Windows Azure and Cloud Computing Posts for 2/21/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure VM Roles, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
David Pallman (@davidpallman) reported on 2/20/2011 that his Complete Windows Azure Storage Samples (REST and .NET side-by-side) are available on CodePlex:
I’ve posted new samples for Windows Azure Storage on CodePlex at http://azurestoragesamples.codeplex.com/. These samples are complete—they show every single operation you can perform in the Windows Azure Storage API against blob, queue, and table storage. In addition, there is both a REST implementation and a .NET StorageClient implementation with identical functionality that you can compare side-by-side.
I decided to put these samples up for 3 reasons:
- First of all, they're part of the code samples for my upcoming book series, The Windows Azure Handbook. Putting them out early gives me an opportunity to get some feedback and refine them.
- Second, although there is a lot of good online information and blogging about Windows Azure Storage, there doesn't seem to be a single sample you can download that does "everything". The Windows Azure SDK used to have a sample like this but no longer does.
- Third, I wanted to give complete side-by-side implementations of the REST and .NET StorageClient library approaches. Often developers starting with Windows Azure Storage are undecided about whether to use REST or the .NET StorageClient library and being able to compare them should be helpful.
These initial samples are all in C# but I would like to add other languages over time (and would welcome assistance in porting). Please do speak up if you encounter bugs, flaws, omissions in the samples -- or if you have suggestions.
Here are some good online resources for Windows Azure Table Storage:
- Windows Azure Storage Documentation: http://msdn.microsoft.com/en-us/library/dd179355.aspx
- Steve Marx's Blog (Microsoft): http://blog.smarx.com/
- Neil Mackenzie's Blog (Windows Azure MVP): http://convective.wordpress.com/
- Other storage samples: http://azuresamples.com/
Bravo, David!
Avkash Chauhan explained System.ArgumentException: Waithandle array may not be empty when uploading blobs in parallel threads in a 2/20/2011 post:
When you are uploading blobs from a stream using multiple roles (web or worker) to a single azure storage location it is possible that you may hit the following exception:
System.ArgumentException: Waithandle array may not be empty.
at Microsoft.WindowsAzure.StorageClient.Tasks.Task`1.get_Result()
at Microsoft.WindowsAzure.StorageClient.Tasks.Task`1.ExecuteAndWait()
at Microsoft.WindowsAzure.StorageClient.CloudBlob.UploadFromStream(Stream source, BlobRequestOptions options)
at Contoso.Cloud.Integration.Azure.Services.Framework.Storage.ReliableCloudBlobStorage.UploadBlob(CloudBlob blob, Stream data, Boolean overwrite, String eTag)Reason:
Solution:
To solve this problem, disable parallel upload feature by setting as below: CloudBlobClient.ParallelOperationThreadCount=1
<Return to section navigation list>
SQL Azure Database and Reporting
The Microsoft Case Studies team posted a 4-page IT Company [INFORM] Quickly Extends Inventory Sampling Solution to the Cloud, Reduces Costs case study abut SQL Azure on 2/18/2011:
Headquartered in Aachen, Germany, INFORM develops software solutions that help companies optimize operations in various industries. The Microsoft Gold Certified Partner developed a web-based interface for its INVENT Xpert inventory sampling application and wanted to extend the application to the cloud to save deployment time and costs for customers. After evaluating Amazon Elastic Compute Cloud and Google App Engine, neither of which easily supports the Microsoft SQL Server database management software upon which its data-driven application is based, INFORM chose the Windows Azure platform, including Microsoft SQL Azure. INFORM quickly extended its application to the cloud, reduced deployment time for customers by 50 percent, and lowered capital and operational costs for customers by 85 percent. Plus, INFORM believes that having a cloud-based solution increases its competitive advantage.
Organization Profile
Established in 1969, INFORM develops software solutions that use Operations Research and Fuzzy Logic to help customers in the transportation and logistics industries optimize their operations.
Business Situation
After creating a web-based interface for its inventory sampling software, INFORM sought a cloud solution that it could deploy quickly and that would work with JavaScript and Microsoft SQL Server.
Solution
In less than three weeks, INFORM migrated its existing database to Microsoft SQL Azure in a multitenant environment and deployed its Java-based inventory optimization application to Windows Azure.
Benefits
- Quick development
- Reduced deployment time by 50 percent
- Lowered customer costs by 85 percent
- Increased competitive advantage
Allen Kinsel asked SQL Azure track at the PASS summit: Is the cloud real or hype? in a 2/11/2011 post (missed when posted):
With SQL Azure (& the cloud in general) becoming more and more mainstream, I’m seriously considering creating a new Azure track for the 2011 Summit. I’m still pulling the attendance & session evaluation scores together from 2009 and 2010 azure sessions to try and determine if its truly a good idea or not.
There’s always a tradeoff: we have a limited amount of sessions available, so creating a track would mean shifting allocations from the other tracks to cover the sessions given but, considering the future it seems to be the right move.
Just thought id throw this quick post out looking for thoughts & feedback
This is the first minor change I’m considering for the 2011 Summit.
The three comments as of 2/21/2011 were in favor of adding a SQL Azure track.
<Return to section navigation list>
MarketPlace DataMarket and OData
Alex James (@adjames) posted Vocabularies to the OData blog on 2/21/2011:
What are vocabularies?
Vocabularies are made up of a set of related 'terms' which when used can express some idea or concept. They allow producers to teach consumers richer ways to interpret and handle data.
Vocabularies can range in complexity from simple to complex. A simple vocabulary might tell a consumer which property to use as an entity's title when displaying it in a form, whereas a more complex vocabulary might tell someone how to convert an OData person entity into a vCard entry.
Here are some simple examples:
- This property should be used as the Title of this entity
- This property has a range of acceptable values (e.g. 1 to 100)
- This entity can be converted into an vCard
- This entity is a foaf:Person
- This navigation property is essentially a 'foaf:Knows [a person]' relationship
- This property is a georss:Point
- Etc
Vocabularies is not a new concept unique to OData, vocabularies are used extensively in the linked data and RDF worlds to great effect, in fact we should be able to re-use many of these existing vocabularies in OData.
Why does OData need vocabularies?
OData is being used in many different verticals now. Each vertical brings its own specific set of requirements and challenges. While some problems are general enough that solving them inside OData adds value to the OData eco-system as a whole, most don't meet that bar.
It seems clear then that we need a mechanism that allows Producers to share more information that 'smarter' Consumers MAY understand enough to enable a higher fidelity experience.
In fact some consumers are already trying to provide a higher fidelity experience, for example Sesame can render the results of OData queries on a map. Sesame does this by looking for specifically named properties, which it 'guesses' represent the entity's location. While this is powerful, it would be much better if it wasn't a 'guess', if the Producer used a well-known vocabulary to tell Consumers which property is the entity's location.
Goals
As with any new feature, we need to agree on a set of goals before we can come up with the right design. To get us started I propose this set of goals:
- Ability to re-use or reference common micro-formats and vocabularies.
- Ability to annotate OData metadata using the terms from a particular vocabulary.
- Both internally (inside the CSDL file returned from $metadata)
- And externally (allowing for third-parties to 'enrich' existing OData services they don't own).
- No matter how the annotation is made, consumers should be able to consume the annotations in much the same way.
- Ability to annotate OData data too? Although this one is beyond the scope of this post.
- Consumers that don't understand a particular vocabulary should still be able to work with services that reference that vocabulary. The goal should be to enrich the eco-system for those who 'optionally' understand the vocabulary.
- We should be able to reference terms from a vocabulary in CSDL, OData Atom and OData JSON.
It is important to note that our goal stops short of specifying how to define the vocabulary itself, or how to capture the semantics of the vocabulary, or how to enforce the vocabulary. Those concerns lay solely with vocabulary writers, and the producers and consumers that profess to understand the vocabulary. By staying out of this business it allows OData to reference many existing vocabularies and micro-formats, without being unnecessarily restrictive on how those vocabularies are defined or the types of semantics they might imply.
Exploration
Today if you ask for an OData services metadata (~/service/$metadata) you get back an EDMX document that contains a CSDL schema. Here is an example.
CSDL already supports annotations, which we could use to refer to a vocabulary and its terms. For example this EntityType definition includes both a structural annotation (validation:Constraint) and a simple attribute annotation (display:Title):
<EntityType Name="Person" display:Title="Firstname Lastname">
<Key>
<PropertyRef Name="ID" />
</Key>
<Property Name="ID" Type="Edm.Int32" Nullable="false" />
<Property Name="Firstname" Type="Edm.String" Nullable="true" />
<Property Name="Lastname" Type="Edm.String" Nullable="true" />
<Property Name="Email" Type="Edm.String" Nullable="true">
<validation:Constraint>
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Property>
<Property Name="Age" Type="Edm.Int32" />
</EntityType>For this to be valid XML the display and validation namespaces would have to be introduced somewhere something like this:
<Schema
xmlns:display="http://odata.org/vocabularies/display"
xmlns:validation="http://odata.org/vocabularies/validation">Here the URL of the xsd reference identifies the vocabulary globally.
While this allows for completely arbitrary annotations and is extremely expressive, it has a number of down-sides:
- Structural annotations (i.e. XML elements) support the full power of XML. While power is good, it comes at a price, and here the price is figuring out how to represent the same thing in say JSON? We could come up with a proposal to make CSDL and OData Atom/JSON completely isomorphic, but is that worth the effort? Probably not.
- There is no way to refer to something, like say a property, so that you can annotate it externally, which is one of our goals.
- If we allow for annotations inline in the data (and let's not forget metadata would just be data in an addressable metadata service) it would change the shape of the resulting JSON structure. For example the javascript expression to access the age property of an entity would need to change from something like object.Age to something like object.Age.Value so that object.Age can hold onto all the 'inline annotations'. This is clearly unacceptable if we want existing 'naive' consumers to continue to work.
OData values:
If we address these issues in turn, one concern for (1) is to restrict the XML available when using a vocabulary to the XML we already know how to convert from XML into JSON, i.e. OData values. For example we take something like this:
<Property Name="Email" Type="Edm.String" Nullable="true">
<validation:Constraint>
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Property>The annotation is pretty simple, and could be modeled as a ComplexType pretty easily:
<ComplexType Name="Constraint">
<Property Name="Regex" Type="Edm.String" Nullable="false" />
<Property Name="ErrorMessage" Type="Edm.String" Nullable="true" />
</ComplexType>In fact if you execute an OData request that just retrieves an instance of this complex type the response would look like this:
<Constraint
p1:type="Namespace.Constraint"
xmlns:p1="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata"
xmlns="http://schemas.microsoft.com/ado/2007/08/dataservices" >
<Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</Regex>
<ErrorMessage>Please enter a valid EmailAddress</ErrorMessage>
</Constraint>And this is almost identical to our original annotation, the only differences being around the xml namespaces.
Which means it is not too much of a stretch to say if your annotation can be modeled as a ComplexType which - of course allow nested complex types properties and multi-value properties too - then the Annotation is simply an OData value.
This is very nice because it means when we do addressable metadata you can in theory write a query like this to retrieve the annotations for a specific property:
~/$metadata.svc/Properties('Namespace.Type.PropertyName')/Annotations
ISSUE: Actually this introduces a problem, since each annotation instance would have a different 'type' we would need to support either ComplexType inheritance (so we can define the annotation as an EntityType with a Value property of type AnnotationValue, but instances of Annotations would invariably have Values derived from the base AnnotationValue type) or mark Annotation as a OpenType or provide a way to specify a property without specifying the type.
Of course today annotations are allowed that can't be modeled as ComplexTypes, so we would need to be able to distinguish those. Perhaps the easiest way is like this:
<Property Name="Email" Type="Edm.String" Nullable="true">
<validation:Constraint m:Type="validation:Constraint" >
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Property>Here the m:Type attribute indicates that the annotation is an OData value. This tells servers and clients that they can if needed convert between CSDL, ATOM and JSON formats using the above rules.
By adopting the OData atom format for annotations we can use a few more OData-ism to get clearer about the structure of the Annotation:
- By default each element in the annotation represents a string but you can use m:Type="***" to change the type to something like Edm.Int32.
e.g. <validation:ErrorSeverity m:Type="Edm.Int32">1</validation:ErrorSeverity>- We can use m:IsNull="true" to tell the difference between an empty string and null.
e.g. <validation:ErrorMessage m:IsNull="true" />This looks good. It supports both constrained (OData values) and unconstrained annotations, and is consistent with the existing annotation support in OData.
Out of line & External Annotations
Now if we turn our attention back to concern (2), this example implicitly refers to its parent; however we need to allow vocabularies to refer to something explicitly. For metadata the most obvious solution is to leverage addressable metadata, which allows you to refer to individual pieces of the metadata.
For example if this URL is the address of the metadata for the Email property: http://server/service/$metadata/Properties('Namespace.Person.Email')
Then this 'free floating' element is 'annotating' the Email property using the 'http://odata.org/vocabularies/constraints' vocabulary:
<Annotation AppliesTo="http://server/service/$metadata/Properties('Namespace.Person.Email')"
xmlns:validation="http://odata.org/vocabularies/constraints">
<validation:Constraint m:Type="validation:Constraint" >
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Annotation>Annotation by reference also neatly sidesteps issue (3), i.e. the object annotated is left structurally unchanged, which means we could use a similar approach to annotate data without breaking code (like a javascript path) that relies on a particular structure.
Another nice side-effect of this design is that you can use it 'inside' the CSDL too, simply by removing the address of the metadata service from the AppliesTo url - since we are in the CSDL we can us 'relative addressing':
<Annotation AppliesTo="Properties('Namespace.Person.Email')"
xmlns:validation="http://odata.org/vocabularies/constraints">
<validation:Constraint m:Type="validation:Constraint" >
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Annotation>Indeed if you have a separate file with many annotations for a particular model, you could group a series of annotations together like this:
<Annotations AppliesTo="http://server/service/$metadata/">
<Annotation AppliesTo="Properties('Namespace.Person.Email')"
xmlns:validation="http://odata.org/vocabularies/constraints">
<validation:Constraint m:Type="validation:Constraint" >
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Annotation>
<Annotation AppliesTo="Properties('Namespace.Customer.Email')"
xmlns:validation="http://odata.org/vocabularies/constraints">
<validation:Constraint m:Type="validation:Constraint" >
<validation:Regex>^[A-Z0-9._%+-]+@[A-Z0-9.-]+\.[A-Z]{2,6}$.</validation:Regex>
<validation:ErrorMessage>Please enter a valid EmailAddress</validation:ErrorMessage>
</validation:Constraint>
</Annotation>
</Annotations>Here the Annotations/@AppliesTo attribute indicates the shared root url for all the annotations, and could be any url that points to a model, be that http, file or whatever.
Vocabulary definitions and semantics
It is important to note, that while we are proposing how to 'bind' or 'apply' a vocabulary, we are *not* proposing how to:
- Define the terms in a vocabulary (e.g. Regex, ErrorMessage)
- Define the meaning or semantics associated with the terms (e.g. Regex should be applied to instance values, if the regex doesn't match an error/exception should be raised with the ErrorMessage).
Clearly however to interoperate two parties must agree on the vocabulary terms available and their meaning. We are however not dictating how that understanding develops. It could be done in many different ways - for example using a Hallway conversation, Word or PDF document, Diagram, or perhaps even an XSD or EDM model.
Who creates vocabularies?
The short answer is 'anyone'.
The more nuanced answer is there are many candidate vocabularies - from georss to vCard to Display to Validations - overtime people and companies from the OData ecosystem will start promoting vocabularies they have an interest in, and as is always the case the most useful will flourish.
Where are we?
I think that this proposal is a good place to gather feedback and think about the scenarios it enables. Using this approach you can imagine a world where:
- A Producer exposes a Data Service without using any terms from a useful vocabulary.
- Someone creates an 'annotation' file that attaches terms from the useful vocabulary to the service, which then enables 'smart consumers' to interact with the Data Service with higher-fidelity.
- The Producer learns of this 'annotation' file and embeds the annotations simply by converting all the 'appliesTo' urls (that are currently absolute) into relative urls.
You can also imagine a world where consumers like Tableau, PowerPivot and Sesame allow users to build up their own annotation files in response to gestures*.
*Gestures - you can think of the various mouse clicks, drags, key presses performed by a user as gestures. So for example right clicking on a column and picking from a list of well-known vocabularies could be interpreted as binding the selected vocabulary to the corresponding property definition. These 'interpretations' could easily be group and stored in an external annotation file.
Summary
I hope that you, like me, can see the potential power and expressiveness that vocabularies can bring to OData. Vocabularies will allow the OData eco-system to connect more deeply with the web and allow for ever richer and more immersive data consumption scenarios.
I really want to hear your feedback on the approach proposed above. The proposal is more exploratory than anything. It's definitely not set in stone, so tell us what you think.
Some specific questions:
- Do you agree that if we have a reference based annotation model, there is no need to support an inline model?
- What do you think of the idea of restricting annotation to the OData type system?
- Do you like the symmetry between in service (i.e. inside $metadata) and external annotations?
- Do we need to define how you attach vocabularies to data too? For example do you have scenarios where each instance has different annotations?
- Are there any particularly cool scenarios you think this enables?
- What vocabularies would you like to see pushed?
Sounds good to me. There’s an ongoing controversy in the OData mailing list about OData’s purported lack of RESTfulness as the result of use of OData-specific URI formats. I would expect similar objections to Vocabularies.
The Silverlight Show announced on 2/21/2011 a Free Telerik Webinar with Shawn Wildermuth - Consuming OData in Windows Phone 7 on 2/23/2011 at 7:00 to 8:00 PST:
Free Telerik Webinar: Consuming OData in Windows Phone 7
Date/Time: Wednesday, February 23, 2011, 10-11 a.m. EST (check your local time)
Guest Presenter: Shawn Wildermuth
The Windows Phone 7 represents a great application platform for the mobile user but being able to access data can take many forms. One particularly attractive choice for data access is OData (since it is a standard that many organizations are using to publish their data). In this talk, Shawn Wildermuth will show you how to build a Windows Phone 7 that accesses an OData feed!
Space is limited. Reserve your webinar seat now!
Find more info on the other upcoming free Telerik WP7 webinars.
SilverlightShow is the Media Partner for Telerik's Windows Phone 7 webinars. Follow all webinar news @silverlightshow.

