Windows Azure and Cloud Computing Posts for 1/18/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Update 1/18/2012 4:15 PM PST: Received my invitation to test-drive Microsoft Codename “Cloud Numerics” and will start working with it tomorrow.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
My (@rogerjenn) Upload Big Data to SQL Azure Federated Databases with BCP Automatically article of 1/18/2012 for Red Gate Software’s ACloudyPlace blog begins:
Distributed databases, such as the Apache Hadoop framework, Amazon Simple DB, and Windows Azure storage, are commonly used to store and manipulate large collections of unstructured data. For example, Yahoo! runs Apache Hadoop and its HDFS file system on more than 10,000 Linux cores to power its Search Webmap. However, most IT organizations favor a RDBMS for storing and querying structured data, such as Web logs and application diagnostics data, as well as financial information. DBAs are familiar with managing RDBMSs with SQL’s data definition and data management languages and most application developers are conversant with its data query language. The learning curve for Apache’s MapReduce software framework, Hive data warehouse infrastructure, Pig data-flow language, Mahout data mining library, ZooKeeper coordination service, and other Hadoop-specific applications is quite steep for most SQL professionals and costly for IT organizations of all sizes.
SQL Azure’s Transact-SQL (T-SQL) dialect implements most SQL Server 2008 R2 keywords, easing the transition from on-premises to public cloud environments. George Huey’s open source SQL Azure Migration Wizard (SQLAzureMW) utility automatically migrates SQL Server 2008 R2 database schemas and data to SQL Azure databases running in Microsoft data centers. So far, the primary restraint on the adoption of popular RDBMSs, such as Microsoft SQL Server, for big-data projects in public cloud environments has been maximum database size. For example, SQL Azure databases were limited in size to 50 GB until December 2011, when Microsoft enabled scaling up to 150 GB. HDFS and SQL Azure provide an original and two replica versions of all data and automatic failover to achieve high reliability.
Scaling Out Relational Databases in Public Clouds with Sharding and Federation
Scaling out web sites with farms of application servers fronted by load-balancers to accommodate spikes in page requests is a common practice, but scaling up database size doesn’t assure sufficient resources to meet surges of connection requests. Microsoft’s “SQL Azure Performance and Elasticity Guide” TechNet wiki article—last updated December 21, 2011—states, “As of this writing, each SQL Azure computer is equipped with 32 GB RAM, 8 CPU cores and 12 hard drives” in its “Performance Profile of a Single SQL Azure Database” section. This statement implies that the amount of RAM, as well as number of cores and hard drives, doesn’t increase with database size. Further, the “SQL Azure Throttling” section of the same article discloses, “To ensure that all subscribers receive an appropriate share of resources and that no subscriber monopolizes resources at the expense of other subscribers, SQL Azure may close or ‘throttle’ subscriber connections under certain conditions. … As the name implies “Engine Throttling” scales back resource usage by blocking connectivity of subscribers that are adversely impacting the overall health of the system. The degree to which a subscriber’s connectivity is blocked ranges from blocking inserts and updates only, to blocking all writes, to blocking all reads and writes.”
To circumvent throttling requires scaling out by partitioning the relational data across multiple databases, a process called sharding, which Microsoft renamed federation. Federation, which arrived in the December 2011 SQL Azure upgrade, also increases database capacity limits by reducing the size of individual databases (shards or federation members) and raises the resources available to each shard’s database engine. If you federate your databases primarily for satisfying surges in query execution, rather than database size reduction, elasticity lets you reduce the number of members by merging their data when demand falls off. SQL Azure Web database pricing is linear with size, $9.99 per GB for 1 to 9 GB, so if you have 9 GB or less data and can shard it into up to nine 1-GB or smaller databases of uniform size, you get up to nine times the potential performance at no additional cost. My Generating Big Data for Use with SQL Azure Federations and Apache Hadoop on Windows Azure Clusters tutorial of 1/8/2012 explains how to set up a sample multi-GB Windows Azure Diagnostics data source (WADPerfCounters) for initial import into SQL Server 2008 R2 SP1 with the BULK INSERT instruction.
Defining the Workflow for Big-Data Federations
Migrating a SQL Server 2008 R2 database to a basic SQL Azure database with the SQL Azure Migration Wizard v3.8 (SQLAzureMW) is a simple two or three step process, which I described for an earlier version in a Using the SQL Azure Migration Wizard v3.3.3 with the AdventureWorksLT2008R2 Sample Database tutorial of 7/18/2010. However, SQLAzureMW isn’t designed to create schemas for federated databases or upload data to them; the new SQLAzureFedMW v1.0 uploads data only. You create the federated database with T-SQL DDL statements in the new SQL Azure Management Portal’s UI or in SQL Server Management Studio 2008 R2 [Express]. Figure 1 shows the steps required to create, populate, and test a six-member federation of WADPerfCounters, with members federated on a federation key of the int data type derived from the CounterName column value.
Figure 1. Workflow to create and populate a six-member SQL Azure federated database from Windows


and continues with summaries of my four current OakLeaf blog posts on the topic:
Generating Big Data for Use with SQL Azure Federations and Apache Hadoop on Windows Azure Clusters
- Creating a SQL Azure Federation in the Windows Azure Platform Portal
- Loading Big Data into Federated SQL Azure Tables with the SQL Azure Federation Data Migration Wizard v1.2 (updated 1/17/2012)
- Adding Missing Rows to a SQL Azure Federation with the SQL Azure Federation Data Migration Wizard v1

Read more.
Ronnie Hoogerwerf (@rhoogerw) posted Announcing Microsoft Codename “Cloud Numerics” on 1/10/2012 (missed when posted):
Today we are announcing the release of the Microsoft Codename “Cloud Numerics” Lab. “Cloud Numerics” is a numerical and data analytics library for data scientists, quantitative analysts, and others that enables the scale-out of data-analytics models written in C# on Azure. “Cloud Numerics “ gives you
- an easy-to-use programming model that hides the complexity of developing distributed algorithms
- access to an comprehensive .NET library of numerical algorithms ranging from basic mathematics to advanced statistics to linear algebra
- the ability [to] deploy your application to Azure and take advantage of the immense compute power available in the cloud
“Cloud Numerics” provides a complete solution for writing and developing distributed applications that run on Windows Azure. To use “Cloud Numerics” you start in Visual Studio with our custom project definition that includes an extensive library of numerical functions. You develop and debug your numerical application on your desktop, using a dataset that is appropriate for the size of your machine. You can read large datasets in parallel, allocate and manipulate large data objects as distributed arrays, and apply numerical functions on these distributed array. When your application is ready and you want to scale-out and run on the cloud you start our deployment wizard, fill out your Azure information, deploy, and run you application.
Do you want to learn more about “Cloud Numerics”? Please visit us on our SQL Azure Labs home page, take a deeper look at the Getting Started material and Sign Up to get access to the installer. Let us know what you think by sending us email at cnumerics-feedback@microsoft.com.

Signed up with status “Pending.” and received my invitation. See the new MSDN CloudNumerics blog for these later, detailed posts:
- The “Cloud Numerics” Programming and runtime execution model (1/11/2012)
- “Cloud Numerics” Example: Latent Semantic Indexing and Analysis (1/13/2012)
- “Cloud Numerics” Example: Distributed Numerics on Azure with F# (1/16/2012)
- “Cloud Numerics” Example: Using the IParallelReader Interface (1/18/2012)
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
No significant articles today.
<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Nevatech (@NevatechInc) announced the release of Sentinet™ version 2.1 on 1/17/2012:
Nevatech releases Sentinet™ version 2.1, a unified on-premises and cloud SOA and APIs management software infrastructure. Sentinet version 2.1 adds a wealth of new features and enhancements to its flagship Sentinet platform, including:
• X.509 Certificates and PKI keys management infrastructure
• Versatile, customizable and extendable Alert System
• Advanced support for transactional and asynchronous messaging
• Advanced routing capabilities• Advanced support for Microsoft Windows Azure cloud platform
• Advanced support for Microsoft Windows Azure AppFabric Service Bus
• Advanced support for Microsoft BizTalk Server
• Numerous runtime extensibility points

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Jan Van der Haegen (@janvanderhaegen) continued his series with Extensions Made Easy: UseSmallImage and custom ordering on 1/18/2011:
Hey guys,
I’m terribly tired, but before hitting my bed I wanted to let you know that EME 1.11.3 is ready, tested, checked in, tested again and published.
The most notable change is that I refactored the EasyCommandExporter a wee bit. It only contains one constructor from now on (I introduced a second a while ago for some Dispatcher finetuning), which contains some mandatory and some optional parameters:
public EasyCommandExporter( string displayName, string description, string groupName, Uri imageUri, Dispatcher dispatcher = Dispatcher.PreferCurrentActiveScreen, //Refactored: overloaded ctor -> optional parameter bool useSmallImage = false, //New optional parameter string prefixUsedForSortingWithinGroup = "" //New optional parameter )UseSmallImage
Set it to true to use a “small” image for your command. Thanks, Kivito, for teaching me about this (I completely missed it). You can vertically stack 3 “small” commands in your ribbon for each “normal” command.
PrefixUsedForSortingWithinGroup
By default, the EME framework sorted your EasyCommands by DisplayName to accomplish consistent ordering.
As falkao indicated, a developer might want to take control of the order in which the commands should be shown. I played around with it a bit and found that:
- ordering the commands yourself is especially useful when mixing “small” and “normal” commands, so you can choose the “small” commands to stack…
- a “prefix” string is easier to maintain than a “priority” integer, especially when adding new commands to the middle of your group…
Ergo, vis-a-vis, the EME framework now sorts your EasyCommands by “{PrefixUsedForSortingWithinGroup} – {DisplayName}”.


