Windows Azure and Cloud Computing Posts for 2/26/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 2/27/2011 with items marked • in the Other Cloud Computing Platforms and Services section.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Robin Shahan (@RobinDotNet) described How to host a ClickOnce deployment in Azure Blob Storage in a 2/13/2011 post (missed when posted):
Now that Microsoft Azure is becoming more widely used, I’m going to do some blogging about it, since I’ve had an opportunity to work with it quite a bit. What better place to start than to do a crossover blog entry on both ClickOnce deployment and Microsoft Azure? So I’m going to show you how to host your ClickOnce deployment in your Azure Blob Storage.
To do this, you need an application that you can use to manage blob storage. I use the Cloud Storage Studio from cerebrata in my example. A free application recommended by Cory Fowler (Microsoft Azure MVP) is the Azure Storage Explorer from codeplex.
Here is the GoldMail that explains this process in detail, complete with screenshots. There is a summary below.
To summarize:
Create a container in blob storage for your ClickOnce deployment. You’ll need the container name when setting your url. I selected ‘clickoncetest’. The only characters allowed are lower case letter, numbers, and the hyphen (-).
In your project properties, set your Publishing Folder Location to somewhere on your local drive. Set the Installation Folder URL to the URL that will point to the container in blob storage that is going to host your deployment.
For example, I set the first one to E:\__Test\clickoncetest. My account is goldmailrobin, so my installation URL will be http://goldmailrobin.blob.core.windows.net/clickoncetest/
Publish your application. Then go to the local folder and copy the files and folders up to the container in blob storage. When you are finished, in the root of that container you should have the deployment manifest (yourapp.application file) and the bootstrapper (setup.exe) (and publish.htm if you included it). You should also have a folder called “Application Files”.
In “Application Files”, you should see the ‘versioned folders’ that contain the assemblies for each version of your application that you have published.
When doing updates, you need to upload the versioned folder for the new update, and replace the files in the root folder (yourapp.application, setup.exe, and publish.htm).
If you have any problems, you can check the MIME types on the published files and make sure they are right. These can be changed for each file if needed. With ClickOnce deployments, you should definitely be using the option that appends .deploy to all of your assemblies, so you should not have any files with unknown extensions. If you want to double-check, the MIME types for a ClickOnce deployment are explained here.
Remember that with Blob Storage, it is not going to be storing the files that is going to be the biggest cost factor, it is going to be the transfer of the files to and from the client.
<Return to section navigation list>
SQL Azure Database and Reporting
Steve Yi posted Real World SQL Azure: Interview with Andreas Falter, Head of Developments, Materials Management Division at INFORM and Karsten Horn, Director of International Sales, Materials Management Division at INFORM to the SQL Azure Team blog on 2/25/2011:
As part of the Real World SQL Azure series, we talked to Andreas Falter, Head of Developments, and Karsten Horn, Director of International Sales, both in the Materials Management Division at INFORM, about using the Windows Azure platform, including SQL Azure, to extend its inventory sampling solution to the cloud. Here's what they had to say:
MSDN: Can you tell us about INFORM and the services you offer?
Horn: INFORM is the Institute for Operations Research and Management. We are a Microsoft Gold Certified Partner that develops IT solutions based on advanced decision support technologies and that complement customers' existing enterprise resource systems to optimize planning and control of business processes. Our customers come from various industries, including discrete manufacturing, wholesale, and process industries.
MSDN: What were some of the challenges that INFORM faced prior to adopting SQL Azure?
Falter: In 2009, we made significant efforts to update the user interface for one of our applications: INVENT Xpert. For the data-intensive inventory sampling solution, we developed a web-based interface using JavaScript. It gave INVENT Xpert a face-lift-it gave us a modern user interface and, because it was web-based, also gave us the ability to offer INVENT Xpert with anywhere, anytime access through any Java-enabled Internet browser. But we didn't want to stop there. We wanted to take the application completely to the cloud, and give customers the ability to use INVENT Xpert, but without adding designated web and database servers to their on-premises infrastructure, as these can be costly and time consuming to deploy.
MSDN: Why did you choose the Windows Azure platform as your solution?
Falter: Deciding on Windows Azure and Microsoft SQL Azure was a quick decision for us. Of course, we looked at Amazon Elastic Compute Cloud and Google App Engine, but neither offered a solution that worked well with Microsoft SQL Server databases, which INVENT Xpert uses extensively. The Windows Azure platform does, plus it supports multiple technologies, such as Java, which is important for our development model. Plus, Microsoft is transparent about its data center locations-our customers want to know that their data is close in proximity to their physical location and with Amazon or Google, we simply couldn't guarantee that it was.
MSDN: Can you describe how INFORM is using SQL Azure to help address your need to provide lower-cost deployment of INVENT Xpert for customers?
Falter: We use a Tomcat web server from Apache to connect through HTTPS protocol to the web-based user interface for INVENT Xpert, which is built on a JavaScript framework. Then, we used worker roles in Windows Azure to deploy the Tomcat web server to the cloud. Our application relies on a relational database structure to manage our customers' inventory data and computational results of inventory sampling. We use SQL Azure for that data, using the same database schema and data structures that we did for the on-premises version of the software. We deployed the SQL Azure database in a multitenant environment, so customers share the INVENT Xpert application, but their data is isolated and protected from each other. We used most of our existing program code and architecture, so moving to Windows Azure and SQL Azure was very easy. We planned on six months, but we completed the migration process in two weeks.
MSDN: What makes your solution unique?
Horn: To our knowledge, we are the only company in our industry segment to offer an inventory sampling solution in the cloud. Our customers want these kinds of cloud-based solutions; we are unique in that we can offer them that. Because we are the first to market, that means we also get the competitive advantage.
MSDN: What kinds of benefits is INFORM realizing with SQL Azure?
Falter: Our customers are important to us, and anything we can offer them to improve operations or their bottom line is a benefit to us. With SQL Azure and Windows Azure, we can offer them a 100-percent cloud-based inventory sampling solution that is faster and less expensive to deploy. We can deploy a new customer and provision a database to SQL Azure in a day, and the entire deployment process is 50 percent faster than previously. Plus, customers do not have to purchase additional hardware and software-an 85-percent savings compared to an on-premises version. What's really great to think about is that as we bring more of our solutions to the cloud, and fine-tune our processes, we expect those savings to grow even more.
- Read the full story at:
www.microsoft.com/casestudies/casestudy.aspx?casestudyid=4000009237- To read more SQL Azure customer success stories, visit:
www.sqlazure.com
Web searches for INFORM lead to Institute for Operations Research and Management Science (INFORMS)
Mark Kromer (@mssqldude) recommended that developers Think About Replacing Uniqueidentifier with Sequence in Denali in a 2/25/2011 post:
As I’ve finally been finding some time recently to play with CTP 1 of SQL Server Denali, I’ve focused a lot of my energy around the Sequence object. This is because I have an Oracle PL/SQL background and used Sequences quite a bit in the old days there.
When talking to SQL Server DBAs and developers about Sequences, the conversation often starts with “this is pretty cool” and something that seems interesting on a forward-looking basis. I mean, in reality, who wants to go back into code and data models and make changes to tables, right? So is there a good case to use the Sequence to replace a table-based ID field like an Identity column or uniqueidentifier?
So far, I’m thinking that uniqueidentifier will be something that you’ll want to look at. The 2 most common constructs in T-SQL for creating ID fields in tables is to use either a uniqueidentifier as the column data type or use an INT with the identity property. The identity property in current SQL Server versions is probably the closest correlation to the new Denali sequence object. But the sequence object nicely encapsulates the IDs away from being tied to any single table or object. I describe this usage futher here.
Certainly you can go back and replace your IDENTITY columns easily with sequence objects because the INT data type is a natural fit for sequence #s. However, removing the identity property is not easy. There is no ALTER statement to do it nice and easy for you. And even though the SSMS GUI supports removing the identity property from a table column specification, the T-SQL that is generated from that action is actually the creation of a COPY of your table and data, drop the original table and re-create a new table without the identity definition! That’s not fun and not good, especially if you have a very large table.
Replacing the GUID field in a UNIQUEIDENTIFIER is not easy, either. You will want to remove that field and replace it with an INT using sequence. But this can only be done if you do not have that field as a foreign key in other tables. However, if you can replace it, do so, especially if you are using the GUID for these purposes: because it has guaranteed uniqueness and you are using it as a clustered index key.
Sequence will be a better option in those instances. The Sequence object has its own T-SQL to manage the #s being fed into your INT field to help with uniqueness when moving the data between instances and the sequential INT value of sequence is a MUCH better clustered key than a GUID. The control that you can have over the sequence separate from the table definition should help eliminate some of the limitations that may have led you to use the uniqueidentifier.
Sequences of the bigint data type will be very important for sharding federated databases when SQL Azure introduces this feature later in 2011. The question is how long it will take the SQL Azure team to support Sequence objects. (Stay tuned for my article about SQL Azure federations in the March 2011 issue of Visual Studio Magazine, which will be posted 3/1/2011. See below)
Michael Desmond posted on 2/25/2011 Inside the March Issue of VSM, which contains details about my (@rogerjenn) “exploration of the new sharding features coming to SQL Azure databases” in the cover story:
Well, it's snowing hard again in the Northeast, and that must mean we're getting ready to debut the next issue of Visual Studio Magazine. Just like last month, we're expecting a foot or more of the good stuff ahead of our issue hitting the streets. And just like last month, we've got a great lineup of how-to features, product reviews and developer insight to offer our readers. Look for the issue to hit our Web site on March 1st.
Our Language Lab columnists are hard at it with in-depth tutorials in our March issue as well. Kathleen Dollard digs deep into ASP.NET MVC 3 this month, introducing the Model-View-Controller programming technology and answering questions on topics like the new Razor view engine and dependency injection. Finally, On VB columnist Joe Kunk offers a primer on getting started with Windows Phone 7 development in Visual Basic. Kunk has been working with WP7 for a few months now and says he's very happy with the platform. Be sure to check out his useful introduction to Microsoft's fast-moving mobile platform.
VSM Tools Editor Peter Vogel has kept busy with in-depth VS Toolbox reviews. He explores Telerik's TeamPulse Silverlight-based team project management suite for Agile development, as well as ComponentOne's Studio for ASP.NET AJAX controls package.
As ever VSM is long on expert opinion and insight, with our columnists looking at how Microsoft manages the gaps. Mark Michaelis has been a Microsoft MVP on C#, VSTS and the Windows SDK for years, and his VS Insider column brings that experience to bear on Microsoft's strategy of mirroring functionality already available in open source solutions. Andrew Brust, meanwhile, weighs in on Microsoft's track record for bridging the gap between legacy and emerging technologies and platforms, from QuickBasic to SQL Azure.
Winter clearly hasn't lost its snowy grip. And with the big plans we have in place for our April issue, I'm a bit worried I may be writing about yet another snowstorm 30 days from now.
Paul Patterson (@PaulPatterson) adds another reason to avoid the uniqueidentifier SQL Server data type in his Entity Framework 4 and SQL UniqueIdentifier Bug workaround post of 2/25/2011:
For the last little while I’ve been banging my head against the desk, trying to figure out an issue when creating records that used a SQL UniqueIdentifier data type. It turns out that the issues I experienced resulted from a bug, or “undocumented feature”, in the way Visual Studio builds entities for a Entity Framework model.
The scenario I have is one where we do some publisher/subscriber database synchronization for our solution. We have a number of clients, including mobile applications, that subscriber to a central SQL database. This resulting configuration on the SQL server database includes uniqueidentifier data type fields appended to the tables used in synchronization processes.
These fields, appropriately named “rowguid”, are configured as UniqueIdentifier data types. When a new row is added to the table, the Default Value or Binding property is configured with a NEWSEQUENTIALID() call.
