Windows Azure and Cloud Computing Posts for 4/8/2013+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
Top Story this week: Scott Guthrie (@scottgu) announced Windows Azure: Active Directory Release, New Backup Service + Web Site Monitoring and Log Improvements in a 4/8/2013 post. See all the WAAD news and walkthrough links in the Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow section.
•• Updated 4/14/2013 with new articles marked ••.
• Updated 4/12/2013 with new articles marked •.
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
•• Philip Fu posted [Sample Of Apr 8th] Table storage paging in Windows Azure to the Microsoft All-In-One Code Framework blog on 4/8/2013:
Sample Download : http://code.msdn.microsoft.com/CSShellPrintImageWithShellE-adda9973
The sample demonstrates how to print an image using ShellExecute to invoke ImageView_PrintTo, equivalent to right clicking on an image and printing. Using the printto verb with ShellExecute may have unpredictable effects since this may be configured differently on different operating systems. The approach demonstrated here invokes ImageView directly with the correct parameters to directly print an image to the default printer.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.
• My (@rogerjenn) HDInsight Service Preview for Azure debunks Hadoop's big data analytics angle article of 4/10/2013 for SearchCloudComputing.com begins:
Microsoft's new Flat Network Storage architecture for its Windows Azure data centers debunks Hadoop's "move compute to the data" truism and enables using highly available and durable blob storage clusters for big data analytics.
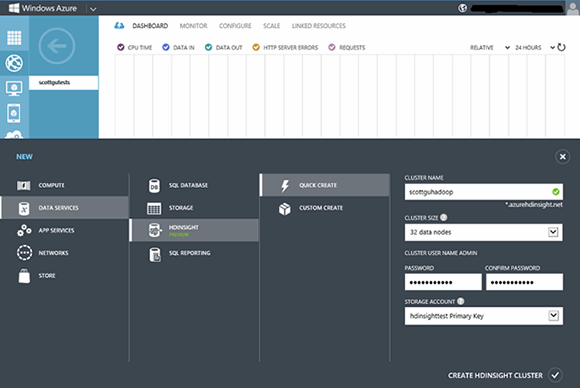
Microsoft corporate vice president Scott Guthrie announced a major upgrade of its HDInsight Service Preview to the Hortonworks Hadoop Data Platform v1.1.0 in March. The updated preview's DevOps features make it easy for developers with a Windows Azure subscription to create high-performance HDInsight compute clusters with the Windows Azure Management Portal (see Figure 1).
Figure 1. Developers or DevOps specialists use the Windows Azure Management Portal to specify the number of compute nodes for an HDInsight Data Services cluster.
The SQL Server group's new version incorporates the following open source Apache Hadoop components and a redistributable Microsoft Java Database Connectivity (JDBC) driver for SQL Server:
- Apache Hadoop, Version 1.0.3
- Apache Hive, Version 0.9.0
- Apache Pig, Version 0.9.3
- Apache Sqoop, Version 1.4.3
- Apache Oozie, Version 3.2.0
- Apache H.Catalog, Version 0.4.1
- Apache Templeton, Version 0.1.4
- SQL Server JDBC Driver, Version 3.0
A cluster consists of an extra-large head node costing $0.48 per hour, and one or more large compute nodes at $0.24 per hour. Therefore, a small-scale cluster with four compute nodes will set users back $1.44 per hour deployed, or about $1,000 per month. (Microsoft bases its charges on a list price of $2.88 per hour but discounts the time to 50% of actual clock hours; learn more about HDInsight Preview pricing here.) The first Hadoop on Windows Azure preview provided a prebuilt, renewable three-node cluster with a 24-hour lifetime; a later update increased the lifetime to five days but disabled renewals. Data storage and egress bandwidth charges aren't discounted in the latest preview, but they're competitive with Amazon Web Services' Simple Storage Service (S3) storage. The discounted Azure services don't offer a service-level agreement.
Moving HDFS storage from the local file system to Windows Azure blobs
One of Hadoop's fundamental DevOps precepts is to "move compute to the data," which ordinarily requires hosting Hadoop Distributed File System (HDFS) data storage files and compute operations in the operating system's file system. Windows Azure-oriented developers are accustomed to working with Azure blob storage, which provides high availability by replicating all stored objects three times. Durability is enhanced and disaster recovery is enabled by geo-replicating the triplicate copy to a Windows Azure data center in the same region after geo-locating the initial and duplicate copies more than 100 miles from the center. For example, an Azure blob store created in Dublin, the West Europe subregion, is auto-replicated to Amsterdam, the North Europe subregion. HDFS doesn't provide such built-in availability and durability features.
HDFS running on the local file system delivered better performance than Azure blobs for MapReduce tasks in the HDInsight service's first-generation network architecture by residing in the same file system as the MapReduce compute executables. Windows Azure storage was hobbled by an early decision to separate virtual machines (VMs) for computation from those for storage to improve isolation for multiple tenants. …


Read more. See updated Links to My Cloud Computing Tips at TechTarget’s SearchCloudComputing and Other Search… Sites for my earlier TechTarget articles.

Alejandro Jezierski (@alexjota) posted Introduction to HCatalog, Pig scripts and heavy burdens on 4/9/2013:
As an eager developer craving for Big Data knowledge, you’ve probably come across many tutorials that explain how to create a simple hive query or pig script, I have. Sounds simple enough, right? Now imagine your solution has evolved from one ad-hoc query, to a full library of hive, pig and Map/reduce scripts, scheduled jobs, etc. Cool! The team has been growing too, so now there’s an admin in charge of organizing and maintaining the cluster and stored data.
The problem
One fine day, you find none of your jobs are working anymore.
Here’s a simple Pig script. It’s only a few lines long, but there’s something wrong in almost every line of this script, considering the scenario I just described:
raw = load ‘/mydata/sourcedata/foo.bar’ using CustomLoader()
as (userId:int, firstName:chararray, lastName:chararray, age:int);
filtered = filter raw by age > 21;
…
store results into = ‘/mydata/output/results.foo’;Problem 1: you’ve hardcoded the location of your data, why would you assume the data will be in the same place? The admin found a better way of organizing data and he restructured the whole file system, didn’t you get the memo?
Problem 2: you’ve been blissfully unaware of the fact that you’ve given your script the responsibility of knowing the format of the raw data, too, by using a custom loader. What if you are not in control of the data you consume? what if the provider found a new awesome format and wants to share with their consumers?
Problem 3: you’re script is also responsible of handling the schema for the data it consumes. Now the data provider has decided to include a new field, remove another few and you wish you’d never got into this whole Big Data thing.
Problem 4: last but not least, several other scripts use the same data, so why would you have metadata related logic duplicated everywhere?
The solution
So, the solution is to go back, change all your scripts and make them work with the new location, new format and new schema and look for a new job. Thanks for watching.
OR, you can use HCatalog.
HCatalog is a table and storage management layer for Hadoop. So, when before you had something like this (note that you would need to write custom loaders for every new format you use):
now you have this:
See how Pig, Hive, MR no longer need to know about data storage or format, they only care about querying, transforming, etc. If we used HCatalog, the script would look something like this:
raw = load `rawdatatable` using HCatLoader();
filtered = filter raw by age > 21;
…
store results into `outputtable`
- Your script no longer knows (or cares) where the data is. It just knows it wants to get data from the “sample” table.
- Your script no longer cares in what format the raw data is in, that is handled by HCatalog, and we use the HCatLoader for that.
- No more defining schema for your raw data in your script. no more schema duplication.
- Other scripts, for example hive, can now share one common general structure for the same data, sharing is good.
Remember, when you setup your HDInsight cluster, remember HCatalog, and let that script do what it was meant to do, perform awesome transformations on your data, and nothing more.
For more information, you can visit HCatalog’s page.
Another cool post Alan Gates





<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
•• Carlos Figueira reported Updates (some API changes) to the Azure Mobile Services iOS SDK in a 4/10/2013 post:
Another quick one today. After some feedback from the community, we released a new version of the Azure Mobile Services iOS SDK which contains, in addition to a few bug fixes, some changes in the method names of some of the classes. Those changes were made to make the iOS SDK more in sync with the design and naming guidelines for other iOS libraries. The new SDK is live, and the Quickstart app which can be downloaded from the Azure Portal is also using the new APIs as well. Finally, our tutorials have also been updated to reflect the naming changes.
The changes are listed below. You can also find the changes to the SDK in our public GitHub repository. The changes were made in this commit.
- MSClient interface
- Class method clientWithApplicationURLString:withApplicationKey: ==> clientWithApplicationURLString:applicationKey:
- Class method clientWithApplicationURL:withApplicationKey: ==> clientWithApplicationURL:applicationKey:
- Initializer initWithApplicationURL:withApplicationKey: ==> initWithApplicationURL:applicationKey:
- Instance method loginWithProvider:onController:animated:completion: ==> loginWithProvider:controller:animated:completion:
- Instance method loginWithProvider:withToken:completion: ==> loginWithProvider:token:completion:
- Instance method getTable: ==> tableWithName:
- Instance method clientwithFilter: ==> clientWithFilter: (capitalization of the ‘W’)
- MSClientConnection interface (mostly internal usage)
- Initializer initWithRequest:withClient:completion: ==> initWithRequest:client:completion:
- MSFilter protocol
- Method handleRequest:onNext:onResponse: ==> handleRequest:next:response:
- MSLogin interface (mostly internal usage)
- Instance method loginWithProvider:onController:animated:completion: ==> loginWithProvider:controller:animated:completion:
- Instance method loginWithProvider:withToken:completion: ==> loginWithProvider:token:completion:
- MSQuery interface
- Instance method initWithTable:withPredicate: ==> initWithTable:predicate:
- MSTable interface
- Initializer initWithName:andClient: ==> initWithName:client:
- Instance method readWhere:completion: ==> readWithPredicate:completion:
- Instance method queryWhere: ==> queryWithPredicate:
That’s it. As usual, please let us know if you have any suggestions / comments / question either by using our MSDN forum or our UserVoice page.

