Windows Azure and Cloud Computing Posts for 10/28/2013+
Top Stories This Week:
- Shayne Burgess (@shayneburgess) reported Windows Azure HDInsight is now Generally Available! on 10/28/2013 in the Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services section below.
- Ruppert Koch reported availability of Partitioned Service Bus Queues and Topics on 10/29/2013 in the Windows Azure Service Bus, BizTalk Services and Workflow section below.
- Jeff Barr (@jeffbarr) reported availability of a Developer Preview - AWS SDK for JavaScript in the Browser and other new AWS features on 10/31/2013 Other Cloud Computing Platforms and Services in the section.
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Caching, SQL Azure Database, and other cloud-computing articles. |
‡ Updated 11/1/2013 with new articles marked ‡
• Updated 11/1/2013 with new articles marked •
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Windows Azure Marketplace DataMarket, Power BI, Big Data and OData
- Windows Azure Service Bus, BizTalk Services and Workflow
- Windows Azure Access Control, Active Directory, and Identity
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure and DevOps
- Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
- Visual Studio LightSwitch and Entity Framework v4+
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
<Return to section navigation list>
• My (@rogerjenn) Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: October 2013 = 100.00% of 10/31/2013 is the 29th month of uptime and response time data:
My (@rogerjenn) live OakLeaf Systems Azure Table Services Sample Project demo project runs two small Windows Azure Web role compute instances from Microsoft’s South Central US (San Antonio, TX) data center. This report now contains more than two full years of monthly uptime data.
…


…

Shayne Burgess (@shayneburgess) reported Windows Azure HDInsight is now Generally Available! in a 10/28/2013 post to the Windows Azure blog:
Today we announced the general availability of the HDInsight Service for Windows Azure. HDInsight is a Hadoop-based service from Microsoft that brings a 100 percent Apache Hadoop solution to the cloud.
HDInsight offers the following benefits:
- Insights with familiar tools: Through deep integration with Microsoft BI tools such as PowerPivot, Power View, HDInsight enables you to easily find insights in data using Hadoop. Seamlessly combine data from several sources, including HDInsight, with Power Query. Easily map your data with the new Power Map, a 3D mapping tool in Excel 2013.
Agility - HDInsight offers agility to meet the changing needs of your organization. With a rich array of Powershell scripts you can deploy and provision a Hadoop cluster in minutes instead of hours or days. If you need a larger cluster, simply delete your cluster and create a bigger one in minutes without losing any data.
- Enterprise-ready Hadoop: HDInsight offers enterprise-class security and manageability. Thanks to a dedicated Secure Node, HDInsight helps you secure your Hadoop cluster. In addition, we simplify manageability of your Hadoop cluster through extensive support for PowerShell scripting.
- Rich Developer Experience: HDInsight offers powerful programming capabilities with a choice of languages including .NET, Java and other languages. .NET developers can exploit the full power of language-integrated query with LINQ to Hive.
Getting Started with HDInsight
An HDInsight cluster can be created from the Windows Azure Management portal by clicking the new button and selecting HDInsight from the Data Services menu. To create an HDInsight cluster specify a name for the cluster, the size of the cluster in number of data nodes and a password for logging in.
A cluster must have at least one storage account associated with it that will be the permanent storage mechanism for that cluster and the region the cluster is created in will always be the same region as the storage account chosen. At the time of general availability the storage account must reside in either West US, East US or North Europe to be associated with an HDInsight cluster. Additional storage accounts can be associated with a cluster using the custom create option.

It will take a few minutes for the cluster to be deployed and configured but once it is ready you will be presented with a getting started screen that provides links to additional help content as well as some sample code to run your first Hadoop job using HDInsight.
If you select the dashboard tab on the HDInsight page for your cluster, you will see the following screen that provides some basic information on the current status of your cluster including the usage in number of cores, job history and linked storage accounts.

Submitting Your First Map Reduce Job
Before you submit your first job you must prepare your development environment to use the HDInsight PowerShell cmdlets. The PowerShell cmdlets require two main components to be installed and configured: Windows Azure Powershell and the HDInsight PowerShell tools. Follow the links on step 1 of the Getting Started screen to setup your environment.
The Getting Started page has a screen that shows sample commands for submitting either a Hive or MapReduce job and we will start by submitting a MapReduce job.
Run the sample using these commands to create the job definition. The job definition contains all the information for your job, for example what mappers and reducers to use, which data to use as input and where to store the output. In this example we are going to use a sample MapReduce program and sample file that are included with the cluster. We will create an output directory in the samples directory to store the results.
$jarFile = "/example/jars/hadoop-examples.jar"
$className = "wordcount"
$statusDirectory = "/samples/wordcount/status"
$outputDirectory = "/samples/wordcount/output"
$inputDirectory = "/example/data/gutenberg"
$wordCount = New-AzureHDInsightMapReduceJobDefinition -JarFile $jarFile -ClassName
$className -Arguments $inputDirectory, $outputDirectory -StatusFolder $statusDirectory
Run these commands to get your subscription information and start execution of the MapReduce program. MapReduce jobs are typically long-running this so example shows how to use the asynchronous commands to kick off execution of the job.
$subscriptionId = (Get-AzureSubscription -Current).SubscriptionId
$wordCountJob = $wordCount | Start-AzureHDInsightJob -Cluster HadoopIsAwesome -
Subscription $subscriptionId | Wait-AzureHDInsightJob -Subscription $subscriptionId
Finally, run this command to retrieve the results of execution and display those on the PowerShell command line.
Get-AzureHDInsightJobOutput -Subscription (Get-AzureSubscription -Current).SubscriptionId -
Cluster bc-newhdstorage -JobId $wordCountJob.JobId –StandardError
The result of a MapReduce job is the information on the execution of the job itself as shown below.

The output of the job was placed in your storage account in the "/samples/wordcount/output" directory. Open the storage viewer in the Windows Azure Portal and navigate to this file to download and view the output file.

Submitting Your First Hive Job
The Getting Started page also has a screen that shows some sample commands for connecting to your cluster and submitting a Hive job. Click the Hive button in the Job type section to see the sample.

Run this sample now by first executing this command in PowerShell to connect to your cluster.
Use-AzureHDInsightCluster HadoopIsAwesome (Get-AzureSubscription -Current).SubscriptionID
Next run this command to submit a HiveQL statement to the cluster. The statement uses a sample Hive table that is setup on the cluster by default when it is created.
Invoke-Hive "select country, state, count(*) as records from hivesampletable group by country, state order by records desc limit 5"
The query is a fairly simple select-groupby and when complete will display the results on the PowerShell command line.

Learn More
In this blog we showed you just how easy it is to get up and running with an HDInsight cluster and begin analyzing your data. There is a lot more you can do and learn with HDInsight like uploading your own data sets, running sophisticated jobs and analyzing your results. For more details on using HDInsight visit the HDInsight documentation page or use the following links to access help articles directly.
- Getting Started with the HDInsight Service
- Provisioning HDInsight clusters
- Submit Hadoop jobs programmatically
- Connect Excel to Windows Azure HDInsight with Power Query
For details on pricing visit the HDInsight pricing details page.








Mary Jo Foley (@maryjofoley) asserted “Microsoft's HDInsight service -- a cloud-based distribution of Hadoop -- is generally available. Microsoft's planned complement for Windows Server has been replaced” in a deck for her Microsoft makes available its Azure-based Hadoop service article of 10/28/2013 for ZDNet’s All About Microsoft blog:
Microsoft's cloud-based distribution of Hadoop -- which it has been developing for the past year-plus with Hortonworks -- is generally available as of October 28.
Microsoft officials also are acknowledging publicly that Microsoft has dropped plans to deliver a Microsoft-Hortonworks developed implementation of Windows Server, which was known as HDInsight Server for Windows. Instead, Microsoft will be advising customers who want Hadoop on Windows Server to go with Hortonworks Data Platform (HDP) for Windows.
Windows Azure HDInsight is "100 percent Apache Hadoop" and builds on top of HDP. HDInsight includes full compatibility with Apache Hadoop, as well as integration with Microsoft's own business-intelligence tools, such as Excel, SQL Server and PowerBI.
"Our vision is how do we bring big data to a billion people," said Eron Kelly, Microsoft's SQL Server General Manager. "We want to make the data and insights accessible to everyone."
Making the Hadoop big-data framework available in the cloud, so that users can spin up and spin down Hadoop clusters when needed is one way Microsoft intends to meet this goal, Kelly said.
Microsoft and Hortonworks originally announced plans to bring the Hadoop big-data framework to Windows Server and Windows Azure in the fall of 2011. Microsoft made a first public preview of its Hadoop on Windows Server product (known officially as HDInsight Server for Windows) available in October 2012.
Microsoft made available its first public preview of its Hadoop on Windows Azure service, known as HDInsight Service, on March 18. Before that, it had made a number of private previews available to select testers.
Hortonworks announced in February this year that its HDP platform was an extension of its two-year-old Hadoop partnership with Microsoft. (HDP didn't exist yet when Microsoft and Hortonworks initially announced their partnership.)
HDP allows users to deploy Hadoop on Windows Server in their own datacenters -- the same way they can already deploy HDP on several Linux distributions. Microsoft and Hortonworks are touting HDP for Windows as offering an easy migration path to HDInsight.
Hortonworks announced general availability of HDP 2.0 last week. Hortonworks will update HDP for Windows Server to take advantage of HDP 2.0 within a month, Kelly said. The pair haven't committed to a timetable as to when they'll update HDInsight to take advantage of HDP 2.0. (It's currently on version 1.3.)
As part of its Hortonworks partnership, Microsoft has contributed back to Apache 25,000 lines of code for inclusion in the Apache Hadoop code base, Kelly said.



The SQL Server Team (@SQLServer) posted Revolutionizing City Planning in the 21st Century with Windows Azure, HDInsight, and SQL Server on 10/30/2013:
If you’ve ever played a video game where you manage a virtual city, you understand how real-time insight into services including emergency response teams and transportation is needed for effective city planning. Until recently, the technologies just weren’t available to support this kind of detailed “big picture” view enjoyed by gamers. However, now that Big Data business intelligence (BI) solutions are a reality, Barcelona, Spain is working to achieve transformative insight so that it can better meet the needs of its citizens.
To test the feasibility of a Big Data BI solution, Barcelona created a pilot that runs on a hybrid cloud based on Windows Azure, Windows Azure HDInsight Service, and Microsoft SQL Server 2012. With it, users can view real-time BI that combines petabytes of existing data in the city’s systems with new, unstructured public data sources such as Twitter, app log files, and GPS signals from cell phone providers. The BI is served up via mobile apps, dashboards, custom reports, and data services.
The variety of technology choices in the Microsoft platform simplified development. For example, engineers met the diverse needs of users and devices using HDInsight and built-in tools in SQL Server, Microsoft Office, and Visual Studio. Engineers were also able to manage the project’s varied data and cost requirements with Apache Hadoop and Azure’s other storage options, which you can read about here.
Everyone wins with this kind of solution. City employees are more productive because they quickly see how services are working from “big picture” views that include detailed numbers and social media feedback. Citizens enjoy a better quality of life because services like emergency teams, transportation, schools, and festivals are customized to meet real needs. Businesses can also increase success by quickly recognizing investment opportunities in specific neighborhoods. Other cities also benefit because they can adopt this repeatable smart-city infrastructure to transform insight, lifestyles, and economic success.
You can learn more about Barcelona’s pilot solution by reading the case study and watching the video here.


