Windows Azure and Cloud Computing Posts for 7/19/2010+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |
![AzureArchitecture2H_thumb[3]](file:///C:/Users/Administrator.OAKLEAF.000/AppData/Local/Temp/WindowsLiveWriter-429641856/supfilesD085F5/AzureArchitecture2H[5].png "AzureArchitecture2H_thumb[3]")
Update 7/15/2010: Diagram above updated with Windows Azure Platform Appliance, announced 7/12/2010 at the Worldwide Partners Conference and Project “Sydney”
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA)
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now freely download by FTP and save the following two online-only PDF chapters of Cloud Computing with the Windows Azure Platform, which have been updated for SQL Azure’s January 4, 2010 commercial release:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available for download at no charge from the book's Code Download page.
Azure Blob, Drive, Table and Queue Services
The Windows Azure Team posted New Windows Azure Service, The Archivist, Helps you Export, Archive and Analyze Tweets on 7/20/2010:
Ever wonder what happens to tweets after they disappear? Would you love a way to keep track of, analyze and even export tweets related to topics you care about? Enter The Archivist, a new lab/website from Mix Online built on Windows Azure that allows you to monitor Twitter, archive tweets, data mine and export archives.
As Microsoft Developer and Archivist creator, Karsten Januszewski explains it, "When you start a search using The Archivist, it will create and monitor an archive based on that search that you can later analyze for insights, trends and other useful information, as well as export for further analysis or reporting."
Get an introduction to The Archivist in Karsten's blog post, read about its evolution in a post by Microsoft Designer, Tim Aidlin, or sit back and let Karsten and Tim explain The Archivist to you in the video, "The Archivist: Your friendly neighborhood tweet archiver" on Channel 9.
Why Windows Azure? Januzewski elaborates, "Windows Azure was a perfect fit for the Archivist for three reasons: first, blob storage is ideally suited to store the tweets, we've already archived more than 60 million tweets; second, the ability to use Windows Azure background worker processes to poll Twitter provides crucial functionality; and, lastly, because Twitter is a global phenomenon, Windows Azure enables The Archivist to effectively scale both the download of archives through the CDN as well as the number of web servers required, based on changing traffic patterns."
And a great part of The Archivist is that all the source code is available for download. Not only is the source code licensed so anyone can run (and enhance) their own instance of the Archivist in Windows Azure, it provides a reference architecture for how to take advantage of features in Windows Azure, such as blob storage and background worker processes.

See my Archive and Mine Tweets In Azure Blobs with The Archivist Application from MIX Online Labs updated 7/11/2010 for more technical details. Give The Archivist a test drive with
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Ryan McMinn explains how to Get to Access Services tables with OData in a 7/20/2010 post to the Microsoft Access Team blog:
OData is a Web protocol for querying and updating data that provides a way to unlock your data and free it from silos that exist in applications today. There are already several OData producers like: IBM WebSphere, Microsoft SQL Azure, SQL Server Reporting Services; and live services like: Netflix or DBpedia among others. SharePoint 2010, is an OData provider as well and this enables Access Services as an OData provider as well. The following walkthrough shows how to extract data using OData from a published Access Northwind web template and consume it using Microsoft PowerPivot for Excel 2010.
Publishing Northwind
First, we’ll need to instantiate the Northwind web database and publish it to SharePoint.
Accessing OData
Access Services 2010 stores it’s data as SharePoint lists; therefore, in order to retrieve tables through OData we’ll need to follow the same recommendations that apply for SharePoint lists. There are a couple blog posts with more details on SharePoint and OData here and here. For our Northwind application, the main OData entry point is located on http://server/Northwind/_vti_bin/listdata.svc. This entry points describes all tables provided by the OData service, for instance, in order to retrieve the Employees table through OData, we would use http://server/Northwind/_vti_bin/listdata.svc/Employees. Additional OData functionality is described in the OData developers page.

Consuming OData
One of the applications that consumes OData, is Microsoft PowerPivot for Excel 2010. In order to import data from Northwind into PowerPivot we can follow these steps:
- From the PowerPivot ribbon, “Get External Data” section, select “From Data Feeds”.
- Enter the OData entry point, for this scenario: http://server/Northwind/_vti_bin/listdata.svc
- Select the desired Northwind tables in the “Table Import Wizard”.
- Finish the wizard to retrieve the data from Access Services.
The Northwind data should be now imported in PowerPivot and ready to be used from Excel.





Wayne Walter Berry posted Introduction to Open Data Protocol (OData) and SQL Azure on 7/20/2010:
The Open Data Protocol (OData) is an emerging standard for querying and updating data over the Web. OData is a REST-based protocol whose core focus is to maximize the interoperability between data services and clients that wish to access that data. It is being used to expose data from a variety of sources, from relational databases like SQL Azure and file systems to content management systems and traditional websites. In addition, clients across many platforms, ranging from ASP.NET, PHP, and Java websites to Microsoft Excel, PowerPivot, and applications on mobile devices, are finding it easy to access those vast data stores through OData as well.
The SQL Azure OData Service incubation (currently in SQL Azure Labs) provides an OData interface to SQL Azure databases that is hosted by Microsoft. Currently SQL Azure OData Service is in incubation and is subject to change. We need your feedback on whether to release this feature. You can provide feedback by emailing SqlAzureLabs@microsoft.com or voting for it at www.mygreatsqlazureidea.com. Another way to think about this is that SQL Azure OData Service provides a REST interface to your SQL Azure data.
The main protocol to call SQL Azure is Tabular Data Stream (TDS), the same protocol used by SQL Server. While SQL Server Management Studio, ADO.NET and .NET Framework Data Provider for SqlServer use TDS the total count of clients that communicate via TDS is not as large as those that speak HTTP. SQL Azure OData Service provides a second protocol for accessing your SQL Azure data, HTTP and REST in the form of the OData standard. This allows other clients that participate in OData standard to gain access to your SQL Azure data. The hope is that because OData is published with an Open Specification Promise there will be an abundance of clients, and server implementations using OData. You can think of ADO.Net providing a rich experience over your data and OData providing a reach experience.
SQL Azure OData Service Security
The first thing that jumps to mind when you consider having a REST interface to your SQL Azure data is how do you control access? The SQL Azure OData Service implementation allows you to map both specific users to Access Control Service (ACS) or to allow anonymous access through a single SQL Azure user.
Anonymous Access
Anonymous access means that authentication is not needed between the HTTP client and SQL Azure OData Service. However, there is no such thing as anonymous access to SQL Azure, so when you tell the SQL Azure OData Service that you allow anonymous access you must specify a SQL Azure user that SQL Azure OData Service can use to access SQL Azure. The SQL Azure OData Service access has the same restriction as the SQL Azure user. So if the SQL Azure user being used in SQL Azure OData Service anonymous access has read-only permissions to the SQL Azure database then SQL Azure OData Service can only read the data in the database. Likewise if that SQL Azure user can’t access certain tables, then SQL Azure OData Service via the anonymous user can’t access these tables.
If you are interested in learning more about creating users on SQL Azure, please see this blog post which shows how to create a read-only user for your database.
Access Control Service
The Windows Azure AppFabric Access Control (ACS) service is a hosted service that provides federated authentication and rules-driven, claims-based authorization for REST Web services. REST Web services can rely on ACS for simple username/password scenarios, in addition to enterprise integration scenarios that use Active Directory Federation Services (ADFS) v2.
In order to use this type of authentication with OData you need to sign up for AppFabric here, and create a service namespace that use with SQL Azure OData Service. In the CTP of SQL Azure OData Service, this allows a single user, which has the same user id as the database user to access SQL Azure OData Service via Windows Azure AppFabric Access Control, using the secret key issued by the SQL Azure Labs portal. It doesn’t currently allow you to integrate Active Directory Federation Services (ADFS) integration, nor map multiple users to SQL Azure permissions.
Security Best Practices
Here are a few best practices around using SQL Azure OData Service:
- You should not allow anonymous access to SQL Azure OData Service using your SQL Azure administrator user name. This allows anyone to read and write from your database. You should always create a new SQL Azure user, please see this blog post.
- You should not allow the SQL Azure user used by SQL Azure OData Service to have write access SQL Azure OData Service via anonymous access, because there is no way to control how much or what type of data they will write.
- Because the browser will not support Simple Web token authentication natively, which is required for SQL Azure OData Service using Windows Azure AppFabric Access Control, you will need to build your own client to do anything but anonymous access. For more information see this blog post. That said, it is easiest while OData is under CTP to just use anonymous access with a read-only SQL Azure user.
Summary
I wanted to cover the basic of OData and a lay of the land around security. This information will surely change as OData matures and migrates from SQL Azure Labs to a production release. Do you have questions, concerns, comments? Post them below and we will try to address them.

