Windows Azure and Cloud Computing Posts for 3/6/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Service
Avkash Chauhan (@avkashchauhan) described Running Apache Mahout at Hadoop on Windows Azure(www.hadooponazure.com) in a 3/6/2012 post:
Once you have access enabled to Hadoop on Windows Azure you can run any [M]ahout sample on head node. I am just trying to run original Apache Mahout (http://mahout.apache.org/) sample which is derived from the clustering sample on Mahout's website (https://cwiki.apache.org/confluence/display/MAHOUT/Clustering+of+synthetic+control+data).
Step 1: Please RDP to your head node and open the Hadoop command line window.
Here you can just launch MAHOUT to see what happens
Step 2: Download necessary data file from the Internet:
download Synthetic control data from http://archive.ics.uci.edu/ml/databases/synthetic_control/synthetic_control.data and place it under c:\apps\dist\mahout\examples\bin\work\synthetic_control.data"
Step 3: Go to folder c:\apps\dist\mahout\examples\bin and Run command "build-cluster-syntheticcontrol.cmd" and select the desired clustering algorithm from the driver script.
c:\Apps\dist\mahout\examples\bin>build-cluster-syntheticcontrol.cmd
"Please select a number to choose the corresponding clustering algorithm"
"1. canopy clustering"
"2. kmeans clustering"
"3. fuzzykmeans clustering"
"4. dirichlet clustering"
"5. meanshift clustering"
Enter your choice:1
"ok. You chose 1 and we'll use canopy Clustering"
"DFS is healthy... "
"Uploading Synthetic control data to HDFS"
rmr: cannot remove testdata: No such file or directory.
"Successfully Uploaded Synthetic control data to HDFS "
"Running on hadoop, using HADOOP_HOME=c:\Apps\dist"
c:\Apps\dist\bin\hadoop jar c:\Apps\dist\mahout\mahout-examples-0.5-job.jar org.apache.mahout.driver.MahoutDriver org.apache.mahout.clustering.synthet
iccontrol.canopy.Job
12/03/06 00:50:10 WARN driver.MahoutDriver: No org.apache.mahout.clustering.syntheticcontrol.canopy.Job.props found on classpath, will use command-lin
e arguments only
12/03/06 00:50:10 INFO canopy.Job: Running with default arguments
12/03/06 00:50:17 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
12/03/06 00:50:18 INFO input.FileInputFormat: Total input paths to process : 1
12/03/06 00:50:20 INFO mapred.JobClient: Running job: job_201203052259_0001
12/03/06 00:50:21 INFO mapred.JobClient: map 0% reduce 0%
12/03/06 00:51:00 INFO mapred.JobClient: map 100% reduce 0%
12/03/06 00:51:11 INFO mapred.JobClient: Job complete: job_201203052259_0001
12/03/06 00:51:11 INFO mapred.JobClient: Counters: 16
12/03/06 00:51:11 INFO mapred.JobClient: Job Counters
12/03/06 00:51:11 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=33969
12/03/06 00:51:11 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
12/03/06 00:51:11 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
12/03/06 00:51:11 INFO mapred.JobClient: Launched map tasks=1
12/03/06 00:51:11 INFO mapred.JobClient: Data-local map tasks=1
12/03/06 00:51:11 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
12/03/06 00:51:11 INFO mapred.JobClient: File Output Format Counters
12/03/06 00:51:11 INFO mapred.JobClient: Bytes Written=335470
12/03/06 00:51:11 INFO mapred.JobClient: FileSystemCounters
12/03/06 00:51:11 INFO mapred.JobClient: FILE_BYTES_READ=130
12/03/06 00:51:11 INFO mapred.JobClient: HDFS_BYTES_READ=288508
12/03/06 00:51:11 INFO mapred.JobClient: FILE_BYTES_WRITTEN=21557
12/03/06 00:51:11 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=335470
12/03/06 00:51:11 INFO mapred.JobClient: File Input Format Counters
12/03/06 00:51:11 INFO mapred.JobClient: Bytes Read=288374
12/03/06 00:51:11 INFO mapred.JobClient: Map-Reduce Framework
12/03/06 00:51:11 INFO mapred.JobClient: Map input records=600
12/03/06 00:51:11 INFO mapred.JobClient: Spilled Records=0
12/03/06 00:51:11 INFO mapred.JobClient: Map output records=600
12/03/06 00:51:11 INFO mapred.JobClient: SPLIT_RAW_BYTES=134
12/03/06 00:51:11 INFO canopy.CanopyDriver: Build Clusters Input: output/data Out: output Measure: org.apache.mahout.common.distance.EuclideanDistance
Measure@1997c1d8 t1: 80.0 t2: 55.0
12/03/06 00:51:11 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
12/03/06 00:51:12 INFO input.FileInputFormat: Total input paths to process : 1
12/03/06 00:51:13 INFO mapred.JobClient: Running job: job_201203052259_0002
12/03/06 00:51:14 INFO mapred.JobClient: map 0% reduce 0%
12/03/06 00:51:58 INFO mapred.JobClient: map 100% reduce 0%
12/03/06 00:52:16 INFO mapred.JobClient: map 100% reduce 100%
12/03/06 00:52:27 INFO mapred.JobClient: Job complete: job_201203052259_0002
12/03/06 00:52:27 INFO mapred.JobClient: Counters: 25
12/03/06 00:52:27 INFO mapred.JobClient: Job Counters
12/03/06 00:52:27 INFO mapred.JobClient: Launched reduce tasks=1
12/03/06 00:52:27 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=30345
12/03/06 00:52:27 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
12/03/06 00:52:27 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
12/03/06 00:52:27 INFO mapred.JobClient: Launched map tasks=1
12/03/06 00:52:27 INFO mapred.JobClient: Data-local map tasks=1
12/03/06 00:52:27 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=15968
12/03/06 00:52:27 INFO mapred.JobClient: File Output Format Counters
12/03/06 00:52:27 INFO mapred.JobClient: Bytes Written=6615
12/03/06 00:52:27 INFO mapred.JobClient: FileSystemCounters
12/03/06 00:52:27 INFO mapred.JobClient: FILE_BYTES_READ=14296
12/03/06 00:52:27 INFO mapred.JobClient: HDFS_BYTES_READ=335597
12/03/06 00:52:27 INFO mapred.JobClient: FILE_BYTES_WRITTEN=73063
12/03/06 00:52:27 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=6615
12/03/06 00:52:27 INFO mapred.JobClient: File Input Format Counters
12/03/06 00:52:27 INFO mapred.JobClient: Bytes Read=335470
12/03/06 00:52:27 INFO mapred.JobClient: Map-Reduce Framework
12/03/06 00:52:27 INFO mapred.JobClient: Reduce input groups=1
12/03/06 00:52:27 INFO mapred.JobClient: Map output materialized bytes=13906
12/03/06 00:52:27 INFO mapred.JobClient: Combine output records=0
12/03/06 00:52:27 INFO mapred.JobClient: Map input records=600
12/03/06 00:52:27 INFO mapred.JobClient: Reduce shuffle bytes=0
12/03/06 00:52:27 INFO mapred.JobClient: Reduce output records=6
12/03/06 00:52:27 INFO mapred.JobClient: Spilled Records=50
12/03/06 00:52:27 INFO mapred.JobClient: Map output bytes=13800
12/03/06 00:52:27 INFO mapred.JobClient: Combine input records=0
12/03/06 00:52:27 INFO mapred.JobClient: Map output records=25
12/03/06 00:52:27 INFO mapred.JobClient: SPLIT_RAW_BYTES=127
12/03/06 00:52:27 INFO mapred.JobClient: Reduce input records=25
12/03/06 00:52:27 WARN mapred.JobClient: Use GenericOptionsParser for parsing the arguments. Applications should implement Tool for the same.
12/03/06 00:52:27 INFO input.FileInputFormat: Total input paths to process : 1
12/03/06 00:52:28 INFO mapred.JobClient: Running job: job_201203052259_0003
12/03/06 00:52:29 INFO mapred.JobClient: map 0% reduce 0%
12/03/06 00:53:46 INFO mapred.JobClient: map 100% reduce 0%
12/03/06 00:58:20 INFO mapred.JobClient: Job complete: job_201203052259_0003
12/03/06 00:58:20 INFO mapred.JobClient: Counters: 16
12/03/06 00:58:20 INFO mapred.JobClient: Job Counters
12/03/06 00:58:20 INFO mapred.JobClient: SLOTS_MILLIS_MAPS=30407
12/03/06 00:58:20 INFO mapred.JobClient: Total time spent by all reduces waiting after reserving slots (ms)=0
12/03/06 00:58:20 INFO mapred.JobClient: Total time spent by all maps waiting after reserving slots (ms)=0
12/03/06 00:58:20 INFO mapred.JobClient: Rack-local map tasks=1
12/03/06 00:58:20 INFO mapred.JobClient: Launched map tasks=1
12/03/06 00:58:20 INFO mapred.JobClient: SLOTS_MILLIS_REDUCES=0
12/03/06 00:58:20 INFO mapred.JobClient: File Output Format Counters
12/03/06 00:58:20 INFO mapred.JobClient: Bytes Written=340891
12/03/06 00:58:20 INFO mapred.JobClient: FileSystemCounters
12/03/06 00:58:20 INFO mapred.JobClient: FILE_BYTES_READ=130
12/03/06 00:58:21 INFO mapred.JobClient: HDFS_BYTES_READ=342212
12/03/06 00:58:21 INFO mapred.JobClient: FILE_BYTES_WRITTEN=22251
12/03/06 00:58:21 INFO mapred.JobClient: HDFS_BYTES_WRITTEN=340891
12/03/06 00:58:21 INFO mapred.JobClient: File Input Format Counters
12/03/06 00:58:21 INFO mapred.JobClient: Bytes Read=335470
12/03/06 00:58:21 INFO mapred.JobClient: Map-Reduce Framework
12/03/06 00:58:21 INFO mapred.JobClient: Map input records=600
12/03/06 00:58:21 INFO mapred.JobClient: Spilled Records=0
12/03/06 00:58:21 INFO mapred.JobClient: Map output records=600
12/03/06 00:58:21 INFO mapred.JobClient: SPLIT_RAW_BYTES=127
C-0{n=21 c=[29.552, 33.073, 35.876, 36.375, 35.118, 32.761, 29.566, 26.983, 25.272, 24.967, 25.691, 28.252, 30.994, 33.088, 34.015, 34.349, 32.826, 31
.053, 29.116, 27.975, 27.879, 28.103, 28.775, 30.585, 31.049, 31.652, 31.956, 31.278, 30.719, 29.901, 29.545, 30.207, 30.672, 31.366, 31.032, 31.567,
30.610, 30.204, 29.266, 29.753, 29.296, 29.930, 31.207, 31.191, 31.474, 32.154, 31.746, 30.771, 30.250, 29.807, 29.543, 29.397, 29.838, 30.489, 30.705
, 31.503, 31.360, 30.827, 30.426, 30.399] r=[0.979, 3.352, 5.334, 5.851, 4.868, 3.000, 3.376, 4.812, 5.159, 5.596, 4.940, 4.793, 5.415, 5.014, 5.155,
4.262, 4.891, 5.475, 6.626, 5.691, 5.240, 4.385, 5.767, 7.035, 6.238, 6.349, 5.587, 6.006, 6.282, 7.483, 6.872, 6.952, 7.374, 8.077, 8.676, 8.636, 8.6
97, 9.066, 9.835, 10.148, 10.091, 10.175, 9.929, 10.241, 9.824, 10.128, 10.595, 9.799, 10.306, 10.036, 10.069, 10.058, 10.008, 10.335, 10.160, 10.249,
10.222, 10.081, 10.274, 10.145]}
Weight: Point:
……...
……..
…….
1.0: [27.414, 25.397, 26.460, 31.978, 26.125, 27.463, 30.489, 34.929, 27.558, 30.686, 27.511, 32.269, 32.834, 27.129, 24.991, 32.610, 25.387,
32.674, 34.607, 33.519, 29.012, 28.705, 32.116, 29.121, 26.424, 33.452, 33.623, 29.457, 35.025, 26.607, 34.442, 34.847, 28.897, 34.439, 32.011, 34.816
, 27.773, 11.549, 20.219, 19.678, 14.715, 14.384, 15.556, 9.573, 10.636, 16.639, 17.236, 19.643, 18.317, 15.323, 19.106, 11.455, 16.888, 18.269, 11.58
3, 112/03/06 00:58:24 INFO driver.MahoutDriver: Program took 493470 ms
After the Mahout job was completed the output was stored as below:
js> #ls Found 3 items drwxr-xr-x - avkash supergroup 0 2012-03-06 01:05 /user/avkash/.oink drwxr-xr-x - avkash supergroup 0 2012-03-06 00:52 /user/avkash/output drwxr-xr-x - avkash supergroup 0 2012-03-06 00:49 /user/avkash/testdata js> #ls /user/avkash/output Found 3 items drwxr-xr-x - avkash supergroup 0 2012-03-06 00:53 /user/avkash/output/clusteredPoints drwxr-xr-x - avkash supergroup 0 2012-03-06 00:52 /user/avkash/output/clusters-0 drwxr-xr-x - avkash supergroup 0 2012-03-06 00:51 /user/avkash/output/dataNow let’s analyz[e] mahout cluster output using clusterdump utility:
Clusterdump utility takes 3 parameters:
- –seqFileDir – this is the path folder where clustering sequence folder is (in this case output/clusters-0)
- –pointsDir – this is the path folder where clustering points folder is (in this case output/clusteredPoints)
- --output– this is the path where you would want to create your analysis result.
- Be sure that this parameter will force to create analysis result text in local machine not on HDFS
Running the command as below:
c:\Apps\dist\mahout\examples\bin>mahout clusterdump --seqFileDir output\clusters-0 --pointsDir output\clusteredPoints --output clusteranalyze.txt
"Running on hadoop, using HADOOP_HOME=c:\Apps\dist"
c:\Apps\dist\bin\hadoop jar c:\Apps\dist\mahout\mahout-examples-0.5-job.jar org.apache.mahout.driver.MahoutDriver clusterdump --seqFileDir output\clusters-0 --pointsDir output\clusteredPoints --output clusteranalyze.txt
12/03/06 21:05:53 WARN driver.MahoutDriver: No clusterdump.props found on classpath, will use command-line arguments only
12/03/06 21:05:53 INFO common.AbstractJob: Command line arguments: {--dictionaryType=text, --endPhase=2147483647, --output=clusteranalyze.txt, --pointsDir=output\clusteredPoints, --seqFileDir=output\clusters-0, --startPhase=0, --tempDir=temp}
12/03/06 21:05:55 INFO driver.MahoutDriver: Program took 2031 ms
Now if you open folder at your machine, will find “clusteranalyze.txt” as below:
Opening clusteranalyze.txt shows the data as below:
Cluster Dumper Reference:




Mary Jo Foley (@maryjofoley) asserted “Microsoft’s coming second technology preview build of Hadoop on Azure may result in the product being released later than March 2012” in her Microsoft to add another preview build, more testers for Hadoop on Azure post of 3/6/2012 to ZDNet’s All About Microsoft blog:
Microsoft is adding a second, previously undisclosed Community Technology Preview (CTP) test build to its Hadoop on Azure roadmap, which could result in the service missing the company’s own release target.
Late last year, Microsoft announced it was partnering with Hortonworks to develop versions of the Hadoop big-data framework for Windows Azure and Windows Server. Microsoft delivered, as promised, a CTP of Hadoop for Azure before the end of calendar 2011.
Last we heard, back in December 2011 — directly from Microsoft’s Alexander Stojanovic, General Manager, Project Founder and Technical Architect behind the project — Microsoft’s plan was to make Hadoop on Azure generally available in March 2012. An internal roadmap that Microsoft shared with some of the Hadoop on Azure testers pegged the general availability date specifically at March 30, 2012.
But on March 6, Microsoft officials said that the company would be rolling out a CTP2 for Hadoop on Azure some time in the first half of 2012. This CTP was not listed on the roadmap that Microsoft made available to its testers in December. Here’s a slide from that roadmap document, dated December 2011, provided to me by one of my contacts:
(click on slide above to enlarge)
Microsoft officials said today they had nothing new to share as to when the Hadoop on Azure offering will be made generally available.
As one tester noted, an additional Hadoop on Azure CTP is a good thing, given many of the technologies on the Hadoop for Azure roadmap, such as the programming toolkit, aren’t really there at present.
Microsoft execs, for their part, are insisting the company is on track with Hadoop on Azure, claiming that the only official guidance the company has provided as to Hadoop availability was back in October 2011, when officials announced the initial CTP dates. (For some reason officials aren’t counting their own Channel 9 interview as “official” information.) …


Mary Jo also reported: “Microsoft plans to grow the number of testers of Hadoop on Azure from the current 400 to 2,000 with CTP2, officials said. The new CTP2 code will include support for Apache Mahout, a collection of machine-learning and data algorithms.”
For my take on Apache Hadoop on Windows Azure, see Introducing Apache Hadoop Services for Windows Azure of 1/31/2012.
Kurt Mackie asserted “One proposal concerns a new JavaScript framework for writing MapReduce programs” in a deck for his Microsoft Broadens Apache Hadoop Contributions article of 3/5/2012 for Redmond Developer News (@RedDevNews):
Microsoft is submitting two new proposals to the Apache Software Foundation to extend Hadoop interoperability with Windows, as part of the company's big data strategy. Hadoop is an open source MapReduce framework sponsored by the Apache Software Foundation that lets users gather business intelligence (BI) from unstructured and structured data at petabyte levels.
One proposal concerns a new JavaScript framework for writing MapReduce programs. The second proposal is focused on the creation of a new open database connectivity (ODBC) driver for Hive, which is Hadoop's data warehouse system.
Tools for Big Data
The addition of the Hive driver will bring Microsoft's BI tools to bear on Hadoop. For instance, Microsoft is touting the use of PowerPivot for Excel, as well as Power View, which will arrive with SQL Server 2012 product this month (Microsoft is planning a SQL Server 2012 "launch event" on Wednesday). Both PowerPivot and Power View can be used to visually display Hadoop query results.Campbell explained during the talk that having Microsoft's BI tools in place for Hadoop is important because researchers need common tools to share their results. He proposed Data Explorer as a solution for such sharing. Data Explorer, offered via Microsoft's SQL Azure Labs, accommodates multiple data formats and ties into the Windows Azure Marketplace, which provides data feeds for a price. Data Explorer for SQL Azure provides "capabilities for data curation, collaboration and mashup," according to Microsoft's datasheet description (PDF).
With Hadoop, the idea is to improve "time to insight" when sifting through masses of data, and data quantity is key. Campbell said that, when using Hadoop, having more data with a less sophisticated algorithm is better than having less data with a more sophisticated algorithm.
Hadoop, largely fostered by Yahoo, has been used for things like social media analytics and ad analytics. It's designed to handle big data at a low cost. For instance, Hadoop is designed to run on commodity hardware and it permits queries to be conducted on big piles of data on an ad hoc basis.
Partner Efforts
Microsoft's main partner on Hadoop is Hortonworks, a key contributor to the open source effort. Hortonworks is collaborating with Microsoft on the Hive ODBC driver and the JavaScript framework. In addition, patches are being contributed to the Apache Software Foundation to enable Apache Hadoop version 1.0 on Windows Server, according to an announcement issued by Hortonworks.Other Microsoft Hadoop partner efforts were announced last week at the Strata Conference. Microsoft is collaborating with Karmasphere to enable Karmasphere's tools on Hadoop for Windows Server and Windows Azure, including Karmasphere Analyst and Karmasphere Studio. Microsoft is also working with Datameer to help make that company's BI tools work with Hadoop on Windows Azure, according to Datameer's announcement. HStreaming and Microsoft have formed a "strategic relationship" that will enable HStreaming's real-time analytics tools to work with Hadoop on Windows Server and Windows Azure. The HStreaming effort is currently open for testing through a Microsoft Community Technology Preview program, according to HStreaming's announcement.
Microsoft has its own SQL Server technology called StreamInsight that's used for complex event processing. Possibly, StreamInsight could be used with Hadoop MapReduce jobs during the reducer phase, according to a Microsoft blog post. The reducer step is part of a three-tier Hadoop structure. Hadoop consists of the Hadoop Distributed File System at its base. Data are mapped via MapReduce. Lastly, the data undergo a reduce operation, which produces a summary of the data after they have been processed in parallel.
"Isotope" Release Plans
Microsoft uses an internal code name, called "Isotope," which describes its Hadoop interoperability efforts with Windows Server and Windows Azure, according to Alex Stojanovic, Microsoft's general manager of Hadoop on Azure and Windows, in a Channel 9 video. In that video, Stojanovic said that Microsoft will deliver Isotope on Azure in March 2012. In June 2012, Microsoft will deliver the general availability release of the "enterprise edition," he added. Microsoft also plans to provide "deep integration" with System Center, he said.According to a tip given to veteran Microsoft observer Mary Jo Foley, the specific delivery dates have been disclosed. Microsoft
willdelivered Hadoop on Windows Azure on March 30, whereas Hadoop on Windows Server is expected to arrive on June 29, according to Foley's source.

Full disclosure: I’m a contributing editor for Visual Studio Magazine, which is published by 1105 Media, which also publishes Redmond Developer News.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Benjamin Guinebertière (@benjguin) described how to Create a SQL Azure database | Créer une base SQL Azure in a 3/6/2012 post:
In order to create a SQL Azure database from the Windows Azure Portal, one first needs to create a SQL Azure Server as explained here.
Then, one has to choose the name and the max size of the database. For the size, it is a good idea to check SQL Azure pricing one the official pricing page (detailed pricing is here).
Once those parameters are known, go to the Windows Azure Portal, select database, and the SQL Azure Server, then click on Create:
Choose the name of the database
Choose the edition and the size of the database. The only difference between the two editions for now is the available max size. web edition is for small databases, business edition is for bigger database.
Click OK
The database is ready.



