Windows Azure and Cloud Computing Posts for 7/24/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

• Updated 7/25/2010 by adding:
- A cloud computing review article by Michael J. Miller in the Windows Azure Platform Appliance (WAPA) section
- A 00:13:02 video archive of Jean Paoli’s “Open Cloud, Open Data” OSCON 2010 keynote in the Windows Azure Infrastructure section,
- Microsoft Project Code-Named “Houston” Services Community Technology Preview Privacy Statement and Dilip Krishnan’s review of Alex James’s series of blog posts about OData services authentication techniques in the SQL Azure Database, Codename “Dallas” and OData section
- Anne Taylor’s How to Move Two-Factor Authentication into the Clouds podcast from ComputerWorld for VeriSign in the Cloud Security and Governance section
- Why OpenStack Has its Work Cut Out by Derrick Harris for GigiOm in the Other Cloud Computing Platforms and Services section
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Azure Blob, Drive, Table and Queue Services
Steven Nagy deep-dives into Azure Table Storage in his Table Storage Retrieval Patterns post of 7/24/2010 to his Above the Cloud blog:
Overview Of Tables
There are three kinds of storage in Windows Azure: Tables, Blobs, and Queues. Blobs are binary large objects and Queues are robust enterprise level communication queues. Tables are non-relational entity storage mechanisms. All storage is three times redundant and available via REST using the ATOM format.
Tables can store multiple entities with different kinds of shapes. That is to say, you can safely store 2 objects in a table that look completely different. For example, a Product entity might have a name and a category, whereas a User entity might have name, date of birth, and login name properties. Despite the difference between these two objects, they can both be stored in the same table in Windows Azure Table Storage.
Some of the reasons we prefer to use Table storage over other database mechanisms (such as Sql Azure) is that it is optimised for performance and scalability. It achieves this through an innate partitioning mechanism based on an extra property assigned to the object, called ‘Partition Key’. Five objects each with different partition keys that are otherwise identical, will be stored on five different storage nodes.
There are a number of ways we can get and put entities into our table storage, and this article will address a few. However before we investigate some scenarios, we need to setup our table and the entities that will go into it.
Setting Up The Table
Before we view the ways we can interact with entities in a table, we must first setup the table. We are going to create a table called ‘Products’ for the purposes of this article. Here is some code that demonstrates how (this could go in Session or Application start events or anywhere you see fit).
var account = CloudStorageAccount.FromConfigurationSetting(“ProductStorage”);
var tableClient = account.CreateCloudTableClient();
tableClient.CreateTableIfNotExist(“Products”);The above code assumes you have a connection string configured already called ‘ProductStorage’ which points to your Windows Azure Storage account (local development storage works just as well for testing purposes).
Setting Up The Entity
For the purposes of this article we are going to put an entity called ‘Product’ into the table. That entity can be a simple POCO (plain old CLR object); only the publicly accessible properties will be persisted and retrievable however. Lets define a simple product entity with a name, category and a price. However all objects stored in tables must also have a row key, partition key, and a time stamp, otherwise we will get errors when we try to persist the item. Here’s our product class:
public class Product { // Required public DateTime Timestamp { get; set; } public string PartitionKey { get; set; } public string RowKey { get; set; } // Optional public string Name { get; set; } public string Category { get; set; } public double Price { get; set; } }Pretty simple eh? However we can clean up some of the code; because the Timestamp, PartitionKey, and RowKey are all required for every single table entity, we could pull those properties out into a base entity class. However we don’t have to; there already exists one in the StorageClient namespace called ‘TableServiceEntity’. It has the following definition:
[CLSCompliant(false)] [DataServiceKey(new string[] {"PartitionKey", "RowKey"})] public abstract class TableServiceEntity { protected TableServiceEntity(string partitionKey, string rowKey); protected TableServiceEntity(); public DateTime Timestamp { get; set; } public virtual string PartitionKey { get; set; } public virtual string RowKey { get; set; } }It makes sense for us to inherit from this class instead. We’ll also follow the convention of having a partition key and row key injected in the constructor on our Product class, while also leaving a parameterless constructor for serialisation reasons:
public class Product : TableServiceEntity { public Product() { } public Product(string partitionKey, string rowKey) : base(partitionKey, rowKey) {} public string Name { get; set; } public string Category { get; set; } public double Price { get; set; } }Done. We’ll use this Product entity from now on. All scenarios below will use a test Product with the following information:
var testProduct = new Product("PK", "1") { Name = "Idiots Guide to Azure", Category = "Book", Price = 24.99 };Scenario 1: Weakly Typed Table Service Context
The easiest way to get started with basic CRUD methods for our entity is by using a specialised ‘Data Service Context’. The Data Service Context is a special class belonging to the WCF Data Services client namespace (System.Data.Services.Client) and relates to a specific technology for exposing and consuming entities in a RESTful fashion. Read more about WCF Data Services here.
In a nutshell, a Data Service Context lets us consume a REST based entity (or list of entities) and that logic is given to us for free in the ‘DataServiceContext’ class, which can be found in the afore mentioned System.Data.Services.Client namespace (you’ll probably need to add a reference). Consuming RESTful services is not an Azure specific thing, which is why we need to import this new namespace.
Because table storage entities act exactly like other RESTful services, we can use a data services context to interact with our entity. Tables and their entities have a few additional bits surrounding them (such as credential information like the 256bit key needed to access the table storage) so we need to be able to include this information with our data context. The Azure SDK makes this easy by providing a class derived from DataServiceContext called ‘TableServiceContext’. You’ll notice that to instantiate one of these we need to pass it a base address (our storage account) and some credentials.
If you review some of the original code above, you’ll notice we created a CloudTableClient based on connection string information in our configuration file. That same table client instance has the ability to create our TableServiceContext, using the code below:
var context = tableClient.GetDataServiceContext();
That’s it! All the explanation above just for one line of code eh? Well hopefully you understand what’s happening when we get that context. It is generating a TableServiceContext which inherits from DataServiceContext which contains all the smarts for communicating to our storage table. Simple.
Now we can call all sorts of methods to create/delete/update our products. We’ll use the ‘testProduct’ defined earlier:
context.AddObject("Products", testProduct); context.SaveChanges(); testProduct.Price = 21.99; context.UpdateObject(testProduct); context.SaveChanges(); var query = context.CreateQuery<Product>("Products"); query.AddQueryOption("Rowkey", "1"); var result = query.Execute().FirstOrDefault(); context.DeleteObject(result); context.SaveChanges();The methods being called here only know about ‘object’, not ‘Product’ and are therefore not type safe. We’ll look at a more type safe example in the next scenario.
Scenario 2: Strongly Typed Table Service Context
In the previous example we saw that the Table Service Context was a generic way to get going with table entities quickly. This works well because we can put any type of entity into the table via the same ‘AddObject’ method. However sometimes in code we like to be more type safe than that and want to enforce that a particular table only accepts certain objects. Or perhaps we want unique data access classes for our different entity types so that we can put some validation in.
Either way, this is relatively easy to achieve by creating our own Data Service Context class. We still need to wrap up table storage credentials, so its actually easier if we inherit from TableServiceContext, as follows:
public class ProductDataContext : TableServiceContext { public ProductDataContext(string baseAddress, StorageCredentials credentials) : base(baseAddress, credentials) { } // TODO }The base constructor of TableServiceContext requires us to supply a base address and credentials, so we simply pass on this requirement. Our constructor doesn’t need to do anything else though.
The next step is to start adding methods to this new class that perform the CRUD operations we require. Let’s start with a simple query:
public IQueryable<Product> Products { get { return CreateQuery<Product>("Products"); } }This will give us a ‘Products’ property on our ProductDataContext that will allow us to query against the product set using LINQ. We’ll see an example of that in a minute. For now, we’ll add in some strongly typed wrappers for the other CRUD behaviours:
public void Add(Product product) { AddObject("Products", product); } public void Delete(Product product) { DeleteObject(product); } public void Update(Product product) { UpdateObject(product); }Nothing very special there, but at least we can enforce a particular type now. Let’s see how this might work in code to make calls to our new data context. As before we’ll assume the table client has already been created from configuration (see ‘Setting Up The Table’ above) and we’ll use the same test product as before:
var context = new ProductDataContext( tableClient.BaseUri.ToString(), tableClient.Credentials ); context.Add(testProduct); context.SaveChanges(); testProduct.Price = 21.99; context.Update(testProduct); context.SaveChanges(); var result = context.Products .Where(x => x.RowKey == "1") .FirstOrDefault(); context.Delete(result); context.SaveChanges();You can see the key differences from the weakly typed scenario mentioned earlier. We now use the new ProductDataContext, however we can’t automatically create it like we can with the generic table context, so we need to instantiate it ourselves, passing the base URI and credentials from the table client. We also use our more explicitly typed methods for our CRUD operations, however you might notice there is a big change in the way we query data. The ‘Products’ property returns IQueryable<Product> which means we can use LINQ to query the table store. Careful though, not all operations are supported by the LINQ provider. For example this will fail:
var result = context.Products.FirstOrDefault(x => x.RowKey == "1");.. because FirstOrDefault is not supported with predicates. However this new query API is much nicer and allows us to do a lot more than we could when the base entity type was unknown by the data context.