Return to section navigation list>
Windows Azure Infrastructure and DevOps
Joel Foreman posted Windows Azure Platform: Januaury 13th Links on 1/18/2012 to the Slalom Consulting blog:
Happy New Year everyone! My first blog of 2012 highlights some of the resources and news around the Windows Azure Platform that caught my eye over the last couple months. Again, this is not a comprehensive list, but pieces that caught my eye in particular.
Learn Windows Azure Event on Channel9: In December, Microsoft hosted an online event for learning Windows Azure. You can watch the event in its entirely, or in specific sections, on Channel9. Speakers include Microsoft technical leaders such as Scott Guthrie, Dave Campbell, and Mark Russinovich. The three of them take open questions from the audience at the end.
- Open Source Updates for Windows Azure: Windows Azure continues to improve its ability to run open source technologies. This post describes some of the recent updates around Node.js, MongoDB, Hadoop, and more.
- SQL Azure Q4 Release: As expected, the Q4 release of SQL Azure shipped late last year. Read about the improvements and features. One nice call out I will make is that while max DB size increased from 50GB to 150GB, Microsoft did not increase the price meaning that there is no price difference for SQL Azure between 50GB-150GB.
- Building and Deploying with Azure 1.6 SDK: Tom Hollander came out with a great blog post talking about how to update your build processes to take advantage of some of the new SDK features for Azure around publishing. He beat me to it! I previously had a post describing one way to manage builds and releases. Rather than update mine, check out Hollander’s post.
- Experience Improvements for Windows Azure: Microsoft highlights some of the experience improvements made late last year for Windows Azure.
- SQL Azure Performance and Elasticity Guide: Here is a good guide that includes a lot of references as well as topics to be considering around tuning SQL Azure.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Iain Thompson (@iainthomson) asserted “Offers future-proofing with unlimited VMs” in a deck for his Microsoft aims at VMware with System Center 2012 article for The Register:
Microsoft is taking the fight to VMware with a new release candidate of Systems Center 2012 which includes a new pricing structure and eight management tools that run on a unified interface. Ever humble, Microsoft is billing it as the future of private cloud systems.
System Center 2012 comes in two flavors – standard and data center editions – but both consist of eight applications that use an integrated installer. A single license will cover a pair of processors, but while standard users can run a couple of virtual operating systems for around $1,300, the data center edition covers unlimited VMs for just over $3,600 – although volume customers should expect serious discounts.
“This is a clear differentiator,” Amy Barzdukas, GM of communications for Microsoft's server and tools business told The Register. “It gives customers the capabilities needed to build and deploy private clouds, without paying a V tax.”
The move will no doubt be noted by VMware and others in the field, but there’s still a way to go. Of the eight modules, five are at release candidate stage and three are still in beta. The final software is expected to ship in the first half of the year and consists of:
Configuration Manager RC: During Tuesday’s launch webcast, Brad Anderson of Redmond’s management and security division said the new code was “the most significant release of Configuration Manager that we’ve ever done,” because Microsoft is changing its IT rules structure from focusing on the device to focusing on the user.
This means that the BOFH can manage a much larger range of devices, including Phone 7, iOS, and Android. But this comes at a cost: the rules system will have to be completely rewritten. “There is some work involved,” Andrew Conway, director of product management for Microsoft System Center, diplomatically told El Reg.
Endpoint Protection RC: This works closely with the config manager for control and reporting, and the new build adds automatic software and signature updates, and user – rather than device – controls. It uses Microsoft’s basic anti-malware engine, and the vulnerability warning system has been made more efficient.
App Controller 2012 Beta: This is designed to let admins upload and manage applications across public and private cloud environments via a single control system. The 2012 build comes with a variety of templates and project tracking and analysis tools.
System Center Service Manager 2012 Beta: These tools are for deploying services across the cloud, with new reporting capabilities that use data warehousing.
Virtual Machine Manager 2012 RC: This build is being touted as Microsoft’s attempt to be more inclusive, and it’s not a bad effort. The manager works with multiple hypervisors, including VMware, Xen and Azure, and can take capacity from all into a single private cloud.
“This is a unique position for Microsoft,” Anderson said. “In our battle with our biggest competitor [Microsoft, like political candidates, seldom name-checks its foes], we’re the heterogeneous provider and they’re not.”
Orchestrator 2012 RC: This Microsoft management tool improves process automation and integrates with management tools from HP, IBM, EMC, BMC, CA, and VMware, supports PowerShell, and uses a standardized ODATA REST-based web service interface.
Operations Manager 2012 RC: This is the unified management tool that Redmond is so proud of, putting public and private cloud management into a single console, using .NET and JEE for monitoring and diagnostics.
Data Protection Manager 2012 Beta: This tool backs up to disk, tape, and cloud storage, and with this release adds single-window management of all security servers along with certificate-based protection, media co-location, and generic data-source coverage.

The Microsoft Server and Cloud Platform Team (@MSServerCloud) recommended on 1/18/2012 that you Learn how T. Rowe Price is Leveraging Private Cloud with System Center 2012:
Check out this video and learn more about how global investment management firm T. Rowe Price is leveraging private cloud.
T. Rowe Price: Customers Bet on the Microsoft Private Cloud to Move Faster, Save Money and Better Compete Today.
“A private cloud is our answer to corralling our server infrastructure into a single entity we can use to more rapidly deliver services that really matter to our business. System Center 2012 is truly a game changer.”

<Return to section navigation list>
Cloud Security and Governance
Scott M. Fulton, III (@SMFulton3) posted The Great Wall of Europe: Fear of the Patriot Act Squeezes EU Out of the Cloud to the ReadWriteCloud blog on 1/18/2011:
Prospective cloud customers - both consumers and enterprises - throughout Europe are wary of the possibility, however remote, that the contents of their cloud deployments may become open to inspection by government authorities. Not European governments, mind you, but American, by virtue of the Patriot Act. Passed into law before legislators ever pondered the prospects of virtual servers in the cloud, the U.S. law grants federal investigators authority, under court order, to ask service providers for information from and about their customers, for use in anti-terrorist surveillance.
Leading U.K.-based telecom analyst firm Informa has been measuring the extent to which European carriers have been withholding their investments in cloud technology, in U.S. dollars. This morning, Informa released its findings, which indicate an almost crippling setback for the continent as it struggles to stay competitive with North America and Asia/Pacific.
According to Informa's figures, carriers worldwide invested about $13.5 billion in 2011 in technology and resources for delivering cloud services to their clients. Of that figure, North America and Asia/Pacific combined accounted for $12 billion, or about 90%. European carriers accounted for only 7% of the world's total carrier cloud investment.
This despite the fact that European carriers and telecom service operators, according to the Informa chart above, account for 24% of the global total number of operators providing service. Over time, that percentage too has been in decline.
Ironically, one of the companies making the most headway last year in designing next-generation carrier-based cloud services has been France-based Alcatel-Lucent. The fear among European customers, including in France, is that once they deploy their services in a hybrid or public cloud, entire virtual machines could travel transparently over countries' jurisdictions into the U.S., where federal regulators might gain the authority to peek into their contents. In a Bloomberg interview this morning, a security engineer with France Telecom articulated the fear of his own customers: "If all the data of enterprises were going to be under the control of the U.S., it's not really good for the future of the European people."
As cloud service providers told me recently, a frequent request of Europe-based customers is that they make express guarantees in their service-level agreements that their data and virtual machines never be migrated to servers under U.S. jurisdiction. And as my friend and colleague Ron Miller reported last September, American companies touting the benefits of the cloud at European customers are met by resistance from would-be customers, some of whom say they would rather do business with Canada than the U.S.
Amid the climate of fear, Informa reports, cloud operators in Latin America, Africa, and the Middle East are growing faster than in Europe, which may be painting a picture of itself as a barricaded fortress in an otherwise burgeoning market.


Lori MacVittie (@lmacvittie) described The Ascendancy of the Application Layer Threat an a 1/18/2012 post to F5’s DevCentral blog:
Many are familiar with the name of the legendary Alexander the Great, if not the specific battles in which he fought. And even those familiar with his many victorious conquests are not so familiar with his contributions to his father’s battles in which he certainly honed the tactical and strategic expertise that led to his conquest of the “known” world.
In 339 BC, for example, then Macedonian King Phillip II – the father of Alexander the Great – became engaged in a battle at Chaeronea against the combined forces of ancient Greece. While the details are interesting, they are not really all that germane to technology except for commentary on what may be* Phillips’ tactics during the battle, as suggested by the Macedonian author Polyaenus:
In another 'stratagem', Polyaenus suggests that Philip deliberately prolonged the battle, to take advantage of the rawness of the Athenian troops (his own veterans being more used to fatigue), and delayed his main attack until the Athenians were exhausted.
-- Battle of Chaeronea (338 BC) (Wikipedia)
This tactic should sound familiar, as it akin in strategy to that of application DDoS attacks today.
THE RISE of APPLICATION LAYER ATTACKS
Attacks at the application layer are here to stay – and we should expect more of them. When the first of these attacks was successful, it became a sure bet that we would see more of them along with more variations on the same theme. And we are. More and more organizations are reporting attacks bombarding them not just at the network layer but above it, at the transport and application layers.
Surely best practices for secure coding would resolve this, you may think. But the attacks that are growing to rule the roost are not the SQLi and XSS attacks that are still very prevalent today. The attacks that are growing and feeding upon the resources of data centers and clouds the globe over are more subtle than that; they’re not about injecting malicious code into data to be spread around like a nasty contagion, they’re DDoS attacks. Just like their network-focused DDoS counterparts, the goal is not infection – it’s disruption.
These attacks exploit protocol behavior as well as potentially missed vulnerabilities in application layer protocols as a means to consume as many server resources as possible using the least amount of client resources. The goal is to look legitimate so the security infrastructure doesn’t notice you, and then slowly leech compute resources from servers until they can’t stand – and they topple.
They’re Phillip’s Macedonians; wearing out the web server until it’s too tired to stand.
These attacks aren’t something listed in the OWASP Top Ten (or even on the OWASP list, for that matter). These are not attacks that can be detected by IPS, IDS, or even traditional stateful firewalls. These technologies focus on data and anomalies in data, not behavior and generally not at the application protocol layer.
For example, consider HTTP Fragmentation attacks.
In this attack, a non-spoofed attacker establishes a valid HTTP connection with a web server. The attacker then proceeds to fragment legitimate HTTP packets into tiny fragments, sending each fragment as slow as the server time out allows, holding up the HTTP connection for a long time without raising any alarms. For Apache and many other web servers designed with improper time-out mechanisms, this HTTP session time can be extended to a very long time period. By opening multiple extended session per attacker, the attacker can silently stop a web service with just a handful of resources.
Multiple Methods in a Single Request is another fine example of exhausting a web server’s resources. The attacker creates multiple HTTP requests, not by issuing them one after another during a single session, but by forming a single packet embedded with multiple requests. This allows the attacker to maintain high loads on the victim server with a low attack packet rate. This low rate makes the attacker nearly invisible to NetFlow anomaly detection techniques. Also, if the attacker selects the HTTP method carefully these attacks will bypass deep packet inspection techniques.
There a number of other similar attacks, all variations on the same theme: manipulation of valid behavior to exhaustion of web server resources with the goal of disrupting services. Eventually, servers crash or become so slow they are unable to adequately service legitimate clients – the definition of a successful DDoS attack.
These attacks are not detectable by firewalls and other security infrastructure that only examine packets or even flows for anomalies because no anomaly exists. This is about behavior, about that one person in the bank line who is acting oddly – not enough to alarm most people but just enough to trigger attention from someone trained to detect it. The same is true of security infrastructure. The only component that will detect such subtle improper behavior is one that’s been designed to protect it.
* It was quite a while ago, after all, and sources are somewhat muddied. Whether this account is accurate or not is still debated.



