Windows Azure and Cloud Computing Posts for 7/23/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI,Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

•• Updated 7/28/2012 at 8:00 AM PDT with new articles marked ••.
• Updated 7/26/2012 at 12:15 PM PDT with new articles marked •. I believe this post sets a new length record.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics, Big Data and OData
- Windows Azure Service Bus, Access Control, Caching, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
•• Brent Stineman (@BrentCodeMonkey) explained The “traffic cop” pattern in a 7/27/2012 post:
So I like design patterns but don’t follow them closely. Problem is that there are too many names and its just so darn hard to find them. But one “pattern” I keep seeing an ask for is the ability to having something that only runs once across a group of Windows Azure instances. This can surface as one-time startup task or it could be the need to have something that run constantly and if one instance fails, another can realize this and pick up the work.
This later example is often referred to as a “self-electing controller”. At the root of this is a pattern I’ve taken to calling a “traffic cop”. This mini-pattern involves having a unique resource that can be locked, and the process that gets the lock has the right of way. Hence the term “traffic cop”. In the past, aka my “mainframe days”, I used this with systems where I might be processing work in parallel and needed to make sure that a sensitive block of code could prevent a parallel process from executing it while it was already in progress. Critical when you have apps that are doing things like self-incrementing unique keys.
In Windows Azure, the most common way to do this is to use a Windows Azure Storage blob lease. You’d think this comes up often enough that there’d be a post on how to do it already, but I’ve never really run across one. That is until today. Keep reading!
But before I dig into the meat of this, a couple footnotes… First is a shout out to my buddy Neil over at the Convective blob. I used Neil’s Azure Cookbook for help me with the blob leasing stuff. You can never have too many reference books in your Kindle library. Secondly, the Windows Azure Storage team is already working on some enhancements for the next Windows Azure .NET SDK that will give us some more ‘native’ ways of doing blob leases. These include taking advantage of the newest features of the 2012-02-12 storage features. So the leasing techniques I have below may change in an upcoming SDK.
Blob based Traffic Cop
Because I want to get something that works for Windows Azure Cloud Services, I’m going to implement my traffic cop using a blob. But if you wanted to do this on-premises, you could just as easily get an exclusive lock on a file on a shared drive. So we’ll start by creating a new Cloud Service, add a worker role to it, and then add a public class to the worker role called “BlobTrafficCop”.
Shell this class out with a constructor that takes a CloudPageBlob, a property that we can test to see if we have control, and methods to Start and Stop control. This shell should look kind of like this:
class BlobTrafficCop { public BlobTrafficCop(CloudPageBlob blob) { } public bool HasControl { get { return true; } } public void Start(TimeSpan pollingInterval) { } public void Stop() { } }Note that I’m using a CloudPageBlob. I specifically chose this over a block blob because I wanted to call out something. We could create a 1tb page blob and won’t be charged for 1 byte of storage unless we put something into it. In this demo, we won’t be storing anything so I can create a million of these traffic cops and will only incur bandwidth and transaction charges. Now the amount I’m saving here isn’t even significant enough to be a rounding error. So just note this down as a piece of trivia you may want to use some day. It should also be noted that the size you set in the call to the Create method is arbitrary but MUST be a multiple of 512 (the size of a page). If you set it to anything that’s not a multiple of 512, you’ll receive an invalid argument exception.
I’ll start putting some buts into this by doing a null argument check in my constructor and also saving the parameter to a private variable. The real work starts when I create three private helper methods to work with the blob lease. GetLease, RenewLease, and ReleaseLease. …

Brent continues with the source code for the three private helper methods.
• Valery Mizonov and Seth Manheim wrote Windows Azure Table Storage and Windows Azure SQL Database - Compared and Contrasted for MSDN in July 2012. From the first few sections:
Reviewers: Brad Calder, Jai Haridas, Paolo Salvatori, Silvano Coriani, Prem Mehra, Rick Negrin, Stuart Ozer, Michael Thomassy, Ewan Fairweather
This topic compares two types of structured storage that Windows Azure supports: Windows Azure Table Storage and Windows Azure SQL Database, the latter formerly known as “SQL Azure.” The goal of this article is to provide a comparison of the respective technologies so that you can understand the similarities and differences between them. This analysis can help you make a more informed decision about which technology best meets your specific requirements.
Introduction
Windows Azure SQL Database is a relational database service that extends core SQL Server capabilities to the cloud. Using SQL Database, you can provision and deploy relational database solutions in the cloud. The benefits include managed infrastructure, high availability, scalability, a familiar development model, and data access frameworks and tools -- similar to that found in the traditional SQL Server environment. SQL Database also offers features that enable migration, export, and ongoing synchronization of on-premises SQL Server databases with Windows Azure SQL databases (through SQL Data Sync).
Windows Azure Table Storage is a fault-tolerant, ISO 27001 certified NoSQL key-value store. Windows Azure Table Storage can be useful for applications that must store large amounts of nonrelational data, and need additional structure for that data. Tables offer key-based access to unschematized data at a low cost for applications with simplified data-access patterns. While Windows Azure Table Storage stores structured data without schemas, it does not provide any way to represent relationships between the data.
Despite some notable differences, Windows Azure SQL Database and Windows Azure Table Storage are both highly available managed services with a 99.9% monthly SLA.
Table Storage vs. SQL Database
Similar to SQL Database, Windows Azure Table Storage stores structured data. The main difference between SQL Database and Windows Azure Table Storage is that SQL Database is a relational database management system based on the SQL Server engine and built on standard relational principles and practices. As such, it provides relational data management capabilities through Transact-SQL queries, ACID transactions, and stored procedures that are executed on the server side.
Windows Azure Table Storage is a flexible key/value store that enables you to build cloud applications easily, without having to lock down the application data model to a particular set of schemas. It is not a relational data store and does not provide the same relational data management functions as SQL Database (such as joins and stored procedures). Windows Azure Table Storage provides limited support for server-side queries, but does offer transaction capabilities. Additionally, different rows within the same table can have different structures in Windows Azure Table Storage. This schema-less property of Windows Azure Tables also enables you to store and retrieve simple relational data efficiently.
If your application stores and retrieves large data sets that do not require rich relational capabilities, Windows Azure Table Storage might be a better choice. If your application requires data processing over schematized data sets and is relational in nature, SQL Database might better suit your needs. There are several other factors you should consider before deciding between SQL Database and Windows Azure Table Storage. Some of these considerations are listed in the next section.
Technology Selection Considerations
When determining which data storage technology fits the purpose for a given solution, solution architects and developers should consider the following recommendations.
As a solution architect/developer, consider using Windows Azure Table Storage when:
- Your application must store significantly large data volumes (expressed in multiple terabytes) while keeping costs down.
- Your application stores and retrieves large data sets and does not have complex relationships that require server-side joins, secondary indexes, or complex server-side logic.
- Your application requires flexible data schema to store non-uniform objects, the structure of which may not be known at design time.
- Your business requires disaster recovery capabilities across geographical locations in order to meet certain compliance needs. Windows Azure tables are geo-replicated between two data centers hundreds of miles apart on the same continent. This replication provides additional data durability in the case of a major disaster.
- You need to store more than 150 GB of data without the need for implementing sharding or partioning logic.
- You need to achieve a high level of scaling without having to manually shard your dataset.
As a solution architect/developer, consider using Windows Azure SQL Database when:
- Your application requires data processing over schematic, highly structured data sets with relationships.
- Your data is relational in nature and requires the key principles of the relational data programming model to enforce integrity using data uniqueness rules, referential constraints, and primary or foreign keys.
- Your data volumes might not exceed 150 GB per a single unit of colocated data sets, which often translates into a single database. However, you can partition your data across multiple sets to go beyond the stated limit. Note that this limit is subject to change in the future.
- Your existing data-centric application already uses SQL Server and you require cloud-based access to structured data by using existing data access frameworks. At the same time, your application requires seamless portability between on-premises and Windows Azure.
- Your application plans to leverage T-SQL stored procedures to perform computations within the data tier, thus minimizing round trips between the application and data storage.
- Your application requires support for spatial data, rich data types, and sophisticated data access patterns through consistent query semantics that include joins, aggregation, and complex predicates.
- Your application must provide visualization and business intelligence (BI) reporting over data models using out-of-the-box reporting tools.
Note: Many Windows Azure applications can take advantage of both technologies. Therefore, it is recommended that you consider using a combination of these options. …
The post continues with many tables of detailed selection criteria.
For a discussion of this topic in an OData context, see Glenn Gailey’s article in the Marketplace DataMarket, Social Analytics, Big Data and OData section below.
Bruno Terkaly (@brunoterkaly) described How to create a custom blob manager using Windows 8, Visual Studio 2012 RC, and the Azure SDK 1.7 in a 7/24/2012 post:
Programmatically managing blobs
- This post has two main objectives: (1) Educate you that you can host web content very economically; (2) Show you how you can create your own blob management system in the cloud.
- Download the source to my VS 2012 RC project:
Download The Source
https://skydrive.live.com/embed?cid=98B7747CD2E738FB&resid=98B7747CD2E738FB%212850&authkey=AAWxTD4cCiYKJ60
http://www.windowsazure.com/en-us/pricing/free-trial/?WT.mc_id=A733F5829- Hosting web content as a blob on Windows Azure is powerful. To start with, it is extremely economical; it doesn't require you to host a web server yourself. As a result blobs are very cost-effective. Secondly, the other powerful aspect of hosting html content as blobs on Windows Azure is that you get that blobs get replicated 3 times. It will always be available, with SLA support.
- I use Windows Azure-hosted blobs for my blog. I store html, javascript, and style sheets. I manage video content as well. You can see my article in MSDN Magazine for further details.
See my article in MSDN Magazine, Democratizing Video Content with Windows Azure Media Services
http://msdn.microsoft.com/en-us/magazine/jj133821.aspx- I could store anything I want. When you visit my blog, you are pulling content from Windows Azure storage services.
- You can dynamically create content and then upload to Azure. I'll show you how to upload the web page as a blob.
- But that web page can be dynamically created based on a database. The code I am about to show is infinitely flexible. You could adapt it to manage all your content programmatically.
- I will illustrate with the latest tools and technologies, as of July 2012. This means we will use:
- Windows 8
- Visual Studio 2012 RC
- Azure SDK and Tooling 1.7
- I assume you have an Azure Account (free trials are available)
2 main blob types
- The storage service offers two types of blobs, block blobs and page blobs.
- You specify the blob type when you create the blob.
- You can store text and binary data in either of "two types of blobs":
- Block blobs, which are optimized for streaming.
- Page blobs, which are optimized for random read/write operations and which provide the ability to write to a range of bytes in a blob.
- Windows Azure Blob storage is a service for storing large amounts of unstructured data that can be accessed from anywhere in the world via HTTP or HTTPS.
- A single blob can be hundreds of gigabytes in size, and a single storage account can contain up to 100TB of blobs.
- Common uses of Blob storage include:
- Serving images or documents directly to a browser
- Storing files for distributed access
- Streaming video and audio
- Performing secure backup and disaster recovery
- Storing data for analysis by an on-premise or Windows Azure-hosted service
- Once the blob has been created, its type cannot be changed, and" it can be updated only by using operations appropriate for that blob type", i.e., writing a block or list of blocks to a block blob, and writing pages to a page blob.
- All blobs reflect committed changes immediately.
- Each version of the blob has a unique tag, called an ETag, that you can use with access conditions to assure you only change a specific instance of the blob.
- Any blob can be leased for exclusive write access.
- When a blob is leased, only calls that include the current lease ID can modify the blob or (for block blobs) its blocks.
- You can assign attributes to blobs and then query those attributes within their corresponding container using LINQ.
- Blobs allow you to write bytes to specific offsets. You can enjoy typical read/write block-oriented operations.
- Note following attributes of blob storage:
- Storage Account
- All access to Windows Azure Storage is done through a storage account. This is the highest level of the namespace for accessing blobs. An account can contain an unlimited number of containers, as long as their total size is under 100TB.
- Container
- A container provides a grouping of a set of blobs. All blobs must be in a container. An account can contain an unlimited number of containers. A container can store an unlimited number of blobs.
- Blob
- A file of any type and size.
- "A single block blob can be up to 200GB in size". "Page blobs, another blob type, can be up to 1TB in size", and are more efficient when ranges of bytes in a file are modified frequently. For more information about blobs, see Understanding Block Blobs and Page Blobs.
- URL format
- Blobs are addressable using the following URL format:
- http://.blob.core.windows.net/
Web Pages as blobs
- As I explained, what I am showing is how I power my blog with Windows Azure [1]. My main blog page starts with an <iframe>[2][3]. This tag lets you embed an html page within an html page. My post is basically a bunch of iframe's glued together. One of those iframe's is a menu I have for articles I have created. It really is a bunch of metro-styled hyperlinks.
- As I said before, this post is about how I power my blog[1]. This post is about generating web content and storing it as a web page blob up in a MS data center. The left frame on my blog is nothing more than an iframe with a web page.[2][3]
- The name of the web page is key_links.html. Key_links.html is generated locally, then uploaded to blog storage.
- The pane on the left here that says Popular Posts. It is just an embedded web page, that is stored as a blob on Windows Azure. I upload the blob through a Windows 8 Application that I am about to build for you.
- The actual one that I use his slightly more complicated. It leverages a SQL Server database that has the source for the content you see in Popular Posts.
- For my blog, all I do is keep a database of up to date. The custom app we are writing generates a custom web page, based on the SQL server data that I previously entered.
- My app then simply loops through the rows in the SQL server database table and generates that colorful grid you see labeled Popular Posts.
- You can see my blob stored here:
- https://brunoblogcontent.blob.core.windows.net/blobcalendarcontent/key_links.html
Dynamically created based on SQL Server Data
- You can navigate directly to my blob content.
- https://brunoblogcontent.blob.core.windows.net/blobcalendarcontent/key_links.html
- The point here is that Key_links.html is generated based on entries in a database table
- You could potentially store the entries in the cloud as well using SQL Database (formerly SQL Azure)
- This post will focus on how you would send key_links.html and host it in the Windows Azure Storage Service
- Here you can see the relationship between the table data and the corresponding HTML content.
- The metro-like web interface you see up there is generated dynamically by a Windows 8 application. We will not do dynamic creation here.
- I used Visual Studio 2012 RC to write the Windows 8 application. To upload the blob of all I needed the Windows Azure SDK and Tooling. …





Denny Lee (@dennylee) posted a Power View Tip: Scatter Chart over Time on the X-Axis and Play Axis post on 7/24/2012:
As you have seen in many Power View demos, you can run the Scatter Chart over time by placing date/time onto the Play Axis. This is pretty cool and it allows you to see trends over time on multiple dimensions. But how about if you want to see time also on the x-axis?
For example, let’s take the Hive Mobile Sample data as noted in my post: Connecting Power View to Hadoop on Azure. As noted in Office 2013 Power View, Bing Maps, Hive, and Hadoop on Azure … oh my!, you can quickly create Power View reports right out of Office 2013.
Scenario
In this scenario, I’d like to see the number of devices on the y-axis, date on the x-axis, broken out by device make. This can be easily achieved using a column bar chart.
Yet, if I wanted to add another dimension to this, such as the number of calls (QueryTime), the only way to do this without tiling is to use the Scatter Chart. Yet, this will not yield the results you may like seeing either.
It does have a Play Axis of Date, but while the y-axis has count of devices (count of ClientID), the x-axis is the count of QueryTime – it’s a pretty lackluster chart. Moving Count of QueryTime to the Bubble Size makes it more colorful but now all the data is stuck near the y-axis. When you click on the play-axis, the bubbles only move up and down the y-axis.
Date on X-Axis and Play Axis
So to solve the problem, the solution is to put the date on both the x-axis and the play axis. Yet, the x-axis only allows numeric values – i.e. you cannot put a date into it. So how do you around this limitation?
What you can do is create a new calculated column:
DaysToZero = -1*(max([date]) – [date])
What this does is to calculate the number of days differing between the max([date]) within the [date] column as noted below.
As you can see, the max([date]) is 7/30/2012 and the [DaysToZero] column has the value of datediff(dd, [Date], max([Date]))
Once you have created the [DaysToZero] column, you can then place this column onto the x-axis of your Scatter Chart. Below is the scatter chart configuration.
With this configuration, you can see events occur over time when running the play axis as noted in the screenshots below.










Paul Miller (@paulmiller) described his GigaOM Pro report on Hadoop and cluster management in a 7/23/2012 post to his Cloud of Data blog:
My latest piece of work for GigaOM Pro just went live. Scaling Hadoop clusters: the role of cluster management is available to GigaOM Pro subscribers, and was underwritten by StackIQ.
Thanks to everyone who took the time to speak with me during the preparation of this report.
As the blurb describes,
From Facebook to Johns Hopkins University, organizations are coping with the challenge of processing unprecedented volumes of data. It is possible to manually build, run and maintain a large cluster and to use it to run applications such as Hadoop. However, many of the processes involved are repetitive, time-consuming and error-prone. So IT managers (and companies like IBM and Dell) are increasingly turning to cluster-management solutions capable of automating a wide range of tasks associated with cluster creation, management and maintenance.
This report provides an introduction to Hadoop and then turns to more-complicated matters like ensuring efficient infrastructure and exploring the role of cluster management. Also included is an analysis of different cluster-management tools from Rocks to Apachi Ambari and how to integrate them with Hadoop.
Compulsory picture of an elephant as it’s a Hadoop story provided by Flickr user Brian Snelson.
Related articles

<Return to section navigation list>
SQL Azure Database, Federations and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
•• Scott M. Fulton (@SMFulton3) asked Big Data: What Do You Think It Is? in a 7/27/2012 article for the ReadWriteCloud:
"Big Data" is the technology that is supposedly reshaping the data center. Sure, the data center isn't as fun a topic as the iPad, but without the data center supplying the cloud with apps, iPads wouldn't nearly as much fun either. Big Data is also the nucleus of a new and growing industry, injecting a much-needed shot of adrenaline in the business end of computing. It must be important; in March President Obama made it a $200 million line item in the U.S. Federal Budget. But what the heck is Big Data?
With hundreds of millions of taxpayer dollars behind it, with billions in capital and operating expenditures invested in it, and with a good chunk of ReadWriteWeb's space and time devoted to it, well, you'd hope that we all pretty much knew what Big Data actually was. But a wealth of new evidence, including an Oracle study reported by RWW's Brian Proffitt last week, a CapGemini survey uncovered by Sharon Fisher also last week, and now a Harris Interactive survey commissioned by SAP, all indicate a disturbing trend: Both businesses and governments may be throwing money at whatever they may think Big Data happens to be. And those understandings may depend on who their suppliers are, who's marketing the concept to them and how far back they began investigating the issue.
That even the companies investing in Big Data have a relatively poor understanding of it may be blamed only partly on marketing. To date, the Web has done a less-than-stellar job at explaining what Big Data is all about. "The reality is, when I looked at these survey results, the first thing I said was, wow. We still don't have people who have a common definition of Big Data, which is a big problem," said Steve Lucas, executive vice president for business analytics at SAP.
The $500 Million Pyramid
The issue is that many companies are just now facing the end of the evolutionary road for traditional databases, especially now that accessibility through mobile apps by thousands of simultaneous users has become a mandate. The Hadoop framework, which emerged from an open source project out of Yahoo and has become its own commercial industry, presented the first viable solution. But Big Data is so foreign to the understanding customers have already had about their own data centers, that it's no wonder surveys are finding their strategies spinning off in various directions.
"What I found surprising about the survey results was that 18% of small and medium-sized businesses under $500 million [in revenue] per year think of Big Data as social- and machine-generated," Lucas continued. "Smaller companies are dealing with large numbers of transactions from their Web presence, with mobile purchases presenting challenges for them. Larger companies have infrastructure to deal with that. So they’re focused ... on things like machine-generated data, cell phones, devices, sensors, things like that, as well as social data."
Snap Judgment
Harris asked 154 C-level executives from U.S.-based multi-national companies last April a series of questions, one of them being to simply pick the definition of "Big Data" that most closely resembled their own strategies. The results were all over the map. While 28% of respondents agreed with "Massive growth of transaction data" (the notion that data is getting bigger) as most like their own concepts, 24% agreed with "New technologies designed to address the volume, variety, and velocity challenges of big data" (the notion that database systems are getting more complex). Some 19% agreed with the "requirement to store and archive data for regulatory and compliance," 18% agreed with the "explosion of new data sources," while 11% stuck with "Other."
All of these definition choices seem to strike a common theme that databases are evolving beyond the ability of our current technology to make sense of it all. But when executives were asked questions that would point to a strategy for tackling this problem, the results were just as mixed.
When SAP's Lucas drilled down further, however, he noticed the mixture does tend to tip toward one side or the other, with the fulcrum being the $500 million revenue mark. Companies below that mark (about 60% of total respondents), Lucas found, are concentrating on the idea that Big Data is being generated by Twitter and social feeds. Companies above that mark may already have a handle on social data, and are concentrating on the problem of the wealth of data generated by the new mobile apps they're using to connect with their customers - apps with which the smaller companies aren't too familiar yet.
"That slider scale may change the definition above or below that $500 million in revenue mark for the company based on their infrastructure, their investment, and their priorities," Lucas said. "They also pointed out that the cloud is a critical part of their Big Data strategy. I took that as a big priority."
Final Jeopardy
So what's the right answer? Here is an explanation of "Big Data" that, I believe, applies to anyone and everyone:
Database technologies have become bound by business logic that fails to scale up. This logic uses inefficient methods for accessing and manipulating data. But those inefficiencies were always masked by the increasing speed and capability of hardware, coupled with the declining price of storage. Sure, it was inefficient, but up until about 2007, nobody really noticed or cared.
The inefficiencies were finally brought into the open when new applications found new and practical uses for extrapolating important results (often the analytical kind) from large amounts of data. The methods we'd always used for traditional database systems could not scale up. Big Data technologies were created to enable applications that could scale up, but more to the point, they addressed the inefficiencies that had been in our systems for the past 30 years - inefficiencies that had little to do with size or scale but rather with laziness, our preference to postpone the unpleasant details until they really became bothersome.
Essentially, Big Data tools address the way large quantities of data are stored, accessed and presented for manipulation or analysis. They do replace something in the traditional database world - at the very least, the storage system (Hadoop), but they may also replace the access methodology.

