Windows Azure and Cloud Computing Posts for 12/26/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
• Updated 1/7/2013 1:00 PM PST with new articles marked •.
Note: This post is updated daily or more frequently, except over the holidays, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
Tyler Doerksen (@tyler_gd) described Windows Azure Table Storage 2.0 – Queries in a 1/2/2013 post:
In the previous blog post I started to talk about the new Azure Storage library (version 2.0). In this entry I want to dig into the query syntax. [Link added.]
If you have used the version 1.x storage library you may have found the experience similar to Entity Repository in that you used a Context object and lots of LINQ. While this was fairly easy to grasp and understand it was difficult to figure out exactly when the code was making the query to the service. Also, it was a bit annoying that you could not use most of the LINQ functions, anything but “Where”, “First” and “Select” would not work and throw an unsupported exception at runtime.
Now in the new Version 2 you can use a
TableQueryobject which gives you more control over the query and exactly what you want to happen.Filters
Table storage uses an ODATA interface which supports a few basic url query functions like filter, top, select, and orderby, plus a few more. The storage client library exposes these through the
TableQueryclass.
In the previous post I demonstrated how to retrieve a single entity using a RowKey/PartitionKey combination. The
TableQueryclass can be used for more complex data queries like the following.
using Microsoft.WindowsAzure.Storage;
using Microsoft.WindowsAzure.Storage.Table;
TableQuery query = new TableQuery().Where(TableQuery.GenerateFilterCondition("Name", QueryComparisons.Equal, "Tyler"));There are 2 main elements to that statement,
GenerateFilterConditionandQueryComparisons. You can use a few variations of these components to get the desired query.
GenerateFilterConditionForGuid
GenerateFilterConditionForLong
GenerateFilterConditionForDouble
GenerateFilterConditionForInt
GenerateFilterConditionForDate
GenerateFilterConditionForBool
GenerateFilterConditionForBinary
QueryComparisons.Equal
QueryComparisons.NotEqual
QueryComparisons.GreaterThan
QueryComparisons.LessThan
QueryComparisons.GreaterThanOrEqual
QueryComparisons.LessThanOrEqualIf you need to combine multiple filters you the
TableQuery.CombineFilters()method.
string filterA = TableQuery.GenerateFilterCondition("PartitionKey", QueryComparisons.Equal, "Winnipeg");
string filterB = TableQuery.GenerateFilterCondition("Name", QueryComparisons.Equal, "Tyler");
string combined = TableQuery.CombineFilters(filterA, TableOperators.And, filterB);
TableQuery query = new TableQuery().Where(combined);Here are the operators you can use.
TableOperators.And
TableOperators.Or
TableOperators.NotThis may seem long-winded but the usage is much more explicit than previous versions.
Selects
The other feature I want to quickly go over is the Select function. With this you can retrieve only the data that you need without excessive network access. This may be important for those using this library on WinRT devices.
CloudTable customerTable = tableClient.GetTableReference("customer");
TableQuery query = new TableQuery().Select(new string[] { "Name" });
customerTable.ExecuteQuery(query);This will retrieve the names of all the customers in the table.
Take
Very simply
query.Take(10);All Together
TableQuery query = new TableQuery().Where(TableQuery.GenerateFilterCondition("Name", QueryComparisons.Equal, "Tyler")).Select(new string[] { "Email" }).Take(5);Take this as a quick introduction to the query syntax. There is so much more that I won’t go into right now. All of the examples are using Dynamic entities but the TableQuery object can also be created with typed entities (
TableQuery<Customer>)



<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
• Bruno Terkaly (@BrunoTerkaly) described Parsing JSON by hand from Azure Mobile Services in a 1/7/2012 post:
This post is about parsing data by hand coming back from Azure Mobile Services.
- It does not rely on the MobileServiceCollectionView to populate controls with data.
- Use the code below if you want more control over the parsing of data.
Problem Based on this post In a previous post, a friend of mine wanted to manually populate a Windows 8 GridView client using data coming back from Azure Mobile Services. http://blogs.msdn.com/b/brunoterkaly/archive/2012/06/15/how-to-provide-cloud-based-json-data-to-windows-8-metro-grid-applications-part-3.aspx#10382750
Use this technique to manually parse JSON data coming back from Azure Mobile Services
- It gives you fine grained control over the parsing of data coming back.
The goal Solution You want to manually populate a gridview or similar control by hand. In other words, you want to parse JSON manually, one record at a time. Rather than getting an entire collection, you can use this technique to parse individual columns and rows. Use the JSONArray technique outlined below. Use the GetData() code below in the public MySampleDataGroup(JsonObject currGroup) constructor.
You will need to edit the code as you see below.
- There is the application key
- There is the DNS name
- Both of these items will differ with your own version of Azure Mobile Services
rZYYXzOAKgiukahLDniLPeydiMpefy22 You get this from the Azure Mobile Services Portal. It is the application key. https://brunotodoservice.azure-mobile.net/tables/TodoItem You get this from the Azure Mobile Services Portal. It is the DNS name you get when you create the service. text A column in your SQL Server Table. The Code to parse data coming back from Azure Mobile Services
public async void GetData()
{
// Part of the namespace "System.Net.Http"
HttpClient client = new HttpClient();
client.DefaultRequestHeaders.Add("X-ZUMO-APPLICATION", "rZYYXzOAKgiukahLDniLPeydiMpefy22");
client.DefaultRequestHeaders.Accept.Add(new MediaTypeWithQualityHeaderValue("application/json"));
//
// Asynchronously call into the web service
//
var response = await client.GetAsync(
new Uri("https://brunotodoservice.azure-mobile.net/tables/TodoItem"));
//
// Read the data as a big string
//
var result = await response.Content.ReadAsStringAsync();
//
// Parse the JSON data
//
var parsedResponse = JsonArray.Parse(result);
//
// Convert to a JSON array
//
JsonArray array = parsedResponse;
IJsonValue outValue;
foreach (var item in array)
{
var obj = item.GetObject();
// Extract the text key. Assume there is a “text” column coming back
if (obj.TryGetValue("text", out outValue))
{
string textValue = outValue.GetString();
}
}
}


• Glenn Gailey (@ggailey777) described Mobile Services Custom Parameters in Windows Store apps in a 1/2/2012 post:
Chris Risner (@chrisrisner) described Common Scenarios with Windows Azure Mobile Services in a 1/5/2012 post:
Windows Azure Mobile Services has been available for over four months now and it’s been getting more awesome every day. If you aren’t already aware, Mobile Services is a turnkey backend solution for making mobile apps. In other words, if you’re building a mobile app but don’t want to worry about coding, testing, deploying, and supporting a backend, you can spin up a Mobile Service and use that as your backend.
This gives you access to tons of features including structured storage, authentication, push notifications, and scheduled backend jobs. If you compare the time it would take you to build all of those features on your own, the time savings is crazy! Today I’m going to collect and present a number of links to solutions for common scenarios and questions that come up when using Mobile Services. As you’ll see, even in this short period of time, lots of people have started to use and enhance Mobile Services.
Mobile Services Dev Center – This is the root of all official Mobile Services reference.
Tutorials on the Dev Center – These links will direct you to different tutorials for specific platforms:
Windows Store
Windows Phone
iOS
Android
Getting started
Starting with data
Validate data with scripts
Paging in queries
Starting with auth
Single sign-on with Live Connect
Authenticating users in scripts
Starting with push notifications
Push notifications to users


*there aren’t any links for Android right now because we don’t have an official SDK. Those will come soon.
Additionally, there are a few tutorials in the Dev Center that aren’t tied to a specific platform:
Using SendGrid – SendGrid is a module you can use to send emails from your Mobile Service scripts
Scheduling backend jobs – One of the capabilities of Mobile Services is to write scripts that can either run on a schedule or on demand in the backend.
Mobile Services Stuff
Windows Azure Mobile Services forum – If you have problems or questions, this is a great place to check and ask. It’s monitored by the product team on a daily basis.
Mobile Services Code Samples – There are quite a few great sample apps here. For now they are all C# and / or JavaScript. This includes the EventBuddy sample seen at during the Build 2012 conference’s day 2 keynote.
Mobile Services SDK Source Code – Shortly after launching Mobile Services, the SDK was released to GitHub. As changes are made to the SDK the version in GitHub will be updated to match.
Mobile Services Reference – This documentation details many of the different concepts and capabilities of Mobile Services.
Service Side Script Reference – While a part of the reference docs above, this is a really handy section so I’m listing it separate.
REST API Reference - This is another part of the reference material above. This goes over the actual REST API created for your Mobile Service. You can use this to figure out how to access your Mobile Service from any other technology that doesn't have a supported SDK.
What is Mobile Services and Why was it made – Josh, one of the creators of Mobile Services, has a nice write up on the motivation for making Mobile Services here.
Using Filters on the Client side – Josh delivers again by explaining how to use Filters to indicate a busy or active status to the client. Code included covers C# and Objective-C.
Unofficial Android SDK – While there isn’t an official SDK or a quick start app (yet), Microsoft MVP, and my friend, Sasha Goldshtein, has worked very hard on an Android SDK for Mobile Services. This thing gives you all of the capabilities of each other platform (data, auth, and push) with easy integration.
Advanced Data
The Mobile Services Pipeline – Here, Josh explains the pipeline for handling data from scripts to storage. Code samples included are in C# and js.
Inserting Multiple Items with One Call – This tutorial will walk you through how to send an array of items over to handle inserting multiple items with one call to Mobile Services (as opposed to one call per item). As a bonus, you’ll see how to handle datetime conversion issues for embedded arrays. Code shown is C#, JS, and Objective-C.
Seeding Tables with Data – This tutorial will explain how to seed your Mobile Services tables with data. It uses the approach of creating a console app in Visual Studio and using AngelaSmith to intelligently fill data objects. While this approach requires Visual Studio and the use of .NET, there is nothing to stop you from taking the same idea and implementing it using another system.
Storing per user data – This tutorial demonstrates two different ways to save and filter by User ID: on the client and on the server. Yavor also explains which approach is better and why. Note that this entry covers a bit of data and a bit of scripts. The code demonstrated is in JS.
Supporting unsupported data types – Currently the number of data types supported by Mobile Services is somewhat limited. Here, Yavor walks through how to handle unsupported types in a C# client using the IDataMemberJsonConverter interface. The code is specific to .NET but the idea could be adopted to other platforms.
Supporting complex types – This is similar to the previous link as it involves using a special converter to convert complex (i.e. objects containing objects) objects into JSON for Mobile Services to handle. Again, the code is specific to .NET but the idea could be adopted to other platforms.
Implementing 1:n table relationships – By default, Mobile Services doesn’t support foreign keys or relationships between tables. This walkthrough will demonstrate how to serialize data for complex objects with complex relationships and then save and read that data on the server. The client side code is C#, however, the server side scripting would be the same for any client side technology.
Uploading images to Blog Storage – By default, Mobile Services uses SQL Database for all of it’s data storage. However, if you want to store a lot of file data, Windows Azure Blob Storage is a much more cost effective medium. This article by Nick will walk you through how you can accomplish this in a secure manner. The client side source code is C# but on the server side, the scripts will be the same regardless of your client.
Accessing your Mobile Services data from Excel – A tutorial on pulling your data from Mobile Services into Microsoft Excel for manipulation and examination.
Deleting Table data from the Portal – An explanation on how to delete individual rows or truncate whole tables using the Mobile Services portal.
Using an Existing Database with Mobile Services – This walks you through connecting an existing database to Mobile Services by changing the table schema. This approach may also require changing column names and data types.
Using an Existing Database without Changing the Schema – This tutorial walks you through how to connect an existing SQL database to Mobile Services without changing the schema. This is particularly useful if you have an existing codebase already accessing your database and don’t want to change the schema.
Advanced Auth
Accessing Provider (Facebook, Google, Microsoft Twitter) APIs for more information – This tutorial will walk you through how to make calls to the different auth providers underlying APIs for more information (for example to get their Facebook username). In addition, Carlos explains how to pull the provider token down to the client so you can access those APIs from the device and not from server side scripts. The code demonstrated here is all server side JS.
Explaining Auth – Yavor walks through how authentication works with Mobile Services as well as some potential issues you may run into.
Generating a Mobile Services Auth Token – When a user authenticates with Mobile Services using a provider, an auth token is generated and returned to the client. Here, Josh explains how to generate one of these tokens manually in the server side scripts.
Fetching User Profile information – Josh delivers another example on how to pull more information from a Provider’s API after a user has authenticated.
Caching the User’s Identity and Setting it on the Client – An explanation on how to store the user’s auth token locally on the client and set it on app relaunch so the user doesn’t have to continually log in.
Handling Expired Tokens – Along with the above link, Josh explains how to handle an expired token if you do choose to store the token locally.
Custom Identity in Mobile Services – Josh finishes his 12-part series on Mobile Services by talking about using a custom identity provider in Mobile Services. Using the tips in this article, you should be able to create your own authentication system with Mobile Services.
Fully Logging out of an iOS App with Mobile Services – When you use Mobile Services to authenticate, you can’t just log the client out by calling a method on the Mobile Services client. This tutorial walks you through the steps taken to fully log a user out.
Advanced Scripts
Script How Tos – This is part of the documentation and reference mentioned above but it’s worth mentioning specifically because it has very simple “How do I do X?” with answers.
Complex query filtering – This tutorial starts with the basic where clause that can be added to filter by UserId and then expands on that to talk about the SQL generated from a filter and how to perform more advanced filtering.
Sending SMS messages from server side scripts – Thanks to integration with Twilio, it is possible to send SMS messages from your server side scripts. You’ll need to look about two-thirds of the way down this entry to see the server side js.
Making HTTP Requests from Scripts – Josh does a nice walkthrough of performing HTTP requests from server side scripts.
Unit Testing your Scripts – An explanation of how to locally unit test your scripts before using them in Mobile Services.
Advanced Scheduler
Checking Tweets from a scheduled script – Yavor walks you through setting up a scheduled script which checks Twitter for related to skiing conditions in the Seattle area. This is all server side scripting and doesn’t affect the client.
Checking Tweets and sending push notifications – Nick walks through setting up a scheduled service which will check Twitter for tweets about a particular alias and will then perform a push notification with the information from that tweet.
Sending Push Notifications – A simple walkthrough for sending push notifications from a scheduled script. Code (for both the client and server side) includes C# for Windows Store and Windows Phone as well as Objective-C for iOS.
Command Line Interface
Setting up the CLI tools and backing up Scripts – Using the Windows Azure Command Line Interface Tools, it’s possible to do many things including creating and setting up your Mobile Service, creating tables, and handling scripts. Here, Josh explains how to use the CLI tools to backup your scripts from Mobile Services to your local computer.
Syncing Server Scripts with local versions – Josh explains how to use Node to sync scripts between your local computer and your Mobile Service. Using this technique, you can make changes on your local computer and they’ll automatically be synced with your Mobile Service.
Creating a Log Watcher – A tutorial for setting up a Log Watcher using the CLI tools. This gives you the ability to see anything that has been logged to your Mobile Service (from the server side scripts) on your local computer without opening the portal.
Videos
Channel 9 Mobile Services Series – We recently added a new series of videos on Mobile Services to Channel 9 (a Microsoft website for video content). Most of the videos are over Windows Store apps but there is one (and will be more) iOS video and some of the videos are cover all platforms. Many of these videos are walkthroughs of the Dev Center tutorials.
Build Conference Mobile Services Videos – Josh Twist has a few videos and comments from his sessions at Microsoft’s Build 2012 conference. These videos demonstrate Josh building a pretty slick Windows Store client for Mobile Services.
That’s it!
For now at least. As more interesting scenarios are realized and examples are created to demonstrate the solution, I’ll keep posting them. For now, this should cover a very large body of possibilities and questions when it comes to using Windows Azure Mobile Services in your applications. If you know of any samples or links that should be here, please let me know. As a reminder, if you haven’t already done so, you can sign up for a free Windows Azure account here.
Bruno Terkaly (@BrunoTerkaly) described The Evolution of Windows Azure Mobile Services in a 1/4/2013 post:
There are a number new features that have been released for Azure Mobile Services. Here are some important links that can get you up to speed quickly and efficiently.
The Azure Mobile Services SDK is Open Source. You can download it here. https://go.microsoft.com/fwLink/p/?LinkID=268375 Getting started tutorial. Using the portal you can create your mobile service, add a database, download and modify your client application (currently iOS and Windows Phone 8, Windows Store, soon Android will come), and test your application. http://www.windowsazure.com/en-us/develop/mobile/tutorials/get-started-with-data-dotnet/ Relational data for your mobile application Supplying data to your iOS, Android or Windows 8/Phone applications. This is a very simple way to provide relational data from SQL Database to mobile applications. You can add tables and access the data in a RESTful way. http://www.windowsazure.com/en-us/develop/mobile/tutorials/get-started-with-data-dotnet/ Server side scripting Validate and modify data using server scripts. These server scripts allow you to run JavaScript code on the server when data is inserted, update, and deleted. You can do things like validate the length of strings and reject strings that are too long. You should always validate user input by testing type, length, format, and range. http://www.windowsazure.com/en-us/develop/mobile/tutorials/validate-modify-and-augment-data-dotnet/ Paging through data When queries from mobile devices use too much data, it is important to use paging to manage the amount of data returned to your mobile applications from Windows Azure Mobile Services. You can use the Take and Skip query methods on the client to request specific pages of data. http://www.windowsazure.com/en-us/develop/mobile/tutorials/add-paging-to-data-dotnet/ Authenticating users Learn how to authenticate users from your app. You can restrict access to specific tables. Microsoft supports Live Connect, Facebook, Twitter, and Google. You can apply a table level permissions for insert, update, delete, and read. The iOS client library for Mobile Services is currently under development on GitHub. http://www.windowsazure.com/en-us/develop/mobile/tutorials/get-started-with-users-dotnet/ Authorizing data access Use server scripts to authorize authenticated users for accessing data in Windows Azure Mobile Services. Learn how to filter queries based on the userId of an authenticated user, ensuring that each user can see only their own data. http://www.windowsazure.com/en-us/develop/mobile/tutorials/authorize-users-in-scripts-dotnet/ Push notifications Use Windows Azure Mobile Services to send push notifications to a Windows Store app, using the Windows Push Notification service (WNS). http://www.windowsazure.com/en-us/develop/mobile/tutorials/get-started-with-push-dotnet/ Push Notifications Part 2 Learn about server side scripts and verifying push notification behavior. http://www.windowsazure.com/en-us/develop/mobile/tutorials/get-started-with-push-dotnet/ Send email from Mobile Services with SendGrid. http://www.windowsazure.com/en-us/develop/mobile/tutorials/send-email-with-sendgrid/ Background processes Schedule backend jobs in Mobile Services. Use the job scheduler functionality in the Management Portal to define server script code that is executed based on a schedule that you define. The job scheduler could be used to archive data records, or issue web requests to get tweets or RSS feeds that could be later saved. You might also wish to resize images or process data that has been sent by the mobile application. http://www.windowsazure.com/en-us/develop/mobile/tutorials/schedule-backend-tasks/

