Windows Azure and Cloud Computing Posts for 12/11/2013+
Top Stories This Week:
- Scott Guthrie (@scottgu) described Windows Azure: New Scheduler Service, Read-Access Geo Redundant Storage, and Monitoring Updates in a 12/12/2013 post to his ASP.NET blog in the Windows Azure Infrastructure and DevOps section.
- Joab Jackson (@Joab_Jackson) reported Microsoft launches network of Azure providers in a 12/12/2013 article for NetworkWorld in the Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds section.
- Lydia Leong (@cloudpundit), Douglas Toombs, Bob Gill, Gregor Petri and Tiny Haynes posted Gartner’s Magic Quadrant for Cloud Infrastructure as a Service on 8/19/2013 (missed when published) in the Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN section:
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Caching, SQL Azure Database, and other cloud-computing articles. |
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Windows Azure Marketplace DataMarket, Power BI, Big Data and OData
- Windows Azure Service Bus, BizTalk Services and Workflow
- Windows Azure Access Control, Active Directory, and Identity
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure and DevOps
- Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
- Visual Studio LightSwitch and Entity Framework v4+
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
<Return to section navigation list>
No significant articles so far this week.

<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Marketplace DataMarket, Cloud Numerics, Big Data and OData
No significant articles so far this week.
<Return to section navigation list>
Windows Azure Service Bus, BizTalk Services and Workflow
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Access Control, Active Directory, Identity and Workflow
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
Lydia Leong (@cloudpundit), Douglas Toombs, Bob Gill, Gregor Petri and Tiny Haynes posted Gartner’s Magic Quadrant for Cloud Infrastructure as a Service on 8/19/2013 (missed when published):
Summary
The market for cloud compute infrastructure as a service (a virtual data center of compute, storage and network resources delivered as a service) is still maturing and rapidly evolving. As each provider has unique offerings, the task of sourcing their services must be handled with care.
Market Definition/Description
Cloud computing is a style of computing in which scalable and elastic IT-enabled capabilities are delivered as a service using Internet technologies. Cloud infrastructure as a service (IaaS) is a type of cloud computing service; it parallels the infrastructure and data center initiatives of IT. Cloud compute IaaS constitutes the largest segment of this market (the broader IaaS market also includes cloud storage and cloud printing). Only cloud compute IaaS is evaluated in this Magic Quadrant; it does not cover cloud storage providers, platform as a service (PaaS) providers, software as a service (SaaS) providers, cloud services brokerages or any other type of cloud service provider, nor does it cover the hardware and software vendors that may be used to build cloud infrastructure. Furthermore, this Magic Quadrant is not an evaluation of the broad, generalized cloud computing strategies of the companies profiled.
In the context of this Magic Quadrant, cloud compute IaaS (hereafter referred to simply as "cloud IaaS" or "IaaS") is defined as a standardized, highly automated offering, where compute resources, complemented by storage and networking capabilities, are owned by a service provider and offered to the customer on demand. The resources are scalable and elastic in near-real-time, and metered by use. Self-service interfaces are exposed directly to the customer, including a Web-based UI and, optionally, an API. The resources may be single-tenant or multitenant, and hosted by the service provider or on-premises in the customer's data center.
We draw a distinction between cloud infrastructure as a service, and cloud infrastructure as a technology platform; we call the latter cloud-enabled system infrastructure (CESI). In cloud IaaS, the capabilities of a CESI are directly exposed to the customer through self-service. However, other services, including noncloud services, may be delivered on top of a CESI; these cloud-enabled services may include forms of managed hosting, data center outsourcing and other IT outsourcing services. In this Magic Quadrant, we evaluate only cloud IaaS offerings; we do not evaluate cloud-enabled services. (See "Technology Overview for Cloud-Enabled System Infrastructure" and "Don't Be Fooled by Offerings Falsely Masquerading as Cloud Infrastructure as a Service" for more on this distinction.)
This Magic Quadrant covers all the common use cases for cloud IaaS, including development and testing, production environments (including those supporting mission-critical workloads) for both internal and customer-facing applications, batch computing (including high-performance computing [HPC]) and disaster recovery. It encompasses both single-application workloads and "virtual data centers" (VDCs) hosting many diverse workloads. It includes suitability for a wide range of application design patterns, including both "cloud-native" application architectures and enterprise application architectures.
This Magic Quadrant primarily evaluates cloud IaaS providers in the context of the fastest-growing need among Gartner clients: the desire to have a "data center in the cloud," where the customer retains most of the IT operations responsibility. Gartner's clients are mainly enterprises, midmarket businesses and technology companies of all sizes, and the evaluation focuses on typical client requirements.
This Magic Quadrant strongly emphasizes self-service and automation in a standardized environment. It focuses on the needs of customers whose primary need is self-service cloud IaaS, although it may be supplemented by a small amount of colocation or dedicated servers. Organizations that need significant customization or managed services for a single application, or that are seeking cloud IaaS as a supplement to a traditional hosting solution ("hybrid hosting"), should consult the Magic Quadrants for Managed Hosting instead ("Magic Quadrant for Managed Hosting, North America," "Magic Quadrant for European Managed Hosting" and "Magic Quadrant for Cloud-Enabled Managed Hosting, Asia/Pacific"). Organizations that do not want self-service, but instead want managed services with an underlying CESI, should consult our Magic Quadrants for data center outsourcing and infrastructure utility services instead ("Magic Quadrant for Data Center Outsourcing and Infrastructure Utility Services, North America" and "Magic Quadrant for Data Center Outsourcing and Infrastructure Utility Services, Europe").
