Windows Azure and Cloud Computing Posts for 12/2/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 12/2/2011 3:00 PM PST with several new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
• Wade Wegner (@WadeWegner) posted CloudCover Episode 66 - Using Windows Azure Storage from the Windows Phone on 12/2/2011:
Join Wade and Steve each week as they cover the Windows Azure Platform. You can follow and interact with the show at @CloudCoverShow.
In this episode, Wade walks through the NuGet packages for Windows Azure storage and Windows Phone, highlighting how easy it is to interact with blobs, tables, and queues, both directly against storage and securely through proxy services.
In the news:
- Windows Azure Storage: A Highly Available Cloud Storage Service with Strong Consistency
- New Webcast Series Explores SQL Azure Data Sync
- ISO 27001 eCertificate
- New Windows Azure Marketplace Data Delivers the Latest Weather and Stock Information
- Unable to find assembly references that are compatible with the target framework 'Silverlight,Version=v4.0, Profile=WindowsPhone71′
• Wely Lau (@wely_live) described Windows Azure Storage Transaction | Unveiling the Unforeseen Cost and Tips to Cost Effective Usage on 12/1/2011:
Background
I was quite surprise when seeing the Storage Transaction bills 2000% more than Storage Capacity, and it’s about 40% of my total bill. Wow… How can that be?
Isn’t that the storage transaction just costs $ 0.01 per 10,000 transactions, but why it’s become so expensive? In fact, this is the component that many people ignore when doing the running cost estimation for Windows Azure project.
Before getting into the detail, let’s refresh our mind to understanding how Windows Azure Storage costs in overview.
Understanding Windows Azure Storage Billing
Brad Calder from Windows Azure Storage Team did a great post on explaining how the billing looks like for Windows Azure Storage including the Capacity, Bandwidth, and Transaction.
In summary, here’re how it costs (as per Nov 2011). Keep in mind that the cost may change (although not very frequent, but who knows)
- Storage Capacity = $0.14 per GB stored per month, based on the daily average
- Storage Transactions = $0.01 per 10,000 transactions
- Data Transfer (Bandwidth)
- Free Ingress (inbound)
- Outbound:
- North America and Europe region = $ 0.15 per GB
- Asia Pacific region = $ 0.20 per GB
Please always refer to the following for latest pricing:
- http://www.microsoft.com/windowsazure/pricing/
- http://www.microsoft.com/windowsazure/pricing-calculator/
Many people argue that Windows Azure Storage is much more cost-effective than SQL Azure.
Well, that’s true in “most of the time”, but not “all the time”.
Understanding How Storage Transaction Charge in More Detail
Now, let’s forget the Storage Capacity and Bandwidth first, let’s talk about Storage Transaction now. It’s considered 1 transaction whenever you “touch” any component of Windows Azure Storage.
- “Touch” means any REST calls or operation including read, write, delete, update.
- “Any Component” means any entity inside Blobs, Tables, or Queues.
Here’re some examples of transactions that extracted from “Understanding Windows Azure Storage Billings” post.
- A single GetBlob request to the blob service = 1 transaction
- PutBlob with 1 request to the blob service = 1 transaction
- Large blob upload that results in 100 requests via PutBlock, and then 1 PutBlockList for commit = 101 transactions
- Listing through a lot of blobs using 5 requests total (due to 4 continuation markers) = 5 transactions
- Table single entity AddObject request = 1 transaction
- Table Save Changes (without SaveChangesOptions.Batch) with 100 entities = 100 transactions
- Table Save Changes (with SaveChangesOptions.Batch) with 100 entities = 1 transaction
- Table Query specifying an exact PartitionKey and RowKey match (getting a single entity) = 1 transaction
- Table query doing a single storage request to return 500 entities (with no continuation tokens encountered) = 1 transaction
- Table query resulting in 5 requests to table storage (due to 4 continuation tokens) = 5 transactions
- Queue put message = 1 transaction
- Queue get single message = 1 transaction
- Queue get message on empty queue = 1 transaction
- Queue batch get of 32 messages = 1 transaction
- Queue delete message = 1 transaction
Scenarios
Having done understanding how the storage transaction charge, considering the following scenarios:
Scenario 1 – Iterating files inside Blob container
An application will organize the blobs in different container per each users. It also allows the users to check size of each container. For that, a function is created to loop through entire files inside the container and return the size in decimal. Now, this functionality is exposed at UI screen. An admin can typically call this function a few times a day.
Some Figures for Illustration
Assuming the following figures are used for illustration:
- I have 1,000 users.
- I have 10,000 of files in average for each container.
- Admin call this function 5 times a day in average.
How much it costs for Storage Transaction per month?
Remember: a single GetBlob request is considered 1 transaction!
1,000 users X 10,000 files X 5 times query X 30 days = 1,500,000,000 transaction
$ 0.01 per 10,000 transactions X 1,500,000,000 transactions = $ 1,500 per month
Well, that’s not cheap at all.
Tips to Bring it Down
- Verify with the admin if they really need to use the function for 5 times a day? Educate them, tell them that each time this function is being called, it roughly costs $ 10 since it involves 10 million transaction (10,000 files X 1,000 users). I bet the admin will also avoid that if he/she knows the cost.
- Do not expose this functionality as real time query to admin. Considering to automatically run this function once in a day, save the size in somewhere. Just let admin to view the daily result (day by day).
With limiting the admin to just only view once a day, what will be the monthly cost looks like:
1,000 users X 10,000 files X 1 times query X 30 days = 300,000,000 transaction
$ 0.01 per 10,000 transactions X 300,000,000 transactions = $ 300 per month
Well, I think that’s fair enough!
Scenario 2 – Worker Role Constantly Pinging Queue
An application enables user to upload some document for processing. The uploaded document will be processed asynchronously at the backend. When processing is done, the user will get notified by email.
Technically, it uses Queue to store and centralize all tasks. Two instances of web roles to take the input and store task as message inside the Queue. On the other hand, 5 instances of Worker Role are provisioned, they will constantly pinging Queue Storage to check if there’s new message to be processed.
The following diagrams illustrates how the architecture may look like.
*icons by http://azuredesignpatterns.com/, David Pallman
Some Figures for Illustration
Assuming the following figures:
- It has 5 instances of Worker Role
- Those Worker Role will constantly get message from Queue (regardless it’s empty or filled)
public override void Run() { while (true) { CloudQueueMessage msg = queue.GetMessage(); if (msg != null) { // process the message } } }
- Those Worker Role will run 24 hours per day, 30 days per month
- It’s stated here that a single queue is able to process up to 500 messages per second. Let’s assume in average, it will process 200 messages per second (considering some tiny latency between Worker Role and Storage)
How much it costs for Storage Transaction per month?
Remember: a GetMessage on Queue function (regardless empty or filled) is considered 1 transaction
200 req X 60 sec X 60 min X 24 hours X 30 days X 5 instances = 2,592,000,000 transactions
$ 0.01 per 10,000 transactions X 2,592,000,000 transactions = $ 2,592 per month
Tips to Bring it Down
Unless there’s [a] requirement to meet certain number of target, otherwise consider to put some Sleep to avoid many of empty message result.
Assuming we put Thread.Sleep(100) = 0.1 second, which means for every second there will be 10 time polling to the queue to check if there’s message.
public override void Run() { while (true) { CloudQueueMessage msg = queue.GetMessage(); if (msg != null) { // process the message } Thread.Sleep(100); } }With that, how much do you think it will cost for a month?
10 req X 60 sec X 60 min X 24 hours X 30 days X 5 instances = 129,600,000 transactions
$ 0.01 per 10,000 transactions X 129,600,000 transactions = $ 129.6 per month
Well, that’s fair enough.
Conclusion
To conclude, this article gives you a view of how Transaction Cost of Windows Azure Transaction may lead to costly charge if it’s not properly used. Different component in Windows Azure Platform charges differently, cloud architect should have deep understanding in order to design scalable, reliable, yet cost-effective solution to customer.
In some case where constantly request is requirement, you may also would like to evaluate using SQL Azure instead of Windows Azure Storage because there will no any storage transaction cost in SQL Azure.
Hopefully by reading this article, you’ll save some money for storage transaction[s].


Mac Slocum (@macslocum) interviewed Alistair Croll and asserted “Smart companies use data to ask the right questions and take swift action” as a deck to his Big data goes to work post to the O’Reilly Radar blog of 11/30/2011:
Companies that are slow to adopt data-driven practices don't need to worry about long-term plans — they'll be disrupted out of existence before those deadlines arrive. And even if your business is on the data bandwagon, you shouldn't get too comfortable. Shifts in consumer tolerances and expectations are quickly shaping how businesses apply big data.
