Windows Azure and Cloud Computing Posts for 11/11/2013+
Top Stories This Week:
- ‡ Brad Anderson (@InTheCloudMSFT) took on Amazon Web Services with his Success with Hybrid Cloud: Why Hybrid? post of 11/14/2013 in the Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds section.
- S. “Soma” Somasegar posted Visual Studio 2013 Launch: Announcing Visual Studio Online to his blog on 11/13/2013 in the Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses section.
- Dan Plastina (@TheRMSGuy) described Office 365 Information Protection using Azure Rights Management in an 11/11/2013 and two earlier posts to the Microsoft Rights Management Service (RMS) Team blog in the Cloud Security, Compliance and Governance section.
- Jeff Barr (@jeffbarr) announced Amazon WorkSpaces - Desktop Computing in the Cloud in an 11/13/2013 post at the end of the Other Cloud Computing Platforms and Services section.
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Caching, SQL Azure Database, and other cloud-computing articles. |
‡ Updated 11/18/2013 with new articles marked ‡.
• Updated 11/16/2013 with new articles marked •.
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Windows Azure Marketplace DataMarket, Power BI, Big Data and OData
- Windows Azure Service Bus, BizTalk Services, Scheduler and Workflow
- Windows Azure Access Control, Active Directory, and Identity
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure and DevOps
- Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
- Visual Studio LightSwitch and Entity Framework v4+
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
<Return to section navigation list>
Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
• Neil MacKenzie (@mknz) explained [LINQ] Queries in the Windows Azure [Table] Storage Client Library v2.1 in a 11/3/2013 post (missed when published):
Windows Azure Storage has been a core part of the Windows Azure Platform since the public preview in 2008. It supports three storage features: Blobs, Queues and Tables. The Blob Service provides high-scale file storage – with prominent uses being: the storage of media files for web sites; and the backing store for the VHDs used as the disks attached to Windows Azure VMs. The Queue Service provides a basic and easy-to-use messaging system that simplifies the disconnected communication between VMs in a Windows Azure cloud service. The Table Service is a fully-managed, cost-effective, high-scale, key-value NoSQL datastore.
The definitive way to access Windows Azure Storage is through the Windows Azure Storage REST API. This documentation is the definitive source of what can be done with Windows Azure Tables. All client libraries, regardless of language, use the REST API under the hood. The Storage team has provided a succession of .NET libraries that sit on top of the REST API. The original Storage Client library had a strong dependence on WCF Data Services, which affected some of the design decisions. In 2012, the Storage team released a completely rewritten v2.0 library which removed the dependence and was more performant.
The Storage Client v2.0 library provided a fluent library for query invocation against Wizard Azure Tables. v2.1 of the library added a LINQ interface for query invocation. The LINQ interface is significantly easier to use than the fluent library while supporting equivalent functionality. Consequently, only the LINQ library is considered in this post.
The MSDN documentation for the Windows Azure Storage Library is here. The Windows Azure Storage team has provided several posts documenting the Table Service API in the .NET Storage v2.x library (2.0, 2.1). Gaurav Mantri has also posted on the Table Service API as part of an excellent series of posts on the Storage v2.0 library. I did a post in 2010 that described the query experience for Windows Azure Tables in the Storage Client v1.x library.
Overview of Windows Azure Tables
Windows Azure Tables is a key-value, NoSQL datastore in which entities are stored in tables. It is a schema-less datastore so that each entity in a table can have a different schema for the properties contained in it. The primary key, and only index, for a table is a combination of the PartitionKey and RowKey that must exist in each row. The PartitionKey specifies the partition (or shard) for an entity while the RowKey provides uniqueness within a partition. Different partitions may be stored on different physical nodes, with the Table Service managing this allocation.
The REST API provides limited query capability. It supports filtering as well as the specification of the properties to be returned. A query can be filtered on combinations of any of the properties in the entity. The right side of each filter must be against a constant, and it is not possible to compare values of different properties. It is also possible to specify a limit on the number of entities to be returned by a query. The general rules for queries are documented here with specific rules for filters provided here.
The Table Service uses server-side paging to limit the amount of data that may be returned in a single query. Server-side paging is indicated by the presence of a continuation token in the response to the query. This continuation token can be provided in a subsequent query to indicate where the next “page” of data should start. A single query has a hard limit of 1,000 entities in a single page and can execute for no more than 5 seconds. Furthermore, a page return is also caused by all the entities hosted on a single physical node having been returned. An odd consequence of this is that it is possible to get back zero entities along with a continuation token. This is caused by the Table Service querying a physical node where no entities are currently stored. The only query that is guaranteed never to return a continuation token is one that filters on both PartitionKey and RowKey. Note that any query which does not filter on either PartitionKey or RowKey will result in a table scan.
The Table Service returns queried data as an Atom feed. This is a heavyweight XML protocol that inflates the size of a query response. The Storage team announced at Build 2013 that it would support the use of JSON in the query response which should reduce the size of a query response. To reduce the amount of data returned by a query, the Table Service supports the ability to shape the returned data through the specification of which properties should be returned for an entity.
The various client libraries provide a native interface to the Table Service that hides much of the complexity of filtering and continuation tokens. For example, the .NET library provides both fluent and LINQ APIs allowing a familiar interaction with Windows Azure Tables.
ITableEntity
The ITableEntity class provides the interface implemented by all classes used to represent entities in the Storage Client library v2.x. ITableEntity defines the following properties:
- ETag- entity tag used for optimistic concurrency
- PartitionKey – partition key for the entity
- RowKey – row key for the entity
- Timestamp – timestamp for last update
The library contains two classes implementing the ITableEntity interface:
TableEntity provides the base class for user-defined classes used to represent entities in the Storage Client library. These derived classes expose properties representing the properties of the entity. DynamicTableEntity is a sealed class which stores the entity properties inside an IDictionary<String,EntityProperty> property named Properties.
The use of strongly-typed classes derived from TableEntity is useful when entities are all of the same type. However, DynamicTableEntity is helpful when handling tables which take full advantage of the schema-less nature of Windows Azure Tables and have entities with different schemas in a single table.
Basic LINQ Query
LINQ is a popular method for specifying queries since it provides a natural syntax that makes explicit the nature of the query and the shape of returned entities. The Storage Client library supports LINQ and uses it to expose various query features of the underlying REST interface to .NET.
A LINQ query is created using the CreateQuery<TEntity>() method of the CloudTable class. TEntity is a class derived from ITableEntity. In the query the where keyword specifies the filters and the select keyword specifies the properties to be returned.
With BookEntity being an entity class derived from TableEntity, the following is a simple example using the Storage Client library of a LINQ query against a table named book:
CloudStorageAccount storageAccount = new CloudStorageAccount(
new StorageCredentials(accountName, accountKey), true);
CloudTableClient tableClient = storageAccount.CreateCloudTableClient();
CloudTable bookTable = tableClient.GetTableReference(“book”);var query = from book in bookTable.CreateQuery<BookEntity>()
where book.PartitionKey == “hardback”
select book;foreach (BookEntity entity in query) {
String name = entity.Name;
String author = entity.Author;
}The definition of the query creates an IQueryable<BookEntity> but does not itself invoke an operation against the Table service. The operation actually occurs when the foreach statement is invoked. This example queries the book table and returns all entities where the PartitionKey property takes the value hardback. A table is indexed on PartitionKey and RowKey and data is returned from a query ordered by PartitionKey/RowKey. In this example the data is ordered by RowKey since the PartitionKey is fixed in the query.
The Storage Client library handles server-side paging automatically when the query is invoked. Consequently, if there are many entities satisfying the query a significant amount of data is returned.
Basic queries can be performed using IQueryable, as above. More sophisticated queries – with client-side paging and asynchronous invocation, for example – are handled by converting the IQueryable into a TableQuery.
Server Side Paging
The Storage library supports server-side paging using the Take() method. This allows the specification of the maximum number of entities that should be returned by query invocation. This limit is performed server-side so can significantly limit the amount of data returned and consequently the time taken to return the data.
For example, the above query can be modified to return a maximum of 10 entities:
var query = (from book in bookTable.CreateQuery<BookEntity>()
where book.PartitionKey == “hardback”
select book).Take(10);Note that this simple query can not by itself be used to page through the data from the client side. Multiple invocations always return the same entities. Paging through the data requires the handling of the continuation tokens returned by the server to indicate that there is additional data satisfying the query.
To handle continuation tokens, the IQueryable must be cast into a TableQuery<TElement>. This can be done either through direct cast or using the AsTableQuery() extension method. TableQuery<TElement> exposes an ExecuteSegmented() method which handles continuation tokens:
public TableQuerySegment<TElement>
ExecuteSegmented(TableContinuationToken continuationToken,
TableRequestOptions requestOptions = null,
OperationContext operationContext = null);This method invokes a query in which the result set starts with the entity indicated by an(opaque) continuation token, which should be null for the initial invocation. It also takes optional TableRequestOption (timeouts and retry policies) and OperationContext (log level) parameters. TableQuerySegment<TElement> is an IEnumerable that exposes two properties: ContinuationToken and Results. The former is the continuation token, if any, returned by query invocation while the latter is a List of the returned entities. A null value for the returned ContinuationToken indicates that all the data has been provided and that no more query invocations are needed.
The following example demonstrates the use of continuation tokens:
TableQuery<BookEntity> query =
(from book in bookTable.CreateQuery<BookEntity>()
where book .PartitionKey == “hardback”
select book).AsTableQuery<BookEntity>();TableContinuationToken continuationToken = null;
do {
var queryResult = query.ExecuteSegmented(continuationToken);foreach (BookEntity entity in queryResult)
{
String name = entity.Name;
String genre = entity.Genre;
}
continuationToken = queryResult.ContinuationToken;
} while (continuationToken != null);The TableQuery class also exposes various asynchronous methods. These include traditional APM methods of the form BeginExecuteSegmented()/EndExecuteSegmented() and modern Task-based (async/await) methods of the form ExecuteSegmentedAsync().
Extension Methods
The TableQueryableExtensions class in the Microsoft.WindowsAzure.Storage.Table.Queryable namespace provides various IQueryable<TElement> extension methods:
AsTableQuery() casts a query to a TableQuery<TElement>. Resolve() supports client-side shaping of the entities returned by a query. WithContext() and WithOptions() allow an operation context and request options respectively to be associated with a query.
Entity Shaping
The Resolve() extension method associates an EntityResolver delegate that is invoked when the results are serialized. The resolver can shape the output of the serialization into some desired form. A simple example of this is to perform client-side modification such as creating a fullName property out of firstName and lastName properties.
The EntityResolver delegate is defined as follows:
public delegate T EntityResolver<T>(string partitionKey, string rowKey,
DateTimeOffset timestamp,
IDictionary<string, EntityProperty> properties, string etag);The following example shows a query in which a resolver is used to format the returned data into a String composed of various properties in the returned entity:
var query =
(from book in bookTable.CreateQuery<DynamicTableEntity>()
where book.PartitionKey == “hardback”
select book).Resolve( (pk,rk,ts,props,etag) =>
String.Format(“{0} wrote {1} in {2}”,
props["Author"].StringValue, props["Name"].StringValue,
props["Year"].Int32Value));More sophisticated resolvers can be defined separately. For example, the following example shows the returned entities being shaped into instances of a Writer class:
EntityResolver<Writer> resolver = (pk, rk, ts, props, etag) =>
{
Writer writer = new Writer()
{
Information = String.Format(“{0} wrote {1} in {2}”,
props["Author"].StringValue, props["Name"].StringValue,
props["Year"].Int32Value)
};
return writer;
};var query =
(from book in bookTable.CreateQuery<DynamicTableEntity>()
where book.PartitionKey == “hardback”
select book).Resolve(resolver);Schema-Less Queries
The DynamicTableEntity class is used to invoke queries in a schema-free manner, since the retrieved properties are stored in a Dictionary. For example, the following example performs a filter using the DynamicTableEntity Properties collection and then puts the returned entities into a List of DynamicTableEntity objects:
var query = (
from entity in bookTable.CreateQuery<DynamicTableEntity>()
where entity.Properties["PartitionKey"].StringValue == “hardback” &&
entity.Properties["Year"].Int32Value == 1912
select entity);List<DynamicTableEntity> books = query.ToList();
The individual properties of each entity are accessed through the Properties collection of the DynamicTableEntity.
Summary
The Windows Azure Storage Client v2.1 library supports the use of LINQ to query a table stored in the Windows Azure Table Service. This library exposes, in a performant .NET library, all the functionality provided by the underlying Windows Azure Storage REST API.


• Bruno Terkaly (@brunoterkaly) described How to upload publicly visible photos from a Windows Store Application to Windows Azure Storage version 2.1 in an 11/4/2013 post (missed when published:
Overview
In this module we learn about uploading photos to Windows Azure Storage using the latest version of the Windows Azure Storage SDK (version 2.1).
Download Visual Studio Solution
Using Pre-Release Windows Azure Storage SDK
NuGet will be used to install the necessary assemblies and references. It represents the fastests and easiest way to support Windows Azure Storage from a Windows Store application.
Objectives
In this hands-on lab, you will learn how to:
- Upload images from a Windows Store application into Windows Azure Storage using Version 2 of the Windows Azure Storage Library.
Setup
In order to execute the exercises in this hands-on lab you need to set up your environment.
- Start Visual Studio
- Signed up with a Window Azure Account
…


Bruno continues with details of the six tasks involved.
… Summary
In this post, you learned a few things:
- How to upload files to Windows Azure Storage from a Windows Store application
- How to use the Windows Azure Portal to create a Storage Account
- How to use Server Explorer to view files in storage
- How to use NuGet to add support for Windows Azure Storage
Alexandre Brisebois (@Brisebois) described how to Create Predictable GUIDs for your Windows Azure Table Storage Entities in a 11/14/2013 post:
This week I was face with an odd scenario. I needed to track URIs that are store in Windows Azure Table Storage. Since I didn’t want to use the actual URIs as row keys I tried to find a way to create a consistent hash compatible with Windows Azure Table Storage Row & Primary Keys. This is when I came across an answer on Stack Overflow about converting URIs into GUIDs.
The "correct" way (according to RFC 4122 §4.3) is to create a name-based UUID. The advantage of doing this (over just using a MD5 hash) is that these are guaranteed not to collide with non-named-based UUIDs, and have a very (very) small possibility of collision with other name-based UUIDs. [source]
Using the code referenced in this answer I was able to put together an IdentityProvider who’s job is to generate GUIDs based on strings. In my case I use it to create GUIDs based on URIs.
public class IdentityProvider
{
public Guid MakeGuid(Uri uri)
{
var guid = GuidUtility.Create(GuidUtility.UrlNamespace, uri.AbsoluteUri);
return guid;
}
}Creating predictable GUIDs can come quite in handy with Windows Azure Table Storage, because it allows you to create a GUID based an entities’ content. By doing so, you can find entities without performing full table scans. Using the following code, found on GitHub, I was able to build an efficient URI matching system. Be sure to give credit if you use it.
using System;
using System.Security.Cryptography;
using System.Text;namespace Logos.Utility
{
/// <summary>
/// Helper methods for working with <see cref="Guid"/>.
/// </summary>
public static class GuidUtility
{
/// <summary>
/// Creates a name-based UUID using the algorithm from RFC 4122 4.3.
/// </summary>
/// <param name="namespaceId">The ID of the namespace.</param>
/// <param name="name">The name (within that namespace).</param>
/// <returns>A UUID derived from the namespace and name.</returns>
/// <remarks>
/// See <a href="http://code.logos.com/blog/2011/04/generating_a_deterministic_guid.html">
/// Generating a deterministic GUID</a>.
/// </remarks>
public static Guid Create(Guid namespaceId, string name)
{
return Create(namespaceId, name, 5);
}/// <summary>
/// Creates a name-based UUID using the algorithm from RFC 4122 4.3.
/// </summary>
/// <param name="namespaceId">The ID of the namespace.</param>
/// <param name="name">The name (within that namespace).</param>
/// <param name="version">The version number of the UUID to create; this value must be either
/// 3 (for MD5 hashing) or 5 (for SHA-1 hashing).</param>
/// <returns>A UUID derived from the namespace and name.</returns>
/// <remarks>
/// See <a href="http://code.logos.com/blog/2011/04/generating_a_deterministic_guid.html">
/// Generating a deterministic GUID</a>.
/// </remarks>
public static Guid Create(Guid namespaceId, string name, int version)
{
if (name == null)
throw new ArgumentNullException("name");
if (version != 3 && version != 5)
throw new ArgumentOutOfRangeException("version", "version must be either 3 or 5.");// convert the name to a sequence of octets
// (as defined by the standard or conventions of its namespace) (step 3)
// ASSUME: UTF-8 encoding is always appropriate
byte[] nameBytes = Encoding.UTF8.GetBytes(name);// convert the namespace UUID to network order (step 3)
byte[] namespaceBytes = namespaceId.ToByteArray();
SwapByteOrder(namespaceBytes);// comput the hash of the name space ID concatenated with the name (step 4)
byte[] hash;
using (HashAlgorithm algorithm = version == 3 ? (HashAlgorithm)MD5.Create() : SHA1.Create())
{
algorithm.TransformBlock(namespaceBytes, 0, namespaceBytes.Length, null, 0);
algorithm.TransformFinalBlock(nameBytes, 0, nameBytes.Length);
hash = algorithm.Hash;
}// most bytes from the hash are copied straight to the bytes of
// the new GUID (steps 5-7, 9, 11-12)
byte[] newGuid = new byte[16];
Array.Copy(hash, 0, newGuid, 0, 16);// set the four most significant bits (bits 12 through 15) of the time_hi_and_version field
// to the appropriate 4-bit version number from Section 4.1.3 (step 8)
newGuid[6] = (byte)((newGuid[6] & 0x0F) | (version << 4));// set the two most significant bits (bits 6 and 7) of the clock_seq_hi_and_reserved
// to zero and one, respectively (step 10)
newGuid[8] = (byte)((newGuid[8] & 0x3F) | 0×80);// convert the resulting UUID to local byte order (step 13)
SwapByteOrder(newGuid);
return new Guid(newGuid);
}/// <summary>
/// The namespace for fully-qualified domain names (from RFC 4122, Appendix C).
/// </summary>
public static readonly Guid DnsNamespace = new Guid("6ba7b810-9dad-11d1-80b4-00c04fd430c8");/// <summary>
/// The namespace for URLs (from RFC 4122, Appendix C).
/// </summary>
public static readonly Guid UrlNamespace = new Guid("6ba7b811-9dad-11d1-80b4-00c04fd430c8");/// <summary>
/// The namespace for ISO OIDs (from RFC 4122, Appendix C).
/// </summary>
public static readonly Guid IsoOidNamespace = new Guid("6ba7b812-9dad-11d1-80b4-00c04fd430c8");// Converts a GUID (expressed as a byte array) to/from network order (MSB-first).
internal static void SwapByteOrder(byte[] guid)
{
SwapBytes(guid, 0, 3);
SwapBytes(guid, 1, 2);
SwapBytes(guid, 4, 5);
SwapBytes(guid, 6, 7);
}private static void SwapBytes(byte[] guid, int left, int right)
{
byte temp = guid[left];
guid[left] = guid[right];
guid[right] = temp;
}
}
}