•• Dhananjay Kumar (@debug_mode) described Working with OData and WinJS ListView in a Metro Application in a 7/27/2012 post:
In this post we will see how to consume Netflix OData feed in HTML based Metro Application. Movies information will be displayed as following. At the end of this post, we should have output as below,
Netflix exposed all movies information as OData and that is publicly available to use. Netflix OData feed of movies are available at following location
http://odata.netflix.com/Catalog/
Essentially we will pull movies information from Netflix and bind it to ListView Control of WinJS. We will start with creating a blank application.
In the code behind (default.js) define a variable of type WinJS List.
Now we need to fetch the movies detail from Netflix. For this we will use xhr function of WinJS. As the parameter of function, we will have to provide URL of the OData feed.
In above code snippet, we are performing following tasks
- Making a call to Netflix OData using WinJS .xhr function
- As input parameter to xhr function, we are passing exact url of OData endpoint.
- We are applying projection and providing JSON format information in URL itself.
- Once JSON data is fetched form Netflix server data is being parsed and pushed as individual items in the WinJS list.
As of now we do have data with us. Now let us go ahead and create a ListView control. You can create WinJS ListView as following. Put below code on the default.html
In above code we are simply creating a WinJS ListView and setting up some basic attributes like layout and itemTemplate. Now we need to create Item Template. Template is used to format data and controls how data will be displayed. Template can be created as following
In above code, we are binding data from the data source to different HTML element controls. At last in code behind we need to set the data source of ListView
Before you go ahead and run the application just put some CSS to make ListView more immersive. Put below CSS in default.css
Now go ahead and run the application. You should be getting the expected output as following







…
Dhananjay continues with the consolidate code for the application.
• Glenn Gailey (@ggailey777) analyzed Windows Azure Storage: SQL Database versus Table Storage in a 7/26/2012 post:
I wrote an article for Windows Azure a while back called Guidance for OData in Windows Azure, where I described options for hosting OData services in Windows Azure. The easiest way to do this is to create a hosted WCF Data Service in Windows Azure that uses EF to access a SQL Database instance as the data source. This lets you access and change data stored in the cloud by using OData. Of course, another option for you is to simply store data directly in the Windows Azure Table service, since this Azure-based service already speaks OData. Using the Table service for storage is less work in terms of setting-up , but using the Table service for storage is fairly different from storing data in SQL Database tables.
Note #1: As tempting as it may seem, do not make the Table service into a data source for WCF Data Services. The Table service context is really just the WCF Data Services client context—and it doesn’t have the complete support for composing all OData queries.
Leaving the discussion of an OData service aside, there really is a fundamental question when it comes to storing data in Windows Azure.
Note #2: The exception is for BLOBs. Never, ever store blobs anywhere but in the Windows Azure Blob service. Even with WCF Data Services, you should store blobs in the Blob service and then implement the streaming provider that is backed by the Blob service.
Fortunately, some of the guys that I work with have just published a fabulous new article that addresses just this SQL Database versus Tables service dilemma, and they do the comparison in exquisite detail. I encourage you to check out this new guidance content.
Windows Azure Table Storage and Windows Azure SQL Database - Compared and Contrasted
This article even compares costs of both options. If you are ever planning to store data in Windows Azure—this article is very much worth your time to read.

For the above article, see the Windows Azure Blob, Drive, Table, Queue and Hadoop Services section above.
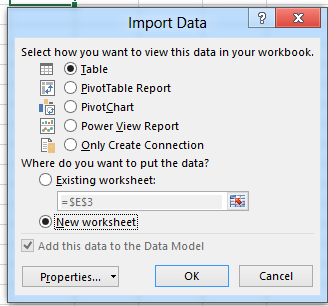
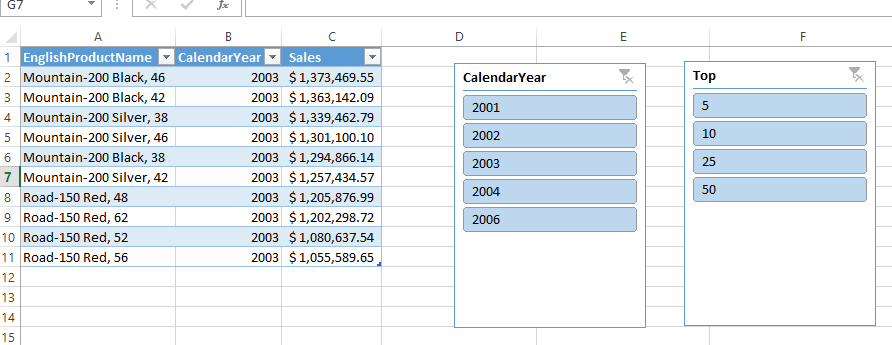
• Kasper de Jonge (@Kjonge) described Implementing Dynamic Top X via slicers in Excel 2013 using DAX queries and Excel Macros, which is of interest to Windows Azure Marketplace DataMarket and OData users, on 7/25/2012:
Our First Post on Excel 2013 Beta!
Guest post by… Kasper de Jonge!
Notes from Rob: yes, THAT Kasper de Jonge. We haven’t seen him around here much, ever since he took over the Rob Collie Chair at Microsoft. (As it happens, “de Jonge” loosely translated from Dutch means “of missing in action from this blog.” Seriously. You can look it up.)
- Excel 2013 public preview (aka beta) is out, which means that now we’re not only playing around with PowerPivot V2 and Power View V1, but now we have another new set of toys to take for a spin. I am literally running out of computers – I’m now running five in my office. Kasper is here to talk about Excel 2013.
- I’ve been blessed with a number of great guest posts in a row, and there’s already one more queued up from Colin. This has given me time to seclude myself in the workshop and work up something truly frightening in nature that I will spring on you sometime next week. But in the meantime, I hand the microphone to an old friend.
Back to Kasper…
Inspired by all the great blog posts on doing a Dynamic Top X reports on PowerPivotPro I decided to try solving it using Excel 2013. As you might have heard Excel 2013 Preview has been released this week, check this blog post to read more about it.
The trick that I am going to use is based on my other blog post that I created earlier: Implementing histograms in Excel 2013 using DAX query tables and PowerPivot. The beginning is the same so I reuse parts of that blog post in this blog.
In this case we want to get the top X products by sum of salesAmount sliced by year (using AdventureWorks). To get started I import the data into Excel. As you might know you no longer need to separately install PowerPivot. Excel 2013 now by default contains our xVelocity in-memory engine and the PowerPivot add-in when you install Excel. When you import data from sources to Excel they will be available in our xVelocity in-memory engine.
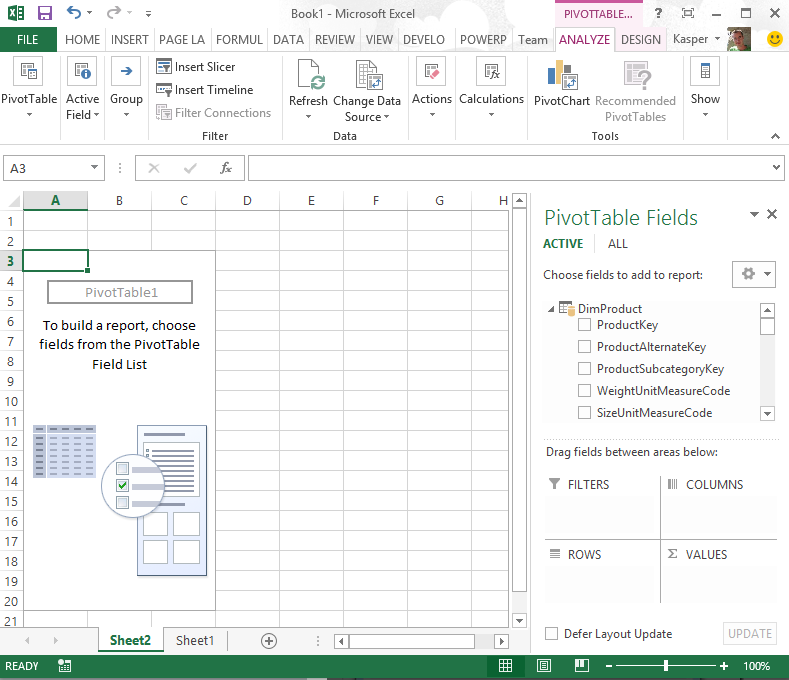
I start by opening Excel 2013, go to the data tab and import from SQL Server:
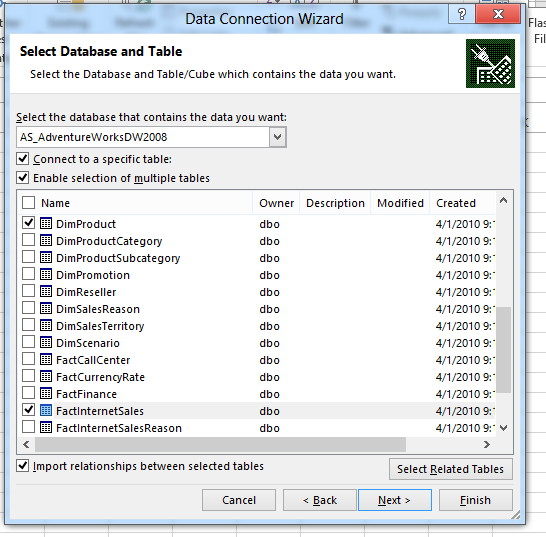
I connect to the database server and database and select the tables DimProduct, DimDate and FactInternetSales:
Key here is to select the checkbox “Enable selection of multiple tables”. As soon as you select that the tables are imported into the xVelocity in-memory engine. Press Finish and the importing starts.
When the import is completed you can select what you want to do with the data, I selected PivotTable:
Now I get the PivotTable:
I am not actually going to use the PivotTable, I need a way to get the top selling products by Sum of salesAmount. First thing that I want to do is create a Sum of SalesAmount measure using the PowerPivot Add-in. With Excel 2013 you will get the PowerPivot add-in together with Excel, all you need to do is enable it.
Click on File, Options, Select Add-ins and Manage Com Add-ins. Press Go.
Now select PowerPivot and press ok:
Now notice that the PowerPivot tab is available in the ribbon, and click on Manage, to manage the model
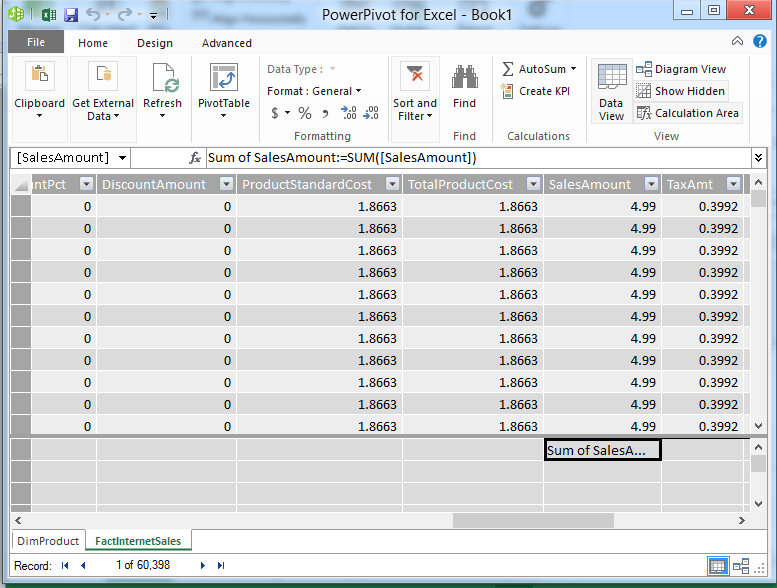
Select the FactInternetSales table, and the SalesAmount column, click AutoSum on the ribbon.
This will create the measure Sum of SalesAmount in the model.
Next up is creating a table that will give us the top 10 Products by Sum of SalesAmount.
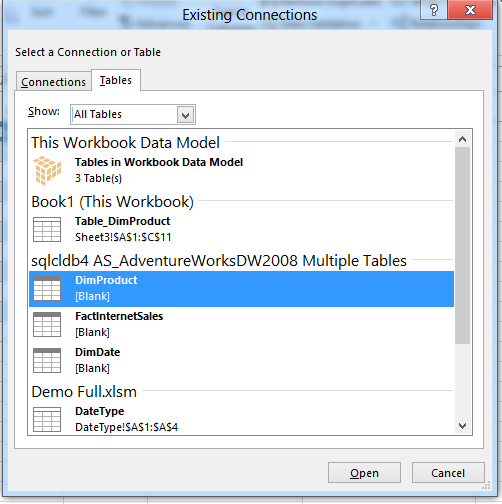
There is no way to get this using a PivotTable, this is where the fun starts. I am going to use a new Excel feature called DAX Query table, this is a hidden feature in Excel 2013 but very very useful! Lets go back to Excel, select the data tab, click on Existing connections and select Tables:
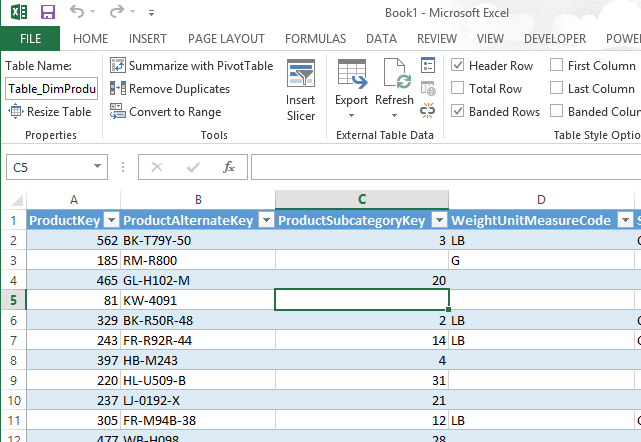
Double click on DimProduct and select Table and New worksheet:
This will add the table to the Excel worksheet as a Excel table:
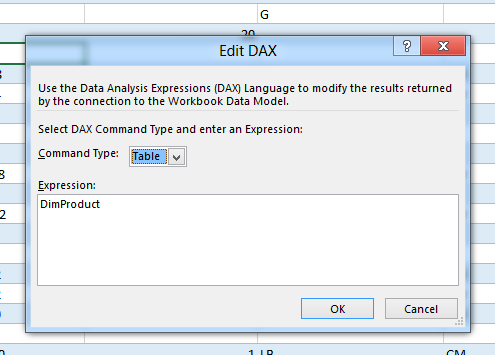
Now this is where the fun starts. Right mouse click on the table, Select Table, Select Edit DAX (ow yes !).
This will open a hidden away Excel dialog without any features like autocomplete and such:
But it will allow us to create a table based on a DAX query that points to the underlying Model. What I have done is create a DAX Query that will give us the Top 10 products filtered by a year and pasted it in the Expression field. When you use a DAX query you need to change the command to type to DAX.
This is the query that will give us the top 10 products by Sum of SalesAmount filtered by Year.:
EVALUATE
ADDCOLUMNS(
TOPN(10,
FILTER(CROSSJOIN(VALUES(DimProduct[Englishproductname])
,VALUES(DimDate[CalendarYear]))
, DimDate[CalendarYear] = 2003
&& [Sum of SalesAmount] > 0
)
, [Sum of SalesAmount])
,”Sales”, [Sum of SalesAmount])
ORDER BY [Sum of SalesAmount] DESCThis results in the following table:
Since DAX queries don’t give formatted results back (unlike MDX) we need to format Sales ourselves using Excel formatting. Now here comes a interesting question, how do we get this to react to input from outside? There is no way to create slicers that are connected to table, so we need to find a way to work around this.
Since this is a native Excel feature now we can actually program these object using an Excel Macro and that is what we are going to do. But first we just add two slicers to the workbook. One for the years and the other one for the TOP X that I want the user to select from.
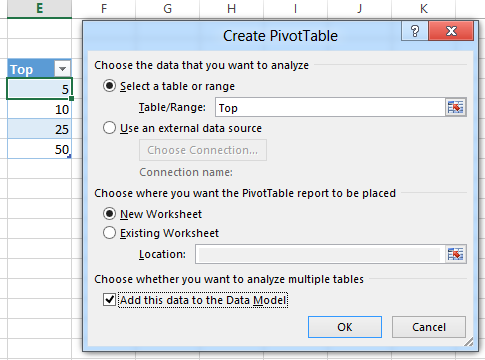
I created a small table that contains the top X values in Excel and pushed that to the model. To do that I selected the table, click insert on the ribbon, PivotTable and select “Add this data to the Data Model”:
After that I created both slicers, both based on model tables, click Insert, Slicer and select “Data Model” and double click on Tables in Workbook Data Model
Now how do we get the query we used in the table to change based on the slicer selection? First I changed the name of the Table to “ProdTable” and Sheet to “TopProducts”.
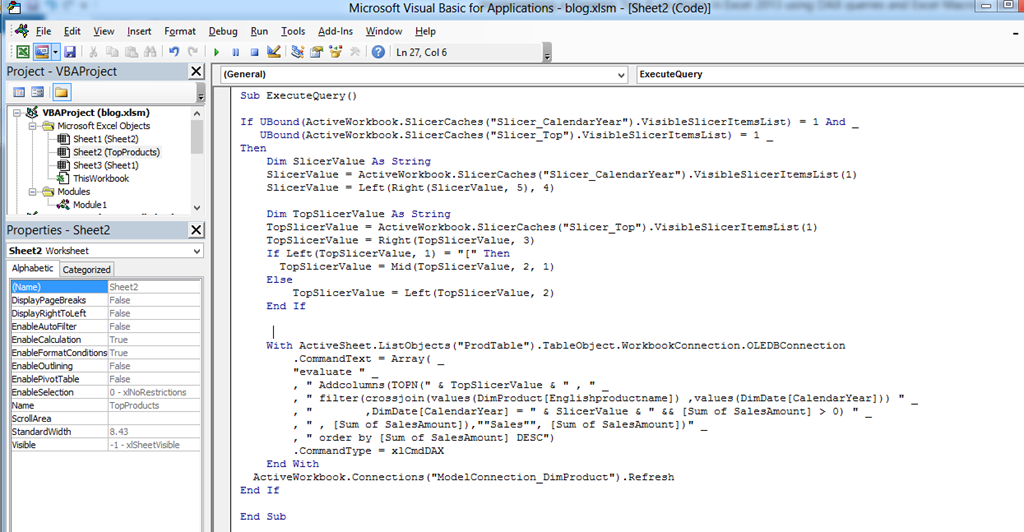
Next I wrote a Marco that will get the values from the Slicers and create a DAX query on the fly and refresh the connection to update the table. I added a procedure to the code for the sheet:
By the way I learned this by starting the Marco recording and start clicking in Excel
just try it, you’ll love it.
This is the Macro I wrote to change the DAX query of the Table based on the slicer values and refresh the table (disclaimer: it will not be foolproof
nor perfect code):
Sub ExecuteQuery()
‘Make sure only one value is selected in both slicers
If UBound(ActiveWorkbook.SlicerCaches(“Slicer_CalendarYear”).VisibleSlicerItemsList) = 1 And _
UBound(ActiveWorkbook.SlicerCaches(“Slicer_Top”).VisibleSlicerItemsList) = 1 _
Then
‘ Get the slicer values from Slicer CalendarYear
Dim SlicerValue As String
SlicerValue = ActiveWorkbook.SlicerCaches(“Slicer_CalendarYear”).VisibleSlicerItemsList(1)
SlicerValue = Left(Right(SlicerValue, 5), 4)
‘ Get the slicer values from Slicer Top
Dim TopSlicerValue As String
TopSlicerValue = ActiveWorkbook.SlicerCaches(“Slicer_Top”).VisibleSlicerItemsList(1)
TopSlicerValue = Right(TopSlicerValue, 3)
If Left(TopSlicerValue, 1) = “[" Then
TopSlicerValue = Mid(TopSlicerValue, 2, 1)
Else
TopSlicerValue = Left(TopSlicerValue, 2)
End If'Load the new DAX query in the table ProdTable
With ActiveSheet.ListObjects("ProdTable").TableObject.WorkbookConnection.OLEDBConnection
.CommandText = Array( _
"evaluate " _
, " Addcolumns(TOPN(" & TopSlicerValue & " , " _
, " filter(crossjoin(values(DimProduct[Englishproductname]) ,values(DimDate[CalendarYear])) ” _
, ” ,DimDate[CalendarYear] = ” & SlicerValue & ” && [Sum of SalesAmount] > 0) ” _
, ” , [Sum of SalesAmount]),”"Sales”", [Sum of SalesAmount])” _
, ” order by [Sum of SalesAmount] DESC”)
.CommandType = xlCmdDAX
End With
‘Refresh the connection (might be hard to find the connection name.
‘If you cant find it use Macro recording
ActiveWorkbook.Connections(“ModelConnection_DimProduct”).Refresh
End IfEnd Sub
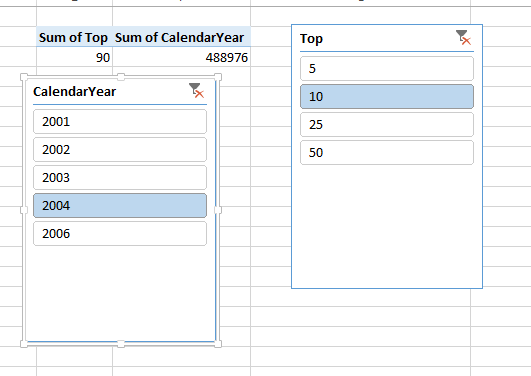
Unfortunately there is no way to react to a slicer click event or something like that. I decided to use a worksheet_change event, now here is another issue. How to get a worksheet to change on a slicer click ?
I decided to create a hidden PivotTable that I connect up to the slicers so clicking would change the PivotTable and hide it behind the slicers:
Now we end up with this worksheet:
Last thing that we need to do is connect the worksheet change event to the procedure we created. I created a procedure that I also added to the code part of the worksheet, it checks if something changes on the TopProducts sheet we execute the refresh of the PivotTable.
Private Sub Worksheet_Change(ByVal Target As Range)
If ActiveSheet.Name = “TopProducts” Then
Call ExecuteQuery
End If
End SubAnd that is all there is to it
Hope you enjoyed Excel 2013 and all the new features that it brings, like Marco’s to the underlying Model and DAX query tables right in Excel !








