Windows Azure and Cloud Computing Posts for 12/12/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Denny Lee announced Microsoft is Helping to make Hadoop easier by going Metro! in a 12/14/2011 post to the Microsoft SQL Server Customer Advisory Team (CAT) Blog:
We are proud to announce that the community technology preview (CTP) of ApacheTM HadoopTM-based Services for Windows Azure (or Hadoop on Azure) is now available. As noted in on the SQL Server Data Platform Insider blog, the CTP is by invite only.
While Hadoop is important to our customers for performance, scalability, and extreme volumes - as noted in our blog What’s so BIG about “Big Data”? – it is a slight paradigm shift for our us in the SQL community. Therefore, one of the great things about our new Hadoop on Azure service is that we’ve made Hadoop go all Metro – that is a Metro UI with a Live Tile implementation.

What is even cooler is that you can interact with with Hadoop, Hive, Pig-Latin, Hadoop Javascript framework, Azure DataMarket, and Excel using the Hadoop on Azure service – check out the Channel 9 video for Hadoop on Azure here for more information.
We’re really excited about this CTP – so if you want an invite code, please check out the fill out the Connect survey. … Invite codes will be given out based on a selection criteria basis so please be patient.
As well, check out all of the great documentation and content so you can keep up to date on Hadoop on Azure:
- Apache Hadoop on Windows Resources: http://social.technet.microsoft.com/wiki/contents/articles/apache-hadoop-on-windows.aspx
- Microsoft Hadoop Distribution Documentation Plan: http://social.technet.microsoft.com/wiki/contents/articles/microsoft-hadoop-distribution-documentation-plan.aspx
- Apache Hadoop-based Services for Windows Azure How-To and FAQ Guide: http://social.technet.microsoft.com/wiki/contents/articles/apache-hadoop-based-services-for-windows-azure-how-to-and-faq-guide.aspx
Thanks!
Isotope PG and CX teams


Didn’t get my invitation yet, so signed up again. Check out Denny’s personal blog.
Val Fontana of the SQL Server Team (@SQLServer) announced Availability of Community Technology Preview (CTP) of Hadoop based Service on Windows Azure in a 12/14/2011 post:
In October at the PASS Summit 2011, Microsoft announced expanded investments in “Big Data”, including a new Apache Hadoop™ based distribution for Windows Server and service for Windows Azure. In doing so, we extended Microsoft’s leadership in BI and Data Warehousing, enabling our customers to glean and manage insights for any data, any size, anywhere. We delivered on our promise this past Monday, when we announced the release of the Community Technology Preview (CTP) of our Hadoop based service for Windows Azure.
- Broader access to Hadoop through simplified deployment and programmability. Microsoft has simplified setup and deployment of Hadoop, making it possible to setup and configure Hadoop on Windows Azure in a few hours instead of days. Since the service is hosted on Windows Azure, customers only download a package that includes the Hive Add-in and Hive ODBC Driver. In addition, Microsoft has introduced new JavaScript libraries to make JavaScript a first class programming language in Hadoop. Through this library JavaScript programmers can easily write MapReduce programs in JavaScript, and run these jobs from simple web browsers. These improvements reduce the barrier to entry, by enabling customers to easily deploy and explore Hadoop on Windows.
- Breakthrough insights through integration Microsoft Excel and BI tools. This preview ships with a new Hive Add-in for Excel that enables users to interact with data in Hadoop from Excel. With the Hive Add-in customers can issue Hive queries to pull and analyze unstructured data from Hadoop in the familiar Excel. Second, the preview includes a Hive ODBC Driver that integrates Hadoop with Microsoft BI tools. This driver enables customers to integrate and analyze unstructured data from Hadoop using award winning Microsoft BI tools such as PowerPivot and PowerView. As a result customers can gain insight on all their data, including unstructured data stored in Hadoop.
- Elasticity, thanks to Windows Azure. This preview of the Hadoop based service runs on Windows Azure, offering an elastic and scalable platform for distributed storage and compute.
We look forward to your feedback! Learn more at www.microsoft.com/bigdata.
Val Fontama
Senior Product Manager
SQL Server Product Management

<Return to section navigation list>
SQL Azure Database and Reporting
Chihan Biyikoglu (@SQLaaS) answered “No” to …So Isn’t the Root Database a Bottleneck for Federations in SQL Azure? on 12/15/2011:
Dan posted a great comment to my previous blog post [see below] and I think the question he is raising is worth a blog post! Thanks for the question Dan!
Here is Dan’s question:
Dan - Tue, Dec 13 2011 11:57 AM
Cihan, thanks for keeping us all posted all the way until the D-day the 12th.
Having followed your posts and some Azure documentation (so far limited), there is 1 simple but key question that keeps bugging me, my team and quite likely many other developers - so far I have not found any reasonable explanation and I fail to understand on HOW and WHY having ALL(!) federation member requests go ALWAYS(!) through ONE(!) Federation Root DB would eliminate the SQL performance bottleneck problem that we are trying to get away with???
…
This is a common confusion I think we create with the root database but root, besides holding onto some metadata, really does not do the processing of transactions when it comes to federations. In fact, unless you have specific processing requests that happen in the root, root stays pretty idle. This is the magic of the USE FEDERATION statement.
Before I go into the detail of USE FEDERATION, let me dive into some architectural details of SQL Azure. SQL Azure physically has a separate layer in front of the database nodes called the services layer (a.k.a the gateway). Services layer owns managing connectivity, translation of logical to physical server names, some TSQL processing and a few other services. Services layer does some complicated TSQL processing; In fact processing of USE FEDERATION statement and all other CREATE/ALTER/DROP FEDERATION statements are done by the services layer not the platform layer (or the database nodes) in SQL Azure. Services layer is a scaled out tier and SQL Azure configuration controls the number of gateway nodes per cluster in SQL Azure. You can see the detailed picture of the layers below. You can find more details on SQL Azure architecture here.

Connections from your applications are distributed over to the services layer nodes through a load balancer. When a connection from a client application comes in, one of the services layer nodes handle the connection, translate which physical server now contains the logical server and database name in the connection string and establishes the connection to the database node in the platform layer.
Ok, so lets go back to federations and how federation do their processing: With federations, applications use the name of the root database in their connection string. At this point, a connection from the app to the services layer node is established (white arrows) and a connection from the services layer node to the root database node is established or if a pooled connection already exists to the root database it is reused (blue arrow).

In federation model, before you do transactional processing we require that you issue a routing statement called USE FEDERATION to work with your scaled-out schema. USE FEDERATION takes a federation name, a federation key value and some attributes. When USE FEDERATION is received by the services layer, the connection from the app to the services layer stay intact but the connection from the services layer to the database node is switched over to the federation member that contain the federation key value provided in the USE FEDERATION statement. So if you execute;
“USE FEDERATION orders_federation(tenant_id=155) …”
Connection from the application to Node#1 in services layer stays intact but the the services layer switches the connection from the root database to the federation member that contain tenant_id value 155 (white arrow from gateway node#1 to orders_federation member database node)

After this point all transaction processing, aside from a few TSQL statement gateway nodes process, happen directly on the federation member node. All your stored procedure executions to queries directly work with the node that contain the federation member which contains tenant_id 155. Each federation member and root database is spread over to various nodes in the platform layer so as more processing hit other federation members that contain tenant_id 655 or 1055, other nodes in the platform layer is engaged in processing those transactions.
At this point you may say, fine the transactional processing is decentralized but how about processing of USE FEDERATION itself? The information in the root database is the only way to figure out which federation member has tenant_id=155 or 655 or 1055? SQL Azure services layer is smart about that as well: For processing this connection routing, gateway nodes do caching of federation metadata and pooling of connections to process the USE FEDERATION command itself. That means while the cache and pool is getting built the root database receive queries asking for the federation map but after things get warmed up, services layer nodes do the heavy lifting.
So with the magic of USE FEDERATION statement both the processing of connection routing and the transaction processing in federation is decentralized! that gives you the ability to do processing much beyond capacity limits of a single node!
Hope this helps explain your question Dan!


Chihan Biyikoglu (@SQLaaS) explained Building Large Scale Elastic Database Tiers with SQL Azure: Introducing Federations in a 12/13/2011 post:
One of the exciting new features in the just-released SQL Azure Q4 2011 Service Release is SQL Azure Federation. In a sentence, SQL Azure Federation enables building elastic and scalable database tiers.
Video Presentation of SQL Azure Federation
Imagine the canonical 3-tier application: these applications handle growing user workloads by adding and removing nodes to their front and middle tiers. Federations extend the same model of scalability to the database tier. With federations applications can scale beyond a single SQL Azure database and harness the capacity of 10s or 100s of nodes. At any point, administrators can play with federation dials to expand and shrink the capacity of their database tier without requiring any application downtime.
Federations provide four key benefits:
- Massive Scale: Federations bring in the sharding pattern in SQL Azure and allow harnessing of massive capacity at the database tier. Combined with the power of SQL Azure, administrators can choose to engage 10s or 100s of nodes within the SQL Azure cluster.
- Best Economics: With federations, database tiers become truly elastic. Administrators can repartition applications based on workload to engage or disengage SQL Azure nodes. With federations, no downtime is required for these repartitioning operations.
- Simplified Development and Administration of Scale-out Database Systems: Federations come with a robust programming and connectivity model for creating dynamic applications. With native tooling support for managing federations and with online repartitioning operations for orchestrating federation at runtime, federations greatly ease management of databases at scale.
- Simplified Multi-tenant Database Tiers: Multi-tenancy provides great efficiencies by increasing the density of tenants per database. However, a static decision on placement of tenants rarely works for the long tail of tenants or for large customers that may hit scale limitations of a single database. With federations applications don’t have to make a static decision about tenant placement. Federations provide repartitioning operations for efficient management of tenant placement and re-placement and can deliver this without any application downtime.
Let's take a look at a sample application of federation to ground these notions. Imagine a web site called Blogs’R’Us that is hosting blogs. At any given day, users create many new blog entries and some of these go viral. However, it is hard to predict which blogs will go viral; so placing these blogs on a static distribution layout means that some servers will be saturated while other servers sit idle. With federations, Blogs’R’Us does not have to be stuck with static partition layout. They can handle the shifts in traffic with federation repartitioning operations and they don’t need to take downtime to redistribute the data.
Let’s look at how one would stand up a federation for Blogs’R’Us: federations are objects within a database, much like tables, views or stored procedures. However they are in one way special; they scale out parts of your schema and data out of the database to other member databases.
Creating a Federation
To create a federation with the news SQL Azure Management Portal, click the New Federation icon on the database page.

CREATE FEDERATION creates the federation and its first federation member. You can view the details of the layout of your federation in the Federations Details page:

Deploying Schema to Federations
Federation members are regular SQL Azure databases and have their private schemas. You can deploy your schema to this federation member using various create statements to create your objects like tables, stored procedures, triggers and views. To connect and deploy your schema, you can click the Query > New Query action on the federation member.

With federations you provide additional annotations to signify federated tables and the federation key. The FEDERATED ON clause is included in CREATE TABLE statements for this purpose. All other objects require no additional annotations.

Scaling-out with Federations
Now that you have deployed your schema, you can scale out your federation to more members to handle larger traffic. You can do that in the Federations Detail page using the SPLIT action.

