Windows Azure and Cloud Computing Posts for 1/23/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |

Note: This post is updated daily or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue and Hadoop Services
- SQL Azure Database, Federations and Reporting
- Marketplace DataMarket, Social Analytics and OData
- Windows Azure Access Control, Service Bus, and Workflow
- Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue and Hadoop Services
Brian Swan (@brian_swan) described Improving Performance by Batching Azure Table Storage Inserts in a 1/25/2012 post to the [Windows Azure’s] Silver Lining blog:
This is a short post to share the results of a little investigation I did that was inspired by comments on a post I wrote about using SQL Azure for handling session data. The comment was by someone reporting that SQL Azure seemed to be faster than Azure Table Storage for handling session data. My experiments show that SQL Azure and Table Storage have very similar performance when doing single writes (YMMV), so I can’t verify or refute the claim. However, I got to wondering which is faster for inserting and retrieving many “rows” of data. I know that Table Storage is supposed to be faster, but I wondered how much faster. So I wrote a two-part PHP script that does the following:
Connects to SQL Azure.
- Inserts 100 rows to an existing database.
- Retrieves the 100 rows.
Here’s the code:
$conn = sqlsrv_connect(SQLAZURE_SERVER_ID.".database.windows.net,1433", array("UID"=>SQLAZURE_USER."@".SQLAZURE_SERVER_ID, "PWD"=>SQLAZURE_PASSWORD, "Database"=>SQLAZURE_DB, "ReturnDatesAsStrings"=>true));for($i = 0; $i < 100; $i++){$id = $i;$data = "GolferMessage".$i;$params = array($id, $data);$stmt1 = sqlsrv_query($conn, "INSERT INTO Table_1 (id, data) VALUES (?,?)", $params);if($stmt1 === false)die(print_r(sqlsrv_errors()));}$stmt2 = sqlsrv_query($conn, "SELECT id, data, timestamp FROM Table_1");while($row = sqlsrv_fetch_array($stmt2, SQLSRV_FETCH_ASSOC)){}Note: The code above uses the SQL Server Driver for PHP to connect to SQL Azure.
The second part of the script does the equivalent for Table Storage:
- Connects to Azure Storage.
- Inserts 100 entities to an existing table.
- Retrieves the 100 entities.
Here’s the code:
$tableStorageClient = new Microsoft_WindowsAzure_Storage_Table('table.core.windows.net', STORAGE_ACCOUNT_NAME, STORAGE_ACCOUNT_KEY);
$batch = $tableStorageClient->startBatch();for($i = 0; $i < 100; $i++){$name = $i;$message = "GolferMessage".$i;$mbEntry = new MessageBoardEntry();$mbEntry->golferName = $name;$mbEntry->golferMessage = $message;$tableStorageClient->insertEntity('MessageBoardEntry', $mbEntry);}$batch->commit();$messages = $tableStorageClient->retrieveEntities("MessageBoardEntry", null, "MessageBoardEntry");foreach($messages as $message){}Note: The code above uses the Windows Azure SDK for PHP to connect to Azure Storage.
The result of the test was that Table Storage was consistently 4 to 5 times faster than SQL Azure (again, YMMV). The key, however, was to use the $tableStorageClient->startBatch() and $batch->commit() methods with Table Storage. Without using batches, Table Storage opens and closes a new HTTP connection for each write, which results in slower performance than SQL Azure (which keeps a connection open for writes). When using batches with Table Storage, the connection is kept open for all writes.
Note: Many thanks to Maarten Balliauw who, when I was perplexed about the results of my tests without batching (I expected Table Storage to be faster, but because I didn’t know about batches for Table Storage, I was not getting the results I expected), suggested I try batching.
The complete script (with set up/tear down of database and Table) is attached in case you want to try for yourself.

Richard Mitchell produced a 00:13:57 SQL Azure Training 7: Blobs video for Red Gate Software’s ACloudyPlace blog:
The Blob – a pun that just won’t die! Also, it’s a Binary large object used in Windows Azure storage and our subject for today.This is the first of a couple videos that’s really delving into Azure Storage, and it’s slightly longer at 13 minutes so let’s begin! There are three main kinds of Blobs:
Simple Blobs – max 64MB used for binary and text files.
Block Blobs – max 200GB used for images/videos. Block Blobs have a little bit more going on than Simple Blobs, which we probably could have figured out from the naming conventions.
Page Blobs – max 1TB – really for Drives, watch the video to find out more.

Full disclosure: I’m a paid contributor to Red Gate Software’s ACloudyPlace blog.
<Return to section navigation list>
SQL Azure Database, Federations and Reporting
Gregory Leake posted Announcing SQL Azure Import/Export Service Now in Production to the Windows Azure Team blog on 1/24/2012:
We are pleased to announce the general availability of SQL Azure Import/Export! Now available as a production service, SQL Azure Import/Export helps organizations deploy on-premises databases to SQL Azure, and archive SQL Azure and SQL Server databases to Windows Azure Storage. Key improvements in the new production release include:
- Increased performance & resiliency
- Progress reporting
- Selective Export
- Production support
- New usage sample EXE
This service is provided free of charge to customers using SQL Azure and Windows Azure Storage. For more information and video tutorials visit the DAC blog.
Benjamin Guinebertière posted B2B: SQL Azure as a meeting point | B2B: SQL Azure comme point de rencontre on 1/22/2012. From the English version:
FABRIKAM is a manufacturing company who has CONTOSO as one of its resellers. FABRIKAM would like to get their sales number thru CONTOSO channel, but CONTOSO does not want to give access to their own database and they don’t have the time to create an application to expose this data.
CONTOSO is willing to put data they have about FABRIKAM products they sell in a CONTOSO database, but CONTOSO cannot expose their database to the Internet either. So they decide to rent a database on the Internet.
SQL Azure is a perfect fit for this. There is no hardware, infrastructure or other high availability mechanisms to worry about, SQL Azure is a relational cloud PaaS level database as a service (note from the author: think I put quite a few keywords in that sentence!!!).
CONTOSO will be able to push filtered data (only FABRIKAM sales data) to a database outside their firewall, and FABRIKAM will be able to query that data with SQL or build reports with SQL Azure Reporting Services.
FABRIKAM creates à SQL Azure server (let’s call it axcdlm02uz.database.windows.net). In this server, they create a SQL Azure database named salesthrucontoso with a dedicated login salesthrucontosodbo.
CONTOSO has communicated to FABRIKAM the range of IP adddresses they use to go to the salesthrucontoso database, so that FABRIKAM can configure SQL Azure server firewall rules
In return, FABRIKAM communicates to CONTOSO all the details to connect to the SQL Azure database:
- server name: axcdlm02uz.database.windows.net
- database name: salesthrucontoso
- login: salesthrucontosodbo and its password
As SQL Azure uses the same tabular data stream (TDS) protocol as SQL Server, CONTOSO can use SQL Server drivers to access SQL Azure. They do it thru their usual ETL(*) tool. So CONTOSO can easily build an interface from their database (SQL Server, or Oracle, DB2, or any other vendor’s database) towards the cloud database and run it everyday so that FABRIKAM easily access their data without any risk to compromise their own internal databases.
(*) ETL = Extract Transform Load.
As an example, SQL Server’s ETL is SSIS (SQL Server Integration Services).


