Windows Azure and Cloud Computing Posts for 2/18/2012+
| A compendium of Windows Azure, Service Bus, EAI & EDI, Access Control, Connect, SQL Azure Database, and other cloud-computing articles. |
Note: This post is updated weekly or more frequently, depending on the availability of new articles in the following sections:
- Windows Azure Blob, Drive, Table, Queue, HDInsight and Media Services
- Windows Azure SQL Database, Federations and Reporting, Mobile Services
- Marketplace DataMarket, Cloud Numerics, Big Data, StreamInsight and OData
- Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
- Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
- Live Windows Azure Apps, APIs, Tools and Test Harnesses
- Visual Studio LightSwitch and Entity Framework v4+
- Windows Azure Infrastructure and DevOps
- Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
- Cloud Security, Compliance and Governance
- Cloud Computing Events
- Other Cloud Computing Platforms and Services
Azure Blob, Drive, Table, Queue, HDInsight and Media Services
Avkash Chauhan (@avkashchauhan) reported Cloud Storage Performance Tests are out and Windows Azure Cloud Storage is #1 in most categories on 2/20/2013:
Window Azure Cloud storage is #1 in most of categories as you can see below:
Cloud Storage Delete Speed Report: (Azure Cloud Storage #1)
Cloud Storage Read Speed Report: (Azure Cloud Storage #1)
Cloud Storage Read/Write Error Report: (Azure Cloud Storage #1)
Cloud Storage Response Time/ UpTime Report: (Azure Cloud Storage #1 in response time)
Windows Azure Cloud Storage is not #1 in uptime due to SIE.
Cloud Storage Scaling Test Report (Azure Cloud Storage in #2 behind Amazon):
Cloud Storage Write Speed Report: (Azure Cloud Storage #1 with all file size)
Read more about Nasuni Cloud Storage Report details here.Read the full details in more here.







If only the Storage Team had renewed its certificate on time!

<Return to section navigation list>
Windows Azure SQL Database, Federations and Reporting, Mobile Services
Josh Twist (@joshtwist) explained Periodic Notifications with Windows Azure Mobile Services in a 2/17/2013 post:
Periodic Notifications, sometimes called pull or polling notifications are an additional way to update live tiles in Windows 8. Mobile Services already has awesome support for sending push notifications to tiles (plus toast and badges) as demonstrated in these tutorials:
It’s just a single line of code to pro-actively update a live tile on a user’s device:
push.wns.sendTileSquarePeekImageAndText01(channelUrl, { text1: "boo", image1src: url });
However, Windows Store apps also support an alternative delivery mechanism where the client application can be instructed to poll a specific URL for tile updates on a periodic basis. This is great in a number of scenarios such as when you have frequently updating tile content and the tile will be the same for large groups of users. The canonical example is probably a news app that updates the top news stories throughout the day.
In this case the content of the tiles are are fixed for all users and, if you’re app is popular, that would be a lot of push notifications to move through (though NotificationHubs are another viable options here – especially for Breaking News where you may not want clients to wait for their next poll). However, for such frequent-rolling less-urgent content, Periodic Notifications are perfect.
Since I’m expecting my app to be popular, I want to avoid having all those requests coming through an API and hitting my database, that’s pointless. Instead I can create the notification tile XML and store it in blob storage at a URL that I’ll tell the client applications to poll as the periodic notification target.
There are two stimulii that I might use to cause me to regenerate the file.
- An event – for example an insert to the ‘story’ table. The idea here is that when an editor updates my Mobile Services database with a new story I could regenerate the file in blob storage.
- On a periodic basis. This is the recommended approach in the Guidelines and checklist for periodic notifications and they suggest setting a period of regeneration for the server file that is equal to the period you specify on the client.
In this case, I’m going to go with step 2 and choose an hourly schedule and naturally I’m going to use Mobile Services’ scheduler to execute a script.
And here’s the script that updates (or creates if necessary) the news.xml file that contains the content to be polled. This is a sample script so I set the content to be a toString of the current time. However, I know you’re an imaginative lot so I’ll let you work out where you want to source your data.
The last step, is to configure my Windows 8 application to poll this url, and it couldn’t be easier.
using Windows.UI.Notifications;// ...
TileUpdater tu = TileUpdateManager.CreateTileUpdaterForApplication(); var uri = new Uri("http://your-account-name.blob.core.windows.net/tiles/news.xml"); tu.StartPeriodicUpdate(uri, PeriodicUpdateRecurrence.HalfHour);
You should put the code above, somewhere in the application that runs every time the application starts or returns from suspension. And in no time at all, you can have a tile that’s always relevant and creates almost zero load on your backend.
It should be noted that there are some features in Periodic Notifications that require custom headers to be sent from the server (x-wns-tag, for example) which you can’t achieve using this approach with blob storage. As ever, stay tuned as the Mobile Services team does move quickly!




<Return to section navigation list>
Marketplace DataMarket, Cloud Numerics, Big Data, StreamInsight and OData
Peter Laudati (@jrzyshr), Brian Hitney and Andrew Duthie (@devhammer) produced Microsoft DevRadio: (Part 2) Using Windows Azure to Build Back-End Services for Windows 8 Apps on 2/20/2013:
Abstract:
Peter Laudati, Brian Hitney and Andrew Duthie are back for part 2 of their series and in today’s episode Andrew shows us how to deploy the OData Service for his Windows 8 app to Windows Azure as well as outlines the advantages and disadvantages to building back-end services via this approach.
After watching this video, follow these next steps:
Step #1 – Try Windows Azure: No cost. No obligation. 90-Day FREE trial.
Step #2 – Download the Tools for Windows 8 App Development
Step #3 – Start building your own Apps for Windows 8
Subscribe to our podcast via iTunes or RSS
If you're interested in learning more about the products or solutions discussed in this episode, click on any of the below links for free, in-depth information:
Register for our Windows Azure Hands-on Lab Online (HOLO) events today!
Blogs:
Videos:
- Microsoft DevRadio: How to Get Started with Windows Azure
- Microsoft DevRadio: (Part 1) What is Windows Azure Web Sites?
- Microsoft DevRadio: (Part 2) Windows Azure Web Sites Explained
Virtual Labs:
Download
- MP3 (Audio only)
- MP4 (iPod, Zune HD)
- High Quality MP4 (iPad, PC)
- Mid Quality MP4 (WP7, HTML5)
- High Quality WMV (PC, Xbox, MCE)
The WCF Data Services Team announced the availability of WCF Data Services 5.3.0 RTW on 2/18/2013:
Today we are releasing an updated version of the WCF Data Services NuGet packages and tools installer. As mentioned in the prerelease blog post, this version of WCF DS has three notable new features as well as over 20 bug fixes.
What is in the release:
Instance annotations on feeds and entries (JSON only)
Instance annotations are an extensibility feature in OData feeds that allow OData requests and responses to be marked up with annotations that target feeds, single entities (entries), properties, etc. WCF Data Services 5.3.0 supports instance annotations in JSON payloads. Support for instance annotations in Atom payloads is forthcoming.
Action Binding Parameter Overloads
The OData specification allows actions with the same name to be bound to multiple different types. WCF Data Services 5.3 enables actions for different types to have the same name (for instance, both a Folder and a File may have a Rename action). This new support includes both serialization of actions with the same name as well as resolution of an action’s binding parameter using the new IDataServiceActionResolver interface.
Modification of the Request URL
For scenarios where it is desirable to modify request URLs before the request is processed, WCF Data Services 5.3 adds support for modifying the request URL in the OnStartProcessingRequest method. Service authors can modify both the request URL as well as URLs for the various parts of a batch request.
This release also contains the following noteworthy bug fixes:
- Fixes an issue where code gen produces invalid code in VB
- Fixes an issue where code gen fails when the Precision facet is set on spatial and time properties
- Fixes an issue where code gen was incorrectly generating the INotifyPropertyChanged code for subtypes in different namespaces
- Fixes an issue where odata.type was not written consistently in fullmetadata mode for JSON
- Fixes an issue where a valid form of Edm.DateTime could not be parsed
- Fixes an issue where the WCF DS client would not send type names for open properties on insert/update
- Fixes an issue where the client Execute() method would fail for a particular payload with DataServiceVersion=1.0
- Fixes an issue where type information was omitted in JSON fullmetadata payloads
- Fixes an issue where open property type information was omitted in JSON update/insert requests
- Fixes an issue where it was not possible to navigate relationships on entities with multi-part keys
Brian Noyes (@briannoyes) explained Consuming an ASP.NET Web API OData Service with Breeze on 2/15/2013:
One of the last things I figured out to include in my Pluralsight course “Building ASP.NET Web API OData Services” (which should be out in a week or two – all done, just waiting for the editorial process to complete) was how to consume my Web API OData services with Breeze.js.
Breeze is a great JavaScript library for including rich service-based data access in HTML 5 / JavaScript applications. It acts as a smart client side repository that can make the retrieve and update service calls for you, caches the data client side so you can avoid unnecessary round trips, does change tracking on the entities so that it knows what to send back for update when you as it to (following a unit-of-work pattern), integrates nicely with Knockout (or other observable-based libraries) and more. Its also capable of consuming both Breeze Web APIs that you can easily set up with their ASP.NET Web API server libraries, or OData services (regardless of what platform those are on).
When it comes to integrating with OData, for now Breeze just supports querying (retrieval) data, not updating through the OData mechanisms. But it provides a nice abstraction layer for doing so because it lets you formulate LINQ-like syntax in your JavaScript code for things like “where” (filter operations at an OData wire level), orderby, top, skip and so on.
So it was a natural fit for the module in my course on consuming OData from .NET and JavaScript clients. Most of getting it working was totally straightforward, I just followed the great documentation on the Breeze site on setting up the Breeze configuration for OData and making the calls. There was one trick that I sorted out with the help of a little code that Ward Bell and the Web API team had been slinging around. Specifically, take note of the comments in Step 4 below about matching up the EDM namespace and the entity type namespace.
So here is a quick walkthrough so others can just take it by the numbers.
Step 1: Create your Web API Project
File > New Project, Web category, MVC 4 Application, select Web API project type.


Delete the ValuesController that it puts in the \Controllers folder.
Step 2: Add the OData NuGet
Right click on the project in Solution Explorer, find Manage NuGet Packages.

Search for OData and find the ASP.NET Web API OData package.

