Windows Azure and Cloud Computing Posts for 12/8/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Avkash Chauhan (@avkashchauhan) reported Windows Azure Table Storage- Partition or Row key length is limited to 256 characters in Storage Emulator in a 12/9/2011 post:
If partition/row key is longer than 256 characters, you will get an error when inserting the data in Azure table storage, while you are running your application in compute emulator or accessing table storage in storage emulator directly. This problem will only happens in Storage Emulator, but will not happen in Windows Azure Table storage in cloud.
The differences between storage emulator (in compute Emulator environment) and Windows Azure Table Storage in cloud are documented at link below:
http://msdn.microsoft.com/en-us/library/windowsazure/gg433135.aspx

<Return to section navigation list>
SQL Azure Database and Reporting
My (@rogerjenn) The SQL Azure Team Unveils a New Server Management UI post of 12/9/2011 begins:
Updated 12/9/2011 at 8:30 AM PST with added steps 17 through 23.
The SQL Azure team has updated the Server Management features of Windows Azure Management Portal’s Database component on 12/8/2011. To view the new pages:
1. Open the Windows Azure Management portal at https://windows.azure.com.
2. Click the Databases button in the navigation pane and select a subscription to activate the Server group (click images for larger view):

Continues with a description of “Updating from Silverlight 4 to Silverlight 5 Developer Edition” and:
Exploring the new SQL Azure Server Manager UI
10. Click Manage in the Server group to open the login page for the SQL Server instance for the subscription you selected in step 2. Type your Administrative user name and password:
11. Click Log On to
peelroll open the new Metro-style Overview page for what formerly was known as the “Database Manager” and “Project ‘Houston’”:
The objective of the new UI is to simplify navigation between administrative and database design tasks and to permit multiple tasks to be performed simultaneously (or nearly simultaneously.) …


See the original post to dig deeper with more screen captures.
Dave Jilk (@djilk) asserted “Most PaaS offerings provide some kind of database services” in a deck for his Different Approaches to Databases in PaaS article of 12/9/2011 for the Azure Cloud on Ulitzer blog:
In an application deployed directly on IaaS, you know and control everything about the database; in a SaaS application you know little and control nothing.
But how does it work in PaaS?
Since a PaaS is essentially a container that runs application code, and virtually every application requires a persistent data store, most PaaS offerings provide some kind of database services. Not surprisingly, Resource PaaS offerings most closely resemble SaaS in that they hide more deployment details, while Server PaaS offerings are more flexible but potentially more complex. (For more on Resource PaaS vs. Server PaaS, see Keys to the PaaSing Game: Multi-Tenancy.) What is surprising is that some Resource PaaS offerings use a proprietary and non-standard database. Let's take a closer look at how several of the leading Platform-as-a-Service offerings handle databases and file system access for applications running on them.
Google's AppEngine
The Google AppEngine PaaS provides permanent storage only through a system called "BigTable," a highly scalable non-relational data store, accessed through a limited SQL-like language called GQL. Because AppEngine only allows applications to use its provided API libraries, using a third-party database or database service is possible but awkward; the code must funnel requests through a URL-fetching API that is subject to various limitations. Although there is no direct access to a filesystem, file-like storage can be achieved through a specialized API built on BigTable.Recognizing that the lack of a relational database has been slowing the adoption of AppEngine, Google released a preview version of Google Cloud SQL in October 2011. Cloud SQL is a database-as-a-service (DBaaS) based on MySQL, offering nearly all MySQL commands, except those involving files. It automatically handles its own variant of geographic replication, but does not allow MySQL replication. During the preview, Cloud SQL databases are limited to 10 GB in size, and can only be accessed through AppEngine applications. The former constraint seems likely to be relaxed when the preview period ends; it is not clear if - or when - the latter will be.
Force.com
Salesforce.com's Force.com also provides a built-in non-relational object database, which was recently split out into a DBaaS called database.com. Database.com is accessed through the proprietary Apex language from within Force.com, or via API calls from outside, using a SQL-like language called SOQL. Configuration is limited to tables and fields only. Force.com applications can only access external databases or file stores through HTTP callouts, which are subject to certain limitations. It seems unlikely that Salesforce.com will offer a relational data store with Force.com, since they have long claimed that their approach is superior. Nevertheless, this limits the customer's ability to port applications in or out, find developers experienced in the approach, or build capabilities that require true relational power.Microsoft Azure
Microsoft [Windows] Azure offers access to the SQL Azure DBaaS, a high-performance, scalable, and fully managed service. Azure applications cannot access external databases, and external applications cannot access SQL Azure[*]; however, SQL Azure databases can be synchronized with on-premises SQL Server databases. Developers can only access database-level configuration, and while there is no filesystem access, file-like storage is available in Azure through a blob-based emulation system. Like AppEngine and Force.com, Azure is something of a walled garden, but in Microsoft's garden at least you have all the basic food groups.
Heroku
Heroku treats the database as distinct from the application container, allowing the application to use any database or database service. It also provides a built-in DBaaS, freeing developers from the need to provision and manage the database deployment. The Heroku DBaaS is based on PostgreSQL, can be operated in a shared or dedicated mode, and can be accessed from external applications as well. Developers have unlimited access to the database (via a database client command line), but no access to database deployment configuration settings or versions, in keeping with the Resource PaaS approach. For similar reasons, Heroku does not allow applications to write to the filesystem; a third-party service or a database-mapped approach is required.CloudFoundry.com
CloudFoundry.com has a DBaaS that supports four different databases natively: MySQL and PostgreSQL for relational, and MongoDB and Redis for NoSQL. Developers have access only to the database and not to its configuration settings. External databases can be accessed via APIs using an HTTP proxy; in the future, a Service Broker is promised that will enable more direct access to external databases and other services. With the recently added Caldecott tool, customers can also tunnel into their CloudFoundry.com database service from the outside. Although it is possible to write to the filesystem in CloudFoundry.com, the files are actually ephemeral and should not be relied upon as a data store. Note, by the way, that CloudFoundry.com is a service that uses the Cloud Foundry open source software as one of its foundational technologies, but the two are distinct.Server PaaS Options
Server PaaS offerings, like AWS Elastic Beanstalk, RightScale, Engine Yard, and Standing Cloud, generally have fewer constraints on the database to be used by the application. Filesystem access by the application is unimpaired in all of these Server PaaS offerings.Both Engine Yard and Standing Cloud automate deployment and management of supported databases, primarily MySQL or PostgreSQL of particular versions. Both also allow database-level and server-level configuration changes, with certain limits. Engine Yard relies on Chef for database deployment, so configuration changes must be performed with a Chef recipe or by working around it. Standing Cloud requires that configuration changes be embedded in a post-deployment script and that the basic deployment structure (filenames and directory paths) remains unchanged. Unsupported databases can also be used by applications running in Engine Yard or Standing Cloud, but they must be deployed and managed separately.
Elastic Beanstalk always requires the developer to deploy and manage the database separately. This can be done within Amazon Web Services using their RDS (Relational Database Service), but it is a separate step that is outside of the PaaS proper. RightScale offers tools (server templates and scripts) that make deployment, integration, and management of the database easier and repeatable, but generally you are on your own. As compensation for the extra effort, of course, you gain complete flexibility.
You may have noticed that I covered these offerings in order of increasing flexibility. When you reached the point in this article where the constraints of the PaaS did not seem too onerous, that suggests a good place to start if you are considering building or moving your application to the cloud. Keep in mind that you may also have different needs for development and test than you do for production - in some cases, scale is crucial; in others, control - and these needs change over time. Because of the inevitability of change, flexibility is important. That's why I recommend that you avoid building an application using a database environment where you would be permanently locked in.