<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Marketplace DataMarket, Cloud Numerics, Big Data and OData
• The WCF Data Services (OData) Team announced a New and improved EULA! for the .NET OData Client and ODataLib on 11/13/2013:
TL;DR: You can now (legally) use our .NET OData client and ODataLib on Android and iOS.
Backstory
For a while now we have been working with our legal team to improve the terms you agree to when you use one of our libraries (WCF Data Services, our OData client, or ODataLib). A year and a half ago, we announced that our EULA would include a redistribution clause. With the release of WCF Data Services 5.6.0, we introduced portable libraries for two primary reasons:
- Portable libraries reduce the amount of duplicate code and #ifdefs in our code base.
- Portable libraries increase our reach through third-party tooling like Xamarin (more on that later).
It took some work to get there, and we had to make some sacrifices along the way, but we are now focused exclusively on portable libraries for client-side code. Unfortunately, our EULA still contained a clause that prevented the redistributable code from being legally used on a platform other than Windows.
OData and Xamarin: Extending developer reach to many platforms
We are really excited about Microsoft’s new collaboration with Xamarin. As Soma says, this collaboration will allow .NET developers to broaden the reach of their applications and skills. This has long been the mantra of OData – a standardized ecosystem of services and consumers that enables consumers on any platform to easily consume services developed on any platform. This collaboration will make it much easier to write a shared code base that allows consumption of OData on Windows, Android or iOS.
EULA change
To fully enable this scenario, we needed to update our EULA. We, along with several other teams at Microsoft, are rolling out a new EULA today that has relaxed the distribution requirements. Most importantly, we removed the clause that prevented redistributable code from being used on Android and iOS.
The new EULA is effective immediately for all of our NuGet packages. This means that (even though we already released 5.6.0) you can create a Xamarin project today, take a new dependency on our OData client, and legally run that application on any platform you wish.
Thanks
As always, we really appreciate your feedback. It frequently takes us some time to react, but the credit for this change is due entirely to customer feedback. We hear you. Keep it coming.
<Return to section navigation list>
Windows Azure Service Bus, Scheduler, BizTalk Services and Workflow
• Guarav Mantri (@gmantri) continued his series with Windows Azure Scheduler Service – Part II: Managing Cloud Services on 11/10/2013:
In the previous post about Windows Azure Scheduler Service, we talked about some of the basic concepts. From this post, we will start digging deep into various components of this service and will focus on managing these components using REST API. As promised in the last post, this and subsequent posts in this series will be code heavy.
In this post we will focus on Cloud Service component of this service and we will see how you can manage Cloud Service using REST API.
Cloud Service
Just to recap from our last post, a cloud service is a top level entity in this service. You would need to create a cloud service first before you can create a job. Few things about cloud service:
- Consider a cloud service as an application in which many of your job will reside and execute. A subscription can have many cloud services.
- A cloud service is data center specific i.e. when you create a cloud service, it resides in a particular data center. If you want your jobs to be performed from many data centers, you would need to create separate cloud services in each data center.
The Code!
Now let’s code! What I have done is created a simple console application and tried to consume REST API there. Before we dig into cloud service, let’s do some basic ground work as we don’t want to write same code over and over again.
Subscription Entity
As mentioned in the previous blog post, to authorize your requests you would need subscription id and a management certificate (similar to authorizing Service Management API requests). To encapsulate that, I created a simple class called “Subscription”.
using System; using System.Collections.Generic; using System.Linq; using System.Security.Cryptography.X509Certificates; using System.Text; using System.Threading.Tasks; namespace SchedulingServiceHelper { /// <summary> /// /// </summary> public class Subscription { /// <summary> /// Subscription id. /// </summary> public Guid Id { get; set; } /// <summary> /// Management certificate /// </summary> public X509Certificate2 Certificate { get; set; } } }Helper
Since we are going to make use of REST API, I created some simple helper class which is responsible for doing web requests and handling responses. Here’s the code for that.
using System; using System.Collections.Generic; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; namespace SchedulingServiceHelper { public static class RequestResponseHelper { /// <summary> /// x-ms-version request header. /// </summary> private const string X_MS_VERSION = "2012-03-01"; /// <summary> /// XML content type request header. /// </summary> public const string CONTENT_TYPE_XML = "application/xml; charset=utf-8"; /// <summary> /// JSON content type request header. /// </summary> public const string CONTENT_TYPE_JSON = "application/json"; private const string baseApiEndpointFormat = "https://management.core.windows.net/{0}"; public static HttpWebResponse GetResponse(Subscription subscription, string relativeUri, HttpMethod method, string contentType, byte[] requestBody = null) { var baseApiEndpoint = string.Format(baseApiEndpointFormat, subscription.Id); var url = string.Format("{0}/{1}", baseApiEndpoint, relativeUri); var request = (HttpWebRequest) HttpWebRequest.Create(url); request.ClientCertificates.Add(subscription.Certificate); request.Headers.Add("x-ms-version", X_MS_VERSION); if (!string.IsNullOrWhiteSpace(contentType)) { request.ContentType = contentType; } request.Method = method.ToString(); if (requestBody != null && requestBody.Length > 0) { request.ContentLength = requestBody.Length; using (var stream = request.GetRequestStream()) { stream.Write(requestBody, 0, requestBody.Length); } } return (HttpWebResponse)request.GetResponse(); } } public enum HttpMethod { DELETE, GET, HEAD, MERGE, PATCH, POST, PUT, } public static class Constants { public const string Namespace = "http://schemas.microsoft.com/windowsazure"; } }Cloud Service Operations
Now we are ready to consume REST API for managing Cloud Service.
Cloud Service Entity
Let’s first create a class which will encapsulate the properties of a cloud service. It’s a pretty simple class. We will use this class throughout this post.
using System; using System.Collections.Generic; using System.IO; using System.Linq; using System.Net; using System.Text; using System.Threading.Tasks; using System.Xml.Linq; namespace SchedulingServiceHelper { public class CloudService { /// <summary> /// Cloud service name. /// </summary> public string Name { get; set; } /// <summary> /// Cloud service label. /// </summary> public string Label { get; set; } /// <summary> /// Cloud service description. /// </summary> public string Description { get; set; } /// <summary> /// Region where cloud service will be created. /// </summary> public string GeoRegion { get; set; } } }Create
As the name suggests, you use this operation to create a cloud service. To create a cloud service, you would need to specify all of the four properties mentioned above. You can learn more about this operation here: http://msdn.microsoft.com/en-us/library/windowsazure/dn528943.aspx.
Here’s a simple function I wrote to create a cloud service. This function is part of the “CloudService” class I mentioned above:
public void Create(Subscription subscription) { try { string requestPayLoadFormat = @"<CloudService xmlns:i=""http://www.w3.org/2001/XMLSchema-instance"" xmlns=""http://schemas.microsoft.com/windowsazure""><Label>{0}</Label><Description>{1}</Description><GeoRegion>{2}</GeoRegion></CloudService>"; var requestPayLoad = string.Format(requestPayLoadFormat, Label, Description, GeoRegion); var relativePath = string.Format("cloudServices/{0}", Name); using (var response = RequestResponseHelper.GetResponse(subscription, relativePath, HttpMethod.PUT, RequestResponseHelper.CONTENT_TYPE_XML, Encoding.UTF8.GetBytes(requestPayLoad))) { var status = response.StatusCode; } } catch (WebException webEx) { using (var resp = webEx.Response) { using (var streamReader = new StreamReader(resp.GetResponseStream())) { string errorMessage = streamReader.ReadToEnd(); } } throw; } }A few things to keep in mind:
- For “GeoRegion” element, possible values are: “uswest“, “useast“, “usnorth“, “ussouth“, “north europe“, “west europe“, “east asia“, and “southeast asia“. Any other values will result in 400 error. I have tried creating a service with each and every one of them and was able to successfully create them. Update: Based on the feedback I received – even though you could create a cloud service in all regions, at the time of writing of this post, Windows Azure only allows you to create a Job Collection in “ussouth” and “north europe” regions. Thus for trying out this service, you may want to create a cloud service in these regions only.
- The name of your cloud service can’t contain any spaces. It can start with a number and can contain both upper and lower case alphabets and can also contain hyphens.
- Since you send “Label” and “Description” as part of XML payload, I’m guessing that you would need to escape them properly like replacing “<” sign with “<” and so on however documentation does not mention any of that. Furthermore I wish they had kept it consistent with other Service Management API calls where elements like these must be Base64 encoded.
Delete
As the name suggests, you use this operation to delete a cloud service. This operation deletes the cloud service and all resources in it thus you would need to be careful when performing this operation. To delete a cloud service, you would just need the name of the cloud service. You can learn more about this operation here: http://msdn.microsoft.com/en-us/library/windowsazure/dn528936.aspx.
Here’s a simple function I wrote to delete a cloud service. This function is part of the “CloudService” class I mentioned above:
public void Delete(Subscription subscription) { try { var relativePath = string.Format("cloudServices/{0}", Name); using (var response = RequestResponseHelper.GetResponse(subscription, relativePath, HttpMethod.DELETE, RequestResponseHelper.CONTENT_TYPE_XML, null)) { var status = response.StatusCode; } } catch (WebException webEx) { using (var resp = webEx.Response) { using (var streamReader = new StreamReader(resp.GetResponseStream())) { string errorMessage = streamReader.ReadToEnd(); } } throw; } }Get
This is one undocumented operation I stumbled upon accidently. This operation returns the properties of a cloud service. The endpoint you would use for performing this operation would be “https://management.core.windows.net/<subscription-id>/cloudServices/<cloud-service-id>” and the HTTP method you would use is “GET”.
Here’s a simple function I wrote to get information about a cloud service. This function is part of the “CloudService” class I mentioned above:
public static CloudService Get(Subscription subscription, string cloudServiceName) { try { var relativePath = string.Format("cloudServices/{0}", cloudServiceName); using (var response = RequestResponseHelper.GetResponse(subscription, relativePath, HttpMethod.GET, RequestResponseHelper.CONTENT_TYPE_XML, null)) { using (var streamReader = new StreamReader(response.GetResponseStream())) { string responseBody = streamReader.ReadToEnd(); XElement xe = XElement.Parse(responseBody); var name = xe.Element(XName.Get("Name", Constants.Namespace)).Value; var label = xe.Element(XName.Get("Label", Constants.Namespace)).Value; var description = xe.Element(XName.Get("Description", Constants.Namespace)).Value; var geoRegion = xe.Element(XName.Get("GeoRegion", Constants.Namespace)).Value; return new CloudService() { Name = name, Label = label, Description = description, GeoRegion = geoRegion, }; } } } catch (WebException webEx) { using (var resp = webEx.Response) { using (var streamReader = new StreamReader(resp.GetResponseStream())) { string errorMessage = streamReader.ReadToEnd(); } } throw; } }Get operation also returns information about all the resources contained in that service. We’ll get back to this function again when we talk about job collections.
List
This is another undocumented operation I stumbled upon accidently. This operation returns the properties of all cloud services in a subscription. The endpoint you would use for performing this operation would be “https://management.core.windows.net/<subscription-id>/cloudServices” and the HTTP method you would use is “GET”.
Here’s a simple function I wrote to get information about all cloud services in a subscription. This function is part of the “CloudService” class I mentioned above:
public static List<CloudService> GetAll(Subscription subscription) { try { using (var response = RequestResponseHelper.GetResponse(subscription, "cloudServices", HttpMethod.GET, RequestResponseHelper.CONTENT_TYPE_XML, null)) { using (var streamReader = new StreamReader(response.GetResponseStream())) { string responseBody = streamReader.ReadToEnd(); List<CloudService> cloudServices = new List<CloudService>(); XElement xe = XElement.Parse(responseBody); foreach (var elem in xe.Elements(XName.Get("CloudService", Constants.Namespace))) { var name = elem.Element(XName.Get("Name", Constants.Namespace)).Value; var label = elem.Element(XName.Get("Label", Constants.Namespace)).Value; var description = elem.Element(XName.Get("Description", Constants.Namespace)).Value; var geoRegion = elem.Element(XName.Get("GeoRegion", Constants.Namespace)).Value; cloudServices.Add(new CloudService() { Name = name, Label = label, Description = description, GeoRegion = geoRegion, }); } return cloudServices; } } } catch (WebException webEx) { using (var resp = webEx.Response) { using (var streamReader = new StreamReader(resp.GetResponseStream())) { string errorMessage = streamReader.ReadToEnd(); } } throw; } }Complete Code
Here’s the complete code for CloudService class with all the operations. …

[Duplicate code elided for brevity]
… Summary
That’s it for this post. I hope you will find it useful. As always, if you find any issues with the code or anything else in the post please let me know and I will fix it ASAP.
In the next post, we will talk about Job Collections so hang tight
• Guarav Mantri (@gmantri) began a Windows Azure Scheduler Service (WASS) series with Windows Azure Scheduler Service – Part I: Introduction on 11/10/2013:
Recently Windows Azure announced a new Scheduler Service in preview. In this blog post, we will talk about some basic stuff to get you started. In the subsequent posts, we will drill down into more details.
What
Let’s first talk about what exactly is this service. As the name suggests, this service allows you to schedule certain tasks which you wish to do on a repeated basis and let Windows Azure take care of scheduler part of that task execution.
For example, you may want to ping your website every minute to see if it is working properly (like checking for HTTP Status 200). You could use this service for that purpose.
Please do realize that it’s a platform service or in other words it provides a scalable platform for task scheduling. The service will not execute the task itself. That’s something you would need to do on your own.
If we take the above example of pinging website, what you can instruct this service to do is ping the website every minute and it will ping the website at the time/interval specified by you and keep the result in job history.Activating
Currently this service is in “Preview” mode thus you would need to activate this service first before you can use it. To activate this service, go to account management portal (https://account.windowsazure.com) and after logging in, click on “preview features” tab and then clicking on “try it now” button next to “Windows Azure Scheduler” to activate this service in your subscription.
That’s pretty much it! Now you’re ready to use this service.
How to Use?
At the time of writing this blog, Windows Azure Portal does not expose any user interface to manage this service. However there’s a REST API which exposes this functionality. You can write an application which consumes this REST API to interact with this service. If you’re a .Net programmer, there is a .Net SDK over the REST API available for you. This is available as a Nuget package which you can get from here: http://www.nuget.org/packages/Microsoft.WindowsAzure.Management.Scheduler/0.9.0-preview.
Sandrino Di Mattia (http://fabriccontroller.net) has written an excellent blog post on using this .Net SDK. I would strongly recommended reading his post about this: http://fabriccontroller.net/blog/posts/a-complete-overview-to-get-started-with-the-windows-azure-scheduler/.
We will focus on REST API in this series of blog posts.
Concepts
Now let’s talk about some concepts associated with this service. In a nutshell, there are three things you would need to understand:
Cloud Service
A cloud service is a top level entity in this service. You would need to create a cloud service first before you can create a job. Few things about cloud service:
- Consider a cloud service as an application in which many of your job will reside and execute. A subscription can have many cloud services.
- A cloud service is data center specific i.e. when you create a cloud service, it resides in a particular data center. If you want your jobs to be performed from many data centers, you would need to create separate cloud services in each data center.
Job Collection
A job collection is the next level in entity hierarchy. This is where you group similar jobs together in a cloud service. Few things about job collection:
- A job collection is responsible for maintaining settings, quotas, and thresholds which are shared by all jobs in that collection.
- Since a job collection is a child entity of a cloud service, it is again data center specific. For a job to be performed from many data centers, you would need to create separate job collections in each cloud service specific to that particular data center.
Job
A job is the actual unit of execution. This is what gets executed at the time specified by you. Few things about jobs:
- At the time of writing this blog, this service allows two kinds of jobs – 1) Invoking a web endpoint over http/https and 2) post a message to a queue.
- Do realize that the service is simply invoking a web endpoint or posting a message to a queue and returns back a result. What you want to do with the result is entirely up to you. For example, you have a log pruning task which you want to execute once every day. You could create a job which will put a message in a Windows Azure Storage Queue of your choice every day. What you do with that message would be entirely up to you.
Job History
As the name suggests, a job history contains the execution history of a job. It contains success vs. failure, as well as any response details.
Alternatives
Now let’s talk about some of the other alternatives available to you when it comes to executing scheduled jobs:
Aditi Task Scheduler
Aditi has a task scheduler service which is very similar in the functionality offered by this service (http://www.aditicloud.com/). Aditi’s service also allows you to ping web endpoints as well as post messages in a queue. Now the question is which one you should use
.
A few things that go in favor of using Aditi’s service are:
- Aditi’s service has been running in production whereas Windows Azure Scheduler Service is in preview so if you have production workloads where you would need this kind of service, you may want to consider Aditi’s service. Having said this, if you have been using Windows Azure Mobile Service’s Scheduling functionality, it has been backed by this service only. So if you’re somewhat concerned about it being in preview, Don’t [be].
At the time of writing, Windows Azure Scheduler Service has lesser features than Aditi’s Service. For example, Aditi’s service allows you to POST data to web endpoints. Also it supports basic authentication. These two features are not there in Windows Azure Scheduling Service as of today.Please see Update below.A few things that go in favor of Windows Azure Scheduler Service are:
- It is integral part of Windows Azure offering.
- Aditi’s service is only offered through Windows Azure Store. Since Windows Azure Store is not available in all countries, you may not be able to avail this service (I know, I’m not) from Aditi. Windows Azure Scheduler Service does not have this restriction.
UPDATE:
Based on the feedback I received, Windows Azure Scheduler Service supports all HTTP Methods (GET, PUT, POST, DELETE, HEAD). Furthermore it also supports basic authentication as well.
Roll Out Your Own
Other alternative would be roll out your own scheduler. I wrote a blog post sometime back which talked about this. You can read the post here: http://gauravmantri.com/2013/01/23/building-a-simple-task-scheduler-in-windows-azure/. If you’re going down this route, my recommendation would be not to implement your own timers but use something like Quartz.net.
REST API
Let’s talk briefly about the REST API to manage scheduler service. We will deal with in more detail in subsequent posts. You can learn more details about the REST API here: http://msdn.microsoft.com/en-us/library/windowsazure/dn479785.aspx.
Authentication
To authenticate your REST API calls to the manage scheduler service, you would use the same logic as you do today with authenticating Service Management API requests i.e. authenticate your requests using X509 Certificate. To learn more about authenticating Service Management API requests, click here: http://msdn.microsoft.com/en-us/library/windowsazure/ee460782.aspx.
Things you could do
At the time of writing of this blog post, here are the few things you could do with REST API:
- Create/Delete/Get/List Cloud Services
- Create/Update/Delete/Get/List Job Collections
- Create/Update/Delete/Get/List Jobs
We will take a deeper look at these operation in next post.
Summary
I’m pretty excited about the availability of this service. In fact, I could think (actually we’re thinking about) of a lot of scenarios where this service can be put to practical use. I hope you have found this post useful. Are you planning on using this service? If you please provide comments and let me and other readers know how you are planning on using this service.
This was pretty simple post with no code to show. In the next post, it will be all about code. I promise.

