Windows Azure and Cloud Computing Posts for 2/3/2011
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
William Vambenepe (@vanbenepe) asserted The API, the whole API and nothing but the API in a 2/3/2011 essay:
When programming against a remote service, do you like to be provided with a library (or service stub) or do you prefer “the API, the whole API, nothing but the API”?
A dedicated library (assuming it is compatible with your programming language of choice) is the simplest way to get invocations flowing. On the other hand, if you expect your client to last longer than one night of tinkering then you’re usually well-advised to resist making use of such a library in your code. Save yourself license issues, support issues, packaging issues and lifecycle issues. Also, decide for yourself what the right interaction model with the remote API is for your app.
One of the key motivations of SOAP was to prevent having to get stubs from the service provider. That remains an implicit design goals of the recent HTTP APIs (often called “RESTful”). You should be able to call the API directly from your application. If you use a library, e.g. an authentication library, it’s a third party library, not one provided by the service provider you are trying to connect to.
So are provider-provided (!) libraries always bad? Not necessarily, they can be a good learning/testing tool. Just don’t try to actually embed them in your app. Use them to generate queries on the wire that you can learn from. In that context, a nice feature of these libraries is the ability to write out the exact message that they put on the wire so you don’t have to intercept it yourself (especially if messages are encrypted on the wire). Even better if you can see the library code, but even as a black box they are a pretty useful way to clarify the more obscure parts of the API.
A few closing comments:
- In a way, this usage pattern is similar to a tool like the WLST Recorder in the WebLogic Administration Console. You perform the actions using the familiar environment of the Console, and you get back a set of WLST commands as a starting point for writing your script. When you execute your script, there is no functional dependency on the recorder, it’s a WLST script like any other.
- While we’re talking about downloadable libraries that are primarily used as a learning/testing tool, a test endpoint for the API would be nice too (either as part of the library or as a hosted service at a well-known URL). In the case of most social networks, you can create a dummy account for testing; but some other services can’t be tested in a way that is as harmless and inexpensive.
- This question of provider-supplied libraries is one of the reasons why I lament the use of the term “API” as it is currently prevalent. Call me old-fashioned, but to me the “API” is the programmatic interface (e.g. the Java interface) presented by the library. The on-the-wire contract is, in my world, called a service contract or a protocol. As in, the Twitter protocol, or the Amazon EC2 protocol, etc… But then again, I was also the last one to accept to use the stupid term of “Cloud Computing” instead of “Utility Computing”. Twitter conversations don’t offer the luxury of articulating such reticence so I’ve given up and now use “Cloud Computing” and “API” in the prevalent way.
[UPDATE: How timely! Seconds after publishing this entry I noticed a new trackback on a previous entry on this blog (Cloud APIs are like military parades). The trackback is an article from ProgrammableWeb, asking the exact same question I am addressing here: Should Cloud APIs Focus on Client Libraries More Than Endpoints?]
Related posts:
William’s point is well taken in Azure’s current StorageClient library.
Joe Giardino provided an Overview of Retry Policies in the Windows Azure Storage Client Library in a 2/2/2011 post to the Windows Azure Storage Team blog:
The RetryPolicies in the Storage Client Library are used to allow the user to customize the retry behavior when and exception occurs. There are a few key points when using RetryPolicies that users should take into consideration, the first is when they are evaluated, and the second is what the ideal behavior for your scenario is.
When the Storage Client Library processes an operation which results in an exception, this exception is classified internally as either “retryable” or “non-retryable”.
- “Non-retryable” exceptions are all 400 ( >=400 and <500) class exceptions (Bad gateway, Not Found, etc.) as well as 501 and 505.
- All other exceptions are “retryable”. This includes client side timeouts.
Once an operation is deemed retryable the Storage Client Library evaluates the RetryPolicy to see if the operation should be retried, and if so what amount of time it should backoff (sleep) before executing the next attempt. One thing to note is that if an operation fails the first two times and succeeds on the third the client will not see the exception as all previous exceptions will have been caught. If the operation results in an error on its last attempt is an exception then the last caught exception is rethrown to the client.
Also, please note that the timeout that is specified is applied to each attempt of a transaction; as such an operation with a timeout of 90 seconds can actually take 90 * (N+1) times longer where N is the number of retry attempts following the initial attempt.
Standard Retry Policies
There are three default RetryPolicies that ship with the Storage Client Library listed below. See http://msdn.microsoft.com/en-us/library/microsoft.windowsazure.storageclient.retrypolicies_members.aspx for full documentation
- RetryPolicies.NoRetry – No retry is used
- RetryPolicies.Retry – Retries N number of times with the same backoff between each attempt.
- RetryPolicies.RetryExponential (Default) – Retries N number of times with an exponentially increasing backoff between each attempt. Backoffs are randomized with +/- 20% delta to avoid numerous clients all retrying simultaneously. Additionally each backoff is between 3 and 90 seconds per attempt (RetryPolicies.DefaultMinBackoff, and RetryPolicies.DefaultMaxBackoff respectively) as such an operation can take longer than RetryPolicies.DefaultMaxBackoff. For example let’s say you are on a slow edge connection and you keep hitting a timeout error. The first retry will occur after ~ 3sec following the first failed attempt. The second will occur ~ 30 seconds following the first retry, and the third will occur roughly 90 seconds after that.
Creating a custom retry policy
In addition to using the standard retry polices detailed above you can construct a custom retry policy to fit your specific scenario. A good example of this is if you want to specify specific exceptions or results to retry for or to provide an alternate backoff algorithm.
The RetryPolicy is actually a delegate that when evaluated returns a Microsoft.WindowsAzure.StorageClient.ShouldRetry delegate. This syntax may be a bit unfamiliar for some users, however it provides a lightweight mechanism to construct state-full retry instances in controlled manner. When each operation begins it will evaluate the RetryPolicy which will cause the CLR to create a state object behind the scenes containing the parameters used to configure the policy.
Example 1: Simply linear retry policy
public static RetryPolicy LinearRetry(int retryCount, TimeSpan intervalBetweenRetries) { return () => { return (int currentRetryCount, Exception lastException, out TimeSpan retryInterval) => { // Do custom work here // Set backoff retryInterval = intervalBetweenRetries; // Decide if we should retry, return bool return currentRetryCount < retryCount; }; }; }The Highlighted blue code conforms to the Microsoft.WindowsAzure.StorageClient.RetryPolicy delegate type; that is a function that accepts no parameters and returs a Microsoft.WindowsAzure.StorageClient.ShouldRetry delegate.
The highlighted yellow code conforms to the signature for the Microsoft.WindowsAzure.StorageClient.ShouldRetry delegate and will contain the specifics of your implementation.
Once you have constructed a retry policy as above you can configure your client to use it via Cloud[Table/Blob/Queue].Client.RetryPolicy = LinearRetry(<retryCount, intervalBetweenRetries>).
Example 2: Complex retry policy which examines the last exception and does not retry on 502 errors
public static RetryPolicy CustomRetryPolicy(int retryCount, TimeSpan intervalBetweenRetries, List<HttpStatusCode> statusCodesToFail) { return () => { return (int currentRetryCount, Exception lastException, out TimeSpan retryInterval) => { retryInterval = intervalBetweenRetries; if (currentRetryCount >= retryCount) { // Retries exhausted, return false return false; } WebException we = lastException as WebException; if (we != null) { HttpWebResponse response = we.Response as HttpWebResponse; if (response == null && statusCodesToFail.Contains(response.StatusCode)) { // Found a status code to fail, return false return false; } } return currentRetryCount < retryCount; }; }; }Note the additional argument statusCodesToFail, which illustrates the point that you can pass in whatever additional data to the retry policy that you may require.
Example 3: A custom Exponential backoff retry policy
public static RetryPolicy RetryExponential(int retryCount, TimeSpan minBackoff, TimeSpan maxBackoff, TimeSpan deltaBackoff) { // Do any argument Pre-validation here, i.e. enforce max retry count etc. return () => { return (int currentRetryCount, Exception lastException, out TimeSpan retryInterval) => { if (currentRetryCount < retryCount) { Random r = new Random(); // Calculate Exponential backoff with +/- 20% tolerance int increment = (int)((Math.Pow(2, currentRetryCount) - 1) * r.Next((int)(deltaBackoff.TotalMilliseconds * 0.8), (int)(deltaBackoff.TotalMilliseconds * 1.2))); // Enforce backoff boundaries int timeToSleepMsec = (int)Math.Min(minBackoff.TotalMilliseconds + increment, maxBackoff.TotalMilliseconds); retryInterval = TimeSpan.FromMilliseconds(timeToSleepMsec); return true; } retryInterval = TimeSpan.Zero; return false; }; }; }In example 3 above we see code similar to the default exponential retry policy that is used by default by the Windows Azure Storage Client Library. Note the parameters minBackoff and maxBackoff. Essentially the policy will calculate a desired backoff and then enforce the min / max boundaries on it. For example, the default minimum and maximum backoffs are 3 and 90 seconds respectively that means regardless of the deltaBackoff or increase the policy will only yield a backoff time between 2 and 90 seconds.
Summary
We strongly recommend using the exponential backoff retry policy provided by default whenever possible in order to gracefully backoff the load to your account, especially if throttling was to occur due to going over the scalability targets posted here. You can set this manually by via [Client].RetryPolicy = RetryPolicies.RetryExponential(RetryPolicies.DefaultClientRetryCount, RetryPolicies.DefaultClientBackoff).
Generally speaking a high throughput application that will be making simultaneous requests and can absorb infrequent delays without adversely impacting user experience are recommended to use the exponential backoff strategy detailed above. However for user facing scenarios such as websites and UI you may wish to use a linear backoff in order to maintain a responsive user experience.
References
Avkash Chuahan (@avkashchauhan) described Windows Azure Storage (Blob, Table, and Queue) Throughput Analyzer Tool by Microsoft Research in a 2/2/2011 post:
Microsoft Research team created a very nice tool called “Azure Throughput Analyzer” to display upload and download throughput between your network and Azure datacenters when you are using Windows Azure Storage. You can use this tool if you are encountering performance problems with Azure storage.
1. If your Application on Windows Azure is accessing Windows Azure Storage then you will run this tool form Windows Azure VM
2. If you are accessing Windows Azure Storage from your office or some other place then you should run this tool from the same location
More info about the tool:
The Microsoft Research eXtreme Computing Group cloud-research engagement team supports researchers in the field who use Windows Azure to conduct their research. As part of this effort, we have built a desktop utility that measures the upload and download throughput achievable from your on-premise client machine to Azure cloud storage (blobs, tables and queue). The download contains the desktop utility and an accompanying user guide. You simply install this tool on your on-premise machine, select a data center for the evaluation, and enter the account details of any storage service created within it. The utility will perform a series of data-upload and -download tests using sample data and collect measurements of throughput, which are displayed at the end of the test, along with other statistics.
You can download the tool from the link below and give a try:
http://research.microsoft.com/en-us/downloads/5c8189b9-53aa-4d6a-a086-013d927e15a7/default.aspx
You can run this test with all 3 types of Windows Azure Storage:
- Windows Azure Blob Storage
- Windows Azure Queue Storage
- Windows Azure Table Storage
You can run test in following category:
- Large Page
- Large Block
- Medium Page
- Medium Block
- Small Page
- Small Block
- Custom Test
I decided to give a quick try using the following setup:
Test Type: Large Page
- BlobSizeinBytes: 104857600
- BlobType: Page
- ContainerPrefix largetestcontainer
- DataMeasurementUnit: Megabytes
- MaxRetries 5
- NumberOfBlogs 1
- NumberOfThreads: 1
- UniSizeInBytes: 4194304
The tools took about to 12 minutes finish the test and the result was as below:
Download Throughput Results:
- Download - Average Work Item Duration In Milliseconds: 3613.166664
- Download - End Time (UTC): 02/03/2011 02:22:13.3440
- Download - First Work Item Duration In Milliseconds: 3806.2177
- Download - Max Work Item Duration In Milliseconds: 4994.2857
- Download - Min Work Item Duration In Milliseconds: 2849.1629
- Download - Start Time (UTC): 02/03/2011 02:20:42.6898
- Download - Throughput (Megabytes/sec) 1.10309303304299
- Download - Total Data Transferred In Bytes: 104857600
- Download - Total Items Transferred: 1
- Download - Total Retries: 0
- Upload Throughput Results:
- Upload - Average Work Item Duration In Milliseconds: 15534.728536
- Upload - End Time (UTC): 02/03/2011 02:20:41.6618
- Upload - First Work Item Duration In Milliseconds: 13895.7948
- Upload - Max Work Item Duration In Milliseconds: 16562.9474
- Upload - Min Work Item Duration In Milliseconds: 13263.7586
- Upload - Start Time (UTC): 02/03/2011 02:14:12.9405
- Upload - Throughput (Megabytes/sec) 0.257253762738625
- Upload - Total Data Transferred In Bytes: 104857600
- Upload - Total Items Transferred: 1
- Upload - Total Retries: 0
Microsoft Research team created a very nice tool called “Azure Throughput Analyz” to display upload and download throughput between your network and Azure datacenters when you are using Windows Azure Storage. You can use this tool if you are encountering performance problems with Azure storage.
You should run this tool depend on how you are accessing the Windows Azure Storage as:
1. If your Application on Windows Azure is accessing Windows Azure Storage then you will run this tool form Windows Azure VM
2. If you are accessing Windows Azure Storage from your office or some other place then you should run this tool from the same location
More info about the tool:
The Microsoft Research eXtreme Computing Group cloud-research engagement team supports researchers in the field who use Windows Azure to conduct their research. As part of this effort, we have built a desktop utility that measures the upload and download throughput achievable from your on-premise client machine to Azure cloud storage (blobs, tables and queue). The download contains the desktop utility and an accompanying user guide. You simply install this tool on your on-premise machine, select a data center for the evaluation, and enter the account details of any storage service created within it. The utility will perform a series of data-upload and -download tests using sample data and collect measurements of throughput, which are displayed at the end of the test, along with other statistics.
You can download the tool from the link below and give a try:
http://research.microsoft.com/en-us/downloads/5c8189b9-53aa-4d6a-a086-013d927e15a7/default.aspx
You can run this test with all 3 types of Windows Azure Storage:
- Windows Azure Blob Storage
- Windows Azure Queue Storage
- Windows Azure Table Storage
You can run test in following category:
- Large Page
- Large Block
- Medium Page
- Medium Block
- Small Page
- Small Block
- Custom Test
I decided to give a quick try using the following setup:
Test Type: Large Page
- BlobSizeinBytes: 104857600
- BlobType: Page
- ContainerPrefix largetestcontainer
- DataMeasurementUnit: Megabytes
- MaxRetries 5
- NumberOfBlogs 1
- NumberOfThreads: 1
- UniSizeInBytes: 4194304
- The tools took about to 12 minutes finish the test and the result was as below:
- Download Throughput Results:
- Download - Average Work Item Duration In Milliseconds: 3613.166664
- Download - End Time (UTC): 02/03/2011 02:22:13.3440
- Download - First Work Item Duration In Milliseconds: 3806.2177
- Download - Max Work Item Duration In Milliseconds: 4994.2857
- Download - Min Work Item Duration In Milliseconds: 2849.1629
- Download - Start Time (UTC): 02/03/2011 02:20:42.6898
- Download - Throughput (Megabytes/sec) 1.10309303304299
- Download - Total Data Transferred In Bytes: 104857600
- Download - Total Items Transferred: 1
- Download - Total Retries: 0
- Upload Throughput Results:
- Upload - Average Work Item Duration In Milliseconds: 15534.728536
- Upload - End Time (UTC): 02/03/2011 02:20:41.6618
- Upload - First Work Item Duration In Milliseconds: 13895.7948
- Upload - Max Work Item Duration In Milliseconds: 16562.9474
- Upload - Min Work Item Duration In Milliseconds: 13263.7586
- Upload - Start Time (UTC): 02/03/2011 02:14:12.9405
- Upload - Throughput (Megabytes/sec) 0.257253762738625
- Upload - Total Data Transferred In Bytes: 104857600
- Upload - Total Items Transferred: 1
- Upload - Total Retries: 0

<Return to section navigation list>
SQL Azure Database and Reporting
Buck Woody (@buckwoody) acknowledged the lack of one in his Where is the SQL Azure Development Environment? post of 2/3/2010:
Recently I posted an entry explaining that you can develop in Windows Azure without having to connect to the main service on the Internet, using the Software Development Kit (SDK) which installs two emulators - one for compute and the other for storage. That brought up the question of the same kind of thing for SQL Azure.