* External databases can access SQL Azure by a simple modification of a SQL Server connection string.
The SQL Azure team has updated the Server Management features of Windows Azure Management Portal’s Database component
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
James Terwilliger described Working With Web Data in Microsoft Codename "Data Explorer" in a 12/9/2011 post to the Microsoft Codename “Data Explorer” blog:
If you are reading this blog post, you are probably aware of the Internet, a veritable cornucopia of data just sitting there waiting for you to use it. Much of that data comes from search engines, social networks, and other interactive media. In this post, we describe the experience of bringing such data into Data Explorer and using it in your mashups. The steps in this post will give details about retrieving and using data from Bing, but can also be used as a template for interacting with other similar sites that have the same interface.
Bringing Web Data into Data Explorer
Let’s begin by seeing how to bring a web data source into Data Explorer. Download and install the "Data Explorer” Desktop Client if you don’t have it yet. Start by creating a new Mashup and you will see the Add Data page.
Using the Add Data button, or the splash screen that appears when opening a new mashup, select the “Web Content” option from the list of available data sources:
Clicking the Web Content button will give a small dialog box where you can put the address of the site at which your precious, precious data is located.
Once you enter an address and click Done, if this is the first time in your mashup that you have used data from that site, you will see a dialog box that asks for credentials.
For most web sites, no credentials are necessary, so just the default option of “Anonymous Access” is the right choice; click Continue to clear the dialog to pull the data into Data Explorer. For most web pages – for instance, a Wikipedia page on frozen yogurt – the most common actions at this point will be to either get access to the raw text of the page (Open As Text in the figure below) or to the structure of the page (Open as Html in the figure below).
If at this point, however, you would like to do more complex, interesting things with our data (and of course, we do), we can access additional features by clicking on the More Tools button.
Doing so will allow us to see other potential actions as buttons, but also the formula bar, which shows us the expression formula that we have built. At this point, it is a simple call to the function Web.Contents with a single argument, the URL of our data source.
Diving Beneath the Surface of the Web
Of course, many sources of data on the web need user input to provide data. Unlike Wikipedia or FreeBase pages and other content pages with relatively static content, search engines and web data portals like Bing or Google have a more interactive interface. These kinds of sites often have two different interfaces. One interface is meant for human beings to ask questions and view data, for instance by going to http://www.bing.com and typing in a search term, resulting in something that looks like this:
The same source may also have an alternative way to access the same data in a way that is more accessible to computers, returning the data in a structured form without all of the pretty formatting. For Bing, that means the same luscious frozen yogurt data as above can be retrieved using a single URL, which returns something like this:
This is the same data, now returned in a much more computer-friendly form. The URL used to retrieve this data looks like this:
http://api.bing.net/json.aspx?Appid=12345&sources=web&query=frozen+yogurt
This URL can be taken apart into several components:
- The base URL http://api.bing.net/json.aspx. This address is the location of the service that we are using. The suffix of the base URL determines what kind of response you would like from the service. If it ends in “json.aspx”, the response will be in JSON format. If it ends in “xml.aspx”, the result will come back in XML format.
- A parameter “Appid”, given a value of “12345”. This API key value is given by the Bing service, and represents an account number that tracks the usage of calls using this kind of interface.
- A parameter “sources”, given a value of “web”. The Bing resource can return many kinds of data, including spell checking, phonebook information, and the web data as shown above.
- A parameter “query”, given a value of “frozen+yogurt”. This parameter is the term for which we search, but properly “escaped” into a valid URL piece by replacing spaces with the “+” character.
These components put together are actually a programmable web interface to all of Bing’s services. More information on that API can be found here, including information about additional parameters that can be used in the URL (for instance, web.count, which determines how many results to return for the query – the default is 10 if no value is given).
Using a Programmable Web API with Data Explorer
When adding a new Web data source from a programmable web source, you can just enter the full URL as constructed above into the same interface as the Wikipedia example:
However, these programmable web interfaces have such a common, consistent interface that Data Explorer offers a slightly cleaner way to access the same data. The Web.Contents function has a second, optional parameter that passes options to the function and makes the construction and use of programmable web URLs a little simpler in a number of ways. For instance, consider the following expression in the Data Explorer formula language:
Web.Contents(“http://api.bing.net/json.aspx”,
[ Query =
[
Appid = “12345”,
sources = “web”,
query = “frozen yogurt"
]
])The “Query” field of the record is itself a record, a collection of name-value pairs that represent the parameters to be added to the URL. Putting this formula into Data Explorer will give you exactly the same result as if you put the full URL into the first parameter.
Notice that in the above formula, we did not need to replace the space character in our search query term. One major advantage in using the additional parameter to Web.Contents is that you do not need to worry about any kind special kind of URL construction or string processing. The function will do all of that for you when it forms the request to the remote web site.
The “Appid” parameter can be treated just like any other parameter in the query. However, many different web data sources use this form of “API key” to grant and track access to web data sources. The name of the parameter may differ between various sites; different sources may call the parameter “APIKey”, “LuggageCombination”, or “Bacon”, but in all cases, the parameter represents the same thing: a value, assigned by the site to a user, to track usage of the API. Data Explorer uses an additional field to encapsulate this “API key” pattern:
Web.Contents(“http://api.bing.net/json.aspx”,
[
ApiKeyName = “Appid”,
Query =
[
sources = “web”,
query = “frozen yogurt"
]
])If you use this extra field, you no longer enter the API key itself as part of the formula. Instead, you enter it when Data Explorer asks you for credentials, like so:
When this credential window comes up, enter the value of your Bing API key into the field marked above. Using the credential store to manage the API key has several key advantages over just treating the key as another query parameter:
- If you send your mashup code or mashup file to someone else, you won’t send your precious key along with it. That way, other people won’t be able to send millions of requests to Google or to Wolfram Alpha and send you the bill. When they try to run the same formula, they will get the same credential window and be able to enter their own key.
- The API key is no longer part of the formula itself, so it won’t show up in things like blog posts talking about Data Explorer.
Using the Result of Programmable Web Calls
The results of a call to a web API may come back in any number of formats, but the most common formats are JSON and XML. The running example so far returns data in the JSON format. Data Explorer has a function, Json.Document, that can parse such data into structured forms that is much simpler to work with and manipulate. To use it, in the formula bar, wrap the current expression inside a call to Json.Document (there is not yet a convenient button to do this, but there will be):
From here, you can navigate through the response until you get to the data that you want, navigating to “SearchResponse”, then “Web”, then “Results”:
The result happens to be a list of records representing the return values from the search query. You may suspect that this data could actually be shaped into a table, and you would be correct – pressing the “Into Table” button will tell Data Explorer to attempt to analyze the current data and see if it can be shaped into a table:
The builder for this function gives you the option to shape the schema of the table, just in case Data Explorer’s analysis of the table is not complete. For instance, if all of the available rows in the table have values for the “Title”, but you want that column to be able to hold null values as well, you would check the checkbox next to “Title” in the builder making the column nullable. However, in this case, the builder gives us the right results by default, so we need not do anything further. We now have a resource in Data Explorer that queries Bing for the search term “frozen yogurt”, and returns the first 10 results as a nicely structured table.
Dust Off Your Propeller Hat
For those of you wanting to stretch your Data Explorer muscles at this point, we go one step further: Let’s turn this resource into our very own Bing search function. We will create a new function that can be called on any search term and return its top ten results, because (contrary to what you may have seen on our blogs so far) there are interesting topics besides frozen yogurt.
Actually, in the Data Explorer formula language, turning a resource into a function – and using it – is quite simple. Begin by viewing the formulas for your current mashup (directions on how to do so can be conveniently found in a previous blog post). You will see a formula that looks like the following:
section Section1;
shared BingFrozenYogurt =
let
BingFrozenYogurt = Json.Document(Web.Contents("http://api.bing.net/json.aspx", [ ApiKeyName = "Appid", Query = [ sources = "web", query = "frozen yogurt" ] ])),
Results = BingFrozenYogurt[SearchResponse][Web][Results],
IntoTable = Results as table [Title = Text.Type, Description = Text.Type, Url = Text.Type, CacheUrl = Text.Type, DisplayUrl = Text.Type, DateTime = Text.Type]
in
IntoTable;
To this formula, we will make three very simple changes:
- Rename the resource to “BingSearch” from “BingFrozenYogurt”
- Add a parameter to the resource, making it into a function that we can call later
- Use the new parameter in place of the existing frozen yogurt search term
The resulting formula will look like this:
section Section1;
shared BingSearch = (searchTerm) =>
let
BingFrozenYogurt = Json.Document(Web.Contents("http://api.bing.net/json.aspx", [ ApiKeyName = "Appid", Query = [ sources = "web", query = searchTerm ] ])),
Results = BingFrozenYogurt[SearchResponse][Web][Results],
IntoTable = Results as table [Title = Text.Type, Description = Text.Type, Url = Text.Type, CacheUrl = Text.Type, DisplayUrl = Text.Type, DateTime = Text.Type]
in
IntoTable;
Clicking “Done” in the formula window will let you view your new resource function:
Notice the “Invoke Function” button in the ribbon. If you click that button, it will allow you to call that function on a value of your choice. Sending “frozen yogurt” to that function will give you the same familiar results that we saw before:
The other button, “Invoke over table”, allows you to choose another resource in your mashup if it is a table and call your function on it, once per row. Using that feature, you can take a table from any other source – SQL, for example – and use your new Bing function to look up search terms for each item. In case your propeller hat is still spinning at this point, there will likely be a blog post in the near future to talk more in-depth about writing and using functions in Data Explorer.
While the examples given in this post have focused on the Bing service, the combination of base URL, API key, and parameters is a common pattern amongst many web data sources that offer a programmable web API. Google, Yahoo, Wolfram Alpha, and Twitter all have interfaces with a similar pattern, and so the steps used above will work for those services as well without trouble.
















Turker Keskinpala (@tkes) posted OData Service Validation Tool Update: 18 new rules to the OData.org wiki on 12/9/2011:
OData Service Validation Tool is updated with 18 new rules. Below is the breakdown of added rules:
- 1 new feed rule
- 8 new entry rules
- 9 new other rules (rules for $value payloads – will find a better name for these rules)
OData Service Validation Codeplex project was also updated with all recent changes.

<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Scott Densmore (@scottdensmore) described Thinktecture IdentityServer v1.0 in a 12/10/2011 post:
If you are interested in Claims Based Identity you have to check this out. I can't recommend this enough. I am really looking forward to the Azure release! [Emphasis added.]
Thinktecture IdentityServer v1.0
Yeah – it is finally done. I just uploaded the v1 bits to Codeplex and the documentation to our server. Here’s the official blurb…
Thinktecture IdentityServer is an open source security token service based on Microsoft .NET, ASP.NET MVC, WCF and WIF.
High level features
- Multiple protocols support (WS-Trust, WS-Federation, OAuth2, WRAP, JSNotify, HTTP GET)
- Multiple token support (SAML 1.1/2.0, SWT)
- Out of the box integration with ASP.NET membership, roles and profile
- Support for username/password and client certificates authentication
- Support for WS-Federation metadata
- Support for WS-Trust identity delegation
- Extensibility points to customize configuration and user management handling
Disclaimer
I did thorough testing of all features of IdentityServer - but keep in mind that this is an open source project and I am the only architect, developer and tester on the team.
IdentityServer also lacks many of the enterprise-level features like configuration services, proxy support, operations integration etc.
I only recommend using IdentityServer if you also understand how it works (to be able to support it). I am offering consulting to help you with customization and lock down - contact me.Up next is v1 of the Azure version. [Emphasis added.]

