Windows Azure and Cloud Computing Posts for 2/13/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

• Updated 2/16/2012 with a few new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services, HPC
Avkash Chauhan (@avkashchauhan) posted Keys to understand relationship between MapReduce and HDFS on 2/15/2012:
Map Task (HDFS data localization):
The unit of input for a map task is an HDFS data block of the input file. The map task functions most efficiently if the data block it has to process is available locally on the node on which the task is scheduled. This approach is called HDFS data localization.
An HDFS data locality miss occurs if the data needed by the map task is not available locally. In such a case, the map task will request the data from another node in the cluster: an operation that is expensive and time consuming, leading to inefficiencies and, hence, delay in job completion.
Clients, Data Nodes, and HDFS Storage:
Input data is uploaded to the HDFS file system in either of following two ways:
- An HDFS client has a large amount of data to place into HDFS.
- An HDFS client is constantly streaming data into HDFS.
Both these scenarios have the same interaction with HDFS, except that in the streaming case, the client waits for enough data to fill a data block before writing to HDFS. Data is stored in HDFS in large blocks, generally 64 to 128 MB or more in size. This storage approach allows easy parallel processing of data.
HDFS-SITE.XML
<property> <name>dfs.block.size</name> <value>134217728</value> ç 128MB Block size </property>OR
<property> <name>dfs.block.size</name> <value>67108864</value> ç 64MB Block size (Default is this value is not set) </property>Block Replication Factor:
During the process of writing to HDFS, the blocks are generally replicated to multiple data nodes for redundancy. The number of copies, or the replication factor, is set to a default of 3 and can be modified by the cluster administrator as below:
HDFS-SITE.XML
<property> <name>dfs.replication</name> <value>3</value> </property>When the replication factor is three, HDFS’s placement policy is to:
- Put one replica on one node in the local rack,
- Another on a node in a different (remote) rack,
- Last on a different node in the same remote rack.
When a new data block is stored on a data node, the data node initiates a replication process to replicate the data onto a second data node. The second data node, in turn, replicates the block to a third data node, completing the replication of the block.
With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.

Steve Peschka continued his series with The Azure Custom Claim Provider for SharePoint Project Part 2 on 2/14/2012:
In Part 1 of this series, I briefly outlined the goals for this project, which at a high level is to use Windows Azure table storage as a data store for a SharePoint custom claims provider. The claims provider is going to use the CASI Kit to retrieve the data it needs from Windows Azure in order to provide people picker (i.e. address book) and type in control name resolution functionality. Now let’s expand on this scenario a little more.
This type of solution plugs in pretty nicely to a fairly common scenario, which is when you want a minimally managed extranet. So for example, you want your partners or customers to be able to hit a website of yours, request an account, and then be able to automatically “provision” that account…where “provision” can mean a lot of different things to different people. We’re going to use that as the baseline scenario here, but of course, let our public cloud resources do some of the work for us.
Let’s start by looking at the cloud components were going to develop ourselves:
- A table to keep track of all the claim types we’re going to support
- A table to keep track of all the unique claim values for the people picker
- A queue where we can send data that should be added to the list of unique claim values
- Some data access classes to read and write data from Azure tables, and to write data to the queue
- An Azure worker role that is going to read data out of the queue and populate the unique claim values table
- A WCF application that will be the endpoint through which the SharePoint farm communicates to get the list of claim types, search for claims, resolve a claim, and add data to the queue
Now we’ll look at each one in a little more detail.
Claim Types Table
The claim types table is where we’re going to store all the claim types that our custom claims provider can use. In this scenario we’re only going to use one claim type, which is the identity claim – that will be email address in this case. You could use other claims, but to simplify this scenario we’re just going to use the one. In Azure table storage you add instances of classes to a table, so we need to create a class to describe the claim types. Again, note that you can instances of different class types to the same table in Azure, but to keep things straightforward we’re not going to do that here. The class this table is going to use looks like this:
namespace AzureClaimsData { public class ClaimType : TableServiceEntity { public string ClaimTypeName { get; set; } public string FriendlyName { get; set; } public ClaimType() { } public ClaimType(string ClaimTypeName, string FriendlyName) { this.PartitionKey = System.Web.HttpUtility.UrlEncode(ClaimTypeName); this.RowKey = FriendlyName; this.ClaimTypeName = ClaimTypeName; this.FriendlyName = FriendlyName; } } }I’m not going to cover all the basics of working with Azure table storage because there are lots of resources out there that have already done that. So if you want more details on what a PartitionKey or RowKey is and how you use them, your friendly local Bing search engine can help you out. The one thing that is worth pointing out here is that I am Url encoding the value I’m storing for the PartitionKey. Why is that? Well in this case, my PartitionKey is the claim type, which can take a number of formats: urn:foo:blah, http://www.foo.com/blah, etc. In the case of a claim type that includes forward slashes, Azure cannot store the PartitionKey with those values. So instead we encode them out into a friendly format that Azure likes. As I stated above, in our case we’re using the email claim so the claim type for it is http://schemas.xmlsoap.org/ws/2005/05/identity/claims/emailaddress.
Unique Claim Values Table
The Unique Claim Values table is where all the unique claim values we get our stored. In our case, we are only storing one claim type – the identity claim – so by definition all claim values are going to be unique. However I took this approach for extensibility reasons. For example, suppose down the road you wanted to start using Role claims with this solution. Well it wouldn’t make sense to store the Role claim “Employee” or “Customer” or whatever a thousand different times; for the people picker, it just needs to know the value exists so it can make it available in the picker. After that, whoever has it, has it – we just need to let it be used when granting rights in a site. So, based on that, here’s what the class looks like that will store the unique claim values:
namespace AzureClaimsData { public class UniqueClaimValue : TableServiceEntity { public string ClaimType { get; set; } public string ClaimValue { get; set; } public string DisplayName { get; set; } public UniqueClaimValue() { } public UniqueClaimValue(string ClaimType, string ClaimValue, string DisplayName) { this.PartitionKey = System.Web.HttpUtility.UrlEncode(ClaimType); this.RowKey = ClaimValue; this.ClaimType = ClaimType; this.ClaimValue = ClaimValue; this.DisplayName = DisplayName; } } }There are a couple of things worth pointing out here. First, like the previous class, the PartitionKey uses a UrlEncoded value because it will be the claim type, which will have the forward slashes in it. Second, as I frequently see when using Azure table storage, the data is denormalized because there isn’t a JOIN concept like there is in SQL. Technically you can do a JOIN in LINQ, but so many things that are in LINQ have been disallowed when working with Azure data (or perform so badly) that I find it easier to just denormalize. If you folks have other thoughts on this throw them in the comments – I’d be curious to hear what you think. So in our case the display name will be “Email”, because that’s the claim type we’re storing in this class.
The Claims Queue
The claims queue is pretty straightforward – we’re going store requests for “new users” in that queue, and then an Azure worker process will read it off the queue and move the data into the unique claim values table. The primary reason for doing this is that working with Azure table storage can sometimes be pretty latent, but sticking an item in a queue is pretty fast. Taking this approach means we can minimize the impact on our SharePoint web site.
Data Access Classes
One of the rather mundane aspects of working with Azure table storage and queues is you always have to write you own data access class. For table storage, you have to write a data context class and a data source class. I’m not going to spend a lot of time on that because you can read reams about it on the web, plus I’m also attaching my source code for the Azure project to this posting so you can [hack] at it all you want.
There is one important thing I would point out here though, which is just a personal style choice. I like to break out all my Azure data access code out into a separate project. That way I can compile it into its own assembly, and I can use it even from non-Azure projects. For example, in the sample code I’m uploading you will find a Windows form application that I used to test the different parts of the Azure back end. It knows nothing about Azure, other than it has a reference to some Azure assemblies and to my data access assembly. I can use it in that project and just as easily in my WCF project that I use to front-end the data access for SharePoint.
Here are some of the particulars about the data access classes though:
- I have a separate “container” class for the data I’m going to return – the claim types and the unique claim values. What I mean by a container class is that I have a simple class with a public property of type List<>. I return this class when data is requested, rather than just a List<> of results. The reason I do that is because when I return a List<> from Azure, the client only gets the last item in the list (when you do the same thing from a locally hosted WCF it works just fine). So to work around this issue I return claim types in a class that looks like this:
namespace AzureClaimsData { public class ClaimTypeCollection { public List<ClaimType> ClaimTypes { get; set; } public ClaimTypeCollection() { ClaimTypes = new List<ClaimType>(); } } }And the unique claim values return class looks like this:namespace AzureClaimsData { public class UniqueClaimValueCollection { public List<UniqueClaimValue> UniqueClaimValues { get; set; } public UniqueClaimValueCollection() { UniqueClaimValues = new List<UniqueClaimValue>(); } } }
- The data context classes are pretty straightforward – nothing really brilliant here (as my friend Vesa would say); it looks like this:
namespace AzureClaimsData { public class ClaimTypeDataContext : TableServiceContext { public static string CLAIM_TYPES_TABLE = "ClaimTypes"; public ClaimTypeDataContext(string baseAddress, StorageCredentials credentials) : base(baseAddress, credentials) { } public IQueryable<ClaimType> ClaimTypes { get { //this is where you configure the name of the table in Azure Table Storage //that you are going to be working with return this.CreateQuery<ClaimType>(CLAIM_TYPES_TABLE); } } } }
- In the data source classes I do take a slightly different approach to making the connection to Azure. Most of the examples I see on the web want to read the credentials out with some reg settings class (that’s not the exact name, I just don’t remember what it is). The problem with that approach here is that I have no Azure-specific context because I want my data class to work outside of Azure. So instead I just create a Setting in my project properties and in that I include the account name and key that is needed to connect to my Azure account. So both of my data source classes have code that looks like this to create that connection to Azure storage:
private static CloudStorageAccount storageAccount; private ClaimTypeDataContext context; //static constructor so it only fires once static ClaimTypesDataSource() { try { //get storage account connection info string storeCon = Properties.Settings.Default.StorageAccount; //extract account info string[] conProps = storeCon.Split(";".ToCharArray()); string accountName = conProps[1].Substring(conProps[1].IndexOf("=") + 1); string accountKey = conProps[2].Substring(conProps[2].IndexOf("=") + 1); storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); } catch (Exception ex) { Trace.WriteLine("Error initializing ClaimTypesDataSource class: " + ex.Message); throw; } } //new constructor public ClaimTypesDataSource() { try { this.context = new ClaimTypeDataContext(storageAccount.TableEndpoint.AbsoluteUri, storageAccount.Credentials); this.context.RetryPolicy = RetryPolicies.Retry(3, TimeSpan.FromSeconds(3)); } catch (Exception ex) { Trace.WriteLine("Error constructing ClaimTypesDataSource class: " + ex.Message); throw; } }
- The actual implementation of the data source classes includes a method to add a new item for both a claim type as well as unique claim value. It’s very simple code that looks like this:
//add a new item public bool AddClaimType(ClaimType newItem) { bool ret = true; try { this.context.AddObject(ClaimTypeDataContext.CLAIM_TYPES_TABLE, newItem); this.context.SaveChanges(); } catch (Exception ex) { Trace.WriteLine("Error adding new claim type: " + ex.Message); ret = false; } return ret; }One important difference to note in the Add method for the unique claim values data source is that it doesn’t throw an error or return false when there is an exception saving changes. That’s because I fully expect that people mistakenly or otherwise try and sign up multiple times. Once we have a record of their email claim though any subsequent attempt to add it will throw an exception. Since Azure doesn’t provide us the luxury of strongly typed exceptions, and since I don’t want the trace log filling up with pointless goo, I don’t worry about it when that situation occurs.
- Searching for claims is a little more interesting, only to the extent that it exposes again some things that you can do in LINQ, but not in LINQ with Azure. I’ll add the code here and then explain some of the choices I made:
public UniqueClaimValueCollection SearchClaimValues(string ClaimType, string Criteria, int MaxResults) { UniqueClaimValueCollection results = new UniqueClaimValueCollection(); UniqueClaimValueCollection returnResults = new UniqueClaimValueCollection(); const int CACHE_TTL = 10; try { //look for the current set of claim values in cache if (HttpRuntime.Cache[ClaimType] != null) results = (UniqueClaimValueCollection)HttpRuntime.Cache[ClaimType]; else { //not in cache so query Azure //Azure doesn't support starts with, so pull all the data for the claim type var values = from UniqueClaimValue cv in this.context.UniqueClaimValues where cv.PartitionKey == System.Web.HttpUtility.UrlEncode(ClaimType) select cv; //you have to assign it first to actually execute the query and return the results results.UniqueClaimValues = values.ToList(); //store it in cache HttpRuntime.Cache.Add(ClaimType, results, null, DateTime.Now.AddHours(CACHE_TTL), TimeSpan.Zero, System.Web.Caching.CacheItemPriority.Normal, null); } //now query based on criteria, for the max results returnResults.UniqueClaimValues = (from UniqueClaimValue cv in results.UniqueClaimValues where cv.ClaimValue.StartsWith(Criteria) select cv).Take(MaxResults).ToList(); } catch (Exception ex) { Trace.WriteLine("Error searching claim values: " + ex.Message); } return returnResults; }The first thing to note is that you cannot use StartsWith against Azure data. So that means you need to retrieve all the data locally and then use your StartsWith expression. Since retrieving all that data can be an expensive operation (it’s effectively a table scan to retrieve all rows), I do that once and then cache the data. That way I only have to do a “real” recall every 10 minutes. The downside is that if users are added during that time then we won’t be able to see them in the people picker until the cache expires and we retrieve all the data again. Make sure you remember that when you are looking at the results.
Once I actually have my data set, I can do the StartsWith, and I can also limit the amount of records I return. By default SharePoint won’t display more than 200 records in the people picker so that will be the maximum amount I plan to ask for when this method is called. But I’m including it as a parameter here so you can do whatever you want.
The Queue Access Class
Honestly there’s nothing super interesting here. Just some basic methods to add, read and delete messages from the queue.
Azure Worker Role
The worker role is also pretty non-descript. It wakes up every 10 seconds and looks to see if there are any new messages in the queue. It does this by calling the queue access class. If it finds any items in there, it splits the content out (which is semi-colon delimited) into its constituent parts, creates a new instance of the UniqueClaimValue class, and then tries adding that instance to the unique claim values table. Once it does that it deletes the message from the queue and moves to the next item, until the it reaches the maximum number of message that can be read at one time (32), or there are no more messages remaining.
WCF Application
As described earlier, the WCF application is what the SharePoint code talks to in order to add items to the queue, get the list of claim types, and search for or resolve a claim value. Like a good trusted application, it has a trust established between it and the SharePoint farm that is calling it. This prevents any kind of token spoofing when asking for the data. At this point there isn’t any finer grained security implemented in the WCF itself. For completeness, the WCF was tested first in a local web server, and then moved up to Azure where it was tested again to confirm that everything works.
So that’s the basics of the Azure components of this solution. Hopefully this background explains what all the moving parts are and how they’re used. In the next part I’ll discuss the SharePoint custom claims provider and how we hook all of these pieces together for our “turnkey” extranet solution. The files attached to this posting contain all of the source code for the data access class, the test project, the Azure project, the worker role and WCF projects. It also contains a copy of this posting in a Word document, so you can actually make out my intent for this content before the rendering on this site butchered it.
Attachment: Azure.zip

Avkash Chauhan (@avkashchauhan) described Hadoop Performance: How storage disk types in individual node will impact the job performance? in a 2/14/2012 post:
As you may have already know that Hadoop Cluster is network and disk, IO intensive. Recently I was trying to run a test scenario where I decided to change SATA hard disk to a high performance SSD Disk while keeping the cluster hardware the same. I was running the terra sort test to validate if having high performance SSD should have impacted the overall performance. I found that having SSD instead of SATA improved the test performance by ~20%.
After that, I tried to dig information on internet about other tests done in similar fashion to see what could be the best practice in this direction. The following recommendation I found from Intel by choosing appropriate combination of disk throughput, in-memory caching, cluster deployment and multi CPU box.
- We found SSDs to be very effective for both read and write operation.
- In-memory caching resulted in better response through setting right amount of “HEAP CACHE” to achieve higher cache hit percentage.
- Cluster environment served the requests faster where as “CPU I/O WAIT” spikes were noticed.
- Overall most of the CPUs remain idle during the test.
In a test demonstrated by Intel, th[e] impact of going from two to four disks in a node (doubling the IO):
- Job was completed in half the time with previous IO
- Increasing server cost by 10% increased, sort performance by 100%.
If we consider MapReduce local directory where mapped files are stored locally, adding multiple same disks to this mount could improve the performance.
Replacing SATA with SSD or PCIe based flash cards can improve IO for certain jobs. Performance increases vary by workload however in a strict sense this increases the per server cost while decreasing the cost per job / transaction.

