Windows Azure and Cloud Computing Posts for 1/28/2013+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
• Update 2/2/2013: Added new articles marked •. Tip: Ctrl+C to copy the bullet to the clipboard, Ctrl+F to open the Find text box, Ctrl+V to paste the bullet, and Enter to find the first instance; click Next for each successive update.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
Brad Severtson (@Brad2435150) explained Azure Vault Storage in HDInsight: A Robust and Low Cost Storage Solution in a 1/29/2013 post:
HDInsight is trying to provide the best of two worlds in how it manages its data.
Azure Vault Storage (ASV) and the Hadoop Distributed File System (HDFS)
implemented by HDInsight on Azure are distinct file systems that are optimized,
respectively, for the storage of data and computations on that data.
ASV providesa highly scalable and available, low cost, long term, and shareable storage option for data that is to be processed using HDInsight.
- The Hadoop clusters deployed by HDInsight on HDFS are optimized for running Map/Reduce (M/R) computational tasks on the data.
HDInsight clusters are deployed in Azure on compute nodes to execute M/R
tasks and are dropped once these tasks have been completed. Keeping the data in
the HDFS clusters after computations have been completed would be an expensive
way to store this data. ASV provides a full featured HDFS file system over
Azure Blob storage (ABS). ABS is a robust, general purpose Azure storage
solution, so storing data in ABS enables the clusters used for computation to
be safely deleted without losing user data. ASV is not only low cost. It has been
designed as an HDFS extension to provide a seamless experience to customers by
enabling the full set of components in the Hadoop ecosystem to operate directly
on the data it manages.In the upcoming release of HDInsight on Azure, ASV will be
the default file system. In the current developer preview on www.hadooponazure.com data stored in
ASV can be accessed directly from the Interactive JavaScript Console by
prefixing the protocol scheme of the URI for the assets you are accessing with
ASV://To use this feature in the current release, you will need
HDInsight and Windows Azure Blob Storage accounts. To access your storage
account from HDInsight, go to the Cluster and click on the Manage Cluster tile.
Click on the Set up ASV button.
Enter the credentials (Name and Passkey) for your Windows Azure Blob Storage account.

Then return to the Cluster and click on the Interactive Console tile to access the JavaScript console.Now to run Hadoop wordcount job with data an ASV container name hadoop use
Hadoop jar hadoop-examples-1.1.0-SNAPSHOT.jar wordcount asv://hadoop/ outputfileThe scheme for accessing data in ASV is asv://container/path
To see the data in asv
#cat asv://hadoop2/data






Denny Lee (@dennylee) described his Big Data, BI, and Compliance in Healthcare session for 24 Hours of PASS (Spring 2013) on 1/29/2013:
If you’re interested in Big Data, BI, and Compliance in Healthcare; check out Ayad Shammout (@aashammout) and my 24 Hours of PASS (Spring 2013) session Ensuring Compliance of Patient Data with Big Data and BI.
To help meet HIPAA and HealthAct compliance – and to more easily handle larger volumes of unstructured data and gain richer and deeper insight using the latest analytics – a medical center is embarking on a Big Data-to-BI project involving HDInsight, SQL Server 2012, Integration Services, PowerPivot, and Power View.
Join this preview of Denny Lee and Ayad Shammout’s PASS Business Analytics Conference session to get the architecture and details behind this project within the context of patient data compliance.




<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
• Steven Martin (@stevemar_msft) reported a SQL Reporting Services Pricing Update for Windows Azure in a 2/1/2013 post:
We are very pleased to announce that we are lowering the price of Windows Azure SQL Reporting by up to 82%! The price change is effective today and is applicable to everyone currently using the service as well as new customers.
To ensure the service is cost effective for lower volume users, we are reducing the price for the base tier and including more granular increments
Effective today, the price for Windows Azure SQL Reporting will decrease from $0.88 per hour for every 200 reports to $0.16 per hour for every 30 reports. With this price decrease, a user who needs 30 reports per hour, for example, will pay $116.80 per month, down from our earlier price of $642.40, a reduction of 81.8%. In addition, the smaller report increment (from 200 to 30) will give customers better utilization and hence lower effective price points.
For more details, see our Pricing Details webpage. For additional Business Analytics capabilities, please visit: http://www.windowsazure.com/en-us/home/features/business-analytics/
As always, we offer a variety of options for developers to use Windows Azure for free or at significantly reduced prices including:
- Free 90 day trial for new users
- Offers for MSDN customers, Microsoft partner network members and startups that provide free usage every month up to $300 per month in value
- Monthly commitment plans that can save you up to 32% on everything you use on Windows Azure
Check out Windows Azure pricing and offers for more details or sign up to get started!


• Craig Kitterman (@craigkitterman) posted Cross-Post: Windows Azure SQL Database and SQL Server -- Performance and Scalability Compared and Contrasted on 2/1/2013:
Editor's note: This post comes from Rick Anderson [avatar below] who is a programmer / writer for the Windows Azure and ASP.NET MVC teams.
Restarts for Web Roles
An often neglected consideration in Windows Azure is how to handle restarts. It’s important to handle restarts correctly, so you don’t lose data or corrupt your persisted data, and so you can quickly shutdown, restart, and efficiently handle new requests. Windows Azure Cloud Service applications are restarted approximately twice per month for operating system updates. (For more information on OS updates, see Role Instance Restarts Due to OS Upgrades.) When a web application is going to be shutdown, the RoleEnvironment.Stopping event is raised. The web role boilerplate created by Visual Studio does not override the OnStop method, so the application will have only a few seconds to finish processing HTTP requests before it is shut down. If your web role is busy with pending requests, some of these requests can be lost.
You can delay the restarting or your web role by up to 5 minutes by overriding the OnStop method and calling Sleep, but that’s far from optimal. Once the Stopping event is raised, the Load Balance (LB) stops sending requests to the web role, so delaying the restart for longer than it takes to process pending requests leaves your virtual machine spinning in Sleep, doing no useful work.
The optimal approach is to wait in the OnStop method until there are no more requests, and then initiate the shutdown. The sooner you shutdown, the sooner the VM can restart and begin processing requests. To implement the optimal shutdown strategy, add the following code to your WebRole class.
The code above checks the ASP.NET request’s current counter. As long as there are requests, the OnStop method calls Sleep to delay the shutdown. Once the current request’s counter drops to zero, OnStop returns, which initiates shutdown. Should the web server be so busy that the pending requests cannot be completed in 5 minutes, the application is shut down anyway. Remember that once the Stopping event is raised, the LB stops sending requests to the web role, so unless you had a massively under sized (or too few instances of) web role, you should never need more than a few seconds to complete the current requests.
The code above writes Trace data, but unless you perform a tricky On-Demand Transfer, the trace data from the OnStop method will never appear in WADLogsTable. Later in this blog I’ll show how you can use DebugView to see these trace events. I’ll also show how you can get tracing working in the web role OnStart method.
Optimal Restarts for Worker Roles
Handling the Stopping event in a worker role requires a different approach. Typically the worker role processes queue messages in the Run method. The strategy involves two global variables; one to notify the Run method that the Stopping event has been raised, and another global to notify the OnStop method that it’s safe to initiate shutdown. (Shutdown is initiated by returning from OnStop.) The following code demonstrates the two global approaches.
When OnStop is called, the global onStopCalled is set to true, which signals the code in the Run method to shut down at the top of the loop, when no queue event is being processed.
Viewing OnStop Trace Data
As mentioned previously, unless you perform a tricky On-Demand Transfer, the trace data from the OnStop method will never appear in WADLogsTable. We’ll use Dbgview to see these trace events. In Solution Explorer, right-click on the cloud project and select Publish.
Download your publish profile. In the Publish Windows Azure Application dialog box, select Debug and select Enable Remote Desktop for all roles.
The compiler removes Trace calls from release builds, so you’ll need to set the build configuration to Debug to see the Trace data. Once the application is published and running, in Visual Studio, select Server Explorer (Ctl+Alt+S). Select Windows Azure Compute, and then select your cloud deployment. (In this case it’s called t6 and it’s a production deployment.) Select the web role instance, right-click, and select Connect using Remote Desktop.
Remote Desktop Connection (RDC) will use the account name you specified in the publish wizard and prompt you for the password you entered. In the left side of the taskbar, select the Server Manager icon.
In the left tab of Server Manager, select Local Server, and then select IE Enhanced Security Configuration (IE ESC). Select the off radio button in the IE ESC dialog box.
Start Internet Explorer, download and install DebugView. Start DebugView, and in the Capture menu, select Capture Global Win32.
Select the filter icon, and then enter the following exclude filter:
For this test, I added the RoleEnvironment.RequestRecycle method to the About action method, which as the name suggests, initiates the shutdown/restart sequence. Alternatively, you can publish the application again, which will also initiate the shutdown/restart sequence.
Follow the same procedure to view the trace data in the worker role VM. Select the worker role instance, right-click and select Connect using Remote Desktop.
Follow the procedure above to disable IE Enhanced Security Configuration. Install and configure DebugView using the instructions above. I use the following filter for worker roles:
For this sample, I published the Azure package, which causes the shutdown/restart procedure.
One last departing tip: To get tracing working in the web roles OnStart method, add the following:
If you’d like me to blog on getting trace data from the OnStop method to appear in WADLogsTable, let me know. Most of the information in this blog comes from Azure multi-tier tutorial Tom and I published last week. Be sure to check it out for lots of other good tips.



















Josh Twist (@joshtwist) described Working with Making Waves and VGTV - Mobile Services in a 1/28/2013 post:
We’ve just published a great case study:
Working with Christer at Making Waves was a blast and they’ve created an awesome Windows 8 application backed by Mobile Services.
Check out Christer and team talking about their experience of using Mobile Services in this short video (< 5 mins)



Angshuman Nayak (@AngshumanNayak) explained Access SQL Azure Data Using Java Script in a 1/28/2013 post to the Windows Azure Cloud Integration Engineering (WACIE) blog:
I regularly access SQL Azure from my .Net code and once a while from Java or Ruby code. But I was just thinking since it’s so easy and not at all different from on premise code can I use a scripting language to access SQL Azure. Is it even possible? To my amusement I was able to get the data from SQL Azure and will detail the steps and code below.
I will start with a caveat though in case you are not writing a fun application for your friends or kids or may be some personal application you want to run on your PC read no further and go to this link instead. Javascript was not developed for data access purpose. The main use of JavaScript is for client side form validation, for AJAX(Asynchronous Java Script and XML) implementation. But since IE has the ability to load ActiveX objects we can still use Java Script to connect to SQL Azure.
So let’s have the ball rolling. I assume there is already a database called Cloud that has a table Employee. This has columns called FirstName and LastName …yeah yeah the same ubiquitous table we all learnt in programming 101 class… whatever.
We will get it done in two steps.
Step 1
Set up a DSN to connect to SQL Azure. Depending on the environment use odbcad32.exe either from (C:\Windows\SysWOW64) for 32bit or from (C:\Windows\System32) for the 64bit. No I am not incorrect the folder with 64 in it’s name has all 32bit binaries and the folder with 32 in it’s name has all 64bit binaries. Create a new system DSN, use the SQL Server Native Client 11 driver, then give the FQDN of the SQL Azure database as below.
Use the Database Name of the database you want to connect to
Check that the test connection succeeds.
Step 2
So now we come to the script part of it. Add a new HTML file in your existing project and replace the code in there with the following.
<!DOCTYPE html PUBLIC "-//W3C//DTD
XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml">
<head>
<title>Untitled Page</title>
<script type="text/javascript" language="javascript" >
function connectDb() {
var Conn = new ActiveXObject("ADODB.Connection");
Conn.ConnectionString = "dsn=sqlazure;uid=annayak;pwd=P@$$word;";
Conn.Open();
var rs = new ActiveXObject("ADODB.Recordset") ;
var strEmpName = " " ;
rs.Open("select * from dbo.Employees", ConnDB, 1, 3);
while (!rs.EOF) {
strEmpName = rs("FirstName") + " " + rs("LastName") + "<br>";
rs.MoveNext;}
test.innerHTML = strEmpName;
}
</script>
</head>
<body>
<p><div id="test"> </div> </p>
<p><input id="button1" type="button" value="GetData" name="button1" onclick="connectDb();"/></p>
</body>
</html>
Modify the highlighted part to use the DSN name, user id, password, table name, column name as per the actual values applicable in your scenario. Now when the HTML page is called and the GetData button clicked it will get the data and display in IE (please note ActiveX works only with IE).
Since you are loading a driver in IE use this setting to suppress warning messages.
Open Internet Explorer -> Tools -> Internet Options -> Security -> Trusted sites -> Sites -> Add this site to the web zone






Josh Twist (@joshtwist) explained Debugging your Mobile Service scripts in a 1/26/2013 post:
During the twelve days of ZUMO, I posted a couple of articles that showed techniques for unit testing your Mobile Service scripts:
And whilst this is awesome, sometimes you really want to be able to debug a script and go past console.log debugging. If you follow this approach to unit testing your scripts then you can use a couple of techniques to also debug your unit tests (and therefore Mobile Service scripts). I recently purchased a copy of WebStorm during their Mayan Calender end of world promotion (bargain) and it’s a nice tool with built-in node debugging. I asked my team mate Glenn Block if he knew how to use WebStorm to debug Mocha tests. Sure enough, he went off, did the research and posted a great article showing how: Debugging mocha unit tests with WebStorm step by step – follow these steps if you own WebStorm.
For those that don’t have a copy of WebStorm, you can still debug your tests using nothing but node, npm and your favorite WebKit browser (such as Google Chrome).
The first thing you’ll need (assuming you already installed node and npm and the mocha framework) is node-inspector. To install node-inspector, just run this command in npm
npm install -g node-inspectorOn my mac, I had to run
sudo npm install -g node-inspectorand enter my password (and note, this can take a while to build the inspector). Next, when you run your unit tests add the --debug-brk switch:
mocha test.js -u tdd --debug-brkThis will start your test and break on the first line. Now you need to start node-inspector in a separate terminal/cmd window:
node-inspector &And you’re ready to start debugging. Just point your webkit browser to the URL shown in the node-inspector window, typically:
http://0.0.0.0:8080/debug?port=5858
Now, unfortunately the first line of code that node and the inspector will break on will be mocha code and it’s all a little big confusing here for a few minutes, but bear with it, because once you’re up and running it gets easier.
The first thing you’ll need to do is advance the script past the line , Mocha = require(‘../’)which will load all the necessary mocha files. Now you can navigate to the file Runnable.js using the left pane.
And in this file, put a break on the first line inside Runnable.prototype.run function:
If you now hit the start/stop button (F8) to run to that breakpoint, the process will have loaded your test files so you can start to add breaks:
Here, I’ve found my test file test.js:
And we’re away. After this, the webkit browser will typically remember your breakpoints so you only have to do this once. So there you go, debugging mocha with node-inspector. Or you could just buy WebStorm