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Avkash Chauhan (@avkashchauhan) asked Configuring Remote Desktop settings in Windows Azure Portal cause role status to change, why? on 12/7/2011:
You may have seen that enabling remote access from Windows Azure management portal, you roles changes status as “waiting for host..” or “updating…” or something in between. Here is some information why it happens:
If you need granular remote desktop access control then you can change configuration as:
- Turn on and off RDP as a whole via Microsoft.WindowsAzure.Plugins.RemoteForwarder.Enabled,
- turn on and off RDP for a specific role via Microsoft.WindowsAzure.Plugins.RemoteAccess.Enabled.
- Making any one of the non-enabled RemoteAccess settings blank will prevent user creation at first. If remote access is enabled you can create remote access users later.
Because all of the operation of the remote desktop feature relies on configuration settings, any change to how remote desktop behaves requires a configuration change. When remote desktop settings are modified on the Portal a new service configuration file is generated with the updated remote desktop settings and then applied to the deployment. That’s why you see your roles change to the Updating state.
What you can do is:
- Enable RDP only when needed and disable it.
- Enable RDP from the start of your deployment and create user as and when needed.
Thanks to Windows Azure Team to providing this information.

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Avkash Chauhan (@avkashchauhan) described Handling issues with your startup task in Windows Azure Application in a 12/11/2011 post:
If you experience your Windows Azure application based startup task or OnStart code does not work correctly, here are a few things you can try to investigate this issue:
- Add some of the diagnostics trace messages in your OnStart() function which will be sent to Azure Table Storage.
- You can also add diagnostics code in your startup task batch file which can send these logs to Azure Storage directly.
- Be sure to have Remote Desktop connection is enabled in your role. If you haven’t see the link below:
- Deploy to your Azure application in the staging slot (you sure can deploy to production slot and test the same, here deployment slot is your choice)
- Login to your Azure Application Role Instance using Remote Desktop Setting
- Now go ahead and kill the role host process (Note: Use this step with your test service, using this step with live service will cause service outage)
- For Web Role – WaWebHost.exe
- For Worker Role – WaWorkerHost.exe
- Step #4 will cause app agent to restart your role host process which will launch your startup task and/or onStart code.
- Now you can look for the startup task execution and OnStart trace messages to understand why there were errors.
- You can also open command prompt in the same approot working folder and launch your startup task batch file to see how it behave.
- if you have to execute two separate commands in startup task and there is a dependency between output of first command and execution of the second command, you can use two startup tasks in your application configuration with "Simple" setting this way all of your start up tasks execute in order. Please remember to exit each startup task batch file properly.

Steve Marx (@smarx) posted a PackAndDeploy project to GitHub on 2/9/2011:
This is a simple scaffold for packaging a Windows Azure app that just runs an executable. The example app being executed is mongoose, but anything could take its place, including apps that don't serve up content on port 80.
Usage
- Edit
WorkerRole\run.cmdto do whatever you want. (Typically launch some sort of web server or a worker process. Either way, that process should run indefinitely.)- Run
run.cmdto build and run the application locally.- Run
pack.cmdto outputPackAndRun.cspkg. That file, along withServiceConfiguration.cscfgis what you need to deploy via the Windows Azure portal (or with some other tool) to get the app running in the cloud.
ServiceDefinition.csdefspecifies the following:
- What size of VM to use (
ExtraSmall)- Any input endpoints (
HttpIn)- What command line to run (
run.cmd)- What environment variables to make available to the app (
ADDRESSandPORT)
WorkerRole\run.cmdis just a script to launchmongoose-0.3.exewith the right parameters (passing the address and port from the environment).
start /wis used to ensure thatrun.cmddoesn't prematurely exit. If the mongoose process ever exits, so willrun.cmd. Windows Azure would then consider the role instance to have failed, and it would restart the instance.

Himanshu Singh posted Real World Windows Azure: Interview with Yun Xu, Sr. Director of Business Development at Gridsum to the Windows Azure Blog on 12/9/2011:
As part of the Real World Windows Azure interview series, I talked to Yun Xu, Sr. director of business development at Gridsum about the migration of its Web Dissector service to Windows Azure. Here’s what he had to say.
Himanshu Kumar Singh: Tell me about Gridsum.
Yun Xu: Based in Beijing, China, Gridsum is a member of the Microsoft Partner Network and an independent software vendor that develops online business optimization solutions to help our customers measure and analyze website performance. (Click here to read the full case study about Gridsum and its solution on Windows Azure.)
HKS: What is Web Dissector?
YX: Web Dissector is an online application built on Microsoft ASP.NET and the .NET Framework that captures users’ website behavior and tracks webpage statistics and conversion rates, and then presents the data in an easy-to-use, web-based interface to help customers analyze the effectiveness of their online marketing initiatives.
Customers pay for Web Dissector based on the number of page views their websites receive in a given month. As visitors view webpages, we’re able to monitor site traffic and capture usage data, which we present to customers so that they can fine-tune their website content to meet business goals.
HKS: What markets do you serve?
YX: We’ve traditionally served customers in mainland China but our online business optimization services have grown in popularity. In particular, Web Dissector has captured the interest of companies in other geographies, including Hong Kong, Europe and the United States.
HKS: What challenges did you face in considering a move into markets beyond China?
YX: We wanted to meet increasing demand for Web Dissector and offer the service to customers outside of China but we already had to devote full-time resources to monitor our existing hosted server infrastructure, which was hosted in China on Rackspace. As we continued to grow, we had to add more servers to accommodate new customers. It became increasingly more difficult and time-consuming to manage our growing infrastructure.
We also knew we needed to host its service in global data centers in order to offer our international customers the same high-performance service that we offers our customers in China. We pride ourselves on delivering a zero-downtime network with 24-hour availability. Our services rely on compute-heavy processes, so we needed the ability to host Web Dissector in global data centers to continue delivering a highly available service. Otherwise, if a customer in the United States is retrieving data from an infrastructure hosted in China, they will experience significant latency.
YX: Following an evaluation of cloud computing services through Microsoft’s BizSpark program in January 2011, we decided to move our Web Dissector service to Windows Azure. In February 2011, we completed the move to Windows Azure, which only took a month because of our familiarity with Windows Communication Foundation and ASP.NET. We needed to modify only a small amount of code to make the move.
HKS: How do you leverage Windows Azure for your services?
YX: We use web roles in Windows Azure to host Web Dissector, which enables us to easily add new web roles to scale up its service and accommodate a growing number of users. By using Windows Azure, we can quickly achieve the scalability we need. It’s just as simple as adding new web roles and we don’t have to worry about procuring and configuring new servers. To better serve our global customers, we also use the Windows Azure Content Delivery Network so we can strategically cache Web Dissector to specific Microsoft data centers and put content closer to our customers’ locations.
HKS: What benefits are you seeing as a result of the move to Windows Azure?
YX: As a result of moving our online business optimization solution to Windows Azure, we have been able to simplify infrastructure maintenance, while still providing a high-performance service to global customers and increasing our revenues.
By relying on Windows Azure to host Web Dissector along with other services in the future, we also can serve more customers than we could with its previous hosting provider. In fact, we expect to increase our revenue by at least 30 percent in the next year as a result of expanding our services outside of China. We could not have done that without Windows Azure.
Windows Azure also gives us the ability to deliver highly available services without network latency—even to customers located outside of mainland China. We’ve started expanding to Hong Kong and plan to soon serve customers in the United States and Europe.
Finally, we now have a full-service cloud platform and do not have to spend considerable time managing and maintaining our virtual infrastructure. We don’t have to worry about installing operating system images, upgrading software, applying updates, or configuring security and firewall settings. Windows Azure takes care of all of those issues for us, and as a result, we reduced the time spent on IT maintenance by 30 percent and can focus on more strategic tasks, such as expanding our business.
Read the full case study about Gridsum. Learn how others are using Windows Azure.

