Windows Azure and Cloud Computing Posts for 2/4/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 2/6/2011 with new items marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database and Reporting
• Ken Lassesen (a.k.a. Dr. GUI, retired) reviewed Final Comments on “Microsoft SQL Azure: Enterprise Application Development”(2010) by PACKT on 2/5/2011:
This is my final comments on the book below (click to go to publisher site).
First, I’m likely a tough reviewer having been a professional technical writer for Microsoft since the mid 1990’s and still doing that occasionally. Second, I’m a pedagogue (ex-teacher for those that are vocabulary challenged) and tend to read stuff at several levels – including suitability for teaching or mentoring.
The first question is what type of book is this? This book will be a useful book on my bookshelf because it touches enough area in sufficient depth to serve as a cookbook for first recipes. The problem is that it try to span too many target audiences and as a result does not make it in any area well.
Is it a Cookbook?
The number of items covered and the crispness of the coverage suggests that it is. The problem is that if I compare it to the classic Cookbooks from O’Reilly, it is both too shallow and too sparse. It’s more a collection of recipes clipped from ‘Women’s Journal’ (or should I say, Microsoft articles and blog posts?). There is a place for that, because it has a linear structure that wandering across microsoft.com lacks.
Is it an Enterprise Book?
Definitely not – there was zero coverage of issues that would be of interest to a SQL Azure serious enterprise application. One key example: there is nothing about tuning indexes – and for SQL Azure that can be critical. I will give a simple example, this morning I tuned a single heavy used query that was looked like it should be run well, 4-6 indices on all of the tables involved etc. The Database Engine Tune Advisor did it magic and did a 94% improvement on it. For SQL Azure (because of billing) could mean the difference between a $1000/month billing and a $60/month billing. Wait a minute… would it be in Microsoft’s Interest to provide easy tools to do this… it would lose $940 of monthly revenue (just loose change)….
The simplest way to see the deficiency is to look at a book like APress’s
Pro SQL Server 2005 and see what is not touched upon. Looking at APress’s offering Pro SQL Azure, I see chapters such as:
- Designing for High Performance
- SQL Azure Design Considerations
- Performance Tuning
Those essential enterprise topics are missing. QED
Is it a “Learning SQL Azure” Book?
It likely comes closest to this but for the fact that there is very sparse guidance to the learner. The collection of recipes without guidance leaves may leave too many learners frustrated instead of assured by the last page.
Is it a VBNet, C# or is a PHP Book?
It tries to do all three resulting in a thick tomb that will only be partially read by most developers. Creating a tomb for each language would likely be a better approach so the book would have greater depth – however, the real issue is how much time a book title starting with “Microsoft SQL Azure” should spend in any specific language? IMHO less than 20% of the book/chapters, ideally 10-15%.
Is it worth buying?
If you are neither a beginner nor responsible for enterprise implementation on SQL Azure, I would say that it’s definitely worth considering. You will likely do a lot of skimming of content and then read carefully the sections that are relevant to your existing style. It may serve well as a stepping stone tomb but it’s useful life is likely to be short but it would likely pay for itself by the time savings it provides.
Next week, I will do a review of another one of PACKT’s books – stay tuned!

I believe Ken meant to say tome, not tomb (as in Grant’s tomb).
Claudio Caldato reported The IndexedDB Prototype Gets an Update in a 2/4/2011 post to the Interoperability @ Microsoft blog:
I'm happy to be able to give you an update today on the IndexedDB prototype, which we released late last year.
The version 1.0 prototype that we released in December was based on an editor's draft specification from November 2, 2010. I'm happy to announce that this new version includes some of the changes that were added to the specification since then, and which bring it in-line with the latest version of the spec that is available on the W3C web site. However, it is important to note that while this prototype is very close to the latest spec, it is not 100 percent compliant.
The protoype forms part of our HTML5 Labs Web site, a place where we prototype early and not yet fully stable drafts of specifications developed by the W3C and other standard organizations. These prototypes will help us have informed discussions with developer communities, and give implementation experience with the draft specifications that will generate feedback to improve the eventual standards. It also lets us give the community some visibility on those specifications we consider interesting from a scenario point of view, but which are still not at the stage where we can consider them ready for official product support.
The goal of IndexedDB is to introduce a relatively low-level API that allows applications to store data locally and retrieve it efficiently, even if there is a large amount of it. The API is low-level to keep it really simple and to enable higher-level libraries to be built in JavaScript and follow whatever patterns Web developers think are useful as things change over time.
Folks from various browser vendors have been working together on this for a while now, and Microsoft has been working closely with the teams at Mozilla, Google and other W3C members that are involved in this to design the API together.
If you notice that this prototype of IndexedDB behaves differently and doesn't work with code you have written, it may be due to some of the following changes:
- VERSION_CHANGE transaction as described in the spec is implemented except for one feature. The feature NOT implemented is the versionchange event to notify other open database connections, as in the specification. The workaround for this is to not launch two Internet Explorer tabs to open the same database.
- The createObjectStore() method of the asynchronous database object is now a synchronous operation as described in the specification. Also, this method can only be called from within the onsuccess() handler of the IDBVersionChangeRequest object returned by the setVersion() method. See the samples in the CodeSnippets folder for the exact syntax.
- The deleteObjectStore() method of the asynchronous database object can only be called from within the onsuccess() handler of the IDBVersionChangeRequest object returned by the setVersion() method. See the samples in CodeSnippets folder for examples.
- The transaction method of the asynchronous database object now accepts parameters as described in the specification. See the sample in the CodeSnippets folder for examples.
- The asynchronous transaction object now implements auto-commit. The Javascript code needs to have the close() method on the asynchronous database object for auto-commit to work. See the samples in the CodeSnippets folder for examples.
The goal of the prototypes is to enable early access to the API and get feedback from Web developers, as well as to keep it up to date with the latest changes in the specifications as they are published. But, since these are early days, remember that there is still time to change and adjust things as needed.
You can find out more about this experimental release and download the binaries from this archive, which contains the actual API implementation plus samples to get you started.
Claudio is Principal Program Manager, Interoperability Strategy Team.
