Windows Azure and Cloud Computing Posts for 2/22/2011+
 | A compendium of Windows Azure, Windows Azure Platform Appliance, SQL Azure Database, AppFabric and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Azure Blob, Drive, Table and Queue Services
- SQL Azure Database and Reporting
- Marketplace DataMarket and OData
- Windows Azure AppFabric: Access Control and Service Bus
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch
- Windows Azure Infrastructure
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
To use the above links, first click the post’s title to display the single article you want to navigate.
Azure Blob, Drive, Table and Queue Services
Paolo Salvatori described Exploring Windows Azure Storage APIs By Building a Storage Explorer Application in a 2/21/2011 post:
Introduction
The Windows Azure platform provides storage services for different kinds of persistent and transient data:
- Unstructured binary and text data
- Binary and text messages
- Structured data
In order to support these categories of data, Windows Azure offer three different types of storage services: Blobs, Queues, and Tables.
The following table illustrates the main characteristics and differences among the storage types supplied by the Windows Azure platform.
Storage Type URL schema Maximum Size Recommended Usage Blob http://[StorageAccount].blob.core.windows.net/[ContainerName]/[BlobName] 200 GB for a Block Blob.
1 TB for a Page BlobStoring large binary and text files Queue http://[StorageAccount].queue.core.windows.net/[QueueName]
8 KB Reliable, persistent messaging between on premises and cloud application.
Small binary and text messagesTable http://[StorageAccount].table.core.windows.net/[TableName]?$filter=[Query] No limit on the size of tables.
Entity size cannot exceed 1 MB.Queryable structured entities composed of multiple properties.
Storage services expose a RESTful interface that provides seamless access to a large and heterogeneous class of client applications running on premises or in the cloud. Consumer applications can be implemented using different Microsoft, third party and open source technologies:
- .NET Framework: .NET applications running on premises or in the cloud applications can access Windows Azure Storage Services by using the classes contained in the Windows Azure Storage Client Library Class Library contained in the Windows Azure SDK.
- Java: the Windows Azure SDK for Java gives developers a speed dial to leverage Windows Azure Storage services. This SDK is used in the Windows Azure Tools for Eclipse project to develop the Windows Azure Explorer feature. In addition, the AppFabric SDK for Java facilitates cross platform development between Java projects and the Windows Azure AppFabric using the service bus and access control.
- PHP: the Windows Azure SDK for PHP enables PHP developers to take advantage of the Windows Azure Storage Services.
The following section provides basic information on Storage Services. For more information on Storage Services, see the following articles:
- “About the Storage Services API” on MSDN.
- “Using the Windows Azure Storage Services” on MSDN.
- “Understanding Data Storage Offerings on the Windows Azure Platform” on TechNet.
Blob Service
The Blob service provides storage for entities, such as binary files and text files. The REST API for the Blob service exposes two resources: Containers and Blobs. A container can be seen as folder containing multiple files, whereas a blob can be considered as a file belonging to a specific container. The Blob service defines two types of blobs:
Block Blobs: this type of storage is optimized for streaming access.
Page Blobs: this type of storage is instead optimized for random read/write operations and provide the ability to write to a range of bytes in a blob.
Containers and blobs support user-defined metadata in the form of name-value pairs specified as headers on a request operation. Using the REST API for the Blob service, developers can create a hierarchical namespace similar to a file system. Blob names may encode a hierarchy by using a configurable path separator. For example, the blob names MyGroup/MyBlob1 and MyGroup/MyBlob2 imply a virtual level of organization for blobs. The enumeration operation for blobs supports traversing the virtual hierarchy in a manner similar to that of a file system, so that you can return a set of blobs that are organized beneath a group. For example, you can enumerate all blobs organized under MyGroup/.
Block Blobs can be created in one of two ways. Block blobs less than or equal to 64 MB in size can be uploaded by calling the Put Blob operation. Block blobs larger than 64 MB must be uploaded as a set of blocks, each of which must be less than or equal to 4 MB in size. A set of successfully uploaded blocks can be assembled in a specified order into a single contiguous blob by calling Put Block List. The maximum size currently supported for a block blob is 200 GB.
Page blobs can be created and initialized with a maximum size by invoking the Put Blob operation. To write contents to a page blob, you can call the Put Page operation. The maximum size currently supported for a page blob is 1 TB.
Blobs support conditional update operations that may be useful for concurrency control and efficient uploading. For more information about the Blob service, see the following topics:
“Understanding Block Blobs and Page Blobs” on MSDN.
"Blob Service Concepts" on MSDN.
“Blob Service API” on MSDN.
“Windows Azure Storage Client Library” on MSDN.
Queue Service
The Queue service provides reliable, persistent messaging between on premises and cloud applications and among different roles of the same Window Azure application. The REST API for the Queue service exposes two types of entities: Queues and Messages. Queues support user-defined metadata in the form of name-value pairs specified as headers on a request operation. Each storage account may have an unlimited number of message queues identified by a unique name within the account. Each message queue may contain an unlimited number of messages. The maximum size for a message is limited to 8 KB. When a message is read from the queue, the consumer is expected to process the message and then delete it. After the message is read, it is made invisible to other consumers for a specified interval. If the message has not yet been deleted at the time the interval expires, its visibility is restored, so that another consumer may process it. For more information about the Queue service, see the following topics:
“Queue Service Concepts” on MSDN.
“Queue Service API” on MSDN.
“Windows Azure Storage Client Library” on MSDN.
Table Service
The Table service provides structured storage in the form of tables. The Table service supports a REST API that is compliant with the WCF Data Services REST API. Developers can use the .NET Client Library for WCF Data Services to access the Table service. Within a storage account, a developer can create one or multiple tables. Each table must be identified by a unique name within the storage account. Tables store data as entities. An entity is a collection of named properties and associated values. Tables are partitioned to support load balancing across storage nodes.
Each table has as its first property a partition key that specifies the partition an entity belongs to. The second property is a row key that identifies an entity within a given partition. The combination of the partition key and the row key forms a primary key that identifies each entity uniquely within the table. In any case, tables should be seen more as a .NET Dictionary object rather than a table in a relation database.In fact, each table is independent of each other and the Table service does not provide join capabilities across multiple tables. If you need a full-fledged relational database in the cloud, you should definitely consider adopting SQL Azure.
Another characteristic that differentiates the table service from a table of a traditional database is that the Table service does not enforce any schema. In other words, entities in the same table are not enforced to expose the same set of properties. However, developers can choose to implement and enforce a schema for individual tables when they implement their solution. For more information about the Table service, see the following topics:
“Table Service Concepts” on MSDN.
“Table Service API” on MSDN.
“Windows Azure Storage Client Library” on MSDN.
"Understanding the Table Service Data Model" on MSDN.
“Querying Tables and Entities” on MSDN.
“Client Applications of ADO.NET Data Services” on MSDN.
Solution
After a slightly long-winded but necessary introduction, we are now ready to dive into some code! When I started to approach Windows Azure and Storage Services in particular, I searched on the internet for some good references, prescriptive guidelines, samples, hands-on-labs and tools. At the end of this article you can find a list of the most interesting resources I found. During my research, I also ran into a couple of interesting tools for managing data on a Windows Azure storage account. In particular, one of them excited my curiosity, the Azure Storage Explorer by Neudesic available for free on CodePlex. Since the only way to truly learn a new technology is using it for solving a real problem, I decided to jump in the mud and create a Windows Forms application to handle Windows Azure Storage Services: Blobs, Queues and Tables. The following picture illustrates the architecture of the application:
Let’s dive into the code. I started creating a helper library called CloudStorageHelper that wraps and extends the functionality supplied by the classes contained in the Windows Azure Storage Client Library. Indeed, there are many samples of such libraries on the internet. For example, on the Windows Azure Code Samples project page on CodePlex you can download a sample client library that provides .NET wrapper classes for REST API operations for Blob, Queue, and Table Storage. …

Paolo continues with the details of his Storage Explorer application.