Wayne Walter Berry describes Handling Transactions in SQL Azure in this 7/19/2010 post to the SQL Azure blog:
Local Transactions
Isolation Level
SQL Azure default database wide setting is to enable read committed snapshot isolation (RCSI) by having both the READ_COMMITTED_SNAPSHOT and ALLOW_SNAPSHOT_ISOLATION database options set to ON, learn more about isolation levels here. You cannot change the database default isolation level. However, you can control the isolation level explicitly on a connect ion. On way to do this you can use any one of these in SQL Azure before you BEGIN TRANSACTION:
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE SET TRANSACTION ISOLATION LEVEL SNAPSHOT SET TRANSACTION ISOLATION LEVEL REPEATABLE READ SET TRANSACTION ISOLATION LEVEL READ COMMITTED SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTEDSET TRANSACTON ISOLATION LEVEL controls the locking and row versioning behavior of Transact-SQL statements issued by a connection to SQL Server and spans batches (GO statement). All of the above works exactly the same as SQL Server.
Distributed Transactions in SQL Azure
SQL Azure Database does not support distributed transactions, which are transactions that multiple transaction managers (multiple resources). For more information, see Distributed Transactions (ADO.NET). This means that SQL Azure doesn’t support the TransactionScope class in .NET and doesn’t allow Microsoft Distributed Transaction Coordinator (MS DTC) to delegate distributed transaction handling.
Because of this you can’t use ADO.NET or MSDTC to commit or rollback transactions to multiple SQL Azure databases or a combination of SQL Azure and on premise SQL Server. This doesn’t mean that SQL Azure doesn’t support transactions, it does. However, it only supports transactions that are committed on the server, not transactions that are being delegated off server by a transaction manager.
Getting It Coded
A common managed programming technique is to create several methods that execute a single statement of stored procedure on SQL Server, and then wrap all these calls within the context of the TransactionScope class. This allows for cleaner code and the ability to execute some of the methods either in or out of the transaction. This technique delegates the transaction handling to the computer running the code (not the SQL Server). With SQL Azure you cannot implement this style of code. However, if all your connections are to the same SQL Azure database you can modify your code and get the same results.
Here is a simplified sample of some typical code using the TransactionScope class:
// Create the TransactionScope to execute the commands, guaranteeing // that both commands can commit or roll back as a single unit of work. using (TransactionScope scope = new TransactionScope()) { using (SqlConnection sqlConnection = new SqlConnection(ConnectionString)) { // Opening the connection automatically enlists it in the // TransactionScope as a lightweight transaction. sqlConnection.Open(); // Create the SqlCommand object and execute the first command. SqlCommand sqlCommand = new SqlCommand("sp_DoThis", sqlConnection); sqlCommand.CommandType = System.Data.CommandType.StoredProcedure; sqlCommand.ExecuteNonQuery(); } using (SqlConnection sqlConnection = new SqlConnection(ConnectionString)) { // Opening the connection automatically enlists it in the // TransactionScope as a lightweight transaction. sqlConnection.Open(); // Create the SqlCommand object and execute the first command. SqlCommand sqlCommand = new SqlCommand("sp_DoThat", sqlConnection); sqlCommand.CommandType = System.Data.CommandType.StoredProcedure; sqlCommand.ExecuteNonQuery(); } // The Complete method commits the transaction. If an exception has been thrown, // Complete is not called and the transaction is rolled back. scope.Complete(); }This code appears pretty wasteful as it has to make two trips to SQL Azure - this is a result of the simplified example. Normally, the code would be divided in multiple methods and called from an outer method where the TransactionScope was declared. Now let’s rewrite the code to work with SQL Azure and still get our two stored procedures executed in the same transaction.
StringBuilder command = new StringBuilder(); command.Append("BEGIN TRY\r\n"); command.Append("BEGIN TRANSACTION\r\n"); command.Append(" EXECUTE sp_DoThis\r\n"); command.Append(" EXECUTE sp_DoThat\r\n"); command.Append("COMMIT TRANSACTION\r\n"); command.Append("END TRY\r\n"); command.Append("BEGIN CATCH\r\n"); // Roll back any active or uncommittable transactions command.Append("IF XACT_STATE() <> 0\r\n"); command.Append("BEGIN\r\n"); command.Append(" ROLLBACK TRANSACTION;\r\n"); command.Append("END\r\n"); command.Append("END CATCH\r\n"); using (SqlConnection sqlConnection = new SqlConnection(ConnectionString)) { // Opening the connection automatically enlists it in the // TransactionScope as a lightweight transaction. sqlConnection.Open(); // Create the SqlCommand object and execute the first command. SqlCommand sqlCommand = new SqlCommand(command.ToString(), sqlConnection); sqlCommand.ExecuteNonQuery(); }This code makes a single trip to SQL Azure and runs the two stored procedures in a transaction context on SQL Azure; nothing is delegated to a transaction manager running on the local computer. This code works on SQL Azure.
Couple of notes about the code above:
- Always use parameterized queries when calling SQL Azure, instead of inline SQL with inline parameters; this reduces the risk of SQL injection. The code above doesn’t have parameters so this is a non-issue.
- There are faster ways of concatenating static strings then use StringBuilder; you could make the code one long static string. …
The Astoria Team posted OData and Authentication – Part 5 – Custom HttpModules on 7/19/2010:
Unfortunately that approach means authentication is not integrated or shared with the rest of your website.
Which means for all but the simplest scenarios a better approach is needed: HttpModules.
HttpModules can do all sort of things, including Authentication, and have the ability to intercept all requests to the website, essentially sitting under your Data Service.
This means you can remove all authentication logic from your Data Service. And create a HttpModule to protect everything on your website - including your Data Service.
Built-in Authentication Modules:
Thankfully IIS ships with a number of Authentication HttpModules:
- Windows Authentication
- Form Authentication
- Basic Authentication
You just need to enable the correct one and IIS will do the rest.
So by the time your request hits your Data Service the user with be authenticated.
Creating a Custom Authentication Module:
If however you need another authentication scheme you need to create and register a custom HttpModule.
So lets take our – incredibly naive – authentication logic from Part 4 and turn it into a HttpModule.
First we need a class that implements IHttpModule, and hooks up to the AuthenticateRequest event something like this:
public class CustomAuthenticationModule: IHttpModule
{
public void Init(HttpApplication context)
{
context.AuthenticateRequest +=
new EventHandler(context_AuthenticateRequest);
}
void context_AuthenticateRequest(object sender, EventArgs e)
{
HttpApplication app = (HttpApplication)sender;
if (!CustomAuthenticationProvider.Authenticate(app.Context))
{
app.Context.Response.Status = "401 Unauthorized";
app.Context.Response.StatusCode = 401;
app.Context.Response.End();
}
}
public void Dispose() { }
}We rely on the CustomAuthenticationProvider.Authenticate(..) method that we wrote in Part 4 to provide the actual authentication logic.
Finally we need to tell IIS to load our HttpModule, by adding this to our web.config:
<system.webServer>
<modules>
<add name="CustomAuthenticationModule"
type="SimpleService.CustomAuthenticationModule"/>
</modules>
</system.webServer>Now when we try to access our Data Service - and the rest of the website – it should be protected by our HttpModule.
NOTE: If it this doesn’t work, you might have IIS 6 or 7 running in classic mode which requires slightly different configuration.Summary.
In part 2 we looked about using Windows Authentication.
And in parts 3, 4 and 5 we covered all the hooks available to Authentication logic in Data Services, and discovered that pretty much everything you need to do is possible.Great.
Next we’ll focus on real world scenarios like:
- Forms Authentication
- Custom Basic Authentication
- OAuthWrap
- OAuth 2.0
- OpenId
- etc…
The Astoria Team also posted OData and Authentication – Part 4 – Server Side Hooks on 7/19/2010:
What however if you need a different authentication scheme?
Well the answer as always depends upon your scenario.
Broadly speaking what you need to do depends upon how your Data Service is hosted. You have three options:
- Hosted by IIS
- Hosted by WCF
- Hosted in a custom host
But by far the most common scenario is…
Hosted by IIS
This is what you get when you deploy your WebApplication project – containing a Data Service – to IIS.
At this point you have two realistic options:
- Create a custom HttpModule.
- Hook up to the DataServices ProcessingPipeline.
Which is best?
Undoubtedly the ProcessingPipeline option is easier to understand and has less moving parts. Which makes it an ideal solution for simple scenarios.
But the ProcessingPipeline is only an option if it makes sense to allow anonymous access to the rest of website. Which is pretty unlikely unless the web application only exists to host the Data Service.
Using ProcessingPipeline.ProcessingRequest
Nevertheless the ProcessingPipeline approach is informative, and most of the code involved can be reused if you ever need to upgrade to a fully fledged HttpModule.
So how do you use the ProcessingPipeline?
Well the first step is to enable anonymous access to your site in IIS:
Next you hookup to the ProcessingPipeline.ProcessingRequest event:
public class ProductService : DataService<Context>
{
public ProductService()
{
this.ProcessingPipeline.ProcessingRequest += new EventHandler<DataServiceProcessingPipelineEventArgs>(OnRequest);
}Then you need some code in the OnRequest event handler to do the authentication:
void OnRequest(object sender,
DataServiceProcessingPipelineEventArgs e)
{
if (!CustomAuthenticationProvider.Authenticate(HttpContext.Current))
throw new DataServiceException(401, "401 Unauthorized");
}In this code we call into a CustomAuthenticationProvider.Authenticate() method.
If everything is okay – and what that means depends upon the authentication scheme - the request is allowed to continue.If not we throw a DataServiceException which ends up as a 401 Unauthorized response on the client.
Because we are hosted in IIS our Authenticate() method has access to the current Request via the HttpContext.Current.Request.
My pseudo-code, which assumes some sort of claims based security, looks like this:
public static bool Authenticate(HttpContext context)
{
if (!context.Request.Headers.AllKeys.Contains("Authorization"))
return false;
// Remember claims based security should be only be
// used over HTTPS
if (!context.Request.IsSecureConnection)
return false;string authHeader = context.Request.Headers["Authorization"];
IPrincipal principal = null;
if (TryGetPrinciple(authHeader, out principal))
{
context.User = principal;
return true;
}
return false;
}What happens in TryGetPrincipal() is completely dependent upon your auth scheme.
Because this post is about server hooks, not concrete scenarios, our TryGetPrincipal implementation is clearly NOT meant for production (!):
private static bool TryGetPrincipal(
string authHeader,
out IPrincipal principal)
{
//
// WARNING:
// our naive – easily mislead authentication scheme
// blindly trusts the caller.
// a header that looks like this:
// ADMIN username
// will result in someone being authenticated as an
// administrator with an identity of ‘username’
// i.e. not exactly secure!!!
//
var protocolParts = authHeader.Split(' ');
if (protocolParts.Length != 2)
{
principal = null;
return false;
}
else if (protocolParts[0] == "ADMIN")
{
principal = new CustomPrincipal(
protocolParts[1],
"Administrator", "User"
);
return true;
}
else if (protocolParts[0] == "USER")
{
principal = new CustomPrincipal(
protocolParts[1],
"User"
);
return true;
}
else
{
principal = null;
return false;
}
}Don’t worry though as this series progresses we will look at enabling real schemes like Custom Basic Auth, OAuthWrap, OAuth 2.0 and OpenId.
Creating a custom Principal and Identity
Strictly speaking you don’t need to set the Current.User, you could just allow or reject the request. But we want to access the User and their roles (or claims) for authorization purposes, so our TryGetPrincipal code needs an implementation of IPrincipal and IIdentity:
public class CustomPrincipal: IPrincipal
{
string[] _roles;
IIdentity _identity;public CustomPrincipal(string name, params string[] roles)
{
this._roles = roles;
this._identity = new CustomIdentity(name);
}public IIdentity Identity
{
get { return _identity; }
}public bool IsInRole(string role)
{
return _roles.Contains(role);
}
}
public class CustomIdentity: IIdentity
{
string _name;
public CustomIdentity(string name)
{
this._name = name;
}string IIdentity.AuthenticationType
{
get { return "Custom SCHEME"; }
}bool IIdentity.IsAuthenticated
{
get { return true; }
}string IIdentity.Name
{
get { return _name; }
}
}Now my authorization logic only has to worry about authenticated users, and can implement fine grained access control.
For example if only Administrators can see products, we can enforce that in a QueryInterceptor like this:
[QueryInterceptor("Products")]
public Expression<Func<Product, bool>> OnQueryProducts()
{
var user = HttpContext.Current.User;
if (user.IsInRole("Administrator"))
return (Product p) => true;
else
return (Product p) => false;
}Summary
In this post you saw how to add custom authentication logic *inside* the Data Service using the ProcessingPipeline.ProcessRequest event.
Generally though when you want to integrate security across your website and your Data Service, you should put your authentication logic *under* the Data Service, in a HttpModule.
More on that next time…

See Mike Taulty published his OData Slides from the NxtGen User Group Festival on 7/19/2010 in the Cloud Computing Events section.
Cihangir Biyikoglu’s Power Tools for Migrating MySql Database from Amazon AWS - Relational Database Service (RDS) to SQL Azure – Part 2: Migrating Databases to SQL Azure appeared in his Your Data in the Cloud MSDN blog on 7/19/2010:
[The] Migration Assistant team will be releasing a great power tool that can help you move your MySql databases directly into SQL Azure. The tool works against MySql instances hosted at Amazon’s Relational Database Service (RDS) as well. Here is a quick video that shows you how to move a database in Amazon AWS RDS service to SQL Azure.
You can find a preview of the tool and more information about the tool here.

