Windows Azure and Cloud Computing Posts for 12/5/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
Chris Klug (@ZeroKoll) explained Adding WCF custom service behaviors in config in a 12/5/2011 post:
Lately I have been working with a bit of WCF for a client, and one of the things I have had to do is to create a service behavior to handle some security things. However, due to the fact that this application needed to run in several different environments, it needed to have different configuration under different circumstances.
The real need was actually to be able to remove the behavior in some circumstances, and add it in some. But I didn’t really want to do it through a bunch of if-statements in my behavior. Instead I wanted it to be done through configuration so that I could turn it on and off using config transforms…
Ok, so how do we do this? Custom service behaviors can be added to a service in several ways. They can be added to the WCF host from code, added as an attribute (also in code) or set up from config. But how do we make it available in config? Well, it isn’t that hard. All you need is an extra class that inherits from BehaviorExtensionElement and overrides 1 method, the CreateBehavior() method, and one property, the BehaviorType property.
It is REALLY simple to implement
public class MyBehaviorExtensionElement : BehaviorExtensionElement
{
protected override object CreateBehavior()
{
return new MyCustomServiceBehavior();
}
public override Type BehaviorType
{
get { return typeof(MyCustomServiceBehavior); }
}
}As you can see, it only needs the inheritance and a way to return the type of the extension as well as an instance of it. Once we have that in place, we can add a behavior extension in web.config as follows
<?xml version="1.0"?>
<configuration>
...
<system.serviceModel>
<extensions>
<behaviorExtensions>
<add name="myBehavior"
type="MyNamespace.MyBehaviorExtensionElement, MyAssembly, Version=1.0.0.0, Culture=neutral, PublicKeyToken=null" />
</behaviorExtensions>
</extensions>
</system.serviceModel>
...
</configuration>and then add it as a behavior like this
<?xml version="1.0"?>
<configuration>
<system.serviceModel>
<services>
...
</services>
<behaviors>
<serviceBehaviors>
<behavior>
<myBehavior /> <!-- Easy as! -->
</behavior>
</serviceBehaviors>
</behaviors>
<extensions>
...
</extensions>
</system.serviceModel>
</configuration>And if you need to remove it in some configuration, just add a config transform that removes it. Or the other way around, leaving it off by default and adding it in deploy… Just remember that the default setting is what will be used when debugging. Transforms only apply when publishing the app…
That’s it! Just a quick tip this time!
Julie Lerman (@julielerman) wrote Handling Entity Framework Validations in WCF Data Services for the December, 2011 issue of MSDN Magazine:
I’m writing this column on the heels of the Microsoft BUILD conference. The core of all of the excitement at BUILD was, of course, the new Metro UI for Windows 8 that sits on top of the new Windows Runtime (WinRT). If you’re a data geek, you might’ve already looked to see what options exist for providing data to “Metro style” apps. In this early preview, you can provide data from file storage or from the Web. If you want to interact with relational data, Web-based options include XML or JSON over HTTP, sockets and services. On the services front, Metro-style apps will provide client libraries for consuming OData, which means that any experience you have today working with OData through the Microsoft .NET Framework, Silverlight or other client libraries will give you a big advantage when you’re ready to consume OData in your Metro-style applications.
With that in mind, I’ll devote this column to working with OData. The Entity Framework (EF) release that contains Code First and the DbContext introduced a new Validation API. I’ll show you how to take advantage of built-in server-side validation when your EF Code First model is being exposed as OData through WCF Data Services.
Validation API Basics
You might already be familiar with configuring attributes such as Required or MaxLength to class properties using Data Annotations or the Fluent API. These attributes can be checked automatically by the new Validation API. “Entity Framework 4.1 Validation,” an article in the MSDN Data Developer Center (msdn.microsoft.com/data/gg193959), demonstrates this, as well as how to apply rules with the IValidatableObject interface and the ValidateEntity method. While you might already be validating Data Annotations and IValidatableObject on the client side, their rules can also be checked on the server side along with any ValidateEntity logic that you’ve added. Alternatively, you can also choose to trigger validation on demand in your server code.
Here, for example, is a simple Person class that uses two Data Annotations (the first specifies that the LastName property is required and the other sets a maximum length for the IdentityCard string field):
- public class Person
- {
- public int PersonId { get; set; }
- public string FirstName { get; set; }
- [Required]
- public string LastName { get; set; }
- [MaxLength(10)]
- public string IdentityCardNumber { get; set; }
- }
By default, EF will perform validation when SaveChanges is called. If either of these rules fails, EF will throw a System.Data.Entity.DbEntityValidationException—which has an interesting structure. Each validation error is described in a DbValidationError, and DbValidationErrors are grouped by object instance into sets of EntityValidationErrors.
For example, Figure 1 shows a DbEntityValidationException that would be thrown if EF detected validation problems with two different Person instances. The first EntityValidationErrors object contains a set of DbValidationErrors for a single Person instance where there were two errors: no LastName and the IdentityCard had too many characters. The second Person instance had a single problem; therefore, there’s only one DbValidationError in the second EntityValidationErrors object.
.png "DbEntityValidationException Contains Grouped Sets of Errors")
Figure 1 DbEntityValidationException Contains Grouped Sets of ErrorsIn the MSDN Data Developer Center article I mentioned, I showed the exception being passed back to a Model-View-Controller (MVC) application that knew how to discover and display the specific errors.
In a distributed application, however, the errors might not make it back to the client side to be used and reported so easily. While the top-level exception may be returned, the client application may have no idea how to drill into a DbEntityValidationException to find the errors. With many apps, you may not even have access to the System.Data.Entity namespace and therefore no knowledge of the DbEntityValidationException.
More problematic is how WCF Data Services transmits exceptions by default. On the client side, you only get a message telling you “An error occurred while processing this request.” But the critical phrase here is “by default.” You can customize your WCF Data Services to parse DbEntityValidationExceptions and return useful error information to the client. This is what I’ll focus on for the rest of this column. …
Read the rest here.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Eric Nelson (@ericnel) advised Do you have an application running on the Windows Azure Platform? Then proudly display the logo! in a 12/5/2011 post:
We have hundreds of software products from UK Independent Software Vendors running on or with the Windows Azure Platform – which is awesome!
However what I rarely see is the Powered by Windows Azure logo.
Come on folks – be proud, get that logo on your website by following the simply steps I previously posted of how to get the logo via Microsoft Platform Ready .
And please do drop me an email if you would like a brief shoutout on this blog for your application.
P.S. If you haven’t yet adopted the Windows Azure Platform then check out Six Weeks of Windows Azure starting January 23rd.
Related Links:
- Detailed overview of Six Weeks of Windows Azure and FAQ.
- Signup for Six Weeks of Windows Azure


