside. At the same time, I'm excited for the next stage of my career as an entrepreneur.On a practical note, this blog isn't going anywhere, though its content will broaden to other topics. I'm still happy to answer questions about blog posts or code I've written over the past few years, so don't hesitate to email me at smarx@smarx.com or ping me on Twitter (@smarx) about anything.

We Azure coders will miss you, Steve!
Avkash Chauhan (@avkashchauhan) described Windows Azure Troubleshooting - Taking specific Windows Azure Instance offline in a 1/27/2012 post:
When you have lots of instances running on Windows Azure, you may need to investigate issues on a specific instance however there is not direct way, you can offline specific instance from your total instances. To investigate a specific instance your first requirement is to take that instance out of the network load-balancer so that you can enable offline troubleshooting. Azure Service Management portal does not provide such functionality however you can use PowerShell and Windows Azure cmdlets on the Compute nodes to remove your instance away from Load Balancer. To use it, you must have Remote login enabled on your Windows Azure application.
- Remote login to your specific instance you would want to make offline
- Launch PowerShell as Administrator
- Run command - Add-PSSnapIn Microsoft.WindowsAzure.ServiceRuntime
- Select ‘R’ to run the untrusted code
- Run command - ‘Set-RoleInstanceStatus –busy’
- Please leave PowerShell window open to keep instance in offline mode (If you will close the PowerShell window the instance will become Active again). You will also see a message about it in PowerShell command window.
- Now it will take about 2-5 minutes and after that time your specific instance will be off line.
The PowerShell command window look like as below:
Now let’s check the Windows Azure Management Portal for instance status:
To verify that we have offline the same instance run PS command “Get-RoleInstance –Current” as below”
After I close the PowerShell Windows my specific instance will become responsive again in next 2-5 minutes as below:
That’s it!!





Nathan Totten (@ntotten) reported Windows Azure Toolkit for Social Games Version 1.2.2 Released in a 1/26/2012 post:
Today, I released version 1.2.2 of the Windows Azure Toolkit for Social Games. You can download the self-extracting package here. This version does not add any new features compared to the last (Version 1.2.0 – Beta), but this release is considered stable. We added a number of performance enhancements as well as optimized the setup of the Autofac dependency injection. The big news with this release is that we have moved the project to Github.
Github
Since we started this project Github has become an increasingly popular place to host the open source projects. Additionally, the Windows Azure SDKs are now open sourced and available on Github. We have seen a great deal of support from the community in this move and believe that Github is the right place to host this toolkit. Our hope is that with the amazing support Github offers for social coding such as forking, pull requests, etc. more users will be able to utilize and contribute to this project.
For those of you that have not used git or Github before I highly recommend watching the Mastering Git video on Tekpub. It costs $15, but it is worth it if you like learning though videos. If you like learning by doing and reading the instructions Github has a great set of help documentation on there site.
Cloning a Repository
Rather than simply downloading the zip or self-extracting package of the Social Gaming Toolkit, you may want to clone the repository. Doing this will make it easier to pull in changes when we release future updates. It also allows you to make local changes to the toolkit and still update code that changes in future versions without loosing all your work.
In order to clone a repository first you must have git installed on your computer. You can download git here. After you have git installed simply open the command prompt and clone the repository using the following command.
git clone git@github.com:WindowsAzure-Toolkits/wa-toolkit-games.gitForking a Project
One of the best features of Github is that you can easily fork projects and make your own edits. If you use this toolkit and want to keep your own version simply create a fork and make your edits. Additionally, if you make a change that you think everyone would benefit from simply send a pull request and request that we add your change to our fork.
Forking a repository is easy. Simply click the fork button and select where you want the fork to live.
After you have forked the project, you can push change[s] to your own repository. If you have a change that you want to be added to the original repository all you have to do is send a pull request.
If your pull request is accepted, your changes will be added to the original repository for everybody to use. Feel free to add features or fix any bugs you find and send us a pull request.
As always, feel free to leave comments, feedback, or suggestions. I would love to hear how you are using the toolkit and what you think about using Github.