Shimon Shlevich, a guest partner, posted PowerPivot & Analysis Services – The Value of Both to the SQL Server blog on 7/19/2010:
As Microsoft PowerPivot is gaining more popularity and exposure, BI professionals ask more and more questions about PowerPivot’s role in the organization in trying to understand what value the new in-memory BI solution from Microsoft brings, along with the benefits and the limitations of it. Is PowerPivot going to replace SQL Server Analysis Services? If so, how soon? What should be done with the existing BI solution? Or maybe both can coexist and serve different needs?
The new in-memory engine is called “Vertipaq”. Vertipaq is claimed to perform much better than classic SSAS engine doing the aggregations and calculations as well as temporary data storage in a computer’s RAM eliminating the slow disk lookup overhead. The first version of this engine is currently released as a part of both Microsoft Office Excel 2010 and the SQL Server 2008 R2 enabling SSAS to work either in classic or the new in-memory mode. The in-memory mode for SSAS is currently only available for PowerPivot created cubes and not for all your classic cubes, however, eventually the new engine will make it to a major SSAS release and will become the new default engine of the SSAS.
Meanwhile, classic SSAS is more functional than PowerPivot in terms of analytics and administration. SSAS has more semantics such as hierarchies, and more administration support such as robust data security functionality. SSAS is probably the richest multidimensional engine on the market today, scalable to support large data amounts and completely enterprise ready. The downside of these capabilities is that SSAS project requires design and planning of the BI solution, implementation, deployment, testing and additional phases. A team of BI developers, IT support, long development cycle and not that frequent updates result with a highly customized, less flexible solution which is good for years and relies on enterprise data which structure does not change that often.
Analysis Services is the corner stone of any corporate infrastructure and it enables users to analyze data that has already been pre-modeled for them by IT. So users can create standard reports, dashboards and KPI’s based on the data there, in a sense, answering ‘known’ questions. PowerPivot, on the other hand, enables users to connect to any data and instantly start modeling and analyzing it “on-the-fly” (without IT defining the cubes and modeling it in advance). PowerPivot essentially enables users to answer those ‘unknown’ questions that can often exist.
How often have you had data was missing from the cube? Or a business user come to ask for a missing metric and you postponed its creation for the next data warehouse update which was postponed and never actually happened? This is where we need self-service BI and this is where PowerPivot comes to help both the business user and the IT team. PowerPivot authoring environment is the same beloved Microsoft Office Excel that everybody has and knows how to use. The simplicity and the familiarity of this desktop tool eliminates the need for additional training and increases the adoption rate. Give them a tool they are not afraid to use and they’ll know how to work with the metrics. Business users are able to just go through any data on their flat spreadsheet and produce a cube from it in a pivot table with only a single mouse click. There are certain limitations there, but the value is still huge – self service BI with zero training required and remarkable engine performance providing instant business value.
That’s why we say SSAS answers your “known” questions and PowerPivot solves the “unknown” ones. Panorama NovaView 6.2 supports both systems and supplies our customers with the same interface and same tools for both SSAS and PowerPivot. NovaView’s unified security layer secures both data sources at the same time and with the same security definitions making administrators’ life easier and making PowerPivot ready for a large enterprise deployment. NovaView BI Server resides in the center of the BI solution and implements the business logic, additional data semantics, and security applied on both SSAS and PowerPivot. It also delivers the data insights over both data sources via the entire suite of NovaView front end tools such as Flash Analytics, Dashboard, Smart Report, Spotlight and more.
By adopting the Microsoft roadmap of self-service BI, Panorama offers intuitive and easy to learn tools which allow business users to connect to either SSAS or PowerPivot cube within seconds. Following the initial connection NovaView users can manipulate the data, build extra calculations, exceptions, charts, KPIs and more. Users can save their work and share it with colleagues by making it publically available, sending by email or via a SharePoint portal. Specifically for PowerPivot, Panorama’s data security layer and rich analytical and dashboarding abilities extend PowerPivot cubes and create an enterprise ready, self-service, in-memory driven BI solution.

Learn more about Panorama for PowerPivot >>
Cihangir Biyikoglu’s Transferring Schema and Data From SQL Server to SQL Azure – Part 1: Tools of 6/30/2010 compares alternative approaches:
Many customers are moving existing workloads into SQL Azure or are developing on premise but move production environments to the SQL Azure. For most folks, that means transferring schema and data from SQL Server to SQL Azure.
When transferring schema and data, there are a few tools to choose from. Here is a quick table to give you the options.
Here is a quick overview of the tools;
Generate Script Wizard
This option is available through Management Studio 2008 R2. GSW has built in understanding of SQL Azure engine type can generate the correct options when scripting SQL Server database schema. GSW provides great fine grained control on what to script. It can also move data, especially if you are looking to move small amounts of data for one time. However for very large data, there are more efficient tools to do the job.
Figure 1. To use generate script wizard, right click on the database then go under tasks and select “Generate Script”.
DAC Packages
DACPacs are a new way to move schema through the development lifecycle. DACPacs are a self contained package of all database schema as well as developers deployment intent so they do more than just move schema between SQL Server and SQL Azure but they can be used for easy transfer of schema between SQL Server and SQL Azure. You can use DACPacs pre or post deployment scripts to move data with DACPacs but again, for very large data, there are more efficient tool to do the job.
Figure 2. To access DAC options, expand the “Management” section in the SQL instance and select “Data-tier Applications” for additional options.
SQL Server Integration Services
SSIS is a best of breed data transformation tools with full programmable flow with loops, conditionals and powerful data transformation tasks. SSIS provides full development lifecycle support with great debugging experience. Beyond SQL Server, It can work with diverse set of data sources and destinations for data movement. SSIS also is the technology that supports easy-to-use utilities like Import & Export Wizard so can be a great powerful tool to move data around. You can access Import and Export Wizard directly from the SQL Server 2008 R2 folder under the start menu
BCP & Bulk Copy API
Bulk Copy utility is both a tool (bcp.exe) and API (System.Data.SqlClient.SqlBulkCopy) to move structured files in and out of SQL Server and SQL Azure. It provides great performance and fine grained control for how the data gets moved. There are a few options that can help fine-tune data import and export performance.
In Part 2 of this post, we’ll take a closer look at bcp and high performance data uploads.



It’s surprising that Cihangir didn’t include the SQL Server Migration Wizard v3.3.3 as an alternative.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Rinat Abdullin posted Lokad CQRS - Advanced Task Scheduling with Calendars in the Cloud on 7/20/2010:
This is the next article in the Learning series for Lokad.CQRS Guidance. In the previous tutorial we've talked about using NHibernate Module to working with relational databases in the cloud. Sample-03 was covered.
Recently there was a question in Lokad community about implementing advanced scheduling capabilities with Lokad Cloud project.
I am considering creating a project to add some additional scheduling functionality to the Lokad.Cloud project. Specifically, I would like to be able to schedule tasks to run at specific times. Does anyone have any thoughts on what they would like to see in this project?
The question is interesting for two reasons:
First, it touches separation of Concerns (SOC) between Lokad.Cloud and Lokad.CQRS.
Second, there already is a reference implementation of advanced calendar scheduler in Lokad.CQRS ecosystem. It was not open sourced before, but now it is.
SoC between Lokad Cloud and Lokad CQRS
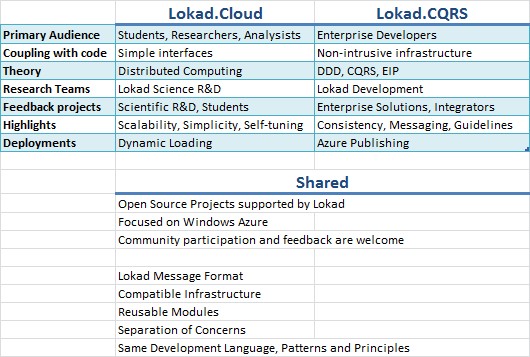
As we've mentioned in the Roadmap earlier, Lokad Cloud and CQRS projects target distinct audiences and scenarios. This helps them to stay focused and concise, reducing complexity and development friction around the frameworks as well as the solutions implemented with them.
Both projects share simple task schedulers that allow to execute commands at predefined intervals of time within your Windows Azure implementation. Yet there are differences.
Lokad.Cloud Task Scheduler is designed for the distributed processing and load balancing tasks, featuring integration with the Web Console, that allows to override timer intervals to fine-tune performance of algorithms on-the-run. That's the kind of functionality that is usually required by the Lokad.Cloud solutions.
Lokad.CQRS task scheduler executes operations at predefined intervals as well. It does not provide default integration with Web UI, instead specifying sleep timeout at the end of each operation. All operations are resolved and reliably executed within a separate IoC Container lifetime scope and transaction, providing native support for working with NHibernate Module and any other operation supporting System.Transactions. Such functionality is required by enterprise and business applications. It also provides foundation for delivering advanced calendar scheduling specific to your project. We'll talk about that later in this article.
Note: As it was mentioned earlier, both Lokad Cloud and Lokad CQRS projects are eventually going to become more interoperable, than they are now. Things like Lokad Message Format and reusable components are being architected into the design to allow building cloud solutions for Windows Azure that share the best of the two worlds: powerful scalability for cloud-intensive operations coupled with flexibility and reliability for enterprise and integration scenarios.
Rinat continues with the details of “Advanced Task Scheduling Implementation.”
Trading Markets reported Siemens PLM Software Partners with Microsoft in this 7/20/2010 article about Product Lifecycle Management:
Siemens PLM Software, a business unit of the Siemens Industry Automation Division and a supplier of product lifecycle management (PLM) software and services, recently announced a joint project with Microsoft Corporation to create what it said will be the PLM industry's first cloud computing-based quality management solution.
The announcement was made at the Microsoft World Partner Conference in Washington, D.C., and represents one of several projects being jointly pursued by Siemens PLM Software and Microsoft to test and validate how cloud computing can be successfully used with PLM to create value for the global manufacturing industry. On June 28 Microsoft conducted a separate PLM-based cloud computing demonstration involving software solutions from Siemens PLM Software in front of more than 1,400 attendees at the Siemens PLM Connection User Conference in Dallas.
"Delivering cloud computing solutions is a part of Microsoft's commitment to ensuring that enterprise customers realize the maximum business value from their IT investments," said Simon Witts, corporate VP, Enterprise and Partner Group (EPG), Microsoft.
DPV, an integral part of the Tecnomatix software suite of digital manufacturing solutions, is the industry's first PLM-based closed loop quality system enabling the collection, management, analysis and reporting of quality measurement information tied directly to real time production results. Tecnomatix DPV leverages Teamcenter software, a PLM system from Siemens PLM Software, enabling the user to incorporate as-built production information, coupled with real time production quality data, in the same environment used to manage the enterprise's product, process and manufacturing data.
Some organizations - such as remote manufacturing locations or outside suppliers - may not require a full PLM resource infrastructure, but can still benefit from this type of management technology. Through their partnership, Siemens PLM Software and Microsoft have joined forces to create an environment in which Tecnomatix DPV and Teamcenter will run in the cloud with the Windows Azure cloud services operating system, and utilize the SQL Azure relational database.
Alex Woodie reported New GXS Analytics App to Live on Microsoft's Azure Cloud in a 7/20/2010 post to the IT Jungle blog:
GXS, which completed its merger with Inovis in early June, is testing a new analytics application designed to give small and mid-sized businesses insight into their supply chain performance and information flows. The offering, called GXS Trading Partner Analytics, is currently undergoing beta tests on the Microsoft Azure cloud computing platform.
GXS is positioning its Trading Partner Analytics as an on-demand extension to GXS Trading Grid, its flagship business-to-business (B2B) messaging service, which is used by more than 100,000 organizations for exchanging business documents such as EDI, XML, and flat files, across a range of protocols.
Trading Partner Analytics, which the company unveiled earlier this year, is designed to give Trading Grid SMBs an aggregate view of their business activitities occurring in the GXS B2B service. The vendor says it will tap data in customers' Trading Grid mailboxes to extract insights and business "signals" that could be of use to a customer.
Some of the types of questions that Trading Partner Analytics will help to answer include: Am I getting more or fewer orders from this customer? Are my suppliers improving their performance, or are they getting worse? And which buyers generate the most purchase order changes?
Using the Azure cloud will also allow GXS to simplify pricing for its new Trading Partner Analytics app. GXS will adopt Azure's "pay-as-you-go" pricing model, whereby users only pay for what they use.
GXS expects to make Trading Partner Analytics available near the end of the year. The offering is also expected to be made available to customers of Inovis (which has a good number of iSeries and System i customers using the TrustedLink software), provided they have adopted the Trading Grid service. The combined company is operating under the GXS name. For more information, visit www.gxs.com.
Jim O’Neil started a new blog series with Azure@home Part 1: Application architecture of 7/19/2010:
This post is part of a series diving into the implementation of the @home With Windows Azure project, which formed the basis of a webcast series by Developer Evangelists Brian Hitney and Jim O’Neil. Be sure to read the introductory post for the context of this and subsequent articles in the series.
As a quick review, the @home with Windows Azure project involves two applications hosted in Windows Azure:
- Azure@home, a cloud application that can be individually deployed to contribute to the Folding@home effort, and
- distributed.cloudapp.net, the project host and reporting site to which each of the Azure@home deployments ‘phone home.’
The relationship of the two applications is depicted in the architecture slide to the right, and for the purposes of this and the subsequent posts in my blog series I’ll be concentrating on the highlighted Azure@home piece (for additional context see the introductory blog post of this series).
Solution structure
The source code for Azure@home is available as both Visual Studio 2008 and Visual Studio 2010 solutions and comprises five distinct projects, as you can see when opening the solution file in Visual Studio or Visual Web Developer Express; I’ll be using Visual Studio 2010 from here on out.
- AzureAtHome, the cloud services project that ‘wraps’ the Azure@home application, which consists of two roles along with configuration data.
- AzureAtHomeEntities, classes implementing the Azure StorageClient API for the Windows Azure storage used by this application.
- FoldingClientMock, a console application that implements the same ‘interface’ as the full FAH console client, and which is used for testing Azure@home in the development fabric.
- WebRole, the public-facing ASP.NET website with two simple pages: one that accepts some input to start the folding process, and the second that reports on progress of the Folding@home work units.
- WorkerRole, a wrapper for the FAH console client which runs infinitely to process work units and record progress.
Application flow
Using the image below, let’s walk through the overall flow of the application and identify where the various Azure concepts – worker roles, web roles, and Azure storage – are employed, and then in the next post, we’ll start pulling apart the code.
Note there are two distinct paths through the application, one denoted by blue, numbered circles and the other by the two green, lettered circles; I’ll start with the blue ones.
- The application kicks off with the launch of a web site hosted within a single instance of a web role. In this case, the site is built using Web Forms, but it could just has easily been an MVC site or Dynamic Data. In fact, you can deploy PHP sites, or pretty much any other web technology as well (although that’s done a bit differently and something I won’t tackle in this particular blog series).
The default.aspx page of the site is a simple interface consisting of a a few standard ASP.NET controls (a couple of TextBoxes, a Hyperlink, and a button) along with the Bing Maps Ajax control. On this page, the user enters his or her name (which will ultimately be recorded at the Folding@home site) and selects a location on the map to provide some input for the Silverlight visualization on the main @home With Windows Azure site.- The information collected from the default.aspx page (user name and lat/long combination) and a few other items are posted to the ASP.NET web site hosted by the Azure web role and then written to a table in Azure storage named client. The page then redirects to the status.aspx page (labeled with the green ‘a’ and which I’ll discuss toward the end of the article).
- Although it appears the application is idle until the user submits the default.aspx page, in actuality each of the deployed worker roles has been continuously polling the client table. Each worker role is a wrapper for a single instance of a Folding@home (FAH) console client process, and it’s the worker’s job to start a FAH process passing in the requisite parameters (one of which is the user name stored within the client table). Until there is a record in the client table, there is nothing for the worker role to do, so it will just sleep for 10 seconds and then check again.
- Once a record appears in the client table (and there will always be at most one record there), the worker role can initiate the FAH console client process (or the FoldingClientMock, when testing) via Process.Start and let it do whatever magic is held within. What happens inside the FAH console client is a black-box in terms of the Azure@home application; at the high level it’s doing some number crunching and reporting information periodically back to one of the servers at Stanford.
- The other thing the FAH process does is update a local text file named unitinfo.txt (in the same directory that the FAH process is running in) to include information on the progress of the individual work unit – specifically the percentage complete.
- Each worker role polls its associated unitinfo.txt file to parse out the percentage complete of the given work unit that it hosts. The polling interval is configurable, but since many of the work units take a day or even longer to complete, the default configuration has it set to 15 minutes.
- After the worker role has parsed the unitinfo.txt file and extracted the percentage of completion, it adds a entry to another Windows Azure Table, this one called workunit, which stores information about the progress of both running and completed work units.
- In conjunction with Step 7, the worker role also makes an HTTP call to a service hosted at distributed.cloudapp.net, passing in the information on the progress of the work unit. distributed.cloudapp.net maintains a record of all work units in every Azure@home deployment (in Azure Table storage, of course!) to report progress and support the Silverlight map.
Steps 5 through 8 continue until the FAH client has completed a work unit, at which point the FAH process (started in step 4) ends, and the worker role reinitiates step 3, the polling process. The client table’s record will be in place then, so the poll will be immediately successful, another FAH process is started, and the cycle continues ad infinitum.
The second path through the application is a simple one.
On load of the default page for the ASP.NET web site, say http://yourapp.cloudapp.net, a check is made as to whether a record exists in the client table. If so, this Azure@home application instance has already been initialized – that is, the user provided their name and location – and so is actively processing work units via however many worker roles were deployed. default.aspx then automatically redirects to the status.aspx page.
- status.aspx simply queries the workunit table in Azure storage to get the status of all on-going and completed work units to display them in the web page, as shown to the right.
Next time we’ll crack open the WebRole code and dive into steps 1 and 2 above.