Doug Rehnstrom posted Windows Azure Training Series – Writing to Blob Storage to the Learning Tree blog on 2/21/2011:
My last couple posts covered the basics of Azure storage. See, Windows Azure Training Series – Understanding Azure Storage and Windows Azure Training Series – Creating an Azure Storage Account. Now let’s write some code.
Accessing Blob Storage
private static CloudBlobClient cloudBlobClient{ get { CloudStorageAccount cloudStorageAccount = CloudStorageAccount.FromConfigurationSetting("DataConnectionString"); return cloudStorageAccount.CreateCloudBlobClient(); } }Creating a Blob Container
Before we can write a blob, we need to create a container for it. It’s just 2 lines of code as shown below. The “containerName” variable is just a string, which represents the name of the container. A container is like a folder on a hard disk.
CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); container.CreateIfNotExist();Uploading Blobs to Containers
The following function writes a file to a blob container. Files can be uploaded using an html file upload control. Notice, you need to first get a reference to the container, and then use the UploadFromStream() method to write the file.
public static void CreateBlob(string containerName, HttpFileCollection files) { CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); foreach (string name in files) { var file = files[name]; string blobName = System.IO.Path.GetFileName(file.FileName); CloudBlob cloudBlob = container.GetBlobReference(blobName); cloudBlob.Metadata["rightanswer"] = file.FileName; cloudBlob.UploadFromStream(file.InputStream); } }Listing the Files in a Blob Container
The following code will list all the files in a container specified.
CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); return container.ListBlobs().ToList();Accessing Blobs
The following code can be used to access a blob. In this case, the first blob in the container specified.
CloudBlob blob; var blobs = cloudBlobClient.GetContainerReference(containerName).ToList(); blob = blobs[0] as CloudBlob;Or, we can access a blob by its name as shown below.
CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); CloudBlob cloudBlob = container.GetBlobReference(blobName);Deleting Blobs
The following code can be used to delete a blob.
CloudBlobContainer container = cloudBlobClient.GetContainerReference(containerName); CloudBlob cloudBlob = container.GetBlobReference(blobName); cloudBlob.Delete();In the next post, we’ll take a look at the code required to write to Windows Azure Table storage.
<Return to section navigation list>
SQL Azure Database and Reporting
No significant articles today.
<Return to section navigation list>
MarketPlace DataMarket and OData
Marcelo Lopez Ruiz described the Design style for OData in datajs in a 2/21/2011 post:
The datajs source code is out there for the world to see. Today I wanted to share a bit about what style we use and why we decided upon it.
After years of writing for the .NET framework, one of my first impulses is to start thinking in terms of objects. However there are a few variations on how you deal with objects in JavaScript and what object-oriented features you decide to leverage. There are no shortage of writings on emulating classical inheritance, supporting C++-style mix-ins, modeling interfaces, using prototypal inheritance, and how to control visibility of variables and object members.
If you found any of the above perplexing, you could do worse than start with Douglas Crockford's site.
To keep in line with our principles, we decided that we didn't want to introduce more complexity than was warranted. The OData support currently implemented in datajs is essentially a communication layer: requests with packets of data go in, and requests with packets of data come out. There are really very few things that need to be modeled as objects, and those are all internal details or advanced extensibility points (like customizing the httpClient layer).
As such, we decided to simply have a good definition for what the packets of data should look like (entries, feeds, etc.), modeled largely after the JSON format that goes on the wire (so it's easy to correlate what Fiddler for example shows with what you have in memory). Then there are a couple of functions to read and write them, and off you go - the entire protocol is now accessible to you in all its goodness, with a uniform, simple interface, and a minimal number of concepts to learn.
As we take on additional areas in the future, we may introduce more object-oriented features, but rest assured that whenever possible, we'd rather design out complexity rather than introduce it and having to solve it.
<Return to section navigation list>
Windows Azure AppFabric: Access Control and Service Bus
Vittorio Bertocci (@vibronet) rhapsodized about Archaeopteryx (an extinct bird species of the Jurassic age) and the demise of CardSpace 2.0 in a 2/21/2011 post:
The archaeopteryx roamed the south of Germany in the late Jurassic. It is considered the very first bird species, although many of its features (teeth, wing claws, bony tail) are clearly still dinosaur-like rather than avian. It had the first ever-recorded asymmetric wing feathers, one key characteristic which helps the lift in the flap of modern birds: however the asymmetry was not yet very pronounced, making flight possible but difficult.
Archaeopteryx has gone extinct 150 million years ago: however it would be foolish to bring that as proof that the body plan of birds is a failure. Birds developed and refined the ideas first appeared in archaeopteryx to their full potential, becoming in the process one of the most successful animal classes on the planet.
If you’ve been following the news in identityland, you already know where I’m going with my little paleontological detour.
Last week we announced that CardSpace 2.0 won’t ship. Predictably, the announcement triggered a wide range of reactions in twitter and the blogoshere. I’ve been asked why I didn’t chime in yet, as the lead author of the book on CardSpace: the easy answer is that I did, as I wrote part of the announcement; the longer one is that last week I was tied up for our biannual internal conference and didn’t have time to sit down and give this the time and attention it deserves. Now I finally found the time. Heck, I even did a (digital) painting for the occasion
More than any other time, please remember this blog’s disclaimer: I am not an official Microsoft spokesperson on this blog, those are my opinions and mine alone.
Why I Produced Less and Less Content for CardSpace
The reasons for which CardSpace 2.0 won’t ship are in the announcement, and there’s not much to add that would not be speculation or 20/20 hindsight: I have my opinions like everybody, of course, but it would not be especially productive (or concise) to list them here. The main thing I can factually report on is why you’ve seen less and less CardSpace content on this blog, and why it never made it in the training kit, in the pre-SaaS version of FabrikamShipping, in FabrikamShipping SaaS and so on. Remember, I have a very specific audience: developers.
When I moved from Italy to Redmond, my first mission was evangelizing the “server side” of WinFx (remember? WCF, WF, CardSpace) for enterprises. At the time I already did a lot of SOA and web services, including ws-trust, and I was very familiar with authentication and authorization issues. As I read about CardSpace, I was absolutely awestruck by the elegance of claims-based identity, the natural way in which it the laws of identity integrated the human factor to the underlying architectural principles, and its enormous potential: I started thinking more and more about it, and wanted everybody to know about the identity metasystem and how it could finally give a both correct and sustainable solution to many identity woes. I blogged, delivered sessions, met customers, wrote samples and even a book. For more paleo, here there’s my first Channel9 appearance from that period.
All that really worked well at the architectural level, where the shift in perspective yielded immediate results in term of rationalizing solution architectures. Moving to the next level, however, proved difficult. I wrestled for the longest time with the lack of tools for issuing tokens for IPs and consuming them for RPs that would preserve the abstraction, without drowning the developer in the details of the protocols we were trying to meta away. Raise your hand if you went through the SimpleSTS.cs and TokenProcessor.cs at least once! Those samples were great for showing the scenarios in action rather than hand waving or whiteboarding them, but going in production was another matter. Writing robust protocol and security code is not for everybody, and the grind it required was in stark contrast with the simple elegance of the high-level idea. Every customer was interested in the idea, but moving to the next level nearly always stumbled on that. So at the time I blamed the lack of tools for the slow adoption.
Nonetheless, I kept posting samples using CardSpace, interleaved with abstract claims posts, and once we got the first tools in Zermatt (the proto-WIF) out I pushed and pushed (walkthroughs, CardSpace-ready VS template, etc). At PDC 2008 we finally announced our more comprehensive initiative, Geneva, and from that moment on the interest in claims accelerated like crazy.
I kept writing about CardSpace, but people were more and more using the new tools for implementing claims-based identity in card-less scenarios. When I had to prioritize the scenarios to cover in the first release ever of the identity training kit, planned for the release of the beta2 of Geneva, I just had to face it: the requests for guidance where overwhelmingly about passive single-sign on, authorization and customization, delegation and similar but not about cards. I had a limited amount of labs I could produce, hence no card-related lab made the cut. And it never made it for all the subsequent content. The tools were there, but developers were simply (more) interested in something else.