PRNewsWire asserted “Integration Offers Unparalleled End-to-End Node.js Development Experience” in the introduction to a Cloud9 IDE to Offer Windows Azure Deployment press release of 1/24/2012 (missed when published):
Cloud9 IDE, Inc., the leading cloud-based Integrated Development Environment (IDE) for web and mobile applications, has announced the availability of Windows Azure deployment from the IDE. Windows Azure is an open cloud platform that enables users to manage applications across a global network of Microsoft-managed datacenters. The integration offers Node.js developers the advantages of a comprehensive cloud-based development environment, paired with Windows Azure's industry-leading ease of use, scalability, and interoperability.
Cloud9 IDE runs in modern web browsers and enables developers to run, debug and deploy Node.js applications from anywhere, at anytime. Integrating the Node.js IDE with Windows Azure allows developers to directly deploy applications and permanently host code on Windows Azure's robust services platform. Developers can instantly benefit from Windows Azure's high availability and 'infinite scale' model, which enables users to deploy enterprise-level applications globally, with the ability to grow or shrink resource usage based on need.
Developers can also take advantage of the Node-specific capabilities offered by both Cloud9 IDE and Windows Azure. Cloud9 IDE offers a variety of Node features, such as syntax highlighting, NPM support, code completion, testing and in-browser debugging. The company also recently announced a variety of tools designed to support the growth of the Node.js community, including Nodebits.org, a blog featuring high-quality Node.js tutorials, and Nodemanual.org, Cloud9 IDE's Node documentation site. Similarly, Node.js developers can utilize Windows Azure's new Node.js Developer Center and Windows Azure SDK for Node.js.
"Windows Azure's adoption of Node.js gives customers new and powerful options that let them take advantage of the openness and flexibility of the cloud," said, Scott Guthrie, Corporate Vice President, Microsoft Server and Tools Business. "By working with Cloud9 IDE, our goal is to make development even easier for customers and to continue to demonstrate our support for interoperability."
The Windows Azure integration marks a significant milestone as Cloud9 IDE continues to revolutionize the landscape of modern-day programming. Developers can now extend the professional Node.js experience offered by Cloud9 IDE onto Windows Azure, for a complete end-to-end development solution.
About Cloud9 IDE
Cloud9 IDE, a leading cloud-based Integrated Development Environment, enables web and mobile developers to work together in remote teams anywhere, anytime. With the rise of JavaScript and the explosion of mobile apps, Cloud9 IDE is leading the revolution with Development as a Service (DaaS) for Node.js, supporting JavaScript and HTML5. Founded in 2010, the company, based in San Francisco and Amsterdam, received additional funding from Accel Partners and Atlassian. To learn more about Cloud9 IDE, please visit www.cloud9ide.com.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Paul Van Bladel (@paulvanbladel) described how to implement Row level security in Visual Studio LightSwitch on 1/29/2012:
Introduction
The previous post covered table level security. Let’s focus now on row level security: which rows can a user see depending on her permission set.
Let’s take in mind the app for managing purchase requests. I have an PurchaseOrder which is initially requested by a company employee (we call them requestors). Before being sent eventually to the vendor, the purchase order first needs to be approved by several other parties: a procurement officers and and Adviser.
Let’s imagine that following row level security rules needs to be implemented:
- requestors can see only their own requests
- procurement officers can only see requests to which they are assigned as procurement officer
- advisers can see only those requests to which they are assigned as adviser.
An important requirement is that it is perfectly possible that users have different roles at the same time: e.g. an adviser can hand in as well a purchase request. This means that she can see requests handed in by her and requests in which she particapates as adviser.
Preprocess query method and permissions
It is clear that the row level security that we want to implement is handled in the ProProcessQuery method associated with the PurchaseRequest entity. Furthermore, the LightSwitch permission mechanism is used as “entry point” to the security implementation.
Let’s keep the data model as simple as possible:
We define 3 permissions in the Access Control Tab of the application properties:
- RLS_ApplyFilteringOnAssociatedRequestor
- RLS_ApplyFilteringOnAssociatedProcurementOfficer
- RLS_ApplyFilteringOnAssociatedAdviser
The RLS stands for Row Level Security. By using this prefix the permissions can be easily identified in the permission list. That’s practical, because row level security permissions have a slightly different semantic than other permissions. A “normal” permission is a kind of additional right in the application. So, more permissions, more rights. That’s kind of different with the row level security permissions. I you have a certain RLS permission, additional filtering on data is applied, so in a way, you have less rights.
What is wrong with the following approach
What is the problem with following code?