This Magic Quadrant evaluates only solutions that are delivered in an entirely standardized fashion — specifically, public cloud IaaS, along with private cloud IaaS that uses the same or a highly similar platform. Although most of the providers in this Magic Quadrant do offer custom private cloud IaaS, we have not considered these offerings in our evaluations. Organizations that are looking for custom-built, custom-managed private clouds should use our Magic Quadrants for data center outsourcing and infrastructure utility services instead (see above). …
Magic Quadrant
Figure 1. Magic Quadrant for Cloud Infrastructure as a Service
Source: Gartner (August 2013)


From the Vendor Strengths and Cautions section:
…
Microsoft
Microsoft is a large ISV with a diverse array of related technology businesses; it is increasingly focused on delivering its software capabilities via cloud services. Its Windows Azure business was previously strictly PaaS, but Microsoft launched Windows Azure Infrastructure Services (which include Virtual Machines and Virtual Networks) into general availability in April 2013, thus entering the cloud IaaS market.
Locations: Windows Azure Infrastructure Services are available in data centers on the East and West Coasts of the U.S., as well as in Ireland, the Netherlands, Hong Kong and Singapore. Microsoft has global sales, and Windows Azure support is provided during local business hours in English, French, German, Italian, Spanish, Japanese, Korean, Mandarin and Portuguese; 24/7 support is provided only in English.
Compute: Windows Azure VMs are fixed-size, paid-by-the-VM, and Hyper-V-virtualized; they are metered by the minute.
Storage: Block storage ("virtual hard disk") is persistent and VM-independent. There is no support for bulk import/export. Object-based cloud storage is integrated with a CDN.
Network: Third-party private connectivity is not supported. Inter-data-center Azure traffic goes over the Internet, not a Microsoft private network. There is no network security as a service.
Other notes: Enterprise-grade support costs extra. The SLA is multi-fault-domain, but does not have any exclusion for maintenance. There is no granular RBAC. Although audit logs are kept, they are retained for less than 60 days. The broader Windows Azure service is a full-featured PaaS offering with significant complementary capabilities, such as database as a service; the Virtual Machines are integrated into the overall offering. Trigger-based autoscaling is in beta.
Recommended use: Test and development for Microsoft-centric organizations; cloud-native applications; use as part of an overall Windows Azure solution.
Strengths
- Microsoft has a vision of infrastructure and platform services that are not only leading stand-alone offerings, but also seamlessly extend and interoperate with on-premises Microsoft infrastructure (rooted in Hyper-V, Windows Server, Active Directory and System Center) and applications, as well as Microsoft's SaaS offerings. Its vision is global, and it is aggressively expanding into multiple international markets.
- Microsoft has built an attractive and easy-to-use UI that will appeal to Windows administrators and developers. The IaaS and PaaS components within Windows Azure feel and operate like part of a unified whole, and Microsoft is making an effort to integrate them with Visual Studio and System Center.
- Microsoft's brand, existing customer relationships and history of running global-class consumer Internet properties have made prospective customers and partners confident that it will emerge as a market leader in cloud IaaS. The number of Azure VMs is growing very rapidly. Microsoft customers who sign a contract can receive their enterprise discount on the service, making it highly cost-competitive. Microsoft is also extending special pricing to Microsoft Developer Network (MSDN) subscribers.
Cautions
- Windows Azure Infrastructure Services are brand-new and consequently lack an operational track record. The feature set is limited and the missing features are ones that are critical to most enterprises. Many features are in "preview" (beta), or "coming soon," and it is not always obvious to the customer which features are still in preview. Although Microsoft has a generally good uptime record with Azure PaaS components, it will be challenged to scale its IaaS business rapidly.
- Microsoft is in the midst of a multiyear initiative to make its on-premises software "cloud first," rather than trying to scale software originally built for on-premises single-enterprise use. It now faces the challenges of getting its core infrastructure technology to operate at cloud scale, managing that infrastructure at cloud scale, and facilitating the ability of customers to move toward more highly automated infrastructure.
- Microsoft has just begun to build an ecosystem of partners around Windows Azure Infrastructure Services, and does not yet have a software licensing marketplace. Furthermore, it has little in the way of enterprise Linux options. Consequently, the offering is currently very Microsoft-centric and appeals primarily to .NET developers. …
Read the entire article here.

