Windows Azure and Cloud Computing Posts for 11/30/2011+
| A compendium of Windows Azure, SQL Azure Database, AppFabric, Windows Azure Platform Appliance and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
I updated my Test-Drive SQL Azure Labs’ New Codename “Data Transfer” Web UI for Copying *.csv Files to SQL Azure Tables or Azure Blobs post on 11/30/2011 to add a tutorial (and warning) for migrating data to Windows Azure blobs:
2. Click the Windows Azure Blob button to open the Enter Your Windows Azure Blob Credentials Page. Complete the required entries and mark the Save Settings check box:
Caution: Be sure to type the Container name in lower case. If you include upper-case letters, you’re likely to encounter an HTTP 500 error when uploading the file. This issue is likely to be resolved shortly.
…
6. Click Import to export the file to to an Azure blob and open the My Data page. Click the Blobs tab to display the result:
7. Click View to open the What Do You Want to Do with FileName.ext? dialog:
8. Click the Open link to display the file in its default viewer, Excel for this example:





Avkash Chauhan (@avkashchauhan) described How the size of an entity is caclulated in Windows Azure table storage in an 11/30/2011 post:
While working with a partner, I had an opportunity to dig about how Azure Table storage size is calculated with respect to entities. As you may know each entity in Windows Azure Table Storage, can have maximum 1 MB space for each individual entity instance. The following expressions shows how to estimate the amount of storage consumed per entity:
- 4 bytes + Len (PartitionKey + RowKey) * 2 bytes + For-Each Property(8 bytes + Len(Property Name) * 2 bytes + Sizeof(.Net Property Type))
The following is the breakdown:
- 4 bytes overhead for each entity, which includes the Timestamp, along with some system metadata.
- The number of characters in the PartitionKey and RowKey values, which are stored as Unicode (times 2 bytes).
- Then for each property we have an 8 byte overhead, plus the name of the property * 2 bytes, plus the size of the property type as derived from the list below.
The Sizeof(.Net Property Type) for the different types is:
- String – # of Characters * 2 bytes + 4 bytes for length of string
- DateTime – 8 bytes
- GUID – 16 bytes
- Double – 8 bytes
- Int – 4 bytes
- INT64 – 8 bytes
- Bool – 1 byte
- Binary – sizeof(value) in bytes + 4 bytes for length of binary array
So let’s calculate the actual entity size in the following example:
<?xml version="1.0" encoding="utf-8" standalone="yes"?> <entry xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns="http://www.w3.org/2005/Atom"> <title /> <updated>2008-09-18T23:46:19.3857256Z<updated/> <author> <name /> </author> <id /> <content type="application/xml"> <m:properties> <d:Address>Mountain View</d:Address> <= String (14 * 2) + 4 = 32 Bytes + 8 Bytes + Len(“Address”)*2 <d:Age m:type="Edm.Int32">23</d:Age><= Int/Int32 = 4 Bytes+ 8 Bytes + Len(“Age”)*2 <d:AmountDue m:type="Edm.Double">200.23</d:AmountDue><= Double = 8 Bytes+ 8 Bytes + Len(“AmountDue”)*2 <d:BinaryData m:type="Edm.Binary" m:null="true" /><= Binary = 4 Bytes+ 8 Bytes + Len(“BinaryData”)*2 <d:CustomerCode m:type="Edm.Guid">c9da6455-213d-42c9-9a79-3e9149a57833</d:CustomerCode><= GUID = 16 Bytes+ 8 Bytes + Len(“CustomerCode”)*2 <d:CustomerSince m:type="Edm.DateTime">2008-07-10T00:00:00</d:CustomerSince><= DateTime = 8 Bytes+ 8 Bytes + Len(“CustomerSince”)*2 <d:IsActive m:type="Edm.Boolean">true</d:IsActive><= Bool = 1 Bytes+ 8 Bytes + Len(“IsActive”)*2 <d:NumOfOrders m:type="Edm.Int64">255</d:NumOfOrders><= Int64 = 8 Bytes+ 8 Bytes + Len(“NumOfOrders”)*2 <d:PartitionKey>mypartitionkey</d:PartitionKey><= Partition Key (14 * 2) = 28 Bytes <d:RowKey>myrowkey1</d:RowKey><= Row Key (9 * 2) = 18 Bytes <d:Timestamp m:type="Edm.DateTime">0001-01-01T00:00:00</d:Timestamp><= DateTime = 8 Bytes+ 8 Bytes + Len(“Timestamp”)*2 </m:properties> </content> </entry>Finally total bytes can be aggregated as below:


See Avkash’s original post for highlighted elements.
Dwight Merriman (@dmerr) described MongoDB on Azure in an 11/30/2011 post:
The MongoDB Replica Set Azure wrapper is currently a preview release. Please provide feedback, mongodb-dev, mongodb-user and IRC #mongodb are good places!
- Getting the package
- Components
- Initial Setup
- Building
- Deploying and Running
- Additional Information
- FAQ/Troubleshooting
- Known issues
The MongoDB Wrapper for Azure allows you to deploy and run a MongoDB replica set on Windows Azure. Replica set members are run as Azure worker role instances. MongoDB data files are stored in an Azure Blob mounted as a cloud drive. One can use any MongoDB driver to connect to the MongoDB server instance. The MongoDB C# driver 1.3 is included as part of the package.
Getting the package
The MongoDB Azure Wrapper is delivered as a Visual Studio 2010 solution with associated source files. The simplest way to get the package is by downloading it from GitHub:
Zip file
tar.gz fileAlternatively, you can clone the repository run the following commands from a git bash shell:
$ cd <parentdirectory> $ git config --global core.autocrlf true $ git clone git@github.com:mongodb/mongo-azure.git $ cd mongo-azure $ git config core.autocrlf trueYou must set the global setting for core.autocrlf to true before cloning the repository. After you clone the repository, we recommend you set the local setting for core.autocrlf to true (as shown above) so that future changes to the global setting for core.autocrlf do not affect this repository. If you then want to change your global setting for core.autocrlf to false run:
$ git config --global core.autocrlf falseComponents
Once you have unzipped the package or cloned the repository, you will see the following components:
- solutionsetup.cmd/ps1 - Scrips used in first time setup
- MongoDBHelper - Helper library (dll) that provides the necessary MongoDB driver wrapper functions. Is used in the ReplicaSetRole but also by any .Net client applications to obtain the connection string. More details can be found in the API document.
- ReplicaSetRole - The library that launches mongod as a member of a replica set. It is also responsible for mounting the necessary blobs as cloud drives.
- MvcMovie - A sample MVC3 web app that demonstrates connecting and working with the mongodb replica set deployed to Azure. In an actual user scenario this will be replaced with the user's actual app.
- MongoDBReplicaSet - The cloud project that provides the necessary configuration to deploy the above libraries to Azure. It contains 2 configurations
- MvcMovie - Web role config for the MvcMovie sample application
- ReplicaSetRole - Worker role config for the actual MongoDB replica set role
Initial Setup
Run solutionsetup.cmd to setup up the solution for building. This script only needs to be run once. This script does the following:
- Creates ServiceConfiguration.Cloud.cscfg as a copy of configfiles/ServiceConfiguration.Cloud.cscfg.ref
- Downloads the MongoDB binaries (currently 2.1.0-pre) to the appropriate solution location
Building
The following are prerequisites:
- .Net 4.0
- Visual Studio 2010 SP1 or Visual Web Developer 2010 Express
- Azure SDK v1.6
- Visual Studio Tools for Azure v1.6
- ASP.Net MVC3 (only needed for the sample application)
Once these are installed, you can open MongoAzure.sln from Visual Studio and build the solution.
Deploying and Running
Running locally on compute/storage emulator
To start, you can test out your setup locally on you development machine. The default configuration has 3 replica set members running on ports 27017, 27018 and 27019 with a replica set name of 'rs'
In Visual Studio run the solution using F5 or Debug->Start Debugging. This will start up the replica set and the MvcMovie sample application.
You can verify this by using the MvcMovie application on the browser or by running mongo.exe against the running instances.
Deploying to Azure
Once you have the application running locally, you can deploy the solution to Windows Azure. Note You cannot execute locally against storage in Azure due to the use of Cloud Drives.
Additional Information
The azure package wraps and runs mongod.exe with the following mongod command line options:
--dbpath --port --logpath --journal --nohttpinterface --logappend --replSetMongoDB 2.1.0-pre is currently used in this package.
MongoDB creates the following containers and blobs on Azure storage:
- Mongo Data Blob Container Name - mongoddatadrive(replica set name)
- Mongo Data Blob Name - mongoddblob(instance id).vhd
FAQ/Troubleshooting
- Can I run mongo.exe to connect?
- Yes if you set up remote desktop. Then you can connect to the any of the worker role instances and run e:\approot\MongoDBBinaries\bin\mongo.exe.
- Role instances do not start on deploy to Azure
- Check if the storage URLs have been specified correctly.
Known issues
<Return to section navigation list>
SQL Azure Database and Reporting
Joel Forman discussed Backing Up SQL Azure Databases in a 12/1/2011 post to the Slalom Blog:
One question that I often am asked from clients is around how to back up SQL Azure databases. In this blog post I will outline some of the capabilities and offerings available in this space.
The first place I start when answering this question is to clarify what the platform provides for you and what it does not. Every SQL Azure database is replicated multiple times for redundancy and recover-ability. This is outstanding in terms of availability and disaster recovery. It means that my application is insulated from a hardware failure on a SQL Server. If there were a problem with my “master”, I may not even know if the platform switches me over to a “slave”. But I do not have access to those replicas. And unfortunately, “point-in-time” copies of my database are not created nor made available to me by default.
A lot of customers have a backup process in place for different reasons. Some take nightly incremental backups of their data for safe keeping. This could insulate them in the case where data was corrupted. Others take backups before major code releases or revisions for rollback capabilities. In these cases, the platform does not provide me with backups of my database automatically, but it does provide different tools to create them.
Creating a Copy
There is a T-SQL command that you can run against your SQL Azure master database to create a point-in-time copy of a SQL Azure database to a new SQL Azure database. Here is an example of that command:
CREATE DATABASE [MyDatabase_Copy1] AS COPY OF [MyDatabase] GOThis is a very useful tool for a variety of scenarios. I have seen this used before major releases for a rollback plan. It is also a good tool to use for developer’s trying to replicate a bug or problem against a copy of a database where the issue exists. One thing to remember when making copies is that you are being billed for each copy that you create. Remember to remove them when you are done.
I have seen some automation put in place that runs this command on a nightly basis to create a nightly backup process. This also contained logic to only keep X number of copies on hand and remove the oldest. This is a viable solution, but there is the associated costs of keeping the copies in the cloud.
SQL Azure Import/Export
The ability to import and export SQL Azure databases via the Data-tier application framework now exists in all Windows Azure data centers. Not only is this a great way to migrate databases to SQL Azure, it is also a great way to back up data from SQL Azure. In the backup scenario, a BACPAC file is created, containing schema and data from the database, and exported as a BLOB to a Windows Azure Storage account. Since BLOB storage is inexpensive (currently $0.14 /GB/Month), this is also a very cost efficient backup solution.The Windows Azure Management Portal allows you to export a SQL Azure database in this fashion with only a few clicks. Follow these easy steps:
1. Sign in to the portal at http://windows.azure.com.
2. Click on “Database” in the lower left navigation.
3. Expand your subscription and click on your SQL Azure server.
4. Highlight the SQL Azure database you wish to export.
5. At the top ribbon, click on “Export”.