partial void PurchaseRequests_All_PreprocessQuery(ref IQueryable<LightSwitchApplication.PurchaseRequest> query) { bool applyRequestorFiltering= this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedRequestor); bool applyProcurementOfficerFiltering = this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedProcurementOfficer); bool applyAdviserFiltering = this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedAdviser); if (applyRequestorFiltering) { query = query.Where(r => r.RequestorUserName == this.Application.User.Name); } if (applyProcurementOfficerFiltering) { query = query.Where(r => r.ProcurementOfficerUserName == this.Application.User.Name); } if (applyAdviserFiltering) { query = query.Where(r => r.AdviserUserName == this.Application.User.Name); } }What is happening here? We first take the 3 permissions in a simple boolean value (e.g. applyRequestorFiltering). Depending on the active filters, a specific predicate will be applied. This all makes sense and this works also perfectly under the assumption that the user has either:
- one of the 3 possible permissions: a single where clause is applied.
- no permission at all: in this case the query will just be returned untouched.
What happens when the user has e.g. both the requestor and the adviser permission? Well, .. the 2 filters are applied but only the Intersection is returned and that’s not what we want. We want the records where the current user is requestor OR where the current user is Adviser.
It’s very tempting to try to combine the 3 predicates in one where clause, but you’ll see you end up with other trouble.
Introducing the ConditionalOr Operator
Try to see what’s happening here:
partial void PurchaseRequests_All_PreprocessQuery(ref IQueryable<LightSwitchApplication.PurchaseRequest> query) { bool applyRequestorFiltering = this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedRequestor); bool applyProcurementOfficerFiltering = this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedProcurementOfficer); bool applyAdviserFiltering = this.Application.User.HasPermission(Permissions.RLS_ApplyFilteringOnAssociatedAdviser); if (!applyRequestorFiltering && !applyProcurementOfficerFiltering && !applyAdviserFiltering) { return; } Expression<Func<PurchaseRequest, bool>> StartWith = r => false; Expression<Func<PurchaseRequest, bool>> requestorPredicate = r => r.RequestorUserName == this.Application.User.Name; Expression<Func<PurchaseRequest, bool>> procurementOfficerPredicate = r => r.ProcurementOfficerUserName == this.Application.User.Name; Expression<Func<PurchaseRequest, bool>> adviserPredicate = r => r.AdviserUserName == this.Application.User.Name; Expression<Func<PurchaseRequest, bool>> predicate = StartWith .ConditionalOr(requestorPredicate, applyRequestorFiltering) .ConditionalOr(procurementOfficerPredicate, applyProcurementOfficerFiltering) .ConditionalOr(adviserPredicate, applyAdviserFiltering); query = query.Where(predicate); }So, we split the 3 permissions into 3 Expressions and we start with a query that’s returning nothing by applying the StartWith expression. Afterwards each filter is applied in a conditional way and Or-ed with the previous expression.
This will give the result we expect: in case a user has multiple permissions, the correct result set is returned.
Of course, we still need the code for the ConditionalOr operator (I found this approach here: http://blogs.msdn.com/b/meek/archive/2008/05/02/linq-to-entities-combining-predicates.aspx):
public static class Utility { public static Expression<T> Compose<T>(this Expression<T> first, Expression<T> second, Func<Expression, Expression, Expression> merge) { // build parameter map (from parameters of second to parameters of first) var map = first.Parameters.Select((f, i) => new { f, s = second.Parameters[i] }).ToDictionary(p => p.s, p => p.f); // replace parameters in the second lambda expression with parameters from the first var secondBody = ParameterRebinder.ReplaceParameters(map, second.Body); // apply composition of lambda expression bodies to parameters from the first expression return Expression.Lambda<T>(merge(first.Body, secondBody), first.Parameters); } public static Expression<Func<T, bool>> And<T>(this Expression<Func<T, bool>> first, Expression<Func<T, bool>> second) { return first.Compose(second, Expression.And); } public static Expression<Func<T, bool>> Or<T>(this Expression<Func<T, bool>> first, Expression<Func<T, bool>> second) { return first.Compose(second, Expression.Or); } public static Expression<Func<T, bool>> ConditionalOr<T>(this Expression<Func<T, bool>> first, Expression<Func<T, bool>> second, bool? doCompose) { if (doCompose.Value == true) { return first.Compose(second, Expression.Or); } else { return first; } } } public class ParameterRebinder : ExpressionVisitor { private readonly Dictionary<ParameterExpression, ParameterExpression> map; public ParameterRebinder(Dictionary<ParameterExpression, ParameterExpression> map) { this.map = map ?? new Dictionary<ParameterExpression, ParameterExpression>(); } public static Expression ReplaceParameters(Dictionary<ParameterExpression, ParameterExpression> map, Expression exp) { return new ParameterRebinder(map).Visit(exp); } protected override Expression VisitParameter(ParameterExpression p) { ParameterExpression replacement; if (map.TryGetValue(p, out replacement)) { p = replacement; } return base.VisitParameter(p); } }Note that you can get the same result by using the excellent LinqKit Predicatebuilder (http://www.albahari.com/nutshell/predicatebuilder.aspx).
Conclusion
Row level security is key in every decent enterprise application. LightSwitch allows to implement row level security in an excellent way. Extending Linq with the conditionalOr operator allows to really tune the row level security at any level.