<Return to section navigation list>
Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
No significant articles so far this week.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
Scott Guthrie (@scottgu) described Windows Azure: New Scheduler Service, Read-Access Geo Redundant Storage, and Monitoring Updates in a 12/12/2013 post to his ASP.NET blog:
This morning we released another nice set of enhancements to Windows Azure. Today’s new capabilities include:
- Scheduler: New Windows Azure Scheduler Service
- Storage: New Read-Access Geo Redundant Storage Option
- Monitoring: Enhancements to Monitoring and Diagnostics for Azure services
All of these improvements are now available to use immediately (note that some features are still in preview). Below are more details about them:
Scheduler: New Windows Azure Scheduler Service
I’m excited to announce the preview of our new Windows Azure Scheduler service. The Windows Azure Scheduler service allows you to schedule jobs that invoke HTTP/S endpoints or post messages to a storage queue on any schedule you define. Using the Scheduler, you can create jobs that reliably call services either inside or outside of Windows Azure and run those jobs immediately, on a regular schedule, or set them to run at a future date.
To get started with Scheduler, you first need to sign-up for the preview on the Windows Azure Preview page. Once you enroll in the preview, you can sign in to the Management Portal and start using it.
Creating a Schedule Job
Once you have the Schedule preview enabled on your subscription, you can easily create a new job following a few short steps:
Click New->App Services->Scheduler->Custom Create within the Windows Azure Management Portal:
Choose the Windows Azure Region where you want the jobs to run from, and then select an existing job collection or create a new one to add the job to:
You can then define you job action. In this case, we are going to create an HTTP action that will do a GET request against a web site (you can also use other HTTP verbs as well as HTTPS):
For processing longer requests or enabling a service to be invoked when offline, you may want to post a message to a storage queue rather than standing up and invoking a web service. To post a message to a storage queue just choose Storage Queue as your action then create or select the storage account and queue to send a request to:
Once you’ve defined the job to perform, you’ll now want to setup the recurrence schedule for it. The recurrence can be as simple as run immediately (useful for testing), at a specific time in the future, or on a recurring schedule:
Once the job is created, the job will be listed in the jobs view:
The jobs view shows a summary status of failures/faults with any job – you can then click the history tab to get even more detailed status (including the HTTP response headers + body for any HTTP based job).
I encourage you to try out the Scheduler – I think you’ll find it a really useful way to automate jobs to happen in a reliable way. The following links provide more information on how to use it (as well as how to automate the creation of tasks from the command-line or your own applications):
- Documentation
- .NET API NuGet Package
- MSDN forum to find answers to all your Scheduler questions
- Feedback and ideas can be posted on the Scheduler feedback forum
- Scheduler Pricing Details page (note there is a free tier included for all subscriptions)
Storage: New Read-Access Geo Redundant Storage Option
I’m excited to announce the preview release of our new Read-Access Geo Redundant Storage (RA-GRS) option. RA-GRS is a major improvement to our Windows Azure Storage Geo Replicated Storage offering. Prior to today, our Geo-Replicated Storage option provided built-in support for automatically replicating your storage data (blobs, queues, tables) from one primary region to another (for example: US East to US West), but access to the secondary location data wasn’t provided except in a disaster scenario which necessitated a storage cluster failover.
With today’s update you can now always have read-access to your secondary storage replica. This enables you to have immediate access to your data in the event of a temporary failure in your primary storage location (and to build-in support within your applications to handle the read fail-over automatically). Today’s update also enables you to test and track the replication of your data so you can easily verify the replication (which happens asynchronously in the background).
Enabling Read Access
In order to enable RA-GRS support, you will need to sign up to the Read Access Geo Redundant Storage Preview on the Windows Azure Preview page. Once you enroll in the preview, you can sign in to the Management Portal and simply navigate to the Configure tab for your Storage Account to enable it on the Storage Account:
Once enabled you can access your secondary storage endpoint location as myaccountname-secondary.<service>.core.windows.net. You can use the same access keys for the the secondary storage location as the ones for your primary storage endpoint.
For additional details on RA-GRS and examples of how to use it, read the storage blog post entry at http://blogs.msdn.com/b/windowsazurestorage/archive/2013/12/04/introducing-read-access-geo-replicated-storage-ra-grs-for-windows-azure-storage.aspx
Monitoring: Enhancements to Monitoring and Diagnostics for Azure services
Today’s update includes several nice enhancements to our monitoring and diagnostics capabilities of Windows Azure:
Monitoring metrics for Premium SQL Databases
With today’s update you can now monitor metrics for the CPU and IO activity of Premium SQL databases, and the storage activity of both Premium and Standard databases. You can find more details on MSDN.
Update to Web Site diagnostics
Previously, you could select an existing blob container when configuring the storage location for your web server HTTP logs.
With this release, you now can additionally create a new blob container to push your web server logs to in a single, consistent configuration experience within the Windows Azure Management Portal. You can do so by simply navigating to the configure tab for your web site, clicking on the manage storage button above, and selecting the option to create a new blob container.
Operation history support for Windows Azure Mobile Services
The Operation Logs feature of Windows Azure allows you to audit/log management operations performed on your Windows Azure Services. You can review them be clicking on the Operating Logs tab within the Management Services extension of the Management Portal:
With today’s update we have added more than 20 new log actions for Windows Azure Mobile Services that will now show up in the operation logs list.
Summary
Today’s release includes a bunch of great features that enable you to build even better cloud solutions. If you don’t already have a Windows Azure account, you can sign-up for a free trial and start using all of the above features today. Then visit the Windows Azure Developer Center to learn more about how to build apps with it.