Marcelo Lopez Ruiz answered Chris Lamont Mankowski’s How can I read and write OData calls in a secure way? (not vulnerable to CSRF for example?) Stack Overflow question of 2/11/2011:
Q: What is the most secure way to open a OData read/GET endpoint without risks to CSRF attacks like this one?
I haven't looked at the source, but how does the MSFT ODATA library compare to jQuery in this regard?
A: OData was designed to prevent the JSON-hijacking attack described in the link by returning only objects as JSON results, which makes the payload an invalid JavaScript program and as such won't be executed by the browser.
This is really independent of whether you use datajs or jQuery. I haven't looked at the exact result you get from jQuery, but I know datajs will "unwrap" the results so you get a more natural-looking result, without any artificial top-level objects.
In particular, the WCF Data Services implementation for .NET doesn't support JSONP out of the box, although there are a couple of popular simple solutions to add it. At that point, though, you've basically opted into allowing the data to be seen from other domains, so this is something that shouldn't be done for user-sensitive data.
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
Rick Garibay posted links to his Building Composite Hybrid App Services with AppFabric presentations on 2/21/2011:
Below are links to my most recent talks on AppFabric including Service Bus (1/12) and bringing it all together with Server AppFabric (2/9).
In the final webcast in my series on AppFabric, I discuss how Windows Server AppFabric extends the core capabilities of IIS and WAS by providing a streamlined on-premise hosting experience for WCF 4 and WF 4 Workflow Services, including elastic scale via distributed caching as well as how Windows AppFabric can benefit your approach to building and supporting composite application services via enhanced lifetime management, tracking and persistence of long-running work flow services all while providing a simple, IT Pro-friendly user interface.
The webcast includes a number of demos including the management of WF 4 Workflow Services on-prem with Server AppFabric as well as composing calls between a WCF service hosted in an Azure Web Role with an on-premise service via AppFabric Service Bus to deliver hybrid platform as a service capabilities today.
Click the ‘Register Here’ button for download details for a recording of each webcast.

January 12: App Fabric + Service Bus February 9: Building Composite Application Services with AppFabric Register Here Register Here
Rick is the General Manager of the Connected Systems Practice at Neudesic
Dominick Baier updated his Thinktecture.IdentityModel CodePlex project on 1/30/2011 (missed when updated):
Over the last years I have worked with several incarnations of what is now called the Windows Identity Foundation (WIF). Throughout that time I continuously built a little helper library that made common tasks easier to accomplish. Now that WIF is near to its release, I put that library (now called Thinktecture.IdentityModel) on Codeplex.
The library includes:
Feel free to contact me via the forum when you have questions or found a bug.
- Extension methods for
- IClaimsIdentity, IClaimsPrincipal, IPrincipal
- XmlElement, XElement, XmlReader
- RSA, GenericXmlSecurityToken
- Extensions to ClaimsAuthorizationManager (inspecting messages, custom principals)
- Logging extensions for SecurityTokenService
- Simple STS (e.g. for REST)
- Helpers for WS-Federation message handling (e.g. as a replacement for the STS WebControl)
- Sample security tokens and security token handlers
- simple access token with expiration
- compressed security token
- API and configuration section for easy certificate loading
- Diagnostics helpers
- ASP.NET WebControl for invoking an identity selector (e.g. CardSpace)
<Return to section navigation list>
Windows Azure VM Roles, Virtual Network, Connect, RDP and CDN
Avkash Chauhan provided a workaround for a Windows OS related Issue when you have VM Role and web/Worker Role in same Windows Azure Application in a 2/21/2011 post:
Issue:
Today, a service in Windows Azure can only support one Operating System selection for the entire service. When a partner selects his/her specific OS, it applies to all Web and Worker roles in the running service.
VM roles have slightly changed this model by allowing the partner to bring their own operating system and define this directly in the service model. Unfortunately, because of an issue in the way the OS is selected for Web and Worker roles, if a partner service has both a VM Role and a Web/Worker role, it is possible that the partner may NOT be able to change the operating system for the Web/Worker role and always be given the default OS for these specific role instances, which is the most recent version of the Windows Azure OS comparable to Server 2008 SP2. The partner will still be able to select the OS version and OS family through the portal; however, it will not be applied to the role instances. This does NOT impact the VM Role OS supplied by the partner.
This issue is due to the way the platform selects the OS using the service model passed by the partner. It will only occur when a VM Role is listed first in the internal service model manifestation. With this listing, the default OS version is applied to all web and worker roles, which becomes the latest version of the Windows Azure OS version comparable to Server 2008 SP2.
Workaround:
The workaround for this issue is fairly trivial. The internal service model manifestation orders the roles based upon their name, in alphabetical order. Therefore, if a partner has a VM Role AND a Web/Worker role in their service, to be able to apply a specific OS, the partner can rename their Web/Worker role with a name that is alphabetically higher than the VM Role. For example, the Web/Worker role could be named, “AWebRole” and the VM Role could be named “VMRole” and the OS selection system would work for this partner because AWebRole is alphabetically higher than VMRole.
What about the fix:
I would say that, this issue is known to Windows Azure team and as VM Role is in BETA so we all can hope for something different by the time VM Role hits RTM however there is nothing conclusive I have to add.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
BusinessWire reported Dell to Collaborate with Microsoft and Stellaris Health Network to Deliver Innovative Software-as-a-Service Analytics Solution for Community Hospitals in a 2/21/2011 press release:
Dell to deliver hosted, software-as-a-service solution using Microsoft Amalga health intelligence platform
- Dell’s hosted, subscription-based service will be designed to provide community hospitals with an affordable reporting program for operational metrics and add-on applications that target key business needs such as regulatory and accreditation compliance
- Solution will enable comparative and best practice data sharing with other participants
ROUND ROCK, Texas & REDMOND, Wash.--(BUSINESS WIRE)--Dell and Microsoft Corp. will collaborate to deliver an analytics, informatics, Business Intelligence (BI) and performance improvement solution designed specifically to meet the needs of community hospitals through an affordable, subscription-based model.
“As a network of community hospitals, we are excited about the ability to more easily and affordably create an interactive environment where our physicians and other clinicians can obtain quality metrics in real-time”
Delivered by Dell as a hosted online service, the solution combines Microsoft Amalga, an enterprise health intelligence platform, with Dell’s cloud infrastructure and expertise in informatics, analytics and consulting. [Link added.]
The new offering will be developed in collaboration with Stellaris Health Network, a community hospital system that consists of Lawrence Hospital Center, Northern Westchester Hospital, Phelps Memorial Hospital Center and White Plains Hospital. These hospitals will serve as the foundation members in the solution development process.
Community hospitals will have access to targeted, focused views of consolidated patient data from source systems across the hospital, enabling organizational leaders, clinicians and physicians to rapidly gain insights into the administrative, clinical and financial data needed to make ongoing operational decisions. This information will further enable hospitals to provide patients with advancing levels of high quality, evidence-based care. In addition, the solution will provide add-on, business-focused applications.
The initial application (The Quality Indicator System or QIS) also will play a key role in helping community hospitals manage quality indicator reporting requirements as mandated by CMS, the Joint Commission and the new meaningful-use measures now mandated under the American Recovery and Reinvestment Act of 2009. This application is unique to the market in that it will go beyond the CMS-required metrics to deliver advanced quality indicator alerts and prevent metrics from being missed. The QIS will capture data as a patient enters the hospital, determine which quality measures may apply to the patient, and then enable the hospital to track and measure compliance throughout the patient’s stay.
Dell is building upon its existing relationship with Stellaris Health Network by conducting a pilot of the solution at the network’s four hospitals in Westchester, N.Y. The pilot will begin in March and will provide Stellaris hospitals with integrated workflow design, documentation integrated within its information system, and advanced reporting of quality measures.
“As a network of community hospitals, we are excited about the ability to more easily and affordably create an interactive environment where our physicians and other clinicians can obtain quality metrics in real-time,” said Arthur Nizza, CEO, Stellaris Health Network. “Through our demonstration project with Dell and Microsoft, we look forward to leveraging the considerable investment our hospitals have made in improving clinical care and patient outcomes by sharing best practices that will further advance the care provided by community hospitals.”
As the collaborative expands to include new members, additional applications will be developed to solve other commonly identified business issues found in the community hospitals such as solutions for turn-around time delays, care coordination, managing avoidable readmissions, and population based healthcare management for chronic conditions.
“Uniting our companies’ complementary strengths in healthcare software, IT services and enterprise-class server systems, Dell and Microsoft are uniquely positioned to bring to market new modular healthcare solutions aimed squarely at the needs of small and mid-sized hospitals,” said Berk Smith, vice president, Dell Healthcare and Life Sciences Services. “We’re excited to collaborate with Microsoft and Stellaris Health to deliver a set of rich informatics, analytics and reporting applications that are not only easy and cost-effective to adopt, but also are designed to create more value out of existing IT systems.”
“In a highly dynamic healthcare landscape, hospitals of all sizes are challenged by a lack of timely access to health data stored in their enterprise technology systems, which has a direct impact on timely decision-making and ultimately the quality of care,” said Peter Neupert, Corporate Vice President, Microsoft Health Solutions Group. “With Dell and Stellaris, our goal is to offer a set of solutions that make it simple for small and mid-sized hospitals, which typically don’t have extensive IT departments, to readily access and analyze the data they need to identify gaps in care quality and take the right steps to make measurable improvements.”
About Dell
Dell (NASDAQ: DELL) listens to its customers and uses that insight to make technology simpler and create innovative solutions that deliver reliable, long-term value. Learn more at www.dell.com. Dell’s Informatics and Analytics Practice spans hospitals, community based healthcare providers, physician services and payer market segments. In each of these segments, the Dell solutions encompass the entire spectrum of healthcare informatics needs including data acquisition, storage, management, analytics, and reporting. Coupled with Dell's expertise in healthcare consulting is a broad depth of knowledge and experience in technology solutions which have made Dell an award winning Technology Services organization worldwide.
About Microsoft in Health
Microsoft is committed to improving health around the world through software innovation. Over the past 13 years, Microsoft has steadily increased its investments in health with a focus on addressing the challenges of health providers, health and social services organizations, payers, consumers and life sciences companies worldwide. Microsoft closely collaborates with a broad ecosystem of partners and delivers its own powerful health solutions, such as Amalga, HealthVault, and a portfolio of identity and access management technologies acquired from Sentillion Inc. in 2010. Together, Microsoft and its industry partners are working to deliver health solutions for the way people aspire to work and live.
About Microsoft
Founded in 1975, Microsoft (Nasdaq: MSFT) is the worldwide leader in software, services and solutions that help people and businesses realize their full potential.
About Stellaris Health Network
Based in Armonk, NY and founded in 1996, HealthStar Network, Inc. (dba Stellaris Health Network) is the corporate parent of Lawrence Hospital Center (Bronxville, NY), Northern Westchester Hospital (Mount Kisco, NY), Phelps Memorial Hospital Center (Sleepy Hollow, NY), and White Plains Hospital (White Plains, NY). In addition to the network of hospitals, Stellaris provides ambulance and municipal paramedic services to Westchester County, New York through Westchester Emergency Medical Services. With nearly $850 million in combined revenue and 1,100 in-patient beds, Stellaris Hospitals account for over a third of the acute care bed capacity in Westchester County. It is one of the largest area employers, with over 5,000 employees and approximately 1,000 voluntary physicians on staff. The Stellaris Hospitals provide multidisciplinary acute care services, as well as a range of community based services such as hospice, home health, behavioral health and physical rehabilitation. As Stellaris pursues new programs and joint ventures, it will continue to evolve as the regions’ leading healthcare system, dedicated to preserving high quality, community-based care for residents of Westchester, Putnam, Rockland, Dutchess, Northern Bronx, and Fairfield Counties.
Dell continues to increase its presence in health information technology (HIT).
Vedaprakash Subramanian, Hongyi Ma, Liqiang Wang, En-Jui Lee and Po Chen posted Azure Use Case Highlights Challenges for HPC Applications in the Cloud on 2/21/2011 to the HPC in the Cloud blog:
We recently had the experience of porting an HPC application, Numerical Generation of Synthetic Seismograms, onto Microsoft’s Windows Azure cloud and have generated some opinions to share about some of the challenges ahead for HPC in the cloud.
Numerical generation of synthetic seismogram is an HPC application that generates seismic waves in three dimensional complex geological media by explicitly solving the seismic wave-equation using numerical techniques such as finite-difference, finite-element, and spectral-element methods. The computation of this application is loosely-coupled and the datasets require massive storage. Real-time processing is a critical feature for synthetic seismogram.
When executing such an application on the traditional supercomputers, the submitted jobs often wait for a few minutes or even hours to be scheduled. Although a dedicated computing cluster might be able to make a nearly real-time response, it is not elastic, which means that the response time may vary significantly when the number of service requests changes dramatically.
Given these challenges and due to the elastic nature of the cloud computing, this seems like an ideal solution for our application, which provides much faster response times and the ability to scale up and down according to the requests.
We have ported our synthetic seismogram application to Microsoft’s Windows Azure. As one of the top competing cloud service providers, Azure provides Platform as a service (PaaS) architecture, where users can manage their applications and the execution environments but do not need to control the underlying infrastructure such as networks, servers, operating system, and storage. This helps the developers focus on the applications rather than manage the cloud infrastructures.
Some useful features Windows Azure for HPC provides for applications include the automatic load balancing and checkpointing. Azure divides its storage abstractions into partitions and provides automatic load balancing of partitions across their servers. Azure monitors the usage pattern of the partitions and servers and adjusts the grouping or splitting of workload among the servers.
Checkpointing is implemented using progress tables, which support restarting previously failed jobs. These store the intermediate persistent state of a long-running job and record the progress of each step. When there is failure, we can look at the progress table and resume from the failover. The progress table is useful when a compute node fails and its job is taken over by another compute node.
Challenges Ahead for HPC in the CloudThe overall performance of our application on Azure cloud is good when compared to the clusters in terms of the execution time and storage cost. However, there are still many challenges for cloud computing, specifically, for Windows Azure.
Dynamic scalability - The first and foremost problem with Azure is that the scalability is not up to the expectation. In our application, dynamic scalability is a major feature. Dynamic scalability means that according to the response time of the user queries, the compute nodes are scaled up and down dynamically by the application. We set the threshold response time to be 2 milliseconds for queries. If the response time of a query exceeds the threshold, it will request to allocate an additional compute node to cope up with the busy queries. But the allocation of a compute node may take more than 10 minutes. Due to such a delay, the newly allocated compute node cannot handle the busy queries in time.
- Vedaprakash Subramanian is a Master student in the department of Computer Science at University of Wyoming.
- Hongyi Ma is a PhD student in the Department of Computer Science at University of Wyoming.
- Liqiang Wang is an Assistant Professor in the Department of Computer Science at the University of Wyoming.
- En-Jui Lee is a PhD student in the Department of Geology and Geophysics at the University of Wyoming.
- Po Chen is currently an Assistant Professor in the Department of Geology and Geophysics at the University of Wyoming.
ItPro.co.uk posted on 2/21/2011 a Dot Net Solutions & Windows Azure: Case Study sponsored by Microsoft:
Dot Net Solutions has leveraged the power, flexibility, security and reliability of Microsoft's Windows Azure platform to create cloud based infrastructure solutions for a variety of clients with a host of different needs.
Dot Net Solutions & Windows Azure
Dot Net Solutions is a technology-focussed systems integrator. It’s one of the UK leaders in helping organisations large and small architect and build business solutions for the Cloud. Customers range from venture backed start-ups to global multinationals.
"There are real cost savings involved in using Windows Azure over either your internal infrastructure or a traditional hosting company. Push everything to the cloud. It doesn't need to fit within one of the classic cloud computing scenarios. With any application, you're going to be able to get massive cost savings."
Dan Scarfe, Chief Executive, Dot Net Solutions