Both my live Windows Azure demo applications have gone through the MPR steps and display the Powered by Windows Azure logo at the top right position:
Brian Swan (@brian_swan) shared his Thoughts on Testing OSS Applications in Windows Azure in a 12/5/2011 post:
I’ve been spending quite a bit of time lately thinking about the best ways to test PHP applications in a Windows Azure environment. I think that, at a high level, my ideas are applicable to any OSS/Azure application that can be tested using any of a variety of testing frameworks. In this post, I want to share my ideas and get your thoughts. Larry and I will follow up in the coming weeks with language-specific details for each of these approaches.
Before I get to my ideas, let me step up on my soap box and say IF YOU ARE NOT TESTING YOUR APPS, YOU SHOUD BE! I don’t feel the need to justify that exclamation…I’ll let Jeff Atwood justify it though: I Pity the Fool Who Doesn’t Write Unit Tests. If you aren’t actually testing your apps now, thinking about testing your apps is, well, better than nothing (but just barely).
Stepping down now…
So, here are my thoughts on how you might test an OSS/Azure application…from “easiest” to “best”. All of these approaches assume that you are deploying a testing framework and test suite with your application.
1. RDP to staging instance and run command-line tests. This approach involves enabling RDP access to a deployment (I’m assuming deployment to a staging slot), opening a command prompt, and running your tests as (many of you) normally would. The benefit to this approach is that you likely won’t have to deviate much from your normal testing routine. The drawbacks are that you have to manually run your tests and disable RDP access to your instances after you push to production.
2. Use a web front-end for running tests. This approach assumes you have a web front-end for your testing framework (like VisualPHPUnit is for PHPUnit). The benefits here are that you can run your tests at any time, in exactly the same way you have been (assuming you’ve been using a web front-end all along). The major drawback is that you will need password-protect your test directory, which takes a bit of figuring out if your not used to using IIS.
3. Use a startup script to automatically run tests upon deployment. This approach involves the most work, but I think it is the most powerful, mostly because it’s automated. The idea is that you specify a startup task in your service definition that runs your test suite and writes the results to a file. To get your hands on that file, you’ll need to configure Azure Diagnostics to write that file to your Azure Storage account. To avoid running the tests in production (which you don’t want to do if the tests take a while to run), you’ll need to write code that determines your Azure environment (staging or production) and only runs your tests in the staging environment.
What are your thoughts on these approaches? Are there others that I’m missing?
As I mentioned earlier, we’ll follow up with more how-to details for these approaches in the coming weeks.