See Simon Munro’s comment regarding the cost of WASS versus Chron.

<Return to section navigation list>
Windows Azure Access Control, Active Directory, Identity and Workflow
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
• Maarten Balliauw (@maartenballiauw) posted Visual Studio Online for Windows Azure Web Sites on 11/13/2013:
Today’s official Visual Studio 2013 launch provides some interesting novelties, especially for Windows Azure Web Sites. There is now the choice of choosing which pipeline to run in (classic or integrated), we can define separate applications in subfolders of our web site, debug a web site right from within Visual Studio. But the most impressive one is this. How about… an in-browser editor for your application?
Let’s take a quick tour of it. After creating a web site we can go to the web site’s configuration we can enable the Visual Studio Online preview.
Once enabled, simply navigate to https://<yoursitename>.scm.azurewebsites.net/dev or click the link from the dashboard, provide your site credentials and be greeted with Visual Studio Online.
On the left-hand menu, we can select the feature to work with. Explore does as it says: it gives you the possibility to explore the files in your site, open them, save them, delete them and so on. We can enable Git integration, search for files and classes and so on. When working in the editor we get features like autocompletion, FInd References, Peek Definition and so on. Apparently these don’t work for all languages yet, currently JavaScript and node.js seem to work, C# and PHP come with syntax highlighting but nothing more than that.
Most actions in the editor come with keyboard shortcuts, for example Ctrl+, opens navigation towards files in our application.
The console comes with things like npm and autocompletion on most commands as well.
I can see myself using this for some scenarios like on-the-road editing from a Git repository (yes, you can clone any repo you want in this tool) or make live modifications to some simple sites I have running. What would you use this for?







• Edu Lorenzo (@edulorenzo) described Creating and Editing a simple website using Visual Studio Online in an 11/13/2013 post:
Ok. So here we are to try and:
- Create a simple website
- Add a folder for an image
- Add an image to the folder
- Display that image on the page
Pretty simple…
I start off with a blank azure website that I just created. Then opened it up with VSOnline.
To “run” this site..
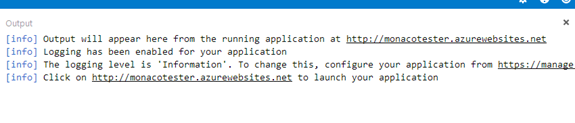
click the Run button.
And VSOnline will give you the result in the Output window
So I click that url and see that the site is up and running.
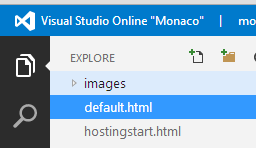
Now I add a new folder to the site
So I now have…
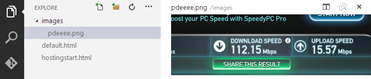
I’ll try to add an image…
Oh wow! Right clicking gives me..
So I try to upload a screenshot from a recent speedtest :p
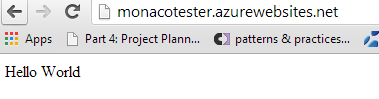
And.. try to add that to the site.

And test…
And while I was editing, I was pleased to see some form of IntelliSense.






• Brent Stineman (@BrentCodeMonkey) posted Monitoring Windows Azure VM Disk Performance on 11/13/2013:
Note: The performance data mentioned here is based on individual results during a limited testing period and should NOT be used as an indication of future performance or availability. For more information on Windows Azure storage performance and availability, please refer to the published SLA.
So I’ve had an interesting experience the last few days that I wanted to take a few minutes to share with the interwebs. Namely, monitoring some Windows Azure hosted virtual machines, not at the VM level, but the storage account that held the virtual machine disks.
The scenario I was facing was a customer that was attempting to benchmark the performance and availability of two Linux based virtual machines that were running an Oracle database. Both machines were extra-large VMs with one running 10 disks (1 os, 1 Oracle, 8 data disks) and the other with 16 disks (14 for data). The customer has been running an automated load against both machines and wanted to get a clear idea of how much they may or may not have been saturating the underlying Windows Azure Storage system as well as what could be contributing to the highly variable Oracle IOPS levels they were seeing.
To support this effort, I dug into something I haven’t looked at in depth for quite some time. Windows Azure Storage Analytics (aka Logging and Metrics). Except this time with a focus on what happens at the storage account with regards to the VM disk activity.
Enable Storage Analytics Proactively
Before we go anywhere, I need to stress that if you want to be able to see what’s going on with Azure Storage and your virtual machine, you’ll need to enable this BEFORE a problem occurs. If you haven’t already enabled logging, the only option you have to try and go “back in time” and look at past behavior is to open up a support ticket. So if you plan to do this type of monitoring, please be certain to enable analytics!
For Windows Azure VM disk metrics, we need to enable analytics on the blob storage account. As the link I just shared will let you know, you will need to call the “Set Blob Service Properties” api to set this (or use your favorite Windows Azure storage utility). I happen to use the Azure Management Studio from Redgate and it allows me to set the properties you see in this screen shot:
With this, I tell Azure Storage that I want it to log all blob operations (Read/Write/Delete) and retain that information for up too two days. I also enable metrics and ask it to retain that data for two days as well.
When I enable logging, Azure Storage will log all operations and persist that information into a series of blob files in a special container in the storage account called $logs. The Logging data will be written to blobs in the same storage account I am monitoring in a special container called $logs. Logs will be spread across multiple blob files as discussed in great detail in the MSDN article “About Storage Analytics Logging“. A word of caution, if the storage account is active, logging will produce a LARGE amount of data. In my case, I was seeing a new 150mb log file approximately every 3 minutes. That’s about 70gb per day. In my case, I’ll be storing about 140gb for my 2 days of retention which is only about $6.70 per month. Given the cost of the VM itself, this was inconsequential. But if I had shifted my retention period to a month… this can start to get pricy. Additionally, the storage transactions needed to write the logs to blog storage count against the account limit of 20,000/tps. To help reduce the risk of throttling coming into play to early, the virtual machines I’m monitoring have each been deployed into their own storage account.
The metrics are much more lightweight. These are written to a table and provide a per hour view of the storage account. These are the same values that get surfaced up in the Windows Azure Management portal storage account dashboard. I could easily retain these for a much longer period since it’s only a handful of rows being inserted per hour.
Storage Metrics – hourly summary
Now that we’ve enabled storage analytics and told it to capture the metrics, we can run our test and sit back and look for data to start coming in. After we’ve run testing for several hours, we can then look at the metrics. Metrics get thrown into a series of tables, but since I only care about the blob account, I’m going to look at $MetricsTransactionsBlob. We’ll have multiple rows per hours and can filter based on the type of operation, or get the roll-up across all operations. For general trends, it’s this latter figure I’m most interested in. So I apply a query against the table to get all user operations, “(RowKey eq ‘user;All’)“. The resulting query gives me 1 row per hour that I can look at to help me get a general idea of the performance of the storage account.
You’ll remember that I opted to put my Linux/Oracle virtual machine into its own storage account. So this hour summary gives me a really good, high level overview of the performance of the virtual machine. Key factors I looked at are: Availability (we want to make sure that’s above the storage account 99.9% SLA), Average End to End Latency, and if we have less than 100% availability, what is the count of the number of errors we saw.
I won’t bore you with specific numbers, but over a 24hr period I lowest availability I saw was 99.993% availability and with the most common errors being Server Timeouts, Client Errors, or Network Errors. Seeing these occasionally, as long as the storage account remains above 99.9% availability, should be considered normal ‘noise’. In the transient nature of the cloud, some errors are simply to be expected. We also kept an eye on average end to end latency which during our testing was fairly consistent in the 19-29ms range.
You can learn more about all the data available in these various storage metrics by reviewing ‘Storage Analytics Metrics Table Schema‘ on MSDN.
When we saw numbers that appears “unusual”, we then took the next logical step and inspected the detailed storage logs.
Blob Storage Logs – the devil is in the details
Alright, so things get a bit messier here. First off, the logs are just delimited format files. And while there the metrics can help tell us which period in time we want to look at, depending on the number of storage operations, we may have several logs we need to slog through (In my case, I was getting about 20 150mb log files per hour). So the first step when digging into the logs is to download them. So either write up some code, grab your favorite utility, or perhaps just log into the management portal and download the files for the timeframe you want to take a closer look at. Once that’s done, it’s time for some Excel (yeah, that spreadsheet thing…. Really).
The log files are semi-colon delimited files. As such, the easiest way I found to do ad-hoc inspection of the files is to open them up in a spreadsheet application like Excel. I open up Excel, then do the whole “File -> Open” thing to select the log file I want to look at. I then tell Excel it’s a delimited file with a semi-colon as the delimiter and in a few seconds it will import the file all nice and spreadsheet for me. But before we start doing anything, let’s talk about the log file format. Since the log file doesn’t contain any headers, we either need to know what columns contain the data we want, or add some headers. For the sake of keeping things easy for you (and saving a copy for myself), I created my own Excel file that already has all the log file fields declared in it. So you can just copy and paste from this spreadsheet into your log file once it’s loaded into Excel. For the remainder of this article, I’m going to assume this is what you’ve done.
With our log file headers, we can now start filtering the data. If we’re looking for errors, the first thing we’ll want to do is open up a log file and filter based on “request status”. To do this, select the “Data” tab and click on “filter”. This allows us to click on the various column headings and filter down what we’re looking at. The shot below shows a log that had a couple of errors in it. So I can easily remove the checkbox on “Success” to drill into those specific errors. This is handy if we want to know exactly what happened as the log also contains a “request-id-header” field. With that value, we can open up a support ticket and ask them to dig into the issue more deeply.
Now this is the first real caution I have. Between the metrics and the logs, we can get a really good idea of what types of errors are happening. But this doesn’t mean that every error should be investigated. With cloud computing solutions, there’s a certain amount of “transient” errors that are simply to be expected. It’s only if you see a prolonged, or persistent issue that you’d really want to dig into the errors in any real depth. One key indicator is to look at the logging metrics and keep an eye on the availability. If it falls below 99.9%, that means there may have been an SLA violation for the storage account. In that case, I’d take a look at the logs for that period and see what types of errors we saw. As long as the issue wasn’t caused by a spike in throttling (meaning we overloaded the system), there may be something worth having support look into. But if we’re at 99.999%, with the occasional network failure, timeout, or ‘client other’, we’re likely just seeing the “noise” one would expect from transient errors as the system adjust and compensates for changes to its underlying fabric.
Now since we’re doing benchmarking tests, there’s one other key thing I look at. The number of operations that are occurring on the blobs that are the various disks mounted into our virtual machine. This is another task where Excel can help out, by adding subtotals. Adding subtotals requires column headings so this is the part when you go “thank you Brent for making it so I just need to copy those in”. You’re welcome. J
The field we want to look at in the logs for our subtotal is the “requested-object-key” field. This value is the specific option in the storage account that was being access (aka the blob file or disk). Going again to the Data tab in Excel, we’ll select “subtotal” and complete the dialog box as shown at the left. This will create subtotals by object (disk) and allow us to see the count of operations against that object. So what we have is the operations performed on that disk during the time period covered by the log file. Using that value, we can then get a fairly good approximation of the “transactions per second” that the disk is generating against storage.
So what did we learn?
If you are doing IO benchmarking of the virtual machine (as I was), you may notice something odd. We observed that our Linux/Oracle Vm was reporting IOPS far above what we saw at the Windows Azure Storage level. This is to be expected because Oracle is trying to help buffer requests itself to increase performance. Add in any disk buffering we may have enabled, and the numbers could skew even further. Ultimately though, what we did establish during out testing was that we knew for certain when we were overloading the Windows Azure storage sub-system and contributing to server slowdowns that way. We were also able to observer several small instances where Oracle performance trailed off somewhat and that these were due to isolated incidents where we saw an increase in various errors or in end to end operation latency.
The host result here is that while virtual machine performance is related to the performance of the underlying storage subsystem, there’s no easy 1-to-1 relation between errors in one and issues in the other. Additionally, as you watch these over time, you understand why virtual machine disk performance can vary over time and shouldn’t be compared to the behaviors we’ve come to expect from a physical disk drive. We have also learned what we need to do to help us more affectively monitor Windows Azure storage so that we can proactively take action to address potential customer facing impacts.
I apologize for all the typos and for not going into more depth on this subject. I just wanted to get this all out into before I fell into the fog of my memory. Hopefully you find it useful.





Stefan Shackow wrote an Introduction to WebSockets on Windows Azure Web Sites on 11/14/2013:
Windows Azure Web Sites has recently added support for the WebSocket protocol. Both .NET developers and node.js developers can now enable and use WebSockets in their applications.
There is a new option on a web site’s Configuration tab to enable WebSockets support for an application.
Once WebSockets has been enabled for a website, ASP.NET (v4.5 and above) and node.js developers can use libraries and APIs from their respective frameworks to work with WebSockets.
ASP.NET SignalR Chat Example
SignalR is an open source .NET library for building real-time web apps that require live HTTP connections for transferring data. There is an excellent site with introductory articles and details on the SignalR library.
Since SignalR natively supports WebSockets as a protocol, SignalR is a great choice for running connected web apps on Windows Azure Web Sites. As an example, you can run this sample chat application on Windows Azure Web Sites.
The screen shot below shows the structure of the SignalR chat sample:
After creating a web application in Windows Azure Web Sites, enabling WebSockets for the application, and uploading the SignalR chat sample, you can run your very own mini-chat room on Windows Azure Web Sites!
The raw HTTP trace (shown below) from Fiddler shows how the WebSockets protocol upgrade request that is sent by the client-side portion of SignalR negotiates a WebSockets connection with the web server:
Request snippet:
GET https://sigr-chat-on-waws.xxxx.net/signalr/connect?transport=webSockets snip HTTP/1.1
Origin: https://sigr-chat-on-waws.xxxx.net
Sec-WebSocket-Key: hv2icF/iR1gvF3h+WKBZIw==
Connection: Upgrade
Upgrade: Websocket
Sec-WebSocket-Version: 13
…
Response snippet:
HTTP/1.1 101 Switching Protocols
Upgrade: Websocket
Server: Microsoft-IIS/8.0
X-Content-Type-Options: nosniff
X-Powered-By: ASP.NET
Sec-WebSocket-Accept: Zb4I6w0esmTDHM2nSpndA+noIvc=
Connection: Upgrade
…To learn more about building real-time web applications with SignalR, there is an extensive tutorial available on the SignalR overview website.
ASP.NET Echo Example
ASP.NET has supported WebSockets since .NET Framework v4.5. Developers will usually want to use higher level libraries like SignalR to abstract away the low-level details of managing WebSockets connections. However for the adventurous developer, this section shows a brief example of using the low-level WebSockets support in ASP.NET.
The ASP.NET Echo example project consists of a server-side .ashx handler that listens and responds on a WebSocket, and a simple HTML page that establishes the WebSocket connection and sends text down to the server.
The .ashx handler listens for WebSockets connection requests:
The .ashx handler listens for WebSockets connection requests:
Once a WebSocket connection is established, the handler echoes text back to the browser:
The corresponding HTML page establishes a WebSocket connection when the page loads. Whenever a browser user sends text down the WebSocket connection, ASP.NET will echo it back.
The screenshot below shows a browser session with text being echo’d and then the WebSockets connection being closed.
Node.js Basic Chat Example
Node.js developers are familiar with using the socket.io library to author web pages with long-running HTTP connections. Socket.io supports WebSockets (among other options) as a network protocol, and can be configured to use WebSockets as a transport when it is available.
A Node.js application should include the socket.io module and then configure the socket in code:
The sample code shown below listens for clients to connect with a nickname (e.g. chat handle), and broadcasts chat messages to all clients that are currently connected.
The following small tweak is needed in web.config for node.js applications using WebSockets:
This web.config entry turns off the IIS WebSockets support module (iiswsock.dll) since it isn’t needed by node.js. Nodej.js on IIS includes its own low-level implementation of WebSockets, which is why the IIS support module needs to be explicitly turned off.
Remember though that the WebSockets feature still needs to be enabled for your website using the Configuration portal tab in the UI shown earlier in this post!
After two clients have connected and traded messages using the sample node.js application, this is what the HTML output looks like:
The raw HTTP trace (shown below) from Fiddler shows the WebSockets protocol upgrade request that is sent by the client-side portion of socket.io to negotiate a WebSockets connection with the web server:
Request snippet:
GET https://abc123.azurewebsites.net/socket.io/1/websocket/11757107011524818642 HTTP/1.1
Origin: https://abc123.azurewebsites.net
Sec-WebSocket-Key: rncnx5pFjLGDxytcDkRgZg==
Connection: Upgrade
Upgrade: Websocket
Sec-WebSocket-Version: 13
…
Response snippet:
HTTP/1.1 101 Switching Protocols
Upgrade: Websocket
Server: Microsoft-IIS/8.0
X-Powered-By: ASP.NET
Sec-WebSocket-Accept: jIxAr5XJsk8rxjUZkadPWL9ztWE=
Connection: Upgrade
…WebSockets Connection Limits
Currently Azure Web Sites has implemented throttles on the number of concurrent WebSockets connections supported per running website instance. The number of supported WebSockets connections per website instance for each scale mode is shown below:
- Free: (5) concurrent connections per website instance
- Shared: (35) concurrent connections per website instance
- Standard: (350) concurrent connections per website instance
If your application attempts to open more WebSocket connections than the allowable limit, Windows Azure Web Sites will return a 503 HTTP error status code.
Note: the terminology “website instance” means the following - if your website is scaled to run on (2) instances, that counts as (2) running website instances.
You Might Need to use SSL for WebSockets!
There is one quirk developers should keep in mind when working with WebSockets. Because the WebSockets protocol relies on certain less used HTTP headers, especially the Upgrade header, it is not uncommon for intermediate network devices such as web proxies to strip these headers out. The end result is usually a frustrated developer wondering why their WebSockets application either doesn't work, or doesn't select WebSockets and instead falls back to less efficient alternatives.
The trick to working around this problem is to establish the WebSockets connection over SSL. The two steps to accomplish this are:
- Use the wss:// protocol identifier for your WebSockets endpoints. For example instead of connecting to ws://mytestapp.azurewebsites.net (WebSockets over HTTP), instead connect to wss://mytestapp.azurewebsites.net (WebSockets over HTTPS).
- (optional) Run the containing page over SSL as well. This isn’t always required, but depending on what client-side frameworks you use, the “SSL-ness” of the WebSockets connection might be derived from the SSL setting in effect for the containing HTML page.
Windows Azure Web Sites supports SSL even on free sites by using a default SSL certificate for *.azurewebsites.net. As a result you don’t need to configure your own SSL certificate to use the workaround. For WebSockets endpoints under azurewebsites.net you can just switch to using SSL and the *.azurewebsites.net wildcard SSL certificate will automatically be used.
You also have the ability to register custom domains for your website, and then configure either SNI or IP-based SSL certificates for your site. More details on configuring custom domains and SSL certificates with Windows Azure Web Sites is available on the Windows Azure documentation website.