The short answer is that there isn’t one. While we’ll make the development experience for all versions of SQL Server, including SQL Azure more easy to write against, you can simply treat it as another edition of SQL Server. For instance, many of us use the SQL Server Developer Edition - which in versions up to 2008 is actually the Enterprise Edition - to develop our code. We might write that code against all kinds of environments, from SQL Express through Enterprise Edition. We know which features work on a certain edition, what T-SQL it supports and so on, and develop accordingly. We then test on the actual platform to ensure the code runs as expected. You can simply fold SQL Azure into that same development process.
When you’re ready to deploy, if you’re using SQL Server Management Studio 2008 R2 or higher, you can script out the database when you’re done as a SQL Azure script (with change notifications where needed) by selecting the right “Engine Type” on the scripting panel:
(Thanks to David Robinson for pointing this out and my co-worker Rick Shahid for the screen-shot - saved me firing up a VM this morning!)
Will all this change? Will SSMS, “Data Dude” and other tools change to include SQL Azure? Well, I don’t have a specific roadmap for those tools, but we’re making big investments on Windows Azure and SQL Azure, so I can say that as time goes on, it will get easier. For now, make sure you know what features are and are not included in SQL Azure, and what T-SQL is supported. Here are a couple of references to help:
General Guidelines and Limitations: http://msdn.microsoft.com/en-us/library/ee336245.aspx
Transact-SQL Supported by SQL Azure: http://msdn.microsoft.com/en-us/library/ee336250.aspx
SQL Azure Learning Plan: http://blogs.msdn.com/b/buckwoody/archive/2010/12/13/windows-azure-learning-plan-sql-azure.aspx

Arshad Ali explained SQL Azure - Getting Started With Database Manager in a 2/3/2011 post to the MSSQLTips blog:
Problem
With SQL Azure, your server and databases are hosted in the cloud and you use SQL Server Management Studio (SSMS) to connect to your SQL Azure database. Do you really need to install the SQL Server client tools to be able to connect to SQL Azure database or is there any other way to connect from any machine without installing the SQL Server client tools (SQL Server Management Studio)?
Solution
The database manager is not a replacement of SQL Server Management Studio (SSMS) as it only supports basic database management tasks though it does not require the user to install SQL Server client tools on their machine to be able to connect and work on SQL Azure. This has been designed specifically for web developers/technology professionals who want a simple and straightforward way to connect to a SQL Azure database, develop, deploy and manage their data. All they need is a web browser with Silverlight and an internet connection.
Launching Database Manager
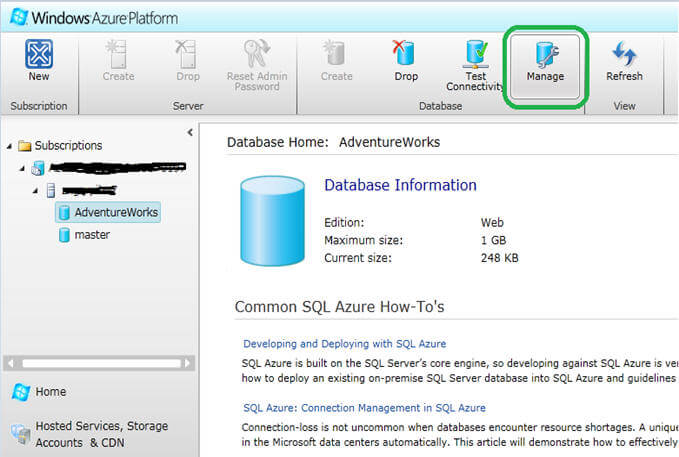
Although you can directly use the URL (https://manage-sgp.cloudapp.net/) to launch the Database Manager, the best practice is to launch database manager directly from the SQL Azure portal, instead of directly using the URL. This ensures that you are running on an instance of database manager that is closest to your SQL Azure datacenter (there are multiple instances of database manager co-located side by side with each SQL Azure datacenter). To launch it from the portal, connect to the SQL Azure portal, select the database on which you want to get connected and click on the Manage menu as shown below.
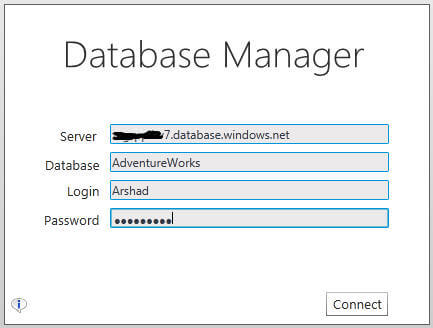
The first screen of the Database Manager is a place where you specify the SQL Azure server name, database name, login name and password. Please note if you are coming from the SQL Azure portal, the SQL Azure server name, database name and login name will automatically populated in the login screen and you simply need to enter the password and click on the Connect button.
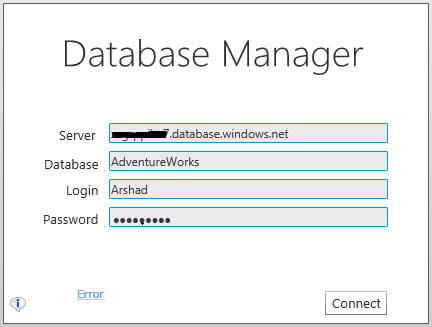
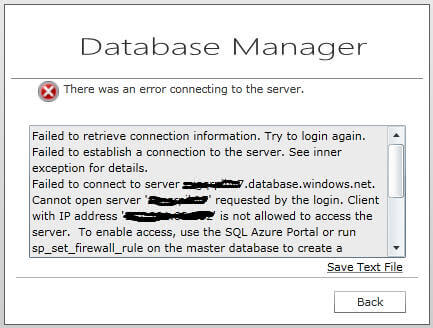
The moment you specify all the required information and click on the Connect button, the Database Manager will try to connect to the specified server and database. In case of any error, an error hyperlink appears on bottom left, to see the error click on the link (as shown in the next image). Click on the Back button to return to "Log on" screen, specify the correct information or resolve the issue and try again.
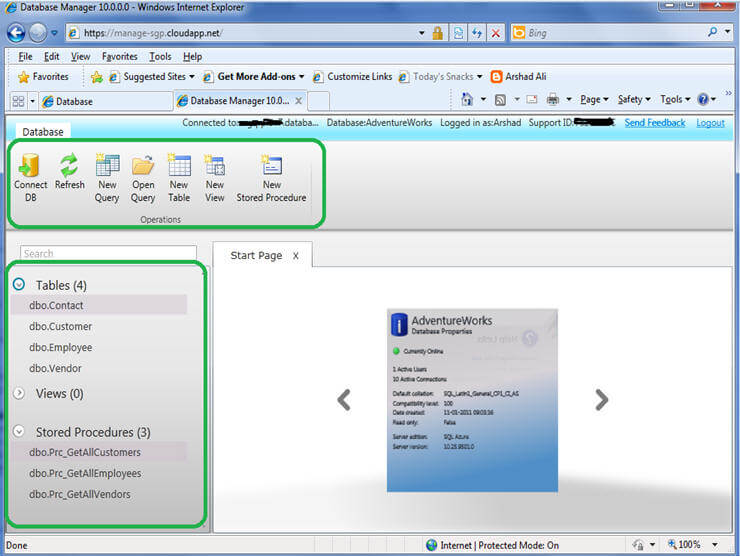
Once connected, on left side you will notice a tree view controller which has Tables, Views and Stored Procedures nodes. You can expand these nodes to see the respective objects under each node. On top you can see a contextual ribbon containing the menu for basic database management tasks. In the detail pane, you can browse different information about the database.
Working with Database Manager
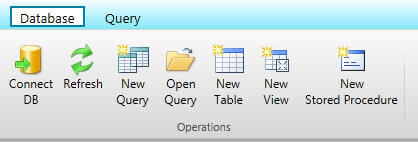
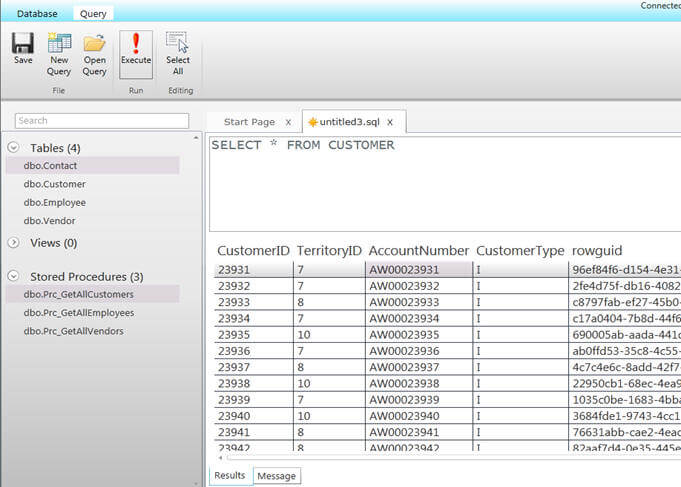
Once connected you will see the contextual ribbon on the top of the screen. For example as you can see two tabs below, the first (Database) tab has commands for general database work where the second (Query) tab has commands for general query related tasks. You can click on the New Query command which will open the query window in the detail pane, write your query and click on the Execute command to execute it. You can also click on the Save command to save your query to your local machine. Likewise if you have query file, you can open it by clicking on the Open Query command.
In SSMS we have Results and Message tabs when a query gets executed, here we also find the same tabs when you execute the query by clicking on the Execute command in the Query ribbon.
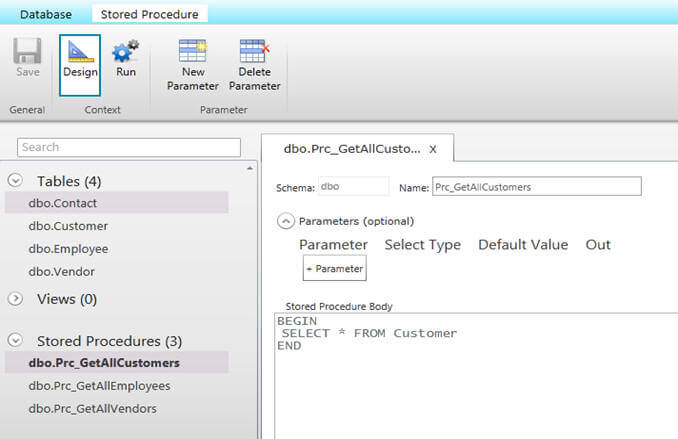
The Database Manager allows you to create and edit stored procedures and while doing this related commands appear in the Stored Procedure ribbon on the top. You can modify the parameter list, modify the body of the procedure and once you are done you can execute your procedure from here as well.
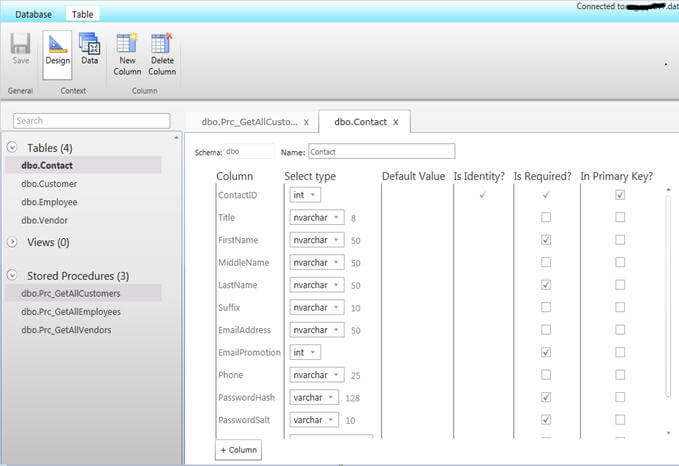
The Database Manager also allows you to create and modify tables and views. For example, as you can see below, I am modifying the Contact table and its related commands appear in the Table ribbon on the top. You can modify the columns, their data types, default values, define an identity, etc...
Notes
- The Database Manager is not intended for creating new databases it is used to manage existing SQL Azure databases.
- The best practice is to launch Database Manager directly from the SQL Azure portal, instead of directly using the URL. This ensures that you are running an instance of Database Manager that is closest to your SQL Azure datacenter (there are multiple instances of Database Manager co-located side by side with each SQL Azure datacenter).
Next Steps
- Review The Database Manager for SQL Azure article on msdn
- Review Known Issues in The Database Manager for SQL Azure article on msdn
- Review other SQL Azure related tips
Lim Guo Hong explained Connecting to SQL Azure with PHP in a 2/3/2011 post:
Credit to Luke Ng.
To start, I would like to first say that although many PHP developers usually recommend MySQL as the accompanying database for PHP, it is not difficult to interface PHP with other databases such as SQL Azure, Microsoft’s cloud-based relational database offering.
PHP connects with SQL Azure in a similar manner as how it does with Microsoft SQL Server, ie through an interface known as the Open Database Connectivity (ODBC), which is actually the standard software interface for accessing databases. Each platform and database has its own implementation following the ODBC standard but for this tutorial, I’ll focus on PHP.
There are a few ways to connect your php site to MS SQL but the 2 main approaches are as shown in Figure 1.0.
1. Using the “php_mssql.dll” php extension requiring MS SQL Client Tools installed (Figure 1.0, right column).
2. Using the “sqlsrv” driver (“Microsoft Drivers for PHP for SQL Server”) requiring MS SQL Native Client installed (Figure 1.0, left column)

Figure 1.0I will be using the 2nd approach for this tutorial because it supports both PHP 5.2 and 5.3, unlike the 1st which is not available for PHP 5.3.
Microsoft Drivers for PHP for SQL Server
As of 1 February 2011, the latest version of the driver is version 2.0.1 (30 November 2010).
You can grab it from ">http://www.microsoft.com/downloads/en/details.aspx?FamilyID=80e44913-24b4-4113-8807-caae6cf2ca05
Once you have installed the drivers, you should see the following in the installation directory:

Figure 2.0We will be using the “php_sqlsrv_53_nts_vc9.dll” library for this tutorial.
• “php_sqlsrv” –> Driver name
• “53” –> PHP 5.3
• “nts” –> Non-thread safe (The PHP FastCGI Handler of IIS handles thread-safe operations for PHP, use the non-thread safe version to reduce performance issues)
• “vc9” –> Library compiled using VS 2008, use vc6 (VS 6) if PHP is running on Apache
Configure PHP
1. Copy “php_sqlsrv_53_nts_vc9.dll” into the “ext” folder of your php installation directory.
2. Edit the php.ini to include the library

Figure 3.0
Microsoft SQL Server 2008 R2 Native Client
In order for the PHP for SQL Server Drivers to work, the necessary SQL Server ODBC drivers must be installed on the web server.
The version of the ODBC driver needed for SQL Azure comes with the SQL Server 2008 R2 Native Client.
You can grab it from http://www.microsoft.com/downloads/en/details.aspx?FamilyID=ceb4346f-657f-4d28-83f5-aae0c5c83d52PHP Syntax
After all the preparation and configuration, here comes the actual thing -> Coding!
This tutorial showcases how to do simple CRUD (Create, Retrieve, Update, Delete) commands.
1. Connect to Database:$serverName = “servername.database.windows.net”;
$connInfo = array(“UID”=>”username@servername”,
“PWD”=>”password”,
“Database”=>”databasename”);
$conn = sqlsrv_connect($serverName, $connInfo);2. Insert data to Database (taking data from a html form text field):
$comment = $_POST["txtComment"];
$comm = “INSERT INTO commentsqlazure (commentContent) VALUES (?)”;
$stmt = sqlsrv_prepare($conn, $comm, array(&$comment));
$result = sqlsrv_execute($stmt);3. Update data in Database:
$Id = $_POST["txtUpdateId"];
$comment = $_POST["txtUpdateComment"];
$comm = “UPDATE commentsqlazure SET commentContent = ? WHERE id = ?”;
$stmt = sqlsrv_prepare($conn, $comm, array(&$comment, &$Id));
$result = sqlsrv_execute($stmt);4. Remove data from Database:
$Id = $_POST["txtRemoveId"];
$comm = “DELETE FROM commentsqlazure WHERE id = ?”;
$stmt = sqlsrv_prepare($conn, $comm, array(&$Id));
$result = sqlsrv_execute($stmt);5. Retrieve data from Database:
$comm = “SELECT id, commentContent FROM commentsqlazure”;
$stmt = sqlsrv_query($conn, $comm);
while($row = sqlsrv_fetch_array($stmt, SQLSRV_FETCH_ASSOC))
{
echo $row["id"].” “.$row["commentContent"].”
“;
}6. Close connection and release resources:
sqlsrv_free_stmt($stmt);
sqlsrv_close($conn);
<Return to section navigation list>
Marketplace DataMarket and OData
Paul Miller reported about Big Data and Zane Adam’s DataMarket sessions at O’Reilly Media’s Strata Conference 2011, Day 2 Keynotes in a 2/3/2011 post:
Day 2, and after yesterday’s tutorials the conference is really getting going.