Cory Fowler (@SyntaxC4) continued his series with Installing PHP on Windows Azure leveraging Full IIS Support: Part 2 on 2/20/2011:
In the last post of this Series, Installing PHP on Windows Azure leveraging Full IIS Support: Part 1, we created a script to launch the Web Platform Installer Command-line tool in Windows Azure in a Command-line Script.
In this post we’ll be looking at creating the Service Definition and Service Configuration files which will describe what are deployment is to consist of to the Fabric Controller running in Windows Azure.
Creating a Windows Azure Service Definition
Unfortunately there isn’t a magical tool that will create a starter point for our Service Definition file, this is mostly due to the fact that Microsoft doesn’t know what to provide as a default. Windows Azure is all about Developer freedom, you create your application and let Microsoft worry about the infrastructure that it’s running on.
Defining a Windows Azure Service
<?xml version="1.0" encoding="utf-8"?> <ServiceDefinition name="PHPonAzure" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition"> <WebRole name="Deployment" vmsize="ExtraSmall" enableNativeCodeExecution="true"> <Startup> <Task commandLine="install-php.cmd" executionContext="elevated" taskType="background" /> </Startup> <Endpoints> <InputEndpoint name="defaultHttpEndpoint" protocol="http" port="80"/> </Endpoints> <Imports> <Import moduleName="RemoteAccess"/> <Import moduleName="RemoteForwarder"/> </Imports> <Sites> <Site name="PHPApp" physicalDirectory=".\Deployment\Websites\MyPHPApp"> <Bindings> <Binding name="HttpEndpoint" endpointName="defaultHttpEndpoint" /> </Bindings> </Site> </Sites> </WebRole> </ServiceDefinition>We will be using a Windows Azure WebRole to Host our application [remember WebRoles are IIS enabled], you’ll notice that our first element within our Service Definition is WebRole. Two Important pieces of the WebRole Element are the vmsize and enableNativeCodeExecution attributes. The VMSize Attribute hands off the VM Sizing requirements to the Fabric Controller so it can allocate our new WebRole. For those of you familiar with the .NET Stack the enabledNativeCodeExecution attribute will allow for FullTrust if set to true, or MediumTrust if set to false [For those of you that aren’t familiar, Here’s a Description of the Trust Levels in ASP.NET]. The PHP Modules for IIS need elevated privileges to run so we will need to set enableNativeCodeExecution to true.
In Part one of this series we created a command-line script that would initialize a PHP installation using WebPI. You’ll notice under the Startup Element, we’ve added our script to a list of Task Elements which defines the startup Tasks that are to be run on the Role. These scripts will run in the order stated with either limited [Standard User Access] or elevated [Administrator Access] permissions. The taskType determines how the Tasks are executed, there are three options simple, background and foreground. Our script will run in the background, this will allow us to RDP into our instance and check the Logs to ensure everything installed properly to test our deployment.
In the Service Definition above we’ve added some additional folders to our deployment, this is where we will be placing our website [in our case, we’re simply going to add an index.php file]. Within the Deployment Folder, add a new folder called Websites, within the new Websites folder, create a folder called MyPHPApp [or whatever you would like it named, be sure to modify the physicalDirectory attribute with the folder name].
Now that our directories have been added, create a new file named index.php within the MyPHPApp folder and add the lines of code below.
<?php phpinfo(); ?>Creating a Windows Azure Service Configuration
Now that we have a Service Definition to define the hard-requirements of our Service, we need to create a Service Configuration file to define the soft-requirements of our Service.
Microsoft has provided a way of creating a Service Configuration from our Service Definition to ensure we don’t miss any required elements.
If you intend to work with Windows Azure Tools on a regular basis, I would suggest adding the Path to the tools to your System Path, you can do this by executing the following script in a console window.
path=%path%;%ProgramFiles%\Windows Azure SDK\v1.3\bin;We’re going to be using the CSPack tool to create our Service Configuration file. To Generate the Service Configuration we’ll need to open a console window and navigate to our project folder. Then we’ll execute the following command to create our Service Configuration (.cscfg) file.
cspack ServiceDefinition.csdef /generateConfigurationFile:ServiceConfiguration.cscfgAfter you run this command take a look at your project folder, it should look relatively close to this:
You’ll notice that executing CSPack has generated two files. First, It has generated our Service Configuration file, which is what we’re interested in. However, the tool has also gone and compiled our project into a Cloud Service Package (.cspkg) file, which is ready for deployment to Windows Azure [we’ll get back to the Cloud Service Package in the next post in this series]. Let’s take a look at the Configuration file.
<?xml version="1.0"?> <ServiceConfiguration xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" serviceName="PHPonAzure" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceConfiguration"> <Role name="Deployment"> <ConfigurationSettings> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.Enabled" value="" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountUsername" value="" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountEncryptedPassword" value="" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteAccess.AccountExpiration" value="" /> <Setting name="Microsoft.WindowsAzure.Plugins.RemoteForwarder.Enabled" value="" /> </ConfigurationSettings> <Instances count="1" /> <Certificates> <Certificate name="Microsoft.WindowsAzure.Plugins.RemoteAccess.PasswordEncryption" thumbprint="0000000000000000000000000000000000000000" thumbprintAlgorithm="sha1" /> </Certificates> </Role> </ServiceConfiguration>Where did all of this come from? Let’s look at a simple table, that matches up how these settings relate to our Service Definition.

For more information on the RemoteAccess and RemoteForwarder check out the series that I did on RDP in a Windows Azure Instance. These posts will also take you through the instructions on how to provide proper values for the RemoteAccess and RemoteForwarder Elements that were Generated by the Import statements in the ServiceDefinition.
- Upload a Certification to an Azure Hosted Service
- Setting up RDP to a Windows Azure Instance: Part 1
- Setting up RDP to a Windows Azure Instance: Part 2
- Connecting to a Windows Azure Instance via RDP
There are two additional attributes in which I would recommend adding to the ServiceConfiguration Element, osFamily and osVersion.
osFamily="2" osVersion="*"These attributes will change the underlying Operating System Image that Windows Azure runs to Windows Server 2008 R2 and sets your Role to automatically update to the new image when available.
You can control the number of instances of your Roles are deployed by changing the value of the count attribute in the Instances Element. For now we’ll leave this value at 1, but keep in mind that Microsoft’s SLA requires 2 instances of your role to be running in order to guarantee 99.95% uptime.
Great Resources
- Cloud Cover Show, Episode 37: Multiple Websites in a Web Role
- Cloud Cover Show, Episode 34: Advanced Startup Tasks and Video Encoding
- Cloud Cover Show, Episode 31: Startup Tasks, Elevated Privileges and Classic ASP
Conclusion
In this entry we created both a Service Definition and a Service Configuration. Service Definitions provide information to the Fabric Controller to create non-changeable configurations to a Windows Azure Role. The Service Configuration file will provide additional information to the Fabric Controller to manage aspects of the environment that may change over time. In the next post we will be reviewing the Cloud Service Package and Deploying our Cloud Service into the Windows Azure Environment.