Thomas W. Shinder, M.D. updated his A Solution for Private Cloud Security article for the TechNet wiki on 1/17/2011:
Welcome to the "A Solution for Private Cloud Security" series of three papers on private cloud security. With increasing numbers of organizations looking to create
cloud-based environments or to implement cloud technologies within their existing data centers, business and technology decision-makers are looking closely at the possibilities and practicalities that these changes involve.
Evidence of this growth of interest in the cloud is shown by organizations such as Gartner, who in their 2011 poll of Chief Information Officers identified cloud computing as the top technology priority
Note:
This document is part of a collection of documents that comprise the Reference Architecture for Private Clouddocument set. The Solution for Private Cloud is a community collaboration project. Please feel free to edit this document to improve its quality. If you would like to be recognized for your work on improving this document, please include your name and any contact information you wish to share at the bottom of this page
Although the increase in business agility coupled with greater flexibility of service provisioning are convincing arguments in favor of moving to the private and hybrid cloud
Microsoft is investing heavily on developing innovative technologies that enable organizations to design and create robust and comprehensive private and hybrid cloud environments. This guidance considers the security aspects of these designs and consists of the following three papers:
Blueprint for A Solution for Private Cloud Security
Design Guide for A Solution for Private Cloud Security
Operations Guide for A Solution for Private Cloud SecurityTogether, these three documents provide a comprehensive explanation of the process for designing and running security for such a private cloud environment. These documents all use the Microsoft Private Cloud Reference Model as the framework for the security discussion.
Download
Figure 1 provides a graphical representation of the documents that comprise the "A Solution for Private Cloud Security" document set. You can download

Figure 1 - Content Map for "A Solution for Private Cloud Security"
Complete Table of Contents for “A Solution for Private Cloud Security”
A Solution for Private Cloud Security
Blueprint for a A Solution for Private Cloud Security
Defining the Private Cloud Security Domain
Private Cloud Reference Model – Security Perspective
- Private Cloud Security Model – Wrapper Functionality
- Private Cloud Security Model – Infrastructure Security
- Private Cloud Security Model – Platform Security
- Private Cloud Security Model – Software Security
- Private Cloud Security Model – Service Delivery Security
- Private Cloud Security Model – Management Security
- Private Cloud Security Model – Client Security
- Private Cloud Security Model – Legal and Compliance Issues
Design Guide for A Solution for Private Cloud Security
Private Cloud Security Design Principles
Private Cloud Security Design Challenges
- Private Cloud Security Design Challenges – Resource Pooling
- Private Cloud Security Design Challenges – Broad Network Access
- Private Cloud Security Design Challenges – On-Demand Self Service
- Private Cloud Security Design Challenges – Rapid Elasticity
- Private Cloud Security Design Challenges – Measured Services
Operations Guide for A Solution for Private Cloud Security
Private Cloud Security Operations Principles
Private Cloud Security Operations Challenges
- Private Cloud Security Design Challenges – Resource Pooling
- Private Cloud Security Design Challenges – Broad Network Access
- Private Cloud Security Design Challenges – On-Demand Self Service
- Private Cloud Security Design Challenges – Rapid Elasticity
- Private Cloud Security Design Challenges – Measured Services
Series Aim
The aim of the Solution for Private Cloud Security documents is to provide you with an architectural view for understanding, designing and operating effective security within a private cloud environment.
Audience
This series targets a range of potential audiences, all of whom fall within the National Institute of Standards and Technology (NIST) definition of a cloud provider. These audiences can include the following cloud roles:
- Decider
- Designer
- Implementer
- Operator
We hope you find this series useful and informative. To provide review comments and feedback, please write to Tom Shinder at tomsh@microsoft.com.
CONTRIBUTORS AND REVIEWERS
We would like to give a heartfelt thanks to the following contributors and reviewers for this beta (v0.95) version of the "A Solution for Private Cloud Security" document set. Without their comprehensive and detailed writing and reviews, this work could not have been possible.Anthony Stevens, Content Master
Dominic Betts, Content Master
Thomas W Shinder, M.D., Microsoft Corporation
Yuri Diogenes, Microsoft Corporation
Fernando Cima, Microsoft Corporation
Frank Koch, Microsoft Corporation
Scott Culp, Microsoft Corporation
Allen Brokken, Microsoft Corporation
The Private Cloud Security v-team, Microsoft Corporation

<Return to section navigation list>
Cloud Computing Events
David Linthicum (@DavidLinthicum) asserted “These days, pretty much any new electronic gizmo has a cloud behind it -- a retail cloud, that is” in a deck for his Why CES 2012 should have been called the Cloud Electronics Show post to InfoWorld’s Cloud Computing blog:
I watched the new product announcements at CES 2012 with much more interest this year. Why? Because the use of cloud computing has gone from few and far between to pretty much anything and everything. CES 2012 shows that shift in no uncertain terms.
The rise of what I call the retail cloud has been a real mover and shaker the past few years. Today, it's reached critical mass as everything from DVD players to TVs, from car entertainment to alarm clocks, comes with some sort of cloud service to support that device.
For example, Mercedes-Benz announced a new cloud-connected dashboard computer called Mbrace2 that provides access to 3G cellular-connected apps such as Facebook and over-the-air software updates. Ford and Toyota are following up with their own cloud-based systems, providing both driving utilities and entertainment.
Other uses of the cloud are more utilitarian, such as providing storage and processing power for mobile devices, which is old news. But now the same computing models are being used for most entertainment devices in your home, even kitchen appliances that provide "smart grid" features such as the ability to transmit their energy usage and cycle down during peak loads. Pretty much anything that costs more than $100 comes with its own Wi-Fi radio these days.
It's interesting how cloud computing has seeped into consumer electronics over time. The ability to add streaming from services such as Netflix to your DVD or TV has been around for a while, but that same cloud is now providing an application development platform for third parties and the ability to store many gigabytes of data. In other words, they are morphing from simple website abstractions to true platforms. …

Read more: next page ›
Martin Ingvar Kofoed Jensen (@IngvarKofoed) posted on 1/18/2012 his Abstract for Danish Developer Conference 2012. Here’s the English version
Scaling and monitoring on Azure - Abstract
On 14 October last year Culture Night official website (kulturnatten.dk) visited by over 60,000 unique visitors and over 500,000 page views on the day Culture Night took place. Despite the massive traffic we managed to create a website that performed very well by using Windows Azure. Azure's out-scaling combined with our custom monitoring enabled us to increase or decrease the number of machines during the day, so the site continued performing as it should.
With new cloud services like Windows Azure, it was much cheaper to handle huge amount of visitors coming to a website using out-scaling. But it is an entirely new set of challenges creating a website that can run on multiple machines simultaneously.
Based on the Composite's experience with the launch of kulturnatten.dk I will in my presentation looking at up- vs. out-scaling and the classic software problems that are with out-scaling. I will also touch on the out-of-the-book solutions in Windows Azure, such as Content Delivery Network (CDN) and the Traffic Manager. Both of which are good services that can be used by out-scaling.
Finally I will talk about monitoring, which makes it possible to increase or decrease the number of machines that handle a website in an intelligently way. Good monitoring makes it possible to act in time and avoid the site goes down. But equally interesting monitoring, makes it possible to turn the number of running machines down and thereby saving money in the end.

Eric Nelson (@ericnel) announced We kick off 12pm Monday 23rd of January using Live Meeting 2007 #6weeksazure on 1/18/2012:
Next Monday we start Six Weeks of Windows Azure with:
The 12pm opening session will look ahead at what you can expect from the six weeks and will offer advice on how best to make use of the time. It will also share tips, tools and resources to help you get going from day one. This is a great time to ask us questions about Six Weeks of Windows Azure and ideally should not be missed.
David and I look forward to seeing you there.
Eric
Live Meeting and Microsoft World Wide Events registration:
We will be using Live Meeting for all the webinars and hopefully by now you (and your colleagues) have signed up via Microsoft World Wide Events to get access to the webinar information (and timely reminders). If you haven’t then please do so asap – register on Microsoft World Wide Events (live id required).
Please take a few minutes between now and Monday to get Live Meeting 2007 installed on your pc and familiarise yourself with how it works.
If you are registered with World Wide Events then you will have details about how to install the client and join the meeting.
However the following link explains more: Joining a Meeting
I have also created a test Live Meeting you can join (live from today until end of Sat 21st) – join now
No audio?
The issue a very small % of users run into is no audio when they join the Live Meeting. These may help:
- Setting up audio http://support.microsoft.com/kb/944600
- Try a USB headset.
- Try not using a USB headset
- Contact Live Meeting technical support http://support.microsoft.com/kb/939099


