Windows Azure and Cloud Computing Posts for 2/20/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Service
The Microsoft Business Intelligence Team (@MicrosoftBI) posted Big Data, Hadoop and StreamInsight™ on 2/22/2012:
With Strata less than a week away, we are kicking off a Big Data blogging series that will highlight Microsoft’s Big Data vision and technologies. Today’s guest post is by Torsten Grabs (torsteng(at)microsoft(dot)com), Principal Program Manager Lead for StreamInsight™ at Microsoft.
At the PASS Summit last October Microsoft announced its roadmap and approach to Big Data. Our goal is to provide insights to all users from all their structured and unstructured data of any size. We will achieve this by delivering a comprehensive Big Data solution that includes an Enterprise-ready Hadoop-based distribution for Windows Server and Windows Azure, insights for everyone through the use of familiar tools, connection to the world’s data for better discovery and collaboration, and an open and flexible platform with full compatibility with Apache Hadoop. Since PASS, I am frequently asked about the interplay between Hadoop, MapReduce, and StreamInsight™.
The first question that I typically ask in return is “Why are you asking?”. Well, as it turns out there are many reasons why you might wish to look into a combination of these technologies. Just looking into any of the definitions used to explain Big Data these days is insightful to answer the question. For our discussion here, let’s pick the one proposed by Gartner, but other definitions will lead to a similar result. Gartner characterizes Big Data as challenges in three distinct areas, characterized by the 3Vs:
- Volume: The volume dimension describes the challenges an organization faces because of the large and increasing amounts of data that need to be stored or analyzed.
- Velocity: The velocity dimension captures the speed at which the data needs to be processed and analyzed so that results are available in a timely manner for an organization to act on the data.
- Variety: The variety dimension finally looks at the different kinds of data that need to be processed and analyzed, ranging from tabular data in relational databases to multimedia content like text, audio or video.
For our discussion here, the first two dimensions, i.e., volume and velocity, are the most interesting dimensions. To cover these dimensions in a Big Data solution, an intuitive approach will lead you to a picture like the one illustrated in Figure 1. It shows the dimensions volume and velocity and overlays it with technologies such as MapReduce or Event Processing.
Figure 1: Covering Gartner's Volume and Velocity dimension
MapReduce technologies such as Hadoop are well-suited to plow through large volumes of data quickly and to parallelize the analysis using MapReduce. The map phase splits the input into different partitions and each partition is processed concurrently before the results are collected by the reducer(s). With vanilla MapReduce, the reducers run independently of each other and can be distributed across different machines. Depending on the size of the data and the speed at which you need the processing done, you can adjust the number of partitions and correspondingly the number of machines that you throw at the problem. This is a great way to process huge data volumes and scale out the processing while at the same time reducing overall end-to-end processing time for a batch of input data. That makes MapReduce a great fit to address the volume dimension of Big Data. While Hadoop is great at batch processing, it is not suitable for analyzing streaming data. Let’s now take a look at the velocity dimension.
Event-processing technologies like Microsoft StreamInsight™ in turn are a good fit to address
challenges from the velocity dimension in Big Data. The obvious benefit with StreamInsight™ is that the processing is performed in an event-driven fashion. That means that processing of the next result is triggered as soon as a new event arrives. If you render your input data as a stream of events you can process these events in a non-batched way, i.e., event by event. If data is continuously arriving in your system, this gives you the ability to react quickly to each incoming event. This is the best way to drive the processing if you need to provide continuous analytics processing over a continuous data feed.Let’s now take a look at the area in Figure 1 where the two technologies intersect, indicated with a question mark in the figure.
A particularly powerful combination of technologies is when MapReduce is used to run scaled out reducers performing complex event processing over the data partitions. Figure 2 illustrates this scenario using Hadoop for MapReduce and StreamInsight™ for complex event processing. Note how the pace of the overall processing is governed by the batches being fed into Hadoop. Each input batch results into a set of output batches where each output batch corresponds to the result produced by one of the reducers. The reducers are now performing complex event processing in parallel over the data from the input batch. While this does not allow for the velocity we get with purely event-driven processing scheme, it does allow us to greatly simplify the coding needed for the reducers to perform complex event processing.
Figure 2: Combining Complex Event Processing with Map Reduce
As it turns out, a lot of scenarios in Big Data can benefit from complex event processing in the reduction phase of MapReduce. For instance, consider all the pre-processing that needs to happen before you can send data into a machine learning algorithm. You may wish to augment time-stamped raw input data with aggregate information like the average value observed in an input field over a week-long moving average window. Another example is to work with trends or slopes and their changes over time as input data to the mining or learning phase. Again, these trends and slopes need to be calculated from the raw data where the built-in temporal processing capabilities of complex event processing would help.
Example: Consider a log of sensor data that we wish to use to predict equipment failures. To prepare the data, we need to augment the sensor values for each week with the average sensor value for that week. To calculate the averages, weeks are from Monday through Sunday and averages are calculated per piece of equipment. Data preparation steps like these are oftentimes required when preparing your data for use in regression. The following table shows some sample input data:




The output with the weekly averages then looks as follows:

The weekly averages in the previous example illustrate how the temporal processing capabilities in complex event processing systems such as StreamInsight™ become crucial steps in the processing pipeline for Big Data applications.
Another prominent example is the detection of complex events like failure conditions or patterns in the input data across input streams or over time. Again, most complex event processing systems today provide powerful capabilities to declaratively express these conditions and patterns, to check for them in the input data, and to compose complex events in the output when a pattern is matched or a condition has been observed. Similar processing has applications in supervised learning where one needs to prepare training data with the classification results, the failure occurrences or derived values that are later used for prediction when executing the model in production. Again, complex event processing systems help here: one can express the processing in a declarative way instead of writing lots of procedural code in reducers.
Example: Consider the following input data.

Given this input data, we want to find complex events that satisfy all of the following conditions:
- An event of kind ‘A’ is followed by an event of kind ‘B;
- Events ‘A’ and ‘B’ occur within a week (i.e. 7 days) from each other;
- Events ‘A’ and ‘B’ occur on the same piece of equipment;
- The payload of ‘A’ is at least 10% larger than the one of ‘B’.
The original events are not re-produced in the output. The output only has a complex event for each occurrence of the pattern in the input. The complex event carries the timestamp of the input event ‘B’ completing the pattern and it carries both payloads. With the example input data from above, note how the second ‘A’ – ‘B’ pair in the input does not qualify since it does not satisfy the predicate over the payloads. Given the above input, we get the following output:

To perform complex event processing over large data volumes for the scenarios and examples outlined in the previous paragraphs, the use of MapReduce is compelling as it allows parallelizing the processing and reducing the amount of time spent waiting for the result. The main requirement is that the input data and calculation can be partitioned so that there are no dependencies between different reducers. In the previous examples, a simple way to do the partitioning is to split by equipment ID. In these examples, all processing is done on a per equipment basis. Similar properties can be found in many Big Data processing scenarios. If the partitioning condition holds one can instantiate the picture from Figure 2 and rely on familiar Hadoop tools to scale the processing and to manage your cluster while expressing the logic of the reducer step in a declarative language. On the Microsoft stack, the combination of Microsoft StreamInsight™ with Microsoft’s Hadoop-based Services for Windows makes it easy to follow this approach.
Microsoft’s software stack provides compelling benefits for Big Data processing along both the volume and velocity dimension of Big Data:
- For batch-oriented processing, Microsoft’s Hadoop-based services provide the MapReduce technology for scale-out across many machines in order to quickly process large volumes of data.
- For event-driven processing, Microsoft StreamInsight™ provides the capabilities to perform rich and expressive analysis over large amounts of continuously arriving data in a highly efficient incremental way.
- For complex event processing at scale, Microsoft StreamInsight™ can run in the reducer step of Hadoop MapReduce jobs on Windows Server clusters to detect patterns or calculate trends over time.
More Information
We’re thrilled to be a top-tier Elite sponsor of the upcoming Strata Conference on February 28th to March 1st 2012 held in Santa Clara California. Learn more about our presence and sessions at Strata as well as our Big Data Solution here.
Following Strata, on March 7th, 2012 we will be hosting an online event that will allow you to immerse yourself in the exciting New World of Data with SQL Server 2012. Learn more here.
Finally, for more information on Microsoft Big Data go to http://www.microsoft.com/bigdata.
I’ll be at the MVP Summit in Redmond that week, so won’t be able to make the Strata Conference. It would be interesting to learn if the Windows Azure Marketplace Datamarket’s Project “Vancouver” for providing data to Codename “Social Analytics” uses StreamInsight to process the Tweet and other data streams.
Avkash Chauhan (@avkashchauhan) described Windows Azure Blob Upload Scenarios in a 2/21/2012 post:
Windows Azure Blob storage API provided following upload scenarios to upload a blob:
Scenario [1]: You can upload a single blob in N parallel threads
In your code if you set CloudBlobClient.ParallelOperationThreadCount = N; then N parallel threads will be used to upload a single blob
Scenario [2]: You can upload multiple M blobs in one single thread for each blob
In your code if you set CloudBlobClient.ParallelOperationThreadCount = 1; then only ONE threads will be used to upload each individual blob.
Instead of uploading a single blob in parallel, if your target scenario is uploading many blobs you may consider enforcing parallelism at the application layer. This can be achieved by performing a number of simultaneous uploads on N blobs while setting CloudBlobClient.ParallelOperationThreadCount = 1 (which will cause the Storage Client Library to not utilize the parallel upload feature).
When uploading many blobs simultaneously, applications should be aware that the largest blob may take longer than the smaller blobs and start uploading the larger blob first. In addition, if the application is waiting on all blobs to be uploaded before continuing, then the last blob to complete may be the critical path and parallelizing its upload could reduce the overall latency.
So if you upload 10 blobs simultaneously you will have total M * 10 threads uploading your blobs.
Scenario [3]: You can upload M blobs in parallel N threads, which means you have total M*N threads uploading the blob.
In your code if you set CloudBlobClient.ParallelOperationThreadCount = M; and have N threads uploading individual blob, and if you upload 10 blobs simultaneously you will have total M * N* 10 threads uploading your blobs.
It is important to understand the implications of using the parallel single blob upload feature at the same time as parallelizing multiple blob uploads at the application layer.
- If your scenario initiates 30 simultaneous blob uploads using the parallel single blob upload feature, the default CloudBlobClient settings will cause the Storage Client Library to use potentially 240 simultaneous put block operations (8 x30) on a machine with 8 logical processors. In general it is recommended to use the number of logical processors to determine parallelism, in this case setting CloudBlobClient.ParallelOperationThreadCount = 1 should not adversely affect your overall throughput as the Storage Client Library will be performing 30 operations (in this case a put block) simultaneously.
- Additionally, an excessively large number of concurrent operations will have an adverse effect on overall system performance due to ThreadPool demands as well as frequent context switches.
- In general if your application is already providing parallelism you may consider avoiding the parallel upload feature altogether by setting CloudBlobClient.ParallelOperationThreadCount = 1.
More Info:

My problem is slow upload speeds on my AT&T commercial DSL connection, so parallel uploads don’t do much for me.
Janakiram MSV described Cloud Storage Choices on Windows Azure in a 2/20/2012 post:
Many architects face the challenge of mapping and aligning the physical architecture with the Cloud architecture. This is primarily due to the wide array of choices on the Cloud and also due to some of the constraints introduced by the Cloud. Storage is one of the most critical factors influencing the availability, reliability and cost of a Cloud application. This article summarizes various Cloud storage choices that are offered by Windows Azure. The objective is to identify the key role played by each of the storage services and highlight the common use case for that service.
In the traditional environments, the storage choices are typically based on the following -
Direct Attached Storage
- In-Memory
- Message Queue
- Storage Area Network
- Network Attached Storage
- Databases
- Archival / Backup
However, on the Cloud, the terminology and the analogy of Storage is different from a classic on-premise storage terminology. For example, emulating SAN or NAS is difficult in the Cloud. But at the same time, Windows Azure offers a variety of storage choices to build web-scale applications on the Cloud. We will now take a look at these choices to understand the scenarios and use cases.
- Local Storage
- Azure Drive
- Azure Blobs
- Azure Tables
- Azure Queues
- Azure Cache
- SQL Azure
- Custom Databases
Local Storage – Every role instance comes with default storage attached to it and this is referred as local storage. Since this is an integral part of the instance, it offers high performance I/O operations and can be treated like a system or boot partition of a Windows machine. Developers can use the standard File I/O API to deal with the file system. Additional storage can be added to the instance by modifying the Service Definition file (*.CSDEF) of the Cloud application. The key thing to remember about the local storage is that it is not durable across the role life cycle. Once a role is terminated, the data in the local storage is lost along with the instance. So, typically local storage is used to move data that needs to be processed from an external durable storage engine like Azure Blob. You can think of it as a scratch disk.
Use Case – Considered to be an intermediary storage to process data that is stored separately on an external durable storage engine.
Azure Drive – To overcome the limitations of local storage, you can rely on Azure Drive. Think of Azure Drive as a pluggable storage device on the Cloud. You can request for an Azure Drive of a specific size, mount it, format it and use it like any other Windows drive. If you prefer, you can format with NTFS and enable encryption at the file system level. All the flushed data is automatically committed to the disk implicitly offering a durable storage option. Since the data is persisted to the Azure Drive which is external to a role instance, in case of an instance failure, the same drive can be attached to another healthy instance to recover the data. Developers will deal with the Azure Drive API only to manage the create, mount and initialize operations and after that the standard file I/O operations can be performed on it.
Use Case – Considered to be an independent and durable storage option that can help to achieve high availability and fail over for Cloud applications.
Azure Blob – Azure Blob storage offers high durability and massively scalable storage engine to develop internet scale applications. It is used to store unstructured binary data like images, documents, videos and other files. Azure Blob exposes REST endpoint to upload and retrieve blobs. When combined with Azure CDN, the objects stored in the Azure Blob will be cached across the edge locations bringing the static data closer to the consumers. Blobs are of two types – 1) Block Blob and, 2) Page Blob. Block blobs are optimized for streaming while Page blobs are optimized for random access. Azure Drive, discussed above is based on the Page Blob.
Use Case – Considered to be a highly durable storage option to keep static data that needs to be close to the consumer when combined with CDN.
Azure Table – Azure Tables are flexible entities that do not impose the requirement of a schema. It is a scale out database engine that can automatically partition the data that can be spread across multiple resources. Azure Tables is the NoSQL offering from Microsoft on the Cloud. It is exposed through standard REST endpoints to perform the normal CRUD operations. Like many scale out NoSQL databases, Azure Tables are eventually consistent. Data that need not comply with the ACID requirements are stored in Azure Tables.
Use Case – Considered to be a scale out database to store data that is written once but read many times.
Azure Queues – Azure Queues bring the asynchronous messaging capabilities to the Cloud. If you are familiar with MSMQ or IBM MQ, you will find the architecture of Azure Queues familiar. By leveraging the Azure Queues, architects can design highly scalable systems on the Cloud. Queues are the preferred mechanism to communicate across multiple role instances within a Cloud application deployed on Windows Azure. They allow us to architect loosely coupled and autonomous services that can independently scale. Messages stored in the Queue are generally delivered in FIFO pattern but this is not guaranteed. By implementing the access, process and delete pattern the right way, guaranteed message delivery can be achieved on Azure Queues. Like most of the Azure Storage services, Queues are also exposed through REST API.
Use Case – Considered to design loosely coupled, autonomous and independent components for the Cloud.
Azure Cache – Azure Cache brings the in-memory caching capabilities to Windows Azure. This is compatible with the Windows Server AppFabric Cache deployed for on-premise applications. Azure Cache comes with ASP.NET session and page output caching providers offering an out of the box experience to .NET developers. It can also be accessed through the REST API to push and retrieve objects into the cache. By storing frequently accessed data in the Azure Cache, expensive round trips to the database can be avoided.This will not only decrease the cost of I/O but also increases the overall responsiveness of the application.
Use Case – Considered to store frequently requested data and access with minimal latnecy to enhance the performance.
SQL Azure – SQL Azure is the Cloud incarnation of the flagship RDBMS, SQL Server from Microsoft. It works on the same principles of SQL Server and is based on the same protocols of SQL Server such as TDS. Developers can move their applications to the Cloud while moving the database to SQL Azure. Just by changing the connection string, applications can talk to SQL Azure. Developers can use their favorite data access model including ODBC, OLEDB or ADO.NET to talk to SQL Azure. It also exposes service management API to enable the logical administration of the database for tasks like creating users, roles and permissions. SQL Azure also includes Reporting Services for visualization and Business Intelligence for analysis. With its Pay-as-you-go model, it makes it extremely affordable to move data driven applications to the Cloud.
Use Case – Considered to build highly scalable and reliable Cloud appliations that require relational database at the data tier
Custom Databases – Though Windows Azure offers Azure Tables as a NoSQL database and SQL Azure for the RDBMS requirements, many customers might want to deploy a NoSQL database like MongoDB, CouchDB or Cassandra on Windows Azure. While these are not offered as managed offerings on subscription, Windows Azure architecture lets you deploy any of them as a part of your application. By wrapping the custom database in a Worker Role, the database can be made available to your application. Of course, the responsibility of managing and maintaining the database is left to the customer. But it is technically possible to run any light weight DB within a Worker Role. Going forward, when VM Roles are available, additional databases can also be deployed with ease.
Use Case – Considered to deploy a proprietary database on Windows Azure as demanded by the application architecture.
This was a quick summary of various storage options provided by Windows Azure. Hope you find this article useful!

