Windows Azure and Cloud Computing Posts for 1/26/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 1/27/2012 with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, Traffic Manager, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Avkash Chauhan (@avkashchauhan) described Node.js and Windows Azure: Creating a blog application using Node.JS and Windows Azure Table & Blob Storage Part 1 in a 1/25/2012 post:
In this example I will create a node.js based blob application which will storage all the blog articles on Azure Storage. When application starts it reads blog article from Windows Azure table storage and then render it using EJS viewer. This sample is part of Azure Node SDK however I am going to enhance it to make it look like a full scale blog application. This is just a start. I will write this blog assume you are a new to node programming. This application uses following node packages:
- Express
- EJS
- Jade
- Stylus
- Azure
- Node-uuid
Let’s start with downloading package one by one:
Express:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install express npm http GET https://registry.npmjs.org/express npm http 200 https://registry.npmjs.org/express npm http GET https://registry.npmjs.org/mime npm http GET https://registry.npmjs.org/qs npm http GET https://registry.npmjs.org/mkdirp/0.0.7 npm http GET https://registry.npmjs.org/connect npm http 304 https://registry.npmjs.org/qs npm http 304 https://registry.npmjs.org/mkdirp/0.0.7 npm http 304 https://registry.npmjs.org/connect npm http 200 https://registry.npmjs.org/mime npm http GET https://registry.npmjs.org/formidable npm http 304 https://registry.npmjs.org/formidable express@2.5.6 ./node_modules/express ├── mime@1.2.4 ├── qs@0.4.0 ├── mkdirp@0.0.7 └── connect@1.8.5EJS:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install ejs npm http GET https://registry.npmjs.org/ejs npm http 304 https://registry.npmjs.org/ejs ejs@0.6.1 ./node_modules/ejsJade:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install jade npm http GET https://registry.npmjs.org/jade npm http 200 https://registry.npmjs.org/jade npm http GET https://registry.npmjs.org/mkdirp npm http GET https://registry.npmjs.org/commander npm http 304 https://registry.npmjs.org/mkdirp npm http 304 https://registry.npmjs.org/commander jade@0.20.0 ./node_modules/jade ├── commander@0.2.1 └── mkdirp@0.3.0Stylus:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install stylus npm http GET https://registry.npmjs.org/stylus npm http 304 https://registry.npmjs.org/stylus npm http GET https://registry.npmjs.org/mkdirp/0.0.7 npm http GET https://registry.npmjs.org/growl/1.1.0 npm http GET https://registry.npmjs.org/cssom/0.2.1 npm http 304 https://registry.npmjs.org/mkdirp/0.0.7 npm http 304 https://registry.npmjs.org/growl/1.1.0 npm http 304 https://registry.npmjs.org/cssom/0.2.1 stylus@0.22.6 ./node_modules/stylus ├── growl@1.1.0 ├── mkdirp@0.0.7 └── cssom@0.2.1
Azure:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install azure npm http GET https://registry.npmjs.org/azure npm http 304 https://registry.npmjs.org/azure npm http GET https://registry.npmjs.org/qs npm http GET https://registry.npmjs.org/mime npm http GET https://registry.npmjs.org/sax npm http GET https://registry.npmjs.org/xmlbuilder npm http GET https://registry.npmjs.org/xml2js npm http GET https://registry.npmjs.org/log npm http 304 https://registry.npmjs.org/qs npm http 304 https://registry.npmjs.org/mime npm http 304 https://registry.npmjs.org/sax npm http 304 https://registry.npmjs.org/xmlbuilder npm http 304 https://registry.npmjs.org/xml2js npm http 304 https://registry.npmjs.org/log azure@0.5.1 ./node_modules/azure ├── xmlbuilder@0.3.1 ├── mime@1.2.4 ├── log@1.2.0 ├── qs@0.4.0 ├── xml2js@0.1.13 └── sax@0.3.5Node-uuid:
C:\Azure\nodeprojects\BlogUsingAzureStorage>npm install node-uuid npm http GET https://registry.npmjs.org/node-uuid npm http 200 https://registry.npmjs.org/node-uuid npm WARN node-uuid@1.3.3 dependencies field should be hash of <name>:<version-range> pairs node-uuid@1.3.3 ./node_modules/node-uuidNow if you will look your application node_modules folder you will all the packages are download as below:
C:\Azure\nodeprojects\BlogUsingAzureStorage>dir node_modules Volume in drive C has no label. Volume Serial Number is 8464-7B7C Directory of C:\Azure\nodeprojects\BlogUsingAzureStorage\node_modules 01/25/2012 11:00 PM <DIR> . 01/25/2012 11:00 PM <DIR> .. 01/25/2012 10:59 PM <DIR> .bin 01/25/2012 11:00 PM <DIR> azure 01/25/2012 10:58 PM <DIR> ejs 01/25/2012 10:57 PM <DIR> express 01/25/2012 10:59 PM <DIR> jade 01/25/2012 11:00 PM <DIR> node-uuid 01/25/2012 10:59 PM <DIR> stylusNow please clone nodeblogwithazurestorage.git repo from GitHub as below:
C:\Azure\nodeprojects\BlogUsingAzureStorage>git clone https://Avkash@github.com/Avkash/nodeblogwithazurestorage.git Cloning into 'nodeblogwithazurestorage'... remote: Counting objects: 16, done. remote: Compressing objects: 100% (14/14), done. remote: Total 16 (delta 0), reused 16 (delta 0) Unpacking objects: 100% (16/16), done.You will see a new folder name “'nodeblogwithazurestorage'” which includes all the files from repo. Please copy all of these files to your root folder so your work folder will look like as below:
C:\Azure\nodeprojects\BlogUsingAzureStorage>dir 01/25/2012 11:25 PM 2,828 blog.js 01/25/2012 11:25 PM <DIR> nodeblogwithazurestorage 01/25/2012 11:00 PM <DIR> node_modules 01/25/2012 11:25 PM 161 package.json 01/25/2012 11:29 PM <DIR> public 01/25/2012 11:29 PM <DIR> routes 01/25/2012 11:25 PM 2,073 server.js 01/25/2012 11:29 PM <DIR> viewsThat’s it. Let’s run it.