For more details about IndexedDB, which is a wrapper around SQL Server Compact, see my Testing IndexedDB with the Trial Tool Web App and Microsoft Internet Explorer 8 or 9 Beta post of 1/7/2011, Testing IndexedDB with the SqlCeJsE40.dll COM Server and Microsoft Internet Explorer 8 or 9 Beta of 1/6/2011, and Testing IndexedDB with the Trial Tool Web App and Mozilla Firefox 4 Beta 8 (updated 1/6/2011).
The SQL Azure Team posted A Case Study: Kelly Street Digital on 2/3/2011:
In 2008, Glen Knowles founded Kelly Street Digital and created Campaign Taxi, an application available by subscription that helps customers track consumer interactions across multiple marketing campaigns. Campaign Taxi features an application programming interface (API) that customers can use to easily set up digital campaigns, add functionality to their websites, store consumer information in a single database, and present the data in reports. Kelly Street Digital uses both Windows Azure and SQL Azure as a foundation for their solution.
Kelly Street Digital used to run their solution on Amazon AWS until mid-2010. They switched to the Windows Azure platform after running a successful pilot. The company migrated the application in six short weeks with a single developer and can now deploy updates of their application in in minutes.
"With Windows Azure, you press a button to test the application in the staging environment," says Knowles. "Then you press another button to put the application into production in the cloud. It's seamless."
When Kelly Street Digital migrated from SQL Server to SQL Azure a developer wrote a single script that ported their data to SQL Azure. Since then, they use Windows Azure Blob storage to backup their SQL Azure data to the cloud, never experiencing any data loss since the move. The greatest benefit yet, Kelly Street Digital is now saving over $4,000 a month since migrating to the Windows Azure Platform.
Benefits:
- Decreased Costs
- Increased Speed
- Tightly integrated technologies
- Improved reliability
- Enhanced scalability
Software
- Windows Azure
- Microsoft SQL Azure
- Windows Azure Platform
- Microsoft Visual Studio 2010
- Microsoft Visual Studio Team Foundation Server 2010
- Microsoft .NET Framework
It's a great example of what partners of ours are doing to offer new capabilities to their customers with the cloud.
To read the entire case study and learn more, go here. Thanks!
<Return to section navigation list>
MarketPlace DataMarket and OData
• Xamlgeek (@thomasmartinsen) delivered a A guide to OData and Silverlight on 2/6/2011:
OData (Open Data Protocol) is a web protocol for querying and updating data build upon web technologies such as HTTP, AtomPub and JSON. OData can be used to expose and access data from a several types of data source like databases, file systems and websites.
OData can be exposed by a variety of technologies – first and foremost .NET but also Java and Ruby. On the client side OData can be accessed by .NET, Silverlight, WP7, JavaScript, PHP, Ruby and Objective-C just to mention some of them. This makes OData very attractive to solutions where data need to be accessed by several clients.
The scope
In this post I will show how to expose data from an existing data source and access the data in a Silverlight application. The data source contains meteorological data about beaches in Copenhagen, Denmark and is hosted in a SQL Azure database.
Expose data
To be able to expose some data I need to get the data from somewhere. I have created a WCF Service Application called “ODataDemo.Services”. In this project I have created a folder called “Models” and added an EF4 model called “BeachDB.edmx”. The model contains one table called “Beaches” and the Entity Container is called “Entities”. So far it’s all standard EF4.
In Visual Studio 2010 we have an item type called “WCF Data Service” that we can use to expose an OData feed with. I have added a new WCF Data Service called “BeachService.svc”. The service inherits from DataService being the main entry point for developing an ADO.NET Data Service. The DataService requires a type that defines the data service. In this case it’s the Entity Container named “Entities” that I specified in the EF4 model.
By default nobody can read the data I’m exposing through the service. I have to specify the access rules explicitly. If I browse to the service I will just get the title of the service.
In the method “InitializeService” I can specify the access rules. In this scenario I want to allow users to read all data.
If I browse to my service again I can see the collection called “beach” is available. If I browse to the collection (“/beach”) I will get a complete list of all beaches available in the data store (about 30 beaches).
I some cases you want to limit the access the data store. One way to do that is by defining some Query Interceptors. As the name tells we can intercept the queries and modify or limit the result set.
On a beach entity I have a property called “IsMarketPlace”. It indicates if the beach is public available or not. I have added a Query Interceptor called “OnQueryBeach” that will make sure that only the beaches marked with IsMarketPlace = true will be returned.
If I try to browse the list of beaches again I will see that the list is now on down to only two beaches as expected.
Access data
Next step is to read the exposed data in a Silverlight browser application. Therefore I have created a new Silverlight Application project called “ODataDemo.Client”.
In Visual Studio 2010 we can access the data from our OData feed by adding a Service Reference that will generate the entities exposed by the feed.
The proxy generated by the Service Reference will also create a DataServiceContext that we can use to run our queries against. In this scenario the DataServiceContext class is called “Entities” taken from the Entity Container.
With the DataServiceContext instantiated, a collection of beaches instantiated and a simple query I’m ready to load some data. When the data is loaded I set the ItemSource of a ListBox that I have added to the start page.
Security
In some scenarios it might not be enough to limit the users’ access to the data using a Query Interceptor and I need a way to identify the users calling my service.
There are several ways to implement authorization. What I will show is a really simplified way to implement authorization and is for demonstration purpose only!
First thing I need to do is to make sure that on every request I get to my service, I need to identify the user calling my service. In the constructor of my service I can subscribe to the ProcessingRequest event. It will fire whenever somebody is requesting the service.
In this case the user will get access if the Authenticate method returns true otherwise the user will get a 401 unauthorized exception. The implementation of Authenticate is really simple and is for demonstration purpose only!
If the header contains “Authorization” with a value of “z7sgeq9n” the user will get access. A real implementation would identify the user and retrieve the users’ roles. In the Query Interceptors I can differentiate the data being returned to the user based on the roles applied to the user.
I need to add the header to my Silverlight application as well. Otherwise I will just get an “Unauthorized exception”. I can add the header information as part of my DataServiceContext object.
With the header information in place I have implemented a simple authorization method to my OData feed.
Related links













• Jonathan McCracken posted WebCamp - Feb 5th - Wrap-Up on 2/6/2011:
First off thanks to everyone who came on Saturday to learn about ASP.NET MVC and OData. I had a really good time and got to meet some very interesting developers.
As promised I've uploaded my QuoteOMatic solution to my blog so you can download it here. I'm also attaching my cheat sheet for the session here.