•• Josh Twist (@joshtwist) described In-App Purchase and Mobile Services in a 4/8/2013 post:
At CocoaConf Dallas this weekend I attended a great presentation by Manton Reece on In-App purchases and subscriptions. In it, he cited a few key points:
- Ideally you would load the list of product IDs from a cloud service rather than baking them into your application
- You should verify your receipts on the server and not trust the client (it's extremely easy to cheat if you do).
- Ideally, the enforcement of your subscription should also occur on the server, because we never trust the client.
Since Mobile Services is…
- Good at storing and fetching data in the cloud
- Capable of executing server code and making HTTP requests from the server to other services
- Understands users and allows developers to enforce an authorization policy
... I thought it would be fun to explore how easy it would be to implement this with Windows Azure Mobile Services.
Note - this is not a tutorial on In-App Purchase. Manton mentioned that he would blog the content from his presentation in which case I'll link to this from here. In the meantime - here are the apple docs which are pretty thorough.
To demonstrate the idea, we're going to take the Mobile Services quickstart and make it subscription based. That is, in order to use the app you must pay a weekly fee otherwise the server will deny access. This will be validated and enforced on the server and associated with a particular user. So if I login to another iOS device and have already paid my subscription - the server will automatically let me use the service based on who I am.
Since we're handling users, we need to add login to our application - to save me from boring you with this code here, check out our easy to follow authentication tutorial or watch Brent's 10 minute video: Authenticating users with iOS and Mobile Services.
Now for the in-app purchase stuff. Assumptions:
- you've configured an app in the iOS provisioning portal for in-app purchase
- you've created some auto-renewable subscriptions for you to play with (I called mine com.foo.weekly, com.foo.monthly)
- you've created some test users in itunes connect to 'buy' subscriptions
Phase I - retrieving the Product IDs
This is straightforward since reading data from Mobile Services is extremely easy. I created a new table 'products' and set all permissions except READ to 'Only Script and Admins' (private). READ I set to Only Authenticated Users because they shouldn't be buying stuff without logging in, that's a requirement of my example (but not all, others may choose to make this data completely public).
First, we need to add some new code to the QSTodoService class, including these properties (not public, so just in the .m file)
// add an MSTable instance to hold the products @property (strong, nonatomic) MSTable *productsTable;// add an MSTable instance to hold the receipts @property (strong, nonatomic) MSTable *receiptsTable;
// add an array property to store the product data loaded from your mobile service @property (strong, nonatomic) NSArray *productData;
// add an array property to the topo of QSTodoService.m @property (strong, nonatomic) NSArray *products;
// add a completion block for the loadproducts callback @property (nonatomic, copy) QSCompletionBlock loadProductsComplete;
And don't forget to initialize those tables in the init method:
self.productsTable = [self.client tableWithName:@"products"]; self.receiptsTable = [self.client tableWithName:@"receipts"];We now need to adjust the code that runs after a successful login to load the products data into an array. Add the following method to your QSTodoService.m and the appropriate signature to your .h file. Note you'll need to link to StoreKit.framework
QSTodoService will also need to implement two protocols to complete the walkthrough. I added these in QSTodoService.m as follows:
@interface QSTodoService()Notice I added UIAlertViewDelegate too, to save time later. We'll need to implement two methods to satisfy these protocols
Notice how we store the products in our products array property. Finally, we add a call to loadProducts to the login callback in QSTodoListViewController
Phase II - enforce access based on receipts stored in the server
We'll need to prevent people from reading their todo lists if they haven't paid up. We can do this with read script on the todoItem table as follows:
Phase III - add purchasing to the client
Now, we'll add code to the client that listens for the status code 403 and if it has received, prompts the user to subscribe to the service. We'll do this inside refreshDataOnSuccess in QSTodoService.m by adding this code:
To handle the response, you'll need to implement UIAlertViewDelegate's didDismissWithButtonIndex on the QSTodoService.m class (this should probably be on the controller, but this blog post is focused on the concepts - the correct pattern for your app is left as an exercise for the reader). We'll also need to complete our implementation of SKPaymentTransactionObserver above
If this is ever to fire, you'll need to add the QSTodoService class as an observer in the init method
[[SKPaymentQueue defaultQueue] addTransactionObserver:self];For this to work, we'll need to create a receipts table. In this case, all operations are locked down except for INSERT which is set to Only authenticated users. Now for the really important part. It's here that we must check the validity of the receipt. We'll also use a technique that I call 'data-swizzling'. It's a lot like method swizzling (which both JavaScript and Objective-C developers are often familiar). In data-swizzling, we have the client insert one thing, but the server script changes the data that actually gets inserted.
In this case, we'll have the client pass the transaction receipt to the receipts table. But then we'll fire this to the App Store to check if it's valid. If it is, we'll receive a detailed response from Apple with contents of the receipt. This is the data we'll insert into the receipts table, along with the current user's userId.
Phase IV - verifying the receipt with apple and storing it in Mobile Services
This really isn't intended to be a full tutorial on In-App purchase and we don't cover a number of topics including restoration of purchases and more, however, hopefully this post has shown how you can leverage Mobile Services to provide a comprehensive In-App Purchase Server and protect your services from customers that haven't paid.
Here's a snap of some of the data stored in my receipt's table, returned from Apple (including our own userId)
And here’s an animated gif showing the flow:





•• Brian Hitney produced Microsoft DevRadio: (Part 4) Using Windows Azure to Build Back-End Services for Windows 8 Apps – Azure Mobile Services on 4/8/2013:
Abstract:
In Part 4 of of their “Using Windows Azure to Build Back-End Services for Windows 8 apps” series Peter Laudati, Brian Hitney and Andrew Duthie show us how to build the same game leaderboard service on top of Windows Azure Mobile Services. Tune in as Andrew demos for us how to get started as well as lays out what some of the +/- are for using Azure Mobile Services for this kind of service. Check out the full article here.
Watch Part 1 | Part 2 | Part 3
After watching this video, follow these next steps:
Step #1 – Try Windows Azure: No cost. No obligation. 90-Day FREE trial.
Step #2 – Download the Tools for Windows 8 App Development
Step #3 – Start building your own Apps for Windows 8
Subscribe to our podcast via iTunes or RSS
If you're interested in learning more about the products or solutions discussed in this episode, click on any of the below links for free, in-depth information:
Register for our Windows Azure Hands-on Lab Online (HOLO) events today!
Blogs:
Videos:
- Microsoft DevRadio: How to Get Started with Windows Azure
- Microsoft DevRadio: (Part 1) What is Windows Azure Web Sites?
- Microsoft DevRadio: (Part 2) Windows Azure Web Sites Explained
- Microsoft DevRadio: How to Integrate TFS Projects with Windows Azure Web Sites
Virtual Labs:
Download
- MP3 (Audio only)
- MP4 (iPod, Zune HD)
- High Quality MP4 (iPad, PC)
- Mid Quality MP4 (WP7, HTML5)
- High Quality WMV (PC, Xbox, MCE)

Nathan Totten (@ntotten) and Nick Harris (@CloudNick) produced Cloud Cover Episode 104: Building cross platform Android and Windows Store apps using Windows Azure Mobile Services on 4/7/2013 (missed when published):
In this episode Nick Harris and Nate Totten demonstrate how you can build cross device platform applications using Windows Azure Mobile Services. In the demo Nick builds both an Android and a Windows Store application that consumes the same set of data from your Mobile Service.


<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data and OData
•• The Data Explorer Team (@DataExplorer) suggested that you Download the latest Data Explorer update: Unpivot feature and search experience improvements in a 4/12/2013 post:
We’d like to let you know that there is an updated build for Data Explorer available. You should see “Auto Update” on your ribbon light up soon. Alternatively, you can go here to download.
In this build, we are introducing a built-in formula for unpivoting columns to rows. Over the past few weeks, many of you have expressed feedback indicating that the ability to unpivot data would be very useful for cleaning up and consuming data for everyday needs. We are happy to provide this as a simple, consistent and intuitive experience.
As an example, consider the following historical population data obtained from the London Datastore.
While this format works well as a report showing population details by year and area, it is not particularly well suited for consumption in analytic/BI scenarios – especially if you were thinking about aggregating or summarizing the data along different dimensions.
Data Explorer now provides the ability to select the columns you would like to unpivot, and accomplish the task in a single click. Here’s the Unpivot menu option you can apply over a selection of columns:
The result of unpivoting yields the following table:
And a few more Data Explorer transformations gives you a nice cleaned up table that can be used for summarizing, or for consumption in PowerPivot or Power View.
This update of Data Explorer also includes a better experience for browsing and using search results. You no longer have to click on the tiny “Use” link in the search results pane – instead you can click on the search result itself. This was a point of confusion for many users, and we hope this improves the general experience.
As always, there are dozens of bug fixes in the update as well.
We hope you enjoy this latest build. Let us know what you think!







•• Derrick Harris (@derrickharris) contributed Microsoft brings 3-D maps to Excel users to the chorus with a post to GigaOm pro on 4/11/2013:
The PC market might be a hot mess right now, but anyone using a Windows machine for data analysis might be rejoicing a bit thanks to a new Excel add-on called GeoFlow. It’s a tool for visualizing geospatial and temporal data, a use case that’s only going to become more common as the internet of things becomes more real and sensors make when and where are as critical as how much.
And now, if you have up to a million rows of these types of data and are on a newish Windows machine, GeoFlow will let you plot the data over Bing Maps. The visualizations actually look pretty good, and time lapse capabilities are always good when time is a variable.
I also like Microsoft’s focus on using the tool for storytelling, citing the ability to share findings through “cinematic, guided video tours.” Even though visualizations are getting much better, more impressive and interactive — especially online — telling a good story with complex data is still pretty difficult.
Of course, GeoFlow is only in Preview mode, so it’s possible there are kinks to work out. And, who knows, maybe early users will roundly dismiss it.
One of California ISO’s massive control rooms:
But it’s definitely trying to solve an increasingly important problem — something you can see at a far greater scale in the work the California ISO is doing with a startup called Space-Time Insight. Other startups — like TempoDB and SpaceCurve (see disclosure)– are even dedicated to building databases to address the oncoming deluge of this data.
GeoFlow actually comes from much larger-scale project, too, for what it’s worth. In a Microsoft Research blog post on Thursday, the company talks about its roots as part of the Worldwide Telescope project that let users explore a high-resolution, interactive map of the universe.
Disclosure: Reed Elsevier, the parent company of science publisher Elsevier, is an investor in SpaceCurve as well as Giga Omni Media, the company that publishes GigaOM.




More disclosure: I’m a registered GigaOm Analyst.
•• Andrew Brust (@andrewbrust) asserted “At the PASS Business Analytics Conference in Chicago, Microsoft announces a public preview of GeoFlow and pumps Excel as the hub for data discovery” in a summary of his With GeoFlow, Microsoft doubles-down on analytics in Excel post of 4/11/2013 from the PASS 2013 conference:
While Gartner and IDC are busy discussing Microsoft's losing ground in the consumer market to Apple and Google, maybe they should consider discussing the gains Microsoft is making against its competitors in the business analytics space.
During the opening keynote at the PASS Business Analytics conference today, Microsoft Technical Fellow Amir Netz and Director of Program Management for Business Intelligence, Kamal Hathi, were busy showing off the kind of data discovery work that business users can do inside Excel.
Disclosure: I am a speaker at the PASS Business Analytics Conference and was involved in its early planning.
8-bit beginnings
Netz came to Microsoft from Israeli BI company Panorama, when the former acquired technology from the latter that would become SQL Server Analysis Services. Netz told the story, complete with photos, of growing up in Israel, being given an Apple II computer by his parents, and becoming fascinated with data and spreadsheets. He started with VisiCalc, and eventually began running his own business doing macro programming for Lotus 1-2-3. Soon enough, Netz moved on to Excel, on the Mac.
Netz and Hathi discussed the simplicity of these tools and contrasted that simplicity with today's analytics landscape of DW, ROLAP, MOLAP, ETL, MDM, Hadoop, Hive, Pig, Sqoop, NoSQL and more. The two men explained in a tongue-and-cheek, if somewhat contrived, manner how they yearned for the data tech simplicity of earlier times.
Data idol
And so back to the spreadsheet we went, as Netz and Hathi used Excel 2013, with PowerPivot, Power View and Data Explorer, to go through reams of Billboard chart data and expose interesting factoids about popular music. Along the way, we discovered that Rihanna has single-handedly brought Barbados into the top tier of pop music countries, and that Roxette is Sweden's best pop ensemble, as far as Billboard chart showings go. (I bet you thought it was ABBA; I know I did.)The last phase of the Microsoft duo's demo? An announcement that the company's project "GeoFlow," a 3D geographical data visualization add-in for Excel, is now available as public preview. GeoFlow mashes up Bing Maps and technology from Microsoft Research to render data in time-lapsed, geographic space. Netz demoed the impressive technology and, as a kicker, did so on what looked to be an 80" Perceptive Pixel touch-screen display, morphing the keynote stage into a quasi news studio.
Fun with data
Netz also talked about the importance of making data fun, and showed how visualizations built in Excel can be shared online, on Office 365. In so doing, he alluded to the same emotional, social approach to data discovery that Tableau has built its entire business on, a business it now aims to take public.The PowerPivot, Data Explorer and now GeoFlow add-ins are available for download. Just be aware that GeoFlow requires the "ProPlus" version of Excel 2013 (via volume license, or an Office 365 subscription that provides access to that version of Excel.) Does this put a damper on Microsoft's "BI for the Masses" story? I'd say so, and I'm hoping some other folks will as well.