<Return to section navigation list>
Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
Joab Jackson (@Joab_Jackson) reported Microsoft launches network of Azure providers in a 12/12/2013 article for Network World:
Microsoft has launched the Cloud OS Network, a global consortium of cloud service providers that offer Windows Azure IaaS (infrastructure-as-a-service).
More than 25 providers have signed up for the network for its initial launch, including Capgemini, Capita IT Services of Glasgow, CGI, Computer Sciences Corporation, Dimension Data of Australia, DorukNet of Turkey, Fujitsu Finland, iWeb of Montreal and Lenovo in China.
Overall, providers in the Cloud OS Network covers over 90 regions worldwide. The companies collectively now serve more than 3 million customers with more than 2.4 million servers across 425 data centers.
Each provider offers Microsoft-validated, cloud-based infrastructure and associated applications, using the Windows Server 2012 R2, Windows System Center 2012 R2 and the Windows Azure Pack, which provides the same Azure IaaS capabilities Microsoft runs with its own offering.
Microsoft launched the Cloud OS Network with the understanding that regional providers worldwide may be better equipped in some cases to provide Azure cloud services than Microsoft itself, explained Eugene Saburi, general manager of Microsoft Cloud OS marketing.
Governments and organizations may have geographical restrictions about where its data is located. A local provider may also offer better network latency times because its data centers are closer to its customers, Saburi said. Regional providers may also know how to more effectively reach the potential customer base.
Users of Azure services could benefit in a number of ways as well, Saburi said. With a number of competing Azure services on hand, an organization can move their workloads from provider to another, should service suffer. This approach also allows customers to use their own copies of Windows System Center 2012 R2 to manage both in-house resources and those in this cloud network.
The Cloud OS network " allows customers to experience boundary-less data centers, being able to move workloads and virtual machines and manage assets whether they are in the data center, in our cloud, or in a partner cloud," Saburi said.

The SQL Server Team (@SQLServer) described SQL Server 2014 Hybrid Cloud Scenarios: Migrating On-Premises SQL Server to Windows Azure Virtual Machines on 12/10/2013:
Those of you who have tried the new version of SQL Server Management Studio might have noticed already that it has a couple of new wizards added. One of those wizards is sitting next to the already existing that has been allowing you to deploy to a Windows Azure SQL Database service (former SQL Azure) and it is called Deploy Database to a Windows Azure Virtual Machine (VM).
You might be wondering why this wizard is here and what it can do. The blog post below tries to provide the answer to this and some of the related questions.
The Path to Windows Azure
We have seen many time that when people are trying a Virtual Machine in the Windows Azure environment they quickly come up with a number of questions. Once the first set of questions is resolved the next wave of questions come up, then the next wave, and a few next waves.
I have tried to compile the list of things you could expect.
- Get access to a Windows Azure.
Logging into a Windows Azure Portal might not be enough to unlock the full power of the Azure. In majority of cases you would need a Management Certificate. There is nothing special about it, except it should be available on the machine you are using, and it should be known to the Windows Azure. This means you should create a certificate somehow. Alternate option is to download Publishing Profile from the Portal. In this case Portal will generate certificate on your behalf, add it to the subscriptions you have access to, and share it with you in the form of XML file.- Create and configure your VM.
When you have an access to the Azure environment you can start creating other pieces you are needed. The first thing to create is a VM. Don’t forget that you need a VM that:
- Has a SQL Server in it and version of the SQL Server is the same or higher as the version of SQL Server you have currently, otherwise your deployment capabilities will be very limited.
- Has an Azure Drive attached, you will need it to store your data.
- In case VM was created in a Cloud Service it should have endpoints configured properly, otherwise please make sure you have Azure VNet and corresponding VPN.
- You should be able to connect to the SQL Server instance meaning connections should be accepted by the SQL Server and customer should be able to authenticate. In case your machine is not joined to domain this means only SQL authentication is available, so don’t forget to set up a SQL login in advance to the instance configuration.
- Windows firewall should allow connections to the SQL server to allow them to go though.
- Plus many other steps needs to be taken.
- Once your target system is set up you need to focus on copying data from the source system. The best option that gives you the most of the recovery capabilities it to use the Azure Storage as an intermediate location. In this case you either copy your files directly using Backup to URL, or backup them locally and then use Azure SDK to upload them to the storage.
- Once data is in the cloud you need to get it to the VM. Depends on the data size you can either pull it to the VM and restore or just use Restore from URL.
Those steps are describing the things need to happen to end up with your workload in Windows Azure VM. There are multiple small details in this process, same as a lot of things to consider. You can consult this article if you need more information on the subject.
The Wizard
You might have question how the process above is related to the wizard described in this post. This is exactly what Deploy Database to a Windows Azure VM wizard does for you, plus a few additional convenience items.
Let’s see how this looks in the wizard.
The first screen tries to provide you an idea of what information might be useful for you during the use of the wizard.