<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Steve Morgan continued his series with Multi-Tenant Data Strategies for Windows Azure – Part 2 for BusinessCloud9 on 2/21/2012:
In Part 1 of this article I explored why Cloud platforms are often considered inherently multi-tenanted. I also looked at how the degree of isolation demanded by your customers is often driven by cost, legislation, security requirements or degrees of paranoia, and explored how as a SaaS vendor, it is important to understand these concerns and to have a well thought out solution for the particular sector that your application targets.
Now I’ll explore separate databases, separate servers and how, by using a hybrid pattern, you can provide a tiered service offering for clients that are willing to share a multi-tenant system.
Separate databases
This pattern is simple to understand and to implement; use a different database for each of your tenants. Like the Schema Isolation pattern, the application should use a tenant-specific connection string, each targeting a different database.
Using separate databases, multi-tenancy concerns are largely eliminated from your data access code. Databases can be versioned independently (though application code will need to be versioned, too). Backup and restore deals only with data for one tenant, so you can roll back a database on their behalf with the minimum of effort.
It’s not all good news, though. The biggest issue is one of cost; in almost every case, you’re going to pay more for multiple SQL Azure databases than you will by servicing all of your clients from just one. You’ll need to configure (and test, please) a backup and restore mechanism for each database. Then there’s the issue of scale. If you have just a handful of tenants, it’s relatively easy to manage one database for each. If you have hundreds or thousands of tenants, it’s going to quickly get out of control.
Separate servers
A logical extension to using separate databases is to isolate data by using different servers. These can be SQL Azure servers or on-premise SQL Servers using a hybrid deployment model.
I don’t consider isolation by SQL Azure server to contribute significantly to a data isolation model; they still sit within the datacentre and you have no control over how they are provisioned. As standard, there’s a limit of 6 servers per subscription and having many servers only increases the administrative overhead. I favour database-level isolation, where requirements demand it. You should only introduce extra servers to overcome the constraint of 150 databases per server.
Separate servers become the option of choice when legislative, legal or policy requirements specify that application data must not reside in the public Cloud . A prime example is a data sovereignty requirement where certain types of data must be held within a specific geographic boundary.
This is a prime concern for many of Fujitsu’s customers, which is why we’ve developed the Fujitsu Hybrid Cloud Services. Data typically resides in a Fujitsu datacentre but the application runs on Windows Azure and Windows Azure Connect provides the secure communications channel between them. [Emphasis added.]
Covering all the bases
If you know your market and can reasonably predict how your multi-tenant application will be used, it should be reasonably straightforward to select a data isolation strategy with an understanding of the benefits and limitations of each.
If you can’t predict the take-up of your application, or if your customer base is likely to span a range of requirements, the good news is that a robust design can target each of these deployment types from a single code-base.
For the schema isolation, separate database and separate server models, the implementation is transparent to the application, over-and-above defining different database connection strings for each tenant. All of these patterns work well where you have a relatively small number of tenants.
If you have a large number of tenants, the row isolation pattern allows better consolidation of data, but this is not transparent to your code; it needs to be designed to be explicit about tenant context.
Consider designing your application to support row isolation and use schema isolation, separate database or separate server when it makes sense to do so.
With such a hybrid pattern, you can offer a tiered service offering low-cost for customers willing to share a multi-tenant system, but doesn’t preclude being able to offer tailored solutions to more demanding customers.

Steve is Principal Customer Solution Architect / Windows Azure Centre of Excellence Lead Architect at Fujitsu UK&I.
See Cihan Biyikoglu (@cihangirb) asserted OData and Federations: yes you can… Just ask Maxim in the Marketplace DataMarket, Social Analytics and OData.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
My (@rogerjenn) Track Consumer Engagement and Sentiment with Microsoft Codename “Social Analytics” article of 2/22/2011 for Red Gate Software’s ACloudyPlace blog begins:
Social analytics is a new marketing-oriented discipline that attempts to measure the engagement of Internet-connected individuals with products, services, brands, celebrities, politicians, and political parties. An important element of social analytics is estimating the opinion of participants about the entities with which they’re engaged by a process commonly called sentiment analysis or opinion mining. Social analytics relies on high-performance computing (HPC) techniques to filter a deluge of user-generated source data from social media sites, such as Twitter and Facebook, and linguistics methods to infer positive or negative sentiment, also called tone, from brief messages. For example, Twitter users generated an estimated 290 million tweets per day in mid-February 2012. Facebook currently receives about one billion posts and 2.7 billion likes/comments per day.
Filtering “firehose” data streams of these magnitudes requires more HPC horsepower than most organizations are willing to devote to yet-unproven analytic techniques, so Microsoft’s SQL Azure Labs introduced its Codename “Social Analytics” Software as a Service (SaaS) application as a private Community Technical Preview (CTP) on October 25, 2011, which was updated on January 30, 2012. The Windows Azure Marketplace DataMarket (Azure DataMarket) currently delivers two no-charge social data streams having fixed topics: Windows 8 and Bill Gates. Microsoft has promised “Future releases will allow you to define your own topic(s) of interest,” but this capability hadn’t arrived by mid-February 2012. The “Social Analytics” CTPs require prospective users to apply for a DataMarket key for their stream of choice by completing a form hosted on Windows Azure. After receiving a key, you can test drive the data set with a sample Silverlight UI – the Engagement Client (see Figure 1) – by following the instructions provided in Microsoft Connect’s Engagement Client – Social Analytics page.
The updated Codename “Social Analytics” CTP’s Engagement Client application with a user-configurable Silverlight UI for a predefined data set filtered for Bill Gates or Windows 8 (as shown here). This configuration’s left pane displays new filtered tweets in real-time, the middle pane shows the number of filtered tweets per day for the last seven days, which is indicative of engagement, and the right pane displays the count of tweets containing the keywords listed. The January 2012 CTP update added five new “analytic widgets” to the client.
Using Graphical Consumers for the Social Analytics API
The Social Analytics API is an alternative to the Engagement Client and lets you access Social Analytics’ Open Data Protocol (OData) streams directly with any application or programming language that can consume OData feeds from the Azure DataMarket. My Use OData to Execute RESTful CRUD Operations on Big Data in the Cloud post of December 2011 to the A Cloudy Place blog describes several OData consumers available from Microsoft and third parties. The PowerPivot for Excel add-in is especially suited for displaying raw Azure DataMarket streams because it provides a Table Import Wizard for connecting to and downloading OData-formatted datasets, as described on Microsoft Connect and shown in Figure 2.
Figure 2. Completing the PowerPivot for Excel’s Table Import Wizard’s Connection and Select Tables/Views dialogs, and clicking Close to dismiss the Wizard displays a small dataset’s content in a worksheet (ContentItemTypes for this example.) Opening a large data set, such as ContentItems (usually ~800,000 items), is time consuming and usually warrants canceling the download.
My Querying Microsoft’s Codename “Social Analytics” OData Feeds with LINQPad blog post describes in detail how to use Joseph Albahari’s free LINQPad utility to display Social Analytics data sets in a data grid (see Figure 3) and export them to Excel.
Figure 3. Opening a large data set, such as ContentItems, in LINQPad displays by default the first 500 or fewer collection items in a table. …




The article continues with “Programming the Social Analytics API with Visual Studio” and “Analyzing the Sentiment of Brief Text Messages” sections and concludes:
The Codename “Social Analytics” API and Microsoft Research’s investment in enhancing the accuracy of sentiment measurement for tweets is a promising advance in obtaining real-time, actionable social Web data for analyzing consumers’ perception of brands, technologies, politicians, celebrities, and many other entities. Analyst Barb Darrow (@gigabarb) asserted “Big data skills bring big dough” in a February 17, 2012 post to Giga Om’s Structure blog. However, it’s not only data scientists who stand to rake in the bucks from petabytes of social data; their employers are sure to take the lion’s share of the largess.
Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog. See my Links to My Cloud Computing Articles at Red Gate Software’s ACloudyPlace Blog post for links to all my ACloudyPlace articles to date. See also the end of the following post for links to my posts to the OakLeaf blog about Codename “Social Analytics.”
Mary Jo Foley (@maryjofoley) reported “Microsoft is leaning toward adding more social analytics and data-enrichment components to its Dynamics CRM update due in the latter half of this year” in a deck for her What's on tap for Microsoft's Dynamics CRM 'R9' update later this year article of 2/22/2012 for ZDNet’s All About Microsoft blog:
…
One possible update coming in R9 will be a souped-up social-analytics capability that builds on top of Microsoft’s “Project Vancouver,” a k a the SQL Azure Social Analytics technology. Social Analytics is currently a SQL Azure Labs test project, not something that’s part of SQL Azure as it exists today.
The idea would be to use the social analytics analysis provided by this hosted service to help CRM users attach value judgments to service incidents. (”How fast do I need to respond to this person tweeting about our product to control the damage?”) Users would be able to manage this information from right inside their standard CRM client, Dewar told me during an in-person meeting this week.
Another possible R9 feature would draw on the data sets available in the Windows Azure Marketplace, Dewar said. The thinking is that users could pull information stored in these datasets to populate/enrich their account and contact information in their CRM clients. For example, a Dynamics CRM user could pull location information from particular data sets and use it to populate their contacts. If/when the data gets updated in the Azure DataMarket, it would also refresh the data in the user’s CRM system.
…


- Twitter Sentiment Analysis: A Brief Bibliography (OakLeaf, 2/17/2012)
- Microsoft tests Social Analytics experimental cloud (SearchCloudComputing.com, 12/1/2012)
- More Features and the Download Link for My Codename “Social Analytics” WinForms Client Sample App (OakLeaf, 12/26/2011)
- New Features Added to My Microsoft Codename “Social Analytics” WinForms Client Sample App (OakLeaf, 11/21/2011)
- Microsoft Codename “Social Analytics” ContentItems Missing CalculatedToneId and ToneReliability Values (OakLeaf, 11/15/2011)
- Querying Microsoft’s Codename “Social Analytics” OData Feeds with LINQPad (OakLeaf, 11/5/2011)
- Problems Browsing Codename “Social Analytics” Collections with Popular OData Browsers (OakLeaf, 11/4/2011)
- SQL Azure Labs Unveils Codename “Social Analytics” Skunkworks Project (OakLeaf, 11/1/2011)
InformationWeek asserted “Your company's all over Facebook and Twitter, but until IT integrates marketing and customer service systems, it's all just show” as a deck for its How To Get From CRM To Social cover story on 2/22/2012:
Check the stats: 845 million people have signed up for Facebook worldwide, 152 million of them in the U.S.--nearly half the U.S. population. No wonder consumer-oriented businesses are obsessed with how to get more out of social media, including Twitter, LinkedIn, and Google+.
For business technology organizations, the challenge is figuring out the intersection between social and everything under the customer relationship management sun. CRM broadly covers the software systems companies use to serve customers, generate sales leads, manage marketing campaigns, and analyze and segment customer data. Making the connection between the people in CRM databases and their social media personas will require companies to build a new level of trust with their customers, based on the promise of better service and value. This social connection is the key to unlocking a deeper understanding of customers and making more cost-effective use of sales, service, marketing, and IT resources. …
Marketing, sales, and customer service execs often start experimenting in the social sphere without IT's help. But companies eventually need to link these efforts to on-premises CRM and marketing campaign management systems and customer data warehouses. IT groups also bring experience in data security and compliance with privacy polices and regulations. And IT can bring a much-needed process rigor: Just 17% of companies polled in our 2012 Social Networking in the Enterprise Survey have a formal process for responding to customer complaints on Facebook, despite two-thirds having a Facebook presence.
Startups Get It
Plenty of well-established companies are just beginning to embrace social: Only 19% of companies have had an external presence on Facebook for more than two years, our survey finds. So there's much to learn from Internet startups such as Adaptu that are born with the assumption of social-savvy service, sales, and marketing.
Adaptu, an online personal financial management and planning service started in 2010, aggregates data from customer financial accounts--banking, investments, mortgage, credit cards, car loans--and delivers budget and financial planning assessments and advice. An Adaptu mobile app includes a "Can I Afford This?" feature that lets people type in a would-be transaction and see how big of a hole it would blow in their budgets.
The service is built largely on Salesforce.com and the Force.com development platform. The customer sees Adaptu branding, but it's Salesforce's online software that handles logins, identity management, and customer service case tracking. For customer service, Adaptu uses Get Satisfaction to provide online self-help services; a customer can also submit a request for help on the site, which starts a case within Salesforce CRM.
But companies can't count on customers diligently exhausting self-service support options before they raise a stink on social networks. So Adaptu uses Radian6 social media monitoring capabilities to capture brand-relevant posts, tweets, and Facebook comments. Radian6 (which Salesforce acquired last year) lists every comment about Adaptu and provides an interface through which company reps can respond to comments directly on Facebook, Twitter, or wherever the message originated.
Adaptu tries to respond in public but resolve in private, tweeting that the customer should email a support question. "If somebody tweets something like 'I can't get my bank to link up,' we want to stop that conversation from happening publicly because it will potentially involve private financial information," says Jenna Forstrom, Adaptu's community manager. If the customer does send an email, it creates a Salesforce case.
But Adaptu tries to keep that CRM case connected to the social persona where it began. Agents ask customers to include their Twitter handle or Facebook name, so the support team knows that the original request came in through social media, and so two case teams aren't chasing the same problem. And once the matter's resolved, Adaptu posts a comment back to the original tweet or Facebook post.
Connecting Facebook and Twitter identities with known customers in your CRM database is important on several levels. From a service perspective, you'll see not just the latest support problem raised in a social comment, but the entire history of support exchanges with that customer. From a sales and marketing perspective, you can correlate social profile information with purchase histories and know more about key customer segments' likes and interests. And with the use of sentiment analysis technologies, you can get trending insight into what the most important customers are saying about your brand, products, and competitors.
The linchpin is that it has to be up to consumers to add their social identities to their profiles. However, as many marketers can attest, offers of discounts and coupons, early product news, sweepstakes entries, or better service often persuade people to grant permission.
Rebooting the Antisocial Network
Why Companies Struggle With Social Networks
Our report explores the problems companies face using social networks for employee collaboration. It's free with registration.
This report includes data and analysis on:
- The poor success rate for in-house social networks
- Social monitoring, staffing, vendors, and strategies