Scenario 3: Using The Repository and Specification Patterns
Before reading on you might want to familiarise yourself with the concepts of these patterns. To prevent blog duplication, please refer to this article that someone smarter than me wrote:
Implementing Repository and Specification patterns using Linq.
The goal is to create a repository class that can take a generic type parameter which is an entity we want to work with. Such a repository class will be reusable for all types of entities but still be strongly typed. We also want to have it abstracted via an interface so that we are never concerned with the concrete implementation. For more information on why this is good practise, please refer to the SOLID principles.
We also want to use the specification pattern to provide filter/search information to our repository. We want to leverage the goodness of LINQ but also explicitly define those filters as specifications so that they are easily identifiable.
I usually find it easiest to start with the interface and worry about the implementation later. Let’s define an interface for a repository that will take any kind of table entity:
public interface IRepository<T> where T : TableServiceEntity { void Add(T item); void Delete(T item); void Update(T item); IEnumerable<T> Find(params Specification<T>[] specifications); void SubmitChanges(); }Seems simple enough, however you might note that our find process is less flexible than in scenario 2 where we could just use LINQ directly against our data service. We want to provide the flexibility of LINQ yet still provide explicitness and reusability of those very same queries. We could add a bunch of methods for each query we want to do. For example, to retrieve a single product, we could create an extra method called ‘GetSingle(string rowkey)’. However that only applies to products, and may not apply to other entity types. Likewise, if we want to get all Products over $15, we can’t do that in our repository because it makes no sense to get all User entities that are over $15.
That’s where the specification pattern comes in. A specification is a piece of information about how to refine our search. Think of it as a search object, except it contains a LINQ expression. We’ll see with an example soon, but lets just define our specification class and adjust our Find method on our IRepository<T> interface first:
IEnumerable<T> Find(params Specification<T>[] specifications); ... public abstract class Specification<T> { public abstract Expression<Func<T, bool>> Predicate { get; } }Our Find method has been adjusted to Find entities that satisfy the specifications provided. And a specification is just a wrapper around a predicate. Oh, and a predicate is just a fancy word for a condition. For example, consider this code:
if (a < 3) a++;
The part that says “a < 3” is the predicate. We can effectively change that same code to the following:
Func<int, bool> predicate = someInt => someInt < 3;if (predicate(a)) a++;It might seem like code bloat in such a simple example, but the ability to reuse a ‘condition’ to check in many places will be a life saver when your systems start to grow. In our case we care about predicates because LINQ is full of them. For example, the “Where” statement takes a predicate in the form of Func<T, bool> (where T is the generic type on your IEnumerable). In fact, this is the exact reason we are also interested in predicates in our specification. Each specification represents some kind of filter. For example:
Products.Where(x => x.Rowkey == “1”)
The part that says x.Rowkey == “1” is a predicate, and can be made reusable as a specification. You’ll see it in action in the final code below, but for now we’ll move on to our Repository implementation. Just keep in mind that we will be reusing those ‘conditions’ and storing them in their own classes.
We’ll focus first on the definition of the repository class and its constructor:
public class TableRepository<T> : IRepository<T> where T : TableServiceEntity { private readonly string _tableName; private readonly TableServiceContext _dataContext; public TableRepository(string tableName, TableServiceContext dataContext) { _tableName = tableName; _dataContext = dataContext; } // TODO CRUD methods }Our table repository implements our interface and most importantly takes a TableServiceContext as one of its constructor parameters. And to complete the interface contract we must also ensure that all generic types used in this repository inherit from TableServiceEntity. Next we’ll add in the Add/Update/Delete methods since they are the easiest:
public void Add(T item) { _dataContext.AddObject(_tableName, item); } public void Delete(T item) { _dataContext.DeleteObject(item); } public void Update(T item) { _dataContext.UpdateObject(item); }Simple enough, since we have the generic table service context at our disposal. Likewise we can add in the SubmitChanges() method:
public void SubmitChanges() { _dataContext.SaveChanges(); }We could just call SaveChanges whenever we add or delete an item, but this makes it more difficult to do batch operations. For example we might want to add 5 products and then submit them all as one query to the table storage API. This method lets us submit whenever we like, which is keeping with the same approach used when creating your own TableServiceContext or using the default one.
Finally, we need to define our Find method which takes zero or more specifications:
public IEnumerable<T> Find(params Specification<T>[] specifications) { IQueryable<T> query = _dataContext.CreateQuery<T>(_tableName); foreach (var spec in specifications) { query = query.Where(spec.Predicate); } return query.ToArray(); }Every specification must have a predicate (refer to the initial definition and you will see the property is defined as ‘abstract’ which means it must be overridden). And a predicate is a Func<T, bool> and the T type is the same type as our repository. Therefore we can simply chain all the predicates together by calling the .Where() extension method on the query over and over for each specification. At the end of the day the code is really quite small.
And that’s all the framework-like code for setting up the Repository and Specification patterns against table storage. To show you how it works we first need a specification that allows us to get a product back based on its row key. Here’s an example:
public class ByRowKeySpecification : Specification<Product> { private readonly string _rowkey; public ByRowKeySpecification(string rowkey) { _rowkey = rowkey; } public override Expression<Func<Product, bool>> Predicate { get { return p => p.RowKey == _rowkey; } } }In this specification, we take a row key in the constructor, and use that in the predicate that gets returned. The predicate simply says: “For any product, only return those products that have this row key”. We can use this specification along with our repository to perform CRUD operations as follows:
var context = tableClient.GetDataServiceContext(); IRepository<Product> productRepository = new TableRepository<Product>("Products", context); productRepository.Add(testProduct); productRepository.SubmitChanges(); testProduct.Price = 21.99; productRepository.Update(testProduct); productRepository.SubmitChanges(); var byRowkey = new ByRowKeySpecification("1"); var results = productRepository.Find(byRowkey); var result = results.FirstOrDefault(); productRepository.Delete(result); productRepository.SubmitChanges();Tada! We now have a strongly typed repository that will work on any entity type you want to use. And the great thing about repositories is that because we have an IRepository abstraction we can implement an ‘in memory’ version of the repository which is very useful for unit testing.
Summary
As we progressed through the three options the amount of code got larger but I think we also got closer to true object oriented programming by the end there. Personally I like to always use repositories and specifications because it means we can write our code in a way that the persistence mechanism is irrelevant. We could easily decide to move products into our Sql Azure database and instead use a SqlRepository<T> instead of the TableRepository<T>.
Hopefully you’ll find the concept useful and aim to start with scenario 3 in all cases. To help you get started, I’ve assembled all 3 options into a reusable library for you, downloadable from here:
Table Storage Examples Library (163 Kb)
In each of the scenario folders you’ll find a single starter class that inherits from the TableStorageTest abstract class; you can look at that class to work out how the particular scenario works.
In the near future I will be looking to create a number of these basic classes as a reusable library to help Windows Azure developers get up and running faster with their applications. But in the mean time, happy coding.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
• Dilip Krishnan’s Series On Available Authentication Mechanisms For OData Services And Clients post of 7/24/2010 to the InfoQ blog reviews Alex James’s series of blog posts about OData services authentication techniques:
The WCF Data Services Team have recently been doing a series on the available authentication mechanisms for client/OData service authentication. OData is an implementation of the ATOMPub protocol with extensions to query and update ATOM resources. From the OData website.
The Open Data Protocol (OData) is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. OData does this by applying and building upon Web technologies such as HTTP, Atom Publishing Protocol(AtomPub) and JSON to provide access to information from a variety of applications, services, and stores. […] OData is being used to expose and access information from a variety of sources including, but not limited to, relational databases, file systems, content management systems and traditional Web sites.
Alex James a Program Manager on the Data Services Team provides a series of articles, in an attempt to field authentication related questions.
- How do you ‘tunnel’ authentication over the OData protocol?
- What hooks should I use in the WCF Data Services client and server libraries?
According to Alex the answer lies in specific usage scenarios; each of which addresses a different type of challenge. He frames the answer as a set of questions that provide insights into the appropriate authentication option.
- How does an OData Consumer logon to an OData Producer?