•• Eron Kelly (@eronkelly) posted Day 2: PASS Business Analytics Conference, New 3D Mapping Analytics Tool for Excel to the SQL Server Team blog on 4/11/2013:
Today at the PASS Business Analytics Conference, Microsoft technical fellow Amir Netz and partner manager Kamal Hathi took to the stage to demonstrate how people experience insights. As mentioned in yesterday’s blog post, understanding how people experience insights is critical to Microsoft as we look to build and improve our data platform.
Today we’re pleased to add another exciting business analytics tool to help customers gain valuable insight from their data. Project codename “GeoFlow” for Excel, available in preview now, is a 3D visualization and storytelling tool that will help customers map, explore and interact with both geographic and chronological data, enabling discoveries in data that might be difficult to identify in traditional 2D tables and charts. With GeoFlow, customers can plot up to a million rows of data in 3D on Bing Maps, see how that data changes over time and share their findings through beautiful screenshots and cinematic, guided video tours. The simplicity and beauty of GeoFlow is something you have to see to understand – check out the video demo and screenshots below. You can also download and try it out firsthand today. It’s an entirely new way to experience and share insights – one we think you’ll enjoy.
For more information on GeoFlow, check out the Excel team’s blog and visit the BI website.
We’ve put a lot of effort into making Excel a self-service BI client, and have worked to equip users with the capabilities they need to take analytics to the next level. Through compelling visualization tools like those in Power View, the modeling and data mashup functionalities in PowerPivot, and the incorporation of a broader range of data types through February’s project codename “Data Explorer” preview, we move toward the democratization of data, and the democratization of insight. GeoFlow takes this one step further, by providing a seamless experience with our other BI tools, and enabling visual storytelling through maps.
Check back here tomorrow for the final installment of this series, where we’ll share some real-life examples of how Microsoft technology contributes to more effective analytics.




• Microsoft’s patterns & practices Team (@mspnp) released an updated alpha version of their Developing Big Data Solutions on Windows Azure guidance on 4/12/2013:
Downloads
Developing Big Data Solutions on Windows Azure: documentation, 5422K, uploaded Today - 0 downloads
Release Notes
This is the second drop of the guidance Developing Big Data Solutions in the Cloud.
From the Preface:
Do you know what visitors to your website really think about your carefully crafted content? Or, if you run a business, can you tell what your customers actually think about your products or services? Did you realize that
your latest promotional campaign had the biggest effect on people aged between 40 and 50 living in Wisconsin (and, more importantly, why)?Being able to get answers to these kinds of questions is increasingly vital in today's competitive environment, but the source data that can provide these answers is often hidden away; and when you can find it, it's very difficult to analyze successfully. It might be distributed across many different databases or files, be in a format that is hard to process, or may even have been discarded because it didn’t seem useful at the time.
To resolve these issues, data analysts and business managers are fast adopting techniques that were commonly at the core of data processing in the past, but have been sidelined in the rush to modern relational database systems and structured data storage. The new buzzword is “Big Data,” and the associated solutions encompass a range of technologies and techniques that allow you to extract real, useful, and previously hidden information from the often very large quantities of data that previously may have been left dormant and, ultimately, thrown away because storage was too costly.
In the days before Structured Query Language (SQL) and relational databases, data was typically stored in flat files, often is simple text format, with fixed width columns. Application code would open and read one or more files sequentially, or jump to specific locations based on the known line width of a row, to read the text and parse it into columns to extract the values. Results would be written back by creating a new copy of the file, or a separate results file.
Modern relational databases put an end to all this, giving us greater power and additional capabilities for extracting information simply by writing queries in a standard format such as SQL. The database system hides all the complexity of the underlying storage mechanism and the logic for assembling the query that extracts and formats the information. However, as the volume of data that we collect continues to increase, and the native structure of this information is less clearly defined, we are moving beyond the capabilities of even enterprise level relational database systems.
Big Data solutions provide techniques for storing vast quantities of structured, semi-structured, and unstructured data that is distributed across many data stores, and querying this data where it's stored instead of moving it all across the network to be processed in one location—as is typically the case with relational
databases. The huge volumes of data, often multiple Terabytes or Petabytes, means that distributed queries are far more efficient than streaming all the source data across a network.Big Data solutions also deal with the issues of data formats by allowing you to store the data in its native form, and then apply a schema to it later, when you need to query it. This means that you don’t inadvertently lose any information by forcing the data into a format that may later prove to be too restrictive. It also means that you can simply store the data now—even though you don’t know how, when, or even whether it will be useful—safe in the knowledge that, should the need arise in the future, you can extract any useful information it contains.
Microsoft offers a Big Data solution called HDInsight, as both an online service in Windows Azure and as an on premises mechanism running on Windows Server. This guide primarily focuses on HDInsight for Windows Azure, but explores more general Big Data techniques as well. For example, it provides guidance on configuring your storage clusters, collecting and storing the data, and designing and implementing real-time and batch queries using both the interactive query languages and custom map/reduce components.
Big Data solutions can help you to discover information that you didn’t know existed, complement your existing knowledge about your business and your customers, and boost competitiveness. By using the cloud as the data store and Windows Azure HDInsight as the query mechanism you benefit from very affordable storage costs (at the time of writing 1TB of Windows Azure storage costs only $95 per month), and the flexibility and elasticity of the “pay and go” model where you only pay for the resources you use.
What This Guide Is, and What It Is Not
Big Data is not a new concept. Distributed processing has been the mainstay of supercomputers and high performance data storage clusters for a long time. What’s new is standardization around a set of open source technologies that make distributed processing systems much easier to build, combined with the need to manage and get information from the ever growing volume of data that modern society generates. However, as with most new technologies, Big Data is surrounded by a great deal of hype that often gives rise to unrealistic
expectations, and ultimate disappointment.Like all of the releases from Microsoft patterns & practices, this guide avoids the hype by concentrating on the “whys” and that “hows”. In terms of the “whys”, the guide explains the concepts of Big Data, gives a focused view on what you can expect to achieve with a Big Data solution, and explores the capabilities of Big Data in detail so that you can decide for yourself if it is an appropriate technology for your own scenarios. The guide does this by explaining what a Big Data solution can do, how it does it, and the types of problems it is designed
to solve.In terms of the “hows” the guide continues with a detailed examination of the typical architectural models for Big Data solutions, and the ways that these models integrate with the wider data management and business information environment, so that you can quickly understand how you might apply a Big Data solution in your own environment.
The guide then focuses on the technicalities of implementing a Big Data solution using Windows Azure HDInsight. It does this by helping you understand the fundamentals of the technology, when it is most useful in different scenarios, and the advantages and considerations that are relevant. This technical good-practice
guidance is enhanced by a series of examples of real-world scenarios that focus on different areas where Big Data solutions are particularly relevant and useful. For each scenario you will see the aims, the design concept, the tools, and the implementation; and you can download the example code to run and experiment with yourself.This guide is not a technical reference manual for Big Data. It doesn’t attempt to cover every nuance of implementing a Big Data solution, or writing complicated code, or pushing the boundaries of what the technology is designed to do. Neither does it cover all of the myriad details of the underlying mechanism—there
is a multitude of books, web sites, and blogs that explain all these things. For example, you won’t find in this guide a list of all of the configuration settings, the way that memory is allocated, the syntax of every type of query, and the many patterns for writing map and reduce components.What you will see is guidance that will help you understand and get started using HDInsight to build realistic solutions capable of answering real world questions.
Who This Guide Is For
This guide is aimed at anyone who is already (or is thinking of) collecting large volumes of data, and needs to analyze it to gain a better business or commercial insight into the information hidden inside. This includes business managers, data analysts, database administrators, business intelligence system architects, and
developers that need to create queries against massive data repositories.The guide includes several examples. Most of these are program language agnostic, although knowledge of TSQL, C#, Java, and the Microsoft .NET Framework will be an advantage when studying the creation of interactive
queries and custom map/reduce components.Why This Guide Is Pertinent Now
Businesses and organizations are increasingly collecting huge volumes of data that may be useful now or in the future, and they need to know how to store and query it to extract the hidden information it contains. This might be webserver log files, click-through data, financial information, medical data, user feedback, or a range of social sentiment data such as tweets or comments to blog posts.
Big Data techniques and mechanisms such as HDInsight provide a mechanism to efficiently store this data, analyze it to extract useful information, and visualize the information in a range of display applications and tools.
It is, realistically, the only way to handle the volume and the inherent semi-structured nature of this data.
No matter what type of service you provide, what industry or market sector you are in, or even if you only run a blog or website forum, you are highly likely to benefit from collecting and analyzing data that is easily available, often collected automatically (such as server log files), or can be obtained from other sources and combined with your own data to help you better understand your customers, your users, and your business; and to help you plan for the future.
A Roadmap for This Guide
This guide contains a range of information to help you understand where and how you might apply Big Data solutions. This is the map of our guide:
- Chapter 1, “What is Big Data?” provides an overview of the principles and benefits of Big Data solutions, and the differences between these and the more traditional database systems, to help you decide where and when you might benefit. This chapter also discusses Windows Azure HDInsight, its place within Microsoft’s wider data platform, and provides a road map for the remainder of the guide.
- Chapter 2, “Getting Started with HDInsight,” explains how you can implement a Big Data solution using Windows Azure HDInsight. It contains general guidance for applying Big Data techniques by exploring in more depth topics such as defining the goals, locating data sources, the typical architectural approaches, and more.
You will find much of the information about the design and development lifecycle of a Big Data solution useful, even if you choose not to use HDInsight as the platform for your own solution.- Chapter 3, “Collecting and Loading Data” explores techniques for loading data into an HDInsight cluster. It shows several different approaches, such as handling streaming data and automating the process.
- Chapter 4, “Performing Queries and Transformations,” describes the tools you can use in HDInsight to query and manipulate data in the cluster. This includes using the interactive console; and writing scripts and commands that are executed from the command line. It also includes advice on testing and debugging queries,
and maximizing query performance.- Chapter 5, “Consuming and Visualizing the Results,” explores the ways that you can transfer the results from HDInsight into analytical and visualization tools to generate reports and charts, and how you can export the results into existing data stores such as databases, data warehouses, and enterprise BI systems.
- Chapter 6, “Configuring, Deploying, and Automating HDInsight,” explores how, if you discover a useful and repeatable process that you want to integrate with your existing business systems, you can automate all or part of the process. The chapter looks at configuring the cluster, deploying your solution, and using workflow tools to automate the process. This chapter is not included in this preview release.
- Chapter 7, “Managing and Monitoring HDInsight,” explores how you can manage and monitor an HDInsight solution. It includes topics such as backing up the data, remote administration, and using the logging capabilities of HDInsight. This chapter is not included in this preview release.
The remaining chapters of the guide concentrate on specific scenarios for applying a Big Data solution, ranging from simple web server log file analysis to analyzing sentiment data such as users’ feedback and comments, and
handling streaming data. Each chapter explores specific techniques and solutions relevant to the scenario, and shows an implementation based on Windows Azure HDInsight. The scenarios the guide covers are:
- Chapter 8, “Scenario 1 - Sentiment Analysis” covers obtaining information about the way that users and customers perceive your products and services by analyzing “sentiment” data. This is data such as emails, comments, feedback, and social media posts that refer to your products and services, or even to a specific topic or market sector that you are interested in investigating. In the example you will see how you can use Twitter data to analyze sentiment for a fictitious company.
- Chapter 9, “Scenario 2 - Enterprise BI Integration” covers one of the most common scenarios for Big Data solutions: analyzing log files to obtain information about visitors or users and visualizing this information in a range of different ways. This information can help you to better understand trends and traffic patterns, plan for the required capacity now and into the future, and discover which services, products, or areas of a website are underperforming. In this example you will see how you can extract useful data and then integrate it with existing BI systems at different levels and by using different tools.
- Chapter 10, “Scenario 3 - Financial Data Analysis”. This scenario covers handling the vast quantities of data generated in the financial world, from simple banking transactions to complex stock trades. One of the major advantages of automating the collection and analysis of all this data is the ability to detect unusual events that may indicate fraudulent activity, as well as using the information to predict future patterns and make appropriate business decisions. This chapter is not included in this preview release.
- Chapter 11, “Scenario 4 - Analyzing Sensor Data”. This scenario covers analyzing usage and activity data send it back to you over the Internet from a range of devices, applications, and services. This may be data generated in response to user actions, data from mobile devices (such as location information), or data from static devices or applications that report status or activity. In fact you may have a multitude of sensors of different types that return data streams, such as web page click-through data, monitoring systems, and other types applications. This chapter is not included in this preview release.
- Finally, Appendix A contains additional information about enterprise data warehouses and BI that you will find helpful when reading Chapter 2 and the Scenarios described in the guide and if you are not familiar with these
systems.