C:\Azure\nodeprojects\BlogUsingAzureStorage>node server.js Express server listening on port 40506 in development modeNow open your browser using http://localhost:40506 or http://127.0.0.1:4506 and you will see the node blog application is running as below:
In next blog:
- We will use Windows Azure Table Storage to store and retrieve Blog articles.
- Change package.json for correct dependencies
- Updating package
- We will deploy this application to Windows Azure


<Return to section navigation list>
SQL Azure Database, Federations and Reporting
• Gregory Leake posted Announcing SQL Azure Data Sync Preview Refresh to the Windows Azure blog on 1/26/2012:
It has been just over three months since we made the SQL Azure Data Sync Preview release available in the Windows Azure portal. We are thrilled with the adoption of the service and are pleased to make available an updated preview release with some requested features and fixes. SQL Azure Data Sync allows organizations to easily synchronize between multiple on-premises databases and SQL Azure cloud databases—a key hybrid IT scenario. If you have not used the Data Sync service and want to learn about it, there is a new video demonstration available that provides an overview of the service capabilities, target scenarios and shows the service in use. There is also a series of videos available on Channel 9 here.
This release addresses several pieces of feedback we’ve heard from customers and brings us a step closer to General Availability. This is the third update to the Preview service since October and contains the following updates:
- Data Sync servers can now be created in all Windows Azure data centers, enabling Data Sync servers to be created close to the SQL Azure databases for the best possible performance.
- The Data Sync section of the Windows Azure portal is now localized in ten languages.
- Miscellaneous fixes and numerous usability improvements including:
- Progress indicators are now available in the log for long running synchronizations.
- Error messages have been improved to better help you troubleshoot problems.
- Synchronization of self-referencing tables is now supported.
- A new version of the Data Sync Agent is available in the Download Center and it is highly recommended that existing agents are updated to the new version (available here).
Here’s a brief summary of the changes we made in the first two service updates:
- Addressed the issue that sometimes led to failed syncs for narrow tables with a small number of columns.
- Allow logins when either username@server or just username are specified.
- Column names with spaces are now supported.
- Columns with a NewSequentialID constraint are converted to NewID for SQL Azure databases in the sync group.
- Both Administrators and non-Administrators are able to install the Data Sync Agent.
- A new version of the Data Sync Agent was made available on the Download Center.
The team is hard at work on future updates as we approach General Availability and we really appreciate your feedback to date! Please keep the feedback coming and use the SQL Azure Forum to ask questions or get assistance with issues. Have a feature you’d like to see in SQL Azure Data Sync? Be sure to vote on features you’d like to see added or updated using the Feature Voting Forum.

Cihan Biyikoglu (@cihangirb) asked How much overcapacity are you running with today? I bet SQL Azure Federations can trim that! in a 1/25/2012 post:
I know I already posted a whole bunch on “why use federations” or “what are federation for” but most conversations on federations, I get the question on ‘why’? so I wanted to go back to basics and what the combination of SQL Azure (a.k.a PaaS database in the cloud) and Federations is a killer combination.
Imagine the isolated capacity you need at the database tier; Here is your capacity for the next 6-18 months and here is what you maintain as capacity on premise; You buy some more HW, fire it up and you get more cores, more memory and more IO capacity etc. You release new functionality that changes your workload, you get more customers, your customers data grows or whatever else that changes your workload over time, you push things to limits so you are under provisioned so you acquire some more HW and life goes on…
The above picture is also the representation of systems with static partitioning or sharding today on any system that offers no repartitioning operations. Lets say you start life with 20-30 partitions, you distribute and size things for the peak loads. Or if you are multi-tenant architecture already, you place 100 or 200 tenants per database or shard. But those tenants change and grow so these static decisions require some level of overprovisioning to be safe because repartitioning is offline and could be error prone every time.
With the cloud, the picture looks like the one below; You provision just in time and simply trace along the capacity line closely.
Federation is there for trimming overcapacity as well. You don’t need to make a static decision about how many tenants to put into a shard, you don’t need to decide how many shards you need for the web app up front for the next 3 months or the year. You can change your mind over time and Federations let you do repartitioning online without downtime so you don’t need to take down the app or the database. If it turns out some tenants grow and you cannot no longer fit 10000 tenants into 1 database and you need to go 5000 tenants per db… OR if you want to handle the black friday or the tax day or the end of month reporting and you need more capacity… OR if your service takes off and you acquire a whole bunch of customers… OR if you release a new version or a new functionality that changes the workload, you can prepare for it with federations. Kick off a SPLIT and it will engage more nodes. All online!