6. In the dialog window, supply the credentials to your SQL Azure server and supply the BLOB name and storage credentials for target storage account where the exported BACPAC file will be saved.

7. Your export job will be started, and you should see the BACPAC file appear shortly at your target location. You can check up on the status of the export job by clicking the “Status” button in the top ribbon.You can import BACPAC files to new SQL Azure databases via the portal as well, following a similar process.
There is a CodePlex site containing SQL DAC examples at http://sqldacexamples.codeplex.com. Here you can find the downloads for the DAC framework dependencies as well as examples on how to use some of the tools. From here, it is easy to learn how to import BACPAC files from SQL Azure to local on-premise SQL Servers. You can also easily see how a backup process could be automated via these tools and commands.
There is a third-party tool, SQL Azure Backup by RedGate, that offers backup services for SQL Azure. There is a free download if you are interested in checking it out.
In summary, while implementing a backup strategy left up to you, there are several tools available that allow you to do so.


Zerg Zergling posted SQL Azure Federations and Open Source Software on 11/28/2011 to the Silver Lining blog:
One of the things that will be introduced in the next update to SQL Azure is a database sharding solution called SQL Azure Federations. Brian and I will have some examples of using this feature with specific languages once it releases, but we thought it would be nice to have an introductory article to explain a little about this feature and what it means to OSS developers.
What is sharding and why is it useful?
Your typical database contains one or more tables, which in turn contain rows that are made up of columns. So what happens when you have so much data that the database has grown to a massive size, you're running out of disk space, you're server can't handle all the incoming connections, or your index is huge and it's impacting your query performance? Often you turn to partitioning the data, splitting it up across multiple databases. Instead of one gigantic database, you now have a bunch of smaller ones. In most cases you wouldn't keep these small databases together on the same server, but instead split them up across multiple servers. This allows you to spread the processing load across multiple machines and scale out instead of up.
There's two ways that databases are typically partitioned: horizontally and vertically. Just think about the rows and columns in your database as a grid view; horizontal partitioning is splitting the rows, while vertical partitioning is splitting the columns. Sharding is a form of horizontal partitioning; breaking up your data at the row level. You end up with a bunch of databases (the shards,) each of which contains a slice of a table. So with sharding, you would end up with multiple databases (shards,) all of which contain the same table (let's say the customers table,) but each database (shard) only contains a specific subset of the total rows in the table.
Sharding can be a little tricky to implement, as you need to come up with a way to split the rows across databases that gives good utilization of all databases, and keeps all the data you commonly query on together. For instance, if you have customer table and an orders table, you might potentially use the customerID value for splitting rows. Rows in both tables that contain values 0-100 would go into databaseA, values 101-200 into databaseB, 201-300 into databaseC, etc. The thing to watch out for here is how you are assigning the customerID value; if you're sequentially assigning it to customers, databaseA is going to fill up before B and C are ever used. Ideally you would want to randomly assign the value so that new customers are spread across the databases.
Another challenge of sharding is that your application often has to have an understanding of the databases (shards) involved in the solution, so that it knows if a request comes in for customerID 167 that it needs to connect to databaseB to retrieve that information.
SQL Azure Federations
SQL Azure Federations is a sharding solution that is built into SQL Azure. One of the features of federations is that you can take a shard, and split it on the fly without any downtime. So you can create a federation that starts with one shard, covering all potential ranges (let's say 0-900 as an example.) If it starts approaching the maximum database size, or if your performance decreases due to large index size, etc., you can issue a command that splits the initial shard into two shards, both of which now cover a portion of the potential ranges for this federation. For example, one might now cover the range of 0-500 while the other covers 501-900.
Federations don't solve the first sharding problem I mention above, you still have to come up with a value to use that determines how you break the rows up across shards and ensure that it allows you to equally utilize the shards, but it does resolve the problem with having to know what database to connect to.
Federation T-SQL Statements
Going to gloss over these for now, as a full reference for them should be available once the feature goes live. But based on past blog posts from the SQL Azure product group, and some published hands on labs, here's what to expect:
CREATE FEDERATION
This statement is used to create a new federation. Here’s an example:
CREATE FEDERATION Orders_Federation (CustID INT RANGE)This would create a new federation named ‘Orders_Federation’. The 'CustID INT RANGE' is the federation distribution key, and specifies how data within this federation will be sharded; by range, using an integer value.
This statement will mark the database you run it in as the federation root database. The federation root database is used when performing some management tasks, and it is also responsible for routing connections to member databases. This command will also create the initial federation member (shard) for this federation. This initial member will cover all values from the min value to max value covered by the distribution type you specified.
Federation members are physically implemented as SQL Azure databases, and can be hosted on separate nodes within the Windows Azure data center. SQL Azure also automatically keeps three copies of them for disaster recovery purposes, just like all other databases in SQL Azure.
USE FEDERATION
This statement is used to connect to a federation. This is where some of the federation magic happens; when connecting to a federation, your application doesn’t need to know anything about the underlying physical federation members, just the federation distribution key. The USE statement will connect to the federation root database, which will then route the connection to the federation member database that contains the rows matching the distribution value you specify. Here’s an example:
USE FEDERATION Orders_Federation (CustID = '100') WITH RESET, FILTERING = OFFThis statement will connect to the Orders_Federation root database, figure out what federation member (shard) contains the value of ‘100’ for the CustID distribution key, and route the connection to that database. FILTERING = OFF instructs the connection to make the entirety of the member database available on this connection. If FILTERING is set to ON, only rows containing the value of ‘100’ will be returned.
You can also connect directly to the federation root by specifying
USE FEDERATION ROOTCREATE TABLE…FEDERATED ON
This statement is used to create federated tables; tables that will have their data partitioned across the federation members (shards). Here’s an example:
CREATE TABLE Customers( CustomerID int NOT NULL, CompanyName nvarchar(50) NOT NULL, FirstName nvarchar(50), LastName nvarchar(50), PRIMARY KEY (CustomerId) ) FEDERATED ON (CustID = CustomerID)Note the FEDERATED ON clause. This associates the CustomerID field of this table with the CustID distribution key for this federation. This is how the federation knows how to split the rows of this table across the federation members (shards). After running this command, the Customers table will exist in every federation member, each of which will cover a subset of the table rows based on the value of the CustomerID field.
You can also create reference tables (tables created without the FEDERATE ON clause,) within a federation member. Generally reference tables hold static information that needs to be used in your queries, such as looking up what state based on a zip code. Since SQL Azure doesn’t support joins across databases, you’d want this reference information to be replicated in each federation member.
ALTER FEDERATION
This is another bit of federation magic; you can alter the federation layout on the fly without incurring any downtime. This includes SPLIT operations that take one of your existing federation members (shards) and splits it into two new members. Here’s an example:
ALTER FEDERATION Orders_Federation SPLIT AT (CustID = '100')This would find the federation member that contains the value ‘100’ for the CustID distribution key, and split it into two new federation members at that value. If this was performed against a federation that contained a single federation member (covering min value to max value for the INT type,) then after the operation the federation would contain two federation members; one containing distribution values from min value to 100 and another containing distribution values from 101 to max.
While this operation is going on, all data contained in the member being split is still available. You’re application has no clue that a split operation is going on (unless it initiated the operation or peeks at metadata about databases,) and queries should operate as normal. Once the operation is complete, rows for federated tables originally contained within the source federation member will now be contained with the two new members.
ALTER FEDERATION also supports DROP, which drops an existing federation member (shard). All data contained in the shard is dropped also, but the distribution range covered by the dropped database will now be covered by an adjacent member database.
There won’t be support for a MERGE operation in this release of federations, however it will be implemented at some point in the future: http://blogs.msdn.com/b/cbiyikoglu/archive/2011/07/11/shipping-fast-sharding-to-federations-in-from-pdc-2010-to-2011.aspx
No matter how many SPLIT or DROP operations you perform on a federation, the federation members will cover the entire range of values specified by the federation distribution key. In this case, the range of values for an INT.
Summary
SQL Azure federations is an upcoming feature of SQL Azure that allows you to dynamically scale your data, and since it’s implemented as SQL Azure Transact-SQL statements, any OSS technology that can talk to SQL Azure can use it.
References
Here’s some reference material that I used while creating this article:
- SQl Azure Federations Hands On Labs – http://msdn.microsoft.com/en-us/hh532130. Use this to get up to speed once federations release.
- Cihan Biyikoglu’s blog posts on SQL Azure Federations – http://blogs.msdn.com/b/cbiyikoglu/archive/tags/federations/. Pretty much everything you ever wanted to know about federations.