Wade Wegner (@WadeWegner) reminded developers in a 12/5/2011 tweet about the new Windows Azure Toolkit for Windows Phone v1.3.2 updated 11/29/2011:
Content
- Overview
- Setup and Configuration
- Toolkit Content
- NEW: Architecture Diagrams
- NEW: FAQs
- Getting Started
- Creating a New Windows Phone Cloud Application
- Running and Going Through the Windows Phone Cloud Application
- Starting the Application
- Authenticating the User (ASP.NET Membership Authentication)
- Authenticating the User (ACS Authentication)
- Sending Microsoft Push Notifications
- Sending Apple Push Notifications
- Working with Tables, Blobs and Queues
- Working with SQL Azure Database
- NEW: BabelCam
- NEW: Tweet Your Blobs
- NEW: CRUD SQL Azure
- User Authentication
- Deploy Your Services to Windows Azure
- NEW: How to obtain a Project Hawaii Application ID
- NEW: How to obtain a Bing Application Id
- NEW: How to obtain a bitly Username and API Key
- NEW: How to create a SQL Azure Database Server
- Troubleshooting
- Change Log
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Chris Yellington explained how to Deploy Visual Studio LightSwitch on a Shared Server in a 12/4/2011 post:
Here is the official documentation on how to publish a LightSwitch application – How to: Deploy a LightSwitch Application. For this example, I’m going to show how to deploy a simple application that does not have any role-based security set up. I’ll show how we can configure that in a later post.
[Note: Beth Massi (@bethmassi) said “/Deploy #LightSwitch by Christian D. Yellington/ is an OLD repost from Beta 1! Update here: http://bit.ly/dU91oT” in a 12/5/2011 tweet.]
So back over on my LightSwitch development machine the first thing we need to do is specify the type of 3-tier deployment we want. In the case of my application, I want it to be a Windows Desktop client because I’m doing some COM automation with Office and I want to run outside of the browser. To specify this, from the menu select Project—> AppName Properties and then select the Application Type tab to choose the type of 3-tier deployment you want.

Next, from the main menu select Build –> Publish AppName to open the LightSwitch Publish Application Wizard. Verify the deployment is 3-tier and then click next to get past the Welcome page. In the Publish Output section you select whether you want to remotely publish to the server or just create a package on disk. If you have installed the Web Deployment Tool on your server (which is automatically installed if you installed the LightSwith Prerequisites above) then you can choose to deploy the application directly to your server by selecting “Remotely publish to a server now”. (UPDATE: To see how to remotely publish see this post.) I can recommend you to try this provider if you want to deploy your Visual Studio LightSwitch on shared hosting environment.For this example I’m going to show how to create and install the package manually so select “Create a package on disk” and then enter LightSwitchTest for the website name and specify a location to where you want the package created. Then click Next.