- How does a WCF Data Service impersonate the OData Consumer so database queries run under context of the consumer?
- How do you integrate an OData Consumer connecting with an OAuth aware OData Producer?
- How do you federate a corporate domain with an OData Producer hosted in the cloud, so apps running under a corporate account can access the OData Producer seamlessly?
Here is an overview of the list of scenarios covered in the series
Windows Authentication – Covers authentication using Windows Credentials. This predominantly supports an intranet-enterprise scenario where the network homogeneity only Windows based servers and clients
Custom Basic Authentication – Covers the case when the basic challenge-response authentication at the infrastructure level (IIS) using a username/password is not sufficient; for e.g. if the user/password store is in a database
Forms Authentication - Covers forms authentication where the method of protection is achieved at the framework level in an IIS hosted ASP.net environment.
ClientSide Hooks – Covers client options when Windows and Basic Authentication doesn’t cut it. “Usually applies if you are using a different authentication scheme, for arguments sake OAuth WRAP, the Credentials property is of no use. You have to get back down to the request and massage the headers directly [e.g. when using] Claims Based Authentication.”
Server Side Hooks – Covers the different OData service hosting options IIS , WCF or custom host and explores the different ways to implement authentication under each host.
The team is, of course, looking for feedback on “any Auth scenarios you want [
us] to explore”. If you’re looking to use OData Services to expose data in a RESTful fashion that’s secure as well, be sure to check out the series.
• Chris Sells’ detailed Open Data Protocol by Example white paper from the MSDN Library of March 2010 is probably the best single overview of OData you’ll find. It begins:
Exposing data-based APIs is not something new. The ODBC (Open DataBase Connectivity) API is a cross-platform set of C language functions with data source provider implementations for data sources as wide ranging as SQL Server and Oracle to comma-separated values and Excel files. If you’re a Windows programmer, you may be familiar with OLEDB or ADO.NET, which are COM-based and.NET-based APIs respectively for doing the same thing. And if you’re a Java programmer, you’ll have heard of JDBC. All of these APIs are for doing CRUD across any number of data sources.
Since the world has chosen to keep a large percentage of its data in structured format, whether it’s on a mainframe, a mini or a PC, we have always needed standardized APIs for dealing with data in that format. If the data is relational, the Structured Query Language (SQL) provides a set of operations for querying data as well as updating it, but not all data is relational. Even data that is relational isn’t often exposed for use in processing SQL statements over intranets, let alone internets. The structured data of the world is the crown jewels of our businesses, so as technology moves forward, so must data access technologies. OData is the web-based equivalent of ODBC, OLEDB, ADO.NET and JDBC. And while it’s relatively new, it’s mature enough to be implemented by IBM’s WebSphere[ii], be the protocol of choice for the Open Government Data Initiative[iii] and is supported by Microsoft’s own SharePoint 2010 and WCF Data Services framework[iv]. In addition, it can be consumed by Excel’s PowerPivot, plain vanilla JavaScript and Microsoft’s own Visual Studio development tool.
In a web-based world, OData is the data access API you need to know. …
Chris continues with the paper; it’s longer than this post.
• The Microsoft Project Code-Named “Houston” Services Community Technology Preview Privacy Statement was made final on 7/16/2010:
Microsoft is committed to protecting your privacy, while delivering software and services that brings you the performance, power, and convenience you desire in your personal computing. This privacy statement explains many of the data collection and use practices of Microsoft Project Code-Named “Houston” Services Community Technology Preview (Project “Houston”). It focuses on features that communicate with the Internet. It does not apply to other online or offline Microsoft sites, products or services.
This pre-release (CTP) of Microsoft Project “Houston” is a database administration tool for SQL Server and SQL Azure users. Users with a SQL Azure account log into Houston by providing their SQL Azure account identity and password and by identifying the database that they will be working with. Houston allows SQL users to develop, deploy, and manage the database. For example, Project “Houston” will make it easier to:
- View statistics about the database and list the objects within the database.
- Author and execute T-SQL queries.
- Design tables and interactively edit table data.
- Create, edit, and execute common database objects including views and stored procedures.
The statement continues with typical sections.
See my Test Drive Project “Houston” CTP1 with SQL Azure updated 7/23/2010 for more information about Project “Houston.”
Doug Rehnstrom’s Planning a Move to the Cloud post of 7/24/2010 to Knowledge Tree’s Cloud Computing blog narrates the steps in moving an SQL Server database to SQL Azure with SQL Azure Data Sync and them migrating data entry operations:
In an earlier post, The Problem with Moving to the Cloud is Everything Works, I wrote about the difficulties of moving a customer’s applications to the cloud. The point was that you need to have a plan to make that transition smooth. Well, we’ve developed at least an initial plan.
First we’re going to use Microsoft Sync Framework to create a SQL Azure version of our database. We’ll also write a .NET program to keep the local database and the SQL Azure version synchronized. At that point everything will keep working as before, and the SQL Azure database will just be a copy.
Step two will be getting our main data entry system working using SQL Azure. This really amounts to changing the connection string. My guess is the program will work fine. Some changes will likely be needed to optimize performance when our data is being accessed over the Internet.
Of course we’ll have to set up a test bed before doing it for real. The cloud will make that simple though.
Next we’ll move the Web apps one by one into Windows Azure. I’m not too worried about that, and to be honest, I don’t care if it takes a while. We always move at a snail’s pace anyway.
Lastly, I want to move file sharing and authentication services into the cloud. I’m not entirely clear about what to do about authenticating users, but I know I can figure that out using the AppFabric.
Then, I’ll turn off the servers and throw them away (well maybe not).
Learning Tree course 2602: Windows® Azure™ Platform Introduction covers each of these technologies; Windows Azure, SQL Azure, Microsoft Sync Framework and the AppFabric. One of the nice aspects of authoring an overview course like this is that it forces me to learn the details of a broad range of technologies and features. This is also exactly what I need for my customer.
I’ll let you know how it goes.
@MS_SQL_Server tweeted on 7/23/2010:

I agree that “it’s not a replacement for SQL Server Management Studio 2008 R2.” See my illustrated Test Drive Project “Houston” CTP1 with SQL Azure post updated 7/23/2010.
Composite C1 claims support for OData via a package called Composite.Tools.OData on this OData page:
Short description
Composite C1 supports OData via a package called Composite.Tools.OData. And thus, you can query the Composite C1 data store using the OData. Data types you define via the UI works as well as the data types that are a part of Composite C1 and installed packages.
How to implement OData support
To start querying the C1 data store using OData:
- Download the Composite.Tools.OData package.
- Install the package on your Composite C1 site as a 'Local package' - you can do this via System | Packages | Installed Packages | Local Packages.
Querying data
Once the package is installed you can query via the OData protocol on the URI the URI as "
http://<hostname>:<port>/OData/OData.svc". On information on what client libraries you can use, please visit the OData SDK page .To get instant LINQ and OData satisfaction, try calling your OData service using LinqPad like this:
- Download, install and run LinqPad (http://www.linqpad.net/)
- In the LinqPad window, click "Add connection".
- In the wizard, select "WCF Data Services" and click "Next".
- In the next window, select "Data Services" for the Provider.
- Type the URI as "
http://<hostname>/OData/OData.svc". (Please replace <hostname> with your hostname.)- Click "OK". LinqPad will populate the right pane with the contents of the selected C1 data store.
- Start writing LINQ...
Technology demo
To get a quick intro to the OData package and examples on how it can expose both native Composite C1 data type and data types you define yourself, watch this video:
Important Notes
- Security is not implemented in the package and it is used solely for technology demonstration.
- Full OData support is not implemented in this demo.
- For easy deployment the OData package will update your web.config and enable WCF services to use multiple site bindings - for more info on this setting, please see Supporting Multiple IIS Site Bindings.
Requirements
Composite C1 version 1.3 or later
Wall-pc posted Sample Databases for SQL Server 2008 R2 (and more) on 7/23/2010:
I updated my development PC to Visual Studio 2010 recently, just prior to the Azure boot camp, and also updated to SQL Server 2008 R2. But, which Sample Databases to use with SQL Server 2008 R2?
