Windows Azure and Cloud Computing Posts for 6/23/2010+
 | Windows Azure, SQL Azure Database and related cloud computing topics now appear in this daily series. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database, Codename “Dallas” and OData
- AppFabric: Access Control and Service Bus
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
 Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Cloud Computing with the Windows Azure Platform published 9/21/2009. Order today from Amazon or Barnes & Noble (in stock.)
Read the detailed TOC here (PDF) and download the sample code here.
Discuss the book on its WROX P2P Forum.
See a short-form TOC, get links to live Azure sample projects, and read a detailed TOC of electronic-only chapters 12 and 13 here.
Wrox’s Web site manager posted on 9/29/2009 a lengthy excerpt from Chapter 4, “Scaling Azure Table and Blob Storage” here.
You can now download and save the following two online-only chapters in Microsoft Office Word 2003 *.doc format by FTP:
- Chapter 12: “Managing SQL Azure Accounts and Databases”
- Chapter 13: “Exploiting SQL Azure Database's Relational Features”
HTTP downloads of the two chapters are available from the book's Code Download page; these chapters will be updated in June 2010 for the January 4, 2010 commercial release.
Azure Blob, Drive, Table and Queue Services
No significant articles today.
<Return to section navigation list>
SQL Azure Database, Codename “Dallas” and OData
Wayne Walter Berry posted his fully illustrated Getting Started With PowerPivot and SQL Azure tutorial on 6/23/2010:
PowerPivot is a powerful, downloadable extension to Microsoft Excel 2010 that allows you to perform business intelligence and analytics against known data sources. One excellent data source you can use is your SQL Azure database. This article will talk about getting started with SQL Azure as a data source, a process that is so easy you will need little help.
One big advantage of using SQL Azure as a data source is that it can be accessed anywhere there is Internet connectivity, and you can store large amounts of data securely and with high availability. Your PowerPivot users can run their reports on the road, without having to VPN into your datacenter. Also, they do not have to travel with a snapshot of data, which is outdated the minute after the snapshot.
Partial Data Scenarios
One scenario is to use SQL Azure Data Sync to push a subset of your full database from your live production SQL Servers in house to a SQL Azure database in the cloud. PowerPivot users could call the SQL Azure database without causing additional strain on your production SQL Server.
Putting only a subset of the database could increase the security of your data. An example of this is uploading the customer’s city, state and sales information, without uploading their name, address, login, and password. This would allow PowerPivot users to aggregate the sales, and product categories against the state of origin, without exposing the sensitive data in your system.
Providing Firewall Access to Your Excel Users
In order to access your SQL Azure database your Excel users will need to have access on the SQL Azure firewall for their client IP address. From their computer they can figure out there client IP address by going to this site: http://whatismyipaddress.com. Then it is up to the SQL Azure administrator to login to the SQL Azure Portal and add that IP address the list of IP addresses allowed access to the SQL Azure server.

Granting Excel User’s Permissions on the SQL Azure Database
One of the best practices for security on SQL Azure to have a login for every user. For PowerPivot, the user just needs read-only access -- they will be using PowerPivot for reporting. This previous blog post, walks the SQL Azure administrator through the steps needed to create a read-only user for a database.
Requirements
The PowerPivot site does a good job of listing all the requirements for PowerPivot, one thing you should know is that PowerPivot is an extension for Microsoft Excel, the version that ships withMicrosoft Office Professional Plus 2010 Microsoft Office Professional Plus 2010 Microsoft Office Professional Plus 2010 Microsoft Office Professional Plus. It is a separate download that needs to be installed after Excel is installed.
Creating a Connection
PowerPivot adds another ribbon on your Excel toolbar. Inside that ribbon you need to open the PowerPivot Window to create connections to data sources.

Once the PowerPivot Window is open you want create a connection that Excel can use to access SQL Azure.

Even though SQL Azure is a database, you don’t want to choose From Database, this will work however it requires extra steps. Instead, choose From Other Sources, this will open the Table Import Wizard and give you a handy visual selector for choosing SQL Azure.

After you choose the Microsoft SQL Azure relational database you are presented with a .NET Data Provider for SQL Server dialog that is correctly configure with encryption enabled.

Here is where you enter the server name, login information and the database they want to attach to. …





Wayne continues with detailed steps to complete entries to the Table Import Wizard’s dialogs.
Erik Ejlskov Jensen posted Walkthrough: Expose SQL Compact data to the world as an OData feed, and access SQL Compact data from Excel 2010 and Silverlight on 6/23/2010:
Currently, SQL Compact data is only available to ADO.NET and OLEDB based Windows client.
Exposing your SQL Compact data as an OData feed allows your data to be consumed by a variety of different client platforms at any location, including:
OData Explorer (Silverlight Application)
PowerPivot for Excel 2010 is a plugin to Excel 2010 that has OData support built-in.
LINQPad is a tool for building OData queries interactively.
Client libraries: Javascript, PHP , Java, Windows Phone 7 Series, iPhone (Objective C), .NET (Including Silverlight)
I will now show you the steps required to expose a SQL Compact database file a an OData feed using Visual Studio 2010, and how to consume this feed from Silverlight and Excel PowerPivot.
Please note that exposing SQL Compact data like this will not scale to 100s of concurrent users. …
Erik continues with an illustrated, how-to walkthrough.
David R. R. Webber announced in his Toward collaborative information sharing essay of 6/23/2010:
However it is very unclear how this utopia is attained and at what costs.
The city of course is looking at their costs of getting data and then supporting that with archives and updates and publication feeds. Having a harmonized approach can potentially significantly reduce deployment and sustainment costs along with potential software development collaboration and cost savings for cities themselves. Having a common view also of course helps solution providers market to cities nationally not just locally. Perhaps the biggest challenge is the unspoken one of complexity. The more one steps into data sharing one sees the opportunity for people to interpose complexity. Keeping things simple, yet consistent and transparent requires constant vigilance and oversight to ensure that solution providers are not injecting their own self-serving complexity. After all complexity costs money to build and support, is a barrier to competitors, and hence vendors are naturally drawn to inject complexity.
This could be the opportunity for standards based development of “CityHallXML” providing the most common information components of financial, infrastructure and performance data along with census and demographic data.
Today also I published a paper on creating dictionaries of information canonical XML components, aligned to the NIEM.gov approach and CEFACT core components model.
http://www.oasis-open.org/committees/document.php?document_id=38385
This juxtaposes with the W3C world view of self-describing data instances and RDF. You have the approach of either the embedded RDF semantics, with all that overhead on each and every data item (aka “Open Data”), or you have this OASIS-based approach of semantics referenced in domain dictionary components and information structure templates that allow comparatively small concise data instances where the XML tags provide the content referencing between content and semantics about the content. …
David continues his essay without further mention of “Open Data” or OData. It appears to me that OData with a standardized taxonomy would satisfy New York City’s requirements.
Marc Schweigert reports about an Open Government Data and Bing Map Apps contest in his 6/23/2010 post:
http://www.bing.com/maps/explore
You have to submit your app for approval. Approved apps show up in the Map Apps gallery:

You bring up the Map Apps gallery by clicking the “MAP APPS” button in the left pane of the Bing Maps UI:

Map Apps are a great way to visualize open Government data that has the necessary location information. So far, I haven’t seen many map apps do this other than the Bing Health Maps application:

I’m keeping my fingers crossed that some of the apps submitted will use publicly available Government data as the source for Bing Map Apps. Will you be the person to submit one and win? I hope so.
Don’t know where to get publicly available Government data? You can find a few over on the producers page of http://odata.org as well as http://data.gov. Most of the Government OData services on the producers page of http://odata.org use the OGDI starter kit created by my team. If you are a Government organization that wants to make your data publicly available on the internet through an OData service, then OGDI is a great way to get started.



The 3DHD blog offers a terse, third-party (hype-free) description and evaluation of Microsoft Codename "Dallas" in this 6/23/2010 post:
Use Dallas to:
- Find premium content to power next-generation killer apps for consumer and business scenarios
- Discover and license valuable data to improve existing applications or reports
- Bring disparate data sets together in innovative ways to gain new insight into business performance and processes
- Instantly and visually explore APIs across all content providers for blob, structured, and real-time web services
- Easily consume third party data inside Microsoft Office and SQL Server for rich reporting and analytics
Benefits
Developers
- Trial subscriptions allow you to investigate content and develop applications without paying data royalties
- Simple transaction and subscription models allow pay as you grow access to multi-million dollar datasets
- Consistent REST based APIs across all datasets facilitate development on any platform
- Visually build and explore APIs, preview results
- Automatic C# proxy classes provide instant object models and eliminate the need to write tedious XML and web service code
Information Workers
- Integration with PowerPivot to easily work with the data in Microsoft Excel
- Simple, predictable licensing models for acquiring content
- Coming soon: ability to consume data from SQL Server, SQL Azure Database, and other Microsoft Office assets
Content Partners
- Easy publication and on-boarding process regardless of blob data, structured data, or dynamic web services
- Developer tooling on the Microsoft platform to ease Visual Studio and .NET development
- Expose your content to Microsoft’s global developer and information worker community
- Content discovery and integration inside Microsoft Office and SQL Server
- Scalable Microsoft cloud computing platform handles storage, delivery, billing, and reporting
Dallas Features
Rich Web Services
- Secure, REST based model for consuming services across the entire content catalog
- Dynamic pagination built into the APIs to simplify access
- Standard ATOM 1.0 feeds are available for most of the services
- Consistent billing, provisioning, and usage reporting across all services
Service Explorer
- C# proxy classes generated to simplify development
- Preview the data in tabular form and as ATOM 1.0 feed, if the service supports ATOM 1.0
- Invoke the service to understand the results that the compiled service call returns
- Find short documentation and sample values for each of the parameters
- Instantly copy the visually built URL for the service call into clipboard to ease development
Marketplace Integration and Discovery Portal
- Easily Discover new data across all domains including consumer and business
- Manage service subscriptions and usage limits
- Manage account keys to access the services
- Get a detailed access report containing the services/datasets that were accessed, grouped by date and by account key
Wayne Walter Berry explains Copying Files to SQL Azure BLOBS in this 6/22/2010 post:
In some scenarios you might wish to deploy images from your desktop directly to SQL Azure into a varbinary(max) column. You can do this with tools like Microsoft SSIS and the BCP utility. However, if you have a directory of images, this tool will allow you to upload them all directly to SQL Azure in a streaming fashion, breaking down the image into blocks that are written individually to SQL Azure.
It doesn’t have to be images. BlobCopy will allow you to upload any data you can store in a file directly to a SQL Azure column.
I made many assumptions about how this tool was to be used; this gave me the advantage of keeping the sample and the code simple. Because the assumptions might not match how you would like to use the tool, I have included the code so that you can tweak it to work as you want. If you can’t figure out how to do what you want, post a comment below and I will try to help. I also emulated many of the BCP parameters to keep the learning curve low.
Here are the assumptions I made:
- You have a directory of files; each file is a row in the database.
- Only the rows you want to update have files in the directory.
- All the files in the directory are to be uploaded when BlobCopy is run.
The name of each file without the extension represents the primary key in the database where the BLOB is written. For example, with the AdventureWorksLTAZ2008R2 database and the SalesLT.Product table the file 884.jpg would go to: ProductId = 884.
8192 bytes of data are uploaded at a time. That is the block size per transaction.
One thing to note is that mid stream failures will leave the BLOB in an unknown state in the database. Each write is a transaction, however the BLOB is broken down into multiple blocks and multiple writes. If you succeed on several writes and then encounter a failure that terminates the process, the BLOB might only be partially written to the database.
Sample
This sample code uses the AdventureWorksLTAZ2008R2 database and writes all files in C:\My Projects\Sql Azure Blog\BlobCopy\Test Files to SalesLT.Product table in the ThumbNailPhoto Column.
BlobCopy.exe AdventureWorksLTAZ2008R2.SalesLT.Product -S tcp:yourServer.database.windows.net -U yourlogin -P yourPassword -K ProductId -B ThumbNailPhoto -F "C:\My Projects\Sql Azure Blog\BlobCopy\Test Files"
Arguments
BlobCopy database_name.schema.table_name -S server_name–U login_id –P password -K primary_key –B blob_column –F folder_of_files
Just like the BCP utility, the first argument is the database, schema, and table of the destination to write the blog.
- -S server_name : Specifies the SQL Azure server to which to connect.
- -U login_id: Specifies the login ID used to connect to SQL Azure.
- -P password: Specifies the password for the login ID. If this option is not used BlobCopy uses the default password (NULL).
- -K primary_key: Specifies the primary key column in the table so that BlobCopy can identify what row to write the blob in. This is the column name, the value of the primary key comes from the file name.
- -B blob_column: Specifies the column in which to write the blob.
- -F folder_of_files: A folder location of the local machine where the blobs are stored as files. One file for each row to be uploaded. The file name is the primary key value that identifies the row.
Additions
These additions to the code, left to the reader, might be useful:
- Move the files after successful upload to another directory.
- Allow the amount of bytes copied in each transaction to be determined by a command argument.
- Handle transient retry as discussed in this blog post.
The Microsoft Silverlight Team posted Consuming OData Feeds (Silverlight QuickStart) on 6/21/2010:
This QuickStart describes how to create a Silverlight client that can consume an OData feed and display feed data in bound data controls. This QuickStart contains the following sections:
- Querying an OData Service
- Handling a Paged Response
- Loading Related Data
- Binding Collections to Controls
- Saving Changes to Data
- Add Service Reference
- Cross-Domain Requests
To view the complete source code for this QuickStart application, see the Silverlight SDK Sample Browser.
Querying an OData Service: This QuickStart shows you how to query an OData-based data service and bind returned data to controls in a Silverlight application. When you click Start in the Silverlight application below, a URI-based query is sent to the Northwind sample data service and an OData feed is returned that contains all Customer entities. The exact URI of each query is displayed in the Query Resources box.