Note: French text has been excised for brevity.
<Return to section navigation list>
MarketPlace DataMarket, Social Analytics, Big Data and OData
Andrew Brust (@andrewbrust) posted SQL Server 2012 RTM: Big deal for Big Data? as the first article for his new Big Data blog for ZDNet on 3/6/2012:
Full disclosure: I am a co-author of an upcoming book on SQL Server 2012, and I do a lot of work with Microsoft.
Why would a new version of SQL Server be a big deal for this blog? As a mainstream relational database, SQL Server would appear to be irrelevant in the Big Data landscape. As it turns out, SQL Server is important in the Big Data world, but not because of the core relational database engine. Microsoft’s data platform strategy involves selling SQL Server with a number of companion products in the same license. Reporting, ETL (Extract, Transform & Load), OLAP (OnLine Analytical Processing), Data Mining, MDM (Master Data Management), Data Quality, Data Visualization and CEP (Complex Event Processing) components are included “in the box” with SQL Server. So SQL Server is more than just an RDBMS (Relational Database Management System).
That’s big, but what’s even bigger is that the team working on this is essentially part of the SQL Server product group at Microsoft. As such, there are a number of integration points between Hadoop and SQL Server’s reporting, analysis and data visualization components. Microsoft has also integrated Hadoop with SQL Server Parallel Data Warehouse edition, the MPP (Massively Parallel Processing) version of SQL Server, as well as with Excel.
Hadoop on Windows is still pre-release technology, but it’s coming sometime between now and July 1st, and SQL Server 2012 is the first version whose Business Intelligence technologies will integrate tightly with it. In fact, as I understand it, the SQL Server-Hadoop integration will even work with Hadoop clusters running on Linux. This may seem unbelievable to many who are familiar with Microsoft’s overall strategy for Windows and SQL Server. But it demonstrates how important Big Data (with Hadoop as its proxy) has become in the market and how Microsoft has decided it is better to add value to a platform of consensus than to ignore or challenge it.
Related stories:

See Beth Massi (@bethmassi) recommended that you Enhance Your LightSwitch Applications with OData in the Visual Studio LightSwitch and Entity Framework v4+ section below..
Mary Jo Foley (@maryjofoley) asserted “Microsoft’s annual internal TechFest research showcase kicks off on March 6. So what better time to check out Trinity, a graph database research project, from Microsoft Research?” in a deck for her Microsoft's Trinity: A graph database with web-scale potential article of 3/5/2012 for ZDNet’s All About Microsoft blog:
It’s a good day when you finally find new information about a Microsoft codename I first heard a couple of years ago, but about which I never could find more information.
One of my readers (thanks, Gregg Le Blanc) sent me a link to a Microsoft Research page on codename Trinity, which is a “graph database and computing platform.”
Given this week is Microsoft’s internal TechFest Microsoft Research event for its employees (with March 6 being the day that Microsoft allows select media and guests to tour some of its exhibits), it’s a good time to talk about yet another Microsoft Research project.
Here’s Microsoft’s explanation of codename Trinity:
“Trinity is a graph database and graph computation platform over distributed memory cloud. At the heart of Trinity is a distributed RAM-based key-value store. As an all-in-memory key-value store, Trinity provides fast random data access. This feature naturally makes Trinity suitable for large graph processing. Trinity is a graph database from the perspective of data management. It is a parallel graph computation platform from the perspective of graph analytics. As a database, it provides features such as data indexing, concurrent query processing, concurrency control. As a computation platform, it provides vertex-based parallel graph computation on large scale graphs.”
And here’s the requisite architectural diagram:
Trinity is built on top of the distributed memory-storage layer called “memory cloud.” Utility tools provided by Trinity include a “fast billion node graph generator,” the Trinity Shell and various management tools. …


Project Trinity was the code name for development of WWII’s Atomic Bomb. It’s not clear to me why Trinity replaced the now-deprecated Dryad project.
A 52-page Trinity Manual v0.6 is available as a PDF.
<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
Himanshu Singh described Cross-post: The Windows Azure Claim Provider for SharePoint Project (Three Part Series) on 3/6/2012:
Microsoft Principal Architect Steve Peschka just finished up an interesting three-part series of posts on his Share-n-dipity blog that detail how to build a custom claims provider for SharePoint that uses Windows Azure as the data source.
- The (Windows) Azure Custom Claim Provider for SharePoint Project Part 1 (posted Feb. 11) outlines the goals for this project.
- The (Windows) Azure Custom Claim Provider for SharePoint Project Part 2 (posted Feb. 14) walks through all the components that run in the cloud on Windows Azure.
- The (Windows) Azure Custom Claim Provider for SharePoint Project Part 3 (posted Feb. 20) walks through the different components used on the SharePoint side.
At the end of this series, Steve says readers should have an end-to-end SharePoint-to-Cloud environment running on Windows Azure. This series includes proof of concept as well as complete source code that you can use as you wish.
To learn more about integrating SharePoint and Windows Azure, be sure to check out the “SharePoint 2010 and Windows Azure Training Course” on MSDN.

No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
Avkash Chauhan (@avkashchauhan) described Enableing gzip compression with Windows Azure CDN through Web Role in a 3/5/2012 post:
CDN picks up compression from the origin and Windows Azure Storage does not support compression directly so if you get CDN content from Azure Storage origin, it will not be compressed. So if you have content hosted at Windows Azure Storage you will not be able to have compressed content. To have compressed content, you would need to host the content at hosted service such as web role as origin. As this type of origin would be IIS based, is a supported way to use compression.
So if you decided to use Web Role for compress CDN original here are the steps to enable compression:
[Step 1] Please add the following elevated startup task in your ServiceDefinition.csdef:
<Task commandLine="StartupTasks\ChangeIisDefaults.cmd" executionContext="elevated" taskType="simple" />
[Step 2] Here is the ChangeIisDefaults.cmd script as below:
%windir%\system32\inetsrv\appcmd set config -section:httpCompression -noCompressionForHttp10:false
%windir%\system32\inetsrv\appcmd set config -section:httpCompression -noCompressionForProxies:false
[Step 3] Please add the following code in your web role OnStart() event:
using Microsoft.Web.Administration;using (var serverManager = new ServerManager()) { Configuration config = serverManager.GetApplicationHostConfiguration(); ConfigurationSection serverRuntimeSection = config.GetSection("system.webServer/serverRuntime", ""); serverRuntimeSection["enabled"] = true; serverRuntimeSection["frequentHitThreshold"] = 1; serverRuntimeSection["frequentHitTimePeriod"] = TimeSpan.Parse("00:00:10"); serverManager.CommitChanges(); }When the CDN endpoint has gzip compression enabled, in the fiddler log you will see the following header info:
Accept-Ranges:bytes Cache-Control:max-age=31536000 Content-Encoding:gzip Content-Length:XXXXX Content-Type:text/css Date:Tue, 12 Jan 2012 22:26:26 GMT ETag:"1d560a2645cc345:0" Last-Modified:Tue, 12 Jan 2012 22:24:15 GMT Server:Microsoft-IIS/7.5 Vary:Accept-Encoding X-Powered-By:ASP.NETSetting “Enable Query String” flag:
By having "Enable query string" flag set on the CDN endpoint you can assure that content will be considered new and new values in the querystring will considered new request and update the CDN with new content. This way new values in the querystring be considered new requests and using random value in the querystring, that should go all the way back to the origin server again.
If you don’t have “enable Query String” flag set then you would need to request Azure CDN team to manually purge to content as there are no customer specific API to do purge old cached CDN content.

<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Jim O’Neil (@jimoneil) describes a new @home with Windows Azure initiative in his Learn the Cloud, Make a Difference post of 3/6/2012:
My colleagues, Brian Hitney and Peter Laudati, and I – AKA the RockPaperAzure guys - have been busy working another on-line activity to highlight what Windows Azure can do and to offer a little added incentive to give the cloud a spin.
Today, we’re launching @home with Windows Azure. The @home ‘brand’ has been applied to a host of distributed computing projects (like SETI@home) which typically involve installing a small application on your machine (“at home”) that runs when the machine is idle. The application executed depends on the nature of the project, but generally it downloads some “task” from a given project’s server, executes it locally, and reports results back to the project server. Essentially, everyone that downloads the application creates a node in a large cluster of computers all working toward a common goal.
Sound familiar? Well, it’s kind of like cloud computing: leverage lots of commodity hardware to process a given job. That coincidence was too much for us to ignore, so we’ve “cloud-ified” one of those distributed projects, namely Folding@home.
Stanford University’s Pande Lab has been sponsoring Folding@home for nearly 12 years, during which they’ve used the results of their protein folding simulations (running on thousands of machines worldwide) to provide insight into the causes of diseases such as Alzheimer’s, Mad Cow disease, ALS, and some cancer-related syndromes.
When you participate in @home with Windows Azure, you’ll leverage a free, 3-month Windows Azure Trial (or your MSDN benefits) to deploy Stanford’s Folding@home application to Windows Azure, where it will execute the protein folding simulations in the cloud, thus contributing to the research effort. Additionally, Microsoft is donating $10 (up to a maximum of $5000) to Stanford’s Pande Lab for everyone that participates.
It’s a great cause and a great use-case for cloud computing, so we do hope you join us in making a difference!


<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Beth Massi (@bethmassi) recommended that you Enhance Your LightSwitch Applications with OData in a 3/6/2012 post:
NOTE: This information applies to LightSwitch in Visual Studio 11 beta.
As John announced Wednesday on the LightSwitch Team Blog, the next version of Visual Studio will include LightSwitch right in the box and there are a lot of awesome new features. My personal favorite is the Open Data Protocol (OData) services support. LightSwitch can now consume as well as produce OData services from it’s middle-tier. This means that applications you create with LightSwitch will automatically expose data as open services which allows a multitude of clients easy (secure) access into your data. It also means that you will be able to consume data services from within LightSwitch in order to enhance the capabilities of your applications. In this post I’m going to show you how you can take advantage of using OData in your LightSwitch applications. In the next post I’ll show you how you can work with the OData services LightSwitch creates. But first, a little background on OData.
What is the Open Data Protocol (OData)?
OData is an open REST-ful protocol for exposing and consuming data on the web. It attempts to break down the silos of data that are common across the web by standardizing on the way that data is accessed. Instead of learning new APIs to access data specific to each application’s web service, OData provides a common way to query and update data via REST. You can learn a lot more about OData at www.odata.org.
OData has been around for a couple years and there are more and more providers of data services popping up all the time all over the web. Within Microsoft, many of our products expose and consume data services via the Open Data Protocol. For instance, SharePoint exposes all of its list data as OData services. Similarly, reports you create with Reporting Services can be exposed via OData. PowerPivot is an add-in to Excel 2010 that allows you to consume data services and perform complex data analysis on them. So it makes perfect sense that LightSwitch, which centers around data, also should work with data services via OData. Many enterprises today use OData as a means to exchange data between systems, partners, as well as provide an easy access into their data stores.
To dive deeper into data services and the OData protocol you can read articles on OData.org, or here on my blog. A really good article I recommend is by Chris Sells - Open Data Protocol by Example.
In this post I’m going to show you how to consume OData in your LightSwitch applications. For this example we’ll use some data from the Azure DataMarket. In my next post I’ll show you how to consume OData services that LightSwitch exposes in other clients, like Excel.
The Azure DataMarket
The Azure DataMarket is a place where producers can host their data sets and people can subscribe to them to enhance their client applications. There are all kinds of datasets you can subscribe to, some are free some are pay. There is weather, traffic, NASA, UN, and all sorts of other kinds of data available that you can use. (Beta Note: Not all of the datasets are compatible with LightSwitch currently but we are working to make more of them compatible for the final release.)
First you need to sign up for an account by navigating to http://datamarket.azure.com/. Once you sign up, you will be given a customer ID and an Account Key. Now you can browse the plethora of data sets available to you in a multitude of categories. Let’s subscribe to a free dataset from Data.gov. In the Search box at the top right of the page search for “Crime” and in the results you will see the Data.gov dataset.
Select the Data.Gov dataset and then click the Sign Up button on the right to activate the subscription. Then click the “Explore this Dataset” link to browse the data.
Click the “Run Query” button and the first 100 rows of the data will be returned to you.
Notice at the top of the page you will see the Service root URL. This is the location of the service that we will use in our LightSwitch application. In this case it’s https://api.datamarket.azure.com/data.gov/Crimes/
Enhancing Contoso Construction with Crime Data
I’m going to take a variation of a sample I built a while ago that is an example of an application that could be used in the construction business. One of the features of this application is that it displays a map screen of the construction project location. From the Project screen users can click the Show Map button to open the map screen which uses a Bing Map control extension (included with the sample) to display the location.
What we’d like to do is also display the crime data to the user so that they can see whether working in that city is generally safe or not. This is information we can get for free from the dataset we just subscribed to from the Azure DataMarket.
Connect LightSwitch to an OData Service
You add an OData service to your LightSwitch application just like you would any other external data source. Right-click on the Data Sources node in the Solution Explorer and then select “Add Data Source” to open the Attach Data Source Wizard. You will now see OData Service as an available choice.
Click Next and enter the service root URL from above. Then for login information choose Other Credentials and enter your DataMarket Customer ID for the username and your Account Key for the password. You can get this information by logging into the DataMarket and navigating to “My Account” https://datamarket.azure.com/account/info.
Click the Test Connection button and select the CityCrime dataset and click Test to make sure everything is working properly.
Click Next and LightSwitch will display all the available entities for you to choose from. Select CityCrime and then name the Data Source “CrimeData” and click Finish.
Next you will see the CrimeData added to the list of data sources in the Solution Explorer and LightSwitch will open the Data Designer where you can model the entities further. You can add business rules, set additional properties as well as add calculated fields. Just like any other external data source, you cannot change the underlying structure of the data, but you can select business types, declarative and custom validations, and configure a variety of other smart defaults.