Barton George (@Barton808) posted Hadoop World, a belated summary on 2/13/2012:
With O’Reilly’s big data conference Strata coming up in just a couple of weeks, I thought I might as well get around to finally writing up my notes from Hadoop World . The event, which was put on by Cloudera, was held last November 8-9 in New York city. There were over 1,400 attendees from 580 companies and 27 countries with two thirds of the audience being technical.
Growing beyond geek fest
The event itself has picked up significant momentum over the last three years going from 500 attendees, to 900 the second year, to over 1400 this past year. The tone has gone from geek-fest to an event focused also on business problems e.g. one of the keynotes was by Larry Feinsmith, managing director of the office of the CIO at JP Morgan Chase. Besides Dell, other large companies like HP, Oracle and Cisco also participated.
As a platinum sponsor, Dell had both a booth and a technical presentation. At the event we announced that we would be open sourcing the Crowbar barclamp for Hadoop and at out booth we showed off the Dell | Hadoop Big Data Solution which is based on Cloudera Enterprise.
Cutting’s observations
Doug Cutting, the father of Hadoop, Cloudera employee and chairman of the Apache software foundation, gave a much anticipated keynote. Here are some of the key things I caught:
- Still young: While Cutting felt that Hadoop had made tremendous progress he saw it as still young with lots of missing parts and niches to be filled.
- Big Top: He talked about the Apache “Bigtop” project which is an open source program to pull together the various pieces of the Hadoop ecosystem. He explained that Bigtop is intended to serve as the basis for the Cloudera Distribution of Hadoop (CDH), much the same way Fedora is the basis for RHEL (Redhat Enterprise Linux).
- “Hadoop” as “Linux“: Cutting also talked about how Hadoop has become the kernel of the distributed OS for big data. He explained that, much the same way that “Linux” is technically only the kernel of the GNU Linux operating system, people are using the word Hadoop to mean the entire Hadoop ecosystem including utilities.
Interviews from the event
To get more of the flavor of the event here is a series of interviews I conducted at the show, plus one where I got the camera turned on me:
- Hadoop World: Cloudera CEO reflects on this year’s event
- Hadoop World: Accel’s $100M Big Data fund
- Hadoop World: Battery Ventures EIR Todd P.
- Hadoop World: Talking to Splunk’s Co-founder
- Hadoop World: NoSQL database MongoDB
- Hadoop World: Talking HBase with Facebook’s Jonathan Gray
- Hadoop World: Ubuntu, Hadoop and Juju
- Hadoop World: Karmasphere and big data intelligence
- Hadoop World: Learning about NoSQL database Couchbase
- Hadoop World: O’Reilly Strata conference chair, Ed Dumbill
Extra-credit reading
Blogs regarding Dell’s crowbar announcement
- Dell to open source software to ease Hadoop install & management
- Developers: How to get involved with Crowbar for Hadoop
- Open source Crowbar code now available for Hadoop
- How to create a Basic or Advanced Crowbar build for Hadoop
Hadoop Glossary
- Hadoop ecosystem
- Hadoop: An open source platform, developed at Yahoo that allows for the distributed processing of large data sets across clusters of computers using a simple programming model. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. It is particularly suited to large volumes of unstructured data such as Facebook comments and Twitter tweets, email and instant messages, and security and application logs.
- MapReduce: a software framework for easily writing applications which process vast amounts of data (multi-terabyte data-sets) in parallel on large clusters of commodity hardware in a reliable, fault-tolerant manner. Hadoop acts as a platform for executing MapReduce. MapReduce came out of Google
- HDFS: Hadoop’s Distributed File system allows large application workloads to be broken into smaller data blocks that are replicated and distributed across a cluster of commodity hardware for faster processing.
- Major Hadoop utilities:
- HBase: The Hadoop database that supports structured data storage for large tables. It provides real time read/write access to your big data.
- Hive: A data warehousing solution built on top of Hadoop. An Apache project
- Pig: A platform for analyzing large data that leverages parallel computation. An Apache project
- ZooKeeper: Allows Hadoop administrators to track and coordinate distributed applications. An Apache project
- Oozie: a workflow engine for Hadoop
- Flume: a service designed to collect data and put it into your Hadoop environment
- Whirr: a set of libraries for running cloud services. It’s ideal for running temporary Hadoop clusters to carry out a proof of concept, or to run a few one-time jobs.
- Sqoop: a tool designed to transfer data between Hadoop and relational databases. An Apache project
- Hue: a browser-based desktop interface for interacting with Hadoop

Wenming Ye delivered a 01:44:43 Building and Running HPC Applications in Windows Azure via Channel9 in February (missed when published)
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Ambrish Mishra described Managing Federations in SQL Azure with the SQL Server Management Studio of SQL Server 2012 RC0 in a 2/15/2012 post to the Windows Azure Team blog:
In this blog post we will cover some new abilities in SQL Server Management Studio 2012 (SSMS) that enhance the ability to work with SQL Azure. Specifically, we will highlight support in SSMS for the new SQL Azure feature known as SQL Azure Federations, which was just introduced this past December. Federations in the SQL Azure database provide the ability to achieve greater scalability and performance from the database tier of the application through horizontal partitioning of data in multiple databases. One or more tables within a database are split by row, and are stored across multiple system-managed databases, called Federation members. This type of horizontal partitioning is often referred to as ‘sharding’. Detailed information about SQL Azure Federation is available on Cihan Biyikoglu’s blog, MSDN Online, and this video demonstration.
The SQL Azure Management Portal and the SQL Server Management Studio (SSMS) of the SQL Server 2012 RC0 release include rich tooling support for managing Federations. One can easily create new Federations, view the Federation meta-data & the Federation members, split Federation members, and work with the database objects in the Federation root and work with the Federation members. The features that were especially built for Federations in SSMS include the following:
Streamlined view in the Object Explorer: If one connects to the SQL Azure virtual server in the SSMS, only the user created databases are listed in the Object Explorer and the GUID-named Federation members are filtered out. This helps in reducing the clutter and makes it easier to work with the databases.
View, create, split and delete Federations: The Federation root database can have more than one Federation and all the Federations are listed under the node titled ‘Federations’ in the object explorer. The right-click context menu on the Federations node and the Federation members have the option to create new Federations, split and delete Federation members, view top 1000 Federation members and connect to a Federation member.
SQL Server Management Studio 2012 Screen Shot: The right-click context menu on a Federation has the options for viewing, splitting and deleting Federation members.
SQL Server Management Studio 2012 Screen Shot: Listing the Top 1000 Federation members in a Federation.
Scripting Federations: The right-click context menu on a Federation provides the option for scripting a Federation. The CREATE To scripting option for a Federation scripts out the layout of the Federation and includes all the splits in the Federation in form of ALTER FEDERATION…SPLIT AT. Running the script will recreate the Federation and all the Federation members in the Federation.
SQL Server Management Studio 2012 Screen Shot: Scripting a Federation.
Connecting to a Federation member: The ‘Connect to a Federation Member’ dialog is used for connecting to a Federation member by specifying a distribution value for the distribution key. The validator in the dialog lists the permissible range for the distribution value based on the data type of the key and also validates that the value is in the correct format and range.
SQL Server Management Studio 2012 Screen Shot: Connect to a Federation member dialog.
Viewing Federation member and the objects in it: After a successful connection to a Federation member, the member is displayed in the Object Explorer in a separate node. The Federation member is listed in a friendly name comprising of <Federation Root Database>::<Federation> (Federation Distribution Key = Range_Low..Range_High). The icon for the Federation member and the Federated table are different from the icons for other databases and tables to make it easy to distinguish Federation objects. The column in the Federated table that is linked to the Federation Distribution Key is labeled as ‘federated’ for easily identifying it. A federated table, when scripted out, is scripted with the ‘FEDERATED ON’ clause that can be used to recreate the table in other Federations.
SQL Server Management Studio 2012 Screen Shot: Viewing Federation member and the objects in it. The T-SQL Editor displays the CREATE To script for the Federated table Customers with the FEDERATED ON clause.
Reconnecting to a Federated member after it splits: A split operation can be in progress for a Federation member while there is a connection to it in the Object Explorer. After the split operation completes, the original Federation member database is deleted and the connection to the member in the Object Explorer becomes invalid. SSMS detects this and pops up a message that the split has completed and provides an option to invoke the ‘Connect to a Federation Member’ dialog to connect to the new Federation member database that now has the data from the original Federation member.
SQL Server Management Studio 2012 Screen Shot: Reconnecting to a Federation member after it splits using the ‘Connect to a Federation Member’ dialog.
Querying the Federation members in the T-SQL Editor: The T-SQL Editor displays the name of the Federation member that it is connected to in the same friendly syntax as used in the Object Explorer. The connection can be easily switched between the Federation root database and the Federation member using the Available Database dropdown control in the T-SQL Editor toolbar. If the USE FEDERATION query is issued to change the connection to another federation member or to the root, the T-SQL Editor detects that the connection has changed and updates the friendly name to the Federation member or the root that it is connected to.
SQL Server Management Studio 2012 Screen Shot: The Federation member is displayed in the same friendly syntax as used in the Object Explorer. The Available Databases dropdown control can be used to change connection to the Federation root.
SQL Server Management Studio 2012 Screen Shot: The friendly name is updated to the Federation member database that the T-SQL Editor is connected if the connection is changed using the T-SQL statement - USE FEDERATION CustomerFederation(cid=100) WITH RESET, FILTERING=OFF
Warning messages: Warning messages alert the users against taking action that can have far reaching impact. For example, if an attempt is made to delete the Federation root database, a warning message is displayed alerting the user that the database has Federations in it and deleting the database will also delete all the Federations in the database.
SQL Server Management Studio 2012 Screen Shot: Warning message when deleting a Federation root database.
With the native support for Federations in SSMS, administrators and developers can work with Federation through an intuitive interface that makes it easy to navigate and manage at scale. We would like to hear feedback on this experience. You can email your feedback to mailto:SAPESupport@microsoft.com.









Steven Martin posted an Announcing Reduced Pricing on SQL Azure and New 100MB Database Option Valentine’s Day article to the Windows Azure blog on 2/14/2012:
To meet evolving customer needs across both ends of the database size spectrum, we are lowering the price of SQL Azure and introducing a 100MB database option.
Today’s price reductions and new entry-level database option are the result of both customer feedback and evolving usage patterns. Specifically, two usage patterns have emerged in the last 18 months. First, many projects start small but need to quickly grow in size. To promote this pattern, we are passing along better economies of scale and options for larger deployments. As your database grows, the price per GB will decline significantly. Second, many cloud adopters and customers with smaller workloads want an inexpensive option for modest usage. Just as we made a 150GB option available for customers with large database needs, we are providing the same level of choice at the other end of the spectrum with the 100MB option for smaller database needs. Today’s announcement is another step in our ongoing journey to help customers with a variety of scenarios embrace Cloud Computing.
The chart below provides a side by side comparison of the cost savings as cloud deployments grow and database sizes increase. Be sure to check out our pricing calculator and pricing page for additional details.

*Previous prices 50GB and larger reflect price cap of $499.95 announced December 12, 2011.
Steven is General Manager, Windows Azure Business Planning.
Cihan Biyiloglu wrote the following tweet on 2/15/2012:
Fantastic new pricing with
#sqlazure. Time to rewrite my "pricing with#sqlfederations" post#sqlserver#azure http://tinyurl.com/8ycjkq6
and replied as follows to my request for an ETA on the update:
@rogerjenn#sqlazure#sqlfederations I hope this week Roger...
Cihan Biyikoglu (@cihangirb) asked Want to demo or show federations to your boss? Here is the full package: Slides and the AdventureWorks database fully scaled-out with Federations in a 2/14/2012 post:
What a great day! first there is some great news on SQL Azure pricing changes and now the AdventureWorks database is out with a new version for SQL Azure and it contains a flavor that is scaled-out with Federations.
http://geekswithblogs.net/ScottKlein [See post below.]
Now you guys have the full package. Sample AdventureWorks with Federations and Slides to go tell your boss, your friends, family members and your personal trainer all about federations. Here are the slides for federations;

Cihan updated his Federations: Building Scalable, Elastic, and Multi-tenant Database Solutions with SQL Azure Tech*Net wiki article on 1/20/2012.
Scott Klein posted a Full Version of AdventureWorks database for SQL Azure and and SQL Azure Federations on 2/14/2012:
Some Background
The AdventureWorks database has been around for over a decade; a staple amongst sample databases. The first version of the AdventureWorks database appeared in time for SQL Server 2000. Microsoft has been good at keeping the AdventureWorks sample database up to date as new versions of SQL Server are released. Case-in-point: SQL Server 2012 is at RC0 and yet you can already find a version of AdventureWorks for it (albeit, it really isn’t that different from the SQL Server 2008 R2 version). They even have multiple versions depending on your needs (Data Warehouse, LT, OLAP, etc).
As a Corporate Technical Evangelist for SQL Azure and somewhat new to Microsoft recently, I was even glad to see a version for SQL Azure. Added to CodePlex in late 2009, the current zip file, AdventureWorks2008R2AZ, contains an install for two databases based on the AdventureWorks database; a small data warehouse database and a small light version of the full AdventureWorks database. However, neither of these database are the full AdventureWorks database that we know and love, so I set out to solve that and make a version for SQL Azure that utilizes the full AdventureWorks database. And, while I was at it, with all of the hype and talk surrounding SQL Azure Federations, I thought it would also be nice to see a Federated version of the AdventureWorks database.
Exciting News
Thus, I am happy to let you know of two new additions to the SQL Azure samples page on CodePlex. Starting today, two new installs are available. The full AdventureWorks database for SQL Azure, and a SQL Azure Federation version of the full AdventureWorks database are now available and can be downloaded from here:
http://msftdbprodsamples.codeplex.com/releases/view/37304
I’ll spend a few minutes and discuss these two databases individually regarding why the efforts were taken to migrate them to SQL Azure and what we hope you will get from them.
Full AdventureWorks for SQL Azure
As far as sample databases go, the AdventureWorks database is the king. It exists simply, yet elegantly, to illustrate the features and functionality of its corresponding version of SQL Server. As such, migrating the full version of the AdventureWorks database to SQL Azure was a must, in part for the following reasons:
- SQL Server as a Service – The primary goal of taking the AdventureWorks database and migrating it to SQL Azure is to show that SQL Azure is SQL Server served up as a PaaS service. Obviously there are some differences in the logical vs. physical administration aspects but the bottom line is that SQL Azure is a cloud-based relational database service that is built on SQL Server technologies, and what better way to prove that by taking an existing on-premises database and showing how easy it is to migrate it to SQL Azure.
- Supported Functionality and Migration Strategies – AS SQL Azure gains adoption, the question continues to exists as to what does it take to migrate an existing on-premises database to SQL Azure, and what functionality is, and is currently not, supported and the steps necessary in the migration process. This example answers those questions.
Everything that needed to be modified, changed, or removed to ensure support for SQL Azure has been documented on the CodePlex page for this database. For example, all ON PRIMARY statements have been removed, and we explain this and the reasons why on the CodePlex page. We list these out so you’ll have an idea of what was needed in order get the AdventureWorks database into SQL Azure.
Given that this is the first fore of the full AdventureWorks database into SQL Azure means there is much more to come.
Full AdventureWorks with SQL Azure Federations
SQL Azure Federations was launched December of 2011. There wasn’t a whole lot of fanfare when it was released but those who have been keeping up with SQL Azure were and certainly are aware of its existence, simply because Microsoft has been talking about it for well over a year. Thus, creating a Federated version of the AdventureWorks database for SQL Azure was also a must with the following thoughts in mind:
- Traction – What a better way to keep momentum going for SQL Azure Federations than to take a well-known sample database and Federate it! Developers can now look at a long-existing sample database that has been federated and use that as a starting point to understanding and working with SQL Azure Federations.
- Example – With SQL Azure Federations so new it makes sense to provide a real-life example on how to Federate an existing database.
- Coolness – Honestly, seeing a Federated version of the AdventureWorks database is just cool. Really.
The current Federated version of the AdventureWorks database federates on Customer. We specifically selected to federate on Customer because it provides a great base to build from. There were several tenants we could have federated on, such as Products or People, but for a first cut, and to help the “transition” into understanding Federations, we decided to start somewhat simple.
The installs for both of the databases, the full non-federated and the federated, is quite easy. Once installed you will be able to see all the databases in SQL Server Management Studio Object Explorer, including the Federation Member as shown in the following figure.
Even cooler is that you can manager your Federations via the SQL Azure Management Portal as shown in the Figure below.
What’s Next
We are already in the process of creating additional, more advanced, versions of this database, which you will see in the coming weeks and months.
Conclusion
As features and functionality is added to SQL Azure, these databases will be updated correspondingly.
Long Live the AdventureWorks database! Love it, use it!