The Microsoft Case Studies team posted a 4-page Learning Content Provider Uses Cloud Platform to Enhance Content Delivery case study abut Windows Azure on 2/18/2011:
Point8020 Limited created ShowMe for SharePoint 2010 to deliver embedded, context-sensitive video help and training for Microsoft SharePoint Server 2010. Point8020 created a new menu option and a context-sensitive tab for the SharePoint Server 2010 ribbon, and it built a rich user interface with Microsoft Silverlight browser technology for displaying videos. Using the Windows Azure platform, the company moved the program’s library of video files to the cloud, enabling much simpler deployment of content updates. Point8020 found that the tight interoperation of Microsoft development tools and technologies enabled rapid development and a fast time-to-market. By using a cloud-based solution, Point8020 has also opened the way for new business models.
Partner Profile
Point8020 Limited was founded in 2007 and has its headquarters in Birmingham, England. The company has 20 employees and additional offices in Oxford, England, and Seattle, Washington.
Business Situation
Point8020 wanted to develop context-sensitive video help within Microsoft SharePoint Server 2010 and enable delivery of video content from a cloud platform.
Solution
Point8020 used Microsoft Silverlight to build a rich user interface for viewing videos within SharePoint Server 2010, and it chose Windows Azure as its cloud platform for storing and delivering videos.
Benefits
- Familiar and powerful tools
- Simplified deployment and updates
- A trusted technology provider
Software and Services
- Windows Azure
- Microsoft Sharepoint Server 2010
- Microsoft Visual Studio 2010
- Microsoft Silverlight
- Windows Azure Platform
- Microsoft SQL Azure
- Bing Technologies
- Microsoft ASP.NET
Steven Ramirez [pictured below] continued his interview of Mike Olsson with a Microsoft IT and the Road to Azure—Part 2 post to The Human Enterprise MSDN Blog on 2/18/2011:
This is the second of a two-part interview with Mike Olsson, Senior Director in Microsoft IT. In Part 1, we discuss how Microsoft IT went “all in,” what they learned along the way and how to decide which applications to migrate.
Steven Ramirez: What is the biggest challenge for developers when moving applications to the cloud?
Mike Olsson: The very biggest challenge to begin with was conceptual—what is it and how does it differ? In the Auction Tool scenario, that was the first hurdle. The architecture and the nature of what you’re doing is substantially different. The cloud is different from a server that I can touch and feel.
SR: And provisioning is different.
MO: Provisioning is different and the processes are different. How do we apply controls? Typically there are controls that are provided by the fact that you need to spend $100,000 on servers. Those controls go away. We need different controls in place.
In other areas, we’re using Visual Studio and .NET so, at the architecture and design level, it’s very different. But at the programmer level, it is substantially the same. So you can at least sit down and know that you’re dealing with tools that you understand and apply yourself to the architectural differences.
There are other differences. I can scale individual pieces of my application depending on demand. The user interface might need more processing power when my app is popular or at the end of the month and my backend jobs might need more processing power overnight. I can scale those independently, which means that there’s a tighter relationship between what the developer puts together and what the Operations guys have to control.
SR: What about training?
MO: Since April last year we have trained around fourteen hundred people in an organization of four thousand. The training for us has been absolutely critical. I think we are at a point now where a large group of people can write an Azure application. Our next step will be to get them to consistently write a good Azure application. The next level of training will depend on the processes and procedures that are put in place. Because we now need to think about how we do source control, how we do deployment, how we deal with permissions.
SR: What are some other challenges?
MO: One of the things that we’ve had to spend a little time on is, getting people to understand that there are no dev boxes in the corner. The environment is ubiquitous and the delineation between dev, test and production is not physical. That can be an interesting discussion. The flip side is, when you move from dev to test to production, you know that every single environment is absolutely identical. And for developers that’s a huge boon.
SR: How does using Azure affect the design of future applications in your opinion?
MO: Designing a new Azure application is much easier than moving an existing one. If you have the environment in mind—you’ve been trained on it—now you can design it with the scalability, the availability and with the bandwidth considerations. You can build a much better app.
SR: And those were the things we always wanted as developers, right? We always wanted the scale, the availability and the bandwidth. Now we’re in a place, it sounds like, where we can actually have those things.
MO: We can have it. Right now we are still thinking about new applications. We have examples of good design but they’re still relatively inside-the-box. I don’t think we’ve seen examples of what will happen when you get a smart developer who suddenly has infinite scalability and enormous flexibility in how he designs his application.
For new applications, the world is your oyster. You really have the flexibility to design the app the way you always wanted to.
SR: One of the things that IT is most concerned with—and has made huge investments in—is Security. Can you talk a little about what you’ve found in moving to the cloud?
MO: The first comment I’ll make is, from a physical security perspective, the folks who run the data centers know how to do that. The platform is secure.
Security is incredibly hard and best left to the professionals. We typically say to people in the class we run that, if you do it right, somewhere in the region of half your application should be dealing with security. The basic rule is, get the professionals involved and listen to them.
SR: And it sounds like this environment lends itself to security, right? In the past it was always, Well, I’ll write my app then we’ll put a layer of security on afterward. It sounds like with Azure, it’s security from the get-go.
MO: Yes. I think there is a perception that, It’s the cloud therefore it’s insecure. But it doesn’t have to be. As long as you go into this thinking about security first, the platform will be every bit as secure as what we have on-premises—maybe more so because it’s uniform, it’s patched, it’s monitored.
SR: In closing, what are three things that customers can do to get started?
MO: The first thing is, get to a definition of the cloud. Understand the Azure environment and what it can do—and it’s relatively easy to do. There’s a lot of information out there.
Second, do some simple segmentation of your application portfolio and understand where to start—the kind of segmentation we did. Business risk on one axis, technical complexity on the other.
And the third thing is, get your feet wet. It’s incredibly cheap and easy to start doing this. The barriers to entry are almost non-existent. And most of our customers already have the basic technical skills in place.
SR: Mike, thanks a lot. I really appreciate it.
MO: My pleasure.
Windows Azure Resources
- “Microsoft IT Developing Applications with Microsoft Azure“ video
- “Microsoft IT’s Lessons Learned: Moving Applications to the Cloud“ video
- “Introducing the Windows Azure Platform“ white paper
- “Windows Azure Security Overview“ white paper
- “Cloud Economics“ white paper
The opinions and views expressed in this blog are those of the author and do not necessarily state or reflect those of Microsoft.
The Microsoft Case Studies team posted Marketing Firm [Definition 6] Quickly Meets Customer Needs with Content Management in the Cloud on 2/17/2011:
Definition 6 is an interactive marketing agency that focuses on creating content-rich, engaging websites. The company uses the Umbraco content management system and wanted to implement a cloud-based hosting option to complement its traditional hosting model, but struggled to find a solution that would integrate with the content management system. Umbraco also recognized the need for a cloud-based solution and developed an accelerator that enables companies to deploy websites that are managed in the Umbraco content management system to the Windows Azure platform. By using the accelerator, Definition 6 migrated Cox Enterprises’ Cox Conserves Heroes website to the Windows Azure platform in two weeks. Definition 6 enjoyed a simple development and deployment process; can now offer customers a cost-effective, cloud-based solution; and is prepared for future business demands.
Organization Size: 150 employees
Organization Profile: Definition 6 is an interactive marketing agency that, in addition to traditional marketing, creates interactive web experiences for several national brands, including Cox Communications.
Business Situation: The marketing agency wanted to offer a cloud-based hosting option for its customers’ websites, but needed one that would integrate with the Umbraco content management system.
Solution: By using an accelerator developed by Umbraco, Definition 6 migrated one of the Cox Enterprises websites to the Windows Azure platform in only two weeks.
Benefits:
- Simplified development and deployment
- Implemented cost-effective, quick hosting option
- Prepared for future business needs
Software and Services:
- Windows Azure
- Microsoft Visual Studio 2008 Professional Edition
- Microsoft SQL Azure
- Microsoft .NET Framework 3.5
- Microsoft .NET Framework 4
<Return to section navigation list>
Visual Studio LightSwitch
Edu Lorenzo explained Creating a workflow with Visual Studio Lightswitch in a 2/21/2011 post:
No, not a SharePoint workflow. That is a totally different task and cannot be done with LS.
The workflow I am referring to is how certain data needs to go from one screen to another.
For all those who have tried VS-LS, it is really a pretty cool tool to create screens for data entry and searching. But what if I want to establish some form of workflow? Maybe creating a new client then going straight to creating a transaction for this new patient? Yes, that is what this installment of my LightSwitch blog will show.
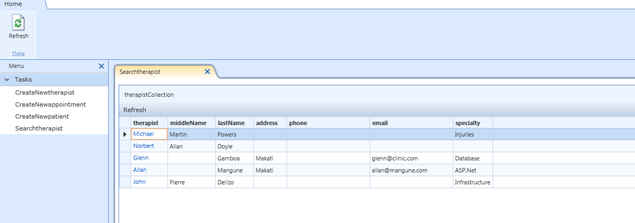
So I start off with a small application that I made for this demo. It is a simple contacts management for a small clinic (am planning to donate this app to my cousin Andrew in Canada who owns a physical therapy and rehabilitation clinic). Here is a screenshot of what I have:
It’s basically your off the shelf application that LightSwitch gives you once you add screens. I just basically have Therapist, Patient and Appointments tables set up, popped out a few screens and there it is.
Although Visual Studio Lightswitch can create a “CreateNewPatient” screen for me (which I have already done), I want to extend this application by adding a workflow. What I want is, after the secretary creates a new Patient, the system should redirect the secretary to create an appointment for that Patient.
Here is how it’s done:
First let’s take a look at the screen for adding a new Patient during design time..
I highlighted two areas; the one on the left is representative of the viewmodel that lightwsitch creates. It shows that we have a “patientProperty” object and a list of properties for this object. At the right area, I highlighted the controls that LightSwitch chose for you. What I want to highlight here, is that lightswitch will do its best to choose the proper control for the proper data type. With that in mind, users should be informed that in order for VS-LS to consistently provide functional UI, you must really design your tables correctly. Choose the proper data type, define the correct relationships and all.
And to illustrate that further, here is a screenshot of the CreateNewAppointment screen that VS-LS created for me based on the datatypes that I chose and the relationships that I defined:
VS-LS chooses an appropriate control to hold/represent the data that you need. A textbox for data entry, Date Picker for the appointmentDate and DateTimePicker for startTime and endTime. Also, you might notice that for the patient and therapist entries, LS chose to use a Modal Window Picker because I have already defined the relationships for these tables.
Here is a screenshot of the relationship definition and see how clearly a relationship can be defined:
Okay. Time to get to the task at hand, adding a “workflow”.
With VS-LS, your screens will have the objects that it created for you as the datasource. It’s pretty much like binding the whole screen to a datasource object and binding each control to a property of your object.
So since what we want is for the application to go straight to the Create New Appointment screen right after a new Patient is created, we will need to do two things:
- Overload the constructor of the create new appointment screen so that it will accept a Patient object and load the properties immediately (so to speak)
- Save the patient data upon creation then call and open the Create New Appointment screen while passing the new patient object.
So let’s modify the Create New Appointment screen to accept an optional parameter on load. Let’s take a look at the default code that LIghtswitch loads on a screen by clicking the “Write Code” button while designing the screen..
public
partial
class
CreateNewappointment{
partial
void CreateNewappointment_BeforeDataInitialize(){
// Write your code here.
this.appointmentProperty = new
appointment();}
partial
void CreateNewappointment_Saved(){
// Write your code here.
this.Close(false);
Application.Current.ShowDefaultScreen(this.appointmentProperty);
}
}
}
There is something worth taking notice of here. There are two events that you will see, BeforeDataInitialize and Saved. What you will see here is that LightSwitch’s code acts on data, rather than the screen/form. The code we have is not UI related code. This further illustrates that VS-LS follows an MVVM pattern. I just want to highlight that although it looks like LightSwitch is just a big wizard, it still follows a tried and tested pattern.
So what do I do with this code? I comment out the code for the Saved() function so I can replace it.
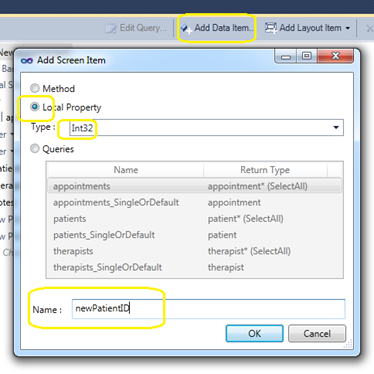
Next I add a new dataItem to my screen that will be my optional parameter to accept the PatientID. This is done by clicking “Add Data Item” and choosing the proper datatype for the parameter we will receive, give it a name and save.
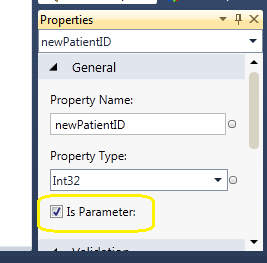
Then I declare that as a Parameter on the properties explorer by checking the Is Parameter checkbox.
Okay, so now we have an optional parameter. Next thing I need to do is to go to the Loaded event of the screen then add some code.
bool hasPatient = false;
partial
void CreateNewappointment_Loaded(){
if (!hasPatient)
{
this.appointmentProperty.patient = this.DataWorkspace.ApplicationData.patients_Single(newPatientID);
hasPatient = true;
}
}
Let us dissect these few lines of code:
bool hasPatient = false; ß this line of code declares a bool variable called hasPatient.. DUH!!!!
This is a much nicer line of code:
this.appointmentProperty.patient = this.DataWorkspace.ApplicationData.patients_Single(newPatientID);
here you will see a lot of things but the most interesting part (at least for me) is the DataWorkspace so I’ll try to expand on that.
The DataWorkspace is the place where LS maintains the “state” of your data. While running your LightSwitch app, you will notice that the tab displays an Asterisk while you are either editing or adding a new row. This tells the user that the data displayed is currently in a “dirty” state and there has been changes. All this happens without you writing any code for that.
Finally, this line basically issues a “select.. where” statement to the database, pretty much like how EF(Entity Framework) does it. I haven’t tried it yet but I think there is a good chance that if one runs profilers, we will see a select statement issued somewhere :p
Now it’s time to tell the CreateNewPatient screen to get the newly saved PatientID and pass it to the CreateNewAppointment screen.
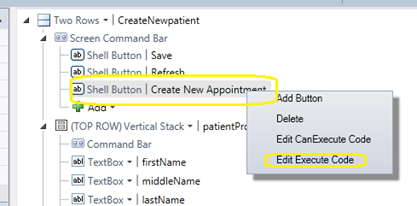
To do that, I’ll add a new button to the CreateNewPatient screen and add some code to open the CreateNewAppointment screen
And as I write the code..
Notice two things:
- I used the “Application” namespace, which is pretty familiar already and..
- The input parameter newPatientID is already showing in the intellisense, which tells us that what we did earlier was correct
So we now supply the newPatientID by getting it from the PatientProperty
Then I removed the code for the Saved method because it closes the form.
Then when I run this and add a new “familiar” patient and his health condition information:
We now see the button I added to open the CreateNewAppointment screen.. and when I click, the application opens the Create new Appointment screen with the Patient’s name loaded automagically!
I’ll still polish this up by adding validation and controlling the flow.
And that’s how you add a “workflow” in a Visual Studio Lightswitch application.