<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
• The WCF Data Services Team announced a WCF Data Services 5.3.0-rc1 Prerelease on 1/31/2013:
Today we released an updated version of the WCF Data Services NuGet packages and tools installer. This version of WCF DS has some notable new features as well as several bug fixes.
What is in the release:
Instance annotations on feeds and entries (JSON only)
Instance annotations are an extensibility feature in OData feeds that allow OData requests and responses to be marked up with annotations that target feeds, single entities (entries), properties, etc. WCF Data Services 5.3.0 supports instance annotations in JSON payloads. Support for instance annotations in Atom payloads is forthcoming.
Action Binding Parameter Overloads
The OData specification allows actions with the same name to be bound to multiple different types. WCF Data Services 5.3 enables actions for different types to have the same name (for instance, both a Folder and a File may have a Rename action). This new support includes both serialization of actions with the same name as well as resolution of an action’s binding parameter using the new IDataServiceActionResolver interface.
Modification of the Request URL
For scenarios where it is desirable to modify request URLs before the request is processed, WCF Data Services 5.3 adds support for modifying the request URL in the OnStartProcessingRequest method. Service authors can modify both the request URL as well as URLs for the various parts of a batch request.
This release also contains the following noteworthy bug fixes:
- Fixes an issue where code gen produces invalid code in VB
- Fixes an issue where code gen fails when the Precision facet is set on spatial and time properties
- Fixes an issue where odata.type was not written consistently in fullmetadata mode for JSON
- Fixes an issue where a valid form of Edm.DateTime could not be parsed
- Fixes an issue where the WCF DS client would not send type names for open properties on insert/update
- Fixes an issue where the WCF DS client could not read responses from service operations which returned collections of complex or primitive types
Youssef Moussaoui (@youssefmss) described Getting started with ASP.NET WebAPI OData in 3 simple steps in a 1/30/2013 post to the .NET Web Development and Tools blog:
With the upcoming ASP.NET 2012.2 release, we’ll be adding support for OData to WebAPI. In this blog post, I’ll go over the three simple steps you’ll need to go through to get your first OData service up and running:
- Creating your EDM model
- Configuring an OData route
- Implementing an OData controller
Before we dive in, the code snippets in this post won’t work if you’re using the RC build. You can upgrade to using our latest nightly build by taking a look at this helpful blog post.
1) Creating your EDM model
First, we’ll create an EDM model to represent the data model we want to expose to the world. The ODataConventionModelBuilder class makes this this easy by using a set of conventions to reflect on your type and come up with a reasonable model. Let’s say we want to expose an entity set called Movies that represents a movie collection. In that case, we can create a model with a couple lines of code:
1: ODataConventionModelBuilder modelBuilder = new ODataConventionModelBuilder();2: modelBuilder.EntitySet<Movie>("Movies");3: IEdmModel model = modelBuilder.GetEdmModel();2) Configuring an OData route
Next, we’ll want to configure an OData route. Instead of using MapHttpRoute the way you would in WebAPI, the only difference here is that you use MapODataRoute and pass in your model. The model gets used for parsing the request URI as an OData path and routing the request to the right entity set controller and action. This would look like this:
1: config.Routes.MapODataRoute(routeName: "OData", routePrefix: "odata", model: model);The route prefix above is the prefix for this particular route. So it would only match request URIs that start with http://server/vroot/odata, where vroot is your virtual root. And since the model gets passed in as a parameter to the route, you can actually have multiple OData routes configured with a different model for each route.
3) Implementing an OData controller
Finally, we just have to implement our MoviesController to expose our entity set. Instead of deriving from ApiController, you’ll need to derive from ODataController. ODataController is a new base class that wires up the OData formatting and action selection for you. Here’s what an implementation might look like:
1: public class MoviesController : ODataController2: {3: List<Movie> _movies = TestData.Movies;4:5: [Queryable]6: public IQueryable<Movie> Get()7: {8: return _movies.AsQueryable();9: }10:11: public Movie Get([FromODataUri] int key)12: {13: return _movies[key];14: }15:16: public Movie Patch([FromODataUri] int key, Delta<Movie> patch)17: {18: Movie movieToPatch = _movies[key];19: patch.Patch(movieToPatch);20: return movieToPatch;21: }22: }There’s a few things to point out here. Notice the [Queryable] attribute on the Get method. This enables OData query syntax on that particular action. So you can apply filtering, sorting, and other OData query options to the results of the action. Next, we have the [FromODataUri] attributes on the key parameters. These attributes instruct WebAPI that the parameters come from the URI and should be parsed as OData URI parameters instead of as WebAPI parameters. Finally, Delta<T> is a new OData class that makes it easy to perform partial updates on entities.
One important thing to realize here is that the controller name, the action names, and the parameter names all matter. OData controller and action selection work a little differently than they do in WebAPI. Instead of being based on route parameters, OData controller and action selection is based on the OData meaning of the request URI. So for example if you made a request for http://server/vroot/odata/$metadata, the request would actually get dispatched to a separate special controller that returns the metadata document for the OData service. Notice how the controller name also matches the entity set name we defined previously. I’ll try to go into more depth about OData routing in a future blog post.
Instead of deriving from ODataController, you can also choose to derive from EntitySetController. EntitySetController is a convenient base class for exposing entity sets that provides simple methods you can override. It also takes care of sending back the right OData response in a variety of cases, like sending a 404 Not Found if an entity with a certain key could not be found. Here’s what the same implementation as above looks like with EntitySetController:
1: public class MoviesController : EntitySetController<Movie, int>2: {3: List<Movie> _movies = TestData.Movies;4:5: [Queryable]6: public override IQueryable<Movie> Get()7: {8: return _movies.AsQueryable();9: }10:11: protected override Movie GetEntityByKey(int key)12: {13: return _movies[key];14: }15:16: protected override Movie PatchEntity(int key, Delta<Movie> patch)17: {18: Movie movieToPatch = _movies[key];19: patch.Patch(movieToPatch);20: return movieToPatch;21: }22: }Notice how you don’t need [FromODataUri] anymore because EntitySetController has already added it for you on its own action parameters. That’s just one of the several advantages of using EntitySetController as a base class.
Now that we have a working OData service, let’s try out a few requests. If you try a request to http://localhost/odata/Movies(2) with an “application/json” Accept header, you should get a response that looks like this:
1: {2: "odata.metadata": "http://localhost/odata/$metadata#Movies/@Element",3: "ID": 2,4: "Title": "Gladiator",5: "Director": "Ridley Scott",6: "YearReleased": 20007: }On the other hand, if you set an “application/atom+xml” Accept header, you might see a response that looks like this:
1: <?xml version="1.0" encoding="utf-8"?>2: <entry xml:base="http://localhost/odata/" xmlns="http://www.w3.org/2005/Atom" xmlns:d="http://schemas.microsoft.com/ado/2007/08/dataservices" xmlns:m="http://schemas.microsoft.com/ado/2007/08/dataservices/metadata" xmlns:georss="http://www.georss.org/georss" xmlns:gml="http://www.opengis.net/gml">3: <id>http://localhost/odata/Movies(2)</id>4: <category term="MovieDemo.Model.Movie" scheme="http://schemas.microsoft.com/ado/2007/08/dataservices/scheme" />5: <link rel="edit" href="http://localhost/odata/Movies(2)" />6: <link rel="self" href="http://localhost/odata/Movies(2)" />7: <title />8: <updated>2013-01-30T19:29:57Z</updated>9: <author>10: <name />11: </author>12: <content type="application/xml">13: <m:properties>14: <d:ID m:type="Edm.Int32">2</d:ID>15: <d:Title>Gladiator</d:Title>16: <d:Director>Ridley Scott</d:Director>17: <d:YearReleased m:type="Edm.Int32">2000</d:YearReleased>18: </m:properties>19: </content>20: </entry>As you can see, the Json.NET and DataContractSerializer-based responses you’re used to getting when using WebAPI controllers gets replaced with the OData equivalents when you derive from ODataController.

<Return to section navigation list>
Windows Azure Service Bus, Caching Access Control, Active Directory, Identity and Workflow
Haishi Bai (@HaishiBai2010) completed his series with New features in Service Bus Preview Library (January 2013) – 3: Queue/Subscription Shared Access Authorization on 1/29/2013:
This is the last part of my 3-part blog series on the recently released Service Bus preview features.
[This post series is based on preview features that are subject to change]
Queue/Subscription Shared Access Authorization
Service Bus uses Windows Azure AD Access Control (a.k.a. Access Control Service or ACS) for authentication. And it uses claims generated by ACS for authorizations. For each Service Bus namespace, there’s a corresponding ACS namespace of the same name (suffixed with “-sb”). In this ACS namespace, there’s a “owner” server identity, for which ACS issues three net.windows.servicebus.action claims with values Manage, Listen, and Send. These claims are in turn used by Service Bus to authorize user for different operations. Because “owner” comes with all three claims, he is entitled to perform any operations that are allowed by Service Bus. I wrote a blog article talking about why it’s a good practice to create additional server identities with minimum access rights - these additional identities can only perform a limited set of operations that are designated to them.
However, there are still two problems: first, the security scope of these claims are global to the namespace. For example, once a user is granted Listen access, he can listen to any queues and subscriptions. We don’t have granular access control at entity level. Second, identity management is cumbersome as you have to go through ACS and manage service identities. With Service Bus preview features, you’ll be able to create authorization rules at entity (queues and subscriptions) level. And because you can apply multiple authorization rules, you can manage end user access rights separately even if they share the same queue or subscription. This design gives you great flexibility in managing access rights.
Now let’s walk through a sample to see how that works. In this scenario I’ll create two queues for three users: Tom, Jack, and an administrator. Tom has send/listen access to the first queue. Jack has send/listen access to the second queue. In addition, he can also receive messages from the first queue. The administrator can manage both queues. Their access rights are summarized in the following table:



- Create a new Windows Console application.
- Install the preview NuGet package:
install-package ServiceBus.Preview.csharpcode, .csharpcode pre {font-size:small;color:black;font-family:consolas, "Courier New", courier, monospace;background-color:#ffffff;} .csharpcode pre {margin:0em;} .csharpcode .rem {color:#008000;} .csharpcode .kwrd {color:#0000ff;} .csharpcode .str {color:#006080;} .csharpcode .op {color:#0000c0;} .csharpcode .preproc {color:#cc6633;} .csharpcode .asp {background-color:#ffff00;} .csharpcode .html {color:#800000;} .csharpcode .attr {color:#ff0000;} .csharpcode .alt {background-color:#f4f4f4;width:100%;margin:0em;} .csharpcode .lnum {color:#606060;}- Implement the Main() method:
static void Main(string[] args) { var queuePath1 = "sasqueue1"; var queuePath2 = "sasqueue2"; NamespaceManager nm = new NamespaceManager( ServiceBusEnvironment.CreateServiceUri("https", "[Your SB namespace]", string.Empty), TokenProvider.CreateSharedSecretTokenProvider("owner", "[Your secret key]")); QueueDescription desc1 = new QueueDescription(queuePath1); QueueDescription desc2 = new QueueDescription(queuePath2); desc1.Authorization.Add(new SharedAccessAuthorizationRule("ForTom", "pass@word1", new AccessRights[] { AccessRights.Listen, AccessRights.Send })); desc2.Authorization.Add(new SharedAccessAuthorizationRule("ForJack", "pass@word2", new AccessRights[] { AccessRights.Listen, AccessRights.Send })); desc2.Authorization.Add(new SharedAccessAuthorizationRule("ForJack", "pass@word2", new AccessRights[] { AccessRights.Listen })); desc1.Authorization.Add(new SharedAccessAuthorizationRule("ForAdmin", "pass@word3", new AccessRights[] { AccessRights.Manage })); desc2.Authorization.Add(new SharedAccessAuthorizationRule("ForAdmin", "pass@word3", new AccessRights[] { AccessRights.Manage })); nm.CreateQueue(desc1); nm.CreateQueue(desc2); }Okay, that’s not the most exciting code. But it should be fairly easy to understand. For each queue I’m attaching multiple SharedAccessAuthorizationRule, in which I can specify the shared key, as well as assigned rights associated with the rule. And I have implemented desired security policy with few lines of code. These entity-level keys have several advantages (comparing to the two problems stated above): first, they provide fine-granular access control. Second, they are easier to manage. And third, when they are compromised, the damage can be constrained within the scope of affected entity or even affected user only.
This concludes my 3-part blog series on Service Bus preview features. Many thanks to Abhishek Lal for help and guidance on the way, and to the friends on Twitter who helped to get the words out.
Guarav Mantri (@gmantri) posted Windows Azure Access Control Service, Windows 8 and Visual Studio 2012: Setting Up Development Environment – Oh My! on 1/28/2013:
Today I started playing with Windows Azure Access Control Service (ACS) and ran into some issues while making a simple application based on the guide here: http://www.windowsazure.com/en-us/develop/net/how-to-guides/access-control/. I had to search for a number of things on the Internet to finally get it working so I thought I would write a simple blog post which kind of summarizes the issues and how to resolve them.
The problems I ran into were because the guide was focused on Windows 7/Visual Studio 2010 and I was using Windows 8/Visual Studio 2012.
It may very well be documented somewhere but I could not find them and there may be many “newbies” like me who are just starting out with ACS on Windows 8/VS 2012 and hopefully this blog post will save some time and frustration implementing this ridiculously easy and useful technology for implementing authentication in their web applications.
With this thought, let’s start
Windows Identity Foundation Setup
When I downloaded and tried to run the “Windows Identity Foundation” from “Windows Identity Foundation” link from above, I got the following message:
I found the solution for this problem on Windows 8 Community Forums: http://answers.microsoft.com/en-us/windows/forum/windows_8-windows_install/error-when-installing-windows-identity-foundation/6e4c65a5-ea24-431c-b4f0-b8740e97cf46?auth=1. Basically, the solution is that you have to enable WIF through “Turn Windows Feature On/Off” functionality. To do so, go to Control Panel –> Programs and Features –> Turn Windows Feature on or off.
Also once WIF is installed, I was able to install Windows Identity Foundation SDK. Prior to that I was not able to do that as well.
Dude, Where’s My “Add STS Reference” Option!
OK, moving on. After following some more steps to a “T”, I ran into the following set of instructions:
So I followed step 1 but could not find “Add STS Reference” option when I right clicked on the solution in Visual Studio. Back to searching and I found a couple of blog posts:
- http://blogs.infosupport.com/equivalent-to-add-sts-reference-for-vs-2012/
- http://www.stratospher.es/blog/post/add-sts-reference-missing-in-visual-studio-2012-rc
Basically what I needed to do was install “Identity and Access Tool” extension. To do so, just click on Tools –> Extensions and Updates… and search for “Identity” as shown below:
One I installed it, I was a happy camper again
And instead of “Add STS Reference” the options’ name is “Identity and Access”.
Configuring Trust between ACS and ASP.NET Web Application
Next step is configuring trust between ACS and ASP.Net Web Application. The steps provided in the guide were for Visual Studio 2010 and clicking on “Identity and Access…” gave me an entirely different window.
Again this blog post from Haishi Bai came to my rescue: http://haishibai.blogspot.in/2012/08/windows-azure-web-site-targeting-net.html. However one thing that was not clear to me (or consider this my complete ignorance
) is from where I’ll get the management key. I logged into the ACS portal (https://<yourservicenamespace>.accesscontrol.windows.net) and first thought I would find the key under “Certificates and keys” section there (without reading much above. You can understand, I was desperate
As I looked around, I found the “Management service” section under “Administration” section and tried to use the key from there.
Clicked on “Generate” button to create a key and used it and voila it worked
Running The Application
Assuming the worst part was over, I followed remaining steps in the guide and pressed “F5” to run the application. But the application didn’t run
. Instead I got this error:
Again I was at the mercy of search engines
For now, I’m happy with what I’ve got and will focus on building some applications consuming ACS and see what this service has to offer.
Alternative Approach
While working on this, I realized an alternative approach to get up and running with ACS. Here’s what you would need to do:
- Create a new Access Control Service in Windows Azure Portal.
- Once the service is active, click on Manage button to manage that service. You will be taken to the ACS portal for your service.
- Configure Identity Providers.
- Get the management key from “Management service” section.
- Head back to Visual Studio project and configure ACS. You would need the name of the service and the management key.
- The tooling in Visual Studio takes care of creating “Relaying party applications” for you based on your project settings.
Summary
I spent considerable amount of time setting up this thing which kind of frustrated me. I hope this post will save you some time and frustration. Also this is the first time I looked at this service so it is highly likely I may have made some mistakes or included them here based on my sheer ignorance. Please feel free to correct me if I have provided incorrect information.













Toon Vanhoutte described the BizTalk 2013: SB-Messaging Adapter in a 1/28/2013 post:
The BizTalk Server 2013 Beta release comes with the SB-Messaging adapter. This adapter allows our on-premise BizTalk environment to integrate seamlessly with the Windows Azure Service Bus queues, topics and subscriptions. Together with my colleague Mathieu, I had a look at these new capabilities.
Adapter Configuration
The configuration of SB-Messaging receive and send ports is really straightforward. BizTalk just needs these properties in order to establish a connection to the Azure cloud:
- Service Bus URL of the queue, topic or subscription:
sb://<namespace>.servicebus.windows.net/<queue_name>
- Access Control Service STS URI:
https://<namespace>-sb.accesscontrol.windows.net/
- Issuer name and key for the Service Bus Namespace
Content Based Routing
Both Service Bus and BizTalk messaging layer offer a publish-subscribe engine, which allows for content based routing. In BizTalk, content based routing is done through context properties, the Azure Service Bus uses Brokered Message properties. A BizTalk context property is a combination of the propertyName and propertyNamespace. In Azure Service Bus, context properties are only defined by a propertyName. How are these metadata properties passed from the cloud to BizTalk and vice versa?
Sending from BizTalk to Service Bus topic
In order to pass context properties to the Service Bus topic, there’s the capability to provide the Namespace for the user defined Brokered Message Properties. The SB-Messaging send adapter will add all BizTalk context properties from this propertyNamespace as properties to the Brokered Message. Thereby, white space is ignored.
Receiving from Service Bus subscription to BizTalk
Also at the receive adapter, there’s the possibility to pass properties to the BizTalk message context. You can specify the Namespace for Brokered Message Properties, so the SB-Messaging adapter will write (not promote) all Brokered Message properties to the BizTalk message context, within the specified propertyNamespace. Be aware when checking the option Promote Brokered Message Properties, because this requires that a propertySchema is deployed which contains all Brokered Message properties.
Receive Port Message Handling
I was interested in the error handling when an error occurs in the receive adapter or pipeline. Will the message be roll backed to the Azure subscription or suspended in BizTalk? Two fault scenarios were investigated.
Receive adapter unable to promote property in BizTalk context
In this case, we configured the receive port to promote the context properties to a propertyNamespace that did not contain all properties of the Brokered Message. As expected, the BizTalk adapter threw an exception:
- The adapter "SB-Messaging" raised an error message. Details "System.Exception: Loading property information list by namespace failed or property not found in the list. Verify that the schema is deployed properly.
The adapter retried 10 times in total and moved afterwards the Brokered Message to the dead letter queue of the Service Bus subscription. Afterwards, BizTalk started processing the next message.
Receive pipeline unable to parse message body
In this simulation we tried to receive an invalid XML message with the XMLReceive pipeline. After the error occurred, we discovered that the message was suspended (persisted) in BizTalk.
WCF-Adapter Framework
It’s a pity to see that this new adapter is not implemented as a WCF-binding. Due to this limitation, we can’t make use of the great extensibility capabilities of the WCF-Custom adapter. The NetMessagingBinding could be used, but I assume some extensibility will be required in order to transform BizTalk context properties into BrokeredMessageProperty objects and vice versa. Worthwhile investigating…
Conclusion
The BizTalk product team did a great job with the introduction of the SB-Messaging adapter! It creates a lot of new opportunities for hybrid applications.
- Dynamically detect the BizTalk Servers of a BizTalk Group during automated deployment Microsoft BizTalk Server 2010 ships with some assemblies that assist you with the administration…
- BizTalk gets a major release: welcome BizTalk 2013 betaMicrosoft has announced the public release of Microsoft BizTalk Server 2013.
- WCF-custom bindings & the 64-bits version of the BizTalk Adapter Pack for .Net 4.0When installing the 64-bits version of the BizTalk LOB Adapter Pack, you may experience that the bin...



Sandrino di Mattia (@sandrinodm) described working around the “Key not valid for use in specified state” exception when working with the Access Control Service in a 1/27/2013 post:
If you’re using the Windows Azure Access Control Service (or any other STS for that matter) this is an issue you might encounter when your Web Role has more than one instance:
[CryptographicException: Key not valid for use in specified state.]
System.Security.Cryptography.ProtectedData.Unprotect(Byte[] encryptedData, Byte[] optionalEntropy, DataProtectionScope scope) +450
Microsoft.IdentityModel.Web.ProtectedDataCookieTransform.Decode(Byte[] encoded) +150As explained in the Windows Azure Training Kit this is caused by the DPAPI:
What does ServiceConfigurationCreated do?
By default WIF SessionTokens use DPAPI to protect the content of Cookies that it sends to the client, however DPAPI is not available in Windows Azure hence you must use an alternative mechanism. In this case, we rely on RsaEncryptionCookieTransform, which we use for encrypting the cookies with the same certificate we are using for SSL in our website.Over a year ago I blogged about this issue but that solution applies to .NET 3.5/4.0 with Visual Studio 2010. Let’s take a look at how you can solve this issue when you’re working in .NET 4.5.
Creating a certificate
So the the first thing you’ll need to do is create a certificate and upload it to your Cloud Service. The easiest way to do this is to start IIS locally and go to the Server Certificates:
Now click the Create Self-Signed Certificate option, fill in the name, press OK, right click the new certificate and choose “Export…“. The next you’ll need to do is go to the Windows Azure Portal and upload the certificate in the Cloud Service. This is possible by opening the Cloud Service and uploading the file in the Certificates tab:
Copy the thumbprint and add it to the certificates of your Web Role. This is possible by double clicking the Web Role in Visual Studio and going to the Certificates tab:
As a result the certificate will be installed on all instances of that Web Role. Finally open the web.config of your web application and add a reference to the certificate under the system.identityModel.services element:
Creating the SessionSecurityTokenHandler
The last thing we need to do is create a SessionSecurityTokenHandler which uses the certificate. To get started add a reference to the following assemblies:
- System.IdentityModel
- System.IdentityModel.Services
Once you added the required references you can add the following code to your Global.asax file:
This code replaces the current security token handler with a new SessionSecurityTokenHandler which uses the certificate we uploaded to the portal. As of now, all instances will use the same certificate to encrypt and decrypt the authentication session cookie.





<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
Maarten Balliauw (@maartenballiauw) described Running unit tests when deploying to Windows Azure Web Sites in a 1/30/2013 post:
When deploying an application to Windows Azure Web Sites, a number of deployment steps are executed. For .NET projects, msbuild is triggered. For node.js applications, a list of dependencies is restored. For PHP applications, files are copied from source control to the actual web root which is served publicly. Wouldn’t it be cool if Windows Azure Web Sites refused to deploy fresh source code whenever unit tests fail? In this post, I’ll show you how.
Disclaimer: I’m using PHP and PHPUnit here but the same approach can be used for node.js. .NET is a bit harder since most test runners out there are not supported by the Windows Azure Web Sites sandbox. I’m confident however that in the near future this issue will be resolved and the same technique can be used for .NET applications.
Our sample application
First of all, let’s create a simple application. Here’s a very simple one using the Silex framework which is similar to frameworks like Sinatra and Nancy.
1 <?php 2 require_once(__DIR__ . '/../vendor/autoload.php'); 3 4 $app = new \Silex\Application(); 5 6 $app->get('/', function (\Silex\Application $app) { 7 return 'Hello, world!'; 8 }); 9 10 $app->run();
Next, we can create some unit tests for this application. Since our app itself isn’t that massive to test, let’s create some dummy tests instead:
1 <?php 2 namespace Jb\Tests; 3 4 class SampleTest 5 extends \PHPUnit_Framework_TestCase { 6 7 public function testFoo() { 8 $this->assertTrue(true); 9 } 10 11 public function testBar() { 12 $this->assertTrue(true); 13 } 14 15 public function testBar2() { 16 $this->assertTrue(true); 17 } 18 }
As we can see from our IDE, the three unit tests run perfectly fine.

Now let’s see if we can hook them up to Windows Azure Web Sites…
Creating a Windows Azure Web Sites deployment script
Windows Azure Web Sites allows us to customize deployment. Using the azure-cli tools we can issue the following command:
1 azure site deploymentscript
As you can see from the following screenshot, this command allows us to specify some additional options, such as specifying the project type (ASP.NET, PHP, node.js, …) or the script type (batch or bash).

Running this command does two things: it creates a .deployment file which tells Windows Azure Web Sites which command should be run during the deployment process and a deploy.cmd (or deploy.sh if you’ve opted for a bash script) which contains the entire deployment process. Let’s first look at the .deployment file:
1 [config] 2 command = bash deploy.sh
This is a very simple file which tells Windows Azure Web Sites to invoke the deploy.sh script using bash as the shell. The default deploy.sh will look like this:
1 #!/bin/bash 2 3 # ---------------------- 4 # KUDU Deployment Script 5 # ---------------------- 6 7 # Helpers 8 # ------- 9 10 exitWithMessageOnError () { 11 if [ ! $? -eq 0 ]; then 12 echo "An error has occured during web site deployment." 13 echo $1 14 exit 1 15 fi 16 } 17 18 # Prerequisites 19 # ------------- 20 21 # Verify node.js installed 22 where node &> /dev/null 23 exitWithMessageOnError "Missing node.js executable, please install node.js, if already installed make sure it can be reached from current environment." 24 25 # Setup 26 # ----- 27 28 SCRIPT_DIR="$( cd -P "$( dirname "${BASH_SOURCE[0]}" )" && pwd )" 29 ARTIFACTS=$SCRIPT_DIR/artifacts 30 31 if [[ ! -n "$DEPLOYMENT_SOURCE" ]]; then 32 DEPLOYMENT_SOURCE=$SCRIPT_DIR 33 fi 34 35 if [[ ! -n "$NEXT_MANIFEST_PATH" ]]; then 36 NEXT_MANIFEST_PATH=$ARTIFACTS/manifest 37 38 if [[ ! -n "$PREVIOUS_MANIFEST_PATH" ]]; then 39 PREVIOUS_MANIFEST_PATH=$NEXT_MANIFEST_PATH 40 fi 41 fi 42 43 if [[ ! -n "$KUDU_SYNC_COMMAND" ]]; then 44 # Install kudu sync 45 echo Installing Kudu Sync 46 npm install kudusync -g --silent 47 exitWithMessageOnError "npm failed" 48 49 KUDU_SYNC_COMMAND="kuduSync" 50 fi 51 52 if [[ ! -n "$DEPLOYMENT_TARGET" ]]; then 53 DEPLOYMENT_TARGET=$ARTIFACTS/wwwroot 54 else 55 # In case we are running on kudu service this is the correct location of kuduSync 56 KUDU_SYNC_COMMAND="$APPDATA\\npm\\node_modules\\kuduSync\\bin\\kuduSync" 57 fi 58 59 ################################################################################################################################## 60 # Deployment 61 # ---------- 62 63 echo Handling Basic Web Site deployment. 64 65 # 1. KuduSync 66 echo Kudu Sync from "$DEPLOYMENT_SOURCE" to "$DEPLOYMENT_TARGET" 67 $KUDU_SYNC_COMMAND -q -f "$DEPLOYMENT_SOURCE" -t "$DEPLOYMENT_TARGET" -n "$NEXT_MANIFEST_PATH" -p "$PREVIOUS_MANIFEST_PATH" -i ".git;.deployment;deploy.sh" 68 exitWithMessageOnError "Kudu Sync failed" 69 70 ################################################################################################################################## 71 72 echo "Finished successfully." 73
This script does two things: setup a bunch of environment variables so our script has all the paths to the source code repository, the target web site root and some well-known commands, Next, it runs the KuduSync executable, a helper which copies files from the source code repository to the web site root using an optimized algorithm which only copies files that have been modified. For .NET, there would be a third action which is done: running msbuild to compile sources into binaries.
Right before the part that reads # Deployment, we can add some additional steps for running unit tests. We can invoke the php.exe executable (located on the D:\ drive in Windows Azure Web Sites) and run phpunit.php passing in the path to the test configuration file:
1 ################################################################################################################################## 2 # Testing 3 # ------- 4 5 echo Running PHPUnit tests. 6 7 # 1. PHPUnit 8 "D:\Program Files (x86)\PHP\v5.4\php.exe" -d auto_prepend_file="$DEPLOYMENT_SOURCE\\vendor\\autoload.php" "$DEPLOYMENT_SOURCE\\vendor\\phpunit\\phpunit\\phpunit.php" --configuration "$DEPLOYMENT_SOURCE\\app\\phpunit.xml" 9 exitWithMessageOnError "PHPUnit tests failed" 10 echo
On a side note, we can also run other commands like issuing a composer update, similar to NuGet package restore in the .NET world:
1 echo Download composer. 2 curl -O https://getcomposer.org/composer.phar > /dev/null 3 4 echo Run composer update. 5 cd "$DEPLOYMENT_SOURCE" 6 "D:\Program Files (x86)\PHP\v5.4\php.exe" composer.phar update --optimize-autoloader 7
Putting our deployment script to the test
All that’s left to do now is commit and push our changes to Windows Azure Web Sites. If everything goes right, the output for the git push command should contain details of running our unit tests:

Here’s what happens when a test fails:

And even better, the Windows Azure Web Sites portal shows us that the latest sources were commited to the git repository but not deployed because tests failed:

As you can see, using deployment scripts we can customize deployment on Windows Azure Web Sites to fit our needs. We can run unit tests, fetch source code from a different location and so on







Don Noonan described Using Windows Azure Virtual Machines to Learn: Networking Basics in a 1/29/2013 post:
Until recently I’ve used a personal hypervisor to experiment and learn new Windows technologies. Over the past few years my personal productivity machines have become more like mini datacenters – tons of cores, memory and storage. You know how it is, you go shopping for a new sub 2 pound / $1K notebook and by the time you click “add to cart” it gained about 4 pounds and $3K.
Enter Windows Azure. With only a browser and an RDP client I can spin up and manage just about anything. In other words, I could get away with an old PC or even a thin client and get out of the personal datacenter business. That $3K notebook just turned into a couple years of compute and storage in a real datacenter.
Don’t already have a Windows Azure account? Go here for a free trial.
Anyway, speaking of experimenting in the cloud, let’s talk about networking in Windows Azure Virtual Machines…
Did I just see a server with a DHCP-assigned IP address?
Windows Azure introduces a new concept when it comes to networking – DHCP for everything regardless of workload. That’s right, even servers are assigned IP addresses via DHCP. This comes as a surprise to hard core server admins. We have become religious about our IP spreadsheets, almost charging people when asked for one of our precious intranet addresses. Like labeling our network cables, this is another thing we’re going to have to let go when migrating workloads to the cloud.
The platform is now our label maker. As long as a virtual machine exists, it will be assigned the same IP address. Wait a minute, I thought DHCP only leased IP addresses out for a finite amount of time. What happens when the lease expires? Well, let’s find out when our lease is up on my domain controller using ipconfig /all:
Wow. Our virtual machine has a lease on 10.1.1.4 for over 100 years. I think we’re good. Even still, the platform automatically renews the lease for a given virtual machine.
What’s the point of subnetting in Windows azure?
Most of the time we subnet to segregate tiers of a service, floors of a building, roles in an organization, or simply to make good use of a given address range. In Windows Azure, I typically use subnets when defining service layers:
In this case we have a simple 3-tier application that uses classic Windows authentication. There is a management subnet containing the domain controllers, a database subnet with SQL servers, and an application subnet with the web front ends.
Here is another type of deployment where we simply wanted to isolate virtual classrooms from each other:
The deployment shared a common Active Directory, however each classroom had its own instructor and students.
What can I do with subnets once they’re created?
Once you have defined your subnets and their services, you can secure those services by applying Windows Firewall rules and settings in a consistent manner. For example, you can define rules where servers on the application subnet (10.1.3.0) should only be able to reach the database subnet (10.1.2.0), and only over ports relevant to the SQL Server database engine service instance (i.e. TCP 1433).
In other words, subnetting in Windows Azure allows you to organize objects in the cloud for many of the same reasons you do on-premise. In this case we’re using it to contain similar services and create logical boundaries to simplify firewall configuration settings. When you create a consistent deployment topology for cloud services in Windows Azure Virtual Machines, you can then take advantage of other Windows technologies such as WMI Filters and Group Policy to automate and apply consistent security settings.
We’ll talk about applying role-specific firewall settings via Group Policy in a future blog.
Don’t already have a Windows Azure account? Go here for a free trial.




Mark Gayler (@MarkGayler) offered Congratulations on the latest development for OVF! in a 1/29/2013 post to the Interoperability @ Microsoft blog:
Interoperability in server and cloud space has found even more evidence with the release announcement of Open Virtualization Format (OVF) 2.0 standard. We congratulate DMTF for this new milestone, a further proof that customers and industry partners care deeply about interoperability and we are proud of our participation to advance this initiative.
Browsing the OVF 2.0 standards specification, it is evident the industry is aligning around common scenarios and it comes as a pleasant surprise how some of those emerging scenarios have been driving our own thinking in the direction for System Center.
Microsoft has collaborated closely with Distributed Management Task Force (DMTF) and our industry partners to ensure OVF provides improved capabilities for virtualization and cloud interoperability scenarios to the benefit of customers.
OVF 2.0 and DMTF are making progress on key emerging patterns for portability of virtual machines and systems, and it’s nice to see OVF being driven by the very same emerging use cases we have been analyzing with our System Center VMM customers such as shared Hyper-V host clusters, encryption for credential management and virtual machine boot order management (not to mention network virtualization, placement groups and multi-hypervisor support).
Portability in the cloud and interoperability of virtualization technologies across platforms using Linux and Windows virtual machines continues to be important to Microsoft and to our customers and are increasingly becoming key industry trends. We continue to assess and improve interoperability for core scenarios using the SC 2012 VMM. We also believe moving in this direction will provide great benefit to our customer and partner eco-system, as well as bring real-world experience to our participation with OVF in DMTF.
See the overview for further details and other enhancements in System Center 2012 VMM.



Vittorio Bertocci (@vibronet) described Running WIF Based Apps in Windows Azure Web Sites in a 1/28/2013 post:
It’s official: I am getting old. I was ab-so-lu-te-ly convinced I already blogged about this, but after the nth time I got asked about this I came to find the link to the post only to find pneumatic vacuum in its place. No joy on the draft folder either… oh well, this won’t take too long to (re?)write anyway. Moreover: in a rather anticlimactic move, I am going to give away the solution right at the beginning of the post.
Straight to the Point
In order to run in Windows Azure Web Sites a Web application which uses WIF for handling authentication, you must change the default cookie protection method (DPAPI, not available on Windows Azure Web Sites) to something that will work in a farmed environment and with the IIS’ user profile load turned off. Sounds like Klingon? Here there’s some practical advice:
- If you are using the Identity and Access Tools for VS2012, just go to the Configuration tab and check the box “Enable Web farm ready cookies”
- If you want to do things by hand, add the following code snippet in your system.identitymodel/identityConfiguration element:
1: <securityTokenHandlers>2: <add type="System.IdentityModel.Services.Tokens.MachineKeySessionSecurityTokenHandler,
System.IdentityModel.Services, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" />3: <remove type="System.IdentityModel.Tokens.SessionSecurityTokenHandler,
System.IdentityModel, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" />4: </securityTokenHandlers>I know, it’s clipped and wrapped badly: eventually I’ll change the blog theme. For the time being, you can copy & paste to see the entire thing.
Note, the above is viable only if you are targeting .NET 4.5 as it takes advantage of a new feature introduced only in the latest version. If you are on .NET 4.0 WIF 1.0 offers you the necessary extensibility points to reproduce the same capability (more details below) however there’s nothing ready out of the box (you could however take a look at the code that Dominick already nicely wrote for you here).
Now that I laid down the main point, in the next section I’ll shoot the emergency flare that will lead your search engine query here.
Again, Adagio
Let’s go through a full cycle of create a WIF app -> deploy it in Windows Azure Web Sites –> watch it fail –> fix it –> verify that it works.
Fire up VS2012, create a web project (I named mine “AlphaScorpiiWebApp”, let’s see who gets the reference ;-)) and run the Identity and Access Tools on it. For the purpose of the tutorial you can pick the local development STS option. Hit F5, and verify that things work as expected (== the Web app will greet you as ‘Terry’).
Did it work? Excellent. Let’s try to publish to Windows Azure Web Site and see what happens. But before we hit Publish, we need to adjust a couple of things. Namely, we need to ensure that the application will communicate to the local development STS the address it will have in Windows Azure Web Sites, rather than the one on localhost:<port> automatically assigned (ah, please remind me to do a post about realm vs. network addresses). That’s pretty easy: go back to the Identity & Access tool, head to the Configure tab, and paste in the Realm and Audience fields the URL of your target Web Site.
Given what we know, we better turn off the custom errors before publishing (usual <customErrors mode="Off">under system.web).
Done that, go ahead and publish. My favorite route is through the Publish… entry in the Solution Explorer, I have a .PublishSettings file I import every time. Ah, don’t forget to check the option “Remove additional files at destination”.
Ready? Hit Publish and see what happens.
Boom! As expected, the authentication fails. Let me paste the error message here, for the search engines’ benefit.
Server Error in '/' Application.
The data protection operation was unsuccessful. This may have been caused by not having the user profile loaded for the current thread's user context, which may be the case when the thread is impersonating.
Description: An unhandled exception occurred during the execution of the current web request. Please review the stack trace for more information about the error and where it originated in the code.
Exception Details: System.Security.Cryptography.CryptographicException: The data protection operation was unsuccessful. This may have been caused by not having the user profile loaded for the current thread's user context, which may be the case when the thread is impersonating.
Source Error:
An unhandled exception was generated during the execution of the current web request. Information regarding the origin and location of the exception can be identified using the exception stack trace below.Stack Trace:
[CryptographicException: The data protection operation was unsuccessful. This may have been caused by not having the user profile loaded for the current thread's user context, which may be the case when the thread is impersonating.] System.Security.Cryptography.ProtectedData.Protect(Byte[] userData, Byte[] optionalEntropy, DataProtectionScope scope) +379 System.IdentityModel.ProtectedDataCookieTransform.Encode(Byte[] value) +52 [InvalidOperationException: ID1074: A CryptographicException occurred when attempting to encrypt the cookie using the ProtectedData API (see inner exception for details). If you are using IIS 7.5, this could be due to the loadUserProfile setting on the Application Pool being set to false. ] System.IdentityModel.ProtectedDataCookieTransform.Encode(Byte[] value) +167 System.IdentityModel.Tokens.SessionSecurityTokenHandler.ApplyTransforms(Byte[] cookie, Boolean outbound) +57 System.IdentityModel.Tokens.SessionSecurityTokenHandler.WriteToken(XmlWriter writer, SecurityToken token) +658 System.IdentityModel.Tokens.SessionSecurityTokenHandler.WriteToken(SessionSecurityToken sessionToken) +86 System.IdentityModel.Services.SessionAuthenticationModule.WriteSessionTokenToCookie(SessionSecurityToken sessionToken) +148 System.IdentityModel.Services.SessionAuthenticationModule.AuthenticateSessionSecurityToken(SessionSecurityToken sessionToken, Boolean writeCookie) +81 System.IdentityModel.Services.WSFederationAuthenticationModule.SetPrincipalAndWriteSessionToken(SessionSecurityToken sessionToken, Boolean isSession) +217 System.IdentityModel.Services.WSFederationAuthenticationModule.SignInWithResponseMessage(HttpRequestBase request) +830 System.IdentityModel.Services.WSFederationAuthenticationModule.OnAuthenticateRequest(Object sender, EventArgs args) +364 System.Web.SyncEventExecutionStep.System.Web.HttpApplication.IExecutionStep.Execute() +136 System.Web.HttpApplication.ExecuteStep(IExecutionStep step, Boolean& completedSynchronously) +69
Version Information: Microsoft .NET Framework Version:4.0.30319; ASP.NET Version:4.0.30319.17929What happened, exactly? It’s a well-documented phenomenon. By default, WIF protects cookies using DPAPI and the user store. When your app is hosted in IIS, its AppPool must have a specific option enabled (“Load User Profile”) in order for DPAPI to access the user store. In Windows Azure Web Sites, that option is off (with good reasons, it can exact a heavy toll on memory) and you can’t turn it on. But hey, guess what: even if you could, that would be a bad idea anyway. The default cookie protection mechanism is not suitable for load balanced scenarios, given that every node in the farm will have a different key: that means that a cookie protected by one node would be unreadable from the other, breaking havoc with your Web app session.
What to do? In the training kit for WIF 1.0 we provided custom code for protecting cookies using the SSL certificate of the web application (which you need to have anyway) – however that is an approach more apt to the cloud services (where you have full control of your certs) rather than WA Web Sites (where you don’t). Other drawbacks included the sheer amount of custom (code required (not staggering, but non-zero either), its complexity (still crypto) and the impossibility of making it fully boilerplate (it had to refer to the coordinates of the certificate of choice).
In WIF 4.5 we wanted to support this scenario out of the box, without requiring any custom code. For that reason, we introduced a cookie transform class that takes advantage of the MachineKey, and all it needs to opt in is a pure boilerplate snippet to be added in the web.config. Sometimes I am asked why we didn't change that to be the default, to which I usually answer: I have people waiting for me at the cafeterias to yell at me for having moved classes under different namespaces (sorry, that’s the very definition of “moving WIF into the framework” :-)), now just imagine what would have happened if we would have changed the defaults :-D.More seriously: you already know what the fix is: it’s one of the two methods described in the “Straight to the Point” section. Apply one of those, then re-publish. You’ll be greeted by the following:
We are Terry again, but this time, as you might notice in the address bar… in the cloud!






Chris Avis described The 31 Days of Servers in the Cloud using Azure IaaS…. in a 1/26/2013 post to the TechNet blogs:
Hiya folks! You probably know that I am a Technology Evangelist (TE) on the US Developer and Platform Evangelism (DPE) team. What you may not know is that there are 12 of us in the United States that are a part of this team (I have linked each of them in the list on the right side of my blog). We have been working on a series of blog posts called “The 31 Days of Servers in the Cloud”. This is a series of posts about leveraging the new VM Role in windows Azure. You may also hear this referred to as Azure IaaS.
Thus far there have been 25 Posts made in the series covering a broad set of topics. There are topics ranging from a basic introduction to Azure IaaS and what it means to you to more specific topics like using PowerShell to create and manage VM’s in Azure. we are laying the groundwork in this series to get you up to speed on using Windows Azure IaaS as another tool for you to build and manage your infrastructure.
If you would like to learn more about Azure IaaS, I encourage you to sign up for a 90 Day Free Trial of Windows Azure!
I also recommend you book mark my blog post and check back each day as we add the final posts to the series! Here is what we have so far….
- Part 1 - 31 Days of Servers in the Cloud: Windows Azure IaaS and You
- Part 2 - 31 Days of Servers in the Cloud: Building Free Lab VMs in the Microsoft Cloud
- Part 3 - 31 Days of Servers in the Cloud: Supported Virtual Machine Operating Systems in the Microsoft Cloud
- Part 4 - 31 Days of Servers in the Cloud: Servers Talking in the Cloud
- Part 5 - 31 Days of Servers in the Cloud: Move a local VM to the Cloud
- Part 6 - 31 Days of Servers in the Cloud: Windows Azure Features Overview
- Part 7 - 31 Days of Servers in the Cloud: Step-by-Step: Build a FREE SharePoint 2013 Lab in the Cloud with Windows Azure
- Part 8 – 31 Days of Servers in the Cloud: Setting up Management (Certs and Ports)
- Part 9 – 31 Days of Servers in the Cloud: Windows Azure and Virtual Networking….What it is
- Part 10 – 31 Says of Servers in the Cloud - Windows Azure and Virtual Networking – Getting Started–Step–by-Step
- Part 11 – 31 Days of Servers in the Cloud - Step-by-Step: Running FREE Linux Virtual Machines in the Cloud with Windows Azure
- Part 12 – 31 Days of Servers in the cloud - Step-by-Step: Connecting System Center 2012 App Controller to Windows Azure
- Part 13 – 31 Days of Servers in the Cloud - Creating Azure Virtual Machines with App Controller
- Part 14 – 31 Days of Servers in the Cloud – How to: Create an Azure VM using PowerShell
- Part 15 – 31 Days of Servers in the Cloud - What Does Windows Azure Cloud Computing REALLY Cost + How to SAVE
- Part 16 – 31 Days of Servers in the Cloud - Consider This, Reasons for Using Windows Azure IaaS
- Part 17 – 31 Days of Servers in the Cloud - Step-by-Step: Templating VMs in the Cloud with Windows Azure and PowerShell
- Part 18 – 31 Days of Servers in the Cloud – How to Delete VHD files in Azure
- Part 19 – 31 Days of Servers in the Cloud - Create a Windows Azure Network Using PowerShell
- Part 20 – 31 Days of Servers in the Cloud - Step-by-Step: Extending On-Premise Active Directory to the Cloud with Windows Azure
- Part 21 – 31 Days of Servers in the Cloud – Beyond IaaS for the IT Pro
- Part 22 – 31 Days of Servers in the Cloud - Using your own SQL Server in Windows Azure
- Part 23 – 31 Days of Servers in the Cloud – Incorporating AD in Windows Azure
- Part 24 – 31 Days of Servers in the Cloud - Connecting Windows Azure PaaS to IaaS
- Part 25 – 31 Days of Servers in the Cloud - Using System Center 2012 SP1 to Store VM’s in Windows Azure
- Part 26 – 31 Days of Servers in the Cloud - Monitoring and Troubleshooting on the Cheap (Meaning: Without System Center)
- Part 27 – 31 Days of Servers in the Cloud - Using Windows Azure VMs to learn: Windows Server 2012 Storage
- Part 28 – 31 Days of Servers in the Cloud – Introduction to Windows Azure Add-Ons from the Windows Azure Store
- Part 29 – 31 Days of Servers in the Cloud - Using Windows Azure VMs to learn: Networking Basics (DHCP, DNS)
- Part 30 – 31 Days of Servers in the Cloud - Using Windows Azure VMs to learn: RDS
- Part 31 – 31 Days of Servers in the Cloud - Our favorite other resources (Links to How-Tos, Guides, Training Resources)
As you can see, we still have 8 more posts to make in the series so check back each day to see what we have added!



<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Avkash Chauhan (@avkashchauhan) described Using Fiddler to decipher Windows Azure PowerShell or REST API HTTPS traffic in a 1/30/2013 post:
If you are using publishsettings with Powershell, you might not be able to decrypt HTTPS traffic. Not sure what the problem is with publishsettings based certificates however I decided to create my own certificate using MAKECERT, and use it with Powershell to get HTTPS decryption working in Fiddler. The following steps are described based on my successful testing:
Step 1: First you would need to create using MAKECERT (Use VS2012 developer command prompt)
makecert -r -pe -n "CN=Avkash Azure Management Certificate" -a sha1 -ss My -len 2048 -sy 24 -b 09/01/2011 -e 01/01/2018
Step 2: Once certificate is created it will be listed in your Current User > Personal (My) store as below:
(Launch > Certmgr.msc to open the certificate mmc in Windows)
Step 3: Get the certificate Thumbprint ID and Serial Number (used in Step #13 to verify) from the certificate as below:
Thumbprint: 55c96e885764055d9beccec34dcd1ea82e601d4b
Serial Number: 85928750c5d9229d437287103ee08a79
Step 4: Now export this certificate to BASE 64 encoded certificate as below an save as CER file locally:
Step 5: Now upload your above created certificate (avkashmgmtBase64.cer) to your Windows Azure Management Portal. Be sure that the same certificate is listed as below:
Step 6: Be sure to have your Fiddler setting configure to decrypt HTTPS traffic as described here:
http://www.fiddler2.com/Fiddler/help/httpsdecryption.asp
Step 7: I would assume that you already have Fiddler installed in your machine. Now create a new copy of avkashmgmtBase64.cer as ClientCertificate.cer.
Copy this certificate @ C:\Users\<Your_User_Name>\Documents\Fiddler2\ ClientCertificate.cer
This is the certificate will be used by Fiddler to decrypt the HTTPS traffic. This is very important step.
Step 8: Now if you have already used Azure Powershell before with publishsettings then you would need to clear those settings. These files are generated every time Windows Azure Powershell connects to Management Portal with different credentials.
Go to the following folder and remove all the files here:
C:\Users\<Your_user_name>\AppData\Roaming\Windows Azure Powershell
Note: if you have Powershell settings based on previous publishsettings configuration this step is must for you.
Step 9: Now create a powershell script and using your certificate Thumbprint which you have collected in step #3 above:
$subID = "_your_Windows_Azure_subscription_ID"
$thumbprint = "55c96e885764055d9beccec34dcd1ea82e601d4b"
$myCert = Get-Item cert:\\CurrentUser\My\$thumbprint
$serviceName = "_provide_some_Azure_Service_Name"
Set-AzureSubscription –SubscriptionName "_Write_Your_Subscription_Name_Here_" -SubscriptionId $subID -Certificate $myCert
Get-AzureDeployment $serviceName
Step 10: Run the above powershell script without without Fiddler running and verify that it is working.
Step 11: Once step #10 is verified, start Fiddler and check HTTP decryption is enabled.
Step 12: Run the powershell again and you will see that HTTPS traffic shown in the Fiddler shows decrypted data.
Step 13: To verify that you are using the correct certificate with Fiddler, what you can do is to open the first connect URL (Tunnel to -> management.core.windows.net:443) and select its properties. In the new windows you can verify that
X-CLIENT_CERT is using the same certificate name which you have created and its serial number match which you have collected in step #3.
Many thanks to Bin Du, Phil Hoff, Daniel Wang (AZURE) for helping me to get it working.







Business Wire reported Genetec Unveils Stratocast: A New Affordable and Easy-to-Use Cloud-Based Video Surveillance Solution on Windows Azure on 1/30/2013:
Genetec™, a pioneer in the physical security industry and a leading provider of world-class unified IP security solutions, today announced Stratocast™, a powerful yet easy-to-use Video Surveillance as a Service (VSaaS) solution powered by Microsoft Corp.'s Windows Azure cloud-computing platform. Stratocast is designed to meet the needs of small and midsized businesses who are looking for a high-end and extremely reliable video security solution without the costs and complexities typically associated with installing and managing on-premise surveillance systems.
MarketWire reported SiSense Expands Its Big Data Cloud Offering, Adds Support for Windows Azure on 1/30/2013:
SiSense and Microsoft Corp. announced today that they are working together to add Windows Azure to SiSense Cloud offer. By installing SiSense on Windows Azure, customers can enjoy the benefits of the company's software in the Cloud as they did on-premises.
And see below:
Andrew Brust (@andrewbrust) asserted “Microsoft is still entering the Big Data Arena. SiSense has fewer than 50 employees. But the two companies' partnership has serious ramifications for cloud analytics” in a deck for his SiSense and Microsoft bring Big Data analytics to the Windows Azure cloud article for ZDNet’s Big Data blog:
Last June, when Microsoft announced a new infrastructure as a service (IaaS) option on its Windows Azure cloud platform, it became much more competitive with Amazon EC2 as a platform for Software as a Service (SaaS) solutions. On the NoSQL side, companies like MongoLab and Cloudant added Azure data centers as deployment targets right alongside their EC2 counterparts.
Today that list of data service providers has grown to include Redwood City, CA and Tel Aviv-based SiSense, and its Prism BI and Big Data Analytics technology. This development has impact on BI, Big Data, Microsoft and the cloud in general, and they’re worth pointing out.
The offering
SiSense’s “ElastiCube” technology is based on a combination columnar database and data visualization platform.
- In common with in-memory technologies like SAP HANA, Prism uses column store technology to make short work of data analysis. But since SiSense uses a hybrid disk-and-memory approach, it runs just fine on conventional servers with conventional (and more affordable) amounts of RAM. A memory-only product like HANA needs much beefier infrastructure.
SiSense Prism also competes with the likes of Tableau and QlikView, which offer data visualization and dashboarding alongside columnar data engines. But QlikView, along with Tableau when used with its built-in engine, can hit limits in scale that SiSense is not vulnerable to. Granted, Tableau can query its data sources directly to avoid such limits, but that can make things more complex, especially in the cloud.
- SiSense licensing is offered on a subscription basis, featuring costs correlated with the number of users. You can install SiSense yourself, on your own servers, on Windows-based Amazon EC2 instances and now on Windows Azure persistent Virtual Machines (VMs). SiSense will support you in all three scenarios.
SiSense’s combination of subscription-based licensing and do-it-yourself (DIY) installation is somewhat unusual. Typically, SaaS-based products put a black box around the infrastructure and give you a Web-based portal to provision your service and get up-and-running. You can hire SiSense to make things more turn-key for you if you want them to, but the installation is pretty straightforward, especially for personnel comfortable with provisioning VMs in the cloud.
To the cloud, and back
But on the Windows Azure platform, the DIY approach has some interesting ramifications. Windows Azure VMs are based on the same format and technology as its Hyper-V on-premises virtualization platform. This means that you can set up SiSense in an on-prem virtualized environment, then move it to the cloud. Or you could do the reverse. Or, by cloning a VM image, you could do both. Or you could change your mind and migrate between cloud and data center, repeatedly.The plot thickens. One issue with BI and Big Data analytics in the cloud is that getting the data to the cloud can be slow and difficult. But for SiSense customers who are already on the Windows Azure platform, and who are keeping some or all of their data in Azure SQL Database (Or SQL Server on an Azure VM), SiSense can read that data quickly. And if the SiSense VM is provisioned in the same data center as the source database(s), customers should be able to avoid data egress charges as well. (Note that this is my own conclusion, and not a selling point conveyed by SiSense.)
So SiSense offers in-memory analytics, with on-prem-to-cloud and cloud-to-on-prem portability, and because it’s not a black box SaaS offering, it can take advantage of data locality and the performance and economic benefits therein.
What would Redmond do?
But what about Microsoft? Its PowerPivot and Analysis Services Tabular mode engines offer column store, in-memory analytics much like SiSense’s and its Power View technology offers interactive data visualization and exploration, which is not unlike SiSense’s. But Microsoft doesn’t offer PowerPivot and Power View as a service on Azure, and yet here it is partnering with SiSense to offer that company’s competing offering. What gives?If we put aside the fact that SiSense’s VP of Marketing, Bruno Aziza, was for many years on the BI team at Microsoft, which I think we should, then there are a couple of important conclusions to draw:
- The IaaS push on Windows Azure is all about agnosticism: you can run most major NoSQL databases instead of Azure SQL Database, and you can do so on Linux as well as Windows. You can host applications written in any number of programming languages (including Java, Node.js, Python and PHP), not just code created in Microsoft’s .NET development environment. And now you can run competing analytics stacks too. Why not? Windows Azure seeks to be a general purpose infrastructure environment. To be competitive, it has to do that.
- The Microsoft Data Platform Group, which is an outgrowth of the SQL Server team, is embracing interoperability. Use Microsoft analytics products with non-Microsoft data sources, or use non-Microsoft analytics products with SQL Database and SQL Server as data sources. You’ll need SQL Server licenses or SQL Database subscriptions or HDInsight/Hadoop services in any case. It’s all good.
Big Cloud
What does this mean for the Big Data analytics world? First, analytics is going mainstream, and can be OpEx-funded through subscription offerings. Second, analytics in the cloud is becoming very practical and can be co-located with transactional databases in the cloud, thus mitigating issues of broadband limits and latency.Microsoft is still entering the Big Data Arena. SiSense has fewer than 50 employees. The partnership may seem of small significance. But its ramifications are Big.


Ryan Dunn (@dunnry) described the Anatomy of a Scalable Task Scheduler in a 1/29/2013 post:
On 1/18 we quietly released a version of our scalable task scheduler (creatively named 'Scheduler' for right now) to the Windows Azure Store. If you missed it, you can see it in this post by Scott Guthrie. The service allows you to schedule re-occurring tasks using the well-known cron syntax. Today, we support a simple GET webhook that will notify you each time your cron fires. However, you can be sure that we are expanding support to more choices, including (authenticated) POST hooks, Windows Azure Queues, and Service Bus Queues to name a few.
In this post, I want to share a bit about how we designed the service to support many tenants and potentially millions of tasks. Let's start with a simplified, but accurate overall picture:
We have several main subsystems in our service (REST API façade, CRON Engine, and Task Engine) and additionally several shared subsystems across additional services (not pictured) such as Monitoring/Auditing and Billing/Usage. Each one can be scaled independently depending on our load and overall system demand. We knew that we needed to decouple our subsystems such that they did not depend on each other and could scale independently. We also wanted to be able to develop each subsystem potentially in isolation without affecting the other subsystems in use. As such, our systems do not communicate with each other directly, but only share a common messaging schema. All communication is done over queues and asynchronously.
REST API
This is the layer that end users communicate with and the only way to interact with the system (even our portal acts as a client). We use a shared secret key authentication mechanism where you sign your requests and we validate them as they enter our pipeline. We implemented this REST API using Web API. When you interact with the REST API, you are viewing fast, lightweight views of your scheduled task setup that reflects what is stored in our Job Repository. However, we never query the Job Repository directly to keep it responsive to its real job - providing the source data for the CRON Engine.
CRON Engine
This subsystem was designed to do as little as possible and farm out the work to the Task Engine. When you have an engine that evaluates cron expressions and fire times, it cannot get bogged down trying to actually do the work. This is a potentially IO-intensive role in the subsystem that is constantly evaluating when to fire a particular cron job. In order to support many tenants, it must be able run continuously without bogging down in execution. As such, this role only evaluates when a particular cron job must run and then fires a command to the Task Engine to actually execute the potentially long running job.
Task Engine
The Task Engine is the grunt of the service and it performs the actual work. It is the layer that will be scaled most dramatically depending on system load. Commands from the CRON Engine for work are accepted and performed at this layer. Subsequently, when the work is done it emits an event that other interested subsystems (like Audit and Billing) can subscribe to downstream. The emitted event contains details about the outcome of the task performed and is subsequently denormalized into views that the REST API can query to provide back to a tenant. This is how we can tell you your job history and report back any errors in execution. The beauty of the Task Engine emitting events (instead of directly acting) is that we can subscribe many different listeners for a particular event at any time in the future. In fact, we can orchestrate very complex workflows throughout the system as we communicate to unrelated, but vital subsystems. This keeps our system decoupled and allows us to develop those other subsystems in isolation.
Future Enhancements
Today we are in a beta mode, intended to give us feedback about the type of jobs, frequency of execution, and what our system baseline performance should look like. In the future, we know we will support additional types of scheduled tasks, more views into your tasks, and more complex orchestrations. Additionally, we have setup our infrastructure such that we can deploy to to multiple datacenters for resiliency (and even multiple clouds). Give us a try today and let us know about your experience.


Chris Avis posted 31 Days of Servers in the Cloud: Introduction to Windows Azure Add-Ons from the Windows Azure Store… in a 1/28/2013 post to the TechNet blogs:
For this installment in the 31 Days of Servers in the Cloud, I want to spend some time introducing you to the Windows Azure Store and Windows Azure Add-Ons.
Much like we can do with our on-premise servers, be that physical or virtual, getting the server up and running is only the first part of the process. Usually the server is being built out for a reason – to become a mail server, store files and data for a department, or provide infrastructure services like DNS, DHCP and our long time friend WINS. But there are countless “add-ons” that have been developed over the years to provide additional features and functionality to those servers. We normally call these add-ons “applications” or “tools”. But ultimately, all of these applications and tools, modify or extend the functionality of the servers we install them to. The good ones actually add something useful on to the server. Things like shell enhancements, management tools, full blown services and just plain cool things to make working with the servers easier or even fun.
Windows Azure is no different.
We (Microsoft) recently announced the availability of some new add-ons that are now available through the Windows Azure Store. That’s right, Windows Azure has a store! The Windows Azure Store (let’s call it the WAS), lets you add features and services to your Azure cloud applications simply and easily. There are already a number of add-ons available through the store. let’s take a look!
Hopefully, you have spent some time getting to know Windows Azure. If not, you can sign up for a FREE 90 Day Trial to Windows Azure right now!
For those that have been playing with Windows Azure, you have probably seen the Add-Ons link in your Azure Management Portal -
Until recently though, there has been anything there to look at. Now when you click on the Add-Ons link, you have access to the WAS where you can “purchase” add-ons. I put purchase in quotes because many of the apps have free trial modes so you can check them out before committing to buy.
Once you get into the Store, you get a listing of the Add-ons available. Currently they are broken into two categories –
App Services - which provide a number of services like monitoring and analytics of your Azure based cloud apps, full MongoDB and MySQLDB implementations, and even email services.
…and Data – for parsing data from a variety of sources like address searches, text translation, and of course, the Bing Search API.
Adding the services is very easy. After clicking on the Add-Ons link in your Azure Management Portal, you will be presented with a list of currently enabled add-ons. in my case, I have not activated anything yet so I am being prompted to Purchase Add-Ons…
Next you will be presented a list of available Add-Ons. From here it is a simple 3-Step process to add and Add-On.
Step 1 – Choose the Add-On - I am going to add the Bing Search API…
Step 2 – Personalize your add-on – Depending on the add-on, you will have some basic information you can alter – The billing options and promotional codes (if any), the name you will use for the app in your Windows Azure instance, and the Region…
Step 3 – Review Purchase – This is a summary of options, definition of legal terms and/or EULA, and the purchase…
Now when you select your Add-Ons menu item, you see Windows Azure creating and enabling the add-on…
Once the status changes from Creating… to Started, you can select an add-on to make changes to its configuration. Most of the Add-Ons will have a Dashboard View where you can quickly look at current configurations, transaction data, and find links to support and other documentation….
In the case of the Bing Search API, there is also an API explorer that lets you look at what API resources are available for the Add-On….
This example is obviously a little more focused on developers. Which leads us to where to get more information if you are interested in developing an add-on yourself. You can download the Windows Azure Store SDK hosted on github.
If you are a Startup and you hurry (There is a Feb 3rd, 2013 Deadline!), you can Apply for the Azure 2013 Microsoft Accelerator for Windows Azure Program. This program is designed to incubate startups that are building apps in the cloud. There is an opportunity for equity investment, co-location space, access to mentors and technical support, and a chance to demo your results to investors.
Wrapping it up….
For now, the Windows Azure Store is only available in a limited number of regions (US, UK, Canada, Denmark, France, Germany, Ireland, Italy, Japan, Spain, and South Korea). But you can expect that to change over the next few weeks and months.
For even more information on the Windows Azure Store and Windows Azure Add-Ons, see the following resources -
- Scott Guthrie’s Blog – Windows Azure Store: New add-ons and expanded availability
- //build/2012 – Windows Azure presentations: Find out more information about Windows Azure from the presentations delivered and the //build/2012 Conference.
- Windows Azure Blog: The latest and greatest information and announcements about all this Windows Azure.
- Windows Azure Events: Find and event in your area (or one you would like to travel to!) to get more information about Windows Azure.
- Windows Azure Partners: Need a qualified Windows Azure vendor to help with a project? Or….Are you a Windows Azure expert? Want to become a partner? Join here!
- Windows Azure Learning Resources: Are you an Educator? Student? Looking for get certified? Start here!













Avkash Chauhan (@avkashchauhan) reported Executing Powershell commands in Windows Azure Web or Worker Role VM Instance return[s an] exception in a 1/28/2013 post:
When trying to run Windows Azure Powershell commands in Windows Azure VM (Web Role or Worker Role) instance you will hit the following exception:
PS D:\Users\avkash> Add-PSSnapin Microsoft.WindowsAzure.ServiceRuntimeAdd-PSSnapin : Cannot add Windows PowerShell snap-in Microsoft.WindowsAzure.ServiceRuntime because it is already added.
Verify the name of the snap-in and try again.
At line:1 char:13
+ Add-PSSnapin <<<< Microsoft.WindowsAzure.ServiceRuntime
+ CategoryInfo : InvalidArgument: (Microsoft.WindowsAzure.ServiceRuntime:String) [Add-PSSnapin], PSArgume ntException
+ FullyQualifiedErrorId : AddPSSnapInRead,Microsoft.PowerShell.Commands.AddPSSnapinCommandThe reason for this exception is conflict between Powershell version required by Windows Azure runtime components. AS you can see below the PS version is incorrectly set in the Azure role instance VM:
To solve this problem you would need to change the PowerShell version in Windows Azure Instance according to your Windows Azure application SDK. For example if your application is based on Windows Azure SDK 1.8 then you will need to change Powershell setting to use SDK 1.8 as below:
Version : 1.8.0.0
That's all you need to get powershell working,




Keydet (@devkeydet) described his CRM Online & Windows Azure Series in a 1/27/2013 post to his Gold Coast blog:
I’ve been working with a few CRM Online customers on some advanced scenarios which require using Windows Azure as part of their overall solution. As a result, I will be publishing series of blog posts and samples which walk you through the following:
- Configuring Single Sign On (SSO)
- Improving the SSO experience
- Calling into CRM Online using impersonation to ActOnBehalfOf the logged in user
- Authenticating to Windows Azure hosted web service from CRM Online Sandbox code
- Executing code behind an organizations firewall using Windows Azure Service Bus or Windows Azure Networking
- Handling the reporting edge cases using Windows Azure SQL Reporting, Windows Azure SQL Database, and Scribe Online
As I get the rest of the posts published, I will update links in this post. This series is a complement to my Design for Online and CRM Online + Windows Azure = Many Possibilities posts.

Steve Plank (@plankytronixx) reported Video: UK’s Biggest Computer Mag Combines Windows 8 App with Azure in a 1/24/2013 post:
I’m sure we’ve all seen Computeractive on the shelves of our newsagents.
When Microsoft releases a new version of Windows, Computeractive does a feature article. This time as well as the print article, they’ve developed a Windows 8 application that uses an Azure back end to deliver video lessons straight in to the app. With their monetisation method – the app paid for itself in 3 weeks.
This was all part of the Microsoft publisher’s innovation programme, created and run by my colleague Adrian Clarke.


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Beth Massi (@bethmassi) listed links for Building a SharePoint App with LightSwitch in a 1/31/2013 post to the Visual Studio LightSwitch Team blog:
I just wanted to let everyone here know that I’ve been having fun using the HTML Client Preview 2 to build a SharePoint app on top of Office 365 using LightSwitch over on my blog.
Although you definitely can still host your apps on your own or in Azure, enabling SharePoint in your LightSwitch apps allows you to take advantage of business data and processes that are already running in SharePoint in your enterprise. Many enterprises today use SharePoint as a portal of information and applications while using SharePoint’s security model to control access permissions. So with the new SharePoint 2013 apps model, we’re bringing the simplicity and ease of building custom business apps with LightSwitch into SharePoint / Office 365. This is very compelling for many businesses.
I’ve got a few posts about it that I think you will like, check them out:


For my experiences with building an SharePoint App with HTML Client Preview 2 autohosted in Windows Azure and problems with the Office Store, see LightSwitch HTML 5 Client Preview 2: OakLeaf Contoso Survey Application Demo on Office 365 SharePoint Site.
• Paul van Bladel (@paulbladel) explained Why serious .Net developers should stop building LOB “frameworks” which are pretentious on the outside and simple on the inside in a 2/1/2013 post:
Introduction
Indeed, a provocative title in this article. For a good understanding what I mean, you should first read my previous article on LightSwitch which is in my view simple on the outside but rich on the inside. A property which I see as a great quality but which sometimes can confuse people and sometimes raises following statement: “it looks simple, so it can’t be good”, which is for the specific case of LightSwitch completely wrong of course.
What are you doing when you don’t use LightSwitch?
Honestly, personally I can hardly imagine any longer.
If you want to build software in a predictable and robust way, you will probably want to use kind of framework approach. I don’t know that many complete end-to-end line of business frameworks. So, in most cases and especially in enterprises, software development teams roll their own framework. In practice, this means bringing together a whole series of technologies, SDKs, design patterns, etc. Mostly, this is done by the most “competent” people of the team and they mostly share a common property: they are quite good in “abstracting” things. Sometimes, they are so good in abstracting things, that in the very end, they are the only persons around that still understand the abstractions they invented. Since they basically bring together a whole series of technologies, which they know quite well but don’t have the complete intimate knowledge about, the eventual framework lacks often coherence and consistency.
Measuring the quality of the framework
Now, let’s stay optimistic and let’s assume your framework leads to good results. What can be the root cause of this? Now let’s suppose that the usage of your framework is highly complex (so… not simple on the outside) because, and I can’t find a less silly example, it uses and requires intimate knowledge about quantum mechanics. How will you measure the qualities of your quantum mechanics based framework? Let’s give it a try.
- The first and most easy explanation can be because your framework is intrinsically extremely good. Great, commercialize it !
- A second reason can be that people using the framework are extremely competent. For example because they have a Phd in quantum mechanics or other sportive disciplines.
- A third reason can be that given the framework’s complexity, less competent people are hindered to use the framework and thus can even not try to produce output by using the framework.
I have no problems with the first two potential root causes, but the third one is slightly increasing my blood pressure. Especially in the situation where the things you are doing “inside” are maybe not simple but not extremely complex neither. Let’s face it: building an advanced line of business app can be difficult, but it’s not the most complex activity in the world. Understanding quantum mechanics or establishing world peace or understanding women logic, just to call something, is more difficult.
Things brings me to completely rephrasing my point:
Never measure the success of a framework based on its artificial entry level barriers.
Lightswitch is such a great example of a framework that is not exposing artificial entry level barriers. That’s why typical Microsoft access developers might like it and see it as a next step in a growth path to scalable apps build on stronger foundations.
LightSwitch, as a framework, is so good that it leads to good design most of the time and discourages automatically bad design in a large series of cases. Just to give one example, LightSwitch will make it you very difficult to do a direct database call from the code behind of a button. When creating a LightSwitch screen, you are even without knowing it applying MVVM. But indeed, when used by people with no vision at all on the architectural foundations of software, you will see once in a while “strange things”. Nothing to do about, but it doesn’t say anything at all about the intrinsic qualities of LightSwitch. People have the right to make mistakes as a process of improving their skills, don’t they?
Conclusion
I have not the skills to provide a complete “epistemologic” analysis on framework design. I’m doing nothing more than sharing some thoughts. I promise next time I’ll write again about a custom control… or maybe about notepad which is both simple on the outside and simple on the inside. Well, I even don’t know how simple it is on the inside, I have never seen the source code


• Paul van Bladel (@paulbladel) answered Why are serious .Net line of business app developers not embracing today LightSwitch? on 2/1/2013:
Introduction
I’m asking a question over here and readers who are familiar with other content on my blog know at least my answer:
Serious .Net line of business application professionals should have been using and exploring already “yesterday” LightSwitch.
Oh no, … not for replacing “full park” their current portfolio of line of business apps with fancy LightSwitch apps. I’m simply talking about making themselves familiar with the LightSwitch concepts and making some first steps in introducing LightSwitch in their portfolio of application frameworks.
A first oversimplified answer
Sometimes, complex matters need a first oversimplified answer. Not to serve as final answer, but simply as a trigger to activate a discussion towards a more nuanced answer.
Following screenshot illustrates my oversimplified answer:
A seasoned LightSwitch developer will directly recognize the above screen. So, what’s my point?
When you do a “start new project” in visual studio 2012 and you select the project type “LightSwitch application”, yes indeed, preferably in c#, you will get the above screen as first acquaintance with LightSwitch.
It allows you to make a first (and that’s also the reason why it happens directly after the start new LightSwitch project) important decision: a line of business app needs data and data definitions. How do you want to start: design your data (=create new table) or leverage an existing database (=attach to external data source).
In order to avoid that the LightSwitch product designers would feel offended, I’ll hurry up to tell you that I simply ADORE this screen. But… adoration is a gift and beauty is in the eye of the beholder…
I’ll try to get a bit closer to my point. If the LightSwitch product designers would decide tomorrow to remove this screen, when speaking about LightSwitch adoption by IT pro’s, would this make any difference? Of course not.
A less simplified answer…
My point is that the above screen is such a great illustration of the fact that LightSwitch is a line of business application framework which takes the following concept extremely serious (at least in my interpretation) :
Simple on the outside, but rich on the inside.
This could have been a quote from the Dalai Lama. I’m following (and reading with great attention) the tweets of His Holiness on twitter, where he has more than 6 million followers and he is following himself… nobody. He simply can’t be wrong.
Personally, I like things or objects which are simple on the outside but rich on the inside. I like also people to whom the same notion applies (my loving wife for example). The reason is that in an interaction with something or someone blessed with this property, you are communicating over an “easy going” interface, and once you are in “communication mode”, you start making discoveries, preferably one by one, in a kind of “evolutionary disclosure mode”. You will never feel directly overwhelmed, because they simply come indeed one by one and they are never smashed into your face. But once you did all the discoveries, you might be overwhelmed by all the rich features, but in the end you will be the most overwhelmed by the fact that all this has been presented to you in a manner of .. simple on the outside and rich on the inside. You are getting closer to my point, aren’t you?
The principle of “Simple on the outside, but rich on the inside” has one drawback (and only one) when it comes to visibility from a more marketing oriented perspective: revealing the richness, requires participating into the process of discovery. A simple or even sophisticated “advertisement” will not solve this, unfortunately.
I will not give you here a complete inventory of the LightSwitch richness. I’m not a marketing guy neither, I’m simple…
Now you know the reason why, at least in my view, currently not enough serious .Net line of business app developers are embracing LightSwitch today. Obviously this is not the complete answer, but I believe that the metaphor is … spot on.



• Paul van Bladel (@paulbladel) continued his prescriptive LightSwitch blogstream with Self-reporting via Excel power pivot in highly deferred execution mode on 2/1/2013:
Introduction
In the enterprise world, reporting is a world on his own. Enterprises have often very sophisticated reporting systems which either exists in isolation and are called from application which have the actual “ownership” on the data for which is report is generated. Ok, this needs some clarification. I’ll address this in a first paragraph. I’ll explore as well how we can easily introduce in the context of LightSwitch the notion of “self-reporting” and I’ll explain why this approach can be from an application security point of view, the best reporting solution. In a last paragraph, I’ll introduce kind of experimental or visionary reporting approach where I promise to explain what I mean with the title of this article.
What’s the problem with reporting systems external to the application?
Enterprises care about security. There are plenty of guidelines which can improve the eventual security level of an application.
For example, authentication is ideally not handled by the application itself, meaning that an application database should better not store passwords or password hashes. Enterprises often have dedicated authentication systems. In a windows environment, using Kerberos based security (windows authentication) is probably the best choice. By doing so, active directory takes care of the authentication and by means of a very intelligent ticketing mechanisms, “authorizations” are passed between systems in a highly secure manner. Also outside your domain, so in a federated context, ADFS (active directory federation services) can elegantly complement this. Proven technology !
Authorization is an other story. It’s about the users role and corresponding permissions for a specific application. Inside the server side application logic, this leads, among others, to row level security both in the retrieve and save pipeline of the business operations that can be performed with the application. A canonical example from the CRM sphere: “the user of the CRM app, the relationship manager, may see his own customers, but not those of other relationship managers. A very simple example which I’ll use in what comes next.
When it comes to reporting, this can become problematic from an application security perspective. Dedicated reporting systems often make a direct connection to the application database. In LightSwitch, implementing the above row level security example is quite trivial. But when my external reporting system makes direct database connections, the rule can easily be bypassed. Obviously, the reporting system can easily implement that same rule as well but that means we are less D.R.Y. (don’t repeat yourself) and worse, when the rule one day changes, we might forgot to implement it in the reporting system. In short, such an external reporting system can be a source of many application security issues !
What’s the solution:
Reporting systems should connect to the application service layer
A LightSwitch app exposes its internal OData service. As a result, when our reporting solution connects to the same service for retrieving the data on which the report is built, we never run in the kind of security trouble described above. When I can see in the application only the customers which are related to me as a relationship manager, the reporting system connecting to the same odata feed, will never make it possible to report on the customers of the other relationship managers.
How does Power Pivot becomes mega power pivot when used in combination with LightSwitch?
Excel Power Pivot is such a self-reporting solution which can simply connect to an odata stream of an application. When using windows authentication from the excel application combined with an https-based data connection we can say that this is the most secure reporting solution.
How can we make self-reporting more user friendly.
Obviously, the most classic approach of reporting is the one where the report is generated by the application itself (server side) and the report is “streamed” to the client. So, this is not the self-reporting scenario. Of course, this “internal reporting solution”, is when it comes to row-level-security completely ok. There are quite some solutions described for applying this approach with LightSwitch. It’s clear that such a scenario, puts some extra load on the server side processing and causes also the data traffic of streaming the report to the client. The load on the server is about the data retrieval, the querying, the report formatting and so on. In the power-pivot scenario part of this is dispatched to the client and furthermore, the user has full degrees-of-freedom when it comes to report formatting, which is great… when he needs this.
As IT guys, we are happy with what excel is offering us when it comes to establishing odata connections to application data feeds. Indeed, simply provide the https address of your data service (in lightswitch, this is the famous ApplicationData.svc) and .. you are all set.
Nonetheless, not every user will be happy with this approach, simply because it’s too technical.
So, I’m currently wondering, but don’t expect over here a full sample with a working solution, if we can not combine the comfort of a report generated by the application with the flexibility of the power pivot approach.
The approach I have in mind boils down to the following:
The user sends from the client side an request to the server for a specific report on a specific (set of) entities. The server will this time not generate a report but streams an excel file to the client side which contains no data at all, but contains the material necessary for simply executing the OData query, so with everything in place (connection strings, user credentials, …) in such a way that one press on the refresh button generates the report. So, the user gets a self-containing excel without odata setup trouble. So, this approach would drastically reduce the load on the server and since there are no data sent over the wire, the response (the excel file) will be delivered in milliseconds to the client.
This explains the second part in the title of this article: the highly deferred execution mode. In Linq terminology, deferred execution means that a Linq query statement is nothing more than the declaration of “an intention”. The formulation of a Linq query will, a such, never trigger database access. The actual database access is “deferred” until the data is really needed. (e.g. by applying a “ToList()” to the entity collection). Linq-beginners often misunderstand these concepts.
The above reporting approach would potentially go one step further and defer the query execution until the user opens the data-less excel file and presses the refresh button. Furthermore, when he opens the same excel the day after, he’ll get the latest data…
Just an idea…
I’m not in the habit of writing LightSwitch related articles without code. This is probably my first code-free post
I’m not sure if the above makes sense and I’m even more wondering if an actual implementation would be feasible.
So, please try it, write an LightSwitch extension for it, take patents, commercialize it, and give me a free licence. Thanks in advance.


Glenn Condron reported EF Power Tools Beta 3 Available in a 1/30/2013 post:
The Entity Framework Power Tools provide additional design-time tools in Visual Studio to help you develop using the Entity Framework. Beta 3 of the Power Tools is now available.
Where do I get it?
The Entity Framework Power Tools are available on the Visual Studio Gallery.
You can also install them directly from Visual Studio by selecting 'Tools -> Extension Manager...' then searching for "Entity Framework Power Tools" in the Online Gallery.
What's new in Beta 3?
Beta 3 is primarily a bug fix release and includes fixes for the following issues:
- EF Power Tools not compatible with VS2012 Update 1
- Microsoft.DbContextPackage.Extensions.ProjectExtensions.InstallPackage(Project project, String packageId) Error
- Power Tools: EF "Reverse Engineer Code First" tool should add reference to EF package if not installed
- Reverse Engineer Code First: Spatial types have wrong namespace
- Classes generated by EF PowerTools should be partial
- Power Tools: Exception from unloaded projects - HRESULT : 0x80004001 (E_NOTIMPL))
- Power Tools: Context menu commands not working in project under solution folder
Future of the Power Tools
We are making an effort to consolidate and simplify the tooling for EF. As part of this effort we will be taking the functionality from the Power Tools and incorporating it into the EF Designer. There is a feature specification on our CodePlex site that outlines some of this work.
This means that we won't be releasing an RTM version of the Power Tools. However, we will continue to maintain Beta releases of the Power Tools until the functionality becomes available in a pre-release version of the EF Designer.
Support
This release is a preview of features that we are considering for a future release and is designed to allow you to provide feedback on the design of these features.
If you have a question, ask it on Stack Overflow using the entity-framework tag.
Compatibility
The Power Tools are compatible with Visual Studio 2010 and 2012 and Entity Framework 4.2 thru 6.0.
There are some temporary limitations that we will address in a future release:
- The 'Generate Views' functionality is currently disabled when using EF6.
- The 'View Entity Data Model (Read-only)' functionality does not work when using EF6 in Visual Studio 2010.
What does it add to Visual Studio?
EF Power Tools Beta 3 is for Code First, model-first, and database-first development and adds the following context menu options to an 'Entity Framework' sub-menu inside Visual Studio.
When right-clicking on a C# project
- Reverse Engineer Code First
This command allows one-time generation of Code First mappings for an existing database. This option is useful if you want to use Code First to target an existing database as it takes care of a lot of the initial coding. The command prompts for a connection to an existing database and then reverse engineers POCO classes, a derived DbContext, and Code First mappings that can be used to access the database.
- If you have not already added the EntityFramework NuGet package to your project, the latest version will be downloaded as part of running reverse engineer.
- The reverse engineer process by default produces a complete mapping using the fluent API. Items such as column name will always be configured, even when they would be correctly inferred by conventions. This allows you to refactor property/class names etc. without needing to manually update the mapping.
- The Customize Reverse Engineer Templates command (see below) lets you customize how code is generated.
- A connection string is added to the App/Web.config file and is used by the context at runtime. If you are reverse engineering to a class library, you will need to copy this connection string to the configuration file of the consuming application(s).
- This process is designed to help with the initial coding of a Code First model. You may need to adjust the generated code if you have a complex database schema or are using advanced database features.
- Running this command multiple times will overwrite any previously generated files, including any changes that have been made to generated files.
- Customize Reverse Engineer Templates
Adds the default reverse engineer T4 templates to your project for editing. After updating these files, run the Reverse Engineer Code First command again to reverse engineer POCO classes, a derived DbContext, and Code First mappings using your project's customized templates.
- The templates are added to your project under the CodeTemplates\ReverseEngineerCodeFirst folder.
When right-clicking on a code file containing a derived DbContext class
- View Entity Data Model (Read-only)
Displays the Code First model in the Entity Framework designer.
- This is a read-only representation of the model; you cannot update the Code First model using the designer.
- View Entity Data Model XML
Displays the EDMX XML representing the Code First model.- View Entity Data Model DDL SQL
Displays the DDL SQL to create the database targeted by the Code First model.- Generate Views
Generates pre-compiled views used by the EF runtime to improve start-up performance. Adds the generated views file to the containing project.
- View compilation is discussed in the Performance Considerations article on MSDN.
- If you change your model then you will need to re-generate the pre-compiled views by running this command again.
When right-clicking on an Entity Data Model (*.edmx) file
- Generate Views
This is the same as the Generate Views command above except that, instead of generating pre-compiled views for a Code First model, it generates them for a model created using the EF Designer.

Beth Massi (@bethmassi) described Sending Email from a LightSwitch SharePoint App using Exchange Online in a 1/28/2013 post:
About a week ago I showed you how to get started building SharePoint 2013 apps with LightSwitch HTML Client Preview 2 by signing up for a free Office 365 developer account and working through the Survey App tutorial. If you missed it:
Get Started Building SharePoint Apps in Minutes with LightSwitch
After working through the tutorial you have a SharePoint app that allows sales representatives of a foods distributor to conduct quality surveys of partner stores. Quality surveys are completed for every product to measure the presence that the product has within the store, like aisle placement, cleanliness, etc. -- and these surveys are performed via the sales rep’s mobile devices on site. They can also take pictures and upload them directly to the SharePoint picture library.
(click images to enlarge)


This tutorial demonstrates how LightSwitch handles the authentication to SharePoint using OAuth for you. It also shows you how to use the SharePoint client object model from server code, as well as writing WebAPI methods that can be called from the HTML client.
Today I want to show you how we can send an email notification to partner stores when a survey is completed. Because this SharePoint App is running in Office 365, I’ll show you how you can take advantage of Exchange Online to send the email.
Sending Email from LightSwitch – Tapping into the Update Pipeline
I’ve written before on how you can send email using Outlook as well as SMTP mail: How To Send HTML Email from a LightSwitch Application
When sending a notification email from the server side, you can tap into the entity_Inserting/ed methods on the server, which is part of the LightSwitch update pipeline. The update pipeline gives you many hooks into events that are happening on the server side when processing entities. To see this, just open up the entity in the data designer and drop down the “write code” button at the top right of the designer:
In this example, we’ll send the email by hooking into the _Inserting method. That way if there is an error sending the email, the user will be notified on screen and the save will not happen. This allows the user to retry the operation. However, you may decide that it’s better to place the code in the _Inserted method instead so that records are always saved regardless if an email can be sent.
Add an Email Field to the App
In order to send an email to the customer, we’ll first need to add a field to capture the email on the Customer entity. Using the data designer, open the Customer entity, add a field called Email of type EmailAddress, and uncheck Required.
Next, add the email field to the AddEditSurveys screen by clicking the +Add button under the first rows layout and selecting “Other Screen Data…”
Then specify the Customer.Email and click OK:
Then change the control to an Email Address Editor and change the display name to “Customer Email”. This will allow sales reps to enter/verify the customer email right on the survey screen.
Adding Code to the Update Pipeline
In the Data Designer, now open the Survey entity and drop down the “write code” button and select Surveys_Inserting method. This will open the ApplicationDataService class where all the server-side processing happens. There is already some code there from one of the steps in the Survey App tutorial which sets the SalesRepName to the logged in user. Now all we need to do is write the code to send the email.
Namespace LightSwitchApplication Public Class ApplicationDataService Private Sub Surveys_Inserting(entity As Survey) entity.SalesRepName = Me.Application.User.Name 'Write code to send email through Exchange online End SubSending Email through Exchange Online
Okay now we’re ready to get dirty and write some code! You can write this code directly in the ApplicationDataService class or you can create your own class like I showed here by flipping to File View and adding your own class file to the Server project. For this example I’ll keep it simple and just add a SendSurveyMail method to the ApplicationDataService class.
Adding Exchange References
The first thing we’ll need to do is add references to the Exchange Web Services Managed API 2.0. The Exchange server assemblies are installed when you install Preview 2. (But you can also install them manually here.)
To add references, in the Solution Explorer first flip to File View:
Then expand the Server project, right-click on References and select “Add Reference…”. Then browse to C:\%ProgramFiles%\Microsoft\Exchange\Web Services\2.0 and add both Microsoft.Exchange.WebServices.dll and Microsoft.Exchange.WebServices.Auth.dll
Next make sure that you set these assemblies to “Copy Local” in the properties window so that when you deploy the app to SharePoint, the assemblies are also deployed.
For the code I’m going to write, I’ll also need a reference to System.Xml.Linq in order to easily create HTML-formatted email. So under the Framework tab on the Add Reference dialog, also tick off the System.Xml.Linq assembly as well. Since this is part of the core framework, we don’t need to Copy Local on this one.
Figuring out the Service.Url
In order to send email through the Exchange online service via Office 365 you’re going to need to know the URL of the Exchange service. Log into your Office 365 account, click the Outlook tab at the top and then select Options under the gear.
Then click the link “Settings for POP or IMAP access…” and you will see your server name. In my case it’s outlook.office365.com.
The service address we need is in this format:
https://servername/EWS/Exchange.asmx
So in my case it’s https://outlook.office365.com/EWS/Exchange.asmx
Another way to obtain this URL programmatically is by using AutoDiscover.
Writing the code
Okay now we’re ready to write the code to send email. I’m going to construct an HTML email and send it from an administrator account, while CC-ing the sales rep email. We can extract the sales rep email from their login. The first thing we’ll need is to import the Exchange web service namespace at the top of the ApplicationDataService class.
Imports Microsoft.Exchange.WebServices.DataNow call a method to send the email from the Surveys_Inserting method.
Private Sub Surveys_Inserting(entity As Survey) entity.SalesRepName = Me.Application.User.Name 'Write code to send email through Exchange online Me.SendSurveyMail(entity) End SubAnd finally, write code for SendSurveyMail. Make sure that you have the correct username/password credentials for sending email. I am using the same administrator I logged into my Office 365 account.
Private Sub SendSurveyMail(entity As Survey) Try If entity.Customer.Email <> "" Then 'Set up the connection the Exchange online service Dim service As New ExchangeService(ExchangeVersion.Exchange2013) service.Credentials = New WebCredentials("username", "password") service.Url = New Uri("https://outlook.office365.com/EWS/Exchange.asmx") 'Get the sales rep email from their logged in username Dim salesRepEmail = entity.SalesRepName. Substring(entity.SalesRepName.LastIndexOf("|") + 1) 'Create a new HTML email message Dim message As New EmailMessage(service) message.Subject = "New survey!" Dim text = <html> <body> <p>Hello <%= entity.Customer.CompanyName %>!</p> <p>We wanted to let you know that a survey has been created about one of your products: <%= entity.Product.ProductName %></p> <p>This is an automated courtesy message, please do not reply directly. If you have any questions please contact your sales rep <%= Application.User.FullName %> at <%= salesRepEmail %></p> <p>Thanks for your business!</p> </body> </html>.ToString Dim body As New MessageBody(BodyType.HTML, text) message.Body = body 'Add the customer email and CC the sales rep message.ToRecipients.Add(entity.Customer.Email) message.CcRecipients.Add(salesRepEmail) 'Send the email and save a copy in the Sent Items folder message.SendAndSaveCopy() End If Catch ex As Exception Throw New InvalidOperationException("Failed to create email.", ex) End Try End SubRun It!
Hit F5 to run the SharePoint app in debug mode. Now when we fill out a new survey we see the customer email address and when we save the survey an email is generated through Exchange online.
Wrap Up
Building SharePoint apps on top of Office 365 gives you a great set of connected services for doing business. And with LightSwitch’s ability to drastically reduce the time to build customized business apps, you now have a robust business platform for building business applications fast on top of Office 365 that can also service your mobile workforce.
I encourage you to learn more at dev.office.com and msdn.com/lightswitch.
















Beth started with the same project as I did for LightSwitch HTML 5 Client Preview 2: OakLeaf Contoso Survey Application Demo on Office 365 SharePoint Site, updated 1/8/2013. For simplicity, I added a date/time item to the properties list.
Return to section navigation list>
Windows Azure Infrastructure and DevOps
• I (@rogerjenn) added my two cents to SearchCloudComputing.com’s The cloud computing market forecast for 2013: Experts predict what to expect, which TechTarget published on 1/31/2013:
We're a full month into 2013, and already, the gyms are empty and the donut shops are full. But the cloud computing market still has 11 months to unfold in all its glory. What will be the big technologies of 2013? And which cloud service providers will impress us most this year?
SearchCloudComputing.com staff asked our contributors to share their thoughts on the year ahead. In this round-up, we asked our cloud experts these three questions:
- What changes can we expect in the cloud computing market in 2013?
- Which cloud vendors will be the big winners of 2013 -- and why?
- What will be the hot technologies for 2013?
…
Roger Jennings
I think 2013 will bring continued growth to all primary cloud services segments; SaaS, PaaS and IaaS combined will grow at a compounded annual growth rate (CAGR) of about 25%. PaaS and Iaas alone will grow from $964 million in 2010 to $3.9 billion in 2013, a CAGR of 60%, according to the 451 Group. Platform-agnostic IaaS will continue to amass the lion's share of revenues, but provider-specific PaaS will gain a larger split of the pie as developers become more comfortable making the transition from on-premises applications.
Amazon will retain its market-leading status by continued price-cutting and frequent introduction of incremental PaaS-like features. Deep-pocketed providers will meet Amazon prices, but firms with smaller-scale operations will be squeezed out, leading to market consolidation. Forrester Research cites Windows Azure's impressive growth; cloud offerings from IBM and HP don't even appear in the "Others" category of Forrester's survey of cloud developer. I'm placing my bets on Amazon and Microsoft as my "cloud providers of choice" for at least the next two years.
Business units' fixation on big data and developers' enthusiasm for high-performance computing (HPC) with Hadoop variants will lead to increasing revenue for IaaS and PaaS providers by renting server clusters. Amazon's Elastic MapReduce and Microsoft's HDInsight Services for Windows Azure probably will capture the majority of Hadoop-oriented customers. Apps for mobile platforms running iOS, Android and, to a much lesser degree, Windows RT and Windows Phone 8, will dominate the cloud client scene from 2013 onward. HTML5 promises OS-agnostic client apps, so HTML5 timesavers (tools), such as the Visual Studio LightSwitch HTML Client extension, will minimize development costs.
…

Click here to read additional answers from Bill Claybrook, Mark Eisenberg and David Linthicum.
• Kevin Remde (@kevinremde) reported The New Blog Series: Migration and Deployment in a 1/31/2013 post:
Just when you thought the fantastic pace of content on our blogs would slow down a bit after completing our “31 Days of Servers in the Cloud” series, we’re starting our new series for February: “Migration and Deployment”.
“So.. is this a February series, with 28 parts and new stuff every day?”
Well.. okay, maybe not quite the same pace as we did in January. We decided to give you (and selfishly, ourselves) the weekends off. But, this actually lends itself to another interesting way to break up the month into specific topic areas; one topic-area-per-week. And in each week, we’ll discuss issues of migration and deployment for and around the platform in question.
Our 4 weeks of topic areas breaks down like this:
- Week #1 (February 4-8): Windows 8
- Week #2 (February 11-15): Windows Server 2012
- Week #3 (February 18-22): Windows Azure
- Week #4 (February 25-28): System Center 2012 App Controller
For example, we’ll be covering topics such as installation requirements and issues, methods for upgrading-in-place or the migration of documents and settings, managing policy and permissions, etc.
“Who is ‘we’? Who are the article authors?”
The authors are me and my amazing teammates – the other Microsoft DPE US IT Pro Technology Evangelists in the United States: Chris Avis, Harold Wong, Brian Lewis, Matt Hester, Keith Mayer, Dan Stolts, Bob Hunt, Yung Chou, Tommy Patterson, and Blain Barton.
And, as in the past, we will also occasionally call upon an MVP or other subject-matter expert to contribute.“Are there any resources that I should have at-the-ready for doing exercises or walking through your step-by-step articles?”
GREAT question. Yes!
- Get your Windows 8 Enterprise Evaluation download here: http://aka.ms/win8Client
- Get Windows Server 2012 Evaluation (.ISO & pre-installed .VHD): http://aka.ms/Server2012
- Start a Windows Azure 90-day free trial: http://aka.ms/90DaysOfAzure
- Download the evaluation of System Center 2012 w/SP1: http://aka.ms/PvtCld
- Take advantage of FREE training at Microsoft Virtual Academy: http://aka.ms/MSVirtAcademy, and
- Take a stab at winning a trip to Las Vegas and the Microsoft Management Summit through the Cloud OS Trivia Challenge: http://aka.ms/CloudOSTrivia
So.. the series is “Migration and Deployment”. The first article (Part 1) is coming on Monday, February 4. And we sincerely hope you enjoy it and will take advantage of the knowledge that we’re sharing.


• David Linthicum (@DavidLinthicum) asserted “Survey: Significant adoption often had nothing to do with IT, suggesting many businesses have pulled ahead of their CIOs” in a deck for his The cloud is coming to your business, like it or not article of 2/1/2013 for InfoWorld’s Cloud Computing blog:
A new survey from Brocade finds the role of the CIO is changing, apparently driven by cloud computing. The survey of 100 CIOs from Europe, the Middle East, and Africa finds that half expect cloud adoption to take less time than required to deal with IT infrastructure issues, such as email and storage.
Moreover, one-third of the CIOs report that cloud computing is already in their enterprises -- and IT had nothing to do with it. Finally, about 70 percent stated that cloud computing services are here to stay, and they would adopt more in the years to come.
We've known for some time that cloud computing is showing up in all enterprises, with or without CIO approval. Although shortsighted CIOs push back hard on those who use cloud services such as Dropbox or Google Apps, CIOs who "get it" are using this interest in cloud computing to move in more productive and innovative directions.
The role of the CIO is not only rapidly changing, but we could witness a shift in the CIOs themselves as a result. I see many IT leaders, including CIOs, who are passive-aggressive around the adoption of the cloud computing -- they're dragging their feet. At some point, the people above and below them will get tired of the constant delays and excuses and swap out those IT execs for more innovative talent. We saw the same pattern around the use of PCs in the 1980s and the adoption of the Internet in the 1990s.
Good CIOs understand the emerging technology, then determine its value for their business. Moreover, they create reasonable plans around the use of this technology as applied to the business. Those CIOs will shine through the adoption of cloud computing -- or any new and emerging technology.

David Linthicum (@DavidLinthicum) explained Why Cloud Computing will define the Value of IT Shops in 2013 in a 1/29/2013 article for GigaOm Pro’s Analyst Blog:
IT keeps plenty busy running the business of IT. Amongst other duties, they support the core production systems, deal with application backlogs, and install new systems to meet the changing needs of the business.
Cloud computing, in many instances, is not as welcome as one might think. To many in IT, it’s another new concept they must deal with, and, given limited resources and time, it’s tough to fit it in to the schedule.
Years ago, many IT shops got into the habit of just saying “No” to anything new. That carries forward to this day.
As cloud computing begins to define its value, it will also define the value of IT. While some IT shops will continue to push back on this technology, typically without even looking under its hood, others will figure out its value and create a plan around the use of this technology.
The metric is simple. Those who explore the newer idea of cloud computing are typically IT shops that are more innovative and efficient. Those who do not explore the value of the cloud probably need some new processes in place, or different leadership, or, they could be underfunded.

Full disclosure: I’m a registered GigaOm Analyst.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today
<Return to section navigation list>
Cloud Security, Compliance and Governance
David Linthicum (@DavidLinthicum) asserted “As cloud providers push 'take it or leave it' contracts, many businesses push back -- or avoid the cloud altogether” in a deck for his Today's cloud contracts are driving away enterprise adoption article of 1/29/2013 for InfoWorld’s Cloud Computing blog:
Cloud computing has a growing problem: Many providers haven't built contract negotiations into their customer on-boarding processes. Instead, they offer "take it or leave it" contracts that protect the provider from everything, transferring all responsibility, liability, and risk to the businesses using the cloud services. Small and medium-sized businesses have accepted such contracts because they can't afford the lawyers to second-guess them. But large businesses have lawyers, and they aren't about to enter into such one-sided contracts.
That reality could inhibit cloud adoption, unless cloud providers get realistic about these contract issues. As Computerworld recently reported, large businesses have already started pushing back on cloud providers about these contracts.
Today, cloud providers typically offer contracts that look more like they came from iTunes than a provider to IT. They're designed like all those consumer contracts that users simply click through until they find the Accept button. That won't fly in large businesses, which have stricter guidelines around managing liability, so enterprises will try to negotiate these contracts.
Here's the rub: Often, there's no one to negotiate with. The contracts are "take it or leave it," presented on a website as part of the signup process, with no enterprise sales group to negotiate with at the cloud provider itself. If large businesses can't negotiate these contracts, expect them to look for a provider that will negotiate -- or simply avoid the public cloud altogether.
If public cloud providers want to move up the food chain, they need to accept the fact that enterprises will require special attention. This includes, dare I say it, human negotiations. Also, they'll neeed to provide wiggle room on dealing with liability and SLA issues.
This could be why latecomers to the cloud computing space, such as Hewlett-Packard, could get a leg up on the current cloud computing leaders, such as Amazon Web Services. Providers like HP understand how to get through these negotiations. To remain leaders, the current cloud leaders need to get a clue and adjust their sales processes accordingly.
These "take it or leave it," one-sided contracts are a clear threat to cloud computing's progress. It would be shameful if cloud computing died due to lawyers and an avoidance of direct dealing with customers.


<Return to section navigation list>
Cloud Computing Events
• Ricardo Villalobos (@ricvilla) suggested on 2/1/2013 that you Mark your calendars! Windows Azure OSS Summit in India, February 2013:
Following the successful Windows Azure OSS Summit that I presented in Paris with David Makogon, Bhushan Nene, and Karandeep Anand; we are now flying around the world to meet with Windows Azure developers in India, where we will be visiting three different cities: Mumbai, Pune and Bangalore.
We will talk about the latest features incorporated into our cloud platform, how to access them from different programming languages such as Java, PHP and Node.js; while showing how to store, extract, transform, and analyze data using popular DB engines like Cassandra and MongoDB. If you are in the area, make sure to drop by!



I won’t be in the area because I’ll be at the Microsoft MVP Summit 2013 on 2/18 through 2/21 in Bellevue and Redmond, WA.
The San Francisco Bay Area Azure Users Group will present Deploying NoSQL Riak on Windows Azure on 2/26/2013 at the Microsoft Office in Westfield Mall:
Tuesday, February 26, 2013, 6:30 PM
Microsoft San Francisco (in Westfield Mall where Powell meets Market Street)
835 Market Street
Golden Gate Rooms - 7th Floor
San Francisco, CA(map)We are in the same building as Westfield Mall; ask security guard to let you on the 7th floor.
Riak is a distributed NoSQL key-value store providing high availability and scalability for your applications. This session would cover Riak's architecture and its deployment on Windows Azure cloud platform.
Pavan Venkatesh, Technical Evangelist at Basho Technologies will talk about
Riak overview
- Riak architecture and its core capability
- Use cases and Riak's core value proposition
- Riak EDS and Riak CS
- Demo on how to install and deploy Riak on Windows Azure Platform
About Pavan:
Pavan has broad experience in the open-source database environment. Before joining Basho, he ran the product team at Schooner Information Technology that was successfully acquired by SanDisk. Prior to Schooner, Pavan was part of the technical sales consulting team for MySQL-Sun-Oracle for over three years. He has helped many clients successfully implement MySQL and MySQL Cluster for high availability use cases. Pavan holds an M.S. in computer science from Syracuse University and a B.E. in electrical and electronics from National Institute of Engineering, India.