The Source Settings screen only want you to provide with two pieces of information:
- Connection to the source server and database
- Where to place backup files (file or UNC path). Please note: this path should look the same for the wizard and the Database Engine
Once you told the wizard where to get the data from you might want to connect to Windows Azure. There are 3 different options:
- Manually provide with the management certificate and paste or type a subscription ID
- Import a publishing profile if you have downloaded it already
- Use you Microsoft Account (former Windows Live ID) to sign in to the portal and allow the Wizard to retrieve publishing profile behind the scenes for you
Once all authentication information is in place we connect to a Windows Azure environment, so you can start configuring it. There are a few things you could do:
- Type a new Cloud Service name (or select it from the list if you already have one)
- Type a new VM name (same as before, you can select it from the list if there are some to select from)
- Select the storage account which is in the same region with the VM (if you don’t have any, don’t worry – wizard will create an account for you)
- Press the Settings… button (One of the most important steps). This button behave differently depending on whether this is a new VM or an existing VM, but in all cases the button needs to be pressed to enter the information that is important for the process.
When you type a new VM name and press the Settings… button a new dialog comes up. If you have seen Windows Azure Portal before you should be familiar with most fields in this new dialog.
Please note: we are trying to warn you if we think that the target SQL Server instance might be lower version than the source instance. Sometimes those are hard errors that doesn’t allow you to continue, when we know for sure that the final configuration will not be compatible, while sometimes we can only guess. In either case the suggestion is to do not ignore those warnings:
When you select the VM that has existed before this makes the dialog look differently.
Please note two things here:
- This is one of the first times SQL Server Cloud Adapter comes up on the screen. This is a new component that runs as a service inside a VM (you can run it on the physical machine too) and does all the magic of the VM configuration. We will spend a bit of time on its capabilities and restrictions a little later.
- Since single Cloud Service can contain multiple VMs sharing the same public IP – this means Cloud Adapter Port might be different for those VMs. Also as the previous phrase suggests this is a public port.
Once you chose settings for a new VM or connected to an existing one the Target Database section became active. Please note that Database name field is editable meaning you can change your mind about database name on the target machine.
Now you are just two easy steps away from having your database in the cloud. The first step is to confirm the selection you have made when following the wizard:
And a second step is to wait until process completes. Depends on the database size and your connection speed the time might differ, but wizard will make sure it is done.
And finally you would see the confirmation screen that also contains a link to the detailed log.
This log is important for most of the troubleshooting actions, same as for digging for details.
The Result
Deploy Database to a Windows Azure VM wizard has guided you through the deployment process. Now this is the right time to observe what the end result is look like.
- You have Virtual Machine running in Windows Azure
- This VM has SQL Server instance configured
- You database is deployed to the instance
However, a few manual steps might be needed.
- You need to add a logins and give those logins access to the database the wizard has deployed.
- If your application would be connecting to the VM from outside – make sure to configure the SQL Server to allow the connectivity.
Finally
The Deploy Database to a Windows Azure VM wizard is in place to simplify the steps needed to have a database in a Windows Azure VM environment. The whole wizard is made around the scenarios when you need your database in the cloud as soon as possible and willing to skip some studying or preparation steps as a tradeoff for the speed of the deployment. The other assumption was that you don’t want to do a deployment manually and prefer SQL Server to do some of this work for you.
The wizard was made as an extremely safe to your data. There is no chance it could delete, overwrite, or even modify your data. All operations it does are read only for the data.
We really hope this new feature will help you to save time during your deployments.













<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+


<Return to section navigation list>
Cloud Security, Compliance and Governance

<Return to section navigation list>
Cloud Computing Events
Tom Kerkhove (@TomKerkhove) posted Taking a look back at CloudBrew to the Codit Europe blog on 12/13/2013:
Last Saturday was the very first edition of CloudBrew, a full-day conference on Windows Azure organized by the Belgian Windows Azure User Group (AZUG) with two track full of international speakers!
Internet of Things
Yves Goeleven started Track 1 with his vision on the “Internet of Things”, how all devices get more and more connected to each other and the history behind it. He gave us an overview of what technologies are currently available for sensors and devices to talk to each other, so we could "pick our poison" since each technology has it's advantage & disadvantage.
He also gave some architectural experiences and the example of a past project for Barco & Kinepolis to integrate their projector-system in their global environment and how Windows Azure filled in the gap.
After Yves gave us the theoretical introduction Andy Cross was up to fill in for Nuno Godinho who was sick. Although his demos weren't working we learned how we could connect from microframework to Windows Azure storage by using his library and simplify the flow. We also saw some of the pitfalls in his demos.
This might seem as a fun topic, and it is, but this could also occur in your day-to-day job for example at the Barco & Kinepolis project.
Big data
Andy was back for more, this time on big data! He introduced us to three different types of data storage for big data - Hadoop, MongoDB & Neo4j.
- Being a big data newbie myself this was very helpful, before I only knew Hadoop does map/reduce on loads and loads of data but there are many more.
- MongoDB offers document based storage with a flexible schema in a JSON-format.
- Neo4j is using relations to link all the data together known as Graphs.
It's good to know these technologies but is still a tough topic to talk about, especially when you have no field experience.
Brewery tour
One of the sweet things about CloudBrew was that it was hosted at the 'Het Anker', a brewery in Mechelen.
In this brewery we got the opportunity to attend a guided tour and learn how they brew beer and their brand new whisky!