Step 3: Define a Data Model
I’m gonna use the venerable Northwind Customers table here to keep it simple. Add a connection string to your web.config:
1: < add name ="NorthwindDbContext" connectionString ="server=.;2: database=Northwind;trusted_Connection=true"3: providerName ="System.Data.SqlClient" />Add a Customers class to the Model folder:
1: public class Customer2: {3: public string CustomerID { get; set; }4: public string CompanyName { get; set; }5: public string Phone { get; set; }6: }And a NorthwindDbContext class (Entity Framework code first approach – could use DB First or any model you want).
1: public class NorthwindDbContext : DbContext2: {3: public DbSet<Customer> Customers { get; set; }4: }Step 4: Define an EDM
Open the App_Start folder in the project, open WebApiConfig.cs. Add a helper method to define an Entity Data Model:
1: public static IEdmModel GetEdmModel()2: {3: ODataModelBuilder builder = new ODataConventionModelBuilder();4: builder.EntitySet<Customer>("Customers");5: builder.Namespace = "WebAPIODataWithBreezeConsumer.Models";6: return builder.GetEdmModel();7: }
The ODataConventionModelBuilder just needs to know the collections you want to expose. It will reflect on the types, and declare all their properties in the EDM with corresponding EDM types, will follow navigation properties to related entities and declare those, and will infer what the entity keys are.
IMPORTANT: Note line 5 – you need to make sure the namespace of the EDM matches the namespace your entity types are contained in.
Step 5: Add an OData Route
In the Register method, add an OData route for your EDM (line 3 below):
1: public static void Register(HttpConfiguration config)2: {3: config.Routes.MapODataRoute("odata", "odata", GetEdmModel());4: config.Routes.MapHttpRoute(5: name: "DefaultApi",6: routeTemplate: "api/{controller}/{id}",7: defaults: new { id = RouteParameter.Optional }8: );9: }The MapODataRoute extension method takes three arguments: a name for the route, a prefix off the site root address where you can get to the EDM model you will expose, and the EDM model itself.
Step 6: Create an EntitySetController
Add a project folder called ODataControllers. Add a class in there called CustomersController, with a base class of EntitySetController<Customer,string>. Add a Get method to it that uses the NorthwindDbContext to return Customers:
1: public class CustomersController : EntitySetController<Customer,string>2: {3: NorthwindDbContext _Context = new NorthwindDbContext();4:5: [Queryable]6: public override IQueryable<Customer> Get()7: {8: return _Context.Customers;9: }10:11: protected override void Dispose(bool disposing)12: {13: base.Dispose(disposing);14: _Context.Dispose();15: }16: }Note the [Queryable] attribute on the Get method – this in combination with the IQueryable return type is what enables OData query syntax. The EntitySetController takes care of making sure the OData formatter is used instead of the default JSON formatter, as well as taking care of mapping OData routing scheme to this controller. The default OData format is JSON-Light (as opposed to JSON-Verbose or ATOM XML).
At this point you have a working OData service. You should be able to hit it in the browser with an address of /odata/Customers and you will get back the customers in the default JSON-Light format. If you want ATOM or JSON-Verbose, you will need to use a tool like Fiddler where you can control the headers.

Step 7: Add DataJS and Breeze.js through NuGet
Go back into Manage NuGet Packages from Solution Explorer and search for Breeze. Select the Breeze for ASP.NET Web Api Projects package and install. Then do the same to find and install DataJS.

Step 8: Create an HTML page + JS with JQuery, Knockout, Q, and Breeze
Go into the Views folder of your Web project and find the /Home/Index.cshtml file. Clear out all the HTML in there and add the following scripts to the top (Note: you can do this by dragging and dropping the script file from the /scripts folder (you may need to update the JQuery and Knockout NuGet packages in your project to match these versions).
1: < script src="~/Scripts/jquery-1.9.1.js"></script>2: < script src="~/Scripts/knockout-2.2.1.js"></script>3: < script src="~/Scripts/q.js"></script>4: < script src="~/Scripts/datajs-1.1.0.js"></script>5: < script src="~/Scripts/breeze.debug.js"></script>Next we need to start building the JavaScript that will use Breeze to execute a query and put it in a view model we can bind to. First step is to initialize Breeze and tell it we will be dealing with OData:
1: < script type ="text/javascript" >1:2: var my = {}; //my namespace3: $(function () {4: var serverAddress = "/odata/";5: breeze.config.initializeAdapterInstances({ dataService: "OData" });6: var manager = new breeze.EntityManager(serverAddress);7: });</ script >Next we need a simple view model that we will data bind to from our HTML, declared inside the script block:
1: my.vm = {2: customers: ko.observableArray([]),3: load: function () {4: }5: }Next the code that calls the load and sets up the data binding with Knockout at the end of our script block, inside the JQuery ready function:
1: my.vm.load();2: ko.applyBindings(my.vm);Next some simple Knockout bound HTML to render the customers (outside the script block obviously):
1: < h2 >Customers (<spandata-bind="text: customers().length"></span>)</h2>2: < table >3: < thead >4: < tr >5: < th >CustomerID</th>6: < th >CompanyName</th>7: < th >Phone</th>8: </ tr >9: </ thead >10: < tbody data-bind ="foreach: customers" >11: < tr >12: < td data-bind ="text: CustomerID" ></ td >13: < td data-bind ="text: CompanyName" ></ td >14: < td data-bind ="text: Phone" ></ td >15: </ tr >16: </ tbody >17: </ table >Step 9: Query Away!
Now all we have to do is flesh out our load method in the view model. All we need to do is form a query and execute it with the Breeze EntityManager, putting the results where we want them – in this case I loop over the results in a success callback function, pushing them into my observable array in my view model. The really cool thing is that Breeze takes care of downloading the OData metadata for the Entity Data Model and automatically creates observable types for the data objects, so the individual objects I am adding into my array are data binding friendly JS types with observable properties.
1: load: function () {2: var query = breeze.EntityQuery.from("Customers");3: manager.executeQuery(query, function (data) {4: var results = data.results;5: $.each(data.results, function (i, c) {6: my.vm.customers.push(c);7: });8: });9: }We can now run and we should get all customers:

The other cool thing is that now we can start formulating more complicated LINQ-like queries with Breeze. instead of just asking for all customers above, we could change it to ask for customers who’s company name starts with B and order by the CustomerID. Just change line 2 above to:
1: var query = breeze.EntityQuery.from("Customers")2: .where("CompanyName","startsWith","B").orderBy("CustomerID");And viola [sic]:

Summary
Web API makes exposing OData services a piece of cake and gives you more power and flexibility to integrate your own business logic and data access than you get in WCF Data Services. Breeze makes a great JavaScript client library to query those services, allowing you to write LINQ like code to formulate your queries. Of course Breeze goes way beyond just letting you query – it gives you a really rich experience for binding, editing, validating, going offline, and then pushing changes to the data back to the server. But those things will have to wait for another post…
Please check out my Pluralsight Course “Building ASP.NET Web API OData Services” (due out by end of February) for the full story on Web API and OData.
You can download the full source code for this sample here.









David Navetta (@DavidNavetta) 2published The Privacy Legal Implications of Big Data: A Primer to the InfoLawGroup blog on 2/12/2013. From the beginning:
By now many lawyers and business managers have heard of the term “Big Data,” but many may not understand exactly what it refers to, and still more likely do not know how it will impact their clients and business (or perhaps it already is). Big Data is everywhere (quite literally). We see it drive the creative processes used by entertainment companies to construct the perfect television series based on their customer’s specific preferences. We see Big Data in action when data brokers collect detailed employment information concerning 190 million persons (including salary information) and sell it to debt collectors, financial institutions and other entities. Big Data is in play when retailers can determine when its customers are pregnant without being told, and send them marketing materials early on in order to win business. Big Data may also eventually help find the cure to cancer and other diseases
The potential uses and benefits of Big Data are endless. Unfortunately, Big Data also poses some risk to both the companies seeking to unlock its potential, and the individuals whose information is now continuously being collected, combined, mined, analyzed, disclosed and acted upon. This post explores the concept of Big Data and some of the privacy-related legal issues and risks associated with it.
1.0 What is “Big Data”?
To understand the legal issues associated with Big Data it is important to understand the meaning of the term. Wikipedia (part of the Big Data phenomenon itself) defines Big Data as follows:
Big Data is a collection of data sets so large and complex that it becomes difficult to process using on-hand database management tools or traditional data processing applications. The challenges include capture, curation, storage, search, sharing, analysis, and visualization.
While the Wikipedia definition highlights the challenges associated with large data sets and understanding the data contained in those sets, a definition by the TechAmerican Foundation also captures the opportunities associated with Big Data:
Big Data is a term that describes large volumes of high velocity, complex and variable data that require advanced techniques and technologies to enable the capture, storage, distribution, management, and analysis of the information.
The Foundation stresses Big Data solutions as part of its attempt to define the term:
Big Data Solutions: Advanced techniques and technologies to enable the capture, storage, distribution, management and analysis of information.
According to the TechAmerican Foundation, Big Data is characterized by three factors: volume, velocity, and variety:


…
David continues with a detailed analysis of big data legal issues.
Matthieu Mezil (@MatthieuMEZIL) posted WCF Data Services vs WAQS – Performance aspect on 2/10/2013 (missed when published):
The main reason why I made WAQS was the query limitations with WCF Data Services and WCF RIA Services.
WAQS changed a lot from June and it has a lot of features in addition of querying from the client on 3 tiers applications.
BTW, ping me if you want to learn more about it.
In previous days, I optimized WAQS. So I wanted to test it vs WCF Data Services to see if WAQS features gain does not have a bad impact on performances.
So I test several simples queries on Contoso database which has more data than Northwind.
Note that, in my test, I use default configuration of WAQS and of WCF Data Services.
This is the result for WCF Data Services:
- Get 18,869 customers: 6,693 ms
var query = _context.DimCustomers;
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar))).ToList();- Get customers CompanyName: 2,652 ms
var query = (DataServiceQuery<DimCustomer>)_context.DimCustomers
.Select(c => new DimCustomer { CustomerKey = c.CustomerKey, CompanyName = c.CompanyName });
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar)))
.Select(c => c.CompanyName).ToList();- Get 100 customers with their online sales: 9,672 ms
var query = (DataServiceQuery<DimCustomer>)_context.DimCustomers
.Expand("FactOnlineSales")
.Take(100);
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar))).ToList();- Get 100 customers with their online sales with products of this ones: 27,021 ms
var query = (DataServiceQuery<DimCustomer>)_context.DimCustomers
.Expand("FactOnlineSales/DimProduct")
.Take(100);
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar))).ToList();- Get 100 customers with their online sales with products and categories of this ones: 42,604 ms
var query = (DataServiceQuery<DimCustomer>)_context.DimCustomers
.Expand("FactOnlineSales/DimProduct/DimProductSubcategory/DimProductCategory")
.Take(100);
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar))).ToList();- Get 200 customers with their online sales with products and categories of this ones: Exception !
var query = (DataServiceQuery<DimCustomer>)_context.DimCustomers
.Expand("FactOnlineSales/DimProduct/DimProductSubcategory/DimProductCategory")
.Take(200);
var customers = (await Task.Factory.FromAsync(query.BeginExecute(null, null),
ar => query.EndExecute(ar))).ToList();Now, the same with WAQS:
- Get 18,869 customers: 3,307 ms (instead of 6,693 ms)
var customers = (await _context.DimCustomers.AsAsyncQueryable().Execute()).ToList();- Get customers CompanyName: 187 ms (instead of 2,652 ms)
var customers = (await _context.DimCustomers.AsAsyncQueryable()
.Select(c => c.CompanyName)
.Execute()).ToList();- Get 100 customers with their online sales: 3,260 ms (au lieu de 9,672 ms)
var customers = (await _context.DimCustomers.AsAsyncQueryable()
.OrderBy(c => c.CustomerKey)
.Take(100)
.IncludeFactOnlineSales()
.Execute()).ToList();- Get 100 customers with their online sales with products of this ones: 4,336 ms (instead of 27,021 ms)
The code is blocked by msmvps. It’s available on my French blog http://blogs.codes-sources.com/matthieu/archive/2013/02/11/wcf-data-services-vs-waqs.aspx. Sorry for that.- Get 100 customers with their online sales with products and categories of this ones: 4,883 ms (instead of 42,604 ms)
The code is blocked by msmvps. It’s available on my French blog http://blogs.codes-sources.com/matthieu/archive/2013/02/11/wcf-data-services-vs-waqs.aspx. Sorry for that.- Get 200 customers with their online sales with products and categories of this ones: 7,029 ms (instead of exception)
The code is blocked by msmvps. It’s available on my French blog http://blogs.codes-sources.com/matthieu/archive/2013/02/11/wcf-data-services-vs-waqs.aspx. Sorry for that.If we do not take in consideration the infinite rate of the last query, WAQS is between 2.02 and 14.18 faster than WCF Data Services with an average of 6,83 in my tests.
That's a load off my mind! :)
// Note that the current version of WAQS is not public yet