The SQL Server Team (@SQLServer) reported Customers get Faster and Better Insight into More Data from More Sources with Windows Azure HDInsight Service on 10/29/2013:
Collecting Big Data is significant only if you can make use of it. With Windows Azure HDInsight Service, organizations can use Apache Hadoop clusters in Windows Azure. Combining the Microsoft platform with open-source tools like Hadoop equates to unprecedented insight into more data, from more sources, in any format—structured and unstructured. Here are a few examples:
Chr. Hansen develops food, pharmaceutical, and agricultural ingredients for global clients. By creating a hybrid cloud solution in less than one week with Windows Azure, HDInsight, and existing SQL Server 2012 databases, the company increased the number of trials it could analyze by 100 times. Read the full story here.
Ascribe is a leading provider of clinical IT solutions in the United Kingdom. To recognize outbreaks of health threats faster, Ascribe created a hybrid cloud solution in just six weeks using Windows Azure, HDInsight, and SQL Server 2012. Now in just seconds, automated processes can analyze millions of records from disparate sources including social media feeds—and deliver potentially life-saving alerts to mobile devices and desktops. Read more here.
Virginia Polytechnic Institute and State University (Virginia Tech) is a leading US research institution that recently implemented an on-demand, cloud computing model using HDInsight. With it, the university is saving money, and researchers working on new cancer therapies and antibiotics are accomplishing more, and enjoying easier access to DNA-sequencing tools and resources. The details are here.
There are lots of Big Data and cloud-service options but what sets Windows Azure HDInsight Service apart is that it’s part of the larger end-to-end Microsoft platform, so you get more than just a service. You get built-in tools for creating highly effective, available, scalable, and affordable enterprise-ready solutions that include BI (supported by SQL Server and Microsoft Office) and mobile apps (created with Visual Studio). On top of that, Windows Azure solutions can run entirely in the cloud—or work with existing systems. You get to choose.
To learn more about what’s possible with the Microsoft platform, read Microsoft’s Cloud OS Vision.


Philip Fu posted [Sample Of Oct 25th] How to transfer IIS logs to storage account in a custom format in Windows Azure to the Microsoft All-In-One Code Framework blog on 10/25/2013:
Sample Download : http://code.msdn.microsoft.com/How-to-transfer-IIS-logs-87479fb8
Because any log file transfer to Azure storage are billable, custom log file before transfer will help you save money. This sample will show you how to custom IIS logs in your Azure web role. This is a frequently asked question in forum, so we provide this sample code to show how to achieve this in .NET.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.


<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
‡ James Serra (@JamesSerra) reported Windows Azure SQL Reporting discontinued in an 11/1/2013 post:
Windows Azure SQL Reporting was the new name of the reporting services component (which was formerly known as SQL Azure Reporting Services) that went live June 12, 2012.
However today, October 31, 2013, notification went out to current Windows Azure SQL Reporting customers that the service will be discontinued in 12 months (October 31, 2014). Customers were directed to migrate their report instances to SQL Server Reporting Services running on Windows Azure Virtual Machines.
SQL Server Reporting Services running on Windows Azure Virtual Machines will provide customers with full native mode feature set, broader data access, and the ability to shut down VMs when not in use for greater flexibility in controlling costs. Current customers will continue to maintain full functionality in their current SQL Reporting deployment for 12 months, while new customers will be directed to use VMs with SSRS for their Azure reporting instances.
More info:
- Use PowerShell to Create a Windows Azure VM With a Native Mode Report Server
- SQL Server Business Intelligence in Windows Azure Virtual Machines
…


• Nick Harris (@cloudnick) and Chris Risner (@chrisrisner) produced Cloud Cover Episode 118: Location based Push Notifications with Windows Azure Notification Hubs on 1/11/2013:
In this episode Nick Harris and Chris Risner are joined by Elio Damaggio, Program Manager on the Windows Azure Notification Hubs team. During this episode you will learn how you can send easily implement location based/geotargeted push notifications using Windows Azure Notification Hubs. Examples of scenarios where this may be useful can include; contextual remionders, weather alerts, retargeting customers of a specific store, sending coupons and marketing promotions by region.
The implementation consisted using the Geolocator class on windows phone to retrieve the users location. As the location of the users device changes the Bing reverse geocoding API is used to turn that lat/long into an address. Each segment of the address is then used to create notification hub tags against the registered push notification channel of the application - for example based on postal code, locality, county, state and country. Then to deliver a notification to a specific area say postal code you simply send a notification to notification hubs targeted at the specific tag of interest. This approach can be used to implement cross platform notifications targeting Windows Phone, Windows Store, Android and iOS apps.
Philip Fu posted [Sample Of Oct 26th] How to horizontally partition data in Windows Azure SQL Database to the Microsoft All-In-One Code Framework blog on 10/26/2013:
Sample Download : http://code.msdn.microsoft.com/How-to-horizontally-2e0dc563
This sample demonstrates how to partition your data in SQL Azure.


<Return to section navigation list>
Windows Azure Marketplace DataMarket, Cloud Numerics, Big Data and OData
The WCF Data Services Team reported the availability of a New version of OData Validator on 10/27/2013:
The OData team has been working on updating the OData Validator tool to support the new JSON format validation. We are pleased to announce that the tool now supports validating your V3 service for all three formats – ATOM, old JSON format (aka JSON Verbose) and the new JSON format. We are also working on adding OData V4 service validation support. We will continue adding more validation rules over the next few months.
Please check out the tool here : http://services.odata.org/validation/ and provide us feedback.
About the tool
OData Validator is an OData protocol validation tool. We have gone through the OData spec and created a set of rules to validate against a given OData payload. You can point the tool to your service and choose what you want to validate. The tool will run the right set of rules against the returned payload and tell you which ones passed and which ones failed. The tool will also link you to the relevant spec section so you can open the spec to see what it says. The tool supports validating various OData payloads like service document, metadata document, feed, entity and error payloads.
<Return to section navigation list>
Windows Azure Service Bus, BizTalk Services and Workflow
Ruppert Koch reported availability of Partitioned Service Bus Queues and Topics in a 10/29/2013 post to the Windows Azure blog:
Editor's Note: This post was written by Ruppert Koch, Program Manager II on the Windows Azure Service Bus team.
Last week Microsoft released the Azure SDK 2.2 and Service Bus SDK 2.2. These SDKs come with a new Service Bus feature: partitioned entities. Using these SDKs (or specifying api-version=2013-10 in your HTTP requests) allows you to create and use partitioned queues and topics on Azure Service Bus. Partitioned queues and topics give you improved reliability. At the same time, you should see higher maximum message throughput in most use cases.
What are partitioned queues and topics?
Whereas a conventional queue or topic is handled by a single message broker and stored in one messaging store, a partitioned queue or topic is handled by multiple message brokers and stored in multiple messaging stores. This means that the overall throughput of a partitioned queue or topic is no longer limited by the performance of a single message broker or messaging store. In addition, a temporary outage of a messaging store does not render a partitioned queue or topic unavailable.
In a nutshell, a partitioned queue or topic works as follows: Each partitioned queue or topic consists of multiple fragments. Each fragment is stored in a different messaging store and handled by a different message broker. When a message is sent to a partitioned queue or topic, Service Bus assigns the message to one of the fragments. The selection is done randomly by Service Bus or by a partition key that can be specified by the sender. When a client wants to receive a message from a partitioned queue or a subscription of a partitioned topic, Service Bus checks all fragments for messages. If it finds any, it picks one and passes that message to the receiver.
Enabling Partitioning
You can choose between three ways to create a partitioned queue or topic. The first method is to create the queue or topic from your application. Enable partitioning by setting the QueueDescription.EnablePartitioning or TopicDescription.EnablePartitioning property to true. These flags must be set at the time the queue or topic is created. It is not possible to change this property on an existing queue or topic.

Alternatively, you can create a partitioned queue or topic in Visual Studio. We added a new checkbox Enable Partitioning in the New Queue and New Topic dialog window.

The third option is the Windows Azure portal. This functionality will become available with the next portal update that is schedule to rollout in a few days.
Note that Azure Service Bus currently allows only 100 partitioned queues or topics per namespace. Furthermore, Partitioned queues and topics are only supported in Azure Service Bus but are not available on Service Bus for Windows Server 1.1.
Use of Partition Keys
When a message is enqueued into a partitioned queue or topic, Service Bus checks for the presence of a partition key. If it finds one it selects the fragment based on that key. If it doesn’t, it selects the fragment based on an internal algorithm.
Using a partition key
Some scenarios, such as sessions or transactions, require messages to be stored in a certain fragment. All of these scenarios require the use of a partition key. All messages that use the same partition key are assigned to the same fragment.
Depending on the scenario, different message properties are used as a partition key:
SessionId. If a message has the SessionId property set, then Service Bus uses the SessionId property as the partition key. This way, all messages that belong to the same session are assigned to the same fragment and handled by the same message broker. This allows Service Bus to guarantee message ordering as well as the consistency of session states.
PartitionKey. If a message has the PartitionKey property set but not the SessionId property, then Service Bus uses the PartitionKey property as the partition key. Use the PartitionKey property to send non-sessionful transactional messages. The partition key ensures that all messages that are sent within a transaction are handled by the same messaging broker.
MessageId. If the queue or topic has the RequiresDuplicationDetection property set to true, then the MessageId property serves as the partition key if the SessionId or a PartitionKey properties are not set. This ensures that all copies of the same message are handled by the same message broker and, thus, allows Service Bus to detect and eliminate duplicate messages
Not using a partition key
In the absence of a partition key, Service Bus distributes messages in a round robin manner to all the fragments of the partitioned queue or topic. If the chosen fragment is not available, Service Bus assigns the message to a different fragment. This way, the send operation succeeds despite the temporary unavailability of a messaging store.
As you can see, a partition key pins a message to a specific fragment. If the messaging store that holds this fragment is unavailable, Service Bus returns an error. In the absence of a partition key, Service Bus is able to pick a different fragment and the operation succeeds. Therefore, it is recommended that you do not supply a partition key unless required.
Using Transactions with Partitioned Entities
Messages that are sent as part of a transaction must specify a partition key. This can be a SessionId, PartitionKey, or MessageId. All messages that are sent as part of the same transaction must specify the same partition key.
You can use the following code to send a transactional message to a partitioned queue:

If you want to send a transactional message to a session-aware topic or queue, the message must have the SessionId property set. As stated above, the SessionId serves as the partition key. If you set PartitionKey property as well, it must be identical to the SessionId property.
Unlike with regular queues or topics, it is not possible to use a single transaction to send multiple messages to different sessions.

Additional Information
Find more detail about the partitioned queues and topics at http://msdn.microsoft.com/en-us/library/dn520246.aspx and check out the Service Bus Partitioned Queue sample.






<Return to section navigation list>
Windows Azure Access Control, Active Directory, Identity and Workflow
• Philip Fu posted [Sample Of Oct 31st] How to call WCF services via Access Control Serivce (ACS) Token in Windows Azure to the Microsoft All-In-One Code Framework blog on 10/31/2013:
Sample Download : http://code.msdn.microsoft.com/How-to-call-WCF-via-Access-1ed01c22
The sample code demonstrates how to invoke the WCF service via Access control service token. Here we create a Silverlight application and a normal Console application client. The Token format is SWT, and we will use password as the Service identities.
Vittorio Bertocci (@vibronet) described Using ADAL’s AcquireTokenBy AuthorizationCode to Call a Web API From a Web App in a 10/29/2013 post:
We are going to publish a sample doing justice to this scenario soon, but in the meanwhile I am getting questions about this multiple times per day hence I think it’s time to whip up a super-quick post and unblock some of you guys.
Wait, what am I talking about? Perhaps I rushed a bit into it … let’s take a step back:
Say that you have a Web application. Say that as part of the functions it perform, your app needs to call a Web API. Say that such Web API is protected by a Windows Azure AD tenant. How do you obtain a token for it?
The answer is – via OAuth2, of course; and via ADAL, if you don’t want to write too much code.
You might have already seen how to use ADAL for obtaining tokens from native applications: the flow for Web applications is a little different.
Web apps are characterized in the OAuth2 spec as “confidential clients”, that is to say clients that can keep a secret: the idea is that what you save on your web server is not accessible to anybody else, hence you can safely save keys there. As such, during the token acquisition flow your app is required to use such a secret to identify itself. In practical terms, this means that when you create your app in the directory tenant you need to have a credential of some sort (a secret, a certificate, etc) assigned to it and later use it from your code. The good news? When you create one Web app with the new VS2013 ASP.NET templates, and you assign read or write directory access rights to it, the creation process itself will provision a secret for your app and will even make you the courtesy of saving it in your web.config, ready for you to use! That secret is put there so that your app can call the Graph API (through another flow, the client credential grant, but that’s a story for another day) but it will just as well for our scenario.
If you want to follow along, this would be a good time to drop in VS2013 and create a new Single Organization – cloud MVC app. Make sure you choose read or write in the bottom dropdown.