When you click the Start button, the LoadAsync method is called on the DataServiceCollection<T> to execute the query and load entities from the response into the binding collection as
Customerobjects. …

The author(s) continue with the remaining sections, which include C# and VB source code.
See Martin Schmidt will present Extreme scaling with SQL Azure at the SQLBits Conference being held in New York City on 9/30 to 10/2/2010 in the Cloud Computing Events section below.
<Return to section navigation list>
AppFabric: Access Control and Service Bus
Wade Wegner posted his Using the .NET Framework 4.0 with the Azure AppFabric SDK on 5/11/2010, but I’m repeating it here because of its importance as more developers adopt Net 4.0 and the AppFabric:
The other day I attempted to build a sample application that communicated with the Azure AppFabric Service Bus by creating a Console application targeting the .NET Framework 4.0. After adding a reference to Microsoft.ServiceBus I was bewildered to see that my Service Bus bindings in the system.ServiceModel section were not recognized.
I soon realized that the issue was the machine.config file. When you install the Azure AppFabric SDK the relevant WCF extensions are added to the .NET Framework 2.0 machine.config file, which is shared by .NET Framework 3.0 and 3.5. However, .NET Framework 4.0 has its own machine.config file, and the SDK will not update the WCF extensions.
Fortunately, there’s an easy solution to this issue: use the CLR’s requiredRuntime feature.
- Create a configuration file named RelayConfigurationInstaller.exe.config in the “C:\%Program Files%\Windows Azure platform AppFabric SDK\V1.0\Assemblies\” folder with the following code:
<?xml version ="1.0"?>
<configuration>
<startup>
<requiredRuntime safemode="true"
imageVersion="v4.0.30319"
version="v4.0.30319"/>
</startup>
</configuration>
- Open up an elevated Visual Studio 2010 Command Prompt, browse to the directory, and run: RelayConfigurationInstaller.exe/ i
Your .NET Framework 4.0 machine.config file will now have the required configuration settings for the Service Bus bindings. Thanks to Vishal Chowdhary for the insight!
If you’re working with the .NET 4.0 and the AppFabric, also check Wade’s Release the hounds – Multicasting with Azure AppFabric and Release the hounds – Multicasting with Azure AppFabric posts which straddle the above.
Host WCF Services in IIS with Service Bus Endpoints
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Rinat Abdullin explains Lokad.CQRS - Plugging NHibernate and Relational Databases into Windows Azure in his post of 6/23/2010:
This is the next article in the Learning series for Lokad.CQRS Guidance. In the previous tutorial we've talked a little bit about Lokad.CQRS App Engine flexibility, while exploring Scheduled Tasks Feature and multiple message dispatching in the Sample 02.
In this article we'll explore NHibernate Module for working with relational databases in the cloud.
Relational Persistence - SQL Azure and NHibernate
Command-Query Responsibility Segregation concept does not imply any specific type of persistence to be used. It is persistence-ignorant and you can leverage various types of storage (often combining them for the greater benefits), while staying rather scalable. For example, you can frequently see that Udi Dahan uses SQL DB persistence in his samples, while Greg Young sometimes advocates Event Sourcing to avoid maintaining parallel realities. Both approaches are valid as a few other options. Choice depends strictly on your project specifics.
As you probably already know, Windows Azure Platform, among over services, offers SQL Azure - reliable and cloud-based relational database. It is offered as a service and provides highly-scalable, reliable database that does not require any management.
In order to work with such SQL database efficiently, one might need to use Object-Relational Mapper (ORM). There are multiple open-source choices out there. My favorite at the moment is NHibernate. It works really well with SQL Azure, as proven by production usage.
Yet, initial application setup often takes a bit of time. You need to get the proper libraries, helper frameworks, wire everything in your IoC Container and keep in mind primary best practices for NHibernate and ORM.
To make things simpler, Lokad CQRS features NHibernate Module which already encapsulates some patterns and practices. It is based on experience of working with this ORM in Windows Azure applications of Lokad (using it with local databases and SQL Azure). In a sense, this module is just a merged package of a few existing assemblies, that includes:
- Core NHibernate Assemblies
- Fluent NHibernate
- LINQ for NHibernate
- Session management wiring for Lokad.CQRS
As you can see, we enormously benefit from the other open source projects here. Additionally integration into the Lokad.CQRS App Engine enforces a few really important guidances on using relational storages for building CQRS applications. While doing that, the code stays rather simple and concise. For example, instead of this code:
using (var session = _factory.OpenSession())
using (var tx = session.BeginTransaction())