Return to section navigation list>
Windows Azure Infrastructure
TechNet has a new ITInsights blog that features Cloud Conversations posts with a Cloud Power theme, which replaces the original We’re All In slogan:

Microsoft commissioned David Linthicum (DavidLinthicum@Microsoft), a Forbes Magazine contributor, to write ROI of the Cloud, Part 1: Paas as a ForbesAdVoice item:

Here’s the full text of David’s article:
This article is commissioned by Microsoft Corp. The views expressed are the author’s own.
Platform-as-a-Service, or PaaS, provides enterprises with the ability to build, test, and deploy applications out of the cloud without having to invest in a hardware and software infrastructure.
One of the latest arrivals in the world of cloud computing, PaaS is way behind IaaS and SaaS in terms of adoption, but has the largest potential to change the way we build and deploy applications going forward. Indeed, my colleague Eric Knorr recently wrote that “PaaS may hold the greatest promise of any aspect of the cloud.” This In-Stat report indicates that PaaS spending will increase 113 percent to about $460 million between 2010 and 2014.
The big guys in this space include Windows Azure (Microsoft), Google App Engine, and Force.com. More recently, Amazon joined the PaaS game with its new “Elastic Beanstalk” offering. The existing SaaS and IaaS players, such as Salesforce.com and Amazon, respectively, see PaaS as a growth area unto itself, as well as a way to upsell their existing SaaS and IaaS services.
However, the business case around leveraging PaaS is largely dependent upon who you are, and how you approach application development. The first rule of leveraging this kind of technology is to determine the true ROI, which in the world of development will be defined by cost savings and efficiencies gained over and above the traditional models.
There are three core things to consider around PaaS and ROI:
- Application development
- Application testing
- Application deployment and management
Application development costs, mostly hardware and software, are typically significant. Back in my CTO days these costs were 10 to 20 percent of my overall R&D costs. This has not changed much today. However, while the potential to reduce costs drives the movement to PaaS, first you need to determine if a PaaS provider actually has a drop-in replacement for your existing application development platform. In most cases there are compromises. You also need to consider the time it will take to migrate over to a PaaS provider, and the fact that you’ll still be supporting your traditional local platform for some time.
Thus the ROI is the ongoing cost trajectory required to support the traditional local application development platform, and the potential savings from the use of PaaS. You need to consider ROI using a 5-year horizon, and make sure to model in training and migration costs as well, which can be significant if there are significant differences in programming language support, as well as supporting subsystems such as database processing.
While your mileage may vary, in my experience most are finding 30 to 40 percent savings, if indeed a PaaS provider is a true fit.
Application testing is really the killer application for PaaS, and it comes with the largest ROI. Why? There is a huge amount of cost associated with keeping extra hardware and software around just for testing purposes. The ability to leverage cloud-delivered platforms that you rent means your costs can drop significantly. Again, consider this using a 5-year horizon. Compare the cost of keeping and maintaining hardware and software for test platforms locally, and the cost of leveraging PaaS for testing. The savings can be as much as 70 to 90 percent in many cases, in my most recent experience. Again, this assumes that you’ll find a PaaS provider that’s close to a drop-in fit for your testing environment.
Finally, application deployment and management on a PaaS provider typically comes with handy features such as auto provisioning and auto scaling. This mean the PaaS provider will auto-magically add server instances as needed to support application processing, database processing, and storage. No more waves of hardware and software procurement cycles, or nights bolting servers into racks in the data center. Thus the ROI is second highest after application testing, and can total as much as 50 to 60 percent reductions in costs.
You also need to consider the cost of migration from the PaaS provider if it breaks bad on you. For instance, the provider could significantly kick up its prices or perhaps shut down, or even kick you off. The tradeoff when leveraging cloud computing is control, and you have to dial-in the risk of losing access to your PaaS provider. While I don’t view this as a significant risk, it should be considered in the context of creating the business case.
Count on a significant amount of change, mostly for the better, as PaaS providers increase the power of their platforms, add many new features, and drop their prices to grab market share. Indeed, while PaaS has been trailing both IaaS and SaaS, most in the industry are seeing the largest percentage of growth around PaaS, and many application development shops are seeing significant ROI from the use of PaaS.
As we all know by now, platforms can quickly and unpredictably evolve as businesses develop new uses for them. So let’s build our 5-year ROI horizons, even as we prepare to be surprised by where are in 5 years.
See also TechNet’s Larry Grothaus wrote Cloud Security with Windows Azure and Microsoft Global Foundation Services on 2/16/2011 in the Cloud Security and Governance section below.
Supporting the new theme, the PCNetlive site posted a link to a Microsoft Cloud Power Customer [PowerPoint] Deck for partner customization:

Most slides have notes to prompt the presenter.
JP Morgenthal asserted Scale is the Common Abstraction of Cloud Computing in a 2/21/2011 essay:
In my experience, for there to be widespread adoption and agreement over a concept, the semantics surrounding that concept must be unique and discrete. If the definition is too broad, there will be too much opportunity for dissenting opinion. NIST’s definition of cloud computing doesn’t really answer the mail when it comes to delivering a definition for cloud computing. In my opinion, it’s nothing more than bucket of attributes that have been previously associated with cloud computing; and attributes do not constitute meaning. To define cloud computing concretely, in a way that can be agreed upon by a majority, we must identify that common abstraction that binds the definition in a unique way.
One thing the NIST definition does well is aggregate the most common elements that people associate with cloud computing today. The characteristics, delivery models and deployment models offer up data that can be analyzed to find that common abstraction that will help foster the definition the industry needs to differentiate cloud computing from other elements of computing that are similar. We need to answer the looming question, “what makes cloud computing different?”
I will not be attempting to put forth my recommendation for a definition in this blog entry. Instead, I am merely attempting to get to a common abstraction can make sense of why these characteristics, delivery models and deployment models make sense together.
For example, without my discovery of a common abstraction, I questioned why Software-as-a-Service (SaaS) is a legitimate aspect of cloud computing. I can clearly see how Infrastructure-as-a-Service (IaaS) and Platform-as-a-Service (PaaS) relate to the essential characteristics as they have direct impact on providing elasticity and scalability. However, the relationship of SaaS to these other two seems contrived and vestigial; a left over from the “cloudy” (pun intended) formation of cloud computing. Indeed, without the common abstraction, SaaS is nothing more than the Application Service Provider (ASP) model renamed. Morevoer, SaaS clouds (yes, pun intended again) understanding since SaaS pertains more to “how a service is delivered” than “what is in the service offering”. Furthermore, the concept of SaaS doesn’t immediately translate well when our focus is on private over public cloud computing. That is, an application served up in a private cloud is typically not considered SaaS.
Of note, I would propose that if we’re moving toward IT service management and delivering IT-as-a-Service (ITaaS), then any applications served by up by IT, be it public or private, should be considered as SaaS. But, this is a debate for another day, the key focus here is to find an common abstraction that allows the definition of cloud computing to hold together regardless of the deployment model.
So, to cut to chase, for me, the common abstraction that allows the NIST proposed definition to stand as a legitimate grouping of attributes is scale. What is different about cloud computing compared to other computing models? Cloud computing focuses on making scalability work at very large scales as part of delivering computing within a service model context. IaaS provides scalability of compute, storage, memory and network resources; PaaS provides scalability of application infrastructure; and SaaS provides scalability of users and licensing.
For years we have been able to scale linearly, but without infinite funds, space and power, eventually, the ability for a single entity to scale will reach a point of saturation. At that point, to continue scaling would require assistance from external partners. However, without a framework and architecture to facilitate extending their own resources into that of their partner’s the entity would still be at a loss to achieve their goal and continue to scale. Cloud computing provides us with that architecture and framework to reach beyond our own limits for scalability.
Perhaps others can find other common abstraction that meet their needs in this regard, but for me, defining cloud computing requires us to answer what is the key differentiator between cloud computing and other computing models e.g. client/server, distributed object computing, mainframe, etc. For me, that key definition is the ability to eliminate the saturation points of scaling computing resources.
Grant Holliday explained using IntelliTrace for Azure without Visual Studio in a 2/20/2011 post:
IntelliTrace is a very useful tool for diagnosing applications on the Windows Azure platform. It is especially invaluable for diagnosing problems that occur during the startup of your roles. You might have seen these sorts of problems when you do a deployment and it gets stuck in the "Starting role" state and continuously reboots.
Publishing via Visual Studio
If you are building and deploying your application using Visual Studio, then it's fairly straightforward to enable IntelliTrace. When you right-click your Cloud Service project and choose Publish…, you're presented with a dialog where you can enable IntelliTrace.
Under the covers, Visual Studio will build the service, create the package, include the IntelliTrace runtime and change the startup task to start IntelliTrace instead of the Azure runtime. Once the intermediate package is created, the tools then go ahead and upload the package and deploy it to Azure.
For the official documentation see Debugging a Deployed Hosted Service with IntelliTrace and Visual Studio on MSDN.
Retrieving IntelliTrace Logs via Visual Studio
Once your role is deployed and IntelliTrace is running, it's fairly straightforward to retrieve and view the logs in Visual Studio. In the Server Explorer toolbar, open the Azure deployment, right-click a role instance and choose View IntelliTrace Logs for that instance.
Under the covers again, Visual Studio communicates with your role, restarts the IntelliTrace log file, downloads it to your machine and opens it. It's actually a little more complicated than that, which I'll cover later on.
Enabling IntelliTrace without Visual Studio
There are many cases where you may not want to build and deploy directly from Visual Studio. For example:
- You have a build server that builds your Cloud Service project into a package.
- You have an operations team that does deployments to Azure and developers don't have direct access to the Azure portal or API.
Visual Studio supports creating a Cloud Service package without deploying it on the Publish dialog. However, when you select that option, it disables the option to enable IntelliTrace.
With a small amount of digging in the C:\Program Files (x86)\MSBuild\Microsoft\Cloud Service\1.0\Visual Studio 10.0\Microsoft.CloudService.targets file, it's easy enough to work out how to create an IntelliTrace enabled package without Visual Studio. At the top of the file, these properties are defined with default values:
<!-- IntelliTrace related properties that should be overriden externally to enable IntelliTrace. -->
<PropertyGroup>
<EnableIntelliTrace Condition="'$(EnableIntelliTrace)' == ''">false</EnableIntelliTrace>
<IntelliTraceConnectionString Condition="'$(IntelliTraceConnectionString)' == ''">UseDevelopmentStorage=true</IntelliTraceConnectionString>
</PropertyGroup>
To enable the IntelliTrace collector in a role, all you need to do is set the EnableIntelliTrace property in MSBuild. For example, here's how to run the build from a command-line:
msbuild WindowsAzureProject1.ccproj /p:EnableIntelliTrace=true;
IntelliTraceConnectionString="BaseEndpoint=core.windows.net;
Protocol=https;AccountName=storageaccountname;AccountKey=storagekey"
/t:PublishOnce the build completes, you are left with a Cloud Service Package file (*.cspkg) and a Cloud Service Configuration file (*.cscfg). These include the IntelliTrace runtime files, a remote-control agent (which is described in the next section) and a startup task.
These package and configuration files can then be handed off to somebody to deploy via the Windows Azure Portal. The Windows Azure Service Management API can also be used from PowerShell or custom code to deploy. If an operations team is managing your Azure deployments, then this is exactly what you want.
How does Visual Studio retrieve logs? It uses IntelliTraceAgentHost.exe
If you look at the intermediate un-packaged (e.g. \bin\Debug\WindowsAzureProject1.csx\roles\WorkerRole1\plugins\IntelliTrace), you'll see that along with the IntelliTrace runtime, there is an additional application: IntelliTraceAgentHost.exe.
If you look at the RoleModel.xml file (e.g. \bin\Debug\WindowsAzureProject1.csx\roles\WorkerRole1\RoleModel.xml), you'll see that it's started as a foreground task along with the IntelliTrace startup task that starts the runtime.
<RoleModel xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:xsd="http://www.w3.org/2001/XMLSchema" name="WorkerRole1" version="1.3.11122.0038" xmlns="http://schemas.microsoft.com/ServiceHosting/2008/10/ServiceDefinition">
<Startup>
<Task commandLine="IntelliTraceStartupTask.exe" executionContext="elevated" relativePath="plugins\IntelliTrace">
<Environment>
<Variable name="IntelliTraceConnectionString" value="%@IntelliTraceConnectionString%" />
</Environment>
</Task>
<Task commandLine="IntelliTraceAgentHost.exe" executionContext="elevated" taskType="foreground" relativePath="plugins\IntelliTrace">
<Environment />
</Task>
</Startup>
This agent is running all the time and is the mechanism by which Visual Studio interacts with the IntelliTrace runtime that is running on a role. It listens on an Azure Queue and responds when somebody in Visual Studio selects View IntelliTrace Logs. The queue name is based upon a hash of the deployment id, role name and instance id of the deployed application.
Once the agent receives a command on the Queue (from somebody choosing View IntelliTrace Logs from Visual Studio), it pushes status messages onto a client response queue. The message looks something like this:
<IntelliTraceAgentRequest Id="7e7d6413d22644b38e3986da24e0c84b" TargetProcessId="0" ResponseQueueName="itraceresp9e221eabf27044d4baccf1a8b7ccf765" />
The stages of the request are:
- Pending
- CreatingSnapshot
- Uploading
- Completed
Because the IntelliTrace runtime is running and writing to the log file, the file is in use and cannot be just copied off disk. It turns out that within IntelliTrace.exe there is a hidden option called copy. When run with this option, IntelliTrace will stop logging to the current file and create a new one. This allows the old file to be read without restarting IntelliTrace and the application that is being traced.
Once the snapshot file has been created, the agent then uploads it to blob storage in the intellitrace container.
When the upload is complete, the agent then pushes a message on the queue which informs Visual Studio where to retrieve the file from. The message looks something like this:
<IntelliTraceAgentResponse RequestId="7e7d6413d22644b38e3986da24e0c84b " Status="Completed" PercentComplete="100">
<Error></Error>
<Logs>
<Log BlobName="320af8081d0143e694c5d885ab544ea7" ProcessName="WaIISHost" IsActive="true" />
<Log BlobName="b60c6aaeb2c445a7ab7b4fb7a99ea877" ProcessName="w3wp" IsActive="true" />
</Logs>
<Warnings />
</IntelliTraceAgentResponse>
Retrieving IntelliTrace Log Files without Visual Studio
Although the View IntelliTrace Logs option in the Server Explorer toolbox works great, it requires you to have the API management certificate and storage account keys for your service. In the scenario where you have a separate operations team that deploys and runs your service, it's unlikely that developers will have access to these keys. It's also unlikely that an operations person will feel comfortable opening Visual Studio and using it to retrieve the logs.
Fortunately, we can use the same API that Visual Studio uses and build our own application that triggers a snapshot and downloads the IntelliTrace file from blob storage.
- Download the source from the attachment at the end of this post.
- Unzip the source and open it in Visual Studio.
- For each project, add references to the following files
- C:\Program Files (x86)\Windows Azure Tools\1.3\Visual Studio 10.0\Microsoft.Cct.IntelliTrace.Client.dll
- C:\Program Files (x86)\Windows Azure Tools\1.3\Visual Studio 10.0\Microsoft.Cct.IntelliTrace.Common.dll
- C:\Program Files\Windows Azure SDK\v1.3\ref\Microsoft.WindowsAzure.StorageClient.dll
- For each project, modify app.config and configure the StorageAccountConnectionString.
IntelliTraceControl.exe
This console application determines the correct queue name and pushes a message on the queue to initiate an IntelliTrace log snapshot. Once the snapshot is uploaded to blob storage, it will return a GUID that represents the object in the blob container.
Usage: IntelliTraceControl.exe <deployment id> <role name> <instance id>
Example: IntelliTraceControl.exe 300f08dca40d468bbb57488359aa3991 WebRole1 0
IntelliTraceDownload.exe
Using the GUID returned from the previous app, this app will connect to blob storage and download the *.iTrace file to your TEMP directory.
Usage: IntelliTraceDownload.exe <guid>
Example: IntelliTraceDownload 84404febbde847348341c98b96e91a2b
Once you have retrieved the file, you can open it in Visual Studio for diagnosing problems.