Cihan Biyikoglu (@cihangirb) continued his series with Fan-out Querying for Federations in SQL Azure (Part 2): Scalable Fan-out Queries with TOP, ORDER BY, DISTINCT and Other Powerful Aggregates, MapReduce Style! on 1/19/2012 (missed when posted):
Welcome back. In the previous post: Introduction to Fan-out Querying, we covered the basics and defined the fragments that make up the fan-out query namely the member and summary queries. Fan-out querying refer to querying multiple members.
Summary queries are required for post processing the member queries. Simply put, summary queries can help reshape the unioned member results into the desired final share. Summary queries refer to object generated by the member queries and depending on the implementation can be executed on the client side or the server side. That said, today Federations do not provide a built in server side processing option for summary queries. Here are a few options for processing summary queries:
- LINQ To DataSets offers a great option for querying datasets. Some examples here. LINQ is best suited for the job in my opinion with flexible language constructs, dynamic execution and parallelism options.
- ADO.Net Expressions in DataSets offers a number of options for summary query processing as well. For example, DataColumn.Expressions allow you to add aggregate expressions to your Dataset for this type of processing. Or you can use DataTable.Compute for processing a rollup value.
- Obviously server-side full fan-out processing is also an option. This option refers to server side running member and summary query in a single round-trip from the client to SQL Azure. However as of Jan 2012, this is not built into SQL Azure Federations. We’ll take a look at a simulated version of this in the sample tool here; You can use the deployment closer to your database for efficiency;
Americas Deployment: http://federationsutility-scus.cloudapp.net/
European Deployment: http://federationsutility-weu.cloudapp.net/
Asian Deployment: http://federationsutility-seasia.cloudapp.net/The tool provides a basic and full ‘fanout’ page. Basic page contains only member queries through a simplified interface. The results are simply unioned (or ‘union all’-ed to be precise) together. Full page provides additional capabilities including member and summary queries. Both member and summary queries is expressed in TSQL. The full page also allows for parallelism and allows specifying a federation key range other than all members. Tool has a help page with detailed notes on each of these capabilities.
Lets dive in and take a look at where summary queries can be useful. We’ll start with Ordering, TOP, aggregations and finally DISTINCT processing. By the way, for the examples in this post, I’ll continue to use the BlogsRUs_DB schema posted at the bottom of this article.
GROUP BY and HAVING with Fan-out Queries
With simple group-by items the rule is simple; if the grouping is aligned to the federation key in fan-out queries in federations, processing of group-by and having needs no special consideration. Simply union the results (or union-all to be precise) and we are done. However processing unaligned groupings (any grouping that does not include the federation key) requires a summary query.
When grouping isn’t aligned to federation key, grouping isn’t completely done with member queries. that means processing HAVING will generate incorrect results in member queries. Lets take the example form the previous post; here is the query simply reporting the months and counts of posts with more than a million posts;
SELECT DATEPART(mm, be.created_date) mon, COUNT(be.blog_entry_title) cnt FROM blog_entries_tbl be GROUP BY DATEPART(mm, be.created_date) HAVING COUNT(be.blog_entry_title) > 100000The grouping on month in each member yields the results from each member but grouping all members isn’t fully done yet! We need to GROUP_BY the same columns and expressions to finish grouping before we can apply the HAVING predicate.
So to correctly process HAVING predicate, we need to push t to the summary query;
SELECT DATEPART(mm, be.created_date) mon, COUNT(be.blog_entry_title) cnt FROM blog_entries_tbl be GROUP BY DATEPART(mm, be.created_date)and the summary query should process the HAVING.
SELECT mon, sum(cnt) FROM #Table GROUP BY mon HAVING sum(cnt) > 100000‘ORDER BY’ and ‘TOP’ with Fan-out Queries:
Lets start with ordering and TOP functionality in TSQL. The member queries can include ORDER BY and TOP but you will need the summary query to reprocess and finalize the ordering and top filtering of the member query results. Take the following example; The query is calculating the top 10 blogs created across the entire BlogsRUs_DB. Remember the blog_entries_tbl is federated on blog_id.
SELECT TOP 10 blog_entry_text FROM blog_entries_tbl ORDER BY created_date DESCHere is how to break this into a fan-out query with a member and a summary query; The #Table in the summary query refer to the resultset generated from the member query.
Member Query:
SELECT TOP 10 blog_entry_text, created_date FROM blog_entries_tbl ORDER BY created_date DESC Summary Query: SELECT TOP 10 blog_entry_text FROM #Table ORDER BY created_date DESCHere is the output for the member query:
And the output with the summary query. Now the output only contains the true TOP 10 rows.
Additive Aggregates: MIN, MAX & SUM with Fan-out Queries:
When the processing of the MIN, MAX and SUM align with a grouping on the federation key, a UNION ALL of the results can simply yield the result. For example the count of blog entries per blog could be proceed with the following query;
SELECT blog_id, COUNT(blog_entry_id) FROM blog_entries_tbl GROUP BY blog_idSame applies to the OVER clause used for defining windows when processing aggregates. that is, as long as the PARTITION BY includes the federation key, a UNION ALL of the results is sufficient for the summary query.
However when the grouping does not align to the federation key, you will need summary queries. Here is the example that gets us the latest date that a blog entry was created. The grouping in the absence of a GROUP BY clause is a single bucket.
SELECT MAX(created_date) FROM blog_entries_tblHere is the way to break this down into a fan-out query;
Member Query:
SELECT MAX(created_date) FROM blog_entries_tbl Summary Query: SELECT MAX(Column1) FROM #TableFan-out Queries Processing AVG and COUNT
Average is a none additive aggregate thus it takes a rewrite to take an average when grouping does not align to the federation key. Here is an example of an average aggregate that aligns with a federation key: the next query calculates the average days between the blog entry and the last comment for the post for bloggers. the inner query gets the MAX date for the last comment on the blog entry. AVG is calculated per blogger for all the blog entries with the days between the create date of the blog and the last comment date on all blog entry.
SELECT blog_id, AVG(LEN(blog_entry_text)) FROM blog_entries_tbl GROUP BY blog_idThere is no need for a summary query other than a UNION ALL of the results when fanning this query out given it is aligned to the federation key: blog_id.
However when the grouping is not aligned, there is work to do! Average and Count are not additive. That is, one cannot take 2 averages and average those to get the correct average or take 2 counts and use another count to calculate the output of 2 counts; we need SUM in the case of 2 counts to correctly get the final correct count and we need to use sum of values we want to average and the item count to calculate avg correctly from multiple member queries. Here is an example: Lets take the average length of blog entries across all each month. This time the grouping is on the month of the blog posts.
SELECT DATEPART(mm,be.created_date) month_of_entry, AVG(LEN(blog_entry_text)) FROM blog_entries_tbl GROUP BY DATEPART(mm,be.created_date)Lets use SUM and COUNT to get to the correct average.
Member Query:
SELECT DATEPART(mm,created_date) month_of_entry, SUM(LEN(blog_entry_text)) sum_len_blog_entry, COUNT(blog_entry_text) count_blog_entry FROM blog_entries_tbl GROUP BY DATEPART(mm,created_date)Summary Query:
SELECT month_of_entry, SUM(sum_len_blog_entry)/SUM(count_blog_entry) avg_len_blog_entry FROM #Table GROUP BY month_of_entry‘DISTINCT’ with Fan-out Queries:
DISTINCT is fairly easy to calculate much like the other additive aggregates. As long as the grouping is on the federation key. When grouping isn’t aligned to the federation key, a summary query reapplying the distinct for de-duplication is needed. Here is the query for DISTINCT count of languages used for blog comments across our entire dataset;
SELECT DISTINCT bec.language_id FROM blog_entry_comments_tbl bec JOIN language_code_tbl lc ON bec.language_id=lc.language_idTo break this apart, you have to run distinct in each member and then rerun the distinct on the summary query much like MIN and MAX;
Member Query:
SELECT DISTINCT bec.language_id FROM blog_entry_comments_tbl bec JOIN language_code_tbl lc ON bec.language_id=lc.language_id Summary Query: SELECT DISTINCT language_id FROM #TableNow lets take a look at some more challenging none additive aggregates.
Fan-out Queries with TON N PERCENT and DISTINCT COUNT
TOP N PERCENT is not as popular as TOP N but for those who use it, lets dissect what you need to do with fanout queries. TOP N PERCENT simply require you collect all results without TOP from members and only apply the TOP N PERCENT in the summary query. Imagine the same query we used for TOP with TOP 10 PERCENT. Query gets latest 10% blog entries.
SELECT TOP 10 PERCENT blog_entry_text FROM blog_entries_tbl ORDER BY created_date DESCHere are the member and summary queries.
Member Query:
SELECT blog_entry_text FROM blog_entries_tbl ORDER BY created_date DESCSummary Query:
SELECT TOP 10 PERCENT blog_entry_text FROM #Table ORDER BY create_date DESCAlarm bell should go off whenever we are not able to push the filtration predicate (TOP clause) down to the member queries. So processing TOP N PERCENT is costlier that TOP N and additive keywords.
DISTINCT COUNT calculation is trivial if grouping is on the federation key. However when grouping isn’t aligned, it takes more work to calculate distinct count given that it isn’t additive. That means; you cannot simply add distinct-counts from each member given you may not know if you are counting certain things multiple times without full de-duplication of all the items. Here is an example; this query get the distinct count of languages per month across the whole resultset:
SELECT DATEPART(mm,created_date), COUNT(DISTINCT bec.language_id) FROM blog_entry_comments_tbl bec JOIN language_code_tbl lc ON bec.language_id=lc.language_id GROUP BY DATEPART(mm,created_date)We need to centralized processing so all comments language ids across days first need to be grouped across all members and then distinct can be calculated on that resultset. Here is the member and summary query for calculating distinct-count:
Member Query:
SELECT DISTINCT DATEPART(mm,created_date), bec.language_id FROM blog_entry_comments_tbl bec JOIN language_code_tbl lc ON bec.language_id=lc.language_idSummary Query:
SELECT Column1, COUNT(DISTINCT language_id) FROM #Table GROUP BY Column1Here is what the member query output looks like;
Here is the output with the summary query;
In conclusion, additive operations like MIN, MAX, COUNT or SUM and predicates like TOP or order by can easily be processed with fan-outs using simple modifications to original queries to break them into member and summary queries. With additive queries big advantage is that you can push these operation to the member queries for efficiencies. In cases where you need to deal with none-additive operations like average, there is some rewrite to help push filtrations and aggregate predicates to member queries. However there are a few cases like TOP N PERCENT or DISTINCT COUNT, where fan-out queries may require larger dataset shoveling thus will be more expensive to calculate because you cannot push these predicates to member queries and can only process them in the summary queries.
*Sample Schema
Here is the schema I used for the sample queries above.
-- Connect to BlogsRUs_DB CREATE FEDERATION Blogs_Federation(id bigint RANGE) GO USE FEDERATION blogs_federation (id=-1) WITH RESET, FILTERING=OFF GO CREATE TABLE blogs_tbl( blog_id bigint not null, user_id bigint not null, blog_title nchar(256) not null, created_date datetimeoffset not null DEFAULT getdate(), updated_date datetimeoffset not null DEFAULT getdate(), language_id bigint not null default 1, primary key (blog_id) ) FEDERATED ON (id=blog_id) GO CREATE TABLE blog_entries_tbl( blog_id bigint not null, blog_entry_id bigint not null, blog_entry_title nchar(256) not null, blog_entry_text nchar(2000) not null, created_date datetimeoffset not null DEFAULT getdate(), updated_date datetimeoffset not null DEFAULT getdate(), language_id bigint not null default 1, blog_style bigint null, primary key (blog_entry_id,blog_id) ) FEDERATED ON (id=blog_id) GO CREATE TABLE blog_entry_comments_tbl( blog_id bigint not null, blog_entry_id bigint not null, blog_comment_id bigint not null, blog_comment_title nchar(256) not null, blog_comment_text nchar(2000) not null, user_id bigint not null, created_date datetimeoffset not null DEFAULT getdate(), updated_date datetimeoffset not null DEFAULT getdate(), language_id bigint not null default 1 primary key (blog_comment_id,blog_entry_id,blog_id) ) FEDERATED ON (id=blog_id) GO CREATE TABLE language_code_tbl( language_id bigint primary key, name nchar(256) not null, code nchar(256) not null ) GO





<Return to section navigation list>
MarketPlace DataMarket, Social Analytics and OData
No significant articles today.
<Return to section navigation list>
Windows Azure Access Control, Service Bus and Workflow
No significant articles today.
<Return to section navigation list>
Windows Azure VM Role, Virtual Network, Connect, RDP and CDN
No significant articles today.
<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
My (@rogerjenn) Deploying “Cloud Numerics” Sample Applications to Windows Azure HPC Clusters post of 1/25/2012 begins:
Introduction
In addition to the basic MSCloudNumerics Visual Studio template and “Cloud Numerics” sample application described in my Introducing Microsoft Codename “Cloud Numerics” from SQL Azure Labs of 1/23/2011, the "Cloud Numerics" Microsoft Connect Site’s Example applications download offers three additional end-to-end examples:
- Latent Semantic Indexing (LSI) document classification example
- Statistics functionality demonstration
- Time-series analysis of cereal yield data
This post describes how to configure and deploy two 8-core HPC clusters hosted in Windows Azure and submit the LSICloudApplication to the Windows Azure HPC Scheduler for processing.
Table of Contents
- Creating a Windows Azure Pay-As-You-Go Subscription
- Learning about the Latent Semantic Indexing Example
- Extracting and Running the Latent Semantic Indexing Example
- Configuring and Deploying the Windows Azure HPC Cluster
- Using the Windows Azure HPC Scheduler Web Portal
- Running the Latent Semantic Indexing Example Locally
…