David Rubenstein reported Team Foundation Service gets first major update in a 12/8/2011 post to the SD Times on the Web blog:
In September, Microsoft took its ALM solution to the cloud with the announcement at the BUILD Conference of Team Foundation Service. The company today has released the first significant feature update since that initial rollout.
Team Foundation Service is basically Team Foundation Server running on the Azure cloud platform, according to Doug Neumann, Microsoft group program manager for Team Foundation Server. The service, he said, “has the next [version 11] release of TFS bits, but this is accessible anywhere and is not limited to the confines of your corporate network.” Team Foundation Service Preview is available, free of cost, by invitation, which can be requested through tfspreview.com.
Among the highlights of the new release are a simplified navigation model, agile product and project management tools, and a customizable e-mail notification option, Neumann said. “The big investment we made is in a great Web experience. We had been focused on the Visual Studio experience, but with the next release, we made a significant investment in the Web experience in terms of performance and user friendliness.”
The simpler navigation model allows users to “get around” with fewer clicks, while the e-mail option enables users to specify their address (or the addresses of an entire team) and subscribe to different kinds of notifications. Neumann said Microsoft has made this available now because it wanted to make the system as secure as possible to reduce the amount of spam users receive through the system.
The tools for agile product and project management “seem Scrum-ish,” he said, but can be used with multiple agile processes, including homegrown processes. The product-management software gives users the ability to create backlogs and prioritize the items therein, as well as to put estimates or story points on those items to project how many sprints will be required to get those items completed, he explained.
“It’s based on past performance,” said Neumann. Users can drag and drop items from the backlog into a sprint and break the requirements down into a set of tasks, he added. …
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) continued her series with Beginning LightSwitch Part 2: Feel the Love - Defining Data Relationships on 12/8/2011:
Welcome to Part 2 of the Beginning LightSwitch series! In the last post we learned about tables, or entities, in LightSwitch and how to use the Data Designer to define them. If you missed it: Beginning LightSwitch Part 1: What’s in a Table? Describing Your Data
In this article I want to focus on data relationships as we build upon the data model we started in part 1. Relationships define how information in one table corresponds to information in another table in a database. Or more generically, relationships define how an entity corresponds to another entity in (or across) a data source. You can think of relationships between entities like relationships between things in everyday life. For instance, the relationship between a school and its students is one that exists in the real world. Similarly, a real-world relationship exists between students and the classes that those students attend. In a data model, you may have one entity that contains students and another that contains classes they are attending. When you tie the two entities together, you create a relationship.
Building a Better Address Book
In the example we started in part 1, we’re building an address book application that manages contacts. In our current data model, we’re only storing one phone number, one email address and one address for our contact.
However, in real life contacts typically have more than one email, phone number, and address information. In order to model this in the database we are building through LightSwitch, we need to define additional tables and relate them to the contact table in a one-to-many relationship. A one-to-many relationship is probably the most common type of relationship you can define. In our case, this means that one contact can have many email addresses. One contact can have many phone numbers. One contact can also have many physical addresses.
Let’s start with email address. If we want to collect multiple email addresses for a contact we have a couple options. One option is to add a fixed number of email properties to our contact in the form of Email1, Email2, Email3. This means that we would never be able to collect more than 3 email addresses for any given contact. Depending on the type of application you are building this may be just fine. But if you start adding too many properties with the same meaning (in this case email) to your table, then it’s time to think of a different strategy. Instead we should create an EmailAddress table and define a one-to-many relationship.
From the Data Designer, click the “New Table” button and define an entity called EmailAddress with two required properties: Email (of type Email Address) and EmailType (of type String).
For EmailType we’ll create an Choice List, which you learned about in Part 1 of the series. This property will capture the type of email, whether that’s Personal or Work. I’ve also chosen to make the maximum length only 25 characters – we won’t ever need all 255.
Why don’t we make the maximum length 8 characters, which is the length of the longest value in the choice list? Because if we need to add a value to the choice list later that is a little longer than 8 characters, then we won’t have to change the data model. Disk space is cheap these days so it’s better to err on the side of longer max lengths so that all your data can fit into the underlying table. This avoids having to change the data model too often.
Defining Relationships in LightSwitch
Now that we have our EmailAddress entity it’s time to define the relationship. Click on the “Relationship…” button at the top of the Data Designer and this will open up the “Add New Relationship” dialog window. In the “To” column select Contact to set up the one-to-many relationship. The multiplicity is set to Many to One by default so we don’t need to change it. Multiplicity defines the type of relationship you want to create. In LightSwitch, you can also specify the multiplicity as One to Zero or One which means that only a maximum of one related entity would be allowed.
For more information on defining different types of relationships see: How to: Define Data Relationships
For information on how to model a many-to-many relationship in LightSwitch see: How to Create a Many-to-Many Relationship
You can also specify what happens to the email addresses when a contact is deleted. By default, this is set to “Restricted”. This means that a user would not be allowed to delete a Contact if they had any Email Addresses. Leaving the setting makes sense if we were working with Customers who had many Orders, for instance, but not in this case. We want LightSwitch to automatically delete any Email Addresses when we delete the Contact, so set the “On Delete Behavior” equal to “Cascade delete”.
The description at the bottom of the dialog is there to help you understand what you are doing when setting up the relationship. Once you click OK you will see the relationship in the Data Designer which will show all direct relationships to the entity you are working with. Notice that a Contact property is now added to the EmailAddress entity. This is called a navigation property and represents the Contact to which the EmailAddress belongs.
Double-click on the Contact entity to open it and you will notice a navigation property to all the EmailAddresses for that Contact. Navigation properties are used by LightSwitch on screens to navigate through your data, so it’s important to model them correctly.
Now that we’ve got the EmailAddress table defined and a relationship set up, we need to delete the Email property we had previously defined on the Contact itself. Select the Email property and hit the Delete key. Alternatively you can right-click and choose Delete on the menu. Do the same to delete the Address1, Address2, City, State, ZIP and Phone properties as well.
Next, let’s add a PhoneNumber table in the same way we added EmailAddress. You might wonder why we need to create a new table separate from the EmailAddress. This is because an EmailAddress and a PhoneNumber are different aspects of a Contact and have no relation to each other except through the Contact itself. Therefore, we need to create a new table.
Click the “Add Table” button and define the PhoneNumber entity with two required properties: Phone (of type Phone Number) and PhoneType (of type String). PhoneType will have a Choice List of “Cell”, “Fax”, “Home”, and Work”.
Next add the relationship to Contact exactly the same way as before. While the PhoneNumber entity is displayed, click the “Relationship…” button at the top of the Data Designer and specify the relationship to the Contact table.
Last but not least, we need to create an Address table to store multiple physical addresses for a Contact. Click the Add Table button and define the Address entity with the following properties AddressType, Address1, Address2, City, State, ZIP. Set the AddressType and Address1 properties as required. We will also specify a Choice List for the the AddressType property with values “Home”, “Work”, and “Other”.
Now set up the relationship for Address exactly as before. While the Address entity is displayed, click the “Relationship…” button and specify the relationship to the Contact table. Again we’ll choose “Cascade delete” so that any Addresses are deleted automatically if a Contact is deleted. This makes sense in the case of Contact because if the user deletes the contact from the system all their information should be automatically deleted. Keep in mind, however, that you may not want this behavior in other applications. For instance if you are building an order entry application you would want to restrict deletion of Customers if they had any Orders in the system in order to keep the Order history intact.
Now when we open the Contact entity in the Data Designer you can see all the direct relationships.
Testing the Address Book
Now that we have the data model designed, let’s quickly test it out by creating a screen. At the top of the Data Designer click the “Screen…” button to open the Add New Screen dialog. We’ll talk more about screens in a future post but for now just select the List and Details screen. Then drop down the Screen Data and select Contacts. Once you do this, you will see checkboxes for the additional related entities we created. Select all of them and click OK.
To build and launch the application hit F5. Now you can enter information using this screen. Click the “+” button on the top of the list box on the left to add new contacts.
Notice that LightSwitch read all the one-to-many relationships we set up in our data model and created a tabbed section of grids below the Contact details for Email Addresses, Phone Numbers and Addresses just like we would expect. The grids are editable by default so you can just type the related data directly into the rows.
Because we defined the relationships properly in our data model, LightSwitch was able to create a very usable screen for entering our data into all the tables in our database without much work at all. In the next post we’ll dive deeper into the Screen Templates and how to customize the layout of screens. Until next time!