The federation page also provides detailed information on the progress of the SPLIT operation. If you refresh after submitting the SPLIT operation, you can monitor the federation operation through the federation page:

As the application scales, more SPLIT points are introduced. As the application workload grows, administrators SPLIT federation into more federation members. Federation easily powers such large scale applications and provides great tooling to help administrators orchestrate at scale.

If you’d like to get further information on how to work with federations, you can refer to SQL Azure online documentation as well as my blog. My short video demonstration of the new SQL Azure Federation feature is also available here. You can also follow updates to federations on twitter via #sqlfederations.
Chihan Biyikoglu (@SQLaaS) described the Billing Model for Federations in SQL Azure Explained! on 12/12/2011:
Now that Federations is live in production, lets talk about how the billing model works for federations. Good news is the model is very simple; With federations, every member can be considered a regular SQL Azure database. In fact, sys.database in master database report all federation members in the list. Federation members are marked using a special flag called is_federation_member in this view to help identify them as such.
#1 – Charges on databases are prorated to a day. For example a single 1GB WEB EDITION database costs roughly $.33 a day.
#2 – All databases that existed in a day are charged even if they existed only for part of the day and was dropped during that day.
#3 – Only databases that are in ready state are charged. Databases that are being built are not charged. Charging is only done after these databases become accessible, that is you can connect and work with them.
Ok lets get started…
Creating Federations
The first federation member is created when the federation is created using the CREATE FEDERATION statement. The member inherit its EDITION and MAXSIZE from the root database. However like a new database. this new federation members contain no data so is an empty database.
Here is an example; Lets assume you have a user database with 25GB of data currently and is set to BUSINESS edition and has a MAXSIZE of 30GB. You decide to scale out the database and create a federation. Your first member created with this federation will have the same EDITION and MAXSIZE properties. However given that the member has no data yet, it will only cost you as much as the smallest BUSINESS edition database – that is 10GB.

Here is SalesDB with federation Orders_Fed after the first member has been modified to a MAXSIZE of 50GB and current data size grew to 48GBs after some data loading to the member.

Repartitioning Operations
Some more time passes and as you ALTER FEDERATION with SPLIT to scale out your database further, new members are created. These new federation members also inherit their properties from the source federation member that is being SPLIT. You can find the details of the SPLIT operation in this article but the important thing to remember is that the SPLIT operation does not reuse an existing database and always creates new databases to keep the operation online. From a billing standpoint, you can think of a SPLIT as two CREATE DATABASE statements to create the 2 new destination members, combined with a single DROP DATABASE to drop the source federation member.
First remember principle #3 above on SQL Azure billing: Only databases that are accessible are charged. So during the SPLIT operation, you don’t pay for the destination members that are created yet. You only pay for these new members after the operation completes.
Also remember principle #1 and #2 above; Billing is prorated to a day and every database is counted even if it existed only for the part of a day. That means the day of the SPLIT you pay for both the source and member federation members. However the day after the SPLIT, source database is no longer charged to you since it is dropped so you only pay for the 2 new members that are in place.
Typically the size of the destination members shrink given data will be filtered at the split point specified by the SPLIT operation. So the 2 new members are charged based on their size after the SPLIT.
Lets continue walking through our example; Imagine the federation member with a current size of 48GB is split into a 29GB and a 19GB federation members, your bill should look like this the day of the SPLIT;

…And should no longer include the source member the day after the SPLIT;

With ALTER FEDERATION to DROP members, we do reuse an existing database so form a billing standpoint, it equates to a DROP DATABASE statement dropping one of the members. In SQL Azure, databases are billed even if they existed only for a part of the day. So the day you run ALTER FEDERATION … DROP you still pay for both members. However here is what the bill will include the day after we run DROP AT (HIGH id=…)

Modifying Federation Member Billing Properties
It is also important to remember that federations are available at all editions; BUSINESS and WEB. You can mix and match EDITION and MAXSIZE setting with root and members. Federation root and each federation member can be altered using the ALTER DATABASE statement with the following options.
ALTER DATABASE database_name {
MODIFY (<edition_options> [, ..n])
}<edition_options> ::= {
(MAXSIZE = {1|5|10|20|30|40|50|100|150} GB)
| (EDITION = {'web' | 'business'})
} [;]You will need the member database name to use ALTER DATABASE. For the member database name. You can figure this out simply using db_name() function after switching to the member using the USE FEDERATION statement. You can follow along this article to figure out a federation members database name and other metadata on members.
Best Practices for Cost Optimizing Your Federations
As the final few words, I wanted to touch on an important topic. How do you cost optimize federations? Given the flexible nature of federation member setting on MAXSIZE and EDITION, I also get a lot of question on how to configure federation members. Should one have larger and fewer federation members OR smaller but many federation members? At the time of the publishing of this article a 50GB SQL Azure database costs the same as 50x 1GB databases. So there is no cost optimization for going with one or the other. However clearly 50x 1GB databases have access to more cores, memory and IO capacity as well as more tempdbs and more log files. Thus for better parallelism the answer is spread to smaller but many members first. Think about scaling up the members when management overhead become a hassle. Given we only support 500 databases per SQL Azure Server, you won’t be able to exceed 498 federation members for now. So that is another point where you will need to think about larger member sizes.
As always, love to hear feedback on your experience with federations and the billing model. you can reach me through the blog or at twitter @cihangirb





Mark Kromer (@mssqldude) described the new UI for SQL Azure Federations in a 12/12/2011 post:
On the latest update to the SQL Azure Database Management Tool, I see that (a) the updated UI looks a lot like the preview of the Project Barcelona SQL Server lineage tool: http://www.sqlmag.com/blog/sql-server-bi-blog-17/business-intelligence/sql-server-denali-dependencies-amp-lineage-140558. And (b) SQL Azure Federations are enabled!

However, this is not yet available for SQL Server traditional on-premises databases and still requires you to manually partition and shard your database applications, but do so using the built-in SQL Azure Federations capability. Check-out this Cloud Ninja sample on Codeplex: http://shard.codeplex.com/. And the coding for SQL Azure Federations looks to be quite nice & easy:
-- Connect to federation
USE FEDERATION Orders_Federation (CustId = '00000000-0000-0000-0000-000000000000') WITH RESET, FILTERING = OFF
GO– Create Customers table
CREATE TABLE Customers( CustomerID uniqueidentifier NOT NULL, CompanyName nvarchar(50) NOT NULL, FirstName nvarchar(50), LastName nvarchar(50), PRIMARY KEY (CustomerId) ) FEDERATED ON (CustId = CustomerID)
GO
And there are screens available to you on the SQL Azure Management Tool to monitor and manage your Federations (which is additionally good since you won’t see this in SSMS as SQL Server does not have this capability of Federations):

That’s just my sample. When you actually start using a sharded database application, this GUI becomes very helpful to watch the Federations SPLIT and grow:

Very, very nice. But for scale-out SQL Server (non-Azure), you will need either PDW or sharding OLTP SQL Server databases with distributed partitioned views or other application-layer mechanisms. For now, that is, anyway.




Wasim Bloch @wasimbloch listed SQL Azure Limitations in a 12/8/2011 post (missed when published):
As we all know about SQL Azure database and it’s advantage, it is important to know what limitations SQL Azure brings in.
Here I have tried to list and brief the SQL Azure limitations which might help you to make appropriate architecture decisions.
Missing required features: Many features which are used on premise SQL database are not available for SQL Azure like CLR, Change Data Capture (CDC), Service Broker, Open XML, XML indexes, Backup/Restore and Jobs.
Size: Maximum size of the SQL Azure database is
50 GB150 GB, so consumer has to build custom data archiving. SQL Azure does not support data compression, while investigating your on-premise database size ensure you are looking at the uncompressed data size.UTC time zone: SQL Azure returns data time function in UTC format, i.e. stores data in UTC date time format. So If your application expect date time format other than UTC, make sure you convert it in application/business logic.
Missing Affinity Group: SQL Azure does not support affinity group, make sure you keep your SQL Azure database close to your application for better connectivity, reduce cost and better through put.
Difficult to Know Database Connection Failure: SQL Azure database connection failure is bit difficult to know as it does not provide exact reason why it failed. Make sure you consider all the error messages listed here in your application logic and log it so you know why connection failed.
Brittle and Laborious Data Sync: You cannot modify existing sync group, to add/remove column, need to create new sync group and drop existing one. No monitoring tool available to monitor SQL Azure data sync. Adding/Removing column on a table will require whole data sync to reset.
Data Sync make database messy: SQL Azure data sync creates 15 objects for every table you setup for sync. One (1) tracking table, 11 stored procedure and 3 triggers being created for the each table to sync.
Missing Backup/Restore: SQL Azure does not support incremental backup. SQL Azure Import/Export is a full backup and writes data to the blog storage which may not acceptable for the high business value data.
Hope you find information’s helpful. As usual, your feedback/suggestions/comments are welcome.

Wasim is a a Solution and Enterprise Architect with over 13 years of experince in IT specializing in Microsoft technology and .NET.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
Chris (Woody) Woodruff (@cwoodruff) continued his series with 31 Days Of OData – Day 5 Addressing Entities In OData on 12/12/2011:
Before we can learn about Addressing Entities in OData, we have to lay the ground work for all OData commanding including queries. We will first detail and demonstrate the Uniform Resource Identifier or URI and then look at a URI for OData.
What is a URI?
An URI is a string that is used to identify a name(URN) or a location to a resource( URL). The URN works like a name of a person or a business name where the URL functions like the physical address of a person or business.
The following are two examples of URI’s
http://services.odata.org/OData/OData.svc
http://services.odata.org/OData/OData.svc/Category(1)/Products?$top=2&$orderby=name
As you can the two URI’s are both OData URI’s. The first is called the Service Root URI and the second is an OData query URI that us requesting the first two Products that are associated to Category 1 returned in alphabetical order.

Service Root URI
Every OData call must include the Service Root URI to interact with an OData feed. Think of the Service Root URI as the location of the OData feed. It represents the HTTP listener that will do the work on the behalf of the consumer of the OData feed based on the URI past the root and the HTTP Verb or Command sent.

You may discover that some OData Service Root URI’s do not end with svc. This can be accomplished with routing the request as shown in Ron Jacob’s blob post here.
Resource Path of the OData URI
The Resource Path of OData request URI functions as the resource locator from the OData consumer. It can be a request to any of the following resources of the OData protocol:
- Single Entity (Baseball Player)
- Collection of Entities (Baseball Players from a team and year)
- Entity relationship between multiple Entities (Batting Statistics for a specific Baseball Player)
- A Property of an Entity (Last Name of a Baseball Player)
- Service Operation
- Other resources

Query Options of the OData URI
We will work through many of the Query options during this blog series. Know that all Query Options in OData request URI’s specify three types of information:
- System Query Options – we will explore this type in detail during this series.
- Custom Query Options – extension point for server specific information. The Custom Query Option is always passed as a name/value pair.
- Service Operation Parameters – used to reference a call Service Operations that reside on the OData feed.

Querying Entities
Addressing single or collections of entities located in an OData feed is akin to the FROM clause of a SQL SELECT statement along with JOINs. By allowing associations between Entities an OData request URI can reach far and wide inside the OData feed to request any shape and collection of data.
The following grammar are the rules that cover all entity query scenarios: single Entity, collection of Entities or single Property of Entity.