<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
My (@rogerjenn) Microsoft tests Social Analytics experimental cloud post of 12/1/2011 to SearchCloudComputing.com asserted “Social media is a gold mine of potential business intelligence about customer opinions. Microsoft's Social Analytics team will use QuickView, an advanced search service, and sentiment analysis technology to mine a mother lode of filtered tweet streams from Windows Azure for real-time, crowd-sourced opinions”:
Social media data is a byproduct of Software as a Service (SaaS) sites like Twitter, Facebook, LinkedIn and StackExchange. And filtered versions of this data are worth millions to retailers, manufacturers, pollsters and politicians, as well as marketing and financial firms and news analysts. QuickView, the advanced search service that uses natural language processing (NLP) technologies, can be used to extract meaningful information from tweets, including sentiment analysis, and then index them in real time.
Industry pundits claim the revenue social media sites garner from syndicating their trove of big data exceeds advertising costs. For example, Twitter reached 250 million tweets per day in mid-October. The company syndicates those tweets to organizations like DataSift, which passes along license fees of $0.01 per 1,000 custom-filtered tweets. DataSift partners, such as Datameer, offer Apache Hadoop-powered big data business intelligence (BI) applications for data visualization and analysis.
Microsoft can see the value of this. This year, the company gained access to the entire Twitter firehose feed. In July, the company reportedly paid Twitter $30 million per year to extend the agreement for the Bing search engine to index tweets in real time. And Microsoft also joined the big data syndication sweepstakes in 2010 when it introduced Windows Azure Marketplace DataMarket, previously called Project “Dallas.”
Social Analytics experimental cloud
In late October, the SQL Azure Labs team announced the private trial of a new Microsoft Codename“Social Analytics” experimental cloud service, which targets organizations that want to integrate social Web information into business applications. The lab offers an Engagement client user interface (UI) for browsing datasets that implement Microsoft’s QuikView technology.
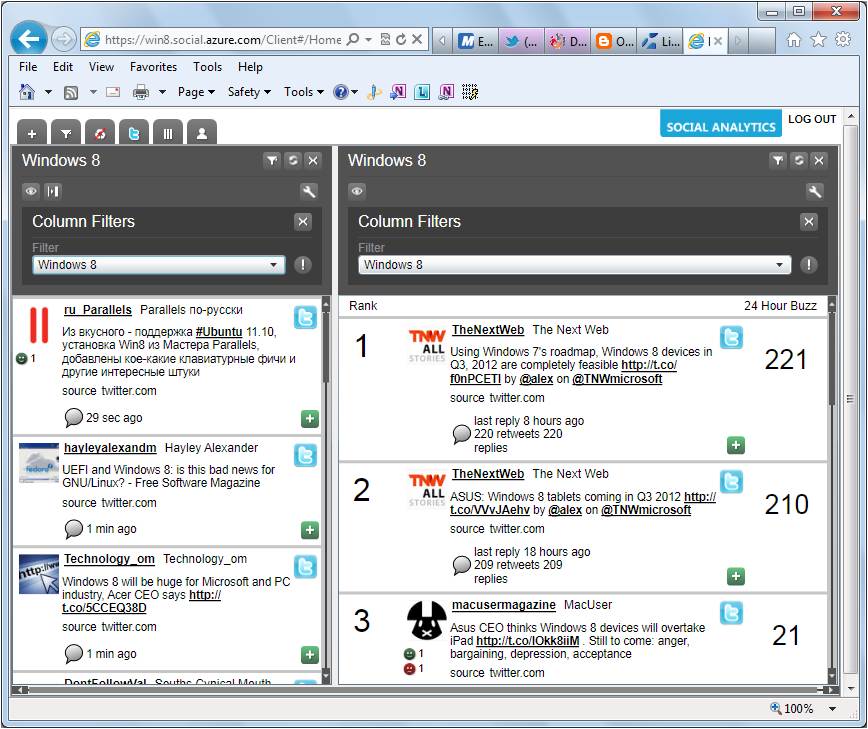
Figure 1
(click to enlarge)Figure 1 shows the Engagement client displaying a live feed of tweets filtered for Windows 8 content in the left pane and tweets ranked by 24-hour buzz in the right pane.
The rate of tweet addition to the left pane depends on the popularity of the topic for which you filter; the Windows 8 dataset received about one new tweet per second over a recent 24-day period. The current “Social Analytics” OData version also supports LINQPadand PowerPivot for Excel clients, but not the DataMarket Add-in for Excel (CPT2) or Tableau Public.
APIs support BI data analysis and collection
To accommodate enterprises that design BI data analysis and collection applications, the Social Analytics team also provides a RESTful application programming interface (API) that supports LINQ queries with a .NET IQueryable interface and returns up to 500 rows per request. For Windows 8, the average data download rate is about 10,000 new tweets per minute with a 3 Mbps DSL connection. Microsoft is currently capturing about 150,000 MessageThreads daily across its environments, including the labs datasets.The company evaluates and discards about 200 to 300 times more content items that don’t meet its criteria for data capture, said Kim Saunders, program manager for Social Analytics at Microsoft. “In the initial lab, our target is to maintain at least 30 days of history. We plan to grow this target over time,” Saunders added.
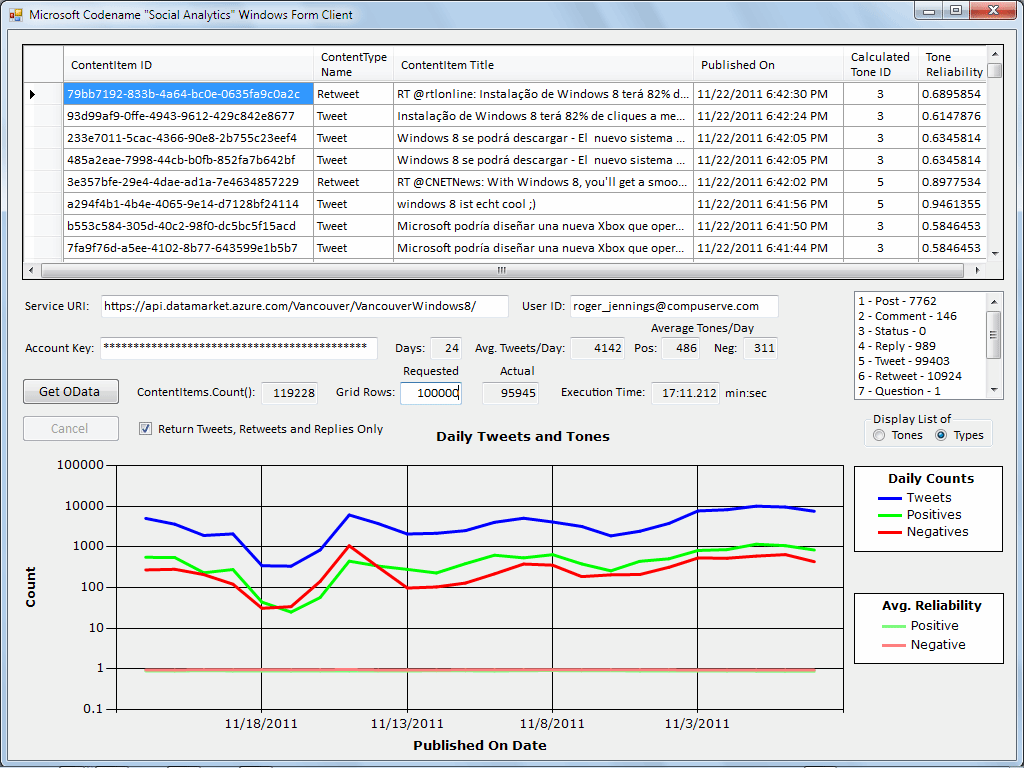
Figure 2
(click to enlarge)
Figure 2 shows a screenshot of Microsoft Codename “Social Analytics” Windows Form Client .NET 4.0 C# application after retrieving 120,000 ContextItems. You can download the project with full source code from my SkyDrive account. Each ContextItem represents an individual tweet from the VancouverWindows8 dataset. (“Vancouver” was the original codename for the service.)
The DataGrid columns display an assigned graphical user ID, the first 50 or so characters of the tweet as the Title, a Calculated Tone ID value (3 is neutral, 4 is negative and 5 is positive), and a Tone Reliability index, which represents the confidence in the correctness of the Tone value, or sentiment. The Tone is based only on English content as it does not support other languages yet; the client application included in the labs equates any Tone with reliability less than 0.8 as neutral, Saunders said. …