Alistair Croll, Strata online program chair, explores these shifts and other data developments in the following interview. Many of these same topics will be discussed at "Moving to Big Data," a free Strata Online Conference being held Dec. 7.
How are consumer expectations about data influencing enterprises?
Alistair Croll: There are two dimensions. First, consumer tolerance for sharing data has gone way up. I think there's a general realization that shared information isn't always bad: we can use it to understand trends or fight diseases. Recent rulings by the Supreme Court and legislation like the Genetic Information Nondiscrimination Act (GINA) offer some degree of protection. This means it's easier for companies to learn about their customers.
Second, consumers expect that if a company knows about them, it will treat them personally. We're incensed when a vendor that claims to have a personal connection with us treats us anonymously. The pact of sharing is that we demand personalization in return. That means marketers are scrambling to turn what they know about their customers into changes in how they interact with them.
What's the relationship between traditional business intelligence (BI) and big data? Are they adversaries?
Alistair Croll: Big data is a successor to traditional BI, and in that respect, there's bound to be some bloodshed. But both BI and big data are trying to do the same thing: answer questions. If big data gets businesses asking better questions, it's good for everyone.
Big data is different from BI in three main ways:
- It's about more data than BI, and this is certainly a traditional definition of big data.
- It's about faster data than BI, which means exploration and interactivity, and in some cases delivering results in less time than it takes to load a web page.
- It's about unstructured data, which we only decide how to use after we've collected it and need algorithms and interactivity in order to find the patterns it contains.
When traditional BI bumps up against the edges of big, fast, or unstructured, that's when big data takes over. So, it's likely that in a few years we'll ask a business question, and the tools themselves will decide if they can use traditional relational databases and data warehouses or if they should send the task to a different architecture based on its processing requirements.
What's obvious to anyone on either side of the BI/big data fence is that the importance of asking the right questions — and the business value of doing so — has gone way, way up.
How can businesses unlock their data? What's involved in that process?
Alistair Croll: The first step is to ask the right questions. Before, a leader was someone who could convince people to act in the absence of clear evidence. Today, it's someone who knows what questions to ask.
Acting in the absence of clear evidence mattered because we lived in a world of risk and reward. Uncertainty meant we didn't know which course of action to take — and that if we waited until it was obvious, all the profit would have evaporated.
But today, everyone has access to more data than they can handle. There are simply too many possible actions, so the spoils go to the organization that can choose among them. This is similar to the open-source movement: Goldcorp took its geological data on gold deposits — considered the "crown jewels" in the mining industry — and shared it with the world, creating a contest to find rich veins to mine. Today, they're one of the most successful mining companies in the world. That comes from sharing and opening up data, not hoarding it.
Finally, the value often isn't in the data itself; it's in building an organization that can act on it swiftly. Military strategist John Boyd developed the observe, orient, decide and act (OODA) loop, which is a cycle of collecting information and acting that fighter pilots could use to outwit their opponents. Pilots talk of "getting inside" the enemy's OODA loop; companies need to do the same thing.
So, businesses need to do three things:
- Learn how to ask the right questions instead of leading by gut feel and politics.
- Change how they think about data, opening it up to make the best use of it when appropriate and realizing that there's a risk in being too private.
- Tune the organization to iterate more quickly than competitors by collecting, interpreting, and testing information on its markets and customers.
What are the most common data roadblocks in companies?
Alistair Croll: Everyone I talk to says privacy, governance, and compliance. But if you really dig in, it's culture. Employees like being smart, or convincing, or compelling. They've learned soft skills like negotiation, instinct, and so on.
Until now, that's been enough to win friends and influence people. But the harsh light of data threatens existing hierarchies. When you have numbers and tests, you don't need arguments. All those gut instincts are merely hypotheses ripe for testing, and that means the biggest obstacle is actually company culture.
Are most businesses still in the data acquisition phase? Or are you seeing companies shift into data application?
Alistair Croll: These aren't really phases. Companies have a cycle — call it a data supply chain — that consists of collection, interpretation, sharing, and measuring. They've been doing it for structured data for decades: sales by quarter, by region, by product. But they're now collecting more data, without being sure how they'll use it.
We're also seeing them asking questions that can't be answered by traditional means, either because there's too much data to analyze in a timely manner, or because the tools they have can't answer the questions they have. That's bringing them to platforms like Hadoop.
One of the catalysts for this adoption has been web analytics, which is, for many firms, their first taste of big data. And now, marketers are asking, "If I have this kind of insight into my online channels, why can't I get it elsewhere?" Tools once used for loyalty programs and database marketing are being repurposed for campaign management and customer insight.
How will big data shape businesses over the next few years?
Alistair Croll: I like to ask people, "Why do you know more about your friends' vacations (through Facebook or Twitter) than about whether you're going to make your numbers this quarter or where your trucks are?" The consumer web is writing big data checks that enterprise BI simply can't cash.
Where I think we'll see real disruption and adoption is in horizontal applications. The big data limelight is focused on vertical stuff today — genomics, algorithmic trading, and so on. But when it's used to detect employee fraud or to hire and fire the right people, or to optimize a supply chain, then the benefits will be irresistible.
In the last decade, web analytics, CRM, and other applications have found their way into enterprise IT through the side door, in spite of the CIO's allergies to outside tools. These applications are often built on "big data," scale-out architectures.
Which companies are doing data right?
Alistair Croll: Unfortunately, the easy answer is "the new ones." Despite having all the data, Blockbuster lost to Netflix; Barnes & Noble lost to Amazon. It may be that, just like the switch from circuits to packets or from procedural to object-oriented programming, running a data-driven business requires a fundamentally different skill set.
Big firms need to realize that they're sitting on a massive amount of information but are unable to act on it unless they loosen up and start asking the right questions. And they need to realize that big data is a massive disintermediator, from which no industry is safe.
This interview was edited and condensed.
Related:
• Chris Czarnecki asked and answered What is Hadoop? in an 11/30/2011 post to the Learning Tree blog:
When teaching Learning Tree’s Cloud Computing course, a common question I am asked is ‘What is Hadoop ?’. There is a large and rapidly growing interest in Hadoop because many organisations have very large data sets that require analysing and this is where Hadoop can help. Hadoop is a scalable system for data storage and processing. In addition its architecture is fault tolerant. A key characteristic is that Hadoop scales economically to handle data-intensive applications making use of commodity hardware.
Example usage scenarios of Hadoop include risk analysis and market trends in large financial data sets, shopper recommendation engines for on-line retailers. Facebook uses Hadoop to analyse user behaviour and the effectiveness of its advetisements. To make all this work, Hadoop creates clusters of machines that can be scaled out and distributes work amongst them. Core to this is the Hadoop distributed file system which enables user data to be split across many machines in the cluster. To enable the data to be processed in parallel, Hadoop uses MapReduce. MapReduce maps the compute task across the cluster and then reduces all the results back into a coherent whole for the user.
Hadoop with MapReduce is an incredibly powerful combination and is available for instance on Amazon AWS as a Cloud Computing service. There are more apache projects built around Hadoop that add to its power including Hive a data warehousing facility that builds structure on the unstructured Hadoop data. The Hadoop database HBase provides real-time read/write and access to Hadoop data and Mahout is a machine learning library that can be used on Hadoop.
In summary, Hadoop is an incredibly powerful large scale data storage and processing facility that when combined with the supporting tools enables businesses to analyse their data in ways that previously required expensive specialist hardware and software. With companies such as Microsoft adopting Hadoop and a large ecosystem of support companies rapidly appearing Hadoop has a big role to play in the business intelligence of particularly medium and large enterprises.


<Return to section navigation list>
SQL Azure Database and Reporting
• Shoshanna Budzianowski (@shoshe) and the “Data Transfer” Labs team (@SQLAzureLabs) posted Announcing Microsoft Codename “Data Transfer” Lab to the SQL Server Team Blog on 12/2/2011:
We are pleased to announce the release of the Microsoft Codename “Data Transfer” Lab. Microsoft Codename "Data Transfer" is an easy-to-use Web application to import your data into SQL Azure or Blob storage. Whether you’re:
- Preparing data for cloud analytics
- Uploading files to power your Azure service or Web application
- Propagating your data to SQL Azure for publication through Windows Azure Marketplace
- Simply testing the Azure platform
Importing your data into Azure is the first step. With Microsoft Codename “Data Transfer” Lab you can now transfer your data into Azure using any standard modern browser. The data transfer service transports files up to 200 MB in size through an HTTP SSL connection. You’ll need to supply your Windows Live ID credentials and Windows Azure account information to the service. If you don’t have an account, click here to sign up for a free trial.