Matt Thalman (@matt_tman) described Creating a Custom Login Page for a LightSwitch Application in a 12/8/2011 post to his From the Depths blog:
When configuring a Visual Studio LightSwitch application to use Forms authentication, the application user is prompted with the following login UI when they open the application:
LightSwitch doesn’t have not have built-in support for customizing this UI. However, since LightSwitch is an ASP-NET based application you can use the features in ASP.NET to workaround this. What I’m going to demonstrate here is how to create an ASPX page that will authenticate the user when they open the app. Since you write the content of the ASPX page, you get to control exactly how it looks to the user. But I’ll make it easy for you by providing some sample markup that you can use and customize.
NOTE:
These instructions are for creating a custom login page for Web-based LightSwitch applications (meaning, the application is hosted within the browser). There isn’t a way to create a custom login page for a Desktop LightSwitch application. In addition, these instructions assume that you have Visual Studio Professional or higher installed in addition to LightSwitch. This isn’t necessarily required, but it makes the task of adding ASPX files to the project simpler; otherwise, you’d have to do this by hand which I won’t be describing in this post.First, let’s start with a brand new LightSwitch project and open up the application properties window:
In the application properties window, select the Access Control tab and enable Forms authentication:
Select the Application Type tab and change the client type to Web:
Now switch Solution Explorer into File View in order to manage the physical files that make up a LightSwitch application:
Next, click the “Show All Files” toolbar button. This shows all the hidden files within the project.
This is what the resulting project looks like now:
Add a new ASPX page to the ServerGenerated project by selecting the ServerGenerated project and hit Ctrl+Shift+A. Then select “Web Form” from the Web node and change the filename to “Home.aspx”. Click the Add button.
Follow the same steps again to add another ASPX file but name this one “Login.aspx”. You should now have two ASPX files in your ServerGenerated project:
Open Login.aspx and paste over the existing markup with the following:
C#:
<%@ Page Title="Log In" Language="C#" AutoEventWireup="true" CodeBehind="Login.aspx.cs" Inherits="LightSwitchApplication.Login" %> <form id="Form1" runat="server"> <div style="text-align:center"> <!— Add an optional image by replacing this fake image URL with your own –> <!--<asp:Image runat="server" ImageUrl="http://contoso.com/logo.gif" />--> <asp:Login runat="server" BackColor="#F7F6F3" BorderColor="#E6E2D8" BorderPadding="4" BorderStyle="Solid" BorderWidth="1px" Font-Names="Verdana" Font-Size="0.8em" ForeColor="#333333"> <InstructionTextStyle Font-Italic="True" ForeColor="Black" /> <LoginButtonStyle BackColor="#FFFBFF" BorderColor="#CCCCCC" BorderStyle="Solid" BorderWidth="1px" Font-Names="Verdana" Font-Size="0.8em" ForeColor="#284775" /> <TextBoxStyle Font-Size="0.8em" /> <TitleTextStyle BackColor="#5D7B9D" Font-Bold="True" Font-Size="0.9em" ForeColor="White" /> </asp:Login> </div> </form>VB:
<%@ Page Title="Log In" Language="vb" AutoEventWireup="true" CodeBehind="Login.aspx.vb" Inherits=".Login" %> <form id="Form1" runat="server"> <div style="text-align:center"> <!— Add an optional image by replacing this fake image URL with your own –> <!--<asp:Image runat="server" ImageUrl="http://contoso.com/logo.gif" />--> <asp:Login runat="server" BackColor="#F7F6F3" BorderColor="#E6E2D8" BorderPadding="4" BorderStyle="Solid" BorderWidth="1px" Font-Names="Verdana" Font-Size="0.8em" ForeColor="#333333"> <InstructionTextStyle Font-Italic="True" ForeColor="Black" /> <LoginButtonStyle BackColor="#FFFBFF" BorderColor="#CCCCCC" BorderStyle="Solid" BorderWidth="1px" Font-Names="Verdana" Font-Size="0.8em" ForeColor="#284775" /> <TextBoxStyle Font-Size="0.8em" /> <TitleTextStyle BackColor="#5D7B9D" Font-Bold="True" Font-Size="0.9em" ForeColor="White" /> </asp:Login> </div> </form>For more details on how to customize the Login control to suit your needs, see the following MSDN article: Customizing the Appearance of ASP.NET Login Controls.
For the Home.aspx page, you can leave the default markup code since this page will never be visible by the user. We’re only going to use it as a redirection mechanism.
NOTE:
This redirection logic is only needed to workaround an issue in LightSwitch V1 where it will remove from the web.config file at publish-time a configuration setting that will deny anonymous users access. If you have the ability to modify your web.config file after the app has been published, you can configure it to deny anonymous users by adding the following to the system.web section of the web.config file:<authorization> <deny users="?"/> </authorization>If you end up doing this, the Home page described in this blog post would not be necessary within your site.
To setup the redirection logic, open up the code-behind for the Home page, Home.aspx.cs, and replace its contents with the following code:
C#:
using System; using System.Web.Security; namespace LightSwitchApplication { public partial class Home : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { if (!this.User.Identity.IsAuthenticated) { FormsAuthentication.RedirectToLoginPage(); } else { this.Response.Redirect(FormsAuthentication.DefaultUrl); } } } }VB:
Imports System.Web.Security Public Class Home Inherits System.Web.UI.Page
Protected Sub Page_Load(ByVal sender As Object, ByVal e As System.EventArgs) _ Handles Me.Load If Not Me.User.Identity.IsAuthenticated Then FormsAuthentication.RedirectToLoginPage() Else Me.Response.Redirect(FormsAuthentication.DefaultUrl) End If End Sub
End ClassNext, we need to configure the default page for the site to use this new Home page. Open the web.config file contained in the ServerGenerated folder. It will have a section that looks like this:
<defaultDocument> <files> <clear /> <add value="default.htm" /> </files> </defaultDocument>To configure the new default page, change “default.htm” to “Home.aspx”.
In addition, we need to configure default.htm to be the page that is redirected to after a successful login. To do this, find the forms element in the web.config file and add the bolded text:
<authentication mode="Forms"> <forms name="CustomLoginApp" defaultUrl="default.htm" /> </authentication>The last step is to configure the main LightSwitch project to be aware of the new ASPX files that were added so that they will be published along with the app. To do this, unload the main LightSwitch project:
With the project unloaded, open the physical .LSPROJ file in the IDE:
Do a search for “_BuildFile” and append the following text within that section of the file:
<_BuildFile Include="ServerGenerated\Login.aspx"> <SubFolder> </SubFolder> <PublishType> </PublishType> </_BuildFile>
<_BuildFile Include="ServerGenerated\Home.aspx"> <SubFolder> </SubFolder> <PublishType> </PublishType> </_BuildFile>Reload the LightSwitch project:
Your LightSwitch app is now configured to use your new custom Login page. When you publish your app and connect to it, you’ll be redirected to your login page. After successfully logging in, you’ll be redirected to the LightSwitch app.













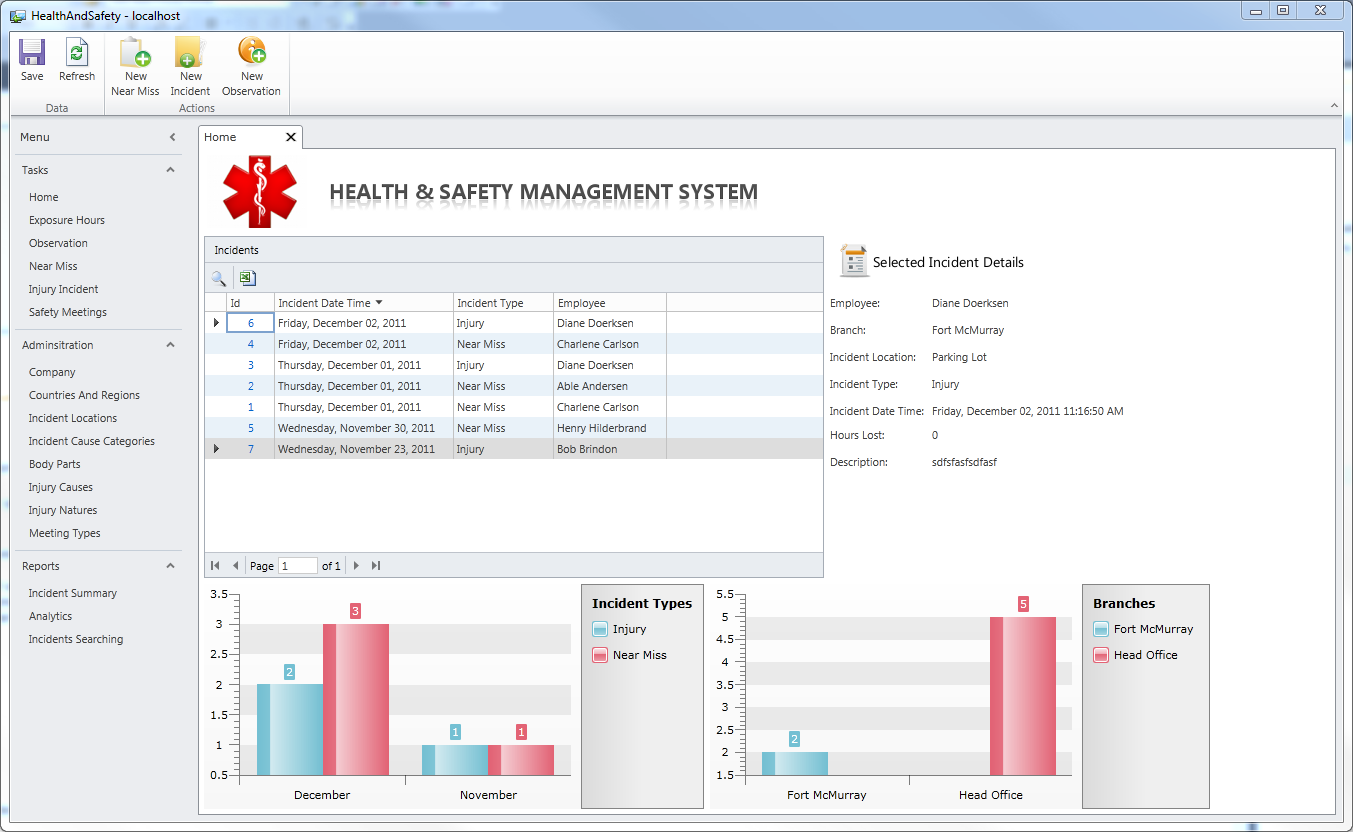
Paul Patterson posted his The Health and Safety Management System - Created with LightSwitch project on 12/8/2011 as an entry in The Code Project’s LightSwitch Star contest:
Hello all! As part of the ever growing number of LightSwitch Star contest participants, here is my submission of an example of what is possible with LightSwitch. Hope you find some useful information her, or at least get inspired to give LightSwitch a try yourself.
Enjoy...
Health & Safety Management System
A solution created with Microsoft Visual Studio LightSwitch.
Introduction
What does your application/extension do? What business problem does it solve?
The Health and Safety Management System is an application that is used to help organizations better manage and mitigate health and safety statistics and KPIs. The solution is designed to empower users with a tool that can be used to capture and report on finely grained health and safety performance metrics.
Workplace safety is serving an ever increasing role with many organizations. Companies are now being held accountable to, not just their own internal stakeholders such as employees and shareholders, but also other external stakeholders such as customers, vendors, and suppliers. Whether it is for internal corporate health and safety concerns, or performance metrics such as KPIs, organizations are putting more and more visibility into health and safety concerns.
Companies are now asking for health and safety accountability from their partners, often before engaging in a relationship. For example, large energy industry companies make it a prerequisite that their vendors have a health and safety program in place with proper record keeping and reporting. Often these relationships include contractual obligations which require the vendor to provide regular health and safety reporting; especially when performing work on a customer work-site.
The Health and Safety Management System has been designed to provide an organization with the means to capture and report on key health and safety metrics. The key value propositions for the Health and Safety Management System include;
- Granular health and safety information gathering, such as;
- Observations - capturing data that identifies health and safety threats and opportunities,
- Near Miss Incidents - incidents that occur and do not result in an injury or time loss, And
- Injury and Time Loss Incidents - managing details about injuries and time loss.
- Flexible and intuitive user configurable reporting, including;
- Several "canned" and built-in reports that can be optionally printed or exported to various formats such as Excel or PDF.
- Powerful OLAP analytics that are highly customizable.
- Flexible user defined querying that can optionally be saved, reloaded, printed, or exported.
- Highly configurable, and is easily customizable for each customer.
- Can be quickly integrated with existing organization systems; such as legacy customer or human resources ERP systems.
- Can be deployed to either the desktop, web, or the cloud.
How many screens and entities does this application have?
Currently, the Health and Safety Management System has;
- 19 screens that provide standard data entry interfaces as well as for various administration tasks such as lookup or reference tables, reporting and analytics, and security, And
- 23 entities (tables).
Did LightSwitch save your business money? How?
LightSwitch provided the means to build the solution very quickly. The quality of the solution matches that of an enterprise class solution that would have taken a great deal of more time and effort to create using other, more common, technologies.
Getting to market quickly is key, as is the quality of the offering. With LightSwitch, a solution can be created using technologies and proven software development best practices. The quality of the solution is something that is automatically applied when using LightSwitch. Enabling the scenarios and requirements was easy using the template based tasks.
Would this application still be built if you didn’t have LightSwitch? If yes, with what?
The solution concept was already on-the-table well before any consideration was being made regarding the technology to use for it. Consideration was made for using one or more technologies, including; ASP.Net MVC, HTML5/JSON, SQL Server, and WCF.
Again, as mentioned earlier, LightSwitch makes for a much faster turnaround in delivery time. Using relatively traditional development technologies would result in much more time before delivering on requirements.
How many users does this application support?
As many as us required. There are no known constraints to suggest that the solution could not be deployed in a large enterprise.
How long did this application take to actually build using LightSwitch?
As of the time of this writing, the solution took only a few days to build. It is estimated that the actual total hours of effort would be 18.
Does this application use any LightSwitch extensions? If so, which ones? Did you write any of these extensions yourself? If so, is it available to the public? Where?
The Health and Safety Management System uses a number of extensions and custom controls. These include:
- Telerik Silverlight Controls - Charting (www.telerik.com/products/silverlight)
- DevExpress LightSwitch Extensions - Reporting (www.devexpress.com/Products/NET/Controls/LightSwitch/
- ComponentOne LightSwitch OLAP Extension - Analytics (www.componentone.com/lightswitch/)
- Microsoft LightSwitch Extensions - Business Entities and Query Filter control (code.msdn.microsoft.com)
A key success factor of the development of this solution is to utilize existing extensions and tools whenever possible. The goal was to deliver on requirements as quickly as possible. Using existing tools offered the opportunity to enable scenarios without having to "reinvent the wheel".
How did LightSwitch make your developer life better? Was it faster to build compared to other options you considered?
LightSwitch made a remarkable impact on the developer experience when using LightSwitch for this solution. The investment in effort and time was considerably less than what it would have taken using the other considered technologies.
Links, Screenshots, Videos
Links
- www.paulspatterson.com My Blog where I talk about all things that are LightSwitch goodness ...
See original post for Screenshots.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
Wade Wegner (@WadeWegner) posted Cloud Cover Episode 67 - Technical Computing with Windows Azure and Wenming Ye on 9/10/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show at @CloudCoverShow.
In this episode, Wade is joined by Wenming Ye—Technical Evangelist for Windows Azure—who explains how to use HPC on Windows Azure. Wenming shows how you can use Windows Azure to process massive amounts of work without having to own a Cray computer (even though he himself has three).