What we want to do is display to the user the probability of being a victim to a violent crime in a specified city. So we need to calculate the ratio of violent crime using a computed property. Click the “Computed Property” button at the top of the Data Designer, call it ViolentCrimeRatio and make it a String. On the Properties window click “Edit Method” and provide the following result.
Private Sub ViolentCrimeRatio_Compute(ByRef result As String) ' Set result to the desired field value If Me.ViolentCrime > 0 Then result = String.Format("1 in {0}", Me.Population \ Me.ViolentCrime) End If End SubWe’re also going to want to set a Summary property for the entity so it displays nicely on screens. Add another computed String property called Summary and write the following code:
Private Sub Summary_Compute(ByRef result As String) ' Set result to the desired field value result = Me.City & ", " & Me.State & ": " & Me.Year End SubThen select the CityCrime entity and at the bottom of the properties window set the Summary Property to the Summary field. At this point we can test out the data set by adding a quick Search Screen and selecting CrimeData.CityCrimes for the screen data.
Hit F5 to build and run the app and open the Search City Crimes screen. Notice that LightSwitch is loading the data asynchronously and paging it for us automatically.
Writing Queries Against an OData Service
Now that we’ve got our connection to the OData service, we want to write a query that pulls the data for a specific City and State. Writing a query against the OData services is the same experience as any other data source in LightSwitch.
To add a new LightSwitch query, right-click on the CityCrimes entity in the Solution Explorer and select “Add Query” to open the Query Designer. Name the query CrimesByCityState. Then add two filter conditions; 1- Where the State is equal to a New Parameter called State, and 2- Where the City is equal to a New Parameter called City. We’ll also sort the results by Year descending.
To test this query really quickly, add another Search Screen and this time select the CrimesByCityState query. When you run this screen, LightSwitch will ask you for the State and City parameters. Because they are both required, once you enter both of them LightSwitch will automatically execute the query. You can choose to make parameters optional in the query designer properties window.
Enhancing the Map Screen with Crime Data
Instead of a separate screen we want to display this information on the Map Screen. Open the MapScreen and click “Add Data Item” at the top of the Screen Designer and select the CrimesByCityState query.
Next add two local properties one for City and one for State by clicking Add Data Item again, this time selecting Local Property of type String.
Now you need to bind these local properties to the query parameters. In the screen designer, select the query parameter State and in the properties window set the Parameter Binding to “State”. Repeat for City by selecting the City query parameter and setting the Parameter Binding to “City”.
You know you have it right when there is a grey arrow from the query parameter to the local property. Finally, select both the local properties and in the property window check “Is Parameter” for both of them. This will allow us to pass in the city and state from the Project screen.
Next, drag the CrimesByCityState from the left onto the content tree where you want it. I’ll add it to the top of the screen and I’m just going to display the two computed properties, Summary and ViolentCrimeRatio. Also, since we’re now filtering the data only a few rows will be returned so I can turn off paging & sorting to save some room on the screen. Select the CrimesByCityState query and in the properties window uncheck “Supports paging” and “Supports searching”. Also since this data is read-only, I’ll remove all the commands from the data grid row command bar.
So after adjusting the visual properties of the screen how we want, the final thing we need to do is pass the city and state into the map screen along with the address. From the ProjectDetail screen select the Show Map button, right-click and select “Edit execute code”, and adjust the code as follows:
Private Sub ShowMap_Execute() 'Show a map of the customer address as well as crime data Me.Application.ShowMapScreen(Me.Project.Customer.FullAddress, Me.Project.Customer.City, Me.Project.Customer.State) End SubNow when we run the application, open the Project Detail screen, and click the Show Map button, it will display the crime data from the OData service on the Azure DataMarket.
Wrap Up
I hope this post has demonstrated how you can use data from OData services inside your LightSwitch applications. Keep in mind that not all services provide all operations against the data (for instance the Crime Data is read only) so that using random OData feeds may not be compatible with LightSwitch if they do not support querying, sorting or filtering. We’re working on guidance that will detail more about what operations are necessary to have a good LightSwitch experience and we will be working with partners to prepare them as we move from Beta to the final release.
I have updated the Contoso Construction application for LightSwitch in Visual Studio 11 Beta so have a look. There are a lot of new features that I took advantage of in there, not just the crime data OData service.
In the next post you will see how LightSwitch creates OData services from the data sources you define and how you can write external clients to get to that data, including business rules and user access control. In Visual Studio 11 beta, LightSwitch is the simplest way to create business applications and data services for the desktop and the cloud.






















Return to section navigation list>
Windows Azure Infrastructure and DevOps
Richard Seroter (@rseroter) described Doing a Multi-Cloud Deployment of an ASP.NET Web Application in a 3/6/2012 post:
The recent Azure outage once again highlighted the value in being able to run an application in multiple clouds so that a failure in one place doesn’t completely cripple you. While you may not run an application in multiple clouds simultaneously, it can be helpful to have a standby ready to go. That standby could already be deployed to backup environment, or, could be rapidly deployed from a build server out to a cloud environment.
If anyone is wondering why multi-cloud deployments are a best practice, see #Azure. And then come see @enstratus.—
James Urquhart (@jamesurquhart) February 29, 2012So, I thought I’d take a quick look at how to take the same ASP.NET web application and deploy it to three different .NET-friendly public clouds: Amazon Web Services (AWS), Iron Foundry, and Windows Azure. Just for fun, I’m keeping my database (AWS SimpleDB) separate from the primary hosting environment (Windows Azure) so that my database could be available if my primary, or backup (Iron Foundry) environments were down.
My application is very simple: it’s a Web Form that pulls data from AWS SimpleDB and displays the results in a grid. Ideally, this works as-is in any of the below three cloud environments. Let’s find out.
Deploying the Application to Windows Azure
Windows Azure is a reasonable destination for many .NET web applications that can run offsite. So, let’s see what it takes to push an existing web application into the Windows Azure application fabric.
First, after confirming that I had installed the Azure SDK 1.6, I right-clicked my ASP.NET web application and added a new Azure Deployment project.

After choosing this command, I ended up with a new project in this Visual Studio solution.

While I can view configuration properties (how many web roles to provision, etc), I jumped right into Publishing without changing any settings. While there was a setting to add an Azure storage account (vs. using local storage), but I didn’t think I had a need for Azure storage.
The first step in the Publishing process required me to supply authentication in the form of a certificate. I created a new certificate, uploaded it to the Windows Azure portal, took my Azure account’s subscription identifier, and gave this set of credentials a friendly name.

I didn’t have any “hosted services” in this account, so I was prompted to create one.

With a host created, I then left the other settings as they were, with the hope of deploying this app to production.

After publishing, Visual Studio 2010 showed me the status of the deployment that took about 6-7 minutes.

An Azure hosted service and single instance were provisioned. A storage account was also added automatically.

I had an error and updated my configuration file to show the error, and that update took another 5 minutes (upon replacing the original). The error was that the app couldn’t load the AWS SDK component that was referenced. So, I switched the AWS SDK dll to “copy local” in the ASP.NET application project and once again redeployed my application. This time it worked fine, and I was able to see my SimpleDB data from my Azure-hosted ASP.NET website.

Not too bad. Definitely a bit of upfront work to do, but subsequent projects can reuse the authentication-related activities that I completed earlier. The sluggish deployment times really stunt momentum, but realistically, you can do some decent testing locally so that what gets deployed is pretty solid.
Deploying the Application to Iron Foundry
Tier3’s Iron Foundry is the .NET-flavored version of VMware’s popular Cloud Foundry platform. Given that you can use Iron Foundry in your own data center, or in the cloud, it’s something that developers should keep a close eye on. I decided to use the Cloud Foundry Explorer that sits within Visual Studio 2010. You can download it from the Iron Foundry site. With that installed, I can right-click my ASP.NET application and choose to Push Cloud Foundry Application.

Next, if I hadn’t previously configured access to the Iron Foundry cloud, I’d need to create a connection with the target API and my valid credentials. With the connection in place, I set the name of my cloud application and clicked Push.

In under 60 seconds, my application was deployed and ready to look at
What if a change to the application is needed? I updated the HTML, right clicked my project and chose to Update Cloud Foundry Application. Once again, in a few seconds, my application was updated and I could see the changes. Taking an existing ASP.NET and moving to Iron Foundry doesn’t require any modifications to the application itself.
If you’re looking for a multi-language, on-or-off premises PaaS, that is easy to work with, then I strongly encourage you to try Iron Foundry out.
Deploying the Application to AWS via CloudFormation
While AWS does not have a PaaS, per se, they do make it easy to deploy apps in a PaaS-like way via CloudFormation. Via CloudFormation, I can deploy a set of related resources and manage them as one deployment unit.
From within Visual Studio 2010, I right-clicked my ASP.NET web application and chose Publish to AWS CloudFormation.

When the wizard launches, I was asked to choose one of two deployment templates (single instance or multiple, load balanced instances).

After selecting the single instance template, I kept the default values in the next wizard page. These settings include the size of the host machine, security group and name of this stack.

On the next wizard pages, I kept the default settings (e.g. .NET version) and chose to deploy my application. Immediately, I saw a window in Visual Studio that showed the progress of my deployment.

In about 7 minutes, I had a finished deployment and a URL to my application was provided. Sure enough, upon clicking that link, I was sent to my web application running successfully in AWS.

Just to compare to previous scenarios, I went ahead and made a small change to the HTML of the web application and once again chose Publish to AWS CloudFormation from the right-click menu.

As you can see, it saw my previous template, and as I walked through the wizard, it retrieved any existing settings and allowed me to make any changes where possible. When I clicked Deploy again, I saw that my package was being uploaded, and in less than a minute, I saw the changes in my hosted web application.

So while I’m still leveraging the AWS infrastructure-as-a-service environment, the use of CloudFormation makes this seem a bit more like an application fabric. The deployments were very straightforward and smooth, arguably the smoothest of all three options shown in this post.
Summary
I was able to fairly easily take the same ASP.NET website and from Visual Studio 2010, deploy to three distinct clouds. Each cloud has their own steps and processes, but each are fairly straightforward. Because Iron Foundry doesn’t require new VMs to be spun up, it’s consistently the faster deployment scenario. That can make a big difference during development and prototyping and should be something you factor into your cloud platform selection. Windows Azure has a nice set of additional services (like queuing, storage, integration), and Amazon gives you some best-of-breed hosting and monitoring. Tier 3’s Iron Foundry lets you use one of the most popular open source, multi-environment PaaS platforms for .NET apps. There are factors that would lead you to each of these clouds.
This is hopefully a good bit of information to know when panic sets in over the downtime of a particular cloud. However, as you build your application with more and more services that are specific to a given environment, this multi-cloud strategy becomes less straightforward. For instance, if an ASP.NET application leverages SQL Azure for database storage, then you are still in pretty good shape when an application has to move to other environments. ASP.NET talks to SQL Server using the same ports and API, regardless of whether it’s using SQL Azure or a SQL instance deployed on an Amazon instance. But, if I’m using Azure Queues (or Amazon SQS for that matter), then it’s more difficult to instantly replace that component in another cloud environment.
Keep all these portability concerns in mind when building your cloud-friendly applications!



