Here’s a stream of consciousness from the morning’s keynotes at this sold-out event.
Conference chair Edd Dumbill is introducing things, talking about William Smith‘s nineteenth century map of geological strata in the British Isles, the rise of industrialisation, and the move to towns. Edd suggests that a similar set of inflections are happening today in the world of data; ‘the start of something big.’
“In the same way that the industrial revolution changed what it meant to be human, the data revolution is changing what it means to be alive.”
The first of this morning’s keynotes; Hilary Mason from link shortener bit.ly.
Data and the people who work with data; “The state of the data union is strong.” Data scientists have an identity – a place to rally around – with Strata.
We have accomplished much, begging, borrowing and stealing from lots of domains. We have the tools. We have the capacity to spin up infrastructure in the Cloud. We have the algorithms to explore data, and to learn from it.
The most important thing we have now that we didn’t have before… is momentum. People are paying attention.
There are still challenges though. Timeliness of data is an issue, especially in real-time. We need to develop systems that can do robust analysis against a moving stream of data. We need to be able to store data in ways that let us operate on it in real-time. Hadoop… amazing ‘because I can run a query and get the result back before I forget why I submitted the query in the first place.’ We need training. We need imagination, not more ad optimisation networks. We have a real opportunity to do something better.
Opportunities (expressed in context of bit.ly); Bit.ly gets lots of data from people shrinking web links. They learn a lot about people; what they like, what they want, what they’re doing. bit.ly also gets rich segmentation data; location, context, etc. bit.ly sees global data, for example clicks on bit.ly links from Egyptian domains.
Now that we have all this data, it offers a window on to the world. What can we do with it? Make the world a better place? What would you do with all of this data?
Next up, James Powell from Thomson Reuters to talk about privacy and behavioural data in B2B contexts. Thomson Reuters gathers large amounts of global data, and filters it for customers. Time and context key; 700,000 updates a second through financial systems, 5,000,000 documents per day served through Open Calais, etc. Thomson Reuters interested in ways to filter information better.
Need to think about B2B implications of behavioural data, especially as we sell/exchange increasing volumes of data with partners. Consumers reasonably comfortable with giving up some personal data in return for a ‘better’ product (Amazon recommendations, etc), that probably doesn’t scale to the enterprise. For example, Open Calais customers submitting large numbers of dummy queries to obfuscate what they’re really looking for…
Key problem that needs to be addressed is ambiguity; many systems in this space still rely upon implicit assumptions, whilst the enterprise is used to explicit contracts. Tension – or recipe for disaster?
Keys to success – need to treat behavioural data differently/better, and avoid the mistake of simply continuing consumer trends.
Next, Mark Madsen from Third Nature, talking about ‘the Mythology of Big Data.’ [Emphasis added.]
Lots of assumptions underlying conversations about Big Data. ‘Every technology carries within itself the seeds of its own destruction.’ Code is a commodity; things that a lot of people have built profitable careers around have started to move down-market. Libraries, packages, etc make it easier for third parties to stitch things together rather than start from scratch.
The central myth underlying Big Data that’s erupted over the past 18-24 months; the myth of the gold rush. Everyone wants to be a data scientist. But just like the gold rush, success takes capital. It takes corporate engagement, and infrastructure. The ‘myth tells us you can go it alone… and you can’t.’
1950s-60s – data as product. 1970s-80s – data as byproduct. 1990s-2000s – data as assset. 2010- data as substrate (data as the basis for competition). ‘The real data revolution is in business structure and processes and how the use information.’
Using Big Data; the point isn’t necessarily about ‘Big.’ Much valuable data inside an enterprise is only GB or TB in size. We get tied up in ‘big’ way too much. It’s not really about data either; it’s about applying data. Without an application, it’s trivia. [Emphasis added.]
Next, Amazon CTO Werner Vogels. An overview of how Amazon Web Services look at the data processing being done on their infrastructure by customers… Government, Finance, COmmerce, Pharma… all making use of tools. Plugging The Fourth Paradigm book from Microsoft Research (which is very good).
Vogels – big data is big data when your data sets become so large that you have to innovate to manage them. Customers view big data as collection and curation of data for competitive advantage… with the presumption that bigger is better. For recommendations etc, that is probably true.
There are a number of categories of data, where quality is far more important than quantity.
In the past, data tended to be collected to answer questions. Now, trend to collecting as much as possible before developing the questions you want answered, and the algorithms you will need to use for the analysis.
To do this, you should not be worried by data storage, data processing, etc – which is why you should embrace the scalable Cloud.
Data analysis pipeline; collect – store – organise – analyse – share.
AWS Import/Export – “you shouldn’t underestimate the bandwidth of a FedEx box.” Indeed.
“This is Day 1 for Cloud infrastructure.’
Next up, Microsoft’s Zane Adam talking about data marketplaces. Windows Azure DataMarket; Data as a Service, free or at cost. One stop shop for data (one of many one stop shops, unfortunately!) DataMarket is interesting… but this is far too much of a product pitch for the keynote track.
90 days since launch – 5,000+ subscriptions, 3 Million transactions to date. Given Microsoft’s presence and reach, aren’t those figures a bit low?
“There’s a lot of data out there… but it’s not all good.” A Data Marketplace gives customers access to good data. Does it? Do Microsoft vet every fact in a submitted data set? What would a single bad data set do to the marketplace’s brand recognition?
I wonder how many of the 3 million transactions were free.
Paul Miller reported on Pete Soderling and Pete Forde’s earlier Strata Conference 2010: Building and Pricing the Data Marketplace session at the O’Reilly Media event in a 2/2/2011 post:
Pete Soderling of Stratus Security and Pete Forde of BuzzData led a session on Building and Pricing the Data Marketplace.
Rough notes follow.
What’s the Data supply business now? What’s a Data Marketplace? How do we get from here to there?
Today, data is a $100Bn global market. But what is data, and why should we care? High value top-down data sets like stock feeds, but also ‘open source upstarts like us;’ excited by open data, hacking, Government data, and mashups. “Lots of people think data should be free… like music and movies.”
There is a huge opportunity for change. There hasn’t been real innovation “since Bloomberg came to town.”
Data products today tightly tied to a value chain, with defensible customers, rich UI, etc. Moving down the value chain, there are products that focus less on building a coherent offer; ‘messy’ data? Marketplace has tended to focus on high end, but opportunities for innovation and disruption throughout value chain.
Data distribution/delivery – do a Bloomberg, and sell a terminal? Do a Nielsen, and build a portal? Offer flat-file dumps by ftp? Offer a feed to large customers from your proprietary system? Or use one of the most highly advanced data distribution mechanisms of our time… and ship a disk in the mail.
Bloomberg… disrupted a business and created competitive advantage by acquiring, integrating and distributing data. But a lot of the data wasn’t proprietary at all… it was simply difficult to reach.
Challenges for current market/ opportunities for new entrants; current high value projects are highly inflexible. Lock-in and control? There are few pricing options for incumbent systems, and they struggle to react as the economics of supplying data alter.
Consumer data is a big opportunity – but we need to crack privacy first. [Pete Soderling]
What do you need to consider when acquiring a data set? Freshness/ currency. Accuracy. Integrity. Licensing. Format. Open Data today; mostly just lists of lists of data. But 10-15 companies working to build data marketplaces that go further.
But what is a Data Marketplace? Numerous definitions.
Data catalogue – like Infochimps. “Pretty cool.” An online mail order catalogue. Microsoft Azure’s solution is offering this sort of solution too. “Catalogue shopping is probably not the future of consuming data.”
Real-time feeds – like Factual, or Gnip… which is ‘seriously rad.’
A huge amount of what we think of as open data (sunlight, world bank, data.gov, etc) comes from a mandate to make data available… but they are really difficult to use.
‘Find it and graph the shit out of it;’ timetric, Iceland’s data marketplace, etc. Visualisation is often the point. But they’re not the sort of site you visit regularly in your data acquisition routine, says Forde.
FluidDB, Freebase et al – the solutions of ‘ambitious nerds.’ ‘Totally awesome,’ but ‘a bit too nerdy.’
Need to develop solutions that solve real problems, rather than developing things just because they’re cool.
So do we need a data marketplace at all? Lots of people think we don’t. Do people in the street need what we’ve got? Probably not. Is Open Data even valuable? “People add value to things that are technically free all the time.”
Maybe the brand is wrong – ‘Data Market’ is not the right concept with which to lead. Infrastructure for data is important, but maybe it doesn’t need a name and identity.
There’s a land grab going on as various entrants round up data and talent as quickly as possible. Maybe we should focus on rounding up some customers?
Lines between ‘open’ data and valuable market data blurring. But we need to get better at explaining why anyone should care. “Data is completely worthless without context.” “There’s an absence of discourse around the data sets themselves.”
Data collaboration hubs; BuzzData and Talis’ Kasabi. Conversation about and around data, in a comfortable environment. Brings people without deep data analysis/ technical skills into the conversation. “Without conversations around data, it never becomes human. It remains cold and alien.”
If you build it, will anyone come? Technical considerations; Data as a Service (DaaS). What is DaaS? It should deliver fresh data. That could mean real-time, but it wouldn’t have to. It just needs to be timely. If you have taken data offline, do you know where it’s from? Do you know when updates become available? Easy integration needs to move us away from proprietary solutions. REST-based apis good, or Microsoft’s ODATA spec. Use cases should become more flexible, supporting integration into a customer’s own chosen apps. But ‘the more flexible access you give to people, the more chance there is they won’t know what to do with it.’
DaaS delivery – how do we get data to people? APIs, downloads, vendor-backed data stores, and data marketplaces all remain options.
Delivery metrics are key; know who your customers are, what data they use, and how. Creates opportunities for pricing based on usage. You don’t always need to license access to the whole database…
Most importantly in a nascent market, pricing needs to remain flexible. “This world is changing fast.”
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
The Windows Azure AppFabric team explained its pricing structure in an MSDN Windows Azure AppFabric FAQ topic:
If you have questions about the Windows Azure AppFabric pricing structure, see the FAQ in the following section. You can also visit the Windows Azure Platform pricing FAQ for general Windows Azure pricing information.
FAQ
- Why do you price the AppFabric Service Bus in this way? What is this “Connection” pricing meter?
Windows Azure AppFabric provides secure connectivity as a service via the AppFabric Service Bus much as Windows Azure provides general-purpose computation and storage as a service. In fact, the AppFabric Service Bus runs directly on Windows Azure compute instances. Therefore, the pricing model for the AppFabric Service Bus is like compute and storage pricing. That is, you pay for connectivity resources as long as you are using them. In the case of the AppFabric Service Bus, the underlying resources that you use include parts of compute instance resources, storage resources, and networking resources.
Because Microsoft designed the AppFabric Service Bus for high efficiency and fluid scale, we can offer a pricing structure that reflects both resources in a single pricing meter that maps to your usage. This is called a “Connection,” which reflects the basic function of the AppFabric Service Bus: to connect two or more applications. To send data to or from the AppFabric Service Bus, whether it is a transactional message or a data stream, you need a connection to the AppFabric Service Bus. You can think of these connections as communication sessions between your application and the AppFabric Service Bus, which your application can “open” or “close” at any time. When you create applications that are connected to the AppFabric Service Bus, we charge you for each connection, instead of for the number of messages or the volume of data. These connections result from opening services, opening client channels, or making HTTP requests against the AppFabric Service Bus.
In most cases, a minimum of one connection will be needed for each device or application instance that connects to the AppFabric Service Bus. For example, if 20 devices each have one application that connects to the AppFabric Service Bus, then 20 connections would be required; if one device has ten applications that each connect to the AppFabric Service Bus, then 10 connections would be required. In certain cases, fewer or more connections may be required.
When your application becomes very active and makes heavier use of that connection, for example by sending a higher volume of messages, your price for that connection is the same (net of the associated data transfer). This per-connection pricing model helps you predict their monthly price effectively, while still giving you the flexibility to increase and decrease your usage as needed.
- How do I know how many AppFabric Service Bus connections I have?
- Your usage may fluctuate, with connections being opened and closed frequently during a given month. To allow for this pattern, we calculate the maximum number of open connections that you use during a given day. During each monthly billing period, we will charge for the average of that daily number, which amounts to a daily pro rata charge.
That means you do not have to pay for every connection that you create; you only pay for the maximum number of connections that were in simultaneous use on any given day during the billing period. It also means that if you increase your usage, the increased usage is charged on a daily pro rata basis; you will not be charged for the whole month at that increased usage level.
For example, a given client application may open and close a single connection many times during a day; this is especially likely if an HTTP binding is used. To the target system, this might appear to be separate, discrete connections, however to the customer this is a single intermittent connection. Charging based on simultaneous connection usage makes sure that you will not be billed multiple times for a single intermittent connection.
- What are some examples of what an AppFabric Service Bus bill would look like?
- Example 1: A composite application that connects an on-premise database to a cloud service uses two connections. In a given month, this customer could pay for both connections individually and the bill would be $7.98. If this customer believed that the number of connections might increase throughout the month, he or she could also opt for the greater predictability of a reserved pack of 5 connections. In this case, the bill would be $9.95 per month even if the number of connections increased from 2 all the way to 5.
Example 2: A second application uses the AppFabric Service Bus to connect a series of handheld devices to an on-premise database. In this case, there is a connection for the database and for the devices. If the customer used 8 connections in the first half of the month and 15 in the second half of the month, the bill could be one of three amounts. He or she could decide to pay on a pure consumption basis, where the bill would be $45.89 (see Note 1). He or she could buy a reserved pack of 25 connections for $49.75, which would create a more predictable price in case the number of connections increased further. Or he or she could buy a reserved pack of 5 connections and pay for any connections greater than this amount on a consumption basis for a total bill of $35.89 (see Note 2), which in this example leads to the lowest bill.
In each case there are no additional charges for payload, but customers would be responsible for ingress or egress charges at the Windows Azure platform rates. If customers use Windows Azure AppFabric Access Control to help secure their connections, they would also incur a charge according to the AppFabric Access Control pricing schedule.
Note
1: $3.99 per connection-month is $0.133 per connection-day. This example has (8 x 15) + (15 x 15) = 225 connection-days. $0.133 x 225 = $45.89.
2: A reserved pack of 5 connections is $9.95 per month. Connections greater than 5 are $0.133 per connection-day. This example has (3 x 15) + (10 x 15) = 195 connection-days beyond the reserved pack amount. ($0.133 x 195) + $9.95 = $35.89.
- Why do you charge in a different way for AppFabric Access Control than you do for AppFabric Service Bus?
- Although applications interact with AppFabric Access Control in a somewhat similar manner to how they interact with the AppFabric Service Bus, by sending and receiving messages, AppFabric Access Control has some fundamental differences in the way it is used. Most importantly, those connections are lightweight and short-lived. That means a single AppFabric Access Control token-processing endpoint can handle connections with many external applications that send token requests. Because of these factors, the primary resource usage corresponds to the processing of token requests: unpackaging and decrypting tokens, performing claims transformation against rules, repackaging and re-encrypting them to be returned to the requestor, and creating and modifying rules. We use the “ACS Transactions” meter to reflect the direct relationship between these transactional operations and resource usage.
- Why does an AppFabric Service Bus Multi-Connection Pack cost less on a per-connection basis than a single connection?
- When you decide to purchase a connection pack, you are in a sense “reserving” those connections. This enables Microsoft to plan ahead in order to provide these connections, before you need them. When many customers purchase connections in this manner, we can plan connection capacity much more efficiently, which significantly lowers the costs of providing those connections. For customers, the resulting benefit is a more predictable bill that is less subject to month-to-month fluctuations. Nevertheless, many customers will prefer the flexibility of purchasing connections on a pay-per-use basis. Customers who need both predictability and flexibility can combine a connection pack with standard pay-per-use connections in a single account. In that case, connections that exceed the purchased pack quantity will be charged at the individual pay-per-use rate, and only when the connection usage exceeds the purchased pack quantity.
- What is the technical definition of an AppFabric Service Bus connection? What actions will trigger a new connection to be counted?
- AppFabric Service Bus connections are opened against a AppFabric Service Bus endpoint (a URI in an AppFabric Service Bus domain) and become billable when an application performs one of the following actions:
- Opens a service on a AppFabric Service Bus endpoint (see Note 1).
- Opens a client channel (see Note 2) that connects to such a service (see Note 1).
- Creates or maintains a message buffer that listens on an AppFabric Service Bus endpoint (see Note 1).