The Windows Azure Team posted Windows Azure Architecture Guide – Part 1 Now Available on 7/18/2010:
As David Aiken recently mentioned on his blog, the Microsoft Patterns & Practices team has just released the Windows Azure Architecture Guide - Volume 1. The first in a planned series about the Windows Azure platform, this book walks readers through how to adapt an existing, on-premises ASP.NET application to one that operates in the cloud. Each chapter explores different considerations including authentication and authorization, data access, session management, deployment, development life cycle and cost analysis.
The book is intended for any architect, developer, or information technology (IT) professional who designs, builds, or operates applications and services that are appropriate for the cloud, works with Windows-based systems and is familiar with the Microsoft .NET Framework, Microsoft Visual Studio, ASP.NET, SQL Server, and Microsoft Visual C#.
Old news but worth repeating.
Anna Isaacs reports Metastorm software now in the clouds in this 7/18/2010 story for The Daily Record:
It’s not especially big news that software provider Metastorm has released another software program that will help its customers manage business processes.
But the fact that Metastorm M3 is the Baltimore-based company’s first “cloud-based” product is noteworthy.
“Cloud-based” is tech speak for software you don’t have install because it’s accessed via the Internet. Think Gmail versus the e-mail application that comes with your computer.
With Metastorm’s product, users can create and update graphical models and collaborate with other users in real time.
“It’s pretty standard for organizations to want to understand how the different components of their business work, so there are tools out there to allow them to graph and model different elements of their business,” said Laura Mooney, vice president of Metastorm, which works with businesses and government organizations to makes businesses more efficient.
Metastorm chose to use a cloud platform, Mooney said, because many of its global customers have employees in different locations, making online access vital for them to collaborate.
So they took the most popular applications used in their products and bundled them up into one program on a cloud platform to be more accessible on a global basis. This program includes model types for organizational charts as well as laying out strategic goals.
Mooney said Metastorm’s competitors offer similar products on a hosted basis — that is, on servers set up in their own facilities that people can connect to remotely. Metastorm’s product, she said, is run on a true cloud platform, Microsoft’s Windows Azure. [Emphasis added.]
Metastorm also released a second cloud-accessible product last week, Smart Business Workplace. Mooney said this program sits across all of Metastorm’s software and allows users to personalize their own workspaces by using data and application mash-ups, which retrieve information from multiple applications and mash it all together into a different way at looking at data.
Metastorm has about 330 employees nationwide. Mooney declined to disclose revenue for the privately held company.
Return to section navigation list>
Windows Azure Infrastructure
David Chou sees Cloud Computing as a New Development Paradigm in this 7/20/2010 post to his Architecture + Strategy blog:
A colleague pointed me to a blog post Cloud this, cloud that, which to me reflects the common perception around cloud computing that it is just another form of server hosting; a deployment/delivery model. Instead of simply trying to re-deploy existing software into the cloud, our opinion is that cloud computing also offers more, in terms of a new way of writing software that exploit cloud computing as a platform; especially when leveraging the new breed of cloud platforms such as Windows Azure.
Just sharing my brief feedback to that blog below; will provide more detailed thoughts on this topic in a later post.
Cloud is indeed what everyone’s talking about right now; kind of like SOA during its heyday but even bigger in magnitude because barrier to entry to cloud computing is a lot lower than SOA and it can yield tangible short-term benefits.
To the question “how much does a software development team need to know about the cloud, beyond how to deploy to it and integrate applications with cloud-based apps?”, to me it depends on what ‘cloud computing’ means to a development team. If cloud computing is just deployment and integration, more like outsourced hosting, then yes, there isn’t much a software development team needs to know.
However, we believe that is just the utility computing aspect, a delivery model, of cloud computing. To truly benefit from cloud computing, software development teams can look at cloud computing as a new development paradigm, and leveraging it as a new paradigm and lead to differentiated value.
Specifically, software that operate[s] in cloud environments can be architected and written differently for the cloud than existing on-premise environments. Traditional n-tier development tends to focus on synchronous end-to-end transaction processing (tightly coupled) and locking concurrency control models, which typically lead to vertically integrated monolithic architectures that rely on clustering fewer and larger hardware to provide scalability/reliability. If we look at cloud computing as a development model, and design/architect towards distributed computing models, different design principles start to emerge. For example, multi-tenancy, eventual consistency (concurrency model), de-normalized and horizontally partitioned and shared-nothing data, asynchronous and parallel distributed processing, process redundancy and idempotency, service-oriented composition, etc.; these lead to horizontally scaling architectures that are consisted of a larger number of smaller and loosely coupled distributed components/services.
Cloud computing supports this type of architecture (especially prevalent in large web applications such as Facebook, Twitter, Google, etc.), and is required for applications that operate at Internet scale – those that need to process massive amounts of transactions or data. The ability to handle such high scale is not something that can be achieved with traditional monolithic architectures, and in fact, is becoming a very significant strategic and competitive advantage to those that can leverage it. This is the true differentiation aspect of cloud computing, and is what software development teams need to know.

The question, of course, is whether “differentiated value” will be more important to cloud purchasers than the purported lack of vendor lock-in offered by open-source clouds.
Petri I. Salonen continued with Law #6 of Bessemer’s Top 10 Cloud Computing Laws and the Business Model Canvas –By definition, your sales prospects are online on 7/18/2010:
I am now in the sixth law in Bessemer’s Top 10 Computing Laws with an emphasis in identifying the prospects that you are going to sell to. The old-fashioned way of selling software is changing in a fundamental way and this also reflects how you view software channels like I described in my previous blog entry and that reflects to Bessemer’s forth law (Law #4) of forgetting what you have learned of software channels. Let’s look at what this fourth law really means for SaaS companies. [Link to Bessemer Venture Partners added.]
Law #6: By definition, your sales prospects are online – Savvy online marketing is a core competence (sometimes the only one) of every successful Cloud business.
The reality in today’s world is that people are searching for products and services using search engines and making their buying decisions based on not only the information in the Internet, but also how other people are rating your product/service. Ten years ago when we were selling software for hundreds of thousands of dollars’ worth, CIOs and decision makers of the buying process did not necessarily go to the Internet and search for your track record of delivery and other key factors that are part of the decision making. I remember vividly that some our clients called organizations such as IDC, Gartner and Forrester to ask about the quality of our product as the digital footprint of a typical software vendor was very minimal.
This trend towards lead generation using search engine optimization (SEO), viral marketing, search engine marketing (SEM), email marketing are things that B2B marketers have been using for a while and traditional software vendors are only now trying to figure out to leverage it. Bessemer refers to organizations such as IBM, SAP, Oracle and their traditional ways of sales and how smaller challengers have a better opportunity to achieve visibility when compared to the large players. There are lots of good books about how the marketing and PR is changing like David MeerMan Scott and his book The New Rules of Marketing and PR: How to Use News Releases, Blogs, Podcasting, Viral Marketing and Online Media to Reach Buyers Directly.
What is changing is also that your web-site is no longer about your great looking graphics, but more about the content and relevancy to your audience. What really matters is what you have to say on your web-site and what type of action the site gives for the prospects that have an interest in your solution. Does your site let the prospect to take action? Based on some studies, even some SaaS companies are failing to lead the prospect to take action or even have something to act upon. This is amazing to me and one wonders if these companies just do not have the DNA of a SaaS company and therefore rather just execute on the traditional enterprise software sales methods. These companies will not survive in the long run and need to get new people onboard that have the right type of mentality.
Even email marketing is in a flux and during the last couple of years, I have seen people getting upset with email blasts that are not relevant to them and this will result in recipients becoming angry at your brand. Some people just do not get it, especially if your email addresses are not based on opt-in policy. This morning I was cleaning my email box from a person that seems to be sending crap to me every second day about topics that I do not care about. What gives him the right to do it? I have never requested him to send me anything and neither have I opted in to any of his web-sites. I hope he reads this blog entry and maybe shifts his thinking about his email marketing strategy.
Is email marketing dead? Probably not, but it is changing as we speak. Email marketing companies such as Exact Target and Constant Contact are acquiring social media solution providers to enhance their solutions with social aspects. Exact Target has acquired CoTweet and Constant Contact acquired NutshellMail. I personally believe that this is not only necessary, but it has to happen as the traditional email marketing needs to evolve to something that benefits the recipient and gives readers the ability to opt-in in a way that they want to such as using Twitter “follow” functionality.
Sales in the SaaS world have to do with getting your brand known in the social media space. That is where you are most likely going to be finding your new leads and that is where you need to convince your leads that your company and your solution/brand is something that they need to be paying attention to. Also, due to the change in revenue model in the software world, SaaS companies can no longer afford expensive inside sales teams like I discussed in my blog entry about sales learning curve and also about the financials in my blog entry of the top 6 financial metrics in the SaaS world that you have to be paying attention to.
Finally, the new way of marketing and creating awareness for your company gives you a tremendous opportunity even if you are a small player. Large companies just aren’t there yet with their social media strategies and if you are small and nimble, you can really make it big. Your SaaS sales have to be high from get-go, you have to generate leads and the old marketing methods are just too slow, so you might want to adjust to the new world of using social media. …