<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
Glen Gailey (@ggailey777) described a New and Improved T4 Template for OData Client and Local Database in a 1/25/2012 post:
If you recall from my previous post Sync’ing OData to Local Storage in Windows Phone (Part 1), I had written a T4 template for my Windows Phone 7.5 (“Mango”) project to generate a proxy client needed to access both an OData service and local database on the device. My template was based on an existing T4 template,which was published in a blog post by Alexey Zakharov on Silverlight Show, that generated a generic OData proxy client. I had promised to publish my first stab a T4 template to generate this hybrid proxy. However, because my original template was based on Alexey’s OSS sample, it was taking a long time to get the go ahead to post it.
A New T4 Template for OData Clients
Fortunately, the other day I heard about a new T4 template written by the OData team to generate an OData client proxy to access an OData v3 data service.
Perfect!
With this new Microsoft-developed template, I have been able to port my previous LINQ-to-SQL additions into a new template without too much work. And, I have now updated my previously published project Using Local Storage with OData on Windows Phone To Reduce Network Bandwidth to now include the actual T4 template. To use this project on your computer, follow the instructions in the main page.
Considerations for My New Hybrid T4 Template
Since I have posted this template to MSDN Samples Gallery Code under the Apache 2.0 license, I should probably mention a few caveats for your using this template:
- This template requires the libraries that are part of WCF Data Services 1.0 (for OData v3), which you can install from the Microsoft WCF Data Services October 2011 CTP. In particular, it uses EDMLib to parse the .edmx metadata.
- The original T4 template that I used as my starting point is a preview version that is published to Nuget.org. Since it’s a preview, I will need to port my updates into the final version, when it becomes available.
- The original T4 template was designed to support the upcoming release of WCF Data Services 1.0, which includes new behaviors like collection properties. My template does not (yet) support collection properties because I have not yet figured out the best way to do this (I will probably have to end up serializing them to string values).
- The original T4 template doesn’t yet include the data contract serialization attributes needed to support tombstoning on Window Phone, so I added those too in my version.
- As before, my template supports complex type properties, but I’m not sure that it will handle nested complex types.
- I’ve tested my template against the Netflix service (since that’s what my sample app consumes), which is the most complex public OData service that I have found. However, I haven’t tested it against a true OData v3 service.
- You have to manually set the namespace and path variable to the generated .edmx file on your local machine (T4 doesn’t support Visual Studio macros).
Installing The Hybrid T4 Template into a New Project
In case you want to try out my T4 template in your own Windows Phone project, here’s how you would do it:
- Make sure that you have NuGet installed. You can install it from here: https://nuget.org/.
- If you haven’t already done so, use the Add Service Reference tool Visual Studio to add a reference to the OData service.
(The template needs the service.edmx file generated by the tool).- In your project, use the NuGet Package Manager Console to download and install the ODataT4-CS package:
PM> Install-Package ODataT4-CS- Remove the Reference.tt template and replace it with the ReferenceWithLocalDatabase.tt template from my sample.
- Open the ReferenceWithLocalDatabase.tt template file and change the value of the MetadataFilepath property in the TransformContext constructor to the location of the .edmx file generated by the service reference and update the Namespace property to a namespace that doesn’t collide with the one generated y the service reference.
Now, when you save the template file, VS should access the local .edmx file to generate a new proxy class in C#.
As I mentioned, I will post an update to my hybrid template after the final T4 template is released by the OData team.
<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
Brian Loesgen (@BrianLoesgen) reported a New Azure ServiceBus Demo Available in a 1/22/2012 post (missed when published):
I’m pleased to announce that I FINALLY have finished and packaged up a cool little ServiceBus demo.
I say “finally” because this demo has a long lifeline, it began over a year ago. I enhanced it, and showed it to a colleague, Tony Guidici, for his comments. He ended up enhancing it, and putting it into his Azure book. I then took it back, enhanced it further, and, well, here it is. Thanks also to my colleagues David Chou and Greg Oliver for their feedback.
- High def video walkthrough: http://youtu.be/xKHl87_BFT0
- Low def video walkthrough: http://youtu.be/c3KLhsjstco
- Complete source code, http://servicebuseventdemo.codeplex.com/
Note that this is based on the current-when-I-did-this version 1.6 of the Azure SDK and .NET libraries.
At a high level, the scenario is that this is a system that listens for events, and when critical events occur, they are multicast to listeners/subscribers through the Azure ServiceBus. The listeners use the ServiceBus relay bindings, the subscribers use the topical pub/sub mechanism of the ServiceBus.
Why relay *and* subscription? They serve different models. For example, using the subscription model, a listener could subscribe to all messages, or just a subset based on a filter condition (in this demo, we have examples of both). All subscribers will get all messages. By contrast, a great example of the relay bindings is having a Web service deployed on-prem, and remoting that by exposing an endpoint on the ServiceBus. The ServiceBus recently introduced a load balancing feature, where you could have multiple instances of the same service running, but if a message is received only one of them is called.
Both models work very well for inter-application and B2B scenarios.
The moving parts in this particular demo look like this:
Subscriptions are shown above as ovals, the direct lines are relay bindings. The red lines are critical events, the black line is all events.