• The Office Developer Center published ProjectData - Project 2013 OData service reference on 7/16/2012 (missed when posted):
The Open Data Protocol (OData) reference for Project Server 2013 Preview documents the entity data model (EDM) for the ProjectData service and shows how to use LINQ queries and REST queries to get report data.
Applies to: Project Server 2013 Preview
The ProjectData service enables REST queries and a variety of OData client libraries to make both online and on-premises queries of reporting data from a Project Web App instance. For example, you can directly use a REST query in web browsers, or use JavaScript to build web apps and client apps for mobile devices, tablets, PCs, and Mac computers. Client libraries are available for JavaScript, the Microsoft .NET Framework, Microsoft Silverlight, Windows Phone 7, and other languages and environments. In Project Server 2013 Preview, the ProjectData service is optimized to create pivot tables, pivot charts, and PowerView reports for business intelligence by using the Excel 2013 Preview desktop client and Excel Services in SharePoint.
For information about a task pane app for Office that runs in Project Professional 2013 Preview and uses JavaScript and JQuery to get reporting data from the ProjectData service, see the Task pane apps in Project Professional section in What's new for developers in Project 2013.
You can access the ProjectData service through a Project Web App URL. The XML structure of the EDM is available through http://ServerName/ProjectServerName/_api/ProjectData/$metadata. To view a feed that contains the collection of projects, for example, you can use the following REST query in a browser: http://ServerName/ProjectServerName/_api/ProjectData/Projects. When you view the webpage source in the browser, you see the XML data for each project, with properties of the Project entity type that the ProjectData service exposes.
The EDM of the ProjectData service is an XML document that conforms to the OData specification. The EDM shows the entities that are available in the reporting data and the associations between entities. The EDM includes the following two Schema elements:
The Schema element for the ReportingData namespace defines EntityType elements and Association elements:
EntityType elements: Each entity type, such as Project and Task, specifies the set of properties, including navigation properties, that are available for that entity. For example, task properties include the task name, task GUID, and project name for that task. Navigation properties define how a query for an entity such as Project is able to navigate to other entities or collections, such as Tasks within a project. Navigation properties define the start role and end role, where roles are defined in an Association element.
Association elements: An association relates one entity to another by endpoints. For example, in the Project_Tasks_Task_Project association, Project_Tasks is one endpoint that relates a Project entity to the tasks within that project. Task_Project is the other endpoint, which relates a Task entity to the project in which the task resides.
The Schema element for the Microsoft.Office.Project.Server namespace includes just one EntityContainer element, which contains the child elements for entity sets and association sets. The EntitySet element for Projects represents all of the projects in a Project Web App instance; a query of Projects can get the collection of projects that satisfy a filter or other options in a query.
An AssociationSet element is a collection of associations that define the primary keys and foreign keys for relationships between entity collections. Although the ~/ProjectData/$metadata query results include the AssociationSet elements, they are used internally by the OData implementation for the ProjectData service, and are not documented.
For a Project Web App instance that contains a large number of entities, such as assignments or tasks, you should limit the data returned in at least one of the following ways. If you don't limit the data returned, the query can take a long time and affect server performance, or you can run out of memory on the client device.
Use a $filter URL option, or use $select to limit the data. For example, the following query filters by project start date and returns only four fields, in order of the project name (the query is all on one line):
http://ServerName/ProjectServerName/_api/ProjectData/Projects?
$filter=ProjectStartDate gt datetime'2012-01-01T00:00:00'&
$orderby=ProjectName&
$select=ProjectName,ProjectStartDate,ProjectFinishDate,ProjectCostGet an entity collection by using an association. For example, the following query internally uses the Project_Assignments_Assignment_Project association to get all of the assignments in a specific project (all on one line):
http://ServerName/ProjectServerName/_api/ProjectData
/Projects(guid'263fc8d7-427c-e111-92fc-00155d3ba208')/AssignmentsDo multiple queries to return data one page at a time, by using the $top and $skip URL options in a loop. For example, the following query gets issues 11 through 20 for all projects, in order of the resource who is assigned to the issue (all on one line):
http://ServerName/ProjectServerName/_api/ProjectData
/Issues?$skip=10&$top=10&$orderby=AssignedToResourceFor information about query string options such as $filter, $orderby, $skip, and $top, see OData: URI conventions.
Note

The ProjectData service does not implement the $links query option or the $expand query option. Excel 2013 Preview internally uses the Association elements and the AssociationSet elements in the entity data model to help create associations between entities, for pivot tables and other constructs.

Chris Webb (@Technitrain) described Consuming OData feeds from Excel Services 2013 in PowerPivot in a 7/24/2012 post:
In yesterday’s post I showed how you could create surveys in the Excel 2013 Web App, and mentioned that I would have liked to consume the data generated by a survey via the new Excel Services OData API but couldn’t get it working. Well, after a good night’s sleep and a bit more tinkering I’ve been successful so here’s the blog post I promised!
With that done, and making sure that my permissions are all in order, I can go into Excel, start the OData feed import wizard (weirdly, the PowerPivot equivalent didn’t work) and enter the URL for the table in my worksheet (called Table1, helpfully):
Here’s what the URL for the Survey worksheet I created in yesterday’s post looks like:
https://mydomain.sharepoint.com/_vti_bin/ExcelRest.aspx/Shared%20Documents/SurveyTest.xlsx/OData/Table1(there’s much more detail on how OData requests for Excel Services can be constructed here).
And bingo, the data from my survey is loaded into Excel/PowerPivot and I can query it quite happily. Nothing to it.
In a way it’s a good thing I’m writing about this as a separate post because I’m a big fan of OData and I believe that the Excel Services OData API is a big deal. It’s going to be useful for a lot more than consuming data from surveys: I can imagine it could be used for simple budgeting solutions where managers input values on a number of spreadsheets, which are then pulled together into a PowerPivot model for reporting and analysis; I can also imagine it being used for simple MDM scenarios where dimension tables are held in Excel so users can edit them easily.
There are some obvious dangers with using Excel as a kind of database in this way, but there are also many advantages too, most of which I outlined in my earlier discussions of data stores that are simultaneously human readable and machine readable (see here and here). I can see it as being the glue for elaborate multi-spreadsheet-based solutions, although it’s still fairly clunky and some of the ideas I saw in Project Dirigible last year are far in advance of what Excel 2013 offers now. It’s good to see Microsoft giving us an API like this though and I’m sure we’ll see some very imaginative uses for it in the future.




<Return to section navigation list>
Windows Azure Service Bus, Access Control Services, Caching, Active Directory and Workflow
•• Haishi Bai (@HaishiBai2010) explained Enterprise Integration Patterns with Windows Azure Service Bus (1) – Dynamic Router in a 7/27/2012 post:
The book Enterprise Integration Patterns by Gregor Hohpe et al. has been sitting on my desk for several years now, and I’ve always been planning writing a library that brings those patterns into easy-to-use building blocks for .Net developers. However , the motion of writing a MOM system by myself doesn’t sound quite plausible to myself, even though I’ve been taking on some insane projects from time to time.
About the project
The project is open source, which can be accessed here. I’m planning to add more patterns to the project on a monthly basis (as I DO, maybe surprisingly, have other things to attend to). I’d encourage you, my dear readers, to participate in the project if you found the project interesting. And you can always send me comments and feedbacks to hbai@microsoft.com. At the time when this post is written, the code is at its infant stage and needs lots of work. For example, one missing part is configuration support, which will make constructing processing pipelines cleaner that it is now. It will be improved over time. Before using the test console application in the solution, you need to modify app.config file to use your own Windows Azure Service Bus namespace info.
Extended Windows Azure Service Bus constructs
As this is the first post of the series, I’ll spend sometime to explain the basic entities used in this project, and then give you an overview of the overall architecture.
Processing Units
Windows Azure Service Bus provides two types of “pipes” – queues and topics, which are fundamental building blocks of a messaging system. Customization points, such as filters, are provided on these pipes so you can control how these pipes are linked into processing pipelines. This works for many of the simple patterns perfectly. However, for more complex patterns, the pipes are linked in more convoluted ways. And very often the connectors among the pipes assume enough significance to be separate entities. In this project I’m introducing “Processing Unit” as separate entities to provide greater flexibilities and capabilities to building processing pipelines. A Processing Unit can be linked to a number of inbound channels, outbound channels as well as control channels. It’s self-contained so it can be hosted in any processes – it can be hosted on-premises or on cloud, in cloud services or console applications, or wherever else. And in most cases you can easily scale out Processing Units by simply hosting more instances. In addition, Processing Units support events for event-driven scenarios.
Channel
Channels are the “pipes” in a messaging system. These are where your messages flow from one place to another. Channels connect Processing Units, forming a Processing Pipeline.
Processing Pipeline
Process Pipelines comprise Processing Units and Channels. It provides management boundaries so that you can construct and manage messaging routes more easily. Here I need to point out that Processing Pipeline is more a management entity than runtime entity. Parts of a Processing Pipeline can be (and usually are) scattered across different networks, machines and processes.
Processing Unit Host
Processing Unit Host, as its name suggests, hosts Processing Units. It manages lifecycle of hosted Processing Units as well as governing overall system resource consumption.
Pattern 1: Dynamic Router
Problem
Message routing can be achieved by a topic/subscription channel with filters that control which recipients get what messages. In other words, messages are broadcasted to all potential recipients before they are filtered by receiver-side filters. If we only want to route messages to specific recipients, Message Routers are more efficient because there’s only one message sent to designated recipient. Further more, routing criteria may be dynamic, requiring the routing Processing Unit to be able to take in feedbacks from recipients so that it can make informed decisions when routing new messages.
Pattern
Dynamic Router pattern is well-defined in Gregor’s book, so I won’t bother to repeat the book here, other than stealing a diagram from it (see below). What’s make this pattern interesting is that the recipients are provided with a feedback channel so that they can report their updated states back to the router to affect future routing decisions. As you can see in the following diagram, the rule processor (as well as its associated storage, which is not shown in the following diagram) doesn’t belong to any specific channels, so it should exist as a separate entity.
In my implementation the Dynamic Message Router is implemented as a Processing Unit, which is hosted independently from message queues. Specifically, DynamicRouter class, which has the root class ProcessingUnit, defines a virtual PickOutputChannel method that returns a index to the channel that is to be selected for next message. The default implementation of this method doesn’t take feedbacks into consideration. Instead, it simply selects output channels in a round-robin fashion:
protected virtual int PickOutputChannel(ChannelMessageEventArgs e) { mChannelIndex = OutputChannels.Count > 0 ? (mChannelIndex + 1) % OutputChannels.Count : 0; return mChannelIndex; }Obviously the method can be overridden in sub classes to implement more sophisticated routing logics. In addition, the Processing Unit can subscribe to MessageReceviedOnChannel on its ControlChannels property to collect feedbacks from recipients. The architecture of the project doesn’t mandate any feedback formats or storage choices, you are pretty much free to implement whatever fits the situation.
Sample Scenario – dynamic load-balancing
In this sample scenario, we’ll implement a Dynamic Message Router that routes messages to least pressured recipients using a simple greedy load-balancing algorithm. The pressure of a recipient is defined as the current workload of that recipient. When the router tries to route a new message, it will always routes the message to the recipient with least workload. This load-balancing scheme often yields better results than round-robin load-balancing. The following screenshot shows the running result of such as scenario. In this scenario, we have 309 second worth of work to be distributed to 2 nodes. If we followed round-robin pattern, this particular work set will take 161 seconds to finish. While using the greedy load-balancing, it took the two nodes 156 seconds to finish all the tasks, which is pretty close to the theoretical minimum processing time – 154.8 seconds. Note that it’s virtually impossible to achieve the optimum result as the calculation assumes any single task can be split freely without any penalties.
This scenario uses GreedyDynamicRouter class, which is a sub class of DynamicRouter. The class subscribes to MessageReceivedOnchannel event of its ControlChannels collection to collect recipient feedbacks, which are encoded in message headers sent back from the recipients. As I mentioned earlier, the architecture doesn’t mandate any feedback formats, the recipients and the router need to negotiate a common format offline, or use the “well known” headers, as used by the GreedyDynamicRouter implementation. This implementation saves all its knowledge about the recipients in memory. But obviously it can be extended to use external storages or distributed caching for the purpose.
Summary
In this post we had a brief overview of the overall architecture of Enterprise Integration Patterns project, and we also went through the first implemented pattern – Dynamic Router. We are starting with harder patterns in this project so that we can validate and improve the overall infrastructure during earlier phases of the project. At this point I haven’t decided which pattern to go after next, but message transformation patterns and other routing patterns are high in the list. See you next time!



•• Vittorio Bertocci (@vibronet, pictured in the middle below) described Identity & Windows Azure AD at TechEd EU Channel9 Live in a 7/27/2012 post:
Is it a month already? Oh boy, apparently I am in full time-warp mode…
Anyhow: as you’ve read, about one month ago I flew to Amsterdam for a very brief 2-days stint at TechEd Europe (pic or it didn’t happen).The morning of the day I was going to fly back, I was walking by the O’Reilly booth… which happened to be in front of the Channel9 Live stage.
My good friend Carlo spotted me, and invited me for a totally impromptu chat for the opening of the Channel9 live broadcasting from TechEd Europe! Who would have thought, luckily I shaved that morning.I enjoyed that ~30 minutes immensely. Carlo and Joey are fantastic anchors, and very smart guys who did all the right questions. If you want a high level overview of Windows Azure AD (say a 100 level) and you don’t mind my heavy accent, then you’ll be happy to know that today the recording of the event just showed up on Channel9’s home page!
If when watching the video you’ll have the impression that it’s just a chat between old friends rather than an interview, that’s because it is exactly it.

•• See the Windows Azure and Office 365 article by Scott Guthrie (@scottgu) in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section below.
Manu Cohen-Yashar (@ManuKahn) described Running WIF Relying parties in Windows Azure in a 7/22/2012 post:
When running in a multi server environment like windows azure it is required to make sure the cookies generated by WIF are encrypted with the same pair of keys so all servers can open them.
Encrypt cookies using RSA
void Application_Start(object sender, EventArgs e) { FederatedAuthentication.ServiceConfigurationCreated += OnServiceConfigurationCreated; } private void OnServiceConfigurationCreated(object sender, ServiceConfigurationCreatedEventArgs e) { List<CookieTransform> sessionTransforms = new List<CookieTransform>(new CookieTransform[] { new DeflateCookieTransform(), new RsaEncryptionCookieTransform(e.ServiceConfiguration.ServiceCertificate), new RsaSignatureCookieTransform(e.ServiceConfiguration.ServiceCertificate) }); SessionSecurityTokenHandler sessionHandler = new SessionSecurityTokenHandler(sessionTransforms.AsReadOnly()); e.ServiceConfiguration.SecurityTokenHandlers.AddOrReplace(sessionHandler); }next upload the certificate to the hosted service and declare it in the LocalMachine certificate store of the running role.
Failing to do the above will generate the following exception when running a relying party in azure: "InvalidOperationException: ID1073: A CryptographicException occurred when attempting to decrypt the cookie using the ProtectedData API". It means that decryption with DPAPI failed. It makes sense because DPAPI key is coupled with the physical machine it is running on.
After changing the encryption policy (like so) make sure to delete all existing cookies other wise you will get the following exception: CryptographicException: ID1014: The signature is not valid. The data may have been tampered with. (It means that an old DPAPI cookie is being processed by the new RSA policy and that will obviously will fail.