My (@rogerjenn) second Testing the StreamInsight Service for Windows Azure article published 2/5/2013 in Red Gate Software’s Simple Talk Newsletter and ACloudyPlace blog begins:
In my previous article StreamInsight Service for Windows Azure about the “Project Austin” StreamInsight service, I explained how to provision it on Windows Azure with Visual Studio 2010 or 2012 and the downloadable AustinCtpSample solution. StreamInsight is a Complex event processing (CEP) application that tracks streams of information that combines data from several sources in order to identify meaningful events and respond to them rapidly.
In this article, I’ll be showing you how to test the StreamInsight Service for Windows Azure CTP with the SampleApplication and EventSourceSimulator projects and use the graphical Event Flow Debugger. To do this, you will need the following: (see StreamInsight Service for Windows Azure).
- Visual Web Developer 2010 Express or Visual Studio Express 2012 for Web or higher version
- Windows Azure SDK v1.7 (June 2012), which includes the Visual Studio Tools for Windows Azure
- A Windows Azure trial or paid subscription, preferably dedicated to StreamInsight
- An invitation to the StreamInsight Service for Windows Azure CTP, the source code and binaries for which you must download and install
- Completion of all sections of Part 1 except “Deleting a Service Instance Deployment”

See the end of the next article regarding the status of “Project Austin.”
My (@rogerjenn) first StreamInsight Service for Windows Azure article published 1/24/2013 Red Gate Software’s Simple Talk Newsletter and ACloudyPlace blog begins:
Introduction: Move Complex Event Processing to the Cloud
The SQL Server team released its StreamInsight v1.0 complex event processing (CEP) feature in April 2010 and followed with SteamInsight as a Windows Azure Service in a private CTP codenamed “Project Austin” in May 2011. Project Austin’s third CTP of August 2012 updates the service to the Windows Azure SDK v1.7 and StreamInsight v2.1.
This article will describe how to provision a “Project Austin” service on Windows Azure with Visual Studio 2010 or 2012 and the downloadable AustinCtpSample solution. A second article will show you how to test the service with the SampleApplication and EventSourceSimulator projects and use the graphical Event Flow Debugger.
Why Complex Event Processing (CEP)
Complex event processing (CEP) is a way of tracking streams of information that combines data from several sources in order to identify meaningful events and respond to them rapidly. It is a hot topic for finance, energy and manufacturing enterprises around the globe, as well as participants in the Internet of Things (IoT) and social computing. Instead of traditional SQL queries against historical data stored on disk, CEP delivers high-throughput, low-latency event-driven analytics from live data streams.
CEP’s most notorious application is high-frequency algorithmic trading (HFAT) on regulated financial exchanges and unregulated over-the-counter (OTC) swaps in what are called “dark pools.” The U.S. Congress’s Dodd-Frank Wall Street Reform and Consumer Protection Act attempts to prevent the HFAT excesses that contributed to tanking the U.S. economy in late 2008. Less controversial CEP uses include real-time utility usage monitoring and billing with SmartMeters for natural gas and electricity, as well as product and personal sentiment analysis inferred from social computing data, such as Twitter streams. Health care providers envision a future in which patients wear blood-pressure, heart-rate and other physiological monitors, which communicate over the Internet to remote CEP apps that report running averages and issue alerts for health-threatening excursions. The largest potential CEP market appears to be real-time reporting of data from environmental sensors to discover actual and potential pollution sources and other threats to the earth and its atmosphere.
Microsoft’s CEP: SteamInsight
Major providers of relational database management systems (RDBMSs) are the primary sources of CEP apps. Microsoft’s Server & Tools Business group released v1 of its SteamInsight CEP feature, together with SQL Server 2008 R2, to manufacturing in May 2011. StreamInsight competes with IBM InfoSphere Streams, Oracle Event Processing (OEP), and SAP Sybase Event Stream Processor/Aleri RAP, as well as offerings from independent CEP specialists, such as StreamBase. Figure 1 represents on-premises StreamInsight architecture.
Figure 1. StreamInsight’s architecture includes sets of Input Adapters for various event sources, a CEP query engine, and Output Adapters for event targets (sinks), which consume the analytic data. StreamInsight Services for Windows Azure adds Output Adapters for Windows Azure blob storage and Windows Azure SQL Database, formerly SQL Azure. Graphic courtesy of Microsoft.
StreamInsight Services for Windows Azure, codenamed “Project Austin”
Recognizing that many enterprises won’t want to make large investments in on-premises hardware for CEP, the SQL Server team introduced a private Community Technical Preview (CTP) of StreamInsight Services for Windows Azure, codenamed “Project Austin,” in May 2011. CTP updates in February, June and August 2012 kept pace with new on-premises StreamInsight versions and Windows Azure SDK upgrades. This article covers the August 2012 update for the Windows Azure SDK v1.7.

It’s unfortunate that the SQL Server team decided to terminate “Project Austin” as described in this message sent to all Project Austin participants, apparently except me:
It has been a few months since you’ve heard from us, and we would like to fill you in on some advancements in the evolution of the Windows Azure StreamInsight Platform.
First off, we would like to thank you for participating in the Microsoft ‘Project Austin’ Customer Technology Preview (CTP). We received very valuable feedback which continues to help us shape the range of our offerings. We recognize that ‘Project Austin’ is as a crucial piece of the cloud data pipeline and are looking for ways to provide a more integrated data pipeline platform. As such, we are pausing the ‘Project Austin’ CTP, and dedicating resources toward evolving the capability of the technology. We feel confident that we are on the right path to providing a richer and even more compelling solution.
As a result of the change in direction, we will be ramping down the existing service by the end of January 2013, and working with our existing customers to transition to the new data pipeline service when it becomes available. If you would like to request an extension period for your project, please reach out directly to Welly Lee [e-mail alias redacted].
We will send a communication containing additional information about the new data pipeline service by Spring 2013.
Thank you again, and we look forward to working with you in the future.
Francois Lascelles (@flascelles) described Enabling token distributors on 2/6/2013 (missed when published:
Are you a token distributor? If you provide an API, you probably are.
One thing I like about tokens is that when they are compromised, your credentials are unaffected. Unfortunately, it doesn’t work so well the other way around. When your password is compromised, you should assume the attacker could get access tokens to act on your behalf too.
In his post The dilemma of the oauth token collector, and in this twitter conversation, Nishant and friends comment on the recent twitter hack and discuss the pros and cons of instantly revoking all access tokens when a password is compromised.
I hear the word of caution around automatically revoking all tokens at the first sign of a credential being compromised but in a mobile world where UX is sacred and where each tapping of password can be a painful process, partial token revocation shouldn’t automatically be ruled out.
Although, as Nishant suggests, “it is usually hard to pinpoint the exact time at which an account got compromised”, you may know that it happened within a range and use the worse case scenario. I’m not saying that was necessarily the right thing to do in reaction to twitter’s latest incident but only revoking tokens that were issued after the earliest time the hack could have taken place is a valid approach that needs to be considered. The possibility of doing this allows the api provider to mitigate the UX impact and helps avoid service interruptions (yes I know UX would be best served by preventing credentials being compromised in the first place).
Of course, acting at that level requires token governance. The ability to revoke tokens is essential to the api proviver. Any token management solution being developed today should pay great attention it. Providing a GUI to enable token revocation is a start but a token management solution should expose an API through which tokens can be revoked too. This lets existing portals and ops tooling programmatically act on token revocation. Tokens need to be easily revoked per user, per application, per creation date, per scope, etc, and per combination of any of these.
Are you a token distributor? You should think hard about token governance. You also think hard about scaling, security, integration to exiting identity assets and interop among other things. We’re covering these and more in this new eBook : 5 OAuth Essentials For APi Access Control. Check it out.

<Return to section navigation list>
Windows Azure Service Bus, Caching, Access Control, Active Directory, Identity and Workflow
Jim O’Neil announced the availability of Practical Azure #12: Caching on 2/22/2013:
“I feel the need. The need for speed" sums ups the role of caching in distributed applications. When your application involves database lookups or service calls, every millisecond of latency adds up, particularly for high demand, “internet scale” solutions. Do you really need to execute a database query each time you’re validating a zip code? How often does your product catalog change – wouldn’t it be more efficient to just hold it in memory versus making a service or SQL call?
Caching is (hopefully) already part of your on-premises solutions, and with Windows Azure Caching you can easily pull in the same functionality but know that it’s backed up by the Windows Azure SLA; “leave the driving to us” in other words. I invite you to take a closer look at this incredibly powerful yet simple to incorporate feature in my latest segment of Practical Azure on MSDN DevRadio.
Go to site for live video content.
Download: MP3 MP4
(iPod, Zune HD)High Quality MP4
(iPad, PC)Mid Quality MP4
(WP7, HTML5)High Quality WMV
(PC, Xbox, MCE)Download:
And here are the Handy Links for this episode:
Lori MacVittie (@lmacvittie) asserted SAML Find Its Cloud Legs in a 2/20/2013 post to F5’s DevCentral blog:
“When I took office, only high energy physicists had ever heard of what is called the World Wide Web... Now even my cat has it's own page.” - Bill Clinton
Despite the slow descent into irrelevance of SOA and its core standards, several of its ancillary standards remain steadfastly alive and in some cases are growing in relevance. In particular, SAML is gaining steam thanks in large part to the explosive adoption of SaaS.
SAML (Security Assertion Markup Language), now on its second major version, was most commonly associated with efforts by the Liberty Alliance (long since defunct and absorbed into the Kantara Initiative) to federate authentication and authorization across the web. The "big deal" with SAML was that it was easily supported by the browser. Of course when it was introduced there were few services enterprises felt needed federation with corporate systems and thus despite the energy surrounding the project it was largely ineffective at producing the desired results.
Fast forward to today and the situation out there has changed. Enterprises are increasingly invested in SaaS (which is still really just a web application) and are growing more aware of the challenges associated with that investment, particularly around identity, access, and control.
Re-enter SAML. This time, with a much better chance of becoming The Standard for federating identity across cloud-deployed applications.
WHY SAML? WHY NOW?
The appeal remains, in large part, due to its focus on the browser through which most if not all enterprise resources are accessed today. Add in a healthy dose of mobile devices, roaming employees, and new off-premise enterprise services and you've got a recipe for SAML's success.
The need for organizations to get a grip on (reassert control over) access and identity management is significant. As we recently learned there are mounting concerns with respect to distributed credentials and unfettered access to corporate applications residing off-premise. SAML 2.0 offers a standards-based, increasingly supported means of accomplishing this feat of wondrous power through a combination of well-defined processes and products (er, services).
Salesforce.com: Configuring SAML Settings for Single Sign-On
Single sign-on is a process that allows network users to access all authorized network resources without having to log in separately to each resource. Single sign-on allows you to validate usernames and passwords against your corporate user database or other client application rather than having separate user passwords managed by Salesforce.
Google: SAML Single Sign-On (SSO) Service for Google Apps
Using the SAML model, Google acts as the service provider and provides services such as Gmail and Start Pages. Google partners act as identity providers and control usernames, passwords and other information used to identify, authenticate and authorize users for web applications that Google hosts.
The list goes on: Concur, SugarCRM, FedEx, RightScale. This is the tip of the iceberg when it comes to SAML. And it's not just vendors offering support, it's users asking for it, coding it into their applications, demanding it.
And why shouldn't they? SAML 2.0 is highly flexible in its ability to provide a standard process through which authentication and authorization to resources can be provided. It provides the process and the payload necessary to unify and federate identity across distributed applications, and it can be easily used in the browser as well as in custom applications. It's a markup language standard transported largely over HTTP.
Because it has well defined processes that describe how to federate identity using an SP (Service Provider) and an IdP (Identity Provider) organizations and vendors alike can cleanly implement support either directly or through a third-party provider like Ping Identity, One Login, or SecureAuth. SAML can support mobile devices and APIs as easily as it can traditional browser-based resources. When used by a cloud access broker acting as an access control gateway, SAML can be used to provide single-sign on for both cloud and data center hosted resources.
It's really quite a flexible little standard that seems to have finally found its sea legs - if by "sea legs" one means cloud legs.


Philip Wu posted [Sample Of Feb 17th] Windows Azure Access Control for Single Sign-On to the Microsoft All-In-One Code Framework blog on 2/17/2013:
Sample Download :
CS Version: http://code.msdn.microsoft.com/CSAzureAccessControlService-7596c358
VB Version: http://code.msdn.microsoft.com/VBAzureAccessControlService-272807b0
This sample code demonstrates how to implement for Access Control Service for your web role application, As we know most of websites and web application has their own user validation system, such simple UserName-Password way, Active Directory, etc. If your web application must support multiple user validation, you must handle different token with different methods, but when you try to move your application to Windows Azure, you will find we can use Access Control for solve this problem, your azure application need only handle one kind of Token from Windows Azure Access Control Service.
You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.

<Return to section navigation list>
Windows Azure Virtual Machines, Virtual Networks, Web Sites, Connect, RDP and CDN
Michael Washam (@MWashamMS) reported Windows Azure IaaS Cmdlets Source Code is Now Available on 2/15/2013:
The 2/11 Release of the Windows Azure PowerShell Cmdlets now includes the IaaS Cmdlets Source Code
Windows Azure PowerShell Source Code
Now that is out of the way we can start working on some new feature work!
Any requests?


<Return to section navigation list>
Live Windows Azure Apps, APIs, Tools and Test Harnesses
Haishi Bai (@haishibai2010) announced on 2/21/2013 the availability of a Learn Windows Azure Cloud Services from Beginning: a Mini Online Course:
I just finished publishing 7 episodes of a new video series, Windows Azure Cloud Services. This series is a mini online course that teaches you Windows Azure Cloud Services from beginning. We'll start our cloud journey by setting up development environment, and then continue to explore some fundamental concepts of Windows Azure Cloud Services. The series builds a solid foundation for you to create highly-available, scalable applications and services using Windows Azure's rich PaaS environment, and to deliver great SaaS solutions to customers anywhere around the world.
There are still more episodes to come, but the first 7 episodes cover all the basic concepts, tools, and procedures you need to know to get started. Here’s the list of episodes:
- Episode 1: Introduction to Windows Azure Cloud Services
- Episode 2: Windows Azure Cloud Services Concepts (Part 1)
- Episode 3: Walkthrough of the Management Portal for Windows Azure Cloud Services
- Episode 4: Windows Azure Cloud Services Concepts (Part 2)
- Episode 5: Introduction to Windows Azure Worker Roles (Part 1)
- Episode 6: Introduction to Windows Azure Worker Roles (Part 2)
- Episode 7: Windows Azure Cloud Services Role Lifecycle
Hope you enjoy the series. If you have any feedbacks, please leave comments on the posts, or send me a message to @HaishiBai2010.

Wes Yanaga reported New Windows Azure Videos on Channel 9 on 2/20/2013:
There is a new landing page on Channel 9 where you can find videos, event recordings and shows about Windows Azure. The page aggregates numerous videos from events like Build and AzureConf and a bunch of new content. The first new videos include these tutorials :
Below you will find a list of some of the newest Windows Azure series available on Channel 9.
Windows Azure Mobile Services Tutorials
App development with a scalable and secure backend hosted in Windows Azure. Incorporate structured storage, user authentication and push notifications in minutes.
Windows Azure Media Services Tutorials
Create, manage and distribute media in the cloud. This PaaS offering provides everything from encoding to content protection to streaming and analytics support.
Windows Azure Virtual Machines & Networking Tutorials
Easily deploy and run Windows Server and Linux virtual machines. Migrate applications and infrastructure without changing existing code.
Windows Azure Web Sites Tutorials
Quickly and easily deploy sites to a highly scalable cloud environment that allows you to start small and scale as traffic grows.
Use the languages and open source apps of your choice then deploy with FTP, Git and TFS. Easily integrate Windows Azure services like SQL Database, Caching, CDN and Storage.
Windows Azure Cloud Services Tutorials
Create highly-available, infinitely scalable applications and services using a rich Platform as a Service (PaaS) environment. Support multi-tier scenarios, automated deployments and elastic scale.
Windows Azure Storage & SQL Database Tutorials
Windows Azure offers multiple services to help manage your data in the cloud. SQL Database enables organizations to rapidly create, scale and extend applications into the cloud with familiar tools and the power of Microsoft SQL Server™ technology. Tables offer NoSQL capabilities at a low cost for applications with simple data access needs. Blobs provide inexpensive storage for data such as video, audio, and images.
Windows Azure Service Bus Tutorials
Service Bus is messaging infrastructure that sits between applications allowing them to exchange messages in a loosely coupled way for improved scale and resiliency.







Brian Benz (@bbenz) reported Ready, set, go download the latest release of the Windows Azure Plugin for Eclipse with Java on 2/6/2013 (missed when published):
It’s ready…the February 2013 Preview release of the Windows Azure Plugin for Eclipse with Java from our team at Microsoft Open Technologies, Inc.
You’ve been asking for the ability to deploy JDKs, servers, and user-defined components from external sources instead of including them in the deployment package when deploying to the cloud, and that’s available in this release. There are also a few other minor updates for components, cloud publishing and Windows Azure properties. Have a look at the latest plugin documentation for a complete list of updates.
Deploy JDKs, Servers and user-defined components from Blob Storage
You can now deploy JDKs, application servers, and other components from public or private Windows Azure blob storage downloads instead of including them in the deployment package used to deploy to the cloud.
Having the option of referring to an external object instead including an object in the deployment package gives you flexibility when building your deployment packages. It also means faster deployment times and smaller deployment packages.
Here’s an example showing inclusion of a JDK. Note the new Deploy from download option:
Note the other tabs for server and applications – those options let you select a server (Tomcat, for example), or any component that you want to include in the install and setup but that you don’t want to include in the deployment package.
Getting the Plugin
Here are complete instructions for downloading and installing the Windows Azure Plugin for Eclipse with Java for the first time, which also works for updates.
Let us know how the process goes and how you like the new features



<Return to section navigation list>
Visual Studio LightSwitch and Entity Framework 4.1+
Paul van Bladel (@paulbladel) described A practical extension method for the modal window enter key “bug” in LightSwitch in a 2/19/2013 post:
Introduction
When you have in a LightSwitch screen, a modal window, there is the annoying behavior that pressing the enter key closes you modal window.
There is a workaround available on the user forum: http://social.msdn.microsoft.com/Forums/en-US/lightswitch/thread/174264d3-f094-46e5-b5a7-6a606916070d?prof=required.
The idea of this workaround is to hook up the “key up” event on every input control of the modal window.
It’s working great, but it can be a source of errors: controls can be renamed, fields can be added, etc. …
Note: See the important update at the end of this post !!
Let’s improve it
Let’s assume we have following modal window with 4 fields: 2 textboxes, a modal window picker and a autocomplete box.
How do we trigger the fix?
partial void SearchCustomers_Created() { this.SuprresEnterKeyForUnderlyingControls("CurrentCustomer"); }As you can see, simply one line of code, an extension method on the ScreenObject. Note that we do not specify the name of the modal window, but the first underlying group control (in my case a rows layout).
Show me the extension class…
using System; using System.Linq; using System.IO; using System.IO.IsolatedStorage; using System.Collections.Generic; using Microsoft.LightSwitch; using Microsoft.LightSwitch.Framework.Client; using Microsoft.LightSwitch.Presentation; using Microsoft.LightSwitch.Presentation.Extensions; using System.Windows.Controls; using Microsoft.LightSwitch.Model; using Microsoft.LightSwitch.Client; using System.Windows; using System.Windows.Input; namespace LightSwitchApplication { public static class IScreenObjectExtensions { public static void SuprresEnterKeyForUnderlyingControls(this IScreenObject screen, string parentControlName) { IContentItemDefinition itemDef = screen.Details.GetModel().GetChildItems(true) .OfType<IContentItemDefinition>() .Where(c => c.Name == parentControlName).FirstOrDefault(); foreach (var item in itemDef.ChildContentItems) { SuppressEnterKey(screen, item); } } private static void SuppressEnterKey(IScreenObject screen, IContentItemDefinition contentItemDefinition) { var proxy = screen.FindControl(contentItemDefinition.Name); proxy.ControlAvailable += (s1, e1) => { UIElement uiElement = e1.Control as UIElement; uiElement.KeyUp += (s2, e2) => { if (e2.Key == Key.Enter || e2.Key==Key.Escape) e2.Handled = true; }; }; } } }Update
Someone on the LightSwitch forum correctly dr[e]w my attention to the fact that things can be more simplified. In fact via model inspection, I retrieve the list of controls present in the modal form. Since I attach the Key up event on a UIElement, the event bubbling mechanism can play it’s role here. So the model inspection is no longer necessary. So, this can simplify the extension method as follows:
public static void SuprresEnterKeyForUnderlyingControls(this IScreenObject screen, string controlName) { screen.FindControl(controlName) .ControlAvailable += (s1, e1) => { (e1.Control as UIElement) .KeyUp += (s2, e2) => { if (e2.Key == Key.Enter) e2.Handled = true; }; }; }Conclusion
What can I say more? Again an example that LightSwitch is simple on the outside, but rich on the inside…

Philip Wu posted [Sample Of Feb 19th] How to implement Pivot and Unpivot in Entity Framework to the Microsoft All-In-One Code Framework blog on 2/19/2013:
Sample Download :
CS Version: http://code.msdn.microsoft.com/CSEFPivotOperation-cbdd79db
VB Version: http://code.msdn.microsoft.com/VBEFPivotOperation-e2fcfad5
This sample demonstrates how to implement the Pivot and Unpivot operation in Entity Framework.
In this sample, we use two classes to store the data from the database by EF, and then display the data in Pivot/Unpivot format.

You can find more code samples that demonstrate the most typical programming scenarios by using Microsoft All-In-One Code Framework Sample Browser or Sample Browser Visual Studio extension. They give you the flexibility to search samples, download samples on demand, manage the downloaded samples in a centralized place, and automatically be notified about sample updates. If it is the first time that you hear about Microsoft All-In-One Code Framework, please watch the introduction video on Microsoft Showcase, or read the introduction on our homepage http://1code.codeplex.com/.


Philip Wu posted [Sample Of Feb 18th] Update POCO entity properties and relationships in EF to the Microsoft All-In-One Code Framework blog on 2/18/2013:
Sample Download: http://code.msdn.microsoft.com/CSEFPOCOChangeTracking-ed4d5c6e
The code sample illustrates how to update POCO entity properties and relationships with/without change tracking proxy.

Paul van Bladel (@paulbladel) provided A downloadable sample for SignalR commanding & toast notifications in LightSwitch on 2/18/2013:
Introduction
I got quite some questions about a working SignalR sample.
Here is one
How?
Server side the SignalR 1.0.0-RC 2 package is installed. If there is trouble with the dlls, inject the nuget package again:
Client side I’m referencing the 2 signalR relevant Dlls from a ReferenceAssemblies folder. If these references are not ok, just link them again manually.
It’s about:
- Microsoft.AspNet.SignalR.Client.dll
- Newtonsoft.Json.dll
I compiled these dlls directly from github.
The toast notifications need the Pixata LightSwitch extension.
Good luck.
Update
Important: No need to use my referenced assemblies. Simply inject in the client side project the SignalR windows Client (it will install the above silverlight dlls)
If you use the downloadable sample, make sure to update also the server nuget package to version 1.0.0 (because this was the release candidate)


Jan Van der Haegen (@janvanderhaegen) posted LightSwitch: technology overview on 2/11/2013:
February ’13 will be a fun month full of LSL (“LightSwitch Lovin’ – highly addictive”), including a very short high-speed demo at MS Web Cafe, and an intensive evening workout co-hosted by community rock star Paul Van Bladel: “Simple on the outside, rich on the inside“.
While prepping, I started drawing a bit to try and capture how LightSwitch manages to take a simple idea, and through a simple IDE allows you to create such an impressive ecosystem.
Here’s 3 of my drawings, feedback appreciated!!
A simple idea
In reality (server)
In reality (client)
PS: When you’re not counting cursive text, since it represents my random thoughts in between my traditional and formal writing style, this has got to be my shortest blog post ever…




")
Return to section navigation list>
Windows Azure Infrastructure and DevOps
My (@rogerjenn) Uptime Report for my Live OakLeaf Systems Azure Table Services Sample Project: January 2013 = 100.00 % of 2/23/2013 is a bit late but reports another month of 100% uptime:
Here’s the report for January 2013, the fifth consecutive month of 100% uptime and the ninth consecutive month of meeting Windows Azure 99.9% uptime SLA:
Note: Pingdom’s report was delayed until 2/18/2013 and arrived while I was in Washington attending Microsoft’s MVP Summit 2013 conference.
…

Five months of 100% uptime doesn’t compensate for the following event.
My (@rogerjenn) Windows Azure Armageddon post of 2/23/2013 begins:
At 12:54 PM on 2/22/2013, I received the following DOWN Alert message from Pingdom for my OakLeaf Systems Azure Table Services Sample Project demo from my Cloud Computing with the Windows Azure Platform book:
When I attempted to run the sample Web Role project at http://oakleaf.cloudapp.net, I received an error message for an unhandled exception stating that an expired HTTPS certificate caused the problem. Here’s the Windows Azure team’s explanation:
Here’s Pingdom’s UP alert at 8:28 PM last night:



…
It’s obvious that some minor functionary in the Windows Azure bureaucracy missed an item on his or her todo list yesterday. It’s equally obvious that this is a helluva way to run a cloud service (with apologies to Peter Arno and John Luther (Casey) Jones.)
Adrian Cockcroft (@adrianco) noted that “Azure had a cert outage a year ago” in a 2/23/2013 Tweet:
Microsoft’s Bill Liang posted a Summary of Windows Azure Service Disruption on Feb 29th, 2012, which was caused by expiration of a “transfer certificate,” on 3/9/2013:
… So that the application secrets, like certificates, are always encrypted when transmitted over the physical or logical networks, the GA creates a “transfer certificate” when it initializes. The first step the GA takes during the setup of its connection with the HA is to pass the HA the public key version of the transfer certificate. The HA can then encrypt secrets and because only the GA has the private key, only the GA in the target VM can decrypt those secrets.
…
When the GA creates the transfer certificate, it gives it a one year validity range. It uses midnight UST of the current day as the valid-from date and one year from that date as the valid-to date. The leap day bug is that the GA calculated the valid-to date by simply taking the current date and adding one to its year. That meant that any GA that tried to create a transfer certificate on leap day set a valid-to date of February 29, 2013, an invalid date that caused the certificate creation to fail. …

The above is only a portion of a long, sad story.
David Pallman posted Glass Half Empty: Understanding Cloud Computing SLAs on 2/23/2013:
Let's talk about Cloud SLAs - a subject that is very important, but nevertheless is frequently misunderstood, over-simplified, or even outright ignored.
As I write this, Windows Azure has had an "up and down" week: on Tuesday 2/19/13, Windows Azure Storage was declared the leader in Cloud Storage by an independent report. A few days later on Friday 2/22/13, Windows Azure Storage suffered a worldwide outage - which shows you what a difference a couple of days can make to cloud vendor reputations.
Given the events of this week, it seems timely to say some things about Cloud SLAs and correct some faulty reasoning that seems prevalent.
Service Level Agreements and High Availability
A service-level agreement is a contract between IT and a business to provide a certain level of service. In an enterprise an SLA could cover many things, including availability, response time, maintenance windows, and recovery time. In today's cloud computing environments, SLAs are largely about availability (uptime). So, let's talk about high availability.
Non-technical people say they want things up "all the time". Of course they do - but that's not reality. The chart below shows the "9s" categories for availability and what that means in terms of uptime.
The key thing to understand is that as you increase the number of 9's the expense of meeting the SLA increases dramatically. Except for very simple systems or individual components, 4 9's is extremely expensive, and not available today in the public cloud. 5 9's or better is prohibitively expensive and quite rare.
Typical Availability Provided in the Cloud is 99.9% to 99.95%
Cloud platforms have individual SLAs for each service. The majority of cloud services have an SLA of 3 9's (99.9%), and some computing services offer 3.5 9's (99.95%). That means, a cloud service could be down 43 minutes a month and still be within its SLA. Is that an acceptable level of service? It depends. It could be a step up for you or a step down for you depending on what SLA you're used to - what does your local enterprise deliver? Interestingly, when I ask this question of clients the answer I receive most often is, "We don't know what our current SLA is"!
Availability Interruptions Don't Play Nice
The table above might lead you to believe that outage time is somehow evenly distributed but there's no guarantee of when an outage will occur or that outages will politely schedule themselves in small pockets of time over the course of the year. A service with a 99.9% SLA could be down 10 minutes a week, but it could also be down 43 minutes a month or even 8 hours straight once a year. You should assume the worst: an outage will occur during business hours on the day you can least afford it. Most cloud SLAs measure the SLA at a monthly level and provide some recompense if it is not met.
SLAs are not guarantees. Every cloud provider has missed meeting its SLA at times.
The Subtlety of SLAs by Service: Your Cloud Service SLA is not your Solution's SLA
Nearly all solutions in the cloud use multiple cloud services (for example, a web site might use Compute, Storage, and Database services). Note that the cloud providers do not provide an SLA for your solution, only for the individual services you consume.
An easy trap to fall into is assuming the minimum SLA for the cloud services you are using translates into an overall SLA for your solution. Let's demonstrate the fallacy of that thinking. Let's say your solution makes use of three cloud services, each with a monthly SLA of 99.9%. On the first day of the month, the first cloud service has a 40-minute outage but is otherwise up the remainder of the month - its still within its SLA. Now let's say the exact thing happens on the second day of the month to the second cloud service. And then, the same thing happens on the third day with your third cloud service. None of those services has violated its SLA, but your solution has been down 120 minutes that month.
The more services you use, the less uptime you can count on. Unless you're feeling lucky.
Using Multiple Data Centers Does Not Magically Increase 9's
I'm often asked if a 4 9's arrangement can be had by leveraging multiple data centers for failover. The answer is NO: while using multiple data centers and having good failover mechanisms in place does increase your likelihood of uptime, it is not a guarantee. Let's consider the best case and worst case scenario where you are using a primary cloud data center and have a failover mechanism in place for a secondary data center that is ready to take over at a moment's notice. In the best case scenario, you experience no downtime at all in the primary data center, never need that second data center, and life is good. It could go that way. In the worst case scenario, you experience downtime in your primary data center and failover to the second data center -- but then that second data center fails too soon thereafter. If you don't think that could happen, consider that some of the cloud outages have been worldwide ones where all data centers are unavailable simultaneously.
Leveraging multiple data centers is a good idea - but don't represent that as adding more 9's to your availabiility. It's not a supportable claim.
How to Approach Cloud SLAs: Pessimistically
The only sane way to approach cloud computing SLAs (or any SLA for that matter) is to be extremely pessimistic and assume the worst possible case. If you can design mitigations and contingency plans for the worst case, you are well-prepared for any eventuality. If on the other hand you are "hoping for the best", your plans are extremely shaky. Murphy's Law should dominate your thinking when it comes to designing for failure.
Do not forget that Cloud SLAs are not a promise, they are a target. There may be some consequences such as refunds if your cloud vendor fails to meet their SLA, but that is usually little consolation for the costs of your business being down.
Cloud SLA Planning Best Practices
- Become fully familiar with the SLA details of each cloud service you consume.
- Keep in mind many cloud services are in preview/beta and may not be backed by any SLA.
- Don't think of an SLA as a guarantee; your cloud provider will not always meet their SLA.
- Do not confuse the availability SLA for individual cloud services with the overall uptime for your solution. There is no SLA for your solution, and the more services you use, the less uptime you are likely to have.
- Do not plan on being lucky.
- Build in contingency planning for a data center failure that allows you to fail-over to another data center. Yes, this will be extra work and increase your costs. Yes, it is worth it.
- Remember that worldwide outages can occur, and you need a contingency plan for that scenario as well.
To Cloud, or Not to Cloud?
Does all of this mean the cloud is a bad place to run your applications? Not at all - it could well be an improvement over what your local experience is. And, there are significant benefits to running in the cloud that may more than offset the inconvenience of occasional downtime. The important thing is that you approach the cloud eyes-open and with realistic expectations.



Kevin Remde (@kevinremde) continued his How Windows Azure Plays Into the Equation – Migration and Deployment (Part 12 of 19) series on 2/22/2013:
As you may remember, last month my team blogged an entire month on using Windows Azure as Infrastructure-as-a-Service (IaaS – pronounced “EYE-yazz”) in our “31 Days of Servers in the Cloud” series.
As part 12 of our 19-part "Migration and Deployment” Series, Tommy Patterson returns to this topic with a good summary and links to resources for working with Windows Azure as an extension of your private cloud.

Kevin Remde (@kevinremde) posted Windows Azure as a PaaS – Migration and Deployment (Part 11 of 19) pm 2/22/2013:
Waaay back in April of 2011 (remember my "Cloudy April" series?) I blogged about what Windows Azure could do for you as a Platform-as-a-Service (or PaaS – pronounced “PaaS”. Not affiliated or to be confused with this popular Easter Egg Coloring company.)
A lot has happened to Windows Azure since then – and it’s all good stuff! In part 11 of our 19-part “Migration and Deployment” series of articles, my phriend from Phoenix, Harold Wong, brings us up-to-speed with what Windows Azure does and how it supports a Platform for your scalable, dynamic, flexible, pay-as-you-go cloud-hosted applications, with a host of new and powerful features.

<Return to section navigation list>
Windows Azure Platform Appliance (WAPA), Hyper-V and Private/Hybrid Clouds
Mary Jo Foley (@maryjofoley) asserted “Microsoft may have finally thrown in the towel on the idea of having certain hardware partners sell preconfigured containers of servers running Windows Azure as a 'private cloud in a box” in a deck for her Windows Azure Appliances: Unplugged at last? article of 2/22/2013 for ZDNet’s All About Microsoft blog:
Microsoft may finally have pulled the plug on its Windows Azure Appliance offering.
In July 2010, Microsoft took the wraps off its plans for the Windows Azure Appliance, a kind of "private-cloud-in-a-box" available from select Microsoft partners. At that time, company officials said that OEMs including HP, Dell and Fujitsu would have Windows Azure Appliances in production and available to customers by the end of 2010. Fujitsu ended up introducing an Azure Appliance product in August 2011; the other two OEM partners never seemed to do so (best I can tell).
This week, I heard from several of my sources that Microsoft has decided to discontinue work on the Azure Appliance concept.
According to one of my sources, Microsoft has decided that its Windows Azure Services approach -- making certain Azure capabilities, such as virtual-machine and web-site hosting, available on Windows Server -- is now the favored approach. Microsoft announced a beta of Azure services in October 2012, and said the final version would be out in early 2013. As far as I know, the final version is still not available at this time. Microsoft officials said Azure Services is initially aimed at hosting providers, but ultimately it could roll out to larger customers.
Late last year, Bill Hilf, General Manager of Azure, hinted that Microsoft might do some "creative things" around service level agreements, allowing enterprise customers to run apps in their own datacenters if they could do so more reliably than Microsoft could with Azure in its own datacenters.
Back to the Azure Appliances. I asked Microsoft officials this week whether it's accurate to say the company has dropped the appliance approach. A spokesperson replied: "Microsoft does not have information to share at this time, but will keep you posted when there is an update."
When I asked HP this week whether the company was still commit[t]ed to delivering an Azure Appliance, I received this statement:
"HP, as a longtime partner to Microsoft, had initially announced that we would support Microsoft Azure.
"HP remains committed to our relationship with Microsoft and will continue to explore hardware, software and services relationships between the two companies to support our respective cloud offerings in the best manner that our joint customers expect."
(In other words, no comment on the appliances. Got to say, the "initially had" part of the comment doesn't make things sound too rosy between Microsoft and HP on the Azure front.)
I've emailed Fujitsu to see whether it's still offering customers the Fujitsu Global Cloud Platform (FGCP/A5). No word back so far. There don't seem to be any new mentions of FGCP/A5 on its Web site. (There is a white paper about it, dating back to October 2011, however.)
Windows Azure Appliances, as initially described, were designed to be preconfigured containers with between hundreds and thousands of servers running the Windows Azure platform. These containers were to be housed, at first, at Dell’s, HP’s and Fujitsu’s datacenters, with Microsoft providing the Azure infrastructure and services for these containers.
In the longer term, Microsoft officials said they expected some large enterprise customers to house the containers in their own datacenters on site — in other words, to run their own “customer-hosted clouds.” Over time, smaller service providers were possibly going to be authorized to make Azure Appliances available to their customers, as well.
It's unclear whether these latter two goals are still on the Azure roadmap, but they could be -- just via a different, non-hardware-partner-centric approach.


Guess I can remove WAPA from this topic now.
<Return to section navigation list>
Cloud Security, Compliance and Governance
Chris Hoff (@Beaker) warned Intel TPM: The Root Of Trust…Is Made In China on 2/22/2013:
This is deliciously ironic.
Intel‘s implementation of the TCG-driven TPM — the Trusted Platform Module — often described as a hardware root of trust, is essentially a cryptographic processor that allows for the storage (and retrieval) and attestation of keys. There are all sorts of uses for this technology, including things I’ve written of and spoken about many times prior. Here’s a couple of good links:
But here’s something that ought to make you chuckle, especially in light of current news and a renewed focus on supply chain management relative to security and trust.
The Intel TPM implementation that is used by many PC manufacturers, the same one that plays a large role in Intel’s TXT and Mt. Wilson Attestation platform, is apparently…wait for it…manufactured in…wait for it…China.
<thud>
I wonder how NIST feels about that? ASSurance.
ROFLCoptr. Hey, at least it’s lead-free. o_O
Talk amongst yourselves.
/Hoff



No significant articles today
<Return to section navigation list>
Cloud Computing Events
Andy Cross (@AndyBareWeb) reported on 2/19/2013 that he’ll be conducting a Global Windows Azure Bootcamp in London on 4/27/2013:
On April 27th 2013, I’m helping to run the London instance of the Global Windows Azure Bootcamp.
It’s a whole day of Windows Azure training, labs, talks and hands on stuff that’s provided free by the community for the community. You can read more about the type of stuff we’re doing here http://magnusmartensson.com/globalwindowsazure-a-truly-global-windows-azure-community-event
We’re covering .net, java and other open stacks on Azure, as well as participating in one of the largest single uses of Azure compute horsepower in the global community’s history. This is going to rock, significantly.
If London is too far, look for a closer event here http://globalwindowsazure.azurewebsites.net/?page_id=151

Carl Otts (@fincooper) described on 2/18/2013 the Global Windows Azure Bootcamp occuring on 4/27/2013:
The community-driven Global Windows Azure Bootcamp is organized around the world simultaneously 27th of April 2013. You can read more about the event and find your local event at http://globalwindowsazure.azurewebsites.net/. Click the image below to see the currently announced locations on a map.
The boot camp is meant for both those just getting to know Windows Azure and those who already master the cloudy platform. For the beginners, there are classroom trainings provided seasoned Windows Azure professionals. For hard-core Windows Azure people there are loads of interesting special topics covered. These include real-life case examples and amazing experiments, one of which may actually break down the global Windows Azure datacenters (see below for a sneak peak)!
Together with some amazing devs, I’m helping our Finnish main organizer, Teemu Tapanila, organize the event. Check out the Finnish event website at http://finlandazure.eventbrite.com/ and stay tuned for more info!
#GlobalWindowsAzure in other blogs
- Steve Spencer – Windows Azure MVP: Global Windows Azure Bootcamp
- Maarten Balliauw – Windows Azure MVP: Global Windows Azure Bootcamp – april 27th


Herve Roggero (@hroggero) reported on 2/17/2013 an Azure Roadshow for IT Pros in Florida:
Hi – this is HUGE!!! Microsoft (Blain Barton) is planning a roadshow in Florida starting in March 2013 until June 2013. We will visit many cities (twice), so if you haven’t signed up yet, now is the time! Space is running short already! I will be one of the presenters at most of the locations, along with Adnan Cartwright, MVP, (www.fisg.us). We will talk IaaS (Infrastructure as a Service) in Microsoft Azure, so don’t miss out!
Here are some key links for you:
The first topics will include Windows Server 2012 Virtual Machines, Early Experts Workshop and Microsoft Virtual Academy; the second visit will include System Center SP1 with Windows Server 2012.
And here is the schedule along with registration links.
About Herve Roggero
Herve Roggero, Windows Azure MVP in South Florida, works for AAJ Technologies (http://www.aajtech.com) and is the founder of Blue Syntax Consulting (http://www.bluesyntax.net). Herve's experience includes software development, architecture, database administration and senior management with both global corporations and startup companies. Herve holds multiple certifications, including an MCDBA, MCSE, MCSD. He also holds a Master's degree in Business Administration from Indiana University. Herve is the co-author of "PRO SQL Azure" and “PRO SQL Server 2012 Practices” from Apress and runs the Azure Florida Association (on LinkedIn: http://www.linkedin.com/groups?gid=4177626).

<Return to section navigation list>
Other Cloud Computing Platforms and Services
Juan Carlos Perez (@JuanCPerezIDG) asserted “Users of products like App Engine, Compute Engine and Big Query will be able to purchase access to a variety of technical support services” in a deck for his Google adds fee-based support services for cloud platform customers article of 2/21/2013 for InfoWorld’s Cloud Computing blog:
Google has launched fee-based support services for customers of its cloud platform and infrastructure products, like App Engine, Compute Engine, Cloud Storage, and Big Query.
Google, often criticized over the years for having weak technical support both for consumers and enterprise customers, rolled out a four-tier support program specifically for customers of its Cloud Platform services.
"Support is as important as product features when choosing a platform for your applications. And let's face it, sometimes we all need a bit of help," wrote Brett McCully, from the Google Cloud Platform Team, in a blog post on Thursday.
The Bronze tier, which is free, includes access to online documentation, community forums and billing help. Building on those services, the Silver tier, which costs $150 per month per account, adds the ability for customers to ask the Cloud Platform support team questions via email related to product functionality, best practices and service errors.
The Gold tier, which starts at $400 per month, adds around-the-clock phone support and consultation on application development, best practices or architecture issues. In the Gold tier, the $400 fee is the minimum charge for all customers, and Google then adds a percentage of the customer's total monthly usage fees for all Cloud Platform products if those fees exceed $4,000 per month, according to the company. For example, a customer that spends between $4,001 and $10,000 per month in usage fees would pay 9 percent of that monthly total to receive Gold-tier service. Those who spend more than $200,000 in monthly usage fees would pay 3 percent. The top Platinum tier gives customers direct access to a technical account management team. To obtain pricing for the Platinum tier customers need to contact Google.
Google commits to responding to issues it deems urgent in four business hours or less for Silver-tier customers, and in an hour or less for Gold-tier and Platinum-tier customers. For non-urgent issues, Google will respond in no more than one business day for Silver-tier and Gold-tier customers, and in no more than four business hours for Platinum-tier customers.
Silver-tier customers can have up to two individuals with access to the Support Portal, while that number rises to five in the Gold tier and to an unlimited number in the Platinum tier.
Google's Cloud Platform services compete against offerings from Amazon's AWS division, Microsoft, IBM, and others.