© Azug
© Azug
Claims model
Last but not least, Magnus Mårtensson took the stage to talk about the 'Claims model'. The claims model is used in authentication where you don't want to be responsible for storing the user's private information because that obviously comes with several consequences. Nonetheless you want a way to authenticate your users. This is where the claims model comes in; you trust a 3th party that "claims" that the user is who he claims he is. e.g.: Facebook authentication.
This session was a good recap and addition to Nuno's session on Windows Azure Active Directory.Conclusion
Let's hope this edition is the beginning of a new tradition that mixes fun and learning. I'm looking forward to the next edition!
If you can't wait and want to attend a global Windows Azure event, and also an attempt for a world record, join the Global Windows Azure Bootcamp on Saturday, March 29, 2014!You can find more photos here or read the storify here.
Thank you speakers, Azug and especially Mike Martin & Maarten Balliauw for making this happen!

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Werner Vogels (@werner) described Taking DynamoDB beyond Key-Value: Now with Faster, More Flexible, More Powerful Query Capabilities in a 12/12/2013 post to his All Things Distributed blog:
We launched DynamoDB last year to address the need for a cloud database that provides seamless scalability, irrespective of whether you are doing ten transactions or ten million transactions, while providing rock solid durability and availability. Our vision from the day we conceived DynamoDB was to fulfil this need without limiting the query functionality that people have come to expect from a database. However, we also knew that building a distributed database that has unlimited scale and maintains predictably high performance while providing rich and flexible query capabilities, is one of the hardest problems in database development, and will take a lot of effort and invention from our team of distributed database engineers to solve.
So when we launched in January 2012, we provided simple query functionality that used hash primary keys or composite primary keys (hash + range). Since then, we have been working on adding flexible querying. You saw the first iteration in April 2013 with the launch of Local Secondary Indexes (LSI). Today, I am thrilled to announce a fundamental expansion of the query capabilities of DynamoDB with the launch of Global Secondary Indexes (GSI). This new capability allows indexing any attribute (column) of a DynamoDB table and performing high-performance queries at any table scale.
Going beyond Key-Value
Advanced Key-value data stores such as DynamoDB achieve high scalability on loosely coupled clusters by using the primary key as the partitioning key to distribute data across nodes. Even though the resulting query functionality may appear more limiting than a relational database on a cursory examination, it works exceedingly well for a wide range of applications as evident from DynamoDB's rapid growth and adoption by customers like Electronic Arts, Scopley, HasOffers, SmugMug, AdRoll, Dropcam, Digg and by many teams at Amazon.com (Cloud Drive, Retail). DynamoDB continues to be embraced for workloads in Gaming, Ad-tech, Mobile, Web Apps, and other segments where scale and performance are critical. At Amazon.com, we increasingly default to DynamoDB instead of using relational databases when we don’t need complex query, table join and transaction capabilities, as it offers a more available, more scalable and ultimately a lower cost solution.
For non-primary key access in advanced key-value stores, a user has to resort to either maintaining a separate table or some form of scatter-gather query across partitions. Both these options are less than ideal. For instance, maintaining a separate table for indexes forces users to maintain consistency between the primary key table and the index tables. On the other hand, with a scatter gather query, as the dataset grows, the query must be scattered more and more resulting in poor performance over time. DynamoDB's new Global Secondary Indexes remove this fundamental restriction by allowing "scaled out" indexes without ever requiring any book-keeping on behalf of the developer. Now you can run queries on any item attributes (columns) in your DynamoDB table. Moreover, a GSI's performance is designed to meet DynamoDB's single digit millisecond latency - you can add items to a Users table for a gaming app with tens of millions of users with UserId as the primary key, but retrieve them based on their home city, with no reduction in query performance.
DynamoDB Refresher
DynamoDB stores information as database tables, which are collections of individual items. Each item is a collection of data attributes. The items are analogous to rows in a spreadsheet, and the attributes are analogous to columns. Each item is uniquely identified by a primary key, which is composed of its first two attributes, called the hash and range. DynamoDB queries refer to the hash and range attributes of items you’d like to access. These query capabilities so far have been based on the default primary index and optional local secondary indexes of a DynamoDB table:
- Primary Index: Customers can choose from two types of keys for primary index querying: Simple Hash Keys and Composite Hash Key / Range Keys. Simple Hash Key gives DynamoDB the Distributed Hash Table abstraction. The key is hashed over the different partitions to optimize workload distribution. For more background on this please read the original Dynamo paper. Composite Hash Key with Range Key allows the developer to create a primary key that is the composite of two attributes, a “hash attribute” and a “range attribute.” When querying against a composite key, the hash attribute needs to be uniquely matched but a range operation can be specified for the range attribute: e.g. all orders from Werner in the past 24 hours, or all games played by an individual player in the past 24 hours.
- Local Secondary Index: Local Secondary Indexes allow the developer to create indexes on non-primary key attributes and quickly retrieve records within a hash partition (i.e., items that share the same hash value in their primary key): e.g. if there is a DynamoDB table with PlayerName as the hash key and GameStartTime as the range key, you can use local secondary indexes to run efficient queries on other attributes like “Score.” Query “Show me John’s all-time top 5 scores” will return results automatically ordered by score.