<Return to section navigation list>
Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
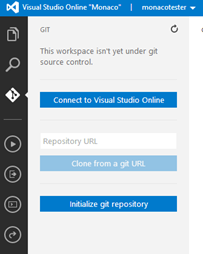
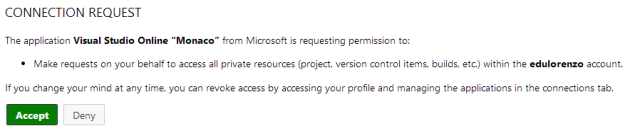
• Edu Lorenzo (@edulorenzo) described connecting Visual Studio Online to Windows Azure in an 11/13/2013 post:
This time.. I’ll connect my VSOnline to an existing TFS (Team Foundation Service) account.
So on Monaco..
Then
Then allow connection
And its done..


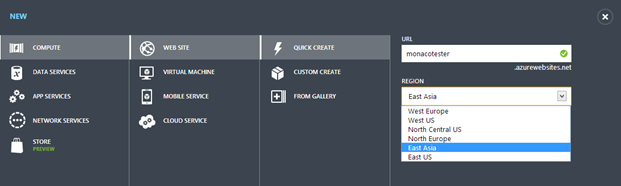
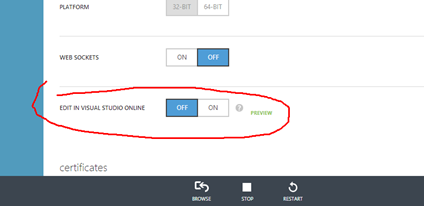
• Edu Lorenzo (@edulorenzo) posted Trying out the Monaco product on 11/13/2013:
So.. I go to my Azure account and create a new WebSite
I click “Configure” on the created site and WHOAH!!!
I hit save for that change then go back to the dashboard. And then again go WHOAH!!!
I click on that.. and Voila! Welcome to Monaco!
I add a new file “default.html” duh…
Of course.. can’t do away with Hello World
And there we go!




S. “Soma” Somasegar (@SSomasegar) posted Visual Studio 2013 Launch: Announcing Visual Studio Online to his blog on 11/13/2013:
Today, I’m very excited to launch Visual Studio 2013 and .NET 4.5.1. I am also thrilled to announce Visual Studio Online, a collection of developer services that runs on Windows Azure and extends the development experience in the cloud. Visual Studio 2013 and Visual Studio Online represent the beginning of a new era for Visual Studio, combining a powerful desktop IDE with rich developer services in the cloud.
As a part of our Cloud OS vision, Visual Studio 2013 and .NET 4.5.1 enable developers to build modern applications. At a time when the devices and services transformation is changing software development across the industry, the developer is at the center of this transformation. Visual Studio 2013, Visual Studio Online, MSDN and Azure offer the most complete experience for modern application development for the cloud.
To summarize some of the key news we shared today:
- Visual Studio 2013 and .NET 4.5.1 are available globally, and provide the best tools for modern application development on all of Microsoft’s latest platforms
Visual Studio Online is a new offering, providing a rich collection of developer services in the cloud that work hand-in-hand with the Visual Studio IDE on the desktop
- Hosted source control, work item tracking, agile planning, build and load testing services that were part of Team Foundation Service are now available in public preview as part of Visual Studio Online
- Visual Studio Online Application Insights is a new service that provides a 360 degree view of your applications health, based on data about availability, performance and usage
- Visual Studio Online “Monaco” is a coding environment for the cloud, in the cloud, offering light-weight, friction free developer experiences in the browser for targeted Azure development scenarios
- Microsoft and Xamarin are collaborating to help .NET developers broaden the reach of their applications to additional devices, including iOS and Android
- Visual Studio 2012 Update 4 is available today
You can get in-depth coverage of all of the Visual Studio 2013 launch details and announcements on Channel 9.
Visual Studio 2013
Visual Studio 2013 is the best tool for developers and teams to build and deliver modern, connected applications on all of Microsoft’s latest platforms. From Windows Azure and Windows Server 2012 R2 to Windows 8.1 and Office 365, Visual Studio 2013 provides development tools that help developers build great applications. Support for live debugging Azure sites from Visual Studio means you can set a breakpoint in a running service in the cloud, and step through it directly from Visual Studio. The new Cloud Business Application project type lets you build next-generation business applications leveraging Office 365 and Azure. And features like Energy Profiling and UI Responsiveness diagnostics make it easier than ever to build 5-star applications for the Windows Store.
For individual developers, Visual Studio 2013 brings great new developer productivity features. Features like Peek Definition and CodeLens provide key information about your code right where you are working in the Visual Studio editor.
And for teams, Visual Studio 2013 and Team Foundation Server 2013 offer new capabilities from Agile Portfolio Management to support for Git source control to the new Team Room feature. In partnership with Windows Server and Systems Center, we’ve enabled some great DevOps scenarios for on premise development. And we’ve integrated new Release Management features to automate deployment and do continuous delivery on the cloud.
For more on what’s new in Visual Studio 2013, .NET 4.5.1 and Team Foundation Server 2013 see What’s New.
Visual Studio Online
Today marks the beginning of a new era for Visual Studio with the availability of Visual Studio Online.
Visual Studio has evolved over the years. Starting with an integrated developer environment for the desktop, Visual Studio expanded to also include team development capabilities on the server with Team Foundation Server. We are now taking the next step, extending the Visual Studio IDE with a collection of developer services, hosted in Azure, which offers the best integrated end-to-end development experience for modern applications.
Today, we are announcing the availability of a broad range of developer services as part of Visual Studio Online. Several services that have been available in Team Foundation Service are now in public preview as part of Visual Studio Online: hosted source control, work item tracking, collaboration and a build service. The elastic load testing service we released in limited preview earlier this year is also now available in public preview as part of Visual Studio Online. In addition, we are announcing two new Visual Studio Online services: Visual Studio Online Application Insights and Visual Studio Online “Monaco”.
Visual Studio Online is free for teams up to 5 users. The combination of Visual Studio Express and the free plan for Visual Studio Online make it simple for developers to get started in a friction-free way. Visual Studio Online is also included as part of MSDN subscriptions. New Visual Studio Online subscription plans, including access to the Visual Studio Professional IDE, are also available starting today. You can check out the plans, and get started with VS Online at http://visualstudio.com/.
Visual Studio Online is made up of many services, including the following:
Hosted Source Control
Visual Studio Online provides developers with hosted source control, using either Git or Team Foundation Version Control (TFVC). The sources for your Visual Studio Online projects are readily available to sync to your desktop when you are logged into Visual Studio.
Work Items and Agile Planning
Whether you are managing a project’s work item backlog or planning for the next sprint, Visual Studio Online provides tools to support you agile development process.
Hosted Build Service
Visual Studio Online includes a hosted build service, making it easy to move your project’s builds to the cloud. Build results are available in both Visual Studio Online and Visual Studio 2013, providing an smooth integrated development experience.
Every Visual Studio Online account provides 60 minutes of free build time per month, making it friction free to get started with hosted build.
Elastic Load Test Service
Performance and load testing are important pieces of the application lifecycle, enabling validation and analysis of the behavior of the application under load. Load testing entails highly dynamic resource needs, quickly scaling up to simulate large numbers of concurrent users. With the Visual Studio Online load testing service, this scalability can be offloaded to the cloud. Visual Studio users get a fully integrated experience in the IDE for managing and running load tests.
The elastic load test service is available in public preview starting today. Visual Studio Ultimate subscribers get 15,000 virtual user minutes per month as part of their subscriptions.
Application Insights
The new Application Insights service enables teams to support agile application delivery across an organization by providing visibility into how an application runs and is being used by customers. Application Insights collects live telemetry data across development, test and production environments and captures availability, performance and usage data, providing development teams with a 360-degree view of an application’s health. More than just a monitoring and analytics tool, Application Insights connects this valuable and actionable application data to the rest of your development lifecycle.
The Application Insights service is available today in limited preview, with initial support for .NET and Java applications running on Windows Server and Windows Azure, as well as Web and Windows Phone 8 applications.
“Monaco”
As we look to extend the desktop IDE with services in the cloud, we naturally asked ourselves about whether it makes sense to offer a development experience directly in the browser. The desktop IDE provides a rich, broad and integrated developer experience for a range of platforms. But we believe there are some scenarios where we can offer light-weight, friction free developer experiences in the browser for targeted platform experience in the cloud.
Visual Studio Online “Monaco” is a coding environment for the cloud, in the cloud. It complements the desktop IDE as a low friction experience that will help you get started, or make quick changes, to an existing cloud service. And it is integrated with Visual Studio Online.
Today, we are releasing a preview of one of the experiences that “Monaco” will provide for Azure Websites. Developers will now be able to edit their sites directly from the web, from any modern browser, on any device.
“Monaco” is already being used as the technology behind other cloud-based developer experience, from Office 365 “Napa” development to SkyDrive file editing.
For more details, see the Visual Studio Online “Monaco” video series on Channel 9.
Partner News
With today’s launch of Visual Studio 2013, we have 123 products from 74 partners available already as Visual Studio 2013 extensions. As part of an ecosystem of developer tools experiences, Visual Studio continues to be a platform for delivering a great breadth of developer experiences.
Xamarin
The devices and services transformation is driving developers to think about how they will build applications that reach the greatest breadth of devices and end-user experiences. We’ve offered great HTML-based cross platform development experiences in Visual Studio with ASP.NET and JavaScript. But our .NET developers have also asked us how they can broaden the reach of their applications and skills.
Today, I am excited to announce a broad collaboration between Microsoft and Xamarin. Xamarin’s solution enables developers to leverage Visual Studio, Windows Azure and .NET to further extend the reach of their business applications across multiple devices, including iOS and Android.
The collaboration between Xamarin and Microsoft brings several benefits for developers today. First, as an initial step in a technical partnership, Xamarin’s next release that is being announced today will support Portable Class Libraries, enabling developers to share libraries and components across a breadth of Microsoft and non-Microsoft platforms. Second, Professional, Premium and Ultimate MSDN subscribers will have access to exclusive benefits for getting started with Xamarin, including new training resources, extended evaluation access to Xamarin’s Visual Studio integration and special pricing on Xamarin products.
Visual Studio 2012 Update 4
As I mentioned last month, since we released Visual Studio 2012 just over a year ago, we’ve seen the fastest adoption ever for a release of Visual Studio, with over 6M downloads.
When we released Visual Studio 2012, we committed to delivering regular updates to provide continuous value to Visual Studio customers. In the last year, we have released 3 updates to Visual Studio. Even better, over 60% of Visual Studio 2012 users are running the updates.
Today, we are making available Visual Studio 2012 Update 4. Update 4 includes bug fixes and product improvements, as well as changes that ensure great compatibility between Visual Studio 2012 and Visual Studio Online.
Conclusion
Today begins a new era for Visual Studio, extending the desktop IDE with a collection of rich developer services in the cloud. The combination of Visual Studio 2013, Visual Studio Online, MSDN and Windows Azure provides the most complete experience for modern application development for the cloud in the era of devices and services. Welcome to Visual Studio 2013 and Visual Studio Online!
Namaste!








Tim Anderson (@timanderson) asserted Visual Studio goes online, kind-of in an 11/13/2013 post:
Microsoft held its official launch for Visual Studio 2013 today, at an event in New York, although the product itself has been available since mid-October. VP Soma Somasegar nevertheless made some new announcements, in particular the availability in preview of an online Visual Studio editor, codenamed Monaco. “Developers will now be able to edit their sites directly from the web, from any modern browser, on any device,” said Somasegar on his blog.
Monaco is not intended as a replacement for the desktop IDE. Instead, it parallels what Microsoft has done with Office, which is to provide a cut-down online editor for occasional use. Monaco currently targets only web applications running on Azure, Microsoft’s public cloud platform. The technology is not altogether new, since it is built on the same base as “Napa”, the online editor for Office 365 applications.
At the launch, Monaco was demonstrated by Erich Gamma, of Design Patterns and Eclipse fame, who says he uses it for real work. He assured us that it is built on web standards and compatible with iOS and Android tablets as well as desktop browsers.
Online editing with Monaco is only one part of what Microsoft now calls Visual Studio Online. The product also includes a hosted version of Team Foundation Server, offering source code control, collaboration tools, and an online build service. These features were already available as part of Team Foundation Service, which is now replaced by Visual Studio Online. If you are happy with the cut-down Visual Studio Express, or already have Visual Studio, then subscription is free for teams of up to five users, with additional users costing $10 per user/month for an introductory period, and rising to $20 per user/month.
Microsoft is also offering Visual Studio Online Professional, which bundling desktop Visual Studio Professional with these online services, for teams of up to 10 users, at $22.50 per user/month rising to $45.00 per user/month. This follows the same model which Adobe adopted for its Creative Cloud, where you get cloud services bundle with tools that run on the desktop.
Pay even more and you can get Visual Studio Online Advanced, which oddly does not include the Professional IDE, but supports unlimited users and has additional reporting and collaboration features, for $30 rising to $60 per user/month.
When does the introductory offer expire? It’s until further notice – 30 days’ notice will be provided before it ends. Confusing.
Somasegar also announced the preview of a new online service called Application Insights. This service analyses and monitors data from .NET or Java applications running on Windows Server or Windows Azure, and .NET applications on Windows Phone 8, reporting on availability, performance and usage.
Another new service is Elastic Load Test (not to be confused with Amazon’s Elastic Compute Cloud), which simulates multiple concurrent users for testing the performance and behaviour of an application under stress. This requires the expensive Visual Studio Ultimate with MSDN subscription, and offers 15,000 virtual user minutes per month, with additional virtual user minutes at $.001 each.
Finally, he announced a partnership with Xamarin to enable development for iOS and Android in C# and Visual Studio, extending the existing Portable Class Libraries so that non-visual code can be shared across different Windows platforms as well as the new mobile target platforms.
I spoke to Xamarin’s Nat Friedman about this and wrote it up on the Register here. [See post below.]
Microsoft’s strategy here is to persuade existing Windows developers, familiar with C#, Visual Studio, and both desktop and ASP.NET applications, to stick with Microsoft’s platform as they migrate towards cloud and mobile. In this context, the heart of Microsoft’s platform is Windows Azure and Office 365, which is why the company can tolerate iOS or Android clients.
The company will also hope that a proliferation of apps which integrate and extend SharePoint online will help drive subscriptions to Office 365.
The latest Visual Studio includes a new Cloud Business App project type, which is an app that sits on Windows Azure and integrates with SharePoint in Office 365. Coding in Visual Studio and deploying to Azure, both for Cloud Business apps and ordinary web applications, is now an easy process, reducing friction for developers deploying to Azure.
More information on Visual Studio Online is here.


Tim Anderson (@timanderson) claimed “All the world's a mobe following open-source hug” in a deck for his Microsoft, Xamarin give Visual Studio a leg-up for... iOS and Android? article of 11/13/2013 for The Register (UK):
Microsoft is giving a leg up to Windows developers building apps for iOS and Android using C# and Visual Studio, with dev specialist Xamarin.
Xamarin has announced support for Portable Class Library (PCL), a subset of the .NET Framework that works across multiple platforms.
The development was made possible after Microsoft last month released PCL to open source.
Members of MSDN are also getting a financial incentive to experiment with the tools and to bring C# onto the non-Microsoft platforms.
They are being offered a 90-day free trial of Xamarin, rather than the normal 30-day period. There are discounted Xamarin subscriptions, such as Xamarin Business for iOS and Android at $1,399 (down from $1,798), and an online Go Mobile training course will be free for MSDN subscribers who sign up before the end of the year.
Nat Friedman, Xamarin chief executive, said the deal really does put Microsoft’s code on non-Microsoft platforms.
“Microsoft long ago had this idea of PCL as a developer tool to share code between different platforms, but their idea of different platforms in the past was Windows Store, Windows Phone, Silverlight and ASP.NET or something like that," he said. "Now they’ve released the PCL reference assemblies as open source, and we are integrating them into Xamarin so you can share code between Windows, Android and iOS."
How deep is the partnership? Developers may be sceptical, based on history. In 2007 Microsoft announced a partnership with Novell to build Moonlight, an open-source version of the Silverlight browser plug-in, but it was a curiously half-hearted partnership. Friedman says this time it is different.
Friedman is closely associated with that history.
Xamarin was formed when Linux shop Novell abandoned Mono, an open-source project to bring Microsoft’s .NET Framework to Linux. It was founded by Miguel de Icaza, the originator of Mono, and Friedman, who’d worked on Mono from its early days.
“I think it’s enormous. It represents a strategic decision that Microsoft made, that people want to build native apps, they want to reach multiple platforms, and Microsoft is trying to give the developer community what they want,” Friedman said.
If Microsoft is serious about becoming a devices and services company, this is a partnership that makes sense, considering that only a small minority of devices run Windows.
Xamarin’s approach to cross-platform development is distinctive in that it does not include the user interface.
…


Read the rest of the article here.
Keith Ward (@VSM_Keith) asserted “At its official Visual Studio 2013 launch today, Redmond moved its flagship integrated development environment further into Windows Azure” in a deck for his Microsoft Announces Visual Studio Online article of 11/13/2013 for Visual Studio Magazine:
On the same day Microsoft officially launched Visual Studio 2013 and the .NET Framework 4.5.1., it also introduced a brand-new service for cloud based development called Visual Studio Online.
Visual Studio 2013 and .NET 4.5.1. were initially released on Oct. 18. Visual Studio Online wasn't part of that release, but is set to become a key piece of Microsoft's efforts to speed up development time by integrating with Windows Azure.
"We're going through a transformation of devices and services, as more and more developers are flocking to the cloud," S. Somasegar, Microsoft's Corporate VP of the Developer Division, said during the launch.
Somasegar used the term "Cloud OS" to describe what he called the platform that allows developers to build applications solely in the cloud, build them locally and move them into the cloud, or some hybrid of cloud and local development.
With Visual Studio Online, Somasegar said, Microsoft is delivering an end-to-end set of services that will enable developers to build apps in the cloud or on devices. He said to think about Visual Studio Online "...as a set of finished developer services that run on Windows Azure, and extends the capabilities of Visual Studio."
Two of the most important new capabilities are "Application Insights" and "Monaco." Application Insights provides information on application performance and usage, by collecting live telemetry data across environments. It gives development teams a "360-degree view of an application's health," Somasegar wrote in a blog entry today.
"Monaco" is the code name for Visual Studio Online's browser-based development tool. "We believe there are some scenarios where we can offer light-weight, friction free developer experiences in the browser for targeted platform experience in the cloud," Somasegar blogged. Monaco allows developers to edit sites on any modern browser and on any device.
Distinguished Engineer Erich Gamma gave a demonstration using Monaco. He coded directly in a browser, and was able to get in-context information, IntelliSense, and do CSS coding and side-by-side editing. He also showed off the ability to rearrange windows, and added that Visual Studio Online uses a "save-less" model, eliminating the need to save work. He called Monaco and "end-to-end story" for lightweight development: he created code, edited and validated the code, and published it to Azure, all from a browser.
Both Monaco and Application Insights are at the preview stage. Somasegar didn't say when they would be finished. Application Insights currently supports .NET and Java applications running on Windows Server, Windows Azure, and Web and Windows Phone 8 apps.
Another advantage of Visual Studio Online is the ability to have roaming settings. "Developers spend a lot of time customizing their environment," Somasegar said at the launch, but when they move to a new machine, those settings don't travel with them. He showed a demo of how that's different with Visual Studio Online. The program was open on two different machines, and he switched the color theme on one machine. Instantly, the color scheme change appeared on the other machine.
Visual Studio 2013 wasn't the only version of Visual Studio to get attention today. Somasegar mentioned that Visual Studio 2012 has had more than 6 million downloads, making it the fastest-adopted version of Visual Studio ever. In addition, Microsoft today released Update 4 for Visual Studio 2012.
Update 4 was first announced last July. The Release Candidate, which came out in September, was mostly bug fixes. But it's been further updated to include better compatibility between Visual Studio 2012 and Visual Studio Online.
At the launch, Microsoft also announced a wider partnership with Xamarin, which makes cross-platform tools that allow .NET developers to use C# and Visual Studio to create apps for both iOS and Android. Xamarin's next release will support Portable Class Libraries, for better sharing of code and components across platforms. In addition, MSDN subscribers will get access to free training in the use of Xamarin as well as discounts on Xamarin products.
Visual Studio Online has a free version for up to five users. There are three versions of the product:
- Basic. Basic has an introductory price of $10 per user, per month, and $20 for the regular price.
- Professional. The introductory price for this is $22.50 per user, per month, and $45 regular price.
- Advanced. The Advanced intro price is $30 per user, per month, and double that for the regular price.
Visual Studio Online requires an account, but no credit card is necessary.