Maintaining the data only in Amazon’s SimpleDB appears to me to defeat the purpose of multi-cloud deployment.
Ray DePena (@Ray DePena) asked “Is the Cloud chasm too wide for legacy players to cross?” in a deck for his Enterprise Cloud Curves Ahead: PaaS Carefully article for the Cloud Interoperability Magazine blog:
We’re seeing a lot of changes in the IT landscape. Oracle buying its way into the Cloud, AMD wants in on the server business, Dell is no longer a PC company, and some legacy players are learning about the Cloud market the hard way (see: Harris Scraps Secure Public Cloud).
Harris claims customers have a preference for on premise (private cloud) solutions, though a McKinsey survey mentioned in the article indicates CIOs will take a “balanced” approach (read: Hybrid Cloud). Besides, acquiring on-premise IT business won’t get easier in the Federal government space with its shift to a Cloud First Policy, nor in State government (see Time For State And Local Govs To Head To The Cloud).Is the Cloud chasm too wide for legacy players (like Harris) to cross?
Everyone in the industry is positioning for the game of the century as a result of the disruptive Cloud forces. As I write this, Bernard Golden, VP of enStratus Networks, just published a post titled, “How Cloud Computing Is Forcing IT Evolution”, and he’s right. This isn’t your usual IT industry innovation disruption, Cloud computing will completely reconfigure every industry where it can be widely adopted (entrepreneurs take note). For SMB, that meant rapid adoption of Software as a Service (SaaS) solutions, for large enterprise it’ll most likely be a challenging trek to Hybrid Cloud and the mid-market may opt for a combination of SaaS and virtual private clouds. What Cloud Flavor Will You Choose?
In any event, the pragmatic reality of large enterprise (as Harris found out), is that mission-critical, legacy, custom, and many integrated applications can’t be easily decoupled from the business, process, or underlying infrastructure and migrated to the public cloud. Even if it was feasible, many enterprises will take a protectionist stance, or are simply not ready culturally, to make such a transition. The inescapable reality for large enterprise is Cloud bifurcation:
- Private Cloud (not popular with some Cloud advocates) for mission-critical applications that have high security, privacy, and regulatory compliance requirements, and
- Public Cloud for applications that do not have the aforementioned requirements.
In other words, Hybrid Cloud, and the path from legacy IT development to Cloud goes through PaaS. PaaS abstracts the underlying infrastructure, allowing developers to be more efficient in the same manner that IaaS is a more efficient way to leverage infrastructure, and SaaS a more efficient way to consume applications. Some of the benefits of PaaS are:
- Developers ability to create and deploy software faster.
- Lower application development risks & costs
- Better security (via common security model)
- Greater scalability, resilience & interoperability
- Faster time to market (TTM) and Return on Investment (ROI)
To get a feel for the state of PaaS affairs I spoke with Bart Copeland, ActiveState CEO, Toph Whitmore, VP of Marketing, and Troy Topnik, Technical Communications Specialist. Bart described the state of the affairs this way:
The PaaS market is at its early stage of growth and does not yet have well-established leaders, best use, business practices or dedicated standards. The adoption of PaaS offerings is still associated with some degree of uncertainty and risk. - Bart Copeland, ActiveState CEO
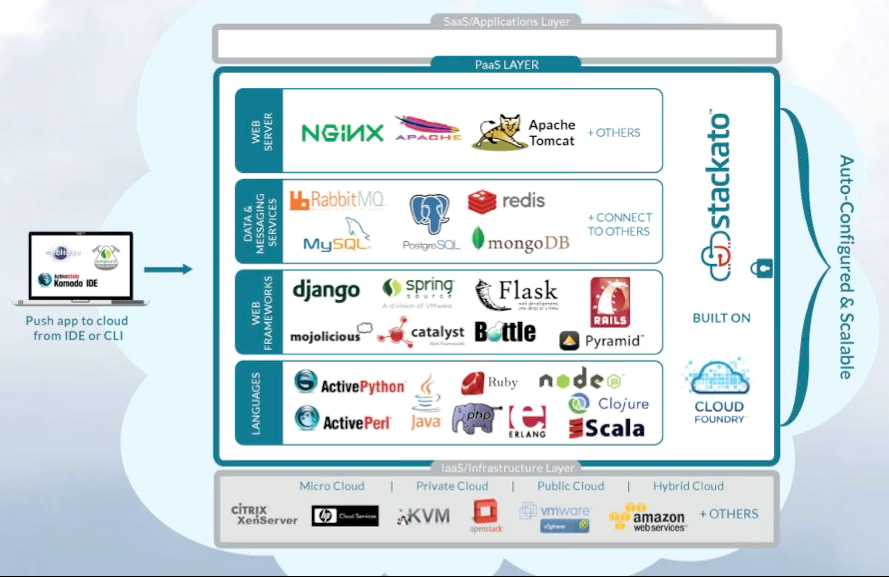
Not an unreasonable characterization of the marketplace. ActiveState, for those that may not know, is focused on the private PaaS segment of the market with their Stackato product (general availability announced just last week). You can try Stackato’s Micro Cloud free of charge or see more information on Stackato. Here’s a high-level depiction of the product:
ActiveState is one of the many PaaS companies in the market today. There is no shortage of players in the PaaS segment. Salesforce’s Force.com / Heroku, Google’s GAE, Microsoft’s Azure, VMware’s Cloud Foundry (not to be confused with the open source project Cloud Foundry.org) CloudBees, RedHat’s OpenShift, Apprenda, Cordys, OrangeScape, Tibco, and AppFog.
As an advocate of Hybrid Cloud, I can see large enterprise’s attraction for a single PaaS platform to run on public and private environments supporting legacy applications, multiple languages, the latest application frameworks, and IaaS Cloud Service Providers like Amazon’s AWS, OpenStack, and VMware vSphere to name just a few.
Some may believe that PaaS is a public cloud only phenomenon, I don’t share that perspective. Though I will concede that private Cloud (and private PaaS) can be a more difficult endeavor for enterprises to undertake. Nevertheless, I have no doubt we will see private clouds and private PaaS right along with them.
You can rest assured that successful journeys to the Cloud will not be made with a traditional application development approach. Ultimately, it will be the PaaS players that capture the heart and mind of the developer community that will successfully lead large enterprise through the Cloud curves ahead.


No significant articles today.
<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
The Microsoft Server and Cloud Platform Team posted ZDNet Debates: Hyper-V or VMware? on 3/6/2012:
Yesterday morning, ZDNet kicked off its Great Debate “Hyper-V or VMware?”, with opening comments from Jason Perlow and Ken Hess. Microsoft supporter Jason Perlow made a strong case for Hyper-V, noting that the functionality in Windows Server “8” Hyper-V exceeds that in vSphere, without the need for the expensive add-ons and third party enhancements that VMware requires.
Reiterating key points from his articles, Windows Server 8: The Ultimate Cloud OS? and Is Microsoft's Hyper-V in Windows Server 8 finally ready to compete with VMware?, Jason states that 2013 will be a big year for Microsoft as CIOs examine the licensing bottom line and evaluate the value that Hyper-V brings as a complete end-to-end virtual infrastructure and private cloud solution.
The debate will resume today at 11:00AM PST. Don’t miss the opportunity to follow the action in real-time and join the conversation on ZDNet!

<Return to section navigation list>
Cloud Security and Governance
Chris Hoff (@Beaker) followed up his below posts with A Funny Thing Happened On My Way To Malware Removal… on 3/6/2012:
This is an update that I originally included with the post describing the malicious infestation of malware on my WordPress site here. I’ve split it out for clarity.
The last 12 hours or so have been fun. I’ve had many other folks join in and try to help isolate and eradicate the malware that plagued my WordPress install (read the original post below.)
I was able to determine that the Dreamhost password compromise in January (correlated against logs) was responsible for the (likely) automated injection of malicious PHP code into a plug-in directory that had poor permissions. This code was BASE64 encoded. It was hard to find.
Further, as was alluded to in my earlier version of this post, the malware itself was adaptive and would only try (based on UA and originating IP) to drop it’s Windows-based trojan executable ONCE by way of a hidden iFrame. Hit it again and you’d never see it.
It was a variant of the Blackhole Exploit kit.
If you ran any up-to-date AV solution (as evidenced by the 6 different brands that people reported,) visiting my site immediately tripped an alert. I run a Mac and up until today didn’t have such a tool installed. I clearly do now as a detective capability. This was a silly thing NOT to do as it costs basically nothing to do so these days.
When I made a backup of the entire directory, my VPS hosting provider THEN decided to run a security scan on the directory (serendipity) and notified me via email that it found the malware in the directory
Thanks. Great timing. The funny thing was that all the activity last night and uploaded telemetry must have set something off in Google because only late last night — 30+ days later — did Google flag the site as potentially compromised. Sigh.
At any rate, I ended up nuking my entire WordPress and mySQL installations and doing a fresh install. I’ve rid myself of almost every plug-in and gone back to a basic theme. I’ve installed a couple of other detective and preventative tools on the site and will likely end up finally putting the site behind CloudFlare for an additional layer of protection.
Really, I should have done this stuff LONG ago…this was my personal failure. I owe it to the kindness and attentiveness of those who alerted me to the fact that their AV sensors tripped.
The interesting note is that most of the security pros I know who run Macs and have visited my site in the last 30 days never knew I was infected. If this were a Mac-targeted malware, perhaps they may have been infected. The point is that while I’m glad it didn’t/couldn’t infect Mac users, I do care that I could have harmed users with other operating systems.
Further, the “ignorance is bliss” approach is personally alarming to me; without a tool which many security pros sleight as “useless,” I would never have know I was infected.
If anything, it should make you think…



SearchSecurity.com interviewed David Navetta at the RSA Conference and posted a Video: PCI liability, HIPAA enforcement rule, breach notification laws on 3/6/2012:
In this interview, recorded at RSA Conference 2012 in San Francisco, David Navetta, an attorney and founding partner with the Denver-based Information Law Group, discusses hot topics in compliance, including why PCI liability matters to the card brands, the effect of the HIPAA enforcement rule and international breach notification laws.
Bruce Kyle announced a new Blog Series -- Windows Azure Security Best Practices in a 3/6/2012 post:
In a series of blog posts, I’ll provide a look into how you can secure your application in Windows Azure. This six-part series describes the threats, how you can respond, what processes you can put into place for the lifecycle of your application, and prescribes a way for you to implement best practices around the requirements of your application. I’ll also show ways for you to incorporate user identity and some of services Azure provides that will enable your users to access your cloud applications in new says.
At first, the steps may seem lengthy. But as you will find, Windows Azure shares the responsibility to help secure your application. By using Windows Azure platform, you are able to take a deeper look into your application and take steps to make your application more secure.
Beginning tomorrow I’ll post a new section each day.
Here are the
links toeach part in this series:Windows Azure Security Best Practices -- Part 1: The Challenges, Defense in Depth. This post describes the threat landscape and introduces the plan for your application to employ defense in depth in partnership with Windows Azure.
Windows Azure Security Best Practices -- Part 2: What Azure Provides Out-of-the-Box. This is an overview that security with Windows Azure is a shared responsibility, and Windows Azure provides your application with important security features. But then again, it also exposes other vulnerabilities that you should consider. In addition, I’ll explore how Microsoft approaches compliance.
Windows Azure Security Best Practices – Part 3: Identifying Your Security Frame. This post explores how you can examine your application and identify attack surfaces. The idea of a Security Frame is a way for you to look at your application to determine treats and your responses, before you even begin coding. I point you to checklists that you can use when you are architecting your application.
Windows Azure Security Best Practices – Part 4: What Else You Need to Do. In addition to protecting your application from threats, there are additional steps you should take when you deploy your application. We provide a list of mitigations that you should employ in your application development and deployment.
Windows Azure Security Best Practices – Part 5: Claims-Based Identity, Single Sign On. User identification represents the keys to accessing data and business processes in your application. In this section, I describe how you can separate user identity and the roles of your user out of your application and make it easier to create single sign on applications.
Windows Azure Security Best Practices – Part 6: How Azure Services Extends Your App Security. Finally, I show how other services in Windows Azure provide secure identity mapping, messaging, and connection to on premises application. This section suggests how you can use Windows Azure Active Directory, Windows Azure Connect, and Service Bus for your cloud applications, on premises applications, and hybrid applications.
The intent of this series is to provide a context for you to learn more and empower you to write great applications for the public cloud.
Learn more at Global Foundation Services Online Security. The Global Foundation Services team delivers trustworthy, available online services that create a competitive advantage for you and for Microsoft’s Windows Azure.