• Carlos Figueira (@carlos_figueira) described Inserting multiple items at once in Azure Mobile Services in a 1/2/2013 post:
With the Azure Mobile Services client SDK, it’s fairly simple to insert an item into a table in Azure. Inserting multiple items can be also done fairly easily, simply inserting one at a time. But there are some scenarios where we want to actually do multiple insertions at once, to minimize the number of networking requests made from the client to the service. In the E2E Test Application that we have for our iOS client, the first thing we do in our query tests is to pre-populate a table with some data (if the table was empty), and since we don’t that to affect the test performance (we use about 250 items), we decided to insert them all at once. This has also been asked in our forums, so I decided to post how I went out to implement it.
The idea is fairly simple: instead of sending one item, we send a list of items which we want to be inserted. At the server side, instead of letting the default behavior for the insert operation kick in, we instead loop through the items and insert them one-by-one. Since the database and the instance running the mobile services are often located in the same datacenter, the latency between the two components is a lot smaller than from the client making the insert call and the mobile service, so we have some significant performance gains. And by having the logic to do multiple insertions at the server side, we don’t need to implement that at the client (doing it in managed code is trivial with the async / await keywords; doing that in iOS or in JavaScript not so much).
The way that I chose to implement the logic was that the service would receive not an array of items directly, but an object with one of its members being the array to be inserted. That’s easier to implement in the managed client (using an IDataMemberJsonConverter instead of an ICustomMobileServiceTableSerialization). For JavaScript it really doesn’t matter, since we’re dealing with JS objects in either case. And for the iOS client, we currently can only do that, since the insert operation only takes a dictionary (not an array) as an argument.
Let’s look at the server script. In this example, we’re adding populating our table called ‘iosMovies’, and the data to be inserted is an array in the “movies” property of the received item. The first thing we do is to check whether we actually need to do the insertion (that’s something specific to the scenario of my app; maybe in your case you always want to do the insertion, so that step won’t be necessary). By reading only the first element of the table, we can check whether the table is populated or not (since this script runs in the “insert’ operation, we assume that the table is either fully populated or it needs the items to be inserted). If the data is already there, we respond with an appropriate status. Otherwise, we proceed with the multiple insert operations.
- function insert(item, user, request) {
- var table = tables.getTable('iosMovies');
- table.take(1).read({
- success: function (items) {
- if (items.length > 0) {
- // table already populated
- request.respond(200, { id: 1, status: 'Already populated' });
- } else {
- // Need to populate the table
- populateTable(table, request, item.movies);
- }
- }
- });
- }
Populating the table with multiple items is done by looping through the items to be inserted, and inserting them one by one (*). Since the insert operation in the table object is asynchronous, we can’t use a simple sequential loop; instead, we’ll insert each element when the callback for the previous one is called. After the last one is inserted, we can then respond to the client with an appropriate status.
There’s one extra step that we had to do in this example, which caught me by surprise at first – updating a field of type Date (or DateTime in the managed client, or NSDate in the iOS client). When I first ran that code, the table was created, and the data was seemingly correct. But when I checked the type of the columns in the database, my field ‘ReleaseDate’ had been translated into a column of type ‘string’. ‘datetime‘ is a supported primitive type in Azure Mobile Services, so I was expecting the column to have the appropriate value. The problem is that dates and strings are transmitted using the same type in JSON, string (there’s no such a thing as a “JSON date”). If a string value arrives with a specific format (the ISO 8601 date format, with millisecond precision), then the Mobile Service runtime converts that value into a JavaScript Date object. However, that conversion is only done in top-level objects – it doesn’t traverse the whole incoming object graph (for performance reasons), so in my case my “date” value ended up as a normal string. To fix that, prior to inserting the data we fixed that by converting the ‘ReleaseDate’ field in in the input array.
- function populateTable(table, request, films) {
- var index = 0;
- films.forEach(changeReleaseDate);
- var insertNext = function () {
- if (index >= films.length) {
- request.respond(201, { id: 1, status: 'Table populated successfully' });
- } else {
- var toInsert = films[index];
- table.insert(toInsert, {
- success: function () {
- index++;
- if ((index % 20) === 0) {
- console.log('Inserted %d items', index);
- }
- insertNext();
- }
- });
- }
- };
- insertNext();
- }
- function changeReleaseDate(obj) {
- var releaseDate = obj.ReleaseDate;
- if (typeof releaseDate === 'string') {
- releaseDate = new Date(releaseDate);
- obj.ReleaseDate = releaseDate;
- }
- }
So that’s the script for the server. Now for the client code. Let’s look at the flavors we have. First, managed code, where we have the classes for that data:
- [DataTable(Name = "w8Movies")]
- public class AllMovies
- {
- [DataMember(Name = "id")]
- public int Id { get; set; }
- [DataMember(Name = "status")]
- public string Status { get; set; }
- [DataMember(Name = "movies")]
- [DataMemberJsonConverter(ConverterType = typeof(MovieArrayConverter))]
- public Movie[] Movies { get; set; }
- }
- public class MovieArrayConverter : IDataMemberJsonConverter
- {
- public object ConvertFromJson(IJsonValue value)
- {
- // unused
- return null;
- }
- public IJsonValue ConvertToJson(object instance)
- {
- Movie[] movies = (Movie[])instance;
- JsonArray result = new JsonArray();
- foreach (var movie in movies)
- {
- result.Add(MobileServiceTableSerializer.Serialize(movie));
- }
- return result;
- }
- }
- [DataTable(Name = "w8Movies")]
- public class Movie
- {
- public int Id { get; set; }
- public string Title { get; set; }
- public int Duration { get; set; }
- public DateTime ReleaseDate { get; set; }
- public int Year { get; set; }
- public bool BestPictureWinner { get; set; }
- public string Rating { get; set; }
- }
And to insert multiple movies at once, we create an instance of our type which holds the array, and call insert on that object:
- Func<int, int, int, DateTime> createDate =
- (y, m, d) => new DateTime(y, m, d, 0, 0, 0, DateTimeKind.Utc);
- AllMovies allMovies = new AllMovies
- {
- Movies = new Movie[]
- {
- new Movie {
- BestPictureWinner = false,
- Duration = 142, Rating = "R",
- ReleaseDate = createDate(1994, 10, 14),
- Title = "The Shawshank Redemption",
- Year = 1994 },
- new Movie {
- BestPictureWinner = true,
- Duration = 175, Rating = "R",
- ReleaseDate = createDate(1972, 3, 24),
- Title = "The Godfather",
- Year = 1972 },
- new Movie {
- BestPictureWinner = true,
- Duration = 200, Rating = "R",
- ReleaseDate = createDate(1974, 12, 20),
- Title = "The Godfather: Part II",
- Year = 1974 },
- new Movie {
- BestPictureWinner = false,
- Duration = 168, Rating = "R",
- ReleaseDate = createDate(1994, 10, 14),
- Title = "Pulp Fiction",
- Year = 1994 },
- }
- };
- try
- {
- var table = MobileService.GetTable<AllMovies>();
- await table.InsertAsync(allMovies);
- AddToDebug("Status: {0}", allMovies.Status);
- }
- catch (Exception ex)
- {
- AddToDebug("Error: {0}", ex);
- }
For Objective-C, we don’t need to create the types, so we can use the NSDictionary and NSArray classes directly. The implementation of the ‘getMovies’ method can be found in our GitHub repository.
- NSArray *movies = [ZumoQueryTestData getMovies];
- NSDictionary *item = @{@"movies" : movies};
- MSTable *table = [client getTable:queryTestsTableName];
- [table insert:item completion:^(NSDictionary *item, NSError *error) {
- if (error) {
- NSLog(@"Error populating table: %@", error);
- } else {
- NSLog(@"Table is populated and ready for query tests");
- }
- }];
Similarly for JavaScript, we can just use “regular” objects and arrays to insert the data:
- var table = client.getTable('w8Movies');
- var allMovies = {
- movies: [
- {
- BestPictureWinner: false,
- Duration: 142,
- Rating: "R",
- ReleaseDate: new Date(Date.UTC(1994, 10, 14)),
- Title: "The Shawshank Redemption",
- Year: 1994
- },
- {
- BestPictureWinner: true,
- Duration: 175,
- Rating: "R",
- ReleaseDate: new Date(Date.UTC(1972, 3, 24)),
- Title: "The Godfather",
- Year: 1972
- },
- {
- BestPictureWinner: true,
- Duration: 200,
- Rating: "R",
- ReleaseDate: new Date(Date.UTC(1974, 12, 20)),
- Title: "The Godfather: Part II",
- Year: 1974
- },
- {
- BestPictureWinner: false,
- Duration: 168,
- Rating: "R",
- ReleaseDate: new Date(Date.UTC(1994, 10, 14)),
- Title: "Pulp Fiction",
- Year: 1994
- }
- ]
- };
- table.insert(allMovies).done(function (inserted) {
- document.getElementById('result').innerText = inserted.status || allMovies.status;
- });
That’s about it. This is one of the ways we have to prevent multiple networking requests between the client and the mobile service to perform multiple insertions at once.
(*) Bonus info: As I mentioned before, this still does multiple calls, between the mobile service and the database, but since they’re co-located, the latency is small. You also can make really only one call, from the service to the database, by using the mssql object, and creating one insert request for multiple rows at once. You’d need to do the translation between the data types and the SQL expression yourself, and use the “union all” trick to create a temporary table and insert from that table – see an example below. Notice that you’d also need to create the table columns (if they don’t exist yet), since the dynamic schema feature doesn’t work with the mssql object – once you go down to that level, you’re in full control of the database communication.
- INSERT INTO w8Movies (Title, [Year], Duration, BestPictureWinner, Rating, ReleaseDate)
- SELECT 'The Shawshank Redemption', 1994, 142, FALSE, 'R', '1994-10-14'
- UNION ALL
- SELECT 'The Godfather', 1972, 175, TRUE, 'R', '1972-03-24'
- UNION ALL
- SELECT 'The Godfather: Part II', 1974, 200, TRUE, 'R', '1974-12-20'
- UNION ALL
- SELECT 'Pulp Fiction', 1994, 168, TRUE, 'R', '1994-10-14'
So which one to use? I really didn’t see much advantage in going full SQL for my scenario. Once a communication between the mobile service and the database is successful, chances are that over the next second or so the subsequent ones will be as well, so doing ~250 insert operations, although not really an atomic transaction, has a very good chance of being one. As usual, it may vary according to the scenario of your application.