Adron Hall (@adron) reported on 1/17/2012 PDX Node.js Conference, cuz’ PDX won’t settle for not having a Node.js Conference!:
Coming up really soon is the PDX Node.js Conference. If anybody is interested in speaking, please submit a proposal. If you’d just like to attend, it is 100% free, just RSVP.
Also, if anyone is interested in taking the train down to Portland, the last two departures that Friday will have a group of attendees going; Train #507 Departing at 2:20pm and #509 departing at 5:30pm from King Street Station. (Schedules)
If anyone is interested in taking the train down please let me know and I’ll help coordinate so we can all get seats (preferably with tables) to hack together while enjoying the scenery.
Core Idea
The idea behind this Node.js Conference is a technology focused, node.js, JavaScript Lib, hacker conference. We felt that there needed to be a more tech focused event around the core technologies so Troy Howard (@thoward37), Jesse Hallet (@hallettj), and I thought “we’ll just get our own thing happening” and thus, PDX Node.js Conference was born.
So check out the site, come share your JavaScript chops, Node.js hacks, favorite js libs, or just come and check out the conference and meet some smart, cool, and sexy people in Portlandia, Oregon.
Click for a massive, full size, huge panoramic shot of Portland from the Aerial Tram.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
James Hamilton described Amazon DynamoDB: NoSQL in the Cloud in a 1/18/2012 post:
Finally! I’ve been dying to talk about DynamoDB since work began on this scalable, low-latency, high-performance NoSQL service at AWS. This morning, AWS announced availability of DynamoDB: Amazon Web Services Launches Amazon DynamoDB – A New NoSQL Database Service Designed for the Scale of the Internet.
In a past blog entry, One Size Does Not Fit All, I offered a taxonomy of 4 different types of structured storage system, argued that Relational Database Management Systems are not sufficient, and walked through some of the reasons why NoSQL databases have emerged and continue to grow market share quickly. The four database categories I introduced were: 1) features-first, 2) scale-first, 3) simple structure storage, and 4) purpose-optimized stores. RDBMS own the first category.
DynamoDB targets workloads fitting into the Scale-First and Simple Structured storage categories where NoSQL database systems have been so popular over the last few years. Looking at these two categories in more detail, Scale-First is:
Scale-first applications are those that absolutely must scale without bound and being able to do this without restriction is much more important than more features. These applications are exemplified by very high scale web sites such as Facebook, MySpace, Gmail, Yahoo, and Amazon.com. Some of these sites actually do make use of relational databases but many do not. The common theme across all of these services is that scale is more important than features and none of them could possibly run on a single RDBMS. As soon as a single RDBMS instance won’t handle the workload, there are two broad possibilities: 1) shard the application data over a large number of RDBMS systems, or 2) use a highly scalable key-value store.
And, Simple Structured Storage:
There are many applications that have a structured storage requirement but they really don’t need the features, cost, or complexity of an RDBMS. Nor are they focused on the scale required by the scale-first structured storage segment. They just need a simple key value store. A file system or BLOB-store is not sufficiently rich in that simple query and index access is needed but nothing even close to the full set of RDBMS features is needed. Simple, cheap, fast, and low operational burden are the most important requirements of this segment of the market.
More detail at: One Size Does Not Fit All.
The DynamoDB service is a unified purpose-built hardware platform and software offering. The hardware is based upon a custom server design using Flash Storage spread over a scalable high speed network joining multiple data centers.
DynamoDB supports a provisioned throughput model. A DynamoDB application programmer decides the number of database requests per second their application should be capable of supporting and DynamoDB automatically spreads the table over an appropriate number of servers. At the same time, it also reserves the required network, server, and flash memory capacity to ensure that request rate can be reliably delivered day and night, week after week, and year after year. There is no need to worry about a neighboring application getting busy or running wild and taking all the needed resources. They are reserved and there whenever needed.
The sharding techniques needed to achieve high requests rates are well understood industry-wide but implementing them does take some work. Reliably reserving capacity so it is always there when you need it, takes yet more work. Supporting the ability to allocate more resources, or even less, while online and without disturbing the current request rate takes still more work. DynamoDB makes all this easy. It supports online scaling between very low transaction rates to applications requiring millions of requests per second. No downtime and no disturbance to the currently configured application request rate while resharding. These changes are done online only by changing the DynamoDB provisioned request rate up and down through an API call.
In addition to supporting transparent, on-line scaling of provisioned request rates up and down over 6+ orders of magnitude with resource reservation, DynamoDB is also both consistent and multi-datacenter redundant. Eventual consistency is a fine programming model for some applications but it can yield confusing results under some circumstances. For example, if you set a value to 3 and then later set it to 4, then read it back, 3 can be returned. Worse, the value could be set to 4, verified to be 4 by reading it, and yet 3 could be returned later. It’s a tough programming model for some applications and it tends to be overused in an effort to achieve low-latency and high throughput. DynamoDB avoids forcing this by supporting low-latency and high throughout while offering full consistency. It also offers eventual consistency at lower request cost for those applications that run well with that model. Both consistency models are supported.
It is not unusual for a NoSQL store to be able to support high transaction rates. What is somewhat unusual is to be able to scale the provisioned rate up and down while on-line. Achieving that while, at the same time, maintaining synchronous, multi-datacenter redundancy is where I start to get excited.
Clearly nobody wants to run the risk of losing data but NoSQL systems are scale-first by definition. If the only way to high throughput and scale, is to run risk and not commit the data to persistent storage at commit time, that is exactly what is often done. This is where DynamoDB really shines. When data is sent to DynamoDB, it is committed to persistent and reliable storage before the request is acknowledged. Again this is easy to do but doing it with average low single digit millisecond latencies is both harder and requires better hardware. Hard disk drives can’t do it and in-memory systems are not persistent so flash memory is the most cost effective solution.
But what if the server to which the data was committed fails, or the storage fails, or the datacenter is destroyed? On most NoSQL systems you would lose your most recent changes. On the better implementations, the data might be saved but could be offline and unavailable. With dynamoDB, if data is committed just as the entire datacenter burns to the ground, the data is safe, and the application can continue to run without negative impact at exactly the same provisioned throughput rate. The loss of an entire datacenter isn’t even inconvenient (unless you work at Amazon :-)) and has no impact on your running application performance.
Combining rock solid synchronous, multi-datacenter redundancy with average latency in the single digits, and throughput scaling to the millions of requests per second is both an excellent engineering challenge and one often not achieved.
More information on DynamoDB:
- Press Release: http://phx.corporate-ir.net/phoenix.zhtml?c=176060&p=irol-newsArticle&ID=1649209&highlight=
- Amazon Web Services detail Page: http://aws.amazon.com/dynamodb/
- Blog entries:
- o Werner: http://www.allthingsdistributed.com/2012/01/amazon-dynamodb.html
- o Jeff Barr: http://aws.typepad.com/aws/2012/01/amazon-dynamodb-internet-scale-data-storage-the-nosql-way.html
- DynamoDB Frequently Asked Questions: http://aws.amazon.com/dynamodb/faqs/
- DynamoDB Pricing: http://aws.amazon.com/dynamodb/pricing/
- GigaOM: http://gigaom.com/cloud/amazons-dynamodb-shows-hardware-as-mean-to-an-end/
- eWeek: http://www.eweek.com/c/a/Database/Amazon-Web-Services-Launches-DynamoDB-a-New-NoSQL-Database-Service-874019/
- Seattle Times: http://seattletimes.nwsource.com/html/technologybrierdudleysblog/2017268136_amazon_unveils_dynamodb_databa.html
Relational systems remain an excellent solution for applications requiring Feature-First structured storage. AWS Relational Database Service supports both the MySQL and Oracle and relational database management systems: http://aws.amazon.com/rds/.
Just as I was blown away when I saw it possible to create the world’s 42nd most powerful super computer with a few API calls to AWS (42: the Answer to the Ultimate Question of Life, the Universe and Everything), it is truly cool to see a couple of API calls to DynamoDB be all that it takes to get a scalable, consistent, low-latency, multi-datacenter redundant, NoSQL service configured, operational and online.