One of the goals we have for this lab is to take the complexity out of typical operations, such as loading structured data in CSV and Excel files into SQL Azure. In the interest of optimizing your time and resources, we’re providing simple parsing, type discovery and conversion over your files. You can choose to keep the defaults we provide, or override them. The transfer service first analyzes the file and presents you with our best guess. You’ll be able to change the table name, column names, and data types before saving the file to SQL Azure.

See my Test-Drive SQL Azure Labs’ New Codename “Data Transfer” Web UI for Copying *.csv Files to SQL Azure Tables or Azure Blobs post of 11/30/2011 for a detailed tutorial.
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
Chris “Woody” Woodruff (@cwoodruff) began his 31 Days of OData – Day 1 Background of OData series on 12/1/2011:
What is the Open Data Protocol?
The official statement for Open Data Protocol (OData) is that is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. Really what that means is that we can select, save, delete and update data from our applications just like we have been against SQL databases for years. The benefit is the ease of setting up and libraries that Microsoft has created for us the developers of Windows Phone 7 Mango apps. The benefit comes from the fact that OData has a standard that allows a clear understanding of the data due to the metadata from the feed.
Behind the scenes, we send OData requests to a web server that has the OData feed through HTTP calls using the protocol for OData. You can read more about OData here.
Where did OData come from?
OData started back in 2007 at the second Microsoft MIX conference. The announcement was an incubation project codenamed Astoria. The purpose of Project Astoria was to find a way to transport data across HTTP in order to architect and develop web based solutions more efficiently. Not until after the project had time to incubate did the OData see patterns occurring that led them to see the vision of the Open Data Protocol. The next big milestone was the 2010 Microsoft MIX Conference where OData was officially announced and proclaimed to the world as a new way to handle data. The rest is history.
Building OData on the Shoulders of Web Protocols
One of the great features of the OData protocol is the use of existing and mature standards. The OData team I feel did a great job identifying and using existing technologies to build upon. The following are the technologies, standards and/or existing protocols that were used in the development of OData:
- HTTP (Hypertext Transfer Protocol)
Really nothing much can be done on the Internet without HTTP so why wouldn’t OData use HTTP for its transport? Most web developers know about HTTP (or should know) so I will not dull you with details.
- Atom (Atom Syndication Format)
Most people know that Atom is used with RSS feeds to aggregate the content to others through HTTP. What you may not have known is how similar a RSS feed is to a database.
- The RSS Feed is a collection of blog posts which can be seen as a Database and a table. Databases I know contain multiple tables so that is that are where OData builds it beyond Atom where it has multiple collections of typed Entities.
- A Blog post inside a RSS feed is similar to a record in a Database table. The blog post has properties like Title, Body and Published Date. These properties can be seen as columns of a database table.
- REST (Representational state transfer)
OData was developed to follow the definition of REST. A RESTful web service or RESTful web API is a web service implemented through HTTP and the principles of REST. It is a collection of resources, with four defined aspects:
- the base URI for the web service, such as http://example.com/resources/
- the Internet media type of the data supported by the web service. This is often JSON, XML or YAML but can be any other valid Internet media type.
- the set of operations supported by the web service using HTTP methods (e.g., GET, PUT, POST, or DELETE).
- The API must be hypertext driven.
What will come with the OData Blog Series?
I hope this blog series will give the community and my readers a new perspective of the OData protocol. We will cover in depth the different areas of the protocols such as datatypes, query options and vocabularies. At the end of the series I hope to have answered many of your questions and also started getting you to identify areas and solutions where OData could add benefits to your solutions, services and products.
I also hope it will raise more questions about OData that I or others can answer and generate new ideas that can add more appeal and features to this exciting protocol.
Being a Data Experience (DX) Expert
At the end of the blog series I hope I will also make more of you Data Experience Experts. That is a new term I think I coined some time ago. What is a Data Experience Expert? Well User Experience is defined in Wikipedia as:
User experience (UX) is the way a person feels about using a product, system or service. User experience highlights the experiential, affective, meaningful and valuable aspects of human-computer interaction and product ownership, but it also includes a person’s perceptions of the practical aspects such as utility, ease of use and efficiency of the system.
Based on the UX definition we could define DX as:
Data experience (DX) is the way a person feels about using data. Data experience highlights the experiential, affective, meaningful and valuable aspects of data interchanges, but it also includes a person’s perceptions of the practical aspects such as ease of use and efficiency of the data and data transportation.
I do hope you will find this definition valuable as you gain more experience with OData and other Data technologies to also pin the title of DX expert to your resume.
<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Grigori Melnik posted Announcing the Enterprise Library Integration Pack for Windows Azure with Autoscaling, Transient Fault Handling and more on 12/2/2011:
Just about a month and a half ago I wrote a blog post announcing the beta release of Wasabi – a new Autoscaling Application Block. Since then we’ve got a lot of positive feedback from customers and internal partners, some of who have made decisions to adopt it even before we shipped the final version. Thank you for beta-testing and for providing meaningful feedback, some of which led us to reconsider earlier decisions and bring back stories we originally punted on (e.g. optimizing around the hour).
Value
For years the Enterprise Library application blocks have helped developers address the typical cross-cutting concerns of enterprise development (such as diagnostic logging, data validation, and exception handing). With over 3.5 million downloads, they take a prominent place in the toolbox of a modern .NET developer. The good news is that most of the Enterprise Library 5.0 application blocks simply work on Windows Azure. However, developing for the Windows Azure platform presents new challenges, including how to make applications more elastic (via autoscaling), and more stable and resilient to transient failures. The Enterprise Library Integration Pack for Windows Azure focuses on addressing these challenges. It provides reusable components and developer’s guidance designed to encapsulate recommended practices which facilitate consistency, ease of use, integration, extensibility, scalability and cost-effectiveness. Developers and IT professionals familiar with other Enterprise Library application blocks as well as those who are new to Enterprise Library will be able to benefit from the comprehensive set of content we are shipping today. You can pick and choose what matters to you and to your app, and adopt only those particular blocks/features.
Highlights
This release includes a comprehensive set of technical content, including:
- Two new application blocks:
- Autoscaling Application Block ("Wasabi") to help you to automatically scale both web and worker roles in Windows Azure by dynamically provisioning/decommissioning roles or throttling. These scaling actions are based on timetables or on metrics collected from the application and/or Windows Azure Diagnostics.
- Transient Fault Handling Application Block ("Topaz") to help you make your Windows Azure application more resilient to transient errors when you are using these cloud services: SQL Azure, Windows Azure Storage, Windows Azure Caching, and Windows Azure Service Bus.
- One new configuration source:
- Blob configuration source to load configuration information from a blob in your Azure Storage account so that you can modify it without having to redeploy your application to Windows Azure.
- Windows PowerShell cmdlets to browse and manipulate the Autoscaling Application Block settings directly from Windows PowerShell.
- Protected configuration provider to allow you to encrypt sections of your configuration files in Windows Azure.
- Updated database creation scripts so that you can migrate your code using the database trace listeners of the Logging Application Block and the Caching Application Block.
- A substantial collection of experience guidance help you ramp up quickly, including:
- Reference documentation
- Developer’s guide
- Tailspin Surveys sample application (reference implementation)
- On-premises sample application for hosting the Autoscaling Application Block and exploratory testing (included with source under (install location)/WindowsAzure/Autoscaling/Hosts/ConsoleAutoscaler)
- Planning worksheet for Wasabi to help you understand the interactions between different timing values governing the overall autoscaling regime.
For detailed change log from Beta to Final and installation instructions, see Release Notes.
How to Get it?
The recommended way to obtain the Enterprise Library Integration Pack for Windows Azure is as NuGet packages. Alternatively, you can download self-extracting zip files with binaries, sources (including tests) and the reference implementation from MSDN. The configuration tool is available as a Visual Studio extension package (VSIX) from the Visual Studio Gallery.
How to Provide Feedback and Get Help?
The Codeplex community site is the place. It includes a discussion forum, issue tracker and additional resources.
As always, we’ll be happy to hear from you about your experience using this new set of features.
Avkash Chauhan (@avkashchauhan) described Windows Azure Cloud Services: How you can choose what is needed and how much it will cost? in a 12/1/2011 post:
This article is written to help everyone who either have an idea or concept and looking cloud services to visualize their concept or those who want to save money and have better extensibilities for their current running business using Windows Azure cloud service. This is how the cost is calculated in cloud services?