If the differences with the native client case would end here, things would be pretty easy; we’d just add to AcquireToken a parameter for passing the client secret and we’d be done. However differences do run a bit a deeper here.
In a native client the main app UI activity is well separated from the token acquisition flow, which takes place in a dedicated browser dialog; but for a Web app all the action takes place entirely in the browser! That means that if the user needs to interact with some external UI in order to grant to the Web app access to the Web API, he/she needs to be shipped out to the authority that renders the consent UI and come back with some artifact showing that consent has indeed been granted. Now, the example I am showing is super special and no UI needs to be actually shown – for 2 reasons:
- Currently the consent for accessing resources in Windows Azure AD is admin based – that means that if the tenant admin consented for one given app/resource to be provisioned in the tenant, direct user consent is not necessary (though user authentication is, given that the token will be issued on per-user basis)
- In this sample I am using the same AAD tenant for both web sign on and for protecting the target API – which means that when being redirected the user will land on the Authorization endpoint already authenticated, hence no UI will be shown.
I am doing this simplified scenario because it’s already 11:40PM and I can’t write this post all night, but in fact it’s perfectly possible for you to use a different tenant or even implement web sign on in completely different fashion, without even using Windows Azure AD. There would simply be more provisioning steps involved.Despite the simplifications afforded by the above, the OAuth2 code grant still requires us to ship the user offsite to obtain an authorization code, retrieve that code once it comes back and use it to call AAD and obtain the necessary token(s).
That flow is heavily dependent on the stack you are using for developing your web app, hence it was not possible for us to wrap it in its entirety in a single call as we’ve done for the native clients. Rather, in ADAL this flow is split in two phases:
- You, the Web app developer, are responsible to initiate the process by redirecting the user to the Windows Azure AD tenant’s Authorization endpoint. It’s pretty straightforward, the parameters are pretty much the same you’d pass to the usual ADAL calls.
You are also responsible to set up a handler/page/action at the configured return URL to retrieve the authorization code- Once you have the code, you can pass it to ADAL along with the client id & secret to obtain an access token, refresh token etc etc as usual.
#1 is the part that is dependent on the development stack, hence it’s up to you to implement it in whatever way is appropriate for the tech you used. #2 is all automated goodness.
So let’s make that happen, shall we?
Navigate to your Windows Azure portal, select the app you create via VS, and click Configure. You’ll get to the screen below.

At the very bottom you’ll see a drop down listing all the Web API provisioned in your tenant (I’ll assume you have at least one; if you don’t, see any of the posts I’ve been publishing ion the last month and you’ll find instructions to create one). Pick the one you like best, then hit Save on the command bar below.
That done, move your attention to the Reply URL section just few lines above.

Go ahead and add a new URL, corresponding to the address on which you’ll want to add logic for handling the return flow carrying the code. Hit save again, then move back to VS2013.
Head to the HomeController, and spend a second to take a look to the list of constants placed there by the template. As mentioned, those are mostly for the benefit of the boilerplate Graph code included in the UserProfile action; but they’ll come in handy for us as well.
The first thing to add is the logic for triggering the token acquisition flow. Here I’ll just pick one of the default actions to host it. Here’s the code, formatted for your screens:
1: public ActionResult About()2: {3: string authorizationUrl = string.Format(4: "https://login.windows.net/{0}/oauth2/authorize?api-version=1.0&response_type=code&client_id={1}&resource={2}&redirect_uri={3}",5: ClaimsPrincipal.Current.FindFirst(TenantIdClaimType).Value,6: AppPrincipalId,7: "http://myadfsvagaries/webapi",8: "https://localhost:44304/Home/CatchCode"9: );10:11: return new RedirectResult(authorizationUrl);12: }The URL is just the standard URL you’ll see for any Authorization endpoint (apart for the resource parameters) but just for excess of clarity
- the base URL is the Windows Azure AD URL + the current tenant identifier (taken from the web sign on claim in line 5, but I could have kept it in config just as well) and the Authorize sub-url
- Line 6 carries the client id of the web app
- line 7 specifies the ID of the Web API we want to call
- line 8 contains the return URL from where we want to retrieve the code – this is the same URL we added in the portal
That done, we just need the code to retrieve the code and use it to get the token(s).
public ActionResult CatchCode(string code) { AuthenticationContext ac = new AuthenticationContext(string.Format("https://login.windows.net/{0}", ClaimsPrincipal.Current.FindFirst(TenantIdClaimType).Value)); ClientCredential clcred = new ClientCredential(AppPrincipalId, AppKey); var ar= ac.AcquireTokenByAuthorizationCode(code, new Uri("https://localhost:44304/Home/CatchCode"), clcred); return View(); }If you followed the other posts on ADAL, you should recognize the generic structure. First we create an AuthenticationContext for the current tenant; then we create a ClientCredential with the id and the secret of the Web app (same thing we’d do for calling the Graph).
The news here is the call not to AcquireToken, but to AcquireTokenByAuthorizationCode – passing the ClientCredential and a return URL (IMPORTANT – it must be the same return URL value used in the code request!).
The reason for the different name is to make it explicit that this is not exactly operating in the same way as the other primitives – apart from the calling pattern, for example, AcquireTokenByAuthorizationCode won’t save tokens in the cache.
Want to give it a spin? Try it! Put a breakpoint on the last line of CatchCode and hit F5. Go through the authentication, then click About. If everything goes well, you should get a nice AuthenticationResult. Let’s take a look at what the debugger tells us:

The main thing I wanted to show you is that the token you get contains claims describing the user, which is one of the main differentiators in respect to other server side flows like the client credentials flow provided OOB for Graph access in the template.
There you have it! This is a very messy and incomplete walkthrough – for example, I didn’t mention at all where you are going to save the tokens you just got – but as I mentioned a good & comprehensive sample is on its way. Hopefully this will help unblock you, feel free to get in touch if you need clarifications!








<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
‡ Tyler Doerksen (@tyler_gd) explained Azure Websites vs Cloud Services in a 11/1/2013 post:
The question of the week is. When do you use Azure Websites as your web platform and when do you use Cloud Services. These two platforms provide similar functionality in that you can deploy your ASP.NET or other IIS based web application projects to either of these platforms. There are some general cases of when to use one over the other and some specific differences that may help in making that decision. In this post I am going to go through these differences and attempt to give some guidance on what to use when.
When to use Websites

You Are Just Starting – Compared to Cloud Services, Websites may not be as flexible but it is definitely easier. You can build your website using Visual Studio, WebMatrix, or any other IDE of your choice without the need for an SDK or any other additional software.
You can deploy to Azure Websites using WebDeploy, FTP, or even DropBox. You can sync your site code straight from GitHub, BitBucket, Codeplex, or TFS Online. It is incredibly easy and require little to know buy-in to Azure if you want to create an IIS website.
You Have a Single Compute Tier – If you are running an application that does not require internal communication then it would be much easier to use Websites. Again, the stance that I usually take is use the easiest option until you are required to change. If you need multiple machines that talk to each other over a private network, then you cannot use Websites and you need to use Cloud Services (or Virtual Machines).
With Websites you can have multiple servers handling requests if you have a high load, however those servers know nothing of each other and do not have internal addresses or endpoints.
Your Site is Written in PHP, Python, or Node.js – This point is not to say that you cannot use these platforms on Cloud Services, it is just easier with Websites because the machines are configured beforehand. With Cloud Services you get a base Azure Image to deploy onto. The Azure Website system uses that same base image however extra software has been installed to IIS for your convenience.
When to use Cloud Services
You Need Machine Level Access – If you compare the underlying platform of Websites and Cloud Services, Cloud Services provides you with a completely provisioned, unique, stateless virtual machine whereas Websites provides pre-configured IIS application pool, and you may be on the same machine as other sites. With IIS there are many restrictions, not the least of them is machine level access. This restriction could affect the base functionality of .NET like using PFX certificates to sign network tokens, or accessing local user profile data.
When deploying to Cloud Services there is no shared option, this deployment owns the entire virtual machine for its lifetime (which could vary, it is not a state-full instance). This gives you much more control over the deployment environment compared to Websites.
You Perform Background Processing – The Cloud Services platform has two different Role Types, a Web Role, and a Worker Role. If you are familiar with on-premise architectures you can compare the two to an IIS Application and a Windows Service. Azure Websites is all IIS, the web server provides the entire platform, there is no room for long running processes or threads that can sit and wait for communication on another port outside of IIS.
If those Windows Service type scenarios are sounding familiar to you, you may need to consider using Cloud Services for the Worker Role capabilities.
Your Application Requires Internal Communication – With Windows Azure services there is a general level of scaleability. Both Cloud Services and Azure Websites can scale up and down as needed, even automatically. However, if you want to use 2 web front-end machines and they need to communicate to each other, you need to use Cloud Services Roles and Instances. Azure Websites take routed requests in a farm of IIS hosting servers, they have no knowledge of other machines in the same site.
Cloud Services however runs as an overall deployment with multiple Roles and each of those Roles can contain multiple Instances. You can scale different components of your system separate from others. Cloud Service deployments also have an internal network all to themselves to use to communicate between the Roles and Instances. The Azure SDK contains .NET Libraries to determine which machine is the current instance and where to contact the others.
Feature Breakdown
For those more specific features that may sway your decision one way or the other, here is a quick table comparing the two.


Summary
If the above information has just left you more confused, here are some basic guidelines that I use for many Azure service match-ups.
Use what you need, until you need more, then switch.
That said, start by creating an Azure Website (hey, it’s free right), get your application out into the world. If you find that you require more complexity and you are considering a multi-tier scenario, consider switching to Cloud Services.
‡ Pradeep M G posted Exploring the AutoScale feature in Windows Azure Websites to the Windows Azure Technical Support Team blog on 10/30/2013:
We recently released a whole lot of updates for Windows Azure platform and one of those updates, is the addition of date based AutoScale scheduling support (set different rules on different dates).
In this blog post we will go over the concepts of auto scale, configuring your website to AutoScale in and out thus saving you operations cost.
Note: AutoScale feature is currently in preview and must be used only for testing purpose. All preview features do not have SLA and are supported through forum.
What is Windows Azure AutoScale?
Let’s say you run a website that sells flowers and its known pattern that traffic to your website increases during Mother’s day, Valentine’s Day etc. Before Windows Azure AutoScale feature was available you had to manually increase the instance count of your websites to be able to efficiently handle the increased load. You had to then again manually decrease the instance count after that peak.
Now with Auto Scale you have the ability to Scale in or out automatically by defining a set of rules.
Windows Azure AutoScale Facts
- AutoScale feature in Windows Azure Websites is available in Standard mode only.
- Ability to AutoScale is supported only for instance count currently.
Enable Windows Azure AutoScale
Before you can start using AutoScale ensure that your website is running in Standard mode.

- Login to your Windows Azure Account.
- Click WEB SITES and then click the NAME of the website on which that you want to configure AutoScale.

3. Click SCALE and then click set up schedule times.

4. In Set up schedule times dialog box under SPECIFIC DATES enter the details in each textbox as per the prompt.
Note: This is the date and time when you want to increase the instance count. At the END TIME your instance count will be automatically reduced to the previous default value.

5. After adding the details, click the tick button at the bottom of Set up schedule times dialog box.
6. From the EDIT SCALE SETTINGS FOR SCHEDULE dropdown choose the NAME you entered in the previous step(in this case it is Diwali).

7. Drag the INSTANCE COUNT slider towards the right to increase the instance count.
8. Click SAVE button on command bar at the bottom, after choosing the required the INSTANCE COUNT.
9. You will received a similar notification under the command bar.

Your AutoScale automation task is saved and your instance will automatically scale out during the defined date and time.
Access AutoScale Operation Logs
You can access the AutoScale operations logs from Dashboard of your website in Windows Azure.
- Login to your Windows Azure Account.
- Click WEB SITES and then click on the NAME of the website for which you want to view the AutoScale logs.
- Click DASHBOARD then click AUTOSCALE OPERATION LOGS

4. Here you will see all the AutoScale operation logs.
Note: You can adjust the date and time, to query the logs relevant to that particular time frame.
5. Choose a particular log by clicking on it, then click Details on the command bar to see more information of the selected operation.