David Linthicum (@DavidLinthicum) described How to Manage Capacity in a Cloud Computing World in a 12/9/2011 guest post to the CloudSleuth blog:
I did a keynote presentation for the Computer Measurement Group (CMM) conference held near me in DC this week. My talk was entitled “Capacity Management in a Cloud Computing World.” You can find the slides here, and they even cite our host as a good way to find the metrics you need to do capacity management for cloud-based resources.
Capacity management is really about creating an approach and plan to assure the business that there will be just enough capacity going forward to, well, run the business. The typical actions are to create complex performance and capacity models to make sure the performance and capacity will be there when you need it.
So, what changes in terms of capacity management in the emerging world of cloud computing? A few things come to mind.
• We can no longer assume that computing capacity is dedicated to a group of users or a group of processes. Everything in a cloud computing environment is shared using some sort of multitenant model. This makes capacity modeling and planning much more complex.
• Auto provisioning makes some aspects of capacity planning not as important since capacity can be allocated when needed. However, cost is a core driver for leveraging cloud computing, and using capacity that’s not needed reduces the value of cloud computing.
• We now have the option to leverage cloud computing systems as needed to cost effectively provide temporary capacity. Called “cloud bursting,” this type of architecture was difficult to cost justify until cloud computing provided us with a cheaper “public” option.Capacity planning and performance monitoring in the emerging world of cloud computing add complexity to existing procedures. It’s really about modeling capacity and performance in a world that shares and distributes more resources.
The only way to do this is to understand the history of a specific cloud computing provider. And the only way to do that is to leverage a cloud performance application to understand both the current state of a cloud computing provider, but also the performance history over a given period of time.
Using this information, we’re able to more accurately determine the capacity of a cloud computing provider, smoothing through the performance spikes and valleys over time. This means we can more accurately model for performance, and thus capacity.
There are really no easy answers here. Cloud computing platforms are shared platforms, thus performance will vary over time given the loads and how well the cloud provider manages the service. Thus, if we plan to move to cloud computing, we better figure out pretty quickly how to manage and deal with the performance characteristics, which are, in many respects, random and dynamic.
When it comes to cloud computing and performance and capacity management, many of the rules are changing, but just as many remain the same. The need for a sound capacity planning exercise continues to add a great deal of value, and removes many risks.

David Linthicum (@DavidLinthicum) asserted “Resources have different availability and costs in the cloud, and the models don't yet reflect that variation” as a deck for his How capacity management changes in the cloud article of 12/8/2011 for InfoWorld’s Cloud Computing blog:
Capacity management is all about creating a plan assuring the business there will be just enough volume (servers, storage, network, and so on) for critical applications and data when needed. This means creating complex performance and power models to make sure you're neither spending too much nor too little money on IT infrastructure.
But what changes for capacity management in the emerging world of cloud computing? A few things come to mind.
- You can no longer assume that computing capacity is dedicated to a group of users or a group of processes. Everything in a cloud computing environment is shared using some sort of multitenant model. This complicates capacity modeling and planning.
- With autoprovisioning, some aspects of capacity planning decrease in importance because capacity can be allocated as needed. However, because cost is a core driver for the use of cloud computing, using capacity that's not needed reduces the cloud's value.
- You can use cloud computing systems as needed to cost-effectively provide temporary capacity. Called "cloud-bursting," the cost of this type of architecture has been difficult to justify until cloud computing provided a cheaper "public" option.
The bad news: Cloud computing providers and the use of cloud computing in enterprises will make the process of capacity planning much more complex. The modeling approaches and technologies are changing to accommodate these added complexities, but many capacity-planning professionals need to update their skills.
The good news: Cloud computing providers will provide more performance and capacity monitoring and management services as time goes on. Their users are demanding them, so those charged with managing capacity and performance will have better interfaces for their tools.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Kristian Nese (@KristianNese) explained how to Make VM Highly Available (VMM 2012) in a 12/11/2011 post:
I get alot of hits on my blog when people search for «how to make existing VMs highlyavailable» or «make VM highly available» etc. And they usually end up with the following post: http://kristiannese.blogspot.com/2010/10/how-to-make-your-existing-vms-highly.html
In VMM2012, this is now easier than ever.
1. First.If you have a VM that is located on some local storage on your Hyper-V host,you can verify this by looking at the hardware for this virtual machine. Select the VM, click properties and navigate to the hardware tab.
2. Shutdown your VM since VMM actually will do an export/import (yes, the same as you could do with Hyper-V Manager), right click your VM and select Migrate Virtual Machine
3. Payattention to this screen shot. You only need to mark the “Make this VM highlyavailable” option, and VMM will trigger the export/import process.
4. You can also specify CSV and the location for your VHD`s
5. VMM will now take care of the rest and do what`s required so that your VM can be highly available. You can also choose to start the VM after the job is done
For more information about the migration options in VMM 2012, check out this post: http://kristiannese.blogspot.com/2011/11/explaining-migration-options-in-vmm.html






Kristian Nese (@KristianNese) described Distributed Key Management (DKM) in VMM 2012 in a 12/11/2011 post:
I was recently asked if I could write a blog post about the Distributed Key Management in VMM 2012.
Fair enough, and it’s worth mention[ing] since it’s required when you’re installing a Highly Available VMM server.
But why write something that someone else already has written in detail?
You guessed it! [Excised] wrote about this earlier this year. [Emphasis added]
Read his blog post here: VMM 2012Distributed Key Management (DKM)