Beth Massi (@bethmassi) posted a Beginning LightSwitch–Address Book Sample on 1/26/2012:
Some folks have been asking for this so I just released the completed Address Book sample that you build step-by-step in the Beginning LightSwitch Article Series.
Download the Address Book Sample
Read the Series
Are you completely new to LightSwitch and software development? Read this entry-level article series to get started with the most important concepts you need to build any LightSwitch application.
- Part 1: What’s in a Table? Describing Your Data
- Part 2: Feel the Love. Defining Data Relationships
- Part 3: Screen Templates, Which One Do I Choose?
- Part 4: Too much information! Sorting and Filtering Data with Queries
- Part 5: May I? Controlling Access with User Permissions
- Part 6: I Feel Pretty! Customizing the "Look and Feel" with Themes
More Information
Visit the LightSwitch Developer Center to download LightSwitch and get started learning.
Download Visual Studio LightSwitch


.png)
.png)
.png)
Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Pallman recommended Taking a Fresh Look at the Windows Azure Development Experience in a 1/27/2012 post:
Windows Azure has grown up over the years since it first debuted in late 2008. In this article we're going to take an updated look at what the cloud developer experience is with Windows Azure today. Here's what we'll cover, which will include a walk-through of developing a cloud application:
- Key Online Resources
- What You Need for Cloud Development
- The Cloud Development Lifecycle
- Application Development Walk-through
Key Online Resources
Azure.com
- Set up an account or a 90-day free trial account
- Estimate your operation costs with a pricing calculator
- See your current and past billing activity
- Visit a developer center
- Download an SDK
- Find documentation
- Go to community forums
- Go to the Windows Azure Management Portal to manage your cloud solutions
Whether you work in C# in Visual Studio or Java or PHP in Eclipse, Microsoft wants developers of all stripes to be able to use the Windows Azure platform. The Developer Centeron Azure.com lets you select your preferrred language/platform and gives you information relevant to the way you want to work.
Windows Azure Management Portal
The Windows Azure Management Portal is where you provision cloud services, manage and deploy your solutions, and view status. You can get here by clicking the Manage link on Azure.com, or by navigating directly to windows.azure.com.
What You Need for Cloud Development
Let's review what you need in order to develop for Windows Azure. You will typically develop and testing your solution locally (using a simulator) before you deploy to a cloud data center.
To Develop Locally
You will need the following in order to develop locally:To Deploy and Run in the Cloud
- A Windows PC (running Windows Vista or later, WIndows 7 recommended)
- A development environment, such as Visual Studio or Eclipse
- The Windows Azure SDK (download from Azure.com), which includes the Windows Azure Simulation Environment
- SQL Server Express
You will need the following in order to deploy to a Windows Azure data center:The Cloud Development Lifecycle
- A Windows Azure account (note there is a 90-trial available, and if you have an MSDN subscription that will also give you some free hours)
In Windows Azure, the pattern is to develop and test locally as much as you can before deploying to the cloud. Once you're ready to run in the cloud, it's typical with the Compute service to first deploy to a Staging slot, test the solution in the cloud, and finally promote from Staging to Production (a one-click operation). After that, you allow people use your application, monitor and manage activity, and scale scale as needed if demand changes.
Eventually you'll want to change something in your solution and then the process repeats. In an upgrade situation, promotion Staging to Production is actually swapping them. This allows you to leave the older deployment in Staging until you're sure Production is working as it should, then you can remove it.
Application Development Walk-through
To illustrate what development is like, let's walk through provisoning, developing, testing, and deploying a cloud solution.
What We'll Build: T-Shirt World
In this example we'll build a simple order entry and order processing application named T-Shirt World. This is a rather simple application--nothing to write home about!--but it's more than a mere Hello, Cloud: it has a front end and a back end, and will make use of multple cloud services.
Activity Flow
There's a 4-step sequence of activity in T-Shirt World:The first two steps happen on the front end, a web page (what we call a Web Role). The last two steps happen on the back end, in a worker process (what we call a Worker Role).
- Submit an Order
- Queue the Order
- Dequeue the Order
- Store the Order in a Database
Cloud Services We'll be Using
Any cloud solution you create is likely to use multiple Windows Azure services. We're going to make use of four Windows Azure services in this sample application:
- Windows Azure Compute - hosts the web role (site) and worker role (back end process)
- Windows Azure Storage - image files for the web site
- Service Bus - we'll use a queue to route orders from front end to back end
- SQL Azure Database - order records …