Another round of thanks to Karl, Vinod, Cengiz, David, and Blake! Thanks for helping and organizing the day.
Hope to see you all out a the .NET User Group or maybe another WebCamp!
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
• The Windows Azure AppFabric Team announced Windows Azure AppFabric CTP February release – Breaking Changes announcement and scheduled maintenance on 2/4/2011:
The next update to the Windows Azure AppFabric LABS environment is scheduled for February 9, 2011 (Wednesday). Users will have NO access to the AppFabric LABS portal and services during the scheduled maintenance down time.
When:
- START: February 9, 2011, 10 am PST
- END: February 9, 2011, 6 pm PST
Impact Alert:
- The AppFabric LABS environment (Service Bus, Access Control, Caching, and portal) will be unavailable during this period. Additional impacts are described below.
Action Required:
- Cache SDK and the Cache service are being refreshed in this release. There are a few breaking changes in the new SDK. As part of this service upgrade existing caches will not be migrated and existing Service Namespaces will be deleted. We advise customers to download the new SDK, provision new cache namespaces endpoints on the portal, recompile their applications with the new SDK and redeploy their applications.
There will be no change or loss of accounts or Service Namespaces for the Service Bus or Access Control services.
Thank you for working in LABS and giving us valuable feedback. Once the update becomes available, we'll post the details via this blog.
Stay tuned for the upcoming LABS release!
David Chou [pictured below] reviewed Richard Seroter’s new Applied Architecture Patterns on the Microsoft Platform book on 2/4/2011:
Just saw a friend, Richard Seroter the “Architect Extraordinaire”, publish a new book from Packt – Applied Architecture Patterns on the Microsoft Platform; his second book after SOA Patterns with BizTalk Server 2009. Even though technical books usually don’t make it onto NY Times Best Sellers and that they usually don’t help the authors retire from their full-time jobs, putting one together and making it through the publishing process is still a very significant effort. Thus I just want to say, congrats Richard! :)
It’s not another one of those “what’s possible with cloud computing” books. The authors took a pragmatic approach to identify and describe today’s real-world architectural issues and patterns, from simple workflows, the requisite pub-sub, content-based routing, message broadcasting, etc., to complex event processing, master data synchronization, handling large data and burst Web traffic; and provided architectural considerations (including on-premises and cloud-based models) and options on how these commonly encountered patterns can be implemented with the components of the Microsoft enterprise platform.
Kudos to the authoring team!
Brian Loesgen wrote Facebook Friends: Facebook and Windows Azure on 2/4/2011:
Facebook has a half-billion users. You have an idea and want to make it available to those users. Problem is, what if it turns out your idea is good, goes viral, and the hordes come beating on your doors to get in?
The article below from Internet.com [by Alexandra Weber Morales] is about a great success story using Windows Azure with Facebook, and an SDK that’s available to get you jump started.
The CTP link is missing but Alik Levin’s Windows Azure AppFabric Access Control Service (ACS) v2 – Programmatically Adding Facebook as an Identity Provider Using Management Service post of 1/13/2011 provide most of the details.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• The Windows Azure Team posted Real World Windows Azure: Interview with Arthur Haddad, Development Lead and Architect at Esri on 2/4/2011:
As part of the Real World Windows Azure series, we talked to Arthur Haddad, Development Lead and Architect at Esri, about using the Windows Azure platform to deliver the company's cloud-based geospatial data service. Here's what he had to say:
MSDN: Tell us about Esri and the services you offer.
Haddad: Esri is a leading developer of Geographic Information System (GIS) technology, earning as high as a one-third share of the worldwide GIS software market. Governments and businesses in dozens of industries use our products to connect business, demographic, research, or environmental data with geographic data from multiple sources.
MSDN: What was the biggest challenge Esri faced prior to implementing the Windows Azure platform?
Haddad: Traditional GIS applications have required a significant investment in software, hardware and development because of their extensive ability for customization. We wanted to reach new markets by developing a lightweight offering that organizations could use to connect enterprise and spatial data, without having to invest in new on-premises infrastructure and staffing. In 2009, we introduced a software solution called MapIt that customers can deploy in their on-premises IT environment; we also wanted to develop a cloud-based version of MapIt.
MSDN: Describe the solution you built with the Windows Azure platform?
Haddad: We built the MapIt Spatial Data Service to work with the Windows Azure cloud services platform and Microsoft SQL Azure. MapIt connects to Windows Azure to prepare and serve data for viewing in a geographical context. Customers can upload map data to SQL Azure and geo-enable existing attribute data to prepare it for use in mapping applications. The MapIt Spatial Data Service connects to SQL Azure and provides a web service interface that allows mapping applications to access the spatial and attribute data that is stored in SQL Azure.
MSDN: What makes your solution unique?
Haddad: We developed the ArcGIS application programming interface (API) for the Microsoft Silverlight browser plug-in and Windows Presentation Foundation. Customers can use ArcGIS to build rich mapping applications with data in SQL Azure or use application solutions developed on Silverlight and integrated with Microsoft Office SharePoint Server 2007 or Microsoft SharePoint Server 2010. What's unique is that when customers deploy MapIt on Windows Azure, they can write a simple application that allows them to use GIS without having to be a GIS expert. It's mapping for everybody and extremely easy to employ.
Esri developed the ArcGIS API for Microsoft Silverlight and Windows Presentation Foundation. This application displays a map provided by Bing Maps, integrated with census data stored in SQL Azure and accessed using the MapIt Spatial Data Service.
MSDN: Have you reached new markets since implementing the Windows Azure platform?
Haddad: By introducing MapIt as a service offered through Windows Azure, we are opening channels with a whole range of new customers. We are reaching new markets among organizations that traditionally have not used GI, and expanding our relationships with customers who want to introduce GIS to other parts of their organization.
MSDN: What benefits have you seen since implementing the Windows Azure platform?
Haddad: One of the key benefits is that we've lowered the cost barrier for customers to adopt GIS technology. Customers can deploy the MapIt service in Windows Azure without having to configure and deploy new hardware and install software packages, which can take weeks or months and cost tens of thousands of dollars-not to mention the ongoing costs associated with IT maintenance, power, and data storage. Also, by taking advantage of Windows Azure, we are offering our customers new ways to deploy new services quickly.