Petri continues with a “Summary of our findings in respect to Business Model Canvas.”
Simeon Simeonov asserts VMware Knows the Cloud Doesn’t Need Server Virtualization in this 7/17/2010 post to the GigaOm blog:
Server virtualization created cloud computing. Without the ability to run multiple logical server instances on a single physical server, the cloud computing economics we know today wouldn’t be possible. Most assume that server virtualization as we know it today is a fundamental enabler of the cloud, but it is only a crutch we need until cloud-based application platforms mature to the point where applications are built and deployed without any reference to current notions of servers and operating systems.
At that point, the value of server virtualization will go down substantially. This fact is not lost on virtualization leader VMware, whose CEO Paul Maritz, less than two years after joining, has positioned the company to cannibalize its own server virtualization business with a move toward platform-as-a-service computing.
At Structure 2010, Maritz said that “clouds at the infrastructure layer are the new hardware.” The unit of cloud scaling today is the virtual server. When you go to Amazon’s EC2 you buy capacity by the virtual server instance hour. This will change in the next phase of the evolution of cloud computing. We are already starting to see the early signs of this transformation with Google App Engine, which has automatic scaling built in, and Heroku with its notion of dynos and workers as the units of scalability.
Developers working on top of Google App Engine and Heroku never have to think about servers, virtual or physical. In a few years, clouds at the application platform layer will be the new hardware. At that time, traditional operating systems and server virtual machines will become much less important to the cloud.
First and foremost, server virtualization generates overhead. VMware performance tests suggest that the overhead is in the 8 to 12 percent range. However, when several virtual machines run on the same server and start competing for hardware and network resources, the overhead is substantially higher. This is waste. It’s expensive. It’s bad for the environment.
Some would argue that this is a necessary, small overhead that provides security and enables great efficiencies in the data center. That’s true in the sense that without virtualization there is no easy way to take many enterprise applications architected in the 80s and 90s, bolted onto a Windows or Linux operating system and relying on resources such as files and sockets, and make them securely run on one physical server. The argument fails, however, when applied to most modern applications, which rely on network-accessible resources such as databases and Web services as opposed to local resources such as files and processes.
Aiding this trend, startups are building custom application virtualization layers that free applications from servers, obviating the need for virtualizing Windows or full-featured Linux OSes. At Structure, Tom Mornini, CTO of Engine Yard, and I spent a fascinating part of an hour with pen and paper drawing diagrams of what the new software stack looks like. Although Engine Yard’s scaling model is still focused on servers, this is an indication of their enterprise go-to-market strategy. Enterprises are still much more comfortable thinking and buying in terms of servers.
Right now, many PaaS companies deploy on virtualized servers because they are small startups that don’t own their own hardware. In the very near future, when a large cloud provider such as Amazon offers a PaaS, that provider will have the option to deploy at least a meaningful portion of the PaaS workloads of their customers against machines running a lean, stripped OS and/or a tiny hypervisor providing the barest minimum isolation from the hardware and no server virtualization layer the way the term is understood today. Multi-tenancy isolation will be achieved at the platform-as-a-service layer, not at the virtual machine layer.
The biggest hindrance to deploying these types of PaaS offerings on public clouds is trust — something Werner Vogels, CTO of Amazon, emphasized in a conversation. Right now AWS trusts the server virtualization tier to provide security and isolation. Technically, this is not harder to do at the PaaS layer. In fact, it is easier — you just have to remove or trap dangerous APIs — but I expect it will still take at least a year or two before the volume of PaaS usage makes it worthwhile for large public cloud providers to go through the effort of eliminating server virtualization overhead.
Enterprise private clouds will need server virtualization for a while, but I expect that market to peak in three years and then begin a steady decline brought about by the commoditization of basic server virtualization we are already seeing and the shift of new development to PaaS. The same will happen with traditional server operating systems. It’s not a question of if, but when.
A year after Maritz took over the reins, VMware bought SpringSource, which offered an application framework, server and management tools with a significant following in the Java developer community. Partnerships with Google around App Engine and Salesforce.com around VMforce quickly followed — putting VMware in the Java PaaS game. VMware has seen the future clearly and is preparing to move up the stack to PaaS offerings.
This was spelled out in May by VMware CTO Steve Herrod: “We are committed to making Spring the best language for cloud applications, even if that cloud is not based on VMware vSphere.” Recently, GigaOM reported that VMware may be talking to Engine Yard, the Ruby on Rails PaaS provider. Whether a deal happens or not, I’m impressed by VMware’s bold approach under Maritz.
Soon we will be able to throw away the server virtualization crutch and, like in that memorable moment from Forrest Gump, we will be able to run leaner and more scalable applications in the cloud on next-generation platforms-as-a-service. For the time being, my call to action is for application developers to stop writing code that directly touches any hardware or operating system objects and try the current generation of platforms-as-a-service.
Simeon Simeonov is founder and CEO of FastIgnite, an executive-in-residence at General Catalyst Partners and co-founder of Better Advertising and Thing Labs. He tweets as @simeons.

Thanks to David Linthicum for the heads-up.
<Return to section navigation list>
Windows Azure Platform Appliance
Cumulux analyzes the Windows Azure [Platform] Appliance in this 7/20/2010 post:
Last week, Microsoft announced the Windows Azure Appliance in an effort to bring its well-received Public Cloud Strategy within the confines of the DMZ. So why is this a big deal ? The Azure appliance is probably the industry’s first private “Platform as a Service” from a major platform vendor. This has the potential to disrupt the cloud computing landscape and this note explore the implications of the Azure appliance.
Large Enterprises
Companies that are adept running their datacenters and looking to dip their toes in cloud computing will find this notion of a private Azure cloud appliance very appealing. In addition to modernizing their application stack to make it more “Service Oriented” and Cloud friendly, the get most of the advantages that Azure provides them without worrying about privacy and compliance. One thing they will miss out on is the dynamic elasticity that they would have got from the public Azure cloud.Service Providers
This is an area which will likely see explosive growth and mass adoption. I predict providers rolling out purpose built clouds catering to industries, regions etc. At this time, many business details like cost, licensing terms, country availability, SLAs etc are not clear and are likely in the process of being defined. Service providers can and probably will roll out custom clouds which cater to specific industry needs like HIPPA/PCI compliance. There is a strong chance that we might soon see clouds for Financial Services, Healthcare, Retail Payments, etc.Government Agencies
Apps.gov is a good example that many Federal, local and State agencies have already started consolidating their data centers and application procurement for common functions. For the last couple of years the Federal Government has been in the forefront of defining Cloud Computing requirements albeit on the Infrastructure as a Service side. The Azure appliance will be interesting to the government for several reasons including data security , privacy and compliance reasons.Why the Azure appliance wont be ubiquitous in the near future:
- Dependency on new purpose built hardware: Although we don’t know what the appliance would cost, requiring customers to buy hardware along with the appliance instead of just making it run on existing hardware will make it a much harder decision. The promise of the cloud was to move away from having to buy significant hardware and invest in managing them in house. The appliance does just that unless things evolve over time.
- Scale: The bar for using the appliance is hundreds/thousands of servers. While this might make sense for a handful of large enterprises or ISVs, it is a significant barrier for most businesses. This leads me to believe that the appliance will be more popular with the service providers first who can build “clusters” of special purpose clouds aimed at specific verticals.
- Operations: Running an appliance that has 1000+ servers is not for the faint of heart. You need to have sophisticated processes ,tools ,skills available to pull it off. Add the complexity of the new world of private clouds, it will take wuite a ramp up before organizations can be mature enough to roll out enterprise wide private cloud offerings that take into account automatic provisioning, metering, chargebacks, dynamic scaling etc.
While it is still early days, I predict that the appliance will continue to lower the barrier to adoption and push the “fence sitters” to try the public Azure on their non-critical assets to get acquainted with the cloud model. Another trend we can expect to see gaining ground is that of “hybrid clouds” or “sometimes cloud” where businesses can use the cloud to process excess capacity needs or use cloud to augment existing capabilities.
One thing is clear with the Azure appliance announcement – Microsoft is no longer afraid to cannibalize Windows Server licenses and perhaps is seeing the potential to winning over converts to its cloud. Though Amazon has a head start, the cloud computing game is just getting started and Microsoft is a market definer in many categories including the one we are discussing here – Private PaaS Clouds.

Derrick Harris explains why Why Microsoft’s PC-Inspired Cloud Strategy Might Work in this 7/18/2010 post to the GigaOm blog:
I wrote a few weeks ago that “Microsoft taught the world how to succeed in PC and business software, but it might [be] teaching the world how to not succeed in cloud computing” However, that’s a fate it could avoid if it just delivered on a clear vision. As I point out in my weekly column for GigaOM Pro, it looks like Microsoft has decided on that vision: Treat cloud computing like it treated the PC business.
With the announcement of Windows Azure Appliances (WAP), Microsoft is once again looking to server makers to sell its software, but now it has added service providers to the mix too. If it’s to make Windows Azure the Windows operating system of cloud computing, its “OEM” partners will be the key.
Historically, most server makers have been content to develop the hardware platform but strike OEM deals for the operating system (along with other components). If application platforms are the operating systems of cloud computing, why not carry this practice over to the cloud? Large hardware vendors like Dell, HP and Fujitsu (who’s already signed on as a service provider) can cloud-optimize their data centers while leaving platform development to Microsoft, VMware, Joyent and anybody else so inclined to sell their platforms to service providers.
Even Rackspace — which could be considered a Microsoft competitor in the cloud — is considering getting in on the WAP action.
Of course, if this pans out at any notable scale, cloud computing could become business as usual for Microsoft. Is cloud computing a low-margin business? It is if you’re selling straight to developers. However, a large distribution channel for Windows Azure — a quality offering in its own right — will attract users. Hoping to capture these users’ dollars, more ISVs will build applications on top of Azure. Seeing a robust ecosystem, even more customers will follow suit. All of a sudden, Windows Azure is a must-have offering for service providers and Microsoft can reap the rewards just as it did with Windows operating systems. Right?
Read the full post from GigaOM Pro here.
Image source: Flickr user Robert Scoble

<Return to section navigation list>
Cloud Security and Governance
HP CTO for Cloud Security Archie Reed and Cloud Security Alliance Executive Director Jim Reavis appear in this 00:03:39 Seven deadly sins of cloud security HP video segment:
Archie Reed and Jim Reavis provide a situational awareness of the threats to help compliment the business strategies and best practices of cloud security by taking a very judicial approach.
There likely are more than 7 deadly sins, but new research from the Cloud Security Alliance has just identified the top 7 threats. Hear from Jim Reavis, executive director from the Cloud Security Alliance, as he explains the risks associated with each and best practices to effectively manage security in the cloud