- Makes an HTTP request to a message buffer or to any service opened on an AppFabric Service Bus endpoint (see Note 3).
1: Billable until closed, deleted, or expired, as appropriate.
2: Includes NetOnewayRelay, NetEventRelay and NetTcpRelay.
3: Includes retrieval (Retrieve, Peeklock, Delete, Unlock) and insertion (Enqueue). The first request to retrieve a message from an existing message buffer is free.
For billing purposes, connections are measured and recorded in 5-minute intervals. The average number of open connections during each interval is recorded. This is to protect you against excessive charges for brief increases in open connections. Therefore, if connections are open for only a short time throughout an interval, for example, 10 seconds, you will not be severely affected.
Special considerations for direct connections: should the AppFabric Service Bus be configured to try a direct socket connection between client and service endpoints, there is no charge for connections after this kind of connection has been established. Note that connections are billable both before the direct connection is made, and if the direct socket connection fails and data again flows through the AppFabric Service Bus.
- Can I “stack” my AppFabric Service Bus purchase? Can I change the size of the pack that I buy?
- You can purchase as many pay-per-use individual connections as you like during any billing period, subject to system quotas and credit limits. You can also purchase up to one connection pack per solution per billing period. If you decide that a larger or smaller pack is needed during a billing period, you can select a different pack size and the difference in price will be assessed on a pro-rated basis. You cannot change the pack size for a given service namespace more than once every seven (7) days. You cannot combine multiple connection packs in a single service namespace.
- What happened to “Message Operations” for the AppFabric Service Bus? Was there something wrong with that pricing model?
- The reason for this change was to make the pricing meter simpler for customers both to understand and to predict, for a variety of uses. Feedback from early customers clearly showed that the message operations pricing model made it difficult to predict consumption and therefore to forecast costs. While computation time and storage volume have corresponding concepts in traditional on-premise computing environments, frequency of message traffic is not something that most customers are accustomed to calculating, let alone forecasting. We chose the connection pricing meter because it corresponds to a more familiar unit of measure for more developers and IT professionals.
The message operations meter was appropriate for uses such as discrete transactional messaging, but it proved more complex in other cases. For example, what occurs if you stream a large file, tunnel a protocol that stays open, or deploy many devices that all "listen" idly all day? In these cases, it can be very difficult to determine what counts as a message, and to predict usage from day to day.
These are common usage scenarios. Our pricing is now more applicable to those situations, incorporating uses such as streamed data, protocol tunneling, and transactional messaging. In addition, the connections meter provides increased predictability, because the price stays the same whether you use a connection more or less frequently, from one month to the next. We believe this AppFabric Service Bus pricing model does a better job of satisfying the “simple, predictable, and versatile” philosophy.
- How do I interpret my AppFabric usage data in the Windows Azure platform usage report?
- The Windows Azure platform usage report is provided in the form of a downloadable text file that contains values in comma-separated format (CSV) for the following AppFabric usage meters:
The account owner of your subscription can view usage information by logging into the Microsoft Online Services Customer Portal and clicking the “View my bills” link. On the page that displays you can view and download both your billed and unbilled usage. Please note that there can be a delay of up to 12 hours for your unbilled usage data to appear.
- AppFabric Service Bus connections (of individual and pack types)
- AppFabric Access Control transactions
- Data transfer (in gigabytes)
The topic continues with examples of usage reports and concludes:
- How is the daily connection number calculated for AppFabric Service Bus?
- The maximum number of open connections is used to calculate your daily charges. For the purposes of billing, a day is defined as the period from midnight to midnight, Coordinated Universal Time (UTC).Each day is divided into 5-minute intervals, and for each interval, the time-weighted average number of open connections is calculated. The daily maximum of these 5-minute averages is then used to calculate your daily connection charge.
- What happens if I have a very brief burst in connection count for the AppFabric Service Bus, for example when one set of devices starts up just as another set shuts down? Will that increase my costs?
- Because the average number of open connections during a 5-minute interval is used to calculate your connection charge, you will not be affected if your number of open connections increases briefly. For example, if one connection is open for the whole interval and another connection overlaps with it by ten seconds, your 5-minute average would be 1 + 10 ÷ (5 x 60) = 1.0333 connections.
- Can I increase or decrease my AppFabric Service Bus connection pack size? How often?
- You can select a different size connection pack at any time. You can increase or decrease that pack size as you want. You can make one of these changes once every seven days.
- Can I have a number of AppFabric Service Bus connections other than the amounts listed? 1, 5, 25, 100, 500?
- You can use individual connections to purchase the exact number of connections you need, anywhere between 1 and 500 connections. If you can forecast your needs in advance, you can select a connection pack in the amount of 5, 25, 100, or 500 connections. In addition, you can supplement your connection packs with individual connections; for example, 5 of pack + 2 of individual = 7 total connections. At this time, other pack sizes smaller than 500 are not available, and you may not purchase more than one pack at a time in a service namespace. Pack sizes larger than 500 may be available on request.
- What if I want to have more than one AppFabric Service Bus pack associated with my account?
- In this case you must create additional service namespaces. For example, if you want to have 200 connections, they must purchase a 100- pack in a first service namespace, and an additional 100-pack in a second service namespace.
- What usage of AppFabric Service Bus and/or AppFabric Access Control is subject to data transfer? What is not?
- Any data transfer throughout a given Windows Azure platform sub-region is provided at no charge. Any data transfer that meets the requirements for the off-peak ingress limited time promotion is provided at no charge. Any data transfer outside a sub-region is subject to ingress or egress charges at the Windows Azure platform rates. For example, if you use the AppFabric Service Bus to communicate between two Windows Azure applications in the same sub-region, you will not incur data transfer charges. However, if you use the AppFabric Service Bus to communicate between regions or sub-regions; for example, to send data from one Windows Azure application in the North Central sub-region to another Windows Azure application in the South Central sub-region, you will incur egress charges at North Central rates and ingress charges at South Central rates. If you use the AppFabric Service Bus to send and not receive data from a Windows Azure application to an application in your own datacenter, you will incur egress charges for your Windows Azure platform usage.
<Return to section navigation list>
Windows Azure Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team sent me the following Notification about Windows Azure SDK November 2010 (v1.3) Refresh email on 2/3/2011 at about 12:15 PM PST" (see the item below for more details):
Windows Azure Customer,
Our data indicates that you have deployments built with Windows Azure SDK 1.3.
We have refreshed the Windows Azure SDK. This refresh contains configuration and security changes that may affect services built using the Windows Azure November 2010 SDK (v 1.3) where a Web Role is deployed with the full IIS feature. We recommend that all customers download and apply the refresh per the instructions below. Please click here for more information.
Applying the fix
To apply the fix
1. Please download and install the refresh of the November 2010 Tools and SDK (recommended).
To upgrade just the SDK please use this link (64 bit) or this link (32 bit).
2. Re-package your service.
3. Upgrade/re-deploy your service in the cloud.
Verifying the fix
To verify the fix has been applied:
Check the version number of 'Windows Azure SDK' after upgrading to this refresh, as displayed under 'Programs and Features'. It should be 1.3.20121.1237.
Please note this is not a monitored alias. For additional questions or support please use the resources available here.
Regards,
The Windows Azure Team
The Windows Azure Team published a detailed Windows Azure Software Development Kit (SDK) Refresh Released post on 2/3/2011:
Overview
This refresh of the Windows Azure November 2010 SDK (SDK 1.3) resolves an issue that affects applications developed using SDK v1.3. We are encouraging affected customers to install the refresh of the SDK and redeploy their application(s).
Who is affected?
This issue affects applications developed using ASP.NET and using the new "Full IIS" feature of SDK v1.3 that have a Web Role deployed. "Web Role" is defined as a single HTTP endpoint and a single HTTPS endpoint for external clients. This is not to be confused with the "Worker Role," which is defined as up to five external endpoints using HTTP, HTTPS or TCP. Each external endpoint defined for a role must listen on a unique port.
In particular, this affects web sites and services that use cookies to maintain state information either within a session or between sessions (if interactions in one session can affect what happens in a subsequent session). These cookies are cryptographically protected so that clients can see that there is state information being passed but cannot see the contents of that state information and cannot change it. In the case of vulnerable Web Roles, it may be possible for clients to determine the contents of the state information (though the client could still not change it). If the web site depended on the client not being able to see the contents, its security could be compromised.
Applying the fix
To apply the fix:
1. Download and install the refresh of the November 2010 Tools and SDK (recommended).
2. To upgrade just the SDK, use this link (64 bit) or this link (32 bit)
After you've applied the fix, you'll have to re-package your service and then upgrade or re-deploy your service in the cloud.
Verifying the fix
To verify the fix has been applied:
1. Check the version number of 'Windows Azure SDK' after upgrading to this refresh, as displayed under 'Programs and Features.' It should be 1.3.20121.1237.
For technical support or to participate in our technical forums, please visit http://www.microsoft.com/windowsazure/support/
Mary Jo Foley (@maryjofoley) posted Windows Azure futures: Turning the cloud into a supercomputer in a 2/3/2011 post to ZDNet’s All About Microsoft blog:
February 1 is considered the “one year” anniversary of Microsoft’s Azure cloud platform (even though February 2 is the actual date that billing was “turned on”).
Last year, Microsoft said it had 10,000 Azure customers; this week officials are saying they have 31,000, though they are refusing to say how many of these are paying customers, how many are divisions of Microsoft, etc.
As I noted last year, Microsoft has been slowly and steadily adding new features to Azure. But I haven’t written much about longer-term Azure futures. Until today.
Bill Hilf, General Manager of the Technical Computing Group (TCG) at Microsoft, isn’t part of the Azure team. But he and his band are doing work on technologies that ultimately may have substantial bearing on the future of Microsoft’s cloud platform. The TCG has a server operating system team, a parallelization team and a team “with the idea of connecting a consumer to a cloud service,” according to Hilf.
The TCG late last year stated its intentions to allow customers to provision and manage Windows Server 2008 R2 HPC nodes in Windows Azure from within on-premises server clusters as part of Service Pack 1 of HPC Server 2008 R2. But Hilf and his team want to go beyond this and turn the cloud into a supercomputer, as Hilf explained to me last week. “We want to take HPC out of niche access,” he said.
This isn’t going to happen overnight, even though the biggest Azure customers today are the ones using HPC on-premises at the current time, Hilf said. HPC and “media” (like the rendering done by customers like Pixar) are currently the biggest workloads for the cloud, Hilf said.
To bridge HPC and Azure, Hilf has a multi-pronged strategy in mind. One of the prongs is Dryad.
Dryad is Microsoft’s competitor to Google MapReduce and Apache Hadoop. In the early phase of its existence, Dryad was a Microsoft Research project dedicated to developing ways to write parallel and distributed programs that can scale from small clusters to large datacenters. Both the Bing and the Xbox Live teams have used Dryad in building their back-end datacenters.There’s a DryadLINQ compiler and runtime that is related to the project. Microsoft released builds of Dryad and DryadLINQ code to academics for noncommercial use in the summer 2009. Microsoft moved Dryad from its research to its Technical Computing Group this year.
“Dryad, in its first iteration, is really for on-premises,” Hilf told me during an interview last week. “Eventually, we’ll roll Dryad up into Azure, as even more data is put in the cloud.”
Go to the next page for more on how Microsoft’s parallel stack comes into play
Read more: 2
Neil MacKenzie (@mknz) explained Persisting IIS Logs in Windows Azure SDK v1.3 in a 2/2/2011 post:
This post is very speculative and may be wrong. If you like to read really solid posts you should probably stop now. I am really posting it for the benefit of anyone else who tries to follow the same route.
The Azure SDK v1.3 release finally provided support for full IIS in an Azure web role. However, there appear to be a number of unresolved problems.
A specific problem is that Windows Azure Diagnostics is not able to persist IIS logs to Azure Storage. This is caused by a permissions issue whereby the Azure Diagnostics Agent doesn’t have the permissions required to access the directory where IIS puts its logs. This occurs even though this directory has been configured to reside in the local storage managed by Azure.
In this post I look at one of the problems and describe a solution to it that appears to work. I have no idea how robust this solution is – and as far as I can tell there is a little bit of voodoo going on. Working on it gave me an unfortunate and close familiarity with the delays in the deploy/delete lifecycle of an Azure service. Hopefully, Microsoft will release an official fix for this problem sooner rather than later. Andy Cross provides an alternative solution on a post on this Azure Forum thread.
The actual permissions problem appears related to the fact that when IIS creates the log directory any permissions in the parent directory are not inherited by the IIS log directory. Christian Weyer has an interesting post describing the issue and showing how to use PowerShell in a startup task to modify the access control list (ACL) for the Azure local storage directories. Unfortunately, this ACL is not inherited by the IIS log directory. An alternate solution of creating the IIS log directory does not work because IIS raises an error when it recognizes that it did not create the log directory.
An obvious way to attack this problem is to let IIS create the log directory and then modify the ACL to allow Windows Azure Diagnostics to access the directory.
The first step is to identify the path to the IIS Logs directory. Wade Wegner has a post showing how to use the ServerManager class to access the IIS configuration. This can be used as follows to get the path to the IIS Logs directory:
private String GetIisLogsPath()
{
String iisLogPath;
String webApplicationProjectName = “Web”;
using (ServerManager serverManager = new ServerManager())
{
Int64 Id = serverManager.Sites[RoleEnvironment.CurrentRoleInstance.Id + "_" +
webApplicationProjectName].Id;
SiteLogFile siteLogFile = serverManager.Sites
[RoleEnvironment.CurrentRoleInstance.Id + "_" +
webApplicationProjectName].LogFile;
iisLogPath = String.Format(@”{0}\W3SVC{1}”, siteLogFile.Directory, Id);
}
return iisLogPath;
}Both the ServerManager class and the ACL modification performed later require that the Azure web role be run with elevated privileges. Note that this elevation only affects the process the web role code runs in and not the separate process IIS runs in. This elevation is achieved by adding the following child element to the WebRole element in the ServiceDefinition.csdef file:
<Runtime executionContext=”elevated”/>
When ported to C#, the ACL fixing part of Christian Weyer’s code becomes:
private void FixPermissions(String path)
{
FileSystemAccessRule everyoneFileSystemAccessRule =
new FileSystemAccessRule(“Everyone”, FileSystemRights.FullControl,
InheritanceFlags.ContainerInherit | InheritanceFlags.ObjectInherit,
PropagationFlags.None, AccessControlType.Allow);
DirectoryInfo directoryInfo = new DirectoryInfo(path);
DirectorySecurity directorySecurity = directoryInfo.GetAccessControl();
directorySecurity.AddAccessRule(everyoneFileSystemAccessRule);
directoryInfo.SetAccessControl(directorySecurity);
}This takes the path to a directory and modifies the ACL so that Everyone has full access rights to the directory and any objects contained in it. This is obviously not the most secure thing to do. The obvious question is what should be used in place of Everyone? I don’t know the answer.
The next step is to configure Windows Azure Diagnostics to persist IIS Logs. This can be done as follows:
private void ConfigureDiagnostics()
{
String wadConnectionString =
“Microsoft.WindowsAzure.Plugins.Diagnostics.ConnectionString”;CloudStorageAccount cloudStorageAccount =
CloudStorageAccount.Parse(RoleEnvironment.GetConfigurationSettingValue
(wadConnectionString));DiagnosticMonitorConfiguration diagnosticMonitorConfiguration =
DiagnosticMonitor.GetDefaultInitialConfiguration();diagnosticMonitorConfiguration.Directories.ScheduledTransferPeriod =
TimeSpan.FromMinutes(1d);DiagnosticMonitor.Start(cloudStorageAccount, diagnosticMonitorConfiguration);
}Brute force trial and error indicated that this was not sufficient to get. Using remote desktop indicated that restarting IIS helped with the transfer. This can be done in code as follows:
private void RestartWebsite()
{
String webApplicationProjectName = “Web”;
using (ServerManager serverManager = new ServerManager())
{
Site site = serverManager.Sites[RoleEnvironment.CurrentRoleInstance.Id + "_" +
webApplicationProjectName];
ObjectState objectState = site.Stop();
objectState = site.Start();
}
}Another thing that appeared to help kick start the transfer of logs to Azure storage was the creation of a file in the IIS Logs directory. This has the odor of voodoo about it. The file can be created as follows:
private void AddPlaceholderFile(String pathName)
{
String dummyFile = Path.Combine(pathName, “DummyFile”);
FileStream writeFileStream = File.Create(dummyFile);
using (StreamWriter streamWriter = new StreamWriter(writeFileStream))
{
streamWriter.Write(“Diagnostics fix”);
}
}There remains the issue of when this reconfiguration must be done. Christian Weyer used a startup task written in PowerShell. I moved it into the overridden RoleEntryPoint.Run() method for the web role. The reason is that when the web role is initially started the IIS Logs directory may not exist when the startup task is being run. To take account of that I checked for existence before modifying the permissions. This led to the following version of Run():
public override void Run()
{
String iisLogsPath = GetIisLogsPath();while (true)
{
Boolean pathExists = Directory.Exists(iisLogsPath);
if (pathExists)
{
FixPermissions(iisLogsPath);
ConfigureDiagnostics();
RestartWebsite();
AddPlaceholderFile(iisLogsPath);
break;
}
Thread.Sleep(TimeSpan.FromSeconds(20d));
}while (true)
{
Thread.Sleep(TimeSpan.FromMinutes(1d));
}
}The outcome of all this is that IIS Logs are persisted to Azure Storage. In my limited testing this transfer was not as frequent as I expected. All in all, I wouldn’t describe this solution as an overwhelming success.