Read the full story at: www.microsoft.com/casestudies/Case_Study_Detail.aspx?CaseStudyID=4000007771.
To read more Windows Azure customer success stories, visit: www.windowsazure.com/evidence.

David Pallman posted Announcing AzureSamples.com on 2/4/2011:
AzureSamples.com is a new web site designed to help you discover Windows Azure samples more readily. Finding samples for Azure has been challenging in the past: there are only a handful of samples in the Windows Azure SDK and the lion’s share of samples are dispersed out on the web, posted by various Microsoft groups and community members. There hasn’t been one place to go to for samples—until now. With AzureSamples.com you can easily find samples in a streamlined way.
Using AzureSamples.com is simple. The site is organized by programming language: C#, VB.NET, Java, PHP, and Everything Else. Within each area, you can filter the samples listed by category (platform service) and search text. Once you find a sample you want, click the blue and white link button at right to navigate to its online home.

We’d love to get as many samples listed as possible—and that's where you can help. If you've written a great Azure sample, or know of one we should be including in our listings, let us know. To get a sample listed, simply navigate to the Submit area of the site and submit information about the sample. We generally get submissions reviewed and listed within 24 hours.
We hope you'll check out AzureSamples.com and let us know how we can improve it.


<Return to section navigation list>
Visual Studio LightSwitch
• Arthur Vickers added Using DbContext in EF Feature CTP5 Part 10: Raw SQL Queries to his Entity Framework v4 CTP5 series on 2/4/2011:
Introduction
In December we released ADO.NET Entity Framework Feature Community Technology Preview 5 (CTP5). In addition to the Code First approach this CTP also contains a preview of a new API that provides a more productive surface for working with the Entity Framework. This API is based on the DbContext class and can be used with the Code First, Database First, and Model First approaches.
This is the tenth post of a twelve part series containing patterns and code fragments showing how features of the new API can be used. Part 1 of the series contains an overview of the topics covered together with a Code First model that is used in the code fragments of this post.
The posts in this series do not contain complete walkthroughs. If you haven’t used CTP5 before then you should read Part 1 of this series and also Code First Walkthrough or Model and Database First with DbContext before tackling this post.
Writing SQL queries for entities
The SqlQuery method on DbSet allows a raw SQL query to be written that will return entity instances. The returned objects will be tracked by the context just as they would be if there were returned by a LINQ query. For example:
using (var context = new UnicornsContext()) { var unicorns = context.Unicorns.SqlQuery(
"select * from Unicorns").ToList(); }Note that, just as for LINQ queries, the query is not executed until the results are enumerated—in the example above this is done with the call to ToList.
Care should be taken whenever raw SQL queries are written for two reasons. First, the query should be written to ensure that it only returns entities that are really of the requested type. For example, when using features such as inheritance it is easy to write a query that will create entities that are of the wrong CLR type.
Second, some types of raw SQL query expose potential security risks, especially around SQL injection attacks. Make sure that you use parameters in your query in the correct way to guard against such attacks.
Writing SQL queries for non-entity types
A SQL query returning instances of any type, including primitive types, can be created using the SqlQuery method on the DbDatabase class. For example:
using (var context = new UnicornsContext()) { var unicornNames = context.Database.SqlQuery<string>( "select Name from Unicorns").ToList(); }The results returned from SqlQuery on DbDatabase will never be tracked by the context even if the objects are instances of an entity type.
Sending raw commands to the database
Non-query commands can be sent to the database using the SqlCommand method on DbDatabase. For example:
using (var context = new UnicornsContext()) { context.Database.SqlCommand( "update Unicorns set Name = 'Franky' where Name = 'Beepy'"); }SqlCommand is sometimes used in a database initializer to perform additional configuration of the database (such as setting indexes) after it has been created by Code First.
Note that any changes made to data in the database using SqlCommand are opaque to the context until entities are loaded or reloaded from the database.
Summary
In this part of the series we looked at ways in which entities and other types can be queried from the database using raw SQL, and how raw non-query commands can be executed on the database.
As always we would love to hear any feedback you have by commenting on this blog post.
For support please use the Entity Framework Pre-Release Forum.
Arthur Vickers
Arthur Vickers continued his Entity Framework v4 CTP5 series with Using DbContext in EF Feature CTP5 Part 9: Optimistic Concurrency Patterns on 2/4/2011:
Introduction
In December we released ADO.NET Entity Framework Feature Community Technology Preview 5 (CTP5). In addition to the Code First approach this CTP also contains a preview of a new API that provides a more productive surface for working with the Entity Framework. This API is based on the DbContext class and can be used with the Code First, Database First, and Model First approaches.
This is the ninth post of a twelve part series containing patterns and code fragments showing how features of the new API can be used. Part 1 of the series contains an overview of the topics covered together with a Code First model that is used in the code fragments of this post.
The posts in this series do not contain complete walkthroughs. If you haven’t used CTP5 before then you should read Part 1 of this series and also Code First Walkthrough or Model and Database First with DbContext before tackling this post.
Optimistic concurrency
This post is not the appropriate place for a full discussion of optimistic concurrency. The sections below assume some knowledge of concurrency resolution and show patterns for common tasks. The basic idea behind optimistic concurrency is that you optimistically attempt to save your entity to the database in the hope that the data there has not changed since the entity was loaded. If it turns out that the data has changed then an exception is thrown and you must resolve the conflict before attempting to save again.
Many of these patterns make use of the topics discussed in the Part 5 of this series—Working with property values.
Resolving concurrency issues when you are using independent associations (where the foreign key is not mapped to a property in your entity) is much more difficult than when you are using foreign key associations. Therefore if you are going to do concurrency resolution in your application it is advised that you always map foreign keys into your entities. All the examples below assume that you are using foreign key associations.
A DbUpdateConcurrencyException is thrown by SaveChanges when an optimistic concurrency exception is detected while attempting to save an entity that uses foreign key associations.