<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Joe Kunk (@JoeKunk) asserted “Learn how to publish data in the Windows Azure Marketplace for a monthly income with just a few hours effort” in a deck for his Selling Data in the Windows Azure Marketplace article of 2/15/2012 for Visual Studio Magazine:
Making your database available for sale on the Microsoft Windows Azure Marketplace is straightforward, especially if you are publishing a SQL Azure table or exposing an OData service over HTTPS for exclusive use by the Marketplace. In just a few hours, your data can be submitted and ready to provide a monthly income without billing hassles.
In my November column, “Free Databases in the Windows Azure Marketplace,” I explored 13 low cost or free databases available for consumption via Web services and provided sample Visual Basic .NET code to access those services via an ASP.NET MVC 3 Web site. The next step is to show you how to get your own applications and data into the Windows Azure Marketplace for sale as a content provider.
Data Publishing
If you have data to publish in the DataMarket section of the Marketplace, the Data Publishing Kit is available for download here. Data can published to the Marketplace using multiple technologies: SQL Azure, a REST-based Web service, a SOAP-based Web service or an OData service.
The communication protocol tabular data stream (TDS) is supported for SQL Azure database tables. HTTP is the only supported transport protocol for REST, SOAP and OData services. The DataMarket, in conjunction with the Xbox and Zune billing system, manages all aspects of the credit card monthly billing including trial offers. Content providers are not involved in billing other than to receive payments. Microsoft retains a 20 percent commission on data subscription sales in the Marketplace.
End users can query the information as if they have access to the SQL Azure database. A query consists of any result set up to 100 rows. More than 100 rows in the result is split among pages; and each page represents a query for billing purposes. Multiple clones of the database can be created and the Marketplace will load balance among the clones. The IP address range 131.107.* must be whitelisted and “Allow Microsoft Services” set to true in the SQL Azure portal.
Publishing data via an OData-based Web service in ATOM format is the native format provided by the DataMarket. Content providers with an OData source pass their service through the DataMarket and the root of their service domain is replaced with the DataMarket service root to ensure proper billing. Otherwise, the data doesn't need to be present in Windows Azure. You can choose to expose service operations that limit the end user to specific information, or expose entity sets which allow flexible queries. The provider determines the number of rows to be returned and when paging is required.
Publishing data via a REST-based Web service is supported if the DataMarket service maps the REST service to an ATOM-based OData service as described above. To do this, all parameters need to be exposed as HTTP parameters. The Web service response must be in an XML format and have only one repeating element that contains the response set. Flexible query is not supported with a REST-based Web service.
Publishing data via a SOAP-based Web service is similar to a REST-based Web service. The only difference: DataMarket service call parameters can be provided in the XML body that's posted to the provider’s service.
For REST or SOAP Web services, a sample result set must be provided with specifications on how to map the data values to the strongly typed values returned by OData. A mapping of all service error codes to HTTP status codes is also required.
OData Service Sample
Providing data to the Windows Azure Marketplace via an OData service is straightforward. Create an OData service in Visual Studio and then make it available on an HTTPS Web site with basic username / password authentication required.
To demonstrate creating a simple OData service, I have created a sample SQL Server 2008 Express database with a single table containing Michigan zip code information as shown in Figure 1. The code download for this article includes a backup of the database and the scripts needed to create the database and populate it with data. Use Microsoft Visual Web Developer 2010 Express or above to create the application. You may also need to install Entity Framework 4.1 or a later version.
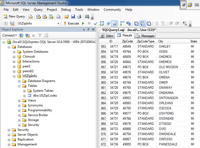
[Click on image for larger view.]Figure 1. Sample data for Windows Azure Marketplace OData provider
Create a Visual Studio ASP.NET Empty Web Application project. Add an ADO.NET Entity Data Model item to the project and follow the wizard prompts to add the USZipCodes table from the USZipInfo database. Next add a WCF Data Service item to the project. Update USZipCodes.svc.vb to initialize your Entity Data Model as shown below. It is acceptable to set the EntitySetRights to AllRead because security will be provided by Internet Information Services and not the application. I recommend that you set your entity PageSize to 100 rows to match the standard return set size in the Windows Azure Marketplace. …

Full disclosure: I’m a contributing editor for Visual Studio Magazine.
Telerik announced OData Binding for their Scheduler component on 2/15/2012:
RadScheduler supports binding to OData feed forth from Q1 2012!
In contrast to the standard WebService binding, the OData binding does not require serialized AppointmentData objects. Instead, the developer is free to expose whatever objects they want as a JSON feed, as long as the data is meaningful to the Scheduler. One can configure the DataKeys in the Odata configuration section.
The OData binding configuration section allows you set the following DataKeys to map the exposed feed to the binding fields:
- DataStartField
- DataEndField
- DataKeyField
- DataDescriptionField
- DataSubjectField
It is necessary to set InitialContainerName property to the OData Entity that contains your appointment data.
Finally, it is possible to chose whether to request the service via normal XHR call or using JSONP. Please have in mind that using JSONP is required if one is binding to a webservice hosted in a different domain. This requirement is due to the XSS restrictions that all browsers conform to.
Grouping by resources is not yet possible in the beta release, however, we will add this functionality for the final Q1 release.

<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
Thirumalai Muniswamy continued his Implementing Azure AppFabric Service Bus - Part 5 series on 2/14/2012:
This continuation post of Implementing Azure AppFabric Service Bus series. Look at the end of this post for other parts.
Till now we had seen developing WCF Service application and exposing to the public using Azure Service Bus and configuring Auto Start capability to the service as it required starting on IIS server restarts automatically.
In this post, I am going to provide a sample client application which consumes the CustomerService built using the WCF Application and exposed in previous posts. This application is a normal ASP.NET application which has the implementation to consume the service exposed on the Service Bus.
- Required a screen to show list of customers in a GridView.
- The screen should also contain an entry form for adding/modifying customer records.
- The user can add a new customer by entering the customer information in the entry form and press Save button.
- The user can select an existing customer by selecting on the GridView using Select column hyperlink.
- On selection of a record, the information about the customer must be populated on the entry screen for updation.
- The user can update the customer information and Save again.
- The user can delete a particular customer using Delete hyperlink on the Delete column in GridView.
This is the functionalities of the screen. Now let’s get start the implementation of client application for consuming the service bus service:
Pre-requisite – As our project is going to be Windows Azure Project, make sure the latest Windows Azure SDK (v 6.0) installed.
Step 1: Open Visual Studio 2010 and select New Project from Start Page (or File => New => Project) for creating new Azure Project.
Step 2: Select the preferred language (here C#) and Windows Azure Project (from Cloud) from the Installed Templates. Enter the project name (DotNetTwitterSOPClient) and preferred Location then press OK to create.
Step 3: The Visual Studio will open New Windows Azure Project window. Select the ASP.NET Web Role from the .NET Framework 4 roles (left panel) and press > button to add to the Windows Azure Solution list. Press OK.
Step 4: Run the project once and verify is it working fine.
Step 5: Before going for functional implementation, let us first design the UI. So open the Default.aspx script source and add the below UI script in between the BodyContent.
<div> <table> <tr> <td>Customer Id</td> <td><asp:TextBox ID="txtCustomerId" runat="server" Width="120px"></asp:TextBox> </td> <td style="width:100px"></td> <td>Company Name</td> <td><asp:TextBox ID="txtCompanyName" runat="server" Width="250px"></asp:TextBox> </td> </tr> <tr> <td>Contact Name</td> <td><asp:TextBox ID="txtContactName" runat="server" Width="300px"></asp:TextBox> </td> <td></td> <td>Contact Title</td> <td><asp:TextBox ID="txtContactTitle" runat="server" Width="250px"></asp:TextBox> </td> </tr> <tr> <td rowspan="3">Address</td> <td rowspan="3"><asp:TextBox ID="txtAddress" runat="server" Width="300px" TextMode="MultiLine" Height="70px"></asp:TextBox> </td> <td rowspan="3"></td> <td>City</td> <td><asp:TextBox ID="txtCity" runat="server" Width="200px"></asp:TextBox> </td> </tr> <tr> <td>Region</td> <td><asp:TextBox ID="txtRegion" runat="server" Width="200px"></asp:TextBox> </td> </tr> <tr> <td>Country</td> <td><asp:TextBox ID="txtCountry" runat="server" Width="200px"></asp:TextBox> </td> </tr> <tr> <td>Phone No</td> <td><asp:TextBox ID="txtPhoneNo" runat="server" Width="200px"></asp:TextBox> </td> <td></td> <td>Fax No</td> <td><asp:TextBox ID="txtFax" runat="server" Width="200px"></asp:TextBox> </td> </tr> <tr> <td colspan="5" style="text-align:center"> <asp:Button ID="btnSave" runat="server" Width="100px" Text="Save" onclick="btnSave_Click" /> <asp:Button ID="btnClear" runat="server" Width="100px" Text="Clear" onclick="btnClear_Click" /> </td> </tr> <tr> <td colspan="5"> <asp:Label runat="server" ID="lblMessage" Text="" CssClass="Message"></asp:Label> <asp:HiddenField ID="hndCustomerId" runat="server" Value="" /> </td> </tr> </table> </div> <div> <asp:GridView ID="grdViewCustomers" runat="server" AllowPaging="True" AutoGenerateColumns="False" TabIndex="1" DataKeyNames="CustomerID" Width="100%" BackColor="White" CellPadding="3" BorderStyle="Solid" BorderWidth="1px" BorderColor="Black" GridLines="Horizontal" OnRowDataBound="grdViewCustomers_RowDataBound" OnPageIndexChanging="grdViewCustomers_PageIndexChanging" OnSelectedIndexChanging="grdViewCustomers_SelectedIndexChanging" OnRowDeleting="grdViewCustomers_RowDeleting"> <Columns> <asp:CommandField ShowSelectButton="True" HeaderText="Select" /> <asp:CommandField ShowDeleteButton="True" HeaderText="Delete" /> <asp:BoundField DataField="CustomerID" HeaderText="Customer ID" /> <asp:BoundField DataField="CompanyName" HeaderText="Company Name" /> <asp:BoundField DataField="ContactName" HeaderText="Contact Name" /> <asp:BoundField DataField="ContactTitle" HeaderText="Contact Title" /> <asp:BoundField DataField="Address" HeaderText="Address" /> <asp:BoundField DataField="City" HeaderText="City" /> <asp:BoundField DataField="Region" HeaderText="Region" /> </Columns> <RowStyle BackColor="White" ForeColor="#333333" /> <FooterStyle BackColor="#5D7B9D" Font-Bold="True" ForeColor="White" /> <PagerStyle BackColor="#284775" ForeColor="White" HorizontalAlign="Right" /> <SelectedRowStyle BackColor="#A5D1DE" Font-Bold="true" ForeColor="#333333" /> <HeaderStyle BackColor="#5D7B9D" Font-Bold="True" ForeColor="White" /> <AlternatingRowStyle BackColor="#E2DED6" ForeColor="#284775" /> </asp:GridView> </div>Here the HTML Script contains controls related entry form and a GridView to show list of customers.
Step 6: There are some events are added in the script file which are required to do the functionalities for the screen. Currently add empty event handler in code behind to make the screen work with no error.
public partial class _Default : System.Web.UI.Page { protected void Page_Load(object sender, EventArgs e) { } protected void grdViewCustomers_RowDataBound(object sender, GridViewRowEventArgs e) { } protected void grdViewCustomers_PageIndexChanging(object sender, GridViewPageEventArgs e) { } protected void btnClear_Click(object sender, EventArgs e) { } protected void grdViewCustomers_SelectedIndexChanging(object sender, GridViewSelectEventArgs e) { } protected void grdViewCustomers_RowDeleting(object sender, GridViewDeleteEventArgs e) { } protected void btnSave_Click(object sender, EventArgs e) { } }Now we are ready for implementation with Service Bus. You can run the project once and verify the screen works fine.
Step 7: We required the Customer entity class defined in WCF Service and exposed on Service Bus for desterilize the message comes from the service. To get the customer service model code, we have to use svcutil utility.
So, open the Visual Studio Command Prompt (2010), switch to required directory and run the below command.svcutil /language:cs /out:proxy.cs /config:app.config http://localhost/DotNetTwitterSOPService/CustomerService.svc
Note: This command must be executed where the WCF Service runs. Because we are creating the code using the locally published url. The url will be specified in Web.Config on WCF Service Project. So you can open the project and get to know the url (or by running the ECF project also can know from the address bar).
Step 8: Add the Customer.cs file created using above command (or create a new Customer.cs file in the project and copy & paste from the Customer.cs file created).
Note:
- Make sure the namespace changed to WebRole namespace (WebRole).
- You required to add System.Runtime.Serialization assembly as reference to the project.
- Delete the code except Customer class such as ICustomerService, ICustomerServiceChannel interfaces and CustomerServiceClient class.
Step 9: As we are going to consume CustomerService from service bus, we required the ICustomerService interface to talk to the service. So, add a new class file to the Web Role (using right click -> Add -> Class) and name it as ICustomerService.cs.
Add the following code in the ICustomerService
[ServiceContract] public interface ICustomerService { [OperationContract] IList GetAll(); [OperationContract] Customer Get(string customerID); [OperationContract] int Create(Customer customer); [OperationContract] int Update(Customer customer); [OperationContract] int Delete(string customerID); [OperationContract] string GetValue(string value); }This is the same interface defined in the WCF Service in Part 3.
Note: You required to add System.ServiceModel assembly as reference in the project and add System.ServiceModel namespace in the namespace section.
Step 10: For connecting the service exposed on the Service Bus, we required the endpoint url (Service URI). But if we are consuming several services in a particular project, the service bus URI will differ for each service. So, we can define some important parameters in the Web.Config and generate the endpoint url in the code when required.I have defined six [five?] important parameters in the appSettings node on Web.Config. Below are the configuration script.
- ServiceNamespace – This is the namespace created in the Management portal under Service Bus, Access Control & caching section. This namespace will be configured in the WCF Service project and exposed to Service Bus.
- IssuerName - IssuerSecret is again from Management portal for security purpose.
- CustomerServiceEndPointNameTcp – for defining the service path defined for TCP protocol (sb:// endpoint).
- CustomerServiceEndPointNameHttp - for defining the service path defined for HTTPS protocol (https:// endpoint).
- ServiceConsumingProtocol – defined the connectivity will be based on which protocol. So we can switch the consuming protocol based on the requirement and network boundaries.
The CustomerServiceEndPointNameTcp, CustomerServiceEndPointNameHttp defines a part of endpoint url. For example, let us take the two endpoint url exposed to public for CustomerService.
https://ComDotNetTwitterSOP.servicebus.windows.net/Http/CustomerService/Test/V0100/
sb://ComDotNetTwitterSOP.servicebus.windows.net/NetTcp/CustomerService/Test/V0100/
The text in blue color defines the service path for each endpoint url.
Step 11: Next, I am going to define a helper class (CustomerHelper) for doing operations with CustomerService deployed on the Service Bus.
The CustomerHelper class has various methods for doing various operations. The list of methods and its usage follows.Step 12: Now we have completed the base work and can start integrating the code with UI. So let’s first start by binding the list of customer records to the GridView.
- Defining a private variable to hold the channel object of ICustomerService at the scope of class.
private ICustomerService channel = null;- OpenChannel() –This method is used to open the channel for making any communication with the service. So this method will be called before any method called on the service.
/// <summary> /// Method to close the Client Channel /// </summary> public void CloseChannel() { ((ICommunicationObject)channel).Close(); }- GetAll() – Method to get all the customers from the database.
/// <summary> /// Method to get all the Customers /// </summary> /// <returns>List of Customers</returns> public IList<Customer> GetAll() { OpenChannel(); IList<Customer> customers = channel.GetAll(); CloseChannel(); return customers; }As defined previously, before calling the GetAll() method at the service, we required to open the channel. So the OpenChannel() used to open the channel and CloseChannel() method used to close the channel.- Get(CustomerID) – Method to get the details of a particular Customer.
/// <summary> /// Method to get a particular Customer based on Customer Id /// </summary> /// <param name="customerID">Customer Id</param> /// <returns>Customer Object</returns> public Customer Get(string customerID) { OpenChannel(); Customer customer = channel.Get(customerID); CloseChannel(); return customer; }- Create(Customer) – For creating a new customer record in the database.
/// <summary> /// Method to create a new Customer record in the system /// </summary> /// <param name="customer">Customer object</param> /// <returns>No of Row affected</returns> public int Create(Customer customer) { OpenChannel(); int intNOfRows = channel.Create(customer); CloseChannel(); return intNOfRows; }- Update(Customer) – For updating an existing customer in the database.
/// <summary> /// Method to Update existing Customer in the System /// </summary> /// <param name="customer">Customer object</param> /// <returns>No of Row affected</returns> public int Update(Customer customer) { OpenChannel(); int intNOfRows = channel.Update(customer); CloseChannel(); return intNOfRows; }- Delete(Customer) – For Deleting an existing customer from the database.
/// <summary> /// Method to Delete an existing Customer from the system /// </summary> /// <param name="customer">Customer object</param> /// <returns>No of Row affected</returns> public int Delete(string customerID) { OpenChannel(); int intNOfRows = channel.Delete(customerID); CloseChannel(); return intNOfRows; }
Add below code in Page Load event and additional methods in code behind.protected void Page_Load(object sender, EventArgs e) { if (!Page.IsPostBack) { ClearScreen(); BindGrid(); } } /// <summary> /// Clearing the screen /// </summary> private void ClearScreen() { txtCustomerId.Text = ""; txtCompanyName.Text = ""; txtContactName.Text = ""; txtContactTitle.Text = ""; txtAddress.Text = ""; txtCity.Text = ""; txtRegion.Text = ""; txtCountry.Text = ""; txtPhoneNo.Text = ""; txtFax.Text = ""; lblMessage.Text = ""; hndCustomerId.Value = ""; } /// <summary> /// Method which binds the data to the Grid /// </summary> private void BindGrid() { try { CustomerHelper helper = new CustomerHelper(); grdViewCustomers.DataSource = helper.GetAll(); grdViewCustomers.DataBind(); } catch (Exception e) { } }Step 13: Add the below code for getting the details of a customer record on click of Select hyperlink on a particular row.protected void grdViewCustomers_SelectedIndexChanging(object sender, GridViewSelectEventArgs e) { hndCustomerId.Value = grdViewCustomers.Rows[e.NewSelectedIndex].Cells[2].Text.Trim(); if (hndCustomerId.Value.Length > 0) { CustomerHelper helper = new CustomerHelper(); Customer customer = helper.Get(hndCustomerId.Value); txtCustomerId.Text = customer.CustomerID; txtCompanyName.Text = customer.CompanyName; txtContactName.Text = customer.ContactName; txtContactTitle.Text = customer.ContactTitle; txtAddress.Text = customer.Address; txtCity.Text = customer.City; txtRegion.Text = customer.Region; txtCountry.Text = customer.Country; txtPhoneNo.Text = customer.Phone; txtFax.Text = customer.Fax; } }Step 14: Add below code for deleting a customer record on click of Delete hyperlink on a particular row.protected void grdViewCustomers_RowDataBound(object sender, GridViewRowEventArgs e) { if (e.Row.RowType == DataControlRowType.DataRow) { e.Row.Cells[1].Attributes.Add("onclick", "return confirm('Are you sure want to delete?')"); } } protected void grdViewCustomers_RowDeleting(object sender, GridViewDeleteEventArgs e) { try { string strCustomerID = grdViewCustomers.Rows[e.RowIndex].Cells[2].Text.Trim(); if (strCustomerID.Length > 0) { CustomerHelper helper = new CustomerHelper(); helper.Delete(strCustomerID); ClearScreen(); BindGrid(); lblMessage.Text = "Record deleted successfully"; } } catch (Exception ex) { lblMessage.Text = "There is an error occured while processing the request. Please verify the code!"; } }Step 15: Add below code saving a customer record when click of Save button.protected void btnSave_Click(object sender, EventArgs e) { try { Customer customer = new Customer(); customer.CustomerID = txtCustomerId.Text; customer.CompanyName = txtCompanyName.Text; customer.ContactName = txtContactName.Text; customer.ContactTitle = txtContactTitle.Text; customer.Address = txtAddress.Text; customer.City = txtCity.Text; customer.Region = txtRegion.Text; customer.Country = txtCountry.Text; customer.Phone = txtPhoneNo.Text; customer.Fax = txtFax.Text; CustomerHelper helper = new CustomerHelper(); if (hndCustomerId.Value.Trim().Length > 0) helper.Update(customer); else helper.Create(customer); ClearScreen(); BindGrid(); lblMessage.Text = "Record saved successfully"; } catch (Exception ex) { lblMessage.Text = "There is an error occured while processing the request. Please verify the code!"; } }Step 16: Below code when page changing the page index.protected void grdViewCustomers_PageIndexChanging(object sender, GridViewPageEventArgs e) { grdViewCustomers.PageIndex = e.NewPageIndex; grdViewCustomers.SelectedIndex = -1; BindGrid(); }Now you can run the project and verify the screen output. Below are the screen output[s] from my client.
Note:
Download the working source code in C# here.
- In some enterprise the firewall stops any communication with public directly. Even my enterprise network boundaries also won’t allow this. I get below error when I consume the service from the app.
The token provider was unable to provide a security token while accessing 'https://comdotnettwittersop-sb.accesscontrol.windows.net/WRAPv0.9/'. Token provider returned message: 'Unable to connect to the remote server'.
In that time, get the proxy address and configure the in the Web.Config settings as below and try again.
- Deleting the customer may not work as the record may referred in other tables.
The other links on Implementing Azure AppFabric Service Bus:
- Implementing Azure AppFabric Service Bus - Part 1
- Implementing Azure AppFabric Service Bus - Part 2
- Implementing Azure AppFabric Service Bus - Part 3
- Implementing Azure AppFabric Service Bus - Part 4
- Implementing Azure AppFabric Service Bus - Part 5













