Windows Azure and Cloud Computing Posts for 11/26/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
• Updated 11/28/2012 5:00 PM PST with new articles marked •.
Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, Hadoop and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access & Identity Control, Active Directory, and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, Hadoop and Media Services
Gaurav Mantri (@gmantri) described Storage Client Library 2.0 – Migrating Blob Storage Code in an 11/28/2012 post:
A few days ago I wrote blog posts about migrating code from storage client library 1.7 to 2.0 to manage Windows Azure Table and Queue Storage. You can read those posts here:
- http://gauravmantri.com/2012/11/17/storage-client-library-2-0-migrating-table-storage-code/
- http://gauravmantri.com/2012/11/24/storage-client-library-2-0-migrating-queue-storage-code/.
In this post, I will talk about migrating code from storage client library 1.7 to 2.0 for managing Windows Azure Blob Storage. I would put changes done to manage blob storage somewhere between table storage and queue storage changes. They’re not as drastic as the ones to the table storage however at the same time they are not as simple as changes done to queue storage. Some methods have been removed completely so if your code made use of those functions, you would have to rewrite those portions of code.
Like the previous posts, I will attempt to provide some code sample through which I will try and demonstrate how you can do some common tasks when working with Azure Blob Storage. What I did is wrote two simple console applications: one which uses storage client library version 1.7 and the other which uses version 2.0 and in those two applications I demonstrated some simple functionality.
Read These First
Since version 2.0 library is significantly different than the previous ones, before you decide to upgrade your code to make use of this version I strongly urge you to read up the following blog posts by the storage team as there’re many breaking changes.
Introducing Windows Azure Storage Client Library 2.0 for .NET and Windows Runtime
Windows Azure Storage Client Library 2.0 Breaking Changes & Migration Guide
Getting Started
Before jumping into the code, there’re a few things I would like to mention:
Storage Client Libraries
To get the reference for storage client library 1.7, you can browse your local computer and navigate to the Azure SDK installation directory (C:\Program Files\Microsoft SDKs\Windows Azure\.NET SDK\2012-10\ref – assuming you have SDK 1.8 installed) and select Microsoft.WindowsAzure.StorageClient.dll from there.
To get the reference for storage client library 2.0 (or the latest version for that matter), I would actually recommend getting this using Nuget. That way you’ll always get the latest version. You can simply get it by executing the following command in Nuget Package Manager console: Install-Package WindowsAzure.Storage. While it’s an easy way to get the latest version upgrades, one must not upgrade it before ensuring the new version won’t break anything in the existing code.
Namespaces
One good thing that is done with version 2.0 is that the functionality is now neatly segregated into different namespaces. For blob storage, following 2 namespaces are used:
using Microsoft.WindowsAzure.Storage.Blob; using Microsoft.WindowsAzure.Storage.Blob.Protocol;Blob Request Options and Operation Context
One interesting improvement that has been done is that with every storage client library function, you can pass 2 additional optional parameters: Blob Request Options and Operation Context. Blob Request Options object allows you to control the retry policies (to take care of transient errors) and some of the server side behavior like request timeout. Operation Context provides the context for a request to the storage service and provides additional runtime information about its execution. It allows you to get more information about request/response plus it allows you to pass a client request id which gets logged by storage analytics. For the sake of simplicity, I have omitted these two parameters from the code I included below.
Operations
Now let’s see how you can perform some operations. What I’ve done is first showed how you did an operation with version 1.7 and then how would you do the same operation with version 2.0.
Create Blob Container
If you’re using the following code with version 1.7 to create a blob container:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); container.CreateIfNotExist();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); container.CreateIfNotExists();Only difference that you will see in the two functions above is version 2.0 is now grammatically correct
[in 1.7, it is CreateIfNotExist() and in 2.0, it is CreateIfNotExists() --> notice an extra “s”].
Delete Blob Container
If you’re using the following code with version 1.7 to delete a blob container:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); container.Delete();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); container.DeleteIfExists();One interesting improvement with 2.0 is that it now eats up “Resource Not Found (HTTP Error Code 404)” exception if you’re trying to delete a blob container which does not exist when you use “DeleteIfExists()” function. With 1.7, you don’t have that option and you would need to handle 404 error in your code. Please note that “Delete()” function is still available in 2.0 on a blob container.
List Blob Containers
If you’re using the following code with version 1.7 to list blob containers in a storage account:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); IEnumerable<CloudBlobContainer> blobContainers = cloudBlobClient.ListContainers();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); IEnumerable<CloudBlobContainer> blobContainers = cloudBlobClient.ListContainers();As you can see, the functionality is same in both versions.
List Blobs
There are many options available to you for listing blobs in a blob container. I will only cover two scenarios here: Listing all blobs in a blob container and listing all blobs which start with specified prefix.
List All Blobs
If you’re using the following code with version 1.7 to list all blobs in a blob container:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); IEnumerable<IListBlobItem> blobs = container.ListBlobs();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); IEnumerable<IListBlobItem> blobs = container.ListBlobs();As you can see, the functionality is same in both versions.
List All Blobs Which Start With Specified Prefix
If you’re using the following code with version 1.7 to list all blobs in a blob container which starts with specified prefix:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); string prefix = "<Some Blob Prefix>"; string blobPrefix = containerName + "/" + prefix; IEnumerable<IListBlobItem> blobs = cloudBlobClient.ListBlobsWithPrefix(blobPrefix, new BlobRequestOptions() { UseFlatBlobListing = true, });With version 2.0, you actually get many options to achieve this. Some of them are:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string prefix = "<Some Blob Prefix>"; IEnumerable<IListBlobItem> blobs = container.ListBlobs(prefix, true);CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); string prefix = "<Some Blob Prefix>"; string blobPrefix = containerName + "/" + prefix; IEnumerable<IListBlobItem> blobs = cloudBlobClient.ListBlobsWithPrefix(blobPrefix, true);Upload Blob
IMO, this is one functionality which has changed considerably between version 1.7 and 2.0. In version 1.7, you had many options to upload a blob (for the sake of simplicity, we’ll restrict ourselves to block blobs only). You could upload a blob from a file, from a byte array, from a text string or a stream. In version 2.0, only option you have is upload from stream. All other methods have been removed. If your code with version 1.7 is making use of the functions which are now removed from 2.0, you could either rewrite those functions to make use of stream or you could write some extension methods. For example, let’s say you’re uploading a blob from a file using the following code with version 1.7:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.UploadFile(filePath);With version 2.0, if you decide to rewrite the above code, you could do something like:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); using (FileStream fs = new FileStream(filePath, FileMode.Open)) { blob.UploadFromStream(fs); }Or, you could write an extension method which will encapsulate uploading to stream functionality. For example:
public static void UploadFile(this CloudBlockBlob blob, string fileName) { using (FileStream fs = new FileStream(fileName, FileMode.Open)) { blob.UploadFromStream(fs); } }Then you would upload blob using this way:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.UploadFile(filePath);Download Blob
Like blob upload, this functionality has also been changed considerably between 1.7 and 2.0. Similar to upload in version 1.7, you had many options to download a blob (again for simplicity, we will focus on block blobs). You could download a blob to a file, to a byte array, to a text string or to a stream. In version 2.0, only option you have is download to stream. All other methods have been removed. If your code with version 1.7 is making use of the functions which are now removed from 2.0, you could either rewrite those functions to make use of stream or you could write some extension methods. For example, let’s say you’re downloading a blob to a file using the following code with version 1.7:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.DownloadToFile(filePath);With version 2.0, if you decide to rewrite the above code, you could do something like:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); using (FileStream fs = new FileStream(filePath, FileMode.Create)) { blob. DownloadToStream(fs); }Or, you could write an extension method which will encapsulate downloading from stream functionality. For example:
public static void DownloadToFile(this CloudBlockBlob blob, string fileName) { using (FileStream fs = new FileStream(fileName, FileMode.Create)) { blob.DownloadToStream(fs); } }Then you would download blob using this way:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string filePath = "<Full File Path e.g. C:\temp\myblob.txt>"; string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.DownloadToFile(filePath);Delete Blob
If you’re using the following code with version 1.7 to delete a blob from a blob container:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.DeleteIfExists();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.DeleteIfExists();As you can see, the functionality is same in both versions.
Copy Blob
As you know, with the release of Blob Storage Service Version 2012-02-12, copy blob operation is an asynchronous operation. You can read more about it here: http://blogs.msdn.com/b/windowsazurestorage/archive/2012/06/12/introducing-asynchronous-cross-account-copy-blob.aspx. Storage client library version 1.7 did not have support for this functionality however storage team released version 1.7.1 which had support for this functionality. So if you’re using the following code with version 1.7.1 to copy blob:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer sourceContainer = cloudBlobClient.GetContainerReference(containerName); CloudBlobContainer targetContainer = cloudBlobClient.GetContainerReference(targetContainerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob sourceBlob = sourceContainer.GetBlockBlobReference(blobName); CloudBlockBlob targetBlob = targetContainer.GetBlockBlobReference(blobName); targetBlob.CopyFromBlob(sourceBlob);You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer sourceContainer = cloudBlobClient.GetContainerReference(containerName); CloudBlobContainer targetContainer = cloudBlobClient.GetContainerReference(targetContainerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob sourceBlob = sourceContainer.GetBlockBlobReference(blobName); CloudBlockBlob targetBlob = targetContainer.GetBlockBlobReference(blobName); targetBlob.StartCopyFromBlob(sourceBlob);Please note that the function in version 2.0 is “StartCopyFromBlob()” where as in version 1.7, it is “CopyFromBlob()”. Please make a note of that.
Snapshot Blob
If you’re using the following code with version 1.7 to take a snapshot of a blob:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.CreateSnapshot();You would use something like this with version 2.0 to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); blob.CreateSnapshot();As you can see, the functionality is same in both versions.
Lease blob
One important improvement that has happened in version 2.0 of storage client library is that it now has full fidelity with the REST API i.e. all the functions exposed through REST API are now available in the storage client library. This was not true with version 1.7. A good example of that is lease blob functionality. In version 1.7, there was no direct function available for acquiring lease on the blob and one would need to resort to the protocol layer (Microsoft.WindowsAzure.StorageClient.Protocol) to perform lease operation. So in order to acquire lease on a blob, if you’re using the following code with version 1.7:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentialsAccountAndKey(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; StorageCredentials credentials = cloudBlobClient.Credentials; Uri transformedUri = new Uri(credentials.TransformUri(blob.Uri.AbsoluteUri)); var req = BlobRequest.Lease(transformedUri, 90, // timeout (in seconds) LeaseAction.Acquire, // as opposed to "break" "release" or "renew" null); // name of the existing lease, if any credentials.SignRequest(req); using (var response = req.GetResponse()) { string leaseId = response.Headers["x-ms-lease-id"]; }With version 2.0, it’s actually quite straight forward and you would use something like this to achieve the same:
CloudStorageAccount storageAccount = new CloudStorageAccount(new StorageCredentials(accountName, accountKey), true); CloudBlobClient cloudBlobClient = storageAccount.CreateCloudBlobClient(); CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); string blobName = "<Blob Name e.g. myblob.txt>"; CloudBlockBlob blob = container.GetBlockBlobReference(blobName); TimeSpan? leaseTime = TimeSpan.FromSeconds(15);//Acquire a 15 second lease on the blob. Leave it null for infinite lease. Otherwise it should be between 15 and 60 seconds. string proposedLeaseId = null;//proposed lease id (leave it null for storage service to return you one). string leaseId = blob.AcquireLease(leaseTime, proposedLeaseId);Closing Thoughts
As I mentioned above and demonstrated through examples, there are a few differences in storage client library 1.7 and 2.0 as far as managing blob storage is concerned. Some of them are quite major while others are quite manageable. However in my opinion they are not as drastic as with the tables and the migration should be considerably smooth.
Finally (as I have been saying repeatedly in past 2 posts), don’t give up on Storage Client Library 1.7 just yet. There’re still some components which depend on 1.7 version. Good example is Windows Azure Diagnostics which still depends on the older version at the time of writing this blog. Good thing is that both version 1.7 and 2.0 can co-exist in a project.
Source Code
You can download the source code for this project from here: Sample Project Source Code
Summary
The examples I presented in this post are quite basic but hopefully they should give you an idea about how to use the latest version of storage client library. In general, I am quite pleased with the changes the team has done. Please feel free to share your experience with migration exercise by providing comments. This will help me and the readers of this blog immensely. Finally, if you find any issues with this post please let me know and I will try and fix them ASAP.