Richard Seroter (@rseroter) described Installing and Testing the New Service Bus for Windows in a 7/17/2012 post (missed when published):
Yesterday, Microsoft kicked out the first public beta of the Service Bus for Windows [Server] software. You can use this to install and maintain Service Bus queues and topics in your own data center (or laptop!). See my InfoQ article for a bit more info. I thought I’d take a stab at installing this software on a demo machine and trying out a scenario or two.
Then I made sure that I installed SQL Server 2008 R2 SPI. Next, I downloaded the Service Bus for Windows executable from the Microsoft site. Fortunately, this kicks off the Web Platform Installer, so you do NOT have to manually go hunt down all the other software prerequisites.
The Web Platform Installer checked my new server and saw that I was missing a few dependencies, so it nicely went out and got them.
After the obligatory server reboots, I had everything successfully installed.
I wanted to see what this bad boy installed on my machine, so I first checked the Windows Services and saw the new Windows Fabric Host Service.
I didn’t have any databases installed in SQL Server yet, no sites in IIS, but did have a new Windows permissions Group (WindowsFabricAllowedUsers) and a Service Bus-flavored PowerShell command prompt in my Start Menu.
Following the configuration steps outlined in the Help documents, I executed a series of PowerShell commands to set up a new Service Bus farm. The first command which actually got things rolling was New-SBFarm:
$SBCertAutoGenerationKey = ConvertTo-SecureString -AsPlainText -Force -String [new password used for cert] New-SBFarm -FarmMgmtDBConnectionString 'Data Source=.;Initial Catalog=SbManagementDB;Integrated Security=True' -PortRangeStart 9000 -TcpPort 9354 -RunAsName 'WA1BTDISEROSB01\sbuser' -AdminGroup 'BUILTIN\Administrators' -GatewayDBConnectionString 'Data Source=.;Initial Catalog=SbGatewayDatabase;Integrated Security=True' -CertAutoGenerationKey $SBCertAutoGenerationKey -ContainerDBConnectionString 'Data Source=.;Initial Catalog=ServiceBusDefaultContainer;Integrated Security=True';When this finished running, I saw the confirmation in the PowerShell window:
But more importantly, I now had databases in SQL Server 2008 R2.
Next up, I needed to actually create a Service Bus host. According to the docs about the Add-SBHost command, the Service Bus farm isn’t considered running, and can’t offer any services, until a host is added. So, I executed the necessary PowerShell command to inflate a host.
$SBCertAutoGenerationKey = ConvertTo-SecureString -AsPlainText -Force -String [new password used for cert] $SBRunAsPassword = ConvertTo-SecureString -AsPlainText -Force -String [password for sbuser account]; Add-SBHost -FarmMgmtDBConnectionString 'Data Source=.;Initial Catalog=SbManagementDB;Integrated Security=True' -RunAsPassword $SBRunAsPassword -CertAutoGenerationKey $SBCertAutoGenerationKey;A bunch of stuff started happening in PowerShell …
… and then I got the acknowledgement that everything had completed, and I now had one host registered on the server.
I also noticed that the Windows Service (Windows Fabric Host Service) that was disabled before, was now in a Started state. Next I required a new namespace for my Service Bus host. The New-SBNamespace command generates the namespace that provides segmentation between applications. The documentation said that “ManageUser” wasn’t required, but my script wouldn’t work without it, So, I added the user that I created just for this demo.
New-SBNamespace -Name 'NsSeroterDemo' -ManageUser 'sbuser';
To confirm that everything was working, I ran the Get-SbMessageContainer and saw an active database server returned. At this point, I was ready to try and build an application. I opened Visual Studio and went to NuGet to add the package for the Service Bus. The name of the SDK package mentioned in the docs seems wrong, and I found the entry under Service Bus 1.0 Beta .
In my first chunk of code, I created a new queue if one didn’t exist.
//define variables string servername = "WA1BTDISEROSB01"; int httpPort = 4446; int tcpPort = 9354; string sbNamespace = "NsSeroterDemo"; //create SB uris Uri rootAddressManagement = ServiceBusEnvironment.CreatePathBasedServiceUri("sb", sbNamespace, string.Format("{0}:{1}", servername, httpPort)); Uri rootAddressRuntime = ServiceBusEnvironment.CreatePathBasedServiceUri("sb", sbNamespace, string.Format("{0}:{1}", servername, tcpPort)); //create NS manager NamespaceManagerSettings nmSettings = new NamespaceManagerSettings(); nmSettings.TokenProvider = TokenProvider.CreateWindowsTokenProvider(new List() { rootAddressManagement }); NamespaceManager namespaceManager = new NamespaceManager(rootAddressManagement, nmSettings); //create factory MessagingFactorySettings mfSettings = new MessagingFactorySettings(); mfSettings.TokenProvider = TokenProvider.CreateWindowsTokenProvider(new List() { rootAddressManagement }); MessagingFactory factory = MessagingFactory.Create(rootAddressRuntime, mfSettings); //check to see if topic already exists if (!namespaceManager.QueueExists("OrderQueue")) { MessageBox.Show("queue is NOT there ... creating queue"); //create the queue namespaceManager.CreateQueue("OrderQueue"); } else { MessageBox.Show("queue already there!"); }After running this (directly on the Windows Server that had the Service Bus installed since my local laptop wasn’t part of the same domain as my Windows Server, and credentials would be messy), as my “sbuser” account, I successfully created a new queue. I confirmed this by looking at the relevant SQL Server database tables.
Next I added code that sends a message to the queue.
//write message to queue MessageSender msgSender = factory.CreateMessageSender("OrderQueue"); BrokeredMessage msg = new BrokeredMessage("This is a new order"); msgSender.Send(msg); MessageBox.Show("Message sent!");Executing this code results in a message getting added to the corresponding database table.
Sweet. Finally, I wrote the code that pulls (and deletes) a message from the queue.
//receive message from queue MessageReceiver msgReceiver = factory.CreateMessageReceiver("OrderQueue"); BrokeredMessage rcvMsg = new BrokeredMessage(); string order = string.Empty; rcvMsg = msgReceiver.Receive(); if(rcvMsg != null) { order = rcvMsg.GetBody(); //call complete to remove from queue rcvMsg.Complete(); } MessageBox.Show("Order received - " + order);When this block ran, the application showed me the contents of the message, and upon looking at the MessagesTable again, I saw that it was empty (because the message had been processed).
So that’s it. From installation to development in a few easy steps. Having the option to run the Service Bus on any Windows machine will introduce some great scenarios for cloud providers and organizations that want to manage their own message broker.
















Abishek Lal described Service Bus [for Windows Server] Symmetry in a 7/16/2012 post (missed when published):
Whether your application runs in the cloud or on premises, it often needs to integrate with other applications or other instances of the application. Windows Azure Service Bus provides messaging technologies including Relay and Brokered messaging to achieve this. You also have the flexibility of using the Azure Service Bus (multi-tenant PAAS) and/or Service Bus 1.0 (for Windows Server). This post takes a look at both these hosting options from the application developer perspective.
The key principle in providing these offerings is to enable applications to be developed, hosted and managed consistently between cloud service and on-premise hosted environments. Most features in Service Bus are available in both environments and only those that are clearly not applicable to a certain hosting environment are not symmetric. Applications can be written against the common set of features and then can be run between these environments with configuration only changes.
Overview
The choice of using Azure Service Bus and Service Bus on-premise can be driven by several factors. Understanding the differences between these offering will help guide the right choice and produce the best results. Azure Service Bus is a multi-tenant cloud service, which means that the service is shared by multiple users. Consuming this service requires no administration of the hosting environment, just provisioning through your subscriptions. Service Bus on-premise is a when you install the same service bits on machines and thus manage tenancy and the hosting environment yourself.
Figure 1: Windows Azure Service Bus (PAAS) and Service Bus On-premise
Development
To use any of the Service Bus features, Windows applications can use Windows Communication Foundation (WCF). For queues and topics, Windows applications can also use a Service Bus-defined Messaging API. Queues and topics can be accessed via HTTP as well, and to make them easier to use from non-Windows applications, Microsoft provides SDKs for Java, Node.js, and other languages.
All of these options will be symmetric between Azure Service Bus and Service Bus 1.0, but given the Beta nature of the release, this symmetry is not yet available. The key considerations are called out below:
Similarities
- The same APIs and SDKs can be used to target Azure Service Bus and Service Bus on-premise
- Configuration only changes can target application to the different environments
- The same application can target both environments
Differences
- Identity and authentication methods will vary thus having application configuration impact
- Latency, throughput and other environmental differences can affect application performance since these are directly tied to the physical hardware that the service is hosted in
- Quotas vary between environments (details here)
It’s important to understand that there is only one instance of Azure Service Bus that is available as a PAAS service but several on-premise environments may exists either thru third-party hosters or self-managed IT departments. Since the service is continually evolving with new features and improvements it is a significant factor in deciding with features to consume based on the environment targeted. Below is a conceptual timeline of how the features will be released (note this does NOT track to any calendar dates):
Figure 2: Client SDK release and compatibility timeline
Application Considerations
The key considerations from an application perspective can be driven by business or engineering needs. The key similarities and differences from this perspective are listed below:
Similarities
- Namespaces are the unit for identity and management of your artifacts
- Queues/Topics are contained within a Namespace
- Claims based permissions can be managed on a per-entity basis
- Size constraints are applied on Queues/Topics
Differences
- Relay messaging is currently unavailable on Service Bus on-premise
- Service Registry is currently available on Service Bus on-premise
- Token based Identity providers for Service are ACS and for on-premise is AD and Self-signed tokens
- SQL Server is the storage mechanism that is provisioned and managed by you for on-premises
- Latency and throughput of messages vary between the environments
- The maximum allowable values for message size and entity size vary
Do give the Service Bus 1.0 Beta a try, following are some additional resources:



<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
•• See the Windows Azure and Office 365 article by Scott Guthrie (@scottgu) in the Live Windows Azure Apps, APIs, Tools and Test Harnesses section below.
• Kristian Nese (@KristianNese) continued his series with Windows Azure Services for Windows Server - Part 2 on 7/26/2012:
In Part 1, we Introduced Windows Azure Services for Windows Server
In Part 2, we will take a closer look at the experience of this solution, already running in Windows Azure and the changes that were announced early in June. This is to help you to better understand Windows Azure in general, and to be able to use it in your strategy and also explain the long term goal of a common experience in cloud computing, no matter if it`s on-premise or public.
I have blogged several times about Windows Azure and that it`s PaaS and not IaaS, even with the VM Role in mind.
A bit of history:
In the early beginning in 2007, Windows Azure did only support ASP.NET for the front-end and .NET in the back-end and was ideal for running Microsoft based code in the cloud and take advantage of Microsoft`s scalable datacenters. The only thing the developer had to focus on was to write code.
Based on feedback from customers, Microsoft had to open up a bit to support various workloads. People wanted to move to cloud computing but didn’t had the time or effort necessary to perform the transition. And of course, it was a huge question about costs as well.
In fact, If you needed to create a hybrid solution back then, you had to code everything. This also included the Service Bus for being able to communicate with on-premise resources or other roles in the cloud. Back in 2010 during PDC, Microsoft announced several new features like VM Role, Azure Connect and Admin mode among others.
Immediately people assumed that this was IaaS.
To make a long story short: Someone tried to move their VMs to Windows Azure (through Visual Studio, which they should consider as odd) and connected their VMs to on-premise resources by installing Azure Connect on their domain controller (also odd).
Things were running for a while, not fast as lightening but it did work, until Windows Azure did reset the image they uploaded. The reason for this was that the VM Role was stateless only.
The whole idea behind the VM role was to make it easier to move existing applications – that also required some manual configuration prior to launching the code for their applications. The developers knew this and was happy, but the IT pros who did misunderstand the concept, was failing beyond recognition. The really key to understand all this is to know cloud computing and its service models. PaaS is very different from IaaS when it comes to responsibility and functionality in the cloud stack. A rule to remember: if things are able to scale out, then it is stateless.
So what did change in June this year?
- Windows Azure is now also considered as an IaaS cloud
When that said, the long term goal for your applications should be to be able to run in a PaaS environment which is considered as the most effective and modern pattern. But you have now an option for your server applications when using IaaS, since IaaS serves to the OS stack in the cloud stack. This means you can put whatever you want into your OS, and that IaaS is basically virtual machines – the most flexible service model in cloud computing.
Comparison of Virtual Machines (IaaS) vs. VM Role
- Virtual Machine has persistent storage, included system partition
- VM Role gives you a stateless VM with pre packed applications for advanced setup of applications
IaaS in Windows Azure introduces the following:
- Support for key server applications
- Easy storage manageability
- High available features
- Advanced networking
- Integration with PaaS (as ‘Cloud Services’ in the new portal)
For us that have been working with infrastructure in general and private cloud, we know what this means. But we still need to dive into the PaaS offering in Windows Azure, although we’re not developers. The reason why I am saying this is because Windows Azure has a goal to deliver the same capabilities with their IaaS offering as with PaaS.
This will include things as VIP swap, fault domains and upgrade domains, affinity groups etc.
In the preview of the new Windows Azure portal you`ll find several images available.
- Windows Server 2008 R2
- Windows Server 2008 R2 with SQL Server 2012 Evaluation
- Windows Server 2012 Release Candidate
- Several versions of LINUX
Virtual Machine Architecture in Windows Azure
It was a question about storage for the persistent storage and Microsoft decided to used what they already had available in Windows Azure Storage, by leverage their Blobs which also creates at least three replicas. By using their existing Blobs in Azure Storage, they had to make several improvements for the overall performance as this was designed for PaaS. This has in turns lead to a greater performance for both PaaS and IaaS as a result of that. (Amazon created a SAN solution for their VM storage).
You will find both Disks and Images in Windows Azure.
Image is a generalized VHD that you can clone and create VMs with.
Disks is the virtual hard disks associated with the VMs – as you already are familiar with through the concept of virtualization.
How many disks you can have attached to a single VM in Azure depends on the ‘VM Size’ like extra small, small, large and extrra large. The good thing though is that you only pay for what you are using (yeah, it`s cloud computing) so that every resources are dynamic.
By default, the OS disk in the VMs supports ReadWrite disk caching, and also ReadOnly.
The data disks supports None, ReadOnly and can be modified using ‘Set-AzureOSDisk’ or ‘Set-AzureDataDisk’ cmdlets. To connect to a VM in Windows Azure, you must use the ‘Connect’ button in the Azure portal to initiate a RDP session, and use the admin login you specified during creation. If it`s a Linux operating system you would use SSH to logon, that you installs on your client computer.
Cloud Service Architecture in Windows Azure
The concept of PaaS in Windows Azure is now called ‘Cloud Service’ and consists of Web Roles and Worker Roles which are running on VM instances.
(Explanation of the difference between Web Role and Worker Role in Windows Azure)
In addition, when you create a stand-alone Virtual Machine in Windows Azure, it`s not bound to a cloud service. But when you are creating an additional VM you can then find an option to bound those VMs into a cloud service. So in other words, you can add virtual machines to existing cloud services.
Each cloud service has their own virtual private network where they can see each other and doesn’t have to communicate through the public IP/DNS name. The drawback for the moment is that it`s not possible that two different cloud services can communicate without going through the public IP/DNS name, but this is a feature that will come in the future. (Announced during TechEd)
Understanding High Availability in Windows Azure
SLA is an everlasting discussion between the vendor and the customer.
When we are talking about SLA we are always thinking about ‘how many nines do we need’. Windows Azure gives you 99,95% availability if you are following the rules and have at least two instances for your roles, and 99,9% for a single role instance.
We have something called Fault Domains and Upgrade Domains in Windows Azure.
Fault Domains represents hardware faults (rack) and default there is two fault domains for each role.
Update Domains represents how to service the roles during updates and default there is five update domains. You can create VM availability sets and spread the VMs on different fault domains
Windows Azure Virtual Networking
As I wrote in the beginning of this article, you could connect your cloud applications with on-premise resources by using Service Bus or Azure Connect. The last alternative was not ideal from an IT pros perspective, as you would have to install this agent on your domain controller. So let`s take a closer look at the enhancement in the networking space in Windows Azure.
You have now full control over VM names and can also take advantage of the Windows Azure provided DNS server, and resolve VMs by name within the same cloud service. If you want to be able to have name resolution between virtual machines and role instances located in the same virtual network but different cloud services, you must use your own DNS server (more about that in a later blog post).
One of the biggest benefit of Windows Azure DNS server is that you won’t get the degraded performance by lookup public IP/DNS when roles and VMs in the same cloud service must communicate, leading to fewer hops, since they are now communicating on the same virtual network, using internal IP`s/names.
As a ‘replacement’ for Azure connect, Windows Azure Virtual Network enables you to design and create secure site-to-site connectivity and protected virtual networks in the cloud.
Define your own address space for virtual networks and virtual networks gateways in the same manner as you would do when you`re working with branch offices.
We will not dive deep into all the details in this blog post, but you must take a moment and plan carefully when you are working with your network design, prior to publishing services and roles in Windows Azure. Consider the following:
- DNS design
- Address Space
- Supported VPN gateway devices
- Internet-accessible IP address for your VPN gateway device
And there`s more…
You can also take advantage of the new offerings like Web Sites and SQL Databases, and this will also be available in ‘Windows Azure Services for Windows Server’, but since this blog is mainly focusing on cloud computing and infrastructure, it will not be covered in this blog post.

• Marc Terblanche explained how to create a Windows Azure Virtual Network VPN with TMG 2010 in a 7/25/2012 post.
[Note: For more information about the Microsoft ForeFront Threat Management Gateway 2010, see the end of this article.]
Microsoft announced Windows Azure Virtual Network and Windows Azure Virtual Machines in June 2012 to provide IaaS ‘Hybrid Cloud’ functionality.
This is still a preview release and Microsoft currently only support specific Cisco and Juniper devices that have been tested. The VPN Devices for Virtual Network page explains that other devices may work as long as they support the following:
- VPN device must have a public facing IPv4 address
- VPN device must support IKEv1
- Establish IPsec Security Associations in Tunnel mode
- VPN device must support NAT-T
- VPN device must support AES 128-bit encryption function, SHA-1 hashing function, and Diffie-Hellman Perfect Forward Secrecy in “Group 2″ mode
- VPN device must fragment packets before encapsulating with the VPN headers
TMG 2010 does support these requirements but getting full connectivity working has proven to be harder than expected. Hopefully this post will save others a lot of time.
Create Azure Virtual Network and Start Gateway
The first step is to create the Azure Virtual Network and Microsoft have a good tutorial explaining it here.
If you will be deploying Active Directory into your Virtual Network, you cannot use Azure DNS and will need to provide details for your AD DNS. More information is available here.
The first VM deployed to each subnet will get the .4 address for example 10.4.3.4. For the DNS question (step 6 in the tutorial) enter the .4 address for your subnet and also add an on-premise DNS server for example 192.168.0.1
It is important to note that once you have created the Virtual Network and deployed a Virtual Machine the configuration cannot be modified, other than adding subnets. Hopefully this is something that will be available once these services are out of beta.
Starting the gateway can take a long time. I haven’t seen any documentation on how it works, but I suspect it is spinning up a VM in the background to act as the Azure VPN endpoint. Once the gateway is created, take note the IP address and Shared Key and we can move on to the TMG configuration.
Create TMG IPsec site-to-site VPN
During the setup of the TMG VPN I had a few times where I thought I had it working only to hit another stumbling block. The summary of the things I needed to change are:
- Setup TMG IPsec with a supported configuration
- Modify TMG network rule and access rule
- Make sure the TMG server has hotfix KB2523881 installed
- Change the TMG network card MTU to 1350
- Disable RPC strict compliance and restart TMG firewall service

[Note: MTU is an abbreviation for Maximum Transmission Unit, the maximum size of a packet that can be transmitted over the network.]
IPsec Configuration
I used the content of this massive MSDN forum post to create the IPsec site-to-site VPN and get traffic flowing with the TMG configuration information coming from David Cervigon.
- Remote Access Policy (VPN) / Remote Sites / Create VPN Site-to-Site Connection
- Choose ‘IP Security protocol (IPsec) tunnel mode
- Remote VPN gateway IP address: enter the Azure Virtual Network gateway provided earlier
- Local VPN gateway IP address: enter the TMG external IP address
- Use pre-shared key for authentication: Enter Shared Key provided earlier
- Remote address ranges: Leave the Azure IP address and enter the Azure network range created earlier for example 10.4.0.0 to 10.4.255.255
- Network rule: Create a route relationship and add other networks if required
- Access rule: Create an access rule and select ‘All outbound traffic’
- Address ranges: Leave the external interface and add the internal network ranges that need to communicate over the VPN
- Create the VPN and edit
- Under Connection / IPsec Settings ensure the following is set:
- Phase I
- Encryption algorithm: AES128
- Integrity algorithm: SHA1
- Diffie-Hellman group: Group 2 (1024 bit)
- Authenticate and generate a new key: 28800 seconds
- Phase II
- Encryption algorithm: AES128
- Integrity algorithm: SHA1
- Session key / Generate a new key every: Both enabled
- Kbytes: 102400000
- Seconds: 3600
- Use Perfect Forward Secrecy (PFS): Not selected
- Diffie-Hellman group: N/A
Below is the TMG IPsec configuration.
TMG Network and Access Rules
The automatically created Network Rule and Access Rule allow only one way initiated traffic.
- Modify the Network rule under Networking / Network Rules and add ‘Internal’ to the source network and ‘Azure’ to the destination network
- Modify the Access rule under Firewall Policy and add ‘Internal’ to the source network and ‘Azure’ to the destination network
Below is the TMG configuration.
TMG Server Hotfix KB2523881
At this point I could see the VPN connect:
However no traffic was flowing. I was running TMG 2010 SP 1 Software Update 1 and after installing hotfix KB2523881 the VPN worked. I tried to install the hotfix on another TMG server with SP 2 and all Windows Updates and it said it was not needed.
This may be included in TMG 2010 SP 2 or as part of another update from Windows Update.(Update 26 July: tcpip.sys and fwpkclnt.sys are updated by Windows hotfix KB2582281 and MS12-032 KB2688338 )TMG Network Card MTU
At this point I could add my first virtual machine, join it to the domain but could not get AD to replicate from on-premise to Azure. The issue was the MTU on the external network card on TMG which was mentioned somewhere in the MSDN forum above. The MTU needs to be set to 1350 to account for the IPsec overhead and the default is 1500.
- Open an administrative command prompt
- Run to show interfaces
- netsh interface ipv4 show interface
- Set external interface MTU
- netsh interface ipv4 set interface “EXT” MTU=1350
Below is a screenshot of the change.
Disable RPC Strict Compliance and Restart TMG Firewall Service
Almost there. The issue I faced now was that my Virtual Machine Domain Controller could not use any DCOM RPC services like certificate self-enrolment and opening the Certificate Authority MMC. TMG blocks all non endpoint mapper RPC traffic like DCOM – more information is available here. I tried disabling RPC strict compliance, changing the DCOM port and creating a custom rule as shown here but it did not work. I eventually tried to disable the RPC filter completely in System / Application Filters which, although drastic, did work. The reason it worked is because it forces a restart of the TMG Firewall service which it turns out is all that was needed to apply the previous configuration changes. I re-enabled the RPC filter and set the DCOM back to standard ports and from my testing the following is needed:
- Right click the Access rule, select ‘Configure RPC protocol’ and uncheck ‘Enforce strict RPC compliance’
- Edit the System policy ‘Firewall Policy / All Tasks / System Policy / Edit System Policy / Authentication Services / Active Directory’ and uncheck ‘Enforce strict RPC compliance’
- Apply the TMG configuration and wait for it to sync
- Important:The next step will disconnect all TMG sessions including VPN, RDP, ActiveSync, OWA etc. so should be performed out of hours
- Restart the ‘Microsoft Forefront TMG Firewall service
It Works!
That should be all that is needed. Not particularly hard but getting all the information and testing took a long time. I hope that this helps somebody and prevents a lot of wasted time.
The next blog will cover PowerShell provisioning the first Domain Controller in Azure so that it can join the on-premise domain and adding other domain joined machines.