The projects in the solutions are:
Their purposes are:
Client
- EventPoint.ConsoleApp: Listens for critical messages multicast through the ServiceBus relay binding
- EventPoint.ConsoleApp.Topics: Listens for critical messages multicast through the ServiceBus eventpoint-topics namespace
- EventPoint.Generator: Test harness, publishes messages to the ServiceBus eventpoint-topics namespace
- EventPoint.Monitor: WinForms app that listens for critical messages multicast through the ServiceBus relay binding
Cloud
- EventPoint.CriticalPersister: Listens for critical messages multicast through the ServiceBus relay binding and persists them to SQL Azure
- EventPoint.Data: Message classes
- EventPoint_WebRole: Table browser UI to see all events that have been persisted to Azure table storage
- EventPoint_WorkerRole: Worker role that sets up eventpoint-topics subscriptions for 1) All events and 2) critical (priority 0) messages that get multicast to the ServiceBus relay
Common
- EventPoint.Common: Config, message factory to support push notifications
- Microsoft.Samples.ServiceBusMessaging: NuGet package to support push notifications
There are a few things you’ll need to do in order to get the demo working. Remarkably few things actually, considering the number of moving parts in the flow diagram!
First off, in the admin portal, you will need to create two ServiceBus namespaces:
NOTE THAT SERVICEBUS NAMESPACES MUST BE GLOBALLY UNIQUE. The ones shown above are ones I chose, if you want to run the code you will have to choose your own and cannot re-use mine (unless I delete them).
The “eventpoint-critical” namespace is used for the relay bindings, the “eventpoint-topics” is used for the pub/sub (apparently you cannot use the same namespace for both purposes, at least at the time this was written). You don’t have to use those names, but if you change them, you’ll need to change them in the config file too, so I’d suggest just leaving it this way.
Because there are multiple types of apps, ranging from Azure worker roles through console and winforms apps, I created a single shared static config class that is shared among the apps. You can, and need to, update the app.config file with your appropriate account information:
Note: there are more things you need to change that did not fit in the screen shot, they will be self-evident when you look at the App.Config file.
To get the ServiceBus issuer name and secret, you may need to scroll as it is bottom-most right-hand side of the ServiceBus page:
Lastly, you’ll need to add the name/creds of your storage account to the Web and worker roles.
When you run the app, five visible projects will start, plus a web role and a worker role running in the emulator.
In the screen shot below, I generated 5 random messages. Three of them were critical, and you can see they were picked up by the console apps and the WinForms app.
Just as with Windows Azure queues, the Azure ServiceBus is a powerful tool you can use to decouple parts of your application. I hope you find this demo helpful, and that it gives you new ideas about how you can use it in your own solutions.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Traffic Manager, Connect, RDP and CDN
Michael Washam (@MWashamMS) announced a New Management API for Windows Azure Traffic Manager in a 1/26/2012 post:
As you may have noticed in the Windows Azure developer portal, we recently released a new management API for Windows Azure Traffic Manager. The new API improves Traffic Manager by allowing developers and IT professionals to script interactions with the service and to interface with the service programmatically.
With the release of the new API, developers now have full access to the management and creation of Traffic Manager policies, including the creation of a profile from scratch. In this post, we’ll walk through how to create, update, and manage profiles using the new API. Documentation for the new Traffic Manager REST APIs can be found here.
Let's look at a typical configuration in the portal to see how we could accomplish the same configuration using the APIs. Before we get started, if you are new to Windows Azure Traffic Manager, I highly recommend reading an overview of how the service works before continuing.
For reference, I have included a screenshot of a configuration I have setup that uses the performance load balancing method to distribute traffic between an application endpoint setup in the North Central US datacenter and the North Europe datacenter.
Figure 1: Traffic Manager Policy PageThe Edit Traffic Manager Policy dialog allows you to configure a Windows Azure Traffic Manager policy in one screen. Behind the scenes there are multiple API calls that create multiple entities on your behalf that represent this policy configuration that you as a developer will need to be aware of.
So how can you accomplish the same configuration programmatically?
Understanding the entities is the first step. The policy represented above consists of a profile with a domain name specified, at least one definition, which in turn consists of the following configuration: load balancing method, DNS TTL, endpoints and a monitoring configuration among other things.Figure 2: Traffic Manager Entities

Each profile can have multiple definitions associated with it. However, only one definition can be active at a time. Creating multiple definitions is not currently exposed in the portal. It is entirely possible to define multiple distinct definitions and provide the ability to switch between them without rebuilding them.POST
https://management.core.windows.net/<subscription-id>/services/WATM/profiles
Figure 3: Create Profile Request Parameters
The Create Profile API requires you to specify a profile name and the Traffic Manager Domain name. The domain name consists of a DNS prefix (host name) and .trafficmanager.net. In the management portal there is not a location for a profile name; this is generated for you when you use the portal. This is not the case when you create the profile programmatically. How the profile name is generated is something important to understand as a developer. When you create a profile from the portal the name is generated by taking the hostname of the domain name you are specifying and appending -trafficmanager-net to it. For example if the domain name you specified was: woodgrove.trafficmanager.net the internal name of the profile would be woodgrove-trafficmanager-net. When creating a profile programmatically the profile name is whatever you pass into the Create Profile API.
POST
Figure 4: Create Definition Request Parameters
Once a profile is created, you can then create a definition using the Create Definition API to specify the rest of your Windows Azure Traffic Manager configuration.
The definition configuration is not as complex as it looks. Defining the monitor consists of specifying the relative path to an HTTP/HTTPS resource that will tell Traffic Manager the health of your application via the returned status code. You may change the port, protocol and the relative path but the remaining settings have to be set to the default values.
Each endpoint consists of the URL to one of the Windows Azure applications that you want managed in the Windows Azure Traffic Manager and a flag indicating whether it is currently enabled or disabled.The URL specified when creating the Traffic Manager profile (<dnsprefix>.trafficmanager.net) will be mapped to one of the specified endpoints when a DNS name is resolved. Which endpoint is resolved is based on the load balancing method specified (Performance, Failover or RoundRobin).