Full disclosure: I’m a contributing editor for Visual Studio Magazine.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
No significant articles so far this week.
<Return to section navigation list>
Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
‡ Brad Anderson (@InTheCloudMSFT) took on Amazon Web Services with his Success with Hybrid Cloud: Why Hybrid? post of 11/14/2013, the second of his Hybrid Cloud series:
Earlier this week [see Brad’s post below] I examined what we at Microsoft mean when we use the term “Hybrid Cloud.” If ever there were a time to get really specific about our vocabulary, this was it!
Now that our definition is clear, I want to go one step further and discuss how this strategy is different from what other cloud providers are offering and why other cloud providers can’t or won’t offer it. I’ll also outline a couple of the direct benefits of Hybrid Cloud deployment (which is a point I’ll return to often throughout this series).
A few months ago I noted that the reason Microsoft focuses so much on consistency across clouds is pretty straightforward: If you have consistency across clouds you can have VM and service mobility, and with a consistent cloud experience you can make decisions about where you want to host your services based on business needs rather than technology limitations.
This perspective is shared increasingly often within the industry, and this forward-thinking approach has significantly impacted the market share of other cloud providers, such as VMware.
Microsoft has focused on creating a hybrid model that is dramatically different and more functional than any other cloud approach in the industry. This hybrid functionality comes in-box, at enterprise scale, within the Windows software you already know and love – and this simplified and streamlined setup is very good news for enterprises that need to simplify and streamline their IT infrastructure.
Don’t get me wrong, I am not downplaying the technical elements at work here. Making a Hybrid Cloud interoperable, enabling friction free data movement, and delivering a seamless end-user experience is an extraordinarily technical process under the hood – but the Hybrid Cloud model shifts much of the burden of these complexities to Microsoft.
Our cloud-first approach to building the products that enable a Hybrid Cloud means that we have already addressed the enormous technical complexities required to make heterogeneous platforms work together, build upon one another, and deliver a unified end-user experience.
The way we apply this cloud-first principle into our public cloud (Azure) and private cloud (Windows Server and System Center) products is a serious point of differentiation between Microsoft and our competitors. The products currently marketed by AWS and VMware are two noteworthy examples.
Amazon’s approach asks organizations to use a cloud that is entirely public (unless you happen to be the CIA) and they insist that private clouds are “ill-advised” and “archaic.” This extreme point of view puts a business in the position of needing to empty its on-prem datacenter into a vast external space. Then, if it wants hybrid functionality, Amazon’s support for VM mobility between the public cloud and on-prem relies on a patchwork of partner solutions that falls well short of the enterprise-grade user experience that’s readily available with System Center and the Windows Azure Pack. If you want to maintain some ownership and control over your data while using the cloud for scale on-demand, AWS is simply not an option.
This point is something that hasn’t been overlooked by the industry. In an earlier post I noted how the strengths of our Hybrid Cloud approach were exposing the gaps in our competitors’ offerings. In particular, I noted that TechCrunch among others have seen that Microsoft’s new services are challenging Amazon. The Hybrid Cloud model is a move away from one-size-fits-all cloud offerings, and it instead provides enterprises with options. These options are a fundamentally different thing from AWS’s current approach; Microsoft’s Hybrid Cloud flexibility is a superior solution for today’s IT challenges.
VMware takes a different approach. As the name suggests, the VMware vCloud Hybrid Service (vCHS) offers a more explicit focus on helping customers with Hybrid solutions. Once you get past a good brand name, however, things get murky.
To begin, VMware simply does not have the experience of running massive, global public cloud services like Microsoft does. I’ve spoken repeatedly on this blog about what we have learned from running the 200+ cloud services we operate in datacenters all over the globe for organizations in every conceivable industry, and the importance of this cannot be overstated. If you are an organization with workloads or data that need to be secure, always available, and high performance – then Microsoft’s Hybrid Cloud approach is second to none. VMware’s weakness in this area is underscored by both a lack of experience and the lack of a truly global datacenter footprint.
If you’re an organization that needs to scale on-demand, rapidly respond to your customers, and maintain total control over your data at all times, the Microsoft Hybrid Cloud model is a pragmatic choice.
The question of “Why build a Microsoft Hybrid Cloud?” is a matter of asking what your organization needs today and five years from today. A Hybrid Cloud enables an organization to optimize IT resources by keeping critical data on-prem, while providing limitless scale, compute, storage, and networking for the countless day-to-day needs of your operation and your workforce. The Hybrid Cloud model creates a self-service, made-to-order cloud service that can be quickly and easily tailored to the needs of your organization.
Here’s another way to look at it: Other cloud providers will never suggest that every enterprise has the same cloud computing needs, but they persist in offering a single, one-size-fits-all cloud solution. Only Microsoft offers the variety of cloud resources capable of supporting the multi-faceted, rapidly changing needs of today’s businesses.
“Why Microsoft’s Hybrid Cloud?” is also a simple matter of money. The Microsoft Hybrid Cloud model gives you the ability to fine tune your cloud for exactly what your organization needs. This means that instead of a one-size-fits-all cloud platform, you can actively upgrade the features you need and eliminate the ones you don’t. This kind of customization means your efficiency can spike while your costs drop. These adjustments and costs savings can be the determining factor when you start to look at your capex and opex budgets.
The Hybrid Cloud also impacts the nature of the information in your datacenter. If you have data that is sensitive, if your industry requires data to stay within your building or your geographic area, if the risk of data loss/failure is pervasive, or if there are civil compliance issues regulating that information – you need total control over where the data goes, how it is accessed, and how it is used. This kind of accessibility, control, and security are hallmarks of the Microsoft Hybrid Cloud model.
These elements and these outcomes will get covered in greater depth in the next post – a detailed look at the specific technology and tools (automation, self-service, templates, etc.) at work within a Hybrid Cloud.


‡ Brad Anderson (@InTheCloudMSFT) began a Hybrid Cloud series with Success with Hybrid Cloud: Defining “Hybrid” on 11/12/2013:
In any region, at any size, in any industry, an enterprise’s IT infrastructure has an enormous impact on the success of that organization. There are as many infrastructure setups and strategies as there are enterprises, with each IT team tailoring it to the unique and changing needs of that business. At Microsoft we are realistic about how quickly and dramatically the needs of a datacenter can change, and that is why we enable a Hybrid Cloud IT model.
This post is the first in a multi-part series that this blog will feature as a detailed overview of Microsoft’s Hybrid Cloud approach to enterprise IT. This series will examine the building/deployment/operation of Hybrid Clouds, how they are used in various industries, how they manage and deliver different workloads, and the technical details of their operation.
The reason I think a Hybrid Cloud is the best strategy for any organization is simple: It can accommodate the way your organization grows, organizes, and operates – in any setting, under any circumstances.
To start, I want to get specific about what Microsoft means when we use the term “Hybrid Cloud” by sharing a few concrete examples:
First, one of the most common hybrid scenarios we are seeing is the use of Windows Azure for a tier of an application. Increasingly often, organizations are moving the web tier of an application to Azure and leaving the middle and data tiers in their datacenter. This setup allows the web tier to seamlessly scale on-demand while the data is kept within the customer’s firewalls. This powerful and scalable combination of public and private cloud resources is the Hybrid Cloud model.
Another example can be seen in how organizations are approaching their disaster recovery needs. Many service providers are now offering business continuity solutions leveraging Hyper-V Replica to back up data from their customer’s datacenter to the service provider – or as a geo-replication between a service provider’s datacenter. Customers are also using Azure as a backup location (this is a topic I’ve discussed previously – here and here).
Getting the maximum value for this type of scenario is easy, thanks to the fact that Windows Server 2012 and 2012 R2 include a license to use Windows Azure Backup (which provides 5GB free backup for each server). In a DR scenario, the Hybrid Cloud gives a customer a complete backup in the cloud that is always available – and this comes at a prince point that is far more reasonable than the traditional tape-based solution.
The Microsoft Hybrid Cloud DR/storage solution got even better last November when we acquired StorSimple. With StorSimple, you can now backup all or selected portions of your data to the cloud. This is something we refer to as cloud-integrated storage – and if you haven’t tried it already, I really recommend it. Cloud-integrated storage allows you to set policies that can take some really specific actions, like leaving the hot blocks of data local and moving the cold blocks to Azure. Then, if a request comes in for the data from the cold blocks it is rapidly served up from Azure. This effectively gives you a bottomless datacenter because you have simple access to an effectively unlimited amount of cloud storage.
These are just a couple of examples of the Hybrid Cloud model, and, over the next several weeks, I will cover many more in greater depth. I’m also going to cover the technical elements that need to be set up and configured to enable these scenarios. For example, how and why you have to seamlessly stretch your network across clouds, as well as how we’ve made BYOIP (Bring Your Own IP Address) simple in Windows Server 2012 R2 so that you can cloud deploy servers that come configured with hard-coded IP addresses.
In this introductory post, let me answer one important question: What factors are driving organizations toward adopting Hybrid Cloud solutions?
First, this approach helps organizations avoid placing all of their eggs in one basket. Having all of your data in a single place makes you vulnerable to the occasional outage, and it also puts you at the mercy of your access to a particular physical or virtual location.
A critical example of this was Hurricane Sandy back in the Fall of 2012. While this storm was wreaking havoc on the east coast, we received feedback from multiple customers who noted that even though their datacenters were literally under water, their businesses kept running without a hitch because they had used Hyper-V Replica. All of their VMs were replicated to an external cloud. This is a great example of a Hybrid Cloud, and this is one of the many reasons that most of the organizations I meet with say they will be (or will continue to) use multiple clouds in the future.
Second, many organizations operate in a highly-regulated industry where the regulatory constraints may dictate where and how they store data. A purely public cloud approach is not likely an option here whereas a Hybrid Cloud may offer the best solution for keeping certain data local while still relying on the flexibility and scale of the public cloud to manage demand.
Third, public clouds offer incredible agility, and agility is the entire reason to use the cloud in the first place. Cloud computing also offers a bargain pricing for infrastructure that is globally accessible, always available, and (in Microsoft’s case) has an iron-clad, monetary-based SLA supporting the availability of your applications. I say “in Microsoft’s case” because Amazon and others will not offer an SLA backed by monetary penalties if their up-time SLA is missed.
Fourth, a lot of companies are asking how much of the technical burden of the cloud should be put on their shoulders – especially for businesses who don’t have (or want!) to include the assembly and maintenance of datacenter infrastructure as a core competency. The Hybrid Cloud model removes these technical roadblocks: We have invested over $15 billion in the last three years building out a global network of datacenters that give any organization the worldwide reach and access to any level of technical resources – whether they need to dive deep into their technical resources, or deploy a plug-and-play PaaS solution. These are core competencies for Microsoft.
The growth and pattern of innovation makes Microsoft’s Hybrid Cloud a very unique thing in the technology industry. We are the only organization in the world that is operating a global, at-scale public cloud and then applying everything we learn into the products we ship. These products are in turn used by enterprises and service providers who then build their own clouds. Putting this technology in the hands of our customers is a very different thing than charging a monthly subscription for a static service. This flexibility and choice is the real power of the Cloud OS.
A core part of this approach is ensuring the Microsoft clouds deliver consistency and seamless mobility so that you are never locked into any single cloud.
Another unique element of Microsoft’s approach is that we are the only public cloud provider operating 200+ at-scale SaaS offerings on that public cloud infrastructure. The reason this is important is simple: Applications drive infrastructure improvements. Windows Server, for example, is a better operating system because of what we learn every day from Azure and these 200+ services running on Windows Server. This means that the applications you get from us to use in your datacenters are also better because the same teams that build and operate these cloud services also deliver applications like Exchange, SharePoint, SQL and System Center (to name a few).
This is all part of our “cloud-first” design principle. We architect and build every single one of our products with cloud scale, security, availability, and operability in mind. We are passionate about innovating and creating new value and new solutions, and we test these features exhaustively within our own cloud services. When these features have been battle-hardened and proven effective, we then deliver them to you in our on-premises products. For an enterprise or a service provider looking for a platform that is stable, reliable, and world-class – this is a big deal.
This approach is not only cloud first, but it is also customer first.
Looking ahead to the coming weeks of this series, you can see an overview of every future “Success with Hybrid Cloud” blog post here.


‡ The Servers and Cloud Platform Team made the Windows Azure Pack: Service Management API Samples - Nov 2013 available for download on 11/15/2013:
Samples to Customize Tenant Portal, Create Resource Provider and Billing Adapters using the Service Management REST API
Details
- Version: 1.0
- Date Published: 11/15/2013
- File name: WindowsAzurePackSamples.zip
- File size: 1.8 MB
All software and documentation in this download is the copyrighted work of Microsoft or its suppliers. Your use of the software and documentation is governed by the terms of the attached license agreement. By using the software and documentation, you accept these license terms. If you do not accept them, do not use the software or documentation.
This download consists of extensibility samples for Windows Azure Pack (WAP). These samples will help you get started on customizing the product to suit your business needs. With this release of Windows Azure Pack, you will be able to use Windows Server 2012 R2, System Center 2012 R2 and Windows Azure Pack in your datacenters to offer the same great experiences that are available on Windows Azure. You can find more information and download the product here.
This download contains samples for the following:
- Theming Kit for the Tenant Site
- .NET Sample Client to demonstrate how to use .NET to call the Service Management REST API's
- Hello World Resource Provider to demonstrate how to create Resource Providers for WAP
- SampleAuthApplication to demonstrate how to authenticate users to make WAP Service Management REST API requests
- Billing Adapter Samples: not yet available. COMING SOON
We would love to hear your feedback about this release, your deployment experience, and your experience with the extensibility documentation and samples.
PR Newswire published an Ipeer Selected by Microsoft and Parallels to Test New Windows Azure Pack Services press release on 11/14/2013:
KARLSTAD, Sweden, November 14, 2013 /PRNewswire via COMTEX/ -- Leading Swedish Cloud provider Ipeer has been selected as one of five service providers in the world to beta test Microsoft Corp.'s recently released Windows Azure Pack technology and deliver it through the Parallels Automation cloud platform. With this solution, Ipeer will be able to offer hosted public and hybrid clouds with enterprise functionality and flexibility consistent with that provided by Windows Azure. Customers will also be able to extend their data centers into this cloud and to easily migrate virtual machines between clouds.
The new Windows Azure Pack is built on Microsoft's latest datacenter software, Windows Server 2012 R2 and System Center 2012 R2, allowing Ipeer to deliver Windows Azure-consistent services from the Ipeer datacenter. The Ipeer solution, which aims to launch by mid-January 2014 as the first Windows Azure-consistent Infrastructure as a Service (IaaS) solution in Scandinavia, will be delivered to customers through a new Application Packaging Standard (APS) package for Parallels Automation.
"Building on the groundbreaking foundation of Windows Server and System Center, Windows Azure Pack provides multi-tenant, self-service cloud functionality that works on top of existing software and hardware investments," said Eugene Saburi, General Manager, Product Marketing, Microsoft. "We are pleased that Ipeer is taking advantage of Windows Azure Pack to deliver a flexible and familiar self-service provisioning and infrastructure management experience to its customers."
"The future of cloud hosting is not one-size fits-all but rather one where corporate clients will want to choose between optimized software and hardware, vendor sizes, location, SLA and pricing, and move between providers. Experience, trust and local presence will remain important when placing critical infrastructure and we welcome Microsoft's and Parallels' clear visions here," said Ipeer CEO Johan Hedlund.
"Customers are looking for local, in-country service providers to deliver the full portfolio of cloud services," said John Zanni, chief marketing officer, Service Provider, Parallels. "Parallels helps service providers, like Ipeer, speed their time to revenue and differentiate as the first in country service provide to offer the latest Windows Azure Pack from Microsoft, enabled for distribution utilizing the APS standard supported by Parallels Automation (APS standard.org)."
Because many of its services take advantage of code originally created for the Windows Azure public cloud, the Windows Azure Pack was designed to inherently meet the scale and performance requirements of modern IT organizations. By bringing together Windows Azure and Parallels technologies, Ipeer continues to innovate and deliver premium solutions for their customers' hosted datacenter needs.
Ipeer is a leading provider of corporate cloud- and hosting services in Sweden, providing a broad portfolio of services to enable optimal solutions. Clients range from smaller start-ups to large e-commerce sites, banks and international corporations. Ipeer has 65 employees, many of which have 15 years' experience from corporate hosting solutions, and a turnover of 50 MSEK (2012). Established in 2006, Ipeer has data centers in Sweden and offices in Karlstad, Stockholm and Bangalore, India. http://www.ipeer.se
Remember when Dell, Fujitsu, and HP were beta testers for the Windows Azure Platform Appliance? If not, the story is here: Just Announced at WPC: the Windows Azure Platform Appliance (7/12/2010). Only Fujitsu implemented it.
Perhaps the other four service providers delivering the Azure Pack will announce themselves shortly.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Amr Altahlawi of the Visual Studio LightSwitch Team (@VSLightSwitch) explained Automatic Row Tracking with [LightSwitch in] Visual Studio 2013 on 11/12/2013:
As databases are used by many applications and many users within those applications, it’s a common practice to log when data was created or last modified. In addition to knowing when the data was changed, knowing who changed the data is a common requirement in business applications. LightSwitch in Visual Studio 2013 introduced a new feature to track the creation and modification of data automatically for you by adding a new set of properties to all entities defined within the intrinsic database (i.e., data tables created as part of the app, not attached data). Those properties are: Created, CreatedBy, Modified and ModifiedBy.


