Windows Azure and Cloud Computing Posts for 12/1/2013+
Top Stories This Week:
- Troy Hunt described Working with 154 million records on Azure Table Storage – the story of “Have I been pwned?” on 12/5/2013 in the Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services section.
- The Windows Azure Storage Team posted Windows Azure Tables: Introducing JSON on 12/5/2013 in the Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services section.
- Steven Martin (@stevemar_msft) posted Expanding Windows Azure Capacity – Brazil to the Windows Azure Team blog on 12/4/2013 in the Windows Azure Infrastructure and DevOps section.
- Ivar Pruijin described the Cloud9 IDE on Google Compute Engine in a 12/7/2013 post to the Google Cloud Platform Blog in the Other Cloud Computing Platforms and Services section.
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Caching, SQL Azure Database, and other cloud-computing articles. |
• Updated 12/8/2013 with new articles marked •.
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Windows Azure Marketplace DataMarket, Power BI, Big Data and OData
- Windows Azure Service Bus, BizTalk Services and Workflow
- Windows Azure Access Control, Active Directory, and Identity
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure and DevOps
- Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
- Visual Studio LightSwitch and Entity Framework v4+
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
<Return to section navigation list>

I’m one of these people that must learn by doing. Yes, I’m sure all those demos look very flashy and the code appears awesome, but unless I can do it myself then I have trouble really buying into it. And I really want to buy into Azure because frankly, it’s freakin’ awesome.
This is not a “yeah but you’re an MVP so you’ve gotta say that / you’re predispositioned to say that / you’re getting kickbacks from Ballmer”. I don’t, I’m not and I wish!
As many of you will know by now, yesterday I launched Have I been pwned? (HIBP) which as I briefly mentioned in that blog post, runs on Windows Azure. Now I’ve run stuff on Azure before, but it’s usually been the classic website and database model translated to the Azure paradigm rather than using the innovative cloud services that Azure does well.
When I came to build HIBP, I had a challenge: How do I make querying 154 million email addresses as fast as possible? Doing just about anything with the data in SQL Server was painfully slow to the extent that I ended up creating a 56GB of RAM Windows Azure SQL Server VM just to analyse it in order to prepare the info for the post I wrote on the insecurity of password hints. Plus, of course, the data will grow – more pwning of sites will happen and sooner or later there’ll be another “Adobe” and we’ll be looking at 300M records that need to be queried.
The answer was Azure Table Storage and as it turns out, it totally rocks.
Azure table storage – the good, the bad and the awesome
“We need a database therefore we need SQL Server.” How many times have you heard this? This is so often the default position for people wanting to persist data on the server and as the old adage goes, this is the hammer to every database requirement which then becomes the nail. SQL Server has simply become “the standard” for many people.
SQL Server is a beast. It does a lot. If in doubt, take a look at the feature comparison and ask yourself how much of this you actually understand. I’ve been building software on it for 15 years and there’s a heap of stuff there I don’t use / understand / can even begin to comprehend. It’s awesome at what it does, but it always does more than I actually need.
Azure Table Storage is simple, at least relatively speaking. You have a table, it’s partitioned, it has rows. You put stuff into that table then you query is back out, usually by referencing the partition and row keys. That’s obviously a simplistic view, things are better explained by Julie Lerman (a proper database person!) in her post on Windows Azure Table Storage – Not Your Father’s Database.
One of the things that attracted me to Table Storage is that it’s not constrained to a server or a VM or any logical construct that’s governed by finite resources (at least not “finite” within a reasonable definition), rather it’s a service. You don’t pay for CPU and RAM or put it on a particular server, you pay for the number of transactions and the amount of storage you need:
In other words, if I want 100GB of storage and I want to hit it 10 million times, it’ll cost me $8 a month. Eight. Two cappuccinos at my local cafe. Compare this to SQL Azure which whilst very good for all the same cloudy reasons (fully managed service, available and scalable on demand, etc.), it costs a hell of a lot more:
That’s $176 a month for the same volume of data and whilst arguably that’s actually a very good deal for a fully managed service for the behemoth that is SQL Server (or at least Azure’s flavour of it), it’s also 22 times more expensive. Of course it’s not an apples and apples comparison; do take a look at Windows Azure Table Storage and Windows Azure SQL Database - Compared and Contrasted for some more perspective, but in my case I only need Table Storage anyway.
So what’s the “bad” bit? It’s something new to learn, a “foreign entity” to most people, if you like. It has it’s own idiosyncrasies, quite different ways of working with data and interacting with the system and you can’t SELECT * FROM Foo. But it’s easy and it is massively impressive and that’s what I want to walk you through here now.
Provisioning the storage and querying the data
Let’s jump right in and I’ll assume you already have an Azure account and know how to find the portal at https://manage.windowsazure.com
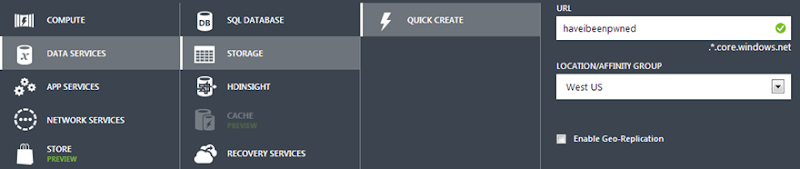
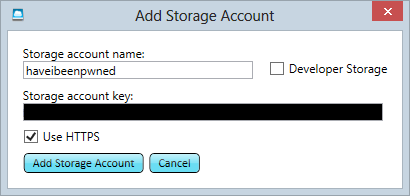
We’ll create a new service and it’s simply going to be a storage account. Unsurprisingly, mine is called “haveibeenpwned” and it’s sitting over on the West Coast of the US (I figured that’s a reasonably central location for the audience):
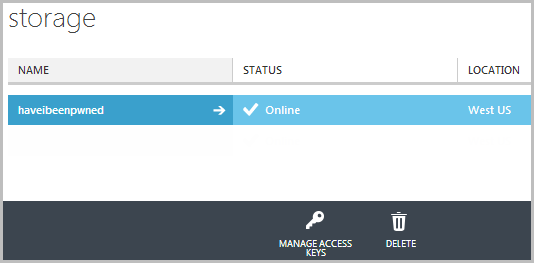
It should go without saying, but you want the storage account located in the same location as where you’ll be putting the things that use it which is predominantly the website in front of it and as you’ll see soon, a VM as well. Once that’s provisioned you’ll find it listed under “Storage” in the portal:
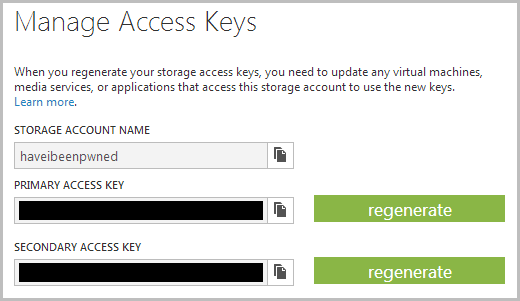
Now, before we can do anything with it we need to connect to it and for that we’ll need an access key. Think of it like the credentials for the account so let’s hit the “MANAGE ACCESS KEYS” icon:
Clearly I’ve obfuscated the keys, but you get the idea. Right, so this is everything we need to connect to Azure Table Storage, now we can just jump into SQL Server Management Studio and… oh yeah, no SQL!
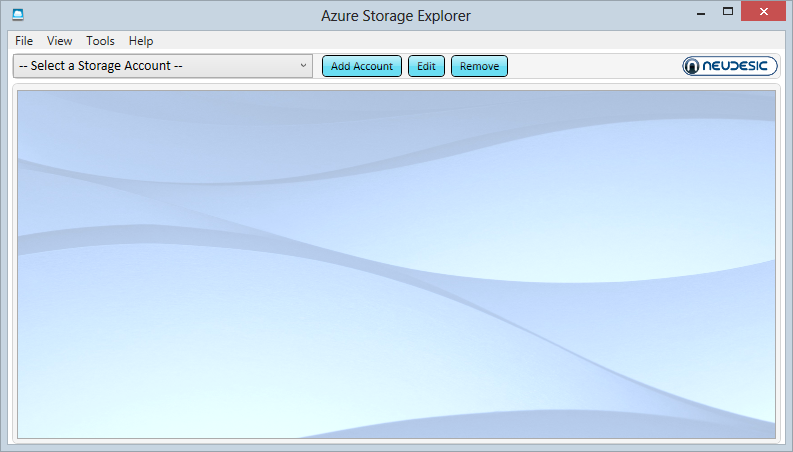
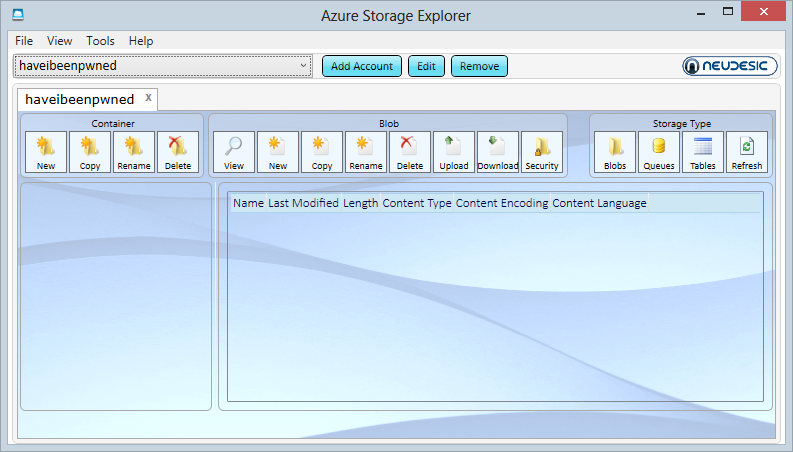
We’ll be accessing data programmatically later on, but for now I just want to browse through it and for that I’ll grab a third party tool. By far the most popular is the Azure Storage Explorer which you can grab for free over on CodePlex. Fire that guy up and you have this:
Let’s now add the account from above and use a secure connection:
And we see… not very much:
We’ll come back to the explorer later on, first we need to understand what those “Storage Type” buttons means and for that we need to talk about what you get in a storage account.
Blobs, queues and tables
In days gone by, binary data loaded into a website (such as images in a content management system) would be stored either on the file system in IIS or within SQL Server. Both options cause problems of different natures and varying degrees. In Azure, you’d load it into blob storage and that’s one of the storage types available. There are other uses for blob storage as well but there’s no need to go into that here.
Another storage type is “queues” which are essentially just message queues. They’re very awesome and serve a very valuable role in providing asynchronicity between system components. Again, won’t go into it here but read up on How to use the Queue Storage Service if it sounds interesting.
And finally there’s Table Storage which is obviously the focus of this post. The main point I wanted to make was that these three paradigms all exist within each and every storage account whether you elect to use them or not.
Moving forward with tables, you can read the long version at How to use the Table Storage Service (and I strongly suggest you do if you’re actually going to use the service), but for now here’s the succinct version:
- One storage account can have many tables.
- Each table has many partitions.
- Each partition has many rows.
- Each row has a partition key, a row key and a timestamp.
You store an entity in the row that inherits from Microsoft.WindowsAzure.Storage.Table.TableEntity.
You create a partition and a row by inserting an entity with a partition key and a row key.
You retrieve a row by searching with the partition and row key and casting the result back to the entity type.
That it in a nutshell and it’s not even the simplistic version – that’s just how it works. There are features and nuances and other things you can do with it but that’s the bulk of it and it’s all I really needed in order to build HIBP. I’m going to step into code shortly but firstly we need to talk about partition design for my particular use case.
Designing the table partitions for HIBP
Conceptually, partitions are not that different to the alphabetised sections of a phonebook (remember those paper ones they used to dump on your doorstep?) Rather than just chucking all the numbers randomly into the book, they’re nicely distributed into 26 different “partitions” (A-Z) then of course each person is neatly ordered alphabetically within there. It does wonderful things in terms of the time is takes to actually find what you need.
In Azure Table Storage, partitions can have a big impact on performance as Julie explains in the earlier mentioned post:
Windows Azure Tables use keys that enable efficient querying, and you can employ one—the PartitionKey—for load balancing when the table service decides it’s time to spread your table over multiple servers.
How you structure your partitions is very dependent on how you want to query your data so let’s touch on that for a moment. Here’s how HIBP is queried by users:
As it turns out, an email address has an organic structure that lends itself very well to being segmented into partitions and rows. Take foo@bar.com – the domain is the partition key and the alias is the row key. By creating a partition for “bar.com” we can make the search for “foo” massively fast as there are only a small portion of the total records in the data set, at least compared to the number of overall records.
Obviously some partitions are going to be very large. In the Adobe breach, there were more than 32 million “hotmail.com” accounts so that’s going to be a big one. A small company with their own domain and only a few people caught up in a breach might just have a few addresses and a very small partition. That doesn’t mean the Hotmail partition will be slow, far from it and I’ll come back to that later on. For now though, let’s move onto the code.
Inserting breach data into Table Storage
Let’s do the “Hello World” of Table Storage using the HIBP data structure. Firstly, we need one little NuGet package and that’s the Windows Azure Storage libraries. Be careful though – don’t take the current version which is 3.0.0. I’ll explain why later when I talk about the emulator (and do check the currency of this statement if you’re reading this in the future), instead run this from the Library Package Manager command line:
Install-Package WindowsAzure.Storage -Version 2.1.0.4Now we’ll use that access key from earlier on and whack it into a connection string and it looks just like this:
<connectionStrings> <add name="StorageConnectionString"
connectionString="DefaultEndpointsProtocol=https;AccountName=haveibeenpwned;AccountKey=mykey" /> </connectionStrings>Just like a SQL connection string (kinda). Note the endpoint protocol – you can go HTTP or HTTPS. Clearly the secure option is preferable.
Into the code itself, we begin by getting a reference to the storage instance:
var connString = ConfigurationManager.ConnectionStrings["StorageConnectionString"].ConnectionString; var storageAccount = CloudStorageAccount.Parse(connString);Now we’ll get a reference to the table within that storage instance and if it doesn’t already exist, we’ll just create it (obviously just a first-run thing):
var tableClient = storageAccount.CreateCloudTableClient(); var table = tableClient.GetTableReference("BreachedAccount"); table.CreateIfNotExists();Before we can start chucking stuff in there, we need that entity I mentioned earlier so let’s create a BreachedAccount that inherits from TableEntity.
public class BreachedAccount : TableEntity { public BreachedAccount() { } public string Websites { get; set; } }Notice how we haven’t created partition or row keys? They’re inherited from the TableEntity and what it means is that we can now do this:
var breachedAccount = new BreachedAccount { PartitionKey = "bar.com", RowKey = "foo", Websites = "Adobe;Stratfor" };Obviously the websites are just semicolon delimited – nothing fancy (in my case I then split this back into a string array later on). Anyway, now we can just save it:
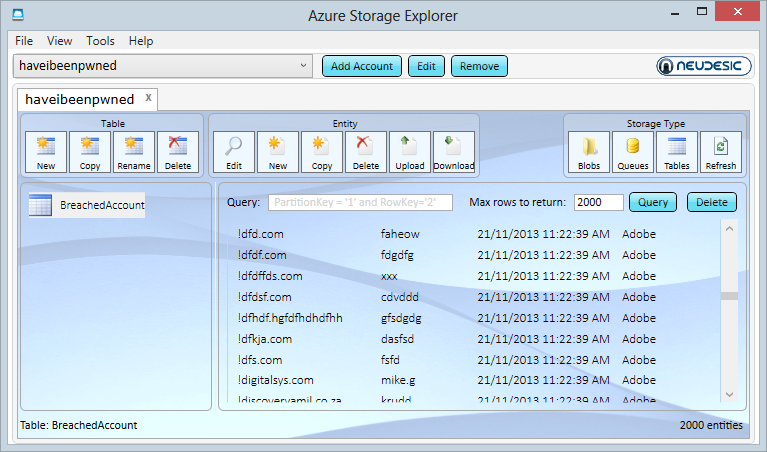
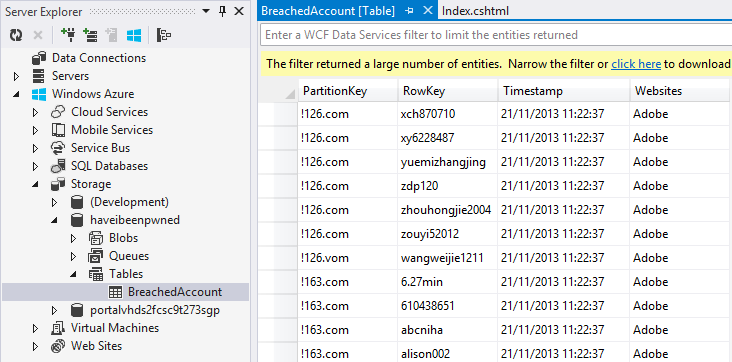
var insertOperation = TableOperation.Insert(breachedAccount); table.Execute(insertOperation);And that’s it, we’re done! Now we can flick back into the Azure Storage Explorer, hit the “Tables” button in the top right, select the “BreachedAccount” table from the left and then “Query” it:
We have data! This is a current live view of what’s in HIBP and I’ve scrolled down to the section with a bunch of what are probably junk accounts (don’t get me started on email address validation again). You can now see the partition key, row key, timestamp and “Websites”. If we were to add another attribute to the BreachedAccount entity then we’ll see that too even though we already have data there conforming to a different schema. That’s the neat thing about many NoSQL database implementations in that you’re not constrained to a single schema within the one container.
It’d be remiss of me not to mention that you can also view this data directly from within Visual Studio in the Server Explorer. The updates to this pushed out in version 2.2 of the Windows Azure SDK six weeks ago make it an absolute cinch in either VS2012 or 2013:
So we’re done, right? Kinda – I don’t really want to do 154 million individual inserts as each connection does have some overhead. What I want to do is batch it and that looks more like this:
var batch = new TableBatchOperation(); batch.Insert(breachedAccount1); batch.Insert(breachedAccount2); batch.Insert(breachedAccount3); table.ExecuteBatch(batch);Batching is about more than just committing a bunch of rows at one time, it also has an impact on cost. Remember how Azure Table Storage charges you $0.0000001 per “transaction”? I’m not made of money so I want to bring that cost down a little and I can do this by batching because a batch is one transaction. However, there are some caveats.
Firstly, you can only batch records into the same partition. I can’t insert foo@bar.com and foo@fizz.com within the same batch. However, I can insert foo@bar.com and buzz@bar.com at the same time as I’m using the domain as the partition key. What this meant is that when I wrote the code to process the records I had to sort the data by domain so that I could keep all the records for the partition together and batch them. This makes sense in the context of Julie’s earlier comment about the partition being tied to a machine somewhere.
Secondly, you can only batch up to 100 rows at a time. Those 32 million Hotmail addresses? That’s 320,000 batches thank you very much. This meant my importer needed to not only enumerate through accounts ordered by domain, but each time it had a collection of 100 it needed it commit them before moving on. Per the previous point, it obviously also had to commit the batch as soon as it got to the next domain as it couldn’t commit to multiple partitions in the one batch.
With all that clear, all I had to do was create a text file with all the 153 million Adobe addresses broken down into alias and domain ordered by the latter then create a little console app to enumerate each row and batch as much as possible. Easy, right? Yes, but we’d be looking at millions of consecutive transactions sent across a high-latency connection – you know how far it is from Sydney to the West Coast of the US? Not only that, but even with low-latency this thing wouldn’t take minutes or hours or possibly even days – I needed more speed.
Turning the import script up to 11
There were two goals for getting this into Table Storage quickly:
- Decrease the latency
- Increase the asynchronicity
The first one is easy and it’s along the lines of what I touched on earlier in relation to when I used the chunky SQL Server VM – just provision a VM in Azure at the same location as the Table Storage and your latency comes down to next to nothing. Obviously I needed to copy the source data up and we’re looking at gigabytes of even compressed records here, but once that was done it was just a matter of running the console app in the VM and that’s the latency issue solved.
Asynchronicity was a bit tricker and I took two approaches. Firstly, we’re living in an era of Async Await so that was the first task (little async joke there!) and I tackled it by sending collections of 20,000 rows at a time to a process that then broke them into the appropriate batches (remember the batch constraints above), fires this off to a task and waited for them all to complete before grabbing the next 20,000. Yes, it meant at best there were 200 async tasks running (assuming optimal batches of 100 rows each), but it actually proved to be highly efficient. Maybe more or less would have been better, I don’t know, it just seemed like a reasonable number.
The other approach to asynchronicity was multi-threading and of course this is a different beast to the parallelism provided by Async Await. Now I could have been clever and done the threading within the console app, but I decided instead to take the poor man’s approach to multithreading and just spin up multiple instances of the console.
To do this I allowed it to be invoked with parameters stating the range of rows it should process – which row should it start at then which row should it finish on. The bottom line was that I could now run multiple instances of the importer with each asyncing batch commits across partitions. So how did it go? Rather well…
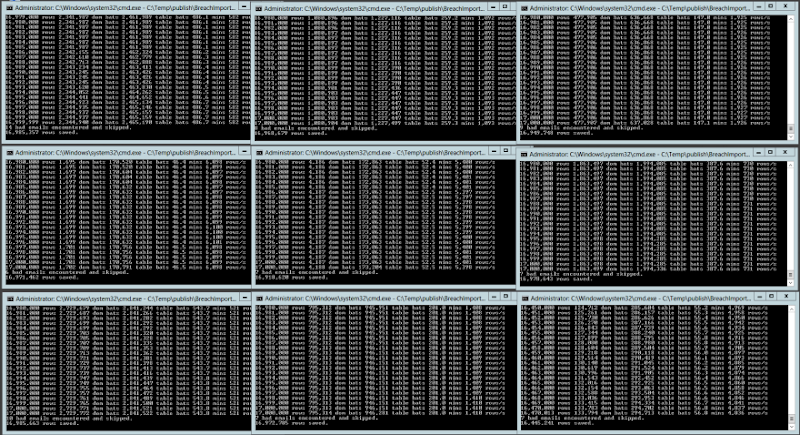
Importing 22,500 rows per second into Azure Table Storage
Up in the Azure VM now and I’m now importing the 153 million Adobe accounts with nine simultaneous instances of the importer (I chose nine because it looked nice on the screen!) each processing 17 million addresses and sending clusters of up to 20,000 domains at once to async tasks that then broke them into batches of 100 records each. It looked like this:
The max throughput I achieved with this in a single console instance was when all 17 million rows were processed in only 47 minutes – that’s a sustained average of over 6,000 rows per second for three quarters of an hour. Then again, the slowest was “only” 521 records per second which meant a 9 hour run time. Why the 12-fold difference in speed? If one chunk of 17 million rows had a heap of email on the same domain (gmail.com, hotmail.com, etc.) then you’d get a lot of very efficient batches. When you have lots of dispersed domains you end up with sub-optimal batches, in other words lots of batches with less than 100 rows. In fact that slowest instance committed nearly 3 million batches so had around 6 rows per batch whilst the fastest only committed just over 170,000 batches so it was almost perfectly optimised.
The bottom line is that if you combine the average speed of each of those nine instances, you end up with a sustained average of about 22,500 inserts per second. Of course this peak is only achieved when all instances are simultaneously running but IMHO, that’s a very impressive number when you consider that the process is reading the data out of a text file, doing some basic validation then inserting it into Table Storage. I honestly don’t know if you’d get that level of success with your average SQL Server instance. I’d be surprised.
Unsurprisingly, the VM did have to work rather hard when running the nine simultaneous importers:
Oh – and this is an 8 core machine too! Mind you, it may be saying something about the efficiency of my code but somehow I don’t think it’s just that. What I find interesting with this is that the CPU is maxed and NIC is pumping out over 100Mbps so the machine is well and truly getting worked; what would the throughput do if I was running two VMs? Or five? Would we be looking at 100,000 rows per second? My inclination is to say “yes” given the way the Table Storage service is provisioned by spreading those partitions out across the Azure infrastructure. Assuming batches were being simultaneously committed across different partitions, we shouldn’t be IO bound on the storage side.
One issue I found was that I’d get to the end of an instance processing its 17 million records and the stats at the end would suggest it had only processed 99.7%+ of addresses. What the?! After a bunch of debugging I found that the async task I was firing off didn’t always start. Now keep in mind that I’m firing off a heap of these at once – at least 200 at once depending on the spread of domains and consequently partition keys – but I also found the same result when re-running and firing off only 5 tasks simultaneously (incidentally, this only increased the duration by about 25% – you can’t just infinitely fire off more async tasks and achieve a linear speed gain). But the results were also inconsistent insofar as there might be a 99.7% success rate on one run then a 99.8% on the next. I’m no expert on async, but my understanding is that there’s no guarantee all tasks will complete even when awaiting “WhenAll”. But in this case, it actually doesn’t matter too much if a small number of records don’t make it if the task doesn’t run, just to be sure though, I ran the whole process again. And again. And Again. Which brings me to the next point – idempotency:
Idempotence is the property of certain operations in mathematics and computer science, that can be applied multiple times without changing the result beyond the initial application.
I used very simple examples in the Table Storage code earlier on – just simple “Insert” statements. When I created the importer though, I ended up using InsertOrReplace which meant that I could run the same process over and over again. If it failed or I wasn’t confident all the tasks completed, I’d just give it another cycle and it wouldn’t break when the data already existed.
Now of course all of this so far has just been about inserting the Adobe data and whilst it’s the big one, it’s also the easiest one insofar as all I had to do was insert new records with a “Websites” value of “Adobe”. Adding the subsequent breaches was a whole new ball game.
Adding additional data breaches
Inserting a clean set of data is easy – just fire and shoot and whack as many rows as you can into each batch. Adding additional rows from subsequent breaches is hard (comparatively) because you can’t be quite so indiscriminate. After the 153 million Adobe records, I moved onto Stratfor which has a “measly” 860,000 email addresses. Now, for each of those Stratfor records (and all the others from subsequent breaches I later imported), I needed to see if the record actually existed already then either add Stratfor to the Adobe entry if it was there already, or just insert a brand new record. This meant that I couldn’t just simply throw batches at the things, I’d need to go through record by record, 860,000 times.
I decided to bring it all back down to basics with this process; no async and I’d run it locally from my machine. I felt I could get away with this simply because the data set was so small in comparison to Adobe and it wouldn’t matter if it took, say, overnight. However, I wasn’t aware of just how slow it would end up being…
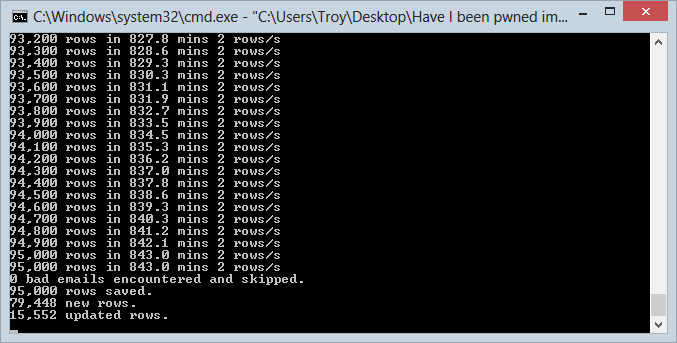
I ran up 9 separate instances of the import process as I’d done earlier with Adobe in the VM and also as per earlier, each one took one ninth of the records in the DB and managed a grand total of… 2 rows per second in each instance. Ouch! Not quite the 6,000 per second I got by sending batches async within the same data centre. Regardless, it took about 14 hours so as a one off for the second largest data set I had, that’s not too bad. Here’s how things looked at the end of the import in one of the nine consoles:
One of the interesting things you’ll see is that more than 15,000 of the rows were updated rather than inserted – these guys were already in the Adobe breach. This was the first real validation that there’d be overlap on the data sets which, of course, is a key part of the rationale for building HIBP in the first place. In fact after the whole Stratfor import completed, the stats showed that 16% of the addresses were common over the breaches.
Later on I did Sony and 17% of the addresses were already in there.
Then Yahoo! and it was 22%.
Before moving on past Stratfor though, I realised I needed to address the speed issue of subsequent breaches. The Strafor example was really just too long to be practical if another large data set came along. Imagine another Adobe in the future – I’d be looking at almost 2 and a half years for the import! Not gonna happen so it’s back to the cloud! Actually, I did fire off the Sony import locally because that was only 37,000 records but Yahoo! was looking at 453,000 and Gawker 533,000. To the cloud!
I pushed the data dump and the console app back to the VM instance I’d done the original Adobe import with and as you’d expect, the throughput shot right up. Now instead of 2 records a second it was running at around 58. Obviously that was much better and the Yahoo! dump went through in only 15 minutes. It’s nowhere near the figure I got with Adobe but without the ability to batch and considering the overhead involved in checking if the record already exists then either updating or inserting, you can understand the perf hit. However at that speed, another Adobe at 153 million records would still take a month. It’s easy to forget just how significant the scale of that dump is, it’s truly unprecedented and it may be a long time before we see something like this again, although we will see it.
Last thing on the VM – it’s still up there (in “The Cloud”, I mean) and it has the console app sitting there waiting to do its duty when next called. All I’ve done is shut the machine down but in doing that I’ve eradicated 100% of the compute cost. When it’s not running you don’t pay for it, the only cost is the storage of the VM image and storage so cheap for tens of GB that we can just as well call it “free”.
Monitoring
One of the the really neat things about Azure in general is the amount of monitoring you have access to and Table Storage is no exception. I didn’t get all of the import process above right the first go, in fact it took multiple attempts over many days to find the “sweet spot”. Here’s a sample of the sort of data I retrieved from the portal at the time:
Of course the really interesting bit is the total requests – on November 21st I saw up to nearly 1.9 million requests in a single hour. Inevitably this was just after kicking everything off then you can see the number start to drop off as individual instances of the console finished their processing. The other two things we see are firstly, the availability remaining at a flat 100% and the success percentage mostly remaining at 100% (I’ll talk more about this later).
Getting the data back out
Ok, so we’ve got data in the system, but that’s just the start. Of course it’s also the hardest bit so that’s good, let’s now pull records back out. Obviously I’ve designed the whole thing to be ultra fast in terms of reading data based on the email address. Remember that this is what I’ve compromised the partition and row keys out of.
It’s pretty much the same deal as earlier in terms of needing a storage account object and then a table client after which you can just invoke the “Retrieve” method and pass it the partition key (the domain) and the row key (the alias):
var retrieveOperation = TableOperation.Retrieve<BreachedAccount>("bar.com", "foo"); var retrievedResult = table.Execute(retrieveOperation); var breachedAccount = (BreachedAccount)retrievedResult.Result;Now sometimes this will actually be null – the email won’t have been found in any breaches – and that actually has an interesting impact on the monitoring which I’ll come back to. All things going to plan though and a valid BreachedAccount with websites comes back out. I’ve done the usual thing of abstracting this away into another project of the app and in fact the web project knows knows nothing of Azure Table Storage, it simply gets a string array of impacted websites back from the method that accepts the email address it search for. It’s dead simple. It’s also fast – too fast!
A serious problem – it’s too damn fast
I did a little private beta test last week as a final sanity check and I kept getting the same feedback – it’s too fast. The response from each search was coming back so quickly that the user wasn’t sure if it was legitimately checking subsequent addresses they entered or if there was a glitch. Terrible problem, right?!
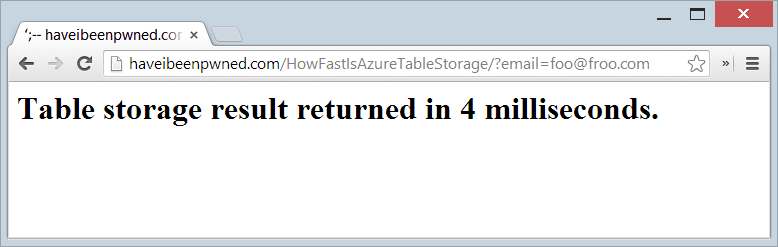
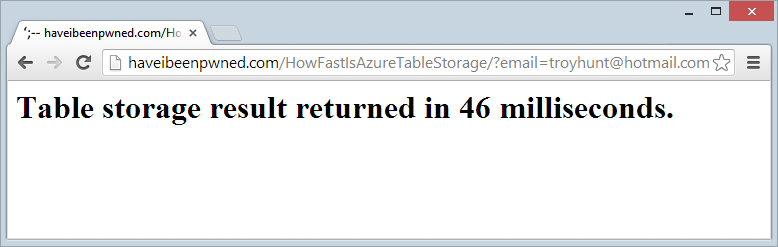
So how fast is too fast? I wrapped a stopwatch around the record retrieval from Table Storage and stood up a live test page, try this: http://haveibeenpwned.com/HowFastIsAzureTableStorage/?email=foo@foo.com
Ah, but you’ve read everything above carefully and realise that the “foo” partition is probably quite small therefore quite fast. Ok, so let’s try it with the largest partition which will be the Hotmail accounts, in fact you can even try this with my personal email address: http://haveibeenpwned.com/HowFastIsAzureTableStorage/?email=troyhunt@hotmail.com
Well that performance is clearly just woeful, let’s refresh:
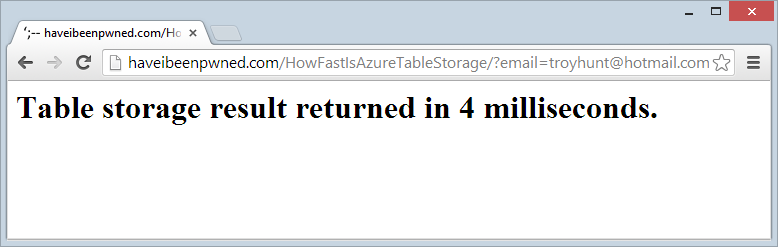
Better :) I don’t know the mechanics of the Azure Table Storage internals, but if I had to speculate it does appear as though some caching is happening or perhaps optimisation of subsequent queries. Regardless, the speed is blistering.
Let us not lose the gravitas of this – that’s 154M records being searched and the connection overhead plus some validation of the email address and then splitting it into partition and row keys and it’s all wrapped up in 4ms. I’m massively impressed with this, it’s hard not to be.
Getting back to it being too fast and the impact on usability, I recall listening to Billy Hollis talking about the value of delays in UX some time back. Essentially he was saying responses that are too fast lose some of the implicit communication that tells the user something is actually happening in the background. I ended up putting a 400ms delay in the JavaScript which invokes the API just to give the UX transitions time to do their thing and communicate that there’s actually some stuff happening. Isn’t that a nice problem to have – slowing the UI down 100-fold because the back end is too fast!
Certainly the feedback on the performance has been fantastic and I’ve seen a lot of stuff like this:
I have a question...how big is the backend to this site? Its average response is about 100ms, which, to me, seems impressively fast considering the number of bulk records and the amount of concurrent traffic that such a site is getting.
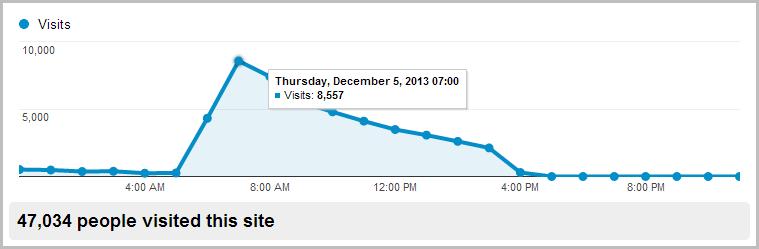
All of that’s great, but what happens at scale? Going fast in isolation is easy, doing it under load is another story. This morning, something happened. I’m not exactly sure what, obviously it got some airtime somewhere, but the end result was a few people swung by at the same time:
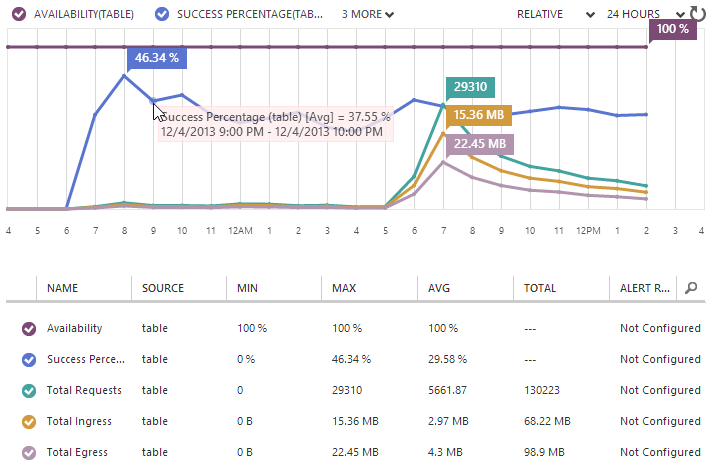
That Google Analytics report is showing eight and a half thousand visitors between 7 and 8am. Obviously they weren’t all hitting it at the same time, but inevitably it had plenty of simultaneous load. So what does that do to the availability of Table Storage? Nothing:
Availability flat-lined at 100% and indeed when I jumped on and tested the speed using the process above that showed 4ms, I saw… 4ms. Refresh 4ms. Refresh 5ms. Damn – a 25% jump! But seriously, the point is that it didn’t even flinch. Granted, this is still a low volume in the grand scheme of large websites, but I wouldn’t expect it to slow down, not when it isn’t constrained to the resources of logical machines provisioned for the single purpose of supporting this site. Instead, it’s scaling out over the vast resources that are within Azure and being simultaneously distributed across thousands and thousands of partitions.
But hang on, what’s all this about the “Success Percentage” tracking at just under 30%?! Why are more than two thirds of the queries “failing”?! As it turns out, they’re not actually failing, they’re simply not returning a row. You see what’s actually happening is that 70% of searches for a pwned email address are not returning a result. This is actually an added benefit for this particular project that I didn’t anticipate – free reporting!
Cost transparency
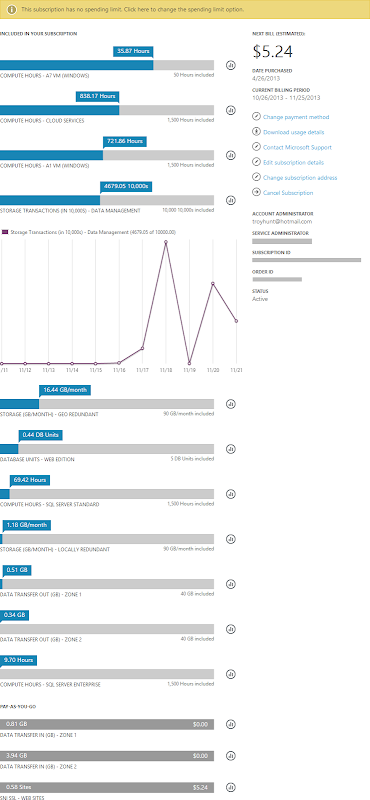
The other thing worth touching on is the ability to track spend. I hear quite a bit from people saying “Oh but if you go to the cloud with commoditised resources that scale infinitely and you become wildly successful your costs can unexpectedly jump”. Firstly, “wildly successful” is a problem most people are happy to have! Secondly, here’s the sort of granularity you have to watch cost:
I have an MSDN Ultimate subscription which gives me (and anyone else with an MSDN subscription) a bunch of free Azure time which is why you see all the “included” components. What I really wanted to get across here though is the granularity available to track the spend. I make it about 14 different aspects of the services I’ve used that are individually monitored, measured and billed.
Within each of these 14 services you then have the ability to drill down and monitor the utilisation over time. Take a look at the storage transactions – I know exactly what I’m using when and assuming I know what’s going on in my software, I also know exactly why I’m using the resource.
To my mind, this is the sort of thing that makes Azure such a great product – it’s not just about the services or the technology or the price, it’s that everything is so transparent and well integrated. I’ve barely scratched the surface of the data that’s available to you about what’s going on in your apps, but hopefully this gives you a sense of what’s available.
Developing locally with the emulator
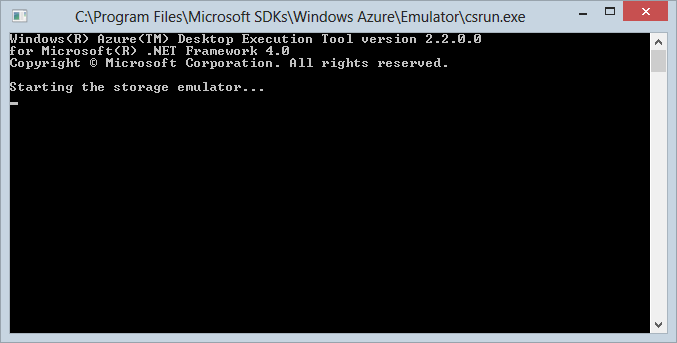
This post wouldn’t be complete without touching on developing against Azure storage locally. I built a lot of this site while sitting on long international flights last week and that simply couldn’t happen if I was dependent on hitting the Azure service in “The Cloud”. This is precisely why we have the Windows Azure Storage Emulator in the Azure SDK (the same one you get the neat Visual Studio integration with I mentioned earlier). Install this guy and run him up in this rich graphical user… uh, I mean command line:
And that’s just fine because once it’s running it just sits there in the background anyway, just like Azure storage proper would. Connecting to it in code is dead easy, just change the connection string as follows:
<add name="StorageConnectionString" connectionString="UseDevelopmentStorage=true;" />This is actually the only connection string I have recorded in the web app. I configured the real connection string (the one we saw earlier) directly within the Azure portal in the website configuration so that’s automatically applied on deploy. This means no creds in the app or in source control (I have a private GitHub repository) which is just the way you want it.
Connecting to the emulator to visually browse through the data is easy, in fact you’ll see a checkbox in the earlier Azure Storage Explorer image when I added the Azure account plus you’ll see it automatically pop up in the Server Explorer in Visual Studio.
The emulator is almost the same as what you’d find in cloudy Azure bar a few minor differences. Oh – and one major difference. Back earlier when I wrote about the Windows Azure Storage libraries on NuGet I said “don’t take the current version”. I started out with version 2,x and built all of HIBP on that using the emulator and everything was roses. Then just as I was getting ready to launch I thought “I know, I’ll make sure all my NuGet packages are current first” which I promptly did and got a nice new shiny version of the storage libraries which then broke everything that hit the emulator.
It turns out that the SDK is on a different release cycle to the libraries and it just so happens that the SDK is now behind the libraries since version 3 launched. tl;dr: until the SDK catches up you need to stick with the old libraries otherwise there’s no local emulator for you.
And that’s it – how’s that compare to trying to SQL Server up and running on your machine?!
In closing…
Obviously I’m excited about Azure. If you’re reading this you probably know what’s it like to pick up something new in the technology world and just really sink your teeth into learning what makes it tick and how to get it to do your bidding. It’s exciting, frustrating and wonderful all at the same time but once you get to grips with it you realise just how much potential it has to change the way we build software and the services we can offer to our customers. The latter point in particular is pertinent when you consider the cost and the ability to rapidly scale and adapt to a changing environment.
Building HIBP was an excellent learning experience and I hope this gives people an opportunity to understand more about Table Storage and the potentially massive scale it can reach at negligible cost. Those headline figures – 22,500 records inserted per second then 154 million records queried to return a result in only 4 milliseconds – are the ones I’ll be touting for a long time to come.




The Windows Azure Storage Team posted Windows Azure Tables: Introducing JSON on 12/5/2013:
Windows Azure Storage team is excited to announce the release of JSON support for Windows Azure Tables as part of version “2013-08-15”. JSON is an alternate OData payload format to AtomPub, which significantly reduces the size of the payload and results in lower latency. To reduce the payload size even further we are providing a way to turn off the payload echo during inserts. Both of these new features are now the default behavior in the newly released Windows Azure Storage Client 3.0 Library.
What is JSON
JSON, JavaScript Object Notation, is a lightweight text format for serializing structured data. Similar to AtomPub, OData extends JSON format by defining general conventions for entities and properties. Unlike AtomPub, parts of the response payload in OData JSON is omitted to reduce the payload size. To reconstitute this data on the receiving end, expressions are used to compute missing links, type and control data. OData supports multiple formats for JSON:
- nometadata – As the name suggests, this format excludes metadata that is used to interpret the data types. This format is the most efficient on transfers which is useful when client is aware on how to interpret the data types for custom properties.
- minimalmetadata – This format contains data type information for custom properties of certain types that cannot be implicitly interpreted. This is useful for query when the client is unaware of the data types such as general tools or Azure Table browsers. However, it still excludes type information for system properties and certain additional information such as edit link, id etc. which can be reconstructed by the client. This is the default level utilized by the Windows Azure Storage Client 3.0 Library
- fullmetadata – This format is useful for generic OData readers that requires type definition for even system properties and requires OData information like edit link, id etc. In most cases for Azure Tables Service, fullmetadata is unnecessary.
For more information regarding the details of JSON payload format and REST API details see Payload Format for Table Service Operation.
To take full advantage of JSON and the additional performance improvements, consider upgrading to Windows Azure Storage Client 3.0 which uses JSON and turns off echo on Insert by default. Older versions of the library do not support JSON.
AtomPub vs JSON format
As mentioned earlier using JSON results in significant reduction in payload size when compared to AtomPub. As a result using JSON is the recommended format and the newly released Windows Azure Storage Client 3.0 Library uses JSON with minimal metadata by default. To get a feel on how JSON request/response looks like as compared to AtomPub, please refer to the Payload Format for Table Service Operations MSDN documentation where payload examples are provided for both AtomPub and JSON format. We have also provided a sample of the JSON payload at the end of this blog.
To compare JSON and AtomPub, we ran the example provided by end of the blog in both JSON and AtomPub and compared the payload for both minimal and no metadata. The example generates 6 requests which includes checking for a table existence, creating the table, inserting 3 entities and querying all entities in that table. The following table summarizes the amount of data transferred back and forth in bytes.
As you can see, and for this example, both minimal and no metadata of the JSON format provide noticeable savings with over 75% reduction in the case of no metadata when compared to AtomPub. This would significantly increase the responsiveness of applications since they spent less time generating and parsing requests in addition to reduced network transfer time.
Other benefits of JSON can be summarized as follow:
- Other than the performance benefits described above, JSON would reduce your cost as you will be transferring less data.
- Combining JSON, CORS and SAS features will enable you to build scalable applications where you can access and manipulate your Windows Azure Table data from the web browser directly through JavaScript code.
- Another benefit of JSON over AtomPub is the fact that some applications may already be using JSON format as the internal object model in which case using JSON with Windows Azure Tables will be a natural transition as it avoids transformations.
Turning off Insert Entity Response Echo Content
In this release, users can further reduce bandwidth usage by turning off the echo of the payload in the response during entity insertion. Through the ODATA wire protocol, echo content can be turned off by specifying the following HTTP header name and value “Prefer: return-no-content”. More information can be found in the Setting the Prefer Header to Manage Response Echo on Insert Operations MSDN documentation. On the Client Library front, no echo is the default behavior of the Windows Azure Storage Client Library 3.0. Note that content echo can still be turned ON for any legacy reasons by setting echoContent to true on the TableOperation.Insert method (example is provided in a subsequent section).
The comparison data provided in the above table was with content echo enabled. However, on a re-run with echo disabled, an additional 30% saving can be seen over JSON NoMetadata payload size. This is very beneficial if the application makes a lot of entity insertions where apart from network transfer reduction application will see great reduction in IO and CPU usage.
Using JSON with Windows Azure Storage Client Library 3.0
The Windows Azure Storage Client Library 3.0 supports JSON as part of the Table Service layer and the WCF Data services layer. We highly recommend our customers to use the Table Service layer as it is optimized for Azure Tables, has better performance as described in here and supports all flavors of JSON format.
Table Service Layer
The Table Service Layer supports all flavors of JSON formats in addition to AtomPub. The format can be set on the CloudTableClient object as seen below:
CloudTableClient tableClient = new CloudTableClient(baseUri, cred)
{
// Values supported can be AtomPub, Json, JsonFullMetadata or JsonNoMetadata
PayloadFormat = TablePayloadFormat.JsonNoMetadata
};Note that the default value is JSON i.e. JSON Minimal Metadata. You can also decide which format to use per request by passing in a TableRequestOptions with your choice of PayLoadFormat to the CloudTable.Execute method.
In order to control the no-content echo for Insert Entity, you can do so by passing in the appropriate value to the TableOperation.Insert method; Note that by default, the client library will request that no-content is echoed back.
Example:
// Note that the default value for echoContent is already false
table.Execute(TableOperation.Insert(customer, echoContent: false));
As you can see, the echoContent is set at the individual entity operation level and therefore this would also be applicable to batch operations when using table.ExecuteBatch.JSON NoMetadata client side type resolution
When using JSON No metadata via the Table Service Layer the client library will “infer” the property types by inspecting the type information on the POCO entity type provided by the client as shown in the JSON example at the end of the blog. (Note, by default the client will inspect an entity type once and cache the resulting information. This cache can be disabled by setting TableEntity.DisablePropertyResolverCache = true;) Additionally, in some scenarios clients may wish to provide the property type information at runtime such as when querying with the DynamicTableEntity or doing complex queries that may return heterogeneous entities. To support this scenario the client can provide a PropertyResolver Func on the TableRequestOptions which allows clients to return an EdmType enumeration for each property based on the data received from the service. The sample below illustrates a PropertyResolver that would allow a user to query the customer data in the example below into DynamicTableEntities.
TableRequestOptions options = new TableRequestOptions()
{
PropertyResolver = (partitionKey, rowKey, propName, propValue) =>
{
if(propName == "CustomerSince")
{
return EdmType.DateTime;
}
else if(propName == "Rating")
{
return EdmType.Int32;
}
else
{
return EdmType.String;
}
};
};
TableQuery<DynamicTableEntity> query = (from ent in complexEntityTable.CreateQuery<DynamicTableEntity>()
select ent).WithOptions(options);WCF Data Services Layer
As mentioned before, we recommend using the Table Service layer to access Windows Azure Tables. However, if that is not possible for legacy reasons, you might find this section useful.
The WCF Data Services Layer payload format as part the Windows Azure Storage Client Library 3.0 defaults to JSON minimal metadata which is the most concise JSON format supported by the .NET WCF Data Services (there is no support for nometadata). In fact, if your application uses projections (i.e. $select) WCF Data Services will revert to using JSON fullmetadata, which is the most verbose JSON format.
If you wish to use AtomPub, you can set such payload format by calling the following method:
// tableDataContext is of TableServiceContext type that inherits from the WCF DataServiceContext class
tableDataContext.Format.UseAtom();
In case you decide you want to switch back to JSON (i.e. minimalmetdata and fullmetdata) you can do so by calling the following method:tableDataContext.Format.UseJson(new TableStorageModel(tableClient.Credentials.AccountName));In order to turn off echoing back content on all Insert Operations, you can set the following property:
// Default value is None which would result in echoing back the content
tableDataContext.AddAndUpdateResponsePreference = DataServiceResponsePreference.NoContent;
Note that both the JSON and no-content echo settings apply to all operations.JSON example using Windows Azure Storage Client 3.0
In this example, we create a simple address book by storing a few customer’s information in a table, and then we query the content of the Customers table using the table service layer of the Storage Client library. We will also use JSON nometadata and ensure that no-content echo is enabled.
Here is some excerpts of code for the example:
const string customersTableName = "Customers";
const string connectionString = "DefaultEndpointsProtocol=https;AccountName=[ACCOUNT NAME];AccountKey=[ACCOUNT KEY]";
CloudStorageAccount storageAccount = CloudStorageAccount.Parse(connectionString);
CloudTableClient tableClient = storageAccount.CreateCloudTableClient();
// Values supported can be AtomPub, Json, JsonFullMetadata or JsonNoMetadata with Json being the default value
tableClient.PayloadFormat = TablePayloadFormat.JsonNoMetadata;
// Create the Customers table
CloudTable table = tableClient.GetTableReference(customersTableName);
table.CreateIfNotExists();
// Insert a couple of customers into the Customers table
foreach (CustomerEntity customer in GetCustomersToInsert())
{
// Note that the default value for echoContent is already false
table.Execute(TableOperation.Insert(customer, echoContent: false));
}
// Query all customers with first letter of their FirstName in between [I-X] and
// with rating bigger than or equal to 2.
// The response have a payload format of JSON no metadata and the
// client library will map the properties returned back to the CustomerEntity object
IQueryable<CustomerEntity> query = from customer in table.CreateQuery<CustomerEntity>()
where string.Compare(customer.PartitionKey,"I") >=0 &&
string.Compare(customer.PartitionKey,"X")<=0 &&
customer.Rating >= 2
select customer;
CustomerEntity[] customers = query.ToArray();Here is the CustomerEntity class definition and the GetCustomersToInsert() method that initializes 3 CustomerEntity objects.
public class CustomerEntity : TableEntity
{
public CustomerEntity() { }
public CustomerEntity(string firstName, string lastName)
{
this.PartitionKey = firstName;
this.RowKey = lastName;
}
[IgnoreProperty]
public string FirstName
{
get { return this.PartitionKey; }
}
[IgnoreProperty]
public string LastName
{
get { return this.RowKey; }
}
public string Address { get; set; }
public string Email { get; set; }
public string PhoneNumber { get; set; }
public DateTime? CustomerSince { get; set; }
public int? Rating { get; set; }
}
private static IEnumerable<CustomerEntity> GetCustomersToInsert()
{
return new[]
{
new CustomerEntity("Walter", "Harp")
{
Address = "1345 Fictitious St, St Buffalo, NY 98052",
CustomerSince = DateTime.Parse("01/05/2010"),
Email = "Walter@contoso.com",
PhoneNumber = "425-555-0101",
Rating = 4
},
new CustomerEntity("Jonathan", "Foster")
{
Address = "1234 SomeStreet St, Bellevue, WA 75001",
CustomerSince = DateTime.Parse("01/05/2005"),
Email = "Jonathan@fourthcoffee.com",
PhoneNumber = "425-555-0101",
Rating = 3
},
new CustomerEntity("Lisa", "Miller")
{
Address = "4567 NiceStreet St, Seattle, WA 54332",
CustomerSince = DateTime.Parse("01/05/2003"),
Email = "Lisa@northwindtraders.com",
PhoneNumber = "425-555-0101",
Rating = 2
}
};
}JSON Payload Example
Here are the 3 different response payloads corresponding to AtomPub, JSON minimalmetadata and JSON nometadata for the query request generated as part of the previous example. Note that the payload have been formatted for readability purposes. The actual wire payload does not have any indentation or newline breaks.
AtomPub
<?xml version="1.0" encoding="utf-8"?>
<feed xml:base="http://someaccount.table.core.windows.net/" xmlns="http://www.w3.org/2005/Atom" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns:georss="http://www.georss.org/georss" xmlns:gml="http://www.opengis.net/gml">
<id>http://someaccount.table.core.windows.net/Customers</id>
<title type="text">Customers</title>
<updated>2013-12-03T06:37:21Z</updated>
<link rel="self" title="Customers" href="Customers" />
<entry m:etag="W/"datetime'2013-12-03T06%3A37%3A20.9709094Z'"">
<id>http://someaccount.table.core.windows.net/Customers(PartitionKey='Jonathan',RowKey='Foster')</id>
<category term="someaccount.Customers" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<link rel="edit" title="Customers" href="Customers(PartitionKey='Jonathan',RowKey='Foster')" />
<title />
<updated>2013-12-03T06:37:21Z</updated>
<author>
<name />
</author>
<content type="application/xml">
<m:properties>
<d:PartitionKey>Jonathan</d:PartitionKey>
<d:RowKey>Foster</d:RowKey>
<d:Timestamp m:type="Edm.DateTime">2013-12-03T06:37:20.9709094Z</d:Timestamp>
<d:Address>1234 SomeStreet St, Bellevue, WA 75001</d:Address>
<d:Email>Jonathan@fourthcoffee.com</d:Email>
<d:PhoneNumber>425-555-0101</d:PhoneNumber>
<d:CustomerSince m:type="Edm.DateTime">2005-01-05T00:00:00Z</d:CustomerSince>
<d:Rating m:type="Edm.Int32">3</d:Rating>
</m:properties>
</content>
</entry>
<entry m:etag="W/"datetime'2013-12-03T06%3A37%3A21.1259249Z'"">
<id>http://someaccount.table.core.windows.net/Customers(PartitionKey='Lisa',RowKey='Miller')</id>
<category term="someaccount.Customers" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<link rel="edit" title="Customers" href="Customers(PartitionKey='Lisa',RowKey='Miller')" />
<title />
<updated>2013-12-03T06:37:21Z</updated>
<author>
<name />
</author>
<content type="application/xml">
<m:properties>
<d:PartitionKey>Lisa</d:PartitionKey>
<d:RowKey>Miller</d:RowKey>
<d:Timestamp m:type="Edm.DateTime">2013-12-03T06:37:21.1259249Z</d:Timestamp>
<d:Address>4567 NiceStreet St, Seattle, WA 54332</d:Address>
<d:Email>Lisa@northwindtraders.com</d:Email>
<d:PhoneNumber>425-555-0101</d:PhoneNumber>
<d:CustomerSince m:type="Edm.DateTime">2003-01-05T00:00:00Z</d:CustomerSince>
<d:Rating m:type="Edm.Int32">2</d:Rating>
</m:properties>
</content>
</entry>
<entry m:etag="W/"datetime'2013-12-03T06%3A37%3A20.7628886Z'"">
<id>http://someaccount.table.core.windows.net/Customers(PartitionKey='Walter',RowKey='Harp')</id>
<category term="someaccount.Customers" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />
<link rel="edit" title="Customers" href="Customers(PartitionKey='Walter',RowKey='Harp')" />
<title />
<updated>2013-12-03T06:37:21Z</updated>
<author>
<name />
</author>
<content type="application/xml">
<m:properties>
<d:PartitionKey>Walter</d:PartitionKey>
<d:RowKey>Harp</d:RowKey>
<d:Timestamp m:type="Edm.DateTime">2013-12-03T06:37:20.7628886Z</d:Timestamp>
<d:Address>1345 Fictitious St, St Buffalo, NY 98052</d:Address>
<d:Email>Walter@contoso.com</d:Email>
<d:PhoneNumber>425-555-0101</d:PhoneNumber>
<d:CustomerSince m:type="Edm.DateTime">2010-01-05T00:00:00Z</d:CustomerSince>
<d:Rating m:type="Edm.Int32">4</d:Rating>
</m:properties>
</content>
</entry>
</feed>JSON minimalmetadata
{
"odata.metadata":"http://someaccount.table.core.windows.net/$metadata#Customers",
"value":[
{
"PartitionKey":"Jonathan",
"RowKey":"Foster",
"Timestamp":"2013-12-03T06:39:56.6443475Z",
"Address":"1234 SomeStreet St, Bellevue, WA 75001",
"Email":"Jonathan@fourthcoffee.com",
"PhoneNumber":"425-555-0101",
"CustomerSince@odata.type":"Edm.DateTime",
"CustomerSince":"2005-01-05T00:00:00Z",
"Rating":3
},
{
"PartitionKey":"Lisa",
"RowKey":"Miller",
"Timestamp":"2013-12-03T06:39:56.7943625Z",
"Address":"4567 NiceStreet St, Seattle, WA 54332",
"Email":"Lisa@northwindtraders.com",
"PhoneNumber":"425-555-0101",
"CustomerSince@odata.type":"Edm.DateTime",
"CustomerSince":"2003-01-05T00:00:00Z",
"Rating":2
},
{
"PartitionKey":"Walter",
"RowKey":"Harp",
"Timestamp":"2013-12-03T06:39:56.4743305Z",
"Address":"1345 Fictitious St, St Buffalo, NY 98052",
"Email":"Walter@contoso.com",
"PhoneNumber":"425-555-0101",
"CustomerSince@odata.type":"Edm.DateTime",
"CustomerSince":"2010-01-05T00:00:00Z",
"Rating":4
}
]
}JSON nometadata
"value":[
{
"PartitionKey":"Jonathan",
"RowKey":"Foster",
"Timestamp":"2013-12-03T06:45:00.7254269Z",
"Address":"1234 SomeStreet St, Bellevue, WA 75001",
"Email":"Jonathan@fourthcoffee.com",
"PhoneNumber":"425-555-0101",
"CustomerSince":"2005-01-05T00:00:00Z",
"Rating":3
},
{
"PartitionKey":"Lisa",
"RowKey":"Miller",
"Timestamp":"2013-12-03T06:45:00.8834427Z",
"Address":"4567 NiceStreet St, Seattle, WA 54332",
"Email":"Lisa@northwindtraders.com",
"PhoneNumber":"425-555-0101",
"CustomerSince":"2003-01-05T00:00:00Z",
"Rating":2
},
{
"PartitionKey":"Walter",
"RowKey":"Harp",
"Timestamp":"2013-12-03T06:45:00.5384082Z",
"Address":"1345 Fictitious St, St Buffalo, NY 98052",
"Email":"Walter@contoso.com",
"PhoneNumber":"425-555-0101",
"CustomerSince":"2010-01-05T00:00:00Z",
"Rating":4
}
]
}Resources
- Windows Azure Storage Release - Introducing CORS, JSON, Minute Metrics, and More
- Windows Azure Storage Client Library (3.0) Binary - http://www.nuget.org/packages/WindowsAzure.Storage
- Windows Azure Storage Client Library (3.0) Source - https://github.com/WindowsAzure/azure-storage-net
Please let us know if you have any further questions either via forum or comments on this post,
Sam Merat, Jean Ghanem, Joe Giardino, and Jai Haridas


My (@rogerjenn) Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: November 2013 = 99.99% begins:
The OakLeaf Systems Azure Table Services Sample Project demo project runs two small Windows Azure Web role compute instances from Microsoft’s South Central US (San Antonio, TX) data center. This report now contains more than two full years of monthly uptime data.



and continues with detailed downtime and response time reports, as well as a table of earlier uptime reports.

<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Marketplace DataMarket, Cloud Numerics, Big Data and OData
No significant articles so far this week.
<Return to section navigation list>
Windows Azure Service Bus, BizTalk Services and Workflow
No significant articles so far this week.

<Return to section navigation list>
Windows Azure Access Control, Active Directory, Identity and Workflow
Alex Simons (@Alex_A_Simons) and Jeff Staiman described Group Management for Admins – Public Preview! in a 12/5/2013 post to the Active Directory blog:
Just this week we've turned on a preview of group management capabilities for directory administrators. This is another free capability for Windows Azure Active Directory. Admins can now add, delete, and manage the membership of security groups directly in Windows Azure AD in the cloud. As you would expect, this capability lets directory administrators create security groups they can use to manage access to applications and to resources, such as SharePoint sites. We will add mail-enabled groups for Exchange in a future release.
And if you're using Windows Azure Active Directory Premium, which I blogged about here, you can use these groups to assign access to SaaS applications.
To help you get started using this new feature, let me introduce Jeff Staiman, a senior program manager on the Active Directory team. He has written a nice step-by-step introduction below.
To try out the group management features, sign in to the Windows Azure Management Portal, and click on Active Directory in the left navigation bar.
Best Regards,
Alex Simons (twitter: @Alex_A_Simons)
Director of Program Management
Active Directory Team
Hi there –
I'm Jeff Staiman, Senior PM on the AD team, writing to introduce you to the preview of the group management capabilities we've recently introduced for directory administrators.
From within the Windows Azure Management Portal you can now:
Create or delete new security groups in Windows Azure Active Directory, and manage membership in these groups. These groups can be used to control access to resources, such as a SharePoint site in Office 365.
See groups in your Windows Azure AD that were synchronized from your local Active Directory, or created in Office 365. The management of these groups remains in your local Active Directory or in Office 365; these groups can't be updated in the Windows Azure Management Portal.
Assign access for a group to a SaaS application, if you're using Windows Azure AD Premium.
Groups in Windows Azure AD
Windows Azure AD stores and manages groups that can be used by applications such as Office 365 to make their access and authorization decisions. Directory administrators can see groups in their Windows Azure AD by signing into the Windows Azure Management Portal, clicking on their directory, and clicking on the new GROUPS tab.
Creating a Group
Once you're on the GROUPS tab, you can create a group by clicking on the ADD GROUP button in the command bar. Then, enter a friendly name for the group. You can optionally enter a description for the group to indicate the intended membership or access to resources of group members.
Fig 1: Creating a new group
Then, click the checkmark in the lower right, and in a few seconds your group is created. You can see the new group on the GROUPS tab.
Fig 2: A new group shown on the GROUPS tab
As shown in Fig 2, groups created in the Windows Azure Management Portal have 'Windows Azure Active Directory' in the 'Sourced From' property. These groups can be managed in the Windows Azure Management Portal, as well as from the PowerShell cmdlets for Windows Azure AD, or using code that programmatically accesses the Windows Azure AD Graph API. You can also see and manage the group in the Office 365 Administration Portal, since Office 365 uses Windows Azure AD as its directory for groups as well as for users.
Adding and removing group members
The most important property of a group is its members. To add and remove members from a group that is sourced from Windows Azure AD, navigate to the GROUPS tab in your directory and click on the group name in the Windows Azure Management Portal. This will open up the group to its MEMBERS tab.
A new group created in the Windows Azure Management Portal will initially have no members. To add members, click the ADD MEMBERS button in the command bar. Select members to be added by clicking on their name in the left hand column of the picker dialog. Once selected, you'll see a green checkmark to the right of the name, and the name will appear in the SELECTED column on the right side of the dialog.
Fig 3: Adding members to a group, with pending addition of three users
To add the selected members to the group, click the checkmark in the lower right of the dialog. Then you will see the MEMBERS tab for the group, which will show the members that you just added to the group.
Fig 4: Membership in a group after adding three members
You can remove a member from a group by selecting the member in the list, and clicking the REMOVE button in the command bar.
Fig 5: Removing a member from a group
Managing Group Properties
If you need to edit the name or description of the group, you can click on the CONFIGURE tab. Type in the new name and/or description, and click SAVE in the command bar.
Fig 6: Editing the properties of a group
You can also find the Object ID for the group on the CONFIGURE tab. The Object ID will be useful if you are writing an application that uses this group to control access to its resources. To learn more about how to use groups to secure access to resources, read our authorization code sample.
Groups Sourced From Local Active Directory or Office 365
If you have configured directory synchronization, you can see groups that have been synchronized from your local Windows Server Active Directory, which have the value 'Local Active Directory' in the 'Sourced From' property. You must continue to manage these groups in your local Active Directory; these groups cannot be managed or deleted in the Windows Azure Management Portal.
If you have Office 365, you can see distribution groups and mail-enabled security groups that were created and managed within the Exchange Admin Center within Office 365. These groups have the value 'Office 365' in the 'Sourced From' property, and must continue to be managed in the Exchange Admin Center.
Fig 7: A directory with one group sourced from Windows Azure AD and one group sourced from Office 365
Deleting a group
You can delete a group by selecting a group in the list of groups and clicking the DELETE button on the command bar. Only groups that are sourced from Windows Azure AD or Office 365 can be deleted in the Windows Azure Management Portal.
To delete a group that is sourced from a Local Active Directory, just delete the group in the local Active Directory. The next time that synchronization is run, the group will be deleted in Windows Azure AD.
Assigning Access for a Group to a SaaS application
One of the cool features of Windows Azure AD Premium is the ability to use groups to assign access to a SaaS application that's integrated with Windows Azure AD. For example, if you want to assign access for the marketing department to use five different SaaS applications, you can create a group that contains the users in the marketing department, and then assign that group to the applications that are needed by users in the marketing department. In that way, you can save time by managing the membership of the marketing department in just one place. Then, users will be assigned to the application when they are added as members of the marketing group, and have their assignments removed from the application when they are removed from the marketing group.
This capability can be used with hundreds of applications that you can add from within the Windows Azure AD Application Gallery.
Fig 8: Windows Azure AD Application Gallery
To assign access to an application, go to the APPLICATIONS tab on your directory. Click on an application that you added from the Application Gallery, then click on the USERS AND GROUPS tab. You will only see the USERS AND GROUPS tab once you have enabled Windows Azure AD Premium.
Fig 9: A Directory with Dropbox for Business, which was added from the Application Gallery
On the USERS AND GROUPS TAB, in the 'Starts with' field, enter the name of the group to which you want to assign access, and click the check mark in the upper right. You only need to type the first part of the group's name. Then, click on the group to highlight it, as shown in Fig 10, then click on the ASSIGN ACCESS button and click YES when you see the confirmation message.
Fig 10: Selecting a group to assign access to an application
You can also see which users are assigned to the application, either directly or by membership in a group. To do this, change the SHOW dropdown from 'Groups' to 'All Users'. The list shows users in the directory and whether or not each user is assigned to the application. The list also shows whether the assigned users are assigned to the application directly (assignment type shown as 'Direct'), or by virtue of group membership (assignment type shown as 'Inherited.')
Fig 11: Users assigned to an application
Next Steps
- Enable administrators to create and manage nested groups in the Windows Azure Management Portal.
- Enable administrators to see and manage the groups in which a particular user is a member.
- Enable end users to create and manage their own groups.
As always, we are very interested in hearing what you think! If you have feedback for us -- experiences you love, find confusing, or hope to see in future -- or if you have questions about how this works, or how the various elements of the experience fit together, please tell us at our forum on TechNet.