The areas of the OData request
Details
Collection
The Collection will cover either a requested Collection of Entities or from a Service Collection which returns a Collection of Entities.KeyPredicate
A predicate that identifies the value(s) of the key Properties of an Entry. If the Entry has a single key Property the predicate may include only the value of the key Property. If the key is made up of two or more Properties, then its value must be stated using name/value pairs. More precisely, the syntax for a KeyPredicate is shown by the following figure.

NavPropSingle
The name of a Navigation Property defined by the Entry associated with the prior path segment. The Navigation Property must identify a single entity (that is, have a “to 1″ relationship).NavPropCollection
Same as NavPropSingle except it must identify a Collection of Entries (that is, have a “to many” relationship).ComplexType
The name of a declared or dynamic Property of the Entry or Complex Type associated with the prior path segment.Property
The name of a declared or dynamic Property of the Entry or Complex Type associated with the prior path segment.We will be looking at many ways to query and shape the data returned from an OData feed in future blog posts. Stay tuned and hope you are enjoying the series. I am working to catch up also.

Glenn Gailey (ggailey777) reported New Windows Azure Guidance Topics Published on 12/12/2011:
Just a quick post to let everyone know that we have just published a new set of Windows Azure prescriptive guidance topics for developers:
Windows Azure Developer Guidance
This release includes two guidance topics I wrote:
These topics are about 90% of where I want them, so overall I am pretty happy with them. I will polish them in a coming release. Feel free to send feedback.
Thanks to the following folks for their advice, help, input, and reviews:
- Ralph Squillace
- Matt Stroshane
- Turker Keskinpala
- Abhiram Chivukula
- Shayne Burgess

<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Christian Weyer (@thinktecture) continued his series with Cross-device/cross-location Pub-Sub (part 2): Using Windows Azure Service Bus Topics Subscriptions in Windows Phone (7.1) on 12/15/2011:
In the previous post [see below] I showed how to use MonoTouch and C# on iOS devices to subscribe to the Windows Azure Service Bus’s topics and subscriptions features.
This time it is a Windows Phone (Mango) client app.
The sending / publishing application is still the same Console application from the last post:

And the nice part about the WP app is that Kellabyte already did the major work for wrapping the Service Bus queues, topics, and subscriptions REST API (also check out her awesome Continuous Client demo which uses the Service Bus).

With her code in place the actual subscribing inside my WP app to the messages in my Service Bus subscriptions is a piece of cake:
[See original post for source code]
And the (again) super spectacular result is that all the messages are being sucked from my subscription and displayed on the phone:
Voila. Sorry – not so exciting as last time. Anyway, here is the download:
- PhoneServiceBusSubscriber.zip (including both the message publisher Console and the Windows Phone 7.1 subscriber)

Christian Weyer (@thinktecture) started a series with Cross-device/cross-location Pub-Sub: Using Windows Azure Service Bus Topics Subscriptions in iOS with MonoTouch on 12/14/2011:
Windows Azure has seen some updates over the past weekend. One small update is that the Service Bus and Access Control Service are no longer marketed inside the Windows Azure AppFabric brand but are now a substantial part of Windows Azure core.
The Windows Azure Service Bus has two basic feature sets:
- relayed messaging (through the Service Bus Relay service)
- brokered messaging (through queues, topics, subscriptions (and the deprecated message buffers)
In this post I show you how to use part of Service Bus’ REST API to create a cross-platform & cross-location publish & subscribe app by leveraging topics and subscriptions.
First of all, let’s launch the wonderful Service Bus Explorer tool and look at my Service Bus namespace:

As we can see there are no topics and subscriptions (and also no queues).
What we are going to do is have a .NET console app running on Windows to create a topic and a subscription on the Service bus with the REST API and send messages to the topic. Here is the essential piece of code to do this:
[See original post for source code.]
Admitted, the actual heavy work is inside the BrokeredMessaging class. This class is just a simple wrapper around the REST API, and you can see some basic operations using WebClient to talk to the Service Bus in the AppFabric SDK samples (e.g. the Management Operations using REST sample).
The BrokeredMessaging helper class can be found in the sample projects download at the end of this post.
After we retrieved a token from ACS we create a topics and a subscription and send out messages in a loop:

These messages are sent to the Service Bus to a durable topic (which uses queues underneath). As long as there is no subscriber which gets and deletes the messages from the subscription we can see the messages sent to the topic in the Service Bus Explorer – here we have sent out 4 messages from the Console application:

Cool.
Now let’s use a subscriber to get the messages from the subscription. My goal was to have a native iOS app but built with C# entirely. Therefore I fired up MonoTouch and created a very simple iPhone app. For the super-sophisticated UI I used MonoTouch.Dialog, a highly recommend UI library to quickly create any forms-over-data user interface for iOS apps.
In order to talk to the Service Bus the MonoTouch project was using the exact same BrokeredMessaging class as my Windows console application. The joy of MonoTouch.
Again, the essential code (after getting a token from ACS) to get and delete messages from the SB subscription looks like this (the messages object is the list of elements in the UI to display the messages).
[See original post for source code.]
Note: it may not be wise to store the Service Bus owner and shared secret directly in the device’s app – you know… or at least store it in the Keychain (sample with MT: http://www.wildsau.net/post/2011/02/01/iOS-Store-passwords-in-the-keychain-using-MonoTouch.aspx).
To convince you that there is no magic or cheating going on, this is the code from BrokeredMessaging to get the message from the subscription (and also delete it):
[See original post for source code.]
Note: Console.WriteLine(…) is the mechanism in MonoTouch to write to debug output. Well…
Whenever we get a real and non-empty message we add it to the list view of our simple iOS app. Voila:

And to prove that everything worked as expected, the subscription is now empty and no more messages are in there:

Bingo!

Windows Azure Service Bus (together with the Windows Azure Access Control Service) enables us to send messages in an async manner to durable storage in the Cloud and subscribing to those messages (via topics and subscriptions) with literally any device, any platform, from any location!
The sample projects for VS 2010 and MonoTouch can be downloaded:
- SBTopicsPublisherREST (VS 2010)
- iServiceBusSubscriber (MonoTouch)
Vittorio Bertocci (@vibronet) reported a Brand New ACS Walkthrough on the New Windows Azure Developer Center on 12/12/2011:
By now, I am sure, you already heard about the flurry of improvements that swept the Azure Land. If you didn’t, please take a moment to go through Bob’s post here: socks will be blown, the Windows Azure team did an *amazing* job.
If you explore the new developer center you’ll eventually land on a brand new howto guide which provides a concise introduction to ACS. If you are new to this space and want to get a feeling of what ACS can do, I am sure you’ll find the new guide useful. If you already know about ACS, you now have a nice, self-contained guide you can use with the ones in your team who need to ramp up.
Have fun, and don’t forget to tune in for tomorrow’s Learn Windows Azure online event! I might even have a brief cameo.


<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
PR Web announced GreenButton Opens Offices in USA to Support Increased Demand for High-Performance Cloud Computing Services in a 12/15/2011 press release:
Company Establishes Silicon Valley and Seattle Offices and Names Mark Canepa to Board of Directors
GreenButton, a New Zealand-based software company specializing in high performance cloud computing, today announced it has officially created a separate subsidiary in the United States opening offices in Palo Alto, California and Seattle, Washington to support the expansion of its technology business in the US. Additionally, the company has announced the appointment of Mark Canepa to its board of directors.
"Our presence in Silicon Valley and Seattle is critical to our success - both are large, diverse and highly literate technology communities," said Scott Houston, CEO of GreenButton. "This set of moves is in response to the increased demand for our services by both ISV's and their users in the US market. We are growing organically and intend to 'follow the sun' to serve our clients better and having the US-based offices gives GreenButton the opportunity to provide 'always on, always available' sales and technical support to our customer base in the US."
The GreenButton™ platform acts as a personal supercomputer, giving software vendors, the enterprise, and end users an end-to-end solution for the cloud market. It enables the managed transition from the desktop or offline world to the online world, ensuring that both the software vendors and software user gain cloud benefits with minimal risk and effort. The GreenButton model allows ISVs to leverage their investment in high end desktop software.
"Cloud computing has the potential to enable scientists and engineers to achieve greater levels of insight and innovation, by providing access to computational tools beyond what they can afford or manage internally," said Addison Snell of Intersect360 Research. "These high-performance computing users already spend over half a billion dollars per year worldwide for resources on public clouds, and we expect consumption will exceed $1 billion by 2015."

Brent Stineman (@BrentCodeMonkey) started a Windows Azure & PHP (for nubs)–Part 1 of 4 series on 12/14/2011:
PHP was my first web development language. I got into web apps just prior to the “Dot Com” boom more than 10 years ago when I was doing “social networking” (we didn’t call it that back then) sites for online games. nfortunately, as a consultant, the skills I get to exercise are often “subject to the demands of the service”. And we don’t really get much call for PHP work these days. I did break those skills back out about a year ago for a project involving a more recent love, Windows Azure for a short yet very sweet reunion. But since then I’ve only gone back to it once or twice for a quick visit.
My how things have changed in the last year.
Change in tooling
So when I worked with PHP last year, I relied on the Windows Azure Tools for Eclipse. It’s still a great toolset that allows for the simple creation and deployment of Windows Azure apps. I loved the level of IDE integration they provided and “built in” support for deployments to the development emulator.
Part of the problem though is that in the last year, it appears that the PHP for Eclipse toolset has lost a bit of steam. Communication isn’t as good as it once was and updates aren’t as frequent. Still a good tool, but it really didn’t seem to be keeping pace with the changes in Azure.
So I ping’d an expert to find out what the latest and greatest was. Turns out things are going command line in a big way with the Windows Azure SDK for PHP. While we do lose the pretty GUI, I can’t say I’m really heart-broken. So lets start by walking through what you need.
Needed Tools
First up, we need to make sure we have the Web Platform Installer because we’re going to use it to snag some of the components we need. The platform installer is nice because it will make sure we have necessary pre-requisites installed and even download them for us if it can.
If you aren’t already a .NET developer, you want to look at start with getting SQL Server Express. Just launch the platform installer and type “SQL server express” into the search box in the top right. Look for “SQL Server Express 2008 R2” and select “install” if its not already.

Do this same thing except search for “Azure” and get the “Windows Azure SDK” and “Windows Azure Libraries”. Lastly, search for PHP and get the latest version of PHP for web matrix.
Lastly, we’ll need to download the PHP SDK for Azure and install it manually by unzipping the file to “C:\Program Files\Windows Azure SDK for PHP”.
Now there’s a lot more to this then what I’ve covered here. For additional, more detailed information I would direct to this this link on setting up PHP on Windows and this link on setting up the PHP SDK.
Our first PHP app
With all the bit installed, we want to do a quick test locally to make sure we have PHP installed and running properly. So fire up the Internet Information Services (IIS) manager (just type “IIS” into the Windows 7 search box) and in there, we’re going to drill down to the default web site and add some stuff in. Open up the branches like you see in the picture below and right click on “Default Web Site” and select “Add Virtual Directory…” from the pop-up menu.
I entered in “phpsample” as the Alias of my test web site and set the physical path to a location just below “C:\inetpub\wwwroot” (the default root location for IIS web sites. I then created a new file named “index.php” and placed it into that location. This file had only a single line of code…
<?php phpinfo(); ?>
Now if you’re not familiar with PHP, this code will give us a dump of all the PHP settings in use by our system. And if we browse to the new web application (you can click on the browse link on the right in IIS Manager, we hopefully get output like this:

Next time on our show…
So that’s it for part 1 of this series. Next time (and hopefully later this week). We’ll create a Windows Azure web application and show how to deploy and test it locally. We’ve only scratched the surface here. So stay tuned! But if you can’t wait, check out Brian Swan’s PHP on Windows Azure Learning path post.