• Maarten Balliauw @martinballiauw reported the availability of his Slides for TechDays Belgium 2012: SignalR presentation on 2/16/2012:
It was the last session on the last day of TechDays 2012 so I was expecting almost nobody to show up. Still, a packed room came to have a look at how to make the web realtime using SignalR. Thanks for joining and for being very cooperative during the demos!
As promised, here are the slides: SignalR. Code, not toothpaste - TechDays Belgium 2012.
You can also find the demo code here: SignalR. Code, not toothpaste - TechDays Belgium 2012.zip (2.74 mb)
View more PowerPoint from Maarten Balliauw
PS: The book on NuGet (Pro NuGet) which I mentioned can be (pre)ordered on Amazon.

Clemens Vasters (@clemensv) described SignalR powered by Service Bus in a 2/13/2012 post:
Our friends over in the ASP.NET team are working on a very nice, lightweight web-browser eventing technology called SignalR. SignalR allows server-pushed events into the browser with a variety of transport options and a very simple programming model. You can get it via NuGet and/or see growing and get the source of on github. There is also a very active community around SignalR chatting on Jabbr.net, a chat system whose user model is derived from IRC, but that runs – surprise – on top of SignalR.
At the core, SignalR is a lightweight message bus that allows you to send messages (strings) identified by a key. Ultimately it’s a key/value bus. If you’re interested in messages with one or more particular keys, you walk up and ask for them by putting a (logical) connection into the bus – you create a subscription. And while you are maintaining that logical connection you get a cookie that acts as a cursor into the event stream keeping track of what you have an have not seen, which is particularly interesting for connectionless transports like long polling.
SignalR implements this simple pub/sub pattern as a framework and that works brilliantly and with great density, meaning that you can pack very many concurrent notification channels on a single box.
What SignalR, out-of-the-box, doesn’t (or didn’t) provide yet is a way to stretch its message bus across multiple nodes for even higher scale and for failover safety.
That’s where Service Bus comes in.
Last week, I built a Windows Azure Service Bus backplane for SignalR that allows deploying SignalR solutions to multiple nodes with message distribution across those nodes and ensuring proper ordering on a per-sender basis as well as node-to-node correctness and consistency for the cursor cookies. That code is Apache licensed and now available on github.
You can use this backplane irrespective where you host solutions that use SignalR, as long as your backend host has access to a Service Bus namespace. That’s obviously best in one of the Windows Azure datacenters, but will work just as well anywhere else, albeit with a few msec more latency.
If you want to try it out, here are the steps (beyond getting the code):
- Make a small SignalR app or take one from the SignalR samples (caveat below)
- Make a Windows Azure account and a Service Bus namespace. For that, follow the same steps as outlined in the Multi-Tier apps tutorial on MSDN.
- Compile the extension project and add it to your SignalR solution
- At initialization time (global.asax, startup, etcetc), you need to reference (using)the SignalR.WindowsAzureServiceBus namespace and then add the following initialization code: AspNetHost.DependencyResolver.UseWindowsAzureServiceBus(“{namespace}“,”{account}”, “{key}”, "{appname}", 2);
- Compile, run
In the above example, {namespace} is the Service Bus namespace you created following the tutorial steps, {account} is likely “owner” (to boot) and {key} is the default key you copied from the portal. {appname} is some string, without spaces, that disambiguates your app from other apps on the same namespace and 2 stands for splitting the Service Bus traffic across 2 topics.
Most of the SignalR samples don’t quite work yet in a scale-out mode since they hold local, per-node state. That’s getting fixed.
If you want to see SignalR and Service Bus in action right this second, you can hop into the Azure chat room on our test deployment of jabbr that runs across 4 nodes.

Steve Peschka began a series with The Azure Custom Claim Provider for SharePoint Project Part 1 on 2/11/2012:
Hi all, it’s been a while since I’ve added new content about SAML claims, so I decided to come back around and write some more about it in a way that links together some of my favorite topics – SharePoint, SAML, custom claims providers, the CASI Kit and Azure. This is the first part in a series in which I will deliver a proof of concept, complete with source code that you can freely use as you wish, that will demonstrate building a custom claims provider for SharePoint, that uses Windows Azure as the data source. At a high level the implementation will look something like this:
- I’ll use Azure queues to route claim information about users and populate Azure table storage
- I’ll have a WCF application that I use to front-end requests for data in Azure table storage, as well as to drop off new items in the queue. We’ll create a trust between the SharePoint site and this WCF application to control who gets in and what they can see and do.
- On the SharePoint side, I’ll create a custom claims provider. It will get the list of claim types I support, as well as do the people picker searching and name resolution. Under the covers it will use the CASI Kit to communicate with Windows Azure.
When we’re done we’ll have a fully end to end SharePoint-to-Cloud integrated environment. Hope you enjoy the results. Look for Part 2 next, where I’ll describe building out the Azure components.
Francois Lascelles described OAuth Token Management in a 2/10/2012 post (missed when published):
Tokens are at the center of API access control in the Enterprise. Token management, the process through which the lifecycle of these tokens is governed emerges as an important aspect of Enterprise API Management.
OAuth access tokens, for example, can have a lot of session information associated to them:
- scope;
- client id;
- subscriber id;
- grant type;
- associated refresh token;
- a saml assertion or other token the oauth token was mapped from;
- how often it’s been used, from where.
While some of this information is created during OAuth handshakes, some of it continues to evolve throughout the lifespan of the token. Token management is used during handshakes to capture all relevant information pertaining to granting access to an API and makes this information available to other relevant API management components at runtime.
During runtime API access, applications present OAuth access tokens issued during a handshake. The resource server component of your API management infrastructure, the gateway controlling access to your APIs, consults the Token management system to assess whether or not the token is still valid and to retrieve information associated to it which is essential to deciding whether or not access should be granted. A valid token in itself is not sufficient, does the scope associated to it grant access to the particular API being invoked? Does the identity (sometimes identities) associated with it also grant access to the particular resource requested? The Token management system also updates the runtime token usage for later reporting and monitoring purposes.
The ability to consult live tokens is important not only to API providers but also to owners of applications to which they are assigned. A Token management system must be able to deliver live token information such as statistics to external systems. An open API based integration is necessary for maximum flexibility. For example, an application developer may access this information through an API Developer Portal whereas a API publisher may get this information through a BI system or ops type console. Feeding such information into a BI system also opens the possibility of detecting potential threats from unusual token usage (frequency, location-based, etc). Monitoring and BI around tokens therefore relates to token revocation.
As one of the main drivers of API consumption in the enterprise is mobile applications, the ability to easily revoke a token when, for example, a mobile device is lost or compromised is crucial to the enterprise. The challenge around providing token revocation for an enterprise API comes from the fact that it can be triggered from so many sources. Obviously, the API provider itself needs to be able to easily revoke any tokens if a suspicious usage is detected or if it is made aware of an application being compromised. Application providers may need the ability to revoke access from their side and, obviously, service subscribers need the ability to do so as well. The instruction to revoke a token may come from Enterprise governance solutions, developer portals, subscriber portals, etc.
Finally, the revocation information is essential at runtime. The resource server authorizing access to APIs needs to be aware of whether or not a token has been revoked.
The management of API access tokens is an essential component of Enterprise API management. This token management must integrate with other key enterprise assets, ideally through open APIs. At the same time, token data must be protected and its access secured.




<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• PRWeb asserted New SaaS Solution Built on Microsoft Windows Azure Empowers Distributed Sales and Marketing Teams to Access and Collaborate on Brand Controlled Collateral Anytime, Anywhere in a deck for a Quark Brand Manager Takes Corporate Marketers to the Cloud press release of 2/15/2012 (via SFGate.com):
Quark today launched Quark Brand Manager™, a Software as a Service (SaaS) solution designed to allow distributed sales and marketing teams to create, customize, and deliver brand-compliant marketing material on-demand. Quark Brand Manager runs natively on the Microsoft Windows Azure platform, providing the most sophisticated design capabilities and secure Cloud-based availability and scalability offered by a brand management solution today.
As a Cloud-based solution, Quark Brand Manager can be deployed within minutes, automates system updates without requiring IT resources, and streamlines production workflows significantly. Designers convert QuarkXPress® and InDesign documents into Quark Brand Manager templates that can then be approved by marketing and customized by field teams through a simple Web interface. With Quark Brand Manager, marketing teams are able to:
- Reduce by up to 50 percent the time it takes to create templates for brand-compliant collateral
- Reduce by up to 90 percent the time it takes field teams to deliver customized collateral to consumers
- Significantly decrease costs by eliminating the need for on-premise infrastructu
"Quark entered the brand management solutions market early with our QuarkXPress Server technology. Now, with Microsoft, we're taking an early lead to leverage the Cloud so that dispersed marketing and sales teams can maintain their most valuable differentiator - their brand," said Ray Schiavone, Quark President and CEO. "As marketing departments take control of budget that was once allocated to IT teams, effective, affordable, and global Cloud-based solutions like Quark Brand Manager will become required resources."
To learn more please visit www.quarkbrandmanager.com/ and download a complimentary copy of the InfoTrends whitepaper "Making the Case for Brand Management" www.quarkbrandmanager.com/making-the-case.html.
If interested in a 30-day trial of Quark Brand Manager, please complete the online registration form to be contacted by a member of the Quark sales team: www.quarkbrandmanager.com/trial.html.
Pricing
Quark Brand Manager pricing starts at $62.50 a month per user with a minimum deployment of 40 users. For more information about pricing, including agency and printer pricing models, please contact info(at)quarkbrandmanager(dot)com.QuarkAlliance™
Quark Brand Manager is the only solution that offers marketing departments and field sales teams optional access to Quark's nationwide network of print providers. All QuarkAlliance members are eligible to be a part of the Quark network of printers. For more information about QuarkAlliance, please visit alliance.quark.com/index.php.About Quark
Founded in Denver in 1981, Quark's vision was to create software that would lay the foundation for modern publishing. For 30 years, Quark has delivered on that promise. Quark's dynamic publishing solutions are setting new standards in automated cross-media publishing by combining the power of XML with flexible layout and design to automate the delivery of customized, intelligent communications across print, the Web, and digital media.Quark, Quark Brand Manager, QuarkXPress and the Quark logo are trademarks or registered trademarks of Quark Software Inc. and its affiliates in the U.S. and/or other countries. All other marks are the property of their respective owners.

Brent Stineman (@BrentCodeMonkey) described Partial [Windows Azure] Service Upgrades in a 2/15/2012 post:
So I as working on an answer for a stack overflow question yesterday and realized it was a topic that I hadn’t put down in my blog yet. So rather than just answer the question, I figured I’d blog about it here so I could include some screen shots and further explanation. The question was essentially how can I control the deployment of individual parts of my service.
NOTE: this post only details doing this via the windows.azure.com portal. We’ll leave doing I programmatically via the management API for another day.
Upgrading a Single Role
This is actually surprising simple. I open up the service, and select the role (not instances) I want to upgrade. Then we can right click and select upgrade, or click on the “upgrade” button on the toolbar.
Either option will launch the “Upgrade Deployment” diaglog box. If you look at this box (and presuming you have the role selected, you’ll notice that in the box, the “Role to Upgrade” option will list the role you had selected. If you didn’t properly select the role, this may list “All”.
Take a peek at the highlighted section of the following screen shot for an example of how this should look.
Note: while creating this post, I did receive an unhandled exception message from the silverlight portal. This has been reported to MSFT and I’ll update his when I get a response.
Manual Upgrades
I’ve run out of time today, but next time I’d like to cover doing a manual upgrade. Of course, I still have two posts in my PHP series I need to finish. So we’ll see which of these I eventually get back around to first.



Liam Cavanagh (@liamca) continued his series with What I Learned Building a Startup on Microsoft Cloud Services: Part 4 – To Build or Buy a Queuing System on 2/15/2012;
I am the founder of a startup called Cotega and also a Microsoft employee within the SQL Azure group where I work as a Program Manager. This is a series of posts where I talk about my experience building a startup outside of Microsoft. I do my best to take my Microsoft hat off and tell both the good parts and the bad parts I experienced using Azure.
Building a Queuing System in SQL Azure
As you might imagine, this is a perfect job for a queue. Most of you would probably start by using Windows Azure queues, but since I am a long time database guy, my preference is to always do as much as I can within the database, simply because that is where I am most comfortable and my queuing needs are pretty simple. I also like to keep things simple and since I was already using SQL Azure for my system database it seemed simpler to use that also for queiing rather than add in another service.
I have to tell you, building a simple queuing system in SQL Azure was way easier than I expected and it worked really well. My queue was in a table called Notifications. When a user adds a new notification in the admin web site, I insert a row into this table with a timestamp of ‘1900/01/01’. Then the worker role which is constantly checking for rows that are less than the current time, picks up these notifications, marks a “Processing Time” field for this row with the current timestamp and starts executing the associated job. When the job is done, the jobs status is marked as complete and the timestamp is updated to some interval past the current time, so that it can be picked up again later on.
Handling Multiple Threads
One of the biggest problems I had to handle was the fact that I have multiple worker roles and then multiple threads within each of those worker roles. With all of these processes it is very possible for a single job to be picked up by more than one thread. To handle this problem, I needed to create a stored procedure that would use a row locking system to ensure that a job could not be picked up by more than one thread. The secret to getting this to work is in the use of WITH (UPDLOCK, READPAST) code. This tells the SQL Azure engine to skip any rows that are locked. The locking ensures no other threads will pick it up. This is what my stored procedure looked like:
create procedure get_next_job as begin
DECLARE @NextId INTEGER
BEGIN TRANSACTION– Find next available item available where the status is enabled
SELECT TOP 1 @NextId = [NotificationId]
FROM [Notifications] WITH (UPDLOCK, READPAST) WHERE [NextRunTime] <= getdate() and [Status] = 1 ORDER BY [NextRunTime] ASC– If found, flag it to prevent being picked up again
IF (@NextId IS NOT NULL)
BEGIN
UPDATE [Notifications]
SET [ProcessingTime] = getdate(),NextRunTime] = dateadd(mi,frequency,[NextRunTime])
WHERE [NotificationId] = @NextId
ENDCOMMIT TRANSACTION
– Now return the queue item, if we have one
IF (@NextId IS NOT NULL)
SELECT [NotificationId], [TableName], [EmailAddress], [ChangeColumn],[ChangeType], [MessageTextColumn], [LastSuccessfulRunValue],[DatabaseConnString], [DatabaseType]FROM [Notifications], [UserDatabases]
WHERE [NotificationId] = @NextId and [Notifications]
.[DatabaseID] = [UserDatabases].[UserDatabaseID]
end
goHandling Orphaned Jobs
The other issue I had to consider is when the machine crashed or the job did not complete. Although this had not happened yet, I am sure at some point it will, so I need to make sure a users job does not get lost forever. This is where the ‘“Processing Time” column comes into play. In the above stored procedure you can see I set this to the current date time. I also know that is should take no more than a minute to complete any job. Therefore, if a job is more than one minute old, I know there was a problem and I can handle it.
Throwing it all away
All of this worked incredibly well and the performance was terrific. Another advantage I found was that regardless of the number of queries I executed against my SQL Azure database, I was guaranteed a fixed cost per month. Best of all that cost was free since I already had a SQL Azure database for my system data. With Windows Azure queues the cost is not fixed, although the cost for this is very low. Ultimately, I decided to throw this all away and move to Windows Azure queues. But I will talk about that more next week.

The patterns & practices (@mspnp) group released WAAG - Part 3 - Release Candidate 2012-02-15 on 2/15/2011:
Revised [Windows Azure Architecture Guide, WAAG] document that incorporates all the feedback we got so far.
- Source Code Release Candidate (2012-02-15)
This is the release candidate of the source code.- Fifth drop (2012-01-24):
We have all the feature included in this drop.- Fourth drop (2011-12-13):
We added many changes in this drop.- Third drop (2011-10-31):
Updated readme.htm. There was no code changes in this drop;- Second drop (2011-10-24):
Added Authentication using ACS; Implemeted Service Bus Topics; Updated Shipping provider for multiple partners. Added Setup project for configuring ACS and Service Bus namespaces;- First drop (2011-10-10):
Included sample source for an on Premise app; Included corresponding soruce for Windows Azure solution. The azure solution useed azure service bus queue to send customer orders.