Resolving optimistic concurrency exceptions with Reload
The Reload method can be used to overwrite the current values of the entity with the values now in the database. The entity is then typically given back to the user in some form and they must try to make their changes again and re-save. For example:
using (var context = new UnicornsContext()) { bool saveFailed; do { saveFailed = false; var unicorn = context.Unicorns.Find(1); unicorn.Name = "Franky"; try { context.SaveChanges(); } catch (DbUpdateConcurrencyException ex) { saveFailed = true; // Update the values of the entity that failed to save
// from the store ex.GetEntry(context).Reload(); } } while (saveFailed); }A good way to see this code working is to set a breakpoint on the SaveChanges call and then modify the unicorn with Id 1 in the database using another tool such as SQL Management Studio. You could also insert a line before SaveChanges to update the database directly using SqlCommand. For example:
context.Database.SqlCommand(
"update Unicorns set Name = 'Linqy' where Id = 1");The GetEntry method on DbUpdateConcurrencyException returns the DbEntityEntry for the entity that failed to update. An alternative for some situations might be to get entries for all entities that may need to be reloaded from the database and call reload for each of these.
Resolving optimistic concurrency exceptions as client wins
The example above that uses Reload is sometimes called database wins or store wins because the values in the entity are overwritten by values from the database. Sometimes you may wish to do the opposite and overwrite the values in the database with the values currently in the entity. This is sometimes called client wins and can be done by getting the current database values and setting them as the original values for the entity. (See Part 5 for information on current and original values.) For example:
using (var context = new UnicornsContext()) { bool saveFailed; var unicorn = context.Unicorns.Find(1); unicorn.Name = "Franky"; do { saveFailed = false; try { context.SaveChanges(); } catch (DbUpdateConcurrencyException ex) { saveFailed = true; // Update original values from the database var entry = ex.GetEntry(context); entry.OriginalValues.SetValues(entry.GetDatabaseValues()); } } while (saveFailed); }Custom resolution of optimistic concurrency exceptions
Sometimes you may want to combine the values currently in the database with the values currently in the entity. This usually requires some custom logic or user interaction. For example, you might present a form to the user containing the current values, the values in the database, and a default set of resolved values. The user would then edit the resolved values as necessary and it would be these resolved values that get saved to the database. This can be done using the DbPropertyValues objects returned from CurrentValues and GetDatabaseValues on the entity’s entry. For example:
using (var context = new UnicornsContext()) { bool saveFailed; var unicorn = context.Unicorns.Find(1); unicorn.Name = "Franky"; do { saveFailed = false; try { context.SaveChanges(); } catch (DbUpdateConcurrencyException ex) { saveFailed = true; // Get the current entity values and the values in the database var entry = ex.GetEntry(context); var currentValues = entry.CurrentValues; var databaseValues = entry.GetDatabaseValues(); // Choose an initial set of resolved values. In this case we // make the default be the values currently in the database. var resolvedValues = databaseValues.Clone(); // Have the user choose what the resolved values should be HaveUserResolveConcurrency(currentValues, databaseValues,
resolvedValues); // Update the original values with the database values and // the current values with whatever the user choose. entry.OriginalValues.SetValues(databaseValues); entry.CurrentValues.SetValues(resolvedValues); } } while (saveFailed); }The stub for HaveUserResolveConcurrency looks like this:
public void HaveUserResolveConcurrency(DbPropertyValues currentValues, DbPropertyValues databaseValues, DbPropertyValues resolvedValues) { // Show the current, database, and resolved values to the user and have // them edit the resolved values to get the correct resolution. }Custom resolution of optimistic concurrency exceptions using objects
The code above uses DbPropertyValues instances for passing around current, database, and resolved values. Sometimes it may be easier to use instances of your entity type for this. This can be done using the ToObject and SetValues methods of DbPropertyValues. For example:
using (var context = new UnicornsContext()) { bool saveFailed; var unicorn = context.Unicorns.Find(1); unicorn.Name = "Franky"; do { saveFailed = false; try { context.SaveChanges(); } catch (DbUpdateConcurrencyException ex) { saveFailed = true; // Get the current entity values and the values in the database // as instances of the entity type var entry = ex.GetEntry(context); var databaseValues = entry.GetDatabaseValues(); var databaseValuesAsUnicorn = (Unicorn)databaseValues.ToObject(); // Choose an initial set of resolved values. In this case we // make the default be the values currently in the database. var resolvedValuesAsUnicorn = (Unicorn)databaseValues.ToObject(); // Have the user choose what the resolved values should be HaveUserResolveConcurrency((Unicorn)entry.Entity, databaseValuesAsUnicorn, resolvedValuesAsUnicorn); // Update the original values with the database values and // the current values with whatever the user choose. entry.OriginalValues.SetValues(databaseValues); entry.CurrentValues.SetValues(resolvedValuesAsUnicorn); } } while (saveFailed); }The stub for HaveUserResolveConcurrency now looks like this:
public void HaveUserResolveConcurrency(Unicorn entity, Unicorn databaseValues, Unicorn resolvedValues) { // Show the current, database, and resolved values to the user and have // them update the resolved values to get the correct resolution. }Summary
In this part of the series we looked at various patterns for resolving optimistic concurrency exceptions, including database wins, client wins, and a hybrid approach in which the user chooses the resolved values.
As always we would love to hear any feedback you have by commenting on this blog post.
For support please use the Entity Framework Pre-Release Forum.
Arthur Vickers
Return to section navigation list>
Windows Azure Infrastructure

Making the switch from IPv4 to IPv6 is not a task anyone with any significant investment in infrastructure wants to undertake. The reliance on IP addresses of infrastructure to control, secure, route, and track everything from simple network housekeeping to complying with complex governmental regulations makes it difficult to simply “flick a switch” and move from the old form of addressing (IPv4) to the new (IPv6). This reliance is spread up and down the network stack, and spans not only infrastructure but the very processes that keep data centers running smoothly. Firewall rules, ACLs, scripts that automate mundane tasks, routing from layer 2 to layer 7, and application architecture are likely to communicate using IPv4 addresses. Clients, too, may not be ready depending on their age and operating system, which makes a simple “cut over” strategy impossible or, at best, fraught with the potential for techncial support and business challenges.
IT’S NOT JUST SIZE THAT MATTERS
The differences between IPv4 and IPv6 in addressing are probably the most visible and oft referenced change, as it is the length of the IPv6 address that dramatically expands the available pool of IP addresses and thus is of the most interest. IPv4 IP addresses are 32-bits long while IPv6 addresses are 128-bits long. But IPv6 addresses can (and do) interoperate with IPv4 addresses, through a variety of methods that allow IPv6 to carry along IPv4 addresses. This is achieved through the use of IPv4 mapped IPV6 addresses and IPv4 compatible IPv6 addresses. This allows IPv4 addresses to be represented in IPv6 addresses.