The article continues with a “Hadoop implementation for Azure still in the works” and concludes:
Microsoft may be late to the social analytics market, but it has the advantages of Microsoft Research’s deep NLP resources, Windows Azure for big data delivery from the cloud, strong relationships with Twitter and Facebook and an up-and-running DataMarket presence -- not to mention very deep pockets.
Following are recent “Social Analytics”-related posts to the OakLeaf Systems blog:
- Twitter Sentiment Analysis: A Brief Bibliography
- More Features and the Download Link for My Codename “Social Analytics” WinForms Client Sample App
- New Features Added to My Microsoft Codename “Social Analytics” WinForms Client Sample App
- My Microsoft Codename “Social Analytics” Windows Form Client Detects Anomaly in VancouverWindows8 Dataset
- Microsoft Codename “Social Analytics” ContentItems Missing CalculatedToneId and ToneReliability Values
- Querying Microsoft’s Codename “Social Analytics” OData Feeds with LINQPad
- Problems Browsing Codename “Social Analytics” Collections with Popular OData Browsers
- Using the Microsoft Codename “Social Analytics” API with Excel PowerPivot and Visual Studio 2010
- SQL Azure Labs Unveils Codename “Social Analytics” Skunkworks Project
Full Disclosure: I’m a paid contributor to the SearchCloudComputing.com blog.
Elisa Flasko (@eflasko) announced New Windows Azure Marketplace Data Delivers the Latest Weather and Stock Information in an 11/30/2011 post:
Today we announce the release of two new data offers that have recently been added to the Windows Azure Marketplace:
- Worldwide Historical Weather Data: Provides weather information including historical daily maximum temperature, minimum temperature, precipitation, dewpoint, sea level pressure, windspeed, and wind gust for thousands of locations around the world. Data is available on-line from 2000 through the current week and historical data is added every week for the previous week for all global locations.
The Stock Sonar: The Stock Sonar Sentiment Service provides sentiment scores for public companies trades on the US stock market. The Stock Sonar retrieves, reads and analyzes information from a wide variety of online sources including articles, blogs, press releases and other publicly available information based on an in-depth understanding of a text's meaning.
The Windows Azure Marketplace is an online market for buying and selling finished Software-as- a-Service (SaaS) applications and premium datasets. The Windows Azure Marketplace helps companies instantly discover premium applications, public domain and trusted commercial data from partners – everything from Health to Retail and Manufacturing applications to demographics, navigation, crime, and web services and algorithms for data cleansing.
Learn more about the Windows Azure Marketplace:
- Whitepaper: Windows Azure Marketplace
- Video: First Look: Windows Azure Marketplace
- Video: Discover and subscribe to data feeds on DataMarket
- Case Studies: Learn how others are using the Marketplace