The UK Windows Azure User Group (ukwaug.net) will hold a Build Open Source Apps on Microsoft’s Cloud conference at the Microsoft London offices on 2/11/2013:
Everything you want to know about Windows Azure without the Windows
Andy Cross @andybareweb - Cloud, Big Data and HPC guy
Planky @plankytronixx
Richard Astbury @richorama
Richard Conway @azurecoder - Cloud,Big Data and HPC guy
Rob Blackwell @RobBlackwell
Simon Evans @simonevans - CTO of Amido
Steve Lamb
<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Jeff Barr (@jeffbarr) reported EC2's M3 Instances Go Global; Reduced EC2 Charges and Lower Bandwidth Prices on 2/1/2013:
We continue to work to make AWS more powerful and less expensive, and to pass the savings on to you. To that end, I have three important announcements:
- EC2's M3 instance family is now available in all AWS Regions including AWS GovCloud (US).
- On-Demand prices for EC2 instances in the M1, M2, M3, and C1 families have been lowered.
- Prices for data transfer between AWS Regions have also been lowered.
M3 Global Rollout
We launched the M3 family of EC2 instances last fall, with initial availability in the US East (Northern Virginia) Region. Also known as the Second Generation Standard Instances, members of the M3 family (Extra Large and Double Extra Large) feature up to 50% higher absolute CPU performance than their predecessors. All instances are 64-bit and are optimized for applications such as media encoding, batch processing, caching, and web serving.
I'm pleased to announce that you can now launch M3 instances in the US East (Northern Virginia), US West (Northern California), US West (Oregon), AWS GovCloud (US), Europe (Ireland), Asia Pacific (Singapore), Asia Pacific (Tokyo), and Asia Pacific (Sydney) Regions. We plan to make the M3 instances available in the South America (Brazil) Region in the coming weeks.
On-Demand Price Reduction
We are reducing the price of On-Demand Amazon EC2 instances running Linux world-wide, effective February 1, 2013.This reduction applies to all members of the M1 (First Generation Standard), M2 (High Memory), M3 (Second Generation Standard), and C1 (High-CPU) families. The size of the reductions vary, but generally average 10-20%. Here are the reductions, by family and by Region:



Pricing for the M3 instances in the Regions where they are newly available already reflect the economies of scale that allowed us to make the reductions that we are announcing today.
As usual, your AWS bill will automatically reflect the lower prices.
Regional Data Transfer Price Reduction
With nine AWS Regions in operation (and more in the works), you can already build global applications that have a presence in two or more Regions.Previously, we have charged normal internet bandwidth prices for data transfer between Regions. In order to make this increasingly common scenario even more cost-effective, we are significantly lowering the cost of transferring data between AWS Regions (by 26% to 83%), effective February 1, 2013. You can already transfer data into a Region at no charge ($0.00 / Gigabyte); this price reduction applies to data leaving one Region for another Region.
Here are the details:
This pricing applies to data transferred out of Amazon EC2 instances, Amazon S3 buckets, and Amazon Glacier vaults.
The new pricing also applies to CloudFront origin fetches. In other words, the cost to use CloudFront in conjunction with static data stored in S3 or dynamic data coming from EC2 will decline as a result of this announcement. This is an important aspect of AWS -- the services become an even better value when used together.
Let's work through an example to see what this means in practice. Suppose you are delivering 100 TB of content per month to your users, with a 10% cache miss rate (90% of the requests are delivered from a cached copy in a CloudFront edge location), and that this content comes from the Standard or Europe (Ireland) Amazon S3 Region. The cost of your origin fetches (from CloudFront to S3) will drop from $1,228.68 to $204.80, an 83% reduction.
Again, your next AWS bill will reflect the lower prices. You need not do anything to benefit.

I assume the Windows Azure team will respond to Amazon’s price move. Stay tuned.
• Jeff Barr (@jeffbarr) described New Locations and Features for the Amazon Simple Workflow Service in a 1/31/2013 post:
The Amazon Simple Workflow Service is a workflow service that you can use to build scalable, resilient applications. You can automate business processes, manage complex cloud applications, or sequence some genes.
Today we are making the Simple Workflow Service available in additional AWS Regions. We are also adding additional support for AWS Identity and Access Management (IAM).Additional Amazon Simple Workflow Locations
You can now run your workflows in any AWS Region in the US, Asia, Europe, or South America, with the exception of the AWS GovCloud (US). See the AWS Global Infrastructure map for a full list of AWS Regions.
Additional IAM Support
You can now use AWS Identity and Access Management to control access to Simple Workflow domains and APIs on a very fine-grained basis.You can use the domain-level permissions to create and control individual Simple Workflow sandboxes for development, QA, and production. You can then use the API-level permissions to restrict access to individual APIs within the sandboxes. You could, for example, restrict creation and activation of workflows to the managers of the respective teams.You can also use IAM to regulate access to certain domains or APIs based on the identity of an application or an entire suite of applications.
This important new feature is available now; you can read more about it in the Simple Workflow documentation.


Stacey Higginbotham (@gigastacey) asserted “Amazon has hopped into the video transcoding business with it’s new Elastic Transcoder service, joining Microsoft, Encoding.com and others as providers of such a service.” in an introduction to her AWS launches transcoding service a week after Microsoft goes after media biz GigaOm article of 1/29/2013:
Amazon Web Services now offers transcoding services in the cloud, a product launch for the cloud computing giant that follows a week after Microsoft announced a similar (but more expansive) service in its Windows Azure cloud. AWS Elastic Transcoder will benefit companies that want to adapt their video files to a variety of consumer devices, from smartphones to big-screen TVs.
Transcoding traditionally has been done on dedicated hardware located inside the data centers and head ends of telecommunications providers and cable operators, or in the data centers of content companies and CDNs. For example, Netflix encodes each movie it has 120 times to meet the needs of all the devices it supports. But as online video becomes more popular and devices proliferate, transcoding becomes an issue for everyone, from small blogs that want to do video to Disney.
Now, instead of buying dedicated hardware and software, they can go to Amazon, which will offer folks 20 minutes of transcoding each month for free. After that, it will charge between 0.015 cents per minute to 0.036 cents per minute depending on whether the customer wants high-definition or standard definition, and where in the world the transcoding will occur.
From the Amazon release:
In addition, Amazon Elastic Transcoder provides pre-defined presets for popular devices that remove the trial and error in finding the right settings and output formats for different devices. The service also supports custom presets (pre-defined settings made by the customer), making it easy for customers to create re-useable transcoding settings for their unique requirements such as a specific video size or bitrate. Finally, Amazon Elastic Transcoder automatically scales up and down to handle customers’ workloads, eliminating wasted capacity and minimizing time spent waiting for jobs to complete. The service also enables customers to process multiple files in parallel and organize their transcoding workflow using a feature called transcoding pipelines. Using transcoding pipelines, customers can configure Amazon Elastic Transcoder to transcode their files when and how they want, so they can efficiently and seamlessly scale for spikey workloads. For example, a news organization may want to have a “high priority” transcoding pipeline for breaking news stories, or a User-Generated Content website may want to have separate pipelines for low, medium, and high resolution outputs to target different devices.
Amazon isn’t the first in the cloud encoding/transcoding market, but it does have the largest customer base in the cloud, including Netflix, which clearly delivers a lot of video. As I mentioned earlier, Microsoft has launched a Media platform service that will include transcoding, aimed at giving customers all the tools it needs to deliver streaming video content online. Microsoft’s service uses the same tools it used to host the London Olympics last year. Other companies such as Encoding.com provide cloud encoding services as well.


Full disclosure: I’m a registered GigaOm Analyst.
Transcoding is interesting to me because I’ve been testing personal video recording (PVR) and other streaming video capabilities of tablets, such as the Surface RT, Nexus 7 and CozySwan UG007, as described in my First Look at the CozySwan UG007 Android 4.1 MiniPC Device post, updated 1/28/2013.
Jeff Barr (@jeffbarr) described The New Amazon Elastic Transcoder in a 1/29/2013 post:
Transcoding is the process of converting a media file (audio or video) from one format, size, or quality to another. Implementing a transcoding system on your own can be fairly complex. You might need to use a combination of open source and commercial code, and you'll need to deal with scaling and storage. You'll probably need to implement a workload management system using message queues or the like. You'll probably need to license audio and video codecs. In short, it isn't as easy as it could be.
The new Amazon Elastic Transcoder makes it easy for you to transcode video files in a scalable and cost-effective fashion. With no start-up costs, your costs are determined by the duration (in minutes) of your transcoded videos. Transcoding of Standard Definition (SD) video (less than 720p) costs $0.015 (one and a half cents) per minute in US East (Northern Virginia). High Definition (HD) video (720p or greater) costs $0.03 (three cents) per minute, also in US East. As part of the AWS Free Usage Tier, the first 20 minutes of SD transcoding or 10 minutes of HD transcoding are provided at no charge.
You can initiate transcoding jobs from the AWS Management Console or through the APIs. You can also arrange to receive notification at various points in the transcoding process.
Transcoding Model
The Amazon Elastic Transcoder takes input from an Amazon S3 bucket, transcodes it, and writes the resulting file to another S3 bucket. You can use the same bucket for input and output, and the buckets can be in any Region. If your transcoding jobs run in a particular Region and retrieve or place content in a different Region, you'll pay the usual AWS data transfer charges.You will create or reference objects of five distinct types each time you transcode a file. You'll start with one or more Input Files, and create Transcoding Jobs in a Transcoding Pipeline for each file. Each job must reference a particular Transcoding Preset, and will result in the generation of a single Output File.
The Elastic Transcoder accepts Input Files in a wide variety of web, consumer, and professional formats. If the file contains multi-track audio, the first two will be passed through to the output, since they're commonly used as the left and right channels.
The Elastic Transcoder generates Output Files. For the first release we are supporting the MP4 container type, the H.264 video codec, and the AAC (Advanced Audio Coding) audio codec.
You'll need to create and named one or more Transcoding Pipelines. When you create the Pipeline you'll specify Input and Output Buckets, an IAM role, and four SNS topics. Notifications will be sent when the Elastic Transcoder starts and finishes each Job, and when it needs to tell you that it has detected an error or warning condition. You can use the same topic for all of the notifications or you can use distinct topics for each one. You can create up to four Transcoding Pipelines per account by default; if you need more just contact us.
After you have created a Pipeline, you need to choose a Transcoding Preset (we've created them for a number of common output formats) or create a custom one. A Preset tells the Elastic Transcoder what settings to use when processing a particular Input File. Presets are named, and can reference another Preset as a base. You can specify many settings when you create a Preset including the sample rate, bit rate, resolution (output height and width), the number of reference and keyframes, a video bit rate, some thumbnail creation options, and more.
The next step is to create a Job (or lots of them, this is a highly scalable service). Each Job must specify a Pipeline, a Preset, and a pair of S3 keys (file names for Input and Output). The Elastic Transcoder can automatically detect the input frame rate, resolution, interlacing, and container type. You have the option to override the automatically detected values by specifying them in the Job, and you can also tell the Elastic Transcoder to rotate the video as needed, in increments of 90 degrees.
Jobs submitted to a Pipeline will be processed in submission order, but one Pipeline may process several of your Jobs simultaneously if resources are available. The amount of clock time needed to process a Job will vary depending on the particulars of the input file and of the settings in the Preset, but will typically be about one third (1/3) of the playing time of the file for a Standard Definition video. For example, a three minute video is generally transcoded in about one minute. You can pause and resume any of your Pipelines if necessary.
Your application can monitor the status of each Job by subscribing to the SNS topics associated with the Pipeline. It can also use the ListJobsByStatus function to find all of the Jobs with a given status (e.g. "Completed") or the GetJob function to retrieve detailed information about a particular job.
Elastic Transcoder in Action
I transcoded a video using the AWS Management Console. Here are some screen shots. I start by creating a Pipeline and setting up SNS notifications:
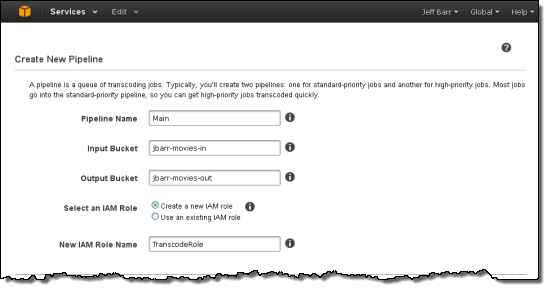
I can see my Pipelines and their status::
Then I select a good Preset:
And create the Job:
I can monitor the Job's status and await completion:
I created an email subscription to an SNS topic to ensure that I would receive a message after each of my videos had been transcoded successfully. Here's what the notification looked like:
Get Started Now
Amazon Elastic Transcoder is available now in the following AWS Regions:
- US East (Northern Virginia).
- US West (Oregon)
- US West (Northern California)
- Europe (Ireland)
- Asia Pacific (Japan)
- Asia Pacific (Singapore
The following AWS tools and SDKs now include support for the Amazon Elastic Transcoder:
- AWS SDK for Ruby.
- AWS SDK for .NET.
- AWS SDK for Java.
- AWS SDK for PHP 2.
- AWS Tools for Windows PowerShell.
- AWS SDK for Node.js.
Learn more about Elastic Transcoder Pricing, read the Developer Guide and you'll be good to go!


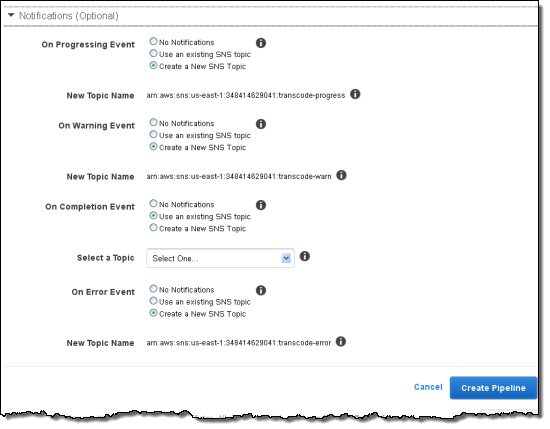
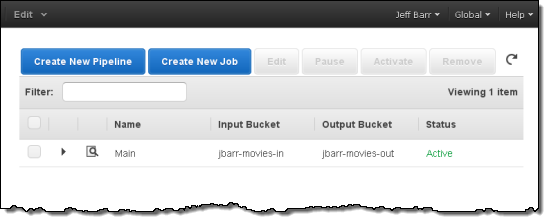
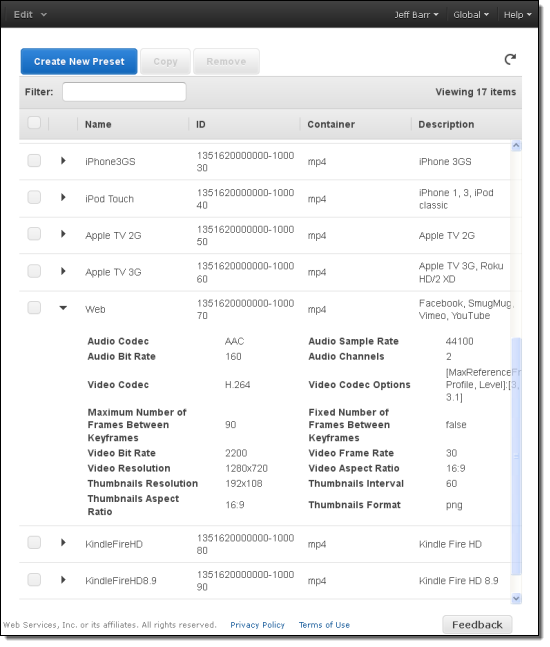
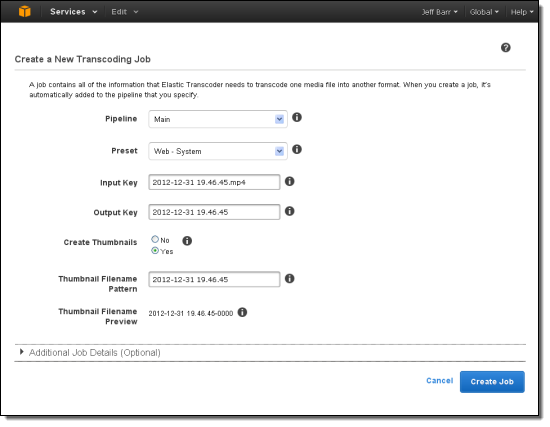
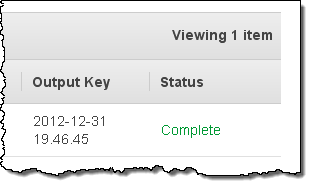
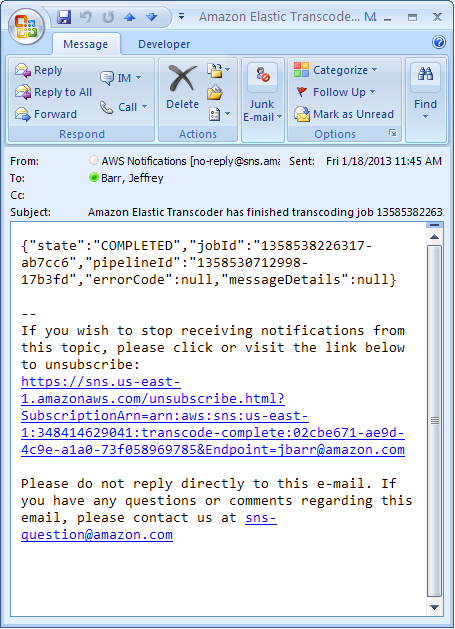
<Return to section navigation list>

















0 comments:
Post a Comment