{
var solution = session.Load<SolutionEntity>(solutionId);
solution.State = SolutionEntityState.Ready;
session.Save(solution);
tx.Commit();
}we can write this equivalent in our CQRS message handlers and scheduled task implementations:
var solution = session.Load<SolutionEntity>(solutionId);
solution.State = SolutionEntityState.Ready;You can jump directly to the module description in Lokad.CQRS or proceed reading below, to explore all these features at work in Sample 03.
By the way, NHibernate module on it's own is also an example of extending configuration syntax of Lokad.CQRS builders. It could actually be used outside of the project to extend your Autofac-powered solution.
Lokad CQRS Sample 03 - Account Balance
Check out Lokad.CQRS Learning Guidance for info on getting source code for the samples.
To keep things simple for you, Lokad CQRS Sample 03 uses NHibernate with SQLite DB engine. If you ever used Mozilla Firefox, Thunderbird, Skype or Apple iOS, then you've already been benefiting from SQLite (which is even used on the embedded devices, starting from various smart-phones and up to guided missile destroyer ships)
This sample should work out-of-the-box in x64 OS (this also applies to the Windows Azure Fabric deployments, which are x64 bit). If you have x86 development OS, please go to the Samples/Library folder and replace SQLite.dll with SQLite.x86.dll version (found in the same folder). ..
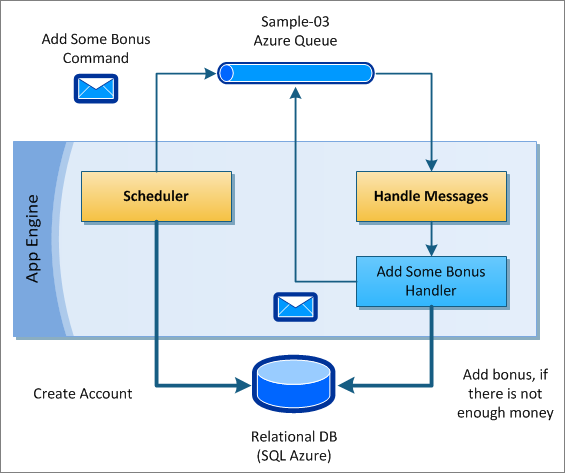
Rinat continues with his tutorial and more source code.
Rinat Abdullin reported Microsoft: Lokad is Windows Azure Platform Partner of the Year on 6/23/2010:
I just wanted to share some exciting news with you. Microsoft has just issued a press release for its upcoming WPC 2010. Lokad is referenced as the winner in Windows Azure Platform Partner of the Year category.
“Lokad’s Lokad.Cloud solution earned them the Microsoft Windows Azure Platform Partner of the Year Award,” said Allison Watson, corporate vice president, Worldwide Partner Group, Microsoft Corp. “Lokad.Cloud facilitates the development of enterprise apps on Windows Azure to bring substantial benefits to the growing community of ISVs who target Windows Azure. Lokad’s early adoption of these technologies and impressive solution has made them a leader in the space.”
I'd like to congratulate Lokad Team working together with Microsoft and Windows Azure teams to achieve this significant milestone.
Stay tuned for more exciting news from Lokad.Cloud and Lokad.CQRS Open Source projects, as we continue to share our passion and experience with the community (while still focusing on delivering outstanding analytics to your business).

I’m adding My congratulations to Joannes Vermorel, the force behind Lokad. His post about the award is Honored by the Windows Azure Partner Award of 2010 of 6/23/2010.
Return to section navigation list>
Windows Azure Infrastructure
Erik Nelson announced the availability of his FREE 96 page book - Windows Azure Platform: Articles from the Trenches Volume One on 6/23/2010:
Developers have been exploring the possibilities opened up by the Windows Azure Platform for Cloud Computing. This book pulls together great articles from many of those developers who have been active with the Windows Azure Platform to hopefully help others become successful. There are twenty articles in this first volume covering everything from getting started to implementing best practices for elastic applications.
The book is available in many forms at http://bit.ly/azuretrenchesbookvol1
It has been a collaborative effort (Check out the journey to get to this) and whilst I get credited with being the author, I can assure you that the real stars are the 15 authors who actually wrote the articles. Well done to all of them! You can check out their mug shots at the end of the book, my favourite being Grace – you will immediately understand why once you have the book. Also a thanks to my colleague Andrew for the smashing cover art:

Steve Nagy notes his contribution to the eBook in has Windows Azure Platform: Articles from the Trenches, Volume One post of 6/23/2010:
Earlier this year Eric Nelson from Microsoft put out the call to Azure authors to build a community eBook about the Windows Azure Platform. Today the book was finally released to web today, and I have 2 articles included: Auto-scaling Azure, and Building Highly Scalable Applications in the Cloud.
I won’t bang on about it here, just check it out for yourself:
David Makogon’s Azure Guest OS 1.4 post of 6/23/2010 explains how to check if your Windows Azure instance is running OS v1.4 and, if not, change to it, as well as its new features:
On June 7, the Azure team introduced the latest SDK, version 1.2, supporting .NET 4 and other goodies. Along with the SDK, the Azure Guest OS was updated to version 1.3.
A few days ago, a new Guest OS appeared: Version 1.4. Assuming Guest OS Auto-Upgrade is enabled, you’ve automatically been upgraded. If you have any older deployments that have a specific OS version in the service configuration file, simply change the OS version to “*”. If you visit the Azure portal, you’ll see this Guest OS:

If you don’t see 1.4, that means your service is set to a specific OS. You can choose 1.4 from the OS Settings… dialog:

What’s new in 1.4?
There are a few changes you should be aware of.
Azure Drive fixes
If you’re taking advantage of Azure Drives in blob storage, be aware that there might be I/O errors under heavy load. OS 1.4 has a fix for this.
WCF Data Services fix
Guest OS 1.3 had a URL-encoding bug affecting Request URI’s when using LINQ. This is now fixed.
Security Patches
The latest security patches, through April 2010, have been applied to Guest OS 1.4, bringing it in line with Windows Server 2008 SP2.
Related Links
- Azure Storage Team blog post announcing Azure Drive Fix
- MSDN Library: Guest OS 1.4 Details, including LINQ details and specific security patches applied


Lori MacVittie asserts Service virtualization is the opposite of – and complementary implementation to – server virtualization in her Service Virtualization Helps Localize Impact of Elastic Scalability post of 6/23/2010 to F5’s DevCentral blog:
One of the biggest challenges with any implementation of elastic scalability as it relates to virtualization and cloud computing is managing that scalability at run-time and at design (configuration) time. The goal is to transparently scale out some service – network or application – in such a way as to eliminate the operational disruption often associated with scaling up (and down) efforts.
Service virtualization allows virtually any service to be transparently scaled out with no negative impact to the service and, perhaps more importantly, to the applications and other services which rely upon that service.
A QUICK PRIMER ON SERVER versus SERVICE VIRTUALIZATION
Service virtualization is the logical opposite of server virtualization. Server virtualization allows one resource to appear to be n resources while service virtualization presents those n resources to appear as one resource. This is the basic premise upon which load balancing is based, and upon which the elastic scalability in cloud computing environments is architected. Service virtualization is necessary to achieve the desired level of transparency in dynamically scaling environments.
One of the side-effects of elastic scalability is a constantly changing network infrastructure, at least from an IP routing point of view. Every device and application – whether virtual or physical – is assigned its own IP address because, well, that’s how networks operate. At least for now. Horizontal scalability is the most common means of achieving elastic scalability (and many, including me, would argue it is the most efficient) but that implies that there exist as many instances of a solution as is required to service demand. Each instance has its own IP address. An environment that leverages horizontal scalability without service virtualization would find itself quickly oversubscribed with managing hundreds or thousands of IP addresses and all the associated network layer protocol configuration required to properly route a request from client to server.
This is part of the “diseconomy of scale” that Greg Ness
often mentions as part of a growing IPAM (IP Address Management) cost-value problem. It is simply not efficient, nor affordable, nor scalable on a human capital level to continually update routing tables on routers, switches, and intermediate devices to keep up with an environment that scales in real time.
This is where service virtualization comes in and addresses most of the challenges associated with elastic scalability.
SCALABILITY DOMAINS
What service virtualization provides is a constant interface to a given application or network service. Whether that’s firewalls or a CRM deployment is irrelevant; if it can be addresses by an IP address it is almost certainly capable of being horizontally scaled and managed via service virtualization. Service
virtualization allows a service to be transparently scaled because clients, other infrastructure services, and applications see only one service, one IP address and that address is a constant. While behind the service virtualization solution – usually a Load balancer or advanced application delivery controller – there will be a variable number of services at any given time as demand requires. There may be only one service to begin with, but as demand increases so will the number of services being virtualized by the service virtualization solution. Applications, clients, and other infrastructure services have no need to know how many services are being virtualized nor should they. Every other service in the datacenter needs only know about the virtual service, which shields them from any amount of volatility that may be occurring “behind the scenes” to ensure capacity meets demand.
This localizes the impact of elastic scalability on the entire infrastructure, constraining the side-effects of dynamism such as ARP storms within “scalability domains”. Each scalability domain is itself shielded from the side-effects of dynamism in other scalability domains because its services always communicate with the virtual service. Scalability domains, when implemented both logically and physically, with a separate network, can further reduce the potential impact of dynamism on application and network performance by walling off the increasing amount of network communication that must occur to maintain high availability amidst a rapidly changing network-layer landscape. The network traffic required to support dynamism can (and probably should) be confined within a scalability domain.
This is, in a nutshell, a service-oriented architecture applied to infrastructure. The difference between a SOI (Service-Oriented Infrastructure) and a SOA (Service-Oriented Architecture) is largely in what type of change is being obfuscated by the interface. In the case of SOA the interface is not supposed to change even though the actual implementation (code) might be extremely volatile. In an SOI the interface (virtual service) does not change even though the implementation (number of services instances) does.
A forward-looking datacenter architecture strategy will employ the use of service virtualization even if it’s not necessary right now. Perhaps it’s the case that one instance of that application or service is all that’s required to meet demand. It is still a good idea to encapsulate the service within a scalability domain to avoid a highly disruptive change in the architecture later on when it becomes necessary to scale out to meet increasing demand. By employing the concept of service virtualization in the initial architectural strategy organizations can eliminate service disruptions because a scalability domain can transparently scale out or in as necessary.
Architecting scalability domains also has the added benefit of creating strategic points of control within the datacenter that allow specific policies to be enforced across all instances of an application or service at an aggregation layer. Applying security, access, acceleration and optimization policies at a strategic point of control ensures that such policies are consistently applied across all applications and services. This further has the advantage of being more flexible, as it is much easier to make a single change to a given policy and apply it once than it is to apply it hundreds of times across all services, especially in a dynamic environment in which it may be easy to “miss” a single application instance.
Scalability domains should be an integral component in any datacenter moving forward. The service virtualization capabilities provide a foundation upon which dynamic scalability and consistent organizational policy enforcement can be implemented with minimal disruption to services and without reliance on individual teams, projects, admins, or developers to ensure policy deployment and usage. Service virtualization is a natural complement to server virtualization and combined with a service oriented architectural approach can provide a strong yet flexible foundation for future growth.