- CPU core are charged per hour basis
- For example Windows Azure single core cost is 12 cents per hour per core
- A dual core machine will cost same as having two instances of single core machine
- File Storage (unstructured content) is charged on monthly basis, with transection and up/down bandwidth consumption
- Windows Azure Storage is charged 14 cents per Giga Byte per month
- 10,000 transection cost 1 cents
- Up/down bandwidth cost range 15-20 cents per Giga byte
- Database Storage (structured content)
- Database storage is cost the size of database you incur however a price range is giving by cloud service provider
- For example SQL Azure is charged on various DB sizes
- 1 GB SQL Azure Database 9.99
- 5 GB SQL Azure Database 49.95
- 10GB SQL Azure Database 99.90
- Database ingress/egress charges are also extra depend on cloud service provider
- Other Database related functionalities may cost extra depend on cloud service provider
- Other connectivity’s components:
- Access Control could be charged per connection bases or you will be given X amount of connection for cost Y
- Web based Cache is charged per size
- Networking connectivity is charged per connection basis
So if you are an entrepreneur looking to adopt cloud for your project or looking to migrate your web based application to cloud, your selection could be any of the above however let’s consider following two types:
Type One:
- CPU Core
- File System Storage (unstructured content)
- Database System (structured content)
- Extra functionalities
Type Two:
- CPU Core
- File System Storage (unstructured content)
- Extra functionalities
Let’s consider you have a concept in your mind which you want to try in Cloud. Consider you would need a quad core machine with 8GB memory to run your application initially. Later you can add multiple virtual machine instances of the same application to expand the service to test scalability. Let’s also consider you would need 10 GB file storage space. To make the application database dependent, let’s consider having a requirement of 10GB database as well. We will calculate how much it will cost to run your application initially and when we test it for scalability for a week how much it would have cost. Because PAAS cloud service provides you virtual machine in cloud you just need your application and supported OS and run time modules to let it run, we will take an example of Windows Azure, as cloud service (PAAS) and see what it will cost to us.
Now let’s consider an example cloud service Windows Azure:
- Azure Core: 12 cents per core so let’s consider having a quad core machine => Cost 48 cents per hour – Total $345.60
- Blob Storage: 14 cents / GB => for 10 GB - Total $1.40
- Let’s consider 5,000,000 Transections in a month – Total $5.00
- Let’s consider 10 GB ingress/egress bandwidth usage => for 20 cents /GB – Total $2.00
- SQL Azure: 10 GB DB => $99.90 / Month – Total $99.90
So for total cost for your application in a month is as below:
Type One:
- 354.60 + 1.40 + 5.00 + 2.00 = $363.00 / month
Type Two:
- 354.60 + 1.40 + 5.00 + 2.00 + 99.90 = $462.90 / month
Now if you want to test capacity with multiple instances:
- Add 9 more instances (total 10) for the same quad core instance for a week (7 days)
- Add $80.64 for a week cost to run 10 virtual machine instance
- Add 50 GB file Storage (unstructured content) for a month (charged monthly)
- Add $7.00 for month
- Add 50 GB Database storage
- Add round $500.00 to the above cost
- If you would want to set up open ID authentication
- $1.99 per 100,000 transactions
As you can understand from above details that if you are an entrepreneurs and looking for cloud to give you head start or want to move you currently running business to cloud. As of now Windows Azure only provides PASS.
Resources:
- Windows Azure Programmer Resources:http://www.microsoft.com/windowsazure/learn/get-started/?campaign=getstarted
- Windows Azure Pricing: http://www.microsoft.com/windowsazure/pricing/
- Windows Azure Pricing Calculator: http://www.microsoft.com/windowsazure/pricing-calculator/?campaign=vw-calc

• Wade Wegner (@WadeWegner) dropped a new Windows Azure Toolkit for Windows Phone v1.3.2 on 11/29/2011:
Content
- Overview
- Setup and Configuration
- Toolkit Content
- NEW: Architecture Diagrams
- NEW: FAQs
- Getting Started
- Creating a New Windows Phone Cloud Application
- Running and Going Through the Windows Phone Cloud Application
- Starting the Application
- Authenticating the User (ASP.NET Membership Authentication)
- Authenticating the User (ACS Authentication)
- Sending Microsoft Push Notifications
- Sending Apple Push Notifications
- Working with Tables, Blobs and Queues
- Working with SQL Azure Database
- NEW: BabelCam
- NEW: Tweet Your Blobs
- NEW: CRUD SQL Azure
- User Authentication
- Deploy Your Services to Windows Azure
- NEW: How to obtain a Project Hawaii Application ID
- NEW: How to obtain a Bing Application Id
- NEW: How to obtain a bitly Username and API Key
- NEW: How to create a SQL Azure Database Server
- Troubleshooting
- Change Log
Videos
If you have questions or feedback, please send an email to waztoolkitwp7@microsoft.com.
• The Microsoft Cast Studies team posted ISV Uses Virtualization Solution to Speed Development, Optimize Cloud Investments on 11/29/2011 (missed when posted):
Uni Micro, a Norway-based software development firm, needed to increase its capacity to respond to new market opportunities. After successfully using Microsoft virtualization tools to trim operating costs and reduce its IT staff’s workload, the company seized the opportunity to adopt Microsoft System Center Virtual Machine Manager 2012. Now, Uni Micro can use dynamic resource pooling and unified cloud management capabilities to boost business agility.
Business Needs
To keep its competitive edge, Uni Micro—an independent software vendor (ISV) and member of the Microsoft Partner Network—depends on its ability to rapidly develop new business management software while keeping its operating costs low. “We only have 60 employees, but we serve a large customer base, so we need to adopt an agile methodology in everything we do,” says Kristian Nese, Chief Information Officer at Uni Micro.The company’s agile approach to management starts with its data center environment. Previously, the company maintained 35 physical servers. Executives found that IT administrators spent dozens of hours each month applying security updates and performing data backup operations on these machines. They also noted that administrators spent a substantial amount of time responding to requests from developers for access to infrastructure resources.

Once we saw how System Center Virtual Machine Manager 2012 could help us increase data center automation and support a more agile development process, it was a simple decision to upgrade.Kristian Nese [Link to blog added.]
Chief Information Officer, Uni MicroIn 2008, Nese led an initiative to pare down the company’s investment in server hardware through the use of virtualization software. The company used the Hyper-V technology in the Windows Server 2008 operating system alongside VMware vSphere Hypervisor technology to move from 35 physical servers to four host systems. Uni Micro used Microsoft System Center Virtual Machine Manager 2008, together with System Center Operations Manager 2007, to manage its Hyper-V clusters.
The company sought to continue building on the time and cost savings it realized after reducing its server hardware by 90 percent. It looked to further increase automation of essential administrative tasks, including provisioning, updating, and monitoring virtual machine clusters. Uni Micro also wanted to make it easier for developers to access storage, compute, and network resources. And, it wanted the ability to use a single tool to monitor services that used both public and private cloud infrastructure.
Solution
Nese, who is a Microsoft Most Valuable Professional (MVP) for System Center Virtual Machine Manager, was excited to gain prerelease access to the latest version of the technology. “Once we saw how System Center Virtual Machine Manager 2012 could help us increase data center automation and support a more agile development process, it was a simple decision to upgrade,” says Nese.Uni Micro was eager to explore the fabric management and private cloud administration capabilities in System Center Virtual Machine Manager. In particular, Nese appreciated the ability to provision bare-metal machines for use in a virtualized cluster. The company eventually plans to standardize its data center on Hyper-V technology. “We made some earlier investments in VMware Workstation,” says Nese. “Because of the enhancements to Virtual Machine Manager 2012, we’ve decided to convert all of our VMware virtual machines to Hyper-V, and we plan to only use Hyper-V in production going forward.”
Uni Micro can also empower its developers by giving them more control in managing the configuration and deployment of services. Administrators can delegate service templates with predefined resource utilization values, which developers can then tailor to specific project requirements. “Our developers see the orientation toward managing services instead of servers in System Center Virtual Machine Manager 2012 as a leap forward,” says Nese. “The configurable templates and other self-service tools give them the power to focus on building applications, instead of worrying about setting up infrastructure.”