Ron B. Knode claims Your Biggest Risk In Cloud Computing — Doing Nothing in this 7/19/2010 post:
Matthew Moore can claim what few others in the still-maturing cloud computing space can claim: direct experience securing a cloud, beyond just the theoretical and postulating. His team has been securing CSC’s private cloud offerings for years.
Moore, Director of Global Security Solutions for the Americas at CSC, oversees a $4.6 billion commercial portfolio with all run-and-maintain, protection and compliance responsibilities falling to him and his team.
And yet, despite constant murmurs in press coverage about IT threats and risks associated with cloud computing, some might find Moore surprisingly upbeat and optimistic.
“A lot of people think of IT security solely in a protective sense, as being defensive,” Moore said in an interview Wednesday for Cloud Security & Trust Week. “But if I spent all my time worrying about the possible threats, just reacting, I can’t focus on the more critical operations of my business.”
Moore described the path of a typical client: A CIO is under pressure from a board of directors or senior executive leadership to “figure out how to get us into cloud.” But this CIO isn’t sure where to begin. It could be a bank with international regulations to adhere to, an industrial company in energy or aerospace and defense with valuable technology to protect — so rushing right into a cloud solution isn’t an option. That’s when they turn to a trusted advisor, Moore said.
“Folks might jump in too quickly,” Moore said. “But they also might not move because they’re too afraid. That’s the biggest risk I see.”
Moore said that not taking action can set an enterprise back from a market dominance perspective. Whatever makes a business competitive, he said, if the cloud can augment that, then it makes sense to do that.
CSC’s business-first approach, or “Right Cloud, Right Way” mantra, comes up at this point in the conversation. With a variety of cloud options — from private, to public, to hybrid clouds — and discrete cloud services for functions such as email and collaboration or application development and testing, an organization can move only those operations that make sense to the cloud, Moore pointed out.
“If there’s something like cloud that takes your business further, your biggest risk is not doing that thing,” he said. “Security should not be just about protecting you, it should be about enabling you.”
We’ll have more to say soon about security and CSC cloud computing offerings, so stay tuned for some big announcements.
Lori MacVittie (@lmacvittie) posits Defeating modern attacks – even distributed ones – isn’t the problem. The problem is detecting them in the first place in her Defeating Attacks Easier Than Detecting Them essay of 7/19/2010:
Last week researchers claimed they’ve discovered a way to exploit a basic security flaw that’s used in software that’s in high use by Web 2.0 applications to essentially support if not single-sign on then the next best thing – a single source of online identity.
The prevalence of OAuth and OpenID across the Web 2.0 application realm could potentially be impacted (and not in a good way) if the flaw were to be exploited. Apparently a similar flaw was used in the past to successfully exploit Microsoft’s Xbox 360. So the technique is possible and has been proven “in the wild.”
The attacks are thought to be so difficult because they require very precise measurements. They crack passwords by measuring the time it takes for a computer to respond to a login request. On some login systems, the computer will check password characters one at a time, and kick back a "login failed" message as soon as it spots a bad character in the password. This means a computer returns a completely bad login attempt a tiny bit faster than a login where the first character in the password is correct. […]
But Internet developers have long assumed that there are too many other factors -- called network jitter -- that slow down or speed up response times and make it almost impossible to get the kind of precise results, where nanoseconds make a difference, required for a successful timing attack.
Those assumptions are wrong, according to Lawson, founder of the security consultancy Root Labs. He and Nelson tested attacks over the Internet, local-area networks and in cloud computing environments and found they were able to crack passwords in all the environments by using algorithms to weed out the network jitter.
Researchers: Password crack could affect millions
ComputerWorld, July 2010
Actually, after reading the first few paragraphs I’m surprised that this flaw wasn’t exploited a lot sooner than it was. The ability to measure fairly accurately the components that make up web application performance is not something that’s unknown, after all. So the claim that an algorithm can correctly “weed out” network latency is not at all surprising.
But what if the performance was randomized by, say, an intermediary interjecting additional delays into the response? You can’t accurately account for something that’s randomly added (or not added, as the case may be) and as long as you seeded the random generation with something that cannot be derived from the context of the session there are few algorithms that could figure out what the random generation seed might be. That’s important because random number generation often isn’t and it can often be predicted based on knowing what was used to seed the generator. So we could defeat such an attack by simply injecting random amounts of delay into the response.
Or, because the attack depends on an observable difference in timing, simply normalizing response times for the login process would also defeat this attack. This is the solution pointed out in another article on the discovery, “OAuth and OpenID Vulnerable to Timing Attack”, in which it is reported developers of impacted libraries indicate that just six lines of code will solve this problem by normalizing response times. This, of course, illustrates a separate problem, which is the reliance on external sources to address security risks that millions may be vulnerable to now because while it’s a simple resolution, it may takes days, weeks, or more before it is available.
This particular attack would indeed be disastrous were it to be exploited given the reliance on these libraries by so many popular web sites. And though the solutions are fairly easy to implement, that isn’t the real problem. The real problem is how difficult such attacks are becoming to detect, especially in the face of the risk incurred by remaining vulnerable while solutions are developed and distributed.
DEFEATING is EASY. DETECTING is HARD.
The trick here, and what makes many modern attacks so dangerous is that it’s really really hard to detect them in the first place.
Any attack that could be distributed across multiple clients – clients smart enough to synchronize and communicate with one another – becomes difficult to detect, especially in a load balanced (elastic) environment in which those requests are likely spread across multiple application instances. The variability in where attacks are coming from makes it very difficult to see an attack occurring in real-time because no single stream exhibits the behavior most security-focused infrastructure watches for.
What’s needed to detect such an attack is to be more concerned with what is being targeted rather than by whom or from where. While you want to keep track of that data the trigger for such brute-force attacks is the target, not the client activity. Attackers are getting smart, they know that repeated attempts at X or Y will be detected and that more than likely they will find their client blacklisted for a period of time (if not permanently) so they’ve come up with alternative methods that “hide” and try to appear like normal requests and responses instead. In fact it could be postulated that it is not repeated attempts to login from a single location that are the problem today, but rather the attempt to repeatedly login from multiple locations across time that’s the problem. So what you have to look for is not necessarily (or only) repeated requests but also at repeated attempts to access specific resources, like a login page.
But a login page is going to see a lot of use so it’s not just the login page you need to be concerned with, but the credentials, as well. In any brute force account level attack there are going to be multiple requests to try to access a resource using the same credentials. That’s the trigger. It requires more context than your traditional connection or request based security triggers because you’re not just looking at IP address, or resource, you’re looking deeper and trying to infer from a combination of data and behavior what’s going on.