David continues with a detailed seven-step walkthrough that ends with “Walk-through Step 7: Deploy to the Cloud.”
David Linthicum (@DavidLinthicum) asserted “Enterprise software providers need to understand the new world order if they and their customers are to succeed” in a deck for his 3 ways big software companies may fail in the cloud article of 1/26/2012 for InfoWorld’s Cloud Computing blog:
Be careful what you wish for: "Big Software" -- the multi-billion-dollar companies selling enterprise software -- have discovered the cloud, and they are now providing cloud apps and services. That should be good news, except that Big Software's history over the last 30 years shows it could easily get the cloud transition wrong -- and harm users in the process.
1. It's not just a platform change. Software providers that look at moving to the cloud as an A-to-A port are in for a surprise. The movement to the cloud needs to come with a complete reworking of the application architecture -- in many cases, from the ground up. Skipping this step means your software won't properly support resource and tenant management; users will quickly feel that limitation, and you'll fail.
2. You can't charge the same amount. Traditional enterprise software providers typically work multi-million-dollar deals with lucrative maintenance agreements. The cloud makes all of that unnecessary, so traditional enterprise providers that insist on receiving the same margins will find out fast that it won't work. The cloud is cheaper for you, so it should be much cheaper for your users as well.
3. It's changing your world. Many in enterprise software don't understand, or perhaps refuse to understand, that their world is changing forever. Can you say Blockbuster meets Netflix? I understand the reality is like turning a battleship because you're so fat and happy with the software profits you've been collecting for years. But the fact of the matter is that the playing field is now much more level. New providers are entering the game, and the cost of switching is actually pretty close to free.
It's time for some companies to get a clue.

Is David’s article directed to Oracle, Microsoft, IBM, HP or all four?
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Mark Hassall (@MSFTmarkhas) reported Dell and Microsoft Deliver a Foundation for Private Cloud in a 1/25/2012 post:
Dell vStart 200 for Microsoft [is] Available Today!
Last week, you heard about System Center and the Microsoft private cloud solution – and how together they help customers and partners move faster, save money and better compete today. Many of our customers are excited about getting the benefits of private cloud today and want to know how they can do that – quickly, simply and cost effectively. Today, we are excited to talk to you about one option that helps you do just that.
As part of our ongoing strategic partnership with Dell to help customers quickly deploy and manage virtualization and private cloud technologies, we’re announcing the availability of Dell vStart 200m, a pre-built, pre-configured, simple and fast path to a Microsoft private cloud.
This Microsoft Private Cloud Fast Track-validated solution brings together the best of Dell and Microsoft technology to give you a turnkey appliance that delivers virtualization, simply and at scale. With this new solution, customers only have to take one step to move from virtualization to private cloud computing – and that is adding Microsoft System Center. Built on Microsoft Hyper-V and Windows Server 2008 R2 DataCenter Edition, which includes unlimited virtualization rights, Dell vStart200m helps customers benefit from the economics of the Microsoft private cloud. Dell vStart 100m, built on Microsoft Hyper-V is also available today.
We are also announcing improved integration of Dell AIM and Microsoft System Center – giving customers deep management insight across infrastructure, operating systems and applications, and providing a simplified, integrated management experience delivered through a “single pane of glass”.
Whether you are ready to start your journey to private cloud or looking for integrated management solutions, Dell and Microsoft are committed to helping you quickly manage and deploy virtualization and private cloud solutions – today.
These new solutions from Dell are available in the U.S., Canada and Mexico in North America and Brazil now and will be available in select countries in EMEA and APJ in the near future. You can learn more about these solutions by visiting dell.com/vstart and dell.com/aim.
Mark is director, WSMM Outbound Marketing
Kevin Remde (@KevinRemde) posted Breaking News: Free Private Cloud “Jump Start” Training on 1/23/2012 (Missed when published):
Microsoft has just scheduled a FREE 2-day training course entitled “Creating and Managing a Private Cloud with System Center 2012 Jump Start”, happening on February 21st-22nd, 2012 from 9:00am to 5:00pm PST.
- Course: “Creating and Managing a Private Cloud with System Center 2012 Jump Start”
- Date/Time: February 21-22, 2012 from 9:00am – 5:00pm PST
- Where: Live virtual classroom (online from wherever you are)
- Cost: FREE!
- Target audience: IT Professionals (IT Implementers, managers, decision makers)
“What’s a ‘Jump Start’ course?”
From the registration page:
“Training specifically designed for experienced technologists whose jobs demand they know how to best leverage new, emerging Microsoft technologies. These advanced courses assume a certain level of expertise and domain knowledge, so they move quickly and cover topics in a fashion that enables teams to effectively map new skills to real-world situations.”
“And.. did you say ‘FREE’?”
Yes, I did.
“Is there anything I can do to get ready for this?
Download and install the System Center 2012 evaluation software: http://aka.ms/PvtCld
Then go to this page for course details, schedule, speakers, registration link, and fabulous prizes.
“Huh? Prizes?”
Not really. I was just seeing if you were still paying attention.