Here is a quick list of selected Sample Databases (incomplete, possibly outdated):
AdventureWorks2008R2AZ.zip SQL Azure (December CTP) AdventureWorks2008R2_RTM.exe AdventureWorks 2008R2 RTM SQL2008R2.All_Product_Samples_Without_DBs.x64.msi SQL Server 2008R2 RTM SQL2008R2.All_Product_Samples_Without_DBs.x86.msi SQL Server 2008R2 RTM SQL2008R2.Analysis_Services.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Analysis_Services.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.Data_Access_and_DP.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Data_Access_and_DP.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.Data_Engine_Admin_Script.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Data_Engine_Admin_Script.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.Data_Engine_and_FTS.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Data_Engine_and_FTS.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.Integration_Services.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Integration_Services.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.Reporting_Services.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.Reporting_Services.Samples.x86.msi SQL Server 2008R2 RTM SQL2008R2.XML.Samples.x64.msi SQL Server 2008R2 RTM SQL2008R2.XML.Samples.x86.msi SQL Server 2008R2 RTM
SQL Server 2008 R2 samples can be downloaded from Microsoft SQL Server Community Projects & Samples, if you pick through all the various options. The site lists many more sample databases, too. I prefer a quick list of downloads specifically for SQL Server 2008 R2. So lets save some time with the above list.
What is missing from the Sample Databases? Maybe SQL Server 2008 R2 samples for Team Foundation Suite (TFS)? More PowerShell examples? Besides SQL Server 2008 R2, how about some sample database references for Windows Phone 7 (WP7)? Maybe some new databases to flush out all the features in Entity Framework? Other suggestions?
<rant> WTF? OMG. HOW ABOUT SOME NOSQL DATABASES. FTW. </rant> … just kidding… maybe.
Other news is that Northwind Community Edition appears dead. But, we can still download the original scripts.
Enjoy.
SQL Azure runs a modified version of SQL Server 2008, but I’ve found that you can migrate AdventureWorks2008R2AZ.zip to SQL Azure with the SQL Azure Migration Wizard v3.3.3 or later and SQL Azure Data Sync.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Ryan Dunn and Steve Marx roast Jim Nakashima in the latest 00:24:09 Cloud Cover Episode 20 - Visual Studio Tools with Jim Nakashima video segment of 7/24/2010:
Join Ryan and Steve each week as they cover the Microsoft cloud. You can follow and interact with the show at @cloudcovershow.

In this episode:
- Learn how to use Visual Studio to browse your Windows Azure compute and storage.
- Learn how to deploy your application directly from Visual Studio.
- Learn how to do historical debugging of your Windows Azure application using IntelliTrace.
- Learn about using the SQL Azure Migration Wizard to help make the move to SQL Azure.
Show links:
Dan Fernandez conducts A screenshot tour of the new Channel 9 which will enter test mode next week. Channel 9 content will be covered by the Creative Commons Attribution-NonCommercial-NoDerivs 3.0 United States license.
Rinat Abdullin describes Lokad CQRS - Using Protocol Buffers Serialization for Azure Messages in this detailed 7/24/2010 tutorial:
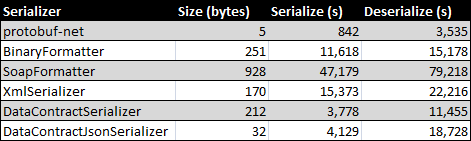
Lokad CQRS, just like any other Application Engine, can use multiple serialization formats to persist and transfer messages. We've tried various options, starting from the XML serialization and up to BinaryFormatter and WCF Data Contracts with binary encoding.
They all had their own issues. Serialization format that had performed best in our production scenarios is called Protocol Buffers.
Protocol Buffers
Protocol Buffers are a way of encoding structured data in an efficient yet extensible format. Google uses Protocol Buffers for almost all of its internal RPC protocols and file formats.
ProtoBuf.NET is a great implementation of ProtoBuf serialization for .NET by Marc Gravel (you probably saw him on the Stack Overflow).
Lokad.CQRS uses ProtoBuf serialization internally for transferring and persisting system message information. ProtoBuf serialization is also the recommended approach for serializing messages in Lokad.CQRS:
- format is extremely compact and fast, better than XML Serialization, Data Contracts or Binary Formatter (see below);
- format is evolution-friendly from the start (renaming, refactoring or evolving messages gets much simpler);
- format is cross-platform.
Here's how the performance looks like, when compared to the other .NET options (details):
However, in Lokad.CQRS you should not worry about these specifics and potential problems that have been taken care of. You just define message contracts with ProtoBuf attributes:
[ProtoContract]
public sealed class PingPongCommand : IMessage
{
[ProtoMember(1)] public int Ball { get; private set; }
[ProtoMember(2)] public string Game { get; private set; }
public PingPongCommand(int ball, string game)
{
Ball = ball;
Game = game;
}
PingPongCommand() { }
}and switch to this serialization in the domain module:
.Domain(d =>
{
// let's use Protocol Buffers!
d.UseProtocolBuffers();
d.InCurrentAssembly();
d.WithDefaultInterfaces();
})More information is available in ProtoBuf in Lokad.CQRS documentation. Additionally, Sample-04 (in the latest Lokad.CQRS code), shows implementation of Ping-Pong scenario with ProtoBuf.
Starting from this sample, we'll be using Protocol Buffers as the default serialization in our samples.
BTW, side effect of using fast and compact ProtoBuf serialization is that it increases overall performance. Smaller messages are less likely to exceed 6144 byte limit of Azure Queues. App Engine handles such messages by saving them in Azure Blob Storage. This essentially allows to persist messages as large as a few GB. Yet, second round-trip to Blob is something that we would want to avoid, if possible. ProtoBuf serialization in Lokad.CQRS helps to significantly improve our chances here.
Arie Jones reported the Latest CRM 4.0 SDK now available in this 7/24/2010 post to the ProgrammersEdge blog:
Now available in the latest SDK is what I believe is one of the most exciting releases fro CRM 4.0 since the launch of Accelerators!
Thanks to contributions from the ADX Studios Team [the SDK] now include[s] the Advanced Developer Extensions. Advanced Developer Extensions for Microsoft Dynamics CRM, also referred to as Microsoft xRM, is a new set of tools included in the Microsoft Dynamics CRM SDK that simplifies the development of Internet-enabled applications that interact with Microsoft Dynamics CRM 4.0. It uses well known ADO.NET technologies. This new toolkit makes it easy for you to build an agile, integrated Web solution!
Advanced Developer Extensions for Microsoft Dynamics CRM supports all Microsoft Dynamics CRM deployment models: On-Premises, Internet-facing deployments (IFDs), and Microsoft Dynamics CRM Online. The SDK download contains everything you need to get started: binaries, tools, samples and documentation.
Now for some cool word bingo on the features! included is:
- An enhanced code generation tool called CrmSvcUtil.exe that generates .NET classes (i.e. Generates a WCF Data Services (Astoria/oData) compatible data context class for managing entities)
- LINQ to CRM
- Portal Integration toolkit
- Connectivity and caching management, which provides improved scalability and application efficiency.
Download it here.
I am downloading it now. [A]s soon as it extracts am going to start playing with these extensions! Hopefully you will see some more detailed posts soon on what’s included and some of the cool things you can build!
The Microsoft Demonstrates Next-Generation CRM Release at Worldwide Partner Conference press release gives further details.
Return to section navigation list>
Windows Azure Infrastructure
• Jean Paoli delivered an “Open Cloud, Open Data” keynote to O’Reilly Media’s OSCON 2010 conference on 7/22/2010. Following is the keynote abstract and a 00:13:21 video archive:
The cloud is all about more connectivity – and interoperability is at the heart of that. Organizations around the world are looking at opportunities to leverage a new wave of cloud technologies. New data sets. New computing power. We believe that making it easy to move data in and out of the cloud, and having developers chose their favorite programming language are essential attributes of an open cloud. Interoperability is at the core of our vision of a cloud that can foster the imaginations of developers, unleash their creativity and enable them to build new breakthrough scenarios.
Jean Paoli is General Manager, Interoperability Strategy at Microsoft, and one of the co-creators of the XML 1.0 standard with the World Wide Web Consortium (W3C). He has long been a strong and passionate advocate of XML and open standards. Jean manages the Interoperability Strategy team that coordinates the technical interoperability activities across Microsoft.
Jean jump-started the XML activity in Microsoft. He created and managed the team that delivered msxml, the software that XML-enabled both Internet Explorer and the Windows operating system. Paoli helped architect Office XML support and was instrumental in creating the newest XML Office application, InfoPath.
Jean is the recipient of multiple industry awards for his role in the XML industry, such as PC Magazine, Technical Excellence Award – co-creator of XML (1998), InfoWorld – Top Technology Innovators Award 2003, IDEAlliance – XML Cup (2004).
Jean wrote the Foreword to my Introducing Microsoft Office InfoPath 2003 title for Microsoft Press.
