Windows Azure and Cloud Computing Posts for 11/28/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

• Updated 11/29/2011 5:00 PM PST with articles marked • in the Marketplace DataMarket, Social Analytics and OData, Live Windows Azure Apps, APIs, Tools and Test Harnesses and Other Cloud Computing Platforms and Services sections.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Alex Popescu (@al3xandru) asked Data Is the New Currency. But Who's Leading the Way? in an 11/29/2011 post to his myNoSQL blog:
In 2005, Tim O’Reilly said: “data is the next Intel Inside“. Today IDC Mario Morales (VP of semiconductor research) says data is the new currency. All’s good until you read the continuation:
And the companies that understand this are the ones already developing the analytics and infrastructure to extract that value—companies like IBM, HP, Intel, Microsoft, TI, Freescale and Oracle.
The article (nb: may require registration) continues by looking at what each of these companies are doing in the Big Data space, but focuses a large part on IBM Watson.
Going back to the question “who’s leading the Big Data way“, let’s take a quick look at the technology behind Watson. According to Jeopardy Goes to Hadoop and About Watson, Watson technology is based on Apache Hadoop, using an IBM language technology built on the Apache UIMA platform and running Linux on IBM boxes.
To me it looks like open source is leading the advances in Big Data and these large organizations are just connecting the dots (as in packaging these technologies for enterprise environments and contributing missing pieces here and there)[1]. When did this happen before?
Or they are very secretive about their internal initiatives and research. ↩

Avkash Chauhan (@avkashchauhan) explained Windows Azure Queue can have 64KB message content and how 64KB content is calculated? on 11/28/2011
Windows Azure Queue can have a message content size up to 64KB per message. This update was included in Version 2011-08-18 and newer. If you are still on [an] old version, then Windows Azure Queue will have 8KB message.
This 64KB [size] refers to the size of the UTF-8 encoded message. The body of the request contains the message data in the following XML format.
A message must be in a format that can be included in an XML request with UTF-8 encoding. In the following example the highlighted message-content is considered as message content and its size can go up to 64 KB.
<QueueMessage> <MessageText>message-content</MessageText> </QueueMessage>So this 64kb actual message content, not the raw message length, or Unicode binary length, or base64 encoded length when sent via http content.
More Info: http://msdn.microsoft.com/en-us/library/dd179346.aspx

See also Liam Cavanagh (@liamca) announced the availability of a new SQL Azure Labs Codename “Data Transfer” project in his How to upload your Excel and CSV data to the Cloud post of 11/28/2011 in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section.
<Return to section navigation list>
SQL Azure Database and Reporting
Cihan Biyikoglu continued his SQL Azure Federations series with Federation Metadata in SQL Azure Part 3 – Monitoring Ongoing Federation Operations on 11/28/2011:
In part 2 we talked about federation metadata history views. Federation history views only report operation[s] that completed. For monitoring ongoing operations federations provide a separate set of dynamic management views under sys.dm_federation_operation*. All federation operations such as CREATE, ALTER or DROP consist of a set of steps that are executed async. With all async commands, a sync part of the command sets up and kicks off the operation first.
Once the sync part is done, the control is returned to the executor of the TSQL. Then, SQL Azure in the background executes the async steps in the background. The initial sync part of these commands also set up the data for monitoring these async federation operations in the sys.dm_federation_operation* views. The views report metadata about the async operation such as the start date and time or the operation type that is running (ex: SPLIT or DROP etc) as well as the current progress of the operation.
Federation operation DMVs provide great information after operations have been kicked off. Here are a few useful queries that can help you monitor your federations;
-- see how long a repartitioning operation has been active select datediff(ss,start_date,getutcdate()) as total_seconds, percent_complete, * from sys.dm_federation_operations GO -- display members with active federation repartitioning operations SELECT fmc.member_id, cast(fmc.range_low as nvarchar) range_low, cast(fmc.range_high as nvarchar) range_high, fops.federation_operation_type FROM sys.federations f JOIN sys.federation_member_distributions fmc ON f.federation_id=fmc.federation_id LEFT OUTER JOIN ( SELECT fo.federation_id, fom.member_id, fo.federation_operation_type, fom.member_type FROM sys.dm_federation_operation_members fom JOIN sys.dm_federation_operations fo ON fo.federation_operation_id = fom.federation_operation_id AND fo.federation_operation_type='ALTER FEDERATION SPLIT' AND fom.member_type='SOURCE') fops ON f.federation_id=fops.federation_id AND fmc.member_id=fops.member_id ORDER BY f.name, fmc.range_low, fmc.range_high GO


See also Liam Cavanagh (@liamca) announced the availability of a new SQL Azure Labs Codename “Data Transfer” project in his How to upload your Excel and CSV data to the Cloud post of 11/28/2011 in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
• Microsoft Pinpoint added an item for my Microsoft Codename “Social Analytics” WinForms Client Sample on 11/29/2011:

Todd Hoff described DataSift Architecture: Realtime Datamining at 120,000 Tweets Per Second in an 11/29/2011 post:
I remember the excitement of when Twitter first opened up their firehose. As an early adopter of the Twitter API I could easily imagine some of the cool things you could do with all that data. I also remember the disappointment of learning that in the land of BigData, data has a price, and that price would be too high for little fish like me. It was like learning for the first time there would be no BigData Santa Clause.
For a while though I had the pleasure of pondering just how I would handle all that data. It's a fascinating problem. You have to be able to reliably consume it, normalize it, merge it with other data, apply functions on it, store it, query it, distribute it, and oh yah, monetize it. Most of that in realish-time. And if you are trying to create a platform for allowing the entire Internet do to the same thing to the firehose, the challenge is exponentially harder.
DataSift is in the exciting position of creating just such a firehose eating, data chomping machine. You see, DataSift has bought multi-year re-syndication rights from Twitter, which grants them access to the full Twitter firehose with the ability resell subsets of it to other parties, which could be anyone, but the primary target is of course businesses. Gnip is the only other company to have these rights.
DataSift was created out of Nick Halstead's, Founder and CTO of DataSift, experience with TweetMeme, a popular real-time Twitter news aggregator, which at one time handled 1.1 billion page views per day. TweetMeme is famous for inventing the social signaling mechanism, better known as the retweet, with their retweet button, an idea that came out of an even earlier startup called fav.or.it (favorite). Imagine if you will a time before like buttons were plastered all over the virtual place.
So processing the TweetMeme at scale is nothing new for the folks at DataSift, what has been the challenge is turning that experience into an Internet-scale platform so that everyone else can do the same thing. That has been a multi-year odyssey.
DataSift is position[ing] themselves as a realtime datamining platform. The platform angle here is really the key take home message. They are pursuing a true platform strategy for processing real-time streams. TweetMeme while successful, could not be a billion dollar company, but a BigData platform could grow that large, so that’s the direction they are headed. A money quote by Nick highlights the logic in neon: "There's no money in buttons, there's money in data."
Part of the strategy behind a platform play is to become the incumbent player by building a giant technological moat around your core value proposition. When others come a knockin they can't cross over your moat because of your towering technological barrier to entry. That's what DataSift is trying to do. The drawbridge on the moat is favored access to Twitter's firehose, but the real power is in the Google quality real-time data processing platform infrastructure that they are trying to create.
DataSift's real innovation is in creating an Internet scale filtering system that can quickly evaluate very large filters (think Lady Gaga follower size) combined with the virtuous economics of virtualization, where the more customers you have the more money you make because they are sharing resources.
How are they making all this magic happen? Let's see...
I described DataSift’s relationship to Microsoft Codename “Social Analytics” in my Microsoft Codename “Social Analytics” Windows Form Client Detects Anomaly in VancouverWindows8 Dataset post of 11/20/2011.
The Microsoft Social Analytics Team described Finding Top Message Threads for a Filter in an 11/28/2011 post:
This is the second post in a series where we explore Entities in the Social Analytics Lab API. Through this series of posts, we will provide details on how the Entities can be used to accomplish some basic scenarios in the Social Analytics lab.
In this scenario we’ll look at identifying top threads for one of the lab datasets. To accomplish this, you will need three Entities in our API (pictured below):
Filters
Filters are a central concept in storing and retrieving data in the Social Analytics Lab. You could think of the set of filters as a list of topics available in an Social Analytics Instance. For example, the Windows 8 lab includes the following filters:
Id
Name
1
DataAcquisition: Windows 8
2
DataAcquisition: Windows 8 on Twitter
3
DataAcquisition: Windows 8 on YouTube
4
Subscription Filter for @g_win8slice
6
Windows 8 and Tablet PCs
7
Windows 8
8
Non-Twitter
10
Windows 8 on Facebook
11
Windows 8 and Applications
12
Windows 8 Design and User Experience
13
Windows 8 and Applications 2
Notice that three of the Filters are labeled as Data Acquisition Filters. Filters can control what activity from social media channels is tracked in an instance of Social Analytics or it can be simply a materialized view over the social data tracked in an instance. With our permissions model for filter definitions, control over what Social Data is tracked in an instance can be controlled while giving many users permissions to define filters that are views over the data.
MessageThreads
We define a MessageThread as a post and all of its replies within a channel. MessageThreads are the primary unit of activity we use to track social channel activity. If you examine the MessageThreads entity, you’ll find a collection of measures described an aggregated view of the thread, including:
- Replies
- Answers
- Likes
- Retweets
- IsQuestion
- IsAnswered
- PositiveSentiment
- NegativeSentiment
The Replies field is a total of all replies of all types in the thread, so you don’t want to sum Replies and Answers etc., or you’ll be double-counting.
FilterResultCaches
FilterResultCaches represents what MessageThreads relate to all filters, and is one of the most useful Entities for analyzing Social Analytics data. Using the following LINQ Query in LinqPad:
( from f in FilterResultCaches orderby f.MessageThread.Replies descending where f.FilterId == 6 && f.MessageThread.Replies > 1 && f.LastUpdatedOn > DateTime.Now.AddDays(-7) select new { f.MessageThread.Replies, f.Site.Name, f.MessageThread.PositiveSentiment, f.MessageThread.NegativeSentiment, f.MessageThread.LastReplyContentItem.Title, f.MessageThread.LastReplyContentItem.HtmlUrl, }).Take(10)We can find the Messagethreads with the most replies during the last 7 days in the “Windows 8 and Tablet PCs” filter:
Replies Name Positive Sentiment Negative Sentiment Title Html Url 126 twitter.com 0 0 RT @TheNextWeb: If the Kindle Fire nearly runs Windows 8, why do we need quad-core Android tablets? http://t.co/fcXyxiU1 by @alex on @TN ... http://twitter.com/RenoYuuki/statuses/138211182040449024 33 twitter.com 0 0 RT @blogtweetz: Nokia Tablet To Debut in Summer 2012 - Powered By Windows 8 ! http://t.co/EniexIKY via @Dazeinfo http://twitter.com/epremierleague/statuses/138931098318155776 13 twitter.com 0 0 RT @9to5mac: How well does Mac OSX run on Samsung’s Windows 8 Tablet? [Video] http://t.co/tvOJVmSj http://twitter.com/carlst3/statuses/139378162495791106 7 twitter.com 0 0 RT @Indiferencia: Nokia lanzará tablet con Windows 8 en junio de 2012 http://t.co/54Wf3Rza http://twitter.com/endamo/statuses/138029411483131905 6 twitter.com 0 0 RT @Entiendelas: Nokia lanzará tablet con Windows 8 en junio de 2012 http://t.co/bMvT7gXr http://twitter.com/Lacangri1412/statuses/137750579417055232 6 twitter.com 0 0 RT @dehaaspeter: BCG: Windows tablet populairder dan iPad van Apple : http://t.co/P4GedXkY #windows8 http://twitter.com/OscarMinkenberg/statuses/139273712657637376 5 twitter.com 0 0 RT @OfficeTH: โอ้วว้าว...!Win8 Tablet บน Nokia จะเฝ้ารออออ!!! http://t.co/4lFOjLmO http://twitter.com/opal_monkey/statuses/138607317817114624 4 twitter.com 0 0 RT @LeaNoticias: Nokia lanzará tablet con Windows 8 en junio de 2012 http://t.co/DjOAGG9k http://twitter.com/daichu_/statuses/138098502550040576 4 twitter.com 1 0 RT @Indiferencia: Nokia lanzará tablet con Windows 8 en junio de 2012 http://t.co/54Wf3Rza http://twitter.com/arknglzintetico/statuses/138627023793954817 4 twitter.com 0 0 RT @freddier: Tablet Samsung con Windows 8 [pic] http://t.co/cyENejTk #techdayschile http://twitter.com/GustavoRiveraMX/statuses/138723108952612864