<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
• Adron Hall (@adron) reported on 1/28/2012 Kav Latiolais Presenting “Better Together: Building Scalable Real Time Collaborative Apps with Node.js” @ #NodePDX:
Kav is coming down from Seattle to present “Better Together: Building Scalable Real Time Collaborative Apps with Node.js”. Here’s his description of the presentation:
If you’re not using node to build collaborative real time applications you might as well be using rails. In this talk we’ll discuss patterns and pitfalls of synchronous node apps. We’ll roll up our sleeves and dig into some code demonstrating patterns that can help you get started building highly interactive applications that sync real time state with Node.js, Socket.io, and Backbone.js. You will leave this talk with insight on how to build synchronous experiences into your applications and avoid some of the pitfalls we’ve suffered.
Kav Latiolais is a principal and co-founder at Liffft in Seattle and has been developing collaborative Node.js applications for the past year with Giant Thinkwell. He once built a horse racing app in 30 minutes on a bet. Before starting his love affair with Node.JS, Socket.IO, and CoffeeScript Kav was a Program Manager at Microsoft tasked with designing Visual Studio. Don’t tell his old coworkers he exclusively uses TextMate on his Air.
If you’d like to come and check out Kav’s Presentation and the other amazing presentations lined up, get involved in some coding, hear what Node.js is all about, or just hang out please RSVP and get the event on your calendar! Besides, what better reason to come visit the amazing city of Portland, Oregon than to come hack some node.js and chill for the weekend!


Tiffany Trader reported Hadoop Summit 2012 Announced to Showcase Apache Hadoop as Next Generation Enterprise Data Platform in a 1/27/2012 post:
Premier Apache Hadoop community event opens call for papers
SUNNYVALE, Calif., Jan. 26 — Hadoop Summit 2012, the premier Apache Hadoop community event, will take place at the San Jose Convention Center, June 13-14, 2012. The event, now expanded to two days, is co-sponsored by Yahoo! and Hortonworks, and will outline the evolution of Apache Hadoop into the next generation enterprise data platform. Hadoop Summit will feature presentations from community developers, experienced users and administrators, as well as a vast array of ecosystem solution providers.
Apache Hadoop is the open source technology at the epicenter of big data and cloud computing. It enables organizations to more efficiently and cost-effectively store, process, manage and analyze the ever-increasing volume of data being created and collected every day. With Apache Hadoop, companies can connect thousands of servers to process and analyze data at supercomputing speed. Yahoo! pioneered Apache Hadoop and is a contributor to and one of the leading users of the big data platform, while Hortonworks is an independent company consisting of key architects and is the leading contributor to the Apache Hadoop technology.
The Hadoop Summit tracks include the following:
- Future of Hadoop: This track will take a technical look at the key projects and research efforts driving innovation in and around the Hadoop platform.
- Deployment and Operations: This track will focus on the deployment and operations of Hadoop clusters with an emphasis on tips, tricks and best practices.
- Enterprise Data Architecture: This track will focus on Hadoop as a data platform and how it fits within broader enterprise data architectures.
- Applications and Data Science: This track will focus on applications, tools, algorithms and data science as well as areas of advanced research and emerging applications that use and extend the Hadoop platform.
- Analytics and Business Intelligence: This track will focus on how Hadoop is powering a new generation of analytics and business intelligence solutions.
- Hadoop in Action: This track will be laser-focused on business innovation and provide concrete examples of how Hadoop is enabling businesses across a wide range of industries to become data driven.
The event's call for papers is now open. The deadline to submit an abstract for consideration is February 22, 2012. The community-driven selection committee will choose the presentations that best highlight innovative use cases on how best to implement Hadoop to extract value from massive data sets and build momentum for the burgeoning Apache Hadoop market. Accepted presenters will be notified on or before March 9, 2012.
Discounted early bird registration is available now through March 30, 2012. To register for the event or to submit a speaking abstract for consideration, visit www.hadoopsummit.org.
Sponsorship packages are also now available. For more information on how to sponsor this year's event please visit: www.hadoopsummit.org/sponsors.
About Hortonworks
Hortonworks was formed in July 2011 by Yahoo! and Benchmark Capital in order to promote the development and adoption of Apache Hadoop, the leading open source platform for storing, managing and analyzing large volumes of data. Together with the Apache community, Hortonworks is making Hadoop more robust and easier to install, manage and use. The company and its founders are leaders in designing and delivering current and future generations of Apache Hadoop and leverage their expertise to provide unmatched technical support, training and certification programs for enterprises, systems integrators and technology vendors, including ISVs, OEMs and service providers. For more information, visit www.hortonworks.com.
About Yahoo!
Yahoo! is the premier digital media company, creating deeply personal digital experiences that keep more than half a billion people connected to what matters most to them, across devices and around the globe. And Yahoo!'s unique combination of Science + Art + Scale connects advertisers to the consumers who build their businesses. Yahoo! is headquartered in Sunnyvale, California. For more information, visit the pressroom or the company's blog, Yodel Anecdotal.
-----
Source: Yahoo! Inc.
David Pallman reported on 1/26/2012 Upcoming Sessions on Web and Cloud at SoCal Code Camp Jan 28 2012:
Here are some talks I and my Neudesic colleageus are giving on web, cloud, and programming at SoCal Code Camp this weekend in Orange County:
SoCal Code CampSat Jan 28 2012 - Sun Jan 29 2012
Mobile & Global with HTML5, MVC and Windows Azure
David Pallmann (@davidpallmann) Sat Jan 28 12:15p
What happens when the web meets the cloud? The modern web (HTML5, mobile devices) is revolutioning the front end and our experiences, while at the same time the cloud (cloud computing, social networks) is revolutioning the back end. Putting them together gives you web-cloud applications that can run anywhere and everywhere.
In this session you'll see how to create solutions that are "mobile & global" by combining HTML5, mobile devices, and open standards on the web client with the MS web platform, Windows Azure cloud computing, and social networking on the web server. We'll progressively develop a "mobile & global" application in 7 steps, starting with design comps and ending with global deployment on 3 continents.
Windows Azure Design Patterns
Mickey Williams (@mickeyw) Sat Jan 28 2:45p
In order to design great cloud solutions architects need to understand the design patterns intrinsic to their cloud platform. In this session we will review the design patterns inherent in the Windows Azure platform services, followed by a discussion of application patterns for combining those services. Design patterns will be reviewed for compute, storage, relational data, communication, security, and networking. Key patterns will be illustrated with application examples.Using Lucene for Full-Text Search in Azure
Mickey Williams (@mickeyw) Sat Jan 28 4:00p
SQL Azure does not currently support full-text indexing. In this talk, we will walk through the use of Lucene to provide full-text search capabilities.F# - Functional Programming Fundamentals
Oleksiy Tereshchenko Sat Jan 28 4:00p
F# is functional programming language. Originally, developed by Microsoft Research. Iit is fully supported by Microsoft Development Division in Visual Studio 2010. Presentation will provide overview of the language and include fundamental programming concepts. Attendees will be able to understand what it is about F# that is interesting and exciting, even if they can’t necessarily see how to apply it themselves just yet.F# - Functional Programming Progamming Techniques
Oleksiy Tereshchenko Sun Jan 29 9:00a
F# is functional programming language. Originally, developed by Microsoft Research, it is fully supported by Microsoft Development Division in Visual Studio 2010. Presentation will provide overview of the functional programming techniques and demonstrate them using calculator parser. Attendees will be able to experience functional style development.