[Emphasis added.]
No significant OData articles today
<Return to section navigation list>
Windows Azure Service Bus, Caching Access Control, Active Directory, Identity and Workflow
Scott Guthrie (@scottgu) announced Windows Azure: Active Directory Release, New Backup Service + Web Site Monitoring and Log Improvements in a 4/8/2013 post:
Today we released some great enhancements to Windows Azure. These new capabilities include:
- Active Directory: General Availability release of Windows Azure AD – it is now ready for production use!
- Backup Service: New Service that enables secure offsite backups of Windows Servers in the cloud
- Web Sites: Monitoring and Diagnostic Enhancements
All of these improvements are now available to start using immediately (note: some services are still in preview). Below are more details on them:
Active Directory: Announcing the General Availability release
I’m excited to announce the General Availability (GA) release of Windows Azure Active Directory! This means it is ready for production use.
All Windows Azure customers can now easily create and use a Windows Azure Active Directory to manage identities and security for their apps and organizations. Best of all, this support is available for free (there is no charge to create a directory, populate it with users, or write apps against it).
Creating a New Active Directory
All Windows Azure customers (including those that manage their Windows Azure accounts using Microsoft ID) can now create a new directory by clicking the “Active Directory” tab on the left hand side of the Windows Azure Management Portal, and then by clicking the “Create your directory” link within it:
Clicking the “Create Your Directory” link above will prompt you to specify a few directory settings – including a temporary domain name to use for your directory (you can then later DNS map any custom domain you want to it – for example: mycompanyname.com):
When you click the “Ok” button, Windows Azure will provision a new Active Directory for you in the cloud. Within a few seconds you’ll then have a cloud-hosted Directory deployed that you can use to manage identities and security permissions for your apps and organization:
Managing Users within the Directory
Once a directory is created, you can drill into it to manage and populate new users:
You can choose to maintain a “cloud only” directory that lives and is managed entirely within Windows Azure. Alternatively, if you already have a Windows Server Active Directory deployment in your on-premises environment you can set it up to federate or directory sync with a Windows Azure Active Directory you are hosting in the cloud. Once you do this, anytime you add or remove a user within your on-premises Active Directory deployment, the change is immediately reflected as well in the cloud. This is really great for enterprises and organizations that want to have a single place to manage user security.
Clicking the “Directory Integration” tab within the Windows Azure Management Portal provides instructions and steps on how to enable this:
Enabling Apps
Starting with today’s release, we are also greatly simplifying the workflow involved to grant and revoke directory access permissions to applications. This makes it much easier to build secure web or mobile applications that are deployed in the cloud, and which support single-sign-on (SSO) with your enterprise Active Directory.
You can enable an app to have SSO and/or richer directory permissions by clicking the new “Integrated Apps” tab within a directory you manage:
Clicking the “Add an App” link will then walk you through a quick wizard that you can use to enable SSO and/or grant directory permissions to an app:
Programmatic Integration
Windows Azure Active Directory supports several of the most widely used authentication and authorization protocols. You can find more details about the protocols we support here.
Today’s general availability release includes production support for SAML 2.0 – which can be used to enable Single Sign-On/Sign-out support from any web or mobile application to Windows Azure Active Directory. SAML is particularly popular with enterprise applications and is an open standard supported by all languages + operating systems + frameworks.
Today’s release of Windows Azure Active Directory also includes production support of the Windows Azure Active Directory Graph – which provides programmatic access to a directory using REST API endpoints. You can learn more about how to use the Windows Azure Active Directory Graph here.
In the next few days we are also going to enable a preview of OAuth 2.0/OpenID support which will also enable Single Sign-On/Sign-out support from any web or mobile application to Windows Azure Active Directory.
For a more detailed discussion of the new Active Directory support released today, read Alex Simons’ post on the Active Directory blog. Also review the Windows Azure Active Directory documentation on MSDN and the following tutorials on the windowsazure.com website.
Windows Azure Backup: Enables secure offsite backups of Windows Servers in the cloud
Today’s Windows Azure update also includes the preview of some great new services that make it really easy to enable backup and recovery protection with Windows Server.
With the new Windows Azure Backup service, we are adding support to enable offsite backup protection for Windows Server 2008 R2 SP1 and Windows Server 2012, Windows Server 2012 Essentials, and System Center Data Protection Manager 2012 SP1 to Windows Azure. You can manage cloud backups using the familiar backup tools that administrators already use on these servers - and these tools now provide similar experiences for configuring, monitoring, and recovering backups be it to local disk or Windows Azure Storage. After data is backed up to the cloud, authorized users can easily recover backups to any server. And because incremental backups are supported, only changes to files are transferred to the cloud. This helps ensure efficient use of storage, reduced bandwidth consumption, and point-in-time recovery of multiple versions of the data. Configurable data retention policies, data compression, encryption and data transfer throttling also offer you added flexibility and help boost efficiency.
Managing your Backups in the Cloud
To get started, you first need to sign up for the Windows Azure Backup preview.
Then login to the Windows Azure Management Portal, click the New button, choose the Recovery Services category and then create a Backup Vault:
Once the backup vault is created you’ll be presented with a simple tutorial that will help guide you on how to register your Windows Servers with it:
Once the servers are registered, you can use the appropriate local management interface (such as the Microsoft Management Console snap-in, System Center Data Protection Manager Console, or Windows Server Essentials Dashboard) to configure the scheduled backups and to optionally initiate recoveries. You can follow these tutorials for these:
- Tutorial: Schedule Backups Using the Windows Azure Backup Agent This tutorial helps you with setting up a backup schedule for your registered Windows Servers. Additionally, it also explains how to use Windows PowerShell cmdlets to set up a custom backup schedule.
- Tutorial: Recover Files and Folders Using the Windows Azure Backup Agent This tutorial helps you with recovering data from a backup. Additionally, it also explains how to use Windows PowerShell cmdlets to do the same tasks.
Within the Windows Azure Management Portal, you can drill into a backup value and click the SERVERS tab to see which Windows Servers have been configured to use it. You can also click the PROTECTED ITEMS tab to view the items that have been backed up from the servers,
Web Sites: Monitoring and Diagnostics Improvements
Today’s Windows Azure update also includes a bunch of new monitoring and diagnostic capabilities for Windows Azure Web Sites. This includes the ability to easily turn on/off tracing and store trace + log information in log files that can be easily retrieved via FTP or streamed to developer machines (enabling developers to see it in real-time – which can be super useful when you are trying to debug an issue and the app is deployed remotely). The streaming support allows you to monitor the “tail” of your log files – so that you only retrieve content appended to them – which makes it especially useful when you clicking want to check something out without having to download the full set of logs.
The new tracing support integrates very nicely with .NET’s System.Diagnostics library as well as ASP.NET’s built-in tracing functionality. It also works with other languages and frameworks. The real-time streaming tools are cross platform and work with Windows, Mac and Linux dev machines.
Read Scott Hanselman’s awesome tutorial and blog post that covers how to take advantage of this new functionality. It is very, very slick.
Other Cool Things
In addition to the features above, there are several other really nice improvements added with today’s release. These include:
- HDInsight: We launched our new HDInsight Hadoop Service 3 weeks ago. Today’s update adds the ability to see diagnostic metrics for your HDInsight services in the Windows Azure Management Portal (they are surfaced in the dashboard view now – just like every other service). This makes it really easy to monitor the number of active map and reduce tasks your service currently is processing.
- Operation Logs: The Windows Azure operation audit logs (which you can view by clicking the “Settings” tab on the left of the Windows Azure Management Portal) now shows the user account name who performed each operation on the account. This makes it much easier to track who did what on your services.
- Media Services: You can now choose from a wider variety of presets when encoding video content with the portal.
- Virtual Machines: We have increased the default OS disk size for new VMs that are created, and now allow you to specify the default user name for the VM.
Summary
The above features are now available to start using immediately (note: some of the services are still in preview). If you don’t already have a Windows Azure account, you can sign-up for a free trial and start using them today. Visit the Windows Azure Developer Center to learn more about how to build apps with it!












Vittorio Bertocci (@vibronet) continued his series with Walkthrough #3: Developing Multi-Tenant Web Applications with Windows Azure AD on 4/9/2013:
Yesterday Windows Azure Active Directory became generally available. As part of the launch we provided three tutorials that not only show you how to tackle important scenarios end to end, but they are also full of useful tricks that can be reused even in different contexts.
As I did yesterday for Walkthrough #1: Adding Sign-On to Your Web Application Using Windows Azure AD, here I am going to call out (for your and search engines’ benefit) the pieces of reusable guidance you can find in Walkthrough #3: Developing Multi-Tenant Web Applications with Windows Azure AD.
You might wonder: what happened to Walkthrough #2? Well, since I didn’t write it (Ed did) I don’t want to risk misrepresenting its content. [Link added below. --rj]
Among other things, the tutorial will teach you:
- How to use the Windows Azure portal to
- “promote” one single tenant application to be available to any other Windows Azure AD tenant admin who consent to grant it directory access rights
- work with the application configuration settings
- Modify WIF settings to handle authentication requirements action by action, as opposed to the default blanket authentication
- change config setings, write a custom Account controller for generating sign n messages programmatically
- integrate with forms authentication redirect mechanisms
- Write a custom ValidatingIssuerNameRegistry implementation to hold a list of issuers outside of the web.config
- Use the Windows Azure AD “tenantless endpoint” to handle sign in flow for multiple tenants at once
- Write logic for refreshing signature check keys in the out-of-web.config custom ValidatingIssuerNameRegistry store
- Implement organizational sign-up: Windows Azure AD consent URL generation logic and associated consent response handling
- Experience just-in-time onboarding
That is quite the list! And yet: if you wrote multi tenant apps handling identity in the past, I am sure you’ll be pleasantly surprised by how easy Windows Azure AD makes the entire thing. Head to the walkthrough and get your hands dirty!