John Bodkin asserted “Microsoft Windows Azure customer [Lokad] builds 'technology that would not exist without the cloud'” as a deck for his Early adopter spells out Microsoft Azure's strengths and shortcomings article of 2/1/2011 for NetworkWorld:
With Microsoft celebrating the first birthday of Windows Azure, few people are as well equipped to discuss the cloud platform's strengths and limitations as Joannes Vermorel.
Vermorel, the founder and CEO of a software development company in Paris, France, called Lokad, jumped on the Azure bandwagon well before the service even went online on Feb. 1, 2010. Because Lokad decided to move most of its infrastructure from hosted servers to the Microsoft cloud, Vermorel and colleagues had to rewrite the company's application infrastructure, and began doing so at the beginning of 2009, when Azure was in beta.
"It took more than 12 months to completely rewrite Lokad from scratch to have cloud-based technology," Vermorel said in an interview with Network World. "At the present time, we have a technology that would not exist without the cloud."
Still, there are a few shortcomings Vermorel urges Microsoft to work on. Redmond recently updated the Windows Azure user interface to make it more attractive and intuitive, but the service console still lags behind those offered by competing cloud services, Vermorel says.
"It was abysmal. Now it's OK. So the trend is good," he says.
Specifically, the user portal lacked multiuser support, which it now has, and is still slow despite a significant speed boost, he says. Before the update, it was tedious to deploy and redeploy services, and "was not very task-oriented," Vermorel says. "It's a more usable interface but they can still do much more and much better."
Lokad's system analyzes sales and demand figures, giving customers the forecasts they need to manage supply and demand, to optimize inventory and staffing levels. For retail, this can mean figuring out which products to keep in the warehouses and at the stores. For banks, it could mean keeping ATMs and branch offices stocked with the right amount of cash.
Lokad, founded in 2008 with an emphasis on data mining and grid computing, has just 11 employees, so managing a large data center would distract from its core mission. At first, the company rented servers from a hosting provider, but "most of the time those servers were doing nothing." At the same time, the hosters didn't provide enough scalability, so "there was never enough processing power" when demand for Lokad's system was high, Vermorel says. Lokad had just half a dozen servers in the U.S. and Europe, and setting up a new server required a big fee.
This hosting model was already a big improvement over owning and managing machines directly, Vermorel says, but what Lokad really needed was the flexibility offered by cloud services. Lokad's system requires heavy allocation and de-allocation of computing resources. If Lokad needs a few thousand servers to run computations for an hour, Azure can provide that. Microsoft and Lokad have developed a tight partnership, with Microsoft naming Lokad its Windows Azure Platform Partner of the Year in 2010.
IN DEPTH: Windows Azure turns 1 in 'anemic' market

<Return to section navigation list>
Visual Studio LightSwitch
Beth Massi (@bethmassi) explained How To Create Outlook Appointments from a LightSwitch Application in a 2/3/2011 post:
Last post I showed how to create email in a couple different ways, one of them being from the LightSwitch UI on the client side that used COM to automate Outlook to create an email. If you missed it here it is:
How To Send HTML Email from a LightSwitch Application
This generated some questions about how to automate Outlook to do other things like add appointments to someone’s calendar. So because of this interest, I’ve decided to continue my series on Office automation from LightSwitch :-). This time I’ll show how to create a client-side helper class that creates and sends appointments through Outlook.
Creating the Outlook Helper Class
We need a helper class on the client so we can call if from a button on our screen. You do this by selecting the “File View” on the Solution Explorer, right-click on the Client project and select Add –> New Class. I named the class “OutlookAppointmentHelper” for this example.
This helper class uses COM automation, a feature of Silverlight 4 and higher. So first we need to check if we’re running out-of-browser on a Windows machine by checking the AutomationFactory.IsAvailable property. Next we need to get a reference to Outlook, opening the application if it’s not already open. The rest of the code just creates the appointment and sends it. In the code below, you could also comment out the call to Send and instead call Display to allow the user to modify the appointment first. NOTE: The key piece of code that enables the sending of the appointment to the toAddress is to set the MeetingStatus property to 1 (olMeeting), otherwise the appointment will just stay on the user’s calendar and wont be sent to the recipient.
Imports System.Runtime.InteropServices.Automation Public Class OutlookAppointmentHelper Const olAppointmentItem As Integer = 1 Const olMeeting As Integer = 1 Shared Function CreateOutlookAppointment(ByVal toAddress As String, ByVal subject As String, ByVal body As String, ByVal location As String, ByVal startDateTime As Date, ByVal endDateTime As Date) As Boolean Dim result = False Try Dim outlook As Object = Nothing If AutomationFactory.IsAvailable Then Try 'Get the reference to the open Outlook App outlook = AutomationFactory.GetObject("Outlook.Application") Catch ex As Exception 'If Outlook isn't open, then an error will be thrown. ' Try to open the application outlook = AutomationFactory.CreateObject("Outlook.Application") End Try If outlook IsNot Nothing Then 'Create the Appointment ' Outlook object model (OM) reference: ' http://msdn.microsoft.com/en-us/library/ff870566.aspx ' Appointment Item members: ' http://msdn.microsoft.com/en-us/library/ff869026.aspx Dim appt = outlook.CreateItem(olAppointmentItem) With appt .Body = body .Subject = subject .Start = startDateTime .End = endDateTime .Location = location .MeetingStatus = olMeeting .Recipients.Add(toAddress) .Save() '.Display() .Send() result = True End With End If End If Catch ex As Exception Throw New InvalidOperationException("Failed to create Appointment.", ex) End Try Return result End Function End ClassAlso note that if you want to add multiple recipients to the appointment you could pass in an array or List(Of String) and loop through that calling .Recipients.Add for each one:
Shared Function CreateOutlookAppointment(ByVal toAddress As List(Of String), ...rest of code .
.
.
Dim appt = outlook.CreateItem(olAppointmentItem) With appt .Body = body .Subject = subject .Start = startDateTime .End = endDateTime
.Location = location
.MeetingStatus = olMeeting
For Each addr In toAddress .Recipients.Add(addr) Next .Save() '.Display() .Send() End WithYou can also add required and optional attendees by setting appropriate properties. Take a look at the object model for the Appointment item for more details.
Calling Code from a Button on a Screen
Here’s how you add a command button to a screen. In the Execute method for the command button is where we add the code to create the appointment. I also want to have the button disabled if AutomationFactory.IsAvailable is False and you check that in the CanExecute method. Here I’m working with an Appointment entity in my data model but the data to feed the appointment can come from anywhere. So here’s the code in my screen:
Private Sub CreateOutlookAppt_CanExecute(ByRef result As Boolean) result = System.Runtime.InteropServices.Automation.AutomationFactory.IsAvailable End Sub Private Sub CreateOutlookAppt_Execute() ' Schedule the appointment via Outlook With Me.Appointment If .Customer.Email <> "" Then If OutlookAppointmentHelper.CreateOutlookAppointment(.Customer.Email, .Subject, .Notes, .Location, .StartTime, .EndTime) Then Me.ShowMessageBox("Appointment has been sent.") End If Else Me.ShowMessageBox("This customer does not have an email address", "Missing Email Address", MessageBoxOption.Ok) End If End With End SubRun this and you will see that when the user clicks the button the appointment is sent and it appears on the user’s calendar.


Return to section navigation list>
Windows Azure Infrastructure
The Windows Azure Team finally announced Windows Azure Extra Small Instances Now Available As Public Beta on 2/2/2011:
At PDC10 last October, we announced a private beta program for the 'Extra Small' Windows Azure Instance. This smaller instance provides developers with a cost-effective training and development environment. Developers can also use the 'Extra Small' instance to prototype cloud solutions at a lower cost. To see a pricing and resource comparison of instance sizes, click here.
Since that time, we've seen a lot of interest in the 'Extra Small' instance so we're pleased to announce all customers can now use the beta version of the Windows Azure Extra Small Instance. To learn how to configure your application to start using Extra Small Windows Azure instances, please refer to this MSDN Library [How to Configure Virtual Machine Sizes] article.
It’s uncommon for Microsoft to charge for a product’s beta version. See my Windows Azure Compute Extra-Small VM Beta Now Available in the Cloud Essentials Pack and for General Use post updated 1/31/2011 and Hanuk’s post below for more details.
Hanu Kommalapati (@hanuk) posted a Windows Azure Capacity Assessment on 2/1/2011:
Windows Azure being a Platform as a Service (PaaS), abstracts away the OS, storage, networking and shares these massive pools of physical resources across virtual instances of applications running on Azure infrastructure. Windows Azure platform defines and enforces policies so that applications running on virtualized infrastructure will play nicely with each other. Awareness of these resource policies is important for assessing the capacity for successful operations and also for predicting the operational expenses for planning purposes.
Bandwidth

Awareness of the above numbers is important for capacity assessment if your application is bandwidth prone. For example, if you need a throughput of 10K requests/sec, with each request with an ingress of 5Kb and an egress of 10Kb, the bandwidth required is : 1200 Mbps. This can be serviced by 12 Small, 6 Medium, 3 Large or 2 XLarge instances just based on arithmetic.
If the request is network IO bound, with less emphasis on CPU cycles/request, distribution of the workload across multiple small instances will give the benefits of the isolation. If one of the roles gets recycled, it will only take down the fewer requests that are inflight with that role.
CPU
The CPU resource policies are implemented implicitly through the Azure Role types; each role comes with a specific number of CPU cores as shown in the table below:

Each core is equivalent to a 64bit 1.6 Ghz processor with a single core on the chip. If you have an existing application that maxes 2-proc (2 cores each) you probably need to look at 4 small instances or use other role types base on simple arithmetic.
CPU intensive workloads like fast Fourier transform (FFT), finite element analysis (FEA), and numerous other algorithms that aid simulations may get benefited my the large number of cores. For a typical data intensive application, one could start with a Small role and progressively change the role type to arrive at an optimal Azure role type through testing.
Memory
Each Azure role instance is provisioned with a pre-configured amount of memory as shown in the Table 3. Role instances get their memory allocations based on the role type, from the remaining memory on the physical server, after the Root OS takes its share. If your application is memory bound due to the way application is architected (e.g. extensive use of in-memory cache or huge object graphs due to the nature of the application object model), either the application needs to be rearchitected to leverage Azure capabilities like AppFabric Cache or select the appropriate role type to fit the application’s memory requirements.

Storage
Table 4 shows the volatile disk storage that will be allocated to each Azure role type. Typical stateless web application may not pay much attention to the local disk but certain stateful applications like full text search engines may store indexes on the local disk for performance reasons. In order for these indexes to survive the role restarts (VM reboot), cleanOnRoleRecycle="false" setting in the service definition will preserve the contents between reboots. If the VM running the role, is relocated to a different physical server due to run time conditions like hardware failure, one has to plan for the reconstruction of the disk contents from a durable storage. Based on the local disk storage needs you may select the appropriate role.

Concurrency and Capacity Assessment
Statelessness on the compute tier and minimizing the surface area of the shared resources (e.g. Azure Storage and/or SQL Azure) between requests is the key for building applications that will have near linear scalability on the compute tier. Windows Azure Storage architecture already accommodates for such near linear scalability if the application is architected to leverage this durable storage appropriately. See the article How to get most out of Windows Azure Tables for best practices on scalable usage of Azure Tables.
If the application leverages SQL Azure, and if it is multi-tenant and the tenants are a few enterprise customers, shared databases for reference data and a database instance per each tenant may not be a bad idea from the perspective of minimizing the surface area between tenants. This architecture will help both from the isolation perspective as well as from the scalability perspective. On the other hand if your solution addresses large number of tenants a shared database approach may be needed. This requires careful design of the database. An old article, coauthored by one of my colleagues Gianpaolo Carraro, Multi-Tenant Data Architecture is still valid in this context. Of course, you need to combine the guidance from this article with the Window Azure size limitations to arrive at the architecture that supports the multi-tenancy needs.
Once the shared resources usage is properly architected for high concurrency, Window Azure capability assessment becomes lot easier.
Capacity Assessment
In a traditional setting where hardware needs to be procured before deployment, one has to assess the capacity and also put together plans for acquiring the resources much early in the project lifecycle. Considering the latencies incurred by the typical enterprise procurement process, one has to be extremely diligent in assessing the capacity needs even before the application architecture is completely baked in.
This has to be complimented by the plan to acquire hardware and software which will base its decisions on less than accurate assessment as input. Due to this, often the resource requirements will be overestimated to account for the possible errors in the assessment process. Temporal unpredictability of the workloads also adds to the burden of capacity assessment process.
In case of cloud computing, and specifically for Azure, one has to have an eye on the architecture implications of the consumed Azure capacity and the ensuing cost of operations, but doesn’t have to know the accurate picture as in traditional deployments.
Once the system is architected for a scale out model, capacity assessment merely becomes an exercise of doing a baseline analysis of the throughput/per role instance and extrapolate the infrastructure for the target peak throughput. Application throughput needs expressed in terms of bandwidth, CPU, memory and to some lesser extent, local storage will play a big role in the selection of the Azure role type. Even though one could architect for near-linear scalability, the implementation will often result in less than perfect solutions. So, baseline assess the throughput (either requests/sec or concurrent users) across various role types and pick one that is optimal for the application. Also, load test more than one role instance to make sure that near linear scalability can be attained by adding more role instances.
Thanks to Microsoft’s David Chou for the heads-up in his Azure Capacity Assessment of 2/2/2011.
Christian Weyer answered Is my cloud still supported (the Windows Azure OS, that is)? in a 2/2/2011 post:
Have you ever asked yourself what the support lifetime of Windows Azure Guest OSes is?
Turns out their lifecycle follows the same timeline as their Windows Server counterparts.
- OS 1.x will follow Windows Server 2008 lifecycle
- OS 2.x will follow Windows Server 2008 R2 lifecycle
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Jay Heiser [pictured below] published on 2/3/2011 Flickr of hope about a professional photographer mistakenly using a consumer photo site (Flickr) to store years of related social content:
Flickr account holder Mirco Wilhelm was shocked to learn that Flickr had accidentally deleted his account, and apparently lacks the ability to restore his 4000 photographs to their site.
This was of course not his primary storage area for 5 years of photographic effort. His account only contained lower resolution copies of work that he has backed up at home. He obviously still has his photographs–loss of his primary data is not the issue or lesson here.
What this guy lost was a form of virtual publication, painfully built up over several years on Flickr. Not only does that ‘published work’ contain a large amount of metadata (tags and comments), accreted over several years by the Internet army, but it also sat within the context of other publications. In short, he lost his links. Five years of community building, online marketing, and a growing search engine presence are missing, and may never be recoverable.
His mistake was to rely on the wrong service provider. He mistook Flickr for a business-oriented site, when it actually is a consumer site. What he should have done was create his own website, using his own domain name, and he should have periodically backed that up to some other location. That would have allowed him to recover his site, restoring the original links. Even if he ended up having to use a new provider, the links would have been fine because he would still have control of his own domain name (the significance of this lesson was painfully learned by millions of GeoCities site holders).
Wilhelm’s fatal error was assuming that a cheap cloud provider would always be there for him, and that he wouldn’t need to take any responsibility for backing up his increasingly rich virtual publication. The comments at the end of the Observer.com article (and a growing number of other commentaries) suggest a widespread misunderstanding about what level of service is actually provided by low-end cloud services:
“We are paying for having our pictures saved on their infrastructure and they’re not even making backups?”
“One should expect the cloud host to be making backups of its own, not only full backups but also incremental backups, as any reasonably mature data processing shop would do”
“Even the cheapest web hosting services provide monthly backups of your info in case [stuff] happens.”