Jeff Barr (@jeffbarr) reported Amazon DynamoDB - Internet-Scale Data Storage the NoSQL Way in a 1/18/2012 post:
We want to make it very easy for you to be able to store any amount of semistructured data and to be able to read, write, and modify it quickly, efficiently, and with predictable performance. We don't want you to have to worry about servers, disks, replication, failover, monitoring, software installation, configuration, or updating, hardware upgrades, network bandwidth, free space, sharding, rearchitecting, or a host of other things that will jump up and bite you at the worst possible time.
We want you to think big, to dream big dreams, and to envision (and then build) data-intensive applications that can scale from zero users up to tens or hundreds of millions of users before you know it. We want you to succeed, and we don't want your database to get in the way. Focus on your app and on building a user base, and leave the driving to us.
Sound good?
Hello, DynamoDB
Today we are introducing Amazon DynamoDB, our Internet-scale NoSQL database service. Built from the ground up to be efficient, scalable, and highly reliable, DynamoDB will let you store as much data as you want and to access it as often as you'd like, with predictable performance brought on by the use of Solid State Disk, better known as SSD.DynamoDB works on the basis of provisioned throughput. When you create a DynamoDB table, you simply tell us how much read and write throughput you need. Behind the scenes we'll set things up so that we can meet your needs, while maintaining latency that's in the single-digit milliseconds. Later, if your needs change, you can simply turn the provisioned throughput dial up (or down) and we'll adjust accordingly. You can do this online, with no downtime and with no impact on the overall throughput. In other words, you can scale up even when your database is handling requests.
We've made DynamoDB ridiculously easy to use. Newly created tables will usually be ready to use within a minute or two. Once the table is ready, you simply start storing data (as much as you want) into it, paying only for the storage that you use (there's no need to pre-provision storage).Again, behind the scenes, we'll take care of provisioning adequate storage for you.
Each table must have a primary index. In this release, you can choose between two types of primary keys: Simple Hash Keys and Composite Hash Key with Range Keys.
- Simple Hash Keys give DynamoDB the Distributed Hash Table abstraction and are used to index on a unique key. The key is hashed over multiple processing and storage partitions to optimally distribute the workload.
- Composite Hash Keys with Range Keys give you the ability to create a primary key that is compose of two attributes -- a hash attribute and a range attribute. When you query against this type of key, the hash attribute must be uniquely matched but a range (low to high) can be specified for the range attribute. You can use this to run queries such as "all orders from Jeff in the last 24 hours."
Each item in a DynamoDB table consists of a set of key/value pairs. Each value can be a string, a number, a string set, or a number set. When you choose to retrieve (get) an item, you can choose between a strongly consistent read and an eventually consistent read based on your needs. The eventually consistent reads consume half as many resources, so there's a throughput consideration to think about.
Sounds great, you say, but what about reliability and data durability? Don't worry, we've got that covered too! When you create a DynamoDB table in a particular region, we'll synchronously replicate your data across servers in multiple zones. You'll never know about (or be affected by) hardware or facility failures. If something breaks, we'll get the data from another server.
I can't stress the operational performance of DynamoDB enough. You can start small (say 5 reads per second) and scale up to 50, 500, 5000, or even 50,000 reads per second. Again, online, and with no changes to your code. And (of course) you can do the same for writes. DynamoDB will grow with you, and it is not going to get between you and success.
As part of the AWS Free Usage Tier, you get 100 MB of free storage, 5 writes per second, and 10 strongly consistent reads per second (or 20 eventually consistent reads per second). Beyond that, pricing is based on how much throughput you provision and how much data you store. As is always the case with AWS, there's no charge for bandwidth between an EC2 instance and a DynamoDB table in the same Region.
You can create up to 256 tables, each provisioned for 10,000 reads and 10,000 writes per seconds. I cannot emphasize the next point strongly enough: We are ready, willing, and able to increase any of these values; simply click here and provide us with some additional information. Our early customers have, in several cases, already exceeded the default limits by an order of magnitude!
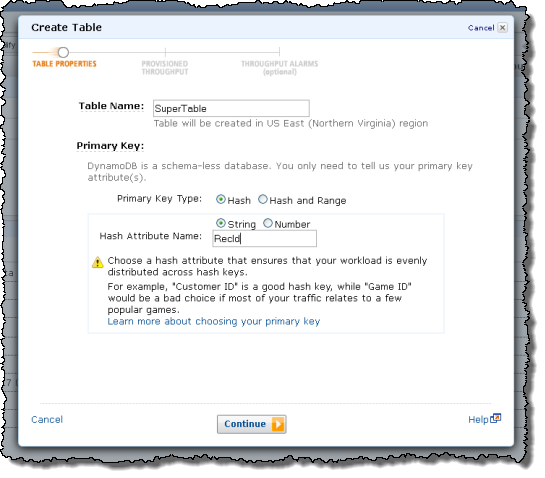
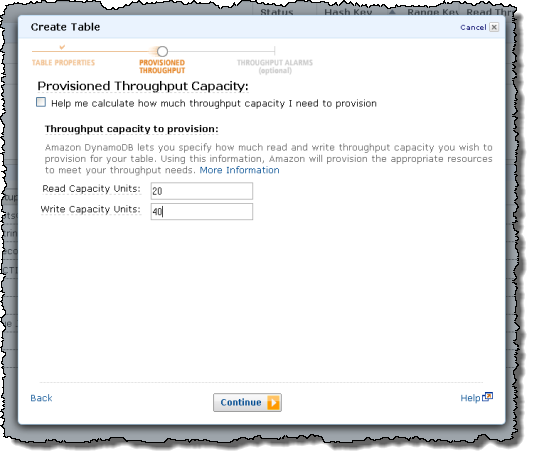
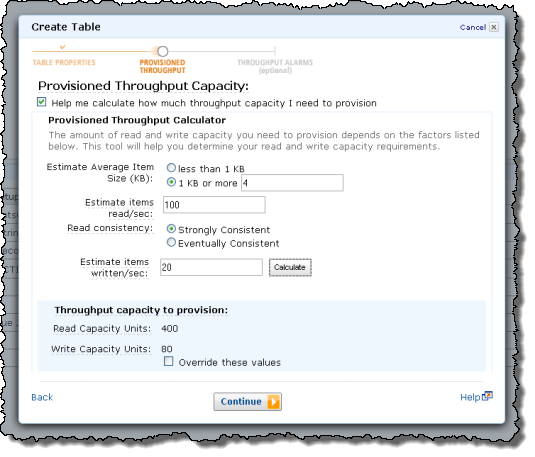
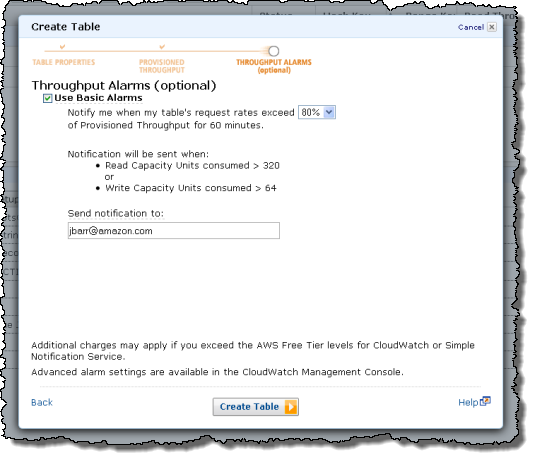
DynamoDB from the AWS Management Console
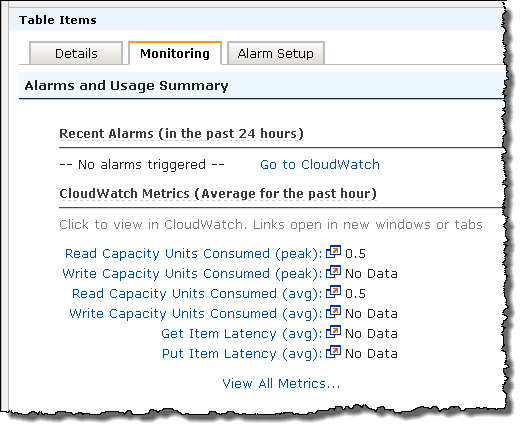
The AWS Management Console has a new DynamoDB tab. You can create a new table, provision the throughput, set up the index, and configure CloudWatch alarms with a few clicks:
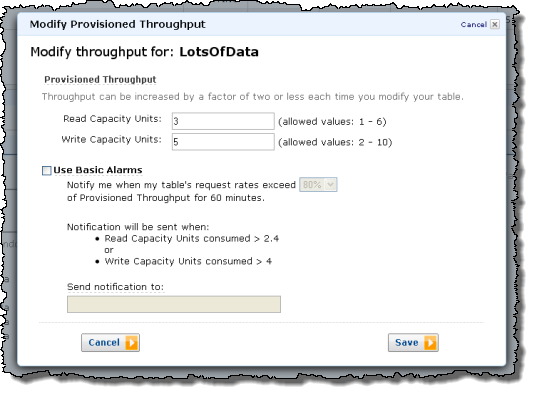
You can enter your throughput requirements manually:
Or you can use the calculator embedded in the dialog:
You can easily set CloudWatch alarms that will fire when you are consuming more than a specified percentage of the throughput that you have provisioned for the table:
You can use the CloudWatch metrics to see when it is time to add additional read or write throughput:
You can easily increase or decrease the provisioned throughput:
Programming With DynamoDB
The AWS SDKs have been updated and now include complete support for DynamoDB. Here are some examples that I put together using the AWS SDK for PHP.The first step is to include the SDK and create a reference object:
require_once("sdk.class.php");
$DDB = new AmazonDynamoDB(array('credentials' => 'production'));Creating a table requires three arguments: a table name, a key specification, and a throughput specification:
// Create a table
$Schema = array('HashKeyElement' =>
array('AttributeName' => 'RecordId',
'AttributeType' => AmazonDynamoDB::TYPE_STRING));
$Throughput = array('ReadsPerSecond' => 5, 'WritesPerSecond' => 5);
$Res = $DDB->create_table(array('TableName' => 'Sample',
'KeySchema' => $Schema,
'ProvisionedThroughput' => $Throughput));After create_table returns, the table's status will be CREATING. It will transition to ACTIVE when the table is provisioned and ready to accept data. You can use the describe_table function to get the status and other information about the table:
$Res = $DDB->describe_table(array('TableName' => 'Sample'));
print_r($Res->body->Table);Here's the result as a PHP object:
CFSimpleXML Object
(
[CreationDateTime] => 1324673829.32
[ItemCount] => 0
[KeySchema] => CFSimpleXML Object
(
[HashKeyElement] => CFSimpleXML Object
(
[AttributeName] => RecordId
[AttributeType] => S
)
)
[ProvisionedThroughput] => CFSimpleXML Object
(
[ReadsPerSecond] => 5
[WritesPerSecond] => 5
)
[TableName] => Sample
[TableSizeBytes] => 0
[TableStatus] => ACTIVE
)It is really easy to insert new items. You need to specify the data type of each item; here's how you do that (the other data type constants are TYPE_ARRAY_OF_STRINGS and TYPE_ARRAY_OF_NUMBERS):
for ($i = 1; $i < 100; $i++)
{
print($i);
$Item = array('RecordId' => array(AmazonDynamoDB::TYPE_STRING => (string) $i),
'Square' => array(AmazonDynamoDB::TYPE_NUMBER => (string) ($i * $i)));
$Res = $DDB->put_item(array('TableName' => 'Sample', 'Item' => $Item));
}Retrieval by the RecordId key is equally easy:
for ($i = 1; $i < 100; $i++)
{
$Key = array('HashKeyElement' => array(AmazonDynamoDB::TYPE_STRING => (string) $i));
$Item = $DDB->get_item(array('TableName' => TABLE,
'Key' => $Key));
print_r($Item->body->Item);
}Each returned item looks like this as a PHP object:
CFSimpleXML Object
(
[RecordId] => CFSimpleXML Object
(
[S] => 44
)
[Square] => CFSimpleXML Object
(
[N] => 1936
)
)The DynamoDB API also includes query and scan functions. The query function queries primary key attribute values and supports the use of comparison operators. The scan function scans the entire table with optional filtering of the results of the scan. Queries are generally more efficient than scans.
You can also update items, retrieve multiple items, delete items, or delete multiple items. DynamoDB includes conditional updates (to ensure that some other write hasn't occurred within a read/modify/write operation as well as atomic increment and decrement operations. Read more in the Amazon DynamoDB Developer Guide.
And there you have it, our first big release of 2012. I would enjoy hearing more about how you plan to put DynamoDB to use in your application. Please feel free to leave a comment on the blog.