Lydia Leong (@cloudpundit) warned Beware misleading marketing of “private clouds” in a 12/9/2011 post:
Many cloud IaaS providers have been struggling to articulate their differentiation for a while now, and many of them labor under the delusion that “not being Amazon” is differentiating. But it also tends to lead them into misleading marketing, especially when it comes to trying to label their multi-tenant cloud IaaS “private cloud IaaS”, to distinguish it from Those Scary And Dangerous Public Cloud Guys. (And now that we have over four dozen newly-minted vCloud Powered providers in the early market-entrance stage, the noise is only going to get worse, as these providers thrash about trying to differentiate.)
Even providers who are clear in their marketing material that the offering is a public, multi-tenant cloud IaaS, sometimes have salespeople who pitch the offering as private cloud. We also find that customers are sometimes under the illusion that they’ve bought a private cloud, even when they haven’t.
I’ve seen three common variants of provider rationalization for why they are misleadingly labeling a multi-tenant cloud IaaS as “private cloud”:
We use a shared resource pool model. These providers claim that because customers buy by the resource pool allocation (for instance, “100 vCPUs and 200 GB of RAM”) and can carve that capacity up into VMs as they choose, that capacity is therefore “private”, even though the infrastructure is fully multi-tenant. However, there is always still contention for these resources (even if neither the provider nor the customer deliberately oversubscribes capacity), as well as any other shared elements, like storage and networking. It also doesn’t alter any of the risks of multi-tenancy. In short, a shared resource pool, versus a pay-by-the-VM model, is largely just a matter of the billing scheme and management convenience, possibly including the nice feature of allowing the customer to voluntarily self-oversubscribe his purchased resources. It’s certainly not private. (This is probably the situation that customers most commonly confuse as “private”, even after long experience with the service — a non-trivial number of them think the shared resource pool is physically carved off for them.)
Our customers don’t connect to us over the Internet. These providers claim that private networking makes them a private cloud. But in fact, nearly all cloud IaaS providers offer multiple networking options other than plain old Internet, ranging from IPsec VPN over the Internet to a variety of private connectivity options from the carrier of your choice (MPLS, Ethernet, etc.). This has been true for years, now, as I noted when I wrote about Amazon’s introduction of VPC back in 2009. Even Amazon essentially offers private connectivity these days, since you can use Amazon Direct Connect to get a cross-connect at select Equinix data centers, and from there, buy any connectivity that you wish.
We don’t allow everyone to use our cloud, so we’re not really “public”. These providers claim to have a “private cloud” because they vet their customers and only allow “real businesses”, however they define that. (The ones who exclude net-native companies as not being “real businesses” make me cringe.) They claim that a “public cloud” would allow anyone to sign up, and it would be an uncontrolled environment. This is hogwash. It can also lead to a false sense of complacency, as I’ve written before — the assumption that their customers are good guys means that they might not adequately defend against customer compromises or customer employees who go rogue.
The NIST definition of private cloud is clear: “Private cloud. The cloud infrastructure is provisioned for exclusive use by a single organization comprising multiple consumers (e.g., business units). It may be owned, managed, and operated by the organization, a third party, or some combination of them, and it may exist on or off premises.” In other words, NIST defines private cloud as single-tenant.
Given the widespread use of NIST cloud definitions, and the reasonable expectation that customers have that a provider’s terminology for its offering will conform to those definitions, calling a multi-tenant offering “private cloud” is misleading at best. And at some point in time, the provider is going to have to fess up to the customer.
I do fully acknowledge that by claiming private cloud, a provider will get customers into the buying cycle that they wouldn’t have gotten if they admitted multi-tenancy. Bait-and-switch is unpleasant, though, and given that trust is a key component of provider relationships as businesses move into the cloud, customers should use providers that are clear and up-front about their architecture, so that they can make an accurate risk assessment.

Tom Nolle (@CIMICorp) asserted Hybrid cloud: The best of public and private clouds in a 12/7/2011 post to the SearchCloudComputing.com blog:
While the term “private cloud” means custom cloud technology for enterprises, most believe their own data centers already provide private clouds services. Since these companies also expect to adopt at least some public cloud services, the next step clearly is to build a hybrid cloud.
But if hybridization isn’t a partnership between a public cloud and a private cloud that are built on common technologies, how does it happen? Companies expect worker application experiences to be transparent to where the application runs, which means either the experiences or the applications must be integrated in a hybrid cloud regardless of how the “private” portion is created.
A hybrid cloud’s success begins by selecting the right integration method.
Building a hybrid cloud with a front-end application
The dominant strategy in creating a hybrid cloud that ties traditional data centers with public cloud services involves the use of a front-end application. Most companies have created Web-based front-end applications that give customers access to order entry and account management functions, for example. Many companies have also used front-end application technologies from vendors like Citrix Systems Inc. to assemble the elements of several applications into a single custom display for end users. You can use either of these front-end methods to create a hybrid cloud.In front-end application-based hybrid models, applications located in the cloud and the data center run normally; integration occurs at the front end. There are no new or complicated processes for integrating data or sharing resources between public and private clouds.
The application front-end integration method can be used with all three public cloud models—Infrastructure as a Service (IaaS), Platform as a Service (PaaS) and Software
Show Me More
- More on Cloud computing and virtualization
- Get help from the community
- Powered by ITKnowledgeExchange.com
as a Service (SaaS). If a new application is cloudsourced or an existing application is moved from the cloud back into the data center, you can easily alter the front-end application and transfer data from the new location.
Using the integrated workflow model for hybrid clouds
The front-end application-based hybrid cloud model has some limitations; it doesn’t allow for resource sharing between the data center and the public cloud. A user sees a composite view of applications, but each runs independently. If an admin wants the public cloud to back up critical applications or provide overflow capacity in peak periods, admins should use the integrated workflow model.To create an integrated workflow model, you can use either enhance virtualization software with cloud resource management components such as vCloud from VMware, or expand the resource-allocation tools associated with most SOA platforms -- Microsoft, Oracle and IBM offer this capability -- to recognize cloud-hosted resources as well as those located in the data center.
All distributed-workflow models for hybrid cloud presume that some element monitors resource availability and assigns resources to tasks as needed. This process will move applications and components within and between the cloud and data center, so it requires a directory function to link a dynamic application’s location to end users.
It’s also essential to ensure the data that applications need is available in the data center and the cloud. This, according to enterprises, is the most problematic issue with distributing workflow in hybrid clouds. Relatively static data can be hosted in both locations, but dynamic data access requires that data center applications and cloud applications are connected to a common repository.
Tightly coupled workflows magnify any delays the communication connection creates between the enterprise data center and the public cloud; this connection will be more costly if you need to improve performance and reduce delays. Any additional costs could limit the value of a hybrid model for some companies; however, Windows Azure is moving toward an integrated workflow model, and it is likely that most PaaS clouds will follow suit.
Nontraditional hybrid cloud: VPN-integrated access
A third way to build a hybrid cloud is by using a VPN-integrated access mode in which public cloud and data center resources are connected to the corporate VPN, allowing end users to access them independently. For some, this isn’t a true hybrid cloud model because the cloud and the data center remain completely independent. But many businesses don’t provide an integrated view of their internal applications, and the VPN-integrated hybrid cloud model replicates their current practices.VPN integration is usually the cheapest and easiest of the three hybrid cloud models. When enterprises examine the practical business costs and benefits of public cloud, they often find it’s most suitable for niche applications that don’t access the company’s core data.
Hosting customer relationship management (CRM) applications as well as payroll, personnel, communications and collaboration apps in the cloud doesn’t require admins to integrate any data or application. It allows companies to focus IT hardware and software investments on core, business-critical applications.
Picking the winning hybrid cloud model
To choose the most appropriate hybrid cloud model, you need to determine which applications can be cloudsourced from a financial perspective. If these applications don’t use large quantities of mission-critical data, then any of the three hybrid approaches will work. However, either the front-end model or the VPN-integrated model will be the most effective, quickest to adopt and least expensive option.The workflow integration model is a better choice for enterprises that have cloud applications that must access core data. In such instances, this option can be more cost effective and secure.
All three of these hybrid cloud models will work with any data center applications -- whether or not they use cloud-specific technology. Enterprises could safely adopt either model and develop it as the company advances its private cloud strategy and expands public cloud usage. That’s a win-win for the cloud.

Full disclosure: I’m a paid contributor to SearchCloudComputing.com.
<Return to section navigation list>
Cloud Security and Governance
The SearchCloudSecurity.com blog reported Federal officials launch cloud computing security standards initiative in a 12/8/2011 post:
The Obama Administration on Thursday launched a program that establishes cloud computing security standards designed to make it easier for federal agencies to assess and acquire cloud services.
The Federal Risk and Authorization Management Program (FedRAMP), developed over the past two years in collaboration with local governments, academia and private industry, sets a standard approach to security assessment, authorization and continuous monitoring for cloud products and services, which every agency will be required to use, Federal CIO Steven VanRoekel said in a blog post.
“This approach uses a ‘do once, use many times’ framework that will save cost, time and staff required to conduct redundant agency security assessments so no one has to reinvent the wheel,” he said.
Agencies spent “hundreds of millions of dollars on these types of activities” last year, he said. With FedRAMP, the government can save 30% to 40% of these costs, he estimated.
VanRoekel issued a memo to federal CIOs that formally established FedRAMP, described its key components, defined agency responsibilities in maintaining the program, and set requirements for agencies using it.
FedRAMP, which includes standardized contract language, will reduce duplicative efforts, inconsistencies and cost inefficiencies, he said. The program will allow the federal government to speed “the adoption of cloud computing by creating transparent standards and processes for security authorizations and allowing agencies to leverage security authorizations on a government-wide scale,” VanRoekel said.
Within 30 days, the CIO Council is scheduled to publish a baseline of security and privacy controls, as well as controls selected for continuous monitoring included within the FedRAMP requirements. The program will begin operations within 180 days.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com, a sister publication to TechTarget’s SearchCloudSecurity.com blog.
<Return to section navigation list>
Cloud Computing Events
James Staten (@staten7) posted Shining The Harsh Light On Cloud Washing to his Forrester blog on 12/8/2011:
For years I have been railing about cloud washing -- the efforts by vendors and, more recently, enterprise I&O professionals to give a cloud computing name to their business-as-usual IT services and virtualization efforts. Now, a cloud vendor, with tongue somewhat in cheek, is taking this rant to the next level.
Appirio, a cloud integration and customization solution provider, has created the cloud computing equivalent of the Razzie Awards to recognize and call out those vendors it and its clients see as the most egregious cloud washing offenders. The first annual Washies will be announced next Wednesday night at The Cigar Bar in San Francisco, and in true Razzie tradition, the nominees are invited to attend and pick up their dubious honors in person. I'm betting that Larry Ellison will be otherwise engaged.
While some will be offended to be nominated, the recognition here is meant to be a bit of a roast to those marketing ahead of their capabilities as well as a fun way to help spread market education about what truly is (and is not) cloud computing. It's understandable why the vendors who cloud wash their solutions do it, as the word can get you a meeting with a key customer and that customer at the end of the day may turn out not to need cloud at all and thus end up buying that vendor's traditional IT solution. Same with I&O pros. If calling your virtualized server environment cloud gets executive pressure off so you can better plan a real cloud strategy, mission accomplished. But this practice creates market confusion and can ultimately hurt the offender as their credibility takes a hit in comparison to true cloud efforts. I&O teams that claim private cloud for their VMware environment and aren't delivering self-service, cloud economics or automation risk losing the trust with their developers who may just turn up their noses at IT and go straight to the public cloud. Try selling them on your true private cloud after that.
As I pointed out in my 2012 cloud computing predictions, the window in which you can get away with cloud washing, is closing fast. The Washies help close this window by bringing such miscommunications out into the light.
Want to get in on the action? You can place your vote for the winners in five categories between now as Tuesday of next week at http://www.cloudwashies.com. Vote today and come blow a raspberry at the winners at the ceremony.