Read more: Page 2: Service With A Tweet , 2, 3, Next Page »
Cihan Biyikoglu (@cihangirb, pictured below) asserted OData and Federations: yes you can… Just ask Maxim in a 2/22/2012 post:
In case you guys have not seen this; Maxim Glukhankov has a new sample on codeplex that shows how to set up OData on top of SQL Azure Federations. Just go under “Source Code” at the top and download!
Not every tool in the world natively understand federations today. OData simplifies life for a lot of the tools that can’t speak ‘sqlfederations’ yet and the list of OData consumers is full with great names like Excel! be able to query your federated data using Excel now that should appeal to many!
You can find the full list here; http://www.odata.org/consumers
Browsers IE, Chrome, Safari etc; Most modern browsers allow you to browse Atom based feeds. Simply point your browser at one of the OData Producers.
Excel 2010: PowerPivot for Excel 2010 is a plugin to Excel 2010 that has OData support built-in.
Client Libraries: Client libraries are programming libraries that make it easy to consume OData services. We already have libraries that target: Javascript, PHP, Java, Windows Phone 7 Series, iPhone (Objective C) and .NET. For a complete list visit the OData SDK.
OData Helper for WebMatrix: The OData Helper for WebMatrix and ASP.NET Web Pages allows you to easily retrieve and update data from any service that exposes its data using the OData Protocol.
Tableau: Tableau - an excellent client-side analytics tool - can now consume OData feeds
Telerik RadGrid for ASP.NET Ajax: RadGrid for ASP.NET Ajax supports automatic client-side databinding for OData services, even at remote URLs (through JSONP), where you get automatic binding, paging, filtering and sorting of the data with Telerik Ajax Grid.
Telerik RadControls for Silverlight and WPF: Being built on a naturally rich UI technology, the Telerik Silverlight and WPF controls will display the data in nifty styles and custom-tailored filters. Hierarchy, sorting, filtering, grouping, etc. are performed directly on the service with no extra development effort.
Telerik Reporting: Telerik Reporting can connect and consume an existing OData feed with the help of WCF Data Services.
Database .NET v3: Database .NET v3 - A free, easy-to-use and intuitive database management tool, supports OData
Pebble Reports: Pebble Reports lets you create reports consisting of tables, charts and crosstabs. Reports can be exported to Word, Excel and PDF formats, or emailed via Outlook.

SAP published Using Code Patterns on the OData Channel - SAP Documentation on 2/21/2012:
Using Code Patterns on the OData Channel
To save yourself time and effort when you define data provider classes and data models for SAP NetWeaver Gateway on the OData Channel, you can use code patterns in the ABAP Workbench design time. The ABAP code patterns generate simple statements that are inserted directly into your source code.
Code Patterns
Depending on your requirements, you can choose from two types of code patterns on the OData Channel:
Data Provision Code Patterns
Metadata Definition Code Patterns
Data Provision Code Patterns
If you are implementing a data provider class on the OData Channel, you can use a Call RFC code pattern for data provision based on the generation tool, Backend Operation Proxy (BOP).
For more information, see Using Data Provision Code Patterns
Metadata Definition Code Patterns
If you are implementing a data model using a code-based approach by implementing the DEFINE method in the model provider class, you can use the code patterns Define Entity Type and Define Complex Type.
For more information, see Using Metadata Definition Code Patterns


<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
Leandro Boffi (@leandroboffi) explained how to Request a token from ADFS using WS-Trust from iOS, Objective-C, IPhone, IPad, Android, Java, Node.js or any platform or language in a 2/20/2012 post:
This is not just a SEO friendly name, in this post I want to show you a very easy way of providing Active Directory authentication in your apps, no matter the platform or language that you use, the only requirement is to be able to make an http post.
Request for a Security Token
To talk with ADFS we must be able to speak WS-Trust protocol, on the .NET platform this is a very easy thing to do thanks to WCF and Windows Identity Foundation frameworks, but regardless the platform make a WS-Trust call is not so hard.
The first thing that we need to know is that WS-Trust protocol defines an standard way of requesting security tokens, based on an XML structure known as Request Security Token or RST, this is an example of that structure:
<trust:RequestSecurityToken xmlns:trust="http://docs.oasis-open.org/ws-sx/ws-trust/200512"> <wsp:AppliesTo xmlns:wsp="http://schemas.xmlsoap.org/ws/2004/09/policy"> <a:EndpointReference> <a:Address>https://yourcompany.com</a:Address> </a:EndpointReference> </wsp:AppliesTo> <trust:KeyType>http://docs.oasis-open.org/ws-sx/ws-trust/200512/Bearer</trust:KeyType> <trust:RequestType>http://docs.oasis-open.org/ws-sx/ws-trust/200512/Issue</trust:RequestType> <trust:TokenType>urn:oasis:names:tc:SAML:2.0:assertion</trust:TokenType> </trust:RequestSecurityToken>Focusing on the basics, there is a couple of fields that are important to us, inside of the RequestSecurityToken element you will find the AppliesTo tag where, using the WS-Addressing standard, we define the scope to which the token is valid, in this case: https://yourcompany.com.
RequestType specifies the action that you want to execute, in our case “Issue”, this means that we want that the (Security Token Service) STS issue a new token, but another option could be renewed an already issued token, in that case the RequestType would be “Renew”.
Finally, the TokenType specifies the type of the token that you want, in our case we are asking for a token based on the SAML 2.0 format.
Doesn’t looks very hard, isn’t? but where do we say who we are? well, one detail that adds a bit of complexity is the fact that all the WS-* protocols stack is build on top of SOAP, so we need to speak SOAP in order to send the token request. Once more, speak SOAP is not so hard, SOAP is also XML-Based, I’m not going to explain the whole SOAP protocol, but you can find the format for a soap message here: http://www.w3.org/2003/05/soap-envelope/
In our case, to talk with ADFS from a native client we going to use username and password security, so this is how the SOAP message will looks like: (I’ve cut some arguments to improve the presentation)
<s:Envelope xmlns:s="http://www.w3.org/2003/05/soap-envelope" xmlns:a="http://www.w3.org/2005/08/addressing" xmlns:u="..."> <s:Header> <a:Action s:mustUnderstand="1"> http://docs.oasis-open.org/ws-sx/ws-trust/200512/RST/Issue </a:Action> <a:To s:mustUnderstand="1">https://yourcompany.com/adfs/services/trust/13/UsernameMixed</a:To> <o:Security s:mustUnderstand="1" mlns:o="..."> <o:UsernameToken u:Id="uuid-6a13a244-dac6-42c1-84c5-cbb345b0c4c4-1"> <o:Username>Leandro Boffi</o:Username> <o:Password Type="...">P@ssw0rd!</o:Password> </o:UsernameToken> </o:Security> </s:Header> <s:Body> <trust:RequestSecurityToken xmlns:trust="http://docs.oasis-open.org/ws-sx/ws-trust/200512"> <wsp:AppliesTo xmlns:wsp="http://schemas.xmlsoap.org/ws/2004/09/policy"> <a:EndpointReference> <a:Address>https://yourcompany.com</a:Address> </a:EndpointReference> </wsp:AppliesTo> <trust:KeyType>http://docs.oasis-open.org/ws-sx/ws-trust/200512/Bearer</trust:KeyType> <trust:RequestType> http://docs.oasis-open.org/ws-sx/ws-trust/200512/Issue </trust:Requesthttps://yourcompany.com/adfs/services/trust/13/UsernameMixedType> <trust:TokenType>urn:oasis:names:tc:SAML:2.0:assertion</trust:TokenType> </trust:RequestSecurityToken> </s:Body> </s:Envelope>To quickly understand the format, the SOAP envelop has two main tags: header and body. The body of our message contains the RST (Request for Security Token) message that we created before. In the header we can find context parameters like, the Uri of the service endpoint (To), the name of the action exposed in that endpoint that you want to execute (Action), remember that in SOAP you can have multiple actions in a single endpoint, and who we are (Security), in this case username and password.
To use UserName and Password authentication we need to look for the action Issue in the endpoint https://yourcompany.com/adfs/services/trust/13/UsernameMixed, so make sure that this endpoint is enabled on ADFS configuration.
Once we have the SOAP message, we just need to send it to the server using a regular HTTP POST, this is an example of how to do it on .NET, but it can be applied to any platform or language:
var client = new WebClient(); client.Headers.Add("Content-Type", "application/soap+xml; charset=utf-8"); var result = client.UploadString( address: "https://yourcompany.com/adfs/services/trust/13/UsernameMixed", method: "POST", data: soapMessage);Make sure that you specify the Content-Type header to “application/soap+xml; charset=utf-8”, what you finally need to send to the server is this:
POST /adfs/services/trust/13/UsernameMixed HTTP/1.1
Connection: Keep-AliveContent-Length: 1862
Content-Type: application/soap+xml; charset=utf-8
Accept-Encoding: gzip, deflate
Expect: 100-continue
Host: localhost
<s:Envelope xmlns:s="http://www.w3.org/2003/05/soap-envelope" xmlns:a="http://www.w3.org/2005/08/addressing" xmlns:u="http://docs.oasis-open.org/wss/2004/01/oasis-200401-wss-wssecurity-utility-1.0.xsd">….</s:Envelope>
I’ve added other headers to be consistent with the HTTP Protocol, but for ADFS just the Content-Type is required.
The Answer: Request Security Token Response
If your credentials were valid, and the scope Uri is the right one, you will get a SOAP response from ADFS. In the body of that message you will get something like this:
<trust:RequestSecurityTokenResponseCollection xmlns:trust="..."> <trust:RequestSecurityTokenResponse> <trust:Lifetime>...</trust:Lifetime> <wsp:AppliesTo xmlns:wsp="http://schemas.xmlsoap.org/ws/2004/09/policy">...</wsp:AppliesTo> <trust:RequestedSecurityToken> <Assertion ID="_fcf06a39-c495-4074-8f22-4a7df6e26513" IssueInstant="2012-02-21T04:27:24.771Z" Version="2.0" xmlns="urn:oasis:names:tc:SAML:2.0:assertion"> <Issuer>http://yourcompany.com/adfs/services/trust</Issuer> <ds:Signature xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:SignedInfo> <ds:CanonicalizationMethod Algorithm="http://www.w3.org/2001/10/xml-exc-c14n#"/> <ds:SignatureMethod Algorithm="http://www.w3.org/2001/04/xmldsig-more#rsa-sha256"/> <ds:Reference URI="#_fcf06a39-c495-4074-8f22-4a7df6e26513"> <ds:Transforms> <ds:Transform Algorithm="http://www.w3.org/2000/09/xmldsig#enveloped-signature"/> <ds:Transform Algorithm="http://www.w3.org/2001/10/xml-exc-c14n#"/> </ds:Transforms> <ds:DigestMethod Algorithm="http://www.w3.org/2001/04/xmlenc#sha256"/> <ds:DigestValue>...</ds:DigestValue> </ds:Reference> </ds:SignedInfo> <ds:SignatureValue>...</ds:SignatureValue> <KeyInfo xmlns="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate>...</ds:X509Certificate> </ds:X509Data> </KeyInfo> </ds:Signature> <Subject> <SubjectConfirmation Method="urn:oasis:names:tc:SAML:2.0:cm:bearer"> <SubjectConfirmationData NotOnOrAfter="2012-02-21T04:32:24.771Z"/> </SubjectConfirmation> </Subject> <Conditions NotBefore="2012-02-21T04:27:24.756Z" NotOnOrAfter="2012-02-21T05:27:24.756Z"> <AudienceRestriction> <Audience>https://yourcompany.com/</Audience> </AudienceRestriction> </Conditions> <AttributeStatement> <Attribute Name="http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name"> <AttributeValue>Leandro Boffi</AttributeValue> </Attribute> <Attribute Name="http://schemas.microsoft.com/ws/2008/06/identity/claims/role"> <AttributeValue>Administrator</AttributeValue> <AttributeValue>Mobile User</AttributeValue> </Attribute> </AttributeStatement> <AuthnStatement AuthnInstant="2012-02-21T04:27:24.724Z"> <AuthnContext> <AuthnContextClassRef> urn:oasis:names:tc:SAML:2.0:ac:classes:Password </AuthnContextClassRef> </AuthnContext> </AuthnStatement> </Assertion> </trust:RequestedSecurityToken> <trust:RequestedAttachedReference>...</trust:RequestedAttachedReference> <trust:RequestedUnattachedReference>...</trust:RequestedUnattachedReference> <trust:TokenType>urn:oasis:names:tc:SAML:2.0:assertion</trust:TokenType> <trust:RequestType>http://docs.oasis-open.org/ws-sx/ws-trust/200512/Issue</trust:RequestType> <trust:KeyType>http://docs.oasis-open.org/ws-sx/ws-trust/200512/Bearer</trust:KeyType> </trust:RequestSecurityTokenResponse> </trust:RequestSecurityTokenResponseCollection>This format is also specified in the WS-Trust protocol as “Request Security Token Response” or RSTR, but for you the most important section of the response is in:
RequestSecurityToeknResponseCollection/RequestSecurityToeknResponse/RequestedSecurityToken
The content of that tag is the security token, in our case a SAML 2.0 token:
<Assertion ID="_fcf06a39-c495-4074-8f22-4a7df6e26513" IssueInstant="2012-02-21T04:27:24.771Z" Version="2.0" xmlns="urn:oasis:names:tc:SAML:2.0:assertion"> <Issuer>http://yourcompany.com/adfs/services/trust</Issuer> <ds:Signature xmlns:ds="http://www.w3.org/2000/09/xmldsig#"> <ds:SignedInfo> <ds:CanonicalizationMethod Algorithm="http://www.w3.org/2001/10/xml-exc-c14n#"/> <ds:SignatureMethod Algorithm="http://www.w3.org/2001/04/xmldsig-more#rsa-sha256"/> <ds:Reference URI="#_fcf06a39-c495-4074-8f22-4a7df6e26513"> <ds:Transforms> <ds:Transform Algorithm="http://www.w3.org/2000/09/xmldsig#enveloped-signature"/> <ds:Transform Algorithm="http://www.w3.org/2001/10/xml-exc-c14n#"/> </ds:Transforms> <ds:DigestMethod Algorithm="http://www.w3.org/2001/04/xmlenc#sha256"/> <ds:DigestValue>...</ds:DigestValue> </ds:Reference> </ds:SignedInfo> <ds:SignatureValue>...</ds:SignatureValue> <KeyInfo xmlns="http://www.w3.org/2000/09/xmldsig#"> <ds:X509Data> <ds:X509Certificate>...</ds:X509Certificate> </ds:X509Data> </KeyInfo> </ds:Signature> <Subject> <SubjectConfirmation Method="urn:oasis:names:tc:SAML:2.0:cm:bearer"> <SubjectConfirmationData NotOnOrAfter="2012-02-21T04:32:24.771Z"/> </SubjectConfirmation> </Subject> <Conditions NotBefore="2012-02-21T04:27:24.756Z" NotOnOrAfter="2012-02-21T05:27:24.756Z"> <AudienceRestriction> <Audience>https://yourcompany.com/</Audience> </AudienceRestriction> </Conditions> <AttributeStatement> <Attribute Name="http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name"> <AttributeValue>Leandro Boffi</AttributeValue> </Attribute> <Attribute Name="http://schemas.microsoft.com/ws/2008/06/identity/claims/role"> <AttributeValue>Administrator</AttributeValue> <AttributeValue>Mobile User</AttributeValue> </Attribute> </AttributeStatement> <AuthnStatement AuthnInstant="2012-02-21T04:27:24.724Z"> <AuthnContext> <AuthnContextClassRef> urn:oasis:names:tc:SAML:2.0:ac:classes:Password </AuthnContextClassRef> </AuthnContext> </AuthnStatement> </Assertion>Once we extract the token from the response, everything gets simpler: Inside of the AttributeStatment section you will have a list of Attribute, this are the claims, information of the user, for example in this token we have three different claims:
- Type: http://schemas.xmlsoap.org/ws/2005/05/identity/claims/name
- Value: Leandro Boffi
- Type: http://schemas.microsoft.com/ws/2008/06/identity/claims/role
- Value: Administrator
- Type: http://schemas.microsoft.com/ws/2008/06/identity/claims/role
- Value: Mobile User
You can use those claims to perform authorization in your application, but also if your app needs to call webservices that rely on your ADFS, you will need to send the entire token in each request that you made to those services (I’ll explain this scenario in a future post).
Security Features
The token has some security features with which we can get us to make our application more secure. I’m not going to explain all the features in this post, but for example, if we want we can verify that no body has modified the token, because it is signed by the issuer (in our case, ADFS). You can find the signature on Assertion/Signature/SignatureValue. This signature is also based on a standard called XML Signature, you can find the specification here: http://www.w3.org/Signature/.
Also another very important feature is the fact that the token has a limited life time, to avoid that somebody use an old token, you can find that in the Assertion/Conditions/NotBefore and NotOnOrAfter.
Conclusion
Integrate the identity of our apps to Active Directory, no matter the platform or the language is possible due to ADFS is based on WS-Trust an standard protocol. If your language do not support WS-Trust natively it requires a bit more of effort, but as we saw in this post it’s not hard at all, you just need an XML template for the SOAP+RST call and an HTTP Post.
Download here the template for doing the SOAP-RST call, just replace the values in brackets with your values and start requesting tokens!