And continues with the remaining sections described in the TOC above.
My (@rogerjenn) Microsoft cloud service lets citizen developers crunch big data article of 1/24/2011 about Microsoft Codename “Data Explorer” for SearchCloudComputing.com begins:
Microsoft is devoting substantial resources to developing codenamed apps and APIs targeting a new breed of IT teams who spelunk actionable business information from massive files, or big data. According to Gartner Research, these “citizen developers” will build at least 25% of new business applications by 2014.
Workgroup and department members often turn to citizen developers to analyze or help them analyze structured information from on-premises and cloud-based Web server log files, semi-structured data from social websites like Twitter and Facebook, as well as hordes of unstructured files, such as Word documents and Excel worksheets.
Historically, IT staffs have written ad-hoc Microsoft Office applications with Excel or Access macros to manage structured data. Microsoft designed Visual Studio LightSwitch as a forms-over-data alternative for EUAD that provides simple data modeling features and easy deployment as on-premises or Windows Azure Web applications.
Microsoft’s LINQ Pack, LINQ to HPC and Project “Daytona” as well as Microsoft Research’s forthcoming open source Excel DataScope app were designed to make unstructured big data analytics in Windows Azure accessible to citizen developers. However, in November 2011, Microsoft announced plans to not release LINQ to HPC to production in favor of Apache Hadoop on Windows Azure, now in invitation-only private preview. To obtain a private preview, you must apply to Microsoft’s team for an invitation to test-drive the platform and its application programming interface (API). It remains to be seen if citizen developers will be capable of populating Hadoop clusters and programming MapReduce analytics.
Figure 1. (Click to enlarge.)
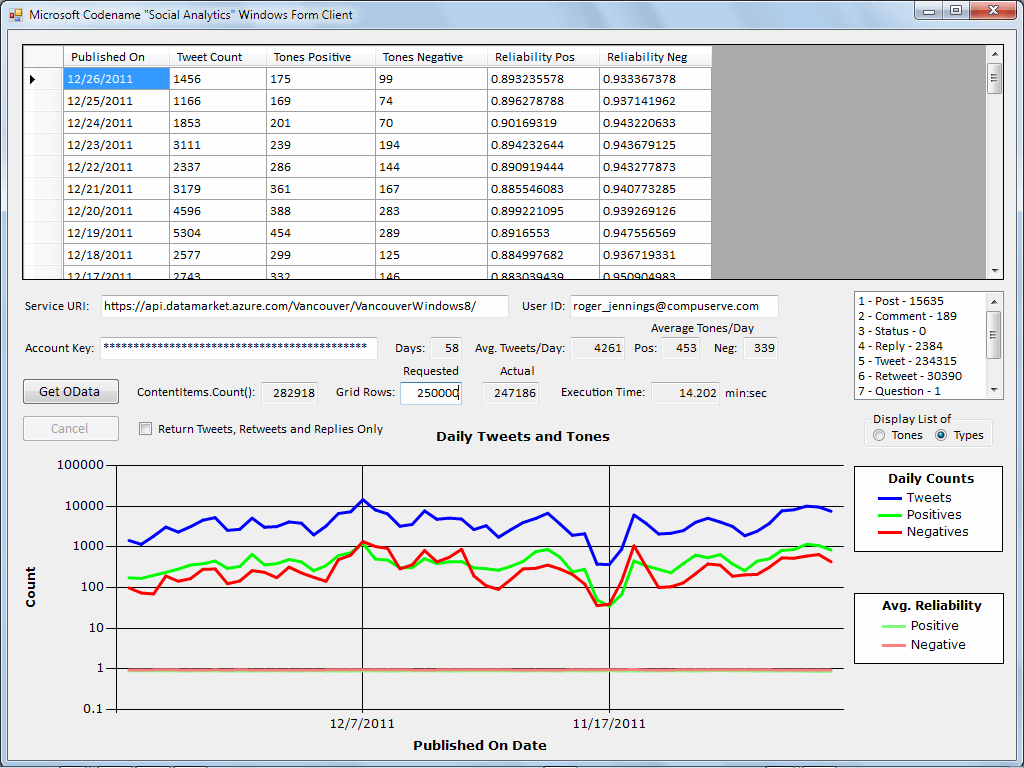
This .NET Windows form app summarizes a stream of Twitter data, including buzz (daily tweet counts) and calculated sentiment (positive and negative tweet tone) about Windows 8, as well as estimated reliability of the sentiment calculations, from a data feed provided by the Codename “Social Analytics” API.New Microsoft products for EUAD
The SQL Azure Labs team released in late 2011 private previews of Codename “Social Analytics”, “Data Explorer” and “Data Transfer,” all of which target EUAD. Social Analytics delivers a real-time stream consisting mostly of Twitter tweets, retweets, replies and direct messages. It also includes a few Facebook “likes,” posts and comments, as well as occasional StackOverflow questions and answers.The Windows Azure Marketplace DataMarket currently supplies two live OData streams that incorporate sentiment data about Windows 8 or Bill Gates. Microsoft's Social Analytics experimental cloud uses a Social Analytics’ API and a downloadable Visual Studio 2010 SP1 Windows application that retrieves, displays and summarizes data from the Windows 8 data feed (see Figure 1.) This app required almost 500 lines of C# code to generate, display and save the summary data as a comma-separated value (CSV) text file. It took me about a day to code and test and is probably too complex for most citizen developers to program.
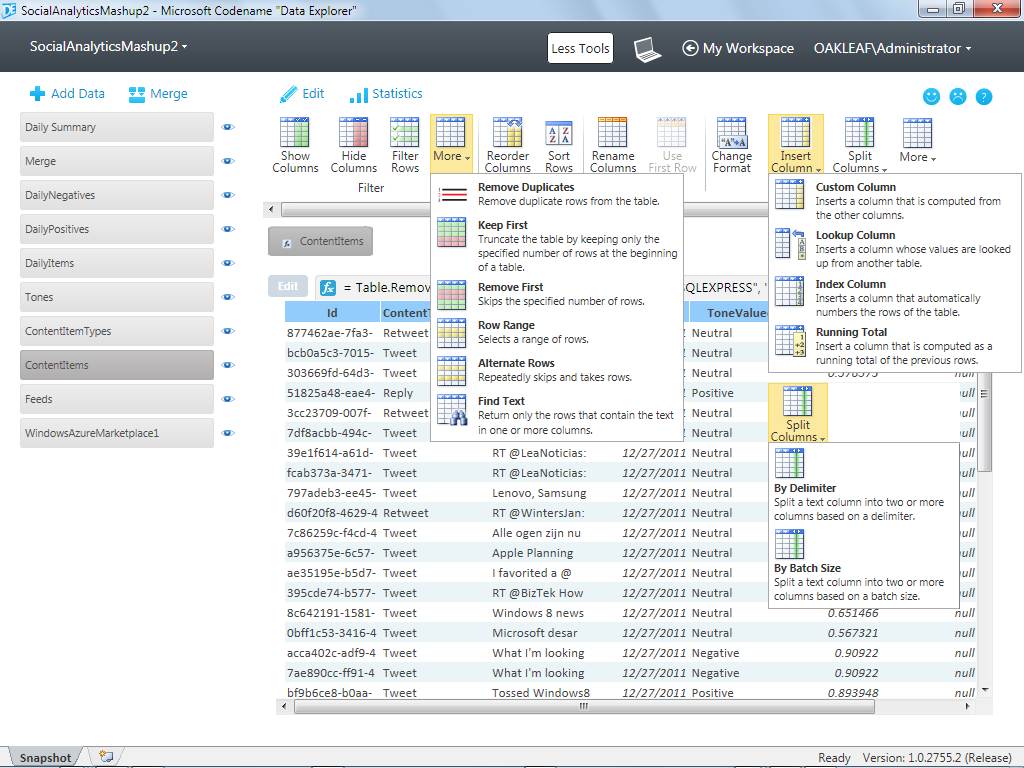
Figure 2. (Click to enlarge.)
Selecting a resource from the list at the left displays 12 tool icons with galleries for more Filters as well as Insert Column and Split Column Transform tools. ContentItems is a table included in the Codename “Data Analytics” VancouverWindows8 data feed from the Windows Azure MarketplaceSimplifying cloud-based mashups
Microsoft touts Codename “Data Explorer” (DE) as a way for ordinary PC users to automatically discover data available to download from the Windows Azure Marketplace; enrich data by combining it in mashups with related data from the Marketplace, Web, databases and other data types; and publish results from cloud-based workspaces stored in Windows Azure. DE also is an easily approachable, composable extract-transform-load (ETL) tool that provides many of the capabilities of SQL Server Integration Services (SSIS) without the long learning curve. DE provides a set of tools to manipulate data resources in the sequence you specify (Figure 2.)Data Explorer lets you emulate a complex set of procedural operations on tabular data, such as those needed to display source data and aggregate the daily buzz and sentiment values shown in Figure 1, by applying tools to resources. ContentItemTypes is an enumeration resource that the Lookup Column tool uses to translate numeric ContentTypeId values to readable ContentTypeName values in the second column of Figure 2’s ContentItems table display.
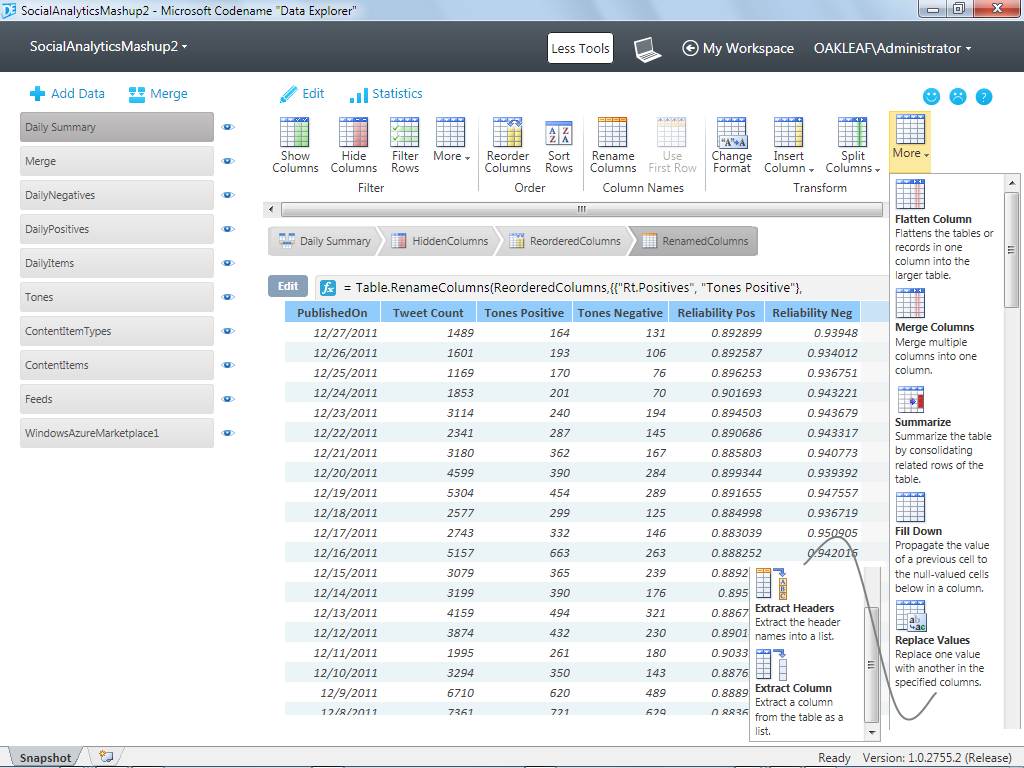
Figure 3. (Click to enlarge.)
The Daily Summary resource delivers a row for each of the 58 days that Social Analytics data was available with a Tweet Count column from Daily Items, Tones Positive and Reliability Pos columns from the Daily Positives table, as well as Tones Negative and Reliabilty Neg columns from Daily Negatives table.The Tones resource provides a similar Lookup Column for ToneValues in the fifth column. Daily Items is the initial table for the DailySummary aggregation resource. Daily Summary has Published On and Tweet Count columns and a row for December 27, 2011 and the preceding 58 days. Merging aggregated DailyPositives and DailyNegatives table resources with the equivalent of an SQL left outer join on the Published On column creates a table with Published On, Tweet Count, Tones Positive, Tones Negative, Reliability Pos and Reliability Neg columns, as shown in Figure 3.
Writing formulas with graphical builder UIs
DE has a full-blown formula-based programming language that’s based on Microsoft’s M (for Modeling) language, a component of the ill-fated Oslo repository database and the Quadrant query and visualization tool. However, most DE users won’t need to write M code because DE’s user interface includes graphical builders for the fx expressions that appear at the top of tables. The following appears at the top of the table in Figure 3:fx = Table.RenameColumns(ReorderedColumns,{{"Rt.Positives", "Tones Positive"}, {"Rt2.Negatives", "Tones Negative"}, {"Rt.ReliabilityPos", "Reliability Pos"}, {"Rt2.ReliabilityNeg", "Reliability Neg"}})
To expose complete multi-line formulas, click the v-shaped icon at the right of the first line.
Following are the formulas for all actions that define the Daily Summary and Merge resources:
shared #"Daily Summary" = let
#"Daily Summary" = Table.Join(Merge,{"PublishedOn"},Table.PrefixColumns(DailyNegatives, "Rt2"),{"Rt2.PublishedOn"},JoinKind.LeftOuter),
HiddenColumns = Table.RemoveColumns(#"Daily Summary",{"Rt.PublishedOn", "Rt2.PublishedOn"}),
ReorderedColumns = Table.ReorderColumns(HiddenColumns,{"PublishedOn", "Tweet Count", "Rt.Positives", "Rt2.Negatives", "Rt.ReliabilityPos", "Rt2.ReliabilityNeg"}),
RenamedColumns = Table.RenameColumns(ReorderedColumns,{{"Rt.Positives", "Tones Positive"}, {"Rt2.Negatives", "Tones Negative"}, {"Rt.ReliabilityPos", "Reliability Pos"}, {"Rt2.ReliabilityNeg", "Reliability Neg"}})
in
RenamedColumns;
shared Merge = Table.Join(DailyItems,{"PublishedOn"},Table.PrefixColumns(DailyPositives, "Rt"),{"Rt.PublishedOn"},JoinKind.LeftOuter);
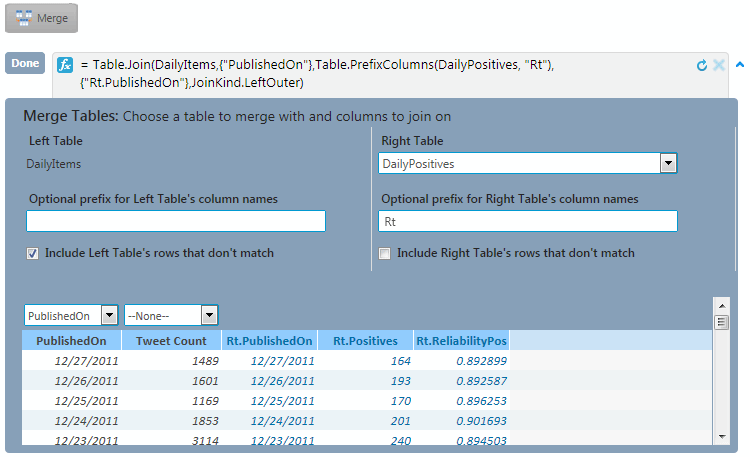
Figure 4. (Click to enlarge.)
All tools have graphical formula builders, which appear when you click the Edit button at the left of the formula. This early version of the graphical UI for the Merge builder requires that you select PublishedOn in one of the lists and add a prefix to the right table’s column names.Figure 4 shows the builder UI for the Merge resource’s action that generates the formula for the left outer join between DailyItems and DailyPositives tables on the PublishedOn field. As noted in my post about problems discovered with values and merging tables in Data Explorer, this builder UI is far less than intuitive and was undergoing usability improvement by the DE team at press time. …