The Windows Azure Team updated the Windows Azure Storage Service Level Agreement (SLA) on 11/27/2012:
The new SLAs are downloadable in 20 languages, presumably for those locales in which Windows Azure is available for production use.
PRNewswire reported Big Data Partnership joins Microsoft Big Data Partner Incubation Program for HDInsight on 11/27/2012:
LONDON, November 27, 2012 - Big Data Partnership, a leading 'Big Data' specialist service provider, today announced that it has been chosen as one of a few select organizations from around the world to participate in the Microsoft Big Data Partner Incubation Program. Big Data Partnership's participation in the program followed a rigorous nomination process that was supported by Microsoft SQL Server global marketing managers and industry leads.
Under this agreement, the two companies will work closely together to drive customer engagement and the roll-out of Microsoft HDInsight, which is Microsoft's distribution of Apache Hadoop for the Windows Azure and Windows Server platforms. Microsoft's HDInsight is an Enterprise-ready Hadoop service based on the Hortonworks Data Platform (HDP), enabling customers to seamlessly store and process data of all types, including structured, unstructured, and real-time data in order to achieve rich insights and drive operational efficiencies and increased revenue opportunities.
Big Data Partnership's inclusion on the Microsoft Big Data Partner Program will deliver many benefits to its clients; enabling them not only to understand the growing variety of the data but also to achieve simplified deployment of solutions via HDInsight.
"Big Data Partnership is excited to work with Microsoft to help accelerate the adoption of its big data solution in Enterprise," said Mike Merritt-Holmes, CEO at Big Data Partnership. "By combining the simplicity of Windows Server with the power and reliability of the Hortonworks Data Platform, we will be able to deliver compelling advanced analytics and ensure that a wider audience reap the benefits big data promises using the familiar tools of Excel, including PowerPivot and Power View. We commend Microsoft for their commitment and contribution to the open source Apache Hadoop community and for helping to democratize big data."
Big Data Partnership is a partner of both Microsoft and Hortonworks, the market-leading pioneer of Apache Hadoop. As a Hortonworks' Certified Training Partner, Big Data Partnership will also be delivering the 'Hortonworks Hadoop on Windows for Developers' training course for customers across Europe in early 2013.
"Microsoft HDInsight will allow customers to run Hadoop on Windows Server and on Windows Azure," said Bob Baker, Director, Microsoft Server and Tools Marketing. "Combined with the business intelligence capabilities of SQL Server 2012, HDInsight enables customers to obtain great insight from structured and unstructured data. We see the services market around these capabilities as growing rapidly, and Big Data Partnership is well positioned to execute. We are pleased that Big Data Partnership is supporting Microsoft HDInsight, and we are excited about the value this relationship will bring to our joint customers."
About Big Data Partnership
Big Data Partnership is the leading UK-based big data specialist solution provider, offering a combination of Professional Services and Training to help enterprise clients unlock the value in complex data.
For more information, visit http://www.bigdatapartnership.com.




<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
Srinivas Manyam Rajaram described HO[W] TO: Use Reusable and Configurable Mock for SQL Azure Transient Fault Handling in an 11/26/2012 post to the Aditi Technologies blog:
I have been working mostly on SQL Azure Transient Fault Handling for the past week and wanted to share some of my learning’s with the Azure community out there.
The Transient Fault Handling Application Block provides infrastructure to develop resilient Azure applications by handling transient faults that occur because of some temporary conditions such as network connectivity issues or service unavailability. Typically, if you retry the operation that resulted in a transient error a short time later you find that the error has disappeared.
Different services can have different transient faults and different applications require different fault handling strategies. The Transient Fault Handling Application Block encapsulates information about the transient faults that can occur when you use the following Windows Azure services in your application:
- SQL Azure
- Windows Azure Service Bus
- Windows Azure Storage
- Windows Azure Caching Service
Creating a Mock by extending the Transient Fault Handling Application block
My focus is on SQL Azure more specifically, but the concepts discussed here can be applied to the other Windows Azure Services such as Service Bus, Storage and Caching too if required.
Transient errors are prone to happen while using the SQL Azure database and as a best practice, every developer is expected to protect the application against SQL Azure Transient errors by applying the Transient Fault Handling Application Block.
The difficult part of the equation is differentiating the transient errors from non-transient errors. You may get the list of all publicly available transient errors related to the SQL Azure database here.
Most of the heavy lifting is done by the Transient Fault Handling Application Block within the classes for us. When I was done with my application development and implemented the Transient Fault Handling Block to it, all I was left with was to test if my code works when there is a transient SQL Azure error. That’s when everything looked grey. I started running the code in local emulator, pointing to the SQL Azure database. The only strategy I could think of for testing my code was to disconnect my code from the Internet when it tried to interact with the SQL Azure. However this strategy did not work out well for me. I am not sure if anyone out there could get it work this way.
To my rescue here, Transient Fault Handling Application Block provides some extension points that can be used to create a mock. Read more hereto find the extension points.
We will specifically use the ITransientErrorDetectionStrategy.IsTransient to create the mock that is built on the existing strategy. The goal here is to create a mock that does not completely override the existing Transient Fault Handling functionality, but the mock is expected to complement the existing functionality.
The solution (Mock.TransientFaultHandling) has the projects mentioned below:


Mock.TFH.Library
This project currently has Mock implementation specific to SQL Azure. This can be extended to other Azure Services too.
Core
The Mock.TFH.Library has a reference to the Transient Fault Handling Application Block to implement the extensions briefly discussed previously.
MockSqlAzureTransientErrorDetectionStrategy implements the ITransientErrorDetectionStrategy. In its IsTransient method it creates a new instance of the SQLAzureTransientErrorDetectionStrategy and passes the exception to see if it is a Transient Error. Following this the SQLException.Numbers from the configuration are loaded and compared against the incoming exception’s number if it is a SQLException. The incoming exception is recursively inspected for SQLException before it is compared against the configuration values. Effectively if the exception is part of base transient errors listed in the Transient Fault Handling Application Block or the exception numbers listed in the configuration file, then it is treated as a transient error.
Configuration
The Transient Fault Handling Application block by default uses the SQLException.Number to identify if a given condition belongs to Transient category. So the core idea here is to inject some SQLException.Numbers in the configuration of the client application, to be treated as Transient error.
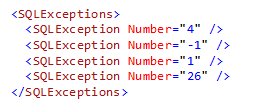
So we have a SQLExceptionElement class that derives from the ConfigurationElement class from the System.Configuration to provide the ability to add an element shown below in the configuration:
There may be cases where you might want to include multiple test conditions in the configuration to be treated as Transient error. So the SQLExceptionsCollection class which inherits the ConfigurationElementCollection class from the System.Configuration provides this functionality. So the configuration can now have a structure defined below:
Then we have the CustomSQLAzureTFHSection inheriting from ConfigurationSection in System.Configuration to bundle our SQLExceptions collection.
Mock.Client.DAL
This project uses the Entity Framework to connect to a SQL database. It hosts the edmx file and the ObjectContext OrganizationEntities. A partial class of OrganizationEntities is created to apply the Transient Fault Handling retry strategy inside the OnContextCreated method. Read more about implementing Transient Fault Handling for SQL Azure and Entity Framework here.
The retry policy is usually created as below:
However in our case, we will be using the mock to create the retry policy. Please find the corresponding code below:
Note: The mock should be used only for test purposes and not in any real environment. So when you deploy your code to any Azure environment, it is recommended to follow one of the below approaches:
- You may uncomment the regular way of applying retry policy and comment the mock way of applying retry policy
- Alternately you may still leave the mock way of creating retry policy but you will have to comment out all SQLException numbers from the configuration file of the client application.
Mock.Client.Web
This is an ASP .Net Web application that uses the Mock.Client.DAL to get / put the data from / to the database. To test the mock the application has few labels and a button to populate the data from the database. When the button is clicked, the first name and last name of the first employee from the Employee table is populated.
Web.config
The web.config should have the below items to make use of the Mock and retry:

Test Approaches:
With on-premise SQL Server
The whole purpose of the Mock is to test if the client code falls back to retry logic in the occurrence of a transient error. With our mock we can make any SQLException.Number to be treated as transient error. This essentially means we are not mandated to test our code with SQL Azure. So to test our client code for retries, we can connect it from emulator or even IIS locally to a local SQL Server database either express or full edition and stop the server when the application try to access the database. This would usually generate a SQLException in the exception chain somewhere depending on whether you are directly using ADO .Net or using Entity Framework. If this SQLException number is not included in the web.config under our custom settings, then the retry would not happen. If the SQLException number is included in the custom settings in the web.config, the retry logic will be reached.
Testing with SQL Azure
To test the client with SQL Azure you may run the client either in the local IIS or in the emulator with the connection strings pointing to the SQL Azure. However turn off the Wi-Fi or disconnect the client from internet when the client tries to make a database call. This would ensure that a SQLException. The number is returned and depending on whether we have the mock turned on or not the retry will be applied.
What are your experiences with SQL Azure Transient Fault Handling? Have you used another test approach?



The Windows Azure Team updated SQL Azure and SQL Reporting Service Level Agreements (SLAs) on 11/25/2012:

Apparently the SLA authors didn’t get the memo about SQL Azure being renamed to Windows Azure SQL Database.

<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
Helmut Krämer (@mobilewhatelse) described Windows 8 Store App: getting connected to SharePoint with Odata in an 11/27/2012 post:
Today we’ll implement a simple “Windows 8 Store App – SharePoint List reader” with OData.
Before we start developing (only a few lines of code) we need the WCF Data Services Tools for Windows Store Apps.
After the download and installation we can start.
Step 1 – exploring the OData service
The OData service is located on your SharePoint installation at /_vti_bin/ListData.svc,
so the URL looks like: http://yoursharepoint:yourport/yoursite/_vti_bin/ListData.svc .So let’s take a look and type your URL into your Internet Explorer, it should look like this (with your lists):
If you see a output like this you are on the right way.
Step 2 – creating a simple app and adding the OData Service Reference
I’ll create a simple Blank APP:
Now in the Solution Explorer go to “References”, right click and choose “Add Service Reference”.
A window opens for the reference, type your URL for the OData Listservice in the “Adress” field und press “GO”. Now (maybe you have to enter your credentials) you can see all your services for consuming your lists on SharePoint:
Great, half work is done!
Step 3 – creating DataServiceCollection and a ListView for displaying the results
In our example we want to display all availiable Tasks. So we have to declare our DataServiceCollection.
For the declaration we have to add following referrences:
Now we add the Listview to the layout with databinding:
Step 4 – adding code for reading tasks
Now we have to implement the method for reading the “OData” Tasks
With LINQ its possible to get the tasks you want (in our example we want all):
Don’t forget the Event(Handler):
Now only one Step is missing.
Step 5 – implement task reading in OnNavigatedTo Event and run the app
OnNavigatedTo:
And run the app:
I know, there some doings on the UI but this app works well












I doubt if the app would make it through the Windows Store qualification process.
Todd Hoff posted BigData using Erlang, C and Lisp to Fight the Tsunami of Mobile Data to his High Scalability blog on 11/26/2012:
This is a guest post by Jon Vlachogiannis. Jon is the founder and CTO of BugSense.
BugSense, is an error-reporting and quality metrics service that tracks thousand of apps every day. When mobile apps crash, BugSense helps developers pinpoint and fix the problem. The startup delivers first-class service to its customers, which include VMWare, Samsung, Skype and thousands of independent app developers. Tracking more than 200M devices requires fast, fault tolerant and cheap infrastructure.
The last six months, we’ve decided to use our BigData infrastructure, to provide the users with metrics about their apps performance and stability and let them know how the errors affect their user base and revenues.
We knew that our solution should be scalable from day one, because more than 4% of the smartphones out there, will start DDOSing us with data.We wanted to be able to:
- Abstract the application logic and feed browsers with JSON
- Run complex algorithms on the fly
- Experiment with data, without the need of a dedicated Hadoop cluster
- Pre-process data and then store them (cutting down storage)
- Be able to handle more than 1000 concurrent request on every node
- Make “joins” in more than 125M rows per app
- Do this without spending a fortune in servers
The solution uses:
Less than 20 large instances running on Azure [Emphasis added.]
- An in-memory database
- A full blown custom LISP language written in C to implement queries, which is many times faster that having a VM (with a garbage collector) online all the time
- Erlang for communication between nodes
- Modified TCP_TIMEWAIT_LEN for an astonishing drop of 40K connections, saving on CPU, memory and TCP buffers
For more information on the BugSense architecture please keep on reading...