Many enterprises are making the exact same mistake, presuming that their provider is backing up their data and capable of restoring it in case of an accident. There are a lot of SaaS applications used by commercial organizations that either have no offline backup at all, or backup is offered as a for-cost option that some buyers avoid. Likewise, users of low-end IaaS services have also experienced unexpected data loss.
Be cautious about vendor spin around misused terms such as RTO and RPO. If your vendor can’t tell you where your data is, including offline backups, then you shouldn’t assume that it ‘is’ at all.
Jay is a Gartner research vice president specializing in the areas of IT risk management and compliance, security policy and organization, forensics, and investigation.
<Return to section navigation list>
Cloud Computing Events
Matt Masson on 2/3/2011 reported the existence of a Tech Ed 2011 – Session Preference Survey:
There is a Session Preference survey up on the Tech Ed North America 2011 site. This is a great way to provide input to the session selection committee. If you plan on attending Tech Ed NA, be sure to fill it out before the survey closes (February 17th).
Searching on cloud returns 56 session candidates in three pages; I voted for most.
I’m surprised that a search on SQL Azure returned only one session and there were no sessions proposed about scaling out SQL Azure (i.e., Federation/sharding). Hopefully, v1 of the SQL Azure Federation CTP will be available at or before Tech Ed NA 2011.
The CloudConnections 2011 event will be held at the Bellagio Hotel, Las Vegas, NV on 4/17 through 4/21/2011:
Cloud Connections brings together business decision makers, IT managers and directors, and developers to explore cloud computing services and products, deepen technical skills, and determine best-practices solutions for implementing private or public cloud infrastructure and services.
- Determine best-practices solutions for implementing private or public cloud infrastructure and services.
- Understand how to leverage and apply ideas and proven examples into your organization
- Learn how to maximize cloud performance and minimize costs
- Learn about identity federation - protocols, architecture and uses
- Compare security solutions for the cloud
- Network with your peers, IT pros, carriers and a wide range of cloud infrastructure, product and service vendors!
Plus learn about industry-changing trends, products, and services from:
- Public cloud service providers (hosting services)
- Infrastructure vendors
- Cloud identity products and services
- Security solution providers
Following are sessions relating to Windows Azure and OData:
- Michael Collier: CDEV11 The Hybrid Windows Azure Application session:
The Windows Azure platform is a fairly feature rich environment. You can run your web applications there. You can run your data processing applications (services) there. But you don’t have to run your entire application there. You can run part of your application in “the cloud”, and part of your application on premise – giving you the best of both worlds. But why would you not put everything in the cloud? Perhaps you don’t need the massive computing power Windows Azure provides, but you would like a cheap an easily accessible data store.
Maybe your application just isn’t ready, yet, to be run in the cloud. Whatever the reason, in this session you will learn the basics for creating a hybrid application which leverages various features of Windows Azure. You will see how to leverage Windows Azure’s rich features and APIs to extend your application to new heights.
- Michele Leroux Bustamante: CDEV02 Why YOU Need AppFabric Access Control
AppFabric Access Control is an essential feature of the Windows Azure platform. It is now a protocol hub in the cloud that allows you to manage trust relationships with partners and other application domains so that your application can focus on one thing: authorizing access for the already authenticated user. No need to implement your own custom Security Token Service to handle these relationships — just move it to the cloud and BAM! Federation bliss.
- Michael Collier: CDEV12 Windows Azure – What, Why, and How
By now you have probably seen all the cool kids talking about cloud computing and how Windows Azure fits into that space. You are definitely feeling the peer pressure to become one of those Azure cool kids, aren’t you? Well, then this session will make you cool again. We will take an introductory look at cloud computing, and how Microsoft’s cloud services operating system, Windows Azure, fits into the picture. We will also explore some common scenarios and potential roadblocks in working in the cloud. Finally, we’ll see just how easy it is to leverage your existing .NET development skills and tools to develop a solution that runs in Windows Azure. By the time we are finished, you’ll be able to hold your head high in the clouds with the other cool kids.
- Michael Collier: CDEV10: Windows Phone 7 and Windows Azure – A Match Made in the Cloud
Mobile platforms such as Windows Phone 7 are the rising stars of consumer and enterprise computing. In order to be successful, mobile applications need to be highly scalable and able to consume data from any location at any time. The Windows Azure Platform is well-suited to provide the scalable compute and storage services for mobile applications and devices. The Windows Azure Platform provides a friendly REST-based API and comfortable development environment, as well as a scalable infrastructure well-suited for mobile applications and devices. In this session, we will explore how easy it is to leverage Windows Azure’s compute, storage, and Content Delivery Network services for your next great Windows Phone 7 application. Coming away from this session you will have a solid understanding of how Windows Phone 7 and Windows Azure are a great couple – a match made in the cloud!
- Shawn Wildermuth: MCP25 OData: A Mobile App Developer’s Friend?

<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum asserted “Although many thought the cloud would stimulate migration to open source technology, enterprises rather move what they already have to the new venue” in a deck for his Amazon's Oracle move shows open source won't gain in the cloud article of 2/3/2011 for InfoWorld’s Cloud Computing blog:
I was not surprised to hear Amazon's announcement that it now rocks Oracle's database in its cloud. Clearly it's a response to Salesforce.com's Database.com, but it also addresses the fact that most enterprises love Oracle[*].
Currently Amazon offers MySQL on demand, an open source relational database. However, I suspect that enterprises and government agencies did not want to give up their existing Oracle installations -- and perhaps for good reason.
Migrating from Oracle is a pretty risky proposition, considering how dependent many applications are on Oracle's features and functions. Indeed, as I work the cloud-migration project circuits, I find that those companies on Oracle stay on Oracle. Although they will consider open source alternatives for some projects, most enterprises and government agencies cite the existing skill sets within the organizations and a successful track record as the reasons they are remaining with Larry.
This is will likely be the norm as more organizations move to the cloud. Other examples of this kind of inertia are those companies that use .Net and SQL Server; they will stay with the Microsoft stack with Windows Azure. Even those that use SaaS versions of their existing enterprise applications may stay loyal to their brand, even though there are other SaaS providers that provide better features and functions. They know what they know.
What's interesting about all this is that the larger software players may actually gain many more users, but make much less money. Also, look at the traditional channels for selling big expensive databases. They are moving to an on-demand model, which goes against the way software giants have done business for the last 30 years. We could see some pushback as they begin to understand the longer-term effects of the movement to the cloud.
The result of all this for most enterprises is that the ostensible cloud effort becomes a mere platform change, not a true migration into the cloud. This "move to an outside platform" approach could be the right move for most of them, all things considered. However, this does not mean that open source tools won't gain in popularity as the cloud progresses. Instead, the status quo will just get a new address.
* I find it difficult to believe that any “enterprises love Oracle.”
Lydia Leong (@cloudpundit) analyzed Amazon Simple Email Service in a 2/3/2011 post to her Cloud Pundit blog:
Last week, Amazon launched its Simple Email Service (SES). SES is an outbound SMTP service, accessible via API or easily integrated into common SMTP servers (Amazon provides instructions for sendmail and postfix). It has built-in rate-limiting and feedback loop statistics (rejected, bounced, complaints). It’s $0.10 per thousand messages. EC2 customers get 2000 messages for free each month. You do, however, have to pay for data transfer.
Sending email from EC2 has long been a challenge. For the obvious reasons, Amazon has had anti-spam measures in place, and the EC2 infrastructure itself is also likely to be automatically eyeballed with suspicion by the anti-spam mechanisms on the receiving email servers. Although addressing issues with Elastic IPs and reverse DNS has helped somewhat, Amazon has struggled with reputation management for its EC2 address blocks, despite attempting to police outbound SMTP from those blocks.
There are various third-party email services (bare-bones as well as sophisticated) that EC2 users have used to work around the problem. Sometimes it’s thrown in as part of another service; for instance, DataPipe includes an external SMTP service as part of its managed services for EC2. Pricewise, though, SES wins hands-down over both a raw delivery service like AuthSMTP and a fancier one like Sendgrid.
My colleagues Matt Cain (email infrastructure) and Adam Sarner (e-marketing) and I will be issuing an event note to Gartner clients in the future, looking at this development in greater detail.
Hopefully, the Azure Team is working on a clone.
Alex Williams asserted With New Release, OpenStack Shows it is a Real Alternative to Proprietary Solutions in a 2/3/2011 post to the ReadWriteCloud blog:
OpenStack continues to gain momentum with a code release today called Bexar, which includes a number of new features that are making it a serious, viable alternative to proprietary virtualization platforms.
Of significant note is OpenStacks's continued acceptance by large vendors. As part of the Bexar release, names for the Texas county, Cisco has joined OpenStack along with Canonical, Extreme Networks and Grid Dynamics.
Most significant, though, is the support for networking and virtualization platform with automatic configuration and portability between OpenStack cloud environments. The additions allow for streamlining of the installation process and the ability for users to pre-install and create their own application environments.
The full list of features in OpenStack Compute include support for:
- IPv6
- Hyper-V
- iSCSI with XenAPI
- XenServer snapshots and raw disk images
According to the OpenStack blog, the object storage release includes:
- Large objects (greater than 5 GB) can now be stored using OpenStack Object Storage. Introducing the concepts of client-side chunking and segmentation now allows virtually unlimited object sizes, limited only by the size of the cluster it is being stored into.
- An experimental S3 compatibility middleware has been added to OpenStack Object Storage.
- Swauth is a Swift compatible authentication and authorization service implemented on top of Swift. This allows the authorization system to scale as well as the underlying storage system and will replace the existing dev_auth service in a future release.
There is also a sub-project code-named Glance, an image discovery
and delivery service that enables portability of workloads between OpenStack clouds.The new release shows the impact cloud management technologies are having on the development of OpenStack. It is providing the automation capabilities for scaling open cloud environments. With that capability and open virtualization, OpenStack is becoming an alternative to proprietary environments
But will the momentum continue? There is a long way to go but this latest release shows that OpenStack is now a viable cloud platform, said George Reese, founder of enStratus in an interview today.
It also shows that OpenStack could b a viable alternative to VMware's vCloud Director, Reese said. He said he is seeing customers who are looking for alternatives to vCloud Director. OpenStack may fit the bill.
Robert Duffner continued his interview series on 2/3/2011 with Thought Leaders in the Cloud: Talking with Reuven Cohen, Founder and CTO of Enomaly:
Reuven Cohen [pictured at right] is the founder and CTO of Toronto-based Enomaly Inc. Founded in 2004, Enomaly develops cloud computing products and solutions, with a focus on service providers. The company's products include Enomaly ECP, a complete revenue-generating cloud platform that enables telcos and hosting providers to deliver infrastructure-on-demand (IaaS) cloud computing services to their customers. Reuven is also the founder of CloudCamp, which takes place at cities worldwide, and Cloud Interoperability Forum. He has consulted with the US, UK, Canadian, and Japanese governments on their cloud strategies.
In this interview, we cover:
- Cloud spot pricing.
- The places for commoditization and differentiation in cloud computing.
- While people think that with cloud, datacenter location doesn't matter, but the opposite is true. The cloud will allow ultra-localization.
- There will be many spot markets for cloud. Some private, and some public.
Robert Duffner: Could you take a moment to introduce yourself?
Reuven Cohen: Sure. I'm the co-founder and CTO at Enomaly Inc., here in Toronto, Ontario. I'm also the instigator of several other cloud-related activities, including Cloud Camp, which is a series of advocacy events held around the globe, in something like 150 locations at this point.
In very broad terms, I am involved with advocating the use and adoption of cloud computing, and I've been very involved in the cloud world for the last several years. The first version of our software was created in 2004, which predates things like Amazon EC2 by a number of years. We also helped define the U.S. Federal definition for cloud computing.
Most recently, we've launched SpotCloud, a spot market for cloud computing.
Robert: You've done a lot of thinking about cloud compute as a commodity. What are your current thoughts on this subject?
Reuven: Most providers of cloud computing resources don't want to be treated as commodity brokers. It's important to make the distinction that, while there is an opportunity around applying a sort of commodity economic model, that doesn't mean that all offerings are necessarily the same.
I've been trying to create a method in which you can commoditize certain computing resources, while not commoditizing the providers of those resources. That's the challenge we face.
Robert: Do you think that offerings in the cloud market are inherently something that's identical, no matter who produces them?
Reuven: The answer is yes and no. We fragment the cloud computing market into a few different pieces. First, at the top, there's software as a service, and to take advantage of software as a service offerings, you need to have a platform. So typically, you're building scalable systems on a platform provided as a service.
Underneath that, you need the actual interface to things like storage, networking, and CPU. Finally, you need an infrastructure that can be provided in an autonomous, easily managed way, so you need an infrastructure as a service. Those are, very generally speaking, the three main parts.
One key issue is the lack of standardization in any of those three parts at this point, although there are similarities. I have focused on the bottom-most layer, and my company provides infrastructure-as-a-service software to hosting providers.
The most basic capabilities required by all infrastructure-as-a-service providers are the ability to start a machine or a virtual machine, the ability to stop a virtual machine, and the ability to handle networking requirements.
When we started to look at commoditizing these functions, we focused on the idea that any infrastructure-as-a-service provider is going to have those three basic requirements, and we created a marketplace that commoditizes those three things.
So we provide the ability to find a cloud provider anywhere in the world based on price and geographic location. That location could be as broad as a whole continent or as narrow as a specific city. For example, we could choose Seoul and deliver a raw disk image that could run on any virtual environment or even actually potentially on a physical environment. We commoditized it based on those criteria.
Robert: You have also said, "To avoid directly competing with regular retail sales of cloud services, spot cloud uses an opaque sales model." Can you take a minute to explain what that means?
Reuven: To understand that, I should probably start with a bit of background on how the spot cloud product came to be. As I mentioned previously, we were one of the first infrastructure-as-a-service companies out there. We created the first version in 2004 and adapted over the years based on the emergence of cloud computing.
Our current customers are generally public cloud-service providers, and most of them are outside of North America. Many of them have just built clouds and hoped that customers would adopt their platforms, but the reality is that they actually need to market their platforms, services, and so forth.
That created a dilemma for us, in the sense that, in order to be successful, we need our customers to grow, and grow quickly. In order to do that, they need to increase their utilization levels, and that doesn't always happen. We were seeing fluctuations in utilization levels based on factors such as time of day, how successfully they were selling services in various parts of the world, and so on.
We needed a way to help our customers increase their utilization rates, making them successful, which ultimately benefits us as well, of course. We had to avoid cannibalizing their retail sales, and in looking at various models, one that really jumped out at us was the concept of an opaque market.
In this model, the buyer specifies what they want to buy, in terms of a quality rating, an amount of RAM, a number of processors, and so on, but they don't actually know who they're buying from until after they've agreed to buy.
And that provides the ability to avoid cannibalizing your existing retail sales, which makes it attractive to service providers who are obviously not keen to sell something that could sell otherwise at a higher margin.
Robert: You recently tweeted that it looks like the top one percent of spot cloud buyers represent 99 percent of the capacity purchased. Can you expand on that?
Reuven: I freely admit that I'm learning a lot in this whole process. First of all, I never expected the amount of interest in this platform that we've received. It's been astounding. We've had so much interest from both the buy and sell sides that it's been spectacular.
And in a sense, we're the first to ever really try this opaque spot market for excess compute capacity, so we don't really have a lot to base the actual business model on. We're learning as we go, and we're also getting a lot of market research done in terms of people who are signing up for it on both the buy and sell sides.
There appear to be some really interesting use cases on the buy side. People who want to buy capacity often need very large amounts of tasking for a very short time, but they're very concerned about where that tasking is.
Consider the case where I need to task a platform or application that I am going to be launching next week. If I get a million users from a particular city, let's say Paris, I want to know how that application performs for a million users from Paris. Although we have a maximum number of people firing up on the buy side, there are likely to be a few in particular who utilize significantly more capacity than the others.
Robert: So infrastructure tends to gravitate toward being a commodity, whereas solutions are differentiated specialty items. Platform as a service is probably somewhere in between. Where do you see platform and software as a service fitting in the future where a significant amount of raw compute is available as a commodity?
Reuven: I was talking to one of our partners a while back, and I asked him what he thinks the future holds for of infrastructure as a service. His answer was, "Platform as a service." The value is in the implementation of the infrastructure, and infrastructure becomes a commodity because that's what it's there to do.
Where some people look for globalization, I look at it the opposite. I look at ultra-localization, or regionalization, which is the ability to adapt to the constraints and fluctuations on the ground in particular places. If I am having a lot of sales success in Tokyo, it makes little sense for me to scale my infrastructure in London. It makes sense for me to scale my infrastructure where my customers are.