Hope this information was informative!!
If you don’t already have a Windows Azure account, you can sign-up for a free trial and start using the Windows Azure Websites and AutoScale features today.








• My (@rogerjenn) Uptime Report for My Live Windows Azure Web Site: October 2013 = 99.63% of 10/31/2013 is the sixth month of data for OakLeaf’s Android MiniPCs and TVBoxes Windows Azure Web Site (WAWS):
My (@rogerjenn) Android MiniPCs and TVBoxes blog runs WordPress on WebMatrix with Super Cache in Windows Azure Web Site (WAWS) Standard tier instance in Microsoft’s West U.S. (Bay Area) data center and ClearDB’s MySQL database (Venus plan). I converted the site from the Shared Preview to the Standard tier on September 7, 2013 in order to store diagnostic data in Windows Azure blobs instead of the file system.
Service Level Agreements aren’t applicable to the Web Services’ Shared tier; only sites in the Standard tier qualify for the 99.9% uptime SLA.
- Running a Shared Preview WAWS costs ~US$10/month plus MySQL charges
- Running a Standard tier instance costs ~US$75/month plus MySQL charges
I use Windows Live Writer to author posts that provide technical details of low-cost MiniPCs with HDMI outputs running Android JellyBean 4.1+, as well as Google’s new Chromecast device. The site emphases high-definition 1080p video recording and rendition.

The site commenced operation on 4/25/2013. To improve response time, I implemented WordPress Super Cache on May 15, 2013. I moved the site’s diagnostic logs from the file system to Windows Azure blobs on 9/7/2013, as reported in my Storing the Android MiniPCs Site’s Log Files in Windows Azure Blobs post.
…







<Return to section navigation list>
Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
‡ Shaun Xu described the Remote Debug Windows Azure Cloud Service in a 11/2/2013 post:
Originally posted on: http://geekswithblogs.net/shaunxu/archive/2013/11/02/remote-debug-windows-azure-cloud-service.aspx
On the 22nd of October Microsoft Announced the new Windows Azure SDK 2.2. It introduced a lot of cool features but one of it shocked most, which is the remote debug support for Windows Azure Cloud Service (a.k.a. WACS).
Live Debug is Nightmare for Cloud Application
When we are developing against public cloud, debug might be the most difficult task, especially after the application had been deployed. In order to minimize the debug effort, Microsoft provided local emulator for cloud service and storage once the Windows Azure platform was announced. By using local emulator developers could be able run their application on local machine with almost the same behavior as running on Windows Azure, and that could be debug easily and quickly. But when we deployed our application to Azure, we have to use log, diagnostic monitor to debug, which is very low efficient.
Visual Studio 2012 introduced a new feature named "anonymous remote debug" which allows any workstation under any user could be able to attach the remote process. This is less secure comparing the authenticated remote debug but much easier and simpler to use. Now in Windows Azure SDK 2.2, we could be able to attach our application from our local machine to Windows Azure, and it's very easy.
How to Use Remote Debugger
First, let's create a new Windows Azure Cloud Project in Visual Studio and selected ASP.NET Web Role. Then create an ASP.NET WebForm application.

Then right click on the cloud project and select "publish". In the publish dialog we need to make sure the application will be built in debug mode, since .NET assembly cannot be debugged in release mode.

I enabled Remote Desktop as I will log into the virtual machine later in this post. It's NOT necessary for remote debug.
And selected "advanced settings" tab, make sure we checked "Enable Remote Debugger for all roles". In WACS, a cloud service could be able to have one or more roles and each role could be able to have one or more instances. The remote debugger will be enabled for all roles and all instances if we checked. Currently there's no way for us to specify which role(s) and which instance(s) to enable.

Finally click "publish" button. In the windows azure activity window in Visual Studio we can find some information about remote debugger.

To attach remote process would be easy. Open the "server explorer" window in Visual Studio and expand "cloud services" node, find the cloud service, role and instance we had just published and wanted to debug, right click on the instance and select "attach debugger".

Then after a while (it's based on how fast our Internet connect to Windows Azure Data Center) the Visual Studio will be switched to debug mode. Let's add a breakpoint in the default web page's form load function and refresh the page in browser to see what's happen.

We can see that the our application was stopped at the breakpoint. The call stack, watch features are all available to use. Now let's hit F5 to continue the step, then back to the browser we will find the page was rendered successfully.
What’s Under the Hood
Remote debugger is a WACS plugin. When we checked the "enable remote debugger" in the publish dialog, Visual Studio will add two cloud configuration settings in the CSCFG file. Since they were appended when deployment, we cannot find in our project's CSCFG file. But if we opened the publish package we could find as below.

At the same time, Visual Studio will generate a certificate and included into the package for remote debugger. If we went to the azure management portal we will find there will a certificate under our application which was created, uploaded by remote debugger plugin.
Since I enabled Remote Desktop there will be two certificates in the screenshot below. The other one is for remote debugger.

When our application was deployed, windows azure system will open related ports for remote debugger. As below you can see there are two new ports opened on my application.

Finally, in our WACS virtual machine, windows azure system will copy the remote debug component based on which version of Visual Studio we are using and start. Our application then can be debugged remotely through the visual studio remote debugger. Below is the task manager on the virtual machine of my WACS application.

Summary
In this post I demonstrated one of the feature introduced in Windows Azure SDK 2.2, which is Remote Debugger. It allows us to attach our application from local machine to windows azure virtual machine once it had been deployed.
Remote debugger is powerful and easy to use, but it brings more security risk. And since it's only available for debug build this means the performance will be worse than release build. Hence we should only use this feature for staging test and bug fix (publish our beta version to azure staging slot), rather than for production.












‡ Christian Martinez of the Azure Customer Acceptance Team (CAT) described Application Request Routing in CSF in a 10/31/2013 post to the Windows Azure blog:
Application Request Routing (or ARR) is probably one of the least talked about but critically important technologies used across Microsoft and helps power things such as Windows Azure Web Sites, Outlook.com, and many other high volume, critical applications. It stands to reason, then, that using it directly in Windows Azure applications is discussed even less. We used it in Cloud Service Fundamentals because one of the patterns CSF shows is splitting work among multiple cloud services and transparently creating an affinity to a cloud service based on the user. This approach is based on prior experience with large customers where cloud services were used as scale units and where having high locality (data is close to the code using it) offered performance benefits . ARR is a natural fit to help us meet the requirements.
At first when you hear multiple Cloud Services you might say, “Hold on second…So you have multiple cloud services. Just use Windows Azure Traffic Manager (WATM)”! Indeed, for most routing needs when you have split work among multiple cloud services for either performance or business continuity reasons WATM is probably the right choice. In this case, however, it did not meet the requirements. WATM offers three methods of load balancing:
- Performance
- Failover
- Round Robin
Those are great but none of them meet the requirement of sending a user to a cloud service based on who they are (as determined by a cookie).
To use ARR we needed 4 things:
- A Windows Azure Cloud Service comprised of Web Roles to host ARR
- A script to install and configure ARR
- Configure ARR rules
- Decide what to do in the case of a user not having a cookie from a previous visit
The details and code for all of which can be found here. Most of these steps are generic to any solution leveraging ARR on Azure so I will only discuss the two CSF-specific parts here:
- Route-by-Cookie rules – What did an ARR routing rule look like for CSF?
- No cookie present – What did we do when there is no cookie and how we did it.
Route by Cookie Rules
The logic to route a user by their cookie looks like this:

Rule configuration is can be a somewhat complex topic but the logic above basically says in English:
If the request is over SSL and is a relative path and contains a user cookie of form userpod=(some number), then capture the part of the cookie after the equals sign and rewrite the destination URL by injecting that captured value.
Sure, it can look a little strange but you will get used to it after a while.
No cookie present
But what do you do in the event that no cookie is detected? There may be several ways to solve it but we decided to create a class which implements two interfaces, IRewriteProvider and IProviderDescriptor. The first interface allows you to use code to return a custom URL based on the request inputs and the second allows you to provide for a simple configuration of your custom inputs. Our code for the provider simply took the configured pods and chose among them in round robin fashion whenever a request without a cookie came in. This is not exciting code in that it amounts to incrementing an integer and then circling around when you hit the last spot.
The configuration code is slightly more interesting -- but not by much:

This results in a grid where for a given pod you can enter a URL. So, the net effect of all this was we had code that was configurable with a set number of addresses to choose if no cookie was present!
Final thoughts
ARR is a powerful tool used widely across Microsoft. This blog gave you the reasons why we used it for the CSF scenario but this scenario only scratched the surface of what ARR can do. For example, one common use we have seen for it is within a cloud service so that routing and load balancing are available in any pattern desired. It’s great if WATM or some other pre-built service can meet your needs but if they can’t don’t overlook this powerful and versatile option.



• Andy Cross (@andybareweb) posted #Codevember on 11/1/2013:
I’m joining Richard Astbury in doing
this: http://coderead.wordpress.com/2013/11/01/one-commit-a-day-codevember/
I am going to be focused on https://github.com/AndyCross/netmfazurestorage – a .net microframework implementation of Azure Storage.


Sandrino Di Mattia (@sandrinodm) described Using ASP.NET App Suspend in your Windows Azure Web Roles (OS Family 4) in a 10/29/2013 post:
Windows Server 2012 R2 was released about 2 weeks ago together with Visual Studio 2013 and the .NET Framework 4.5.1. One of the updated features in Windows Server 2012 R2 is IIS 8.5 which introduces the Idle Worker Process Page-out functionality, adding suspend support to your application pools. This is similar to the tombstoning support in Windows Phone / Windows Store applications.
ASP.NET App Suspend is the managed implementation of this new functionality and will improve the startup time of your .NET web applications running in IIS. The .NET Framework Blog explains that this is perfect for hosting companies but even if you’re only running a single site you’ll feel the difference.
Let’s take a look at some numbers…
Without App Suspend
So I deployed a simple ASP.NET MVC application as a Windows Azure Web Role and I’m hitting it for the first time. The first time I visit the application it takes 3.39 seconds to load the page (this is because the application needs to start for the first time).

Now after this first request the application pool has been “warmed up” and as you can see all other requests execute very fast. In this case it took about 26 ms:

The page load time will remain like this until the application pool recycles. Let’s wait until that happens (for testing purposes I changed the Idle Timeout to 1 minute). In the next screenshot you’ll see what you would expect:

After an application pool recycle the application needs to reinitialize and initial load is similar to the one we’ve see in the first step.
With App Suspend
Let’s take a look at what happens when we enable App Suspend. The very first request still takes a few seconds to load.

There’s nothing special about the second request either, it’s still very fast.

Now for the last test we wait until the application pool recycles and try hitting it again. And this is where you’ll see App Suspend kicking in. Thanks to App Suspend the application wasn’t terminated but it was suspended instead. This reduced the application pool load time from 3.41 seconds to 41 milliseconds. The very first request will always take some time, but after you’ll notice the reduced startup time.

App Suspend in your Web Role
Now let’s see how we can enable App Suspend for web applications running in a Web Role.
Since this feature depends on IIS8 you’ll need to make sure that your application runs on OS Family 4 (Windows Server 2012 R2). The OS Family of your project can be changed in the ServiceConfiguration.*.cscfg files:
The next thing we need to do is reference the Microsoft.Web.Administration NuGet package (make sure that Copy Local is set to true). This is because we’ll be writing some code to enable App Suspend on our application pool. But before we can do that we need to make sure that the Web Role process (which runs the code in WebRole.cs) has sufficient permissions to access IIS. This is possible by changing the execution context of the role to elevated in the ServiceDefinition.csdef file:

The last thing we need to do is write the code that will enable App Suspend for the application pool:
Based on the name of the current instance we’re able to find the main site with its application pool. Once we have the name of the application pool we can access the ProcessModel which allows us to specify the idleTimeoutAction. By setting this to 1 and saving the changes we’ve activated App Suspend. If you want to test if it really works I suggest you uncomment the line which specifies the idleTimeout. By uncommenting that line you’ll be changing the idle timeout to 1 minute, which is low enough to test application pool recycles.