Read more.
<Return to section navigation list>
Windows Azure Service Bus, Access Control Services, Caching, Active Directory and Workflow
• Alex Simons reported Windows Azure now supports federation with Windows Server Active Directory in an 11/27/2012 post:
Yesterday we shared that Windows Azure Active Directory (AD) has processed 200 BILLION authentications . Today I’m excited to share some great identity-related improvements we’ve made to Windows Azure that leverage the capabilities of Windows Azure AD. The number one identity management feature that Windows Azure customers request is the ability for organizations to use their on-premise corporate identities in Windows Server Active Directory to deliver single sign-on (SSO) access to the Windows Azure Management Portal and centralized user access management.
Starting today, the Windows Azure Management portal is now integrated with Windows Azure AD and supports federation with a customers on-premise Windows Server AD. In addition this integration means that the millions of Office 365 customers can use the same tenants and identities they use for Office 365 to manage sign-on and access to Windows Azure.
There are many advantages to using federation with Windows Azure. For IT professionals, it means:
- Subscription management for Windows Azure can now be tied to an employees’ status at your company. If an employee leaves your company, their federated access to the Windows Azure Management Portal can be turned off by deactivating them or removing them from your on-premises Windows Server Active Directory.
- Your corporate administrator can control credential policy for the Windows Azure Management portal through Windows Server Active Directory, including setting password policies, workstation restrictions, two factor authentication requirements and lock-out controls.
- Users no longer have to remember a different set of credentials for Windows Azure. Instead by using SSO and Federation, the same set of credentials are used across their PC, your work network and Windows Azure, lowering the chance of employees forgetting their credentials and making central management and reset of passwords easier and lower cost.
- User passwords never leave your on-premise Windows Server AD: Users login using your on-premise Windows Server AD Federation Server so their identities and credentials are mastered and validated on-premise. Their passwords are never moved to the cloud.
- You can require multifactor authentication, such as a smartcard & pin or RSA SecureID in addition to standard username and password authentications.
For developers and operators who access the Management Portal, federation means:
- When you log into your domain joined Windows PC you will be seamlessly authenticated with the Windows Azure Management Portal.
- If you are logging in from a non-domain-joined machine, such as personal device at home, you can use the same corporate credentials you use on your work PC.
- You will receive Windows Azure service notification emails via your corporate email address.
Overall, federation can be used to greatly increase the security of your company’s cloud assets and intellectual property.
Using your existing Organizational accounts to access Windows Azure
There are two simple sign-in methods you can use with your existing Organizational Account powered by Windows Azure AD to sign-in to Windows Azure. This includes the Organizational Account you might already use to log into Office 365.1. Use the Windows Azure sign-in page
You can use the standard Windows Azure sign-in page that you use to access the Windows Azure Management Portal. To sign-in with your Office 365 organizational account, click the link named Already use Office 365? as shown in the following
diagram.
2. Bypass the Windows Azure sign-in page
Alternatively, you can bypass the sign-in page prompts by adding your company’s existing federated domain name to the end of the Windows Azure Management Portal URL. For example from a domain joined machines, point your browser to https://windows.azure.com/contoso.com. If your company has setup federation with Windows Azure AD or if you are already logged into Office 365, you will be logged in to Windows Azure automatically.To illustrate how this works, let’s use an example of a user named Andrew who works for a fictitious company named Identity365.net. The company has an existing Office 365 subscription and they’ve previously set up federation with Windows Azure AD.
To access Windows Azure, Andrew logs in to his domain joined PC and types the URL for Windows Azure, but adds his company’s domain name to the end of the URL (https://windows.azure.com/identity365.net).
Windows Azure AD recognizes that identity365.net is a federated domain, and silently redirects Andrew to his organization’s on-premises Active Directory Federation Service (AD FS) server. Andrew’s organization has configured their AD FS server to require multifactor authentication because they manage medical records using Windows Azure, and they must be HIPPA compliant.
Andrew then inserts his smartcard and selects his name from the list above. His PC then prompts him for the smartcard PIN:

Once he enters his smartcard pin, he is automatically signed into the Management Portal.
If Andrew doesn’t provide a smartcard, or uses the wrong pin, his company’s Windows Server AD FS denies him access. By default, Windows Server AD FS will show the standard HTTP 403 Forbidden response code for when improper credentials are submitted during sign-in, but this can be customized to provide a more user-friendly behavior:
How federated access works with Windows Azure
The following illustrations shows how federated access works between Windows Azure AD, the Windows Azure Management Portal, Windows Server AD FS and your company’s on-premises Windows Server Active Directory:Step 1: User logs into the local domain-joined corporate PC
The following actions occur automatically:
- The local domain controller validates the user’s credentials.
- The domain controller generates Kerberos Ticket Granting Ticket valid for X hours. The default is 600 minutes [10 hours], but is configurable by local IT admin policy.
- Alternatively, local IT admin policy may require multifactor login to the local desktop. If that isthe case, theKerberos Ticket Granting Ticket will record the multifactor claims.

Step 2: User types the Windows Azure Portal with his company name
The user types http://windows.azure.com/fabrikam.com
The following actions occur automatically:
- The Windows Azure Management Portal parses the URL and extracts the domain name of fabrikam.com.
- The Management Portal then performs a redirect to Windows Azure AD, passing the requested home-realm as a query string (whr=fabrikam.com).

Step 3: Windows Azure AD performs look up and then redirect
The following actions then occur automatically:
- Windows Azure AD looks up the DNS name of the on-premise AD FS server that has been previously configured for the fabrikam.com home-realm.
- It then redirects the client PC to the required AD FS server DNS name (sts.fabrikam.com).

Step 4: On-Premises AD FS sends authentication challenge sends SAML token
The following actions now occur automatically:
- The on-premises AD FS server challenges the client PC by requesting authentication.
- The clientPC's browser passes the previously-generated Kerberos Ticket Granting Ticket to the on-premise KDC (ticket granting server), requesting a Service Ticket.
- The KDC issues the client a Service Ticket, containing the multifactor claims (this assumes that IT policy forced smartcard authentication at desktop login time, otherwise, AD FS can challenge to present a smartcard during this Windows Azure Management Portal login sequence).
- The client PC presents the Service Ticket to AD FS. AD FS validates the Kerberos ticket and generates a signed SAML token for Windows Azure AD in the next step. AD FS will only send the signed SAML token if the credentials are valid.

Step 5: AD FS redirects back to Windows Azure AD
The following actions occur automatically:
- AD FS performs a redirect with the signed SAML claims as a form POST back to Windows Azure AD, attesting to the valid credentials.
- The SAML claims do not contain the corporate credentials. The actual user credentials never leave the local site.

Step 6: AD FS Authentication Challenge
In the final step, the following actions occur automatically:
- Windows Azure AD transforms the AD FS SAML tokens to its own signed identity claims for the Windows Azure Management Portal.
- It then performs a POST back to the Management Portal.
- The Management Portal decrypts the Windows Azure AD claims, extracts the user’s local identity pointer, and looks up the user’s Windows Azure subscription based on that identity.
- The user is now authenticated into the Windows Azure Management Portal via multifactor authentication.

To learn more about how you can set up single sign on between your company’s on-premises directory and Windows Azure Active Directory, click here.
If your company is already using Office 365 or another Microsoft cloud servie backed by Windows Azure AD, you can immediately get started by purchasing a new Windows Azure subscription using your corporate identity. To start the purchasing process, visit http://account.windowsazure.com/yourcompanyname.com, replacing the last portion of the URL with your corporate DNS name.










• Amr Abulnaga (@amrabulnaga) posted Azure Access Control Service on 11/25/2012 (missed when published):
Cloud computing has became one of the popular most reliable things in business now a days that most of the new businesses go to it as it costs a lot less than buying their own storage and making their own systems.
So with all of the people that wants to access their services on the cloud there has to be an authentication process where each user trying to access the services on the cloud must be authorized with an access specially that users accessing these services are from different identity providers.
In conclusion Access Control Service is way of authenticating and authorizing users accessing the applications and services on cloud through different identity providers instead of implementing user’s ACS each time he accesses the cloud. ACS integerates with well known standard identity providers like Windows Live ID, Yahoo, Google and Facebook.


Bill Hilf (@bill_hilf) reported Windows Azure Active Directory Processes 200 Billion Authentications - Connecting People, Data and Devices Around The Globe on 11/27/2012:
At Microsoft, we have been on a transformative journey to cloud computing and we have been working with customers every step of the way. Millions of customers have embraced the cloud and we are excited to share the news that we’ve reached a major milestone in cloud scale computing. Since the inception of the authentication service on the Windows Azure platform in 2010, we have now processed 200 BILLION authentications for 50 MILLION active user accounts. In an average week we receive 4.7 BILLION authentication requests for users in over 420 THOUSAND different domains. This is a massive workload when you consider others in the industry are attempting to process 7B logins per year, Azure processes close to that amount in a week.
These numbers sound big right? They are. To put it into perspective, in the 2 minutes it takes to brew yourself a single cup of coffee, Windows Azure Active Directory (AD) has already processed just over 1 MILLION authentications from many different devices and users around the world. Not only are we processing a huge number of authentications but we’re doing it really fast! We respond to 9,000 requests per second and in the U.S. the average authentication takes less than 0.7 seconds. That’s faster than you can get your coffee from your cup and into your mouth! (Do not attempt this at home :-))!
While cloud computing is certainly evolving, Microsoft has been delivering cloud services for some time. Six years ago we introduced cloud productivity services and Live@edu was one of the first offerings for our education customers. This enabled universities to get out of email and infrastructure administration and focus on their core strengths of educating the future generation in higher education. Today Live@edu has transformed into Office365 for Education and has expanded to deliver anywhere access to email, calendars, Office Web Apps, video and online meetings, and document-sharing.
As we continue to evolve our cloud services it may not be widely known that all of the Microsoft Office365 authentication is driven through Windows Azure AD. And that’s not all, Windows Azure AD is also the directory for many of Microsoft’s first party cloud-based SaaS offerings for our customers including Microsoft Dynamics CRM Online, Windows Server Online Backup, Windows Intune, and as we’ll discuss tomorrow, Windows Azure itself.
In addition, Windows Azure AD goes beyond the first party services delivered from Microsoft. It is being used by our customers and third party developers as well. By using Windows Azure AD we deliver cloud based authentication services for you at scale with fast response and, if desired, enable federation and synchronization with your existing on-premise Windows Server Active Directory (AD). This is important as Gartner estimates that 95% of organizations already have Active Directory deployed in their environment.
By connecting your existing Windows Server AD to Windows Azure AD you can manage a hybrid environment that provides unified authentication and access management for both cloud and on premise services and servers, eliminating the need to maintain new, independent cloud directories. In addition, Windows Azure AD supports multiple protocols and token types, therefore apps that use it can be accessed from any device that supports an industry standard web browser including smartphones, tablets, and multiple PC, desktop and server operating systems.
There are a few key concepts where we’d like to offer more insight. First, Windows Azure AD has been architected to operate in the cloud as a multitenant service with high scale, high availability, and integrated disaster recovery – this goes far beyond taking AD and simply running it within a virtual machine in a hosted environment.
- Authentication requests (e.g. to service user logins) are sent from the user and/or devices to Windows Azure AD. Authentication types vary but some common examples include refreshing your Outlook email from your phone or logging in to the Windows Azure Management portal.
- Federation is the ability for Azure Active Directory and your existing on premise infrastructure to work together delivering a single sign on experience for users while keeping user passwords on-premise in a company’s servers. Federation also gives IT the option to require multifactor authentication for increased security.
- Single-Sign On is the ability for a person to login in once and not have to re-enter their credentials each time when accessing different services or applications. It’s an important part of the Azure AD because it delivers a secure, yet simple way for your users to connect to their resources running on Azure.
One of my favorite stories about how customers are taking advantage of a ‘hybrid’ architecture, leveraging Azure, maintaining IT control while saving costs and improving their end-user experience, is from Georgia State University.
Georgia State University (GSU) switched to cloud based Microsoft Office365 and saved $1 Million in operating costs to better support mobile and remote workers using PCs, Macs and various mobile devices and to better interoperate with already-planned on-premise deployments, including Windows Server Active Directory and Microsoft Office applications. “We’re saving the equivalent of 2.5 full time employees who no longer have to deal with on premises server administration,” says J.L. Albert Associate Provost and Chief Information Officer.
During this effort Microsoft worked with GSU to ensure that their on premise AD would fully support Office365 with federated identity and single sign-on capabilities – all integrated using Windows Azure Active Directory. This approach allowed GSU’s IT department to maintain only one user ID and password per employee, saving time for both IT staff and users, enabling them to repurpose IT resources to higher priority projects. “Using a single sign-on integrates everything for us and saves us valuable time versus the multiple processes we had before,” says Bill Gruska, Director of IT Production Services.
For more details on how we’re using Windows Azure Active Directory to enable authentication and single sign on for Microsoft’s software as a service offerings, and how you, as a Developer or an IT Pro, can leverage Windows Azure AD, check out John Shewchuk’s blog posts on Reimagining Active Directory Part 1 and Part 2 as well as Alex’s Simon’s posts Enhancements to Windows Azure Active Directory Preview . Go ahead and give it a try. You can check out the Windows Azure Active Directory Preview here.