Glenn Gailey (@ggailey777) continued his Dealing with Binary Resource Streams and Tombstoning series on 11/28/2011:
Sync’ing OData to Local Storage in Windows Phone (Part 3)
If you have been following this series, you know that I have been demonstrating a way to persist data from an OData feed to a local Windows Phone (“Mango”) device. Just to refresh, here are the benefits of maintaining a local cache of data:
- Reduced amount of network traffic. This is the most important benefit to caching data locally. Otherwise, every time the app starts it has to hit the OData feed to load initial data, which is a huge waste of bandwidth for OData feeds that are relatively static.
- Improved load time. It’s much faster to load data from the device than to make an HTTP request to the OData service.
- App don’t need network access to start. When the app is dependent on remote data, it can’t really start well without a connection.
- Puts the user in control. Users can decide on if and when to sync the local data to the OData service, since most of them pay for their data.
- Reduced tombstoning serialization. When the entities are stored in local database, they can be retrieved from there, which means they don’t need to be serialized and tombstoned.
As of the last post, I was working on getting a nice solution to requesting and storing media resources, in this case binary image files. It turns out that, in general, the OData client library and Silverlight APIs make it rather easy to request binary data as streams from the data service and use this stream to create an image to store locally in isolated storage.
Requesting and Storing the Media Resource Stream
As I mentioned in an earlier post, a great solution (as long as you aren’t sending updates to the data service) is to create a new binding property in a partial class of the entity that returns the read stream URI. This time, because you are storing and retrieving of binary image data yourself, you need the extension property to return the actual BitmapImage for binding, which means you must deal with streams and not just the URI (and let the binding do the work).
Here is the partial class that defines the DefaultImage property:
// Extend the Title class to bind to the media resource URI. public partial class Title { private BitmapImage _image; // Returns the media resource URI for binding. public BitmapImage DefaultImage { get { if (_image == null) { // Get the URI for the media resource stream. return App.ViewModel.GetImage(this); } else { return _image; } } set { _image = value; OnPropertyChanged("DefaultImage"); } } }The GetImage method on the ViewModel first checks isolated storage for the image, and if it’s not there it makes an asynchronous BeginGetReadStream call to data service:
// Calls into the DataServiceContext to get the URI of the media resource. public BitmapImage GetImage(object entity) { // First check for the image stored locally. // Obtain the virtual store for the application. IsolatedStorageFile isoStore = IsolatedStorageFile.GetUserStoreForApplication(); Title title = entity as Title; MergeOption cacheMergeOption; Uri entityUri; // Construct the file name from the entity ID. string fileStorageName = string.Format("{0}\\{1}.png", isoPathName, title.Id); if (!isoStore.DirectoryExists(isoPathName)) { // Create a new folder if it doesn't exist. isoStore.CreateDirectory(isoPathName); } // We need to handle the case where we have stored the entity but not the image. if (!isoStore.FileExists(fileStorageName)) { // Try to get the key of the title entity; if it's not in the DataServiceContext, // then the entity comes from // the local database and it is not in the DataServiceContext, which means that // we need to request it again to get the URI of the media resource. if (!_context.TryGetUri(entity, out entityUri)) { // We need to attach the entity to request it from the data service. _context.AttachTo("Titles", entity); if (_context.TryGetUri(entity, out entityUri)) { // Cache the current merge option and change it to overwrite changes. cacheMergeOption = _context.MergeOption; _context.MergeOption = MergeOption.OverwriteChanges; // Request the Title entity again from the data service. _context.BeginExecute<Title>(entityUri, OnExecuteComplete, entity); // Reset the merge option. _context.MergeOption = cacheMergeOption; } } else { DataServiceRequestArgs args = new DataServiceRequestArgs(); // If the file doesn't already exist, request it from the data service. _context.BeginGetReadStream(title, args, OnGetReadStreamComplete, title); } // We don't have an image yet to set. return null; } else { using (var fs = new IsolatedStorageFileStream(fileStorageName, FileMode.Open, isoStore)) { // Return the image as a BitmapImage. // Create a new bitmap image using the memory stream. BitmapImage imageFromStream = new BitmapImage(); imageFromStream.SetSource(fs); // Return the bitmap. return imageFromStream; } } }When the request is completed, the OnGetReadStream callback method is invoked, where EndGetReadStream is called first to write the stream to local storage and then to set the DefaultImage property of the specific Title entity, which causes the binding to be updated with the image.
private void OnGetReadStreamComplete(IAsyncResult result) { // Obtain the virtual store for the application. IsolatedStorageFile isoStore = IsolatedStorageFile.GetUserStoreForApplication(); Title title = result.AsyncState as Title; if (title != null) { // Use the Dispatcher to ensure that the // asynchronous call returns in the correct thread. Deployment.Current.Dispatcher.BeginInvoke(() => { try { // Get the response. DataServiceStreamResponse response = _context.EndGetReadStream(result); // Construct the file name from the entity ID. string fileStorageName = string.Format("{0}\\{1}.png", isoPathName, title.Id); // Specify the file path and options. using (var isoFileStream = new IsolatedStorageFileStream(fileStorageName, FileMode.Create, isoStore)) { //Write the data using (var fileWriter = new BinaryWriter(isoFileStream)) { byte[] buffer = new byte[1000]; int count = 0; // Read the returned stream into the new file stream. while (response.Stream.CanRead && (0 < ( count = response.Stream.Read(buffer, 0, buffer.Length)))) { fileWriter.Write(buffer, 0, count); } } } using (var bitmapFileStream = new IsolatedStorageFileStream(fileStorageName, FileMode.Open, isoStore)) { // Return the image as a BitmapImage. // Create a new bitmap image using the memory stream. BitmapImage imageFromStream = new BitmapImage(); imageFromStream.SetSource(bitmapFileStream); // Return the bitmap. title.DefaultImage = imageFromStream; } } catch (DataServiceClientException) { // We need to eat this exception so that loading can continue. // Plus there is a bug where the binary stream gets /// written to the message. } }); } }Note that there currently is a bug where the client doesn’t correctly handle a 404 response from BeginGetReadStream (which Netflix returns) when that response contains an image stream, and it tries to write the binary data to the Message property of the DataServiceClientException that is generated. During debug, this did cause my VS to hang when I moused-over the Message property, so watch out for that.
Getting the Media Resource for a Stored Entity
Loading the media resource actually gets a little complicated for the case where you have stored the entity in local database, but for some reason you don’t also have the image file stored. The issue is that you only store the entity itself in the local database, but each tracked entity in the DataServiceContext has a companion EntityDescriptor object that contains non-property metadata from the entry in the OData feed, including the read stream URI. You first need to call AttachTo, which starts tracking the entity and creates a new EntityDescriptor. However, only the key URI value gets set in this new EntityDescriptor, which is immutable and is inferred from the metadata. The context has no way to guess about the read stream URI, which can be changed by the data service at any time. This means to get the read stream, you need to first call BeginExecute<T> to get the complete MLE (with the missing entry info including the read stream URI) from the data service. the following section from a previous code snippet is the part that checks the context for the entity, and if it’s not there, it requests it again from the data service:
// Try to get the key of the title entity; if it's not in the DataServiceContext, // then the entity comes from the local database and it is not in the // DataServiceContext, which means that we need to request it again to get // the URI of the media resource. if (!_context.TryGetUri(entity, out entityUri)) { // We need to attach the entity to request it from the data service. _context.AttachTo("Titles", entity); if (_context.TryGetUri(entity, out entityUri)) { // Cache the current merge option and change it to overwrite changes. cacheMergeOption = _context.MergeOption; _context.MergeOption = MergeOption.OverwriteChanges; // Request the Title entity again from the data service. _context.BeginExecute<Title>(entityUri, OnExecuteComplete, entity); // Reset the merge option. _context.MergeOption = cacheMergeOption; } } else { DataServiceRequestArgs args = new DataServiceRequestArgs(); // If the file doesn't already exist, request it from the data service. _context.BeginGetReadStream(title, args, OnGetReadStreamComplete, title); } // We don't have an image yet to set. return null; }Because this method requires two call to the data service (one to refresh the entity and the second to get the stream), it might be better to store a generic not found image rather than make two calls. Another option would be to further extend the entity type on the client to include a property that can be used to store the read stream URI. Then, you can just make a regular HttpWebRequest to the URI , now stored with the entity, to get the image from the data service—one request instead of two. (This would be another property that must be removed from a MERGE/PATCH/POST request for entities that are not read-only.) Less request, but a bit more complex still.
Tombstoning with Locally Stored Entity Data
I mentioned that one of the benefits of storing entity data in local database was (potentially) simplified tombstoning, and in this exact scenario of read-only data, this is the case. By always trying to load from the local database (and isolated storage) first, we don’t need to serialize entity data during tombstoning. Notice that in the SaveState and RestoreState methods we are only persisting the current page number and the selected title, instead of using the DataServiceState to serialize out all the in-memory data tracked by the DataServiceContext:
// Return a collection of key-value pairs to store in the application state. public List<KeyValuePair<string, object>> SaveState() { // Since we are storing entities in local database, // we don't need to store the OData client objects. List<KeyValuePair<string, object>> stateList = new List<KeyValuePair<string, object>>(); stateList.Add(new KeyValuePair<string, object>("CurrentPage", CurrentPage)); stateList.Add(new KeyValuePair<string, object>("SelectedTitle", SelectedTitle)); return stateList; } // Restores the view model state from the supplied state dictionary. public void RestoreState(IDictionary<string, object> storedState) { // Restore view model data. _currentPage = (int)storedState["CurrentPage"]; this.SelectedTitle = storedState["SelectedTitle"] as Title; }Of course, this also get more complicated when we need to support data updates because we need to attach objects from the local database to the DataServiceContext before we can send changes to the data service, and DataServiceContext is where changes are tracked.
Conclusion
The sample that I put together is based on the OData client library for Windows Phone and is limited to download-only. This solution for persisting entity data from an OData service in local database (and isolated storage for blobs) is probably best for reference data or for data that is relatively static. For data that changes frequently or that must be updated by the client, you probably need to continue to request fresh data from the data service on startup. You could also use timestamp properties in the data model to implement a more incremental kind of downloading of updated entities, but you will be unable to detect deletes from the data services. Also, you will need to first re-attach stored entities to the DataServiceContext to leverage the conflict detection and identity management facilities provided by the client. Then you can request all entities in the feed with a timestamp value greater than the last download date, and use a MergeOption value of OverwriteChanges to make sure that the client is updated with server values (of course the DataContext will need to be updated with the new values too). Another option might be to use the DataServiceState to serialize and persist an entire context and collections in local storage as serialized XML. How you handle this will depend greatly on your scenario, how often the data changes, and how much data your application must deal with to run.
As you can see, compared to the total problem set of maintaining OData entities offline, this solution is rather basic (it does what it does by leveraging the local database), but it’s not truly “sync,” despite the title of the series. In the next post, I plan to discuss another option that provide a much more traditional and comprehensive kind of bi-directional synchronization between data on the Windows Phone device and data in the cloud by using an OData-based sync service.
Stay tuned…