Hanuk Kommalapati (@hanuk) described Generating SSH keys for Linux on Windows Azure –updated on 10/29/2013:
This is a modification to the post I did a while ago: http://blogs.msdn.com/b/hanuk/archive/2012/06/07/generating-ssh-key-pair-for-linux-vm-deployment-on-windows-azure.aspx. Install openssl and edit OPENSSL_HOME before executing this script.
The following shell script will help generate the necessary keys for Window Azure Linux deployments on Windows 7 or Windows 8 clients:



All the keys generated are PEM (base-64) formatted with the suffix _rsa_pvt.pem meant for converting into .ppk format to be used inside putty.exe from
Windows. Assuming that our RSA formatted key is dbsrv_rsa_pvt.pem, this can be converted to .ppk format using the following sequence on puttygen.exe: Conversions –> Import key –> Save private key. Make sure to enter the pass phrase if you need to add additional measure of security to the SSH interaction.Following are the examples of usage:
Example 1: Clear text private key
gensshkey_win dbsrv
Example 2: Clear text private key
gensshkey_win dbsrv pass@word1
While creating the Linux VM on Windows Azure, use the public key with the suffix _x509_pub.pem for SSH certificate.
Philip Fu posted [Sample Of Oct 27th] How to use Bing Translator API in Windows Azure to the Microsoft All-In-One Code Framework blog on 10/27/2013:
This Sample will show you how to use Bing translator, when you get it from Azure market place.
Here provide three scenarios that we usually choose. Each page uses a different interface for get data from Bing translator.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
‡ David Fellows (@Dave_Fellows) answered Why Window Azure? in a 10/30/2013 post to the Green Button blog:
A lot of our customers – including large Enterprises and Software Vendors – ask our opinion on the best cloud platform to run their applications and workloads. Two to three years ago there was only one decision to make; to Cloud or not to Cloud? Amazon Web Services was the de facto standard for those pioneers who chose Cloud. Fast forward to today, the decision to use the cloud is now the no-brainer for most businesses, however, with the cloud market becoming such a fiercely competitive space, ripe with innovation and differing strategies, the decision of which cloud becomes the more critical and daunting one.
When I read analyst opinion comparing the major cloud offerings, I’m surprised to see Windows Azure is often omitted. This leads me to believe these analysts are clearly not doing their homework or, they don’t have a deep understanding of the cloud and how this relates to the challenges businesses are faced with today.
Amazon Web Services are numero uno right now – that’s not up for debate. However, I see Windows Azure as the clear runner up and hot on Amazon’s heels. My prediction? Hold on to your seats for this one. I predict that Windows Azure will take the lead in 2-3 years’ time.
The momentum of Windows Azure is truly impressive. Microsoft, who have been criticized in the past for moving too slowly to capitalize on industry trends, have really proven the naysayers wrong with the speed and agility in which they have innovated and improved their cloud offering. If you look at Scott Guthrie’s blog, which is a good yardstick for the pace of Azure development, there have been 18 major announcements on new Azure features in the last 7 months! Scott Guthrie, affectionately known as “The Gu”, is the VP of Windows Azure and is essentially a god to Microsoft developers. While Scott has clearly made a monumental impact to Windows Azure and demonstrated impressive leadership since being promoted to run Azure in 2011, there is also a team of incredibly smart and visionary engineers that have designed and built a platform that is second to none. Yes you heard me right, putting market share aside, I believe Windows Azure is the most complete and capable offering in the market today. Big call huh?
Aside from the many commercial and enterprise-focused features (Backup services, Active Directory, Managed SQL Server, Hadoop as a Service etc), that make Azure a natural fit for most organizations, we at GreenButton are excited by some of the lesser-known capabilities. The GreenButton Cloud Fabric platform for cloud-enabling and managing Big Compute and Big Data apps can place heavy demands on infrastructure, particularly when you look at the more traditional High Performance Computing (HPC) workloads such as Seismic Processing, Computational Fluid Dynamics and Genomic Sequencing algorithms. Many of these applications require extremely low latency networks to join many computers together in a cluster. The expensive network configurations are typically built around Infiniband and use Remote Direct Memory Access (RDMA) to provide around 2 micro seconds latency. None of the major cloud providers support Infiniband today. Microsoft however announced their new HPC hardware complete with Infiniband a little while ago and we expect to see this coming online soon. The cloud has long been perceived by many of the HPC traditionalists as an inappropriate or ill-equipped alternative for High Performance Technical Computing – particularly for those workloads that require very low latency networks. This perception is rapidly changing as both Commercial and Research & Science facilities are finding the massive economic benefits the cloud offers for these spikey-by-nature workloads hard to resist. With this latest offering, Microsoft claim a real leadership position in this space. Of course those with HPC applications will want to talk to us to get their workloads ported to the cloud and manage data and governance without any fuss…
We have other strategic partners who certainly have their strengths. HP are a late starter but making notable progress on articulating a thought out strategy. IBM shouldn’t be underestimated with their acquisition of SoftLayer and their High Performance Computing and Analytics pedigree. VMware still dominate the Private Cloud and have a seamless Hybrid Cloud offering now. But I see Microsoft best positioned to make the most impact in the near term.
Microsoft is in the process of shifting to a more functional organization across Devices & Consumer and Commercial. Within those groups we should expect to see more collaboration and more tightly integrated products and services. This is an exciting transition and one which should deliver a more connected and seamless experience to customers.
Microsoft have demonstrated a strategy towards offering vertically integrated services. Windows Azure Media Services is a good example. I think this is bang on from a strategy point of view; Customers want higher-value services that are consumed on-demand. They also want these services to be connected with their existing ecosystems. This is surely the end goal of all this cloud malarkey.
It’s an incredibly exciting industry to be a part of right now. Our vision has always been to make the power of on-demand computing available to anyone at the push of a button – whether you’re a “one-man-band” or a Fortune 500. To consumerize High Performance Computing. To allow the little guy to compete with the largest in their industry without constraints. Microsoft and Windows Azure are playing a key role in the realization of this disruptive vision.


Alejandro Jezierski (@alexjota) described Cloud Design Patterns, new drop on Codeplex in a 10/29/2013 post:
We made a new drop of the Cloud Design Patterns book on codeplex.
The drop includes the following patterns and related guidance:

This is still work in progress, and in future releases we will include new patterns, guidance, as well as some code samples to get you started.

The Microsoft Server and Cloud Platform Team (@MSCloud) announced One Stop Shopping for Microsoft Server and Cloud Community Resources in a 10/29/2013 post:
Providing information to our community is important to us. There are a number of channels we use to get the word out on promotions, great technical content, and fun contests. The Microsoft Server and Cloud business is growing, as is the community of developers and IT professionals.
We recently launched a number of new areas on Microsoft.com to give you better perspective on the Cloud OS vision we have, the investments we are making, and how to get information for evaluation and implementation purposes. In addition to the stories and articles, we also launched a new Community area.

The Server and Cloud Community area is organized by product. You’ll see customer case studies and testimonials, links to our blogs, Facebook and Twitter accounts, YouTube video area, and technical forums. Now it’s very easy to find all of those resources, and discover the great content we publish. The following Windows Server screen snip is an example of its respective section.

We hope you like the new Community page and one stop shopping for your social media preferences. As always, tell us what you like or dislike about the information. Thank you for being our customer and part of our community.

<Return to section navigation list>
Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
• David Gordon announced on 10/30/2013 a Hybrid heaven: Systems Centre Virtual Machine Manager and Windows Azure RegCast for 11/14/2013 at 11:00 GMT (3:00 AM PST):
We show you how to get them on the same page
Hands-on On 14 November at 11.00 GMT we will be broadcasting a live training session on the Microsoft network virtualization technologies of Windows Hyper-V, Systems Centre Virtual Machine Manager (SCVM) and Windows Azure – all working together in Hybrid data centre solution.
For you, dear reader, it’s free to watch from the comfort of your sofa, desk or bed. All we ask is that you come along with questions, the more the merrier. We have Paul Gregory from QA Training doing the question- wrangling – as well as the actual training sessions and demos – while The Register’s effervescent Tim Phillips will be running the show and keeping it all moving along nicely.
It promises to be an interesting gig. It will demonstrate how Microsoft technologies – including the Windows Azure pack – enable on-premise, hybrid, hosted and public Azure solutions. It will also show the deployment of an application using the Microsoft hybrid cloud model: effectively deploying a web front-end application within Windows Azure communicating with a SQL back-end stored in a private cloud on premise solution.
If that sounds like your bag, then rush along and register, for free, here or just magically add it to your calendar by clicking on this this handy little link (iCal).
Seems rather early for us on the US Pacific Coast:

Microsoft TechNet updated the Windows Azure Pack for Windows Server documentation on 10/17/2013 (missed when pubished):
Applies To: Windows Azure Pack for Windows Server
Windows Azure Pack for Windows Server is a collection of Windows Azure technologies, available to Microsoft customers at no additional cost for installation into your data center. It runs on top of Windows Server 2012 R2 and System Center 2012 R2 and, through the use of the Windows Azure technologies, enables you to offer a rich, self-service, multi-tenant cloud, consistent with the public Windows Azure experience.
Windows Azure Pack includes the following capabilities:
- Management portal for tenants – a customizable self-service portal for provisioning, monitoring, and managing services such as Web Sites, Virtual Machines, and Service Bus.
- Management portal for administrators – a portal for administrators to configure and manage resource clouds, user accounts, and tenant offers, quotas, and pricing.
- Service management API – a RESTful API that helps enable a range of integration scenarios including custom portal and billing systems.
- Web Sites – a service that helps provide a high-density, scalable shared web hosting platform for ASP.NET, PHP, and Node.js web applications. The Web Sites service includes a customizable web application gallery of open source web applications and integration with source control systems for custom-developed web sites and applications.
- Virtual Machines – a service that provides infrastructure-as-a-service (IaaS) capabilities for Windows and Linux virtual machines. The Virtual Machines service includes a VM template gallery, scaling options, and virtual networking capabilities.
- Service Bus – a service that provides reliable messaging services between distributed applications. The Service Bus service includes queued and topic-based publish/subscribe capabilities.
- SQL and MySQL – services that provide database instances. These databases can be used in conjunction with the Web Sites service.
- Automation and Extensibility – the capability to automate and integrate additional custom services into the services framework, including a runbook editor and execution environment.
Get started with Windows Azure Pack
- Review the Windows Azure Pack installation requirements.
- Install Windows Azure Pack: Portal and API Express - install all components on a single machine. Requires Windows Server 2012 or Windows Server 2012 R2.
- Install Windows Azure Pack components on multiple machine - Download and install the Windows Azure Pack components from Web Platform Installer. After you install the Web Platform Installer, click Products -> Windows Azure to see all available components. Requires Windows Server 2012 or Windows Server 2012 R2.
- Follow the step-by-step instructions in Deploy Windows Azure Pack for Windows Server.
- Provision and configure services in Windows Azure Pack
- Release Notes
- Forums
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
‡ Rowan Miller released the source code for Entity Framework 6 to CodePlex on 10/31/2013:
What is EF
Entity Framework (EF) is an object-relational mapper that enables .NET developers to work with relational data using domain-specific objects. It eliminates the need for most of the data-access code that developers usually need to write.
Entity Framework is actively developed by the Entity Framework team which is assigned to the Microsoft Open Tech Hub and in collaboration with a community of open source developers. Together we are dedicated to creating the best possible data access experience for .NET developers.
How do I use EF
If you want to use an officially supported Entity Framework release to develop your applications then head to msdn.com/data/ef where you can find installation information, documentation, tutorials, samples, and videos.
If you want to try out the latest changes that have not been officially released yet, signed nightly builds of the Entity Framework code base are made available
What’s going on
Want to know what the future holds for Entity Framework? We update our roadmap regularly and we post specific feature specifications and design meeting notes publicly for review.
How do I contribute
There are lots of ways to contribute to the Entity Framework project including testing out nighty builds, reporting bugs, suggesting features, reviewing feature specifications as well as contributing code.
Note: that all code submissions will be rigorously reviewed and tested by the Entity Framework team, and only those that meet an extremely high bar for both quality and design/roadmap appropriateness will be merged into the source.