Walkthrough #2 is Using the Graph API to Query Windows Azure AD. It appears Vittorio forgot to include a link.
Vittorio Bertocci (@vibronet) began a series with Walkthrough #1: Adding Sign-On to Your Web Application Using Windows Azure AD on 4/8/2013:
[Art by Sean.]
As you probably already heard, today Windows Azure AD GA’d. Yeahh!
Earlier today I gave a super quick overview of the new features, and I mentioned that Edward Wu and myself inked the first walkthroughs guiding you through the main scenarios supported in this release.
Those documents are massive, more than a 100 Word pages in total. They’re also chock-full of actionable tricks and sub-tasks, that can come in handy also outside of the scenario described by the walkthrough itself but can also be hard to find.
In this post (and the next) I’ll highlight some of the key areas covered by the walkthroughs, hoping that (with the help of the search engines) this will help you to connect you with the content carrying the answer you seek.
Let’s start with “Adding Sign-On to Your Web Application Using Windows Azure AD”. As the name suggests, this tutorial helps you to provision, develop and deploy a single-tenant web application which uses Windows Azure AD for authentication. Among other things, the tutorial will teach you:
- How to use the Windows Azure portal to
- create a new Windows Azure AD directory tenant, as part of your Microsoft Account-based Windows Azure subscription
- create new directory users
- register an application to enable Web sign on
- How to use the Identity and Access Tool for Visual Studio 2012 to configure an MVC 4 app to connect with your Windows Azure AD tenant for sign on
- What claims you can expect to receive (full list and semantic)
- How to code federated sign out for your app
- How to code automatic refresh of the Windows Azure AD signing keys to automatically handle rollover
- How to modify the identity settings in the portal and in config to deploy your application to Windows Azure Web Sites
- How to interpret all of the WIF-related config elements that are necessary for the scenario to work
Not bad, right? The sign out and automatic keys refresh are definitely topics that would deserve their own posts (in fact I have them in the pipeline, the key refresh one is already out) but the others as well can occasionally save the day.
Hopefully this will entice you to read and follow the walkthrough! If you do, please let us know how we can improve those.



Alex Simons (@Alex_A_Simons) reported Windows Azure Active Directory: Ready for Production with over 265 Billion Authentications & 2.9 Million Organizations Served! on 4/8/2013:
Last week we shared how Enterprises can benefit by integrating Windows Azure into their business strategy. Having a strong enterprise identity strategy is a key component for enabling new applications and infrastructure in the cloud. Today, we’re excited to share that Windows Azure Active Directory (AD) has reached general availability and is now ready for production use!
Windows Azure Active Directory is the world’s largest cloud based, enterprise quality, internet scale Identity and Access Management Solution. Today over 2.9 million businesses, government bodies and schools are already enjoying the benefits of Windows Azure Active Directory, using it to manage access to Office365, Dynamics CRM online, Windows Intune and Windows Azure.
Windows Azure AD is a cloud based Identity Service built to support global scale, reliability and availability for our customers and comes at no cost for the base directory. This cloud based directory makes it easy to:
- Manage employee access to cloud based line-of-business apps, Microsoft cloud services like Office 365, and third party SAAS applications.
- Deliver a Single Sign-On experience for cloud applications eliminating the need for multiple usernames and passwords and limiting helpdesk calls and password resets.
- Revoke access to cloud based business applications when an employee leaves the company or changes jobs.
- Manage federation and access to cloud facing services for partners and customers.
Windows Azure AD is an enterprise grade, high availability cloud service run from 14 datacenters spread across the United States, Europe and Asia. Over the last 90 days, Windows Azure AD has processed over 65 billion authentication requests while maintaining 99.97% or better monthly availability. No other cloud directory offers this level of enterprise reliability or proven scale.
For companies who already run Windows Server Active Directory on-premises, Windows Azure AD is a natural extension for enabling existing identities in the cloud. Based on open standards including SAML, OData and WS-FED, Windows Azure AD works with any modern browsers running on a PC, tablet or mobile device and can be easily integrated into applications running on a multitude of platforms from Microsoft and 3rd parties.
In making Windows Azure AD available for production usage, we’ve also made two feature improvements Windows Azure Customers and cloud application developers will be interested in:
- Ability to add a Windows Azure Active Directory to your Azure subscription for customers who use Microsoft accounts for logging into Azure.
- Granting and revoking application directory access permissions have been greatly simplified.
With this latest release, existing Windows Azure customers who log in using a Microsoft account can now add a Windows Azure AD tenant and use it to manage access to Azure for their employees with either Microsoft accounts or Azure AD accounts.
We’ve also updated our samples and developer documentation with the biggest updates to the application registration process, so if you are a developer, you’ll definitely want to read up on that. You can find all of our documentation including step by step guides protocols and APIs, how to manage your tenant including managing users, setting up 2FA, and extending your on-premises AD to AAD.
Throughout the developer preview over 3500 companies tried Windows Azure Active Directory. I’d like to thank all of you who participated for your interest, participation and feedback – your efforts have been invaluable to us!
Finally, I’d like to close by inviting all of you to get your own Windows Azure AD cloud directory today. All you have to do is sign up for Windows Azure Trial.



<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
WenMing Le (@wenmingle) explained Data Science in a Box using IPython: Installing IPython notebook (2/4) on 4/9/2013:
In the previous blog, we demonstrated how to create a Windows Azure Linux VM in detail. We will continue the installation process for the IPython notebook and related packages.
Python 2.7 or 3.3
One of the discussions that happened at the Python in Finance conference is which version of Python you should use? My personally opinion is that unless you have a special need, you should stick with Python 2.7. 2.7 comes as the default on most of the latest Linux distros. Until 3.3 becomes the default Python interpreter on your OS, it is better to use 2.7.
The Basics of package management for Python
There are several ways you can get Python packages installed. The easiest is probably by running the OS default installer, but sometimes it may not have the latest version in the version of Linux you are running. For Ubuntu, apt-get is the installer for the OS. apt-get will install your packages in
/usr/lib/python/dist-packages.Another option is to use easy_install. Easy install is part of Python, not part of the Ubuntu OS. We need to have python-setuptools package installed using apt-get first, before being able to use it. If you use easy_install, all your packages will end up in /usr/
local/lib/python/site-packages instead.
type sudo apt-get install python-setuptools
PIP is another tool for installing and managing python packages, it is recommended over easy_install. For our purposes, we simply will use which ever of these tools that can install our packages easily and correctly.
Type sudo apt-get install python-pip. This might take a few minutes as pip has many dependency packages that it must install.
Installing IPython, Tornado web server, Matplotlib and other packages
Matplotlib is a popular 2D plotting library, it is one of IPython notebook’s component. As you interact with the Notebook, plots are generated on the server using matplotlib and sent for displaying in your web browser.
To install, type: sudo apt-get install python-matplotlib
IPython notebook is browser based, it uses the Tornado webserver. The Python-based Tornado webserver supports web sockets for interactive and efficient communication between the webserver and the browser.
To install, type: sudo apt-get install python-tornado
Upon completion, we will now install Python itself. The IPython team recommends installing through easy_install to get the latest package from their website.
sudo easy_install http://github.com/ipython/ipython/tarball/master
This should install version 1.0 dev version of IPython.
We also need to install a package called Pyzmq, Zero MQ is a very fast networking package that IPython uses for its clustered configuration. IPython is capable of interactively controlling a cluster of machines and run massively parallel Big Compute and Big Data applications.
Type: sudo apt-get install python-zmq
Finally, Jinja2, is a fast, modern and designer friendly templating language for Python is is now required for IPython notebook.
Type: sudo apt-get install python-jinja2
Configuring IPython notebook
Type: ipython profile create nbserver to create a profile. The command generates a default in your home directory under .ipython/profile_nbserver/ipython_config.py Note that any directory starts with a “.” is a hidden directory in Linux. You must type ls –al to see it.
The .ipython directory is shown below in blue.
Once we’ve created a profile, the next step is to create an SSL certificate and generate a password to protect the notebook webpage.
Type: cd ~\.ipython\profile_nbserver to switch into the profile we just created.
Then, type: openssl req -x509 -nodes -days 365 -newkey rsa:1024 -keyout mycert.pem -out mycert.pem to create a certificate. Below is a sample session we used to create the certificate.
Since this is a self-signed certificate, the notebook your browser will give you a security warning. For long-term production use, you will want to use a properly signed certificate associated with your organization. Since certificate management is beyond the scope of this demo, we will stick to a self-signed certificate for now.
The next step is to create a password to protect your notebook.
Type: python -c "import IPython;print IPython.lib.passwd()" # password generation
Next, we will edit the profile's configuration file, the
ipython_notebook_config.pyfile in the profile directory you are in. This file has a number of fields and by default all are commented out. You can open this file with any text editor of your liking, and you should ensure that it has at least the following content, you may use either the Unix vi editor or nano which would be easier for beginners.Make sure you make a copy of the sha1:c70c9b9671ef:43cf678c8dcae580fb87b2d18055abd084d0e2ad string you got from the python password generator line above.
Type: nano ipython_config.py
This will go into the editor, copy the appropriate line into your editor. Note # is the comment sign for Python.
c = get_config() # This starts plotting support always with matplotlib c.IPKernelApp.pylab = 'inline' # You must give the path to the certificate file. # If using a Linux VM: c.NotebookApp.certfile = u'/home/azureuser/.ipython/profile_nbserver/mycert.pem' # Create your own password as indicated above c.NotebookApp.password = u'sha1:c70c9b9671ef:43cf678c8dcae580fb87b2d18055abd084d0e2ad' #use your own # Network and browser details. We use a fixed port (9999) so it matches # our Windows Azure setup, where we've allowed traffic on that port c.NotebookApp.ip = '*' c.NotebookApp.port = 8888 c.NotebookApp.open_browser = FalseConfigure the Windows Azure Virtual Machines Firewall
This was done in Post 1 of this blog series. Please see Create your first Linux Virtual Machine section of the blog.Run the IPython Notebook
At this point we are ready to start the IPython Notebook. To do this, navigate to the directory you want to store notebooks in and start the IPython Notebook Server:
Type: ipython notebook --profile=nbserverYou should now be able to access your IPython Notebook at the address
https://[Your Chosen Name Here].cloudapp.net.In our case it is: https://ipythonvm.cloudapp.net
Type in the Password you set when you ran the python -c "import IPython;print IPython.lib.passwd()" command.
Once logged in, you should see an empty directory. Click on “New NoteBook” to start.
To reward your hard work, we’ll have IPython notebook plot a few donuts for us. You can copy and paste the code from: http://matplotlib.org/examples/api/donut_demo.html Please your cursor to the end of the last line, Press shift + Enter to run the code right after the last line. If all goes well, you should see a set of 4 chocolate donuts almost instantly.
Conclusion
In the second part of this blog series, we showed you the minimum steps to install the IPython notebook inside a Windows Azure VM running Linux Ubuntu 12.10. In the next blog, we’ll take a look at a few popular, common packages for machine learning, data analysis, and scientific Computing. If you have questions, please contact me at @wenmingye on twitter.