I continue with the details of “Publishing your big data mashup.”
Full disclosure: I’m a paid contributor to Search Cloud Computing.com.
My (@rogerjenn) Introducing Microsoft Codename “Cloud Numerics” from SQL Azure Labs post of 1/23/2012 begins:
Introduction
Table of Contents
- “Cloud Numerics” Background
- The MSCloudNumerics.sln Project Template and Sample Solution
- “Cloud Numerics” Prerequisites
- Installing the HPC and “Cloud Numerics” Components
- “Cloud Numerics” Mathematic Libraries for .NET
- “Cloud Numerics” Distributed Array, Algorithm and Runtime Libraries for .NET
- Limitations of “Cloud Numerics”
- Running the MSCloudNumerics Sample Project Locally
- References
Updated 1/25/2012: My (@rogerjenn) Deploying “Cloud Numerics” Sample Applications to Windows Azure HPC Clusters of 1/25/2012 describes how to configure and deploy two 8-core HPC clusters hosted in Windows Azure and submit the Latent Semantic Indexing (LSICloudApplication) project to the Windows Azure HPC Scheduler for processing
“Cloud Numerics” Background
Codename “Cloud Numerics” is the latest in a series of new SQL Azure Labs tools for managing and analyzing Big Data in the Cloud with Windows Azure and SQL Azure. Ronnie Hoogerwerf’s introductory The “Cloud Numerics” Programming and runtime execution model post of 1/11/2012 to the Microsoft Codename “Cloud Numerics” blog begins:
Microsoft Codename “Cloud Numerics” is a new .NET® programming framework tailored towards performing numerically-intensive computations on large distributed data sets. It consists of
- a programming model that exposes the notion of a partitioned or distributed array to the user
- an execution framework or runtime that efficiently maps operations on distributed arrays to a collection of nodes in a cluster
an extensive library of pre-existing operations on distributed arrays and tools that simplify the deployment and execution of a “Cloud Numerics” application on the Windows Azure™ platform
Writing numerical algorithms is challenging and requires thorough knowledge of the underlying math; typically this line of work is the realm of experts with job titles such as: data scientist, quantitative analyst, engineer, etc. Writing numerical algorithms that scale-out to the cloud is even harder. At the same time the ever increasing appetite for and availability of data is making it more and more important to be able to scale-out data analytics models and this is exactly what “Cloud Numerics” is all about. For example, with “Cloud Numerics” it is possible to write document classification applications using powerful linear algebra and statistical methods, such as Singular Value Decomposition or Principle Component Analysis, or to write applications that search for correlations in financial time series or genomic data that work on today’s cloud-scale datasets. [Links added.]
“Cloud Numerics” provides a complete [C#] solution for writing and developing distributed applications that run on Windows Azure. To use “Cloud Numerics” you start in Visual Studio with our custom project definition that includes an extensive library of numerical functions. You develop and debug your numerical application on your desktop, using a dataset that is appropriate for the size of your machine. You can read large datasets in parallel, allocate and manipulate large data objects as distributed arrays, and apply numerical functions on these distributed array[s]. When your application is ready and you want to scale-out and run on the cloud you start our deployment wizard, fill out your Azure information, deploy, and run you[r] application.
…
An important takeaway from the preceding excerpt is that the BigData input to “Cloud Numerics” applications must be a partitioned or distributed numeric array. You can load data into distributed arrays with data that implements the Numerics.Distributed.IO.ParallelReader interface or is processed by the sample Distributed.IO.CSVLoader class, which implements that interface.
Note: Source code for the Distributed.IO.CSVLoader class is included in the Cloud Numerics - Examples download, which is described in the “Install the HPC and ‘Cloud Numerics’ Components” section below.
Ronnie’s Using Data post of 1/20/2012 is a useful reference for array data; it contains the following topics:
A rectangular array of numbers, symbols or expressions is called a matrix. Wikipedia has very detailed Matrix Theory and Linear Algebra topics. Matrix theory is a part of linear algebra.


My article continues with the “The MSCloudNumerics.sln Project Template and Sample Solution” and later topics.
Toddy Mladenov described Accessing Windows Azure REST APIs with cURL in a 1/25/2012 post:
Tonight I was playing with cURL on my Mac wondering how easy would it be to develop few scripts to manage Windows Azure applications from non-Windows machine. As it turns out getting access to Windows Azure REST APIs was quite simple. Here are the steps I had to go though in order to be able to receive valid response from the APIs:
Set up Windows Azure management certificate from your Mac machine
openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout azure-cert.pem -out azure-cert.pemDuring the creation openssl will ask you for all the necessary information like country name, organization name etc. and at the end will generate .pem file that contains the public and the private key.
In order to upload the certificate to your Windows Azure subscription using the Management Portal though you need to have the certificate in PKCS12 (or .pfx) format. Here is the openssl command that will do the work:
openssl pkcs12 -export -out azure-cert.pfx -in azure-cert.pem -name "My Self Signed Cert"Now that you have the PKCS12 file you can go ahead and upload this to your Management Certificates using the portal.
Update: By writing this in the middle of the night I totally messed up what you need to do. PKCS12 you need if you want to enable SSL for your service. For management you only need the public key that you can export in .CER file. Here is the command that you use for this:
openssl x509 -outform der -in azure-cert.pem -out azure-cert.cerNow you can upload the .CER to the Management Certificates section using the portal.
The initial set-up is done!
Using cURL to Access Windows Azure REST APIs
Now that you have the cert created and uploaded to Windows Azure you can easily play with the REST APIs. For example if you want to list all your existing hosted services you can use the List Hosted Services API as follows:
curl -E [cert-file] -H "x-ms-version: 2011-10-01" "https://management.core.windows.net/[subscr-id]/services/hostedservices"where:
cert-fileis the path to the .pem file containing the certificatesubscr-idis your Windows Azure subscription IDDon't forget to specify the version header (the -H flag for cURL) else Windows Azure will return an error. As a result of the call above you will receive XML response with list of all the hosted services in your Windows Azure subscriptioin.
You can access any of the REST APIs by manually constructing the request and the URL as described in the Windows Azure Service Management REST API Reference.
I didn't get to any of my planned scripts but I can explore the APIs easily cURL.
You might like:


Bruce Kyle reported MSDN Subscribers Receive Up to $3,700 in Annual Windows Azure Benefits in a 1/25/2012 post to the US ISV Evangelism blog:
If you are an existing Visual Studio Professional, Premium or Ultimate with MSDN subscriber, you get free access to Windows Azure each month, and up to $3,700.00 in annual Windows Azure benefits at no charge.
This offer provides a base level of Compute, Storage, SQL Azure database, Access Control, Service Bus and Caching each month at no charge.
You can easily track what resources you’ve used on Windows Azure by clicking the “Account” tab of the www.windowsazure.com web-site. This is another new feature we added to Windows Azure last month, and it allows customers (both free trial and paid) to easily see what resources they’ve used and how much it is costing them.
Benefits are offered world-wide.
Get more details, see Get up to $3,700.00 in annual Windows Azure benefits at no charge.
Getting Started with MSDN Subscription
There are several ways to get an MSDN Subscription:
- Purchase one of Visual Studio subscription offers.
- Qualify for the Silver or Gold ISV Competency (or other competencies)
- If you are a startup, join BizSpark.
Or if you are in an enteprise, there’s a good chance you already have access to it.
How to Purchase an MSDN Subscriptions
To buy or renew a MSDN subscription please contact your Microsoft Partner or local Reseller.
Purchasing more than one license? Microsoft Volume Licensing offers flexible licensing solutions for companies needing multiple licenses and helps volume customers save time & money.
Also Available as Benefit through Microsoft Partner Network
Another way you may have an MSDN Subscription is through the Microsoft Partner Network.
ISVs can earn the ISV Competency and receive MSDN Subscriptions that entitle you to compute hours and benefits on Windows Azure.
To qualify for the Silver ISV Competency:
- Deliver one product or application that has passed one qualifying Microsoft Platform Test. (Get details.)
- Provide three verifiable customer references. (Get details.)
- Complete a full profile and pay the silver membership fee
You can use the License Calculator to help you better understand your software benefits based on the type and number of competencies you earn.
To get started, see ISV Competency Requirements.
BizSpark for Startups
BizSpark will fast-track the success of your startup with software, support & visibility. One of the benefits of the program is to help jumpstart your business. If you are a development company, privately held, less than three years old, and are making less than $1 million/year (US) in revenue, you qualify. Sign up for BizSpark.

I use my MSDN Subscription benefit to run the publicly accessible demonstration of GridView paging and iterative operations on Northwind Customer entities in Windows Azure Table Storage with the OakLeaf Systems Azure Table Services Sample Project demo from my Cloud Computing with the Windows Azure Platform book.
Brian Goldfarb (@bgoldy) posted Announcing Native Windows Azure Libraries and Special Free Pricing Using SendGrid for Windows Azure Customers to the Widows Azure Blog on 1/25/2012:
Last week our friends over at SendGrid shipped new native libraries on GitHub (C#, Node.JS) for Windows Azure developers that make it extremely easy to integrate their mail service into any application built and running in Windows Azure. In addition, SendGrid launched a new offer for Windows Azure customers that provides 25,000 free emails a month! We’ve heard from customers consistently that sending email was too hard and we listened! See detailed, step by step tutorials written by us on how to use SendGrid with Windows Azure in the Developer Center (C#, Node, PHP, Java).
Sending email from Windows Azure has never been so easy. For example, with C#:
Add the SendGrid NuGet package to your Visual Studio project by entering the following command in the NuGet Package Manager Console window:
PM > Install-Package SendGrid
Add the following namespace declarations:
using System.Net; using System.Net.Mail; using SendGridMail; using SendGridMail.Transport;It can be this easy
// Create an email message and set the properties. SendGrid message = SendGrid.GenerateInstance(); message.AddTo("anna@contoso.com"); message.From = new MailAddress("john@contoso.com", "John Smith"); message.Subject = "Testing the SendGrid Library"; message.Text = "Hello World!"; // Create an SMTP transport for sending email. var transport = SMTP.GenerateInstance(new NetworkCredential("username", "password")); // Send the email. transport.Deliver(message);Signup for 25,000 free emails a month today!

Wade Wegner (@WadeWegner) described s cause of the Cannot create database ‘DevelopmentStorageDb20110816′ for the Windows Azure Storage Emulator problem in a 1/25/2012 post:
Have you seen this error before? If you’ve spent any time with the Windows Azure storage emulator it’s highly probable. Here’s the full text:
Added reservation for http://127.0.0.1:10000/ in user account COMPUTER\User. Added reservation for http://127.0.0.1:10001/ in user account COMPUTER\User. Added reservation for http://127.0.0.1:10002/ in user account COMPUTER\User. Creating database DevelopmentStorageDb20110816... Cannot create database 'DevelopmentStorageDb20110816' : CREATE DATABASE permission denied in database 'master'. One or more initialization actions have failed. Resolve these errors before attempting to run the storage emulator again. These errors can occur if SQL Server was installed by someone other than the current user. Please refer to http://go.microsoft.com/fwlink/?LinkID=205140 for more details.And an image of the error:
There are a number of ways to resolve this issue and, like others, I have my favorite approach. I have a script that I run which will add the executing user to the SQL Server sysadmin role.
I’ve published the entire script here: https://gist.github.com/1677788. Simply download and unzip the file. Open up an elevated command prompt and execute the file (i.e. run addselftosqlsysadmin.cmd). Once the script is executed the user can successfully initialize the storage emulator.


Don Pattee reported the availability of REST API docs [for Windows HPC Server 2008 R2 SP2 in Windows Azure] on MSDN on 1/25/2012:
I know there were a bunch of folks waiting on this, so I'm happy to say the REST API documentation for the HPC Pack 2008 R2 SP3 release is available.
Windows HPC Server 2008 R2 with Service Pack 2 (SP2) provides access to the HPC Job Scheduler Service by using an HTTP web service that is based on the representational state transfer (REST) model. You can use this REST API to create client applications that users can use to define, submit, modify, list, view, requeue, and cancel jobs.
Check it out at http://msdn.microsoft.com/en-us/library/hh560254(VS.85).aspx and http://msdn.microsoft.com/en-us/library/hh560258(VS.85).aspx

See my Deploying “Cloud Numerics” Sample Applications to Windows Azure HPC Clusters post of 1/25/2012 for details of uploading HPC Clusters to Windows Azure and running .NET numeric analysis applications in the clusters.
<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Jan Van der Haegen (@janvanderhaegen) described MyBizz Portal: The “smallest” LightSwitch application you have ever seen (LightSwitch Star Contest entry) in a 1/24/2012 post:
Dear blog reader, thank you (again) for taking the time to come to my blog and read about my LightSwitch adventures. In this blog post series, you find my (elaborate) submission to the CodeProject LightSwitch Star Contest. If you enjoy this article, it would like it if you tweet about it, link from your site to it or send me your firstborn daughter as a token of gratitude, however it would also mean a lot to me if you hopped over to the CodeProject site and voted on the submission as you see fit. You can also leave any questions, remarks or comments there, however there’s a very good chance that (especially in the distant future) I’ll get your feedback much quicker if you just post on the bottom of this blog post.
Link to CodeProject submission…
Addicted to the power of LightSwitch since the first time I ever saw a demo of it, I immediately realized that LightSwitch offered me a window of opportunity to found my own software company, which will officially be born on April 2nd 2012 (after office hours at first)… LightSwitch is a truly unique tool to write small to medium-sized business applications in virtually no time, with enough flexibility to avoid hitting a “brick wall”, which is all-to-often the case in classic RAD frameworks. The previous sentence contains a lot of LightSwitch praising and loving, but also contains one of my biggest worries. What about large enterprise application? What if my applications start off small, but become giant successes? Will my beloved technology become a burden once business starts growing?
- Can LightSwitch handle extremely large applications? Is there a limit on how much functionality I can fit in one LSML? Will an enterprise LightSwitch application load fast enough?
- Can LightSwitch handle horizontal scaling scenarios? Can I do a distributed installation of a LightSwitch application over several servers to support a massive amount of simultaneous users?
- How can I reuse screens and entities between my customers when they have similar needs? Is a VSIX extension really the only way? And will I be able to partially update one functionality without fear of breaking other parts of the application?
- LightSwitch can help me develop at lightning speed, but is that the only aspect of a smooth running company? How can LightSwitch help me to align customers, developers, salesmen, … Or help me keep track of versions, servers, feature requests, installations, …
- How are multiple developers going to work on the same LightSwitch application? Merging the LSML file on a daily bases will be a hell…
Will LightSwitch not only lift me up my feet, but still carry me once I hit cruise speed?
One night – for some reason, my best ideas always hit me about 4-5 hours before my alarm clock tells me to get up and get ready for work – I remembered an essay which contained the statement that “our vision on reality is shaped, and thus limited, by the language that we use“. By simply using a different lingo (the one used when talking about enterprise service oriented architecture taxonomy), my vision of LightSwitch, and thus its limitations, drastically changed.
LightSwitch taxonomy 1o1
LightSwitch application (LS APP)
To try to speak the same language again, let’s have a quick look at the anatomy of one of the most “complex” LightSwitch applications that we can develop today. Not mentioning cosmetic extensions, a LightSwitch application itself will generate three core components: a single SilverLight application, that connects to a single WCF service, which in turn connects to a single SQL database, and perhaps you’ll use one of three other datasources: an external database, a sharepoint database, or an external WCF RIA Service.
This is what we formerly called a LightSwich application, however from now on a LightSwitch app will be considered no more than a LightSwitch project structure in Visual Studio…
When creating a new LightSwitch application, you can choose to think about the result as a “module”. A LightSwitch “module” should immediately shape the mental picture that what you are designing is a well-scoped, reusable part of a greater organism.
LightSwitch Entity Module (LS EM)
A LightSwitch Entity Module is a LS APP that has the only responsibility to design simple database entities on which other modules can perform CRUD operations. It contains no business logic or validation. (Note: a LS APP will generate a WCF service and a rather empty SilverLight component as well, we’ll just never use them.)
External Process Module (EX PcM)
An External Process Module is any module that can provide access to external processes to the end-user, or to our LightSwitch Process Modules. By external I am not necessarily trying to indicate that the source code of those modules is not under our control, but merely referring to the fact that they are not written in LightSwitch.
LightSwitch Process Module (LS PcM)
A LightSwitch Process Module is a LS APP that implements a particular business process. It (optionally) contains its own entities, logic, screens, and references whatever LS EM, EX PcM or other LS PcM it needs to materialize that business process.
Any LightSwitch Module needs careful scoping / designing before development, but this is especially easy to violate when talking about LS PcM. Consider the functionality of managing customers for my software company. My sales force needs software to work with those customers, so that they can schedule meetings to talk about improvements or new feature requests. The development team will need software to work with these customers as well, so that they can implement user stories for them, contact them to discuss that implementation, … Engineering will also need software to work with these customers, as they’ll want to keep track of the installed software versions, the servers, staging areas, … And finally, the accountant will need these customers in his accounting suite, so that he/she can bill the customer correctly. Although it might seem a good idea to create a “Manage Customers LightSwitch Process Module”, it’s a much better and maintainable idea to create four separate LS PcM, because you are dealing with four separate business processes, each with its own logic, references and screens, and most likely with a shared “Customer LS EM” containing common “Customer” entities. The four separate LS PcM will not only be smaller and more maintainable, but they will load faster too.
LightSwitch Utility Module (LS UM)
A LightSwitch Utility Module is a non-application specific module that provides some reusable functionality. Ideally, but not always, you can package these as a VSIX extension. Good examples are generic reporting extensions, logging functionality, or the built-in LightSwitch security module (users, groups & rights).
LightSwitch Portal Module (LS PtM)
A lot of the popular application frameworks, such as PRISM or Caliburn, implement the concept of a “shell”, which blends together different modules or subsystems into a single UI at runtime. Even after numerous attempts I still haven’t succeeded to implement this runtime weaving in LightSwitch. However, you can still create a LS APP that provides a rather similar experience to the end-user, considering you can host a web browser in a LightSwitch (desktop) app (thanks Tim Leung for that article, you’re a genius!), and a SilverLight application (LS PcM) is hosted in a normal web page:
Above is my first succeeded attempt to create a LightSwitch Portal Module. I was working on a proof-of-concept of two interacting LightSwitch applications (hence the “student”/”teacher” entities) when I read Tim Leung’s article. I just had to try it right there right then. If you click on the image and pay attention to the web page property, you’ll see that you could create and test your own LS PtM with two simple LS APPs, right from the Visual Studio debugger!
A LightSwitch Portal Module is a LS APP that provides a user a single entry point into a Business Network and the ability to “portal” to the process module of his choice.
Business Network.
A Business Network is a collection of different modules that support a company in its business. This network can be partially or completely private (not accessible outside the company domain for example). It can contain numerous External and LightSwitch Modules. Business networks of allied companies could also partially overlap.
MyBizz network
In the picture above you can see a (simplified) example of such a network. Two actually. The network on the left is the network that will fulfill my startup’s needs, the network on the right is one that I created for demo purposes… Let’s just say – to avoid legal matters – that “a certain real estate company” already saw this “demo that I just had lying around” and “might” become my first paying customer on April 2nd. Both networks happen to be distributed over both a private (Windows 2008) and a public (Windows Azure) server, totaling 4 servers…
What the picture doesn’t show, is that both networks actually overlap. It would be more obvious if I’d draw the dependencies between the different components, but that quickly turns the overview into a messy web… The demo customer’s skinrepository pulls resources from my business (central) skin repository, my STS (see later: single-sign-on) is a trusted STS of the demo customer’s STS, and his MITS (My Issue Tracking System) reads and writes to my PITS (Public Issue Tracking System). Our two Business Networks contain over 235 entities, hundreds of screens, about every extension I could think of writing (including the Achievements extension to encourage my sales force to write up decent specs for each customer requirement, for which they earn points, which could be materialize in a bonus plan, meanwhile making the work for the developer easier… and a very early alpha version of the skinning extension…), almost all of the free extensions I could get my hands on (thanks to all the community contributors!), and some commercial extensions.
MyBizz Portal
I’m still playing around with the portal application at the moment, but have come to a point where I am satisfied enough to “reveal it to the public”.
Getting started with MyBizz Portal…
Upon a “clean” install, an administrator user can start the application, and after logging in is greeted with the main – and only – screen of the application…
To explain what you are seeing here… I have a LS EM that contains the core data, one of the entities is called a “MyBizzModule”. In my portal application, I connect to that data, and show it in a custom Silverlight Control. Because there are no other screens, and no commands, I opted to use a blank shell extension.
Because there’s only one module configured (in other words: only one MyBizzModule record in the database), the only option this application offers us now is to click the lonely red box icon at the bottom…
When clicked, the module opens and displays it’s login screen to us… (You might have to enlarge the image to see that it’s actually a LightSwitch application being shown IN another LightSwitch application).
Single-Sign-On
After logging in, we can see the main screen of the module. This LS PcM allows us to manage all the modules in a Business Network, only one is configured at the moment.

Name, Image and Portal site should need no explanation, but the fourth one is a very special one which will take more than an hour to explain in detail.In my Business Network, I have a WCF service that fulfills the role of a Security Token Service. The login screens used throughout the Business Network are actually all “hacked” custom implementations. Instead of authenticating with the current LightSwitch application, they request an encrypted token from the STS, and use that token as a key to log in – or, and only if automatic authentication fails, present the login screen to the user.
When I logged in to the portal application, the portal application kept the token in memory.
Now, if I check the “Include Security Token” checkbox, and portal to the module, the encrypted token will be passed in the query (I did the same thing with the “LightSwitch Deep Linking“) to the module. The “hacked” login screen will pick up the token and try to use that token to log in automagically. This functionality will be really important for the end-user, we do not want him to enter a username & password every time he/she portals to a different module, hence the “single-sign-on”…
Another major benefit is that one STS can “trust” another STS. This means that I can log on to my Business Network, and navigate to a “public” module from an allied company’s Network. That module will recognize that the token I’m trying to use was issued from my STS, and map my claims (permissions) accordingly.
Another thing that I’m trying to pass through, is information about the “default skin” that should be used. This feature is in an EXTEMELY early alpha stage, so I wont go into it too deep.
Last property, the required claim, simply allows the administrator to indicate that only users with the given permission (claim) can view / use the module, allowing fine-tuning of users&groups at a much higher level than the classic screens & entities level that we LightSwitch developers have been doing so far…
Moving on
Enough explaining, let’s give that module some values & restart the application (changes in the configured modules still require a restart at this point… ).
You can see that the “Cosmopolitan.Blue” skin has been loaded (unfinished, based on a Silverlight theme and the LightSwitch Metro theme sources), and that I did not need to log on a second time to enter the module… (Well, kind of hard to post a screenshot of the latter.)
Let’s have some fun and add two sample modules, one portal to Twitter and one to MSDN.
Clicking the bird in the middle shows that the portal application is (obviously) not limited to LS PcM alone, any link that can be shown in a web browser will do…
Finally, just to show my custom SilverLight control – 3 icons really don’t do it justice, these screenshots below are from my Business Network as it is today, roughly 2 months before my company will actually be born…
Which results in this layout…
And for bonus points…
Basic questions
What does your application (or extension) do? What business problem does it solve?
From a technical point of view: it’s a webbrowser wrapper with an advanced URL management system.
From a LightSwitch point of view: it’s a LightSwitch application that manages my LightSwitch applications.
From a functional point of view: it’s an application that allows a user to portal anywhere he wants ( / is allowed to ) inside my LightSwitch Business Network…
From a personal point of view: it’s the last of the missing pieces of the puzzle, it will help me manage my startup (customers, sales force, expenses, keeping track of projects & LightSwitch applications, …) , and gave me the confidence that truly anything is possible with LightSwitch.
How many screens and entities does this application have?
The application has 1 screen and 1 entity.
Additional questions
Did LightSwitch save your business money? How?
Not yet, but I strongly believe it will save me loads once my company is born… I can however say that without LightSwitch, the chances of me starting a company after my day job, and actually produce working software, would pretty much be zero.
Would this application still be built if you didn’t have LightSwitch? If yes, with what?
Most likely, it wouldn’t have been built.
How many users does this application support?
In theory, over 7,023,324,899; especially since the modules can be deployed on and load balanced over seperate servers. The databases would be the only bottleneck.
How long did this application take to actually build using LightSwitch?
Less than a week. Most time was spent trying to make a radial ItemsControl. I have limited experience as a developer, and none as a designer… Another two evenings were spent to write this article & take the screenshots. The LightSwitch part took me 15 minutes.
(Developing both Business Networks took me 6+ months, ofcourse)
Does this application use any LightSwitch extensions? If so, which ones? Did you write any of these extensions yourself? If so, is it available to the public? Where?
- LightSwitch Extensions Made Easy – homebrewn and available to public at the time of writing in the MSDN gallery.
- LightSwitch blank shell – homebrewn, a good example can be found on the LightSwitchHelpWebSite.
The LS PcM in the Business Networks also use…
- LightSwitch Achievements – homebrewn and part of a blog post series, so available to public soon.
- LightSwitch STS – homebrewn and won’t be available to public anytime soon, however I’m porting the ability to inject a custom login screen to EME soon.
- LightSwitch Skin Studio – homebrown and available to public later this year… Much, much later…
- Many, many, many commercial and free extensions – a special thanks to the LightSwitch crew, Allesandro, Tim, Yann, Bala and Michael for contributing so much to the community! (So sorry in advance if I forgot anyone special!!)
How did LightSwitch make your developer life better? Was it faster to build compared to other options you considered?
LightSwitch gave me an incredible passion & energy to build applications that support the customer’s process, I wouldn’t find the energy to do this in any other technology that I know of at the time of writing… It does all the tedious and boring tasks for you with a few clicks, and let’s you focus on what really makes your application stand out.
Additional additional questions
Can LightSwitch handle extremely large applications? Is there a limit on how much functionality I can fit in one LSML? Will an enterprise LightSwitch application load fast enough?
Yes, if you find any way to split your extremely large applications in many different modules, and bring them all together, there should be no limits for any LightSwitch developer. The solution I choose (using a webbrowser control) fits my business’ needs perfectly, and because modules are only loaded when you actually access them, drastically reduces the load time of the application.
Can LightSwitch handle horizontal scaling scenarios? Can I do a distributed installation of a LightSwitch application over several servers to support a massive amount of simultaneous users?
Yes, it does!
How can I reuse screens and entities between my customers when they have similar needs? Is a VSIX extension really the only way? And will I be able to partially update one functionality without fear of breaking other parts of the application?
A VSIX is one way, and sometimes the best way. If you truly want to reuse screens & entities, distributing your application over multiple, reusable modules, adds a whole new dimension of benefits to the LightSwitch way of development.
LightSwitch can help me develop at lightning speed, but is that the only aspect of a smooth running company? How can LightSwitch help me to align customers, developers, salesmen, … Or help me keep track of versions, servers, feature requests, installations, …
LightSwitch helped me build several LS PcM to keep track of my business process in just a couple of days…
How are multiple developers going to work on the same LightSwitch application? Merging the LSML file on a daily bases will be a hell…
Not if they work on one module each…
Where is the source?
- You wish
(Although parts could be polished, then published on my blog, on demand).