Werner Vogels (@werner) described Amazon DynamoDB – a Fast and Scalable NoSQL Database Service Designed for Internet Scale Applications in a 1/18/2012 post to his All Things Distributed blog:
Today is a very exciting day as we release Amazon DynamoDB, a fast, highly reliable and cost-effective NoSQL database service designed for internet scale applications. DynamoDB is the result of 15 years of learning in the areas of large scale non-relational databases and cloud services. Several years ago we published a paper on the details of Amazon’s Dynamo technology, which was one of the first non-relational databases developed at Amazon. The original Dynamo design was based on a core set of strong distributed systems principles resulting in an ultra-scalable and highly reliable database system. Amazon DynamoDB, which is a new service, continues to build on these principles, and also builds on our years of experience with running non-relational databases and cloud services, such as Amazon SimpleDB and Amazon S3, at scale. It is very gratifying to see all of our learning and experience become available to our customers in the form of an easy-to-use managed service.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast performance at any scale. Today’s web-based applications often encounter database scaling challenges when faced with growth in users, traffic, and data. With Amazon DynamoDB, developers scaling cloud-based applications can start small with just the capacity they need and then increase the request capacity of a given table as their app grows in popularity. Their tables can also grow without limits as their users store increasing amounts of data. Behind the scenes, Amazon DynamoDB automatically spreads the data and traffic for a table over a sufficient number of servers to meet the request capacity specified by the customer. Amazon DynamoDB offers low, predictable latencies at any scale. Customers can typically achieve average service-side in the single-digit milliseconds. Amazon DynamoDB stores data on Solid State Drives (SSDs) and replicates it synchronously across multiple AWS Availability Zones in an AWS Region to provide built-in high availability and data durability.
History of NoSQL at Amazon – Dynamo
The Amazon.com ecommerce platform consists of hundreds of decoupled services developed and managed in a decentralized fashion. Each service encapsulates its own data and presents a hardened API for others to use. Most importantly, direct database access to the data from outside its respective service is not allowed. This architectural pattern was a response to the scaling challenges that had challenged Amazon.com through its first 5 years, when direct database access was one of the major bottlenecks in scaling and operating the business. While a service-oriented architecture addressed the problems of a centralized database architecture, each service was still using traditional data management systems. The growth of Amazon’s business meant that many of these services needed more scalable database solutions.
In response, we began to develop a collection of storage and database technologies to address the demanding scalability and reliability requirements of the Amazon.com ecommerce platform. We had been pushing the scalability of commercially available technologies to their limits and finally reached a point where these third party technologies could no longer be used without significant risk. This was not our technology vendors’ fault; Amazon's scaling needs were beyond the specs for their technologies and we were using them in ways that most of their customers were not. A number of outages at the height of the 2004 holiday shopping season can be traced back to scaling commercial technologies beyond their boundaries.
Dynamo was born out of our need for a highly reliable, ultra-scalable key/value database. This non-relational, or NoSQL, database was targeted at use cases that were core to the Amazon ecommerce operation, such as the shopping cart and session service. Any downtime or performance degradation in these services has an immediate financial impact and their fault-tolerance and performance requirements for their data systems are very strict. These services also require the ability to scale infrastructure incrementally to accommodate growth in request rates or dataset sizes. Another important requirement for Dynamo was predictability. This is not just predictability of median performance and latency, but also at the end of the distribution (the 99.9th percentile), so we could provide acceptable performance for virtually every customer.
To achieve all of these goals, we needed to do groundbreaking work. After the successful launch of the first Dynamo system, we documented our experiences in a paper so others could benefit from them. Since then, several Dynamo clones have been built and the Dynamo paper has been the basis for several other types of distributed databases. This demonstrates that Amazon is not the only company than needs better tools to meet their database needs.
Lessons learned from Amazon's Dynamo
Dynamo has been in use by a number of core services in the ecommerce platform, and their engineers have been very satisfied by its performance and incremental scalability. However, we never saw much adoption beyond these core services. This was remarkable because although Dynamo was originally built to serve the needs of the shopping cart, its design and implementation were much broader and based on input from many other service architects. As we spoke to many senior engineers and service owners, we saw a clear pattern start to emerge in their explanations of why they didn't adopt Dynamo more broadly: while Dynamo gave them a system that met their reliability, performance, and scalability needs, it did nothing to reduce the operational complexity of running large database systems. Since they were responsible for running their own Dynamo installations, they had to become experts on the various components running in multiple data centers. Also, they needed to make complex tradeoff decisions between consistency, performance, and reliability. This operational complexity was a barrier that kept them from adopting Dynamo.
During this period, several other systems appeared in the Amazon ecosystem that did meet their requirements for simplified operational complexity, notably Amazon S3 and Amazon SimpleDB. These were built as managed web services that eliminated the operational complexity of managing systems while still providing extremely high durability. Amazon engineers preferred to use these services instead of managing their own databases like Dynamo, even though Dynamo's functionality was better aligned with their applications’ needs.
With Dynamo we had taken great care to build a system that met the requirements of our engineers. After evaluations, it was often obvious that Dynamo was ideal for many database use cases. But ... we learned that engineers found the prospect of running a large software system daunting and instead looked for less ideal design alternatives that freed them from the burden of managing databases and allowed them to focus on their applications.
It became obvious that developers strongly preferred simplicity to fine-grained control as they voted "with their feet" and adopted cloud-based AWS solutions, like Amazon S3 and Amazon SimpleDB, over Dynamo. Dynamo might have been the best technology in the world at the time but it was still software you had to run yourself. And nobody wanted to learn how to do that if they didn’t have to. Ultimately, developers wanted a service.
History of NoSQL at Amazon - SimpleDB
One of the cloud services Amazon developers preferred for their database needs was Amazon SimpleDB. In the 5 years that SimpleDB has been operational, we have learned a lot from its customers.
First and foremost, we have learned that a database service that takes away the operational headache of managing distributed systems is extremely powerful. Customers like SimpleDB’s table interface and its flexible data model. Not having to update their schemas when their systems evolve makes life much easier. However, they most appreciate the fact that SimpleDB just works. It provides multi-data center replication, high availability, and offers rock-solid durability. And yet customers never need to worry about setting up, configuring, or patching their database.
Second, most database workloads do not require the complex query and transaction capabilities of a full-blown relational database. A database service that only presents a table interface with a restricted query set is a very important building block for many developers.
While SimpleDB has been successful and powers the applications of many customers, it has some limitations that customers have consistently asked us to address.
Domain scaling limitations. SimpleDB requires customers to manage their datasets in containers called Domains, which have a finite capacity in terms of storage (10 GB) and request throughput. Although many customers worked around SimpleDB’s scaling limitations by partitioning their workloads over many Domains, this side of SimpleDB is certainly not simple. It also fails to meet the requirement of incremental scalability, something that is critical to many customers looking to adopt a NoSQL solution.
Predictability of Performance. SimpleDB, in keeping with its goal to be simple, indexes all attributes for each item stored in a domain. While this simplifies the customer experience on schema design and provides query flexibility, it has a negative impact on the predictability of performance. For example, every database write needs to update not just the basic record, but also all attribute indices (regardless of whether the customer is using all the indices for querying). Similarly, since the Domain maintains a large number of indices, its working set does not always fit in memory. This impacts the predictability of a Domain’s read latency, particularly as dataset sizes grow.
Consistency. SimpleDB’s original implementation had taken the "eventually consistent" approach to the extreme and presented customers with consistency windows that were up to a second in duration. This meant the system was not intuitive to use and developers used to a more traditional database solution had trouble adapting to it. The SimpleDB team eventually addressed this issue by enabling customers to specify whether a given read operation should be strongly or eventually consistent.Pricing complexity. SimpleDB introduced a very fine-grained pricing dimension called “Machine Hours.” Although most customers have eventually learned how to predict their costs, it was not really transparent or simple.
Introducing DynamoDB
As we thought about how to address the limitations of SimpleDB and provide 1) the most scalable NoSQL solution available and 2) predictable high performance, we realized our goals could not be met with the SimpleDB APIs. Some SimpleDB operations require that all data for a Domain is on a single server, which prevents us from providing the seamless scalability our customers are demanding. In addition, SimpleDB APIs assume all item attributes are automatically indexed, which limits performance.
We concluded that an ideal solution would combine the best parts of the original Dynamo design (incremental scalability, predictable high performance) with the best parts of SimpleDB (ease of administration of a cloud service, consistency, and a table-based data model that is richer than a pure key-value store). These architectural discussions culminated in Amazon DynamoDB, a new NoSQL service that we are excited to release today.
Amazon DynamoDB is based on the principles of Dynamo, a progenitor of NoSQL, and brings the power of the cloud to the NoSQL database world. It offers customers high-availability, reliability, and incremental scalability, with no limits on dataset size or request throughput for a given table. And it is fast – it runs on the latest in solid-state drive (SSD) technology and incorporates numerous other optimizations to deliver low latency at any scale.
Amazon DynamoDB is the result of everything we’ve learned from building large-scale, non-relational databases for Amazon.com and building highly scalable and reliable cloud computing services at AWS. Amazon DynamoDB is a NoSQL database service that offers the following benefits:
Managed. DynamoDB frees developers from the headaches of provisioning hardware and software, setting up and configuring a distributed database cluster, and managing ongoing cluster operations. It handles all the complexities of scaling and partitions and re-partitions your data over more machine resources to meet your I/O performance requirements. It also automatically replicates your data across multiple Availability Zones (and automatically re-replicates in the case of disk or node failures) to meet stringent availability and durability requirements. From our experience of running Amazon.com, we know that manageability is a critical requirement. We have seen many job postings from companies using NoSQL products that are looking for NoSQL database engineers to help scale their installations. We know from our Amazon experiences that once these clusters start growing, managing them becomes the same nightmare that running large RDBMS installations was. Because Amazon DynamoDB is a managed service, you won’t need to hire experts to manage your NoSQL installation—your developers can do it themselves.
Scalable. Amazon DynamoDB is designed to scale the resources dedicated to a table to hundreds or even thousands of servers spread over multiple Availability Zones to meet your storage and throughput requirements. There are no pre-defined limits to the amount of data each table can store. Developers can store and retrieve any amount of data and DynamoDB will spread the data across more servers as the amount of data stored in your table grows.
Fast. Amazon DynamoDB provides high throughput at very low latency. It is also built on Solid State Drives to help optimize for high performance even at high scale. Moreover, by not indexing all attributes, the cost of read and write operations is low as write operations involve updating only the primary key index thereby reducing the latency of both read and write operations. An application running in EC2 will typically see average service-side latencies in the single-digit millisecond range for a 1KB object. Most importantly, DynamoDB latencies are predictable. Even as datasets grow, latencies remain stable due to the distributed nature of DynamoDB's data placement and request routing algorithms.
Durable and Highly Available. Amazon DynamoDB replicates its data over at least 3 different data centers so that the system can continue to operate and serve data even under complex failure scenarios.
Flexible. Amazon DynamoDB is an extremely flexible system that does not force its users into a particular data model or a particular consistency model. DynamoDB tables do not have a fixed schema but instead allow each data item to have any number of attributes, including multi-valued attributes. Developers can optionally use stronger consistency models when accessing the database, trading off some performance and availability for a simpler model. They can also take advantage of the atomic increment/decrement functionality of DynamoDB for counters.
Low cost. Amazon DynamoDB’s pricing is simple and predictable: Storage is $1 per GB per month. Requests are priced based on how much capacity is reserved: $0.01 per hour for every 10 units of Write Capacity and $0.01 per hour for every 50 units of Read Capacity. A unit of Read (or Write) Capacity equals one read (or write) per second of capacity for items up to 1KB in size. If you use eventually consistent reads, you can achieve twice as many reads per second for a given amount of Read Capacity. Larger items will require additional throughput capacity.
In the current release, customers will have the choice of using two types of keys for primary index querying: Simple Hash Keys and Composite Hash Key / Range Keys:
Simple Hash Key gives DynamoDB the Distributed Hash Table abstraction. The key is hashed over the different partitions to optimize workload distribution. For more background on this please read the original Dynamo paper.
Composite Hash Key with Range Key allows the developer to create a primary key that is the composite of two attributes, a “hash attribute” and a “range attribute.” When querying against a composite key, the hash attribute needs to be uniquely matched but a range operation can be specified for the range attribute: e.g. all orders from Werner in the past 24 hours, all log entries from server 16 with clients IP addresses on subnet 192.168.1.0
Performance Predictability in DynamoDB
In addition to taking the best ideas of Dynamo and SimpleDB, we have added new functionality to provide even greater performance predictability.
Cloud-based systems have invented solutions to ensure fairness and present their customers with uniform performance, so that no burst load from any customer should adversely impact others. This is a great approach and makes for many happy customers, but often does not give a single customer the ability to ask for higher throughput if they need it.
As satisfied as engineers can be with the simplicity of cloud-based solutions, they would love to specify the request throughput they need and let the system reconfigure itself to meet their requirements. Without this ability, engineers often have to carefully manage caching systems to ensure they can achieve low-latency and predictable performance as their workloads scale. This introduces complexity that takes away some of the simplicity of using cloud-based solutions.
The number of applications that need this type of performance predictability is increasing: online gaming, social graphs applications, online advertising, and real-time analytics to name a few. AWS customers are building increasingly sophisticated applications that could benefit from a database that can give them fast, predictable performance that exactly matches their needs.
Amazon DynamoDB’s answer to this problem is “Provisioned Throughput.” Customers can now specify the request throughput capacity they require for a given table. Behind the scenes, DynamoDB will allocate sufficient resources to the table to predictably achieve this throughput with low-latency performance. Throughput reservations are elastic, so customers can increase or decrease the throughput capacity of a table on-demand using the AWS Management Console or the DynamoDB APIs. CloudWatch metrics enable customers to make informed decisions about the right amount of throughput to dedicate to a particular table. Customers using the service tell us that it enables them to achieve the appropriate amount of control over scaling and performance while maintaining simplicity. Rather than adding server infrastructure and re-partitioning their data, they simply change a value in the management console and DynamoDB takes care of the rest.
Summary
Amazon DynamoDB is designed to maintain predictably high performance and to be highly cost efficient for workloads of any scale, from the smallest to the largest internet-scale applications. You can get started with Amazon DynamoDB using a free tier that enables 40 million of requests per month free of charge. Additional request capacity is priced at cost-efficiently hourly rates as low as $.01 per hour for 10 units of Write Capacity or 50 strongly consistent units of Read Capacity (if you use eventually consistent reads you can get twice the throughput at the same cost, or the same read throughput at half the cost) Also, replicated solid state disk (SSD) storage is $1 per GB per month. Our low request pricing is designed to meet the needs of typical database workloads that perform large numbers of reads and writes against every GB of data stored.
To learn more about Amazon DynamoDB its functionality, APIs, use cases, and service pricing, please visit the detail page at aws.amazon.com/DynamoDB and also the Developer Guide. I am excited to see the years of experience with systems such as Amazon Dynamo result in an innovative database service that can be broadly used by all our customers.