Liam Cavanagh (@liamca) described Helping to Save the Environment with Eye on Earth – FoodWatch in a 12/14/2011 post:
Today at the Eye on Earth summit in Abu Dhabi, Jacqueline McGlade, European Environment Agency (EEA) Executive Director, announced a new FoodWatch program that is part Eye on Earth network from the EEA. The main goal of FoodWatch is to give people an opportunity to share environmental data and local information on varieties of edible plants with some of the best ways to use energy for cooking and water for growing crops.
A key part of this initial FoodWatch program is the WonderBag from Natural Balances. This is an amazing cooking bag that helps to reduce the amount of energy it takes to cook food by 30%! There are already over 150,000 bags in homes around South Africa. You can see some map visualizations of the carbon savings and distribution here.
You can learn more about FoodWatch and the EyeOnEarth network here.

Nick Harris announced Windows Azure Toolkit for Windows 8 Version 1.1.0 CTP Released in a 12/13/2011 post:
Today we released version 1.1.0 (CTP) of the Windows Azure Toolkit for Windows 8. This release includes the following changes to the Windows Azure toolkit for Windows 8:
- Dependency Checker updated to reference latest releases.
- MVC Website code cleanup and improvements to send notifications dialog
- WNS Recipe Updated WNS Recipe to add Audio support.
- NuGets project template refactored to make use of NuGets which people can also use directly in their existing apps.
- WnsRecipe NuGet created – a managed API for sending Toast, Tile and Badge notifications and handling Auth against WNS
- WindowsAzure.Notifications NuGet – registration service for clients to register their Channel URI from WNS
- WindowsAzure.Common NuGet - Helpers for working with Windows Azure
- notification.js created for client apps to easily communicate the Registration Service i.e WindowsAzure.Notifications NuGet.
- Samples The samples are currently undergoing churn and will be updated in the coming drop. Added Margie’s Travel CTP as a Sample application
As a brief preview to the CTP toolkit check out this 3 minute video to see how you can get a jump start using Windows Azure Toolkit for Windows 8 to send Push Notifications with Windows Azure and the Windows Push Notification Service (WNS). This demonstration uses the Windows Azure Toolkit for Windows 8 that includes full end to end scenario for Tile and Badge notifications with Toast notifications only a drop down away


[Visit site to view video.]
Note: This release is a ‘CTP’ release as it has not yet gone through our full QA process. We have released this as a CTP as it updates a number of key issues that users were facing with dependency checks and the file new project experience. We will be releasing a final version of the 1.1.x branch in the coming days once it has undergone the full QA tests and also has refreshed documentation. Until this updated drop is made the CTP is the recommended download for users to proceed with.
Avkash Chauhan (@avkashchauhan) described MATLAB and Windows Azure in a 12/13/2011 post:
There are couple of things you could do while planning to run MATLAB on Windows Azure. Here i will provide a few resources to get your started. I am also working on a Windows Azure SDK 1.6 and MATLAB Runtime 7.1 installer based sample also, which I will release shortly.
Getting Started with Application Deployment with the Windows Azure HPC Scheduler (Document Walhthrough)
Windows Azure HPC Scheduler code sample: Overview (Video instructions - part 1)
Watch Video about running Windows Azure HPC Scheduler code sample: Publish the service (Video instructions - Part 2)
Step by Step hands on training guide to use Windows HPC with Burst to Windows Azure:
- http://msdn.microsoft.com/en-us/hh237282
- http://msdn.microsoft.com/en-us/hpcazurebursttrainingcourse_mpisamples_unit
Learn more about Message Passing Interface (MPI): MPI is a platform-independent standard for messaging between HPC nodes. Microsoft MPI (MS MPI) is the MPI implementation used for MPI applications executed by Windows HPC Server 2008 R2 SP2. Integration of Windows HPC Server 2008 R2 SP2 with Windows Azure supports running MPI applications on Windows Azure nodes.
You can use Windows Azure HPC Scheduler (follow link below for more info)
Using MATLAB with Windows Azure HPC Scheduler SDK:
In MATLAB Parallel Computing Toolbox, you can find MATLAB MPI implementation MPICH2 MPI.
Windows Azure HPC Scheduler allows for spawning worker nodes on which MPI jobs can be run. With a local head node and for compute-bound workloads you could
- have Matlab cloudbursting to Azure via MPI
- use a local non-Matlab WS2008R2 master node and run MPI jobs using common numeric libraries
Installing MATLAB Runtime with your Windows Azure application:
To install MCR (MATLAB Compiler Runtime) in Windows Azure you could do the following:
- Create a Startup task to download MCR zip and then install it.
- Learn More about Startup task here
- You can use Azure BootStrapper application to download and install very easily
- If you are using Worker role and want set a specific application as role entry point
Other Useful Resources:
Some case studies from Curtin University, Australia, using MATLAB and Windows Azure:
- http://www.microsoft.com/casestudies/Case_Study_Detail.aspx?CaseStudyID=4000009336
- http://www.curtin.edu.au/research/areas-of-strength/ict/news/oct-11/dna-sequencing-in-azure.cfm
A bunch of Microsoft Research Projects specially ModisAzure use MATLAB on Azure which you can find as the link below:
A presentation done by Techila's at Microsoft TechDays 2011 presentation showed MATLAB code running in Windows Azure.
- Presentation Document: http://cid-4f013ad0e7321227.office.live.com/self.aspx/TD2011fi/techdays2011-techila%5E_final.pdf
- Presentation video: http://blogs.msdn.com/b/uk_faculty_connection/archive/2011/11/20/matlab-and-r-on-windows-azure-via-techila.aspx

M. Sawicki reported Azure + Java = Cloud Interop: New Channel 9 Video with GigaSpaces Posted in a 12/12/2011 post to the Interoperability @ Microsoft blog:
Today[*] Microsoft is hosting the Learn Windows Azure broadcast event to demonstrate how easy it is for developers to get started with Windows Azure. Senior Microsoft executives like Scott Guthrie, Dave Campbell, Mark Russinovich and others will show how easy it is to build scalable cloud applications using Visual Studio. The event is be broadcasting live and will also be available on-demand.
For Java developers interested in using Windows Azure, one particularly interesting segment of the day is a new Channel 9 video with GigaSpaces. Their Cloudify offering helps Java developers easily move to their applications, without any code or architecture changes, to Windows Azure
We understand that developers want to use the tools that best fit their experience, skills, and application requirements, and our goal is to enable that choice. In keeping with that, we are extremely happy to be delivering new and improved experiences for popular OSS technologies such as Node.js, MongoDB, Hadoop, Solr and Memcached on Windows Azure.
You can find all the details on the full Windows Azure news here, and more information on the Open Source updates here.
* Channel9 presented the Learn Windows Azure event on 12/13/2011 and offers an archive of keynotes and sessions here.
Gianugo Rabellino (@gianugo) described an Openness Update for Windows Azure on 12/12/2011:
As Microsoft’s Senior Director of Open Source Communities, I couldn’t be happier to share with you today an update on a wide range of Open Source developments on Windows Azure.
As we continue to provide incremental improvements to Windows Azure, we remain committed to working with developer communities. We’ve spent a lot of time listening, and we have heard you loud and clear.
In keeping with that goal, we are extremely happy to be delivering new and improved experiences for Node.js, MongoDB, Hadoop, Solr and Memcached on Windows Azure.
This delivers on our ongoing commitment to provide an experience where developers can build applications on Windows Azure using the languages and frameworks they already know, enable greater customer flexibility for managing and scaling databases, and making it easier for customers to get started and use cloud computing on their terms with Windows Azure.
Here are the highlights of today’s announcements:
* We are releasing the Windows Azure SDK for Node.js as open source, available immediately on Github. These libraries are the perfect complement to our recently announced contributions to Node.js and provide a better Node.js experience on Windows Azure. Head to the Windows Azure Developer Center for documentation, tutorial, samples and how-to guides to get you started with Node.js on Windows Azure.
* We will also be delivering the Node package manager for Windows (npm) code to allow use of npm on Windows for simpler and faster Node.js configuration and development. Windows developers can now use NPM to install Node modules and take advantage of its automated handling of module dependencies and other details.
* To build on our recent announcement about Apache Hadoop, we are making available a limited preview of the Apache Hadoop based distribution service on Windows Azure. This enables Hadoop apps to be deployed in hours instead of days, and includes Hadoop Javascript libraries and powerful insights on data through the ODBC driver and Excel plugin for Hive. Read more about this on the Windows Azure team blog. If you are interested in trying this preview, please complete the form here with details of your Big Data scenario. Microsoft will issue an access code to select customers based on usage scenarios.
* For all of you NoSQL fans, we have been working closely with 10Gen and the MongoDB community in the past few months, and if you were at at MongoSV last week you have already seen MongoDB running on Windows Azure. Head out to the 10Gen website to find downloads, documentation and other document-oriented goodies. If you’re using the popular combination of Node.js and MongoDB, a simple straightforward install process will get you started on Windows Azure. Learn more here.
* For Java developers, take a look at the updated Java support, including a new and revamped Eclipse plugin. The new features are too many to list for this post, but you can count on a much better experience thanks to new and exciting functionality such as support for sticky sessions and configuration of remote Java debugging. Head over to the Windows Azure Developer Center to learn more.
* Does your application need advanced search capabilities? If so, the chances are you either use or are evaluating Solr, and so the good news for you is that we just released a set of code tools and configuration guidelines to get the most out of Solr running on Windows Azure.
We invite developers to try out the tools, configuration and sample code for Solr tuned for searching commercial and publisher sites. The published guidance showcases how to configure and host Solr/Lucene in Windows Azure using multi-instance replication for index-serving and single-instance for index generation with a persistent index mounted in Windows Azure storage.
* Another great example of OSS on Windows Azure is the use of Memcached server, the popular open-source caching technology, to improve the performance of dynamic web applications. Maarten Balliauw recently blogged about his MemcacheScaffolder, which simplifies management of Memcached servers on the Windows Azure platform. That blog post is only focused on PHP, but the same approach can be used by other languages supported by Memcached as well.
* Scaling data in the Cloud is very important. Today, the SQL Azure team made SQL Azure Federation available. This new feature provides built-in support for data sharding (horizontal partitioning of data) to elastically scale-out data in the cloud. I am thrilled to announce that concurrent with the release of this new feature, we have released a new specification called SQL Database Federations, which describes additional SQL capabilities that enable data sharding (horizontal partitioning of data) for scalability in the cloud, under the Microsoft Open Specification Promise. With those additional SQL capabilities, the database tier can provide built-in support for data sharding to elastically scale-out data in the cloud, as covered in Ram Jeyaraman’s post on this blog.
In addition to all this great news, the Windows Azure experience has also been significantly improved and streamlined. This includes simplified subscription management and billing, a guaranteed free 90-day trial with quick sign-up process, reduced prices, improved database scale and management, and more. Please see the Windows Azure team blog post for insight on all the great news.
As we enter the holiday season, I’m happy to see Windows Azure continuing on its roadmap of embracing OSS tools developers know and love, by working collaboratively with the open source community to build together a better cloud that supports all developers and their need for interoperable solutions based on developer choice.
In conclusion, I just want to stress that we intend to keep listening, so please send us your feedback. Rest assured we’ll take note!