As you can see from the table above, these new fields make use of the new data types that have been introduced in Visual Studio 2013, DateTimeOffset and the Person type. While these fields are not intended to implement full database auditing, they are a huge productivity boost when you need to display, query, or correlate user activity in your application. Let’s go through an example to see how this works.
Assume you are building an order tracking system. You have 3 entities (Products, Orders, OrderDetails) and you have the requirement to track who created and modified the order and its details. Before the release of Visual Studio 2013, you had to manually add properties to each table and write special code to track who created/modified the data. Now this is built in! You have the option to turn this feature on or off for any internal entities you have modeled in the Data Designer.
When you model your entities using the Data Designer, you will now see that there is a new option in the property window under the General category called “Enable Created/Modified properties” which is checked by default.
When this option is selected, it indicates that the application will track the creation/modification of data for this entity by adding the above properties. Those properties are hidden in the Data Designer but can be seen in the Screen designer so you can optionally display these fields on screens.
With these new fields, it is very easy to filter records that were created by a user. For example, say we want to only display data on a screen that was created by the logged in user. Simply create a query using the Query Designer and add a filter where the CreatedBy field equals the new global value Current User.
When we run the application and insert some order details, you’ll see that the application saves who created/modified the data and the time as well.
If you are upgrading your project from a previous release to Visual Studio 2013, the Enable Created/Modified properties option is not turned on by default, however, you may enable them as long as there are no existing properties with the same names. Enabling these properties will validate these properties don’t currently exist. If any do exist, a message will be displayed and you will need to remove (or rename) them if you want to make use of this feature.
Under the covers, LightSwitch determines what identity to store in the CreatedBy and ModifiedBy fields based on the authentication type of the application. This mechanism is built into the new Person Type. Furthermore, LightSwitch populates the values for CreatedBy and ModifiedBy fields before the save pipeline process starts, so you can use them in your business logic if you need to. For more information please read: Using the Person Business type.
This is another one of those features we added in Visual Studio 2013 in response to customer feedback. We hope that this proves useful in your applications. Please install the Visual Studio 2013, try it and let us know what you think by leaving a comment below or visiting the forum.





• Paul S. Patterson (@PaulPatterson) began a series with LightSwitch Multi-tenancy – Introduction on 11/7/2013 (missed when published):
It would appear that the top suggested topic on the PaulSPatterson.UserVoice.com site is the Automated Multi-tenant Applications topic. I kinda figured it would be a popular suggestion because it is one that I have been wanting to try for some time now.
So, with that being said, I am going to create a proof-of-concept multi-tenancy solution using LightSwitch, and blog about it in the hopes that you can learn from what I do (and do not). Keep in mind that I just said I am going to create something. I have only just started investigating how to do this, and haven’t actually started anything yet.
Proof-Of-Concept
Before I hunker down with the low level stuff, it would help op define some scope for my proof-of-concept. I thought I’d brainstorm a bit and jot down a bit of a usage scenario to help me set some boundaries about what I am going to be doing.
I am thinking of this as a usage scenario…
- A person will navigate to a New Tenant registration System (web site).
- The person will enter information about their organization, as well as information about their default tenant administrator user.
- The System will save the new Tenant information, as well as create the default Tenant Administrator User.
- The System will send an Email with a hyperlink containing unique new user registration confirmation code.
- The User will open the email and navigate to the registration confirmation website using the URL in the email.
- The System will inspect the confirmation code and activate the new User.
- The System will then present the User with the login screen (for the LightSwitch application)
- The user will enter their credentials and press the login button.
- The System will evaluate the login credentials to authenticate the user.
- The System will present the User with the home screen.
- The System will perform data actions that are in the context of the Tenant that the User is for. No other Tenant data will be accessible to the user.
Albeit there is some work to do for the registration system, but that is something that needs to happen anyway. But before I even start on that, I want to take a look at some high-level concepts that talk to multi-tenant architectures.
Data Isolation
One of the first articles I found, and arguably the most relevant to what I am trying to achieve, is this 2006 MSDN article titled Multi-Tenant Data Architecture. The article talks about three approaches to managing multi-tenant data, which is essentially what I want to do.
What I need to first determine is what degree of isolation I want to use for the data in my application. Do I need to have tenant data completely isolated from other tenant data, such as in separate databases, or can the data for each tenant reside within a shared environment?
(image source: Microsoft - http://msdn.microsoft.com/en-us/library/aa479086.aspx)
Let’s have a bit of a discussion on this degree of isolation stuff.
Separate Databases
The first approach would be isolate the data by creating separate databases for each tenant. This would certainly provide for an easy way to logically separate the data for each tenant. To implement this approach, I would have to create functionality that provisions a new database for each new tenant registration. I would then have to engineer the LightSwitch client to dynamically connect to the appropriate database with each user log in. To me, this would require more maintenance work than I am willing and able to perform.
Separate Schemas
I suppose I could try and stick with one database and then create separate database schemas for each tenant, but how much different, really, is that to using separate databases? Yeah, I can take advantage of the fact that I am using just one database, however I still have the same scale application connectivity functionality and maintenance , for the most part anyway, as that of having the separate databases. So where am I better off on this one?
Same Database
How sharing all tenant data in one database, with one schema? Having a shared repository for all tenant data would certainly mitigate most of my concerns regarding database maintenance. The single database and schema would eliminate the need to have any requirement for dynamic data connections.
LightSwitch has the flexibility to be able to apply row level filtering to data sources. This is a great feature that presents an excellent opportunity to abstract and contextualize tenant data in the application. By applying filtering to the data, I should be able to serve up only the data the logged in user has access to.
(image source: Microsoft - http://msdn.microsoft.com/en-us/library/aa479086.aspx)
My Approach
Well, you can probably already tell which approach I am going to take with the creating of this prof-of-concept. I am going to use a single database, with a single schema. I am going to leverage row-level filtering to only allow users to work with the data for the tenant that the user is attached to.
Having said that, here is what I intend to do:
- Create a Tenant Registration system – an ASP.Net MVC web application
- Create a user registration confirmation messaging system
- Use an Azure SQL database as the data store
- Use SendGrid for messaging
- Build a LightSwitch application
- Leverage row level filtering,
- possibly use some kind of pattern so that the filtering is applied globally, rather than manually creating filters for each data entity.
Well? How does all that sound? Let the journey begin!


Rowan Miller reported EF6.0.2 Nightly Builds Available in a 11/13/2013 post:
We recently blogged about our plans to publish a 6.0.2 patch release to address some issues in the 6.0.0 and 6.0.1 releases. The changes in this release will improve performance and fix some bugs introduced in the EF6 release.
Try out the nightly builds
Because this patch will go straight to RTM, we need your help to try out the nightly builds and let us know if the issues are fixed and/or if you encounter any new issues.
We’ve started pushing 6.0.2 builds to the same MyGet feed we push nightly builds of our master branch to (currently the 6.1 code base that we are working on).
Not all the fixes for 6.0.2 are checked in at the time this post was published. You can keep track of what issues we are planning to address in 6.0.2 (and the state of the fix) on our CodePlex site.
Configuring NuGet
You need to configure NuGet to use the feed that contains nightly builds.
- In Visual Studio select Tools –> Library Package Manager –> Package Manager Settings
- Select Package Sources from the left pane
- Enter Nightly Builds as the Name and https://www.myget.org/F/aspnetwebstacknightly/ as the Source
- Click Add and then OK
Using a Nightly Build
Once the nightly feed is configured you can add the latest build of the 6.0.2 NuGet package:
- In Visual Studio select Tools –> Library Package Manager –> Package Manager Console
- At the command prompt you can run the Install-Package command specifying a version that includes the current date. The format for this command is Install-Package EntityFramework –Pre –Version 6.0.2-nightly-2<two_digit_month><two_digit_day>
- For example, today’s date is November-13 so you can run Install-Package EntityFramework –Pre –Version 6.0.2-nightly-21113 to get today’s build
Note: If you do not specify a version, or if you install via the NuGet UI, you will get the latest 6.1 build which includes fixes that will not be included in the 6.0.2 release.
Nightly builds are typically available on MyGet by 10am PST each day, but from time to time things happen and they may be later.


<Return to section navigation list>
Cloud Security, Compliance and Governance
Dan Plastina (@TheRMSGuy) described Office 365 Information Protection using Azure Rights Management in an 11/11/2013 post to the Microsoft Rights Management Service (RMS) Team blog:
If your organization is already using or planning on moving to Office 365, information protection is available to you via Azure Rights Management. Whether your information is on Office 365, mobile devices, computers, cloud drives, or file shares, you can now use Azure RMS to protect your data wherever it goes. Azure RMS provides your users an easy way to protect data, and for your IT pros to apply additional controls across the organization.
Azure RMS is included with E3, E4, A3, A4, plans, or you can purchase Azure RMS as a standalone subscription. For more information about licensing, please view this post. There are several different services that integrate with Azure RMS: Office, SharePoint Online and Exchange Online.
Exchange Online
Exchange Online offers a very rich set of features that are integrated with Azure RMS.
- Rights Management in Exchange Online enables users to view and create rights-protected messages in Outlook, Outlook Web App via a browser, OWA for iPad and iPhone.
- In addition, devices that have integrated with Exchange Active Sync for Rights Management, such as Windows Phone 8, enable users to view protected messages. Your users will always have a way to view rights protected content.
Exchange Online also uses RMS in conjunction with rich controls to protect your content via Transport rules and data leakage prevention (DLP). An organization using DLP with Transport rules provides a backstop to help prevent the inadvertent data leaks, and to help you meet compliance requirements by ensuring that your data is protected with your organization’s policies. For example, automated rules can be created to look for patterns of company confidential R&D information, payment card information, social security numbers, or patient data in health care organizations. Once such data is identified by Exchange Online that meets your criteria, the message can then be protected by using Rights Management and ensure that only the intended recipients have access to the message.
To aid with discovery, Exchange Online also provides search indexing on rights protected content and journal decryption to ensure your organization can use automated reasoning tools with the rights protected content.
SharePoint Online
Rights Management is supported within SharePoint Document Libraries. After configuring SharePoint for Rights Management, when a user downloads a file from a document library, RMS protection is applied according to the permissions that you specify. If the user is accessing SharePoint Online and does not have Microsoft Office installed, the protected content can also be viewed using a web browser and the Office Web Access Companion with SharePoint Online.
SharePoint provides a rich set of controls when using Rights Management. These controls includes a set of granular permissions to specify what a user can do after downloading the document. For example, cannot print, read only, and the ability to force a user to request permissions every time the document is opened.
In addition, Rights Management can also be enabled on SkyDrive Pro, to ensure your users’ data is always protected regardless of the storage location.
Applications
Rights Management is supported within Office 2010 and Office 2013. In addition, you can use the Rights Management Application (RMS App). This is a new application that works within the file explorer, Microsoft Office, and with many of today's popular devices to provide a streamlined experience to share content within and outside of your organization. The RMS App supports Windows, Windows Phone 8, iPhone, iPad, and Android. We’ll discuss our collaboration capabilities more in a later post. To use Office 2010 with Azure RMS, you must install the RMS App, which configures Office 2010 to work with Azure RMS. Here is a link to the user guide for the RMS App.
Migrating to Office 365
If your organization is in the process of migrating to Office 365 (you have users on Exchange Server or using SharePoint on premises), we have a new feature called the RMS connector that will enable protected content to work with your online services as well as your on-premises servers. Learn more about the RMS connector here: http://technet.microsoft.com/en-us/library/dn375964.aspx.
How do I get started?
In just a few minutes by using the following steps, you can enable Azure RMS, SharePoint Online, and Exchange Online to enable information protection. Do I really mean a few minutes? Yes, just a few minutes.
If you want to try this for yourself, by using a Trial Office 365 subscription, sign up here.
Activate Azure RMS
1. Login to the Office 365 Portal at http://portal.microsoftonline.com
2. Go to service settings.

3. Select rights management, and then click Manage.

4. Click activate.

5. Confirm you want to activate Rights Management.

6. RMS is now activated and users can now protect files by using the RMS Application or Microsoft Office.

Enable SharePoint Online RMS Integration
1. Go to service settings, click sites, and then click View site collections and manage additional settings in the SharePoint admin center.

2. Go to Information Rights Management.

3. Select Use the IRM service specified in your configuration.

4. Click OK.

Enable a SharePoint Online Document Library to use RMS
1. Go to a document library and click PAGE.

2. Click Library Settings.

3. Click Information Rights Management.

4. Select Restrict permissions on this library on download and add your policy title and policy description. Click SHOW OPTIONS to configure additional RMS settings on the library, and then click OK.

Start using RMS functionality in SharePoint Online
1. Create a new document or upload an existing document to the document library with RMS enabled.
2. Download a document from the library. The document will be RMS protected.
Enable Exchange Online
1. Connect to your Exchange Online account by using Windows PowerShell
2. Login with this command:
- $LiveCred = Get-Credential
3. Begin configuration of Exchange Online:
( If you haven't previously run Windows PowerShell remote commands for Exchange Online, run the following command: set-executionpolicy remotesigned )
- $Session = New-PSSession -ConfigurationName Microsoft.Exchange -ConnectionUri https://ps.outlook.com/powershell/ -Credential $LiveCred -Authentication Basic –AllowRedirection
- Import-PSSession $Session
4. Run the following commands to enable Rights Management within Exchange Online:
- Set-IRMConfiguration –RMSOnlineKeySharingLocation "https://sp-rms.na.aadrm.com/TenantManagement/ServicePartner.svc"
- Import-RMSTrustedPublishingDomain -RMSOnline -name "RMS Online"
- Set-IRMConfiguration -InternalLicensingEnabled $true
For regions outside North America, substitute .NA. with .EU. for the European Union, and .AP. for Asia
e.g.: https://sp-rms.eu.aadrm.com/TenantManagement/ServicePartner.svc
e.g.: https://sp-rms.ap.aadrm.com/TenantManagement/ServicePartner.svcOptionally test the configuration by running the following command:
- Test-IRMConfiguration -sender user@company.onmicrosoft.com















Dan Plastina (@TheRMSGuy) explained Rights Management Licensing Terms (for Orgs and ISVs) in a 11/8/2013 post:
As you all know by now, Microsoft Rights Management service (RMS) has released a significant update. Many of you have asked for details on the licensing terms... what's this going to cost me? Given I have X, do I need to get Y or not? etc. Here are the terms, grouped by organizational profile. This blog focuses on the Azure RMS service. The AD RMS service licensing terms remain unchanged. I do apologize for what may appear as duplicated text for those reading them all. As usual, let us know if you have questions.
Office 365 -based Organization
- Office 365 uses Azure RMS as the basis of its many information protection capabilities
- Azure RMS is offered as a user subscription license
- Each Azure RMS user subscription covers the use of any RMS-enlightened application.
- When sharing with other organizations, their use of 'RMS for Individuals' (http://portal.aadrm.com) is free.
- Consumption of rights protected content is free
- A license is required to protect content.
- Note that content protected 'on behalf of' a user also requires a license as that is considered protecting content. For example using SharePoint IRM-enabled document libraries and Exchange transport rules results in protecting files for many users; each of which requires an RMS license. We hope that you see this as being pretty logical -- Not having this clause would mean that Exchange would only need one license to perform DLP (data loss prevention) for a 200,000 person org.
- For smaller organizations, purchases of Azure RMS are done in the Office 365 portal
- Office 365 E3/E4 and A3/A4 SKUs include capabilities from Azure RMS at no extra charge
- Other Office 365 SKUs can use Azure RMS via an 'Add-On' (e.g.: K1, E1, A1, P1, P2)
- Azure RMS can be paid for in monthly or annual terms (this last part is pending deployment but we will be adding it for convenience; to match the annual payment models available of parent SKUs such as E1).
- For larger organizations, purchases are made by contacting your Microsoft sales associate. Standalone Azure RMS is included in the November Price list for each of the Microsoft Enterprise Volume License programs (EA/EAS/EES).
On-Premises Organizations using Azure RMS
- On-premises organizations can use Azure RMS (instead of a traditional ADRMS server)
- On-premises versions of Exchange and SharePoint use the RMS Connector. The RMS connector use is included at no added charge.
- Azure RMS is offered as a user subscription license.
- Holders of an Core CAL access licenses seats should purchase Azure RMS via their enterprise agreement (EA) sales channel.
- Holders of an ECAL (Enterprise Client) access licenses seats or RMS CAL seats should purchase a discounted 'Step-up' SKU to license Azure RMS. Azure RMS subscription rights include rights for use of AD RMS on-premises.
- Each Azure RMS user subscription covers the use of any RMS-enlightened application.
- When sharing with other organizations, their use of 'RMS for Individuals' (http://portal.aadrm.com) is free.
- Consumption of rights protected content is free
- A license is required to protect content.
- Note that content protected 'on behalf of' a user also requires a license as that is considered protecting content. For example using SharePoint IRM-enabled document libraries and Exchange transport rules results in protecting files for many users; each of which requires an RMS license. We hope that you see this as being pretty logical -- Not having this clause would mean that Exchange would only need one license to perform DLP (data loss prevention) for a 200,000 person org.
- For smaller organizations, purchases are made by visiting the Office 365 portal. A Standalone Azure RMS offer can now be purchased independently of Office 365.
- For larger organizations, purchases are made by contacting your Microsoft sales associate. Standalone Azure RMS is included in the November Price list for each of the Microsoft Enterprise Volume License programs (EA/EAS/EES).
Solution Partners
Solutions partners find themselves needing to perform protection operations on data for other organizations. In these use cases, the solution partner asks their customers to bring their own licenses (BYOL) as part of their Azure Active Directory configuration. We do things this way given the above terms outline a model where an organization pays only once for the right "to use RMS with any enlightened application or service".
For example, let's say a CAD company builds a virtual 'Construction meeting room' for 3 organizations to collaborate. The files are protected by the CAD company for the use of the other organizations. In this case the CAD firm is permitted to protect the files 'on behalf' of the other organizations using an instance of the Azure RMS service. They simply require that every user from each of these other organizations purchase licenses for all of their users visiting this meeting room. As you look at implementing this offering, please be sure to contact us at AskIPTeam@microsoft.com to discuss your specific use pattern. This pattern would apply to most 'virtual meeting room' type services. We thought you'd like this one... after all, what better of a price than free!.
Also note that there is no 'mega solution offer' model where a partner acts as the RMS server for many companies (or many virtual rooms). Though possible today with SPLA ADRMS licensing terms, it's highly ill advised as the same RMS root security key would be protecting data for different organizations. Each virtual room should be a different Azure RMS tenant with its own root security key. This way important actions such as retiring a Azure RMS subscription have the expected effect of killing all remaining protected content. Again, as you look at implementing RMS in your service, please be sure to contact us at AskIPTeam@microsoft.com to discuss your specific use pattern.
If you have any specific questions please contact your Microsoft sales associate. They'll help you out, or they'll know where to find us. If you prefer to ask us directly then send the question(s) to AskIPTeam@microsoft.com but please CC your Microsoft sales contact.