On the next page you specify the Database Configuration details. You can either create a new database or specify a database that needs to be updated. This refers specifically to the intrinsic database that is maintained by every LightSwitch application and exists regardless of whether you create new tables or attach to an existing database for your data. For the first deployment of the application you are always going to want to select the New Database option as you won’t have one created yet. If you are publishing an update to an existing application then you would select Update Existing option.

Next click Publish and this will create a .ZIP file package in the publish location you specified. Copy that application package over to your web server.Installing the LightSwitch Application Package on the Server
Back on the web server, navigate to the C:\LightSwitchTest folder and delete the Default.htm file we created earlier for testing. Then open up IIS Manager and right-click on the Default Web Site and select Deploy –> Import Application.

Browse to the .ZIP application package that we created then click Next, verify the virtual directory name and click Next. The contents of the package will be then be displayed.

Click Next and enter the remaining database details – specifying .\SQLEXPRESS as the local SQL Express server name, and entering the SQL Server user name and password we created above.

Click Next and this will kick off the installation that should be pretty quick. Once it completes you should be able to see your database in SQL Server Management Studio and all the web application files on disk.Using Windows Integrated Security from the Web Application to the Database
Like I mentioned earlier, typically you want to set up Windows Integrated security between your web application and database. It’s a lot easier this way because you don’t have to worry about managing user names and passwords in a bunch of application connection strings. It also is a lot more secure — right now our username and password to the database is being stored in clear text on the web application’s Web.config.
Since we’ve configured our LightSwitchAppPool to run under the LightSwitchApp user identity we created earlier, we can change the connection string in the Web.config to use integrated security and the middle-tier will connect to the database under this windows account instead. In IIS Manager right-click on the LightSwitchTest web application and select Explore to navigate to the physical folder. Open the Web.config in notepad and remove the uid and password and add Integrated Security=SSPI:
<?xml version=”1.0″ encoding=”utf-8″?>
<configuration>
<appSettings> … </appSettings>
<connectionStrings>
<add connectionString=”Data
ource=.\SQLEXPRESS;Database=OMS;Integrated Security=SSPI;” />
</connectionStrings>
<system.web> …Save the file. The last thing to do is add access to the application database (in my case I named it OMS). Open up SQL Server Management Studio again, expand the Security –> Logins node in the Object Explorer and double-click on the LightSwitchApp windows login account we added earlier. The Login properties are displayed. Select the User Mapping page and check off the application database to allow access then under the database role membership check db_owner and click OK:

NOTE: These steps should not be necessary at RTM once we are allowed to specify integrated security when installing a LightSwitch application package.Launching the LightSwitch Application
Now for the fun part! Head over to a networked machine and navigate your favorite browser to the site http://<servername>/LightSwitchTest and you should see a “Install Silverlight” graphic on the page if you don’t have Silverlight installed. Install it then refresh the page and you will see the install page for your application:

Click the big blue “Install…” button and after a few seconds the application will launch out of browser and an application icon will be placed on the desktop. Woo hoo!