Chris Hoff (@Beaker) described Why Steeling Your Security Is Less Stainless and More Irony… in a 3/5/2012 post:
Earlier today I wrote about the trending meme in the blogosphere/security bellybutton squad wherein the notion that security — or the perceived lacking thereof — is losing the “war.”
My response was that the expectations and methodology by which we measure success or failure is arbitrary and grossly inaccurate. Furthermore, I suggest that the solutions we have at our disposal are geared toward solving short-term problems designed to generate revenue for vendors and solve point-specific problems based on prevailing threats and the appetite to combat them.
As a corollary, if you reduce this down to the basics, the tools we have at our disposal that we decry as useless often times work just fine…if you actually use them.
For most of us, we do what we can to provide appropriate layers of defense where possible but our adversaries are crafty and in many cases more skilled. For some, this means our efforts are a lost cause but the reality is that often times good enough is good enough…until it isn’t.
Like it wasn’t today.
Let me paint you a picture.
A few days ago a Wired story titled “Is antivirus a waste of money?” hit the wires that quoted many (of my friends) as saying that security professionals don’t run antivirus. There were discussions about efficacy, performance and usefulness. Many of the folks quoted in that article also run Macs. There was some interesting banter on Twitter also.
If we rewind a few weeks, I was contacted by two people a few days apart, one running a FireEye network-based anti-malware solution and another running a mainstream host-based anti-virus solution.
Both of these people let me know that their solutions detected and blocked a Javascript-based redirection attempt from my blog which runs a self-hosted WordPress installation.
I pawed through my blog’s PHP code, turned off almost every plug-in, ran the exploit scanner…all the while unable to reproduce the behavior on my Mac or within a fresh Windows 7 VM.
The FireEye report ultimately was reported back as a false positive while the host-based AV solution couldn’t be reproduced, either.
Fast forward to today and after I wrote the blog “You know what’s dead? Security…” I had a huge number of click-throughs from my tweet.
The point of my blog was that security isn’t dead and we aren’t so grossly failing but rather suffering a death from a thousand cuts. However, while we’ve got a ton of band-aids, it doesn’t make it any less painful.
Speaking of pain, almost immediately upon posting the tweet, I received reports from 5-6 people indicating their AV solutions detected an attempted malicious code execution, specifically a Javascript redirector.
This behavior was commensurate with the prior “sightings” and so with the help of @innismir and @chort0, I set about trying to reproduce the event.
@chort0 found that a hidden iFrame was redirecting to a site hosting in Belize (screen caps later) that ultimately linked to other sites in Russia and produced a delightful greeting which said “Gotcha!” after attempting to drop an executable.
Again, I was unable to duplicate and it seemed that once loaded, the iFrame and file dropper did not reappear. @innismir didn’t get the iFrame but grabbed the dropped file.
This led to further investigation that it was likely this was an embedded compromise within the theme I was using. @innismir found that the Sakura theme included “…woo-tumblog [which] uses a old version of TimThumb, which has a hole in it.”
I switched back to a basic built-in theme and turned off the remainder of the non-critical plug-ins.
Since I have no way of replicating the initial drop attempt, I can only hope that this exercise which involved some basic AV tools, some browser debug tools, some PCAP network traces and good ole investigation from three security wonks has paid off…
ONLY YOU CAN PREVENT MALWARE FIRES (so please let me know if you see an indication of an attempted malware infection.)
Now, back to the point at hand…I would never have noticed this (or more specifically others wouldn’t) had they not been running AV.
So while many look at these imperfect tools as a failure because they don’t detect/prevent all attacks, imagine how many more people I may have unwittingly infected accidentally.
Irony? Perhaps, but what happened following the notification gives me more hope (in the combination of people, community and technology) than contempt for our gaps as an industry.
I plan to augment this post with more details and a conclusion about what I might have done differently once I have a moment to digest what we’ve done and try and confirm if it’s indeed repaired. I hope it’s gone for good.
Thanks again to those of you who notified me of the anomalous behavior.
What’s scary is how many of you didn’t.
Is security “losing?”
Ask me in the morning…I’ll likely answer that from my perspective, no, but it’s one little battle at a time that matters.
/Hoff
Related articles
- Security professionals DO use anti-virus (eset.com)
- Report: malware pushed by affiliate networks remains the primary growth factor of the cybercrime ecosystem (zdnet.com)
- A Blogger’s Worst Nightmare – Your site has been hacked by malware! (bpwebnews.com)
- You Know What’s Dead? Security… (rationalsurvivability.com)


Where did Beaker’s squirrel avatar go?
Chris Hoff (@Beaker) asked and answered You Know What’s Dead? Security… in a 3/5/2012 post:
…well, it is if you listen to many of the folks who spend their time trawling about security conferences, writing blogs (like this one) or on podcasts, it is. I don’t share that opinion, however.
Lately there’s been a noisy upswing in the security echo chamber of people who suggest that given the visibility, scope, oft-quoted financial impact and reputational damage of recent breaches, that “security is losing.”
{…losing it’s mind, perhaps…}
What’s troubling about all this hen pecking is that with each complaint about the sorry state of the security “industry,” there’s rarely ever offered a useful solution that is appropriately adoptable within a reasonable timeframe, that satisfies a business condition, and result in an outcome that moves the needle to the “winning” side of the meter.
I was asked by Martin Mckeay (@mckeay) in a debate on Twitter, in which I framed the points above, if “…[I] don’t see all the recent breaches as evidence that we’re losing…that so many companies compromised as proof [that we're losing.]”
My answer was a succinct “no.”
What these breaches indicate is the constant innovation we see from attackers, the fact that companies are disclosing said breaches and the relative high-value targets admitting such. We’re also seeing the better organization of advanced adversaries whose tactics and goals aren’t always aligned with the profiles of “hackers” we see in the movies.
That means our solutions aren’t aligned to the problems we think we have nor the motivation and tactics of the attackers that these solutions are designed to prevent.
The dynamic tension between “us” and “them” is always cyclical in terms of the perception of who is “winning” versus “losing.” Always has been, always will be. Anyone who doesn’t recognize patterns in this industry is either:
- New
- Ignorant
- Selling you something
- …or all of the above
Most importantly, it’s really, really important to recognize that the security “industry” is in business to accomplish one goal:
Make money.
It’s not a charity. It’s not a cause. It’s not a club. It’s a business.
The security industry — established behemoths and startups alike — are in the business of being in business. They may be staffed by passionate, idealistic and caring individuals, but those individuals enjoy paying their mortgages.
These companies also provide solutions that aren’t always ready from the perspective of market, economics, culture, adoptability, scope/impact of problem, etc. This is why I show the Security Hamster Sine Wave of Pain and why security, much like bell bottoms, comes back into vogue in cycles…generally when those items above converge.
Now, if you overlay what I just said with the velocity and variety of innovation without constraint that attackers play with and you have a clearer picture of why we are where we are.
Of course, no rant like this would be complete without the anecdotal handwaving bemoaning flawed trust models and technology, insecure applications and those pesky users…sigh.
The reality is that if we (as operators) are constrained to passive defense and are expected to score progress in terms of moving the defensive line forward versus holding ground, albeit with collateral damage, then yes…we’re losing.
If, rather, we assess our ability to influence outcomes such that the business can function at an acceptable level of risk, where “winning” and “losing” aren’t measured in emotional baggage or absolutes, then perhaps more often than not, we’d be winning instead of whining.
It’s all a matter of perspective, really.
I think staring at things other than one’s bellybutton can deliver some.
Try it. It won’t hurt. Promise.
/Hoff
Related articles
- Bringing Sexy back (to Security): Mike’s RSAC 2012 Wrap-up (securosis.com)
- Hacking breach made us stronger says RSA (go.theregister.com)
- Building/Bolting Security In/On – A Pox On the Audit Paradox! (rationalsurvivability.com)
- PSA: Paula Deen, Sausage Pancake Egg Sandwiches & Security… (rationalsurvivability.com)


<Return to section navigation list>
Cloud Computing Events
Jeff Price announced a 3/23 Azure Architecture Design Workshop at Microsoft SF in a 3/6/2012 message:
Please join a cloud expert from Terrace Software for an Azure Rapid Architecture Design Workshop. This technical session will solicit input and collaboration from attendees regarding real-world application challenges and how they can be (or cannot be) solved in the cloud. The session will include:
- An open discussion of some of the application challenges which our attendees are facing.
- A whiteboard session focusing on architecting optimized Azure applications.
- An exploration of Azure's PaaS service model with real world implementation scenarios.
- A walk through of the secret sauce of Azure design-cost based architecture.
Topics include:
- How to "SaaS-ify" your on-premises application in the cloud.
- Should you move an entire application to the cloud or just selectively migrate key components using a hybrid cloud architecture?
- How to decompose on-premises applications to achieve maximum scalability in the cloud.
- Optimizing heterogeneous data storage, including Tables, Blobs, SQL Azure, and Content Delivery Networks, all in accordance with international privacy and data protection laws.
- Azure Cloud 101:
- Scaling, queues and asynchronous processing
- Azure data storage, retry policies and OData
- Caching, session management and persistence
- Deployment, diagnostics and monitoring
- Integration with other systems, both on-premises and external
- Security, authentication and authorization, OpenID and OAuth
- Cost forecasting for a sample Azure application
Attendees will take away highly impactful information, design patterns and cost forecasts for a modern, elastic Azure software deployment.
- Session Title: Azure Rapid Architecture Design Workshop
- Session Date, Time and Location: Friday, March 23, 2012, 9:15 a.m. - 11:45 a.m. (Registration at 9:00 a.m.)
- Microsoft Corporation
835 Market Street, Suite 700
San Francisco, CA- Link for Registration and Details: Click to Register
Please feel free to forward this invitation to interested colleagues.
<Return to section navigation list>
Other Cloud Computing Platforms and Services
Joe Brockmeier (@jzb) reported Google Slashes Storage Prices: Still no GDrive in a 3/6/2012 post to the ReadWriteCloud blog:
Google announced today that it's dropping its pricing on Google Cloud Storage and its integration with several enterprise storage offerings. Google's updated pricing scheme puts it roughly in line with Amazon's S3, but what else does Google have to offer except a new pricing scheme?
I spoke to Google's product manager for Cloud Storage, Navneet Joneja on Monday about the pricing change and how Google stands out in storage.
First, Joneja emphasizes Google's performance and scalability. Unfortunately, Google won't make with much in the way of details about its underlying infrastructure. (For example, does Google use SSD or standard drives? They won't say.)
The big argument for Google's offering, says Joneja, is what you can do with data when you've got it in Google Cloud Storage. Developers using Google Cloud Storage can tap into Google's App Engine and Google Big Query as well.
The pricing changes, says Joneja, should drop pricing by as much as 15% – depending on how much storage is used. Like Amazon S3, Google has a tiered pricing model that includes three dimensions, how much data is stored, amount of transfer, and the requests.
The request and data transfer pricing aren't changing, but they've shaved the cost of storage. Previously the first tier, up to 1TB, was priced at $0.13 per GB. Now it's at $0.12 up to 1TB. The next 9TB was priced at $0.12 per GB, but is now $0.105 per GB.
The partnering companies Google announced today are Gladinet, Panzura, Storsimple, TwinStrata and Zmanda. So far, most of the solutions that Google is announcing don't seem to be using Cloud Storage in conjunction with other Google services, but perhaps we'll be seeing a few more offerings that combine App Engine or Big Query and storage.
Google Cloud Storage is available in two regions. Joneja says customers can choose from two containers, either in the U.S. or Europe. Currently, Google does not offer a region in Asia.
With the staggering growth of Amazon S3, it should be interesting to see if Google is able to cut in on Amazon's action significantly.
No doubt quite a bit of S3's growth owes to Dropbox, which uses Amazon S3. I did ask Joneja if the slew of partnerships announced today meant that Google preferred to let customers build solutions rather than offering is own (fabled) GDrive. Unfortunately, but not surprisingly, Google is still not commenting on when or if we'll be seeing GDrive.