Matt Wrock described how to Track Nuget Downloads using OData, RSS and Ifttt.com in an 11/28/2011 post:
In this post I am going to show you how you can be notified of new downloads of any Nuget package via email from a service that will poll Nuget every 15 minutes. If email sounds overly intrusive, there are other options. So If this sounds interesting, read on.
If you have open source projects hosted on Nuget and you are a bit on the OCD (obsessive compulsive disorder) side, you are frequently tempted to wander over to Nuget.org and check out your download stats. Well, I have finally started to notice that I spend a fair amount of time every day, checking the Nuget site as well as other sites that may provide key indicators of my projects’ health. For instance I like to check for new followers or twitter mentions. Unfortunately, a lot of this time is spent simply waiting for a web page to load and reveal to me that there is no new information. So not only is this unproductive but it can lead to negative thoughts and emotions.
There are many pharmaceutical options available here, but I am not a Medical doctor and it would be unwise for me to give advise of a psychiatric nature. However I do have some technical solutions that simply require a computer with access to the world wide web. If you lack either of these, I have nothing to offer and you should now leave this page.
Ok. good. It’s just you and me now….hmm…this is uncomfortably intimate. No matter…
Switch from a Pull to a Push model
What I found myself craving was a way to let all of this information come to me and announce to me that there is new data rather than me having to spend time pinging several sources for what is likely to be no new information. In my case, I really wanted my phone to beep or vibrate when I get a new download, follower or mention. For me, this would not be a nuisance given the small amount of data. If you owned jQuery, you may want a more unobtrusive notification. Fortunately the solution I am about to propose can channel notifications through a variety of mediums.
Enter If-this-then-that ifttt.com
A few months ago I noticed a new referring link on my blog from a domain called ifttt.com. I visited the link and perused the site and discovered that it provided a way of creating sort of mash ups of various social media. ifttt stands for If This Then That. And the site simply allows you to create rules of If something occurs (new tweet, RSS feed item, DropBox item, etc.) Then some other thing should be triggered such as an email sent or a tweet or facebook update, etc. I have to admit my initial impression was “That’s dumb.” Then about a week later Scott Hanselman blogged about this service having been duly impressed by its offerings. I still didn’t really get it.
Not sure why I didn’t see the value right away but I see it now. Last week I setup a number of tasks that have freed me of the constant compulsion to check these various web sites for new data. I have a rule that will send me an email whenever my project has a new Github follower or a new mention on twitter. I have tasks that tell me when I have new stack overflow comments or new stack overflow points. All of these tasks were relatively easy to set up using ifttt.com. ifttt’s very friendly GUI provides an extremely simple way to send an email to yourself triggered by a new tweet or RSS feed item.
Here is an example of the task that sends me an email when my project RequestReduce is mentioned on twitter:
It is honestly trivial to set this up.
But Nuget Has no RSS Feed with items representing downloads
Currently Nuget provides no RSS feed or any notification option for subscribing to download stats beyond what is displayed on the project search results and individual project details pages. I don’t know if there are plans to implement this by the Nuget team in the near future, but I wanted something up and running soon that didn’t need to be polished.
All Nuget data available from the website is exposed through an OData feed
I knew that the data I was interested in was available via OData. There are a few posts out there that talk about this. I found that David Ebbo’s post had the detail I deeded to get started. With the name of any Nuget package Id, you can get its total download count via the public Nuget OData endpoint at http://packages.nuget.org/v1/FeedService.svc.
Here is an example query using LinqPad:
Creating a custom RSS Feed to broadcast new downloads
Currently as far as I can tell, there is no facility built into ifttt to consume this OData format. Yes, you can expose OData as an ATOM feed but given the Nuget schema, this would only be useful if you wanted to be notified of new versions. Essentially each version is a child entity of the master Packages entity. DownloadCount is simply a property associated with each version. Note that a version has both a VersionDownloadCount and a DownloadCount. The first is simply the count for a single version and the latter is the aggregate count of all combined versions released in a single package.
At first I tried playing with Yahoo Pipes and some other online RSS builder apps but none of these was going to work. At least not simply. I didn’t want to spend a lot of time on this since what I wanted was really quite simple and could be coded up fairly trivially. So I ended up just writing my own feed generator and I took the opportunity to create my first Azure application. I plan to blog more specifically on the azure specific details later and how they differed from my work with an AppHarhor application.
Here is the RSS Generator code:
public class FeedHandler : IHttpHandler
{
private const string NugetServiceUri = "http://packages.nuget.org/v1/FeedService.svc";
private readonly IDictionary<string, IList<SyndicationItem>>
packageDownloadCounts = new ConcurrentDictionary<string, IList<SyndicationItem>>();
public bool IsReusable
{
get { return true; }
}
public void ProcessRequest(HttpContext context)
{
var packageName = context.Request.QueryString["packageId"];
var nugetContext = new Nuget.GalleryFeedContext(new Uri(NugetServiceUri));
var last = (
from x in nugetContext.Packages
where x.Id == packageName && x.IsLatestVersion
select new { x.DownloadCount, x.Version }).First();
var items = GetSyndicationItems(packageName, last.DownloadCount);
var nugetUrl = string.Format(
"{0}/Packages(Id='{1}',Version='{2}')", NugetServiceUri, packageName, last.Version);
var feed = new SyndicationFeed("Nuget Download Count Feed",
"Provides the current total download count for a Nuget Package",
new Uri(nugetUrl), nugetUrl, items.Last().LastUpdatedTime,
items);
using (var xmlWriter = XmlWriter.Create(context.Response.OutputStream))
{
feed.SaveAsRss20(xmlWriter);
xmlWriter.Flush();
xmlWriter.Close();
}
context.Response.ContentType = "text/xml";
context.Response.End();
}
private IList<SyndicationItem> GetSyndicationItems(string packageName, int count)
{
IList<SyndicationItem> items;
lock (packageName)
{
if (packageDownloadCounts.ContainsKey(packageName))
items = packageDownloadCounts[packageName];
else
{
items = new List<SyndicationItem>();
packageDownloadCounts.Add(packageName, items);
}
var title = string.Format("{0} has {1} total downloads", packageName, count);
if (!items.Any(x => x.Title.Text == title))
items.Add(new SyndicationItem(
title,
"",
new Uri(string.Format("http://nuget.org/packages/{0}",
packageName)), Guid.NewGuid().ToString(),
new DateTimeOffset(DateTime.UtcNow)));
while (items.Count > 20)
items.RemoveAt(0);
}
return items;
}
}You can grab the full Visual Studio Solution from https://github.com/mwrock/NugetDownloadFeed. Not much happening here. Its just a handler that takes a packageId in the query string and then checks the odata feed to see if there are more downloads than there were since the last time it checked. If there are, it creates a new feed item.
ifttt.com will poll this feed every 15 minutes. I currently have this feed up and running at http://wrock.cloudapp.net/downloadFeed.axd. Anyone is free to use it but I provide no guarantee for stability or longevity. That said, I have no plan to change the endpoint or bring it down. However, I may clean the code up a bit and offer it as a Nuget package so that anyone can host their own feed.
Consuming the feed from an ifttt.com Recipe
Beyond the creation of “one off” tasks. ifttt provides a means of encapsulating common task logic into a reusable “Recipe.” These are handy if you find yourself creating the same task again and again with the only difference being a single variable. In my case here, I wanted to create three tasks. One for each of my Nuget projects. It also seemed reasonable that others may want to make use of this as well. So I created a recipe that anyone can use in order to create their own Nuget Download Notification task. Simply create an ifttt account (Super fast and easy to do) and go here: http://ifttt.com/recipes/9302.
As the directions state, simply replace my Package Id RequestReduce with the Package Id that you are interested in.
If you do not want to be notified by email, you have several different options. You could have it tweet from a specific account, send an SMS message or create an Evernote entry. And there are many more options than that.
I’d really like to hand it to the folks at @ifttt for creating this ingenious service and wish them the best of success!




<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Dhananjay Kumar (@debug_mode) described Supported Token Formats and Protocols in ACS in an 11/28/2011 post:
To get authenticated via Windows Azure ACS [the] relying party need[s] to obtain a token. Token[s] can be in different formats.
Possible token formats are as below,
SAML 1.1 and SAML 2.0
- It stands for Security Assertion Markup language.
- It is wildly used token format.
- It is used in Single sign on
- It is used in clam based authentication
- it provides a XML schema for token and protocol used in authentication
- SAML version 2.0 was approved as an OASIS Standard in March 2005
- There are two types of schema for SAML
SWT
- It stands for Simple Web Token.
- It works on Simple Web Token specification.
- SWT work on key value pair. All the required information is present in form of encrypted key value pair.
- Key value pairs are relying party specific.
There are few keys which have to be present always in SWT token. They are as below,
Supported Protocols
ACS has to use some protocols to communicate either with the service or web application. Supported protocols are as below
Supported Token Protocols combination
ACS sends tokens over the protocol supported on the token format. Supported token and protocols are as below






<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• My (@rogerjenn) Test-Drive SQL Azure Labs’ New Codename “Data Transfer” Web UI for Copying *.csv Files to SQL Azure Tables or Azure Blobs post of 11/29/2011 provides step-by-step instructions for migrating *.csv files to new SQL Azure tables:
… To give Codename “Data Transfer” a test-drive, do the following:
1. Navigate to https://web.datatransfer.azure.com/ and register with your Windows Live ID to open the landing page:

Note: A What file designations are we missing? link isn’t visible in the preceding screen capture. Click the link to open a Tell Us Where Else You Would Like Us to Send Your Data text to add an additional Windows Azure data type. I requested Windows Azure Tables, which I understand is a feature currently under consideration.
Saving *.csv Files to SQL Azure Tables
…
3. Complete the form:

Note: Missing or invalid entries are emphasized in red when you click the Next button. Retyping the entry doesn’t remove the red tinge.
…
9. Click the Data icon to open a grid to display the new ContentItems table’s rows:

Detailed instructions for migrating data to Windows Azure blobs will be added tomorrow (11/30/2011).
Note: See the Liam Cavanagh (@liamca) announced the availability of a new SQL Azure Labs Codename “Data Transfer” project in his How to upload your Excel and CSV data to the Cloud post of 11/28/2011 article below (in this section.)
David Gristwood pointed out An interesting Windows Azure architectural discussion – synchronizing multiple nodes by Josh Twist in an 11/29/2011 post:
One of the interesting architectural discussions that comes up when designing highly scalable systems, such as those that run on Windows Azure, is how to co-ordinate multiple “nodes” so that they use use unique keys within an application or system. It sounds a fairly trivial task, but as with lots of engineering issues, when you examine it in more depth, there is more to this than first appears.
Fortunately, a colleague of mine, Josh Twist, who used to work at Microsoft in the UK, but now a Program Manager in the Windows Azure team, wrote an interesting article on this subject in MSDN Magazine, and I have pointed a few folk to the article, so its well worth a read.
.jpg "Nodes Polling a Central Status Flag")
Avkash Chauhan (@avkashchauhan) described a Silverlight front end calling to WCF Service, all in one Windows Azure Web Role Sample in an 11/29/2011 post:
I was asked recently to provide a sample which has Windows Azure Web Role with Silverlight front end, calling to WCF service which is hosted in the same Windows Azure Web Role. I decided to share those details and sample with everyone. This sample is very back code generate all through respective wizard and templates. I just added a few things to get them all working in one sample.
Create a cloud project name SLWCFWebRole and add WCF Service Web Role name WCFServiceWebRole as below:
Now add a new Silverlight project name SilverlightApp to your SLWCFWebRole application which is set to have:
- SilverlightApp is hosted in existing Web Role
- “Enable WCF RIA Services” to connect with WCF Service hosted in SLWCFWebRole
Now we need to add the WCF Service reference to our SilverlightApp. You can use several ways to get it included in the application.
Here, I just launched, WCFServiceWebRole in my browser so I can get active service URL (http://localhost:37000/Service1.svc ) to add in my SilverlightApp:
Once I have the active service URL http://localhost:37000/Service1.svc I added it to my SilverlightApp as below:
After it you will see that ServiceReference1 is included in your SilverlightApp as below:
If you open ServiceReferences.ClientConfig you will see the URL for the Web Service as below:
<configuration> <system.serviceModel> <bindings> <basicHttpBinding> <binding name="BasicHttpBinding_IService1" maxBufferSize="2147483647" maxReceivedMessageSize="2147483647"> <security mode="None" /> </binding> </basicHttpBinding> </bindings> <client> <endpoint address="http://localhost:37000/Service1.svc" binding="basicHttpBinding" bindingConfiguration="BasicHttpBinding_IService1" contract="ServiceReference1.IService1" name="BasicHttpBinding_IService1" /> </client> </system.serviceModel> </configuration>Very Important:
- You should remember that when your WCF Web Role application will run in Compute Emulator it will not use http://localhost/* instead it will use IP address as http://127.0.0.1:81/
- Also when the same application will run in Windows Azure cloud the URL will be something http://<your_service_name>.cloudapp.net
- So when you run this application in Compute Emulator or Windows Azure Cloud, you would need to change the about endpoint address to correct one.
Now let’s add necessary code in SilverlightApp to make a call to WCF Service as below:
Edit MainPage.xaml to add one label and TextBox name TextBox1 as below:
Now edit MainPage.xaml.cs as below to initialize WCF Service reference ServiceReference1 and then implement a call to service contact “GetData” as below:
public partial class MainPage : UserControl { public MainPage() { InitializeComponent(); ServiceReference1.Service1Client client = new ServiceReference1.Service1Client(); client.GetDataCompleted += new EventHandler<ServiceReference1.GetDataCompletedEventArgs>(client_GetDataCompleted); client.GetDataAsync(20); // Here we are passing integer 20 from Silverlight app to WCF Service } void client_GetDataCompleted(object sender, ServiceReference1.GetDataCompletedEventArgs e) { textBox1.Text = e.Result.ToString(); // Here we are receiving the results "string + Int value" from WCF Service and then writing into // Silverlight app text box } }Now set SilverlightAppTestPage.aspx as your startup page in WCFServiceWeRole and launch your application in Compute Emulator.
You will see the web page was launched however you will see the following Exception:
Error: An error occurred while trying to make a request to URI 'http://localhost:37000/Service1.svc'. This could be due to attempting to access a service in a cross-domain way without a proper cross-domain policy in place, or a policy that is unsuitable for SOAP services. You may need to contact the owner of the service to publish a cross-domain policy file and to ensure it allows SOAP-related HTTP headers to be sent. This error may also be caused by using internal types in the web service proxy without using the InternalsVisibleToAttribute attribute. Please see the inner exception for more details.
The exception occurred only because ServiceReferences.ClientConfig is pointing to http://localhost:37000/Service1.svc to connect to WCF Service which is wrong as we are running this application in Windows Azure Compute Emulator at http://127.0.0.1:81/Service1.svc as below:
Now let modify ServiceReferences.ClientConfig to point correctly to WCF Service in compute Emulator as below:
<configuration> <system.serviceModel> …….. <client> <endpoint address="http://127.0.0.1:81/Service1.svc" binding="basicHttpBinding" bindingConfiguration="BasicHttpBinding_IService1" contract="ServiceReference1.IService1" name="BasicHttpBinding_IService1" /> </client> </system.serviceModel> </configuration>Run the application again in Windows Azure Compute Emulator and you will see the correct and expected result as below:
Now to run this application in Windows Azure, you can add clientaccesspolicy.xml in the WCFServiceWebRole application as below:
<?xml version="1.0" encoding="utf-8"?> <access-policy> <cross-domain-access> <policy> <allow-from http-request-headers="SOAPAction"> <domain uri="*"/> </allow-from> <grant-to> <resource path="/" include-subpaths="true"/> </grant-to> </policy> </cross-domain-access> </access-policy>Now you can deploy this application to Windows Azure Cloud however you would need to make a necessary change to reflect correct WCF endpoint URL when application is running in Windows Azure Cloud. This change is made again in ServiceReferences.ClientConfig.
For example your Windows Azure service name is “TestSLWCFWebRole” then you can edit ServiceReferences.ClientConfig as below:
<configuration> <system.serviceModel> …….. <client> <endpoint address="http://testslwcfwebrole.cloudapp.net/Service1.svc" binding="basicHttpBinding" bindingConfiguration="BasicHttpBinding_IService1" contract="ServiceReference1.IService1" name="BasicHttpBinding_IService1" /> </client> </system.serviceModel> </configuration>Now you can package and deploy this service to Windows Azure Service TestSLWCFWebRole, production slot and you will see the correct and expected results:
You can download the full sample from codeplex:










Matthew Weinberger (@M_Wein) reported Microsoft Brings Cloud Integrator Nimbo into Azure’s Inner Circle in an 11/29/2011 post to the TalkinCloud blog:
Microsoft has invited New York-based cloud integrator and service provider Nimbo into its Windows Azure Circle Program, which enables Microsoft partners to advise on the future of the platform-as-a-service cloud.
“We work with the Windows Azure Platform because of its powerful toolset and familiar development environment. Our customers have responded favorably to its flexibility both in pricing and depth of features,” said Washington Leon-Jordan, Nimbo’s vice president of Technology, in a prepared statement.
And as a member of this Windows Azure Circle Program, Nimbo claimed its customers will benefit from the expanded access to Microsoft’s cloud team and resources. And in return, Microsoft gets to pick Nimbo’s collective brains about features, services and outreach that Windows Azure needs to focus on to compete in the crowded PaaS market.
Between this and the recent expansion of the Cloud Champions Club, it seems as though Microsoft is really looking to bring partners deeper into its cloud ecosystem and roadmap. TalkinCloud will continue to track Microsoft’s cloud partner momentum, so stay tuned.
Read More About This Topic

Michael Kan (@Michael_Kan) asserted “Agreeya Mobility will build applications that can draw on data from Azure, Sharepoint and other Microsoft apps” in a deck for his Protocol deal to bring compatible Microsoft apps to iOS, Android article of 11/29/2011 for Network World:
Microsoft said on Tuesday it will license the protocols for many of its enterprise systems to a company that will develop compatible applications for non-Microsoft mobile operating systems, including Google's Android and Apple's iOS.
The goal with the applications is to make it easier for employees to use their consumer gadgets for work, said Microsoft's Sandy Gupta, general manger for its open solutions group.
By licensing Microsoft's protocols, Agreeya will be able to build, for example, an application that will allow workers to view documents on SharePoint on their personal device.
The employee could then print documents on a company printer. "Obviously, this is one step, a concrete step, allowing enterprise services to interoperate with mobile applications," Gupta said.
Microsoft has made similar licensing agreements with other providers to develop such apps, but those were intended for only one device or one type of operating system, Gupta said. The latest agreement will mean a wider range of mobile devices will be included, he said.
Agreeya Mobility, a subsidiary of Agreeya Solutions, works with device manufacturers mainly in Asia to develop software products for handsets and tablets. The company plans to launch the suite of apps in March, said Agreeya Mobility CEO Krish Kupathil.
Several manufacturers are already testing the applications, although Kupathil declined to name the companies. Agreeya wants to work with manufacturers to embed the applications on their devices. The products will also be made available in application stores and other outlets.

Liam Cavanagh (@liamca) announced the availability of a new SQL Azure Labs Codename “Data Transfer” project in his How to upload your Excel and CSV data to the Cloud post of 11/28/2011:
As a SQL Azure Program Manager at Microsoft, one of the most common questions we get from customers is how to get their data into the cloud. Just like SQL Server, SQL Azure has import tools like BCP that allow you to build scripts to load your data. I have never been completely happy with these solutions because for many people, they just want a quick and easy way to load their data and don’t want to mess around with complex command line tools or deal with firewall issues associated with connecting on-premises systems to the cloud. That was a primary reason why our group chose to create a SQL Azure Lab called: Microsoft Codename “Data Transfer”.
A big piece of the work that we do for you is in what we call “Data Type Guessing”. This is where we look at your file and makes some guesses as to the best data-type to use when creating the SQL Azure table. Much of this is based on the years of experience we have gained from the SQL Server Integration Services (SSIS) technology. Although these guesses can be over-ridden by more advanced users, it is our belief that most people will just want to get it up there so that they can continue with their work.
I hope you will give this Data Transfer service a try and let me know what you think. Do you like the idea? Are there other sources, destinations or new features you would like us to add?
I can be contacted by email at: Liam <dot> Cavanagh AT Microsoft <dot> com.