For example, here is a table named Company configured with a uniqueidentifier type field named rowguid, and the Default Value or Binding property is configured to use a default value of NEWSEQUENTIALID() – which is basically a new GUID value.
Uniqueidentifier field.
Using the Entity Framework designer in Visual Studio, you would expect that when adding the table as an entity to the designer that the uniqueidentifier field (my “rowguid” named field) would be added and configured properly. In some ways it “kinda sorta” does configure it properly. It treats the field as any other field. The problem comes in when you start to use the entity framework to add records.
Let’s say a call goes out to add a record using the Company entity in the model. Using the entity framework, the call would be something like this…
MyEntities.AddToCompanies(myNewCompany)When I did this call, the record was added to the database, however the rowguid field was created with a value of “00000000-0000-0000-000000000000″. Why? Probably because the entity framework defaulted the uniqueidentifier value as such; all zeros. I suppose this would be fine if I knew there would be only one record in the table. But that would defeat the purpose of using a field that is supposed to represent a unique value.
Seems the problem lies in the way the designer handles this property.
The Company entity in the designer.
The “rowguid” property does not get configured with the necessary StoreGeneratedPattern property. I’ll update this using the designer…
StoreGeneratedPattern property
But looking at the actual .edmx model, the StoreGeneratedPattern property that is set does not stick…
<EntityType Name="Company"> <Key> <PropertyRef Name="CompanyID" /> </Key> <Property Name="CompanyID" Type="int" Nullable="false" StoreGeneratedPattern="Identity" /> <Property Name="CompanyName" Type="nvarchar" MaxLength="50" /> <Property Name="CreatedBy" Type="int" /> <Property Name="CreatedDate" Type="datetime" /> <Property Name="LastUpdatedBy" Type="int" /> <Property Name="LastUpdatedDate" Type="datetime" /> <Property Name="CompanyKey" Type="nvarchar" MaxLength="50" /> <Property Name="rowguid" Type="uniqueidentifier" Nullable="false" /> </EntityType>So what’s a person to do? Seems that this issue can be resolved by manually updating the .edmx file that Visual Studio uses when designing the entity model. Unfortunately my model contains a LOT of entities, and I don’t want to spend a bunch of time manually editing this file. Others have found workarounds for this same problem however to me they seemed to be overkill for such a simple problem. I know that Microsoft will come out with a resolution eventually, so until then, I leverage the all mighty power of the Quick Replace tool in Visual Studio.
I opened my entity framework model .edmx file using the Visual Studio XML editor (right-click the .edmx file and select Open With…, then select XMS (Text) Editor from the Open With dialog). Then, using the handy dandy Find and Replace tool, I do a Quick Replace on all the “rowguid” fields, adding the StoreGeneratedPattern property wherever it is needed.
Find and Replace to the rescue.
That’s all there is to it. No addin, extension, or fancy abstracted code to fix the issue. Again, Microsoft will come up with a fix eventually. Until then, this simple little process works just fine. Adding a record works as expected, using a unique guid value each time.
Yay! A proper unique identifier





It’s likely that this bug will affect Visual Studio LightSwitch, so cross-referenced.
<Return to section navigation list>
MarketPlace DataMarket and OData
Christian Weyer published Materials for my sessions at BASTA! Spring 2011 on 2/26/2011:
… as promised!
And thanks to everybody who came to my and the other thinktecture guys’ sessions.
It was a truly awesome BASTA! conference (again)
Glen Gailey (@ggailey777) explained Getting JSON Out of WCF Data Services on 2/25/2011:
I was working with Ralph and a few other folks in my team on an internal project that required us to pass an OData feed from our own Windows Azure-hosted WCF Data Service to Windows Azure Marketplace DataMarket. In the process of doing this, I was reminded that, as others like Josh Einstein and Chris Love have already blogged about, WCF Data Services doesn’t support the $format query option out of the box. Rather, it basically just ignores it. As such, the data service is designed to only respond with a JSON-formatted response when a request has an Accept header value of application/json. However, because MarketPlace requires that all OData system query options be supported when you bring your own OData data feed, we needed to enable this query option in our data service.
First…some background
How do I enable support for $format
To enable this support in WCF Data Services, you need to basically get the incoming request, remove the $format query option from the URI, and then change the Accept header to application/json. Luckily, there is code out their that does this for you in these WCF Data Services extension projects.
- JSONP and URL-controlled format support for ADO.NET Data Services (on the old MSDN code gallery)
- WCF Data Services Toolkit (on CodePlex)
You can add this functionality to your data service by downloading one of these projects, adding the code to your WCF Data Services project, and turning it on in one of these ways:
- JSONP and URL project—when you add the JSONPSupportBehaviorAttribute to your data service class, the the service can handle the $format query option $format=json. In my case, I also further modified this project to also handle $format=atom required by DataMarket.
- WCF Data Services Toolkit—when your service inherits from the ODataService<T> class included in the WCF Data Services Toolkit project, then your implementation already includes support for both $format=json and JSONP. For more information, see Building Real-World OData Services.
Azret Botash posted OData and OAuth – Part 3 - Federated logins with Twitter, Google, Facebook to the DevExpress Community blog on 2/25/2011:
It’s time to look at OAuth protocol itself. In short, OAuth is a token based authentication that became popular in recent years due to the adoption by big web giants like Google, Twitter, Facebook etc.
There is a lot of good material on the web explaining the protocol flow in great details:
- http://hueniverse.com/oauth/
- http://www.viget.com/extend/oauth-by-example/
- http://dev.twitter.com/pages/auth
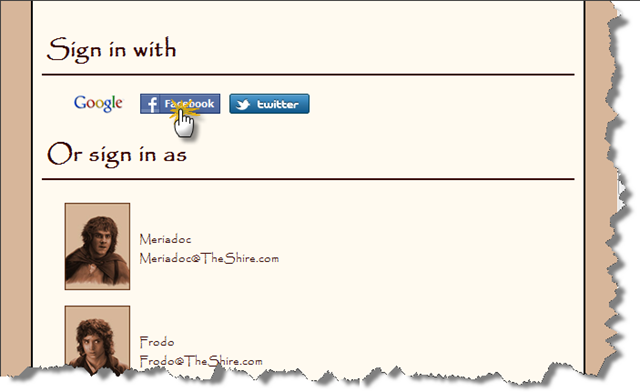
For us, it’s important because The Hobbit’s Bank Of the Shire exposes developer API and we want to make sure that any client app that is to use this API will not know the credentials of our members. And because everyone who lives in the Shire has an account on Twitter or Facebook and they would like to be able to sign into their accounts using those identities. Let’s start by adding support for federated logins: “Sign in with”

When “signing in with”, we’ll redirect to the same Signin action on the AccountController with a parameter that tells us what service to use for authentication. Let’s start with Twitter (OAuth 1.0):
<a href='@Url.Action("signin", "account", new { oauth_service = "tw" })' style="float:left; margin-left:10px;"> <img style="float:left; border:0px; " src='@Url.Content("~/Content/Twitter.png")' alt="" /> </a>public ActionResult Signin(Nullable<Guid> id) { string service = Request.QueryString.Get("oauth_service"); if (String.Equals(service, "tw", StringComparison.InvariantCultureIgnoreCase)) { return Redirect( AuthenticationService.GetAuthorizeUriForTwitter(Request.Url) ); } MixedAuthenticationTicket ticket = MembershipService.CreateTicketForPrincipal(id); if (Impersonate(ticket, true)) { return RedirectToAction("", "home"); } return View(new Signin(MembershipService.GetPrincipals())); }AuthenticationService.GetAuthorizeUriForTwitter will make call to http://twitter.com/oauth/request_token to get the request token. Once the token is issued, it will return a URL to the http://twitter.com/oauth/authorize so the user can grant the access. (A complete OAuth flow for twitter is published here: http://dev.twitter.com/pages/auth). We’ll also need to register The Hobbit’s Bank Of the Shire with Twitter so that we are issued a Consumer Key and Consumer Secret: Twitter App Registration https://dev.twitter.com/apps/new.
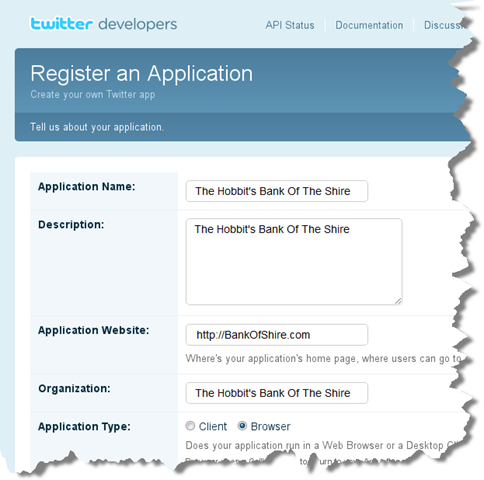
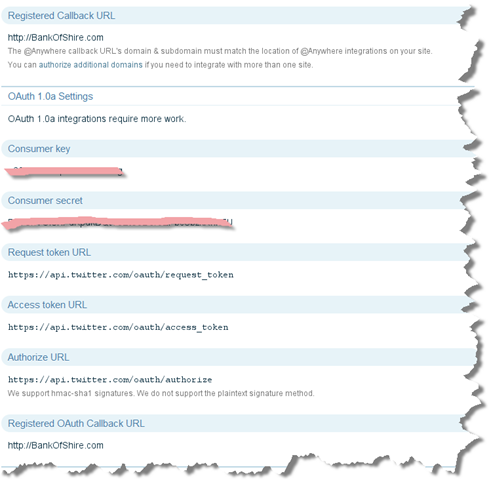
The Consumer Key and Consumer Secret is securely kept in the Web.config. Especially the Consumer Secret, as it’s used for signing the requests and only The Hobbit’s Bank Of the Shire and Twitter should know the value.
<appSettings> <add key="Twitter_Consumer_Key" value="YOUR CONSUMER KEY" /> <add key="Twitter_Consumer_Secret" value="YOUR CONSUMER SECRET" /> </appSettings>Back to AuthenticationService.GetAuthorizeUriForTwitter, takes in a Uri parameter for the callback. We’ll use the same Signin action. Once redirected back, we’ll acquire an access token from twitter and sign in as that twitter user:
public ActionResult Signin(Nullable<Guid> id) { string service = Request.QueryString.Get("oauth_service"); if (String.Equals(service, "tw", StringComparison.InvariantCultureIgnoreCase)) { return Redirect( AuthenticationService.GetAuthorizeUriForTwitter(Request.Url) ); } MixedAuthenticationTicket ticket = MixedAuthenticationTicket.Empty; string callback = Request.QueryString.Get("oauth_callback"); if (String.Equals(callback, "tw", StringComparison.InvariantCultureIgnoreCase)) { ticket = AuthenticationService.FromTwitter(Request); if (Impersonate(ticket, true)) { return RedirectToAction("", "home"); } }ticket = MembershipService.CreateTicketForPrincipal(id); if (Impersonate(ticket, true)) { return RedirectToAction("", "home"); } return View(new Signin(MembershipService.GetPrincipals())); }


and we’re back on our property

Google & Facebook
We’ll follow the same pattern for Google and Facebook. Key difference is that Facebook uses OAuth 2.0 protocol. More here.