WenMing Le (@wenmingle) began a four-part series with Data Science in a Box using IPython: Creating a Linux VM on Windows Azure (1/4) on 4/9/2013:
I just returned from the Python in Finance Conference in New York, I would like to thank Bank of America and Andrew Shepped organizing the event. It was not difficult to see the popularity of Python in the financial community; the event was quickly sold out with over 400 attendees. I gave a 35 minute talk on Python and Windows Azure, and was pleasantly surprised by the amount of interests from the audience and there after. The purpose of this tutorial series is to help you to get IPython notebook installed and start playing with machine learning, and other data science packages in Python.
IPython: Convenience leads to mainstream popularity
One Python package that really stood out at the conference was the IPython notebook. Almost every single presenter mentioned the greatness of IPython notebook. It is a web based Python environment that makes sharing Python code/projects that much easier. IPython was developed by my former colleagues from Tech-X corp and alumni, Brian Granger and Fernando Perez from the CU Boulder Physics dept. Over the years, I have collaborated, and helped to fund some of the work for the project to get IPython running smoothly, especially on Windows HPC Server and on Windows Azure cluster. It is good to see these investments have paid off and benefited the Python community greatly. Most recently, Microsoft External Research has made a sizable donation to the IPython foundation to further support the community, the announcement was made at PyCon this year.
Due to high demand from recent conferences, we’ll do a walk through of the installation process with more details for those who are new to either IPython or Windows Azure. The original instructions can be found on the official site of Windows Azure.
Windows Azure free trial sign up
Windows Azure is Microsoft’s Cloud platform, [which] supports both Windows, and Linux VMs. The free trial gives you 3 months free with 750 core hours each month, 70 GB free storage and so on. The Sign up process is quick and completely risk free, your credit card will NOT be charged until you specifically instructing Azure to do so. You will need a liveID.
Sign up link: http://www.windowsazure.com/en-us/pricing/free-trial/?WT.mc_id=directtoaccount_control
Login and sign up for the Virtual Machine Preview Feature
Since Windows Azure Virtual Machines or our IaaS (infrastructure as a service) is still in preview, you will need to log in through the portal and then enable the preview feature at: https://account.windowsazure.com/PreviewFeatures
Click on Try it now to enable the preview feature. You will get queued for approval. This process may take a few minutes to a day depending on availability. For us, it became available instantly by going back to and refresh the Windows Azure dashboard.
Upon signing up for the VM preview feature, Virtual Machines menu item appears in the dashboard.
Create your first Linux Virtual Machine
IPython works really well for both Windows and Linux instances. In this tutorial, I would like to take this opportunity to show majority of the readers here who are Windows users how to get up and running on Linux. As I believe that a good developer should be tools and platform agnostic.
Click on +NEW, then select Compute and Virtual Machine
Use the QUICK CREATE option. Fill out the fields with DNS Name, this is the name of your machine. I picked Ubuntu 12.10, this is a preferred VM on the IPython development team. You may want to pick a smaller VM size for the trial, as it may run out much quicker with the Extra large. Pick a Secure Password. It is also recommended that you pick a data center closer to where you are. Click on Create A virtual Machine. A Virtual machine along with a storage account will be automatically created for you.
To understand how IaaS Virtual Machines work, please take a look at the diagram below. Windows Azure virtual machines are much more advanced than simple machine hosting. When we normally buy a server box, we use its disks for keeping the OS and data, but if the disk dies it will have to be replaced. If the server dies, we will have to get a new server. In Windows Azure Virtual machine, a user no longer have to worry about such hardware failures or down time. In case there’s hardware failures on the physical host that hosts your VM, your VM can be moved onto a different host. In order to do this, the VM does not use local physical hard drive, but instead it uses virtual drives sitting on Windows Azure Storage remotely. Windows Azure Storage keeps 3 copies of your Image in case of physical drive failures on Windows Azure storage itself. Such architecture gives us flexibility, reliability and great service level for preventing down time. You can also attach multiple drives to the VM depending on its size. For an extra large instance, we can attach up to 16 drives at 1TB each. You can read more about Windows virtual machines here.
It only takes a few minutes to provision a Windows Azure Virtual Machine. IPythonVM’s status is now running.
Configuring your VM for log in
SSH details or the default way of logging into a Linux machine are at the bottom of the Dashboard page. In case you want to change the port to its default 22 instead of randomly selected port 50390 listed here, you will need to do that on the End points Tab at the top of the page.
Click on Edit the endpoint at the bottom and change the public port to 22 from 50390. This may take a few seconds for the changes to reflect.
To expose the IPython notebook webserver, we need to add an additional end point. We will be running the web server internally at port 8888, and expose it at 443 as the public end point.
Click on Add Endpoint
Port 443 has been created for the IPython VM.
Log into Your Windows Azure Linux VM
Download Putty or your favorite SSH client to login. Use the full hostname displayed on the dashboard for your VM.
Accept the remote SSH key, then type in your user name and password to login. By default it is azureuser and the passwd you created.
Security Updates and patches
Linux machines that are not secure are the primary attack targets on the internet. [It] is advised that you immediately and frequently update your VM with security patches. The commands are simple:
- sudo apt-get update // note that sudo allows you to run command as the super user (root), you will need to type in your own password.
- sudo apt-get upgrade // once in a while you may want to upgrade your packages too.
- adduser allows you to add additional users.
update command results above.
upgrade may ask for user input and will take a while to complete.
Conclusion
This is the first in a blog series that shows you how to turn a Windows Azure VM into a powerful IPython-based machine learning in a box solution. If you have questions please contact me via @wenmingye on twitter. In the next tutorial we are ready to get all the Python packages installed.























<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
•• Brian Benz (@bbenz) announced MS Open Tech releases open source Jenkins plugin for using Windows Azure Blob service as a repository in a 4/12/2013 post to the Interoperability @ Microsoft blog:
Continuous integration (CI), where software teams integrate their work continuously into frequent builds in an Agile environment, has been around for a relatively long time. Tools for managing the CI process have been around too, and have been gaining in popularity in the last few years, as the CI process becomes more complicated and the benefits of CI become more obvious. CI tools can be used in conjunction with existing SCM version control tools to manage today’s complex build, test and deployment processes that SCM tools and processes don’t cover completely on their own.
Jenkins is a popular open source CI tool, with many installations and extensions, as well as strong community commitment. For this reason Microsoft Open Technologies, Inc. has released a Jenkins plugin for using Windows Azure’s Blob Storage service as a repository of build artifacts.
Using our Jenkins plugin can improve your CI process by using the Windows Azure Storage plugin to manage artifact storage in a Windows Azure Blob. Choosing the Windows Azure Blob service to store your build artifacts ensures that you have all the resources you need each time a build is required, all in a safe and reliable yet centralized location, with configurable access permissions. This takes a load off on-premise network bandwidth and storage, and improves continuous build performance.
We’ve also open-sourced our plugin to share with the community. Source code for the plugin is available on Github here.
Setting up a Jenkins Continuous Integration Server on Windows Azure
The plugin works with any Jenkins CI installation. VM Depot, MS Open Tech’s community-driven repository of Linux Virtual Machines, also has several preconfigured Linux and Jenkins Virtual Machines ready to quickly get Jenkins up and running in a Windows Azure Linux VM. For more information on setting up VM Depot Virtual Machines on Windows Azure, follow this link.
It’s also easy to set up a custom instance of Jenkins on a customized Windows Azure Virtual Machine. Here are some great resources to get started.
For source code versioning and repository management, Jenkins on Windows Azure can use the built-in CVS or Subversion instances that are downloaded with Jenkins, or you can connect to any code management repository source that a plugin exists for, including Team Foundation Server (via the Jenkins TFS plugin), or the GitHub plugin.
Once you have a code repository and a Jenkins instance set up, you’re ready to configure Jenkins for build management and deployment. We’ve created a detailed tutorial here on how to set up and use the plugin.
Configure Jenkins Projects to manage Build Artifacts
To install the plugin, go to Manage Jenkins > Manage Plugins, select the Available Plugins tab and select the Windows Azure Storage Plugin from the Artifact Uploaders Category.
After selecting Install without Restart, you should see a confirmation screen like this one when done:
Set up your Windows Azure Storage Account Configuration
After the plugin is installed, the first step you should take is to configure one or more Windows Azure storage accounts for Jenkins to use. You do that using Jenkins’ Configure System page, in the Windows Azure Storage Account Configuration section:
Configure Projects to use Windows Azure Blob Storage
After you have configured your storage account(s), you can start adding this new Post-Build action to your jobs: Upload artifacts to Windows Azure Blob Storage:
Selecting and configuring this option will enable you to work with your artifacts using Azure Blob Storage services, which helps with management and speed of integration. For more information on the configuration options, please refer to our tutorial.
Next Steps
We’re excited to be participating in the Jenkins ecosystem to enable build artifacts to be stored in Windows Azure storage. As always, we’re looking for ways to make it easier for developers to interact with Windows Azure services in any way we can, so if you have suggestion on what we can do to improve interoperability between Jenkins and Windows Azure, let us know!






•• David Gristwood (@ScroffTheBad) described How Windows Azure helps us weather mad Brits know even more about the weather! in a 4/11/2013 post:
We Brits love to talk about the weather. So, how handy, that as part of the Coalition Government data transparency plans, they publish data from all 150 weather stations and 5,000 forecast sites in the UK. Since launching the data feed, the Met Office datasets have seen a steady increase in the number of data subscriptions – currently registering at a huge 555,000 transactions per month, on average. And the[y] publish which countries are most interested in the data, and yes, the UK is the biggest user, but surprisingly, the US is not far behind:
Microsoft has been supporting the UK Government Transparency Agenda through data.gov.uk, with the hourly Met Office weather opendata feed hosted by Windows Azure Datamarket in the cloud, and this weather data features a staggering 250m rows of data per hour, on average.
Read more about how this has been done, and how you can access this data at Microsoft UK Government Blog