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
See Steve Morgan continued his series with Multi-Tenant Data Strategies for Windows Azure – Part 2 for BusinessCloud9 in the SQL Azure Database, Federations and Reporting section above.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Stuart Sumner (@StuartSumner) posted Analysis: Industry reaction to the CloudStore to the computing.co.uk blog on 2/22/2012:
The government this week launched its CloudStore, making 1,700 IT services available to public-sector organisations via the cloud.
The service, which the government says is still in its pilot phase, is currently little more than a list of approved suppliers and services.
While this is certainly helpful for public-sector organisations looking to procure IT services, it falls some way short of being the ‘appstore' that many, the government included, are calling it.
A press release on the Cabinet Office's website currently proclaims: "[Cloudstore], the online appstore of the government's G-Cloud framework for cloud-based ICT services, is open for business."
Further development is expected on the initiative, which could eventually see it turn it into a place where services can be directly downloaded.
Until that point it remains a catalogue complete with service details and pricing information, with the aim of enabling public-sector bodies to make faster and better informed procurement decisions.
Minister for the Cabinet Office Francis Maude emphasises these points, and adds that public-sector IT procurement will also become more transparent.
"The launch of CloudStore is an important milestone in the government's ICT strategy to deliver savings and an IT system fit for the 21st century. Simply stated, purchasing services from CloudStore will be quicker, easier, cheaper and more transparent for the public sector and suppliers alike."
Encouraging small business
Maude says that the pricing information will ensure that suppliers remain competitive, helping to drive costs down, and encourage public sector take-up of services from SMEs.
"By creating a competitive marketplace, the G-Cloud framework will constantly encourage service providers to improve the quality and value of the solutions they offer, reducing the cost to taxpayers and suppliers. And it gives SME suppliers of niche products the same opportunities as bigger organisations supplying services."
There have been signs recently that the government is attempting to live up to its promise to outsource more contracts to SMEs, with the HMRC's £2.8bn contract with Capgemini renegotiated recently to allow some of the work, and funds, to go elsewhere.
But are all the SMEs listed on CloudStore capable of delivering what they promise? Tola Sargeant, director at analyst firm TechMarketView, welcomes the initiative, but casts doubt on its ability to follow through on its promise.
"After a quick play with CloudStore it's clear it is designed very much as a catalogue for commodity products – it's difficult to compare companies on the basis of anything but price," says Sargeant.
"It will undoubtedly drive much faster adoption of cloud services, provide greater visibility for SMEs, lead to a more competitive market and save the government money in the long term.
"But in the short term, my concern is whether some of the smaller suppliers on the framework have the capability to deliver the services required reliably at volume."
The SMEs themselves are delighted to be involved. Among the SMEs listed is Huddle, a provider of secure cloud collaboration and storage services. Huddle CEO Alastair Mitchell highlighted the cost savings that the framework agreement is likely to bring.
"The framework enables organisations to make the move from costly on-premise legacy ICT systems to innovative cloud-based technologies much faster and creates real competition in the government cloud services marketplace," he said.
"Securing government technology deals has long been an area dominated by integrators and technology goliaths and this framework has now leveled the playing field," added Mitchell.
The enterprise view
Despite this levelling, the corporate giants listed on the site are similarly welcoming of the initiative.
Mark Gorman, director, public sector for EMC UK, highlights the improved ability of public-sector organisations to innovate.
"The ambition to separate the issue of infrastructure from applications will empower the government to roll out innovations more quickly, at cost and energy requirements an order of magnitude lower than in the past."
However, the industry is not universally positive. Lynn Collier, senior director of cloud, file and content, at Hitachi Data Systems EMEA, whose firm is not on the supplier list, warned that the CloudStore raises questions about security and service level commitments.
"How is data being protected and what regulatory requirements does the use of public clouds expose an organisation to? And what level of predictability will an organisation have in regard to service level agreement compliance?" asks Collier.
"In response to this, the public sector needs to carefully think about the approach to information management by portioning different types of data into confidential and non-confidential sets and to classify the service level agreement required in relation to availability, access and redundancy," she adds.
The CloudStore lists its available products as including all flavours of cloud serivce, infrastructure-as-a-service (IaaS), platform-as-a-service (PaaS) and software-as-a-service (SaaS). There is also a category for specialist services such as configuration, management and monitoring.
Further reading