<Return to section navigation list>
Windows Azure AppFabric: Apps, Access Control, WIF and Service Bus
Richard Seroter (@rseroter) continued his Interview Series: Four Questions With … Clemens Vasters on 12/1/2011:
Greetings and welcome to the 36th interview in my monthly series of chat with thought leaders in connected technologies. This month we have the pleasure of talking to Clemens Vasters who is Principal Technical Lead on Microsoft’s Windows Azure AppFabric team, blogger, speaker, Tweeter, and all around interesting fellow. He is probably best known for writing the blockbuster book, BizTalk Server 2000: A Beginner’s Guide. Just kidding. He’s probably best known as a very public face of Microsoft’s Azure team and someone who is instrumental in shaping Microsoft’s cloud and integration platform.
Let’s see how he stands up to the rigor of Four Questions.
Q: What principles of distributed systems do you think play an elevated role in cloud-driven software solutions? Where does “integrating with the cloud” introduce differences from “integrating within my data center”?
A: I believe we need to first differentiate “the cloud” a bit to figure out what elevated concerns are. In a pure IaaS scenario where the customer is effectively renting VM space, the architectural differences between a self-contained solution in the cloud and on-premises are commonly relatively small. That also explains why IaaS is doing pretty well right now – the workloads don’t have to change radically. That also means that if the app doesn’t scale in your own datacenter it also won’t scale in someone else’s; there’s no magic Pixie dust in the cloud. From an ops perspective, IaaS should be a seamless move if the customer is already running proper datacenter operations today. With that I mean that they are running their systems largely hands-off with nobody having to walk up to the physical box except for dealing with hardware failures.
The term “self-contained solution” that I mentioned earlier is key here since that’s clearly not always the case. We’ve been preaching EAI for quite a while now and not all workloads will move into cloud environments at once – there will always be a need to bridge between cloud-based workloads and workloads that remain on-premises or workloads that are simply location-bound because that’s where the action is – think of an ATM or a cashier’s register in a restaurant or a check-in terminal at an airport. All these are parts of a system and if you move the respective backend workloads into the cloud your ways of wiring it all together will change somewhat since you now have the public Internet between your assets and the backend. That’s a challenge, but also a tremendous opportunity and that’s what I work on here at Microsoft.
In PaaS scenarios that are explicitly taking advantage of cloud elasticity, availability, and reach – in which I include “bring your own PaaS” frameworks that are popping up here and there – the architectural differences are more pronounced. Some of these solutions deal with data or connections at very significant scale and that’s where you’re starting to hit the limits of quite a few enterprise infrastructure components. Large enterprises have some 100,000 employees (or more), which obviously first seems like a lot; looking deeper, an individual business solution in that enterprise is used by some fraction of that work-force, but the result is still a number that makes the eyes of salespeople shine. What’s easy to overlook is that that isn’t the interesting set of numbers for an enterprise that leverages IT as a competitive asset – the more interesting one is how they can deeply engage with the 10+ million consumer customers they have. Once you’re building solutions for an audience of 10+ million people that you want to engage deeply, you’re starting to look differently at how you deal with data and whether you’re willing to hold that all in a single store or to subject records in that data store to a lock held by a transaction coordinator. You also find that you can no longer take a comfy weekend to upgrade your systems – you run and you upgrade while you run and you don’t lose data while doing it. That’s quite a bit of a difference.
Q: When building the Azure AppFabric Service Bus, what were some of the trickiest things to work out, from a technical perspective?
A: There are a few really tricky bits and those are common across many cloud solutions: How do I optimize the use of system resources so that I can run a given target workload on a minimal set of machines to drive down cost? How do I make the system so robust that it self-heals from intermittent error conditions such as a downstream dependency going down? How do I manage shared state in the system? These are the three key questions. The latter is the eternal classic in architecture and the one you hear most noise about. The whole SQL/NoSQL debate is about where and how to hold shared state. Do you partition, do you hold it in a single place, do you shred it across machines, do you flush to disk or keep in memory, what do you cache and for how long, etc, etc. We’re employing a mix of approaches since there’s no single answer across all use-cases. Sometimes you need a query processor right by the data, sometimes you can do without. Sometimes you must have a single authoritative place for a bit of data and sometimes it’s ok to have multiple and even somewhat stale copies.
I think what I learned most about while working on this here were the first two questions, though. Writing apps while being conscious about what it costs to run them is quite interesting and forces quite a bit of discipline. I/O code that isn’t fully asynchronous doesn’t pass code-review around here anymore. We made a cleanup pass right after shipping the first version of the service and subsequently dropped 33% of the VMs from each deployment with the next rollout while maintaining capacity. That gain was from eliminating all remaining cases of blocking I/O. The self-healing capabilities are probably the most interesting from an architectural perspective. I published a blog article about one of the patterns a while back [here]. The greatest insight here is that failures are just as much part of running the system as successes are and that there’s very little that your app cannot anticipate. If your backend database goes away you log that fact as an alert and probably prevent your system from hitting the database for a minute until the next retry, but your system stays up. Yes, you’ll fail transactions and you may fail (nicely) even back to the end-user, but you stay up. If you put a queue between the user and the database you can even contain that particular problem – albeit you then still need to be resilient against the queue not working.
Q: The majority of documentation and evangelism of the AppFabric Service Bus has been targeted at developers and application architects. But for mature, risk-averse enterprises, there are other stakeholders like Operations and Information Security who have a big say in the introduction of a technology like this. Can you give us a brief “Service Bus for Operations” and “Service Bus for Security Professionals” summary that addresses the salient points for those audiences?
A: The Service Bus is squarely targeted at developers and architects at this time; that’s mostly a function of where we are in the cycle of building out the capabilities. For now we’re an “implementation detail” of apps that want to bet on the technology more than something that an IT Professional would take into their hands and wire something up without writing code or at least craft some config that requires white-box knowledge of the app. I expect that to change quite a bit over time and I expect that you’ll see some of that showing up in the next 12 months. When building apps you need to expect our components to fail just like any other, especially because there’s also quite a bit of stuff that can go wrong on the way. You may have no connectivity to Service Bus, for instance. What the app needs to have in its operational guidance documents is how to interpret these failures, what failure threshold triggers an alert (it’s rarely “1), and where to go (call Microsoft support with this number and with this data) when the failures indicate something entirely unexpected.
From the security folks we see most concerns about us allowing connectivity into the datacenter with the Relay; for which we’re not doing anything that some other app couldn’t do, we’re just providing it as a capability to build on. If you allow outbound traffic out of a machine you are allowing responses to get back in. That traffic is scoped to the originating app holding the socket. If that app were to choose to leak out information it’d probably be overkill to use Service Bus – it’s much easier to do that by throwing documents on some obscure web site via HTTPS. Service Bus traffic can be explicitly blocked and we use a dedicated TCP port range to make that simple and we also have headers on our HTTP tunneling traffic that are easy to spot and we won’t ever hide tunneling over HTTPS, so we designed this with such concerns in mind. If an enterprise wants to block Service Bus traffic completely that’s just a matter of telling the network edge systems.
However, what we’re seeing more of is excitement in IT departments that ‘get it’ and understand that Service Bus can act as an external DMZ for them. We have a number of customers who are pulling internal services to the public network edge using Service Bus, which turns out to be a lot easier than doing that in their own infrastructure, even with full IT support. What helps there is our integration with the Access Control service that provides a security gate at the edge even for services that haven’t been built for public consumption, at all.
Q [stupid question]: I’m of the opinion that cold scrambled eggs, or cold mashed potatoes are terrible. Don’t get me started on room-temperature french fries. Similarly, I really enjoy a crisp, cold salad and find warm salads unappealing. What foods or drinks have to be a certain temperature for you to truly enjoy them?
A: I’m German. The only possible answer here is “beer”. There are some breweries here in the US that are trying to sell their terrible product by apparently successfully convincing consumers to drink their so called “beer” at a temperature that conveniently numbs down the consumer’s sense of taste first. It’s as super-cold as the Rockies and then also tastes like you’re licking a rock. In odd contrast with this, there are rumors about the structural lack of appropriate beer cooling on certain islands on the other side of the Atlantic…
Thanks Clemens for participating! Great perspectives.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Adam Hall (@Adman_NZ) explained Managing and Monitoring Windows Azure applications with System Center 2012 in a 12/1/2011 post to the Microsoft Server and Platform blog:
System Center 2012 delivers the capability to manage your applications across both on-premises Private Clouds and also in the public cloud with Windows Azure. This capability allows you to choose which location is best suited to your needs, which best delivers on your requirements and be able to manage all of your applications across all locations with a single solution set.
In my previous two posts I have covered the topics of application performance monitoring and application self service. In this post I am going to cover a topic that brings the topics of monitoring, management and self service all together, and show you how we manage and monitor applications that are deployed on Windows Azure.
If you are not familiar with Windows Azure then this is a great place to learn and get started! And if you’re wondering just what you could do with Windows Azure, have a browse through the scenarios.
- Upload our application files to Windows Azure
- Deploy our application with our chosen configuration
- Monitor the newly deployed Azure application with Operations Manager
Working with application resources
System Center 2012 allows you to manage the Windows Azure application resources as well as the storage locations. App Controller allows you to work with Windows Azure storage, such as creating storage accounts and containers, uploading, moving and deleting application resources.
The screenshots below show how easy it is to copy application resource files from a local file share into Windows Azure.
Simply copy the files from the local file share:
Then navigate to your Windows Azure storage location, right-click and choose paste. The files are then uploaded:
Nice and easy!
Deploying Windows Azure applications
Now that we have uploaded the required application resources, we can deploy the application. As we have previously covered, App Controller provides application self service, enabling us to deploy the application from within the comfort of our web console!
We simply click on the Deploy button, choose which Windows Azure subscription to deploy to:
Configure the application:
And then choose the application configuration and package files that we uploaded:
After we start the deployment, App Controller keeps us updated with the progress:
And just like that, we have deployed our Windows Azure application! Incredibly easy and fast
.
Monitoring Windows Azure applications
We recently released the Windows Azure Management pack for Operations Manager, which allows you to connect your on-premises Operations Manager implementation to Windows Azure. When you do this, you can see the applications you have across multiple subscriptions:
You can see the health state of your Windows Azure applications:
And finally you can gain instant visibility into the application status with the dynamically built Windows Azure application diagram view:
You can even use the drag-and-drop Distributed Application authoring console to build a view across applications running both on-premises and Windows Azure!
And with that, we have covered the 3 topics, and gone from uploading the application resources, through deploying the application and then configuring the monitoring of the application.
How easy was that!
Calls to Action!
It looks great, you want to get started and test this out for yourself? No problem!
- Get involved in the Community Evaluation Program (CEP). We are running a private cloud evaluation program starting in November where we will step you through the entire System Center Private Cloud solution set, from Fabric and Infrastructure, through Service Delivery & Automation and Application Management. Sign up here.
- Download the App Controller 2012 Beta here
- Download the Operations Manager 2012 Release Candidate here
- Download the Windows Azure Management Pack here
- Learn about Windows Azure here
- Browse through the Windows Azure scenarios to get some ideas on where to start












See my Configuring the Systems Center Monitoring Pack for Windows Azure Applications on SCOM 2012 Beta post of 9/7/2011 for a similar SCOM 2012 walkthrough.
Panagiotis Kefalidis (@pkefal) described Running JBoss 7 on Windows Azure in a 12/1/2011 post:
I’m going to start a series of posts to explain how we made JBoss run on Windows Azure, not just on standalone mode but with full cluster support.
Let me start with one simple definition, I’m NOT a Java guy, but I work with some very talented people under the same roof and under the same practice at Devoteam.
“An integrated, enterprise-grade demo of a Windows Azure cloud setup, containing a .NET front-end, a JEE application in the cloud and a local mainframe instance; completely integrated.”
We used:
- mod_cluster
- jGroups
- mod_proxy
The basic reason behind choosing JBoss, besides the fact that our customers use it also, was that it’s open and free and open means that we can change whatever we want to make it work and fit in our environment.
One of those talented guys Francois Hertay, modified the code for cluster discovery (jGroups) already provided to make it work in a more robust way and more important, make it work with JBoss 7 because it currenctly works only with version 6. We still use the BLOB approach but we changed it a little bit to make it more robust. In a typical enterprise scenario we have the proxies in front of the JBoss cluster and mod_proxy is also the one achieving the much needed state consistency as you might already know that Windows Azure is using a non-sticky load balancer. Also, based on the dynamic nature of how a Windows Azure instance behaves, it was impossible to have static IPs for the proxies and the instances and it was obvious we needed a little something for:
- Discovering the proxies and announce them to the JBoss cluster
- Make sure that this is removed when a proxy goes down or when a new node joins the cluster, it finds the proxies and registers them
We needed something different as mod_proxy uses multicast to announce itself to the cluster and this is not supported in Windows Azure. The solution was to create our own home-brewed announcer service and will take care of this.
Our final setup was 1 WorkerRole for the Proxy and 1 WorkerRole for the JBoss node.
We choose this setup so we can independently scale either the proxies or the JBoss nodes, which is pretty typical in an Enterprise environment.
On the next post, I will explain how the Announcement Service works and what can be improved in the future in the service.