Avkash Chauhan (@avkashchauhan) explained Solving SSL Certificate expiration problem with an existing Windows Azure Application in a 2/14/2012 post:
Recently I was working on an issue where the SSL certificate was expired and due to it, the user were warned to not to use site. The certificate expiration was visible as below:
- Get the new SSL certificate from the Certification Authority for the same domain, by using a machine which has IIS to generate the CRI and submit the CRI to CA so you can get certificate chain (root cert, intermediate cert and domain cert). This is mostly done on a Windows Server machine with IIS on which the domain specific website exists.
- Install the SSL certificate chain on development machine and export the PFX
- Upload the PFX at Windows Azure Management Portal in Service Certificate section
- Add correct certificate thumb ID to your Windows Azure application endpoint
- Repackage Windows Azure application and update it on portal
What if you don’t have access to any of that, Windows Server machine, Visual Studio, previous website etc. To make the problem little more complicated what if the application owner have no access to original Visual Studio application project or CSPKG/CSCFG” because the application was completed by someone else who is nowhere to found.
So if you don’t have anything [but] just a Windows 7 machine, you still can work out this issue as below:
- Enable IIS in your Windows 7 machine
- Use IIS to generate CRI for your domain by entering correct domain specific details for your application
- Get the CRI and submit to your “Certification Authority” and received the certificates (root certificate, intermediate certificates and domain certificates). This could be CRT, P7B files etc.
- Now in IIS, import the certificates in “Server Certificate” section at root of the IIS. You can provide the CRT/P7B files and it will be accepted.
- Once certificate is imported in IIS, you can see it listed in the “Server Certificate” list
- Verify that you have all 3 root certificate, intermediate certificates and domain certificates linked together to your domain certificate
- Now [yo]u can install the domain certificate just by use the certificate install option within the certificate
- Now you can also export the domain certificate to PFX, by selecting “export the private key” option in certificate export wizard. Enter the password to protect the private key. This will give you a PFX file for your domain certificate which includes the full certificate chain.
- Now take the PFX and upload to Windows Azure Management Portal in Service Certificate section
- Verify that you have all 3 (root certificate, intermediate certificates and domain certificates) available at the portal and get the domain certificate thumbprint ID.
- Now Edit the Service Configuration file on Portal to replace old expired certificate Thumb ID to new PFX certificate Thumb ID.
Once configuration update is completed you will see your SSL related problem is resolved.



Bruce Kyle explained Deploying Your Applications on Windows Azure in a 2/14/2012 post to the US ISV Evangelists blog:
Writing an application is one thing. Your application has been designed, built, and tested. Yet deploying the application can be an adventure in its own right. Successful ISVs build and deploy often, sometimes continuously. And then run tests to be sure the application functions as expected and runs at as expected at scale.
You are able to provision the required components in the Windows Azure Management Portal, upload the service package, and configuring the service. You test your application in a staging environment and then promote it to production once you are satisfied that it is operating according to your expectations.
After you have set up your Windows Azure account, each step along the way can be done:
- Done from within Azure portal itself
- Automated by PowerShell scripts
- Within familiar tools, such as Visual Studio.
- Within your application using the Hosted Service REST API.
- Command line tooling in the Windows Azure SDK for Node.js
- Through third party tools such as Cloud9, an online environment for development of JavaScript and HTML5 applications
Each of these helps you package (zip) your application and upload it to Windows Azure along with some XML configuration files. The configuration information is used by Azure to figure out how many role instances to provision for each role, determines what OS version and components to put on each role instance, installs your uploaded code on each role instance, and boots them.
So within a few minutes after uploading the files, Windows Azure provisions your role instances and your application is up and running.
Once your role instances (that is, VMs running your application code) are up and running, Windows Azure constantly monitors them to ensure high availability of your applications. If one of your application processes terminates due to an unhandled exception, Windows Azure automatically restarts your application process on the role instance. If the hardware that is running your role instance experiences a failure, Windows Azure detects this, automatically provisions a new role instance, and boots it on other hardware, again ensuring high availability for your application.
You can get a good overview at Deploying and Updating Windows Azure Applications.
Learning How to Deploy Your Applications
A great place to get started is with a lab in the Windows Azure Training Developer Kit entitled, Deploying Applications in Windows Azure. In this hands-on lab, you learn how to:
- Use the Windows Azure Management Portal to create storage accounts and hosted service components
- Deploy service component packages using the Windows Azure Management Portal user interface
- Change configuration settings for a deployed application
- Test deployments in a separate staging environment before deployment to final production
- Use Windows PowerShell to deploy, upgrade, and configure Windows Azure services programmatically
- Use the Windows Azure Tools for service deployment from Visual Studio
- Secure your Windows Azure application with SSL
Automatically Maintaining Your Application
You may want to increase or decrease the number of role instances that your application is using within your program. For example, you may want to increase the number of Web roles whenever the number of concurrent users exceeds some threshold. You can also reduce the number of instances when the users falls. This is done using the Windows Azure Service Management API.
You can use the API to check errors, maintain certificates, define the data centers where your application is hosted, and more.
Traffic Manager
In addition you can use the APIs with Windows Azure Traffic Manager.
Windows Azure Traffic Manager enables you to manage and distribute incoming traffic to your Windows Azure hosted services whether they are deployed in the same data center or in different centers across the world. In this hands-on lab, you will explore different load balancing policies available in Traffic Manager and how you can use them to enhance performance, increase availability, and balance traffic to your hosted services.
Updating Your Application
Anytime you want to update your application — for example, to fix a bug or add a small feature — you can create a new CSPKG file containing the new code and upload it to Windows Azure via the Windows Azure Management Portal or by calling the Upgrade Deployment REST API. You can alternatively deploy your application directly from Windows Azure tooling, such as the Visual Studio tooling in the Windows Azure SDK for .NET or the command line tooling in the Windows Azure SDK for Node.js.
Staging Your Application
One of the great features in Windows Azure is to stage your application, try it and test it online, and then move it into your production site.
You deploy your application in the same way, but instead of putting it directly in service, you can send it into a staging instance.
Windows Azure deploys your new application to a new set of role instances and Windows Azure assign a globally unique identifier (GUID) as a special DNS prefix when an application is deployed to the staging environment. The new version of your application is now up and running in your desired data center and accessible for you to test at guid.cloudapp.net.
Your production application is still running. When it is time, you can swap the two versions. Windows Azure puts your storage version into production by performing what is called a Virtual IP (VIP) Swap. This causes Windows Azure to reprogram the load balancer so that it now directs client traffic sent to prefix.cloudapp.net to the instances running the new version of your code.
And should things not go as planned, the older version is still ready. You can swap them back if you need.
Learn More
You can learn more about getting started see Windows Azure Developer Center.
You can try out the features described here for free. See Windows Azure 3 Month free trial.
The Windows Azure Training Course includes a comprehensive set of hands-on labs and videos that are designed to help you quickly learn how to use Windows Azure services and SQL Azure.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Matt Thalman described a LightSwitch Trick: Display Loading Message while a Screen is Loading in a 2/15/2012 post:
In the LightSwitch apps that I create, I have a common pattern where I display a “Loading” message in the title bar of a screen while it is loading and then set it to its actual screen name once it’s finished. In particular, this is useful for screens whose title is dependent on the data that is loaded by the screen, such as a customer detail screen whose title is the name of the customer.
This is just a nice little tweak to the UI that’s quite simple to implement. Here’s how:
Ensure that focus is set to your screen’s content tree and choose the InitializeDataWorkspace event from the Write Code dropdown button:
In the method stub that gets generated, add the following code (replacing CustomerDetail with your actual screen name):
C#:
partial void CustomerDetail_InitializeDataWorkspace(
List<IDataService> saveChangesTo) { this.DisplayName = "Loading..."; }VB:
Private Sub CustomerDetail_InitializeDataWorkspace(saveChangesTo _
As System.Collections.Generic.List(Of Microsoft.LightSwitch.IDataService)) Me.DisplayName = "Loading..." End SubAnd that’s all you have to do if you are using a Details screen template. That’s because for a Details screen, LightSwitch automatically generates code for the entity property’s Loaded event to update the display name based on the entity’s data.
The InitializeDataWorkspace event is used because that’s the very first event that the screen raises. So within that event, the screen’s display name is immediately set to “Loading…”. Then, once the data is loaded, code runs in the Loaded event that explicitly sets the screen’s display name to the desired value.
If you wanted to apply this technique to a non-Details screen, you would do the same thing as above but additionally you would need to implement the Loaded event for one of your screen’s entity or collection properties that would set the DisplayName of the screen. For example, here’s how I’ve done it for my Customers Grid screen:
C#:
partial void Customers_Loaded(bool succeeded) { this.DisplayName = "Customers"; }VB:
Private Sub Customers_Loaded(succeeded As Boolean) Me.DisplayName = "Customers" End SubThe end result is that you see this while the screen is loading:
and this once it’s finished loading:





Matt works on the Visual Studio LightSwitch team as a Senior Software Development Engineer.
The Entity Framework Team posted a Sneak Preview: Entity Framework 5.0 Performance Improvements on 2/14/2012:
An O/RM, like any layer of abstraction, introduces overhead to data access. In EF 5.0 we have taken steps to reduce this overhead and improve performance. As a result in one of our tests, repeat execution time of the same LINQ query has been reduced by around 6x. We also have an end-to-end application that we use for performance testing that is running 67% faster.
LINQ to Entities Query Repeat Execution Time
In EF 5.0 we are introducing automatic compilation of LINQ to Entities queries. From the first version of EF, developers have been able to compile LINQ queries explicitly by calling CompiledQuery.Compile, but many developers either were not aware of this ability or found the API harder to work with than regular LINQ. In EF 5.0 we took on some of this work for you, so that the translation of inline LINQ queries is now cached without having to use CompiledQuery. This improvement, together with an optimization in how we evaluate query parameter values, has had a profound impact on the query performance of EF:
The graph above represents the relative time spent in the execution of a query that retrieves an entity by its key. The same logical query was executed via ADO.NET, LINQ to SQL and several EF methodologies. In the benchmark, the query is executed in a loop using different key values each time. From the graph above we can see that before these performance improvements, executing a LINQ to Entities query for the second time took 23.14 times as long as the same SQL query using classic ADO.NET. With automatic query compilation and the changes to parameter evaluation, we’ve improved the performance of LINQ to Entities queries nearly 600% when compared against EF 4.0. As a bonus, EF 4.0 applications will get this performance improvement for free by just upgrading to .NET 4.5.
End-to-End Performance
It would be amazing if we could give you 600% improved performance across the board. Unfortunately, most applications do more interesting things than run the same query repeatedly. Internally we have a suite of performance tests that run a variety of operations designed to simulate the typical usage a real-world application would have. We set thresholds based on the performance of EF 4.0 to ensure that we do not regress performance. These test runs are showing a 67% performance increase over EF 4.0 since we upgraded the server to EF 5.0:
We Aren’t Done Yet!
This means that many real-world applications will automatically show substantially improved performance when they start using EF 5.0. Naturally, how much faster a specific application will become will depend on many variables that would be impossible to predict in a benchmark.
We aren’t done improving performance yet, but we’re excited about how much faster EF 5.0 is. These numbers are based on an internal build, but we’re working hard to get a build available for public verification of these improvements.
As always, your feedback is important to us. Feel free to leave comments or concerns below.


Matthieu Mezil (@MatthieuMEZIL) continued his series with EF: why Include method is an anti-pattern IMHO? Part 5: many to many relationships on 2/13/2012:
I recently blogged to explain why I found that Include method is an anti-pattern IMHO.
- EF: Why Include method is an anti-pattern IMHO?
- EF: Why Include method is an anti-pattern IMHO even with many to one navigation properties? 2/3
- EF: Why Include method is an anti-pattern IMHO? 3/3
- EF- Why Include method is an anti-pattern IMHO- Conclusion
But I didn’t show how to do it with many to many relationships.
I will do on this post.
This is my model:
I have 1000 products, 100 categories and 4497 associations in my DB.
I use a local DB what is better for EF Include. // Don’t forget it, it would be worse for EF Include method with SQL Azure or any far DB… Moreover, the bigger entities are, the worse it is for the EF Include. In my case, entities are really very very short
The “official” way to get the 100 first Products with their Categories is the following:
var products = context.Products.Include("Categories").Take(100).ToList();
Now my way is the following:
object categoriesLock = new object();object productsCategoriesLock = new object();Task productsCategoriesTask = new Task(() =>{using (var productsCategoriesContext = new Many2ManyIncludeEntities()){var productsCategoriesIds = productsCategoriesContext.Products.Take(100).SelectMany(p => p.Categories.Select(c => new { p.ProductId, c.CategoryId })).ToList();lock (productsCategoriesLock){var loadedProducts = context.ObjectStateManager.GetObjectStateEntries(EntityState.Unchanged).Select(ose => ose.Entity).OfType<Product>().ToList();var loadedCategories = context.ObjectStateManager.GetObjectStateEntries(EntityState.Unchanged).Select(ose => ose.Entity).OfType<Category>().ToList();foreach (var pc in productsCategoriesIds){var product = loadedProducts.FirstOrDefault(p => p.ProductId == pc.ProductId);var category = loadedCategories.FirstOrDefault(c => c.CategoryId == pc.CategoryId);if (product != null && category != null)product.Categories.Attach(category);}}}});Task categoriesTask = new Task(() =>{lock (productsCategoriesLock){productsCategoriesTask.Start();using (var categoriesContext = new Many2ManyIncludeEntities()){categoriesContext.Categories.MergeOption = MergeOption.NoTracking;var categories = categoriesContext.Categories.Where(c => c.Products.Any(p => categoriesContext.Products.Take(100).Contains(p))).ToList();lock (categoriesLock){foreach (var c in categories)context.Categories.Attach(c);}}}});lock (categoriesLock){categoriesTask.Start();var products = context.Products.Take(100).ToList();}Task.WaitAll(categoriesTask, productsCategoriesTask);So my code is really more complex but what about performance?
Even with worse condition for my way (local DB, very short entities), my way is really better: for the first execution, EF Include executes it on 835 ms when mine is 130 (6.42 faster). For the second an other ones, EF Include executes it on 342 ms vs 72 for mine (4.75 faster).
Now you have the choice between performance vs. simplicity.


Julie Lerman (@julielerman) described Using T4Scaffolding to Create DbContext and Repository from Domain Classes in a 2/11/2012 post:
You may already be familiar with the fact that ASP.NET MVC 3 tooling includes a scaffolding option that let’s you point to a domain class and automatically build a Controller, a set of Views and if it does not exist yet, an Entity Framework DbContext class expose that class. The controller CRUD code uses the DbContext to perform it’s operations. Scott’s Guthrie & Hanselman both introduced us to this in blog posts last spring and I’ve certainly demo’d it way too many times.
This is handy but it puts all of the data access code into the controller. In other words, the controller works directly with the DbContext to perform queries & updates (etc).
If you have been paying attention, you may also be aware of the MVCScaffolding NuGet package that adds to these capabilities.
With this installed there are two new templates added to the MVC Add Controller wizard, one which adds a simple repository to the mix.
MVCScaffolding relies on another NuGet package, T4Scaffolding which contains many of the scaffolding templates used by MVCScaffolding.
I was working on the back end of a new app that may or may not have MVC as it’s front end UI. I had created my domain classes and the next step was to create a DbContext to wrap them as well as repositories. I didn’t want to code those by hand. I wanted that MVC tooling to get some of the grunt work out of the way for me. A little reading helped me learn that I could use the T4Scaffolding directly to get the same DbContext & Repository creation without being part of an MVC app (i.e. no controllers or views created).
Here’s how I worked it out.
In my solution where I already had my DomainClasses project, I added a new project, Data Layer.
I then installed Entity Framework via NuGet into this project:
Notice that NuGet automatically picks up the the latest version of EF, 4.3. I could have used the Package Manager Library UI to install EF, but since I had to the rest in the console window, I’m just doing all of these tasks in the console window.
Next, I install T4Scaffolding.
Important Pointers!
- Currently, T4 Scaffolding will install EF 4.1 if you don’t already have EF 4.1 or greater in your project. That’s why I installed EF first, so I can be sure to use the newest version.
- In the package manager console window, I have my default project pointing to DataLayer. I often forget to specify the project and install NuGet packages into the wrong project.

With the package installed, I can now start working towards letting it build out the context & repository for me.
First I need to reference DomainClasses from the DataLayer project
Then I build the solution so that DataLayer can see the DomainClasses for the next step.
Now in the Package Manager Console Window, I’ll use the command to build the repository code. The T4 template that builds the context & repo is called repository. The command is scaffold. I want to run scaffold using the repository template and base the output on my Alias class. I must use Alias’ fully qualified name so that it can be found.
The command is
scaffold repository DomainClasses.AliasHowever, I want to specify the name of my context. The default will be DataLayerContext (using the project name). I want it to be TwitterContext.
scaffold repository DomainClasses.Alias -DbContextType:TwitterContext
The result is that a new context & repository class get created in the target project (DataLayer).
There’s some default behavior that is not exactly to my liking and I can use additional parameters as well as modify the T4 template (here’s a post from Steve Sanderson as part of the MVC Scaffolding series that will help with that) but for now I’m happy to just move files around, which I’ll do shortly.
Here’s the context class.
public class TwitterContext : DbContext { public DbSet<DomainClasses.Alias> Aliases { get; set; } }Now I’ll add another class from my domain model to the mix: Tweet.
Notice that since TwitterContext already existed, we don’t get a second context class, the template alters the existing one:
public class TwitterContext : DbContext { public DbSet<DomainClasses.Alias> Aliases { get; set; } public DbSet<DomainClasses.Tweet> Tweets { get; set; } }Finally, I’ll just move things around so they are more to my liking:
I’ve created a Repositories project that has references to EF4.3, DataLayer and DomainClasses.
Now I can use the context & repos as they are or take the generated code (which has saved me a lot of time) and tweak it to my needs. But this has taken a lot of the repetitive typing away from me and started me on a path of success. Happiness.
Thanks to Steve Sanderson & others who worked on this tooling!
(Oh and if you could modify the template to pull in “latest version of EntityFramework.dll”, that would be handy.)