I’ve recommended that Liam’s team add the capability to upload *.csv files to Windows Azure Tables. I understand that the team is considering doing so.
Robin Shahan (@RobinDotNet) described a Windows Azure Compute Emulator Won’t Start And SDK-Tools-1.6 problem in an 11/27/2011 post:
After we upgraded to Azure SDK 1.5, one of our developers (Mike) had a problem. When he would try to run his Azure web role in the development fabric, it would sit there packaging up the deployment for an extraordinarily long time, and then give a popup message saying “Unable to connect to dfService”.
At this point, Mike had two choices. He could create a new profile without a space in the username and try to move everything over to it — you can do this by copying the old profile to the new. But he didn’t want to change his username. So he took the second option and followed the instructions in this MSDN article to set up an environment variable called _CSRUN_STATE_DIRECTORY to a path that didn’t have any spaces.
I know a lot of people have hit this problem, so I was wondering if they fixed this bug with the new SDK/Tools 1.6 that came out recently. I have a VHD that I use for maintaining our Office Add-ins – it has Windows 7, Visual Studio 2010, and Office 2007 installed in it. It hasn’t been updated for about three months, but I figured I could install Windows Updates and upgrade it to SDK 1.5/Tools 1.4 and see if I could reproduce the error.
It turns out the dang VHD didn’t have Azure tools installed at all. This means it also didn’t have SQLServer or IIS or the MVC tools upgrade, let alone about 50 Windows Updates.
After spending the morning (seriously, it took about 4 hours) updating and installing, I finally got to the point where I had Azure Tools 1.4 and Azure SDK 1.5 installed. I set up a new user profile with a space in it, and reproduced the problem. I also added the Environment variable and verified that it fixed the problem, and removed it and verified that the problem occurred again. I wanted to make sure all of the possibilities were covered, this was actually the exact problem we had seen, and that the problem was occurring again after removing the eivnronment variable so I could verify for sure that installing SDK 1.6 fixed it (or not).
Next I went out and tracked down the 1.6 tools. The main install page is here. You can use the Web Platform Installer, but I wanted to install the components manually. There is a link to the manual instructions on that page, and they are here.
I downloaded the 64-bit versions of everything. Since I’d already been through this, IIS and MVC, etc., were already installed and up-to-date; I only had to install the Azure components.
Interestingly enough, they have now split this into four bits, installable in this order:
- Windows Azure Authoring Tools – November 2011 (this is the SDK)
- Windows Azure Emulator – November 2011
- Windows Azure Libs for .NET – November 2011
- Windows Azure Tools – November 2011.
So I installed them, one by one, in the recommended order. (Do you think they split them up into separate bits so they can release just the changes to each bit in the future? I would think this also allows them to release changes to one bit at a time, which could allow them more flexiblity in their releases, because they can release fixes or updates to one instead of having to wait until they have enough to make a full release. I don’t work for Microsoft, so I don’t know for sure, that that’s my theory.)
On the original information page for the SDK, it said I should read about Known Issues in Windows Azure before installing. Like most developers, I chose to read that AFTER installing everything instead of before. (Come on, admit it, you do that too.)
That’s a very nice web page, with documentation of problems found in each version of the SDK/Tools, such as the problem with the IIS logs in 1.3 and 1.4, and the problem with the Dev Fabric starting up in 1.5. And yes, there’s one entry for 1.6. Turns out there’s a problem with one of the dll’s getting installed correctly in the GAC. The instructions say to do this:
- Open the Control Panel.
- Right-click Windows Azure Emulators – November 2011.
- Click Change.
- Follow the steps in the wizard to reinstall the compute emulator.
Well, this didn’t work for me. It asked for the location of an msi under my profile that I didn’t have. This might be because I didn’t use the Web Installer, I don’t know. But I re-ran the msi for the Windows Azure Emulator and did a Repair, and then ran the gacutil command listed in the article, and the dll is there.
I didn’t run the gacutil command beforehand, so I don’t know if the dll was there before and this upgraded it, or if it added the dll, or if it was there before and it didn’t upgrade it and I have a false sense of security, but I’m going with it until I have a problem.
It took me so long to get everything installed, I almost forgot what the point was. In case you’ve forgotten, the point was to see if having spaces in your profile still prevented the compute emulator from starting up. So I started up Visual Studio and tried running my WCF service in the development fabric on the account with spaces in it. And it worked. So the answer is yes, they fixed it.
Also, they corrected the spelling of “remaping” to “remapping” – this shows up in the output window in Visual Studio when you run your Azure application and it remaps ports. Sure, this doesn’t keep anything from working, but it’s nice to see they fixed that too.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) reported on 11/28/2011 I’m Speaking at Sac.NET User Group Tomorrow, Nov 29th!:
Tomorrow evening I’ll be presenting Visual Studio LightSwitch to Sac.NET in the Sacramento area. Please come join us! I always try and make it a fun and lively presentation and I’ll have tons of demos. Here are the details:
When: Tuesday, November 29th at 6:00 PM
Where: Rancho Cordova Library, 9845 Folsom Blvd, Rancho Cordova, CA 95827
Building Business Applications in Light Speed using Visual Studio LightSwitchVisual Studio LightSwitch is the simplest way to build business applications for the desktop and cloud for developers of all skill levels. LightSwitch simplifies the development process by letting you concentrate on the business logic, while LightSwitch handles the common tasks for you. In this demo-heavy session, you will see, end-to-end, how to build and deploy a data-centric business application using LightSwitch. You will also see how professional developers can enhance the LightSwitch experience by tapping into its rich extensibility model.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Lori MacVittie (@lmacvittie) asserted #devops An ecosystem-based data center approach means accepting the constancy of change… in an introduction to her Ecosystems are Always in Flux post of 11/28/2011 to F5’s DevCenter blog:
It is an interesting fact of life for aquarists that the term “stable” does not actually mean a lack of change. On the contrary, it means that the core system is maintaining equilibrium at a constant rate. That is, the change is controlled and managed automatically either by the system itself or through the use of mechanical and chemical assistance.
Sometimes, those systems need modifications or break (usually when you’re away from home and don’t know it and couldn’t do anything about it if you did anyway but when you come back, whoa, you’re in a state of panic about it) and must be repaired or replaced and then reinserted into the system. The removal and subsequent replacement introduces more change as the system attempts to realign itself to the temporary measures put into place and then again when the permanent solution is again reintroduced.
A recent automatic top-off system failure reminded me of this valuable lesson as I tried to compensate for the loss while waiting for a replacement. This 150 gallon tank is its own ecosystem and it tried to compensate itself for the fluctuations in salinity (salt-to-water ratio) caused by a less-than-perfect stop-gap measure I used while waiting a more permanent solution. As I was checking things out after the replacement pump had been put in place, it occurred to me that the data center is in a similar position as an ecosystem constantly in flux and the need for devops to be able to automate as much as possible in a repeatable fashion as a means to avoid incurring operational risk.
PROCESS is KEY
The reason my temporary, stop-gap measure was less than perfect was that the pump I used to simulate the same auto-top off process was not the same as the one used by the failed pump. The two systems were operationally incompatible. One monitored the water level and automatically pumped fresh water into the tank as a means to keep the water level stable while the other required an interval based cycle that pumped fresh water for a specified period of time and then shut off. To correctly configure it meant determining the actual flow rate (as opposed to the stated maximum flow rate) and doing some math to figure out how much water was actually lost on daily basis (which is variable) and how long to run the pumps to replace that loss over a 24 hour period.
Needless to say I did not get this right and it had unintended consequences. Because the water level increased too far it caused a siphon break to fail which resulted in even more water being pumped into the system, effectively driving it close to hypo-salinity (not enough salt in the water) and threatening the existence of those creatures sensitive to salinity levels (many corals and some invertebrates are particularly sensitive to fluctuations in salinity, among other variables).
The end result? By not nailing down the process I’d opened a potential hole through which the stability of the ecosystem could be compromised. Luckily, I discovered it quickly because I monitor the system on a daily basis, but if I’d been away, well, disaster may have greeted me on return.
The process in this tale of near-disaster was key; it was the poor automation of (what should be) a simple process.
This is not peculiar to the ecosystem of an aquarium, a fact of which Tufin Technologies recently reminded us when it published the results of a survey focused on change management. The survey found that organizations are acutely aware of the impact of poorly implemented processes and the (often negative) impact of manual processes in the realm of security:
66% of the sample felt their change management processes do or could place the organization at risk of a breach. The main reasons cited were lack of formal processes (56%), followed by manual processes with too many steps or people in the process (29%).
DEVOPS is CRITICAL to MAINTAINING a HEALTHY DATA CENTER ECOSYSTEM
The Tufin survey focused on security change management (it is a security focused organization, so no surprise there) but as security, performance, and availability are intimately related it seems logical to extrapolate that similar results might be exposed if we were to survey folks with respect to whether or not their change management processes might incur some form of operational risk.
One of the goals of devops is to enable successful and repeatable application deployments through automation of the operational processes associated with a deployment. That means provisioning of the appropriate security, performance, and availability services and policies required to support the delivery of the application. Change management processes are a part of the deployment process – or if they aren’t, they should be to ensure success and avoid the risks associated with lack of formal processes or too many cooks in the kitchen with highly complex manually followed recipes. Automation of configuration and policy-related tasks as well as orchestration of accepted processes is critical to maintaining a healthy data center ecosystem in the face of application updates, changes in security and access policies, as well as adjustments necessary to combat attacks as well as legitimate sudden spikes in demand.
More focus on services and policy as a means to not only deploy but maintain application deployments is necessary to enable IT to continue transforming from its traditional static, manual environment to a dynamic and more fluid ecosystem able to adapt to the natural fluctuations that occur in any ecosystem, including that of the data center.