• Rowan Miller reported EF6 Performance Issues in a 10/31/2013 post to the ADO.NET Blog:
The most common issue being encountered is a significantly slower startup time when running with the debugger attached. Here is a complete list of the performance related issues we are tracking.
- [Performance] Startup time is bad with debugger attached
- [Performance] Entity materialization slower in EF6.0.1
- [Performance] EF6 startup performance issue (without debugger attached)
When will a fix be available?
We are working to put together a 6.0.2 patch release that addresses the performance issues and some other high priority bugs. We are working to make this patch available quickly, but we also want to make sure we capture as many issues as possible and perform adequate testing to ensure we don’t introduce new issues. While we don’t have definite plans for a release date yet, we’re aiming to make it available in November.
You can view the issues being tracked for inclusion in this patch on our CodePlex site. Note that some issues are still being investigated and won’t show up in the 6.0.2 release until we have identified the root cause.
Why did you miss this stuff?
Unfortunately it is not practical - or even possible - to cover every scenario in our suite of performance tests. Some of these issues have exposed holes in our test suite that we are working to fill. Other issues only manifest when certain model sizes/shapes/patterns are present and they just happen to be areas that are not covered by our test suite.
We realize that reliable performance is important to you, your business, and your customers and we don’t take this situation lightly. In addition to rounding out our performance test suite we will also be reviewing the issues identified in EF6 to understand how we can avoid such issues in the future.
The already released 6.0.1 patch release
The 6.0.0 version of the EF package needed to be locked down early to be included in Visual Studio, ASP.NET, etc. After this lock down we identified some other performance issues that we felt needed to be addressed ASAP.
At the same time we released 6.0.0 we also published a 6.0.1 patch release that addressed these issues. If you install from NuGet you will automatically get the latest patch version. If you use a VS2013 project template that already has EF6 installed, or if the EF6 tooling installs the NuGet package for you, we would recommend updating to the latest patch version. You can do this by running Update-Package EntityFramework in Package Manager Console.
You can see a complete list of the individual fixes in this patch on our CodePlex site.
Improving startup performance with Ngen
Prior to EF6, a large portion of Entity Framework was included in the .NET Framework. This meant that most of Entity Framework automatically has native image generation run on it to reduce the just-in-time (JIT) compilation cost.
Because EF6 ships as a completely out-of-band release, native image generation is no longer performed automatically. This can result in an increased warm-up time for your application while JIT compilation occurs – we have seen results of around 1 second.
To remove this JIT time you can use Ngen to generate native images for the EntityFramework assembly on your machine.
- Run the Developer Command Prompt for VS2013 as an administrator
You can find the command prompt under Program Files (x86)\Microsoft Visual Studio 12.0\Common7\Tools\Shortcuts\- Navigate to the directory that contains EntityFramework.dll
This will be something like <my_solution_directory>\packages\EntityFramework.6.0.1\lib\net45- Run Ngen Install EntityFramework.dll
Make sure you read the Ngen.exe one-page documentation in MSDN to determine what strategy makes more sense for you. Not all scenarios will benefit equally from an ngen’d EntityFramework assembly. Furthermore, as with any use of ngen, determine if your scenario degrades when ngen isn’t applied with Hard Binding. Test your options and do what gives you best results.

Matt Sampson (@TrampSansTom) described an HTML Upload Control For LightSwitch SharePoint Apps! in a 10/29/2013 post:
(And it’s available through NuGet!)
For a while now I’ve been seeing quite a few requests from users for a simple, pluggable, HTML Control that can be used to upload files in a LightSwitch application.
What I’m going to do here is show you how you can use a NuGet package to add an HTML Control to a SharePoint enabled LightSwitch HTML Application. This post is strictly for those LightSwitch apps that are enabled for SharePoint (also known as Cloud Business Apps now), but in a future post I do plan to do an HTML Upload Control for vanilla LightSwitch apps that aren’t enabled for SharePoint.
Here’s the breakdown on what we are going to do here:
- Create a SharePoint enabled LightSwitch HTML Application
- Add a simple table and screen
- Add a SharePoint List to our project
- Add a NuGet Package that I made to make it easier to create our upload control
- With the help of the NuGet package, and the SharePoint List, we can then make a screen with a simple upload control
Make a SharePoint enabled LightSwitch app
Launch Visual Studio 2013, and select “File –> New Project”. For this example we’ll use a “Cloud Business App” project. This will make us a SharePoint Enabled LightSwitch App.

My project is called “AllMyBooks”. As you might guess, I’m going to use this project to catalogue some books that I own.
I need some way to keep track of my data, so we’ll create a basic entity that will store some information about the books, and then a screen that will allow me to view, add, and edit the list of books (later on we’ll add a control to upload images of the books).
I’ve made an entity that has a few fields to track some data about the book. You’ll notice I have an “ImageUrl” field that we’ll use to track the actual location of the image that we’ll be uploading use the upload control later.

I’ll need a couple simple screens to view the data. Nothing fancy, just a simple Browse screen, and an Add/Edit screen.
Right click on the Screens folder in your HTML Client project, and select “Add Screen…”. Add a Browse screen for the Book entity. After you do this, in the screen designer, right click on the “Command Bar” and select “Add Button…”. Then select “Choose an existing method –> Add/Edit”. This will allow you to then create a new Add/Edit screen for the Book entity.
For the Add/Edit screen, I’ve changed the layout a bit so that all the fields are in the “Left” row. And I’ve changed the “Image Url” field so that is of type “Web Address Viewer”. This will make the URL a clickable link.

Next we’ll want to add Custom Control to this screen. We’ll come back to it later, but for now just add it by selecting the “New Custom Control” link in the drop down menu like so:

Select the default values for the custom control and hit OK. In the properties pane, change the display name to something like “Image Upload”.
In the designer, navigate back to your Browse screen, right click on the Command Bar and add another button. Select “Choose an existing method” and select “View Selected”. This will allow us to View our record after creating it.
This isn’t required, but I’m going to make one small change to the View screen, to make it look a bit cooler. Drag and drop the “ImageUrl” field onto Rows Layout – left. So you should have two “Image Url” fields now. One will just be the plain URL of the image. The other is going to actually be an image. You can accomplish that by switching it’s type to “image” like so:

We should have our basic screens done now, so let’s move on to adding the SharePoint List to our project.
Add a List to our SharePoint Project
Adding a SharePoint List is pretty straightforward and useful for all types of scenarios. We’re going to add a Document Library List to our SharePoint project which is where all our “uploaded” images will actually be stored (you can store almost any type of file into a Document Library, but for this example I’m storing images).
To get started, in the Solution Explorer, right click the SharePoint project and select “Add –> New Item –> List”. I’m calling my list “BookList”. The name is important, and we’ll need to remember it for later.
You should be prompted to select what type of list you want. Select “Document Library” for the type.

As the name implies, Document Libraries are perfect for storing almost any type of file in SharePoint.
Now that we’ve added it to the project, we can move onto adding our NuGet package.
Add the NuGet package
You can find the NuGet package here – LightSwitch SharePoint Upload Control. (Hopefully by the time this blog goes live, you should be able to find the package by navigating to Tools –> Library Package Manager –> Manage NuGet Packages, and then searching online for it).
If you can’t find the package online, you can download it from the above link, and then tell the NuGet Package Manager where to find it on your machine. Just navigate to Tools->Options->Package Manager->Package Sources. And add an entry for where the NuGet package can be found (e.g. c:\Documents\Downloads).
When you install the package, make sure it’s only installed for the HTML Client project, like so:

This NuGet package has 2 JavaScript files that are added to your HTML Client “Scripts” folder. This 2 files have all the code you need to handle uploading and interacting with the SharePoint Document Library list we added earlier.
At this point we just need to “plug” this code into our LightSwitch project.Write a couple lines of code
Before we can add the code to our custom control, we’ll need to let the default.htm file know where to find these 2 new JavaScript files we’ve added.
In the solution explorer, under your HTML Project, open up the default.htm file, and right below the “<script>” entry for the globalize.min.js file, add these 2 lines:
<script type="text/javascript" src="Scripts/SingleUpload.js"></script><script type="text/javascript" src="Scripts/sharepoint.js"></script>Almost there, now we need to update our custom control. So open up the screen designer for the Add/Edit screen we made earlier.
Select the “Custom Control” field on the screen.
Under the properties click the “Edit Render Code” link –>

This will bring us into the code editor for the render method. This method is called to handle “rendering” this custom control on our HTML screen.
My code for this method looks like so:
/// <reference path="../GeneratedArtifacts/viewModel.js" /> /// <reference path="../Scripts/SingleUpload.js" /> var myUpload; myapp.AddEditBook.ScreenContent_render = function (element, contentItem) { // Write code here. myUpload = new SingleUpload(element, "BookList"); };You can see that I added a “<reference path>” at the top of the file to the SingleUpload.js. This isn’t essential, but I do this to enable intellisense for all the methods and variables that exist in the SingleUpload JavaScript file.
The rest of the code is pretty simple, I’m creating a new “instance” of the SingleUpload “class”, and storing that in my global variable: “var myUpload”. All I have to pass into SingleUpload() is the current HTML element so that the upload control can be added, and the name of the SharePoint list that we created earlier, which is “BookList”.
On a later post I’ll go over in detail what is happening inside this SingleUpload JS file, but for now just understand that it handles creating the basic HTML control and uploading files to SharePoint’s document library.
One last line of code to write, I want to automatically save the URL of the file we are uploading to the Book.ImageUrl field on my entity. This is easy to accomplish by overriding the “beforeApplyChanges” method for our Add/Edit screen like so (paste this into the same JS file as the render method above):
myapp.AddEditBook.beforeApplyChanges = function (screen) { // Write code here. // get sp document URL from here if (myUpload._fileUrl) { screen.Book.ImageUrl = myUpload._fileUrl; } };This is a simple method that first verifies that the “_fileUrl” property exists. It may not exist, for example, if we didn’t upload an image. Next we take that URL and store it in the Book.ImageUrl field for this new record we are creating.
GO!
That is that. Now it’s time to “F5” the app and see how it looks in SharePoint at runtime.
(After the app launches the first time it sometimes needs around 20 extra seconds to finish “loading” and initializing the document library list that we added earlier. Otherwise you might get an error when trying to upload a file.)
Now let’s make a record and try everything out.
Click the “Add Book” button to launch the Add/Edit screen. At this point you can fill out some basic information about the book. You’ll see the custom control at the bottom, and it should look like a familiar Browse Files control you’ve probably seen elsewhere.
Once the upload starts you’ll see a message - “Upload has started, please be patient” (uploads can take a while for very large files). During this process, the file is being added to the Document Library. And after it’s completed, and we save, we will store the direct URL to the entry in the Document Library.
And once it has completed, you can save out the record.
You’ll remember that when the record is saved, we also added code to save the URL of the Document Library into our ImageUrl field. You can now view this URL by selecting the record in our list and pressing “View Book”.
And of course the link will re-direct you right to the Document Library entry that contains the image file we uploaded.


Hope you like it! – Let me know if you have any feedback below.