The Microsoft ForeFront Threat Management Gateway (TMG) 2010 is software that implements a security appliance, which consists of two components:
-
Forefront Threat Management Gateway 2010 Server: Provides URL filtering, antimalware inspection, intrusion prevention, application and network-layer firewall and HTTP/HTTPS inspection in a single solution.
-
Forefront Threat Management Gateway Web Protection Service: Provides continuous updates for malware filtering and access to cloud-based URL filtering technologies aggregated from multiple web security vendors to protect against the latest Web-based threats. Forefront TMG Web Protection Service is licensed separately on a subscription basis.
You can read more about the TMG 2010 and sign up for a free trial here. According to the its datasheet, TMG 2010 has the following system requirements:
Forefront TMG 2010 requires a server with a 64-bit processor and, at minimum, the following: 2 processor cores, 2 GB of RAM, 2.5 GB available hard drive space, one compatible Network Interface Card, and a local hard disk partition formatted in NTFS. Supports Windows Server® 2008 SP2 or Windows Server 2008 R2.
I’m surprised that the TMG 2010 isn’t a supported internet security appliance as it’s a Microsoft product.
Maarten Balliauw (@maartenballiauw) described Hands-on Windows Azure Services for Windows with Windows Azure in a 7/24/2012 post:
A couple of weeks ago, Microsoft announced their Windows Azure Services for Windows Server. If you’ve ever heard about the Windows Azure Appliance (which is vaporware imho :-)), you’ll be interested to see that the Windows Azure Services for Windows Server are in fact bringing the Windows Azure Services to your datacenter. It’s still a Technical Preview, but I took the plunge and installed this on a bunch of virtual machines I had lying around. In this post, I’ll share you with some impressions, ideas, pains and speculations.
Note: Currently only SQL Server, MySQL, Web Sites and Virtual Machines are supported in Windows Azure Services for Windows Server. Not storage, not ACS, not Service Bus, not...
You can sign up for my “I read your blog plan” at http://cloud.balliauw.net and create your SQL Server databases on the fly! (I’ll keep this running for a couple of days, if it’s offline you’re too late).
My setup
Since I did not have enough capacity to run enough virtual machines (you need at least four!) on my machine, I decided to deploy the Windows Azure Services for Windows Server on a series of virtual machines in Windows Azure’s IaaS offering.
You will need servers for the following roles:
- Controller node (the management portal your users will be using)
- SQL Server (can be hosted on the controller node)
- Storage server (can be on the cntroller node as well)
If you want to host Windows Azure Websites (shared hosting):
- At least one load balancer node (will route HTTP(S) traffic to a frontend node)
- At least one frontend node (will host web sites, more frontends = more websites / redundancy)
- At least one publisher node (will serve FTP and Webdeploy)
If you want to host Virtual Machines:
- A System Center 2012 SP1 CTP2 node (managing VM’s)
- At least one Hyper-V server (running VM’s)
Being a true ITPro (forgot the <irony /> element there…), I decided I did not want to host those virtual machines on the public Internet. Instead, I created a Windows Azure Virtual Network. Knowing CIDR notation (<irony />), I quickly crafted the BalliauwCloud virtual network: 172.16.240.0/24.
So a private network… Then again: I wanted to be able to access some of the resources hosted in my cloud on the Internet, so I decided to open up some ports in Windows Azure’s load balancer and firewall so that my users could use the SQL Sever both internally (172.16.240.9) and externally (sql1.cloud.balliauw.net). Same with high-density shared hosting in the form of Windows Azure Websites by the way.
Being a Visio pro (no <irony /> there!), here’s the schematical overview of what I setup:
Nice, huh? Even nicer is my to-be diagram where I also link crating Hyper-V machines to this portal (not there yet…):
My setup experience
I found the detailed step-by-step installation guide and completed the installation as described. Not a great success! The Windows Azure Websites feature requires a file share and I forgot to open up a firewall port for that. The result? A failed setup. I restarted setup and ended with 500 Internal Server Terror a couple of times. Help!
Being a Technical Preview product, there is no support for cleaning / restarting a failed setup. Luckily, someone hooked me up with the team at Microsoft who built this and thanks to Andrew (thanks, Andrew!), I was able to continue my setup.
If everything works out for your setup: enjoy! If not, here’s some troubleshooting tips:
Keep an eye on the C:\inetpub\MgmtSvc-ConfigSite\trace.txt log file. It holds valuable information, as well as the event log (Applications and Services Log > Microsoft > Windows > Antares).
If you’re also experiencing issues and want to retry installation, here are the steps to clean your installation:
- On the controller node: stop services:
net stop w3svc
net stop WebFarmService
net stop ResourceMetering
net stop QuotaEnforcement- In IIS Manager (inetmgr), clean up the Hosting Administration REST API service. Under site MgmtSvc-WebSites:
- Remove IIS application HostingAdministration (just the app, NOT the site itself)
- Remove physical files: C:\inetpub\MgmtSvc-WebSites\HostingAdministration- Drop databases, and logins by running the SQL script: C:\inetpub\MgmtSvc-ConfigSite\Drop-MgmtSvcDatabases.sql
- (Optional, but helped in my case) Repair permissions
PowerShell.exe -c "Add-PSSnapin WebHostingSnapin ; Set-ReadAccessToAsymmetricKeys IIS_IUSRS"- Clean up registry keys by deleting the three folders under the following registry key (NOT the key itself, just the child folders):
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\IIS Extensions\Web Hosting Framework
Delete these folders: HostingAdmin, Metering, Security- Restart IIS
net start w3svc- Re-run the installation with https://localhost:30101/
Configuration
After installation comes configuration. Configuration depends on the services you want to offer. I’m greedy so I wanted to provide them all. First, I registered my SQL Server and told the Windows Azure Services for Windows Server management portal that I have about 80 GB to spare for hosting my user’s databases. I did the same with MySQL (setup is similar):
You can add more SQL Servers and even define groups. For example, if you have a SQL Server which can be used for development purposes, add that one. If you have a high-end, failover setup for production, you can add that as a separate group so that only designated users can create databases on that SQL Server cluster of yours.
For Windows Azure Web Sites, I deployed one node of every role that was required:
What I liked in this setup is that if I want to add one of these roles, the only thing required is a fresh Windows Server 2008 R2 or 2012. No need to configure the machine: the Windows Azure Services for Windows Server management portal does that for me. All I have to do as an administrator in order to grow my pool of shared resources is spin up a machine and enter the IP address. Windows Azure Services for Windows Server management portal takes care of the installation, linking, etc.
The final step in offering services to my users is creating at least one plan they can subscribe to. Plans define the services provided as well as the quota on these services. Here’s an example quota configuration for SQL Server in my “Cloud Basics” plan:
Plans can be private (you assign them to a user) or public (users can self-subscribe, optionally only when they have a specific access code). …







Maarten goes on to illustrate “The End User Experience” with Windows Azure Services and concludes:
Conclusion
I’ve opened this post with a “Why?”, let’s end it with that question. Why would you want to use this? The product was announced on Microsoft’s hosting subsite, but the product name (Windows Azure Services for Windows Server) and my experience with it so far makes me tend to think that this product is a fit for any enterprise!
You will make your developers happy because they have access to all services they are getting to know and getting to love. You’ll be able to provide self-service access to SQL Server, MySQL, shared hosting and virtual machines. You decide on the quota. You manage this. The only thing you don’t have to manage is the actual provisioning of services: users can use the self-service possibilities in Windows Azure Services for Windows Server.
Want your departments to be able to quickly setup a Wordpress or Drupal site? No problem: using Web Sites, they are up and running. And depending on the front-end role you assign them, you can even put them on internet, intranet or both. (note: this is possible throug some Powershell scripting, by default it's just one pool of servers there)
The fact that there is support for server groups (say, development servers and high-end SQL Server clusters or 8-core IIS machines running your web applications) makes it easy for administrators to grant access to specific resources while some other resources are reserved for production applications. And I suspect this will extend to the public cloud making it possible to go hybrid if you wish. Some services out there, some in your basement.
I’m keeping an eye on this one.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Scott Guthrie (@scottgu) introduced Windows Azure and Office 365 in a 7/26/2012 post:
Last week’s Beta release of Microsoft Office 365 and SharePoint introduced several great enhancements, including a bunch of developer improvements. Developers can now extend SharePoint by creating web apps using ASP.NET (both ASP.NET Web Forms and now ASP.NET MVC), as well as extend SharePoint by authoring custom workflows using the new Workflow Framework in .NET 4.5.
Even better, the web and workflow apps that developers create to extend SharePoint can now be hosted on Windows Azure. We are delivering end-to-end support across Office 365 and Windows Azure that makes it super easy to securely package up and deploy these solutions.
Developing Windows Azure Web Sites Integrated with Office 365
Last month we released a major update to Windows Azure. One of the new services introduced with that release was a capability we call Windows Azure Web Sites - which enables developers to quickly and easily deploy web apps to Windows Azure. With the new Office, SharePoint Server 2013 and Office 365 Preview released last week, developers can now create apps for Office and SharePoint and host them on Windows Azure.
You can now use any version of ASP.NET (including ASP.NET Web Forms, ASP.NET MVC and ASP.NET Web Pages) to create apps for SharePoint, and authenticate and integrate them with Office 365 using OAuth 2 and Windows Azure Active Directory. This enables you to securely create/read/update data stored within SharePoint, and integrate with the rich data and document repositories in Office 365.
In addition to enabling developers to host these web apps on their own with Windows Azure, the new version of Office 365 and SharePoint also now enable developers to package and upload custom web apps to Office 365. End users can then browse these apps within the new Office and SharePoint Store available within Office 365 and choose to install them for their SharePoint solutions. Doing so will cause Office 365 to automatically deploy and provision a copy of the app as a Windows Azure Web Site, and Office 365 will then manage it on behalf of the end-customer who installed it. This provides a really compelling way for developers to create and distribute custom web apps that extend SharePoint to customers, and optionally monetize these solutions through the Store.
You can learn more about how to build these solutions as well as the new cloud app model for Office and SharePoint here, and more about how to build apps for SharePoint here.
Developing Windows Azure Workflows Integrated with Office 365
The new version of SharePoint also now enables developers to execute custom .NET 4.5 Workflows in response to SharePoint actions (for example: an end user uploading a document, or modifying items within a SharePoint list). The introduction of .NET 4.5 Workflows enables SharePoint workflows that are more:
- expressive: by introducing stages and looping, and taking advantage of .NET 4.5 flowchart workflows
- connected: by supporting the ability to call REST and OData web services, as well as ASP.NET Web API endpoints
- unbounded: by running workflows outside of the SharePoint server in a robust, scalable, and consistent workflow host
With this month’s Office 365 Preview, developers can now easily author and upload workflows to their SharePoint solutions. Office 365 now uses a new Windows Azure Workflow service to automatically execute these within Windows Azure. Developers and Office 365 customers do not have to setup anything within Windows Azure to enable this (nor even have a Windows Azure account) – as the end-to-end integration is provided automatically by Office 365 and Windows Azure.
You can author these workflows using either the Office SharePoint Designer or from within Visual Studio 2012. In the Office SharePoint Designer, users will be able to build .NET 4.5 workflows either through a visual designer:
Or within a text view (similar to the Outlook Rules wizard):
Developers can use the new Workflow designer and Office Developer Tooling within Visual Studio 2012:
The workflow support provides a really easy way to customize the behavior of actions within SharePoint, and run this custom logic within Windows Azure. All of this can be done without the developer or IT Professional customizing SharePoint having to deploy any app themselves (nor even sign-up for a Windows Azure account – Office 365 takes care of it all). Because workflows can also now make asynchronous REST and OData calls within a workflow, it is also now really easy to author workflows that call custom functionality and services you might have running in Windows Azure (for example: a service written using ASP.NET Web API) and integrate that data or logic with your SharePoint solution.
Summary
This summer’s updates of Windows Azure and Office 365 provide a wealth of new cloud capabilities. You can use each of the services independently, or now take advantage of them together to develop even more compelling end-to-end solutions. Visit the Office Developer Center to learn more and get started today.
Hope this helps.







Nathan Totten (@ntotten) described a Windows Azure Web Sites Modern Application Sample – Cloud Survey in a 7/24/2012 post:
If you had a chance to watch the Windows Azure Web Site session at Learn Windows Azure you may have noticed an application used in the demos called Cloud Survey. The Cloud Survey sample is a modern web application that is build using ASP.NET MVC 4, ASP.NET Web API, SignalR, and Ember.js. This application is designed to be deployed and run on Windows Azure Web Sites and uses SQL Databases for persistence.
Today, I have published the entire source of the Cloud Survey application to Github and made it available under the Apache license. You can get download the source directly from Github. You can also see a live demo of the site deployed to Windows Azure Web Sites (username: admin; password: Contoso123!).
You can find a step-by-step tutorial on how to publish and use the Cloud Survey sample in the README. Additionally, I have recorded a screencast demonstrating and explaining the various features of the Cloud Survey application. You can view the screencast below or on Channel 9.
I hope you enjoy this sample. Please let me know if you have any questions or feedback.
[Download the source code:]
cloudsurvey_hd.mp4

David Makogon posted ISV Guest Post Series: iVoteSports Scales its Baseball-Focused Mobile Game App with Windows Azure on 7/24/2012:
Editor’s Note: Today’s post, written by Bill Davidheiser [pictured at right], Chief Architect and Co-founder of iVoteSports, describes how the company uses Windows Azure to power its iVoteSports MLB-focused mobile game.
We started iVoteSports.com (sold on the Apple, Android and Amazon app markets) with a fairly simple idea that most sports, like baseball, can be broken down into games within the game. For example every baseball inning has many at-bats and each individual batter has a number of potential outcomes for his at-bat such as a walk, strike and home run.
Determining the winner of a live sporting event is challenging due the volume and frequency of events. Using baseball as an example: Each game has 9 or more innings with 6 at-bats per inning, and each at-bat has at least 3 events (strike, ball, etc). This, coupled with a volume of 162 games per team per regular season, creates a tremendous volume of events that cannot be managed by a human umpire – at least not within the practical resource constraints of our game. To address this, we created a way to programmatically determine outcomes using crowd sourcing concepts.
WINDOWS AZURE DESIGN AND FLUCTUATING TRAFFIC
As mentioned, the nature of live sporting events is that a lot of people get together in relatively short time period (around 3 hours) and then they rapidly disperse. Since the iVoteSports application is played during the live game, it needs to support these dramatic usage spikes.
This type of fluctuating demand is perfect for a cloud application. In our idle state we maintain two small (single-core) Windows Azure web role instances. However, as many players come on board, we can quickly add web instances, scaling out as demand ramps up. The trigger point for adding additional instances intra-day is based mostly on processor utilization: if we are consistently exceeding 80% we will add additional instances.
In future versions we will programmatically add instances via the management API, taking advantage of the Microsoft Enterprise Library’s Autoscaling Application Block (WASABi), but for now scaling is performed manually. For days that have enough popular games to require increased capacity, we can proactively increase the instance counts.
The actual build-out of iVoteSports turned out to more closely resemble a multi-tier enterprise application than a mobile game. We have distinct concepts of presentation, application and data layers.
Since the database is multi-tenant, user id’s are associated with all tables that deal with activities such as keeping score, making a prediction, or asserting an outcome. Our views, UDF and stored procedure development was pretty much exactly like what would be created for a typical .Net application. Since only user prediction and outcome information is kept from day to day (stats and schedule data is archived) the 150GB Windows Azure SQL Database limit is not an issue.
Our initial decision to use SQL Database was driven mostly by the desire to create optimized TSQL that could be changed on the fly without need to redeploy code. For our next generation of the game, we will likely migrate some, if not all, of our data structures to the more cost effective Windows Azure Table Storage.
As a side note, a mobile app that has a lot of the logic in the server has nice benefits. Web developers get spoiled in the ability to push out a hot-fix in near real time to correct bugs. Unfortunately when a bug is found in mobile code there is nothing real-time about the fix. In the case of Apple, it could take as much as a week to get the change approved.
THE MOBILE APP

Our presentation tier is the mobile device. We started by creating a lightweight API that was really optimized for unpredictable traffic between a wide range of mobile devices – including the really old phones unable to make rapid network calls. The test case was an antique 1st generation Droid that had such an overburdened processor it would take an Angry Bird around 5 seconds to cross the screen.While security is not a major issue with the game, we implemented authentication enforced by coupling the email address with the physical device ID. If needed in the future, we can derive a security token used for role based authorization of certain functions.
All traffic originating from the mobile devices are stateless and effectively synchronous. Each mobile device will perform a lightweight sever poll every few seconds to check if there are messages waiting. If messages are waiting, a more expensive data exchange call is made.
PROBABILITIES AND POINTS
Probabilities are central to our game. The probability of a play outcome is driven off a handful of key influences such as historical event outcomes (fly-outs are more common than walks), player match-ups (batter-X does well against pitcher-Y) and player aptitude (batter hits .240). There are of course other factors such as stadium, injury and weather that play a part in the probability, but on average these factors are minimal and mostly just applicable to a local sports bookie.
Mashing key influences together produces a combined probability that can be converted to winnable points for the predictor of the play outcome. We call that prediction an iVote. For example: a home run against Casey Jones batting against Joe Throwhard will earn 30 points for a correct iVote while a home run predication for a weaker batter than Casey may give the opportunity for 100 points. Las Vegas people commonly refer to this as a “point spread.”
Taking it one step further, when many people are involved with the same play, point motivations can be created to encourage less popular predictions to be made and keep a more even distribution of iVotes. This concept is roughly patterned after a what is often known to as “Spread Betting.”
It is important to note that even though iVoteSports.com deals with a lot of gambling concepts, we are in no way a gambling application. There are only points involved – never actual money.
STATISTICS FEEDS
Adding current stats allows up to make the game quite a bit more interesting by preloading batting line-ups, showing player bios and trivia, and of course use the most current stats so that our probability calculations are using good data.
We get two types of data from Stats.com: daily and pre-game. The daily data includes schedule, roster and player statistics and are loaded into our SQL Database at 4am Pacific time each morning. The pre-game data is loaded about 15 minutes before each baseball game starts and contains the starting batting line-up for each team along with the starting pitchers.
OUTCOME DETERMINATIONS
Programmatic determination of an event’s outcome is quite difficult. This is not an issue when a trusted official is recording each event, but as mentioned earlier using a human official was not a scalable answer for our mobile app where we can have dozens of games occurring at once at many different times of the day.
Crowdsourcing design patterns turned out to be an excellent answer for us. As documented by many excellent articles and practical examples such as the Truthsquad Experiment, if you get enough people saying that something is true then it probably is. Of course there are caveats to “collective truth” such as ensuring against collaborators and having less than a critical mass of people. However these challenges can be mitigated and on the whole crowdsourcing is a mathematically proven approach and quite effective for our purpose.
As shown in the graph ‘Relation of assertions to accuracy,’ when we reach the critical mass of players in a given event asserting an outcome we gain have confidence the assertion accurately represents the outcome. For example, if we have 30% users from the total population that say a specific event occurred (such as a player has struck out) we have a confidence exceeding 50% that we have a confirmed, actual outcome.
Confidence greater than 60% allows us to not only reward the people that predicted correctly but penalize those that appeared to have cheated by saying they iVoted right when they really didn’t.
LESSONS LEARNED
We feel very comfortable with our overall design; specifically by running a large component of our game in Windows Azure, we will be able to rapidly develop to new presentation platforms.
We found the Windows Azure SQL Database query optimization process to be more challenging than with regular SQL server. We used the now discontinued RedGate backup utility to create a local copy of the DB and then ran the SQL Profiler, feeding the results into the SQL DB Tuning Advisor. We manually applied the Tuning Advisor suggested indexes to our SQL Database via SQL Management Studio. Hopefully Microsoft will give tools to improve this process in the near future. The main Windows Azure lesson we learned during the development process had to do with deployment. We initially used the web role’s web deploy option without realizing that the VM would be reset on a periodic basis. The non-persistent nature of web deploy will cause the deployment to be reverted back to its original state when the web role VM is re-imaged. When re-imaging occurs, Microsoft does not send notification – at least no notification that we were aware of. This caused confusion when our application kept reverting back to older behavior.
However overall we had an excellent experience with Windows Azure. With unpredictable and rapid demand variations, Windows Azure proved to be an ideal operational platform for our game. In addition the development tools gave us good productivity with short learning curves.
While technical in nature, we hope the end result is an easy to use and entertaining sports game. To check out the results of our work, please visit us at www.ivotesports.com.