James Staten (@staten7) posted his Top 10 Cloud Predictions for 2012: The Awkward Teenage Years Are Upon Us to the Forrester blogs on 11/28/2011:
As 2011 begins to wind down, we can look back on the progress made over the last 11 months with a lot of pride. The market stepped significantly forward with big gains in adoption by leaders Amazon Web Services (AWS) and Rackspace, significant growth in the use of clouds for big data, training, test and development, the creation of landmark new services and the dawning of the App-Internet era. Cloud technologies matured nearly across the board as did transparency, security and best practice use and adoption. But there’s much more growth ahead as the cloud is no longer a toddler but has entered the awkward teenage years.
And much as found in human development the cloud is now beginning to fight for its own identity, independence and place in society. The next few years will be a painful period of rebellion, defiance, exploration, experimentation and undoubtedly explosive creativity. While many of us would prefer our kids go from the cute pre-teen period straight to adulthood, we don’t become who we are without surviving the teenage years. For infrastructure & operations professionals, charged with bringing predictability to our company’s use of IT, this coming era of cloud computing will push us well outside of our comfort zone.
We’ve all lived through market transitions like this one before but probably have forgotten that we were teens when the technologies we helped cement in place during that year were too. Cloud computing won’t play out exactly like client-server or the Internet era did, but there are strong similarities and the early years were the most painful. To that aim, it’s time to put our soothsayer’s hat back on and read the tarot for cloud in 2012. Here is what we expect over the next year and what you as the I&O parent should do about it.
1. Shadow IT enters the light – deal with it. Tell me if this sounds familiar. A business leader invests in a new technology without the involvement of the IT team. He builds upon this investment creating new workflows, services and capabilities that become, he thinks, integral to doing business. Then the technology in question falls over. A frantic call comes in to the help desk that IT needs to take over the management and support of this “critical” application. Get ready for a lot more of this in 2012. Several I&O teams got this wakeup call in April 2011 when AWS had its well-publicized outage. While the I&O parent wanted to hold up this event and say, “See, I told you these services weren’t mature,” the developers response was, “well I ain’t moving.” You can get ready for this by proactively engaging your developers and getting your hands dirty with these cloud services. Do it today.
2. The uncool attempting to be cool – not cool. As a teen, you know it when you see it. Sadly many a marketer continues to try and latch onto a rebellious movement without the rebellion and just looks stupid. We have a name for this in the cloud market – cloudwashing. And sadly we’ve let more companies and I&O teams get away with this than we should. Expect that to stop in 2012 as the early adopters of cloud computing have enough experience now to see through these guises. In 2012, if your so-called cloud services aren’t highly standardized and automated capabilities delivering economies of scale, autonomy to the client and flexible cost control you will become uncool. And in business that means unprofitable. Don’t let your private cloud efforts be uncool.
3. A risky idea lands a big fish in jail. It’s a classic storyline that you can find any night on the Lifetime television network. A teen rebelling to show his independence pushes the limits going too far and ending up afoul of authority. Sadly, it’s the so-called good kids who draw the most attention when this happens. In 2012 we can almost count on the same playing out in the enterprise market. The most likely place will be an empowered business leader running afoul of compliancy laws which continue to evolve in arrears of technology advancement. But that excuse won’t be a quality defense. You can prevent the two a.m. trip to bail out your empowered employees by getting in front of the issue through education and best practice sharing. Publish a cloud use policy today that states how your company can best use these new technologies and write it using language that shows how to do it safely and encourages collaboration. Telling your teens don’t do cloud will just encourage misuse.
4. Conservative leaders ban the cloud as unhealthy. Hollywood has taught us that you can’t ban dancing in rural Texas but still conservative governments try. The reasoning is always the same – we are taking this action to protect our citizens and the community. While we don’t expect to see anyone try to outlaw cloud computing there’s already legislation underway in several countries to ban the use of cloud services not resident within that country. The US Patriot Act had an initial chilling effect on international companies using cloud but led to strong overseas expansion in 2011. As the recession slides on even the most successful cloud companies won’t be able to build data centers to bring their services into every country and if your legislators thinks this means jobs then your country could be next. If your politicians start acting this way, make your voice heard. The Internet knows no bounds and neither should the cloud.
5. The channel will face the music – reselling isn’t good enough anymore. For years I and my analyst brethren have been telling the value-added reseller market that they need to move away from revenue dependence on the resell of goods and services. Many have listened and now garner more revenue from consulting and unique intellectual property. Those who haven’t will get a serious wake-up call in 2012 – the cloud doesn’t need you. Cloud services are a direct-sell business and standardized, Internet-resident services don’t need local relationships to reach their customers. There’s nothing to install, customization is minimal and margins are thin and volume-based. For the channel to survive it must add value around cloud services and there’s plenty of opportunity to go around. As we’ve stated many times, while cloud services are standardized how each company uses them is not and that’s where all the opportunity lies. Just as I&O plays a role in supplementing the services provided by the cloud the channel needs to provide expertise that’s hard to find (and hire) in house.
6. Cloud cred will matter. As we enter 2012 there are far more job openings for cloud experts than there are qualified candidates to fill them and in 2012 this will become perhaps the biggest market growth inhibitor. And the hiring process is rapidly becoming untenable as hiring managers often don’t know what to look for and candidates are listing cloud experience on their resumes that they can’t actually back up. Businesses needs signs of credibility and candidates need true training to fill this gap. HP and EMC have seized on this issue in Q4 both launching cloud training and certification programs for I&O professionals. A handful of universities have added cloud development courses (and even degrees) to their engineering schools. In 2012, get ready for an explosion in this market. But in the meantime, if you have true cloud credibility you will find other ways of telling the world...
7. Cloud battles will showcase talent and advance best practices. You won’t have to go to 8 Mile to see it, but you won’t find it at CloudExpo either. Developers and operations professionals who are pushing the cloud limits are starting to show off their skills to their peers but those who labor for brand names can’t do it in the public light, so they are finding other ways to showcase their skills. For every official corporate cloud project there is today, there are 2 to 3 innovative start-up or test and development projects being built by the same people. Some of these are simply showcases for their skills that can be shared with friends, built upon or attacked to make them better. They are often used as a test bed to drive enhancements to the corporate effort. But increasingly these micro-efforts are being used to backup claims on a resume or take its place. The biggest users of cloud computing are in the audience for these efforts and when they find one that is legit, the designer quickly finds a job offer in their in-box. These showcases are being privately shared today and every talented cloud developer is looking to get noticed for their props. You can fuel this by sponsoring this activity in a hosted private cloud or within your public cloud tenancy. AWS encourages it with its free-for-a-year very small VMs. The events market can fuel these efforts by creating unconferences for this purpose. Look for the first of these in 2012.
8. Monkeys will go legit. Skateboarding used to be menacing to pedestrians and building managers until they built skate parks. Now Joe Citizen is safe to walk around and top skateboarders make millions. In the last several years, Netflix decided that disruptive behavior like this was a good thing and started menacing its developers with what it calls Chaos Monkeys, evil code crashers that invade its core services and take them down. These autobots got their thrill from goofy-footing over API calls, crashing executables and taking threads for thrill rides through endless loops. Its monkeys taught developers to code around the monkeys and the result was better code, higher uptime and leaner services. In the cloud, services are built over commodity infrastructure that is not only less reliable but expected to fail. If your code can’t handle this, it doesn’t belong in the skate park. In 2012, expect to see monkeys become a true part of the development process for cloud-targeted applications. Open source and at least one commercial monkey suite will come to market making all of us better and as a result...
9. Your company will survive a major cloud outage. It happens to every cloud service. The sooner you learn to deal with cloud outages the better off you will be. If you have seen any Jackass movie you know that young people seem to be able to withstand an incredible amount of punishment. Put us old-line parents through the same and we might not come out of the hospital. Applications sadly hold to this metaphor. Pick up a traditional application from your data center and move it, unchanged to the cloud, and you are simply asking for trouble. This is why the cloud is dominated by new applications today. As you look to migrate more of your application portfolio to the cloud you will have to transition these applications to the new architecture, preparing them to survive component failures, service outages and “noisy neighbors.” As you gain experience with this you will start to identify the patterns of design and replication that get you past these annoyances. For every company that went down in the cloud last year there were a third as many who didn’t. Next year, that surviving company will be you. That’s when you will know you can invest more in the cloud. Which will mean…
10. You will finally have to budget for public cloud spend. And this won’t be easy. Budgeting for your teen is a ridiculous challenge as you have to support their seemingly fickle swings between interests (basketball one day, band the next, a burgeoning rap career, then YouTube reality superstar after that) and the long term costs of college and when they graduate and come home to live with you for ten more years. Budgeting for cloud is just as challenging and requires I&O professionals to get comfortable with change. In IT we have had it easy thus far, as nearly every piece of technology could be bought outright or contracted long term – 3-5 years with a healthy discount for loyalty. Clouds are pay per use platforms and that’s a good thing as you don’t want to lock in your commitments to them because the use patterns will change over time. Long term, yes, you will be facing on-going cloud consumption bills and you can count on them being higher than you’d like. Right now, you can minimize costs by embracing cloud economics and working with your developers and business units to understand the cost models and how to leverage them most cost effectively. To do this, you have to engage with them on how they are using the cloud today, and through direct hands-on experience yourself, guide them on how to make better use of the cloud without incurring undo expenses.
While the idea of corporate IT being invaded by a bunch of teens may sound daunting remember that you once were one yourself; as were the technologies you take for granted today. Think back on how you survived then and making the most of cloud in 2012 will become clear and a lot less scary.
The prediction season is upon us.
Simon Munro (@simonmunro) described Business Oriented Autoscaling in an 11/28/2011 post:
When extolling the virtues of cloud computing we often proudly mention ‘infinite scalability’ without giving a moments thought to the infinitely large bill as an unfortunate side effect. Take a scenario where an application is under load and needs to be scaled up significantly.
Ops: We have noticed a massive spike in traffic, what should we do?
Business: If you add more nodes, will it handle the traffic?
Ops: Yes, but it will cost eleventy dollars an hour.
Business: Any idea where the traffic is from?
Ops: We’re seeing a lot of referrals from Google ads.
Business: Okay. Add the nodes, I’ll get back to you in an hour
<two hours later>
Business: It seems that an adwords campaign is underway, so leave the nodes running.
Ops: How long will it run for?
Business: It will run for the rest of the week
Ops: Okay, I’ll put in some bids for reserved compute for the rest of the week, it should bring the costs down by 7%.
Business: Great, but keep an eye on the load and shut some of the nodes down on Friday if the traffic is still high.
The point of the above hypothetical scenario is to illustrate that although we can scale based on technical metrics, those metrics should only be used for temporary scaling. It is only once we have input from business that we can make better scaling decisions.
Current autoscale mechanisms are based on simple metrics, not those that interface with the business. The interface with business still involves people and cannot be automated. This means that for all our fancy scalability that we have in our cloud platform, the process of scaling itself is not scalable.
With cloud computing we want to automate as much as possible and have come a long way (for example, automating the recycling of virtual machines), but the ability to autoscale is still immature. Individual applications may implement some of this in a bespoke fashion, but frameworks and environments need to exist in order to provide a standardised and simplified method to interface with the business, so that we can embed the functionality in our applications.
Describing the simple (and simply drawn process below)
- We still need autoscaling as we want to respond immediately but the subsequent steps are the most crucial.
- We need to know if there is a good reason for the current load. Perhaps there is a planned campaign that is underway and we need to look in the system that has special offers and sales, vouchers, advertising campaigns or even customer complaints in the CRM system.
- We should also be able to determine the business value of the load. Perhaps we can look to see if the increase in traffic results in extra orders, bookings or decreased call centre calls. (This may need to be delayed so that we can see the impact of the extra load as it propagates through various systems).
- We then make a decision as to whether there is any value in maintaining the added scale or if the dial should be turned back and service degraded.
If anyone has built something like this that they have applied generically to their applications, tell us about it in the comments. Likewise, if anyone is building (or has built) such a framework, we would be interested in hearing about it.
It is probably a few years down the line, but these are the sorts of issues that we need to focus on once we have the simple stuff (like keeping n instances running) sorted out. The value of cloud computing has to be arguable and articulated to business and until we can show how scaling works that makes sense to business, they will never get what we mean by ‘infinite scalability’.


Robert Cathey (@robertcathey) described Two Disruptions for the Price of One in an 11/28/2011 post:
We stand at the beginning of a Cambrian explosion of new business models, driven by the colliding disruptions of cloud computing and mobile ecosystems.
A conversation last week between Randy Bias and mobile analyst/Asymco founder Horace Dediu maps out how this diversity of new business models will evolve. Hosted at 5by5, Randy and Horace discuss the emergence of the “super platform” that is making it all possible. The first 20 minutes or so sets the table, with a discussion of how cloud computing and mobile ecosystems fit the definition of disruption theory. Then, Randy and Horace dig in:
- Enterprise hardware vendors are facing big challenges because their legacy computing model is at odds with the way web-scale clouds are being built to support emerging mobile ecosystems.
- Web-scale solutions are simple, and simplicity – in the hardware, architecture, stacks, networking – is critical to designing large systems that can be cost-effectively supported.
- Google operates as many as 10,000 physical servers with one employee. You can’t do that without a radical new approach to data center architecture.
- Apple, Android and other mobile device platforms are defining the post-PC era because of their ability to collect user-level data and take it to a cloud-based backend where it is aggregated and analyzed. Then, data can be fed into a wealth of new application concepts that offer previously impossible benefits at very low cost to users.
- A look at how we’ve shifted from a hardware-centric view of the world (hardware availability) to a platform-centric view (ecosystems) to a super-platform-centric view (ecosystems enabled by cloud). Examples include iOS, Silk browser, Siri, Facebook, and Android. Users extract new value from trading personal data for aggregate knowledge.
- Net-centric business models take advantage of aggregated data from users to provide them with new and very compelling ways to understand the world they live in and interact with it. The Quantitative Self Movement and other crowdsource apps are examples of powerful concepts that were not possible before powerful edge devices connected to web-scale cloud.
- This, coupled with voice, location-based services, augmented reality and situational awareness, puts us on the front end of an explosion of new app and business model possibilities.
- What do mobile network operators bring to the table that’s more valuable than AWS? A global footprint. Ownership of the IP backbone. Ownership of mobile network. OSS/BSS (billing system) integration. Low latency.
Randy and Horace conclude with a discussion of the utility business model and how IT organizations are adapting their thinking to embrace it.
Listen in on their conversation and check out Horace’s post, then tell us how you see the “twin disruptions” unfolding.