You’ll find more about his keynote to the OSCON 2010 conference in his Interoperability Elements of a Cloud Platform Outlined at OSCON post to the Interoperability @ Microsoft blog of 7/22/2010, which was previously reported here. Following is a partial capture of the landing page for microsoft’s new Cloud Services Interoperability site:

Charles Babcock claimed “Emerging tech always comes with a learning curve. Here are some real-world lessons from early adopters” as a preface to his feature-length Cloud Computing Comes Down To Earth article of 7/24/2010 for InformationWeek:
Businesses are testingcloud computing and, in a few cases, beginning deployment. They're after increased flexibility, agility, and economies of scale, but IT veterans know such gains won't be effortless. There's a steep learning curve with this new computing model.
One of the biggest lessons so far is that it's hard to know precisely what your systems are doing in a public cloud environment. Yes, Amazon.com's CloudWatch and services like it will tell whether your workloads are operating, but they don't tell how well apps are performing, such as if they're choking on I/O overload.
SAP's Marge Breya provides a demonstration of the latest BusinessObjects Explorer On Demand, as well as two brand new products not even in beta yet: Kona (a cloud-based BI tool) and 12 Sprints (a collaborative decision making tool, also in the cloud)
Even when there's an outright failure, it can be hard to get the information you need. When part of an Amazon data center in northern Virginia suffered primary and backup power failures on Dec. 9, it took 34 minutes before the news was posted on Amazon's Service Health Dashboard. Amazon acknowledged the outage and offered updates, but it was up to customers to assess the impact. To know whether their workloads were down, companies had to subscribe to CloudWatch--not everybody does--or a service such as VMware's CloudStatus or Alternate Networks' network monitoring, or check directly if a failover activated backup servers, which Amazon encourages you to set up for each workload.
Cloud computing service providers, like their customers, are in learning mode during this break-in period. They include infrastructure veterans Amazon, Google, IBM, Microsoft, and Terremark; outsourcers such as CSC; telecom giants Verizon and AT&T; and newcomers Cloud.com, Engine Yard, Heroku, and many others. If they're candid, they acknowledge they're venturing into unexplored terrain.
How to seamlessly connect enterprise apps with customers, suppliers and trading partners
Strategic Approach To App Integration
Microsoft, which started charging for its Azure cloud services in February, admits it still has work to do, especially in the area of cloud monitoring tools. Enterprise early adopters are in a position to shape how vendors build out these services. A private cloud appliance recently launched by Microsoft is being co-developed with eBay, which will initially use it for the relatively low-volume Garden by eBay service, where it tests partner's ideas and new applications, and eventually for basic auction services, says VP of technology James Barrese.
Even if companies are only testing cloud services, they should explore the inevitable problems that go with an emerging technology, as well as the potential competitive advantages. InformationWeek sought out early adopters to gauge how they're doing in both respects.
Know What Customers See
Jason Spitkoski, CTO of startup Schedule Bin, has a lot riding on cloud computing, a commitment that was seriously tested last month. Schedule Bin will use public cloud infrastructure to offer online applications that let businesses schedule employee work shifts or track teams as they execute tasks. Spitkoski looked at Amazon's EC2 but opted for Google's App Engine cloud service, which he says is better suited for making changes or adding new apps. Schedule Bin's applications, due to go live this summer, are built in Python, making them a good match for App Engine, which runs Python and Java apps.
Google App Engine has proved a solid platform, though its underlying Datastore system, which provides storage for Web apps, went through a very rocky stretch. In May, Datastore suffered three service interruptions, one lasting 45 minutes. In early June, Google stopped charging for Datastore, acknowledging that, since April, latency in retrieving data had become 2.5 times greater than in January to March.
By mid-June, Spitkoski was worried--Schedule Bin's beta customers had noticed a slowdown. "We have demos with potentially large customers soon, and I'm concerned that the apparent slowness will be brought up," he said in an e-mail interview.
Spitkoski considered how much to talk about the cloud infrastructure with customers; he wanted to put the focus on Schedule Bin's features, not on the cloud service that enabled them, or any problems Google is having. "We want to keep the demo straightforward and to the point, which means we don't want to get into fuzzy discussions about clouds, or what we think Google is thinking," he said.
Given Datastore's performance problems, Spitkoski was on the bubble, contemplating switching cloud providers at a time when most of Schedule Bin's development work was complete. "The timing couldn't be worse if we were forced to suspend our customer efforts and focus instead on switching cloud providers," he said.
Fortunately, the crisis passed. By the end of June, a relieved Spitkoski found that Google had "vastly improved" Datastore's performance. "I'm now completely satisfied with Google's App Engine," he now says.
Satisfied, but wiser about overly relying on a single cloud vendor. "I will always have an eye open for alternatives," Spitkoski says.
Enterprise IT teams could face a similar dilemma--getting deep into cloud development before realizing they bet on the wrong vendor. The better approach is to keep researching alternatives.
On the other hand, it can also make sense to work closely with a cloud services provider. With enterprise customers in particular, there's a chance to mold a cloud offering in a way that suits your company's needs if you have a good relationship with the vendor and the resources to collaborate.
Cloud Is Under Construction
Kelley Blue Book is one of the high-profile customers of Microsoft's Azure cloud service, having tested it as a way of handling traffic spikes on the Blue Book Web site, which offers used-car pricing information. If Azure made it possible for Kelley to abandon its second data center, the company could potentially save at least $100,000 a year, says Andy Lapin, Kelley's director of enterprise architecture.
But Lapin doesn't think he can see clearly enough into how well his applications are running in Azure. Microsoft released monitoring and diagnostic APIs late last year, but workload monitoring systems from Microsoft and other vendors are still lacking, he says. Lapin halted the planned off-loading of Web traffic spikes until better tools come along.
Lapin also warns that some concepts that sound a lot like those used in enterprise IT operations may be different when applied to the cloud. For example, the description of Azure's Table Storage service sounds familiar. The service "offers structured storage in the form of tables," according to Microsoft Developer Network documentation.
When Lapin sees that, he thinks in terms of relational database tables, but that's not how Table Storage works. It "isn't really like a big, flat table," he says. "You really only get indexing on a single column so, while you can query any column, performance optimization is very different from using SQL Server."
Google App Engine's Datastore tables have similar limitations. In general, cloud systems don't do joins across tables or deep indexing, the kind of ad hoc information sorting that relational databases specialize in.
If that drawback sounds like a minor thing, listen to Oliver Jones, an experienced Microsoft .Net developer who writes about coding on his Deeper Design blog. In March, about a month after Azure came out of beta, Jones shared his initial experience with Azure Table Storage: "It looks fairly full featured. However, it is not. At almost every turn I have ended up bashing my head against a Table Storage limitation. Debugging these problems has been a bit of a nightmare." Investigate such warnings before turning your development team loose on it.
One selling point for Azure is the presumed degree to which it will work with Microsoft products already in place. Microsoft says all SQL Server queries will translate to run on SQL Azure, its cloud database. In general, however, be careful about assuming compatibility between existing enterprise systems and those in the cloud.
Beware Assumptions
Innovest Systems is a supplier of software as a service for trust accounting and wealth management firms. It provides online decision-support and accounting for companies with a total of $250 billion in investments, including Mitsubishi UFJ, so availability and reliability of its services are critical.
To deliver its SaaS apps, Innovest previously managed its own hardware in a co-located facility run by an outsourcer, Savvis. Between 2004 and 2008, Innovest migrated its production environments to Savvis-hosted virtual servers. More recently, this platform has evolved into what Savvis calls its Dedicated Symphony cloud service, a form of private cloud computing where servers in an otherwise multitenant cloud are reserved for one customer.
A dedicated cloud made a lot of sense to Ray Umerley, chief security officer at Innovest. "We had always struggled with co-located services. We had to maintain hot backups on standby," he says. "Whenever anything stopped, somebody had to go over there and change a tape or a drive." With the Symphony service, Innovest designed the facilities that it wanted down to the specific policies in the firewall protecting the servers, and Savvis installed them and ensured that they ran.
Over the course of their six-year relationship, Innovest had built a close partnership with Savvis and concluded it could trust private-cloud-style operations to its outsourcing partner. A big step was the move from co-location services, in which Umerley and other technical people had to periodically adjust equipment at the Savvis facility, to letting Savvis technicians take over that function. Teams from the two companies covered myriad operational details so that Innovest could guarantee to its customers that their data was being handled in a way that met strict regulations.
Despite all the preparation, just weeks before the switch-over the teams realized they had overlooked a fundamental detail: Innovest ran Windows applications and Savvis-hosted Windows servers, but the version supported by Savvis was Windows Server 2003, while Innovest apps were still on Windows 2000. With 15 days till deployment, Innovest's IT team swung into high gear and migrated the key applications to Windows 2003.