Elizabeth White asserted “The European Environment Agency, Esri and Microsoft launch new online community and application development platform” as a deck for her Eye on Earth Enables Cloud-Based Environmental Data Sharing from the Azure cloud report on 11/30/2011:
The European Environment Agency (EEA), Esri and Microsoft Corp. on Thursday announced, at the 17th Conference of the Parties (COP17) to the United Nations Framework Convention on Climate Change, the launch of the Eye on Earth network, an online community for developing innovative services that map environmental parameters. The new cloud computing-based network provides a collaborative online service for hosting, sharing and discovering data on the environment and promotes the principles of public data access and citizen science. In addition, the organisations also announced NoiseWatch, a new web service available on the Eye on Earth network that measures noise in 164 European cities.
"The launch of the Eye on Earth network is a great leap forward in helping organisations provide the public with authoritative data on the environment and in helping citizens around the world better understand some of the most pressing environmental challenges in their local area," said Jacqueline McGlade, executive director of EEA. "With the input of environmental stakeholders globally, we're pleased to see the network expand and become a vital service for those interested in learning more about the environment. Environmental policy makers also have a new tool to understand and visualise environmental information to support good environmental policy making."
The network is being launched with three Eye on Earth services available - WaterWatch, AirWatch and NoiseWatch, which are being made available today at COP17. WaterWatch uses the EEA's environmental data to monitor and display water quality ratings across Europe's public swimming sites. Also built from the EEA's data, AirWatch illustrates air quality ratings in Europe. NoiseWatch combines the EEA's data with input from citizens. Noise Meter, a new mobile application for noise level readings available on mobile operating systems Android, iOS and Windows Phone 7.5, allows users to take noise level readings from their mobile devices and instantly upload them into NoiseWatch's database.
"With the launch of the new Eye on Earth network, citizens, governments and scientists now have an easy-to-use, scalable platform for collecting, sharing and visualising the world's critical environmental data," said Rob Bernard, chief environmental strategist at Microsoft. "I am excited by the possibilities that technology provides to transform data into powerful, visual maps that everyone can interact with. The impact of projects such as Eye on Earth shows the potential that new types of partnerships and technology can yield."
"Eye on Earth allows for extensive collaboration among European agencies and communities," said Jack Dangermond, Esri president. "This platform, based on ArcGIS Online, is putting environmental information into the hands of many. It equips people with tools and information to engage in conversation, analysis, reporting and policy making. In addition, this platform, developed for Europe, can be implemented in other countries and regions of the world."
Next week at the Eye on Earth Summit in Abu Dhabi, a Rio+20 preparatory meeting, a consortium of partners will meet to re-affirm the importance of providing environmental data through the Eye on Earth network.
More information about Eye on Earth is available at http://www.eyeonearth.org.

Avkash Chauhan (@avkashchauhan) explained How your Web site binding works when a Windows Azure Webrole runs in Compute Emulator? in an 11/30/2011 post:
When you run your web role (ASP.NET Web site) in compute emulator (development fabric), you will see following things happen in your machine while running your Web site:
- A listener is created so you can access your site at http://127.0.0.1:81 (Port and IP address could change for multiple roles and instances)
- Looking into IIS you will see the Web site has a binding to some arbitrary port number (mostly 5121 or some port number close to it).
- In the compute emulator, the emulated load balancer listens on your web site port (in this case #81) and forwards traffic to all instances in your web role
- Compute emulator is configured to only listen on loopback.
- Because compute emulator is configured to only listen loopback address, requests from a different host could not be forwarded.
- Means, if you create an arbitrary DNS name in your hosts file that maps to your loopback address, you wouldn’t be able to hit your site on port 81.
- To solve above behavior, you can use a port forwarder.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) described Beginning LightSwitch: Getting Started in a 12/1/2011 post:
For the month of December I’m going to write a series of posts aimed at the beginner developer getting up to speed with Visual Studio LightSwitch. At least I’m going to try ;-). It’s been a while since I was a beginner myself and started cobbling lines of code together – in fact, I started when I was 8 years old on an Atari 400. However, folks have told me I have a knack for this writing thing ;-) so I’m going to attempt to put myself in a beginner’s shoes and try to explain things as clear as I can.
There’s a ton of information out there on building LightSwitch applications, especially on the LightSwitch Developer Center but here I want to pull together a cohesive set of entry-level articles that focus on the most important concepts you need to learn in order to build any LightSwitch application. By the way, if you aren’t familiar with what LightSwitch is and what it can do I encourage you to check out the product overview here.
Here’s what I’m thinking for the series:
- What's in a Table? - Describing your Data
- Feel the Love - Defining Data Relationships
- Screen Templates - Which One Do I Choose?
- Too much information! - Sorting and Filtering Data with Queries
- May I? - Controlling Access with User Permissions
- I Feel Pretty! - Customizing the "Look and Feel" with Themes
Before we get started with the series, the first thing to do is make sure you’re all set up with LightSwitch by visiting the LightSwitch Developer Center. There on the home page you will see clear steps to get started.
Download Visual Studio LightSwitch
Watch the instructional LightSwitch "How Do I?" videos
Ask questions in the LightSwitch forums
If you click on “Get essential training” then you will be taken to the Learn page which is broken down into the sections, Getting Started, Essential Topics and Advanced Topics. If you’re a beginner, the getting started section is what you want to start with:
Getting Started
Are you completely new to Visual Studio LightSwitch? This information will help you get started using LightSwitch to develop business applications for the desktop or the cloud. Be sure to check out the step-by-step “How Do I”videos.
Create Your First LightSwitch Application
Watch the LightSwitch How Do I Videos
Download the Visual Studio LightSwitch Training Kit
Get Started with the LightSwitch Starter Kits
The first link is to a step-by-step walkthrough that shows you how to quickly build a simple contact manager. It should take you 5 to 10 minutes to complete the application so it’s a great place to start. Then you can move onto the “How Do I” videos for more step-by-step video lessons to build a simple order entry application. If you want a super-quick way to get an application started, check out the starter kits. There’s currently six available for you to choose from and are full working applications you can use.
So do your homework kids, and in the next post we’ll start to dive into the series starting with my favorite topic – Data!


Rowan Miller of the ADO.NET Entity Framework Team announced Code First Migrations: Beta 1 Released in an 11/29/2011 post:
At the end of September we released Alpha 3 of Code First Migrations. Based on Alpha 2 and Alpha 3 feedback your telling us that we are building the right thing… so it’s time to start improving quality and working towards our first go-live release. Today we are making Beta 1 available which is our first step in that direction.
What Changed
This release has been primarily about improving quality and cleaning up the API surface ready to RTM. There aren’t any significant changes to the user experience.
Some more notable changes include:
- Class and method renames. We’ve done a lot of renaming and refactoring since Alpha 3. There are some important notes in the next section about how these changes affect migrations that were generated with Alpha 3.
- Migrations will now create indexes on foreign key columns.
- Improved model change detection. We fixed a number of bugs in the way we look for changes in your model and scaffold migrations. This includes things such as detecting CascadeDelete changes on relationships.
Upgrading From Alpha 3
If you have Alpha 3 installed you can use the ‘Update-Package EntityFramework.Migrations’ command in Package Manager Console to upgrade to Beta 1. You will need to close and re-open Visual Studio after updating, this is required to reload the updated command assemblies.
You will also need to update any existing code to reflect a series of class and method renames:
- The Settings class has been renamed to Configuration. When you update the NuGet package you will get a new Configuration.cs (or Configuration.vb) file added to your project. You will need to remove the old Settings file. If you added any logic for seed data etc. you will need to copy this over to the new Configuration class before removing Settings.
(This file rename is a result of us changing the base class for this class from DbMigrationContext to DbMigrationsConfiguration)- If you have existing migrations that call ChangeColumn you will need to update them to call AlterColumn instead.
- There is a designer code file associated with each migration in your project, for migrations generated with Alpha 3 you will need to edit this file. You will need to add a using statement for System.Data.Entity.Migrations.Infrastructure and change the references to IDbMigrationMetadata to IMigrationMetadata.
RTM as EF4.3
So far we have been shipping Migrations as a separate EntityFramework.Migrations NuGet package that adds on to the EntityFramework package. As our team has been looking at the grow-up story to Migrations from a Code First database that was created by just running a Code First application it’s becoming clear that Migrations is a very integral part of Code First. We’ve also heard feedback that we need to reduce the number of separate components that make up EF. Because of this we are planning to roll the migrations work into the EntityFramework NuGet package so that you get everything you need for Code First applications in a single package. This will be the EF4.3 release.
The timeline to our first RTM of Code First Migrations depends on the feedback we get on this release but we are currently aiming to have a go-live release available in early 2012. We’re planning to make a Release Candidate available before we publish the final RTM.
What’s Still Coming
Beta 1 only includes the Visual Studio integrated experience for Code First Migrations. We also plan to deliver a command line tool and an MSDeploy provider for running Code First Migrations.
We are planning to include the command line tool as part of the upcoming RTM.
We’re working with the MSDeploy team to get some changes into the next release of MSDeploy to support our new provider. Our MSDeploy provider will be available when the next version of MSDeploy is published. This will be after our initial RTM of Code First Migrations.
Getting Started
There are two walkthroughs for Beta 1. One focuses on the no-magic workflow that uses a code-based migration for every change. The other looks at using automatic migrations to avoid having lots of code in you project for simple changes.
- Code First Migrations: Beta 1 ‘No-Magic’ Walkthrough
- Code First Migrations: Beta 1 ‘With-Magic’ Walkthrough (Automatic Migrations)
Code First Migrations Beta 1 is available via NuGet as the EntityFramework.Migrations package.
Support
This is a preview of features that will be available in future releases and is designed to allow you to provide feedback on the design of these features. It is not intended or licensed for use in production. If you need assistance we have an Entity Framework Pre-Release Forum.
Rowan also published Code First Migrations: Beta 1 ‘No-Magic’ Walkthrough and Code First Migrations: Beta 1 ‘With-Magic’ Walkthrough (Automatic Migrations) on the same date.
Beth Massi (@bethmassi) posted LightSwitch Community & Content Rollup–November 2011 on 11/30/2011:
A couple months ago I started posting a rollup of interesting community happenings, content, and sites popping up. If you missed those rollups you can check them out here, lot of great content and exciting events happened:
- LightSwitch Community & Content Rollup–September 2011
- LightSwitch Community & Content Rollup–October 2011
Here’s a rollup of LightSwitch goodies for November:
“LightSwitch Star” Contest
Do you have what it takes to be a LightSwitch Star? Show us your coolest, most productive, LightSwitch business application and you could win a Laptop and other great prizes!
Last month The Code Project launched the “LightSwitch Star” contest. You just answer some questions and email them a screenshot or two. They’re looking for apps that show off the most productivity in a business as well as apps that use extensions in a unique, innovative way. Check out the contest page on The Code Project for details.
There were some really cool applications submitted in November! Some were real production apps and some were samples/tutorials. Here’s a breakdown of what was submitted. Vote for your favorites! Prizes are given away each month.
6 Production Apps
- Church+ - Church+ is a comprehensive, extensive and integrated church management application
- Engineering App - A business application for a structural and architectural engineering company
- Favourite Food App - The app was created to help remember favourite food
- LightSwitch Timetable Management Application - A LightSwitch application used to manage the resources needed to build university timetables
- PTA LightSwitch - A LightSwitch application manages student, parent, and staff information
- Security Central - Security Central is a role based application designed for Corporate Legal and Physical Security Departments
7 Tutorials/Samples
- Acquiring images from scanners and Webcams in Visual Studio LightSwitch
- How to integrate Usercontrols in LightSwitch Application
- LightSwitch: Integrating The ComponentOne Scheduler
- LightSwitch Online Ordering System
- Manage existing users and roles using a LightSwitch application
- Migrating Access To LightSwitch
- Using Silverlight Pie Charts in Visual Studio LightSwitch
LightSwitch Developer Center: Free Video Training from Pluralsight
We added over an hour and a half of video training to the Developer Center “How Do I” video page graciously donated by Pluralsight! Check out the modules we added:
We also updated the essential learning topics with new content and organized the learning sections better so have a look at all the new training available on the LightSwitch Developer Center!
Notable Content this Month
Here’s some more of the fun things the team and community released in November.
Extensions released in November (see all 64 of them here!):
Build your own extensions by visiting the LightSwitch Extensibility page on the LightSwitch Developer Center.
Team Articles:
- MSDN Magazine November Issue: Deploying LightSwitch Applications to Windows Azure
- Common Validation Rules in LightSwitch Business Applications
- Using the Save and Query Pipeline to “Archive” Deleted Records
Community Content:
- Changing Connection Strings in LightSwitch
- Connecting To A .CSV or Excel File Directly With LightSwitch
- Create a screen which Edit and Add Records in a LightSwitch Application
- How to integrate Usercontrols in LightSwitch Application?
- Native XAML Reporting: Integrating Infragistics Netadvantage Reporting in Visual Studio LightSwitch Applications
- LightSwitch Chat Application Using A Data Source Extension
- Migrating Access to LightSwitch
- Using Visual Studio LightSwitch with MySQL
Samples (see all of them here):
- Common Validation Rules in LightSwitch Business Applications
- How to Open Screen or Entity Designer from Code in LightSwitch with Macro
- How to Set Default Browser for LightSwitch Web Application with Macro
LightSwitch Team Community Sites
The Visual Studio LightSwitch Facebook Page has been increasing in activity lately. Become a fan! Have fun and interact with us on our wall. Check out the cool stories and resources.
Also here are some other places you can find the LightSwitch team:
LightSwitch MSDN Forums
LightSwitch Developer Center
LightSwitch Team Blog
LightSwitch on Twitter (@VSLightSwitch, #VisualStudio #LightSwitch)Join Us!
The community has been using the hash tag #LightSwitch on twitter when posting stuff so it’s easier for me to catch it. Join the conversation! And if I missed anything please add a comment to the bottom of this post and let us know!