Joel Forman (@seattlejoel) described the last six month of Windows Azure and SQL Azure updates in his Windows Azure Platform: November 21st Links post of 11/28/2011 to the Slalom Consulting blog:
Well, it has been a long time since I last posted about some Azure news. In reality it has been a few months, but as time goes in “cloud-years”, it has been ages. Actually, come to think of it, “cloud years” and “dog years” have to be a pretty similar metric. So lets get caught up on Azure of the past “cloud year” (a.k.a. last few months).
Service Bus – Queues, Topics, and Subscriptions
Windows Azure Storage – Analytics and Geo-Replication
This enhancement to Windows Azure Storage allows for the ability to track, analyze, and debug storage activity. For example, you can see all requests against a given BLOB, or view summary metrics around number of requests or storage capacity. These new capabilities will give a lot more visibility into the traffic of applications using Windows Azure storage. Read about storage analytics here. Furthermore, the platform has introduced geo-replication for Windows Azure blobs, tables, and queues. This means that your data will be backed up across data centers automatically by the platform. Read about geo-replication here.
SQL Azure – Q4 Release
SQL Azure announced an upcoming Q4 release, due out before the end of 2011. The maximum database size will increase from 50 GB to 150 GB with this release. SQL Azure Federations will also be fully available. Read more about this release here.SQL Azure Import/Export
Through recent updates to the Windows Azure portal, it has become very easy to import and export data to/from SQL Azure. From within the portal, I am able to export a backup of my SQL Azure database (bacpac) to Windows Azure BLOB storage, with just a few clicks. I can leverage some new Data-tier application framework libraries, available with SQL Server “Denali” CTP 3, to move data in and out of on-premise SQL Servers as well. These two combined capabilities make moving data in and out of the cloud very easy. See some examples from CodePlex here.Windows Azure Toolkit for Android, Toolkit Updates for iOS and WP7
Windows Azure is very compelling as a service tier for mobile applications. It is great to see Microsoft investing in this area through the different Windows Azure toolkits available for the different platforms. Android was the latest to release, with the iOS and WP7 toolkit already being out there and seeing additional updates. There are a lot of great new NuGet packages for WP7 as well.Windows Azure and Windows 8
At the BUILD conference in September, we got a sneak peak of how Azure will support metro-style applications in Windows 8. It is easy to see how features like the Access Control Service, Storage, SQL Azure, and CDN will offer great out-of-the-box building blocks for metro applications. There are some great sessions available from the conference available for viewing. Check out material from the conference here.Windows Azure SDK – Version 1.6
In November, Microsoft released the latest version of the Windows Azure SDK, version 1.6. You can read more about the features of the release here. In my opinion, Microsoft continues to round out the SDK with nice add-ins. For example, this SDK makes publishing, both from Visual Studio and from a build machine, easier to manage. Its also important to note that an updated to the Windows Azure Platform Training Kit accompanies every SDK release. This is the best place to get started with Windows Azure. Check out the release here.Windows Azure HPC Scheduler SDK
Alongside the latest Azure SDK comes the Windows Azure HPC Scheduler SDK. This SDK works with the Windows Azure SDK to assist in building HPC applications that use large amounts of resources running in parallel. This SDK can be downloaded from here.I will try to get back into the frequency of posting more detailed news and resources, hopefully on the “cloud quarter” rather than the “cloud year”. In the mean time, hope this gets you caught up.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Dan Berthiaume asserted Misconceptions Hinder SMB Hybrid Cloud Adoption in an 11/29/2011 post to the TalkinCloud blog:
Although delivery of IT infrastructure via the cloud has the potential to provide substantial cost savings, several popular misconceptions are preventing wider adoption of cloud-based IT outsourcing and hybrid clouds, according to a recent webinar from Everest Group.
For MSPs and cloud integrators, cloud-based IT outsourcing can offer predictable costs but it also introduces a potentially disruptive business model. But especially in the case of MSPs serving SMBs, who are more prone to shy away from transitional projects that appear costly, time-consuming or difficult, getting past misplaced client apprehension about the cloud poses a challenge.
Using information from the Everest Group webinar, here’s a look at the opportunities and misperceptions facing hybrid cloud services.
Hybrid Cloud Services Can Be 1/3 Cheaper
By using a hybrid model of cloud-based IT outsourcing, customers can save 30% or more of the cost associated with traditional infrastructure delivery Everest claimed. Hybrid cloud computing maximizes savings by letting users maintain their “base” computing hours in a private, dedicated cloud, shifting base workloads to low-usage “valleys” whenever possible and then shifting peak workloads to on-demand public clouds with a pay-as-you-go model. This eliminates spend on unused peak capacity.
Combating Three Cloud Misconceptions
Although its popularity is growing, especially among larger enterprises, the cloud has not yet become the standard platform for IT outsourcing. Everest Group identifies three key perceived constraints that are unnecessarily preventing wider adoption of cloud-based IT outsourcing:
- contractual;
- incentive alignment with existing IT outsourcing vendor(s); and
- market immaturity.
In terms of perceived contractual constraints, many IT outsourcing customers assume their contracts limit services that can be outsourced to other providers. In addition, IT outsourcing customers often believe their workloads don’t meet the revenue minimums of cloud-based providers. These concerns may be especially prevalent among SMBs, who do not usually negotiate contracts from a position of strength and have smaller workloads.
In reality, Everest Group says most IT outsourcing contracts do not have exclusivity clauses and that the demand of most users will exceed the revenue floor of a cloud-based service contract.
Another perceived constraint to wider adoption of cloud-based IT outsourcing is an assumption that existing vendors can easily and quickly migrate their services to the cloud. However, Everest Group finds that many traditional IT service vendors face a 30% to 40% revenue hit on client cloud migration, and that there are significant gaps in cloud delivery platforms and skillsets among these vendors.
For SMBs, there is even less likelihood an existing vendor will want to migrate them to the cloud, considering the smaller revenue they represent. This gives SMBs and even greater incentive to turn their cloud-based IT outsourcing over to an MSP specializing in the SMB arena.
Furthermore, despite a widespread view of the cloud services market as being immature, Everest Group analysis shows cloud solutions are currently being used across a variety of enterprise use cases, including core areas such as transactional applications.
By educating their SMB clients on the substantial cost savings a cloud transition can provide and revealing the fallacies behind common assumptions about cloud-based IT services, MSPs can earn a profit while helping SMBs save money. What better way to do business?
Read More About This Topic

Geva Perry (@gevaperry) posted Public Vs. Private Cloud (yes, that old debate) to his Thinking Out Cloud blog on 11/28/2011:
Hope everyone in the U.S. had a great Thanksgiving.
This is a quick follow up on my previous post, 10 Predictions About Cloud Computing, which received quite a bit of attention in the cloudosphere. Specifically, my second point there, which stated:
Public Rules: Internal clouds will be niche. In the long-run, Internal Clouds (clouds operated in a company's own data centers, aka "private clouds") don't make sense. The economies of scale, specialization (an aspect of economies of scale, really) and outsourcing benefits of public clouds are so overwhelming that it will not make sense for any one company to operate its own data centers. Sure, there need to be in place many security and isolation measures, and feel free to call them "private clouds" -- but they will be owned and operated by a few major public providers.
A couple of weeks ago I had an interesting conversation with Marten Mickos, CEO of Eucalyptus (and of MySQL fame), a private cloud platform provider. I explained that I believe that Internal Private Clouds (i.e., clouds operated on a company's own servers), will become a niche in the long run.
Surprisingly, Marten did not disagree, but he made the following very good point. If we look a few years ahead, let's say 2015, the IaaS market in total will be a roughly $20 billion market according to estimates by IDC and others. If private IaaS is anywhere between 10% to 20% of that, certainly within the bounds of the definition of a "niche", we're still looking at a multi-billion dollar market. Enough to sustain the success of several startups and large vendors.
Point well taken.
The other follow up on this topic is a reference to my friend Nati Shalom's post on the topic. It's a good read with good arguments.

Lydia Leong (@cloudpundit) asserted Private clouds aren’t necessarily more secure in an 11/28/2011 post:
Eric Domage, an analyst over at IDC, is being quoted as saying, “The decision in the next year or two will only be about the private cloud. The bigger the company, the more they will consider the private cloud. The enterprise cloud is locked down and totally managed. It is the closest replication of virtualisation.” The same article goes on to quote Domage as cautioning against the dangers of the public cloud, and, quoting the article: “He urged delegates at the conference to ‘please consider more private cloud than public cloud.’”
I disagree entirely, and I think Domage’s comments ignore the reality of what is going on within enterprises, both in terms of their internal private cloud initiatives, as well as their adoption of public cloud IaaS. (I assume Domage’s commentary is intended to be specific to infrastructure, or it would be purely nonsensical.)
While not all IaaS providers build to the same security standards, nearly all build a high degree of security into their offering. Furthermore, end-to-end encryption, which Domage claims is unavailable in public cloud IaaS, is available in multiple offerings today, presuming that it refers to both end-to-end network encryption, along with encryption of both storage in motion and storage at rest. (Obviously, computation has to occur either on unencrypted data, or your app has to treat encrypted data like a passthrough.)
And for the truly paranoid, you can adopt something like Harris Trusted Cloud — private or public cloud IaaS built with security and compliance as the first priority, where each and every component is checked for validity. (Wyatt Starnes, the guiding brain behind this, founded Tripwire, so you can guess where the thinking comes from.) Find me an enterprise that takes security to that level today.
I’ve found that the bigger the company, the more likely they are to have already adopted public cloud IaaS. Yes, it’s tactical, but their businesses are moving faster than they can deploy private clouds, and the workloads they have in the public cloud are growing every day. Yes, they’ll also build a private cloud (or in many cases, already have), but they’ll use both.
The idea that the enterprise cloud is “locked down and totally managed” is a fantasy. Not only do many enterprises struggle with managing the security within private clouds, many of them have practically surrendered control to the restless natives (developers) who are deploying VMs within that environment. They’re struggling with basic governance, and often haven’t extended their enterprise IT operations management systems successfully into that private cloud. (Assuming, as the article seems to imply, that private cloud is being used to refer to self-service IaaS, not merely virtualized infrastructure.)
The head-in-the-sand “la la la public cloud is too insecure to adopt, only I can build something good enough” position will only make an enterprise IT manager sound clueless and out of touch both with reality and with the needs of the business.
Organizations certainly have to do their due diligence — hopefully before, and not after, the business is asking what cloud infrastructure solutions can be used right this instant. But the prudent thing to do is to build expertise with public cloud (or hosted private cloud), and for organizations which intend to continue running data centers long-term, simultaneously building out a private cloud.

<Return to section navigation list>
Cloud Security and Governance
Jay Heiser posted Bulletproof Contracts to his Gartner blog on 11/28/2011:
With the understanding that I am not a lawyer, and Gartner is not a law firm, here’s my brief summary of the contractual language dealing with SaaS security as provided by a prominent vendor:
- We believe that we obey the law. If there are any questions pertaining to how your data is handled within our system, it is YOUR problem.
- We won’t give your data to the police. Unless we do give it to the police.
- When this contract is over, you may have the ability to get your data back, but that is your problem, not ours.
- If one of your customers contacts us, we won’t give them anything. Unless we are forced to give them something.
- We will store the data in whatever country we want.
- We might have third parties help us with this, and they of course would be held to the same weak levels of standard as we contractually obligate ourselves to follow.
- You the customer are obligated to obey the law at all times, even if you have no idea what that may entail. (Guess what happens if there is a dispute with us and our lawyers can find some way to demonstrate that you didn’t completely follow the law.)
- We will follow appropriate security measures—as understood by us.
- We will back up your data at least once a week, we will review our procedures periodically, although this seems unnecessary, given that none of these procedures were knowingly designed to fail. If we have the slightest plan for testing our ability to recover, we are not sharing it with you and we hope that you won’t ask that question.
- If any of our support personal ever accesses your data, by definition, it is necessary access.
I make light of the sort of legalistic word games typical of SaaS contracts, but given the constant stream of complaints from Gartner clients about this form of service, who can blame me for being more than skeptical? If a potential buyer is looking for a contract that clearly protects their interests, and is presented with an inflexible document that, in highly obtuse language, spends far more time describing what the vendor will NOT do than what they intend to do, why shouldn’t buyers be frustrated? As long as enough buyers are willing to give money to a service provider on the basis of what amounts to that provider saying that they will try to do a good job, and without actually accepting any significant level of risk if they don’t, then who can blame them?