Now we have a 3-tier out-of-browser LightSwitch application deployed and running smooth.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Lee Thompson asserted Companies have plenty of monitoring, what they don’t have is control in a 12/5/2011 post to the dev2ops blog:
I was honored to be asked to speak at DevOps Days in Manila and just got off stage. I was blown away when I found out over 400 people signed up to attend. Speaking gives me a chance to unload a bunch of baggage I’ve been carrying around years.
We all bring a lot of baggage with us into a job. The older you are, the more you bring. The first part of my career I did 10 years of real-time industrial control software design, implementation, and integration way way back before the web 1.0 days. Yes, I wrote the software for the furniture Homer Simpson sat in front of at the nuclear plant that was all sticky with donut crumbs...
I took that manufacturing background baggage to E*TRADE in ’96 where I ran into fellow dev2ops contributor Alex Honor who brought his Aimes Research Laboratory baggage of (at the time) massive compute infrastructure and mobile agents. We used to drink a bunch of coffee and try to figure out how this whole internet e-commerce thing needed to be put together. We’d get up crazy early at 4:30AM, listen to Miles, and watch the booming online world wake up and trade stocks and by 9:00AM have a game plan formulated to make it better.
My manufacturing background was always kicking in at those times looking for control points. Webserver hits per second, firewall MBits/sec, Auth success or fail per second, trades per second, quotes per second, service queue depths, and the dreaded position request response time. I was quite sure there was a correlation algorithm between these phenomena and I could figure it out if I had a few weeks that I didn’t have. I also knew that once I figured it out, the underlying hardware, software, network, and user demand would change radically throwing my math off. Controlling physical phenomena like oil, paper, and pharmaceutical products followed the math of physics. We didn’t have the math to predict operating system thread/process starvation and it took us years to figure out OS context switches per second has a huge kernel scaleability issue not often measured or written about.
One particularly busy morning in late ’96 Alex was watching our webserver, pointed at a measurement on the screen and said, “I think we’re gonna need another webserver”. With that, we also needed to figure out how to loadbalance webservers. As usual for the era, two webservers was a massive understatement. Within a year, there was more compute infrastructure at E*TRADE supporting the HTTPS web pages then the rest of the trading system and the trading system had been in place for 12 years by this time... Analytics of measurements (accompanied by jazz music) became an important part of our decision making.
Alex and I were also convinced in early ’97 that sound manufacturing principles used in the physical world made a ton of sense to apply to virtual online world of the internet. I’m still surprised the big control systems vendors like Honeywell and Emerson haven’t gotten into data center control. No matter, the DevOps community can make progress on it as its so complimentary to DevOps goals and its what the devops-toolchain project is all about.
Get a bunch of DevOps folks together and the topic of monitoring comes up every time. I always have to ask “Are you happy with it?” and the answer is always “no” (though I don’t think anyone at Etsy was there). When you drill into what’s wrong with their monitoring, you may find that most companies have plenty of monitoring, what they don’t have is control.
Say your app in production runs 100 logins/sec and you are getting nominally 3 username/password failures a second. While the load may go up and down, you learn that that the 3% ratio is nominal and in control. If the ratio increments higher, that may be emblematic of a script kiddie running a dictionary attack or the password hash database is offline or a application change making it harder for users to properly input their credentials. If it drops down, that may indicate a professional psyber criminal is running an automated attack and getting through the wire. Truman may or may not of said “if you want a new idea, read an old book”. In this case, you should be reading about “Statistical Process Control” or SPC. It was heavily used during WWII. With our login example, the ratio of success to failed login attempts would be “Control Charted” and the control chart would evaluate weather the control point was “in control” or “out of control” based on defined criteria like standard deviation thresholds.
Measurement itself is a very low level construct providing the raw material for the control goal. You have to go through several more toolchain layers before you get to the automation you are looking for. We hit upon this concept in our talk at Velocity in 2010...
Manufacturing has come a long long way since WWII. Toyota built significantly on SPC methodologies that eventually became the development of “Lean Manufacturing”; a big part of the reason Toyota became the worlds largest automobile manufacturer in 2008. A key part of lean is Value Stream Mapping which is “used to analyze and design the flow of materials and information required to bring a product or service to a consumer” (wikipedia).
Value Stream Mapping a typical online business through marketing, product, development, qa, and operations flows minimally will help effectively communicate rolls, responsibilities, and work flows through your org. More typically it becomes a tool to get to a “future state” which has eliminated waste and increase effectiveness of the org, even when nothing physical was “manufactured”. I find agile development, devops, and continuous deployment goals all support lean manufacturing thinking. My personal take is that ITIL has similar goals, but is more of process over people approach instead of a people over process approach and it’s utility will be dependent on the organizations management structure and culture. I prefer people over process, but I do reference ITIL every time I find a rough or wasteful organizational process for ideas on recommending a future state.
I was lucky enough to catch up with Alex, Anthony, and Damon over dinner and we were talking big about DevOps and Lean. Anthony mentioned that “we use value stream mapping in all of our DevOps engagements to make sure we are solving the right problem”. That really floored me on a few levels. First off, it takes Alex’s DevOps Design Patterns and DevOps Anti-Patterns to the next level similar to SPC to Lean adding a formalism to the DevOps implementation approach. It also adds a self correcting aspect to a companies investment into DevOps optimizations. I’ve spoken with many companies who made huge investments in converting to Agile development without any measurable uptick in product deployment rates. While these orgs haven’t reverted back to a waterfall approach as they like the iterative and collaborative approach, they hit the DevOps gap head on.
“We use Value-Stream Mapping in all of our DevOps engagements to make sure we are solving the right problem”
-Anthony Shortland (DTO Solutions)Practicers of Lean Manufacturing see this all the time. Eliminating one bottleneck just flows downstream to the next bottleneck. To expect greater production rates, you have to look at the value stream in its entirety. If developers were producing motors instead of software functions, a value stream manager would see huge inventory build up of the motors which produce no value to the customer and identify the overproduction as waste. Development is a big part of the value stream and making that more efficient is a really good idea. But a measurement of the release backlog growing is seldom measured or managed. If you treat your business as a Digital Information Manufacturing plant and manage it appropriately to that goal, you can avoid the frequent mistake Anthony and other Lean practitioners are talking about where you solve a huge problem without benefiting the business or the customer.
To sum up, DevOps inspired technology can learn quite a bit from Lean Manufacturing and Value Stream Mapping. This DevOps stuff is really hard and you’ll need to leverage as much as possible. Always remember that “Good programmers are lazy” and its good when you apply established tools and techniques. If you don’t think your working in a Digital Information Manufacturing plant, I bet your CEO does.