<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
No significant articles today
<Return to section navigation list>
Windows Azure Service Bus, Caching Access Control, Active Directory, Identity and Workflow
• Jeffrey Schwartz (@JeffreySchwartz) asserted “Active Directory took its first step into the cloud with Office 365, but Microsoft is upping the ante with free access control in the forthcoming Windows Azure Active Directory” in a deck for his Windows Azure Active Directory: Taking AD Deeper into the Cloud article of 1/3/2012 for Redmond Channel Partner magazine:
A vast majority of organizations have long relied on Microsoft Active Directory for single sign-on authentication and authorization to key internal resources. While AD isn't an endangered species, it's changing with the rapid growth of cloud services and Bring Your Own Device (BYOD) policies that require customers to provide access to employee-owned PCs, tablets and smartphones.
AD made its move to the cloud in 2011 with the launch of Office 365, when Microsoft permitted customers to federate their AD domains to services. Now user AD credentials can be found in other Microsoft cloud offerings including the online versions of its Dynamics applications and Windows Intune.
The next step for the cloud migration of AD is to move to the Microsoft Windows Azure service. In beta now, Microsoft recently said it will offer access control in Windows Azure Active Directory (WAAD) free of charge upon release.
"If you're building a service in Windows Azure, you can create your own tenant in Azure and create users and we let you manage those users, who can be connected to your cloud services," Uday Hegde, principal group program manager for Active Directory at Microsoft, told RCP last month. Furthermore, Hegde said Windows Server customers running AD on-premises can connect to WAAD and avail themselves of all its features.
Microsoft is betting its large customer base running AD will propagate it to WAAD. It stands to reason that those who move Windows Server applications to Windows Azure or build new ones will provide authentication services through WAAD.
But will WAAD provide the means of single sign-on and authentication in the cloud that AD delivers in the datacenter today? There's a lot of money betting against that. There are a number of players offering cloud-based Identity Management as a Service (IDMaaS) solutions, which leverage AD and WAAD to provide single sign-on to other resources such as Software as a Service (SaaS) offerings from Google, Salesforce.com and Workday, among hundreds more.
Among those providers are Centrify, Ping Identity, Okta and Symplified. Just last month, Okta received a cash infusion of $25 million in Series C funding led by Sequoia Capital, bringing the total amount it has raised to $52 million.
Okta, like many of its rivals, is using AD and WAAD APIs to enable single sign-on to SaaS and traditional apps. "A CIO wants to have one single identity system that connects them to these different applications," says Okta VP Eric Berg.
Centrify, which just launched its new DirectControl for SaaS, authenticates users via its AD credentials to access SaaS solutions. Like Okta, Centrify's cloud-based identity service doesn't aim to compete with WAAD, but to connect to it. "Our cloud offering is in effect an identity bridge to a customer's Active Directory," says Centrify CEO Tom Kemp.
As SaaS and BYOD become more pervasive, these and other third-party IDMaaS gateways will help bridge AD to these solutions, but don't appear likely to obviate it.
More Columns by Jeff Schwartz:


Full disclosure: I’m a contributing editor for Visual Studio Magazine, a sister publication of 1105 Media’s Redmond Channel Partner.
Vittorio Bertocci (@vibronet) analyzed OAuth 2.0 and Sign-In in a 1/2/2013 post:
[A huge THANK YOU to my friend Mike Jones for his invaluable feedback and advice about this long and complicated post]
If there’s a question that I dread receiving – and I receive it very often nonetheless, even from colleagues - is the following:
“Why can’t I provision in ACS OAuth 2.0 providers in the same way as I provision OpenID providers?”
Or its alternative, linearly-dependent formulation:
“Provider X supports OAuth 2.0; ACS supports OAuth 2.0. How can I connect the two?”
I dread it, because the question in itself is an indication that the asker uses “OAuth 2.0” in its conversational meaning, as opposed to referring to the actual specification and all that entails. For the non-initiated the term “OAuth” has come to be a catch-all term that expresses intentions and beliefs about what one “authentication protocol” should be and do, rather than what it actually does (and how). Therefore, the answer will have to include lots of context-setting and myth-debunking; in fact, the entirety of the answer is context setting, as once the asker knows how OAuth 2.0 really works the question becomes a non-sequitur.
As I am currently sitting on a long flight (I won’t tell you from where, or you’ll hate me :-)) with a batteryful of a laptop, this seems the ideal time to work through that. Be warned, though: this post is a bit philosophical in nature, no coding instructions or walkthroughs here. You must be in the right mood to read it, just like I had to wait to be in the right mood to write it. Also, as everything you read here, this is purely my opinion and does not necessarily reflect the position of my employer or of my esteemed colleagues. Finally: please don’t get the wrong impression from this post. I love OAuth 2.0, I am super-glad it is gaining ground and I like to believe we are contributing to spreading it further with our offering. I just want to save you wasting cycles on expecting it to deliver on something that it doesn’t do.
Short note: if you are not in the mood of reading a long & winding post, here there’s a spoiler. OAuth 2.0 is not a sign-in protocol. Sign-in can be implemented by augmenting OAuth, and people routinely do so; however, unless they’re using the OpenID Connect profile of OAuth 2.0 – see the end of this post, no two providers are alike and that forces library implementers to cover them by enumeration, supplying modules for every provider, rather than by providing a generic protocol implementation as it is standard practice for OpenID, WS-Federation, SAML and the like. If you want a good example of that, take a look at the modules list of everyauth. The rest of the post substantiates this statement, going in greater details.
Some Confusion Is Normal
Even if you don’t drop the words “chamfered” or “skeumorphism” very often in your conversations, chances are that you were exposed in some measure to the renewed interest in Design. You might even have gone as far as reading “The design of everyday things”, a beautiful classic from Don Norman that I cannot recommend enough, no matter what your discipline is. When I read that book, quite a few years back, I learned about a concept that I believe helps describing what’s going on with our question. I am talking about the concept of affordance. More specifically, perceived affordance. In a nutshell, the affordance of an object is the set of things/actions that can be done with it: a door affords being opened (by pushing or pulling), a chair to be sat upon, a hammer to be handled. The perceived affordance is the set of visual aspects in an object that give hints on how it can be operated: a door handle invites grabbing and (depending on the shape) turning or pushing, a chair offers a slat and rigid surface at the right height, a hammer has a handle that invites brandishing.
As soon as you recognize that something is a door, no matter how weirdly shaped or placed, you will instantly know what to expect from it: you can open and close it, you can use it for moving between adjacent environments, you might need to unlock it, and so on. That holds even if the specific instance does not offer the specific perceived affordances necessary for a given operation, as you can generalize it from other instances of the door class you encountered in the past.
How’s all this even remotely relevant to the issue at hand? Getting there…
Although they have no physical reality or appearance to offer, authentication protocols are tools from the architect’s and the developer’s conceptual toolbox. As such, they have a number of common uses that the developer and the architect will come to expect from every instance of the “authentication protocol” class. Namely, one common affordance of authentication protocols is “authenticate users with provider A to access a resource on another provider B”. That works for a long list of protocols: SAML, WS-Federation, OpenID 2.0, OpenID Connect, WS-Trust, even Kerberos.
It is that affordance that allows us platform providers to create development libraries that secure your resources without knowing in advance who the identity provider will be, or services that allow you to dynamically plug new identity providers without knowing anything but the protocol they support and he coordinates that the given protocol mandates.
So, what’s the problem with applying the above to OAuth 2.0? Well, here there’s the kicker:
OAuth 2.0 is not an authentication protocol.
I can almost hear you protest! We’ll get to the technical details in a moment, but just want to acknowledge that I understand the reaction. The “OAuth 2.0 is a sign in protocol” narrative had innumerable boosters in the public literature: “Facebook uses OAuth 2.0 for signing you in!” and “In order to sign in our Web site via Twitter, go through their OAuth consent page” and many others. In fact, using OAuth 2.0 as a building block for implementing a sign in flow is not only perfectly possible, but quite handy too: a LOT of Web applications take advantage of that, and it works great. But that does NOT mean that OAuth2 *is* an authentication protocol, with all the affordances you’ve come to expect from one, as much as using chocolate to make fudge does not make (chocolate == fudge) true.
[Unless they are using OpenID Connect] Every provider chooses how to layer the sign-in function on top of OAuth 2.0, and the various implementations do not interoperate: both because of sheer chance (two developers implementing a class for the same concept will not produce the same type, even if they use the same language) and because almost always that’s not one explicit goal of those solutions. Usually providers want to offer access for their users to their own resources; the only external factor is that they want to do so even for applications developed by third parties. That does entail crossing a boundary, which is the staple of authentication protocols; but it happens to be a different boundary than the one you’d normally traverse when implementing sing-in. More details below.
Crossing Boundaries
Let’s decompose a classic App-RP-IP authentication flow, then a canonical OAuth 2.0 flow. We’ll see that the two approaches are designed to cross different chasms: that has consequences that become evident when we try to apply one approach to the problem that the other approach was designed to solve.
Classic App-IP-RP Authentication Protocol Flow
In a classic authentication protocol, a resource outsources authentication to an external authority. The resource can be called relying party (RP), service provider and similar; the identity provider can be called IdP, OpenID Provider, and so on, depending on your protocol of choice; but the conceptual roles remain the same. The RP and the IP can be run by completely different business entities, and in fact most protocols assume that that is the case. The boundary to be crossed is the one between the identity provider and the resource. That entails establishing messages for invoking the provider asking for an authentication operation and messages/formats for flowing back to the resource the outcome of the authentication operation. The outcome must be presented in a way that admits verification from the resource. Every other detail about the implementation of identity provider and resource can be ignored, as adherence to the protocol as described is all that’s needed to carry an authentication operation.
The figure above shows a classic flow for nondescript sign-in protocol; the app can be a browser or a rich client app; the IP can be implemented with an STS or whatever other construct that can authenticate users and spit out tokens; and the token is represented as the usual pentagon carrying the signature of its issuer. I am not going to walk you though that flow here, you’ll find countless similar diagrams explained in details in the last 9 years of posts.
Different authentication protocols have different strictness levels on how the authentication results should be represented: the SAML protocol will only use SAML tokens, WS-Federation admits arbitrary token types (though in practice it almost always uses SAML tokens as well), but in general the idea is that the format is well-known to the resource, which can validate its source and parse it for meaningful info (e.g. user claims). This is NOT optional: the resource knows nothing about the provider apart from the protocol it uses and associated coordinates, hence agreement on the token format is essential.
Another interesting thing to note is that the application used by user or accessing the resource plays absolutely no part in the authentication flow. In most protocols the identity provider will not care about what app the user is leveraging for performing authentication, but only about the credentials (hence the identity) of the user; and the resource won’t care about that either, only validating that the token comes from the right issuer, has not be tampered with, contains the required user info, and so on. The next example is venturing a bit in the inter-reign between authentication and authorization, but I think it captures an important intuition about the general point hence I’ll go ahead anyway. Say that Judy is trying to open a Word document from a SharePoint library: her ability of doing so will depend on the permissions granted to her account and the restrictions assigned to the document, the fact that she is using IE or Firefox will play no part in the authorization decision. The same can be said for all of the rich clients using traditional authentication protocols to call web services.
Canonical OAuth 2.0 Flow
The OAuth 2.0 protocol is aimed at authorizing rather than authenticating. There’s more: its aim is to authorize applications, an artifact that was not playing an explicit role in the flow described in the earlier section.
Applications are the main actor here: the user is involved at the moment of granting his/her permission to the app to access the resource on his behalf, but after that the user might disappear from the picture and the app might keep to access the resource, unattended.
I am sure you already know the canonical story for explaining the problem that OAuth 2.0 was designed to solve:
- A user keeps his/her pictures at Web application A
- The user wants to use Web application B to print those pictures
OAuth 2.0 provides a way for the user to authorize the Web application B to access his/her pictures on A, without having to share his/her A credentials with B. The importance of that accomplishment cannot be overstated: with the explosion of APIs which heralded the rise of the programmable Web, the password relinquishing anti-pattern was going to be completely unsustainable. OAuth is one of the key elements that is fueling the current API wave, and that is a Good Thing.
Given that the regular reader of this blog might be more familiar with the federation protocols than with OAuth 2.0, I’ll fix a quick walkthrough for one of the most common flows (OAuth 2.0 supports many). Note that not all the legs I’ll describe are part of the framework in the spec: here my purpose is to help you to understand the scenario end to end, and to that purpose I’ll have to add a bit of color and throw some simplifying assumptions here and there. If OAuth2 normative reference is what you seek, please refer to the actual specification! (in fact, there are two of those you want to look at: RFC 6749 and RFC 6750).
I will introduce the OAuth 2.0 canonical roles during the walkthrough, with the hope that seeing them in action right away will make them easier to grok their function. Here is what happened in the figure above:
- Say that Marla navigated to a Web site that offers picture print services. We will call that Web site “Client”, for reasons that will become evident momentarily.
Marla wants to print pictures she uploaded to another Web site, let’s call it A again. The Client happens to offer the possibility of sourcing pictures from A: there is a big button on the page that says “Print pictures from Web site A”, and she pushes it.- The client redirects Marla’s browser to an Authorization Server (AS for short). The AS is an intermediary, an entity that is capable of
- authenticating Marla to A,
- asking her if she consents to the Client app accessing her pictures (up to and including what the Client can do with those: read them? modify them? etc) and
- issuing a token for the client that can be used to carry the actions Marla consented to.
The redirect message carries the ID of the Client, which must be known beforehand by the AS; what the Client intends to do with the resource; and some other stuff required to make the flow function (e.g. a return URL to return results back to the client).
The AS, and specifically its Authorization Endpoint (it has more than one), takes care of rendering all the necessary UI for authenticating Marla, assist her in the decision to grant or deny access to resources, and so on.- Assuming that Marla give her consent, the AS generates a Code (think of it as a nonspecific string) and sends it back to Marla’s browser with a redirect command toward the return URL specified by the Client
- The browser honors the redirect and passes the Code to the Client
- The Client engages with another endpoint on AS, the Token Endpoint. Note that from now on all communications will be server to server, Marla might close the browser, shut down her computer and go for a coffee and this part of the flow will still take place.
The Client sends a message to the token endpoint containing the just-obtained Code, which proves that Marla consented to the actions that the Client wants to do. Furthermore, the message contains the Client’s own credentials: the same Client ID sent in 2, and some secret (the Client Secret) that the AS can use to verify the identity of the Client and use it in the authorization process. For example; say that Web site A is offering its API under some throttling agreement, and that the Client already exceeded its quota of daily tokens: in that case, even if Marla consented to granting Client access to her pictures, the Client won’t get the token that would be necessary to do so.
In this case let’s assume that everything is OK; the AS issues to the client an Access Token, which can be used to secure calls to the A API which offer access to Marla’s pictures. I can’t believe I made it this far without telling you that in the OAuth 2.0 spec parlance Marla’s pictures are a Protected Resource (PR), and that the A Web Site is the Resource Server (RS).
In the same leg the AS can also issue a Refresh Token, which is one of the most interesting features of OAuth 2.0 but can be safely ignored for today’s discussion.- Client can finally access the PR. OAuth 2.0 defines how to use the Access Token in the context of HTTP calls, and Client will have to stick with that; but if it does so, it will be able to access Marla’s pictures programmatically and incorporate them within its own user experience & logic. The miracle of the programmable Web renews itself.
Wow, that took much longer than I expected; and I left out a criminally high number of details! Hopefully this gave you an idea of how one of the most common OAuth2 flows works. Let’s see if we can work with that to extract some insights.
The first observation is obvious. I guess that’s pretty clear that this flow does NOT represent a sign-in operation.
Actually, a sign-in might take place: in #2 Marla had to authenticate (or have a valid session) with A in order to prove she is the Resource Owner hence competent to grant or deny access to it. However OAuth 2.0 does not specify how the authentication operation should take place, or even which outcome it should have: OAuth is interested in what takes place AFTER authentication, that is to say consent granting and consequent Code issuing. If we want to use OAuth as sign-in protocol, the sign-in that takes place in #2 does not help.The second is a tad more subtle. If somebody felt the need to regulate how this flow should take place, it is reasonable to assume that there is a boundary to cross: and the boundary to be crossed is the one that separates the Client from the AS+RS combination. True, the letter of the specification does not position this boundary as the obvious and only one: AS and RS can be separated entities as well, owned and ran by different businesses. In practice, however, the specification does describe all communications between the Client and AS+RS, though it does not give details on AS-RS exchanges. This means that if your solution calls for distinct & separate AS and RS, you’ll have to fill the blanks on your own: which in turn means that how you will fill those blanks will be almost certainly different from how others in the industry will solve the same problem.
Too abstract for your tastes? Here there’s some *circumstantial* evidence that keeping AS and RS under the same roof is baked in OAuth’s common usage, if not the spec itself.
- The AS must know how to authenticate users who keep resources at the RS
- The AS must know the resources (and their affiliation with respective owners) kept at the RS well enough to render relevant UI for the resource owner to express preferences (which resources? what actions can be performed on them?)
- The RS must be able to validate tokens issued by the AS and understand their authorization directives well enough to enforce them, yet the OAuth 2.0 spec does not mandate specific token formats, callbacks from the RS to the AS for validation, or any other mechanism that would regulate RS-AS communications, offline or online
- In almost all of the OAuth 2.0 solutions found in the wild the AS and the RS positively, consistently live under the same roof. Think of Facebook and Twitter.
You know, it even makes complete business sense. If you have a Web site and you want to offer an API for other Web sites, those other Web sites are the entities you want to enter in a relationship with; those are the ones that you want to charge, throttle, block when something goes wrong, and so on. Again, you just need to look at the market and what happens when an API provider changes its policies to understand what are the parties entering in a contract here, and what is the boundary that needs regulation in this scenario.
The Trivial Mapping: PR as RP, AS as IP, Client as “App”
Still with me? Excellent. Let’s get back to the original problem; why can’t I just bake into ACS (or a library) the use of OAuth 2.0 as a sign-in protocol so that it will work with all the “OAuth2 providers” out there without custom code, just like it does for OpenID or WS-Federation providers?
To learn more about the problem, let’s simply try to use OAuth 2.0 to perform a sign-in flow. What I observed is that people tend to map OAuth2 roles to sign-in protocol roles, according to correspondences that make just too much intuitive sense to ignore. You can see such mapping in the diagram above, where I pasted the two flows (sans individual steps, for the sake of readability) and highlighted the correspondences. Let’s spend few words about those; just remember, intuition can be very treacherous ;-).
- The protected resource/resource server is the entity we seek access to, hence it must be the relying party counterpart: right? The even almost have the same acronym!
- The authorization server authenticates users and issues tokens; and anything that issues tokens can be thought as an STS, isn’t it? And has is an STS, if not the arm of the IP? It’s settled, then: AS == IP.
- The client app is what requests and uses the token; it is also what the users operates in order to perform the desired function: that seems to be a pretty natural fit for the app/client/user agent role in a sign-in protocol. True, it is a bit troubling the fact that in OAuth2 the Client is a role that is much more in focus (and with lots more rules to obey) than the app/client/user agent in sing-in protocols is; OTOH we ran out of entities to map, hence our hands are kind of tied here. Like some nasty element in an equation we are trying to simplify, we can always hope it will cancel out as we move forward.
Does that mapping make sense to you? It usually does; also, it can be made to work and can be quite useful. However, in order to apply this approach you need to handle a couple of thorny issues; and in the process you’ll *have* to occasionally go beyond what the specification mandates, introducing elements that make your solution (and everybody else’s) potentially unique hence non-interoperable out of the box.
Say what you will about service orientation, but it is a very powerful way of thinking about distributed systems. Just glancing at the diagram above you should detect a capital sin occurring not once, but twice: the proposed mapping violates boundaries.
- In a classic sign-in scenario, there is a boundary that separates IP and RP. Per our mapping, that induces a boundary between AS and RS/PR: but OAuth2 describes no such boundary!
In our discussion above we have seen how OAuth 2.0 does not really regulate communications between RS/PR and AS. Whereas in a sign-in protocol – say WS-Federation – the RP knows how to generate a sign-in request for the IP and knows how to validate incoming tokens, in OAuth 2.0 you’ll find a big blank there; co-located AS and PR do not have issues with this, but here you *have* to fill the blank. You’ll have to pick a token format to accept, and you’ll need to establish how to tell if a token is valid: that might entail deciding what are the signing credentials used by the AS, how they are used and getting a hold on the necessary bits; or some other method to validate incoming tokens. Ah, and let’s not forget about extracting claims! They might not be strictly necessary for the sign-in in itself, but experience shows that usually you want some user info contextually to the sign-in operation.
What format will you choose? Whatever you’ll pick, chances are that others will pick something different. Furthermore, people have no way of knowing (programmatically, as in via metadata) what you have chosen.
It gets worse: if you own the RP and you want to work with an existing “OAuth 2.0 provider” (hopefully the expression is changing its meaning for you as we dig deeper in what it actually entails) chances are that its AS and RS/PR are co-located, per the above. In that case its access tokens might be opaque strings in a format you have no hope to crack from your own RP. To make an extreme example: if an AS issues an access token that is simply the primary key of a table in a DB, only a co-located RS/PR which can access the same DB will be able to consume the token; but if you throw a boundary in the picture, as it would happen for a RP (==RS/PR in our mapping) ran by a third party, direct token validation is no longer possible (but don’t completely forget the scenario, as we’ll revisit it in the next section).- In a traditional sign-in scenario, the client/app/user agent used to access the resource is simply not a factor in deciding whether the user should be signed in or not. However in OAuth 2.0 the Client, to which our lower-case client/app/user agent is mapped in this approach, is not only a factor: the Client has its own identity, and that identity is an important element in the AS’ decisions. There is a boundary between the Client and the AS+PR, and as we saw this has important consequences that induce ripples in the mechanics of how Client-AS communications are implemented. Even ignoring the matter of the Client secret, which is not mandatory in all flows: most existing “OAuth 2.0 providers” in existence will expect to know beforehand the identity of the Client, and that means that your transparent sign-in clients will suddenly need to acquire some measure of corporeity. You’ll have to assign Client IDs and use them when requesting codes & tokens; what’s more, you’ll have to provision those, often by registering your client with the AS. Funny story, tho: very often your existing sign-in client apps will not have an obvious business reason for having their own identity, which means that you’ll have to work something out for sheer implementation reasons. That can be pretty onerous: imagine a rich client app that, as long as the user has valid credentials, with traditional sign-in protocols would do its job no matter how old the bits are or from where they are ran. The same app with an ID would now need that ID provisioned with the AS, distributed to (or with) the rich client app, have that ID maintained when it expires or gets blocked for some reasons, and so on.
Remember the example we mentioned earlier in which Marla could be denied access because the Client itself exceeded its daily amount of tokens it can be issued? That’s one example of things that might happen when the client app is not transparent. Also: I subtly shifted the conversation to rich client apps, but imagine what you would do when the client is a browser.
Most of the issues here can be worked around if you own all of the elements in the scenario: for example, you might decide to admit anonymous clients or have special IDs that you reuse across the board (not commenting on whether that would be a good idea or not, that’s for another day). That said: you can see how all this might be a problem if you’d want to be able to use “OAuth 2.0 providers” for sign-in flows out of the box. In all likelihood, existing providers would want to know the identity of your client app, but more often than not your client would not have an identity of its own, adding it might not be a walk in the park and the way in which you’d provision it varies wildly between providers (think of the differences in app provisioning flows between Facebook, Twitter and Live) and it often entails manual steps through web UIs.Lots of words there! You can’t say you weren’t warned :-) Let me summarize.
Treating AS as an IP, RS/PR as RP and clients as Clients does not enable you to take advantage of OAuth 2.0 providers for sign-in scenarios without requiring you to write custom code. That mapping violates various boundaries, which in turn requires you to fill blanks in the specs (like which token format will be used for access tokens) or find out how every provider decided to fill those blanks. Furthermore, there might be providers that simply do not admit this kind of mapping (think opaque tokens that cannot be validated without sharing memory with the AS).
That does not mean that this approach is not viable, only that it is not generally applicable if all you know is that you want to “talk to an OAuth 2.0 provider”.Yes, intuition can be misleading, but it is really the case to say that it’s all in our head. You really cannot blame a PR for not being an RP, or an AS for not being a perfect match for an IP. That’s not what they were designed for, and you can’t blame a screw for not being a nail just because they both have a head and you are used to going around with a hammer.
But let’s not give up yet! Maybe the problem will yield, if we attack it from a different angle.
Alternative Mapping: Client as RP, AS+PR as IP
Let’s shuffle the cards a little. The issue with the former mapping was that we focused on the individual nodes of the graphs, instead of trying to preserve their topologies (and with it the boundary constraints).
Here there’s an idea: what if we’d use the Client to model an RP, and the AS+PR/RS to play the role of the IP? Counterintuitive, true, but think about it for a moment:
- The boundary crossing constraints would be preserved
- Instead of “traditional” token validation, a RP could consider a user signed in if it can obtain an access token and successfully access a PR/RS on the user’s behalf
- Keeping PR/RS and AS together saves us from having to define how they communicate with each other; furthermore, that assumption happens to be a good fit for most of the existing providers
- Usually RPs need to be provisioned by the IP before tokens for them can be requested. A RP=>Client mapping is compatible with both the need to assign to the Client an identity and the need to provision it with the AS
MUCH better, right? This does sound much more viable, and it is. LOTS of sign-in solutions layered on top of OAuth 2.0 operate on this principle.
However, it still does not make possible to create a generic library or a service that would allow to implement sign-in with any “OAuth2 provider” without provider-specific code. That is actually pretty easy to explain. Although you might achieve some level of generality for obtaining the access token (task made difficult by the plethora of sub-options/custom parameters/profile differences that characterize the various providers) you’d still have to deal with the fact that every provider offers different protected resources and different APIs to access them. There would be no generic call you could bake in your hypothetical library to prove that your access token is valid, nor fixed user properties you could use to reliably obtain what you need to know about your incoming users. And what holds for a library, holds for products and services that would be built with it.Wrap-Up, and the Right Way to Go About It: OpenID Connect
Between the description of the trivial mapping and the Client=>RP one, I hope I managed to answer the question I opened the post with.
Q: “Why can’t I provision in ACS OAuth 2.0 providers in the same way as I provision OpenID providers?”
A: “Because OpenID is a sign-in protocol, and OAuth 2.0 is an authorization framework. OAuth 2.0 cannot be used to implement a sign-in flow without adding provider-specific knowledge. Also, there’s a long blog post with the details.”
This would be a good time to remind you that as usual, THIS ENTIRE POST is all my own personal opinion. Please take it with a huge grain of NaCl.
Also, I ended up writing this post thru THREE intercontinental flights: not very relevant to the topic at hand, but wanted to dispel the notion that I am very prolific :-)That settled, the fact that the Client=>RP does not solve the issue really leaves with a bitter aftertaste. We were so close!
As it turns out, dear reader, we are not the only ones feeling that way.Have you ever heard of OpenID Connect? OpenID Connect is the next version of OpenID. It is layered on top of OAuth 2.0, and is very much a sign-in protocol.
One way to think about it is that OpenID Connect formalizes the Client=>RP approach, by providing the details of how to express user info as protected resource, how to redeem access tokens and even which token format should be used (the JSON Web Token: what else? :-)).
OpenID Connect is still a draft specification, but it is enjoying a lot of mindshare and is rapidly spreading through the industry: it will help providers to build on top of their existing investment on OAuth 2.0, and consumers to take advantage of their services for sign-in flows. Yes, even with generic libraries :-)







<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
• Maarten Balliauw (@maartenballiauw) published Tales from the trenches: resizing a Windows Azure virtual disk the smooth way on 1/7/2012:
We’ve all been there. Running a virtual machine on Windows Azure and all of a sudden you notice that a virtual disk is running full. Having no access to the hypervisor nor to its storage (directly), there’s no easy way out…
Big disclaimer: use the provided code on your own risk! I’m not responsible if something breaks! The provided code is as-is without warranty! I have tested this on a couple of data disks without any problems. I've tested this on OS disks and this sometimes works, sometimes fails. Be warned.
Download/contribute: on GitHub
When searching for a solution to this issue,the typical solution you’ll find is the following:
- Delete the VM
- Download the .vhd
- Resize the downloaded .vhd
- Delete the original .vhd from blob storage
- Upload the resized .vhd
- Recreate the VM
- Use diskpart to resize the partition
That’s a lot of work. Deleting and re-creating the VM isn’t that bad, it can be done pretty quickly. But doing a download of a 30GB disk, resizing the disk and re-uploading it is a serious PITA! Even if you do this on a temporary VM that sits in the same datacenter as your storage account.
Last saturday, I was in this situation… A decision would have to be made: spend an estimated 3 hours in doing the entire download/resize/upload process or reading up on the VHD file format and finding an easier way. With the possibility of having to fall back to doing the entire process…
Being a bit geeked out, I decided to read up on the VHD file format and download the specs.
Before we dive in: why would I even read up on the VHD file format? Well, since Windows Azure storage is used as the underlying store for Windows Azure Virtual Machine VHD’s and Windows Azure storage supports byte operations without having to download an entire file, it occurred to me that combining both would result in a less-than-one-second VHD resize. Or would it?
Note that if you’re just interested in the bits to “get it done”, check the last section of this post.
Researching the VHD file format specs
The specs for the VHD file format are publicly available. Which means it shouldn't be to hard to learn how VHD files, the underlying format for virtual disks on Windows Azure Virtual Machines, are structured. Having fear of extremely complex file structures, I started reading and found that a VHD isn’t actually that complicated.
Apparently, VHD files created with Virtual PC 2004 are a bit different from newer VHD files. But hey, Microsoft will probably not use that old beast in their datacenters, right? Using that assumption and the assumption that VHD files for Windows Azure Virtual Machines are always fixed in size, I learnt the following over-generalized lesson:
A fixed-size VHD for Windows Azure Virtual Machines is a bunch of bytes representing the actual disk contents, followed by a 512-byte file footer that holds some metadata.
Maarten Balliauw – last SaturdayA-ha! So in short, if the size of the VHD file is known, the offset to the footer can be calculated and the entire footer can be read. And this footer is just a simple byte array. From the specs:
Let’s see what’s needed to do some dynamic VHD resizing…
Resizing a VHD file - take 1
My first approach to “fixing” this issue was simple:
- Read the footer bytes
- Write null values over it and resize the disk to (desired size + 512 bytes)
- Write the footer in those last 512 bytes
Guess what? I tried mounting an updated VHD file in Windows, without any successful result. Time for some more reading… resulting in the big Eureka! scream: the “current size” field in the footer must be updated!
So I did that… and got failure again. But Eureka! again: the checksum must be updated so that the VHD driver can verify the footer is valid!
So I did that… and found more failure.
*sigh* – the fallback scenario of download/resize/update came to mind again…
Resizing a VHD file - take 2
Being a persistent developer, I decided to do some more searching. For most problems, at least a partial solution is available out there! And there was: CodePlex holds a library called .NET DiscUtils which supports reading from and writing to a giant load of file container formats such as ISO, VHD, various file systems, Udf, Vdi and much more!
Going through the sources and doing some research, I found the one missing piece from my first attempt: “geometry”. An old class on basic computer principles came to mind where the professor taught us that disks have geometry: cylinder-head-sector or CHS information for the disk driver which can use this info for determining physical data blocks on the disk.
Being lazy, I decided to copy-and-adapt the Footer class from this library. Why reinvent the wheel? Why risk going sub-zero on the WIfe Acceptance Factor since this was saturday?
So I decided to generate a fresh VHD file in Windows and try to resize that one using this Footer class. Let’s start simple: specify the file to open, the desired new size and open a read/write stream to it.
1 string file = @"c:\temp\path\to\some.vhd"; 2 long newSize = 20971520; // resize to 20 MB 3 4 using (Stream stream = new FileStream(file, FileMode.OpenOrCreate, FileAccess.ReadWrite)) 5 { 6 // code goes here 7 }
Since we know the size of the file we’ve just opened, the footer is at length – 512, the Footer class takes these bytes and creates a .NET object for it:
1 stream.Seek(-512, SeekOrigin.End); 2 var currentFooterPosition = stream.Position; 3 4 // Read current footer 5 var footer = new byte[512]; 6 stream.Read(footer, 0, 512); 7 8 var footerInstance = Footer.FromBytes(footer, 0);
Of course, we want to make sure we’re working on a fixed-size disk and that it’s smaller than the requested new size.
1 if (footerInstance.DiskType != FileType.Fixed 2 || footerInstance.CurrentSize >= newSize) 3 { 4 throw new Exception("You are one serious nutcase!"); 5 }
If all is well, we can start resizing the disk. Simply writing a series of zeroes in the least optimal way will do:
1 // Write 0 values 2 stream.Seek(currentFooterPosition, SeekOrigin.Begin); 3 while (stream.Length < newSize) 4 { 5 stream.WriteByte(0); 6 }
Now that we have a VHD file that holds the desired new size capacity, there’s one thing left: updating the VHD file footer. Again, the Footer class can help us here by updating the current size, original size, geometry and checksum fields:
1 // Change footer size values 2 footerInstance.CurrentSize = newSize; 3 footerInstance.OriginalSize = newSize; 4 footerInstance.Geometry = Geometry.FromCapacity(newSize); 5 6 footerInstance.UpdateChecksum();
One thing left: writing the footer to our VHD file:
1 footer = new byte[512]; 2 footerInstance.ToBytes(footer, 0); 3 4 // Write new footer 5 stream.Write(footer, 0, footer.Length);
That’s it. And my big surprise after running this? Great success! A VHD that doubled in size.
So we can now resize VHD files in under a second. That’s much faster than any VHD resizer tool you find out here! But still: what about the download/upload?
Resizing a VHD file stored in blob storage
Now that we have the code for resizing a local VHD, porting this to using blob storage and more specifically, the features provided for manipulating page blobs, is pretty straightforward. The Windows Azure Storage SDK gives us access to every single page of 512 bytes of a page blob, meaning we can work with files that span gigabytes of data while only downloading and uploading a couple of bytes…
Let’s give it a try. First of all, our file is now a URL to a blob:
1 var blob = new CloudPageBlob( 2 "http://account.blob.core.windows.net/vhds/some.vhd", 3 new StorageCredentials("accountname", "accountkey));
Next, we can fetch the last page of this blob to read our VHD’s footer:
1 blob.FetchAttributes(); 2 var originalLength = blob.Properties.Length; 3 4 var footer = new byte[512]; 5 using (Stream stream = new MemoryStream()) 6 { 7 blob.DownloadRangeToStream(stream, originalLength - 512, 512); 8 stream.Position = 0; 9 stream.Read(footer, 0, 512); 10 stream.Close(); 11 } 12 13 var footerInstance = Footer.FromBytes(footer, 0);
After doing the check on disk type again (fixed and smaller than the desired new size), we can resize the VHD. This time not by writing zeroes to it, but by calling one simple method on the storage SDK.
1 blob.Resize(newSize + 512);
In theory, it’s not required to overwrite the current footer with zeroes, but let’s play it clean:
1 blob.ClearPages(originalLength - 512, 512);
Next, we can change our footer values again:
1 footerInstance.CurrentSize = newSize; 2 footerInstance.OriginalSize = newSize; 3 footerInstance.Geometry = Geometry.FromCapacity(newSize); 4 5 footerInstance.UpdateChecksum(); 6 7 footer = new byte[512]; 8 footerInstance.ToBytes(footer, 0);
And write them to the last page of our page blob:
1 using (Stream stream = new MemoryStream(footer)) 2 { 3 blob.WritePages(stream, newSize); 4 }
And that’s all, folks! Using this code you’ll be able to resize a VHD file stored on blob storage in less than a second without having to download and upload several gigabytes of data.
Meet WindowsAzureDiskResizer
Since resizing Windows Azure VHD files is a well-known missing feature, I decided to wrap all my code in a console application and share it on GitHub. Feel free to fork, contribute and so on. WindowsAzureDiskResizer takes at least two parameters: the desired new size (in bytes) and a blob URL to the VHD. This can be a URL containing a Shared Access SIgnature.
Now let’s resize a disk. Here are the steps to take:
- Shutdown the VM
- Delete the VM -or- detach the disk if it’s not the OS disk
- In the Windows Azure portal, delete the disk (retain the data!) do that the lease Windows Azure has on it is removed
- Run WindowsAzureDiskResizer
- In the Windows Azure portal, recreate the disk based on the existing blob
- Recreate the VM -or- reattach the disk if it’s not the OS disk
- Start the VM
- Use diskpart / disk management to resize the partition
Here’s how fast the resizing happens:
Woah! Enjoy!
We’re good for now, at least until Microsoft decides to switch to the newer VHDX file format…
Download/contribute: on GitHub







Bruno Terkaly (@brunoterkaly) announced availability of his Video Introduction: Windows Azure Web Sites – Start for free, enjoy unlimited possibilities on 1/5/2013:
This post is about Azure Web Sites.
- Get started for free and scale as you go
- Azure Web Sites is a cloud platform across shared and reserved instances for greater isolation and performance.
- Use any tool or OS to build a web site with ASP.NET, PHP or Node.js and deploy in seconds.
It’s easy to deploy web sites to the cloud as-is.
- If your site is built with ASP.NET, PHP or Node.js, it will run on Windows Azure Web Sites.
- Get a head start using open source
- Launch a site with a few clicks using popular open source apps like WordPress, Joomla!, Drupal, DotNetNuke and Umbraco.
Take advantage of integrated source control
- With Windows Azure Web Sites you can deploy directly from your source code repository.
- Simply ‘git push’ from the Git repository of your choice or connect your Team Foundation Service projects and enjoy continuous source integration.
- Automated deployment has never been so easy.
Videos
Deployment Help with Deployment (ASP.NET Web apps, Visual Studio, TFS, Git) http://go.microsoft.com/fwlink/?LinkId=254423&clcid=0x409 Node.js Deployment How to deploy Node.js with GIT or FTP http://go.microsoft.com/fwlink/?LinkId=254424&clcid=0x409 Open Source Leverage existing frameworks: WordPress, Drupal, Joomla, Umbraco, DotNetNuke http://go.microsoft.com/fwlink/?LinkId=254425&clcid=0x409 Scaling to reserved VM Instances If you are lucky enough to exceed the capabilities of FREE Azure Web Sites, this video shows you how to upgrade to reserved VM instances. http://go.microsoft.com/fwlink/?LinkId=254426&clcid=0x409


Wely Lau (@wely_live) explained Preserving Static IP Address in Windows Azure in a 1/4/2013 post:
It is a pretty common practice to use an IP address to provide access on whitelisting service. As an example a trading partner Contoso only allows my company Northwind to access their web service. Only the predefined IP address will be accepted by Contoso while others will be denied.
The question now is: Am I able to preserve the IP address of my Windows Azure application in the cloud environment? This article is to explain how to preserve a static IP address for both PaaS and IaaS.
While there is internal IP address being assigned to each VM, this article emphasizes on public VIP (virtual IP address). We don’t really care about the internal IP address since it’s invisible to external parties.
PaaS: Web and Worker Role
In PaaS, the IP address is assigned on the deployment (either production or staging) of our service package. The IP address will be stay static through the lifecycle of service deployment. As of today, there’s no way to reserve an IP address outside the lifetime of the deployment:
“Windows Azure currently does not support a customer reserving a VIP outside of the lifetime of a deployment.”
The following diagram illustrates how the deployment looks like:
You won’t lose your IP address
- Operations including in-place upgrade, VIP swap, and scaling will not make you to lose your public IP address.
- Fortunately, you will also never lose your IP Address in any case of hardware failure recovery.
You will lose your IP address
- When you delete a deployment of a cloud service, you will lose the IP address. Windows Azure will assign you another new public IP address on the new deployment.
Thus, please be reminded that do not delete the deployment if you want your IP address to be persisted. You should always consider using in-place upgrade or VIP swap to keep the public VIP.
IaaS: Virtual Machine
There is only production deployment in IaaS Virtual Machine. The IP address is assigned when a VM attached to an empty cloud service.

The left hand side of the following figure shows the assignment of a public VIP when VM 1 is being created. The right hand side of the figure shows that there isn’t any IP address change when a new VM attached to the existing cloud service.
You won’t lose your IP address
- Operations including vertical scale (changing size of VM) and adding new VM to cloud service will not make you to lose your public IP address.
- Likewise PaaS, you will also never lose your IP Address in any case of hardware failure recovery.
You will lose your IP address
- When there isn’t any VM attached to a cloud service, you will lose the IP address. This can be shown with the following figure.
What if you really need to delete a VM but you don’t want to lose the public VIP? The workaround is to deploy a “dummy” VM for a time being until the new deployment is done. This will ensure that your public VIP will be retained.
Conclusion
To conclude, this article explains under certain circumstances, you will lose or will not lose the public VIP of your Windows Azure service. It also covers both PaaS and IaaS on how they differs each other on deployment management. Hope this gives you better insight on managing your Windows Azure public VIP.








Brian Noyes (@briannoyes) described Scaling Windows Azure Web Sites from Free/Shared to Reserved in a 1/2/2013 post:
Last week DasBlog freaked out on my blog and pegged the CPU on my Windows Azure Web Sites (WAWS) hosted blog. Because I had it configured as a Shared instance (which allows me to point my custom briannoyes.net and briannoyes.com domains at it from DNS), there are Usage Quotas that kicked in for how much CPU time your site can consume in a given window and my site got suspended for exceeding those quotas. As a result, my blog was down for almost a 24 hour period until the quota gets reset.
When I discovered the problem (thanks to @MLaritz for alerting me via Twitter), I thought “well, I can just scale it up to a Reserved instance for a period until the quota gets reset and then can scale back down.”
What surprised me was when I tried to do that I got the following warning:
"This will upgrade all web sites in the West US region to Reserved mode. This will take several minutes to complete and your sites will keep running during the process."
I had two other sites on the same account in the same sub-region, and this made it sound like they were each going to become a Reserved instances (billing out at ~$57/mo instead of ~$10/mo for shared). So I instead opted for waiting and letting my blog be down for a day.
I followed up with the Azure team and was pointed to this great post by Brent Stineman. The important subtlety here is that yes, in fact all of my sites would have been moved to a Reserved instance, but they would all be moved to a single instance and it would basically become a dedicated VM acting as a shared host for all of my sites, which I could then scale as appropriate. That means if you have more than 6 sites you would actually save money compared to the shared hosting option. Well, in my case I only had three and it would have been a little more expensive, but no where near what I thought it was telling me – that I would jump to paying 6 X 3 = 18 times as much.
So just realize that when you scale from Shared to Reserved mode and you get this notice, it means those sites will be moved together to a single reserved instance, not individual instances.



<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
• Cory Fowler (@SyntaxC4) described a Fix for WordPress Plugin Update Issues on Windows Azure Web Sites on 1/6/2012:
A while back I posted an article called Workaround for deleted folder still exists in Windows Azure Web Sites, which talks about how to get around an issue specifically with WordPress plugin upgrading. Recently, on twitter there have been a few people running into this issue, so I thought I would go into a little bit more detail on the issue and how to work around it, permanently.
The Cause of the WP Plugin Issue
In order to dig to the root of the problem, let’s take a few steps back here and get a little bit better of an understanding of the different pieces at play.
PHP
PHP is an interpreted language, simply put it is not compiled into machine code, but instead read and executed step-by-step by an interpreter in this instance, the PHP runtime.
This means that every line would need to be read, interpreted and executed on each request. Which in computer science we understand is not very efficient. For this reason PHP can employ caching to avoid parsing every instruction on each request, instead it stores a certain amount of interpreted instructions in shared memory.
IIS
It’s no secret that Windows Azure Web Sites leverages IIS as it’s Web Server. IIS uses FastCGI to interact with the PHP Interpreter. With the Web Server being able to interact with an interpreter, we have the means to serve up PHP code on IIS. As stated above, PHP can leverage a cache in order to avoid parsing each line of a script, enter WinCache.
WinCache
WinCache is installed and enabled by default for PHP Runtimes maintained by the Windows Azure Web Sites team.
WinCache is a caching system which can be enabled for PHP application which run on Windows leveraging IIS. This is done by Installing WinCache, then adding a reference to
php_wincache.dllfrom within yourphp.inifile.By default, Windows Azure Web Sites has PHP 5.3 installed with WinCache 1.1.
Now that we have a better understanding of the different pieces involved, let’s take a closer look at the issue at hand.
There is a bug in WinCache 1.1 [Bug #59352] which causes a lock on a folder which isn’t released until IIS is restarted, which is why this workaround is effective at fixing the issue.
How to Resolve the Plugin Updating Issue
The resolution is fairly simple. The bug has been fixed in a newer release of WinCache (version 1.3 which works with PHP 5.4).
Recently, PHP 5.4 was enabled in Windows Azure Web Sites making the fix as simple as following these steps to Enable PHP 5.4 in Windows Azure Web Sites.


• Philip Fu posted [Sample Of Jan 6th] How to use Bing Translator API in Windows Azure to the Microsoft All-In-One Code Framework blog on 1/6/2012:
Sample Download :
CS Version: http://code.msdn.microsoft.com/CSAzureBingTranslatorSample-7c3a2d9b
VB Version: http://code.msdn.microsoft.com/VBAzureBingTranslatorSample-e0cfc6f7
This Sample will show you how to use Bing translator, when you get it from Azure market place.
Here provide three scenarios that we usually choose. Each page uses a different interface for get data from Bing translator.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.
Brian Hitney reported a Rock, Paper, Azure Re-launch! in a 1/4/2013 post:
I’m a little late getting this out (pesky vacations and all) but we re-launched Rock, Paper, Azure (RPA) a few weeks back with weekly competitions!
What is Rock, Paper, Azure? In short, it’s a game, primarily for developers. It’s also a fun way to learn programming, as the concept is simple however winning is not. You write code that plays a modified Rock, Paper, Scissors like game and tries to beat everyone else doing the same.
The code that you download has everything ready to go, so you just need to worry about implementing some logic. No advanced degree required!
We developed RPA as a teaching tool for the cloud. The RPA site and game engine all run in Windows Azure, and it’s a good example of building a scalable application: when the game engine is under demand, such as during our prize rounds, we’ve been able to scale up to keep up with the bot submissions. As a player, you’ll get to try out Windows Azure and learn a little about it along the way. You can also win some great stuff – like a Microsoft Surface, Kinect, and Best Buy gift cards!
Check it out at http://www.rockpaperaure.com – have fun playing!


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Michael Washington (@ADefWebserver) explained Saving Data In The Visual Studio LightSwitch HTML Client (Including Automatic Saves) in a 1/6/2012 post:
As covered in the article, The LightSwitch HTML Client: An Architectural Overview (Stephen Provine), the LightSwitch HTML Client uses SDI (Single Document Interface) rather than MDI (Multiple Document Interface). Essentially you now have a single data workspace in the LightSwitch HTML Client application, instead of multiple data workspaces that you have with the LightSwitch Silverlight Client. This provides the LightSwitch HTML Client an advantage in that you can now easily create workflows that separate a task among multiple screens or tabs.
The implementation of this necessitates the concept of Navigation Boundaries. When a user navigates in your LightSwitch HTML Client application (whether to a different tab, dialog pop up, or page), a boundary is crossed, and as the designer of the LightSwitch HTML Client application, you have to instruct LightSwitch on how it is to handle any data that is on the screen the user is navigating away from.
The three Navigation Boundary options are:
None (or Back) – Navigation just occurs (note, this is the only option when navigating between tabs on a screen)
- Nested – A new change set is started and Ok/Cancel buttons are displayed on the new screen to indicate what should happen with the nested change data.
- Save – If there are changes to the current screen, a box appears asking the user to save or discard the data.
Example Application

For our example, we will use a simple two table application that tracks the sales for sales people.

Next, we will create a simple screen that will display the sales people.

The screen has a dialog pop up that allows us to add new sales people.
Navigation Boundary – None

To demonstrate the None navigation option, we will create another screen.

We add a Screen that displays the sales for each SalesPerson.

Our challenge now, is to navigate from the list of sales people (BrowseSalesPersons) to the BrowseSales screen.

We open the BrowseSalesPerson screen, click on the List control, then select the Tap action.

We then choose the showBrowseSales screen and then Back (the None Navigation Boundary option).

When we run the application, we can create a new unsaved person, yet still navigate away without saving the unsaved record.

However, the save button will save all changes, even the ones from the previous screen.
Navigation Boundary – Nested

We can return to the BrowseSalesPerson screen, click on the List control, then select the Tap action.
We can now choose the showBrowseSales screen and then OK/Cancel (the Nested Navigation Boundary option).

Now, when we navigate to the next screen, we must accept or reject any changes.
Also, the save button is no longer available, all saves must be on the first screen.
Navigation Boundary – Save

We can return to the BrowseSalesPerson screen, click on the List control, then select the Tap action.
We can now choose the showBrowseSales screen and then Save (the Save Navigation Boundary option).

Now, if we try to navigate away from the screen and there are unsaved changes, we must save or reject them before navigation is allowed.
Automatic Save (And Refresh)
At the time of this writing, the LightSwitch HTML Client is still in preview. We can expect additional functionality in the future release. For now, any updates to the data require the user to explicitly press the save button. This is not optimal in all situations.
For example, we now desire the ability to delete all the sales records for a single sales person, then automatically switch back to the main page. To implement this, we can use the method described in the article Retrieving The Current User In The LightSwitch HTML Client.

First we switch to File View.

We then add a page to the Server project using the following code:
using System;using System.Collections.Generic;using System.Linq;using System.Web;namespace LightSwitchApplication.Web{public class DeleteRecords : IHttpHandler{public void ProcessRequest(HttpContext context){// Get the LightSwitch serverContextusing (var serverContext = LightSwitchApplication.Application.CreateContext()){// Minimal security is to check for IsAuthenticatedif (serverContext.Application.User.IsAuthenticated){if (context.Request.QueryString["SalesPersonId"] != null){// The Salesperson was passed as a parameter// Note that better security would be to check if the current user// should have the ability to delete the records// 'serverContext.Application.User.Name' returns the current userint intSalesPersonId = Convert.ToInt32(context.Request.QueryString["SalesPersonId"]);// Get the Sales records to deletevar result = from Sales in serverContext.DataWorkspace.ApplicationData.Sales.GetQuery().Execute()where Sales.SalesPerson.Id == intSalesPersonIdselect Sales;// Loop through each record foundforeach (var item in result){// Delete the recorditem.Delete();// Save changesserverContext.DataWorkspace.ApplicationData.SaveChanges();}// Return a response// We could return any potential errorscontext.Response.ContentType = "text/plain";context.Response.Write(“complete”);}}}}public bool IsReusable{get{return false;}}}}(this code uses the new serverContext API)

We switch back to Logical View, open the BrowseSales screen, add a button, then select Edit Execute Code for the button.
We use the following code:
myapp.BrowseSales.DeleteAll_execute = function (screen) {// Get selected SalesPersonIdvar SalesPersonId = screen.SalesPersonId;$.ajax({type: 'post',data: {},url: '../web/DeleteRecords.ashx?SalesPersonId=' + SalesPersonId,success: function success(result) {// Navigate back to main pagemyapp.showBrowseSalesPersons(msls.BoundaryOption.none);}});};

When we run the application, we can add sales for a sales person, then simply click the DELETE ALL button…

…the records will be deleted, and we will be automatically navigated back to the main page.
LightSwitch Help Website Articles
- Creating A Desktop Experience Using Wijmo Grid In LightSwitch HTML Client
- Creating ASP.NET Web Forms CRUD Pages Using ServerApplicationContext
- Using Promises In Visual Studio LightSwitch
- Retrieving The Current User In The LightSwitch HTML Client
- Writing JavaScript That Implements The Binding Pattern In Visual Studio LightSwitch
- Implementing The Wijmo Radial Gauge In The LightSwitch HTML Client
- Writing JavaScript In LightSwitch HTML Client Preview
- Creating JavaScript Using TypeScript in Visual Studio LightSwitch
- Theming Your LightSwitch Website Using JQuery ThemeRoller
- Using Toastr with Visual Studio LightSwitch HTML Client (Preview)
LightSwitch Team HTML and JavaScript Articles
- Custom Controls and Data Binding in the LightSwitch HTML Client (Joe Binder)
- Creating Screens with the LightSwitch HTML Client (Joe Binder)
- The LightSwitch HTML Client: An Architectural Overview (Stephen Provine)
- Writing JavaScript Code in LightSwitch (Joe Binder)
- New LightSwitch HTML Client APIs (Stephen Provine)
- A New API for LightSwitch Server Interaction: The ServerApplicationContext
- Building a LightSwitch HTML Client: eBay Daily Deals (Andy Kung)
Special Thanks
A special thanks to LightSwitch team members Joe Binder and Stephen Provine for their valuable assistance.
Download Code
The LightSwitch project is available at http://lightswitchhelpwebsite.com/Downloads.aspx
(you must have HTML Client Preview 2 or higher installed to run the code)




Chakkaradeep Chandran explained Debugging Remote Event Receivers with Visual Studio, which is useful when working with LightSwitch’s HTML 5 Client Preview 2 on 1/3/2013:
Introduction
One of the new features introduced for SharePoint development in the Microsoft Office Developer Tools for Visual Studio 2012 – Preview 2 is the ability to use a remote development environment to build apps for SharePoint. With previous versions of the SharePoint tools in Visual Studio, developers had to install SharePoint Foundation or SharePoint Server locally before they could build SharePoint solutions in Visual Studio. With SharePoint 2013, you can build apps for SharePoint targeting a remote SharePoint 2013 site (installed in a remote server) or SharePoint 2013 Online (Office 365). You don’t have to install SharePoint locally to build apps for SharePoint.
Figure 1. SharePoint 2013 remote development
Remote development allows you to deploy and debug an app for SharePoint on a remote SharePoint website. When there is a web project involved, as in the case of autohosted or provider-hosted apps, debugging is achieved by running the web project locally on Internet Information Services (IIS) Express.
Figure 2. Apps for SharePoint debugging experience
During remote app development, you create remote event receivers and app event receivers to handle events such as list events, list item events, and app events. If you are new to remote event receivers, get a quick overview in Handling events in apps for SharePoint.
However, debugging a remote event receiver locally is challenging because the locally running IIS Express would typically not be reachable from the remote SharePoint server. When the remote SharePoint server cannot reach the local development machine due to network boundaries, some extra work is required to invoke the remote event receiver.
Figure 3. Debugging remote event receivers
This blog post describes how to use the Windows Azure Service Bus to work around the network boundary issue so as to enable remote event receiver debugging when using a remote development for building apps for SharePoint with the Preview 2 release.
- Sample project
- Add a remote event receiver
- Windows Azure Service Bus to the rescue
- Add Service Bus extensions to the web project
- Update the app manifest
- Debug the remote event receiver
- Publish your app to the marketplace
- Download the sample app
- Remote event debugging FAQ
Sample project
I have a simple autohosted app that adds items to a contacts list.
Here’s how it looks:
Figure 4. Autohosted app that adds items to a contacts list
Add Contact will add the contact with the given first name and last name. However, as you can see, it does do not set the full name of the contact. The full name can be as simple as (First Name + “ “ + Last Name).
Here is the snapshot of Solution Explorer:
Figure 5. Project in Solution Explorer
Add a remote event receiver
Let’s use a remote event receiver to set the FullName property of a contact.
You can add a new remote event receiver by right-clicking the app for SharePoint project and choosing Add, New Item, Remote Event Receiver.
Let’s name the remote event receiver ContactsListRER.
Figure 6. Adding a remote event receiver
When you click Add, a wizard starts. For this example, we will handle the following event: An item was added.
Figure 7. SharePoint Customization Wizard
This adds the ContactsListRER.svc—a remote event receiver service—to the web project:
Figure 8. Remote event receiver service added
At the same time, a remote event receiver item is added to the app for SharePoint project:
Figure 9. Remote event receiver item added
Open ContactsListRER.svc.cs and replace the ProcessOneWayEvent code with the following code:
public void ProcessOneWayEvent(SPRemoteEventProperties properties) { using (ClientContext clientContext = TokenHelper.CreateRemoteEventReceiverClientContext(properties)) { if (clientContext != null) { string firstName = properties.ItemEventProperties.AfterProperties[ "FirstName" ].ToString(); string lastName = properties.ItemEventProperties.AfterProperties[ "LastNamePhonetic" ].ToString(); List lstContacts = clientContext.Web.Lists.GetByTitle( properties.ItemEventProperties.ListTitle ); ListItem itemContact = lstContacts.GetItemById( properties.ItemEventProperties.ListItemId ); itemContact["FullName"] = String.Format("{0} {1}", firstName, lastName); itemContact.Update(); clientContext.ExecuteQuery(); } } }The code retrieves the item properties FirstName and LastName and generates the full name. It then updates the FullName property with the full name value.
The remote event receiver’s Elements.xml file provides the information to SharePoint as to where the remote event receiver service is hosted. If you look through the file’s contents, you will see the Url property:
<?xml version="1.0" encoding="utf-8"?> <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Receivers ListTemplateId="10000"> <Receiver> <Name>ContactsListRER.svcItemAdded</Name> <Type>ItemAdded</Type> <SequenceNumber>10000</SequenceNumber> <Url>~remoteAppUrl/ContactsListRER.svc.svc</Url> </Receiver> </Receivers> </Elements>Notice that the following token is used to resolve the remote App Url: ~remoteAppUrl
- ~remoteAppUrl will be replaced with http://localhost:[port-number] when you are debugging locally in your development environment as the web project is hosted in IIS Express.
- ~remoteAppUrl will be replaced with the Windows Azure instance when the app is deployed to the SharePoint Online site.
- For provider-hosted apps, you can replace this value with the actual service Url
During F5 (debugging), if you are building a high trust app, you may not have any issues calling the remote event receiver service as long as your local SharePoint instance can reach the service. However, if SharePoint is not able to reach the service, the remote event receiver will fail to work in debugging mode.
Windows Azure Service Bus to the rescue
Windows Azure Service Bus provides a hosted, secure connectivity options for Windows Communication Foundation (WCF) and other service endpoints, including REST (Representational State Transfer) endpoints that would otherwise be difficult or impossible to reach. Most importantly, Service Bus endpoints can be located behind network address translation (NAT) boundaries or dynamically assigned IP addresses. This means that the Service Bus Relay can expose select WCF services that reside within your internal network to the public cloud, without having to open a firewall connection or requiring any changes to your network infrastructure.
We will use the Service Bus to create and host the remote event receiver service in a Service Bus endpoint, and update the remote App Url to be the Service Bus endpoint. This will then enable SharePoint to directly talk to the Service Bus endpoint, which will then call back to your service running in IIS Express.
To use Windows Azure Service Bus, the following things are required:
- Register a Windows Azure account and then a Service Bus namespace. See Managing Service Bus Service Namespaces for more information about managing namespaces.
- If you are behind a firewall, a proxy client (such as TMG proxy client) may be required depending on your network topology.
Add Service Bus extensions to the web project
In order to work with the Service Bus, we will need to reference Service Bus assemblies in the web project.
We can make use of the Service Bus NuGet package to reference the assemblies:
- Right-click the web project, and select Manage NuGet Packages.
- Search for the following package online: windowsazure.servicebus.
- Select Windows Azure Service Bus and then select Install.
This will install the NuGet package
The next step is to update the web.config file to create and host the Service Bus endpoint. Replace the entire code within the <system.servicemodel> with the following:
<system.serviceModel> <bindings> <basicHttpBinding> <!--Used by app for SharePoint--> <binding name="secureBinding"> <security mode="Transport" /> </binding> </basicHttpBinding> <!-- Service Bus Binding --> <basicHttpRelayBinding> <binding name="BasicHttpRelayBindingConfig"> <security relayClientAuthenticationType="None" /> </binding> </basicHttpRelayBinding> <!-- Service Bus Binding --> </bindings> <protocolMapping> <add binding="basicHttpBinding" scheme="https" bindingConfiguration="secureBinding" /> </protocolMapping> <extensions> <!-- In this extension section we are introducing all known service
bus extensions. Users can remove the ones they don't need. --> <behaviorExtensions> <add name="transportClientEndpointBehavior" type=
"Microsoft.ServiceBus.Configuration.TransportClientEndpointBehaviorElement, Microsoft.ServiceBus, Version=1.8.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" /> <add name="serviceRegistrySettings" type="Microsoft.ServiceBus.Configuration.ServiceRegistrySettingsElement, Microsoft.ServiceBus, Version=1.8.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" /> </behaviorExtensions> <bindingExtensions> <add name="basicHttpRelayBinding" type=
"Microsoft.ServiceBus.Configuration.BasicHttpRelayBindingCollectionElement, Microsoft.ServiceBus, Version=1.8.0.0, Culture=neutral, PublicKeyToken=31bf3856ad364e35" /> </bindingExtensions> </extensions> <!-- Service Bus Binding --> <services> <clear /> <service name="[your RER service class name with namespace]" behaviorConfiguration="default"> <endpoint address="[your IIS Express http address]" binding="basicHttpBinding" contract="Microsoft.SharePoint.Client.EventReceivers.IRemoteEventService"/> <endpoint address="[your IIS Express http address]/mex" binding="mexHttpBinding" contract="IMetadataExchange" /> <endpoint address="[your service bus namespace]/[your address]" contract="Microsoft.SharePoint.Client.EventReceivers.IRemoteEventService" binding="basicHttpRelayBinding" bindingConfiguration="BasicHttpRelayBindingConfig" behaviorConfiguration="sharedCredentials" /> </service> </services> <behaviors> <serviceBehaviors> <behavior name="default"> <!-- To avoid disclosing metadata information, set the values below to false before deployment. --> <serviceMetadata
httpGetEnabled="true"
httpsGetEnabled="true"/> <!-- To receive exception details in faults for debugging purposes, set the value below to true. Set to false before deployment to avoid disclosing exception information. --> <serviceDebug includeExceptionDetailInFaults="true" /> </behavior> </serviceBehaviors> <endpointBehaviors> <behavior name="sharedCredentials"> <transportClientEndpointBehavior
credentialType="SharedSecret"> <clientCredentials> <sharedSecret issuerName="[your service bus issuer name]" issuerSecret="[your service bus secret]" /> </clientCredentials> </transportClientEndpointBehavior> <serviceRegistrySettings discoveryMode="Public" /> </behavior> </endpointBehaviors> </behaviors> <!-- Service Bus Binding --> </system.serviceModel>Replace the following with your own values:
Text to replace
Replace with
Comments
[your RER service class name with namespace]
Generated remote event receiver class in the web project
For example: SharePointAppREDWeb.ContactsListRER
Double-click the .svc in the web project to view the RER class name.
[your IIS Express http address]
IIS Express HTTP Port
You can get the IIS Express port numbers from the web project properties pane
[your service bus namespace]/[your address]
Windows Azure Service Bus Namespace and your choice of address
You will need to sign up for a Windows Azure Service Bus account and create a namespace.
You can use any name for the address name, and it denotes the service you are hosting in the Service Bus namespace. For example: https://spappdebug.servicebus.windows.net/hellospservice
[your service bus issuer name]
Service Bus Namespace Issuer Name
You can get this from your Service Bus Access Key properties.
[your service bus secret]
Service Bus Namespace Secret
You can get this from your Service Bus Access Key properties.
You can get this from your Service Bus Access Key properties.
One last change to the web project is to set the ContactsListRER.svc as the start page. This will enable IIS Express to automatically host the service and create the Service Bus endpoint as specified in the web.config file:
- Right-click ContactsListRER.svc.
- Select Set as Start Page.
Update the remote app Url in the SharePoint project
In the app for SharePoint project:
- Open ContactsListRER | Elements.xml
- Replace the Url property for the event receiver with [your service bus namespace]/[your address].
Text to replace
Replace with
Comments
[your service bus namespace]/[your address]
Windows Azure Service Bus Namespace and your choice of address
The same values as the corresponding entries in web.config
Below is the updated Elements.xml:
<?xml version="1.0" encoding="utf-8"?> <Elements xmlns="http://schemas.microsoft.com/sharepoint/"> <Receivers ListTemplateId="10000"> <Receiver> <Name>ContactsListRER.svcItemAdded</Name> <Type>ItemAdded</Type> <SequenceNumber>10000</SequenceNumber> <!--<Url>~remoteAppUrl/ContactsListRER.svc</Url>--> <Url>https://spappdebug.servicebus.windows.net/rerdemo</Url> </Receiver> </Receivers> </Elements>Update the app manifest
In order for SharePoint to call back to the Service Bus endpoint address, we will need to update the DebugInfo in the app manifest. This will tell SharePoint that it is safe to make the external call (outside of SharePoint).
In the app for SharePoint project:
- Right-click AppManifest.xml, and select View Code.
- Replace <AutoDeployedWebApplication/> with the following code:
<AutoDeployedWebApplication> <DebugInfo ClientSecret="[your client secret from web.config]" AppUrl="[IIS Express https address];[service bus namespace]/[address];" /> </AutoDeployedWebApplication>
Text to replace Replace with [IIS Express https address] [service bus namespace]/[address] IIS Express HTTPS Port You can get the IIS Express port numbers from the web project properties pane Windows Azure Service Bus Namespace and your choice of address The same values as the corresponding entries in web.config Debug the remote event receiver
Now that we have updated the required project artifacts to use the Service Bus, we are ready to debug the app.
- Go ahead and set a breakpoint in the ProcessOneWayEvent method in the remote event receiver.
- Press F5 to debug the app.
- WCF Test Client will start.
This will host your service in IIS Express and the Service Bus.- Ignore any IMetadataExchange errors:

Figure 10. WCF Test Client error- Once the services are hosted, you should see something similar (you can safely ignore the schema errors):

Figure 11. WCF Test Client- Now let’s click Add Contact.
- After a few seconds, you should see the breakpoint hit:

- Press F10 to continue to the next step or F5 to continue debugging.
- Now click Get Contacts in the app, and you should see the full name property set:

Figure 12. Clicking Get Contacts in the app to see the full name property setPublish your app to the marketplace
Since we added the service bus assemblies and the modified web.config file, the changes will be persisted when you package the app to publish in the marketplace.
We highly recommend that you remove the Service Bus assemblies and revert the web.config changes before publishing to the marketplace.
This requires the following changes:
- In the app for SharePoint project:
- Open the remote event receiver Elements.xml, and update the Url property with the ~remoteAppUrl token.
- Right-click AppManifest.xml, and choose View Code:
§ Replace the <AutoDeployedWebApplication> section with the following:<AutoDeployedWebApplication/>
- In the web project:
- Replace the <system.servicemodel> section in the web.config file with the following:
<system.serviceModel> <bindings> <basicHttpBinding> <!--Used by app for SharePoint--> <binding name="secureBinding"> <security mode="Transport" /> </binding> </basicHttpBinding> </bindings> <protocolMapping> <add
binding="basicHttpBinding"
scheme="https"
bindingConfiguration="secureBinding" /> </protocolMapping> </system.serviceModel>
- Uninstall the Service Bus NuGet package.
Download the sample app
You can download the sample app here:
Download SharePointAppRED.zip.
Remote event debugging FAQ
- What about app events?
This blog post only works for remote event receivers, and not app events.- How do I know my service is hosted in the Service Bus?
Once the WCF client has successfully hosted all your services, browse to your Service Bus namespace in your browser, and you should see your endpoint:
Figure 13. Browsing to the Service Bus namespace- The remote event receiver does not hit the breakpoint, so what is wrong?
Depending on the event, the remote event may be synchronous or asynchronous. It might take a few more seconds or more to hit your breakpoint if it is asynchronous.
Events that are “* being *”—like “item is being added”, “item is being deleted”—are synchronous.
Events that are “* was *”—like “item was added”, “item was deleted”—are asynchronous.- Can I debug more than one remote event receiver?
This blog post covers debugging only one remote event receiver at a time.














Return to section navigation list>
Windows Azure Infrastructure and DevOps
Bruno Terkaly (@brunoterkaly) asserted Windows Azure has become very comprehensive in a 1/5/2013 post:
What is the Windows Azure Platform?
- Windows Azure is an open and flexible cloud platform that enables you to quickly build, deploy and manage applications across a global network of Microsoft-managed datacenters.
- You can build applications using any language, tool or framework.
- You can integrate your public cloud applications with your existing IT environment.
There is an SLA
- Windows Azure delivers a 99.95% monthly SLA
- Azure offers Platform as a Service Capabilities
- This enables you to build and run highly available applications without focusing on the infrastructure.
- It provides automatic OS and service patching, built in network load balancing and resiliency to hardware failure.
- It supports a deployment model that enables you to upgrade your application without downtime.
- Azure is http-based and based on open standards
- Features and services are exposed using open REST protocols.
- Choose the language that works best
- The Windows Azure client libraries are available for multiple programming languages, and are released under an open source license and hosted on GitHub.
- Scale automatically and with a minimum of effort
- It is a fully automated self-service platform that allows you to provision resources within minutes.
- Elastically grow or shrink your resource usage based on your needs.
- You only pay for the resources your application uses.
- Global footprint
- Windows Azure is available in multiple datacenters around the world, enabling you to deploy your applications close to your customers.
- Windows Azure’s distributed caching and CDN services allow you to reduce latency and deliver great application performance anywhere in the world.
- Support for many, many data stores
- You can store data using relational SQL databases, NoSQL table stores, and unstructured blob stores, and optionally use Hadoop and business intelligence services to data-mine it.
- Bridge On-Premises Applications and Cloud Applications
- You can take advantage of Windows Azure’s robust messaging capabilities to enable scalable distributed applications, as well as deliver hybrid solutions that run across a cloud and on-premises enterprise environment.
Web Sites Start small and for free. Deploy to a highly scalable services and grow your hosting power as your customers grow.
Leverage Open source. Deploy with FTP, Git, Team Foundation Server.
Leverage SQL database, Caching, and CDN, and Azure Stroage Services (massively scalable tables, blobs, queues).http://www.windowsazure.com/en-us/home/features/web-sites/ Virtual Machines Run Windows Server 2008 R2, Windows Server 2012, OpenLogic CentOS, SUSE Linux Enterprise Server, Ubuntu, SQL Server 2012, BizTalkServer 2013.
Migrate workloads without changing code.
Connect on-premises corporate network to virtual machines running in the cloud.http://www.windowsazure.com/en-us/home/features/virtual-machines/ Mobile Services Leverage SQL Server in a RESTful manner with a minimum of fuss.
Implement user authentication, push notifications very easily.
Support iOS, Windows Phone 8, and Windows Store apps.
Augment your data operations with custom logic like sending push notifications, SMS, and email.
Include user auth through Windows Live, Facebook, Twitter, or Google.http://www.windowsazure.com/en-us/home/features/mobile-services/ Media Encode your video content for multiple devices, such as Xbox, Windows Phone, iOS, Android, HTML5, Flash, Silverlight.
Automate the whole process, even adding watermarks.
Stream your content. Build your own NetFlix service.http://www.windowsazure.com/en-us/home/features/media-services/
See my article here: http://msdn.microsoft.com/en-us/magazine/jj133821.aspx.Cloud Services This is the sweet spot for Microsoft hosting of your solutions.
This is Platform as a Service. Build advanced multi-tier scenarios.
Automate your deployment.
Scale up or down based on need, either through your own scripts or based on the performance of your services automatically.
Leverage the 8 global data centers throughout the world.
Cloud Service applications can be internet-facing public web applications.
Cloud service applications can be web sites and ecommerce solutions.
They can be background processes for other work, such as processing orders or analyzing data.
You can use a variety of different programming languages.
There are specific software development kits (SDKs), such as Python, Java, node.JS and .NET.http://www.windowsazure.com/en-us/home/features/cloud-services/ Big Data HDInsight is in preview mode and is a service that offers 100% Apache Hadoop compatible services.
Deploy a Hadoop cluster in just minutes.
Query structured or unstructured data of any size.
Leverage query frameworks such as Hive, Pig, Hadoop Common.
Take advantage of Excel, PowerPivot, Powerview, SQL Server Analysis Services and Reporting Services.https://www.hadooponazure.com/

My (@rogerjenn) Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: December 2012 = 100.00 % of 1/3/2012 chronicled the fourth consecutive month of 100% uptime for Windows Azure Compute:
My (@rogerjenn) live OakLeaf Systems Azure Table Services Sample Project demo runs two small Windows Azure Web role instances from Microsoft’s South Central US (San Antonio, TX) data center. This report now contains more than a full year of uptime data.
Here’s the report for December 2012, the fourth consecutive month of 100% uptime:


Read more.
Paul McDougall (@PaulMcDougall) asserted “Azure enhancements leave Microsoft well positioned against cloud competitors in 2013, analyst says” in a deck for his Microsoft Tries To Outflank Amazon With Azure Upgrades article of 1/3/2012 for InformationWeek:
Microsoft's move to add infrastructure and enhanced virtual machine support to its Azure platform gives its cloud offering the ability to match Amazon's infrastructure-as-a-service (IaaS) product while still providing customers with richer platform-as-a-service (PaaS) options, according to one analyst who believes Microsoft is well positioned to gain cloud momentum in 2013.
"We remain positive on Azure, due to its high compatibility with existing enterprise software," said Mark Moerdler, senior software analyst at Bernstein Research, in a note published Wednesday.
Microsoft last year launched a Community Technology Preview of persistent-state Virtual Machine support for Azure, effectively creating a hypervisor in the sky that lets enterprises upload VMs running Linux, SharePoint, SQL Server or other "stateful" applications. The move expanded the capabilities of Azure, which Microsoft had always positioned as a PaaS offering, into the IaaS realm.
Under the PaaS model, customers' apps and services run on a cloud stack that's preconfigured by the vendor, while IaaS provides customers with basic infrastructure, on top of which they can build their own stacks and services while maintaining more management responsibility over the setup.
Moerdler said in an interview that Microsoft is now able to offer customers the best of both worlds, which could entice more enterprises to its cloud services. "With Azure, they can run VMs, but they can do more than that, in that they can allow you to be able to step up to a more cloud-based solution," said Moerdler.
Moerdler defines a truly cloud-based solution as one that uses a multi-tenant architecture. The difference between multi-tenant and simple virtualization is, generally, that in the former scenario a single instance of an application services multiple clients, while in the latter multiple instances of an app are run across virtual machines. Multi-tenant architectures are thought by many experts to be more robust and scalable than virtualized setups.
Azure "is competing against Amazon Web Services in Infrastructure-as-a-Service in terms of virtualization, but they give you this opportunity of saying you can go and become a truly cloud-based model if you so desire," said Moerdler, who rates Microsoft shares as "Outperform".
Moerdler believes Azure also holds another, potentially significant advantage over AWS, as well as over competing PaaS providers such as Oracle and Salesforce's Heroku -- its native compatibility with Microsoft's on-premises products like Windows Server 2012 and SQL Server. That should, theoretically at least, make it easier for Microsoft-centric enterprises to move operations to the cloud when they so choose.
"Most apps can be moved to Azure fairly easily initially in a VM and then expanded, adding cloud functionality later," said Moerdler, who co-founded records management specialist MDY Advanced Technologies prior to joining Bernstein.
Microsoft hosts Azure at eight, company-owned data centers located around the world. To further bolster its cloud, Microsoft in December added job scheduler support for Windows Azure Mobile Services, improved scaling for Azure website services and support for SQL Data Sync Services from within the Azure Management Portal.
More Azure rollouts are expected throughout 2013.

Tiernan Ray (@barronstechblog) reported MSFT: Structure of ‘Azure’ May Lend Cloud Advantage, Says Bernstein in a 1/2/2012 post to Barron’s Tech Trader Daily column:
Bernstein Research’s Mark Moerdler this morning reiterates an Outperform rating on shares of Microsoft (MSFT), and a $38 price target, reflecting on a presentation his firm hosted on December 5th by Doug Hauger, the head of the company’s “Windows Azure” cloud computing effort, about which Moerdler writes that he has a positive view.
Azure, which is a “platform as a service,” or PaaS, offering, offers a bunch of different capabilities, Hauger told Bernstein, including “unified management, common identity, and integrated virtualization.”
Moerdler’s main conclusion appears to be that Microsoft benefits from both using its own software “stack” of application programming interfaces (API) and also from the ability to move existing software into the cloud without a lot of re-writing:
In delivering Azure, Microsoft leverages its expertise in running some of the largest cloud services and platforms, such as Bing, Xbox and Office 365 […] In terms of competitive differentiation, we understand that Azure leverages key Microsoft environments and thus integrates well with existing on-premise environment. Plus, most apps can be moved to Azure fairly easily initially in a VM and then expanded, adding Cloud functionality later on (e.g., multi-tenant databases). This is in contrast to some PaaS environments, in which apps have to be first optimized for the PaaS environment before migrating over. In addition, Azure is built as a platform, and optimized for PaaS, while some competitors such as Salesforce.com (CRM) started out in the SaaS layer. Microsoft is, as compared to many IaaS and PaaS vendors, leveraging its own software stack while many have to leverage third party databases, operating system, management tools, virtualization technologies etc. We believe that this should significantly improve the overall margin of the solution.
Microsoft shares today are up 46 cents, or 1.7%, at $27.18.

• David Linthicum (@DavidLinthicum) asserted “Now that 2013 is here, we need to make four improvements to cloud computing -- and its users” as a deck for his The 4 cloud computing resolutions you should make for 2013 article of 1/1/2012 for InfoWorld’s Cloud Computing blog:
It's 2013. Cloud computing is another year older. As adopters, we're making fewer mistakes, but I suspect we'll repeat many of the same errors from 2012.
Now is the time to work on cloud computing improvements, to set reasonable goals -- and to make sure we live up to them. To that end, here are four cloud computing resolutions for 2013 I suggest we all adopt:
1. I resolve not to "cloud-wash." 2012 was another year of cloud everything. Virtually all products had some cloud spin, no matter what it was or the type of problem it solved. The truth is that cloud computing should be a specific type of technology that includes attributes such as on-demand, self-provisioned, elastic, and metered by use. By calling everything "cloud," the vendors look silly -- and they sow confusion.
2. I resolve not to use cloud computing for everything. Many IT pros try to put cloud computing square pegs into enterprise round holes. Cloud computing is not a fit in all instances, considering the cost and complexity it can bring. Do your homework -- this means understanding the needs of the business and the problem you're looking to solve. Moreover, make sure there's a clear business case for the cloud.
3. I resolve to always consider management, performance, and service governance. IT pros and providers who stand up systems that use cloud computing often forget about the fact that you have to operate the thing. Management is required to monitor the cloud-based system and keep things working, as well as deal with performance issues during operations. Finally, service governance is required to deal with the APIs that are externalized or consumed. If you don't address these issues, your cloud is doomed -- it's that simple.
4. I resolve not to question cloud security before I understand the technology. In many instances, enterprise IT pushes back on cloud computing because it isn't considered secure. The truth is that data and systems residing in public or private clouds are as secure as you make them. Typically, cloud-based systems can be more secure than existing internal systems if you do the upfront work required. Proclaiming a product's security (or lack thereof) before understanding exactly what it entails is at best counterproductive -- and often just plain wrong.
If you make and meet these four resolutions, your life will be much less complicated this year. Have a great 2013!