Benefits
By upgrading to System Center Virtual Machine Manager 2012, Uni Micro has experienced the following benefits:
- Deploys Virtualized Infrastructure 100 Percent Faster
Uni Micro can now deploy Hyper-V clusters to bare-metal machines and automate critical management functions, such as updating host servers and applying resource optimization, and can set up new virtualized infrastructure twice as fast as it could before. “We only have to mount the servers into the rack in our data center and we can count on System Center Virtual Machine Manager 2012 to handle just about everything else,” says Nese.- Increases Agility for Application Development
Because administrators can dynamically allocate cloud infrastructure resources through the use of service templates, they can help developers at Uni Micro build, test, and deploy applications faster. “Before, we assigned a fixed set of storage, network, and compute resources for each project, which limited flexibility,” says Nese. “Now, we can use resource pooling, so if we want to create a new product to respond to a market opportunity, we can do all of the development and testing in the cloud. And, with the elasticity that the cloud provides, we can meet demand in a much more agile way.”- Optimizes Virtualization Investments, Creates New Cloud Opportunities
By adopting System Center Virtual Machine Manager 2012, Uni Micro is able to extend the value of its existing investments in Microsoft virtualization technology and manage cross-platform data center components—all through a single solution. In conjunction with System Center App Controller 2012, the company can use the solution with Windows Azure to explore the benefits of moving applications between cloud environments. “With System Center Virtual Machine Manager 2012, we have all the tools we need to make the most of the cloud, based on the changing needs of our customers and our business,” says Nese.For more information about other Microsoft customer successes, please visit:
www.microsoft.com/casestudies
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Linthicum (@DavidLinthicum) asserted “Expect to see data transfer limits as commercial and data center networks get maxed out” as a deck for his The cloud is growing faster than the networks it relies on report of 12/2/2011 to InfoWorld’s Cloud Computing blog:
According to a recent Cisco report, annual global data center IP traffic will reach 4.8 zettabytes (that's 4.8 million petabytes) by 2016. In 2015, global data center IP traffic will reach 402 exabytes (that's 402,000 petabytes) per month. What's more, global data center IP traffic will increase fourfold over the next five years. Overall data center IP traffic will grow 33 percent per year from 2010 to 2015.
Cloud computing is driving much of this growth, both from business and consumer usage. "The evolution of cloud services is driven in large part by users' expectations to access applications and content anytime, from anywhere, over any network, and with any device," the Cisco report says. Indeed, by 2014, more than 50 percent of all workloads will be processed in the cloud.
What does this mean for you?
The need for more bandwidth persists, for one. We want ubiquitous access to network resources, and that's not just a trend, it's a movement. We already understood this as 2G led to 3G and now 4G. Also, there's the constant upgrading of pipes in and out of data centers, as well as within data centers.
But even as broadband providers and data centers alike increase their network capacity, I suspect we'll soon hit walls within many enterprises and ISPs, and perhaps limits will be placed on the amount of data that can move from place to place. Certainly, cable operators are suggesting they'll do this, and cellular carriers and some DSL providers have already moved this way. I also see such restrictions imposed by cloud storage providers, including Box.net, Dropbox, Mozy, Carbonite, and even Amazon.com's S3.
We'll have to figure out the bandwidth issues along with the rise of cloud computing, somehow, some way. The growth of cloud computing will outpace the growth of network infrastructure, and that will mean both enterprise IT and consumers will have to make some tough calls.

Barb Darrow (@gigabarb) listed 4 Azure milestones Microsoft must hit — and soon in an 11/29/2011 post to Giga Om’s Structure blog (missed when published):
Next year could be a very big year for Windows Azure, Microsoft’s nearly two-year-old Platform-as-a-Service (PaaS). And, it better be, given the investment in manpower and dollars Microsoft poured into the effort, which has not been as widely adopted as the company must have hoped. (Publicly, company execs are very happy with Azure’s traction, of course.)
All that can change if Microsoft delivers on promises to open up deployment options for Azure and to offer more bite-sized chunks of Azure services in Infrastructure-as-a-Service (IaaS) form. If it does that well and in a reasonable amount of time, Microsoft — which has always been chronically late – will be tardy to the party but will get there in time to make an impression. After all, we are still relatively early in the cloud era. Here’s what Microsoft needs to do for Azure in the next few months:
Azure must run outside Microsoft data centers.
The company has to make Azure available outside its own four walls. Right now, if you want to run apps on Windows Azure, they run in Microsoft data centers (or, since August, in Fujitsu data centers). Fujitsu also recently launched a hybrid option that allows it to run brand-new apps in Azure and connect them to legacy apps on its other cloud platform. We’re still waiting for Hewlett-Packard and Dell Azure implementations. (HP could announce this at its HP Discover show this week.) Down the road, all this work by hardware makers should result in an “Azure Appliance” architecture that would enable other data centers to run the PaaS.
Microsoft must offer VM Roles and Server AppV for IaaS fans.
Microsoft needs to offer more bare-bones chunks of Azure services — akin to Amazon’s EC2. That’s why Microsoft needs to get VM Roles in production mode as soon as possible. VM Roles, in beta for a year, allows organizations to host their own virtual machines in the Azure cloud. Also coming is Microsoft Server AppV which should make it easier for businesses to move server-side applications from on-premises servers to Azure. “VM roles and Server AppV are the two IaaS components that Microsoft has not yet pushed into production. It still seems Microsoft hasn’t really focused on the IaaS aspect of Azure,” said Rob Sanfilippo, research VP with Directions on Microsoft. As Microsoft adds IaaS capabilities to Azure, Amazon is also adding PaaS perks like Elastic Beanstalk to its portfolio, so these companies are on a collision course.
System Center 2012 has to ease app migration and management.
Microsoft needs to make it easier for customers wanting to run private and public cloud implementations to manage both centrally. That’s the promise of Microsoft System Center 2012, due in the first half of 2012. With this release, customers that now must use System Center Virtual Machine Manager for private cloud and the Windows Azure interface for Azure will be able to manage both from the proverbial ”one pane of glass.” That’s a good thing, but not good enough. “It’s nice that System Center will be able to monitor stuff in both places, but what we need to be able to run stuff in either place,” said a .NET developer who tried Azure but moved to AWS.
Microsoft must eat its own Azure “dog food.”
Right now, precious few Microsoft applications run on Azure. There even seems to be confusion at Microsoft about this. One executive said Xbox Live, parts of CRM Online and Office 365 run on Azure, only to be contradicted by a spokesperson who came back to say none of them actually do. Bing Games, however, do run on Azure. No matter: This is a schedule issue, as almost all these applications predate Azure. The next release of Dynamics NAV ERP application will be the first Microsoft business application to run fully on Azure. There is no official due date, but Dynamics partners expect it next year. Three other Dynamics ERP products will follow. Directionally, Azure is where all Microsoft apps are going. “Our goal, of course, is that everything will be running on Azure,” said Amy Barzdukas, general manager of Microsoft’s server and tools unit.
In summary: It’s not too late for Azure, but …
Microsoft has to get these things done — and soon — to counter AWS momentum and also that of rival PaaS offerings like Salesforce.com’s Heroku and Red Hat’s OpenShift which draw new-age, non-.NET oriented Web developers. Recent Gartner research shows PaaS will be a hot segment going forward. The researcher expects PaaS revenue to hit the $707 million by the end of this year, up from $512 million for 2010. And it expects PaaS revenue to reach $1.8 billion in 2015. That’s good growth, but here will be more of the aforementioned players fighting for that pie. This is going to get good as younger cloud-era rivals are fighting to make Microsoft — the on-premises software giant — irrelevant in this new arena. But one thing rivals in other eras have learned: It’s idiotic to underestimate this company.

The erstwhile Windows Azure Platform Appliance (WAPA) isn’t receiving much love from its purported partners except Fujitsu. AFAIK, HP didn’t mention a WAPA entrant at HP Discover Las Vegas (June) or Vienna (11/30 through 12/1/2011). See Vawn Himmelsbach’s HP cloud rollout emphasizes hybrid environments post of 12/2/2011 to IT World Canada. Dell paid only lip service (a static Web page on the Dell site) to WAPA in 2011. Diverting PaaS resources to compete with AWS in the IaaS market doesn’t sound like a good business strategy to me. Implementing HPC and Big Data on Windows Azure with Hadoop and MapReduce, rather than Dryad and DryadLINQ, is a step in the right direction. Microsoft needs to extend its ISO and SAS 70 certifications from datacenter-only to Windows Azure and SQL Azure-inclusive, as I asserted in my Where is Windows Azure’s Equivalent of Office 365’s “Security, Audits, and Certifications” Page? post of 11/17/2011.