Dan Plastina (@TheRMSGuy) announced The NEW Microsoft RMS has shipped! on 11/5/2013 (missed when published):
I have the honor of sharing that the new RMS offering is now live, in general availability! We’re announcing the final release of all SDKs, most Apps, related services, and we’re giving details on how you can explore each of them. Lots more news coming over the coming weeks so follow us on Twitter @TheRMSGuy for up to the moment updates.
Why should you care? The new Microsoft RMS enables organizations to share sensitive documents within their organization or to other organizations with unprecedented ease. These documents can be of any type, and you can consume them on any device. Given the protection scheme is very robust, the file can even be openly shared… even on consumer services like SkyDrive/DropBox/GDrive.
This is the first of many blogs on the final release. If you’d like more immediate background information on Microsoft Rights Management, check out this TechEd Talk. I’ll also strongly recommend you read the new RMS whitepaper for added details. We have an updated website with per role subsites and we’ll soon post RMS flyers. We also have user forums.
Thanks,
Dan
In short, here is what we’re promising at this juncture:
Users:
- I can protect any file type
- I can consume protected files on devices important to me
- I can share with anyone
- Initially, I can share with any business user; they can sign up for free RMS
- I can eventually share with any individual (e.g. MS Account, Google IDs in CY14)
- I can sign up for a free RMS capability if my company has yet to deploy RMS
ITPro:
- I can keep my data on-premises if I don’t yet want to move to the cloud
- I am aware of how my protected data is used (near realtime logging)
- I can control my RMS ‘tenant key’ from on-premises
- I can rely on Microsoft in collaboration with its partners for complete solutions
These promises combine to create two very powerful scenarios:
- Users can protect any file type. Then share the file with someone in their organization, in another organization, or with external users. They can feel confident that the recipient will be able to use it.
- ITPros have the flexibility in their choice of storage locale for their data, and Security Officers have the flexibility of maintaining policies across these various storage classes. It can be kept on premises, placed in a business cloud data store such as SharePoint, or it can placed pretty much anywhere and remain safe (e.g. thumb drive, consumer-grade cloud drives, etc.).
The RMS whitepaper offers plenty of added detail.
User experience of sharing a document
Here’s a quick fly-by through one of the many end-to-end user experiences. We’ve chosen the very common ‘Sensitive Word document’ scenario. While in Word, you can save a document and invoke SHARE PROTECTED (added by the RMS application):
You are then offered the protection screen. This screen will be provided by the SDK and thus will be the same in all RMS-enlightened applications:
When you have finished addressing and selecting permissions, click SEND. An email will be created that is ready to be sent but you we let you edit it first:
The recipient of this email can simply open the document.
If you’re a hands-on learner, just send us an email using this link and we’ll invite you to consume a protected document the same way partner of yours would.
If the user does not have access to RMS, they can sign up for free. (Yes, free). In this flow the user will simply provide the email address they use in their day-to-day business. (That’s right, you won’t need to create a parallel free-email account to consume sensitive work documents.) We’ll ask the user to verify possession via a challenge/response, and then give them access to both consume and produce RMS protected content. (Yes, they can not only consume but also share their own sensitive documents as a free evaluation.)
The user can consume the content. Here we’ll show you how that looks like on an iPhone. In this case they got an email with a protected image (PJPG). They open it and are greeted with a login prompt so we can verify their right to view the protected image. Once verified, the user is granted access to see the image and to review the rights offered to them (click on the info bar):
With this covered, let’s jump into the specifics of what we’re releasing…
Foundational Developer SDKs
Today we are offering you 6 SDKs in RELEASE form. Those SDKs target Windows for PCs, Windows Store Apps, Windows for Phone 8, iOS, Android, and Mac OSX.
It’s worth noting the Windows SDK offers a powerful FILE API that is targeted at solution providers and IT Pros. This Windows-based SDK has already been released. It will let you protect any file via PowerShell script as well. E.g. Using the FileAPI and PowerShell you can protect a PDF or an Office document, natively, without any additional software.
The RMS sharing application
Today we’re releasing the RMS sharing application. It is available on: Windows for PCs, Windows for Phone 8, iOS, and Android. The Windows store application and Mac OSX will be forthcoming (Spring CY13).
You can get the application and sign up for free RMS here.
The applications let you consume ‘generically protected’ content (PFILEs), protected text and image formats, and also now lets you generated protected images right from the device. We call this the ‘Secure whiteboard’ feature: Take a photo of the meeting room whiteboard and share it with all attendees, securely. This said, we recognize it can serve many other creative uses.
It's important to note that Office itself is not yet available in full form on all mobile devices so consumption of natively protected Office files is limited until such time that Microsoft Office is released on your desired platform. In the meantime, you can protect Office files using the [x] Allow consumption on all devices option. This will result in the share of a generically protected (PFILE) Office file. e.g.: Here we show that My Sensitive Document.Docx will be generically protected to the PFILE format. This results in the recipients getting a protected file -- one that requires authorization, that can be audited on each use, and that can expire on the date you set -- but this file will have to be shared without the finely granular rights that you might desire (thus the slider control is disabled). These good things will come in time. This said, it's worth calling out that this flow lets your iOS and Android recipients consume the protected content you send to them in their respective applications (e.g.: on iOS you can open the Word document in Pages).
The Azure RMS Service
The above offers are bound to the Azure RMS service. This service has been in worldwide production since late 2012 as it powers the Office 365 integrated RMS features. We’ve added support for the new mobile SDKs and RESTful endpoints but overall, that service has been up and running in 6 geographies worldwide (2x EU, 2x APAC, 2x US) and is fully fault tolerant (Active-Active for the SaaS geeks amongst you).
We’re also offering the BYOK – Bring Your Own Key – capability discussed in the whitepaper. This ensures that your RMS tenant key is treated with utmost care within a Thales hardware security module. This capability prevents export of the key even with a quorum of administrator cards! You can learn more about HSMs from partner Thales here.
We’re also offering near-realtime logging of all activities related to RMS and key usage. Simply point Azure RMS to Azure blob storage and the logging begins.
The bridge to on-premises
Today we’re also announcing the RMS connector. This connector enables your on-premises Exchange servers and on-premises SharePoint servers to make use of all the above. It’s a simple relay that ‘connects’ these servers to Azure RMS. The RMS connector is easy to configure and lightweight to run.
To download the connector: http://go.microsoft.com/fwlink/?LinkId=314106
RMS connector documentation: http://technet.microsoft.com/en-us/library/dn375964.aspx
The RMS for individuals offer
As called out above, not everyone will have RMS in their company, so we’ll offer RMS to individuals for free within organizations. This offer is located at http://portal.aadrm.com. If you share with others, they can simply sign up. If you are the first one to the party, you can simply sign up. No strings attached.
Wrapping up, we hope you’ll agree that we did pretty well at solving a long-standing issue of persistent data protection. We’ve done so in a way that can also be used within your organization and that honors the critical needs of your IT staff. We’re offering you immediate access to evaluate all the relevant parts: SDKs, Apps, Azure service, connectors, and the self-sign up portal. For each, I’ve given shared with you links to help you get started.
We’ve got a flurry of daily blog posts coming our over the next 2 weeks on Planning, Licensing, Step-by-Step guides, and some coverage of specific scenarios. Stay in touch via twitter: @TheRMSGuy Don't hesitate to let us know what you'd like to hear about!











<Return to section navigation list>
Cloud Computing Events
No significant articles so far this week.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeffrey Schwartz (@JeffreySchwartz) explained Why Amazon Could See Slow Uptake for Its Cloud VDI Service in an 11/15/2013 article for Redmond Magazine:
When Amazon announced plans to disrupt the virtual desktop infrastructure (VDI) market Wednesday by launching WorksSpaces at its re:Invent customer and partner conference in Las Vegas, Citrix shares dropped 4.5 percent on the news. Amazon pitched its desktop-as-a-service offering as a more affordable approach to traditional VDI offered by Citrix, VMware and Microsoft. That's because with WorksSpaces, IT can spin up virtual desktops without buying hardware or software just as they can with Amazon's cloud and storage portfolio of services.
Given its track record in upending traditional business models, one doesn't want to ignore Amazon when it offers anything new (remember Borders?). But analysts I spoke with following the announcement noted Amazon is not likely to take the VDI world by storm overnight for a variety of reasons. Maybe that's why Citrix shares are inching back up today?
One noteworthy barrier to adoption of Amazon WorkSpaces is the end user. When Amazon launched EC2 over seven years ago, it gave developers a way to bypass IT to quickly procure infrastructure. End users on the other hand are not clamoring for VDI, said Forrester analyst David Johnson. "There aren't employees inside a company that are going to run out and sign up for Amazon desktops," Johnson said. Desktop as a service will appeal to those who need "pop-up-desktops" for contractors or to quickly get projects started, Johnson said.
A Forrester survey last quarter found that 11 percent of SMBs and enterprises in North America and Europe are including desktop as a service within the next 12 months. This is up from 5 percent during the same time last year. Looking beyond one year, 12 percent said they are planning hosted desktops, up from 7 percent last year.
When it comes to overall plans for VDI, 52 percent said it was a high priority, up from 48 percent last year and 43 percent in 2011, according to Forrester. IDC's current forecast for client virtualization spending overall this year is $175 million. It projects next year it will rise to $311 million and hit $600 million by 2016.
Although VDI deployments that use public cloud infrastructure are part of a small but emerging piece of that market, Microsoft recently made its Remote Desktop Services (RDS) available for Windows Azure. Amazon WorksSpaces gives users their own instance using portions of Windows Server 2008 R2 and renders a user interface that looks like Windows 7. "There are positives and negatives to both approaches but at the end of the day it's similar for the end user," Waldman said.
Meanwhile VMware also has its sights on offering a desktop as a service VDI offering with its recent acquisition of Desktone and Citrix is also developing a similar offering. But Waldman said large enterprises are wary of putting user data in the cloud. "We see enterprises taking a slow cautious approach to cloud hosted virtual desktops. However, for small and mid-sized companies where VDI is too expensive and complex to get up and running, it makes it more accessible to them."
The most likely candidates for Amazon WorkSpaces are those that are already using Amazon's cloud infrastructure services, Waldman noted. But there's a case to be made that many IT pros will consider Microsoft's RDS, because of the application compatibility, Waldman said.
"While 95 percent of apps can work on client or server, many apps were poorly written and literally hard coded to run on a client operating system," he said. "Even though apps written for Windows can run on Windows Server, there are many instances it would not because of that one bad line of code."
While there are solutions to remediate that, such as Citrix's AppDNA, it could be a showstopper for those looking for quick deployments.
Are you considering a desktop-as-a-service VDI deployment? If so, which offering sounds most appealing?



See Jeff Barr’s post of 11/13/2013 announcing Amazon Work Spaces near the end of this post. My Using Microsoft’s Remote Desktop App with a Tronsmart MK908 MiniPC and Using Citrix Receiver for Android with a Tronsmart MK908 MiniPC articles of 10/27/2013 describe Microsoft’s and Citrix’s current approach to VDI for other operating systems, in this case Android. My Using the Microsoft Dynamics CRM App for Android with the MK908 post of 10/31/2013 describes a new Microsoft SaaS client.
• Mary Jo Foley (@maryjofoley) asserted “Microsoft is believed to be building a Windows Azure-hosted desktop virtualization service that could be available on a pay-per-use basis” in a summary of her Microsoft readies 'Mohoro' Windows desktop as a service article of 5/1/2013:
… The same way that Windows Intune is the cloud complement to System Center, Mohoro seems to be the cloud version of Remote Desktop/Remote App.
This is like "Remote App as a hosted service," said one of my contacts. It could be for companies who want thin clients or to run legacy apps on new PCs. Right now, companies have to have their own servers in the equation to do this, but "with Mohoro, you click a few buttons, deploy your apps, use Intune to push out configuration to all of your company's devices, and you're done," my contact added. …
Full disclosure: I’m a contributing editor for Visual Studio Magazine, a sister publication of 1105 Media’s Redmond Magazine.
Ashlee Vance (@valleyhack) reported IBM Faces a Crisis In the Cloud in an 11/15/2013 article for Bloomberg Business Week:
IBM (IBM) is having an identity crisis, and it sure is something to watch.
You may have heard about Big Blue’s recent ad campaign that takes a dig at Amazon.com (AMZN). In its marketing material, IBM claims to power 270,000 more websites than Amazon, via its cloud computing service. It’s a flimsy jab at Amazon because IBM has been a major laggard in the cloud rental market, having bought its way into the business in July with its acquisition of SoftLayer Technologies.
Far from being a cloud pioneer, IBM has spent most of the past few years downplaying services such as Amazon’s as insecure, low-margin businesses of little interest to a serious computing company. “You can’t just take a credit card and swipe it and be on our cloud,” IBM executive Ric Telford told me in early 2011. The company’s pitch to customers was that it knew them intimately and its cloud system was safer. But thousands of startups, including Dropbox and Netflix (NFLX), were more than happy to swipe their credit cards and get going on Amazon.
STORY: Another Amazon Outage Exposes the Cloud's Dark Lining
IBM’s cloud strategy has been complicated by questions about its accounting. The company disclosed in July that the U.S. Securities and Exchange Commission was investigating IBM’s cloud-revenue figures. More recently, IBM lost out to Amazon–twice–in a bid for a CIA cloud contract. With the CIA using Amazon, IBM’s security pitch is a much tougher sell. Its $2 billion purchase of SoftLayer, and its use of SoftLayer’s cloud tech instead of its own, appears to strike a final blow to IBM’s old cloud strategy.
IBM’s reluctance to enter the credit card-swiping end of the cloud business was in keeping with its shift away from low-margin disk drives, PCs, and networking gear toward higher-profit software and services. The company wanted to sell cloud services to large corporate users willing to pay a premium for some hand-holding, not retreat into by-the-hour computer rentals. Unfortunately for IBM, the market and equipment have matured so much that fewer and fewer customers need much hand-holding these days. Even the most arcane data-center equipment is getting easier and easier to use.
Let’s be clear: There’s plenty of work left for an IBM to do. The healthcare.gov debacle shows just how awful some technology projects can still get. But IBM’s revenue will keep falling with this strategy in place, as other companies turn to it less and less. …

Read the rest of the story here.
Jeff Barr (@jeffbarr, pictured below) announced Coming Soon - Global Secondary Indexes for Amazon DynamoDB in a 11/14/2013 post:
Amazon.com CTO Werner Vogels gave a sneak peek at a new feature for Amazon DynamoDB earlier today.
Planned for launch within weeks, the new Global Secondary Indexes will give you the flexibility to query your DynamoDB tables in new and powerful ways.
At present, you can query the table using a hash key or a composite (hash and range) key. With the upcoming release of Global Secondary Indexes, you will be able to create up to five secondary indexes when you create a table, each referencing a particular attribute. You can then issue DynamoDB queries and scans that make use of the indexes. You can also choose to project any desired attributes into an index. Doing so allows DynamoDB to handle certain scans and queries using only the index, leading to even greater efficiency.
This new feature will be ready for general use before too long. Stay tuned to the blog for more information!