As of today, in my experience the scenarios that developers want the most are around single sign-on, be it on-premises or in the cloud: expecting the identity of the caller to be inferred from the context is pretty much the opposite than putting the user in charge of which persona he/she wants to be, which claims should be disclosed and so on. Yes, home realm discovery remains a problem, and CardSpace offered a great solution for it: but as soon as people heard that it required a client component, they moved on.
I am far too invested in the idea to be impartial about CardSpace not shipping. But I have to admit that if even for my deliverables, very small when compared to product development and multi-year support commitments, I had at a certain point to start cutting its presence, then I must accept that data-driven decisions must sometimes contrast with my opinions and expectations. Innovation can be proposed and even promoted, but not shoved down the throat.
CardSpace 2.0 Won’t Ship: Your Argument is Invalid
As mentioned, I’ve seen a lot of commentary in Twitter and blogs on this. Many posted measured and thoughtful blogs or tweets. Some other… well, I am not sure if they were deliberate attempts at demagogy (FUD) or if the tendency to linkbaiting/easy headlines finally atrophied the collective modus ponens muscle. Instead of going after specific examples, anyway, let me take a positive attitude here and stress few key points. You do remember what I mentioned about the whole thing being 100% my personal opinion, right?
Three years ago I wrote the first 165 pages of Understanding CardSpace, the ones describing the problems with traditional identity management and exploring the identity metasystem in details. I stand behind those pages today: they could have easily appeared in my latest Programming Windows Identity Foundation book, as the issues we deal with and the intellectual tools we use in claims based identity remain the same, CardSpace or not CardSpace.
Have you been at some Microsoft technology conference lately? Claims are everywhere, in keynote demos and numerous, all-times-popular sessions (you can thank SharePoint for the last one), in more and more products and services. For me it’s a joy to look at those full rooms, see people from the community using WIF for solving their problems in new ways, and many other similar things that were science fiction at the times of SimpleSTS.cs. Claims based identity is an incredible success, and it is still growing at crazy pace.Wait, that? Does that mean that the Selector was useless after all? Far from it. In my opinion, the above just means that the current claims uptake is mainly taking place in the business world. In the business world the user tends to carry a strong context which can disambiguate a lot of situations, and in general many decisions are taken in advance by the administrators: the tendency is precisely toward guiding and constraining the user on predetermined paths, rather than granting him/her more control over how their identity(ies) flows. Note, I am not passing any judgment about if that’s ethic or not, just stating things I’ve observed.
Now, that doesn’t mean that a Selector is useless in business context? Again, no. There are still many complicated problems we don’t have a good solution for, that a selector would indeed solve: from the home realm discovery (with cards is pretty trivial) to offering an authentication experience for rich clients calling web services (today’s solution of popping up or hosting a browser are less than clean, if you ask me). That just means that the problems being tackled now are perceived as more urgent than those ones, but the matter is not solved: just delayed.
For the non-business word, what should I say? The “today’s youngsters don’t care about privacy, look at pleaserobme.com, etc” is now pretty trite, hence I won’t inflict it to you: but it is true that people seem content with oversharing and living behind few walled gardens, even if often the way in which their identity information is handled is lax to say the least. If you don’t care about security, an antivirus warning you that a website contains malware is just an annoyance; if you don’t care of controlling with whom your identity is shared with and to which extent, a selector is just a burden.
And yet, and yet… all that oversharing notwithstanding, people DO care about what happens to their identity after all: simply put, they usually realize it when it is too late (job lost, broken relationships, and so on). I think that many of the identity issues we observe today would simply not take place if only users were more aware of what Sherry Turkles calls their mixed self, or better the various facets of it. A selector would help people to develop an awareness of who they are online, and with it it would come more awareness and control about who can see what. A selector would also help with many of the issues that are being reported about OpenID lately, such as helping users to remember which identity they used for signing up with a certain service.
Today’s majority of approaches come from the web: but reality is that certain problems are just too complicated without being able to enlist the client as active part of the solution. Unfortunately seeing this requires to walk down from the current local maxima before being able to climb to the next, taller one; but once again, innovation cannot be shoved down anybody’s throat. In any case, I am pretty sure that the time for a selector will come; it may not look like our idea of it today, but it will come.
Correlation is Not Causation, Especially When It’s Not Even Correlation
Let me summarize my main point here, in case it got lost in my hopeless logorrhea.
The fact that CardSpace is no longer shipping does not diminish in any way the power of claims-based identity, much like the fact that you won’t spot archaeopteryx during a hike doesn’t mean that those feather thingies weren’t such a great idea after all.
But oh, what a magnificent view it must have been.

<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Avkash Chauhan described Handling "An unexpected error occurred: Server operation did not finish within user specified timeout '90' seconds.." with CSUPLOAD in Windows Azure VM Role in a 2/22/2011 post:
When you try to upload a VHD using CSUPLOAD tool, it is possible you may receive the following error:
"An unexpected error occurred: Server operation did not finish within user specified timeout '90' seconds, check if operation is valid or try increasing the timeout."
Here are a few suggestions to solve this problem:
- Try again later with the same command that was used before and it is possible the CSUPLOAD recognized the previously uploaded blob, and committed the VHD immediately. This will take a few minutes and your VHD will be ready to use.
- There is also another solution which requires a little configuration change and re upload of the same VHD:
Edit csupload.exe.config which is located in the same folder as csupload.exe exactly in C:\program files\windows azure sdk\v1.3\bin
Try chaning the uploadBlockSizeInKb to a smaller value than the default 1024 and also reduce the “maxUploadThreads” value to “1” or lower then default 8 as below:
<csupload
uploadBlockSizeInKb="1024" ç* Change it to 512KB or 768KB
maxUploadThreads="8" ç change this value to 1 (or try with lower values then 8)
ignoreServerCertificateErrors="false"
maxVHDMountedSizeInMB="66560"
/>
In some cases the above steps solved the problem.
* As I recall, “ç” (c-cedilla) is “j” in Turkish, but I don’t know what Chauhan had in mind for its use above.
Lai Hoong Fai’s Extending Your On-Premises Apps with the Windows Azure Platform Cloud Power presentation slide deck (*.pdf) covers the Windows Azure Virtual Network, SQL Azure Data Sync and Windows App Fabric’s Service Bus and Access control:

Lai Hoong Fai is Web & Cloud Strategy Lead, Microsoft Malaysia
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
The Windows Azure Team posted Announcing NEW Windows Azure Platform Introductory Special - Includes 750 Free Hours of Windows Azure Extra-Small Instance and More on 2/22/2011:
Recognizing all the doors that the cloud opens for the developer community, we continue to look for ways to make it even easier to get started. For those developers who have yet to experience what it's like to build and deploy applications on the Windows Azure platform, we're unveiling a new Introductory Special offer as part of the Cloud Power campaign.
The upgraded Introductory Special offer now includes 750 free hours of the Windows Azure extra-small instance, 25 hours of the Windows Azure small instance and more, until June 30, 2011. This extended free trial will allow developers to try out the Windows Azure platform without the need for up-front investment costs.
To see full details of the new Introductory Special and to sign up, please click here. To see a list of all offers, please visit the offers page.
It’s not that NEW! I wrote a How much are free cloud computing services worth? tip for SearchCloudComputing.com, which published on 2/8/2011 and included details of the Cloud Essentials Pack. The introductory offer is quite similar to the Cloud Essentials pack; here’s one of my tables from the tip:

Perhaps what’s new is that the new offer isn’t restricted to Microsoft Partners, expires on 6/30/2011, has only 500 MB of storage, 10,000 storage transactions, and the SQL Azure database benefit expires in 90 days.
Matthew Weiberger offered on 2/22/2011 a third-party view in a Microsoft And Dell Team Up For Small Hospital SaaS post to the TalkinCloud blog:
Microsoft and Dell have announced a partnership to deliver analytics, business intelligence (BI), informatics, and performance improvement solutions to small community hospitals by way of the cloud. Microsoft is providing the software platform and Dell is handling the delivery, infrastructure, and — most relevantly for TalkinCloud readers — the implementation and delivery. The upshot: Channel partners in the health care vertical could start seeing Dell Consulting more frequently.