For Example:
WoodGroveUS.cloudapp.net could reside in the North Central data center.
WoodGroveEU.cloudapp.net could reside in the North Europe data center.WoodGrove.trafficmanager.net would be the parent domain name that when resolved would be mapped to one of the data center endpoints.
PUT
https://management.core.windows.net/<subscription-id>/services/WATM/profiles/<profile-name>
Figure 5: Update Profile Request Parameters
There can be multiple definitions associated with a profile but only at most one can be active at a time. For a Traffic Manager profile to be active you must enable one of the definitions associated with the profile. You enable a definition by calling the Update Profile API passing in the version that was returned when you called the Create Definition API.
Managing Existing Profiles and Definitions
Beyond the core operations of creating a profile and its associated definitions, the Traffic Manager REST API also supports List Profiles, Get Profile, List Definitions, Get Definition and Delete Profile. These APIs provide full functionality for building an application to manage Windows Azure Traffic Manager configurations.
If you would like to automate the management of your Windows Azure Traffic Manager profiles but you do not want to write code against the REST API to do it we also have an answer for you. We have updated the Windows Azure PowerShell Cmdlets (now version 2.2) to have full support for the Windows Azure Traffic Manager.
Windows Azure Traffic Manager Cmdlets
- New-TrafficManagerProfile
- Get-TrafficManagerProfile
- Remove-TrafficManagerProfile
- Set-TrafficManagerProfile
- Get-TrafficManagerDefinition
- New-TrafficManagerDefinition
- Add-TrafficManagerEndpoint
- New-TrafficManagerEndpoint
- Set-TrafficManagerEndpoint
- Remove-TrafficManagerEndpoint
- New-TrafficManagerMonitor
Here is an example of how you can use PowerShell to create a new profile and definition:

Windows Azure Traffic Manager is a key technology for enabling global and highly available applications. The new REST APIs will allow application developers to build applications that make the management of Traffic Manager a native part of their application. We have also opened the door for automating deployments to Windows Azure customers by exposing this functionality in the new release of the Windows Azure PowerShell Cmdlets 2.2.





<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Tim Huckaby interviewed Vishwas Lele in a 00:05:42 Bytes by MSDN: January 24 - Vishwas Lele video on 1/26/2012:
Join Tim Huckaby, Founder of InterKnowlogy and Actus Software, and Vishwas Lele, CTO of Applied Information Sciences, as they discuss the latest announcements around Windows Azure from the Build 2011 Conference. Vishwas is the king of Azure and has worked with many companies including ISV’s, point of sale systems, start-ups and more to migrate to Windows Azure. One new feature in Windows Azure announced at Build that Vishwas is excited about is, the geo-replication capability where you can geo-replicate one Windows Azure storage account in one data center to another data center. This is a great interview showing exciting times in the Azure world with many more changes to come!
About Vishwas
Vishwas Lele is an AIS Chief Technology Officer and is responsible for the company vision and execution of creating business solutions using .NET technologies. Vishwas brings over 20 years of experience and thought leadership to his position, and has been at AIS for 17 years. A noted industry speaker and author, Vishwas is the Microsoft Regional Director for the Washington, D.C. area.
About Tim
Tim Huckaby is focused on the Natural User Interface (NUI)- Touch, Gesture, and Neural, in Rich Client Technologies on a broad spectrum of devices
Tim has been called a "Pioneer of the Smart Client Revolution" by the press. Tim has been awarded many times for the highest rated technical presentations and keynotes for Microsoft and many other technology conferences around the world. Tim has been on stage with, and done numerous keynote demos for many Microsoft executives including Bill Gates and Steve Ballmer.
Tim founded InterKnowlogy, a custom application development company, in 1999 and Actus Interactive Software in 2011 and has over 30 years of experience including serving on a Microsoft product team as a development lead on an architecture team on a Server Product. Tim is a Microsoft Regional Director, a Microsoft MVP and serves on many Microsoft councils and boards like the Microsoft .NET Partner Advisory Council.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+


Satish Kumar wrote a Microsoft Visual Studio LightSwitch 2011 Review for Software News Daily on 1/25/2012:
Many organizations are constantly looking to address their business needs with flexible and scalable applications. In most cases, the time and resources necessary to build those applications are not always available.
Here’s the solution: Microsoft Visual Studio LightSwitch 2011 has the potential to meet these business needs.
Microsoft Visual Studio LightSwitch 2011 is a flexible development tool that helps developers to rapidly develop polished and fantastic business applications for the desktop as well as the Cloud.

With an intuitive development environment, timesaving tools and templates, Visual Studio LightSwitch helps speed the development process. It also reduces the complexity from user-interface design to Windows Azure cloud deployment. LightSwitch is essential in the development of affordable, scalable custom software solutions that connect with existing applications, legacy systems and web services. It automatically handles the routine code and lets you focus on developing the custom logic that makes your application unique. It facilitates comprehensive and user friendly views of your business data.
Key Features of LightSwitch 2011
- LightSwitch 2011 supports exporting data to Microsoft Office Excel for easy reporting.
- The asynchronous data loading routines help in building load-responsive applications.
- The built-in authentication models provide all the users with varying degrees of authorization and accessibility.
- Automatic generation of administration console.