Lori continues with a THIS SITUATION will BECOME the STATUS QUO topic.
Chris Hoff’s (@Beaker) On Amrit Williams’ (BigFix) Beyond The Perimeter Podcast post of 7/18/2010 points to his recent podcast:
My good friend Amrit Williams (@amrittsering) from BigFix (congrats on the IBM acquisition!) has an awesome Podcast titled “Beyond the Perimeter.”
He was nice enough to invite me to record episode 93 titled “Is Trust the Real Barrier To Cloud Computing?” (ultimately points you to an iTunes subscription.)
We spoke for almost an hour on all sorts of great discussion points related to Cloud Computing, specifically focusing on Trust (which I define in context as Security, Compliance, Control, Reliability and Privacy.)
We also spoke about the Cloud Security Alliance, CloudAudit and the HacKid conference — three things I am very passionate about.
Thanks Amrit, great conversation as usual.
The Cloud Ventures Network’s The ROI for Cloud Computing post of 7/15/2010 asserts:
New research from HP shows that potential IT spending on new technologies is held back by 'Innovation Gridlock'.
It describes "a situation where the IT organization is blocked from driving new business innovation because the majority of funding is consumed in operating the current environment.”
Complexity Cost
What this means is that many large organizations have been around for so long that they have built up an IT estate that features many different technologies deployed at different times, and they are layered atop one another rather than being replaced. This ranges right back through old mainframes, client/server and numerous other trends that have occured, and so a 'complexity cost' grows.As these technologies age they become increasingly obsolete and therefore difficult to change, in terms of modifying the software, connecting it to new systems or replacing it all together. The software skills die away, the hardware can't be replaced and so on, and as this accumulates across many systems so Innovation Gridlock happens. The IT organization continues to acquire the personnel to support these systems and so ultimately they grow into an organization operating in a 'maintenance mode' only.
The core issue at stake here is that the organization runs their business processes on this platform, and so their 'business agility' becomes equally congealed. Changing how they work, improving processes, adopting new technologies, all becomes harder and harder to do.
For organizations like government this is clearly a painful issue, as it means there is less advancement in areas like Healthcare or in the case management abilities of social workers, and so forth.
Cloud computing - Unlocking Business Value
Therefore before diving into the technical details of Cloud Computing, it's helpful to first understand the core business benefit that this new technology represents, which is exactly a solution to this problem. It offers the key to freeing up this gridlock.Cloud technology can be utilized internally as well as via public hosting, and this can be used to enable an "innovation platform", the SaaS (Software as a Service) approach makes new applications available in a faster and easier manner, making IT more dynamic. This can provide 'Web 2.0', mobile, XML and other key technologies that can facilitate exciting new business models.
This automation can be applied to other areas too, like data-centre operations, to build an overall compelling business case. Although there is a lot of hype about Cloud computing equally it also offers 'jam today', practical improvements that can turn into real business benefits now, not at some distant point in the future.
Part of this is because it's fundamentally not actually a new technology, but rather the latest phase in an ongoing evolution of Internet-centric "utility computing" that has been underway for a number of years. To illustrate both points check out this white paper I wrote in 2002:
"XML Web services - Jam today, not tomorrow" [Requires site registration.] The objective was the same, to explain the Business Value of the technology, and although the names have changed the core principles have remained the same and thus offer the same benefits.
Fundamentally this technology offers virtualization and workflow automation for IT infrastructure, so that the repeated "manual labour" can be systemized to reduce HR cost and downtime through eliminating operator error. Via an XML "services grid" this can happen across multiple data-centres so that very high levels of redundancy are also achieved, greatly reducing the risk of downtime.
Therefore investment in one technology capability will yield multiple business benefits, streamlining cash flow while gaining "burst capacities" for core IT infrastructure like bandwidth, storage and servers.
It also highlights the type of deal opportunities this market will present.
The vendors who were profiled in this article were essentially the Cloud software providers of the time, and all were quickly acquired by the big players moving into the market, such as Sun and Terraspring, Veritas buying Jareva and also Ejasent, as well as IBM grabbing ThinkDynamics.
Sun touted their N1 vision as the equivalent to Cloud at the time, as did HP with their Utility Data-Centre vision, ultimately killed in 2004 but as described in this white paper it offered a solution for automating data-centre operations.
A couple of clicks on the same news web site and you can learn that the news today is that HP is getting back into the same game, and with the recent CA acquisition of 3Tera we are likely to see a similar same pattern of events, only on a muuuch larger scale.
Cloud Ventures Network
Join in! our Linkedin industry networking group is @ http://cloud-ventures.net
Ellen Messmer asserts “Cloud vendors put shroud of secrecy around data centre” as a preface to her Cloud computing secrecy raises IT security risks Network World post of 7/6/2010, which I missed at the time:
Despite how attractive cloud computing can sound as an outsourcing option, there's widespread concern that it presents a security and legal minefield for businesses and government. Cloud service providers often cultivate an aura of secrecy about data centres and operations, claiming this stance improves their security even if it leaves everyone else in the dark.
Businesses and industry analysts are getting fed up with this cloud computing version of "don't ask, don't tell," where non-disclosure agreements (NDA) dominate, questions aren't answered, and data centre locations and practices are treated like national security secrets. But public cloud service providers argue their penchant for secrecy is appropriate for the cloud model - and at any rate, everyone's doing it.
They often hold out their SAS-70 audit certifications to appease any worry (though some don't have even that).
"The business data you store in Google's cloud is safe," said Google product marketing manager Adam Swidler at the recent Gartner security conference held in National Harbor, Md. He emphasised that Google's multi-tenant distributed model entails "splicing data across many hard drives" so that in this "hardened Linux stack" there's a "quick update of all fragments of all files in the hard drives," a process he called "obfuscated files."
Swidler acknowledged there has been some secrecy about where things are located because "we think it's a security risk." Nonetheless, "Google is trying to open up a little transparency in what we do," he said.
Currently, the information Google will disclose publicly or even under NDA won't satisfy everyone, Swidler acknowledged. "It's not enough for everybody. Some people do want to go deeper."
The location of data centres is a big issue in contract negotiations, where legislative and judicial issues abound. For instance, the location of data is an issue under some data-privacy laws, such as those from the European Union. But while customers often care about where their data is physically located, Google "believes this notion of where is data physically located is a bit antiquated," Swidler said. Many disagree, however.
Customers want to know where a cloud provider's data centre is, said Kurt Jackson, managing director in a Pitney Bowes division called OnDemand that offers software-as-a-service applications, such as maps for city services, to business and government customers.
The willingness of cloud provider Terremark to allow site visits and to discuss details about its data centres and its physical and network security was critical in the decision to use Terremark, Jackson said. "If you're running in Miami, you know you're in Miami," he said. "Some other providers just aren't as transparent."
The argument over transparency vs. secrecy in cloud computing is leading to a culture clash between the more traditional ways of handling data outsourcing and the newer cloud-computing utility methods and mindset.
Gartner analyst John Pescatore said it's simply not possible to know whether Google's technique of "hiding the data in a million places" is good security or not since there's no way to evaluate it. Speaking at the Gartner security conference, he said SAS-70 certification of any public cloud provider may be considered adequate for some customers, and not others. "SAS-70 is pretty meaningless from a security level, but it makes auditors happy."
Organizations with certain kinds of sensitive data are simply unlikely to find public cloud computing a right fit until the day comes when they can be sure their favorite security mechanisms are running in their cloud environment, Pescatore said.
Cloud computing challenges traditional notions about auditing and security, and it's possible a new way of auditing needs to evolve.
"If your service provider won't give you information about security processes and plans in order to do what's necessary, you shouldn't trust that provider," said Andreas Antonopoulos, an analyst with Nemertes Research.
The old idea of "security by obscurity," which suggests you can defend your security position best by keeping mum about everything, is misguided, he said. "It doesn't work. There's always someone who knows," Antonpoulos said. If you hear someone try to get your business by uttering that phrase, "run far and fast."
Analysing the fine print
Legal experts took notice when the City of Los Angeles posted its contract with Google related to the city's migration to Google email and collaboration services with the help of IT services firm CSC.
David Navetta, an attorney at Information Law Group, recently completed an analysis of the lengthy contracts with Google and CSC to determine how each side fared in defining responsibilities related to a potential data breach and indemnification of damages.
He notes Google is defined in the arrangement as a CSC "subcontractor" and "therefore, as respects indemnification for a breach of confidentiality obligations or for lost City Data, CSC would be responsible to pay for Google's act or error." However, he thinks the term "lost data" should have been defined more clearly in the contracts.
Speaking in general about the job of evaluating and approving cloud services contracts, Navetta said it's common to encounter a rushed environment where cloud service providers insist they don't have time to discuss details and don't want to make changes.
"The usual line is 'we can't do this one change for one customer,'" Navetta said. Security and legal are typically "on the same side of the aisle," while the IT department wants to get something done quickly to save money. He said cloud providers often don't want to "let people truly look under the hood" and using them "constitutes a trade-off because you're losing control."
Not surprisingly, large companies and government agencies can be expected to obtain more concessions from cloud-service providers. But not all organisations have found they fret over contracts.
Lincoln Cannon, director of Web systems at Merit Medical Systems, said the manufacturer has taken a few steps into cloud computing with Google Apps and Telania's eLeap for sales training, as well as Amazon for development work related to a new corporate website.
The providers' boilerplate legal agreements were given to the legal department, which redlined them and went back and forth until both partners were satisfied, Cannon said. "The legal team was perfectly happy with Google Apps," he said. The most concern over cloud computing probably came from the CIO because of his data-protection responsibilities related to Sarbanes-Oxley regulations, Cannon said.
Not all cloud service providers harp on secrecy, either.
Cloud infrastructure services provider ReliaCloud has two data centers in the Minneapolis/St. Paul area, and has about 100 cloud customers using its new VMware-based environment built on a management platform designed by Cloud.com, said CTO Jason Baker.
However, most of the hosting provider's 5,000 customers continue to use the more traditional method the firm offers that entails use of dedicated servers in cages, Baker said. The idea of cloud computing is still very new and customers are still trying to understand what's different. But Baker said he's convinced a shared-tenant virtual-machine-based cloud service carries some inherent security attributes in terms of high availability that can't be matched by dedicated servers.
"It's more reliable," he said. "If your application is running on one physical box, the customer would experience downtime. But in a cloud, we have a pool of virtual machines, and if one physical node goes down, we would automatically start somewhere else in the cloud." In addition, he said, use of some APIs in the future could allow customers' applications to sense when an increase in computing power is needed and execute that at once.
Unlike some cloud providers, Baker will willingly tell you about security defences in use, such as the Cisco ASA firewall.
The question for customers is how far the public cloud providers are going to pull back the kimono, said HP's chief security strategist Chris Whitener. "You should sort of insist on that," he said.
<Return to section navigation list>
Cloud Computing Events
In conjunction with the Worldwide Partners Conference 2010, the Microsoft Partner Network offers a Windows Azure Platform Introductory Special for Partners:
This promotional offer for members of the Microsoft Partner Network enables you to try a limited amount of the Windows Azure platform at no charge.
Included each month at no charge:
- Windows Azure
- 25 hours of a small compute instance [US$2.85]
- 500 MB of storage [US$0.075]
- 10,000 storage transactions [US$0.01]
- SQL Azure
- 1GB Web Edition database (available for first 3 months only) [US$9.49]
- AppFabric
- 100,000 Access Control transactions [US$1.8905]
- 2 Service Bus connections [US$7.581]
- Data Transfers (per region)
- 500 MB in [US$0.05]
- 500 MB out [US$0.075]
Any monthly usage in excess of the above amounts will be charged at the standard rates. This introductory special will end on October 31, 2010 and all usage will then be charged at the standard rates.
Monthly values added above include the 5% partner discount on Windows Azure Platform services and total US$22.0215/month. The free quotas seem quite parsimonious to me. Partners will incur a charge of $79.344 if they accidentally leave their small compute instance running for a month. Partners can sign up here.
James Staten reminds readers on 7/20/2010 that the 00:21:00 video of his The partner opportunity in cloud computing - Microsoft WPC session is available:
What is the opportunity for Microsoft partners (or other VARs, SIs, ISVs and technologists) in the emerging cloud computing space? Don't think of cloud as a threat but as an opportunity to ratchet up your value to the business my evangelizing and encouraging their transition to the cloud. How? At the recent Microsoft Worldwide Partner Conference I addressed this issue in an Expo Theater presentation. Missed it? Now you haven't:

From the abstract on the WPC 2010 site:
- How to tell a true cloud solution and its relative maturity from simple cloud washing.
- The truth behind the economics of cloud computing.
- The best places to start and strategies to build your own path to cloud efficiency.
Scott Bekker delivers 11 Takeaways from Microsoft's WPC in this 7/20/2010 article for Redmond Channel Partner Online:
Another Microsoft Worldwide Partner Conference is in the bag. Here are 11 key takeaways from the 2010 WPC:
1. Microsoft wants partners to be "all-in" on the cloud. Nearly everything was about cloud computing. That was a little weird for partners coming in from countries where BPOS and other offerings haven't rolled out yet, but pretty compelling for U.S. partners.
2. Keep an eye on the Windows Azure Appliance. The 900-server, private cloud enclosures are supposed to be coming this year from HP, Dell and Fujitsu -- extending Microsoft's cloud story.
3. Dynamics CRM Online. Margins jump to 40 percent in year one, and 6 percent recurring -- a huge bump from the old 18/6 mix. The offer is only guaranteed to be in place for a year. At the same time, partners are getting 250 Dynamics CRM Online seats for internal use.
4. Cloud Pack Essentials. A quick and dirty set of tools for partners to start moving their business onto the cloud.
5. Cloud Accelerate. A new badge to help born-on-the-cloud partners stand out.
6. Steve Ballmer seemed down. Kevin Turner was at the top of his aggressive game. Outgoing WPG CVP Allison Watson seemed wistful. New Worlwide Partner Group Corporate VP Jon Roskill was approachable.
7. Full speed ahead on the Microsoft Partner Network. New channel chief Roskill has no plans to pause the implementation. New benefits and requirements go online in October, barring technical complications.
8. Gold is back, sort of. The new Gold Certified Partner level will be out when MPN goes into full effect, but the Competencies and Advanced Competencies have been renamed Silver Competencies and Gold Competencies.
9. Microsoft is eyeing MSPs. With Windows InTune and future scaled-down Azure appliances, Microsoft is paying attention to the managed service provider market.
10. The heavy layoffs just ahead of WPC caused scheduling turmoil for partners and vendors, many of whose contacts were suddenly gone.
11. Nonetheless, partner enthusiasm was pretty high, with many partners telling us Microsoft seemed to have its mojo back. Partner attendance was huge at a reported 9,300 out of about 14,000 total attendees.
Joe Panattieri claims Microsoft Cloud Channel Team Pursues Managed Hosters at HostingCon in this 7/19/2010 post:
Microsoft continues its All In cloud computing push at HostingCon this week in Austin, Texas. During HostingCon, Michael Joffe (senior product manager, Windows Server) and Trina Horner (pictured, US SaaS/cloud channel development strategist) are expected to describe Microsoft’s cloud strategy to scores of Web hosts, managed hosting providers and service providers. Still, Microsoft will need to maintain a careful balancing act as it pitches cloud computing to large hosting partners and small MSPs. Here’s why.
No doubt, Microsoft has made quantifiable progress with its cloud computing strategy. Roughly 8,000 partners have sold BPOS (Business Productivity Online Suite) to two or more customers. And during Microsoft Worldwide Partner Conference 2010 (WPC10) last week, CEO Steve Ballmer communicated some clear milestones to partners.
Microsoft Channel Chief Jon Roskill offered additional cloud perspectives during this WPC10 press conference:
Mike Taulty published his OData Slides from the NxtGen User Group Festival on 7/19/2010:
I did a short session on the Open Data Protocol (OData) last week at the NxtGen User Group and I thought I’d share the slides here.
There are quite a few builds/animations in that slide-deck so I’d suggest that downloading it will produce a better experience than viewing it on SlideShare.