The solution itself, built on the Microsoft Amalga enterprise health intelligence platform, is designed to give even the smallest hospitals with modest IT budgets and staff an easy and affordable way to manage the quality of patient care. The initial application, the so-called Quality Indicator System, or QIS, aims to alert medical staff when compliance with quality-of-care measures isn’t being met. But Microsoft says the offering will expand as the solution matures.
If it’s successful, the combined Microsoft/Dell solution could lead to some impressive wins in the hospital space. But with Dell providing the professional consulting services to help with deployment, TalkinCloud is wondering where the channel fits in.
Follow Talkin’ Cloud via RSS, Facebook and Twitter. Sign up for Talkin’ Cloud’s Weekly Newsletter, Webcasts and Resource Center. Read our editorial disclosures here.
Read More About This Topic
No significant articles today.
<Return to section navigation list>
Visual Studio LightSwitch
Edu Lorenzo described Customizing some Lightswitch Application items in a 2/21/2011 post:
Just recently, I tried creating a small app using Visual Studio Lightswitch and found a few items I wanted to edit to make the app a bit more presentable. And there is a nice thing I noticed too..
This is how my app currently looks like..
Notice how a lot of the items I highlighted look.. well.. stupid?
Well it’s a good thing that the LightSwitch application that we made, allows us to customize the screen using a.. ahhmm.. “Customize Screen” button.. duh!
And clicking that button, takes the application to a customization mode where we can change headers, labels and other on-screen items.
So I go ahead and click on that, edit my screen and here is what it looks like afterwards.
Notice the difference in the labels?
Now here is a cool thing.. if you edit the form in the Customize Screen mode.. save.. then close the app.. it goes back to your designer right? Now see what hitting Ctrl-Z can do.. nice eh?



John Rivard and Steve Aronsen co-authored Inside Visual Studio LightSwitch for the March/April 2011 issue of CoDe Magazine:

Microsoft Visual Studio LightSwitch uses a model-centric architecture for defining, building, and executing a 3-tier LightSwitch application.
A model-centric architecture uses models to describe the structure and semantics of an end-to-end application. The applications that you build with LightSwitch have a traditional N-tier architecture.
In this article we discuss the LightSwitch model-centric approach and the main elements of a LightSwitch model. We’ll also look at the runtime architecture tiers (presentation, service, and data) and how they relate to the model.
Model-centric Architecture
Models sit at the center of the LightSwitch design time and runtime architecture. We will discuss several elements of the LightSwitch model-centric architecture: building blocks, models, designers, runtime, APIs and extensions.
Building blocks are the core concepts or vocabulary used to describe an application. Some of the LightSwitch building blocks include:
- EntityType and Query: describes the shape of data and queries against that data. Example of entity types are Customer, PurchaseOrder and ExchangeRate. Examples of queries are SalesByMonth and ActiveCustomers.
- Screen and Control: describes a screen, the controls it contains and its visual layout. Examples of screens are CustomerScreen and OrderEntry.
Building blocks have relationships to each other as well, with, for example, screens binding to queries that return entities.
Creating a project in LightSwitch creates a model, which contains a description of the application in terms of building blocks. The developer uses LightSwitch to create a model containing screens, entities, queries and so forth that describe the application.
Thus models are the core construct used to build applications, not code. The LightSwitch development environment contains a set of designers that know how to create models according to the building blocks, such as the screen, query and entity designers. Thus we see that many of the building blocks are top-level concepts in the LightSwitch development environment, while others are created on the developer’s behalf.
Models are just data without a runtime to give them behavior. The LightSwitch runtime loads the application, authorizes access, renders screens, retrieves data, runs business logic and many other tasks. It reads the model to perform many functions. The LightSwitch runtime does most of its work by employing many other Microsoft technologies that are integrated together according to best architectural practices for building business applications. These include Silverlight for rendering and client logic, WCF for communications, ADO.NET Entity Framework for data access, ASP.NET for authentication and diagnostics and much more. This integrated set of functionality is one of the greatest benefits of the tool: selecting the right technologies for the job and combining them effectively takes a lot of time and expertise.
While much can be done declaratively through modeling, coding is still important and LightSwitch provides APIs to do so. They can be divided into two kinds. The first are APIs for interacting with the runtime, such as to read or write data. The API also includes classes that are generated from model elements. For example, a Customer class is generated from a Customer entity, enabling business logic to be written against the Customer class. The runtime raises numerous events where business logic can be written.
The runtime also provides numerous extension points, enabling the addition of new controls, data types, visual themes, screen templates and more.
LightSwitch Application Model
When you use LightSwitch to create a model, you’ll see top-level concepts in the designer like Data Sources and Screens. These concepts are grounded in the LightSwitch building blocks. Some of the building blocks are concrete and have direct expression in the design environment such as a screen. Some of the building blocks are more abstract and used only under-the-hood.
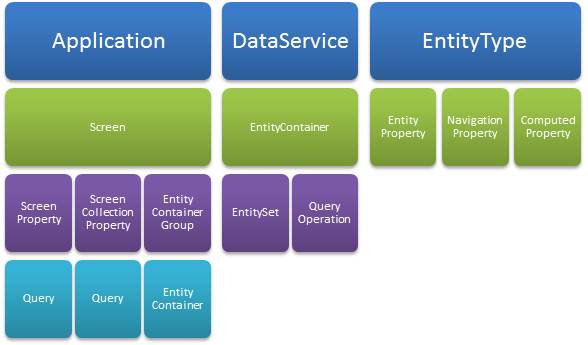
Figure 1 shows some of the major LightSwitch building blocks.
Figure 1: Major LightSwitch building blocks.
The Application building block refers to the client, which is composed primarily of Screens. A screen has properties that describe the data that the screen works with. There are simple ScreenProperties and ScreenCollectionProperties that hold lists of entities. A screen property can be initialized from a Query.
A Screen has access to all of the data sources in the application via an EntityContainerGroup, referred to at runtime as the DataWorkspace, which comprises a set of EntityContainers, where each EntityContainer is associated with a specific data source.
A DataService defines the service tier and exposes data from a specific data source. A DataService implements an EntityContainer. The EntityContainer describes the shape of the data in the service. This is one of the under-the-hood concepts in LightSwitch. The designer defines an EntityContainer implicitly as you add elements to a data source.
An EntityContainer has EntitySets and QueryOperations. An EntitySet is analogous to a database table. It is the logical location where instances of entities live. QueryOperations return a selection of entities from an EntitySet or from another QueryOperation.
An EntityType represents a specific kind of business data. For example, a Customer, an Invoice, a Book or a TimeCardEntry. EntityTypes can have KeyProperties, EntityProperties, and NavigationProperties. KeyProperties are determined by the designer. A normal EntityProperty can store simple data values, or it can be a computed value that is not stored. NavigationProperties define links to related EntityTypes, for example, the Customer for an Order.
EntityTypes are shared between the presentation and the service tier. The associated business logic (such as data validation) is executed identically on both tiers.
Building Blocks and DSLs
The set of building blocks in a model-centric architecture is often called a domain-specific language (DSL). In modeling parlance, each building block is a LightSwitch metatype, while the set of building blocks and their relationships is the LightSwitch metamodel. LightSwitch models are stored as part of the project in files having the .LSML extension. …
- Read More: 2, 3
- Page 1: Inside Visual Studio LightSwitch
- Page 2: Runtime Architecture
- Page 3: Data Service Access
John is a Principal Architect and Steve is a Distinguished Engineer at Microsoft.
See also Beth Massi (@bethmassi) reported The Code Project Virtual Tech Summit Premieres Tomorrow Feb 23rd in a 2/22/2011 post in the Cloud Computing Events section below. She’s presenting a session with the same title as John and Steve’s.
Return to section navigation list>
Windows Azure Infrastructure
Phil Wainwright posted Loosely coupled crowd development on 2/21/2011 to ZDNet’s Software as Services blog:
The further that SaaS vendors penetrate into the higher echelons of enterprise computing, the more they’re accused, like the pigs running the show at the end of George Orwell’s Animal Farm, of becoming just like the establishment vendors they claim so much to despise. Complex implementation projects, multi-year contracts with payment upfront, deal sizes that run to six- or seven-figure sums, alliances with the established global SIs, and account management teams recruited from the ranks of old-guard vendors such as Oracle, IBM and HP. Meet the new boss, same as the old boss.