It remains to be see how the availability of DynamoDB will affect the Windows Azure Storage team’s future plans for improving Windows Azure table storage services.
Jonathan Ellis (@spyced) compares Cassandra and Amazon DynamoDB in a 1/18/2012 post to the DataStax blog:
Today Amazon announced DynamoDB, a hosted database for Amazon Web Services.
With DynamoDB, Amazon and Cassandra come full circle: just as Cassandra was inspired by Amazon’s 2007 Dynamo paper, DynamoDB has adopted many of the improvements Cassandra has made since then.
Here’s a summary of how DynamoDB compares to Cassandra:
Cassandra DynamoDB Scalability limits Millions of ops/s 10,000-40,000 ops/s* Largest value supported 2GB 64KB Tuneable consistency Yes For some operations Idempotent write batches Yes No Conditional updates No Yes Time-to-live support Yes No Key + columns data model Yes Yes Indexes on column values Yes No Hadoop integration M/R, Hive, Pig M/R, Hive Composite key support Yes Yes Multi-DC support Yes (configurable) Yes Integrated caching Yes Unclear High performance on commodity disks Yes No Monitorable Yes No Backups Low-impact snapshot + incremental Manually with EMR Deployable Anywhere Only on AWS *More available by request

The original Dynamo design had a primitive key/value data model. This has serious implications: to update a single field, then entire value must be read, updated, and re-written. (Other NoSQL databases have grafted a document API onto a key/value engine; this is one reason their performance suffers compared to Cassandra.) Another direct consequence is requiring complex vector clocks to handle conflicts from concurrent updates to separate fields. Cassandra was one of the first NoSQL databases to offer a more powerful ColumnFamily data model, which DynamoDB’s strongly resembles.

However, secondary indexes were one of the best-received features when Cassandra introduced them a year ago. Going back to only being able to query by primary key would feel like a big step backwards to me now.[*]
Like Cassandra, DynamoDB offers Hadoop integration for analytical queries. It’s unclear if DynamoDB is also able to partition analytical workloads to a separate group of machines the way you can with Cassandra and DataStax Enterprise. Realtime and analytical workloads have very different performance characteristics, so partitioning them to avoid resource conflicts is necessary at high request volumes.
Hadoop is rapidly becoming the industry standard, so it makes sense to offer Hadoop support instead of an incompatible custom API. It’s worth noting that Cassandra supports Pig as well as Hive on top of Hadoop. Many many people think pig is a better fit for the underlying map/reduce engine.
Cassandra has been in production in many demanding environments for years now, so it’s no surprise that Cassandra has a substantial lead in delivering real-world features like backup. Cassandra’s log-structured storage engine — which is also the reason Cassandra runs so performantly without SSDs — allows both full and incremental backups with no impact on performance. (You can then upload your backup files with a tool like tablesnap).
As an engineer, it’s nice to see so many of Cassandra’s design decisions imitated by Amazon’s next-gen NoSQL product. I feel like a proud uncle! But in many important ways, Cassandra retains a firm lead in power and flexibility
* I’ve been clamoring (without success) for secondary indexes on Windows Azure table storage for about three years.
Irmee Santiago-Layo (@irmee_layo) reported Oracle Buildup on Cloudera’s Huge Data Ride in a 1/18/2011 post to the CloudTimes blog:
Oracle mounted on its Big Data, Hadoop last October, this was after everyone thought that Larry Ellison, CEO will announce their roll up of their open-source elephant. It turned out, however, that everyone’s assumptions were wrong.
The truth is, Oracle had made an OEM agreement with Cloudera, the largest commercial Big Data appliance reducer and mapper. Cloudera will link CDH3 version of Hadoop, plus it will have Cloudera Manger 3.7 as add-on.
Oracle has CDH3 on its core Hadoop, but customers need not worry because they will not be limited to NoSQL because Cetin Ozbutin, vice president of data warehousing technologies already announced that customers will now have access to Hadoop Distributed File System (HDFS). That is, if customers do not want to run on Oracle’s NoSQL. In addition, they will also have access to HBase, which is similar to Google’s BigTable data storage. The Big Data Appliance runs on Oracle’s community NoSQL and on Java’s HotSpot VM atop Oracle Enterprise Linux.
Oracle could have easily grabbed Apache Hadoop like how it did with Red Hat’s Enterprise Linux, but Ozbuton said they had to evaluate other Hadoop providers’ MapR and Hortonworks.
Ozbuton said, “We did consider a lot of different options, but we thought it best to partner with Cloudera. Cloudera is obviously the leader in this area and we have expertise in other areas that are complementary.”
What is significant to look into is the fact that the Big Data Appliance is not just an Oracle and Cloudera partnership. Ozbuton prides in saying that their IT spent several months of fine tuning their hardware configuration, algorithms, plug-ins and data storage.
Ozbuton says that the Big Data Appliance has superb features from its 18 Sun Fire x86 server nodes to its huge 144GB of memory. Plus they also have the right mix up of I/O and network bandwidth system. It costs at $450,000 per rack, which includes licenses to the core Oracle software and a lifetime OEM license to CDH3.
In addition to all these, Oracle hopes to roll out the Big Data Appliance and link it with other Hadoop data stores. First among these links is the Oracle Loader for Hadoop that allowed data migration from Oracle 11g R2 databases to Hadoop data stores. Second, was the Oracle Data Integrator for Hadoop that generates MapReduce code automatically. Third, is the Direct Connection for HDFS that allows file system mapping and fourth, is the R Connector for Hadoop.
These applications have definitely placed Oracle on the open-source statistics and analysis and all these cost $2,000 per server processor.