The SQL Server Team (@SQLServer) invited you on 1/26/2012 to Join us March 7, 2012 for the Virtual Launch of SQL Server 2012!:
On March 7, 2012 we are hosting the SQL Server 2012 Virtual Launch Event (VLE), to share the latest on SQL Server 2012 and the evolution of the Microsoft data platform. Through our VLE, anyone, anywhere in the world can simply log in and be a part of this amazing experience – consuming content at your own pace while still experiencing all the benefits of a tradeshow event.
You want to learn from SQL Server insiders
Learn more about the new features of SQL Server 2012 through access to more than 30 sessions. Our experts will demonstrate how your business can go further, forward, faster by capitalizing on mission critical capabilities, new features that drive true business insights and the most cloud-ready SQL Server ever.You want to engage with Partners and Customers
Visit our Partner Pavilion to discuss how partner and pioneer customer solutions integrate with SQL Server 2012.You want to chat live with product experts and MVPs
Chat live with product experts and MVPs to get the inside scoop. Our team will be on hand to answer questions about SQL Server 2012 and network in the virtual lounge.You want to engage with the community – and maybe win a prize!
Participate in virtual launch activities like the keynote speech, technical demos and networking lounge, and collect points to earn cool prizes such as cash gift cards, SQL Server Gear, and Xbox systems. The more points you earn, the bigger your prize could be!Register today at: www.sqlserverlaunch.com