If my customers have a better experience on my platform or my application, I'm going to have a happier customer, better sales, more return users, and a more successful company. And that's the opportunity that this cloud of clouds, or this regionalization of compute resources, is really enabling.
The reality of today is that we've got one-size-fits-all clouds, but that's not where we're going. We can't just blindly scale for everyone, anywhere.
Robert: When I'm out meeting customers, we talk about infrastructure, platform, and software as a service. I'm seeing the lines blurring between infrastructure and platform as a service. Heroku, which offers a platform as a service, but built on Amazon infrastructure, is a really good example of that.
Reuven: That's true, and the fact that Microsoft has been building data centers around the globe is a good indication of where things are moving. We're moving to a network-based world where unfortunately, the desktop is less important than the app. The Internet is the platform, and the location matters. I think you're right that there is a blurring of where the underlying infrastructure is and where the platform is.
Ultimately, I think that when we talk about cloud computing, we're really talking about the Internet as the operating environment.
Robert: Last February, James Urquhart wrote a post called "Cloud Computing and Commodity," where he states that commoditization will happen at a granular level. He says, "technologies will standardize various components and features, but services themselves can and will be differentiated and often add significant value over those base capabilities." What are your thoughts on that?
Reuven: I completely agree. I think he's saying that it's the application that matters, not the infrastructure. If you look at the companies that are most successful today, they are the ones who are able to adapt quickly. They are the ones who are able to take mountains of data and transform them into information, because it's not the data that matters, it's the information. That transformation of data requires an adequate amount of computing resources to actually work on that transformation.
The cloud provides the basic engine that enables anyone with a credit card to compete with the largest companies on the globe. Anyone with a really good idea can scale quickly and efficiently, and that is revolutionary in a lot of ways.
Robert: Some data centers meet certain levels of regulatory compliance, and others don't. Because some applications are governed by very specific regulations, I run into a lot of examples where customers are fundamentally prohibited from putting certain kinds of data in a public cloud. How does that factor into a spot market?
Reuven: As I mentioned before, we're learning as we go here, and a lot of the specifications for clouds being built are the result of requests from end customers. One interesting possibility is a sort of private exchange, or private spot market, for companies that are all governed by similar regulatory controls.
Those requirements could be based on an industry vertical, or they could be based on geography, for example. The European Union has introduced requirements that compute capacity on exchanges must be located within the EU.
I think we're going to see rapid evolution in the area of specialized requirements such as these, and that's going to be quite an exciting part of this new opportunity.
Robert: One of our major data centers is located in San Antonio, and one of the customers there is the taxing authority for their country, i.e., the equivalent of our IRS. Starting this year, they're going to automate the electronic storage of invoices for tax purposes. So, for example, if you go to Wal Mart and purchase office supplies, all those receipts get stored in the cloud. It blows me away that they're storing them in the United States.
As far as I know, they are the only government that's doing this, but I wonder what it could mean, as a case study to other governments. They might see the need to look at getting past regulations to deliver innovative solutions to their citizens.
Reuven: It shows that their government is treating their tax IT system in the same way a business would. So when you look at the opportunities in business, you'll see a French company hosting their data in United States, not because it is in the United States but because they can get the best price, so they can get the best bandwidth, and they can get a deal that works best for them as a business.
The problem for a lot of governments is that they're constrained by the regulatory controls of their own country. Particularly in countries that may be referred to as having fast-growing or emerging economies, they don't have that infrastructure in place. They've got one of two options: either to build infrastructure at great cost or go find the infrastructure somewhere else and hopefully not put their mission-critical data in there.
In Canada, we actually have the exact opposite problem, although we do have a much more developed infrastructure. Basically the Canadian government says you can't host Canadian government data, websites, and so on outside the Canadian geography.
That's also an opportunity for cloud providers, and that's why Microsoft is spending billions of dollars on data centers all over the world. You might build cloud data points in Mexico, Japan, and Korea so you can serve those local populations better.
Robert: Do you see certain aspects of cloud, such as storage for example being commoditized faster than things like compute?
Reuven: Well, storage has always been more easily commoditized because of the file system. The big differentiation we have today is the object-based approach versus that traditional approach that I always call the POSIX style.
They both solve different problems, but POSIX is a perfect example of commoditization. We've got a general way to interact with file system. I think it certainly is easier in some regards, because it is lower in the stack, and I think the lower in the stack you get, the easier it is to commoditize. The object-based approach was popularized by things like Amazon S3.
Robert: Obviously, it's a lot harder to take existing applications and move them to the cloud versus architecting a brand new application for the cloud. At the same time, the specific operating system and type of hardware that you're running are becoming less important.
How do you think that's going to impact how development languages are going to play into cloud application development? I'm anxious to see if that's going to change the adoption of certain languages that are used to write cloud applications. Do you have any thoughts on that?
Reuven: That inevitably leads to the question of lock in, and specifically where and how you are going to be locked in. The answer isn't a simple one. Regardless of the platform, at some point you're always going to have to choose a programming language, a development environment, and a number of other things.
The question is what that means down the road, when the technologies inevitably evolve. Generally, my rule of thumb is that the value is going to be in your information and how easily and readily you can work with that information.
Developers making those sorts of decisions must always ask themselves how easily they can take their information, move it, and work on it somewhere else. Where possible, you should develop in such a way that you don't care about any particular machine, whether it's physical or virtual. You should build applications to consider that the underlying architecture may come and go.
Likewise, you should build fault tolerance into applications that takes into consideration that you may lose a node, or even part of the world. That shouldn't affect the overall availability of the application. The Internet should be applied as an architectural model, and the cloud is a metaphor for the Internet in a lot of ways.
Robert: Where are you seeing the most uptake or developer interest with regard to cloud apps; is it Ruby, Java, Python?
Reuven: Programming has always been a personal relationship, and it goes through phases. Ultimately, most programming languages do the same thing, just in slightly different ways. For example, we're a big Python shop. I like Python as a CTO because I can read it and understand it. I don't do much programming anymore, and so I just look at it occasionally.
I don't think you should be constrained by the popularity of any given particular programming language. You should choose what works best with your brain.
Robert: Do you have any closing thoughts?
Reuven: I think we are on the verge of the transformation to really treating computing resources like a commodity, the same way we treat energy. Eventually, we will have the ability to do things like futures, derivatives, and buying and selling things that may not exist today.
But you can't do that until you have a spot market, so the first step in this commoditization of computing is to be able to sell what is available right now, and that's the spot market. The next step is going to involve things like futures and derivatives. I think that that's going to happen in the short term, and there's a lot of interest in this from a whole variety of sectors.
I believe that computing resources are going to be the next big commodity market. All the signs I see today are pointing in that general direction, so it's a pretty exciting place to be.
Robert: Thanks, Reuven. This has been a great talk.
Reuven: Thank you.
Derrick Harris reported CloudBees Java Platform Is Open for Business in a 1/31/2011 post to Giga Om’s Structure blog:
Just two months after announcing its initial funding and a month after hurriedly closing a deal to acquire competitor Stax Networks (in response to Red Hat (s rht) buying Makara and Salesforce.com (s crm) buying Heroku), CloudBees’ RUN@cloud Java (s orcl) Platform-as-a-Service (PaaS) is available for public use. CloudBees, which is headquartered in Lewes, Del., should be commended for such fast turnaround on its mission to integrate its technology with the existing Stax Networks platform and make the offering available while some other Java-focused PaaS options are still in development.
As I detailed shortly after CloudBees announced its presence in November 2010 with $4 million in funding, there are plenty of PaaS offerings now supporting Java, although very few support Java only. By buying Stax Networks, CloudBees reduced that number by one. Presently, RUN@cloud is the only Java-only PaaS ready for public consumption — CumuLogic’s software will enter its beta period in a few weeks, and we haven’t heard much about VMforce (s vmw) since Salesforce.com and VMware announced it to much pomp and circumstance last April. Amazon Web Services’ (s amzn) Elastic Beanstalk also deserves mention, although it intentionally offers more administrative control than do most PaaS offerings, which use abstraction as a selling point.
Here’s a refresher on CloudBees and why it thinks it’s prepared to be a leading voice in the cloud computing community: The company has strong JBoss ties, with former JBoss CTO Sacha Labourey serving as CEO; JBoss founder Marc Fleury and JBoss EVP Bob Bickel are investors, and Bickel is a CloudBees adviser. RUN@cloud is infrastructure-agnostic software, which means it can run pretty much wherever customers prefer to run it, including on an internal cloud, and Labourey told me in December that it will expand its Java support in the near term before expanding into supporting multiple languages. CloudBees also offers a development platform called DEV@cloud, which is based on the Jenkins (formerly “Hudson”) continuous integration tool.
The race is on to see which PaaS offering(s) will win the hearts and minds of Java developers. Each is a little different and each has its unique value proposition, and it’s entirely possible, actually, that there will be plenty of Java development business to go around. But the first step is to make the product available and start luring developers, and, among Java-only platforms, CloudBees is certainly a frontrunner in that regard.
Image courtesy of Flickr user trawin.
Related content from GigaOM Pro (sub req’d):
Guy Harrison posted Real World NoSQL: MongoDB at Shutterfly to Giga Om’s Structure blog on 1/28/2010 (missed when published):
Edit Note: This is the second on a multi-part series of posts exploring the use cases for NoSQL deployments in the real world. Other published case studies include Hbase and Cassandra.
With all the excitement surrounding the relatively recent wave of non-relational – otherwise known as “NoSQL” – databases, it can be hard to separate the hype from the reality. There’s a lot of talk, but how much NoSQL action is there in the real world? In this series, we’ll take a look at some real-world NoSQL deployments.
Initially, Shutterfly considered open-source databases like MySQL and PostgreSQL. However, during the evaluation and concurrent re-architecting of the application, it became apparent that a non-relational database might be a better fit for Shutterfly’s data needs, potentially improving programmer productivity as well as performance and scalability. “There are tradeoffs, so we had to convince ourselves that a less mature non-transactional data store would work,” says Gorman.
Shutterfly looked at a wide variety of alternative database systems, including Cassandra, CouchDB and BerkeleyDB, before settling on the MongoDB document-oriented database. MongoDB stores data in a variant of the JSON (JavaScript Object Notation) format; each document is self describing and can have a complex internal structure.
The document approach matched the Shutterfly XML format while providing scale-out and failover replication. Moving to a document model wasn’t that big a step, according to Gorman: “If you are at the kind of scale where you would be looking at MongoDB, then you probably already have figured out you need to de-normalize your data.”
Like most NoSQL solutions, MongoDB provides a very different model for transactions and consistency – generally not providing immediately consistent or multi-object transactions. Consequently, Shutterfly has deployed MongoDB only for those parts of the application where strict consistency isn’t critical, such as the metadata associated with uploaded photos. For those parts of the application which require stronger consistency, or a richer transactional model – billing and account management perhaps– the traditional RDBMS is still in place. Those parts of the application that were moved to MongoDB were re-engineered with the simpler transactional model in mind.
Despite the significant effort and risks that accompany such a significant architectural shift, Shutterfly reports significant payoffs in terms of time-to-market, cost and performance. Furthermore, MongoDB has relieved a mismatch between the object model used by the application and the underlying database model. In the relational world, this mismatch is usually hidden by the Object Relational Mapping (ORM) which translates between the object and relational models. However, this obfuscation leads to performance and manageability issues. With MongoDB “you have an optimized stack, no ORM complexity, and you have better overall performance,” says Gorman. “At least that’s the hope.”
The compromises required by MongoDB – changes to the data model and transactional paradigms in particular – have required Shutterfly to make significant engineering investments. But so far, Shutterfly is happy with its decision. “I am a firm believer in choosing the correct tool for the job, and MongoDB was a nice fit, but not without compromises,” says Gorman. “In our case, those compromises were relatively small.”
Guy Harrison is a director of research and development at Quest Software, and has over 20 years of experience in database design, development, administration, and optimization. He can be found on the internet at www.guyharrison.net, on e-mail at guy.harrison@quest.com and is @guyharrison on twitter.
Related content from GigaOM Pro (sub req’d):

Todd Hoff’s monumental What the heck are you actually using NoSQL for? post of 12/6/2011 to the High Scalability blog appeared in my Atom/RSS feed reader today. This article is repeated here because I believe it’s the most comprehensive analysis of NoSQL use cases to appear so far:
It's a truism that we should choose the right tool for the job. Everyone says that. And who can disagree? The problem is this is not helpful advice without being able to answer more specific questions like: What jobs are the tools good at? Will they work on jobs like mine? Is it worth the risk to try something new when all my people know something else and we have a deadline to meet? How can I make all the tools work together?
In the NoSQL space this kind of real-world data is still a bit vague. When asked, vendors tend to give very general answers like NoSQL is good for BigData or key-value access. What does that mean for for the developer in the trenches faced with the task of solving a specific problem and there are a dozen confusing choices and no obvious winner? Not a lot. It's often hard to take that next step and imagine how their specific problems could be solved in a way that's worth taking the trouble and risk.
Let's change that. What problems are you using NoSQL to solve? Which product are you using? How is it helping you? Yes, this is part the research for my webinar on December 14th, but I'm a huge believer that people learn best by example, so if we can come up with real specific examples I think that will really help people visualize how they can make the best use of all these new product choices in their own systems.
Here's a list of uses cases I came up with after some trolling of the interwebs. The sources are so varied I can't attribute every one, I'll put a list at the end of the post. Please feel free to add your own. I separated the use cases out for a few specific products simply because I had a lot of uses cases for them they were clearer out on their own. This is not meant as an endorsement of any sort. Here's a master list of all the NoSQL products. If you would like to provide a specific set of use cases for a product I'd be more than happy to add that in.
General Use Cases
These are the general kinds of reasons people throw around for using NoSQL. Probably nothing all that surprising here.
- Bigness. NoSQL is seen as a key part of a new data stack supporting: big data, big numbers of users, big numbers of computers, big supply chains, big science, and so on. When something becomes so massive that it must become massively distributed, NoSQL is there, though not all NoSQL systems are targeting big. Bigness can be across many different dimensions, not just using a lot of disk space.
- Massive write performance. This is probably the canonical usage based on Google's influence. High volume. Facebook needs to store 135 billion messages a month. Twitter, for example, has the problem of storing 7 TB/data per day with the prospect of this requirement doubling multiple times per year. This is the data is too big to fit on one node problem. At 80 MB/s it takes a day to store 7TB so writes need to be distributed over a cluster, which implies key-value access, MapReduce, replication, fault tolerance, consistency issues, and all the rest. For faster writes in-memory systems can be used.
- Fast key-value access. This is probably the second most cited virtue of NoSQL in the general mind set. When latency is important it's hard to beat hashing on a key and reading the value directly from memory or in as little as one disk seek. Not every NoSQL product is about fast access, some are more about reliability, for example. but what people have wanted for a long time was a better memcached and many NoSQL systems offer that.
- Flexible schema and flexible datatypes. NoSQL products support a whole range of new data types, and this is a major area of innovation in NoSQL. We have: column-oriented, graph, advanced data structures, document-oriented, and key-value. Complex objects can be easily stored without a lot of mapping. Developers love avoiding complex schemas and ORM frameworks. Lack of structure allows for much more flexibility. We also have program and programmer friendly compatible datatypes likes JSON.
- Schema migration. Schemalessness makes it easier to deal with schema migrations without so much worrying. Schemas are in a sense dynamic, because they are imposed by the application at run-time, so different parts of an application can have a different view of the schema.
- Write availability. Do your writes need to succeed no mater what? Then we can get into partitioning, CAP, eventual consistency and all that jazz.
- Easier maintainability, administration and operations. This is very product specific, but many NoSQL vendors are trying to gain adoption by making it easy for developers to adopt them. They are spending a lot of effort on ease of use, minimal administration, and automated operations. This can lead to lower operations costs as special code doesn't have to be written to scale a system that was never intended to be used that way.
- No single point of failure. Not every product is delivering on this, but we are seeing a definite convergence on relatively easy to configure and manage high availability with automatic load balancing and cluster sizing. A perfect cloud partner.
- Generally available parallel computing. We are seeing MapReduce baked into products, which makes parallel computing something that will be a normal part of development in the future.
- Programmer ease of use. Accessing your data should be easy. While the relational model is intuitive for end users, like accountants, it's not very intuitive for developers. Programmers grok keys, values, JSON, Javascript stored procedures, HTTP, and so on. NoSQL is for programmers. This is a developer led coup. The response to a database problem can't always be to hire a really knowledgeable DBA, get your schema right, denormalize a little, etc., programmers would prefer a system that they can make work for themselves. It shouldn't be so hard to make a product perform. Money is part of the issue. If it costs a lot to scale a product then won't you go with the cheaper product, that you control, that's easier to use, and that's easier to scale?