James Downey (@james_downey) asserted Cloud Foundry Evolves in a 1/18/2012 post:
Cloud Foundry, the open-source Platform-as-a-Service (PaaS) solution from VMware, continues to gain community support and evolve toward a more diverse, -ready platform. Last night at the Silicon Valley Cloud Computing Group meet up in Palo Alto, VMware engineers and representatives from several community partners spoke of recent progress and future plans.
Building on Cloud Foundry’s extension framework for languages and services, Uhuru Software has added .Net support to Cloud Foundry, enabling .Net developers to create applications in Visual Studio and deploy them directly to a Cloud Foundry-based private or public cloud. AppFog has added PHP support, and ActiveState has added Perl and Python support. Jaspersoft has extended Cloud Foundry with BI support, including user-friendly wizards for building reports and dashboards and direct support for the document-oriented MongoDB as a data source.
Scalr, whose founder, Sebastian Stadil, organizes the cloud computing group, demonstrated tooling for deploying a Cloud Foundry cluster. The graphical, web-based tool builds up a configuration for each server and calls web services to spin up the instances.
And VMware itself continues to make major contributions to Cloud Foundry. Patrick Chanezon and Ramnivas Laddad from VMware demonstrated Micro Cloud Foundry, a Cloud Foundry cluster with all components running on one virtual machine. This capability makes it possible for developers to spin up a PaaS instance on their laptop, deploy an application, and debug. Using an Eclipse plugin, Laddad gave a demo of debugging a cloud application that mirrored the experience of debugging traditional applications.
During a closing panel, VMware and partner representatives clarified the distinction between CloudFoundry.org and CloudFoundry.com. CloudFoundry.org hosts the open-source software development project, which enables organizations to run their own private or public PaaS cloud. This codebase will grow to support multiple languages and services. CloudFoundry.com is a public instance of Cloud Foundry run by VMware. Like other hosted instances of Cloud Foundry, CloudFoundry.com supports only a subset of the languages and services provided for by the open-source Cloud Foundry code. Despite the expansion of the code base, hosting providers must limit their offerings to services that they have the operational expertise to support.
In light of the rapid growth and expanding ecosystem, Jeremy Voorhis, a senior engineer at AppFog, suggested that VMware create an independent governance body to direct the future development of Cloud Foundry and to mediate potential conflicts between contributors. A few meet-up participants supported the suggestion. While all agreed that VMware has done a fabulous job of starting the project and building an ecosystem, those who raised the suggestion were concerned that conflicts were inevitable and that it would be better to build up a governance system in preparation. Representatives from VMware responded that they did not oppose the idea but did not consider governance a priority given the platform’s early stage of development.
The meet up made one thing clear, that extensiblity (see my post from last May) has made Cloud Foundry into a dynamic platform that has caught the attention of the open-source community.

The Datanami Staff (@datanami) reported Fujitsu Lets Big Data Cloud Flag Fly on 1/18/2012:
This week Fujitsu announced that it would be rolling out its cloud-based Data Utilization Platform Services, an offering that is a mesh of a number of their products with a focus on handling large data sets.
This marks the release of a central component of the company’s Convergence Services Platform, which represents Fujitsu’s cloud and big data strategies in tandem. At the time of the announcement of the Convergence news, Fujitsu said they were working on a PaaS platform to collect diverse data, integrate it and process it in real-time.
According to Fujitsu, the Data Utilization Platform Services will offering just-about-everything-data-related-as-a-service (JAEDRaaS). From gathering, compiling, and integrating massive amounts of data from sensors, data streams and other sources of diverse information—to the processing of the data with an emphasis on real time or batch, depending on the workload.
And here is something rather funny about this news, by the way. Just two days before the actual release of Fujitsu’s news we published an article here discussing the Evolving Art (and Business) of Data Curation. While it wasn’t the focus of the article, the point was made that for some strange reason no vendors have tapped into the value of calling what they do “data curation” despite the fact that it might be in their best interest to do so.
Whether sheer coincidence or not, Fujitsu is calling attention to its own “data curation” services, making them the first major vendor to hop on board with the name trend that could be the next big buzzword in big data speak.
Fujitsu has created a companion to the DUPS (I see why they never gave Data Utilization Platform Service its own acronym now) in the form of their new Data Curation Services offering. The company says that this will “provide total support for these new ways of leveraging data, including customer data analysis and its application to business operations.”
Both DUPS and their data curation services fall under the overarching umbrella of Fujitsu Convergence Services, which is the larger term that encompasses “collecting, storing and analyzing massive amounts of data and integrating it with knowledge in a feedback loop to society.” Both the Data Utilization Platform and Data Curation Services are central to the Convergence strategy—and all three tie together Fujitsu’s approach to big data.
Related Stories

I wonder if this new services uses and services from Fujitsu’s Windows Azure Platform Appliance (WAPA) implementation.
Barton George (@barton808) continued his series with Web Glossary part two: Data tier on 1/18/2012:
Here is part two of three of the Web glossary I complied. As I mentioned in my last two entries, in compiling this I pulled information from various and sundry sources across the Web including wikipedia, community and company web sites and the brain of Cote. …
General terms
- Structured data: Data that can be organized in a structure e.g. rows or columns so that it is identifiable. The most universal form of structured data is a database like SQL or Access.
- Unstructured data: Data that has no identifiable structure. Unstructured data typically includes bitmap images/objects, text and other data types that are not part of a database. Most enterprise data today can actually be considered unstructured. An email is considered unstructured data.
- Big Data: Data characterized by one or more of the following characteristics: Volume – A large amount of data, growing at large rates; Velocity – The speed at which the data must be processed and a decision made; Variety – The range of data, types and structure to the data
- Relational Databases (RDBMS) Management Systems: These databases are the incumbents in enterprises today and store data in rows and columns. They are created using a special computer language, structured query language (SQL), that is the standard for database interoperability. Examples: IBM DB2, MySQL, Microsoft SQL Server, PostgreSQL, Oracle RDBMS, Informix, Oracle Rdb, etc.
- NoSQL: refers to a class of databases that 1) are intended to perform at internet (Facebook, Twitter, LinkedIn) scale and 2) reject the relational model in favor of other (key-value, document, graph) models. They often achieve performance by having far fewer features than SQL databases and focus on a subset of use cases. Examples: Cassandra, Hadoop, MongoDB, Riak
- Recommendation engine: A recommendation engine takes a collection of frequent itemsets as input and generates a recommendation set for a user by matching the current user’s activity against the discovered patterns. The recommendation engine is on-line process, therefore its efficiency and scalability are key, e.g. people who bought X often also bought Y.
- Geo-spatial targeting: the practice of mapping advertising, offers and information based on geo location.
- Behavioral targeting: a technique used by online publishers and advertisers to increase the effectiveness of their campaigns. Behavioral targeting uses information collected on an individual’s web-browsing behavior, such as the pages they have visited or the searches they have made, to select which advertisements to display to that individual.
- Clickstream analysis: On a Web site, clickstream analysis is the process of collecting, analyzing, and reporting aggregate data about which pages visitors visit in what order – which are the result of the succession of mouse clicks each visitor makes (that is, the clickstream). There are two levels of clickstream analysis, traffic analysis and e-commerce analysis.
Projects/Entities
- Gluster: a software company acquired by Red Hat that provides an open source platform for scale-out Public and Private Cloud Storage.
- Relational Databases
- MySQL: the most popular open source RDBMS. It represents the “M” in the LAMP stack. It is now owned by Oracle.
- Drizzle: A version of MySQL that is specifically targeted the cloud. It is currently an open source project without a commercial entity behind it.
- Percona: A MySQL support and consulting company that also supports Drizzle.
- PostgreSQL: aka Postgres is is an object-relational database management system (ORDBMS) available for many platforms including Linux, FreeBSD, Solaris, Windows and Mac OS X.
- Oracle DB – not used so much in new WebTech companies, but still a major database in the development world.
- SQL Server – Microsoft’ s RDBMS
NoSQL Databases
- MongoDB: an open source, high-performance, database written in C++. Many Linux distros include a MongoDB package, including CentOS, Fedora, Debian, Ubuntu and Gentoo. Prominent users include Disney interactive media group, New York Times, foursquare, bit.ly, Etsy. 10gen is the commercial backer of MongoDB.
- Riak: a NoSQL database/datastore written in Erlang from the company Basho. Originally used for the Content Delivery Network Akamai.
- Couchbase: formed from the merger of CouchOne and Membase. It offers Couchbase server powered by Apache CouchDB and is available in both Enterprise and Community editions. The author of CouchDB was a prominent Lotus Notes architect.
- Cassandra: A scalable NoSQL database with no single points of failure. A high-scale, key/value database originating from Facebook to handle their message inboxes. Backed by DataStax, which came out of Rackspace.
- Mahout: A Scalable machine learning and data mining library. An analytics engine for doing machine learning (e.g., recommendation engines and scenarios where you want to infer relationships).
- Hadoop ecosystem
- Hadoop: An open source platform, developed at Yahoo that allows for the distributed processing of large data sets across clusters of computers using a simple programming model. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. It is particularly suited to large volumes of unstructured data such as Facebook comments and Twitter tweets, email and instant messages, and security and application logs.
- MapReduce: a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner. Hadoop acts as a platform for executing MapReduce. MapReduce came out of Google
- HDFS: Hadoop’s Distributed File system allows large application workloads to be broken into smaller data blocks that are replicated and distributed across a cluster of commodity hardware for faster processing.
- Major Hadoop utilities:
- HBase: The Hadoop database that supports structured data storage for large tables. It provides real time read/write access to your big data.
- Hive: A data warehousing solution built on top of Hadoop. An Apache project
- Pig: A platform for analyzing large data that leverages parallel computation. An Apache project
- ZooKeeper: Allows Hadoop administrators to track and coordinate distributed applications. An Apache project
- Oozie: a workflow engine for Hadoop
- Flume: a service designed to collect data and put it into your Hadoop environment
- Whirr: a set of libraries for running cloud services. It’s ideal for running temporary Hadoop clusters to carry out a proof of concept, or to run a few one-time jobs.
- Sqoop: a tool designed to transfer data between Hadoop and relational databases. An Apache project
- Hue: a browser-based desktop interface for interacting with Hadoop
- Cloudera: a company that provides a Hadoop distribution similar to the way Red Hat provides a Linux distribution. Dell is using Cloudera’s distribution of Hadoop for its Hadoop solution.
- Solr: an open source enterprise search platform from the Apache Lucene project. Backed by the commercial company Lucid Imagination.
- Elastic Search: an open source, distributed, search engine built on top of Lucene (raw search middleware).
Extra-credit reading


<Return to section navigation list>

















1 comments:
As a Dell employee I think your article about cloud computing is quite impressive. I think cloud computing is a technology that uses the internet and central remote servers to maintain data and applications.
Post a Comment