But the real disconnect between IPv4 and IPv6 is in the differences in their headers. It is these differences that cause IPv4 and IPv6 to be incompatible. An IPv4 packet header is a fixed length, 40 bytes long. An IPv6 packet header is variable length, and can be up to 60 bytes long. Traditional IP “options” are carried within the IPv4 header, while in IPv6 these options are appended after the header, allowing for more flexibility in extended options over time. These differences are core to the protocol and therefore core to the packet processing engines that drive most routers and switches. Unless network infrastructure is running what is known as a “dual stack”, i.e. two independent networking stacks that allow the processing and subsequent translation of the two protocols, the infrastructure cannot easily handle both IPv4 and IPv6 at the same time.
INVESTMENT and RISK of MIGRATION too HIGH
This makes the task of migrating a massive effort, one that most organizations have continued to put off even though the days of IPv4 address availability are dwindling.
Expert had estimated that public IPv4 addresses will be depleted by the year 2012 which makes it imperative that service providers, hosting companies, and cloud computing providers migrate sooner rather than later or risk being unable to provide services to customers. David Meyer of ZDNet brought this issue to the fore in “IPv4 addresses: Less than 10pc still available” noting that there is little impetus for organizations to make the switch from IPv4 to IPv6 despite continued depletion of IPv4 addresses:
IPv4 and IPv6 addresses are not compatible. Pawlik [NRO chairma] said it was technically feasible to make the two types of IP address talk to each other, but it would be best for companies and ISPs to switch to IPv6 as soon as possible, to keep networks stable and avoid complexity when IPv4 addresses run out.
…/p>
Pawlik also conceded that many businesses are putting off the switch to IPv6 because, even when all public IPv4 addresses have been allocated, they will continue to be able to allocate private IPv4 addresses internally. However, he stressed that anyone running public-facing websites will have to make their sites visible as IPv6 addresses, as their users will be on IPv6 addresses in the future.
The reality is that we’re running out of IPv4 address spaces a lot faster than that. Consider this more recent coverage (Jan 2011) that estimates all available IPv4 address blocks will be officially “gone” in early February 2011:
It's likely that this week or next, the central supplier of Internet Protocol version 4 (IPv4) addresses will dole out the last ones at the wholesale level. That will set the clock ticking for the moment in coming months when those addresses will all be snapped by corporate Web sites, Internet service providers, or other eventual owners.
And that means it's now a necessity, not a luxury, to rebuild the Net on a more modern foundation called IPv6.
Read more: http://news.cnet.com/8301-30685_3-20029721-264.html#ixzz1CFkxJGz4
The last 5 blocks of addresses “each with 16.8 million addresses”, were distributed to the regional registries earlier this week. It is expected such allotments will be depleted in six to nine months.” (Internet Runs out of addresses as devices grow – Boston.com)
It is the organizational reliance on IP addresses in the network and application infrastructure and how thoroughly permeated throughout configurations and even application logic IP addresses are that make Pawlik’s statement quite true. Because organizations can continue to leverage IPv4 internally – and thus make no changes to its internal architecture, infrastructure, and applications – it is unlikely they will feel pressure to migrate. The effort associated with the changes required to migrate along with the possible requirement to invest in solutions that support IPv6 make it financially difficult for many organizations to justify, especially given that they can technically continue to utilize IPv4 internally with very few ramifications.
But as Pawlik also points out, externally it is important to make that migration as more and more users are migrated off of IPv4 and onto IPv6 by service providers. The ramifications of not migrating public facing services to IPv6 is that eventually those services will be unreachable and unusable by customers, partners, and users who have made the move to IPv6.
HOW to EAT YOUR CAKE and HAVE it TOO
There are a variety of ways in which both IPv4 and IPv6 can be made “compatible” from a data center networking point of view.
Tunneling IPv6 via IPv4 to allow individual hosts on an IPv4 network to reach the IPv6 network is one way, but requires that routers are able to be configured to support such encapsulation. Hybrid networking stacks on hosts makes the utilization of IPv6 or IPv4 much simpler, but does not necessarily help routing IPv6 through an IPv4 network. Most methods effectively force configuration and potentially architectural changes to support a dual IP version environment, which for many organizations is exactly what they were trying to avoid in the first place: disruptive, expensive changes in the infrastructure.
There is a way to support IPv6 externally while making relatively no changes to the organizational network architecture. An IPv6 gateway can provide the
translation necessary to seamlessly support both IPv6 and IPv4. Employing an IPv6 gateway insulates organizations from making changes to internal networks and applications while supporting IPv6 clients and infrastructure externally.
The right IPv6-enabled solution can also help with migration internally. For example, an enabled application delivery controller like F5 BIG-IP LTM (Local Traffic Manager) can act as an IPv4 to IPv6 gateway, and vice-versa, by configuring a virtual server using one IP address version and pool members using the other version. This allows organizations to mix and match IP versions within their application infrastructure as they migrate on their own schedule toward a completely IPv6 network architecture, internally and externally.
For more complete data center enablement, deploying a gateway such as F5’s IPv6 Gateway Module can provide the translation necessary to enable the entire organization to communicate with IPv6 regardless of IP version utilized internally. A gateway translates between IP versions rather than leveraging tunneling or other techniques that can cause confusion to IP-version specific infrastructure and applications. Thus if an IPv6 client communicates with the gateway and the internal network is still completely IPv4, the gateway performs a full translation of the requests bi-directionally to ensure seamless interoperation. This allows organizations to continue utilizing their existing investments – including network management software and packaged applications that may be under the control of a third party and are not IPv6 aware yet – but publicly move to supporting IPv6.
Additionally, F5 BIG-IP Global Traffic Manager (GTM) handles IPv6 integration natively when answering AAAA (IPv6) DNS requests and includes a checkbox feature to reject IPv6 queries for Wide IPs that only have IPv4 addresses, which forces the client DNS resolver to re-request asking for the IPv4 address. This solves a common problem with deployment of dual stack IPv6 and IPv4 addressing. The operating systems try to query for an IPv6 address first and will hang or delay if they don’t get a rejection. GTM solves this problem by supporting both address schemes simultaneously.
THERE’S NO REASON LEFT NOT to SUPPORT IPv6
Literally, this is true because IPv4 addresses are nearly gone by the time you’ve read this post.