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Lori MacVittie (@lmacvittie) asserted In a service-focused, platform-based infrastructure offering, the form factor is irrelevant as an introduction to her Red Herring: Hardware versus Services post to F5’s DevCentral blog of 11/30/2011:.
One of the most difficult aspects of cloud, virtualization, and the rise of platform-oriented data centers is the separation of services from their implementation. This is SOA applied to infrastructure, and it is for some reason a foreign concept to most operational IT folks – with the sometimes exception of developers. But sometimes even developers are challenged by the notion, especially when it begins to include network hardware.
ARE YOU SERIOUSLY?
The headline read: WAN Optimization Hardware versus WAN Optimization Services. I read no further, because I was struck by the wrongness of the declaration in the first place. I’m certain if I had read the entire piece I would have found it focused on the operational and financial benefits of leveraging WAN optimization as a Service as opposed to deploying hardware (or software a la virtual network appliances) in multiple locations. And while I’ve got a few things to say about that, too, today is not the day for that debate. Today is for focusing on the core premise of the headline: that hardware and services are somehow at odds. Today is for exposing the fallacy of a premise that is part of the larger transformational challenge with which IT organizations are faced as they journey toward IT as a Service and a dynamic data center.
This transformational challenge, often made reference to by cloud and virtualization experts, is one that requires a change in thinking as well as culture. It requires a shift from thinking of solutions as boxes with plugs and ports and viewing them as services with interfaces and APIs. It does not matter one whit whether those services are implemented using hardware or software (or perhaps even a combination of the two, a la a hybrid infrastructure model). What does matter is the interface, the API, the accessibility as Google’s Steve Yegge emphatically put it in his recent from-the-gut-not-meant-to-be-public rant. What matters is that a product is also a platform, because as Yegge so insightfully noted:
A product is useless without a platform, or more precisely and accurately, a platform-less product will always be replaced by an equivalent platform-ized product.
A platform is accessible, it has APIs and interfaces via which developers (consumer, partner, customer) can access the functions and features of the product (services) to integrate, instruct, and automate in a more agile, dynamic architecture.
Which brings us back to the red herring known generally as “hardware versus services.”
HARDWARE is FORM-FACTOR. SERVICE is INTERFACE.
This misstatement implies that hardware is incapable of delivering services. This is simply not true, any more than a statement implying software is capable of delivering services would be true. That’s because intrinsically nothing is actually a service – unless it is enabled to do so. Unless it is, as today’s vernacular is wont to say, a platform.
Delivering X as a service can be achieved via hardware as well as software. One need only look at the varied offerings of load balancing services by cloud providers to understand that both hardware and software can be service-enabled with equal alacrity, if not unequal results in features and functionality. As long as the underlying platform provides the means by which services and their requisite interfaces can be created, the distinction between hardware and “services” is non-existent.
The definition of “service” does not include nor preclude the use of hardware as the underlying implementation. Indeed, the value of a “service” is that it provides a consistent interface that abstracts (and therefore insulates) the service consumer from the underlying implementation. A true “service” ensures minimal disruption as well as continued compatibility in the face of upgrade/enhancement cycles. It provides flexibility and decreases the risk of lock-in to any given solution, because the implementation can be completely changed without requiring significant changes to the interface.
This is the transformational challenge that IT faces: to stop thinking of solutions in terms of deployment form-factors and instead start looking at them with an eye toward the services they provide. Because ultimately IT needs to offer them “as a service” (which is a delivery and deployment model, not a form factor) to achieve the push-button IT envisioned by the term “IT as a Service.”