- Registering for Google Consumer Key and Consumer Secret : https://www.google.com/accounts/ManageDomains
- Registering for Facebook App ID and App Secret: http://www.facebook.com/developers/createapp.php
public ActionResult Signin(Nullable<Guid> id) { string service = Request.QueryString.Get("oauth_service"); if (String.Equals(service, "tw", StringComparison.InvariantCultureIgnoreCase)) { return Redirect( AuthenticationService.GetAuthorizeUriForTwitter(Request.Url) ); } else if (String.Equals(service, "g", StringComparison.InvariantCultureIgnoreCase)) { return Redirect( AuthenticationService.GetAuthorizeUriForGoogle(Request.Url) ); } else if (String.Equals(service, "fb", StringComparison.InvariantCultureIgnoreCase)) { return Redirect( AuthenticationService.GetAuthorizeUriForFacebook(Request.Url) ); } MixedAuthenticationTicket ticket = MixedAuthenticationTicket.Empty; string callback = Request.QueryString.Get("oauth_callback"); if (String.Equals(callback, "tw", StringComparison.InvariantCultureIgnoreCase)) { ticket = AuthenticationService.FromTwitter(Request); } else if (String.Equals(callback, "g", StringComparison.InvariantCultureIgnoreCase)) { ticket = AuthenticationService.FromGoogle(Request); } else if (String.Equals(callback, "fb", StringComparison.InvariantCultureIgnoreCase)) { ticket = AuthenticationService.FromFacebook(Request); } else { ticket = MembershipService.CreateTicketForPrincipal(id); } if (Impersonate(ticket, true)) { return RedirectToAction("", "home"); } return View(new Signin(MembershipService.GetPrincipals())); }
and we’re back on our property
We now know how to do a “Sign in with”. All the Hobbits want to start using this feature right away. Unfortunately, we don’t have the ability to resolve federated identities back to our Principal object. We’ll cover this in the next post.
Download source code for Part 3
- Part 1: Introduction
- Part 2: FormsAuthenticationTicket & MixedAuthentication
- Part 3: Understanding OAuth 1.0 and OAuth 2.0, Federated logins using Twitter, Google and Facebook
- Part 4, 5: Implementing OAuth 1.0 Service Providers (storing and caching tokens, distributed caches (memcached, velocity))
- Part 6: Securing OData feeds without query interceptors
- Part 7: Client Apps

<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
See Jobs/ITWorld Canada shed more light on WAPA with this SENIOR Software Development Engineer (SDE) Job posting of 2/26/2011 in the Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds section below.
The Windows Azure App Fabric Team reminded developers about the February 2011 Releases of the Identity Training Kit & the MSDN Online Identity Training Course on 2/25/2011:
Read this blog post by Vittorio Bertocci, one of our Windows Azure AppFabric evangelists, regarding the most recent updates to the Identity Developer Training Kit and the first release of the MSDN-hosted Identity Developer Training Course.
If you are already using the Access Control service, or would like to get started, these would be very useful resources.
You can start using our CTP services in our LABS/Preview environment at: https://portal.appfabriclabs.com/ to get a feel for the features and enhancements that are going to be released soon. Just sign up and get started.
You can also start using our production services free of charge using our free trial offers. Just click on the image below.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
The Windows Azure Team posted UPDATED: 24 Nodes Available Globally for the Windows Azure CDN Including New Node in Doha, QT on 2/24/2011:
2/24/11 UPDATE: We're excited to announce a new node in Doha, QT to improve performance for clients on the QTel and affiliated networks.
US EMEA Rest of World
- Ashburn, VA
- Bay Area, CA
- Chicago, IL
- San Antonio, TX
- Los Angeles, CA
- Miami, FL
- Newark, NJ
- Seattle, WA
- Amsterdam, NL
- Doha, QT NEW
- Dublin, IE
- London, GB
- Moscow, RU
- Paris, FR
- Stockholm, SE
- Vienna, AT
- Zurich, CH
- Hong Kong, HK
- São Paulo, BR
- Seoul, KR
- Singapore, SG
- Sydney, AU
- Taipei, TW
- Tokyo, JP
Offering pay-as-you-go, one-click-integration with Windows Azure Storage, the Windows Azure CDN is a system of servers containing copies of data, placed at various points in our global cloud services network to maximize bandwidth for access to data for clients throughout the network. The Windows Azure CDN can only deliver content from public blob containers in Windows Azure Storage - content types can include web objects, downloadable objects (media files, software, documents), applications, real time media streams, and other components of Internet delivery (DNS, routes, and database queries).
For details about pricing for the Windows Azure CDN, read our earlier blog post here.
*A Windows Azure CDN customer's traffic may not be served out of the physically "closest" node; many factors are involved including routing and peering, Internet "weather", and node capacity and availability. We are continually grooming our network to meet our Service Level Agreements and our customers' requirements.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
David Hardin published WAD is Built on ETW as the first episode of his Windows Azure Diagnostics Series on 2/26/2011:
Windows Azure Diagnostics (WAD) is built upon Event Tracing for Windows (ETW). To get the most out of WAD and future Azure product offerings you need to understand and use ETW. Here is a little ETW primer and how it relates to WAD:
1. ETW is the efficient kernel-level tracing facility built into Windows. Microsoft products leverage ETW extensively including Windows Azure Diagnostics. Here is ETW’s architecture:
[Image from http://msdn.microsoft.com/en-us/library/aa363668(v=VS.85).aspx]
2. .NET has a legacy tracing capability from .NET 1.1 within the System.Diagnostics namespace implemented in the Trace, Debug, Switch, TraceListener, and derived classes. This legacy capability was built without ETW integration and has some performance issues.
3. To improve tracing performance .NET 2.0 enhanced the Diagnostics namespace by adding the TraceSource and SourceSwitch classes. TraceSource is the preferred, best performing way to trace information from .NET code; no not use Trace or Debug.
4. To integrate .NET tracing with ETW, .NET 3.5 added the System.Diagnostics.Eventing namespace with the EventProvider and EventProviderTraceListener classes. The EventProvider class is an implementation of an ETW Provider shown in the diagram above; it is the gateway from .NET to ETW. The EventProviderTraceListener is the gateway from .NET tracing to the EventProvider class and hence ETW’s efficient and high performance tracing.
5. Here is WAD’s architecture:
[Image from http://msdn.microsoft.com/en-us/magazine/ff714589.aspx; a must read article]
6. The yellow and red portions of the WAD diagram are the .NET tracing discussed in #2 and #3 above. The Microsoft product teams have already added many TraceSources within their framework code and you should do the same within your code. The recommendation is to create at least one unique TraceSource per application or assembly.
7. The black arrows coming out of the red TraceSource portions of the WAD diagram are configured in web.config / app.config. The arrows go to TraceListeners. Out of the box .NET provides around ten TraceListeners. Enterprise Library adds a dozen more in its Logging.TraceListeners and Logging.Data namespaces. The various TraceLiseners have different performance characteristics so pick wisely given your requirements and prefer ones that use ETW.
8. WAD implements a TraceListener called DiagnosticMonitorTraceListener which is shown in the purple box on the diagram above. The listener writes events to WADLogsTable in Azure Table Storage. DiagnosticsMonitorTraceListener is typically wired up in the web.config / app.config as show:
<system.diagnostics><sharedListeners><add name= "azureDiagnosticsTraceListener " type= "Microsoft.WindowsAzure.Diagnostics.DiagnosticMonitorTraceListener, Microsoft.WindowsAzure.Diagnostics, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35 "><filter type= "" /></add></sharedListeners><sources><!-- TraceSource.* related settings --><source name= "WAD_Example " switchName= "logSwitch "><listeners><add name= "azureDiagnosticsTraceListener " /></listeners></source></sources><switches><add name= "logSwitch " value= "Information " /><!-- see System.Diagnostis.SourceLevels --></switches><trace><listeners><add name= "azureDiagnosticsTraceListener " /></listeners></trace></system.diagnostics>9. Additionally WAD can read from the Windows Event Logs, event counters, custom files, and ETW directly. WAD is one of the ETW Consumers shown in the diagram in #1 above.
10. WAD uses an xpath type expression, which you specify, to filter the Windows Event Logs prior to WAD writing the events to WADWindowsEventLogsTable in Azure Table Storage. If you need to write to the Windows Event Log, the preferred approach is to add an EventLogTraceListener to the config shown above instead of writing to it directly using EventLog.WriteEntry().
For more posts in my WAD series:

.png "Figure 1 High-Level Overview of Windows Azure Diagnostics")
David Hardin announced a new Windows Azure Diagnostics Series in a 2/26/2010 post:
http://blogs.msdn.com/b/davidhardin/archive/tags/wad/ [See item above.]
Dave’s biplane looks to me like a PT-17 (Stearman).
The Windows Azure Team reported a Real World Windows Azure: Interview with Nick Beaugeard, Managing Director, HubOne in a 2/25/2011 post:
As part of the Real World Windows Azure series, we talked to Nick Beaugeard, Managing Director at HubOne, about using the Windows Azure platform to transform the company into one of the major cloud services providers in Australia. Here's what he had to say:
MSDN: Tell us how HubOne got started as a cloud services provider.
Beaugeard: We were developing enterprise software but we had no customers. I got a call from a friend who manufactures pet products. He needed help troubleshooting an issue with Microsoft Exchange Server. I found that the company was running a host of enterprise software in the middle of a warehouse. I introduced my friend to the Microsoft Business Productivity Online Standard Suite from Microsoft Online Services, a set of messaging and collaboration tools delivered as a subscription service. It was our first customer and it was a massive success. The pet products company had been paying U.S.$50,000 annually for IT support, and has now reduced its IT expenses to less than $5,000 a year.
MSDN: What kinds of cloud services do you offer customers?
Beaugeard: On July 1, 2010, we rebranded HubOne as a professional consulting service organization for customers who want to take advantage of opportunities to conduct business in the cloud. HubOne offers a managed migration process from an on-premises or hosted solution to the cloud platform and it provides 24-hour support services.
MSDN: Describe how you changed your business model to become a cloud services provider.
Beaugeard: We decided to use cloud services to run HubOne and we would offer only products and services that would provide the highest quality and the greatest reliability. We also determined that the 15 employees at HubOne no longer needed an office; we could communicate by using online productivity tools and hold meetings at local pubs. If the cloud works for HubOne, I can say to a customer, "This is how my company works and it's really cool." That's a really good selling point."
The whole HubOne.com site-including a public website, customer portal, partner portal, and e-commerce ordering solution-is a single Windows Azure application.
MSDN: Describe the HubOne web portal.
Beaugeard: The whole HubOne.com site-including a public website, customer portal, partner portal, and e-commerce ordering solution-is a single Windows Azure application. Customers and partners authenticate to the HubOne web portal with Windows Live credentials. Once customers sign in, they can access the HubOne knowledge base, order services, and monitor account activity.
MSDN: What do you like about the Windows Azure platform?
MSDN: How did your developers transition to cloud services integrators?
Beaugeard: Our developers can create applications and services on Windows Azure by using their existing expertise with the Microsoft .NET Framework, a platform for building applications. The company develops applications by using Microsoft Visual Studio 2010 and Microsoft Visual Studio Team Foundation Server 2010, which automates and streamlines the software delivery process. We then move the code to the Windows Azure platform.
MSDN: How many customers do you have now?
Beaugeard: HubOne has more than 600 customers including a number of enterprise accounts. In October 2010, the Australian Financial Review (AFR.com) named HubOne as one of the country's top-10 rising business stars. We're aiming to be the leading cloud provider in the Asia Pacific region within three years.
MSDN: What benefits have you seen since implementing the Windows Azure platform?
Beaugeard: It's still early in the cloud computing era, so people talk a lot about the cost of acquisition. There are upfront costs, but we don't have to buy servers and infrastructure. People forget about the permanent IT cost reductions. At HubOne, we have removed 90 percent of the complexity of an IT environment and about 60 percent of the management costs, year after year. That's the massive economic shift in cloud computing and it's those ongoing economics are what really change the game.