<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
Joshua Hoffman wrote Cloud Computing: The Power of System Center in the Cloud for TechNet Magazine’s 2/2011 issue:
Windows Server 2008 R2 and System Center can accelerate your adoption of an IT-as-a-service model, which enables greater business agility, scalability and flexibility.
This concept of IT as a Service – encompassing the delivery of software, infrastructure, and platforms – offers organizations greater flexibility in leveraging the power of IT to meet their business needs than has been ever available before. However, often we think of cloud computing solely within the framework of the “public cloud.” That is to say, as a service purchased from a hosting provider, leveraging resources that are shared with other businesses, and accessible via public networks. But the benefits of cloud computing exist on a spectrum, and often they can be realized in a “private cloud” model; delivering the same levels of scalability and elasticity, along with usage-based cost structures that come with public cloud computing, but leveraging resources completely dedicated to the needs of your own organization.
In this article, we’ll talk about Microsoft solutions, powered by Windows Server 2008 R2 and System Center, that can help you simplify and accelerate your adoption of private cloud computing, and in doing so, realize the benefits of increased performance, improved reliability, enhanced business agility and cost efficiency that the cloud has to offer.
Infrastructure Foundations of a Private Cloud Solution
Microsoft Windows Server 2008 R2 with Hyper-V
The host servers are one of the critical components of a dynamic, virtual infrastructure. The host servers, running Windows Server 2008 R2 with Hyper-V technology, provide the foundation for running virtual machine guests and also provide the management interface between the guests and Microsoft System Center Virtual Machine Manager.
By consolidating multiple server roles into virtualized environments running on a single physical machine, you not only make more effective use of your hardware, but you also unlock the potential to realize the benefits of Infrastructure-as-a-Service, scaling your infrastructure quickly, adding virtual resources to take on new workloads or meet increased demand whenever necessary.
We’ll talk more later in this article about the process of migrating your existing infrastructure to a virtualized, private cloud environment. In the meantime, for detailed guidance on how to get started installing and configuring Microsoft Windows Server 2008 R2 Hyper-V, see the Hyper-V Getting Started Guide.
System Center Virtual Machine Manager 2008 R2
The primary tool for managing a virtual private cloud infrastructure will be System Center Virtual Machine Manager (VMM). System Center Virtual Machine Manager can scale across a wide range of virtual environments, ranging from a single server for smaller environments to a fully distributed enterprise environment that manages hundreds of hosts running thousands of virtual machines.
There are some key benefits of managing your virtualized infrastructure with VMM, including:
- Virtualization support for virtual machines running on Windows Server 2008 Hyper-V, Microsoft Virtual Server and VMware ESX
- End-to-end support for consolidating physical servers onto a virtual infrastructure
- Performance and Resource Optimization (PRO) for dynamic and responsive management of virtual infrastructure (requires System Center Operations Manager)
- Intelligent Placement of virtual workloads on the best-suited physical host servers
- A complete library to centrally manage all the building blocks of the virtual datacenter
System Center Virtual Machine Manager provides a critical layer of management and control that is key to realizing the efficiencies of a private cloud model. VMM not only provides a unified view of your entire virtualized infrastructure across multiple host platforms and myriad guest operating systems, but it also delivers a powerful toolset to facilitate onboarding new workloads quickly and easily. For example, the P2V conversion wizard included in VMM simplifies the process of converting existing physical workloads to virtualized machines. And in conjunction with System Center Operations Manager, the Performance and Resource Optimization feature provides dynamic reallocation of virtualized workloads to ensure that you’re getting the most out of your physical hardware resources.
For detailed guidance on how to get started installing and configuring System Center Virtual Machine Manager 2008 R2, see the Virtual Machine Manager Deployment Guide.
SCVMM 2008 R2 Self-Service Portal 2.0
Self-service functionality is a core component of delivering IT as a service. Using the Microsoft System Center Virtual Machine Manager Self-Service Portal 2.0, enterprise datacenters can provide Infrastructure-as-a-Service to business units within their own organization. The self-service portal provides a way for groups within a business to manage their own IT needs while the centralized infrastructure organization manages a pool of physical resources (servers, networks, and related hardware).
The self-service portal has four components:
- VMSSP website. A Web-based component that provides a user interface to the self-service portal. Through the VMMSSP website, infrastructure administrators can perform various tasks such as pooling infrastructure assets in the self-service portal, extending virtual machine actions, creating business unit and infrastructure requests, validating and approving requests, and provisioning virtual machines (using the self-service virtual machine provisioning feature). Administrators can also use the VMMSSP website to view information related to these tasks.
- VMMSSP database. A SQL Server database that stores information about configured assets, information related to business units and requests, and information about what has been provisioned to various business units. The database also stores the XML that encodes default and customized virtual machine actions and other information related to the configuration of the self-service portal.
- VMMSSP server. A Windows service that runs default and customized virtual machine actions that the user requests through the VMMSSP website.
- Reporting Dashboard. A reporting service built on Windows SharePoint Services 3.0 SP2. The Dashboard provides out-of-the-box reports and the ability to quickly produce custom reports.
Business units that enroll in the self-service portal system can use the portal to address a number of key functions. For example, through the use of standardized forms, business units can request new infrastructures or changes to existing infrastructure components. Each business unit can submit requests to the infrastructure administrator. The standardized forms ensure that the infrastructure administrator has all of the information needed to fulfill the requests without needing to repeatedly contact the business unit for details.
Individual business units can also be empowered to create and manage their own virtual machines. The VMMSSP website includes self-service provisioning forms that business units can use to create virtual machines. When a business unit submits a request to create virtual machines, the self-service portal starts an automated provisioning process creates the virtual machines more quickly and efficiently than a manual process. Each business unit can also designate its own administrators, advanced operators, and users, freeing IT resources for other tasks.
Infrastructure administrators can realize a number of benefits from the self-service portal as well. By simplifying the process of enrolling business units and defining their needs up front, on-boarding new workloads is no longer a manual task. The self-service portal collects information about a business unit and about the resources they want to set up. The process of validating and provisioning resources for business units is simplified as well. Datacenter administrators can use the self-service portal to assign resources based on business unit requests. Finally, changes to resources follow a request-and-approve life cycle, and the requests remain on record in the database, dramatically reducing the administrative burden of change control and management.
Migrating to the Cloud
Once the key components of your private cloud infrastructure are in place, you can begin evaluating existing workloads and migrating them to your virtualized environment. When identifying the best candidates for P2V conversion, consider converting these types of computers, in order of preference:
- Non business-critical underutilized computers. By starting with the least utilized computers that are not business critical, you can learn the P2V process with relatively low risk. Web servers may make good candidates.
- Computers with outdated or unsupported hardware that needs to be replaced.
- Computers with low utilization that are hosting less critical in-house applications.
- Computers with higher utilization that are hosting less critical applications.
- The remaining underutilized computers.
- In general, business-critical applications, such as e-mail servers and databases that are highly utilized, should only be virtualized to the Hyper-V platform in the Windows Server 2008 (64-bit) operating system.
As mentioned earlier, VMM simplifies Physical-to-Virtual (P2V) migrations by providing a task-based wizard to automate much of the conversion process. Additionally, since the P2V process is completely scriptable, you can initiate large-scale P2V conversions through the Windows PowerShell command line. See Converting Physical Computers to Virtual Machines in VMM for a complete walkthrough and step-by-step instructions.
Beyond the Foundations
Building your private cloud infrastructure extends beyond the foundations of a virtualized, self-service infrastructure. Though the ability to quickly scale application and service delivery through a flexible Infrastructure-as-a-Service model is a core component, delivering an end-to-end datacenter and private cloud solution goes much further. The ability to monitor, manage, and maintain the environment is critical to the effective delivery of IT services. Additionally, ensuring compliance and good governance, streamlining service delivery based on best practices, and achieving even greater efficiency through process automation are all key pillars of a cloud computing environment. Fortunately, System Center continues to deliver solutions to help you get there.
System Center Operations Manager delivers 360-degree operational insight across your entire infrastructure, whether it’s deployed on physical datacenter, private cloud, or public cloud resources. Providing seamless integration with Windows Server 2008 and Virtual Machine Manager, System Center Operations Manager helps you monitor the state and health of your computing resources regardless of how and where they’re deployed, helping you reduce the cost of IT management by identifying and potentially remediating issues before they interfere with service delivery.
Within a private cloud architecture, System Center Configuration Manger continues to provide the same degree of systems management and administration that IT professionals have come to expect. The ability to assess, deploy, update and configure resources using Configuration Manager persists as workloads are migrated into a cloud environment, giving administrators the necessary assurance that their resources are well maintained and protected.
System Center Service Manager provides built-in processes based on industry best practices for incident and problem resolution, change control, and asset lifecycle management. Service Manager provides integration across the entire System Center suite, including Operations Manager and Configuration Manager, to collect information and knowledge about infrastructure operations, and help administrators continuously meet and adapt to changing service level requirements. Together with Opalis, a new addition to the System Center suite, administrators can also automate IT processes for incident response, change and compliance, and service-lifecycle management.
Expanding into the Public Cloud
It’s entirely possible that even after building out your own private cloud environment, your business requirements may dictate the need for greater computing capacity than you would want to host or manage entirely on your own. Fortunately, Windows Azure can provide hosted, on-demand computing resources that can be seamlessly integrated with your existing private cloud infrastructure. Business applications can be deployed on the Windows Azure Platform, adding compute and storage resources that scale to meet demand. Using the Windows Azure VM Role, customized virtual machines – just like the ones you’ve built within your private cloud – can even be hosted on Windows Azure resources, providing additional scalability and capacity whenever it’s needed.
All of the solutions we’ve discussed in this article are capable of delivering IT as a Service across private cloud, public cloud and hybrid architectures. For example, the Windows Azure Application Monitoring Management Pack for System Center Operations Manager provides the same operational insight for applications hosted on the Windows Azure platform that administrators have come to expect from on-premises solutions. And System Center Service Manager and Opalis help deliver process automation, compliance, and SLA management with a service-optimized approach that spans your infrastructure.
What we’ve discussed here today is just the tip of the iceberg. We’ve shown how adopting an IT-as-a-Service model enables greater business agility, scalability and flexibility than has ever been possible before. For more information on how to get started, be sure to visit microsoft.com/privatecloud.
Joshua is a former editor of TechNet Magazine and now is a freelance author and consultant. He wrote four of the February edition’s seven articles.
Thomas Maurer continued his Hyper-V on Cisco UCS series with Cisco UCS Hyper-V Cluster – Install Blade Servers – Part 3 on 3/21/2011:
After you have created a new Hyper-V 2008 R2 ISO Installation image you can now start to install the Cisco Blade Servers. There are many ways (WDS, Virtual Media) how you can deploy the Hyper-V Image on your Blade Nodes. I will use the Virtual Media to install the Blade Notes in this guide.
- Start the KVM Console in the UCS Manager

- Attach the Hyper-V 2008 R2 Image to the Virtual Media

- Now do the standard Hyper-V installation. With the Image we created Hyper-V will have all the drivers you need.