R “Ray” Wang’s Event Report: Microsoft Worldwide Partner Conference 2010 of 7/18/2010 begins:
Microsoft kicked off arguably one of the best WPC’s in history at the Washington, DC, Convention Center. From tremendous networking opportunities to keynotes from Bill Clinton, the time was well spent despite the scorching summer heat. As expected, the key theme was Cloud, Cloud, Cloud; and Azure, Azure, Azure. In a quick and unscientific survey of 62 Microsoft Partners, only 11 truly understood how they would adopt Azure. More importantly, only 5 out of the 11 partners who understood Azure could figure out a viable revenue model. The inability to come up with a viable business model on Azure could quickly become Microsoft’s Achilles heel in gaining market adoption. …
The Bottom Line For Buyers (Clients) – Expect Azure Solutions To Take Some Time To Mature
Read more … See also Ray’s News Analysis: Infor Bets On Microsoft of 6/25/2010.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Andrew R. Hickey’s Amazon, IBM Tops In Cloud Computing: Report article of 7/20/2010 for ChannelWeb regurgitates BTC Logic’s opinions:
Amazon (NSDQ:AMZN) and IBM (NYSE:IBM) are the kings of cloud computing, according to a new report released by research and analysis firm BTC Logic.
According to the quarterly report from BTC Logic, Amazon and IBM beat out the others in seven categories - cloud foundations, cloud infrastructure, cloud network services, cloud platforms, cloud applications, cloud security and cloud management - to be deemed "cloud champions." BTC Logic found that Amazon and IBM each ranked within the top five in four separate categories. Amazon received high marks in cloud infrastructure, network services, platform and management while IBM ranked well for cloud infrastructure, platform, security and management.
Meanwhile, BTC Logic ranked a host of other companies "cloud heavyweights" based on their rankings. While they ranked high, the heavyweights didn't capture top spots in as many categories as Amazon and IBM. The heavyweights include Cisco Systems, Citrix, EMC, Google, Level 3, Microsoft, Oracle, Red Hat, Salesforce.com, Symantec and VMware, BTC Logic's report indicated.
But despite their ranking has heavyweights, cloud computing mainstays Google (NSDQ:GOOG) and Microsoft (NSDQ:MSFT), which are also among the most vocal vendors when it comes to cloud computing, failed to take the top spot in any of the seven categories presented in the report. Microsoft's highest ranking came in the cloud foundation category where it placed second for Hyper-V. Google's highest was also a No. 2 spot, which for Google was in the cloud applications category where Google Apps to second place to Salesforce.com and its AppExchange.
BTC Logic also listed a number of up-and-comers that it considers "cloud contenders." The contenders are ATI Network Services, Aylus Networks, Rackspace, SAP (NYSE:SAP)/business Objects (NSDQ:BOBJ ), Sonoa Systems, Taleo and Terremark.
The purpose of the report and the ranking of cloud computing companies, BTC Logic said, was to serve as a gauge of the cloud computing market and to alleviate confusion.
"The cloud computing marketplace still has a confusing array of vendors, each promoting their own solutions, and a steady increase in the number of new products and services," the company said in the report.
BTC Logic also cautioned that enterprises are not yet ready to trust applications and data in cloud computing environments due to issues around security, privacy and data location.
"Enterprises have only slowly been embracing cloud because of the need to evaluate multiple vendors; valid fears about security, privacy, data integrity and governance; and a widely held belief that cloud computing is an IT opportunity more than a key business lever," the report noted.
Amazon Web Services certainly deserves coronation as a “king of cloud computing” but adding IBM to cloud royalty at this time is a stretch of major proportions. I don’t believe that BTC Logic has the qualifications to rank cloud providers; the firm is not an accepted cloud “thought leader” by my measure. (This is the first I’ve heard of BTC Logic.)
Redmonk’s Michael Coté interviews Rackspace’s Jonathan Bryce in OpenStack – an open source cloud platform 00:16:00 video segment (with transcript) of 7/19/2010:
Rackspace announced the OpenStack project today, open sourcing much of the software it uses to run its own cloud. [Michael Coté, right] spoke with Rackspace’s Jonathan Bryce [left] on the topic to get an in-depth overview, discuss Rackspace’s intentions, and explore the operational future of OpenStack.
This is a big announcement in the cloud world, further widening the technologies that are available to start crafting public and private clouds. The nature of Rackspace as not a software company is also interesting to watch here, as well as what partners do with the project.

Geva Perry’s Rackspace Open Sources Its Cloud Platform: OpenStack of 7/19/2010 analyzes Rackspace’s new OpenStack offering:
Today Rackspace announced it is open sourcing its cloud platform and releasing it as a project called OpenStack together with others. The code should be available for download (if not now then in a few hours) on http://OpenStack.org. From the official press release:
OpenStack will include several cloud infrastructure components, the first being OpenStack Object Storage, a fully distributed object store based on Rackspace Cloud Files, available today at OpenStack.org. The second component, OpenStack Compute, will be a massively scalable compute-provisioning engine based on the NASA Nebula compute project and Rackspace Cloud Servers technology, available later in 2010. Any organization will be able to turn physical hardware into massively scalable and extensible cloud environments using the same code currently in production serving tens of thousands of customers and large government projects.
In addition to NASA's contribution of Nebula, a number of other companies has seemed to line up behind the project. AMD, Citrix, Dell, CloudKick, Intel, Limelight, Puppet Labs, RightScale and Zenoss all participated in an OpenStack design summit hosted by Rackspace last week in Austin.
Back in February I wrote a blog post titled Rackspace: The Avis of Cloud Computing? in which I analyzed how Rackspace is competing with Amazon in the Infrastructure-as-a-Service space. I ended the post with the following paragraph:
“Finally, one more factor will play an important role in the success of each of the cloud providers, and that is the ecosystem that evolves around their products. That means management, automation and monitoring tools (e.g., RightScale, CloudKick, enStratus), Machine Image support (such as the AMIs from Red Hat/Jboss on EC2) and other ancillary products and services that form a "whole product". Amazon has the lead here as of now, but Rackspace seems to be working hard to catch up.”
And indeed today's announcement appears to be the culmination of a lot of that hard work. A smart move by Rackspace that encourages the ecosystem even further.
It also looks like we are entering the "Stack Wars", with the two leading IaaS cloud stacks being Amazon's (with Eucalyptus as the private cloud version of the Amazon stack) and now OpenStack. It will be interesting to see how VMWare, Microsoft and Google all respond to this move.
This will clearly have an impact on the cloud platform startups who were going for an open source strategy, namely Enomaly and Cloud.com. Rumor has it that the latter are already planning to support OpenStack and base their product on it. [Update: In the comments below, Peder Ulander from Cloud.com confirms their participation in CloudStack].
Also of interest is how this will affect proposed standards, such as OCCI.

James Staten asserts As cloud platforms battle for credibility, OpenStack is pretty solid in this 7/19/2010 post to the Forrester Research blog:
- Some are seeking credibility based on their affinity with the underlying technology. VMware hopes to give vCloud credibility through its strong market share with ESX.
- Others are seeking credibility by leveraging a de facto standard cloud platform. Eucalyptus and Nimbula are building their case by claiming API-compatibility with Amazon Web Services’ Elastic Compute Cloud.
- Still others are leveraging their technology expertise or credibility in related spaces. Univa, CA, Tibco, Platform Computing and others are leveraging strengths in workload automation to make a case for their offering. NewScale is doing the same from a strong position in service catalogs and provisioning automation.
But are any of these claims all that credible? And can you really trust that they can make the leap from these foundations to delivering a truly scalable, reliable, offering that provides the robust feature set provided by some of the leading public IaaS clouds today? The short answer is we really don’t know. While each claim a few customer references - whether named or not - few really portray a story of maturity yet. And that’s what most enterprises tell us they are looking for — and are waiting for.
Today, yet another vendor threw its hat into this ring but might just have the more credible story enterprise infrastructure & operations professionals have been waiting on. Rackspace is arguably one of the top five public IaaS clouds in the market and today announced it is open sourcing its cloud platform. OpenStack, according to the San Antonio-based hoster, is the full software stack behind its Cloud Servers and Cloud Files offerings. The software, which will be licensed under Apache 2, will be available to competing hosting companies, enterprises and governments to implement.
Hard to beat the credibility of this platform being run by a top five IaaS provider. The appeal is obvious if you are a hosting company because there are strong similarities between your business and Rackspace and thus the solution should be relatively applicable. It’s also potentially more appealing from a profit point of view than Microsoft Windows Azure platform appliance or vCloud as there’s no one you have to share the revenue with. There will no doubt be some skepticism by hosters that Rackspace is holding back something that will help them maintain their advantage.
Being the Rackspace stack may not sway a lot of corporate and government customers for fear that deploying a service provider-oriented software stack just won’t fit how enterprises operate. What might, though, is to have one of their peers implement OpenStack too and help show the way - NASA Nebula. For those not familiar with this project, it is an effort inside the space agency to convert its data center, which historically had been dedicated to HPC work, into an IaaS platform for other government agencies to share - think of it as an example of NIST’s community cloud. NASA’s Chris Kemp, the CTO behind this project, is a thought leader among government IT and Nebula has gained significant credibility amongst its peers, who are all crafting their own cloud strategies. His implementation of (and contributions to) OpenStack shows that the Rackspace cloud platform isn’t specific to service provider environments.
Rackspace will need a heck-o-lot-more government and enterprise private cloud deployments before we can declare OpenStack a leader but this is a very nice start.

Tim Anderson (@timanderson) asserts OpenStack takes on Amazon with open source cloud computing in this 7/19/2010 post:
Today’s big open source announcement is OpenStack, an open source cloud platform that aims to be an non-proprietary alternative to Amazon’s Elastic Computer Cloud (EC2) and Simple Storage Service (S3).
On July 19, 2010, we announced that we are opening the code on our cloud infrastructure. That’s big news for us and for the hosting industry in general. The result? Cloud technology will never look back.
The full press release is here. The initial offering is a distributed object store and a virtual machine provisioning engine.
OpenStack is not itself a cloud provider. Rather, it is offering software that lets you build a cloud, either for public or private use. Therefore, it is of immediate use only to large organisations, though for smaller users it might make sense to purchase services from an OpenStack provider since you are protected against lock-in.
The OpenStack cloud is IAAS – infrastructure as a service – offering storage and virtual machine instances. Therefore it is going up against Amazon rather than, say, Salesforce.com or Google App Engine. It is also an open source alternative to Microsoft Azure, which is also available (or will be) for both public and private clouds.
Looking at Right Scale’s comment, it seems that concern about Amazon taking over this market is a key driver behind the initiative:
From the RightScale perspective we will of course continue to support a variety of public and private clouds. We already have basic support for RackSpace’s API, which OpenStack will start out with, and we have a number of implementations under way with Eucalyptus and Cloud.com which we’re looking forward to multiply. At the same time, having many fragmented cloud efforts doesn’t really help build a compelling alternative to Amazon which keep adding incredible new features at a blazing pace. And the industry needs an alternative to Amazon, not because of some problem with AWS, but because in the long run cloud computing cannot fulfill its promise to revolutionizing the way computing is consumed if there aren’t a multitude of vendors with offerings targeting different use-cases, different needs, different budgets, different customer segments, etc. OpenStack promises to build enough momentum to create an exciting cloud offering that is as feature rich as AWS, that is implemented by a number of service providers, like RackSpace, and that enterprises can also run internally, like NASA.
For more information see the OpenStack site.
Related posts:

Be sure to read the comment about Tim’s post by Thorsten von Eicken.
William Vambenepe’s (@vambenepe) Introducing the Oracle Cloud API of 7/18/2010 begins:
Oracle recently published a Cloud management API on OTN and also submitted a subset of the API to the new DMTF Cloud Management working group. The OTN specification, titled “Oracle Cloud Resource Model API”, is available here. In typical DMTF fashion, the DMTF-submitted specification is not publicly available (if you have a DMTF account and are a member of the right group you can find it here). It is titled the “Oracle Cloud Elemental Resource Model” and is essentially the same as the OTN version, minus sections 9.2, 9.4, 9.6, 9.8, 9.9 and 9.10 (I’ll explain below why these sections have been removed from the DMTF submission). Here is also a slideset that was recently used to present the submitted specification at a DMTF meeting.
So why two documents? Because they serve different purposes. The Elemental Resource Model, submitted to DMTF, represents the technical foundation for the IaaS layer. It’s not all of IaaS, just its core. You can think of its scope as that of the base EC2 service (boot a VM from an image, attach a volume, connect to a network). It’s the part that appears in all the various IaaS APIs out there, and that looks very similar, in its model, across all of them. It’s the part that’s ripe for a simple standard, hopefully free of much of the drama of a more open-ended and speculative effort. A standard that can come out quickly and provide interoperability right out of the gate (for the simple use cases it supports), not after years of plugfests and profiles. This is the narrow scope I described in an earlier rant about Cloud standards:
I understand the pain of customers today who just want to have a bit more flexibility and portability within the limited scope of the VM/Volume/IP offering. If we really want to do a standard today, fine. Let’s do a very small and pragmatic standard that addresses this. Just a subset of the EC2 API. Don’t attempt to standardize the virtual disk format. Don’t worry about application-level features inside the VM. Don’t sweat the REST or SOA purity aspects of the interface too much either. Don’t stress about scalability of the management API and batching of actions. Just make it simple and provide a reference implementation. A few HTTP messages to provision, attach, update and delete VMs, volumes and IPs. That would be fine. Anything else (and more is indeed needed) would be vendor extensions for now.
Of course IaaS goes beyond the scope of the Elemental Resource Model. We’ll need load balancing. We’ll need tunneling to the private datacenter. We’ll need low-latency sub-networks. We’ll need the ability to map multi-tier applications to different security zones. Etc. Some Cloud platforms support some of these (e.g. Amazon has an answer to all but the last one), but there is a lot more divergence (both in the “what” and the “how”) between the various Cloud APIs on this. That part of IaaS is not ready for standardization. …
Read more …
<Return to section navigation list>

















{kind=link}