Nathan Totten (@ntotten) started a series with Facebook Apps and Windows Azure Web Sites (Part 1 – Getting Started) on 7/23/2012:
Windows Azure Web Sites (WAWS) is a great platform for deploying Facebook Applications. Not only is it super easy to deploy your application to WAWS, but it is also free to get started. This post is the first in a three part series about building Facebook Apps and deploying them to Windows Azure Web Sites.
To begin I have created an ASP.NET MVC 4 using the basic project template.
Next, add the Facebook C# SDK to the project using NuGet by running the following command.
Install-Package Facebook
Next, we need to build the basic components of the application. I am going to add three controllers – HomeController, AccountController, and AppController. Additionally, I am going to add two views App/Index.cshtml and Home/Index.cshtml. The App/Index view will be show to authenticated users and the Home/Index view will be the public landing page for the application.
The AccountController won’t have any views in our simple application; it will only be used to perform the server-side functions for Facebook Authentication. In a real application you may want to use the AccountController to handle alternate authentication methods and tasks like resetting your account password.
Now that we have our basic application shell setup we need create a Facebook Application on Facebook’s developer site. For this demo I am actually going to create two different applications – one will be used for local development and the other will be used for production deployments. This is a common practice for Facebook developers. When you login to Facebook’s developer site click the “Create New App” button. You will need to perform these steps twice, once for local development and once for production. I tend to use the naming convention “MyAppName – Local” for my local test app and “MyAppName” for my production app. You could also have a “MyAppName – Staging” for a staging app if you wanted.
After each of your applications are created you will be taken to the app information page. You will see both your App Id and App Secret on these pages. Save this information for both apps as you will need it in the next step.
Next set the App Id and App Secret values in our web.config files so we can use them in our application. We can use Web.config transforms in order to set the appropriate Facebook application for local development or production. For local development add the following keys to your Web.config file.
<appSettings> ... <add key="FacebookAppId" value="your_local_app_id"/> <add key="FacebookAppSecret" value="your_local_app_secret" /> </appSettings>For the production environment add the following keys to your Web.Release.config file.
<appSettings> <add key="FacebookAppId" value="your_prod_app_id" xdt:Transform="SetAttributes" xdt:Locator="Match(key)"/> <add key="FacebookAppSecret" value="your_prod_app_secret" xdt:Transform="SetAttributes" xdt:Locator="Match(key)" /> </appSettings>Next we will setup our MVC Application for user authentication using Facebook’s OAuth API. To begin, we set a page that will be secured. Open your AppController and add the [Authorize] attribute to the controller as shown below. This will ensure that only authorized users can access this page.
[Authorize] public class AppController : Controller { // // GET: /App/ public ActionResult Index() { return View(); } }The next step is to create our Facebook login action. We will do this in the AccountController. To begin, rename the Index action to Login. Next we need to create the Facebook OAuth url and redirect our user there. You can see below how to do this using the Facebook C# SDK.
public class AccountController : Controller { // // GET: /Account/Login public ActionResult Login() { // Build the Return URI form the Request Url var redirectUri = new UriBuilder(Request.Url); redirectUri.Path = Url.Action("FbAuth", "Account"); var client = new FacebookClient(); // Generate the Facebook OAuth URL // Example: https://www.facebook.com/dialog/oauth? // client_id=YOUR_APP_ID // &redirect_uri=YOUR_REDIRECT_URI // &scope=COMMA_SEPARATED_LIST_OF_PERMISSION_NAMES // &state=SOME_ARBITRARY_BUT_UNIQUE_STRING var uri = client.GetLoginUrl(new { client_id = ConfigurationManager.AppSettings["FacebookAppId"], redirect_uri = redirectUri.Uri.AbsoluteUri, scope = "email", }); return Redirect(uri.ToString()); } }Next, go ahead and run the site and navigate to http://localhost:####/App, where #### is the port number your site is running on. Because the AppController requires users to be authenticated you will be redirected to the Facebook OAuth page. However, you will notice that Facebook will give you an error as shown below.
This error is caused by our redirect_uri not being set as our Site url in the Facebook App settings. To remedy this go back to your Facebook App settings and set the value of Site url equal to the local url your application is running. You can see this setting below. Note, we will need to perform this same step on the production app as well.
After you have saved this setting, return navigate your browser again to http://localhost:####/App. You will now be redirected to the Facebook OAuth dialog asking you to authorize your application.
After you click “Go to App” Facebook will redirect the user to the URL specified in the redirect_uri parameter as specified above. In this case the redirect_uri is http://localhost:####/Account/FbAuth. We have not created this page so you will receive a 404 error.
The FbAuth action that Facebook will redirect the user is responsible for reading the Facebook authorization result information, validating that information, and setting the user authentication cookie. You can perform these actions with the code below.
public ActionResult FbAuth(string returnUrl) { var client = new FacebookClient(); var oauthResult = client.ParseOAuthCallbackUrl(Request.Url); // Build the Return URI form the Request Url var redirectUri = new UriBuilder(Request.Url); redirectUri.Path = Url.Action("FbAuth", "Account"); // Exchange the code for an access token dynamic result = client.Get("/oauth/access_token", new { client_id = ConfigurationManager.AppSettings["FacebookAppId"], redirect_uri = redirectUri.Uri.AbsoluteUri, client_secret = ConfigurationManager.AppSettings["FacebookAppSecret"], code = oauthResult.Code, }); // Read the auth values string accessToken = result.access_token; DateTime expires = DateTime.UtcNow.AddSeconds(Convert.ToDouble(result.expires)); // Get the user's profile information dynamic me = client.Get("/me", new { fields = "first_name,last_name,email", access_token = accessToken }); // Read the Facebook user values long facebookId = Convert.ToInt64(me.id); string firstName = me.first_name; string lastName = me.last_name; string email = me.email; // Add the user to our persistent store var userService = new UserService(); userService.AddOrUpdateUser(new User { Id = facebookId, FirstName = firstName, LastName = lastName, Email = email, AccessToken = accessToken, Expires = expires }); // Set the Auth Cookie FormsAuthentication.SetAuthCookie(email, false); // Redirect to the return url if availible if (String.IsNullOrEmpty(returnUrl)) { return Redirect("/App"); } else { return Redirect(returnUrl); } }That is everything required to authenticate a user with Facebook. Now all that remains is to publish the site to Windows Azure Web Sites. If you don’t already have a Windows Azure account you can sign up for a free trial on WindowsAzure.com. If you already have an account login in the new management portal and click “New” and click “Web Site”. Select quick create and fill in the form as shown below. Use your own URL for your application.
Click “Create Web Site” and wait a few seconds for your site to be created. After the site is ready click the name to go to the web site dashboard. On the dashboard page you will see a set of links on the left side under the heading “quick glance”. Click the link titled “Download publish profile” as show.
A file, called a publish profile, will be downloaded that contains all the information necessarily to publish your web site to Windows Azure right from Visual Studio.
Back in Visual Studio right-click on your project and click “Publish”.
This will open the Web Publish dialog. In this dialog click “Import” and select the publish profile that you downloaded in the previous step.
After you have imported the publish profile the Publish Web window will populate with the information needed to publish your website. Click “Publish” to publish your site.
After the publish process has completed your website will open. As noted above, we need to set the production Facebook App with the correct site Url in the same way we did with our local application. To do this open your Facebook App settings in the Facebook developer portal and set the Site Url to your Windows Azure Web Site Url (http://yoursitename.azurewebsites.net). With this step complete you can now navigate to http://yoursitename.azurewebsites.net/App and login with your Facebook account.
You can find the entire source for this demo application on Github. Additionally, keep an eye out on this blog for two additional posts on Facebook development with Windows Azure Websites.













Bruce Kyle posted an ISV Video: Windows Azure Performance Management, Monitoring Using AppDynamics to the US ISV Evangelism blog on 7/23/2012:
Customers seeking to simply migrate their applications to the cloud and use traditional server monitoring tools or legacy Application Performance Management (APM) software quickly find themselves stymied. Such obsolete strategies require manual configuration and instrumentation, and they are incapable of monitoring highly elastic cloud environments without producing gaping blind spots.
ISV Video: Windows Azure Performance Management, Monitoring Using AppDynamics
In contrast, AppDynamics' automatic instrumentation and configuration make it a perfect fit for managing cloud environments with a high rate of change. In addition, AppDynamics' auto-scaling feature allows Windows Azure customers to automatically provision Windows Azure resource based on the performance and throughput of business transactions.
- Monitor the health of their Windows Azure application
- Troubleshoot performance problems in real time
- Rapidly diagnose root cause of performance problems
- Dynamically scale up and scale down their Windows Azure application
With the release of AppDynamics Pro 3.4.3, Windows Azure customers can now monitor and troubleshoot applications that leverage:
- Windows Azure Compute
- Windows Azure Service Bus
- Windows Azure SQL
- Windows Azure Storage
To provide the best possible solution for Windows Azure users, AppDynamics has made available its multi-tenant Monitoring-as-a-Service platform within Windows Azure itself. This minimizes the network bandwidth costs for Windows Azure customers using AppDynamics because they will not have to transfer monitoring data outside of Windows Azure. In addition, online support, documentation and training are all available directly through the Windows Azure Marketplace.
AppDynamics is available now on the Windows Azure Marketplace. Free trials of AppDynamics Pro for Windows Azure last for 30 days and then revert to AppDynamics Lite for Windows Azure, which is currently free. For more information, please visit www.appdynamics.com/azure
.NET application owners who currently manage production applications in their own physical data center can also benefit from AppDynamics. To take advantage of AppDynamics free solution for .NET monitoring, please visit www.appdynamics.com/free or register to try AppDynamics Pro for 30 days at http://www.appdynamics.com/30-day-trial.php
About AppDynamics
AppDynamics is a leading provider of Software-as-Service (SaaS) and on-premise application performance management for modern application architectures in both the cloud and the data center. The company delivers solutions for highly distributed and agile environments, helping companies such as Priceline, TiVo, AMICA Insurance, Hotels.com, StubHub, DSW, Staples, Insight Technologies, Abercrombie & Fitch, and Cornell University monitor, troubleshoot, diagnose, and scale their production applications. Over 80,000 people have downloaded AppDynamics Lite, the company's free troubleshooting solution for Java/.NET, and the company was recognized as an APM Innovator by Gartner.

Sebastian Waksmundzki described The Power of the Worker Role: Windows Azure + Microsoft Dynamics CRM 2011 Better Together, Part Three in a 7/19/2012 post to the MSDynamicsWorld.com blog:
If you are using Windows Azure, then you have probably noticed huge amount of recent changes. We have a new portal which looks and functions very nicely, more IaaS, and a lot of extended capabilities.Scott Guthrie published a summary article on his blog about new Azure 2.0 that is worth a look.
But enough theory let’s present our…
Business Problem
Company XYZ is adding more and more customers and they need to perform more and more periodic jobs. Two of these jobs in particular are consuming a lot of resources. One is generation and transfer of invoices and the other is monitoring of their SLA’s (Service Level Agreements).
Generation of invoices seems like a pretty simple job, but our company has many to prepare and they are generated as PDF files. That process happens only during the last two days of every month. In the old days they would have needed to invest in a new server to perform that task effectively and the server would be fully utilized over those two days only. Now they have access to the Windows Azure platform and worker roles. The worker role is designed to execute long-running processes. It can connect to their Dynamics CRM systems, generate PDF files, and attach those PDFs to emails or SharePoint libraries.
And because a worker role uses the same principle as other Azure Services, it can be scaled on demand. Combining the strength of the Windows Azure Diagnostics API and the Service Management API makes really easy to implement custom logic for auto-scaling Azure Services. That means Company XYZ will pay only for effective usage of compute when they will need it. And if suddenly the number of invoices increases, they will be able to handle that very quickly without ordering and waiting for new hardware.
The worker role comes in very handy for all sorts of monitoring type activities. Usually in the Dynamics CRM world all kind of SLAs are handled by workflow and that works quite well usually. But workflows have some limitations when it comes to quick, scalable behaviour, and also it is difficult to run workflows across multiple instances of Dynamics CRM. For that reason, XYZ invested in one central, scalable SLA monitor in an Azure worker role that monitors not just Dynamics CRM cases, but also other systems.
Summary
Worker roles can be very handy for Dynamics CRM implementations and other business applications that require periodic activities and reliable background processes. They provide effective scalability, very good elasticity, and full control over background processes. Yet again, Azure plus Dynamics CRM 2011 prove to be good match

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Paul van Bladel (@paulbladel) described how to Inject dynamically a column with data-aware icons in a lightswitch datagrid in a 7/25/2012 post:
Introduction
There is no out-of-the-box solution in LightSwitch to show an icon in a datagrid based on the current row data (e.g. show an exclamation mark for customers satisfying a certain condition (or predicate). In many cases, developers would create a custom control for this. That’s a good solution but time-consuming and since LightSwitch is all about saving time and focussing and the business part of the application…. we need something better.
What do we have in mind?
This:
As you can see, an exclamation mark is shown for customers from Belgium.
How do we want to inject such an icon column?
We want that injecting such a column is simple, preferably in 2 lines of code:
public partial class SearchCustomers { partial void SearchCustomers_Created() { Predicate<Customer> predicate = (c) => c.Country.Equals("belgium", StringComparison.InvariantCultureIgnoreCase); this.FindControl("grid").InjectColumnWithIcon<Customer, Customer.DetailsClass>(predicate,"important.png"); } }The first line is specifying our predicate or the condition under which we want to show the icon. In our case: customers from Belgium deserve an exclamation mark.
The second line is rendering the grid with the “icon column”.
Which is the base infrastructure we need?
Allow me first to tell you that my implementation is heavily inspired by an exquisite technique introduced by Jewel Lambert. See: http://dotnetlore.com/vertical-column-header-text-in-lightswitch-grids/ and here: http://social.msdn.microsoft.com/Forums/en-US/lightswitch/thread/3e7993c0-e51b-40bb-981d-99bcf878eb64
public static class GridExtensions { public static void InjectColumnWithIcon<TEntity, TDetails>(this IContentItemProxy gridProxy, Predicate<TEntity> predicate, string imagefileName) where TEntity : EntityObject<TEntity, TDetails> where TDetails : EntityDetails<TEntity, TDetails>, new() { EventHandler<ControlAvailableEventArgs> gridProxy_ControlAvailable = null; gridProxy_ControlAvailable = (s1, e1) => { BitmapImage bitmapImage = GetBitmapImage(imagefileName); DataGrid dataGrid = e1.Control as DataGrid; var col = new DataGridTemplateColumn(); var xaml = @"<DataTemplate xmlns=""http://schemas.microsoft.com/winfx/2006/xaml/presentation""> <Image Height =""25"" Width=""25"" /> </DataTemplate>"; var dataTemplate = XamlReader.Load(xaml) as DataTemplate; col.CellTemplate = dataTemplate; col.IsReadOnly = true; dataGrid.Columns.Insert(0, col); dataGrid.LoadingRow += new EventHandler<DataGridRowEventArgs>((s2, e2) => { TEntity currentEntity = e2.Row.DataContext as TEntity; if (predicate(currentEntity)) { DataGridColumn column = dataGrid.Columns[0]; Image image = column.GetCellContent(e2.Row) as Image; image.Source = bitmapImage; } }); gridProxy.ControlAvailable -= gridProxy_ControlAvailable; }; gridProxy.ControlAvailable += gridProxy_ControlAvailable; } private static BitmapImage GetBitmapImage(string fileName) { byte[] bytes = GetImageByName(fileName); using (MemoryStream ms = new MemoryStream(bytes)) { var bi = new BitmapImage(); bi.SetSource(ms); return bi; } } private static byte[] GetImageByName(string fileName) { Assembly assembly = Assembly.GetExecutingAssembly(); fileName = Application.Current.Details.Name + ".Resources." + fileName; using (Stream stream = assembly.GetManifestResourceStream(fileName)) { if (stream == null) return null; byte[] buf = new byte[stream.Length]; stream.Read(buf, 0, (int)stream.Length); return buf; } } }How do I have to include my icon in the silverlight project?
Include your icon (or image) in the Resource folder of the client project.
Make sure to mark is as embedded resource:
Source Code
Can be downloaded here: InjectColumnWithIcons
Conclusion
A simple solution for something that would take hours to implement in a regular line of business framework. In lightSwitch it takes now 1 minute





Paul Patterson (@PaulPatterson) posted Microsoft LightSwitch – List of Printers on 7/24/2012:
An interesting LightSwitch question came up on the MSDN forums. A developer was asking how to get a list of printers from the “server” side of a LightSwitch application. I posted an answer (see here), however thought it worth while re-posting the information here.
By the way; I am using Visual Studio 2012 RC for this.
Open up the LightSwitch solution in File View. Then, in the Server project, create a custom class file named Printing…
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.Drawing; using System.Drawing.Printing; namespace LightSwitchApplication { public class Printing { public IEnumerable<string> GetServerPrinters() { List<string> listOfPrinters = new List<string>(); foreach (string printer in PrinterSettings.InstalledPrinters) { listOfPrinters.Add(printer); } return listOfPrinters; } } }Then go back into the Logical View of the solution, and create a table named Printer…
I have a Home screen that is the default screen that opens whenever my LightSwitch application runs. On this Home screen I have query that auto executes. In this example, the query that auto executes on the screen is named Companies….
What I then do is select to add code to the Query_Executing code on the ApplicationDataService class of the Server project. I did this by going back to my Companies table and selecting selecting the Query_Executing item in the Write Code drop down…
In the Query_Executing method, I added the following code…
partial void Query_Executing(QueryExecutingDescriptor queryDescriptor) { if (queryDescriptor.Name == "Companies") LoadPrinters(); }The above code evaluates which query is being run, and then calls a LoadPrinter method I created (also in the same ApplicationDataService class file), which happens to look like this…
public void LoadPrinters() { Printing printing = new Printing(); IEnumerable<string> listOfPrinters = printing.GetServerPrinters(); IEnumerable<Printer> printers = DataWorkspace.ApplicationData.Printers.GetQuery().Execute(); foreach (Printer p in printers) p.Delete(); foreach (string printerName in listOfPrinters) { Printer newprinter = DataWorkspace.ApplicationData.Printers.AddNew(); newprinter.PrinterName = printerName; } DataWorkspace.ApplicationData.SaveChanges(); }What will happen is; each time a query is executed, if the query is the name of the query on my screen (which is Companies), the LoadPrinters() method fires. This LoadPrinters method refreshes the Printer table with a list of printers configured on the server. I can then use that Printer table in a drop down list, or whatever, on the client





Return to section navigation list>
Windows Azure Infrastructure and DevOps
•• David Linthicum (@DavidLinthicum) asserted “New high-performance public cloud offerings deliver what IT can't afford to implement in-house” in a deck for his The data center you dream of is in the cloud post of 7/27/2012 to InfoWorld’s Cloud Computing blog:
Last week, Amazon Web Services' High I/O Quadruple Extra Large instance in Elastic Cloud Compute (EC2) made its debut. It provides 2TB of local SSD-backed storage with 60.5GB of RAM running on eight virtual cores. Most enterprises can't afford such high-performance data center equipment, and the cloud providers are hoping that the capacity, formerly only dreamed of, might draw faster cloud adoption.
Many organizations look to public cloud providers to provide access to commodity hardware and software, but it's clear the state-of-the-art computing and storage services offered well exceed what's considered "commodity." Of course, there are higher rates for accessing the fast stuff.
Even if your company has the money to create its own hypercapacity data center, the reality is that many enterprises need access to high-performance compute services for small periods, such as to run monthly reports or to handle seasonal transaction spikes. For such episodic usage, it's tough to justify spending millions of dollars on top-shelf hardware that most of the time will sit idle. That's the real value of high-end cloud offerings: You rent high-performance computing only when you need it -- and avoid a truckload of expense.
If you compare commodity cloud services to the cost of doing it yourself, you typically find a small savings in the cloud. The bigger advantages are usually around convenience and lower management overhead, not equipment costs. But the equation on the high-performance end is quite different: The cost delta is much larger in favor of the cloud providers. Simply put, cloud-based high-performance computing yields substantially better ROI than its DIY equivalent.
As enterprises and government agencies continue to grow the use of big data systems and other compute- and I/O-intensive tasks, the demand for high-performance computing will increase significantly. In the world of high-performance computing, the case for buying your own gear simply doesn't make as much financial sense as getting it from the cloud.