It all starts to look as though SaaS isn’t the disruptive force its proponents claim it is. Perhaps the established conventional software vendors are right after all when they say that the only reason SaaS seems better, faster, cheaper is because it lacks the sophistication to satisfy top-class enterprise needs. If it ever evolves sufficiently to match those needs, the end result will look no different from the incumbents, they argue.
The counterpoint is to observe that, if you take a disruptive innovation and smother it in products and practices better suited to its establishment rivals, then it’s bound to get bogged down. What is the point of inventing a completely new approach to application development and deployment, only to saddle it with outdated implementation practices, brittle integration technologies and bureaucratic lifecycle management? SaaS vendors should be more wary. All the energy and potential of SaaS is getting squeezed out and drained away by the old deployment and management models. To reverse the familiar phrase, if you wear the pig’s lipstick, don’t be surprised if you end up looking like a pig.
In the past decade, SaaS has evolved enormously in terms of the application platforms themselves, but progress has barely started when it comes to applying cloud models to the implementation and lifecycle management processes. If cloud services are going to avoid the fate I’ve outlined above, then there needs to be a disruptive change in those areas, just as much as in the platforms themselves. This revolution won’t be complete until the current business models of the global SIs — Accenture, Deloitte, IBM and the others — are as comprehensively undermined as those of the software vendors they’ve traditionally worked with.
Last week saw the launch of an initiative that perhaps models the shape of this impending disruptive change. Cloud integrator Appirio [disclosure: a recent client] announced CloudSpokes, which aims to bring a crowdsourced, community approach to enterprise cloud development tasks. The idea is very similar to what 99Designs does for web design projects: organizations post specifications for tasks they want done and a price they’re willing to pay, and any community member is free to do the work in the hope of being selected as the contest winner and walking off with the money.
The idea is to prime the pump for this loosely coupled model of cloud development as a counterbalance to the current dominance of traditional, high-overhead methodologies espoused by the global SIs. To that end, Appirio is committing an initial $1 million-worth of contest tasks to start building community momentum. It’s also a necessary investment to fine-tune the model until it works, as Appirio’s co-founder and CMO Narinder Singh explained to me last week:
“We have to create liquidity in the market. We’re teaching our people how to break down problems into components. We need to understand as an organization how to use this resource.”
Software development is not like web design, with clear-cut, established demarcations between different types of task. To have any success with CloudSpokes, and forge a truly loosely coupled development cloud, people are going to have to learn how to break down their projects into discrete tasks that the community will be able to make sense of. That may be a big ask.
“As companies build on the cloud in the right way, this process should become natural,” said Dave Messinger, chief architect and evangelist for CloudSpokes at Appirio, who previously architected TopCoder, a similar community that targets traditional development platforms. He explained that the best type of task to submit to CloudSpokes would be, “Things that you can specify well. You know what the inputs and the output are but you don’t know the algorithms, the best way to code it. A well scoped, well defined piece of work like that works really well.”
There are so many reasons why I want this to work: to speed the progress of cloud applications; to share best practice and high-quality output; to help strong, instinctive cloud developers win visibility and better leverage for their talents; to give the bloated, inefficient global SIs their comeuppance.
“With CloudSpokes as a community,” Narinder told me, “the idea [is] creating a marketplace and showing the contrast with what you can achieve with the cloud. We’ll benefit because other people won’t be as willing to cannibilize their traditional business as we are.”
Celebrating the match of cloud meet crowd in a blog post, he added:
“CloudSpokes will create transparency for the market around cloud platforms and cloud development. Market pricing and past results will show what it really costs to do something in the cloud, by platform, type of problem, sophistication and more.”
This all sounds really good, but like Dennis Howlett, who is just as intrigued, I have to wonder whether it will work. Ever since the dawn of computing, there’s always been this nagging itch to scratch, this feeling that most of the code a developer is building for any given project has already been built somewhere else, if only it could be reused. This sense of waste has inspired successive advances: indirection, subroutines, object orientation, separation of concerns, request brokers, service oriented architecture, virtualization, platform-as-a-service. It’s impossible to resist the allure of every new idea that promises a way of sourcing the best possible code without having to reinvent the wheel every flipping time.
Could CloudSpokes, or something like it, win widespread acclaim as the next solution to this age-old problem? I’d like to think so, I really would.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private Clouds
Buck Woody (@buckwoody) described a Windows Azure Use Case: Hybrid Applications in a 2/22/2011 post:
This is one in a series of posts on when and where to use a distributed architecture design in your organization's computing needs. You can find the main post here: http://blogs.msdn.com/b/buckwoody/archive/2011/01/18/windows-azure-and-sql-azure-use-cases.aspx
Description:
- Private data (do not want to send or store sensitive data off-site)
- High dollar investment in current infrastructure
- Applications currently running well, but may need additional periodic capacity
- Current applications not designed in a stateless fashion
In these situations, a “hybrid” approach works best. In fact, with Windows Azure, a hybrid approach is an optimal way to implement distributed computing even when the stipulations above do not apply. Keeping a majority of the computing function in an organization local while exploring and expanding that footprint into Windows and SQL Azure is a good migration or expansion strategy.
A “hybrid” architecture merely means that part of a computing cycle is shared between two architectures. For instance, some level of computing might be done in a Windows Azure web-based application, while the data is stored locally at the organization.
Implementation:
There are multiple methods for implementing a hybrid architecture, in a spectrum from very little interaction from the local infrastructure to Windows or SQL Azure. The patterns fall into two broad schemas, and even these can be mixed.
1. Client-Centric Hybrid Patterns
In this pattern, programs are coded such that the client system sends queries or compute requests to multiple systems. The “client” in this case might be a web-based codeset actually stored on another system (which acts as a client, the user’s device serving as the presentation layer) or a compiled program. In either case, the code on the client requestor carries the burden of defining the layout of the requests.
While this pattern is often the easiest to code, it’s the most brittle. Any change in the architecture must be reflected on each client, but this can be mitigated by using a centralized system as the client such as in the web scenario.
2. System-Centric Hybrid Patterns
Another approach is to create a distributed architecture by turning on-site systems into “services” that can be called from Windows Azure using the service Bus or the Access Control Services (ACS) capabilities. Code calls from a series of in-process client application. In this pattern you move the “client” interface into the server application logic.
If you do not wish to change the application itself, you can “layer” the results of the code return using a product (such as Microsoft BizTalk) that exposes a Web Services Definition Language (WSDL) endpoint to Windows Azure using the Application Fabric. In effect, this is similar to creating a Service Oriented Architecture (SOA) environment, and has the advantage of de-coupling your computing architecture. If each system offers a “service” of the results of some software processing, the operating system or platform becomes immaterial, assuming it adheres to a service contract.
There are important considerations when you federate a system, whether to Windows or SQL Azure or any other distributed architecture. While these considerations are consistent with coding any application for distributed computing, they are especially important for a hybrid application.
Connection resiliency - Applications on-premise normally have low-latency and good connection properties, something you’re not always guaranteed in a distributed and hybrid application. Whether a centralized client or a distributed one, the code should be able to handle extended retry logic.
Authorization and Access - In a single authorization environment like a Active Directory domain, security is handled at a user-password level. In a distributed computing environment, you have more options. You can mitigate this with using The Windows Azure Application Fabric feature of ACS to make the Azure application aware of the App Fabric as an ADFS provider. However, a claims-based authentication structure is often a superior choice.
Consistency and Concurrency - When you have a Relational Database Management System (RDBMS), Consistency and Concurrency are part of the design. In a Service Architecture, you need to plan for sequential message handling and lifecycle.
Resources:
How to Build a Hybrid On-Premise/In Cloud Application: http://blogs.msdn.com/b/ignitionshowcase/archive/2010/11/09/how-to-build-a-hybrid-on-premise-in-cloud-application.aspx
General Architecture guidance: http://blogs.msdn.com/b/buckwoody/archive/2010/12/21/windows-azure-learning-plan-architecture.aspx



Jim Strikeleather posted Cloud service brokerage to Dell’s The IT Executive blog on 2/22/2011:
According to Gartner, through 2015, cloud service brokerage (CSB) will represent the single largest revenue growth opportunity in cloud computing. But like so many areas of cloud computing, there is confusion about both the terms and the very nature of this technology and concept.
The brokerage market will be just as diverse as the cloud is. There will be brokers that do nothing but perform a management and integration service across multiple clouds and cloud type vendors for infrastructure and platform needs. The cloud computing landscape is evolving rapidly, with more and more players introducing cloud products and services of all kinds. Most recently we’ve seen the announcements by VMware partners including Terremark, BlueLock and others, as well as the introduction of Rackspace’s Cloud Servers. EMC is planning to offer a compute cloud in addition to its existing Atmos storage cloud. And Dell is taking a broad approach through partnerships with Microsoft (Windows Azure Platform appliance), VMware and helping develop Open Stack.
As the proliferation of offerings continues to accelerate, IT managers have questions about how to proceed: How can you evaluate the range of potential cloud offerings to find the right match? How do you route an application or workload to a target cloud and make sure that it works? How do you integrate it with other applications running back in the data center? Even within a single cloud, deploying an application requires learning the provider’s operating environment, management tools, and business terms and conditions. Doing this for every cloud provider you may wish to utilize is likely to prove daunting and not cost-effective. In a cloud environment characterized by multiple providers, each with its own service terms, operating platforms, management systems, security levels and disaster recovery approaches, the specialized expertise and value-add of a cloud service broker will help IT managers find the right cloud offering, deploy their application in the cloud and manage it properly.
Brokers will also form around domain areas (pharmaceuticals, IT, soft goods retail, process manufacturing, etc.) or applications areas (supply chain management, enterprise resource planning, human resources, payroll, etc.) and perhaps even combinations of the two – so that they become shopping centers from which companies can assemble the necessary services and functionalities for their businesses.
In a similar vein, we can expect the rise of cloud services brokers that specialize in data, a consequence of the evolving connectivity of things and the concurrent big data deluge. These brokers will specialize in the collection and storage of domain, industry or applications area data and the associated analytics. An example of this could be a clearinghouse for point of sale (POS) data collected across retailers and made available to manufacturers.
It is likely that the real evolution of cloud services brokers will actually be the logical extension to current business process outsourcing services (BPO) to include more end-to-end and higher-level knowledge skills incorporated with applications (or application components) and data. One can easily imagine everything that is not core to a business or not directly creating value to a business’ customers eventually being outsourced. For example, the simple process of hiring someone could be done completely virtually by using multiple applications, databases, services and external businesses via the cloud.
I even suspect there will be a transitional market opportunity for companies to sell excess capacity on their internal systems via cloud brokers, especially as they move their hygienic and housekeeping systems to the cloud. You already see this with Toronto-based Enomaly, which lets companies buy and sell unused cloud computing capacity in a clearinghouse called SpotCloud. It also gives companies the ability to switch services on demand to get the best price while still receiving a single bill.
And lastly, there is the traditional broker – companies like Sterling Commerce – who can route purchases or services requests to the “best” provider and are likely to arise to deal with the variety of offerings. Think of it as “least-cost routing” for cloud computing. The benefits of this cloud and/or process fitting will soon become apparent, whereby cloud service brokers use specialized tools to identify the most appropriate resource, and then map the requirements of an enterprise application or process to it. Cloud service brokers will be able to automatically route data, applications and infrastructure needs based on key criteria such as price, location (including many legislative and regulatory jurisdictional data storage location requirements), latency needs, SLA level, supported operating systems, scalability, backup/disaster recovery capabilities and regulatory requirements. IT and business process managers will be able to run applications or route work flows where they truly belong, while the broker takes care of the underlying details that make the cloud so compelling. For example, if you are hiring an employee in India, some of the BPO activities might be routed to a different service provider than if you were hiring someone in Russia or China or the U.S.
So, given that “cloud services broker” is about as well defined as a marshmallow, what can we say about them?
Well, I agree with Gartner – the market, however it evolves, will be huge. “Cloud” has taken so much friction out of the economics of IT that a long tail will be in full effect, with countless different service offerings to be evaluated, chosen from, integrated with, managed, etc. – and companies will gladly pass that pain off to a broker.
Jim is Dell’s Chief Innovation Officer
I believe Jim conflated data brokerage with IaaS/Paas compute/storage brokerage services in this article.
<Return to section navigation list>
Cloud Security and Governance
Greg Shields asked and answered Q: What's National Institute of Standards and Technology (NIST) Special Publication (SP) 800-144? in a 2/22/2011 post to WindowsIT Pro:
A: Nothing in government IT happens without documentation that allows it to happen and defines how it should happen. Depending on what kind of government you work with, some of that documentation may come from the U.S. government's NIST. These are the people responsible for keeping the official inch and the official pound. They're also responsible for keeping, for example, the official desktop configuration standard for Windows 7.
The government recognizes that cloud computing is an emerging technology, but directives and guidance are required before its agencies can begin using cloud computing technologies. That guidance begins with SP 800-144, "Guidelines on Security and Privacy in Public Cloud Computing."
Private sector IT isn't required to follow the government's lead or advice in these matters, but publications like SP 800-144 often assist in defining policies that help the rest of us out. For example, Chapter 5 of SP 800-144 includes guidance on addressing security and privacy issues when outsourcing to cloud providers that you might find helpful.
Grab your copy of SP 800-144 from the NIST website. You might find it useful in keeping your data safe as you move it into the cloud.
Dana Gardner asserted “As we move forward, cloud computing is going to give us an opportunity to reinvent how we do security” in a deck for his As Cyber Security Risks Grow, Best Practices Must Keep Pace post of 2/22/2011:
Looking back over the past few years, it seems like cyber security and warfare threats are only getting worse. We've had the Stuxnet Worm, the WikiLeaks affair, China-originating attacks against Google and others, and the recent Egypt Internet blackout.
But, are cyber security dangers, in fact, getting that much worse? And are perceptions at odds with what is really important in terms of security protection? How can businesses best protect themselves from the next round of risks, especially as cloud computing, mobile, and social media and networking activities increase? How can architecting for security become effective and pervasive?
We posed these and other serious questions to a panel of security experts at the recent The Open Group Conference, held in San Diego the week of Feb. 7, to examine the coming cyber security business risks, and ways to head them off.The panel: Jim Hietala, the Vice President of Security at The Open Group; Mary Ann Mezzapelle, Chief Technologist in the CTO's Office at HP, and Jim Stikeleather, Chief Innovation Officer at Dell Services. The discussion was moderated by BriefingsDirect's Dana Gardner, Principal Analyst at Interarbor Solutions.
Here are some excerpts:
Stikeleather: The only secure computer in the world right now is the one that's turned off in a closet, and that's the nature of things. You have to make decisions about what you're putting on and where you're putting it on. I's a big concern that if we don't get better with security, we run the risk of people losing trust in the Internet and trust in the web.
When that happens, we're going to see some really significant global economic concerns. If you think about our economy, it's structured around the way the Internet operates today. If people lose trust in the transactions that are flying across it, then we're all going to be in pretty bad world of hurt.
One of the things that you're seeing now is a combination of security factors. When people are talking about the break-ins, you're seeing more people actually having discussions of what's happened and what's not happening. You're seeing a new variety of the types of break-ins, the type of exposures that people are experiencing. You're also seeing more organization and sophistication on the part of the people who are actually breaking in.
The other piece of the puzzle has been that legal and regulatory bodies step in and say, "You are now responsible for it." Therefore, people are paying a lot more attention to it. So, it's a combination of all these factors that are keeping people up at night.
A major issue in cyber security right now is that we've never been able to construct an intelligent return on investment (ROI) for cyber security.We're starting to see a little bit of a sea change, because starting with HIPAA-HITECH in 2009, for the first time, regulatory bodies and legislatures have put criminal penalties on companies who have exposures and break-ins associated with them.