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Chris Hoff (@Beaker) posted With Cloud, The PaaSibilities Are Endless… on 1/26/2012:
I read a very interesting article from ZDNet UK this morning titled “Amazon Cuts Off Stack at the PaaS”
The gist of the article is that according to Werner Vogels (@werner,) AWS’ CTO, they have no intention of delivering a PaaS service and instead expect to allow an ecosystem of PaaS providers, not unlike Heroku, to flourish atop their platform:
“We want 1,000 platforms to bloom,” said Vogels, before explaining Amazon has “no desire to go and really build a [PaaS].”
That’s all well and good, but it lead me to scratch my head, especially with regard to what I *thought* AWS already offered in terms of PaaS with BeanStalk, which is described thusly in their FAQ:
- Q: What is AWS Elastic Beanstalk?
- AWS Elastic Beanstalk makes it even easier for developers to quickly deploy and manage applications in the AWS Cloud. Developers simply upload their application, and Elastic Beanstalk automatically handles the deployment details of capacity provisioning, load balancing, auto-scaling, and application health monitoring.
- Q: How is AWS Elastic Beanstalk different from existing application containers or platform-as-a-service solutions?
- Most existing application containers or platform-as-a-service solutions, while reducing the amount of programming required, significantly diminish developers’ flexibility and control. Developers are forced to live with all the decisions pre-determined by the vendor – with little to no opportunity to take back control over various parts of their application’s infrastructure. However, with AWS Elastic Beanstalk, developers retain full control over the AWS resources powering their application. If developers decide they want to manage some (or all) of the elements of their infrastructure, they can do so seamlessly by using AWS Elastic Beanstalk’s management capabilities.
- While these snippets from the FAQ certainly seem to describe infrastructure components that enable PaaS (meta-PaaS?) when you combine the other elements of AWS’ offerings, it sure as heck sounds like PaaS regardless of what you call it.
- In fact, a Twitter exchange with @GeorgeReese, @krishnan and @jamessaull well summarized the headscratching:
- With all those components, AWS can certainly enable PaaS platforms like Heroku to “flourish.”
- However, suggesting that despite having all the raw components and not pointing to it and saying “PaaS” is like having all the components to assemble a bomb, not package it as such, and declaring it’s not dangerous because in that state it won’t go off.
- I’d say the potential for going BOOM! are real. It appears Marten Mickos was hinting at the same thing:
However, Mickos disputed Vogels’ claim that Amazon is going to let a thousand platforms bloom.
“He will always say that, and Amazon will slowly take a step higher and higher,” he said, before pointing to Beanstalk as an example. “[But] in my view PaaS has middleware components… and I could agree that it is okay to add [those] to an IaaS.”
In the long term, as I’ve stated prior, the value in platforms will be in how easy they make it for developers to create and deliver applications fluidly.
I may not be as good at marketing as some, but that sounds less like an infrastructure-centric business model and much more like an application-centric one.
Moving on up is where it’s at. I saw the scratching on the cave walls when I wrote “Silent Lucidity: IaaS — Already A Dinosaur. The Evolution of PaaSasarus Rex” back in 2009.
What do you think? Is AWS being coy?
Related articles
- Understanding PaaS (shop.oreilly.com)
- PaaS Makes Progress in 2011 (readwriteweb.com)
- Deploy Your Own Platform as a Service (PaaS) for .NET Applications in Minutes with Apprenda (rackspace.com)



Jeff Barr (@jeffbarr) described New Tagging for Auto Scaling Groups in a 1/26/2012 post:
You can now add up to 10 tags to any of your Auto Scaling Groups. You can also, if you'd like, propagate the tags to the EC2 instances launched from your groups.
Adding tags to your Auto Scaling groups will make it easier for you to identify and distinguish them.
Each tag has a name, a value, and an optional propagation flag. If the flag is set, then the corresponding tag will be applied to EC2 instances launched from the group. You can use this feature to label or distinguish instances created by distinct Auto Scaling groups. You might be using multiple groups to support multiple scalable applications, or multiple scalable tiers or components of a single application. Either, way the tags can help you to keep your instances straight.
Read more in the newest version of the Auto Scaling Developer Guide.


Sounds to me like a minor but useful feature.
Damon Edwards (@damonedwards) reported Crowbar is quietly getting more interesting (video) in a 1/25/2012 post to his dev2ops: delivering change blog:
Crowbar is an interesting project that I've covered before. Born out of Dell's cloud group, much of the initial buzz described it as an installer for the cloud era... "kickstart on steroids", if you will.
Crowbar's close association with the OpenStack project has further cemented its reputation as an installer to watch. But's it's Crowbar's quiet potential as a stack management tool that is the most interesting. Through the use of barclamps (Crowbar's modules) you can tell Crowbar to build a full stack from the BIOS config all the way up to your middleware and applications. John Willis on an episode of DevOps Cafe called it "Data Center as Code".
Crowbar barclamps are also an interesting way for independent projects or vendors to ensure that their projects/products can be easily integrated into a custom platform (today this type of focus is usually in the context of making things work on OpenStack). Want to add a new component to your platform? Grab the barclamp and Crowbar will know how to do the rest. Or at least that is the promise. The project is still young and the community is still forming.
Leading open source software projects is new territory for Dell, as a company, but the Crowbar team does seem committed and community focused. I've heard some grumbles from developers that barclamp development and testing cycles can be a bit tedious due to the nature of what you are building. But no reason to believe that those types of issues won't get sorted out over time.
A couple of Crowbar related videos are below:
The first video was made by my DTO Solutions colleague, Keith Hudgins, after he wrote a barclamp for Zenoss. It's a short demo and tour that can give you a feel for Crowbar and Barclamps.
The next video is Barton George (Dell) interviewing Rob Hirshfeld (Dell). They start off talking about the Hadoop barclamp but quickly getting into a broader discussion about Crowbar.

<Return to section navigation list>

















0 comments:
Post a Comment