•• Barb Darrow (@gigabarb) posted Microsoft pins Azure outage on network miscue on 7/27/2012:
A misconfigured network device caused Windows Azure to crash and burn in Europe yesterday. In a blog post, Microsoft said it is still digging into the root cause of the outage and will report back next week.
Thursday’s Windows Azure outage in Europe was caused by a misconfigured network device, according to Microsoft.
The interruption impacted our Compute Service and resulted in connectivity issues for some of our customers in the sub-region. The service interruption was triggered by a misconfigured network device that disrupted traffic to one cluster in our West Europe sub-region. Once a set device limit for external connections was reached, it triggered previously unknown issues in another network device within that cluster, which further complicated network management and recovery.
He added that the team is still investigating the full root cause of the incident and will report back in the blog next week.
This was the second major Windows Azure glitch in the last few months, after the big “leap day” outage. Microsoft is trying to build Azure into a viable competitor to Amazon Web Services — although Azure started out as a platform as a service, while Amazon is more basic infrastructure as a service. Both of the behemoths, however, are moving into each other’s turf.
And neither is immune from snafus. Amazon suffered two high-profile outages earlier this summer.
Related research and analysis from GigaOM Pro

Mike Neil’s post of 7/27/2012 is Windows Azure Service Interruption in Western Europe Resolved, Root Cause Analysis Coming Soon. I reported return to service on 7/26/2012 (see post below.)
• Barb Darrow (@gigabarb) reported a Windows Azure outage hits Europe in a 7/26/2012 post to the GigaOm Structure blog:
For anyone needing a reminder that no computing cloud is perfect — Microsoft’s Windows Azure cloud went down in Europe on Thursday. Few details are available, but Microsoft says it’s on the case.
Just in time for the Olympics, there’s a Windows Azure outage in Europe.
“We are experiencing an availability issue in the West Europe sub-region, which impacts access to hosted services in this region. We are actively investigating this issue and working to resolve it as soon as possible. Further updates will be published to keep you apprised of the situation. We apologize for any inconvenience this causes our customers.”
According to an update posted one hour later, the troubleshooting and data gathering continued.
This is just the latest reminder that while the cloud offers customers great scale and potential cost savings, not even the largest, most well financed public clouds are immune from downtime. Windows Azure experienced a widely publicized “Leap Day” outage in early March. Amazon, the largest public cloud provider, was hit by several outages at its U.S. east data center over the past few months.



Stay tuned for updates.
My update for the Windows Azure Compute service in the West Europe data center:

GoogleTalk was down for about five hours this morning, too:

And so was Twitter, which became live again the last time I tested it (11:00 AM PDT):

Bad day in the cloud for lotsa folks.
David Linthicum (@DavidLinthicum) asserted “IT is placing different barriers to cloud adoption than it did four years ago, as old objections are overcome” in a deck for his 3 new roadblocks to cloud computing post of 7/24/2012 to InfoWorld’s Cloud Computing blog:
When it comes to adopting the cloud, enterprise IT remains split, with some for, some against, and the rest still waiting to see more results before jumping in. That's typical for new technology adoption, given the large number of changes -- both opportunuties and risks -- that cloud computing engenders.
But I've noticed the internal IT roadblocks for moving to the cloud are changing now that the cloud push is four years old and not exactly so new or undefined. Of course, you still hear about the old concerns -- control, security, and compliance -- but new issues have arisen, including talent, infrastructure readiness, and budget.
Are these new roadblocks real problems or just a new set of excuses to say no or stay on the fence?
There is indeed a talent shortage -- for now. If you move to Amazon Web Services, Google, or Microsoft Azure, who will maintain those cloud-based systems internally? IT managers are talking to recruiters and getting spooked around how much money cloud developers and admins are commanding these days, on top of the thin prospects for even finding qualified candidates.
Infrastructure readiness refers to the ability for the existing networks and computers that will consume cloud services to perform at the levels required. It's true that many enterprises will have to upgrade their existing infrastructure to support the requirements of moving some systems to public and hybrid clouds.
The budget roadblock is a bit of a wild card. Many companies move to cloud computing to save money, so it's hard at first glance to understand why a limited budget be a consideration. As a matter of fact, an initial investment is typically required, and many IT shops have static budgets that must be closely managed. They can't spend $5 million upfront to reduce their IT costs from $100 million to $75 million annually. That seems like a silly reason, but anyone who has battled budgets in larger organizations understands this common issue.
Even as some roadblocks to adopting the cloud are fading, new ones emerge. That's not bad, and the roadblocks aren't always excuses to say no. There will always be a reason to move to the cloud -- and reasons not to. It's not the worst development, as it ensures that the technology and best practices improve.

J. C. Hornbeck reported Update Rollup 2 for System Center 2012 is now available for download in a 7/24/2012 post:
This rollup includes updates for App Controller, Data Protection Manager (DPM), Operations Manager (OpsMgr), Orchestrator, Service Manager (SCSM) and Virtual Machine Manager (VMM). Download links, installation instructions and the list of issues fixed for each component are documented in the following KB:
KB2706783 - Description of Update Rollup 2 for System Center 2012 (http://support.microsoft.com/kb/2706783)
[Emphasis added.]
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
•• Tom Shinder (@tshinder) reported Microsoft Private Cloud Fast Track Information New and Improved in a 7/27/2012 post:
So you’ve had an earful about cloud computing and you’ve read all about it. You’ve decided that maybe private cloud is something that you need to look info. Maybe you’ve read through the entire Reference Architecture for Private Cloud and get what the difference is between a private cloud and a traditional data center. You even understand that private cloud is difference than just a highly virtualized infrastructure and know that some applications might not be a best fit for private cloud while other applications have been waiting for private cloud.
If some or all of this is true, you’re probably curious about how do you build a private cloud infrastructure. What are the hardware and software requirement and how to you put the whole thing together?
One answer is the Microsoft Private Cloud Fast Track. What is Private Cloud Fast Track? The Microsoft Private Cloud Fast Track Program is a joint effort between Microsoft and several private cloud hardware partners. The goal of the Private Cloud Fast Track program is to help you decrease the time, complexity, and risk of implementing a Microsoft private cloud.
The Microsoft Private Cloud Fast guidance includes:
Reference implementation guidance
We’ve tested the configurations in the lab and validated this guidance for implementing multiple Microsoft products and technologies with hardware that meets specific hardware requirements that are vendor-agnostic. You can use this information to implement a private cloud infrastructure with hardware you already own or plan to purchase.
The Fast Track document set consists of the following:
- Reference Architecture Guide: This guide details a reference architecture that incorporates many Microsoft product and consulting team best practices. The architecture is the foundation for a highly available, scalable, secure, and manageable private cloud with high performance. While all organizations will find it of value, it will prove most useful to medium through large enterprise environments.
- Reference Deployment Guide: This guide provides detailed installation and configuration steps to deploy the physical architecture detailed in the reference architecture guide.
- Reference Operations Guide: This guide includes many of the operational tasks that are often executed in a private cloud environment.
Reference implementations
Microsoft hardware partners define physical architectures with compute, network, storage, and value-added software components that meet (or exceed) the minimum hardware requirements defined in the reference implementation documents. Each reference implementation is validated by Microsoft and made available for you to purchase. Further details can be found by reading the information at Private Cloud How To Buy.You have the choice of building the solution by using the reference implementation documents or you can purchase a reference implementation from a Microsoft hardware partner that couples the guidance with optimized hardware configurations. Although both options decrease the time, cost, and risk in implementing private clouds, purchasing a reference implementation from a Microsoft hardware partner will result in the fastest, lowest-risk solution. This is because all of the hardware and software best practices have been determined by both Microsoft and hardware partners’ engineering teams. With all of this up front work having been done for you it might prove to be the most inexpensive option for your organization.


<Return to section navigation list>
Cloud Security and Governance
Stevan Vidich reported a Security, Privacy & Compliance Update: Microsoft Offers Customers and Partners a HIPAA Business Associate Agreement (BAA) for Windows Azure in a 7/25/2012 post to the Widows Azure Blog:
I’m pleased to announce that we have achieved the most important compliance milestone for our health customers: enabling the physical, technical, and administrative safeguards required by HIPAA and the HITECH Act inside Windows Azure core services, and offering a HIPAA BAA to our EA (Enterprise Agreement/volume licensing) customers and partners in the health industry.
HIPAA and the HITECH Act are United States laws that apply to most doctors’ offices, hospitals, health insurance companies, and other companies involved in the healthcare industry that may have access to patient information (called Protected Health Information or PHI). In many circumstances, for a covered healthcare company to use a service like Windows Azure, the service provider must agree in writing to adhere to certain security and privacy provisions set forth in HIPAA and the HITECH Act.
On July 24th, we updated the Windows Azure Trust Center and made available a HIPAA BAA that includes Windows Azure breach monitoring and notification at the platform level for the following core services:
- Cloud Services (Web and Worker roles)
- Storage (Tables, Blobs, Queues)
- Virtual Machines (Infrastructure-as-a-Service)
- Networking (Windows Azure Connect, Traffic Manager, and Virtual Network)
Cloud computing made it possible for heath customers to quickly and cost effectively leverage big data technologies, augment storage needs, accelerate development and testing of new solutions, etc. The existence of Windows Azure BAA means that covered healthcare entities can now leverage Windows Azure core services in a pure public cloud platform, as well as a hybrid cloud configuration that extends their existing on premises assets and investments through the public cloud.
Earlier in 2012, Microsoft announced the availability of a BAA that covers Microsoft Office 365 and Dynamics CRM Online. The extension of this BAA to also cover Windows Azure core services is a significant accomplishment. With this BAA now in place, Microsoft is offering something unprecedented in the health IT market – a complete range of public, private and hybrid cloud solutions that support covered healthcare entities’ compliance needs. Rather than go to multiple cloud vendors for productivity, collaboration, application hosting, data storage, and relationship management, Microsoft’s customers can consolidate on one cloud, with one infrastructure partner with a common security and privacy framework that caters specifically to the needs of healthcare covered entities.
Covered entities can now confidently migrate and extend their datacenters on their terms into the public, private, or hybrid clouds, realizing immediate cost savings, organizational agility, and enabling collaboration across the care continuum. While Windows Azure includes features to help enable customer’s privacy and security compliance, customers are responsible for ensuring that their particular use of Windows Azure complies with HIPAA, the HITECH Act, and other applicable laws and regulations.
For more information about how health organizations can leverage cloud services to dramatically lower IT costs and drive greater productivity and collaboration, visit Microsoft in Health blog.
Phil Cox (@sec_prof) described PCI Compliance in the Public IaaS Cloud: How I Did It in a 7/24/2012 post to the RightScale blog:
Over the past few years, I have heard many folks assert that one can be a PCI compliant merchant using public IaaS cloud and I have heard just as many state that it’s not possible. In retrospect, I have found most of them – including myself – to be misinformed. After gaining more firsthand experience, I feel confident telling you where I sit at this state in the game on the question: “Can I be PCI compliant using a public IaaS cloud?”
To cut to the chase: The answer is yes, and the hardest part is knowing what you need to do, which I want to help you with here. I am a former Qualified Security Assessor (QSA) and have participated in multiple PCI working groups. As the Director of Security and Compliance for RightScale, I can speak for where we see things, but the information, processes, and opinions I express here are mine alone and are not intended to represent any guidance from the PCI Security Standards Council (SSC) or any card brand.
I’ll first talk about foundational principles and mindsets, then go through each PCI Data Security Standard (DSS) requirement and I’ll give you my “How I did it.” Note that you may disagree, and that is fine. A healthy discussion on this topic is beneficial to everyone! So with that, let’s get started.
Setting the Foundation for PCI Compliance
You will need to understand some foundational assumptions and working rules I go by. First, here are three environment assumptions/guidelines:
- All Cardholder Data (CHD) will be housed in the IaaS provider. There is no other managed hosting or physical system in the design.
- The application is structured into 3 tiers: Load balancer, app server, DB server.
- Dev and Test are separate and have NO CHD, and thus are outside of Cardholder Data Environment (CDE). Thus the design only deals with production systems.
And the foundational assumptions/rules:
- You will need to choose an IaaS Cloud Service Provider (CSP) that:
- Is on the “Approved Service Providers” list for one of the major card brands (for example the VISA list). If they are not listed, but have done a Level 2 assessment and can show you their Report on Compliance (RoC), that may suffice, depending on your situation.
- Will sign a contract that states they must protect CHD in accordance with PCI DSS to the extent it applies to them. This is basically covered if they have done (a) above.
- Note: The reason you need a PCI compliant IaaS CSP is because they control the physical systems up to, and including, the hypervisor. They will be responsible for the PCI DSS compliance of that part of the stack.
- Find a QSA who knows cloud technology or has the knowledge internally. Note that IMHO very few organizations have the depth of knowledge needed in this area, and will likely get it wrong if they don’t get help.
- A good choice is the QSA who did the assessment for your IaaS CSP.
- Design your application:
- Do not store the Primary Account Number (PAN) if you do not need it. Many payment processors have mechanisms for recurring billing or credits. Depending on your situation, it is highly likely that you do not need to store the PAN, thus making your life significantly easier from a PCI DSS compliance standpoint.
- If you are going to store PAN, then the design of crypto mechanism and, more importantly, the key management of data in the DB, is critical. This is really not a “cloud” thing, and is dealt with in any PCI application that stores CHD.
- Terminate SSL/TLS at the load balancer and run all other traffic over the private interface/network. This assumes that the “private” interfaces have been designed to meet the definition of “non-public” as far as PCI DSS. This is the case with Amazon Web Services. Traffic between the private IP addresses can be considered a private network and not require encryption. This does not mean that you can’t or shouldn’t do it, just that you do not have to in order to meet PCI DSS requirements.
- Use host-based firewalls for isolation on the individual virtual machines.
- Using “security groups” or other hypervisor-based filtering is likely acceptable, but I like the control of the firewall at the host. Use them both if you want, but be careful of conflicts.
- I’d recommend using a tool such as CloudPassage to manage the firewall rules. This give the separation of duty that PCI DSS requires, and will make achieving compliance much easier.
- I recommend using an IaaS cloud management solution. In my case, I am managing my PCI environment with RightScale, so some of my descriptions are based on that solution, but the principles I used can be applied regardless of the tools you use.
- Disclaimer: The RightScale platform has not undergone a Level 1 assessment, and thus is not on the list of “Approved Service Providers.” I use the fact that RightScale has the available documentation to help me “prove” that the SaaS Platform meets the PCI DSS requirements (using my previous QSA experience). Simply, our ability and willingness to be transparent and helpful in the assessment is key.
How to Determine Scope and Requirement Applicability
I use the following questionnaire for each system/application to determine what is in scope for my PCI assessment:
- Does it “store/process/transmit” a Primary Account number (PAN)? If yes, in scope.
- Can it be used to “directly manage” (i.e., make changes) on a system component in #1? If yes, in scope.
- Does it provide ancillary services (e.g., DNS, NTP) to a system component in #1? If yes, in scope.
- Are they segmented? Host-based firewalls restrict all other traffic, so out of scope.
Once I determine that a system/application is in scope, I use the following questionnaire to figure out what requirements need to be met by the component:
- Does it ”store/process/transmit” a PAN? Then review the system component in view of all requirements (1-12). Example is front-end web server.
- Can it be used to directly manage a system component in #1? Then review in context of Requirement 1, 2, 4, 5, 6.{1,2,4}, 7, 8, 10.{1-7}. Example is RightScale.
- Does it provide services to a system component in #1 and do I own/manage it? Then review in context of Requirement 1, 2, 4, 5, 6.{1,2,4}, 7, 8, 10.{1-7}. Example is central log collection system.
- Is it a 3rd party that provides services to a system component in #1 and I only have a SaaS/API interface to it? Then rely on contracts and review my configuration setting in context of Requirement 7, 8, 10.{1-7}. Example is DNS service.
Note: A realistic working definition of “connected to” (as defined in the PCI DSS) has never been made IMHO, so I used a pragmatic/risk-based definition in my scoping process. At some level, only an air-gap would suffice, which is ridiculous.
The Top-Level PCI DSS Requirements and Public IaaS Cloud
I’ve listed the 12 top-level PCI DSS requirements along with a brief “gist” of how I did it (or would do it if it applied) for RightScale. The full document is 37+ pages – too long for a blog post. The good news is that you can get the full paper here on PCI DSS requirements and public IaaS cloud.
Req Description My Summary 1 Install and maintain a firewall configuration to protect cardholder data
- Rely on CSP for HW->Hypervisor related compliance
- Design the application and communications flows so they can be secured
- The state of networking features make cloud “different” than traditional environments. This will have an affect on how you provide isolation for scoping. Currently host-based firewalls or similar technology is the most likely solution implement appropriate restriction. It is what I use
- Review/audit regularly to make sure design and implementations have not changed. Since hosts come and go more frequently, so need for regular review is increased. Nice aspect of the cloud is that since automation is part of the DNA, automation of these reviews is easier
2 Do not use vendor-supplied defaults for system passwords and other security parameters
- Rely on CSP for HW->Hypervisor related compliance
- Make sure to change the defaults- I use RightScale ServerTemplates™ to enforce this, as well as provide version control of configurations
- Note: The cloud actually helps you with in this area (usually), as you should have had to think how to build systems. There is not “throw in the CD, plug in the cable, and leave it”. So, you should have a leg up in this area when using a cloud technology
3 Protect stored cardholder data
- Rely on CSP for HW->Hypervisor related compliance
- Gets down to not storing what you don’t need, good crypto selection, and proper key management
- For non-DB-based encryption, use of a third party like TrendMicro SecureCloud (or similar) is a big help here
- Note: Cloud really is not an issue here, as you have many of the same concerns in a managed hosting environment. The main difference is between owned or third-party infrastructure.
4
Encrypt transmission of cardholder data across open, public networks
- Rely on CSP for HW->Hypervisor related compliance- Use SSL to the Load Balancer, private network behind that
- Use well-vetted VPN if linking networks
- Note: No huge difference between cloud or hosted here. The cloud issues in this area are more around maturity of the networking stacks (e.g., arguably easier to slap in a physical VPN concentrator and hookup networks). This will change as the technology matures
5
Use and regularly update anti-virus software or programs
- Rely on CSP for HW->Hypervisor related compliance
- Not much specific to a “cloud” deployment, except that serves come and go more frequently, so you need to make sure the solution is operating. If I had Windows systems for servers, I’d be using RightScale ServerTemplates to make sure things were configured correctly
- Note: Nice aspect of the cloud is that since automation is part of the DNA, automation of this should actually make it easier to meet the requirements
6
Develop and maintain secure systems and applications
- Rely on CSP for HW->Hypervisor related compliance
- The “what” (securing systems) is not really a “cloud” specific problem, but the “how” is. I use RightScale ServerTemplates and built in versioning to makes it easy and provide change tracking. You can choose how you want to do it, just do it
- Note: Nice aspect of the cloud is that since automation is part of the DNA, automation of these should actually make it easier to meet the requirements
7
Restrict access to cardholder data by business need to know
- Rely on CSP for HW->Hypervisor related compliance
- Again, not the “What to do” that is the issue, but “How to do it”. I use the Role-Based Access Control (RBAC) and ServerTemplate features of RightScale and a strict provisioning policy to get this done. You can choose any method that works
- Note: Really no different than a hosted environment
8
Assign a unique ID to each person with computer access
- Rely on CSP for HW->Hypervisor related compliance
- Another “Not What but How”. You guessed it, I use a combination of RightScale, policies, and regular audits. You can choose any method that works
- Note: Really no different than a hosted environment
9
Restrict physical access to cardholder data
- Rely on CSP for HW->Hypervisor related compliance
- You need to worry about user systems and any hard copy
- Note: Really no different than a hosted environment
10
Track and monitor all access to network resources and cardholder data
- Rely on CSP for HW->Hypervisor related compliance
- Use RightScale to configure systems and send local system and application logs to central log server. You can choose any method that works for you
- Note: Public cloud does make this different. The lack of transparency into some of the devices you don’t have access to (e.g., hypervisor logs) needs to be taken into account
11 Regularly test security systems and processes
- Rely on CSP for HW->Hypervisor related compliance
- I do internal as well as third-party testing
- Note: Coordination with the CSP when doing testing may be something that is new and require modification of your process
12
Maintain a policy that addresses information security for all personnel
- Rely on CSP for HW->Hypervisor related compliance
- Ensure policy states the requirements for need to know access to CHD
- Ensure that if you share CHD with others, contracts state they must protect CHD in accordance with PCI DSS
- Have an incident response plan and make sure it works!
- Make sure you have appropriate policies and can prove that you are doing what they say
- Note: The policies need to exist with or without the cloud. Biggest difference here is working with contracts to make sure appropriate language is included


Summary
Having worked with a number of customers on their PCI compliance strategy, I am definitely of the opinion that you CAN be PCI compliant operating in a public IaaS cloud. A lot of the work to get there is actually relatively standard and the hardest part is knowing what you need to do and what you have to rely on your partners to do.
As is common practice, you need to have “proof” for what you assert. When it comes to partners, you have two mechanisms to get that “proof” for their parts: They can get onto the list of PCI approved Service Providers or they can be transparent and willing to work with you to document their compliance adherence. In reality, both options require you to do your due diligence on the partner, one just makes it a easier in some regards.
The other key aspect of PCI compliance is making sure you manage the system components correctly. The industry knows how to manage traditional environments, but the nuances of public IaaS cloud can make mistakes more egregious. Thus it is critical that you manage the systems components correctly. I believe that the functionality that RightScale gives me in terms of management and governance of system components is invaluable (otherwise I would be working elsewhere). With that said, there are other management options (other vendors, do-it-yourself, or a combination) that you can leverage to make it happen. Just make it happen.
PCI compliance in a public IaaS cloud is a very touchy subject, and it should not be. This is my attempt to shed some light on an area that I think has too much mystery around it. I hope you find it useful.
<Return to section navigation list>
Cloud Computing Events
•• Doug Mahugh (@dmahugh) described Microsoft’s participation in OSCON 2012 with a 7/27/2012 post to the Interoperability @ Microsoft blog:
It was great to see everyone at OSCON last week! The MS Open Tech team had a fun and productive week meeting new people, reconnecting with old friends, learning about the latest OSS trends, and playing with the amazing 82" Perceptive Pixel touch screen at our booth. Julian Cash took over 4000 photos of visitors to the booth, and if you were one of the lucky people who spent time making creative photos with him, stay tuned. We'll post an update shortly when all of the photos have been uploaded to his web site.
If you weren't able to attend OSCON this year, you can find speaker slides and videos on the OSCON web site. Those videos are also a great resource for those who attended the conference -- for example, I've just finished watching Laurie Petrycki's interview with Alex Payne about Scala's interesting combination of functional and object-oriented programming language constructs.
Thanks to all the hard-working event organizers, exhibitors, sponsors, and attendees who made OSCON such a well-run and successful show!