What are Global Secondary Indexes?
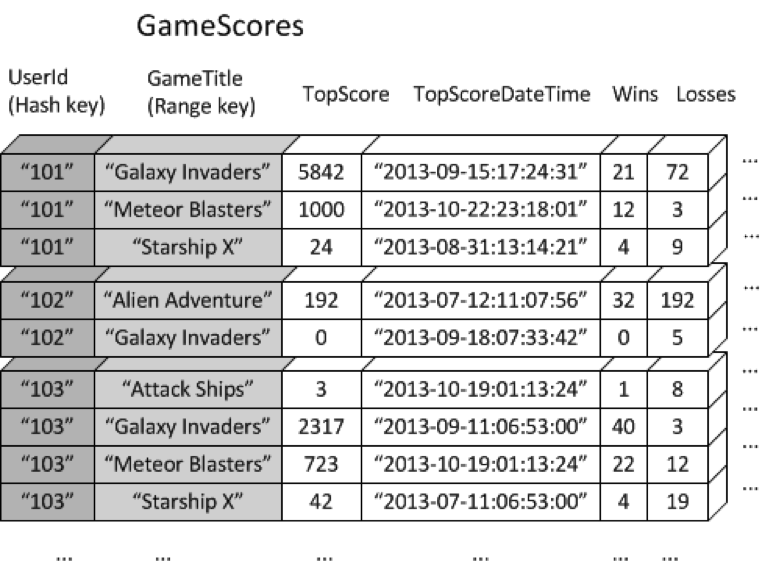
Global secondary indexes allow you to efficiently query over the whole DynamoDB table, not just within a partition as local secondary indexes, using any attributes (columns), even as the DynamoDB table horizontally scales to accommodate your needs. Let’s walk through another gaming example. Consider a table named GameScores that keeps track of users and scores for a mobile gaming application. Each item in GameScores is identified by a hash key (UserId) and a range key (GameTitle). The following diagram shows how the items in the table would be organized. (Not all of the attributes are shown)
Now suppose that you wanted to write a leaderboard application to display top scores for each game. A query that specified the key attributes (UserId and GameTitle) would be very efficient; however, if the application needed to retrieve data from GameScores based on GameTitle only, it would need to use a Scan operation. As more items are added to the table, scans of all the data would become slow and inefficient, making it difficult to answer questions such as
- What is the top score ever recorded for the game "Meteor Blasters"?
- Which user had the highest score for "Galaxy Invaders"?
- What was the highest ratio of wins vs. losses?
To speed up queries on non-key attributes, you can specify global secondary indexes. For example, you could create a global secondary index named GameTitleIndex, with a hash key of GameTitle and a range key of TopScore. Since the table's primary key attributes are always projected into an index, the UserId attribute is also present. The following diagram shows what GameTitleIndex index would look like:
Now you can query GameTitleIndex and easily obtain the scores for "Meteor Blasters". The results are ordered by the range key, TopScore.
Efficient Queries
Traditionally, databases have been scaled as a whole –tables and indexes together. While this may appear simple, it masked the underlying complexity of varying needs for different types of queries and consequently different indexes, which resulted in wasted resources. With global secondary indexes in DynamoDB, you can now have many indexes and tune their capacity independently. These indexes also provide query/cost flexibility, allowing a custom level of clustering to be defined per index. Developers can specify which attributes should be “projected” to the secondary index, allowing faster access to often-accessed data, while avoiding extra read/write costs for other attributes.
Start with DynamoDB
The enhanced query flexibility that global and local secondary indexes provide means DynamoDB can support an even broader range of workloads. When designing a new application that will operate in the AWS cloud, first take a look at DynamoDB when selecting a database. If you don’t need the table join capabilities of relational databases, you will be better served from a cost, availability and performance standpoint by using DynamoDB. If you need support for transactions, use the recently released transaction library. You can also use GSI features with DynamoDB Local for offline development of your application. As your application becomes popular and goes from being used by thousands of users to millions or even tens of millions of users, you will not have to worry about the typical performance or availability bottlenecks applications face from relational databases that require application re-architecture. You can simply dial up the provisioned throughput that your app needs from DynamoDB and we will take care of the rest without any impact on the performance of your app.
Dropcam tells us that they adopted DynamoDB for seamless scalability and performance as they continue to innovate on their cloud based monitoring platform which has grown to become one of the largest video platforms on the internet today. With GSIs, they do not have to choose between scalability and query flexibility and instead can get both out of their database. Guerrilla Games, the developer of Killzone Shadow Fall uses DynamoDB for online multiplayer leaderboards and game settings. They will be leveraging GSIs to add more features and increase database performance. Also, Bizo, a B2B digital marketing platform, uses DynamoDB for audience targeting. GSIs will enable lookups using evolving criterion across multiple datasets.
These are just a few examples where GSIs can help and I am looking forward to our customers building scalable businesses with DynamoDB. I want application writers to focus on their business logic, leaving the heavy-lifting of maintaining consistency across look-up attributes to DynamoDB. To learn more see Jeff Barr’s blog and the DynamoDB developer guide.