Derrick Harris (@derrickharris) posted It’s cloud prediction time: IDC, Gartner (and I) weigh in on 12/1/2011 to Giga Om’s Structure blog:
Analyst powerhouses IDC and Gartner both rolled out their latest cloud computing and big data predictions and statistics Thursday morning, and while some are bold, others might have you saying “Duh.” Here’s what they have to say, and how that squares with what I see.
On big data
“Big Data will earn its place as the next ‘must have’ competency in 2012″ (IDC). It’s hard to dispute this, if it hasn’t earned that status already. However, IDC does rely on some questionable logic to support its claim. It predicts that 2.43 zettabytes of unstructured data will be created in 2012, but much of that is only a big data problem to the degree it requires a lot of storage. Photo, video and music files will comprise a lot of that volume, and I think we’re a ways of way from doing meaningful analysis of those data types at a broad scale.
“2012 is likely to be a busy year for Big Data-driven mergers and acquisitions” (IDC). On this prediction, I think IDC is spot on. That being said, I don’t know exactly where those acquisitions will happen. NoSQL database vendors (for example, the red-hot 10gen) seem like ripe targets because they’re gaining steam among enterprises, yet only Oracle has really put forth the effort to develop its own. On the Hadoop front, Cloudera has been adamant about not being for sale, and many of the up-the-stack analytics startups (with the exception of Datameer, perhaps) are just too young.
In the general analytics space, companies such as ParAccel, Infobright, Kognitio, Quantivo and Attivio come to mind as potential targets.
“Through 2015, more than 85 percent of Fortune 500 organizations will fail to effectively exploit big data for competitive advantage” (Gartner). Wow! I guess it depends on how Gartner defines “exploit,” but I would argue that most of the Fortune 500 is already at least experimenting with activities such as sentiment analysis and data mining with Hadoop, which should result in some competitive advantage. Gartner does make a valid point about the velocity of data streams and the timeliness of data processing, though. If organizations focus too heavily and invest too much on early-stage uses of big data tools without looking to the future, they might not be prepared to fully exploit big data technologies as an engine for real-time decisionmaking.
On cloud computing
“[In 2012,] 80% of new commercial enterprise apps will be deployed on cloud platforms” (IDC). Eighty percent seems like a very high number, but without having read the report, it’s tough to gauge how accurate this prediction might be. If IDC is defining commercial as being customer-facing, and enterprise apps include even those apps by web startups, 80 percent might be perfectly reasonable. The percentage of apps deployed on the cloud will certainly rise as startups launch and use cloud platforms almost exclusively. And enterprises deploying new, non-mission-critical apps or apps not containing sensitive data (e.g., web sites and mobile apps) certainly are looking more at cloud-based options.
“Amazon Web Services [will] exceed $1 billion in cloud services business in 2012 with Google’s Enterprise business to follow within 18 months” (IDC). I think Amazon Web Services will do that in 2011. Google following suit by mid-2013 seems reasonable, too. I haven’t seen Google’s “Other revenue” line item analyzed like I have for Amazon, but Google pegged it at $385 million during the third quarter. Somewhere in there is its Google Apps and App Engine revenue.
“IDC … expects a merger and acquisition (M&A) feeding frenzy.” Yup. And it’s probably right that SaaS companies will prove more appealing than PaaS providers in the next year. After seeing Microsoft’s trials and tribulations with Windows Azure, I don’t think too many large vendors are looking to jump headlong into that space just yet. One interesting prediction from IDC: Microsoft will buy Netflix to serve as a marketplace for apps and content.
“By 2016, 40 percent of enterprises will make proof of independent security testing a precondition for using any type of cloud service” (Gartner). Oh, yeah, this is going to happen. Not only will there be a third-party certification process as Gartner suggests, but I think there will be a strong tie to cloud computing insurance, as well. The safer a cloud is, the lower companies’ insurance premiums will be when using that cloud. Rather than viewing this process as some implicit acknowledgement that the cloud isn’t secure, I think cloud providers will embrace it as an opportunity to prove just how secure they are.
“At year-end 2016, more than 50 percent of Global 1000 companies will have stored customer-sensitive data in the public cloud” (Gartner). Gartner rationalizes this prediction in terms of cost savings for organizations, but I’d argue it’s directly related to the previous prediction about security testing. As cloud computing security improves, in general, and is bolstered by independent certifications and insurance policies, companies will feel a lot more comfortable putting sensitive data in the cloud. Furthermore, although most cloud providers will likely never put real skin in the game, cloud insurance will assure companies that they’ll be compensated in the case of data loss or security breach.
“By 2015, the prices for 80 percent of cloud services will include a global energy surcharge” (Gartner). I don’t see this happening. Unless, of course, we’re talking only about enterprise-grade cloud providers that already allow for negotiated contracts or co-located private clouds. The type of cloud business model pioneered by Amazon Web Services — now utilized by almost every developer-focused cloud service — relies too heavily on simplicity in pricing to include surcharges and other fees that will seem like nickel-and-diming to customers. That being said, if data center energy costs — which appear to be shrinking, actually — start to outweigh economies of scale for a provider like AWS, there’s no reason prices have to keep falling as precipitously as they have been.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
O’Reilly Media announced the Moving to Big Data: Free Strata Online Conference to be held 12/7/2011 at 9 AM PST:
In this free online event, being held Dec. 7, 2011, at 9AM Pacific, we'll look at how big data stacks and analytical approaches are gradually finding their way into organizations as well as the roadblocks that can thwart efforts to become more data driven. (This Strata Online Conference is sponsored by Microsoft.)
Moving to Big Data
Everyone buys in to the mantra of the data-driven enterprise. Companies that put data to work make smarter decisions than their competitors. They can engage customers, employees, and partners more effectively. And they can adapt faster to changing market conditions. It's not just internal data, either: a social, connected web has given us new firehoses to drink from, and combining public and private data yields valuable new insights.
Unfortunately for many businesses, the information they need is languishing in data warehouses. It's accessible only to Business Intelligence experts and database experts. It's encased in legacy databases with arcane interfaces.
Big Data promises to unlock this data for the entire company. But getting there will be hard: replacing decades-old platforms and entire skill sets doesn't happen overnight. In this online event, we'll look at how Big Data stacks and analytical approaches are gradually finding their way into organizations, as well as the roadblocks that can thwart efforts to become more data-driven.
Agenda/Schedule
Introduction: Dealing With New Expectations (15m)
These days, invention happens with consumers, and then gradually infiltrates corporations. Change is hard to resist, but companies will try. They’ll fail, mainly because every employee is also a digital citizen, dragging their expectations into the boardroom and the shop floor. Why do we know more about what our friends had for lunch than about the health of our sales pipeline, or where our trucks are?
In this opening presentation, Strata chair Alistair Croll will set the stage for today’s discussion, looking at modern expectations of visualization, data analysis, and realtime information and how these will force a sea change within enterprises.
Top-down: What CEOs Can Do to Accelerate Data Mindsets (15m)
Speakers: Diego Saenz (Data Driven CEO)
Jonathan Bruner (Forbes Media)
By putting data to work, companies can outmaneuver their markets. Doing so is as much a cultural change as it is a technical one. In this session, Jonathan Bruner of Forbes talks with Diego Saenz, a veteran of Fortune 500 companies and startups—and the founder of the Data-Driven CEO—to understand how the irresistible force of Big Data meets the immovable mountain of Big Enterprise.
Web Analytics: The Enterprise Gateway Drug to Big Data? (15m)
Speaker: Justin Cutroni (Cardinal Path)
Many organizations are already using powerful Big Data analysis tools, which collect information from thousands of sources and store them in shared, NoSQL-based data systems. They just don’t realize it.
Web Analytics tools have come a long way since their early days counting page views and visits. Today, nearly any event, regardless of what device it happens on, can be collected and analyzed with speed and precision. While analytics is still predominantly the domain of web analysts and the marketing team, there’s no reason these tools can’t also be used to track call center times, retail store traffic, social media mentions, and more.
In this session, Analytics expert and O’Reilly Author Justin Cutroni will look at how analytics tools have changed. Using the example of Google Analytics, which can collect information from almost any device or program that can generate an HTTP request. He’ll show how, with a well-defined data extraction API, the information can easily be ported to other tools for integration and analysis. He’ll look at how analytics tools can be put to work beyond the website, in effect becoming many companies’ first taste of Data Warehousing and BI, and address some of the challenges associated with using a traditional web analytics tool as a massive data collection platform.