CloudTweaks passed along BusinessWire’s New AMD Opteron(TM) 4000 Series Platform – AMD Announces Low Cost Chip for Cloud Servers press release of 6/23/2010:
At the GigaOm Structure Cloud Computing and Internet Infrastructure conference, AMD … today announced availability of the new AMD Opteron(TM) 4000 Series platform. This is the first server platform designed from the beginning to meet the specific requirements of cloud, hyperscale data center, and SMB customers needing highly flexible, reliable, and power-efficient 1 and 2P systems. This platform is also available for high-end embedded systems such as telecom servers, storage, and digital signage, through AMD Embedded Solutions. Systems from Acer Group, Dell, HP, SGI, Supermicro, ZT Systems, and numerous other channel partners are expected beginning today and in the coming months.
“Until now, customers wanting to build a dense and power-efficient cloud or hyperscale data center had to shoehorn expensive, higher-end solutions into their computing environment, or they had to choose low-power client-based designs that may not have offered the right level of performance and server functionality,” said Patrick Patla, corporate vice president and general manager, Server and Embedded Division, AMD. “With the AMD Opteron 4000 Series platform, these customers now have a server platform that is extremely power- and cost-efficient, allows a high degree of customization, and is also an ideal solution for high-end embedded systems.”
- Power remains the number one concern in the data center. The AMD Opteron 4000 Series platform offers four- and six-core performance at less than 6W per core, reduces power up to 24% over the previous generation³, and allows more than double the servers within the same power budget as previous generation platforms³.
- The current business climate means many customers must look closely at capital expenditures and re-evaluate IT budgets. In addition to on-going savings associated with ultra power-efficient platforms, the AMD Opteron 4100 Series processor offers price points as low as $99 and is a no-compromise, trusted server-class processor with full feature sets.
- The AMD Opteron 4100 Series processor is ideal for custom-designed servers because it allows for smaller heat sinks, power supplies, and fans, as well as low voltage memory to help improve power efficiency. Depending on how the system will be used, customization also allows unnecessary, power-consuming features to be eliminated, further driving cost and power efficiency.
- This platform is available with embedded industry-standard 5+2 years longevity and provides the power, price, and performance balance required for high-end, commercial-class embedded systems with specific target markets and long product life cycles.
- While highly flexible, the AMD Opteron 4000 Series platform is chipset-consistent with the 8- and 12-core AMD Opteron 6000 Series platform and is planned to support the new “Bulldozer” core, planned for 2011. …
<Return to section navigation list>
Cloud Security and Governance
David Schwartz asserts “The question isn't whether the cloud is secure, but whether your provider can show you what's behind the curtain” in his Cloud Visibility article for the July 2010 issue of the Redmond Channel Partner Online newsletter:
Security is the deal breaker for many organizations reluctant to move their enterprise applications and critical data into the cloud. A survey commissioned by Microsoft late last year of IT and business decision-makers found that 75 percent see security as a key risk associated with cloud computing. Some experts will argue, however, that many cloud services are more secure than the in-house enterprise systems where many apps now reside.
Even in scenarios where that is the case, running enterprise data in the cloud means there are certain controls that are not only out of IT's hands, but also aren't visible to administrators or other stakeholders. As such, storing data in the cloud poses certain risk and compliance questions that aren't easy to resolve.
Consider this: Do you know the credentials of those running the systems in cloud services or the ratio of technicians per server? Is it one for every 500 or 1,000 servers? Where is your data being hosted, and on how many different instances? When data is deleted, is it completely eliminated from all servers? How, when and where is it being backed up? What precautions are in place to ensure data on one virtual machine doesn't spill over onto another hypervisor? Your data may be encrypted, but how do you know someone working for your cloud provider hasn't figured a way to decrypt your data?
These are a few of the numerous questions that many cloud providers aren't necessarily answering completely -- or at the very least aren't consistently doing so, some experts warn.
"Not being able to have that visibility and that comfort level that your cloud provider is doing the things that are important to you from a security perspective is slowing down cloud adoption in the enterprise," argues Scott Sanchez, a Certified Information Systems Security Professional (CISSP) and director of the security portfolio at Unisys Corp.
"It's one thing for the provider to say, 'Trust us,'" Sanchez adds. "We let the client pull back the curtain; we let them see audit results; we let them talk to our security folks. Unless you're perhaps one of the top five or 10 clients Amazon has in their cloud, they're not going to give you any of that information. All you get is a little Web page that says, 'We take all the security precautions,' and, frankly, I know they do, as does Rackspace and all the other main cloud providers. But they don't want to tell the public about it; their clients are kind of left to guess."
The Creation of CloudAudit
It's an issue that for years has concerned Christopher Hoff, director of Cloud and Virtualization Solutions for Data Center Solutions at Cisco Systems Inc. That's why Hoff spearheaded an effort called CloudAudit that seeks to develop standards for how cloud providers release information to prospective and existing enterprise clients that can satisfy their compliance and internal governance requirements.Major cloud providers -- including Amazon.com Inc., Google Inc., Microsoft, Unisys, Rackspace U.S. Inc. and others -- are among those participating in the group, Hoff says, but that doesn't necessarily mean that they're broadly committed to supporting the specs that are released at this point in time. Nevertheless, observers in CloudAudit, which is working closely with the Cloud Security Alliance (CSA), can potentially standardize the way information is shared by cloud providers.
"Cloud computing providers, especially the leading ones, are being overrun by requests for audit information because the level of abstraction that they provide -- by virtue of their service definition -- means in many cases the transparency and visibility decreases."
Christopher Hoff, Director, Cloud and Virtualization Solutions for Data Center Solutions, Cisco Systems Inc., and Founder, CloudAudit:"Cloud computing providers, especially the leading ones, are being overrun by requests for audit information because the level of abstraction that they provide -- by virtue of their service definition -- means in many cases the transparency and visibility decreases. [This] causes an even more-important need for these questions to be answered," Hoff says.
"As they're getting overrun, it sure would be great to have a standard way of answering those questions once, and answering them dynamically, inasmuch as supplying information that relates to these compliance frameworks and questions, and making those answers available in a secure way to duly authorized consumers of that information," Hoff adds. "That could be people looking to evaluate your service, the consumer, auditors, security teams; it could be regulators, or it could be your own operational staff, for that matter." …
Jeff concludes with a Q&A sessions with Computer Security Alliance founder and Executive Director Jim Reavis.