Lori MacVittie (@lmacvittie) added Understanding web #acceleration techniques and when to apply them as an introduction to her WILS: WPO versus FEO post of 12/5/2011:
We’ve already discussed the difference between acceleration and optimization, so now it’s time to quickly dig into the difference between the two major types of acceleration: WPO (Web Performance Optimization) and FEO (Front End Optimization).
The difference is important because each technique is effective at addressing different performance bottlenecks, and obviously applying the wrong solution to the problem will not provide the desired results, i.e. fast, fast, fast web applications.
WPO focuses on content delivery, which means it applies different optimization techniques to counter poorly performing networks and servers. WPO will use various TCP optimizations to redress issues in the network related to TCP connections between the client and the server such as retransmission storms caused by overly congested network conditions. WPO will also apply compression to content to minimize the size and reduce the number of packets that must traverse the network. This is a boon over higher latency and/or lower bandwidth connections in improving transfer speed.
FEO, on the other hand, focuses on content transformation. This requires actually changing the content in some way as a means to improve overall performance. Modifying (often merely adding) cache control headers can dramatically improve performance by forcing the use of caching on infrequently changing content. Similarly, techniques like domain sharding that increase the parallelization of requests can reduce the transfer time for what are increasingly large object sets, resulting in (at least perceived) improvements in performance.
Some FEO solutions further manipulate the actual content of the page, rearranging the objects and elements so as to be optimally retrieved and rendered by the browser being used. As the way in which rendering engines work varies from browser to browser, this can actually have a significant impact on the (at least perceived) performance of a web application. FEO solutions are best for complex web pages with many elements and objects, as these benefit from techniques like caching and domain sharding because the bottleneck is in the number of requests required to retrieve a page as opposed to transfer speed. The use of FEO is a primary means of improving performance to not only mobile clients but especially mobile clients over mobile networks. Elimination of white space and comments (minification), image optimization (removal of EXIF data, for example) is particularly effective at reducing content size and therefore improving performance for mobile clients.
The best solution is, of course, an intelligent acceleration intermediary capable of determining based on context which combination of the two techniques will optimally improve performance, as it is generally true that no single technique will unilaterally improve performance.