Microsoft Public Relations reported Microsoft Teams Up With NBC Sports Group to Deliver Compelling Sports Programming Across Digital Platforms Using Windows Azure Media Services in a 4/89/2013 press release:
LAS VEGAS — April 9, 2013 — Today at the National Association of Broadcasters Show, Microsoft Corp. and NBC Sports Group announced they are partnering to use Windows Azure Media Services across NBC Sports’ digital platforms, including NBCSports.com, NBCOlympics.com and GolfChannel.com.
Through the agreement, which rolls out this summer, Microsoft will provide both live-streaming and on-demand viewing services for more than 5,000 hours of games and events on devices, such as smartphones, tablets and PCs. These services will allow sports fans to be able to relive or catch up on their favorite events and highlights that aired on NBC Sports Group platforms.
Rick Cordella, senior vice president and general manager of digital media at NBC Sports Group discusses how they use Windows Azure across their digital platforms. [Visit site for video.]
“NBC Sports Group is thrilled to be working with Microsoft,” said Rick Cordella, senior vice president and general manager of digital media at NBC Sports Group. “More and more of our audience is viewing our programming on Internet-enabled devices, so quality of service is important. Also, our programming reaches a national audience and needs to be available under challenging network conditions. We chose Microsoft because of its reputation for delivering an end-to-end experience that allows for seamless, high-quality video for both live and video-on-demand streaming.”
NBC Sports Group’s unique portfolio of properties includes the Sochi 2014 Winter Olympic Games, “Sunday Night Football,” Notre Dame Football, Premier League soccer, Major League Soccer, Formula One and IndyCar racing, PGA TOUR, U.S. Open golf, French Open tennis, Triple Crown horse racing, and more.
“Microsoft is constantly looking for innovative ways to utilize the power of the cloud, and we see Windows Azure Media Services as a high-demand offering,” said Scott Guthrie, corporate vice president at Microsoft. “As consumer demand for viewing media online on any available device grows, our partnership with NBC Sports Group gives us the opportunity to provide the best of cloud technology and bring world-class sporting events to audiences when and where they want them.”
Microsoft has a broad partner ecosystem, which extends to the cloud. To bring the NBC Sports Group viewing experience to life, Microsoft is working with iStreamPlanet Co. and its live video workflow management product Aventus. Aventus will integrate with Windows Azure Media Services to provide a scalable, reliable, live video workflow solution to help bring NBC Sports Group programming to the cloud.
NBC Sports Group and iStreamPlanet join a growing list of companies, including European Tour, deltatre, Dolby Laboratories Inc. and Digital Rapids Corp., which are working with Windows Azure to bring their broadcasting audiences or technologies to the cloud.
In addition to Media Services, Windows Azure core services include Mobile Services, Cloud Services, Virtual Machines, Websites and Big Data. Customers can go to http://www.windowsazure.com for more information and to start their free trial.
…
Read More: Scott Guthrie, Consumer, Business Decision Makers, Cloud Computing, Windows Azure
- Microsoft Teams Up With NBC Sports Group to Deliver Compelling Sports Programming Across Digital Platforms Using Windows Azure April 09, 2013
- Domino’s Pizza, Xerox and Pedcor Count on Microsoft Hyper-V and Private Cloud April 08, 2013
- elicit Helps Improve Your Website’s Searchability April 03, 2013
- App Offers Flurry of Exciting Features for Skiers March 14, 2013
- 'Classed In' Brings Private Social Networks to Schools March 07, 2013


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+

• See Beth Massi (@bethmassi) reported her LightSwitch All Day Training at DevTeach, Toronto in May session on 4/9/2013 in the Cloud Computing Events section below.

Return to section navigation list>
Windows Azure Infrastructure and DevOps
•• David Linthicum (@DavidLinthicum) asserted “The cloud infrastructure standard has grown remarkably fast, but we're just at the beginning of the journey” in a deck for his OpenStack's Grizzly rev: What's new, what it means post of 4/9/2013 for InfoWorld’s Cloud Computing blog:
You can tell the OpenStack conference is almost upon us because a new rev, code-named Grizzly, is about to hit the streets. So what's new in the latest version?
First, it adds support for VMware ESX and Microsoft Hyper-V hypervisors. To this point, OpenStack was largely KVM- and Xen-focused. VMware had been another OpenStack holdout, but it joined the effort last summer (or should I say, jumped on the bandwagon).
Second, there is more scalability. (But isn't there always in new releases?) The new Cells capability also lets customers manage multiple OpenStack compute environments as a single entity.
Finally, there are new block storage options, as well as better drivers and support for storage from Ceph, Coraid, Hewlett-Packard, Huawei, IBM, NetApp, Red Hat (Gluster), SolidFire, and Zadara.
Keep in mind that this new code goes out to the technology providers that use OpenStack, and they have to merge this new code into their code tree. It's going to take some time before testing is complete and it's ready for distribution.
The rise of OpenStack has been nothing but amazing over the last year, and as interest in both open source and cloud computing has exploded, this cloud standard has found both a great niche and many followers. However, interest does not equal deployments. Although OpenStack is widely used, we're not at a point where we can call it an operational success.
There are many missing features in OpenStack that enterprises typically seek in an IaaS cloud, some of which Grizzly has stepped up and provided. However, the maturation of this open source standard will take years. Many companies with many different agendas drive OpenStack, and the dynamic slows down the process. More companies will jump on the bandwagon over the next year, and some will try to highjack OpenStack for their own purposes.
Putting the obvious issues aside around the maturation of a standard, OpenStack seems to be moving right along and is actually exceeding expectations. It's an interesting concept to watch emerge, grow, and now quickly mature. As more OpenStack goes into production, we'll learn more about the true value of this technology standard. I'll keep an eye on it.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
• Charles Babcock (@babcockcw) reported Microsoft Adds Cloud Chargeback To Windows Server in a 4/12/2013 article for InformationWeek’s Cloud Infrastructure blog:
Microsoft has teamed up with a third-party software producer to give Windows Server 2012 and the System Center management system its own billing and chargeback mechanism for use with Microsoft's Azure cloud services.
The third party is Cloud Cruiser, maker of the billing analytics and chargeback system, Cloud Cruiser Enterprise Edition. Cloud Cruiser isn't associated exclusively with Windows Azure cloud services. On the contrary, its system supports supplying billing information through HP Cloud Service Automation 3.1, VMware's vCloud Director and Amazon Web Services' operations API. It also supports supplying billing information with OpenStack-based clouds, including Rackspace, and cloud infrastructure built using Cisco Intelligent Automation for Cloud.
By building use of Cloud Cruiser into Windows Server 2012 and System Center 2012 Service Pack 1, Microsoft is gaining an edge in supporting hybrid cloud operations in its Windows Server customer base. Chargeback is a key component enabling cloud computing and tying responsibility for use to business users.
Microsoft made the announcement Tuesday at the Microsoft Management Summit going on this week at the Mandalay Bay conference center in Las Vegas.
The addition of Cloud Cruiser gives customers interested in hybrid cloud computing "the ability to deploy on-premises, in a hosted cloud and in Windows Azure," said Brian Hillger, director of server and tools marketing. If companies are striving for efficient operations with a combination of on-premises and public cloud computing, adding Cloud Cruiser can increase the effectiveness of such a combination, he said.
Part of the issue with hybrid cloud operation is company employees gain the ability to self provision virtual servers. IT management and business management may or may not be aware of what they're doing and what the likely bill is going to be. Gaining visibility into usage and the likely bill that will result is one of the functions of Cloud Cruiser.
"When customers spin up services across a diverse computing environment, costs can rocket out of control quickly," said Nick van der Zweep, Cloud Cruiser VP of products. By automating chargeback, IT managers can inform business users of the expense of the use associated with their activity and bill their respective departments, if that's the way the company has set up use of Azure. "The more self-service that public and private computing resources become, the more critical is the need for rich cost transparency and financial accountability," van der Zweep said.

<Return to section navigation list>
Cloud Security, Compliance and Governance
Angus Kidman (@gusworldau) listed Top 10 Lesser-Known Facts About Windows Azure Security in a 4/12/2013 post to LifeHacker Australia:
The first rule of cloud security club is that you never talk about cloud security club, but we’ve decided to ignore that rule. Here are ten lesser-known aspects of how Microsoft tries to ensure that its Windows Azure cloud offering stays secure.
“Security’s the biggest blocker not just for Azure adoption but for cloud adoption generally,” Stevan Vidich, director of Windows Azure marketing, noted at the Microsoft Management Summit (MMS) in Las Vegas earlier this week. Presumably to dispel that paranoia, his presentation (which we’ve already drawn on briefly to discuss Microsoft’s future Azure data centre plans) offered up a stack of insights into the approach used to secure Azure.
10. You can go on a tour of the Azure data centres. Customers who are keen to tour one of the eight Azure locations are encouraged to do so. “I tend to have a very different discussion with customers who have gone to Dublin or Chicago or Singapore,” Vidich said. Like most data centres, security is tight: server cages are locked, you can’t enter them without completing two-factor authentication, and the entire facility is monitored 24/7 by video. Nonetheless, if you’re planning on spending big money in Singapore or Amsterdam, the option is there.
9. That won’t help you much if you have nefarious intentions. “There is no way to access Azure on-premises from the physical location,” Vidich said. “You cannot get into the fabric and administer all those facilities. All the administration is done from our network operations centre in Redmond. Being on site does not mean you get to see Azure in action.”
“You cannot walk up and put your finger onto a hard drive and say ‘that’s where my data is’ either, because the fabric will move data as you see fit,” he added. “A sliver of your data might be on a given drive on a day but not on another day.”
8. Penetration testing happens, but you’re not supposed to see it. So you can’t break in physically, but that’s not where most attacks would happen anyway, and we all know it. “Customers are often concerned about specific targeted attacks on their own applications,” Vidich said. “Windows Azure does penetration testing internally with our own teams on a continuous basis We also hire independent third party firms to do pen testing on the platform services.”
That sounds good, but you’ll largely have to take Microsoft’s word for it. “We do not publish or make these pen test results available to customers but we retained NCC Group to do pen testing accreditation for the UK government and that pen test report is available to customers under a non-disclosure agreement.” (We’re back to that cloud security club rule again, aren’t we?)
7. Microsoft staff also have to jump through hoops. To be clear, Microsoft doesn’t make life much easier for its own workers. Forget a staff member trying to jump across networks for a quick peek at the Azure data. “It’s not possible to get into the Azure domain simply by being on our Microsoft corporate Active Directory,” Vidich said.
Even the people writing code for Azure itself are subjected to scrutiny. “We perform full virus scans on all code before deploying. Only code with a clean scan via Forefront will be deployed.”
Obviously there are occasions where staffers do need to access the system (via so-called ‘jump boxes’), but the process is tightly controlled. Access to the Azure fabric requires prior authorisation, the use of a specific two-factor authentication system which requires a smart card, and access is generally restricted to a period of no more than six hours. “We have to be able to provide a full audit trail of these types of activities,” Vidich said.
7. Controlling leeches and DDOS wannabes.. One obvious temptation for hack-happy types would be to try and grab resources from other Azure users, but Vidich says that’s not possible. “The fabric controller will make sure that all of the VMs deployed into the Azure fabric will get the resources they paid for. It’s not possible for an infected VM to consume unlimited resources and starve its neighbours.”
Those protections also reduce the risk of an internal attack. “The packet filtering which we enforce on all traffic originating from VMs prevents spoofing attacks on the platform and stops the VMs from communicating with protected infrastructure devices.”
There are also additional layers designed to reduce the risk of a distributed denial of service (DDOS) attack. “Just about everything in Windows Azure is custom built and proprietary, including protection against DDOS attacks,” Vidich said. “We use standard DDOS mitigation techniques, but we also have dedicated third-party DDOS systems in place. Windows Azure also monitors for internally-initiated DDOS attacks and will remove offending VMs.”
5. Sometimes, you’re on your own. . While Microsoft monitors its fabric for potentially iffy activity, it generally takes a hands-off attitude to individual applications. “It is not possible for us to monitor your individual apps and tell you ‘hey, something funky’s going on’,” Vidich said. In other words: What you do inside your own virtual machines is your own affair.
4. Change happens faster, but not too fast. That hands-off attitude is also evident in the support cycle for Azure apps, which is driven by both security and performance concerns. While the traditional Windows platform has long run on a 5+5model (five years of guaranteed support and five years of extended support), that wasn’t feasible for Azure. “That had to be changed in the world of online services,” Vidich said. “What we did was we came up with the notion of disruptive change. If our changes mean changes to app configuration, we guarantee we’ll give you 12 months notice before making a disruptive change to the platform.” The big lesson? Never assume your code is super-permanent — a healthy attitude when it comes to security as well.
3. Cloud providers throw out hard drives — carefully. Inevitably, hard drives within the Azure data centres are retired. To ensure data isn’t compromised, they are put through a 7-pass wiping process. “Those drives which cannot spin we will physically shred and pulverise,” Vidich said. Awesome, but we’d like to see a video.
2. How to delete your own data. Getting rid of data on your own servers can be challenging. With Azure, built-in systems for redundancy make it even trickier, but it is possible.
“When you put data into Windows Azure storage, we have local redundant storage,” Vidich said. Your data is kept in triplicate across three physically separate domains If one part of the infrastructure goes down, it can provision another copy At any given time, there are always three copies of your data at the primary location. And unless you choose to disable, we will also geo-replicate to a secondary site at least 400 miles away and keep it in triplicate there too.”
So what happens when you decide to wipe something? “When you delete a blob or a table entity, we will immediately delete that entry from the index used to access data at the primary location, and then asynchronously delete it from geo-replicated copies.”
Does that create any risk that someone else might be able to read your data? Vidich offers an empatic ‘no’. “If you check yourself, you won’t find it. Windows Azure customers never have access to raw storage. Before storage can be provisioned, it has to be overwritten. Data is allocated sparsely. When you create a virtual disk, we create a table mapping the virtual disk to physical disk, and it’s empty. The very first time you write to virtual disk, we allocate space then place a pointer into that table. Attempts to read a space they haven’t written to would only return 0s as physical space hasn’t been allocated. Even though we don’t give you a contractual guarantee that says we will overwrite deleted data, we do make it impossible for anyone to provision data that hasn’t been overwritten or to read data that you have deleted.
1. Need logs? Get a lawyer. So with all this protected data, what happens if things get nasty, your company gets sued and someone is demanding access to evidence from your Azure-based systems? “If you as a customer are involved in a legal case and you need access to platform level logs, we will help you with that request,” Vidich said. “Logs will be sanitised and apply only to that customer account.
“What we cannot do is give you platform-level logs that pertain to another customer.” That would require a court order or subpoena. If that’s what you’re being forced to spend time on, chances are it’s not a good day at the office.”