See Desire Athow reported Breaking : Panda Security To Partner With Microsoft On Cloud-based Antivirus Services in the Cloud Security and Governance section below.
Neil MacKenzie (@mknz) posted Node.js, Windows Azure (and socket.io) on 2/21/2012:
The Windows Azure Platform now supports various application-hosting environments including:
Node.js is a lightweight platform, developed by Ryan Dahl (@ryah), for building highly-scalable network applications written in JavaScript. In particular, it can be used to develop and deploy web servers. socket.io is a Node.js package that provides a simple way to access HTML5 web sockets thereby facilitating the creation of applications supporting browser-to-browser conversation. The Node.js documentation is here.
This post is a brief introduction to Node.js and socket.io with that introduction being focused on the implementation of Node.js inside the Windows Azure environment.
Node.js
Node.js is an application hosting environment developed in C++ and using the Google V8 JavaScript engine to host applications written in JavaScript. An essential feature of applications written in Node.js is the heavy use of callbacks making support for an asynchronous programming model more natural. Node.js can be downloaded directly from the Node.js website.
Hello World in Node.js
The following example demonstrates how easy it is to write a website serving a single Hello World web page.
var port = 81;
var http = require(‘http’);var app = http.createServer(function (req, res) {
res.writeHead(200, {‘Content-Type’: ‘text/plain’});
res.end(‘Hello World\n’);
});app.listen(port);
console.log(‘Server running on port ‘ + port);When the above code is saved in a file named server.js the following command can be used to launch the web server:
node server.js
The require() statement imports the Node.js http module into the application where it is used to create an HTTP server. The parameter to the createServer() method is an anonymous callback function invoked each time the server receives a request. This callback is passed the request and response streams for the request. In the example, a response header is added before res.end() is invoked to write Hello World to the response and flush the response back to the client. app.listen() starts the server listening on port 81.
This simple program demonstrates several features common to Node.js applications:
- the use of require() to import modules into the application
- the creation of a server
- the use of listen() to start the listening process
Application Frameworks
A web application can be coded directly in JavaScript and deployed as a website hosted in Node.js. As in other web-development environments it is common to use an application framework to structure the application and enforce a separation of concerns that aids the development of large-scale applications.
Many Node.js samples use the Express framework. This uses routes and views directories to store application routes and views. Express supports various view engines including Jade and EJS (embedded JavaScript). These provide different ways to specify the appearance of a web page.
The following commands can be invoked to download the Express module and create a default Node.js web server using the Express framework and the Jade view engine:
npm install express
.\node_modules\.bin\express
npm installnode app.js
This starts a web server, listening on port 3000, which responds with the web page defined in views\index.jade.
Node Package Manager (NPM)
The Node Package Manager (NPM) is an application that simplifies the local installation for the thousands of packages that have been created for Node.js. NPM stores downloaded packages in a node_modules folder under the invocation directory. It is possible to specify that downloaded packages be stored globally but, in general, they should be regarded as part of the application they are being used in and stored locally (which is the default).
The package.json file associated with a downloaded package specifies dependencies on other packages that it may have. NPM recursively downloads these dependent packages into a node_modules directory associated with the initial package. The NPM is invoked as follows:
npm install packageName
Windows Azure
Microsoft supports Node.js as a first-class development environment for Windows Azure. The Windows Azure developers portal has a section devoted to Node.js that contains various samples and a download link for the Windows Azure SDK for Node.js.
The SDK is installed in the following directory:
%ProgramFiles(x86)%\Microsoft SDKs\Windows Azure\Nodejs
The installation process creates a link on the Start menu for the Windows Azure PowerShell for Node.js which launches a PowerShell console with the Windows Azure Node.js cmdlets preloaded. These cmdlets can be used to manage the creation and deployment of hosted services both in the development and Windows Azure environment. As is typical with Windows Azure development environments, the PowerShell console should be launched using Run as Administrator.
The cmdlets include the following:
- New-AzureService serviceName
- Add-AzureNodeWorkerRole roleName
- Add-AzureNodeWebRole roleName
- Start-AzureEmulator
- Stop-AzureEmulator
These can be used sequentially to create a Windows Azure hosted service with zero or more web and worker roles and then deploy them to the compute emulator before tearing down the service. The developer portal has a sample that does precisely this. Other cmdlets support the deployment of the hosted service to Windows Azure.
Web Roles and Worker Roles
The Windows Azure SDK for Node.js implements web and worker roles in different ways leading to differences in the supported functionality. Specifically, since http.sys does not support HTML5 web sockets it is not possible to use them in a Node.js (or any) application deployed to a web role. Web sockets are supported for Node.js (or any) application deployed to a worker role. One benefit of using a web role is that, as shown by Aaron Stannard (@Aaronontheweb) in this post, IIS can handle the launching of multiple node.exe instances automatically. Otherwise, Node.js would only be able to use a single core, even in a multi-core instance.
A web role is implemented using a special IISNode module which is loaded as additional ASP.NET module in IIS. When creating a Windows Azure package for deployment, the packager creates a startup task to perform various tasks including installing IISNode in the web role instance. In the development machine, IISNode is installed in:
%ProgramFiles(x86)%\Microsoft SDKs\iisnode
A worker role is implemented using the new ProgramEntryPoint functionality exposed in ServiceDefinition.csdef which allows an arbitrary program to be specified as the role entry point. Specifically, on startup a worker role hosting a Node.js application invokes the following program entry point:
node.exe .\server.js
An obvious implication is that the Node.js application must be in a file named server.js – although it can import additional modules.
It is remarkably easy to port a Node.js application to Windows Azure. A particularly impressive sample on the Windows Azure developer portal takes a standard example from the socket.io website and ports it to Windows Azure by changing only two lines of code. One change is simply to the location of a module while the other is the specification of the port to listen on in a Windows Azure friendly manner. Specifically, when using Windows Azure SDK for Node.js it is necessary to specify the listening port using:
process.env.port
which allows the application to access the correct Windows Azure endpoint.
Furthermore, it can sometimes be helpful to test Node.js applications directly, using node.exe, without launching the Windows Azure development environment. This is feasible because of the simple manner with which Node.js applications are inserted into the development environment.
Node.js Packages for Windows Azure
The Windows Azure SDK for Node.js does not provide access to the various Windows Azure SDKs. In keeping with the style of Node.js applications, this SDK is instead deployed as a set of Node.js packages for Windows Azure which are downloaded into a Node.js application using
npm install azure
The packages expose Node.js APIs for:
- Windows Azure Storage Service (blobs, tables and queues)
- Service Bus Brokered Messaging (queues, topics and subscriptions)
The Windows Azure developer portal has a complete example showing how to access Windows Azure Table service from a Node.js application developed using Express/Jade. When the azure packages are installed, examples of all the supported functionality are installed in the node_modules\azure\examples directory for the application.
Some Node.js on Windows Azure Links
Glenn Block (@gblock) has an interesting Channel 9 interview in which he describes Node.js on Windows Azure. Matt Harrington (@mh415) has a post describing the environment variables available when using the Node.js azure packages as well as a post showing how to log messages. Aaron Stannard has a post on using the Node.js packages for Windows Azure outside the compute emulator.
socket.io
Guillermo Rauch (@rauchg) developed socket.io, a Node.js package that simplifies the creation of web applications supporting real-time communication between browsers and devices. The github repository and documentation for socket.io is here. The canonical example of a socket.io application is a chat application supporting a conversation between clients.
socket.io supports various transports including:
- web socket
- html file
- xhr-polling
- jsonp – polling
By default, the transports are used in that priority and socket.io automatically degrades a connection when the transport is not supported. Web sockets are not supported by IIS so, as mentioned earlier, a worker role must be used if web socket support is desired for a socket.io application hosted in Windows Azure. Similarly, IE9 does not support web sockets so IE9 use again leads to a degraded connection. (Hint: the Chrome browser provides a better development experience since it does not suffer any connection degradation delay.)
socket.io implements the Node.js EventEmitter interface and so provides a nice demonstration of idiomatic Node.js. The EventEmitter interface comprises:
- emitter.addListener(event, listener)
- emitter.on(event, listener)
- emitter.once(event, listener)
- emitter.removeListener(event, listener)
- emitter.removeAllListeners([event])
- emitter.setMaxListeners(n)
- emitter.listeners(event)
- emitter.emit(event, [arg1], [arg2], [...])
- Event: ‘newListener’
This interface supports the association of named events (or messages) with callbacks. Specifically, emitter.emit() sends a named event while emitter.on() listens for a named event and associates a callback with it. A socket.io application is created by the mutual exchange of named events between the client and the server.
A core sockets object manages connections. It handles a connection event by creating a socket object and passing that to the callback associated with the connection event. The socket object handles individual connections and listens for the disconnect event. It also supports named events that contain the conversation messages providing the application functionality.
Simple Windows Azure Application using socket.io
A very basic socket.io application hosted in the Windows Azure development environment can be created as follows:
- Start the Windows Azure PowerShell for Node.js console (using Run as Administrator)
- cd to some directory
- Type New-AzureService chat
- Type Add-AzureNodeWorkerRole
- cd WorkerRole1
- Type npm install socket.io
- Open server.js in some editor (e.g., Sublime Text 2) and replace the contents with the following:
// Import various modules and start listening for socket.io connections
var app = require(‘http’).createServer(handler)
, io = require(‘socket.io’).listen(app)
, fs = require(‘fs’);// Configure the port to run in the Windows Azure emulator
var port = process.env.port || 81;// start listening for HTTP connections
app.listen(port);
// The handler function returns index.html to the browser
function handler (req, res) {
fs.readFile(__dirname + ‘/index.html’, function (err, data) {
if (err) {
res.writeHead(500);
return res.end(‘Error loading index.html’);
}
res.writeHead(200);
res.end(data);
});
}// Handle ‘connection’ events
io.sockets.on(‘connection’, function (socket) {
socket.emit(‘fromServer’, { message: ‘Connected’ });socket.on(‘message’, function (data) {
socket.emit(‘message’, { message: ‘Message forwarded’ });
socket.broadcast.emit(‘message’, { message: data.message });
});
});
- Create a file named index.html (in the same directory) and copy the following into it:
<html>
<head>
<script src=”/socket.io/socket.io.js”></script>
<script src=”http://ajax.aspnetcdn.com/ajax/jQuery/jquery-1.7.1.min.js”></script>
<script>
var socket = io.connect(‘http://localhost:81′);socket.on(‘fromServer’, function (data) {
displayMessage(data.message);
});socket.on(‘message’, function (data) {
displayMessage(data.message);
});function sendMessage()
{
socket.emit(‘message’, { message: $(‘#MessageText’).val() });
};function displayMessage( message ) {
$(‘#Output’).text(message);
};
</script>
<head>
<body>
Message:<input id=”MessageText” type=”text”/>
<input type=”button” value=”Send message” onclick=”sendMessage();”/>
<div id=”Output”/>
<br/>
</body>
</html>io.sockets.on(‘connection’, function (socket) {
socket.emit(‘fromServer’, { message: ‘Connected’ });socket.on(‘message’, function (data) {
socket.emit(‘message’, { message: ‘Message forwarded’ });
socket.broadcast.emit(‘message’, { message: data.message });
});
});
- Type Start-AzureEmulator –launch
Start multiple browser windows pointing to http://localhost:81.
The UI is simple – with a message box, a Send message button and a status line below. After a few seconds, the status line should display Connected. When a message is typed in one of the message boxes and submitted, the status line in the current windows displays “Message forwarded” while the status line in the other windows displays the message text. Using the appropriate developer tools for the browser it is possible to find out the transport used for communication between the browser and the server.
- Type Stop-AzureEmulator to shutdown the compute emulator.
This demonstration is very simple with the Node.js server serving up a simple web page to the browsers. The server listens for socket.io connections and on receiving one sends a connected message back to the client and sets up a socket listener for an event named message. On receiving such an event the socket responds by sending an event named fromServer with content Message forwarded back to the client and broadcasts an event named message, containing the message text, to all other clients. On loading, the browser connects to the server and, on connection, adds listeners for two events named fromServer and message. On receiving an event, the response is displayed in the status line. When the button is clicked, socket.emit() is invoked to send the message to the server.
This is a trivial demonstration that shows how easy it is to implement a Node.js application using socket.io inside Windows Azure. Mariano Vazquez uses an equally simple demonstration in a blog post in which he provides additional information about configuring the transport used by the connection.


Martin Ingvar Kofoed Jensen (@IngvarKofoed) described Auto updating webrole in a 2/20/2012 post:
While working on a cool Windows Azure deployment package for Composite C1 I did a lot of deployments. The stuff I did, like reconfiguring the IIS, needed testing on an actual Azure hosted service and not just the emulator. Always trying to optimize, I thought if ways to get around all this redeploying and came up with the idea of making it possible to change the WebRole behavior at run time. Then I could just “inject” a new WebRole and start testing without having to wait on a new deployment. After some fiddling around I found a really nice solution and will present it here!
Solution description
This is a fairly simple task and all the code needed is shown here:
/* Creating domain */ AppDomainSetup domainSetup = new AppDomainSetup(); domainSetup.PrivateBinPath = folder; domainSetup.ApplicationBase = folder; AppDomain appDomain = AppDomain.CreateDomain(“MyAssembly”, null, domainSetup); /* Creating remove proxy object */ IDynamicWebRole dynamicWebRole = (IDynamicWebRole)appDomain.CreateInstanceAndUnwrap( “MyAssembly”, “MyAssembly.MyDynamicWebRole, MyAssembly”); /* Calling method */ dynamicWebRole.Run();
Common interface: IDynamicWebRole
The code for the IDynamicWebRole interface is in its own little assembly. And the code shown here and can be changed as you wish.
interface IDynamicWebRole { void Run(); }There is no actual need for an interface, but both the Azure WebRole project and the assembly project that contains the actuall IDynamicWebRole implementation needs to share a type. So that’s why I created this interface and put it in its own assembly. The assemblies/projects in play is shown in this figure:
Now its time to look at the more interesting code in the WebRole. It’s where all the magic is going on!
The WebRole implementation
The WebRole implementation is rather complex. The WebRole needs to periodicly look for new versions of the IDynamicWebRole implementation and when there is a new version, download it, start new AppDomain and create a remote instance of the IDynamicWebRole implementation. Here is all the code for the WebRole. After the code, I will go into more detail on how this works.
public class WebRole : RoleEntryPoint { /* Initializes these */ private readonly CloudBlobClient _client; private readonly string _assemblyBlobPath = "mycontainer/MyAssembly.dll"; private readonly string _dynamicWebRoleHandlerTypeFullName = "MyAssembly.MyDynamicWebRole, MyAssembly"; private AppDomain _appDomain = null; private IDynamicWebRole _dynamicWebRole; private volatile bool _keepRunning = true; private DateTime _lastModifiedUtc = DateTime.MinValue; public override void Run() { int tempFolderCounter = 0; while (_keepRunning) { CloudBlob assemblyBlob = _client.GetBlobReference(_assemblyBlobPath); DateTime lastModified = assemblyBlob.Properties.LastModifiedUtc; if (lastModified > _lastModifiedUtc) { /* Stop running appdomain */ if (_appDomain != null) { AppDomain.Unload(_appDomain); _appDomain = null; } /* Create temp folder */ string folder = Path.Combine( AppDomain.CurrentDomain.BaseDirectory, tempFolderCounter.ToString()); tempFolderCounter++; Directory.CreateDirectory(folder); /* Copy needed assemblies to the folder */ File.Copy("DynamicWebRole.dll", Path.Combine(folder, "DynamicWebRole.dll"), true); File.Copy("Microsoft.WindowsAzure.StorageClient.dll", Path.Combine(folder, "Microsoft.WindowsAzure.StorageClient.dll"), true); /* Download from blob */ string filename = _assemblyBlobPath.Remove(0, _assemblyBlobPath.LastIndexOf('/') + 1); string localPath = Path.Combine(folder, filename); assemblyBlob.DownloadToFile(localPath); string assemblyFileName = Path.GetFileNameWithoutExtension(localPath); /* Create new appdomain */ AppDomainSetup domainSetup = new AppDomainSetup(); domainSetup.PrivateBinPath = folder; domainSetup.ApplicationBase = folder; _appDomain = AppDomain.CreateDomain(assemblyFileName, null, domainSetup); /* Create IDynamicWebRole proxy instance for remoting */ _dynamicWebRole = (IDynamicWebRole)_appDomain.CreateInstanceAndUnwrap( assemblyFileName, _dynamicWebRoleHandlerTypeFullName); /* Start the dynamic webrole in other thread */ /* so we can continue testing for new assebmlies */ /* Thread will end when the appdomain is unloaded by us */ new Thread(() => _dynamicWebRole.Run()).Start(); _lastModifiedUtc = lastModified; } Thread.Sleep(30 * 1000); } } public override void OnStop() { _keepRunning = false; } }I have omitted all the exception handling to make the code more readable an easier to understand.
IDynamicWebRole implementation
The last thing we need is to implement the IDynamicWebRole interface and have it in its own assembly. There is two important things when implementing the interface for the remoting to work and that is implementing MarshalByRefObject class and overriding the InitializeLifetimeService method. This is shown in the following code:
public class MyDynamicWebRole : MarshalByRefObject, IDynamicWebRole { public void Run() { /* Put your webrole implementation here */ } public override object InitializeLifetimeService() { /* This is needed so the proxy dont get recycled */ return null; } }Thats all there is to it, enjoy! :)


Jialiang Ge @jialge posted a [Sample of Feb 20th] Configure SSL for specific pages in Windows Azure to the Microsoft All-In-One Code Framework blog on 2/20/2012:
Sample Download: http://code.msdn.microsoft.com/CSAzureSSLForPage-e844c9fe
Today’s code sample demonstrates how to configure SSL for specific page(s) while hosting the application in Windows Azure.
If you are developing applications in Windows Azure or if you are learning Windows Azure, we hope that the Microsoft All-In-One Code Framework sample would reduce your effort in this typical Windows Azure programming scenario.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.
Introduction
While hosting the applications in Azure, developers are required to modify IIS settings to suit their application requirements. Many of these IIS settings can be modified only programmatically and developers are required to write code, startup tasks to achieve what they are looking for. One common thing customer does while hosting the applications on-premise is to mix the SSL content with non-SSL content. In Azure, by default you can enable SSL for entire site. There is no provision to enable SSL only for few pages. Hence, i have written sample that customers can use it without investing more time to achieve the task.
Building the Sample
This sample needs to be configured with sitename before running it.
1. Under OnStart() Method, Locate following line, read and make changes to this line of code as per comments below.
// Since we are looking to enable SSL for only specific page, get the section // of configuration which needs to be changed for specific location // Website name can be obtained using RoleEnvironment.CurrentRoleInstance.Id // and then append "_" along with actual site name specified in ServiceDefinition.csdef // Default name of the website is Web. If you have specified different sitename, // please replace "Web" with the specified name in below line of code. ConfigurationSection section = config.GetSection("system.webServer/security/access", RoleEnvironment.CurrentRoleInstance.Id + "_Web" + "/sslpage.aspx");2. If you need to enable SSL for multiple pages, below lines should be repeated in the code. Highlighted portion is where you need to replace with page name you are trying to configure SSL for.
ConfigurationSection section = config.GetSection("system.webServer/security/access", RoleEnvironment.CurrentRoleInstance.Id + "_Web" + "/sslpage.aspx"); // Get the sslFlags attribute which is used for configuring SSL settings ConfigurationAttribute enabled = section.GetAttribute("sslFlags"); // Configure sslFlags value as "ssl". This will enable "Require SSL" flag enabled.Value = "Ssl";3. In the sample, I have configured https endpoint, RDP access using the certificates I have on my machine. You would need to re-configure certificates using the ones you have on your machine or create new certificates for these purposes. To change the certificates, Open the project, go to the properties of the sslRole as shown below and modify the highlighted certificates.
Running the Sample
Configure the variables as mentioned in the “Building the sample” section and then run the sample by clicking F5 in VS or build the sample and run the exe. Once you confirm that the sample is working, take the code from OnStart() method and incorporate with actual application.
Using the Code
Add references to Microsoft.Web.Administration (location: <systemdrive>\system32\inetsrv) assembly and add below using statement to your project
using Microsoft.Web.Administration;Code to configure SSL is below:
// Create new ServerManager object to modify IIS7 configuration ServerManager serverManager = new ServerManager(); // Retrieve Current Application Host Configuration of IIS Configuration config = serverManager.GetApplicationHostConfiguration(); // Since we are looking to enable SSL for only specific page, get the section // of configuration which needs to be changed for specific location // Website name can be obtained using RoleEnvironment.CurrentRoleInstance.Id // and then append "_" along with actual site name specified in ServiceDefinition.csdef // Default name of the website is Web. If you have specified different sitename, // please replace "Web" with the specified name in below line of code. ConfigurationSection section = config.GetSection("system.webServer/security/access", RoleEnvironment.CurrentRoleInstance.Id + "_Web" + "/sslpage.aspx"); // Get the sslFlags attribute which is used for configuring SSL settings ConfigurationAttribute enabled = section.GetAttribute("sslFlags"); // Configure sslFlags value as "ssl". This will enable "Require SSL" flag enabled.Value = "Ssl"; // Save the changes. If role is not running under elevated executionContext, // this line will result in exception. serverManager.CommitChanges();More Information
Exercise 4: Securing Windows Azure with SSL
http://msdn.microsoft.com/en-us/gg271302