- Use the right data model for the right problem. Different data models are used to solve different problems. Much effort has been put into, for example, wedging graph operations into a relational model, but it doesn't work. Isn't it better to solve a graph problem in a graph database? We are now seeing a general strategy of trying find the best fit between a problem and solution.
- Avoid hitting the wall. Many projects hit some type of wall in their project. They've exhausted all options to make their system scale or perform properly and are wondering what next? It's comforting to select a product and an approach that can jump over the wall by linearly scaling using incrementally added resources. At one time this wasn't possible. It took custom built everything, but that's changed. We are now seeing usable out-of-the-box products that a project can readily adopt.
- Distributed systems support. Not everyone is worried about scale or performance over and above that which can be achieved by non-NoSQL systems. What they need is a distributed system that can span datacenters while handling failure scenarios without a hiccup. NoSQL systems, because they have focussed on scale, tend to exploit partitions, tend not use heavy strict consistency protocols, and so are well positioned to operate in distributed scenarios.
- Tunable CAP tradeoffs. NoSQL systems are generally the only products with a "slider" for choosing where they want to land on the CAP spectrum. Relational databases pick strong consistency which means they can't tolerate a partition failure. In the end this is a business decision and should be decided on a case by case basis. Does your app even care about consistency? Are a few drops OK? Does your app need strong or weak consistency? Is availability more important or is consistency? Will being down be more costly than being wrong? It's nice to have products that give you a choice.
More Specific Use Cases
- Managing large streams of non-transactional data: Apache logs, application logs, MySQL logs, clickstreams, etc.
- Syncing online and offline data. This is a niche CouchDB has targeted.
- Fast response times under all loads.
- Avoiding heavy joins for when the query load for complex joins become too large for a RDBMS.
- Soft real-time systems where low latency is critical. Games are one example.
- Applications where a wide variety of different write, read, query, and consistency patterns need to be supported. There are systems optimized for 50% reads 50% writes, 95% writes, or 95% reads. Read-only applications needing extreme speed and resiliency, simple queries, and can tolerate slightly stale data. Applications requiring moderate performance, read/write access, simple queries, completely authoritative data. Read-only application which complex query requirements.
- Load balance to accommodate data and usage concentrations and to help keep microprocessors busy.
- Real-time inserts, updates, and queries.
- Hierarchical data like threaded discussions and parts explosion.
- Dynamic table creation.
- Two tier applications where low latency data is made available through a fast NoSQL interface, but the data itself can be calculated and updated by high latency Hadoop apps or other low priority apps.
- Sequential data reading. The right underlying data storage model needs to be selected. A B-tree may not be the best model for sequential reads.
- Slicing off part of service that may need better performance/scalability onto it's own system. For example, user logins may need to be high performance and this feature could use a dedicated service to meet those goals.
- Caching. A high performance caching tier for web sites and other applications. Example is a cache for the Data Aggregation System used by the Large Hadron Collider.
- Voting.
- Real-time page view counters.
- User registration, profile, and session data.
- Document, catalog management and content management systems. These are facilitated by the ability to store complex documents has a whole rather than organized as relational tables. Similar logic applies to inventory, shopping carts, and other structured data types.
- Archiving. Storing a large continual stream of data that is still accessible on-line. Document-oriented databases with a flexible schema that can handle schema changes over time.
- Analytics. Use MapReduce, Hive, or Pig to perform analytical queries and scale-out systems that support high write loads.
- Working with heterogenous types of data, for example, different media types at a generic level.
- Embedded systems. They don’t want the overhead of SQL and servers, so they uses something simpler for storage.
- A "market" game, where you own buildings in a town. You want the building list of someone to pop up quickly, so you partition on the owner column of the building table, so that the select is single-partitioned. But when someone buys the building of someone else you update the owner column along with price.
- JPL is using SimpleDB to store rover plan attributes. References are kept to a full plan blob in S3.
- Federal law enforcement agencies tracking Americans in real-time using credit cards, loyalty cards and travel reservations.
- Fraud detection by comparing transactions to known patterns in real-time.
- Helping diagnose the typology of tumors by integrating the history of every patient.
- In-memory database for high update situations, like a web site that displays everyone's "last active" time (for chat maybe). If users are performing some activity once every 30 sec, then you will be pretty much be at your limit with about 5000 simultaneous users.
- Handling lower-frequency multi-partition queries using materialized views while continuing to process high-frequency streaming data.
- Priority queues.
- Running calculations on cached data, using a program friendly interface, without have to go through an ORM.
- Unique a large dataset using simple key-value columns.
- To keep querying fast, values can be rolled-up into different time slices.
- Computing the intersection of two massive sets, where a join would be too slow.
- A timeline ala Twitter.
Redis Use Cases
Redis is unique in the repertoire as it is a data structure server, with many fascinating use cases that people are excited to share.
- Calculating whose friends are online using sets.
- Memcached on steroids.
- Distributed lock manager for process coordination.
- Full text inverted index lookups.
- Tag clouds.
- Leaderboards. Sorted sets for maintaining high score tables.
- Circular log buffers.
- Database for university course availability information. If the set contains the course ID it has an open seat. Data is scraped and processed continuously and there are ~7200 courses.
- Server for backed sessions. A random cookie value which is then associated with a larger chunk of serialized data on the server) are a very poor fit for relational databases. They are often created for every visitor, even those who stumble in from Google and then leave, never to return again. They then hang around for weeks taking up valuable database space. They are never queried by anything other than their primary key.
- Fast, atomically incremented counters are a great fit for offering real-time statistics.
- Polling the database every few seconds. Cheap in a key-value store. If you're sharding your data you'll need a central lookup service for quickly determining which shard is being used for a specific user's data. A replicated Redis cluster is a great solution here - GitHub use exactly that to manage sharding their many repositories between different backend file servers.
- Transient data. Any transient data used by your application is also a good fit for Redis. CSRF tokens (to prove a POST submission came from a form you served up, and not a form on a malicious third party site, need to be stored for a short while, as does handshake data for various security protocols.
- Incredibly easy to set up and ridiculously fast (30,000 read or writes a second on a laptop with the default configuration)
- Share state between processes. Run a long running batch job in one Python interpreter (say loading a few million lines of CSV in to a Redis key/value lookup table) and run another interpreter to play with the data that’s already been collected, even as the first process is streaming data in. You can quit and restart my interpreters without losing any data.
- Create heat maps of the BNP’s membership list for the Guardian
- Redis semantics map closely to Python native data types, you don’t have to think for more than a few seconds about how to represent data.
- That’s a simple capped log implementation (similar to a MongoDB capped collection)—push items on to the tail of a ’log’ key and use ltrim to only retain the last X items. You could use this to keep track of what a system is doing right now without having to worry about storing ever increasing amounts of logging information.
- An interesting example of an application built on Redis is Hurl, a tool for debugging HTTP requests built in 48 hours by Leah Culver and Chris Wanstrath.
- It’s common to use MySQL as the backend for storing and retrieving what are essentially key/value pairs. I’ve seen this over-and-over when someone needs to maintain a bit of state, session data, counters, small lists, and so on. When MySQL isn’t able to keep up with the volume, we often turn to memcached as a write-thru cache. But there’s a bit of a mis-match at work here.
- With sets, we can also keep track of ALL of the IDs that have been used for records in the system.
- Quickly pick a random item from a set.
- API limiting. This is a great fit for Redis as a rate limiting check needs to be made for every single API hit, which involves both reading and writing short-lived data.
- A/B testing is another perfect task for Redis - it involves tracking user behaviour in real-time, making writes for every navigation action a user takes, storing short-lived persistent state and picking random items.
- Implementing the inbox method with Redis is simple: each user gets a queue (a capped queue if you're worried about memory running out) to work as their inbox and a set to keep track of the other users who are following them. Ashton Kutcher has over 5,000,000 followers on Twitter - at 100,000 writes a second it would take less than a minute to fan a message out to all of those inboxes.
- Publish/subscribe is perfect for this broadcast updates (such as election results) to hundreds of thousands of simultaneously connected users. Blocking queue primitives mean message queues without polling.
- Have workers periodically report their load average in to a sorted set.
- Redistribute load. When you want to issue a job, grab the three least loaded workers from the sorted set and pick one of them at random (to avoid the thundering herd problem).
- Multiple GIS indexes.
- Recommendation engine based on relationships.
- Web-of-things data flows.
- Social graph representation.
- Dynamic schemas so schemas don't have to be designed up-front. Building the data model in code, on the fly by adding properties and relationships, dramatically simplifies code.
- Reducing the impedance mismatch because the data model in the database can more closely match the data model in the application.
VoltDB Use Cases
VoltDB as a relational database is not traditionally thought of as in the NoSQL camp, but I feel based on their radical design perspective they are so far away from Oracle type systems that they are much more in the NoSQL tradition.
- Application: Financial trade monitoring
- Data source: Real-time markets
- Partition key: Market symbol (ticker, CUSIP, SEDOL, etc.)
- High-frequency operations: Write and index all trades, store tick data (bid/ask)
- Lower-frequency operations: Find trade order detail based on any of 20+ criteria, show TraderX's positions across all market symbols
- Application: Web bot vulnerability scanning (SaaS application)
- Data source: Inbound HTTP requests
- Partition key: Customer URL
- High-frequency operations: Hit logging, analysis and alerting
- Lower-frequency operations: Vulnerability detection, customer reporting
- Application: Online gaming leaderboard
- Data source: Online game
- Partition key: Game ID
- High-frequency operations: Rank scores based on defined intervals and player personal best
- Lower-frequency transactions: Leaderboard lookups
- Application: Package tracking (logistics)
- Data source: Sensor scan
- Partition key: Shipment ID
- High-frequency operations: Package location updates
- Lower-frequency operations: Package status report (including history), lost package tracking, shipment rerouting
- Application: Ad content serving
- Data source: Website or device, user or rule triggered
- Partition key: Vendor/ad ID composite
- High-frequency operations: Check vendor balance, serve ad (in target device format), update vendor balance
- Lower-frequency operations: Report live ad view and click-thru stats by device (vendor-initiated)
- Application: Telephone exchange call detail record (CDR) management
- Data source: Call initiation request
- Partition key: Caller ID
- High-frequency operations: Real-time authorization (based on plan and balance)
- Lower-frequency operations: Fraud analysis/detection
- Application: Airline reservation/ticketing
- Data source: Customers (web) and airline (web and internal systems)
- Partition key: Customer (flight info is replicated)
- High-frequency operations: Seat selection (lease system), add/drop seats, baggage check-in
- Lower-frequency operations: Seat availability/flight, flight schedule changes, passenger re-bookings on flight cancellations
Analytics Use Cases
Kevin Weil at Twitter is great at providing Hadoop use cases. At Twitter this includes counting big data with standard counts, min, max, std dev; correlating big data with probabilities, covariance, influence; and research on Big data. Hadoop is on the fringe of NoSQL, but it's very useful to see what kind of problems are being solved with it.
- How many request do we serve each day?
- What is the average latency? 95% latency?
- Grouped by response code: what is the hourly distribution?
- How many searches happen each day at Twitter?
- Where do they come from?
- How many unique queries?
- How many unique users?
- Geographic distribution?
- How does usage differ for mobile users?
- How does usage differ for 3rd party desktop client users?
- Cohort analysis: all users who signed up on the same day—then see how they differ over time.
- Site problems: what goes wrong at the same time?
- Which features get users hooked?
- Which features do successful users use often?
- Search corrections and suggestions (not done now at Twitter, but coming in the feature).
- What can web tell about a user from their tweets?
- What can we tell about you from the tweets of those you follow?
- What can we tell about you from the tweets of your followers?
- What can we tell about you from the ratio of your followers/following?
- What graph structures lead to successful networks? (Twitter’s graph structure is interesting since it’s not two-way)
- What features get a tweet retweeted?
- When a tweet is retweeted, how deep is the corresponding retweet three?
- Long-term duplicate detection (short term for abuse and stopping spammers)
- Machine learning. About not quite knowing the right questions to ask at first. How do we cluster users?
- Language detection (contact mobile providers to get SMS deals for users—focusing on the most popular countries at first).
- How can we detect bots and other non-human tweeters?
Poor Use Cases
- OLTP. Outside VoltDB, complex multi-object transactions are generally not supported. Programmers are supposed to denormalize, use documents, or use other complex strategies like compensating transactions.
- Data integrity. Most of the NoSQL systems rely on applications to enforce data integrity where SQL uses a declarative approach. Relational databases are still the winner for data integrity.
- Data independence. Data outlasts applications. In NoSQL applications drive everything about the data. One argument for the relational model is as a repository of facts that can last for the entire lifetime of the enterprise, far past the expected life-time of any individual application.
- SQL. If you require SQL then very few NoSQL system will provide a SQL interface, but more systems are starting to provide SQLish interfaces.
- Ad-hoc queries. If you need to answer real-time questions about your data that you can’t predict in advance, relational databases are generally still the winner.
- Complex relationships. Some NoSQL systems support relationships, but a relational database is still the winner at relating.
- Maturity and stability. Relational databases still have the edge here. People are familiar with how they work, what they can do, and have confidence in their reliability. There are also more programmers and toolsets available for relational databases. So when in doubt, this is the road that will be traveled.
Related Articles
- Hacker News and Reddit thread on this Post. More use case suggestions there.
- List of NoSQL Systems
- Pig - infrastructure to support ad-hoc analysis of very large data sets.
- Digging Deeper Into Data With Hadoop By Gary Orenstein
- NoSQL East 2009 - Summary of Day 1 by Eivind Uggedal
- The “NoSQL” approach: struggling to see the benefits by Neil Saunders
- Design Patterns for DistributedNon-Relational Databases by Todd Lipcon.
- The Future Is Big Data in the Cloud By Ping Li
- One size does not fit all: “document stores”, “nosql databases” , ODBMSs by Roberto V. Zicari
- NoSQL is for niches By Dana Blankenhorn.
- MongoDB Use Cases
- MongoDB and Ecommerce by Kyle Banker
- Archiving - a good MongoDB use case?
- Five Reasons to Use NoSQL by Jeremiah Peschka
- The Business Case for NoSQL, NoETL and NoProblems by Loraine Lawson
- Is It Time For NoETL? by Seth Grimes
- Holy Large Hadron Collider, Batman!
- I Can't Wait for NoSQL to Die by Ted Dziuba.
- NoSQL Basics, Benefits and Best-Fit Scenarios by Curt Monash
- Redis Tutorial by Simon Willison
- Why I Like Redis by Simon Willison
- Redis: Lightweight key/value Store That Goes the Extra Mile by Jeremy Zawodny
- Remote Dictionary Server
- Is NoSQL for me? I’m just a small fish by Hadi Hariri
- Why Big Enterprises are Interested in NoSQL by Jon Moore
- Visual Guide to NoSQL Systems by Nathan Hurst
- You Can't Sacrifice Partition Tolerance by Coda Hale
- NoSQL Netflix Use Case Comparison by Adrian Cockcroft
- Comparison guide of horizontally scalable datastores by Rick Cattell
- Weak Consistency and CAP Implications by Ilya Grigorik
- Schema-Free MySQL vs NoSQL by Ilya Grigorik
- Neo4j - 5 Cool Graph Examples
- Has anyone used Graph-based Databases
- Neotechnology Uses Cases
- CouchOne Ataxo Case Study
- NOSQL: scaling to size and scaling to complexity by Emil Eifrem
- NoSQL, NoProblem (Not Really… but it’s still awesome) by Jeremy Pinkham
- An Expert's Guide to Oracle Technology by Lewis Cunningham
- NoSQL vs SQL, Why Not Both? By Alaric Snell-Pym
- Databases: relational vs object vs graph vs document by On Target
- Use cases are driving the divergence, and the convergence, of NoSQL solutions by James Phillips
- The beginning of the end of NoSQL by Matthew Aslett
- Going NoSQL with MongoDB by Ted Neward
- NoSQL Ecosystem by Jonathan Ellis
- The New Dimension of NoSQL Scalability: Complexity by Alex Popescu
- Quick Reference to Alternative data storages by Alex Popescu
- 6 Reasons Why Relational Database Will Be Superseded by Robin Bloor
- NoSQL Misconceptions by Ben Scofield
- SQL Databases Don't Scale by Adam Wiggins
- “One Size Fits All”: An Idea Whose Time Has Come and Gone by Michael Stonebraker and Uğur Çetintemel
- Future of RDBMS is RAM Clouds & SSD by Ilya Grigorik
To scale or not to scale: Key/Value, Document, SQL, JPA by Uri Cohen

Tod’s NoSQL bibliography alone is worth the price of admission.
<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment