Windows Azure and Cloud Computing Posts for 9/30/2013+
Top Stories This Week:
- Microsoft achieves FedRAMP JAB P-ATO for Windows Azure on 9/30/2013 according to the Wall Street Journal (see the press release in the Cloud Security, Compliance and Governance section below.)
- Windows 8.1 RTM and updated Sample Apps for Visual Studio 2013 RC are available for download (see the Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses section below.)
- Sam Vanhoutte provided a Feature comparison between BizTalk Server and BizTalk Services (see the Windows Azure Service Bus, BizTalk Services and Workflow section below.)
| A compendium of Windows Azure, Service Bus, BizTalk Services, Access Control, Caching, SQL Azure Database, and other cloud-computing articles. |
‡ Updated 10/5/2013 with new articles marked ‡.
• Updated 10/3/2013 with new articles marked •.
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Windows Azure Marketplace DataMarket, Power BI, Big Data and OData
- Windows Azure Service Bus, BizTalk Services and Workflow
- Windows Azure Access Control, Active Directory, and Identity
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
- Windows Azure Infrastructure and DevOps
- Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
- Visual Studio LightSwitch and Entity Framework v4+
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
<Return to section navigation list>
Brian O’Donnell began a series with Windows Azure and the future of the personalized web : Intro with a 10/4/2013 post to Perficient’s Microsoft Technologies blog:
The internet is becoming increasingly personalized. It has transitioned from indexing massive wells of information to delivering personalized information, or recommendations based on complex searches. Evidence of this is seen in Google’s Knowledge graph, Amazon, the Bing engine, Facebook friends and twitter recommending people you may be interesting in following. Recommendations are everywhere on the web and with the introduction of HDInsight on Windows Azure the personalized web will grow even larger. HDInsight is an implementation of Apache Hadoop running natively within Windows Server. Hadoop is a very powerful distributed computing solution that can process massive quantities of data.
Incorporating “non-Microsoft” technologies baked into Microsoft based services and products is a newer development. The benefits to the IT professional are infinite. Let us take HDInsight as an example. For those not familiar with Linux and installing Hadoop on a distribution of clustered nodes the process can be frustrating and time consuming (to say the least). There are many guides on line and each guide pertains to its own flavor of Linux (Gentoo vs. Red Hat vs. Ubuntu vs. CentOS etc.). The process has gotten better over the years but is still quite cumbersome. To create a Hadoop cluster within Windows Azure, simply create an HDInsight cluster from the dashboard. In a few minutes you have a fully functional Hadoop cluster ready for processing.
You may be asking yourself; “Hadoop is a distributed computing system, what does it have to do with recommendations?”. Mahout is the answer. Mahout is an open source machine learning engine that is also managed by Apache. It contains many different types of algorithms and features, but one of its most prominent is its recommendation engine. The installation process is trivial so you will have Mahout up and running in an HDInsight cluster in no time. To install Mahout on your cluster download the latest release in zip file format from the Mahout website. Copy the zip file to your one of your cluster nodes and extract the contents to C:\apps\dist. That’s it! Not only have you just installed Mahout, but you have also deployed it to your Hadoop cluster.
Next I will walk through the installation process and use Mahout to process data.

‡ Kevin Kell posted Big Data on Azure – HDInsight to the Learning Tree blog on 10/3/2013:
The HDInsight service on Azure has been in preview for some time. I have been anxious to start working with it as the idea of being able to leverage Hadoop using my favorite .NET programming language has a great appeal. Sadly I had never been able to successfully launch a cluster. Not, that is, until today. Perhaps I had not been patient enough in previous attempts, although on most tries I waited over an hour. Today, however, I was able to launch a cluster in the West US region that was up and running in about 15 minutes.
Once the cluster is running it can be managed through a web-based dashboard. It appears, however, that the dashboard will be eliminated in the future and that management will be done using PowerShell. I do hope that some kind of console interface remains but that may or may not be the case.
Figure 1. HDInsight Web-based dashboard
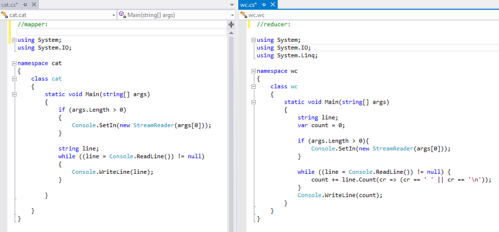
To make it easy to get started Microsoft provides some sample job flows. You can simply deploy any or all of these jobs to the provisioned cluster, execute the job and look at the output. All the necessary files to define the job flow and programming logic are supplied. These can also be downloaded and examined. I wanted to use a familiar language to write my mapper and reducer so I selected the C# sample. This is a simple word count job which is quite commonly used as an easily understood application of Map/Reduce. In this case the mapper and reducer are just simple C# console programs that read and write to stdin and stdout which are redirected to files or Azure Blob storage in the job flow.
Figure 2. Word count mapper and reducer C# code
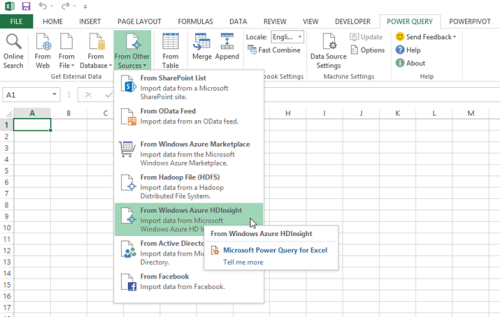
One thing that is pretty cool about the Microsoft BI stack is that it is pretty straightforward to work with HDInsight output using the Microsoft BI Tools. For example the output from the job above can be consumed in Excel using the Power Query add-in.
Figure 3. Consuming HDInsight data in Excel using Power Query
That, however, is a discussion topic for another time!
If you are interested in learning more about Big Data, Cloud Computing or using Excel for Business Intelligence why not consider attending one of the new Learning Tree courses?




Neil MacKenzie (@nmkz) posted an Introduction to Windows Azure Media Services on 9/30/2013:
Windows Azure Media Services (WAMS) is a PaaS offering that makes it easy to ingest media assets, encode them and then perform on-demand streaming or downloads of the resulting videos.
The WAMS team has been actively proselytizing features as they become available. Mingfei Yan (@mingfeiy) has a number of good posts and she also provided the WAMS overview at Build 2013. Nick Drouin has a nice short post with a minimal demonstration of using the WAMS SDK to ingest, process and smooth stream a media asset. John Deutscher (@johndeu) has several WAMS posts on his blog including an introduction to the MPEG DASH preview on WAMS. Daniel Schneider and Anthony Park did a Build 2013 presentation on the MPEG DASH preview.
Windows Azure Media Services is a a multi-tenant service with shared encoding and shared on-demand streaming egress capacity. The basic service queues encoding tasks to ensure fair distribution of compute capacity and imposes a monthly egress limit for streaming. Encoding is billed depending on the quantity of data processed, while streaming is billed at the standard Windows Azure egress rates. It is possible to purchase reserved units for encoding to avoid the queue – with each reserved unit being able to perform a single encoding task at a time (additional simultaneous encoding tasks would be queued). It is also possible to purchase reserved units for on-demand streaming – with each reserved unit providing an additional 200Mbps of egress capacity. Furthermore, the Dynamic Packaging for MPEG-DASH preview is available only to customers which have purchased reserved units for on-demand streaming.
The entry point to the WAMS documentation is here. The Windows Azure Media Services REST API is the definitive way to access WAMS from an application. The Windows Azure Media Services SDK is a .NET library providing a more convenient way to access WAMS. As with most Windows Azure libraries, Microsoft has deployed the source to GitHub. The SDK can be added to a Visual Studio solution using NuGet.
The Windows Azure SDK for Java also provides support for WAMS development. The Developer tools for WAMS page provides links to these libraries as well as to developer support for creating on-demand streaming clients for various environments including Windows 8, Windows Phone, iOS and OSMF.
The Windows Azure Portal hosts a getting started with WAMS sample. The Windows Azure Management Portal provides several samples on the Quick Start page for a WAMS account.
Windows Azure Media Services Account
The Windows Azure Management Portal provides a UI for managing WAMS accounts, content (assets), jobs, on-demand streaming and media processor. A WAMS account is created in a specific Windows Azure datacenter. Each account has an account name and account key, that the WAMS REST API (and .NET API) uses to authenticate requests. The account name also parameterizes the namespace for on-demand streaming (e.g., http://MyMediaServicesAccount.origin.mediaservices.windows.net).
Each WAMS account is associated with one or more Windows Azure Storage accounts, and are used to store the media assets controlled by the WAMS account. The association of a storage account allows the WAMS endpoint to be used as a proxy to generate Windows Azure Storage shared-access signatures that can be used to authenticate asset uploads and downloads from/to a client without the need to expose storage-account credentials to the client.
Workflow for Handling Media
The workflow for using WAMS is:
- Setup – create the context used to access WAMS endpoints.
- Ingestion – upload one or more media files to Windows Azure Blob storage where they are referred to as assets.
- Processing – perform any required process, such as encoding, to create output assets from the input assets.
- Delivery – generate the locators (URLs) for delivery of the output assets as either downloadable files or on-demand streaming assets.
Setup
WAMS exposes a REST endpoint that must be used by all operations accessing the WAMS account. These operations use a WAMS context that manages authenticated access to WAMS capabilities. The context is exposed as an instance of the CloudMediaContext class.
The simplest CloudMediaContext constructor for this class takes an account name and account key. Newing up a CloudMediaContext causes the appropriate OAuth 2 handshake to be performed and the resulting authentication token to be stored in the CloudMediaContext instance. Behind the scenes, the initial connection is against a well-known endpoint (https://media.windows.net/), with the response containing the the actual endpoint to use for this WAMS account. The CloudMediaContext constructor handles with initial authentication provided by the WAMS account name and account key and subsequent authentication provided by an OAuth 2 token.
CloudMediaContext has a number of properties, many of which are IQueryable collections of information about the media services account and its current status including:
- Assets – an asset is a content file managed by WAMS.
- IngestManifests – an ingest manifest associates a list of files to be uploaded with a list of assets.
- Jobs – a job comprises one or more tasks to be performed on an asset.
- Locators – a locator associates an asset with an access policy and so provides the URL with which the asset can be accessed securely.
- MediaProcessors – a media processor specifies the type of configurable task that can be performed on an asset.
These are “expensive” to populate since they require a request against the WAMS REST API so are populated only on request. For example, the following retrieves a list of jobs created in the last 10 days:
The filter is performed on the server, with the filter being passed in the query string to the appropriate REST operation. Documentation on the allowed query strings seems light.
Note that repopulating the collections requires a potentially expensive call against the WAMS REST endpoint. Consequently, the collections are not automatically refreshed. Accessing the current state of a collection – for example, to retrieve the result of a job – may require newing up a new context to access the collection.
Ingestion
WAMS tasks perform some operation that converts an input asset to an output asset. An asset comprises one or more files located in Windows Azure Blob storage along with information about the status of the asset. An instance of an asset is contained in a class implementing the IAsset interface which exposes properties like:
- AssetFiles – the files managed by the asset.
- Id – unique Id for the asset.
- Locators – a locator associates an asset with an access policy and so provides the URL with which the asset can be accessed securely.
- Name – friendly name of the asset.
- State – current state of the asset (initialized, published, deleted).
- StorageAccountName – name of the storage account in which the asset is located.
The ingestion step of the WAMS workflow does the following:
- creates an asset on the WAMS server
- associates files with the asset
- uploads the files to the Windows Azure Blob storage
The asset maintains the association between the asset Id and the location of the asset files in Windows Azure Blob storage.
WAMS provides two file uploading techniques.
- individual file upload
- bulk file ingestion
Individual file upload requires the creation of an asset and then a file upload into the asset. The following example is a basic example of uploading a file to WAMS:
WAMS uses the asset as a logical container for uploaded files. In this example, WAMS creates a blob container with the same name as the asset.Id and then uploads the media file into it as a block blob. The asset provides the association between WAMS and the Windows Azure Storage Service.
This upload uses one of the WAMS methods provided to access the Storage Service. These methods provide additional functionality over that provided in the standard Windows Azure Storage library. For example, they provide the ability to track progress and completion of the upload.
When many files must be ingested an alternative technique is to create an ingestion manifest, using a class implementing the IIngestManifest interface, providing information about the files to be uploaded. The ingest manifest instance then exposes the upload URLs, with a shared access signature, which can be used to upload the files using the Windows Azure Storage API.
Note that the asset Id is in the form: nb:cid:UUID:ceb012ff-7c38-46d5-b58b-434543cd9032. The UUID is the container name which will contain all the media files associated with the asset.
Processing
WAMS supports the following ways of processing a media asset:
- Windows Azure Media Encoder
- Windows Azure Media Packager
- Windows Azure Media Encryptor
- Storage Decryption
The Windows Azure Media Encoder takes an input media asset and performs the specified encoding on it to create an output media asset. The input media asset must have been uploaded previously. WAMS supports various file formats for audio and video, and supports many encoding techniques which are specified using one of the Windows Azure Media Encoder presets. For example, the VC1 Broadband 720P preset creates a single Windows Media file with 720P variable bit rate encoding while the VC1 Smooth Streaming preset produces a Smooth Streaming asset comprising a 1080P video with variable bit rate encoding at 8 bitrates from 6000 kbps to 400kbps. The format for the names of output media assets created by the Windows Azure Media Encoder is documented here.
The Windows Azure Media Packager provides an alternate method to create Smooth Streaming or Apple Http Live Streaming (HLS) asset. The latter cannot be created using the Windows Azure Media Encoder. Rather than use presets, the Windows Azure Media Packager is configured using an XML file.
The Windows Azure Media Encryptor is used to manage the encryption of media assets, which is used in the digital rights management (DRM) of output media assets. The Windows Azure Media Encryptor is configured using an XML file.
Windows Azure Storage Encryption is used to decrypt media assets.
Media assets are processed by the creation of a job comprising one or more tasks. Each task uses one of the WAMS processing techniques described above. For example, a simple job may comprise a single task that performs a VC1 Smooth Streaming encoding task to create the various output media files required for the smooth streaming of an asset.
For example, the following sample demonstrates the creation and submission of a job comprising a single encoding task.
This sample creates a job with some name on the WAMS context. It then identifies an appropriate WAMS encoder and uses that to create a VC1 Broadband 720p encoding task which is added to the job. Then, it identifies an asset already attached to the context, perhaps the result of a prior ingesting on it, and adds it as an input to the task. Finally, it adds a new output asset to the task and submits.
When completed, the output asset files will be stored in the container identified by the asset Id for the output asset of the task. There are two files created in this sample:
- SomeFileName_manifest.xml
- SomeFileName_VC1_4500kbps_WMA_und_ch2_128kbps.wmv
The manifest XML file provides metadata – such as bit rates – for the audio and video tracks in the output file.
Delivery
WAMS supports both on-demand streaming and downloads of output media assets. The files associated with an asset are stored in Windows Azure Blob Storage and require appropriate authentication before they can be accessed. Since the processed files are typically intended for wide distribution some means must be provided whereby they can be accessed without the need to share the highly-privileged account key with the users.
WAMS provides different techniques for accessing the files depending on whether they are intended for download or smooth streaming. It uses and provides API support for the standard Windows Azure Storage shared-access signatures for downloading media files to be downloaded. For streaming media it hosts an endpoint that proxies secured access to the files in the asset.
For both file downloads and on-demand streaming, WAMS uses the an IAccessPolicy to specify the access permissions for a media resource. The IAccessPolicy is then associated with an ILocator for an asset to provide the path with which to access the media files.
The following sample shows how to generate the URL that can be used to download a media file:
The resulting URL can be used to download the media file in code or using a browser. No further authentication is needed since the query string of the URL contains a shared-access signature. A download URL looks like the following:
The following sample shows how to generate the URL for on-demand streaming:
This generates a URL for a on-demand streaming manifest. The following is an example manifest URL:
This manifest file can be used in a media player capable of supporting smooth streaming. A demonstration on-demand streaming player can be accessed here.
Summary
The Windows Azure Media Services team has done a great job in creating a PaaS media ingestion, processing and content-provision service. It is easy to setup and use, and provides both Portal and API support.



<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
‡‡ Alexandre Brisebois (@Brisebois) described Creating NONCLUSTERED INDEXES on Massive Tables in Windows Azure SQL Database in a 9/29/2013 post:
There are times on Windows Azure SQL Database when tables get to a certain size and that trying to create indexes results in timeouts.
A few months ago when I started to get these famous timeouts, I had reached 10 million records and I felt like I was looking for a needle in a hay stack!
This blog post is all about creating NONCLUSTERED INDEXES, I will try to go over best practices and reasons to keep in mind when you use them in Windows Azure SQL Database.
Interesting Facts
- If a CLUSTERED INDEX is present on the table, then NONCLUSTERED INDEXES will use its key instead of the table ROW ID.
- To reduce the size consumed by the NONCLUSTERED INDEXES it’s imperative that the CLUSTERED INDEX KEY is kept as narrow as possible.
- Physical reorganization of the CLUSTERED INDEX does not physically reorder NONCLUSTERED INDEXES.
- SQL Database can JOIN and INTERSECT INDEXES in order to satisfy a query without having to read data directly from the table.
- Favor many narrow NONCLUSTERED INDEXES that can be combined or used independently over wide INDEXES that can be hard to maintain.
- Create Filtered INDEXES to create highly selective sets of keys for columns that may not have a good selectivity otherwise.
- Use Covering INDEXEs to reduce the number of bookmark lookups required to gather data that is not present in the other INDEXES.
- Covering INDEXES can be used to physically maintain the data in the same order as is required by the queries’ result sets reducing the need for SORT operations.
- Covering INDEXES have an increased maintenance cost, therefore you must see if performance gain justifies the extra maintenance cost.
- NONCLUSTERED INDEXES can reduce blocking by having SQL Database read from NONCLUSTERED INDEX data pages instead of the actual tables.
Creating a NONCLUSTERED INDEX
In order to look at a few examples lets start with the following table.
CREATE TABLE [dbo].[TestTable] (
[Id] UNIQUEIDENTIFIER DEFAULT (newid()) NOT NULL,
[FirstName] NVARCHAR (10) NOT NULL,
[LastName] NVARCHAR (10) NOT NULL,
[Type] INT DEFAULT ((0)) NOT NULL,
[City] NVARCHAR (10) NOT NULL,
[Country] NVARCHAR (10) NOT NULL,
[Created] DATETIME2 (7) DEFAULT (getdate()) NOT NULL,
[Timestamp] ROWVERSION NOT NULL,
PRIMARY KEY NONCLUSTERED ([Id] ASC)
);GO
CREATE CLUSTERED INDEX [IX_TestTable]
ON [dbo].[TestTable]([Created] ASC);
The table has a CLUSTERED INDEX on the Created column. The reasons why this might be an interesting choice for the CLUSTERED INDEX were discussed in my previous blog post about building Clustered Indexes on non-primary key columns in Windows Azure SQL Database.
For the sake of this example, lets imagine that this table contains roughly 30 millions records. Creating a NONCLUSTERED INDEX on this table might result in a timeout or an aborted transaction due to restrictions imposed by Windows Azure SQL Database. One of these restrictions, is that a transaction log cannot exceed 1GB in size.
On Windows Azure SQL Database, you must use the ONLINE=ON option in order to reduce locking and the transaction log size. Furthermore, this option will greatly reduce your chances of getting a timeout.
CREATE INDEX [IX_TestTable_Country_City_LastName_FirstName]
ON [dbo].[TestTable]
([Country] ASC,[City] ASC,[LastName] ASC,[FirstName] ASC)
WITH(ONLINE=ON);Creating a Filtered NONCLUSTERED INDEX
A where clause is added to the index. This results in a Filtered index and greatly helps to create smaller and more effective INDEXES. I recommend taking a closer look at this type of index because bytes are precious on Windows Azure SQL Database.
CREATE INDEX [IX_TestTable_Type_LastName_FirstName_where_Type_greater_than_1]
ON [dbo].[TestTable]
([Type] ASC,[LastName] ASC,[FirstName] ASC)
WHERE [Type] > 1
WITH(ONLINE=ON);Creating a Covering NONCLUSTERED INDEX
The include clause can be used to include columns that are selected by the queries but that are not filtered upon through where clauses. The include clause can also be used to include columns that cannot be added to the INDEX key.
CREATE INDEX [IX_TestTable_Covering_Index]
ON [dbo].[TestTable]
([Type] ASC,[LastName] ASC,[FirstName] ASC)
INCLUDE([City], [Country], [Id])
WITH(ONLINE=ON);


Philip Fu posted [Sample Of Sep 30th] How to view SQL Azure Report Services to the Microsoft All-In-One Code Framework blog on 9/30/2013:
Sample Download : http://code.msdn.microsoft.com/CSAzureSQLReportingServices-e3ffff52
The sample code demonstrates how to access SQL Azure Reporting Service.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.


<Return to section navigation list>
Windows Azure Marketplace DataMarket, Cloud Numerics, Big Data and OData
‡‡ Leo Hu explained oData and JSON Format in a 10/4/2013 post:
The Open Data Protocol (OData) is a data access protocol built on core protocols like HTTP and commonly accepted methodologies like REST for the web. OData provides a uniform way to query and manipulate data sets through CRUD operations (create, read, update, and delete).
JSON is a lightweight data-interchange format. It is easy for humans to read and write. It is easy for machines to parse and generate. JSON is a text format that is completely language independent. JSON is built on a collection of name/value pairs realized in most modern languages.
OData’s JSON format extends JSON by defining a set of canonical annotations for control information such as ids, types, and links, and custom annotations MAY be used to add domain-specific information to the payload.
A key feature of OData’s JSON format is to allow omitting predictable parts of the wire format from the actual payload. Expressions are used to compute missing links, type information, and other control data on client side. Annotations are used in JSON to capture control information that cannot be predicted (e.g., the next link of a collection of entities) as well as a mechanism to provide values where a computed value would be wrong (e.g., if the media read link of one particular entity does not follow the standard URL conventions).
Computing values from metadata expressions on client side could be very expense. To accommodate for this the Accept header allows the client to control the amount of control information added to the response.
This doc is aiming to provide a quick overview of what’s the JSON payload would be look like in various typical scenarios.
Data model Used for the Sample
We use the Northwind database as the SQL sample database in all our JSON examples. Northwind is a fictitious company that imports and exports foods globally. The Northwind sample database provides a good database structure for our JSON experiment.
Please see http://msdn.microsoft.com/en-us/library/ms227484(v=vs.80).aspx to get instructions of how to setup the database with your sqlserver
The following database diagram illustrates the Northwind database structure:
Response payload samples
This section provides JSON samples of response payloads for the payload kinds supported in OData. The samples are based on a northwind domain.
Read an EntitySet
http://services.odata.org/V3/OData/OData.svc/Products?$format=json
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#Products",
"value":[
{
"ID":0,
"Name":"Bread",
"Description":"Whole grain bread",
"ReleaseDate":"1992-01-01T00:00:00",
"DiscontinuedDate":null,
"Rating":4,
"Price":"2.5"
},
{
"ID":1,
"Name":"Milk",
"Description":"Low fat milk",
"ReleaseDate":"1995-10-01T00:00:00",
"DiscontinuedDate":null,
"Rating":3,
"Price":"3.5"
},
{
"ID":2,
"Name":"Vint soda",
"Description":"Americana Variety - Mix of 6 flavors",
"ReleaseDate":"2000-10-01T00:00:00",
"DiscontinuedDate":null,
"Rating":3,
"Price":"20.9"
},
…
]
}Read an Entity
http://services.odata.org/V3/OData/OData.svc/Products(2)?$format=json
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#Products/@Element",
"ID":2,
"Name":"Vint soda",
"Description":"Americana Variety - Mix of 6 flavors",
"ReleaseDate":"2000-10-01T00:00:00",
"DiscontinuedDate":null,
"Rating":3,
"Price":"20.9"
}Read Property
http://services.odata.org/V3/OData/OData.svc/Products(2)/Description?$format=json
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#Edm.String",
"value":"Americana Variety - Mix of 6 flavors"
}http://odataservices.azurewebsites.net/OData/OData.svc/Products(0)/Name?$format=application/json
{
"odata.metadata":"http://odataservices.azurewebsites.net/OData/OData.svc/$metadata#Edm.String",
"value":"Bread"
}Remove an Entity
DELETE http://services.odata.org/V3/(S(ettihtez1pypsghekhjamb1u))/OData/OData.svc/Products(200) HTTP/1.1
DataServiceVersion: 1.0;NetFx
MaxDataServiceVersion: 3.0;NetFx
Accept: application/json;odata=minimalmetadata
Accept-Charset: UTF-8
User-Agent: Microsoft ADO.NET Data Services
Host: services.odata.org
Create an Entry
POST http://services.odata.org/v3/(S(ettihtez1pypsghekhjamb1u))/odata/odata.svc/Products HTTP/1.1
DataServiceVersion: 3.0;NetFx
MaxDataServiceVersion: 3.0;NetFx
Content-Type: application/json;odata=minimalmetadata
Accept: application/json;odata=minimalmetadata
Accept-Charset: UTF-8
User-Agent: Microsoft ADO.NET Data Services
Host: services.odata.org
Content-Length: 180
Expect: 100-continue
{
"odata.type":"ODataDemo.Product",
"Description":null,
"DiscontinuedDate":null,
"ID":200,
"Name":"My new product from leo",
"Price":"5.6",
"Rating":0,
"ReleaseDate":"0001-01-01T00:00:00"
}Update an Entry with PATCH and PUT
PATCH
Services SHOULD support PATCH as the preferred means of updating an entity. PATCH provides more resiliency between clients and services by directly modifying only those values specified by the client.
PATCH http://services.odata.org/V3/(S(ettihtez1pypsghekhjamb1u))/OData/OData.svc/Products(200) HTTP/1.1
DataServiceVersion: 3.0;NetFx
MaxDataServiceVersion: 3.0;NetFx
Content-Type: application/json;odata=minimalmetadata
Accept: application/json;odata=minimalmetadata
Accept-Charset: UTF-8
User-Agent: Microsoft ADO.NET Data Services
Host: services.odata.org
Content-Length: 180
Expect: 100-continue
{
"Name":"Update name from leo"
}PUT
Services MAY additionally support PUT, but should be aware of the potential for data-loss in round-tripping properties that the client may not know about in advance, such as open or added properties, or properties not specified in metadata. Services that support PUT MUST replace all values of structural properties with those specified in the request body
PUT http://services.odata.org/V3/(S(ettihtez1pypsghekhjamb1u))/OData/OData.svc/Products(200) HTTP/1.1
DataServiceVersion: 3.0;NetFx
MaxDataServiceVersion: 3.0;NetFx
Content-Type: application/json;odata=minimalmetadata
Accept: application/json;odata=minimalmetadata
Accept-Charset: UTF-8
User-Agent: Microsoft ADO.NET Data Services
Host: services.odata.org
Content-Length: 180
Expect: 100-continue
{
"odata.type":"ODataDemo.Product",
"Description":null,
"DiscontinuedDate":null,
"ID":200,
"Name":"Update name from leo",
"Price":"5.6",
"Rating":0,
"ReleaseDate":"0001-01-01T00:00:00"
}Read Complex Type
http://services.odata.org/V3/OData/OData.svc/Suppliers(1)/Address?$format=json
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#ODataDemo.Address",
"Street":"NE 40th",
"City":"Redmond",
"State":"WA",
"ZipCode":"98052",
"Country":"USA"
}Read Entry with expanded navigation links
http://odataservices.azurewebsites.net/OData/OData.svc/Products(0)/Category?$expand=ID&$format=json
{
"odata.metadata":"http://odataservices.azurewebsites.net/OData/OData.svc/$metadata#Categories/@Element",
"ID":0,
"Name":"Food"
}Read Service document
http://odataservices.azurewebsites.net/OData/OData.svc/?$format=json
{
"odata.metadata":"http://odataservices.azurewebsites.net/OData/OData.svc/$metadata",
"value":[
{
"name":"Products",
"url":"Products"
},
{
"name":"Advertisements",
"url":"Advertisements"
},
{
"name":"Categories",
"url":"Categories"
},
{
"name":"Suppliers",
"url":"Suppliers"
}
]Read an EntitySet with full metadata
http://services.odata.org/V3/OData/OData.svc/Products?$format=application/json;odata=fullmetadata
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#Products",
"value":[
{
"odata.type":"ODataDemo.Product",
"odata.id":"http://services.odata.org/V3/OData/OData.svc/Products(0)",
"odata.editLink":"Products(0)",
"Category@odata.navigationLinkUrl":"Products(0)/Category",
"Category@odata.associationLinkUrl":"Products(0)/$links/Category",
"Supplier@odata.navigationLinkUrl":"Products(0)/Supplier",
"Supplier@odata.associationLinkUrl":"Products(0)/$links/Supplier",
"ID":0,
"Name":"Bread",
"Description":"Whole grain bread",
"ReleaseDate@odata.type":"Edm.DateTime",
"ReleaseDate":"1992-01-01T00:00:00",
"DiscontinuedDate":null,
"Rating":4,
"Price@odata.type":"Edm.Decimal",
"Price":"2.5"
},
{
"odata.type":"ODataDemo.Product",
"odata.id":"http://services.odata.org/V3/OData/OData.svc/Products(1)",
"odata.editLink":"Products(1)",
"Category@odata.navigationLinkUrl":"Products(1)/Category",
"Category@odata.associationLinkUrl":"Products(1)/$links/Category",
"Supplier@odata.navigationLinkUrl":"Products(1)/Supplier",
"Supplier@odata.associationLinkUrl":"Products(1)/$links/Supplier",
"ID":1,
"Name":"Milk",
"Description":"Low fat milk",
"ReleaseDate@odata.type":"Edm.DateTime",
"ReleaseDate":"1995-10-01T00:00:00",
"DiscontinuedDate":null,
"Rating":3,
"Price@odata.type":"Edm.Decimal",
"Price":"3.5"
},
]
}Read an Entity with full metadata
http://services.odata.org/V3/OData/OData.svc/Products(2)?$format=application/json;odata=fullmetadata
{
"odata.metadata":"http://services.odata.org/V3/OData/OData.svc/$metadata#Products/@Element",
"odata.type":"ODataDemo.Product",
"odata.id":"http://services.odata.org/V3/OData/OData.svc/Products(2)",
"odata.editLink":"Products(2)",
"Category@odata.navigationLinkUrl":"Products(2)/Category",
"Category@odata.associationLinkUrl":"Products(2)/$links/Category",
"Supplier@odata.navigationLinkUrl":"Products(2)/Supplier",
"Supplier@odata.associationLinkUrl":"Products(2)/$links/Supplier",
"ID":2,
"Name":"Vint soda",
"Description":"Americana Variety - Mix of 6 flavors",
"ReleaseDate@odata.type":"Edm.DateTime",
"ReleaseDate":"2000-10-01T00:00:00",
"DiscontinuedDate":null,
"Rating":3,
"Price@odata.type":"Edm.Decimal",
"Price":"20.9"
}Read Entry with expanded navigation links with full metadata
{
"odata.metadata":"http://odataservices.azurewebsites.net/OData/OData.svc/$metadata#Categories/@Element",
"odata.type":"ODataDemo.Category",
"odata.id":"http://odataservices.azurewebsites.net/OData/OData.svc/Categories(0)",
"odata.editLink":"Categories(0)",
"Products@odata.navigationLinkUrl":"Categories(0)/Products",
"Products@odata.associationLinkUrl":"Categories(0)/$links/Products",
"ID":0,
"Name":"Food"
}


<Return to section navigation list>
Windows Azure Service Bus, BizTalk Services and Workflow
• Sam Vanhoutte (@SamVanhoutte) provided a Feature comparison between BizTalk Server and BizTalk Services in a 10/3/2013 post to his Codit.eu blog:
I have given quite some sessions and presentations recently on Windows Azure BizTalk Services. We had the opportunity to work together with the product team on WABS as a strategic Launch Partner. I had a lot of discussions and questions on the technology and a lot of these questions were focused on a comparison with BizTalk Server…
Therefore, I decided to create this blog post, I created a comparison table, much like the comparison tables you can see on consumer web sites (for mobile phones, computers, etc…)
If you need more information or have some feedback, don’t hesitate to contact me.
Connectivity & adapters
Some adapters are not applicable in cloud services (File, for example), where others are. BizTalk Services has a lot of adapters not available. Custom adapters can only be written through the outbound WCF bindings.



Core messaging capabilities
The biggest difference here is the routing pattern that is totally different between both products. More can be read in an earlier post: Windows Azure Bridges & Message Itineraries: an architectural insight. If you want durable messaging, Service Bus queues/topics are the answer, but the biggest problem is that WABS cannot have subscriptions or queues as sources for bridges.

Message processing
We have good feature parity here on these items. The main thing missing would be JSON support. For that, we have written a custom component already that supports JSON.

Management & deployment experience
In my opinion, this is where the biggest challenge lies for WABS. Administration and management is really not what we are used with BizTalk Server. Configuration is very difficult (no binding file concept) and endpoint management is also not that easy to do.

Trading partner management & EDI
The TPM portal of WABS is really very nice and much friendlier than the BizTalk admin console of BizTalk. The biggest issue with EDI is the fact that there is no possibility to extend and customize the EDI bridge…

Extensibility
Luckily the product team did good efforts to add extensibility and the usability of custom bridge components should still be evolved well.

Security

Added value services
This is really where BizTalk Server leads, compared to WABS. And for most real solutions, these services are often needed.


<Return to section navigation list>
Windows Azure Access Control, Active Directory, Identity and Workflow
‡ Pradeep reported Windows Azure Active Directory Has Processed Over 430 Billion User Authentications in a 10/3/2013 post to Microsoft-News.com:
Windows Azure AD is the Microsoft’s Active Directory in the cloud. It offers enterprise class identity services in the cloud with support for multi-factor authentication and more. Microsoft yesterday announced no.of new features and stats about Azure AD yesterday.
As of yesterday, we have processed over 430 Billion user authentications in Azure AD, up 43% from June. And last week was the first time that we processed more than 10 Billion authentications in a seven day period. This is a real testament to the level of scale we can handle! You might also be interested to learn that more than 1.4 million business, schools, government agencies and non-profits are now using Azure AD in conjunction with their Microsoft cloud service subscriptions, an increase of 100% since July.
And maybe even more amazing is that we now have over 240 million user accounts in Azure AD from companies and organizations in 127 countries around the world. It is a good thing we’re up to 14 different data centers – it looks like we’re going to need it.
Also they announced these free enhancements for Windows Azure AD:
- SSO to every SaaS app we integrate with – Users can Single Sign On to any app we are integrated with at no charge. This includes all the top SAAS Apps and every app in our application gallery whether they use federation or password vaulting. Unlike some of our competitors, we aren’t going to charge you per user or per app fees for SSO. And with 227 apps in the gallery and growing, you’ll have a wide variety of applications to choose from.
- Application access assignment and removal – IT Admins can assign access privileges to web applications to the users in their directory assuring that every employee has access to the SAAS Apps they need. And when a user leaves the company or changes jobs, the admin can just as easily remove their access privileges assuring data security and minimizing IP loss
- User provisioning (and de-provisioning) –IT admins will be able to automatically provision users in 3rd party SaaS applications like Box, Salesforce.com, GoToMeeting. DropBox and others. We are working with key partners in the ecosystem to establish these connections, meaning you no longer have to continually update user records in multiple systems.
- Security and auditing reports – Security is always a priority for us. With the free version of these enhancements you’ll get access to our standard set of access reports giving you visibility into which users are using which applications, when they were using and where they are using them from. In addition, we’ll alert you to un-usual usage patterns for instance when a user logs in from multiple locations at the same time. We are doing this because we know security is top of mind for you as well.
Our Application Access Panel – Users are logging in from every type of devices including Windows, iOS, & Android. Not all of these devices handle authentication in the same manner but the user doesn’t care. They need to access their apps from the devices they love. Our Application Access Panel is a single location where each user can easily access and launch their apps.



• Vittorio Bertocci (@vibronet) explained Provisioning a Windows Azure Active Directory Tenant as an Identity Provider in an ACS Namespace–Now Point & Click! in a 10/3/2013 post:
About one year ago I wrote a post about how to provision a Windows Azure AD tenant as an identity provider in an ACS namespace.
Lots of things changed in a year! Since then, we spoke more at length about the relationship between AAD and ACS. If you didn’t read that post, please make a quick jaunt there as it’s super important you internalize its message before reading what I’ll write here. Done? excellent!
In the past year Windows Azure AD made giant steps in term of usability and features set, and hit general availability. That means that many of the artisanal steps I described in the old walkthrough are no longer necessary today. In fact, you can do everything I’ve described there just by filling forms in the Windows Azure portal!
The idea behind the scenario remains the same. You have a web application which trusts an ACS namespace. You want one or more Ad tenants to be available among the identity providers in that namespace. Hence what you need to do is
- Provision in the AAD tenant the ACS namespace in form of a web app (so that it can be a recipient of tokens issued by AAD)
- Provision in the ACS namespace the STS associated to the AAD tenant
The rest is usual ACS: create RPs, add rules, the usual drill (which can be automated by the Identity and Access tool in VS2012. No equivalent capability in VS2013 exists, see the note at the beginning of the post).
Too abstract? Let’s turn this into instructions.
Provision in the AAD tenant the ACS namespace in form of a web app
Here I’ll assume you already have a Windows Azure subscription, an ACS namespace and a Windows Azure AD tenant. Let’s say that your namespace is https://justforyoumaarten.accesscontrol.windows.net.
Navigate to https://manage.windowsazure.com/, sign in, head to the AD tab, click on your directory, click on the applications header, and hit the “ADD” button on the bottom center area of the command bar.
Leave the default (web application), assign a name you’ll remember and move to the next screen.
Here, paste the namespace in both fields. Why? Simple. The URL is where the token will be redirected upon successful auth, and you want that to be the ACS namespace. The URI is the audience for which the token will be scoped to, and any value OTHER than the entityID of the ACS namespace (as you find it in the ACS metadata docs) would be interpreted by ACS as a replayed token from some MITM. Sounds like Klingon? Don’t worry! That’s a level of detail you don’t need to deal with, as long as you follow the above instructions exactly.
Move to the next screen.
ACS will make no attempts to call the Graph, hence you can leave the default (SSO) and finalize.
Congratulations! Now your AD tenant knows about your ACS namespace and can issue tokens for it!
Provision in the ACS namespace the STS associated to the AAD tenant
Time to do the same in the opposite direction. Before you leave the app list, there’s a last thing we need to do here: click on the “view endpoints” command on the bottom of the bar.
When you do so, the portal will display the collection of endpoints that you need to know if you want to interact with your AAD tenant at the protocol level:
You’ll want to put in the clipboard the fed metadata document, as it will be what we will use for introducing our AAD tenant to the ACS namespace.
Click the big back arrow on the top left corner of the screen, which will bring you back to the top level active directory screen. This time, click on the header access control namespaces.
Here you’ll find your namespace. Select it, then click on the “manage” button in the bottom command bar. That will lead you to the ACS portal for managing the namespace.
Head to the Identity providers section. Once here, select WS-Federation identity provider and click next:
Choose anything you want as display name and login link text. Paste the address of the AAD tenant’s federation metadata in the URL text field of the metadata section.
and you’re done! Hit Save.
App work
All the service side work for enabling the scenario is done. All that’s left is the work you’d need to do for every RP app you want to create in the ACS namespace. For that, the instructions are pretty much the same as in the old post: use the identity and access tool for VS2012, and that will take care of creating the RP entry, create the associated rules, configure your app to outsource web sign on to ACS, and so on. I won’t repeat the step by step instructions here, but to show my good faith I’ll throw in a couple of screenshots to demonstrate that it works on my machine®.
Here there’s the tool, hooked up to the ACS NS:
Here there’s the familiar HRD page:
Pick AAD and…
…you get in with your organizational account.
Neat, if I may say so myself!
Wrap
I’ve been wanting to write this post for a while, but of course I never found the time… then, about 30 mins ago somebody on a mail thread asked if there was a point & click solution for this scenario. I sat down, went through the motions while occasionally snapping screenshots and writing my rambling instructions… I was prepared to go to sleep much later, and instead here there’s the finished post already! I love how Windows Azure AD matured as a technology in such a short time.















Vittorio Bertocci (@vibronet) posted Getting Acquainted with ADAL’s Token Cache on 10/1/2013:
A token cache has been one of the top requests from the development community since I have been in the business of securing remote resources. It goes back to the first days of the Web Service Enhancements; it got even more pressing with WCF, where having token instances buried in channels often led to gimmicks and hacks; its lack became obvious when WIF introduced CreatingChannelWithIssuedToken to allow (tease?) you to write your own, without providing one out of the box.
Well, my friends: rejoice! ADAL, our first client-only developer’s library, features a token cache out of the box. Moreover, it offers you a model to plug your own to match whatever storage type and isolation level your app requires.
In this post I am going to discuss concrete aspects of the cache and disregard most of the why’s behind the choices we made. There’s a more abstract discussion to be had about what “session” really means for native clients, and – although in my mind the two are inextricably entangled – I’ll make an effort to keep most theory out, and tackle that in a later post.
Why a Client Side Cache?
Here there’s a quick positioning of ADAL’s cache. “Cache” is a pretty loaded term, and its use here is somewhat special: it’s important to wrpa your head around what we are trying to enable here.
Performance and As Little User Prompting As Possible
Quick, what’s the first purpose of a cache that comes to mind? That’s right: performance. I’ll keep data close to my heart, so that when I need it again it will be right here, FAST.
That is one of the raison d’être of the ADAL cache, of course. Acquiring tokens entails putting stuff in and out of a wire, occasionally doing crypto, and so on: that’s expensive stuff. But it’s not the only reason.
Those issues might not be as pressing for an interactive application as they are for a backend or a middle tier. Think about it: your app only needs to appear snappy to ONE user at a time, and that user’s reaction times are measured in the tenth of seconds it takes for the dominoes of the synapses to fall over each other as neurotransmitters travel back & fro.
In the case of native applications, the performance requirements might be more forgiving; but performance is not the only parameter that can test the user’s patience. For example: there are few things that can annoy a user more than asking him/her to enter and re-enter credentials. Once the user actively participated to an authentication flow, you better hold on to the resulting token for as long as it is viable and ask for the user’s help again only when absolutely necessary. Fail to do so, and your app will be the recipient of their wrath (low ratings, angry reviews, uninstalls, personal attacks).
Well, good news everyone! The ADAL cache helps you to store the tokens you acquire, and retrieves them automatically when they are needed again. It keeps the number user prompts as low as it is “physically” possible.
In fact, it goes much farther than that: if the authority provides mechanisms for silently refreshing access tokens, as Windows Azure AD and Windows Server AD do, ADAL will take advantage of that feature to silently obtain new access tokens. You just keep calling AcquireToken, all of this is completely transparent to you. [Emphasis added.]
If none of those silent method for obtaining tokens work out, only then ADAL resorts to show up the authentication dialog (and even in that case, there might be a cookie which will spare your user from having to do anything. More about that below).
Multiple Users and Application State
That alone would have been enough value for us to implement the feature, but in fact there’s more. Unfortunately this is the part that would benefit from the theoretical discussion I want to postpone, but I don’t think I’ll be able to avoid mentioning it at least a bit here.
In web apps you typically sign in as a given user, and you are that user for the duration of the session. When you sign out, all the artifacts in the session associated to that user are flushed out.
A native app can work that way too, if it is a client for a specific service; but in fact, that might not be the case. Sometimes rich clients will allow you to connect multiple accounts at once, from different providers (think a mail client connecting to many web mail services, or a calendar app aggregating multiple calendar services) or even from the same (thin of an admin sometimes acting as himself, sometimes acting as his boss).If you’d be dealing with a single user, flushing out a session might be implemented by simply clearing up the entire cache; but for multiple users, you need to get finer control. When the end user wants to disconnect a specific account you need to selectively find all the tokens associated to that account only, and get rid of them without disturbing the rest of the cache.
Now, you can repeat the same reasoning for any entity that is relevant when requesting tokens: resources (the app might aggregate multiple services), providers, everything that comes to mind.Fortunately, ADAL can help you with all of the above – thanks to a small shift in perspective: instead of being locked up in some private variable, ADAL’s cache is fully accessible to you. You can query it using your favorite combination of LINQ and lambda notation, and do whatever you’d expect to be able to do with an IDictionary<>.
Important: as long as you don’t need advanced session manipulation, the cache remains fully transparent to you. AcquireToken will consult the cache on your behalf without asking you to know any of the underlying details. The ability of querying the cache is on top of its traditional use.
How AcquireToken Works with the Cache
ADAL comes with an in-memory cache out of the box. Unless you explicitly pass at AuthenticationContext construction time an instance of your own cache class (or NULL if you want to opt out from caching) ADAL will use its default implementation.
The default implementation lives in memory, is static (e.g. every AuthenticationContext created in the application shares the store and searches the same collection) and (beware!) is not thread safe. If you want a different isolation model, or to persist data, you can plug your own. This is the only extensibility point in the entire ADAL! I’ll touch on that later.
As you use AcquireToken, you’ll be using the cache without even knowing it’s there. I already went through this in the post about AuthenticationResult, and although it’s tempting to go through this again now that you know a bit more about the cache, that would make the post grow far beyond what I intended. If you didn’t read that post, please head there and sweep through that before reading further. I’ll wait.
[…time passes…]
Welcome back!
Here is a flow chart that might help to get an idea of what AcquireToken actually does with the cache. At the cost of being boring: you don’t need to know any of that in order to use AcquireToken taking advantage of the cache. This is only meant for people who want to know more, and to help you troubleshoot if the behavior you observe is not in line with what you expect. To that end: please remember that Windows Azure AD and Windows Server AD have small differences here.
The Cache Structure
The cache structure is pretty simple; it’s a IDictionary<TokenCacheKey,string>.
You are not supposed to know, given that you would never need to look into that directly, but the Value side of the KeyValuePair contains, in fact, the entire AuthenticationResult for the entry.
The thing that should get your interest, conversely, is TokenCacheKey. Here it is:
That’s mostly a flattened view of the AuthenticationResult info, except for the actual tokens.
In the opening of the post I said that the cache serves two purposes, helping AcquireToken to prompt as little as possible and helping you to assess & manipulate the token collection (hence, the session state) of your client.
AcquireToken uses only a subset of the key members, typically the ones that affect the contract between the client and the target resource (Authority, ClientId, Resource) and the mechanics of the authentication itself (ExpiresOn, UserId). None of the other entries come into play during AcquireToken.
All the other info are there mostly for your benefit: instead of forcing you to remember those extra settings in your own store every time you get back an AuthenticationResult and later join them to the cache, we save them for you directly there. That allows you to use them in your own queries, for display purposes or for whatever other function your scenario might require.And apropos, here there are few examples of queries you might want to do.
AuthenticationContext ac = new AuthenticationContext("hahha"); var allUsersInMyBelly = ac.TokenCacheStore.GroupBy(p => p.Key.UserId).Select(grp => grp.First());The query above returns a cache entry for each unique users – where “user” is used in the sense of UserId, see this post for an explanation of what that really means for ADFS & ACS). You might want to use this query for finding out how many/which unique users are connected to your application, for example to enumerate them in your UX.
var allTokensForAResource = ac.TokenCacheStore.Where(p => p.Key.Resource == https://localhost:9001);The query above is very straightforward, it lists all the tokens scoped for a given resource. You might want to use that to discover which users (and/or which authorities) in your app currently have access to it.
var allUsersInMyBellyThatCanAccessAGivenResource = ac.TokenCacheStore.Where( p => p.Key.Resource == "https://localhost:9001").GroupBy( p => p.Key.UserID).Select( grp => grp.First());I knooow, I am terrible at formatting those things… but I have to do something to get it to fit in this silly blog’s theme! But I digress. This query
combines the first two to return all the users that have access to a specific resource.
foreach (var s in ac.TokenCacheStore.Where (p => p.Key.UserId == "vittorio@cloudidentity.net").ToList()) mac.Cache.Remove(s.Key);The query above deletes all the tokens associated to a specific user.
bool IsItGood = ac.TokenCacheStore.Where( p => p.Key == "https://localhost:9001").First().Key.ExpiresOn > DateTime.Now;Finally, this one tells you if the access token for a given resource is about to expire. This one can come in handy when you know that there are clock skews in your system (ADAL does not take clock skew considerations into account, given that they’re largely a matter between the authority ant the resource).
Dude, Get Your Own
I expect that many, many scenarios will require a persistent cache which can survive app shutdowns and restarts. That will likely means using different persistent store types for different apps, in all likelihood the same persistent storage you already use for your own app data.
Furthermore: different apps will require different isolation levels, perhaps segregating token cache stores per AuthenticationContext instance, tenancy boundaries and whatever else your unique scenario calls for.That’s why we made an exception to the otherwise ADAL’s adamant rule “as little knobs as the main scenarios require”, and made the cache pluggable.
You can easily write your own cache, all you need to do is implementing an IDictionary<TokenCacheKey, string>. Our most excellent SDET extraordinaire Srilatha Inavolu created a good example of custom cache, which saves tokens in CredMan: you can see her implementation here.
Now, I heard from some early adopters that implementing IDictionary requires fleshing out a lot of methods, and it could have been done with a far slimmer API surface. That is true: that said, we believe that there will be far more people querying the cache than people implementing custom cache classes. Furthermore, whereas querying the cache will be most often than not entangled in each app’s unique logic (hence bad candidates for componentization and reuse), custom cache classes are components that might end up being implemented by few gurus in the community and downloaded ad libitum by everybody else. And those gurus can most certainly implement the 15 required methods in their sleep.
Given the above, we choose to use an IDictionary to give you something extremely familiar to work with. Identity is complicated enough, we didn’t want you to have to learn yet another way of querying a collection.
This had other tradeoffs (KeyValuePair is a struct, which makes LINQ materialization problematic; implementing an efficient cache on the middle tier will require extra care) but after much thought we believe this will serve well our mainline scenario, native clients. If you have feedback please let us know, we can always adjust the aim in v2!
Wrap
You asked for a client side token cache: you got it!
ADAL’s cache plays an essential role in keeping complexity out of your native applications, while at the same time taking full advantage of the OAuth2 features (like refresh tokens) and AD features (like multi-resource refresh tokens) to reduce user prompts to a minimum and keep your app as snappy as possible.
I believe that one of the reasons for which we were able to add cache support is that ADAL makes the token acquisition operation very explicit, providing a very natural plug for it. WCF buried the token acquisition in channels and proxies, but in so doing it tied the acquired token lifecycle to the lifecycle of the channel itself and made it hard to aggregate all tokens for the app.
This, coupled to the fact that REST services greatly diminish the need for a structured proxy, makes me hopeful that ADAL’s model is actually an improvement and will make your life easier in that department!





<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
‡ Kevin Remde (@KevinRemde) continued his series with Why doesn’t remote desktop to my Windows Azure VM work? (So many questions. So little time. Part 48.) on 10/4/2013:
An attendee at our IT Camp in Saint Louis a few weeks ago had an problem that is understandable:
“Thanks for training session, I have a question. Tried to RDP one of my VM’s at work and I can’t connect. Possible firewall port issue? I am going to try and connect from home tonight.”
You're already onto the issue. It’s important to remember that the port that you’re using for RDP is not the traditional 3389.
“It’s not? How does that work?”
Let’s step back for a second and consider what you see when you first create a virtual machine in Windows Azure and you get to the screen where “endpoints” are defined. By default, it looks something like this…
…Notice that, even though the operating system is going to have Remote Desktop enabled and will be listening on the traditional port 3389, the external “public port” value that will be redirected to the “private port” 3389 is going to be something different.
“Why?”
Security. We take the extra precaution of randomizing this port so that tools that are scanning for open 3389 ports out there won’t find those machines and then start attempting to log in.
So the answer to your question: Yes, it’s a firewall issue. And I bet it worked from home later that night.
---
Let’s go one step further here and propose a couple of solutions to this, in case you also run into this problem.
Solution #1: Open up the proper outbound firewall ports
In the properties of your virtual machine, you can find what “public port” was assigned to the VM under the endpoints tab…
So this web server of mine is answering to my RDP requests via my ability to connect to it’s service URL and port 56537. Since I am not restricting outbound ports, this isn’t a problem for me. But knowing what this port is can help you understand what needs to be opened for a particular machine.
“Is there a range of ports that I need to have open outbound?”
The port that will be assigned automatically is going to come from the “ephemeral port range” for dynamic or private ports (as defined by the Internet Assigned Numbers Authority) of 49152 to 65535. So if you simply enable outbound connections through that range, the defaults should work well for you.
Solution #2: Modify the VM End Points
You’ll note on the above picture that there is an “edit” option. You have the ability to edit and assign whatever port you want for the public port value. For example, I could do this…
…and just use port 3389 directly. Of course, this would defeat the purpose for using a random, non-standard port for remote desktop connections. But it could be done.
Solution #3: Use some other remote desktop-esque tool over some other port.
The server you’re running as a VM in Windows Azure is your machine, so there’s no reason you couldn’t install some other tool of choice for doing management or connecting to a remote desktop type of connection. Understand the application, what port needs to be enabled on the firewall of the server, and then add that port as an endpoint; either directly mapped with the same public/private port or using some other public port. It is entirely configurable and flexible. And as long as you’ve enabled the public port value as a port you’re allowing outbound from your workplace, you’re golden.
Solution #4: Use a Remote Desktop Gateway
How about instead of connecting to machines directly, you do something more secured, manageable, and along the same lines of what you would consider for allowing secured access into your own datacenter remote desktop session hosts: Configure one server as the gateway for access to the others. In this way you have the added benefits of just one open port; and that port is SSL (443). You’re very likely already allowing out port 443 for anyone doing secured browsing (HTTPS://…), so the firewall won’t get in the way.





No significant articles so far this week.

<Return to section navigation list>
Windows Azure Cloud Services, Caching, APIs, Tools and Test Harnesses
‡ Eduard Koller (@eduardk) offered A sneak peek at four new Nagios and Zabbix plugins for Windows Azure in a 9/19/2013 post to the Interoperability @ Microsoft blog (missed when published):
Busy times at MS Open Tech! Today we’d like to share with the Azure community a sneak peek at our work on four new plugins for Nagios and Zabbix. It’s early days, but we care about your feedback and love working in the open, so effective today you can take a look at our github repo and see what we are working on to make monitoring on Azure easy and immediate for users of Nagios and Zabbix.
What you can play with today is:
- A plugin for Windows Azure Storage, that will allow you to monitor ingress, egress, requests, success ratio, availability, latency, and more
- A plugin for Windows Azure SQL Databases, that will allow you to monitor ingress, egress, requests, success ratio, availability, latency, etc
- A plugin for Windows Azure Active directory, that will allow you to monitor changes in user and group information (userdelta, groupdelta)
- A plugin for Windows Azure Platform-as-a-Service (PaaS) Worker Roles, that will allow you to monitor cpu, memory, asp.net stats, web service stats, and other compute stats
Note that all compute plugins can be also used to monitor Windows Azure Infrastructure-as-a-Service (IaaS) Virtual Machines
The steps for installing and running the plugins are documented in this ReadMe.
Nagios and Zabbix have established themselves as popular choices for lightweight enterprise-class IT and infrastructure monitoring and alerting. The vibrant open source community built around Nagios has contributed hundreds of plugins (most of which are also compatible with Zabbix) to enable developers, IT professionals and DevOps pros to monitor a variety of entities, from servers to databases to online services. We love to help our customers that know and use those tools, and we are committed to supporting monitoring on Azure using open source technologies.
This is a work in progress, and we’d love to hear from users to make our implementation of these popular tools the best it can be. The Plugins are available on our github repo, and we welcome your feedback and contributions. Send us a pull request if you’d like to contribute to these projects, or leave a comment/email if you have some feedback for us. See you on github!

• Riccardo Becker (@riccardobecker) posted The Wireframe of Geotopia on 10/3/2013:
Using the Visual Studio 2013 RC, I created a cloud project with an ASP.NET webrole. When you add a webrole to your cloud project, the screen below appears.
I want to create an MVC app and want to use Windows Azure Active Directory authentication. To enable this you need to create a new Directory in your Active Directory in the Windows Azure portal. When you create a new directory, this screen appears.
Add some users to your directory. In this case, I have "riccardo@geotopia.onmicrosoft.com" for now.
Go back to Visual Studio and select the Change Authencation button. Next, select the Organization Acounts and fill in your directory.
When you click Ok now you need to login with the credentials of one of your users you created in your directory. I log in with riccardo@geotopia.onmicrosoft.com. Next, select Create Project and your MVC5 app is ready to go. Before this application is able to run locally, in your development fabric, you need to change the return URL in the Windows Azure portal. Go to applications in the designated Directory on the Windows Azure portal.
The newly created MVC project appears there, in my case it's Geotopia.WebRole. In this screen you see the app url which points to https://localhost:44305. This URL is NOT correct when you run the MVC5 app as a cloud project in the development fabric. Click the application in the portal and select Configure. Change the app URL and the return URL to the correct url when your app runs locally in development fabric.
In my case: https://localhost:8080. When you run your app, you get a warning about a problem with the security certificate, but you can ignore this for now. After logging in succesfully, you will be redirected to the correct return URL (configured in the portal) and showing you that you are logged in. I also created a bing map which centers on the beautiful Isola di Dino in Italy with a bird's eye view.
In the next blog I will show how to create a Geotopic on the Bing Map and how to store it in Table Storage and how add your own fotographs to it to show your friends how beautiful the places are you visited. This creates an enriched view, additional to the bing map.





• The Windows Azure CAT Team (@WinAzureCAT) described Cloud Service Fundamentals – Caching Basics in a 10/3/2013 post:
The "Cloud Service Fundamentals" application, referred to as "CSFundamentals," demonstrates how to build database-backed Azure services. In the previous DAL – Sharding of RDBMS blog post, we discussed a technique known as sharding to implement horizontal scalability in the database tier. In this post, we will discuss the need for Caching, the considerations to take into account, and how to configure and implement it in Windows Azure.
The distributed cache architecture is built on scale-out, where several machines (physical or virtual) participate as part of the cluster ring with inherent partitioning capabilities to spread the workload. The cache is a <key, value> lookup paradigm and the value is a serialized object, which could be the result set of a far more complex data store operation, such as a JOIN across several tables in your database. So, instead of performing the operation several times against the data store, a quick key lookup is done against the cache.
Understanding what to cache
You first need to analyze the workload and decide the suitable candidates for caching. Any time data is cached, the tolerance of “staleness” between the cache and the “source of truth” has to be within acceptable limits for the application. Overall, the cache can be used for reference (read only data across all users) such as user profile, user session (single user read-write), or in some cases for resource data (read-write across all users using lock API). And in some cases the particular dataset may not be ideally suited for caching – for example, if a particular data set is changing rapidly, or the application cannot tolerate staleness, or you need to perform transactions.
Capacity Planning
A natural next step is to estimate the caching needs of your application. This involves looking at a set of metrics, beyond just the cache size, to come up with a starting sizing guide.
- Cache Size: Amount of memory needed can be roughly estimated using the average object size and number of objects.
- Access Pattern & Throughput requirements: The read-write mix provides an indication of new objects being created, rewrite of existing objects or reads of objects.
- Policy Settings: Settings for Time-To-Live (TTL), High Availability (HA), Expiration Type, Eviction policy.
- Physical resources: Outside of memory, the Network bandwidth and CPU utilization are also key. Network bandwidth may be estimated based on specific inputs, but mostly this has to be monitored and then used as a basis in re-calculation.
A more detailed capacity planning spreadsheet is available at http://msdn.microsoft.com/en-us/library/hh914129
Azure Caching Topology
The table below lists out the set of PAAS options available on Azure and provides a quick description
Type
Description
In-Role dedicated
In the dedicated topology, you define a worker role that is dedicated to Cache. This means that all of the worker role's available memory is used for the Cache and operating overhead. http://msdn.microsoft.com/en-us/library/windowsazure/hh914140.aspx
In-Role co-located
In a co-located topology, you use a percentage of available memory on application roles for Cache. For example, you could assign 20% of the physical memory for Cache on each web role instance. http://msdn.microsoft.com/en-us/library/windowsazure/hh914128.aspx
Windows Azure Cache Service
The Windows Azure Cache Service, which currently (in Sep 2013) is in Preview. Here are a set of useful links: http://blogs.msdn.com/b/windowsazure/archive/2013/09/03/announcing-new-windows-azure-cache-preview.aspx
http://msdn.microsoft.com/en-us/library/windowsazure/dn386094.aspx
Windows Azure Shared Caching
Multi-tenanted caching (with throttling and quotas) which will be retired no later than September 2014. More details are available at http://www.windowsazure.com/en-us/pricing/details/cache/. It is recommended that customers use one of the above options for leveraging caching.
Implementation details
The CSFundamentals application makes use of In-Role dedicated Azure Caching to streamline reads of frequently accessed information - user profile information, user comments. The In-Role dedicated deployment was preferred, since it isolates the cache-related workload. This can then be monitored via the performance counters (CPU usage, network bandwidth, memory, etc.) and cache role instances scaled appropriately.
NOTE: The New Windows Azure Cache Service was not available during implementation of CSFundamentals. It would have been a preferred choice if there was a requirement for the cached data to be made available outside of the CSFundamentals application.
The ICacheFactory interface defines the GetCache method signature. ICacheClient interface defines the GET<T> and PUT<T> methods signature.
public interface ICacheClient
AzureCacheClient is the implementation of this interface and has the references to the Windows Azure Caching client assemblies, which were added via the Windows Azure Caching NuGet package.
Because the DataCacheFactory object creation establishes a costly connection to the cache role instances, it is defined as static and lazily instantiated using Lazy<T>.
The app.config has auto discovery enabled and the identifier is used to correctly point to the cache worker role:
<autoDiscover isEnabled="true" identifier="CSFundamentalsCaching.WorkerRole" />
NOTE: To modify the solution to use the new Windows Azure Cache Service, replace the identifier attribute with the cache service endpoint created from the Windows Azure Portal. In addition, the API key (retrievable via the Manage Keys option on the portal) must be copied into the ‘messageSecurity authorizationInfo’ field in app.config.
The implementation of the GET<T> and PUT<T> methods uses the BinarySerializer class, which in turn leverages the Protobuf class for serialization and deserialization. protobuf-net is a .NET implementation of protocol buffers, allowing you to serialize your .NET objects efficiently and easily. This was added via the protobuf-net NuGet package.
Serialization produces a byte[] array for the parameter T passed in, which is then stored in Windows Azure Cache cluster. In order to return the object requested for the specific key, the GET method uses the Deserialize method.
This blog provides an overview of Caching Basics. For more details, please refer to ICacheClient.cs, AzureCacheFactory.cs, AzureCacheClient.cs and BinarySerializer.cs in the CloudServiceFundamentals Visual Studio solution.





The Windows Store Team announced Windows 8.1 RTM has arrived and “MSDN and TechNet subscribers can download Windows 8.1 RTM, Visual Studio 2013 RC, and Windows Server 2012 R2 RTM builds today” on 9/30/2013. From MSDN’s Windows 8.1 Enterprise (x64) - DVD (English) Details:
- Release Notes: Important Issues in Windows 8.1
- Download Windows 8.1 RTM app samples This sample pack includes all the app code examples developed and updated for Windows 8.1 RTM. These samples should only be used with the released version of Windows 8.1 and Visual Studio 2013 RC. The sample pack provides a convenient way to download all the samples at once. The samples in this sample pack are available in C#, C++, and JavaScript.
Steve Guggenheimer (@StevenGuggs) provides Visual Studio 2013 RC details in his earlier Download Windows 8.1 RTM, Visual Studio 2013 RC and Windows Server 2012 R2 RTM Today post of 9/10/2013:
Starting today, we will extend availability of our current Windows 8.1, Windows 8.1 Pro and Windows Server 2012 R2 RTM builds to the developer and IT professional communities via MSDN and TechNet subscriptions. The Windows 8.1 RTM Enterprise edition will be available through MSDN and TechNet for businesses later this month. Additionally, today we’re making available the Visual Studio 2013 Release Candidate which you can download here.
We heard from you that our decision to not initially release Windows 8.1 or Windows Server 2012 R2 RTM bits was a big challenge for our developer partners as they’re readying new Windows 8.1 apps and for IT professionals who are preparing for Windows 8.1 deployments. We’ve listened, we value your partnership, and we are adjusting based on your feedback. As we refine our delivery schedules for a more rapid release cadence, we are working on the best way to support early releases to the various audiences within our ecosystem.
In providing the best developer tools to our customers, Visual Studio 2013 RC enables development teams to build, deliver and manage compelling apps that take advantage of today’s devices and services. With the release of Visual Studio 2013 RC, we’ve made available additional features and functionality to enhance developer and development team productivity and agility. For more information of what’s new in Visual Studio 2013 see today’s blog post from S. Somasegar.
With these updated platform and tools bits, developers will be able to build and test their Windows 8.1 apps. The RTM versions of tools, services, and platform are required for store submissions which will open up for new Windows 8.1 apps beginning at general availability on October 18.
Given the accelerated rate of technological advancement we continue to see in the industry and here at Microsoft, it’s an exciting time to be an app builder. We recognize the critical role developers play—the breadth of our apps ecosystem is a key pillar of the Windows experience. It’s an essential end-to-end relationship – we deliver the tools, services and platform to give developers the flexibility and opportunity to innovate and build experiences for Windows that make all our lives more productive and fun.
We also recognize that our commercial customers need time to perform application compatibility and other testing and validation to best plan for their Windows 8.1 deployments following general availability on October 18.
The primary purpose of Windows 8.1 RTM and Visual Studio 2013 RC availability is for testing as our engineering teams continue to refine and update the product and tools in preparation for Windows 8.1 general availability on October 18 and the release of Visual Studio 2013 RTW. Third party apps may require final refinement to onboard into the Windows Store at the October 18 GA milestone. However, we’re confident this pre-release will enable developers to ready their Windows 8.1 apps for customers while validating their existing apps function as expected on Windows 8.1
Similarly, we continue to validate the Windows Server 2012 R2 software with our partners and expect to make further updates to the build for general availability on October 18 as well.
We are pleased to provide non-production support for Windows Store app development and testing for Windows 8.1, via forums and assisted support channels. For links to those resources, along with existing Windows 8 support options, please visit the Dev Center support options page. We will also provide assisted support for Windows 8.1 RTM and Windows Server 2012 R2 RTM through standard commercial support channels.
We are excited about the innovation we are delivering in such a short amount of time, and are pleased to be able to share these pre-releases with the communities. Thanks for your continued support and feedback, you can reach out to me anytime, either using the comments here or on twitter @StevenGuggs.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
‡ My (@rogerjenn) Microsoft continues to improve Windows Azure autoscaling features article of 10/3/2013 for TechTarget’s SearchCloudComputing.com begins:
Paying only for what you use is a major cloud computing selling point, especially to budget-conscious IT execs. But using only what you "need" is easier said than done if developers must roll their own code to automatically add or remove additional compute resources in response to changing demand.
Autoscaling has been the most common economic justification for enterprise cloud computing. Windows Azure introduced built-in autoscaling management for cloud services, websites and mobile services at its 2013 Build Developers Conference. Since then, it has been adding more features to appeal to even the most critical enterprise DevOps teams and finance execs.
Amazon Web Services has offered autoscaling in its Elastic Compute Cloud (EC2) public cloud since 2009; however, Microsoft Windows Azure didn't feature it until this year. Previously, enterprises could have autoscaling in Azure through third-party service Paraleap Technology's AzureWatch. The Azure team has since incrementally improved its autoscaling, monitoring and diagnostics features.
The need for autoscaling arose from public-facing websites and services exhibiting a combination of predictable and unpredictable traffic variations, which can cause unacceptable response times or even total outages. But unanticipated viral events or publicity can cause large, unforeseen increases in Web server load in just an hour or two. As a result, Internet startups that encounter notoriety often have been knocked completely out of service.
DevOps teams can customize data center orchestration software from a variety of sources, such as Microsoft System Center or Puppet Labs Enterprise, to match on-premises resources with cyclic traffic demands. However, most startups or enterprises can't realistically devote capital investment to data center facilities that are used only for a fraction of the day or a few times per year. …

Read the entire post here (requires free registration.)
<Return to section navigation list>
Windows Azure Pack, Hosting, Hyper-V and Private/Hybrid Clouds
‡ Anders Ravnholt (@AndersRavnholt) described Configuring SPF and Windows Azure Pack for IaaS usage and metering in a 10/1/2013 post to the Building Clouds Blog:
After configuring VMM and OM for IaaS usage and metering in the previous blog post (here) it’s now time to configuring SPF and Windows Azure Pack to import Usage data from Operations Manager Data Warehouse into Windows Azure Pack (WAP) Usage Database.
The series includes the following posts:
- IaaS Usage and Service Reporting using System Center 2012 R2 and Windows Azure Pack
- Configuring VMM and OM for IaaS usage and metering.
- Configuring SPF and Windows Azure Pack for IaaS usage and metering. (This blog post)
- Installing & configuring Service Reporting for IaaS usage and metering.
Service Provider Foundation has a usage module that WAP uses to collect data from Operations Manager data warehouse. In this blog post we will go over how to configure the following:
- Configure SPF to extract data from Operations Manager Data Warehouse
- Configure WAP to connect to SPF Usage Service
- Verify that Data is being stored in the WAP usage database
The following things must be configured before starting on this guide
- Completing all steps and pre-requisites from the previous blog post: Configuring VMM and OM for IaaS usage and metering
The Environment:
Configure SPF to extract data from Operations Manager Data Warehouse
The usage module in SPF needs to be configured using PowerShell. With SPF there is a set of commands that enables you to configure settings in SPF. By using these commands you can tell SPF where the Operations Manager Server and Data Warehouse database are located.
To configure SPF Usage do the following:1. Logon to the SPF server as an Administrator
2. Open IIS Manager Console
3. Select Application Pools
4. Check the identity for the Usage Application (eg. Contoso\!spf)
5. Close the IIS console
6. Open Computer Management Console > Local Users Groups > Groups
7. Verify that the SPF Usage Application Identity user is member of the local SPF_Usage users group, if not add the user to the group
8. Open PowerShell console with administrative privilege
9. Run the following commands (change values in “<>” with your own values):
Import-module spfadmin
# Provide server name to the OM DW SQL instance
$OMDWSqlServer = "<SCOM DW DB SQL Server>”
Example: $OMDWSqlServer = "DB04.contoso.com"
# Provide server name to the OM RMS Server
$OMServer = "<SCOM RMS Server Name>"
Example: $OMServer = "OM01.contoso.com"
# Register the SCOM Data Warehouse instance to SPF usage metering
$stamp = Get-SCSPFStamp;
$server = New-SCSPFServer -Name $OMServer -ServerType OMDW -Stamps $stamp[0];
For SPF Preview use the following command:
$setting = New-SCSPFSetting -Name $OMDWSqlServer -SettingString "Data Source=$OMDWSqlServer;Initial Catalog=OperationsManagerDW;Integrated Security=True" -SettingType DatabaseConnectionString –Server $server
For SPF RTM use the following command:
$setting = New-SCSPFSetting -Name $OMDWSqlServer –Value "Data Source=$OMDWSqlServer;Initial Catalog=OperationsManagerDW;Integrated Security=True" -SettingType DatabaseConnectionString –Server $server
Example:
To verify if the setting has been applied to SPF run the following command:
Get-SCSPFSetting
10. Logon to the SQL Server that hosts the SCOM DW DB as SQL Admin
11. Start SQL Management Studio
12. Select Security > Logins
13. Right Click on Logins folder and select “New Login”
14. Add the SPF Usage Application Identity user for Login name. eg. Contoso\!spf
15. Select User Mapping under “Select a page”
16. Select OperationsManagerDW and select OpsMgrReader under “Database role membership”
17. Click Ok
18. Right Click OperationsManagerDW under Database and select Properties
19. Select Permissions and pick the user just added under User and Roles.
20. Verify that the user has Execute permission on the database, if not assign this permission as shown below.
21. Close SQL Management Studio
Configure WAP to connect to SPF Usage Service
The Usage module inside WAP uses SPF to collect data from Operations Manager Data Warehouse. For WAP usage to collect this data we need to tell WAP where the SPF Usage service is located.
To enable this in WAP do the following
1. Start a browser that has access to the WAP Admin Portal and login in as administrator
2. Select VM Clouds from the main menu
3. Select the VM Clouds Configuration from the VM Clouds menu
4. Select Register Service Provider Usage
5. Provide information for each field as given in the example below and Click Ok.
NB: Remember to add /Usage after the port number for the SPF usage service.
Verify that Data is being stored in the WAP usage database
To verify that IaaS data is being stored in the WAP Usage Database do the following:
1. Logon the WAP Database as Administrator
2. Start SQL Management Studio
3. Select Databases > Tables
4. Right Click on Usage.Records and select “Select Top 1000 Rows”
5. Verify that the result returns Data with ResourceId “VM Utilization”
6. Close the SQL Management Studio Console
Now that we see data in the WAP Usage DB, we have successfully integrated SPF and Windows Azure Pack.
This will now enable us to configure Service Reporting and using billing adapters against Windows Azure Pack.
In the next blog post I will go through how Service Reporting can be configured.
- Installing & configuring Service Reporting for IaaS usage and metering
My colleague KR Kandavel is working on a series of blog posts explaining how you can build a billing adapter.
- Link to blog post coming soon
See you next time for more blogging about Windows Azure Pack & System Center 2012 R2 :-)










<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
‡‡ Julie Lerman (@julielerman) announced a Coding for Domain-Driven Design: Tips for Data-Focused Devs series in a 10/6/2013 post:
In honor of the 10th Anniversay of Eric Evan’s book: Domain Driven Design, Tackling Complexity in the Heart of Software (Addison-Wesley Professional, 2003), I’ve written a 3-part series for my MSDN Data Points column.
August 2013: Data Points: Coding for Domain-Driven Design: Tips for Data-Focused Devs
Domain Driven Design can help handle complex behaviors when building software. But for data-driven devs, the change in perspective isn’t always easy. Julie Lerman shares some pointers that helped her get comfortable with DDD.
September 2013:Data Points: Coding for Domain-Driven Design: Tips for Data-Focused Devs, Part 2
In the second column in her series on Domain Driven Design, Julie Lerman shares more tips for data-first developers who are interested in benefiting from some of the coding patterns of DDD.
October 2013: Data Points: Coding for Domain-Driven Design: Tips for Data-Focused Devs, Part 3
Julie Lerman explores two important technical patterns of Domain Driven Design (DDD) coding--unidirectional relationships and the importance of balancing tasks between an aggregate root and a repository--and how they apply to the Object Relational Mapper (ORM), Entity Framework.


Philip Fu posted [Sample Of Oct 3rd] How to import/export the XML files using Code First in EF on 10/3/2013:
Sample Download : http://code.msdn.microsoft.com/CSEFStoreXmlFiles-d58d5702
This sample demonstrates how to import/export the XML into/from database using Code First in EF.
We implement two ways in the sample:
- Using LinqToXml to import/export the XML files;
- Using the XmlColumn to store the Xml files.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.

Ravi Eda continued the Visual Studio Lightswitch Team Development Series – Part 5: Leveraging Code Analytics on 9/30/2013:
This article demonstrates the usage of code analytic tools available for LightSwitch in Visual Studio 2013. Analytic tools that will be covered include - Code Analysis, Code Metrics, Code Maps and Remote Debugging.
Code analysis tools enable developers to improve their code. These tools help find code issues early in the development cycle, find bug patterns, and complement traditional testing techniques. These tools enable developers to follow standard design and coding practices that improve maintainability, readability and minimize complexity of the code. These tools are invaluable in a team development setting where multiple developers work on the project, and new developers who are unfamiliar with the code base are required to ramp up quickly and contribute.
To show the usefulness of these tools, let us take an example wherein a simple LightSwitch application is developed. To keep things simple, this example considers a one person team developing the application.
Scenario
A manager of a software development team, let us call him John, would like to host a morale event for his team. To keep most members on the team happy, John would like to have the employees vote for morale events. The event that gets the maximum votes will be chosen as the morale event for the team. To keep things orderly, John wants to allow each employee to cast no more than three votes. John learns that LightSwitch is the simplest way to build a ballot application that fits this need.
John quickly comes up with a ballot application that contains a table named MoraleEventVote with three properties as described below:
- VoteFor – a choice list of morale events available for the team to vote
- VotedBy – will be set to the name of the current employee casting the vote
- InvalidVote – to determine if a vote is valid. If an employee had already used all three permissible votes, any new vote after that will be deemed invalid for that employee.
To implement the necessary business logic for these properties, John adds code to the _Inserting event via the Data Designer, which ends up in the ApplicationDataService class.
C#:
public int vote; public int Vote_Count { get { return vote; } set { this.vote = value; } } partial void MoraleEventVotes_Inserting(MoraleEventVote entity) { // Get the name of the current Windows user. String currentUser = this.Application.User.FullName; // Get the first name of the user.
//Assumed that a space exists between first and last name. entity.VotedBy = currentUser.Substring(0, currentUser.LastIndexOf(' ')); // Get the number of votes casted by the current user. vote = DataWorkspace.ApplicationData.MoraleEventVotes.
Where(p => p.VotedBy.Equals(currentUser)).Count(); // Invalidate the current vote if more than three votes were already casted. if (vote >= 3) { entity.InvalidVote = true; } else { entity.InvalidVote = false; } }VB:
Public vote As Integer Public Property Vote_Count() As Integer Get Return vote End Get Set(value As Integer) Me.vote = value End Set End Property Private Sub MoraleEventVotes_Inserting(entity As MoraleEventVote) ' Get the name of the current Windows user. Dim currentUser As String = Me.Application.User.FullName ' Get the first name of the user.
' Assumed that a space exists between first and last name. entity.VotedBy = currentUser.Substring(0, currentUser.LastIndexOf(" "c)) ' Get the number of votes casted by the current user. vote = DataWorkspace.ApplicationData.MoraleEventVotes. Where(Function(p) p.VotedBy.Equals(currentUser)).Count() ' Invalidate the current vote if more than three votes were already casted. If vote >= 3 Then entity.InvalidVote = True Else entity.InvalidVote = False End If End SubA couple of screens are added to allow employees to cast their votes. John finds that Windows authentication is most appropriate for an internal team application like this one so he sets that up. Finally, he uses the LightSwitch publish wizard to deploy the application to one of the IIS machines available for the team. John launches the app and performs security administration so that ProjectManager permission is assigned to each project manager in his team.
The rest of this article will demonstrate how code analytics will enable John to produce an app that is more maintainable, less complex and readable.
Code Analysis
Code Analysis is a tool that enables developers to discover potential issues such as design problems, naming issues, globalization, maintainability, interoperability, usage violations and non-secure data access. New features were added to Code Analysis in Visual Studio 2012 and Visual Studio 2013.
LightSwitch in Visual Studio 2013 introduced a flattened project structure in the Solution Explorer. This structure enables Code Analysis tools to run successfully on LightSwitch projects. So just like any other Visual Studio solution, to run Code Analysis on a LightSwitch solution, select “Run Code Analysis on Solution” option from the context menu of root node in Solution Explorer. Code Analysis can be run for each project within the solution. Note: Code Analysis runs on projects with managed code, like the Server project. It does not apply to JavaScript-based projects, like the HTML client project.
Let us see if Code Analysis can help John identify any code convention violations in the ballot application. Notice that there will be no warnings in the Code Analysis results window. The default rule set for Code Analysis is set to “Microsoft Managed Recommended Rules”. This rule set did not find any violations in the ballot application. Change the rule set to “Microsoft All Rules” and re-run Code Analysis by clicking “Run Code Analysis on Solution” as shown in the previous screenshot. Now there will be some warnings displayed. The Code Analysis results window provides the option to sort and filter these warnings. John wrote the logic in the ApplicationDataService class so let us focus on Code Analysis warnings that come from that class. There should be two warnings as shown in the screenshot below. Note that the screenshot shown here is for C# code, however, the equivalent code in VB would cause the same two warnings.
“CA1051 Do not declare visible instance fields” - This refers to the code statement where the variable “vote” has access modifier as public.
“CA1707 Identifiers should not contain underscores” - This refers to the underscore in “Vote_Count”.
So let us fix these code issues.
A good coding practice is to control the set and get operations for a variable like “vote”. These operations should happen through the accessor methods. This will be possible when the access modifier for the variable is private. So to fix the first Code Analysis warning, change the access modifier for vote from public to private.
Following a naming convention improves readability and thus maintainability of the code. Naming convention in .NET does not recommend underscore characters in identifier names. So to fix the second Code Analysis warning, just remove the underscore character in “Vote_Count”.
After these two fixes, select Solution from Analyze dropdown located in Code Analysis results window. This will re-run Code Analysis on the solution. This time there should be no warnings in the results. John’s ballot application complies with .NET code conventions.
Code Metrics
Code Metrics enables developers to understand the current state of project, evaluate design, and follow best software development practices.
To run Code Metrics on a LightSwitch solution, select “Calculate Code Metrics” option from context menu of the root node in the Solution Explorer. Code Metrics can be generated at the project level as well. Similar to Code Analysis, JavaScript projects, like the HTML client project, do not support Code Metrics.
Run Code Metrics for the ballot application as shown in the screenshot below:
The Code Metrics Results window will display the metrics generated for the ballot application as shown in the screenshot below:
C#:
VB:
Notice the values of Maintainability Index, Cyclomatic Complexity and Lines of Code for MoraleEventVotes_Inserting method. These values will change if the code were to be refactored. For example, the code that checks for the number of votes the current user casted can be refactored as shown below.
C#:
// Get the number of votes casted by the current user. // Invalidate the current vote if more than three votes were already casted. entity.InvalidVote = (DataWorkspace.ApplicationData.MoraleEventVotes. Where(p => p.VotedBy.Equals(currentUser)).Count() >= 3);VB:
' Get the number of votes casted by the current user. ' Invalidate the current vote if more than three votes were already casted. entity.InvalidVote = (DataWorkspace.ApplicationData.MoraleEventVotes. Where(Function(p) p.VotedBy.Equals(currentUser)).Count() >= 3)This refactoring makes “vote” and “VoteCount” unnecessary. So let us delete those members and re-run Code Metrics. Observe that in both C# and VB projects Maintainability Index increased, Cyclomatic Complexity and Lines of Code decreased, which generally indicates the new code is better.
C#:
VB:
Code Analysis, Code Metrics and other analysis tools can also be accessed through “ANALYZE” menu in Visual Studio menu bar.
Code Maps
Code Maps is a more user-friendly approach to creating and viewing a Dependency Graph of the code under development. This visualization is very helpful when the code base is large or unfamiliar.
Thanks to the new project structure in LightSwitch, this also allows generation of Code Maps. To generate a Code Map, select “Show on Code Map”, from context menu of a code file in Solution Explorer.
The Code Map for ApplicationDataService class is shown below. Notice that this visualization clearly shows the relationships between MoraleEventVotes_Inserting method and the member variables “VoteCount” and “vote”.
Remote Debugging
Static code analysis tools cannot find errors that can happen while the app is running. For example, in the ballot application John assumed that all users will have a space separating their first and last names as shown in the following code:
C#
// Get the name of the current Windows user. String currentUser = this.Application.User.FullName; // Get the first name of the user. Assumed that a space exists between first and last name. entity.VotedBy = currentUser.Substring(0, currentUser.LastIndexOf(' '));VB:
' Get the name of the current Windows user.
Dim currentUser As String = Me.Application.User.FullName
' Get the first name of the user. Assumed that a space exists between first and last name.
entity.VotedBy = currentUser.Substring(0, currentUser.LastIndexOf(" "c))However, if an employee does not have a space between his/her first and last name then that employee will not be able to vote. The app would throw a runtime error as shown in the screenshot below:
While developing the app, it is quite difficult for John to think of an edge case scenario where a user’s first and last name is not space separated. Static tools such as Code Analysis, Code Metrics and Code Maps will not identify this error since the flaw is in implementation of the logic and not in the code syntax. Manual code inspection such as code reviews from an expert may identify this flaw and produce better code that can handle such edge cases. Otherwise, this type of error can be found only when the app is live.
Say Bob is a user of John’s app and does not enter a last name. Bob launches the ballot application and attempts to vote. Bob runs into the error message shown above and is blocked from adding his vote. Neither does Bob have access to source code of the ballot app nor does he have access to the IIS machine that hosts the app. So Bob reports the error message to John. So to investigate this error, John enables diagnostics for the ballot application. Trace data shows that the error was caused due to a System.ArgumentOutOfRangeException “at System.String.Substring(Int32 startIndex, Int32 length)” in MoraleEventVotes_Inserting. In this simple example, it is easy to locate the line where the Substring method in invoked. Beyond this John does not have other debug information such as local variable values when this error happened. In such situations, Remote Debug option in Visual Studio is invaluable. Here is how John can use Remote Debug option to investigate the issue Bob is facing:
- On IIS machine:
- Install and configure remote debug
- Launch msvsmon.exe process to run as administrator. Note down the port number that will be listening to remote debug connections.
- On Bob’s machine:
- Launch the ballot app. This will start w3wp process on IIS machine.
- On John’s machine:
- Open the ballot app in Visual Studio
- Set breakpoint in MoraleEventVotes_Inserting at the statement that calls Substring method.
- Launch Visual Studio’s Attach to Process window.
- Set Transport to Default
- In the textbox against Qualifier, enter IIS machine name, a colon and the port number from step 1.2. For example, “MyIIS:4018”. If the remote debug connection is successful then the list of processes available for debug are displayed.
- Select w3wp process from the above list
- Ask Bob to enter a vote in the running app (step 2.1). Now the breakpoint set in step 3.2 will be hit.
Standard Visual Studio debug information such as Locals, Watch, Threads, Modules and Call Stack will be available for the developer. Now John can diagnose exactly what is happening in the running application and easily fix it.
One may wonder if Code Map can be used to visualize call stack. Yes it is possible in Visual Studio 2013. To get this visualization, select “Show Call Stack on Code Map” from context menu of Call Stack window as shown in the screenshot below:
This will generate the Code Map for the call stack as shown in the screenshot below:
Conclusion
The changes we made in the Solution Explorer enables a lot more capabilities in Visual Studio to be applied to LightSwitch solutions. This includes Code Analysis, Code Metrics and Code Map features. Please let us know what you think by downloading Visual Studio 2013 RC today and adding a comment below, or starting a conversation in the forums!













<Return to section navigation list>
Cloud Security, Compliance and Governance
The Wall Street Journal published a Microsoft achieves FedRAMP JAB P-ATO for Windows Azure press release on 9/30/2013:
Windows Azure is the first public cloud platform, with infrastructure services and platform services, to receive a Provisional Authority to Operate from the FedRAMP Joint Authorization Board.
REDMOND, Wash., Sept. 30, 2013 /PRNewswire/ -- Microsoft Corp. announced Monday that its public cloud platform, Windows Azure, has been granted Provisional Authorities to Operate (P-ATO) from the Federal Risk and Authorization Management Program (FedRAMP) Joint Authorization Board (JAB). Windows Azure is an open and flexible cloud platform that enables customers to quickly build, deploy and manage applications across a global network of Microsoft-managed datacenters.
Windows Azure is the first public cloud platform, with infrastructure services and platform services, to receive a JAB P-ATO. This level of federal compliance helps assure Microsoft customers that Windows Azure has undergone the necessary security assessments. This opens the door for agencies to quickly meet U.S. government Cloud First Computing initiatives and realize the benefits of the cloud using Windows Azure.
"Given the rigorous process involved in achieving this level of FedRAMP compliance, which includes a greater depth of review than that of an agency-level authorization, Microsoft customers using Windows Azure can trust it meets FedRAMP's rigorous standards," said Susie Adams, chief technology officer, Microsoft Federal. "This is the highest level of FedRAMP ATO available, and it is a great honor for Microsoft to receive this certification. In addition, the pragmatic and holistic approach we took in achieving the provisional ATO for Windows Azure and its underlying datacenters will help pave the way for FedRAMP P-ATOs for even more Microsoft cloud services."
"With the June 2014 FedRAMP security requirements deadline rapidly approaching, it is paramount for cloud service providers and agencies to get compliant ATOs in place," said Matt Goodrich, program manager for FedRAMP's Program Management Office at the U.S. General Services Administration. "The announcement today of Microsoft's provisional authorizations for Windows Azure demonstrates that different types of cloud services -- public to private and infrastructure to software -- can meet the rigorous security requirements for FedRAMP."
FedRAMP is a U.S. government-wide program that provides a standardized approach to security assessment, authorization and continuous monitoring for cloud products and services. The JAB is the primary governance group of the FedRAMP program, consisting of the chief information officers of the Department of Defense, the Department of Homeland Security and the U.S. General Services Administration. …

Just in time for the government shutdown.
<Return to section navigation list>
Cloud Computing Events
Neil MacKenzie (@nmkz) reported Windows Azure Developer Camps in Northern California on 10/4/2013:
Satory Global is conducting two free one-day, instructor-led training events in the Windows Azure Developer Camps series put on by Microsoft. These events provide a great opportunity to get started with Windows Azure through a mixture of presentations and hands-on labs.
We will start with the basics and build on to more advanced topics, featuring instructor led hands-on labs for:
- Windows Azure Web Sites and Virtual Machines using ASP.NET & SQL Server
- Deploying Cloud Services in Windows Azure
- Exploring Windows Azure Storage for Visual Studio 2012
November 6, Sunnyvale, CA
Silicon Valley Moffett Towers (Map)
1020 Enterprise Way
Building B
Sunnyvale
California 94089
United StatesMore details and registration for the Sunnyvale event is here.
November 7, San Francisco, CA
Microsoft Office (Map)
835 Market Street
Suite 700
San Francisco
California 94103More details and registration for the San Francisco event is here.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
‡ Derrick Harris (@derrickharris) asserted For better or worse, HP has finally found its cloud religion in a 10/5/2013 article for GigaOm’s Cloud blog:
In cloud computing, there is a cult of Amazon Web Services that’s very large and growing, but it’s not necessarily for everyone. That’s because the religion of cloud computing is very much like any other religion: There are some core tenets everyone believes — in this case, let’s say on-demand provisioning, resilience and the existence of virtual machines — but that core is surrounded by different sects and congregations. They all practice their beliefs in those core tenets, as well as some of their own design, in different ways.
HP company is now a devout member of the enterprise cloud faith. Its gospel preaches, among other things, that users that don’t buy into an all virtual-environment will still want physical gear, highly regulated companies will demand at least hybrid environments, and that large enterprises with lots of legacy software (and/or) technical debt will still expect a slow transition and lots of handholding. Increasingly, it also preaches OpenStack.
HP Vice President of Product Marketing and Cloud Evangelist Margaret Dawson came on the Structure Show this week to explain how HP interprets the enterprise cloud scripture. Here are some highlights from Dawson’s appearance but, as usual, you’ll want to listen to the whole show to get the whole picture (download options below).
On all the competing interests in the OpenStack community
“Any open source movement, and OpenStack would be no exception, is always very much a coopetition type of reality,” Dawson said. “… We’re always gonna have that natural collaboration and friction when it comes to the fact that at the end of the day we’re all here to make money and make our customers happy.”
HP is very involved with the OpenStack community on all levels, she elaborated, but out in the market everyone needs their own special sauce to distinguish themselves. She wouldn’t comment on the likelihood of HP releasing its Cloud OS management layer as essentially a separate OpenStack distribution, but she did acknowledge that customers want to use it even outside their HP services.
“It’s simplifying some things that are still a little bit complex from an OpenStack perspective,” Dawson noted.
On what the cloud means for HP’s server business
“I used to speak at some conferences about what I jokingly said: ‘Behind every cloud is a data center in disguise,’” Dawson said. “Because we really do forget about the huge amount of infrastructure that is going into cloud computing worldwide.”
She noted the types of data centers and infrastructure that companies such as Facebook and Google are building, and the huge scale at which they’re doing it. But, she added, companies like HP still have to innovate if they expect to sell servers into these next-generation data centers. She thinks HP’s Atom-based Moonshot servers show it still has a few good ideas up its sleeve.
Margaret Dawson at Structure: Europe 2013.
On the the significance of big OpenStack users like PayPal
“At the end of the day, what the customer wants is everything to work together. Unfortunately, that’s still Narnia and fairy dust,” Dawson said. “… There’s still no magic dust that allows us to have everything across our legacy [and] new infrastructure just work hand in hand and move data back and forth.”
By doing things like rebuilding AWS-based tools to work on OpenStack, she thinks users like PayPal can show the community can make innovation on other platforms work for OpenStack. They could even help tie together some of these disparate systems.
On whether HP should try to compete with AWS for developers
“We have thousands of [individual developers] on our cloud today,” Dawson said. “… I think that will always play a role, but when we think about our core cloud strategy and customer, it’s absolutely the enterprise.”
That wasn’t always the case for HP, but it seems to have seen the light. Its customers want consultation, guidance and a slow transition from old to new. Even within the OpenStack community, Dawson noted, “Everybody is finding a way to compete effectively, to grow their business, to provide their customers what they want. And not everyone is going after that same customer base.”
On how many OpenStack companies the market can support
“I think there’ll be consolidation, I’m sure we’ll see continued movement in terms of companies working together or being acquired – that’s just natural market movement in the technology development,” Dawson said. “We always see this natural cadence or flow of how things consolidate or de-centralize, and I’m sure we’ll see the same thing with OpenStack.”
Margaret Dawson photo by Anna Gordon/GigaOM.




• Barbara Darrow (@gigabarb) reported Verizon launches new built-from-scratch enterprise cloud in a 10/3/2013 article for GigaOm’s Cloud blog:
New Verizon Cloud, parlaying CloudStack and Xen, promises easy movement of VMware workloads, the end of the noisy-neighbor … pretty much cloud nirvana. Now comes the hard part: winning users.
Verizon isn’t the first name that comes to mind when you think of enterprise cloud, but it’s fielded respectable, mostly VMware-based cloud services for some time. Now it’s shaking things up a bit with a new enterprise cloud based on optimized Xen hypervisors and which borrows heavily from CloudStack. (Verizon cautioned against saying it is based on CloudStack. Hmmm.)
John Considine, Verizon’s CTO wants you to know that the company spent 5 years researching cloud and built this new Verizon Cloud offering from the ground up. “We used Xen hypervisor as baseline and enhanced that to allow higher performance and have more control over performance and enhanced it to run different VM formats natively,” he said in an interview.
“If you now use VMware in the enterprise and want to move workloads or use the same golden image and tools and drivers … you can’t quite do that in Amazon which dictates the kernels and drivers you use. We enhanced the hypervisor to support VMware drivers and toolsets,” he said.’
Can Verizon Cloud compete with Amazon and the biggest boys?
That would be a big deal if it works as advertised. Most enterprises now rely heavily on VMware in-house and want a way to move some of at workloads to the cloud. Such “seamlessness” of migration is one of the key sales pitches for VMware’s new vCloud Hybrid Services public cloud, for example, Verizon will be competing for those same customers.
The Verizon Cloud will let enterprises dial up (or down) and pay for performance requirements depending on VMs, storage, network as needed, CTO John Considine said in an interview.
“We offer reserved performance — for every VM, you can set the performance level. Or you can say I want this NIC to run at this speed or i want disk to run at 100 or 1,000 IOPS, you can do that,” he said. ”The whole notion of the noisy neighbor is off the table.”
That ”noisy neighbor” syndrome occurs in shared multi-tenant infrastructure when someone else on the same virtual machine hogs resources hurting the performance of your workload.
Considine announced the public beta of Verizon Cloud on Thursday at Interop. A private beta has been running since December 2012. Much of the heavy lifting for this cloud comes out of Cloudswitch, a Burlington, Mass. company Verizon bought two years ago.
A long road ahead
The jury is out whether Verizon will soon be counted in the top tier of cloud providers. While it does have some of the enterprise customers AWS craves, it does not have the same huge brand recognition. If the CIO of a major company thinks “cloud” he or she will think AWS way before Verizon.
GigaOM Research Analyst David Linthicum said the current Verizon/Terremark cloud hasn’t set the world on fire, but it does offer sound options. And, Terremark itself has a good reputation in government accounts — and that arena is becoming hotly contested as AWS and Google create government-specific clouds.
This is clearly an ambitious undertaking and some analysts gave Verizon props for doing its homework.”Please God, nobody start calling it ‘cloud 2.0′ but that’s kind of what it is,” said 451 Research Analyst Carl Brooks via email. “It has technical stuff baked in that earlier IaaS services have had to glue on after the fact; it is starting from where other services ended up after 5 years of evolution and development with commercial gear designed with IaaS in mind. That is huge when it comes to speeding up innovation.”
I have a few nagging questions about today’s news.
First, why is the Terremark name conspicuously missing here? Verizon bought Terremark, a provider of cloud services in 2011 for $1.4 billion. And up till now the Terremark name was closely associated with Verizon’s cloud effort. Update: ITWorld reports that Terremark will continue to be the brand of the legacy cloud services.
Second, Why the insistence on saying Verizon Cloud “borrows heavily” from but is not based on CloudStack?
And, critically for the enterprise accounts Verizon wants to capture, how easily will VWware workloads really carry over to this new infrastructure?
But perhaps most importantly, will Verizon be able to woo big enterprise customers that want to take advantage of the flexibility and scale of cloud infrastructure but may be nervous about deploying on Amazon. And can Verizon offer pricing that’s even in the ballpark with AWS?
In other words: Stay tuned.
Note: This story was updated at 9:06 a.m. with additional information on the Terremark branding.




Full disclosure: I’m a registered GigiaOm Analyst.
• David Linthicum (@DavidLinthicum) asserted “Last week's OpenWorld announcements were surprisingly impressive, but Oracle must do more to lead, not just follow” in a deck for his Don't laugh: Oracle could be a serious cloud contender article of 10/1/2013 for InfoWorld’ Cloud Computing blog:
Last week, at its OpenWorld conference, Oracle announced 10 additional cloud services, to join its existing set of SaaS offerings. The new services include Compute Cloud and Object Storage Cloud, essentially clones of Amazon Web Services' offerings. The other 10 services follow much the same pattern, including a marketplace service that looks a lot like Salesforce.com's AppExchange, Java Cloud, and Mobile Cloud. Oracle's moves may bring to mind that annoying kid in algebra who copied your homework 10 minutes before class.
It's obvious that these services, like the other ones Oracle announced at OpenWorld, are responses to the movements of the other cloud computing providers. Oracle is merely following its cloud rivals.
Oracle being Oracle, most of its customers will follow it through thick and thin. But I believe those customers would strongly prefer Oracle to be innovative, not imitative, in the fast-growing world of cloud computing.
Oracle has some great achievements to build on, including existing cloud services that no one has heard about or talks about but are actually decent works. Backed by solid technology, Oracle's database business has its hooks into most major Global 2000 companies for good reason.
By and large, however, Oracle has largely been a joke in the cloud, relative to its size and ability to impact the market. Initially Oracle seemed to push back on the concept of cloud computing, but now is playing catch-up by replicating others' popular cloud services in the hopes that the Oracle brand and thousands of white-belted salespeople will cause these services to pick up steam.
It no longer works that way.
I'm telling Oracle the same thing I tell other large companies that believe they can copy their way to success in the cloud: You have to figure out how to be innovative in this space, meaning you must build a product that others have yet to think up. If you show up late and replicate, chances are you won't claim much of the market, and your brand will take a hit.
I'm sure Oracle won't listen to me -- but it should.

• Jason Bloomberg (@TheEbizWizard) asserted Nirvanix Shutdown: You Ain’t Seen Nothin’ Yet to DevX.com’s DevExtra Editor’s blog on 10/1/2013:
The Cloud storage marketplace got quite a stare last week when storage provider Nirvanix abruptly closed its doors. Fortunately, they provided their customers with a few days to get their data off of the Nirvanix servers, but those customers are still left scrambling to move their bits to another provider without any business downtime.
The lesson for everyone who wasn’t a Nirvanix customer, however, wasn’t that you just dodged a bullet. On the contrary, the lesson is that the Nirvanix death spiral is but a hint of turbulence to come. We’re all so enamored of Cloud that we forget the entire space is still an emerging market, and emerging markets are inherently chaotic. Expect to see many other spectacular flameouts before the dust has settled.
In fact, the demise of Nirvanix could have been worse. They may have shuttered their doors without providing their customers a time window (and the necessary connectivity) to move their stuff off of the doomed drives. And what if they had declared a liquidation bankruptcy? Those drives may have ended up auctioned to the highest bidder – customer data included.
Does that mean that you should avoid the Cloud entirely until it’s matured? Possibly, but probably not – especially if you understand how the Cloud deals with failure. Remember, instead of trying to avoid failure, the Cloud provides automated recovery from failure. Furthermore, this principle is more than simply a configuration difference. It’s a fundamental architectural principle – a principle that should apply to all aspects of your Cloud usage, even if a service provider goes out of business.
Which Cloud company ended up on the positive side of this news? Oxygen Cloud – a Cloud storage broker I wrote about over two years ago. Oxygen Cloud abstracts the underlying storage provider, allowing you to move data off of one provider and onto another, in a way that is at least partially automated. And as you would expect, the entire Cloud brokerage marketplace is now forming, and the Nirvanix debacle will only serve to accelerate its adoption.
The silver lining to the Nirvanix Cloud story, therefore, is that following Cloud architecture best practices should help insulate you from the turbulent nature of the Cloud marketplace itself. But only, of course, if you get the architecture right.


According to Jeff Barr (@jeffbarr), Max Spevack of the AWS Kernel and Operating Systems (KaOS) team brings news of the latest Amazon Linux AMI in this 9/30/2013 post:
It’s been another six months, so it’s time for a fresh release of the Amazon Linux AMI. Today, we are pleased to announce that the Amazon Linux AMI 2013.09 is available.
This release marks the two year anniversary of the public Amazon Linux AMI GA. As always, our roadmap and new features are heavily driven by customer requests, so please continue to let us know how we can improve the Amazon Linux AMI for your needs and workloads.
Our 2013.09 release contains several new features that are detailed below. Our release notes contain additional release information, including more detailed lists of new and updated packages.
- Kernel 3.4.62 - We have upgraded the kernel to version 3.4.62, which follows the long-term release 3.4.x kernel series that we introduced in the 2013.03 AMI.
- AWS Command Line Interface 1.1 - The AWS Command Line Interface has celebrated its GA release in the interval since we introduced the Developer Preview version in the 2013.03 Amazon Linux AMI. We provide the latest version of this python-based interface to AWS, including command-line completion for bash and zsh. The tool is pre-installed on the Amazon Linux AMI as the aws-cli package.
- GPT partitioning on HVM AMIs - The root device of the Amazon Linux HVM AMI is now partitioned using the GPT format, where previous releases used the MBR format. The partition table can be manipulated by GPT-aware tools such as parted and gdisk.
- Improved Ruby 1.9 Support - We've improved the Ruby 1.9 experience on the Amazon Linux AMI, including the latest patch level (ruby19-1.9.3-448). Our Ruby 1.9 packages fix several other bugs, including a load issue with rake, and a fixed bigdecimal so that Ruby on Rails is easier to install. Furthermore, Ruby now has alternatives support in the Amazon Linux AMI. You can switch between Ruby 1.8 and 1.9 with one command.
- RPM 4.11.1 and Yum 3.4.3 - The core components of RPM and Yum have been updated to newer versions, with RPM 4.11 and Yum 3.4.3 being featured in this release. Both of these updates provide numerous bug fixes, performance improvements, and new features.
- R 3.0 - Last year we added R to the Amazon Linux AMI repositories based on your requests. With this release, we have updated R to 3.0.1, following the upstream release of R 3.0.
- Nginx 1.4.2 - Based on your requests, we have upgraded to Nginx 1.4.2. This replaces the 1.2.x Nginx packages that we had previously delivered in the Amazon Linux AMI repositories.
The Amazon Linux AMI 2013.09 is available for launch in all regions.
The Amazon Linux AMI is a rolling release, configured to deliver a continuous flow of updates that allow you to move from one version of the Amazon Linux AMI to the next. In other words, Amazon Linux AMIs are treated as snapshots in time, with a repository and update structure that gives you the latest packages that we have built and pushed into the repository. If you prefer to lock your Amazon Linux AMI instances to a particular version, please see the Amazon Linux AMI FAQ for instructions
As always, if you need any help with the Amazon Linux AMI, don’t hesitate to post on the EC2 forum, and someone from the team will be happy to assist you.

<Return to section navigation list>

















0 comments:
Post a Comment