")
")








Return to section navigation list>
Windows Azure Infrastructure and DevOps
William Bellamy posted Troubleshooting Best Practices for Developing Windows Azure Applications to the MSDN Library on 1/24/2012. From the introduction:
Author: William Bellamy, Microsoft Principal Escalation Engineer
Contributors:
- Bryan Lamos, Microsoft Senior Program Manager, Product Quality
- Kevin Williamson, Microsoft Senior Escalation Engineer, Azure Developer Support
- Pranay Doshi, Microsoft Senior Program Manager, Windows Azure Production Services
- Tom Christian, Microsoft Senior Escalation Engineer, Azure Developer Support
Published: January 2012
This paper focuses on the different troubleshooting challenges and recommended approaches to design and develop more supportable applications for Microsoft’s Windows Azure platform. When (and not if) a problem occurs, time is of the essence. Proper planning can enable you to find and correct problems without having to contact Microsoft for support. The approach advocated in this paper will also speed the resolution of problems that require Microsoft assistance.
This paper is intended to be a resource for technical software audiences: software designers, architects, IT Professionals, System Integrators, developers and testers who design, build and deploy Windows Azure solutions.
We assume that you have a basic understanding of the application development lifecycle of a Windows Azure application, including terminology and the various components of the Windows Azure development and runtime environment.
We also assume that basic guidelines for Windows Azure will be followed, such as using the latest version of the Windows Azure SDK and testing code changes before they are put into production.
This paper is organized into two sections:
- Overview of Windows Azure diagnostic resources:
- Windows Azure resources
- Third-party resources
- Best practices for supportable design, development and deployment:
- Before you deploy your application.
- Fail fast design and monitoring.
- What to do when a problem happens.
- Starting with a Strategy
- Overview of Windows Azure Diagnostic Resources
- Designing More Supportable Windows Azure Services
- Putting It All Together: Creating More Supportable Windows Azure Applications
- Conclusion
- References
- Appendix A: Glossary
- Appendix B: Web Role Code Sample
- Appendix C: Worker Role Code Sample
- Appendix D: ServiceDefinition.csdef
- Appendix E: ServiceConfiguration.Local.cscfg
- Appendix F: diagnostics.wadcfg
- Appendix G: Default Configuration
 Summary
Summary<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
No significant articles today.
<Return to section navigation list>
Cloud Security and Governance
No significant articles today.
<Return to section navigation list>
Cloud Computing Events
Glenn Block (@gblock) reported Windows Azure[, Scott Guthrie] and Cloud9 IDE at Node Summit in a 1/24/2012 post:
Last month we launched our new Windows Azure SDK for Node.js. The release came after months of hard work between Microsoft and Joyent. Since that time we’ve seen a lot of excitement in the Node community around the support for Node.js in Windows Azure. We’re thankful for all the support!
Additionally, Scott showed a new way to deploy to Azure, Cloud9 IDE!
Cloud9 IDE offers a cross-platform, browser-based development environment for Node.js. It is one of the de-facto tools for Node developers today. Cloud9 runs completely in the browser, and it’s available to developers working on any OS. In the second part of his keynote, Scott demonstrated using Cloud9 IDE on a Mac to build and deploy an application to Azure.
With Cloud9 IDE you can easily create a new Node application, connect it to your Windows Azure account, and deploy. Cloud9 makes it easier for you by packaging up source, creating your hosted service, and publishing the package. It supports publishing to Staging and Production and offers Windows Azure portal integration. Combining that with Cloud9’s integration with distributed version control providers like GitHub and BitBucket offers a fantastic experience!
Below you can see a screenshot of the new Cloud9 experience.
Along with the announcement, we’ve published a brand new tutorial on our Node.js dev center to show you how easy it is to get started developing for Windows Azure in Cloud9. In addition, check out these resources from Cloud9 about their Windows Azure support.
We are very excited about the collaboration with Cloud9 and the opportunity to offer both Windows and non-Windows developers an awesome experience developing for Windows Azure.
Read more about this announcement in the most recent posts on the Cloud9 and Interoperability @ Microsoft blogs.



<Return to section navigation list>
Other Cloud Computing Platforms and Services
Jeff Barr (@jeffbarr) reported The AWS Storage Gateway - Integrate Your Existing On-Premises Applications with AWS Cloud Storage on 1/25/2012:
Warning: If you don't have a data center, or if all of your IT infrastructure is already in the cloud, you may not need to read this post! But feel free to pass it along to your friends and colleagues.
The Storage Gateway
Our new AWS Storage Gateway service connects an on-premise software appliance with cloud-based storage to integrate your existing on-premises applications with the AWS storage infrastructure in a seamless, secure, and transparent fashion. Watch this video for an introduction:
Data stored in your current data center can be backed up to Amazon S3, where it is stored as Amazon EBS snapshots. Once there, you will benefit from S3's low cost and intrinsic redundancy. In the event you need to retrieve a backup of your data, you can easily restore these snapshots locally to your on-premises hardware. You can also access them as Amazon EBS volumes, enabling you to easily mirror data between your on-premises and Amazon EC2-based applications.
You can install the AWS Storage Gateway's software appliance on a host machine in your data center. Here's how all of the pieces fit together:
The AWS Storage Gateway allows you to create storage volumes and attach these volumes as iSCSI devices to your on-premises application servers. The volumes can be Gateway-Stored (right now) or Gateway-Cached (soon) volumes. Gateway-Stored volumes retain a complete copy of the volume on the local storage attached to the on-premises host, while uploading backup snapshots to Amazon S3. This provides low-latency access to your entire data set while providing durable off-site backups. Gateway-Cached volumes will use the local storage as a cache for frequently-accessed data; the definitive copy of the data will live in the cloud. This will allow you to offload your storage to Amazon S3 while preserving low-latency access to your active data.
Gateways can connect to AWS directly or through a local proxy. You can connect through AWS Direct Connect if you would like, and you can also control the amount of inbound and outbound bandwidth consumed by each gateway. All data is compressed prior to upload.
Each gateway can support up to 12 volumes and a total of 12 TB of storage. You can have multiple gateways per account and you can choose to store data in our US East (Northern Virginia), US West (Northern California), US West (Oregon), EU (Ireland), Asia Pacific (Singapore), or Asia Pacific (Tokyo) Regions.
The first release of the AWS Storage Gateway takes the form of a VM image for VMware ESXi 4.1 (we plan on supporting other virtual environments in the future). Adequate local disk storage, either Direct Attached or SAN (Storage Area Network), is needed for your application storage (used by your iSCSI storage volumes) and working storage (data queued up for writing to AWS). We currently support mounting of our iSCSI storage volumes using the Microsoft Windows and Red Hat iSCSI Initiators.Up and Running
During the installation and configuration process you will be able to create up to 12 iSCSI storage volumes per gateway. Once installed, each gateway will automatically download, install, and deploy updates and patches. This activity takes place during a maintenance window that you can set on a per-gateway basis.The AWS Management Console includes complete support for the AWS Storage Gateway. You can create volumes, create and restore snapshots, and establish a schedule for snapshots. Snapshots can be scheduled at 1, 2, 4, 8, 12, or 24 hour intervals. Each gateway reports a number of metrics to Amazon CloudWatch for monitoring.
The snapshots are stored as Amazon EBS (Elastic Block Store) snapshots. You can create an EBS volume using a snapshot of one of your local gateway volumes, or vice versa. Does this give you any interesting ideas?
The Gateway in Action
I expect the AWS Storage Gateway will be put to use in all sorts of ways. Some that come to mind are:
- Disaster Recovery and Business Continuity - You can reduce your investment in hardware set aside for Disaster Recovery using a cloud-based approach. You can send snapshots of your precious data to the cloud on a regular and frequent basis and you can use our VM Import service to move your virtual machine images to the cloud.
- Backup - You can back up local data to the cloud without worrying about running out of storage space. It is easy to schedule the backups, and you don't have to arrange to ship tapes off-site or manage your own infrastructure in a second data center.
- Data Migration - You can now move data from your data center to the cloud, and back, with ease.
Security Considerations
We believe that the AWS Storage Gateway will be at home in the enterprise, so I'll cover the inevitable security questions up front. Here are the facts:
- Data traveling between AWS and each gateway is protected via SSL.
- Data at rest (stored in Amazon S3) is encrypted using AES-256.
- The iSCSI initiator authenticates itself to the target using CHAP (Challenge-Handshake Authentication protocol).
Costs
All AWS users are eligible for a free trial of the AWS Storage Gateway. After that, there is a charge of $125 per month for each activated gateway. The usual EBS snapshot storage rates apply ($0.14 per Gigabyte-month in the US-East Region), as do the usual AWS prices for outbound data transfer (there's no charge for inbound data transfer). More pricing information can be found on the Storage Gateway Home Page. If you are eligible for the AWS Free Usage Tier, you get up to 1 GB of free EBS snapshot storage per month as well as 15 GB of outbound data transfer.On the Horizon
As I mentioned earlier, the first release of the AWS Storage Gateway supports Gateway-Stored volumes. We plan to add support for Gateway-Cached volumes in the coming months.We'll add more features to our roadmap as soon as our users (this means you) start to use the AWS Storage Gateway and send feedback our way.
Learn More
You can visit the Storage Gateway Home Page or read the Storage Gateway User Guide to learn more.We will be hosting a Storage Gateway webinar on Thursday, February 23rd. Please attend if you would like to learn more about the Storage Gateway and how it can be used for backup, disaster recover, and data mirroring scenarios. The webinar is free and open to all, but space is limited and you need to register!



Andrew R. Hickey (@andrewrhickey) reported IBM Joins Google, Microsoft In Cloud Productivity War in a 1/24/2012 post to CRN:
IBM is looking to flex its cloud muscle against rivals Google and Microsoft with a cloud-based productivity and collaboration play that pits the three tech titans against each other for cloud dominance.
Dubbed IBM Docs, Big Blue's new cloud productivity offering, which IBM unveiled in a brief video, includes a word processing application, spreadsheets and slide presentation software. IBM Docs is tied into IBM's SmartCloud for Social Business suite, which is the new moniker bestowed upon IBM LotusLive.
IBM Docs puts IBM in a three-way battle for cloud productivity as it squares off in the cloud against Google Docs and Microsoft Office 365. According to IBM, IBM Docs is now in beta and will be available this year.
"IBM Docs allows organizations, both inside and outside the firewall, to simultaneously collaborate on word processing, spreadsheet and presentation documents in the cloud to improve productivity," IBM said in a statement. "IBM Docs authors will be able to store and share documents in IBM SmartCloud, co-edit documents in real time or assign users sections of the document so they can work privately easing the management of multiple revisions from multiple authors in team-based documents."
But cloud solution providers said it's too soon to tell whether IBM Docs will shake up the market, but it does validate that the cloud market is growing and desktop software is on its way out.
"Whether or not IBM Docs is a threat to Google Docs remains to be seen; they have a long way to go before reaching the mainstream mindshare and market share already achieved by Google," said Michael Cohn, founder and senior vice president of marketing for Atlanta-based Cloud Sherpas, a major Google cloud provider. "That said, IBM is a smart company. To see them enter the cloud productivity space is another clear indication that the days of desktop software are numbered."
Allen Falcon, CEO of Cumulus Global, a Westborough, Mass.-based cloud solution provider said IBM Docs is a logical extension of LotusLive as IBM looks to stem declining market share. Though he hasn't yet gotten a real feel for IBM Docs, Falcon added that "Lotus has long-enough been an also-ran in this space, so it will be interesting to see if IBM can gain traction."
IBM Docs comes as part of a sweeping cloud and social assault that IBM has planned in the new year. And at the heart of it is the ability to apply data analytics to social and cloud initiatives.
Along with access to IBM Docs, IBM SmartCloud for Social Business offers single-click access to social networking, file sharing, online meetings, e-mail, calendar and instant messaging to enable internal and external collaboration.
The Armonk, N.Y.-based tech giant also rallied around the new social revolution with the beta of the next release of its enterprise social networking platform, IBM Connections which offers wikis, blogs and activities for collaboration while also offering access to e-mail, calendar and business tasks from the social networking platform. The landing page in Connections offers a single point for users to view and interact with content from a third party along with their company's content.
IBM also launched IBM Connections Enterprise Content Edition, which is an integrated social content management solution combining social networking with enterprise content management, compliance and control.
"There is boundless opportunity for social business to transform how we connect people and processes, and increase the speed and flexibility of business," said Alistair Rennie, general manager of IBM's Social Business unit, in a statement. "A successful social business can break down barriers to collaboration and put social networking in the context of everyday work, from the device or delivery vehicle of your choice, to improve productivity and speed decision-making."

Jeff Barr (@jeffbarr) described how to Launch Relational Database Service Instances in the Virtual Private Cloud
You can now launch Amazon Relational Database Service (RDS) DB instances inside of a Virtual Private Cloud (VPC).
Some Background
The Relational Database Service takes care of all of the messiness associated with running a relational database. You don't have to worry about finding and configuring hardware, installing an operating system or a database engine, setting up backups, arranging for fault detection and failover, or scaling compute or storage as your needs change.
The Virtual Private Cloud lets you create a private, isolated section of the AWS Cloud. You have complete control over IP address ranges, subnetting, routing tables, and network gateways to your own data center and to the Internet.
Here We Go
Before you launch an RDS DB Instance inside of a VPC, you must first create the VPC and partition its IP address range in to the desired subnets. You can do this using the VPC wizard pictured above, the VPC command line tools, or the VPC APIs.Then you need to create a DB Subnet Group. The Subnet Group should have at least one subnet in each Availability Zone of the target Region; it identifies the subnets (and the corresponding IP address ranges) where you would like to be able to run DB Instances within the VPC. This will allow a Multi-AZ deployment of RDS to create a new standby in another Availability Zone should the need arise. You need to do this even for Single-AZ deployments, just in case you want to convert them to Multi-AZ at some point.
You can create a DB Security Group, or you can use the default. The DB Security Group gives you control over access to your DB Instances; you can allow access from EC2 instances with specific EC2 Security Group or VPC Security Groups membership, or from designated ranges of IP addresses. You can also use VPC subnets and the associated network Access Control Lists (ACLs) if you'd like. You have a lot of control and a lot of flexibility.
The next step is to launch a DB Instance within the VPC while referencing the DB Subnet Group and a DB Security Group. With this release, you are able to use the MySQL DB engine (we plan to additional options over time). The DB Instance will have an Elastic Network Interface using an IP address selected from your DB Subnet Group. You can use the IP address to reach the instance if you'd like, but we recommend that you use the instance's DNS name instead since the IP address can change during failover of a Multi-AZ deployment.
Upgrading to VPC
If you are running an RDB DB Instance outside of a VPC, you can snapshot the DB Instance and then restore the snapshot into the DB Subnet Group of your choice. You cannot, however, access or use snapshots taken from within a VPC outside of the VPC. This is a restriction that we have put in to place for security reasons.Use Cases and Access Options
You can put this new combination (RDS + VPC) to use in a variety of ways. Here are some suggestions:
- Private DB Instances Within a VPC - This is the most obvious and straightforward use case, and is a perfect way to run corporate applications that are not intended to be accessed from the Internet.
- Public facing Web Application with Private Database - Host the web site on a public-facing subnet and the DB Instances on a private subnet that has no Internet access. The application server and the RDB DB Instances will not have public IP addresses.
Your Turn
You can launch RDS instances in your VPCs today in all of the AWS Regions except AWS GovCloud (US). What are you waiting for?




Barton George (@Barton808) completed his series with Web Glossary part three: Infrastructure tier on 1/24/2011:
This is the last in my three-part Web Glossary series. As I previously explained, in compiling this I pulled information from various and sundry sources across the Web including Wikipedia, community and company web sites and the brain of Cote.
The idea behind the glossary is to help our teams get a better understand of the wild and wacky world of the Web and Web developers as we move forward with our Web|Tech vertical. I figured I might as also share it with a few friends.
Today’s focus, having worked our way down from the top, is the infrastructure tier (with a short catch-all bucket at the end , “Misc.”)
Infrastructure
General Terms
- DevOps: The goal of the DevOps movement is to drive out inefficiency in web shops by bridging the gap (and lessening conflict) between traditional development activity and operations activity. It seeks to address this issue by providing tools and practices to bring these two groups closer together and provide for greater automation of processes. Key tools in this effort are Opscode’s Chef and Puppet lab’s Puppet which automate the set-up and management of infrastructure.
- PUE: Power Usage Effectiveness is a measure of how efficiently a computer data center uses its power; specifically, how much of the power is actually used by the computing equipment (in contrast to cooling and other overhead). PUE is the ratio of total amount of power used by a computer data center facility to the power delivered to computing equipment. The closer to 1.0, the better the PUE.
- Distributed management: refers to the setup, provisioning, maintenance and management of the scale-out infrastructure (either physical or virtual) that has historically been characteristic of web firms and is increasing typical within traditional enterprise customers. This includes players like Chef and Puppet for provisioning and configuration, New Relic and Splunk for monitoring and management, and Loggly/Eucalyptus/OpenStack/ VMware for management monitoring.
Projects/Entities
- Crowbar: Crowbar is a Dell-developed open source software framework designed to speed up the installation and configuration of open source cloud software onto bare metal systems. By automating the process, Crowbar can reduce the time needed for installation from days to hours. The software is modular in design so while the basic functionality is in Crowbar itself, “barclamps” sit on top of it to allow it work with a variety of projects. There have been barclamps built for OpenStack, Hadoop, CloudFoundry and Dreamhost.
- Ubuntu: The most popular desktop linux distribution. On the server side they are supporting OpenStack and have an offering called the Ubuntu Enterprise Cloud. Backed by the commercial company Canonical.
- Puppet: a configuration management tool designed to automate the set up and management of infrastructure. A key DevOps tool. It is produced by Puppet labs
- Chef: a configuration management tool designed to automate the set up and management of infrastructure. A key DevOps tool. It is produced by Opscode, who hosts a cloud-based version of Chef called the Opscode Platform.
- Nagios: a popular open source computer system and network monitoring software application. It watches hosts and services, alerting users when things go wrong and again when they get better.
- Ganglia: an open source scalable distributed monitoring system for high-performance computing systems such as clusters and grids.
Misc
- LAMP stack: Open source stack that provides a viable general purpose web server. The name comes from the first letters of its components: Linux, Apache web server, MySQL and PHP (or Perl or Python). LAMP has become a de facto development standard and is an excellent example of how open source software has made its way into enterprise environments through unofficial channels.
- Apache Software Foundation: A decentralized group of developers that produce open source software under the Apache license. Notable projects include: Apache web server, Hadoop, CouchDB, Cassandra, Tomcat, Subversion
- Nginx: an open source web server that recently has been gaining considerable traction
- Recipes: They encapsulate collections of software resources which are executed in the order defined to configure a system.
Extra-credit reading


Werner Vogels (@werner) described Expanding the Cloud - The AWS Storage Gateway in a 1/23/2012 post to his All Things Distributed blog:
Today Amazon Web Services has launched the AWS Storage Gateway, making the power of secure and reliable cloud storage accessible from customers’ on-premises applications.
We have been working closely with our customers on their requests to bring the power of the Amazon Web Services cloud closer to their existing on-premises compute infrastructures. The Amazon Virtual Private Cloud extends on-premises compute with all the power of AWS, making it elastic, scalable and highly reliable. AWS Identity and Access Management brings together on-premises and cloud identity management. VM Import allows our customers to move virtual machine images from their datacenters to the Cloud and Amazon Direct Connect makes the network latencies and bandwidth between on-premises and AWS more predictable. With the launch of the AWS Storage Gateway our customers can now integrate their on-premises IT environment with AWS’s storage infrastructure.
The AWS Storage Gateway is a service connecting an on-premises software appliance with cloud-based storage. Once the AWS Storage Gateway’s software appliance is installed on a local host, you can mount Storage Gateway volumes to your on-premises application servers as iSCSI devices, enabling a wide variety of systems and applications to make use of them. Data written to these volumes is maintained on your on-premises storage hardware while being asynchronously backed up to AWS, where it is stored in Amazon S3 in the form of Amazon EBS snapshots. Snapshots are encrypted to make sure that customers do not have to worry about encrypting sensitive data themselves. When customers need to retrieve data, they can restore snapshots locally, or create Amazon EBS volumes from snapshots for use with applications running in Amazon EC2.
Here are three example use cases that we envision for the AWS Storage Gateway. The first one is using the AWS Storage Gateway to back up your data to Amazon S3’s highly reliable storage environment. Amazon S3 is designed to sustain the concurrent loss of data in two facilities, redundantly storing your data on multiple devices across multiple facilities in an AWS Region. So, backing up your data to Amazon S3 means a lot less headaches worrying about your local storage environment.
The second use case is where customers want to move data between local infrastructure and the Amazon Web Services cloud to provide access to applications and other computations running in Amazon EC2. The use of the Amazon EBS snapshot format means the data that was on-premises can be restored as an Amazon EBS volume mounted to an Amazon EC2 instance.
The third use case, cloud-based Disaster Recovery, is a specific variation of the previous two. If there is a failure in your local infrastructure, you can quickly launch a DR environment in Amazon EC2 which will have full access to the data snapshots backed up into Amazon S3 by the AWS Storage Gateway.
For more information on the AWS Storage Gateway, you can visit the detail page Jeff Barr over at the AWS Developer Blog has more details.



Jo Maitland (@JoMaitlandSF) posted Updated: AWS DynamoDB and the eventual consistency issue to GigaOm Pro (subscription or free trial required) on 1/19/2012:
Amazon’s new NoSQL database service DynamoDB launched this week, not with a bang but a whimper. Minutes into the live stream announcing the service, the video link went down, which was a bummer for the hundreds of people who tuned in and kicked off lots of jokes on Twitter about cloud database services and the notion of “eventual consistency” being a synonym for “inconsistency.” DynamoDB is a NoSQL database service that will run in the AWS cloud, but in the world of cloud computing and the Internet at large, predictability and consistency are often a stretch. What does this mean for developers using the service?
Behind the jokes is an interesting and complex issue that companies using cloud services will need to embrace. We have come to expect that modern distributed systems supporting large web applications must provide low read and write latency. Think of entering your info when purchasing something on the web: One or two seconds too long and you’re out and onto the next website. To achieve this low latency, cloud systems often eschew protocols that guarantee consistency and instead opt for eventual consistency protocols. This means there is no guarantee on the recency of the version of data you are seeing except that the system will “eventually” return the most recent version in the absence of new writes. But how “eventual” is eventual consistency? …

Jo continues with an update to the post.
Full Disclosure: I’m a GigaOm Pro analyst.
<Return to section navigation list>


















0 comments:
Post a Comment