Avkash Chauhan (@avkashchauhan) posted a Windows Azure SDK for Node.js Installation Walkthrough on 12/12/2011:
Learn more about Windows Azure SDK announcement:
Visit http://www.windowsazure.com/en-us/develop/overview/ to download the SDK:


Once you start the installer, you will see the list of components will be installed as below:

Once the installer will be start, about 4 components as shown below will be installed:

Once the installation is completed, you will be greeted with the dialog below:

Finally you can verify that “Windows Azure SDK for Node.js” is installed:

You can also verify that following 4 components are installed in the programs list:

That’s it!








Elizabeth White described a “New solution based on Microsoft Dynamics CRM to support Nissan's relationships with its customers and partners” in a deck for her crosoft and Nissan Establish Strategic Relationship report of 12/12/2011:
Microsoft Corp. and Nissan Motor Co. Ltd. on Monday announced a strategic relationship to collaborate and create a next-generation dealer management system based on Microsoft Dynamics CRM. Using the powerful foundation of Microsoft Dynamics CRM and the automotive industry expertise of Nissan, the two companies will blend dealer and customer relationship management and social collaboration tools into a solution that will help Nissan develop a stronger relationship with its customers, drive dealer sales and increase market share on a global scale. The solution will then utilize the Windows Azure platform, taking advantage of the economies of scale and flexibility offered by Microsoft's public cloud offerings.
"Nissan delivers some of the most innovative vehicles in the automotive industry, and we bring that same innovation and passion to ensure customer and partner satisfaction," said Andy Palmer, executive vice president, Nissan. "We are delighted to be working with Microsoft to deliver the next-generation dealer management system. Nissan is seeking a solution that will help meet our business needs, especially to better understand our customers and dealers. This will enhance our sales and brand power as we enter a new growth phase under our midterm business plan, Nissan Power 88."
The new dealer management system will initially be rolled out to Nissan's dealership networks in Japan and other strategic regions across the globe. The system will have the flexibility to be customized for the needs of a specific country, region or automotive manufacturer, with broader availability to be explored in the future. Nissan also intends to explore how Microsoft Dynamics CRM and Windows Azure can work together as a platform to deploy applications across the company's global network and to standardize its information architecture on the cloud.

Bruno Terkaly (@brunoterkaly) posted a Video Tutorial - How to install and run Node.js on Windows competitor on 12/12/2011:
What this post is about
This post is about getting Node.js up and running on a Windows Platform. This step will be followed by some guidance on how to host Node.js in a Microsoft Cloud Data Center, called Windows Azure.
Node.js is a software system designed for writing highly-scalable internet applications, notably web servers.
Video Content

This post is about getting Node.js up and running on a Windows Platform. This step will be followed by some guidance on how to host Node.js in a Microsoft Cloud Data Center, called Windows Azure.
Node.js is a software system designed for writing highly-scalable internet applications, notably web servers.
What makes Node.js compelling is the fact that is is based on the JavaScript language, opening the door for developers to not only write client side JavaScript put also server side.Node.js is built for scale, using event-driven, asynchronous I/O to minimize overhead and maximize scalability.
Video Content

This content shows 3 basic steps:

Source Code

Watch the video
Video of Installing
and Running Node.jshttp://brunoblogfiles.com/videos/Node_js_Install.wmv
Conclusions
Future content will explain more complex topics, like using Socket.IO and Express. Migrating applications to the Microsoft Cloud (Windows Azure) will also be explained and demonstrated.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) continued her series with Beginning LightSwitch Part 3: Screen Templates, Which One Do I Choose? on 12/14/2011:
Welcome to Part 3 of the Beginning LightSwitch series! In part 1 and part 2 we learned about entities and relationships in LightSwitch and how to use the Data Designer to define them. If you missed them:
In this post I want to talk about screens. Screens are a common term in everyday life usually denoting a television or computer screen – the shiny thing we look at to interact with the device. In LightSwitch screens present data to the user and form the majority of the application’s user interface (UI). The default LightSwitch application shell presents screens in the center of the application window in a tabbed display. At the top is a ribbon of commands Save and Refresh, and on the left is the navigation menu.

Screens also allow users to search for, edit, insert and delete data in the backend data sources. LightSwitch makes the creation of screens really simple by providing templates you can choose from. You can then use them as is, or customize them further for your needs. Once you have some entities defined (like you learned in the previous posts) then you are ready to create screens.
Choosing a Screen Template
You can add a screen to your project by clicking the “+ Screens…” button at the top of the Data Designer or by right-clicking on the Screens folder in the Solution Explorer and selecting “Add Screen…”

When you do this the “Add New Screen” dialog appears which asks you to select a screen template as well as the data you want to display on the screen. There are five screen templates in Visual Studio LightSwitch; the Details Screen, Editable Grid Screen, List and Details Screen, New Data Screen, and Search Data Screen. Depending on the screen template you choose, your options in the “Screen Data” section on the right changes.

When you select the Screen Data drop down, you select the entity you want to use on the screen. On any screen template you choose, the controls are created in a similar way by looking at the entity definition. For instance, the labels for required properties appear as bold text. Also by default, screens use controls that match the underlying data types. So for instance, an editable String property is represented by a TextBox control, a Boolean becomes a CheckBox control, a Phone Number type gets the Phone Number control, etc. This is why it’s important to model your data correctly before creating screens. Although you can customize most of these things on a screen-by-screen basis, LightSwitch reads the settings in your data model to create smart defaults, speeding up the time it takes to create the application.
Let’s walk through this list of screen templates and some guidelines on why you would choose them.
List and Details Screen
You use the List and Details Screen when you want to see a list of all the records in a table and edit their details on one screen. By default, the screen contains two areas. On the left you will see a list that displays the summary of each record. On the right, it displays the details about the record that is selected. You can also choose to add any related entities to the screen and they will display below the detail controls in a grid. Users can use the search & sort functionality on the list to find records and then edit them all on one screen.
Use this template if you want to allow users to modify all the records in your table on one screen with no additional workflow. This can be particularly well suited for tables that have a smaller number of rows (records), like administration screens, and where only a few users would be modifying the data at the same time. Like all screens that work with multiple data rows, the query will return 45 rows of data at a time by default (you can change this on the screen properties). So it’s usually better to choose entities that don’t have too many or large fields so the application stays responsive as the database grows.

Editable Grid Screen
Similar to the List and Details Screen, you can also use the Editable Grid Screen when you want to modify all the records at the same time on one screen. In this case though, users are presented with a grid of data to edit in a tabular format. Users can press Tab to move from field to field to make changes and edit everything inline. You’ll want to choose this template if your users need to enter a lot of data quickly into a single table like maintenance and lookup tables or where you would only be editing a subset of fields so the user doesn’t need to scroll too much horizontally.

Details Screen
The Details Screen allows you to edit a single row of data from a table and optionally, any related data. When you click on a link or button to open a single record, the Details screen for that entity is displayed. LightSwitch generates a default details screen for you automatically at runtime if you do not create one yourself. Typically you will want to show all the editable properties for an entity on this screen as well as any related grids of data. This screen template has an additional option in the Add New Screen dialog. Once you select the Screen Data, you will see a checkbox “Use as Default Details Screen” which means to open this screen anytime the user opens a single record from this table anywhere in the system. This is also specified in the Data Designer for the “Default Screen” property for the entity.

New Data Screen
The New Data Screen allows you to insert new rows into a table one at a time. By default, the screen contains entries for every field of data. Although you can add related entities to this screen as grids, you may want to choose a small subset of just the required or common fields and then flow to another screen to enter the rest. LightSwitch will automatically open the default Details screen after the user saves so this type of “Add New, Save, then Edit” workflow is automatically set up for you.

Search Data Screen
You use the Search Data Screen when you want a user to be able to locate a single row of data in a table and then open another screen to edit just that row. By default, the screen displays a read-only grid of all the rows in a single table (again only 45 are returned at a time by default). To search for a record, you use the search box at the top right of the screen. The search returns all the rows where any string field matches the search term. Clicking on the summary link for the record opens the Details Screen. It is a very common workflow to have users search for records first before allowing edits to them so the search screen provides this behavior automatically. Typically this should be the first screen a user interacts with for large sets of data because it puts them into an efficient workflow that keeps the system responsive even as the database grows.

Adding Screens to the Address Book Application
Now that you understand what each screen template gives you, let’s create some screens for the Address Book application we’ve been building in this series. At the end of the previous posts we used the List and Details screen so that we could quickly test our data model. If the number of contacts you expect in your address book is relatively small (say less than 100), that screen may be enough to use for the entire application. Users can use the search functionality on the list to find contacts and then edit them all on one screen.
However, if we wanted to manage thousands of contacts for a business and allow multiple users accessing that data, it’s probably better to put users into a workflow where they first search for a contact and then can either edit one at a time or add a new one if they don’t find the contact they were looking for. It’s always good to create a simple flowchart of how the application should work:

First the user searches for a contact and if found then open the Contact Details screen and let them edit all the related contact data. Once the user saves the screen the data is simply redisplayed on the same screen until they close it. If the user does not find the contact they were looking for, they open the New Contact screen which allows them to enter just the contact entity data. When they Save, the Contact Details screen opens and they can finish entering any related data if they need.
So we just need three screens for our Address Book application; Search Data Screen, New Data Screen, and Details Screen. The order you create your screens is the default order in which they are displayed on the navigation menu. Note that Detail screens will not show up on the navigation menu because a specific record must be selected first. The first screen you create is the first one that is opened by default when the application starts so we’ll want to create the Search Screen first. You can change the screen navigation and how screens appear in the menu by right-clicking on the Solution Explorer and choosing “Edit Screen Navigation”. For a video demonstration on how to edit the screen navigation see: How Do I: Modify the Navigation of Screens in a LightSwitch Application?
So first create the Search Contact Screen by right-clicking on the Solution Explorer and selecting “Add Screen..” to open the Add New Screen dialog. Select the Search Data Screen template and then select the Contacts Screen Data and click OK.

Next create the New Data Screen in the same manner. This time, select the New Data Screen template. Then select the Contact entity for the Screen Data but do not select any related data. Then click OK

Finally we will add the Details Screen the same way but this time select all the related entities; EmailAddresses, PhoneNumbers, and Addresses. Also leave the “Use as Default Details Screen” checked.

Run it!
Now that we have all our screens defined hit F5 to build and run the application and let’s see what we get. You will notice that the Search screen opens right away and on the navigation menu we have both Search Contacts and Create New Contact screens available. I only have a couple rows of test data in here but if I had hundreds of contacts, LightSwitch would display only 45 rows at a time and we would use the paging control at the bottom of the grid to retrieve the next set of rows.