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Kostas Christodoulou reported availability of an Application Logo Sample for Visual Studio LightSwitch on 2/22/2012:
[My] Application Logo post had the dazzling number of 4 questions regarding how to use the code. So as I promised to the last guy that asked how to use the extension class I created a small sample and uploaded to msdn's Lightswitch samples. You can find it here

Beth Massi (@bethmassi) posted a Trip Report–Techdays 2012 Netherlands on 2/21/2012:
Last week I had the pleasure of speaking again at Techdays Netherlands on Visual Studio LightSwitch. It’s my third time speaking there and the venue is top-notch at the World Forum in The Hague.
Check out all the session recordings for Techdays 2012 on Channel 9.
Introducing Visual Studio LightSwitch
My first session was in a big room that had about 100 people, almost all of them professional developers (they get paid to write code everyday). In this session we build my version of the Vision Clinic application from scratch, end-to-end, including security and deployment. We do write some code but only some simple business rules and calculated fields, and in the end we have a full-blown business application. The goal is to show what LightSwitch can do for you out of the box without having to know any details of the underlying .NET technologies upon which it is built. The recording is available on Channel 9. I suggest downloading the High Quality WMV:
Video Presentation: Introduction to Visual Studio LightSwitch
When I asked who had downloaded LightSwitch already, about 75% raised their hand. I also asked how many people were not professional developers (didn’t get paid to write code) and a few people raised their hand. This is pretty much what I expected since this was a pro developer conference. What I showed in the session is pretty close to what I included in the LightSwitch Training Kit. If you look under the “LightSwitch Overview” on the right-hand sidebar on the opening page of the training kit, you will see the complete demo code and demo script that you can use for training folks at your local user groups. :-)
I also brought some LightSwitch Reviewer’s Guides that marketing created to help convince business decision makers of the value of using LightSwitch. I ran out of them within seconds. I was able to snag the PDF version that you can download here:
Visual Studio LightSwitch Reviewer’s Guide
Here are some more resources to check out that will help introduce you to Visual Studio LightSwitch:
- LightSwitch Developer Center & Learning Center
- Beginning LightSwitch Article Series
- LightSwitch How Do I Videos
- LightSwitch Samples
- LightSwitch Team Blog
- LightSwitch Forums
LightSwitch Advanced Development and Customization Techniques
In this session I showed some more advanced development and different levels of customization that you can do to your LightSwitch applications. There were about 75 people in the session. I was happy to see so many people ready to dive deeper. I started off by showing the Contoso Construction sample application that has some more advanced features like:
- “Home screen” with static images and text and completely custom screen layouts
- Personalization with My Appointments displayed on log in
- “Show Map..” links under the addresses in data grids
- Picture editors
- Reporting via COM interop to Word
- Import data from Excel
- Composite LINQ queries to retrieve/aggregate data
- Custom report filter builder
- Sending email in response to events on the save pipeline
Download the Contoso Construction Sample
This session demonstrated the many levels of LightSwitch customization from simple code customizations and custom classes all the way to building full blown extensions. I showed how to access the code behind queries so you can write more advanced LINQ statements. I showed some advanced layout techniques for screens. I also showed how to flip to File View and access client and server projects in order to add your own classes. We injected some business rules into the save pipeline in order to email new, updated and canceled appointments. I also showed off the LightSwitch entity API to create an audit trail, and I demonstrated the free Office Integration Pack extension from Grid Logic to create reports with Word and import data from Excel.
I went through the 6 LightSwitch extensibility points. Shells, themes, screen templates, business types, custom controls and custom data sources. I showed how to install and enable them and then we built a theme. I showed off the LightSwitch Extensibility Toolkit which helps LightSwitch extension developers build these types of extensions. LightSwitch extensions are similar to other Visual Studio extensions, they are also VSIX packages you just click on to install and manage via the Tools –> Extension Manager. Here are some more resources for building LightSwitch extensions:
Also check out all the available LightSwitch extensions on Visual Studio Gallery. In particular I recommend these free ones:
As well as ones available from our partners, like:
- DevExpress XtraReports for LightSwitch
- ComponentOne OLAP for LightSwitch
- Document Toolkit for LightSwitch
LightSwitch Masterclass
I came in a day early to speak at a local user group outside of Amsterdam at Sogeti. It started off a little loud because we were sitting near the kitchen in the cafeteria but once they cleaned up, it quieted down. I didn’t mind too much because I’m good at yelling ;-).
There was about 50 people in the Masterclass and I demoed LightSwitch for about two and a half hours. I basically did the two presentations above back-to-back. I got a lot of good feedback and people seemed to really enjoy the class. Afterwards, a lot of us hung out and drank real Heineken and pondered the meaning of software development. Thanks to Michiel van Otegem for organizing this and thanks to all of those who attended.
Fun Stuff
Anytime you attend a conference you get to have fun, especially ones in the Netherlands ;-). One particular highlight was that I got to meet Jan Van der Haegen in person. Jan is a “LightSwitch hacker” so-to-speak and avid blogger. He is one of the most passionate people I know about software design and LightSwitch development. He drove 3 hours from Belgium to The Hague to see me and we chatted for hours. He gave me a lot of great feedback about how to improve the LightSwitch development experience and extensibility model.
We decided to tag along with Gill Clereen and Bart De Smet for dinner where we talked about life, code and everything in between. Jan and I shared a bottle of wine which was an awesome Petite Syrah from a local (to me) Livermore winery -- Concannon Vineyards. It was so cool to see it on the menu that I had to order it. However we didn’t finish it and in Europe they do not have the concept of take out (a.k.a. doggie bag). So they struggled to find a bag for us and ended up giving us one from what I’m told is a five and dime store. LOL. Here’s a (really bad) picture of Bart holding the bag, Jan in the middle and Gill on the right.
Until next time, Netherlands!



A bit underexposed, Beth.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
David Linthicum (@DavidLinthicum) asked “Application programming interfaces can make or break a cloud service -- so why are so many so poor?” in a deck to his Lack of good API design hurts the cloud article of 2/22/2012 for InfoWorld’s CloudComputing blog:
APIs are fine-grain services that may be called by other systems, applications, or even people to provide access to core cloud services. They can be used for putting information into cloud storage, pulling information from cloud storage, updating a cloud-based database, validating data, monitoring a network -- pretty much anything you can think of.
The trouble arises when you look at the design of these APIs. They vary from the well thought out, well tested, and correctly deployed to those that fall into the category of "What were they thinking?" Unfortunately, I see more "What were they thinking?" APIs these days than good ones.
There are two major tips to remember when you design an API for a cloud system, whether it's for simple storage or access to advanced high-performance computing cycles:
1. Fine-grain APIs and services trump coarse-grain varieties
There's always an argument around API functionality, but the best practice is to put very little in each API. Although this approach means you may need to invoke many primitive APIs at the same time to get the desired behavior, having more fine-grain APIs provides better control over cloud services.Some people claim there's a performance penalty for having multiple fine-grain services rather than a few coarse-grain ones. I rarely see such a penalty, so my advice is when in doubt, break it out. If you experience performance issues, you can then combine the fine-grain services and their API with a coarse-grain version.
2. Error processing and recovery should be designed in
APIs often fail, yet entire applications are written to depend on hundreds of APIs working together. If a single API fails, the entire system is hosed.API developers need to design in error handing and recovery mechanisms to deal with any potential failure, thus keeping the APIs and their services available. This means resources need to automatically restart, communication links need to be reestablished, and so on -- APIs and their services need to be resilient.
I suspect developers will put more effort into the design and the deployment of cloud APIs in the next few years. They'll simply have to: As public and private clouds get more pervasive, any vulnerable APIs will cause major problems whether for an internal cloud or an external cloud provider's business. I hope the cloud providers will meet the challenge sooner than later.

Lori MacVittie (@lmacvittie) explained The Conflation of Pay-as-you-Grow Hardware with On-Demand in a 2/22/2012 post:
Today’s post is brought to you by the Law of Diminishing Returns
The conflation of “pay-as-you-grow” with “on-demand” tends to cause confusion in the realm of networking and hardware. This is because of the way in which networking vendors have attempted to address the demand of organizations to pay only for what you use and to expand on-demand. The premise is that costs grow proportionally with capacity. In cloud computing organizations achieve this. As more capacity (resources from hardware) are necessary, they are provisioned an paid for. On-demand scale. The costs per transaction (or user) remain consistent with growth because there is a direct relationship between an increase in capacity (hardware resources such as memory and CPU) and capacity.
Networking vendors have attempted to simulate this capability through licensing based restrictions, allowing customers to initially provision resources at a much lower cost per transaction. The fallacy in this scheme is that, unlike cloud computing, no additional capacity (hardware resources) are ever provisioned. It is only the artificial limitation on the use of that capacity that is lifted at a price during the “growth” stage. Regardless of form-factor, this has a profound impact on the cost-per-transaction (or user) and, it turns out, on the scalability of performance.
The difference between the two models is significant. A “pay-as-you-grow” licensing-based model is like having a great kitchen that is segmented. You can only use a portion of it initially. If you need to use more because you’re giving a dinner party, you can pay for anther segment. The capabilities of the kitchen don’t change, just how much of you can use. Conversely, an on-demand model such as is offered by cloud lets you start out with a standard-sized kitchen, and if you need more room you tack on another kitchen, increasing not only size, but capability. If you’ve ever cooked for a large number of people, you know that one oven is likely not enough, but that’s what you get with “pay-as-you-grow” – one oven with initially limited access to it. The on-demand model gives you two. Or three, or as many as you need to make dinner for your guests.
SCALE of PERFORMANCE
While appearing more cost effective at the outset, “pay-as-you-grow” strategies do not always provide for the scalability of all performance metrics.
This is because licensing restrictions do not impact the underlying hardware capacity, and it is the hardware capacity and load that is always the most constraining factor for performance. As utilization of hardware increases, capacity degrades, albeit in some cases more slowly than others. The end result is that scale-by-license produces increasingly diminishing returns on performance. This is true whether we’re considering layer 4 throughput or layer 7 requests per second, two common key performance metrics for application delivery solutions.
The reason for this is simple – you aren’t increasing the underlying speed or capacity, you’re only the load that can be handled by the device. That means the overall utilization is higher, and it is nearly a priori knowledge in networking that as utilization (load) increases, performance and capacity degrade. The result is uneven scalability as you progress through the “upgrade” of licenses. You’re still paying the same amount per increase, but each increase nets you less capacity and slower performance than the upgrade before.
Conversely, a true on-demand model, based on the same premises as cloud computing, scales more linearly. Upgrading four times nets you four times the performance at four times the cost, because the resources available also increase four times. Cost and performance scale equally with a platform-based model. Licensing-based models do not, nay they cannot, because they aren’t scaling out resources, they’re only scaling out what portion of the resources you have access to.
It’s a subtle difference but one that has a significant impact on capacity and performance.
ECONOMY of SCALE
As has been noted, as utilization of hardware increases, capacity degrades.
When we start looking at the total costs when compared to the scaling value received, it becomes apparent that the pay-as-you-grow model produces increasing costs per transaction while the platform-based model produces decreasing costs per transaction. This is simply a matter of math. If each upgrade in a pay-as-you-grow model increases the overall cost by 1/4, but returns increasingly smaller performance and capacity gains, you end up with a higher cost per transaction. Conversely, a more linear on-demand approach actually ends up producing slightly lower or consistent costs per transaction.
The economy of scale is important as it’s a fairly common financial metric used to evaluate infrastructure as it directly translates into business costs and can be used to adjust pricing and facilitate estimated expenses.
This disparity is not one that is often considered up front, as it is usually the up-front, capital investment that is most important to the initial decision. This oversight, however, almost always proves to be problematic as it is rarely the case that an organization does not need additional capacity and performance, and thus the long-term costs of Pay-as-you-Grow result in a much poorer return on investment in terms of performance than a Platform-based scalability model.
DISRUPTION and CapEx
The arguments against a platform-based model generally consist of disruptiveness of upgrades and initial costs.
Disruption is a valid concern and it is almost always true that hardware-based devices require a certain amount of disruption to upgrade. The lifting of an artificially imposed limitation on the amount of existing hardware that can be utilized, conversely, does not. This is where the cloud computing on-demand (i.e. throw more (virtual) hardware at the problem) usually diverges from the on-demand model used to scale out networking hardware, such as an application delivery controller.
The introduction of virtual application delivery controllers and the ability to seamlessly scale out in a model similar to cloud computing eliminates the disruption-based argument. There do exist models and technology which closely models a cloud computing on-demand scalability strategy that are as non-disruptive as scaling out via a licensing-based model.
This leaves the initial cost argument, which generally boils down to a CapEx versus OpEx argument. You are going to pay over the long run, the question is whether you pay up front or over time and what the return on those investments will ultimately be.
Just don’t let the conflation of cloud computing’s on-demand with pay-as-you-grow licensing-based models obscure what those real costs will be.