- Read the full story at:
www.microsoft.com/casestudies/casestudy.aspx?casestudyid=4000009043- To read more Windows Azure customer success stories, visit: www.windowsazure.com/evidence

Microsoft’s Public Sector Developer blog described methods to Dynamically scale your Windows Azure service instances… on 2/18/2011 (missed when posted):
a) Make a change to the service configuration files associated with your cloud service/application on the Windows Azure portal or using free command line tools (http://archive.msdn.microsoft.com/azurecmdlets) – Easy manual step, and may be sufficient for certain set of scenarios.
b) Leverage a third-party product to manage their Windows Azure (virtual machine) instances and monitor their services hosted on Windows Azure. – Comprehensive tool acquired for a fee from a third-party vendor will provide more capabilities beyond just scaling the VM instances. You can search for these third-party tools, talk to the vendors, learn about their capabilities and then make an informed decision.
c) DIY (Do-It-Yourself) approach that uses custom application to scale Windows Azure VM instances – Some may choose this, potential less expensive, option for more control over how the scaling is done. Such application could be deployed either in Windows Azure (as part of the service it controls or separately, and be shared to control more services) or on premises.
- One of our customers, Idaho Department of Labor, deployed a high-value application on Windows Azure (described in this blogpost) and also built an open-source utility (in the shape of Windows Service) to dynamically scale their Windows Azure virtual machine instances. Custom Windows Service (deployed and running on-premise/on-your-server) is completely configurable via an xml file wherein you can specify information about your Windows Azure service/application and the manner in which the virtual instances should be scaled-up or down. One could scale (dial-up or down) the instances based on CPU load or the day/time of the week. Windows Service utility to scale the instances was written by Greg Gipson (Lead Architect and Developer at Idaho Department of Labor) and the source-code has been published on codeplex http://azureinstancemanager.codeplex.com/
Here are some other articles/resources you can check out as well.
- Performance-Based Scaling: http://msdn.microsoft.com/en-us/magazine/gg232759.aspx
- Code approach: http://code.msdn.microsoft.com/azurescale
- Multithreading approach:
- Windows Azure Application Monitoring Management Pack (RC version) http://www.microsoft.com/downloads/en/details.aspx?FamilyID=4f05f282-f23a-49da-8133-7146ee19f249
Thanks to Greg Gipson (Lead Architect and Developer at Idaho Department of Labor) for publishing the Windows Service utility on codeplex. http://azureinstancemanager.codeplex.com/ Hope you will find it useful, enhance (as you see fit) it for yourself and contribute it back to the community (same codeplex site).
Ben Lobaugh posted Deploying a Java application to Windows Azure with Command-line Ant on 2/17/2011 to the Microsoft Platform & Java Interoperability blog (missed when posted):
Recommended Reading
- Understanding Windows Azure
- Getting the Windows Azure Pre-Requisites Via Manual Installation
- Getting the Windows Azure Pre-Requisites Via Automatic Web Platform Installer
Whether you are building a brand new application, or already have something built and wish to take advantage of the high availability and scalability of the Windows Azure cloud, this tutorial will show you how to package and deploy your application and runtime elements.
Download the Windows Azure Starter Kit for Java
To start things out we need to go download the Windows Azure Starter Kit for Java from the CodePlex project page.
The files can be found at: http://wastarterkit4java.codeplex.com/
The Windows Azure Starter Kit for Java uses Apache Ant as part of the build process. If you are not familiar with Ant, go check the installation manual which can be found at http://ant.apache.org/manual/index.html. Ant can be downloaded from the Apache project page at http://ant.apache.org
Note: Ant requires several environment variables to be set, ANT_HOME, CLASSPATH, and JAVA_HOME. Ensure these are set correctly. See http://ant.apache.org/manual/install.html#setup
Inside the Windows Azure Starter Kit for Java
The file you just downloaded is a Zip file that contains a template project. You need to first extract the project. This is a pretty straight forward process. Right click on the archive, choose "Extract All…" and select the destination to extract the project to.
If you look inside this archive you will find the typical files that constitute a Java project, as well as several files we built that will help you test, package and deploy your application to Windows Azure.
The main elements of the template are:
- .cspack.jar: Contains that java implementation of windowsazurepackage ant task.
- ServiceConfiguration.cscfg: This is Azure service configuration file. See the "What next?" section for more details.
- ServiceDefinition.csdef This is Azure service definition file. See the "What next?" section for more details.
- Helloworld.zip: This Zip is provided as a very simple sample application. Since we want to build a snazzy web application we can safely delete this file.
Note: Do not delete the util folder! This folder contains needed project files.- startup.cmd: This script is run each time your Worker Role starts. Here you will define anything that needs to take place on startup, such as starting a Java server, or firing off a background service.
- unzip.vbs: Simple script we provided to make it easy to unzip zipped archives.
Select the Java server environment
The project template is designed to work with multiple Java server environments.
As we progress through this tutorial I will show you how to setup two servers, Tomcat and Jetty. You are definitely not limited to using only these two servers.
Download the server distribution and copy it into the \approot folder of the project. We do not need to extract the server from the archive file. The startup.cmd script will take care of the extraction for us.
The packages I am using can be found at
- Tomcat - http://tomcat.apache.org/download-70.cgi
Download the correct Core edition for your machine
Installation Instructions: http://tomcat.apache.org/tomcat-7.0-doc/setup.html- Jetty - http://download.eclipse.org/jetty/7.2.2.v20101205/dist/jetty-distribution-7.2.2.v20101205.zip
Installation Instructions: http://wiki.eclipse.org/Jetty/Howto/Install_JettyUsing Tomcat server
Using Jetty server
Author note: I have placed each archive in it's own directory because I feel it is easier to quickly find files in the file tree this way. You are not forced to repeat this in your project. You may place the files wherever you like in your approot folder, just be sure to update the startup.cmd script with the correct paths.
Select the Java Runtime Environment
As with the server, feel free to choose whatever Java runtime environment you are comfortable with using. For this sample, I will be using the Java Runtime Environment (JRE) shipped by Oracle. Download the JRE and copy it in the approot folder. You do not have to extract the JRE.
The Oracle JRE can be found at http://www.oracle.com/technetwork/java/javase/downloads/index.html
Unfortunately there is not a Zip version of the JRE, only the installer. The solution therefore seems to be creating your own Zip. I created mine by zipping C:\Program Files\Java\jre6
Note: For more information on this issue see this stackoverflow article http://stackoverflow.com/questions/1619662/where-can-i-get-the-latest-jre-jdk-as-a-zip-file-i-mean-no-exe-installer
Prepare your Java application
Go ahead and delete the HelloWorld.zip file.
Note: Do not delete the util folder! This folder contains needed project files.Start off by creating a simple HelloWorld.jsp in the approot folder. Later you can expand the application by copying in your current application, or creating the application code directly in the approot folder.
HelloWorld.jsp
<%@ page language="java" contentType="text/html; charset=ISO-8859-1"
pageEncoding="ISO-8859-1"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html>
<head>
<metahttp-equiv="Content-Type"content="text/html; charset=ISO-8859-1">
<title>Insert title here</title>
</head>
<body>
<%!
public String GetString() {
return "\"Look! I work!\"";
}
%>
The Java Server is Running = <%= GetString() %>
</body>
</html>Configure project files startup.cmd and ServiceDefinition.csdef:
The next step is to edit the startup.cmd and ServiceDefinition.csdef files with the appropriate commands relative to the server environment.
Open startup.cmd inside the approot\util folder and replace the content with the following commands, for either Jetty or Tomcat.
Tomcat
@REM unzip Tomcat cscript /B /Nologo util\unzip.vbs Tomcat\apache-tomcat-7.0.6-windows-x64.zip . @REM unzip JRE cscript /B /Nologo util\unzip.vbs JRE\jre6.zip . @REM copy project files to server md apache-tomcat-7.0.6\webapps\myapp copy HelloWorld.jsp apache-tomcat-7.0.6\webapps\myapp @REM start the server cd apache-tomcat-7.0.6\bin set JRE_HOME=..\..\jre6 startup.batJetty
@REM unzip Jetty cscript /B /Nologo util\unzip.vbs Jetty\jetty-distribution-7.2.2.v20101205.zip . @REM unzip JRE cscript /B /Nologo util\unzip.vbs JRE\jre6.zip . @REM copy project files to server md jetty-distribution-7.2.2.v20101205\webapps\myapp copy HelloWorld.jsp jetty-distribution-7.2.2.v20101205\webapps\myapp @REM start the server cd jetty-distribution-7.2.2.v20101205 start ..\jre6\bin\java.exe -jar start.jarSave startup.cmd and open ServiceDefinition.csdef in your main project folder. We need to add an endpoint so we can get to our application in the browser later. Add the following line right before the closing <WorkerRole> tag. This tag tells theWindows Azure load balancer to forward port 80 traffic to port 8080 on the machine running the Azure instance.The configuration is the same for either Jetty or Tomcat.
<Endpoints>
<InputEndpointname="Http"protocol="tcp"port="80"localPort="8080"/>
</Endpoints>Your ServiceDefinition.csdef should now look similar too:
<?xmlversion="1.0"encoding="utf-8"?>
<ServiceDefinitionname="WindowsAzureCloudServiceProject"xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<WorkerRolename="WorkerRole1">
<Startup>
<!-- Sample startup task calling startup.cmd from the role's approot\util folder -->
<TaskcommandLine="util\startup.cmd"executionContext="elevated"taskType="simple"/>
</Startup>
<Endpoints>
<InputEndpointname="Http"protocol="tcp"port="80"localPort="8080"/>
</Endpoints>
</WorkerRole>
</ServiceDefinition>Starting the local Windows Azure cloud platform
There are two options for starting the local Windows Azure cloud platform, via the GUI or via the command-line. The GUI is simple and easy to use, while the command-line is useful in scripts and automation.
Starting the local Windows Azure cloud platform via the GUI
In the Start Menu you will to find the "Windows Azure SDK", click on it. Click on "Compute Emulator". You may also start the Storage Emulator from the Start Menu.
You will now have an icon in you system tray. From that icon you can open the Compute Emulator UI, Storage Emulator UI, Start/Stop Compute Emulator, and Start/Stop Storage Emulator (Storage Emulator is not needed for this sample).
Starting the local Windows Azure cloud platform via the command-line
To start the local Windows Azure cloud platform via the command-line ensure you have a Windows Azure SDK Command Prompt open. You can get to the command prompt via the Start Menu (see image above):
Type the following command to start the emulator.
csrun /devfabricsc:start[Optional] If your sample application is using any of the Windows Azure Storage features (Blogs, Tables, Queues), then type the following command to start the storage emulator
csrun /devstore:startIf you would like to see all the options available to csrun type the following command
csrun /?Build the package
Still inside the Windows Azure SDK Environment prompt, navigate to your project directory. Building the application is as simple as running the following command.
ant -buildfile package.xmlThe command tells Ant to use the information contained within the package.xml file to build your application. Be patient, this could take some time depending on the size of your application and the resources available on your machine. If the build was successful you should see output similar to:
Note: If you receive a "BUILD FAILED … The package directory does not exist" message you may need to manually create the deploy directory.The final step is to descend into the deploy directory and run the server.
cd deploy csrunYour application should now be running on port 8080. Open your web browser and type http://localhost:8080/myapp/HelloWorld.jsp into the URL bar.
Packaging the application for deployment on Windows Azure
Now I need to talk a little more about the package.xml file. If you open the package.xml file you will find a specific tag that controls whether your application is built for local development or production on the Windows Azure cloud. The tag you are looking for in package.xml is:
<windowsazurepackage
sdkdir="${wasdkdir}"
packagefilename="WindowsAzurePackage.cspkg"
packagedir="${wapackagedir}"
packagetype="local"
projectdir="${basedir}"
definitionfilename="ServiceDefinition.csdef"
configurationfilename="ServiceConfiguration.cscfg"
>Take note of the packagetype attribute. This attribute can be set to either local or cloud. When packagetype="local" your application will be built into the exact structure that will be on the Windows Azure cloud, however it is not archived for upload. If packagetype="cloud" your application will be built and archived as a .cspkg file. You can then log in to the Windows Azure Portal and upload the .cspkg and .cscfg files to deploy your application in the cloud.