- After the Installation is finished and you set the local administrator password. I change the IP Address of the Server and install the latest updates.





Related Posts:
- Cisco UCS Hyper-V Cluster – Create Hyper-V Image for Blade Servers – Part 2
- Cisco UCS Hyper-V Cluster – Part1
- Cisco UCS and Microsoft Hyper-V R2
- Cheatsheet: Configuring a Server Core installation #1
- Add Drivers to Windows Installation ISO
Thomas works as a System Engineer in Switzerland for a national provider.
Arnie Smith posted a link to a Building Your Cloud Plan video to the PrivateCloud blog on 2/21/2011:
“Want to get the best return on investment in the cloud? Before you decide which of your core business processes can benefit from cloud computing, you need to think about data requirements, security, and redundancy.
”This “InformationWeek” video is hosted by Mike Healey, president of Yeoman Technology Group and contributing editor for “InformationWeek”.
<Return to section navigation list>
Cloud Security and Governance
Lori MacVittie (@lmacvittie) asserted Recognizing the relationship between and subsequently addressing the three core operational risks in the data center will result in a stronger operational posture as an introduction to her Operational Risk Comprises More Than Just Security post of 2/21/2011 to F5’s DevCentral blog:
Risk is not a synonym for lack of security. Neither is managing risk a euphemism for information security. Risk – especially operational risk – compromises a lot more than just security.
In operational terms, the chance of loss is not just about data/information, but of availability. Of performance. Of customer perception. Of critical business functions. Of productivity. Operational risk is not just about security, it’s about the potential damage incurred by a loss of availability or performance as measured by the business. Downtime costs the business; both hard and soft costs are associated with downtime and the numbers can be staggering depending on the particular vertical industry in which a business may operate. But in all cases, regardless of industry, the end-result is the same: downtime and poor performance are risks that directly impact the bottom line.
Operational risk comprises concerns regarding:
- Performance
- Availability / reliability
- Security
These three concerns are intimately bound up in one another. For example, a denial of service attack left unaddressed and able to penetrate to the database tier in the data center can degrade performance which may impact availability – whether by directly causing an outage or through deterioration of performance such that systems are no longer able to meet service level agreements mandating specific response times. The danger in assuming operational risk is all about security is that it leads to a tunnel-vision view through which other factors that directly impact operational reliability may be obscured. The notion of operational risk is most often discussed as it relates to cloud computing , but it is only that cloud computing raises the components of operational risk to a visible level that puts the two hand-in-hand.
CONSISTENT REPETITION of SUCCESSFUL DEPLOYMENTS
When we talk about repeatable deployment processes and devops, it’s not the application deployment itself that we necessarily seek to make repeatable – although in cases where scaling processes may be automated that certainly aids in operational efficiency and addresses all facets of operational risk.
It’s the processes – the configuration and policy deployment – involving the underlying network and application network infrastructure that we seek to make repeatable, to avoid the inevitable introduction of errors and subsequently downtime due to human error. This is not to say that security is not part of that repeatable process because it is. It’s to say that it is only one piece of a much larger set of processes that must be orchestrated in such a way as to provide for consistent repetition of successful deployments that alleviates operational risk associated with the deployment of applications.
Human error by contractor Northrop Grumman Corp. was to blame for a computer system crash that idled many state government agencies for days in August, according to an external audit completed at Gov. Bob McDonnell's request.
The audit, by technology consulting firm Agilysis and released Tuesday, found that Northrop Grumman had not planned for an event such as the failure of a memory board, aggravating the failure. It also found that the data loss and the delay in restoration resulted from a failure to follow industry best practices.
At least two dozen agencies were affected by the late-August statewide crash of the Virginia Information Technologies Agency. The crash paralyzed the departments of Taxation and Motor Vehicles, leaving people unable to renew drivers licenses. The disruption also affected 13 percent of Virginia's executive branch file servers.
-- Audit: Contractor, Human Error Caused Va Outage (ABC News, February 2011)
There are myriad points along the application deployment path at which an error might be introduced. Failure to add the application node to the appropriate load balancing pool; failure to properly monitor the application for health and performance; failure to apply the appropriate security and/or network routing policies. A misstep or misconfiguration at any point in this process can result in downtime or poor performance, both of which are also operational risks. Virtualization and cloud computing can complexify this process by adding another layer of configuration and policies that need to be addressed, but even without these technologies the risk remains.
There are two sides to operational efficiency – the deployment/configuration side and the run-time side. During deployment it is configuration and integration that is the focus of efforts to improve efficiency. Leveraging devops and automation as a means to create a repeatable infrastructure deployment process is critical to achieving operational efficiency during deployment.
Achieving run-time operational efficiency often utilizes a subset of operational deployment processes, addressing the critical need to dynamically modify security policies and resource availability based on demand. Many of the same processes that enable a successful deployment can be – and should be – reused as a means to address changes in demand. Successfully leveraging repeatable sub-processes at run-time, dynamically, requires that operational folks – devops – takes a development-oriented approach to abstracting processes into discrete, repeatable functions. It requires recognition that some portions of the process are repeated both at deployment and run-time and then specifically ensuring that the sub-process is able to execute on its own such that it can be invoked as a separate, stand-alone process.
This efficiency allows IT to address operational risks associated with performance and availability by allowing IT to react more quickly to changes in demand that may impact performance or availability as well as failures internal to the architecture that may otherwise cause outages or poor performance which, in business stakeholder speak, can be interpreted as downtime.
RISK FACTOR: Repeatable deployment processes address operational risk by reducing possibility of downtime due to human error.
ADAPTION within CONTEXT
Performance and availability are operational concerns and failure to sustain acceptable levels of either incur real business loss in the form of lost productivity or in the case of transactional-oriented applications, revenue.
These operational risks are often addressed on a per-incident basis, with reactive solutions rather than proactive policies and processes. A proactive approach combines repeatable deployment processes to enable appropriate auto-scaling policies to combat the “flash crowd” syndrome that so often overwhelms unprepared sites along with a dynamic application delivery infrastructure capable of automatically adjusting delivery policies based on context to maintain consistent performance levels.
Downtime and slowdown can and will happen to all websites. However, sometimes the timing can be very bad, and a flower website having problems during business hours on Valentine’s Day, or even the days leading up to Valentine’s Day, is a prime example of bad timing.
In most cases this could likely have been avoided if the websites had been better prepared to handle the additional traffic. Instead, some of these sites have ended up losing sales and goodwill (slow websites tend to be quite a frustrating experience).
At run-time this includes not only auto-scaling, but appropriate load balancing and application request routing algorithms that leverage intelligent and context-aware health-monitoring implementations that enable a balance between availability and performance to be struck. This balance results in consistent performance and the maintaining of availability even as new resources are added and removed from the available “pool” from which responses are served. Whether these additional resources are culled from a cloud computing provider or an internal array of virtualized applications is not important; what is important is that the resources can be added and removed dynamically, on-demand, and their “health” monitored during usage to ensure the proper operational balance between performance and availability. By leveraging a context-aware application delivery infrastructure, organizations can address the operational risk of degrading performance or outright downtime by codifying operational policies that allow components to determine how to apply network and protocol-layer optimizations to meet expected operational goals.
A proactive approach has “side effect” benefits of shifting the burden of policy management from people to technology, resulting in a more efficient operational posture.
RISK FACTOR: Dynamically applying policies and making request routing decisions based on context addresses operational risk by improving performance and assuring availability.
Operational risk comprises much more than simply security and it’s important to remember that because all three primary components of operational risk – performance, availability and security – are very much bound up and tied together, like the three strands that come together to form a braid. And for the same reasons a braid is stronger than its composite strands, an operational strategy that addresses all three factors will be far superior to one in which each individual concern is treated as a stand-alone issue.