- A simple and innate way of setting user roles and permissions.
- The pre-built components and templates of LightSwitch 2011 are absolutely extensible.
- LightSwitch 2011 ships with a set of Application Shells that gives a feel of popular Microsoft software.
- It consists of predefined data types for commonly used fields like email addresses and phone numbers.
Major Benefits
- You can easily enhance the functionality of LightSwitch application by adding extensions from third party vendors.
- It is very easy to collect, analyze and reuse the content from various sources such as Microsoft SQL Azure, Microsoft SQL Server, Microsoft SharePoint, Oracle and other databases.
- As LightSwitch 2011 handles the code, you can create user friendly business applications.
- It helps in building the applications with built-in paging, filtering and sorting capabilities. This makes it easier in handling huge amounts of data.
- The development environment simplifies all the phases of the development by providing assistance as and when required.
- You can create custom business logic and rules that are unique to a particular business and the users.
- You can change the behavior and appearance of an application by just changing one setting of shell and theme extensions.
- With LightSwitch 2011, you can build applications that can be deployed to desktop clients, browser clients or through the Cloud. You can choose the deployment method according to your requirements.
As you create a new LightSwitch project, the only decision you need to make is whether to use Visual C# or Visual Basic. The projects are logically 3-tier applications and follow n-tier best practices. They also utilize Entity Framework and RIA services.
Microsoft Visual Studio LightSwitch 2011 is in stock at SoftwareMedia.com!
Satish also includes a link to a 00:02:12 promotional video in his post.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Mary Jo Foley (@maryjofoley) asserted “Microsoft is moving steadily ahead with its plan to enable Linux to run on its Windows Azure cloud platform” in a deck for her Microsoft seeking open-source expert to help put Linux on Azure article for ZDNet’s All About Microsoft blog:
As I blogged earlier this month, Microsoft is preparing to enable Linux to run on its Windows Azure cloud platform. A test build of the coming Linux virtual-machine capability is slated for March, according to my contacts.
For those still doubting this is on the Microsoft roadmap, I’ve got a new piece of evidence. A contact of mine provided me with a link to a Microsoft job posting for a software development engineer at Microsoft that calls for some serious Linux credentials.
Here is the pertinent part of the post:
SR Software Development Engineer (SDE) Job
Date: Jan 22, 2012
Location: Redmond, WA, US
Job Category: Software Engineering: Development
Location: Redmond, WA, US
Job ID: 764856-52821
Division: Server & Tools BusinessSenior Software Development Engineer/Linux Virtualization
This position requires a proven track record in the open source community.
The Windows Interoperability Team at Microsoft has an immediate opening for a senior software development engineer. The purpose of this position is to become a key member of a highly specialized development team whose mission is to identify, define, scope, implement and drive to completion software projects that promote full, transparent interoperability between Windows and Linux in Microsoft virtual and cloud environments.
The primary responsibilities for this position are the following:
Define and scope open source projects designed to enable Linux on Microsoft’s virtualization and cloud platforms
Work directly with the Linux kernel community to develop Linux device drivers and kernel technology to support Linux on Microsoft platforms
Work with Microsoft product groups to help ensure the design and implementation of Microsoft virtualization and cloud technology will support Linux architectures and runtime paradigms.
…


Mary Jo continues with the job qualifications and a report about a forthcoming IaaS workshop.
Gavin Clarke (@gavin_clarke) asserted “Cloud biz falls short of $80m revenue target” in a deck for his Microsoft's magic bullet for Azure: Red Hat Linux article of 1/26/2012 for The Register:
If Microsoft loves money, and it does, then making Linux publicly available on its proprietary Azure cloud can't come soon enough.
Last June Microsoft ran a build of Linux on its Windows Azure compute fabric in the labs of the Server and Tools division, which is responsible for its cloud.
What flavour of Linux? Red Hat, sources close to the company now tell The Reg.
That's a critical pick given North Carolina's favourite brand of Linux continues to reign as the market's number-one distro and is a preferred choice for Windows shops when going Linux.
Microsoft now loves Linux when it's running as a virtualised instance on its gear.
By embracing Linux, Microsoft managed to contain the Penguin's once rapid advance in the server room and, according to IDC, Windows now accounts for nearly 50 per cent of server revenues compared to just under 20 per cent for Linux.
The closed, controlled environment of the server room however is no longer Microsoft's big problem: it's the cloud.
We knew that several years into Windows Azure, Microsoft's cloud platform was struggling, only we didn't know by how much. Now we have some unofficial figures.
Sources tell us the revenue target for Windows Azure in Microsoft's current fiscal year, which started on 1 July 2011, is $80m - a relatively modest number for a company the size of Microsoft. Halfway in, it looks like the target will be missed and come in at $60m, The Reg has been told.
We asked Microsoft to comment on the numbers, but the company declined.
How that $80m figure compares
To give some perspective: Microsoft's Server and Tools division, which runs Azure, raked in an overall $4.7bn for the most recent quarter, up 11 per cent. Amazon, the game everybody wants to beat, in October reported $407m revenue for a business segment it calls "other". That segment contains money made from EC2 as the retailer doesn't break out cloud figures.
Amazon also doesn't release customer data, but does tell you how much data is pouring through its cloud: 566 billion objects by the end of 2011, almost double the number of 2010. To help contain that and grow, Amazon opened three data centres in 2011.