If you click on the last name of a contact it will open the details screen which allows us to edit all the contact information. Notice that LightSwitch also creates links in the first column of the related grids so that you can click on them and open additional detail screens for those records as well.

If the user does not see the contact in the list, they can click on the Create New Contact screen to enter new data.

Then once they save this screen, the Contact Details Screen opens for further editing of all the contact information.

If the Search screen is still open, the user can see newly added records by clicking the Refresh button on the ribbon.

Notice we have a LOT of functionality and a totally working Address Book application by just creating a data model and picking some screen templates.
Customizing Screen Layouts
As I mentioned earlier, all the screen templates are totally customizable so you can use them as-is or modify the layouts completely for your needs. In fact, you as the developer can change the layouts of screens while the application is running. When you are developing your application within Visual Studio LightSwitch you will see a “Design Screen” button at the top right of the running application window. Open a screen and then click that button to open the Screen Customization Mode. Here you can manipulate the content tree exactly how you like and see your changes in real time.

This comes in extremely handy for quickly modifying the order of fields as well as what, where, and how things are displayed on the screen. However, in order to customize your screen with code or additional data you will need use the Screen Designer back in Visual Studio. For more information on using the Screen Designer to customize screens see: Tips and Tricks for Using the Screen Designer.
For more information on building and customizing screens see the Working with Screens learn topic on the LightSwitch Developer Center and LightSwitch Tips & Tricks on dnrTV.
Wrap Up
As you can see the built-in screen templates provide a ton of functionality for you. We now have a fully functional Address Book application and there was no need to write any code to do it! Next post we’ll look at queries and how to design them in order to filter and sort data on our screens exactly how we want. Until next time!



















Return to section navigation list>
Windows Azure Infrastructure and DevOps
My (@rogerjenn) The Windows Azure Website Gets a Major-Scale Metro-Style Makeover and Greatly Improved User Experience post of 12/11/2011 (updated 12/13/2011) started with:
The Windows Azure Team updated the main Windows Azure Web Site with a major restructuring and Metro facelift on 12/10/2011 (click image for 1024 x 1265 px screen captures):


and continued with …
Bob Kelly’s Improved Developer Experience, Interoperability, and Scalability on Windows Azure post of 12/12/2011 to the Windows Azure blog highlights key new features announced today:
- New Developer Experience and Enhanced Interoperability—Access to Azure libraries for .NET, Java, and Node.js is now available under Apache 2 open source license and hosted on GitHub, a new Windows Azure SDK for Node.js makes Windows Azure a first-class environment for Node applications, and a limited preview of an Apache Hadoop based service for Windows Azure enables Hadoop apps to be deployed in hours instead of days
- Easier to Get Started and Simplified Subscription Management—Revamped Dev Centers for multiple languages with helpful content and tutorials, a new sign-up process with spending caps makes sign-up simple, fast and ensures a completely free 90 day trial. View real-time usage and billing details directly from the Windows Azure Management Portal and see expected costs with a simplified pricing calculator.
- Improved Database Scale—Three times the maximum database size for SQL Azure (at no additional cost—details below), and SQL Azure Federation, a new sharding pattern that simplifies elastic scale-out
- Better Overall Value—New price cap for the largest SQL Azure databases reduces effective price per gigabyte by 67 percent, Data Transfer prices in North America and Europe have been reduced by 25 percent, and Service Bus usage is now free through March 2012.
Read Bob’s entire post for details about signing up for the limited Apache Hadoop preview.
New 90-Day Windows Azure and SQL Azure Trial for New Users
A 90-day free trial for all new users with the following resources and a guarantee of no billing surprises caused by exceeding the free quotas. From the new Azure site:
Each month, the free trial will allow you to use
- Compute: 750 hours of a Small Compute Instance* (can run one small instance full-time or other sizes at their equivalent ratios)
- Storage: 20GB with 50k Storage transactions
- Data Transfers: 20GB outbound / Unlimited inbound data transfer
- Relational Database: 1GB Web Edition SQL Azure database
- Access Control: 100k transactions
- Service Bus: Free through March 31, 2012
- AppFabric Caching: 128MB cache
We require a credit card or debit card for identification, but you are capped by default at the free level to ensure you will never be charged. Here is how it works:
For all new subscriptions, we set a $0 (USD) Spending Limit on your subscription so you don’t accidently exceed the monthly benefit shown above. If you use more in a month than the above amounts, you will exceed your $0 (USD) Spending Limit and your service will be disabled for that month. Your service will be re-enabled at the start of your next billing period and, while your storage accounts and databases are retained with no loss of data, you will need to redeploy your hosted service(s). If you choose to turn off your Spending Limit, any overage, i.e., monthly usage in excess of the above amounts, will be charged at the Pay-As-You-Go rates.
After the first 3 months, if you wish to continue using your subscription, simply turn off your Spending Limit and your subscription automatically converts to a Pay-As-You-Go subscription. Otherwise, your subscription will expire after 3 months.
Read more about how Spending Limit works.
Monthly usage in excess of the monthly amounts included with your offer will be charged at the Pay-As-You-Go rates.
Clicking the Pricing menu link opens a new, Compact Pricing Calculator for basic Windows Azure options. These starter choices provide two small-instance VMs to enable the compute Service Level Agreement (SLA), the smallest SQL Azure database, and nominal blob/table storage and outbound bandwidth limits:

View the entire post here.
Avkash Chauhan (@avkashchauhan) described Exploring Windows Azure Package contents in a 12/11/2011 post:
As you may know when you finally package the Windows Azure application the final product you get is a package (CSPKG) file and your original service configuration (CSCFG) file. Starting from Windows Azure SDK 1.5, CSPKG file is unencrypted and actually a ZIP package, which you can just unzip and visualize its contents.
Let’s dig inside the CSPKG:

Now you will see a CSSX file inside the ZIP, CSSX file is where all of your application related files are packaged. Extracting the CSSX file from the main package ZIP file and then rename the CSSX file to ZIP now. Now unziping the CSSX you will see the package contents exactly same as in your Application folder.

Your Visual Studio Application Folder look like as below:

Now if you RDP to Azure VM and look for drive E:\ you will see the same folder setup because everything in your CSSX file is used to create a drive (Mostly E:\) in Azure VM:





The Real World Windows Azure Guidance team updated Windows Azure Field Notes on 12/9/2011 (missed when published:
The Field Notes series is written by Windows Azure specialists within Microsoft and presented by Worldwide Windows Azure Community - Microsoft Services.
Integrated Solution Field Notes:
- Using Windows Azure Connect to Integrate On-Premises Web Services
By Anna Skobodzinski
This article describes how to use Windows Azure Connect to create a low-latency connection between Windows Azure and an on-premise service.- Integrating On-Premises Web Services with Windows Azure Service Bus and Port Bridge
By Tejaswi Redkar
This article shows how to use the Windows Azure Service Bus to integrate a Windows Azure application with on-premises services, including FAST.- Parallel Uploads to Windows Azure Blob Storage via a Silverlight Control
By Rahul Rai
This article walks through a Silverlight application that uses multi-threading to quickly upload data to Windows Azure blob storage.- Integrating On-premises Search Engines with Windows Azure Web Applications
By Tejaswi Redkar
This article describes a process for migrating an existing web application to Windows Azure while continuing to use Google Search Appliance to index the site and database.- Indexing Windows Azure Storage from an on-premises Fast ESP 5.3
By Nagendra Mishr
This article describes the implementation of a hybrid system that uses FAST ESP 5.3 to index content in Windows Azure Storage.
- Calling the Windows Azure Storage API Asynchronously
By Tejaswi Redkar
This article demonstrates how to call the Windows Azure storage APIs asynchronously with a regular callback delegate and also with lambda expressions.- Using Certificate-Based Encryption in Windows Azure Applications
By Walter Myers III
This article with sample code demonstrates how to use certificate-based encryption to overcome potential problems that can occur with key storage.See Also: Concepts
Real World Windows Azure Guidance
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Alan Le Marquand posted Announcing the release of the Understanding Microsoft’s High Availability Solutions course on 12/13/2011:
The Microsoft Virtual Academy team would like to announce the release of the Understanding Microsoft’s High Availability Solutions course.
This course covers the best ways to provide continual availability to all applications, services, servers and VMs in your datacenter. The modules will cover all the planning, deployment and management considerations for bringing high-availability to every components of your datacenter or Private Cloud.
By the end of this course you will have an understanding of the basics of each of Microsoft’s HA solutions and when each of them should be used. You will understand all the different methods you can use to keep your services up and running.
Technologies that will be covered in this course include:-
- Hyper-V,
- Failover Clustering,
- Network Load Balancing,
- SQL Server,
- Exchange Server,
- IIS, DFS-R, DNS
- And every System Center product (including SC 2012) with a focus on Virtual Machine Manager (VMM).
After completing this course, try out what you’ve learnt by downloading Windows Server 2008 R2 and System Center from the TechNet Evaluation Center.
<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) posted Stuff I’ve Really Wanted To Blog About But Haven’t Had the Time… on 12/12/2011:
This is more a post-it note to the Universe simultaneously admitting both blogging bankruptcy as well as my intention to circle back to these reminders and write the damned things:
- @embrane launches out of stealth and @ioshints, @etherealmind and @bradhedlund all provide very interesting perspectives on the value proposition of Heleos – their network service virtualization solution. One thing emerges: SDN is the next vocabulary battleground after Cloud and Big Data
- With the unintentional assistance of @swardley who warned me about diffusion S-curves and evolution vs. revolution, I announce my plan to launch a new security presentation series around the juxtaposition and overlay of Metcalfe’s + HD Moore’s + (Gordon) Moore’s+ (Geoffrey) Moore’s Laws. I call it the “Composite Calculus of Cloud Computing Causality.” I’m supposed to add something about Everett Rogers.
- Paul Kedrosky posts an interesting graphic reflecting a Gartner/UBS study on cloud revenues through 2015. Interesting on many fronts: http://twitpic.com/7rx1y7
- Ah, FedRAMP. I’ve written about it here. @danphilpott does his usual bang-on job summarizing what it means — and what it doesn’t in “New FedRAMP Program: Not Half-Baked but Not Cooked Through”
- This Layer7-supplied @owasp presentation by Adam Vincent on Web Services Hacking and Hardening is a good basic introduction to such (PDF.)
- via @hrbrmstr, Dan Geer recommends “America the Vulnerable” from Joel Brenner on “the next great battleground; Digital Security.” Good read.
- I didn’t know this: @ioshints blogs about the (Cisco) Nexus 1000V and vMotion Sad summary: you cannot vMotion across two vDS (and thus two NX1KV domains/VSMs).
- The AWS patchocalypse causes galactic panic as they issue warnings and schedules associated with the need to reboot images due to an issue that required remediation. Funny because of how much attention needing to patch a platform can bring when people set their expectations that it won’t happen (or need to.) Can’t patch that… ;(
- @appirio tries to make me look like a schmuck in the guise of a “publicly nominated award for worst individual cloudwasher.” This little gimmick backfires when the Twitterverse exploits holes in the logic of their polling engine they selected and I got over 800,000 votes for first place over Larry Ellison and Steve Ballmer. Vote for Pedro
More shortly as I compile my list.