Windows Azure storage pricing is US$0.14/GB per month on a pay-as-you-go basis and $0.01 per 10,000 transactions. Following are prices for six-month commitments:

See the Windows Azure Storage page for more pricing details.
Simon Munro (@simonmunro) asserted AWS doesn’t want you to cloud burst in a 3/6/2012 post:
AWS doesn’t want cloud bursting, where customers come to the platform and retreat to their on-premise infrastructure when the work is done. AWS is keen to get you to commit to longer term reserved instances and is adjusting their pricing accordingly.
There is nothing like a price drop in Jeff Barr’s midnight AWS announcements to get everybody excited in the morning. What interests me is not the price drop per se, nor the inevitable demand for competitors to follow, nor the back and forth comparison with traditional managed hosting that will get underway (again). What is interesting is the increasing differential between the price drop for on demand versus reserved instances.
As James has pointed out, reserved instance pricing is important in developing a cost model for cloud applications and over time, but the gathering of data and analysis can get a bit tricky. EC2 reserved instance pricing page reckons that reserved instance pricing will save between 50% and 70% of your EC2 costs (RDS has similar savings for reserved databases) — which is a compelling proposition.
Anecdotal evidence (read “I may or may not have heard it somewhere”) suggests that a lot of AWS business is for cloud bursting — where AWS is used, not as the primary platform, but one to use occasionally. It would also seem that the ‘occasionally’ refers to development and test capacity, rather than an architecture engineered to use AWS as a true cloud bursting platform for a production system. By creating a huge differential between on demand and reserved instances, AWS may be presenting the teaser to convert those ‘cloud burst’ uses into long term deployments. After all, if it is cheap enough to use on demand (which it must be otherwise customers would build their own) then being able to drop the price of something that customers know works (technically) by an additional 50% may push the decision makers in favour of AWS. But those savings only come from long term commitments (3 years), which is enough time to ensure that the particular application is committed to AWS, with others to follow.
While reductions in cloud costs are welcome, the fundamental problem of figuring out the costs, cost benefits and ‘in the box’ comparisons continue to be difficult. I have discussed this as an engineering problem and people always wade dangerously into the debate, as Jeff Barr did recently, and there is some tricky analysis required. Pricing is still far to complex and the models too immature to be convincing in front of the CFO, or whoever controls the budget, and private cloud advocates, who have been doing pricing for a while, can almost always bulldoze a public cloud pricing model. Rather than only a few pennies saved on EC2 savings, I would like to see some rich, capable pricing tools and models emerging.


Jeff Barr (@jeffbarr) reported Surprise! The EC2 CC2 Instance Type uses a Sandy Bridge Processor... on 3/6/2011:
We like to distinguish our Cluster Compute instances from the other instance types by providing details about the actual processor (CPU) inside. When we launched the CC2 (Cluster Compute Eight Extra Large) instance type last year we were less specific than usual, stating only that each instance contained a pair of 8-core Xeon processors, each Hyper-Threaded, for a total of 32 parallel execution units.
If you are a student of the Intel architectures, you probably realized pretty quickly that Intel didn't actually have a processor on the market with these particular specs and wondered what was going on.
Well, therein lies a tale. We work very closely with Intel and were able to obtain enough pre-release Xeon E5 ("Sandy Bridge") chips last fall to build, test, and deploy the CC2 instance type. We didn't publicize or expose this information and simply announced the capabilities of the instance.
Earlier today, Intel announced that the Xeon E5 is now in production and that you can now buy the same chips that all EC2 users have had access to since last November. You can now write and make use of code that takes advantage of Intel's Advanced Vector Extensions (AVX) including vector and scalar operations on 256-bit integer and floating-point values. These capabilities were a key in an cluster of 1064 cc2.8xlarge instances making it to the 42nd position at last November’s Top500 supercomputer list clocking in at over 240 Teraflops.
I am happy to say that we now have plenty of chips, and there is no longer any special limit on the number of CC2 instances that you can use (just ask if you need more). Customers like InhibOx are using cc2.8xlarge instances for building extremely large customized virtual libraries for their customers - to support computational chemistry in drug discovery. In addition to computational chemistry customers have been using this instance type for a variety of applications ranging from image processing to in-memory databases.
On a personal note, my son Stephen is working on a large-scale dynamic problem solver as part of his PhD research. He recently ported his code from Python to C++ to take advantage of the Intel Math Kernel Library (MKL) and some other parallel programming tools. I was helping him to debug an issue that prevented him from fully exploiting all of the threads. Once we had fixed it, it was pretty cool to see his CC2 instance making use of all 32 threads (image via htop):
And what are you doing with your CC2? Leave us a comment and share....




Jeff Barr (@jeffbarr) announced Dropping Prices Again-- EC2, RDS, EMR and ElastiCache in a 3/5/2011 post:
AWS works hard to lower our costs so that we can pass those savings back to our customers. We look to reduce hardware costs, improve operational efficiencies, lower power consumption and innovate in many other areas of our business so we can be more efficient. The history of AWS bears this out -- in the past six years, we’ve lowered pricing 18 times, and today we’re doing it again. We’re lowering pricing for the 19th time with a significant price decrease for Amazon EC2, Amazon RDS, Amazon ElastiCache and Amazon Elastic Map Reduce.
Amazon EC2 Price Drop
First, a quick refresher. You can buy EC2 instances by the hour. You have no commitment beyond an hour and can come or go as you please. That is our “On-Demand” model.
If you have predictable, steady-state workloads, you can save a significant amount of money by buying EC2 instances for a term (one year or three year). In this model, you purchase your instance for a set period of time and get a lower price. These are called “Reserved Instances,” and this model is the equivalent to buying or leasing servers, like folks have done for years, except EC2 passes its benefit of substantial scale to its customers in the form of low prices. When people try to compare EC2 costs to doing it themselves, the apples to apples comparison is to Reserved Instances (although with EC2, you don't have to staff all the people to build / grow / manage the Infrastructure, and instead, get to focus your scarce resources on what really differentiates your business or mission).
Today’s Amazon EC2 price reduction varies by instance type and by Region, with Reserved Instance prices dropping by as much as 37%, and On-Demand instance prices dropping up to 10%. In 2006, the cost of running a small website with Amazon EC2 on an m1.small instance was $876 per year. Today with a High Utilization Reserved Instance, you can run that same website for less than 1/3 of the cost at just $250 per year - an effective price of less than 3 cents per hour. As you can see below, we are lowering both On-Demand and Reserved Instances prices for our Standard, High-Memory and High-CPU instance families. The chart below highlights the price decreases for Linux instances in our US-EAST Region, but we are lowering prices in nearly every Region for both Linux and Windows instances.
For a full list of our new prices, go to the Amazon EC2 pricing page.
We have a few flavors of Reserved Instances that allow you to optimize your cost for the usage profile of your application. If you run your instances steady state, Heavy Utilization Reserved Instances are the least expensive on a per hour basis. Other variants cost a little more per hour in exchange for the flexibility of being able to turn them off and save on the usage costs when you are not using them. This can save you money if you don’t need to run your instance all of the time. For more details on which type of Reserved Instances are best for you, see the EC2 Reserved Instances page.
Save Even More on EC2 as You Get Bigger
One misperception we sometimes hear is that while EC2 is a phenomenal deal for smaller businesses, the cost benefit may diminish for large customers who achieve scale. We have lots of customers of all sizes, and those who take the time to rigorously run the numbers see significant cost advantages in using EC2 regardless of the size of their operations.Today, we’re enabling customers to save even more as they scale -- by introducing Reserved Instance volume tiers. In order to determine what tier you qualify for, you add up all of the upfront Reserved Instance payments for any Reserved Instances that you own. If you own more than $250,000 of Reserved Instances, you qualify for a 10% discount on any additional Reserved Instances you buy (that discount applies to both the upfront and the usage prices). If you own more than $2 Million of Reserved Instances, you qualify for a 20% discount on any new Reserved Instances you buy. Once you cross $5 Million in Reserved Instance purchases, give us a call and we will see what we can do to reduce prices for you even further – we look forward to speaking with you!
Price Reductions for Amazon RDS, Amazon Elastic MapReduce and Amazon ElastiCache
These price reductions don’t just apply to EC2 though, as Amazon Elastic MapReduce customers will also benefit from lower prices on the EC2 instances they use. In addition, we are also lowering prices for Amazon Relational Database Service (Amazon RDS). Prices for new RDS Reserved Instances will decrease by up to 42%, with On-Demand Instances for RDS and ElastiCache decreasing by up to 10%.Here’s a quick example of how these price reductions will help customers save money. If you are a game developer using a Quadruple Extra Large RDS MySQL 1-year Heavy Utilization Reserved Instance to power a new game, the new pricing will save you over $550 per month (or 39%) for each new database instance you run. If you run an e-commerce application on AWS using an Extra Large multi-AZ RDS MySQL instance for their always-on database will save you more than $445 per month (or 37%) by using a 3-year Heavy Utilization Reserved Database Instance. If you added a two node Extra Large ElastiCache cluster for better performance, you will save an additional $80 per month (or 10%). For a full list of the new prices, go to the Amazon RDS pricing page, Amazon ElastiCache pricing page, and the Amazon EMR pricing page.
Real Customer Savings
Let’s put these cost savings into context. One of our fast growing customers was primarily running Amazon EC2 On-Demand instances, running 360,000 hours last month using a mix of M1.XL, M1.large, M2.2XL and M2.4XL instances. Without this customer changing a thing, with our new EC2 pricing, their bill will drop by over $25,000 next month, or $300,000 per year – an 8.6% savings in their On-Demand spend. This customer was in the process of switching to 3-year Heavy Utilization Reserved Instances (seeing most of their instances are running steady state) for a whopping savings of 55%. Now, with the new EC2 price drop we're announcing today, this customer will save another 37% on these Reserved Instances. Additionally, with the introduction of our new volume tiers, this customer will add another 10% discount on top of all that. In all, this price reduction, the new volume discount tiers, and the move to Reserved Instances will save the customer over $215,000 per month, or $2.6 million per year over what they are paying today, reducing their bill by 76%!Many of our customers were already saving significant amounts of money before this price drop, simply by running on AWS. Samsung uses AWS to power its “smart hub” application – which powers the apps you can use through their TVs – and they recently shared with us that by using AWS they are saving $34 million in capital expenses over 2 years and reducing their operating expenses by 85%. According to their team, with AWS, they met reliability and performance objectives at a fraction of the cost they would have otherwise incurred.
Another customer example is foursquare Labs, Inc., They use AWS to perform analytics across more than 5 million daily check-ins. foursquare runs Amazon Elastic MapReduce clusters for their data analytics platform, using a mix of High Memory and High CPU instances. Previously, this EMR analytics cluster was running On-Demand EC2 Instances, but just recently, foursquare decided they would buy over $1 million of 1-year Heavy Utilization Reserved Instances, reducing their costs by 35% while still using some On-Demand instances to provide them with the flexibility to scale up or shed instances as needed. However, the new EC2 price drop lowers their costs even further. This price reduction will help foursquare save another 22%, and their overall EC2 Reserved Instance usage for their EMR cluster qualifies them for the additional 10% volume tier discount on top of that. This price drop combined with the move to Reserved Instances will help foursquare reduce their EC2 instance costs by over 53% from last month without sacrificing any of the scaling provided by EC2 and Elastic MapReduce.
As we continue to find ways to lower our own cost structure, we will continue to pass these savings back to our customers in the form of lower prices. Some companies work hard to lower their costs so they can pocket more margin. That’s a strategy that a lot of the traditional technology companies have employed for years, and it’s a reasonable business model. It’s just not ours. We want customers of all sizes, from start-ups to enterprises to government agencies, to be able to use AWS to lower their technology infrastructure costs and focus their scarce engineering resources on work that actually differentiates their businesses and moves their missions forward. We hope this is another helpful step in that direction.