Both parties knew each other's operations well and thought they were practicing the utmost due diligence as they approached the transfer date. The version of Windows Server involved was something so obvious that everyone assumed it would be the first issue considered, not the last. Since Innovest's launch of Symphony services, everything has run fine, and Umerley gives Savvis high marks for offering visibility into its architecture, engineering, and security.
When making a move into the cloud, "know your provider well," Umerley cautions. That means scrutinizing its security practices, and knowing how the provider keeps its data handling in compliance with regulations that govern your business. Umerley recommends being open and putting the pressure on the vendor to spot potential problems. "Be sure to state: 'Here's what we have. Tell us what we will have to change,'" he says.
Watch Where The Data Goes
Don't necessarily write off cloud computing just because sensitive data is involved. But watch that data closely.
Manpower CIO Denis Edwards is eager for his IT teams to experiment with cloud development, to speed up development and cut costs. But he also has a clear policy about data governance: Developers don't have blanket approval to move data into the cloud.
A project with a certain data set may get the OK through Manpower's data governance process. However, if that project expands to more data, it requires a new approval. Don't let sensitive data creep into the cloud as a project's scope expands.
On the other hand, don't assume that the cloud's a nonstarter just because there's sensitive data involved. Some of the most interesting applications will be those where sensitive data stays on-premises yet gets shared or used in some way through cloud services.
That's happening at Lipix, a nonprofit formed two years ago for the purpose of easing the exchange of information among healthcare providers on Long Island in New York. In one year, CTO Mark Greaker has used CSC's CloudLab to establish a central index of patient records being used at 22 of the 25 competing hospitals in the region. The index now covers about 1 million patient records, but the records stay within the hospitals.
How does that work? Greaker has an edge server in each hospital linked to Lipix's index, which resides on servers in the CSC cloud. Greaker adds a hospital every two to three months to the master index, and when he does, he goes to a CSC portal and commissions a virtual server with the CPU, memory, and storage that the hospital needs. The index tells a doctor where a patient's record is, and the doctor can see a read-only version over a messaging system. About 1,000 of Long Island's physicians are using the system, and Greaker has a $9 million grant to reach another roughly 2,000 within three years. With employees focused on establishing the system, not racking hardware, "I've been surprised how quickly we've been able to design and build it," he says.
Platforms Matter
Russell Taga is a VP of engineering at Howcast, a startup trying to capitalize on the explosion of Internet video by specializing in the "how-to" niche. Howcast keeps its catalog of videos in a cloud service run by Engine Yard; 90% of the content is made by contributors not employed by Howcast. It also links to videos elsewhere on the Web, including YouTube.
Howcast builds Ruby-based apps, which proved to be an important factor in choosing its cloud vendor. The startup's Web applications let people search for, create, and edit videos. For it to succeed, however, Taga believes his firm must make it easier for people to produce and air high-quality how-to videos, so he's focused on developing better Ruby-based online applications to aid amateur video makers.
Engine Yard employs leading Ruby developers such as Yehuda Katz, and Howcast is able to tap into that expertise. Taga's company started out as a Java shop, but found it took too long to build and revise code in Java. Many of his developers were familiar with Ruby on Rails as a framework supported language that allows frequent apps changes. Engine Yard meets the table stakes requirement of a cloud provider: "They're stable and keep us up and running," Taga says. At the same time, "they're in touch with the latest software," serving as a trusted adviser as it pushes Ruby in new directions.
Shape The Cloud's Future
Don't like what you see in the cloud? Change it.
Amazon, Google, Microsoft, and others show a keen desire to address unmet needs. The environment's changing fast. Amazon says new services such as Elastic Block Storage and new types of servers such as Cluster Compute Instance came from feedback from developer customers. In the weeks that we researched this story, App Engine's Datastore problems got ironed out enough that Schedule Bin's Spitkoski went from doubtful about his future with Google to being an enthusiastic endorser of App Engine--though one who now stays open to alternatives.
EBay has just emerged as a strong partner of Microsoft's in shaping an internal cloud appliance suitable for building private clouds. The online auction site is looking several years into the future, toward making its IT infrastructure--which handled about $60 billion of auctions last year--easier to manage and more scalable. EBay wants more cloud-like characteristics in its data centers, so resources can be managed as a unit of pooled, virtualized servers and storage.
Yet eBay doesn't see a public cloud infrastructure as viable for its computing needs in the near term. "A lot of today's [public] cloud isn't capable of operating in the mission-critical space," such as transaction processing, says technology VP Barrese.
With Microsoft as its cloud partner, eBay gets someone else to build that environment, while keeping open the option of hybrid environments--and not necessarily only from Microsoft Azure. "There's a lot of potential for Microsoft to set a cloud standard," says Barrese.
Early cloud implementers, even on a much smaller scale, should heed Barrese's assumption that any cloud supplier is a close business partner, looking for and able to accept direction from the customer. There are a lot of mistakes being made and lessons being learned. Vendors are as new at delivering cloud services as customers are at using them, and may prove surprisingly malleable to committed customers. "This is a journey," says Barrese. "We're still in an early day of cloud computing."
Charles Babcock is editor at large for InformationWeek and author of the book "Management Strategies For The Cloud Revolution."
<Return to section navigation list>
Windows Azure Platform Appliance
• Michael J. Miller begins his The Changing Cloud Platforms: Amazon, Google, Microsoft, and More article of 7/19/2010 for the Forward Thinking … PC Magazine blog with a cliché:
"Cloud computing" means different things to different people. Some use the term when talking about what we used to call "software as service": applications that are Web-hosted, from webmail to Salesforce.com and beyond. Others use it primarily to mean using publicly available computers, typically on an as-needed basis, instead of buying their own servers.
Still others use it to mean accessing both data and applications from the Web, allowing cross-organization collaboration. And some use it to describe "private clouds" that they are building within their organizations, to make better use of their data centers and network infrastructure, and to assign costs based on usage. In short, the term cloud computing is now so broad that it covers pretty much any way of using the Internet beyond simple browsing.
For me, one of the most interesting things happening in this sphere is the emergence of new platforms for writing and running applications in the cloud. Over the past two years, since I wrote about the emerging platforms of Amazon, Google, and Microsoft, these three vendors have moved in very different directions. After some recent announcements, I thought I'd revisit the topic to look at the state of these platforms. …
Michael continues with analyses of the current status of Amazon Web Services, Rackspace and OpenStack, Salesforce.com, VMware, Force.com and finally Azure:
The other platform that gets a lot of attention is Microsoft's Windows Azure, which has officially been available only since its developer conference last November. Azure is clearly a "platform as a service" offering in that it is a closed platform running Microsoft software and is aimed at developers who use Microsoft's development tools, notably the .NET framework. But it offers pricing based on computer services and storage, much like offerings from Amazon and other cloud infrastructure providers.
The basic platform includes Windows Azure, which offers the computing and the storage; SQL Azure, a cloud-based relational database; and AppFabric (formerly called .NET Services), which includes access-control middleware and a service bus to connect various services, whether built in Azure or outside applications. This month, Microsoft released a new version of AppFabric that supports Flash and Silverlight.
Until now, Azure was available only from Microsoft's own datacenters, but the company just took the first steps towards making Azure available for organizations to deploy within their infrastructures. Microsoft announced the Windows Azure platform appliance, which consists of Windows Azure and SQL Azure on Microsoft-specified hardware. This appliance--which sounds like it's actually a large collection of physical servers--is designed for service providers, governments, and large enterprises.
Note this is very different from letting individual customers set up their own servers to run Azure; Microsoft and its partners will be managing the servers themselves, though companies can host their own data. Initially, Microsoft said Dell, Fujitsu, and HP would all be running such appliances in their own data centers and selling services to their customers, based on this appliance. eBay is also an early customer, using the appliance in its data center. I would expect that over time, this would be made available to more customers, and probably offer tighter links between on-premises and cloud servers.
Azure's initial target seems to be mainly corporate developers, people who already use Microsoft's developer tools, notably Visual Studio and the .NET framework. (Microsoft is also trying to compete with VMware in offering virtualization tools to cloud service providers, but that's another topic.)
Larger service providers such as HP and IBM also have their own cloud offerings, typically aimed at providing customized services to very large corporate accounts. IBM recently announced a new development and test environment on its own cloud. But in general, these tend to be company-specific choices rather than the "self-service" cloud platforms the more general platforms provide.
And I've talked to a number of very large customers who are deploying "private clouds": using their own infrastructures with virtualization and provisioning, as part of efforts to make their data centers more efficient.
Cloud platforms are still emerging, and there are still plenty of issues, from the typical concerns about management and security, to portability of applications and data from one cloud provider to another. But it's clear that cloud platforms and services are getting more mature and more sophisticated at a very rapid clip, and many--if not most--of the developers I know are either using these technologies or are actively considering them.