<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Joe Onisick listed 5 Steps to Building A Private Cloud in a 12/1/2011 article for InformationWeek::reports:
IT at Your Service
A private cloud data center architecture enables IT to serve the business by, for example, quickly provisioning new services and adding elasticity to better handle outages and demand spikes. Getting there isn’t necessarily easy, but it’s worthwhile. In our previous report, The Human Factor in Private Cloud Deployments, we laid out an eight-step plan to change the way people--executives, business leads, end users and IT employees alike--think about the intersection of business objectives and technology. That mindset is just as important as tackling the technological challenges of matching the type of private cloud with the services your IT organization delivers, so consider the human element before you start reading vendor spec sheets.
In this report, we’ll discuss the five stages by which most IT teams we work with actually build their private clouds: standardization, consolidation, virtualization, automation and orchestration. (S3981211)
Table of Contents
3 Author's Bio
4 IT at Your Service
4 Figure 1: Technology Decisions Guided by the Idea of Data Center Convergence
5 Stage 1: Standardization
5 Figure 2: Implementation of a Private Cloud Strategy
6 Figure 3: Interest in Single-Manufacturer Blade Systems
7 Figure 4: Factors Impacting Move to 10 Gbps Ethernet: 2012 vs. 2010
8 Figure 5: Single vs. Multiple Hypervisors
9 Stage 2: Consolidation
9 Figure 6: Interest in Combined-Manufacturer Complete Systems
10 Figure 7: Top Drivers for Adopting Technologies Supporting Convergence
11 Stage 3: Virtualization
11 Figure 8: Impact of FCoE and 10 Gbps Ethernet Deployment on Fibre Channel
12 Figure 9: Deployed Technologies
13 Stage 4: Automation
13 Stage 5: Orchestration
15 Related ReportsAbout the Author
Joe Onisick is technical solutions architect and founder of Define the Cloud and works for a systems integrator leading the analysis and adoption of emerging data center technologies and practices. Joe is a data center architect with over twelve years’ experience in servers, storage virtualization and networks. …
Yung Chou announced on 11/30/2011 “Hands-On” Training Covering Windows Server 2008 Hyper-V on 12/15/2011 at Microsoft’s Alpharetta, GA office:
Please download and install the trials of Windows Server 2008 R2 SP1 and System Center 2012 beforehand, so we can minimize the time needed to get your laptops ready before sessions. To just learn Hyper-V, SCVMM 2012 is not needed. However later when learning virtualization and building private cloud, you will need to have SCVMM capability.
NOTE: You will need to bring your own laptop to do the hand-on exercises.
Laptop Requirements:
4GB RAM
At least 20GB of free disk space
x64 compatible processor with Intel VT or AMD-V technology
Basic install of Windows Server 2008 R2
Where?
Microsoft Alpharetta Office: 1125 Sanctuary Parkway, Suite 300, Alpharetta, GA
For those who would like to attend a similar event in Microsoft Charlotte or Durham office, please comment this blog and indicate preferred month and city. Depending on the demands, we may schedule additional deliveries.
How Do I Register?
You have the option of coming in the morning or afternoon. Click on the registration link for the camp you wish to attend:
Topics Covered:
Enabling the Hyper-V role
Configuring Virtual Networks
Virtual Network Management
Configure Hyper-V User Settings
Manage the Virtual Machine Connection Application
Create VHDs with the Virtual Disk Wizard
Manage and Edit Virtual Disks
Deploy New VMs
Export & Import a VM
Manage Snapshots
<Return to section navigation list>
Cloud Security and Governance
Jay Heiser asked Is a cloud safer than a mattress? in a 12/1/2011 post to his Gartner blog:
I heard a story on the radio today about an old man who had donated an overcoat to charity, forgetting that one of the pockets contained his life savings. It seems that he was one of those people who are uncomfortable with the idea of trusting their money to a bank. Its been suggested more than once that avoiding public cloud computing is tantamount to keeping your money in a mattress. Given what’s happened over the last 4 years, why would anyone automatically assume that the use of banks represents a low level of risk?
The history of banking has been checkered with countless failures. Many people and many institutions have been ruined when their financial institution failed. Today, in many parts of the world, your money is safer in a bank than it is in your mattress, but this is a recent and unique situation in the several millenia evolution of the banking sector. Banks were not really ‘safe’ until risk transference mechanisms were developed in the 20th century, and only national governments had the ability to underwrite the risks, insuring individual deposits and in some cases, intervening to ensure the economic viability of a major bank. Given the European debt crisis, this seems a particularly apt time to question the relative advantages of mattresses and banks.
Banks are highly-regulated institutions and their customers can rely on multiple forms of government intervention, and consumers can rely on government insurance to prevent the complete loss of deposits. Bank customers benefit from huge levels of transparency. In contrast, clouds are a brand new form of depository institution with minimal transparency, no risk transference mechanisms, and no expectation that national governments consider them too big to fail.
In practice, moderately-skilled private individuals, let alone small to medium business, are able to provide an in-house IT service that far exceeds the reliability of a mattress as a piggy bank. Individuals have no ability to create duplicate copies of cash, but data can be easily backed up and stored off site. Cash must be physically protected from theft, but data can be encrypted. The suggestion that the avoidance of public cloud computing is tantamount to keeping your life savings in a mattress is a deeply flawed one, if not an outright lie.
<Return to section navigation list>
Cloud Computing Events
Jim O’Neil published his December Tech Calendar for New England on 11/30/2011. Here’s a partial preview:

Check out Jim’s post for the live version for the entire month.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
D. Britton Johnson of the SQL Server Team posted The First Private Cloud Appliance on 12/1/2011:
What’s inside the new HP Enterprise Database Consolidation Appliance?
On Sept 13th, we launched the new HP Database Consolidation Appliance which supports deploying 1000’s of workloads in a private cloud infrastructure. The solution is specifically designed for I/O intensive workloads and can load balance a complex mix of workloads across multiple racks that are required in a true private cloud appliance deployment.
I’d like to spend a few minutes talking about my favorite aspects of the appliance.
The First Private Cloud Appliance – Factory Built
It takes an imagination to really grok what we mean by “factory-built” appliance. It is easy to imagine that the hardware is racked, powered, and wired, but one of the key investments we’ve made in the factory process working with HP is to make sure the software is installed and configured in the factory. What does that mean? It means when the appliance is first powered up, it is an operational multi-server Hyper-V failover cluster. You won’t see some BIOS screen asking for boot media, or a sysprep’d OS asking pre-installation information, rather the appliance is functional pending security and network configuration to complete the delivery process. The complex configuration of the host environment, management software components, and private cloud infrastructure has been completed in the factory. That means customers can expect a consistent appliance experience when they take delivery of their private cloud appliance. We believe this especially important given the complexity of the appliance which integrates more than 25 software components.Elegant, High-Performance, Cost-Effective Hardware
One of my favorite aspects of the appliance is how well we evolved the hardware solution. The finished solution changed from what we initially expected and in fact we were able to eliminate 12 switches and more than a hundred cables per rack in the final design. Here’s a picture of what would be a ½ rack or the bottom of a full rack appliance.
If a customer were to build this out of typical 2U servers, there would be somewhere around 18-20 cables per servers connected into 8 different pairs of switches – the appliance design eliminates a rat’s nest of cables without compromising performance. In the end we developed a more reliable, serviceable appliance that supports a scale-out model. It also is optimized so that upgrading a ½ rack to a full rack requires ZERO new cables to the servers; simply connect the storage blocks together and to the storage switch. To me that is “Elegant” enterprise systems design.
Scale-out Design
The elegant hardware design also allows a scale-out architecture. Not only can a customer purchase a ½ rack as a starting point, that ½ rack can be upgraded to a full rack without shutting down the running appliance. Additional racks can be added and for customers with substantial needs they can even put many racks into an HP POD – a container-based datacenter with the opportunity to add custom L2 network and optional UPS infrastructure. You can think of this private cloud appliance as supporting a “thin provisioning” model – you can buy as much as you think you need and add more if you need to, when you need to. This is an interesting attribute, for some customers it means they can start with a ½ rack without knowing exactly what they need, use the built-in tools to help size their workload needs and then add capacity as needed when needed.
Well that covers my short list. If you want to learn more take a look at www.microsoft.com/appliances and take a look at this video.


I thought the Windows Azure Platform Appliance (WAPA) as implemented commercially by Fujitsu was the first Private Cloud appliance.
Jo Maitland (@JoMaitlandSF) asked HP turns to cloud computing, but can it execute? in an 11/30/2011 post to the SearchCloudComputing.com blog:
To divert customer attention from the executive shuffling and corporate drama of earlier this year, HP released a handful of new cloud products and services for enterprises. What's unclear, however, is whether IT shops will stick with HP through the tough times.
HP’s latest updates are just the tip of the iceberg in terms of transforming its products and services to meet the requirements for cloud computing. In the meantime, the company has thousands of HP shops on its side that are in no rush to overhaul their IT infrastructure.
HP has gotten the memo on cloud computing; at least they didn’t say anything incredibly wrong in this announcement
Carl Brooks, analyst for Tier1 Research
In some cases companies like Maersk Line, the world's largest shipping company, would sooner hand over the department lock, stock and barrel to HP and swallow the cost. Maersk Line will spend an eye-popping $150 million to build a private cloud using HP technology and services. The shipping giant chose HP based on its existing relationship with the vendor. HP has supplied the shipping company with servers, storage, networking equipment and PCs for years.
“Cloud is a relationship sell,” said Gary Mazzaferro, an independent cloud computing adviser. “It's about trust, and companies rarely switch vendors.” HP has decades of history with many customers and they will go with it based on that alone, he said.
Not everyone is buying this premise. Rick Parker, IT director in the entertainment industry, said HP’s announcements are "cloud buzzwords that will result in overpriced outsourced failures.” He noted that the Maersk Line deal was a classic outsourcing arrangement that has nothing to do with cloud computing. “Until you fix the IT organization and break up the silos, cloud is not going to work,” Parker added.
And analysts say HP’s cloud strategy is a work in progress.
“HP has gotten the memo on cloud computing; at least they didn’t say anything incredibly wrong in this announcement,” said Carl Brooks, analyst for Tier1 Research.
HP has placed a heavy emphasis on partners and service providers, because that’s where the action is right now, Brooks added. Service providers are forging ahead building clouds, while enterprises are in the first phase of a gradual transition.
HP recognizes that, and also recognizes that most enterprise cloud plans probably include a service provider for infrastructure on some level, whether it’s public cloud participation or hosted private clouds.
“The basic economic calculus underlying cloud computing as a whole is that someone else can do infrastructure better than you can, so HP needs to make sure it’s in there on the ground floor with more ‘A game’ than just hardware,” Brooks said. …


<Return to section navigation list>


















0 comments:
Post a Comment