<Return to section navigation list>
Cloud Computing Events
•• Scott Guthrie (@scottgu) announced Windows Azure Global Bootcamp on April 27th – sign up now in a 4/12/2013 post:
On April 27, something very cool is happening. A bunch of Windows Azure MVP's and community activists are organizing a Global Windows Azure Bootcamp. This is a completely free, one-day training event for Windows Azure, all organized by the community, and presented in person all over the World.
I’m not sure if this is the largest community event ever - it is very cool to see how many places this event is happening. Below is the location map as it stands today – and new locations are being added daily. Right now there are almost 100 locations and several thousand attendees already registered to take part. Browse the location listings to find a location near you.
If you are interested in learning about Windows Azure or want more info, checkout the Global Windows Azure Bootcamp website to learn more about the bootcamps. Then find a location near you, sign-up and attend the event for free, and get involved with the Windows Azure community near you!



• The Visual Studio Live! team posted The Visual Studio Live! interview with Michael Washington (@ADefWebServer) to YouTube on 4/10/2013:
Michael Washington talks about mobile development with LightSwitch, which now comes free with Visual Studio.

Full dislclosure: I’m a contributing editor of 1105 Media’s Visual Studio Magazine. 1105 Media is the producer of Visual Studio Live! conferences.
• Beth Massi (@bethmassi) reported her LightSwitch All Day Training at DevTeach, Toronto in May session on 4/9/2013:
Just announced! I’ll be delivering an all-day training at DevTeach again – this time in Toronto on May 25th! This was a huge success when I did it in Montreal so I’m happy to do this again. This time though, I have a lot of new content related to the release of the HTML client and SharePoint 2013 support in Visual Studio 2012 Update 2.
Here are the details: Mastering LightSwitch in Visual Studio 2012
LightSwitch in Visual Studio 2012 is the easiest way to create modern line of business applications for the enterprise. In this training you will learn how to build connected business applications that can be deployed to Windows Azure or Office 365 and run on the desktop as well as modern mobile devices. We’ll start with the basics of building the middle-tier services and data entry screens with simple validations and then we’ll move into more advanced scenarios like writing complex business rules and processes.
You’ll gain a full understanding of the architecture of a LightSwitch application and how it embraces best practices in n-tier design while handling all of the plumbing code for you. Learn how to integrate multiple data sources like SharePoint and OData services, as well as data validation, authentication, and access control. See how to access the LightSwitch data services from other clients and platforms and how to extend the middle-tier with your own services using WebAPI. You’ll learn the ins-and-outs of the data and screen designers to maximize your productivity as well as how to build LightSwitch SharePoint 2013 apps. You’ll also see how to create HTML5\JavaScript clients that can run on any modern mobile device as well as advanced customization techniques to provide customized UI’s & dashboards for mobile users.
Learn more about LightSwitch on the Developer Center.
Full day workshop for only $25.00
Date: Saturday May 25th, 2013
Location: Delta Meadowvale (6750 Mississauga Road , Toronto, ON)Click here for more details & to register!
Hope to see you there!


Beth also will present a Building Mobile Business Apps with Visual Studio LightSwitch session at Falafel Software’s Falafel-Con 2013 conference to be held June 10th and 11th at Microsoft's Silicon Valley Campus:
With the recent addition of HTML5 support, Visual Studio LightSwitch remains the easiest way to create modern line of business applications for the enterprise. In this demo-heavy session, see how to build and deploy data-centric business applications that run in Azure and provide rich user experiences tailored for modern devices. We’ll cover how LightSwitch helps you focus your time on what makes your application unique, allowing you to easily implement common business application scenarios—such as integrating multiple data sources, data validation, authentication, and access control—as well as leveraging Data Services created with LightSwitch to make data and business logic available to other applications and platforms. You will also see how developers can use their knowledge of HTML5 and JavaScript to customize their apps with custom controls, client-side logic, and CSS themes.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
•• Jeff Barr (@jeffbarr) announced AWS Storage Gateway Now Supports Microsoft Hyper-V on 4/11/2013:
The AWS Storage Gateway can now be run in the Microsoft Hyper-V virtualization environment. You can use the Storage Gateway to marry your existing on-premises storage systems with the AWS cloud for backup, departmental file share storage, or disaster recovery.
With today's launch of support for Hyper-V, you can now use the Storage Gateway on-premises in two of the most popular virtualization environments: Microsoft Hyper-V and VMware ESXi. You can also run the Storage Gateway on Amazon EC2. This allows you to mirror your on-premises environment in the AWS cloud for on-demand computing and disaster recovery (DR).
About the Storage Gateway
The AWS Storage Gateway combines a software appliance (a virtual machine image that installs in your on-premises IT environment) and Amazon S3 storage. You can use the Storage Gateway to support several different file sharing, backup, and disaster recovery use cases. For example, you can use the Storage Gateway to host your company's home directory files in Amazon S3 while keeping copies of recently accessed files on-premises for fast access. This minimizes the need to scale your local storage infrastructure.
As part of the installation process for the Storage Gateway, you will create one or more storage volumes. The AWS Storage Gateway gives you two options:
Gateway-Cached Volumes store your primary data in S3 and retain frequently accessed data locally. Volumes can be up to 32 TB in size, but you need just a fraction of that amount of local storage. This gives you the ability to trade off overall storage performance and cost, fine-tuning the balance as needed to best serve your application and your users. For example, in a remote office scenario, as your storage footprint increases, you can increase utilization of your Gateway-Cached volume in Amazon S3, without having to physically allocate additional on-premisse storage in the remote office.
Gateway-Stored Volumes store all of your data locally with an asynchronous backup to S3 at the time and frequency of your choice for durable, off-site backups. These volumes can be up to 1 TB in size, and you'll need that amount of local storage.
You can create multiple volumes on each of your Storage Gateways, in your choice of sizes. Each volume appears as an iSCSI target and can be attached and used just like a local storage volume would be.
Storage Gateway in Action
Jollibee Foods Corporation (JFC) is using the AWS Storage Gateway to backup and mirror their Oracle databases from their on-premises data center to AWS. JFC is the largest fast food chain in the Philippines with revenues well over 2 Billion USD and presence in more than a dozen countries worldwide. They like the operational simplicity the Storage Gateway enables, making backup of their multiple TB-sized database snapshots to AWS easy and efficient. The Storage Gateway also provides them access to the same database snapshots for use in Amazon EC2, providing a cost-effective in-cloud DR solution.Getting Started
If you have never used the Storage Gateway before, you can sign up for a 60 day free trial. If you are eligible for the AWS Free Usage Tier, you will receive 1 GB of snapshot storage and 15 GB of data transfer out (aggregated across all AWS services).The AWS Storage Gateway User Guide will give you all of the information that you need to get started.


Jeff Barr (@jeffbarr) reported AWS Elastic Beanstalk for .NET now Supports VPC, RDS, and Configuration Files in a 4/8/2013 post:
AWS Elastic Beanstalk for .NET now supports the Amazon Virtual Private Cloud (VPC), seamlessly integrates with the Amazon Relational Database Service (RDS), and can be customized using configuration files.
Elastic Beanstalk allows you to easily deploy and manage .NET applications on AWS. Because Elastic Beanstalk leverages Windows Server 2008 R2 and Windows Server 2012, you can run .NET applications with minimal changes.
VPC Integration
With Amazon VPC, you can set up your own virtual network and you can configure Elastic Beanstalk to run your .NET applications inside of this logically isolated section of the AWS cloud. For example, you can create a private subnet where you host your Elastic Beanstalk backend services and then expose the public-facing web application in a public subnet. Visit the AWS Elastic Beanstalk Developer Guide to learn more about Using AWS Elastic Beanstalk with Amazon VPC.
RDS Integration
If your application relies on a relational database, you can easily configure an Amazon RDS DB Instance for your Elastic Beanstalk .NET application. Using the AWS Toolkit for Visual Studio or the AWS Management Console, you can add an RDS DB Instance with just a few clicks. The connection information is automatically exposed to your application through a connection string. Visit Using Amazon RDS in the AWS Elastic Beanstalk Developer Guide.
Configuration Files
Elastic Beanstalk configuration files are YAML text files that allow you to customize your environment in two ways:
- You can customize the software running inside your environment by downloading files, running commands, installing agents and packages, and setting environment variables.
- You can provision and configure additional resources such as DynamoDB tables, SQS queues, and CloudWatch alarms.
For example, if your application requires write permissions to app_data, you can grant it these permissions using the following configuration file:
container_commands:
01-changeperm:
command: icacls "C:/inetpub/wwwroot/myapp/App_Data" /grant DefaultAppPool:(OI)(CI)F > log.txt 2>&1
cwd: "C:/inetpub/wwwroot/myapp"Visit Customizing and Configuring AWS Elastic Beanstalk Environments in the AWS Elastic Beanstalk Developer Guide to learn more about configuration files and for additional examples.



<Return to section navigation list>

















0 comments:
Post a Comment