Michael J. Miller is senior vice president for technology strategy at Ziff Brothers Investments, a private investment firm. Until late 2006, Miller was the Chief Content Officer for Ziff Davis Media, responsible for overseeing the editorial positions of Ziff Davis's magazines, websites, and events.
<Return to section navigation list>
Cloud Security and Governance
• Anne Taylor’s How to Move Two-Factor Authentication into the Clouds podcast from ComputerWorld for VeriSign (requires web site registration) carries this description:
Two-factor authentication (2FA) delivered via the cloud provides a high level of security without high cost.
This Webcast highlights its many benefits:
- Reduced infrastructure costs – no on premise hardware
- Reduced IT burden – no internal expertise required
- Scalability and flexibility – dial up or dial down as needed
- Improved responsiveness and compliance – outside experts keep up with regulation changes
- Anytime, anywhere access to corporate applications
Andrew Conrad-Murray asks “Is the cloud insecure? Maybe. But that's not the first question IT should ask” as a preface to his Cloud Security: Perception Is Reality article of 7/24/2010 for InformationWeek, which begins:
As a result, this CTO's company, which had deployed its applications on top of Amazon's Web service offering, is bugging out of the public cloud and into a private co-location facility. While he believes his team can configure the Amazon service to be just as secure as the on-site option, and the cloud's low startup costs and rapid deployment benefits are attractive, he had to ask: Could the model cost us business?
No matter how many times public cloud providers assert--often correctly--that data is well-protected on their servers, they just can't shake the insecurity rap. And that means CIOs need to ask not just whether the cloud makes business sense, but whether their customers will see it that way. They may not: Security tops the list of cloud worries in every InformationWeek Analytics cloud survey we've deployed. In our 2010 Cloud GRC Survey of 518 business technology professionals, for example, respondents who use or plan to use these services are more worried about the cloud leaking information than they are about performance, maturity, vendor lock-in, provider viability, or any other concern.
That doesn't mean businesses are shunning the cloud. Of those respondents who do use or plan to use these providers, within the next two years, 20% say up to half of their IT services will come from the cloud; an additional 45% say a quarter of their IT services could be delivered that way. The benefits, such as lower deployment costs and faster time to market, are just too attractive, particularly in today's business climate of stagnant budgets and staffing uncertainty. Still, your customers have legitimate questions about running applications in the cloud, whether on infrastructure-as-a service (IaaS) or platform-as-a-service (PaaS) environments. IT must help the business be prepared with good answers to the two main questions we raise, and others specific to the product. It may make the difference between winning business and losing confidence.
First, customers will look for assurance that an application that runs on PaaS is as secure as an application that runs behind an on-premises firewall. The answer will normally be "No--unless it is." It's an irritating response, but that's because cloud security is frustrating. Here's the breakdown.
A Web application you develop and deploy in a PaaS environment is no more--and no less--secure than a Web app you develop and deploy yourself. The basic principles of secure application development don't change because of the cloud. "Cross-site scripting is still cross-site scripting. There's not much difference whether it's in-house or PaaS," says Brian Chess, chief scientist and co-founder of Fortify Software, an application security testing company. The upshot? Developers must be trained to write secure software, regardless of where that software runs. Applications must be tested regularly to ensure that the inevitable vulnerabilities are found and remediated. Building and running an application on top of Windows Azure, Google App Engine, or Engine Yard doesn't excuse an organization from following these principles. …
Download the entire article as an InformationWeek::Analytics Cloud Computing Brief here.
Stephanie Balaouras posted Building The High-Performance Security Organization to the Forrester blogs on 7/23/2010:
I just completed my second quarter as the Research Director of Forrester’s Security and Risk team. Since no one has removed me from my position, I assume I’m doing an OK job. Q2 was another highly productive quarter for the team. We published 20 reports, ran a security track at Forrester’s IT Forum in Las Vegas and Lisbon, and fielded more than 506 client inquiries.
In April, I discussed the need to focus on the maturity of the security organization itself. I remain convinced that this is the most important priority for security and risk professionals. If we don’t change, we’ll always find ourselves reacting to the next IT shift or business innovation, never predicting or preparing for it ahead of time. It reminds me of the Greek myth of Sisyphus. Sisyphus was a crafty king who earned the wrath of the Gods. For punishment, the Gods forced him to roll a huge boulder up a steep hill, only to watch it roll back down just before he reached the top — requiring him to begin again. Gods tend to be an unforgiving lot, so Sisyphus has to repeat this process for the rest of eternity.
If my protestations don’t convince you, perhaps some data will. The following are the top five Forrester reports read by security and risk professionals in Q2:
- Security Organization 2.0: Building A Robust Security Organization
- Twelve Recommendations For Your 2010 Information Security Strategy
- CISO Handbook: Presenting To The Board
- SOC 2.0: Virtualizing Security Operations
- Market Overview: Managed Security Services
These reports focus on overall information security and risk strategy, the structure of the security organization itself, and the redesigning of traditional security operations. What you don’t see on this list are reports about point security products. In fact, even if I expanded this to the top 10 reports, the first reference to technology doesn’t occur until No. 10: HeatWave: Hot Client Security Technologies For Big Spenders And Bargain Hunters. Even this report has less to do with technology and more to do with peer comparison — giving clients a view into what technologies their peers are purchasing.
Here’s another data point to consider: According to Forrester’s Enterprise And SMB IT Security Survey, North America And Europe, Q3 2009, approximately 6% of enterprises cited “unavailability of products/services that meet our needs” as a major security challenge. There is a plethora of available security products and services; in fact, too many of us buy point products without using them in a coordinated fashion or as part of a holistic information risk management strategy.
That’s why much of our Q3 and Q4 research themes as well as the theme of our upcoming Security Forum will continue to focus on “Building The High-Performance Security Organization.” We’re using the image of a winning cycling team as a representation of the high-performance security organization. I chose this image because high-performance cycling and security teams surprisingly have some of the same requirements. Allow me to explain:
- Strategy, organization, and teamwork: Although only one cyclist wins the race, it requires a team of cyclists with specialized roles and skills to achieve victory. A good security organization needs an overarching strategy, well-defined responsibilities, and strong governance.
- Effective processes: The team uses a series of tactics to help the leader win. Team members take turns shielding him from the wind and pacing the team up the hills, etc. Likewise, the security organization needs solid processes in place for everything from identity and access management to secure application development to overall information risk management.
- Architecture and technology: The cycle plays a critical role. Over the years, improvements in suspension and braking make for a safer and more comfortable ride, and advances in material technology have made cycles much more lightweight. Likewise, security organizations must implement the architectures and technologies that balance security and compliance with flexibility and operational efficiency. I want to emphasize here that yes, technology is important, but too often that’s all we focus on. You can have the latest, greatest bike but it can’t pedal itself across the finish line and a single cyclist could never win the Tour de France alone.
I read today that a herd of sheep disrupted the Tour de France. No one was injured, but cyclists did have to brake suddenly and in some cases swerve around the sheep. It’s likely the sheep were just befuddled and lost, but there’s a part of me that would like to think it was a coordinated attack. So sheep aren’t the equivalent of an advanced persistent threat (unless you frequently drive in the countryside of France), but it is a good example of risk or incident that you could reasonably predict and prepare for, since the tour takes cyclists up through the countryside.
If improving the performance of your security organization is one of your top priorities, I hope you can join us at our upcoming Security Forum. If you can’t, I hope you’ll take the time to tell us about your priorities and toughest challenges and if they line up with what we’re seeing from our clients and research.
Save an additional $200 off the Early Bird rate when you register by August 6th with promo code SF10BLG.
<Return to section navigation list>
Cloud Computing Events
Paola Garcia Juarez (@pgarciaj13) announced Cloud Camp Brasilia to be held 8/18/2010 from 6:00 PM to 10:00 PM (GMT-0300) co-located with CONSEGI in Brasilia-DF, Brazil:
Tentative Schedule:
6:00pm Networking Receiption
6:30pm Welcome & Intros
6:45pm Lightning Talks
7:15pm Unpanel8:00pm Round 1: Open Spaces
8:45pm Round 2: Open Spaces
9:30pm Wrap Up
9:45pm End
Click here for EventBrite entries for future CloudCamps. Paola says Cloud Computing at Lima is in the works for 11/19 and 11/20/2010 , but it isn’t listed yet.
Forrester Research will hold its Security Forum 2010 on 9/16 and 9/27/2010 at the Westin Copley Place in Boston, MA:
This year’s Security Forum will focus on: 1) evaluating the maturity and effectiveness of the security organization; 2) laying out a road map for architectural optimization and innovation; and 3) ensuring that the right skills, incentives, and metrics are in place for the long-term success of the security program.