The package.xml is a very powerful build file with many options for customizing your application. The file contains a wealth of comments that describe many of the options available to you. Take some time and familiarize yourself with the comments as this file will be incredibly useful to you in future projects.
Note: Please do not try to change the name of your worker role until you have read the article on Changing the name of your Worker Role.
Deploying your application to the Windows Azure cloud
Deploying your application to the Windows Azure cloud is as simple as logging in to the Windows Azure Portal and uploading the .cspkg and .cscfg files creating when you built your package for the cloud.
For specific details on deploying please see the following articles:
http://msdn.microsoft.com/en-us/library/gg433027.aspx
http://msdn.microsoft.com/en-us/windowsazure/ff798117.aspxCongratulations, you now have successfully setup and run your first Windows Azure application! Check out the links in the "What next?" section for more examples.
What next?
- Windows Azure SDK Schema Reference (Detailed usage of the .cscfg and .csdef files)








Robin Shahan (@RobinDotNet) described Azure Tools/SDK 1.3 and IIS Logging in a 2/16/2011 post (missed when posted):
The article blithely throws this solution your way: “To access the files programmatically, create a startup task with elevated privileges that manually copies the logs to a location that the diagnostic monitor can read. Doesn’t that sound easy? Not so much.
I started a thread in the MSDN Forum and my good friend Peter Kellner opened up a problem ticket with Azure support. So I finally have a solution, with input from and my thanks to Steve Marx (Microsoft Azure Team), Andy Cross, Christian Weyer (MVP), Ruidong Li (Microsoft Azure support), Neil Mackenzie (Azure MVP), and Cory Fowler (Azure MVP). Sometimes it takes a village to fix a problem. I have to give most of the credit to Ruidong Li, who took the information from Steve Marx and Christian Weyer on startup tasks and PowerShell and ran with it.
I’m going to give all the info for getting the IIS logs and IIS Failed Request logs working. The basic information is available from many sources, including this article by Andy Cross.
For the IIS Failed Request logs, you have to put this in your web.config.
<!-- This is so the azure web role will write to the iis failed request logs--> <tracing> <traceFailedRequests> <add path="*"> <traceAreas> <add provider="ASP" verbosity="Verbose" /> <add provider="ASPNET" areas="Infrastructure,Module,Page,AppServices" verbosity="Verbose" /> <add provider="ISAPI Extension" verbosity="Verbose" /> <add provider="WWW Server" areas="Authentication,Security,Filter,StaticFile,CGI,Compression,Cache,RequestNotifications,Module" verbosity="Verbose" /> </traceAreas> <failureDefinitions timeTaken="00:00:15" statusCodes="400-599" /> </add> </traceFailedRequests> </tracing>In the OnStart method of your WebRole, you need this:
//from http://blog.bareweb.eu/2011/01/implementing-azure-diagnostics-with-sdk-v1-3/ // Obtain a reference to the initial default configuration. string wadConnectionString = "Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString"; CloudStorageAccount storageAccount = CloudStorageAccount.Parse(RoleEnvironment.GetConfigurationSettingValue(wadConnectionString)); RoleInstanceDiagnosticManager roleInstanceDiagnosticManager = storageAccount.CreateRoleInstanceDiagnosticManager(RoleEnvironment.DeploymentId, RoleEnvironment.CurrentRoleInstance.Role.Name, RoleEnvironment.CurrentRoleInstance.Id); DiagnosticMonitorConfiguration config = DiagnosticMonitor.GetDefaultInitialConfiguration(); config.ConfigurationChangePollInterval = TimeSpan.FromSeconds(30.0); //transfer the IIS and IIS Failed Request Logs config.Directories.ScheduledTransferPeriod = TimeSpan.FromMinutes(1.0); //set the configuration for use roleInstanceDiagnosticManager.SetCurrentConfiguration(config);If you publish it at this point, you get no logs in blob storage, and if you RDP into the instance there will be no IIS Failed Request logs. So let’s add a startup task (per Christian Weyer and Steve Marx) to “fix” the permissions.
First, create a small file called FixDiag.cmd with Notepad, and put this line of code in it. This is going to be the command executed when the role instance starts up. Add this file to your project and set the Build Action to “Content” and “Copy to Output Directory” to “copy always” so it will include the file in the deployment when you publish your application to Azure. Here are the contents of the file.
powershell -ExecutionPolicy Unrestricted .\FixDiagFolderAccess.ps1>>C:\output.txtThis is going to run a script called FixDiagFolderAccess.ps1 and output the results to C:\output.txt. I found the output file to be really helpful when trying to figure out if my script was actually working or not. So what does the powershell script look like?
Here’s the first bit. This loads the Microsoft.WindowsAzure.ServiceRuntime assembly. If it’s not available, it waits a few seconds and loops around and tries again. Then it gets the folder where the Diagnostics information is stored.
echo "Output from Powershell script to set permissions for IIS logging." Add-PSSnapin Microsoft.WindowsAzure.ServiceRuntime # wait until the azure assembly is available while (!$?) { echo "Failed, retrying after five seconds..." sleep 5 Add-PSSnapin Microsoft.WindowsAzure.ServiceRuntime } echo "Added WA snapin." # get the DiagnosticStore folder and the root path for it $localresource = Get-LocalResource "DiagnosticStore" $folder = $localresource.RootPath echo "DiagnosticStore path" $folderThis is the second part. This handles the Failed Request log files. Following Christian’s lead, I’m just setting this to give full access to the folders. What’s new is I’m creating a placeholder file in the FailedReqLogFiles\Web folder. If you don’t do that, MonAgentHost.exe will come around and delete the empty Web folder that was created during app startup. If the folder isn’t there, when IIS tries to write the failed request log, it gives a “directory not found” error.
# set the acl's on the FailedReqLogFiles folder to allow full access by anybody. # can do a little trial & error to change this if you want to. $acl = Get-Acl $folder $rule1 = New-Object System.Security.AccessControl.FileSystemAccessRule( "Administrators", "FullControl", "ContainerInherit, ObjectInherit", "None", "Allow") $rule2 = New-Object System.Security.AccessControl.FileSystemAccessRule( "Everyone", "FullControl", "ContainerInherit, ObjectInherit", "None", "Allow") $acl.AddAccessRule($rule1) $acl.AddAccessRule($rule2) Set-Acl $folder $acl mkdir $folder\FailedReqLogFiles\Web "placeholder" >$folder\FailedReqLogFiles\Web\placeholder.txtNext, let’s handle the IIS logs. The credit for this goes to Rudy with Microsoft Azure Support. This creates a placeholder file, and then it retrieves the folders under Logfiles\Web looking for one that starts with W3SVC – this is the folder the IIS logs will end up in. There won’t be any the first time because the folder is not created until the web application is loaded the first time.
In the first incarnation of this code, it just waited a specific amount of time and then set the folder ACLs. The problem was that there seems to be some kind of race condition, and it appeared that if it didn’t start up before the Azure process that copies the logs started up, then you could set the permissions on the folders all day long and it wouldn’t ever transfer the log files. So this code forces it to download the page, which causes the IIS logging to start, and it beats the race condition (or whatever the problem is). At any rate, this works every time.
mkdir $folder\Logfiles\Web "placeholder" >$folder\Logfiles\Web\placeholder.txt # Get a list of the directories for the regular IIS logs. # You have to wait until they are actually created, # which is why there's a loop here. # Just keep looking until you find the folder(s). $dirs = [System.IO.Directory]::GetDirectories($folder + "\\Logfiles\\web\\", "W3SVC*") $ip = (gwmi Win32_NetworkAdapterConfiguration | ? { $_.IPAddress -ne $null }).ipaddress $ip echo "dirs.count" $dirs.count while ($dirs.Count -le 0) { Sleep 10 $bs = (new-object System.Net.WebClient).DownloadData("http://" + $ip[0]) echo "in the loop" $dirs = [System.IO.Directory]::GetDirectories($folder + "\\Logfiles\\Web\\", "W3SVC*") echo "dirs" $dirs echo "dirs[0]" $dirs[0] echo "dirs.count" $dirs.count } echo "after while loop" echo "dirs[0]" $dirs[0]Now that there’s a folder and you know where it is, set the permissions on it.
# Now set the ACLs on the "first" directory you find. (There's only ever one.) $acl = Get-Acl $dirs[0] $acl.AddAccessRule($rule1) $acl.AddAccessRule($rule2) Set-Acl $dirs[0] $aclThis powershell script should be called FixDiagFolderAccess.ps1 (it needs to match the name specified in FixDiag.cmd). Add this to your project and as before, set the Build Action to “Content” and “Copy to Output Directory” to “Copy Always”.
In your Service Configuration file, you need to add this to the end of the <ServiceConfiguration> element. In order for the –ExecutionPolicy flag to work, you must be running in Windows Server 2008 R2, which has PS2.
osFamily="2" osVersion="*"In your Service Definition file, you will need to specify the Startup Task. This goes right under the opening element for the <WebRole>. As recommended by Steve Marx, I’m running this as a background task. That way if there is a problem and it loops forever or won’t finish for some reason, I can still RDP into the machine. Also, in order to set the ACL’s, I need to run this with elevated permissions.
<Startup> <Task commandLine="FixDiag.cmd" executionContext="elevated" taskType="background" /> </Startup>So that should set you up for a web application. You can get your IIS logs and IIS Failed Request logs transferred automatically to blob storage where you can view them easily. And if you RDP into your instances, you can look at both sets of logs that way as well.
What if you have a WCF service, and no default web page? In the line that does the WebClient.DownloadData, just add the name of your service, so it looks like this:
$bs = (new-object System.Net.WebClient).DownloadData("http://" + $ip[0] + "MyService.svc")What if your WCF service or web application only exposes https endpoints? I don’t know. I’m still searching for an answer to that question. I tried using https instead of http, and I get some error about it being unable to create the trust relationship. At this point, I’ve spent so much time on this, I have to just enable RDP on the services with https endpoints and access the logging by RDP’ing into the instance. If you have any brilliant ideas, please leave a comment.
<Return to section navigation list>
Visual Studio LightSwitch

Return to section navigation list>
Windows Azure Infrastructure
Dana Gardner asked “How much of cloud services that come with a true price benefit will be able to replace what is actually on the ground?” as a preface to his anel: Cloud Computing Spurs Transition Phase for Enterprise Architecture post to his BriefingsDirect blog on 2/26/2011:
Welcome to a special discussion on predicting how cloud computing will actually unfold for enterprises and their core applications and services in the next few years. Part of The Open Group 2011 Conference in San Diego the week of Feb. 7, a live, on-stage panel examined the expectations of new types of cloud models -- and perhaps cloud specialization requirements -- emerging quite soon.
By now, we're all familiar with the taxonomy around public cloud, private cloud, software as a service (SaaS), platform as a service (PaaS), and my favorite, infrastructure as a service (IaaS). But we thought we would do you all an additional service and examine, firstly, where these general types of cloud models are actually gaining use and allegiance, and look at vertical industries and types of companies that are leaping ahead with cloud. [Disclosure: The Open Group is a sponsor of BriefingsDirect podcasts.]
Then, second, we're going to look at why one-size-fits-all cloud services may not fit so well in a highly fragmented, customized, heterogeneous, and specialized IT world -- which is, of course, the world most of us live in.
How much of cloud services that come with a true price benefit -- and that’s usually at scale and cheap -- will be able to replace what is actually on the ground in many complex and unique enterprise IT organizations? Can a few types of cloud work for all of them?