Paul Patterson described Microsoft LightSwitch – Add Granularity to Reference Data in a 2/9/2012 post (missed when published):
A nifty little feature that the A Little Productivity application includes is the ability to add granularity to the information about the costs that get applied to quotes and jobs. This article demonstrates a simple little technique for creating composite reference data.
A Little Productivity is simple little Microsoft Visual Studio LightSwitch project that was created to help manage a small service based business. I figured that this project would be an excellent resource for people to use as a launch pad to learning some LightSwitch development techniques; which is why the source is available for download.
One of the objectives I wanted to achieve with the solution was to be able to manage the costs on jobs at a very granular level. To achieve this granularity, I used a few techniques that you might be able to leverage when designing the data in your own LightSwitch solution.
Separation of Concerns
In my previous article I talked about the data-first approach to developing with LightSwitch. In that article I mentioned how I separated out the types of costs into three distinct entities (tables). These three entities include; expenses, labour, and materials. By separating out those details into their own entities, I set up the framework for applying the specialized processing that I needed for each of those entities.
Expenses are pretty straight forward. In most cases an expense is charged back to a customer at cost. There is typically no mark-up or additional pricing applied to an expense. A meal is a good example of an expense where you would charge the customer just the cost of the item at the cost you were incurred.
Materials are items that I want to keep track of both the cost of the item, as well as apply a price that I want to apply to the customer. These materials are generally items that I may either keep in an inventory, or acquire for the purpose of the job. In any case, there is an overhead that needs to be applied to the item, and that overhead is reflected into the price that is charged to the customer.
Labour is an interesting detail item. Like a material, labour has a cost associated to it. Labour also has many more inputs into how that cost is define. What if I pay different rates for different resources, even if each of those resources have the same title or position? This is a good example of why I separated out labour into its own entity. I want to make sure that I can implement the special processes needed to mitigate the a labour detail item, such as applying unique charge out rates for similar labour types.
Costing
To gain greater control of how much it costs me to do business, I want to be able to later analyse exactly how much it cost me to do something, at the time I incurred the cost. Looking at revenues will certainly give me the insight into how my financials are performing at a point in time, however I can’t I really measure that against how effective my pricing is and what I am charging customers. So, I applied some simple techniques in my data design to help me better measure and report on what is also important – my profitability.
The following sections talk about the predefined quote and job details that are used as references for building quotes and jobs.
Expenses
Starting with expenses I created a high-level expenses category entity. Then I created an expense entity and applied a relationship to the expenses category. An expense must belong to an expense category.
The following image shows an example of the screen where I maintain these expenses…
In the expenses entity, I include properties of Unit Cost and Unit Price. For expenses where I want to default a cost or price, I entered the values when creating the expenses. For other expenses that I don’t know what the amounts are, until the expense is incurred, I leave at $0.00.
Here is the design of the Expense entity…
Note the SummaryExpenseName computed field in the Expense entity designer. This is a computed field used as the summary value for screens, which make it much more intuitive when seeing the selected expense on the screen. The computed result is simply the expense category name and the expense name.
Materials
Next is the material entity which I want to use to manage item level costing and default pricing. Using this entity, I can create an inventory of materials that is available to me when creating the items on my quotes or jobs.
Just like the expense entity, I created a materials category entity. The materials that get added to each category include costing and pricing information that I want to default when adding the items to a quote or job.
Remember, these entities are just for reference and used as a repository of selectable items that I can apply to quotes and jobs. The idea is that the reference entity data is used to default the values, such as costs and prices, at the time the items are added. For example, a material item is added to a job and by default the cost and price is defined for that job detail. I can optionally change the cost and price specifically for the job, which does not change my reference cost or pricing – a tremendously valuable opportunity for when I start doing my job costing analysis and profitability reporting later down the road.
Labour
Labour is a fun entity to work with. There are a number of other factors that go into defining the cost, and pricing, of labour. Things like; how much you are paying someone to do the job, the type of rates to use for the job, and event the type of labour being performed. I want to define each of these kinds of factors for costing out labour, so, I designed a number of entities to allow me to do this.
In my design, I created a labour charge out entity which is essentially made up of three things; the title of the resource doing the labour, the type of labour, and the type of rate being applied to the labour.
Here is an example of how this is applied…
This granularity applied to the labour entity provides me a great deal of flexibility in defining my labour costing. When I start adding some human resources features to the application, I can then leverage the existing labour title and type entities as part of an overall employee management process. With a little more creativity I can start defining exactly who is working on a job, or maybe even add some time sheet type features too. Hmmm, the possibilities!
Proof is in the Pudding
Now that I have a bunch of detail item references, creating quotes and jobs is easy…
Again, the point being is that now I can quickly add detail items to my quotes and jobs, and have those items default with costs and pricing. Once added, those costs and pricing can then be updated on the job or quote, without effecting the defaulted reference costs and pricing – a huge value proposition when doing the analysis of my profitability.
Go ahead and download the source for this A Little Productivity application and try it out. Let me know how you make out with it







Return to section navigation list>
Windows Azure Infrastructure and DevOps
Shameer (@shameer) described The DevOps – NoOps Debate in a 2/15/2012 post to Redgate Software’s ACloudyPlace blog:
It all started when GigaOM published an infographic, “Why 2013 is the year of ‘NoOps’ for programmers” created by Lucas Carlson, CEO of AppFog. Now, NoOps is not a new concept. In fact, this was not even the first time someone used the phrase NoOps to talk about the advantages brought by platform services.
In April 2011, Forrester published Augment DevOps with NoOps, which states that “the goal of NoOps is to completely automate the application deployment (aka Lifecycle management), monitoring and management of infrastructure”. In November 2011, ReadWriteCloud published an article, “From DevOps to NoOps: 10 Cloud Services You Should Be Using”. Even then there was not much public debate about this within the community. But, since GigaOM published this sponsored article, as some commenters have claimed, a number of people have come out against the idea of NoOps and claimed that the role of DevOps is not going to diminish in the near future. Carlson has had a tough time explaining his stand to the community. Here are some of my thoughts on NoOps and why it’s not a compelling concept.
Pre NoOps – DevOps
Before we proceed, let me tell you something about DevOps. Wikipedia defines DevOps as a
set of principles, methods and practices for communication, collaboration and integration between software development (application/software engineering) and IT operations (systems administration/infrastructure) professionals.
As a descendant of Agile development methodology, DevOps is inherently agile. Thismakes it applicable in a wide range of contexts, especially to companies that have frequent release cycles. DevOps aims to ensure continuous delivery and consistency, focusing on the ability of systems to dynamically adapt to business requirements. Specifically, DevOps makes use of automation to streamline the application lifecycle. A DevOps-toolchain has been created to help with parts of this process, such as automated provisioning, managing VCS, issue tracking, deployment and so on. As a whole the process brings agility to a business through a better alignment of its IT provision. To achieve these goals, DevOps professionals interact with developers, operations, and QA. Consequently, software engineers working in DevOps require a certain level of operations knowledge and involvement.
PaaS and NoOps
So-called NoOps can be considered a by-product of PaaS. PaaS, by definition, is a cloud service delivery model and one of the most important evolutions of the cloud concept. It’s a place where people can try out their ideas with much lower upfront costs. Start-ups can easily bootstrap their ideas without having to worry about infrastructure, enabling them to market products quicker than the traditional route. PaaS also has many other advantages that are already well known.
On the other hand, PaaS can’t cut down costs exponentially, as claimed in Carlson’s infographic. For instance, if you go for the Gold cloud from PHPFog (who offer comparatively attractive pricing, I acknowledge), it will cost around $1000 a year. Compared with the cost of buying the hardware, you can easily own one or two such servers. For an actual cost cutting, many organizations will look for a hybrid cloud strategy where they can integrate existing infrastructure with cloud. Any PaaS service is not going to be that cost effective beyond a certain point. Also, PaaS doesn’t get rid of Ops. Instead, someone else, at a Cloud provider, is doing much of the Ops for the consumer. At most, PaaS merely separates Ops from the developers and provides it as a service. And that’s why even people from AppFog are annoyed by the phrase NoOps.
From the PaaS consumer perspective, I don’t think you can simply sit, code, and later deploy your application without worrying about scalability, monitoring, and any other Ops jobs. You should definitely monitor the application, gather metrics, and optimize the environment and application to the best possible level. If this involves any monitoring tool or service at all, you need to make sure its functioning well. All of these are nothing but Ops jobs.
Allspaw makes this clear from his comment on “What is NoOps anyhow”.
Are you
- Gathering metrics on how your application is performing? Congrats, you’re doing ‘operations’
- Taking action (automated or not) based on feedback loops that you’ve built around faults and performance of your application? Congrats, you’re doing ‘operations’
- Alerting someone to complex failures? Congrats, you’re doing ‘operations’
- Making informed decisions about datastores, external APIs, storage, etc. based on technical requirements? Congrats, you’re doing ‘operations’
In his later explanation AppFog blog, Carlson agrees there is a certain level of Ops in NoOps. He says
“the point isn’t that ops are going away, but they’re going away for developers”.
But there is also another problem. In so-called NoOps, where developers consume PaaS services and the providers do the rest for them, the aforementioned responsibilities will fall on developers. Eventually they will become Devs+Ops.
Adrian Cockcroft from Netflix argued that they run NoOps. But it is clear from his later comment that they make use of DevOps to meet the market dynamics, and that’s not NoOps. They have a reliability engineer with a DevOps skillset, who doesn’t code, but communicates with Devs to make changes.
I would say NoOps can’t be used in the same context where we use DevOps. Or, rather, do not use NoOps for the time being. Let’s reserve that word for something in future. We are all concerned with solving business problems, rather than political issues. So-called NoOps is a political problem, and it cannot solve business problems. DevOps, on the other hand, enables organizations to react to market requirements quickly, which means it can solve business problems quickly.
Conclusion
NoOps is actually a bad name for an apparently good idea. But it won’t solve the problem even if we call it LessOps; I am sure there are plenty of Ops peoples in AppFog. Apart from that, from the consumer side, someone needs to monitor the service and decide the strategies. One of the problems with the “AppFog NoOps” movement is its bias towards start-ups. Most of the metrics in the infographic are talking about the differences for start-ups in the PaaS and noPaaS eras. But there is a much, much bigger community outside which doesn’t fit in this movement.
Starting a new business is not all about launching an instance from the dashboard. There are many Ops activities involved. Organizations will need to find their own way to minimize the cost and increase the profit. So there is always room for Ops and, like Spike Morelli said, “The year of NoOps will never come”. People will continue to call so-called NoOps “PaaS”. Let’s try not to mix the two. It’s quite certain that PaaS has its own potential market and it will flourish in 2012-13, but not because of NoOps. It’s because of the advantages of PaaS such as lower upfront cost, less risk, and faster time to market that’s going to make it a success.

Full disclosure: I’m a paid contributor to the ACloudyPlace blog.
Janakiram MSV posed Analyzing the PaaS Landscape – Microsoft Windows Azure on 2/14/2012:
Having covered Cloud Foundry, Force.com, Google App Engine and Red Hat OpenShift, we now take a look at Microsoft’s PaaS offering, Windows Azure.
Though Windows Azure Platform is designed for the developers building applications on the Microsoft platform, developers building applications on Java and PHP environments can also leverage this. Microsoft is investing in the right set of tools and plug-ins for Eclipse and other popular developer environments.
For a detailed analysis of the current PaaS landscape, Click here for the Slide Deck from the Webinar Navigating the PaaS Maze in the Cloud.
Let me first explain each of the components of Windows Azure Platform and then walk you through the scenarios for deploying applications on this platform.
Windows Azure
Windows Azure is the heart & soul of the Azure Platform. It is the OS that runs on each and every server running in the data centers across multiple geographic locations. It is interesting to note that Windows Azure OS is not available as a retail OS. It is a homegrown version exclusively designed to power Microsoft’s Cloud infrastructure. Windows Azure abstracts the underlying hardware and brings an illusion that it is just one instance of OS. Because this OS runs across multiple physical servers, there is a layer on the top that coordinates the execution of processes. This layer is called the Fabric. In between the Fabric and the Windows Azure OS, there are Virtual Machines (VM) that actually run the code and the applications. As a developer, you will only see two services at the top of this stack. They are 1) Compute and, 2) Storage.Compute
You interact with the Compute service when you deploy your applications on Windows Azure. Applications are expected to run within one of the three roles called Web Role, Worker Role and VM Role. Web Role is meant to host typical ASP.NET web applications or any other CGI web applications. Worker Role is to host long running processes that do not have any UI. Think of the Web Role as an IIS container and the Worker Role as the Windows Services container. Web Role and Worker Role can talk to each other in multiple ways. The Web Role can also host WCF Services that expose a HTTP endpoint. The code within Worker Role will run independent of the Web Role. Through the Worker Role, you can port either .NET applications or native COM applications to Windows Azure. Through Worker Role, Windows Azure offers support for non-MS environments like PHP, Java and Node.js. VM Role enables running applications within a custom Windows Server 2008 R2 image. This will enable enterprises to easily port applications that have dependencies or 3rd party components and legacy software.Storage
When you run an application, you definitely need storage to either store the simple configuration data or more complex binary data. Windows Azure Storage comes in three flavors. 1) Blobs, 2) Tables and, 3) Queues.Blobs can store large binary objects like media files, documents and even serialized objects. Table offers flexible name/value based storage. Finally, Queues are used to deliver reliable messages between applications. Queues are the best mechanism to communicate between Web Role and Worker Role. The data stored in Azure Storage can be accessed through HTTP and REST calls.
Service Bus
This service enables seamless integration of services that run within an organization behind a firewall with those services that are hosted on the Cloud. It forms a secure bridge between the legacy applications and the Cloud services. Service Bus provides secure connectivity between on-premise and Cloud services. It can be used to register, discover and consume services irrespective of their location. Services hosted behind firewalls and NAT can be registered with the Service Bus and these services can be then invoked by the Cloud Services. The Service Bus abstracts the physical location of the service by providing a URI that can be invoked by any potential consumer.Access Control Service
Access Control is a mechanism to secure your Cloud services and applications. It provides a declarative way of defining rules and claims through which callers can gain access to Cloud services. Access Control rules can be easily and flexibly configured to cover a variety of security needs and different identity-management infrastructures. Access Control enables enterprises to integrate their on-premise security mechanisms like Active Directory with the Cloud based authentication. Developers can program Access Control through simple WCF based services.Caching
Caching provides an in-memory caching service for applications hosted on Windows Azure. This avoids the disk I/O and enables applications to quickly fetch data from a high-speed cache. Cache can store multiple types of data including XML, Binary, Rows or Serialized CLR Objects. Web applications that need to access read-only frequently can access the cache for better performance. ASP.NET developers can move the session to Cache to avoid single-point-of failure.SQL Azure
SQL Azure is Microsoft SQL Server on the Cloud. Unlike Azure Storage, which is meant for unstructured data, SQL Azure is a full-blown relational database engine. It is based on the same DB engine of MS SQL Server and can be queried with T-SQL. Because of its fidelity with MS SQL, on-premise applications can quickly start consuming this service. Developers can talk to SQL Azure using ADO.NET or ODBC API. PHP developers can consume this through native PHP API. Through the Microsoft SQL Azure Data Sync, data can be easily synchronized between on-premise SQL Server and SQL Azure. This is a very powerful feature to build hubs of data on the Cloud that always stay in sync with your local databases. For all practical purposes, SQL Azure can be treated exactly like a DB server running in your data center without the overhead of maintaining and managing it by your teams. Because Microsoft is responsible for installation, maintenance and availability of the DB service, business can only focus on manipulating and accessing data as a service. With the Pay-as-you-go approach, there is no upfront investment and you will only pay for what you use.Let’s take a look at some of the scenarios that customers target on Microsoft Windows Azure Platform.
Scalable Web Application
Because Windows Azure Platform is based on the familiar .NET platform, ASP.NET developers can design and develop web applications on fairly inexpensive machines and then deploy them on Azure. This will empower the developers to instantly scale their web apps without worrying about the cost and the complexity of infrastructure needs. Even PHP developers can enjoy the benefits of elasticity and pay-by-use attributes of the platform.Compute Intensive Application
Windows Azure Platform can be used to run process intensive applications that occasionally need high end computing resources. By leveraging the Worker Role, developers can move code that can run across multiple instances in parallel. The data generated by either Web Role or On-Premise applications can be fed to the Worker Roles through Azure Storage.Centralized Data Access
When data has to be made accessible to a variety of applications running across the browser, desktop and mobile, it makes sense to store that in a central location. Azure Cloud based storage can be great solution for persisting and maintaining data that can be easily consumed by desktop applications, Silverlight, Flash and AJAX based web applications or mobile applications. With the Pay-as-you-grow model, there is no upfront investment and you will only pay for what you use.Hybrid Applications (Cloud + On-Premise)
There may be a requirement for extending a part of an application to the Cloud or building a Cloud façade for an existing application. By utilizing the services like Service Bus and Access Control, on-premise applications can be seamlessly and securely extended to the Cloud. Service Bus and a technology called Azure Direct Connect can enable the Hybrid Cloud scenario.Cloud Based Data Hub
Through SQL Azure, companies can securely build data hubs that will be open to trading partners and mobile employees. For example, the Inventory of a manufacturing company can be securely hosted on the Cloud that is always in sync with the local inventory database. The Cloud based DB will be opened up for B2B partners to directly query and place orders. SQL Azure and the SQL Azure Data Sync will enable interesting scenarios.