KEY QUESTIONS THAT THIS FORUM WILL ANSWER
- How do you measure the maturity and the effectiveness of the security and risk management practice and build a road map for the future?
- How do you build a data security architecture to protect information no matter who has it and where it rests?
- How can you apply enterprise risk management disciplines to information security?
- How do you embed security throughout the network, not just on the perimeter?
Register here.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Derrick Harris explains Why OpenStack Has its Work Cut Out in this 7/25/2010 post to the GigaOm blog:
This week, a relatively large group of technology companies, along with NASA, launched OpenStack, an open source project designed to give businesses and service providers a top-to-bottom, and already proven, cloud computing platform. I’m all for openness, but as I discuss in my weekly column at GigaOM Pro, it’s do not too difficult to play devil’s advocate and make the case that OpenStack won’t create true rivals for leading cloud providers or cloud software vendors.
Assuming the provisioning engine comes to fruition, OpenStack will undoubtedly see adoption from service providers wanting to offer cloud computing, enterprises wanting to build their own internal clouds, and IT vendors looking to beef up their cloud software offerings. If all comes together as planned, it should be a very nice solution. Just like everywhere else in life, competition in the cloud is a great thing.
However, competition for dollars and developers is plentiful, including large cloud providers, software vendors and even other open source options. The idea of a network of interoperable OpenStack-based public and internal clouds is appealing, but it would require stealing business and developers from a wide variety of other proven, innovative and commercially supported offerings.
Even within the OpenStack membership, conflicts of interest exist. How supportive can Rackspace really be of other service providers without cannibalizing its own cloud revenue? Plus, it’s also considering offering Windows Azure as a service. Dell already sells Joyent’s cloud software, and it’s also an early Windows Azure Appliance partner. If Dell does offer OpenStack as an open source alternative, it will be just that — an alternative. Other partners will support the OpenStack platform, but that’s on top of existing support for AWS, VMware and other industry-leading offerings. Supporting OpenStack is one thing, but pushing it to the exclusion of other options is something else.
Is OpenStack important? Yes. Will OpenStack attract a broad community of users? Yes. Will OpenStack-based offerings and deployments gather enough market share to make current leaders lose sleep? That’s not such an obvious answer.
Read the entire column here.
Maureen O’Gara claimed “It set in play OpenStack, an open source cloud platform” in a preface to her Rackspace Wants to Define the Cloud post of 7/24/2010:
Rackspace Hosting wants to be the one that defines the public and private commodity cloud.
So the other day - in the name of fostering standards, ensuring cloud interoperability and defeating vendor lock-in - it set in play OpenStack, an open source cloud platform to which it immediately contributed the code to its Cloud Files Amazon S2-like storage widgetry and promised to kick in its Amazon EC2-like Cloud Servers code once it's ready.
Cloud Files and Cloud Servers is the stuff that powers Rackspace's public cloud and the reference implementations that come of the OpenStack effort will be free. There will be no dual-licenses like Eucalyptus Systems, the other open source cloud where ex-MySQL chief Marten Mickos is now CEO. RackSpace says it will put all its code out under the Apache 2.0 license.
Obviously it thinks this will work and it won't wind up in the poor house. It believes users aren't going cloud for fear of lock-in by Amazon, Microsoft, Verizon or Google and that it can thrive on its reputation for support.
Anyway, for star power it brought NASA into the game.
NASA, which is hardly what you'd call a commodity player, just got involved a few weeks ago. It's supposed to contribute technology from its large-scale Nebula private infrastructure cloud platform.
Apparently what NASA's got that's interesting to RackSpace is what the space agency calls a fabric controller and what other people might simply call the proprietary glueware to hold an immense data-dripping cloud together. Otherwise, Nebula looks like Eucalyptus, which in turn is compatible with Amazon EC2. NASA is partial to Ubuntu and Python.
Then Rackspace went out looking for converts.
It reportedly got 150 people representing 40 companies to come to a four-day design summit at its headquarters in Texas to talk about roadmaps, design processes and development processes and at the end 25 of them or so lent their names to the effort, 15 of them even left coders behind validating code.
The signatories included AMD, Citrix, Cloud.com, Cloudkick, Cloudscaling, CloudSwitch, Dell, enStratus, FathomDB, Intel, iomart Group, Limelight, Nicira, NTT Data, Opscode, Peer 1, Puppet Labs, RightScale, Riptano, Scalr, SoftLayer, Sonian, Spiceworks, Zenoss and Zuora.
Citrix, for one, means to ensure there's Xen support for the thing. RackSpace uses Xen; NASA uses KVM. RackSpace claims OpenStack will eventually be hypervisor-agnostic.
AMD is looking to optimize its chips for any serious venture; RackSpace uses some AMD boxes but mostly it's on Intel. And Cloud.com means to support the effort in its own open source cloud stack.
Besides the distributed object store from Cloud Files and some other Cloud Files infrastructure components, OpenStack is supposed to get a hugely scalable compute-provisioning engine called OpenStack Compute out of a combination of Nebula and Cloud Servers. The engine, based on RackSpace APIs, is supposed to be available later this year. First release is set for October.
RackSpace CTO Jonathan Bryce said OpenStack would also include the Rabbit MQ messaging system and the SQL Lite relational database.
Rackspace and NASA are supposed to use OpenStack to power their cloud platforms, and Rackspace has dedicated open source developers and resources to develop and evangelize OpenStack among enterprises and service providers. It has yet to exhaust its European and Asian convert possibilities.
For its part NASA would rather be in the space race than the cloud business and is perfectly willing for others to meet its requirements.
See http://openstack.org.

Audrey Watters’ SaaS Lessons Learned post of 7/24/2010 to the ReadWriteCloud blog quotes Dharmesh Shah’s “SaaS startup lessons” that apply to cloud-computing users offering subscription-based SaaS apps:
As we wrote last week, the most common mistakes that SaaS providers make often involve errors made while balancing the incoming subscription receipts with the need to go out and spend some money to acquire new subscribers.
Dharmesh Shah, CTO and founder of HubSpot, recently blogged his thoughts on a similar topic: the insights he's gleaned from the B2B SaaS startup. Describing these as "non-obvious SaaS startup lessons," Shah's blog post contains a list seven important observations.
You are financing your customers
Most SaaS businesses are subscription-based. If you include a "30-day free trial," then it will be quite some time before revenue comes in. Cash flow issues arise as a result because while subscription dollars come in over time, sales and marketing costs are incurred at the start. "The higher your sales growth, the larger the gap in cash-flows," Shah writes. "This is why SaaS companies often raise large amounts of capital."
Retaining customers is critical
Unlike the ol' software licensing fee model, you aren't getting cash up front from customers who download and install your product. Although this model did utilize renewal fees as a way to maintain revenue, under the SaaS model, all revenue is, in Shah's words, "some sort of recurring revenue." He suggests you determine your total costs for customer acquisition and your monthly subscription revenue. If the acquisition cost is $1000, for example, and the monthly subscription revenue is $100, then you need to retain a customer for at least 10 months to recover that initial acquisition cost.
It's software, but there are hard costs
True, you aren't shipping disks, CDs, and DVDs, but there are still substantial infrastructure costs. "By the time you get a couple of production instances, a QA instance, some S3 storage, perhaps some software load-balancing, and maybe 50% of someone's time to manage it all (because any one of those things will degrade/fail), you're talking about real money. Too many non-technical founders hand-wave the infrastructure costs because they think 'hey we have cloud computing now, we can scale as we need it.' That's true, you can scale as you need it, but there are some real dollars just getting the basics up and running." Shah recommends talking to other SaaS companies who are willing to share some of their data so you can gauge what your hosting costs might be.
It pays to know your funnel
As early as possible, ascertain the shape of your marketing and sales funnel. What drives prospective customers? What is the conversion rate of visitors to your site? "The better you know your funnel the better decisions you will make as to where to invest your limited resources."
You need knobs and dials in the business
Although there are lots of things you can adjust in the SaaS business - pricing, packaging, features, trial duration for example - it is tempting to adjust too many things at once or adjust things too soon. Shah does caution that experimentations with pricing should always take care of early customers with some sort of grandfathering clause.
Visibility and brakes let you go faster
Because of the shorter operational cycle of SaaS businesses, Shah contends, you are able to identify when "bad things start to happen" more quickly.
User interface and experience counts
A good user interface is crucial to obtain and retain customers, and so design needs to be a key element of your SaaS. "Start recruiting great design and user experience talent now."
If you're an SaaS company, what other "lessons learned" would you add to this great list?
<Return to section navigation list>
