Here to help us better understand the quest for "fit for purpose" cloud balance and to predict, at least for some time, the considerable mismatch between enterprise cloud wants and cloud provider offerings, is our panel: Penelope Gordon, co-founder of 1Plug Corp., based in San Francisco; Mark Skilton, Director of Portfolio and Solutions in the Global Infrastructure Services with Capgemini in London; Ed Harrington, Principal Consultant in Virginia for the UK-based Architecting the Enterprise organization; Tom Plunkett, Senior Solution Consultant with Oracle in Huntsville, Alabama, and TJ Virdi, Computing Architect in the CAS IT System Architecture Group at Boeing based in Seattle. The discussion was moderated by BriefingsDirect's Dana Gardner, Principal Analyst at Interarbor Solutions.
Here are some excerpts:
Gordon: A lot of companies don’t even necessarily realize that they're using cloud services, particularly when you talk about SaaS. There are a number of SaaS solutions that are becoming more and more ubiquitous.
I see a lot more of the buying of cloud moving out to the non-IT line of business executives. If that accelerates, there is going to be less and less focus. Companies are really separating now what is differentiating and what is core to my business from the rest of it.There's going to be less emphasis on, "Let’s do our scale development on a platform level" and more, "Let’s really seek out those vendors that are going to enable us to effectively integrate, so we don’t have to do double entry of data between different solutions. Let's look out for the solutions that allow us to apply the governance and that effectively let us tailor our experience with these solutions in a way that doesn’t impinge upon the provider’s ability to deliver in a cost effective fashion."
That’s going to become much more important. So, a lot of the development onus is going to be on the providers, rather than on the actual buyers.
Enterprise architects need to break out of the idea of focusing on how to address the boundary between IT and the business and talk to the business in business terms.
One way of doing that that I have seen as effective is to look at it from the standpoint of portfolio management. Where you were familiar with financial portfolio management, now you are looking at a service portfolio, as well as looking at your overall business and all of your business processes as a portfolio. How can you optimize at a macro level for your portfolio of all the investment decisions you're making, and how the various processes and services are enabled? Then, it comes down to a money issue.
Shadow IT
Harrington: We're seeing a lot of cloud uptake in the small businesses. I work for a 50-person company. We have one "sort of" IT person and we do virtually everything in the cloud. We have people in Australia and Canada, here in the States, headquartered in the UK, and we use cloud services for virtually everything across that. I'm associated with a number of other small companies and we are seeing big uptake of cloud services.
We talked about line management IT getting involved in acquiring cloud services. If you think we've got this thing called "shadow IT" today, wait a few years. We're going to have a huge problem with shadow IT.
From the architect’s perspective, there's lot to be involved with and a lot to play with. There's an awful lot of analysis to be done -- what is the value that the cloud solution being proposed is going to be supplying to the organization in business terms, versus the risk associated with it? Enterprise architects deal with change, and that’s what we're talking about. We're talking about change, and change will inherently involve risk.
The federal government has done some analysis. In particular, the General Services Administration (GSA), has done some considerable analysis on what they think they can save by going to, in their case, a public cloud model for email and collaboration services. They've issued a $6.7 million contract to Unisys as the systems integrator, with Google being the cloud services supplier.
So, the debate over the benefits of cloud, versus the risks associated with cloud, is still going on quite heatedly.
Skilton: From personal experience, there are probably three areas of adaptation of cloud into businesses. For sure, there are horizontal common services to which, what you call, the homogeneous cloud solution could be applied common to a number of business units or operations across a market.
But we're starting to increasingly see the need for customization to meet vertical competitive needs of a company or the decisions within that large company. So, differentiation and business models are still there, they are still in platform cloud as they were in the pre-cloud era.But, the key thing is that we're seeing a different kind of potential that a business can do now with cloud -- a more elastic, explosive expansion and contraction of a business model. We're seeing fundamentally the operating model of the business growing, and the industry can change using cloud technology.
So, there are two things going on in the business and the technologies are changing because of the cloud.
... There are two more key points. There's a missing architecture practice that needs to be there, which is a workload analysis, so that you design applications to fit specific infrastructure containers, and you've got a bridge between the the application service and the infrastructure service. There needs to be a piece of work by enterprise architects (EAs) that starts to bring that together as a deliberate design for applications to be able to operate in the cloud. And the PaaS platform is a perfect environment.
The second thing is that there's a lack of policy management in terms of technical governance, and because of the lack of understanding. There needs to be more of a matching exercise going on. The key thing is that that needs to evolve.
Part of the work we're doing in The Open Group with the Cloud Computing Work Group is to develop new standards and methodologies that bridge those gaps between infrastructure, PaaS, platform development, and SaaS.
Plunkett: Another place we're seeing a lot of growth with regard to private clouds is actually on the defense side. The U.S. Defense Department is looking at private clouds, but they also have to deal with this core and context issue. The requirements for a [Navy] shipboard system are very different from the land-based systems.
Ships have to deal with narrow bandwidth and going disconnected. They also have to deal with coalition partners or perhaps they are providing humanitarian assistance and they are dealing even with organizations we wouldn’t normally consider military. So they have to deal with lots of information, assurance issues, and have completely different governance concerns that we normally think about for public clouds.
We talked about the importance of governance increasing as the IT industry went into SOA. Well, cloud is going to make it even more important. Governance throughout the lifecycle, not just at the end, not just at deployment, but from the very beginning.
If you think we've got this thing called "shadow IT" today, wait a few years. We're going to have a huge problem with shadow IT.
You mentioned variable workloads. Another place where we are seeing a lot of customers approach cloud is when they are starting a new project. Because then, they don’t have to migrate from the existing infrastructure. Instead everything is brand new. That’s the other place where we see a lot of customers looking at cloud, your greenfields.
Virdi: I think what we are really looking [to cloud] for speed to put new products into the market or evolve the products that we already have and how to optimize business operations, as well as reduce the cost. These may be parallel to any vertical industries, where all these things are probably going to be working as a cloud solution.
How to measure and create a new product or solutions is the really cool things you would be looking for in the cloud. And, it has proven pretty easy to put a new solution into the market. So, speed is also the big thing in there.All these business decisions are going to be coming upstream, and business executives need to be more aware about how cloud could be utilized as a delivery model. The enterprise architects and someone with a technical background needs to educate or drive them to make the right decisions and choose the proper solutions.
It has an impact how you want to use the cloud, as well as how you get out of it too, in case you want to move to different cloud vendors or providers. All those things come into play upstream, rather than downstream.
You probably also have to figure out how you want to plan to adapt to the cloud. You don’t want to start as a Big Bang theory. You want to start in incremental steps, small steps, test out what you really want to do. If that works, then go do the other things after that.
Gordon: One example in talking about core and context is when you look in retail. You can have two retailers like a Walmart or a Costco, where they're competing in the same general space, but are differentiating in different areas.
Walmart is really differentiating on the supply chain, and so it’s not a good candidate for public cloud computing solutions. That might possibly be a candidate for private cloud computing.
But that’s really where they're going to invest in the differentiating, as opposed to a Costco, where it makes more sense for them to invest in their relationship with their customers and their relationship with their employees. They're going to put more emphasis on those business processes, and they might be more inclined to outsource some of the aspects of their supply chain.
Hard to do it alone
Skilton: The lessons that we're learning in running private clouds for our clients is the need to have a much more of a running-IT-as-a-business ethos and approach. We find that if customers try to do it themselves, either they may find that difficult, because they are used to buying that as a service, or they have to change their enterprise architecture and support service disciplines to operate the cloud.Also, fundamentally the data center and network strategies need to be in place to adopt cloud. From my experience, the data center transformation or refurbishment strategies or next generation networks tend to be done as a separate exercise from the applications area. So a strong, strong recommendation from me would be to drive a clear cloud route map to your data center.
Harrington: Again, we're back to the governance, and certification of some sort. I'm not in favor of regulation, but I am in favor of some sort of third-party certification of services that consumers can rely upon safely. But, I will go back to what I said earlier. It's a combination of governance, treating the cloud services as services per se, and enterprise architecture.
Plunkett: What we're seeing with private cloud is that it’s actually impacting governance, because one of the things that you look at with private cloud is charge-back between different internal customers. This is forcing these organizations to deal with complexity, money, and business issues that they don't really like to do.
Nowadays, it's mostly vertical applications, where you've got one owner who is paying for everything. Now, we're actually going back to, as we were talking about earlier, dealing with some of the tricky issues of SOA.
Securing your data
Virdi: Private clouds actually allow you to make more business modular. Your capability is going to be a little bit more modular and interoperability testing could happen in the private cloud. Then you can actually use those same kind of modular functions, utilize the public cloud, and work with other commercial off-the-shelf (COTS) vendors that really package this as new holistic solutions.Configuration and change management -- how in the private cloud we are adapting to it and supporting different customer segments is really the key. This could be utilized in the public cloud too, as well as how you are really securing your information and data or your business knowledge. How you want to secure that is key, and that's why the private cloud is there. If we can adapt to or mimic the same kind of controls in the public cloud, maybe we'll have more adoptions in the public cloud too.
Gordon: I also look at it in a little different way. For example, in the U.S., you have the National Security Agency (NSA). For a lot of what you would think of as their non-differentiating processes, for example payroll, they can't use ADP. They can't use that SaaS for payroll, because they can't allow the identities of their employees to become publicly known.
Anything that involves their employee data and all the rest of the information within the agency has to be kept within a private cloud. But, they're actively looking at private cloud solutions for some of the other benefits of cloud.
In one sense, I look at it and say that private cloud adoption to me tells a provider that this is an area that's not a candidate for a public-cloud solution. But, private clouds could also be another channel for public cloud providers to be able to better monetize what they're doing, rather than just focusing on public cloud solutions.
Impact on mergers and acquisitions
Plunkett: Not to speak on behalf of Oracle, but we've gone through a few mergers and acquisitions recently, and I do believe that having a cloud environment internally helps quite a bit. Specifically, TJ made the earlier point about modularity. Well, when we're looking at modules, they're easier to integrate. It’s easier to recompose services, and all the benefits of SOA really.That kind of thinking, the cloud constructs applied up at a business architecture level, enables the kind of business expansion that we are looking at.
Gordon: If you are going to effectively consume and provide cloud services, if you do become much more rigorous about your change management, your configuration management, and if you then apply that out to a larger process level. Some of this comes back to some of the discussions we were having about the extra discipline that comes into play.
So, if you define certain capabilities within the business in a much more modular fashion, then, when you go through that growth and add on people, you have documented procedures and processes. It’s much easier to bring someone in and say, "You're going to be a product manager, and that job role is fungible across the business."
That kind of thinking, the cloud constructs applied up at a business architecture level, enables the kind of business expansion that we are looking at.Harrington: [As for M&As], it depends a lot on how close the organizations are, how close their service portfolios are, to what degree has each of the organizations adapted the cloud, and is that going to cause conflict as well. So I think there is potential.
Skilton: Right now, I'm involved in merging in a cloud company that we bought last year in May ... It’s kind of a mixed blessing with cloud. With our own cloud services, we acquire these new companies, but we still have the same IT integration problem to then exploit that capability we've acquired.
Each organization in the commercial sector can have different standards, and then you still have that interoperability problem that we have to translate to make it benefit, the post merger integration issue. It’s not plug and play yet, unfortunately.
But, the upside is that I can bundle that service that we acquired, because we wanted to get that additional capability, and rewrite design techniques for cloud computing. We can then launch that bundle of new service faster into the market.
You might also be interested in:
- Examining the Current State of the Enterprise Architecture Profession with the Open Group's Steve Nunn
- Explore the role and impact of the Open Trusted Technology Forum to help ensure secure IT products in global supply chains
- Infosys Survey Shows Enterprise Architecture and Business Architecture on Common Ascent to Strategy Enablers
- The Open Group's Cloud Work Group Advances Understanding of Cloud-Use Benefits for Enterprises

David Linthicum asserted Cloud Integration Challenges Taking Us Back in Time in a 2/26/2011 post to ebizQ’s Where SOA Meets cloud blog:
It's a bit curious to me that most implementing cloud computing are struggling with the concept of integration, a topic that's near and dear to my heart. More surprising they are doing this as if integration itself was a new topic.