Werner Vogels (@werner) seconded Amazon Web Services’ pricing motion with Driving Compute Cost Down for AWS Customers in a 3/5/2012 post:
AWS today announced a substantial price drop from March 1, 2012 for many of the Amazon EC2, Amazon RDS, and Amazon ElastiCache instances types around the world. For example, the popular m1.small instance type will see a price drop of 6% for EC2 On-Demand usage and 33% for EC2 Reserved Instance usage. Some of the other instance types have even greater savings: for example, the high memory M2 instances will see a 10% price cut for On Demand and 37% for Reserved instances. Similarly, Amazon RDS will cut its On-Demand prices by up to 10% and Reserved Instance prices by up to 42%. Amazon ElastiCache customers will see their prices drop by up to 10%, depending on their cache node types.
Driving costs down for our customers is part of the DNA of Amazon and therefore also part of the DNA of AWS. Customers are often surprised when our Solution Architects that are working with them have a relentless focus on helping customers to reduce their AWS bill wherever possible. We strongly believe that if we can help our customers reduce their costs, they are likely to be more successful in the long term. The relationship with our customers often becomes more that of a partnership as AWS truly has the customer’s best interest at heart and we are equally interested in their long-term success.
We will continue to drive AWS prices down, even without any competitive pressure to do so. And we will work hard to do this across all the different services, such as the price reduction for Amazon S3 and EBS last moth. I recently ran into a customer who explained that his invoice processing consolidation project was supposed to pay for itself within two years, but because of the continuous AWS price drops they were able to do it in 9 months. I am pretty sure that customer will adjust this estimate favorably again after today’s announcement.
Reducing pricing is not just a matter of passing on the benefits of economies of scale, although that certainly plays a role. We continuously apply all our innovative skills to the design of datacenters, servers, storage, network, etc. to drive new efficiencies and higher reliability. Experiences with the highly scalable, ultra-efficient supply chains of Amazon.com drive great new innovations in the highly redundant supply chains for AWS, which lead to new efficiencies that we can pass on to our customers. Also on the business model side, we continue to innovate, as the introduction of Reserved Instances and Spot Instances have helped customers make significant savings. With the new announcement, we have introduced volume discount tiers for Reserved Instances, which will provide additional discounts of 10% and 20%, both of which are in addition to the price cuts available to all customers, to further help customers drive down costs as they scale on AWS infrastructure.
For more details on the new pricing, visit the EC2 pricing page, RDS pricing page, ElastiCache page, forum announcement, and the AWS developer blog.


I contend that Microsoft’s recent price reductions for SQL Azure and Windows Azure Compute services represent competitive pressure.
Peter Bailis (@pbailis) asked What's Wrong with Amazon's DynamoDB Pricing? in a 3/4/2012 post:
There’s no good reason why strong consistency should cost double what eventual consistency costs. Strong consistency in DynamoDB shouldn’t cost Amazon anywhere near double and wouldn’t cost you double if you ran your own data store. While the benefit to your application may not be worth this high price, hiding consistency statistics encourages you to overpay.
Amazon recently released an open beta for DynamoDB, a hosted, “fully managed NoSQL database service.” DynamoDB automatically handles database scaling, configuration, and replica maintenance under a pay-for-throughput model. Interestingly, DynamoDB costs twice as much for consistent reads compared to eventually consistent reads. This means that if you want to be guaranteed to read the data you last wrote, you need to pay double what you could be paying otherwise.
Now, I can’t come up with any good technical explanation for why consistent reads cost 2x (and this is what I’m handsomely compensated to do all day). As far as I can tell, this is purely a business decision that’s bad for users:
- The cost of strong consistency to Amazon is low, if not zero. To you? 2x.
- If you were to run your own distributed database, you wouldn’t incur this cost (although you’d have to factor in hardware and ops costs).
- Offering a “consistent write” option instead would save you money and latency.
- If Amazon provided SLAs so users knew how well eventual consistency worked, users could make more informed decisions about their app requirements and DynamoDB. However, Amazon probably wouldn’t be able to charge so much for strong consistency.
I’d love if someone (read: from Amazon) would tell me why I’m wrong.
The cost of consistency for Amazon is low, if not zero. To you? 2x.
Regardless of the replication model Amazon chose, I don’t think it’s possible that it’s costing them 2x to perform consistent reads compared to eventually consistent reads:
Dynamo-style replication. If Amazon decided to stick to their original Dynamo architecture, then all reads and writes are sent to all replicas in the system. When you perform an eventually consistent read, it means that DynamoDB gives you an answer when the first replica (or first few replicas) reply. This cuts down on latency: after all, waiting for the first of three replicas to reply is faster than waiting for a single replica to respond! However, all of the replicas will eventually respond to your request, whether you wait for them or not.
This means that eventually consistent reads in DynamoDB would use the same number of messages, amount of bandwidth, and processing power as strongly consistent reads. It shouldn’t cost Amazon any more to perform consistent reads, but it costs you double.
If you ran your own Dynamo-style NoSQL database, like Riak, Cassandra, or Voldemort, you wouldn’t have this artificial cost increase when choosing between eventual and strongly consistent reads.
Possible explanations: Maybe Amazon didn’t adopt the Dynamo design’s “send-to-all” semantics. This would save bandwidth but cause a significant latency hit. However, Amazon might save in terms of messages and I/O without compromising latency if they chose not to send read requests to remote sites (e.g., across availability zones) for eventually consistent reads . Another possibility is that, because eventual consistency is faster, transient effects like queuing are reduced, which helps with their back-end provisioning. Regardless, none of these possibilities necessitate a 2x price increase. Note that the Dynamo model covers most variants of quorum replication plus anti-entropy. edit: As I mentioned, it’s possible that weak consistency saves an extra I/O per read. However, I’m still unconvinced that this leads to a 2x TCO increase.
Cost to Amazon: probably zero
Master-slave replication. If Amazon has chosen a master-slave replication model in DynamoDB, eventually consistent reads could go to a slave, reducing load on the master. However, this would mean Amazon is performing some kind of monetary-cost-based load-balancing, which seems strange and hard to enforce. Even if this is the case, is doubling the price really the right setting for proper load-balancing at all times and for all data? Is the 2x cost bump really necessary? I’m not convinced.
If you ran your own NoSQL store that used master-slave replication, like HBase or MongoDB, you wouldn’t be faced with this 2x cost increase for strong consistency.
Cost to Amazon: increased master load. 2x load? Probably not, given proper load balancing.
Read vs. Write Cost
Amazon decided to place this extra charge on the read path. Instead, they could have offered a “consistent write” option, where all subsequent reads would return the data you wrote. This would slow down consistent writes (and speed up reads). I’d wager that a vast majority of DynamoDB operations are reads, so this “consistent write” option would decrease revenue compared to the current “consistent read” option. So, compared to a consistent write option, you’re currently getting charged more, and the majority of your DynamoDB operations are slower.
FUD Helps Sell Warranties
Amazon is vague about eventual consistency in DynamoDB. Amazon says that:
Consistency across all copies of data is usually reached within a second. Repeating a[n eventually consistent] read after a short time should return the updated data.
What does “usually” mean? What’s “a short time”? These are imprecise metrics, and they certaintly aren’t guarantees. This may be intentional.
Best Buy tries to sell you an in-house extended warranty when you buy a new gadget. Most of the time, you don’t buy the warranty because you make a judgment that the chance of failure isn’t worth the price of the warranty. With DynamoDB, you have no idea what the likelihood of inconsistency is, except that “a second” is “usually” long enough. What if you don’t want to wait? What about the best case? Or the worst? Amazon could release a distribution for these delays so you could make an informed decision, but they don’t. Why not?
It’s not for technical reasons. Amazon has to know this distribution. I’ve spent the last six months thinking about how to provide SLAs for consistency. Our new techniques show that you can make predictions with arbitrary precision simply by measuring message delays. Even without our work, I’d bet all my chips on the fact that Amazon has tested the hell out of their service and know exactly how eventual eventual consistency is in DynamoDB. After all, if the window of inconsistency was prohibitively long, it’s unlikely that Amazon would offer eventual consistency as an option in the first place.
With more information, most customers probably wouldn’t pay 2x
So why doesn’t Amazon release this data to customers? There are several business reasons that disincentivize them from doing so, but the basic idea is that it’s not clear that strong consistency delivers a 2x value to the customer in most cases. However, without the data, customers can’t make this call for themselves without a lot of benchmarking. And profiling doesn’t buy you any guarantees like an SLA.
If users knew what “usually” really meant, they could make intelligent decisions about pricing. How many people would pay double for strong consistency if they’d only have to wait a few tens of milliseconds on average for consistent read, or, conversely, that data would be at most a few tens of milliseconds stale? What if 99.9% of reads were fresh within 100ms? 200ms? 500ms? 1000ms? Without the distribution, it’s hard to judge whether eventual consistency works for a given app.
Related: if your probability of consistent reads is sufficiently high (say, 99.999%) after normal client-side round-trip times (which are often long), do you really care about strong consistency? If you did, you could also intentionally block your readers until they would read consistent data with a high enough probability.
If you have ”stickiness” and your requests are always sent to a given DynamoDB instance (which you can’t enforce but is a likely design choice!), then you may never read inconsistent data, even under eventual consistency. Even if this happens only some of the time, you’ll see less stale data. This is due to what are known as session guarantees.
It’s not specified how much slower a consistent read is compared to an eventually consistent read, so it’s possible that the wait time until (a high probability of) consistency plus the latency of an eventually consistent read is actually lower than the latency of a strongly consistent read.
If you store timestamps with your data, you can guarantee you don’t read old data (another session guarantee) and, if you’re dissatisfied, you can repeat your eventually consistent read. You can calculate the expected cost of reading consistent data across multiple eventually consistent reads—if you have this data.
I don’t think many people would pay 2x for their reads if they were provided with this data or some consistency SLA. Maybe some total rockstars are okay with this vagueness, but it sure seems hard to design a reliable service without any consistency guarantees from your backend. By only giving users an extremely conservative upper bound on the eventuality of reads (say, if your clients switch between data centers between reads and writes and DynamoDB experiences extremely high message delays), Amazon may be scaring the average (prudent) user into paying more than they probably should.
Conclusion
Strong consistency in DynamoDB probably doesn’t cost Amazon much (if anything) but it costs you twice as much as eventual consistency. It’s highly likely that Amazon has quantitative metrics for eventual consistency in DynamoDB, but keeping those numbers private makes you more likely to pay extra for guaranteed consistency. Without those numbers, it’s much harder for you to reason about your application’s behavior under average-case eventual consistency.
Sometimes you absolutely need strong consistency. Pay in those cases. However, especially for web data, eventual is often good enough. The current problem with DynamoDB is that, because customers don’t have access to quantitative metrics about their window of inconsistency, it’s easy for Amazon to set prices irrationally high.
Disclaimer: I (perhaps obviously) have no privileged knowledge of Amazon’s AWS architecture (or any other parts of Amazon, for that matter). I just happen to spend a lot of time thinking about and working on cool distributed systems problems.
Peter is a University of California at Berkeley (my Alma Mater) Computer Science grad student in Distributed systems.
<Return to section navigation list>


















0 comments:
Post a Comment