<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
Cameron Rogers posted a Recap: #AzureChat - Virtual Machines and Autoscaling on 12/6/2013:
Thank you to everyone who joined Corey Sanders and Stephen Siciliano for an #AzureChat. It was great to hear the community’s voice in this live discussion about two of our favorite topics--Virtual Machines and Autoscaling. Below is a recap in case you missed the chat or want to explore the links for more in-depth content on the topics discussed.
Q1: Do I have to be a developer to use Windows AzureVMs?
A1: You don't have to be a developer. With our large range of capabilities, Developers, DevOps, and IT Pros are all welcome. - @CoreySandersWAQ2: How can I get started with Windows Azure VMs?
A2: So easy to answer. :) Go here, http://qub.me/y8u4q1 , get a free trial and have a blast. Linux, Windows, Oracle - @CoreySandersWAQ3: How can I manage VMs in Windows Azure?
A3: You can manage using Azure portal (with the power of monitoring/autoscale) or using existing on-prem tools via VNETs. - @CoreySandersWAQ4: Are there easy ways for me to automate the creation of different types of Virtual Machines?
A4: We have a fantastic script center allowing easy automation using PowerShell: http://qub.me/WudbPw . VMs+disks, SharePoint... - @CoreySandersWAQ5: How do you expose endpoints to your VM that are accessible only to your Cloud Services?
A5: You can control access to the VM or Cloud Service by setting an ACL on the public IP: http://qub.me/ZXBCma - @CoreySandersWAQ6: How do I export a VM from on-prem to Windows Azure?
A6: Because we just run Windows Server 2012 Hyper-V in Azure, moving a VM should be just move the VHD and boot. A snap.
Community Response: It depends upon whether you want to use the VM as the base for a set of images, or if you just want to suck it in. - @CTO_Reed
Host Response: @CTO_Reed Agreed. You can either upload the VHD or start in the cloud and build from there! - @CoreySandersWA
Community Response: Then just upload it as a "disk" rather than an "image" and start it up! - @CTO_ReedQ7: Can Autoscale automatically deploy new VM’s?
A7: No, you'll need to provision/fully set up the VM's you'll need in advance, then we'll turn them on/off to save you money. - @iscsusQ8: For Dev/Test scenarios, can Autoscale scale to 0 VMs?
A8: Yes! Using Scheduled Autoscale you can have all of your VM’s turn off at night or on the weekends. - @iscsus
Response: Can't we try manually shutdown? - @milson
Response: You can also manually shut down -- but then it won't automatically turn on in the morning when you start work :) - @iscsusCommunity Questions:
Question: When are you going to implement something like AWS's elastic ips? - @JoshGlazebrook
Answer: Yes, we gotta add that. Depending upon what you are trying to do, we may have some options for you, even today. - @iscsusQuestion: Reasons to use a VM over a Cloud Service? - @andhopkins
Answer: A VM gives me greater control but more work. -@jonstellwagen
Answer: .@jonstellwagen Couldn't have said it better myself. VMs = Control and Cloud Services = Ease to deploy/manage. - @CoreySandersWAQuestion: When are we getting multiple public IP's for the VM's on Azure? - @Evron19
Response: Eamonn, are you looking for multiple public IPs on a single VM? Load-balanced? - @CoreySandersWA
Response: Hey Corey, case is for multiple SSL sites on one VM. I know we can use SNI etc but not completely supported etc - @Evron19
Answer: For SSL, SNI is ok but does have some limitations (Windows XP, yes?). Good f/b for future plans. - @CoreySandersWAQuestion: Do you have plans to allow autoscaling by both CPU and Queue simultaneously? - @thomento
Answer: No immediate plans to support both in the UI, but we did just release a new sdk http://po.st/m7uzAk . In the SDK (on nuget http://po.st/O8DOrp ) you can create any set of scale rules based on different metrics. - @iscsus
Response: I didn’t know, if you use the SDK… does that conflict with the UI? I like having the UI to add-hoc configuration. - @thomento
Response: yes, it may be possible to use the SDK to create settings the UI doesn't understand - in that case you can't use both - @iscsusQuestion: How long should it take for a CPU autoscale rule to kick in? Yesterday I was seeing 30+ mins. - not sure what to expect though. - @rickraineytx
Answer: By default, autoscale takes the average CPU over 45 minutes - this means it could be 30+ min after a spike. But, with the sdk (http://po.st/O8DOrp ) you can manually set different time periods to average metrics over. - @iscsus
Response: 30+ min? What does it “10 minutes after last scale action” in the UI mean then? - @thomento
Response: Yes, that was my experience. I too was wondering then about the last scale action as it can be as small as 5.- @rickraineytx
Response: So there are 2 different scenarios-if you start w/0 cpu and go to 80 quickly, it can take 30+ minutes because we average over 45 min. But if your cpu avg is already high, there could be actions every 10min. - @iscsus
Response: This is not clear in the UI (which is the best UI BTW). I would love to be able to change that in the UI. - @thomento
Response: Good point :) we're always working on improving the ui so thx for the feedback. - @iscsus
Response: We have a work around, not ideal but would really like to see this. It's in Azure Websites i think? - @Evron19
Response: Yup, good feedback. It is easy on Azure WebSites: http://qub.me/12iNvo - @CoreySandersWAQuestion: Do each of the VM's need to be configured the same to use AutoScale? - @jonstellwagen
Answer: autoscale works for the stateless part of your app (eg iis), you can't store state on the vm's. Files are fine - @iscsusQuestion: What are the provisions for big data on Windows Azure? - @milson
Answer: Check out our AWESOME HDInsight service that allows you to do Hadoop on Azure: http://qub.me/qywONP - @CoreySandersWA

Mark Brown (@markjbrown) posted Obtaining a Certificate for use with Windows Azure Web Sites (WAWS) to the Windows Azure blog on 12/5/2013:
Editor's Note: This post was written by Erez Benari, Program Manager on the Windows Azure Web Sites Team.
With the increase in cybercrime in recent years, securing your website with SSL is becoming a highly sought-after feature, and Windows Azure Web Sites provides support for it. To use it, you need to upload your certificate to Azure, and assign it to your site. Getting a certificate can be challenging, because the process involves several steps. In this guide we will describe the following ways to obtain a certificate:
- Using DigiCert’s certificate utility
- Using CertReq
- Using IIS
Background
The process of generating a certificate is comprised of two parts. First, the user creates a Certificate Signing Request, which is a textual file containing the details of the request. The user gives this file to his certificate provider of choice, and in return, gets a Certificate Response file, which he then installs on his server to complete the process and have a full certificate. To use this with your Windows Azure Web Sites, there’s a 3rd part where you export the certificate to a PFX file, which you can upload to your Azure account.
Most server products have some built in mechanism to generate the CSR files and process the Certificate Response file. In IIS, for example, this is a button on Actions pane:
If you are a seasoned IIS administrator and have a server at your disposal, this is all pretty simple and straight forward. If not, this guide offers two other ways to do this.
Note: In all the following procedures, all 3 parts must be performed on the same computer. The reason for this is that the CSR request generates a private encryption/decryption key that is unique to this computer. If you try to complete the process on another computer, the Certificate Response would have no key to match, and will fail.
Create a CSR using DigiCert’s Certificate Utility
DigiCert’s Certificate Utility is a 3rd party tool that was designed to make the process of generating a CSR easier by providing a simple graphic user interface for the process. This is by far the easiest way to do this, but the DigiCert Certificate Utility is not a Microsoft tool, and it is not supported by Microsoft. You can download the tool here. This tool can be used with any certificate provider. The steps are:
- Run the utility and click Create CSR on the top-right corner:
- Type in the URL for your website, and the other details.
- Select the key length. Note that Microsoft recommends a key length of 2048 bit
- Click Generate and receive the CSR code:
- Use the resulting CSR code to purchase your certificate. Most providers will ask you to paste the text into their web page, while others may require you to save it to a file and upload it to their website. In return, they will provide you with a file carrying the .CER extension. Save this file on the computer you performed the CSR request on.
- To complete the process, click Import on the top-right corner of the DigiCert utility, and navigate to the .CER file you received from your certificate provider. ***
- Once this has completed, you will see the new cert in the tool. Click on it, and click Export Certificate on the bottom of the certificate list screen:
- Select to export the private key, and to export to a PFX file, which you can use with Azure Web Sites. Set a password for the export, which you will use later when uploading it to Azure:
*** Some certificate providers might provide the certificate in a format that is not compatible with DigiCert’s utility. If the import does not succeed, you can use the utility described next to complete the process – follow step 5 in the next section to do this.
Create a CSR using the command-line tool CertReq
CertReq is a tool that is built into any modern version of the Windows operating system. It is designed to take a simple text file with some parameters, and produce a CSR file that you can send to your certificate provider. Once the provider has returned a CER file, you can use CertReq to complete the request. At that point, you can use the Windows Certificate Management console to export the certificate into the PFX format that Windows Azure Web Sites uses. Here are the steps for this:
- Create an input file for CertReq. This is a simple text file that contains some details about your certificate. The most important one is the Subject Name, which would need to match the URL of the site you intend to use the certificate for. The following sample is a standard request, but if you like, you can read the documentation of CertReq and adjust the parameters to match your needs.
Adjust the highlighted portion to your site’s address. For example, if your site is going to be https://www.contoso.com, then the line would be:
Subject = "CN=www.contoso.com"
You can also adjust other properties of the request, but this is an advanced task. Visit this page for details about other options you can configure for CertReq.
- Save the file on your hard drive as a text file, and then open a CMD window and navigate to where you saved the file.
- Type the command CertReq –new MyRequest.txt MyRequest.csr, where MyRequest.txt is the name of the file you saved in the previous step, and MyRequest.csr is a target file name that will be created:
- Use the resulting MyRequest.csr file to purchase your certificate. Most providers will ask you to upload the file to their servers. Some providers might ask you to paste the content of the file into their web page (you can open the file in Notepad). In return, the provider will give you a file carrying the .CER extension. Copy this file to the computer you performed the CSR request on.
- In a CMD window, navigate to where you stored the .CER file, and type CertReq –accept –user MyCertificate.cer.
- Open your certificate management console by pressing the Windows+R key combination and typing certmgr.msc and then Enter
- In the certificate manager, navigate to Personal/Certificates. Your new certificate should be there:
- Right-click on the certificate and choose All Tasks/Export
- In the wizard, select YES to export the private key, and on the next page, Personal Information Exchange – PKCS #12:
- On the next page, enable the password option, and type in a password of your choice. You will use it later when uploading the certificate. On the next page, type in a target path and name for the exported file:
- That’s it – the new PFX file can be uploaded to your account in Azure and used with your websites.
Create a CSR using IIS
If you have an IIS Server at your disposal, you can use it to generate the certificate. If you don’t, you can easily install it on any computer running Windows (Server or Client). The steps are:
- Install IIS on the computer you wish to do this on.
- Open the IIS management console
- Click on your computer name on the left, then on Server Certificate in the middle, and then on Create Certificate Request on the right action pane:
- In the wizard, fill in the target URL for the site (without the HTTPS:// prefix) and the other details. Note that Microsoft recommends a key length of 2048 bit:
- Complete the wizard and use the resulting CSR file to purchase your certificate. Most providers will ask you to upload the file to their servers. Some providers might ask you to paste the content of the file into their web page (you can open the file in Notepad). In return, the provider will give you a file carrying the .CER extension. Copy this file to the computer you performed the CSR request on.
- In the IIS console, click Complete Certificate Request in the action pane.
- Follow steps 6 through 11 in the previous section to export the certificate to a PFX file, which you can use with Azure Web Sites.
Next steps
Now that you have a certificate in the form of a PFX file, you can upload it to your Azure account and use it with web sites and other services. Visit this article for further information about this process. In some situations, your certificate needs might be different. For example, if you want to use a SAN certificate, or a self-signed certificate, the process for getting those are different. You can read about those here.
