The issue is one of context, more so than technology when considering that we've been doing integration well for over 15 years, and thus it's just a matter of carrying those concepts and technology to the world of the cloud. However, as it was back in the 90s when I wrote the EAI book, many are approaching cloud integration as if we are starting over. That's a big mistake.
What's key to remember about integration, cloud or not, is that it's actually about the free flow of information between systems that deal with information differently. Thus, you have to adjust information as it's transmitted between systems, or how each deals with system semantics. For example, in moving information from SAP ERP to Salesforce.com, at some time you need to deal with the different ways that each structures data around the concepts of customer, sales, inventory, etc..
Not a ton changes when dealing with cloud computing, other than the fact that you may be dealing with systems that are outside of the firewall, and not under your direct control. However, they also typically provide well-defined and easy to use interfaces, or APIs, which allow access to core information or services. Indeed, I would consider it much easier to connect and integrate existing SaaS and IaaS clouds than traditional enterprise systems.
The core message here is that we need to learn from the past, and don't assume we're starting from scratch when dealing with cloud computing. The patterns, the technology, the problems, and the solutions are largely the same.
.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
Jobs/ITWorld Canada shed more light on WAPA with this SENIOR Software Development Engineer (SDE) Job posting of 2/26/2011:
Job Category: Software Engineering: Development Location: Redmond, WA, US Job ID: 748580-36605 Division: Server & Tools Business Our job is to drive the next generation of the security and identity support for Windows Azure and we need a senior development talent. [Emphasis added.]
We are the AAD Storage team and are part of the Directory, Access and Identity Platform (DAIP) team which owns Active Directory and its next generation cloud equivalents. AAD Storage team's job is to design and build [a] scalable, distributed storage model that will become the foundation for the Azure Active Directory implementation.
As part of this charter we also directly own delivering in the near future the next generation security and identity service that will enable Windows Azure and Windows Azure Platform Appliance to boot up.
If you have great passion for the cloud, for excellence in engineering, and hard technical problems, our team would love to talk with you about this rare and unique opportunity. In this role you will:
- Work with the talented team of SDEs designing and implementing directory storage model that will scale to cover Windows Azure customer's needs
- Contribute to the relationship between DAIP and the Windows Azure teams in addressing the next generation security and identity infrastructure for Windows Azure's customers
- Contribute broadly to the product in areas including storage, sync, infrastructure and service delivery
- Provide leadership in component and feature design, coding, engineering
-------------
- Location: Redmond , Washington
- Salary/Rate: USD
- Advertised By: Microsoft
- Reference: JS1161422/3231125
- Date Posted: 26/02/2011 7:34:05 AM
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
David Navetta posted A Novel Data Security Law Proposed in Colorado to the Information Law Group blog on 2/24/2011:
There has been a lot of buzz around various privacy and security bills presented on the Federal level, including the reintroduction of the BEST PRACTICES ACT and a new privacy bill put out by Congresswoman Speier that brings "do-not-track" into the fray (not to mention the previously introduced Boucher Bill, which is now missing its named sponsor). Yet, for the most part, these types of bills have languished on the Federal level, while interesting new approaches race ahead from State legislatures (see for example, SB1386, Minnesota’s Plastic Card Protection Act, Massachusetts’ 201 CMR 17:00, et. seq., Nevada’s Security of Personal Information Law, and Washington state’s PCI Law) Over the past couple years, many predicted that new state laws would follow the lead of states like Nevada and Massachusetts, and some anticipated we could see a situation where 50 different privacy/security laws existed in each state. Now it looks like we are beginning to see some renewed activity on the state level. In Hawaii we have a proposed bill that would require breached entities to provide credit monitoring and call center services to impacted individuals. In my home state, Colorado, a legislator (Dan Pabon) has proposed a novel bill that takes a new approach to incentivizing companies to implement good security. In this post, we take a look at the highlights of the Colorado bill.
Colorado HB 11-1225 – An Information Security Carrot
Regulation is achieved via the “carrot” or the “stick” (and sometimes both). This is true in the information security context as well. For example, to incentivize encryption of personal information, breach notice laws use a stick: those that fail to encrypt may have to provide notice to affected individuals in the event of a security breach. In the credit card breach context, a Washington state law provides banks with a stick (e.g. the right to seek fraud and reissuance expenses from breached merchants), but also provides those merchants with a shield to block that stick (e.g. validation of PCI compliance blocks a bank’s ability to recover). In HB 11-1225, Colorado state legislator, Dan Pabon, apparently wants to give the carrot a chance. In the process, I am told that part of the goal is to make Colorado the “Delaware” of data storage. Here is how it works.
Immunity from Liability. Under HB 11-1225, if certain conditions are met (discussed below) a person or entity operating in Colorado that owns, licenses or maintains computerized data that includes “personal information” shall not be liable for civil damages resulting from a breach of data security due to its acts or omissions that are in good faith, and not grossly negligent or willful and wonton. So essentially, this would provide immunity from negligence claims. In order to receive this protection, two conditions must be satisfied: (1) the breach must have been caused by an unauthorized third party, or an employee or agent acting outside the scope of his employment; and (2) the person or entity must have been certified by a “qualified information technology auditor or assessor” as having used “best practices of data security and meeting information technology standards” established by an authorized state entity.
Rebuttable Presumption of Non-Negligence. Even if a breached organization has not been certified as compliant with best practices/information technology standards, it can achieve certain protections under the bill. In court, an organization can establish a rebuttable presumption that it was not negligent if it can produce evidence that the organization implemented best practices and was compliant with technology security standards established pursuant to the bill.
Consumers’ Right to Petition Court for Subpoena. The bill provides persons whose personal information was compromised or who are victims of a computer crime, to seek a petition from a court impelling the breached organization or any third party to produce “any” information concerning the unauthorized access to personal information or the computer crime. This information may be obtained in order to facilitate the detection, apprehension and prosecution of the computer crime or breach.
Key Definitions. “Personal information” as defined under the bill is broader than definitions in most breach notice laws. One defined category of personal information is information that can be used, alone or in conjunction with any other information, to obtain cash, credit, property, services, or any other thing of value, or to make a financial payment, including personal identification number, credit card number, banking card number, checking account number, etc. Personal information is also defined as information that can be used, alone or in conjunction with other information, to identify a specific individual, including name, date of birth, social security number, government ID, passport number, etc.
In order to be a “qualified information technology auditor or assessor” one must be certified by a nationally recognized organization or association as having expertise in data security, and cannot have any convictions involving moral turpitude offenses. The bill indicates that the CIO of the State of Colorado is required to establish an entity to maintain a list of the nationally recognized IT associations that may certify a person’s qualifications in data security systems for purposes of the bill.
Establishing Best Practices and Information Technology Security Standards. One of the key challenges for implementing this HB 11-1225 (should it become law in its current form) is going to be the establishment of best practices and IT security standards. On this issue the bill requires the CIO of the State of Colorado to create an “entity” to establish these best practices and standards for commercial entities and persons that own, license or maintain computerized data that includes personal information. The bill does not provide additional guidance as to how those best practices shall be determined, or whether there will be one set of best practices that will apply to all entities (regardless of size, complexity or resources).
Analysis and Observations
Novel approaches to information security and privacy legislation are, of course, welcomed. The questions remain, however. Will it work? Will it pass? Unclear at this point. Below are a few observations pertaining to these questions.
- Does a duty exist to safeguard personal information under common law negligence principles? Surprisingly, at this point we have very little case law directly on point that delves into this issue. However, a recent Illinois appellate court recently ruled that a common law duty to safeguard personal information did not exist. In contrast, we are aware of cases that did find a duty to secure personal information, but both were in the banking context and were arguably based mainly on the expectations that arise in that context (e.g. banking customers are specifically providing their money to banks for safeguarding, among other reasons). If indeed, no case law establishing such a duty exists in Colorado, the question becomes whether the existence of a law providing immunity for negligence implies that the duty exists. Worse (from the company point of view), it is possible that the best practices established under the bill could end up establishing a standard of care, in and of themselves (where one may arguably not exist).
- Even if such a duty does exist, do the “good faith” and “gross negligence “exceptions” effectively eat the immunity? In the wake of a data breach where a plaintiff’s attorney has filed a lawsuit, you can bet that any and all potential theories of liability will be alleged. That of course may include allegations of gross negligence and “bad faith.” One of the benefits of HB 11-1225, assuming only a negligence claim is alleged, would be the ability of defendants to have lawsuits dismissed early, perhaps in a motion to dismiss or motion for summary judgment phase. However, if gross negligence, bad faith or other non-negligence claims are alleged, the plaintiff may have a better chance to get past early motions to dismiss. If that is the case, plaintiffs will still have litigation leverage (regardless of whether they have a truly winning case). In fact, we are aware of one case in Federal court in Michigan that allowed a case to go to trial based on the issue of "good faith" behavior in the context of security. These “exceptions,” therefore, could undermine the effectiveness of the immunity granted in HB 11-1225. Of course, much more research is necessary to look into these issues.
- Is the jurisdictional scope of the immunity too narrow? At this stage in the game a large percentage of companies, big and small, conduct business with residents of more than one state (and in many cases all 50 states), and even with people residing outside of the United States. While HB 11-1225 may provide immunity from negligence claims for cases contained in Colorado, it may not help with lawsuits, for example, filed in other jurisdictions or Federal court where Colorado law is not the choice of law. So, if the goal of the law is to become the "Delaware of data storage", it may not be effective to shield companies that deal with personal information from non-Colorado states. That all said, there may be jurisdictional arguments that would preclude plaintiffs residing in other states from pursuing a company storing data in Colorado (although making and prevailing in such arguments in court can be an expensive process in and of itself). In addition, a choice of law provision in contracts with out-of-state counter parties might also do the trick to keep the immunity intact.
- Can the “entity” established by the State actually establish best practices that can work universally and result in good security? Legislating security controls is not an easy task. Two general approaches are used typically. One approach does not require specific controls, but rather mandates “reasonable” “adequate” “comprehensive” or “appropriate” security. The other method is more prescriptive in its approach, and seeks to require specific controls that certain entities must implement (e.g. Massachusett’s and Nevada’s personal information security laws). The risk of a prescriptive approach is the “check list” mentality whereby organizations simply address the specific requirements and don’t actually worry about truly securing themselves (this is a criticism of PCI, the ultimate prescriptive standard). However, even those taking a prescriptive approach may reference various risk factors that relate to the sensitivity of the data and the size, complexity and resources of the company trying to comply. The challenge for the entity developing these best practices is to provide enough clarity/certainty so companies have confidence that they are truly in the safe harbor, and yet to provide enough flexibility to allow companies of all shapes and sizes to get into the safe harbor in a relatively cost-efficient and realistic fashion. The failure to solve this problem could undermine the efficacy of the legislation if it perceived to be unfair or discriminatory to small and medium-sized businesses who may have neither the expertise nor resources to implement a highly prescriptive set of controls.
- A Shift of Liability to the Auditors? On the one hand, this bill may serve as a business bonanza for IT security auditors who are called into validate compliance with the best practices laid out by the act. On the other hand, a mistake in validating the compliance of a company that suffers a breach could potentially lead to a lawsuit against not only the breached company, but the auditor as well. While a third party affected individual may have difficulty holding an IT security auditor liable without a contract, precedent may exist by analogy to accountants. Moreover, there is at least one known case (Merrick Bank v. Savvis) where an IT assessor (in this case a payment card security assessor) was sued by a party that relied on its compliance findings. So, from a “passability” point of view, does the IT security assessment community get on board or do they demand some of their own immunity in exchange for supporting this bill?