There are two parts to that. One, we've never been truly able to gauge how big the risk really is. So, for one person it maybe a 2, and most people it's probably a 5 or a 6. Some people may be sitting there at a 10. But, you need to be able to gauge the magnitude of the risk. And, we never have done a good job of saying what exactly the exposure is or if the actual event took place. It's the calculation of those two that tell you how much you should be able to invest in order to protect yourself.
We're starting to see a little bit of a sea change, because starting with HIPAA-HITECH in 2009, for the first time, regulatory bodies and legislatures have put criminal penalties on companies who have exposures and break-ins associated with them.
So we're no longer talking about ROI. We're starting to talk about risk of incarceration , and that changes the game a little bit. You're beginning to see more and more companies do more in the security space.
Mezzapelle: First of all we need to make sure that they have a comprehensive view. In some cases, it might be a portfolio approach, which is unique to most people in a security area. Some of my enterprise customers have more than a 150 different security products that they're trying to integrate.
Their issue is around complexity, integration, and just knowing their environment -- what levels they are at, what they are protecting and not, and how does that tie to the business? Are you protecting the most important asset? Is it your intellectual property (IP)? Is it your secret sauce recipe? Is it your financial data? Is it your transactions being available 24/7?
It takes some discipline to go back to that InfoSec framework and make sure that you have that foundation in place, to make sure you're putting your investments in the right way.
... It's about empowering the business, and each business is going to be different. If you're talking about a Department of Defense (DoD) military implementation, that's going to be different than a manufacturing concern. So it's important that you balance the risk, the cost, and the usability to make sure it empowers the business.
Hietala: One of the big things that's changed that I've observed is if you go back a number of years, the sorts of cyber threats that were out there were curious teenagers and things like that. Today, you've got profit-motivated individuals who have perpetrated distributed denial of service attacks to extort money.
Now, they’ve gotten more sophisticated and are dropping Trojan horses on CFO's machines and they can to try in exfiltrate passwords and log-ins to the bank accounts.
We had a case that popped up in our newspaper in Colorado, where a mortgage company, a title company lost a million dollars worth of mortgage money that was loans in the process of funding. All of a sudden, five homeowners are faced with paying two mortgages, because there was no insurance against that.
When you read through the details of what happened it was, it was clearly a Trojan horse that had been put on this company's system. Somebody was able to walk off with a million dollars worth of these people's money.
State-sponsored acts
So you've got profit-motivated individuals on the one side, and you've also got some things happening from another part of the world that look like they're state-sponsored, grabbing corporate IP and defense industry and government sites. So, the motivation of the attackers has fundamentally changed and the threat really seems pretty pervasive at this point.Complexity is a big part of the challenge, with changes like you have mentioned on the client side, with mobile devices gaining more power, more ability to access information and store information, and cloud. On the other side, we’ve got a lot more complexity in the IT environment, and much bigger challenges for the folks who are tasked for securing things.
Stikeleather: One other piece of it is require an increased amount of business knowledge on the part of the IT group and the security group to be able to make the assessment of where is my IP, which is my most valuable data, and what do I put the emphasis on.
One of the things that people get confused about is, depending upon which analyst report you read, most data is lost by insiders, most data is lost from external hacking, or most data is lost through email. It really depends. Most IP is lost through email and social media activities. Most data, based upon a recent Verizon study, is being lost by external break-ins.
When you move from just "I'm doing security" to "I'm doing risk mitigation and risk management," then you have to start doing portfolio and investment analysis in making those kinds of trade-offs.
We've kind of always have the one-size-fits-all mindset about security. When you move from just "I'm doing security" to "I'm doing risk mitigation and risk management," then you have to start doing portfolio and investment analysis in making those kinds of trade-offs.
...At the end of the day it's the incorporation of everything into enterprise architecture, because you can't bolt on security. It just doesn't work. That’s the situation we're in now. You have to think in terms of the framework of the information that the company is going to use, how it's going to use it, the value that’s associated with it, and that's the definition of EA. ...
It's one of the reasons we have so much complexity in the environment, because every time something happens, we go out, we buy any tool to protect against that one thing, as opposed to trying to say, "Here are my staggered differences and here's how I'm going to protect what is important to me and accept the fact nothing is perfect and some things I'm going to lose."
Mezzapelle: It comes back to one of the bottom lines about empowering the business. It means that not only do the IT people need to know more about the business, but the business needs to start taking ownership for the security of their own assets, because they are the ones that are going to have to belay the loss, whether it's data, financial, or whatever.
We need to connect the dots and we need to have metrics. We need to look at it from an overall threat point of view, and it will be different based on what company you're about.
They need to really understand what that means, but we as IT professionals need to be able to explain what that means, because it's not common sense. We need to connect the dots and we need to have metrics. We need to look at it from an overall threat point of view, and it will be different based on what company you're about.
You need to have your own threat model, who you think the major actors would be and how you prioritize your money, because it's an unending bucket that you can pour money into. You need to prioritize.
The way that we've done that is this is we've had a multi-pronged approach. We communicate and educate the software developers, so that they start taking ownership for security in their software products, and that we make sure that that gets integrated into every part of portfolio.The other part is to have that reference architecture, so that there’s common services that are available to the other services as they are being delivered and that we can not control it but at least manage from a central place.
Stikeleather: The starting point is really architecture. We're actually at a tipping point in the security space, and it comes from what's taking place in the legal and regulatory environments with more-and-more laws being applied to privacy, IP, jurisdictional data location, and a whole series of things that the regulators and the lawyers are putting on us.
One of the things I ask people, when we talk to them, is what is the one application everybody in the world, every company in the world has outsourced. They think about it for a minute, and they all go payroll. Nobody does their own payroll any more. Even the largest companies don't do their own payroll. It's not because it's difficult to run payroll. It's because you can’t afford all of the lawyers and accountants necessary to keep up with all of the jurisdictional rules and regulations for every place that you operate in.
Data itself is beginning to fall under those types of constraints. In a lot of cases, it's medical data. For example, Massachusetts just passed a major privacy law. PCI is being extended to anybody who takes credit cards.
Because all these adjacencies are coming together, it's a good opportunity to sit down and architect with a risk management framework. How am I going to deal with all of this information?
The security issue is now also a data governance and compliance issue as well. So, because all these adjacencies are coming together, it's a good opportunity to sit down and architect with a risk management framework. How am I going to deal with all of this information?
Risk management
Hietala: I go back to the risk management issue. That's something that I think organizations frequently miss. There tends to be a lot of tactical security spending based upon the latest widget, the latest perceived threat -- buy something, implement it, and solve the problem.Taking a step back from that and really understanding what the risks are to your business, what the impacts of bad things happening are really, is doing a proper risk analysis. Risk assessment is what ought to drive decision-making around security. That's a fundamental thing that gets lost a lot in organizations that are trying to grapple the security problems.
Stikeleather: I can argue both sides of the [cloud security] equation. On one side, I've argued that cloud can be much more secure. If you think about it, and I will pick on Google, Google can expend a lot more on security than any other company in the world, probably more than the federal government will spend on security. The amount of investment does not necessarily tie to a quality of investment, but one would hope that they will have a more secure environment than a regular company will have.
You have to do your due diligence, like with everything else in the world. I believe, as we move forward, cloud is going to give us an opportunity to reinvent how we do security.
On the flip side, there are more tantalizing targets. Therefore they're going to draw more sophisticated attacks. I've also argued that you have statistical probability of break-in. If somebody is trying to break into Google, and you're own Google running Google Apps or something like that, the probability of them getting your specific information is much less than if they attack XYZ enterprise. If they break in there, they are going to get your stuff.
Recently I was meeting with a lot of NASA CIOs and they think that the cloud is actually probably a little bit more secure than what they can do individually. On the other side of the coin it depends on the vendor. You have to do your due diligence, like with everything else in the world. I believe, as we move forward, cloud is going to give us an opportunity to reinvent how we do security.
I've often argued that a lot of what we are doing in security today is fighting the last war, as opposed to fighting the current war. Cloud is going to introduce some new techniques and new capabilities. You'll see more systemic approaches, because somebody like Google can't afford to put in 150 different types of security. They will put one more integrated. They will put in, to Mary Ann’s point, the control panels and everything that we haven't seen before.