Glad to see the Hoff bogging in addition to Tweeting for a change.
<Return to section navigation list>
Cloud Computing Events
Eric Nelson (@ericnel) posted Slides and Links from Windows Azure Discovery Workshop Dec 13th on 12/13/2011:
On Tuesday David and I delivered a Windows Azure Discovery Workshop in Reading – with festive mince pies, duck, turket and bailey infused desert. A big thank you to everyone who attended and the great discussions we had – and Merry Xmas!
Slides
Links
Eric Nelson http://www.ericnelson.co.uk
- David Gristwood http://blogs.msdn.com/david_gristwood
- Get better connected with our team http://bit.ly/ukisvfirststop (Blog/Twitter/LinkedIn/FREE Events)
- 10 Questions
2b Will it run Foo?
http://things.smarx.com/ great example of what is possible
- 3 How Big.
- 150,000 Tickets in 10 seconds. Flavorus Case Study
- SQL Azure Federations
- Multi tenanted Federations example http://shard.codeplex.com/
- SQL Azure Federation Data Migration Wizard
- 3 Soft Limits. http://www.microsoft.com/windowsazure/support/ to ask for soft limits to change
- 5 SQL Server vs SQL Azure.
- A great place to start – technet wiki on SQL Azure
- SQL Azure Throttling
- More on SQL Azure Throttling
- SQL Azure vs SQL Server MSDN Documentation
- 6 How fast is it
- Design Targets
- http://azurescope.cloudapp.net/ for benchmark results and scripts
- 7 Autoscaling
- 8 How secure is it
- 9 How much will it cost http://www.microsoft.com/windowsazure/pricing-calculator/
Related Links:
- http://www.sixweeksofazure.co.uk for FREE assistance starting January 23rd
- Sign up to Microsoft Platform Ready for assistance on the Windows Azure Platform


Brian Hitney announced Just One More Week To Enter The Rock Paper Azure Fall Sweepstakes! on 12/12/2011:
Week #3 of the Rock Paper Azure Challenge ended at 6pm EST on 12/9/2011. That means another five contestants just won $50 Best Buy gift cards! Congratulations to the following players for having the Top 5 bots for Week #3:
- AmpaT
- choi
- Protist
- RockMeister
- porterhouse

Does your bot have what it takes to win? There is one more week to try and find out, now through December 16th, 2011. Visit the Rock Paper Azure Challenge site to learn more about the contest and get started.
Remember, there are two ways to win:
Sweepstakes
To enter the sweepstakes all you have to do is enter a bot, any bot – even the pre-coded ones we provide – into the game between now and 6 p.m. ET on Dec. 16th. No ninja coding skills need – heck, you don’t even need Visual Studio or a Windows machine to participate!

At 6 pm ET on Friday, December 16, 2011 the "Fall Sweepstakes" round will be closed and no new entries will be accepted. Shortly thereafter, four bots will be drawn at random for the Grand Prize (trip to Cancun, Mexico), First Prize (Acer Aspire S3 laptop), Second Prize (Windows Phone), and Third Prize (XBox w/Kinect bundle).
Competition
For the type-A folks, we’re keen on making this a competitive effort as well, so each week - beginning Nov. 25th and ending Dec. 16th - the top FIVE bots on the leaderboard will win a $50 Best Buy Gift card. If your bot is good enough to be in the top five on successive weeks, you’ll take home a gift card each of those weeks too. Of course, since you’ve entered a bot, you’re automatically in the sweepstakes as well!
Note: As with past iterations of the challenge, even though you can iterate and upload updated bots for the competition, you will only be entered into the sweepstakes one time.
You know what they say… you gotta be in it to win it! Good luck to all players in week #4!

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Werner Vogels (@werner) posted Expanding the Cloud – Introducing the AWS South America (Sao Paulo) Region on 12/14/2011:
Today, Amazon Web Services is expanding its worldwide coverage with the launch of a new AWS Region in Sao Paulo, Brazil. This new Region has been highly requested by companies worldwide, and it provides low-latency access to AWS services for those who target customers in South America.
South America is one of the fastest growing economic regions in the world. In particular, South American IT-oriented companies are seeing very rapid growth. Case in point: over the past 10 years IT has risen to become 7% of the GDP in Brazil. With the launch of the South America (Sao Paolo) Region, AWS now provides companies large and small with infrastructure that allows them to get to market faster while reducing their costs which enables them to focus on delivering value, instead of wasting time on non-differentiating tasks.
Local companies have not been the only ones to frequently ask us for a South American Region, but also companies from outside South America who would like to start delivering their products and services to the South American market. Many of these firms have wanted to enter this market for years but had refrained due to the daunting task of acquiring local hosting or datacenter capacity. These companies can now benefit from the fact that the new Sao Paulo Region is similar to all other AWS Regions, which enables software developed for other Regions to be quickly deployed in South America as well.
Several prominent South American customers have been using AWS since the early days. The new Sao Paulo Region provides better latency to South America, which enables AWS customers to deliver higher performance services to their South American end-users. Additionally, it allows them to keep their data inside of Brazil. In the words of Guilherme Horn, the CEO of ÓRAMA, a Brazilian financial services firm and AWS customer: “The opening of the South America Sao Paulo Region will enable greater flexibility in developing new services as well as guarantee that we will always be compliant to the needs of the regulations of the financial markets.”
You can learn more about our growing global infrastructure footprint at http://aws.amazon.com/about-aws/globalinfrastructure. Please also visit the AWS developer blog for more great stories from our South American customers.


Jeff Barr (@jeffbarr) reported Now Open - South America (Sao Paulo) Region - EC2, S3, and Much More on 12/14/2011:
With the paint barely dry on our US West (Oregon) Region, we are now ready to expand again. This time we are going South of the Equator, to Sao Paulo, Brazil. With the opening of this new Region, AWS customers in South and Central America can now enjoy fast, low-latency access to the suite of AWS infrastructure services.
New Region
The new South America (Sao Paulo) Region supports the following services:
- Amazon Elastic Compute Cloud (EC2) and related services (Elastic Block Store, Virtual Private Cloud, Elastic Load Balancing, and Auto Scaling).
- Amazon Simple Storage Service (S3).
- Amazon SimpleDB.
- Amazon Relational Database Service (RDS).
- Amazon Simple Queue Service (SQS).
- Amazon Simple Notification Service (SNS).
- Amazon Elastic MapReduce.
- AWS CloudFormation.
- Amazon CloudWatch.
We already have an Edge Location for Route 53 and CloudFront in Sao Paulo.
This is our eighth Region, and our first in South America (see the complete AWS Global Infrastructure Map for more information). You can see the full list in the Region menu of the AWS Management Console:
You can launch EC2 instances or store data in the new Region by simply making the appropriate selection from the menu.
New Resources
Portions of the AWS web site are now available in Portuguese. You can switch languages using the menu in the top right:
We now have an AWS team (sales, marketing, and evangelism to start) in Brazil. Our newest AWS evangelist, Jose Papo, is based in Sao Paulo. He will be writing new editions of the AWS Blog in Portuguese and Spanish.
Customers
We already have some great customers in Brazil. Here's a sampling:
- Peixe Urbano is the leading online discount coupon site in Brazil. They launched on AWS and have scaled to a top 50 site with no capital expenditure.
- Gol Airlines (one of the largest in Brazil) uses AWS to provide in-flight wireless service to customers.
- The R7 news portal is one of the most popular sites in Brazil. The site makes use of CloudFront, S3, and an auto-scaled array of EC2 instances.
- Orama is a financial institution with a mission of providing better access to investments for all Brazilians. They run the majority of their customer relationship systems on AWS.
- Itaú Cultural is a non-profit cultural institute. The institute's IT department is now hosting new projects on AWS.
- Casa & Video is one of Brazil's largest providers of electronics and home products. They have turned to AWS to handle seasonal spikes in traffic.
Solution Providers
Our ISV and System Integrator partner ecosystem in Brazil includes global companies such as Accenture, Deloitte, and Infor along with local favorites Dedalus and CI&T.


Jeff Barr (@jeffbarr) announced New - SMTP Support for the Amazon Simple Email Service (SES) on 12/14/2011:
We have added an SMTP interface to the Amazon Simple Email Service (SES) to make it even easier for you to send transactional or bulk email. We've had a lot of requests for this feature and I am confident that it will be really popular. There's a new SMTP item in the SES tab of the AWS Management Console:
This items leads to a page containing all of the information that you need to have in order to make use of SMTP with SES:
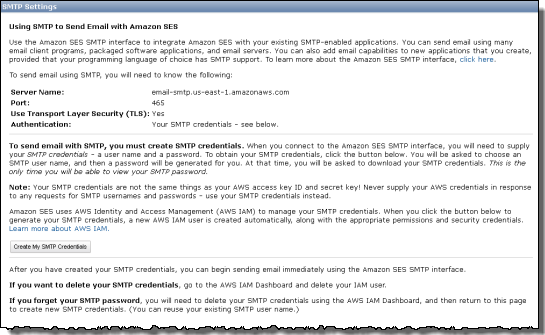
You no longer need to write any code to gain the efficiency and deliverability benefits of SES. Instead, you use the SES tab of the AWS Management Console to create an SMTP user and a set of credentials, and then you use those credentials to configure the email client of your choice:
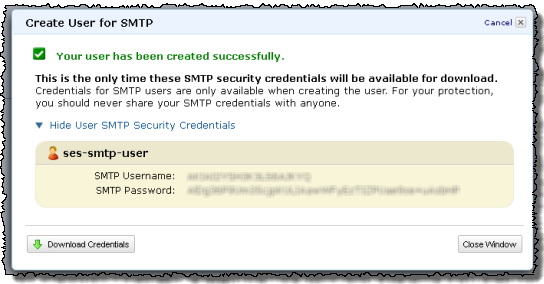
This simple process also creates an IAM user with the appropriate permissions and policies. Credentials in hand, you can configure your mail client (Thunderbird, Outlook, and so forth) to use SMTP for mail delivery.
You will still need to verify the source ("from") addresses that you plan to use to send email, and you'll also need to request production access in order to increase your sending limits. You can initiate both of these tasks from the console:
The newest version of the SES Developer Guide includes a new section on the SMTP interface, with complete directions for configuring SMTP client apps, packaged software, application code (including a PHP + MySQL example), and server-side mail transfer agents (MTAs) including Sendmail, Postfix, and Exim.