Take a Lesson from the Research World (15m)
Speaker: Kaitlin Thaney (Digital Science)
The Web has transformed not only the way we approach modern day science, but a number of other facets of the research cycle: tools for analysis, mediums which now serve as “information inputs”, how we exchange ideas and even discover knowledge. This shift in practice, understanding and resources is happening at a broader scale, extending beyond the traditional research environment on the institutional level to big business and industry. But the machine is not nearly as well-oiled as we’d like to think, and there are still breaks in the system keeping us from doing more efficient work.
In this talk, Kaitlin will posit that we’re not only “getting this wrong” in the academic research context, but that these problems are also finding their way in to the broader research enterprise. She’ll look at how financial, social and technical constraints are affecting the way we perceive and handle information, and what the best means forward to fixing the breaks in the system is.
Is it Still Big Data if it Fits in Your Pocket? (15m)
Speaker: Dave Campbell (Microsoft)
Big Data is all the rage. While the big data systems, patterns, and value were initially demonstrated at Petabyte scale with large scale Internet services, Big Data is applicable in any organization, regardless of organization size or volume of data. In fact, many early adopters of Big Data technologies in the commercial space are seeing significant top and bottom line enhancements through their use of these emerging technologies. The ultimate question is around new business value gets created out of the abundant “ambient data” produced by existing and emerging IT systems. How do we transform these raw data into new knowledge that matters for the business in an efficient fashion?
Microsoft Fellow David Campbell has spent time over the last several years trying to answer many of these questions to his own satisfaction, particularly determining how “data finds data” and how to turn data into knowledge in new ways. As part of the journey he’s witnessed a number of natural patterns that emerge in big data processing as well as encountered many companies that are understanding how to think differently about their data influx and use technology as a key differentiator in this strategy. In this short talk he will present examples of success from several industries and describe several Big Data patterns and illustrate them across a scale spectrum from megabytes to 100s of petabytes. Finally, he will offer some thoughts around how the market may evolve in response to these opportunities.
How Will Deep Q&A Impact the Use of Analytics in Business? (15m)
Speaker: Christer Johnson (IBM)
What if you could ask your business a question? In February 2011, a computer named Watson beat two all-time Jeopardy champions. Watson included many innovative artificial intelligence breakthroughs in deep question and answer technology. How will this kind of technology change the way businesses work? If we can apply algorithms and natural language processing to the entire body of an organization’s data—emails, documents, calendars, and more—we can perform “deep Q&A” and change how companies think. In this session, Christer Johnson, who leads advanced analytics and optimization services, will look at how systems like Watson can transform enterprise use of Big Data.
How to Get There from Here: The Road to Enterprise Data (15m)
Speaker: Lynn Langit (Teaching Kids Programming)
How will companies familiar with BI and SQL gradually embrace unstructured data and noSQL models? Will this be through a “layer” of SQL emulation? Through an Excel plug-in that generates Hadoop workloads? A rethinking on the part of database vendors? Or something else entirely?
In this session, cloud and data expert Lynn Langit explores the roadmap to Big Data adoption by traditional enterprise IT and corporate software developers.
Speaker: Alistair Croll (Bitcurrent)
Closing Remarks
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jinesh Varia (@jinman) posted Introducing AWS Simple Icons for your Architecture Diagrams to the Amazon Web Services blog on 12/2/2011:
Cloud Computing has shifted the focus more than ever to architecture of an application. In order to get the maximum benefit of on-demand infrastructure, it is important to invest time in your architectures.
A diagram is worth a thousand words. An architecture diagram is probably worth a million to architects and developers. Its is one of easiest and simplest ways to communicate quickly about your application, its architectures and its topology. We want you to share your AWS-powered cloud architectures with us so we (and our partners) can give you feedback.
Hence, we have created AWS Simple Icons for most of our services and features. They are now available in our Architecture Center for download. Customers and partners can use them to create consistent-looking diagrams and share with us and the rest of the world. We have also included several example architecture digrams and guidelines on how to use these icons in your diagrams. These icons are simple by design so that you can incorporate them in your whitepapers, presentations and other places that you see fit. We are releasing multiple formats (PPTX, VISIO Stencil, SVG, EPS, Online tools) so that you can use the tools that you love.

This is our first release of the icon set. We plan to keep the icon set up-to-date with our latest and greatest services and features and enhance the tools and resources so that it even easier for you to communicate with us. Your feedback is extremely important to us and hence please use the comments section if you have any feedback.

Inspired by David Pallman’s Azure-oriented but generic icons?
• Lydia Leong (@CloudPundit) described Cloud IaaS feature sets and target buyers in an 12/2/2011 post:
As I noted previously, cloud IaaS is a lot more than just self-service VMs. As service providers strive to differentiate themselves from one another, they enter a software-development rat race centered around “what other features can we add to make our cloud more useful to customers”.
However, cloud IaaS providers today have to deal with two different constituencies — developers (developers are the face of business buyers) and IT Operations. These two groups have different priorities and needs, and sometimes even different use cases for the cloud.
IaaS providers may be inclined to cater heavily towards one group or the other, and selectively add features that are critical to the other group, in order to ease buying frictions. Others may decide to try to appeal to both — a strategy likely to be available only to those with a lot of engineering resources at their disposal. Over time (years), there will be convergence in the market, as all providers reach a certain degree of feature parity on the critical bits, and then differentiation will be on smaller bits of creeping featurism.
Take a feature like role-based access control (RBAC). For the needs of a typical business buyer — where the developers are running the show on a project basis — RBAC is mostly a matter of roles on the development team, likely in a fairly minimalistic way, but fine-grained security may be desired on API keys so that any script’s access to the API is strictly limited to just what that script needs to do. For IT Operations, though, RBAC needs tend to get blown out into full-fledged lab management — having to manage a large population of users (many of them individual developers) who need access to their own pools of infrastructure and who want to be segregated from one another.
Some providers like to think of the business buyer vs. IT Operations buyer split as a “new applications” vs. “legacy applications” split instead. I think there’s an element of truth to that, but it’s often articulated as “commodity components that you can self-assemble if you’re smart enough to know how to architect for the cloud” vs. “expensive enterprise-class gear providing a safe familiar environment”. This latter distinction will become less and less relevant as an increasing number of providers offer multi-tiered infrastructure at different price points within the same cloud. Similarly, the “new vs. legacy apps” distinction will fade with feature-set convergence — a broad-appeal cloud IaaS offering should be able to support either type of workload.
But the buying constituencies themselves will remain split. The business and IT will continue to have different priorities, despite the best efforts of IT to try to align itself closer to what the business needs.

James Staten (@Staten7) posted Lauren E. Nelson’s When will we have IaaS Cloud Standards? Not till 2015 article to his Forrester blog on 12/2/2011:
Guest post from I&O Researcher Lauren E Nelson (pictured at right.)
If you’re sitting on the sidelines waiting for IaaS to become more standardized, stop it. You’ll be waiting there till 2015, while everyone else is building fundamental skills and ramping up their cloud knowledge. So jump in the game already!
In Forrester’s latest report, The State Of Infrastructure-As-A-Service Cloud Standards, we took a long look at the efforts in place today that drive cloud standardization and were not impressed. While there’s lots of efforts taking place, progress thus far is miniscule. But that shouldn’t be a big surprise to anyone familiar with the standardization process since:
a. Standards are always in arrears of best practice maturity
b. Collaboration is often time consuming, delaying the creation and ratification process
But why 2015? Standards organizations are still exploring the market needs — which means that by the time they identify where to focus and actually develop a proposed standard it will be at least a year for now. From there it will be a long year of committee meetings to vet and vote on the standard itself and build momentum for its release. And if the standard makes it to release and there’s enough market momentum behind that proposed standard, it will be another year or two before there’s significant adoption where it actually becomes a market standard. The standards timeline is easily three to four years out.
And frankly, waiting for standards isn't a good enough excuse to not be leveraging cloud services. The values they deliver today are too compelling to wait and nearly every cloud service is built upon the existing Internet and web services standards are already exist. While you may risk lock-in or may have to back out of some of your decisions when standard do form, you will have gained significant experience and business value that will make such efforts a minor annoyance by comparison.
Check out the full report to find out who the big players are in cloud standardization and what you specifically should be doing in the meantime. And if you’re inspired to talk with your peers and Forrester analysts about this topic, leave a comment here or look to post on our I&O community site.


Jeff Barr (@jeffbarr) reported Additional Reserved Instance Options for Amazon EC2 on 12/1/2011:
If you have watched the cavalcade of AWS releases over the last couple of years, you may have noticed an interesting pattern. We generally release a new service or a major new feature with a model or an architecture that leaves a lot of room to add more features later. We like to start out simple and to add options based on feedback from our customers.