Microsoft's struggle towards cloud revenue is believable. In the last year or so, Microsoft's been tweaking and re-working Windows Azure pricing with the direction consistently towards cheaper at the low end as an on-ramp for new developers. Microsoft claims to have more than 10,000 Windows Azure customers; if that's correct then they are either paying tiny amounts of money for the service or paying nothing because Microsoft is giving it away to existing Windows shops.
Microsoft's been trying to emulate Amazon as a haven for developers of all languages and tools: it's made Azure friendly for Java and PHP in addition to .NET. It's used startups and internet companies as poster children to lure consumers and web entrepreneurs to Azure. …


Gavin continues with a “There's no business like Node.js business” section.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Brian Loesgen (@BrianLoesgen) reported new Azure Discovery Events in a 1/22/2012 post:
We are going to be running another series of Windows Azure Discovery events in US West region.
Azure Discovery Events
Date
Location
Time
Registration January 31, 2012
Redmond, WA
9:00 AM – 1:00 PM
Register here February 8, 2012
Boulder, CO
9:00 AM – 1:00 PM
Register here February 27, 2012
Mountain View, CA
9:00 AM – 1:00 PM
Register here March 1, 2012
Irvine, CA
9:00 AM – 1:00 PM
Register here
To register by phone, call: 1.877.MSEVENT (1.877.673.8368).
<Return to section navigation list>
Other Cloud Computing Platforms and Services
AT&T (@ATTBusiness) announced the availability of its new AT&T Cloud Architect Public, Private and Bare Metal Instances in Web page that appeared 1/26/2012:
AT&T Cloud Architect - Public Instance
Start here, scale there
Whether you need at-the-ready cloud resources for rapid deployment, extra compute capacity for unexpected workloads or a short-term testing and development platform without a long-term investment, consider a public instance from AT&T Cloud Architect.
It can be a great starting point for gaining basic cloud benefits and a scalable springboard into other cloud server solutions that meet more specialized computing needs.
A public instance from AT&T Cloud Architect lets you turn computing capacity up when you need it and down when you don’t via our online customer portal, where it’s also fast and easy to reconfigure and resize cloud servers on the fly. A monthly fee or pay-as-you go pricing makes this multi-tenant cloud solution both flexible and affordable. Start your cloud servers now.
AT&T Cloud Architect provides a scalable stepping stone into the cloud.
Standard Configuration Pricing
Monthly and Hourly plans include unlimited inbound and private network bandwidth. Monthly plans include 1000GB of outbound bandwidth per month ($0.10/GB charge for additional bandwidth). Hourly plans do not include any outbound bandwidth ($0.10/GB for all outbound bandwidth).
Local Storage Based

AT&T’s pricing is competitive, but I haven’t found SLA details so far.
Jeff Barr (@jeffbarr, pictured below) published AWS HowTo: Using Amazon Elastic MapReduce with DynamoDB (Guest Post) as a guest post on 1/25/2012:
Today's guest blogger is Adam Gray. Adam is a Product Manager on the Elastic MapReduce Team.
-- Jeff;
Apache Hadoop and NoSQL databases are complementary technologies that together provide a powerful toolbox for managing, analyzing, and monetizing Big Data. That’s why we were so excited to provide out-of-the-box Amazon Elastic MapReduce (Amazon EMR) integration with Amazon DynamoDB, providing customers an integrated solution that eliminates the often prohibitive costs of administration, maintenance, and upfront hardware. Customers can now move vast amounts of data into and out of DynamoDB, as well as perform sophisticated analytics on that data, using EMR’s highly parallelized environment to distribute the work across the number of servers of their choice. Further, as EMR uses a SQL-based engine for Hadoop called Hive, you need only know basic SQL while we handle distributed application complexities such as estimating ideal data splits based on hash keys, pushing appropriate filters down to DynamoDB, and distributing tasks across all the instances in your EMR cluster.
In this article, I’ll demonstrate how EMR can be used to efficiently export DynamoDB tables to S3, import S3 data into DynamoDB, and perform sophisticated queries across tables stored in both DynamoDB and other storage services such as S3.
We will also use sample product order data stored in S3 to demonstrate how you can keep current data in DynamoDB while storing older, less frequently accessed data, in S3. By exporting your rarely used data to Amazon S3 you can reduce your storage costs while preserving low latency access required for high velocity data. Further, exported data in S3 is still directly queryable via EMR (and you can even join your exported tables with current DynamoDB tables).
The sample order data uses the schema below. This includes Order ID as its primary key, a Customer ID field, an Order Date stored as the number of seconds since epoch, and Total representing the total amount spent by the customer on that order. The data also has folder-based partitioning by both year and month, and you’ll see why in a bit.
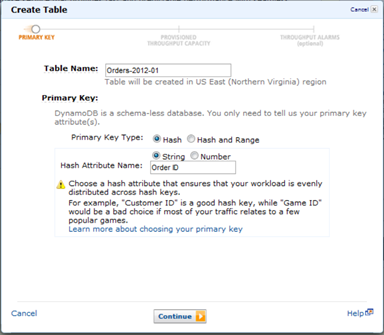
Creating a DynamoDB Table
Let’s create a DynamoDB table for the month of January, 2012 named Orders-2012-01. We will specify Order ID as the Primary Key. By using a table for each month, it is much easier to export data and delete tables over time when they no longer require low latency access.