If you have problems running the code, check the comments to Matt’s article.
<Return to section navigation list>
Cloud Security, Compliance and Governance

<Return to section navigation list>
Cloud Computing Events
Taylor Rhyne (@taylorwrhyne) reported an Upcoming Webinar: Windows Azure for IT Pros to be held on 11/6/2013:
Microsoft’s Windows Azure is a secure, standards compliant, scalable cloud computing offering. It provides a simple, comprehensive, and powerful platform for the creation of web applications and services. As an open and flexible cloud platform, it allows organizations to build, deploy and manage applications across a global network of datacenters. You can build applications using your choice of language, tool and/or framework. And it works with the infrastructure you already own, providing a cost-effective means to enhancing your business continuity strategy.
If you are looking to learn more about Azure, join us on Wednesday, November 6th at 1 p.m. CT for the webinar, Windows Azure for IT Pros. Presenter Adetayo ‘Tayo’ Adegoke is a senior solutions architect in Perficient’s Microsoft practice, focused on implementing SharePoint, cloud, and virtualization solutions for clients. During this session, he’ll provide an introduction to Windows Azure, covering topics such as:
- Cloud jargon in plain English
- What is Windows Azure and how can it help me?
- Running web sites and VMs in the cloud
- What else can I put in the cloud / what else can I use the cloud for?
- How can I use the cloud?
- How do I manage this?
To register for the webinar, click here.
Windows Azure for IT Pros
Wednesday, November 6, 2013
1:00 p.m. CT

<Return to section navigation list>
Other Cloud Computing Platforms and Services
‡ Jeff Barr (@jeffbarr) reported availability of a Developer Preview - AWS SDK for JavaScript in the Browser on 10/31/2013:
Would you like to build rich, browser-based applications that make direct calls to AWS services without the need for any server-side code?
If so, I invite you to take a look at the developer preview of our new AWS SDK for JavaScript. You can make direct calls to the following AWS services:
- Amazon S3 to store and retrieve objects at any scale.
- Amazon SQS to read from and write to message queues.
- Amazon SNS to generate and process notifications to mobile devices and other distributed services.
- Amazon DynamoDB to store and retrieve any amount of data, at any access rate.
The SDK supports access to all of the functionality provided by each of the services listed above. You can create and populate S3 buckets, manage message queues, create, populate, and query DynamoDB tables, and much more!
Getting Started
Add the following tag to your HTML file to get started:<script src="https://sdk.amazonaws.com/js/aws-sdk-2.0.0-rc1.min.js"></script>There are no dependencies, but you may find higher-level JavaScript libraries such as jQuery useful when you build your rich, interactive applications.
If you plan to use the S3 APIs you will first need to enable CORS (Cross-Origin Resource Sharing) on the target buckets. Using the AWS Management Console, create or open a bucket, click on Properties, and Edit CORS Configuration. The sample configuration in the box below will allow your application to perform GET, PUT, POST, and DELETE operations on the objects in the bucket:
<?xml version="1.0" encoding="UTF-8"?> <CORSConfiguration xmlns="http://s3.amazonaws.com/doc/2006-03-01/"> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>GET</AllowedMethod> <AllowedMethod>PUT</AllowedMethod> <AllowedMethod>POST</AllowedMethod> <AllowedMethod>DELETE</AllowedMethod> </CORSRule> </CORSConfiguration>Amazon DynamoDB, Amazon SQS, and Amazon SNS now support CORS, so you can start calling these services with no additional configuration.
I should note that the policy above is more permissive than necessary. For a production application, the <AllowedOrigin> tag on your bucket’s CORS policy should allow requests only from the domain that is hosting your JavaScript. If your JavaScript is coming from www.example.com, you should use a tag like this in your policy:
<AllowedOrigin>http://www.example.com</AllowedOrigin>Authentication and Access Control
If you have used the AWS SDKs and APIs in the past, you know that each request must be signed with your AWS credentials. You almost certainly don't want to include your credentials in your HTML or your JavaScript where anyone could find and use them. Instead, you should use our web identity federation feature to authenticate the users of your application. By incorporating WIF into your application, you can use a public identity provider (Facebook, Google, or Login with Amazon) to initiate the creation of a set of temporary security credentials.Amazon DynamoDB now supports fine-grained access control (see my new post for more information). You can now assign permissions at the item or attribute level (or both) to your authenticated users. For example, a user can have read access to an entire table and write access to the rows (items) that they own. Read the documentation on Fine-Grained Access Control for Amazon DynamoDB to learn more.
Similarly, when using Amazon S3 with web identity federation, you can tailor read and write access to the needs of each user at the prefix or object level.
To learn more about how to configure web identity federation, read the guide on Creating Temporary Security Credentials for Mobile Apps Using Identity Providers.
Using the SDK
The AWS SDK for JavaScript uses the same programming model in the browser and in server-side Node.js code.I wrote a little function to list the objects in an S3 bucket and display them as images. Here's the code:
<script type="text/javascript"> var s3BucketName = 'jbarr-site'; function listObjs() { var s3 = new AWS.S3({ params: {Bucket: s3BucketName} }); s3.listObjects(function(error,data) { if (error === null) { var html_keys = 'Object Keys:<br />'; var html_imgs = ''; jQuery.each(data.Contents, function(index, obj) { html_keys += (index + ': ' + obj.Key + '<br />'); html_imgs += "<img src='" + "https://s3.amazonaws.com/" + s3BucketName + "/" + obj.Key + "'/><br/>"; }); jQuery("#objKeys").html(html_keys); jQuery("#objImgs").html(html_imgs); } else { console.log(error); } }); } </script>The function is invoked using a button and generates output into a pair of HTML <div> elements:
<button onclick="listObjs()">S3 - List Objects</button> <div id="objKeys"></div> <div id="objImgs"></div>The S3 bucket contains four images:
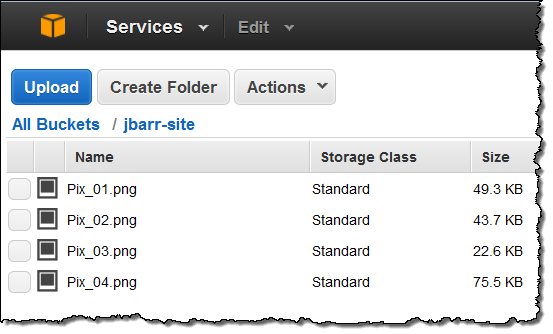
Here's what the page looks like before I push the button:
And here's what it looks like after I push the button and the code runs:

As you can see, you could create a very simple photo album with a very modest amount of code. Since there's no server-side code at all, you don't even need a web server to host your application. Deploying your web application can be as simple as uploading it to your S3 bucket with public-read permissions. Think about the implications of this architecture, and let me know what you come up with!
Here's some very simple uploading code:
<script> function uploadFile() { var s3 = new AWS.S3({ params: {Bucket: s3BucketName} }); var file = document.getElementById('fileToUpload').files[0]; if (file) { s3.putObject({Key: file.name, ContentType: file.type, Body: file, ACL: "public-read"}, function (err, data) { if (data !=== null) { alert("Got it!"); } else { alert("Upload failed!"); } }); } } </script>This function is invoked by a button. Use the Browse button to select an image to upload before clicking the Upload to S3 button:
<input type="file" id="fileToUpload"/> <button onclick="uploadFile()">Upload to S3</button>Learn More
Here are some resources to help get you started with the AWS SDK for JavaScript:
- AWS SDK for JavaScript in the Browser
- AWS JavaScript Developer Center
- Getting Started with JavaScript in the Browser
- Developer Guide for the AWS SDK for JavaScript
- API Reference for the AWS SDK for JavaScript
Talk to Us
This is a Developer Preview, and we will make changes based on your feedback. Visit the AWS SDK for JavaScript Forum to leave feedback and to connect with other users of the SDK.
The AWS team is on a roll this month.
• Jeff Barr (@jeffbarr) described Cross-Region Snapshot Copy for Amazon RDS on 10/31/2013:
I know that many AWS customers are interested in building applications that run in more than one of the eight public AWS regions. As a result, we have been working to add features to AWS to simplify and streamline the data manipulation operations associated with building and running global applications. In the recent past we have given you the ability to copy EC2 AMIs, EBS Snapshots, and DynamoDB tables between Regions.
RDS Snapshot Copy
Today we are taking the next logical step, giving you the ability to copy Amazon RDS (Relational Database Service) snapshots between AWS regions. You can initiate the copy from the AWS Management Console, the AWS Command Line Interface (CLI), or through the Amazon RDS APIs. Here's what you will see in the Console:
You can copy snapshots of any size, from any of the database engines (MySQL, Oracle, or SQL Server) that are supported by RDS. Copies can be moved between any of the public AWS regions, and you can copy the same snapshot to multiple Regions simultaneously by initiating more than one transfer.
As is the case with the other copy operations, the copy is done on an incremental basis, and only the data that has changed since the last snapshot of a given Database Instance will be copied. When you delete a snapshot, deletion is limited to the data that will not affect other snapshots.
There is no charge for the copy operation itself; you pay only for the data transfer out of the source region and for the data storage in the destination region. You are not charged if the copy fails, but you are charged if you cancel a snapshot that is underway at the time.
Democratizing Disaster Recovery
One of my colleagues described this feature as "democratizing data recovery." Imagine all of the headaches (and expense) that you would incur while setting up the network, storage, processing, and security infrastructure that would be needed to do this on your own, without the benefit of the cloud. You would have to acquire co-lo space, add racks, set up network links and encryption, create the backups, and arrange to copy them from location to location. You would invest thousands of dollars in infrastructure, and the same (if not more) in DBA and system administrator time.All of these pain points (and the associated costs) go away when you copy backups from Region to Region using RDS.


• Jeff Barr (@jeffbarr) announced Fine-Grained Access Control for Amazon DynamoDB in a 10/30/2013 post:
I truly enjoy the process of putting blog posts together for new AWS services and features. Many features started out as specific requests from one of the hundreds of thousands of AWS users. With "customer obsession" as one of our core values, all of us on the AWS team do everything that we can to listen to our customers and to make sure that their feedback ends up in the Inbox of the right service team.
Amazon DynamoDB has become very popular with developers in a very short time. Many developers are using building mobile apps and online games using DynamoDB. Apps of this type can benefit from DynamoDB's scalability, flexibility, and efficiency. These apps generally use a single table to store information for the entire user base, which can easily grow to the millions or tens of millions of users. This scenario requires the use of a proxy tier between the app and DynamoDB in order to handle authentication and authorization.
The proxy introduces additional latency and complexity, not to mention the added expense. We saw this proxy-based architecture frequently. In most cases the proxy did nothing more than regulate access to particular items and (occasionally) attributes.
Fine-Grained Access Control for DynamoDB
To make it easier for you to implement the use case that I described above, we are launching Fine-Grained Access Control for DynamoDB today. You can now use AWS Identity and Access Management (IAM) policies to regulate access to items and attributes stored in DynamoDB tables, without the need for a middle-tier proxy as illustrated above.Here are some of the things that you can build using fine-grained access control:
- A mobile app that displays information for nearby airports, based on the user's location. The app can access and display attributes such airline names, arrival times, and flight numbers. However, it cannot access or display pilot names or passenger counts.
- A mobile game which stores high scores for all users in a single table. Each user can update their own scores, but has no access to the other ones.
The IAM Condition element is used to implement fine-grained access control. You can use this element to allow or deny access to items and attributes based on the needs of your application. Here are your options:
Horizontal - You can selectively hide or expose specific DynamoDB items in a particular table by matching on hash key values:
Vertical - You can selectively hide or expose specific attributes of all of the DynamoDB items in a particular table by matching on attribute names:
Combined - You can exercise horizontal and vertical control in the same policy:
You can combine these options with the IAM Action element to exercise even more control. For example, you can create read-only variants of the options described above by allowing only GetItem and Query in your policy.
Using Fine-Grained Access Control
Visit the Fine-Grained Access Control section of the DynamoDB Developer Guide to learn how to create an access policy, create an IAM role, and assign your access policy to the role. We also have a collection of sample policies.The trust policy of the role determines which identity providers are accepted (e.g. Login with Amazon, Facebook, or Google) and the access policy determines which AWS resources (e.g. the DynamoDB tables, items, and attributes) can be accessed.
Here is a very simple policy. Each authenticated user has read-only access to their own items in the GameScores table:
{ "Version": "2012-10-17", "Statement": [{ "Effect": "Allow", "Action": [ "dynamodb:GetItem", "dynamodb:BatchGetItem", "dynamodb:Query" ], "Resource": ["arn:aws:dynamodb:us-west-2:123456789012:dynamodb:table/GameScores"], "Condition": { "ForAllValues:StringEquals": { "dynamodb:LeadingKeys": ["${www.amazon.com:user_id}"] } } }] }Your code will use the role to obtain temporary security credentials for DynamoDB by calling the AssumeRoleWithWebIdentity function of the AWS Security Token Service.
You can use the new DynamoDB Policy Generator to create your first policy. Go to the DynamoDB Console, select the table, and click the Access Control button:
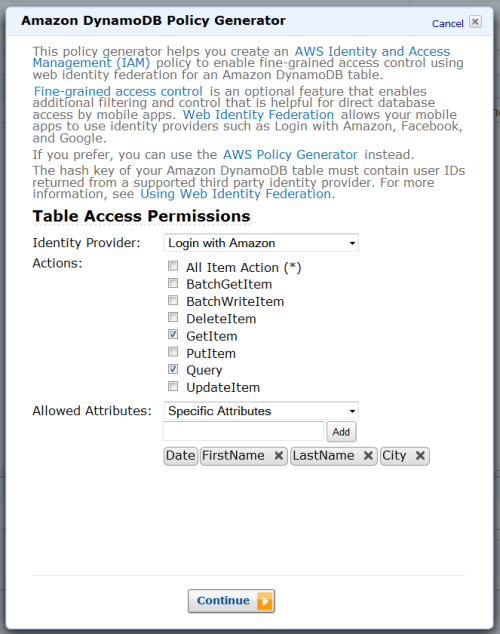
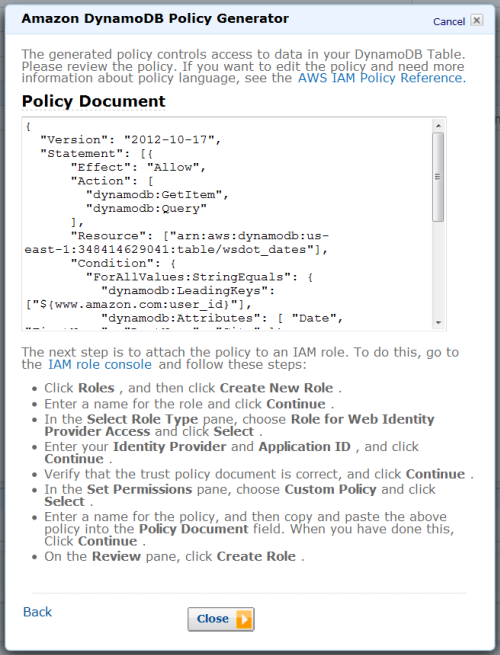
After you create it, head over to the IAM Console, create a role for Web Identity Provider access with no permissions, and then paste the policy into the role.
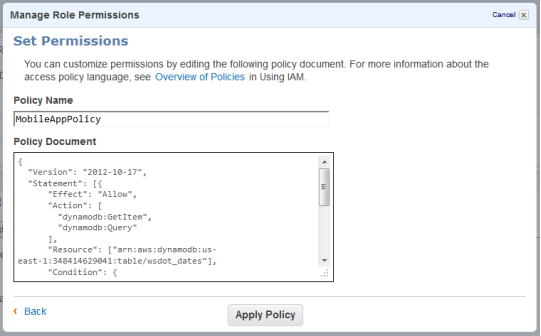
Watch and Learn
We have created a video tutorial to help you to get started with Fine-Grained Access Control for DynamoDB:I hope that you find this powerful new access control feature to be of value. Leave me a comment and let me know what you think!