My (@rogerjenn) Uptime Report for My Live Windows Azure Web Site: November 2013 = 99.92% of 12/5/2013 begins:
OakLeaf Systems’ Android MiniPCs and TVBoxes blog runs WordPress on WebMatrix with Super Cache in Windows Azure Web Site (WAWS) Standard tier instance in Microsoft’s West U.S. (Bay Area) data center and ClearDB’s MySQL database (Venus plan). I converted the site from the Shared Preview to the Standard tier on September 7, 2013 in order to store diagnostic data in Windows Azure blobs instead of the file system.
Service Level Agreements aren’t applicable to the Web Services’ Shared tier; only sites in the Standard tier qualify for the 99.9% uptime SLA.
- Running a Shared Preview WAWS costs ~US$10/month plus MySQL charges
- Running a Standard tier instance costs ~US$75/month plus MySQL charges
I use Windows Live Writer to author posts that provide technical details of low-cost MiniPCs with HDMI outputs running Android JellyBean 4.1+, as well as Google’s new Chromecast device. The site emphases high-definition 1080p video recording and rendition.
The site commenced operation on 4/25/2013. To improve response time, I implemented WordPress Super Cache on May 15, 2013. I moved the site’s diagnostic logs from the file system to Windows Azure blobs on 9/7/2013, as reported in my Storing the Android MiniPCs Site’s Log Files in Windows Azure Blobs post.





Mike McKeown (@nwoekcm) continued his series with SQL Server on IaaS VM – Capture Azure VM Image with SQL Server on 12/4/2013:
This is the third post for the mini-series entitled “Hosting SQL Server in Window Azure IaaS Fundamentals”. In this post I will teach you about capturing an Azure VM Image with SQL Server. This is a very powerful option for creating an image from a SQL Server Azure IaaS VM via the process known as “capturing”.
The reason you want to capture an existing VM image from Azure running SQL Server is simplicity as well as the fact that you want to create multiple VMs running SQL Server. Remember that we previously discussed the difference between an Azure image and disk and the use cases for both. This is one of those use cases where you want to use Azure to create an image, and then capture it to use it to create other VMs running SQL Server. The capture process uses an existing Azure VM running SQL Server to create a VM image. This allows us to then create many SQL Server VMs from that image as we want.
Just want to introduce the PowerShell commands to stop the VM then to Capture the VM. Will not spend a lot of time on the parameters for this as you can find them all documented online. But you will stop the VM using Stop-AzureVM then save it as an image.
Create Azure VM and Capture as an Image
Here are the steps we will go through to create a SQL Server VM then capture it as an image.
- BP Create Affinity group (for this and rest of demos). Affinity group provides a high degree of co-location within a data center to avoid randomized placement of resources. Tries to do same cluster and even same rack if possible.
- BP Create storage account
- Create existing Azure VM running SQL Server
- Log into VM and run sysprep. If you don’t do this the portal will not allow you to create image.
- Once it completes try to RDP in again – you cant
- Shutdown the image (enabled capture)
- “Capture” the image (deletes the VM). If I try to capture without checking sysprep box it will not allow me to do this.
- The VM from which this image is captured is no longer viable to run as a VM once it is captured. In fact, once the VM is captured it will be deleted from the Virtual Machines section and moved under Azure images.
- Show VHD is now gone as well as is VM
- Show the image VHD under Images VM tab
Capture VM Image from Azure VM
Once the image is captured the image appears in the VM Image Gallery. From there you can then create new SQL Server VMs from it as many as you want.
Continuing our introduction of PowerShell commands here we want to create the VM from the image. Just want to make you aware of the New-AzureQuickVM command and its many parameters which you would use here.
- Using VM Gallery to create a new Azure VM from captured image>
- Realize that regardless of the VM size of the captured VM you can create any size VM you want from that image up to and including Extra Large. Note you can’t create a VM from an image or a disk with a size above that. So if the VM you captured was a size Large, you can create a VM of size small, a VM of size Medium, etc. But you cannot create a A6 (4 cores, 28 GB) or A7 (8 cores, 56 GB).
We are not going to connect to SQL Server Mgmt Studio in this lesson as we have a more appropriate place in a later lesson.
A small but occasionally important difference between creating a VM from an image that is not a stock Azure Gallery image (uploaded sysprepd / captured VM) and one that is a stock image is that you CANNOT specify the storage account with which the new VM will be associated. By default you create the new VM in the storage account.Summary
In this module I discussed how to use an existing Azure VM instance to create an image, then taking that image and creating one or more VMs from that. We also mentioned about how you attach disks to the VM but did not show it as we will show it in a more applicable demo. But I wanted to introduce that concept at this point in time so you will be familiar with the process when we encounter it.



<Return to section navigation list>
Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
Pradeep Kumar of the Windows Azure Cloud Integration Engineering Team described a fix for ASP.NET Session state broken after migrating from Windows Azure shared Cache to Role Based Cache on 12/6/2013:
Windows Azure Shared Cache feature is going to depreciate soon and right now Microsoft is not allowing the end users to create new shared cache namespace from the management portal.
One of the Microsoft partner, who was leveraging Shared Cache to managing the ASP.NET Session state for their Deployed CloudServices got this information from some resources, and approached me to understand the alternatives. I have suggested them to go for a Role based cache feature as mentioned in this article, and provided below mentioned msdn document for smooth migration from shared cache to Role based Cache :
- Migrate from Windows Azure Shared Caching to In-Role Cache http://msdn.microsoft.com/en-us/library/windowsazure/hh914160.aspx
This particular partner was on Windows Azure SDK 1.7, which doesn’t support the Role based Cache (RTM) feature, so they have migrated their CloudService application to latest version of Windows Azure SDK, and then migrated to Role based cache by following the above mentioned msdn article. The migration part went smoothly, however while accessing the session state from application, they were start getting below mentioned exception.
“Session state can only be used when enableSessionState is set to true, either in a configuration file or in the Page directive.
Please also make sure that System.Web.SessionStateModule or a custom session state module is included in the
<configuration>\<system.web>\<httpModules> section in the application configuration.”I am providing the complete investigation details below, so that, this could be helpful to troubleshoot, if you ever came across similar issue. Incase if you’re not interested in the complete investigation details, please scroll down to bottom of this page, and you can implement the suggestions provided under RESOLUTION section.
INVESTIGATION DETAILS
> In general, the above mentioned exception related to ASP.NET sessions will be thrown due to one of the below reasons
- Session is not configured properly or explicitly disabled the SessionState by changing enableSessionState property to false.
- The modules/binaries for session state management were missing
> Rule out the possible configuration, I have reviewed the web.config and page directive, however, I couldn’t find any thing suspicions, which caused this behavior.
> Rule out the issue with the cache module, I have manually checked the project references for cache references added by Cache SDK 2.2 NuGet package,and I can see all the required binaries for managing role based cache were already added in the project reference.
> To get the more granular details on the issue, I have created a new .aspx page, and added below mentioned code snippet to add data to the Cache object.
<snip>
DataCacheFactory factory = new DataCacheFactory();
DataCache cache = factory.GetCache("default");
cache.Put("itemData", "datacache");
<snip>> After running the page with above code snippet throws more meaningful error message as mentioned below :
System. MissingFieldException was unhandled by user code
HResult=-2146233071
Message=Field not found: 'Microsoft.Fabric.Common.IOCompletionPortWorkQueue.WORKER_THREAD_IDLE_WAIT_TIME'.
Source=Microsoft.ApplicationServer.Caching.Client
StackTrace:
at Microsoft.ApplicationServer.Caching.DataCacheFactory.GetNewClientDrm(String cacheName, SimpleSendReceiveModule tempModule,
at Microsoft.ApplicationServer.Caching.DataCacheFactory.CreateRoutingClient(String cacheName, NamedCacheConfiguration config,
at Microsoft.ApplicationServer.Caching.DataCacheFactory.CreateNewCacheClient(DataCacheDeploymentMode mode, String cacheName,
at Microsoft.ApplicationServer.Caching.DataCacheFactory.GetCache(String cacheName, CreateNewCacheDelegate cacheCreationDelegate,
at Microsoft.ApplicationServer.Caching.DataCacheFactory.GetCache(String cacheName)
at eLearnWebRole.Test.Page_Load(Object sender, EventArgs e) in D:\Asp.Net\eLearnWeb\eLearnWebRole\Test.aspx.vb:line 11
at System.Web.UI.Control.OnLoad(EventArgs e)
at System.Web.UI.Control.LoadRecursive()
at System.Web.UI.Page.ProcessRequestMain(Boolean includeStagesBeforeAsyncPoint, Boolean includeStagesAfterAsyncPoint)
> So based on the above exception we reviewed the ‘Microsoft.ApplicationServer.Caching.Client’ binary location and noticed that reference was loaded from project bin directory instead of from NuGet package directory, so able to fix the problem after referencing the binary from NuGet package directory [The same fix will be applicable if you reference the binary from Windows Azure SDK folder ( ….\Program Files\Microsoft SDKs\Windows Azure\.NET SDK\.. ]
RESOLUTION
The session related exception was caused due to not referring appropriate version of cache binaries. So to fix the issue, please make sure you’re referring required Cache binaries either from NuGet Package Directory [ …\<project name> \packages\Microsoft.WindowsAzure.Caching.2.2.0.0\lib\net40-full) ] or from the latest SDK folder [ ….\Program Files\Microsoft SDKs\Windows Azure\.NET SDK\.. ]
It is recommended to go through below mentioned Windows Azure Cache articles :
- Best Practices for using Windows Azure Cache/Windows Server Appfabric Cache
- http://blogs.msdn.com/b/jagan_peri/archive/2012/09/09/best-practices-for-using-windows-azure-cache-windows-server-appfabric-cache.aspx
- Capacity Planning Considerations for In-Role Cache (Windows Azure Cache)
- http://msdn.microsoft.com/en-us/library/hh914129


Return to section navigation list>
Windows Azure Infrastructure and DevOps
Steven Martin (@stevemar_msft) posted Expanding Windows Azure Capacity – Brazil to the Windows Azure Team blog on 12/4/2013:
Earlier today during an event in Sao Paulo, Brazil, I announced our plans to open a Windows Azure Region in Brazil. We expect the region to come online in early 2014 and are delighted to announce that we will begin to on-board preview customers in the next 4 to 6 weeks. This announcement represents our first major expansion into South America, building on our previously announced expansions into Japan, Australia, and China through our partner 21Vianet.
With the opening of this region, new and existing customers in Brazil -- including those that have been with us since our country launch back in the spring of 2010-- will experience better performance through reduced latency and will have the ability to keep their data in the country. As the rules and regulations on data management continue to evolve in Brazil, customers using the Brazil Region will be able to opt for Locally Redundant Storage (LRS), which will maintain three copies of their data and will not replicate their data outside of the country. Geo Redundant Storage (GRS) remains the default option when creating a storage account because it provides our highest level of durability by storing data in a second region, in this case our US South Central region for customers using the Brazil Region as their primary.
It’s an exciting time to be expanding into Brazil, and today’s announcement represents our continued commitment to growing the global presence of Windows Azure and to our Brazilian customers like Boa Vista Serviços, Globosat, and Linx that rely on Windows Azure to run their businesses.


Julie Bennani described Windows Azure Partner Program Updates. What you need to know. in an 11/25/2013 post to the Worldwide Partner Conference blog (missed when published):
Recently, we made a decision to modify the release timeline for partner program changes that were announced at the Worldwide Partner Conference (WPC) in July 2013. I’d like to take this opportunity to talk about how these changes reflect a simpler, more measured approach.
We heard your feedback and are responding
When you choose to partner with us, our commitment is to help make it the best business decision you can make. We continually strive to offer a world-class commercial partner program, resources and experiences to allow your organization to pursue new business opportunities with minimal disruption. Since WPC, we received a lot of feedback that more time was needed to prepare for cloud mainstreaming and that we must approach these changes more simply - both were core to this decision.
What’s changing and when?
We have divided what was announced in July at WPC into two program releases in calendar year 2014, one in February and one in late Q3 calendar year. How that impacts you depends on your level of partnership and business model.
Coming in February 2014
Mainstreamed Internal Use Rights for Microsoft cloud services: Today, only members of our cloud incubation programs (Cloud Essentials, Cloud Accelerate, etc.) have internal use rights for Microsoft cloud services like Office365, Windows Intune, Azure and CRM Online. We are very excited to announce that in February, we will offer cloud Internal Use Rights (IUR) benefits to all partners in a competency or subscribing to Microsoft Action Pack.
Revamped Microsoft Action Pack subscription (MAPs): We are launching a brand new cloud-focused version of MAPs that gives partners more choice and provides content and training organized and optimized for specific partner business models like hosting, application development, custom services, managed services, reselling and device design and development.
Cloud Essentials Retires: Complementing the launch of a new MAPs, we are retiring the Cloud Essentials program. Net new enrollment into Cloud Essentials will stop with the February 2014 release. Cloud IUR rights for existing Cloud Essentials partners will extend until June 30, 2014 – at that time all partners must transition into either the new MAPs or a competency to continue to use our Cloud IUR.
…
Coming late Q3 of 2014
Remaining Incubation cloud programs will be retiring: Cloud Accelerate, Cloud Deployment and Azure Circle programs will phase out at this time. We will allow new partners to join these programs until this time to enable partners to continue to earn cloud accelerator incentives. Please keep in mind that for new partners to get Cloud IUR after the February release, they will need to earn these rights via MAPs or by earning a competency.
…
I doubt if partners like me were clamoring for cancellation of the Cloud Essentials program, whose benefits I use to run OakLeaf’s Android MiniPCs and TVBoxes blog.
<Return to section navigation list>
Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
No significant articles so far this week.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+