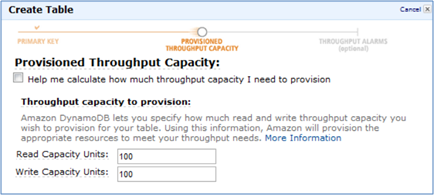
As no other applications will be using our DynamoDB table, let’s tell EMR to attempt to use 100% of the available read throughput (by default it tries to use 50%). Keep in mind that this is a best effort attempt and not a guarantee for throughput usage. You should also note that this setting can adversely affect the performance of other applications that are simultaneously using your DynamoDB table and should be set cautiously.
Launching an EMR Cluster
Please follow Steps 1-3 in the EMR for DynamoDB section of the Elastic MapReduce Developer Guide to launch an interactive EMR cluster and SSH to its Master Node to begin submitting SQL-based queries. Note that we recommend you use at least three instances of m1.large size for this sample.At the
hadoopcommand prompt for the current master node, typehive. You should see a hive prompt:hive>As no other applications will be using our DynamoDB table, let’s tell EMR to use 100% of the available read throughput (by default it will use 50%). Note that this can adversely affect the performance of other applications simultaneously using your DynamoDB table and should be set cautiously.
SET dynamodb.throughput.read.percent=1.0;
Creating Hive Tables
Outside data sources are referenced in your Hive cluster by creating an EXTERNAL TABLE. First let’s create an EXTERNAL TABLE for the exported order data in S3. Note that this simply creates a reference to the data, no data is yet moved.CREATE EXTERNAL TABLE orders_s3_export ( order_id string, customer_id string, order_date int, total double )
PARTITIONED BY (year string, month string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
LOCATION 's3://elastic-mapreduce/samples/ddb-orders' ;You can see that we specified the data location, the ordered data fields, and the folder-based partitioning scheme.
Now let’s create an EXTERNAL TABLE for our DynamoDB table.
CREATE EXTERNAL TABLE orders_ddb_2012_01 ( order_id string, customer_id string, order_date bigint, total double )
STORED BY 'org.apache.hadoop.hive.dynamodb.DynamoDBStorageHandler' TBLPROPERTIES (
"dynamodb.table.name" = "Orders-2012-01",
"dynamodb.column.mapping" = "order_id:Order ID,customer_id:Customer ID,order_date:Order Date,total:Total"
);This is a bit more complex. We need to specify the DynamoDB table name, the DynamoDB storage handler, the ordered fields, and a mapping between the EXTERNAL TABLE fields (which can’t include spaces) and the actual DynamoDB fields.
Now we’re ready to start moving some data!
Importing Data into DynamoDB
In order to access the data in our S3 EXTERNAL TABLE, we first need to specify which partitions we want in our working set via the ADD PARTITION command. Let’s start with the data for January 2012.ALTER TABLE orders_s3_export ADD PARTITION (year='2012', month='01') ;
Now if we query our S3 EXTERNAL TABLE, only this partition will be included in the results. Let’s load all of the January 2012 order data into our external DynamoDB Table. Note that this may take several minutes.
INSERT OVERWRITE TABLE orders_ddb_2012_01
SELECT order_id, customer_id, order_date, total
FROM orders_s3_export ;Looks a lot like standard SQL, doesn’t it?
Querying Data in DynamoDB Using SQL
Now let’s find the top 5 customers by spend over the first week of January. Note the use of unix-timestamp as order_date is stored as the number of seconds since epoch.SELECT customer_id, sum(total) spend, count(*) order_count
FROM orders_ddb_2012_01
WHERE order_date >= unix_timestamp('2012-01-01', 'yyyy-MM-dd')
AND order_date < unix_timestamp('2012-01-08', 'yyyy-MM-dd')
GROUP BY customer_id
ORDER BY spend desc
LIMIT 5 ;Querying Exported Data in S3
It looks like customer: ‘c-2cC5fF1bB’ was the biggest spender for that week. Now let’s query our historical data in S3 to see what that customer spent in each of the final 6 months of 2011. Though first we will have to include the additional data into our working set. The RECOVER PARTITIONS command makes it easy toALTER TABLE orders_s3_export RECOVER PARTITIONS;
We will now query the 2011 exported data for customer ‘c-2cC5fF1bB’ from S3. Note that the partition fields, both month and year, can be used in your Hive query.
SELECT year, month, customer_id, sum(total) spend, count(*) order_count
FROM orders_s3_export
WHERE customer_id = 'c-2cC5fF1bB'
AND month >= 6
AND year = 2011
GROUP BY customer_id, year, month
ORDER by month desc;Exporting Data to S3
Now let’s export the January 2012 DynamoDB table data to a different S3 bucket owned by you. We’ll first need to create an EXTERNAL TABLE for that S3 bucket. Note that we again partition the data by year and month.CREATE EXTERNAL TABLE orders_s3_new_export ( order_id string, customer_id string, order_date int, total double )
PARTITIONED BY (year string, month string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
LOCATION 's3://';Now export the data from DynamoDB to S3, specifying the appropriate partition values for that table’s month and year.
INSERT OVERWRITE TABLE orders_s3_new_export
PARTITION (year='2012', month='01')
SELECT * from orders_ddb_2012_01;Note that if this was the end of a month and you no longer needed low latency access to that table’s data, you could also delete the table in DynamoDB. You may also now want to terminate your job flow from the EMR console to ensure you do not continue being charged.
That’s it for now. Please visit our documentation for more examples, including how to specify the format and compression scheme for your exported files.
-- Adam Gray, Product Manager, Amazon Elastic MapReduce.



<Return to section navigation list>

















0 comments:
Post a Comment