Jay is a Gartner research vice president specializing in the areas of IT risk management and compliance, security policy and organization, forensics, and investigation.
<Return to section navigation list>
Cloud Computing Events
Himanshu Singh posted Calling All UK Developers: FREE Six Weeks of Windows Azure Program Kicks Off January 23, 2012 on 11/29/2011:
Microsoft UK Windows Azure Evangelists Eric Nelson and David Gristwood are pulling together what promises to be a great way for UK companies to really dig deep into Windows Azure. Starting January 23, 2012 they will offer Six Weeks of Windows Azure, a program that will provide FREE assistance to UK companies who want to build or extend applications with Windows Azure. During the six weeks they will deliver a series of webinars, surgeries and online support which will cover both the commercial and technical aspects of adopting Windows Azure. These activities will be delivered primarily as an online experience with a focus on making sure participants get lots of opportunities to ask questions and get great advice.
- Why cloud may be relevant to your applications and your adoption options
- How to start and how to be successful – both in terms of business transformation and technology choices
- Free online help to actually get your application designed, built, tested and deployed
- Advice on marketing and selling your application
Click here to read more about the program and to sign up.

Alan Smith reported on 11/29/2011 a SWAG & SWENUG Security in the Cloud & Julfest event in Stockholm, Sweden on 12/1/2011 from 6:00 to 10:00 PM GMT + 1:00
Sergio Molaro and Robert Folkesson will be presenting on different aspects of cloud security, there will be good food, good drinks and prizes in a great location. If you are in Stockholm it’s free to register to attend here .
Tony Bailey asserted We Come To You: Discover Windows Azure with a list of events taking place in the eastern US during December 2011 and January 2012:
There are quite a few ways to learn more about how Windows Azure can cut development times and enter new markets faster.
One way is to attend an in-person event for half a day.
Date: 12/5/2011 10:00 AM - 1:30 PM
Location: Tampa Florida 33609 United States
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032499953&culture=en-us
Date: 12/7/2011 10:00 AM - 1:30 PM
Location: Washington District of Columbia 20015 United States
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032499954&culture=en-us
Date: 1/24/2012 10:00 - 1:30 PM
Location: New York New York 10104 United States
https://msevents.microsoft.com/CUI/EventDetail.aspx?EventID=1032499955&culture=en-usMore in-person events are listed here.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Klint Finley (@klintron) reported Amazon Web Services Planning Real-Time, Big Data Stream Processing Service in an 11/29/2011 post to the Services Angle blog:
According to a job ad posted by Amazon Web Services, the company is planning to launch a new service for processing streams of big data. Here’s the job listing:
Amazon Web Services is looking for a Senior Development Manager to lead the team that is building a disruptive new service for processing Big Data streams. Our globally distributed service must be able to process over 2 million records per second at launch, and eventually scale to handle over 100x that traffic. It is equally critical that our platform provide highly available, highly reliable processing of data in near-realtime. If you’re a distributed systems guru who thinks about data in terms of exabytes, this is your dream job.
We are seeking a seasoned manager and technical thought leader with a strong track record of owning successful products. You’ll build and manage a strong team in a fast-paced, startup-like environment. As a technical leader, you’ll need to be a pragmatic visionary that can translate business needs into workable technology solutions that scale both technologically and operationally. Given our rapid growth, you’ll need to be able to lead the organization through change, evolution, and sustained growth as well as be able and willing to roll up your sleeves and get hands on when necessary.
Basic Qualifications
- 5+ years experience building and managing high performance software teams
- 5+ years of OO software development experience in C++ or Java (preferably both)
- Bachelor’s or Master’s degree in Computer Science or a related discipline
- Experience building and operating extremely high volume and highly scalable web services
- Experience building and operating highly available, 24×7 services
Preferred Qualifications
- Experience building and operating globally distributed systems
- Experience with Hadoop, MapReduce, or other Big Data processing platforms
It’s not entirely clear based on this whether AWS is building its own stream processing software, or if it will be offering a service based on existing software (such as Storm, Apache S4, HStreaming, Streambase etc). But it sounds based on this listing like AWS is building its own processing system based on Hadoop.
There have been a few academic projects to implement stream computing on AWS (see here and here for example), and HStreaming can be implemented on AWS as well.
Real-time data processing was a hot topic at Hadoop World. The session on real-time analytics with Hadoop overflowed.


Sounds to me like competition for Microsoft Codename “Data Analytics” and DataSift.
Joe Brockmeier (@jzb) reported Cisco, Google Ventures and VMware Back Puppet Labs with $8.5 Million in an 11/29/2011 post to the ReadWriteCloud blog:
Puppet Labs announced today that it is receiving $8.5 million in Series C financing from Google Ventures, Cisco and VMware. The new round of financing brings Puppet Labs up to $15.75 million, which begs the question – what does the IT automation company need with that kind of dosh?
Luke Kanies, CEO of Puppet Labs, says that the money is going into development, marketing and sales. Kanies says that the company is looking to grow faster than "organic growth" would carry the company.
But, Kanies says that the company originally didn't set out to raise quite as much as they did in this round. According to Kanies, the company happened to find three investors that "get the disruptive trend" of IT automation. VMware and Cisco are using Puppet in their own environments, and seeing customers using Puppet as well.
Google is also using Puppet, but it's important to understand that Google Ventures is strictly a financial investment arm, not a strategic one. Google Ventures partner Karim Faris says that they look to invest in businesses that are "irrelevant or strategic" as long as they look like a good investment. "They may be strategic [to Google] and that's great, but that's not how we look to invest."
That said, Faris says Google Ventures did take notice of Google's use of Puppet as well as a "groundswell of support" from engineers for Puppet. "When people you know and trust, engineers, come in and say 'have you seen this tool?' that's what piques my attention."
Faris says that Google Ventures was "excited about two trends" with Puppet – the flock of enterprises moving to cloud services, and the "rise of DevOps."
Plans for Puppet
With the additional funding under its belt, expect to see Puppet further building out its sales and marketing efforts in 2012.
I wondered if Puppet might be looking into a hosted model, similar to Opscode's hosted version. Kanies says no. "We don't plan on adding a hosting model. It might be an interesting business in three to five years, and it's a good way for customers to experiment with the product, but we already have good ways to experiment now" with downloadable VMs with Puppet.
Kanies did hint that Puppet would be doing more with the data it collects from hosts. "Understand the insight we bring to the table. Puppet knows more about your infrastructure than anybody else." For example, Kanies says that Puppet can produce full configuration graphs of every machine it monitors, which can give companies a lot of information about their systems he says they can't get from other tools.
"Some of the data is monitoring data, but this is much more about configuration data, when you updated a package, changed a user password, added a user... Puppet can give you that very easily, no one else can today."
In the next few years, Kanies says that Puppet will be "doubling down on insight we can give to customers."
Puppet is also improving its Windows story, which is crucial for companies that have mixed environments. While the enterprise product does not have a Windows build, Kanies says that the open source release of Puppet does support Windows clients. Puppet Labs will support using the open source client to check into enterprise hosts. So don't expect to use Windows as a server/host for Puppet anytime soon, but if you need to monitor and work with Windows hosts, he says Puppet can do that today.
Don't expect to see an IPO in 2012 from Puppet, says Kanies. "We're not quite at that point yet, hopefully in 2013. This round is about letting us grow faster than we can organically. We are building a company for the long term, not building a company to sell."
Puppet is in a fairly interesting place, particularly if it expands its features around host data and does more with its Windows integration.


Barton George (@Barton808) described How to create a Basic or Advanced Crowbar build for Hadoop in an 11/29/2011 post:
As I mentioned in my previous entry, the code for the Hadoop barclamps is now available at our github repo. [See Barton’s other post below.]
To help you through the process, Crowbar lead architect Rob Hirschfeld has put together the two videos below. The first, Crowbar Build (on cloud server), shows you how to use a cloud server to create a Crowbar ISO using the standard build process. The second, Advanced Crowbar Build (local) shows how to build a Crowbar v1.2 ISO using advanced techniques on a local desktop using a virtual machine.
Crowbar Build (on cloud server)
Advanced Crowbar Build (local)

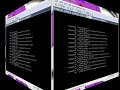
Barton George (@Barton808) announced Open source Crowbar code now available for Hadoop in an 11/29/2011 post:
Earlier this month we announced that Dell would be open sourcing the Crowbar “barclamps” for Hadoop. Well today is the day and the code is now available at our github repo.
Whats a Crowbar barclamp?
If you haven’t heard of project Crowbar it’s a software framework developed at Dell that started out as an installation tool for OpenStack. As the project grew beyond installation to include monitoring capabilities, network discovery, performance data gathering etc., the developers behind it, Rob Hirschfeld and Greg Althaus, decided to rewrite it to allow modules to plug into the basic Crowbar functionality. These modules or “barclamps” allow the framework to be used by a variety of projects. Besides the OpenStack and Hadoop barclamps written by Dell, VMware created a Cloud Foundry barclamp and DreamHost created a Ceph barclamp.
To help you get your bearings
As I mentioned in the opening paragraph, the code for the Hadoop barclamp is now available. To help you get started, below are a couple of videos that Rob put together. The first walks you through how to install Crowbar and the second one explains how to use Crowbar to deploy Hadoop.
Extra-credit reading


Jeff Barr (@jeffbarr) posted a status report for Amazon CloudFront Update - Fall 2011 on 11/29/2011:
Amazon CloudFront has been a big hit. We're adding customers, locations, and features at a rapid clip. Let's take a look at what's been going on.
Lots of Customers
We now have over 20,000 active* CloudFront customers; this is double the number of customers we had at this time last year. Based on a quick search of CDN vendor web sites and public financial reports, we believe that this would make Amazon CloudFront the largest global CDN according to published customer counts. We are seeing strong usage from the enterprise (PBS, IMDB, and Sega, to name a few) and from startups (Encoding.com and Rent Jungle, among many others). These customers use CloudFront to deliver their content at high speed with low latency.

* - Active means that the customer has used CloudFront in the given month.Customers come to CloudFront because it is easy to get started (see the CloudFront Getting Started Guide for more information). Once on board, they stay because they are pleased with the scalability, performance, and the pay-as-you-go pricing model.
Because CloudFront is part of the AWS family, it works really well with our other services. You can store your static content in Amazon S3 and create a CloudFront distribution from an S3 bucket in minutes. You can generate dynamic or streamed content in an Amazon EC2 instance and, once again, set up a distribution in a matter of minutes.
Lots of Features
The team has been focusing on new features for CloudFront. We recently added AWS Identity and Access Management Support and Live Streaming. Before that we added enhanced Management Console support, private content, live streaming with Adobe Flash Media Server, HTTPS support, request logging, custom origins, and more.Lots of Edge Locations
We now have 21 edge locations including Sao Paolo, Brazil (our first location in South America), Paris (launched in February), and Stockholm (launched in June). We have also added a second location in Los Angeles (California) to increase connectivity and to provide even better service for our customers. Requests for objects are intelligently routed to these edge locations for lowest possible latency. We will continue to be smart about where we add new locations and only add them where we can drive measurable improvements in performance and lower latency. This ensures that our customers continue to benefit from even lower prices as we scale.Lower Pricing
We lowered our prices for CloudFront this past July. At that time we reduced CloudFront's data transfer pricing in the US and Europe, and we added a 5 PB usage tier at a correspondingly lower cost. We also lowered the cost of transferring data out of Amazon EC2 and Amazon S3, further reducing your costs when you use either of those two services as your origin server. We will continue to lead the CDN industry in driving prices down for our customers.With CloudFront‘s pricing, you only pay for your actual usage. You can find pricing for CloudFront and all other AWS Services on the AWS pricing page. Although most of our customers appreciate and take advantage of the pay-as-you-go nature of CloudFront, we also offer lower prices for customers that are able to commit to a certain level of usage.
Awards and Recognition
Earlier this month, CloudFront won the Reader's Choice award in the Delivery Network category at the Streaming Media Europe Conference. This is the second year that CloudFront has been recognized in this way. It is also cool to see a number of other AWS and CloudFront customers on the list including Sorenson Media and Wowza Media.


<Return to section navigation list>

















0 comments:
Post a Comment