I wouldn’t be surprised to see Oracle receive a Razzie. See my Oracle Offers Database, Java and Fusion Apps Slideware in Lieu of Public Cloud post of 9/4/2011.
Eric Nelson (@ericnel) posted Live from Microsoft Redmond: Learn Windows Azure Tues Dec 13th 5pm to 1am UK time (9:00 AM to 5:00 PM PST) on 12/8/2011:
This online event promises to be a great way to spend a Tuesday evening with Microsoft technical leaders Scott Guthrie, Dave Campbell and Mark Russinovich
and… if you are UK based, why not also sign up for Six Weeks of Windows Azure, starting January 23rd 2012 and all completely FREE.
We will cover the following topics at the Learn Windows Azure event on Tuesday:
5:00p.m. – Getting Started with Windows Azure
Learn how to get started building applications for Windows Azure with the Windows Azure SDK & Tools from Microsoft Corporate VP Scott Guthrie.
6:45p.m. – Cloud Data & Storage
Join Microsoft Technical Fellow Dave Campbell and learn how to use SQL Azure and Windows Azure storage services in your cloud applications.
8:15p.m. – Channel9 Cloud Cover Show Live
Join Steve Marx and Wade Wegner for this special live edition to see some fresh Windows Azure demos and hear answers to common Windows Azure questions.
9:30p.m. – Developing Windows Azure Applications with Visual Studio
In this session, Jay Schmelzer will show you how to use Visual Studio to its full potential to develop, debug, and deploy cloud applications.
10:45p.m. – Building Scalable Cloud Applications
Do you want to build applications that are highly scalable, loosely coupled, and highly available? Then tune in for this session to learn about key Windows Azure services and patterns from David Aiken.
12:00a.m. – Expert Panel Q&A featuring Scott Guthrie, Dave Campbell, and Mark Russinovich!
Submit your questions over Twitter with the #WindowsAzure hashtag and have them answered live during the event by senior Microsoft engineering leaders.
Related Links:
- Detailed overview of Six Weeks of Windows Azure and FAQ.
- Signup for Six Weeks of Windows Azure

Don’t miss it! Subtract 8 from GMT above for PST.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Matthew Weinberger (@M_Wein) reported HP, Microsoft Partner on Cloud Services Delivery Strategy in a 12/9/2011 post to the TalkinCloud blog:
HP and Microsoft have signed a four-year deal under which HP Enterprise Services will resell and deliver a wide range of Microsoft public, private and hybrid cloud solutions — including Microsoft Office 365.
As per the official press release, HP will be wrapping the Microsoft products in its own branded value-added services. To be more precise:
- Private cloud solutions include HP Enterprise Cloud Services – Messaging, HP Enterprise Cloud Services – Collaboration and HP Enterprise Cloud Services – Real-Time Collaboration. But what HP’s really offering is Microsoft Exchange Server 2010, SharePoint Server 2010 and Lync Server 2010, hosted from one of its dedicated “private” clouds at a data center.
- For the public cloud market, HP will resell Microsoft Office 365, but Microsoft still will handle delivery.
- But for customers who want hybrid solutions, HP will offer the aforementioned private cloud products integrated with Microsoft Office 365, which includes multitenant cloud-hosted versions of the same.
Initial availability later this month for these joint HP/Microsoft cloud solutions will be limited to the United States, United Kingdom, Canada and Australia. HP is promising a global rollout down the line.
It’s obvious what HP gets out of this: While moves such as the adoption of the OpenStack cloud platform have given rise to the HP Instant-On Enterprise concept, it still lacks a real collaboration solution of its own. Partnering with longtime industry ally Microsoft only makes sense in that regard.
As for Microsoft, its VP of the Enterprise Partner Group Mark Hill spelled it out in that release:
“Microsoft is committed to putting the unique and ever-evolving needs of customers at the core of cloud innovation. This alliance with HP not only broadens Microsoft’s geographic reach, it gives customers maximum flexibility to choose a cloud computing solution that meets their organization’s specialized messaging and collaboration needs.”
I’ve expressed a lot of skepticism about Microsoft Office 365 and its channel play. But it seems to be building plenty of momentum within the cloud services channel and without, and when two titans such as HP and Microsoft team up, you know there are going to be ripples.
Read More About This Topic
See my A First Look at HP Cloud Services post of 12/7/2011 for details of HP Cloud Services.
Jeff Barr (@jeffbarr) announced Amazon S3 - Multi-Object Delete in a 12/9/2011 post:
Amazon S3's new Multi-Object Delete gives you the ability to delete up to 1000 objects from an S3 bucket with a single request. If you are planning to delete large numbers of objects from S3 then you can quickly do so by using Multi-Object Delete. You can also delete object versions (in buckets where S3 object versioning has been enabled) by including Version Ids in the request.
Net-Net: Your application will make fewer calls to S3, each call will do more work, and the application will probably run faster as a result. Overall performance gains will vary depending on network latency between your client application and Amazon S3 and the number of objects in the request.
Multi-Object Delete provides you two response modes – verbose and quiet. The default XML response to a Multi-Object Delete request will include a status element (<Deleted> or <Error>) for every object. You can enable Quiet mode in the request if all you need are the <Error> elements.
We have updated the AWS SDKs for Java, Ruby, PHP, and .NET and you can get started today.
You can read more about this new function in the S3 documentation.
Update: Products with support for this new feature include CloudBerry Explorer and Bucket Explorer.


The Datanami blog reported Red Hat Throws Cap into Big Data Storage Arena in a 12/9/2011 post:
This week Red Hat released a scale-out storage product designed to contend with unstructured data, marking another move outside of what one might consider their main bread and butter, although then again, Red Hat has never settled for merely pitching their open source mainstay.
By leveraging their Gluster storage buy in October and using Linux to back the solid technology, the Red Hat Storage Appliance could bring the company even further into the fold of many enterprise shops. This appliance, which is built on GlusterFS 3.2 and Red Hat Enterprise Linux 6.1 “enables enterprises to treat physical storage as a virtualized, standardized and scale-on-demand pool while continuing to provide the flexibility, performance and quality required for open source enterprise environments across physical and cloud deployments.”
Red Hat says that the emphasis on open source and cost-effectiveness make them a prime option for IT shops with a mixed bag of data demands, both in terms of their workloads and the types of environments they’re running across. A spokesperson for Red Hat pointed to the suitability for this appliance for digital media and content delivery networks, near-line storage, file sharing, backup and archival environments.
At the time of the acquisition, Red Hat talked about their Gluster acquisition as central to their overall cloud and virtualization strategy. While it’s definitely a component in this week’s release, the big data angle is the central element, at least in terms of how the company is positioning the new appliance. In October, Red Hat stated that in terms of big data, Gluster’s play to provide highly scalable storage for unstructured data while still maintaining the interoperability benefits of NAS made it attractive.
Red Hat claimed back in October that Gluster was a target because “it is a pure software solution, able to run on commodity storage hardware.” They said that this was the key differentiator since other potential targets for acquisition required purchase of specialized vendor-specific hardware.
For now, many are probably looking to the same offering with the additional I/O boost that comes with the updates in RHEL 6.2. The emphasis of this update was actually targeted at big data demands, with increased performance for enterprise I/O and storage performance. It is also an update that includes parallel NFS, which could provide the scalability that many environments require. According to Red Hat, the release of 6.2 (much quieter than most of their others) boosts I/O sppeds up to 30 percent with the addition of a few new protocols, including XPS.
As one commentator noted today, one of the reasons why Red Hat will be the first billion dollar open source company is that they’ve looked far beyond mere Linux to see what’s possible with the open source platform in the cloud, on the desktop and now as the basis of a storage software appliance.
Related Stories


Robert Cathey described Three Lessons from AWS Rolling Reboots in a 12/9/2011 post to the Cloudscaling blog:
Three takeaways from the AWS rolling reboot of EC2 instances:
Architecting apps to be cloud-ready is key
- Architecting massive-scale clouds to handle massive-scale updates is critical to a successful security strategy; see #1
- AWS again shows that the web scale cloud model has distinct advantages over enterprise clouds running legacy enterprise apps that can’t support rapid cycling of many VMs in a short period of time
Here’s a roundup of what else is being said:

<Return to section navigation list>

















0 comments:
Post a Comment