Martin Tantow asserted PaaS on a Continued Strategic Growth in a 2/12/2012 post to the CloudTimes blog:
Platform as a service (PaaS) remains to be the core element of cloud computing in any personal or business solutions. Any changes, therefore, to its make up will definitely affect cloud vendors and users according to the research analyst Gartner.
Vice president and Gartner analyst, Yefim Natis said, “With large and growing vendor investment in PaaS, the market is on the cusp of several years of strategic growth, leading to innovation and likely breakthroughs in technology and business use of all of cloud computing. Users and vendors of enterprise IT software solutions that are not yet engaged with PaaS must begin building expertise in PaaS or face tough challenges from competitors in the coming years.”
PaaS refers to a platform that is composed of layers of cloud technology framework that holds all application services needed by any business enterprise. They are also referred to as middleware because of the stack of layers of end-to-end software in the cloud. It is a cloud platform that integrates all applications needed by a business from operating systems, data storage, virtualization requirements and networks. The scope of PaaS’s comprehensive services include application development tools, functionality of application servers, database management, portal service products, middleware integration, business process tools and many others.
PaaS is still at its young stage according to Gartner and there are yet to be leaders in this arena in terms of business practices and standards. In the meantime, while all these are still being developed there may still be risks uncertainties from its use.
“However, PaaS products are likely to evolve into a major component of the overall cloud computing market, just as the middleware products including application servers, database management systems (DBMSs), integration middleware and portal platforms are the core foundation of the traditional software industry. The tension between the short-term risk and the long-term strategic imperative of PaaS will define the key developments in the PaaS market during the next two to three years,” Natis said.
New developments to PaaS are expected to be out towards the end of 2012 and 2013. By 2016, it is projected that new and upgraded PaaS offerings will be largely distributed by 2016. PaaS models will be made from new programming models, new PaaS market leaders and fresh business practices and standards. While all these are taking place consumers may have to deal with the unpredictable PaaS market.
“While there are clear risks associated with the use of services in the new and largely immature PaaS market, the risk of avoiding the PaaS market is equally high. The right strategy for most mainstream IT organizations and software vendors is to begin building familiarity with the new cloud computing opportunities by adopting some PaaS services now, albeit with the understanding of their limitations and with the expectation of ongoing change in the market offerings and use patterns,” Natis concluded.

Joel Foreman reported on 2/10/2012 the availability of a Windows Azure Real World Guidance Article on MSDN:
I am pleased to announce that fellow Slalom colleague Stephen Roger and I recently had an article we wrote published on MSDN. Microsoft supports a collection of articles on MSDN called Real World Windows Azure Guidance, where people from the technology community can share real experiences on using the Windows Azure platform.
- Comparing performance of a web application under load for different instance sizes;
- Factoring in a hypothetical usage pattern to understand scaling implications for instance sizes; and
- Evaluating cost when scaling for different instance sizes.
Please check out the article when you get a chance!

Mary Jo Foley (@maryjofoley) asked Can Microsoft Save Windows Azure? in a 2/2/2012 article for Redmondmag.com (missed when published):
Microsoft is slowly but surely working to make its Windows Azure cloud platform more palatable to the masses -- though without the benefit of roadmap leaks, it would be hard for most customers to know this.
When Microsoft began cobbling together its Windows Azure cloud plans back in 2007, there was a grand architectural plan. In a nutshell, Microsoft wanted to recreate Windows so that Redmond could run users' applications and store their data across multiple Windows Server machines located in Microsoft's (plus a few partners') own datacenters. In the last five years, Microsoft has honed that vision but has never really deviated too far from its original roadmap.
For Platform as a service (PaaS) purists -- and Microsoft-centric shops -- Windows Azure looked like a distributed-systems engineer's dream come true. For those unwilling or unable to rewrite existing apps or develop new ones that were locked into the Microsoft System Center- and .NET-centric worlds, it was far less appealing.
How many external, paying customers are on Windows Azure? Microsoft officials won't say -- and that's typically a sign that there aren't many. My contacts tell me that even some of the big Azure wins that Microsoft trumpeted ended up trying Windows Azure for one project and then quietly slinking away from the platform. However, Windows Azure is no Windows Vista. Nor is it about to go the way of the Kin. But without some pretty substantial changes, it's not on track to grow the way Microsoft needs it to.
This fact hasn't been lost on the Microsoft management. Starting last year, Microsoft began making a few customer- and partner-requested tweaks to Windows Azure around pricing. Then the 'Softies started getting a bit more serious about providing support for non-Microsoft development tools and frameworks for Windows Azure. Developer champion and .NET Corporate Vice President Scott Guthrie traded his red shirt for an Azure-blue one (figuratively -- still not yet literally) and moved to work on the Windows Azure application platform.
Starting around March this year, Microsoft is slated to make some very noticeable changes to Windows Azure. That's when the company will begin testing with customers its persistent virtual machine that will allow users to run Windows Server, Linux(!), SharePoint and SQL Server on Windows Azure -- functionality for which many customers have been clamoring. This means that Microsoft will be, effectively, following in rival Amazon's footsteps and adding more Infrastructure as a Service components to a platform that Microsoft has been touting as pure PaaS.
The first quarterly update to Windows Azure this year -- if Microsoft doesn't deviate from its late 2011 roadmap -- will include a number of other goodies, as well, such as the realization of some of its private-public cloud migration and integration promises. If you liked Microsoft's increased support for PHP, Java, Eclipse, Node.js, MongoDB and Hadoop from last year, take heart that the Windows Azure team isn't done improving its support for non-Microsoft technologies. Also on the Q1 2012 deliverables list is support for more easily developing Windows Azure apps not just on Windows, but also on Macs and Linux systems.
Microsoft's new focus with Windows Azure is to allow users to start where they are rather than making them start over. That may sound like rhetoric, but it's actually a huge change, both positioning- and support-wise for Microsoft's public cloud platform. Not everyone -- inside or outside the company -- agrees that this is a positive. Hosting existing apps in the cloud isn't the same as re-architecting them so they take advantage of the cloud. It will be interesting to see whether users who are tempted by the "new" Windows Azure are happy with the functionality for which they've been clamoring.

The new pricing for SQL Azure announced on 2/14/2012 is a step in the right direction (see the SQL Azure Database, Federations and Reporting section above.)
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Bruno Terkaly (@brunoterkaly) recommended downloading Building Hybrid Applications in the Cloud on Windows Azure–Guidance in a 2/15/2012 post:
Download the free book: Building Hybrid Applications in the Cloud on Windows Azure.
Table of Contents


Anant Sundaram (@sunananth) described Application Management in a Private Cloud with System Center 2012 in a 2/15/2012 post to the Microsoft Server and Cloud Platform Team blog:
Working in enterprise IT organizations here and at other companies has convinced me that applications are the lifeblood of any business. I used to be amazed at how quickly the CIO would get involved if a revenue generating application wasn’t performing as expected. To become a trusted partner to the business, an IT professional has to internalize the reality that infrastructure exists to support applications; thus our assertion that the Microsoft private cloud is focused on the application. This blog is about how the application management capabilities in System Center 2012 empower you in delivering applications more cost-effectively, quickly and reliably to your business.
Empowering the application owners across the organization is key to realizing the IT as a Service vision of private cloud computing. The premise behind creating and delegating private cloud infrastructure is to provide a simple self-service experience to application owners to provision and elastically scale applications as per business requirements.
Why Choose a Microsoft Private Cloud?
The Microsoft private cloud gives you deep application insight, and management of services, as well as virtual machines. The Microsoft private cloud lets you deliver applications as a service across their lifecycle. You can deploy applications on a self-service basis, and manage them across private cloud and public cloud (Windows Azure) environments. You can elastically scale the application based on what your business needs. You can even virtualize server applications to simplify deployment and upgrading. And with deep insight into the performance of your applications, you can remediate issues faster, before they become show-stoppers. The result is better SLA’s, better customer satisfaction, and a new level of agility across the board.
Deep Application Insight
System Center 2012 delivers rich diagnostics to enable you deliver predictable application service levels. Using the Operations Manager component you can isolate the root cause of the application performance issues down to the offending line of code pretty efficiently (see illustration below), even when you have not written the application code yourself. You can send all the details about the failing code section to your application development counterpart pretty easily. Using the connector between Operations Manager and Visual Studio (currently in CTP), you can create a work item in the developer’s queue so it can be triaged as soon as possible. By creating a process and tool-driven approach, we mitigate the possibility of finger pointing and delays in addressing operational issues with your business-critical applications.
Delivering Applications as a Service
System Center 2012 offers you the ability to define standardized application blueprints - called service templates - which can be used to automatically deploy application services to shared resource pools. Defining your application requirements with a repeatable construct like service templates makes deployments faster and less error-prone. Once service templates are defined, your application owners can go to the App Controller component of System Center 2012 where they can easily specify configuration requirements like application topology, scale-out rules, health thresholds, and upgrade rules and then kick-start a “one-click deployment”. App Controller also provides a compelling visualization of the of the application service, including all the requested service tiers and the pooled resources (see illustration below).
How to Get Started
If you want to get started deploying application services to your private cloud, download the Microsoft System Center 2012 Release Candidate and give it a try. You can also request to join our Community Evaluation Program.
You should also check out these related posts for additional details:
- Announcing New System Center 2012 Pre-Releases: Delivering Self-Service Application Management with the Microsoft Private Cloud
- Application Deployment Models in a Private Cloud
- App Controller Enabling Application Self-Service
- Application Performance Monitoring with System Center 2012
- Managing and Monitoring Windows Azure Applications with System Center 2012
Finally, you can check out how our customers are benefiting from the Microsoft private cloud:




Kevin Remde (@KevinRemde) answered Where CAN’T You Use Hyper-V? (So Many Questions. So Little Time. Part 11) in a 2/15/2012 post:
A question I’ve actually heard several times before came up again at our TechNet Event in Kansas City several weeks ago:
“Can I use Hyper-V as a VM (within Windows 7)?”
No.
“Can you elaborate?”
Absolutely.
First of all, Hyper-V is a role added to Windows Server 2008 and Windows Server 2008 R2. Hyper-V can’t be run inside of a virtual machine – even one that supports Windows Server 2008 R2 – because in order to work Hyper-V requires at a minimum:
- An x64-based processor,
- A processor that supports Intel VT or AMD-V technology, and
- Hardware-enforced Data Execution Prevention (DEP) - available and enabled.
(Check out THIS PAGE for the full list of Hyper-V requirements.)
The problem with a virtual machine, whether it’s running on Hyper-V, Windows Virtual PC (the one that runs on Windows 7), or VMware, is that the virtualized processor that the running operating system sees is not a processor capable of running Hyper-V. So, while it would be cool to virtualize the actual virtualization platform, that’s not something that you can currently do.
An additional note regarding your question about Windows 7 specifically is that Windows Virtual PC running on Windows 7 doesn’t support 64-bit guest operating systems. So you can’t run the current Windows Server 2008 R2 as a virtual machine under Windows Virtual PC anyway. The good news is that Microsoft announced that we will include Hyper-V within the successor to Windows 7, currently codename “Windows 8”.

No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
Esmaeil described Threat Modeling of the Cloud in a 2/13/2012 post:
If there’s one problem in cloud computing you have to revisit regularly, it’s security. Security concerns, real or imagined, must be squarely addressed in order to convince an organization to use cloud computing. One highly useful technique for analyzing security issues and designing defenses is threat modeling, a security analysis technique long used at Microsoft. Threat modeling is useful in any software context, but is particularly valuable in cloud computing due to the widespread preoccupation with security. It’s also useful because technical and non-technical people alike can follow the diagrams easily. At some level this modeling is useful for general cloud scenarios, but as you start to get specific you will need to have your cloud platform in view, which in my case is Windows Azure. [Emphasis added.]
To create our threat model, we’ll start with the end result we’re trying to avoid: data in the wrong hands.
Next we need to think about what can lead to this end result that we don’t want. How could data of yours in the cloud end up in the wrong hands? It seems this could happen deliberately or by accident. We can draw two nodes, one for deliberate compromise and one for accidental compromise; we number the nodes so that we can reference them in discussions. Either one of these conditions is sufficient to cause data to be in the wrong hands, so this is an OR condition. We’ll see later on how to show an AND condition.
Let’s identify the causes of accidental data compromise (1.1). One would be human failure to set the proper restrictions in the first place: for example, leaving a commonly used or easily-guessed database password in place. Another might be a failure on the part of the cloud infrastructure to enforce security properly. Yet another cause might be hardware failure, where a failed drive is taken out of the data center for repair. These and other causes are added to the tree, which now looks like this:
We can now do the same for the deliberately compromised branch (1.2). Some causes include an inside job, which could happen within your business but could also happen at the cloud provider. Another deliberate compromise would be a hacker observing data in transmission. These and other causes could be developed further, but we’ll stop here for now.
If we consider these causes sufficiently developed, we can explore mitigations to the root causes, the bottom leaves of the tree. These mitigations are shown in circles in the diagram below (no mitigation is shown for the “data in transmission observed” node because it needs to be developed further). For cloud threat modeling I like to color code my mitigations to show the responsible party: green for the business, yellow for the cloud provider, red for a third party.
You should not start to identify mitigations until your threat tree is fully developed, or you’ll go down rabbit trails thinking about mitigations rather than threats. Stay focused on the threats. I have deliberately violated this rule just now in order to show why it’s important. At the start of this article we identified the threat we were trying to model as “data in the wrong hands”. That was an insufficiently described threat, and we left out an important consideration: is the data intelligible to the party that obtains it? While we don’t want data falling into the wrong hands under any circumstances, we certainly feel better off if the data is unintelligible to the recipient. The threat tree we have just developed, then, is really a subtree of a threat we can state more completely as: Other parties obtain intelligible data in cloud. The top of our tree now looks like this, with 2 conditions that must both be true. The arc connecting the branches indicates an AND relationship.
The addition of this second condition is crucial, for two reasons. First, failing to consider all of the aspects in a threat model may give you a false sense of security when you haven’t examined all of the angles. More importantly, though, this second condition is something we can easily do something about by having our application encrypt the data it stores and transmits. In contrast we didn’t have direct control over all of the first branch’s mitigations. Let’s develop the data intelligible side of the tree a bit more. For brevity reasons we’ll just go to one more level, then stop and add mitigations.
Mitigation is much easier in this subtree because data encryption is in the control of the business. The business merely needs to decide to encrypt, do it well, and protect and rotate its keys. Whenever you can directly mitigate rather than depending on another party to do the right thing you’re in a much better position. The full tree that we’ve developed so far now looks like this.
Since the data intelligible and data in the wrong hands conditions must both be true for this threat to be material, mitigating just one of the branches mitigates the entire threat. That doesn’t mean you should ignore the other branch, but it does mean one of the branches is likely superior in terms of your ability to defend against it. This may enable you to identify a branch and its mitigation(s) as the critical mitigation path to focus on.
While this example is not completely developed I hope it illustrates the spirit of the technique and you can find plenty of reference materials for threat modeling on MSDN. Cloud security will continue to be a hot topic, and the best way to make some headway is to get specific about concerns and defenses. Threat modeling is a good way to do exactly that.








<Return to section navigation list>
Cloud Computing Events
Michael Collier (@MichaelCollier) announced on 2/14/2012 that he’ll present at the Detroit Day of Azure on 3/24/2012:
I’m thrilled to be speaking at the Detroit Day of Azure on Saturday, March 24th. This is going to be a one day event that will cover many areas of the Windows Azure platform. I’ll be giving two presentations, “The Hybrid Windows Azure Application” and “Windows Phone 7 and Windows Azure – A Match Made in the Cloud”.
Check out this speaker lineup!
- Dennis Burton
- Jason Follas
- John Ferringer
- David Giard
- Joe Kunk
- Jennifer Marsman
- Jeff Nuckolls
- Brian Prince
- Mark Stanislav
- Brent Stineman
- Mike Wood
That’s a pretty impressive list of Windows Azure MVPs, Microsoft evangelists, and cloud gurus. This is going to be fun!!
Registration is now open at http://detroitdayofazure.com/. You can get in on the early bird pricing now for just $10. That’s a great deal!