The urgency with which NRO chariman Pawlik speaks on the subject of IPv6 is real. There is an increasing number of users accessing the Web via mobile devices, and it is in the telco and service provider markets that we see the most momentum toward mass adoption of IPv6.
IDC also reported in its new Marketplace Model and Forecast report that more than a quarter of the world's population, or 1.6 billion people, used the Internet in 2009 on a PC, mobile phone, video-game console, or other device. By 2013, that number is expected to rise to 2.2 billion.
-- InformationWeek, “1 Billion Mobile Internet Devices Seen By 2013”
The rapid increase in mobile devices is also driving providers to adopt IPv6 as they build out their next generation networks to support a massive subscriber base. Unless organizations adopt a strategy that includes supporting IPv6 at least externally, it is likely that they will begin to experience fewer and fewer visitors and customers as more people worldwide adopt, albeit unknowingly, IPv6.
Supporting IPv6 can be a fairly simple exercise that incurs very little costs when compared to a complete architectural overhaul of the data center. There’s just no good reason to ignore the growing need, and about 2.2 billion good reasons to do something about it sooner rather than later.


Charles Babcock (asserted “It won't be enough to just move workloads into the cloud; it'll still be necessary to integrate with other apps residing there” in a preface to his Integration In The Cloud, The Sleeper Issue article for InformationWeek of 1/24/2011 (missed when published):
I'm beginning to think the unanswered question about cloud computing is integration. Sure it's easy to provision servers with a workload in the cloud, assign storage, even create an instant recovery system in a neighboring availability zone. But after that, what can you connect it to?
Integration was the problem in the previous cycle of computing. That was when everything was under one roof. What's to keep it from being an even bigger issue in the cloud era? Talend and Jitterbit may be part of the answer, since the cloud seems to like open source code, and the two of them have sustained a prolonged output of open source connectors and adapters. Still you need the expertise of working with all of those moving parts.
With data taking center stage in every organization, the ability to make sense and take action on that data is vital. Technology like Many Eyes will make that process more inviting.
It seems to me the cloud itself has to serve as part of the solution. It's not enough to merely duplicate everything we did inside the data center again outside in the cloud. That sounds so Sterling Commerce/ Progress Software/Iona-ish oriented. Oh, that's right, Progress acquired Iona three-years ago.
The workload in the cloud is going to have the same need to connect to a particular database (whether a standard relational system or a non-standard structure), to other applications, and to a multitude of data-generating sources. One way to describe the shortcomings of the current environment, however, is to imagine developing an application in the cloud that will need to connect to the mainframe. There are no mainframe services in the x86-based cloud. How are you going to test the application to know whether it really taps into the customer information control system (CICS)?
Discover how on-demand services can solve the ten biggest email management challenges that small businesses find daunting
John Michelsen, chief scientist of cloud development, virtualization, and testing software provider iTKO, says this is "the wires hanging out of the cloud" problem. You've developed software that you need to test, but you can't give it a realistic run because there's no equivalent to a mainframe system in the cloud environment. In a test, your application issues a call to the mainframe's information management system (IMS), but the wire over which the call went out is disconnected, hanging loose, unable to allow the software complete its function. Michelsen wouldn't be Michelsen if he wasn't sure he's got the answer, which is: specialized modules that can mimic mainframe functions in the cloud, allowing the application to function as if it were attached to the target system.
But I'm looking for a more generic solution. Why can't the cloud help solve the problem that arises as it starts to run more and more enterprise workloads?
Read more: Page 2: One Solution: The Internet As A Service Bus
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
Judith Horowitz asked and tried to answer What’s a private cloud anyway?
So in a perfect world all data centers be magically become clouds and the world is a better place. All kidding aside..I am tired of all of the hype. Let me put it this way. All data centers cannot and will not become private clouds– at least not for most typical companies. Let me tell you why I say this. There are some key principles of the cloud that I think are worth recounting:
- A cloud is designed to optimize and manage workloads for efficiency. Therefore repeatable and consistent workloads are most appropriate for the cloud.
- A cloud is intended to implement automation and virtualization so that users can add and subtract services and capacity based on demand.
- A cloud environment needs to be economically viable.
Why aren’t traditional data centers private clouds? What if a data center adds some self-service and virtualization? Is that enough? Probably not. A typical data center is a complex environment. It is not uncommon for a single data center to support five or six different operating systems, five or six different languages, four or five different hardware platforms and perhaps 20 or 30 applications of all sizes and shapes plus an unending number of tools to support the management and maintenance of that environment. In Cloud Computing for Dummies, written by the team at Hurwitz & Associates there is a considerable amount written about this issue. Given an environment like this it is almost impossible to achieve workload optimization. In addition, there are often line of business applications that are complicated, used by a few dozen employees, and are necessary to run the business. There is simply no economic rational for such applications to be moved to a cloud — public or private. The only alternative for such an application would be to outsource the application all together.
So what does belong in the private cloud? Application and business services that are consistent workloads that are designed for be used on demand by developers, employees, or partners. Many companies are becoming IT providers to their own employees, partners, customers and suppliers. These services are predictable and designed as well-defined components that can be optimized for elasticity. They can be used in different situations — for a single business situation to support a single customer or in a scenario that requires the business to support a huge partner network. Typically, these services can be designed to be used by a single operating system (typically Linux) that has been optimized to support these workloads. Many of the capabilities and tasks within this environment has been automated.
Could there be situations where an entire data center could be a private cloud? Sure, if an organization can plan well enough to limit the elements supported within the data center. I think this will happen with specialized companies that have the luxury of not supporting legacy. But for most organizations, reality is a lot messier.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Randy Bias (@randybias) recommended Conferences Past and Future: Cloud Frontier & Cloud Connect 2011 in a 2/3/2011 post to his CloudScaling blog:
As many of you know, we were exceptionally busy in 2010, building Infrastructure-as-a-Service (IaaS) clouds in South Korea. This culminated in the launch of KT’s public cloud and the Cloud Frontier 2011 conference in early December. I provided a keynote speech there that I thought was pretty good and brought together, for the first time in public, a lot of our philosophy.
The thinking behind this presentation will also deeply influence the upcoming keynote I have at Cloud Connect 2011 in early March. Cloud Connect is quickly becoming one of the best cloud computing conferences out there. Alistair Croll does a fantastic job of bringing in more than just the vendors and hype. The net result is a ‘frothy’ discussion that provides a lot of value.