The CloudTimes blog posted a summary of Gartner and IDC Cloud Predictions on 12/4/2011:
Gartner and IDC, two of the respected authorities in cloud computing recently released their fearless, bold predictions for 2012.
Huge Data Storage
“Big Data will earn its place as the next ‘must have’ competency in 2012″ (IDC). It’s difficult to question that statement if the basis is only the current trend right now. The statement remains questionable because the IDC data only comes from the big data problem in relation to its demand. IDC predicted 2.43 zettabytes of data will need to be created in 2012. These data storage demand will be used mostly for social media like videos, photos and music files.
“2012 is likely to be a busy year for Big Data-driven mergers and acquisitions” (IDC). This prediction is hot spot because a lot of acquisitions have and are still taking place. Among the companies that are ripe for any merger include NoSQL, Red-Hot 10gen, Kognito, ParAccel, Cloudera, Infobright, Quantivo and Attivo.
“Through 2015, more than 85 percent of Fortune 500 organizations will fail to effectively exploit big data for competitive advantage” (Gartner). This prediction may be a little off because at the moment most of the Fortune 500 companies are already experimenting like what they did with Hadoop. Gartner added that companies who are investing heavily on big data storage may not fully utilize it to their advantage because they may not be ready for it.
Cloud Computing
“In 2012, 80% of new commercial enterprise apps will be deployed on cloud platforms” (IDC). 80% is very high, but if the focus of this figure includes web startups the numbers may be reasonable.
“Amazon Web Services will exceed $1 billion in cloud services business in 2012 with Google’s Enterprise business to follow within 18 months” (IDC). This prediction may already be happening with Amazon Web Services, but wit Google this may come around by mid of 2013. IDC feels that the mergers will be more appealing with Saas companies other than PaaS. One of the major mergers that will take place is the acquisition of Microsoft of NetFix.
“By 2016, 40 percent of enterprises will make proof of independent security testing a precondition for using any type of cloud service” (Gartner). This trend will be a solid tie up for cloud vendors and insurance services to affirm their security claims.
“At year-end 2016, more than 50 percent of Global 1000 companies will have stored customer-sensitive data in the public cloud” (Gartner). Although Gartner feels this is because of the cost savings, others say that this is due to the improved cloud security platform. More and more companies may feel that placing more data in the cloud is secure and very useful, which is backed up by improved certification and insurance policies.
“By 2015, the prices for 80 percent of cloud services will include a global energy surcharge” (Gartner). This is a business model that Amazon Web Services started and is not being utilized by other cloud services. Its framework is developer- based that relies on simple pricing schemes plus additional charges.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
K. Scott Morrison (@KScottMorrison) posted Gartner AADI 2011 Presenation Video: API Management, Governance & OAuth on 12/5/2011:
I delivered a talk all about API governance at last week’s Gartner Application Architecture, Development and Integration (AADI) summit in Las Vegas. I was the lunch time entertainment on Wednesday. The session was packed—in fact, a large number of people were turned away because we ran out of place settings. Fortunately, a video of the session is now available, so if you were not able to attend, you can now watch it online.
In this talk I explore how governance is changing in the API world. I even do a live OAuth demonstration using people, instead of computers. Unlike the classic “swim lane” diagrams that only show how OAuth works, this one also teaches you why the protocol operates as it does. (If you want to skip directly to the OAuth component, it begins at around 22 minutes.)