We database-oriented developers have been asking for secondary indexes on Window Azure tables since their introduction for many years. They’ve been promised from the git-go, but never delivered.
Jeff Barr (@jeffbarr) reported Now Available - Global Secondary Indexes for Amazon DynamoDB in a 12/12/2013 post:
As I promised a few weeks ago, Amazon DynamoDB now supports Global Secondary Indexes. You can now create indexes and perform lookups using attributes other than the item's primary key. With this change, DynamoDB goes beyond the functionality traditionally provided by a key/value store, while retaining the scalability and performance benefits that have made it so popular with our customers.
You can now create up to five Global Secondary Indexes when you create a table, each referencing either a hash key or a hash key and a range key. You can also create up to five Local Secondary Indexes, and you can choose to project some or all of the table's attributes into each of the table’s indexes.
Creating Global Secondary Indexes
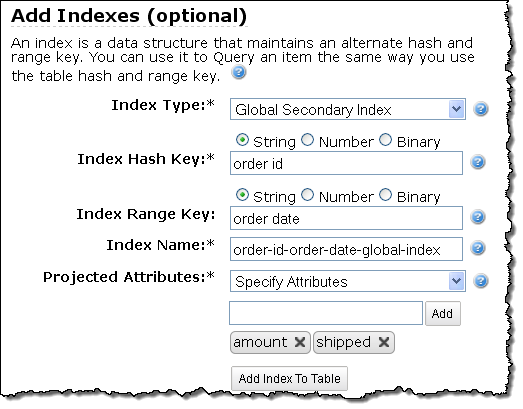
The AWS Management Console now allows you to specify any desired Global Secondary Indexes when you create the table:
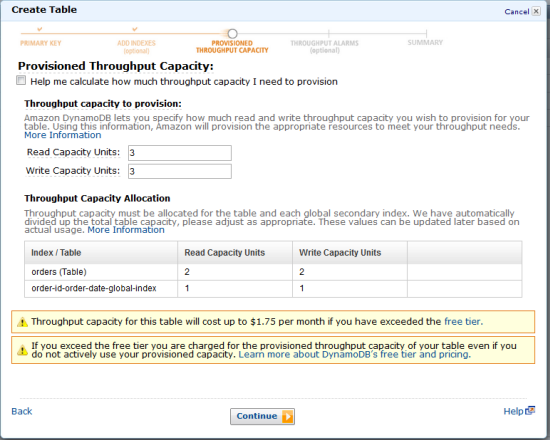
As part of the table creation process you can also provision throughput for the table and for each of the Global Secondary Indexes:
You can also create tables and the associated indexes using the AWS CLI or the DynamoDB APIs.
Local or Global
If you have been following the continued development of DynamoDB, you may recall that we launched Local Secondary Indexes earlier this year. You may be wondering why we support both models while also trying to decide where each one is appropriate.
Let's quickly review the DynamoDB table model before diving in. Each table has a specified attribute called a hash key. An additional range key attribute can also be specified for the table. The hash key and optional range key attribute(s) define the primary index for the table, and each item is uniquely identified by its hash key and range key (if defined). Items contain an arbitrary number of attribute name-value pairs, constrained only by the maximum item size limit. In the absence of indexes, item lookups require the hash key of the primary index to be specified.
The Local and Global Index models extend the basic indexing functionality provided by DynamoDB. Let’s consider some use cases for each model:
- Local Secondary Indexes are always queried with respect to the table's hash key, combined with the range key specified for that index. In effect (as commenter Stuart Marshall made clear on the preannouncement post), Local Secondary Indexes provide alternate range keys. For example, you could have an Order History table with a hash key of customer id, a primary range key of order date, and a secondary index range key on order destination city. You can use a Local Secondary Index to find all orders delivered to a particular city using a simple query for a given customer id.
- Global Secondary Indexes can be created with a hash key different from the primary index; a single Global Secondary Index hash key can contain items with different primary index hash keys. In the Order History table example, you can create a global index on zip code, so that you can find all orders delivered to a particular zip code across all customers. Global Secondary Indexes allow you to retrieve items based on any desired attribute.
Both Global and Local Secondary Indexes allow multiple items for the same secondary key value.
Local Secondary Indexes support strongly consistent reads, allow projected and non-projected attributes to be retrieved via queries and share provisioned throughput capacity with the associated table. Local Secondary Indexes also have the additional constraint that the total size of data for a single hash key is currently limited to 10 gigabytes.
Global Secondary Indexes are eventually consistent, allow only projected attributes to be retrieved via queries, and have their own provisioned throughput specified separately from the associated table.
As I noted earlier, each Global Secondary Index has its own provisioned throughput capacity. By combining this feature with the ability to project selected attributes into an index, you can design your table and its indexes to support your application's unique access patterns, while also tuning your costs. If your table is "wide" (lots of attributes) and an interesting and frequently used query requires a small subset of the attributes, consider projecting those attributes into a Global Secondary Index. This will allow the frequently accessed attributes to be fetched without expending read throughput on unnecessary attributes.
This feature is available now and you can start using it today!


No significant articles so far this week.
<Return to section navigation list>

















{kind=link}
0 comments:
Post a Comment