David Kearns asserts “Just-in-time provisioning can be as useful within the enterprise as it is between two enterprises, or an enterprise and a cloud-based service provider” in his 'Just-in-time' provisioning for the cloud post of 6/22/2010 to NetworkWorld’s Security blog:
Last issue we looked at Nishant Kaushik's vast exploration of federated provisioning for cloud-based services. Like Nishant, I think "just-in-time" provisioning is the way to go.
Just-in-time provisioning, typically instituted as attribute-based authorization, can be as useful within the enterprise as it is between two enterprises, or an enterprise and a cloud-based service provider (SP). Where I differ from Nishant, though, is that I believe -- at least for the foreseeable future -- that there needs to be an existing relationship between the enterprise hosting the user to be provisioned and the enterprise, or SP, that's providing the service.
Nishant recognizes this when, in discussing the Security Assertion Markup Language (SAML) mechanism called "Attribute Query," which does provide a so-called "back channel" for the identity provider and the service provider to carry on a conversation (about the user's attributes) without impeding the "front channel," typically browser-based workflow. He notes: "However, this does mean that it isn't truly on-the-fly, since the SAML spec would require that a trust relationship be defined between the two sides ahead of time."
I contend that this pre-defined trust relationship will always be necessary, but it doesn't impede just-in-time provisioning, either.
- Simply put, very few people within an enterprise are empowered to contract for services entirely on their own. Approvals are needed if only for the expenditure of funds. When talking about what can be seen as "IT services" (which cloud-based services are, just as much as enterprise-server-based services are) even more approvals would be needed since, in most cases, pricing is on a per user basis with discounts for quantity. There's also the issue of interactivity -- if everyone got to choose a different cloud-based word processor, how easily could documents be shared -- and how difficult (if at all possible) would collaboration be?
No, cloud services need to be chosen ahead of time, and fees and subscriptions determined before any user can be provisioned to them.
But the provisioning can still be done on a just-in-time (whenever the user needs to use a contracted service) basis using do-it-yourself provisioning. SAML Attribute Query would be an excellent protocol and method for doing this. Each time (beginning with the first time) that a user attempts to access the cloud-based service his attributes are checked to see if he is authorized for that service, or for a particular role in that service.
The attributes themselves are granted, modified and removed in the enterprise's corporate directory using standard, "old-fashioned" provisioning tools, triggered by HR events, or by requests from line-of-business managers.
Now it's your turn -- is there a flaw in my logic, or have I found the flow in Nishant's?
<Return to section navigation list>
Cloud Computing Events
Martin Schmidt will present Extreme scaling with SQL Azure at the SQLBits Conference being held in New York City on 9/30 to 10/2/2010:
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Cloud Computing News and Resources reported NASDAQ selects XigniteOnDemand platform to build NASDAQ Data-On-Demand, a cloud-based computing solution on 6/24/2010:
The NASDAQ OMX Group, Inc , the world’s largest exchange company, and Xignite, Inc., the leading cloud services provider of on-demand data distribution technologies, today announced that NASDAQ has selected the XigniteOnDemand platform to build NASDAQ Data-On-Demand, a cloud-based computing solution for historical tick data distribution.
NASDAQ plans to launch Data-on-Demand in the second half of 2010 to provide easy and flexible access to large amounts of detailed historical NASDAQ Level 1 trade and quote data for all U.S.-listed securities. Tick data is increasingly used in quantitative environments for back testing of algorithmic trading strategies. As the securities trading industry pushes the limits of high frequency trading, algorithms require ever more rigorous back testing and fine tuning based on actual historical data. Obtaining and collecting tick data can be onerous and time-consuming as firms are required to establish feeds and maintain large amounts of data on-hand. By providing this data on-demand and allowing it to be purchased on-line, Data-on-Demand will make it easier than ever for firms to back-test their strategies.
“We are always looking to reduce costs of consuming data,” said Randall Hopkins, NASDAQ OMX’s Senior Vice President of Global Data Products. “Today our customers spend a large amount on technology infrastructure, not the market data itself. With Data-on-Demand, we want to drastically cut data management costs by running the technology infrastructure on the cloud for our clients and delivering to them the data they need, when they need it, and how they need it.”
Unlike traditional means of market data delivery, such as feeds and files, on-demand market data distribution gives applications a way to cherry pick the specific subset of data that the application needs with pinpoint accuracy. Instead of combing through very large data sets of historical tick data, developers will be able to program their applications to select very specific data sets and obtain them on-demand and process them instantly. Data-on-Demand will also allow clients to download large tick data subsets on a scheduled basis.
“NASDAQ has decided to bring significant cost savings to one of the industry’s highest priority requirements–timely access to high quality market replay information–by leveraging the industry’s most powerful technology innovation today–on-demand cloud computing,” said Stephane Dubois, CEO of Xignite. “This clearly shows NASDAQ’s commitment to staying ahead of their customers’ needs and reducing their costs. We are thrilled to partner with them on this industry-leading solution.”
It would be interesting to learn if NASDAQ has plans to provide an OData feed.
Ben Kepes analyzes another private-cloud startup in his Private Cloud Redux – Nimbula Bets on Today’s Reality post of 6/23/2010:
A number of cloud commentators seem to get all pent up and in a state of agitated hand-wringing about private cloud. “But it’s not the true cloud” they say, having some sort of dogmatic view over what is, and isn’t cloud. In my mind – so long as it’s scalable and abstracts management away from the user, I’ll consider it able to be called cloud. This of course is different from the “Private, on-premise, customer owned, physical virtual clouds” that one vendor mentioned at last year’s CloudConnect event!
Anyway – into the emotional fray that private clouds seems to generate comes Nimbula. Nimbula comes from royal blood, being founded by the team that developed the Amazon’s EC2, arguably the granddaddy of cloud infrastructure. Nimbula has obtained $5.75 million in series A funding and has a who’s who of former Amazon and VMWare execs as its founders.
I spoke to Chris Pinkham, Nimbula CEO. He stated Nimbula’s mission is simply put:
to Blend Amazon EC2-like scale, agility and efficiency, with private infrastructure customization and control.
To that end they’re launching their product Nimbula Director today. Director is a product that seeks to manage both on-premise and off-premise resources. Director is a cloud operating system that is designed for scalability, ease of use, flexibility, reliability, and security. It:
- Installs on bare metal
- Allows for a heterogeneous configuration
- Across thousands of nodes
- Provides an automated control plane
- Is reliable and distributed
- Needs minimal configuration
- Includes dynamic Resource Discovery
The diagram below shows what Nimbula Director will actually provide:

According to the briefing I received from Nimbula, they’re built with a focus on the following area:
Scalability – The Nimbula cloud OS is designed for linear scaling from a few up to hundreds of thousands of notes. This allows an organization to grow, and grow quickly.
Ease of use – A highly automated, hands-off install requiring minimal configuration or interaction dramatically reduces the complexity of deploying an on-premise cloud. Racks come online automatically in under 15 minutes. Management of cloud services is largely automated, significantly improving operational efficiency.
Flexibility – The Nimbula cloud OS supports controlled federation to external private and public clouds like EC2 as needed by the customer during peak times or for specific applications.
Reliability – With no single point of failure, the Nimbula cloud OS employs sophisticated fail over mechanisms to ensure system integrity and resilience.
Security – A robust and flexible policy based authorization system supporting multi tenancy provides mature and reliable security, and sophisticated cloud management control
Nimbula is under a beta trial with half a dozen or so customers. They plan to expose their beta more widely in Q3 this year with a formal product launch at the end of the year.

Alex Williams asks Weekly Poll: Is Salesforce.com Chatter Really That Unique? Does it Matter? in this 6/23/2010 post:
It all sounds good when Salesforce.com CEO Mark Benioff is on stage like he was today, stirring the faithful with his rousing presence. If you ever get the chance, go see Benioff present. He has a style that's part P.T. Barnum, part passionate geek.
With Chatter, Salesforce.com is embracing the concept of the activity stream. And customers do seem to like the flow that comes with a river of news. Geeks have been shouting about this style of receiving news for years. RSS initiated many of us to the way data can flow into our aggregarors. We first heard Dave Winer talk about the concept. It has since become a foundation element in the user experience for a line of apps such as Twitter, Facebook and Friendfeed.
We mentioned several companies in a previous post today that make activity streams a part of its core offering. Blogtronix, Jive Software and SAP Streamwork are a few others that have previously developed activity streams into its infrastructure.
So that leads to our question of the week: Is Salesforce.com Chatter Really That Unique? Does it Matter if it is not?
We can't expect too much objectivity from competitors. They've been doing their fair share of squawking today in reaction to the Chatter marketing juggernaut. ..
Alex continues with answers from Blogtronix Founder Vassil Mladjov, Bantam Live, Peter Coffee of Salesforce.com, CRM Outsiders, and Sameer Patel.
Rick Swanborg wrote his Intel Builds a Private Cloud article for NetworkWorld’s DataCenter blog on 6/18/2010:
Intel's research and development group was the first internal segment to increase efficiency with an infrastructure- and platform-as-a-service approach, improving its server utilization rate from 59 percent in the first half of 2006 to 80 percent today. By reducing infrastructure spending and avoiding building new data center facilities, the company expects to save nearly $200 million. Following this success, Intel decided in early 2009 to build an enterprise private cloud for its office and enterprise groups.
The Situation: From 2005 to 2006, the demand for new business lines dramatically increased the number of design teams in motion--all of which operated on a non-shared and underutilized infrastructure. This, paired with the fact that R&D represents the vast majority of Intel's infrastructure, made it the logical place to start a transformation to IaaS and PaaS.
What They Did: Intel implemented a grid computing solution inside its R&D environment that features both IaaS and PaaS attributes. The solution is accessible via a self-service portal and command-line interfaces. The portal allows users to provision key infrastructure services--such as storage--in hours instead of months. Perhaps most important, this approach allows Intel to measure what users are consuming.
IT cloud engineering lead Das Kamhout says, "Overall, this represents a dramatic change in mind-set," says Kamhout. "On-demand self-service allows IT to get out of the way of the business so we can up level IT and be a strategic business partner. And with transparent costs, R&D departments across Intel now know what they're costing and what they're consuming."
Why It Was Unique: The combination of the on-demand self-service portal across Intel's entire infrastructure, together with the ability to measure consumption, ensures there is minimal misuse of capacity, thereby allowing IT to efficiently support rapid growth while maintaining high availability of services.
The Takeaway: Having proved that an IaaS approach could work for R&D, Intel IT built the case for replicating those efforts across the organization. The office and enterprise groups' efforts are now under way, with a focus on pervasive virtualization and on-demand self-service for an enterprise private cloud.

<Return to section navigation list>
