Conclusion
Overall, Representative Pabon’s bill represents a very interesting approach to data security regulation, and we applaud his efforts and creativity. There may be some hurdles to overcome to see this passed, and a vigorous debate on its mechanics is necessary. We will keep you up to date on its progress.
David is one of the Founding Partners of the Information Law Group. He has practiced law for more than fourteen years, including technology, privacy, information security and intellectual property law. He is also a Certified Information Privacy Professional through the International Association of Privacy Professionals.
.
Jonathan Penn posted The Reemergence Of Endpoint Protection to his Forrester blog on 2/25/2011:
I found the RSA Conference completely exhausting, but also intellectually invigorating. (Shameless plug: you can see me speaking on an RSA Keynote panel about the future of authentication here.) I came away with a much clearer picture of the trends shaping the future evolution of our market.
The first one I want to talk about is the reemergence of the endpoint as a key element of security architecture.
As our IT environments have evolved, we’ve moved a lot of our security controls into the network and into applications. While these technologies and services will remain relevant and investment in them will continue increase, I predict a radical swing back to the endpoint as a focus for security.
I see this driven by four major market trends:
- Virtualization. With virtualization, security functions that existed on the network (firewall, IPS, WAF, etc.) are moving on the host, integrating through APIs like vShield to capture inter-VM traffic. Moreover, it makes no sense to copy the model we have today of procuring a different function from different vendors and putting multiple agents onto servers. Instead, we will inexorably, and quickly, follow what happened at the desktop: vendors will consolidate functions into single-agent ‘suites’ with unified management and reporting.
- Device diversity and employee mobility. The floodgates are open: empowered employees demand broad device support. iPhones, Android phones, and iPads are making their way into the enterprise at an amazing pace. People are also bringing their own PCs – and Macs – into the enterprise, or connecting them from home and demanding access to a broad set of applications. IT and IT Security have no choice but to accede to these demands and embrace these trends – to do otherwise would result in their irrelevance. As we see greater device diversity, and these devices are hopping in and out of the network, it becomes more imperative than ever to deploy controls on these devices to protect them from attack as well as to protect the business from inappropriate data transfer.
- Embedded security. We’re on the cusp of an explosion in IP enabled devices, of which smartphones and tablets are only the beginning. It’s extending to smart utility meters, healthcare devices, automobiles, consumer electronics, industrial controls, public kiosks, and many more areas. Security must be embedded into the devices at the system level to ensure system integrity and data protection.
- The threat landscape. What do the three biggest security incidents of 2010 – Aurora, Stuxnet, and WikiLeaks – have in common? All involved attacks on the endpoint (respectively: exploitation of a zero-day IE vulnerability, worm infiltration of a closed network through a USB, and data exfiltration via a USB).
Each of these trends is a disruptive market force in its own right, which is why we presently see immature or incomplete solutions from vendors. Yet moving forward, security vendors, service providers, and enterprises will need to adjust the balance of their security investments in favor of endpoint security controls.
This will have a dramatic effect on the market landscape as well as the practice of security.
<Return to section navigation list>
Cloud Computing Events
No significant articles today.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
SearchCloudComputing published my (@rogerjenn) Choosing from the major Platform as a Service providers article on 2/25/2011. From the RSS feed:
Many organizations prefer Platform as a Service offerings for their cloud needs. Our expert compares options from Google, Microsoft and Amazon.
• Jo Maitland asked Sun Microsystems: The real inventor of cloud computing? in a 2/25/2011 post to SearchCloudComputing.com:
I missed the last Churchill Club event, the one where Larry Ellison pitched a fit over cloud computing, deftly switching the audience’s attention to his favorite topic (himself) rather than the cloud, about which he had nothing sensible to say.
“We were the first company to...really embrace open source.”
Sun co-founder Scott McNealy
The mood was very different at last night’s Churchill Club dinner in Silicon Valley, where Sun co-founder and former CEO Scott McNealy talked about the inevitable shift to cloud. He said the biggest inhibitor to cloud computing was that everyone is still "building their own Frankenstein and just trying to get to 2.0 … it isn’t going to happen with that mindset."
Given the opportunity to start another company today, he said, "the last thing I’d do is buy a computer, or build a computer; I'd do the Amazon Web Services thing.”
Sadly, Sun had an Amazon Web Services thing. It was Sun Cloud Compute -- based on Solaris 10, Sun Grid Engine and Java -- created long before AWS went mainstream but killed by Oracle soon after Sun Microsystems was bought.
McNealy added that cloud computing started with TCP-IP and open source.
"We were the first company to put it on every computer that shipped and to really embrace open source,” he said.
He also mentioned that NFS and building Solaris with multithreading and virtualization were all enabling technologies for cloud. Sun’s logo back in the mid-80s was, after all, "the network is the computer." Those words seem very prescient now.
R.I.P. Sun Microsystems, perhaps the real inventor of cloud computing.

Jo Maitland is the Senior Executive Editor of SearchCloudComputing.com.
Full disclosure: I’m a paid contributor to SearchCloudComputing.com (see link to my article above.)
Update 2/27/2011: Marketwire offered more details about the event in its Churchill Club Presents: Scott McNealy in Conversation With Ed Zander press release of 2/17/2011.
Livestream: The Churchill Club has partnered with FORA.tv to bring Scott McNealy in Conversation with Ed Zander LIVE to audiences from around the world, and later on-demand. Visit FORA.tv to view more programs from the Churchill Club and other premium event partners.
Jamal Mazhar asked Is Amazon following Kaavo in Cloud Management? in a 2/25/2011 post to the Kaavo blog:
Today I received an email from Amazon announcing their AWS CloudFormation Service. Basically to automate the deployment of complex applications or workloads Amazon is allowing users to capture all the deployment information in one template. They call the template “Stack”. Taking a top down view of the deployment and capturing all the information for deploying and managing an application or workload in the cloud in one place is at the heart of Kaavo’s Application centric approach. We released GA version of Kaavo IMOD in early 2009 to enable automatic deployment and runtime management of complex application and workloads in the cloud. Kaavo IMOD allows users to capture entire information for any complex application or workload deployment and runtime management in one template, we call it System Definition.
Although this is the first release of CloudFormation Service and it is still in very nascent stages of providing a full application centric solution, there are a lot of similarities with Kaavo’s solution, especially if you start replacing the term “System” used by Kaavo with the term ”Stack” used by Amazon, e.g., they have stack events (similar to System events in Kaavo’s solution). They even have deployment timeout similar to how Kaavo IMOD allows you to specify timeouts for deployments. The biggest difference is Kaavo has implemented a general purpose application centric management solution which works for other clouds as well not just Amazon and allows hybrid cloud deployments. Using Kaavo IMOD you can deploy applications or workloads across integrated public or private clouds. Currently Kaavo fully supports public clouds by IBM, Amazon, RackSpace, Terremark, and in the private cloud space we support IBM Cloud, Eucalyptus, and vCloud API. We are taking it as “imitation is the greatest form of flattery” and this is a great validation of what we are doing at Kaavo. It is very humbling to see that Amazon which is considered as a leader in the IaaS space is following Kaavo to deliver application centric management of cloud resources. [Emphasis added.]
And maybe a bit scary, too?
Alex Williams posted Comic-Con Seeks the Super Strengths and the Amazing Shrinking Abilities of the Cloud to the ReadWriteCloud on 2/25/2011:
Scaling up is one thing. Scaling down can be an entirely different and complex matter. Conversation naturally leads us to talk about the limitless possibilities of the cloud but increasingly, we are seeing the need for the capability to scale back infrastructure, too.
There are a number of reasons for this that point to the requirements for treating data as a flowing stream that has significant business implications.
TicketLeap came into Comic-Con International after doing a test run that showed how important it was to have the ability to scale up. But when it came down to the opening day, something happened. The ticket demand was equivalent to selling out the Super Bowl in a few hours.
TicketLeap had things ready to go with its cluster on Amazon Web Services. According to the TicketLeap blog:
- Introduced an administrative "High Volume Mode" for events that allows TicketLeap to lock event data into cache. This includes data such as: event title/description/etc, ticket type title/description/etc. No need to fetch this data from the database unless needed.
- Optimized all queries throughout the checkout process reducing joins, reducing subqueries, and adding indexes where appropriate.
- Increased the `ulimit` on our webservers to handle more connections into our platform
- Increased the number of fastcgi processes spawned for our application
- Introduced a queueing system to throttle orders per second to manageable size.
- Ran extensive load testing on pure request load, pure checkout load, and a blend of request/checkout load. We used a tool called BrowserMob. It's awesome and we highly recommend checking it out.
But the problem was not in scaling up. There were plenty of servers. In fact, there were too many servers. The servers could not handle the load due to nearly all the connections in the MySQL database getting tied up doing DNS resolution. TicketLeap scaled back the servers to open up lanes for the data to flow. This relieved the system and the tickets once again were being sold without the headache of being super slow. It turned out to be an error that in many ways TicketLeap could not control. Its goes into detail on its site about the issue.
The sheer amount of data had to be controlled in order for Comi-Con to sell its tickets. The economic impact could have been considerable if the system broke down. Comi-Con needed the broad capabilities of the cloud but also the ability to scale back so the client could be served.
There are plenty of lessons here. It takes careful planning to determine how an information architecture will function under such demands. If not careful, the data can cause a jam that has serious business implications.
James Niccolai reported “The chip maker has written some APIs to reveal a PC's performance characteristics to the online service it is connecting to” in a preface to his Intel plots 'client-aware' cloud services article of 2/25/2011 for InfoWorld’s Cloud Computing blog:
Intel wants the cloud to be a bit smarter.
The company is developing technologies that would allow applications and services delivered over the Internet to know more about the client device they are being accessed from, be it a PC, a tablet, or a smartphone, and to tailor the services accordingly.
It doesn't sound that new: Application servers already tailor content to fit the screen of a smartphone, for example. But Intel wants to go a step further and provide detailed information about the processor type, the available bandwidth, and even the amount of battery power left.
That should allow websites and advertisers to make wider use of rich content, such as high-definition video, instead of having to cater to a "lowest common denominator." They could deliver one version of a site to customers on a high-speed Wi-Fi network, for example, and a simple Web page to customers on a weak cellular connection.
It could also benefit e-commerce sites. For example, Amazon.com could warn customers with full shopping carts that their laptop battery was running low and advise them to check out quickly, or tell them their selections will be retained if they go offline and have to log in again later.
The technology isn't complicated. Intel has published beta versions of APIs (application programming interfaces) for accessing data about a device's processor, bandwidth, and battery life. Web developers can employ the APIs by adding some fairly simple Javascript to their applications, said Daniel Chang, director of strategic alliances at NetSuite, which is piloting the technology.
NetSuite is best known for its online CRM (customer relationship management) applications, but it also hosts e-commerce websites for about 2,000 businesses. A half dozen of those stores, mostly those that want to display rich content such as high-definition video, are testing the APIs, Chang said. Gproxy, a Web design and hosting company in Miami, is part of the same pilot program.
"The technology is already there, it's just a question of adoption," Chang said.
One challenge for Intel is getting the main Web browsers to implement its APIs. The company said it's in talks with "a broad range" of service providers, software vendors and PC makers about supporting the technology, but it won't yet say who. In the meantime, e-commerce sites testing the APIs have to ask their end users to download a browser plug-in.
Intel says the processor API should work with devices based on x86 chips from other vendors. It hasn't tested it with non-Intel processors, but the API uses the CPU ID and the "processor brand string" to determine the processor type, and these are parts of the standard x86 instruction set, said Greg Boitano, marketing manager for Intel's Business Client Platform division.
"It's not necessarily exclusive to one chip provider or another. It's really more about the value you deliver through that chip," he said.
However, the processor API doesn't work with ARM-based chips, at least in its current version, cutting out most smartphones and tablets.
Read more: 2, next page ›
<Return to section navigation list>

















0 comments:
Post a Comment