Google is following Microsoft’s lead with paid support services for Windows Azure.
Jeff Barr (@jeffbarr) described Three New Features for AWS CloudFormation in a 2/19/2013 post:
AWS CloudFormation gives you an easy way to create and manage a collection of related AWS resources. You define a template (or use one of ours) and hand it over to CloudFormation. It will take care of creating all of the necessary AWS resources (a stack), in the proper order.
Today we are introducing three new features to add additional power and flexibility to CloudFormation: provisioning of EBS-Optimized Auto Scaling Groups, rolling deployments of Auto Scaling Groups, and cancellation of stack updates.
Let's look at each one...
Provisioning EBS-Optimized EC2 Instances
EBS-Optimized EC2 instances deliver dedicated network throughput (500 Mbps or 1000 Mbps depending on the instance type) between EC2 and Amazon Elastic Block Store (EBS). You can now request EBS-Optimized EC2 instances for Auto Scaling Groups in your CloudFormation templates by using the EbsOptimized key as follows:"Resources" : {
"myLCOne" : {
"Type" : "AWS::AutoScaling::LaunchConfiguration",
"Properties" : {
"ImageId" : { "Fn::FindInMap" : [ "AWSRegionArch2AMI", {"Ref":"AWS::Region"}, "64" ] },
"EbsOptimized" : "true",
"InstanceType" : "m1.large"
}
},Rolling Deployments of Auto Scaling Groups
CloudFormation has the ability to make changes to an Auto Scaling Group (a variable sized collection of EC2 instances governed by scaling rules that allow the group to expand or contract in response to changing requirements).Today's new feature allows you to perform a rolling deployment of an Auto Scaling Group within a CloudFormation stack. Instead of updating all of the instances in a group at the same time, you can now replace or modify the instances in a step-by-step fashion, with control over minimum group size during the update, the number of instances to update concurrently, and a pause time between batches of updates. The information is specified in an update policy. To learn more about update policies, check out the AWS CloudFormation User Guide.
"ASG1" : {
"Type" : "AWS::AutoScaling::AutoScalingGroup",
"UpdatePolicy" : {
"AutoScalingRollingUpdate" : {
"MaxBatchSize" : "2",
"MinInstancesInService" : "6",
"PauseTime" : "0"
}
},This feature will increase availability of your application during an update.
Cancellation of Stack Updates
You now have the ability to cancel a stack update that's underway. This will interrupt the operation and trigger a rollback. The cancel operation can be used in concert with update policies to automate the cancellation and rollback of a deployment.Here's one way that you can us cancellations and rolling deployments together:
- Initiate a stack update using a template that includes a fairly generous pause time (perhaps as long as several minutes) between batches of concurrent upgrades.
- Wait for the first round of updates to complete.
- Validate that the new instance(s) perform as expected (this must occur within the pause time specified in the update policy).
- Cancel the update (triggering a rollback) if the validation fails.
Learn More
Consult the CloudFormation User Guide to learn more about these new features.


Jeff Barr (@jeffbarr) announced AWS OpsWorks - Flexible Application Management in the Cloud Using Chef in a 2/18/2013 post:
It’s been over six years since we launched Amazon EC2. After that launch, we’ve delivered several solutions that make it easier for you to deploy and manage applications.
Two years ago we launched AWS CloudFormation to provide an easy way to create a collection of related AWS resources and provision them in an orderly and predictable fashion and AWS Elastic Beanstalk that allows users to quickly deploy and manage their applications in the AWS cloud. As our customers run more applications on AWS they are asking for more sophisticated tools to manage their AWS resources and automate how they deploy applications.
AWS OpsWorks features an integrated management experience for the entire application lifecycle including resource provisioning, configuration management, application deployment, monitoring, and access control. It will work with applications of any level of complexity and is independent of any particular architectural pattern.
AWS OpsWorks was designed to simplify the process of managing the application lifecycle without imposing arbitrary limits or forcing you to work within an overly constrained model. You have the freedom to design your application stack as you see fit.
You can use Chef Recipes to make system-level configuration changes and to install tools, utilities, libraries, and application code on the EC2 instance within your application. By making use of the AWS OpsWorks event model, you can activate the recipes of your choice at critical points in the lifecycle of your application. AWS OpsWorks has the power to install code from a wide variety of source code repositories.
There is no additional charge for AWS OpsWorks. You pay only for the AWS resources (EC2 instances, EBS volumes, and so forth) that your application uses.
AWS OpsWorks is available today and you can start using it now!
AWS OpsWorks Concepts
Let's start out by taking a look at the most important AWS OpsWorks concepts.An AWS OpsWorks Stack contains a set of Amazon EC2 instances and instance blueprints (which OpsWorks calls Layers) that are used to launch and manage the instances. Each Stack hosts one or more Applications. Stacks also serve as a container for the other user permissions and resources associated with the Apps. A Stack can also contain references to any number of Chef Cookbooks.
Each Stack contains a number of Layers. Each Layer specifies the setup and configuration of a set of EC2 instances and related AWS resources such as EBS Volumes and Elastic IP Addresses. We've included Layers for a number of common technologies including Ruby, PHP, Node.js, HAProxy, Memcached, and MySQL. You can extend these Layers for your own use, or you can create custom Layers from scratch. You can also activate the Chef Recipes of your choice in response to specific events (Setup, Configure, Deploy, Undeploy, and Shutdown).
AWS OpsWorks installs Applications on the EC2 instances by pulling the code from one or more code repositories. You can indicate that the code is to be pulled from a Git or Subversion repository, fetched via an HTTP request, or downloaded from an Amazon S3 bucket.
After you have defined a Stack, its Layers, and its Applications, you can create EC2 instances and assign them to specific Layers. You can launch the instances manually, or you can define scaling based on load or by time. Either way, you have full control over the instance type, Availability Zone, Security Group(s), and operating system. As the instances launch, they will be configured to your specifications using the Recipes that you defined for the Layer that contains the instance.
AWS OpsWorks will monitor your instances and report metrics to Amazon CloudWatch (you can also use Ganglia if you'd like). It will automatically replaced failed instances with fully configured fresh ones.
You can create and manage your AWS OpsWorks Stacks using the AWS Management Console]. You can also use it via the OpsWorks API.
AWS OpsWorks in Action
Let's take a quick look at the AWS OpsWorks Console. The welcome page provides you with a handy overview of the steps you'll take to get started:
Start out by adding a Stack. You have full control of the Region and the default Availability Zone. You can specify a naming scheme for the EC2 instances in the Stack and you can even select a color to help you distinguish your Stacks:
AWS OpsWorks will assign a name to each EC2 instance that it launches. You can select one of the following themes for the names:
You can add references to one or more Chef Cookbooks:
Now you can add Layers to your Stack:
You can choose one of the predefined Layer types or you can create your own custom Layer using community cookbooks for software like PostgreSQL, Solr, and more:
When you add a Layer of a predefined type, you have the opportunity to customize the settings as appropriate. For example, here's what you can customize if you choose to use the Ruby on Rails Layer:
You can add custom Chef Recipes and any additional software packages to your Layer. You can also ask for EBS Volumes or Elastic IP Addresses and you can configure RAID mount points:
You can see the built-in Chef recipes that AWS OpsWorks includes. You can also add your own Chef Recipes for use at various points in the application lifecycle. Here are the built-in Recipes included with the PHP Layer:
Here's what my Stack looks like after adding four layers (yours will look different, depending on the number and type of Layers you choose to add):
Applications are your code. You can add one or more Applications to the Stack like this. Your options (and this screen) will vary based on the type of application that you add:
With the Stack, the Layers, and the Applications defined, it is time to add EC2 instances to each Layer. As I noted earlier, you can add a fixed number of instances to a Layer or you can use time or load-based scaling, as appropriate for your application:
You can define time-based scaling in a very flexible manner. You can use the same scaling pattern for each day of the week or you can define patterns for particular days, or you can mix and match:
With everything defined, you can start all of the instances with a single click (you can also control them individually if you'd like):
Your instances will be up and running before long:
Then you can deploy your Applications to the instances:
You have the ability to control exactly which instances receive each deployment. AWS OpsWorks pulls the code from your repository and runs the deploy recipes on each of the selected instances to configure all the layers of your app. Here’s how it works. When you deploy an app, you might have a recipe on your database Layer that performs a specific configuration task, such as creating a new table. The recipes on your Layers let you to simplify the configuration steps across all the resources in your application with a single action.
Of course, there are times that you may need to get onto the instances. AWS OpsWorks helps here, too. You can configure SSH keys for each IAM user as well as configure which IAM users can use sudo.
At the top level of AWS OpsWorks, you can manage the entire Stack with a couple of clicks:
I hope that you have enjoyed this tour of AWS OpsWorks. I've shown you the highlights; there's even more functionality that you'll discover over time as you get to know the product.
AWS OpsWorks Demo
Watch this short (5 minute) video to see a demo of AWS OpsWorks:Getting Started
As always, we have plenty of resources to get you going:
Looking Ahead
Today, OpsWorks provides full control of software on EC2 instances and lets you use Chef recipes to integrate with AWS resources such as S3 and Amazon RDS. Moving forward, we plan to introduce integrated support for additional AWS resource types to simplify the management of layers that don’t require deep control. As always, your feedback will help us to prioritize our development effort.What Do You Think?
I invite you to give AWS OpsWorks a whirl and let me know what you think. Feel free to leave a comment!