I’ve been waiting for more than two years for the promised secondary indexes on Windows Azure Tables.
Jeff Barr (@jeffbarr) described Amazon Kinesis - Real-Time Processing of Streaming Big Data on 11/14/2013:
Imagine a situation where fresh data arrives in a continuous stream, 24 hours a day, 7 days a week. You need to capture the data, process it, and turn it into actionable conclusions as soon as possible, ideally within a matter of seconds. Perhaps the data rate or the compute power required for the analytics varies by an order of magnitude over time. Traditional batch processing techniques are not going to do the job.
Amazon Kinesis is a managed service designed to handle real-time streaming of big data. It can accept any amount of data, from any number of sources, scaling up and down as needed.
You can use Kinesis in any situation that calls for large-scale, real-time data ingestion and processing. Logs for servers and other IT infrastructure, social media or market data feeds, web clickstream data, and the like are all great candidates for processing with Kinesis.
Let's dig into Kinesis now...
Important Concepts
Your application can create any number of Kinesis streams to reliably capture, store and transport data. Streams have no intrinsic capacity or rate limits. All incoming data is replicated across multiple AWS Availability Zones for high availability. Each stream can have multiple writers and multiple readers.
When you create a stream you specify the desired capacity in terms of shards. Each shard has the ability to handle 1000 write transactions (up to 1 megabyte per second -- we call this the ingress rate) and up to 20 read transactions (up to 2 megabytes per second -- the egress rate). You can scale a stream up or down at any time by adding or removing shards without affecting processing throughput or incurring any downtime, with new capacity ready to use within seconds. Pricing (which I will cover in depth in just a bit) is based on the number of shards in existence and the number of writes that you perform.
The Kinesis client library is an important component of your application. It handles the details of load balancing, coordination, and error handling. The client library will take care of the heavy lifting, allowing your application to focus on processing the data as it becomes available.
Applications read and write data records to streams. Records can be up to 50 Kilobytes in length and are comprised of a partition key and a data blob, both of which are treated as immutable sequences of bytes. The record's partition determines which shard will handle the data blob; the data blob itself is not inspected or altered in any way. A sequence number is assigned to each record as part of the ingestion process. Records are automatically discarded after 24 hours.
The Kinesis Processing Model
The "producer side" of your application code will use the PutRecord function to store data in a stream, passing in the stream name, the partition key, and the data blob. The partition key is hashed using an MD5 hashing function and the resulting 128-bit value will be used to select one of the shards in the stream.
The "consumer" side of your application code reads through data in a shard sequentially. There are two steps to start reading data. First, your application uses GetShardIterator to specify the position in the shard from which you want to start reading data. GetShardIterator gives you the following options for where to start reading the stream:
- AT_SEQUENCE_NUMBER to start at given sequence number.
- AFTER_SEQUENCE_NUMBER to start after a given sequence number.
- TRIM_HORIZON to start with the oldest stored record.
- LATEST to start with new records as they arrive.
Next, your application uses GetNextRecords to retrieve up to 2 megabytes of data per second using the shard iterator. The easiest way to use GetNextRecords is to create a loop that calls GetNextRecords repeatedly to get any available data in the shard. These interfaces are, however, best thought of as a low-level interfaces; we expect most applications to take advantage of the higher-level functions provided by the Kinesis client library.
The client library will take care of a myriad of details for you including fail-over, recovery, and load balancing. You simply provide an implementation of the IRecordProcessor interface and the client library will "push" new records to you as they become available. This is the easiest way to get started using Kinesis.
After processing the record, your consumer code can pass it along to another Kinesis stream, write it to an Amazon S3 bucket, a Redshift data warehouse, or a DynamoDB table, or simply discard it.
Scaling and Sharding
You are responsible for two different aspects of scalability - processing and sharding. You need to make sure that you have enough processing power to keep up with the flow of records. You also need to manage the number of shards.Let's start with the processing aspect of scalability. The easiest way to handle this responsibility is to implement your Kinesis application with the Kinesis client library and to host it on an Amazon EC2 instance within an Auto Scaling group. By setting the minimum size of the group to 1 instance, you can recover from instance failure. Set the maximum size of the group to a sufficiently high level to ensure plenty of headroom for scaling activities. If your processing is CPU-bound, you will want to scale up and down based on the CloudWatch CPU Utilization metric. On the other hand, if your processing is relatively lightweight, you may find that scaling based on Network Traffic In is more effective.
Ok, now on to sharding. You should create the stream with enough shards to accommodate the expected data rate. You can then add or delete shards as the rate changes. The APIs for these operations are SplitShard and MergeShards, respectively. In order to use these operations effectively you need to know a little bit more about how partition keys work.
As I have already mentioned, your partition keys are run through an MD5 hashing function to produce a 128-bit number, which can be in the range of 0 to 2127-1. Each stream breaks this interval into one or more contiguous ranges, each of which is assigned to a particular shard.
Let's start with the simplest case, a stream with a single shard. In this case, the entire interval maps to a single shard. Now, things start to heat up and you begin to approach the data handling limit of a single shard. It is time to scale up! If you are confident that the MD5 hash of your partition keys results in values that are evenly distributed across the 128-bit interval, then you can simply split the first shard in the middle. It will be responsible for handling values from 0 to 263-1, and the new shard will be responsible for values from 263 to 2127-1.
Reality is never quite that perfect, and it is possible that the MD5 hash of your partition keys isn't evenly distributed. In this case, splitting the partition down the middle would be a sub-optimal decision. Instead, you (in the form of your sharding code) would like to make a more intelligent decision, one that takes the actual key distribution into account. To do this properly, you will need to track the long-term distribution of hashes with respect to the partitions, and to split the shards accordingly.
You can reduce your operational costs by merging shards when traffic declines. You can merge adjacent shards; again, an intelligent decision will maintain good performance and low cost. Here's a diagram of one possible sequence of splits and merges over time:
Kinesis Pricing
Kinesis pricing is simple: you pay for PUTs and for each shard of throughput capacity. Let’s assume that you have built a game for mobile devices and you want to track player performance, top scores, and other metrics associated with your game in real-time so that you can update top score dashboards and more.Let’s also assume that each mobile device will send a 2 kilobyte message every 5 seconds and that at peak you’ll have 10,000 devices simultaneously sending messages to Kinesis. You can scale up and down the size of your stream, but for simplicity let’s assume it’s a constant rate of data.
Use this data to calculate how many Shards of capacity you’ll need to ingest the incoming data. The Kinesis console helps you estimate using a wizard, but let’s do the math here. 10,000 (PUTs per second) * 2 kilobytes (per PUT) = 20 megabytes per second. You will need 20 Shards to process this stream of data.
Kinesis uses simple pay as you go pricing. You pay $0.028 per 1,000,000 PUT operations and you pay $0.015 per shard per hour. For one hour of collecting game data you’d pay $0.30 for the shards and about $1.01 for the 36 million PUT calls, or $1.31.Kinesis From the Console
You can create and manage Kinesis streams using the Kinesis APIs, the AWS CLI, and the AWS Management Console. Here's a brief tour of the console support.Click on the Create Stream button to get started. You need only enter a stream name and the number of shards to get started:
The console includes a calculator to help you estimate the number of shards you need:
You can see all of your streams at a glance:
And you can view the CloudWatch metrics for each stream:
Getting Started
Amazon Kinesis is available in limited preview and you can request access today.


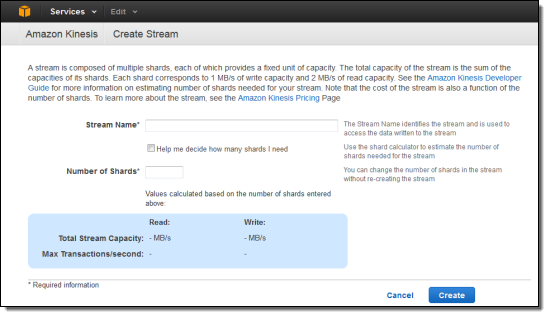
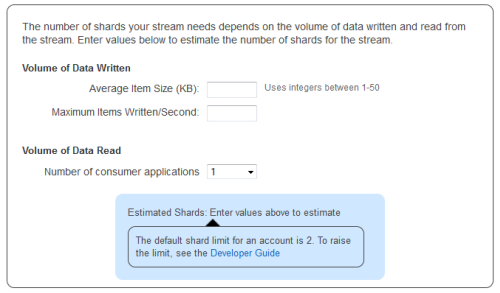
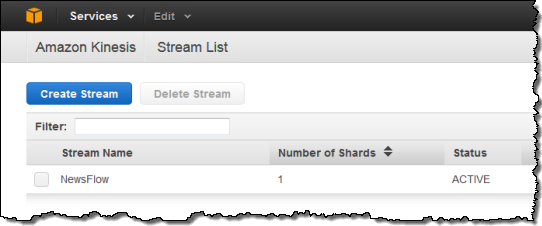
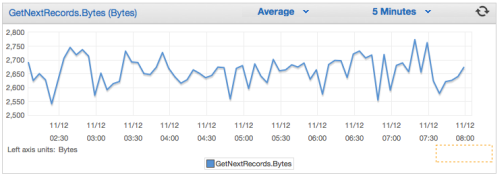
Jinesh Varia (@jinman) posted TCO Comparison: Amazon WorkSpaces and Traditional Virtual Desktop Infrastructure (VDI) on 11/13/2013:
Today, we announced Amazon WorkSpaces, a fully managed desktop computing solution in the cloud. Amazon WorkSpaces delivers a user’s documents, applications and resources to tablets, PCs, and Macs. The service has the benefits of on-premises VDI – such as mobility and security – combined with all the powerful AWS benefits – such as pay-as-you-go and simplified management.
With Amazon WorkSpaces, you don’t have to purchase, install, and maintain datacenter hardware or virtual desktop software. The Amazon WorkSpaces service does all this heavy lifting for you. With a few clicks of a mouse in the AWS Management Console, you can create your high-quality desktop experience for any number of users. The Amazon WorkSpaces service provisions a WorkSpace for each user and users can connect to their workspace using tablets, PCs, and Macs. When your organization grows and needs to scale with users, you do not need to procure new hardware or install new complex VDI software. You tell the service how many new WorkSpaces you need and what bundle to use. The service will provision the hardware based on the bundle configuration and provide a consistent high-quality desktop experience to each user. You pay only for the WorkSpaces you provision each month. When you need to turn off a user’s WorkSpace – for example, a contractor leaves your company after completing her assignments – you can stop paying for the WorkSpace at the end of the month.
Scenario (1000 Users)
To help you understand how cost-effective Amazon WorkSpaces is, we put together a Total Cost of Ownership (TCO) model for a scenario that delivers virtual desktop solution to users on-premises. In our model, we consider a 1000 user VDI solution. You can use this model as a starting point in your evaluation of virtual desktop solutions, and compare the TCO with a solution that uses Amazon WorkSpaces. Scaling this number up or down will impact the fixed cost per user.
Scenario Assumptions
For each user, we need to consider the computing experience we will deliver. We assume that the users are office workers who generally perform productivity tasks such as editing documents, building spreadsheets, browsing the intranet, sending e-mail, updating forms etc.
Now, if these users are going to use VDI, they need a solution that will allow them to save documents and settings, customize with their own applications, and have a persistent experience similar to a traditional desktop. To deliver this experience, we need a persistent virtual machine, with performance that is similar in perception to a traditional desktop. Users will also need dedicated storage for saving and retrieving their documents, with performance that is indistinguishable from using a local file store. To meet these requirements, we can size a virtual desktop as a virtual machine with 1 virtual CPU, 4 GiB of memory, and 50 GB of user data store. We also need to include storage for an OS volume, which we will assume adds another 50 GB.
Counting all the Costs
When determining the TCO of a cloud-based service, it’s easy to overlook several cost factors such as administration and license management costs, which can lead to an inaccurate and incomplete comparison. Additionally, in the case of a VDI solution, people often forget to include software costs. To obtain an accurate apples-to-apples comparison, you must include all of the different cost factors involved in deploying and managing a VDI solution, which means:
- Server Hardware Costs - for hosting the virtual desktop and for managing the control plane for the system, you need server hardware to run Windows Server OS, Microsoft SQL Server Database and access gateways.
- Storage Hardware Costs - you need Network-Attached Storage for persistent desktops.
- Network Hardware Costs - you need networking gear to connect all the servers, storage, and control plane with users.
- Hardware Maintenance Costs - hardware failures are unavoidable, so you will incur ongoing expenses for keeping the system functioning to spec.
- Power and Cooling Costs - once the servers start running, you must consider the operational expenses of both powering and cooling the servers
- Data Center Space Costs - you need real estate space to rack and stack the physical server
- Software Costs – to use VDI, you need VDI software that will allow you to set up and manage users, and their virtual desktop environments. While the software license costs might vary depending on the vendor you select, we believe their costs are comparable relative to the value they deliver.
- Administration Costs – setting up and managing hardware infrastructure, VDI environments and desktops is difficult and needs specialist IT staff. We believe you need at least two specialists per 1000 users to manage your desktop solution. We assume fully loaded cost of full-time IT specialist in the US is $150K/year. Your admin costs might vary based on your location and the experience levels of your staff.
Summary and Analysis
For a fair comparison, we have used amortized monthly costs. For example, hardware acquisition costs and administration costs are calculated per month. Typically, these costs are incurred upfront with long-term contracts. In our excel spreadsheet model, we clearly state our detailed assumptions for each cost item so you can adjust them based on your own research or quotes from your hardware vendors and co-location providers.


Jeff Barr (@jeffbarr) announced Amazon WorkSpaces - Desktop Computing in the Cloud in an 11/13/2013 post:
Once upon a time, enterprises had a straightforward way to give each employee access to a desktop computer. New employees would join the organization and receive a standard-issue desktop, preconfigured with a common set of tools and applications. This one-size-fits all model was acceptable in the early days of personal computing, but not anymore.
Enterprise IT has been engaged in a balancing act in order to meet the needs of a diverse and enlightened user base. They must protect proprietary corporate data while giving employees the ability to work whenever and wherever they want, while using the desktop or mobile device of their choice.
Our new Amazon WorkSpaces product gives Enterprise IT the power to meet this challenge head-on. You, the IT professional, can now provision a desktop computing experience in the cloud for your users. Your users can access the applications, documents, and intranet resources that they need to get their job done, all from the comfort of their desktop computer, laptop, iPad, or Android tablet.
Let's take a look at the WorkSpaces feature set and use cases. We'll also take a look at it from the viewpoint of an IT professional, and then we'll switch roles and see what it looks like from the user's point of view.
WorkSpaces Feature Set
Amazon WorkSpaces provides, as I have already mentioned, a desktop computing experience in the cloud. It is easy to provision and maintain, and can be accessed from a wide variety of client devices.
The IT professional chooses to supply each user with a given WorkSpaces Bundle. There are four standard bundles. Here are the hardware specifications for each one:
- Standard - 1 vCPU, 3.75 GiB of memory, and 50 GB of persistent user storage.
- Standard Plus - 1 vCPU, 3.75 GiB of memory, and 50 GB of persistent user storage.
- Performance - 2 vCPU, 7.5 GiB of memory, and 100 GB of persistent user storage.
- Performance Plus - 2 vCPU, 7.5 GiB of memory, and 100 GB of persistent user storage.
All of the bundles include Adobe Reader, Adobe Flash, Firefox, Internet Explorer 9, 7-Zip, the Java Runtime Environment (JRE), and other utilities. The Standard and Performance Plus bundles also include Microsoft Office Professional and Trend Micro Worry-Free Business Security Services. The bundles can be augmented and customized by the IT professional in order to meet the needs of specific users.
Each user has access to between 50 and 100 GB of persistent AWS storage from their WorkSpace (the precise amount depends on the bundle that was chosen for the user). The persistent storage is backed up to Amazon S3 on a regular basis, where it is stored with 99.99999999% durability and 99.99% availability over the course of a year.
Pricing is on a per-user, per-month basis, as follows:
- Standard - $35 / user / month.
- Standard Plus - $50 / user / month.
- Performance - $60 / month.
- Performance Plus - $75 / user / month.
WorkSpaces Use Cases
I believe that you will find many ways to put WorkSpaces to use within your organization after you have spent a little bit of time experimenting with it. Here are a few ideas to get you started:Mobile Workers - Allow users to access their desktops from iPads, Kindles, and Android tablets so that they can be productive while connected and on-the-go.
Secure WorkSpaces - You can meet stringent compliance requirements and still deliver a managed desktop experience to your users.
Students, Seasonal, and Temporary Workers - Provision WorkSpaces on an as-needed basis so that students, seasonal workers, temporary workers, and consultants can access the applications that they need, then simply terminate the WorkSpace when they leave.
Developers - Provide local and remote developers with the tools that they need to have in order to be productive, while ensuring that source code and other intellectual property are protected.
WorkSpaces for the IT Professional
Let's take a look at Amazon WorkSpaces through the eyes of an IT professional tasked with providing cloud desktops to some new employees. All of the necessary tasks can be performed from the WorkSpaces Console:
Start by choosing a WorkSpaces profile:
Add new users by name and email address:
You can provision up to five WorkSpaces at a time. They will be provisioned in less than 20 minutes and invitations will be sent to each user via email.
As the administrator, you can manage all of your organization's WorkSpaces through the console:
WorkSpaces for the User
Ok, now let's turn the tables and take a look at Amazon WorkSpaces from the user's point of view!Let's say that your administrator has gone through the steps that I outlined above and that a new WorkSpace has been provisioned for you. You will receive an email message like this:
The email will provide you with a registration code and a link to the client download. Download the client to your device, enter the registration code, and start using your WorkSpace:
WorkSpaces delivers a Windows 7 desktop experience:
Persistent storage for the WorkSpace is mapped to the D: drive:
WorkSpaces can also be accessed from iPads, Kindles, and Android tablets. Here's the desktop experience on the Kindle:
Behind the Scenes
If you already know a thing or two about AWS, you may be wondering what happens when you start to use Amazon WorkSpaces.A Virtual Private Cloud (VPC) is created as part of the setup process. The VPC can be connected to an on-premises network using a secure VPN connection to allow access to an existing Active Directory and other intranet resources.
WorkSpaces run on Amazon EC2 instances hosted within the VPC. Communication between EC2 and the client is managed by the PCoIP (PC-over-IP) protocol. The client connection must allow TCP and UDP connections on port 4172, along with TCP connections on port 443.
Persistent storage is backed up to Amazon S3 on a regular and frequent basis.
Preview WorkSpaces
You can register now in order to get access to the WorkSpaces preview as soon as it is available.



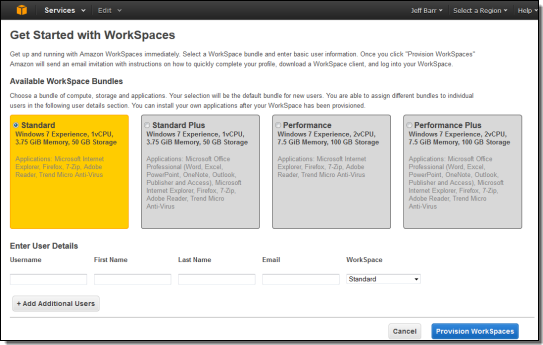
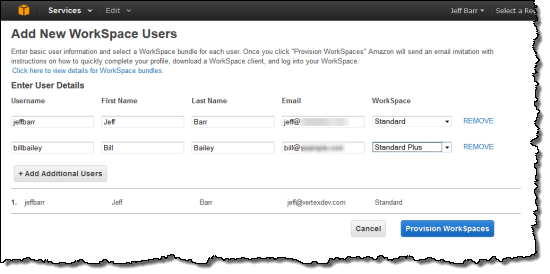
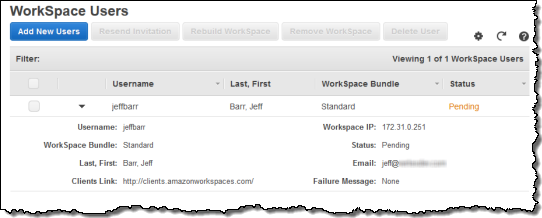
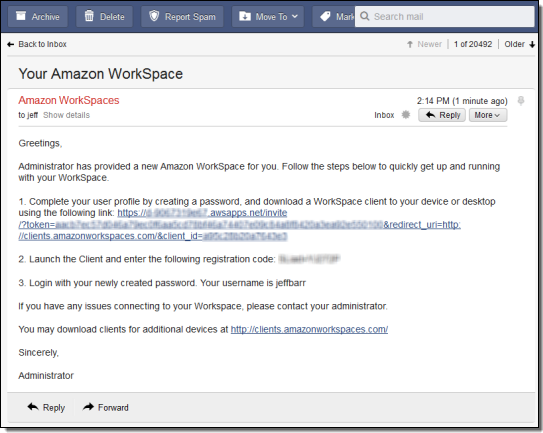
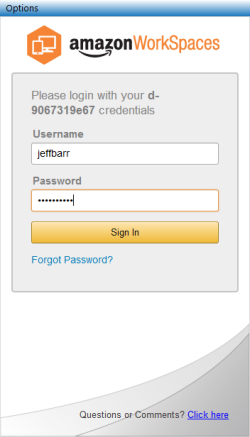

<Return to section navigation list>

















0 comments:
Post a Comment