• Werner Vogels (@werner) described Simplifying Mobile App Data Management with DynamoDB's Fine-Grained Access Control in a 10/30/2013 post:
Speed of development, scalability, and simplicity of management are among the critical needs of mobile developers. With the proliferation of mobile devices and users, and small agile teams that are tasked with building successful mobile apps that can grow from 100 users to 1 million users in a few days, scalability of the underlying infrastructure and simplicity of management are more important than ever. We created DynamoDB to make it easy to set up and scale databases so that developers can focus on building great apps without worrying about the muck of managing the database infrastructure. As I have mentioned previously, companies like Crittercism and Dropcam have already built exciting mobile businesses leveraging DynamoDB. Today, we are further simplifying mobile app development with our newest DynamoDB feature, Fine-Grained Access Control, which gives you the ability to directly and securely access mobile application data in DynamoDB.
One of the pieces of a mobile infrastructure that developers have to build and maintain is the fleet of proxy servers that authorize requests coming from millions of mobile devices. This proxy tier allows vetted requests to continue to DynamoDB and then filters responses so the user only receives permitted items and attributes. So, if I am building a mobile gaming app, I must run a proxy fleet that ensures “johndoe@gmail.com” only retrieves his game state and nothing else. While Web Identity Federation, which we introduced a few months back, allowed using public identity providers such as Login with Amazon, Facebook, or Google for authentication, it still required a developer to build and deploy a proxy layer in front of DynamoDB for this type of authorization
With Fine-Grained Access Control, we solve this problem by enabling you to author access policies that include conditions that describe additional levels of filtering and control. This eliminates the need for the proxy layer, simplifies the application stack, and results in cost savings. Using access control this way involves a setup phase of authenticating the user (step 1) and obtaining IAM credentials (step 2). After these steps, the mobile app may directly perform permitted operations on DynamoDB (step 3).
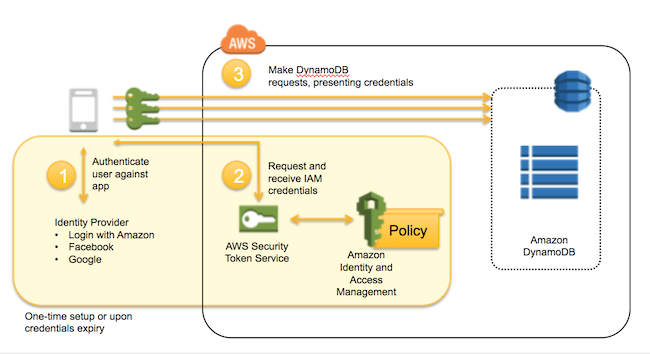
With today’s launch, apps running on mobile devices can send workloads to a DynamoDB table, row, or even a column without going through an intervening proxy layer. For instance, the developer of a mobile app will use Fine-Grained Access Control to restrict the synchronization of user data (e.g. Game history) across the many devices the user has the app installed on. This capability allows apps running on mobile devices to modify only rows belonging to a specific user. Also, by consolidating users’ data in a DynamoDB table, you can obtain real-time insights over the user base, at large scale, without going through expensive joins and batch approaches such as scatter / gather.
To get started, please see the Fine-Grained Access Control documentation and Jeff Barr’s blog.


Jeff Barr (@jeffbarr) described Search and Browse Amazon CloudWatch Metrics in the Console in a 10/30/2013 post:
Amazon CloudWatch monitors your AWS cloud resources and the applications that you run on AWS. The basic unit of monitoring is a metric. Amazon EC2, Amazon RDS, and other AWS services collect metrics and forward them to CloudWatch, where they are stored for two weeks. The metrics can be graphed, and they can also be used to raise alerts and to drive Auto Scaling decisions. You can manage your metrics using the AWS Management Console.
Today we are making the console even better, giving you the ability to search for specific metrics and to browse all available metrics by category. Many of our customers have asked for a faster and more productive way to find the metrics that are of interest to them and we are happy to oblige.
Search
You can now search through all of your CloudWatch metrics in seconds, even if you have hundreds of thousands of them. Matches are displayed when you press the Enter key:
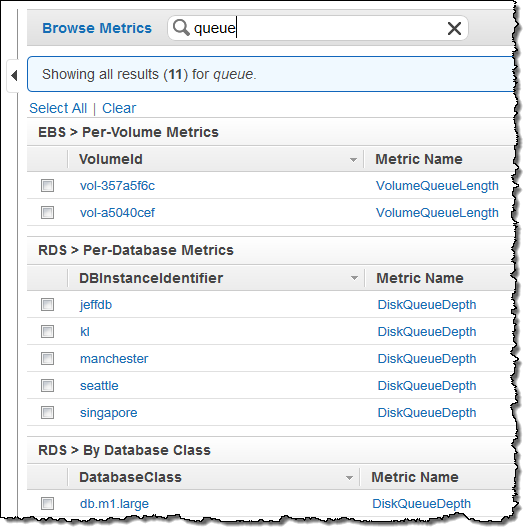
You can click on a highlighted term to add it to your search. After you locate and select the desired metric(s), you can click on the Update Graph button to display a colorful graph:
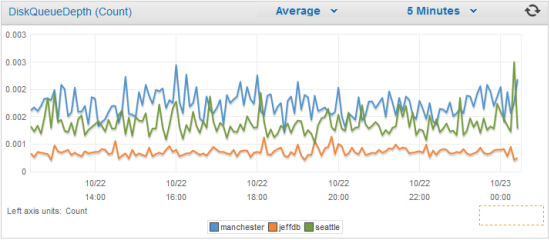
If you are viewing metrics with different units, drag a metric from the center legend into the box on the right to get a secondary Y-axis. This will make things easier to see.
Browse
You can now click the Browse Metrics button in the CloudWatch dashboard to view your metrics organized by category. Click on a category to view a set of related metrics, and then click on a highlighted term to narrow down to the desired metric(s). This is also a good way to become familiar with new metrics as we introduce them, or when you start to use new services.
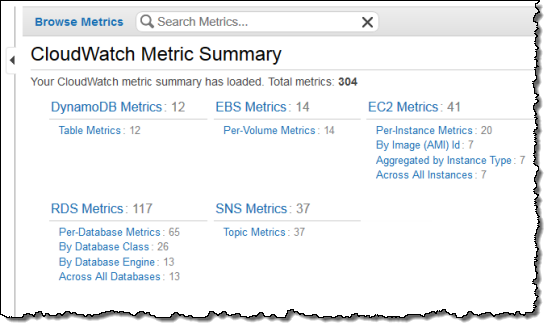
As always, these new features are available now and you can start using them today!


Jeff Barr (@jeffbarr) announced Elastic MapReduce Updates - Hadoop 2.0 and More on 10/29/2013:
The Amazon Elastic MapReduce (EMR) team has been hard at work on a series of updates and new features. You now have access to Hadoop 2.2 and new versions of Hive,Pig, HBase, and Mahout. Cluster startup time has been reduced, S3DistCp (for data movement), has been augmented, and MapR M7 is now supported.
If you are already using Hadoop to do large-scale parallel processing, the value and appeal of these features should be self-evident! If you are new to this whole world and want to learn more, you might want to start by reading the Hadoop Tutorial. Then you can get started with EMR by following our step-by-step tutorial.
More Info
Elastic MapReduce now supports version 2.2 of Hadoop. Among other things, this release supports YARN, which allows Hadoop to behave in Platform as a Service (PaaS) fashion. We have a number of Hadoop Amazon Machine Images (AMIs) to choose from; consult our AMI version table to learn more.
Along with Hadoop 2.2, EMR’s latest Amazon Machine Image (3.0.0) - also comes with HBase 0.94.7 and Mahout 0.8. HBase is a popular NoSQL database for Hadoop. EMR provides some special features for HBase including backup/restore using S3. Mahout is an equally popular machine learning library for Hadoop. The latest EMR AMI runs on Amazon Linux (previous AMIs used Debian), and also includes major upgrades to Perl, PHP, Python, R, and Ruby. You can learn more about AMI 3.0.0 here.
Hive is a popular data warehouse system for Hadoop. It has been upgraded from version 0.8.1.8 to 0.11.0.1, gaining a number of features in the process including support for the Optimized Row Columnar (ORC) file format and additional windowing and analytics functions. Learn how to use Hive with Elastic MapReduce.
Pig is an analytics platform that is often used for ETL (Extract / Transform / Load) processing. It has been upgraded from version 0.9.2.2 to 0.11.1.1. This version adds new data types, functions, and operators. Learn how to Process Data with Pig.
EMR clusters now start up about 60 seconds faster and the team continues to bring down the average startup time. S3DistCp uses Hadoop to efficiently transfer data between S3 buckets and HDFS. The new version does a better job of handling S3 metadata such as the S3 storage class during copy operations.
As I discussed earlier this year, MapR M7, a premium offering of Apache HBase, is now supported. MapR M7 lets you run production HBase applications by providing capabilities such as seamless splits, no compactions, instant recovery from failures, point-in-time recovery, full HA, mirroring, and consistent low latency.
As always, these features are available now and you can start using them today!


<Return to section navigation list>

















0 comments:
Post a Comment