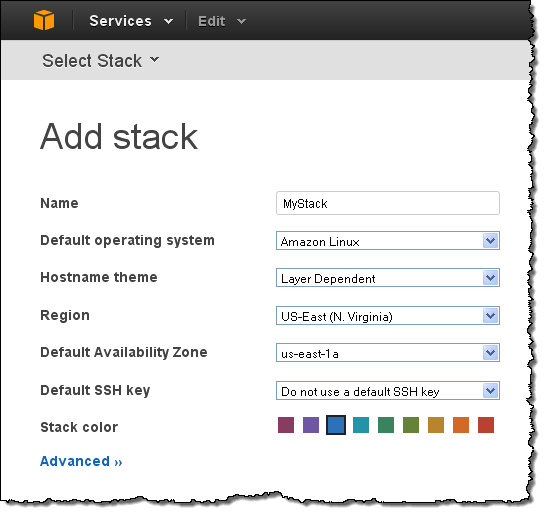

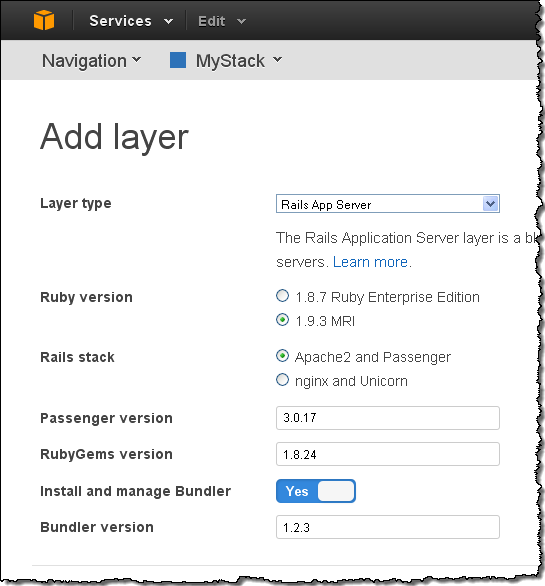



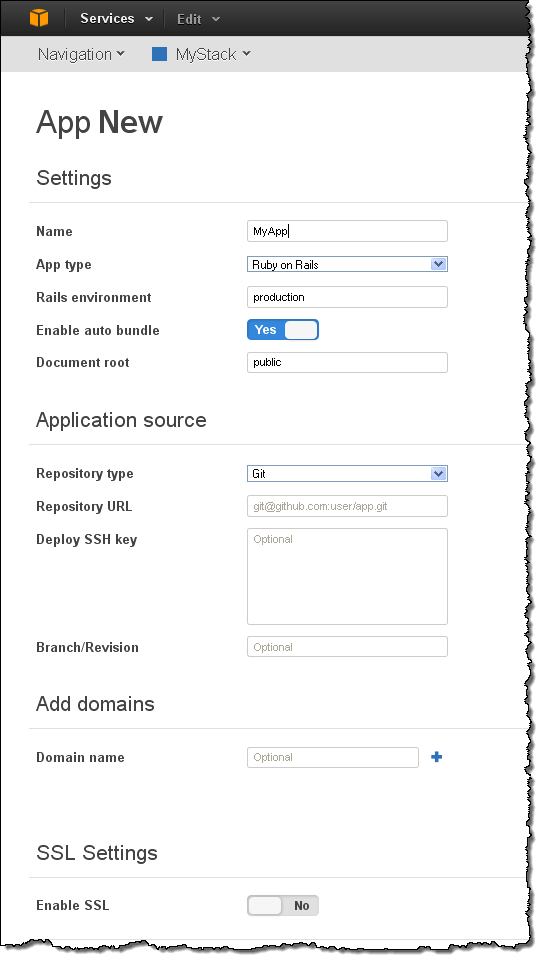
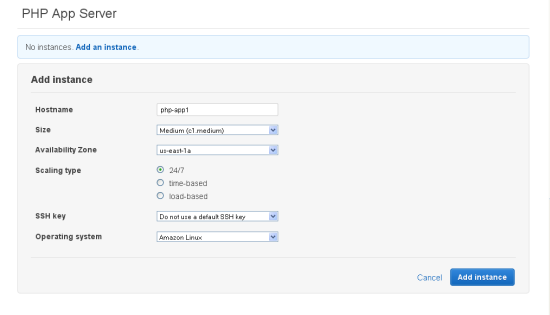
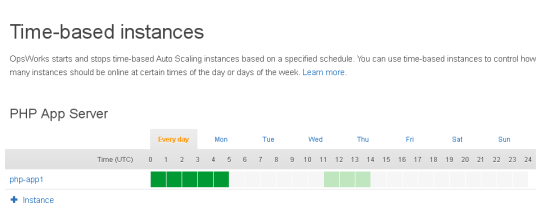




Werner Vogels (@werner) posted Expanding the Cloud - Introducing AWS OpsWorks, a Powerful Application Management Solution on 2/18/2013:
Today Amazon Web Services launched AWS OpsWorks, a flexible application management solution with automation tools that enable you to model and control your applications and their supporting infrastructure. OpsWorks allows you to manage the complete application lifecycle, including resource provisioning, configuration management, application deployment, software updates, monitoring, and access control.
As with all the AWS Application Management services AWS OpsWorks is provided at no additional charge. AWS customers only pay for those resources that they have used.
Simplified Application Management
OpsWorks is designed for IT administrators and ops-minded developers who want an easy way to manage applications of nearly any scale and complexity without sacrificing control. With OpsWorks you can create a logical architecture, provision resources based on that architecture, deploy your applications and all supporting software and packages in your chosen configuration, and then operate and maintain the application through lifecycle stages such as auto-scaling events and software updates.
Application management has traditionally been complex and time consuming because developers have had to choose among different types of application management options that limited flexibility, reduced control, or required time to develop custom tooling. Designed to simplify processes across the entire application lifecycle, OpsWorks eliminates these challenges by providing an end-to-end flexible, automated solution that provides more operational control over applications:
- Flexible – OpsWorks is designed to support a wide variety of application architectures and can work with any software that has a scripted installation. Because OpsWorks uses the Chef framework, developers can use existing recipes or leverage hundreds of community-built configurations.
- Automated – OpsWorks uses automation to simplify operations. OpsWorks provides an event-driven configuration system with rich deployment tools that allow you to efficiently manage applications over their lifetime, including support for customizable deployments, rollback, patch management, auto scaling, and auto healing. You can roll out an application update by simply updating a single configuration and clicking a button, reducing the time spent on routine tasks. For example, OpsWorks can set up instances to host your apps based on the exact configurations that you specify (code to deploy, RAID configuration, etc.), scale your apps using load-based or time-based auto scaling, and maintain the health of your apps by detecting and replacing failed instances. When a new app server instance starts, OpsWorks will use built-in recipes to configure the app server software and deploy your apps, and can also apply your specified recipes to make changes to your database and monitoring infrastructure.
- Operational Control – OpsWorks promotes conventions and sane defaults, such as template security groups, but also supports the ability to customize any aspect of an application’s configuration. You can then reproduce the exact configuration on new instances and apply changes to all instances, ensuring consistent configuration at any time. With support for scripted changes using Chef recipes at defined stages in the application lifecycle, you have fine-grained control of your application and its interaction with related components. Your recipes can be stored with your source code, making it easy to track changes. From one-time deployments to auto scaled growth, your application will reflect your settings through its complete lifecycle.
AWS OpsWorks Unique Features
Customers for a long time have been asking for an Application Management solution that allows them to manage the whole application lifecycle. OpsWorks has some unique features that help customers achieve this:
Model and support any application
You can deploy your application in the configuration you choose on Amazon Linux and Ubuntu. OpsWorks lets you model your application with layers. Layers define how to configure a set of resources that are managed together. For example, you might define a web layer for your application that consists of EC2 instances, EBS volumes including RAID configuration and mount points, and Elastic IPs. You can also define the software configuration for each layer, including installation scripts and initialization tasks. When an instance is added to a layer, OpsWorks automatically applies the specified configuration.OpsWorks provides pre-defined layers for common technologies such as Ruby, PHP, HAProxy, Memcached, and MySQL. OpsWorks promotes conventions but is flexible enough to let you customize any aspect of your environment. You can extend or modify pre-defined layers, or create your own from scratch. Because OpsWorks supports Chef recipes, you can leverage hundreds of community-built configurations such as PostgreSQL, Nginx, and Solr. For example, you can create an application that consists of multiple Python apps installed on Django connected to a CouchDB database.
Automate tasks
OpsWorks enables you to automate management actions so that they are performed automatically and reliably. You can benefit from automatic failover, package management, EBS volume RAID setup, and rule-based or time-based auto scaling. Common tasks automatically handled for you, and you can also extend and customize that automation. OpsWorks supports continuous configuration through lifecycle events that automatically update your instances’ configuration to adapt to environment changes, such as auto scaling events. With OpsWorks there is no need to log in to several machines and manually update your configuration. Whenever your environment changes, OpsWorks updates your configuration.Control access
OpsWorks lets you control access to your application. You choose which IAM users should have access to the application’s resources, and assign permissions that define what they can do. These controls can prevent users from inadvertently changing production resources. An event view shows change history to simplify root cause analysis.AWS Application Management Solutions
With the availability of AWS OpsWorks Amazon Web Services now has a number of different Application Management Services that address the different needs of Administrators and Developers.
- AWS Elastic Beanstalk is an easy-to-use solution for building web apps and web services with popular application containers such as Java, PHP, Python, Ruby and .NET. You upload your code and Elastic Beanstalk automatically does the rest. Elastic Beanstalk supports the most common web architectures, application containers, and frameworks.
- AWS OpsWorks is a powerful end-to-end solution that gives you an easy way to manage applications of nearly any scale and complexity without sacrificing control. You model, customize, and automate the entire application throughout its lifecycle. OpsWorks provides integrated experiences for IT administrators and ops-minded developers who want a high degree of productivity and control over operations
- AWS CloudFormation is a building block service that enables customers to provision and manage almost any AWS resource via a domain specific language. You define JSON templates and use them to provision and manage AWS resources, operating systems and application code. CloudFormation focuses on providing foundational capabilities for the full breadth of AWS, without prescribing a particular model for development and operations.
Next to these solutions you can of course manage your compute resources directly, for example using CloudWatch, AutoScaling and Elastic Load Balancing. There are also various free tools available such for example Asgard the Management and Deployment tool made available by Netflix. Also many AWS partners provide commercial solutions for managing you applications.
Summary
With the launch of AWS OpsWorks customers now have a very powerful solution that allows them to manage their application easily without giving up control. For more information on AWS OpsWork visit their detail page. For a comparison of the different Application Management services visit this overview page. For a hands-on overview of AWS OpsWork visit the AWS developer blog.
AWS OpsWorks is built on technology developed by Berlin company Peritor, the creators of Scalarium, which was acquired by AWS in 2012.


Updated my (@rogerjenn) off-topic First Look at the CozySwan UG007 Android 4.1 MiniPC Device post as follows:
Update 2/23/2013: Chris Velazco reported that the new HP Slate 7-inch Android tablet uses a RockChip CPU from China’s Fuzhou Rockchips Electronics company in his HP’s Android-Powered Slate 7 Tablet Is Cheap And It Works, But Is That Really Enough? TechCrunch article of 2/23/2013. The UG007 uses the RockChip RK3066 with the ARMv7 CPU instruction set.
Update 2/17/2013: Added details of the US$499 Xi3 Modular Computer in an Xi3 Corporation’s x64 Modular Computer section to the Introduction and Background section.
Update 2/11/2013: GeekBuying.com recently began offering the UG007 Mini PC Android 4.1.1 TV Box Dual Core Cortex-A9 RK3066 1GB RAM 8G Storage HDMI USB Black for US$56.99 (see the end of the Introduction and Background section) and Forbes Magazine reported 1 million Raspberry Pis have been sold (see the Building a Low-Cost Media Center with XBMC Running on a Raspberry Pi section.)



<Return to section navigation list>
