<Return to section navigation list>
Cloud Computing Events
No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) described Amazon ElastiCache - Support in Four Additional Regions, CloudFormation Support, Free Webinar in a 12/5/2011 post:
I've got lots of Amazon ElastiCache news for you today! We've enabled ElastiCache in four additional AWS Regions and we have also added AWS CloudFormation support.
New Regions
We launched ElastiCache back in August (read my blog post to learn more), in the US East (Northern Virginia) Region. As I have mentioned in the past, we often launch new services in a single Region and then expand to other regions as quickly as possible.
Today we are enabling ElastiCache in four new Regions: US West (N. California), EU West (Dublin), Asia Pacific (Singapore), and Asia Pacific (Tokyo). You can now add a managed, in-memory cache to your AWS applications in a matter of minutes.
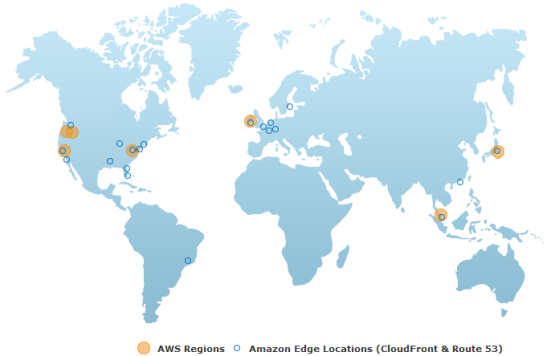
While I am talking about Regions and services, I should mention the new AWS Global Infrastructure map. The map shows the current set of AWS Regions and Edge Locations (for CloudFront and Route 53):
You can hover your mouse over any of the Regions (orange circles) or Edge Locations (blue circles) to learn more:
CloudFormation Support
You can now provision, configure, and deploy ElastiCache Cache Cluster using an AWS CloudFormation template (read more about CloudFormation in another one of my blog posts). The templates can specify Cache Clusters, Cache Parameter Groups, and Cache Security Groups.
We have put together a sample CloudFormation template for ElastiCache (excerped above). If you haven't had the chance to learn much about CloudFormation, you may want to take some time to study this template to get a better understanding of what you can do. In just 318 lines, the template creates the following AWS resources:
- Amazon EC2 instance.
- EC2 security group with ports 22 (SSH) and 80 (HTTP) open.
- ElastiCache Cache Cluster with a specified number of nodes.
- Cache Security Group, allowing access only from the EC2 instance.
- IAM user with permission limited to the ability to call two CloudFormation functions and one ElastiCache function.
The template also arranges to install four additional packages on the EC2 instance, along with a set of AWS credentials. It installs and updates some configuration files, enables the HTTPD service, disables the Sendmail service, and installs a simple PHP program to exercise the Cache Cluster. It does not, however, make your breakfast. Seriously, take some time to examine this template. I believe you'll walk away with a better understanding of CloudFormation and perhaps some ideas for ways that you can use it to manage and launch your own application stacks.
ElastiCache Webinar
We'll be running a free webinar on December 6th to teach you how to Turbo-charge Your Web Apps Using Amazon ElastiCache. Space is limited; sign up now if you are interested in attending.




Robert Cathey (@robertcathey) posted CloudBeat 2011: Uncomfortable Choices on the Road to Cloud Computing on 12/5/2011:
Building a cloud that works like AWS or Google involves a complete rethink of just about every concept considered canonical in enterprise IT for the past 20 years.
This is the message Randy Bias and Lew Tucker (Vice President and CTO, Cloud Computing at Cisco) delivered on the main stage CloudBeat 2011 last Wednesday.
High-level takeaways from the video (embedded below) include:
Enterprise IT is not ready to do real cloud. AWS is growing phenomenally: perhaps $1b in 2011 revenue and a 100% CAGR. But even with this market approval, enterprise IT is not psychologically prepared to run their infrastructure the way AWS does. Most large enterprises and service providers still design with the philosophy that each application architecture drives its own infrastructure architecture. The only successful public clouds turn that idea on its head.
Uptime at scale is in the software, not the hardware. Designing failover into the software – rather than the hardware – is another source of dissonance when moving from the enterprise IT mindset to cloud design. At scale, you cannot avoid hardware failure, so successful public clouds manage it though software architecture.
Open source is only part of the answer. Open source software is the only way to go if you want to build a cloud the way AWS and Google do. It’s not easy, though. More than 80% of your time will be spent dealing with issues beyond the cloud OS.
People do not need need to know what’s in the box. The box delivers an SLA and a set of services. It’s an appliance. This defines the move toward a utility computing model. You get one of 2-3 configurations for different classes of workloads, and that’s it.
If you skip through the introductions, the video is just under 20 minutes.
<Return to section navigation list>

















0 comments:
Post a Comment