Besides a keynote, I’m running the Private Cloud track and a number of other Cloudscalers will be presenting in other tracks including DevOps & Automation.
I strongly recommend you sign up for Cloud Connect. If you register by this Friday it’s $400 off!
We also have two free conference passes. We are trying to figure out some kind of non-cheesy way to give these out. Competitions, etc. seem a bit overdone. If you have any suggestions for how we could give these out to the readership here in a way that is congruous with our general blogging values (high content, high value), please comment below.
Meanwhile, embedded below is my keynote from Cloud Frontiers 2011 in early December of last year. It’s in three parts (after the break below) and is HD quality, so I recommend full screen.
See Randy’s post for the keynotes.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jeff Barr reported Amazon Web Services is beefing up its marketing department with an Open Positions on the AWS Marketing Team post of 2/4/2011:
We have just opened up some new positions on the AWS Marketing Team:
Product Marketing Manager (Seattle, Job 133399) - Support the ongoing marketing needs of product teams, ie. managing launches, reviewing launch content, driving product-specific campaigns, and managing Customer Advisory Board.
Marketing Communications Manager (Seattle, Job 133423) - Manage content development/approval/publication process, author website content, whitepapers, articles, and tools.Vertical Marketing Manager (Seattle, Job 133420) - Build an effective marketing plan to drive awareness and adoption of AWS in one of several key market verticals.
Enterprise Marketing Manager (Seattle, Job 116508) - Drive awareness and adoption of AWS among enterprise customers.
Marketing Manager, EMEA (UK or Luxembourg, Job 111357) - Drive the success of AWS among startups/small businesses and enterprise customers in Europe, the Middle East, and Africa (EMEA).
AWS Technical Evangelist (Seattle, Job 132578) - combine your unbridled enthusiasm and aptitude for technology with your unmatched creativity to build relationships with key industry influencers and technologists. Use your communication skills to share your knowledge with a diverse audience of customers, from students to CIOs.
You can apply through the links above, or you can simply email your resume to webservicesresumes@amazon.com. Be sure to include the job number if you apply via email.
• Mark Shuttleworth reviewed a Private cloud “in a box” from Dell in a 2/4/2011 post:
It just got a lot easier, and faster, to get a cloud in the house. Simply buy a starting cloud from Dell, and add to it as you need it to grow. You’ll get a reference architecture of Ubuntu Enterprise Cloud on Dell’s cloud-focused, dense PowerEdge C servers, fully supported, with professional services if you need to stretch it in your own unique direction and want a little help.
It’s taken a hard year of what El Reg rather accurately and poignantly described as futzing around, to make all of the pieces fit together smoothly so it can Just Work, Ubuntu style. Think of that as a year of futzing you don’t have to do yourself.
Eucalyptus, which powers this EC2-compatible private cloud solution, is flexible in how its configured. We wanted to make sure that flexibility was expressed in the solution, and that there’s a clean path forward as the UEC platform evolves, or Eucalyptus adds new capabilities. We know this is an area of rapid change and wanted to make sure early adopters can keep up with that over time. We put a lot of work into making Ubuntu upgrades smooth, and aimed for the same simplicity here. As Marten Mickos of Eucalyptus blogged, “One of the main ideas behind private clouds is to make computing more agile, and these Dell-UEC boxes take this agility benefit to the next level.”
I’d like to thank the team at Dell, Eucalyptus and Canonical that did all the futzing on your behalf. It’s a job very well done. Enjoy!
Mark is founder of the Ubuntu Project, a popular Linux-based operating system that is freely available worldwide for desktops and servers.
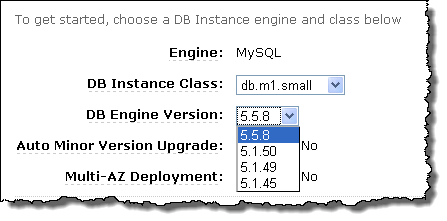
Jeff Barr (@jeffbarr) posted Amazon RDS: MySQL 5.5 Now Available to the Amazon Web Services blog on 2/4/2011:
We do not currently support MySQL 5.5's semi-synchronous replication, pluggable authentication, or proxy users. If these features would be of value to you, perhaps you could leave a note in the RDS Forum.
To create a new MySQL 5.5 DB Instance, just choose the DB Engine Version of 5.5.8 in the AWS Management Console. Because it is so easy to create a new DB Instance, you should have no problem testing your code for compatibility with this new version before using it in production scenarios.
Chris Czarnecki described Developing Java Applications for Google App Engine in a 2/4/2011 post to the Learning Tree blog:
For anybody building and deploying Java Web applications, whether internal business applications or public facing applications for general usage, hosting the application is a primary consideration. Google App Engine (GAE) provides a hosting environment that is potentially suitable for both types of applications. Before choosing GAE as the deployment environment a number of decisions, both technical and commercial must be made.
From a technical view, key questions include are what version of Java Standard Edition (JSE) is supported ?, is all of enterprise Java supported (JEE) ?, are there any special configuration files required ? and many others too. Business considerations include what is cost of the service, what is the support available, the reliability, vendor lock-in etc.
GAE runtime environment uses Java 6 so supports developing applications using Java 5 or 6. The runtime environment has some restrictions which enable it to provide scaling and reliability. A GAE application must not :
- Write to the filesystem- Google provides a datastore as an alternative
- Open a socket – Google provides a URLFetch service as an alternative
- Spawn a new thread
In addition to these high level restrictions then Google publish a white list of the available Java classes from Java SE that can be used. From enterprise Java GAE supports the full Servlet and JSP API’s enabling developers to write applications using Frameworks built on these technologies, such as Spring MVC, Struts etc.
Whilst initially appearing somewhat restrictive, GAE does provide a large number of features and facilities for developers to not only host but also build scalable Java Web applications. I will detail these in further posts. Understanding the limitations/restrictions of Cloud Computing providers is vital when considering their adoption as well as the definite benefits they can bring. If you would like to know more about GAE and other Cloud Computing providers such as Amazon EC2 and Azure, why not consider attending the Learning Tree Cloud Computing Course.
<Return to section navigation list>

















0 comments:
Post a Comment