So, you'll see better security there. However, in the interim, a lot of the software-as-a-service (SaaS) providers, some of the simpler platform-as-a-service (PaaS) providers haven’t made that kind of investment. You're probably not as secured in those environments.
Lowers the barrier
Mezzapelle: For the small and medium size business cloud computing offers the opportunity to be more secure, because they don't necessarily have the maturity of processes and tools to be able to address those kinds of things. So, it lowers that barrier to entry for being secure.For enterprise customers, cloud solutions need to develop and mature more. They may want to do with hybrid solution right now, where they have more control and the ability to audit and to have more influence over things in specialized contracts, which are not usually the business model for cloud providers.
I would disagree with Jim Stikeleather in some aspects. Just because there is a large provider on the Internet that’s creating a cloud service, security may not have been the key guiding principle in developing a low-cost or free product. So, size doesn't always mean secure.
You have to know about it, and that's where the sophistication of the business user comes in, because cloud is being bought by the business user, not by the IT people. That's another component that we need to make sure gets incorporated into the thinking.
Stikeleather: I am going to reinforce what Mary Ann said. What's going on in cloud space is almost a recreation of the late '70s and early '80s when PCs came into organizations. It's the businesspeople that are acquiring the cloud services and again reinforces the concept of governance and education. They need to know what is it that they're buying.
There will be some new work coming out over the next few months that lay out some of the tough issues there and present some approaches to those problems.
I absolutely agree with Mary. I didn't mean to imply size means more security, but I do think that the expectation, especially for small and medium size businesses, is they will get a more secure environment than they can produce for themselves.
Hietala: There are a number of different groups within The Open Group doing work to ensure better security in various areas. The Jericho Forum is tackling identity issues as it relates to cloud computing. There will be some new work coming out of them over the next few months that lay out some of the tough issues there and present some approaches to those problems.
We also have the Open Trusted Technology Forum (OTTF) and the Trusted Technology Provider Framework (TTPF) that are being announced here at this conference. They're looking at supply chain issues related to IT hardware and software products at the vendor level. It's very much an industry-driven initiative and will benefit government buyers, as well as large enterprises, in terms of providing some assurance of products they're procuring are secure and good commercial products.
Also in the Security Forum, we have a lot of work going on in security architecture and information security management. There are a number projects that are aimed at practitioners, providing them the guidance they need to do a better job of securing, whether it's a traditional enterprise, IT environment, cloud and so forth. Our Cloud Computing Work Group is doing work on a cloud security reference architecture. So, there are number of different security activities going on in The Open Group related to all this.
<Return to section navigation list>
Cloud Computing Events
Beth Massi (@bethmassi) reported The Code Project Virtual Tech Summit Premieres Tomorrow Feb 23rd in a 2/22/2011 post:
I’ll be presenting at the Code Project’s virtual tech summit on LightSwitch. This is a free, online “conference” with both Visual Studio developer and Agile tracks. Check out the agenda:
The Code Project Virtual Tech Summit Agenda
Here’s my session which will premiere at 3:15pm PST tomorrow and will be available on demand for 90 days:
Introduction to Visual Studio LightSwitch
LightSwitch is a new product in the Visual Studio family aimed at developers who want to easily create business applications for the desktop or the cloud. It simplifies the development process by letting you concentrate on the business logic while LightSwitch handles the common tasks for you. In this demo-heavy session, you will see, end-to-end, how to build and deploy a data-centric business application using LightSwitch. Well also go beyond the basics of creating simple screens over data and demonstrate how to create screens with more advanced capabilities.
Sanjay Jain (@SanjayJain369) announced on 2/22/2011 the Microsoft US Public Sector CIO Summit 2011 event of 2/22 to 2/24/2011 in Redmond, WA:
I am looking forward to experience our annual Microsoft Public Sector CIO Summit during February 22 - 24, 2011, at Microsoft Conference Center in Redmond, WA. This summit brings together leaders from Federal, State & Local Governments, Education and Health organizations throughout the US to discuss the key issues facing public sector organizations and discover new innovative technology solutions.
I will be presenting Dynamics CRM 2011 session along with a cool Grants Manager (leveraging CRM Online, Azure, Bing) demo by InfoStrat and a surprise announcement by Christine Zmuda, Director - Strategic Alliances.
I can’t wait to congratulate several Public Sector Partners, who recently successfully completed CRM 2011 Online Pilot; see the press-release highlighting their successes.
This will be an action packed week learning so much about growing Public Sector business, key issues and ways we can address them, and of-course meeting several leaders. If you are around and would like to chat, feel free to ping me.
Sanjay Jain
ISV Architect Evangelist
Microsoft Corporation
Blog: http://Blogs.msdn.com/SanjayJain
Twitter: http://twitter.com/SanjayJain369

<Return to section navigation list>
Other Cloud Computing Platforms and Services
The HPC in the Cloud blog reported Enhanced Tools Arrive for Big Data Developers Reliant on Hadoop in a 2/22/2011 post:
In the past, Apache Hadoop and Hive software were only open to developers with advanced UNIX/Linux skills or those who were able to create their own Hadoop cluster and install Hive.
Karmasphere, which describes itself as the “big data intelligence software company that brings Hadoop power to developers and analysts” seeks to remove some of the barriers to getting started with large data sets by providing a ready-made environment to analyze Hadoop data on a desktop (versus using command-line tools).
When a user is prepared to deploy to an actual Hadoop cluster, Karmasphere allows them to migrate to any distribution of Hadoop, “including Cloudera, CDH and Elastic MapReduce with one click.”
Karmasphere introduced Karmasphere Studio 1.6 and Karmasphere Analyst 1.1 today, both of which are targeted toward big data developers and analysts.
The Karmasphere Studio release is for developing, debugging, deploying and monitoring MapReduce applications. The company states that the new version “scales for ultra-large environments, supporting jobs with a half million tasks and eases workstation-based prototyping by creating sample data sets from Hadoop clusters with a single click.”
Karmasphere Analyst provides SQL access and insight into data on Hadoop clusters and according to the company “improves performance, storing UDF files on Hadoop clusters to avoid uploading for each analysis; it automatically generates tables to save time for each analysis and via the interface users directly manage or stop long-running Hive jobs.
Chris Czarnecki explained Java Application Storage Options for Google App Engine in a 2/21/2011 post to the Learning Tree blog:
For Java developers building applications for deployment to the Google App Engine (GAE) data storage is a primary consideration. Web applications typically connect to a relational database for storage. On first glance at GAE it is surprising to see that there is no relational database facility. How then do applications persist, query and retrieve data ?
GAE provides Java developers with three options for persisting data. Standard Java provides two API’s for persisting objects to relational databases, JPA and JDO. GAE provides support for both of these libraries which means that developers can write code using these standard API’ as though the application is using a relational database. GAE stores the data behind the scenes in its own scalable storage facility. In this way the application code is not tied to GAE API’s and can be readily ported to other platforms. The other storage option available is to use GAE’s datastore facility which is a scalable, schemaless storage facility that can be queried based on object properties. The datastore is accessible via a simple Java API. The GAE JDO and JPA implementations map data to the datastore.
From this discussion it is clear that developing applications for the cloud, there are many options for storage, provided by many different vendors. If you would like to learn more about these why not consider attending Learning Trees Cloud Computing course where we discuss these storage facilities in detail and compare and contrast them on both technical and commercial merits.
Google claims they’re working on an RDBMS for GAE.
<Return to section navigation list>
Technorati Tags: Windows Azure, Windows Azure Platform, Azure Services Platform, Azure Storage Services, Azure Table Services, Azure Blob Services, Azure Drive Services, Azure Queue Services, SQL Azure Database, SADB, Open Data Protocol, OData, Windows Azure AppFabric, Azure AppFabric, Windows Server AppFabric, Server AppFabric, Cloud Computing, Visual Studio LightSwitch, LightSwitch, Hadoop, Hive, Karmasphere, Google App Engine, Amazon Web Services, AWS, Amazon SimpleDB, Amazon RDS


















0 comments:
Post a Comment