Doug is a Senior Technical Evangelist with Microsoft Open Technologies, Inc.
Tim O’Brien (@_TimOBrien) posted Announcing BUILD 2012 to the Channel9 blog on 7/25/2012:
In January we shared some thoughts on our approach to developer events, including a commitment to come back with more on our plans for an event this coming fall. Well, here it is: our next developer conference will be this fall, and it's (again) called BUILD. It will be held on Microsoft's campus in Redmond, Washington, from October 30th until November 2nd. Yes, that's right ... it's the week after Windows 8 becomes generally available worldwide. And in addition to Windows 8, we will have lots of other stuff to talk about, too: Windows Azure, Windows Phone 8, Windows Server 2012, Visual Studio 2012, and much more. [Emphasis added.]
So what happens next? Well, at 8AM Pacific time on 8.8 (see what we just did there?), we will open registration for BUILD 2012 at www.buildwindows.com. At that point, we'll start sharing details over time about keynoters, sessions, content, and more, but for the time being, set a reminder for August 8th.
That's it for now. Because my thesaurus was unable to suggest a decent synonym for "super excited", let's just say we're stoked about BUILD 2012, and we hope to see you there.

Michael Collier (@MichaelCollier) gave a post mortem of his What’s New for the Windows Azure Developer? Lots!! (Presentation) to mid-western and eastern US user groups in a 7/23/2012 post:
Recently I had the pleasure of presenting about new Windows Azure features at a few excellent user groups Michigan (Ann Arbor and Lansing) and Boston, MA. It was great getting to share the updated Windows Azure story with so many passionate developers!
- Ann Arbor .NET Developer’s Group
- Greater Lansing User Group for .NET
During this presentation we covered Windows Azure Web Sites and Windows Azure Virtual Machines – probably two of the biggest recent platform enhancements. We also touched on updates to the Windows Azure storage features, Visual Studio tooling updates, and well as a few nice productivity boosters in the Windows Azure SDK.
If you’d like to check out this presentation, you can view it on my SlideShare page.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Stacey Higginbotham (@gigastacey) asserted “Google Fiber just launched today to offer faster acces to consumers with a TV product, a terabyte of free storage in G Drive and more. The search giant will even offer free access at what it deems “average” Internet speeds of 5Mbps down.” in a deck for her Google Fiber: Here’s what you need to know post of 7/26/2012 to the GigaOm blog:
Google launched its fiber to the home network today and the biggest surprise is probably that the gigabit speeds are aimed at consumers only. The search giant’s fiber network, which will cost $70 for Internet only and $120 for fiber plus TV, is a killer wrapper for Google’s cloud, consumer and tablet products, some of which will be included in the fiber and TV package.

The pricing details
There will be three packages available to Kansas City residents, all of which will require a $300 connection fee to help cover the cost of connecting the home to the fiber infrastructure:
Google Fiber+TV: This package includes symmetrical gigabit (the same broadband speeds on the upload and download side) speedsas well as the newly launched Google TV product, which includes local channels, integration with YouTube and Netflix as well as what Google calls “fiber channels.” It doesn’t sound like this package involves traditional pay TV channels such as ESPN or Disney.
The package includes a Nexus 7 tablet, which will be used a remote control for the TV, although residents will also get a traditional Bluetooth remote control as well. Google will also release an iOS app for controlling the Google Fiber TV product on iPhones or iPads. A variety of sleek, black boxes such as a Wi-Fi router and a 2-terabyte storage box will also come with this package as well as a free terabyte of storage in Google’s cloud locker, G Drive. The total cost for this package is $120 per month and if customers sign a two-year contract Google will waive te $300 connection fee.
Google Fiber TV interface.
Google Fiber: For those that don’t care for the TV package and just want a gigabit connection, there’s a package that includes the free terabyte at GDrive as well as a Wi-Fi router. This package costs $70 a month and for users who sign a 1-year contract Google will waive the $300 connection fee.
Free “average” Internet: In what may be the most disruptive announcement, and is also an indication of Google’s desire to connect as many people as fast as possible to the network, it will offer 5 Mbps download speeds and 1 Mbps upload speeds for free to any household in the fiber footprint. Those homes can’t waive the construction fee, but Google will let them pay $25 a month if the sign an annual contract.
OMG, when can people get this?
Google has a somewhat complicated plan to determine where it will deploy the fiber. It has divided the city into “fiberhoods” with roughly 800 homes in each one. Residents of those ‘hoods will have the next six weeks to get their neighbors on board and signed up to buy Google Fiber and Google will then deploy fiber to the neighborhoods with the highest number of committed residents. It’s similar to the method Google used to select a town to deploy Google fiber, and makes a ton of sense when it comes to recouping the costs of deploying fiber.
So consumers of Kansas City will get Internet access with products and services that could tremendously undercut the Internet access businesses of Time Warner Cable and AT&T, which are the dominant ISPs in the area. But businesses will have to wait.
The lack of business access seemed to dismay some Kansas City businesspeople in chats with some of them ahead of the event. Others tried to put a positive spin on the news, such as Perry Puccetti, the CEO of Triplei and the head of KCnext, tech trade organization in Kansas City said, “Google Fiber’s initial focus on residential customers, and mobile workers is exciting, and, as the CEO of a small technology consulting firm we look forward to the day we have access as well.”


Related research and analysis from GigaOM Pro
The camel’s nose is under the tent. Does my Nexus 7 have a hidden TV remote control feature? Google Play’s Samsung remote control apps that would work with my Samsung Smart TV are incompatible with the Nexus 7.
• Jeff Barr (@jeffbarr) reported AWS Management Console Improvements (EC2 Tab) in a 7/24/2012 post:
We recently made some improvements to the EC2 tab of the AWS Management Console. It is now easier to access the AWS Marketplace and to configure attached storage (EBS volumes and ephemeral storage) for EC2 instances.
Marketplace Access
This one is really simple, but definitely worth covering. You can now access the AWS Marketplace from the Launch Instances Wizard:
After you enter your search terms and click the Go button, the Marketplace results page will open in a new tab. Here's what happens when I search for wordpress:
Storage Configuration
You can now control the storage configuration of each of your EC2 instances at launch time. This new feature is available in the Console's Classic Wizard:
There's a whole lot of power hiding behind that seemingly innocuous Edit button! You can edit the size of the root EBS volume for the instance:
You can create EBS volumes (empty and of any desired size, or from a snapshot) and you can attach them to the device of your choice:
You can also attach the instance storage volumes to the device of your choice:
These new features are available now and you can use them today!







Joe Panettieri (@joepanettieri) reported Google Cloud Partner Program: Big Data Companies Jump In in a 7/24/2012 post to the TalkinCloud blog:
When the Google Cloud Partner Program launched today, numerous cloud services providers (CSPs), integrators, consultants and Big Data software companies announced support for the effort. But who exactly is jumping on the Google Cloud Partner Program bandwagon? Here’s an early list of supporters, and what they had to say.
The initial partners include (but are not limited to…)
- Agosto Inc., a Google Apps cloud services consulting firm. Agosto provides Google Cloud services and solutions including Google App Engine development, Google Cloud Storage, and Google APIs to help customers build and run applications, host sites and store and access data.
- CliQr Technologies provides a cloud application management platform, named CloudCenter. The company claims to simplify the process of on-boarding, testing and securely running applications on any private, public or hybrid cloud, including Google’s Compute Engine cloud service.
- Informatica Corp., a data integration software company, allows enterprises to securely move data to and from their on-premise and cloud IT systems and Google Cloud services such as Google Cloud Storage and Google BigQuery. The secret sauce is Informatica Cloud Connector for Google Cloud.
- Jaspersoft, a business intelligence platform provider. Jaspersoft is making available an open source connector for Google BigQuery customers who want to run business intelligence reports and analytics on the Google Cloud Platform. This technology connector brings Jaspersoft’s BI tools into the Google Cloud Platform, offering integrated access to reporting and business analytics.
- MapR Technologies, which offers an enterprise-grade distribution for Apache Hadoop. Back in June, MapR said it will make its Hadoop distribution available on Google Compute Engine. Now, customers can provision large MapR clusters on demand and take advantage of the cloud-based solution.
- Pervasive Software is preparing Pervasive RushAnalyzer for Google BigQuery. Users will be able to query multi-terabyte datasets to discover patterns and correlations that can transform their business, Pervasive claims.
- QlikTech helps customers and partners to build Business Discovery solutions that take advantage of the computing power and scalability of Google’s Cloud Platform.
- SADA Systems is applying software development expertise to Google App Engine, Google Cloud Storage, Google BigQuery and Google Compute Engine.
- SQLstream offers Big Data solutions that allow customers to act instantly on new information as it arrives, improving operational efficiency and driving new revenue opportunities, the company claims.
- Talend, provider of Open Studio for Big Data. The open source big data integration solution combines the power of Talend with Google BigQuery’s real-time analytics.
That’s just a sampling of first-round partners. Talkin’ Cloud will be watching to see which partners next jump into Google’s Cloud.
Read More About This Topic

I’m waiting now for an invitation to run MapR’s Hadoop/MapReduce implementation on the Google Compute Engine.
Joe Panettieri (@joepanettieri) announced Google Cloud Partner Program: Google Apps Resellers Join In in a 7/24/2012 post to the TalkinCloud blog:
The Google Cloud Partner Program, launched today, is designed for service partners and technology partners. But it may also appeal to existing Google Apps Authorized Resellers. In fact, some resellers are already jumping into the Google Cloud Partner Program. Think of it this way: Most Google partners already see the opportunity to move customers onto Google Apps (SaaS). But the Google Cloud Partner Program allows partners to move additional customer applications and services on the Google Compute Engine and Google App Engine (IaaS and PaaS).
Translation: The Google Apps Authorized Reseller Program and now the Google Cloud Partner Program together give channel partners every major cloud service they need (IaaS, PaaS, SaaS) for end-customer services.
Initial Examples of Success
Google today offered six examples of how partners can benefit/already benefit from the new cloud partner program.
On the service provider front the examples include…
- Business apps: Ci&T, a global systems integrator, built a quotation app on Google App Engine to help an insurance provider provide better policy quotes to customers.
- Mobile apps: Agosto built a smartphone app running on Google App Engine to help the Minneapolis Loppet Foundation register participants in a Nordic ski event.
- Social apps: PA Consulting built a crowd-sourced app on Google App Engine and Google Maps for MetOffice to provide richer, up-to-date local weather forecasts around the world.
Meanwhile, technology partners can us the Cloud Partner Program to plug into such services as…
- Google Compute Engine: Allows partners to configure and manage applications running on Google’s infrastructure.
- Google BigQuery: Partners can import data from existing on-premise and cloud data sources into BigQuery for analysis.
- Google Cloud Storage: Partners can offer active archiving, backup and recovery, and primary storage solutions.
Google Apps Resellers Join In
Take a closer look at the Google Cloud Partner program and you’ll notice quite a few Google Apps Authorized Resellers jumping into the game. Examples include Cloud Sherpas and SADA Systems, both of which rank among the world’s top 100 cloud services providers, according to Talkin’ Cloud’s second-annual Top 100 CSP research.
More than 6,000 companies are Google Apps Authorized Resellers. I’ll be curious to see how many of those resellers become Google Cloud Partner Program Members, moving customer systems onto Google’s cloud.
Google in recent days also confirmed its commitment to enterprise customers, stating that the Apps business was gaining critical mass. At the same time, software partners like BetterCloud are promoting Google Apps management tools designed for channel partners and customers.
Fierce Competition for Cloud Partners
Still, the competition remains fierce. Microsoft is adjusting its Office 365 partner program to give partners end-customer billing capabilities (a long-desired feature that Google Apps already offers). And the Office 365-Windows Azure combo essentially counters Google Apps, Google Compute Engine and Google App Engine. Plus, Amazon continues to attract partners that are loading customer workloads into Amazon’s cloud.
Read More About This Topic

Marcia Savage (@marciasavage) reported AWS security now documented in CSA STAR in a 7/24/2012 post to TechTarget’s SearchCloudSecurity.com blog:
The 800-pound gorilla of the Infrastructure as a Service (IaaS) world – Amazon Web Services (AWS) -- has joined the Cloud Security Alliance’s Security, Trust and Assurance Registry (STAR).
AWS filed its documentation to CSA STAR late last week. Launched by the CSA about a year ago, STAR is an online registry where cloud providers voluntarily submit documentation of their security controls. The registry, which is freely available, has been growing slowly, but with the addition of AWS, it took a big leap forward in its mission to increase cloud provider security transparency and help cloud computing customers make better decisions about the security of their services.
The AWS security STAR entry is a 42-page document (.pdf) on the cloud giant's risk and compliance practices. It includes information on AWS's security certifications (e.g., ISO 27001) and the company's responses to the CSA Consensus Assessments Initiative Questionnaire. The questions cover common security-related concerns for cloud customers, such as data isolation and location.
For example, with regards to its ability to logically segment or encrypt customer data, AWS said it has strong tenant isolation capabilities, but notes that customers retain control and ownership of their data, and it's their responsibility to encrypt it.
On the data location front, Amazon said in its documentation that customers can designate which AWS physical region their data and servers are located; the company won't move the data without notifying the customer unless required to comply with a government request. At the same time, Amazon said it won't hesitate to challenge orders from law enforcement if it thinks the orders lack a solid basis.
With the addition of Amazon, STAR now has 12 entries, including three from Microsoft. Verizon's Terremark subsidiary is another new addition, having added documentation in June.
The participation of AWS may be a sign that STAR is turning into the vehicle for peer pressure that CSA leaders had hoped. One of the CSA's primary goals is to advocate for the security needs of cloud customers and the on-going need for cloud transparency.


Full Disclosure: I’m a paid contributor to Tech Target’s SearchCloudComputing.com blog.
James Staten (@staten7) posted Gelsinger Brings The "H" Word To VMware to his Forrester Research blog on 7/23/2012:
The long-rumored changing of the guard at VMware finally took place last week and with it came down a stubborn strategic stance that was a big client dis-satisfier. Out went the ex-Microsoft visionary who dreamed of delivering a new "cloud OS" that would replace Windows Server as the corporate standard and in came a pragmatic refocusing on infrastructure transformation that acknowledges the heterogeneous reality of today's data center.
Paul Maritz will move into a technology strategy role at EMC where he can focus on how the greater EMC company can raise its relevance with developers. Clearly, EMC needs developer influence and application-level expertise, and from a stronger, full-portfolio perspective. Here, his experience can be more greatly applied -- and we expect Paul to shine in this role. However, I wouldn't look to see him re-emerge as CEO of a new spin out of these assets. At heart, Paul is more a natural technologist and it's not clear all these assets would move out as one anyway.
Pat Gelsinger's move into the VMware CEO role signals a need for refocus on holding share and increasing profits from the core data center infrastructure layer. The CloudFoundry announcement last year and the strategy to create a new vertically integrated platform from infrastructure up through middleware was taking longer to gain traction than expected. It was also muddying VMware's traditionally strong infrastructure virtualization story -- right when they could least afford it. Microsoft, Oracle, Citrix, and other virtualization management vendors and of course the public IaaS market were all capitalizing on this with maturing infrastructure virtualization stories and pushed for enterprises to create islands of hypervisors and thus breaking the VMware stronghold.
At the same time, enterprises have been voicing strong concerns about VMware lock-in. The result was more push-back by customers on long-term enterprise agreements with VMware and a reluctance to commit to VMware-only management stacks. When every competitor is touting their heterogeneity, it was becoming increasingly hard for VMware to convince customers that a single-vendor virtualization strategy was a long term bet worth making.
Meanwhile, vCloud Director has been struggling, as customers remain unprepared (from an operational maturity perspective) to deploy and manage a private cloud. Through discussions with Forrester enterprise clients we found more customers had purchased vCloud Director as part of their VMware enterprise license renewal but had not deployed it in production. …


Brian Proffitt (@TheTechScribe) posted VMware Denies Cloud Spin-Off Rumors - Keeps Focus on Platform-as-a-Service to the ReadWriteCloud blog on 7/20/2012:
Rumors of a VMware/EMC spin-off are “completely unfounded,” according to a company executive, who sees little chance that VMware will change its approach to cloud computing during its current transition in leadership.
Earlier this week, the company announced that VMware CEO Paul Maritz is being replaced by EMC COO Pat Gelsinger. But the rumors didn’t stop there. Reports circulated that Maritz would head up a VMware spinoff combining cloud assets from VMware and parent company EMC.
“None of that is founded,” VMware’s VP of Cloud Services Matthew Lodge emphasized in an interview Thursday.
Lodge’s denial addressed not only the possibility of a spin-off, but also the existence of Project Rubicon, allegedly a joint EMC/VMware Infrastructure-as-a-Service (IaaS) project mentioned by various media outlets (including this one) earlier in the week. Lodge also described such a project’s existence as “unfounded.”
Paas, Not IaaS
In fact, IaaS is not really where VMware wants to be. According to Lodge, VMware’s strategy is strictly centered on Platform-as-a-service (PaaS), represented by its flagship open source PaaS project Cloud Foundry.
IaaS is used when cloud clients outsource all of their operational hardware elements, such as storage, networking and servers. The virtualization and operating system layers are also included. The Infrastructure-as-a-Service provider actually owns and maintains the physical hardware, but the client has to provide additional tools, such as middleware software to manage their servers. PaaS, on the other hand, provides all of those features and the middleware and database software… so all PaaS clients have to do is bring their applications and data.
Perhaps the best-known example of IaaS in action is Amazon Web Services (AWS), which provides customers virtual machine images with a preloaded operating system. The customer has to manage each virtual image, maintaining and upgrading it as needed. Third-party middleware like Eucalyptus is used to provision the virtual machines.
Rather than go head-to-head with IaaS providers like AWS, Google Compute Engine and Microsoft’s Windows Azure, VMware is taking the PaaS role in the cloud sector.
Cloud Foundry is the center of VMware’s two-fold strategy:
First, VMware capitalizes on its huge vSphere virtualization market share (estimated to be in the 80% range), encouraging that existing customer base to migrate their existing virtual infrastructure to the cloud. Because it’s a PaaS solution, an app that works on a “local” vSphere virtual machine will easily move to a cloud-based vSphere VM.
The other side of the strategy is targeting new app developers and demonstrating the advantages of PaaS over IaaS for developers keen on the cloud.
“AWS and Google are not good for moving existing apps to the cloud,” Lodge claimed. “They are better for developers writing new apps from scratch.”
Help Moving Apps to the Cloud
Rewriting existing apps to be cloud friendly can be a massive undertaking. It can be done, certainly: Lodge related how Netflix’s development team essentially rewrote all of its code to take advantage of cloud computing. “They basically wrote their own PaaS, which shows how talented they are.”
Mere mortals may not have that kind of time or energy, Lodge said, which is where Cloud Foundry comes in. It handles all of the virtual machines and infrastructure issues for the developer, so the app they’re coding doesn’t have to.
Thus far, VMware’s PaaS-centric strategy seems to be working. By focusing its attention on working with partners in the PaaS space, the company is not grabbing cloud headlines to rival Amazon, Google and Microsoft, but it has a fast-growing presence.
“We’re on over 130 clouds in 26 countries,” Lodge boasted. “Not even AWS has that kind of footprint.”
If it ain’t broke, don’t fix it, seems to be the current feeling in the halls of VMware. If Gelsinger sticks to this course under his tenure, don’t look for an IaaS play from VMware anytime soon.

<Return to section navigation list>

