TechNet’s Larry Grothaus wrote Cloud Security with Windows Azure and Microsoft Global Foundation Services on 2/16/2011:
With the RSA conference occurring this week and cloud computing being such a high interest topic, the two worlds of cloud and security are receiving increased visibility in the trade press. The Cloud Security Alliance, which Microsoft is part of, also held their Cloud Security Alliance Summit this week, with it being co-located with RSA. I included a brief mention of the Summit earlier in my blog post about Vivek Kundra’s (CIO for the Whitehouse) participation in it discussing the “Federal Cloud Computing Strategy” paper.
I wanted to take a few minutes to share some of the information and a video available from Microsoft that discusses securing cloud environments, whether that is the public Windows Azure cloud or the Microsoft Global Foundation Services cloud offerings which hosts SaaS applications like SharePoint Online and Exchange Online.
If your company or you are considering creating and deploying cloud applications on Windows Azure, I’d recommend reviewing the Windows Azure Security Overview at this location. It covers the identity and access management model, the physical security features, as well as information on Microsoft operations personnel. The paper is intended for Technical Decision Makers considering the Windows Azure platform, as well as for developers looking to create applications to run on the environment.
The other area I wanted to touch on is Microsoft Global Foundation Services (GFS) which host cloud SaaS applications such as SharePoint Online and Exchange Online. There was exciting news back in December when the Microsoft cloud infrastructure received its Federal Information Security Management Act of 2002 (FISMA) Authorization to Operate (ATO). In the blog announcing this it states:
Meeting the requirements of FISMA is an important security requirement for US Federal agencies. The ATO was issued to Microsoft’s Global Foundation Services organization. It covers Microsoft’s cloud infrastructure that provides a trustworthy foundation for the company’s cloud services, including Exchange Online and SharePoint Online, which are currently in the FISMA certification and accreditation process.
There’s a good whitepaper titled “Information Security Management System for Microsoft Cloud Infrastructure” located here which covers online security and compliance of the GPS cloud infrastructure. This paper covers three key programs:
- Information Security Management Forum – A structured series of management meetings in specific categories for managing the ongoing operations of securing the cloud infrastructure.
- Risk Management Program – A sequence of processes for identifying, assessing, and treating information security risks and for enabling informed risk management decisions.
- Information Security Policy Program – A structure process for reviewing information security policy and for making changes when deemed necessary.
Finally, I found this brief video with Pete Boden, GM Online Services Security & Compliance at Microsoft, which discusses cloud computing and security. He talks about the need to shift the way that threats and risks are analyzed, as well as using standards and third parties to evaluate Microsoft’s security in our cloud datacenters. Check out the video for more information on securing and protecting your cloud computing assets here. [It’s embedded in the original version.]
Security is a critical factor when considering any IT decision, especially one that moves data out of on-site datacenters. Customers want a trusted company with proven security procedures and processes in place - Microsoft is committed to delivering on these needs for customers.
I hope you find the information useful. If you have any questions or feedback, please let me know in the comments section. If you’re looking for more information on what Microsoft has to offer businesses, check out the Cloud Power site here.
Joshua Hoffman wrote Windows Azure: Understanding Security Account Management in Windows Azure for TechNet Magazine’s 2/2011 issue:
Cloud computing is the closest thing to a major paradigm shift the IT industry has seen since the Internet itself. Faster bandwidth, cheaper storage, and robust virtualization technology have made the vision of Software as a Service a reality. The cloud delivers scalable, elastic, pay-as-you-go systems that meet the demands of the “do-more-with-less” generation.
While cloud computing relieves much of the infrastructure-management responsibility, security remains a critical concern. Security still requires the same degree of thought and attention as a physical datacenter. As applications and services migrate to cloud computing platforms such as Windows Azure, you must continue to play an active role in managing access, securing communications and ensuring the protection of critical business data.
There are several recommended approaches to security management for applications and services hosted on Windows Azure. There are also best practices for creating and managing administrative accounts, using certificates for authentication, and handling transitions when employees begin or terminate employment.
Account Ownership
The Microsoft Online Services Customer Portal (MOCP) handles all Windows Azure account management and billing. Through the MOCP, you can sign up for Windows Azure services, add additional services such as SQL Azure and create new instances of existing services (referred to as subscriptions).
Subscriptions are really the “billing boundary” for Windows Azure services. You’ll want to maintain separate subscriptions for each application (or collection of applications) that require a different billing structure. For example, you can create separate subscriptions with individual billing details if you have different departments all hosting applications on Windows Azure, but requiring separate billing.
You’ll need to identify an “account owner” account and a “service administrator” account for each subscription. Each of these accounts is associated with a Windows Live ID. The account owner is responsible for managing the subscription and billing through the MOCP. The account admin has to manage the technical aspects of the subscription, including the creation of hosted services, through the Windows Azure Management Portal.
Creating unique accounts for each of these roles is strongly recommended. These accounts should exist independent of individual accounts. In other words, don’t use your personal Windows Live ID as the account owner or service administrator account in organizational- or team-based settings. Instead, create unique accounts (perhaps using a naming scheme such as AO[unique ID]@live.com for account owners and AA[unique ID]@live.com for account administrators), with passwords that can be managed, and reset when necessary, at a centralized level.
Once you’ve created a subscription, your account administrators can manage hosted services through the Windows Azure Management Portal. They can access this using the service administrator account credentials. Once they’re logged in, they can start by creating a new Hosted Service (see Figure 1).
.jpg "Figure 1 Creating a new Hosted Service in Windows Azure")
Figure 1 Creating a new Hosted Service in Windows Azure
When creating a new Hosted Service, you’ll be prompted to specify a name for your service. You’ll also have to provide a URL prefix and deployment options. You can also choose a pre-existing package (.cspkg) and configuration file (.cscfg) from a development environment like Visual Studio (if you already have packaged applications).
From the Hosted Services Tab on the left side of the portal, select User Management. From here, you can add additional co-administrators to the subscription (see Figure 2). This gives you some additional flexibility in providing access to your hosted application administration.
.jpg "Figure 2 Adding new administrators to the subscription")
Figure 2 Adding new administrators to the subscription
Certificate Management
Certificates are a key component of Windows Azure security. There are two different kinds of certificates that play a role in securing your applications or services: service certificates and management certificates.
Service certificates are traditional SSL certificates used to secure endpoint communications. If you’ve ever configured SSL security for a Web site hosted on IIS for example, you’re familiar with this type of certificate. You need service certificates for production deployments issued by a trusted root certificate authority (CA). Therefore, you’ll need to purchase them from a third-party like VeriSign or DigiCert.
The list of trusted root CAs is maintained here (for Microsoft Windows) and here (for Microsoft Windows Phone 7). The name of your SSL certificate must match your Web site’s domain name. So you’ll need a DNS CNAME entry to map yourapp.cloudapp.net (the domain name for your application provided by Windows Azure) to www.yourcompany.com. For security purposes, you can’t buy a certificate mapping to the yourapp.cloudapp.net. Only Microsoft can issue certificates for cloudapp.net, though you can create your own self-signed certificate for development purposes.
Self-signed certificates should be used for testing purposes only, as they will not be trusted by end-user web browsers. You’ll notice during testing that your own browser will point out the non-trusted certificate, or that API calls made using Windows Communications Foundation (WCF) will fail. This does not mean that the certificate isn’t working, but that it isn’t trusted by a root CA. Within a browser, this is generally an accepted annoyance during testing, but certainly not an experience you want your end-users to have.
In order to run testing with API calls, you’ll need to add code to bypass certificate validation, or add the self-signed service certificate’s root CA certificate to the Trusted Root Certification Authorities certificate store using either the Certificate Management MMC, batch commands, or via code. Microsoft’s David Hardin has written more on this issue on his blog.
You’ll need to provide Windows Azure service certificates in the Personal Information Exchange (.pfx) format. To create your own self-signed service certificate with “password” as the placeholder password (you can change this in the final command to suit your preferences), open a Visual Studio command prompt and execute the following commands:
Copy Code
makecert -r -pe -n "CN=yourapp.cloudapp.net" -b 01/01/2000 -e 01/01/2036 -eku 1.3.6.1.5.5.7.3.1 -ss my -sky exchange -sp "Microsoft RSA SChannel Cryptographic Provider" -sy 12 -sv SSLDevCert.pvk SSLDevCert.cer del SSLDevCert.pfx pvk2pfx -pvk SSLDevCert.pvk -spc SSLDevCert.cer -pfx SSLDevCert.pfx -po passwordYou can upload SSL service certificates from the Hosted Services tab of the Windows Azure Management Portal by clicking Add Certificate and specifying the password (see Figure 3).
.jpg "Figure 3 Adding a service certificate in Windows Azure")
Figure 3 Adding a service certificate in Windows Azure
Management certificates are the other type of certificate used by Windows Azure. The Windows Azure Tools for Microsoft Visual Studio use management certificates to authenticate developers for your Windows Azure deployment. The CSUpload command-line tool also uses management certificates to deploy virtual machine role images, as do Windows Azure Service Management REST API requests.
The Windows Azure Service Management Cmdlets use management certificates for Windows PowerShell. You can use the Windows Azure PowerShell cmdlets to easily execute and automate Windows Azure-based system deployment, configuration and management.
You must provide Windows Azure management certificates in X.509 (.cer) format. To create your own self-signed management certificates, open a Visual Studio command prompt and execute the following command:
Copy Code
makecert -r -pe -a sha1 -n "CN=Windows Azure Authentication Certificate" -ss my -len 2048 -sp "Microsoft Enhanced RSA and AES Cryptographic Provider" -sy 24 ManagementApiCert.cerUpload management certificates using the Windows Azure Management Platform by selecting Management Certificates from the left-hand panel, then choose Add Certificate (see Figure 4). For more information on creating your own certificates for Windows Azure, see the MSDN library article, “How to Create a Certificate for a Role.”
.jpg "Figure 4 Adding a management certificate in Windows Azure")
Figure 4 Adding a management certificate in Windows Azure
Employee Transitions
One of the primary advantages of a cloud computing solution is that it’s hosted off-premises by a third party. Right away, this provides a layer of physical redundancy from your own location. However, it also means that when an employee leaves your organization—whether voluntarily or not—it’s more difficult to restrict access to your resources.
As a result, it’s particularly important to follow some key steps whenever there’s a change affecting approved access to your cloud computing resources. The first step is to reset passwords for any service administrator accounts to which the former employee had access. If you have established unique and independent account owner and service administrator IDs that you can centrally manage, that will simplify this process.
If you’re unable to reset the password for the service administrator account, you can log in to the MOCP as the account owner. Update the account listed as the service administrator. You should also remove any accounts listed as co-administrators through the Windows Azure Management Portal.
The second step is to reissue any pertinent management certificates. These certificates provide a means of authentication to your hosted service through Visual Studio and Windows Azure APIs. Therefore, you can no longer trust these once an employee has terminated employment. Even if the employee’s work machine is left behind, they may have taken a copy of the certificate with them through other means.
To reissue management certificates, simply re-execute the command specified earlier and remove the old management certificates from the Windows Azure Management Portal. Upload the new management certificates and distribute them to all authorized employees. You only need to follow these steps for management certificates. You don’t need to reissue service certificates because they only provide encryption, not authentication.
Despite having your applications hosted in the cloud, you still have to be fully involved in their security architecture. (For additional resources on this topic, be sure to see the MSDN library page, Security Resources for Windows Azure.) Follow these best practices for both account and certificate management. This will help ensure that your organization can fully benefit from cloud computing, without compromising the safety and security of your critical business information.
Thanks to David Hardin of Microsoft IT and Daniel Odievich of the Microsoft Developer and Platform Evangelism Team, along with the partnership of the Security Talk Series for their assistance in the development of this article.
Joshua is a former editor of TechNet Magazine and now is a freelance author and consultant. He wrote four of the February edition’s seven articles.
ItPro.co.uk posted on 1/17/2011 Privacy in the cloud sponsored by Microsoft (missed when posted):
Moving to the cloud can bring many advantages such as reduced hardware costs, improved efficiency and better fault tolerance, but many still worry about privacy.
A new generation of technology is transforming the world of computing. Advances in Internet-based data storage, processing, and services—collectively known as “cloud computing”—have emerged to complement the traditional model of running software and storing data on personal devices or on-premises networks. Many familiar software programs, from email and word processing to spreadsheets, are now available as cloud services. Many of these applications have been offered over the Internet for years, so cloud computing might not feel particularly new to some users.
These advantages are leading governments, universities, and businesses of all sizes to move mission-critical services such as customer relationship management, enterprise resource planning, and financial data management into the cloud. At the same time, the unique attributes of cloud computing are raising important business and policy considerations regarding how individuals and organizations handle information and interact with their cloud provider.
In the traditional information technology (IT) model, an organization is accountable for all aspects of its data protection regime, from how it uses sensitive personal information to how it stores and protects such data stored on its own computers. Cloud computing changes the paradigm because information flows offsite to datacenters owned and managed by cloud providers.
Cloud customers remain ultimately responsible for controlling the use of the data and protecting the legal rights of individuals whose information they have gathered. But defining the allocation of responsibilities and obligations for security and privacy between cloud customers and cloud providers—and creating sufficient transparency about the allocation—is a new challenge. It is important for customers and their cloud providers to clearly understand their role and be able to communicate about compliance requirements and controls across the spectrum of cloud services.
Microsoft understands that strong privacy protections are essential to build the trust needed for cloud computing to reach its full potential. We invest in building secure and privacy-sensitive systems and datacenters that help protect individuals’ privacy, and we adhere to clear, responsible policies in our business practices—from software development through service delivery, operations, and support.

Click the link to read the full White Paper: View PDF
<Return to section navigation list>
Cloud Computing Events
Rackspace will present a CloudU Cloudonomics: The Economics of Cloud Computing Webinar featuring Ben Kepes, Bernard Gordon and Lew Morman on 3/24/2011 at 11:00 AM PST:


Download the Cloudonomics whitepaper (PDF) here.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Roman Irani reported Google Revs Its App Engine With Infrastructure Updates in a 2/21/2011 post to the Programmable Web blog:
Google continues to push away at improving its platform-as-a-service offering, the Google App Engine API. It has already seen two minor releases this year with the latest release bringing in much needed updates to the XMPP and Task Queue APIs. An earlier release in the year focused on the High Replication Datastore, that was clearly targeted to mission critical applications.
The announcement post [of 2/11/2011] highlights the main features available in the latest version. The release is available for both Python and Java.
The XMPP API is a key service available in the Google App Engine infrastructure to allow your application to send and receive messages from any XMPP-compliant messaging service, such as Google Talk. The key features added in 1.4.2 release are to do with Subscription and Presence notifications. Your Application can now get notified if a user signs in and out and when their status changes. Your application can also announce its presence details to the users by sending the application’s presence via the sendPresence() call. Optionally, this can include a status message.
The Task Queue API service allows for background processing by inserting tasks (web hooks) into a queue. App Engine will then execute them subject to some criteria. The Task Queue API enhancements include a programmatic way to delete your tasks. Additionally, the API now has a maximum execution rate of 100 tasks per minute and allowing an application to specify the maximum number of concurrent requests per queue.
The App Engine team has an updated roadmap for the product, too. Upcoming features include SSL for non-appspot.com domains, data store import/export tools and integration with the Google Storage API.
Related ProgrammableWeb Resources:
Google App Engine API Profile, 80 mashups.
Alex Popescu posted HBase Internals: Visualizing HBase Flushes And Compactions to his MyNoSQL blog on 2/21/2011:
HBase Internals: Visualizing HBase Flushes And Compactions:
Outerthought folks[1] have put together a great visual and technical explanation of HBase flushes and compaction for usual scenarios like insert, delete, multi-column families, multi-regions:
When something is written to HBase, it is first written to an in-memory store (memstore), once this memstore reaches a certain size, it is flushed to disk into a store file (everything is also written immediately to a log file for durability). The store files created on disk are immutable. Sometimes the store files are merged together, this is done by a process called compaction.
Just an example, the HBase basic compaction process:
Outerthought guys are producing the Lily CMS which is built on top of HBase.
Chris Czarnecki described Amazon AWS and Amazon EC2 in a 2/20/2011 post to the Knowledge Tree blog:
One of the questions that is often raised on the Learning Trees Cloud Computing course is what is the difference between Amazon AWS and Amazon EC2. Both words are widely used when describing Amazons Cloud Computing offerings, but often the difference is not clear. The aim of this post is to explain the differences.
Starting with Amazon Web Services (AWS), these are a set of remote computing services (Web Services) that together make up a computing cloud delivered, on demand over the Internet. There are a wide range of services provided, such as:
- Amazon Elastic Block Storage (EBS) providing block storage devices
- Amazon Relational Data Service (RDS) providing MySQL and Oracle databases
- Amazon Simple Email Service (SES) providing bulk email sending facilities
- Amazon Route 53 providing a scalable Domain Name System
The above list is just a small fragment of the total services that together enable an organisation to provision Infrastructure as a Service (IaaS) on demand from Amazon.
So where does Amazon EC2 fit in ? Amazon Elastic Compute Cloud (EC2) is one of the services provided by Amazon Web Services and provides access to server instances on demand as a service. EC2 is a core part of AWS providing the compute facility for organisations. Amazon provide various server images that users can provision as well as the ability for users to create their own virtual machine images for use on EC2.
So summarising, AWS is a set of services that form Amazons IaaS offering. These can be used individually or integrated to form a coherent whole. EC2 is one of the services that make up AWS – probably the most important one. If you would like to know more about AWS and EC2 and how they compare with offerings from other vendors, why not consider attending Learning Tree’s Cloud Computing course where we explain and contrast the Cloud Computing products from major vendors such as Amazon, Google and Microsoft.
The Unbreakable Cloud blog posted Riak EnterpriseDS from Basho: Another NoSQL Database for Cloud on 2/20/2011:
Riak, an open source and dynamo inspired NoSQL database. According to Basho Techonologies, Inc, the NoSQL database is very fault tolerant, highly scalable, highly available and can be replicated. In a distributed configuration, no single central master node. The developer has full control on how the fault tolerant can be configured in the cluster of nodes. All noSQL databases, by default, can run in an elastic cloud so Riak can run in the cloud.
Basho is also releasing an enterprise edition with the support which is called as riak EnterpriseDS. As the cluster expands, the storage expands but the throughput and the latency does not change when you use Riak.
Riak is a key-value store and the back end storage is called bitcask. It is a low latency and high throughput storage backend which interfaces with Riak. Riak can be used for varying uses including but not limited to:
- As a key/value store
- To store value of varying content types
- As a filesystem
- As a session-store
- To manage user-profiles
- To store caches
- To manage geographically-distributed data
Comcast is one of the clients using riak according to basho.com. To download a trial version, please click here: Download Riak
A video demo from Basho is here: Setting up a Three Node Riak Cluster from Basho Technologies on Vimeo
Klint Finley [pictured below] reported a NoSQL Benchmark Open-Sourced in a 2/13/2011 post to the ReadWriteHack blog:
Earlier this month Belgian computer science student Dory Thibault posted a slide deck with the surprising results of a benchmark comparing Cassandra, HBase, MongoDB and Riak. The benchmarks are a part of his mater's thesis, and the slides were difficult to interpret without the accompanying oral presentation.
Thibault has now open-sourced the benchmarks so that others can check his work. "I would like to say that all of this benchmark is an idea that is quite recent and I'm still working on it," Thibault writes. "That means that there could be bugs in my code, errors in my configuration of the various clusters and other kinds of problems."
Here's the [updated] presentation:
Comparing noSQL databases : benchmarkView more presentations from Thibault Dory.
<Return to section navigation list>

















0 comments:
Post a Comment