The Windows Azure Team updated Service Bus, Access Control and Caching Service Level Agreements (SLAs) on 11/25/2012:
The new SLAs are downloadable in 20 languages, presumably for those locales in which Windows Azure is available for production use.
No significant articles today

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
• Avkash Chauhan (@avkashchauhan) published Microsoft Server Products and Microsoft License Mobility for Cloud environment on 11/27/2012:
License Mobility Through Software Assurance:
With License Mobility through Software Assurance, you can deploy certain server application licenses purchased under your Volume Licensing agreement in an Authorized Mobility Partner’s datacenter.

- Extend the value of your server application license by deploying them on-premises or in the cloud.
- Take advantage of the lowest cost computing infrastructure for changing business priorities.
http://www.microsoft.com/licensing/software-assurance/license-mobility.aspx
Microsoft License Mobility through Software Assurance for Microsoft Windows Server Applications on AWS:
Microsoft has announced a new benefit, called License Mobility through Software Assurance, which allows Microsoft customers to more easily move current on-premises Microsoft Server application workloads to Amazon Web Services (AWS), without any additional Microsoft software license fees.
- Microsoft Exchange Server
- Microsoft SharePoint Server
- Microsoft SQL Server Standard Edition
- Microsoft SQL Server Enterprise Edition
- Microsoft Lync Server
- Microsoft System Center Server
- Microsoft Dynamics CRM Server
http://aws.amazon.com/windows/mslicensemobility/
Support policy for Microsoft software running in non-Microsoft hardware virtualization software:
Support policy for Microsoft SQL Server products that are running in a hardware virtualization environment
This includes:
- Running SQL Server in Microsoft Hyper-V based virtualized environment
- Running SQL Server in partner supported virtualized environment
Microsoft server software support for Windows Azure Virtual Machines:
http://support.microsoft.com/kb/2721672
1. Microsoft SharePoint Server
Microsoft SharePoint Server 2010 and later is supported on Windows Azure Virtual Machines.
Support and licensing for Windows Azure in SharePoint 2013: http://technet.microsoft.com/en-us/library/jj154957
2. Microsoft SQL Server
64-bit versions of Microsoft SQL Server 2008 and later are supported: http://support.microsoft.com/?id=956893.
3. Windows Server
Windows Server 2008 R2 and later versions are supported for the following roles:
- Active Directory Domain Services
- Active Directory Federation Services
- Active Directory Lightweight Directory Services
- Application Server
- DNS Server
- Fax Server
- Network Policy and Access Services
- Print and Document Services
- Web Server (IIS)
- Windows Deployment Services
- Windows Server Update Services
- File Services
The following features are not supported on Windows Azure Virtual Machines:
- BitLocker
- Failover Clustering
- Network Load Balancing.

Note that Remote Desktop Services (formerly Terminal Services) are specifically not supported.
Brady Gaster (@bradygaster) continued his Solving Real-world Problems with Windows Azure Web Sites series with Connecting Windows Azure Web Sites to On-Premises Databases Using Windows Azure Service Bus on 11/26/2012:
The third post in the Solving Real-world Problems with Windows Azure Web Sites blog series I’ll demonstrate one manner in which a web site can be connected to an on-premises enterprise. A common use-case for a web site is to collect data for storage in a database in an enterprise environment. Likewise, the first thing most customers want to move into the cloud is their web site. Ironically, the idea of moving a whole enterprise architecture into the cloud can appear to be a daunting task. So, if one wants to host their site in the cloud but keep their data in their enterprise, what’s the solution? This post will address that question and point out how the Windows Azure Service Bus between a Windows Azure Web Site and an on-premises database can be a great glue between your web site and your enterprise.
We have this application that’d be great as a cloud-based web application, but we’re not ready to move the database into the cloud. We have a few other applications that talk to the database into which our web application will need to save data, but we’re not ready to move everything yet. Is there any way we could get the site running in Windows Azure Web Sites but have it save data back to our enterprise? Or do we have to move everything or nothing works?
I get this question quite frequently when showing off Windows Azure Web Sites. People know the depth of what’s possible with Windows Azure, but they don’t want to have to know everything there is to know about Windows Azure just to have a web site online. More importantly, most of these folks have learned that Windows Azure Web Sites makes it dirt simple to get their ASP.NET, PHP, Node.js, or Python web site hosted into Windows Azure. Windows Azure Web Sites provides a great starting point for most web applications, but the block on adoption comes when the first few options are laid out, similar to these:
- It is costing us increased money and time to manage our web sites so we’re considering moving them into Windows Azure Web Sites
- It will it cost us a lot of money to move our database into the cloud
- We don’t have the money to rework all the applications that use that database if moving it to the cloud means those applications have to change.
- We can’t lose any data, and the enterprise data must be as secure as it already was, at the very least.
- Our web sites need to scale and we can’t get them what we need unless we go to Windows Azure Web Sites.
This is a common plight and question whenever I attend conferences. So, I chose to take one of these conversations as a starting point. I invented a customer situation, but one that emulates the above problem statement and prioritizations associated with the project we have on the table.
Solving the Problem using Windows Azure Service Bus
The first thing I needed to think about when I was brought this problem would be the sample scenario. I needed to come up with something realistic, a problem I had seen customers already experiencing. Here’s a high-level diagram of the idea in place. There’s not much to it, really, just a few simple steps.

In this diagram I point out how my web site will send data over to the Service Bus. Below the service bus layer is a Console EXE application that subscribes to the Service Bus Topic the web application will be publishing into the enterprise for persistence. That console EXE will then use Entity Framework to persist the incoming objects – Customer class instances, in fact – into a SQL Server database.
The subscription internal process is also exploded in this diagram. The Console EXE waits for any instance of a customer being thrown in, and it wakes up any process that’s supposed to handle the incoming instance of that object.
The Console EXE that runs allows the program to subscribe to the Service Bus Topic. When customers land on the topics from other applications, the app wakes up and knows what to do to process those customers. In this first case, the handler component basically persists the data to a SQL Server installation on their enterprise.
Code Summary and Walk-through
This example code consists of three projects, and is all available for your perusal as a GitHub.com repository. The first of these projects is a simple MVC web site, the second is console application. The final project is a core project that gives these two projects a common language via a domain object and a few helper classes. Realistically, the solution could be divided into 4 projects; the core project could be divided into 2 projects, one being the service bus utilities and the other being the on-premises data access code. For the purposes of this demonstration, though, the common core project approach was good enough. The diagram below shows how these projects are organized and how they depend on one another.

The overall idea is simple - build a web site that collects customer information in a form hosted in a Windows Azure Web Site, then ship that data off to the on-premises database via the Windows Azure Service Bus for storage. The first thing I created was a domain object to represent the customers the site will need to save. This domain object serves as a contract between both sides of the application, and will be used by an Entity Framework context class structure in the on-premises environment to save data to a SQL Server database.
With the domain language represented by the Customer class I’ll need some Entity Framework classes running in my enterprise to save customer instances to the SQL database. The classes that perform this functionality are below. They’re not too rich in terms of functionality or business logic implementation, they’re just in the application’s architecture to perform CRUD operations via Entity Framework, given a particular domain object (the Customer class, in this case).
This next class is sort of the most complicated spot in the application if you’ve never done much with the Windows Azure Service Bus. The good thing is, if you don’t want to learn how to do a lot with the internals of Service Bus, this class could be reused in your own application code to provide a quick-and-dirty first step towards using Service Bus.
The ServiceBusHelper class below basically provides a utilitarian method of allowing for both the publishing and subscribing features of Service Bus. I’ll use this class on the web site side to publish Customer instances into the Service Bus, and I’ll also use it in my enterprise application code to subscribe to and read messages from the Service Bus whenever they come in. The code in this utility class is far from perfect, but it should give me a good starting point for publishing and subscribing to the Service Bus to connect the dots.
Now that the Service Bus helper is there to deal with both ends of the conversation I can tie the two ends together pretty easily. The web site’s code won’t be too complicated. I’ll create a view that site users can use to input their customer data. Obviously, this is a short form for demonstration purposes, but it could be any shape or size you want (within reason, of course, but you’ve got ample room if you’re just working with serialized objects).
If I’ve got an MVC view, chances are I’ll need an MVC action method to drive that view. The code for the HomeController class is below. Note, the Index action is repeated – one to display the form to the user, the second to handle the form’s posting. The data is collected via the second Index action method, and then passed into the Service Bus.
The final piece of code to get this all working is to write the console application that runs in my enterprise environment. The code below is all that’s needed to do this; when the application starts up it subscribes to the Service Bus topic and starts listening for incoming objects. Whenever they come in, the code then makes use of the Entity Framework classes to persist the Customer instance to the SQL Server database.
Now that the code’s all written, I’ll walk you through the process of creating your Service Bus topic using the Windows Azure portal. A few configuration changes will need to be made to the web site and the on-premise console application, too, but the hard part is definitely over.
Create the Service Bus Topic
Creating a Service Bus topic using the Windows Azure portal is relatively painless. The first step is to use the New menu in the portal to create the actual Service Bus topic. The screen shot below, from the portal, demonstrates the single step I need to take to create my own namespace in the Windows Azure Service Bus.

Once I click the Create a New Topic button, the Windows Azure portal will run off and create my very own area within the Service Bus. The process won’t take long, but while the Service Bus namespace is being created, the portal will make sure I know it hasn’t forgotten about me.

After a few seconds, the namespace will be visible in the Windows Azure portal. If I select the new namespace and click the button at the bottom of the portal labeled Access Key, a dialog will open that shows me the connection string I’ll need to use to connect to the Service Bus.

I’ll copy that connection string out of the dialog. Then, I’ll paste that connection string into the appropriate place in the Web.config file of the web application. The screen shot below shows the Web.config file from the project, with the appropriate appSettings node highlighted.

A similar node also needs to be configured in the console application’s App.config file, as shown below.

In all, there are only two *.config files that need to be edited in the solution to get this working – the console application’s App.config file and the web application’s Web.config file. Both of these files are highlighted in the solution explorer view of the solution included with this blog post.

With the applications configured properly and the service bus namespace created, I can now run the application to see how things work.
Running the Code
Since I’ll be using Entity Framework to scaffold the SQL Server database on the fly, all I’ll need to do to set up my local enterprise environment is to create a new database. The screen shot below shows my new SQL database before running the console application on my machine. Note, there are no tables or objects in the database yet.

The first thing I’ll do to get running is to debug the console application in Visual Studio. I could just hit F5, but I’ll be running the web application in debug mode next. The idea here is to go ahead and fire up the console application so that it can create the database objects and prepare my enterprise for incoming messages.

The console application will open up, but will display no messages until it begins processing Customer objects that land on the Service Bus. To send it some messages, I’ll now debug the web application, while leaving the console application running locally.

When the web site fires up and opens in my web browser, I’ll be presented the simple form used to collect customer data. If I fill out that form and click the Save button, the data will be sent into the Service Bus.

By leaving the console application running as I submit the form, I can see the data coming into my enterprise environment.

Going back into SQL Server Management Studio and refreshing the list of tables I can see that the Entity Framework migrations ran perfectly, and created the table into which the data will be saved. If I select the data out of that table using a SQL query, I can verify that indeed, the data was persisted into my on-premises database.

At this point, I’ve successfully pushed data from my Windows Azure Web Site up into the Service Bus, and then back down again into my local enterprise database.
Summary
One of the big questions I’ve gotten from the community since the introduction of Windows Azure Web Sites to the Windows Azure platform is on how to connect these sites to an enterprise environment. Many customers aren’t ready to move their whole enterprise into Windows Azure, but they want to take some steps towards getting their applications into the cloud. This sort of hybrid cloud setup is one that’s perfect for Service Bus. As you’ve seen in this demonstration, the process of connecting a Windows Azure Web Site to your on-premises enterprise isn’t difficult, and it allows you the option of moving individual pieces as you’re ready. Getting started is easy, cheap, and will allow for infinite scaling opportunities. Find out how easy Windows Azure can be for Web Sites, mobile applications, or hybrid situations such as this by getting a free trial account today. I’m sure you’ll see that pretty much anything’s possible with Windows Azure.
