<Return to section navigation list>
Cloud Security, Compliance and Governance

<Return to section navigation list>
Cloud Computing Events
No significant articles so far this week.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Ivar Pruijin described the Cloud9 IDE on Google Compute Engine in a 12/7/2013 post to the Google Cloud Platform Blog:
Cloud9 IDE moves your entire development flow onto the cloud by offering an online development environment for web and mobile applications. With Cloud9 IDE developers write code, debug, and deploy their applications, and easily collaborate with others - all right in the cloud. We’ve worked hard to ensure that our online development environment is easy, powerful, and a thrill to use.
Google Compute Engine recently got us very excited about the possibilities for Cloud9 IDE. So much so, that we built support for Compute Engine into the backend of the soon-to-be-released major update of Cloud9 IDE! We’ve seen major improvements in speed, provisioning and the ability to automate deployments and management of our infrastructure. In this article we’ll talk about those experiences and what benefits Compute Engine offers to a complex web application like ours.
Speed
When building a hosted IDE, latency is a big concern. You want files to open instantly, step debug through your code without delays, and interact with the terminal as if it all was running locally. Every millisecond of delay we reduce is an immediate usability improvement. Due to the global reach of Google’s fiber network and its huge ecosystem of peering partners, we’ve been able to achieve major speed improvements!
Let’s look at this in some more detail. We’ve optimized our architecture to require just one hop between the hosted workspace and the browser running Cloud9. This intermediate layer is our virtual file system server (VFS). VFS connects to the hosted workspaces and provides a REST & WebSocket interface to the client running in the browser. Initially we expected the lowest latency when placing the VFS server close to the hosted workspaces and possibly in the same data center. Surprisingly it turned out that placing the VFS server as close as possible to the user resulted in way smaller latencies. This is where Google’s advantage in networking really comes into play. A round trip from our Amsterdam office to a hosted workspace at the US east coast is about 50% faster when connecting through a VFS server in a Google European data center!
In order to select the closest VFS server we use latency based DNS routing. This alone perceivably improves the responsiveness of Cloud9 in general. Users who use SSH workspaces, live outside of the US or are travelling a lot will especially feel the difference.
Fast & easy Provisioning & Infrastructure Management
There are other things we like about Google Compute Engine. The management interface is great:
It is very responsive and offers metrics on the running VM, like live CPU metrics. Everything you can do in the web console can be performed using Google’s REST interface and the very powerful command line client, too. Throughout the UI you’ll find hints of how to perform the same action using REST or the command line. This allowed us to completely script the deployment of new servers and the management of our infrastructure.
The integrated login system is another strong point of Google Compute Engine (and for Google Cloud Platform as a whole). It allows us to assign different set of permissions to every user being part of the c9.io domain. We can sign in to Google Compute Engine using our regular email/password credentials (we already use Google Apps), and a two factor authentication policy for strong security is available as well.
What’s next?
Our upcoming release is scheduled to go GA in Q1 of 2014. The backend of this new version supports Google Compute Engine next to the infrastructure that we already have and will allow our users to get a workspace in the closest region near them. So far we couldn't be happier. The performance of the VMs and virtual disks are great, the pricing is competitive and Google is really helpful and responsive. As we roll out the new version of Cloud9 IDE we’ll continue working on our Compute Engine support.




• Quentin Hardy (@qhardy) announced Google Joins a Heavyweight Competition in Cloud Computing in a 12/3/2013 New York Times article:
Google already runs much of the digital lives of consumers through email, Internet searches and YouTube videos. Now it wants the corporations, too.
The search giant has for years been evasive about its plans for a so-called public cloud of computers and data storage that is rented to individuals and businesses. On Tuesday, however, it will announce pricing, features and performance guarantees aimed at companies ranging from start-ups to multinationals.
It is the latest salvo in an escalating battle among some of the most influential companies in technology to control corporate and government computing through public clouds. That battle, which is expected to last years and cost the competitors billions of dollars annually in material and talent, already includes Microsoft, IBM and Amazon.
As businesses move from owning their own computers to renting data-crunching power and software over the Internet, this resource-rich foursome is making big promises about computing clouds. Supercomputing-based research, for example, won’t be limited to organizations that can afford supercomputers. And tech companies with a hot idea will be able to get big fast because they won’t have to build their own computer networks.
Take Snapchat, the photo-swapping service that recently turned down a multibillion-dollar takeover offer from Facebook. It processes 4,000 pictures a second on Google’s servers but is just two years old and has fewer than 30 employees. The company started out working with a Google service that helps young companies create applications and was chosen by Google to be an early customer of its cloud.
Working with Google has allowed Snapchat to avoid spending a lot to support its users. “I’ve never owned a computer server,” said Bobby Murphy, a co-founder and the chief technical officer of Snapchat.
That is a big shift from the days when, for young companies, knowing how to build a complex data center was just as important as creating a popular service.
“These things are incredibly fast — setting up new servers in a minute, when it used to take several weeks to order, install and test,” said Chris Gaun, an analyst with Gartner. “Finance, product research, crunching supercomputing data like genomic information can all happen faster.”
Amazon’s cloud, called Amazon Web Services, was arguably the pioneer of the public cloud and for now is the largest player. Amazon says its cloud has “hundreds of thousands” of customers. Though most of these are individuals and small businesses, it also counts big names like Netflix, which stopped building its own data centers in 2008 and was completely on Amazon’s cloud by 2012. All of Amazon’s services are run inside that cloud, too.
A more traditional consumer goods company, 3M, uses Microsoft’s public cloud, called Azure, to process images for 20,000 individuals and companies in 50 countries to analyze various product designs. Microsoft says Azure handles 100 petabytes of data a day, roughly 700 years of HD movies.
“People started out building things on Amazon’s service, but now there are a few big players,” said Mr. Murphy. “Hopefully the time between an idea and its implementation can get even quicker.”
Google is cutting prices for most of its services like online data storage and computer processing by 10 percent and its high-end data storage prices by 60 percent, while offering access to larger and more complex computing systems. Google is also guaranteeing that critical projects will remain working 99.95 percent of the time, far better performance than in most corporate data centers.
“People make a mistake thinking this is just a version of the computers on their desks, at a lower cost,” said Greg DeMichillie, director of Google’s public cloud platform. “This is lots of distributed computing intelligence, not just in computers and phones, but in cars, in thermometers, everywhere. The demand will only increase.” …



Read more 2, Next Page »
Jeffrey Schwartz (@JeffreySchwartz) reported Google's New Cloud Service Doesn't Do Windows in a 12/6/2013 post to his Scwartz Report blog for 1105 Media’s Redmond Magazine:
Google this week became the latest major player to launch an infrastructure-as-a-service (IaaS) cloud offering with the general availability of the Google Compute Engine. In so doing, Google is now challenging other major providers of IaaS including Amazon Web Services, Microsoft, Rackspace, IBM, HP, AT&T, Verizon and VMware.
But if you're looking to provision Windows Server in Google's new cloud, you'll have to wait. Right now Google Compute Engine doesn't support Windows Server or VMware instances. During the preview, launched in May, Google Compute Engine only supported Debian and CentOS. Now that it's generally available, Google said customers can deploy any out-of-the-box Linux distribution including Red Hat Enterprise Linux (in limited preview now), SUSE and FreeBSD.
Despite shunning Windows, at least for now, it's ironic to note that one of the leaders of Google Compute Engine also was a key contributor to Microsoft's original .NET development team over a decade ago. Greg DeMichelle, director of Google's public cloud platform, was responsible for the overall design and feature set for Visual C# and C++ and a founding member of the C# language team.
After leaving Microsoft, DeMichelle joined the research firm Directions on Microsoft and also wrote a column for Redmond sister publication Redmond Developer News magazine, where I was executive editor several years ago. (RDN was folded into Visual Studio Magazine in 2009). I reached out to DeMichelle but haven't heard back yet but I do hope to catch up with him and hear more about Google's plans for supporting Windows -- or lack thereof.
Some analysts believe despite Google's late entry, it will be a force to be reckoned with in the IaaS world. In a blog post Monday announcing the launch, Google pointed to several early customers including Snapchat, Cooladata, Mendelics, Evite and Wix. Google reduced the cost of its service by 10 percent and DeMichelle made no secret in an interview with The New York Times that he believes Google is better positioned to take on Amazon Web Services, where he briefly worked prior to joining Google earlier this year.
Like Microsoft, Google entered the enterprise cloud fray years ago by offering a platform as a service (PaaS), known as Google App Engine. Monday's official release of Google Compute Engine means customers can now deploy virtual machines and stand-up servers in its public cloud.
Google is touting the fact that using live migration technology it can perform datacenter maintenance without downtime. "You now get all the benefits of regular updates and proactive maintenance without the downtime and reboots typically required," Google VP Ari Balogh wrote in Monday's blog post. "Furthermore, in the event of a failure, we automatically restart your VMs and get them back online in minutes. We've already rolled out this feature to our U.S. zones, with others to follow in the coming months."
Galogh added Google is seeing demand for large instances to run CPU and memory-intensive applications such as NoSQL databases. Google will offer 16-core instances with up to 104 GB of RAM. The company is now offering those large instance types in limited preview only.
As I noted, Google has lowered the price of its standard instances by 10 percent over the price it offered during the preview period. It also lets customers purchase capacity in increments of 10 minutes, according to its price list. With Google now officially in the game, 2014 promises to be a telling year as to which of the major providers can give Amazon a run for its money. But unless Google introduces Windows Server support, it'll miss out on a key piece of the market.


Full disclosure: I’m a contributing editor to 1105 Media’s Visual Studio Magazine.
Jeff Barr (@jeffbarr) posted New Resource-Level Permissions for AWS OpsWorks on 12/5/2013:
My colleague Chris Barclay (pictured below) reports on an important new feature for AWS OpsWorks!
-- Jeff;
I am pleased to announce that AWS OpsWorks now supports resource-level permissions. AWS OpsWorks is an application management service that lets you provision resources, deploy and update software, automate common operational tasks, and monitor the state of your environment. You can optionally use the popular Chef automation platform to extend OpsWorks using your own custom recipes.
With resource-level permissions you can now:
Grant users access to specific stacks, making management of multi-user environments easier. For example, you can give a user access to the staging and production stacks but not the secret stack.
- Set user-specific permissions for actions on each stack, allowing you to decide who can deploy new application versions or create new resources on a per-stack basis for example.
- Delegate management of each OpsWorks stack to a specific user or set of users.
- Control user-level SSH access to Amazon EC2 instances, allowing you to instantly grant or remove access to instances for individual users.
A simple user interface in OpsWorks lets you select a policy for each user on each stack depending on the level of control needed:
- Deny blocks the user’s access to this stack.
- IAM Policies Only bases a user’s permissions exclusively on policies attached to the user in IAM.
- Show combines the user’s IAM policies with permissions that provide read-only access to the stack’s resources.
- Deploy combines the user’s IAM policies with Show permissions and permissions that let the user deploy new application versions.
- Manage combines the user’s IAM policies with permissions that provide full control of this stack.
These policies make it easy to quickly configure a user with the right permissions for the tasks they need to accomplish. You can also create a custom IAM policy to fine-tune their permissions.
Let’s see this in action. In this example we have two users defined in the IAM console: Chris and Mary.
Let’s give Chris the AWS OpsWorks Full Access policy; Mary doesn’t need any IAM policy to use OpsWorks.
Now go to the OpsWorks console, open the Users view, and import Chris and Mary.
You can then go to a stack and open the Permissions view to designate OpsWorks permissions for each user. Give Mary Manage permissions for the MyWebService stack. Chris should already be able to access this stack because you attached the AWS OpsWorks Full Access policy to his user in IAM.
To remove Chris’ access to this stack, simply select the Deny radio button next to Chris. Your Permissions view will now look like this:
Chris can no longer view or access the stack because the explicit Deny overrides his user’s AWS OpsWorks Full Access policy. Mary can still access the stack and she can create, manage and delete resources.
But assume that this is a production stack and you don’t want Mary to be able to stop instances. To make sure she can’t do that, you can create a custom policy in the IAM console.
Go to the IAM console, select the user Mary and then click Attach User Policy. Add this custom policy:
What does this policy mean? Here are the pieces:
- "Action": "opsworks:Stop*" means this applies to any OpsWorks API action that begins with Stop.
- "Effect": "Deny" tells OpsWorks to deny that action request.
- "Resource": "arn:aws:opsworks:*:*:stack/2860c9c8-9d12-4cc1-aed1-xxxxxxxx" specifies that this statement applies only to resources in the specified stack. If Mary was using other stacks, this policy would not apply and she could perform stop actions if she had Manage access.
After applying the policy, you can return to the OpsWorks console and view a running instance as user Mary.
You can see that Mary can no longer stop this instance.
Behind the scenes, a user’s OpsWorks and IAM permissions are merged and then evaluated to determine whether a request is allowed or denied. In Mary’s case, the Manage user policy that you applied in OpsWorks allows her to stop instances in that stack. However, the explicit Deny on Stop* actions in her IAM user policy overrides the Allow in her OpsWorks policy. To learn more about policy evaluation, see the IAM documentation.
Once the user’s action has been evaluated, OpsWorks carries out the request. The user doesn’t actually need permissions to use underlying services such as Amazon EC2 – you give those permissions to the OpsWorks service role. This gives you control over how resources are administered without requiring you to manage user permissions to each of the underlying services. For example, a policy in IAM might deny Mary the ability to create instances within EC2 (either explicitly, or by simply not giving her explicit permission to do so). But Mary’s OpsWorks Manage policy allows her to create instances within an OpsWorks stack. Since you can define the region and VPC that each stack uses, this can help you comply with organizational rules on where instances can be launched.
Resource-level permissions give you control and flexibility for how to manage your applications. Try it and let us know what you think! For more information, please see the OpsWorks documentation.
-- Chris Barclay, Senior Product Manager



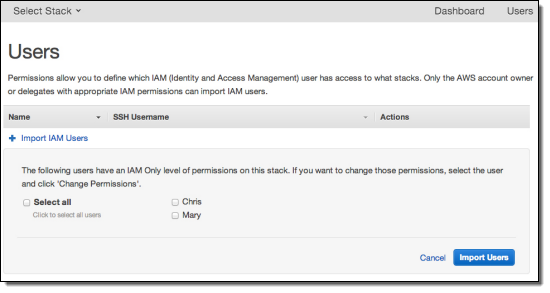
<Return to section navigation list>

















0 comments:
Post a Comment