Derrick Harris (@derrickharris) reported .NET comes to Cloud Foundry in a 6/13/2011 post to Giga Om’s Structure blog:
Up-and-coming Infrastructure-as-a-Service provider Tier3 has made a significant contribution to the Platform-as-a-Service world by releasing a .NET implementation of the Cloud Foundry PaaS project. Launched by VMware (s vmw) in April, Cloud Foundry initially supported a variety of languages and frameworks, but it was by no means representative of the entire development community. It’s getting there, however: Tier3′s .NET contribution joins ActiveState’s addition of Python and Django and AppFog’s PHP stewardship.
Support for .NET is particularly critical given the large number of enterprise programmers that rely on the framework for developing Windows applications. Presently, Microsoft (s msft) Windows Azure is the most widely known PaaS offering touting strong .NET support, but it is hindered in part by the platform’s usability and in part because it’s only a public cloud. Startup AppHarbor is also pushing a .NET PaaS. Iron Foundry, Tier3′s Cloud Foundry implementation, will allow new PaaS providers to offer support for .NET applications and also will give companies wanting to build their own internal PaaS offerings the code to get started (something Apprenda already does via its
SaaSGridApprenda Platform product).
Technically, Iron Foundry and Cloud Foundry are separate at this point, but Tier3 and VMware acknowledge they are working together to align Iron Foundry with the core Cloud Foundry code and developer tools, and I have been told that VMware will officially support .NET within Cloud Foundry at some point.
Developers can access Iron Foundry via a Windows version of Cloud Foundry Explorer or a Visual Studio plug-in for Cloud Foundry, and the code will be available on GitHub under the Apache 2.0 license. The company is also offering a “full testbed environment” that lets programmers experiment with Iron Foundry free for 90 days, although applications are limited to one web and one database instance apiece.
Tier3 is an IaaS provider by nature, and Iron Foundry is its foray into PaaS, which many consider the future of cloud computing. While Iron Foundry is still just a project like its Cloud Foundry namesake, Tier3 founder and CTO Jared Wray told me that Tier3 will have a PaaS product at some point, and Iron Foundry almost certainly will be at the core.


Richard Seroter (@rseroter) provided a First Look: Deploying .NET Web Apps to Cloud Foundry via Iron Foundry on 12/12/2011:
It’s been a good week for .NET developers who like the cloud. First, Microsoft makes a huge update to Windows Azure that improves everything from billing to support for lots of non-Microsoft platforms like memcached and Node.js. Second, there was a significant announcement today from Tier 3 regarding support for .NET in a Cloud Foundry environment.
I’ve written a bit about Cloud Foundry in the past, and have watched it become one of the most popular platforms for cloud developers. While Cloud Foundry supports a diverse set of platforms like Java, Ruby and Node.js, .NET has been conspicuous absent from that list. That’s where Tier 3 jumped in. They’ve forked the Cloud Foundry offering and made a .NET version (called Iron Foundry) that can run by an online hosted provider, or, in your own data center. Your own private, open source .NET PaaS. That’s a big deal.
I’ve been working a bit with their team for the past few weeks, and if you’d like to read more from their technical team, check out the article that I wrote for InfoQ.com today. Let’s jump in and try and deploy a very simple RESTful WCF service to Iron Foundry using the tools they’ve made available.
Demo
First off, I pulled the source code from their GitHub library. After building that, I made sure that I could open up their standalone Cloud Foundry Explorer tool and log into my account. This tool also plugs into Visual Studio 2010, and I’ll show that soon.

It’s a nice little tool that shows me any apps I have running, and lets me interact with them. But, I have no apps deployed here, so let’s change that! How about we go with a very simple WCF contract that returns a customer object when the caller hits a specific URI. Here’s the WCF contract:
[ServiceContract] public interface ICustomer { [OperationContract] [WebGet(UriTemplate = "/{id}")] Customer GetCustomer(string id); } [DataContract] public class Customer { [DataMember] public string Id { get; set; } [DataMember] public string FullName { get; set; } [DataMember] public string Country { get; set; } [DataMember] public DateTime DateRegistered { get; set; } }The implementation of this service is extremely simple. Based on the input ID, I return one of a few different customer records.
public class CustomerService : ICustomer { public Customer GetCustomer(string id) { Customer c = new Customer(); c.Id = id; switch (id) { case "100": c.FullName = "Richard Seroter"; c.Country = "USA"; c.DateRegistered = DateTime.Parse("2011-08-24"); break; case "200": c.FullName = "Jared Wray"; c.Country = "USA"; c.DateRegistered = DateTime.Parse("2011-06-05"); break; default: c.FullName = "Shantu Roy"; c.Country = "USA"; c.DateRegistered = DateTime.Parse("2011-05-11"); break; } return c; }My WCF service configuration is also pretty straightforward. However, note that I do NOT specify a full service address. When I asked one of the Iron Foundry developers about this he said:
When an application is deployed, the cloud controller picks a server out of our farm of servers to which to deploy the application. On that server, a random high port number is chosen and a dedicated web site and app pool is configured to use that port. The router service then uses that URL (http://server:49367) when requests come in to http://<application>.foundry.gs
I’m not ready to deploy this application. While I could use the standalone Cloud Foundry Explorer that I showed you before, or even the vmc command line, the easiest one is the Visual Studio plug in. By right-clicking my project, I can choose Push Cloud Foundry Application which launches the Cloud Foundry Explorer.

Now I can select my existing Iron Foundry configuration named Sample Server (which points to the Iron Foundry endpoint and includes my account credentials), select a name for my application, choose a URL, and pick both the memory size (64MB up to 2048MB) and application instance count.

The application is then pushed to the cloud. What’s awesome is that the application is instantly available after publishing. No waits, no delays. Want to see the app in action? Based on the values I entered during deployment, you can hit the URL at http://serotersample.foundry.gs/CustomerService.svc/CustomerService/100.

Sweet. Now let’s check out some diagnostic info, shall we? I can fire up the standalone Cloud Foundry Explorer and see my application running.

What can I do now? On the right side of the screen, I have options to change/add URLs that map to my service, increase my allocated memory, or modify the number of application instances.

On the bottom left of the this screen, I can find out details of the instances that I’m running on. Here, I’m on a single instance and my app has been running for 5 minutes.

Finally, I can provision application services associated with my web application.

Let’s change my instance count. I was blown away when I simply “upticked” the Instances value and instantly I saw another instance provisioned. I don’t think Azure is anywhere near as fast.


What if I like using the vmc command line tool to administer my Iron Foundry application? Let’s try that out. I went to the .NET version of the vmc tool that came with the Iron Foundry code download, and targeted the API just like you would in “regular” Cloud Foundry.

It’s awesome (and I guess, expected) that all the vmc commands work the same and I can prove that by issuing the “vmc apps” command which should show me my running applications.

Not everything was supported yet on my build, so if I want to increase the instance count or memory, I’d jump back to the Cloud Foundry Explorer tool.
Summary
What a great offering. Imagine deploying this within your company as a way to have a private PaaS. Or using it as a public PaaS and have the same deployment experience for .NET, Java, Ruby and Node applications. I’m definitely going to troll through the source code since I know what a smart bunch build the “original” Cloud Foundry and I want to see how the cool underpinnings of that (internal pub/sub, cloud controller, router, etc) translated to .NET.
I encourage you to take a look. I like Windows Azure, but more choice is a good thing and I congratulate the Tier 3 team on open sourcing their offering and doing such a cool service for the community













Todd Hoff (@highscalability) described Netflix: Developing, Deploying, and Supporting Software According to the Way of the Cloud in a 12/12/2011 post to his High Scalability Blog:
At a Cloud Computing Meetup, Siddharth "Sid" Anand of Netflix, backed by a merry band of Netflixians, gave an interesting talk: Keeping Movies Running Amid Thunderstorms. While the talk gave a good overview of their move to the cloud, issues with capacity planning, thundering herds, latency problems, and simian armageddon, I found myself most taken with how they handle software deployment in the cloud.
I've worked on half a dozen or more build and deployment systems, some small, some quite large, but never for a large organization like Netflix in the cloud. The cloud has this amazing capability that has never existed before that enables a novel approach to fault-tolerant software deployments: the ability to spin up huge numbers of instances to completely run a new release while running the old release at the same time.
The process goes something like:
- A canary machine is launched first with the new software load running real traffic to sanity test the load in a production environment. If the canary doesn't die they move on with the complete upgrade.
- Spin up an entirely new cluster of instances to run the new software release. For Netflix this could be hundreds of machines.
- Keep the old cluster running on the old release, but tell your load balancer to switch all requests to the new cluster running the new release.
- Let the new cluster bake for a while.
- If there aren't any problem tear down the old cluster and the new cluster is now the operational cluster of record.
- If there are problems redirect requests to the old cluster, tear down the new cluster, and figure out what went wrong.
- Downstream services see the same traffic volume, so the process is transparent.
Previously:
- You would never have enough free machines that new code could run in parallel with the old. That would be over provisioning to an impossible to afford degree. That made clumsy rolling upgrades the technique of choice.
- It's unlikely you would have the load balancer infrastructure under enough programmer control to pull off the switch and rollback. That stuff in usually under the control of the network group and they don't like messing with their configuration.
The cloud makes both of these concerns old school. The elasticity of the cloud (blah blah) makes spinning up enough instances for a hosting a new release both affordable and easy. The load balancer infrastructure in the cloud both has an API and is usually under programmer control, so programmers can mess everything up with abandon.
You might at this point raise your hand and say: what about that database? Schema migration issues are always a pain, so this approach does not apply to the database. The database service layer still uses a rolling upgrade path, but it is hidden behind an API and load balancer so the process is somewhat less painful to clients.
How Netflix's Team Organization Implies a Software Architecture and Policies
Netflix has some attributes about their software team infrastructure and software architecture that makes this approach a good fit for them:
- Their architecture is service based. Many small teams of 3-5 person teams are completely responsible for their service: development, support, deployment. They are on the pager if things go wrong so they have every incentive to get it right. Doubly so because most of Netflix's traffic happens on the weekend and who wants to get paged on the weekend?
- There's virtually no process at Netflix. They don't believe in it. They don't like to enforce anything. It slows progress and stunts innovation. They want high velocity development. Each team can do what they want and release whenever the want how often they want. Teams release software all the time, independent of each other. They call this an "optimistic" approach to development.
- Optimism causes outages. If you are going to be optimistic and have an absence of process, you have to have a way to detect problems and recover from them. Netflix's Chaos Monkey approach was created to find any problems caused by their optimism. Similarly, their rollback approach to software releases makes deployment almost hitless and transparent, so you can tolerate faults in a release. Code is first tested in a staging environment, but production is always the real test.
Use Load Balancers for Isolation
Their architecture is divided into layers: an Internet facing Edge layer; Middle layer serving the edge layer; Backend layer. All this rests on Amazon services. Each layer is fronted by a load balancer and each layer has the ultimate goal of being auto scaling.
The load balancer allows the isolation of components. It's possible to spin up a parallel cluster and route requests behind the load balancer without any other service layer having an idea that it is being done.
For the Internet facing services they use Amazon's load balancers because they have public IP addresses. For the other layers they use their own service discovery service which handles load balancing internally.
Function follows form. We conform to and innovate on the capabilities of the underlying system and our forms eventually come to reflect that function. It will be curious to see how experience in the cloud will cause changes in long held development practices. That's the Way of the Cloud.
Related Articles

<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, SQL Azure Database, SQL Azure Sharding, Open Data Protocol, OData, Windows Azure AppFabric, Azure AppFabric, Windows Server AppFabric, Server AppFabric, Cloud Computing, Visual Studio LightSwitch, LightSwitch, Amazon Web Services, AWS, Hadoop, Apache Hadoop, Hadoop on Azure, Windows Azure HPC Scheduler, HPC, node.js, Cloud Foundry, Iron Foundry, Netflix, Java, Cloudify

















{kind=link}
0 comments:
Post a Comment