For example, we launched EC2 Reserved Instances with a pricing model that provides increasing cost savings over EC2's On-Demand Instances as usage approaches 100% in exchange for a one-time up-front payment to reserve the instance for a one or three year period. If utilization of a particular EC2 instance is at least 24% over the period, then a three year Reserved Instance will result in a costs savings over the user of an On-Demand Instance.
The EC2 Reserved Instance model has proven to be very popular and it is time to make it an even better value! We are introducing two new Reserved Instance models: Light Utilization and Heavy Utilization Reserved Instances. You can still leverage the original Reserved Instance offerings, which will now be called Medium Utilization Reserved Instances, as well as Spot and On-Demand Instances.
If you run your servers more than 79% of the time, you will love our new Heavy Utilization Reserved Instances. This new model is a great option for customers that need a consistent baseline of capacity or run steady state workloads. With the Heavy Utilization model, you will pay a one-time up-front fee for a one year or three year term, and then you'll pay a much lower hourly fee (based on the number of hours in the month) regardless of your actual usage. In exchange for this commitment you'll be able to save up to 58% over On-Demand Instances.
Alternatively, you might have periodic workloads that run only a couple of hours a day or a few days per week. Perhaps you use AWS for Disaster Recovery, and you use reserved capacity to allow you to meet potential demand without notice. For these types of use cases, our new Light Utilization Reserved Instances allow you to lower your overall costs by up to 33%, allowing you to pay the lowest available upfront fee for the Reserved Instance with a slightly higher hourly rate when the instance is used.
One way to determine which pricing model to use is by choosing the Reserved Instance pricing model assuming you are optimizing purely for the lowest effective cost. The chart below illustrates your effective hourly cost at each level of utilization. As you can see, if your instances run less than ~15% of the time or if you are not sure how long you will need your instance, you should choose On-Demand instances. Alternatively, if you plan to use your instance between ~15% and ~40% of the time, you should use Light Utilization Reserved Instances. If you plan to use your instance more than ~40% of the time and want the flexibility to shut off your instance if you don’t need it any longer, then the Medium Utilization Reserved Instance is the best option. Lastly, if you plan to use your instance more than ~80% of the time (basically always running), then you should choose Heavy Utilization Reserved Instances.
Alternatively, you may want to purchase your Reserved Instances by trading off the amount of savings to the upfront fee. As an example, let’s evaluate the 3-year m1.xlarge Reserved Instance. Light Utilization Reserved Instances save you up to 33% off the On-Demand price, and just require a $1200 upfront fee. These Reserved Instances provide a great way to get a discount off of the On-Demand price with very little commitment. Medium Utilization Reserved instances save you up to 49% off the On-Demand price and require a $2800 upfront fee. The second option provides you the flexibility to turn off your instances and receive a significant discount for a little higher upfront fee. Heavy Utilization Reserved instances save the most, around 59%, but require an upfront fee of $3400. Additionally, with this option you are committing to pay for your instance whether you plan to use it or not. This option provides significant savings assuming that you know you plan to run your instance all or most of the time. The following table illustrates these savings:
As an example, let's say that you run a web site, and that you always need at least two EC2 instances. For the US business day you generally need one or two more, and at peak times you need three additional instances on top of that. Once a day you also do a daily batch run that takes two or three hours on one instance. Here's one way to use the various types of EC2 instances to your advantage:
- Two Heavy Utilization Reserved Instances - Handle normal load.
- Two Medium Utilization Reserved Instances, as needed - Scale up for the US business day.
- Three On-Demand Instances, as needed - Scale up more for peak times.
- One Light Utilization Reserved Instance, as needed - Handle daily batch run.
Or, graphically:
The usage payment for Heavy Utilization and Light Utilization Reserved Instances will be billed monthly along with your normal AWS usage.
We've also streamlined the process of purchasing Reserved Instances using the AWS Management Console so that it is now easier to purchase multiple Reserved Instances at once (the console has acquired a shopping cart):
We are continuously working to find ways to pass along additional cost savings, and we believe that you will like these new Reserved Instance options. We recommend that you review your current usage to determine if you can benefit from using these changes. To learn more about this feature and all available Amazon EC2 pricing options, please visit the Amazon EC2 Pricing and the Amazon EC2 Reserved Instance pages.


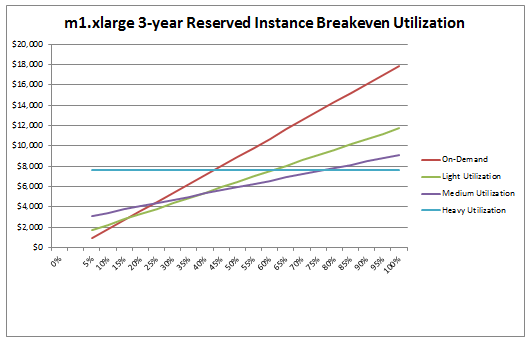
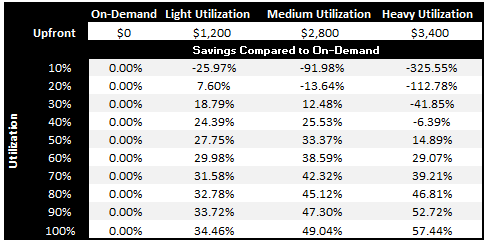
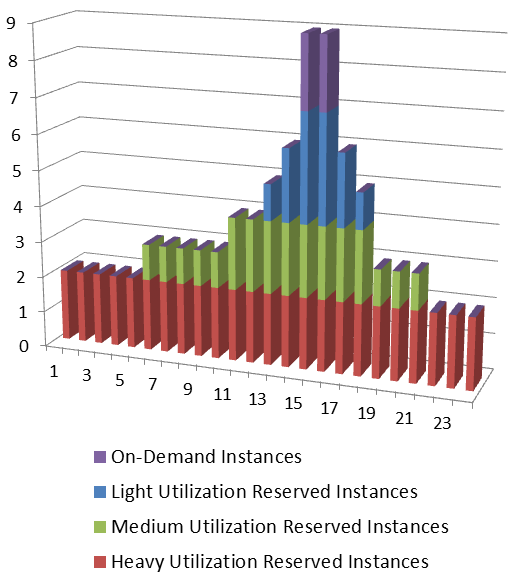
An interesting approach to selective price cuts in an increasingly competitive market.
Derrick Harris (@derrickharris) reported HPCC Systems tunes big data platform for Amazon cloud in an 11/30/2011 post to Giga Om’s Structure blog:
HPCC Systems, the division of LexisNexis pushing a big-data, processing-and-delivery platform, has tuned its software to run on Amazon’s cloud computing platform. Interested developers can now experiment with the open-source software without having to wrangle physical servers for that purpose, which brings HPCC one step closer to establishing itself as a viable alternative to the uber-popular Hadoop framework.
When I last spoke with HPCC Systems CTO Armando Escalante in September, he explained that although he thinks his company will have little trouble attracting risk-averse large enterprise and government customers, it will be tougher to establish a developer ecosystem similar to what Hadoop has built. As good as HPCC might be — and at least some analysts are starting to sing its praises — having a vibrant community goes a long way.
Hadoop has no shortage of startups, large vendors and individual developers committed to it already. That gives potential users the confidence that not only will Hadoop products be supported for a long time, but that the code will continue to improve and interoperate across a variety of different vendors’ data products, Hadoop-based or not.
Making HPCC run on AWS – or any cloud — is a good start for HPCC Systems, as it provides a low-risk option for developers to get started on the platform. It will be even more appealing when HPCC’s software is supported by AWS’s Elastic MapReduce service, which the company says is the next step. Assuming one has data there to work with, the cloud is a great place to get started with big data tools because they generally require server clusters that are cheaper to rent than to buy in the short term.
Technically, HPCC has only tuned a portion of its platform — the Thor Data Refinery Cluster — to run on Amazon Web Services, but that’s the part that matters most. Thor does the data-processing for HPCC, which makes it the apples-to-apples comparison with Hadoop. The platform also consists of the Roxie Data Query Cluster, a data-warehouse and query layer that’s akin to the higher-level Hive and HBase projects that have been developed for Hadoop.
HPCC Systems is quick to point out, however, that its platform all utilizes a single language, Enterprise Control Language, whereas Hadoop itself uses MapReduce, but projects such as HBase and Hive have their own languages.
Related research and analysis from GigaOM Pro:
Subscriber content. Sign up for a free trial.


<Return to section navigation list>

















0 comments:
Post a Comment