No significant articles today

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
WenMing Yi described Running Weather Research Forecast as a Service on Windows Azure in an 11/26/2012 post:

About 9 months ago, I deployed a Weather forecast demo at an internal Microsoft event, Techfest. The demo uses real data from NOAA and predicts high resolution weather forecast up to the next 3 days running a HPC modeling code called WRF. Since then, I’ve received a great deal of interest from others, and we’ve renovated the site with a new design. Before long, this became a more permanent service that is used by me and many others as a Windows Azure “Big Compute” demo at many events such as TechEd, BUILD, and most recently at SuperComputing 2012. Someone recently reminded me of the dramatic thunder rolling in live at TechED in Orlando as I demoed the service predicting rain coming. I am also aware that many of my colleagues have been using it for their own travel and events. The service now has over 8 million objects and estimated 5 TB worth of simulation data saved, it is starting to look more like a Big Data demo.
The service is available at http://weatherservice.cloudapp.net, whose home page is shown above. I’ve been frequently asked about the technical details on this, so here is a brief explanation. The service makes use of the industry standard MPI library to distribute the computations across processors. It utilizes a Platform as a Service (PaaS) version of Windows Azure HPC Scheduler to manage the distribution and executing forecast jobs across the HPC cluster created on Windows Azure. To keep this simple, Azure Blob and Table storage are used to keep track of jobs and store intermediate and final results. This loosely-coupled design allows Jobs/work to be done by on-premise super computers to post their results just as easily as Windows Azure Compute nodes. Since regular Azure nodes are connected via GigE, we’ve decided to run forecast jobs on only one X-Large instance, but things will soon change as the new Windows Azure Hardware becomes available.
Weather forecasts are generated with the Weather Research and Forecasting (WRF) Model, a mesoscale numerical weather prediction framework designed for operational forecasting and atmospheric research needs. The overall forecast processing workflow includes preprocessing of inputs, geographical coordinates, duration of forecast, to WRF, generation of the forecast results, and post-processing of the results and formatting them for display. The workflow is wrapped into a 1000 line PowerShell script, and run as an HPC Job.
The demo web service contains an agent that performs computations for a weather forecast in a geographic area of roughly 180 square kilometers(Plotted). The area is treated as a single unit of work and scaled out to multiple machines (cores in the case of Windows Azure) forecasting precipitation, temperature, snow, water vapor and wind temperature. A user can create a new forecast by simply positioning the agent on the map. The front-end will then monitor the forecast’s progress. The front-end consists of an ASP.NET MVC website that allows users to schedule new forecast job, view all forecast jobs as a list, view the details of forecast job, display single forecast job results, and display all forecast job results in a visual gallery, on the map or as timeline.
After a forecast computation is completed, intermediate results are converted to a set of images (animation) for every two hours of the forecast’s evolution. These flat images are processed into Bing Map Tiles, using specialized software that geo-tags the images, warps them to Bing Map projection, and generates sets of tiles for various map zoom levels.
Processing Summary
Pre-Processing of Forecast Data
There are two categories of input data to the WRF forecast software: geographical data and time-sensitive, low resolution forecast data used as initial and boundary condition data for the WRF software. The geographical data changes very little over time and hence is considered static for forecast purposes. The low resolution forecast data, however, is updated by NOAA every 6 hours and so must be retrieved on a regular basis via ftp to Azure resources. Schtasks.exe was good enough for what we needed. The preparation of geographical and low resolution forecast data are done by a set of programs within a framework called WPS, which stands for WRF Preprocessing System. WPS is used to prepare a domain (region of the Earth) for WRF. The main programs in WPS are geogrid.exe, ungrib.exe and metgrid.exe. The principal tasks of each program are as follows:
Geogrid:
- Defines the model horizontal domain
- Horizontally interpolates static data to the model domain
- Output conforms to the WRF I/O API
Ungrib:
- Decodes Grib Edition 1 and 2 data (Grib is the file format of the NOAA forecast data)
- Uses tables to decide which variables to extract from the data
- Supports isobaric and generalized vertical coordinates
- Output is in a non-WRF-I/O-API form, referred to as an intermediate format
Metgrid:
- Ingest static data and raw meteorological fields
- Horizontally interpolate meteorological fields to the model domain
- Output conforms to WRF I/O API
The WRF Preprocessing System (WPS) is the set of three programs whose collective role is to prepare input to the real.exe program for real-data simulations. Each of the three programs described above performs one stage of the preparation and is linked to the other programs as shown in Figure 1. Input to the programs is through the namelist file "namelist.wps". Each main program has an exclusive namelist record (named "geogrid", "ungrib", or "metgrid", respectively), and the three programs have a group record (named "share") that each program reads.
Figure 1. The data flow between the programs of the WPS.
Forecast Generation
- Real.exe is the initialization module for WRF for “real” input data to WRF. It uses the data generated by the routines above. Configuration parameters are provided in the file ‘namelist.input’.
- WRF generates the final forecast results. The output from WRF is then geo-referenced, re-projected and tiled for display on Bing Maps and as movie forecast histories in the demo web service. This is the longest running part of the process, it takes 5-6 hours to complete using 1 instance of the current standard X-Large VM with 8 CPU cores. Windows version of the code is built using PGI compiler, since then we have built MINGW64 bits, as well as Intel FORTRAN versions.
- Forecasts for the Azure demo are generated over a 180 km x 180 km region of the Earth using a nested grid geometry determined to be an optimal balance between forecast resolution and computational complexity. The outermost grid has a node spacing of 9 km and covers a horizontal area of 540km x 540km. Within this grid is another grid with 3 km node spacing (3:1 increased spatial resolution within the outmost grid) that covers a 180km x 180km region. Within this grid is a second increased resolution grid that covers 60km x 60km. While computations are performed over all grids by necessity to match boundary conditions, output is only stored for the middle grid since it provides sufficient resolution for the web demo.
Post-Processing of Forecast Results
Each forecast output is written as a png file at each time step. Each file is then geo-referenced, that is, selected pixel values in the image must be labeled with a specific latitude/longitude pair. Then each file is geographically re-projected so that it overlays properly on Bing Maps. Lastly, the re-projected file must be divided into a set of smaller image files, or tiles, to support the zoom/pan capabilities of Bing Maps and other AJAX-based web mapping platforms.
These post-processing steps are accomplished with three programs from the GDAL open source geospatial library (www.gdal.org), as follows:
- Gdal_translate:
- Converts file from png to geospatial Tiff (geoTiff) format
- Assigns geo-referencing (“ground control points”) to specified pixel values
- Labels the output (geoTiff) file’s header with map projection information
- Gdalwarp:
- Geographically reprojects the output file from gdal_translate to the map projection of Bing Maps
- Gdal2tiles.py:
- A python script that generates tiles from the output file from gdalwarp
- Zoom levels are specified on the command line
You can find out more details on each of these steps through the detailed logs and “show logs” page we provide for each of the simulation runs.



The Bay Area is scheduled to have five days of constant precip beginning on 11/27/2012, so I’ve started a new forecast.
The Windows Azure Team updated the Windows Azure Compute Service Level Agreement (SLA) on 11/25/2012:
The new SLAs are downloadable in 20 languages, presumably for those locales in which Windows Azure is available for production use.

<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
• Rowan Miller described EF Fixes in Visual Studio 2012 Update 1 in an 11/27/2012 post to the ADO.NET blog:
Visual Studio 2012 Update 1 is now available for download. This update includes three bug fixes for the Entity Framework Designer for Visual Studio 2012.
- Nesting an .edmx file under a project folder would stop the code from being automatically regenerated when you saved changes to the edmx file. This was the highest voted issue on our CodePlex site and is fixed in VS2012 Update 1.
- The changes we made to code generation for models created in the EF Designer in Visual Studio 2012 were causing significantly more virtual memory to be used when working with an EF model in Visual Studio. VS2012 Update 1 includes a fix that reduces virtual memory usage below what it was in Visual Studio 2010. More details about this issue are available on our CodePlex site.
- The EF Designer in VS2012 introduced a new feature that updated facets of entity properties (such as length, precision, etc.) based on the facets of the corresponding database column. This is done to propagate changes the user made to the database to the entities. However, with some database providers, such as Oracle, the discrepancy is intentional and facet propagation was producing invalid models. VS2012 Update 1 disables facet propagation for all providers except SQL Server. More details about this issue are available on our CodePlex site.

Paul van Bladel (@paulbladel) described how to Automatically deploy a LightSwitch-ready hosting website with ability to set the https certificate in an 11/27/2012 post:
Introduction
My previous post covered an end-to-end approach for deploying a Lightswitch-ready application pool. We’ll try in this post to do the same for an hosting website (in which you can deploy a LightSwitch application)
Create a Pre-Template website
Change the standard http binding to port 1 and select a physical path:
Make sure you have a server certificate installed on your IIS which you will use for actual web sites. On the other hand, for this preparation step, we need a dummy certificate (can be a self-signed one).
So, if you consult the certificate window in your IIS, you should have:
Create an https binding and attach the dummyCertificate to the port. The portnumber should be set to 2.
So, this gives:
Export now this site as a server package:
Select as follows:
Save the package to “PreTemplateWebSitePackage” en provide a password when asked.
Massage the pre template website package to a template website package
First create an xml file named “” with following content:
<parameters> <!-- declare parameter for Http Binding --> <parameter name="Site-http" description="Site Http Binding"> <parameterEntry kind="DestinationBinding" scope="Site" match=":1:" /> </parameter> <parameter name="Site-https" description="Site Https Binding"> <parameterEntry kind="DestinationBinding" scope="Site" match=":2:" /> </parameter> <parameter name="Application Pool" description="app pool"> <parameterEntry kind="DeploymentObjectAttribute" scope="appHostConfig" match="application/@applicationPool" /> </parameter> </parameters>Run now following command file (make sure msdeploy is in your path environment settings):
SET PreTemplateWebSitePackage="PreTemplateWebSitePackage.zip" SET TemplateWebSitePackage="TemplateWebSitePackage.zip" SET DeclareParametersFile="DeclareWebSiteParameters.xml" SET WebDeployFullPath="C:\Program Files\IIS\Microsoft Web Deploy V3\" d: cd D:\Deploy\WebSiteManagement %WebDeployFullPath%msdeploy.exe -verb:sync -source:package=%PreTemplateWebSitePackage%,encryptpassword="secret" -dest:package=%TemplateWebSitePackage%,encryptpassword="secret" -declareParamFile:%DeclareParametersFile% pauseOk, we have now our template website package !
Create a new website based on our template package and update also the ssl certificate
Create a new xml file called “WebSiteParameters”
<parameters> <setParameter name="Site-http" value="*:101:"/> <setParameter name="Site-https" value="*:1010:"/> <setParameter name="Application Pool" value="MyNewAppPool"/> </parameters>As you can see, these parameters will update the http en https port and sets the application pool. There is nothing in this parameter file to update the certificate.
Following command will deploy the web site:
SET _siteName="NEWSITE" SET _destinationWebSitePhysicalPath="C:\inetpub\NEWSITE" SET _computeName="localhost" SET TemplateWebSitePackage="TemplateWebSitePackage.zip" SET TemplateWebSitePackage="TemplateWebSitePackage.zip" SET ParametersFile="WebSiteParameters.xml" SET WebDeployFullPath="C:\Program Files\IIS\Microsoft Web Deploy V3\" SET _dummyPassword="secret" SET _httpsSiteCertificate="ee05abbcbb462f1825cdfa39ed37aa96e06687b1" d: cd D:\Deploy\WebSiteManagement %WebDeployFullPath%msdeploy -verb:sync -source:package=%TemplateWebSitePackage%,encryptpassword=%_dummyPassword% -dest:appHostConfig=%_siteName%,computerName=%_computeName% -setParamFile=%ParametersFile% -replace:objectName=virtualDirectory,targetAttributeName=physicalPath,match="^C:\\inetpub\\PreTemplateWebSite",replace=%_destinationWebSitePhysicalPath% -replace:objectName=httpCert,targetAttributeName=hash,replace=%_httpsSiteCertificate%Conclusion
Playing around with ssl certificate is not an issue any longer.









Paul van Bladel (@paulbladel) described how to Automatically deploy a LightSwitch-ready application pool with ability to set the app pool Identity in an 11/27/2012 post:
Introduction
This post elaborates further on my previous post on Integrating hosting web site creation in an automated LightSwitch factory. There were still two important missing pieces:
- setting the application pool identity to a specific windows user
- attaching a server ssl certificate to the ssl port of your hosting LightSwitch website.
This post will focus solely on full-blown application pool deployment. In a next post I will cover the scenario of the ssl certificate. We can functionally separate the application pool deployment and the hosting website deployment. It’s perfectly possible to deploy first a new application pool without prior knowledge about the website. Only, what you probably need when deploying a new website is the name of the newly created application pool and attach it to your new website.
The general approach with webdeploy is:
- create a pre-template package from an existing ‘model’ application pool and massage this package in such a way it is “open for extension”, meaning it can be used with some additional parameters (e.g. the app pool Identity credentials). The massaged pre-template package will be our template application pool package.
- use the template package in all further app pool deployments with specific parameters (from a web deploy script)
Generate a pre-template for an application pool
From the IIS manager, create a new application pool
Call the application pool “PreTemplateAppPool”:
The settings so far, of the application pool, doesn’t really matter, because we will override the values later on based on a parameter file.
Go now to the the advanced settings:
and change the Identity (which is by default an ApplicationPoolIdentity. This should become a “specific user”. Why? The reason is because we connect to our sql server database via integrated security (much safer than using sql server authentication !). This means that our application pool must run under a specific domain account that has access to the sql server database.
So click on Identity and change to Custom Account:
We’ll need here an existing domain account, but the account may be deleted directly after the creation of our template application pool package. Remember, we will override these credentials anyhow in an actual application pool package. But we need this “placeholder” in the application pool manifest because webdeploy is very strong in overriding values, but not in creating values.
Export now the application pool:
Click on Manage components:
And update as follows:
Make sure the path matches the name of our PreTemplateAppPool. Click next – next and provide as package name: PreTemplateAppPoolPackage.zip. Provide also a password (I use here as example: “secret”). You’ll need this password afterwards !
Massage the pre-template application pool package towards a template application pool package.
The result of this step will be our final TemplateAppPoolPackage.zip. This step exists in creating some attached parameters to our pre-template package in such a way we can introduce parameters when doing a real applicatin pool deployment.
First, make an xml file called DeclareAppPoolParameters.xml with following content:
<parameters> <parameter name="managedPipelineMode" description="managedPipelineMode Classic or Integrated" defaultValue="Integrated"> <parameterValidation type = "RegularExpression" validationString = "(Integrated|Classic)"/> <parameterEntry type="DeploymentObjectAttribute" scope="appPoolConfig" match="//@managedPipelineMode" /> </parameter> <parameter name="identityType" description="Application Pool Identity type under which an application pool's worker process runs." defaultValue="NetworkService"> <parameterValidation type = "RegularExpression" validationString = "(NetworkService|SpecificUser)"/> <parameterEntry type="DeploymentObjectAttribute" scope="processModel" match="/processModel/@identityType" /> </parameter> <parameter name="username" description="Domain user name" defaultValue="domain\username"> <parameterValidation type = "RegularExpression" validationString = "(?=^.{8,}$)((?=.*\d)|(?=.*\W+))(?![.\n])(?=.*[A-Z])(?=.*[a-z]).*$"/> <parameterEntry type="DeploymentObjectAttribute" scope="processModel" match="/processModel/@userName" /> </parameter> <parameter name="password" description="Password of the domain user" tags="password" defaultValue="DefaultPassword"> <parameterEntry type="DeploymentObjectAttribute" scope="processModel" match="/processModel/@password" /> </parameter> <parameter name="managedRuntimeVersion" description="managedRuntimeVersion" defaultValue="v4.0"> <parameterValidation kind="RegularExpression" validationString="(v2.0|v4.0)" /> <parameterEntry kind="DeploymentObjectAttribute" scope="appPoolConfig" match="//@managedRuntimeVersion" /> </parameter> </parameters>Run following script over the preTemplate application pool package:
"C:\Program Files\IIS\Microsoft Web Deploy V3\msdeploy.exe" -verb:sync -source:package="D:\Deploy\AppPoolManagement\PreTemplateAppPoolPackage.zip",encryptpassword="secret" -dest:package="D:\Deploy\AppPoolManagement\TemplateAppPoolPackage.zip",encryptpassword="secret" -declareParamFile:"D:\Deploy\AppPoolManagement\DeclareAppPoolParameters.xml" pauseNote that the destination package is the “TemplateAppPoolPackage”, the base for our future application pool deployments ! This package is now “parameter-ready”.
You may also delete now the PreTemplateAppPool from IIS and you may also delete the user account we used as “placeholder” identity in this package.
It’s advised to place the path to the msdeploy version you use (note there is both a 64 and 32 bit version !) into your PATH environment variable of your server.
Deploy an application pool fully automated
Create an new xml file with your application pool specific parameters (call the file AppPoolParameters.xml):
<parameters> <setParameter name="managedPipelineMode" value="Integrated" /> <setParameter name="identityType" value="SpecificUser" /> <setParameter name="username" value="myrealdomain\myrealappPoolUser" /> <setParameter name="password" value="myRealPassword" /> <setParameter name="managedRuntimeVersion" value="v4.0" /> </parameters>For a LightSwitch application:
- the pipeline mode should be “Integrated”;
- the IdentityType should be “SpecificUser”;
- the managedRunTimeVersion should be “v4.0″.
Note that this package is ready for future LightSwitch upgrades, which might run under version 4.5 or higher !
The followiing script will do the deployment (DeployNewAppPool.cmd):
SET TemplateAppPoolPackage="TemplateAppPoolPackage.zip" SET AppPoolName="MyAppPool" SET ComputerName="localhost" SET AppPoolParametersFile="AppPoolParameters.xml" %comspec% /c msdeploy.exe -verb:sync -source:package=%TemplateAppPoolPackage%,encryptpassword="secret" -dest:appPoolConfig=%AppPoolName%,computerName=%ComputerName% -setParamFile=%AppPoolParametersFile% > output.log 2> erroutput.log echo off if %errorlevel%==0 ( echo successfully deployed the app pool ) else ( echo Problem installing the app pool, check the log file ! )You should run this script from the folder where your template package and parameter file is stored !
You can integrate this script in anything you want, errors will be logged in a log file.
Note that the application pool name (in my example “MyNewAppPool”) is not specified as a parameter in the AppPoolParameters.xml but it’s entered in the msdeploy script itself. (I didn’t find a way to incorporate this as a parameter, in fact I think it’s impossible anyhow)
Of course, the application pool name is quite import because this will be the “link” to the website package we’ll create in my next blog post.
So, these are the files needed:
Conclusion
Quite a bit of work to make the initial application pool package, but when it’s up and running, it is a huge time-saver !










Rowan Miller posted Entity Framework Links #2 to the ADO.NET blog on 11/26/2012:
This is the second post in a regular series to recap interesting articles, posts and other happenings in the EF world.
The EF Team is now on Twitter and Facebook, follow us to stay updated on a daily basis.
Our team recently announced the release of EF6 Alpha 1, the first preview of the EF6 release. The announcement post contains a bunch of links to walkthroughs and specifications for the exciting new features. There are some features we plan to include in the final release of EF6 that aren't included in Alpha 1, see the Roadmap page for a complete list of EF6 features.
Brice Lambson started a blog series on using EF with third party databases, so far he has covered SQLite, MySQL and PostgreSQL.
At the //build/ conference, Rowan Miller presented on Building data centric applications for web, desktop and mobile with Entity Framework 5. You can get the source code from the session on his blog.
Julie Lerman blogged about making your way around the Open Source Entity Framework CodePlex Site and about her experience digging in to Multi-Tenant Migrations with EF6 Alpha.
We published some new content to the EF site, including Stored Procedures with Multiple Result Sets, WinForms Data Binding, Entity Splitting with the EF Designer, and Table Splitting with the EF Designer.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
• Yogeeta Kumari Yadav described HOW TO: Set Up a Build Environment in TFS 2010 in an 11/28/2012 post to the Aditi Technologies blog:
Visual Studio Team Foundation Server 2012 (TFS) is a collaboration platform at the core of Microsoft's application lifecycle management (ALM) solution.
Managing source control in a relatively large team is difficult, and a common consequence is that build errors might occur. So, when other team members use the latest version they might end up with build errors.It is a good idea to set up a build system, if you are looking for one or more of the following requirements:
- Team members are not allowed to check-in if the solution is not compiling
- If code analysis issues are not fixed
- Emails can be triggered for those whose check-in broke the build
- Projects alert on check-in/build success/build failure to the team
- Scheduling build to be generated at fixed intervals
Assumption: The person configuring the build system must have admin privileges on the TFS Project.
Configuring the build:
1. Open Visual Studio as Administrator.
2. Connect to Team explorer and select the project for which you want to set up build system.
3. Right click on Builds; New Build Definition.
4. New Build Definition Wizard appears as shown below:
5. Enter the Build Definition Name.
6. Select Trigger option from left side pane. Select the type of build option suitable for your project. For example, if you select Continuous Integration, each check-in will be a build whereas if we set up gated check-in only if changes are building successfully.
7. Now what are the projects that need to be on build? Select process tab from left pane and configure Projects To Build:
You can click on the ellipsis button to browse and add projects to build.
8. Now where this build information will get stored? We need to setup a build drop folder on TFS server. Please contact your TFS administrator to create a drop folder in TFS.
You can specify the drop folder location as shown in snapshot below:
9. Now the TFS is configured. But how will team members learn whether a build has succeeded or not? For this configure email-ids of team members in Project Alerts option.
Team Menu-> Project Alerts
So now the build system is configured. This avoids the overhead of checking history about whose check-in caused the build to fail or if code analysis was done or not, and running test cases again and again with each build. Setting up a build definition also provides options to run all dlls with *tests while generating a build. So if any test case fails, the build will also fail and team members will be notified.









• Magnus Martensson delivered a 01:00:26 Continuous Delivery Zen with Windows Azure presentation to the Windows AzureConf 2012, which Channel9 posted on 11/14/2012 (missed when posted):
Ever felt that you spend more time packing deployments, configuring test environments and deploying the latest build in order to please the testers than you spend writing actual code? Had your flow interrupted by the boss wanting a demo environment set up for a customer demo? Fortunately built into the Windows Azure Platform there is great support for Continuous Delivery of the greatness that you just built. With little work, you can set up automated builds, test runs and deployments so that you may focus on what’s important - your next delivery. If you want full control of your whole process you can use third-party continuous integration options with Windows VMs. Through Power Shell there is support for any scenario. For those who are really brave you can even set up push from your development box via Git to live production environments with no downtime! In this word of high demand for delivery and agility everything that can be automated must be automated. Automate, automate, automate!
Related Resources
David Linthicum (@DavidLinthicum) asserted “The Folded-Arm Gang of IT naysayers can be helped along to adopting cloud computing with two basic steps” in a deck for his How AWS can conquer enterprise IT's resistance to public clouds article of 11/27/2012 for InfoWorld’s Cloud Computing blog:
Amazon Web Services' Reinvent conference this week is sold out -- not surprising, given AWS's strong adoption by small and medium-sized businesses for infrastructure cloud services (IaaS) and its growth in platform services (PaaS).
But as successful as AWS has become, many Global 2000 enterprises still refuse to put their processes and data on the AWS public IaaS cloud. I call them the Folded-Arm Gang: IT staffers in larger companies who quickly point out that AWS, or any public cloud, is not ready for enterprise-cloud computing. The Folded-Arm Gang doesn't consider any public cloud to be reliable, secure, or safe.
To date, only about 30 percent of AWS's business is with larger enterprises. That's the bad news. The good news is that the adoption by Global 2000 enterprises seems to be growing, as big IT moves from testing and deployment of very small workloads to mission-critical processing. Despite the resistance of the Folded-Arm Gang, tight budgets drive much of this movement, along with AWS's ability to prove itself over the last few years, despite a few well-publicized outages.
How can AWS move more big enterprises' processing into its cloud? Based on what I hear from my large enterprise clients, I have two suggestions:
1. Communicate better with IT management. AWS is great at communicating with developers. In fact, it's the best I've seen at doing so. But AWS doesn't communicate well with the enterprise IT leaders who make the big decisions. That IT leadership is the Folded-Arm Gang today, and AWS needs to get those arms unfolded.
2. Create and promote a process to access the true value of a public cloud, as well as a path to get there. For the most part, IT in smaller organizations has flocked to AWS because the technology is good. To get into larger accounts, AWS needs to provide a way to calculate the actual value of using this technology, given that budget factors weigh largely in big enterprise IT strategies.
AWS also needs to provide a clear process for building new systems on AWS and migrating data and applications to AWS. Because the Folded-Arm Gang is so focused on economics and objections, it's less likely to be proactive in finding ways to justify, much less adopt, the public cloud on its own.
Of course, the Cloud Computing blog is meant to advise cloud adopters, not cloud providers. But if cloud providers don't do their part to work with recalcitrant enterprises, the benefit of the cloud won't get the reach it should. If AWS -- or any cloud provider -- learns how to work better with enterprises, then enterprise IT will be more likely to implement vast improvements in its services to the business. That's the endgame -- or should be, even for the Folded-Arm Gang.

![image_thumb11[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjhJN1hS37ZcRIe8GGJQnV_kP4WiFLvv9DecdFQxhx_CjpG_LjwQQZ3y_YfkcUAN1-r90ZLqSZnKNqVXkmZDgEKc46Jh3_GImUncv5ynImCzU3xu-NVrgEV-g_FGjocEsZojBCiQHJb/s1600-h/image_thumb11%25255B1%25255D%25255B11%25255D.png "image_thumb11[1]")
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
BusinessWire reported Apprenda 4.0 Platform as a Service (PaaS) Sets New Model for Enterprise Cloud Computing and Extends Datacenter to Windows Azure in an 11/27/2012 press release:
Apprenda, a private platform-as-a-service (PaaS) for developing, delivering and managing next-generation cloud applications, today launched version 4.0 of its flagship platform.
Apprenda 4.0 will set the model for how to modernize existing mission-critical enterprise applications and build new cloud architected applications and services, extending its leadership in best-of-breed support for Windows-based cloud environments.
Enterprises Extend Datacenter to Windows Azure
Apprenda connects Windows Server 2012 environments with cloud-based Windows Azure resources, achieving a hybrid cloud PaaS approach for enterprises. Windows Azure users can use Apprenda to develop, deploy and manage cloud applications without conflict with private PaaS.
“Windows Azure is a global, scalable cloud platform that gives developers flexibility to target public, private, and hybrid cloud environments,” said Bill Hilf, General Manager, Windows Azure Marketing. “Apprenda helps enterprises utilize Windows Azure’s strengths so that applications can take advantage of public and private PaaS scenarios.”
Single-Click Hybrid Cloud
Apprenda enterprises want hybrid cloud architectures. In 4.0, IT can apply resource policies to infrastructure and applications in seconds, moving them with a simple single-click feature across the boundaries from private to public cloud or can set policies for doing so automatically based on business needs and parameters.
“Hybrid cloud is helping traditional enterprises become more comfortable with Net-based application development,” said James Governor, RedMonk founding analyst. “Organizations want common tooling for deployment, monitoring, security and management across public and private cloud; Apprenda is targeting this deployment flexibility directly with its 4.0 release.”
Enterprises Easily Embrace Mobile, Other App Patterns
As enterprises extend their application portfolios to embrace mobile, multi-tenant and other cloud application types, Apprenda extends its market-leading developer cloud platform for deployment and management with technology that helps keep the focus on product innovation. As a best-of-breed platform for Windows Server and .NET, Apprenda 4.0 adds support for all Windows and Visual Studio integration and extends support for all of Microsoft’s latest releases, including .NET 4.5, SQL Server 2012, and Windows Server 2012.
Developers increase productivity in building next generation cloud architected applications and modernizing existing application portfolio with minimal adjustment to code.
Apprenda 4.0 has best-in-class operation advancements in third-party authorization and authentication systems designed to improve agility in application deployment and deployment policies to implement governance, risk management and compliance (GRC). With new System Center 2012 integration, Apprenda can run across multiple datacenters (private/public/hosted) and yet be managed centrally.
About Apprenda
Apprenda is a platform-as-a-service (PaaS) that transforms how enterprises can develop, deliver and manage next generation applications in a public, private or hybrid cloud environment. Apprenda’s platform makes writing and managing enterprise cloud applications easy and efficient, without compromise. The Apprenda PaaS equips enterprises with the runtime, APIs and tools that allow them to easily build, deploy and manage cloud applications using today’s skillsets and investments. By decoupling applications from infrastructure and developers from IT, Apprenda empowers organizations to achieve significant cost savings and massive productivity improvements that result in better business.

<Return to section navigation list>
Cloud Security and Governance

<Return to section navigation list>
Cloud Computing Events
Himanshu Singh (@himanshuks) reported on 11/26/2012 Windows Azure to Sponsor, Present at MongoSV on 12/4/2012:
Windows Azure is pleased to sponsor MongoSV on December 4th, an annual one-day conference in Silicon Valley, CA dedicated to the open source, non-relational database MongoDB. This year’s conference includes over 50 sessions by 10gen engineers and MongoDB users from companies such as foursquare, Github, Apollo Group (University of Pheonix), AOL, and more.
Over the past three years, the NoSQL movement has been growing at 82% compounded annually. Since the first annual NoSQL Now last year, 10gen has had over 1,000,000 downloads, tripled the size of its employee base and gained additional VC funding to be around $75M in total.
The conference will feature a talk entitled “The Three aaS's of MongoDB in Windows Azure” by Senior Cloud Architect David Makogon, Senior Technical Evangelist Doug Mahugh, and 10gen engineer, Sridhar Nanjundeswaran. The talk will discuss how MongoDB can be deployed to Windows Azure via PaaS or IaaS, as well as the new SaaS option. This session will show all three approaches and compare each.
For more information, check out the agenda or 10gen’s blog post Get Ready for MongoSV. Register now with the Discount code “azure20” and receive 20% off.

Ricardo Villalobos (@ricvilla) suggested on 11/26/2012 Mark your calendars! Windows Azure OSS Summit in Paris, France; December 4th, 2012:
One of the biggest myths about Windows Azure is that it was created with only .NET developers in mind. The reality is that my team has helped multiple companies around the world implement cloud solutions using a variety of programming languages, including Java, PHP, Node.js and Python, among others. Also, it’s not difficult to find architectures taking advantage of multiple database engines, including MongoDB or Cassandra running on Linux distros. In order to share these experiences, and help cloud developers around the world design and implement similar solutions, we have created the Windows Azure OSS summits, with the first one taking place in Paris, France on December 4th, 2012. In case you are around, more information can be found here.
My good friend and colleague David Makogon will be co-presenting with me different topics, including OSS programming techniques, best practices for data storage, and hybrid PaaS – IaaS architectures. Karandeep Anand – Principal Group Manager for Windows Azure – will be delivering the keynote, covering the latest and greatest on our cloud platform.
Stay tuned! a Windows Azure OSS Summit might be coming to a city near you soon.

<Return to section navigation list>
Other Cloud Computing Platforms and Services
• Andy Jassy announced Amazon Redshift, a cloud-based data warehousing service, at about 00:54:20 in his re: Invent conference keynote on 11/28/2012:
View AWS Sr. Vice President Andy Jassy's keynote presentation as we kick off AWS re: Invent with the latest news and innovations of our services. You'll also hear customers and partners share how they're innovating with AWS.

From the keynotes slides captured online:

Excel PowerPivot and SQL Server PowerView are conspicuous by their absence in the above slide.
Following are initial pricing and availability slides:

Jeff Barr (@jeffbarr) described Amazon Redshift - The New AWS Data Warehouse in an 11/28/2012 post:
You may have noticed that we announced Amazon Redshift today – a data warehouse service that is a lot faster, simpler, and less expensive than alternatives available today.
Let's Talk About Data
A data warehouse is a specialized type of relational database, optimized for high-performance analysis and reporting of transactions. It collects current and historical transactional data from many disparate operational systems (manufacturing, finance, sales, shipping, etc.) and pulls it together in one place to guide analysis and decision-making. Without a data warehouse, a business lacks an integrated view of its data. Essential reports aren't available in time, visibility into changes that affect the business is reduced, and business suffers.
To date, setting up, running, and scaling a data warehouse has been complicated and expensive. Maintaining and monitoring all the moving parts (hardware, software, networking, storage) requires deep expertise across a number of disciplines. At scale, even comparatively simple things like loading or backing up data get hard. Getting fast performance requires mastery of complicated query plans, access methods, and indexing techniques. No surprise, traditional data warehouses have been seen as gold-plated, premium-priced products with substantial upfront costs.
Enter Amazon Redshift
Amazon Redshift makes it easy for you setup, run, and scale a data warehouse of your own. AWS customers such as Netflix, JPL, and Flipboard have been testing it as part of a private beta. We are launching Amazon Redshift in a limited public beta mode today.Amazon Redshift is a massively parallel, fully-managed data warehouse service, designed for data sets from hundreds of gigabytes to several petabytes in size, and appropriate for an organization of any size — from a startup to a multi-national — at a price point that will take you by surprise. Amazon Redshift is fully managed, so you no longer need to worry about provisioning hardware, installation, configuration or patching of system or database software, Because your business is dependent on your data, Amazon Redshift takes care to protect it by replicating all data within the cluster as well as in S3.
Amazon Redshift won't break the bank (or your credit card, since it is completely pay-as-you-go). We did the math and found that it would generally cost you between $19,000 and $25,000 per terabyte per year at list prices to build and run a good-sized data warehouse on your own. Amazon Redshift, all-in, will cost you less than $1,000 per terabyte per year. For that price you get all of the benefits that I listed above without any of the operational headaches associated with building and running your own data warehouse.
Like every AWS service, you can create and manipulate an Amazon Redshift cluster using a set of web service APIs. You can create a cluster programmatically, keep it around as long as you need it, and then delete it, all with a couple of calls. Of course, you can also create and manage your Amazon Redshift cluster using the AWS Management Console.
Let's take a deeper look at Amazon Redshift!
Amazon Redshift Architecture
An active instance of Amazon Redshift is called a Data Warehouse Cluster, or just a cluster for short. You can create single node and multi-node clusters. Single node clusters store up to 2 TB of data and are a great way to get started. You can convert a single node cluster to a multi-node cluster as your needs change. Each multi-node cluster must include a Leader Node and two or more Compute Nodes. A Leader Node manages connections, parses queries, builds execution plans, and manages query execution in the Compute Nodes. The Compute Nodes store data, perform computations, and run queries as directed by the Leader Node.Amazon Redshift nodes come in two sizes, the hs1.xlarge and hs1.8xlarge, which hold 2 TB and 16 TB of compressed data, respectively. An Amazon Redshift cluster can have up to 32 hs1.xlarge nodes for up to 64 TB of storage or 100 hs1.8xlarge nodes for up to 1.6 PB of storage. We currently set a maximum cluster size of 40 nodes (640 TB of storage) by default. If you need to store more than 640 TB of data, simply fill out [this form] to request a limit increase. Keep in mind that Amazon Redshift is a column-oriented database and that it is able to compress data to a higher degree than is generally possible with a traditional row-oriented database.
The Leader Node of each cluster is accessible through ODBC and JDBC endpoints, using standard PostgreSQL drivers. The Compute Nodes run on a separate, isolated network and are never accessed directly. Amazon Redshift is ANSI SQL compatible, and should work with your existing BI tools. Jaspersoft and Microstrategy have already certified that it works with their tools, and others will soon follow.
Amazon Redshift is designed to retain data integrity in the face of disk and node failures. The first line of defense consists of two replicated copies of your data, spread out over up to 24 drives on different nodes within your data warehouse cluster. Amazon Redshift monitors the health of the drives and will switch to a replica if a drive fails. It will also move the data to a health drive if possible, or to a fresh node if necessary. All of this happens without any effort on your part, although you may see a slight performance degradation during the re-replication process
Pricing
Like every other part of AWS, Amazon Redshift is priced on a pay-as-you-go basis. You pay only for the resources that you use, and there are no minimums. Billing begins when your cluster is available and you are billed based on the number of Compute Nodes in the cluster. We don’t charge for the leader node, network transfers in or out, and only charge for S3 storage once it exceeds the provisioned size of your cluster. Pricing is below:
Amazon Redshift keeps two copies of each block of data within the cluster, and maintains a free space buffer in case drives fail and their data needs to be re-distributed across the other drives in the cluster. This focus on durability and reliability is the reason for the 3:1 ratio between raw and available disk storage on these instances. The $999 price per terabyte per year mentioned above is based on the 16 TB of available storage.
Getting Started With Amazon Redshift
Here's what you need to do to get started with Amazon Redshift:
- Provision a Cluster
- Download Drivers
- Get a SQL Client
- Load Data
Clusters are provisioned using the AWS Management Console. Clicking the Launch DW Cluster button initiates the provisioning process. Here's the first page:
Once the cluster is up and running, the JDBC and ODBC connection strings are available in the console:
JDBC and ODBC drivers are available from a number of locations. You'll need to find appropriate drivers for your SQL client and operating system and install them. Here are some to get you started:
- ODBC - http://ftp.postgresql.org/pub/odbc/versions/msi/psqlodbc_08_04_0200.zip (psqlODBC installer for Windows).
- JDBC - http://jdbc.postgresql.org/download/postgresql-8.4-703.jdbc4.jar (platform neutral JDBC driver).
You can connect to Amazon Redshift using many different SQL client applications including SQL Workbench.
The final step is to load data. You can bulk load data from Amazon S3 into an Amazon Redshift database with a single command:
copy table_name FROM 's3://your_bucket/your_prefix’ CREDENTIALS ‘aws_access_key_id=your_access_key_id;aws_secret_access_key=your_aws_secret_access_key' gzip emptyasnull blanksasnull maxerror 5 ignoreblanklines;
To take advantage of parallelism, you can split your data into multiple files within the folder and the bulk load command will load the data in parallel into each Compute Node.
Tool Support
A number of vendors are already providing tools that have been tested with Amazon Redshift and they're available in the AWS Marketplace. Here's a sampling of what's there now:
- Vendor1 - ???
- ... - ???
- VendorN - ???
And That's That
As I noted earlier, Amazon Redshift is available in limited preview form. You can apply here if you are interested in participating. As you can tell from what I've written above, this is a rich and powerful product, and I'll have a lot more to say about it in the future. Let me know what you think!