William Vambenepe (@vambenepe) asserted PaaS lets you pick the right tool for the job, without having to worry about the additional operational complexity in a 12/30/2012 post:
In a recent blog post, Dan McKinley explains “Why MongoDB Never Worked Out at Etsy“. In short, the usefulness of using MongoDB in addition to their existing MySQL didn’t justify the additional operational complexity of managing another infrastructure service.
This highlights the least appreciated benefit of PaaS: PaaS lets you pick the right tool for the job, without having to worry about the additional operational complexity.
I tried to explain this a year ago in this InfoQ article. But the title was cringe-worthy and the article was too long.
So this blog will be short. I even made the main point bold; and put it in the title.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today
<Return to section navigation list>
Cloud Security, Compliance and Governance
• Chris Hoff (@Beaker) analyzed NIST’s Trusted Geolocation in the Cloud: PoC Implementation in a 12/22/2012 post (missed when posted):
I was very interested and excited to learn what NIST researchers and staff had come up with when I saw the notification of the “Draft Interagency Report 7904, Trusted Geolocation in the Cloud: Proof of Concept Implementation.”
It turns out that this report is an iteration on the PoC previously created by VMware, Intel and RSA back in 2010 which utilized Intel’s TXT, VMWare’s virtualization platform and the RSA/Archer GRC platform, as this one does.
I haven’t spent much time to look at the differences, but I’m hoping as I read through it that we’ve made progress…
You can read about the original PoC here, and watch a video from 2010 about it here. Then you can read about it again in its current iteration, here (PDF.)
I wrote about this topic back in 2009 and still don’t have a good firm answer to the question I asked in 2009 in a blog titled “Quick Question: Any Public Cloud Providers Using Intel TXT?” and the follow-on “More On High Assurance (via TPM) Cloud Environments”
At CloudConnect 2011 I also filmed a session with the Intel/RSA/VMware folks titled “More On Cloud and Hardware Root Of Trust: Trusting Cloud Services with Intel® TXT”
I think this is really interesting stuff and a valuable security and compliance capability, but is apparently still hampered with practical deployment challenges.
I’m also confused as to why RSA employees were not appropriately attributed under the NIST banner and this is very much a product-specific/vendor-specific set of solutions…I’m not sure I’ve ever seen a NIST-branded report like this.
At any rate, I am interested to see if we will get to the point where these solutions will have more heterogeneous uptake across platforms.
/Hoff


No significant articles today
<Return to section navigation list>
Cloud Computing Events
The San Francisco Bay Area Azure Developers group will host New year, new cloud: Windows Azure Basics on 1/8/2013 at 6:30 PM:
Location: Microsoft San Francisco (in Westfield Mall where Powell meets Market Street)
Start 2013 learning about Microsoft Cloud solutions. In this first meetup of the year, we will explore the basics of Windows Azure, show you how to develop for Windows Azure, as well as explain the migration process for existing applications.
The breakdown of the meetup:
- Intro to Azure Services (Eugene Chuvyrov, 30 minutes)
- Developing for Azure (Bruno Terkaly, 30 minutes)
- Migrating existing applications to Azure (Robin Shahan, 30 minutes)
Session details:
1. Eugene will introduce the Windows Azure platform, explain Platform as a Service vs. Infrastructure as a Service offerings, and go over compute instances, database and storage solutions on Azure.
2. Bruno will present a number of introductory examples of using Azure. He will address deployment and writing code, minimizing PowerPoint. He will also discuss augmented reality and connecting the cloud with Windows 8, iOS, and Android clients. He will discuss working with Twilio and how to incorporate SMS messaging into your applications. Bruno will also review his various articles published in MSDN Magazine.
3. As VP of Technology at GoldMail, Robin had the opportunity to migrate entire infrastructure from a hosted environment of hardware servers running asmx web services, windows services, web applications, and SQLServer to Windows Azure and SQL Azure. In this session, she will discuss the whys and wherefores of migrating from this old-school environment to Microsoft Azure, problems they had with their migration and how they resolved them, and how things have been going since then. Questions and discussion are welcome.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Andrew Brust (@andrewbrust) asked “Curious how to go about doing Hadoop in Amazon's cloud? Here's some guidance” in a deck for his Big Data on Amazon: Elastic MapReduce, step by step slideshow (29 slides):
Pick a distro
Amazon refers to the process of standing up an EMR cluster as creating a "job flow." You can do this from the command line, using a technique we'll detail later, but you can also do it from your browser. Just navigate to the EMR home page in the AWS console at https://console.aws.amazon.com/elasticmapreduce, and click the Create New Job Flow button at the top left. Doing so will bring up the Create a New Job Flow dialog box (a wizard, essentially), the first screen of which is shown here.
An EMR cluster can use Amazon's own distribution of Hadoop, or MapR's M3 or M5 distrubution instead. M5 carries a premium billing rate as it not MapR's open source distro.



Jeff Barr (@jeffbarr) described AWS Management Console Improvements - Tablet and Mobile Support in a 1/4/2013 post:
Managing your AWS resources has become easier and more direct over the years! Let's do a quick recap before we dig in:
- We launched Amazon SQS (2004) and Amazon S3 (2006) as pure APIs, with no tool support whatsoever. Developers were quick to build all sorts of interesting tools around the web service APIs.
- Later in 2006, we introduced Amazon EC2, this time with a set of command-line tools.
- Sometime in 2007 we entered the visual, browser-based era with the release of ElasticFox.
- In early 2009 we released the AWS Management Console and have focused our development efforts there ever since that launch.
Over the years we've made many incremental improvements to the AWS Management Console. We've also improved the overall look and feel a couple of times. The goal remains unchanged - to provide you with a clean and efficient way to see and manage your AWS resources.
Today we are ready to take another step forward. We're making some big improvements to the existing Console, and we're also introducing a brand-new Console App for Android devices. In this post I'll give you a visual tour of both applications..
AWS Management Console Improvements
We heard your feedback that the growing number of services in the Management Console (21 and counting), increased service functionality, and new form factors such as tablets, required an update to our designs. Our focus is to make AWS easier to use by increasing customizability and improving information display on your screen of choice.We started with a focus on customization to make the Console work better for you. We moved Region selection into the Console’s navigation and made it work seamlessly across all of the services. You can also customize the Console navigation with shortcuts to the AWS services that you use the most often:
We learned that many Console users spent a lot of time alternately selecting one of a pair of AWS resources in order to compare and contrast certain settings. This wasn't a good use of your time, so we added inline resource summaries to give you quick access to key resource attributes.
We then reviewed the Console's information management and display features to improve readability and to put your information front and center. We learned that monitoring resource statistics is one of the most frequent actions and users wanted more space to view graphs. The new Monitoring View makes it easier for you to see statistics for your resources. You can easily filter your resources and hit the new Select All button to see stacked graphs for your resources. You can even change this view to see all the graphs or individual large graphs on one screen.
We also learned that many users wanted as much space as possible for table information. To accommodate this, we added a collapse option to the side navigation pane and moved the table details to let the table fill the screen.
Expanded Collapsed Finally, we know that many of you use (or would like to use) the Console from your tablet device, so we now support endless scrolling within the current page. Your resources are just a swipe away! We also optimized the use of horizontal and vertical space and made the buttons and selectors large enough to ensure easy access.
These improvements will be rolled out across the AWS services on slightly different schedules. We look forward to your feedback on these new designs!
AWS Management Console App
This new app provides mobile-relevant tasks that are a good companion to the full web experience including the ability to quickly and easily view and manage your existing EC2 instances and CloudWatch alarms from your Android phone. You can view your total AWS service charges and switch between AWS accounts and regions from within the app. As with the web-based management console, sign-in is as simple as entering your AWS or IAM credentials.You can:
- View a summary of your EC2 instances, CloudWatch alarms, total service charges, and the AWS Service Health status, with optional filtering on the instances and alarms.
- Look at EC2 instance metrics and status checks to check the state of your environment.
- Stop or reboot your EC2 instances.
- List CloudWatch alarms by state or time.
- View CloudWatch graphs.
- Examine the automated actions configured for each CloudWatch alarm.
- View detailed AWS service health status, including recent AWS service events and notifications.
Here's a tour:
We plan to add support for additional services very quickly, so stay tuned (and use the app's feedback function to tell us what you think). We are also planning to support mobile devices running other operating systems.
Download the AWS Management Console for Android and get started today.



Paul MacNamara asserted “Amazon Web Services takes a cookie-cutter approach to saying it’s sorry” in a deck for his Why Amazon’s apologies all sound the same story of 1/2/2013 for NetworkWorld’ Bussblog:
When a company is compelled to apologize as often as Amazon Web Services has been of late, perhaps expediency does dictate a cut-and-paste approach to the process.
But that doesn't exactly exude sincerity.
(Sorriest tech companies of 2012)
From Amazon's response to its latest outage, which hit on Christmas Eve:
Last, but certainly not least, we want to apologize. We know how critical our services are to our customers' businesses, and we know this disruption came at an inopportune time for some of our customers. We will do everything we can to learn from this event and use it to drive further improvement in the ELB service.
Sincerely,
The AWS Team
In response to its Oct. 22, 2012 AWS outage:
We apologize for the inconvenience and trouble this caused for affected customers. We know how critical our services are to our customers' businesses, and will work hard (and expeditiously) to apply the learning from this event to our services. ...
Sincerely,
The AWS Team
In response to its July 2, 2012 AWS outage:
Sincerely,
The AWS Team
In response to its Aug. 7, 2011 EC2, EBS outage in Europe:
Sincerely,
The AWS Team
In response to its April 29, 2011 EC2, RDS outages:
Sincerely,
The AWS Team
At least we can rest assured that Amazon knows how critical its services are to its customers. Sincerely.

Jeff Barr (@jeffbarr) announced Root Domain Website Hosting for Amazon S3 on 12/27/2012:
As you may already know, you can host your static website on Amazon S3, giving you the ability to sustain any conceivable level of traffic, at a very modest cost, without the need to set up, monitor, scale, or manage any web servers. With static hosting, you pay only for the storage and bandwidth that you actually consume.
S3's website hosting feature has proven to be very popular with our customers. Today we are adding two new options to give you even more control over the user experience:
- You can now host your website at the root of your domain (e.g. http://mysite.com).
- You can now use redirection rules to redirect website traffic to another domain.
Root Domain Hosting
Your website can now be accessed without specifying the “www” in the web address. Previously, you needed to use a proxy server to redirect requests for your root domain to your Amazon S3 hosted website. This introduced additional costs, extra work, and another potential point of failure. Now, you can take advantage of S3’s high availability and scalability for both “www” and root domain addresses. In order to do this, you must use Amazon Route 53 to host the DNS data for your domain.Follow along as I set this up using the AWS Management Console:
- In the Amazon S3 Management Console, create an S3 bucket with the same name as your www subdomain, e.g. www.mysite.com. Go to the tab labeled Static Website Hosting and choose the option labeled Enable website hosting. Specify an index document (I use index.html) and upload all of your website content to this bucket.
- Create another S3 bucket with the name of the root domain, e.g. mysite.com . Go to the tab labeled Static Website Hosting, choose the option labeled Redirect all requests to another host name, and enter the bucket name from step 1:
- In the Amazon Route 53 Management Console, create two records for your domain. Create an A (alias) record in the domain's DNS hosted zone, mark it as an Alias, then choose the value that corresponds to your root domain name:
Create an Alias (A) record and set the value to the S3 website endpoint for the first bucket (the one starting with www).
Redirection Rules
We're also enhancing our website redirection functionality. You can now associate a set of redirection rules to automatically redirect requests. The rules can be used to smooth things over when you make changes to the logical structure of your site. You can also use them to switch a page or a related group of pages from static to dynamic hosting (on EC2 or elsewhere) as your site evolves and your needs change.Amazon CTO Werner Vogels has already started using root domain support for his blog. Check out his post for more information. Our walkthrough on setting up a static website using Amazon S3, and see the Amazon S3 Developer Guide contains even more information.
If you are looking for some sites to help you build and maintain a static web site, you may enjoy Mick Gardner's recent post, An Introduction to Static Site Generators.


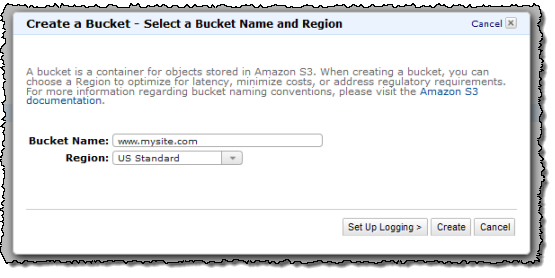
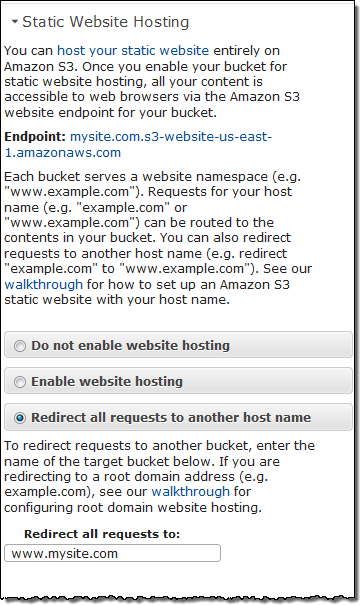
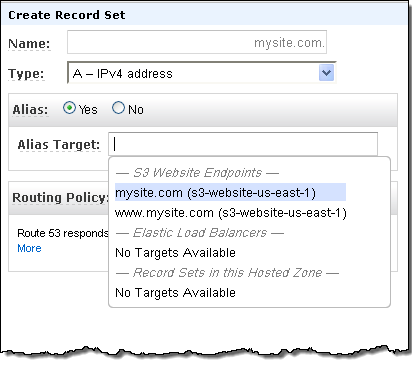
Werner Vogels (@werner) chimed in with My Best Christmas Present – Root Domain Support for Amazon S3 Website Hosting on 12/27/2012:
I have been a big fan of the Amazon S3 Static Website Hosting feature since its launch and this blog happily is being served from it. S3 is not only a highly reliable and available storage service but also one of the most powerful web serving engines that exists today. By storing your website in Amazon S3, you suddenly no longer have to worry about scaling, replication, performance, security, etc. All of that is handled seamlessly by S3.
As such I am very happy that the Amazon S3 team has finally knocked off the last piece of dependency on an external infrastructure piece. Until the launch today of S3 Website Root Domain support you could not host your website at the root domain, but only at a subdomain. For example this website is served from the www.allthingsdistributed.com domain. To have visitors also be able to type in allthingsdistributed.com (without the www) I had to make use of a “naked domain redirect” service. I happily made use of the great service that the folks at wwwizer (thanks!!) provided. However I can now rely on the excellent reliability and scalability of Amazon S3 for the redirect as well.
With the launch of the support for hosting root domains in Amazon S3 Website Hosting, I now can manage the whole site via Amazon S3 and Amazon Route 53 (AWS’s DNS service). Each service has one new feature. Route 53 can now specify that a root domain (e.g. allthingsdistributed.com) use an S3 Website alias. And, S3 Website Hosting can redirect that incoming traffic to your preferred domain name (e.g. www.allthingsdistributed.com).
I needed to take only two steps to get this working for All Things Distributed:
- In the first step I created a new Amazon S3 bucket with the root domain name and enabled it for Website hosting. The URL for this is then http://allthingsdistributed.com.s3-website-us-east-1.amazonaws.com/ In the website hosting section I selected the new option to “Redirect all request to another hostname” which in my case is www.allthingsdistributed.com.
- Then in the Route 53 console I assign the new URL (http://allthingsdistributed.com.s3-website-us-east-1.amazonaws.com/) as an IPv4 Address Alias to the allthingsdistributed.com record.
This is of course if you want both DNS names to end up at the same website. But the new Route 53 functionality by itself allows you to send traffic to your Amazon S3 website hosted at the root domain, which was something that was not possible before. You can read more about this functionality with the walkthrough for setting up a static website in S3.
Christmas couldn’t have been better this year thanks to the Amazon S3 and Route 53 teams.


<Return to section navigation list>

















0 comments:
Post a Comment