Joannes Vermorel (@vermorel) answered Cloud questions from Syracuse University, NY in a 2/22/2012 post:
A few days ago, I received a couple of questions from a student of Syracuse University, NY who is writing a paper about cloud computing and virtualization. Questions are relatively broad, so I am taking the opportunity to directly post here the answers.
What was the actual technical and business impact of adopting cloud technology?
The technical impact was a complete rewrite of our codebase. It has been the large upgrade ever undertaken by Lokad, and it did span over 18 months, more or less mobilizing the entire dev workforce during the transition.
As far business is concerned, it did imply that most of the business of Lokad during 2010 (the peak of our cloud migration) has been stalled for a year or so. For a young company, 1 year of delay is a very long time.
On the upside, before the migration to the cloud, Lokad was stuck with SMBs. Serving any mid-large retail network was beyond our technical reach. With the cloud, processing super-large retail networks had become feasible.
What, if any, negative experience did Lokad encounter in the course of migrating to the cloud?
Back in 2009, when we did start to ramp up our cloud migration efforts, the primary problem was that none of us at Lokad had any in-depth experience of what the cloud implies as software architecture is concerned. Cloud computing is not just any kind of distributed computing, it comes with a rather specific mindset.
Hence, the first obstacle was to figure out by ourselves patterns and practices for enterprise software on the cloud. It has been a tedious journey to end-up with Lokad.CQRS which is roughly the 2nd generation of native cloud apps. We rewrote everything for the cloud once, and then we did it again to get sometime simpler, leaner, more maintainable, etc.
Then, at present time, most our recurring cloud problems come from integrations with legacy pre-Web enterprise software. For example, operating through VPNs from the cloud tends to be a huge pain. In contrast, modern apps that offer REST API are a much more natural fit for cloud apps, but those are still rare in the enterprise.
From your current perspective, what, if anything, would you have done differently?
Tough question, especially for a data analytics company such as Lokad where it can take 1 year to figure out the 100 magic lines of code that will let you outperform the competion. Obviously, if we had to rewrite again Lokad from scratch, it would take us much less time. However it would be dismissing that the bulk of the effort has been the R&D that made our forecasting technology cloud native.
- It took us too long to decide to ditch SQL entirely in favor of some native cloud storage (basically the Blob Storage offered by Windows Azure). [Emphasis added.]
- SOAP was a somewhat similar case. It took us a long time to give up on SOAP in favor of REST.
In both cases, the problem was that we had (or maybe it was just me) not been fully accepting the extent of the implications of a migration toward the cloud. We remained stuck for months with older paradigms that caused a lot of uneeded frictions. Giving up on those from Day 1 would have save a lot of efforts.

Brian Gracely (@bgracely) posted [NEW] Cloud Computing for Business Managers - Whiteboard Videos on 2/22/2012:
As a follow-up to the previous series of Cloud Computing whiteboard videos, primarily focused on the technology aspects, we decided to create some videos that speak to business managers. The topics include:
- IT is the New Marketing Engine
- Shadow IT - Building an IT overlay team
- Open Up Your Business Knowledge to the World (APIs, Open Data)
- Uncovering New Markets from Digital Noise (Big Data)
- Expensing Your IT Budget on a Credit Card? (OPEX vs. CAPEX)
- Build a Fence, Build a Team, Build a Community (Evolving IT)
We realize that these might turn off some of the technologists that listen to our podcast. We'll apologize in advance for that, but we believe that Cloud Computing is about more than just the technology. It's a shift in how the business uses technology (costs, flexibility) and how the business can leverage technology (connect with customers, analyze markets, etc.). If the business people don't understand this shift in their words, it will be very difficult for the new technologies to be adopted.
As always, you're feedback and suggestions on new videos is greatly appreciated.


Abishek Lal posted Azure Datacenter IP Ranges on 2/21/2012 to the Rock-Scissors-Paper-Cloud blog:
When using Window Azure Service Bus Relay Bindings, you need to open outbound TCP connections from on-premise servers. If your firewall configuration restricts outbound traffic, you will need to perform the addition step of opening your outbound TCP port range 9350-9353 to the IP range associated with your selected regional data center. Those IP ranges are listed below:
IP Ranges (updated as of 2/20/2012)
United States (South/Central)
65.55.80.0/20, 65.54.48.0/21, 65.55.64.0/20, 70.37.48.0/20, 70.37.64.0/18, 10.14.0.0/16, 10.115.0.0/16, 10.13.0.0/17, 10.13.128.0/18, 10.13.192.0/19, 65.52.32.0/21, 70.37.160.0/21, 157.55.176.0/20, 157.55.103.48/28, 10.186.64.0/18, 157.55.192.0/22, 157.55.103.32/28, 10.186.160.0/19, 157.55.196.0/22, 157.55.200.0/22. 157.55.153.224/28, 157.55.80.0/22, 157.55.84.0/22, 10.174.192.0/18
United States (North/Central)
207.46.192.0/20, 65.52.0.0/19, 65.52.192.0/19, 65.52.48.0/20, 209.240.220.0/23, 65.52.106.240/28, 65.52.106.16/28, 65.52.107.0/28, 65.52.106.224/28, 65.52.106.32/27, 65.52.106.64/27, 65.52.106.160/27, 65.52.106.192/27, 65.52.106.96/27, 65.52.106.128/27, 157.55.136.0/21, 10.26.0.0/17, 10.28.0.0/17, 10.28.128.0/17, 10.29.0.0/19, 157.55.160.0/20, 157.55.60.224/28, 10.186.0.0/18, 157.55.24.0/21, 157.55.208.0/21, 157.55.60.240/28, 10.186.128.0/19, 157.55.151.0/28, 157.55.216.0/22, 157.55.220.0/22, 157.55.73.32/28, 157.56.8.0/22, 157.56.12.0/22, 157.56.24.160/28, 65.52.232.0/22, 65.52.236.0/22, 157.56.24.176/28, 65.52.240.0/22, 65.52.244.0/22, 157.56.24.192/28, 157.56.28.0/22, 157.55.252.0/22, 10.174.128.0/18, 10.174.112.0/20, 10.114.128.0/17
United States (North/West)
10.7.0.0/17, 10.7.128.0/18, 10.7.192.0/19, 10.8.0.0/17, 10.114.67.160/27, 10.114.90.192/27, 10.114.70.0/23, 10.11.108.0/22, 10.11.112.0/21, 10.11.120.0/23, 10.114.82.0/23, 10.114.84.0/22, 65.55.25.112/28, 65.52.98.96/28, 65.52.103.128/27, 65.52.103.160/27, 65.52.98.96/28, 65.55.19.64/26, 65.52.99.0/24, 65.52.101.0/24, 65.55.25.96/28, 65.55.32.0/20, 70.37.0.0/19, 70.37.32.0/20, 209.240.212.0/23, 209.240.214.0/23, 209.240.218.0/23, 209.240.222.0/23, 10.21.192.0/18, 10.12.0.0/18, 10.12.128.0/17, 10.113.0.0/16Europe (North)
10.18.0.0/16, 213.199.160.0/20, 213.199.184.0/21, 10.17.0.0/17, 94.245.112.0/20, 94.245.88.0/21, 94.245.104.0/21, 65.52.64.0/20, 65.52.224.0/22, 65.52.228.0/22, 65.52.248.0/21, 10.3.0.0/17, 10.211.0.0/17, 10.211.128.0/17, 10.26.128.0/17, 157.55.3.0/24, 10.119.192.0/18, 168.63.32.0/19 Europe (West), 157.55.9.112/28, 157.55.12.0/28, 157.55.10.0/27, 157.55.10.32/27, 157.55.10.64/26, 10.53.144.0/20, 10.53.128.0/23, 94.245.97.0/24, 10.9.223.0/24, 10.112.192.0/23, 65.52.128.0/19, 10.61.0.0/16, 213.199.128.0/21, 213.199.180.112/28, 213.199.180.32/28, 213.199.180.96/28, 213.199.180.192/26, 213.199.183.0/24, 157.55.8.128/28, 157.55.8.144/28, 157.55.8.160/28, 157.55.8.64/26, 10.119.128.0/18, 168.63.0.0/19Asia (Southeast)
207.46.48.0/20, 111.221.16.0/21, 111.221.80.0/20, 111.221.96.0/20, 10.210.128.0/17, 10.210.20.0/22, 10.25.192.0/18, 10.15.0.0/16, 10.146.192.0/18, 168.63.160.0/19Asia (East)
10.9.252.0/24, 111.221.64.0/22, 207.46.72.0/26, 207.46.89.16/28, 207.46.95.32/27, 207.46.77.224/28, 10.23.184.0/22, 10.25.32.0/21, 65.52.160.0/19, 10.62.0.0/16, 207.46.87.0/24, 207.46.67.160/27, 207.46.67.192/27, 10.146.128.0/18, 168.63.128.0/19
I wonder why Abishek didn’t post this information to the Windows Azure blog.
Geva Perry (@gevaperry) asserted Cloud Computing Adoption is Bottom-Up in a 2/20/2012 post to his Thinking Out Cloud blog:
Last week I gave a keynote presentation at the CloudConnect conference in Santa Clara. The title of the presentation was: "Surprise! Your Enterprise is Already Using the Public Cloud."
Regular readers of this blog (or those who work with me) know I go on about this a lot: In the enterprise, cloud computing services (IaaS, PaaS, SaaS) are being adopted bottom-up. In other words, by the rank & file (developers, IT admins, business folk) and not top-down with a big strategic decision by the CIO.
That's what the keynote was about and the title was addressing the CIO, who is the last to know about cloud computing adoption within his or her organization.
If you're interested in this topic you can watch the video of the presentation (you need to scroll down to get to it) on the CloudConnect web site.
You can also read this very good summary of my talk by Rich Miller on Data Center Knowledge.
And finally, here are the actual slides via SlideShare: CloudConnect 2012: Surprise! Your enterprise is already using cloud computing
View more PowerPoint from gevaperry

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Desire Athow reported Breaking : Panda Security To Partner With Microsoft On Cloud-based Antivirus Services in a 2/22/2012 post to the ITProPortal blog:
Panda Security has teamed up with Microsoft to develop cloud-based antivirus security services based on Microsoft's own platform, Windows Azure, one more step away from desktop-bound security solutions towards SaaS ones.
The first product based on the partnership is Panda Cloud Office Protection 6.0, which is currently in beta and can be downloaded here.
The security company, which has remodelled itself as a Cloud Security one, says that it decided to migrate to Windows Azure in order to manage an even larger number of computers while rolling out the service to new territories and maintaining maximum uptime.
Panda Security says Windows Azure reduces the time it requires to deploy a new product version, cuts down operating and maintenance costs by nearly a third, enhances user-perceived application performance and improves certification and quality assurance processes.
The sixth version of Panda Cloud Office Protection allows devices (PCs, Servers and corporate laptops) to be managed remotely from anywhere through its web-based console and includes the ability to block dangerous malware activity.


<Return to section navigation list>
Cloud Computing Events
Jeremy Crittendon reported the availability of CloudConnect 2012 Free Presentations in *.pdf format in a 2/22/2011 message:
Tuesday, February 14 9:00 AM–11:00 AM Presentation], Author, Thinking Out Cloud
Keynote Speaker - Jesse Robbins [Keynote Speaker - Lew Tucker [Keynote Speaker - Bill Gillis [Keynote Speaker - Alistair Croll [Keynote Speaker - Becky Swain [Keynote Speaker - Jan Jackman [11:15 AM–12:15 PM 12:40 PM–1:00 PM 1:15 PM–1:35 PM 1:15 PM–2:15 PM 3:00 PM–3:20 PM 3:35 PM–3:55 PM 3:45 PM–4:30 PM Wednesday, February 15 9:00 AM–11:00 AM 11:15 AM–12:15 PM 12:40 PM–1:00 PM 3:35 PM–3:55 PM 3:45 PM–4:30 PM
Cihan Biyikoglu (@cihangirb) will present “Inside SQL Azure: Self Governing, Self-Healing, Massively Scalable Database Service in the Cloud” as one of the 12 Hours of SQL Server presentation at 22:12 to 23:12 CET on 2/24/2012:
Cihan Biyikoglu
is a Program Manager in SQL Azure covering the programmability surface for SQL Azure. These days, Cihan is focused on SQL Azure enabling scale-out programmability models for SQL Azure through a new concept called Federations. Prior to joining the SQL Azure team, Cihan was the program manager at Microsoft HealthVault platform and SQL Server as part of the SQLCAT team. Earlier, Cihan also worked on database technologies including Illustra and Informix Dynamic Server at Informix. Cihan Biyikoglu has a masters in Database Systems from University of Westminster in the UK and Computer Engineering degree from Yildiz Technical University in Turkey.