Matthew Weinberger (@M_Wein) reported Cloud Connect Santa Clara: Oh, It’s On. And We’re Ready in a post of 2/14/2012 to the TalkinCloud blog:
For best results, listen to Survivor’s “Eye of the Tiger” while reading this … After weeks of planning, coordination and training, Cloud Connect Santa Clara is finally upon us — that time when every cloud vendor not big or egotistical enough to throw its own show is gathering here in Silicon Valley to show off their wares. Here’s a quick preview of the first day to whet your whistle ahead of my first wave of cloud dispatches from the front line.
The first day’s keynotes seem to be rapid-fire, featuring Thinking Out Cloud (a cloud blog — hey, where’s my invitation to keynote?), OpsCode, Cisco Systems, LinkedIn, Beth Israel Deaconess Medical Center, Bitcurrent, the Cloud Security Alliance and IBM discussing their current views of the cloud, all in the span of about two hours.
Afterward, I’ll be running around meeting with cloud thought leaders while the general attendance will be enjoying panels covering the “love story” between Rackspace and OpenStack Object Storage (Swift), cloud design, cloud economics and vendor-specific presentations on the benefits of one model over another.
There are 90(!) exhibitors on the show floor this year. I’m going to try to do everything and see everything — in fact, feel free to ping me on Twitter at @m_wein if you see something cool that I should pay attention to. Assuming I’m alive in the evening, both IBM and Rackspace are sponsoring after-events, and hopefully I’ll score some updates on their cloud strategy while I’m in attendance.
Some other quick, cool things I’ve learned about Cloud Connect:
- This is the first time the conference has had Mobile Cloud, Big Data Processing and Organizational Readiness tracks.
- Yesterday saw the first-ever Carrier Cloud Forum, designed to highlight the communications/telecom service provider segment of the cloud market.
- Cloud Network of Women (CloudNOW) will be hosting its-first ever Top Women in Cloud awards luncheon at Cloud Connect. Rock on.
By the time you read this, I’ll very likely be sipping my coffee and preparing for the first day’s start. And you can already see a few of the earliest Cloud Connect dispatches on TalkinCloud today.
Let’s do this thing, Cloud Connect.
Read More About This Topic

Alan Smith reported Sweden Windows Azure Group (SWAG) Meeting, 20th September February in Stockholm on 2/13/2012:
For the first SWAG meeting of 2012 Ludwig Ahrle and Mikael Eriksson will present two developer focused sessions covering the work they have been doing for Curvande on the Windows Azure platform. This will be a great opportunity to see real-world Azure development hands-on.
The presentations will take place between 18:00 and 20.30, with a 30 minute break for food, there will then be a chance to take a drink, chat and mingle with the presenters and other SWAG members.
Register here.
Sign up to join Sweden Windows Azure Group here.
Not sure how Alan confused September with February.
David Pallman posted a CloudFest Denver Recap on 2/12/2012:
I had a great time at CloudFest Denver last Thursday (Feb 9)--the show had a lot of energy and a really high level of tweeting on the #cloudfest hashtag. Neudesic was among the exhibitors and sponsors and provided two speakers--Mike Erickson (Windows Azure Diagnostics) and myself (Windows Azure Design Patterns, When Worlds Collide: HTML5 Meets the Cloud).
At this conference we also debuted AttendeeBee, a mobile/social/cloud app attendees use to tweet, share their location, and rate sessions. Attendees get more points the more they use AttendeeBee, increasing their chances of winning our giveaway, an XBox/Kinect bundle in this case. At the Neudesic booth, attendees can see the entire conference at a glance on a large monitor, including a leaderboard. This provides an element of gamification. AttendeeBee worked pretty well on its maiden voyage and we have some good ideas on where to take it next.
You can view my presentations below.


<Return to section navigation list>
Other Cloud Computing Platforms and Services
David Linthicum (@DavidLinthicum) asserted “The market doesn't need another stand-alone cloud storage service, but integrating Gdrive with Google Apps makes sense” in a deck for his Why Google's Gdrive won't set the cloud on fire article of 2/14/2012 for InfoWorld’s Cloud Computing blog:
Google's Drive, aka Gdrive, cloud storage service is finally due for release, more than four years after it was first rumored in 2007. Clearly, users want cloud storage, both at the enterprise and the retail levels. Just look at the success of Dropbox and Box.net, not to mention Amazon.com's S3. Of course Apple is in that game as well with its iCloud document-syncing cloud service. I use them all.
So what's new with Gdrive? Not much.
We've been able to store stuff for free using Google Apps for years. Moreover, we've had other more retail-oriented cloud storage systems, such as Dropbox, that already work pretty well and have been battle-tested. While I wouldn't put state secrets on these services just yet, their security is much better than a USB thumb drive's, which is the real-world alternative for most users.
Gdrive enters an established market as a me-too offering, competing against respected providers with cheap and even free versions. It's hard to imagine Gdrive will have much of an impact, but its integration with Google Apps and Google's App Engine PaaS could make Gdrive the default cloud storage service for existing Google business users.
Even so, Gdrive is still a yawner. The cloud storage providers have not seen a dramatic growth at the retail level, nor have they seen the bidding wars break out, such as an Apple taking a run at a Dropbox. (Apple reportedly considers cloud storage a feature, not a product.) Google is hoping that this current lack of market excitement means potential for a big payoff later on cloud usage becomes more and more common, especially across diverse devices -- and thus believes it has time to establish itself as a major provider.
But we don't need another pure cloud storage service. We have Dropbox and Box.net on the low end and S3 on the high end. Dozens of others, such as Accellion and YouSendIt, exist as well, especially in the enterprise-managed space that's trying to assert itself.
Rather than offer a stand-alone service, Google should simply bake Gdrive into Google Apps and App Engine, where it will get plenty use. Google will look silly if Gdrive comes in near the bottom of the cloud storage list, and it needs to understand that its has bigger fish to fry than cloud storage.


Joe Panettieri (@joepanettieri) reported Ingram Micro, VMware Partner on Service Provider Licensing in a 2/14/2012 post to the TalkinCloud blog:
Ingram Micro, the massive IT distributor, has scored global distribution rights to sell VMware under a service provider licensing model. The news, which surfaced at VMware Partner Exchange in Las Vegas, could provide a further boost to Ingram Micro’s ambitious cloud aggregator strategy.
The straightforward news: Ingram Micro is now “authorized as a global VMware Service Provider Program (VSPP) aggregator.”
But what exactly does that mean?
- First, Ingram Micro’s channel partners can leverage VMware’s pay-as-you-go (i.e., service provider) licensing model.
- Second, it’s a safe guess that VMware will work more closely with Ingram Micro Cloud — a cloud aggregator site — to promote its software out to Ingram’s channel partner base.
The Ingram Micro Cloud offers dozens of SaaS applications that channel partners can source on behalf of their customers. Moreover, the Ingram Micro Cloud allows channel partners to maintain control of end-customer pricing and end-customer billing for cloud services, a big plus for channel partners who want to maintain close customer relationships.
In a prepared statement, VMware VP Doug Smith specifically pointed to VMware’s growing relationship with Ingram Micro Cloud. Smith stated: “By authorizing Ingram Micro to sell VMware-based cloud services globally and via the Ingram Micro Cloud, we’re building on our success, expanding our reach and providing VMware partners with additional enablement and sales support.”
Most major distributors, including Tech Data and Synnex, are launching cloud initiatives of their own. Synnex, for one, earlier today unveiled the CONVERGESolv Enterprise Utility Data Center, a holistic utility computing solution in the channel. Talkin’ Cloud will be back with more insights soon.
Read More About This Topic

Randy Bias (@randybias) described Cloudscaling’s New Strategy: Open Cloud infrastructure in a 2/13/2012 post to his CloudScaling blog:
Over the past two years, I’ve talked at length about the emerging success gap between ‘enterprise cloud’ and the AWS model. In the past, I’ve asserted that these two different approaches to cloud service very different kinds of applications: legacy apps vs. greenfield apps. Or more appropriately: enterprise applications vs. cloud-ready applications. Even before this, I argued that private clouds *can* be real, if built in the model of successful public AWS-style clouds.
We believe that enterprise clouds have a place in furthering virtualization and server consolidation. Virtualization 2.0, if you will. This approach to building infrastructure clouds is important. This is what we call an ‘enterprise cloud,’ and the market for this approach exists as can be seen from VCE Vblock.
We also believe that Amazon Web Services and Rackspace Cloud’s success, as highlighted by the lack of success by public *enterprise* clouds, can’t be ignored. These public clouds are hosting a new generation of cloud-ready, elastic applications deployed by everyone from a single developer up to Fortune 10 companies. We call this an ‘open cloud’.
Enterprise clouds and open clouds are on completely different tracks, servicing completely different needs. Businesses need not only an enterprise cloud strategy, but an open cloud strategy.
Some businesses might mix an enterprise cloud with an open cloud for different workloads. Or, they might adopt enterprise cloud for internal enterprise apps, and open cloud for external-facing, cloud-ready apps such as new web and mobile applications. There could be many permutations, but it’s critical for your business to understand the requirements of next-generation cloud-ready apps and support their deployment, because enterprise clouds for these types of applications are not the answer. Only the open cloud approach allows us to manage ‘shadow IT’, enable security & compliance, drive greater business value, and support the emergence of cloud-ready applications as a growth engine.
Enterprise Cloud Litmus Test
Not sure how to know what your current strategy is or what kind of cloud you are building? Here’s a simple assessment that’s good for cloud service providers building private/public clouds or enterprise IT teams building an internal private cloud.Ask yourself these questions:
- Does this cloud focus on migration of existing applications in enterprise datacenters? (features like hypervisor compatibility, live migration, high availability SAN storage, etc.)
- Is it expensive, complex, and labor-intensive to operate?
- Do you find name-brand hardware throughout, creating lock-in?
- Does it encourage very complex networking?
- Are users obligated to contracts and monthly invoices? (no variable pricing options)
- Does it provide arbitrary ‘pools’ of ‘resources’ the the end-user has to carve up manually? (i.e. clock cycles, RAM, storage)
- Are you still in vendor-lock-in land? Delivering F5-as-a-service or Netscaler-as-a-service rather than Load-Balancing-as-a-Service?
If more than half of these are true, you are probably looking at a cloud built with enterprise computing technology.
Open Cloud Litmus Test
On the other hand, here’s a test for open clouds, whether public or private, or internal/external:
- Can you spin up 1,000 virtual servers in < 5 minutes?
- Are your tenants focused on using cloud-ready management platforms like RightScale and enStratus?
- Can you run a big data or Hadoop job on 1,000+ VMs for an hour without the system falling over?
- Are the basic networking and networking services (e.g. load balancing) simple, straightforward, and end-user manageable?
- Is it using standards-based APIs, de facto or not? (AWS? OpenStack?)
- Is the underlying physical infrastructure and cloud operations team focused on: homogeneity, modularity, common denominator solutions, and automation?
- Can you compete successfully against Amazon Web Services on price and service levels combined?
As in the previous test, if more than half of these are true for you, then you are probably looking at an open cloud.
What the market is telling us
We’ve learned about these two clouds through experiences talking and deploying with our customers. They’ve told us that they need a solution in addition to their existing enterprise cloud.You see it in almost every enterprise cloud deployment: The project moves along only so far before the team realizes it’s not servicing certain requirements. As the market has evolved, customers have started telling us that they want cloud infrastructure designed for cloud-ready apps. They want a more open approach, one that saves them from vendor lock-in and excessive software taxation. Our customers are also telling us that they are *not* looking for technology, but rather proven, production-grade solutions.
In line with that, we are announcing the industry’s first comprehensive solution for designing, building and operating open cloud infrastructure for cloud-ready applications: the Cloudscaling Open Cloud System.
What are cloud-ready applications?
Cloud-ready applications are designed to take advantage of the economics and agility achievable by using open cloud infrastructure. These applications differ fundamentally from traditional applications in that they are more elastic in nature, manage their own data replication, are designed-for-failure, horizontally scalable, and use automated DevOps-style management frameworks. Cloud-ready applications manage failure in software, while legacy enterprise architectures manage failure in hardware. This important distinction eliminates typical enterprise application dependencies on expensive and proprietary infrastructure solutions.Cloud-ready applications can be designed from the ground up to leverage open cloud infrastructure. In some cases, they can be legacy apps that have been re-architected or containerized to run on open cloud infrastructure.
Skating to where the puck is going to be
That’s what we’re betting the company on. While there’s going to be a big market for enterprise clouds into the foreseeable future, our product strategy anticipates an accelerating adoption curve for infrastructure that’s flexible, scalable and economical: open cloud infrastructure.Simplicity scales.

Randy appears to be overhyping open.
Jeff Barr (@jeffbarr) warned Be Careful When Comparing AWS Costs... in a 2/11/2012 post to his Amazon Web Services blog:
Earlier today, GigaOM published a cost comparison of self-hosting vs. hosting on AWS [See post below.] I wanted to bring to your attention a few quick issues that we saw with this analysis:
Lower Costs in Other AWS Regions - The comparison used the AWS costs for the US West (San Francisco) Region, ignoring the fact that EC2 pricing in the US East (Northern Virginia) and US West (Oregon) is lower ($0.76 vs. $0.68 for On-Demand Extra Large Instances).
Three Year Reserved Instances - The comparison used one year Reserved Instances, but a three year amortization schedule for the self-hosted hardware. You save over 22% by using three year Reserved Instances instead of one year Reserved Instances, and the comparison is closer to apples-to-apples.
High Utilization Reserved Instances - The comparison used a combination of Medium Utilization Reserved Instances and On-Demand Instances. Given the predictable traffic pattern in the original post, a blend of High and Low Utilization Reserved Instances would reduce your costs, and still give you the flexibility to easily scale up and scale down that you don't get with traditional hosting.
Load Balancer (and other Networking) Costs - The self-hosted column does not include the cost of a redundant set of load balancers. They also need top-of-rack switches (to handle what is probably 5 racks worth of servers) and a router.
No Administrative Costs - Although the self-hosted model specifically excludes maintenance and administrative costs, it is not reasonable to assume that none of the self-hosted hardware will fail in the course of the three year period. It is also dangerous to assume that labor costs will be the same in both cases, as labor can be a significant expense when you are self-hosting.
Data Transfer Costs - The self-hosted example assumes a commit of over 4 Gbps of bandwidth capacity. If you have ever contracted for bandwidth & connectivity at this scale, you undoubtedly know that you must actually commit to a certain amount of data transfer, and that your costs will change significantly if you are over or under your commitment.
We did our own calculations taking in to account only the first four issues listed above and came up with a monthly cost for AWS of $56,043 (vs. the $70,854 quoted in the article). Obviously each workload differs based on the nature of what resources are utilized most.
These analyses are always tricky to do and you always need to make apples-to-apples cost comparisons and the benefits associated with each approach. We're always happy to work with those wanting to get in to the details of these analyses; we continue to focus on lowering infrastructure costs and we're far from being done.

Charlie Oppenheimer asked Which is less expensive: Amazon or self-hosted? in a 2/11/2012 post to the GigaOm blog:
Amazon Web Services (AWS), as the trailblazing provider of Infrastructure as a Service (IaaS), has changed the dialog about computing infrastructure. Today, instead of simply assuming that you’ll be buying and operating your own servers, storage and networking, AWS is always an option to consider, and for many new businesses, it’s simply the default choice.
I’m a huge fan of cloud computing in general and AWS in particular. But I’ve long had an instinct that the economics of the choice between self-hosted and cloud provider had more texture to it than the patently attractive sounding “10 cents an hour,” particularly as a function of demand distribution. As a case in point, Zynga has made it known that for economic reasons, they now use their own infrastructure for baseline loads and use Amazon for peaks and variable loads surrounding new game introductions.
An analysis of the load profiles
To tease out a more nuanced view of the economics, I’ve built a detailed Excel model that analyzes the relative costs and sensitivities of AWS versus self-hosted in the context of different load profiles. By “load profiles,” I mean the distribution of demand over the day/month as well as relative needs for bandwidth versus compute resources. The load profile is the key factor influencing the economic choice because it determines what resources are required and how heavily these resources are utilized.
The model provides a simple way to analyze various load profiles and allows one to skew the load between bandwidth-heavy, compute-heavy or any combination. In addition, the model presents the cost of operating 100 percent on AWS, 100 percent self-hosted as well as all hybrid mixes in between.
In a subsequent post, I will share the model and describe how you can use it for scenarios of interest to you. But for this post, I will outline some of the conclusions that I’ve derived from looking at many different scenarios. In most cases, the analysis illustrates why intuition is right (for example, that a highly variable compute load is a slam dunk for AWS). In other cases, certain high-sensitivity factors become evident and drive the economic answer. There are also cases where a hybrid infrastructure is at least worthy of consideration.
To frame an example analysis, here is the daily distribution of a typical Internet application. In the model, traffic distribution is an input from which bandwidth requirements are computed. The distribution over the day reflects the behavior of the user base (in this case, one with a high U.S. business-hour activity peak). Computing load is assumed to follow traffic according to a linear relationship, i.e. higher traffic implies higher compute load.
Note that while labor costs are included in the model, I am leaving them out of this example for simplicity. Because labor is a mostly fixed cost for each alternative, it will tend not to impact the relative comparison of the two alternatives. Rather, it will impact where the actual break-even point lies. If you use the model to examine your own situation, then of course I would recommend including the labor costs on each side.
For this example, to compute costs for Amazon, I have assumed Standard Extra Large instances and ELB load balancer for the Northern California region. The model computes the number of instances required for each hour of the day. Whenever the economics dictate it, the model applies as many AWS Reserved Instances (capacity contracts with lower variable costs) as justified and fills in with on-demand instances as required. Charges for data are computed according to the progressive pricing schedule that Amazon publishes. To compute costs for self-hosting, I assume co-location with the peak number of Std-XL-equivalent servers required, each loaded to no more than 80 percent of capacity. The costs of hardware are amortized over 36 months. Power is assumed to be included with rackspace fees. Bandwidth is assumed to be obtained on a 95th percentile price basis.
Now let’s look at a sensitivity analysis. Notice in the above example, that a bit more than half of the total cost for each alternative is for bandwidth/data transfer charges ($35,144 for self-hosted at $8/Mbps and $36,900 for AWS). This is important because while Amazon pricing is fixed and published, 95th percentile pricing is highly variable and competitive
The chart above shows total costs as a function of co-location bandwidth pricing. AWS costs are independent of this and thus flat. What this chart shows is that self-hosting costs less for any bandwidth pricing under about $9.50 per Mbps/Month. And if you can negotiate a price as low as $4, you’d be saving more than 40 percent to self-host. I’ll leave discussion of the hybrid to another post.
This should provide a bit of a feel for how I’ve been conducting these analyses. Above is a visual summary of how different scenarios tend to shake out. The intuitive conclusion that the more spiky the load, the better the economics of the AWS on-demand solution is confirmed. And similarly, the flatter or less variable the load distribution, the more self-hosting appears to make sense. And if you’ve got a situation that uses a lot of bandwidth, you need to look more closely at potential self-hosted savings that could be feasible with negotiated bandwidth reductions.


<Return to section navigation list>

















0 comments:
Post a Comment