Werner Vogels (@werner) posted Expanding the Cloud – Announcing Amazon Redshift, a Petabyte-scale Data Warehouse Service on 11/28/2012:
Today, we are excited to announce the limited preview of Amazon Redshift, a fast and powerful, fully managed, petabyte-scale data warehouse service in the cloud. Amazon Redshift enables customers to obtain dramatically increased query performance when analyzing datasets ranging in size from hundreds of gigabytes to a petabyte or more, using the same SQL-based business intelligence tools they use today. Customers have been asking us for a data warehouse service for some time now and we’re excited to be able to deliver this to them.
Amazon Redshift uses a variety of innovations to enable customers to rapidly analyze datasets ranging in size from several hundred gigabytes to a petabyte and more. Unlike traditional row-based relational databases, which store data for each row sequentially on disk, Amazon Redshift stores each column sequentially. This means that Redshift performs much less wasted IO than a row-based database because it doesn’t read data from columns it doesn’t need when executing a given query. Also, because similar data are stored sequentially, Amazon Redshift can compress data efficiently, which further reduces the amount of IO it needs to perform to return results.
Amazon Redshift’s architecture and underlying platform are also optimized to deliver high performance for data warehousing workloads. Redshift has a massively parallel processing (MPP) architecture, which enables it to distribute and parallelize queries across multiple low cost nodes. The nodes themselves are designed specifically for data warehousing workloads. They contain large amounts of locally attached storage on multiple spindles and are connected by a minimally oversubscribed 10 Gigabit Ethernet network. This configuration maximizes the amount of throughput between your storage and your CPUs while also ensuring that data transfer between nodes remains extremely fast.
When you provision an Amazon Redshift cluster, you can select from 1 to 100 nodes depending on your storage and performance requirements and easily scale up or down as those requirements change. You have a choice of two node types when provisioning a cluster, an extra large node (XL) with 2TB of compressed storage or an eight extra large (8XL) with 16TB of compressed storage. Amazon Redshift’s MPP architecture makes it easy to resize your cluster to keep pace with your storage and performance requirements. You can start with 2TB of capacity in your data warehouse cluster and easily scale up to a petabyte and more.
Parallelism isn’t just about queries. Amazon Redshift takes it a step further by applying it operations like loads, backups, and restores. For example, when loading data from Amazon S3, you simply issue a SQL copy command with the location of your S3 bucket. Redshift analyzes the contents of your bucket and parallel loads each node simultaneously, taking advantage of the increased bandwidth of multiple connections to S3. If you choose to load your data in a round robin fashion, you’re done. If you choose a hash-partitioning scheme, your data is automatically redistributed to the correct node. Amazon Redshift also extends this parallelism to backups, which are taken from each node and are automated, continuous, and incremental. Restoring a cluster from an S3 backup is also a node-parallel operation. With all of these operations, our goal is to minimize the time you spend performing operations with large data sets.
The result of our focus on performance has been dramatic. Amazon.com’s data warehouse team has been piloting Amazon Redshift and comparing it to their on-premise data warehouse for a range of representative queries against a two billion row data set. They saw speedups ranging from 10x – 150x!
Until now, these levels of performance and scalability were prohibitively expensive. I’m happy to say that this is not how we do things at Amazon. You can get started with a single 2TB Amazon Redshift node for $0.85/hour On-Demand and pay by the hour with no long-term commitments or upfront costs. This works out to $3,723 per terabyte per year. If you have stable, long running workloads, you can take advantage of our three year reserved instance pricing to lower Redshift’s price to under $1,000 per terabyte per year, one tenth the price of most data warehousing solutions available to customers today. In the case of Amazon.com’s data warehouse team, their existing data warehouse is a multi-million dollar system with 32 nodes, 128 CPUs, 4.2TB of RAM, and 1.6PB of disk. They achieved their speedups with an Amazon Redshift cluster with 2 8XL nodes and an effective 3 year reserved instance price of $3.65/hour, or less than $32,000 per year.
In addition to being expensive, self-managed on-premise data warehouses require significant time and resource to administer. Loading, monitoring, tuning, taking backups, and recovering from faults are complex and time-consuming tasks. Amazon Redshift changes this by managing all the work needed to set up, operate, and scale a data warehouse enabling you to focus on analyzing your data and generating business insights.
We designed Amazon Redshift with integration and compatibility in mind. Redshift integrates with Amazon Simple Storage Service (S3) and Amazon DynamoDB, with support for Amazon Relational Database Service (RDS) and Amazon Elastic MapReduce coming soon. You can connect your SQL-based clients or business intelligence tools to Amazon Redshift using standard PostgreSQL drivers over JDBC or ODBC connections. Jaspersoft and MicroStrategy have already certified Amazon Redshift for use with their platforms, with additional business intelligence tools coming soon.
I believe that Amazon Redshift’s combination of performance, price, manageability, and compatibility will make analyzing larger and larger data sets economically justifiable. I look forward to seeing how our customers put this technology to work.
To learn more about Amazon Redshift, visit the AWS blog and sign up for an invitation to the limited preview at http://aws.amazon.com/redshift.


• Saroj Kar reported Google and Tableau Software Partner for the Next Step in (Big) Data Visualization in an 11/27/2012 post:
While the most presentations around big data underlying the processing systems will be deployed in the enterprise, Google built a service that will analyze the cloud of large volumes of data.
Google’s BigQuery service could help companies analyze their data without the need to build infrastructure. The service is designed primarily for use by corporate users and allows analyzing large amounts of data in a cloud environment. Now Google and Tableau Software, the leader of business intelligence provider, announced a partnership to bring together two of the hottest trends in IT – big data and data visualization.
A big data tool is only as good as the data that feeds into it. Business intelligence startup Tableau Software has earned rave reviews for turning data computations into beautiful graphics, but now the company is busy expanding its pool of partners and building “connectors” – technology that enables external data sources like Salesforce.com and Microsoft and Oracle servers to seamlessly plug into its software. Tableau’s direct connection to BigQuery enables users to take advantage of its visualization software with Google Analytics.
It’s all part of Tableau’s strategy of allowing customers to work with their data no matter where it lives. The move means Tableau users will now be able to use its visualization software to interact with data on Google Analytics (used to track website traffic) as well as Google’s BigQuery cloud-based service, which lets businesses run queries on extremely large datasets.
BigQuery’s query performance at scale combined with Tableau’s fast and easy analytics puts powerful visualization and business intelligence directly into the hands of business users. The combination of BigQuery and Tableau enables users to ask complex business questions and get results quickly, in effect allowing them to have an interactive conversation with their data.
This partnership also provides big data users the ability to design Business Discovery solutions by leveraging the computing power and scalability of the Google cloud platform. Thanks to the extended features and custom connector, the solution provides seamless integration with BigQuery. Data processing and calculation are made through Google Compute Engine and big data solutions such as interactive tools and dashboard are processed by Google BigQuery prediction API. This allows users to run queries across multiple data tables even up to billions of rows and terabytes of data.
Related Articles:

Jinesh Varia (@jinman) described how to Enable Single Sign On to the AWS Management Console in an 11/27/2012 post:
AWS Identity and Access Management (IAM) enables you to create and manage IAM users and manage access to your AWS account. Some customers have told us that they prefer leveraging their existing corporate identities to access AWS services and resources via identity federation. Today, we’re making it even easier for you to get started with federation to AWS using a new pre-packaged sample application.
The sample illustrates how customers using Windows Active Directory (AD) can easily configure Single Sign-On (SSO) to the AWS Management Console. Implementing SSO means that your users no longer have to remember yet another password and that you don’t have to manage users and passwords within both AD and AWS. The sample includes a setup wizard to help you get up and running in minutes to try out federation to AWS and includes everything required for you to enable your users to Single Sign-On to the AWS Management Console.
Here’s How It Works
Here's the basic flow of an AD user who wants to access the AWS Management Console:
- User signs on to the corporate network with their AD credentials. The sample creates an internal website that hosts a proxy server. A user browses to that website. The site authenticates the user against AD and displays a set of IAM roles that are determined by the user’s AD group membership.
- The user selects the desired role and clicks on Sign in to AWS Management Console. Behind the scenes, the proxy calls the AWS Security Token Service (STS) to assume the selected role. The response includes temporary security credentials. Using these credentials, the federation proxy constructs a temporary sign-in URL.
- User is redirected to the temporary sign-in URL and is automatically signed in to the AWS Management Console, without being prompted for another username and password. The user is limited to the privileges defined in the role they selected.
By default, the console session will expire after one hour and the console will be inaccessible. This helps protect your AWS account in the case where users mistakenly leave their computers unlocked while signed in to the console. When the session expires the user will be redirected to a page that includes a URL to the site that hosts the federation proxy. Clicking the URL will re-direct the user to the site that hosts the federation proxy so they can re-authenticate.
For additional information and a link to download the sample, please visit the AWS Management Console Federation Proxy Sample download page or attend Jeff Wierer's talk "SEC302: Delegating Access to Your AWS Environment" at AWS re: Invent on Nov 28th - Wednesday 3:25 PM (Venetian, Room 3401A)

![image_thumb11[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEjVBSf22zuH6pHI3WBaQDNwVrJcBko7yXcWhQF3Sgvrgwe_Iazgi49ESl1hk1cSsutyzNN1pWXgoZLfPMewEmQzhmGc45nDnebz7oP9SVAFYqCYsBw6AWT31tdNmIEqWpNeJ0pr_ssz/s1600-h/image_thumb11%25255B1%25255D%25255B7%25255D.png "image_thumb11[1]")

Brandon Butler (@BButlerNWW) asserted “Google rolls out major expansion of cloud compute and storage options in Europe; drops compute prices by 5%, storage prices by 20%” in a deck for his Google offers 10 times as many cloud computing options, plus drops prices story of 11/26/2012 for NetworkWorld:
Google on Monday announced a significant ramp-up of its infrastructure as a service (IaaS) cloud offering, upping the number of virtual machine sizes available on its platform across the United States and Europe from four to 40.
In addition to the new instance types, the company trimmed the price of its Google Compute Engine service by about 5% and reduced the price of its Google Cloud Storage by 20%. In a blog post, the company also launched a beta program that provides "reduced availability" storage to customers for up to 30% off, but without a service-level agreement (SLA).
DEAL OR NO DEAL? Google says press release reporting acquisition is false
The moves signal something of a race to the bottom for cloud providers seeking to offer the lowest cost and widest breadth of cloud services and instance types for customers. Amazon Web Services, for example, last month announced the 21st price reduction for its IaaS cloud products since the company launched its service in 2006. AWS is continuing its geographic expansion as well, having recently added an Australian region on top of its cloud services that are already available in Europe, South America and both the East and West coasts of the United States.
WHO'S WHO: Gartner's Magic Quadrant shakes down the IaaS cloud market
FREE CLOUDS! 12 free cloud storage options
Google has been slowly but surely rounding out its cloud strategy over the past year. The company originally launched a platform as a service (PaaS) application development platform named Google App Engine, but added IaaS offering pay-as-you-go compute and storage options earlier this year.
Microsoft has taken the same path with its Azure offering, which was originally released as a PaaS and later added an IaaS component.
Today's announcement is the first significant expansion of Google's IaaS product, with the newest instance types including high-memory, high CPU and diskless configurations.
Instance types of Google Compute Engine (GCE) now range from the smallest single virtual core with 3.75GB of memory and 420GB of local disk price for $0.138 per hour in the U.S., to an eight virtual core instance that includes 30GB of memory and up to 2x 1770GB of local disk space, or a diskless option rising to a cost of $1.104 per hour. Google also dropped the price of its original four instance types by 5%.
In addition to the new GCE instance types, the company announced a price reduction of 20% for Google Storage. Object storage in Google's cloud is now $0.095 per GB up to 1TB, then $0.085 per GB up to 9TB, and the price continues to fall as additional storage is placed in the cloud. Ingress of data is free, but egress starts at $0.12 per GB for 1TB.
By comparison, Amazon Web Service's compute instance types start at $0.065 per hour for a 1.7GB memory and 160GB instant storage Linux-based single-core virtual machine, and range up to a high input/output 16 virtual core instance type with two SSD-backed 1024GB instant storage and 60.5GB of memory for $3.10 per hour. …


![image_thumb11[1]](https://blogger.googleusercontent.com/img/b/R29vZ2xl/AVvXsEj5zOSQcBFFavcsgBYsw5Ilyc8YRgyNJMMA1VMNwRNwCWnuSu47HXJOsQ2IzJ0gHA4sfrm7tUffr3P_merZTcNIyHFKuczOMiX2svBySEYsPVB8mGTeDfh19pWWc5vl_IXc726K-u0V/s1600-h/image_thumb11%25255B1%25255D%25255B3%25255D.png "image_thumb11[1]")
<Return to section navigation list>


















0 comments:
Post a Comment