Andy Cross (@andybareweb) reported a UKWAUG Meeting 6th March, Yossi Dahan on Mobile Development and Windows Azure on 2/22/2012:
Finding it easier these days to use wordpress than our self made site “blog”! Forgive the user group advert therefore where we should definitely have a content post update. The truth is that Andy and I have had our heads down working on our first project which is a grid for Excel power users in the cloud. We’ve been dissecting HPC Server and Azure and really not liking what we’ve seen so have tried to supplement and add protocols to make it more friendly. A tall order whichever way you look at it. Anyway, we’ll be presenting on HPC Server and Azure in “6 weeks of azure”, an excellent Microsoft program run by evangelist Eric Nelson. Additionally we’ll be discussing “Big Compute and Big Data” for half an hour in our Techdays presentation on the 21st March, we have some of you for 2 hours and we’ll probably cover a whole host of deployment, diagnostics and other types of problem you’ll encounter in the real world. Maybe we’ll look at some strategies and common requests to build and deploy things too.
Anyway, this post is to let everyone know that Yossi Dahan, esteemed Microsoft Biztalk and Integration architect will be discussing Mobile Development with Windows Azure on the 6th March in Liverpool Street. This will be a great talk and Yossi will be going through WP7 demos and also relaying how you can build Azure applications using Android and iOS platforms.
In addition we have Simon Hart, former MVP and current architect for Gold Partner Smart421 showing us a pub/sub reference architecture using services and Becky Martin of Integrity Software doing a short tip of the month on Continuous Integration and Agile with Windows Azure.
If you haven’t registered with the site already please register here to attend http://www.ukwaug.net (on the Register page funnily enough!) and then click on the March meeting. If you do need to cancel for any reason try and let us know 24 hours before as we have limitations on numbers and can always accept someone else.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) posted Amazon Simple Workflow - Cloud-Based Workflow Management on 2/21/2012:
Simple Workflow
Today we are introducing the Amazon Simple Workflow service, SWF for short. This new service gives you the ability to build and run distributed, fault-tolerant applications that span multiple systems (cloud-based, on-premise, or both). Amazon Simple Workflow coordinates the flow of synchronous or asynchronous tasks (logical application steps) so that you can focus on your business and your application instead of having to worry about the infrastructure.
Why?
We want to make it easier for you to build distributed, fault-tolerant, cloud-based applications! In our own work with systems of this type, we have learned quite a bit. For example:
- The applications often incorporate a workflow -- A series of steps that must take place in a predefined order, with opportunities to adjust the workflow as needed by making decisions and by handling special cases in a structured fashion.
- The workflow often represents a business process - Think about all of the steps involved in processing an order on your favorite e-commerce site. Charging your credit card, updating your order history, arranging for the items to be shipped, shipping the items, tracking the shipment, replenishing inventory, handling returns, and much more.
- Processes can be complex - Years ago, I was told that a single Amazon.com order needed to make its way through at least 40 different states or steps before it was considered complete. I am sure that the process has become even more complex over time.
- Flexibility is key - Earlier attempts to specify and codify a workflow in declarative form have proven to be rigid and inflexible. At some point, procedural code becomes a necessity.
- Ease of use is important - It should be possible to design and implement these applications without spending a lot of time acquiring specialized skills.
You can use Simple Workflow to handle many types of multi-stage operations including traditional business processes (handling an order or adding a new employee), setting up a complex multi-tiered application, or even handling the decision-making process for a multi-player online game.
Some Definitions
Let's start by defining a couple of terms:
- A Workflow is the automation of a business process.
- A Domain is a collection of related Workflows.
- Actions are the individual tasks undertaken to carry out a Workflow.
- Activity Workers are the pieces of code that actually implement the tasks. Each kind of Worker has its own Activity Type.
- A Decider implements a Workflow's coordination logic.
Let's say that we have an image processing workflow, and that it has the following tasks:
- Accept uploaded file.
- Store file in Amazon S3.
- Validate file format and size.
- Use Amazon Mechanical Turk to classify the image.
- If the image is unacceptable, send an error message using Amazon SES and terminate the workflow.
- If the image is acceptable, check the user's balance in the accounting system.
- Launch an EC2 instance.
- Wait for the EC2 instance to be ready, and then configure it (keys, packages, and so forth).
- Convert the image to PNG format and generate a series of image thumbnails.
- Upload the PNG image and the thumbnails to Amazon S3.
- Adjust the user's balance in the accounting system.
- Create an entry in the appropriate database table.
- Send a status message to the user, again using Amazon SES.
Tasks 1 through 12 make up the Workflow. Each of the tasks is an Action. The code to implement each action is embodied in a specific Activity Worker.
The workflow's Decider is used to control the flow of execution from task to task. In this case, the Decider would make decisions based on the results of steps 4 (Mechanical Turk) and 6 (balance check). There's a nice, clean separation between the work to be done and the steps needed to do it.
Here's a picture:
What Does Simple Workflow Do?
Simple Workflow provides you with the infrastructure that you need to implement workflows such as the one above. It does all of the following (and a lot more):
- Stores metadata about a Workflow and its component parts.
- Stores tasks for Workers and queue them until a Worker needs them.
- Assigns tasks to Workers.
- Routes information between executions of a Workflow and the associated Workers.
- Tracks the progress of Workers on Tasks, with configurable timeouts.
- Maintains workflow state in a durable fashion.
Because the Workers and Deciders are both stateless, you can respond to increased traffic by simply adding additional Workers and Deciders as needed. This could be done using the Auto Scaling service for applications that are running on Amazon EC2 instances the AWS cloud.
Your Workers and your Deciders can be written in the programming language of your choice, and they can run in the cloud (e.g. on an Amazon EC2 instance), in your data center, or even on your desktop. You need only poll for work, handle it, and return the results to Simple Workflow. In other words, your code can run anywhere, as long as it can "see" the Amazon Simple Workflow HTTPS endpoint. This gives you the flexibility to incorporate existing on-premise systems into new, cloud-based workflows. Simple Workflow lets you do "long polling" to reduce network traffic and unnecessary processing within your code. With this model, requests from your code will be held open for up to 60 seconds if necessary.
Inside the Decider
Your Decider code simply polls Simple Workflow asking for decisions to be made, and then decides on the next step. Your code has access to all of the information it needs to make a decision including the type of the workflow and a detailed history of the prior steps taken in the workflow. The Decider can also annotate the workflow with additional data.Inside the Workers
Your Worker code also polls Simple Workflow, in effect asking for work that needs to be done. It always polls with respect to one or more Task Lists, so that one Worker can participate in multiple types of Workflows if desired. It pulls work from Task Lists, does the work, updates the Workflow's status, and goes on to the next task. In situations that involve long-running tasks, the worker can provide a "heartbeat" update to Simple Workflow. Deciders can insert Markers into the execution history of a Workflow for checkpointing or auditing purposes.Timeouts, Signals, and Errors
Simple Workflow's Timeouts are used to ensure that an execution of a Workflow runs correctly. They can be set as needed for each type of Workflow. You have control over the following timeouts:
- Workflow Start to Close - how long an execution can take to complete.
- Decision Task Start to Close - How long a Decider can take to complete a decision task.
- Activity Task Start to Close - How long an Activity Worker can take to process a task of a given Activity Type.
- Activity Task Heartbeat - How long an Activity Worker can run without providing its status to Simple Workflow.
- Activity Task Schedule to Start - How long Simple Workflow waits before timing out a task if no workers are available to perform the task.
- Activity Task Schedule to Close - How long Simple Workflow will wait between the time a task is scheduled to the time that it is complete.
Signals are used to provide out-of-band information to an execution of a Workflow. You could use a signal to cancel a Workflow, tell it that necessary data is ready, or to provide information about an emergent situation. Each Signal is added to the Workflow's execution history and the Workflow's Decider controls what happens next.
Simple Workflow will make sure that execution of each Workflow proceeds as planned, using the Timeouts mentioned above to keep the Workflow from getting stuck if a task takes too long or if there is no activity code running.
Getting Started
Here's what you need to do to get started with Amazon Simple Workflow:
- Write your Worker(s) using any programming language.
- Write your Decider, again in any programming language.
- Register the Workflow and the Activities.
- Run the Workers and the Decider on any host that can "see" the Simple Workflow endpoint.
- Initiate execution of a Workflow.
- Monitor progress of the Workflow using the AWS Management Console.
The AWS Flow Framework
In order to make it even easier for you to get started with Amazon Simple Workflow, the AWS SDK for Java now includes the new AWS Flow Framework. This new framework includes a number of programming constructs that abstract out a number of task coordination details. For example, it uses a programming model based on Futures to handle dependencies between tasks. Initiating a Worker task is as easy as making a method call, and the framework takes care of the Workers and the Decision Tasks behind the scenes.Simple Workflow API Basics
You can build your Workflow, your Workers, and your Decider, with just a handful of Simple Workflow APIs. Here's what you need to know to get started:
- Workflow Registration - The RegisterDomain, RegisterWorkflowType, and RegisterActivityType calls are used to register the various components that make up a Workflow.
- Implementing Deciders and Workers - The PollForDecisionTask call is used to fetch decision tasks, and the RespondDecisionTaskCompleted call is used to signal that a decision task has been completed. Similarly, the PollForActivityTask call is used to fetch activity tasks and the RespondActivityTaskCompleted call is used to signal that an activity task is complete.
- Starting a Workflow - The StartWorkflowExecution call is used to get a Workflow started.
The Amazon Simple Workflow API Reference contains information about these and other APIs.
AWS Management Console Support
The AWS Management Console includes full support for Amazon Simple Workflow. Here's a tour, starting with the main (dashboard) page:
Register a workflow domain
Register a workflow for a workflow domain
Register an activity within a workflow:
Initiate execution of a workflow:
Provide input data to an execution:
See all of the currently executions of a given workflow:
Pricing
Like all of the services in the AWS Cloud, Amazon Simple Workflow is priced on an economical, pay-as-you-go basis. First, all AWS customers can get started for free. You can initiate execution of 1,000 Workflows and 10,000 tasks per month and you can keep them running for a total of 30,000 workflow-days (one workflow active for one day is equal to one workflow-day).Beyond that, there are three pricing dimensions:
- Executions - You pay $0.0001 for every Workflow execution, and an additional $0.000005 per day if they remain active for more than 24 hours.
- Tasks, Signals, and Markers - You pay $0.000025 for every task execution, timer, signal, and marker.
- Bandwidth - You pay $0.10 for the first Gigabyte of data transferred in. There is no charge for the first Gigabyte of data transferred out, and the usual tiered AWS charges after that.
Amazon Simple Workflow in Action
Here are some ways that people are already putting Amazon Simple Workflow to use:
- RightScale is using it to ensure fault-tolerant execution of their server scaling workflow. Read Thorsten von Eicken's post, RightScale Server Orchestration and Amazon SWF Launch, for more information.
- NASA uses Simple Workflow to coordinate the daily image processing tasks for the Mars Exploration Rovers. Read our new case study, NASA JP and Amazon SWF, to see how they do it.
- Sage Bionetworks coordinates complex, heterogeneous scientific workflows. Check out the new case study, Sage Bionetworks and Amazon SWF, for complete information.
Go With the Flow
I am very interested in hearing about the applications and Workflows that you implement with Amazon Simple Workflow. Please feel free to leave a comment or to send me some email.


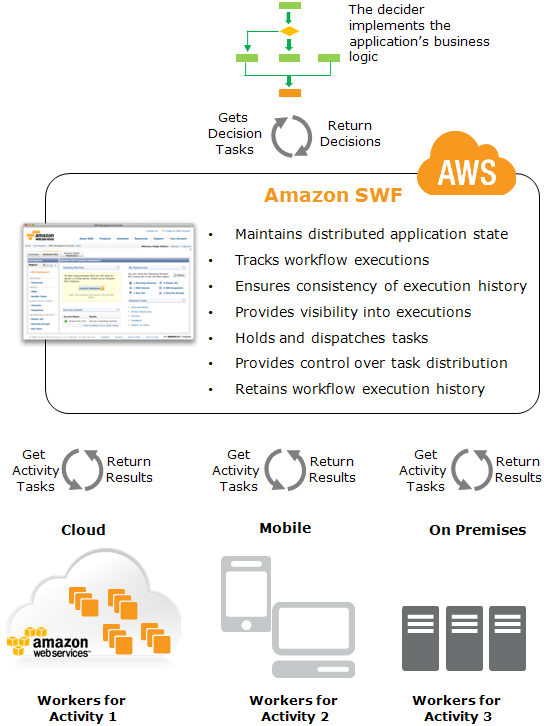







Amazon SWF appears to be AWS’ answer to Microsoft’s Workflow Foundation Activity Pack for Windows Azure CTP 1 released on 9/1/2011.
Werner Vogels (@werner) added Expanding the Cloud – The Amazon Simple Workflow Service to his All Things Distributed blog on 2/22/2012:
Today AWS launched an exciting new service for developers: the Amazon Simple Workflow Service. Amazon SWF is an orchestration service for building scalable distributed applications. Often an application consists of several different tasks to be performed in particular sequence driven by a set of dynamic conditions. Amazon SWF makes it very easy for developers to architect and implement these tasks, run them in the cloud or on premise and coordinate their flow. Amazon SWF manages the execution flow such that the tasks are load balanced across the registered workers, that inter-task dependencies are respected, that concurrency is handled appropriately and that child workflows are executed.
A growing number of applications are relying on asynchronous and distributed processing, with scalability of the application as the primary motivation. By designing autonomous distributed components, developers get the flexibility to deploy and scale out parts of the application independently as load increases. The asynchronous and distributed model has the benefits of loose coupling and selective scalability, but it also creates new challenges. Application developers must coordinate multiple distributed components to get the desired results. They must deal with the increased latency and unreliability inherent in remote communication. Components may take extended periods of time to complete tasks, requests may fail and errors originating from remote systems must be handled. Today, to accomplish this, developers are forced to write complicated infrastructure that typically involves message queues and databases along with complex logic to synchronize them. All this ‘plumbing’ is extraneous to business logic and makes the application code unnecessarily complicated and hard to maintain.
Amazon SWF enables applications to be built by orchestrating tasks coordinated by a decider process. Tasks represent logical units of work and are performed by application components that can take any form, including executable code, scripts, web service calls, and human actions. Developers have full control over implementing and orchestrating tasks, without worrying about underlying complexities such as tracking their progress and keeping their state.
Developers implement workers to perform tasks. They run their workers either on cloud infrastructure, such as Amazon EC2, or on-premise. Tasks can be long-running, may fail, may timeout and may complete with varying throughputs and latencies. Amazon SWF stores tasks for workers, assigns them when workers are ready, tracks their progress, and keeps their latest state, including details on their completion. To orchestrate tasks, developers write programs that get the latest state of tasks from Amazon SWF and use it to initiate subsequent tasks in an ongoing manner. Amazon SWF maintains an application’s execution state durably so that the application can be resilient to failures in individual application components.
An important feature of Amazon SWF is the auditability; Amazon SWF gives visibility into the execution of each step in the application. The Management Console and APIs let you monitor all running executions of the application. The customer can zoom in on any execution to see the status of each task and its input and output data. To facilitate troubleshooting and historical analysis, Amazon SWF retains the history of executions for any number of days that the customer cab specify, up to a maximum of 90 days.
Amazon SWF provides a collection of very powerful building blocks that also can be used to build higher-level execution engines. Some of our early customers used Amazon SWF to implement their domain specific languages (DL) for specialized business process execution, This is an area where I think the availability of Amazon SWF will drive a lot of innovation.
As part of the AWS SDK, the AWS Flow Framework helps developers create Amazon SWF based application quickly and easily. The Java version of the SDK includes really cool integration at the language level, making it easy for developers to automatically transform java code into tasks, create the right dependencies, and manage the execution of the workflow. This brings the power that some languages with built-in distribution and concurrency like Erlang offer to Java.
For more insight into workflow execution, task coordination, task routing, task distribution, exception handling, child workflows, timers, signals, markers and much more see the Amazon SWF detail page. More information about the SDK see the developers guide. As always The AWS developer blog has additional details. At the Rightscale blog Thorsten von Eicken talks about their use of SWF.


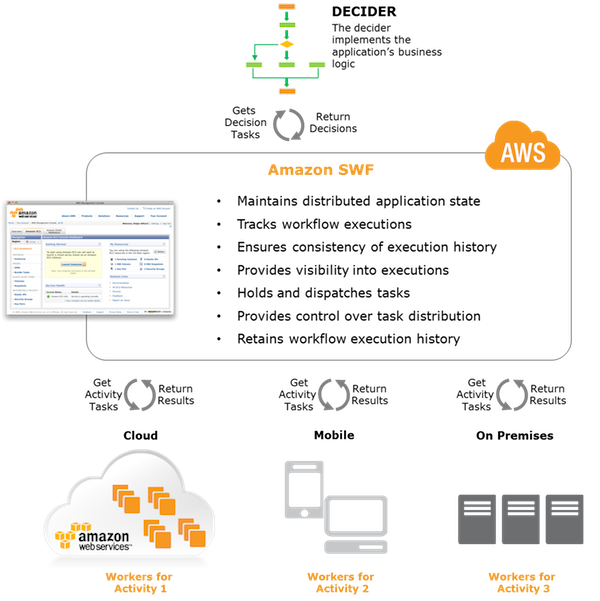
Randy Bias (@randybias) posted Architectures for open and scalable clouds #ccevent on 2/21/2012:
Below is [a link to] the presentation I gave at this year’s 2012 Cloud Connect in Santa Clara. It was extremely well received. Better than I expected really, given it’s last minute nature. For some, I think a lot of the architectural and design patterns aren’t new, but perhaps they haven’t been portrayed in quite this way before. For others, a lot of these ideas and content are new.
Regardless, I got some props from Adrian Cockcroft, one of the primary cloud architects for Netflix. I think very highly of Netflix approach to re-architecting their application to be ‘cloud-ready’ and to achieve high levels of uptime on AWS EC2. If Adrian thinks this is right on, then it must be.
Enjoy.
Architectures for open and scalable clouds
View more presentations from Randy Bias

<Return to section navigation list>

















0 comments:
Post a Comment